rclone multi-thread copy is slow on local write #3419
Comments
|
Multithread copy is a definite win for copying over the network. I can see why it wouldn't be a win for the local backend though as in general IO through the kernel isn't optimised for writing many streams at once. What do you think we should do - disable it for local -> local copies? Or do you think there is a way we can fix multithread copy? Making this bigger would probably help rclone/fs/operations/multithread.go Line 16 in 6f87267 |
|
I think that disabling the multithread copy for local to local copy makes sense. The issue is that network I/O can be nowadays faster than disc. Probably not on my laptop but running that on a beefy server in AWS reading from S3 in the same region can. We can always manually disable that. I spotted something weird not sure why this is happening. Take a look at the timings everything finishes fast but the first stream, we have When I change nr of steams to 2 it is similar Any thoughts @ncw ? |
Before this change, if the caller didn't provide a hint, we would calculate all hashes for reads and writes. The new whirlpool hash is particularly expensive and that has become noticeable. Now we don't calculate any hashes on upload or download unless hints are provided. This means that some operations may run slower and these will need to be discovered! It does not affect anything calling operations.Copy which already puts the corrects hints in.
Before this change for a post copy Hash check we would run the hashes sequentially. Now we run the hashes in parallel for a useful speedup. Note that this refactors the hash check in Copy to use the standard hash checking routine.
|
Ah ha, well spotted... That lead to a string of improvements which I'll go into in detail here! I pressed CTRL-\ in that pause at the end, and one of the goroutines is doing this As in computing the hash... By default the local backend will compute all the hashes and the whirlpool hash is particularly expensive. I recently fixed a similar problem in rcat c014b2e. And the reason it only affects the first chunk is this that the local backend calculates all the hashes only if you start reading from 0. If set the default hashes to for the local backend to be none then I get this, so no long pause on first segment However I see the hashes aren't parallelized.... Parallizing them gives so quite a big improvement! I don't think we are going to improve that since the multithread transfer has to read the source twice and both write and read back the destination, whereas the non multhread copy only has to read the source once (the hash is cacluated as it goes) and write the file once (again the hash is calculated as it goes). You can disable the post copy checksum with I put in a fix for that too... These results don't take into account Note the ~3 seconds of user time for calculating the hashes. Note Here is a beta with those things in (or pull from Can you have a play and tell me what you think? https://beta.rclone.org/branch/v1.48.0-152-gf9276355-fix-3419-multithread-beta/ (uploaded in 15-30 mins) |
|
Thanks, will take a look at it on Monday.
|
Before this change, if the caller didn't provide a hint, we would calculate all hashes for reads and writes. The new whirlpool hash is particularly expensive and that has become noticeable. Now we don't calculate any hashes on upload or download unless hints are provided. This means that some operations may run slower and these will need to be discovered! It does not affect anything calling operations.Copy which already puts the corrects hints in.
Before this change for a post copy Hash check we would run the hashes sequentially. Now we run the hashes in parallel for a useful speedup. Note that this refactors the hash check in Copy to use the standard hash checking routine.
|
I've updated according to your comments on the commit and added the final bit of the jigsaw - disabling multithread copies on local -> local copies Please have a go with this and tell me what you think! https://beta.rclone.org/branch/v1.48.0-169-g784e5448-fix-3419-multithread-beta/ |
|
I suppose you can drop e3008c9. |
|
I think that I was thinking that with 43a6774 in place the idea was to check if it's local or not. Checking if |
|
I think it would be a good idea to be explicit in the logs whenever the hash is/was calculated. For instance here it's very clear But here the hash is calculated but no sign of it in the logs |
You get that long debug if the hashes differ. If they are the same then rclone just carries on. Do you think a single DEBUG for
Even though it is the same line of code as the next patch the commit message tells a different story!
You are probably right!
Yes you are right about this. It isn't actually that easy to tell if a backend is the local backend! Yes you are right OpenWriterAt isn't brilliant as a detection mechanism. For example SFTP could support OpenWriterAt easily enough... I'll have another go. As for checking the unwrapped Fs, that was my first attempt, however I discovered that mult-thread-copy for a crypt backend wrapping a local backend is much faster than a single thread copy. I think that is because the crypto can then use multiple CPUs! So I think what I should be checking is if sourceFs == local && destFS == local and not unwrapping stuff. ... Did you have a go with the performance? What do you think now? |
Sounds good, how about throttling?
Yes it's clearly better now, there are some things I do not understand and did not take the effort to properly profile it. Rclone seems to be doing something it spends significant amount of time in user space |
What do you mean about throttling? You can use
Great!
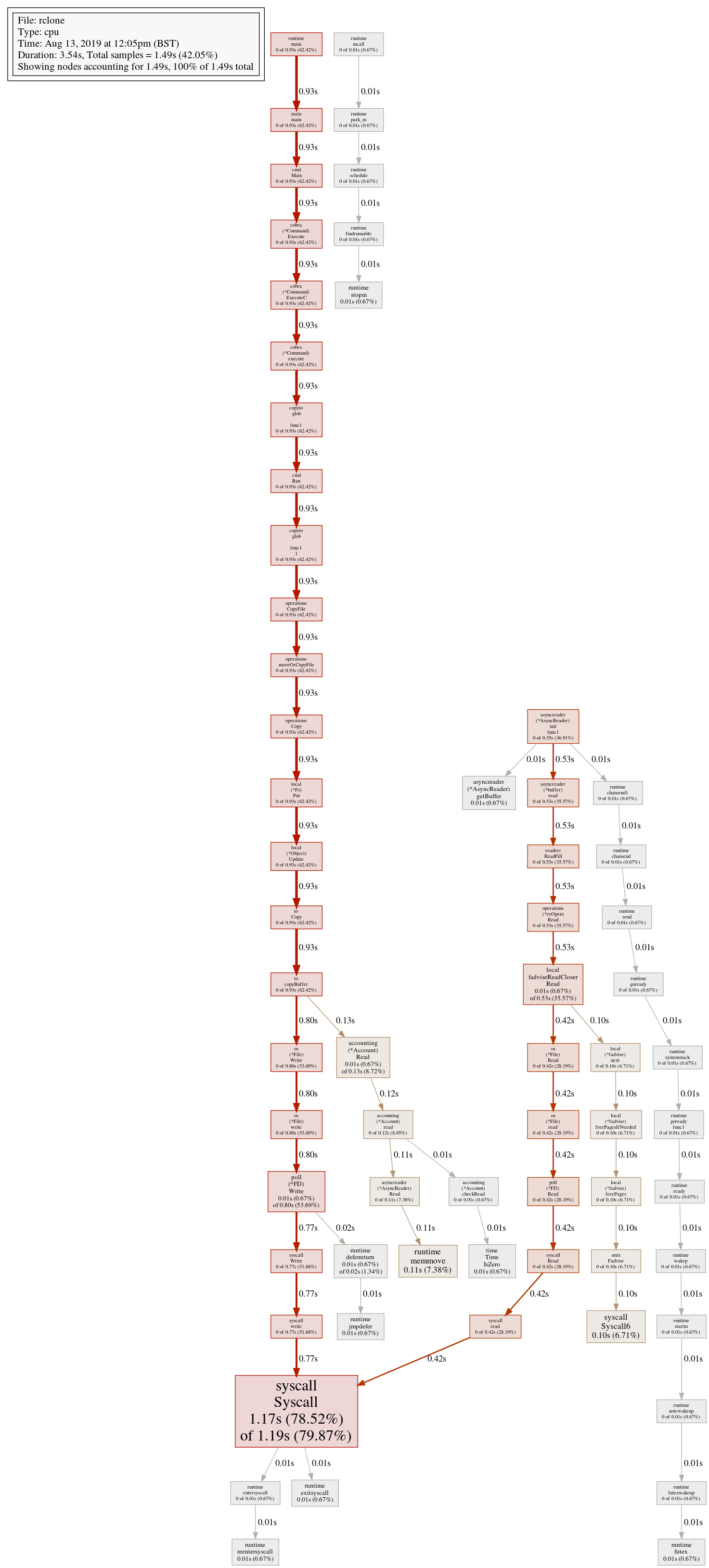
I did a CPU profile on rclone and I got this result
So you can see that almost all the time is being used by syscall.Syscall and this is split between the read path and write path as you might expect. Those times are elapsed times not CPU times though time reported Rclone almost certainly does more memory copies than it needs to and that is something that could be optimised I think. Rclone implements the io.Reader interface extensively. I suspect implementing io.ReaderFrom in a few strategic places would fix this. (or maybe io.WriterTo) Anyway, I'm happy with the performance for the moment! |
|
On Tue, Aug 13, 2019 at 1:22 PM Nick Craig-Wood ***@***.***> wrote:
So I think what I should be checking is if sourceFs == local && destFS ==
local and not unwrapping stuff.
Sounds good, how about throttling?
What do you mean about throttling? You can use --bwlimit if you want to
throttle the speed.
I was just thinking if it influences the strategy, maybe not.
Did you have a go with the performance? What do you think now?
Yes it's clearly better now,
Great!
there are some things I do not understand and did not take the effort to
properly profile it. Rclone seems to be doing something it spends
significant amount of time in user space User time (seconds): 0.16 and
CPU usage is over 100% which is kind of surprising.
I did a CPU profile on rclone and I got this result
Command being timed: "rclone copyto --ignore-checksum --cpuprofile cpu.prof 1GB 1G.copy"
User time (seconds): 0.22
System time (seconds): 1.38
Percent of CPU this job got: 45%
Elapsed (wall clock) time (h:mm:ss or m:ss): 0:03.55
Average shared text size (kbytes): 0
Average unshared data size (kbytes): 0
Average stack size (kbytes): 0
Average total size (kbytes): 0
Maximum resident set size (kbytes): 31264
Average resident set size (kbytes): 0
Major (requiring I/O) page faults: 0
Minor (reclaiming a frame) page faults: 2943
Voluntary context switches: 3446
Involuntary context switches: 174
Swaps: 0
File system inputs: 2097240
File system outputs: 2097160
Socket messages sent: 0
Socket messages received: 0
Signals delivered: 0
Page size (bytes): 4096
Exit status: 0
[image: profile001]
<https://user-images.githubusercontent.com/536803/62936961-0dd75900-bdc3-11e9-9951-8078084dc0aa.png>
(pprof) top20
Showing nodes accounting for 1.49s, 100% of 1.49s total
Showing top 20 nodes out of 66
flat flat% sum% cum cum%
1.17s 78.52% 78.52% 1.19s 79.87% syscall.Syscall
0.11s 7.38% 85.91% 0.11s 7.38% runtime.memmove
0.10s 6.71% 92.62% 0.10s 6.71% syscall.Syscall6
0.01s 0.67% 93.29% 0.53s 35.57% github.com/rclone/rclone/backend/local.fadviseReadCloser.Read
0.01s 0.67% 93.96% 0.13s 8.72% github.com/rclone/rclone/fs/accounting.(*Account).Read
0.01s 0.67% 94.63% 0.01s 0.67% github.com/rclone/rclone/fs/asyncreader.(*AsyncReader).getBuffer
0.01s 0.67% 95.30% 0.80s 53.69% internal/poll.(*FD).Write
0.01s 0.67% 95.97% 0.02s 1.34% runtime.deferreturn
0.01s 0.67% 96.64% 0.01s 0.67% runtime.exitsyscall
0.01s 0.67% 97.32% 0.01s 0.67% runtime.futex
0.01s 0.67% 97.99% 0.01s 0.67% runtime.jmpdefer
0.01s 0.67% 98.66% 0.01s 0.67% runtime.reentersyscall
0.01s 0.67% 99.33% 0.01s 0.67% runtime.stopm
0.01s 0.67% 100% 0.01s 0.67% time.Time.IsZero
0 0% 100% 0.93s 62.42% github.com/rclone/rclone/backend/local.(*Fs).Put
0 0% 100% 0.93s 62.42% github.com/rclone/rclone/backend/local.(*Object).Update
0 0% 100% 0.10s 6.71% github.com/rclone/rclone/backend/local.(*fadvise).freePages
0 0% 100% 0.10s 6.71% github.com/rclone/rclone/backend/local.(*fadvise).freePagesIfNeeded
0 0% 100% 0.10s 6.71% github.com/rclone/rclone/backend/local.(*fadvise).next
0 0% 100% 0.93s 62.42% github.com/rclone/rclone/cmd.Main
So you can see that almost all the time is being used by syscall.Syscall
and this is split between the read path and write path as you might expect.
Those times are elapsed times not CPU times though
time reported User time (seconds): 0.22 so if we ignore the syscall time
then we are left with the major CPU usage being runtime.memmove so
copying buffers about.
Rclone almost certainly does more memory copies than it needs to and that
is something that could be optimised I think.
Rclone implements the io.Reader <https://golang.org/pkg/io/#Reader>
interface extensively. I suspect implementing io.ReaderFrom
<https://golang.org/pkg/io/#ReaderFrom> in a few strategic places would
fix this.
Anyway, I'm happy with the performance for the moment!
Looking at the graph I think that
* fadvise syscall can be called in a go routine not to block the read flow
in
https://github.com/rclone/rclone/blob/master/backend/local/fadvise_unix.go#L80
* accounting is accountable for the `0.11s 7.38% 85.91% 0.11s 7.38%
runtime.memmove` which I think could be avoided
Any thoughts?
… —
You are receiving this because you authored the thread.
Reply to this email directly, view it on GitHub
<#3419?email_source=notifications&email_token=AAMLACQOV76DAYEJMI3LVSDQEKKPFA5CNFSM4IKIUVIKYY3PNVWWK3TUL52HS4DFVREXG43VMVBW63LNMVXHJKTDN5WW2ZLOORPWSZGOD4FLIFI#issuecomment-520795157>,
or mute the thread
<https://github.com/notifications/unsubscribe-auth/AAMLACXCD37A5NQHOATAC4DQEKKPFANCNFSM4IKIUVIA>
.
--
Michał
|
Before this change, if the caller didn't provide a hint, we would calculate all hashes for reads and writes. The new whirlpool hash is particularly expensive and that has become noticeable. Now we don't calculate any hashes on upload or download unless hints are provided. This means that some operations may run slower and these will need to be discovered! It does not affect anything calling operations.Copy which already puts the corrects hints in.
Before this change for a post copy Hash check we would run the hashes sequentially. Now we run the hashes in parallel for a useful speedup. Note that this refactors the hash check in Copy to use the standard hash checking routine.
Before this change we didn't calculate or check hashes of transferred files if --size-only mode was explicitly set. This problem was introduced in 20da3e6 which was released with v1.37 After this change hashes are checked for all transfers unless --ignore-checksums is set.
...unless --multi-thread-streams has been set explicitly Fixes #3419
|
I'd send a patch to fadvise to issue syscall on a dedicated routine. |
|
Here is the patch #3440, after applying that it looks much better, but still accounting is an issue.
|

|
@ncw if I comment out The pprof graph looks perfect!
So my question is why do we need this buffering? |

|
Excellent analysis :-)
It is read-ahead buffering, so by default rclone tries to get 16M ahead in a stream. It was put in originally to solve performance problems with reading from Windows disks, so one thread could be reading ahead while the other was writing. It is used by people who like to stream media off I think your patch would be equivalent to doing So we could skip the buffering if doing a local -> local copy easily enough. That might degrade performance on Windows though. |
Before this change, if the caller didn't provide a hint, we would calculate all hashes for reads and writes. The new whirlpool hash is particularly expensive and that has become noticeable. Now we don't calculate any hashes on upload or download unless hints are provided. This means that some operations may run slower and these will need to be discovered! It does not affect anything calling operations.Copy which already puts the corrects hints in.
Before this change for a post copy Hash check we would run the hashes sequentially. Now we run the hashes in parallel for a useful speedup. Note that this refactors the hash check in Copy to use the standard hash checking routine.
Before this change we didn't calculate or check hashes of transferred files if --size-only mode was explicitly set. This problem was introduced in 20da3e6 which was released with v1.37 After this change hashes are checked for all transfers unless --ignore-checksums is set.
...unless --multi-thread-streams has been set explicitly
|
That's fine by me but maybe |
|
I discovered another issue on the hot path. If you take a look at the Every 80 writes we get a lock. I'm pretty sure this one is caused by https://github.com/rclone/rclone/blob/master/fs/accounting/accounting.go#L31, I read the comment on it and do not fully understand it. Can we use atomics here? |
Before this change, if the caller didn't provide a hint, we would calculate all hashes for reads and writes. The new whirlpool hash is particularly expensive and that has become noticeable. Now we don't calculate any hashes on upload or download unless hints are provided. This means that some operations may run slower and these will need to be discovered! It does not affect anything calling operations.Copy which already puts the corrects hints in.
Before this change for a post copy Hash check we would run the hashes sequentially. Now we run the hashes in parallel for a useful speedup. Note that this refactors the hash check in Copy to use the standard hash checking routine.
Before this change we didn't calculate or check hashes of transferred files if --size-only mode was explicitly set. This problem was introduced in 20da3e6 which was released with v1.37 After this change hashes are checked for all transfers unless --ignore-checksums is set.
...unless --multi-thread-streams has been set explicitly
|
I've merged the commits so far to master so they can get some testing in the wider world...
Just for local -> local copies? Or for everything?
The problem is that Read() and Close() can be called concurrently. This is because the http transport caches open connections This was put in as 74994a2 There is a discussion here: https://groups.google.com/forum/#!topic/golang-dev/0Nl6k5Sj6UU It might be that the mutex is no longer needed.. I tried to make the original test code go wrong with go1.12 but failed. It goes wrong with go1.5. However removing that mutex makes me nervous... I would have thought that mutex isn't under contention. Do why does it appear in strace? I thought there was a fast path for unlocked mutex? // Lock locks m.
// If the lock is already in use, the calling goroutine
// blocks until the mutex is available.
func (m *Mutex) Lock() {
// Fast path: grab unlocked mutex.
if atomic.CompareAndSwapInt32(&m.state, 0, mutexLocked) {
if race.Enabled {
race.Acquire(unsafe.Pointer(m))
}
return
}I tried using go's mutex profiling tools and it says there aren't any contended mutexes? |
|
I need to do some more experimentation, will be off for a couple of days. |
|
Overall the large amount of The performance now is good 👍 Thanks for your work on it @ncw. |
|
I did a block profile that points to
|

|
Thank you for your help in this issue - I think we've made significant progress speeding rclone up :-) I'll close this issue for now, but do make more issues if you think there is more we can fix! |
What is the problem you are having with rclone?
Rclone takes significantly more time to write a file than
cpunix command.I traced it down to multi-thread copy being slow, at least in that case.
I conducted an experiment where we have 1GB a file that is not cached and try to copy that to an empty directory. With
cpwe have runtime of about a second.While with rclone it's like 15s.
This is quite surprising as plain
io.Copycode is almost as fast ascpWhat is your rclone version (output from
rclone version)commit d51a970
Which OS you are using and how many bits (eg Windows 7, 64 bit)
Linux lh 5.2.5-200.fc30.x86_64 #1 SMP Wed Jul 31 14:37:17 UTC 2019 x86_64 x86_64 x86_64 GNU/Linux
Which cloud storage system are you using? (eg Google Drive)
Only local
The command you were trying to run (eg
rclone copy /tmp remote:tmp)rclone copy 1GB.bin.1 /var/empty/rclone
A log from the command with the
-vvflag (eg output fromrclone -vv copy /tmp remote:tmp)When running without the multi-thread copy - we have 10x improvement.
The text was updated successfully, but these errors were encountered: