+
+> [!Important]
+>
+> We are working on Chinese-to-English translation. For more information please see [#914](https://github.com/krahets/hello-algo/issues/914).
+
+## About
+
+This open-source project aims to create a free and beginner-friendly crash course for data structures and algorithms.
+
+- Animated illustrations, easy-to-understand content, and a smooth learning curve help beginners explore the "knowledge map" of data structures and algorithms.
+- Run code with just one click, helping readers improve their programming skills and understand the working principle of algorithms and the underlying implementation of data structures.
+- We encourage readers to help each other. Questions and comments are usually replied to within two days.
+
+If you find this book helpful, please give it a Star :star: to support us, thank you!
+
+## Endorsements
+
+> "An easy-to-understand book on data structures and algorithms, which guides readers to learn by minds-on and hands-on. Strongly recommended for algorithm beginners!"
+>
+> **—— Junhui Deng, Professor of Computer Science, Tsinghua University**
+
+> "If I had 'Hello Algo' when I was learning data structures and algorithms, it would have been 10 times easier!"
+>
+> **—— Mu Li, Senior Principal Scientist, Amazon**
+
+## Contribution
+
+This open-source book is continuously being updated, and we welcome your participation in this project to provide better learning content for readers.
+
+- [Content Correction](https://www.hello-algo.com/en/chapter_appendix/contribution/): Please help us correct or point out mistakes in the comments section such as grammatical errors, missing content, ambiguities, invalid links, or code bugs.
+- [Code Transpilation](https://github.com/krahets/hello-algo/issues/15): We look forward to your contributions in various programming languages. We currently support 12 languages including Python, Java, C++, Go, and JavaScript.
+- [Chinese-to-English](https://github.com/krahets/hello-algo/tree/en): We would love to invite you to join our translation team. The members are mainly from computer-science-related fields, English majors, and native English speakers.
+
+We welcome your valuable suggestions and feedback. If you have any questions, please submit Issues or reach out via WeChat: `krahets-jyd`.
+
+We would like to dedicate our thanks to all the contributors of this book. It is their selfless dedication that has made this book better. They are:
+
+
+
+!!! abstract
+
+ Complexity analysis is like a space-time guide in the vast universe of algorithms.
+
+ It leads us to explore deeply in the dimensions of time and space, in search of more elegant solutions.
diff --git a/docs-en/chapter_computational_complexity/iteration_and_recursion.assets/iteration.png b/docs-en/chapter_computational_complexity/iteration_and_recursion.assets/iteration.png
new file mode 100644
index 0000000000..8f0ac49689
Binary files /dev/null and b/docs-en/chapter_computational_complexity/iteration_and_recursion.assets/iteration.png differ
diff --git a/docs-en/chapter_computational_complexity/iteration_and_recursion.assets/nested_iteration.png b/docs-en/chapter_computational_complexity/iteration_and_recursion.assets/nested_iteration.png
new file mode 100644
index 0000000000..d46f7ef869
Binary files /dev/null and b/docs-en/chapter_computational_complexity/iteration_and_recursion.assets/nested_iteration.png differ
diff --git a/docs-en/chapter_computational_complexity/iteration_and_recursion.assets/recursion_sum.png b/docs-en/chapter_computational_complexity/iteration_and_recursion.assets/recursion_sum.png
new file mode 100644
index 0000000000..e649551479
Binary files /dev/null and b/docs-en/chapter_computational_complexity/iteration_and_recursion.assets/recursion_sum.png differ
diff --git a/docs-en/chapter_computational_complexity/iteration_and_recursion.assets/recursion_sum_depth.png b/docs-en/chapter_computational_complexity/iteration_and_recursion.assets/recursion_sum_depth.png
new file mode 100644
index 0000000000..a5692eacd3
Binary files /dev/null and b/docs-en/chapter_computational_complexity/iteration_and_recursion.assets/recursion_sum_depth.png differ
diff --git a/docs-en/chapter_computational_complexity/iteration_and_recursion.assets/recursion_tree.png b/docs-en/chapter_computational_complexity/iteration_and_recursion.assets/recursion_tree.png
new file mode 100644
index 0000000000..5bbc53a34c
Binary files /dev/null and b/docs-en/chapter_computational_complexity/iteration_and_recursion.assets/recursion_tree.png differ
diff --git a/docs-en/chapter_computational_complexity/iteration_and_recursion.assets/tail_recursion_sum.png b/docs-en/chapter_computational_complexity/iteration_and_recursion.assets/tail_recursion_sum.png
new file mode 100644
index 0000000000..c678438a8c
Binary files /dev/null and b/docs-en/chapter_computational_complexity/iteration_and_recursion.assets/tail_recursion_sum.png differ
diff --git a/docs-en/chapter_computational_complexity/iteration_and_recursion.md b/docs-en/chapter_computational_complexity/iteration_and_recursion.md
new file mode 100644
index 0000000000..0878e09bfc
--- /dev/null
+++ b/docs-en/chapter_computational_complexity/iteration_and_recursion.md
@@ -0,0 +1,194 @@
+# Iteration vs. Recursion
+
+In data structures and algorithms, it is common to repeat a task, which is closely related to the complexity of the algorithm. There are two basic program structures that we usually use to repeat a task: iteration and recursion.
+
+## Iteration
+
+An "iteration iteration" is a control structure that repeats a task. In iteration, a program repeats the execution of a piece of code until the condition is no longer satisfied.
+
+### For Loops
+
+`for` loops are one of the most common forms of iteration, **suitable when the number of iterations is known in advance**.
+
+The following function implements the summation $1 + 2 + \dots + n$ based on a `for` loop, and the result is recorded using the variable `res`. Note that `range(a, b)` in Python corresponds to a "left-closed-right-open" interval, which is traversed in the range $a, a + 1, \dots, b-1$.
+
+```src
+[file]{iteration}-[class]{}-[func]{for_loop}
+```
+
+The figure below shows the flow block diagram of this summation function.
+
+
+
+The number of operations in this summation function is proportional to the size of the input data $n$, or a "linear relationship". In fact, **time complexity describes this "linear relationship"**. This is described in more detail in the next section.
+
+### While Loop
+
+Similar to a `for` loop, a `while` loop is a way to implement iteration. In a `while` loop, the program first checks the condition at each turn, and if the condition is true, it continues, otherwise it ends the loop.
+
+Below, we use a `while` loop to realize the summation $1 + 2 + \dots + n$ .
+
+```src
+[file]{iteration}-[class]{}-[func]{while_loop}
+```
+
+In `while` loops, since the steps of initializing and updating condition variables are independent of the loop structure, **it has more degrees of freedom than `for` loops**.
+
+For example, in the following code, the condition variable $i$ is updated twice per round, which is not convenient to implement with a `for` loop.
+
+```src
+[file]{iteration}-[class]{}-[func]{while_loop_ii}
+```
+
+Overall, **`for` loops have more compact code and `while` loops are more flexible**, and both can implement iteration structures. The choice of which one to use should be based on the needs of the particular problem.
+
+### Nested Loops
+
+We can nest one loop structure inside another, using the `for` loop as an example:
+
+```src
+[file]{iteration}-[class]{}-[func]{nested_for_loop}
+```
+
+The figure below gives the block diagram of the flow of this nested loop.
+
+
+
+In this case, the number of operations of the function is proportional to $n^2$, or the algorithm's running time is "squared" to the size of the input data $n$.
+
+We can continue to add nested loops, and each nest is a "dimension up", which will increase the time complexity to "cubic relations", "quadratic relations", and so on.
+
+## Recursion
+
+ "Recursion recursion is an algorithmic strategy to solve a problem by calling the function itself. It consists of two main phases.
+
+1. **recursive**: the program calls itself deeper and deeper, usually passing smaller or simpler arguments, until a "termination condition" is reached.
+2. **Recursion**: After the "termination condition" is triggered, the program returns from the deepest level of the recursion function, level by level, aggregating the results of each level.
+
+And from an implementation point of view, recursion code contains three main elements.
+
+1. **Termination condition**: used to decide when to switch from "recursive" to "inductive".
+2. **Recursion call**: corresponds to "recursion", where the function calls itself, usually with smaller or more simplified input parameters.
+3. **return result**: corresponds to "return", returning the result of the current recursion level to the previous one.
+
+Observe the following code, we only need to call the function `recur(n)` , and the calculation of $1 + 2 + \dots + n$ is done:
+
+```src
+[file]{recursion}-[class]{}-[func]{recur}
+```
+
+The figure below shows the recursion of the function.
+
+
+
+Although iteration and recursion can yield the same results from a computational point of view, **they represent two completely different paradigms for thinking about and solving problems**.
+
+- **Iteration**: solving problems "from the bottom up". Start with the most basic steps and repeat or add to them until the task is completed.
+- **Recursion**: solving problems "from the top down". The original problem is broken down into smaller subproblems that have the same form as the original problem. Next, the subproblem continues to be broken down into smaller subproblems until it stops at the base case (the solution to the base case is known).
+
+As an example of the above summation function, set the problem $f(n) = 1 + 2 + \dots + n$ .
+
+- **Iteration**: the summation process is simulated in a loop, iterating from $1$ to $n$ and executing the summation operation in each round to find $f(n)$.
+- **Recursion**: decompose the problem into subproblems $f(n) = n + f(n-1)$ and keep (recursively) decomposing until the base case $f(1) = 1$ terminates.
+
+### Call The Stack
+
+Each time a recursion function calls itself, the system allocates memory for the newly opened function to store local variables, call addresses, other information, and so on. This results in two things.
+
+- The context data for a function is stored in an area of memory called "stack frame space" and is not freed until the function returns. As a result, **recursion is usually more memory-intensive than iteration**.
+- Recursion calls to functions incur additional overhead. **Therefore recursion is usually less time efficient than loops**.
+
+As shown in the figure below, before the termination condition is triggered, there are $n$ unreturned recursion functions at the same time, **with a recursion depth of $n$** .
+
+
+
+In practice, the depth of recursion allowed by a programming language is usually limited, and too deep a recursion may result in a stack overflow error.
+
+### Tail Recursion
+
+Interestingly, **if a function makes a recursion call only at the last step before returning**, the function can be optimized by the compiler or interpreter to be comparable to iteration in terms of space efficiency. This situation is called "tail recursion tail recursion".
+
+- **Ordinary recursion**: when a function returns to a function at a higher level, it needs to continue executing the code, so the system needs to save the context of the previous call.
+- **tail recursion**: the recursion call is the last operation before the function returns, which means that the function does not need to continue with other operations after returning to the previous level, so the system does not need to save the context of the previous function.
+
+In the case of calculating $1 + 2 + \dots + n$, for example, we can implement tail recursion by setting the result variable `res` as a function parameter.
+
+```src
+[file]{recursion}-[class]{}-[func]{tail_recur}
+```
+
+The execution of tail recursion is shown in the figure below. Comparing normal recursion and tail recursion, the execution point of the summation operation is different.
+
+- **Ordinary recursion**: the summing operation is performed during the "return" process, and the summing operation is performed again after returning from each level.
+- **Tail recursion**: the summing operation is performed in a "recursion" process, the "recursion" process simply returns in levels.
+
+
+
+!!! tip
+
+ Note that many compilers or interpreters do not support tail recursion optimization. For example, Python does not support tail recursion optimization by default, so even if a function is tail recursive, you may still encounter stack overflow problems.
+
+### Recursion Tree
+
+When dealing with algorithmic problems related to divide and conquer, recursion is often more intuitive and easier to read than iteration. Take the Fibonacci sequence as an example.
+
+!!! question
+
+ Given a Fibonacci series $0, 1, 1, 2, 3, 5, 8, 13, \dots$ , find the $n$th number of the series.
+
+Let the $n$th number of the Fibonacci series be $f(n)$ , which leads to two easy conclusions.
+
+- The first two numbers of the series are $f(1) = 0$ and $f(2) = 1$.
+- Each number in the series is the sum of the previous two numbers, i.e. $f(n) = f(n - 1) + f(n - 2)$ .
+
+Recursion code can be written by making recursion calls according to the recursion relationship, using the first two numbers as termination conditions. Call `fib(n)` to get the $n$th number of the Fibonacci series.
+
+```src
+[file]{recursion}-[class]{}-[func]{fib}
+```
+
+Looking at the above code, we have recursively called two functions within a function, **this means that from one call, two call branches are created**. As shown in the figure below, this recursion will result in a recursion tree with the number of levels $n$.
+
+
+
+Essentially, recursion embodies the paradigm of "breaking down a problem into smaller sub-problems", and this divide and conquer strategy is essential.
+
+- From an algorithmic point of view, many important algorithmic strategies such as searching, sorting algorithm, backtracking, divide and conquer, dynamic programming, etc. directly or indirectly apply this way of thinking.
+- From a data structure point of view, recursion is naturally suited to problems related to linked lists, trees and graphs because they are well suited to be analyzed with the idea of partitioning.
+
+## Compare The Two
+
+To summarize the above, as shown in the table below, iteration and recursion differ in implementation, performance and applicability.
+
+
Table Comparison of iteration and recursion features
+
+| | iteration | recursion |
+| ------------------- | ------------------------------------------------------- | ------------------------------------------------------------------------------------------------------------------------------------- |
+| implementation | circular structure | function call itself |
+| time-efficient | typically efficient, no function call overhead | overhead on every function call |
+| Memory Usage | Usually uses a fixed size of memory space | Cumulative function calls may use a lot of stack frame space |
+| Applicable Problems | For simple cyclic tasks, code is intuitive and readable | For sub-problem decomposition, such as trees, graphs, divide and conquer, backtracking, etc., the code structure is concise and clear |
+
+!!! tip
+
+ If you find the following solutions difficult to understand, you can review them after reading the "Stack" chapter.
+
+So what is the intrinsic connection between iteration and recursion? In the case of the recursive function described above, the summing operation takes place in the "return" phase of the recursion. This means that the function that is initially called is actually the last to complete its summing operation, **This mechanism works in the same way as the stack's "first in, last out" principle**.
+
+In fact, recursion terms like "call stack" and "stack frame space" already imply a close relationship between recursion and the stack.
+
+1. **Recursive**: When a function is called, the system allocates a new stack frame on the "call stack" for the function, which is used to store the function's local variables, parameters, return address, and other data.
+2. **Return to**: When a function completes execution and returns, the corresponding stack frame is removed from the "call stack", restoring the function's previous execution environment.
+
+Thus, **we can use an explicit stack to model the behavior of the call stack**, thus transforming recursion into an iteration form:
+
+```src
+[file]{recursion}-[class]{}-[func]{for_loop_recur}
+```
+
+Observing the code above, it becomes more complex when recursion is converted to iteration. Although iteration and recursion can be converted to each other in many cases, it is not always worth doing so for two reasons.
+
+- The transformed code may be more difficult to understand and less readable.
+- For some complex problems, simulating the behavior of the system call stack can be very difficult.
+
+In short, **the choice of iteration or recursion depends on the nature of the particular problem**. In programming practice, it is crucial to weigh the advantages and disadvantages of both and choose the appropriate method based on the context.
diff --git a/docs-en/chapter_computational_complexity/performance_evaluation.md b/docs-en/chapter_computational_complexity/performance_evaluation.md
new file mode 100644
index 0000000000..a6af765399
--- /dev/null
+++ b/docs-en/chapter_computational_complexity/performance_evaluation.md
@@ -0,0 +1,49 @@
+# Evaluation Of Algorithm Efficiency
+
+In algorithm design, we aim to achieve two goals in succession:
+
+1. **Finding a Solution to the Problem**: The algorithm needs to reliably find the correct solution within the specified input range.
+2. **Seeking the Optimal Solution**: There may be multiple ways to solve the same problem, and our goal is to find the most efficient algorithm possible.
+
+In other words, once the ability to solve the problem is established, the efficiency of the algorithm emerges as the main benchmark for assessing its quality, which includes the following two aspects.
+
+- **Time Efficiency**: The speed at which an algorithm runs.
+- **Space Efficiency**: The amount of memory space the algorithm consumes.
+
+In short, our goal is to design data structures and algorithms that are both "fast and economical". Effectively evaluating algorithm efficiency is crucial, as it allows for the comparison of different algorithms and guides the design and optimization process.
+
+There are mainly two approaches for assessing efficiency: practical testing and theoretical estimation.
+
+## Practical Testing
+
+Let's consider a scenario where we have two algorithms, `A` and `B`, both capable of solving the same problem. To compare their efficiency, the most direct method is to use a computer to run both algorithms while monitoring and recording their execution time and memory usage. This approach provides a realistic assessment of their performance, but it also has significant limitations.
+
+On one hand, it's challenging to eliminate the interference of the test environment. Hardware configurations can significantly affect the performance of algorithms. For instance, on one computer, Algorithm `A` might run faster than Algorithm `B`, but the results could be the opposite on another computer with different specifications. This means we would need to conduct tests on a variety of machines and calculate an average efficiency, which is impractical.
+
+Furthermore, conducting comprehensive tests is resource-intensive. The efficiency of algorithms can vary with different volumes of input data. For example, with smaller data sets, Algorithm A might run faster than Algorithm B; however, this could change with larger data sets. Therefore, to reach a convincing conclusion, it's necessary to test a range of data sizes, which requires excessive computational resources.
+
+## Theoretical Estimation
+
+Given the significant limitations of practical testing, we can consider assessing algorithm efficiency solely through calculations. This method of estimation is known as 'asymptotic complexity analysis,' often simply referred to as 'complexity analysis.
+
+Complexity analysis illustrates the relationship between the time (and space) resources required by an algorithm and the size of its input data. **It describes the growing trend in the time and space required for the execution of an algorithm as the size of the input data increases**. This definition might sound a bit complex, so let's break it down into three key points for easier understanding.
+
+- In complexity analysis, 'time and space' directly relate to 'time complexity' and 'space complexity,' respectively.
+- The statement "as the size of the input data increases" highlights that complexity analysis examines the interplay between the size of the input data and the algorithm's efficiency.
+- Lastly, the phrase "the growing trend in time and space required" emphasizes that the focus of complexity analysis is not on the specific values of running time or space occupied, but on the rate at which these requirements increase with larger input sizes.
+
+**Complexity analysis overcomes the drawbacks of practical testing methods in two key ways:**.
+
+- It is independent of the testing environment, meaning the analysis results are applicable across all operating platforms.
+- It effectively demonstrates the efficiency of algorithms with varying data volumes, particularly highlighting performance in large-scale data scenarios.
+
+!!! tip
+
+ If you're still finding the concept of complexity confusing, don't worry. We will cover it in more detail in the subsequent chapters.
+
+Complexity analysis provides us with a 'ruler' for evaluating the efficiency of algorithms, enabling us to measure the time and space resources required to execute a given algorithm and to compare the efficiency of different algorithms.
+
+Complexity is a mathematical concept that might seem abstract and somewhat challenging for beginners. From this perspective, introducing complexity analysis at the very beginning may not be the most suitable approach. However, when discussing the characteristics of a particular data structure or algorithm, analyzing its operational speed and space usage is often inevitable.
+
+Therefore, it is recommended that before diving deeply into data structures and algorithms, **one should first gain a basic understanding of complexity analysis. This foundational knowledge will facilitate the complexity analysis of simple algorithms.**
+
diff --git a/docs-en/chapter_computational_complexity/space_complexity.assets/space_complexity_common_types.png b/docs-en/chapter_computational_complexity/space_complexity.assets/space_complexity_common_types.png
new file mode 100644
index 0000000000..31b4891c00
Binary files /dev/null and b/docs-en/chapter_computational_complexity/space_complexity.assets/space_complexity_common_types.png differ
diff --git a/docs-en/chapter_computational_complexity/space_complexity.assets/space_complexity_exponential.png b/docs-en/chapter_computational_complexity/space_complexity.assets/space_complexity_exponential.png
new file mode 100644
index 0000000000..f6ff889bae
Binary files /dev/null and b/docs-en/chapter_computational_complexity/space_complexity.assets/space_complexity_exponential.png differ
diff --git a/docs-en/chapter_computational_complexity/space_complexity.assets/space_complexity_recursive_linear.png b/docs-en/chapter_computational_complexity/space_complexity.assets/space_complexity_recursive_linear.png
new file mode 100644
index 0000000000..7a3f372251
Binary files /dev/null and b/docs-en/chapter_computational_complexity/space_complexity.assets/space_complexity_recursive_linear.png differ
diff --git a/docs-en/chapter_computational_complexity/space_complexity.assets/space_complexity_recursive_quadratic.png b/docs-en/chapter_computational_complexity/space_complexity.assets/space_complexity_recursive_quadratic.png
new file mode 100644
index 0000000000..e11cc168ec
Binary files /dev/null and b/docs-en/chapter_computational_complexity/space_complexity.assets/space_complexity_recursive_quadratic.png differ
diff --git a/docs-en/chapter_computational_complexity/space_complexity.assets/space_types.png b/docs-en/chapter_computational_complexity/space_complexity.assets/space_types.png
new file mode 100644
index 0000000000..a8cc1986f1
Binary files /dev/null and b/docs-en/chapter_computational_complexity/space_complexity.assets/space_types.png differ
diff --git a/docs-en/chapter_computational_complexity/space_complexity.md b/docs-en/chapter_computational_complexity/space_complexity.md
new file mode 100644
index 0000000000..5dadce191f
--- /dev/null
+++ b/docs-en/chapter_computational_complexity/space_complexity.md
@@ -0,0 +1,780 @@
+# Space Complexity
+
+The space complexity is used to measure the growth trend of memory consumption as the scale of data increases for an algorithm solution. This concept is analogous to time complexity by replacing "runtime" with "memory space".
+
+## Algorithmic Correlation Space
+
+The memory space used by algorithms during its execution include the following types.
+
+- **Input Space**: Used to store the input data for the algorithm.
+- **Temporary Space**: Used to store variables, objects, function contexts, and other data of the algorithm during runtime.
+- **Output Space**: Used to store the output data of the algorithm.
+
+In general, the "Input Space" is excluded from the statistics of space complexity.
+
+The **Temporary Space** can be further divided into three parts.
+
+- **Temporary Data**: Used to store various constants, variables, objects, etc., during the the algorithm's execution.
+- **Stack Frame Space**: Used to hold the context data of the called function. The system creates a stack frame at the top of the stack each time a function is called, and the stack frame space is freed when the function returns.
+- **Instruction Space**: Used to hold compiled program instructions, usually ignored in practical statistics.
+
+When analyzing the space complexity of a piece of program, **three parts are usually taken into account: Temporary Data, Stack Frame Space and Output Data**.
+
+
+
+=== "Python"
+
+ ```python title=""
+ class Node:
+ """Classes""""
+ def __init__(self, x: int):
+ self.val: int = x # node value
+ self.next: Node | None = None # reference to the next node
+
+ def function() -> int:
+ """"Functions"""""
+ # Perform certain operations...
+ return 0
+
+ def algorithm(n) -> int: # input data
+ A = 0 # temporary data (constant, usually in uppercase)
+ b = 0 # temporary data (variable)
+ node = Node(0) # temporary data (object)
+ c = function() # Stack frame space (call function)
+ return A + b + c # output data
+ ```
+
+=== "C++"
+
+ ```cpp title=""
+ /* Structures */
+ struct Node {
+ int val;
+ Node *next;
+ Node(int x) : val(x), next(nullptr) {}
+ };
+
+ /* Functions */
+ int func() {
+ // Perform certain operations...
+ return 0;
+ }
+
+ int algorithm(int n) { // input data
+ const int a = 0; // temporary data (constant)
+ int b = 0; // temporary data (variable)
+ Node* node = new Node(0); // temporary data (object)
+ int c = func(); // stack frame space (call function)
+ return a + b + c; // output data
+ }
+ ```
+
+=== "Java"
+
+ ```java title=""
+ /* Classes */
+ class Node {
+ int val;
+ Node next;
+ Node(int x) { val = x; }
+ }
+
+ /* Functions */
+ int function() {
+ // Perform certain operations...
+ return 0;
+ }
+
+ int algorithm(int n) { // input data
+ final int a = 0; // temporary data (constant)
+ int b = 0; // temporary data (variable)
+ Node node = new Node(0); // temporary data (object)
+ int c = function(); // stack frame space (call function)
+ return a + b + c; // output data
+ }
+ ```
+
+=== "C#"
+
+ ```csharp title=""
+ /* Classes */
+ class Node {
+ int val;
+ Node next;
+ Node(int x) { val = x; }
+ }
+
+ /* Functions */
+ int Function() {
+ // Perform certain operations...
+ return 0;
+ }
+
+ int Algorithm(int n) { // input data
+ const int a = 0; // temporary data (constant)
+ int b = 0; // temporary data (variable)
+ Node node = new(0); // temporary data (object)
+ int c = Function(); // stack frame space (call function)
+ return a + b + c; // output data
+ }
+ ```
+
+=== "Go"
+
+ ```go title=""
+ /* Structures */
+ type node struct {
+ val int
+ next *node
+ }
+
+ /* Create node structure */
+ func newNode(val int) *node {
+ return &node{val: val}
+ }
+
+ /* Functions */
+ func function() int {
+ // Perform certain operations...
+ return 0
+ }
+
+ func algorithm(n int) int { // input data
+ const a = 0 // temporary data (constant)
+ b := 0 // temporary storage of data (variable)
+ newNode(0) // temporary data (object)
+ c := function() // stack frame space (call function)
+ return a + b + c // output data
+ }
+ ```
+
+=== "Swift"
+
+ ```swift title=""
+ /* Classes */
+ class Node {
+ var val: Int
+ var next: Node?
+
+ init(x: Int) {
+ val = x
+ }
+ }
+
+ /* Functions */
+ func function() -> Int {
+ // Perform certain operations...
+ return 0
+ }
+
+ func algorithm(n: Int) -> Int { // input data
+ let a = 0 // temporary data (constant)
+ var b = 0 // temporary data (variable)
+ let node = Node(x: 0) // temporary data (object)
+ let c = function() // stack frame space (call function)
+ return a + b + c // output data
+ }
+ ```
+
+=== "JS"
+
+ ```javascript title=""
+ /* Classes */
+ class Node {
+ val;
+ next;
+ constructor(val) {
+ this.val = val === undefined ? 0 : val; // node value
+ this.next = null; // reference to the next node
+ }
+ }
+
+ /* Functions */
+ function constFunc() {
+ // Perform certain operations
+ return 0;
+ }
+
+ function algorithm(n) { // input data
+ const a = 0; // temporary data (constant)
+ let b = 0; // temporary data (variable)
+ const node = new Node(0); // temporary data (object)
+ const c = constFunc(); // Stack frame space (calling function)
+ return a + b + c; // output data
+ }
+ ```
+
+=== "TS"
+
+ ```typescript title=""
+ /* Classes */
+ class Node {
+ val: number;
+ next: Node | null;
+ constructor(val?: number) {
+ this.val = val === undefined ? 0 : val; // node value
+ this.next = null; // reference to the next node
+ }
+ }
+
+ /* Functions */
+ function constFunc(): number {
+ // Perform certain operations
+ return 0;
+ }
+
+ function algorithm(n: number): number { // input data
+ const a = 0; // temporary data (constant)
+ let b = 0; // temporary data (variable)
+ const node = new Node(0); // temporary data (object)
+ const c = constFunc(); // Stack frame space (calling function)
+ return a + b + c; // output data
+ }
+ ```
+
+=== "Dart"
+
+ ```dart title=""
+ /* Classes */
+ class Node {
+ int val;
+ Node next;
+ Node(this.val, [this.next]);
+ }
+
+ /* Functions */
+ int function() {
+ // Perform certain operations...
+ return 0;
+ }
+
+ int algorithm(int n) { // input data
+ const int a = 0; // temporary data (constant)
+ int b = 0; // temporary data (variable)
+ Node node = Node(0); // temporary data (object)
+ int c = function(); // stack frame space (call function)
+ return a + b + c; // output data
+ }
+ ```
+
+=== "Rust"
+
+ ```rust title=""
+ use std::rc::Rc;
+ use std::cell::RefCell;
+
+ /* Structures */
+ struct Node {
+ val: i32,
+ next: Option>>,
+ }
+
+ /* Creating a Node structure */
+ impl Node {
+ fn new(val: i32) -> Self {
+ Self { val: val, next: None }
+ }
+ }
+
+ /* Functions */
+ fn function() -> i32 {
+ // Perform certain operations...
+ return 0;
+ }
+
+ fn algorithm(n: i32) -> i32 { // input data
+ const a: i32 = 0; // temporary data (constant)
+ let mut b = 0; // temporary data (variable)
+ let node = Node::new(0); // temporary data (object)
+ let c = function(); // stack frame space (call function)
+ return a + b + c; // output data
+ }
+ ```
+
+=== "C"
+
+ ```c title=""
+ /* Functions */
+ int func() {
+ // Perform certain operations...
+ return 0;
+ }
+
+ int algorithm(int n) { // input data
+ const int a = 0; // temporary data (constant)
+ int b = 0; // temporary data (variable)
+ int c = func(); // stack frame space (call function)
+ return a + b + c; // output data
+ }
+ ```
+
+=== "Zig"
+
+ ```zig title=""
+
+ ```
+
+## Calculation Method
+
+The calculation method for space complexity is pretty similar to time complexity, with the only difference being that the focus shifts from "operation count" to "space usage size".
+
+On top of that, unlike time complexity, **we usually only focus on the worst-case space complexity**. This is because memory space is a hard requirement, and we have to make sure that there is enough memory space reserved for all possibilities incurred by input data.
+
+Looking at the following code, the "worst" in worst-case space complexity has two layers of meaning.
+
+1. **Based on the worst-case input data**: when $n < 10$, the space complexity is $O(1)$; however, when $n > 10$, the initialized array `nums` occupies $O(n)$ space; thus the worst-case space complexity is $O(n)$.
+2. **Based on the peak memory during algorithm execution**: for example, the program occupies $O(1)$ space until the last line is executed; when the array `nums` is initialized, the program occupies $O(n)$ space; thus the worst-case space complexity is $O(n)$.
+
+=== "Python"
+
+ ```python title=""
+ def algorithm(n: int):
+ a = 0 # O(1)
+ b = [0] * 10000 # O(1)
+ if n > 10:
+ nums = [0] * n # O(n)
+ ```
+
+=== "C++"
+
+ ```cpp title=""
+ void algorithm(int n) {
+ int a = 0; // O(1)
+ vector b(10000); // O(1)
+ if (n > 10)
+ vector nums(n); // O(n)
+ }
+ ```
+
+=== "Java"
+
+ ```java title=""
+ void algorithm(int n) {
+ int a = 0; // O(1)
+ int[] b = new int[10000]; // O(1)
+ if (n > 10)
+ int[] nums = new int[n]; // O(n)
+ }
+ ```
+
+=== "C#"
+
+ ```csharp title=""
+ void Algorithm(int n) {
+ int a = 0; // O(1)
+ int[] b = new int[10000]; // O(1)
+ if (n > 10) {
+ int[] nums = new int[n]; // O(n)
+ }
+ }
+ ```
+
+=== "Go"
+
+ ```go title=""
+ func algorithm(n int) {
+ a := 0 // O(1)
+ b := make([]int, 10000) // O(1)
+ var nums []int
+ if n > 10 {
+ nums := make([]int, n) // O(n)
+ }
+ fmt.Println(a, b, nums)
+ }
+ ```
+
+=== "Swift"
+
+ ```swift title=""
+ func algorithm(n: Int) {
+ let a = 0 // O(1)
+ let b = Array(repeating: 0, count: 10000) // O(1)
+ if n > 10 {
+ let nums = Array(repeating: 0, count: n) // O(n)
+ }
+ }
+ ```
+
+=== "JS"
+
+ ```javascript title=""
+ function algorithm(n) {
+ const a = 0; // O(1)
+ const b = new Array(10000); // O(1)
+ if (n > 10) {
+ const nums = new Array(n); // O(n)
+ }
+ }
+ ```
+
+=== "TS"
+
+ ```typescript title=""
+ function algorithm(n: number): void {
+ const a = 0; // O(1)
+ const b = new Array(10000); // O(1)
+ if (n > 10) {
+ const nums = new Array(n); // O(n)
+ }
+ }
+ ```
+
+=== "Dart"
+
+ ```dart title=""
+ void algorithm(int n) {
+ int a = 0; // O(1)
+ List b = List.filled(10000, 0); // O(1)
+ if (n > 10) {
+ List nums = List.filled(n, 0); // O(n)
+ }
+ }
+ ```
+
+=== "Rust"
+
+ ```rust title=""
+ fn algorithm(n: i32) {
+ let a = 0; // O(1)
+ let b = [0; 10000]; // O(1)
+ if n > 10 {
+ let nums = vec![0; n as usize]; // O(n)
+ }
+ }
+ ```
+
+=== "C"
+
+ ```c title=""
+ void algorithm(int n) {
+ int a = 0; // O(1)
+ int b[10000]; // O(1)
+ if (n > 10)
+ int nums[n] = {0}; // O(n)
+ }
+ ```
+
+=== "Zig"
+
+ ```zig title=""
+
+ ```
+
+**In recursion functions, it is important to take into count the measurement of stack frame space**. For example in the following code:
+
+- The function `loop()` calls $n$ times `function()` in a loop, and each round of `function()` returns and frees stack frame space, so the space complexity is still $O(1)$.
+- The recursion function `recur()` will have $n$ unreturned `recur()` during runtime, thus occupying $O(n)$ of stack frame space.
+
+=== "Python"
+
+ ```python title=""
+ def function() -> int:
+ # Perform certain operations
+ return 0
+
+ def loop(n: int):
+ """Loop O(1)"""""
+ for _ in range(n):
+ function()
+
+ def recur(n: int) -> int:
+ """Recursion O(n)"""""
+ if n == 1: return
+ return recur(n - 1)
+ ```
+
+=== "C++"
+
+ ```cpp title=""
+ int func() {
+ // Perform certain operations
+ return 0;
+ }
+ /* Cycle O(1) */
+ void loop(int n) {
+ for (int i = 0; i < n; i++) {
+ func();
+ }
+ }
+ /* Recursion O(n) */
+ void recur(int n) {
+ if (n == 1) return;
+ return recur(n - 1);
+ }
+ ```
+
+=== "Java"
+
+ ```java title=""
+ int function() {
+ // Perform certain operations
+ return 0;
+ }
+ /* Cycle O(1) */
+ void loop(int n) {
+ for (int i = 0; i < n; i++) {
+ function();
+ }
+ }
+ /* Recursion O(n) */
+ void recur(int n) {
+ if (n == 1) return;
+ return recur(n - 1);
+ }
+ ```
+
+=== "C#"
+
+ ```csharp title=""
+ int Function() {
+ // Perform certain operations
+ return 0;
+ }
+ /* Cycle O(1) */
+ void Loop(int n) {
+ for (int i = 0; i < n; i++) {
+ Function();
+ }
+ }
+ /* Recursion O(n) */
+ int Recur(int n) {
+ if (n == 1) return 1;
+ return Recur(n - 1);
+ }
+ ```
+
+=== "Go"
+
+ ```go title=""
+ func function() int {
+ // Perform certain operations
+ return 0
+ }
+
+ /* Cycle O(1) */
+ func loop(n int) {
+ for i := 0; i < n; i++ {
+ function()
+ }
+ }
+
+ /* Recursion O(n) */
+ func recur(n int) {
+ if n == 1 {
+ return
+ }
+ recur(n - 1)
+ }
+ ```
+
+=== "Swift"
+
+ ```swift title=""
+ @discardableResult
+ func function() -> Int {
+ // Perform certain operations
+ return 0
+ }
+
+ /* Cycle O(1) */
+ func loop(n: Int) {
+ for _ in 0 ..< n {
+ function()
+ }
+ }
+
+ /* Recursion O(n) */
+ func recur(n: Int) {
+ if n == 1 {
+ return
+ }
+ recur(n: n - 1)
+ }
+ ```
+
+=== "JS"
+
+ ```javascript title=""
+ function constFunc() {
+ // Perform certain operations
+ return 0;
+ }
+ /* Cycle O(1) */
+ function loop(n) {
+ for (let i = 0; i < n; i++) {
+ constFunc();
+ }
+ }
+ /* Recursion O(n) */
+ function recur(n) {
+ if (n === 1) return;
+ return recur(n - 1);
+ }
+ ```
+
+=== "TS"
+
+ ```typescript title=""
+ function constFunc(): number {
+ // Perform certain operations
+ return 0;
+ }
+ /* Cycle O(1) */
+ function loop(n: number): void {
+ for (let i = 0; i < n; i++) {
+ constFunc();
+ }
+ }
+ /* Recursion O(n) */
+ function recur(n: number): void {
+ if (n === 1) return;
+ return recur(n - 1);
+ }
+ ```
+
+=== "Dart"
+
+ ```dart title=""
+ int function() {
+ // Perform certain operations
+ return 0;
+ }
+ /* Cycle O(1) */
+ void loop(int n) {
+ for (int i = 0; i < n; i++) {
+ function();
+ }
+ }
+ /* Recursion O(n) */
+ void recur(int n) {
+ if (n == 1) return;
+ return recur(n - 1);
+ }
+ ```
+
+=== "Rust"
+
+ ```rust title=""
+ fn function() -> i32 {
+ // Perform certain operations
+ return 0;
+ }
+ /* Cycle O(1) */
+ fn loop(n: i32) {
+ for i in 0..n {
+ function();
+ }
+ }
+ /* Recursion O(n) */
+ void recur(n: i32) {
+ if n == 1 {
+ return;
+ }
+ recur(n - 1);
+ }
+ ```
+
+=== "C"
+
+ ```c title=""
+ int func() {
+ // Perform certain operations
+ return 0;
+ }
+ /* Cycle O(1) */
+ void loop(int n) {
+ for (int i = 0; i < n; i++) {
+ func();
+ }
+ }
+ /* Recursion O(n) */
+ void recur(int n) {
+ if (n == 1) return;
+ return recur(n - 1);
+ }
+ ```
+
+=== "Zig"
+
+ ```zig title=""
+
+ ```
+
+## Common Types
+
+Assuming the input data size is $n$, the figure illustrates common types of space complexity (ordered from low to high).
+
+$$
+\begin{aligned}
+O(1) < O(\log n) < O(n) < O(n^2) < O(2^n) \newline
+\text{constant order} < \text{logarithmic order} < \text{linear order} < \text{square order} < \text{exponential order}
+\end{aligned}
+$$
+
+
+
+### Constant Order $O(1)$
+
+Constant order is common for constants, variables, and objects whose quantity is unrelated to the size of the input data $n$.
+
+It is important to note that memory occupied by initializing a variable or calling a function in a loop is released once the next iteration begins. Therefore, there is no accumulation of occupied space and the space complexity remains $O(1)$ :
+
+```src
+[file]{space_complexity}-[class]{}-[func]{constant}
+```
+
+### Linear Order $O(N)$
+
+Linear order is commonly found in arrays, linked lists, stacks, queues, and similar structures where the number of elements is proportional to $n$:
+
+```src
+[file]{space_complexity}-[class]{}-[func]{linear}
+```
+
+As shown in the figure below, the depth of recursion for this function is $n$, which means that there are $n$ unreturned `linear_recur()` functions at the same time, using $O(n)$ size stack frame space:
+
+```src
+[file]{space_complexity}-[class]{}-[func]{linear_recur}
+```
+
+
+
+### Quadratic Order $O(N^2)$
+
+Quadratic order is common in matrices and graphs, where the number of elements is in a square relationship with $n$:
+
+```src
+[file]{space_complexity}-[class]{}-[func]{quadratic}
+```
+
+As shown in the figure below, the recursion depth of this function is $n$, and an array is initialized in each recursion function with lengths $n$, $n-1$, $\dots$, $2$, $1$, and an average length of $n / 2$, thus occupying $O(n^2)$ space overall:
+
+```src
+[file]{space_complexity}-[class]{}-[func]{quadratic_recur}
+```
+
+
+
+### Exponential Order $O(2^N)$
+
+Exponential order is common in binary trees. Looking at the figure below, a "full binary tree" of degree $n$ has $2^n - 1$ nodes, occupying $O(2^n)$ space:
+
+```src
+[file]{space_complexity}-[class]{}-[func]{build_tree}
+```
+
+
+
+### Logarithmic Order $O(\Log N)$
+
+Logarithmic order is commonly used in divide and conquer algorithms. For example, in a merge sort, given an array of length $n$ as the input, each round of recursion divides the array in half from its midpoint to form a recursion tree of height $\log n$, using $O(\log n)$ stack frame space.
+
+Another example is to convert a number into a string. Given a positive integer $n$ with a digit count of $\log_{10} n + 1$, the corresponding string length is $\log_{10} n + 1$. Therefore, the space complexity is $O(\log_{10} n + 1) = O(\log n)$.
+
+## Weighing Time And Space
+
+Ideally, we would like to optimize both the time complexity and the space complexity of an algorithm. However, in reality, simultaneously optimizing time and space complexity is often challenging.
+
+**Reducing time complexity usually comes at the expense of increasing space complexity, and vice versa**. The approach of sacrificing memory space to improve algorithm speed is known as "trading space for time", while the opposite is called "trading time for space".
+
+The choice between these approaches depends on which aspect we prioritize. In most cases, time is more valuable than space, so "trading space for time" is usually the more common strategy. Of course, in situations with large data volumes, controlling space complexity is also crucial.
diff --git a/docs-en/chapter_computational_complexity/summary.md b/docs-en/chapter_computational_complexity/summary.md
new file mode 100644
index 0000000000..6deb872ece
--- /dev/null
+++ b/docs-en/chapter_computational_complexity/summary.md
@@ -0,0 +1,49 @@
+# Summary
+
+### Highlights
+
+**Evaluation of Algorithm Efficiency**
+
+- Time and space efficiency are the two leading evaluation indicators to measure an algorithm.
+- We can evaluate the efficiency of an algorithm through real-world testing. Still, it isn't easy to eliminate the side effects from the testing environment, and it consumes a lot of computational resources.
+- Complexity analysis overcomes the drawbacks of real-world testing. The analysis results can apply to all operating platforms and reveal the algorithm's efficiency under variant data scales.
+
+**Time Complexity**
+
+- Time complexity is used to measure the trend of algorithm running time as the data size grows., which can effectively evaluate the algorithm's efficiency. However, it may fail in some cases, such as when the input volume is small or the time complexities are similar, making it difficult to precisely compare the efficiency of algorithms.
+- The worst time complexity is denoted by big $O$ notation, which corresponds to the asymptotic upper bound of the function, reflecting the growth rate in the number of operations $T(n)$ as $n$ tends to positive infinity.
+- The estimation of time complexity involves two steps: first, counting the number of operations, and then determining the asymptotic upper bound.
+- Common time complexities, from lowest to highest, are $O(1)$, $O(\log n)$, $O(n)$, $O(n \log n)$, $O(n^2)$, $O(2^n)$, and $O(n!)$.
+- The time complexity of certain algorithms is not fixed and depends on the distribution of the input data. The time complexity can be categorized into worst-case, best-case, and average. The best-case time complexity is rarely used because the input data must meet strict conditions to achieve the best-case.
+- The average time complexity reflects the efficiency of an algorithm with random data inputs, which is closest to the performance of algorithms in real-world scenarios. Calculating the average time complexity requires statistical analysis of input data and a synthesized mathematical expectation.
+
+**Space Complexity**
+
+- Space complexity serves a similar purpose to time complexity and is used to measure the trend of space occupied by an algorithm as the data volume increases.
+- The memory space associated with the operation of an algorithm can be categorized into input space, temporary space, and output space. Normally, the input space is not considered when determining space complexity. The temporary space can be classified into instruction space, data space, and stack frame space, and the stack frame space usually only affects the space complexity for recursion functions.
+- We mainly focus on the worst-case space complexity, which refers to the measurement of an algorithm's space usage when given the worst-case input data and during the worst-case execution scenario.
+- Common space complexities are $O(1)$, $O(\log n)$, $O(n)$, $O(n^2)$ and $O(2^n)$ from lowest to highest.
+
+### Q & A
+
+!!! question "Is the space complexity of tail recursion $O(1)$?"
+
+ Theoretically, the space complexity of a tail recursion function can be optimized to $O(1)$. However, most programming languages (e.g., Java, Python, C++, Go, C#, etc.) do not support auto-optimization for tail recursion, so the space complexity is usually considered as $O(n)$.
+
+!!! question "What is the difference between the terms function and method?"
+
+ A *function* can be executed independently, and all arguments are passed explicitly. A *method* is associated with an object and is implicitly passed to the object that calls it, allowing it to operate on the data contained within an instance of a class.
+
+ Let's illustrate with a few common programming languages.
+
+ - C is a procedural programming language without object-oriented concepts, so it has only functions. However, we can simulate object-oriented programming by creating structures (struct), and the functions associated with structures are equivalent to methods in other languages.
+ - Java and C# are object-oriented programming languages, and blocks of code (methods) are typically part of a class. Static methods behave like a function because it is bound to the class and cannot access specific instance variables.
+ - Both C++ and Python support both procedural programming (functions) and object-oriented programming (methods).
+
+!!! question "Does the figure "Common Types of Space Complexity" reflect the absolute size of the occupied space?"
+
+ No, that figure shows the space complexity, which reflects the growth trend, not the absolute size of the space occupied.
+
+ For example, if you take $n = 8$ , the values of each curve do not align with the function because each curve contains a constant term used to compress the range of values to a visually comfortable range.
+
+ In practice, since we usually don't know each method's "constant term" complexity, it is generally impossible to choose the optimal solution for $n = 8$ based on complexity alone. But it's easier to choose for $n = 8^5$ as the growth trend is already dominant.
diff --git a/docs-en/chapter_computational_complexity/time_complexity.assets/asymptotic_upper_bound.png b/docs-en/chapter_computational_complexity/time_complexity.assets/asymptotic_upper_bound.png
new file mode 100644
index 0000000000..eecaef86c8
Binary files /dev/null and b/docs-en/chapter_computational_complexity/time_complexity.assets/asymptotic_upper_bound.png differ
diff --git a/docs-en/chapter_computational_complexity/time_complexity.assets/time_complexity_common_types.png b/docs-en/chapter_computational_complexity/time_complexity.assets/time_complexity_common_types.png
new file mode 100644
index 0000000000..f2221f3da4
Binary files /dev/null and b/docs-en/chapter_computational_complexity/time_complexity.assets/time_complexity_common_types.png differ
diff --git a/docs-en/chapter_computational_complexity/time_complexity.assets/time_complexity_constant_linear_quadratic.png b/docs-en/chapter_computational_complexity/time_complexity.assets/time_complexity_constant_linear_quadratic.png
new file mode 100644
index 0000000000..c45fd7afe6
Binary files /dev/null and b/docs-en/chapter_computational_complexity/time_complexity.assets/time_complexity_constant_linear_quadratic.png differ
diff --git a/docs-en/chapter_computational_complexity/time_complexity.assets/time_complexity_exponential.png b/docs-en/chapter_computational_complexity/time_complexity.assets/time_complexity_exponential.png
new file mode 100644
index 0000000000..20f77bfad6
Binary files /dev/null and b/docs-en/chapter_computational_complexity/time_complexity.assets/time_complexity_exponential.png differ
diff --git a/docs-en/chapter_computational_complexity/time_complexity.assets/time_complexity_factorial.png b/docs-en/chapter_computational_complexity/time_complexity.assets/time_complexity_factorial.png
new file mode 100644
index 0000000000..e62e1702ff
Binary files /dev/null and b/docs-en/chapter_computational_complexity/time_complexity.assets/time_complexity_factorial.png differ
diff --git a/docs-en/chapter_computational_complexity/time_complexity.assets/time_complexity_logarithmic.png b/docs-en/chapter_computational_complexity/time_complexity.assets/time_complexity_logarithmic.png
new file mode 100644
index 0000000000..354ac82ae3
Binary files /dev/null and b/docs-en/chapter_computational_complexity/time_complexity.assets/time_complexity_logarithmic.png differ
diff --git a/docs-en/chapter_computational_complexity/time_complexity.assets/time_complexity_logarithmic_linear.png b/docs-en/chapter_computational_complexity/time_complexity.assets/time_complexity_logarithmic_linear.png
new file mode 100644
index 0000000000..ad3040172f
Binary files /dev/null and b/docs-en/chapter_computational_complexity/time_complexity.assets/time_complexity_logarithmic_linear.png differ
diff --git a/docs-en/chapter_computational_complexity/time_complexity.assets/time_complexity_simple_example.png b/docs-en/chapter_computational_complexity/time_complexity.assets/time_complexity_simple_example.png
new file mode 100644
index 0000000000..b10793083a
Binary files /dev/null and b/docs-en/chapter_computational_complexity/time_complexity.assets/time_complexity_simple_example.png differ
diff --git a/docs-en/chapter_computational_complexity/time_complexity.md b/docs-en/chapter_computational_complexity/time_complexity.md
new file mode 100644
index 0000000000..0e68c42adc
--- /dev/null
+++ b/docs-en/chapter_computational_complexity/time_complexity.md
@@ -0,0 +1,1092 @@
+# Time Complexity
+
+Runtime can be a visual and accurate reflection of the efficiency of an algorithm. What should we do if we want to accurately predict the runtime of a piece of code?
+
+1. **Determine the running platform**, including hardware configuration, programming language, system environment, etc., all of which affect the efficiency of the code.
+2. **Evaluates the running time** required for various computational operations, e.g., the addition operation `+` takes 1 ns, the multiplication operation `*` takes 10 ns, the print operation `print()` takes 5 ns, and so on.
+3. **Counts all the computational operations in the code** and sums the execution times of all the operations to get the runtime.
+
+For example, in the following code, the input data size is $n$ :
+
+=== "Python"
+
+ ```python title=""
+ # Under an operating platform
+ def algorithm(n: int):
+ a = 2 # 1 ns
+ a = a + 1 # 1 ns
+ a = a * 2 # 10 ns
+ # Cycle n times
+ for _ in range(n): # 1 ns
+ print(0) # 5 ns
+ ```
+
+=== "C++"
+
+ ```cpp title=""
+ // Under a particular operating platform
+ void algorithm(int n) {
+ int a = 2; // 1 ns
+ a = a + 1; // 1 ns
+ a = a * 2; // 10 ns
+ // Loop n times
+ for (int i = 0; i < n; i++) { // 1 ns , every round i++ is executed
+ cout << 0 << endl; // 5 ns
+ }
+ }
+ ```
+
+=== "Java"
+
+ ```java title=""
+ // Under a particular operating platform
+ void algorithm(int n) {
+ int a = 2; // 1 ns
+ a = a + 1; // 1 ns
+ a = a * 2; // 10 ns
+ // Loop n times
+ for (int i = 0; i < n; i++) { // 1 ns , every round i++ is executed
+ System.out.println(0); // 5 ns
+ }
+ }
+ ```
+
+=== "C#"
+
+ ```csharp title=""
+ // Under a particular operating platform
+ void Algorithm(int n) {
+ int a = 2; // 1 ns
+ a = a + 1; // 1 ns
+ a = a * 2; // 10 ns
+ // Loop n times
+ for (int i = 0; i < n; i++) { // 1 ns , every round i++ is executed
+ Console.WriteLine(0); // 5 ns
+ }
+ }
+ ```
+
+=== "Go"
+
+ ```go title=""
+ // Under a particular operating platform
+ func algorithm(n int) {
+ a := 2 // 1 ns
+ a = a + 1 // 1 ns
+ a = a * 2 // 10 ns
+ // Loop n times
+ for i := 0; i < n; i++ { // 1 ns
+ fmt.Println(a) // 5 ns
+ }
+ }
+ ```
+
+=== "Swift"
+
+ ```swift title=""
+ // Under a particular operating platform
+ func algorithm(n: Int) {
+ var a = 2 // 1 ns
+ a = a + 1 // 1 ns
+ a = a * 2 // 10 ns
+ // Loop n times
+ for _ in 0 ..< n { // 1 ns
+ print(0) // 5 ns
+ }
+ }
+ ```
+
+=== "JS"
+
+ ```javascript title=""
+ // Under a particular operating platform
+ function algorithm(n) {
+ var a = 2; // 1 ns
+ a = a + 1; // 1 ns
+ a = a * 2; // 10 ns
+ // Loop n times
+ for(let i = 0; i < n; i++) { // 1 ns , every round i++ is executed
+ console.log(0); // 5 ns
+ }
+ }
+ ```
+
+=== "TS"
+
+ ```typescript title=""
+ // Under a particular operating platform
+ function algorithm(n: number): void {
+ var a: number = 2; // 1 ns
+ a = a + 1; // 1 ns
+ a = a * 2; // 10 ns
+ // Loop n times
+ for(let i = 0; i < n; i++) { // 1 ns , every round i++ is executed
+ console.log(0); // 5 ns
+ }
+ }
+ ```
+
+=== "Dart"
+
+ ```dart title=""
+ // Under a particular operating platform
+ void algorithm(int n) {
+ int a = 2; // 1 ns
+ a = a + 1; // 1 ns
+ a = a * 2; // 10 ns
+ // Loop n times
+ for (int i = 0; i < n; i++) { // 1 ns , every round i++ is executed
+ print(0); // 5 ns
+ }
+ }
+ ```
+
+=== "Rust"
+
+ ```rust title=""
+ // Under a particular operating platform
+ fn algorithm(n: i32) {
+ let mut a = 2; // 1 ns
+ a = a + 1; // 1 ns
+ a = a * 2; // 10 ns
+ // Loop n times
+ for _ in 0..n { // 1 ns for each round i++
+ println!("{}", 0); // 5 ns
+ }
+ }
+ ```
+
+=== "C"
+
+ ```c title=""
+ // Under a particular operating platform
+ void algorithm(int n) {
+ int a = 2; // 1 ns
+ a = a + 1; // 1 ns
+ a = a * 2; // 10 ns
+ // Loop n times
+ for (int i = 0; i < n; i++) { // 1 ns , every round i++ is executed
+ printf("%d", 0); // 5 ns
+ }
+ }
+ ```
+
+=== "Zig"
+
+ ```zig title=""
+ // Under a particular operating platform
+ fn algorithm(n: usize) void {
+ var a: i32 = 2; // 1 ns
+ a += 1; // 1 ns
+ a *= 2; // 10 ns
+ // Loop n times
+ for (0..n) |_| { // 1 ns
+ std.debug.print("{}\n", .{0}); // 5 ns
+ }
+ }
+ ```
+
+Based on the above method, the algorithm running time can be obtained as $6n + 12$ ns :
+
+$$
+1 + 1 + 10 + (1 + 5) \times n = 6n + 12
+$$
+
+In practice, however, **statistical algorithm runtimes are neither reasonable nor realistic**. First, we do not want to tie the estimation time to the operation platform, because the algorithm needs to run on a variety of different platforms. Second, it is difficult for us to be informed of the runtime of each operation, which makes the prediction process extremely difficult.
+
+## Trends In Statistical Time Growth
+
+The time complexity analysis counts not the algorithm running time, **but the tendency of the algorithm running time to increase as the amount of data gets larger**.
+
+The concept of "time-growing trend" is rather abstract, so let's try to understand it through an example. Suppose the size of the input data is $n$, and given three algorithmic functions `A`, `B` and `C`:
+
+=== "Python"
+
+ ```python title=""
+ # Time complexity of algorithm A: constant order
+ def algorithm_A(n: int):
+ print(0)
+ # Time complexity of algorithm B: linear order
+ def algorithm_B(n: int):
+ for _ in range(n):
+ print(0)
+ # Time complexity of algorithm C: constant order
+ def algorithm_C(n: int):
+ for _ in range(1000000):
+ print(0)
+ ```
+
+=== "C++"
+
+ ```cpp title=""
+ // Time complexity of algorithm A: constant order
+ void algorithm_A(int n) {
+ cout << 0 << endl;
+ }
+ // Time complexity of algorithm B: linear order
+ void algorithm_B(int n) {
+ for (int i = 0; i < n; i++) {
+ cout << 0 << endl;
+ }
+ }
+ // Time complexity of algorithm C: constant order
+ void algorithm_C(int n) {
+ for (int i = 0; i < 1000000; i++) {
+ cout << 0 << endl;
+ }
+ }
+ ```
+
+=== "Java"
+
+ ```java title=""
+ // Time complexity of algorithm A: constant order
+ void algorithm_A(int n) {
+ System.out.println(0);
+ }
+ // Time complexity of algorithm B: linear order
+ void algorithm_B(int n) {
+ for (int i = 0; i < n; i++) {
+ System.out.println(0);
+ }
+ }
+ // Time complexity of algorithm C: constant order
+ void algorithm_C(int n) {
+ for (int i = 0; i < 1000000; i++) {
+ System.out.println(0);
+ }
+ }
+ ```
+
+=== "C#"
+
+ ```csharp title=""
+ // Time complexity of algorithm A: constant order
+ void AlgorithmA(int n) {
+ Console.WriteLine(0);
+ }
+ // Time complexity of algorithm B: linear order
+ void AlgorithmB(int n) {
+ for (int i = 0; i < n; i++) {
+ Console.WriteLine(0);
+ }
+ }
+ // Time complexity of algorithm C: constant order
+ void AlgorithmC(int n) {
+ for (int i = 0; i < 1000000; i++) {
+ Console.WriteLine(0);
+ }
+ }
+ ```
+
+=== "Go"
+
+ ```go title=""
+ // Time complexity of algorithm A: constant order
+ func algorithm_A(n int) {
+ fmt.Println(0)
+ }
+ // Time complexity of algorithm B: linear order
+ func algorithm_B(n int) {
+ for i := 0; i < n; i++ {
+ fmt.Println(0)
+ }
+ }
+ // Time complexity of algorithm C: constant order
+ func algorithm_C(n int) {
+ for i := 0; i < 1000000; i++ {
+ fmt.Println(0)
+ }
+ }
+ ```
+
+=== "Swift"
+
+ ```swift title=""
+ // Time complexity of algorithm A: constant order
+ func algorithmA(n: Int) {
+ print(0)
+ }
+
+ // Time complexity of algorithm B: linear order
+ func algorithmB(n: Int) {
+ for _ in 0 ..< n {
+ print(0)
+ }
+ }
+
+ // Time complexity of algorithm C: constant order
+ func algorithmC(n: Int) {
+ for _ in 0 ..< 1000000 {
+ print(0)
+ }
+ }
+ ```
+
+=== "JS"
+
+ ```javascript title=""
+ // Time complexity of algorithm A: constant order
+ function algorithm_A(n) {
+ console.log(0);
+ }
+ // Time complexity of algorithm B: linear order
+ function algorithm_B(n) {
+ for (let i = 0; i < n; i++) {
+ console.log(0);
+ }
+ }
+ // Time complexity of algorithm C: constant order
+ function algorithm_C(n) {
+ for (let i = 0; i < 1000000; i++) {
+ console.log(0);
+ }
+ }
+
+ ```
+
+=== "TS"
+
+ ```typescript title=""
+ // Time complexity of algorithm A: constant order
+ function algorithm_A(n: number): void {
+ console.log(0);
+ }
+ // Time complexity of algorithm B: linear order
+ function algorithm_B(n: number): void {
+ for (let i = 0; i < n; i++) {
+ console.log(0);
+ }
+ }
+ // Time complexity of algorithm C: constant order
+ function algorithm_C(n: number): void {
+ for (let i = 0; i < 1000000; i++) {
+ console.log(0);
+ }
+ }
+ ```
+
+=== "Dart"
+
+ ```dart title=""
+ // Time complexity of algorithm A: constant order
+ void algorithmA(int n) {
+ print(0);
+ }
+ // Time complexity of algorithm B: linear order
+ void algorithmB(int n) {
+ for (int i = 0; i < n; i++) {
+ print(0);
+ }
+ }
+ // Time complexity of algorithm C: constant order
+ void algorithmC(int n) {
+ for (int i = 0; i < 1000000; i++) {
+ print(0);
+ }
+ }
+ ```
+
+=== "Rust"
+
+ ```rust title=""
+ // Time complexity of algorithm A: constant order
+ fn algorithm_A(n: i32) {
+ println!("{}", 0);
+ }
+ // Time complexity of algorithm B: linear order
+ fn algorithm_B(n: i32) {
+ for _ in 0..n {
+ println!("{}", 0);
+ }
+ }
+ // Time complexity of algorithm C: constant order
+ fn algorithm_C(n: i32) {
+ for _ in 0..1000000 {
+ println!("{}", 0);
+ }
+ }
+ ```
+
+=== "C"
+
+ ```c title=""
+ // Time complexity of algorithm A: constant order
+ void algorithm_A(int n) {
+ printf("%d", 0);
+ }
+ // Time complexity of algorithm B: linear order
+ void algorithm_B(int n) {
+ for (int i = 0; i < n; i++) {
+ printf("%d", 0);
+ }
+ }
+ // Time complexity of algorithm C: constant order
+ void algorithm_C(int n) {
+ for (int i = 0; i < 1000000; i++) {
+ printf("%d", 0);
+ }
+ }
+ ```
+
+=== "Zig"
+
+ ```zig title=""
+ // Time complexity of algorithm A: constant order
+ fn algorithm_A(n: usize) void {
+ _ = n;
+ std.debug.print("{}\n", .{0});
+ }
+ // Time complexity of algorithm B: linear order
+ fn algorithm_B(n: i32) void {
+ for (0..n) |_| {
+ std.debug.print("{}\n", .{0});
+ }
+ }
+ // Time complexity of algorithm C: constant order
+ fn algorithm_C(n: i32) void {
+ _ = n;
+ for (0..1000000) |_| {
+ std.debug.print("{}\n", .{0});
+ }
+ }
+ ```
+
+The figure below shows the time complexity of the above three algorithmic functions.
+
+- Algorithm `A` has only $1$ print operations, and the running time of the algorithm does not increase with $n$. We call the time complexity of this algorithm "constant order".
+- The print operation in algorithm `B` requires $n$ cycles, and the running time of the algorithm increases linearly with $n$. The time complexity of this algorithm is called "linear order".
+- The print operation in algorithm `C` requires $1000000$ loops, which is a long runtime, but it is independent of the size of the input data $n$. Therefore, the time complexity of `C` is the same as that of `A`, which is still of "constant order".
+
+
+
+What are the characteristics of time complexity analysis compared to direct statistical algorithmic running time?
+
+- The **time complexity can effectively evaluate the efficiency of an algorithm**. For example, the running time of algorithm `B` increases linearly and is slower than algorithm `A` for $n > 1$ and slower than algorithm `C` for $n > 1,000,000$. In fact, as long as the input data size $n$ is large enough, algorithms with "constant order" of complexity will always outperform algorithms with "linear order", which is exactly what the time complexity trend means.
+- The **time complexity of the projection method is simpler**. Obviously, neither the running platform nor the type of computational operation is related to the growth trend of the running time of the algorithm. Therefore, in the time complexity analysis, we can simply consider the execution time of all computation operations as the same "unit time", and thus simplify the "statistics of the running time of computation operations" to the "statistics of the number of computation operations", which is the same as the "statistics of the number of computation operations". The difficulty of the estimation is greatly reduced by considering the execution time of all operations as the same "unit time".
+- There are also some limitations of **time complexity**. For example, although algorithms `A` and `C` have the same time complexity, the actual running time varies greatly. Similarly, although the time complexity of algorithm `B` is higher than that of `C` , algorithm `B` significantly outperforms algorithm `C` when the size of the input data $n$ is small. In these cases, it is difficult to judge the efficiency of an algorithm based on time complexity alone. Of course, despite the above problems, complexity analysis is still the most effective and commonly used method to judge the efficiency of algorithms.
+
+## Functions Asymptotic Upper Bounds
+
+Given a function with input size $n$:
+
+=== "Python"
+
+ ```python title=""
+ def algorithm(n: int):
+ a = 1 # +1
+ a = a + 1 # +1
+ a = a * 2 # +1
+ # Cycle n times
+ for i in range(n): # +1
+ print(0) # +1
+ ```
+
+=== "C++"
+
+ ```cpp title=""
+ void algorithm(int n) {
+ int a = 1; // +1
+ a = a + 1; // +1
+ a = a * 2; // +1
+ // Loop n times
+ for (int i = 0; i < n; i++) { // +1 (execute i ++ every round)
+ cout << 0 << endl; // +1
+ }
+ }
+ ```
+
+=== "Java"
+
+ ```java title=""
+ void algorithm(int n) {
+ int a = 1; // +1
+ a = a + 1; // +1
+ a = a * 2; // +1
+ // Loop n times
+ for (int i = 0; i < n; i++) { // +1 (execute i ++ every round)
+ System.out.println(0); // +1
+ }
+ }
+ ```
+
+=== "C#"
+
+ ```csharp title=""
+ void Algorithm(int n) {
+ int a = 1; // +1
+ a = a + 1; // +1
+ a = a * 2; // +1
+ // Loop n times
+ for (int i = 0; i < n; i++) { // +1 (execute i ++ every round)
+ Console.WriteLine(0); // +1
+ }
+ }
+ ```
+
+=== "Go"
+
+ ```go title=""
+ func algorithm(n int) {
+ a := 1 // +1
+ a = a + 1 // +1
+ a = a * 2 // +1
+ // Loop n times
+ for i := 0; i < n; i++ { // +1
+ fmt.Println(a) // +1
+ }
+ }
+ ```
+
+=== "Swift"
+
+ ```swift title=""
+ func algorithm(n: Int) {
+ var a = 1 // +1
+ a = a + 1 // +1
+ a = a * 2 // +1
+ // Loop n times
+ for _ in 0 ..< n { // +1
+ print(0) // +1
+ }
+ }
+ ```
+
+=== "JS"
+
+ ```javascript title=""
+ function algorithm(n) {
+ var a = 1; // +1
+ a += 1; // +1
+ a *= 2; // +1
+ // Loop n times
+ for(let i = 0; i < n; i++){ // +1 (execute i ++ every round)
+ console.log(0); // +1
+ }
+ }
+ ```
+
+=== "TS"
+
+ ```typescript title=""
+ function algorithm(n: number): void{
+ var a: number = 1; // +1
+ a += 1; // +1
+ a *= 2; // +1
+ // Loop n times
+ for(let i = 0; i < n; i++){ // +1 (execute i ++ every round)
+ console.log(0); // +1
+ }
+ }
+ ```
+
+=== "Dart"
+
+ ```dart title=""
+ void algorithm(int n) {
+ int a = 1; // +1
+ a = a + 1; // +1
+ a = a * 2; // +1
+ // Loop n times
+ for (int i = 0; i < n; i++) { // +1 (execute i ++ every round)
+ print(0); // +1
+ }
+ }
+ ```
+
+=== "Rust"
+
+ ```rust title=""
+ fn algorithm(n: i32) {
+ let mut a = 1; // +1
+ a = a + 1; // +1
+ a = a * 2; // +1
+
+ // Loop n times
+ for _ in 0..n { // +1 (execute i ++ every round)
+ println!("{}", 0); // +1
+ }
+ }
+ ```
+
+=== "C"
+
+ ```c title=""
+ void algorithm(int n) {
+ int a = 1; // +1
+ a = a + 1; // +1
+ a = a * 2; // +1
+ // Loop n times
+ for (int i = 0; i < n; i++) { // +1 (execute i ++ every round)
+ printf("%d", 0); // +1
+ }
+ }
+ ```
+
+=== "Zig"
+
+ ```zig title=""
+ fn algorithm(n: usize) void {
+ var a: i32 = 1; // +1
+ a += 1; // +1
+ a *= 2; // +1
+ // Loop n times
+ for (0..n) |_| { // +1 (execute i ++ every round)
+ std.debug.print("{}\n", .{0}); // +1
+ }
+ }
+ ```
+
+Let the number of operations of the algorithm be a function of the size of the input data $n$, denoted as $T(n)$ , then the number of operations of the above function is:
+
+$$
+T(n) = 3 + 2n
+$$
+
+$T(n)$ is a primary function, which indicates that the trend of its running time growth is linear, and thus its time complexity is of linear order.
+
+We denote the time complexity of the linear order as $O(n)$ , and this mathematical notation is called the "big $O$ notation big-$O$ notation", which denotes the "asymptotic upper bound" of the function $T(n)$.
+
+Time complexity analysis is essentially the computation of asymptotic upper bounds on the "number of operations function $T(n)$", which has a clear mathematical definition.
+
+!!! abstract "Function asymptotic upper bound"
+
+ If there exists a positive real number $c$ and a real number $n_0$ such that $T(n) \leq c \cdot f(n)$ for all $n > n_0$ , then it can be argued that $f(n)$ gives an asymptotic upper bound on $T(n)$ , denoted as $T(n) = O(f(n))$ .
+
+As shown in the figure below, computing the asymptotic upper bound is a matter of finding a function $f(n)$ such that $T(n)$ and $f(n)$ are at the same growth level as $n$ tends to infinity, differing only by a multiple of the constant term $c$.
+
+
+
+## Method Of Projection
+
+Asymptotic upper bounds are a bit heavy on math, so don't worry if you feel you don't have a full solution. Because in practice, we only need to master the projection method, and the mathematical meaning can be gradually comprehended.
+
+By definition, after determining $f(n)$, we can get the time complexity $O(f(n))$. So how to determine the asymptotic upper bound $f(n)$? The overall is divided into two steps: first count the number of operations, and then determine the asymptotic upper bound.
+
+### The First Step: Counting The Number Of Operations
+
+For the code, it is sufficient to calculate from top to bottom line by line. However, since the constant term $c \cdot f(n)$ in the above $c \cdot f(n)$ can take any size, **the various coefficients and constant terms in the number of operations $T(n)$ can be ignored**. Based on this principle, the following counting simplification techniques can be summarized.
+
+1. **Ignore the constant terms in $T(n)$**. Since none of them are related to $n$, they have no effect on the time complexity.
+2. **omits all coefficients**. For example, loops $2n$ times, $5n + 1$ times, etc., can be simplified and notated as $n$ times because the coefficients before $n$ have no effect on the time complexity.
+3. **Use multiplication** when loops are nested. The total number of operations is equal to the product of the number of operations of the outer and inner levels of the loop, and each level of the loop can still be nested by applying the techniques in points `1.` and `2.` respectively.
+
+Given a function, we can use the above trick to count the number of operations.
+
+=== "Python"
+
+ ```python title=""
+ def algorithm(n: int):
+ a = 1 # +0 (trick 1)
+ a = a + n # +0 (trick 1)
+ # +n (technique 2)
+ for i in range(5 * n + 1):
+ print(0)
+ # +n*n (technique 3)
+ for i in range(2 * n):
+ for j in range(n + 1):
+ print(0)
+ ```
+
+=== "C++"
+
+ ```cpp title=""
+ void algorithm(int n) {
+ int a = 1; // +0 (trick 1)
+ a = a + n; // +0 (trick 1)
+ // +n (technique 2)
+ for (int i = 0; i < 5 * n + 1; i++) {
+ cout << 0 << endl;
+ }
+ // +n*n (technique 3)
+ for (int i = 0; i < 2 * n; i++) {
+ for (int j = 0; j < n + 1; j++) {
+ cout << 0 << endl;
+ }
+ }
+ }
+ ```
+
+=== "Java"
+
+ ```java title=""
+ void algorithm(int n) {
+ int a = 1; // +0 (trick 1)
+ a = a + n; // +0 (trick 1)
+ // +n (technique 2)
+ for (int i = 0; i < 5 * n + 1; i++) {
+ System.out.println(0);
+ }
+ // +n*n (technique 3)
+ for (int i = 0; i < 2 * n; i++) {
+ for (int j = 0; j < n + 1; j++) {
+ System.out.println(0);
+ }
+ }
+ }
+ ```
+
+=== "C#"
+
+ ```csharp title=""
+ void Algorithm(int n) {
+ int a = 1; // +0 (trick 1)
+ a = a + n; // +0 (trick 1)
+ // +n (technique 2)
+ for (int i = 0; i < 5 * n + 1; i++) {
+ Console.WriteLine(0);
+ }
+ // +n*n (technique 3)
+ for (int i = 0; i < 2 * n; i++) {
+ for (int j = 0; j < n + 1; j++) {
+ Console.WriteLine(0);
+ }
+ }
+ }
+ ```
+
+=== "Go"
+
+ ```go title=""
+ func algorithm(n int) {
+ a := 1 // +0 (trick 1)
+ a = a + n // +0 (trick 1)
+ // +n (technique 2)
+ for i := 0; i < 5 * n + 1; i++ {
+ fmt.Println(0)
+ }
+ // +n*n (technique 3)
+ for i := 0; i < 2 * n; i++ {
+ for j := 0; j < n + 1; j++ {
+ fmt.Println(0)
+ }
+ }
+ }
+ ```
+
+=== "Swift"
+
+ ```swift title=""
+ func algorithm(n: Int) {
+ var a = 1 // +0 (trick 1)
+ a = a + n // +0 (trick 1)
+ // +n (technique 2)
+ for _ in 0 ..< (5 * n + 1) {
+ print(0)
+ }
+ // +n*n (technique 3)
+ for _ in 0 ..< (2 * n) {
+ for _ in 0 ..< (n + 1) {
+ print(0)
+ }
+ }
+ }
+ ```
+
+=== "JS"
+
+ ```javascript title=""
+ function algorithm(n) {
+ let a = 1; // +0 (trick 1)
+ a = a + n; // +0 (trick 1)
+ // +n (technique 2)
+ for (let i = 0; i < 5 * n + 1; i++) {
+ console.log(0);
+ }
+ // +n*n (technique 3)
+ for (let i = 0; i < 2 * n; i++) {
+ for (let j = 0; j < n + 1; j++) {
+ console.log(0);
+ }
+ }
+ }
+ ```
+
+=== "TS"
+
+ ```typescript title=""
+ function algorithm(n: number): void {
+ let a = 1; // +0 (trick 1)
+ a = a + n; // +0 (trick 1)
+ // +n (technique 2)
+ for (let i = 0; i < 5 * n + 1; i++) {
+ console.log(0);
+ }
+ // +n*n (technique 3)
+ for (let i = 0; i < 2 * n; i++) {
+ for (let j = 0; j < n + 1; j++) {
+ console.log(0);
+ }
+ }
+ }
+ ```
+
+=== "Dart"
+
+ ```dart title=""
+ void algorithm(int n) {
+ int a = 1; // +0 (trick 1)
+ a = a + n; // +0 (trick 1)
+ // +n (technique 2)
+ for (int i = 0; i < 5 * n + 1; i++) {
+ print(0);
+ }
+ // +n*n (technique 3)
+ for (int i = 0; i < 2 * n; i++) {
+ for (int j = 0; j < n + 1; j++) {
+ print(0);
+ }
+ }
+ }
+ ```
+
+=== "Rust"
+
+ ```rust title=""
+ fn algorithm(n: i32) {
+ let mut a = 1; // +0 (trick 1)
+ a = a + n; // +0 (trick 1)
+
+ // +n (technique 2)
+ for i in 0..(5 * n + 1) {
+ println!("{}", 0);
+ }
+
+ // +n*n (technique 3)
+ for i in 0..(2 * n) {
+ for j in 0..(n + 1) {
+ println!("{}", 0);
+ }
+ }
+ }
+ ```
+
+=== "C"
+
+ ```c title=""
+ void algorithm(int n) {
+ int a = 1; // +0 (trick 1)
+ a = a + n; // +0 (trick 1)
+ // +n (technique 2)
+ for (int i = 0; i < 5 * n + 1; i++) {
+ printf("%d", 0);
+ }
+ // +n*n (technique 3)
+ for (int i = 0; i < 2 * n; i++) {
+ for (int j = 0; j < n + 1; j++) {
+ printf("%d", 0);
+ }
+ }
+ }
+ ```
+
+=== "Zig"
+
+ ```zig title=""
+ fn algorithm(n: usize) void {
+ var a: i32 = 1; // +0 (trick 1)
+ a = a + @as(i32, @intCast(n)); // +0 (trick 1)
+
+ // +n (technique 2)
+ for(0..(5 * n + 1)) |_| {
+ std.debug.print("{}\n", .{0});
+ }
+
+ // +n*n (technique 3)
+ for(0..(2 * n)) |_| {
+ for(0..(n + 1)) |_| {
+ std.debug.print("{}\n", .{0});
+ }
+ }
+ }
+ ```
+
+The following equations show the statistical results before and after using the above technique, both of which were introduced with a time complexity of $O(n^2)$ .
+
+$$
+\begin{aligned}
+T(n) & = 2n(n + 1) + (5n + 1) + 2 & \text{complete statistics (-.-|||)} \newline
+& = 2n^2 + 7n + 3 \newline
+T(n) & = n^2 + n & \text{Lazy Stats (o.O)}
+\end{aligned}
+$$
+
+### Step 2: Judging The Asymptotic Upper Bounds
+
+**The time complexity is determined by the highest order term in the polynomial $T(n)$**. This is because as $n$ tends to infinity, the highest order term will play a dominant role and the effects of all other terms can be ignored.
+
+The table below shows some examples, some of which have exaggerated values to emphasize the conclusion that "the coefficients can't touch the order". As $n$ tends to infinity, these constants become irrelevant.
+
+
Table Time complexity corresponding to different number of operations
+
+| number of operations $T(n)$ | time complexity $O(f(n))$ |
+| --------------------------- | ------------------------- |
+| $100000$ | $O(1)$ |
+| $3n + 2$ | $O(n)$ |
+| $2n^2 + 3n + 2$ | $O(n^2)$ |
+| $n^3 + 10000n^2$ | $O(n^3)$ |
+| $2^n + 10000n^{10000}$ | $O(2^n)$ |
+
+## Common Types
+
+Let the input data size be $n$ , the common types of time complexity are shown in the figure below (in descending order).
+
+$$
+\begin{aligned}
+O(1) < O(\log n) < O(n) < O(n \log n) < O(n^2) < O(2^n) < O(n!) \newline
+\text{constant order} < \text{logarithmic order} < \text{linear order} < \text{linear logarithmic order} < \text{square order} < \text{exponential order} < \text{multiplication order}
+\end{aligned}
+$$
+
+
+
+### Constant Order $O(1)$
+
+The number of operations of the constant order is independent of the input data size $n$, i.e., it does not change with $n$.
+
+In the following function, although the number of operations `size` may be large, the time complexity is still $O(1)$ because it is independent of the input data size $n$ :
+
+```src
+[file]{time_complexity}-[class]{}-[func]{constant}
+```
+
+### Linear Order $O(N)$
+
+The number of operations in a linear order grows in linear steps relative to the input data size $n$. Linear orders are usually found in single level loops:
+
+```src
+[file]{time_complexity}-[class]{}-[func]{linear}
+```
+
+The time complexity of operations such as traversing an array and traversing a linked list is $O(n)$ , where $n$ is the length of the array or linked list:
+
+```src
+[file]{time_complexity}-[class]{}-[func]{array_traversal}
+```
+
+It is worth noting that **Input data size $n$ needs to be determined specifically** according to the type of input data. For example, in the first example, the variable $n$ is the input data size; in the second example, the array length $n$ is the data size.
+
+### Squared Order $O(N^2)$
+
+The number of operations in the square order grows in square steps with respect to the size of the input data $n$. The squared order is usually found in nested loops, where both the outer and inner levels are $O(n)$ and therefore overall $O(n^2)$:
+
+```src
+[file]{time_complexity}-[class]{}-[func]{quadratic}
+```
+
+The figure below compares the three time complexities of constant order, linear order and squared order.
+
+
+
+Taking bubble sort as an example, the outer loop executes $n - 1$ times, and the inner loop executes $n-1$, $n-2$, $\dots$, $2$, $1$ times, which averages out to $n / 2$ times, resulting in a time complexity of $O((n - 1) n / 2) = O(n^2)$ .
+
+```src
+[file]{time_complexity}-[class]{}-[func]{bubble_sort}
+```
+
+## Exponential Order $O(2^N)$
+
+Cell division in biology is a typical example of exponential growth: the initial state is $1$ cells, after one round of division it becomes $2$, after two rounds of division it becomes $4$, and so on, after $n$ rounds of division there are $2^n$ cells.
+
+The figure below and the following code simulate the process of cell division with a time complexity of $O(2^n)$ .
+
+```src
+[file]{time_complexity}-[class]{}-[func]{exponential}
+```
+
+
+
+In practical algorithms, exponential orders are often found in recursion functions. For example, in the following code, it recursively splits in two and stops after $n$ splits:
+
+```src
+[file]{time_complexity}-[class]{}-[func]{exp_recur}
+```
+
+Exponential order grows very rapidly and is more common in exhaustive methods (brute force search, backtracking, etc.). For problems with large data sizes, exponential order is unacceptable and usually requires the use of algorithms such as dynamic programming or greedy algorithms to solve.
+
+### Logarithmic Order $O(\Log N)$
+
+In contrast to the exponential order, the logarithmic order reflects the "each round is reduced to half" case. Let the input data size be $n$, and since each round is reduced to half, the number of loops is $\log_2 n$, which is the inverse function of $2^n$.
+
+The figure below and the code below simulate the process of "reducing each round to half" with a time complexity of $O(\log_2 n)$, which is abbreviated as $O(\log n)$.
+
+```src
+[file]{time_complexity}-[class]{}-[func]{logarithmic}
+```
+
+
+
+Similar to the exponential order, the logarithmic order is often found in recursion functions. The following code forms a recursion tree of height $\log_2 n$:
+
+```src
+[file]{time_complexity}-[class]{}-[func]{log_recur}
+```
+
+Logarithmic order is often found in algorithms based on the divide and conquer strategy, which reflects the algorithmic ideas of "dividing one into many" and "simplifying the complexity into simplicity". It grows slowly and is the second most desirable time complexity after constant order.
+
+!!! tip "What is the base of $O(\log n)$?"
+
+ To be precise, the corresponding time complexity of "one divided into $m$" is $O(\log_m n)$ . And by using the logarithmic permutation formula, we can get equal time complexity with different bases:
+
+ $$
+ O(\log_m n) = O(\log_k n / \log_k m) = O(\log_k n)
+ $$
+
+ That is, the base $m$ can be converted without affecting the complexity. Therefore we usually omit the base $m$ and write the logarithmic order directly as $O(\log n)$.
+
+### Linear Logarithmic Order $O(N \Log N)$
+
+The linear logarithmic order is often found in nested loops, and the time complexity of the two levels of loops is $O(\log n)$ and $O(n)$ respectively. The related code is as follows:
+
+```src
+[file]{time_complexity}-[class]{}-[func]{linear_log_recur}
+```
+
+The figure below shows how the linear logarithmic order is generated. The total number of operations at each level of the binary tree is $n$ , and the tree has a total of $\log_2 n + 1$ levels, resulting in a time complexity of $O(n\log n)$ .
+
+
+
+Mainstream sorting algorithms typically have a time complexity of $O(n \log n)$ , such as quick sort, merge sort, heap sort, etc.
+
+### The Factorial Order $O(N!)$
+
+The factorial order corresponds to the mathematical "permutations problem". Given $n$ elements that do not repeat each other, find all possible permutations of them, the number of permutations being:
+
+$$
+n! = n \times (n - 1) \times (n - 2) \times \dots \times 2 \times 1
+$$
+
+Factorials are usually implemented using recursion. As shown in the figure below and in the code below, the first level splits $n$, the second level splits $n - 1$, and so on, until the splitting stops at the $n$th level:
+
+```src
+[file]{time_complexity}-[class]{}-[func]{factorial_recur}
+```
+
+
+
+Note that since there is always $n! > 2^n$ when $n \geq 4$, the factorial order grows faster than the exponential order, and is also unacceptable when $n$ is large.
+
+## Worst, Best, Average Time Complexity
+
+**The time efficiency of algorithms is often not fixed, but is related to the distribution of the input data**. Suppose an array `nums` of length $n$ is input, where `nums` consists of numbers from $1$ to $n$, each of which occurs only once; however, the order of the elements is randomly upset, and the goal of the task is to return the index of element $1$. We can draw the following conclusion.
+
+- When `nums = [? , ? , ... , 1]` , i.e., when the end element is $1$, a complete traversal of the array is required, **to reach the worst time complexity $O(n)$** .
+- When `nums = [1, ? , ? , ...]` , i.e., when the first element is $1$ , there is no need to continue traversing the array no matter how long it is, **reaching the optimal time complexity $\Omega(1)$** .
+
+The "worst time complexity" corresponds to the asymptotic upper bound of the function and is denoted by the large $O$ notation. Correspondingly, the "optimal time complexity" corresponds to the asymptotic lower bound of the function and is denoted in $\Omega$ notation:
+
+```src
+[file]{worst_best_time_complexity}-[class]{}-[func]{find_one}
+```
+
+It is worth stating that we rarely use the optimal time complexity in practice because it is usually only attainable with a small probability and may be somewhat misleading. **whereas the worst time complexity is more practical because it gives a safe value for efficiency and allows us to use the algorithm with confidence**.
+
+From the above examples, it can be seen that the worst or best time complexity only occurs in "special data distributions", and the probability of these cases may be very small, which does not truly reflect the efficiency of the algorithm. In contrast, **the average time complexity of can reflect the efficiency of the algorithm under random input data**, which is denoted by the $\Theta$ notation.
+
+For some algorithms, we can simply derive the average case under a random data distribution. For example, in the above example, since the input array is scrambled, the probability of an element $1$ appearing at any index is equal, so the average number of loops of the algorithm is half of the length of the array $n / 2$ , and the average time complexity is $\Theta(n / 2) = \Theta(n)$ .
+
+However, for more complex algorithms, calculating the average time complexity is often difficult because it is hard to analyze the overall mathematical expectation given the data distribution. In this case, we usually use the worst time complexity as a criterion for the efficiency of the algorithm.
+
+!!! question "Why do you rarely see the $\Theta$ symbol?"
+
+ Perhaps because the $O$ symbol is so catchy, we often use it to denote average time complexity. However, this practice is not standardized in the strict sense. In this book and other sources, if you encounter a statement like "average time complexity $O(n)$", please understand it as $\Theta(n)$.
diff --git a/docs-en/chapter_data_structure/classification_of_data_structure.assets/classification_logic_structure.png b/docs-en/chapter_data_structure/classification_of_data_structure.assets/classification_logic_structure.png
new file mode 100644
index 0000000000..f7c515e587
Binary files /dev/null and b/docs-en/chapter_data_structure/classification_of_data_structure.assets/classification_logic_structure.png differ
diff --git a/docs-en/chapter_data_structure/classification_of_data_structure.assets/classification_phisical_structure.png b/docs-en/chapter_data_structure/classification_of_data_structure.assets/classification_phisical_structure.png
new file mode 100644
index 0000000000..11958abe4c
Binary files /dev/null and b/docs-en/chapter_data_structure/classification_of_data_structure.assets/classification_phisical_structure.png differ
diff --git a/docs-en/chapter_data_structure/classification_of_data_structure.assets/computer_memory_location.png b/docs-en/chapter_data_structure/classification_of_data_structure.assets/computer_memory_location.png
new file mode 100644
index 0000000000..c29923bcd6
Binary files /dev/null and b/docs-en/chapter_data_structure/classification_of_data_structure.assets/computer_memory_location.png differ
diff --git a/docs-en/chapter_data_structure/classification_of_data_structure.md b/docs-en/chapter_data_structure/classification_of_data_structure.md
new file mode 100644
index 0000000000..4ec268b1db
--- /dev/null
+++ b/docs-en/chapter_data_structure/classification_of_data_structure.md
@@ -0,0 +1,49 @@
+# Classification Of Data Structures
+
+Common data structures include arrays, linked lists, stacks, queues, hash tables, trees, heaps, and graphs. They can be divided into two categories: logical structure and physical structure.
+
+## Logical Structures: Linear And Non-linear
+
+**Logical structures reveal logical relationships between data elements**. In arrays and linked lists, data are arranged in sequential order, reflecting the linear relationship between data; while in trees, data are arranged hierarchically from the top down, showing the derived relationship between ancestors and descendants; and graphs are composed of nodes and edges, reflecting the complex network relationship.
+
+As shown in the figure below, logical structures can further be divided into "linear data structure" and "non-linear data structure". Linear data structures are more intuitive, meaning that the data are arranged linearly in terms of logical relationships; non-linear data structures, on the other hand, are arranged non-linearly.
+
+- **Linear data structures**: arrays, linked lists, stacks, queues, hash tables.
+- **Nonlinear data structures**: trees, heaps, graphs, hash tables.
+
+
+
+Non-linear data structures can be further divided into tree and graph structures.
+
+- **Linear structures**: arrays, linked lists, queues, stacks, hash tables, with one-to-one sequential relationship between elements.
+- **Tree structure**: tree, heap, hash table, with one-to-many relationship between elements.
+- **Graph**: graph with many-to-many relationship between elements.
+
+## Physical Structure: Continuous vs. Dispersed
+
+**When an algorithm is running, the data being processed is stored in memory**. The figure below shows a computer memory module where each black square represents a memory space. We can think of the memory as a giant Excel sheet in which each cell can store data of a certain size.
+
+**The system accesses the data at the target location by means of a memory address**. As shown in the figure below, the computer assigns a unique identifier to each cell in the table according to specific rules, ensuring that each memory space has a unique memory address. With these addresses, the program can access the data in memory.
+
+
+
+!!! tip
+
+ It is worth noting that comparing memory to the Excel sheet is a simplified analogy. The actual memory working mechanism is more complicated, involving the concepts of address, space, memory management, cache mechanism, virtual and physical memory.
+
+Memory is a shared resource for all programs, and when a block of memory is occupied by one program, it cannot be used by other programs at the same time. **Therefore, considering memory resources is crucial in designing data structures and algorithms**. For example, the algorithm's peak memory usage should not exceed the remaining free memory of the system; if there is a lack of contiguous memory blocks, then the data structure chosen must be able to be stored in non-contiguous memory blocks.
+
+As shown in the figure below, **Physical structure reflects the way data is stored in computer memory and it can be divided into consecutive space storage (arrays) and distributed space storage (linked lists)**. The physical structure determines how data is accessed, updated, added, deleted, etc. Logical and physical structure complement each other in terms of time efficiency and space efficiency.
+
+
+
+**It is worth stating that all data structures are implemented based on arrays, linked lists, or a combination of the two**. For example, stacks and queues can be implemented using both arrays and linked lists; and implementations of hash tables may contain both arrays and linked lists.
+
+- **Array-based structures**: stacks, queues, hash tables, trees, heaps, graphs, matrices, tensors (arrays of dimension $\geq 3$), and so on.
+- **Linked list-based structures**: stacks, queues, hash tables, trees, heaps, graphs, etc.
+
+Data structures based on arrays are also known as "static data structures", which means that such structures' length remains constant after initialization. In contrast, data structures based on linked lists are called "dynamic data structures", meaning that their length can be adjusted during program execution after initialization.
+
+!!! tip
+
+ If you find it difficult to understand the physical structure, it is recommended that you read the next chapter, "Arrays and Linked Lists," before reviewing this section.
diff --git a/docs-en/chapter_data_structure/index.md b/docs-en/chapter_data_structure/index.md
new file mode 100644
index 0000000000..9d332b8231
--- /dev/null
+++ b/docs-en/chapter_data_structure/index.md
@@ -0,0 +1,13 @@
+# Data Structure
+
+
+
+!!! abstract
+
+ Data structures are like a solid and varied framework.
+
+ It provides a blueprint for the orderly organization of data upon which algorithms can come alive.
diff --git a/docs-en/chapter_introduction/algorithms_are_everywhere.assets/binary_search_dictionary_step1.png b/docs-en/chapter_introduction/algorithms_are_everywhere.assets/binary_search_dictionary_step1.png
new file mode 100644
index 0000000000..d1f59f0e12
Binary files /dev/null and b/docs-en/chapter_introduction/algorithms_are_everywhere.assets/binary_search_dictionary_step1.png differ
diff --git a/docs-en/chapter_introduction/algorithms_are_everywhere.assets/binary_search_dictionary_step2.png b/docs-en/chapter_introduction/algorithms_are_everywhere.assets/binary_search_dictionary_step2.png
new file mode 100644
index 0000000000..ba245a05d3
Binary files /dev/null and b/docs-en/chapter_introduction/algorithms_are_everywhere.assets/binary_search_dictionary_step2.png differ
diff --git a/docs-en/chapter_introduction/algorithms_are_everywhere.assets/binary_search_dictionary_step3.png b/docs-en/chapter_introduction/algorithms_are_everywhere.assets/binary_search_dictionary_step3.png
new file mode 100644
index 0000000000..d57a19f1ac
Binary files /dev/null and b/docs-en/chapter_introduction/algorithms_are_everywhere.assets/binary_search_dictionary_step3.png differ
diff --git a/docs-en/chapter_introduction/algorithms_are_everywhere.assets/binary_search_dictionary_step4.png b/docs-en/chapter_introduction/algorithms_are_everywhere.assets/binary_search_dictionary_step4.png
new file mode 100644
index 0000000000..ea2d617015
Binary files /dev/null and b/docs-en/chapter_introduction/algorithms_are_everywhere.assets/binary_search_dictionary_step4.png differ
diff --git a/docs-en/chapter_introduction/algorithms_are_everywhere.assets/binary_search_dictionary_step5.png b/docs-en/chapter_introduction/algorithms_are_everywhere.assets/binary_search_dictionary_step5.png
new file mode 100644
index 0000000000..ee4363e619
Binary files /dev/null and b/docs-en/chapter_introduction/algorithms_are_everywhere.assets/binary_search_dictionary_step5.png differ
diff --git a/docs-en/chapter_introduction/algorithms_are_everywhere.assets/greedy_change.png b/docs-en/chapter_introduction/algorithms_are_everywhere.assets/greedy_change.png
new file mode 100644
index 0000000000..1a77933387
Binary files /dev/null and b/docs-en/chapter_introduction/algorithms_are_everywhere.assets/greedy_change.png differ
diff --git a/docs-en/chapter_introduction/algorithms_are_everywhere.assets/playing_cards_sorting.png b/docs-en/chapter_introduction/algorithms_are_everywhere.assets/playing_cards_sorting.png
new file mode 100644
index 0000000000..bc23edcf37
Binary files /dev/null and b/docs-en/chapter_introduction/algorithms_are_everywhere.assets/playing_cards_sorting.png differ
diff --git a/docs-en/chapter_introduction/algorithms_are_everywhere.md b/docs-en/chapter_introduction/algorithms_are_everywhere.md
new file mode 100644
index 0000000000..47e0e2c630
--- /dev/null
+++ b/docs-en/chapter_introduction/algorithms_are_everywhere.md
@@ -0,0 +1,56 @@
+# Algorithms Are Everywhere
+
+When we hear the word "algorithm", we naturally think of mathematics. However, many algorithms do not involve complex mathematics but rely more on basic logic, which is ubiquitous in our daily lives.
+
+Before we formally discuss algorithms, an interesting fact is worth sharing: **you have already learned many algorithms unconsciously and have become accustomed to applying them in your daily life**. Below, I will give a few specific examples to prove this point.
+
+**Example 1: Looking Up a Dictionary**. In a standard dictionary, each word corresponds to a phonetic transcription and the dictionary is organized alphabetically based on these transcriptions. Let's say we're looking for a word that begins with the letter $r$. This is typically done in the following way:
+
+1. Open the dictionary around its midpoint and note the first letter on that page, assuming it to be $m$.
+2. Given the sequence of words following the initial letter $m$, estimate where words starting with the letter $r$ might be located within the alphabetical order.
+3. Iterate steps `1.` and `2.` until you find the page where the word begins with the letter $r$.
+
+=== "<1>"
+ 
+
+=== "<2>"
+ 
+
+=== "<3>"
+ 
+
+=== "<4>"
+ 
+
+=== "<5>"
+ 
+
+The skill of looking up a dictionary, essential for elementary school students, is actually the renowned binary search algorithm. Through the lens of data structures, we can view the dictionary as a sorted "array"; while from an algorithmic perspective, the series of operations in looking up a dictionary can be seen as "binary search".
+
+**Example 2: Organizing Playing Cards**. When playing cards, we need to arrange the cards in ascending order each game, as shown in the following process.
+
+1. Divide the playing cards into "ordered" and "unordered" parts, assuming initially that the leftmost card is already ordered.
+2. Take out a card from the unordered part and insert it into the correct position in the ordered part; once completed, the leftmost two cards will be in an ordered sequence.
+3. Continue the loop described in step `2.`, each iteration involving insertion of one card from the unordered segment into the ordered portion, until all cards are appropriately ordered.
+
+
+
+The above method of organizing playing cards is essentially the "insertion sort" algorithm, which is very efficient for small datasets. Many programming languages' sorting library functions include insertion sort.
+
+**Example 3: Making Change**. Suppose we buy goods worth $69$ yuan at a supermarket and give the cashier $100$ yuan, then the cashier needs to give us $31$ yuan in change. They would naturally complete the thought process as shown below.
+
+1. The options are currencies smaller than $31$, including $1$, $5$, $10$, and $20$.
+2. Take out the largest $20$ from the options, leaving $31 - 20 = 11$.
+3. Take out the largest $10$ from the remaining options, leaving $11 - 10 = 1$.
+4. Take out the largest $1$ from the remaining options, leaving $1 - 1 = 0$.
+5. Complete the change-making, with the solution being $20 + 10 + 1 = 31$.
+
+
+
+In the aforementioned steps, at each stage, we make the optimal choice (utilizing the highest denomination possible), ultimately deriving at a feasible change-making approach. From the perspective of data structures and algorithms, this approach is essentially a "greedy" algorithm.
+
+From preparing a dish to traversing interstellar realms, virtually every problem-solving endeavor relies on algorithms. The emergence of computers enables us to store data structures in memory and write code to call CPUs and GPUs to execute algorithms. Consequently, we can transfer real-life predicaments to computers, efficiently addressing a myriad of complex issues.
+
+!!! tip
+
+ If concepts such as data structures, algorithms, arrays, and binary search still seem somewhat obsecure, I encourage you to continue reading. This book will gently guide you into the realm of understanding data structures and algorithms.
diff --git a/docs-en/chapter_introduction/index.md b/docs-en/chapter_introduction/index.md
new file mode 100644
index 0000000000..e85a23b368
--- /dev/null
+++ b/docs-en/chapter_introduction/index.md
@@ -0,0 +1,13 @@
+# Introduction to Algorithms
+
+
+
+
+
+
+
+!!! abstract
+
+ A graceful maiden dances, intertwined with the data, her skirt swaying to the melody of algorithms.
+
+ She invites you to a dance, follow her steps, and enter the world of algorithms full of logic and beauty.
diff --git a/docs-en/chapter_introduction/summary.md b/docs-en/chapter_introduction/summary.md
new file mode 100644
index 0000000000..acfa2d4a5d
--- /dev/null
+++ b/docs-en/chapter_introduction/summary.md
@@ -0,0 +1,9 @@
+# Summary
+
+- Algorithms are ubiquitous in daily life and are not as inaccessible and complex as they might seem. In fact, we have already unconsciously learned many algorithms to solve various problems in life.
+- The principle of looking up a word in a dictionary is consistent with the binary search algorithm. The binary search algorithm embodies the important algorithmic concept of divide and conquer.
+- The process of organizing playing cards is very similar to the insertion sort algorithm. The insertion sort algorithm is suitable for sorting small datasets.
+- The steps of making change in currency essentially follow the greedy algorithm, where each step involves making the best possible choice at the moment.
+- An algorithm is a set of instructions or steps used to solve a specific problem within a finite amount of time, while a data structure is the way data is organized and stored in a computer.
+- Data structures and algorithms are closely linked. Data structures are the foundation of algorithms, and algorithms are the stage to utilize the functions of data structures.
+- We can liken data structures and algorithms to building blocks. The blocks represent data, the shape and connection method of the blocks represent data structures, and the steps of assembling the blocks correspond to algorithms.
diff --git a/docs-en/chapter_introduction/what_is_dsa.assets/assembling_blocks.jpg b/docs-en/chapter_introduction/what_is_dsa.assets/assembling_blocks.jpg
new file mode 100644
index 0000000000..288d6e3fd1
Binary files /dev/null and b/docs-en/chapter_introduction/what_is_dsa.assets/assembling_blocks.jpg differ
diff --git a/docs-en/chapter_introduction/what_is_dsa.assets/relationship_between_data_structure_and_algorithm.png b/docs-en/chapter_introduction/what_is_dsa.assets/relationship_between_data_structure_and_algorithm.png
new file mode 100644
index 0000000000..404e8fe380
Binary files /dev/null and b/docs-en/chapter_introduction/what_is_dsa.assets/relationship_between_data_structure_and_algorithm.png differ
diff --git a/docs-en/chapter_introduction/what_is_dsa.md b/docs-en/chapter_introduction/what_is_dsa.md
new file mode 100644
index 0000000000..bb95fc4f9a
--- /dev/null
+++ b/docs-en/chapter_introduction/what_is_dsa.md
@@ -0,0 +1,53 @@
+# What is an Algorithm
+
+## Definition of an Algorithm
+
+An "algorithm" is a set of instructions or steps to solve a specific problem within a finite amount of time. It has the following characteristics:
+
+- The problem is clearly defined, including unambiguous definitions of input and output.
+- The algorithm is feasible, meaning it can be completed within a finite number of steps, time, and memory space.
+- Each step has a definitive meaning. The output is consistently the same under the same inputs and conditions.
+
+## Definition of a Data Structure
+
+A "data structure" is a way of organizing and storing data in a computer, with the following design goals:
+
+- Minimize space occupancy to save computer memory.
+- Make data operations as fast as possible, covering data access, addition, deletion, updating, etc.
+- Provide concise data representation and logical information to enable efficient algorithm execution.
+
+**Designing data structures is a balancing act, often requiring trade-offs**. If you want to improve in one aspect, you often need to compromise in another. Here are two examples:
+
+- Compared to arrays, linked lists offer more convenience in data addition and deletion but sacrifice data access speed.
+- Graphs, compared to linked lists, provide richer logical information but require more memory space.
+
+## Relationship Between Data Structures and Algorithms
+
+As shown in the diagram below, data structures and algorithms are highly related and closely integrated, specifically in the following three aspects:
+
+- Data structures are the foundation of algorithms. They provide structured data storage and methods for manipulating data for algorithms.
+- Algorithms are the stage where data structures come into play. The data structure alone only stores data information; it is through the application of algorithms that specific problems can be solved.
+- Algorithms can often be implemented based on different data structures, but their execution efficiency can vary greatly. Choosing the right data structure is key.
+
+
+
+Data structures and algorithms can be likened to a set of building blocks, as illustrated in the figure below. A building block set includes numerous pieces, accompanied by detailed assembly instructions. Following these instructions step by step allows us to construct an intricate block model.
+
+
+
+The detailed correspondence between the two is shown in the table below.
+
+
Table Comparing Data Structures and Algorithms to Building Blocks
+
+| Data Structures and Algorithms | Building Blocks |
+| ------------------------------ | --------------------------------------------------------------- |
+| Input data | Unassembled blocks |
+| Data structure | Organization of blocks, including shape, size, connections, etc |
+| Algorithm | A series of steps to assemble the blocks into the desired shape |
+| Output data | Completed Block model |
+
+It's worth noting that data structures and algorithms are independent of programming languages. For this reason, this book is able to provide implementations in multiple programming languages.
+
+!!! tip "Conventional Abbreviation"
+
+ In real-life discussions, we often refer to "Data Structures and Algorithms" simply as "Algorithms". For example, the well-known LeetCode algorithm problems actually test both data structure and algorithm knowledge.
diff --git a/docs-en/chapter_preface/about_the_book.assets/hello_algo_mindmap.jpg b/docs-en/chapter_preface/about_the_book.assets/hello_algo_mindmap.jpg
new file mode 100644
index 0000000000..9b0727f47f
Binary files /dev/null and b/docs-en/chapter_preface/about_the_book.assets/hello_algo_mindmap.jpg differ
diff --git a/docs-en/chapter_preface/about_the_book.md b/docs-en/chapter_preface/about_the_book.md
new file mode 100644
index 0000000000..3a0dca00d4
--- /dev/null
+++ b/docs-en/chapter_preface/about_the_book.md
@@ -0,0 +1,45 @@
+# The Book
+
+The aim of this project is to create an open source, free, novice-friendly introductory tutorial on data structures and algorithms.
+
+- Animated graphs are used throughout the book to structure the knowledge of data structures and algorithms in a way that is clear and easy to understand with a smooth learning curve.
+- The source code of the algorithms can be run with a single click, supporting Java, C++, Python, Go, JS, TS, C#, Swift, Rust, Dart, Zig and other languages.
+- Readers are encouraged to help each other and make progress in the chapter discussion forums, and questions and comments can usually be answered within two days.
+
+## Target Readers
+
+If you are a beginner to algorithms, have never touched an algorithm before, or already have some experience brushing up on data structures and algorithms, and have a vague understanding of data structures and algorithms, repeatedly jumping sideways between what you can and can't do, then this book is just for you!
+
+If you have already accumulated a certain amount of questions and are familiar with most of the question types, then this book can help you review and organize the algorithm knowledge system, and the repository source code can be used as a "brushing tool library" or "algorithm dictionary".
+
+If you are an algorithm expert, we look forward to receiving your valuable suggestions or [participate in the creation together](https://www.hello-algo.com/chapter_appendix/contribution/).
+
+!!! success "precondition"
+
+ You will need to have at least a basic knowledge of programming in any language and be able to read and write simple code.
+
+## Content Structure
+
+The main contents of the book are shown in the figure below.
+
+- **Complexity Analysis**: dimensions and methods of evaluation of data structures and algorithms. Methods of deriving time complexity, space complexity, common types, examples, etc.
+- **Data Structures**: basic data types, classification methods of data structures. Definition, advantages and disadvantages, common operations, common types, typical applications, implementation methods of data structures such as arrays, linked lists, stacks, queues, hash tables, trees, heaps, graphs, etc.
+- **Algorithms**: definitions, advantages and disadvantages, efficiency, application scenarios, solution steps, sample topics of search, sorting algorithms, divide and conquer, backtracking algorithms, dynamic programming, greedy algorithms, and more.
+
+
+
+## Acknowledgements
+
+During the creation of this book, I received help from many people, including but not limited to:
+
+- Thank you to my mentor at the company, Dr. Shih Lee, for encouraging me to "get moving" during one of our conversations, which strengthened my resolve to write this book.
+- I would like to thank my girlfriend Bubbles for being the first reader of this book, and for making many valuable suggestions from the perspective of an algorithm whiz, making this book more suitable for newbies.
+- Thanks to Tengbao, Qibao, and Feibao for coming up with a creative name for this book that evokes fond memories of writing the first line of code "Hello World!".
+- Thanks to Sutong for designing the beautiful cover and logo for this book and patiently revising it many times under my OCD.
+- Thanks to @squidfunk for writing layout suggestions and for developing the open source documentation theme [Material-for-MkDocs](https://github.com/squidfunk/mkdocs-material/tree/master).
+
+During the writing process, I read many textbooks and articles on data structures and algorithms. These works provide excellent models for this book and ensure the accuracy and quality of its contents. I would like to thank all my teachers and predecessors for their outstanding contributions!
+
+This book promotes a hands-on approach to learning, and in this respect is heavily inspired by ["Hands-On Learning for Depth"](https://github.com/d2l-ai/d2l-zh). I highly recommend this excellent book to all readers.
+
+A heartfelt thank you to my parents, it is your constant support and encouragement that gives me the opportunity to do this fun-filled thing.
diff --git a/docs-en/chapter_preface/index.md b/docs-en/chapter_preface/index.md
new file mode 100644
index 0000000000..bfe6ffda7d
--- /dev/null
+++ b/docs-en/chapter_preface/index.md
@@ -0,0 +1,13 @@
+# Preface
+
+
+
+!!! abstract
+
+ Algorithms are like a beautiful symphony, with each line of code flowing like a rhythm.
+
+ May this book ring softly in your head, leaving a unique and profound melody.
diff --git a/docs-en/chapter_preface/suggestions.assets/code_md_to_repo.png b/docs-en/chapter_preface/suggestions.assets/code_md_to_repo.png
new file mode 100644
index 0000000000..0b33c528f7
Binary files /dev/null and b/docs-en/chapter_preface/suggestions.assets/code_md_to_repo.png differ
diff --git a/docs-en/chapter_preface/suggestions.assets/download_code.png b/docs-en/chapter_preface/suggestions.assets/download_code.png
new file mode 100644
index 0000000000..421bc7bff9
Binary files /dev/null and b/docs-en/chapter_preface/suggestions.assets/download_code.png differ
diff --git a/docs-en/chapter_preface/suggestions.assets/learning_route.png b/docs-en/chapter_preface/suggestions.assets/learning_route.png
new file mode 100644
index 0000000000..bf51ef72f5
Binary files /dev/null and b/docs-en/chapter_preface/suggestions.assets/learning_route.png differ
diff --git a/docs-en/chapter_preface/suggestions.md b/docs-en/chapter_preface/suggestions.md
new file mode 100644
index 0000000000..d19ca9bc25
--- /dev/null
+++ b/docs-en/chapter_preface/suggestions.md
@@ -0,0 +1,224 @@
+# How To Read
+
+!!! tip
+
+ For the best reading experience, it is recommended that you read through this section.
+
+## Conventions Of Style
+
+- Those labeled `*` after the title are optional chapters with relatively difficult content. If you have limited time, it is advisable to skip them.
+- Proper nouns and words and phrases with specific meanings are marked with `"double quotes"` to avoid ambiguity.
+- Important proper nouns and their English translations are marked with `" "` in parentheses, e.g. `"array array"` . It is recommended to memorize them for reading the literature.
+- **Bolded text** Indicates key content or summary statements, which deserve special attention.
+- When it comes to terms that are inconsistent between programming languages, this book follows Python, for example using $\text{None}$ to mean "empty".
+- This book partially abandons the specification of annotations in programming languages in exchange for a more compact layout of the content. There are three main types of annotations: title annotations, content annotations, and multi-line annotations.
+
+=== "Python"
+
+ ```python title=""
+ """Header comments for labeling functions, classes, test samples, etc.""""
+
+ # Content comments for detailed code solutions
+
+ """
+ multi-line
+ marginal notes
+ """
+ ```
+
+=== "C++"
+
+ ```cpp title=""
+ /* Header comments for labeling functions, classes, test samples, etc. */
+
+ // Content comments for detailed code solutions.
+
+ /**
+ * multi-line
+ * marginal notes
+ */
+ ```
+
+=== "Java"
+
+ ```java title=""
+ /* Header comments for labeling functions, classes, test samples, etc. */
+
+ // Content comments for detailed code solutions.
+
+ /**
+ * multi-line
+ * marginal notes
+ */
+ ```
+
+=== "C#"
+
+ ```csharp title=""
+ /* Header comments for labeling functions, classes, test samples, etc. */
+
+ // Content comments for detailed code solutions.
+
+ /**
+ * multi-line
+ * marginal notes
+ */
+ ```
+
+=== "Go"
+
+ ```go title=""
+ /* Header comments for labeling functions, classes, test samples, etc. */
+
+ // Content comments for detailed code solutions.
+
+ /**
+ * multi-line
+ * marginal notes
+ */
+ ```
+
+=== "Swift"
+
+ ```swift title=""
+ /* Header comments for labeling functions, classes, test samples, etc. */
+
+ // Content comments for detailed code solutions.
+
+ /**
+ * multi-line
+ * marginal notes
+ */
+ ```
+
+=== "JS"
+
+ ```javascript title=""
+ /* Header comments for labeling functions, classes, test samples, etc. */
+
+ // Content comments for detailed code solutions.
+
+ /**
+ * multi-line
+ * marginal notes
+ */
+ ```
+
+=== "TS"
+
+ ```typescript title=""
+ /* Header comments for labeling functions, classes, test samples, etc. */
+
+ // Content comments for detailed code solutions.
+
+ /**
+ * multi-line
+ * marginal notes
+ */
+ ```
+
+=== "Dart"
+
+ ```dart title=""
+ /* Header comments for labeling functions, classes, test samples, etc. */
+
+ // Content comments for detailed code solutions.
+
+ /**
+ * multi-line
+ * marginal notes
+ */
+ ```
+
+=== "Rust"
+
+ ```rust title=""
+ /* Header comments for labeling functions, classes, test samples, etc. */
+
+ // Content comments for detailed code solutions.
+
+ /**
+ * multi-line
+ * marginal notes
+ */
+ ```
+
+=== "C"
+
+ ```c title=""
+ /* Header comments for labeling functions, classes, test samples, etc. */
+
+ // Content comments for detailed code solutions.
+
+ /**
+ * multi-line
+ * marginal notes
+ */
+ ```
+
+=== "Zig"
+
+ ```zig title=""
+ // Header comments for labeling functions, classes, test samples, etc.
+
+ // Content comments for detailed code solutions.
+
+ // Multi-line
+ // Annotation
+ ```
+
+## Learn Efficiently In Animated Graphic Solutions
+
+Compared with text, videos and pictures have a higher degree of information density and structure and are easier to understand. In this book, **key and difficult knowledge will be presented mainly in the form of animations and graphs**, while the text serves as an explanation and supplement to the animations and graphs.
+
+If, while reading the book, you find that a particular paragraph provides an animation or a graphic solution as shown below, **please use the figure as the primary source and the text as a supplement and synthesize the two to understand the content**.
+
+
+
+## Deeper Understanding In Code Practice
+
+The companion code for this book is hosted in the [GitHub repository](https://github.com/krahets/hello-algo). As shown in the figure below, **the source code is accompanied by test samples that can be run with a single click**.
+
+If time permits, **it is recommended that you refer to the code and knock it through on your own**. If you have limited time to study, please read through and run all the code at least once.
+
+The process of writing code is often more rewarding than reading it. **Learning by doing is really learning**.
+
+
+
+The preliminaries for running the code are divided into three main steps.
+
+**Step 1: Install the local programming environment**. Please refer to [Appendix Tutorial](https://www.hello-algo.com/chapter_appendix/installation/) for installation, or skip this step if already installed.
+
+**Step 2: Clone or download the code repository**. If [Git](https://git-scm.com/downloads) is already installed, you can clone this repository with the following command.
+
+```shell
+git clone https://github.com/krahets/hello-algo.git
+```
+
+Of course, you can also in the location shown in the figure below, click "Download ZIP" directly download the code zip, and then in the local solution.
+
+
+
+**Step 3: Run the source code**. As shown in the figure below, for the code block labeled with the file name at the top, we can find the corresponding source code file in the `codes` folder of the repository. The source code files can be run with a single click, which will help you save unnecessary debugging time and allow you to focus on what you are learning.
+
+
+
+## Growing Together In Questioning And Discussion
+
+While reading this book, please don't skip over the points that you didn't learn. **Feel free to ask your questions in the comment section**. We will be happy to answer them and can usually respond within two days.
+
+As you can see in the figure below, each post comes with a comment section at the bottom. I hope you'll pay more attention to the comments section. On the one hand, you can learn about the problems that people encounter, so as to check the gaps and stimulate deeper thinking. On the other hand, we expect you to generously answer other partners' questions, share your insights, and help others improve.
+
+
+
+## Algorithm Learning Route
+
+From a general point of view, we can divide the process of learning data structures and algorithms into three stages.
+
+1. **Introduction to Algorithms**. We need to familiarize ourselves with the characteristics and usage of various data structures and learn about the principles, processes, uses and efficiency of different algorithms.
+2. **Brush up on algorithm questions**. It is recommended to start brushing from popular topics, such as [Sword to Offer](https://leetcode.cn/studyplan/coding-interviews/) and [LeetCode Hot 100](https://leetcode.cn/studyplan/top-100- liked/), first accumulate at least 100 questions to familiarize yourself with mainstream algorithmic problems. Forgetfulness can be a challenge when first brushing up, but rest assured that this is normal. We can follow the "Ebbinghaus Forgetting Curve" to review the questions, and usually after 3-5 rounds of repetitions, we will be able to memorize them.
+3. **Build the knowledge system**. In terms of learning, we can read algorithm column articles, solution frameworks and algorithm textbooks to continuously enrich the knowledge system. In terms of brushing, we can try to adopt advanced brushing strategies, such as categorizing by topic, multiple solutions, multiple solutions, etc. Related brushing tips can be found in various communities.
+
+As shown in the figure below, this book mainly covers "Phase 1" and is designed to help you start Phase 2 and 3 more efficiently.
+
+
diff --git a/docs-en/chapter_preface/summary.md b/docs-en/chapter_preface/summary.md
new file mode 100644
index 0000000000..1f1b6c315f
--- /dev/null
+++ b/docs-en/chapter_preface/summary.md
@@ -0,0 +1,8 @@
+# Summary
+
+- The main audience of this book is beginners in algorithm. If you already have some basic knowledge, this book can help you systematically review your algorithm knowledge, and the source code in this book can also be used as a "Coding Toolkit".
+- The book consists of three main sections, Complexity Analysis, Data Structures, and Algorithms, covering most of the topics in the field.
+- For newcomers to algorithms, it is crucial to read an introductory book in the beginning stages to avoid many detours or common pitfalls.
+- Animations and graphs within the book are usually used to introduce key points and difficult knowledge. These should be given more attention when reading the book.
+- Practice is the best way to learn programming. It is highly recommended that you run the source code and type in the code yourself.
+- Each chapter in the web version of this book features a discussion forum, and you are welcome to share your questions and insights at any time.
\ No newline at end of file
diff --git a/docs-en/index.assets/animation.gif b/docs-en/index.assets/animation.gif
new file mode 100644
index 0000000000..c38f2ed407
Binary files /dev/null and b/docs-en/index.assets/animation.gif differ
diff --git a/docs-en/index.assets/btn_chinese_edition.svg b/docs-en/index.assets/btn_chinese_edition.svg
new file mode 100644
index 0000000000..f8a4b21d7b
--- /dev/null
+++ b/docs-en/index.assets/btn_chinese_edition.svg
@@ -0,0 +1 @@
+
\ No newline at end of file
diff --git a/docs-en/index.assets/btn_chinese_edition_dark.svg b/docs-en/index.assets/btn_chinese_edition_dark.svg
new file mode 100644
index 0000000000..e96c12f382
--- /dev/null
+++ b/docs-en/index.assets/btn_chinese_edition_dark.svg
@@ -0,0 +1 @@
+
\ No newline at end of file
diff --git a/docs-en/index.assets/btn_download_pdf.svg b/docs-en/index.assets/btn_download_pdf.svg
new file mode 100644
index 0000000000..e486da9534
--- /dev/null
+++ b/docs-en/index.assets/btn_download_pdf.svg
@@ -0,0 +1 @@
+
\ No newline at end of file
diff --git a/docs-en/index.assets/btn_download_pdf_dark.svg b/docs-en/index.assets/btn_download_pdf_dark.svg
new file mode 100644
index 0000000000..99266fde52
--- /dev/null
+++ b/docs-en/index.assets/btn_download_pdf_dark.svg
@@ -0,0 +1 @@
+
\ No newline at end of file
diff --git a/docs-en/index.assets/btn_read_online.svg b/docs-en/index.assets/btn_read_online.svg
new file mode 100644
index 0000000000..ba1d2c6844
--- /dev/null
+++ b/docs-en/index.assets/btn_read_online.svg
@@ -0,0 +1 @@
+
\ No newline at end of file
diff --git a/docs-en/index.assets/btn_read_online_dark.svg b/docs-en/index.assets/btn_read_online_dark.svg
new file mode 100644
index 0000000000..debaba56c6
--- /dev/null
+++ b/docs-en/index.assets/btn_read_online_dark.svg
@@ -0,0 +1 @@
+
\ No newline at end of file
diff --git a/docs-en/index.assets/comment.gif b/docs-en/index.assets/comment.gif
new file mode 100644
index 0000000000..7e69eefc40
Binary files /dev/null and b/docs-en/index.assets/comment.gif differ
diff --git a/docs-en/index.assets/conceptual_rendering.png b/docs-en/index.assets/conceptual_rendering.png
new file mode 100644
index 0000000000..4f9a14acb4
Binary files /dev/null and b/docs-en/index.assets/conceptual_rendering.png differ
diff --git a/docs-en/index.assets/hello_algo_header.png b/docs-en/index.assets/hello_algo_header.png
new file mode 100644
index 0000000000..aff19ebe44
Binary files /dev/null and b/docs-en/index.assets/hello_algo_header.png differ
diff --git a/docs-en/index.assets/hello_algo_mindmap_tp.png b/docs-en/index.assets/hello_algo_mindmap_tp.png
new file mode 100644
index 0000000000..b3aea43a56
Binary files /dev/null and b/docs-en/index.assets/hello_algo_mindmap_tp.png differ
diff --git a/docs-en/index.assets/running_code.gif b/docs-en/index.assets/running_code.gif
new file mode 100644
index 0000000000..50c57feb8c
Binary files /dev/null and b/docs-en/index.assets/running_code.gif differ
diff --git a/docs-en/index.md b/docs-en/index.md
new file mode 100644
index 0000000000..305ff4c89c
--- /dev/null
+++ b/docs-en/index.md
@@ -0,0 +1,173 @@
+---
+comments: true
+glightbox: false
+hide:
+ - footer
+ - toc
+ - edit
+---
+
+
+
+
+
+
+
Hello Algo
+
+
Data Structures and Algorithms Crash Course with Animated Illustrations and Off-the-Shelf Code
"An easy-to-understand book on data structures and algorithms, which guides readers to learn by minds-on and hands-on. Strongly recommended for algorithm beginners!"
+
—— Junhui Deng, Professor of Computer Science, Tsinghua University
+
+
+
Quote
+
"If I had 'Hello Algo' when I was learning data structures and algorithms, it would have been 10 times easier!"
+
—— Mu Li, Senior Principal Scientist, Amazon
+
+
+
+---
+
+
+
+
+
Animated illustrations
+
+
+
Easy to understandSmooth learning curve
+
+
+
+
+
+
"A picture is worth a thousand words."
+
+
+
+
+
+
+
Off-the-Shelf Code
+
+
+
Multi programming languagesRun with one click
+
+
+
+
+
"Talk is cheap. Show me the code."
+
+
+
+
+
+
Learning Together
+
+
+
Discussion and questions welcomeReaders progress together
+
+
+
+
+
+
"Chase the wind and moon, never stopping"
+
"Beyond the plains, there are spring mountains"
+
+
+---
+
+
Preface
+
+Two years ago, I shared the "Sword Offer" series of problem solutions on LeetCode, which received much love and support from many students. During my interactions with readers, the most common question I encountered was "How to get started with algorithms." Gradually, I developed a deep interest in this question.
+
+Blindly solving problems seems to be the most popular method, being simple, direct, and effective. However, problem-solving is like playing a "Minesweeper" game, where students with strong self-learning abilities can successfully clear the mines one by one, but those with insufficient foundations may end up bruised from explosions, retreating step by step in frustration. Thoroughly reading textbooks is also common, but for students aiming for job applications, the energy consumed by graduation, resume submissions, and preparing for written tests and interviews makes tackling thick books a daunting challenge.
+
+If you are facing similar troubles, then you are lucky to have found this book. This book is my answer to this question, not necessarily the best solution, but at least an active attempt. Although this book won't directly land you an Offer, it will guide you through the "knowledge map" of data structures and algorithms, help you understand the shape, size, and distribution of different "mines," and equip you with various "demining methods." With these skills, I believe you can more comfortably solve problems and read literature, gradually building a complete knowledge system.
+
+I deeply agree with Professor Feynman's saying: "Knowledge isn't free. You have to pay attention." In this sense, this book is not entirely "free." To not disappoint the precious "attention" you pay to this book, I will do my utmost, investing the greatest "attention" to complete the creation of this book.
+
+
Author
+
+Yudong Jin([Krahets](https://leetcode.cn/u/jyd/)), Senior Algorithm Engineer in a top tech company, Master's degree from Shanghai Jiao Tong University. The highest-read blogger across the entire LeetCode, his published ["Illustration of Algorithm Data Structures"](https://leetcode.cn/leetbook/detail/illustration-of-algorithm/) has been subscribed to by over 300k.
+
+---
+
+
Contribution
+
+This book is continuously improved with the joint efforts of many contributors from the open-source community. Thanks to each writer who invested their time and energy, listed in the order generated by GitHub:
+
+
+
+The code review work for this book was completed by Gonglja, gvenusleo, hpstory, justin‐tse, krahets, night-cruise, nuomi1, Reanon, and sjinzh (listed in alphabetical order). Thanks to them for their time and effort, ensuring the standardization and uniformity of the code in various languages.
+
+
 +
+
+
+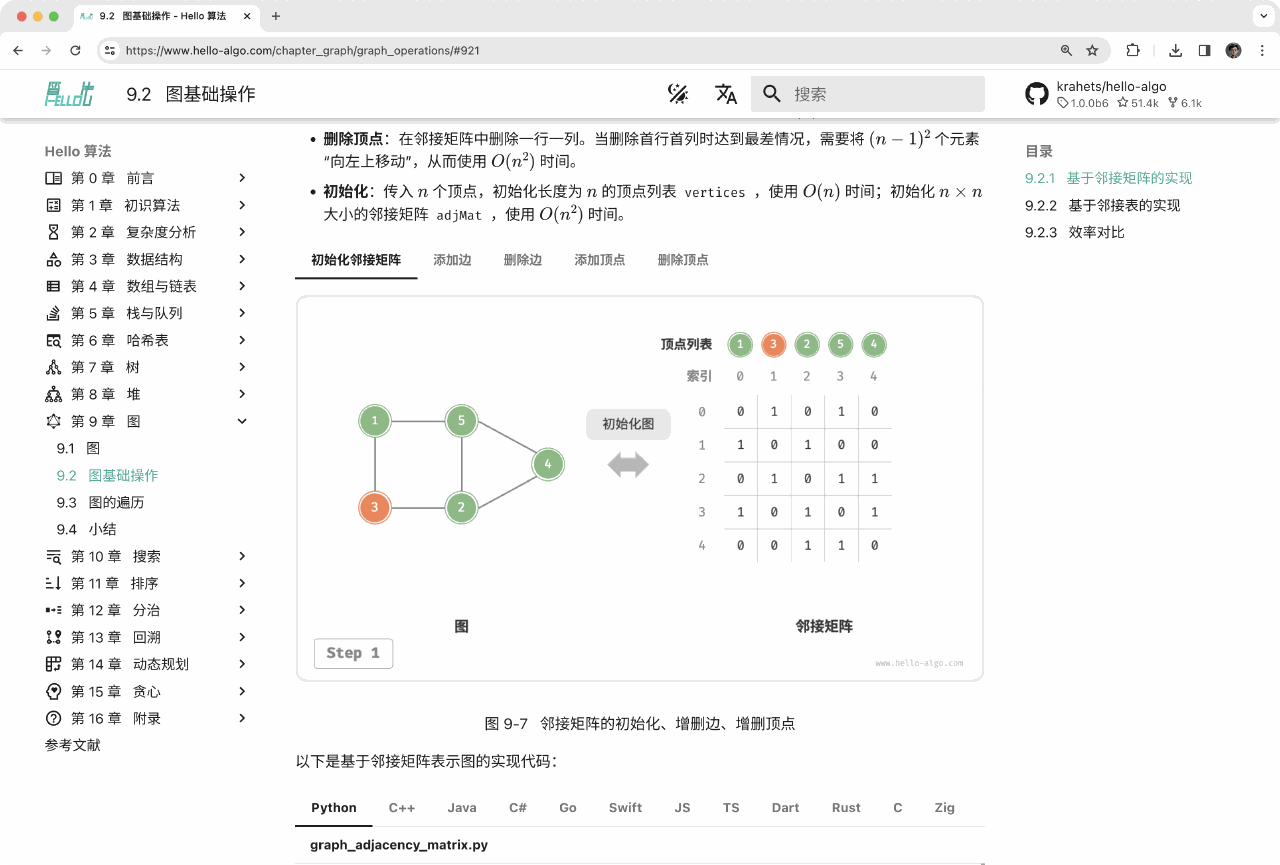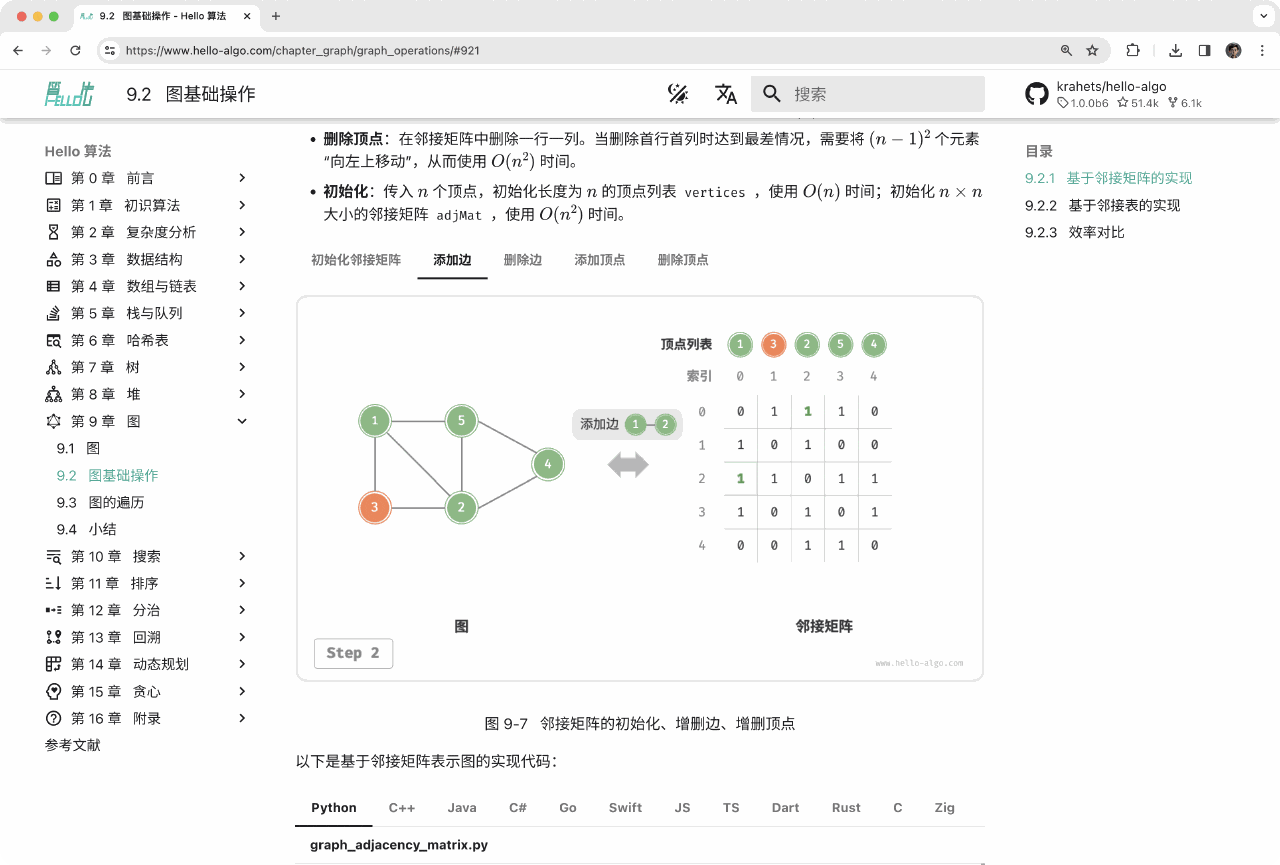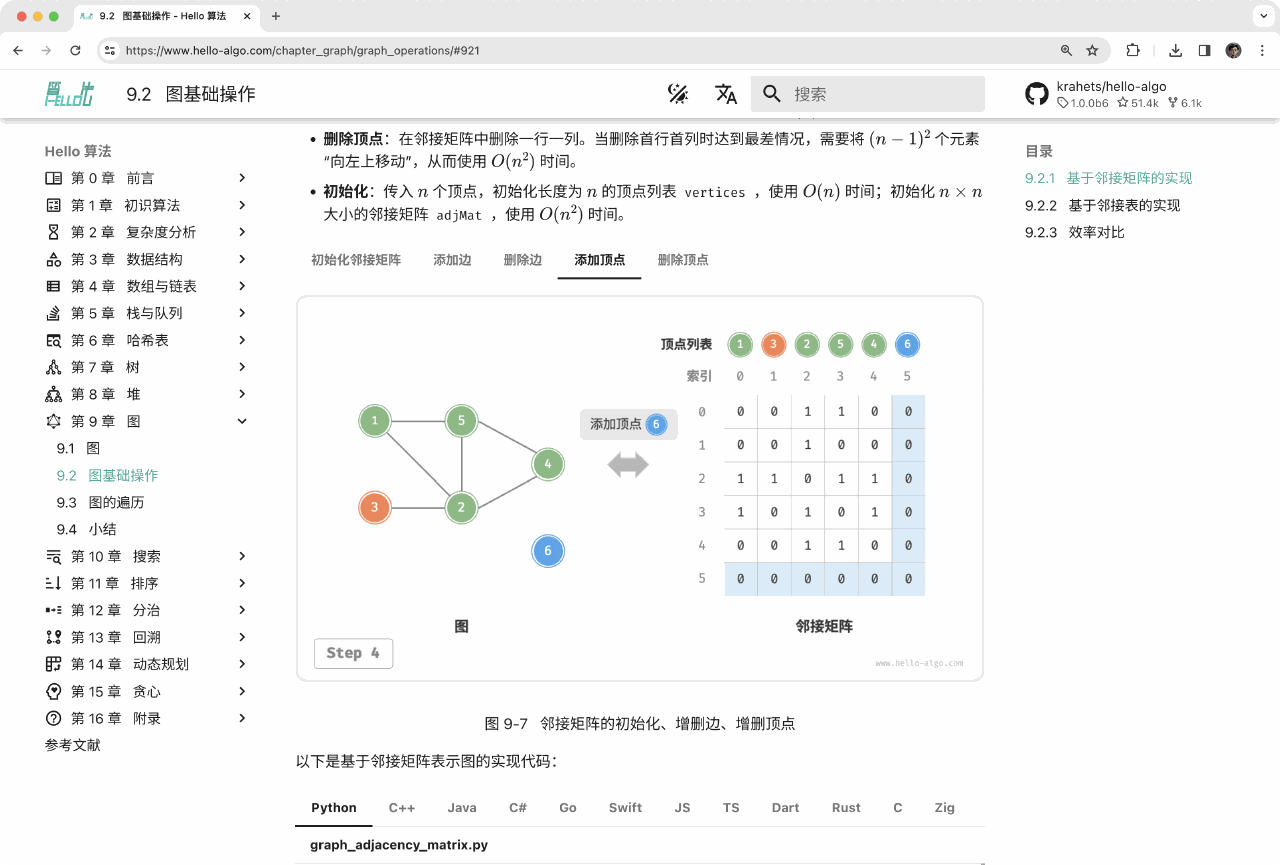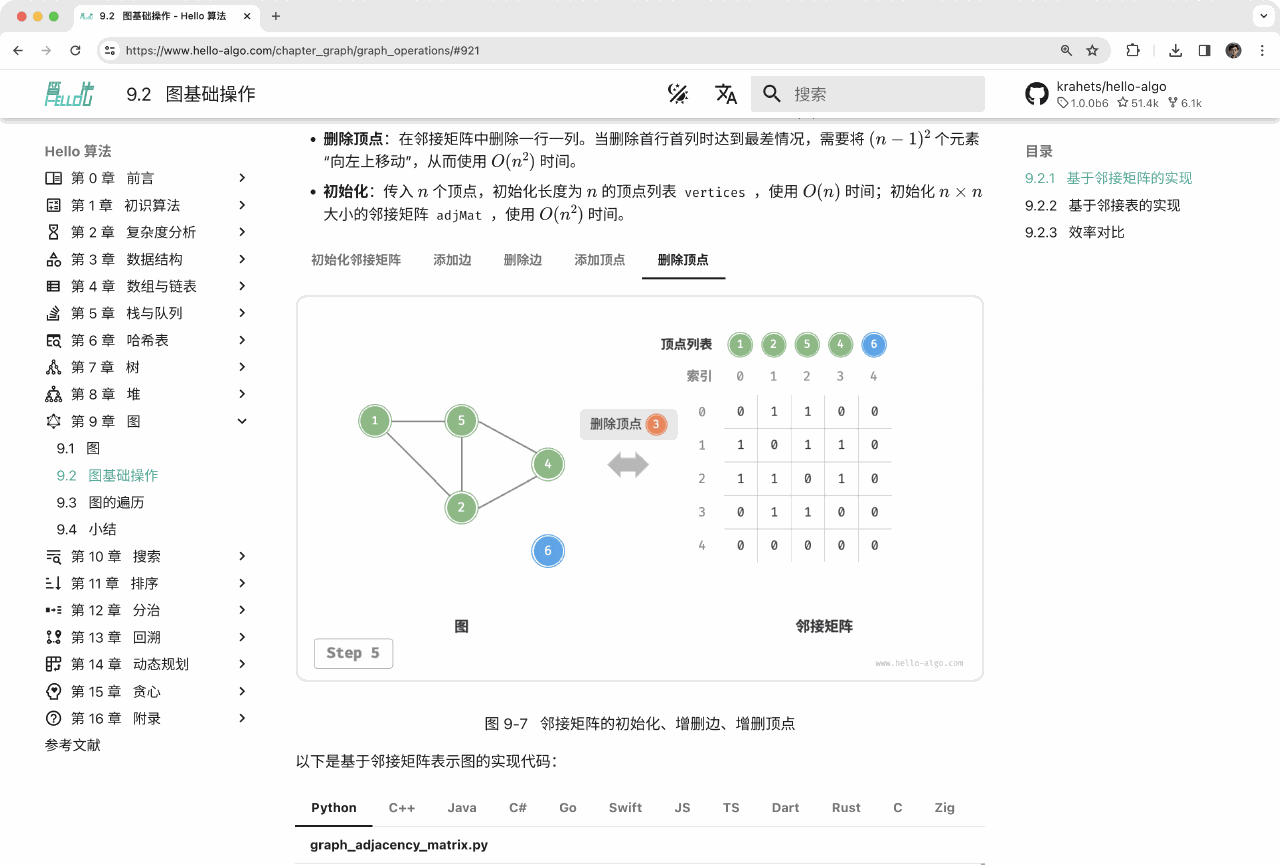 +
+  +
+
 +
+
+
+ 
 +
+  +
+ +
+ +
+  +
+ GongljaC, C++
GongljaC, C++ gvenusleoDart
gvenusleoDart hpstoryC#
hpstoryC# justin-tseJS, TS
justin-tseJS, TS krahetsJava, Python
krahetsJava, Python night-cruiseRust
night-cruiseRust nuomi1Swift
nuomi1Swift ReanonGo, C
ReanonGo, C sjinzhRust, Zig
sjinzhRust, Zig


 +
+  +
+  +
+