Implement fast pass for CPU scalars /number literals #29915
Conversation
|
Some before/after numbers would be great |
aten/src/ATen/native/Fill.cpp
Outdated
| // but we also want to skip compute_types which in not avoidable | ||
| // in TensorIterator for now. | ||
| if (self.device() == at::kCPU && self.numel() == 1) { | ||
| AT_DISPATCH_ALL_TYPES(self.scalar_type(), "fill_out", [&]() { |
There was a problem hiding this comment.
Test failures reminds me that all types are not really all types. I'm experimenting locally to see which is the best macro to use. But the rest of the PR is ready for review. ;)
There was a problem hiding this comment.
The rest of the PR looks good :-)
aten/src/ATen/native/Fill.cpp
Outdated
| template <typename scalar_t> | ||
| inline void fill_fast(Tensor& self, Scalar value_scalar) { | ||
| auto value = value_scalar.to<scalar_t>(); | ||
| scalar_t * dptr = reinterpret_cast<scalar_t *>(self.data_ptr()); |
There was a problem hiding this comment.
Use of a reinterpret_cast here shouldn't be necessary; data_ptr gives you a void* so you can just static cast it.
0f8e225
to
1b18169
Compare
| // In the future when we remove the overhead of device dispatch, we'll happily | ||
| // revert this to following: | ||
| // auto result = at::empty({}, options); | ||
| at::AutoNonVariableTypeMode non_var_type_mode(true); |
There was a problem hiding this comment.
@ezyang @ngimel I did a minor change in the latest commit since empty_cpu requires VariableTypeId to be excluded.
Currently I'm using the AutoNonVariableTypeMode here to turn it off and then directly call into empty_cpu. Alternatively I can also use auto result = at::empty({}, options) but there's a small difference in perf (of the same script in description).
(On a debug build)
## with AutoNonVariableTypeMode + empty_cpu
61.3 µs ± 165 ns per loop (mean ± std. dev. of 7 runs, 10000 loops each)
## with at::empty
63.1 µs ± 173 ns per loop (mean ± std. dev. of 7 runs, 10000 loops each)
Since the total time before this PR was ~80us, the 2us difference here doesn't sound too appealing. But I'm putting it here, just checking whether we want this 2us when we know for sure something is definitely on CPU.
There was a problem hiding this comment.
Use of AutoNonVariableTypeMode here is fine. (It's a bit of black magic inserting these, but that's what we're doing right now.)
|
Hmmm my favorite circleci jobs are not showing. trying closing and reopening |
There was a problem hiding this comment.
@ailzhang has imported this pull request. If you are a Facebook employee, you can view this diff on Phabricator.
There was a problem hiding this comment.
@ailzhang has imported this pull request. If you are a Facebook employee, you can view this diff on Phabricator.
Summary:
The main changes in this PR are:
- skip device dispatch for CPU scalars (number literals also fall into this). In most cases scalars should be on CPU for best perf, but if users explicitly put on other device, we will respect that setting and exit fast pass.
- directly manipulate Tensor data_ptr when filling scalar into a 1-element tensor.
Some perf benchmark numbers:
```
## Before
In [4]: def test(x):
...: x = x + 2
...: return x
...:
In [5]: with torch.no_grad():
...: x = torch.ones(100)
...: %timeit {test(x)}
...:
79.8 µs ± 127 ns per loop (mean ± std. dev. of 7 runs, 10000 loops each)
## After
In [2]: def test(x):
...: x = x + 2
...: return x
...:
In [3]: with torch.no_grad():
...: x = torch.ones(100)
...: %timeit {test(x)}
...:
60.5 µs ± 334 ns per loop (mean ± std. dev. of 7 runs, 10000 loops each)
```
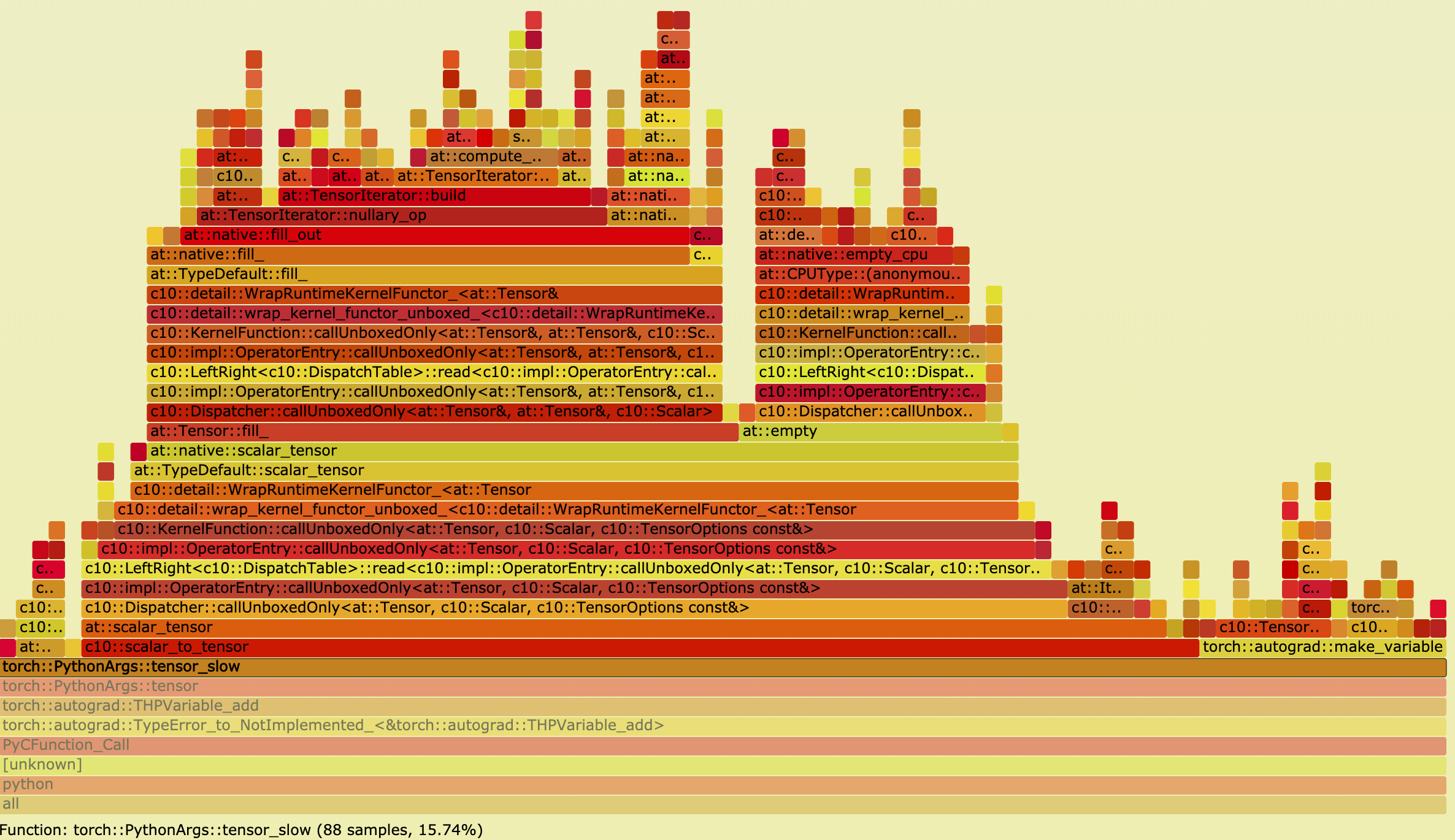
Before the patch `tensor_slow` took 15.74% of total time.
<img width="1186" alt="Screen Shot 2019-11-15 at 12 49 51 PM" src="https://user-images.githubusercontent.com/5248122/68976895-cc808c00-07ab-11ea-8f3c-7f15597d12cf.png">
After the patch `tensor_slow` takes 3.84% of total time.
<img width="1190" alt="Screen Shot 2019-11-15 at 1 13 03 PM" src="https://user-images.githubusercontent.com/5248122/68976925-e28e4c80-07ab-11ea-94c0-91172fc3bb53.png">
cc: roosephu who originally reported this issue to me.
Pull Request resolved: pytorch/pytorch#29915
Differential Revision: D18584251
Pulled By: ailzhang
fbshipit-source-id: 2353c8012450a81872e1e09717b3b181362be401
{kind=link}
{kind=link}
The main changes in this PR are:
Some perf benchmark numbers:
[update 11/19/2019]: the old numbers are based on a debug build, updated with a normal build numbers.
Before the patch


tensor_slowtook 15.74% of total time.After the patch
tensor_slowtakes 3.84% of total time.cc: @roosephu who originally reported this issue to me.