From ce22497b25c081ebbef91dc2fad04cdba9fef51f Mon Sep 17 00:00:00 2001
From: humu789 <88702197+humu789@users.noreply.github.com>
Date: Tue, 30 Aug 2022 19:46:37 +0800
Subject: [PATCH] [Docs] Add docs and update algo README (#259)
* docs v0.1
* update picture links in algo README
---
configs/distill/mmcls/abloss/README.md | 3 +-
configs/distill/mmcls/byot/README.md | 3 +-
configs/distill/mmcls/dafl/README.md | 3 +-
configs/distill/mmcls/dfad/README.md | 2 +-
configs/distill/mmcls/dkd/README.md | 2 +-
configs/distill/mmcls/fitnet/README.md | 3 +-
configs/distill/mmcls/kd/README.md | 2 +-
configs/distill/mmcls/ofd/README.md | 4 +-
configs/distill/mmcls/rkd/README.md | 2 +-
configs/distill/mmcls/wsld/README.md | 2 +-
configs/distill/mmcls/zskt/README.md | 4 +-
configs/distill/mmdet/cwd/README.md | 3 +-
configs/distill/mmdet/fbkd/README.md | 3 +-
configs/distill/mmseg/cwd/README.md | 2 +-
configs/nas/mmcls/darts/README.md | 2 +-
configs/nas/mmcls/spos/README.md | 3 +-
configs/nas/mmdet/detnas/README.md | 2 +-
configs/pruning/mmcls/autoslim/README.md | 4 +-
docs/en/advanced_guides/algorithm.md | 265 ++++++++++++
.../apply_existing_algorithms_to_new_tasks.md | 81 ++++
.../customize_architectures.md | 259 ++++++++++++
.../customize_mixed_algorithms.md | 158 +++++++
docs/en/advanced_guides/delivery.md | 218 ++++++++++
docs/en/advanced_guides/mutable.md | 393 ++++++++++++++++++
docs/en/advanced_guides/mutator.md | 240 +++++++++++
docs/en/advanced_guides/recorder.md | 346 +++++++++++++++
docs/en/get_started/model_zoo.md | 26 ++
docs/en/get_started/overview.md | 110 +++++
docs/en/user_guides/1_learn_about_config.md | 7 +
29 files changed, 2132 insertions(+), 20 deletions(-)
diff --git a/configs/distill/mmcls/abloss/README.md b/configs/distill/mmcls/abloss/README.md
index 308edc799..05fb00014 100644
--- a/configs/distill/mmcls/abloss/README.md
+++ b/configs/distill/mmcls/abloss/README.md
@@ -8,7 +8,8 @@
An activation boundary for a neuron refers to a separating hyperplane that determines whether the neuron is activated or deactivated. It has been long considered in neural networks that the activations of neurons, rather than their exact output values, play the most important role in forming classification friendly partitions of the hidden feature space. However, as far as we know, this aspect of neural networks has not been considered in the literature of knowledge transfer. In this pa- per, we propose a knowledge transfer method via distillation of activation boundaries formed by hidden neurons. For the distillation, we propose an activation transfer loss that has the minimum value when the boundaries generated by the stu- dent coincide with those by the teacher. Since the activation transfer loss is not differentiable, we design a piecewise differentiable loss approximating the activation transfer loss. By the proposed method, the student learns a separating bound- ary between activation region and deactivation region formed by each neuron in the teacher. Through the experiments in various aspects of knowledge transfer, it is verified that the proposed method outperforms the current state-of-the-art [link](https://github.com/bhheo/AB_distillation)
-
+ +
## Results and models
diff --git a/configs/distill/mmcls/byot/README.md b/configs/distill/mmcls/byot/README.md
index b20137221..5d9422d7a 100644
--- a/configs/distill/mmcls/byot/README.md
+++ b/configs/distill/mmcls/byot/README.md
@@ -6,7 +6,8 @@ Convolutional neural networks have been widely deployed in various application s
## Pipeline
-
+
+
## Results and models
diff --git a/configs/distill/mmcls/dafl/README.md b/configs/distill/mmcls/dafl/README.md
index 820d7772d..98939ebdb 100644
--- a/configs/distill/mmcls/dafl/README.md
+++ b/configs/distill/mmcls/dafl/README.md
@@ -8,7 +8,8 @@
Learning portable neural networks is very essential for computer vision for the purpose that pre-trained heavy deep models can be well applied on edge devices such as mobile phones and micro sensors. Most existing deep neural network compression and speed-up methods are very effective for training compact deep models, when we can directly access the training dataset. However, training data for the given deep network are often unavailable due to some practice problems (e.g. privacy, legal issue, and transmission), and the architecture of the given network are also unknown except some interfaces. To this end, we propose a novel framework for training efficient deep neural networks by exploiting generative adversarial networks (GANs). To be specific, the pre-trained teacher networks are regarded as a fixed discriminator and the generator is utilized for deviating training samples which can obtain the maximum response on the discriminator. Then, an efficient network with smaller model size and computational complexity is trained using the generated data and the teacher network, simultaneously. Efficient student networks learned using the pro- posed Data-Free Learning (DAFL) method achieve 92.22% and 74.47% accuracies using ResNet-18 without any training data on the CIFAR-10 and CIFAR-100 datasets, respectively. Meanwhile, our student network obtains an 80.56% accuracy on the CelebA benchmark.
-
+
+
## Results and models
diff --git a/configs/distill/mmcls/byot/README.md b/configs/distill/mmcls/byot/README.md
index b20137221..5d9422d7a 100644
--- a/configs/distill/mmcls/byot/README.md
+++ b/configs/distill/mmcls/byot/README.md
@@ -6,7 +6,8 @@ Convolutional neural networks have been widely deployed in various application s
## Pipeline
-
+
+
## Results and models
diff --git a/configs/distill/mmcls/dafl/README.md b/configs/distill/mmcls/dafl/README.md
index 820d7772d..98939ebdb 100644
--- a/configs/distill/mmcls/dafl/README.md
+++ b/configs/distill/mmcls/dafl/README.md
@@ -8,7 +8,8 @@
Learning portable neural networks is very essential for computer vision for the purpose that pre-trained heavy deep models can be well applied on edge devices such as mobile phones and micro sensors. Most existing deep neural network compression and speed-up methods are very effective for training compact deep models, when we can directly access the training dataset. However, training data for the given deep network are often unavailable due to some practice problems (e.g. privacy, legal issue, and transmission), and the architecture of the given network are also unknown except some interfaces. To this end, we propose a novel framework for training efficient deep neural networks by exploiting generative adversarial networks (GANs). To be specific, the pre-trained teacher networks are regarded as a fixed discriminator and the generator is utilized for deviating training samples which can obtain the maximum response on the discriminator. Then, an efficient network with smaller model size and computational complexity is trained using the generated data and the teacher network, simultaneously. Efficient student networks learned using the pro- posed Data-Free Learning (DAFL) method achieve 92.22% and 74.47% accuracies using ResNet-18 without any training data on the CIFAR-10 and CIFAR-100 datasets, respectively. Meanwhile, our student network obtains an 80.56% accuracy on the CelebA benchmark.
-
+ +
## Results and models
diff --git a/configs/distill/mmcls/dfad/README.md b/configs/distill/mmcls/dfad/README.md
index 74a65925d..ac86adb2b 100644
--- a/configs/distill/mmcls/dfad/README.md
+++ b/configs/distill/mmcls/dfad/README.md
@@ -8,7 +8,7 @@
Knowledge Distillation (KD) has made remarkable progress in the last few years and become a popular paradigm for model compression and knowledge transfer. However, almost all existing KD algorithms are data-driven, i.e., relying on a large amount of original training data or alternative data, which is usually unavailable in real-world scenarios. In this paper, we devote ourselves to this challenging problem and propose a novel adversarial distillation mechanism to craft a compact student model without any real-world data. We introduce a model discrepancy to quantificationally measure the difference between student and teacher models and construct an optimizable upper bound. In our work, the student and the teacher jointly act the role of the discriminator to reduce this discrepancy, when a generator adversarially produces some "hard samples" to enlarge it. Extensive experiments demonstrate that the proposed data-free method yields comparable performance to existing data-driven methods. More strikingly, our approach can be directly extended to semantic segmentation, which is more complicated than classification, and our approach achieves state-of-the-art results.
-
+
+
## Results and models
diff --git a/configs/distill/mmcls/dfad/README.md b/configs/distill/mmcls/dfad/README.md
index 74a65925d..ac86adb2b 100644
--- a/configs/distill/mmcls/dfad/README.md
+++ b/configs/distill/mmcls/dfad/README.md
@@ -8,7 +8,7 @@
Knowledge Distillation (KD) has made remarkable progress in the last few years and become a popular paradigm for model compression and knowledge transfer. However, almost all existing KD algorithms are data-driven, i.e., relying on a large amount of original training data or alternative data, which is usually unavailable in real-world scenarios. In this paper, we devote ourselves to this challenging problem and propose a novel adversarial distillation mechanism to craft a compact student model without any real-world data. We introduce a model discrepancy to quantificationally measure the difference between student and teacher models and construct an optimizable upper bound. In our work, the student and the teacher jointly act the role of the discriminator to reduce this discrepancy, when a generator adversarially produces some "hard samples" to enlarge it. Extensive experiments demonstrate that the proposed data-free method yields comparable performance to existing data-driven methods. More strikingly, our approach can be directly extended to semantic segmentation, which is more complicated than classification, and our approach achieves state-of-the-art results.
-
+ ## Results and models
diff --git a/configs/distill/mmcls/dkd/README.md b/configs/distill/mmcls/dkd/README.md
index 95e0b5703..84db5dc3f 100644
--- a/configs/distill/mmcls/dkd/README.md
+++ b/configs/distill/mmcls/dkd/README.md
@@ -8,7 +8,7 @@
State-of-the-art distillation methods are mainly based on distilling deep features from intermediate layers, while the significance of logit distillation is greatly overlooked. To provide a novel viewpoint to study logit distillation, we reformulate the classical KD loss into two parts, i.e., target class knowledge distillation (TCKD) and non-target class knowledge distillation (NCKD). We empirically investigate and prove the effects of the two parts: TCKD transfers knowledge concerning the "difficulty" of training samples, while NCKD is the prominent reason why logit distillation works. More importantly, we reveal that the classical KD loss is a coupled formulation, which (1) suppresses the effectiveness of NCKD and (2) limits the flexibility to balance these two parts. To address these issues, we present Decoupled Knowledge Distillation (DKD), enabling TCKD and NCKD to play their roles more efficiently and flexibly. Compared with complex feature-based methods, our DKD achieves comparable or even better results and has better training efficiency on CIFAR-100, ImageNet, and MS-COCO datasets for image classification and object detection tasks. This paper proves the great potential of logit distillation, and we hope it will be helpful for future research. The code is available at https://github.com/megvii-research/mdistiller.
-
+
## Results and models
diff --git a/configs/distill/mmcls/dkd/README.md b/configs/distill/mmcls/dkd/README.md
index 95e0b5703..84db5dc3f 100644
--- a/configs/distill/mmcls/dkd/README.md
+++ b/configs/distill/mmcls/dkd/README.md
@@ -8,7 +8,7 @@
State-of-the-art distillation methods are mainly based on distilling deep features from intermediate layers, while the significance of logit distillation is greatly overlooked. To provide a novel viewpoint to study logit distillation, we reformulate the classical KD loss into two parts, i.e., target class knowledge distillation (TCKD) and non-target class knowledge distillation (NCKD). We empirically investigate and prove the effects of the two parts: TCKD transfers knowledge concerning the "difficulty" of training samples, while NCKD is the prominent reason why logit distillation works. More importantly, we reveal that the classical KD loss is a coupled formulation, which (1) suppresses the effectiveness of NCKD and (2) limits the flexibility to balance these two parts. To address these issues, we present Decoupled Knowledge Distillation (DKD), enabling TCKD and NCKD to play their roles more efficiently and flexibly. Compared with complex feature-based methods, our DKD achieves comparable or even better results and has better training efficiency on CIFAR-100, ImageNet, and MS-COCO datasets for image classification and object detection tasks. This paper proves the great potential of logit distillation, and we hope it will be helpful for future research. The code is available at https://github.com/megvii-research/mdistiller.
-
+ ## Results and models
diff --git a/configs/distill/mmcls/fitnet/README.md b/configs/distill/mmcls/fitnet/README.md
index 23cfe1d2d..c6ff4ad13 100644
--- a/configs/distill/mmcls/fitnet/README.md
+++ b/configs/distill/mmcls/fitnet/README.md
@@ -20,7 +20,8 @@ allows one to train deeper students that can generalize better or run faster, a
controlled by the chosen student capacity. For example, on CIFAR-10, a deep student network with
almost 10.4 times less parameters outperforms a larger, state-of-the-art teacher network.
-
+
## Results and models
diff --git a/configs/distill/mmcls/fitnet/README.md b/configs/distill/mmcls/fitnet/README.md
index 23cfe1d2d..c6ff4ad13 100644
--- a/configs/distill/mmcls/fitnet/README.md
+++ b/configs/distill/mmcls/fitnet/README.md
@@ -20,7 +20,8 @@ allows one to train deeper students that can generalize better or run faster, a
controlled by the chosen student capacity. For example, on CIFAR-10, a deep student network with
almost 10.4 times less parameters outperforms a larger, state-of-the-art teacher network.
-
+ +
## Results and models
diff --git a/configs/distill/mmcls/kd/README.md b/configs/distill/mmcls/kd/README.md
index 13cbf1b52..0dcde2dd3 100644
--- a/configs/distill/mmcls/kd/README.md
+++ b/configs/distill/mmcls/kd/README.md
@@ -8,7 +8,7 @@
A very simple way to improve the performance of almost any machine learning algorithm is to train many different models on the same data and then to average their predictions. Unfortunately, making predictions using a whole ensemble of models is cumbersome and may be too computationally expensive to allow deployment to a large number of users, especially if the individual models are large neural nets. Caruana and his collaborators have shown that it is possible to compress the knowledge in an ensemble into a single model which is much easier to deploy and we develop this approach further using a different compression technique. We achieve some surprising results on MNIST and we show that we can significantly improve the acoustic model of a heavily used commercial system by distilling the knowledge in an ensemble of models into a single model. We also introduce a new type of ensemble composed of one or more full models and many specialist models which learn to distinguish fine-grained classes that the full models confuse. Unlike a mixture of experts, these specialist models can be trained rapidly and in parallel.
-
+
## Results and models
diff --git a/configs/distill/mmcls/ofd/README.md b/configs/distill/mmcls/ofd/README.md
index e96ecd256..d7d4045b5 100644
--- a/configs/distill/mmcls/ofd/README.md
+++ b/configs/distill/mmcls/ofd/README.md
@@ -8,11 +8,11 @@ We investigate the design aspects of feature distillation methods achieving netw
### Feature-based Distillation
-
+
### Margin ReLU
-
+
## Results and models
diff --git a/configs/distill/mmcls/rkd/README.md b/configs/distill/mmcls/rkd/README.md
index 6a0d36237..382ffdd93 100644
--- a/configs/distill/mmcls/rkd/README.md
+++ b/configs/distill/mmcls/rkd/README.md
@@ -20,7 +20,7 @@ proposed method improves educated student models with a significant margin.
In particular for metric learning, it allows students to outperform their
teachers' performance, achieving the state of the arts on standard benchmark datasets.
-
+
## Results and models
diff --git a/configs/distill/mmcls/wsld/README.md b/configs/distill/mmcls/wsld/README.md
index 6a507f54a..5019ddd0a 100644
--- a/configs/distill/mmcls/wsld/README.md
+++ b/configs/distill/mmcls/wsld/README.md
@@ -21,7 +21,7 @@ empirically find that completely filtering out regularization samples also deter
weighted soft labels to help the network adaptively handle the sample-wise biasvariance tradeoff. Experiments on standard evaluation benchmarks validate the
effectiveness of our method.
-
+
+
## Results and models
diff --git a/configs/distill/mmcls/kd/README.md b/configs/distill/mmcls/kd/README.md
index 13cbf1b52..0dcde2dd3 100644
--- a/configs/distill/mmcls/kd/README.md
+++ b/configs/distill/mmcls/kd/README.md
@@ -8,7 +8,7 @@
A very simple way to improve the performance of almost any machine learning algorithm is to train many different models on the same data and then to average their predictions. Unfortunately, making predictions using a whole ensemble of models is cumbersome and may be too computationally expensive to allow deployment to a large number of users, especially if the individual models are large neural nets. Caruana and his collaborators have shown that it is possible to compress the knowledge in an ensemble into a single model which is much easier to deploy and we develop this approach further using a different compression technique. We achieve some surprising results on MNIST and we show that we can significantly improve the acoustic model of a heavily used commercial system by distilling the knowledge in an ensemble of models into a single model. We also introduce a new type of ensemble composed of one or more full models and many specialist models which learn to distinguish fine-grained classes that the full models confuse. Unlike a mixture of experts, these specialist models can be trained rapidly and in parallel.
-
+
## Results and models
diff --git a/configs/distill/mmcls/ofd/README.md b/configs/distill/mmcls/ofd/README.md
index e96ecd256..d7d4045b5 100644
--- a/configs/distill/mmcls/ofd/README.md
+++ b/configs/distill/mmcls/ofd/README.md
@@ -8,11 +8,11 @@ We investigate the design aspects of feature distillation methods achieving netw
### Feature-based Distillation
-
+
### Margin ReLU
-
+
## Results and models
diff --git a/configs/distill/mmcls/rkd/README.md b/configs/distill/mmcls/rkd/README.md
index 6a0d36237..382ffdd93 100644
--- a/configs/distill/mmcls/rkd/README.md
+++ b/configs/distill/mmcls/rkd/README.md
@@ -20,7 +20,7 @@ proposed method improves educated student models with a significant margin.
In particular for metric learning, it allows students to outperform their
teachers' performance, achieving the state of the arts on standard benchmark datasets.
-
+
## Results and models
diff --git a/configs/distill/mmcls/wsld/README.md b/configs/distill/mmcls/wsld/README.md
index 6a507f54a..5019ddd0a 100644
--- a/configs/distill/mmcls/wsld/README.md
+++ b/configs/distill/mmcls/wsld/README.md
@@ -21,7 +21,7 @@ empirically find that completely filtering out regularization samples also deter
weighted soft labels to help the network adaptively handle the sample-wise biasvariance tradeoff. Experiments on standard evaluation benchmarks validate the
effectiveness of our method.
-
+ ## Results and models
diff --git a/configs/distill/mmcls/zskt/README.md b/configs/distill/mmcls/zskt/README.md
index 02f09e194..51ca46b07 100644
--- a/configs/distill/mmcls/zskt/README.md
+++ b/configs/distill/mmcls/zskt/README.md
@@ -10,11 +10,11 @@ Performing knowledge transfer from a large teacher network to a smaller student
## The teacher and student decision boundaries
-
+
## Results and models
diff --git a/configs/distill/mmcls/zskt/README.md b/configs/distill/mmcls/zskt/README.md
index 02f09e194..51ca46b07 100644
--- a/configs/distill/mmcls/zskt/README.md
+++ b/configs/distill/mmcls/zskt/README.md
@@ -10,11 +10,11 @@ Performing knowledge transfer from a large teacher network to a smaller student
## The teacher and student decision boundaries
-
+ ## Pseudo images sampled from the generator
-
+
## Pseudo images sampled from the generator
-
+ ## Results and models
diff --git a/configs/distill/mmdet/cwd/README.md b/configs/distill/mmdet/cwd/README.md
index be3328d79..e3b555f58 100644
--- a/configs/distill/mmdet/cwd/README.md
+++ b/configs/distill/mmdet/cwd/README.md
@@ -8,7 +8,8 @@
Knowledge distillation (KD) has been proven to be a simple and effective tool for training compact models. Almost all KD variants for dense prediction tasks align the student and teacher networks' feature maps in the spatial domain, typically by minimizing point-wise and/or pair-wise discrepancy. Observing that in semantic segmentation, some layers' feature activations of each channel tend to encode saliency of scene categories (analogue to class activation mapping), we propose to align features channel-wise between the student and teacher networks. To this end, we first transform the feature map of each channel into a probability map using softmax normalization, and then minimize the Kullback-Leibler (KL) divergence of the corresponding channels of the two networks. By doing so, our method focuses on mimicking the soft distributions of channels between networks. In particular, the KL divergence enables learning to pay more attention to the most salient regions of the channel-wise maps, presumably corresponding to the most useful signals for semantic segmentation. Experiments demonstrate that our channel-wise distillation outperforms almost all existing spatial distillation methods for semantic segmentation considerably, and requires less computational cost during training. We consistently achieve superior performance on three benchmarks with various network structures.
-
+
+
## Results and models
diff --git a/configs/distill/mmdet/fbkd/README.md b/configs/distill/mmdet/fbkd/README.md
index b64e460b0..bc6d38f68 100644
--- a/configs/distill/mmdet/fbkd/README.md
+++ b/configs/distill/mmdet/fbkd/README.md
@@ -8,7 +8,8 @@
Knowledge distillation, in which a student model is trained to mimic a teacher model, has been proved as an effective technique for model compression and model accuracy boosting. However, most knowledge distillation methods, designed for image classification, have failed on more challenging tasks, such as object detection. In this paper, we suggest that the failure of knowledge distillation on object detection is mainly caused by two reasons: (1) the imbalance between pixels of foreground and background and (2) lack of distillation on the relation between different pixels. Observing the above reasons, we propose attention-guided distillation and non-local distillation to address the two problems, respectively. Attention-guided distillation is proposed to find the crucial pixels of foreground objects with attention mechanism and then make the students take more effort to learn their features. Non-local distillation is proposed to enable students to learn not only the feature of an individual pixel but also the relation between different pixels captured by non-local modules. Experiments show that our methods achieve excellent AP improvements on both one-stage and two-stage, both anchor-based and anchor-free detectors. For example, Faster RCNN (ResNet101 backbone) with our distillation achieves 43.9 AP on COCO2017, which is 4.1 higher than the baseline.
-
+
## Results and models
diff --git a/configs/distill/mmdet/cwd/README.md b/configs/distill/mmdet/cwd/README.md
index be3328d79..e3b555f58 100644
--- a/configs/distill/mmdet/cwd/README.md
+++ b/configs/distill/mmdet/cwd/README.md
@@ -8,7 +8,8 @@
Knowledge distillation (KD) has been proven to be a simple and effective tool for training compact models. Almost all KD variants for dense prediction tasks align the student and teacher networks' feature maps in the spatial domain, typically by minimizing point-wise and/or pair-wise discrepancy. Observing that in semantic segmentation, some layers' feature activations of each channel tend to encode saliency of scene categories (analogue to class activation mapping), we propose to align features channel-wise between the student and teacher networks. To this end, we first transform the feature map of each channel into a probability map using softmax normalization, and then minimize the Kullback-Leibler (KL) divergence of the corresponding channels of the two networks. By doing so, our method focuses on mimicking the soft distributions of channels between networks. In particular, the KL divergence enables learning to pay more attention to the most salient regions of the channel-wise maps, presumably corresponding to the most useful signals for semantic segmentation. Experiments demonstrate that our channel-wise distillation outperforms almost all existing spatial distillation methods for semantic segmentation considerably, and requires less computational cost during training. We consistently achieve superior performance on three benchmarks with various network structures.
-
+
+
## Results and models
diff --git a/configs/distill/mmdet/fbkd/README.md b/configs/distill/mmdet/fbkd/README.md
index b64e460b0..bc6d38f68 100644
--- a/configs/distill/mmdet/fbkd/README.md
+++ b/configs/distill/mmdet/fbkd/README.md
@@ -8,7 +8,8 @@
Knowledge distillation, in which a student model is trained to mimic a teacher model, has been proved as an effective technique for model compression and model accuracy boosting. However, most knowledge distillation methods, designed for image classification, have failed on more challenging tasks, such as object detection. In this paper, we suggest that the failure of knowledge distillation on object detection is mainly caused by two reasons: (1) the imbalance between pixels of foreground and background and (2) lack of distillation on the relation between different pixels. Observing the above reasons, we propose attention-guided distillation and non-local distillation to address the two problems, respectively. Attention-guided distillation is proposed to find the crucial pixels of foreground objects with attention mechanism and then make the students take more effort to learn their features. Non-local distillation is proposed to enable students to learn not only the feature of an individual pixel but also the relation between different pixels captured by non-local modules. Experiments show that our methods achieve excellent AP improvements on both one-stage and two-stage, both anchor-based and anchor-free detectors. For example, Faster RCNN (ResNet101 backbone) with our distillation achieves 43.9 AP on COCO2017, which is 4.1 higher than the baseline.
