@@ -256,3 +256,4 @@ git push origin
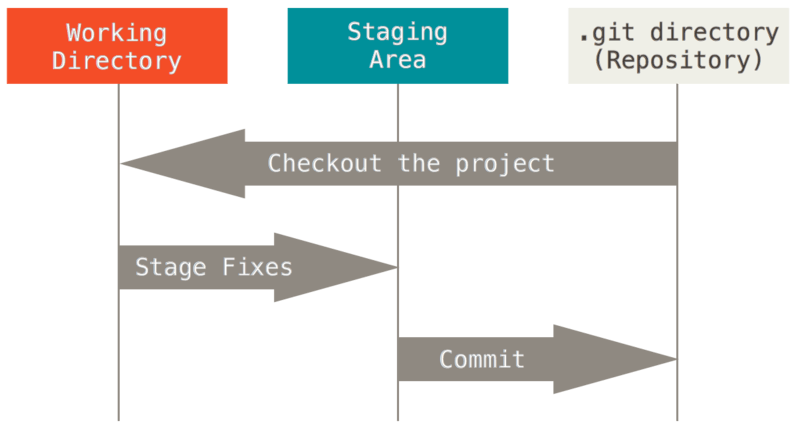
- [图解Git](http://marklodato.github.io/visual-git-guide/index-zh-cn.html)
- [猴子都能懂得Git入门](https://backlog.com/git-tutorial/cn/intro/intro1_1.html)
- https://git-scm.com/book/en/v2
+- [Generating a new SSH key and adding it to the ssh-agent](https://help.github.com/en/articles/generating-a-new-ssh-key-and-adding-it-to-the-ssh-agent)
diff --git "a/docs/tools/\351\230\277\351\207\214\344\272\221\346\234\215\345\212\241\345\231\250\344\275\277\347\224\250\347\273\217\351\252\214.md" "b/docs/tools/\351\230\277\351\207\214\344\272\221\346\234\215\345\212\241\345\231\250\344\275\277\347\224\250\347\273\217\351\252\214.md"
new file mode 100644
index 00000000000..55c89645362
--- /dev/null
+++ "b/docs/tools/\351\230\277\351\207\214\344\272\221\346\234\215\345\212\241\345\231\250\344\275\277\347\224\250\347\273\217\351\252\214.md"
@@ -0,0 +1,149 @@
+最近很多阿里云双 11 做活动,优惠力度还挺大的,很多朋友都买以最低的价格买到了自己的云服务器。不论是作为学习机还是部署自己的小型网站或者服务来说都是很不错的!
+
+但是,很多朋友都不知道如何正确去使用。下面我简单分享一下自己的使用经验。
+
+总结一下,主要涉及下面几个部分,对于新手以及没有这么使用过云服务的朋友还是比较友好的:
+
+1. 善用阿里云镜像市场节省安装 Java 环境的时间,相关说明都在根目录下的 readme.txt. 文件里面;
+2. 本地通过 SSH 连接阿里云服务器很容易,配置好 Host地址,通过 root 用户加上实例密码直接连接即可。
+3. 本地连接 MySQL 数据库需要简单配置一下安全组和并且允许 root 用户在任何地方进行远程登录。
+4. 通过 Alibaba Cloud Toolkit 部署 Spring Boot 项目到阿里云服务器真的很方便。
+
+**[活动地址](https://www.aliyun.com/1111/2019/group-buying-share?ptCode=32AE103FC8249634736194795A3477C4647C88CF896EF535&userCode=hf47liqn&share_source=copy_link)** (仅限新人,老用户可以考虑使用家人或者朋友账号购买,推荐799/3年 2核4G 这个性价比和适用面更广)
+
+### 善用阿里云镜像市场节省安装环境的时间
+
+基本的购买流程这里就不多说了,另外这里需要注意的是:其实 Java 环境是不需要我们手动安装配置的,阿里云提供的镜像市场有一些常用的环境。
+
+> 阿里云镜像市场是指阿里云建立的、由镜像服务商向用户提供其镜像及相关服务的网络平台。这些镜像在操作系统上整合了具体的软件环境和功能,比如Java、PHP运行环境、控制面板等,供有相关需求的用户开通实例时选用。
+
+具体如何在购买云服务器的时候通过镜像创建实例或者已有ECS用户如何使用镜像可以查看官方详细的介绍,地址:
+
+https://help.aliyun.com/knowledge_detail/41987.html?spm=a2c4g.11186631.2.1.561e2098dIdCGZ
+
+### 当我们成功购买服务器之后如何通过 SSH 连接呢?
+
+创建好 ECS 后,你绑定的手机会收到短信,会告知你初始密码的。你可以登录管理控制台对密码进行修改,修改密码需要在管理控制台重启服务器才能生效。
+
+你也可以在阿里云 ECS 控制台重置实例密码,如下图所示。
+
+
+
+**第一种连接方式是直接在阿里云服务器管理的网页上连接**。如上图所示, 点击远程连接,然后输入远程连接密码,这个并不是你重置实例密码得到的密码,如果忘记了直接修改远程连接密码即可。
+
+**第二种方式是在本地通过命令或者软件连接。** 推荐使用这种方式,更加方便。
+
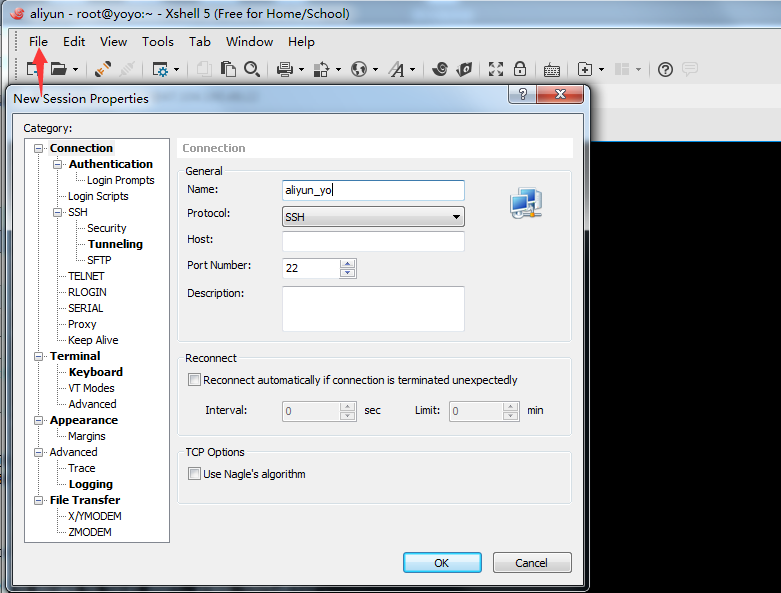
+ **Windows 推荐使用 Xshell 连接,具体方式如下:**
+
+> Window电脑在家,这里直接用找到的一些图片给大家展示一个。
+
+
+
+
+
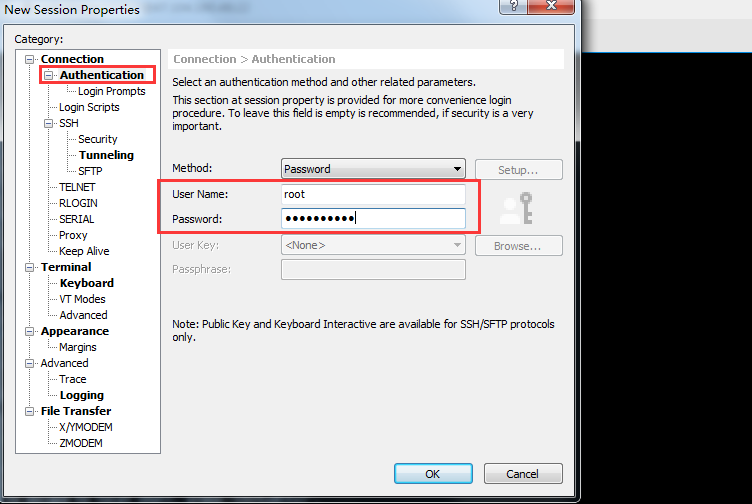
+接着点开,输入账号:root,命名输入刚才设置的密码,点ok就可以了
+
+
+
+**Mac 或者 Linux 系统都可以直接使用 ssh 命令进行连接,非常方便。**
+
+成功连接之后,控制台会打印出如下消息。
+
+```shell
+➜ ~ ssh root@47.107.159.12 -p 22
+root@47.107.159.12's password:
+Last login: Wed Oct 30 09:31:31 2019 from 220.249.123.170
+
+Welcome to Alibaba Cloud Elastic Compute Service !
+
+ 欢迎使用 Tomcat8 JDK8 Mysql5.7 环境
+
+ 使用说明请参考 /root/readme.txt 文件
+```
+
+我当时选择是阿里云提供好的 Java 环境,自动就提供了 Tomcat、 JDK8 、Mysql5.7,所以不需要我们再进行安装配置了,节省了很多时间。另外,需要注意的是:**一定要看 /readme.txt ,Tomcat、 JDK8 、Mysql5.7相关配置以及安装路径等说明都在里面。**
+
+### 如何连接数据库?
+
+ **如需外网远程访问mysql 请参考以上网址 设置mysql及阿里云安全组**。
+
+
+
+Mysql为了安全性,在默认情况下用户只允许在本地登录,但是可以使用 SSH 方式连接。如果我们不想通过 SSH 方式连接的话就需要对 MySQL 进行简单的配置。
+
+```shell
+#允许root用户在任何地方进行远程登录,并具有所有库任何操作权限:
+# *.*代表所有库表 “%”代表所有IP地址
+mysql> GRANT ALL PRIVILEGES ON *.* TO 'root'@'%' IDENTIFIED BY "自定义密码" WITH GRANT OPTION;
+Query OK, 0 rows affected, 1 warning (0.00 sec)
+#刷新权限。
+mysql>flush privileges;
+#退出mysql
+mysql>exit
+#重启MySQL生效
+[root@snailclimb]# systemctl restart mysql
+```
+
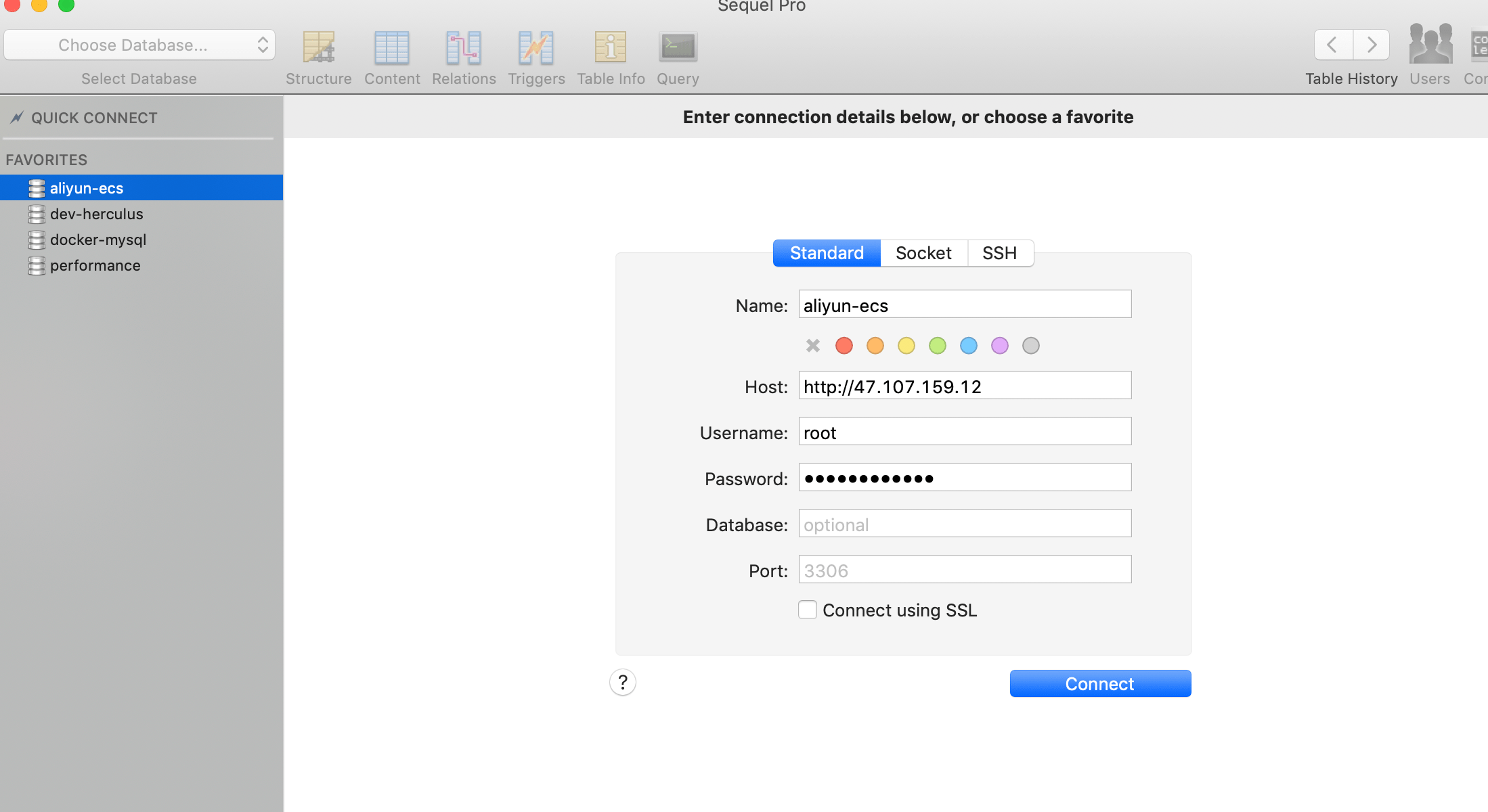
+这样的话,我们就能在本地进行连接了。Windows 推荐使用Navicat或者SQLyog。
+
+> Window电脑在家,这里用 Mac 上的MySQL可视化工具Sequel Pro给大家演示一下。
+
+
+
+### 如何把一个Spring Boot 项目部署到服务器上呢?
+
+默认大家都是用 IDEA 进行开发。另外,你要有一个简单的 Spring Boot Web 项目。如果还不了解 Spring Boot 的话,一个简单的 Spring Boot 版 "Hello World "项目,地址如下:
+
+https://github.com/Snailclimb/springboot-guide/blob/master/docs/start/springboot-hello-world.md 。
+
+**1.下载一个叫做 Alibaba Cloud Toolkit 的插件。**
+
+
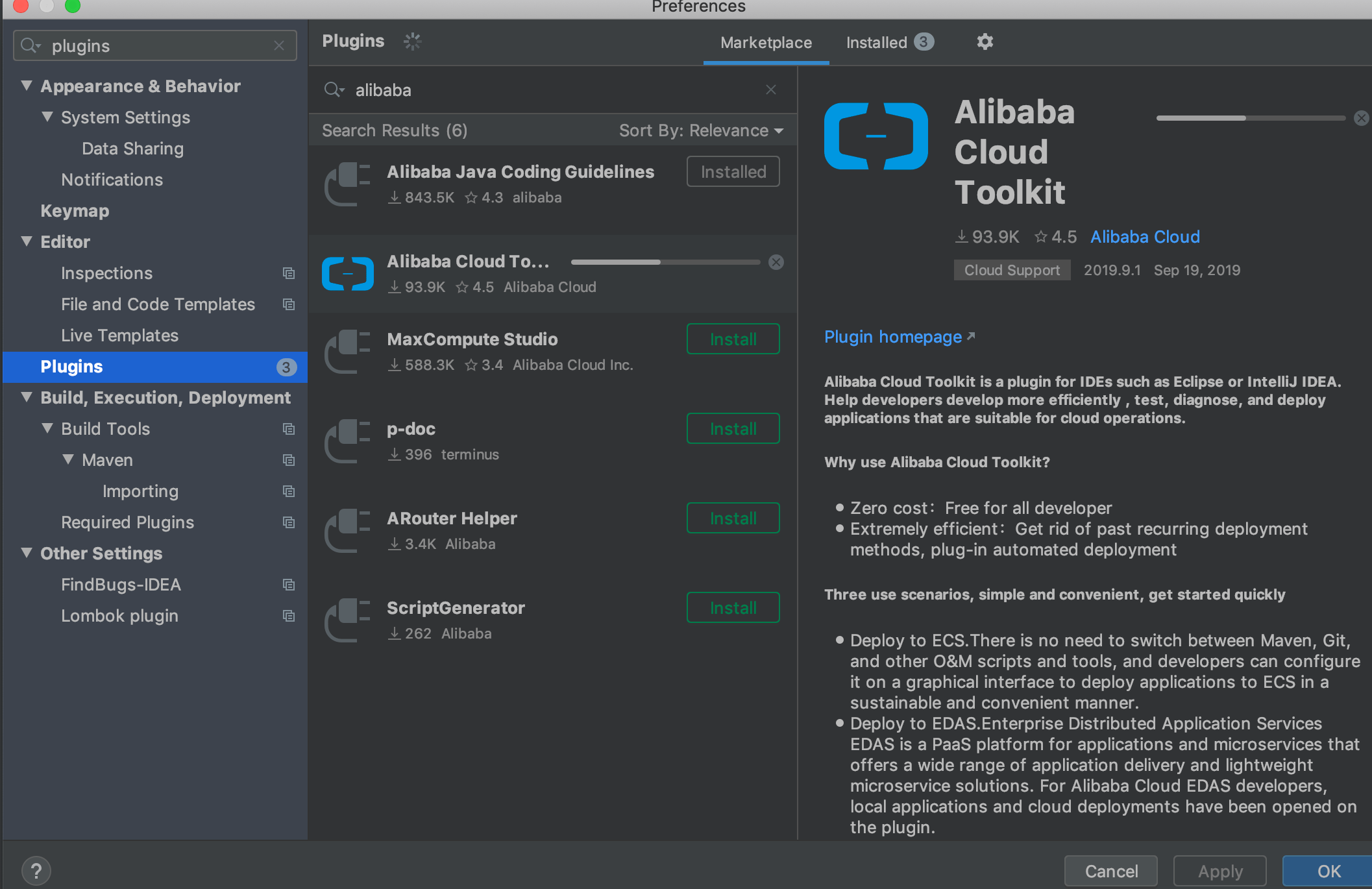
+
+**2.进入 Preference 配置一个 Access Key ID 和 Access Key Secret。**
+
+
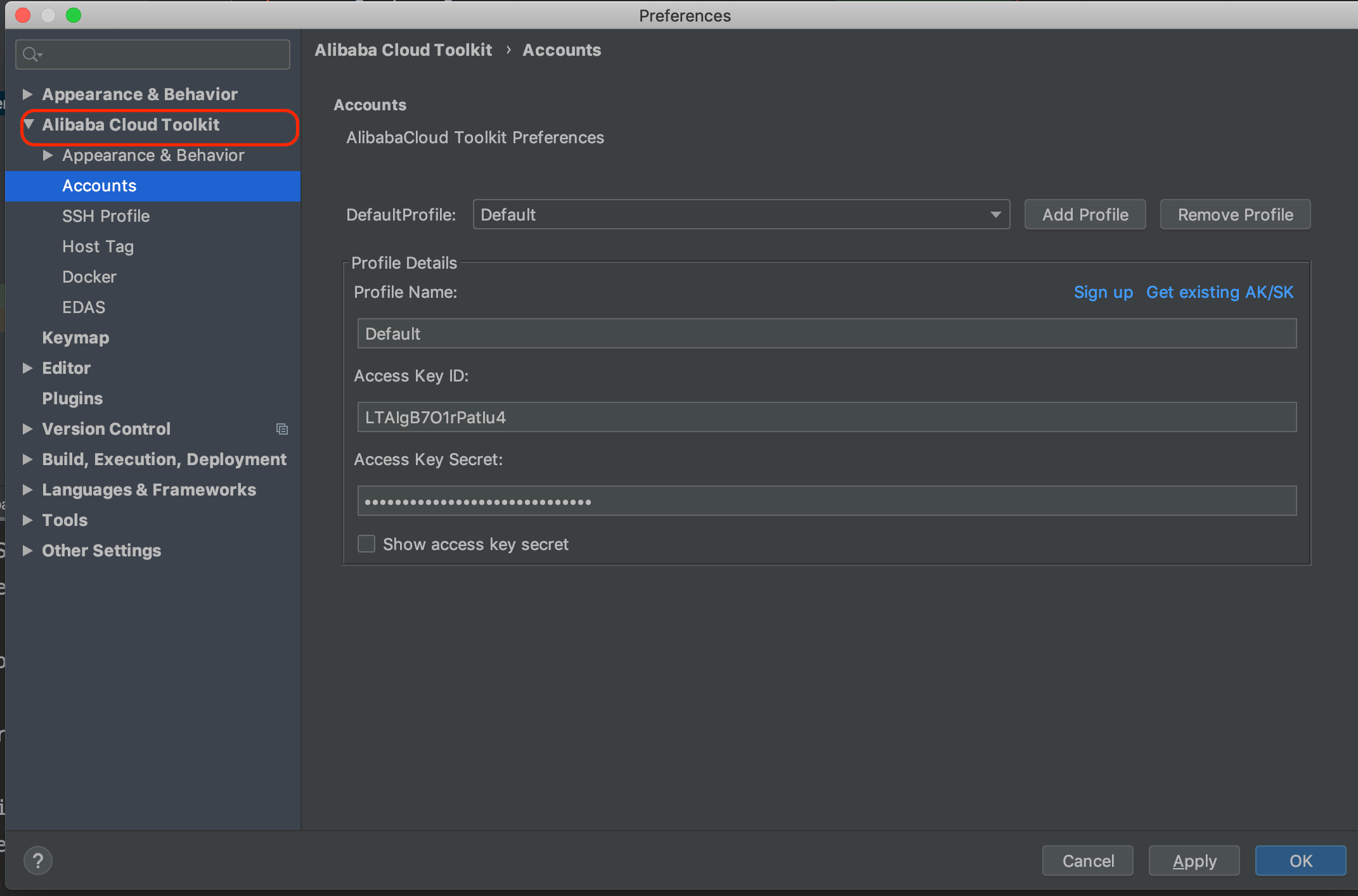
+
+**3.部署项目到 ECS 上。**
+
+
+
+
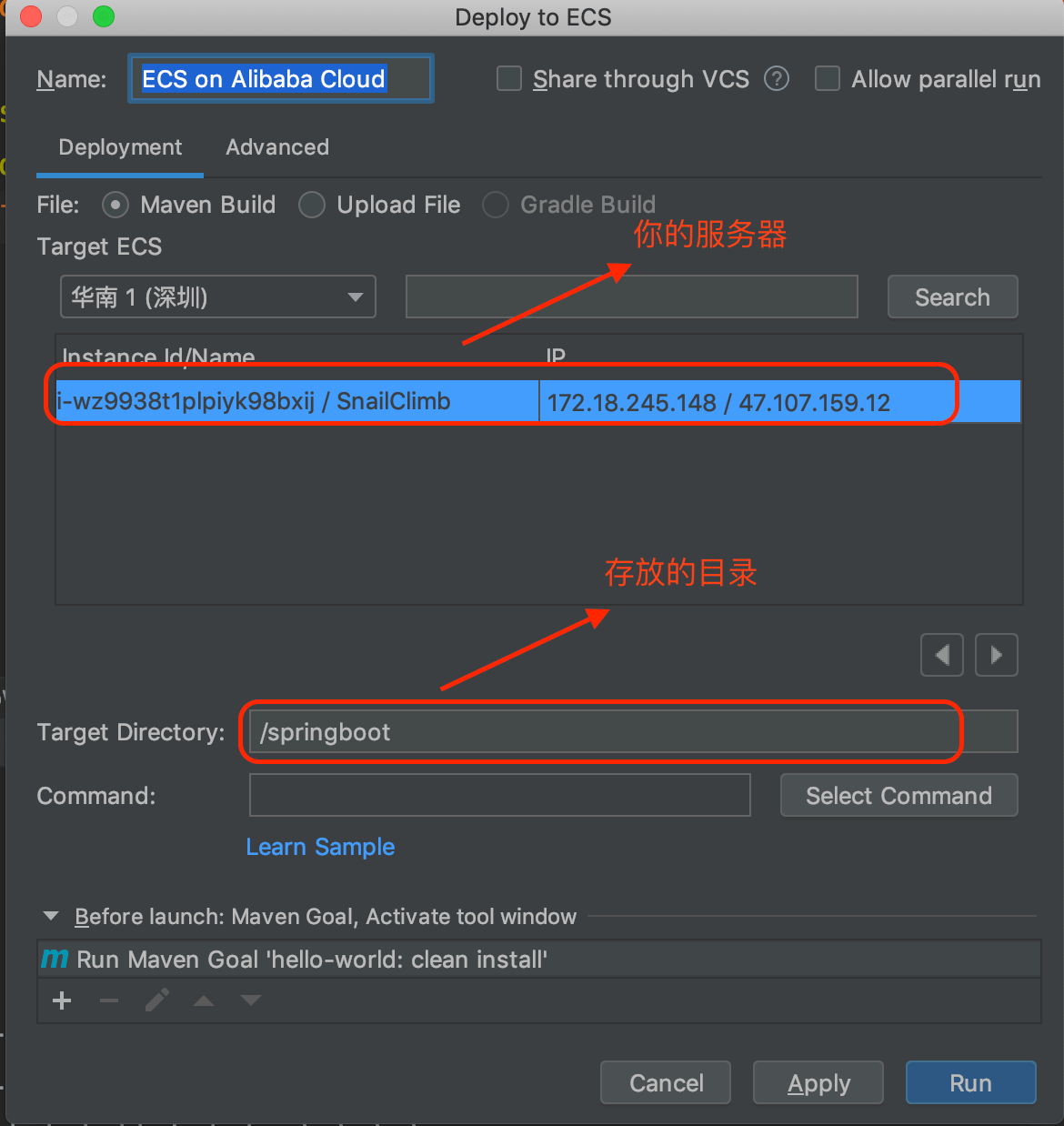
+
+按照上面这样填写完基本配置之后,然后点击 run 运行即可。运行成功,控制台会打印出如下信息:
+
+```shell
+[INFO] Deployment File is Uploading...
+[INFO] IDE Version:IntelliJ IDEA 2019.2
+[INFO] Alibaba Cloud Toolkit Version:2019.9.1
+[INFO] Start upload hello-world-0.0.1-SNAPSHOT.jar
+[INFO][##################################################] 100% (18609645/18609645)
+[INFO] Succeed to upload, 18609645 bytes have been uploaded.
+[INFO] Upload Deployment File to OSS Success
+[INFO] Target Deploy ECS: { 172.18.245.148 / 47.107.159.12 }
+[INFO] Command: { source /etc/profile; cd /springboot; }
+ Tip: The deployment package will be temporarily stored in Alibaba Cloud Security OSS and will be
+ deleted after the deployment is complete. Please be assured that no one can access it except you.
+
+[INFO] Create Deploy Directory Success.
+
+[INFO] Deployment File is Downloading...
+[INFO] Download Deployment File from OSS Success
+
+[INFO] File Upload Total time: 16.676 s
+```
+
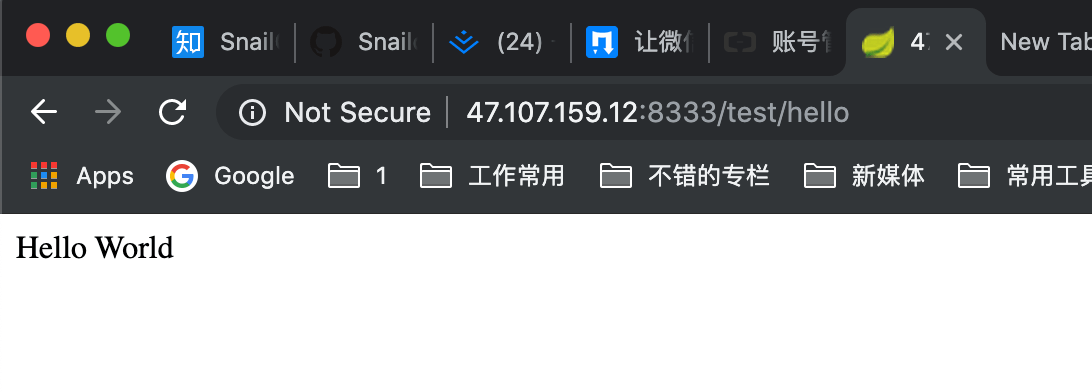
+ 通过控制台答应出的信息可以看出:通过这个插件会自动把这个 Spring Boot 项目打包成一个 jar 包,然后上传到你的阿里云服务器中指定的文件夹中,你只需要登录你的阿里云服务器,然后通过 `java -jar hello-world-0.0.1-SNAPSHOT.jar`命令运行即可。
+
+```shell
+[root@snailclimb springboot]# ll
+total 18176
+-rw-r--r-- 1 root root 18609645 Oct 30 08:25 hello-world-0.0.1-SNAPSHOT.jar
+[root@snailclimb springboot]# java -jar hello-world-0.0.1-SNAPSHOT.jar
+```
+
+ 然后你就可以在本地访问访问部署在你的阿里云 ECS 上的服务了。
+
+
+
+**[推荐一下阿里云双11的活动:云服务器1折起,仅86元/年,限量抢购!](https://www.aliyun.com/1111/2019/group-buying-share?ptCode=32AE103FC8249634736194795A3477C4647C88CF896EF535&userCode=hf47liqn&share_source=copy_link)** (仅限新人,老用户可以考虑使用家人或者朋友账号购买,推荐799/3年 2核4G 这个性价比和适用面更广)
\ No newline at end of file
diff --git "a/docs/\345\205\254\344\274\227\345\217\267\345\216\206\345\217\262\346\226\207\347\253\240\346\261\207\346\200\273.md" "b/docs/\345\205\254\344\274\227\345\217\267\345\216\206\345\217\262\346\226\207\347\253\240\346\261\207\346\200\273.md"
new file mode 100644
index 00000000000..da66dbc9c13
--- /dev/null
+++ "b/docs/\345\205\254\344\274\227\345\217\267\345\216\206\345\217\262\346\226\207\347\253\240\346\261\207\346\200\273.md"
@@ -0,0 +1,209 @@
+## 热文
+
+
+
+- [盘点阿里巴巴 15 款开发者工具](https://mp.weixin.qq.com/s?__biz=Mzg2OTA0Njk0OA==&mid=2247485159&idx=1&sn=c97c087c45ad6dfc0ef61d80a9d0f702&scene=21#wechat_redirect)
+- [蚂蚁金服2019实习生面经总结(已拿口头offer)](https://mp.weixin.qq.com/s?__biz=Mzg2OTA0Njk0OA==&mid=2247485147&idx=1&sn=90e525a83a451d8c20298a7ef2d35ab9&scene=21#wechat_redirect)
+- [一千行 MySQL 学习笔记](https://mp.weixin.qq.com/s?__biz=Mzg2OTA0Njk0OA==&mid=2247485025&idx=1&sn=1f4e19fc77af28f6795feff6ce7465b9&scene=21#wechat_redirect)
+- [可能是把Java内存区域讲的最清楚的一篇文章](https://mp.weixin.qq.com/s?__biz=Mzg2OTA0Njk0OA==&mid=2247485068&idx=1&sn=c37267fe59978dbfcd6a9a54eee1c502&scene=21#wechat_redirect)
+- [搞定 JVM 垃圾回收就是这么简单](https://mp.weixin.qq.com/s?__biz=Mzg2OTA0Njk0OA==&mid=2247484877&idx=1&sn=f54d41b68f0cd6cc7c0348a2fddbda9f&chksm=cea24a06f9d5c3102bfef946ba6c7cc5df9a503ccb14b9b141c54e179617e4923c260c0b0a01&token=1082669959&lang=zh_CN&scene=21#wechat_redirect)
+- [【原创】Java学习路线以及方法推荐](https://mp.weixin.qq.com/s?__biz=Mzg2OTA0Njk0OA==&mid=2247485290&idx=1&sn=569fa9724aae83bff3a353aefc5b7f1c&scene=21#wechat_redirect)
+- [技术面试复习大纲](https://mp.weixin.qq.com/s?__biz=Mzg2OTA0Njk0OA==&mid=2247485505&idx=1&sn=f7d916334c078bc3fdc2933f889b5016&chksm=cea2478af9d5ce9cafcfe9a053e49e84296d8b1929f79844bba59c8c3d8b56753f34a2c2f6a9&token=1701499214&lang=zh_CN&scene=21#wechat_redirect)
+
+## Java
+
+### 必看书籍
+
+- [Java学习必备书籍推荐终极版!](https://mp.weixin.qq.com/s?__biz=Mzg2OTA0Njk0OA==&mid=2247485113&idx=1&sn=e4dd1bb22778e4e9139bf29d98a7492b&chksm=cea24972f9d5c064e5b454b84b9bc0d42f4aec007f20f79b564398e6dec7c0cdcda0e64193b5&token=1482344439&lang=zh_CN&scene=21#wechat_redirect)
+
+### 基础
+
+- [关于Java基础你不得不会的34个问题](https://mp.weixin.qq.com/s?__biz=Mzg2OTA0Njk0OA==&mid=2247485015&idx=1&sn=5daa243c3359b88fc88b951f9d08b273&chksm=cea2499cf9d5c08a7698559a2fc27078c6b35856bc2d3588172bf64708c115d4b35d3de80cd9&token=1913747689&lang=zh_CN&scene=21#wechat_redirect)
+- [剖析面试最常见问题之 Java 基础知识](https://mp.weixin.qq.com/s?__biz=Mzg2OTA0Njk0OA==&mid=2247485173&idx=1&sn=9605f89ed0893b674d14b0c8cf4dc942&chksm=cea2493ef9d5c028a969bb89b53f48fbdd72b975319a844319e3111b15d5dbbc350d91ea5b5a&token=1667678311&lang=zh_CN&scene=21#wechat_redirect)
+
+### Java8新特性
+
+- [Java 8 新特性最佳指南](https://mp.weixin.qq.com/s?__biz=Mzg2OTA0Njk0OA==&mid=2247484744&idx=1&sn=9db31dca13d327678845054af75efb74&chksm=cea24a83f9d5c3956f4feb9956b068624ab2fdd6c4a75fe52d5df5dca356a016577301399548&token=1082669959&lang=zh_CN&scene=21#wechat_redirect)
+- [看完这篇文章,别说自己不会用Lambda表达式了!](https://mp.weixin.qq.com/s?__biz=Mzg2OTA0Njk0OA==&mid=2247485425&idx=1&sn=3cc01bc7c42549b6b6aa62b3656e02d1&chksm=cea2483af9d5c12cd10174dac4465a631b14a6d6a09495b018a98e01c698e86368d26b3be03d&token=1667678311&lang=zh_CN&scene=21#wechat_redirect)
+
+### JVM
+
+- [Java内存区域](https://mp.weixin.qq.com/s?__biz=Mzg2OTA0Njk0OA==&mid=2247485068&idx=1&sn=c37267fe59978dbfcd6a9a54eee1c502&scene=21#wechat_redirect)
+- [垃圾回收](https://mp.weixin.qq.com/s?__biz=Mzg2OTA0Njk0OA==&mid=2247484877&idx=1&sn=f54d41b68f0cd6cc7c0348a2fddbda9f&chksm=cea24a06f9d5c3102bfef946ba6c7cc5df9a503ccb14b9b141c54e179617e4923c260c0b0a01&token=1082669959&lang=zh_CN&scene=21#wechat_redirect)
+- [谈Java类文件结构](https://mp.weixin.qq.com/s?__biz=Mzg2OTA0Njk0OA==&mid=2247485250&idx=2&sn=33793bcce3f2ff31b83cf2f9c32df153&scene=21#wechat_redirect)
+- [类加载过程](https://mp.weixin.qq.com/s?__biz=Mzg2OTA0Njk0OA==&mid=2247485264&idx=2&sn=8c97f7e7d7ad36bc50e713572dbd1529&scene=21#wechat_redirect)
+
+### 并发编程
+
+- [并发编程面试必备:JUC 中的 Atomic 原子类总结](https://mp.weixin.qq.com/s?__biz=Mzg2OTA0Njk0OA==&mid=2247484834&idx=1&sn=7d3835091af8125c13fc6db765f4c5bd&chksm=cea24a69f9d5c37ff88a8328214cb48b06afb9dc82e46cd924d2595f109ea28922212f9e653c&token=1082669959&lang=zh_CN&scene=21#wechat_redirect)
+- [并发编程面试必备:AQS 原理以及 AQS 同步组件总结](https://mp.weixin.qq.com/s?__biz=Mzg2OTA0Njk0OA==&mid=2247484832&idx=1&sn=f902febd050eac59d67fc0804d7e1ad5&chksm=cea24a6bf9d5c37d6b505fe1d43e4fb709729149f1f77344b4a0f5956cab5020a2e102f2adf2&token=1082669959&lang=zh_CN&scene=21#wechat_redirect)
+- [BATJ都爱问的多线程面试题](https://mp.weixin.qq.com/s?__biz=Mzg2OTA0Njk0OA==&mid=2247484831&idx=1&sn=e22d2832a436dbb94233272429d4c4c4&chksm=cea24a54f9d5c3420e96aa94e3d893f4cf825852fff0b4a7e4e241cc229f4666f3dc4d53955e&token=1082669959&lang=zh_CN&scene=21#wechat_redirect)
+- [通俗易懂,JDK 并发容器总结](https://mp.weixin.qq.com/s?__biz=Mzg2OTA0Njk0OA==&mid=2247484797&idx=1&sn=e28462eec497e38053d9fb9ba17ff022&chksm=cea24ab6f9d5c3a05b5ad36111e93d824ce964442366bc8add1cd77cb432057e4995592c8024&token=1082669959&lang=zh_CN&scene=21#wechat_redirect)
+
+### 代码质量
+
+- [八点建议助您写出优雅的Java代码](https://mp.weixin.qq.com/s/o3BGTdAa8VufcIKU0ScBqA)
+- [十分钟搞懂Java效率工具Lombok使用与原理](https://mp.weixin.qq.com/s?__biz=Mzg2OTA0Njk0OA==&mid=2247485385&idx=2&sn=a7c3fb4485ffd8c019e5541e9b1580cd&chksm=cea24802f9d5c1144eee0da52cfc0cc5e8ee3590990de3bb642df4d4b2a8cd07f12dd54947b9&token=1667678311&lang=zh_CN#rd)
+- [如何写出让同事无法维护的代码?](https://mp.weixin.qq.com/s?__biz=Mzg2OTA0Njk0OA==&mid=2247485413&idx=2&sn=70336d94018ad93d67cfacb4aeceb01b&chksm=cea2482ef9d5c1382d8a009e2ecd680c3b6ac3c7c02810af8901970e69c431273113ca7e4447&token=1667678311&lang=zh_CN#rd)
+- [Code Review最佳实践](https://mp.weixin.qq.com/s?__biz=Mzg2OTA0Njk0OA==&mid=2247485494&idx=1&sn=c7f160fd1bb13a20b887493003acbbf9&chksm=cea247fdf9d5ceebf3b98bd7c524d0ecc672d4bcb10a70fae90390abd862538aa3283c93375b&token=1701499214&lang=zh_CN&scene=21#wechat_redirect)
+- [后端开发必备的 RestFul API 知识](https://mp.weixin.qq.com/s?__biz=Mzg2OTA0Njk0OA==&mid=2247485510&idx=1&sn=e9273322ae638c8465a606737109ab97&chksm=cea2478df9d5ce9b58b9ff1f1e2ecca99e961b911adcec3d5a579b41e01151160cfb2891d91b&token=1701499214&lang=zh_CN&scene=21#wechat_redirect)
+
+## 网络
+
+- [搞定计算机网络面试,看这篇就够了(补充版)](https://mp.weixin.qq.com/s?__biz=Mzg2OTA0Njk0OA==&mid=2247484889&idx=1&sn=5f9e6f5c29f9514701c246573d15d9fa&chksm=cea24a12f9d5c3041efd5cf864eb69b76aea6ef9c000a72b16d54794aab97d4fb53515a77147&token=1082669959&lang=zh_CN#rd)
+
+## 系统设计
+
+### Spring
+
+- [Spring常见问题总结(补充版)](https://mp.weixin.qq.com/s?__biz=Mzg2OTA0Njk0OA==&mid=2247485576&idx=1&sn=f993349f12650a68904e1d99d2465131&chksm=cea24743f9d5ce55ffe543a0feaf2c566382024b625b59283482da6ab0cbcf2a3c9dc5b64a53&token=2133161636&lang=zh_CN#rd)
+- [面试官:“谈谈Spring中都用到了那些设计模式?”。](https://mp.weixin.qq.com/s?__biz=Mzg2OTA0Njk0OA==&mid=2247485303&idx=1&sn=9e4626a1e3f001f9b0d84a6fa0cff04a&chksm=cea248bcf9d5c1aaf48b67cc52bac74eb29d6037848d6cf213b0e5466f2d1fda970db700ba41&token=1667678311&lang=zh_CN#rd)
+- [可能是最漂亮的Spring事务管理详解](https://mp.weixin.qq.com/s?__biz=Mzg2OTA0Njk0OA==&mid=2247484943&idx=1&sn=46b9082af4ec223137df7d1c8303ca24&chksm=cea249c4f9d5c0d2b8212a17252cbfb74e5fbe5488b76d829827421c53332326d1ec360f5d63&token=1082669959&lang=zh_CN#rd)
+- [SpringMVC 工作原理详解](https://mp.weixin.qq.com/s?__biz=Mzg2OTA0Njk0OA==&mid=2247484846&idx=1&sn=490014ea65669c1a1e73e25d7b9fa569&chksm=cea24a65f9d5c373d31d6cdd61297db21de63462c1c03c34b7025a0d0b93f1182b2ad7e33cab&token=1082669959&lang=zh_CN#rd)
+- [Spring编程式和声明式事务实例讲解](https://mp.weixin.qq.com/s?__biz=Mzg2OTA0Njk0OA==&mid=2247484942&idx=1&sn=b0d9e6f1af243bbf7f34ede5a6d2277d&chksm=cea249c5f9d5c0d3da9206b753bb7734d47d8d8b43edcc02bdf6f139e34e1db512cf5ed32217&token=1082669959&lang=zh_CN#rd)
+- [一文轻松搞懂Spring中bean的作用域与生命周期](https://mp.weixin.qq.com/s?__biz=Mzg2OTA0Njk0OA==&mid=2247484865&idx=2&sn=178c6e64e6c12172e77efdd669eb86a7&chksm=cea24a0af9d5c31c389ae7817613a336f00c330021f73c90afe383c8caf6ea07a9e1f949c68d&token=1082669959&lang=zh_CN#rd)
+
+### SpringBoot
+
+- [超详细,新手都能看懂 !使用SpringBoot+Dubbo 搭建一个简单的分布式服务](https://mp.weixin.qq.com/s?__biz=Mzg2OTA0Njk0OA==&mid=2247484809&idx=1&sn=a789eba40404e6501d51b24345b28906&chksm=cea24a42f9d5c3544babde7f33790fc54f02ebc2f589ce9fa116bbb9c7b0c0cfb1bc314d17de&token=1082669959&lang=zh_CN#rd)
+- [基于 SpringBoot2.0+优雅整合 SpringBoot+Mybatis](https://mp.weixin.qq.com/s?__biz=Mzg2OTA0Njk0OA==&mid=2247484805&idx=2&sn=0e148af5baebae53b3fd365cff689046&chksm=cea24a4ef9d5c35862efc9c67b0619f7e8ade4b75e1001189ededccd8fd35ca5cd19fda074b9&token=1082669959&lang=zh_CN#rd)
+- [新手也能实现,基于SpirngBoot2.0+ 的 SpringBoot+Mybatis 多数据源配置](https://mp.weixin.qq.com/s?__biz=Mzg2OTA0Njk0OA==&mid=2247484803&idx=1&sn=9179890db39721a59bb815b7f985ec2d&chksm=cea24a48f9d5c35e73d3df4b29d340e1a4c76d43b220c0f9535e77b43a74ff049ee7b89a4a38&token=1082669959&lang=zh_CN#rd)
+- [SpringBoot 整合 阿里云OSS 存储服务,快来免费搭建一个自己的图床](https://mp.weixin.qq.com/s?__biz=Mzg2OTA0Njk0OA==&mid=2247484801&idx=1&sn=22d97f9c963d45820559d7226874e33f&chksm=cea24a4af9d5c35cac3177921801287b1ad983eabb6e18cf30302fc235b7f699401510ea2a59&token=1082669959&lang=zh_CN#rd)
+- [Spring Boot 实现热部署的一种简单方式](https://mp.weixin.qq.com/s?__biz=Mzg2OTA0Njk0OA==&mid=2247485586&idx=2&sn=01788bf8c64de91d085a01c1f4f5159d&chksm=cea24759f9d5ce4fe914aa43e517f16b7f4066de3096be09d01500596ca63ad9f1eef4b8fffa&token=2133161636&lang=zh_CN#rd)
+- [SpringBoot 处理异常的几种常见姿势](https://mp.weixin.qq.com/s?__biz=Mzg2OTA0Njk0OA==&mid=2247485568&idx=2&sn=c5ba880fd0c5d82e39531fa42cb036ac&chksm=cea2474bf9d5ce5dcbc6a5f6580198fdce4bc92ef577579183a729cb5d1430e4994720d59b34&token=2133161636&lang=zh_CN#rd)
+- [5分钟搞懂如何在Spring Boot中Schedule Tasks](https://mp.weixin.qq.com/s?__biz=Mzg2OTA0Njk0OA==&mid=2247485563&idx=1&sn=7419341f04036a10b141b74624a3f8c9&chksm=cea247b0f9d5cea6440759e6d49b4e77d06f4c99470243a10c1463834e873ca90266413fbc92&token=2133161636&lang=zh_CN#rd)
+
+### MyBatis
+
+- [面试官:“谈谈MyBatis中都用到了那些设计模式?”。](https://mp.weixin.qq.com/s?__biz=Mzg2OTA0Njk0OA==&mid=2247485369&idx=1&sn=a493d646e126cd1c19ce9f1fc9c724c9&chksm=cea24872f9d5c16462d82f033699d7ad3177964100f8c8958ce9b8e0872e246f552ae6ac423f&token=1667678311&lang=zh_CN#rd)
+
+## 数据库
+
+### MySQL
+
+- [MySQL知识点总结[修订版]](https://mp.weixin.qq.com/s?__biz=Mzg2OTA0Njk0OA==&mid=2247485390&idx=1&sn=43511395093d2e0deb64f89c8af1805e&chksm=cea24805f9d5c113026292c7681238b1c65c09958588aa5c70e37249e384f5c965f87ef438ad&token=1667678311&lang=zh_CN#rd)
+- [【思维导图-索引篇】搞定数据库索引就是这么简单](https://mp.weixin.qq.com/s?__biz=Mzg2OTA0Njk0OA==&mid=2247484848&idx=1&sn=77a0e6e82944ec385f5df17e91ce3bf2&chksm=cea24a7bf9d5c36d4b289cccb017292f9f36da9f3c887fd2b93ecd6af021fcf30121ba09799f&token=1082669959&lang=zh_CN#rd)
+- [一条SQL语句在MySQL中如何执行的](https://mp.weixin.qq.com/s/QU4-RSqVC88xRyMA31khMg)
+- [一文带你轻松搞懂事务隔离级别(图文详解)](https://mp.weixin.qq.com/s/WhK3SrkMDTj1_o2zp64ArQ)
+- [详记一次MySQL千万级大表优化过程!](https://mp.weixin.qq.com/s/SbpM_q_-nIKJn7_TSmrW8A)
+
+### Redis
+
+- [史上最全Redis高可用技术解决方案大全](https://mp.weixin.qq.com/s?__biz=Mzg2OTA0Njk0OA==&mid=2247484850&idx=1&sn=3238360bfa8105cf758dcf7354af2814&chksm=cea24a79f9d5c36fb2399aafa91d7fb2699b5006d8d037fe8aaf2e5577ff20ae322868b04a87&token=1082669959&lang=zh_CN#rd)
+- [redis 总结——重构版](https://mp.weixin.qq.com/s?__biz=Mzg2OTA0Njk0OA==&mid=2247484858&idx=1&sn=8e222ea6115e0b69cac91af14d2caf36&chksm=cea24a71f9d5c367148dccec3d5ddecf5ecd8ea096b5c5ec32f22080e66ac3c343e99151c9e0&token=1082669959&lang=zh_CN#rd)
+
+## 面试相关
+
+- [面试中常见的几道智力题 来看看你会做几道?](https://mp.weixin.qq.com/s?__biz=Mzg2OTA0Njk0OA==&mid=2247484923&idx=1&sn=e1fd890a1a7290f996dc8d7ca4b2d599&chksm=cea24a30f9d5c326f5498929decb7b2d9e39d8806b74c823ccf46fe9fba778d5d9aa644292db&token=1082669959&lang=zh_CN#rd)
+- [面试中常见的几道智力题 来看看你会做几道(2)?](https://mp.weixin.qq.com/s?__biz=Mzg2OTA0Njk0OA==&mid=2247484917&idx=1&sn=8587b384b42927618067c0e3a56083a9&chksm=cea24a3ef9d5c328a5fd97441de1ccfaf42f9296e5f491b1fa4be9422431d6f26dac36a75e16&token=1082669959&lang=zh_CN#rd)
+- [[算法总结] 搞定 BAT 面试——几道常见的子符串算法题](https://mp.weixin.qq.com/s?__biz=Mzg2OTA0Njk0OA==&mid=2247484869&idx=1&sn=785d0dce653aa1abdbc542007da830e8&chksm=cea24a0ef9d5c31853ae1114844041f12daf88ef753fb019980e466f32922c50d332e1d1fc2c&token=1082669959&lang=zh_CN#rd)
+- [[BAT面试必备] ——几道常见的链表算法题](https://mp.weixin.qq.com/s?__biz=Mzg2OTA0Njk0OA==&mid=2247484862&idx=1&sn=015a4eb2f66978010d68c1305a46cfb5&chksm=cea24a75f9d5c363683aadf3ac434b8baf9ff5be8d2939d7875ebb3a742780b568a0926a2cc4&token=1082669959&lang=zh_CN#rd)
+- [如何判断一个元素在亿级数据中是否存在?](https://mp.weixin.qq.com/s?__biz=Mzg2OTA0Njk0OA==&mid=2247484796&idx=1&sn=25c190a95ac53b81063f7acda936c994&chksm=cea24ab7f9d5c3a1819605008bfc92834eddf37ca3ad24b913fab558b5d00ed5306c5d6aab55&token=1082669959&lang=zh_CN#rd)
+- [可能是一份最适合你的后端面试指南(部分内容前端同样适用)](https://mp.weixin.qq.com/s?__biz=Mzg2OTA0Njk0OA==&mid=2247484840&idx=1&sn=cf4611ac290ae3cbb381fe52aa76b60b&chksm=cea24a63f9d5c375215f7539ff0f3d6320f091d5f8b73e95c724ec9a31d3b5baa98c3f5a1012&token=1082669959&lang=zh_CN#rd)
+- [GitHub 上四万 Star 大佬的求职回忆](https://mp.weixin.qq.com/s?__biz=Mzg2OTA0Njk0OA==&mid=2247484802&idx=1&sn=58e204718559f6cf94d3d9cd9614ebc2&chksm=cea24a49f9d5c35f8d53f79801aea21fdd3c06ff4b6c16167e8211f627eea8c5a0ce334fd240&token=1082669959&lang=zh_CN#rd)
+- [这7个问题,可能大部分Java程序员都比较关心吧!](https://mp.weixin.qq.com/s?__biz=Mzg2OTA0Njk0OA==&mid=2247484786&idx=1&sn=4f61c62c0213602a106ce20db7768a93&chksm=cea24ab9f9d5c3afe7b5c90f6a8782adef93e916a46685aa8c46b752fddadf88273748c7f1ab&token=1082669959&lang=zh_CN#rd)
+- [2018年BATJ面试题精选](https://mp.weixin.qq.com/s?__biz=Mzg2OTA0Njk0OA==&mid=2247484774&idx=1&sn=2aaaafcecd2bc6b519a11fa0fc1f66fa&chksm=cea24aadf9d5c3bb69359b0973930387885de75b444837df4f34ac14eebbabe498605660ae48&token=1082669959&lang=zh_CN#rd)
+- [一位大佬的亲身经历总结:简历和面试的技巧](https://mp.weixin.qq.com/s?__biz=Mzg2OTA0Njk0OA==&mid=2247485409&idx=1&sn=47b09ec432929306d39762b13364b04b&chksm=cea2482af9d5c13cc91e8e679f0b823e667b616866519af1523d1d8b4e550cfdaa2f57b21bf3&token=1667678311&lang=zh_CN#rd)
+- [包装严重的IT行业,作为面试官,我是如何甄别应聘者的包装程度](https://mp.weixin.qq.com/s?__biz=Mzg2OTA0Njk0OA==&mid=2247485404&idx=1&sn=b0c5b9e55bb6f7e71585c1b2e769fd87&chksm=cea24817f9d5c101cfa45a5d2707445030259f030d91f48c068450c5a280457ee25fa51b3f24&token=1667678311&lang=zh_CN#rd)
+- [面试官:你是如何使用JDK来实现自己的缓存(支持高并发)?](https://mp.weixin.qq.com/s?__biz=Mzg2OTA0Njk0OA==&mid=2247485347&idx=1&sn=8da3919089909d39dbf0745225ca0dad&chksm=cea24868f9d5c17eaec7eba2a4a3b63ed46dff87cb08b3f5d491e96890d8f375735cfcc77562&token=1667678311&lang=zh_CN#rd)
+
+### 面经
+
+- [5面阿里,终获offer](https://mp.weixin.qq.com/s?__biz=Mzg2OTA0Njk0OA==&mid=2247484747&idx=1&sn=bff601fd1d314f670cb44171ea1925dd&chksm=cea24a80f9d5c396619acaa9f77207019f72d43749559b5a401359915e01b51598a687c48203&token=1082669959&lang=zh_CN#rd)
+- [记一次蚂蚁金服的面试经历](https://mp.weixin.qq.com/s/LIhtyspty9Kz1qRg1b8N-w)
+- [2019年蚂蚁金服、头条、拼多多的面试总结](https://mp.weixin.qq.com/s?__biz=Mzg2OTA0Njk0OA==&mid=2247485167&idx=1&sn=a35fad235a6bb2b6e31f1ff37e72bfd7&chksm=cea24924f9d5c032cbbeffc87cd366e9aa7b209897a26ad5c7f7b1b766b3c34a2c9b6870006c&token=1667678311&lang=zh_CN#rd)
+- [蚂蚁金服2019实习生面经总结(已拿口头offer)](https://mp.weixin.qq.com/s/ktq2UOvi5qI1FymWIgp8jw)
+- [2019年蚂蚁金服面经(已拿Offer)!附答案!!](https://mp.weixin.qq.com/s?__biz=Mzg2OTA0Njk0OA==&mid=2247485251&idx=1&sn=21e5da0d76dd71d165f19015ebeba780&chksm=cea24888f9d5c19e041a145e6da3d4fa94f63b34c71d43f10c29340c7d51a4a23971904d19b5&token=1667678311&lang=zh_CN#rd)
+
+### 备战面试系列
+
+- [【备战春招/秋招系列】程序员的简历就该这样写](https://mp.weixin.qq.com/s?__biz=Mzg2OTA0Njk0OA==&mid=2247484830&idx=1&sn=2e868311f79f4a52a0f3be383050c810&source=41#wechat_redirect)
+- [【备战春招/秋招系列】初出茅庐的程序员该如何准备面试?](https://mp.weixin.qq.com/s?__biz=Mzg2OTA0Njk0OA==&mid=2247484829&idx=1&sn=29e0e08d9da0f343f14c16bb3ac92beb&chksm=cea24a56f9d5c340ecb67a186b3c8fb5ef30ff481bfbdec3249f2145b3f376fd2d6dc19fbefc&token=1082669959&lang=zh_CN#rd)
+- [【备战春招/秋招系列】Java程序员必备书单](https://mp.weixin.qq.com/s?__biz=Mzg2OTA0Njk0OA==&mid=2247484826&idx=1&sn=cf015aca00e420d476c3cb456a11d994&chksm=cea24a51f9d5c34730dcdb538c99cb58d23496ebe8c51fb191dd629ab28c802f97662aef3366&token=1082669959&lang=zh_CN#rd)
+- [【备战春招/秋招系列】面试官问你“有什么问题问我吗?”,你该如何回答?](https://mp.weixin.qq.com/s?__biz=Mzg2OTA0Njk0OA==&mid=2247484755&idx=1&sn=4a09256062642c714f83ed03cb083846&chksm=cea24a98f9d5c38e8e040c332bf58ccac48a93190e059b9f39e4249eae579b8d32238cea88dd&token=1082669959&lang=zh_CN#rd)
+- [【备战春招/秋招系列】美团面经总结基础篇 (附详解答案)](https://mp.weixin.qq.com/s?__biz=Mzg2OTA0Njk0OA==&mid=2247484825&idx=1&sn=a0ec65a5f2b268a6f4d22c3bb9790126&chksm=cea24a52f9d5c344922e4dcd4b9650d63ad5c4d843208e3fb7f21bcffa144a6bab0d748cdfbb&token=1082669959&lang=zh_CN#rd)
+- [【备战春招/秋招系列】美团面经总结进阶篇 (附详解答案)](https://mp.weixin.qq.com/s?__biz=Mzg2OTA0Njk0OA==&mid=2247484822&idx=1&sn=efefe8a5a1ff9a54a57601edab134a04&chksm=cea24a5df9d5c34b36e8b12beb574ca31ae771de3881237c4f02be61b52e38f763d2d6137dd3&token=1082669959&lang=zh_CN#rd)
+- [【备战春招/秋招系列】美团Java面经总结终结篇 (附详解答案)](https://mp.weixin.qq.com/s?__biz=Mzg2OTA0Njk0OA==&mid=2247484815&idx=1&sn=4dd1a280fb95c59366c73897c77049fb&chksm=cea24a44f9d5c3524b301ecf313382ea78b6ac821b4d5e9f9cf51346fc10839c1e234e7cb3ed&token=1082669959&lang=zh_CN#rd)
+
+### 面试现场
+
+- [【面试现场】如何实现可以获取最小值的栈?](https://mp.weixin.qq.com/s?__biz=Mzg2OTA0Njk0OA==&mid=2247484863&idx=2&sn=ac674bb0cf29b782aa0e6e9365defa4b&chksm=cea24a74f9d5c362b22459ceda77e635366a17175cd30bbdce14bc729e5417b137175a90331b&token=1082669959&lang=zh_CN#rd)
+- [【面试现场】为什么要分稳定排序和非稳定排序?](https://mp.weixin.qq.com/s?__biz=Mzg2OTA0Njk0OA==&mid=2247484856&idx=2&sn=af47a53a913b42b064a6e158d165fd2f&chksm=cea24a73f9d5c365084c65d30372f1ae35893ad3ec751da71e14ce5fda07b17ab5f0da90f663&token=1082669959&lang=zh_CN#rd)
+- [【面试现场】如何找到字符串中的最长回文子串?](https://mp.weixin.qq.com/s?__biz=Mzg2OTA0Njk0OA==&mid=2247484855&idx=1&sn=e75a06c56fe3b8802f18b04ef4df1c43&chksm=cea24a7cf9d5c36ab8090506442fa131a3d332343e953567c5f78dbef5aed0b6ed317b25af9f&token=1082669959&lang=zh_CN#rd)
+- [【面试现场】如何在10亿数中找出前1000大的数](https://mp.weixin.qq.com/s?__biz=Mzg2OTA0Njk0OA==&mid=2247484845&idx=1&sn=6a235c6181c0f46630a9a22ef762a23b&chksm=cea24a66f9d5c3709e9618a1e418535d467053273123b81fda3897b4431a02a105703fd22644&token=1082669959&lang=zh_CN#rd)
+
+## 算法
+
+- [【算法技巧】位运算装逼指南](https://mp.weixin.qq.com/s?__biz=Mzg2OTA0Njk0OA==&mid=2247485292&idx=1&sn=330e7f8c972bd7ed368aca7ccb434493&chksm=cea248a7f9d5c1b1f5387adbda961f0aa02c6f575fd9367937b9c15be1b241222b340f61dc5e&token=1667678311&lang=zh_CN#rd)
+
+## Github 热门Java项目推荐
+
+- [近几个月Github上最热门的Java项目一览](https://mp.weixin.qq.com/s?__biz=Mzg2OTA0Njk0OA==&mid=2247484908&idx=1&sn=a95d37194f03b7e4aae1612e1785bf44&chksm=cea24a27f9d5c331d818fa1b2b564f9d5e9ff245a969a50e98944b909d6e45c0ebde544f982e&token=1082669959&lang=zh_CN#rd)(2018-07-20)
+- [推荐10个Java方向最热门的开源项目(8月)](https://mp.weixin.qq.com/s?__biz=Mzg2OTA0Njk0OA==&mid=2247484876&idx=1&sn=3cab92ee5bda6b47bf7232724461f6a3&chksm=cea24a07f9d5c31106d0806b1bd8bae8821511b0a32879fb4f4b3bec7823db1f62e23821b07b&token=1082669959&lang=zh_CN#rd)( 2018-08-28)
+- [Github上 Star 数相加超过 7w+ 的三个面试相关的仓库推荐](https://mp.weixin.qq.com/s?__biz=Mzg2OTA0Njk0OA==&mid=2247484819&idx=1&sn=6d83101ee504a6ab19ef07fb32650876&chksm=cea24a58f9d5c34ef9f3a7374c5147b1ff85e18ca4e59e21c4edf7d63bc1bd8c5c241e0c532b&token=1082669959&lang=zh_CN#rd)( 2018-11-17)
+- [11月 Github Trending 榜最热门的 10 个 Java 项目](https://mp.weixin.qq.com/s?__biz=Mzg2OTA0Njk0OA==&mid=2247484805&idx=1&sn=acee5bd6c3f861c65be3a2fb8843e1f5&chksm=cea24a4ef9d5c358c263cb4605acc6b6254635c28c496a9a10aee0dc80293f457a9af2e90d1c&token=1082669959&lang=zh_CN#rd)( 2018-12-01)
+- [盘点一下Github上开源的Java面试/学习相关的仓库,看完弄懂薪资至少增加10k](https://mp.weixin.qq.com/s?__biz=Mzg2OTA0Njk0OA==&mid=2247484789&idx=1&sn=2ad9fabb8fc7fae3bd3756ea05594344&chksm=cea24abef9d5c3a889b6cb8e00cb18abbb694d189c84a24fa1ed337ad4c56194cd39316dc6a5&token=1082669959&lang=zh_CN#rd)( 2018-12-24)
+- [12月GithubTrending榜Java项目总结,多了几个新面孔](https://mp.weixin.qq.com/s?__biz=Mzg2OTA0Njk0OA==&mid=2247484784&idx=1&sn=3c98b2e6aa97014a8fb4bf837be40f52&chksm=cea24abbf9d5c3ad3ab779749f6a75ed9bc4321986056a65f5f04033c9cc626a382ebe597278&token=1082669959&lang=zh_CN#rd)(2019-01-02)
+- [1月份Github上收获最多star的10个项目](https://mp.weixin.qq.com/s?__biz=Mzg2OTA0Njk0OA==&mid=2247484761&idx=1&sn=db6441c08f5ae8d75978384108cc852d&chksm=cea24a92f9d5c3846858a91aa7dc6b258f91407e2a22a1c7b2e46a8e5dd4d9a9ef443eed3b0e&token=1082669959&lang=zh_CN#rd)(2019-02-01)
+- [2019年2月份Github上收获最多Star的10个Java项目](https://mp.weixin.qq.com/s?__biz=Mzg2OTA0Njk0OA==&mid=2247484749&idx=1&sn=a66a1e3707839454539d93499dcadfad&chksm=cea24a86f9d5c3902d07fc4614347606200536ddf9ee7464fe12bbbce5c1bd186ad9894f13e3&token=1082669959&lang=zh_CN#rd)(2019-03-05)
+- [3月Github最热门的10个Java开源项目](https://mp.weixin.qq.com/s/HYXFWeko2tGPCWhy-yrtEw)
+- [五一假期充电指南:4月Github最热门的Java项目推荐](https://mp.weixin.qq.com/s/3485Z0cbD1FvcWZMQTnRsw)
+
+## 架构
+
+- [8 张图读懂大型网站技术架构](https://mp.weixin.qq.com/s?__biz=Mzg2OTA0Njk0OA==&mid=2247484863&idx=1&sn=8b7c8ce77f5927564d69587688114c79&chksm=cea24a74f9d5c362b7140d18bfc198e7f39572b938e597d1725e4dcf541a12b33d8db6ac1b45&token=1082669959&lang=zh_CN#rd)
+- [【面试精选】关于大型网站系统架构你不得不懂的10个问题](https://mp.weixin.qq.com/s?__biz=Mzg2OTA0Njk0OA==&mid=2247484760&idx=1&sn=c41df36f538ab3d8907e23bf8f6d2cd5&chksm=cea24a93f9d5c3851f8a699fdf068f767e3571c38e1b2995297a3e5725f9ad024c6de2bcb100&token=1082669959&lang=zh_CN#rd)
+- [分布式系统的经典基础理论](https://mp.weixin.qq.com/s?__biz=Mzg2OTA0Njk0OA==&mid=2247484941&idx=1&sn=e0812a9ccfde06550e24c23c4bb5ef1d&chksm=cea249c6f9d5c0d0bd16fc26c7af606c775868f1f06d81fbff2f8093d2a686c3b3befe9b971c&token=1082669959&lang=zh_CN#rd)
+- [软件开发的七条原则](https://mp.weixin.qq.com/s?__biz=Mzg2OTA0Njk0OA==&mid=2247484938&idx=1&sn=597b1aec42d22caad051b3694816fb27&chksm=cea249c1f9d5c0d73bcedc02499cb44822f6b5ab9dcccd7f1a03f830aed158a1b9abec416efc&token=1082669959&lang=zh_CN#rd)
+- [关于分布式计算的一些概念](https://mp.weixin.qq.com/s?__biz=Mzg2OTA0Njk0OA==&mid=2247484935&idx=2&sn=2394583a73b41cca431e392a28b0b4cb&chksm=cea249ccf9d5c0da5d1d4b8cf2dffb00ae1b6b605afe6da426112f3208898c2cca6249865146&token=1082669959&lang=zh_CN#rd)
+
+## 工具
+
+- [Git入门看这一篇就够了!](https://mp.weixin.qq.com/s/ylyHOuEPX4tDvOc7-SxMmw)
+- [团队开发中的 Git 实践](https://mp.weixin.qq.com/s?__biz=Mzg2OTA0Njk0OA==&mid=2247485550&idx=1&sn=a0fa847b009c3c8c60c20773f0870dbf&chksm=cea247a5f9d5ceb317906f37d7dfbd44aebbe2206764cd8b50a25110c3125c7be3507ce3729e&token=2133161636&lang=zh_CN#rd)
+- [IDEA中的Git操作,看这一篇就够了!](https://mp.weixin.qq.com/s?__biz=Mzg2OTA0Njk0OA==&mid=2247485578&idx=1&sn=8f8ab9d597e1448053e5da380fff3e54&chksm=cea24741f9d5ce5791722dd3da12dfa3de5aa9d742e0cc78d0b72a89d75a48e6d84512265c30&token=2133161636&lang=zh_CN#rd)
+- [一文搞懂如何在Intellij IDEA中使用Debug,超级详细!](https://mp.weixin.qq.com/s?__biz=Mzg2OTA0Njk0OA==&mid=2247485250&idx=1&sn=9e1f270996441094104a06fc909c60f5&chksm=cea24889f9d5c19fbc6024779ca476a3ee141efa457fc86cc8c33a8f06a1c2b1e7b4922426c2&token=1667678311&lang=zh_CN#rd)
+- [十分钟搞懂Java效率工具Lombok使用与原理](https://mp.weixin.qq.com/s?__biz=Mzg2OTA0Njk0OA==&mid=2247485385&idx=2&sn=a7c3fb4485ffd8c019e5541e9b1580cd&chksm=cea24802f9d5c1144eee0da52cfc0cc5e8ee3590990de3bb642df4d4b2a8cd07f12dd54947b9&token=913106598&lang=zh_CN&scene=21#wechat_redirect)
+
+## 效率
+
+- [推荐几个可以提升工作效率的Chrome插件](https://mp.weixin.qq.com/s?__biz=Mzg2OTA0Njk0OA==&mid=2247485315&idx=1&sn=f5e91a9386a6911acbff4d7721065563&chksm=cea24848f9d5c15ec3bc0efab93351ca7481a609e901d9c9c07816a7a9737cdcdc1b5f6497db&token=1667678311&lang=zh_CN#rd)
+
+## 思维开阔
+
+- [不就是个短信登录API嘛,有这么复杂吗?](https://mp.weixin.qq.com/s?__biz=Mzg2OTA0Njk0OA==&mid=2247485181&idx=1&sn=7a7a7ce0671e8c5456add8da098501c2&chksm=cea24936f9d5c020fa1e339a819a17e7ae6099f1c5072d9ea235cf9fca45437d96cb117f7f10&token=1667678311&lang=zh_CN#rd)
+
+## 进阶
+
+- [可能是把Docker的概念讲的最清楚的一篇文章](https://mp.weixin.qq.com/s?__biz=Mzg2OTA0Njk0OA==&mid=2247484921&idx=1&sn=d40518712a04b3c37d7c8fcd3e696e90&chksm=cea24a32f9d5c3243db78a227ba4e77618e679bbc856cf1974fccbd474c44847672f21658147&token=1082669959&lang=zh_CN#rd)
+- [后端必备——数据通信知识(RPC、消息队列)一站式总结](https://mp.weixin.qq.com/s?__biz=Mzg2OTA0Njk0OA==&mid=2247484920&idx=1&sn=c7167df0b36522935896565973d02cc9&chksm=cea24a33f9d5c325fc663c95ebc221060ae2d5eeee254472558a99fdfc2837b31d3b9ae51a12&token=1082669959&lang=zh_CN#rd)
+- [可能是全网把 ZooKeeper 概念讲的最清楚的一篇文章](https://mp.weixin.qq.com/s?__biz=Mzg2OTA0Njk0OA==&mid=2247484868&idx=1&sn=af1e49c5f7dc89355255a4d46bafc005&chksm=cea24a0ff9d5c3195a690d2c85f09cd8901717674f52e10b0e6fd588d69de15de76b8184307d&token=1082669959&lang=zh_CN#rd)
+- [外行人都能看懂的SpringCloud,错过了血亏!](https://mp.weixin.qq.com/s?__biz=Mzg2OTA0Njk0OA==&mid=2247484813&idx=1&sn=d87c01aff031f35be6b88a61f5782da5&chksm=cea24a46f9d5c35023a54e20fa1319b4cd31c33b094e2fd161bb8667ab77b8b403af62cfb3b5&token=1082669959&lang=zh_CN#rd)
+- [关于 Dubbo 的重要入门知识点总结](https://mp.weixin.qq.com/s?__biz=Mzg2OTA0Njk0OA==&mid=2247484753&idx=1&sn=32d987bf9f6208e30326877b111cad61&chksm=cea24a9af9d5c38cc7eb4d9bfeaa07e72003a1bf304a0fedc3fabb2a87f01c98b5a7d1c80d53&token=1082669959&lang=zh_CN#rd)
+- [Java 工程师成神之路 | 2019正式版](https://mp.weixin.qq.com/s?__biz=Mzg2OTA0Njk0OA==&mid=2247484759&idx=1&sn=5a706091c1db2b585f0a93c75bca14da&chksm=cea24a9cf9d5c38a245bdc63a0c90934b02f582c34a8dfb4ef01cd149d4829d799cb9e9bd464&token=1082669959&lang=zh_CN#rd)
+- [聊一聊开发常用小工具](https://mp.weixin.qq.com/s?__biz=Mzg2OTA0Njk0OA==&mid=2247484769&idx=1&sn=0968ce79f4d31d982b9f1ce24b051432&chksm=cea24aaaf9d5c3bc5feb0ef4e814990c9e108b72a0691193b1dda29642ee2ff74da5026016f6&token=1082669959&lang=zh_CN#rd)
+- [新手也能看懂,消息队列其实很简单](https://mp.weixin.qq.com/s?__biz=Mzg2OTA0Njk0OA==&mid=2247484794&idx=1&sn=61585fe69eedb3654ee2f9c9cd67e1a1&chksm=cea24ab1f9d5c3a7fd07dd49244f69fc85a5a523ee5353fc9e442dcad2ca0dd1137ed563fcbe&token=1082669959&lang=zh_CN#rd)
+
+## 杂文闲记
+
+- [一只准准程序员的唠叨](http://mp.weixin.qq.com/s?__biz=Mzg2OTA0Njk0OA==&mid=2247484932&idx=1&sn=a4f3057ecd4412cb8b18e92058b29680&chksm=cea249cff9d5c0d97580310f6666a4e0c42cfd1ba13dd759850e489c9386dce8c5c35b0a1a95&token=1082669959&lang=zh_CN#rd)(2018-06-09)
+- [说几件近期的小事](https://mp.weixin.qq.com/s?__biz=Mzg2OTA0Njk0OA==&mid=2247484900&idx=1&sn=745e8f6027da369ef5f8e349cb5d6657&chksm=cea24a2ff9d5c339c925322ffacdc72dd37bda63238dfb3452540085c1695681e2e79070e2a7&token=1082669959&lang=zh_CN#rd)(2018-08-02)
+- [选择技术方向都要考虑哪些因素](https://mp.weixin.qq.com/s?__biz=Mzg2OTA0Njk0OA==&mid=2247484898&idx=1&sn=fd2ebf9ffd37ab5de1de09cd3272ac0a&chksm=cea24a29f9d5c33fa48f5a57de864cd9382a730578fb18d78b7f06b45504aede18b235b9bc9e&token=1082669959&lang=zh_CN#rd)(2018-08-04)
+- [结束了我短暂的秋招,说点自己的感受](https://mp.weixin.qq.com/s?__biz=Mzg2OTA0Njk0OA==&mid=2247484842&idx=1&sn=4489dfab0ef2479122b71407855afc71&chksm=cea24a61f9d5c3774a8ed67c5fcc3234cb0741fbe831152986e5d1c8fb4f36a003f4fb2f247e&token=1082669959&lang=zh_CN#rd)(2018-10-22)
+- [【周日闲谈】最近想说的几件小事](https://mp.weixin.qq.com/s?__biz=Mzg2OTA0Njk0OA==&mid=2247484818&idx=1&sn=e14b0a08537456eb15ba49cf5e70ff74&chksm=cea24a59f9d5c34fe0a9e0567d867b85a81d1f19b0ea8e6a3c14161e436508de9adfeb2a5e6a&token=1082669959&lang=zh_CN#rd)(2018-11-18)
+- [做公众号这一年的经历和一件“大事”](http://mp.weixin.qq.com/s?__biz=Mzg2OTA0Njk0OA==&mid=2247484746&idx=1&sn=a519a9e3d638bff5c65008f7de167e4b&chksm=cea24a81f9d5c397ca9ac5668ba6cb18b38065e0e282a34ebc077a2dea98de3f1eb285ea5f09&token=1082669959&lang=zh_CN#rd)(2019-03-10)
+- [几经周折,公众号终于留言功能啦!](https://mp.weixin.qq.com/s?__biz=Mzg2OTA0Njk0OA==&mid=2247485007&idx=1&sn=096a436cd6a9251c23b8effc3cfa5076&chksm=cea24984f9d5c092d1f7740d1c3e0ea347562ba0aa597507ce275c5bdf1c8bd608328ee756ba&token=1082669959&lang=zh_CN#rd)(2019-03-15)
+- [写在毕业季的大学总结!细数一下大学干过的“傻事”。](https://mp.weixin.qq.com/s?__biz=Mzg2OTA0Njk0OA==&mid=2247485358&idx=1&sn=3aaf1163fe13351e06c76b70f2bd33bd&chksm=cea24865f9d5c1735b51c707c8f5ade16af7eca304540205ab0fb1284f99034d418b9858d7db&token=1667678311&lang=zh_CN#rd) (2019-06-11)
+- [入职一个月的职场小白,谈谈自己这段时间的感受](https://mp.weixin.qq.com/s?__biz=Mzg2OTA0Njk0OA==&mid=2247485540&idx=1&sn=4492eece8f7738e99350118040e14a79&chksm=cea247aff9d5ceb9e7c67f418d8a8518c550fd7dd269bf2c9bdef83309502273b4b9f1e7021f&token=1333232257&lang=zh_CN&scene=21#wechat_redirect)
+
+## 其他好文推荐
+
+- [谈恋爱也要懂https](https://mp.weixin.qq.com/s?__biz=Mzg2OTA0Njk0OA==&mid=2247484821&idx=1&sn=e6ce4ec607a6c9b20edbd64fbeb0f6c5&chksm=cea24a5ef9d5c3480d3de284fc1038b51c2464152e25a350960efd81acd21f71d7e0eeb78c77&token=1082669959&lang=zh_CN#rd)
+- [快速入门大厂后端面试必备的 Shell 编程](https://mp.weixin.qq.com/s?__biz=Mzg2OTA0Njk0OA==&mid=2247484810&idx=1&sn=0b622ae617b863ef1cc3a32c17b8b755&chksm=cea24a41f9d5c357199073c1e4692b7da7dcbd1809cf634a6cfec8c64c12250efc5274992f06&token=1082669959&lang=zh_CN#rd)
+- [为什么阿里巴巴禁止工程师直接使用日志系统(Log4j、Logback)中的 API](https://mp.weixin.qq.com/s?__biz=Mzg2OTA0Njk0OA==&mid=2247484808&idx=1&sn=4774ecc18069e4ddc85f68877cff1ae3&chksm=cea24a43f9d5c35520a454d51e72c6084d38f505969835011f4dd36f76c78303af46780802c9&token=1082669959&lang=zh_CN#rd)
+- [一文搞懂 RabbitMQ 的重要概念以及安装](https://mp.weixin.qq.com/s?__biz=Mzg2OTA0Njk0OA==&mid=2247484792&idx=1&sn=d34fdbb6cb21c231361038a7317ac2a4&chksm=cea24ab3f9d5c3a5c742de10cd0f7c77425b2144c86d2515d3e5d2011f4d16af12110c2de986&token=1082669959&lang=zh_CN#rd)
+- [漫话:如何给女朋友解释什么是RPC](https://mp.weixin.qq.com/s?__biz=Mzg2OTA0Njk0OA==&mid=2247484795&idx=1&sn=64eb2dcac07cf6904ca79b14f408df9e&chksm=cea24ab0f9d5c3a6970c3fbbdcaa16d5230b51abed9bacd1cd2ea3192cccea4aba0ef2d1a9de&token=1082669959&lang=zh_CN#rd)
+- [Java人才市场年度盘点:转折与终局](https://mp.weixin.qq.com/s?__biz=Mzg2OTA0Njk0OA==&mid=2247484779&idx=1&sn=a930b09a1783bca68e927cbe7d7a54a6&chksm=cea24aa0f9d5c3b6864ab3585a4cc5de1fa89ffc07538f2c55382776bfee0c369d7d74af7c79&token=1082669959&lang=zh_CN#rd)
+- [Github 上日获 800多 star 的阿里微服务架构分布式事务解决方案 FESCAR开源啦](https://mp.weixin.qq.com/s?__biz=Mzg2OTA0Njk0OA==&mid=2247484776&idx=2&sn=bcd1cf6d72653bfff83724f1dbae0425&chksm=cea24aa3f9d5c3b5e9667f1e15f295d323efb3b2c8da6c9059f5e8b5e176b9cb1bf80cd1a78f&token=1082669959&lang=zh_CN#rd)
+- [Cloud Toolkit新版本发布,开发效率 “biu” 起来了](https://mp.weixin.qq.com/s?__biz=Mzg2OTA0Njk0OA==&mid=2247484771&idx=2&sn=0eef929baacca950099ea8651f0e5cb2&chksm=cea24aa8f9d5c3bed5f359e6da981ac950dca8f31a93f1fe321d7de7908d843855604e79a4da&token=1082669959&lang=zh_CN#rd)
+- [我觉得技术人员该有的提问方式](https://mp.weixin.qq.com/s/eTEah5WOdfC3EAPbhpOKBA)
\ No newline at end of file
diff --git a/docs/index.html b/index.html
similarity index 84%
rename from docs/index.html
rename to index.html
index f6ebaf23a7d..83d0a7d737d 100644
--- a/docs/index.html
+++ b/index.html
@@ -16,9 +16,9 @@
name: 'JavaGuide',
repo: 'https://github.com/Snailclimb/JavaGuide',
maxLevel: 3,//最大支持渲染的标题层级
- homepage: 'HomePage.md',
coverpage: true,//封面,_coverpage.md
auto2top: true,//切换页面后是否自动跳转到页面顶部
+ //ga: 'UA-138586553-1',
//logo: 'https://my-blog-to-use.oss-cn-beijing.aliyuncs.com/2019-3logo-透明.png' ,
search: {
//maxAge: 86400000, // 过期时间,单位毫秒,默认一天
@@ -33,9 +33,12 @@
-
+
-
+
 +
+
+## 目录
+
+- [Java](#java)
+ - [基础](#基础)
+ - [容器](#容器)
+ - [并发](#并发)
+ - [JVM](#jvm)
+ - [I/O](#io)
+ - [Java 8](#java-8)
+ - [编程规范](#编程规范)
+- [网络](#网络)
+- [操作系统](#操作系统)
+ - [Linux相关](#linux相关)
+- [数据结构与算法](#数据结构与算法)
+ - [数据结构](#数据结构)
+ - [算法](#算法)
+- [数据库](#数据库)
+ - [MySQL](#mysql)
+ - [Redis](#redis)
+- [系统设计](#系统设计)
+ - [设计模式(工厂模式、单例模式 ... )](#设计模式)
+ - [常用框架(Spring、Zookeeper ... )](#常用框架)
+ - [数据通信(消息队列、Dubbo ... )](#数据通信)
+ - [网站架构](#网站架构)
+- [面试指南](#面试指南)
+ - [备战面试](#备战面试)
+ - [常见面试题总结](#常见面试题总结)
+ - [面经](#面经)
+- [工具](#工具)
+ - [Git](#git)
+ - [Docker](#Docker)
+- [资料](#资料)
+ - [书单](#书单)
+ - [Github榜单](#Github榜单)
+- [待办](#待办)
+- [说明](#说明)
+
+## Java
+
+### 基础
+
+* [Java 基础知识回顾](java/Java基础知识.md)
+* [Java 基础知识疑难点总结](java/Java疑难点.md)
+* [J2EE 基础知识回顾](java/J2EE基础知识.md)
+
+### 容器
+
+* [Java容器常见面试题/知识点总结](java/collection/Java集合框架常见面试题.md)
+* [ArrayList 源码学习](java/collection/ArrayList.md)
+* [LinkedList 源码学习](java/collection/LinkedList.md)
+* [HashMap(JDK1.8)源码学习](java/collection/HashMap.md)
+
+### 并发
+
+* [Java 并发基础常见面试题总结](java/Multithread/JavaConcurrencyBasicsCommonInterviewQuestionsSummary.md)
+* [Java 并发进阶常见面试题总结](java/Multithread/JavaConcurrencyAdvancedCommonInterviewQuestions.md)
+* [并发容器总结](java/Multithread/并发容器总结.md)
+* [乐观锁与悲观锁](essential-content-for-interview/面试必备之乐观锁与悲观锁.md)
+* [JUC 中的 Atomic 原子类总结](java/Multithread/Atomic.md)
+* [AQS 原理以及 AQS 同步组件总结](java/Multithread/AQS.md)
+
+### JVM
+* [一 Java内存区域](java/jvm/Java内存区域.md)
+* [二 JVM垃圾回收](java/jvm/JVM垃圾回收.md)
+* [三 JDK 监控和故障处理工具](java/jvm/JDK监控和故障处理工具总结.md)
+* [四 类文件结构](java/jvm/类文件结构.md)
+* [五 类加载过程](java/jvm/类加载过程.md)
+* [六 类加载器](java/jvm/类加载器.md)
+
+### I/O
+
+* [BIO,NIO,AIO 总结 ](java/BIO-NIO-AIO.md)
+* [Java IO 与 NIO系列文章](java/Java%20IO与NIO.md)
+
+### Java 8
+
+* [Java 8 新特性总结](java/What's%20New%20in%20JDK8/Java8Tutorial.md)
+* [Java 8 学习资源推荐](java/What's%20New%20in%20JDK8/Java8教程推荐.md)
+
+### 编程规范
+
+- [Java 编程规范](java/Java编程规范.md)
+
+## 网络
+
+* [计算机网络常见面试题](network/计算机网络.md)
+* [计算机网络基础知识总结](network/干货:计算机网络知识总结.md)
+* [HTTPS中的TLS](network/HTTPS中的TLS.md)
+
+## 操作系统
+
+### Linux相关
+
+* [后端程序员必备的 Linux 基础知识](operating-system/后端程序员必备的Linux基础知识.md)
+* [Shell 编程入门](operating-system/Shell.md)
+
+## 数据结构与算法
+
+### 数据结构
+
+- [数据结构知识学习与面试](dataStructures-algorithms/数据结构.md)
+
+### 算法
+
+- [算法学习资源推荐](dataStructures-algorithms/算法学习资源推荐.md)
+- [几道常见的字符串算法题总结 ](dataStructures-algorithms/几道常见的子符串算法题.md)
+- [几道常见的链表算法题总结 ](dataStructures-algorithms/几道常见的链表算法题.md)
+- [剑指offer部分编程题](dataStructures-algorithms/剑指offer部分编程题.md)
+- [公司真题](dataStructures-algorithms/公司真题.md)
+- [回溯算法经典案例之N皇后问题](dataStructures-algorithms/Backtracking-NQueens.md)
+
+## 数据库
+
+### MySQL
+
+* [MySQL 学习与面试](database/MySQL.md)
+* [一千行MySQL学习笔记](database/一千行MySQL命令.md)
+* [MySQL高性能优化规范建议](database/MySQL高性能优化规范建议.md)
+* [数据库索引总结](database/MySQL%20Index.md)
+* [事务隔离级别(图文详解)](database/事务隔离级别(图文详解).md)
+* [一条SQL语句在MySQL中如何执行的](database/一条sql语句在mysql中如何执行的.md)
+
+### Redis
+
+* [Redis 总结](database/Redis/Redis.md)
+* [Redlock分布式锁](database/Redis/Redlock分布式锁.md)
+* [如何做可靠的分布式锁,Redlock真的可行么](database/Redis/如何做可靠的分布式锁,Redlock真的可行么.md)
+
+## 系统设计
+
+### 设计模式
+
+- [设计模式系列文章](system-design/设计模式.md)
+
+### 常用框架
+
+#### Spring
+
+- [Spring 学习与面试](system-design/framework/spring/Spring.md)
+- [Spring 常见问题总结](system-design/framework/spring/SpringInterviewQuestions.md)
+- [Spring中bean的作用域与生命周期](system-design/framework/spring/SpringBean.md)
+- [SpringMVC 工作原理详解](system-design/framework/spring/SpringMVC-Principle.md)
+- [Spring中都用到了那些设计模式?](system-design/framework/spring/Spring-Design-Patterns.md)
+
+#### ZooKeeper
+
+- [ZooKeeper 相关概念总结](system-design/framework/ZooKeeper.md)
+- [ZooKeeper 数据模型和常见命令](system-design/framework/ZooKeeper数据模型和常见命令.md)
+
+### 数据通信
+
+- [数据通信(RESTful、RPC、消息队列)相关知识点总结](system-design/data-communication/summary.md)
+- [Dubbo 总结:关于 Dubbo 的重要知识点](system-design/data-communication/dubbo.md)
+- [消息队列总结](system-design/data-communication/message-queue.md)
+- [RabbitMQ 入门](system-design/data-communication/rabbitmq.md)
+- [RocketMQ的几个简单问题与答案](system-design/data-communication/RocketMQ-Questions.md)
+
+### 网站架构
+
+- [一文读懂分布式应该学什么](system-design/website-architecture/分布式.md)
+- [8 张图读懂大型网站技术架构](system-design/website-architecture/8%20张图读懂大型网站技术架构.md)
+- [【面试精选】关于大型网站系统架构你不得不懂的10个问题](system-design/website-architecture/【面试精选】关于大型网站系统架构你不得不懂的10个问题.md)
+
+## 面试指南
+
+### 备战面试
+
+* [【备战面试1】程序员的简历就该这样写](essential-content-for-interview/PreparingForInterview/程序员的简历之道.md)
+* [【备战面试2】初出茅庐的程序员该如何准备面试?](essential-content-for-interview/PreparingForInterview/interviewPrepare.md)
+* [【备战面试3】7个大部分程序员在面试前很关心的问题](essential-content-for-interview/PreparingForInterview/JavaProgrammerNeedKnow.md)
+* [【备战面试4】Github上开源的Java面试/学习相关的仓库推荐](essential-content-for-interview/PreparingForInterview/JavaInterviewLibrary.md)
+* [【备战面试5】如果面试官问你“你有什么问题问我吗?”时,你该如何回答](essential-content-for-interview/PreparingForInterview/如果面试官问你“你有什么问题问我吗?”时,你该如何回答.md)
+* [【备战面试6】美团面试常见问题总结(附详解答案)](essential-content-for-interview/PreparingForInterview/美团面试常见问题总结.md)
+
+### 常见面试题总结
+
+* [第一周(2018-8-7)](essential-content-for-interview/MostCommonJavaInterviewQuestions/第一周(2018-8-7).md) (为什么 Java 中只有值传递、==与equals、 hashCode与equals)
+* [第二周(2018-8-13)](essential-content-for-interview/MostCommonJavaInterviewQuestions/第二周(2018-8-13).md)(String和StringBuffer、StringBuilder的区别是什么?String为什么是不可变的?、什么是反射机制?反射机制的应用场景有哪些?......)
+* [第三周(2018-08-22)](java/collection/Java集合框架常见面试题.md) (Arraylist 与 LinkedList 异同、ArrayList 与 Vector 区别、HashMap的底层实现、HashMap 和 Hashtable 的区别、HashMap 的长度为什么是2的幂次方、HashSet 和 HashMap 区别、ConcurrentHashMap 和 Hashtable 的区别、ConcurrentHashMap线程安全的具体实现方式/底层具体实现、集合框架底层数据结构总结)
+* [第四周(2018-8-30).md](essential-content-for-interview/MostCommonJavaInterviewQuestions/第四周(2018-8-30).md) (主要内容是几道面试常问的多线程基础题。)
+
+### 面经
+
+- [5面阿里,终获offer(2018年秋招)](essential-content-for-interview/BATJrealInterviewExperience/5面阿里,终获offer.md)
+- [蚂蚁金服2019实习生面经总结(已拿口头offer)](essential-content-for-interview/BATJrealInterviewExperience/蚂蚁金服实习生面经总结(已拿口头offer).md)
+- [2019年蚂蚁金服、头条、拼多多的面试总结](essential-content-for-interview/BATJrealInterviewExperience/2019alipay-pinduoduo-toutiao.md)
+
+## 工具
+
+### Git
+
+* [Git入门](tools/Git.md)
+
+### Docker
+
+* [Docker 入门](tools/Docker.md)
+* [一文搞懂 Docker 镜像的常用操作!](tools/Docker-Image.md)
+
+## 资料
+
+### 书单
+
+- [Java程序员必备书单](data/java-recommended-books.md)
+
+### Github榜单
+
+- [Java 项目月榜单](github-trending/JavaGithubTrending.md)
+
+***
+
+## 待办
+
+- [x] [Java 8 新特性总结](./java/What's%20New%20in%20JDK8/Java8Tutorial.md)
+- [x] [Java 8 新特性详解](./java/What's%20New%20in%20JDK8/Java8教程推荐.md)
+- [ ] Java 多线程类别知识重构(---正在进行中---)
+- [x] [BIO,NIO,AIO 总结 ](./java/BIO-NIO-AIO.md)
+- [ ] Netty 总结(---正在进行中---)
+- [ ] 数据结构总结重构(---正在进行中---)
+
+## 公众号
+
+- 如果大家想要实时关注我更新的文章以及分享的干货的话,可以关注我的公众号。
+- 由本文档衍生的专为面试而生的《Java面试突击》V2.0 PDF 版本公众号后台回复 **"Java面试突击"** 即可免费领取!
+- 一些Java工程师常用学习资源公众号后台回复关键字 **“1”** 即可免费无套路获取。
+
+
+
+
+## 目录
+
+- [Java](#java)
+ - [基础](#基础)
+ - [容器](#容器)
+ - [并发](#并发)
+ - [JVM](#jvm)
+ - [I/O](#io)
+ - [Java 8](#java-8)
+ - [编程规范](#编程规范)
+- [网络](#网络)
+- [操作系统](#操作系统)
+ - [Linux相关](#linux相关)
+- [数据结构与算法](#数据结构与算法)
+ - [数据结构](#数据结构)
+ - [算法](#算法)
+- [数据库](#数据库)
+ - [MySQL](#mysql)
+ - [Redis](#redis)
+- [系统设计](#系统设计)
+ - [设计模式(工厂模式、单例模式 ... )](#设计模式)
+ - [常用框架(Spring、Zookeeper ... )](#常用框架)
+ - [数据通信(消息队列、Dubbo ... )](#数据通信)
+ - [网站架构](#网站架构)
+- [面试指南](#面试指南)
+ - [备战面试](#备战面试)
+ - [常见面试题总结](#常见面试题总结)
+ - [面经](#面经)
+- [工具](#工具)
+ - [Git](#git)
+ - [Docker](#Docker)
+- [资料](#资料)
+ - [书单](#书单)
+ - [Github榜单](#Github榜单)
+- [待办](#待办)
+- [说明](#说明)
+
+## Java
+
+### 基础
+
+* [Java 基础知识回顾](java/Java基础知识.md)
+* [Java 基础知识疑难点总结](java/Java疑难点.md)
+* [J2EE 基础知识回顾](java/J2EE基础知识.md)
+
+### 容器
+
+* [Java容器常见面试题/知识点总结](java/collection/Java集合框架常见面试题.md)
+* [ArrayList 源码学习](java/collection/ArrayList.md)
+* [LinkedList 源码学习](java/collection/LinkedList.md)
+* [HashMap(JDK1.8)源码学习](java/collection/HashMap.md)
+
+### 并发
+
+* [Java 并发基础常见面试题总结](java/Multithread/JavaConcurrencyBasicsCommonInterviewQuestionsSummary.md)
+* [Java 并发进阶常见面试题总结](java/Multithread/JavaConcurrencyAdvancedCommonInterviewQuestions.md)
+* [并发容器总结](java/Multithread/并发容器总结.md)
+* [乐观锁与悲观锁](essential-content-for-interview/面试必备之乐观锁与悲观锁.md)
+* [JUC 中的 Atomic 原子类总结](java/Multithread/Atomic.md)
+* [AQS 原理以及 AQS 同步组件总结](java/Multithread/AQS.md)
+
+### JVM
+* [一 Java内存区域](java/jvm/Java内存区域.md)
+* [二 JVM垃圾回收](java/jvm/JVM垃圾回收.md)
+* [三 JDK 监控和故障处理工具](java/jvm/JDK监控和故障处理工具总结.md)
+* [四 类文件结构](java/jvm/类文件结构.md)
+* [五 类加载过程](java/jvm/类加载过程.md)
+* [六 类加载器](java/jvm/类加载器.md)
+
+### I/O
+
+* [BIO,NIO,AIO 总结 ](java/BIO-NIO-AIO.md)
+* [Java IO 与 NIO系列文章](java/Java%20IO与NIO.md)
+
+### Java 8
+
+* [Java 8 新特性总结](java/What's%20New%20in%20JDK8/Java8Tutorial.md)
+* [Java 8 学习资源推荐](java/What's%20New%20in%20JDK8/Java8教程推荐.md)
+
+### 编程规范
+
+- [Java 编程规范](java/Java编程规范.md)
+
+## 网络
+
+* [计算机网络常见面试题](network/计算机网络.md)
+* [计算机网络基础知识总结](network/干货:计算机网络知识总结.md)
+* [HTTPS中的TLS](network/HTTPS中的TLS.md)
+
+## 操作系统
+
+### Linux相关
+
+* [后端程序员必备的 Linux 基础知识](operating-system/后端程序员必备的Linux基础知识.md)
+* [Shell 编程入门](operating-system/Shell.md)
+
+## 数据结构与算法
+
+### 数据结构
+
+- [数据结构知识学习与面试](dataStructures-algorithms/数据结构.md)
+
+### 算法
+
+- [算法学习资源推荐](dataStructures-algorithms/算法学习资源推荐.md)
+- [几道常见的字符串算法题总结 ](dataStructures-algorithms/几道常见的子符串算法题.md)
+- [几道常见的链表算法题总结 ](dataStructures-algorithms/几道常见的链表算法题.md)
+- [剑指offer部分编程题](dataStructures-algorithms/剑指offer部分编程题.md)
+- [公司真题](dataStructures-algorithms/公司真题.md)
+- [回溯算法经典案例之N皇后问题](dataStructures-algorithms/Backtracking-NQueens.md)
+
+## 数据库
+
+### MySQL
+
+* [MySQL 学习与面试](database/MySQL.md)
+* [一千行MySQL学习笔记](database/一千行MySQL命令.md)
+* [MySQL高性能优化规范建议](database/MySQL高性能优化规范建议.md)
+* [数据库索引总结](database/MySQL%20Index.md)
+* [事务隔离级别(图文详解)](database/事务隔离级别(图文详解).md)
+* [一条SQL语句在MySQL中如何执行的](database/一条sql语句在mysql中如何执行的.md)
+
+### Redis
+
+* [Redis 总结](database/Redis/Redis.md)
+* [Redlock分布式锁](database/Redis/Redlock分布式锁.md)
+* [如何做可靠的分布式锁,Redlock真的可行么](database/Redis/如何做可靠的分布式锁,Redlock真的可行么.md)
+
+## 系统设计
+
+### 设计模式
+
+- [设计模式系列文章](system-design/设计模式.md)
+
+### 常用框架
+
+#### Spring
+
+- [Spring 学习与面试](system-design/framework/spring/Spring.md)
+- [Spring 常见问题总结](system-design/framework/spring/SpringInterviewQuestions.md)
+- [Spring中bean的作用域与生命周期](system-design/framework/spring/SpringBean.md)
+- [SpringMVC 工作原理详解](system-design/framework/spring/SpringMVC-Principle.md)
+- [Spring中都用到了那些设计模式?](system-design/framework/spring/Spring-Design-Patterns.md)
+
+#### ZooKeeper
+
+- [ZooKeeper 相关概念总结](system-design/framework/ZooKeeper.md)
+- [ZooKeeper 数据模型和常见命令](system-design/framework/ZooKeeper数据模型和常见命令.md)
+
+### 数据通信
+
+- [数据通信(RESTful、RPC、消息队列)相关知识点总结](system-design/data-communication/summary.md)
+- [Dubbo 总结:关于 Dubbo 的重要知识点](system-design/data-communication/dubbo.md)
+- [消息队列总结](system-design/data-communication/message-queue.md)
+- [RabbitMQ 入门](system-design/data-communication/rabbitmq.md)
+- [RocketMQ的几个简单问题与答案](system-design/data-communication/RocketMQ-Questions.md)
+
+### 网站架构
+
+- [一文读懂分布式应该学什么](system-design/website-architecture/分布式.md)
+- [8 张图读懂大型网站技术架构](system-design/website-architecture/8%20张图读懂大型网站技术架构.md)
+- [【面试精选】关于大型网站系统架构你不得不懂的10个问题](system-design/website-architecture/【面试精选】关于大型网站系统架构你不得不懂的10个问题.md)
+
+## 面试指南
+
+### 备战面试
+
+* [【备战面试1】程序员的简历就该这样写](essential-content-for-interview/PreparingForInterview/程序员的简历之道.md)
+* [【备战面试2】初出茅庐的程序员该如何准备面试?](essential-content-for-interview/PreparingForInterview/interviewPrepare.md)
+* [【备战面试3】7个大部分程序员在面试前很关心的问题](essential-content-for-interview/PreparingForInterview/JavaProgrammerNeedKnow.md)
+* [【备战面试4】Github上开源的Java面试/学习相关的仓库推荐](essential-content-for-interview/PreparingForInterview/JavaInterviewLibrary.md)
+* [【备战面试5】如果面试官问你“你有什么问题问我吗?”时,你该如何回答](essential-content-for-interview/PreparingForInterview/如果面试官问你“你有什么问题问我吗?”时,你该如何回答.md)
+* [【备战面试6】美团面试常见问题总结(附详解答案)](essential-content-for-interview/PreparingForInterview/美团面试常见问题总结.md)
+
+### 常见面试题总结
+
+* [第一周(2018-8-7)](essential-content-for-interview/MostCommonJavaInterviewQuestions/第一周(2018-8-7).md) (为什么 Java 中只有值传递、==与equals、 hashCode与equals)
+* [第二周(2018-8-13)](essential-content-for-interview/MostCommonJavaInterviewQuestions/第二周(2018-8-13).md)(String和StringBuffer、StringBuilder的区别是什么?String为什么是不可变的?、什么是反射机制?反射机制的应用场景有哪些?......)
+* [第三周(2018-08-22)](java/collection/Java集合框架常见面试题.md) (Arraylist 与 LinkedList 异同、ArrayList 与 Vector 区别、HashMap的底层实现、HashMap 和 Hashtable 的区别、HashMap 的长度为什么是2的幂次方、HashSet 和 HashMap 区别、ConcurrentHashMap 和 Hashtable 的区别、ConcurrentHashMap线程安全的具体实现方式/底层具体实现、集合框架底层数据结构总结)
+* [第四周(2018-8-30).md](essential-content-for-interview/MostCommonJavaInterviewQuestions/第四周(2018-8-30).md) (主要内容是几道面试常问的多线程基础题。)
+
+### 面经
+
+- [5面阿里,终获offer(2018年秋招)](essential-content-for-interview/BATJrealInterviewExperience/5面阿里,终获offer.md)
+- [蚂蚁金服2019实习生面经总结(已拿口头offer)](essential-content-for-interview/BATJrealInterviewExperience/蚂蚁金服实习生面经总结(已拿口头offer).md)
+- [2019年蚂蚁金服、头条、拼多多的面试总结](essential-content-for-interview/BATJrealInterviewExperience/2019alipay-pinduoduo-toutiao.md)
+
+## 工具
+
+### Git
+
+* [Git入门](tools/Git.md)
+
+### Docker
+
+* [Docker 入门](tools/Docker.md)
+* [一文搞懂 Docker 镜像的常用操作!](tools/Docker-Image.md)
+
+## 资料
+
+### 书单
+
+- [Java程序员必备书单](data/java-recommended-books.md)
+
+### Github榜单
+
+- [Java 项目月榜单](github-trending/JavaGithubTrending.md)
+
+***
+
+## 待办
+
+- [x] [Java 8 新特性总结](./java/What's%20New%20in%20JDK8/Java8Tutorial.md)
+- [x] [Java 8 新特性详解](./java/What's%20New%20in%20JDK8/Java8教程推荐.md)
+- [ ] Java 多线程类别知识重构(---正在进行中---)
+- [x] [BIO,NIO,AIO 总结 ](./java/BIO-NIO-AIO.md)
+- [ ] Netty 总结(---正在进行中---)
+- [ ] 数据结构总结重构(---正在进行中---)
+
+## 公众号
+
+- 如果大家想要实时关注我更新的文章以及分享的干货的话,可以关注我的公众号。
+- 由本文档衍生的专为面试而生的《Java面试突击》V2.0 PDF 版本公众号后台回复 **"Java面试突击"** 即可免费领取!
+- 一些Java工程师常用学习资源公众号后台回复关键字 **“1”** 即可免费无套路获取。
+
+ -
-  +
+ 

 +
+ +
+



 +
+ +
+ +
+ +
+