diff --git a/ChangeLog.md b/ChangeLog.md
index 517aa7443..640d01c25 100644
--- a/ChangeLog.md
+++ b/ChangeLog.md
@@ -3,7 +3,16 @@
## NSQ Binaries
* 0.2.16 - rc.1
- * #90/#108 performance optimizations / IDENTIFY protocol support in nsqd
+
+ **Upgrading from 0.2.15**: there are no backward incompatible changes in this release.
+
+ However, this release introduces the `IDENTIFY` command (which supersedes sending
+ metadata along with `SUB`) for clients of `nsqd`. The old functionality will be
+ removed in a future release.
+
+ * #90/#108 performance optimizations / IDENTIFY protocol support in nsqd. For
+ a single consumer of small messages (< 4k) increases throughput ~400% and
+ reduces # of allocations ~30%.
* #105 nsq_to_file --filename-format parameter
* #103 nsq_to_http handler logging
* #102 compatibility with Go tip
@@ -42,6 +51,22 @@
## NSQ Go Client Library
* 0.2.5 - rc.1
+
+ **Upgrading from 0.2.4**: There are no backward incompatible changes to applications
+ written against the public `nsq.Reader` API.
+
+ However, there *are* a few backward incompatible changes to the API for applications that
+ directly use other public methods, or properties of a few NSQ data types:
+
+ `nsq.Message` IDs are now a type `nsq.MessageID` (a `[16]byte` array). The signatures of
+ `nsq.Finish()` and `nsq.Requeue()` reflect this change.
+
+ `nsq.SendCommand()` and `nsq.Frame()` were removed in favor of `nsq.SendFramedResponse()`.
+
+ `nsq.Subscribe()` no longer accepts `shortId` and `longId`. If upgrading your consumers
+ before upgrading your `nsqd` binaries to `0.2.16-rc.1` they will not be able to send the
+ optional custom identifiers.
+
* #90 performance optimizations
* #81 reader performance improvements / MPUB support
* 0.2.4 - 2012-10-15
diff --git a/docs/design.md b/docs/design.md
index e29043b5e..c8de6098e 100644
--- a/docs/design.md
+++ b/docs/design.md
@@ -1,5 +1,7 @@
## NSQ Design
+NOTE: for accompanying visual illustration see this [slide deck][slides].
+
### Simplifying Configuration and Administration
A single `nsqd` instance is designed to handle multiple streams of data at once. Streams are called
@@ -15,6 +17,10 @@ client. For example:
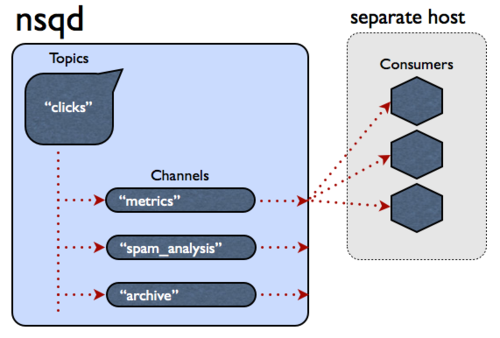
+To summarize, messages are multicast from topic -> channel (every channel receives a copy of all
+messages for that topic) but evenly distributed from channel -> consumers (each consumer receives a
+portion of the messages for that channel).
+
**NSQ** also includes a helper application, `nsqlookupd`, which provides a directory service where
consumers can lookup the addresses of `nsqd` instances that provide the topics they are interested
in subscribing to. In terms of configuration, this decouples the consumers from the producers (they
@@ -189,3 +195,4 @@ interfaces, and iteratively build functionality.
[golang]: http://golang.org
[go_at_bitly]: http://word.bitly.com/post/29550171827/go-go-gadget
[simplequeue]: https://github.com/bitly/simplehttp/tree/master/simplequeue
+[slides]: https://speakerdeck.com/snakes/nsq-nyc-golang-meetup
diff --git a/docs/images/nsq_patterns.001.png b/docs/images/nsq_patterns.001.png
new file mode 100644
index 000000000..92f8e4996
Binary files /dev/null and b/docs/images/nsq_patterns.001.png differ
diff --git a/docs/images/nsq_patterns.002.png b/docs/images/nsq_patterns.002.png
new file mode 100644
index 000000000..12799c8c0
Binary files /dev/null and b/docs/images/nsq_patterns.002.png differ
diff --git a/docs/images/nsq_patterns.003.png b/docs/images/nsq_patterns.003.png
new file mode 100644
index 000000000..e497ee5b8
Binary files /dev/null and b/docs/images/nsq_patterns.003.png differ
diff --git a/docs/images/nsq_patterns.004.png b/docs/images/nsq_patterns.004.png
new file mode 100644
index 000000000..0d176f0e8
Binary files /dev/null and b/docs/images/nsq_patterns.004.png differ
diff --git a/docs/images/nsq_patterns.005.png b/docs/images/nsq_patterns.005.png
new file mode 100644
index 000000000..494e1206b
Binary files /dev/null and b/docs/images/nsq_patterns.005.png differ
diff --git a/docs/images/nsq_patterns.006.png b/docs/images/nsq_patterns.006.png
new file mode 100644
index 000000000..b23b88dd5
Binary files /dev/null and b/docs/images/nsq_patterns.006.png differ
diff --git a/docs/patterns.md b/docs/patterns.md
new file mode 100644
index 000000000..f3fb79c2d
--- /dev/null
+++ b/docs/patterns.md
@@ -0,0 +1,197 @@
+This document describes some NSQ patterns that solve a variety of common
+problems.
+
+DISCLAIMER: there are *some* obvious technology suggestions but this document
+generally ignores the deeply personal details of choosing proper tools, getting
+software installed on production machines, managing what service is running
+where, service configuration, and managing running processes (daemontools,
+supervisord, init.d, etc.).
+
+### Metrics Collection
+
+Regardless of the type of web service you're building, in most cases you're
+going to want to collect some form of metrics in order to understand your
+infrastructure, your users, or your business.
+
+For a web service, most often these metrics are produced by events that happen
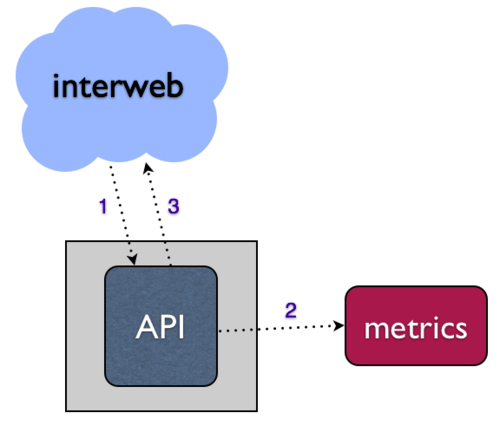
+via HTTP requests, like an API. The naive approach would be to structure
+this synchronously, writing to your metrics system directly in the API request
+handler.
+
+
+
+ * What happens when your metrics system goes down?
+ * Do your API requests hang and/or fail?
+ * How will you handle the scaling challenge of increasing API request volume
+ or breadth of metrics collection?
+
+One way to resolve all of these issues is to somehow perform the work of
+writing into your metrics system asynchronously - that is, place the data in
+some sort of local queue and write into your downstream system via some other
+process (consuming that queue). This separation of concerns allows the system
+to be more robust and fault tolerant. At bitly, we use NSQ to achieve this.
+
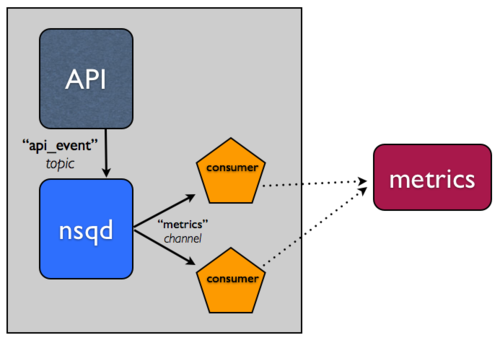
+Brief tangent: NSQ has the concept of **topics** and **channels**. Basically,
+think of a **topic** as a unique stream of messages (like our stream of API
+events above). Think of a **channel** as a *copy* of that stream of messages
+for a given set of consumers. Topics and channels are both independent queues,
+too. These properties enable NSQ to support both multicast (a topic *copying*
+each message to N channels) and distributed (a channel *equally dividing* its
+messages among N consumers) message delivery.
+
+For a more thorough treatment of these concepts, read through the [design
+doc][design_doc] and [slides from our Golang NYC talk][golang_slides],
+specifically [slides 19 through 33][channel_slides] describe topics and
+channels in detail.
+
+
+
+Integrating NSQ is straightforward, let's take the simple case:
+
+ 1. Run an instance of `nsqd` on the same host that runs your API application.
+ 2. Update your API application to write to the local `nsqd` instance to
+ queue events, instead of directly into the metrics system. To be able
+ to easily introspect and manipulate the stream, we generally format this
+ type of data in line-oriented JSON. Writing into `nsqd` can be as simple
+ as performing an HTTP POST request to the `/put` endpoint.
+ 3. Create a consumer in your preferred language using one of our
+ [client libraries][client_libs]. This "worker" will subscribe to the
+ stream of data and process the events, writing into your metrics system.
+ It can also run locally on the host running both your API application
+ and `nsqd`.
+
+Here's an example worker written with our official [Python client
+library][pynsq]:
+
+Python Example Code
+
+In addition to de-coupling, by using one of our official client libraries,
+consumers will degrade gracefully when message processing fails. Our libraries
+have two key features that help with this:
+
+ 1. **Retries** - when your message handler indicates failure, that information is
+ sent to `nsqd` in the form of a `REQ` (re-queue) command. Also, `nsqd` will
+ *automatically* time out (and re-queue) a message if it hasn't been responded
+ to in a configurable time window. These two properties are critical to
+ providing a delivery guarantee.
+ 2. **Exponential Backoff** - when message processing fails the reader library will
+ delay the receipt of additional messages for a duration that scales
+ exponentially based on the # of consecutive failures. The opposite sequence
+ happens when a reader is in a backoff state and begins to process
+ successfully, until 0.
+
+In concert, these two features allow the system to respond gracefully to
+downstream failure, automagically.
+
+### Persistence
+
+Ok, great, now you have the ability to withstand a situation where your
+metrics system is unavailable with no data loss and no degraded API service to
+other endpoints. You also have the ability to scale the processing of this
+stream horizontally by adding more worker instances to consume from the same
+channel.
+
+But, it's kinda hard ahead of time to think of all the types of metrics you
+might want to collect for a given API event.
+
+Wouldn't it be nice to have an archived log of this data stream for any future
+operation to leverage? Logs tend to be relatively easy to redundantly backup,
+making it a "plan z" of sorts in the event of catastrophic downstream data
+loss. But, would you want this same consumer to also have the responsibility
+of archiving the message data? Probably not, because of that whole "separation
+of concerns" thing.
+
+Archiving an NSQ topic is such a common pattern that we built a
+utility, [nsq_to_file][nsq_to_file], packaged with NSQ, that does
+exactly what you need.
+
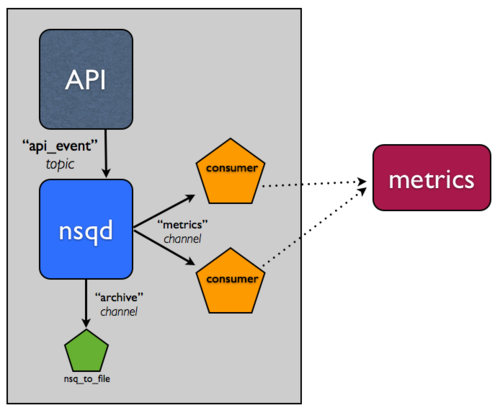
+Remember, in NSQ, each channel of a topic is independent and receives a
+*copy* of all the messages. You can use this to your advantage when archiving
+the stream by doing so over a new channel, `archive`. Practically, this means
+that if your metrics system is having issues and the `metrics` channel gets
+backed up, it won't effect the separate `archive` channel you'll be using to
+persist messages to disk.
+
+So, add an instance of `nsq_to_file` to the same host and use a command line
+like the following:
+
+```
+/usr/local/bin/nsq_to_file --nsqd-tcp-address=127.0.0.1:4150 --topic=api_requests --channel=archive
+```
+
+
+
+### Distributed Systems
+
+You'll notice that the system has not yet evolved beyond a single production
+host, which is a glaring single point of failure.
+
+Unfortunately, building a distributed system [is hard][dist_link].
+Fortunately, NSQ can help. The following changes demonstrate how
+NSQ alleviates some of the pain points of building distributed systems
+as well as how its design helps achieve high availability and fault tolerance.
+
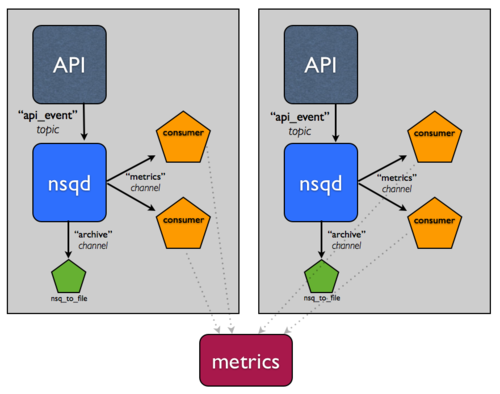
+Let's assume for a second that this event stream is *really* important. You
+want to be able to tolerate host failures and continue to ensure that messages
+are *at least* archived, so you add another host.
+
+
+
+Assuming you have some sort of load balancer in front of these two hosts you
+can now tolerate any single host failure.
+
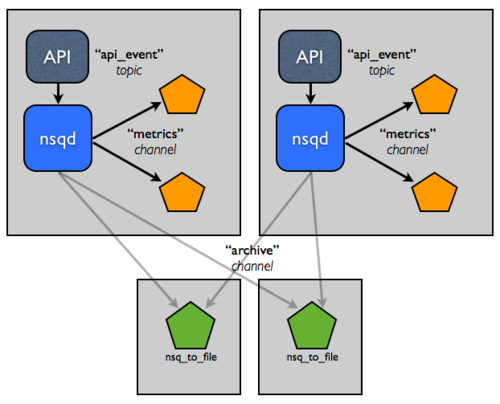
+Now, let's say the process of persisting, compressing, and transferring these
+logs is affecting performance. How about splitting that responsibility off to
+a tier of hosts that have higher IO capacity?
+
+
+
+This topology and configuration can easily scale to double-digit hosts, but
+you're still managing configuration of these services manually, which does not
+scale. Specifically, in each consumer, this setup is hard-coding the address
+of where `nsqd` instances live, which is a pain. What you really want is for
+the configuration to evolve and be accessed at runtime based on the state of
+the NSQ cluster. This is *exactly* what we built `nsqlookupd` to
+address.
+
+`nsqlookupd` is a daemon that records and disseminates the state of an NSQ
+cluster at runtime. `nsqd` instances maintain persistent TCP connections to
+`nsqlookupd` and push state changes across the wire. Specifically, an `nsqd`
+registers itself as a producer for a given topic as well as all channels it
+knows about. This allows consumers to query an `nsqlookupd` to determine who
+the producers are for a topic of interest, rather than hard-coding that
+configuration. Over time, they will *learn* about the existence of new
+producers and be able to route around failures.
+
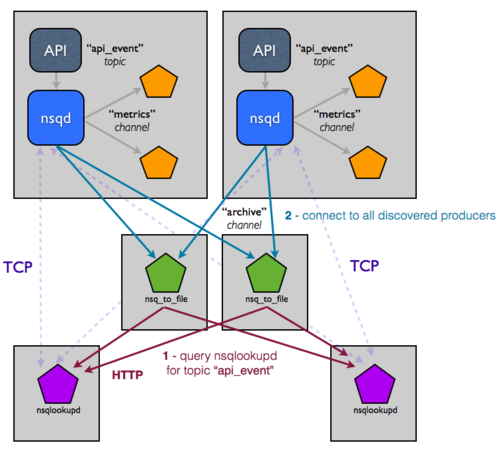
+The only changes you need to make are to point your existing `nsqd` and
+consumer instances at `nsqlookupd` (everyone explicitly knows where
+`nsqlookupd` instances are but consumers don't explicitly know where
+producers are, and vice versa). The topology now looks like this:
+
+
+
+At first glance this may look *more* complicated. It's deceptive though, as
+the effect this has on a growing infrastructure is hard to communicate
+visually. You've effectively decoupled producers from consumers because
+`nsqlookupd` is now acting as a directory service in between. Adding
+additional downstream services that depend on a given stream is trivial, just
+specify the topic you're interested in (producers will be discovered by
+querying `nsqlookupd`).
+
+But what about availability and consistency of the lookup data? We generally
+recommend basing your decision on how many to run in congruence with your
+desired availability requirements. `nsqlookupd` is not resource intensive and
+can be easily homed with other services. Also, `nsqlookupd` instances do not
+need to coordinate or otherwise be consistent with each other. Consumers will
+generally only require one `nsqlookupd` to be available with the information
+they need (and they will union the responses from all of the `nsqlookupd`
+instances they know about). Operationally, this makes it easy to migrate to a
+new set of `nsqlookupd`.
+
+[channel_slides]: https://speakerdeck.com/snakes/nsq-nyc-golang-meetup?slide=19
+[client_libs]: https://github.com/bitly/nsq#client-libraries
+[design_doc]: https://github.com/bitly/nsq/blob/master/docs/design.md
+[golang_slides]: https://speakerdeck.com/snakes/nsq-nyc-golang-meetup
+[pynsq]: https://github.com/bitly/pynsq
+[nsq_to_file]: https://github.com/bitly/nsq/blob/master/examples/nsq_to_file/nsq_to_file.go
+[dist_link]: https://twitter.com/b6n/status/276909760010387456
diff --git a/docs/protocol.md b/docs/protocol.md
index 2c2489ed1..63a7f1ed9 100644
--- a/docs/protocol.md
+++ b/docs/protocol.md
@@ -18,7 +18,9 @@ For `nsqd`, there is currently only one protocol:
### V2 Protocol
-After authenticating, in order to begin consuming messages, a client must `SUB` to a channel.
+After authenticating, the client can optionally send an `IDENTIFY` command to provide custom
+metadata (like, for example, more descriptive identifiers). In order to begin consuming messages, a
+client must `SUB` to a channel.
Upon subscribing the client is placed in a `RDY` state of 0. This means that no messages
will be sent to the client. When a client is ready to receive messages it should send a command that
@@ -32,14 +34,29 @@ seconds, `nsqd` will timeout and forcefully close a client connection that it ha
Commands are line oriented and structured as follows:
+ * `IDENTIFY` - update client metadata on the server
+
+ IDENTIFY\n
+ [ 4-byte size in bytes ][ N-byte JSON data ]
+
+ NOTE: this command takes a size prefixed JSON body, relevant fields:
+
+ - an identifier used as a short-form descriptor (ie. short hostname)
+ - an identifier used as a long-form descriptor (ie. fully-qualified hostname)
+
+ NOTE: there is no success response
+
+ Error Responses:
+
+ E_INVALID
+ E_BAD_BODY
+
* `SUB` - subscribe to a specified topic/channel
- SUB \n
+ SUB \n
- a valid string
- a valid string (optionally having #ephemeral suffix)
- - an identifier used as a short-form descriptor (ie. short hostname)
- - an identifier used as a long-form descriptor (ie. fully-qualified hostname)
NOTE: there is no success response
@@ -67,6 +84,25 @@ Commands are line oriented and structured as follows:
E_BAD_MESSAGE
E_PUT_FAILED
+ * `MPUB` - publish multiple messages to a specified **topic**:
+
+ MPUB \n
+ [ 4-byte size in bytes ][ N-byte binary data ]... (repeated times)
+
+ - a valid string
+ - a string representation of integer N
+
+ Success Response:
+
+ OK
+
+ Error Responses:
+
+ E_MISSING_PARAMS
+ E_BAD_TOPIC
+ E_BAD_BODY
+ E_PUT_FAILED
+
* `RDY` - update `RDY` state (indicate you are ready to receive messages)
RDY \n
diff --git a/nsqd/channel.go b/nsqd/channel.go
index f1d3abc69..3152c254d 100644
--- a/nsqd/channel.go
+++ b/nsqd/channel.go
@@ -513,9 +513,6 @@ func (c *Channel) inFlightWorker() {
// generic loop (executed in a goroutine) that periodically wakes up to walk
// the priority queue and call the callback
-//
-// if the first element on the queue is not ready (not enough time has elapsed)
-// the amount of time to wait before the next iteration is adjusted to optimize
func (c *Channel) pqWorker(pq *pqueue.PriorityQueue, mutex *sync.Mutex, callback func(item *pqueue.Item)) {
ticker := time.NewTicker(defaultWorkerWait)
for {