-
+ +
## Results and models
diff --git a/configs/distill/mmseg/cwd/README.md b/configs/distill/mmseg/cwd/README.md
index be3328d79..d65c6cda2 100644
--- a/configs/distill/mmseg/cwd/README.md
+++ b/configs/distill/mmseg/cwd/README.md
@@ -8,7 +8,7 @@
Knowledge distillation (KD) has been proven to be a simple and effective tool for training compact models. Almost all KD variants for dense prediction tasks align the student and teacher networks' feature maps in the spatial domain, typically by minimizing point-wise and/or pair-wise discrepancy. Observing that in semantic segmentation, some layers' feature activations of each channel tend to encode saliency of scene categories (analogue to class activation mapping), we propose to align features channel-wise between the student and teacher networks. To this end, we first transform the feature map of each channel into a probability map using softmax normalization, and then minimize the Kullback-Leibler (KL) divergence of the corresponding channels of the two networks. By doing so, our method focuses on mimicking the soft distributions of channels between networks. In particular, the KL divergence enables learning to pay more attention to the most salient regions of the channel-wise maps, presumably corresponding to the most useful signals for semantic segmentation. Experiments demonstrate that our channel-wise distillation outperforms almost all existing spatial distillation methods for semantic segmentation considerably, and requires less computational cost during training. We consistently achieve superior performance on three benchmarks with various network structures.
-
+
## Results and models
diff --git a/configs/nas/mmcls/darts/README.md b/configs/nas/mmcls/darts/README.md
index 09bbfa80e..912dfb314 100644
--- a/configs/nas/mmcls/darts/README.md
+++ b/configs/nas/mmcls/darts/README.md
@@ -8,7 +8,7 @@
This paper addresses the scalability challenge of architecture search by formulating the task in a differentiable manner. Unlike conventional approaches of applying evolution or reinforcement learning over a discrete and non-differentiable search space, our method is based on the continuous relaxation of the architecture representation, allowing efficient search of the architecture using gradient descent. Extensive experiments on CIFAR-10, ImageNet, Penn Treebank and WikiText-2 show that our algorithm excels in discovering high-performance convolutional architectures for image classification and recurrent architectures for language modeling, while being orders of magnitude faster than state-of-the-art non-differentiable techniques. Our implementation has been made publicly available to facilitate further research on efficient architecture search algorithms.
-
+
## Results and models
diff --git a/configs/nas/mmcls/spos/README.md b/configs/nas/mmcls/spos/README.md
index 890085054..f66ac904d 100644
--- a/configs/nas/mmcls/spos/README.md
+++ b/configs/nas/mmcls/spos/README.md
@@ -9,7 +9,8 @@
We revisit the one-shot Neural Architecture Search (NAS) paradigm and analyze its advantages over existing NAS approaches. Existing one-shot method, however, is hard to train and not yet effective on large scale datasets like ImageNet. This work propose a Single Path One-Shot model to address the challenge in the training. Our central idea is to construct a simplified supernet, where all architectures are single paths so that weight co-adaption problem is alleviated. Training is performed by uniform path sampling. All architectures (and their weights) are trained fully and equally.
Comprehensive experiments verify that our approach is flexible and effective. It is easy to train and fast to search. It effortlessly supports complex search spaces (e.g., building blocks, channel, mixed-precision quantization) and different search constraints (e.g., FLOPs, latency). It is thus convenient to use for various needs. It achieves start-of-the-art performance on the large dataset ImageNet.
-
+
+
## Introduction
diff --git a/configs/nas/mmdet/detnas/README.md b/configs/nas/mmdet/detnas/README.md
index 726347f6f..3eca077f4 100644
--- a/configs/nas/mmdet/detnas/README.md
+++ b/configs/nas/mmdet/detnas/README.md
@@ -8,7 +8,7 @@
Object detectors are usually equipped with backbone networks designed for image classification. It might be sub-optimal because of the gap between the tasks of image classification and object detection. In this work, we present DetNAS to use Neural Architecture Search (NAS) for the design of better backbones for object detection. It is non-trivial because detection training typically needs ImageNet pre-training while NAS systems require accuracies on the target detection task as supervisory signals. Based on the technique of one-shot supernet, which contains all possible networks in the search space, we propose a framework for backbone search on object detection. We train the supernet under the typical detector training schedule: ImageNet pre-training and detection fine-tuning. Then, the architecture search is performed on the trained supernet, using the detection task as the guidance. This framework makes NAS on backbones very efficient. In experiments, we show the effectiveness of DetNAS on various detectors, for instance, one-stage RetinaNet and the two-stage FPN. We empirically find that networks searched on object detection shows consistent superiority compared to those searched on ImageNet classification. The resulting architecture achieves superior performance than hand-crafted networks on COCO with much less FLOPs complexity.
-
+
## Introduction
diff --git a/configs/pruning/mmcls/autoslim/README.md b/configs/pruning/mmcls/autoslim/README.md
index ca9f1de4d..9a533eb4f 100644
--- a/configs/pruning/mmcls/autoslim/README.md
+++ b/configs/pruning/mmcls/autoslim/README.md
@@ -9,7 +9,9 @@
We study how to set channel numbers in a neural network to achieve better accuracy under constrained resources (e.g., FLOPs, latency, memory footprint or model size). A simple and one-shot solution, named AutoSlim, is presented. Instead of training many network samples and searching with reinforcement learning, we train a single slimmable network to approximate the network accuracy of different channel configurations. We then iteratively evaluate the trained slimmable model and greedily slim the layer with minimal accuracy drop. By this single pass, we can obtain the optimized channel configurations under different resource constraints. We present experiments with MobileNet v1, MobileNet v2, ResNet-50 and RL-searched MNasNet on ImageNet classification. We show significant improvements over their default channel configurations. We also achieve better accuracy than recent channel pruning methods and neural architecture search methods.
Notably, by setting optimized channel numbers, our AutoSlim-MobileNet-v2 at 305M FLOPs achieves 74.2% top-1 accuracy, 2.4% better than default MobileNet-v2 (301M FLOPs), and even 0.2% better than RL-searched MNasNet (317M FLOPs). Our AutoSlim-ResNet-50 at 570M FLOPs, without depthwise convolutions, achieves 1.3% better accuracy than MobileNet-v1 (569M FLOPs).
-
+
+
+
## Introduction
diff --git a/docs/en/advanced_guides/algorithm.md b/docs/en/advanced_guides/algorithm.md
index 48de5f33d..cd5056167 100644
--- a/docs/en/advanced_guides/algorithm.md
+++ b/docs/en/advanced_guides/algorithm.md
@@ -1 +1,266 @@
# Algorithm
+## Introduction
+
+### What is algorithm in MMRazor
+
+MMRazor is a model compression toolkit, which includes 4 mianstream technologies:
+
+- Neural Architecture Search (NAS)
+- Pruning
+- Knowledge Distillation (KD)
+- Quantization (come soon)
+
+And in MMRazor, `algorithm` is a general item for these technologies. For example, in NAS,
+
+[SPOS](https://github.com/open-mmlab/mmrazor/blob/master/configs/nas/spos)[ ](https://arxiv.org/abs/1904.00420)is an `algorithm`, [CWD](https://github.com/open-mmlab/mmrazor/blob/master/configs/distill/cwd) is also an `algorithm` of knowledge distillation.
+
+`algorithm` is the entrance of `mmrazor/models` . Its role in MMRazor is the same as both `classifier` in [MMClassification](https://github.com/open-mmlab/mmclassification) and `detector` in [MMDetection](https://github.com/open-mmlab/mmdetection).
+
+### About base algorithm
+
+In the directory of `models/algorith``ms`, all model compression algorithms are divided into 4 subdirectories: nas / pruning / distill / quantization. These algorithms must inherit from `BaseAlgorithm`, whose definition is as below.
+
+```Python
+from typing import Dict, List, Optional, Tuple, Union
+from mmengine.model import BaseModel
+from mmrazor.registry import MODELS
+
+LossResults = Dict[str, torch.Tensor]
+TensorResults = Union[Tuple[torch.Tensor], torch.Tensor]
+PredictResults = List[BaseDataElement]
+ForwardResults = Union[LossResults, TensorResults, PredictResults]
+
+@MODELS.register_module()
+class BaseAlgorithm(BaseModel):
+
+ def __init__(self,
+ architecture: Union[BaseModel, Dict],
+ data_preprocessor: Optional[Union[Dict, nn.Module]] = None,
+ init_cfg: Optional[Dict] = None):
+
+ ......
+
+ super().__init__(data_preprocessor, init_cfg)
+ self.architecture = architecture
+
+ def forward(self,
+ batch_inputs: torch.Tensor,
+ data_samples: Optional[List[BaseDataElement]] = None,
+ mode: str = 'tensor') -> ForwardResults:
+
+ if mode == 'loss':
+ return self.loss(batch_inputs, data_samples)
+ elif mode == 'tensor':
+ return self._forward(batch_inputs, data_samples)
+ elif mode == 'predict':
+ return self._predict(batch_inputs, data_samples)
+ else:
+ raise RuntimeError(f'Invalid mode "{mode}". '
+ 'Only supports loss, predict and tensor mode')
+
+ def loss(
+ self,
+ batch_inputs: torch.Tensor,
+ data_samples: Optional[List[BaseDataElement]] = None,
+ ) -> LossResults:
+ """Calculate losses from a batch of inputs and data samples."""
+ return self.architecture(batch_inputs, data_samples, mode='loss')
+
+ def _forward(
+ self,
+ batch_inputs: torch.Tensor,
+ data_samples: Optional[List[BaseDataElement]] = None,
+ ) -> TensorResults:
+ """Network forward process."""
+ return self.architecture(batch_inputs, data_samples, mode='tensor')
+
+ def _predict(
+ self,
+ batch_inputs: torch.Tensor,
+ data_samples: Optional[List[BaseDataElement]] = None,
+ ) -> PredictResults:
+ """Predict results from a batch of inputs and data samples with post-
+ processing."""
+ return self.architecture(batch_inputs, data_samples, mode='predict')
+```
+
+As you can see from above, `BaseAlgorithm` is inherited from `BaseModel` of MMEngine. `BaseModel` implements the basic functions of the algorithmic model, such as weights initialize,
+
+batch inputs preprocess (see more information in `BaseDataPreprocessor` class of MMEngine), parse losses, and update model parameters. For more details of `BaseModel` , you can see docs for `BaseModel`.
+
+`BaseAlgorithm`'s forward is just a wrapper of `BaseModel`'s forward. Sub-classes inherited from BaseAlgorithm only need to override the `loss` method, which implements the logic to calculate loss, thus various algorithms can be trained in the runner.
+
+
+
+## How to use existing algorithms in MMRazor
+
+1. Configure your architecture that will be slimmed
+
+- Use the model config of other repos of OpenMMLab directly as below, which is an example of setting Faster-RCNN as our architecture.
+
+```Python
+_base_ = [
+ 'mmdet::_base_/models/faster_rcnn_r50_fpn.py',
+]
+
+architecture = _base_.model
+```
+
+- Use your customized model as below, which is an example of defining a VGG model as our architecture.
+
+> How to customize architectures can refer to our tutorial: [Customize Architectures](https://mmrazor.readthedocs.io/en/latest/tutorials/Tutorial_3_customize_architectures.html#).
+
+```Python
+default_scope='mmcls'
+architecture = dict(
+ type='ImageClassifier',
+ backbone=dict(type='VGG', depth=11, num_classes=1000),
+ neck=None,
+ head=dict(
+ type='ClsHead',
+ loss=dict(type='CrossEntropyLoss', loss_weight=1.0),
+ topk=(1, 5),
+ ))
+```
+
+2. Apply the registered algorithm to your architecture.
+
+> The arg name of `algorithm` in config is **model** rather than **algorithm** in order to get better supports of MMCV and MMEngine.
+
+Maybe more args in model need to set according to the used algorithm.
+
+```Python
+model = dict(
+ type='BaseAlgorithm',
+ architecture=architecture)
+```
+
+> About the usage of `Config`, refer to [Config ‒ mmcv 1.5.3 documentation](https://mmcv.readthedocs.io/en/latest/understand_mmcv/config.html) please.
+
+3. Apply some custom hooks or loops to your algorithm. (optional)
+
+- Custom hooks
+
+```Python
+custom_hooks = [
+ dict(type='NaiveVisualizationHook', priority='LOWEST'),
+]
+```
+
+- Custom loops
+
+```Python
+_base_ = ['./spos_shufflenet_supernet_8xb128_in1k.py']
+
+# To chose from ['train_cfg', 'val_cfg', 'test_cfg'] based on your loop type
+train_cfg = dict(
+ _delete_=True,
+ type='mmrazor.EvolutionSearchLoop',
+ dataloader=_base_.val_dataloader,
+ evaluator=_base_.val_evaluator)
+
+val_cfg = dict()
+test_cfg = dict()
+```
+
+## How to customize your algorithm
+
+### Common pipeline
+
+1. Register a new algorithm
+
+Create a new file `mmrazor/models/algorithms/{subdirectory}/xxx.py`
+
+```Python
+from mmrazor.models.algorithms import BaseAlgorithm
+from mmrazor.registry import MODELS
+
+@MODELS.register_module()
+class XXX(BaseAlgorithm):
+ def __init__(self, architecture):
+ super().__init__(architecture)
+ pass
+
+ def loss(self, batch_inputs):
+ pass
+```
+
+2. Rewrite its `loss` method.
+
+```Python
+from mmrazor.models.algorithms import BaseAlgorithm
+from mmrazor.registry import MODELS
+
+@MODELS.register_module()
+class XXX(BaseAlgorithm):
+ def __init__(self, architecture):
+ super().__init__(architecture)
+ ......
+
+ def loss(self, batch_inputs):
+ ......
+ return LossResults
+```
+
+3. Add the remaining functions of the algorithm
+
+> This step is special because of the diversity of algorithms. Some functions of the algorithm may also be implemented in other files.
+
+```Python
+from mmrazor.models.algorithms import BaseAlgorithm
+from mmrazor.registry import MODELS
+
+@MODELS.register_module()
+class XXX(BaseAlgorithm):
+ def __init__(self, architecture):
+ super().__init__(architecture)
+ ......
+
+ def loss(self, batch_inputs):
+ ......
+ return LossResults
+
+ def aaa(self):
+ ......
+
+ def bbb(self):
+ ......
+```
+
+4. Import the class
+
+You can add the following line to `mmrazor/models/algorithms/``{subdirectory}/``__init__.py`
+
+```CoffeeScript
+from .xxx import XXX
+
+__all__ = ['XXX']
+```
+
+In addition, import XXX in `mmrazor/models/algorithms/__init__.py`
+
+5. Use the algorithm in your config file.
+
+Please refer to the previous section about how to use existing algorithms in MMRazor
+
+```Python
+model = dict(
+ type='XXX',
+ architecture=architecture)
+```
+
+### Pipelines for different algorithms
+
+Please refer to our tutorials about how to customize different algorithms for more details as below.
+
+1. NAS
+
+[Customize NAS algorithms](https://mmrazor.readthedocs.io/en/latest/tutorials/Tutorial_4_customize_nas_algorithms.html#)
+
+2. Pruning
+
+[Customize Pruning algorithms](https://mmrazor.readthedocs.io/en/latest/tutorials/Tutorial_5_customize_pruning_algorithms.html)
+
+3. Distill
+
+[Customize KD algorithms](https://mmrazor.readthedocs.io/en/latest/tutorials/Tutorial_6_customize_kd_algorithms.html)
\ No newline at end of file
diff --git a/docs/en/advanced_guides/apply_existing_algorithms_to_new_tasks.md b/docs/en/advanced_guides/apply_existing_algorithms_to_new_tasks.md
index 71bc4bfe0..3e2f8e394 100644
--- a/docs/en/advanced_guides/apply_existing_algorithms_to_new_tasks.md
+++ b/docs/en/advanced_guides/apply_existing_algorithms_to_new_tasks.md
@@ -1 +1,82 @@
# Apply existing algorithms to new tasks
+Here we show how to apply existing algorithms to other tasks with an example of [SPOS ](https://github.com/open-mmlab/mmrazor/tree/dev-1.x/configs/nas/mmcls/spos)& [DetNAS](https://github.com/open-mmlab/mmrazor/tree/dev-1.x/configs/nas/mmdet/detnas).
+
+> SPOS: Single Path One-Shot NAS for classification
+>
+> DetNAS: Single Path One-Shot NAS for detection
+
+**You just need to configure the existing algorithms in your config only by replacing** **the architecture of** **mmcls** **with** **mmdet****'s**
+
+You can implement a new algorithm by inheriting from the existing algorithm quickly if the new task's specificity leads to the failure of applying directly.
+
+SPOS config VS DetNAS config
+
+- SPOS
+
+```Python
+_base_ = [
+ 'mmrazor::_base_/settings/imagenet_bs1024_spos.py',
+ 'mmrazor::_base_/nas_backbones/spos_shufflenet_supernet.py',
+ 'mmcls::_base_/default_runtime.py',
+]
+
+# model
+supernet = dict(
+ type='ImageClassifier',
+ data_preprocessor=_base_.preprocess_cfg,
+ backbone=_base_.nas_backbone,
+ neck=dict(type='GlobalAveragePooling'),
+ head=dict(
+ type='LinearClsHead',
+ num_classes=1000,
+ in_channels=1024,
+ loss=dict(
+ type='LabelSmoothLoss',
+ num_classes=1000,
+ label_smooth_val=0.1,
+ mode='original',
+ loss_weight=1.0),
+ topk=(1, 5)))
+
+model = dict(
+ type='mmrazor.SPOS',
+ architecture=supernet,
+ mutator=dict(type='mmrazor.OneShotModuleMutator'))
+
+find_unused_parameters = True
+```
+
+- DetNAS
+
+```Python
+_base_ = [
+ 'mmdet::_base_/models/faster_rcnn_r50_fpn.py',
+ 'mmdet::_base_/datasets/coco_detection.py',
+ 'mmdet::_base_/schedules/schedule_1x.py',
+ 'mmdet::_base_/default_runtime.py',
+ 'mmrazor::_base_/nas_backbones/spos_shufflenet_supernet.py'
+]
+
+norm_cfg = dict(type='SyncBN', requires_grad=True)
+
+supernet = _base_.model
+
+supernet.backbone = _base_.nas_backbone
+supernet.backbone.norm_cfg = norm_cfg
+supernet.backbone.out_indices = (0, 1, 2, 3)
+supernet.backbone.with_last_layer = False
+
+supernet.neck.norm_cfg = norm_cfg
+supernet.neck.in_channels = [64, 160, 320, 640]
+
+supernet.roi_head.bbox_head.norm_cfg = norm_cfg
+supernet.roi_head.bbox_head.type = 'Shared4Conv1FCBBoxHead'
+
+model = dict(
+ _delete_=True,
+ type='mmrazor.SPOS',
+ architecture=supernet,
+ mutator=dict(type='mmrazor.OneShotModuleMutator'))
+
+find_unused_parameters = True
+```
\ No newline at end of file
diff --git a/docs/en/advanced_guides/customize_architectures.md b/docs/en/advanced_guides/customize_architectures.md
index 2e94c780b..59c5092ee 100644
--- a/docs/en/advanced_guides/customize_architectures.md
+++ b/docs/en/advanced_guides/customize_architectures.md
@@ -1 +1,260 @@
# Customize Architectures
+Different from other tasks, architectures in MMRazor may consist of some special model components, such as **searchable backbones, connectors, dynamic ops**. In MMRazor, you can not only develop some common model components like other codebases of OpenMMLab, but also develop some special model components. Here is how to develop searchable model components and common model components.
+
+> Please refer to these documents as follows if you want to know about **connectors** and **dynamic ops**.
+>
+> [Connector 用户文档](https://aicarrier.feishu.cn/docx/doxcnvJG0VHZLqF82MkCHyr9B8b)
+>
+> [Dynamic op 用户文档](https://aicarrier.feishu.cn/docx/doxcnbp4n4HeDkJI1fHlWfVklke)
+
+## Develop searchable model components
+
+1. Define a new backbone
+
+Create a new file `mmrazor/models/architectures/backbones/searchable_shufflenet_v2.py`, class `SearchableShuffleNetV2` inherits from `BaseBackBone` of mmcls, which is the codebase that you will use to build the model.
+
+```Python
+# Copyright (c) OpenMMLab. All rights reserved.
+import copy
+from typing import Dict, List, Optional, Sequence, Tuple, Union
+
+import torch.nn as nn
+from mmcls.models.backbones.base_backbone import BaseBackbone
+from mmcv.cnn import ConvModule, constant_init, normal_init
+from mmcv.runner import ModuleList, Sequential
+from torch import Tensor
+from torch.nn.modules.batchnorm import _BatchNorm
+
+from mmrazor.registry import MODELS
+
+@MODELS.register_module()
+class SearchableShuffleNetV2(BaseBackbone):
+
+ def __init__(self, ):
+ pass
+
+ def _make_layer(self, out_channels, num_blocks, stage_idx):
+ pass
+
+ def _freeze_stages(self):
+ pass
+
+ def init_weights(self):
+ pass
+
+ def forward(self, x):
+ pass
+
+ def train(self, mode=True):
+ pass
+```
+
+2. Build the architecture of the new backbone based on `arch_setting`
+
+```Python
+@MODELS.register_module()
+class SearchableShuffleNetV2(BaseBackbone):
+ def __init__(self,
+ arch_setting: List[List],
+ stem_multiplier: int = 1,
+ widen_factor: float = 1.0,
+ out_indices: Sequence[int] = (4, ),
+ frozen_stages: int = -1,
+ with_last_layer: bool = True,
+ conv_cfg: Optional[Dict] = None,
+ norm_cfg: Dict = dict(type='BN'),
+ act_cfg: Dict = dict(type='ReLU'),
+ norm_eval: bool = False,
+ with_cp: bool = False,
+ init_cfg: Optional[Union[Dict, List[Dict]]] = None) -> None:
+ layers_nums = 5 if with_last_layer else 4
+ for index in out_indices:
+ if index not in range(0, layers_nums):
+ raise ValueError('the item in out_indices must in '
+ f'range(0, 5). But received {index}')
+
+ self.frozen_stages = frozen_stages
+ if frozen_stages not in range(-1, layers_nums):
+ raise ValueError('frozen_stages must be in range(-1, 5). '
+ f'But received {frozen_stages}')
+
+ super().__init__(init_cfg)
+
+ self.arch_setting = arch_setting
+ self.widen_factor = widen_factor
+ self.out_indices = out_indices
+ self.conv_cfg = conv_cfg
+ self.norm_cfg = norm_cfg
+ self.act_cfg = act_cfg
+ self.norm_eval = norm_eval
+ self.with_cp = with_cp
+
+ last_channels = 1024
+ self.in_channels = 16 * stem_multiplier
+
+ # build the first layer
+ self.conv1 = ConvModule(
+ in_channels=3,
+ out_channels=self.in_channels,
+ kernel_size=3,
+ stride=2,
+ padding=1,
+ conv_cfg=conv_cfg,
+ norm_cfg=norm_cfg,
+ act_cfg=act_cfg)
+
+ # build the middle layers
+ self.layers = ModuleList()
+ for channel, num_blocks, mutable_cfg in arch_setting:
+ out_channels = round(channel * widen_factor)
+ layer = self._make_layer(out_channels, num_blocks,
+ copy.deepcopy(mutable_cfg))
+ self.layers.append(layer)
+
+ # build the last layer
+ if with_last_layer:
+ self.layers.append(
+ ConvModule(
+ in_channels=self.in_channels,
+ out_channels=last_channels,
+ kernel_size=1,
+ conv_cfg=conv_cfg,
+ norm_cfg=norm_cfg,
+ act_cfg=act_cfg))
+```
+
+3. Implement`_make_layer` with `mutable_cfg`
+
+```Python
+@MODELS.register_module()
+class SearchableShuffleNetV2(BaseBackbone):
+
+ ...
+
+ def _make_layer(self, out_channels: int, num_blocks: int,
+ mutable_cfg: Dict) -> Sequential:
+ """Stack mutable blocks to build a layer for ShuffleNet V2.
+ Note:
+ Here we use ``module_kwargs`` to pass dynamic parameters such as
+ ``in_channels``, ``out_channels`` and ``stride``
+ to build the mutable.
+ Args:
+ out_channels (int): out_channels of the block.
+ num_blocks (int): number of blocks.
+ mutable_cfg (dict): Config of mutable.
+ Returns:
+ mmcv.runner.Sequential: The layer made.
+ """
+ layers = []
+ for i in range(num_blocks):
+ stride = 2 if i == 0 else 1
+
+ mutable_cfg.update(
+ module_kwargs=dict(
+ in_channels=self.in_channels,
+ out_channels=out_channels,
+ stride=stride))
+ layers.append(MODELS.build(mutable_cfg))
+ self.in_channels = out_channels
+
+ return Sequential(*layers)
+
+ ...
+```
+
+4. Implement other common methods
+
+You can refer to the implementation of `ShuffleNetV2` in mmcls for finishing other common methods.
+
+5. Import the module
+
+You can either add the following line to `mmrazor/models/architectures/backbones/__init__.py`
+
+```Python
+from .searchable_shufflenet_v2 import SearchableShuffleNetV2
+
+__all__ = ['SearchableShuffleNetV2']
+```
+
+or alternatively add
+
+```Python
+custom_imports = dict(
+ imports=['mmrazor.models.architectures.backbones.searchable_shufflenet_v2'],
+ allow_failed_imports=False)
+```
+
+to the config file to avoid modifying the original code.
+
+6. Use the backbone in your config file
+
+```Python
+architecture = dict(
+ type=xxx,
+ model=dict(
+ ...
+ backbone=dict(
+ type='mmrazor.SearchableShuffleNetV2',
+ arg1=xxx,
+ arg2=xxx),
+ ...
+```
+
+## Develop common model components
+
+Here we show how to add a new backbone with an example of `xxxNet`.
+
+1. Define a new backbone
+
+Create a new file `mmrazor/models/architectures/backbones/xxxnet.py`, then implement the class `xxxNet`.
+
+```Python
+from mmengine.model import BaseModule
+from mmrazor.registry import MODELS
+
+@MODELS.register_module()
+class xxxNet(BaseModule):
+
+ def __init__(self, arg1, arg2, init_cfg=None):
+ super().__init__(init_cfg=init_cfg)
+ pass
+
+ def forward(self, x):
+ pass
+```
+
+2. Import the module
+
+You can either add the following line to `mmrazor/models/architectures/backbones/__init__.py`
+
+```Python
+from .xxxnet import xxxNet
+
+__all__ = ['xxxNet']
+```
+
+or alternatively add
+
+```Python
+custom_imports = dict(
+ imports=['mmrazor.models.architectures.backbones.xxxnet'],
+ allow_failed_imports=False)
+```
+
+to the config file to avoid modifying the original code.
+
+3. Use the backbone in your config file
+
+```Python
+architecture = dict(
+ type=xxx,
+ model=dict(
+ ...
+ backbone=dict(
+ type='xxxNet',
+ arg1=xxx,
+ arg2=xxx),
+ ...
+```
+
+How to add other model components is similar to backbone's. For more details, please refer to other codebases' docs.
\ No newline at end of file
diff --git a/docs/en/advanced_guides/customize_mixed_algorithms.md b/docs/en/advanced_guides/customize_mixed_algorithms.md
index e96ee039e..8a63ce5d6 100644
--- a/docs/en/advanced_guides/customize_mixed_algorithms.md
+++ b/docs/en/advanced_guides/customize_mixed_algorithms.md
@@ -1 +1,159 @@
# Customize mixed algorithms
+Here we show how to customize mixed algorithms with our algorithm components. We take [AutoSlim ](https://github.com/open-mmlab/mmrazor/tree/dev-1.x/configs/pruning/mmcls/autoslim)as an example.
+
+> **Why is AutoSlim a mixed algorithm?**
+>
+> In [AutoSlim](https://github.com/open-mmlab/mmrazor/tree/dev-1.x/configs/pruning/mmcls/autoslim), the sandwich rule and the inplace distillation will be introduced to enhance the training process, which is called as the slimmable training. The sandwich rule means that we train the model at smallest width, largest width and (n − 2) random widths, instead of n random widths. And the inplace distillation means that we use the predicted label of the model at the largest width as the training label for other widths, while for the largest width we use ground truth. So both the KD algorithm and the pruning algorithm are used in [AutoSlim](https://github.com/open-mmlab/mmrazor/tree/dev-1.x/configs/pruning/mmcls/autoslim).
+
+1. Register a new algorithm
+
+Create a new file `mmrazor/models/algorithms/nas/autoslim.py`, class `AutoSlim` inherits from class `BaseAlgorithm`. You need to build the KD algorithm component (distiller) and the pruning algorithm component (mutator) because AutoSlim is a mixed algorithm.
+
+> You can also inherit from the existing algorithm instead of `BaseAlgorithm` if your algorithm is similar to the existing algorithm.
+
+> You can choose existing algorithm components in MMRazor, such as `OneShotChannelMutator` and `ConfigurableDistiller` in AutoSlim.
+>
+> If these in MMRazor don't meet your needs, you can customize new algorithm components for your algorithm. Reference is as follows:
+>
+> [Tutorials: Customize KD algorithms](https://aicarrier.feishu.cn/docx/doxcnFWOTLQYJ8FIlUGsYrEjisd)
+>
+> [Tutorials: Customize Pruning algorithms](https://aicarrier.feishu.cn/docx/doxcnzXlPv0cDdmd0wNrq0SEqsh)
+>
+> [Tutorials: Customize KD algorithms](https://aicarrier.feishu.cn/docx/doxcnFWOTLQYJ8FIlUGsYrEjisd)
+
+```Python
+# Copyright (c) OpenMMLab. All rights reserved.
+from typing import Dict, List, Optional, Union
+import torch
+from torch import nn
+
+from mmrazor.models.distillers import ConfigurableDistiller
+from mmrazor.models.mutators import OneShotChannelMutator
+from mmrazor.registry import MODELS
+from ..base import BaseAlgorithm
+
+VALID_MUTATOR_TYPE = Union[OneShotChannelMutator, Dict]
+VALID_DISTILLER_TYPE = Union[ConfigurableDistiller, Dict]
+
+@MODELS.register_module()
+class AutoSlim(BaseAlgorithm):
+ def __init__(self,
+ mutator: VALID_MUTATOR_TYPE,
+ distiller: VALID_DISTILLER_TYPE,
+ architecture: Union[BaseModel, Dict],
+ data_preprocessor: Optional[Union[Dict, nn.Module]] = None,
+ init_cfg: Optional[Dict] = None,
+ num_samples: int = 2) -> None:
+ super().__init__(architecture, data_preprocessor, init_cfg)
+ self.mutator = self._build_mutator(mutator)
+ # `prepare_from_supernet` must be called before distiller initialized
+ self.mutator.prepare_from_supernet(self.architecture)
+
+ self.distiller = self._build_distiller(distiller)
+ self.distiller.prepare_from_teacher(self.architecture)
+ self.distiller.prepare_from_student(self.architecture)
+
+ ......
+
+ def _build_mutator(self,
+ mutator: VALID_MUTATOR_TYPE) -> OneShotChannelMutator:
+ """build mutator."""
+ if isinstance(mutator, dict):
+ mutator = MODELS.build(mutator)
+ if not isinstance(mutator, OneShotChannelMutator):
+ raise TypeError('mutator should be a `dict` or '
+ '`OneShotModuleMutator` instance, but got '
+ f'{type(mutator)}')
+
+ return mutator
+
+ def _build_distiller(
+ self, distiller: VALID_DISTILLER_TYPE) -> ConfigurableDistiller:
+ if isinstance(distiller, dict):
+ distiller = MODELS.build(distiller)
+ if not isinstance(distiller, ConfigurableDistiller):
+ raise TypeError('distiller should be a `dict` or '
+ '`ConfigurableDistiller` instance, but got '
+ f'{type(distiller)}')
+
+ return distiller
+```
+
+2. Implement the core logic in `train_step`
+
+In `train_step`, both the `mutator` and the `distiller` play an important role. For example, `sample_subnet`, `set_max_subnet` and `set_min_subnet` are supported by the `mutator`, and the function of`distill_step` is mainly implemented by the `distiller`.
+
+```Python
+@MODELS.register_module()
+class AutoSlim(BaseAlgorithm):
+
+ ......
+
+ def train_step(self, data: List[dict],
+ optim_wrapper: OptimWrapper) -> Dict[str, torch.Tensor]:
+
+ def distill_step(
+ batch_inputs: torch.Tensor, data_samples: List[BaseDataElement]
+ ) -> Dict[str, torch.Tensor]:
+ ......
+
+ ......
+
+ batch_inputs, data_samples = self.data_preprocessor(data, True)
+
+ total_losses = dict()
+ # update the max subnet loss.
+ self.set_max_subnet()
+ ......
+ total_losses.update(add_prefix(max_subnet_losses, 'max_subnet'))
+
+ # update the min subnet loss.
+ self.set_min_subnet()
+ min_subnet_losses = distill_step(batch_inputs, data_samples)
+ total_losses.update(add_prefix(min_subnet_losses, 'min_subnet'))
+
+ # update the random subnet loss.
+ for sample_idx in range(self.num_samples):
+ self.set_subnet(self.sample_subnet())
+ random_subnet_losses = distill_step(batch_inputs, data_samples)
+ total_losses.update(
+ add_prefix(random_subnet_losses,
+ f'random_subnet_{sample_idx}'))
+
+ return total_losses
+```
+
+3. Import the class
+
+You can either add the following line to `mmrazor/models/algorithms/nas/__init__.py`
+
+```Python
+from .autoslim import AutoSlim
+
+__all__ = ['AutoSlim']
+```
+
+or alternatively add
+
+```Python
+custom_imports = dict(
+ imports=['mmrazor.models.algorithms.nas.autoslim'],
+ allow_failed_imports=False)
+```
+
+to the config file to avoid modifying the original code.
+
+4. Use the algorithm in your config file
+
+```Python
+model= dict(
+ type='mmrazor.AutoSlim',
+ architecture=...,
+ mutator=dict(
+ type='OneShotChannelMutator',
+ ...),
+ distiller=dict(
+ type='ConfigurableDistiller',
+ ...),
+ ...)
+```
\ No newline at end of file
diff --git a/docs/en/advanced_guides/delivery.md b/docs/en/advanced_guides/delivery.md
index 97715e016..c65f8da43 100644
--- a/docs/en/advanced_guides/delivery.md
+++ b/docs/en/advanced_guides/delivery.md
@@ -1 +1,219 @@
# Delivery
+## Introduction of Delivery
+
+`Delivery` is a mechanism used in **knowledge distillation****,** which is to **align the intermediate results** between the teacher model and the student model by delivering and rewriting these intermediate results between them. As shown in the figure below, deliveries can be used to:
+
+- **Deliver the output of a layer of the teacher model directly to a layer of the student model.** In some knowledge distillation algorithms, we may need to deliver the output of a layer of the teacher model to the student model directly. For example, in [LAD](https://arxiv.org/abs/2108.10520) algorithm, the student model needs to obtain the label assignment of the teacher model directly.
+- **Align the inputs of the teacher model and the student model.** For example, in the MMClassification framework, some widely used data augmentations such as [mixup](https://arxiv.org/abs/1710.09412) and [CutMix](https://arxiv.org/abs/1905.04899) are not implemented in Data Pipelines but in `forward_train`, and due to the randomness of these data augmentation methods, it may lead to a gap between the input of the teacher model and the student model.
+
+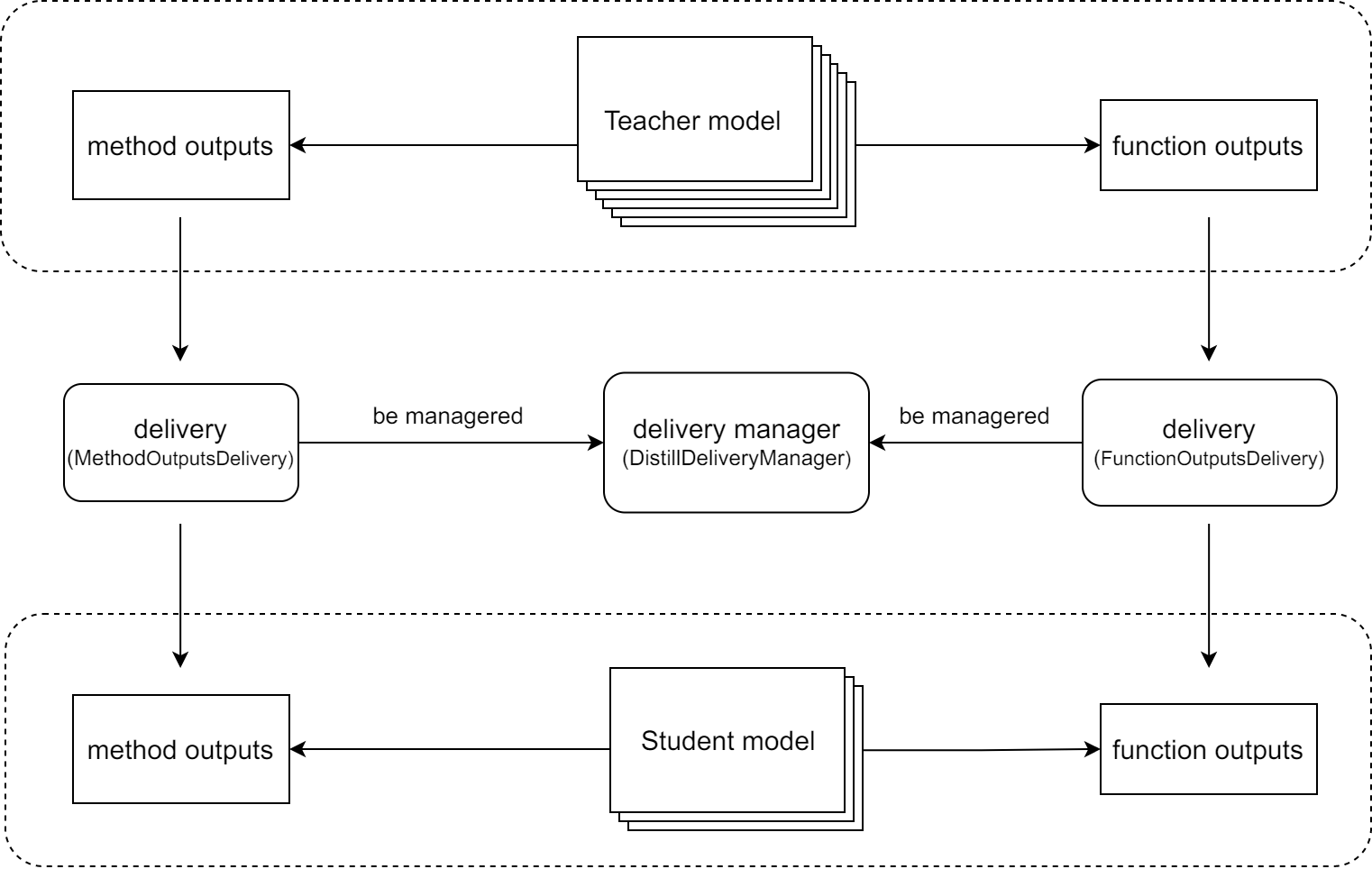
+
+In general, the delivery mechanism allows us to deliver intermediate results between the teacher model and the student model **without adding additional code**, which reduces the hard coding in the source code.
+
+## Usage of Delivery
+
+Currently, we support two deliveries: `FunctionOutputs``Delivery` and `MethodOutputs``Delivery`, both of which inherit from `DistillDiliver`. And these deliveries can be managed by `Distill``Delivery``Manager` or just be used on their own.
+
+Their relationship is shown below.
+
+
+
+
+
+
+### FunctionOutputsDelivery
+
+`FunctionOutputs``Delivery` is used to align the **function's** intermediate results between the teacher model and the student model.
+
+> When initializing `FunctionOutputs``Delivery`, you need to pass `func_path` argument, which requires extra attention. For example,
+`anchor_inside_flags` is a function in mmdetection to check whether the
+anchors are inside the border. This function is in
+`mmdet/core/anchor/utils.py` and used in
+`mmdet/models/dense_heads/anchor_head`. Then the `func_path` should be
+`mmdet.models.dense_heads.anchor_head.anchor_inside_flags` but not
+`mmdet.core.anchor.utils.anchor_inside_flags`.
+
+#### Case 1: Delivery single function's output from the teacher to the student.
+
+```Python
+import random
+from mmrazor.core import FunctionOutputsDelivery
+
+def toy_func() -> int:
+ return random.randint(0, 1000000)
+
+delivery = FunctionOutputsDelivery(max_keep_data=1, func_path='toy_module.toy_func')
+
+# override_data is False, which means that not override the data with
+# the recorded data. So it will get the original output of toy_func
+# in teacher model, and it is also recorded to be deliveried to the student.
+delivery.override_data = False
+with delivery:
+ output_teacher = toy_module.toy_func()
+
+# override_data is True, which means that override the data with
+# the recorded data, so it will get the output of toy_func
+# in teacher model rather than the student's.
+delivery.override_data = True
+with delivery:
+ output_student = toy_module.toy_func()
+
+print(output_teacher == output_student)
+```
+
+Out:
+
+```Python
+True
+```
+
+#### Case 2: Delivery multi function's outputs from the teacher to the student.
+
+If a function is executed more than once during the forward of the teacher model, all the outputs of this function will be used to override function outputs from the student model
+
+> Delivery order is first-in first-out.
+
+```Python
+delivery = FunctionOutputsDelivery(
+ max_keep_data=2, func_path='toy_module.toy_func')
+
+delivery.override_data = False
+with delivery:
+ output1_teacher = toy_module.toy_func()
+ output2_teacher = toy_module.toy_func()
+
+delivery.override_data = True
+with delivery:
+ output1_student = toy_module.toy_func()
+ output2_student = toy_module.toy_func()
+
+print(output1_teacher == output1_student and output2_teacher == output2_student)
+```
+
+Out:
+
+```Python
+True
+```
+
+
+
+### MethodOutputsDelivery
+
+`MethodOutputs``Delivery` is used to align the **method's** intermediate results between the teacher model and the student model.
+
+#### Case: **Align the inputs of the teacher model and the student model**
+
+Here we use mixup as an example to show how to align the inputs of the teacher model and the student model.
+
+- Without Delivery
+
+```Python
+# main.py
+from mmcls.models.utils import Augments
+from mmrazor.core import MethodOutputsDelivery
+
+augments_cfg = dict(type='BatchMixup', alpha=1., num_classes=10, prob=1.0)
+augments = Augments(augments_cfg)
+
+imgs = torch.randn(2, 3, 32, 32)
+label = torch.randint(0, 10, (2,))
+
+imgs_teacher, label_teacher = augments(imgs, label)
+imgs_student, label_student = augments(imgs, label)
+
+print(torch.equal(label_teacher, label_student))
+print(torch.equal(imgs_teacher, imgs_student))
+```
+
+Out:
+
+```Python
+False
+False
+from mmcls.models.utils import Augments
+from mmrazor.core import DistillDeliveryManager
+```
+
+The results are different due to the randomness of mixup.
+
+- With Delivery
+
+```Python
+delivery = MethodOutputsDelivery(
+ max_keep_data=1, method_path='mmcls.models.utils.Augments.__call__')
+
+delivery.override_data = False
+with delivery:
+ imgs_teacher, label_teacher = augments(imgs, label)
+
+delivery.override_data = True
+with delivery:
+ imgs_student, label_student = augments(imgs, label)
+
+print(torch.equal(label_teacher, label_student))
+print(torch.equal(imgs_teacher, imgs_student))
+```
+
+Out:
+
+```Python
+True
+True
+```
+
+The randomness is eliminated by using `MethodOutputsDelivery`.
+
+
+
+### 2.3 DistillDeliveryManager
+
+`Distill``Delivery``Manager` is actually a context manager, used to manage delivers. When entering the `Distill``Delivery``Manager`, all delivers managed will be started.
+
+With the help of `Distill``Delivery``Manager`, we are able to manage several different DistillDeliveries with as little code as possible, thereby reducing the possibility of errors.
+
+#### Case: Manager deliveries with DistillDeliveryManager
+
+```Python
+from mmcls.models.utils import Augments
+from mmrazor.core import DistillDeliveryManager
+
+augments_cfg = dict(type='BatchMixup', alpha=1., num_classes=10, prob=1.0)
+augments = Augments(augments_cfg)
+
+distill_deliveries = [
+ ConfigDict(type='MethodOutputs', max_keep_data=1,
+ method_path='mmcls.models.utils.Augments.__call__')]
+
+# instantiate DistillDeliveryManager
+manager = DistillDeliveryManager(distill_deliveries)
+
+imgs = torch.randn(2, 3, 32, 32)
+label = torch.randint(0, 10, (2,))
+
+manager.override_data = False
+with manager:
+ imgs_teacher, label_teacher = augments(imgs, label)
+
+manager.override_data = True
+with manager:
+ imgs_student, label_student = augments(imgs, label)
+
+print(torch.equal(label_teacher, label_student))
+print(torch.equal(imgs_teacher, imgs_student))
+```
+
+Out:
+
+```Python
+True
+True
+```
+
+## Reference
+
+[1] Zhang, Hongyi, et al. "mixup: Beyond empirical risk minimization." *arXiv* abs/1710.09412 (2017).
+
+[2] Yun, Sangdoo, et al. "Cutmix: Regularization strategy to train strong classifiers with localizable features." *ICCV* (2019).
+
+[3] Nguyen, Chuong H., et al. "Improving object detection by label assignment distillation." *WACV* (2022).
\ No newline at end of file
diff --git a/docs/en/advanced_guides/mutable.md b/docs/en/advanced_guides/mutable.md
index 1067112fb..26d3825df 100644
--- a/docs/en/advanced_guides/mutable.md
+++ b/docs/en/advanced_guides/mutable.md
@@ -1 +1,394 @@
# Mutable
+## Introduction
+
+### What is Mutable
+
+`Mutable` is one of basic function components in NAS algorithms and some pruning algorithms, which makes supernet searchable by providing optional modules or parameters.
+
+To understand it better, we take the mutable module as an example to explain as follows.
+
+
+
+
+As shown in the figure above, `Mutable` is a container that holds some candidate operations, thus it can sample candidates to constitute the subnet. `Supernet` usually consists of multiple `Mutable`, therefore, `Supernet` will be searchable with the help of `Mutable`. And all candidate operations in `Mutable` constitute the search space of `SuperNet`.
+
+> If you want to know more about the relationship between Mutable and Mutator, please refer to [Mutator 用户文档](https://aicarrier.feishu.cn/docx/doxcnmcie75HcbqkfBGaEoemBKg)
+
+### Features
+
+#### 1. Support module mutable
+
+It is the common and basic function for NAS algorithms. We can use it to implement some classical one-shot NAS algorithms, such as [SPOS](https://arxiv.org/abs/1904.00420), [DetNAS ](https://arxiv.org/abs/1903.10979)and so on.
+
+#### 2. Support parameter mutable
+
+To implement more complicated and funny algorithms easier, we supported making some important parameters searchable, such as input channel, output channel, kernel size and so on.
+
+What is more, we can implement **dynamic op** by using mutable parameters.
+
+#### 3. Support deriving from mutable parameter
+
+Because of the restriction of defined architecture, there may be correlations between some mutable parameters, **such as concat and expand ratio.**
+
+> If conv3 = concat (conv1, conv2)
+>
+> When out_channel (conv1) = 3, out_channel (conv2) = 4
+>
+> Then in_channel (conv3) must be 7 rather than mutable.
+>
+> So use derived mutable from conv1 and conv2 to generate in_channel (conv3)
+
+With the help of derived mutable, we can meet these special requirements in some NAS algorithms and pruning algorithms. What is more, it can be used to deal with different granularity between search spaces.
+
+### Supported mutables
+
+
+
+As shown in the figure above.
+
+- **White blocks** stand the basic classes, which include `BaseMutable` and `DerivedMethodMixin`. `BaseMutable` is the base class for all mutables, which defines required properties and abstracmethods. `DerivedMethodMixin` is a mixin class to provide mutable parameters with some useful methods to derive mutable.
+
+- **Gray blocks** stand different types of base mutables.
+ > Because there are correlations between channels of some layers, we divide mutable parameters into `MutableChannel` and `MutableValue`, so you can also think `MutableChannel` is a special `MutableValue`.
+
+ For supporting module and parameters mutable, we provide `MutableModule`, `MutableChannel` and `MutableValue` these base classes to implement required basic functions. And we also add `OneshotMutableModule` and `DiffMutableModule` two types based on `MutableModule` to meet different types of algorithms' requirements.
+
+ For supporting deriving from mutable parameters, we make `MutableChannel` and `MutableValue` inherit from `BaseMutable` and `DerivedMethodMixin`, thus they can get derived functions provided by `DerivedMethodMixin`.
+
+- **Red blocks** and **green blocks** stand registered classes for implementing some specific algorithms, which means that you can use them directly in configs. If they do not meet your requirements, you can also customize your mutable based on our base classes. If you are interested in their realization, please refer to their docstring.
+
+## How to use existing mutables to configure searchable backbones
+
+We will use `OneShotMutableOP` to build a `SearchableShuffleNetV2` backbone as follows.
+
+1. Configure needed mutables
+
+```Python
+# we only use OneShotMutableOP, then take 4 ShuffleOP as its candidates.
+_STAGE_MUTABLE = dict(
+ _scope_='mmrazor',
+ type='OneShotMutableOP',
+ candidates=dict(
+ shuffle_3x3=dict(type='ShuffleBlock', kernel_size=3),
+ shuffle_5x5=dict(type='ShuffleBlock', kernel_size=5),
+ shuffle_7x7=dict(type='ShuffleBlock', kernel_size=7),
+ shuffle_xception=dict(type='ShuffleXception')))
+```
+
+2. Configure the `arch_setting` of `SearchableShuffleNetV2`
+
+```Python
+# Use the _STAGE_MUTABLE in various stages.
+arch_setting = [
+ # Parameters to build layers. 3 parameters are needed to construct a
+ # layer, from left to right: channel, num_blocks, mutable_cfg.
+ [64, 4, _STAGE_MUTABLE],
+ [160, 4, _STAGE_MUTABLE],
+ [320, 8, _STAGE_MUTABLE],
+ [640, 4, _STAGE_MUTABLE]
+]
+```
+
+3. Configure searchable backbone.
+
+```Python
+nas_backbone = dict(
+ _scope_='mmrazor',
+ type='SearchableShuffleNetV2',
+ widen_factor=1.0,
+ arch_setting=arch_setting)
+```
+
+Then you can use it in your architecture. If existing mutables do not meet your needs, you can also customize your needed mutable.
+
+## How to customize your mutable
+
+### About base mutable
+
+Before customizing mutables, we need to know what some base mutables do.
+
+**BaseMutable**
+
+In order to implement the searchable mechanism, mutables need to own some base functions, such as changing status from mutable to fixed, recording the current status and current choice and so on. So in `BaseMutable`, these relevant abstract methods and properties will be defined as follows.
+
+```Python
+# Copyright (c) OpenMMLab. All rights reserved.
+from abc import ABC, abstractmethod
+from typing import Dict, Generic, Optional, TypeVar
+
+from mmengine.model import BaseModule
+
+CHOICE_TYPE = TypeVar('CHOICE_TYPE')
+CHOSEN_TYPE = TypeVar('CHOSEN_TYPE')
+
+class BaseMutable(BaseModule, ABC, Generic[CHOICE_TYPE, CHOSEN_TYPE]):
+
+ def __init__(self,
+ alias: Optional[str] = None,
+ init_cfg: Optional[Dict] = None) -> None:
+ super().__init__(init_cfg=init_cfg)
+
+ self.alias = alias
+ self._is_fixed = False
+ self._current_choice: Optional[CHOICE_TYPE] = None
+
+ @property
+ def current_choice(self) -> Optional[CHOICE_TYPE]:
+ return self._current_choice
+
+ @current_choice.setter
+ def current_choice(self, choice: Optional[CHOICE_TYPE]) -> None:
+ self._current_choice = choice
+
+ @property
+ def is_fixed(self) -> bool:
+ return self._is_fixed
+
+ @is_fixed.setter
+ def is_fixed(self, is_fixed: bool) -> None:
+ ......
+ self._is_fixed = is_fixed
+
+ @abstractmethod
+ def fix_chosen(self, chosen: CHOSEN_TYPE) -> None:
+ pass
+
+ @abstractmethod
+ def dump_chosen(self) -> CHOSEN_TYPE:
+ pass
+
+ @property
+ @abstractmethod
+ def num_choices(self) -> int:
+ pass
+```
+
+**MutableModule**
+
+Inherited from `BaseModule`, `MutableModule` not only owns its basic functions, but also needs some specialized functions to implement module mutable, such as getting all choices, executing forward computation.
+
+```Python
+# Copyright (c) OpenMMLab. All rights reserved.
+from abc import abstractmethod
+from typing import Any, Dict, List, Optional
+
+from ..base_mutable import CHOICE_TYPE, CHOSEN_TYPE, BaseMutable
+
+class MutableModule(BaseMutable[CHOICE_TYPE, CHOSEN_TYPE]):
+
+ def __init__(self,
+ module_kwargs: Optional[Dict[str, Dict]] = None,
+ **kwargs) -> None:
+ super().__init__(**kwargs)
+
+ self.module_kwargs = module_kwargs
+
+ @property
+ @abstractmethod
+ def choices(self) -> List[CHOICE_TYPE]:
+ """list: all choices. All subclasses must implement this method."""
+
+ @abstractmethod
+ def forward(self, x: Any) -> Any:
+ """Forward computation."""
+
+ @property
+ def num_choices(self) -> int:
+ """Number of choices."""
+ return len(self.choices)
+```
+
+If you want to know more about other types mutables, please refer to their docstring.
+
+### Steps of customizing mutables
+
+There are 4 steps to implement a custom mutable.
+
+1. Registry a new mutable
+
+2. Implement abstract methods.
+
+3. Implement other methods.
+
+4. Import the class
+
+Then you can use your customized mutable in configs as in the previous chapter.
+
+Let's use `OneShotMutableOP` as an example for customizing mutable.
+
+#### 1. Registry a new mutable
+
+First, you need to determine which type mutable to implement. Thus, you can implement your mutable faster by inheriting from correlative base mutable.
+
+Then create a new file `mmrazor/models/mutables/mutable_module/``one_shot_mutable_module`, class `OneShotMutableOP` inherits from `OneShotMutableModule`.
+
+```Python
+# Copyright (c) OpenMMLab. All rights reserved.
+import random
+from abc import abstractmethod
+from typing import Any, Dict, List, Optional, Union
+
+import numpy as np
+import torch.nn as nn
+from torch import Tensor
+
+from mmrazor.registry import MODELS
+from ..base_mutable import CHOICE_TYPE, CHOSEN_TYPE
+from .mutable_module import MutableModule
+
+@MODELS.register_module()
+class OneShotMutableOP(OneShotMutableModule[str, str]):
+ ...
+```
+
+#### 2. Implement abstract methods
+
+##### 2.1 Basic abstract methods
+
+These basic abstract methods are mainly from `BaseMutable` and `MutableModule`, such as `fix_chosen`, `dump_chosen`, `choices` and `num_choices`.
+
+```Python
+@MODELS.register_module()
+class OneShotMutableOP(OneShotMutableModule[str, str]):
+ ......
+
+ def fix_chosen(self, chosen: str) -> None:
+ """Fix mutable with subnet config. This operation would convert
+ `unfixed` mode to `fixed` mode. The :attr:`is_fixed` will be set to
+ True and only the selected operations can be retained.
+ Args:
+ chosen (str): the chosen key in ``MUTABLE``. Defaults to None.
+ """
+ if self.is_fixed:
+ raise AttributeError(
+ 'The mode of current MUTABLE is `fixed`. '
+ 'Please do not call `fix_chosen` function again.')
+
+ for c in self.choices:
+ if c != chosen:
+ self._candidates.pop(c)
+
+ self._chosen = chosen
+ self.is_fixed = True
+
+ def dump_chosen(self) -> str:
+ assert self.current_choice is not None
+
+ return self.current_choice
+
+ @property
+ def choices(self) -> List[str]:
+ """list: all choices. """
+ return list(self._candidates.keys())
+
+ @property
+ def num_choices(self):
+ return len(self.choices)
+```
+
+##### 2.2 Specified abstract methods
+
+In `OneShotMutableModule`, sample and forward these required abstract methods are defined, such as `sample_choice`, `forward_choice`, `forward_fixed`, `forward_all`. So we need to implement these abstract methods.
+
+```Python
+@MODELS.register_module()
+class OneShotMutableOP(OneShotMutableModule[str, str]):
+ ......
+
+ def sample_choice(self) -> str:
+ """uniform sampling."""
+ return np.random.choice(self.choices, 1)[0]
+
+ def forward_fixed(self, x: Any) -> Tensor:
+ """Forward with the `fixed` mutable.
+ Args:
+ x (Any): x could be a Torch.tensor or a tuple of
+ Torch.tensor, containing input data for forward computation.
+ Returns:
+ Tensor: the result of forward the fixed operation.
+ """
+ return self._candidates[self._chosen](x)
+
+ def forward_choice(self, x: Any, choice: str) -> Tensor:
+ """Forward with the `unfixed` mutable and current choice is not None.
+ Args:
+ x (Any): x could be a Torch.tensor or a tuple of
+ Torch.tensor, containing input data for forward computation.
+ choice (str): the chosen key in ``OneShotMutableOP``.
+ Returns:
+ Tensor: the result of forward the ``choice`` operation.
+ """
+ assert isinstance(choice, str) and choice in self.choices
+ return self._candidates[choice](x)
+
+ def forward_all(self, x: Any) -> Tensor:
+ """Forward all choices. Used to calculate FLOPs.
+ Args:
+ x (Any): x could be a Torch.tensor or a tuple of
+ Torch.tensor, containing input data for forward computation.
+ Returns:
+ Tensor: the result of forward all of the ``choice`` operation.
+ """
+ outputs = list()
+ for op in self._candidates.values():
+ outputs.append(op(x))
+ return sum(outputs)
+```
+
+#### 3. Implement other methods
+
+After finishing some required methods, we need to add some special methods, such as `_build_ops`, because it is needed in building candidates for sampling.
+
+```Python
+@MODELS.register_module()
+class OneShotMutableOP(OneShotMutableModule[str, str]):
+ ......
+
+ @staticmethod
+ def _build_ops(
+ candidates: Union[Dict[str, Dict], nn.ModuleDict],
+ module_kwargs: Optional[Dict[str, Dict]] = None) -> nn.ModuleDict:
+ """Build candidate operations based on choice configures.
+ Args:
+ candidates (dict[str, dict] | :obj:`nn.ModuleDict`): the configs
+ for the candidate operations or nn.ModuleDict.
+ module_kwargs (dict[str, dict], optional): Module initialization
+ named arguments.
+ Returns:
+ ModuleDict (dict[str, Any], optional): the key of ``ops`` is
+ the name of each choice in configs and the value of ``ops``
+ is the corresponding candidate operation.
+ """
+ if isinstance(candidates, nn.ModuleDict):
+ return candidates
+
+ ops = nn.ModuleDict()
+ for name, op_cfg in candidates.items():
+ assert name not in ops
+ if module_kwargs is not None:
+ op_cfg.update(module_kwargs)
+ ops[name] = MODELS.build(op_cfg)
+ return ops
+```
+
+#### 4. Import the class
+
+You can either add the following line to `mmrazor/models/mutables/mutable_module/__init__.py`
+
+```Python
+from .one_shot_mutable_module import OneShotMutableModule
+
+__all__ = ['OneShotMutableModule']
+```
+
+or alternatively add
+
+```Python
+custom_imports = dict(
+ imports=['mmrazor.models.mutables.mutable_module.one_shot_mutable_module'],
+ allow_failed_imports=False)
+```
+
+to the config file to avoid modifying the original code.
+
+Customize `OneShotMutableOP` is over, then you can use it directly in your algorithm.
\ No newline at end of file
diff --git a/docs/en/advanced_guides/mutator.md b/docs/en/advanced_guides/mutator.md
index a5e125528..f450652bd 100644
--- a/docs/en/advanced_guides/mutator.md
+++ b/docs/en/advanced_guides/mutator.md
@@ -1 +1,241 @@
# Mutator
+
+
+## Introduction
+
+### What is Mutator
+
+**Mutator** is one of algorithm components, which provides some useful functions used for mutable management, such as sample choice, set choicet and so on. With Mutator's help, you can implement some NAS or pruning algorithms quickly.
+
+### What is the relationship between Mutator and Mutable
+
+
+
+
+In a word, Mutator is the manager of Mutable. Each different type of mutable is commonly managed by their one correlative mutator, respectively.
+
+As shown in the figure, Mutable is a component of supernet, therefore Mutator can implement some functions about subnet from supernet by handling Mutable.
+
+### Supported mutators
+
+In MMRazor, we have implemented some mutators, their relationship is as below.
+
+
+
+
+`BaseMutator`: Base class for all mutators. It has appointed some abstract methods supported by all mutators.
+
+`ModuleMuator`/ `ChannelMutator`: Two different types mutators are for handling mutable module and mutable channel respectively.
+
+> Please refer to [Mutable 用户文档 ](https://aicarrier.feishu.cn/docs/doccnc6HAhAsilBXGGR9kzeeK8d)for more details about different types of mutable.
+
+`OneShotModuleMutator` / `DiffModuleMutator`: Inherit from `ModuleMuator`, they are for implementing different types algorithms, such as [SPOS](https://arxiv.org/abs/1904.00420), [Darts](https://arxiv.org/abs/1806.09055) and so on.
+
+`OneShotChannelMutator` / `SlimmableChannelMutator`: Inherit from `ChannelMutator`, they are also for meeting the needs of different types algorithms, such as [AotuSlim](https://arxiv.org/abs/1903.11728).
+
+## How to use existing mutators
+
+You just use them directly in configs as below
+
+```Python
+supernet = dict(
+ ...
+ )
+
+model = dict(
+ type='mmrazor.SPOS',
+ architecture=supernet,
+ mutator=dict(type='mmrazor.OneShotModuleMutator'))
+```
+
+If existing mutators do not meet your needs, you can also customize your needed mutator.
+
+## How to customize your mutator
+
+All mutators need to implement at least two of the following interfaces
+
+- `prepare_from_supernet()`
+ - Make some necessary preparations according to the given supernet. These preparations may include, but are not limited to, grouping the search space, and initializing mutator with the parameters needed for itself.
+
+- `search_groups`
+ - Group of search space.
+
+ - Note that **search groups** and **search space** are two different concepts. The latter defines what choices can be used for searching. The former groups the search space, and searchable blocks that are grouped into the same group will share the same search space and the same sample result.
+
+ - ```Python
+ # Example
+ search_space = {op1, op2, op3, op4}
+ search_group = {0: [op1, op2], 1: [op3, op4]}
+ ```
+
+There are 4 steps to implement a custom mutator.
+
+1. Registry a new mutator
+
+2. Implement abstract methods
+
+3. Implement other methods
+
+4. Import the class
+
+Then you can use your customized mutator in configs as in the previous chapter.
+
+Let's use `OneShotModuleMutator` as an example for customizing mutator.
+
+### 1.Registry a new mutator
+
+First, you need to determine which type mutator to implement. Thus, you can implement your mutator faster by inheriting from correlative base mutator.
+
+Then create a new file `mmrazor/models/mutators/module_mutator/one_shot_module_mutator`, class `OneShotModuleMutator` inherits from `ModuleMutator`.
+
+```Python
+from mmrazor.registry import MODELS
+from .module_mutator import ModuleMutator
+
+@MODELS.register_module()
+class OneShotModuleMutator(ModuleMutator):
+ ...
+```
+
+### 2. Implement abstract methods
+2.1. Rewrite the `mutable_class_type` property
+
+```Python
+@MODELS.register_module()
+class OneShotModuleMutator(ModuleMutator):
+
+ @property
+ def mutable_class_type(self):
+ """One-shot mutable class type.
+ Returns:
+ Type[OneShotMutableModule]: Class type of one-shot mutable.
+ """
+ return OneShotMutableModule
+```
+
+2.2. Rewrite `search_groups` and `prepare_from_supernet()`
+
+As the `prepare_from_supernet()` method and the `search_groups` property are already implemented in the `ModuleMutator` and we don't need to add our own logic, the second step is already over.
+
+If you need to implement them by yourself, you can refer to these as follows.
+
+2.3. **Understand** **`search_groups`****(optional)**
+
+Let's take an example to see what default `search_groups` do.
+
+```Python
+from mmrazor.models import OneShotModuleMutator, OneShotMutableModule
+
+class SearchableModel(nn.Module):
+ def __init__(self, one_shot_op_cfg):
+ # assume `OneShotMutableModule` contains 4 choices:
+ # choice1, choice2, choice3 and choice4
+ self.choice_block1 = OneShotMutableModule(**one_shot_op_cfg)
+ self.choice_block2 = OneShotMutableModule(**one_shot_op_cfg)
+ self.choice_block3 = OneShotMutableModule(**one_shot_op_cfg)
+
+ def forward(self, x: Tensor) -> Tensor:
+ x = self.choice_block1(x)
+ x = self.choice_block2(x)
+ x = self.choice_block3(x)
+
+ return x
+
+supernet = SearchableModel(one_shot_op_cfg)
+mutator1 = OneShotModuleMutator()
+# build mutator1 from supernet.
+mutator1.prepare_from_supernet(supernet)
+>>> mutator1.search_groups.keys()
+dict_keys([0, 1, 2])
+```
+
+In this case, each `OneShotMutableModule` will be divided into a group. Thus, the search groups have 3 groups.
+
+If you want to custom group according to your requirement, you can implement it by passing the arg `custom_group`.
+
+```Python
+custom_group = [
+ ['op1', 'op2'],
+ ['op3']
+]
+mutator2 = OneShotMutator(custom_group)
+mutator2.prepare_from_supernet(supernet)
+```
+
+Then `choice_block1` and `choice_block2` will share the same search space and the same sample result, and `choice_block3` will have its own independent search space. Thus, the search groups have only 2 groups.
+
+```Python
+>>> mutator2.search_groups.keys()
+dict_keys([0, 1])
+```
+
+### 3. Implement other methods
+
+After finishing some required methods, we need to add some special methods, such as `sample_choices` and `set_choices`.
+
+```Python
+from typing import Any, Dict
+
+from mmrazor.registry import MODELS
+from ...mutables import OneShotMutableModule
+from .module_mutator import
+
+@MODELS.register_module()
+class OneShotModuleMutator(ModuleMutator):
+
+ def sample_choices(self) -> Dict[int, Any]:
+ """Sampling by search groups.
+ The sampling result of the first mutable of each group is the sampling
+ result of this group.
+ Returns:
+ Dict[int, Any]: Random choices dict.
+ """
+ random_choices = dict()
+ for group_id, modules in self.search_groups.items():
+ random_choices[group_id] = modules[0].sample_choice()
+
+ return random_choices
+
+ def set_choices(self, choices: Dict[int, Any]) -> None:
+ """Set mutables' current choice according to choices sample by
+ :func:`sample_choices`.
+ Args:
+ choices (Dict[int, Any]): Choices dict. The key is group_id in
+ search groups, and the value is the sampling results
+ corresponding to this group.
+ """
+ for group_id, modules in self.search_groups.items():
+ choice = choices[group_id]
+ for module in modules:
+ module.current_choice = choice
+
+ @property
+ def mutable_class_type(self):
+ """One-shot mutable class type.
+ Returns:
+ Type[OneShotMutableModule]: Class type of one-shot mutable.
+ """
+ return OneShotMutableModule
+```
+
+### 4. Import the class
+
+You can either add the following line to `mmrazor/models/mutators/module_mutator/__init__.py`
+
+```Python
+from .one_shot_module_mutator import OneShotModuleMutator
+
+__all__ = ['OneShotModuleMutator']
+```
+
+or alternatively add
+
+```Python
+custom_imports = dict(
+ imports=['mmrazor.models.mutators.module_mutator.one_shot_module_mutator'],
+ allow_failed_imports=False)
+```
+
+to the config file to avoid modifying the original code.
+
+Customize `OneShotModuleMutator` is over, then you can use it directly in your algorithm.
\ No newline at end of file
diff --git a/docs/en/advanced_guides/recorder.md b/docs/en/advanced_guides/recorder.md
index 659538b15..a74984484 100644
--- a/docs/en/advanced_guides/recorder.md
+++ b/docs/en/advanced_guides/recorder.md
@@ -1 +1,347 @@
# Recorder
+
+
+## Introduction of Recorder
+
+`Recorder` is a context manager used to record various intermediate results during the model forward. It can help `Delivery` finish data delivering by recording source data in some distillation algorithms. And it can also be used to obtain some specific data for visual analysis or other functions you want.
+
+To adapt to more requirements, we implement multiple types of recorders to obtain different types of intermediate results in MMRazor. What is more, they can be used in combination with the `RecorderManager`.
+
+In general, `Recorder` will help us expand more functions in implementing algorithms by recording various intermediate results.
+
+## Usage of Recorder
+
+Currently, we support five `Recorder`, as shown in the following table
+| FunctionOutputsRecorder | Record output results of some functions |
+| ----------------------- | ------------------------------------------- |
+| MethodOutputsRecorder | Record output results of some methods |
+| ModuleInputsRecorder | Record input results of nn.Module |
+| ModuleOutputsRecorder | Record output results of nn.Module |
+| ParameterRecorder | Record intermediate parameters of nn.Module |
+
+All of the recorders inherit from `BaseRecorder`. And these recorders can be managed by `RecorderManager` or just be used on their own.
+
+Their relationship is shown below.
+
+
+
+
+
+
+### FunctionOutputsRecorder
+
+`FunctionOutputsRecorder` is used to record the output results of intermediate **function**.
+
+> When instantiating `FunctionOutputsRecorder`, you need to pass `source` argument, which requires extra attention. For example,
+`anchor_inside_flags` is a function in mmdetection to check whether the
+anchors are inside the border. This function is in
+`mmdet/core/anchor/utils.py` and used in
+`mmdet/models/dense_heads/anchor_head`. Then the `source` argument should be
+`mmdet.models.dense_heads.anchor_head.anchor_inside_flags` but not
+`mmdet.core.anchor.utils.anchor_inside_flags`.
+
+#### Example
+
+Suppose there is a toy function named `toy_func` in toy_module.py.
+
+```Python
+import random
+from typing import List
+from mmrazor.structures import FunctionOutputsRecorder
+
+def toy_func() -> int:
+ return random.randint(0, 1000000)
+
+# instantiate with specifing used path
+r1 = FunctionOutputsRecorder('toy_module.toy_func')
+
+# initialize is to make specified module can be recorded by
+# registering customized forward hook.
+r1.initialize()
+with r1:
+ out1 = toy_module.toy_func()
+ out2 = toy_module.toy_func()
+ out3 = toy_module.toy_func()
+
+# check recorded data
+print(r1.data_buffer)
+```
+
+Out:
+
+```Python
+[75486, 641059, 119729]
+```
+
+Test Correctness of recorded results
+
+```Python
+data_buffer = r1.data_buffer
+print(data_buffer[0] == out1 and data_buffer[1] == out2 and data_buffer[2] == out3)
+```
+
+Out:
+
+```Python
+True
+```
+
+To get the specific recorded data with `get_record_data`
+
+```Python
+print(r1.get_record_data(record_idx=2))
+```
+
+Out:
+
+```Python
+119729
+```
+
+
+
+### MethodOutputsRecorder
+
+`MethodOutputsRecorder` is used to record the output results of intermediate **method**.
+
+#### Example
+
+Suppose there is a toy class `Toy` and it has a toy method `toy_func` in toy_module.py.
+
+```Python
+import random
+from mmrazor.core import MethodOutputsRecorder
+
+class Toy():
+ def toy_func(self):
+ return random.randint(0, 1000000)
+
+toy = Toy()
+
+# instantiate with specifing used path
+r1 = MethodOutputsRecorder('toy_module.Toy.toy_func')
+# initialize is to make specified module can be recorded by
+# registering customized forward hook.
