NVIDIA GPU Reservation needs to be added to workload form #5005
Comments
|
The task here is:
If the value is not a number is 0, the resource limit/request for gpus should be removed. Otherwise it should be set to the value in the input box. The code for cpu/memory limits/reservations is in the For this GPU setting, the key to use is Unlike for the CPU and Memory, we only have 1 input box and we use the value in this for both the limits and requests. You can test this feature by ensuring that the yaml created for a container contains the correct gpu limits/requests settings. |
|
No validation template was filled out for this, but I can try and go off @nwmac 's comment here: #5005 (comment) for what to look for. Validation FailedWhile the resource limit was properly set as expected and is present in the UI, the request value was not set. Based on the earlier comment, I expected these to have the same value. Let me know if I am wrong there. Reproduction steps
Validation steps
This was also validated for other non-Pod workload types (CronJobs, DaemonSets, Deployments, StatefulSets). Screenshots from those resources are not included for brevity's sake. StatefulSets seem to have a separate issue that required me to use the yaml to set the servicename, but that appears to be unrelated to this change.
|



|
@neillsom The value is being set as a string, where it should be an number - see YAML: (Should not be quoted) Also, the ask here is to use the same value for requests, so we should duplicate the value, so you'd get: This isn't strictly necessary, but mirrors the Ember UI - this was what was referred to originally on this ticket by: Unlike for the CPU and Memory, we only have 1 input box and we use the value in this for both the limits and requests. |
|
@nwmac This string issue appears to be coming from the backend. We are sending a number but receiving a string. I'll create another PR for the limits/requests issue. |


|
Confirmed with @catherineluse and @gaktive to add |
|
PR #5424 addresses this and it was merged. |
|
Validation Passed Reproduction steps
Validation steps
This was also validated for other non-Pod workload types (CronJobs, DaemonSets, Deployments, StatefulSets). Screenshots from those resources are not included for brevity's sake. Notes on other workload types
Notes
|
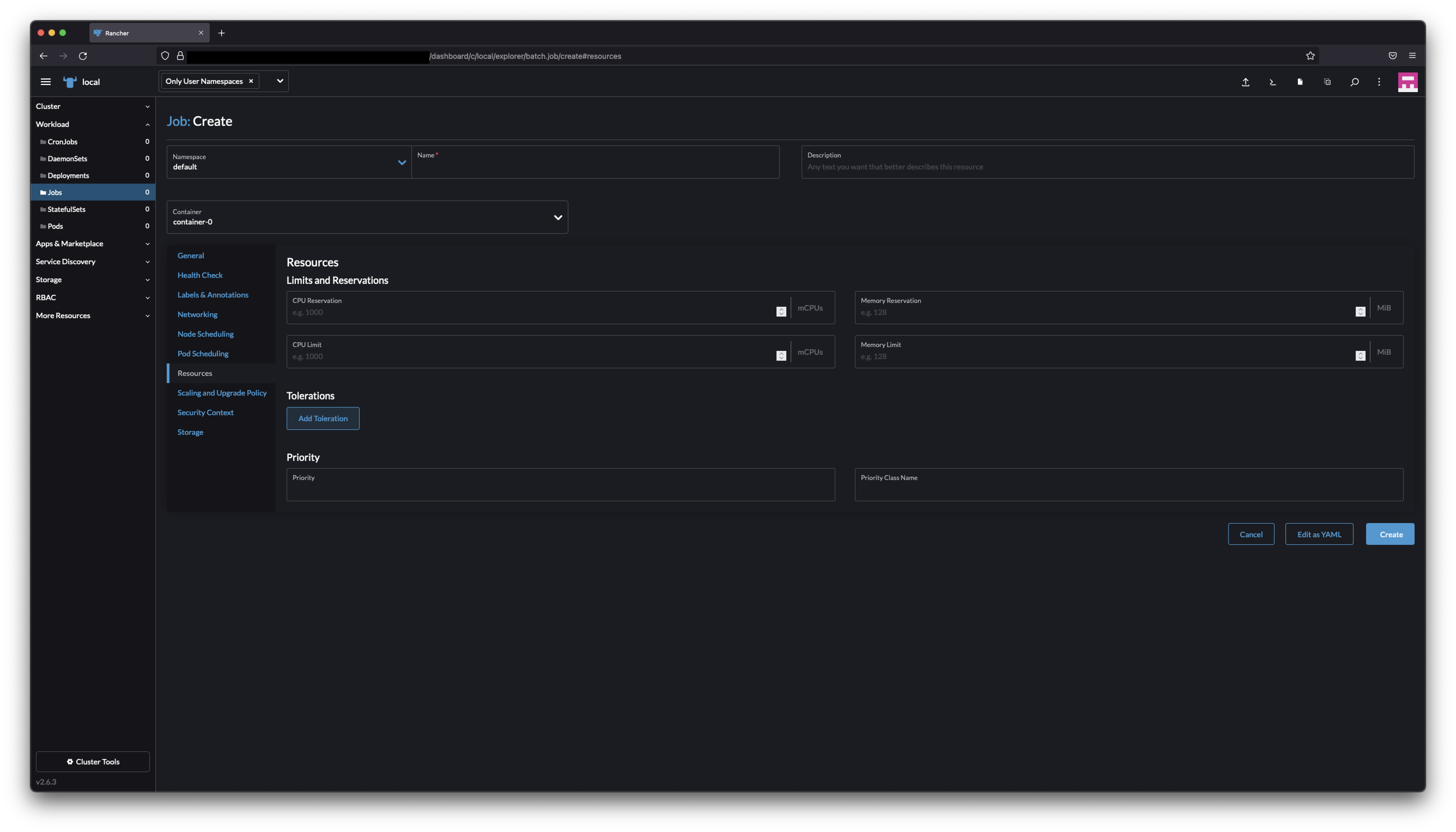

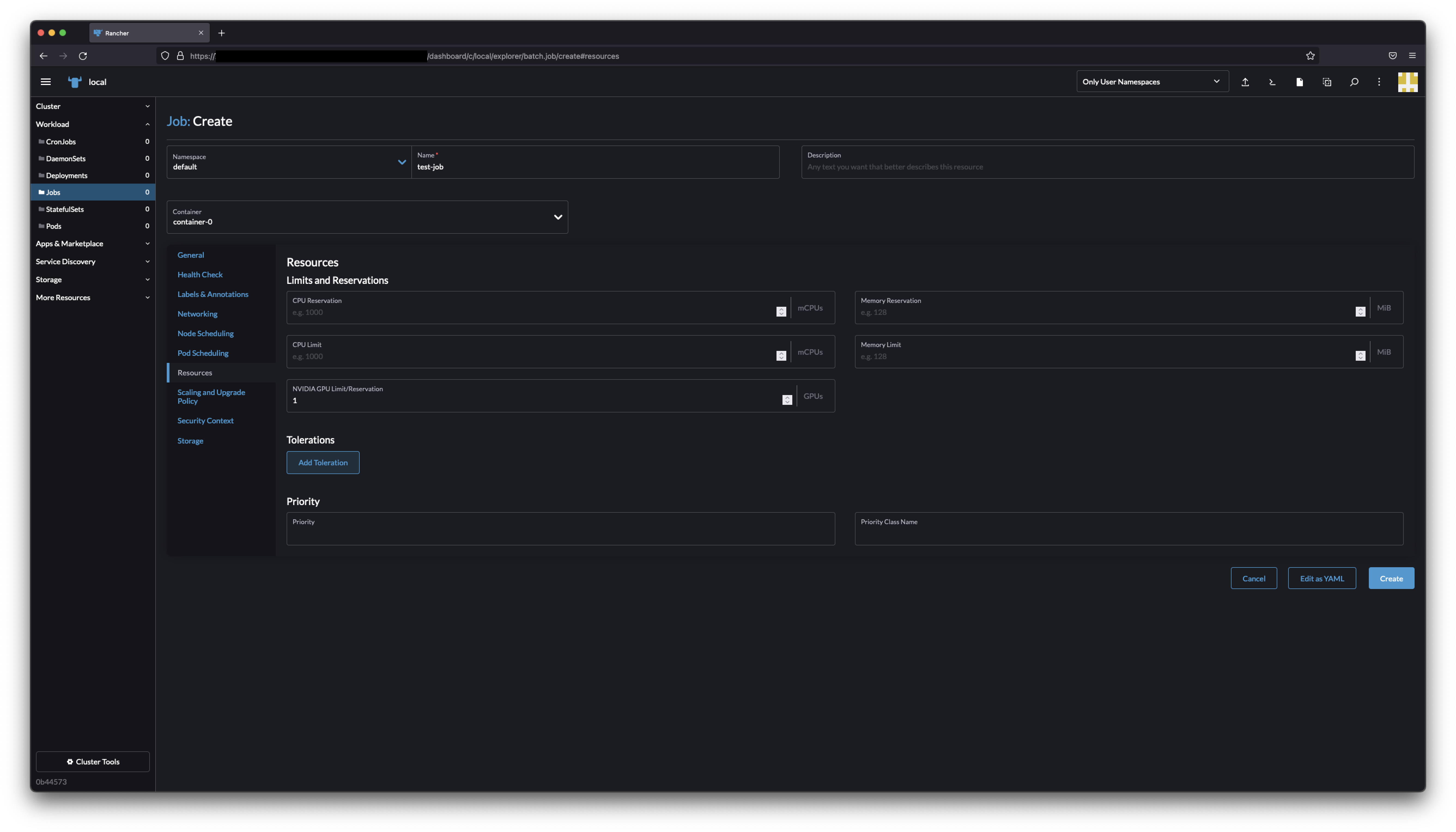

|
Verified on v2.6-head c2d8e32
|
Someone in the Rancher users slack asked why the GPU reservation form is not in v2.6.x but used to be in v2.5.
It looks like the field was intended to be added to v2.6.x as it is mentioned in this comment about the design of the form: #267 (comment)
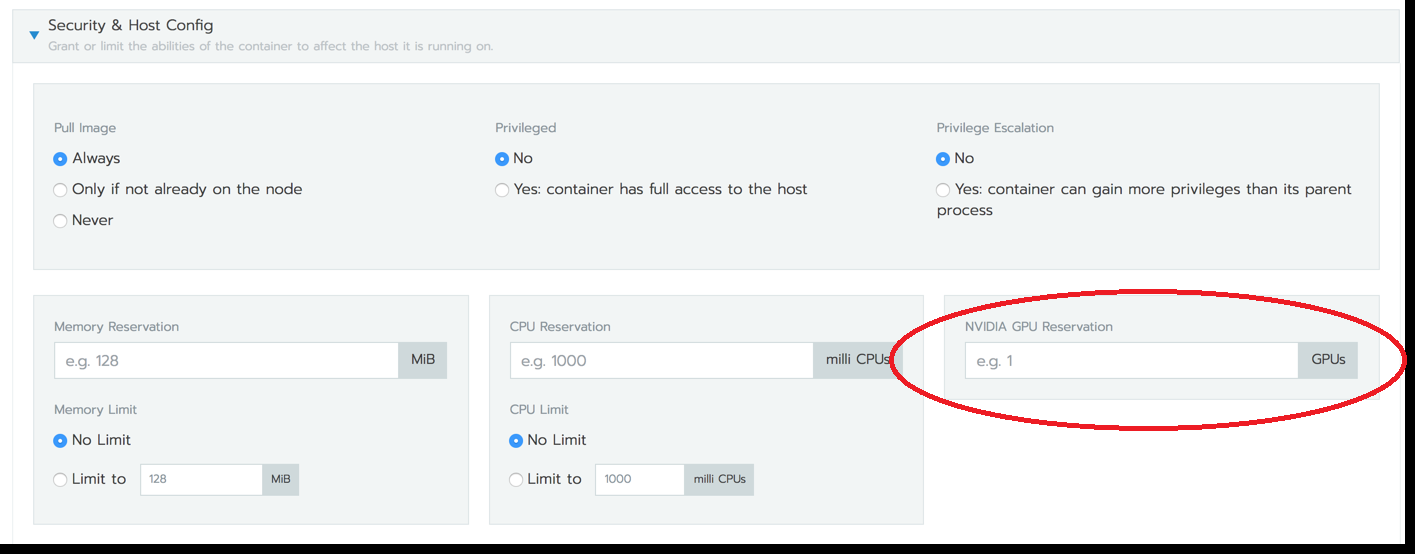
The field would be added to the resources tab:

Ember UI for reference:
The text was updated successfully, but these errors were encountered: