@@ -549,14 +488,10 @@ Voici un premier résumé, accompagné d'un comparatif avec `R`
| Opération | pandas | dplyr (`R`) | data.table (`R`) |
|-------------------------------|--------------|----------------|----------------------------|
| Récupérer le nom des colonnes | `df.columns` | `colnames(df)` | `colnames(df)` |
-| Récupérer les indices[^4] | `df.index` | |`unique(df[,get(key(df))])` |
-| Récupérer les dimensions | `df.shape` | `c(nrow(df), ncol(df))` | `c(nrow(df), ncol(df))` |
+| Récupérer les indices | `df.index` | |`unique(df[,get(key(df))])` |
+| Récupérer les dimensions | `df.shape` | `dim(df)` | `dim(df)` |
| Récupérer le nombre de valeurs uniques d'une variable | `df['myvar'].nunique()` | `df %>% summarise(distinct(myvar))` | `df[,uniqueN(myvar)]` |
-::: {.cell .markdown}
-[^4]: Le principe d'indice n'existe pas dans `dplyr`. Ce qui s'approche le plus des indices, au sens de
-`pandas`, sont les *clés* en `data.table`.
-:::
### Statistiques agrégées
@@ -773,7 +708,7 @@ df_example
L'objectif du [TP pandas](#pandasTP) est de se familiariser plus avec ces
commandes à travers l'exemple des données des émissions de C02.
-Les opérations les plus fréquentes en SQL `sont` résumées par le tableau suivant.
+Les opérations les plus fréquentes en `SQL` sont résumées par le tableau suivant.
Il est utile de les connaître (beaucoup de syntaxes de maniement de données
reprennent ces termes) car, d'une
manière ou d'une autre, elles couvrent la plupart
@@ -788,6 +723,21 @@ des usages de manipulation des données
| Effectuer une opération par groupe | `GROUP BY` | `df.groupby('Commune').mean()` | `df %>% group_by(Commune) %>% summarise(m = mean)` | `df[,mean(Commune), by = Commune]` |
| Joindre deux bases de données (*inner join*) | `SELECT * FROM table1 INNER JOIN table2 ON table1.id = table2.x` | `table1.merge(table2, left_on = 'id', right_on = 'x')` | `table1 %>% inner_join(table2, by = c('id'='x'))` | `merge(table1, table2, by.x = 'id', by.y = 'x')` |
+Quelques uns de ces concepts illustrés:
+
+::: {layout-ncol=2}
+
+
+
+
+
+
+
+
+
+:::
+
+
### Opérations sur les colonnes: `select`, `mutate`, `drop`
Les `DataFrames` pandas sont des objets *mutables* en langage `Python`,
@@ -958,7 +908,7 @@ L'image suivante, issue de
représente bien la manière dont fonctionne l'approche
`split`-`apply`-`combine`
-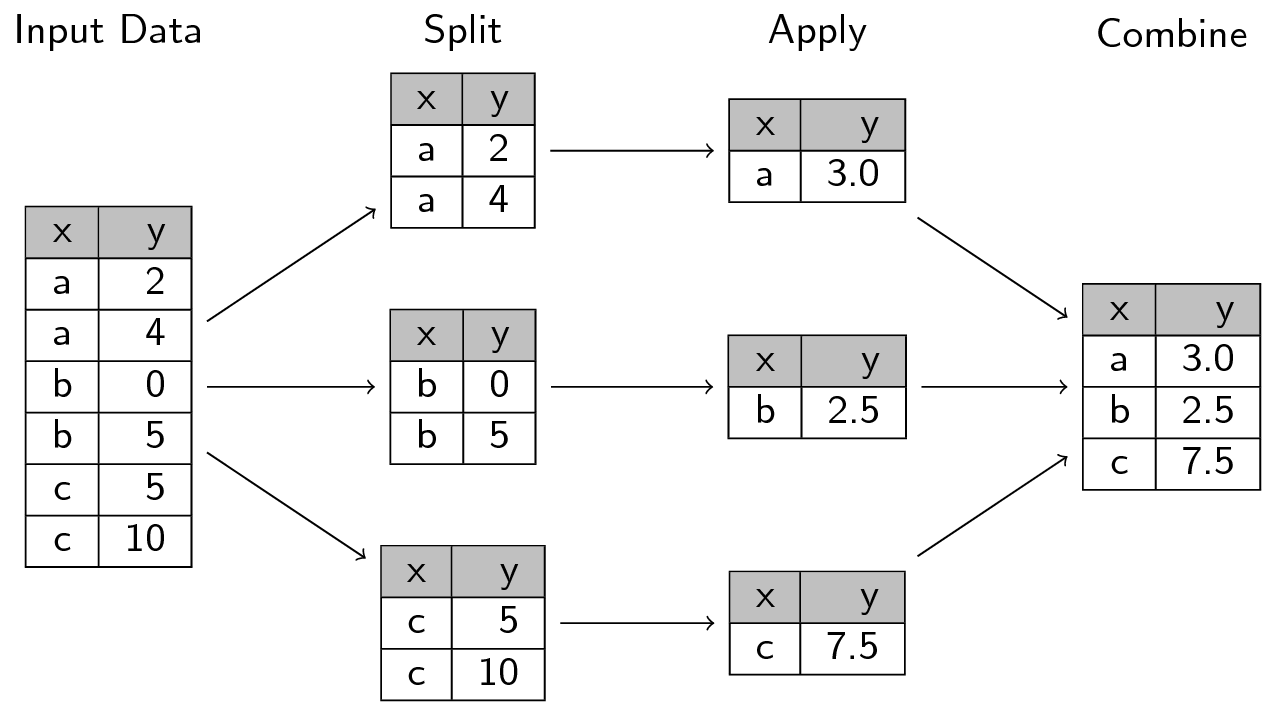
+{fig-width=70%}
Ce [tutoriel](https://realpython.com/pandas-groupby/) sur le sujet
diff --git a/content/manipulation/02b_pandas_TP.qmd b/content/manipulation/02b_pandas_TP.qmd
index b64dbee71..86d558f50 100644
--- a/content/manipulation/02b_pandas_TP.qmd
+++ b/content/manipulation/02b_pandas_TP.qmd
@@ -19,9 +19,8 @@ description: |
ce chapitre vise à illustrer les fonctionalités du _package_
à partir de données d'émissions de gaz à effet de serre
de l'[`Ademe`](https://data.ademe.fr/).
-echo: true
-output: false
-image: featured_tp_pandas.png
+echo: false
+image: panda_stretching.png
---
Les exemples de ce TP sont visualisables sous forme de `Jupyter Notebooks`:
@@ -42,31 +41,49 @@ print_badges("content/manipulation/02b_pandas_TP.qmd")
```
:::
-Dans ce tutoriel `Pandas`, nous allons utiliser deux sources de données :
+Dans cette série d'exercices `Pandas`,
+nous allons découvrir comment manipuler plusieurs
+jeux de données avec `Python`.
-* Les émissions de gaz à effet de serre estimées au niveau communal par l'`ADEME`. Le jeu de données est
-disponible sur [data.gouv](https://www.data.gouv.fr/fr/datasets/inventaire-de-gaz-a-effet-de-serre-territorialise/#_)
-et requêtable directement dans python avec
-[cet url](https://koumoul.com/s/data-fair/api/v1/datasets/igt-pouvoir-de-rechauffement-global/convert).
-`pandas` offre la possibilité d'importer des données directement depuis un url. C'est l'option
-prise dans ce tutoriel.
-Si vous préfèrez, pour des
-raisons d'accès au réseau ou de performance, importer depuis un poste local,
-vous pouvez télécharger les données et changer
-les commandes d'import avec le chemin adéquat plutôt que l'url.
+Si vous êtes intéressés par `R`,
+une version très proche de ce TP est
+disponible dans [ce cours](https://rgeo.linogaliana.fr/exercises/r-wrangling.html).
+
+
+Dans ce tutoriel, nous allons utiliser deux sources de données :
+* Les émissions de gaz à effet de serre estimées au niveau communal par l'`ADEME`. Le jeu de données est
+disponible sur [data.gouv](https://www.data.gouv.fr/fr/datasets/inventaire-de-gaz-a-effet-de-serre-territorialise/#_)
+et requêtable directement dans `Python` avec
+[cet url](https://koumoul.com/s/data-fair/api/v1/datasets/igt-pouvoir-de-rechauffement-global/convert) (ce sera l'objet du premier exercice)[^notedownload].
* Idéalement, on utiliserait directement les données
[disponibles sur le site de l'Insee](https://www.insee.fr/fr/statistiques/3560121) mais celles-ci nécessitent un peu de travail
de nettoyage qui n'entre pas dans le cadre de ce TP.
-Pour faciliter l'import de données Insee, il est recommandé d'utiliser le package
-[`pynsee`](https://github.com/InseeFrLab/Py-Insee-Data) qui simplifie l'accès aux données
+Pour faciliter l'import de données Insee, il est recommandé d'utiliser les _packages_
+[`doremifasol`](https://github.com/InseeFrLab/DoReMIFaSol) et [`insee`](https://github.com/pyr-opendatafr/R-Insee-Data) qui simplifient l'accès aux données
de l'Insee disponibles sur le site web [insee.fr](https://www.insee.fr/fr/accueil)
-ou via des API[^1].
+ou via des API.
+
+[^notedownload]:
+
+ `Pandas` offre la possibilité d'importer des données directement depuis un url. C'est l'option
+ prise dans ce tutoriel. Si vous préfèrez, pour des
+ raisons d'accès au réseau ou de performance, importer depuis un poste local,
+ vous pouvez télécharger les données et changer
+ les commandes d'import avec le chemin adéquat plutôt que l'url.
-[^1]: Toute contribution sur ce package, disponible sur [Github](https://github.com/InseeFrLab/Py-Insee-Data) est bienvenue !
+La librairie `pynsee` n'est pas installée par défaut avec `Python`. Avant de pouvoir l'utiliser,
+il est nécessaire de l'installer:
-Après avoir installé la librairie [`Pynsee`](https://github.com/InseeFrLab/pynsee) (voir l'[introduction à `Pandas`](course/manipulation/02a_pandas_tutorial)), nous suivrons les conventions habituelles dans l'import des packages :
+```{python}
+#| eval: false
+#| echo: true
+!pip install pynsee
+```
+Toutes les dépendances indispensables étant installées, il suffit
+maintenant d'importer les librairies qui seront utilisées
+pendant ces exerices:
```{python}
#| echo: true
@@ -78,55 +95,42 @@ import pynsee
import pynsee.download
```
-## Exploration de la structure des données
-
-Commencer par importer les données de l'Ademe à l'aide du package `pandas`. Vous pouvez nommer le `DataFrame` obtenu `df`.
-
-```{python}
-#| echo: true
+## Importer les données
-df = pd.read_csv("https://koumoul.com/s/data-fair/api/v1/datasets/igt-pouvoir-de-rechauffement-global/convert", sep=",")
-```
+### Import d'un csv de l'Ademe
-Pour les données de cadrage au niveau communal (source Insee), le package `pynsee` facilite grandement la vie.
-La liste des données disponibles est [ici](https://inseefrlab.github.io/DoReMIFaSol/articles/donnees_dispo.html).
-En l'occurrence, on va utiliser les données Filosofi (données de revenus) au niveau communal de 2016.
-Le point d'entrée principal de la fonction `pynsee` est la fonction `download_file`.
-Le code pour télécharger les données est le suivant :
+L'URL d'accès aux données peut être conservé dans une variable _ad hoc_:
```{python}
#| echo: true
-
-df_city = pynsee.download.download_file("FILOSOFI_COM_2016")
+url = "https://koumoul.com/s/data-fair/api/v1/datasets/igt-pouvoir-de-rechauffement-global/convert"
```
+L'objectif du premier exercice est de se familiariser à l'import et l'affichage de données
+avec `Pandas`.
+
::: {.cell .markdown}
```{=html}
-
-
Note
+
+
Exercice 1: Importer un CSV et explorer la structure de données
```
-La fonction `download_file` attend un identifiant unique
-pour savoir quelle base de données aller chercher et
-restructurer depuis le
-site [insee.fr](https://www.insee.fr/fr/accueil).
+1. Importer les données de l'Ademe à l'aide du package `Pandas` et de la commande consacrée pour l'import de csv. Nommer le `DataFrame` obtenu `emissions`[^nomdf].
+2. Utiliser les fonctions adéquates pour les 10 premières valeurs, les 15 dernières et un échantillon aléatoire de 10 valeurs grâce aux méthodes adéquates du _package_ `Pandas`.
+3. Tirer 5 pourcent de l'échantillon sans remise.
+4. Ne conserver que les 10 premières lignes et tirer aléatoirement dans celles-ci pour obtenir un DataFrame de 100 données.
+5. Faire 100 tirages à partir des 6 premières lignes avec une probabilité de 1/2 pour la première observation et une probabilité uniforme pour les autres.
-Pour connaître la liste des bases disponibles, vous
-pouvez utiliser la fonction `meta = pynsee.get_file_list()`.
-Celle-ci renvoie un `DataFrame` dans lequel on peut
-rechercher, par exemple grâce à une recherche
-de mot clé:
-```{python}
-#| echo: true
+
+
+En cas de blocage à la question 1
+
-meta = pynsee.get_file_list()
-meta.loc[meta['label'].str.contains(r"Filosofi.*2016")]
-```
+Lire la documentation de `read_csv` (très bien faite) ou chercher des exemples
+en ligne pour découvrir cette fonction.
-Ici, `meta['label'].str.contains(r"Filosofi.*2016")` signifie:
-"_`pandas` trouve moi tous les labels où sont contenus les termes Filosofi et 2016._"
- (`.*` signifiant "_peu m'importe le nombre de mots ou caractères entre_")
+
```{=html}
@@ -134,101 +138,173 @@ Ici, `meta['label'].str.contains(r"Filosofi.*2016")` signifie:
```
:::
-::: {.cell .markdown}
-```{=html}
-
-
Exercice 1: Afficher des données
+[^nomdf]: Par manque d'imagination, on est souvent tenté d'appeler notre
+_dataframe_ principal `df` ou `data`. C'est souvent une mauvaise idée puisque
+ce nom n'est pas très informatif quand on relit le code quelques semaines
+plus tard. L'autodocumentation, approche qui consiste à avoir un code
+qui se comprend de lui-même, est une bonne pratique et il est donc recommandé
+de donner un nom simple mais efficace pour connaître la nature du _dataset_ en question.
+
+```{python}
+#| label: exo1-q1
+# Question 1
+emissions = pd.read_csv(url, sep=",")
```
+```{python}
+#| output: false
+#| label: exo1-q2
+# Question 2
+emissions.head(2)
-L'objectif de cet exercice est de vous amener à afficher des informations sur les données dans un bloc de code (notebook) ou dans la console
-
-Commencer sur `df`:
+emissions.head(10)
+emissions.tail(15)
+emissions.sample(10)
-1. Utiliser les méthodes adéquates pour les 10 premières valeurs, les 15 dernières et un échantillon aléatoire de 10 valeurs
-2. Tirer 5 pourcent de l'échantillon sans remise
-3. Ne conserver que les 10 premières lignes et tirer aléatoirement dans celles-ci pour obtenir un DataFrame de 100 données.
-4. Faire 100 tirages à partir des 6 premières lignes avec une probabilité de 1/2 pour la première observation et une probabilité uniforme pour les autres
-5. Faire la même chose sur `df_city`.
+# Question 3
+emissions.sample(frac = 0.05)
-```{=html}
-
+# Question 4
+emissions.head(10).sample(n = 100, replace = True)
+
+# Question 5
+emissions.head(6).sample(n = 100, replace = True, weights = [0.5] + [0.1]*5)
```
+
+## Premières manipulations de données
+
+Le chapitre précédent évoquait quelques manipulations traditionnelles
+de données. Les principales sont rappelées ici:
+
+::: {.content-visible when-format="html"}
+
+:::: {layout-ncol=2}
+
+
+
+
+
+
+
+
+
+::::
+
:::
+::: {.content-visible when-format="ipynb"}
-```{python}
-#| echo: false
-# Question 1
-df.head(10)
-df.tail(15)
-df.sample(10)
+{fig-width="50%"}
+{fig-width="50%"}
-# Question 2
-df.sample(frac = 0.05)
+{fig-width="50%"}
+{fig-width="50%"}
-# Question 3
-df[:10].sample(n = 100, replace = True)
+{fig-width="50%"}
-# Question 4
-df[:6].sample(n = 100, replace = True, weights = [0.5] + [0.1]*5)
+:::
-# Question 5
-df_city.head(10)
-df_city.tail(15)
-df_city.sample(10)
-df_city.sample(frac = 0.05)
-df_city[:10].sample(n = 100, replace = True)
-df_city[:6].sample(n = 100, replace = True, weights = [0.5] + [0.1]*5)
-```
+La _cheatsheet_ suivante est très pratique puisqu'elle illustre ces différentes
+fonctions. Il est recommandé de régulièrement
+la consulter :
-Cette première approche exploratoire donne une idée assez précise de la manière dont les données sont organisées.
-On remarque ainsi une différence entre `df` et `df_city` quant aux valeurs manquantes :
-la première base est relativement complète, la seconde comporte beaucoup de valeurs manquantes.
-Autrement dit, si on désire exploiter `df_city`, il faut faire attention à la variable choisie.
+{width=70%}
+L'objectif du prochain exercice est de se familiariser aux principales manipulations de données
+sur un sous-ensemble de la table des émissions de gaz carbonique.
::: {.cell .markdown}
```{=html}
-
Exercice 2: structure des données
+ Exercice 2: Découverte des verbes de Pandas pour manipuler des données
```
+En premier lieu, on propose de se familiariser avec les opérations sur
+les colonnes.
-La première chose à vérifier est le format des données,
-afin d'identifier des types de variables qui ne conviennent pas
+1. Créer un _dataframe_ `emissions_copy` ne conservant que les colonnes
+`INSEE commune`, `Commune`, `Autres transports` et `Autres transports international`
-Ici, comme c'est `pandas` qui a géré automatiquement les types de variables,
-il y a peu de chances que les types ne soient pas adéquats mais une vérification ne fait pas de mal.
+
+
+Indice pour cette question
+
-1. Vérifier les types des variables.
-S'assurer que les types des variables communes aux deux bases sont cohérents.
-Pour les variables qui ne sont pas en type `float` alors qu'elles devraient l'être, modifier leur type.
+{fig-width=50%}
-Ensuite, on vérifie les dimensions des `DataFrames` et la structure de certaines variables clés.
-En l'occurrence, les variables fondamentales pour lier nos données sont les variables communales.
-Ici, on a deux variables géographiques: un code commune et un nom de commune.
+
-2. Vérifier les dimensions des DataFrames
+2. Comme les noms de variables sont peu pratiques, les renommer de la
+manière suivante:
+ + `INSEE commune` $\to$ `code_insee`
+ + `Autres transports` $\to$ `transports`
+ + `Autres transports international` $\to$ `transports_international`
-3. Vérifier le nombre de valeurs uniques des variables géographiques dans chaque base. Les résultats apparaissent-ils cohérents ?
+
+
+Indice pour cette question
+
-4. Identifier dans `df_city` les noms de communes qui correspondent à plusieurs codes communes et sélectionner leurs codes. En d'autres termes, identifier les `CODGEO` tels qu'il existe des doublons de `LIBGEO` et les stocker dans un vecteur `x` (conseil: faire attention à l'index de `x`)
+{fig-width=50%}
-On se focalise temporairement sur les observations où le libellé comporte plus de deux codes communes différents
+
-5. Regarder dans `df_city` ces observations
+3. On propose, pour simplifier, de remplacer les valeurs manquantes (`NA`)
+par la valeur 0[^na]. Utiliser la
+méthode [`fillna`](https://pandas.pydata.org/docs/reference/api/pandas.DataFrame.fillna.html)
+pour transformer les valeurs manquantes en 0.
-6. Pour mieux y voir, réordonner la base obtenue par order alphabétique
+4. Créer les variables suivantes:
+ - `dep`: le département. Celui-ci peut être créé grâce aux deux premiers caractères de `code_insee` en appliquant la méthode `str` ;
+ - `transports_total`: les émissions du secteur transports (somme des deux variables)
-7. Déterminer la taille moyenne (variable nombre de personnes: `NBPERSMENFISC16`) et quelques statistiques descriptives de ces données.
-Comparer aux mêmes statistiques sur les données où libellés et codes communes coïncident
+
+
+Indice pour cette question
+
-8. Vérifier les grandes villes (plus de 100 000 personnes),
-la proportion de villes pour lesquelles un même nom est associé à différents codes commune.
+{fig-width=50%}
+
+
+
+
+5. Ordonner les données du plus gros pollueur au plus petit
+puis ordonner les données
+du plus gros pollueur au plus petit par département (du 01 au 95).
+
+
+
+Indice pour cette question
+
+
+{fig-width=50%}
+
+
+
+6. Ne conserver que les communes appartenant aux départements 13 ou 31.
+Ordonner ces communes du plus gros pollueur au plus petit.
+
+
+
+Indice pour cette question
+
+
+{fig-width=50%}
+
+
+
+7. Calculer les émissions totales par départements
+
+
+
+Indice pour cette question
+
+
+* _"Grouper par"_ = `groupby`
+* _"émissions totales"_ = `agg({***: "sum"})`
+
+
-9. Vérifier dans `df_city` les villes dont le libellé est égal à Montreuil.
-Vérifier également celles qui contiennent le terme 'Saint-Denis'
```{=html}
@@ -236,92 +312,169 @@ Vérifier également celles qui contiennent le terme 'Saint-Denis'
:::
```{python}
-#| echo: false
-
+#| output: false
# Question 1
-print("base df")
-print(df.dtypes)
-print("\nbase df_city")
-print(df_city.dtypes)
+emissions_copy = emissions.loc[
+ :,
+ ["INSEE commune", "Commune", "Autres transports", "Autres transports international"]
+]
-# Il faut changer les types de toutes les variables de df_city à l'exception des codes et libellés de commune.
-df_city[df_city.columns[2:len(df_city.columns)]] = df_city[df_city.columns[2:len(df_city.columns)]].apply(pd.to_numeric)
-print("\nbase df_city corrigée")
-print(df_city.dtypes)
-```
+# Question 2
+emissions_copy = emissions_copy.rename({
+ "INSEE commune": "code_insee",
+ "Autres transports": "transports",
+ "Autres transports international": "transports_international"
+}, axis = 1)
-```{python}
-#| echo: false
+# Question 3
+emissions_copy = emissions_copy.fillna(0)
-# Question 2
-print(df.shape)
-print(df_city.shape)
+# Question 4
+emissions_copy['dep'] = emissions_copy['code_insee'].str[:2]
+emissions_copy['transports_total'] = emissions_copy['transports'] + emissions_copy['transports_international']
+
+# Question 5
+data_sorted = emissions_copy.sort_values("transports_total", ascending = False)
+data_sorted
+emissions_copy.sort_values(by = ["dep","transports_total"], ascending = [True, False])
+
+# Question 6
+emissions_hg_bdr = (emissions_copy
+ .loc[emissions_copy['dep'].isin(["13","31"])]
+ .sort_values("transports", ascending = False)
+)
+
+# Question 7
+emissions_copy.groupby("dep").agg({"transports_total": "sum"})
```
-```{python}
-#| echo: false
+A la question 5, quand on ordonne les communes exclusivement à partir de la variable
+`transports_total`, on obtient ainsi:
-# Question 3
-print(df[['INSEE commune', 'Commune']].nunique())
-print(df_city[['CODGEO', 'LIBGEO']].nunique())
-# Résultats dont l'ordre de grandeur est proche. Dans les deux cas, #(libelles) < #(code)
+```{python}
+data_sorted.head(3)
```
+A la question 6, on obtient ce classement :
+
```{python}
-#| echo: false
+emissions_hg_bdr.head(3)
+```
-# Question 4
-x = df_city.groupby('LIBGEO').count()['CODGEO']
-x = x[x>1]
-x = x.reset_index()
-x
+
+### Import des données de l'Insee
+
+En ce qui concerne nos informations communales, on va utiliser l'une des
+sources de l'Insee les plus utilisées : les données [`Filosofi`](https://www.insee.fr/fr/metadonnees/source/serie/s1172).
+Afin de faciliter la récupération de celles-ci, nous allons
+utiliser le _package_ communautaire `pynsee` :
+
+
+
+::: {.cell .markdown}
+```{=html}
+
+
Note
```
+Le _package_ `pynsee` comporte deux principaux points d'entrée:
+
+- Les API de l'Insee, ce qui sera illustré dans le chapitre consacré.
+- Quelques jeux de données directement issus du site web de
+l'Insee ([insee.fr](https://www.insee.fr/fr/accueil))
+
+Dans ce chapitre, nous allons exclusivement utiliser cette deuxième
+approche. Cela se fera par le module `pynsee.download`.
+
+La liste des données disponibles depuis ce _package_ est [ici](https://inseefrlab.github.io/DoReMIFaSol/articles/donnees_dispo.html).
+La fonction `download_file` attend un identifiant unique
+pour savoir quelle base de données aller chercher et
+restructurer depuis le
+site [insee.fr](https://www.insee.fr/fr/accueil).
+
+
+
+Connaître la liste des bases disponibles
+
+
+Pour connaître la liste des bases disponibles, vous
+pouvez utiliser la fonction `meta = pynsee.get_file_list()`
+après avoir fait `import pynsee`.
+Celle-ci renvoie un `DataFrame` dans lequel on peut
+rechercher, par exemple grâce à une recherche
+de mot clé:
+
```{python}
-#| echo: false
-# Question 5
-df_city[df_city['LIBGEO'].isin(x['LIBGEO'])]
+#| echo: true
+
+meta = pynsee.get_file_list()
+meta.loc[meta['label'].str.contains(r"Filosofi.*2016")]
```
-```{python}
-#| echo: false
-# Question 6
-df_city[df_city['LIBGEO'].isin(x['LIBGEO'])].sort_values('LIBGEO')
+Ici, `meta['label'].str.contains(r"Filosofi.*2016")` signifie:
+"_`pandas` trouve moi tous les labels où sont contenus les termes Filosofi et 2016._"
+ (`.*` signifiant "_peu m'importe le nombre de mots ou caractères entre_")
+
+
+
+```{=html}
+
```
+:::
+
+On va utiliser les données Filosofi (données de revenus) au niveau communal de 2016.
+Ce n'est pas la même année que les données d'émission de CO2, ce n'est donc pas parfaitement rigoureux,
+mais cela permettra tout de même d'illustrer
+les principales fonctionnalités de `Pandas`
+
+Le point d'entrée principal de la fonction `pynsee` est la fonction `download_file`.
+
+Le code pour télécharger les données est le suivant :
```{python}
-#| echo: false
-# Question 7
-print(df_city[df_city['LIBGEO'].isin(x['LIBGEO'])]['NBPERSMENFISC16'].describe())
-print(df_city[~df_city['LIBGEO'].isin(x['LIBGEO'])]['NBPERSMENFISC16'].describe())
+#| echo: true
+#| output: false
+from pynsee.download import download_file
+filosofi = download_file("FILOSOFI_COM_2016")
```
+Le _DataFrame_ en question a l'aspect suivant :
+
```{python}
-#| echo: false
-# Question 8
-df_big_city = df_city[df_city['NBPERSMENFISC16']>100000].copy()
-df_big_city['probleme'] = df_big_city['LIBGEO'].isin(x['LIBGEO'])
-df_big_city['probleme'].mean()
-df_big_city[df_big_city['probleme']]
+filosofi.sample(5)
```
+Un simple coup d'oeil sur les données
+donne une idée assez précise de la manière dont les données sont organisées.
+On remarque que certaines variables de `filosofi` semblent avoir beaucoup de valeurs manquantes
+alors que d'autres semblent complètes.
+Si on désire exploiter `filosofi`, il faut faire attention à la variable choisie.
+
+
```{python}
-#| echo: false
-# Question 9
-df_city[df_city.LIBGEO == 'Montreuil']
-df_city[df_city.LIBGEO.str.contains('Saint-Denis')].head(10)
+df = emissions.copy()
+df_city = filosofi.copy()
```
-Ce petit exercice permet de se rassurer car les libellés dupliqués
-sont en fait des noms de commune identiques mais qui ne sont pas dans le même département.
-Il ne s'agit donc pas d'observations dupliquées.
-On se fiera ainsi aux codes communes, qui eux sont uniques.
+Notre objectif à terme va être de relier l'information contenue entre ces
+deux jeux de données. En effet, sinon, nous risquons d'être frustré: nous allons
+vouloir en savoir plus sur les émissions de gaz carbonique mais seront très
+limités dans les possibilités d'analyse sans ajout d'une information annexe
+issue de `filosofi`.
+
## Les indices
-Les indices sont des éléments spéciaux d'un DataFrame puisqu'ils permettent d'identifier certaines observations.
+Les indices sont des éléments spéciaux d'un `DataFrame` puisqu'ils permettent d'identifier certaines observations.
Il est tout à fait possible d'utiliser plusieurs indices, par exemple si on a des niveaux imbriqués.
+Pour le moment, on va prendre comme acquis que les codes communes (dits aussi codes Insee) permettent
+d'identifier de manière unique une commune. Un exercice ultérieur permettra de s'en assurer.
+
+`Pandas` propose un système d'indice qui permet d'ordonner les variables mais également de gagner
+en efficacité sur certains traitements, comme des recherches d'observations. Le prochain
+exercice illustre cette fonctionnalité.
+
::: {.cell .markdown}
```{=html}
@@ -330,23 +483,26 @@ Il est tout à fait possible d'utiliser plusieurs indices, par exemple si on a d
```
-A partir de l'exercice précédent, on peut se fier aux codes communes.
+On suppose ici qu'on peut se fier aux codes communes.
1. Fixer comme indice la variable de code commune dans les deux bases.
Regarder le changement que cela induit sur le *display* du `DataFrame`
2. Les deux premiers chiffres des codes communes sont le numéro de département.
-Créer une variable de département `dep` dans `df` et dans `df_city`
+Créer une variable de département `dep` dans `emissions` et `filosofi`
3. Calculer les émissions totales par secteur pour chaque département.
-Mettre en log ces résultats dans un objet `df_log`.
-Garder 5 départements et produire un `barplot`
+Mettre en _log_ ces résultats dans un objet `emissions_log`.
+Garder 5 départements et produire un `barplot` grâce à la méthode _plot_ (la
+figure n'a pas besoin d'être vraiment propre, c'est seulement pour illustrer
+cette méthode)
-4. Repartir de `df`.
+4. Repartir de `emissions`.
Calculer les émissions totales par département et sortir la liste
des 10 principaux émetteurs de CO2 et des 5 départements les moins émetteurs.
-Sans faire de *merge*,
-regarder les caractéristiques de ces départements (population et niveau de vie)
+Essayer de comprendre pourquoi ce sont ces départements qui apparaissent en tête
+du classement. Pour cela, il peut être utile de regarder les caractéristiques de ces
+départements dans `filosofi`
```{=html}
@@ -354,110 +510,100 @@ regarder les caractéristiques de ces départements (population et niveau de vie
:::
```{python}
-#| echo: false
+#| output: false
+
# Question 1
-display(df)
-df = df.set_index('INSEE commune')
-display(df)
+display(emissions)
+emissions = emissions.set_index('INSEE commune')
+display(emissions)
-display(df_city)
-df_city = df_city.set_index('CODGEO')
-display(df_city)
+display(filosofi)
+filosofi = filosofi.set_index('CODGEO')
+display(filosofi)
```
```{python}
-#| echo: false
+#| output: false
+
# Question 2
-df['dep'] = df.index.str[:2]
-df_city['dep'] = df_city.index.str[:2]
+emissions['dep'] = emissions.index.str[:2]
+filosofi['dep'] = filosofi.index.str[:2]
```
```{python}
-#| echo: false
+#| output: false
+
# Question 3
-df_log = df.groupby('dep').sum(numeric_only = True).apply(np.log)
-print(df_log.head())
-df_log.sample(5).plot(kind = "bar")
+emissions_log = emissions.groupby('dep').sum(numeric_only = True).apply(np.log)
+print(emissions_log.head())
+emissions_log.sample(5).plot(kind = "barh")
```
```{python}
#| echo: false
# Question 4
## Emissions totales par département (df)
-df_emissions = df.reset_index().set_index(['INSEE commune','dep']).sum(axis = 1, numeric_only = True).groupby('dep').sum(numeric_only = True)
-#df.reset_index().groupby('dep').sum(numeric_only = True).sum(axis = 1, numeric_only = True).head() #version simplifiee ?
-gros_emetteurs = df_emissions.sort_values(ascending = False).head(10)
-petits_emetteurs = df_emissions.sort_values().head(5)
+emissions_totales = (
+ emissions
+ .reset_index()
+ .groupby("dep")
+ .sum(numeric_only = True)
+ .sum(axis = 1, numeric_only = True)
+)
+gros_emetteurs = emissions_totales.sort_values(ascending = False).head(10)
+petits_emetteurs = emissions_totales.sort_values().head(5)
## Caractéristiques des départements (df_city)
print("gros emetteurs")
-print(df_city[df_city['dep'].isin(gros_emetteurs.index)][['NBPERSMENFISC16','MED16']].mean())
+display(
+ filosofi.loc[
+ filosofi['dep'].isin(gros_emetteurs.index), ['NBPERSMENFISC16','MED16']
+ ].mean(numeric_only = True)
+ )
print("\npetits emetteurs")
-print(df_city[df_city['dep'].isin(petits_emetteurs.index)][['NBPERSMENFISC16','MED16']].mean())
+display(
+ filosofi.loc[
+ filosofi['dep'].isin(gros_emetteurs.index), ['NBPERSMENFISC16','MED16']
+ ].mean(numeric_only = True)
+ )
# Les petits emetteurs sont en moyenne plus pauvres et moins peuplés que les gros emetteurs
```
-::: {.cell .markdown}
-```{=html}
-
-
Exercice 4: performance des indices
-```
-
-Un des intérêts des indices est qu'ils permettent des agrégations efficaces.
-
-1. Repartir de `df` et créer une copie `df_copy = df.copy()` et `df_copy2 = df.copy()` afin de ne pas écraser le DataFrame `df`
-
-2. Utiliser la variable `dep` comme indice pour `df_copy` et retirer tout index pour `df_copy2`
-
-3. Importer le module `timeit` et comparer le temps d'exécution de la somme par secteur, pour chaque département, des émissions de CO2
-
-```{=html}
-
-```
-:::
-
-```{python}
-#| echo: false
-# Question 1
-df_copy = df.copy()
-df_copy2 = df.copy()
-```
-
-```{python}
-#| echo: false
-# Question 2
-df_copy = df_copy.set_index('dep')
-df_copy2 = df_copy2.reset_index()
-```
+En pratique, l'utilisation des indices en `Pandas` peut être piégeuse, notamment lorsqu'on
+associe des sources de données.
+Il est plutôt recommandé de ne pas les utiliser ou de les utiliser avec parcimonie,
+cela pourra éviter de mauvaises surprises.
-```{python}
-#| echo: false
-#| eval: false
-# Question 3
-%timeit df_copy.drop('Commune', axis = 1).groupby('dep').sum(numeric_only = True)
-%timeit df_copy2.drop('Commune', axis = 1).groupby('dep').sum(numeric_only = True)
-# Le temps d'exécution est plus lent sur la base sans index par département.
-```
## Restructurer les données
-On présente généralement deux types de données :
+Quand on a plusieurs informations pour un même individu ou groupe, on
+retrouve généralement deux types de structure de données :
* format __wide__ : les données comportent des observations répétées, pour un même individu (ou groupe), dans des colonnes différentes
* format __long__ : les données comportent des observations répétées, pour un même individu, dans des lignes différentes avec une colonne permettant de distinguer les niveaux d'observations
-Un exemple de la distinction entre les deux peut être pris à l'ouvrage de référence d'Hadley Wickham, *R for Data Science*:
+Un exemple de la distinction entre les deux peut être pris à l'ouvrage de référence d'Hadley Wickham, [*R for Data Science*](https://r4ds.hadley.nz/):
-
+
L'aide mémoire suivante aidera à se rappeler les fonctions à appliquer si besoin:
-
+{fig-width=60%}
Le fait de passer d'un format *wide* au format *long* (ou vice-versa)
peut être extrêmement pratique car certaines fonctions sont plus adéquates sur une forme de données ou sur l'autre.
-En règle générale, avec `Python` comme avec `R`, les formats *long* sont souvent préférables.
+
+En règle générale, avec `Python` comme avec `R`, les __formats *long* sont souvent préférables__.
+Les formats _wide_ sont plutôt pensés pour des tableurs comme `Excel` ou on dispose d'un nombre réduit
+de lignes à partir duquel faire des tableaux croisés dynamiques.
+
+Le prochain exercice propose donc une telle restructuration de données.
+Les données de l'ADEME, et celles de l'Insee également, sont au format
+_wide_.
+Le prochain exercice illustre l'intérêt de faire la conversion _long_ $\to$ _wide_
+avant de faire un graphique.
::: {.cell .markdown}
```{=html}
@@ -465,7 +611,7 @@ En règle générale, avec `Python` comme avec `R`, les formats *long* sont souv
Exercice 5: Restructurer les données: wide to long
```
-1. Créer une copie des données de l'`ADEME` en faisant `df_wide = df.copy()`
+1. Créer une copie des données de l'`ADEME` en faisant `df_wide = emissions.copy()`
2. Restructurer les données au format *long* pour avoir des données d'émissions par secteur en gardant comme niveau d'analyse la commune (attention aux autres variables identifiantes).
@@ -479,20 +625,20 @@ En règle générale, avec `Python` comme avec `R`, les formats *long* sont souv
:::
```{python}
-#| echo: false
+#| output: false
#| label: question1
# Question 1
-df_wide = df.copy()
-df_wide[['Commune','dep', "Agriculture", "Tertiaire"]].head()
+emissions_wide = emissions.copy()
+emissions_wide[['Commune','dep', "Agriculture", "Tertiaire"]].head()
```
```{python}
-#| echo: false
+#| output: false
#| label: question2
# Question 2
-df_wide.reset_index().melt(id_vars = ['INSEE commune','Commune','dep'],
+emissions_wide.reset_index().melt(id_vars = ['INSEE commune','Commune','dep'],
var_name = "secteur", value_name = "emissions")
```
@@ -501,41 +647,97 @@ df_wide.reset_index().melt(id_vars = ['INSEE commune','Commune','dep'],
#| label: question3
# Question 3
-(df_wide.reset_index()
- .melt(id_vars = ['INSEE commune','Commune','dep'],
- var_name = "secteur", value_name = "emissions")
- .groupby('secteur').sum(numeric_only = True).plot(kind = "barh")
+emissions_totales = (emissions_wide.reset_index()
+ .melt(
+ id_vars = ['INSEE commune','Commune','dep'],
+ var_name = "secteur", value_name = "emissions"
+ )
+ .groupby('secteur')
+ .sum(numeric_only = True)
)
+
+emissions_totales.plot(kind = "barh")
```
```{python}
-#| echo: false
+#| output: false
#| label: question4
# Question 4
-(df_wide.reset_index().melt(id_vars = ['INSEE commune','Commune','dep'],
- var_name = "secteur", value_name = "emissions")
- .groupby(['secteur','dep']).sum(numeric_only=True).reset_index().sort_values(['dep','emissions'], ascending = False).groupby('dep').head(1)
+top_commune_dep = (
+ emissions_wide
+ .reset_index()
+ .melt(
+ id_vars = ['INSEE commune','Commune','dep'],
+ var_name = "secteur", value_name = "emissions")
+ .groupby(['secteur','dep'])
+ .sum(numeric_only=True).reset_index()
+ .sort_values(['dep','emissions'], ascending = False)
+ .groupby('dep').head(1)
)
```
+## Combiner les données
+
+### Travail préliminaire
+
+Jusqu'à présent lorsque nous avons produit des statistiques descriptives,
+celles-ci étaient univariées, c'est-à-dire que nous produisions de l'information
+sur une variable mais nous ne la mettions pas en lien avec une autre. Pourtant,
+on est rapidement amené à désirer expliquer certaines statistiques agrégées à partir
+de caractéristiques issues d'une autre source de données. Cela implique
+donc d'associer des jeux de données,
+autrement dit de mettre en lien deux jeux de données
+présentant le même niveau d'information.
+
+On appelle ceci faire un _merge_ ou un _join_. De manière illustrée,
+ceci revient à effectuer ce type d'opération:
+
+
+
+
+Avant de faire ceci, il est néanmoins nécessaire de s'assurer que les variables
+communes entre les bases de données présentent le bon niveau d'information.
+
::: {.cell .markdown}
```{=html}
-
Exercice 6: long to wide
+ Exercice 3: structure des données
```
-Cette transformation est moins fréquente car appliquer des fonctions par groupe, comme nous le verrons par la suite, est très simple.
+La première chose à vérifier est le format des données,
+afin d'identifier des types de variables qui ne correspondraient pas
+entre les bases de données.
+Une vérification ne fait pas de mal.
+
+1. Vérifier les types des variables.
+S'assurer que les types des variables communes aux deux bases sont cohérents.
+Pour les variables qui ne sont pas en type `float` alors qu'elles devraient l'être, modifier leur type.
+
+Ensuite, on vérifie les dimensions des `DataFrames` et la structure de certaines variables clés.
+En l'occurrence, les variables fondamentales pour lier nos données sont les variables communales.
+Ici, on a deux variables géographiques: un code commune et un nom de commune.
+
+2. Vérifier les dimensions des _DataFrames_.
+
+3. Vérifier le nombre de valeurs uniques des variables géographiques dans chaque base. Les résultats apparaissent-ils cohérents ?
+
+4. Identifier dans `filosofi` les noms de communes qui correspondent à plusieurs codes communes et sélectionner leurs codes. En d'autres termes, identifier les `CODGEO` tels qu'il existe des doublons de `LIBGEO` et les stocker dans un vecteur `x` (conseil: faire attention à l'index de `x`).
-1. Repartir de `df_wide = df.copy()
+On se focalise temporairement sur les observations où le libellé comporte plus de deux codes communes différents
+
+5. Regarder dans `filosofi` ces observations.
-2. Reconstruire le DataFrame, au format long, des données d'émissions par secteur en gardant comme niveau d'analyse la commune puis faire la somme par département et secteur
+6. Pour mieux y voir, réordonner la base obtenue par order alphabétique.
-3. Passer au format *wide* pour avoir une ligne par secteur et une colonne par département
+7. Déterminer la taille moyenne (variable nombre de personnes: `NBPERSMENFISC16`) et quelques statistiques descriptives de ces données.
+Comparer aux mêmes statistiques sur les données où libellés et codes communes coïncident.
-4. Calculer, pour chaque secteur, la place du département dans la hiérarchie des émissions nationales
+8. Vérifier les grandes villes (plus de 100 000 personnes),
+la proportion de villes pour lesquelles un même nom est associé à différents codes commune.
-5. A partir de là, en déduire le rang médian de chaque département dans la hiérarchie des émissions et regarder les 10 plus mauvais élèves, selon ce critère.
+9. Vérifier dans `filosofi` les villes dont le libellé est égal à Montreuil.
+Vérifier également celles qui contiennent le terme _'Saint-Denis'_.
```{=html}
@@ -543,54 +745,101 @@ Cette transformation est moins fréquente car appliquer des fonctions par groupe
:::
```{python}
-#| echo: false
+#| output: false
+
# Question 1
+print("base df")
+print(df.dtypes)
+print("\nbase df_city")
+print(df_city.dtypes)
-df_wide = df.copy()
+# Il faut changer les types de toutes les variables de filosofi à l'exception des codes et libellés de commune.
+df_city[df_city.columns[2:len(df_city.columns)]] = df_city[df_city.columns[2:len(df_city.columns)]].apply(pd.to_numeric)
+print("\nbase df_city corrigée")
+print(df_city.dtypes)
```
```{python}
-#| echo: false
+#| output: false
+
# Question 2
+print(df.shape)
+print(df_city.shape)
+```
-df_long_agg = (df_wide.reset_index()
- .melt(id_vars = ['INSEE commune','Commune','dep'],
- var_name = "secteur", value_name = "emissions").groupby(["dep", "secteur"]).sum(numeric_only = True)
-)
+```{python}
+#| output: false
-df_long_agg.head()
+# Question 3
+print(df[['INSEE commune', 'Commune']].nunique())
+print(df_city[['CODGEO', 'LIBGEO']].nunique())
+# Résultats dont l'ordre de grandeur est proche. Dans les deux cas, #(libelles) < #(code)
```
```{python}
-#| echo: false
-# Question 3
+#| output: false
-df_wide_agg = df_long_agg.reset_index().pivot_table(values = "emissions", index = "secteur", columns = "dep")
+# Question 4
+x = df_city.groupby('LIBGEO').count()['CODGEO']
+x = x[x>1]
+x = x.reset_index()
+x
+```
-df_wide_agg.head()
+```{python}
+#| output: false
+# Question 5
+df_city[df_city['LIBGEO'].isin(x['LIBGEO'])]
```
```{python}
-#| echo: false
-# Question 4
+#| output: false
+# Question 6
+df_city[df_city['LIBGEO'].isin(x['LIBGEO'])].sort_values('LIBGEO')
+```
-df_wide_agg.rank(axis = 1)
+```{python}
+#| output: false
+# Question 7
+print(df_city[df_city['LIBGEO'].isin(x['LIBGEO'])]['NBPERSMENFISC16'].describe())
+print(df_city[~df_city['LIBGEO'].isin(x['LIBGEO'])]['NBPERSMENFISC16'].describe())
```
```{python}
-#| echo: false
-# Question 5
+#| output: false
+# Question 8
+df_big_city = df_city[df_city['NBPERSMENFISC16']>100000].copy()
+df_big_city['probleme'] = df_big_city['LIBGEO'].isin(x['LIBGEO'])
+df_big_city['probleme'].mean()
+df_big_city[df_big_city['probleme']]
+```
-df_wide_agg.rank(axis = 1).median().nlargest(10)
+```{python}
+#| output: false
+# Question 9
+df_city[df_city.LIBGEO == 'Montreuil']
+df_city[df_city.LIBGEO.str.contains('Saint-Denis')].head(10)
```
-## Combiner les données
+Ce petit exercice permet de se rassurer car les libellés dupliqués
+sont en fait des noms de commune identiques mais qui ne sont pas dans le même département.
+Il ne s'agit donc pas d'observations dupliquées.
+On peut donc se fier aux codes communes, qui eux sont uniques.
+
+
+### Associer des données
-Une information que l'on cherche à obtenir s'obtient de moins en moins à partir d'une unique base de données. Il devient commun de devoir combiner des données issues de sources différentes. Nous allons ici nous focaliser sur le cas le plus favorable qui est la situation où une information permet d'apparier de manière exacte deux bases de données (autrement nous serions dans une situation, beaucoup plus complexe, d'appariement flou). La situation typique est l'appariement entre deux sources de données selon un identifiant individuel ou un identifiant de code commune, ce qui est notre cas.
-Il est recommandé de lire [ce guide assez complet sur la question des jointures avec R](https://www.book.utilitr.org/03_fiches_thematiques/fiche_joindre_donnees) qui donne des recommandations également utiles en `python`.
+Une information que l'on cherche à obtenir s'obtient de moins en moins à partir d'une unique base de données. Il devient commun de devoir combiner des données issues de sources différentes.
+
+Nous allons ici nous focaliser sur le cas le plus favorable qui est la situation où une information permet d'apparier de manière exacte deux bases de données (autrement nous serions dans une situation, beaucoup plus complexe, d'appariement flou). La situation typique est l'appariement entre deux sources de données selon un identifiant individuel ou un identifiant de code commune, ce qui est notre cas.
+
+Il est recommandé de lire [ce guide assez complet sur la question des jointures avec R](https://www.book.utilitr.org/03_fiches_thematiques/fiche_joindre_donnees) qui donne des recommandations également utiles en `Python`.
+
+Dans le langage courant du statisticien,
+on utilise de manière indifférente les termes *merge* ou *join*. Le deuxième terme provient de la syntaxe `SQL`.
+Quand on fait du `Pandas`, on utilise plutôt la commande _merge_.
-On utilise de manière indifférente les termes *merge* ou *join*. Le deuxième terme provient de la syntaxe SQL. En `pandas`, dans la plupart des cas, on peut utiliser indifféremment `df.join` et `df.merge`

@@ -601,13 +850,39 @@ On utilise de manière indifférente les termes *merge* ou *join*. Le deuxième
Exercice 7: Calculer l'empreinte carbone par habitant
```
+En premier lieu, on va calculer l'empreinte carbone de chaque commune.
+
+
1. Créer une variable `emissions` qui correspond aux émissions totales d'une commune
-2. Faire une jointure à gauche entre les données d'émissions et les données de cadrage. Comparer les émissions moyennes des villes sans *match* (celles dont des variables bien choisies de la table de droite sont NaN) avec celles où on a bien une valeur correspondante dans la base Insee
+2. Faire une jointure à gauche entre les données d'émissions et les données de cadrage[^notebiais].
+
+[^notebiais]: Idéalement, il serait nécessaire de s'assurer que cette jointure n'introduit
+pas de biais. En effet, comme nos années de référence ne sont pas forcément identiques,
+il peut y avoir un _mismatch_ entre nos deux sources. Le TP étant déjà long, nous n'allons pas dans cette voie.
+Les lecteurs intéressés pourront effectuer une telle analyse en exercice supplémentaire.
-3. Faire un *inner join* puis calculer l'empreinte carbone (l'émission rapportée au nombre de ménages fiscaux) dans chaque commune. Sortir un histogramme en niveau puis en log et quelques statistiques descriptives sur le sujet.
+3. Calculer l'empreinte carbone (émissions totales / population).
-4. Regarder la corrélation entre les variables de cadrage et l'empreinte carbone. Certaines variables semblent-elles pouvoir potentiellement influer sur l'empreinte carbone ?
+A ce stade nous pourrions avoir envie d'aller vers la modélisation pour essayer d'expliquer
+les déterminants de l'empreinte carbone à partir de variables communales.
+Une approche inférentielle nécessite néanmoins pour être pertinente de
+vérifier en amont des statistiques descriptives.
+
+4. Sortir un histogramme en niveau puis en log de l'empreinte carbone communales.
+
+Avec une meilleure compréhension de nos données, nous nous rapprochons
+de la statistique inférentielle. Néanmoins, nous avons jusqu'à présent
+construit des statistiques univariées mais n'avons pas cherché à comprendre
+les résultats en regardant le lien avec d'autres variables.
+Cela nous amène vers la statistique bivariée, notamment l'analyse des corrélations.
+Ce travail est important puisque toute modélisation ultérieure consistera à
+raffiner l'analyse des corrélations pour tenir compte des corrélations croisées
+entre multiples facteurs. On propose ici de faire cette analyse
+de manière minimale.
+
+
+5. Regarder la corrélation entre les variables de cadrage et l'empreinte carbone. Certaines variables semblent-elles pouvoir potentiellement influer sur l'empreinte carbone ?
```{=html}
@@ -615,51 +890,50 @@ On utilise de manière indifférente les termes *merge* ou *join*. Le deuxième
:::
```{python}
-#| echo: false
+#| output: false
# Question 1
df['emissions'] = df.sum(axis = 1, numeric_only = True)
```
```{python}
-#| echo: false
+#| output: false
# Question 2
df_merged = df.merge(df_city, how = "left", left_index = True, right_index = True)
print(df_merged[df_merged['LIBGEO'].isna()]['emissions'].mean())
print(df_merged[~df_merged['LIBGEO'].isna()]['emissions'].mean())
-
```
```{python}
-#| echo: false
+#| output: false
# Question 3
df_merged = df.merge(df_city, left_index = True, right_index = True)
df_merged['empreinte'] = df_merged['emissions']/df_merged['NBPERSMENFISC16']
-
-df_merged['empreinte'].plot(kind ="hist")
-np.log(df_merged['empreinte']).plot.hist()
-df_merged['empreinte'].describe()
```
-
```{python}
-#| echo: false
+#| output: false
# Question 4
-
-df_merged.corr(numeric_only=True)['empreinte'].nlargest(10)
-# Les variables en lien avec le transport.
+df_merged['empreinte'].plot(kind = 'hist')
+np.log(df_merged['empreinte']).plot(kind = 'hist')
+df_merged['empreinte'].describe()
```
+A l'issue de la question 5, le graphique des corrélations est le suivant:
+
```{python}
-#| output: false
#| echo: false
-np.log(df_merged['empreinte']).plot.hist()
-plt.savefig("featured_tp_pandas.png")
-```
+# Question 5
+correlation = df_merged.corr(numeric_only=True)['empreinte']
+correlation = correlation.reset_index()
+correlation = correlation.loc[~correlation['index'].isin(["empreinte","emissions"])]
+correlation['empreinte'].nlargest(10)
+correlation.set_index("index")['empreinte'].plot(kind = "barh")
+```
## Exercices bonus
diff --git a/requirements.sh b/requirements.sh
new file mode 100644
index 000000000..51058c151
--- /dev/null
+++ b/requirements.sh
@@ -0,0 +1,2 @@
+sudo apt get update && \
+ sudo apt install graphviz
\ No newline at end of file
diff --git a/requirements.txt b/requirements.txt
index 10dd1ed56..2cff884f3 100644
--- a/requirements.txt
+++ b/requirements.txt
@@ -1,7 +1,7 @@
pynsee
xlrd
contextily
-cartiflette @ git+https://github.com/inseefrlab/cartiflette@main
+cartiflette @ git+https://github.com/inseefrlab/cartiflette@80b8a5a28371feb6df31d55bcc2617948a5f9b1a
graphviz
plotnine
geoplot