I decided to re-implement the project using a deep learning approach with PyTorch, and compare the results with the regular machine learning approach I had taken before. I tried and compared a few neural networks such as FC / RNN (LSTM / GRU) (with and without Embedding). The FC network performed well in the simpler Binary Classification task, whereas the RNN networks performed significantly better in the more challenging tasks. The embedding layer did not help at all, so I didn't include it in the results (but it can be found in the code). I compiled the best results in the following table (evaluation was done using a 6-fold cross validation):
| Classifier | Binary Nativity Classification | 21 Languages Classification | 4 Language Families Classification |
|---|---|---|---|
| Logistic Regression Classifier | 93% | 57% | 77% |
| FC | 95% | 4% | 70% |
| RNN | 95% | 62% | 84% |
As can be seen in the table above, the Fully Connected (FC) network was good enough for the Binary Classificaiton, but was significantly out-performed by the RNN network in the other more complex tasks. The most notable thing in this table is that RNN (deep learning) out-performed the regular Machine Learning approach (Logistic Regression Classifier) by about 4% points on average.
It's worth mentioning that I used the same feature encoding method in both approaches (the regular machine learning approach, and the deep learning approach), as I used a list of common English function words and the top 1000 POS trigrams in the corpus, and encoded them to their tf-idf values.
Please find the notebook native_language_classification_dl.ipynb for a full walkthrough of my code in PyTorch (refresh if it doesn't load).
To find more about this project, please read the reamaining of this document.
This project is an attempt to implement the integral part of the paper Native Language Cognate Effects on Second Language Lexical Choice [1], in which the authors try to distinguish the native languages of Reddit posters, using Machine Learning (ML) and Natural Language Processing (NLP), relying on their Reddit posts which are written in a high-level English.
Although the authors have released both their dataset and cleanup code publicly, I've created this project from scratch, including fetching the reddit posts using the PRAW library [3] and cleaning them with my own cleanup scripts. The choice of the subreddits to fetch the data from was based on several aspects, such as mother tongue variety and, most importantly, labels. The authors have picked subreddits that the users flair tags are almost guaranteed1 to be the posters' country of origin (e.g. Germany / US / Spain / etc.), so they could be used as the ground truth labels. It's worth mentioning, however, that the authors' dataset is much larger than mine (8GB vs. 111MB). The size differences are due to several reasons:
- I have used only 2 subreddits (r/AskEurope, r/Europe), whereas the authors have used an additional 3: r/EuropeanCulture, r/EuropeanFederalists r/Eurosceptics.
- I was limited by PRAW's 1000 items limitation.
- The authors have used a clever technique of database expansion, by mining the redditors' personal public profiles and collecting their posts even from outside the 5 main subreddits, after validating their country of origin.
- I don't have enough resources to process such a big database.
1"Almost guaranteed" because there might be some noise, but the authors have validated this information in a very high confidence using several ways, which are mentioned in this paper and their other paper [2].
In order to run the code, please follow the following steps:
- Install Python.
- Clone the repository.
- Run
install_dependencies.bat(Windows) orinstall_dependencies.sh(Linux) to setup the virtual environment and install the required libraries.
From now onward, you should be running the scripts from inside the virtual environment.
If you want to use the existing database, skip to step 9. - Create a reddit app at: reddit authorized apps.
- Run the script
fetch_data.pywith your app's client ID, secret, and your user agent:
python fetch_data.py --id <app id> --secret <app secret> --agent <user agent> - Manually remove unwanted noise files, and merge files denoting the same country (e.g. "USA", "US", "United States").
- Run
preprocessing.py. - If you want to see some data visualization graphs such as sentences average and median lengths etc., run
data_visualization.py. - Run
features_bldr.py. - Run
classfication.py. The results path will be printed in the console at the end.
The authors have divided their work to 3 tasks:
- Binary Nativity Classification: Distinguish native vs. non-native English speakers.
- Language Classification: Detect the native language of the original poster, among 31 different languages.
- Language Family Classification: Classify posts according to the poster's language family. Language families are:
English: Australia, UK, New Zealand, US, Canada.
Germanic: Austria, Denmark, Germany, Iceland, Netherlands, Norway, Sweden.
Romance: France, Italy, Mexico, Portugal, Romania, Spain.
Slavic: Bosnia, Bulgaria, Croatia, Czech, Latvia, Lithuania, Poland, Russia, Serbia, Slovakia, Slovenia, Ukraine.
The authors report the following accuracy results for tasks 1,2,3 respectively: 90.8%, 60.8%, 82.5% (using 10 fold cross validation).
It's also worth mentioning that the authors have relied solely on lexical / syntactic features, as opposed to context and social network features which they have mentioned in their other paper [2]. For example some of the features they mention are part of speech (POS) ngrams, function words, and most common words in the database. This is important mainly because the task of the paper (as its title implies) is to recognize the cognate effects of the writers' first language (L1) that are reflected on their second language (L2). I.e. they hypothesize that the effect of L1 is so powerful (in means of word and grammar choice) that it's clearly reflected on L2. For example (from my findings), it turns out that Polish people use the combination "IN JJ NN" ('Preposition' 'Adjective' 'Singular Noun') way more often than native English speakers do, and "NN IN DT" trigrams ('Singular Noun' 'Preposition', 'Determiner') way less. An example of the former is: "in old building" in the sentence:
"Mainly because most people don't trust the water quality in Poland nor the water pipes since most people live in old building and they are scared that they are somehow polluted"
Hereby I try to reproduce the authors' results with my own model. Before starting, it's worth mentioning that the task of native language identification from reddit posts would not be an easy one for a human (rather than a computer), since according to the authors' findings, the non-native reddit posters are at a near-native English level (even higher than advanced TOEFL learners). This assesment was done using various measures such as type-to-token ratio (TTR), average age-of-acquisition of lexical items, and mean word rank, but it's also a well known fact among redditors:

My own results for Tasks 1,2,3 are: 93%, 57.1%, 77.3% respectively.
Following is a more comprehensive walkthrough of the classification process, which was done using a Logistic Regression Classifier in all the tasks.
First, for a sanity check, I used a Logistic Regression classifier with the binary occurrences of the top 1000 words used in the database as a feature vector. Namely, my feature table at cell [i,j] contained True if word j appeared in text i that's being classified, and False otherwise. Expectedly, the results were very high (97% accuracy using 10 fold cross validation), affirming the soundness of the database:
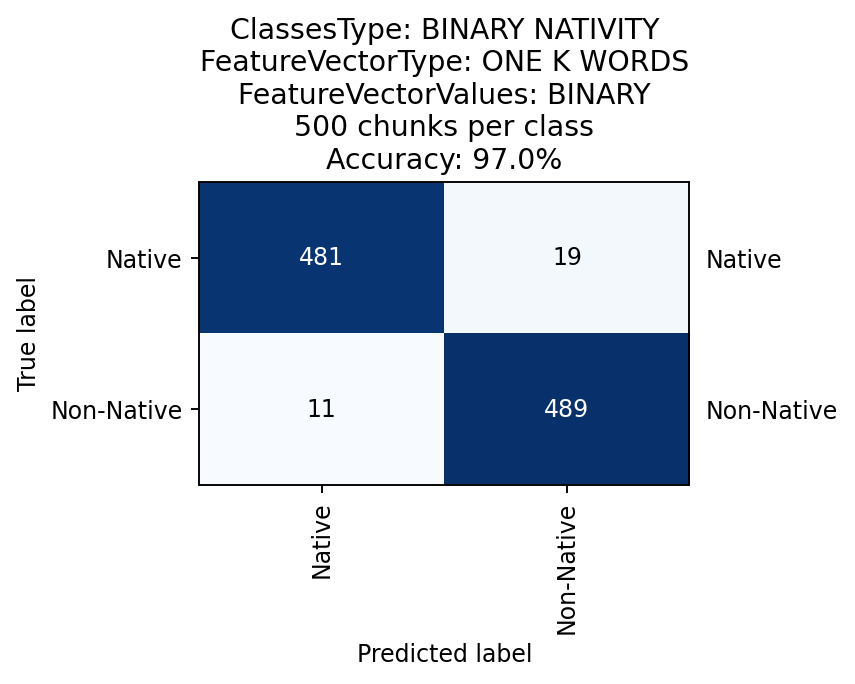
Although this has achieved a very high accuracy, it is an expected and not a very interesting result. As mentioned earlier, the main interest here is to perform the task by relying only on semantic features. Thus, I used the same Logistic Regression classifier, but this time with different features: the corpus's top 1000 POS trigrams, and a list of widely used English function words (for example see [4] for common English function words). The results were quite satisfying as well (about the same as the authors'):

Once again, using the top 1000 words binary features, I achieved very good results (87% accuracy). Note that a baseline random chance classifier would have a 1/21=4.7% accuracy.

As mentioned earlier, these results are not interesting, but merely serve as a sanity check for the database. However, it might be worthy to examine the most important features determined by the classifier (click the image for an interactive plot (produced by PlotLy)):

This is a column-wise heatmap, in which the rows are classes (countries) and the columns are features selected as "best features" by the classifier, so that cell [i,j] is how many times the word j appeared in documents of class i. Being a column-wise heatmap, it grants us the benefit of easily identifing each feature's distribution across the different countries. For example we can see that the word "austria" is mostly used by Austrian authors, whereas the word "german" by German authors, and so on. This strengthens the assumption that people tend to mention their own culture and countries more often than others.
Moving on to the more interesting semantic-features results, here is the confusion matrix of country classification, using only common function words and the top 1000 POS trigrams:

As can be seen in the confusion matrix above, I have achieved a satisfying accuracy of 57.1% (authors' is 60.8% with even more languages). As explained earlier, the random chance baseline accuracy for 21 languages would be 4.7%, so 57% is a very high accuracy compared to that (click to see an interactive heatmap of the best features selected by the classifier (produced by Plotly)). Also, notice that most errors occur between "close countries" (countries in the same language family) - such as the English speaking countries, or the Romance-language countries, which leads us to the 3rd and final classification task.
In this task I try to classify the languages into 4 language families: English / Germanic / Romance / Slavic (hover to see details - link is not active).
Using the same features that I had used in the other 2 tasks (function words and POS trigrams), I achieved a 77.3% accuracy:

Finally, here's a teaser I made to show the classification process in action while analyzing the tokens in a text, and classifying it correctly as Italian. Each token is colored according to the language it mostly contributes to. Some tokens are analyzed behind the scenes according to their POS tags.

In this project I have successfully reproduced the authors' results in identifying the original posters' native languages, using NLP techniques. The small differences in the results (in favor of the authors) might be due to various reasons, including but not limited to:
- Database size (theirs is much larger).
- Database cleaning (for example, they replaced URLs with the URL token, whereas I simply removed them; and replaced non-English words with the UNK token, whereas I treated them as normal tokens).
- Their token tagging was more accurate, as a result of using Spacy[5] for named entities identification, as well as the 'truecasing' technique to distinguish between abbreviations and regular words such as 'US' (United States) and 'us' (pronoun).
[1] Rabinovich, Ella, Yulia Tsvetkov, and Shuly Wintner. "Native language cognate effects on second language lexical choice." Transactions of the Association for Computational Linguistics 6 (2018): 329-342. Available at: https://transacl.org/ojs/index.php/tacl/article/view/1403.
[2] Goldin, Gili, Ella Rabinovich, and Shuly Wintner. "Native language identification with user generated content." Proceedings of the 2018 conference on empirical methods in natural language processing. 2018. Available at: https://www.aclweb.org/anthology/D18-1395/
[3] PRAW, The Python Reddit API Wrapper. Available at: https://praw.readthedocs.io/en/latest/
[4] Function words list: https://semanticsimilarity.files.wordpress.com/2013/08/jim-oshea-fwlist-277.pdf
[5] Spacy: Industrial-Strength Natural Language Processing. Available at: https://spacy.io/