+r1.initialize()
+
+with r1:
+ out1 = toy.toy_func()
+ out2 = toy.toy_func()
+ out3 = toy.toy_func()
+
+# check recorded data
+print(r1.data_buffer)
+```
+
+Out:
+
+```Python
+[217832, 353057, 387699]
+```
+
+Test Correctness of recorded results
+
+```Python
+data_buffer = r1.data_buffer
+print(data_buffer[0] == out1 and data_buffer[1] == out2 and data_buffer[2] == out3)
+```
+
+Out:
+
+```Python
+True
+```
+
+To get the specific recorded data with `get_record_data`
+
+```Python
+print(r1.get_record_data(record_idx=2))
+```
+
+Out:
+
+```Python
+387699
+```
+
+### ModuleOutputsRecorder and ModuleInputsRecorder
+
+`ModuleOutputsRecorder`'s usage is similar with `ModuleInputsRecorder`'s, so we will take the former as an example to introduce their usage.
+
+#### Example
+
+> Different `MethodOutputsRecorder` and `FunctionOutputsRecorder`, `ModuleOutputsRecorder` and `ModuleInputsRecorder` are instantiated with module name rather than used path, and executing `initialize` need arg: `model`. Thus, they can know actually the module needs to be recorded.
+
+Suppose there is a toy Module `ToyModule` in toy_module.py.
+
+```Python
+import torch
+from torch import nn
+from mmrazor.core import ModuleOutputsRecorder
+
+class ToyModel(nn.Module):
+ def __init__(self):
+ super().__init__()
+ self.conv1 = nn.Conv2d(1, 1, 1)
+ self.conv2 = nn.Conv2d(1, 1, 1)
+
+ def forward(self, x):
+ x1 = self.conv1(x)
+ x2 = self.conv1(x + 1)
+ return self.conv2(x1 + x2)
+
+model = ToyModel()
+# instantiate with specifing module name.
+r1 = ModuleOutputsRecorder('conv1')
+
+# initialize is to make specified module can be recorded by
+# registering customized forward hook.
+r1.initialize(model)
+
+x = torch.randn(1, 1, 1, 1)
+with r1:
+ out = model(x)
+
+print(r1.data_buffer)
+```
+
+Out:
+
+```Python
+[tensor([[[[0.0820]]]], grad_fn=), tensor([[[[-0.0894]]]], grad_fn=)]
+```
+
+Test Correctness of recorded results
+
+```Python
+print(torch.equal(r1.data_buffer[0], model.conv1(x)))
+print(torch.equal(r1.data_buffer[1], model.conv1(x + 1)))
+```
+
+Out:
+
+```Python
+True
+True
+```
+
+### ParameterRecorder
+
+`ParameterRecorder` is used to record the intermediate parameter of `nn.``Module`. Its usage is similar to `ModuleOutputsRecorder`'s and `ModuleInputsRecorder`'s, but it instantiates with parameter name instead of module name.
+
+#### Example
+
+Suppose there is a toy Module `ToyModule` in toy_module.py.
+
+```Python
+from torch import nn
+import torch
+from mmrazor.core import ModuleOutputsRecorder
+
+class ToyModel(nn.Module):
+ def __init__(self):
+ super().__init__()
+ self.toy_conv = nn.Conv2d(1, 1, 1)
+
+ def forward(self, x):
+ return self.toy_conv(x)
+
+model = ToyModel()
+# instantiate with specifing parameter name.
+r1 = ParameterRecorder('toy_conv.weight')
+# initialize is to make specified module can be recorded by
+# registering customized forward hook.
+r1.initialize(model)
+
+print(r1.data_buffer)
+```
+
+Out:
+
+```Python
+[Parameter containing: tensor([[[[0.2971]]]], requires_grad=True)]
+```
+
+Test Correctness of recorded results
+
+```Python
+print(torch.equal(r1.data_buffer[0], model.toy_conv.weight))
+```
+
+Out:
+
+```Python
+True
+```
+
+### RecorderManager
+
+`RecorderManager` is actually context manager, which can be used to manage various types of recorders.
+
+With the help of `RecorderManager`, we can manage several different recorders with as little code as possible, which reduces the possibility of errors.
+
+#### Example
+
+Suppose there is a toy class `Toy` owned has a toy method `toy_func` in toy_module.py.
+
+```Python
+import random
+from torch import nn
+from mmrazor.core import RecorderManager
+
+class Toy():
+ def toy_func(self):
+ return random.randint(0, 1000000)
+
+class ToyModel(nn.Module):
+ def __init__(self):
+ super().__init__()
+ self.conv1 = nn.Conv2d(1, 1, 1)
+ self.conv2 = nn.Conv2d(1, 1, 1)
+ self.toy = Toy()
+
+ def forward(self, x):
+ return self.conv2(self.conv1(x)) + self.toy.toy_func()
+
+# configure multi-recorders
+conv1_rec = ConfigDict(type='ModuleOutputs', source='conv1')
+conv2_rec = ConfigDict(type='ModuleOutputs', source='conv2')
+func_rec = ConfigDict(type='MethodOutputs', source='toy_module.Toy.toy_func')
+# instantiate RecorderManager with a dict that contains recorders' configs,
+# you can customize their keys.
+manager = RecorderManager(
+ {'conv1_rec': conv1_rec,
+ 'conv2_rec': conv2_rec,
+ 'func_rec': func_rec})
+
+model = ToyModel()
+# initialize is to make specified module can be recorded by
+# registering customized forward hook.
+manager.initialize(model)
+
+x = torch.rand(1, 1, 1, 1)
+with manager:
+ out = model(x)
+
+conv2_out = manager.get_recorder('conv2_rec').get_record_data()
+print(conv2_out)
+```
+
+Out:
+
+```Python
+tensor([[[[0.5543]]]], grad_fn=)
+```
+
+Display output of `toy_func`
+
+```Python
+func_out = manager.get_recorder('func_rec').get_record_data()
+print(func_out)
+```
+
+Out:
+
+```Python
+313167
+```
\ No newline at end of file
diff --git a/docs/en/get_started/model_zoo.md b/docs/en/get_started/model_zoo.md
index 9cd17f5d4..e2ad66278 100644
--- a/docs/en/get_started/model_zoo.md
+++ b/docs/en/get_started/model_zoo.md
@@ -1 +1,27 @@
# Model Zoo
+
+## Baselines
+
+### CWD
+
+Please refer to [CWD](https://github.com/open-mmlab/mmrazor/blob/master/configs/distill/cwd) for details.
+
+### WSLD
+
+Please refer to [WSLD](https://github.com/open-mmlab/mmrazor/blob/master/configs/distill/wsld) for details.
+
+### DARTS
+
+Please refer to [DARTS](https://github.com/open-mmlab/mmrazor/blob/master/configs/nas/darts) for details.
+
+### DETNAS
+
+Please refer to [DETNAS](https://github.com/open-mmlab/mmrazor/blob/master/configs/nas/detnas) for details.
+
+### SPOS
+
+Please refer to [SPOS](https://github.com/open-mmlab/mmrazor/blob/master/configs/nas/spos) for details.
+
+### AUTOSLIM
+
+Please refer to [AUTOSLIM](https://github.com/open-mmlab/mmrazor/blob/master/configs/pruning/autoslim) for details.
diff --git a/docs/en/get_started/overview.md b/docs/en/get_started/overview.md
index 07dd0c5c7..67164285f 100644
--- a/docs/en/get_started/overview.md
+++ b/docs/en/get_started/overview.md
@@ -1 +1,111 @@
# Overview
+## Why MMRazor
+
+MMRazor is a model compression toolkit for model slimming, which includes 4 mainstream technologies:
+
+- Neural Architecture Search (NAS)
+- Pruning
+- Knowledge Distillation (KD)
+- Quantization (come soon)
+
+It is a part of the [OpenMMLab](https://openmmlab.com/) project. If you want to use it now, please refer to [Get Started](https://mmrazor.readthedocs.io/en/latest/get_started.html).
+
+### Major features:
+
+- **Compatibility**
+
+MMRazor can be easily applied to various projects in OpenMMLab, due to the similar architecture design of OpenMMLab as well as the decoupling of slimming algorithms and vision tasks.
+
+- **Flexibility**
+
+Different algorithms, e.g., NAS, pruning and KD, can be incorporated in a plug-n-play manner to build a more powerful system.
+
+- **Convenience**
+
+With better modular design, developers can implement new model compression algorithms with only a few codes, or even by simply modifying config files.
+
+
+
+## Design and Implement
+
+
+### Design
+
+There are 3 layers (**Application** / **Algorithm** / **Component**) in overview design. MMRazor mainly includes both of **Component** and **Algorithm**, while **Application** consist of some OpenMMLab upstream repos, such as MMClassification, MMDetection, MMSegmentation and so on.
+
+**Component** provides many useful functions for quickly implementing **Algorithm.** And thanks to OpenMMLab 's powerful and highly flexible config mode and registry mechanism**, Algorithm** can be conveniently applied to **Application.**
+
+How to apply our lightweight algorithms to some upstream tasks? Please refer to the below.
+
+### Implement
+
+In OpenMMLab, implementing vision tasks commonly includes 3 parts (model / dataset / schedule). And just like that, implementing lightweight model also includes 3 parts (algorithm / dataset / schedule) in MMRazor.
+
+`Algorithm` consist of `architecture` and `components`.
+
+`Architecture` is similar to `model` of the upstream repos. You can chose to directly use the original `model` or customize the new `model` as your architecture according to different tasks. For example, you can directly use ResNet-34 and ResNet-18 of MMClassification to implement some KD algorithms, but in NAS, you may need to customize a searchable model.
+
+`Compone``n``ts` consist of various special functions for supporting different lightweight algorithms. They can be directly used in config because of registered into MMEngine. Thus, you can pick some components you need to quickly implement your algorithm. For example, you may need `mutator` / `mutable` / `searchle backbone` if you want to implement a NAS algorithm, and you can pick from `distill loss` / `recorder` / `delivery` / `connector` if you need a KD algorithm.
+
+Please refer to the next section for more details about **Implement**.
+
+> The arg name of `algorithm` in config is **model** rather than **algorithm** in order to get better supports of MMCV and MMEngine.
+
+## Key concepts
+
+For better understanding and using MMRazor, it is highly recommended to read the following user documents according to your own needs.
+
+**Global**
+
+- [Algorithm](https://aicarrier.feishu.cn/docs/doccnw4XX4zCRJ3FHhZpjkWS4gf)
+
+**NAS & Pruning**
+
+- [Mutator](https://aicarrier.feishu.cn/docs/doccnYzs6QOjIiIB3BFB6R0Gaqh)
+- [Mutable](https://aicarrier.feishu.cn/docs/doccnc6HAhAsilBXGGR9kzeeK8d)
+- [Pruning graph](https://aicarrier.feishu.cn/docs/doccns6ziFFUvJDvhctTjwX6BBh)
+- [Dynamic op](https://aicarrier.feishu.cn/docx/doxcnbp4n4HeDkJI1fHlWfVklke)
+
+**KD**
+
+- [Delivery](https://aicarrier.feishu.cn/docs/doccnCEBuZPaLMTsMS83OoYJt4f)
+- [Recorder](https://aicarrier.feishu.cn/docs/doccnFzxHCSUxzohWHo5fgbI9Pc)
+- [Connector](https://aicarrier.feishu.cn/docx/doxcnvJG0VHZLqF82MkCHyr9B8b)
+
+## User guide
+
+We provide more complete and systematic guide documents for different technical directions. It is highly recommended to read them if you want to use and customize lightweight algorithms better.
+
+- Neural Architecture Search (to add link)
+- Pruning (to add link)
+- Knowledge Distillation (to add link)
+- Quantization (to add link)
+
+## Tutorials
+
+We provide the following general tutorials according to some typical requirements. If you want to further use MMRazor, you can refer to our source code and API Reference.
+
+**Tutorial list**
+
+- [Tutorial 1: Overview](https://mmrazor.readthedocs.io/en/latest/tutorials/Tutorial_1_overview.html#)
+- [Tutorial 2: Learn about Configs](https://mmrazor.readthedocs.io/en/latest/tutorials/Tutorial_2_learn_about_configs.html)
+- [Toturial 3: Customize Architectures](https://mmrazor.readthedocs.io/en/latest/tutorials/Tutorial_3_customize_architectures.html)
+- [Toturial 4: Customize NAS algorithms](https://mmrazor.readthedocs.io/en/latest/tutorials/Tutorial_4_customize_nas_algorithms.html)
+- [Tutorial 5: Customize Pruning algorithms](https://mmrazor.readthedocs.io/en/latest/tutorials/Tutorial_5_customize_pruning_algorithms.html)
+- [Toturial 6: Customize KD algorithms](https://mmrazor.readthedocs.io/en/latest/tutorials/Tutorial_6_customize_kd_algorithms.html)
+- [Tutorial 7: Customize mixed algorithms](https://mmrazor.readthedocs.io/en/latest/tutorials/Tutorial_7_customize_mixed_algorithms_with_out_algorithms_components.html)
+- [Tutorial 8: Apply existing algorithms to new tasks](https://mmrazor.readthedocs.io/en/latest/tutorials/Tutorial_8_apply_existing_algorithms_to_new_tasks.html)
+
+
+
+## F&Q
+
+If you encounter some trouble using MMRazor, you can find whether your question has existed in **F&Q(to add link)**. If not existed, welcome to open a [Github issue](https://github.com/open-mmlab/mmrazor/issues) for getting support, we will reply it as soon.
+
+
+## Get support and contribute back
+
+MMRazor is maintained on the [MMRazor Github repository](https://github.com/open-mmlab/mmrazor). We collect feedback and new proposals/ideas on Github. You can:
+
+- Open a [GitHub issue](https://github.com/open-mmlab/mmrazor/issues) for bugs and feature requests.
+- Open a [pull request](https://github.com/open-mmlab/mmrazor/pulls) to contribute code (make sure to read the [contribution guide](https://github.com/open-mmlab/mmcv/blob/master/CONTRIBUTING.md) before doing this).
\ No newline at end of file
diff --git a/docs/en/user_guides/1_learn_about_config.md b/docs/en/user_guides/1_learn_about_config.md
index 27a4b6df9..103e3538f 100644
--- a/docs/en/user_guides/1_learn_about_config.md
+++ b/docs/en/user_guides/1_learn_about_config.md
@@ -1 +1,8 @@
# Learn about Configs
+
+## Directory structure of configs in mmrazor
+
+
+
+## More about config
+Please refer to config.md in mmengine.
\ No newline at end of file
+
## Results and models
diff --git a/configs/distill/mmseg/cwd/README.md b/configs/distill/mmseg/cwd/README.md
index be3328d79..d65c6cda2 100644
--- a/configs/distill/mmseg/cwd/README.md
+++ b/configs/distill/mmseg/cwd/README.md
@@ -8,7 +8,7 @@
Knowledge distillation (KD) has been proven to be a simple and effective tool for training compact models. Almost all KD variants for dense prediction tasks align the student and teacher networks' feature maps in the spatial domain, typically by minimizing point-wise and/or pair-wise discrepancy. Observing that in semantic segmentation, some layers' feature activations of each channel tend to encode saliency of scene categories (analogue to class activation mapping), we propose to align features channel-wise between the student and teacher networks. To this end, we first transform the feature map of each channel into a probability map using softmax normalization, and then minimize the Kullback-Leibler (KL) divergence of the corresponding channels of the two networks. By doing so, our method focuses on mimicking the soft distributions of channels between networks. In particular, the KL divergence enables learning to pay more attention to the most salient regions of the channel-wise maps, presumably corresponding to the most useful signals for semantic segmentation. Experiments demonstrate that our channel-wise distillation outperforms almost all existing spatial distillation methods for semantic segmentation considerably, and requires less computational cost during training. We consistently achieve superior performance on three benchmarks with various network structures.
-
+
## Results and models
diff --git a/configs/nas/mmcls/darts/README.md b/configs/nas/mmcls/darts/README.md
index 09bbfa80e..912dfb314 100644
--- a/configs/nas/mmcls/darts/README.md
+++ b/configs/nas/mmcls/darts/README.md
@@ -8,7 +8,7 @@
This paper addresses the scalability challenge of architecture search by formulating the task in a differentiable manner. Unlike conventional approaches of applying evolution or reinforcement learning over a discrete and non-differentiable search space, our method is based on the continuous relaxation of the architecture representation, allowing efficient search of the architecture using gradient descent. Extensive experiments on CIFAR-10, ImageNet, Penn Treebank and WikiText-2 show that our algorithm excels in discovering high-performance convolutional architectures for image classification and recurrent architectures for language modeling, while being orders of magnitude faster than state-of-the-art non-differentiable techniques. Our implementation has been made publicly available to facilitate further research on efficient architecture search algorithms.
-
+
## Results and models
diff --git a/configs/nas/mmcls/spos/README.md b/configs/nas/mmcls/spos/README.md
index 890085054..f66ac904d 100644
--- a/configs/nas/mmcls/spos/README.md
+++ b/configs/nas/mmcls/spos/README.md
@@ -9,7 +9,8 @@
We revisit the one-shot Neural Architecture Search (NAS) paradigm and analyze its advantages over existing NAS approaches. Existing one-shot method, however, is hard to train and not yet effective on large scale datasets like ImageNet. This work propose a Single Path One-Shot model to address the challenge in the training. Our central idea is to construct a simplified supernet, where all architectures are single paths so that weight co-adaption problem is alleviated. Training is performed by uniform path sampling. All architectures (and their weights) are trained fully and equally.
Comprehensive experiments verify that our approach is flexible and effective. It is easy to train and fast to search. It effortlessly supports complex search spaces (e.g., building blocks, channel, mixed-precision quantization) and different search constraints (e.g., FLOPs, latency). It is thus convenient to use for various needs. It achieves start-of-the-art performance on the large dataset ImageNet.
-
+
+
## Introduction
diff --git a/configs/nas/mmdet/detnas/README.md b/configs/nas/mmdet/detnas/README.md
index 726347f6f..3eca077f4 100644
--- a/configs/nas/mmdet/detnas/README.md
+++ b/configs/nas/mmdet/detnas/README.md
@@ -8,7 +8,7 @@
Object detectors are usually equipped with backbone networks designed for image classification. It might be sub-optimal because of the gap between the tasks of image classification and object detection. In this work, we present DetNAS to use Neural Architecture Search (NAS) for the design of better backbones for object detection. It is non-trivial because detection training typically needs ImageNet pre-training while NAS systems require accuracies on the target detection task as supervisory signals. Based on the technique of one-shot supernet, which contains all possible networks in the search space, we propose a framework for backbone search on object detection. We train the supernet under the typical detector training schedule: ImageNet pre-training and detection fine-tuning. Then, the architecture search is performed on the trained supernet, using the detection task as the guidance. This framework makes NAS on backbones very efficient. In experiments, we show the effectiveness of DetNAS on various detectors, for instance, one-stage RetinaNet and the two-stage FPN. We empirically find that networks searched on object detection shows consistent superiority compared to those searched on ImageNet classification. The resulting architecture achieves superior performance than hand-crafted networks on COCO with much less FLOPs complexity.
-
+
## Introduction
diff --git a/configs/pruning/mmcls/autoslim/README.md b/configs/pruning/mmcls/autoslim/README.md
index ca9f1de4d..9a533eb4f 100644
--- a/configs/pruning/mmcls/autoslim/README.md
+++ b/configs/pruning/mmcls/autoslim/README.md
@@ -9,7 +9,9 @@
We study how to set channel numbers in a neural network to achieve better accuracy under constrained resources (e.g., FLOPs, latency, memory footprint or model size). A simple and one-shot solution, named AutoSlim, is presented. Instead of training many network samples and searching with reinforcement learning, we train a single slimmable network to approximate the network accuracy of different channel configurations. We then iteratively evaluate the trained slimmable model and greedily slim the layer with minimal accuracy drop. By this single pass, we can obtain the optimized channel configurations under different resource constraints. We present experiments with MobileNet v1, MobileNet v2, ResNet-50 and RL-searched MNasNet on ImageNet classification. We show significant improvements over their default channel configurations. We also achieve better accuracy than recent channel pruning methods and neural architecture search methods.
Notably, by setting optimized channel numbers, our AutoSlim-MobileNet-v2 at 305M FLOPs achieves 74.2% top-1 accuracy, 2.4% better than default MobileNet-v2 (301M FLOPs), and even 0.2% better than RL-searched MNasNet (317M FLOPs). Our AutoSlim-ResNet-50 at 570M FLOPs, without depthwise convolutions, achieves 1.3% better accuracy than MobileNet-v1 (569M FLOPs).
-
+
+
+
## Introduction
diff --git a/docs/en/advanced_guides/algorithm.md b/docs/en/advanced_guides/algorithm.md
index 48de5f33d..cd5056167 100644
--- a/docs/en/advanced_guides/algorithm.md
+++ b/docs/en/advanced_guides/algorithm.md
@@ -1 +1,266 @@
# Algorithm
+## Introduction
+
+### What is algorithm in MMRazor
+
+MMRazor is a model compression toolkit, which includes 4 mianstream technologies:
+
+- Neural Architecture Search (NAS)
+- Pruning
+- Knowledge Distillation (KD)
+- Quantization (come soon)
+
+And in MMRazor, `algorithm` is a general item for these technologies. For example, in NAS,
+
+[SPOS](https://github.com/open-mmlab/mmrazor/blob/master/configs/nas/spos)[ ](https://arxiv.org/abs/1904.00420)is an `algorithm`, [CWD](https://github.com/open-mmlab/mmrazor/blob/master/configs/distill/cwd) is also an `algorithm` of knowledge distillation.
+
+`algorithm` is the entrance of `mmrazor/models` . Its role in MMRazor is the same as both `classifier` in [MMClassification](https://github.com/open-mmlab/mmclassification) and `detector` in [MMDetection](https://github.com/open-mmlab/mmdetection).
+
+### About base algorithm
+
+In the directory of `models/algorith``ms`, all model compression algorithms are divided into 4 subdirectories: nas / pruning / distill / quantization. These algorithms must inherit from `BaseAlgorithm`, whose definition is as below.
+
+```Python
+from typing import Dict, List, Optional, Tuple, Union
+from mmengine.model import BaseModel
+from mmrazor.registry import MODELS
+
+LossResults = Dict[str, torch.Tensor]
+TensorResults = Union[Tuple[torch.Tensor], torch.Tensor]
+PredictResults = List[BaseDataElement]
+ForwardResults = Union[LossResults, TensorResults, PredictResults]
+
+@MODELS.register_module()
+class BaseAlgorithm(BaseModel):
+
+ def __init__(self,
+ architecture: Union[BaseModel, Dict],
+ data_preprocessor: Optional[Union[Dict, nn.Module]] = None,
+ init_cfg: Optional[Dict] = None):
+
+ ......
+
+ super().__init__(data_preprocessor, init_cfg)
+ self.architecture = architecture
+
+ def forward(self,
+ batch_inputs: torch.Tensor,
+ data_samples: Optional[List[BaseDataElement]] = None,
+ mode: str = 'tensor') -> ForwardResults:
+
+ if mode == 'loss':
+ return self.loss(batch_inputs, data_samples)
+ elif mode == 'tensor':
+ return self._forward(batch_inputs, data_samples)
+ elif mode == 'predict':
+ return self._predict(batch_inputs, data_samples)
+ else:
+ raise RuntimeError(f'Invalid mode "{mode}". '
+ 'Only supports loss, predict and tensor mode')
+
+ def loss(
+ self,
+ batch_inputs: torch.Tensor,
+ data_samples: Optional[List[BaseDataElement]] = None,
+ ) -> LossResults:
+ """Calculate losses from a batch of inputs and data samples."""
+ return self.architecture(batch_inputs, data_samples, mode='loss')
+
+ def _forward(
+ self,
+ batch_inputs: torch.Tensor,
+ data_samples: Optional[List[BaseDataElement]] = None,
+ ) -> TensorResults:
+ """Network forward process."""
+ return self.architecture(batch_inputs, data_samples, mode='tensor')
+
+ def _predict(
+ self,
+ batch_inputs: torch.Tensor,
+ data_samples: Optional[List[BaseDataElement]] = None,
+ ) -> PredictResults:
+ """Predict results from a batch of inputs and data samples with post-
+ processing."""
+ return self.architecture(batch_inputs, data_samples, mode='predict')
+```
+
+As you can see from above, `BaseAlgorithm` is inherited from `BaseModel` of MMEngine. `BaseModel` implements the basic functions of the algorithmic model, such as weights initialize,
+
+batch inputs preprocess (see more information in `BaseDataPreprocessor` class of MMEngine), parse losses, and update model parameters. For more details of `BaseModel` , you can see docs for `BaseModel`.
+
+`BaseAlgorithm`'s forward is just a wrapper of `BaseModel`'s forward. Sub-classes inherited from BaseAlgorithm only need to override the `loss` method, which implements the logic to calculate loss, thus various algorithms can be trained in the runner.
+
+
+
+## How to use existing algorithms in MMRazor
+
+1. Configure your architecture that will be slimmed
+
+- Use the model config of other repos of OpenMMLab directly as below, which is an example of setting Faster-RCNN as our architecture.
+
+```Python
+_base_ = [
+ 'mmdet::_base_/models/faster_rcnn_r50_fpn.py',
+]
+
+architecture = _base_.model
+```
+
+- Use your customized model as below, which is an example of defining a VGG model as our architecture.
+
+> How to customize architectures can refer to our tutorial: [Customize Architectures](https://mmrazor.readthedocs.io/en/latest/tutorials/Tutorial_3_customize_architectures.html#).
+
+```Python
+default_scope='mmcls'
+architecture = dict(
+ type='ImageClassifier',
+ backbone=dict(type='VGG', depth=11, num_classes=1000),
+ neck=None,
+ head=dict(
+ type='ClsHead',
+ loss=dict(type='CrossEntropyLoss', loss_weight=1.0),
+ topk=(1, 5),
+ ))
+```
+
+2. Apply the registered algorithm to your architecture.
+
+> The arg name of `algorithm` in config is **model** rather than **algorithm** in order to get better supports of MMCV and MMEngine.
+
+Maybe more args in model need to set according to the used algorithm.
+
+```Python
+model = dict(
+ type='BaseAlgorithm',
+ architecture=architecture)
+```
+
+> About the usage of `Config`, refer to [Config ‒ mmcv 1.5.3 documentation](https://mmcv.readthedocs.io/en/latest/understand_mmcv/config.html) please.
+
+3. Apply some custom hooks or loops to your algorithm. (optional)
+
+- Custom hooks
+
+```Python
+custom_hooks = [
+ dict(type='NaiveVisualizationHook', priority='LOWEST'),
+]
+```
+
+- Custom loops
+
+```Python
+_base_ = ['./spos_shufflenet_supernet_8xb128_in1k.py']
+
+# To chose from ['train_cfg', 'val_cfg', 'test_cfg'] based on your loop type
+train_cfg = dict(
+ _delete_=True,
+ type='mmrazor.EvolutionSearchLoop',
+ dataloader=_base_.val_dataloader,
+ evaluator=_base_.val_evaluator)
+
+val_cfg = dict()
+test_cfg = dict()
+```
+
+## How to customize your algorithm
+
+### Common pipeline
+
+1. Register a new algorithm
+
+Create a new file `mmrazor/models/algorithms/{subdirectory}/xxx.py`
+
+```Python
+from mmrazor.models.algorithms import BaseAlgorithm
+from mmrazor.registry import MODELS
+
+@MODELS.register_module()
+class XXX(BaseAlgorithm):
+ def __init__(self, architecture):
+ super().__init__(architecture)
+ pass
+
+ def loss(self, batch_inputs):
+ pass
+```
+
+2. Rewrite its `loss` method.
+
+```Python
+from mmrazor.models.algorithms import BaseAlgorithm
+from mmrazor.registry import MODELS
+
+@MODELS.register_module()
+class XXX(BaseAlgorithm):
+ def __init__(self, architecture):
+ super().__init__(architecture)
+ ......
+
+ def loss(self, batch_inputs):
+ ......
+ return LossResults
+```
+
+3. Add the remaining functions of the algorithm
+
+> This step is special because of the diversity of algorithms. Some functions of the algorithm may also be implemented in other files.
+
+```Python
+from mmrazor.models.algorithms import BaseAlgorithm
+from mmrazor.registry import MODELS
+
+@MODELS.register_module()
+class XXX(BaseAlgorithm):
+ def __init__(self, architecture):
+ super().__init__(architecture)
+ ......
+
+ def loss(self, batch_inputs):
+ ......
+ return LossResults
+
+ def aaa(self):
+ ......
+
+ def bbb(self):
+ ......
+```
+
+4. Import the class
+
+You can add the following line to `mmrazor/models/algorithms/``{subdirectory}/``__init__.py`
+
+```CoffeeScript
+from .xxx import XXX
+
+__all__ = ['XXX']
+```
+
+In addition, import XXX in `mmrazor/models/algorithms/__init__.py`
+
+5. Use the algorithm in your config file.
+
+Please refer to the previous section about how to use existing algorithms in MMRazor
+
+```Python
+model = dict(
+ type='XXX',
+ architecture=architecture)
+```
+
+### Pipelines for different algorithms
+
+Please refer to our tutorials about how to customize different algorithms for more details as below.
+
+1. NAS
+
+[Customize NAS algorithms](https://mmrazor.readthedocs.io/en/latest/tutorials/Tutorial_4_customize_nas_algorithms.html#)
+
+2. Pruning
+
+[Customize Pruning algorithms](https://mmrazor.readthedocs.io/en/latest/tutorials/Tutorial_5_customize_pruning_algorithms.html)
+
+3. Distill
+
+[Customize KD algorithms](https://mmrazor.readthedocs.io/en/latest/tutorials/Tutorial_6_customize_kd_algorithms.html)
\ No newline at end of file
diff --git a/docs/en/advanced_guides/apply_existing_algorithms_to_new_tasks.md b/docs/en/advanced_guides/apply_existing_algorithms_to_new_tasks.md
index 71bc4bfe0..3e2f8e394 100644
--- a/docs/en/advanced_guides/apply_existing_algorithms_to_new_tasks.md
+++ b/docs/en/advanced_guides/apply_existing_algorithms_to_new_tasks.md
@@ -1 +1,82 @@
# Apply existing algorithms to new tasks
+Here we show how to apply existing algorithms to other tasks with an example of [SPOS ](https://github.com/open-mmlab/mmrazor/tree/dev-1.x/configs/nas/mmcls/spos)& [DetNAS](https://github.com/open-mmlab/mmrazor/tree/dev-1.x/configs/nas/mmdet/detnas).
+
+> SPOS: Single Path One-Shot NAS for classification
+>
+> DetNAS: Single Path One-Shot NAS for detection
+
+**You just need to configure the existing algorithms in your config only by replacing** **the architecture of** **mmcls** **with** **mmdet****'s**
+
+You can implement a new algorithm by inheriting from the existing algorithm quickly if the new task's specificity leads to the failure of applying directly.
+
+SPOS config VS DetNAS config
+
+- SPOS
+
+```Python
+_base_ = [
+ 'mmrazor::_base_/settings/imagenet_bs1024_spos.py',
+ 'mmrazor::_base_/nas_backbones/spos_shufflenet_supernet.py',
+ 'mmcls::_base_/default_runtime.py',
+]
+
+# model
+supernet = dict(
+ type='ImageClassifier',
+ data_preprocessor=_base_.preprocess_cfg,
+ backbone=_base_.nas_backbone,
+ neck=dict(type='GlobalAveragePooling'),
+ head=dict(
+ type='LinearClsHead',
+ num_classes=1000,
+ in_channels=1024,
+ loss=dict(
+ type='LabelSmoothLoss',
+ num_classes=1000,
+ label_smooth_val=0.1,
+ mode='original',
+ loss_weight=1.0),
+ topk=(1, 5)))
+
+model = dict(
+ type='mmrazor.SPOS',
+ architecture=supernet,
+ mutator=dict(type='mmrazor.OneShotModuleMutator'))
+
+find_unused_parameters = True
+```
+
+- DetNAS
+
+```Python
+_base_ = [
+ 'mmdet::_base_/models/faster_rcnn_r50_fpn.py',
+ 'mmdet::_base_/datasets/coco_detection.py',
+ 'mmdet::_base_/schedules/schedule_1x.py',
+ 'mmdet::_base_/default_runtime.py',
+ 'mmrazor::_base_/nas_backbones/spos_shufflenet_supernet.py'
+]
+
+norm_cfg = dict(type='SyncBN', requires_grad=True)
+
+supernet = _base_.model
+
+supernet.backbone = _base_.nas_backbone
+supernet.backbone.norm_cfg = norm_cfg
+supernet.backbone.out_indices = (0, 1, 2, 3)
+supernet.backbone.with_last_layer = False
+
+supernet.neck.norm_cfg = norm_cfg
+supernet.neck.in_channels = [64, 160, 320, 640]
+
+supernet.roi_head.bbox_head.norm_cfg = norm_cfg
+supernet.roi_head.bbox_head.type = 'Shared4Conv1FCBBoxHead'
+
+model = dict(
+ _delete_=True,
+ type='mmrazor.SPOS',
+ architecture=supernet,
+ mutator=dict(type='mmrazor.OneShotModuleMutator'))
+
+find_unused_parameters = True
+```
\ No newline at end of file
diff --git a/docs/en/advanced_guides/customize_architectures.md b/docs/en/advanced_guides/customize_architectures.md
index 2e94c780b..59c5092ee 100644
--- a/docs/en/advanced_guides/customize_architectures.md
+++ b/docs/en/advanced_guides/customize_architectures.md
@@ -1 +1,260 @@
# Customize Architectures
+Different from other tasks, architectures in MMRazor may consist of some special model components, such as **searchable backbones, connectors, dynamic ops**. In MMRazor, you can not only develop some common model components like other codebases of OpenMMLab, but also develop some special model components. Here is how to develop searchable model components and common model components.
+
+> Please refer to these documents as follows if you want to know about **connectors** and **dynamic ops**.
+>
+> [Connector 用户文档](https://aicarrier.feishu.cn/docx/doxcnvJG0VHZLqF82MkCHyr9B8b)
+>
+> [Dynamic op 用户文档](https://aicarrier.feishu.cn/docx/doxcnbp4n4HeDkJI1fHlWfVklke)
+
+## Develop searchable model components
+
+1. Define a new backbone
+
+Create a new file `mmrazor/models/architectures/backbones/searchable_shufflenet_v2.py`, class `SearchableShuffleNetV2` inherits from `BaseBackBone` of mmcls, which is the codebase that you will use to build the model.
+
+```Python
+# Copyright (c) OpenMMLab. All rights reserved.
+import copy
+from typing import Dict, List, Optional, Sequence, Tuple, Union
+
+import torch.nn as nn
+from mmcls.models.backbones.base_backbone import BaseBackbone
+from mmcv.cnn import ConvModule, constant_init, normal_init
+from mmcv.runner import ModuleList, Sequential
+from torch import Tensor
+from torch.nn.modules.batchnorm import _BatchNorm
+
+from mmrazor.registry import MODELS
+
+@MODELS.register_module()
+class SearchableShuffleNetV2(BaseBackbone):
+
+ def __init__(self, ):
+ pass
+
+ def _make_layer(self, out_channels, num_blocks, stage_idx):
+ pass
+
+ def _freeze_stages(self):
+ pass
+
+ def init_weights(self):
+ pass
+
+ def forward(self, x):
+ pass
+
+ def train(self, mode=True):
+ pass
+```
+
+2. Build the architecture of the new backbone based on `arch_setting`
+
+```Python
+@MODELS.register_module()
+class SearchableShuffleNetV2(BaseBackbone):
+ def __init__(self,
+ arch_setting: List[List],
+ stem_multiplier: int = 1,
+ widen_factor: float = 1.0,
+ out_indices: Sequence[int] = (4, ),
+ frozen_stages: int = -1,
+ with_last_layer: bool = True,
+ conv_cfg: Optional[Dict] = None,
+ norm_cfg: Dict = dict(type='BN'),
+ act_cfg: Dict = dict(type='ReLU'),
+ norm_eval: bool = False,
+ with_cp: bool = False,
+ init_cfg: Optional[Union[Dict, List[Dict]]] = None) -> None:
+ layers_nums = 5 if with_last_layer else 4
+ for index in out_indices:
+ if index not in range(0, layers_nums):
+ raise ValueError('the item in out_indices must in '
+ f'range(0, 5). But received {index}')
+
+ self.frozen_stages = frozen_stages
+ if frozen_stages not in range(-1, layers_nums):
+ raise ValueError('frozen_stages must be in range(-1, 5). '
+ f'But received {frozen_stages}')
+
+ super().__init__(init_cfg)
+
+ self.arch_setting = arch_setting
+ self.widen_factor = widen_factor
+ self.out_indices = out_indices
+ self.conv_cfg = conv_cfg
+ self.norm_cfg = norm_cfg
+ self.act_cfg = act_cfg
+ self.norm_eval = norm_eval
+ self.with_cp = with_cp
+
+ last_channels = 1024
+ self.in_channels = 16 * stem_multiplier
+
+ # build the first layer
+ self.conv1 = ConvModule(
+ in_channels=3,
+ out_channels=self.in_channels,
+ kernel_size=3,
+ stride=2,
+ padding=1,
+ conv_cfg=conv_cfg,
+ norm_cfg=norm_cfg,
+ act_cfg=act_cfg)
+
+ # build the middle layers
+ self.layers = ModuleList()
+ for channel, num_blocks, mutable_cfg in arch_setting:
+ out_channels = round(channel * widen_factor)
+ layer = self._make_layer(out_channels, num_blocks,
+ copy.deepcopy(mutable_cfg))
+ self.layers.append(layer)
+
+ # build the last layer
+ if with_last_layer:
+ self.layers.append(
+ ConvModule(
+ in_channels=self.in_channels,
+ out_channels=last_channels,
+ kernel_size=1,
+ conv_cfg=conv_cfg,
+ norm_cfg=norm_cfg,
+ act_cfg=act_cfg))
+```
+
+3. Implement`_make_layer` with `mutable_cfg`
+
+```Python
+@MODELS.register_module()
+class SearchableShuffleNetV2(BaseBackbone):
+
+ ...
+
+ def _make_layer(self, out_channels: int, num_blocks: int,
+ mutable_cfg: Dict) -> Sequential:
+ """Stack mutable blocks to build a layer for ShuffleNet V2.
+ Note:
+ Here we use ``module_kwargs`` to pass dynamic parameters such as
+ ``in_channels``, ``out_channels`` and ``stride``
+ to build the mutable.
+ Args:
+ out_channels (int): out_channels of the block.
+ num_blocks (int): number of blocks.
+ mutable_cfg (dict): Config of mutable.
+ Returns:
+ mmcv.runner.Sequential: The layer made.
+ """
+ layers = []
+ for i in range(num_blocks):
+ stride = 2 if i == 0 else 1
+
+ mutable_cfg.update(
+ module_kwargs=dict(
+ in_channels=self.in_channels,
+ out_channels=out_channels,
+ stride=stride))
+ layers.append(MODELS.build(mutable_cfg))
+ self.in_channels = out_channels
+
+ return Sequential(*layers)
+
+ ...
+```
+
+4. Implement other common methods
+
+You can refer to the implementation of `ShuffleNetV2` in mmcls for finishing other common methods.
+
+5. Import the module
+
+You can either add the following line to `mmrazor/models/architectures/backbones/__init__.py`
+
+```Python
+from .searchable_shufflenet_v2 import SearchableShuffleNetV2
+
+__all__ = ['SearchableShuffleNetV2']
+```
+
+or alternatively add
+
+```Python
+custom_imports = dict(
+ imports=['mmrazor.models.architectures.backbones.searchable_shufflenet_v2'],
+ allow_failed_imports=False)
+```
+
+to the config file to avoid modifying the original code.
+
+6. Use the backbone in your config file
+
+```Python
+architecture = dict(
+ type=xxx,
+ model=dict(
+ ...
+ backbone=dict(
+ type='mmrazor.SearchableShuffleNetV2',
+ arg1=xxx,
+ arg2=xxx),
+ ...
+```
+
+## Develop common model components
+
+Here we show how to add a new backbone with an example of `xxxNet`.
+
+1. Define a new backbone
+
+Create a new file `mmrazor/models/architectures/backbones/xxxnet.py`, then implement the class `xxxNet`.
+
+```Python
+from mmengine.model import BaseModule
+from mmrazor.registry import MODELS
+
+@MODELS.register_module()
+class xxxNet(BaseModule):
+
+ def __init__(self, arg1, arg2, init_cfg=None):
+ super().__init__(init_cfg=init_cfg)
+ pass
+
+ def forward(self, x):
+ pass
+```
+
+2. Import the module
+
+You can either add the following line to `mmrazor/models/architectures/backbones/__init__.py`
+
+```Python
+from .xxxnet import xxxNet
+
+__all__ = ['xxxNet']
+```
+
+or alternatively add
+
+```Python
+custom_imports = dict(
+ imports=['mmrazor.models.architectures.backbones.xxxnet'],
+ allow_failed_imports=False)
+```
+
+to the config file to avoid modifying the original code.
+
+3. Use the backbone in your config file
+
+```Python
+architecture = dict(
+ type=xxx,
+ model=dict(
+ ...
+ backbone=dict(
+ type='xxxNet',
+ arg1=xxx,
+ arg2=xxx),
+ ...
+```
+
+How to add other model components is similar to backbone's. For more details, please refer to other codebases' docs.
\ No newline at end of file
diff --git a/docs/en/advanced_guides/customize_mixed_algorithms.md b/docs/en/advanced_guides/customize_mixed_algorithms.md
index e96ee039e..8a63ce5d6 100644
--- a/docs/en/advanced_guides/customize_mixed_algorithms.md
+++ b/docs/en/advanced_guides/customize_mixed_algorithms.md
@@ -1 +1,159 @@
# Customize mixed algorithms
+Here we show how to customize mixed algorithms with our algorithm components. We take [AutoSlim ](https://github.com/open-mmlab/mmrazor/tree/dev-1.x/configs/pruning/mmcls/autoslim)as an example.
+
+> **Why is AutoSlim a mixed algorithm?**
+>
+> In [AutoSlim](https://github.com/open-mmlab/mmrazor/tree/dev-1.x/configs/pruning/mmcls/autoslim), the sandwich rule and the inplace distillation will be introduced to enhance the training process, which is called as the slimmable training. The sandwich rule means that we train the model at smallest width, largest width and (n − 2) random widths, instead of n random widths. And the inplace distillation means that we use the predicted label of the model at the largest width as the training label for other widths, while for the largest width we use ground truth. So both the KD algorithm and the pruning algorithm are used in [AutoSlim](https://github.com/open-mmlab/mmrazor/tree/dev-1.x/configs/pruning/mmcls/autoslim).
+
+1. Register a new algorithm
+
+Create a new file `mmrazor/models/algorithms/nas/autoslim.py`, class `AutoSlim` inherits from class `BaseAlgorithm`. You need to build the KD algorithm component (distiller) and the pruning algorithm component (mutator) because AutoSlim is a mixed algorithm.
+
+> You can also inherit from the existing algorithm instead of `BaseAlgorithm` if your algorithm is similar to the existing algorithm.
+
+> You can choose existing algorithm components in MMRazor, such as `OneShotChannelMutator` and `ConfigurableDistiller` in AutoSlim.
+>
+> If these in MMRazor don't meet your needs, you can customize new algorithm components for your algorithm. Reference is as follows:
+>
+> [Tutorials: Customize KD algorithms](https://aicarrier.feishu.cn/docx/doxcnFWOTLQYJ8FIlUGsYrEjisd)
+>
+> [Tutorials: Customize Pruning algorithms](https://aicarrier.feishu.cn/docx/doxcnzXlPv0cDdmd0wNrq0SEqsh)
+>
+> [Tutorials: Customize KD algorithms](https://aicarrier.feishu.cn/docx/doxcnFWOTLQYJ8FIlUGsYrEjisd)
+
+```Python
+# Copyright (c) OpenMMLab. All rights reserved.
+from typing import Dict, List, Optional, Union
+import torch
+from torch import nn
+
+from mmrazor.models.distillers import ConfigurableDistiller
+from mmrazor.models.mutators import OneShotChannelMutator
+from mmrazor.registry import MODELS
+from ..base import BaseAlgorithm
+
+VALID_MUTATOR_TYPE = Union[OneShotChannelMutator, Dict]
+VALID_DISTILLER_TYPE = Union[ConfigurableDistiller, Dict]
+
+@MODELS.register_module()
+class AutoSlim(BaseAlgorithm):
+ def __init__(self,
+ mutator: VALID_MUTATOR_TYPE,
+ distiller: VALID_DISTILLER_TYPE,
+ architecture: Union[BaseModel, Dict],
+ data_preprocessor: Optional[Union[Dict, nn.Module]] = None,
+ init_cfg: Optional[Dict] = None,
+ num_samples: int = 2) -> None:
+ super().__init__(architecture, data_preprocessor, init_cfg)
+ self.mutator = self._build_mutator(mutator)
+ # `prepare_from_supernet` must be called before distiller initialized
+ self.mutator.prepare_from_supernet(self.architecture)
+
+ self.distiller = self._build_distiller(distiller)
+ self.distiller.prepare_from_teacher(self.architecture)
+ self.distiller.prepare_from_student(self.architecture)
+
+ ......
+
+ def _build_mutator(self,
+ mutator: VALID_MUTATOR_TYPE) -> OneShotChannelMutator:
+ """build mutator."""
+ if isinstance(mutator, dict):
+ mutator = MODELS.build(mutator)
+ if not isinstance(mutator, OneShotChannelMutator):
+ raise TypeError('mutator should be a `dict` or '
+ '`OneShotModuleMutator` instance, but got '
+ f'{type(mutator)}')
+
+ return mutator
+
+ def _build_distiller(
+ self, distiller: VALID_DISTILLER_TYPE) -> ConfigurableDistiller:
+ if isinstance(distiller, dict):
+ distiller = MODELS.build(distiller)
+ if not isinstance(distiller, ConfigurableDistiller):
+ raise TypeError('distiller should be a `dict` or '
+ '`ConfigurableDistiller` instance, but got '
+ f'{type(distiller)}')
+
+ return distiller
+```
+
+2. Implement the core logic in `train_step`
+
+In `train_step`, both the `mutator` and the `distiller` play an important role. For example, `sample_subnet`, `set_max_subnet` and `set_min_subnet` are supported by the `mutator`, and the function of`distill_step` is mainly implemented by the `distiller`.
+
+```Python
+@MODELS.register_module()
+class AutoSlim(BaseAlgorithm):
+
+ ......
+
+ def train_step(self, data: List[dict],
+ optim_wrapper: OptimWrapper) -> Dict[str, torch.Tensor]:
+
+ def distill_step(
+ batch_inputs: torch.Tensor, data_samples: List[BaseDataElement]
+ ) -> Dict[str, torch.Tensor]:
+ ......
+
+ ......
+
+ batch_inputs, data_samples = self.data_preprocessor(data, True)
+
+ total_losses = dict()
+ # update the max subnet loss.
+ self.set_max_subnet()
+ ......
+ total_losses.update(add_prefix(max_subnet_losses, 'max_subnet'))
+
+ # update the min subnet loss.
+ self.set_min_subnet()
+ min_subnet_losses = distill_step(batch_inputs, data_samples)
+ total_losses.update(add_prefix(min_subnet_losses, 'min_subnet'))
+
+ # update the random subnet loss.
+ for sample_idx in range(self.num_samples):
+ self.set_subnet(self.sample_subnet())
+ random_subnet_losses = distill_step(batch_inputs, data_samples)
+ total_losses.update(
+ add_prefix(random_subnet_losses,
+ f'random_subnet_{sample_idx}'))
+
+ return total_losses
+```
+
+3. Import the class
+
+You can either add the following line to `mmrazor/models/algorithms/nas/__init__.py`
+
+```Python
+from .autoslim import AutoSlim
+
+__all__ = ['AutoSlim']
+```
+
+or alternatively add
+
+```Python
+custom_imports = dict(
+ imports=['mmrazor.models.algorithms.nas.autoslim'],
+ allow_failed_imports=False)
+```
+
+to the config file to avoid modifying the original code.
+
+4. Use the algorithm in your config file
+
+```Python
+model= dict(
+ type='mmrazor.AutoSlim',
+ architecture=...,
+ mutator=dict(
+ type='OneShotChannelMutator',
+ ...),
+ distiller=dict(
+ type='ConfigurableDistiller',
+ ...),
+ ...)
+```
\ No newline at end of file
diff --git a/docs/en/advanced_guides/delivery.md b/docs/en/advanced_guides/delivery.md
index 97715e016..c65f8da43 100644
--- a/docs/en/advanced_guides/delivery.md
+++ b/docs/en/advanced_guides/delivery.md
@@ -1 +1,219 @@
# Delivery
+## Introduction of Delivery
+
+`Delivery` is a mechanism used in **knowledge distillation****,** which is to **align the intermediate results** between the teacher model and the student model by delivering and rewriting these intermediate results between them. As shown in the figure below, deliveries can be used to:
+
+- **Deliver the output of a layer of the teacher model directly to a layer of the student model.** In some knowledge distillation algorithms, we may need to deliver the output of a layer of the teacher model to the student model directly. For example, in [LAD](https://arxiv.org/abs/2108.10520) algorithm, the student model needs to obtain the label assignment of the teacher model directly.
+- **Align the inputs of the teacher model and the student model.** For example, in the MMClassification framework, some widely used data augmentations such as [mixup](https://arxiv.org/abs/1710.09412) and [CutMix](https://arxiv.org/abs/1905.04899) are not implemented in Data Pipelines but in `forward_train`, and due to the randomness of these data augmentation methods, it may lead to a gap between the input of the teacher model and the student model.
+
+
+
+In general, the delivery mechanism allows us to deliver intermediate results between the teacher model and the student model **without adding additional code**, which reduces the hard coding in the source code.
+
+## Usage of Delivery
+
+Currently, we support two deliveries: `FunctionOutputs``Delivery` and `MethodOutputs``Delivery`, both of which inherit from `DistillDiliver`. And these deliveries can be managed by `Distill``Delivery``Manager` or just be used on their own.
+
+Their relationship is shown below.
+
+
+
+
+
+
+### FunctionOutputsDelivery
+
+`FunctionOutputs``Delivery` is used to align the **function's** intermediate results between the teacher model and the student model.
+
+> When initializing `FunctionOutputs``Delivery`, you need to pass `func_path` argument, which requires extra attention. For example,
+`anchor_inside_flags` is a function in mmdetection to check whether the
+anchors are inside the border. This function is in
+`mmdet/core/anchor/utils.py` and used in
+`mmdet/models/dense_heads/anchor_head`. Then the `func_path` should be
+`mmdet.models.dense_heads.anchor_head.anchor_inside_flags` but not
+`mmdet.core.anchor.utils.anchor_inside_flags`.
+
+#### Case 1: Delivery single function's output from the teacher to the student.
+
+```Python
+import random
+from mmrazor.core import FunctionOutputsDelivery
+
+def toy_func() -> int:
+ return random.randint(0, 1000000)
+
+delivery = FunctionOutputsDelivery(max_keep_data=1, func_path='toy_module.toy_func')
+
+# override_data is False, which means that not override the data with
+# the recorded data. So it will get the original output of toy_func
+# in teacher model, and it is also recorded to be deliveried to the student.
+delivery.override_data = False
+with delivery:
+ output_teacher = toy_module.toy_func()
+
+# override_data is True, which means that override the data with
+# the recorded data, so it will get the output of toy_func
+# in teacher model rather than the student's.
+delivery.override_data = True
+with delivery:
+ output_student = toy_module.toy_func()
+
+print(output_teacher == output_student)
+```
+
+Out:
+
+```Python
+True
+```
+
+#### Case 2: Delivery multi function's outputs from the teacher to the student.
+
+If a function is executed more than once during the forward of the teacher model, all the outputs of this function will be used to override function outputs from the student model
+
+> Delivery order is first-in first-out.
+
+```Python
+delivery = FunctionOutputsDelivery(
+ max_keep_data=2, func_path='toy_module.toy_func')
+
+delivery.override_data = False
+with delivery:
+ output1_teacher = toy_module.toy_func()
+ output2_teacher = toy_module.toy_func()
+
+delivery.override_data = True
+with delivery:
+ output1_student = toy_module.toy_func()
+ output2_student = toy_module.toy_func()
+
+print(output1_teacher == output1_student and output2_teacher == output2_student)
+```
+
+Out:
+
+```Python
+True
+```
+
+
+
+### MethodOutputsDelivery
+
+`MethodOutputs``Delivery` is used to align the **method's** intermediate results between the teacher model and the student model.
+
+#### Case: **Align the inputs of the teacher model and the student model**
+
+Here we use mixup as an example to show how to align the inputs of the teacher model and the student model.
+
+- Without Delivery
+
+```Python
+# main.py
+from mmcls.models.utils import Augments
+from mmrazor.core import MethodOutputsDelivery
+
+augments_cfg = dict(type='BatchMixup', alpha=1., num_classes=10, prob=1.0)
+augments = Augments(augments_cfg)
+
+imgs = torch.randn(2, 3, 32, 32)
+label = torch.randint(0, 10, (2,))
+
+imgs_teacher, label_teacher = augments(imgs, label)
+imgs_student, label_student = augments(imgs, label)
+
+print(torch.equal(label_teacher, label_student))
+print(torch.equal(imgs_teacher, imgs_student))
+```
+
+Out:
+
+```Python
+False
+False
+from mmcls.models.utils import Augments
+from mmrazor.core import DistillDeliveryManager
+```
+
+The results are different due to the randomness of mixup.
+
+- With Delivery
+
+```Python
+delivery = MethodOutputsDelivery(
+ max_keep_data=1, method_path='mmcls.models.utils.Augments.__call__')
+
+delivery.override_data = False
+with delivery:
+ imgs_teacher, label_teacher = augments(imgs, label)
+
+delivery.override_data = True
+with delivery:
+ imgs_student, label_student = augments(imgs, label)
+
+print(torch.equal(label_teacher, label_student))
+print(torch.equal(imgs_teacher, imgs_student))
+```
+
+Out:
+
+```Python
+True
+True
+```
+
+The randomness is eliminated by using `MethodOutputsDelivery`.
+
+
+
+### 2.3 DistillDeliveryManager
+
+`Distill``Delivery``Manager` is actually a context manager, used to manage delivers. When entering the `Distill``Delivery``Manager`, all delivers managed will be started.
+
+With the help of `Distill``Delivery``Manager`, we are able to manage several different DistillDeliveries with as little code as possible, thereby reducing the possibility of errors.
+
+#### Case: Manager deliveries with DistillDeliveryManager
+
+```Python
+from mmcls.models.utils import Augments
+from mmrazor.core import DistillDeliveryManager
+
+augments_cfg = dict(type='BatchMixup', alpha=1., num_classes=10, prob=1.0)
+augments = Augments(augments_cfg)
+
+distill_deliveries = [
+ ConfigDict(type='MethodOutputs', max_keep_data=1,
+ method_path='mmcls.models.utils.Augments.__call__')]
+
+# instantiate DistillDeliveryManager
+manager = DistillDeliveryManager(distill_deliveries)
+
+imgs = torch.randn(2, 3, 32, 32)
+label = torch.randint(0, 10, (2,))
+
+manager.override_data = False
+with manager:
+ imgs_teacher, label_teacher = augments(imgs, label)
+
+manager.override_data = True
+with manager:
+ imgs_student, label_student = augments(imgs, label)
+
+print(torch.equal(label_teacher, label_student))
+print(torch.equal(imgs_teacher, imgs_student))
+```
+
+Out:
+
+```Python
+True
+True
+```
+
+## Reference
+
+[1] Zhang, Hongyi, et al. "mixup: Beyond empirical risk minimization." *arXiv* abs/1710.09412 (2017).
+
+[2] Yun, Sangdoo, et al. "Cutmix: Regularization strategy to train strong classifiers with localizable features." *ICCV* (2019).
+
+[3] Nguyen, Chuong H., et al. "Improving object detection by label assignment distillation." *WACV* (2022).
\ No newline at end of file
diff --git a/docs/en/advanced_guides/mutable.md b/docs/en/advanced_guides/mutable.md
index 1067112fb..26d3825df 100644
--- a/docs/en/advanced_guides/mutable.md
+++ b/docs/en/advanced_guides/mutable.md
@@ -1 +1,394 @@
# Mutable
+## Introduction
+
+### What is Mutable
+
+`Mutable` is one of basic function components in NAS algorithms and some pruning algorithms, which makes supernet searchable by providing optional modules or parameters.
+
+To understand it better, we take the mutable module as an example to explain as follows.
+
+
+
+
+As shown in the figure above, `Mutable` is a container that holds some candidate operations, thus it can sample candidates to constitute the subnet. `Supernet` usually consists of multiple `Mutable`, therefore, `Supernet` will be searchable with the help of `Mutable`. And all candidate operations in `Mutable` constitute the search space of `SuperNet`.
+
+> If you want to know more about the relationship between Mutable and Mutator, please refer to [Mutator 用户文档](https://aicarrier.feishu.cn/docx/doxcnmcie75HcbqkfBGaEoemBKg)
+
+### Features
+
+#### 1. Support module mutable
+
+It is the common and basic function for NAS algorithms. We can use it to implement some classical one-shot NAS algorithms, such as [SPOS](https://arxiv.org/abs/1904.00420), [DetNAS ](https://arxiv.org/abs/1903.10979)and so on.
+
+#### 2. Support parameter mutable
+
+To implement more complicated and funny algorithms easier, we supported making some important parameters searchable, such as input channel, output channel, kernel size and so on.
+
+What is more, we can implement **dynamic op** by using mutable parameters.
+
+#### 3. Support deriving from mutable parameter
+
+Because of the restriction of defined architecture, there may be correlations between some mutable parameters, **such as concat and expand ratio.**
+
+> If conv3 = concat (conv1, conv2)
+>
+> When out_channel (conv1) = 3, out_channel (conv2) = 4
+>
+> Then in_channel (conv3) must be 7 rather than mutable.
+>
+> So use derived mutable from conv1 and conv2 to generate in_channel (conv3)
+
+With the help of derived mutable, we can meet these special requirements in some NAS algorithms and pruning algorithms. What is more, it can be used to deal with different granularity between search spaces.
+
+### Supported mutables
+
+
+
+As shown in the figure above.
+
+- **White blocks** stand the basic classes, which include `BaseMutable` and `DerivedMethodMixin`. `BaseMutable` is the base class for all mutables, which defines required properties and abstracmethods. `DerivedMethodMixin` is a mixin class to provide mutable parameters with some useful methods to derive mutable.
+
+- **Gray blocks** stand different types of base mutables.
+ > Because there are correlations between channels of some layers, we divide mutable parameters into `MutableChannel` and `MutableValue`, so you can also think `MutableChannel` is a special `MutableValue`.
+
+ For supporting module and parameters mutable, we provide `MutableModule`, `MutableChannel` and `MutableValue` these base classes to implement required basic functions. And we also add `OneshotMutableModule` and `DiffMutableModule` two types based on `MutableModule` to meet different types of algorithms' requirements.
+
+ For supporting deriving from mutable parameters, we make `MutableChannel` and `MutableValue` inherit from `BaseMutable` and `DerivedMethodMixin`, thus they can get derived functions provided by `DerivedMethodMixin`.
+
+- **Red blocks** and **green blocks** stand registered classes for implementing some specific algorithms, which means that you can use them directly in configs. If they do not meet your requirements, you can also customize your mutable based on our base classes. If you are interested in their realization, please refer to their docstring.
+
+## How to use existing mutables to configure searchable backbones
+
+We will use `OneShotMutableOP` to build a `SearchableShuffleNetV2` backbone as follows.
+
+1. Configure needed mutables
+
+```Python
+# we only use OneShotMutableOP, then take 4 ShuffleOP as its candidates.
+_STAGE_MUTABLE = dict(
+ _scope_='mmrazor',
+ type='OneShotMutableOP',
+ candidates=dict(
+ shuffle_3x3=dict(type='ShuffleBlock', kernel_size=3),
+ shuffle_5x5=dict(type='ShuffleBlock', kernel_size=5),
+ shuffle_7x7=dict(type='ShuffleBlock', kernel_size=7),
+ shuffle_xception=dict(type='ShuffleXception')))
+```
+
+2. Configure the `arch_setting` of `SearchableShuffleNetV2`
+
+```Python
+# Use the _STAGE_MUTABLE in various stages.
+arch_setting = [
+ # Parameters to build layers. 3 parameters are needed to construct a
+ # layer, from left to right: channel, num_blocks, mutable_cfg.
+ [64, 4, _STAGE_MUTABLE],
+ [160, 4, _STAGE_MUTABLE],
+ [320, 8, _STAGE_MUTABLE],
+ [640, 4, _STAGE_MUTABLE]
+]
+```
+
+3. Configure searchable backbone.
+
+```Python
+nas_backbone = dict(
+ _scope_='mmrazor',
+ type='SearchableShuffleNetV2',
+ widen_factor=1.0,
+ arch_setting=arch_setting)
+```
+
+Then you can use it in your architecture. If existing mutables do not meet your needs, you can also customize your needed mutable.
+
+## How to customize your mutable
+
+### About base mutable
+
+Before customizing mutables, we need to know what some base mutables do.
+
+**BaseMutable**
+
+In order to implement the searchable mechanism, mutables need to own some base functions, such as changing status from mutable to fixed, recording the current status and current choice and so on. So in `BaseMutable`, these relevant abstract methods and properties will be defined as follows.
+
+```Python
+# Copyright (c) OpenMMLab. All rights reserved.
+from abc import ABC, abstractmethod
+from typing import Dict, Generic, Optional, TypeVar
+
+from mmengine.model import BaseModule
+
+CHOICE_TYPE = TypeVar('CHOICE_TYPE')
+CHOSEN_TYPE = TypeVar('CHOSEN_TYPE')
+
+class BaseMutable(BaseModule, ABC, Generic[CHOICE_TYPE, CHOSEN_TYPE]):
+
+ def __init__(self,
+ alias: Optional[str] = None,
+ init_cfg: Optional[Dict] = None) -> None:
+ super().__init__(init_cfg=init_cfg)
+
+ self.alias = alias
+ self._is_fixed = False
+ self._current_choice: Optional[CHOICE_TYPE] = None
+
+ @property
+ def current_choice(self) -> Optional[CHOICE_TYPE]:
+ return self._current_choice
+
+ @current_choice.setter
+ def current_choice(self, choice: Optional[CHOICE_TYPE]) -> None:
+ self._current_choice = choice
+
+ @property
+ def is_fixed(self) -> bool:
+ return self._is_fixed
+
+ @is_fixed.setter
+ def is_fixed(self, is_fixed: bool) -> None:
+ ......
+ self._is_fixed = is_fixed
+
+ @abstractmethod
+ def fix_chosen(self, chosen: CHOSEN_TYPE) -> None:
+ pass
+
+ @abstractmethod
+ def dump_chosen(self) -> CHOSEN_TYPE:
+ pass
+
+ @property
+ @abstractmethod
+ def num_choices(self) -> int:
+ pass
+```
+
+**MutableModule**
+
+Inherited from `BaseModule`, `MutableModule` not only owns its basic functions, but also needs some specialized functions to implement module mutable, such as getting all choices, executing forward computation.
+
+```Python
+# Copyright (c) OpenMMLab. All rights reserved.
+from abc import abstractmethod
+from typing import Any, Dict, List, Optional
+
+from ..base_mutable import CHOICE_TYPE, CHOSEN_TYPE, BaseMutable
+
+class MutableModule(BaseMutable[CHOICE_TYPE, CHOSEN_TYPE]):
+
+ def __init__(self,
+ module_kwargs: Optional[Dict[str, Dict]] = None,
+ **kwargs) -> None:
+ super().__init__(**kwargs)
+
+ self.module_kwargs = module_kwargs
+
+ @property
+ @abstractmethod
+ def choices(self) -> List[CHOICE_TYPE]:
+ """list: all choices. All subclasses must implement this method."""
+
+ @abstractmethod
+ def forward(self, x: Any) -> Any:
+ """Forward computation."""
+
+ @property
+ def num_choices(self) -> int:
+ """Number of choices."""
+ return len(self.choices)
+```
+
+If you want to know more about other types mutables, please refer to their docstring.
+
+### Steps of customizing mutables
+
+There are 4 steps to implement a custom mutable.
+
+1. Registry a new mutable
+
+2. Implement abstract methods.
+
+3. Implement other methods.
+
+4. Import the class
+
+Then you can use your customized mutable in configs as in the previous chapter.
+
+Let's use `OneShotMutableOP` as an example for customizing mutable.
+
+#### 1. Registry a new mutable
+
+First, you need to determine which type mutable to implement. Thus, you can implement your mutable faster by inheriting from correlative base mutable.
+
+Then create a new file `mmrazor/models/mutables/mutable_module/``one_shot_mutable_module`, class `OneShotMutableOP` inherits from `OneShotMutableModule`.
+
+```Python
+# Copyright (c) OpenMMLab. All rights reserved.
+import random
+from abc import abstractmethod
+from typing import Any, Dict, List, Optional, Union
+
+import numpy as np
+import torch.nn as nn
+from torch import Tensor
+
+from mmrazor.registry import MODELS
+from ..base_mutable import CHOICE_TYPE, CHOSEN_TYPE
+from .mutable_module import MutableModule
+
+@MODELS.register_module()
+class OneShotMutableOP(OneShotMutableModule[str, str]):
+ ...
+```
+
+#### 2. Implement abstract methods
+
+##### 2.1 Basic abstract methods
+
+These basic abstract methods are mainly from `BaseMutable` and `MutableModule`, such as `fix_chosen`, `dump_chosen`, `choices` and `num_choices`.
+
+```Python
+@MODELS.register_module()
+class OneShotMutableOP(OneShotMutableModule[str, str]):
+ ......
+
+ def fix_chosen(self, chosen: str) -> None:
+ """Fix mutable with subnet config. This operation would convert
+ `unfixed` mode to `fixed` mode. The :attr:`is_fixed` will be set to
+ True and only the selected operations can be retained.
+ Args:
+ chosen (str): the chosen key in ``MUTABLE``. Defaults to None.
+ """
+ if self.is_fixed:
+ raise AttributeError(
+ 'The mode of current MUTABLE is `fixed`. '
+ 'Please do not call `fix_chosen` function again.')
+
+ for c in self.choices:
+ if c != chosen:
+ self._candidates.pop(c)
+
+ self._chosen = chosen
+ self.is_fixed = True
+
+ def dump_chosen(self) -> str:
+ assert self.current_choice is not None
+
+ return self.current_choice
+
+ @property
+ def choices(self) -> List[str]:
+ """list: all choices. """
+ return list(self._candidates.keys())
+
+ @property
+ def num_choices(self):
+ return len(self.choices)
+```
+
+##### 2.2 Specified abstract methods
+
+In `OneShotMutableModule`, sample and forward these required abstract methods are defined, such as `sample_choice`, `forward_choice`, `forward_fixed`, `forward_all`. So we need to implement these abstract methods.
+
+```Python
+@MODELS.register_module()
+class OneShotMutableOP(OneShotMutableModule[str, str]):
+ ......
+
+ def sample_choice(self) -> str:
+ """uniform sampling."""
+ return np.random.choice(self.choices, 1)[0]
+
+ def forward_fixed(self, x: Any) -> Tensor:
+ """Forward with the `fixed` mutable.
+ Args:
+ x (Any): x could be a Torch.tensor or a tuple of
+ Torch.tensor, containing input data for forward computation.
+ Returns:
+ Tensor: the result of forward the fixed operation.
+ """
+ return self._candidates[self._chosen](x)
+
+ def forward_choice(self, x: Any, choice: str) -> Tensor:
+ """Forward with the `unfixed` mutable and current choice is not None.
+ Args:
+ x (Any): x could be a Torch.tensor or a tuple of
+ Torch.tensor, containing input data for forward computation.
+ choice (str): the chosen key in ``OneShotMutableOP``.
+ Returns:
+ Tensor: the result of forward the ``choice`` operation.
+ """
+ assert isinstance(choice, str) and choice in self.choices
+ return self._candidates[choice](x)
+
+ def forward_all(self, x: Any) -> Tensor:
+ """Forward all choices. Used to calculate FLOPs.
+ Args:
+ x (Any): x could be a Torch.tensor or a tuple of
+ Torch.tensor, containing input data for forward computation.
+ Returns:
+ Tensor: the result of forward all of the ``choice`` operation.
+ """
+ outputs = list()
+ for op in self._candidates.values():
+ outputs.append(op(x))
+ return sum(outputs)
+```
+
+#### 3. Implement other methods
+
+After finishing some required methods, we need to add some special methods, such as `_build_ops`, because it is needed in building candidates for sampling.
+
+```Python
+@MODELS.register_module()
+class OneShotMutableOP(OneShotMutableModule[str, str]):
+ ......
+
+ @staticmethod
+ def _build_ops(
+ candidates: Union[Dict[str, Dict], nn.ModuleDict],
+ module_kwargs: Optional[Dict[str, Dict]] = None) -> nn.ModuleDict:
+ """Build candidate operations based on choice configures.
+ Args:
+ candidates (dict[str, dict] | :obj:`nn.ModuleDict`): the configs
+ for the candidate operations or nn.ModuleDict.
+ module_kwargs (dict[str, dict], optional): Module initialization
+ named arguments.
+ Returns:
+ ModuleDict (dict[str, Any], optional): the key of ``ops`` is
+ the name of each choice in configs and the value of ``ops``
+ is the corresponding candidate operation.
+ """
+ if isinstance(candidates, nn.ModuleDict):
+ return candidates
+
+ ops = nn.ModuleDict()
+ for name, op_cfg in candidates.items():
+ assert name not in ops
+ if module_kwargs is not None:
+ op_cfg.update(module_kwargs)
+ ops[name] = MODELS.build(op_cfg)
+ return ops
+```
+
+#### 4. Import the class
+
+You can either add the following line to `mmrazor/models/mutables/mutable_module/__init__.py`
+
+```Python
+from .one_shot_mutable_module import OneShotMutableModule
+
+__all__ = ['OneShotMutableModule']
+```
+
+or alternatively add
+
+```Python
+custom_imports = dict(
+ imports=['mmrazor.models.mutables.mutable_module.one_shot_mutable_module'],
+ allow_failed_imports=False)
+```
+
+to the config file to avoid modifying the original code.
+
+Customize `OneShotMutableOP` is over, then you can use it directly in your algorithm.
\ No newline at end of file
diff --git a/docs/en/advanced_guides/mutator.md b/docs/en/advanced_guides/mutator.md
index a5e125528..f450652bd 100644
--- a/docs/en/advanced_guides/mutator.md
+++ b/docs/en/advanced_guides/mutator.md
@@ -1 +1,241 @@
# Mutator
+
+
+## Introduction
+
+### What is Mutator
+
+**Mutator** is one of algorithm components, which provides some useful functions used for mutable management, such as sample choice, set choicet and so on. With Mutator's help, you can implement some NAS or pruning algorithms quickly.
+
+### What is the relationship between Mutator and Mutable
+
+
+
+
+In a word, Mutator is the manager of Mutable. Each different type of mutable is commonly managed by their one correlative mutator, respectively.
+
+As shown in the figure, Mutable is a component of supernet, therefore Mutator can implement some functions about subnet from supernet by handling Mutable.
+
+### Supported mutators
+
+In MMRazor, we have implemented some mutators, their relationship is as below.
+
+
+
+
+`BaseMutator`: Base class for all mutators. It has appointed some abstract methods supported by all mutators.
+
+`ModuleMuator`/ `ChannelMutator`: Two different types mutators are for handling mutable module and mutable channel respectively.
+
+> Please refer to [Mutable 用户文档 ](https://aicarrier.feishu.cn/docs/doccnc6HAhAsilBXGGR9kzeeK8d)for more details about different types of mutable.
+
+`OneShotModuleMutator` / `DiffModuleMutator`: Inherit from `ModuleMuator`, they are for implementing different types algorithms, such as [SPOS](https://arxiv.org/abs/1904.00420), [Darts](https://arxiv.org/abs/1806.09055) and so on.
+
+`OneShotChannelMutator` / `SlimmableChannelMutator`: Inherit from `ChannelMutator`, they are also for meeting the needs of different types algorithms, such as [AotuSlim](https://arxiv.org/abs/1903.11728).
+
+## How to use existing mutators
+
+You just use them directly in configs as below
+
+```Python
+supernet = dict(
+ ...
+ )
+
+model = dict(
+ type='mmrazor.SPOS',
+ architecture=supernet,
+ mutator=dict(type='mmrazor.OneShotModuleMutator'))
+```
+
+If existing mutators do not meet your needs, you can also customize your needed mutator.
+
+## How to customize your mutator
+
+All mutators need to implement at least two of the following interfaces
+
+- `prepare_from_supernet()`
+ - Make some necessary preparations according to the given supernet. These preparations may include, but are not limited to, grouping the search space, and initializing mutator with the parameters needed for itself.
+
+- `search_groups`
+ - Group of search space.
+
+ - Note that **search groups** and **search space** are two different concepts. The latter defines what choices can be used for searching. The former groups the search space, and searchable blocks that are grouped into the same group will share the same search space and the same sample result.
+
+ - ```Python
+ # Example
+ search_space = {op1, op2, op3, op4}
+ search_group = {0: [op1, op2], 1: [op3, op4]}
+ ```
+
+There are 4 steps to implement a custom mutator.
+
+1. Registry a new mutator
+
+2. Implement abstract methods
+
+3. Implement other methods
+
+4. Import the class
+
+Then you can use your customized mutator in configs as in the previous chapter.
+
+Let's use `OneShotModuleMutator` as an example for customizing mutator.
+
+### 1.Registry a new mutator
+
+First, you need to determine which type mutator to implement. Thus, you can implement your mutator faster by inheriting from correlative base mutator.
+
+Then create a new file `mmrazor/models/mutators/module_mutator/one_shot_module_mutator`, class `OneShotModuleMutator` inherits from `ModuleMutator`.
+
+```Python
+from mmrazor.registry import MODELS
+from .module_mutator import ModuleMutator
+
+@MODELS.register_module()
+class OneShotModuleMutator(ModuleMutator):
+ ...
+```
+
+### 2. Implement abstract methods
+2.1. Rewrite the `mutable_class_type` property
+
+```Python
+@MODELS.register_module()
+class OneShotModuleMutator(ModuleMutator):
+
+ @property
+ def mutable_class_type(self):
+ """One-shot mutable class type.
+ Returns:
+ Type[OneShotMutableModule]: Class type of one-shot mutable.
+ """
+ return OneShotMutableModule
+```
+
+2.2. Rewrite `search_groups` and `prepare_from_supernet()`
+
+As the `prepare_from_supernet()` method and the `search_groups` property are already implemented in the `ModuleMutator` and we don't need to add our own logic, the second step is already over.
+
+If you need to implement them by yourself, you can refer to these as follows.
+
+2.3. **Understand** **`search_groups`****(optional)**
+
+Let's take an example to see what default `search_groups` do.
+
+```Python
+from mmrazor.models import OneShotModuleMutator, OneShotMutableModule
+
+class SearchableModel(nn.Module):
+ def __init__(self, one_shot_op_cfg):
+ # assume `OneShotMutableModule` contains 4 choices:
+ # choice1, choice2, choice3 and choice4
+ self.choice_block1 = OneShotMutableModule(**one_shot_op_cfg)
+ self.choice_block2 = OneShotMutableModule(**one_shot_op_cfg)
+ self.choice_block3 = OneShotMutableModule(**one_shot_op_cfg)
+
+ def forward(self, x: Tensor) -> Tensor:
+ x = self.choice_block1(x)
+ x = self.choice_block2(x)
+ x = self.choice_block3(x)
+
+ return x
+
+supernet = SearchableModel(one_shot_op_cfg)
+mutator1 = OneShotModuleMutator()
+# build mutator1 from supernet.
+mutator1.prepare_from_supernet(supernet)
+>>> mutator1.search_groups.keys()
+dict_keys([0, 1, 2])
+```
+
+In this case, each `OneShotMutableModule` will be divided into a group. Thus, the search groups have 3 groups.
+
+If you want to custom group according to your requirement, you can implement it by passing the arg `custom_group`.
+
+```Python
+custom_group = [
+ ['op1', 'op2'],
+ ['op3']
+]
+mutator2 = OneShotMutator(custom_group)
+mutator2.prepare_from_supernet(supernet)
+```
+
+Then `choice_block1` and `choice_block2` will share the same search space and the same sample result, and `choice_block3` will have its own independent search space. Thus, the search groups have only 2 groups.
+
+```Python
+>>> mutator2.search_groups.keys()
+dict_keys([0, 1])
+```
+
+### 3. Implement other methods
+
+After finishing some required methods, we need to add some special methods, such as `sample_choices` and `set_choices`.
+
+```Python
+from typing import Any, Dict
+
+from mmrazor.registry import MODELS
+from ...mutables import OneShotMutableModule
+from .module_mutator import
+
+@MODELS.register_module()
+class OneShotModuleMutator(ModuleMutator):
+
+ def sample_choices(self) -> Dict[int, Any]:
+ """Sampling by search groups.
+ The sampling result of the first mutable of each group is the sampling
+ result of this group.
+ Returns:
+ Dict[int, Any]: Random choices dict.
+ """
+ random_choices = dict()
+ for group_id, modules in self.search_groups.items():
+ random_choices[group_id] = modules[0].sample_choice()
+
+ return random_choices
+
+ def set_choices(self, choices: Dict[int, Any]) -> None:
+ """Set mutables' current choice according to choices sample by
+ :func:`sample_choices`.
+ Args:
+ choices (Dict[int, Any]): Choices dict. The key is group_id in
+ search groups, and the value is the sampling results
+ corresponding to this group.
+ """
+ for group_id, modules in self.search_groups.items():
+ choice = choices[group_id]
+ for module in modules:
+ module.current_choice = choice
+
+ @property
+ def mutable_class_type(self):
+ """One-shot mutable class type.
+ Returns:
+ Type[OneShotMutableModule]: Class type of one-shot mutable.
+ """
+ return OneShotMutableModule
+```
+
+### 4. Import the class
+
+You can either add the following line to `mmrazor/models/mutators/module_mutator/__init__.py`
+
+```Python
+from .one_shot_module_mutator import OneShotModuleMutator
+
+__all__ = ['OneShotModuleMutator']
+```
+
+or alternatively add
+
+```Python
+custom_imports = dict(
+ imports=['mmrazor.models.mutators.module_mutator.one_shot_module_mutator'],
+ allow_failed_imports=False)
+```
+
+to the config file to avoid modifying the original code.
+
+Customize `OneShotModuleMutator` is over, then you can use it directly in your algorithm.
\ No newline at end of file
diff --git a/docs/en/advanced_guides/recorder.md b/docs/en/advanced_guides/recorder.md
index 659538b15..a74984484 100644
--- a/docs/en/advanced_guides/recorder.md
+++ b/docs/en/advanced_guides/recorder.md
@@ -1 +1,347 @@
# Recorder
+
+
+## Introduction of Recorder
+
+`Recorder` is a context manager used to record various intermediate results during the model forward. It can help `Delivery` finish data delivering by recording source data in some distillation algorithms. And it can also be used to obtain some specific data for visual analysis or other functions you want.
+
+To adapt to more requirements, we implement multiple types of recorders to obtain different types of intermediate results in MMRazor. What is more, they can be used in combination with the `RecorderManager`.
+
+In general, `Recorder` will help us expand more functions in implementing algorithms by recording various intermediate results.
+
+## Usage of Recorder
+
+Currently, we support five `Recorder`, as shown in the following table
+| FunctionOutputsRecorder | Record output results of some functions |
+| ----------------------- | ------------------------------------------- |
+| MethodOutputsRecorder | Record output results of some methods |
+| ModuleInputsRecorder | Record input results of nn.Module |
+| ModuleOutputsRecorder | Record output results of nn.Module |
+| ParameterRecorder | Record intermediate parameters of nn.Module |
+
+All of the recorders inherit from `BaseRecorder`. And these recorders can be managed by `RecorderManager` or just be used on their own.
+
+Their relationship is shown below.
+
+
+
+
+
+
+### FunctionOutputsRecorder
+
+`FunctionOutputsRecorder` is used to record the output results of intermediate **function**.
+
+> When instantiating `FunctionOutputsRecorder`, you need to pass `source` argument, which requires extra attention. For example,
+`anchor_inside_flags` is a function in mmdetection to check whether the
+anchors are inside the border. This function is in
+`mmdet/core/anchor/utils.py` and used in
+`mmdet/models/dense_heads/anchor_head`. Then the `source` argument should be
+`mmdet.models.dense_heads.anchor_head.anchor_inside_flags` but not
+`mmdet.core.anchor.utils.anchor_inside_flags`.
+
+#### Example
+
+Suppose there is a toy function named `toy_func` in toy_module.py.
+
+```Python
+import random
+from typing import List
+from mmrazor.structures import FunctionOutputsRecorder
+
+def toy_func() -> int:
+ return random.randint(0, 1000000)
+
+# instantiate with specifing used path
+r1 = FunctionOutputsRecorder('toy_module.toy_func')
+
+# initialize is to make specified module can be recorded by
+# registering customized forward hook.
+r1.initialize()
+with r1:
+ out1 = toy_module.toy_func()
+ out2 = toy_module.toy_func()
+ out3 = toy_module.toy_func()
+
+# check recorded data
+print(r1.data_buffer)
+```
+
+Out:
+
+```Python
+[75486, 641059, 119729]
+```
+
+Test Correctness of recorded results
+
+```Python
+data_buffer = r1.data_buffer
+print(data_buffer[0] == out1 and data_buffer[1] == out2 and data_buffer[2] == out3)
+```
+
+Out:
+
+```Python
+True
+```
+
+To get the specific recorded data with `get_record_data`
+
+```Python
+print(r1.get_record_data(record_idx=2))
+```
+
+Out:
+
+```Python
+119729
+```
+
+
+
+### MethodOutputsRecorder
+
+`MethodOutputsRecorder` is used to record the output results of intermediate **method**.
+
+#### Example
+
+Suppose there is a toy class `Toy` and it has a toy method `toy_func` in toy_module.py.
+
+```Python
+import random
+from mmrazor.core import MethodOutputsRecorder
+
+class Toy():
+ def toy_func(self):
+ return random.randint(0, 1000000)
+
+toy = Toy()
+
+# instantiate with specifing used path
+r1 = MethodOutputsRecorder('toy_module.Toy.toy_func')
+# initialize is to make specified module can be recorded by
+# registering customized forward hook.
+r1.initialize()
+
+with r1:
+ out1 = toy.toy_func()
+ out2 = toy.toy_func()
+ out3 = toy.toy_func()
+
+# check recorded data
+print(r1.data_buffer)
+```
+
+Out:
+
+```Python
+[217832, 353057, 387699]
+```
+
+Test Correctness of recorded results
+
+```Python
+data_buffer = r1.data_buffer
+print(data_buffer[0] == out1 and data_buffer[1] == out2 and data_buffer[2] == out3)
+```
+
+Out:
+
+```Python
+True
+```
+
+To get the specific recorded data with `get_record_data`
+
+```Python
+print(r1.get_record_data(record_idx=2))
+```
+
+Out:
+
+```Python
+387699
+```
+
+### ModuleOutputsRecorder and ModuleInputsRecorder
+
+`ModuleOutputsRecorder`'s usage is similar with `ModuleInputsRecorder`'s, so we will take the former as an example to introduce their usage.
+
+#### Example
+
+> Different `MethodOutputsRecorder` and `FunctionOutputsRecorder`, `ModuleOutputsRecorder` and `ModuleInputsRecorder` are instantiated with module name rather than used path, and executing `initialize` need arg: `model`. Thus, they can know actually the module needs to be recorded.
+
+Suppose there is a toy Module `ToyModule` in toy_module.py.
+
+```Python
+import torch
+from torch import nn
+from mmrazor.core import ModuleOutputsRecorder
+
+class ToyModel(nn.Module):
+ def __init__(self):
+ super().__init__()
+ self.conv1 = nn.Conv2d(1, 1, 1)
+ self.conv2 = nn.Conv2d(1, 1, 1)
+
+ def forward(self, x):
+ x1 = self.conv1(x)
+ x2 = self.conv1(x + 1)
+ return self.conv2(x1 + x2)
+
+model = ToyModel()
+# instantiate with specifing module name.
+r1 = ModuleOutputsRecorder('conv1')
+
+# initialize is to make specified module can be recorded by
+# registering customized forward hook.
+r1.initialize(model)
+
+x = torch.randn(1, 1, 1, 1)
+with r1:
+ out = model(x)
+
+print(r1.data_buffer)
+```
+
+Out:
+
+```Python
+[tensor([[[[0.0820]]]], grad_fn=), tensor([[[[-0.0894]]]], grad_fn=)]
+```
+
+Test Correctness of recorded results
+
+```Python
+print(torch.equal(r1.data_buffer[0], model.conv1(x)))
+print(torch.equal(r1.data_buffer[1], model.conv1(x + 1)))
+```
+
+Out:
+
+```Python
+True
+True
+```
+
+### ParameterRecorder
+
+`ParameterRecorder` is used to record the intermediate parameter of `nn.``Module`. Its usage is similar to `ModuleOutputsRecorder`'s and `ModuleInputsRecorder`'s, but it instantiates with parameter name instead of module name.
+
+#### Example
+
+Suppose there is a toy Module `ToyModule` in toy_module.py.
+
+```Python
+from torch import nn
+import torch
+from mmrazor.core import ModuleOutputsRecorder
+
+class ToyModel(nn.Module):
+ def __init__(self):
+ super().__init__()
+ self.toy_conv = nn.Conv2d(1, 1, 1)
+
+ def forward(self, x):
+ return self.toy_conv(x)
+
+model = ToyModel()
+# instantiate with specifing parameter name.
+r1 = ParameterRecorder('toy_conv.weight')
+# initialize is to make specified module can be recorded by
+# registering customized forward hook.
+r1.initialize(model)
+
+print(r1.data_buffer)
+```
+
+Out:
+
+```Python
+[Parameter containing: tensor([[[[0.2971]]]], requires_grad=True)]
+```
+
+Test Correctness of recorded results
+
+```Python
+print(torch.equal(r1.data_buffer[0], model.toy_conv.weight))
+```
+
+Out:
+
+```Python
+True
+```
+
+### RecorderManager
+
+`RecorderManager` is actually context manager, which can be used to manage various types of recorders.
+
+With the help of `RecorderManager`, we can manage several different recorders with as little code as possible, which reduces the possibility of errors.
+
+#### Example
+
+Suppose there is a toy class `Toy` owned has a toy method `toy_func` in toy_module.py.
+
+```Python
+import random
+from torch import nn
+from mmrazor.core import RecorderManager
+
+class Toy():
+ def toy_func(self):
+ return random.randint(0, 1000000)
+
+class ToyModel(nn.Module):
+ def __init__(self):
+ super().__init__()
+ self.conv1 = nn.Conv2d(1, 1, 1)
+ self.conv2 = nn.Conv2d(1, 1, 1)
+ self.toy = Toy()
+
+ def forward(self, x):
+ return self.conv2(self.conv1(x)) + self.toy.toy_func()
+
+# configure multi-recorders
+conv1_rec = ConfigDict(type='ModuleOutputs', source='conv1')
+conv2_rec = ConfigDict(type='ModuleOutputs', source='conv2')
+func_rec = ConfigDict(type='MethodOutputs', source='toy_module.Toy.toy_func')
+# instantiate RecorderManager with a dict that contains recorders' configs,
+# you can customize their keys.
+manager = RecorderManager(
+ {'conv1_rec': conv1_rec,
+ 'conv2_rec': conv2_rec,
+ 'func_rec': func_rec})
+
+model = ToyModel()
+# initialize is to make specified module can be recorded by
+# registering customized forward hook.
+manager.initialize(model)
+
+x = torch.rand(1, 1, 1, 1)
+with manager:
+ out = model(x)
+
+conv2_out = manager.get_recorder('conv2_rec').get_record_data()
+print(conv2_out)
+```
+
+Out:
+
+```Python
+tensor([[[[0.5543]]]], grad_fn=)
+```
+
+Display output of `toy_func`
+
+```Python
+func_out = manager.get_recorder('func_rec').get_record_data()
+print(func_out)
+```
+
+Out:
+
+```Python
+313167
+```
\ No newline at end of file
diff --git a/docs/en/get_started/model_zoo.md b/docs/en/get_started/model_zoo.md
index 9cd17f5d4..e2ad66278 100644
--- a/docs/en/get_started/model_zoo.md
+++ b/docs/en/get_started/model_zoo.md
@@ -1 +1,27 @@
# Model Zoo
+
+## Baselines
+
+### CWD
+
+Please refer to [CWD](https://github.com/open-mmlab/mmrazor/blob/master/configs/distill/cwd) for details.
+
+### WSLD
+
+Please refer to [WSLD](https://github.com/open-mmlab/mmrazor/blob/master/configs/distill/wsld) for details.
+
+### DARTS
+
+Please refer to [DARTS](https://github.com/open-mmlab/mmrazor/blob/master/configs/nas/darts) for details.
+
+### DETNAS
+
+Please refer to [DETNAS](https://github.com/open-mmlab/mmrazor/blob/master/configs/nas/detnas) for details.
+
+### SPOS
+
+Please refer to [SPOS](https://github.com/open-mmlab/mmrazor/blob/master/configs/nas/spos) for details.
+
+### AUTOSLIM
+
+Please refer to [AUTOSLIM](https://github.com/open-mmlab/mmrazor/blob/master/configs/pruning/autoslim) for details.
diff --git a/docs/en/get_started/overview.md b/docs/en/get_started/overview.md
index 07dd0c5c7..67164285f 100644
--- a/docs/en/get_started/overview.md
+++ b/docs/en/get_started/overview.md
@@ -1 +1,111 @@
# Overview
+## Why MMRazor
+
+MMRazor is a model compression toolkit for model slimming, which includes 4 mainstream technologies:
+
+- Neural Architecture Search (NAS)
+- Pruning
+- Knowledge Distillation (KD)
+- Quantization (come soon)
+
+It is a part of the [OpenMMLab](https://openmmlab.com/) project. If you want to use it now, please refer to [Get Started](https://mmrazor.readthedocs.io/en/latest/get_started.html).
+
+### Major features:
+
+- **Compatibility**
+
+MMRazor can be easily applied to various projects in OpenMMLab, due to the similar architecture design of OpenMMLab as well as the decoupling of slimming algorithms and vision tasks.
+
+- **Flexibility**
+
+Different algorithms, e.g., NAS, pruning and KD, can be incorporated in a plug-n-play manner to build a more powerful system.
+
+- **Convenience**
+
+With better modular design, developers can implement new model compression algorithms with only a few codes, or even by simply modifying config files.
+
+
+
+## Design and Implement
+
+
+### Design
+
+There are 3 layers (**Application** / **Algorithm** / **Component**) in overview design. MMRazor mainly includes both of **Component** and **Algorithm**, while **Application** consist of some OpenMMLab upstream repos, such as MMClassification, MMDetection, MMSegmentation and so on.
+
+**Component** provides many useful functions for quickly implementing **Algorithm.** And thanks to OpenMMLab 's powerful and highly flexible config mode and registry mechanism**, Algorithm** can be conveniently applied to **Application.**
+
+How to apply our lightweight algorithms to some upstream tasks? Please refer to the below.
+
+### Implement
+
+In OpenMMLab, implementing vision tasks commonly includes 3 parts (model / dataset / schedule). And just like that, implementing lightweight model also includes 3 parts (algorithm / dataset / schedule) in MMRazor.
+
+`Algorithm` consist of `architecture` and `components`.
+
+`Architecture` is similar to `model` of the upstream repos. You can chose to directly use the original `model` or customize the new `model` as your architecture according to different tasks. For example, you can directly use ResNet-34 and ResNet-18 of MMClassification to implement some KD algorithms, but in NAS, you may need to customize a searchable model.
+
+`Compone``n``ts` consist of various special functions for supporting different lightweight algorithms. They can be directly used in config because of registered into MMEngine. Thus, you can pick some components you need to quickly implement your algorithm. For example, you may need `mutator` / `mutable` / `searchle backbone` if you want to implement a NAS algorithm, and you can pick from `distill loss` / `recorder` / `delivery` / `connector` if you need a KD algorithm.
+
+Please refer to the next section for more details about **Implement**.
+
+> The arg name of `algorithm` in config is **model** rather than **algorithm** in order to get better supports of MMCV and MMEngine.
+
+## Key concepts
+
+For better understanding and using MMRazor, it is highly recommended to read the following user documents according to your own needs.
+
+**Global**
+
+- [Algorithm](https://aicarrier.feishu.cn/docs/doccnw4XX4zCRJ3FHhZpjkWS4gf)
+
+**NAS & Pruning**
+
+- [Mutator](https://aicarrier.feishu.cn/docs/doccnYzs6QOjIiIB3BFB6R0Gaqh)
+- [Mutable](https://aicarrier.feishu.cn/docs/doccnc6HAhAsilBXGGR9kzeeK8d)
+- [Pruning graph](https://aicarrier.feishu.cn/docs/doccns6ziFFUvJDvhctTjwX6BBh)
+- [Dynamic op](https://aicarrier.feishu.cn/docx/doxcnbp4n4HeDkJI1fHlWfVklke)
+
+**KD**
+
+- [Delivery](https://aicarrier.feishu.cn/docs/doccnCEBuZPaLMTsMS83OoYJt4f)
+- [Recorder](https://aicarrier.feishu.cn/docs/doccnFzxHCSUxzohWHo5fgbI9Pc)
+- [Connector](https://aicarrier.feishu.cn/docx/doxcnvJG0VHZLqF82MkCHyr9B8b)
+
+## User guide
+
+We provide more complete and systematic guide documents for different technical directions. It is highly recommended to read them if you want to use and customize lightweight algorithms better.
+
+- Neural Architecture Search (to add link)
+- Pruning (to add link)
+- Knowledge Distillation (to add link)
+- Quantization (to add link)
+
+## Tutorials
+
+We provide the following general tutorials according to some typical requirements. If you want to further use MMRazor, you can refer to our source code and API Reference.
+
+**Tutorial list**
+
+- [Tutorial 1: Overview](https://mmrazor.readthedocs.io/en/latest/tutorials/Tutorial_1_overview.html#)
+- [Tutorial 2: Learn about Configs](https://mmrazor.readthedocs.io/en/latest/tutorials/Tutorial_2_learn_about_configs.html)
+- [Toturial 3: Customize Architectures](https://mmrazor.readthedocs.io/en/latest/tutorials/Tutorial_3_customize_architectures.html)
+- [Toturial 4: Customize NAS algorithms](https://mmrazor.readthedocs.io/en/latest/tutorials/Tutorial_4_customize_nas_algorithms.html)
+- [Tutorial 5: Customize Pruning algorithms](https://mmrazor.readthedocs.io/en/latest/tutorials/Tutorial_5_customize_pruning_algorithms.html)
+- [Toturial 6: Customize KD algorithms](https://mmrazor.readthedocs.io/en/latest/tutorials/Tutorial_6_customize_kd_algorithms.html)
+- [Tutorial 7: Customize mixed algorithms](https://mmrazor.readthedocs.io/en/latest/tutorials/Tutorial_7_customize_mixed_algorithms_with_out_algorithms_components.html)
+- [Tutorial 8: Apply existing algorithms to new tasks](https://mmrazor.readthedocs.io/en/latest/tutorials/Tutorial_8_apply_existing_algorithms_to_new_tasks.html)
+
+
+
+## F&Q
+
+If you encounter some trouble using MMRazor, you can find whether your question has existed in **F&Q(to add link)**. If not existed, welcome to open a [Github issue](https://github.com/open-mmlab/mmrazor/issues) for getting support, we will reply it as soon.
+
+
+## Get support and contribute back
+
+MMRazor is maintained on the [MMRazor Github repository](https://github.com/open-mmlab/mmrazor). We collect feedback and new proposals/ideas on Github. You can:
+
+- Open a [GitHub issue](https://github.com/open-mmlab/mmrazor/issues) for bugs and feature requests.
+- Open a [pull request](https://github.com/open-mmlab/mmrazor/pulls) to contribute code (make sure to read the [contribution guide](https://github.com/open-mmlab/mmcv/blob/master/CONTRIBUTING.md) before doing this).
\ No newline at end of file
diff --git a/docs/en/user_guides/1_learn_about_config.md b/docs/en/user_guides/1_learn_about_config.md
index 27a4b6df9..103e3538f 100644
--- a/docs/en/user_guides/1_learn_about_config.md
+++ b/docs/en/user_guides/1_learn_about_config.md
@@ -1 +1,8 @@
# Learn about Configs
+
+## Directory structure of configs in mmrazor
+
+
+
+## More about config
+Please refer to config.md in mmengine.
\ No newline at end of file