ELF OpenGo model v2 is released #2212
Comments
|
nice job, @roy7 can you set a test? |
|
It needs to be converted first to LZ format. |
|
According to https://arxiv.org/abs/1902.04522, "The final model is approximately 150 ELO |
|
the paper says az mthod is better than agz according to their test train |
|
@alreadydone the weight is 20x256, not 20x224 any more |
|
a bit disapoint |
|
@sethtroisi does your code effect the strength |
|
many ladder games should try at 3200 visits, or try native engine |
|
@l1t1 No it's just changing a name so that the script works. @wonderingabout I'm playing 3200 playout games on fast.cloudygo.com |
|
big thanks, native engine ? edit : oh still lz but i would still try native |
|
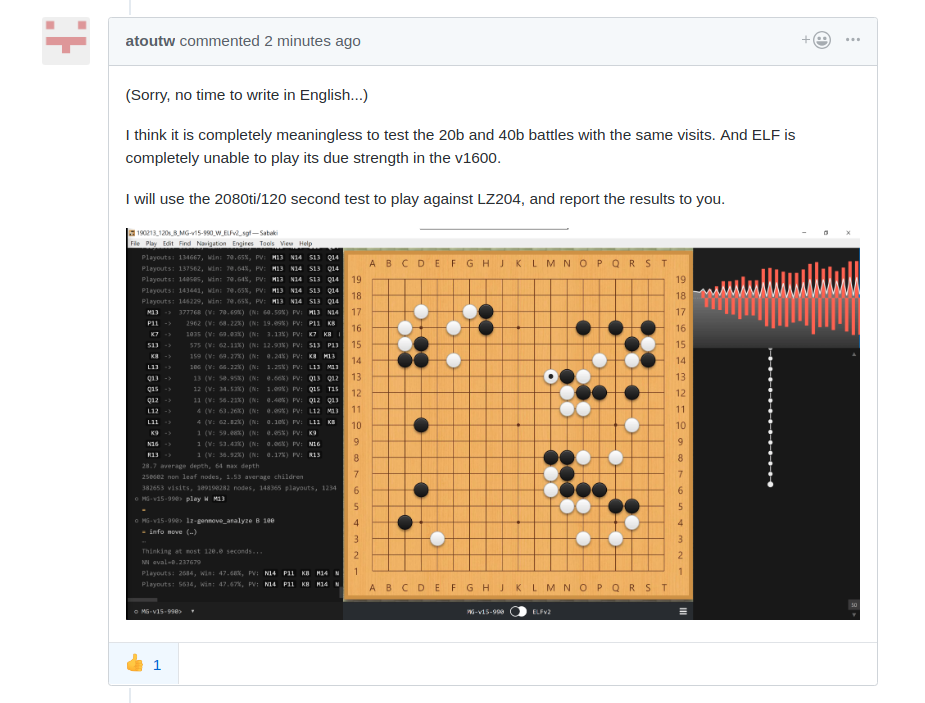
(抱歉,沒時間用英文寫...) 我覺得用同樣visits測試20b和40b的對戰是完全沒有意義的。而且ELF在v1600完全無法發揮應有實力。 我會用2080ti/120秒測試和LZ204對戰,再向各位報告結果。
|

translation : " And ELF is completely unable to play its due strength in the v1600." thanks @atoutw 👍 |
|
|
@atoutw
|

|
Are ELF models able to convert into the quantized ver for LZ? Maybe it can save some traffic. Sinces they are some refenrence points. |
|
:)
|
|
@wonderingabout |
|
haha, thank you for the thank you 🥇 |
|
A link included in the paper is alive now and contains rich information: http://facebook.ai/developers/tools/elf-opengo Links to all models (network weight files) and training data (selfplay json url)!! https://dl.fbaipublicfiles.com/elfopengo/v2_training_run/urls.csv Windows binary of "native" engine: https://dl.fbaipublicfiles.com/elfopengo/play/play_opengo_v2.zip (1.35 GB) "hawk eye" analysis of historical games, self-play games, analysis with different nets: hawkeye.txt Ladder test suite: https://github.com/pytorch/ELF/tree/master/ladder_suite |
|
Regarding the first match LZ204 vs Elfv2 on zero.sjeng.org, there is a strange thing, that already happened in the past while matching one of bjiyxjo 15b net against Elfv1: there were two short games (~94 moves) where Elf, and only elf side, played weird moves (second lines or in the middle of nowhere). In todays match, in 5 games played by the same client 9, Elfv2 plays total crap in the opening, doesn't resign properly (2 games last 400+ moves). Here are two such games: Corrupt client ? If not malvolent, why only Elf side each time ? Pb with that client witn the elf converted weight file ? .... |
|
i got tired of always mentioning this human behaviour, while no one was willing to take measures for it, so ... same as usual ? too bad, but what can i do except moving on ? |
|
Same thing for 10 games played by client 23 in this match elfv1 vs elfv2. But this time, both sides play crap moves, what matches my hypothesis that there is a clien out there that screws only with elf% weights. |
|
@wonderingabout did you test the native engine vs lz ? |
|
paper updated https://arxiv.org/abs/1902.04522v2 |
|
Very minor edits. Some spacing changes on first page page 12: The asynchronous approach achieves |
|
I reported the missing value on their issues. By the way, the blog post is now accessible: https://ai.facebook.com/blog/open-sourcing-new-elf-opengo-bot-and-go-research/
:) |
|
no, not yet, i definitely would like to, and more importantly see if native elf can finally be exported to gtp2ogs |
|
i try to use gogui, but it didnt work under |
|
i think you need to read the documentation, but no idea what it says @l1t1 |
|
elf's play_opengo_v2.zip has a readme.pdf it says Step 1: Double click the “run.bat” to start Sabaki (we use Sabaki version 35 as our front-end); |
|
i'm too busy to look at this atm sorry @l1t1 i hope other people who tried the windows native pre built binary can help you with their feedback |
|
df_console.exe only works at sabaki 35. probably because of their limited list_commands (their gtp version is 2). i currently use sabaki 35 to play it against various minigo and lz versions. you may also tinker with the available parameters in df_console.exe --help. one thing i notice is that it doesn't support multi-gpu. so far i'm unable to make it print the pv and winrates per move, maybe someone can figure it out. |
|
from elf readme. of https://github.com/pytorch/ELF Running a Go bot Here is a basic set of commands to run and play the bot via the GTP protocol: |
|
I have tested 2 mathes, LZ 05d10f27 vs ELFv2. |
|
elfv2 p800 win lz204 on cgos |
|
ELFv2 seems very keen on playing out Mi Yuting's Dagger (小芈飞刀, [a recent example of which is in LG championship game 2) but does not always correctly handle it, from what I heard. |
|
ELFv2 (model 1290) self-play white winrate: 58.6% (7810/13319) (the model chosen for release based on pairwise model comparisons) |
|
@alreadydone the text elfv2 and elf is a bit mislead |
|
typo 1228 ->1290 |
|
I just verified CRC32 = 3E459311 for both pretrained-go-19x19-v2.bin and https://dl.fbaipublicfiles.com/elfopengo/v2_training_run/models/1290000.bin.
|
|
if you have windows pc, fc /b is ok, nevertheless, crc is also good |
|
@alreadydone you quote is right, but the next statement isn
|
|
prototype is ELFv0. 150 Elo is maybe not too far off? thanks I didn't know about |
|
i read the paper again, and I see, prototype means elfv0 |
|
A net's rating on zero.sjeng.org is probably anchored to its last opponent (I think the net needs to appear to the left and its opponent to the right for the match to adjust the net's rating), so it only takes a single match into account, and the result can depend on luck and be unreliable ... There's no Bradley-Terry model implemented as far as I know. |
|
Yes @alreadydone is exactly correct. Minigo has the fancy eval system in place, we just have a very basic A-B comparison where we always compare against the current best network and chain the promotions together to have a sense of progress. |
|
https://cloudygo.com/ringmaster/ has some leelazero crosstable |
|
https://cloudygo.com/leela-zero-v3/eval-graphs has a better setup for crosstable. |
|
@sethtroisi I don't see any ELF models in your link. Should we convert some ELF models and match them against Minigo v15 because 20b/19b models are more comparable (at equal playouts)? The best models can be seen from the paper (see plot below) and downloaded from https://dl.fbaipublicfiles.com/elfopengo/v2_training_run/urls.csv. |

https://github.com/pytorch/ELF/releases/tag/pretrained-go-19x19-v2
The text was updated successfully, but these errors were encountered: