Conv2DTranspose - error due to Slice operation with None shape #801
Comments
|
PR #797 should not impact the conv_transposed/BiasAdd node. Can you share the model? Also, are you able to reproduce the error without the changes in the PR ? |
|
I see the comment from issue #790 -- looks like you are not able to share the model :/ Can you re-create a smaller model with similar behavior and upload? It looks like the shape information for input[0] is missing (quite odd). You should be able to set a breakpoint in TF2ONNX and inspect the ctx object to see if the input exists or not. It seems like the input node does not exist (and hence no shape), but would require a debugger to verify. shape0 = ctx.get_shape(node.input[0]) #<-- here
shape1 = ctx.get_shape(node.input[1])
if node.inputs[1].type == 'Const' and len(shape1) == 1:
new_broadcast_shape = [shape1[0]] + [1] * (len(shape0) - 2) |
|
Hi, First of all, here's the log with more verbose output: I notice two things: Why does the Now, the step-by step debugging:
With the following parameters:
In this case, both
This function returns Hope this extra debugging information helps figuring out the issue. Otherwise I'll try to come with a reproducible sample :) Thanks a lot! |
|
Hi again! Got a reproducible model for you :) It contains simply the Conv2D Transpose. I attach the script to generate it is well as the protobuf. The error is the same as before: Thanks! |
|
What version of TF are you using? Using your script to generate a TF model (call it Model B), I was able to convert the pb model to onnx successfully, using TF 1.14, using the master branch of TF2ONNX. However, the original model you shared (call it Model A) shows the same error that you posted above. Model A looks different from Model B (see below). The same script generated 2 different looking models ( ? ) -- are you using TF 2.0? Can you try switching to TF 1.14? EDIT -- ideally, the TF version should not matter, since TF2ONNX operators on the graph directly. However, the different graphs seem to indicate 2 different implementations of the Conv2DTranspose operator. It's possible that one of the implementations is not correct and was patched. Model A
Model B
Conversion log for Model B |
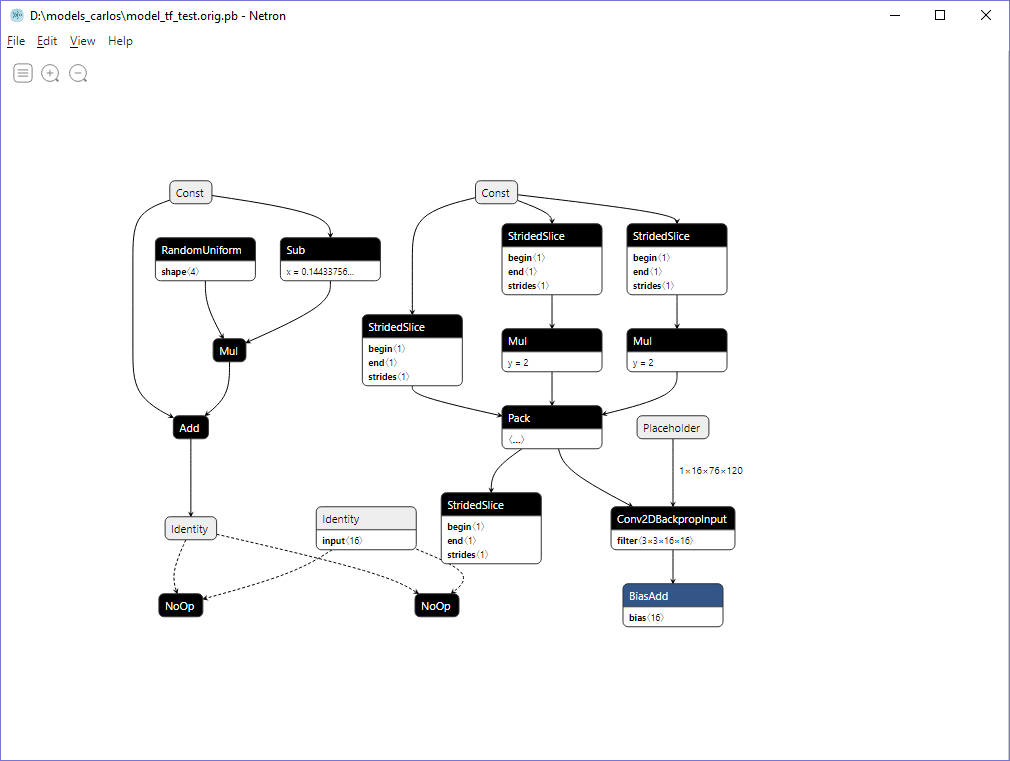
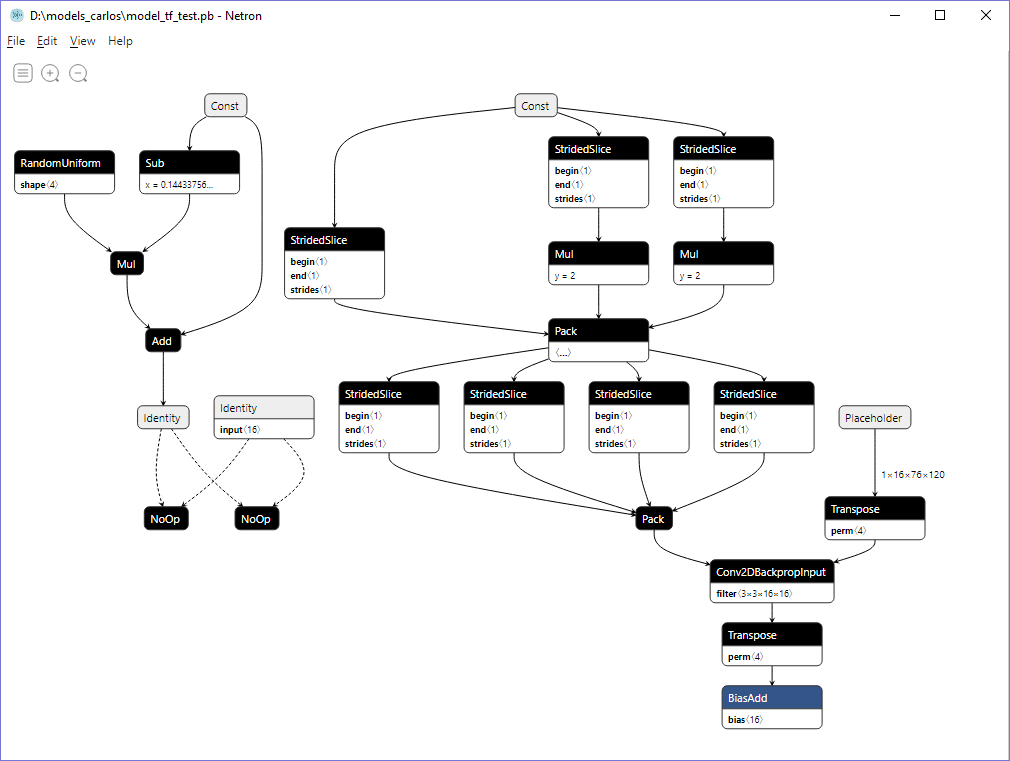
|
Wow, that's very strange! Here's my TensorFlow version: Are you using the CPU or GPU version? I'm verifying checksums but unfortunately the models seem to contain some time information, since the checksum varies every time I generate the model. I'll check the models with your tools as well. My current commands are: This is tested on latest tf2onnx master (3b4f375) Just in case, I'm also using Python 3.6.9. |
|
Bingo, I uninstalled the GPU version and installed the CPU one, and it works now! Not sure what to make out of this though :) We do have some layers in our network that only have GPU implementation, so I guess we still want to freeze our graph using the GPU version of TF? |
|
Good to know the difference is from CPU vs GPU implementation. A graph should be able to run on any hardware however. I'll investigate to see why the conversion is failing for the GPU version of the graph. |
|
We do remove all device information from the model so in theory gpu should not have an impact (and I never saw an issue). But I can take a closer look how we could get here. Using the gpu (that really don't help us) has the disadvantage that another app might be using the memory in which case tf2onnx would fail without good reason. I have a bug to bind tf2onnx to cpu here: #606 which I should fix. |
Thanks @guschmue . The Onnx graphs are agnostic of the hardware, so every graph runs on every hardware to produce exactly the same results. TF graphs should be similar (I have not see any counter-example so far). It seems bug #606 is running unit tests and pre-trained model tests, where tf2onnx should be forced to run on cpu. In this case though, the graph generated by TF-GPU package is different from TF-CPU package when using the exact same Python code. In theory, it seems like both should both be convertible to Onnx (but only 1 converts successfully). |
|
#606 is for example: you have a model in a jupyter notebook and you convert the model in the same notebook ... depending on how you write the notebook a session might be still open and the gpu memory could be allocated to the model ... tf2onnx would fail. In tensorflow - the model is aware of the device various nodes run on so it is possible that some optimizer kicks in and applies device specific optimizations. |
That's not necessarily true, as there are some layers with some configurations that only have GPU implementation, right? For example we have a layer with "channels_first" configuration that only has GPU implementation, whereas "channels_last" has both implementations. Since it doesn't have CPU implementation it cannot be deployed into a protobuf because the model cannot be instantiated. I don't remember exactly what layer it was, will come back with that info. |
Thanks! -- an example in TF would be great (i.e. a graph that is valid only for GPU but not for CPU). In ONNX, a graph is always valid for every type of hardware, if it consists of the standard set of operators. The operators will always have a CPU implementation, but may additionally contain a GPU implementation for acceleration (depending on the runtime). When a graph is run in a session, only the operators with a GPU implementation will execute on GPU, while the remaining operators execute on a CPU. |
|
Hi! Here's an example similar to the one I sent before, but using "Conv2D" instead of "Conv2DTranspose". When running on TF-CPU, I get the following error: |
|
Thanks for the sample script! According to the documentation https://www.tensorflow.org/api_docs/python/tf/compat/v1/layers/conv2d,, NCHW tensors (i.e. the option This seems to be a rare case of of an operator having a GPU implementation before CPU implementation is finished, rather than a graph that is only valid for CPU. If the operator is updated to support NCHW tensors, the graph would run fine on CPU as well (i.e. graph is valid, but implementation of operator on CPU is lacking as of this time). In ONNX there is no such case (i.e. a CPU implementation is always present for every operator). It seems that in TF there is no such guarantee. It seems like the GPU graph that you generated should convert to ONNX as well. I'll investigate further to see why it does not. |
|
Thanks for the help! Let me know if you need anything :) |
|
Hi! Did you make any progress on this one? Anything I can help with? |
|
@carlosgalvezp -- sorry for the delay. There's a shape inference error which requires a bit more debugging. Hopefully will resolve this shortly. |
|
@carlosgalvezp , can you use the master branch of tf2onnx to convert this model? You should now be able to convert the model generated from the TensorFlow-GPU 1.14 package successfully now, due to a combination of fixes. Also, I tested that the model loads in OnnxRuntime without any shape inference errors. Feel free to close out this issue if the solution works for you. |
|
Works like a charm on latest master, thanks a lot!! I had to choose opset 11 for it to work, not sure if it's expected. Closing the issue :) |
|
I had the same issue. Downgrading |
Hi!
I found some issue when converting a frozen network to ONNX. The problem comes with
Conv2DTranspose(btw, is it officially supported? I can't find it in the list). Here comes the error, running from this PR: #797The problem comes from
Slice__1179:0havingNoneshape. This layer is not part of the frozen model, but instead is inserted by ONNX (I believe) here:https://github.com/onnx/tensorflow-onnx/blob/master/tf2onnx/onnx_opset/nn.py#L288
That
slice_nodevariable has shapeNonewhen created.Why is that happening? Let me know if I can provide with more information to help figure this out.
Thanks!
The text was updated successfully, but these errors were encountered: