Bienvenue chez Redwood! Si vous ne l’avez pas encore fait, prenez le temps de lire Redwood README pour en savoir un peu plus sur les origines de Redwood et les problèmes qu'il entend résoudre. Redwood assemble plusieurs technologies de façon inédite et qui correspond à ce que nous pensons être le futur des applications web avec base de données.
Dans ce didacticiel, nous allons construire un moteur de blog. En réalité, un blog n’est probablement pas le candidat idéal pour une application construite avec Redwood: les articles peuvent être enregistrés dans un CMS et générées statiquement sous la forme de fichiers HTML servis par un CDN. Ceci étant, la plupart des développeurs comprennent intuitivement ce que recouvre ce type d’application, et un blog présente toutes les caractéristiques que nous souhaitons mettre en lumière. Nous avons donc décidé d'en construire un malgré tout.
Peut-être souhaitez-vous voir ce didacticiel en vidéo? C’est ici :
Ce didacticiel suppose que vous soyez déjà familier avec quelques concepts fondamentaux :
Vous pouvez tout à fait compléter ce didacticiel sans savoir quoique ce soit sur ces technologies, mais il est possible que vous soyez un peu perdu par certains termes que nous utiliserons sans forcément les expliquer au préalable. D'une façon générale, il est toujours utile de savoir où se situe les frontières et pouvoir distinguer par exemple ce qui provient de React de ce qui est ajouté par Redwood.
Pendant l’installation, RedwoodJS commence par verifier si votre système possède les versions requises de Node et Yarn :
- node: ">=12"
- yarn: ">=1.15"
👉 Important: Si votre système ne repond pas à ces prérequis, l’installation se soldera par une ERREUR. Vérifiez en exécutant les commandes suivantes dans un terminal:
node --version
yarn --version
Procédez aux mises à jour le cas échéant, puis relancez l’installation de RedwoodJS lorsque vous êtes prêt !
Installer Node et Yarn
Il y a différentes façons d’installer Node.js et Yarn. Si vous procédez à leur installation pour la première fois, nous vous recommandons de suivre les points suivants :
Yarn
- Nous recommandons de suivre les instructions fournies sur Yarnpkg.com.
Node.js
- Pour les utilisateurs de Linux et Mac,
nvmest un excellent outil pour gérer plusieurs versions de Node sur un même système. Il demande un petit effort à mettre en place. Dans les deux cas, utiliser la version la plus récente de Nodejs.org fonctionne très bien.
- Pour les utilisateurs de Mac, si vous avez dejà installé Homebrew, vous pouvez l’utiliser pour installer
nvm. Dans le cas contraire, suivez les instructions d'installation pournvm.- Pour les utilisateurs de Linux, vous pouvez suivre les instructions d'installation pour
nvm.- Nous recommandons aux utilisateurs de Windows de visiter Nodejs.org pour savoir comment procéder.
Si vous êtes un peu perdu au moment de choisir quelle version de Node utiliser, nous vous recommandons la plus récente LTS avec un numéro de version pair, actuellement il s'agit de la v12.
Nous utiliserons yarn (yarn est un pré-requis) pour créer la structure de base pour notre application :
yarn create redwood-app ./redwoodblog
Vous obtenez ainsi un nouveau répertoire redwoodblog contenant plusieurs sous-répertoires et fichiers. Déplacez-vous dans ce répertoire, puis lancez le serveur de développement :
cd redwoodblog
yarn redwood dev
Votre navigateur web devrait se lancer automatiquement et ouvrir http://localhost:8910 laissant apparaître la page d’accueil de Redwood.

Mémoriser le numéro de port est très simple, comptez simplement: 8-9-10!
Maintenant que nous avons le squelette de notre application Redwood, c'est le bon moment pour enregistrer notre travail avec un premier commit... au cas où.
git init
git add .
git commit -m 'Premier commit'
Examinons maintenant les fichiers et répertoires qui ont été créés pour nous (laissons de côté les fichiers de configuration sur lesquels nous reviendrons plus tard)
├── api
│ ├── prisma
│ │ ├── schema.prisma
│ │ └── seeds.js
│ └── src
│ ├── functions
│ │ └── graphql.js
│ ├── graphql
│ ├── lib
│ │ └── db.js
│ └── services
└── web
├── public
│ ├── README.md
│ ├── favicon.png
│ └── robots.txt
└── src
├── Routes.js
├── components
├── index.css
├── index.html
├── index.js
├── layouts
└── pages
├── FatalErrorPage
│ └── FatalErrorPage.js
└── NotFoundPage
└── NotFoundPage.js
Au premier niveau nous avons deux répertoires, api et web. Redwood sépare le backend (api) et le frontend (web) au sein du projet. (Yarn qualifie cette séparation de "workspaces". Avec Redwood, on fait plutôt référence aux "côtés" web et api de l'application). Ainsi, lorsque plus tard vous serez amené à ajouter des packages, il vous faudra préciser dans quel côté ils doivent aller. Par exemple, (inutile d'exécuter ces commandes):
yarn workspace web add marked
yarn workspace api add better-fs
A l'intérieur du répertoire api se trouve deux sous-répertoires :
-
prismacontient du code d'infratructure relatif à la base de donnéeschema.prismacontient le schéma de la base de données (ses tables et ses colonnes)seeds.jsest utilisé pour initialiser la base de données avec les données de base nécessaire à votre application (utilisateur admin, configuration diverses..).
Lorsque nous aurons créé notre première table dans la base de données, nous trouverons également à cet endroit une base de données SQLite sous la forme d’un fichier
dev.db, ainsi qu’un répertoiremigrationscontenant des captures successives du schéma au fil de son évolution. -
srccontient l'ensemble du code côté backend.api/srccontient quatre répertoires supplémentaires :functionscontiendra toutes les fonctions lambda utilisées par votre application en plus du fichiergraphql.jsgénéré automatiquement par Redwood. Ce dernier fichier est requis pour utiliser une API GraphQL.graphqlcontient votre schéma GraphQL écrit au format SDL (Schema Definition Language). Les fichiers SDL se terminent par.sdl.js.libcontient un seul fichier,db.js, qui instancie le client Prisma utilisé pour dialoguer avec la base de données. Vous pouvez parfaitement personnaliser ce fichier en ajoutant des options supplémentaires. Vous pouvez utiliser ce répertoire pour tout code relatif au côté API de votre application qui ne trouverai pas sa place dansfunctionsouservices.servicescontient la logique métier de votre application. Lorsque vous effectuez une requête ou une mutation de données via GraphQL, ce code se trouve ici dans un format réutilisable depuis d’autres endroits de votre application.
Et nous en avons terminé avec la partie backend.
srccontient plusieurs sous-répertoires :componentscontient vos composants React traditionnels ainsi que les Cells introduites par Redwood (nous y reviendrons bientôt en détail).layoutscontient du code HTML sous forme de composants qui viennent entourer le contenu de votre application et sont partagés par les différentes Pages.pagescontient des composants souvent insérés dans les Layouts et qui constituent les points d'entrées de votre application pour une URL donnée (une URL comme/articles/hello-worldcorrespondra ainsi à une page tandis que/contact-uscorrespondra à une autre page). Chaque nouvelle application comprend deux pages par défaut :NotFoundPage.jsqui est utilisée lorsqu’aucune route n’est trouvée par le routeur (voirRoutes.jsplus bas).FatalErrorPage.jsqui est utilisée lorsqu’une erreur survient, qu’elle n’a pas été gérée, et qu’il n’est pas possible de poursuivre plus avant sans faire exploser l’application (en général il s’agit d’une page blanche).
publiccontient des ressources non utilisées par vos composants React (En bout de chaîne, ces ressources seront copiées sans être modifiées dans le répertoire racine de l’application finale):favicon.pngest l’icône utilisée par les onglets des navigateurs lorsqu’une page est ouverte (par défaut il s’agit du logo RedwoodJS).robots.txtest utilisé pour controller ce que les moteurs de recherche sont autorisé à indexer.README.mdexplique comment, et quand, utiliser le répertoirepublicpour vos ressources statiques. Il mentionne également les bonnes méthodes pour importer des ressources à l'intérieur des composants via Webpack. Vous pouvez également lire à ce sujet ce fichier README.md sur GitHub.
index.cssest l'endroit par défaut où placer vos règles CSS. Il existe cependant d’autres possibilités avancées.index.htmlest le point d’entrée React standard de votre application.index.jscontient le code de démarrage pour une application Redwood.Routes.jscontient les définitions des routes de l’application afin de faire correspondre chaque URL à une Page.
Donnons à nos utilisateurs quelque chose de plus à contempler que la page d'accueil de Redwood. Utilisons la commande redwood pour créer une première page :
yarn redwood generate page home /
Cette commande fait les choses suivantes :
- Création de
web/src/pages/HomePage/HomePage.js. Redwood prend le nom spécifié comme premier argument, le met en majuscules et le suffixe avec "Page" pour construire votre nouveau composant de type Page. - Création d’un fichier de test du composant
web/src/pages/HomePage/HomePage.test.jsavec un simple test d’exemple à l’intérieur. Vous écrivez toujours les tests de vos composants, n’est-ce pas ?? - Création d’un fichier Storybook
web/src/pages/HomePage/HomePage.stories.js. Storybook est un outil formidable pour développer efficacement et organiser vos composants. Si vous souhaitez en savoir plus jetez un oeuil à ce sujet sur le forum Redwood pour apprendre comment l’utiliser. - Ajout d’une
<Route>dansweb/src/Routes.jsqui fait correspondre le chemin/à la nouvelle page HomePage.
Import automatique des pages dans le fichier Routes
Si vous regardez dans Routes, vous constaterez mention d'un composant,
HomePage, qui n'est présent nulle part ailleurs. Redwood importe automatiquement toutes les pages dans le fichier Routes puisque nous aurons besoin de toutes les référencer de toute façon. Cela permet de s'épargner unimportmassif qui viendrait encombrer le fichier Routes.
En réalité, cette page est déjà active (et votre navigateur l’a rechargée pour vous) :

D’accord, ça ne flatte pas encore la rétine mais c’est un début! Ouvrez cette page dans votre éditeur, modifiez un peu le texte et sauvegardez. Votre navigateur devrait recharger la page avec vos modifications.
Ouvrez web/src/Routes.js et observez la route qui vient d’être créée :
<Route path="/" page={HomePage} name="home" />Essayez de modifier cette route de la façon suivante:
<Route path="/hello" page={HomePage} name="home" />Dès que vous ajoutez votre première route, la page d'accueil par défaut de Redwood disparaît. Désormais, lorsqu'aucune route ne peut être trouvée pour l'URL demandée, Redwood va retourner la page NotFoundPage. Modifiez l'URL de votre navigateur pour ouvrir http://localhost:8910/hello, vous devriez voir de nouveau le contenu de HomePage.js.
Modifiez à nouveau la route pour revenir à son état initial / avant de continuer.
Ajoutons donc une page "About" à notre blog de manière à ce que personne n'ignore qui se trouve derrière cette application exceptionnelle. Nous allons créer une nouvelle page en utilisant redwood:
yarn redwood generate page about
Remarquez que nous n'avons pas spécifié de chemin cette fois-ci, uniquement le nom de la page. En effet, si vous ne le précisez pas, la commande redwood generate page créera une Route en lui donnant pour chemin le nom de la page préfixé par un slash /. Dans le cas présent, ce sera donc /about.
Fragmenter le code pour chaque page
Au fur et à mesure que vous ajoutez des pages à votre application, vous pouvez légitimement vous inquiéter du fait que le navigateur va devoir télécharger un volume initial de données toujours croissant. Soyez rassuré! Redwood va automatiquement fragmenter le code pour chaque page de telle façon que le chargement soit toujours extrêmement véloce. Vous pouvez donc créer autant de pages que vous le souhaitez sans vous inquiéter outre mesure de la taille finale du bundle webpack. Si, dans le cas contraire, vous souhaitez que certaines pages soient spécifiquement intégrées dans le bundle principal, il vous est possible de personaliser cette fonctionalité.
http://localhost:8910/about devrait maintenant pointer sur votre nouvelle page. Bien entendu, absolument personne ne va trouver cette page de votre blog en modifiant manuellement l'URL! Ajoutons donc un lien depuis la page d'accueil vers la page About, et vice-versa. Nous commencerons par créer un simple header et une barre de navigation dans HomePage.js:
// web/src/pages/HomePage/HomePage.js
import { Link, routes } from '@redwoodjs/router'
const HomePage = () => {
return (
<>
<header>
<h1>Redwood Blog</h1>
<nav>
<ul>
<li>
<Link to={routes.about()}>A Propos</Link>
</li>
</ul>
</nav>
</header>
<main>Home</main>
</>
)
}
export default HomePage
Remarquons ici plusieurs points :
-
Redwood adore les "Function Components". Nous ferons un usage fréquent des "React Hooks" au fil de l'élaboration de notre blog, et ces derniers ne sont actifs que dans les "function components". Vous êtes libres d'utiliser des "class components", mais nous vous recommandons de les éviter sauf cas particulier.
-
Les balises Redwood
<Link>, dans leur usage le plus simple, prennent un seul attributto. Cet attributtoappelle une "named route function" de façon à générer l'URL correcte. Cette fonction possède le même nom que l'attributnameprésent sur la<Route>:<Route path="/about" page={AboutPage} name="about" />Si vous n'aimez pas le nom que la commande
redwood generateutilise pour votre route, vous pouvez parfaitement le changer dans le fichierRoutes.js! Les routes nommées sont extrêmement utiles car, si vous désirez modifiez le chemin associé avec une route, il vous suffit de le modifier dans le fichierRoutes.jset immédiatement tous les liens qui utilisent cette route pointerons au bon endroit. Vous pouvez également passer directement une chaîne de caractères à l'attributto, mais alors vous ne bénéficiez plus de ce mécanisme bien utile.
Une fois sur la page "About", nous n'avons aucun moyen de revenir en arrière. Pour y remédier, ajoutons également un lien à cet endroit:
// web/src/pages/AboutPage/AboutPage.js
import { Link, routes } from '@redwoodjs/router'
const AboutPage = () => {
return (
<>
<header>
<h1>Redwood Blog</h1>
<nav>
<ul>
<li>
<Link to={routes.about()}>About</Link>
</li>
</ul>
</nav>
</header>
<main>
<p>
Ce site est créé avec pour seule intention de démontrer la puissance créative de Redwood! Oui, c'est très
impressionant :D
</p>
<Link to={routes.home()}>Retour à la page d'accueil</Link>
</main>
</>
)
}
export default AboutPage
Bien! Affichons cette page dans le navigateur and vérifions que nous pouvons aller et venir entre les différentes pages.
En tant que développeur de classe cosmique, vous avez probablement repéré ce copier-coller un peu lourd du <header>. Nous aussi. C'est la raison pour laquelle Redwood dispose d'un petite chose bien pratique appelé "Layout"."
Une façon de résoudre la duplication du <header> aurait pu être de créer un composant <Header> et l'inclure à la fois dans HomePage et AboutPage. C'est valide! Mais il y a beaucoup mieux... Dans l'idéal, votre code ne devrait comporter qu'une seule et unique balise <header>.
Lorsque vous regardez à ces deux pages, quelle est leur raison d'être principale? Toutes deux ont un peu de contenu à afficher. Toutes deux ne devraient pas avoir à connaître ce qui vient avant ce contenu (comme un <header>), ou après ce même contenu (comme un <footer>). C'est exactement ce que font les "Layouts": ils entourent une page dans un composant qui va ensuite afficher à l'intérieur le contenu de la page:

Utilisons Redwood pour générer un layout contenant ce <header> :
yarn redwood g layout blog
raccourci
generateDésormais nous utiliserons le raccourci
gà la place degenerate
Ce faisant, nous avons créé le fichier web/src/layouts/BlogLayout/BlogLayout.js et un son fichier de test associé. Nous appellerons ce dernier le "blog" layout car nous aurons certainement d'autres layout plus tard (un layout "admin" par exemple).
Supprimez ce <header> de HomePage et AboutPage et copier son contenu à l'intérieur du layout. Supprimons également le doublon de la balise <main> par la même occasion.
// web/src/layouts/BlogLayout/BlogLayout.js
import { Link, routes } from '@redwoodjs/router'
const BlogLayout = ({ children }) => {
return (
<>
<header>
<h1>Redwood Blog</h1>
<nav>
<ul>
<li>
<Link to={routes.about()}>About</Link>
</li>
</ul>
</nav>
</header>
<main>{children}</main>
</>
)
}
export default BlogLayout
children est l'endroit où la magie opère! Toute page passée en argument à un layout s'affiche là. Pour en revenir à HomePage et AboutPage, en les entourant simplement au sein du <BlogLayout>, nos deux pages ne font désormais que ce qu'elles sont supposées faire: afficher leur contenu. Nous pouvons maintenant supprimer les imports de Linket Route puisqu'ils figurent également dans le Layout.
// web/src/pages/HomePage/HomePage.js
import BlogLayout from 'src/layouts/BlogLayout'
const HomePage = () => {
return <BlogLayout>Home</BlogLayout>
}
export default HomePage
// web/src/pages/AboutPage/AboutPage.js
import { Link, routes } from '@redwoodjs/router'
import BlogLayout from 'src/layouts/BlogLayout'
const AboutPage = () => {
return (
<BlogLayout>
<p>
Ce site est créé avec pour seule intention de démontrer la puissance créative de Redwood! Oui, c'est très
impressionant :D
</p>
<Link to={routes.home()}>Return home</Link>
</BlogLayout>
)
}
export default AboutPage
L'alias
srcRemarquez que l'import utilise
src/layouts/BlogLayoutet non../src/layouts/BlogLayoutou./src/layouts/BlogLayout. Pouvoir se contenter d'ajouter uniquementsrcest un petit apport bien pratique de Redwood:srcest un alias pour le chemin du répertoiresrcdu workspace courant. En d'autres termes, lorsque vous travaillez dansweb,srcpointe versweb/src. Et lorsque vous travaillez dansapiil pointe versapi/src.
Revenez donc dans votre navigateur, et vous devriez alors voir...... rien de nouveau. Et c'est très bien! Votre layout fonctionne parfaitement.
Pourquoi certaines choses sont nommées d'une certaine façon?
Il est possible que vous ayez remarqué quelques répetitions dans le nom des fichiers utilisés par Redwood. Ainsi les pages se trouvent dans un répertoire appelé
/pages, et contiennent de nouveauPagedans leur nom. Idem pour les Layouts. Pourquoi de choix?Lorsque vous avez des dizaines de fichiers ouverts dans votre éditeur de code, il est facile de se perdre. C'est d'autant plus le cas lorsque vous avez des fichiers aux noms similaires dans des répertoires différents. A l'usage, il nous est apparut que cette petite répetition dans les noms était au final bien pratique lorsqu'il s'agit de repérer un fichier précis parmi tous les onglets ouverts..
Le plugin React Developer Tools peut également vous aider à distinguer les fichiers entre eux.

Ajoutons encore un autre <Link> de façon à ce que le titre et le logo pointent vers la page d'accueil:
// web/src/layouts/BlogLayout/BlogLayout.js
import { Link, routes } from '@redwoodjs/router'
const BlogLayout = ({ children }) => {
return (
<>
<header>
<h1>
<Link to={routes.home()}>Redwood Blog</Link>
</h1>
<nav>
<ul>
<li>
<Link to={routes.about()}>About</Link>
</li>
</ul>
</nav>
</header>
<main>{children}</main>
</>
)
}
export default BlogLayout
Enfin nous pouvons éliminer de la page About le lien "Retour à la page d'accueil" devenu superflu (ainsi que les imports Link et routes associés).
// web/src/pages/AboutPage/AboutPage.js
import BlogLayout from 'src/layouts/BlogLayout'
const AboutPage = () => {
return (
<BlogLayout>
<p>
Ce site est créé avec pour seule intention de démontrer la puissance créative de Redwood! Oui, c'est très
impressionant :D
</p>
</BlogLayout>
)
}
export default AboutPageLa seconde partie du didacticiel est disponible en video ici:
Ces deux pages sont plutôt sympas, mais un blog sans article c'est tout de même un peu léger! Travaillons sur ce point à présent.
Pour les besoins de ce didacticiel, nous allons récupérer nos articles depuis la base de données. Puisque les bases de données relationelles sont encore aujourd'hui au coeur de beaucoup d'applications complexes (ou moins complexes d'ailleurs), nous avons fait en sorte de réserver un traitement de première classe aux accès SQL. Dans une application Redwood, tout part du schéma.
Nous devons identifier quelles données seront nécessaires pour un article. Plus tard nous ajouterons d'autres éléments, mais pour commencer nous avons besoin de ceci:
ìdl'identifiant unique pour un article (chaque table de notre base de données aura également un identifiant tel que celui-ci)titlele titre de l'articlebodyle contenu de l'articlecreatedAtun 'timestamp' correspondant au moment où l'article est enregistré dans la base de données
Nous utilisons Prisma Client JS pour parler vac la base de données. Prisma possède aun autre librairie, appellée Migrate, qui nous permet de mettre à jour le schéma de la base de données en capturant chaque changement successif. Chacun de ces changement est appelé migration, et cette librairie Migrate en créé un nouveau à chaque modification du schéma.
Tout d'abord, définissons la structure d'un article de notre blog dans la base de données. Ouvrez api/prisma/schema.prisma et ajoutez la définition de la table Post (supprimez au passage tous les modèles présents par défaut dans ce fichier). Une fois terminé, le fichier se présente ainsi:
// api/prisma/schema.prisma
datasource DS {
provider = "sqlite"
url = env("DATABASE_URL")
}
generator client {
provider = "prisma-client-js"
binaryTargets = "native"
}
model Post {
id Int @id @default(autoincrement())
title String
body String
createdAt DateTime @default(now())
}
Cette série d'instructions signifie que nous voulons créer une table Post avec les éléments suivants:
- Un champ
idde typeInt, nous précisions à Prisma que cette colonne constitue un identifiant@id(de façon à pouvoir créer des relations avec d'autres tables) et que la valeur par@defaultcorrespond à la fonction Prismaautoincrement()impliquant que la base de données insèrera une nouvelle valeur automatiquement lorsqu'un enregistrement est créé. - Un champ
titlede typeString - Un champ
bodyégalement de typeString - Un champ
createdAtde typeDateTimeavec une valeur par@defaultégale ànow()pour chaque nouvel enregistrement (ainsi nous n'avons pas à nous en charger dans l'application, la base de données le fera pour nous)
Identifiant de type Integer vs. identifiant de type String
Pour le didacticiel, nous resterons simple et utiliserons un identifiant de type Integer. Ceci étant, une application plus évoluée pourra utiliser un identifiant de type CUID ou UUID. Tous deux sont pris en charge par Prisma. Dans ce cas, vous utiliseriez un champ de type
Stringau lieu deInt, etcuid()ouuuid()au lieu deautoincrement():
id String @id @default(cuid())Notez que l'utilisation d'un identifiant de type Integer permet d'obtenir des url plus simples comme https://redwoodblog.com/posts/123 instead of https://redwoodblog.com/posts/eebb026c-b661-42fe-93bf-f1a373421a13.
Allez voir la documentation officielle de Prisma pour plus de détails sur les champs identifiants.
Bon, la création du schéma : c'est fait! Maintenant ce que nous vonlons c'est capturer son état pour en faire une migration:
yarn redwood db save create posts
Ce faisant, vous venez de nommer votre première migration "create posts". Redwood ne tient pas compte de ce nom, mais il est recommandé de choisir un nom significatif pour les autres développeurs de votre équipe.
Une fois la commande exécutée, vous pourrez constater la création d'un nouveau sous-répertoire dans api/prisma/migrations avec un timestamp et le nom que vous avez donné votre migration. Ce sous-répertoire contient quelques fichiers: une capture du schéma de la base dans schema.prisma, ainsi que la suite de directives que Prima utilise pour effectuer les modifications dans steps.json).
Nous allons maintenant appliquer cette migration avec cette commande:
yarn rw db up
Raccourçi
redwoodDésormais, nous utiliserons dans nos commandes la forme courte
rwà la place deredwood.
L'exécution de cette commande permet à Prisma d'appliquer les changements sur la base de données, en l'espèce la création d'une nouvelle table Post avec les champs définis plus haut.
Nous n'avons pas encore décidé du look de notre site, mais ne serait-il pas extra si nous pouvions commencer à manipuler nos articles de blog, commencer à créer quelques pages rapidement le temps que l'équipe chargée du design rende sa copie? Heureusement pour nous, "Incroyable" est le petit nom de Redwood :)
Générons tout ce sont nous avons besoin pour réaliser un CRUD (Create, Retrieve, Update, Delete) (Créer, Récupérer, Mettre à jour, Supprimer) sur nos articles. Redwood a justement un generateur spécialement fait pour ça :
yarn rw g scaffold post
Ouvrons la page http://localhost:8910/posts et constatons le résultat:
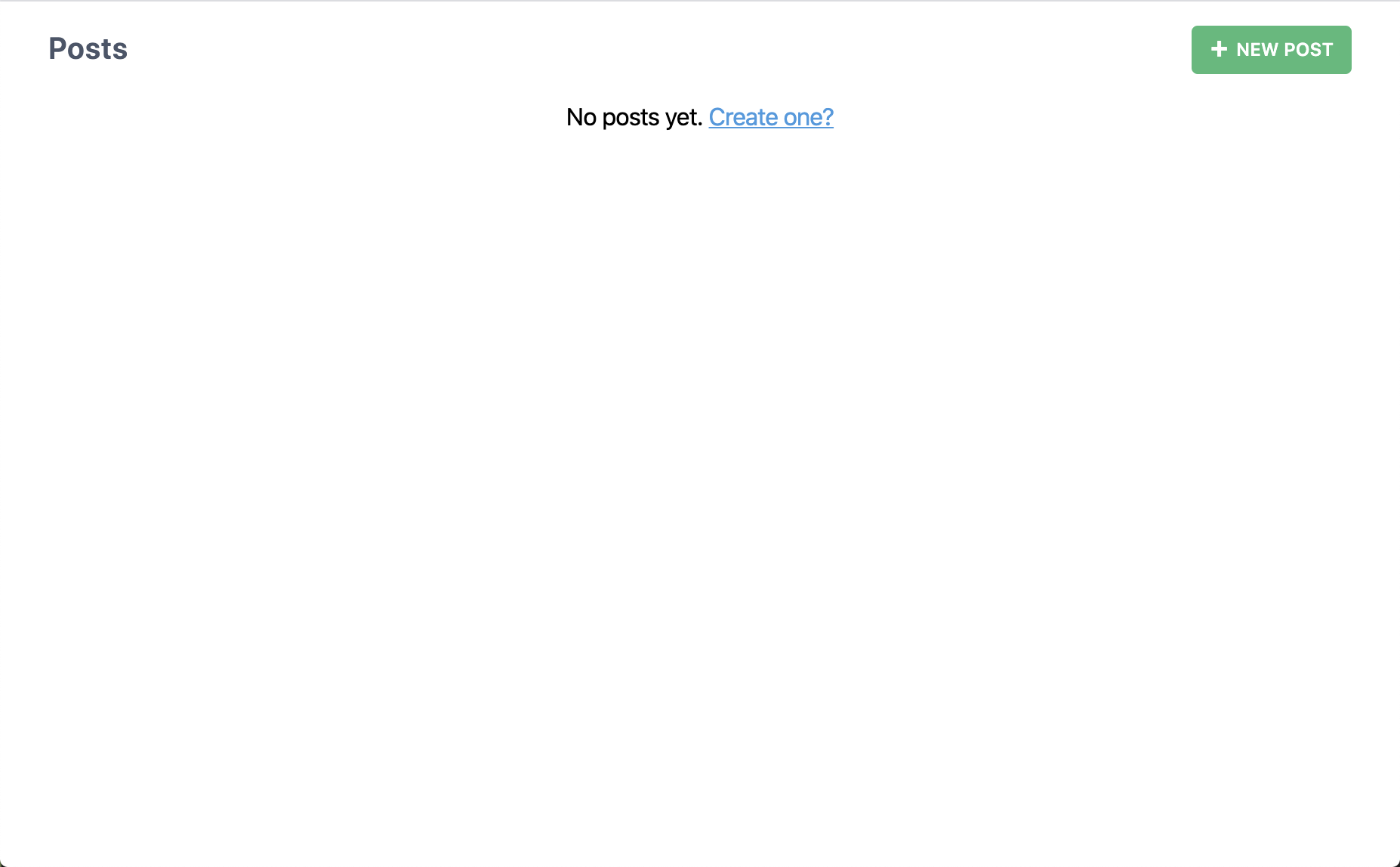
Humm.. ça n'est pas beaucoup plus que ce que nous avions obtenu losque nous avions créé notre première page. Que se passe-t-il lorsque nous cliquons sur le bouton "New Post" (Nouvel Article) ?
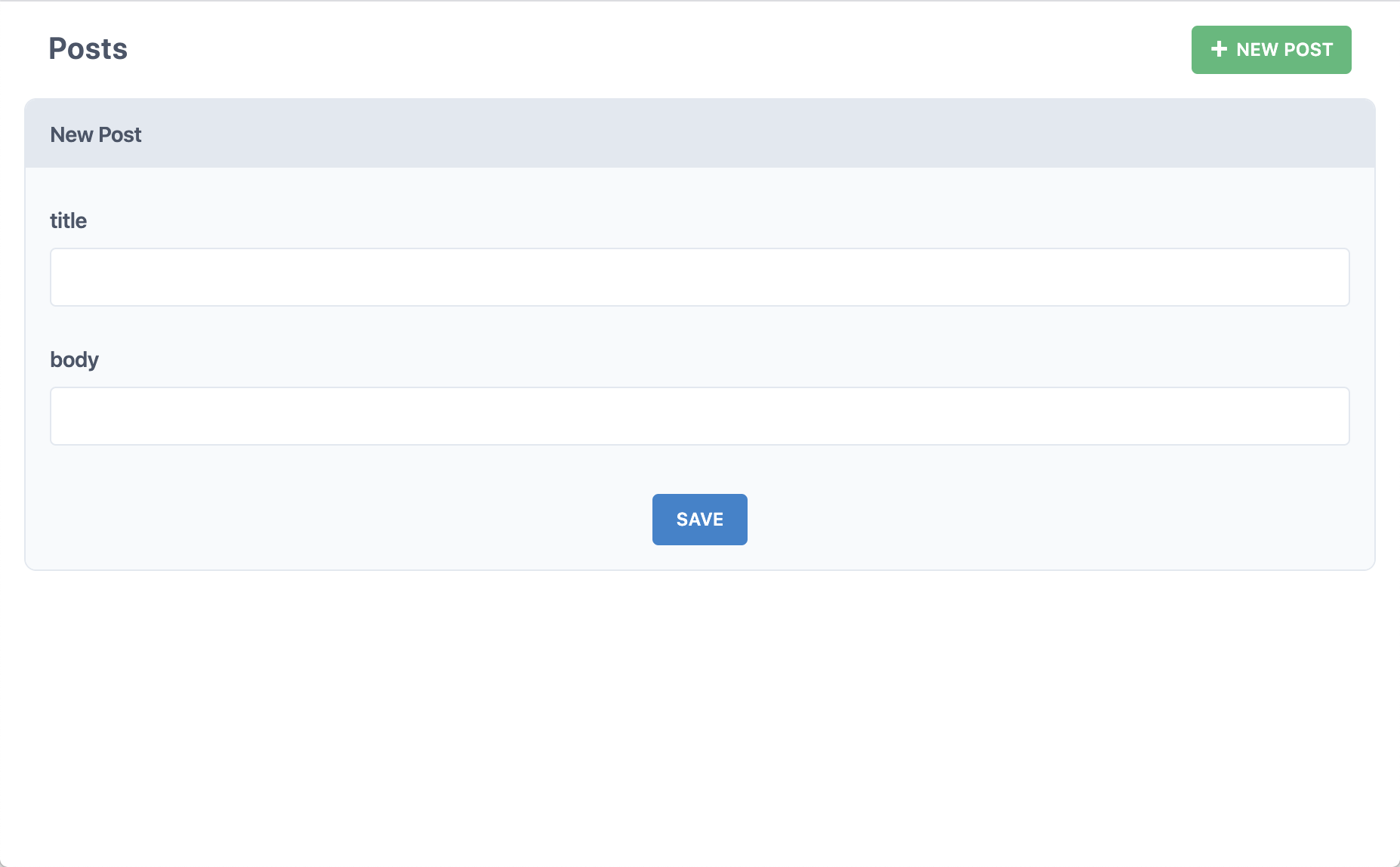
Ah, maintenant on commence à parler sérieusement! Remplissez donc les champs title (titre) et body (contenu), puis cliquez sur "Save" pour enregistrer.
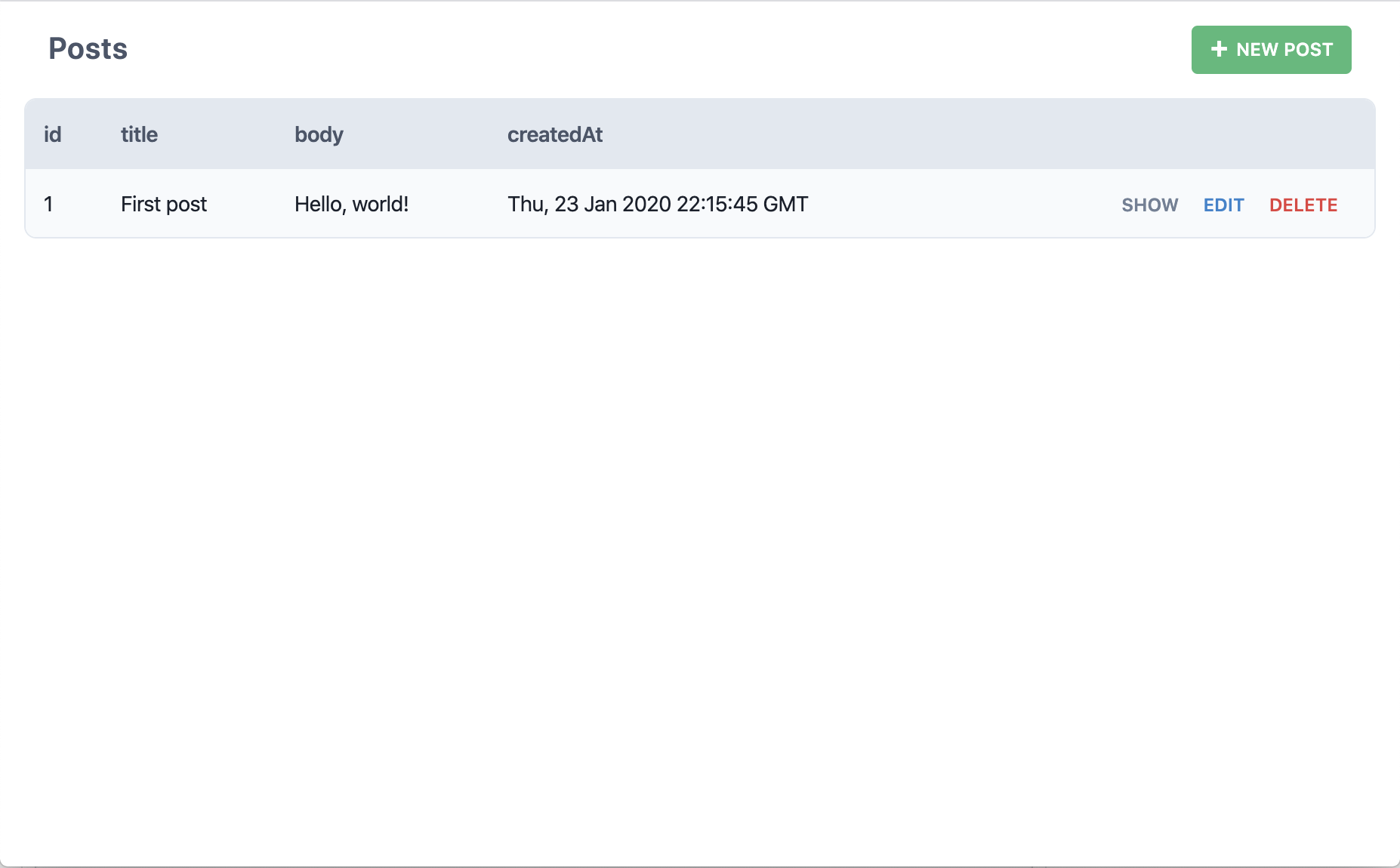
Venons-nous bien de créer un nouvel article? Exactement! Essayez-donc d'en créer d'autres.
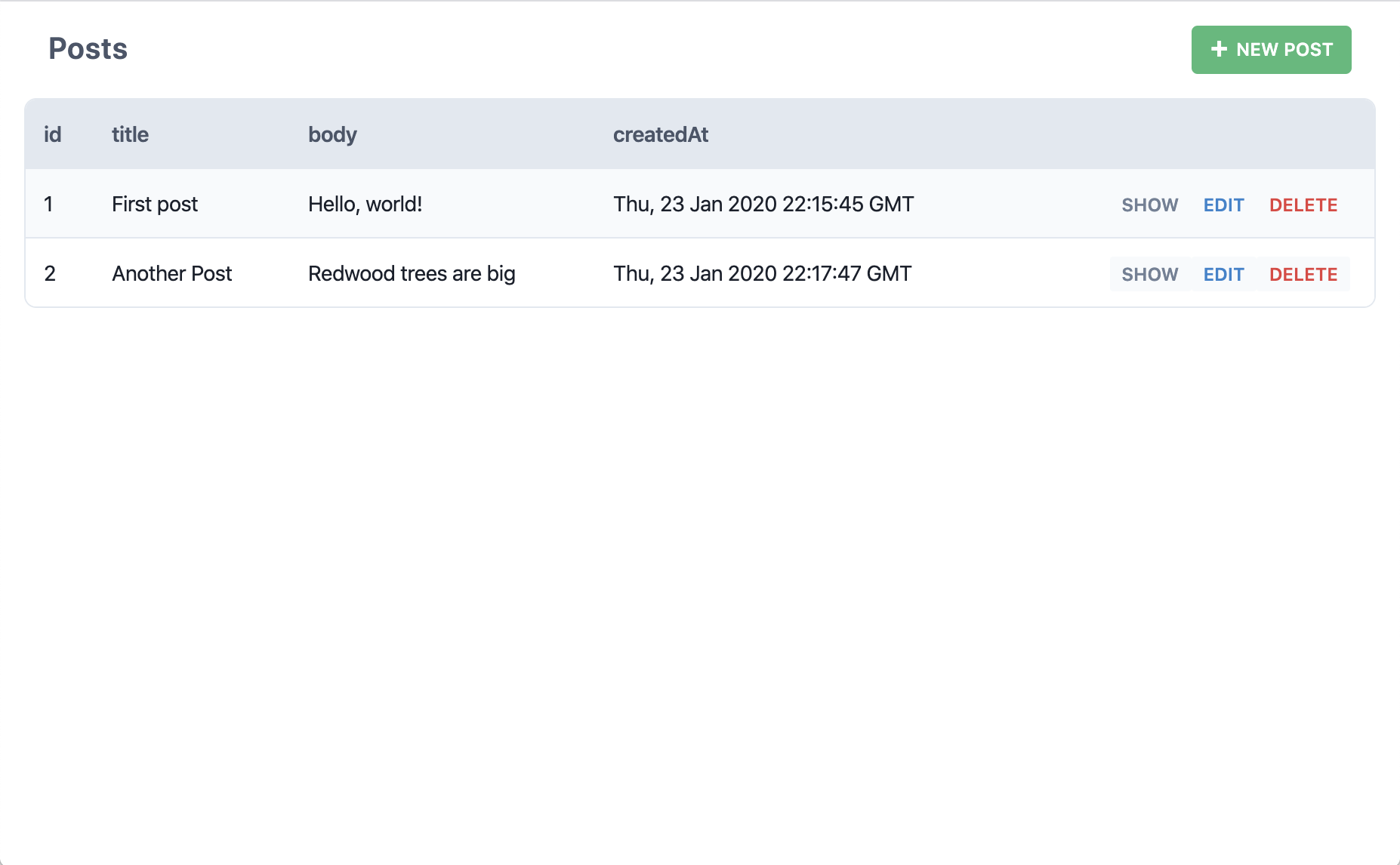
Et maintenant, que se passe-t-il lorsqu'on clique sur "Edit" (éditer) pour l'un de ces articles?
D'accord, et en cliquant sur le bouton "Delete" (supprimer)?
Oui c'est bien ça, en une seule commande, Redwood à créé l'ensemble des pages, composants et services nécessaires aux opérations usuelles de manipulation des articles. Pas même besoin d'ouvrir le gestionnaire de base de données. Redwood appelle ceci des scaffolds. Pas mal, non?
Voici dans le détail ce qui arrive lorsqu'on execute la commande yarn rw g scaffold post :
- Ajout d'un fichier SDL pour définir quelques requêtes et mutations GraphQL dans
api/src/graphql/posts.sdl.js - Ajout d'un fichier service
api/src/services/posts/posts.jsqui permet au client Javascript Prisma de manipuler la base de données - Ajout de quelques pages dans
web/src/pages:EditPostPagepour éditer un articleNewPostPagepour créer un nouvel articlePostPagepour montrer les détails d'un articlePostsPagepour lister tous les articles
- Ajout de routes pour ces nouvelles pages dans
web/src/Routes.js - Ajout de trois cells dans
web/src/components:EditPostCellcellule permettant de récupérer un article pour l'éditerPostCellcellule permettant de récupérer un article pour l'afficherPostsCellcellule permettant de récupérer tous les articles
- Ajout de quatre composants également dans
web/src/components:NewPostaffiche le formulaire permettant la création d'un nouvel articlePostaffiche un article en particulierPostFormle formulaire utilisé à la fois par les composants de création et d'édition d'un ariclePostsaffiche la table avec l'ensemble des articles
Générateurs et conventions de nommage
Vous remarquerez que certains fichiers générés ont un nom au pluriel, et d'autres au singulier. Cette convention est empruntée au framework Ruby on Rails. Lorsque vous avez à traiter d'un multiple de quelque chose (comme par exemple une liste d'articles), on utilisera le pluriel. Dans le cas contraire (par exemple la création d'un nouvel article), on utilisera le singulier. C'est aussi plus naturel lorsque l'on parle: "montre moi une liste d'articles" vs. "je vais créer un nouvel article".
Pour ce qui concerne les générateurs:
- Les fichiers de Services sont toujours au pluriel.
- Les méthodes dans les Services sont au singulier ou au pluriel selon qu'ils retournent plusieurs articles ou un seul article (
postsvs.createPost).- les fichiers SDL sont toujours au pluriel.
- Les pages générées par une commande de scaffold sont au pluriel ou au singulier selon que la page manipule plusieurs ou un seul article. Notez que lorsque vous utilisez vous-même un commande
pageen dehors d'un scaffold, le nom utilisé sera simplement celui que vous donnerez.- Les Layouts utilisent le nom que vous leur donnez
- Les composants et les cellules sont au pluriel ou au singulier selon le contexte lorsqu'ils sont générés par scaffolding. Dans le cas contraire, ils utilisent simplement le nom que vous leur donnez.
Remarquez également que seul le nom de la table en base de données et au singulier ou au pluriel, et pas le mot complet. Ainsi on a
PostsCell, et nonPostCells.Vous n'avez pas à suivre cette convention de façon obligatoire lorsque vous créez vos propres composants, pages, etc... Ceci étant nous vous le recommandons chaudement. Au bout du compte, la communauté Ruby on Rails a fini par s'attacher à cette convention, et ce même si au départ de nombreuses personnes s'y étaient opposées. "Give it five minutes" comme disent les anglo-saxons.
Nous pouvons commencer à remplacer ces pages les unes après les autres au fur et à mesure que l'équipe chargée du design nous donne des éléments, ou bien nous pouvons simplement les déplacer dnas la partie "administration" de notre site, et commencer à créer nos propres pages. Ceci étant, la partie publique du site ne va certainement pas autoriser les utilisateurs à créer, éditer ou supprimer les articles. Que peuvent donc faire les utilisateurs?
- Voir la liste des articles (sans liens pour éditer ou supprimer)
- Voir le détail d'un article
Puisque nous voudront probablement conserver un moyen de créer et éditer des articles plus tard, conservons les pages générées par scaffolding et créons-en de nouvelles pour ces deux cas de figure.
Nous avons déjà la HomePage, pas besoin de créer celle-ci donc. Nous souhaitons afficher une liste d'articles à l'utilisateur donc nous allons devoir ajouter ça. Nous avons besoin de récupérer le contenu depuis la base de données, et nous ne voulons pas que l'utilisateur soit face à une page blanche le temps du chargement (conditions réseau dégradées, serveur géographiquement distant, etc...), donc nous voudrons montrer une sorte de message de chargement et/ou une animation. D'autre part, si une erreur se produit, nous devrons faire en sorte de la prendre en charge. Enfin, nous devrons également prendre en compte le cas où le blog ne contient encore aucun article.
Wow... notre première page et il semble que nous ayons déjà à nous inquiéter de tant de choses... mais est-ce véritablement le cas ?
Ce que nous cherchons à faire ici constituent en réalité des objectifs partagés par la plupart des applications web. Nous voulions voir s'il était possible de faciliter la vie aux développeurs. Nous pensons être arrivé à réaliser quelque chose d'utile. Nous appelons ça les Cells (ou cellules en français). Les Cells proposent une approche simple et déclarative pour récupérer des données au sein de vos composants. (Vous pouvez lire la documentation complète à propos des Cells. You can read the full documentation about Cells ici.
Lorsque vous créez une nouvelle Cell, vous exportez quelques constantes, toujours nommées de façon identique, et Redwood s'appuie dessus pour mettre en place la mécanique. Une Cell ressemble typiquement à ceci:
export const QUERY = gql`
query {
posts {
id
title
body
createdAt
}
}
`
export const Loading = () => <div>Chargement...</div>
export const Empty = () => <div>Aucun article disponible!</div>
export const Failure = ({ error }) => (
<div>Erreur lors du chargement des articles: {error.message}</div>
)
export const Success = ({ posts }) => {
return posts.map((post) => (
<article>
<h2>{post.title}</h2>
<div>{post.body}</div>
</article>
))
}Lorsque React affiche ce composant, Redwood va:
- Exécuter la requête
QUERYet afficher le composantLoadingjusqu'à ce qu'une réponse soit reçue - Lorsque la requête retourne une réponse, il va afficher un des trois états suivants:
- S'il y a eu une erreur, le composant
Failure - Si aucune donnée n'est retournée (c'est à dire
nullou un tableau vide), le composantEmpty - Dans le cas contraire (ni erreur, ni vide), le composant
Success
- S'il y a eu une erreur, le composant
Il existe également quelques outils supplémentaire pour générer le cycle de vie du composant comme beforeQuery (pour manipuler les propriétés passées à QUERY) et afterQuery (pour manipuler les données retournées par GraphQL avant qu'elles ne soient transmises au composant Success)
Le minimum dont vous avez besoin pour une Cell sont les exports QUERY et Success. Si vous n'exportez pas Empty, Success recevra les données vides. Si vous n'exportez pas Failure, les éventuelles erreurs seront envoyées à la console.
Pour déterminer dans quels cas utiliser les Cells, gardez en tête qu'elles sont utiles lorsque vos composants ont besoin de récupérer des données depuis la base, ou depuis tout autre service qui pourrait avoir un délai de réponse. Laissez Redwood se charger de jongler avec les états, de manière à pouvoir porter votre attention sur le comportement attendu de vos composants correctement affichés avec leur données.
La page d'accueil affichant une liste d'articles est un candidat parfait pour réaliser notre première cellule. Naturellement, nous avons prévu un générateur pour ça:
yarn rw g cell BlogPosts
L'exécution de cette commande provoque la création d'un nouveau fichier /web/src/components/BlogPostsCell/BlogPostsCell.js (et son fichier de test associé) avec un peu de code par défaut pour vous faciliter la tâche:
// web/src/components/BlogPostsCell/BlogPostsCell.js
export const QUERY = gql`
query BlogPostsQuery {
blogPosts {
id
}
}
`
export const Loading = () => <div>Loading...</div>
export const Empty = () => <div>Empty</div>
export const Failure = ({ error }) => <div>Error: {error.message}</div>
export const Success = ({ blogPosts }) => {
return JSON.stringify(blogPosts)
}Lorsque vous utilisez le générateur, vous pouvez employer le type de casse qui vous plaît. Redwood fera en sorte de s'adapter pour créer une cellule avec un nom de fichier correct. Ainsi toutes les commandes ci-dessous aboutissent à créer un fichier avec le même nom:
yarn rw g cell blog_posts yarn rw g cell blog-posts yarn rw g cell blogPosts yarn rw g cell BlogPostsVous devez juste pensez à indiquer d'une façon ou d'une autre que vous utilisez plusieurs mots. Appeler
yarn redwood g cell blogpostssans utiliser aucune casse pour séparer "blog" et "posts" va générer un fichierweb/src/components/BlogpostsCell/BlogpostsCell.js.
Pour vous aider à être efficace, le générateur suppose que vous utiliserez une requête racine GraphQL nommées de la même façon que votre Cell et écrit pour vous une requête minimale pour récupérer des données depuis la base. Dans le cas présent, la requête a donc été nommée blogPosts. Cependant, ce nom de requête n'est pas valide par rapport à ce qui a déjà été créé dans nos fichiers SDL et Service. Nous devons donc renommer blogPosts en posts à la fois dans le nom de la requête GraphQL et dans la propriété passée à Success:
// web/src/components/BlogPostsCell/BlogPostsCell.js
export const QUERY = gql`
query BlogPostsQuery {
posts {
id
}
}
`
export const Loading = () => <div>Loading...</div>
export const Empty = () => <div>Empty</div>
export const Failure = ({ error }) => <div>Error: {error.message}</div>
export const Success = ({ posts }) => {
return JSON.stringify(posts)
}
Insérons cette Cell dans notre HomePage et voyons ce qui se passe:
// web/src/pages/HomePage/HomePage.js
import BlogLayout from 'src/layouts/BlogLayout'
import BlogPostsCell from 'src/components/BlogPostsCell'
const HomePage = () => {
return (
<BlogLayout>
<BlogPostsCell />
</BlogLayout>
)
}
export default HomePage
Le navigateur devrait en principe montrer un tableau avec un peu de contenu (en supposant que vous ayez créé un article à l'étape du scaffolding un peu plus tôt). Impeccable!

Dans le composant
Success, d'où vient doncposts?Remarquez que dans le composant
QUERY, nous avons nommée notre requêteposts. Quelque soit le nom de la requête, ce sera le nom de la propriété qui sera transmise au composantSuccesset qui contiendra vos données. Vous pouvez toutefois créer un alias de la façon suivante:export const QUERY = gql` query BlogPostsQuery { postIds: posts { id } } `De cette manière la propriété
postIdssera transmise àSuccessau lieu deposts
En plus de l'identifiant id qui a été ajouté dans QUERY par le générateur, récupérons également le titre, le contenu et la date de création de l'article:
// web/src/components/BlogPostsCell/BlogPostsCell.js
export const QUERY = gql`
query BlogPostsQuery {
posts {
id
title
body
createdAt
}
}
`
La page devrait désormais afficher un dump de l'ensemble des données pour tous les articles enregistrés:

Success est ni plus ni moins qu'un bon vieux composant React, vous pouvez donc le modifier simplement pour afficher chaque article dans un format un peu plus sympa et lisible:
// web/src/components/BlogPostsCell/BlogPostsCell.js
export const Success = ({ posts }) => {
return posts.map((post) => (
<article key={post.id}>
<header>
<h2>{post.title}</h2>
</header>
<p>{post.body}</p>
<div>Créé le: {post.createdAt}</div>
</article>
))
}
Et ce faisant, nous avons maintenant notre blog! Ok, à ce stade c'est encore le plus basique et hideux blog jamais vu sur Internet.. mais c'est déjà quelque chose! (Pas d'inquiétude, nous avons encore un tas de fonctionnalités à ajouter)

Pour résumer, qu'avons nous réalisé jusqu'ici ?
- Génération de la page d'accueil
- Génération du Layout pour notre blog
- Définition du schéma de la base de données
- Application d'une migrations pour mettre à jour la base de données et créer une table
- Réalisation d'un Scaffold pour créer une interface CRUD sur la table
- Création d'une Cell pour charger les donner et gérer les états "loading", "empty", "failure" et enfin "success".
- Ajout de la Cell à notre page d'accueil
En réalité, cette différentes étapes sont ni plus ni moins ce qui deviendra votre façon habituelle d'ajouter de nouvelles fonctionnalités dans une application Redwood.
Jusqu'ici, hormis un peu de code HTML, nous n'avons pas écrit grand chose à la main. En particulier, nous n'avons pratiquement pas eu à écrire de code pour récupérer les données depuis la base. Le développement web s'en trouve facilité et devient même agréable, qu'en pensez-vous?
Redwood apprécie GraphQL. Nous pensons qu'il s'agit de l'API pour l'avenir. Notre implémentation de GraphQL is construite avec Apollo. Voici comment une requête GraphQL classique fonctionne dans votre application:

La partie frontend de l'application s'appuie sur Apollo Client pour créer une requête GraphQL. Celle-ci est ensuite envoyée à Apollo Server qui s'exécute dans une fonction lambda AWS serverless.
Les fichiers *.sdl.js qui se trouvent dans le répertoire api/src/graphql définissent les types GraphQL Object, Query et Mutation et donc l'interface de votre API.
En principe, vous devriez écrire une "resolver map" qui contiendrait l'ensemble de vos "resolvers" de façon à ce qu'Apollo sache comment les brancher à vos fichiers SDL. Cependant, inscrire votre logique métier directement dans votre "resolver map" aurait pour conséquence la création d'un énorme fichier ne favorisant pas la réutilisation. Vous pourriez également extraire toute cette logique dans une librairie de fonctions que vous importeriez et appelleriez depuis votre "resolver map", en ayant toutefois à vous rappeller de passer tous les arguments nécessaires. Humm.. c'est beaucoup d'efforts pour au final une masse de code de toute façon peu réutilisable.
Redwood s'y prend autrement! Voos rappellez-vous le répertoire api/src/services? Redwood va automatiquement importer et brancher vos "resolvers" depuis les services vers vos fichiers SDL. Dans le même temps, Redwood vous permet d'écrire vos "resolvers" de façon à ce qu'ils soient facilement appellés comme de simples fonctions depuis d'autres "resolvers" ou d'autres services. Cela fait pas mal de choses étonnantes à intégrer, il est temps de passer à un exemple.
Observez donc le morceau de code SDL javascript suivant :
// api/src/graphql/posts.sdl.js
export const schema = gql`
type Post {
id: Int!
title: String!
body: String!
createdAt: DateTime!
}
type Query {
posts: [Post!]!
post(id: Int!): Post!
}
input CreatePostInput {
title: String!
body: String!
}
input UpdatePostInput {
title: String
body: String
}
type Mutation {
createPost(input: CreatePostInput!): Post!
updatePost(id: Int!, input: UpdatePostInput!): Post!
deletePost(id: Int!): Post!
}
`A partir de ce fichier SDL, Redwood va aller chercher les cinq "resolvers" suivants dans api/src/services/posts/posts.js :
posts()post({id})createPost({input})updatePost({id, input})deletePost({id})
Pour implémenter ces cinq "resolvers", il vous suffit de les exporter depuis vos fichiers services. Vos resolvers vont habituellement récupérer les données depuis une base de données, mais en réalité ils peuvent faire ce que vous souhaitez du moment qu'ils retournent le type de données qu'Apollo s'attend à recevoir comme défini dans posts.sdl.js.
// api/src/services/posts/posts.js
import { db } from 'src/lib/db'
export const posts = () => {
return db.post.findMany()
}
export const post = ({ id }) => {
return db.post.findOne({
where: { id },
})
}
export const createPost = ({ input }) => {
return db.post.create({
data: input,
})
}
export const updatePost = ({ id, input }) => {
return db.post.update({
data: input,
where: { id },
})
}
export const deletePost = ({ id }) => {
return db.post.delete({
where: { id },
})
}Apollo suppose que ces fonctions retournent des "promises", ce que
dbfait parfaitement.dbest une instance dePrismaClient. Apollo attend sagement que ces promises s'achèvent avant de répondre avec le résultat de vos requêtes. De cette manière, vous n'avez pas à gérer vous-même lesasync/await, ou autres callbacks.
Vous êtes parfaitement fondé à vous interroger sur la raison pour laquelle nous appelons ces fichiers des "services". Bien que le blog que nous construisons ensemble ne soit pas assez complexe pour le montrer, les services sont conçus pour être une abstraction qui couvre plus qu'une simple table de la base de données. Une application plus avancée pourrait par exemple avoir un service nommé "facturation" qui reposerait à fois sur les tables transactions et souscriptions. Certaines des fonctionnalités de ce service pourraient être exposées via GraphQL, mais pas forcément toutes.
Vous n'avez pas besoin d'exposer chaque fonction de votre service via GraphQL. Si vous ne les déclarez pas dans dans vos types Query ou Mutation, ils n'existerons tout simplement pas pour GraphQL. Mais vous pourrez toujours les utiliser vous-même. Les services ne sont ni plus ni moins que des fonctions javascript que vous pouvez utiliser où bon vous semble :
- Depuis un autre service
- Dans une autre fonction lambda créée par vous-même
- Depuis une autre API, complètement séparée
En organisant votre application autour de services bien définis, et en proposant une API pour chacun de ces services (à la fois pour un usage interne, et pour GraphQL), vous contribuerez naturellement à respecter la règle dite de "separation of concerns" (SoC). Selon toute probabilité, cela vous permettra de favoriser la maintenance de votre code dans le temps.
Revenons-en à notre flux de données: Apollo a créé un "resolver" qui, dans notre cas, récupère les données depuis une base de données. Apollo reconstruit l'objet en ne retournant que les couples clé/valeur demandés dans la requête GraphQL. Enfin, Apollo emballe la réponse au format GraphQL et la retourne au navigateur.
Si vous utilisez une Cell Redwood, vos données seront dès lors disponible dans votre compsant Success, prêtes à être affichées comme avec n'importe quel composant React.
Maintenant que notre page d'accueil liste l'ensemble des articles de notre blog, il est temps de créer une page présentant le détail d'un article. Commençons par générer une page et sa route associée:
yarn rw g page BlogPost
Remarquez que nous ne pouvons pas nommer cette page
Postcar une autre page homonyme a déjà été crée lors de notre précédente démonstration du scaffolding.
Pour chaque article listé sur la page d'accueil, ajoutons un lien qui pointe vers notre nouvelle page (sans oublier au passage les imports pour Link et routes):
// web/src/components/BlogPostsCell/BlogPostsCell.js
import { Link, routes } from '@redwoodjs/router'
// QUERY, Loading, Empty and Failure definitions...
export const Success = ({ posts }) => {
return posts.map((post) => (
<article key={post.id}>
<header>
<h2>
<Link to={routes.blogPost()}>{post.title}</Link>
</h2>
</header>
<p>{post.body}</p>
<div>Créé le: {post.createdAt}</div>
</article>
))
}
Si vous cliquez sur le lien, vous deviez voir s'afficher un peu de texte issu de BlogPostPage. Mais ce dont nous avons vraiment besoin, c'est de pouvoir préciser quel article nous souhaitons afficher. Ce que nous cherchons a obtenir en définitive, c'est une URL du type /blog-post/1. Pour cela, nous allons dire au routeur que notre url comporte une partie variable supplémentaire:
// web/src/Routes.js
<Route path="/blog-post/{id}" page={BlogPostPage} name="blogPost" />Notez l'ajout de {id} dans notre route. Redwood nomme ceci un paramètre de route. Ces paramètres de route signifie la chose suivante: "quelque soit la valeur à cette position, elle sera référencée par le nom utilisé entre les accolades".
Cool, cool, cool. Maintenant, nous devons donc construire un lien qui possède cet identifiant:
// web/src/components/BlogPostsCell/BlogPostsCell.js
<Link to={routes.blogPost({ id: post.id })}>{post.title}</Link>Pour les routes avec paramètres, un objet est attendu pour chaque paramètre. Si vous cliquez sur le lien d'un article, vous constaterez qu'en effet il pointe désormais vers /blog-post/1 (ou /blog-post/2, etc... selon l'article).
OK, donc l'identifiant se trouve bien dans l'URL. Et maintenant que fait-t-on pour afficher le bon article? On dirait bien que nous allons devoir récupérer les données depuis la base. Vous l'aurez compris, c'est le bon moment pour utiliser une Cell:
yarn rw g cell BlogPost
Nous allons ensuite utiliser cette Cell dans notre page BlogPostPage (et pendant que nous y sommes, nous insèrerons notre page dans notre Layout BlogLayout):
// web/src/pages/BlogPostPage/BlogPostPage.js
import BlogLayout from 'src/layouts/BlogLayout'
import BlogPostCell from 'src/components/BlogPostCell'
const BlogPostPage = () => {
return (
<BlogLayout>
<BlogPostCell />
</BlogLayout>
)
}
export default BlogPostPageMaintenant, à l'intérieur de notre Cell, nous avons besoin d'accéder à ce paramètre de route {id} qui contient l'identifiant de notre article en base de données. Pour ce faire, mettons à jour la requête de façon à ce qu'elle accepte une variable en entrée. Modifions également le nom de la requête blogPost en post.
// web/src/components/BlogPostCell/BlogPostCell.js
export const QUERY = gql`
query BlogPostQuery($id: Int!) {
post(id: $id) {
id
title
body
createdAt
}
}
`
export const Loading = () => <div>Loading...</div>
export const Empty = () => <div>Empty</div>
export const Failure = ({ error }) => <div>Error: {error.message}</div>
export const Success = ({ post }) => {
return JSON.stringify(post)
}
Okay, on approche du but! Ceci étant, d'où vient donc ce $id? Redwood a plus d'un tour dans son sac. Chaque fois que vous ajoutez un paramètre de route, ce paramètre est automatiquement accessible dans la page qui correspond. Ce qui signifie que vous pouvez modifier la page BlogPostPage de la façon suivante:
// web/src/pages/BlogPostPage/BlogPostPage.js
const BlogPostPage = ({ id }) => {
return (
<BlogLayout>
<BlogPostCell id={id} />
</BlogLayout>
)
}
id existe déjà sans effort supplémentaire puisque nous avons nommé notre paramètre de route {id}. Merci qui? Merci Redwood! Mais comment se fait-il que cet id finisse par devenir un paramètre GraphQL $id? Redwood s'en charge également pour vous! Par défaut, chaque propriété que vous donnez à une Cell devient automatiquement un variable disponible pour une requête GraphQL. Incroyablement simple, et pourtant vrai :)
D'ailleurs on peut le prouver! Essayez maintenant d'aller voir un article and — ... uh oh. Hmm:

Au passage le code d'erreur que vous voyez s'afficher provient de la section
Failurede votre Cell!
Si vous examinez la console de votre navigateur, vous constaterez la présence d'une erreur GraphQL:
[GraphQL error]: Message: Variable "$id" got invalid value "1";
Expected type Int. Int cannot represent non-integer value: "1",
Location: [object Object], Path: undefined
Il s'avère que les paramètres de route sont extraits des URL sous la forme de chaînes de caractères, et dans le cas présent GraphQL s'attend à recevoir un identifiant sous la forme d'un entier. Nous pourrions simplement utiliser la fonction javascript parseInt() afin de convertir notre paramètre de route vers un entier avant de le passer à BlogPostCell. Mais honnêtement, on peut faire bien mieux que ça!
Et si vous aviez la possibilité de demander cette conversion directement dans le chemin de la route? Et bien devinez-quoi, vous pouvez! Redwood appelle ça les paramètres de route typés ("route param types" en anglais). Et c'est aussi simple que d'ajouter :Int à notre paramètre de route:
What if you could request the conversion right in the route's path? Well, guess what: you can! Introducing route param types. It's as easy as adding :Int to our existing route param:
// web/src/Routes.js
<Route path="/blog-post/{id:Int}" page={BlogPostPage} name="blogPost" />Voilà! Non seulement vous allez convertir sans effort le paramètre id en un entier avant de la passer à votre Page, mais en bonus vous faîtes en sorte que la route n'applique que si id représente effectivement un entier, c'est à dire une suite de chiffres. Dans le cas contraire, le routeur essaiera d'autres routes. S'il ne s'en trouve aucune à s'appliquer, le routeur affichera la page NotFoundPage.
Que se passe-t-il si je veux passer d'autres propriétés à ma Cell dont je n'ai pas besoin dans la requête, mais qui me sont utile dans les composants Success/Loader/etc... ?
Toutes les propriétés que vous donnez à votre Cell seront automatiquement disponibles pour ses composants internes. Seuls ceux qui se se trouvent dans la liste des variables GraphQL seront transmises à la requête. Vous avez ainsi le meilleur des deux mondes! Dans l'affichage de notre article ci-dessus, si vous désirez montrer par exemple un nombre au hasard (pour des raisons evidentes liées à ce didacticiel :D), il vous suffit de passer cette propriété à votre Cell:
<BlogPostCell id={id} rand={Math.random()} />Et ensuite vous la récupérez avec le résulat de la requête ans le composant (et même avec l'identifiant de l'article si vous le souhaitez): And get it, along with the query result (and even the original
idif you want) in the component:export const Success = ({ post, id, rand }) => { //... }Merci Redwood!
Maintenant, affichons un véritable article au lieu d'un simple dump du résultat de la requête. Il semble que ce soit l'endroit parfait pour utiliser un bon vieux composant puisque nous affichons les articles de façon identique (pour l'instant) à la fois sur la page d'accueil et sur la page de détail.
yarn rw g component BlogPost
L'exécution de cette commande créé le composant BlogPost dans le fichier web/src/components/BlogPost/BlogPost.js, accompagné de son fichier de test:
// web/src/components/BlogPost/BlogPost.js
const BlogPost = () => {
return (
<div>
<h2>{'BlogPost'}</h2>
<p>{'Find me in ./web/src/components/BlogPost/BlogPost.js'}</p>
</div>
)
}
export default BlogPostVous remarquerez peut-être que nous n'avons ici aucun
importrelatif à la librairieReact. Il s'agit pourtant bien d'un classique composant React. En réalité, nous (la "Redwood dev team") sommes un peu fatigués d'avoir à importer constamment les mêmes fichiers de la même manière... alors nous avons fait en sorte que Redwood le fasse pour nous, et donc pour vous!
Supprimons la partie de code qui affiche l'article dans BlogPostCell, et mettons la plutôt ici. Ce faisant, passons à notre nouveau composant la propriété post:
// web/src/components/BlogPost/BlogPost.js
import { Link, routes } from '@redwoodjs/router'
const BlogPost = ({ post }) => {
return (
<article>
<header>
<h2>
<Link to={routes.blogPost({ id: post.id })}>{post.title}</Link>
</h2>
</header>
<div>{post.body}</div>
</article>
)
}
export default BlogPost
Mettons à jour BlogPostsCell et BlogPostCell pour utiliser notre composant d'affichage commun:
// web/src/components/BlogPostsCell/BlogPostsCell.js
import BlogPost from 'src/components/BlogPost'
// Loading, Empty, Failure...
export const Success = ({ posts }) => {
return posts.map((post) => <BlogPost key={post.id} post={post} />)
}
// web/src/components/BlogPostCell/BlogPostCell.js
import BlogPost from 'src/components/BlogPost'
// Loading, Empty, Failure...
export const Success = ({ post }) => {
return <BlogPost post={post} />
}
Et nous y sommes! Nous devrions maintenant pouvoir aller et venir à notre guise entre la page d'accueil et les articles.
Si vous appréciez ce que vous venez de voir sur le routeur, vous pouvez en apprendre plus dans le guide qui lui est consacré.
Un petit état des lieux de ce que nous avons réalisé:
- Création d'une nouvelle page pour afficher un article
- Ajout d'une route prenant en char l'identifiant
idd'un article sous la forme d'un paramètre de route - Création d'une Cell permettant de récupérer et afficher un article
- Constat de la capacité de Redwood à vous mettre de bonne humeur en vous donnant accès à
idlà où vous en avez besoin tout en le convertissant au format numérique à la volée - Transformation de l'affichage d'un article en un composant React classique pouvant être partagé à plusieurs endroits dans l'interface (en l'espèce dans la page d'accueil et la page de détail)
Attendez! Ne partez pas! Vous deviez bien vous douter que ça allait venir, non? Rassurez-vous, pour les formulaires aussi, Redwood a trouvé une façon de faire qui les rend moins pénible que d'habitude. En fait, Redwood pourrait même vous faire aimer les formulaires. Bon, aimer est peut-être un peu fort. Disons apprécier travailler avec les formulaires, ou à tout le moins les tolérer?
La troisième partie du didacticiel en video commence ici:
Nous avons déjà un formulaire ou deux dans notre application; vous rappellez-vous notre scaffolding avec les articles? Ils fonctionnaient plus bien, non? Alors, a quel point est-ce difficile de reproduire ces formulaires? (Si vous n'avez pas encore eu la curiosité d'aller voir le code généré, ce qui va suivre va vous surprendre)
Construisons donc le formulaire le plus élémentaire qui soit pour notre blog, et utile de surcroît, celui qui permettra à vos lecteurs de vous contacter.
yarn rw g page contact
Après avoir exécuté cette commande, nous pouvons ajouter un lien vers Contact dans notre Layout:
// web/src/layouts/BlogLayout/BlogLayout.js
import { Link, routes } from '@redwoodjs/router'
const BlogLayout = ({ children }) => {
return (
<>
<header>
<h1>
<Link to={routes.home()}>Redwood Blog</Link>
</h1>
<nav>
<ul>
<li>
<Link to={routes.about()}>About</Link>
</li>
<li>
<Link to={routes.contact()}>Contact</Link>
</li>
</ul>
</nav>
</header>
<main>{children}</main>
</>
)
}
export default BlogLayout
And then use the BlogLayout in the ContactPage:
// web/src/pages/ContactPage/ContactPage.js
import BlogLayout from 'src/layouts/BlogLayout'
const ContactPage = () => {
return <BlogLayout></BlogLayout>
}
export default ContactPage
Vérifiez que tout fonctionne correctement, puis passons aux réjouïssances.
Les formulaires avec React sont surtout connus pour être particulièrement agaçants à construire. Il existes les Controlled Components, les Uncontrolled Components, diverses librairies tierces et enfin pas mal d'astuces diverses pour essayer de les rendre aussi simples qu'ils sont sensés être selon les spécifications HTML: un champ <input> avec un attribut name qui sera envoyé quelque part lorsque l'utilisateur clique sur un bouton.
Nous pensons que Redwood fait quelques pas dans la bonne direction, non seulement en vous libérant d'avoir à écrire un tans de code relatif aux composants controllés (controlled components), mais aussi en s'occupant de gérer automatiquement les validations et éventuelles erreurs. Regardons ensemble comment tout celà fonctionne.
Avant de commencer, ajoutons quelques classes CSS pour que les formulaires par défaut s'affichent correctement sans que nous ayons à alourdir notre code avec des attributs style un peu partout. Pour le moment nous écrirons ces règles dans le fichier index.css situé dans le répertoire web/src:
/* web/src/index.css */
button, input, label, textarea {
display: block;
outline: none;
}
label {
margin-top: 1rem;
}
.error {
color: red;
}
input.error, textarea.error {
border: 1px solid red;
}Pour l'instant nous n'allons pas faire dialoguer notre formulaire de contact avec la base de données, raison pour laquelle nous ne générons pas une Cell. Nous allons simplement ajouter le formulaire à notre page. Dans Redwood, la création d'un formulaire débute par... attention à la surprise...une balise <Form>:
// web/src/pages/ContactPage/ContactPage.js
import { Form } from '@redwoodjs/forms'
import BlogLayout from 'src/layouts/BlogLayout'
const ContactPage = () => {
return (
<BlogLayout>
<Form></Form>
</BlogLayout>
)
}
export default ContactPage
Humm, OK... pour le moment rien d'incroyable. Ajoutons un premier champ que l'on puisse au moins afficher quelque chose. Redwood propose une variété de type de champs parmi lesquels se trouve <TextField>. Ce dernier correspond à un champ text tout ce qu'il y a de plus basique. Il possède un attribut name de telle façon que lorsqu'un formulaire contient de multiples champs, il soit possible de savoir lequel contient telle ou telle donnée.
// web/src/pages/ContactPage/ContactPage.js
import { Form, TextField } from '@redwoodjs/forms'
import BlogLayout from 'src/layouts/BlogLayout'
const ContactPage = () => {
return (
<BlogLayout>
<Form>
<TextField name="input" />
</Form>
</BlogLayout>
)
}
export default ContactPage
Enfin quelque chose s'affiche! Pas encore très intéressant toutefois. Ajoutons un bouton "envoyer".
// web/src/pages/ContactPage/ContactPage.js
import { Form, TextField, Submit } from '@redwoodjs/forms'
import BlogLayout from 'src/layouts/BlogLayout'
const ContactPage = () => {
return (
<BlogLayout>
<Form>
<TextField name="input" />
<Submit>Save</Submit>
</Form>
</BlogLayout>
)
}
export default ContactPage
Nous obtenons ce qu'on peut considérer comme un véritable et authentique formulaire! Essayez de saisir quelque chose et cliquez sur le bouton. Rien n'explose, mais nous n'avons aucune indication que le formulaire à bien été envoyé (et vous aurez noté l'apparition d'une erreur dans la console). Voyons à présent comment récupérer les données depuis nos champs de formulaire.
De façon similaire à un formulaire HTML, une balise <Form> possède un "handler" onSubmit. Ce handler sera appelé avec un seul argument: un unique objet contenant l'ensemble des champs du formulaire.
// web/src/pages/ContactPage/ContactPage.js
const ContactPage = () => {
const onSubmit = (data) => {
console.log(data)
}
return (
<BlogLayout>
<Form onSubmit={onSubmit}>
<TextField name="input" />
<Submit>Save</Submit>
</Form>
</BlogLayout>
)
}
Essayons maintenant de saisir quelques mots puis soumettre ce formulaire:
Extra! Rendons le formulaire un peu plus utile en ajoutant quelques champs supplémentaires. Nous renommons ainsi notre premier champ en name puis ajoutons les champs email et message:
// web/src/pages/ContactPage/ContactPage.js
import { Form, TextField, TextAreaField, Submit } from '@redwoodjs/forms'
import BlogLayout from 'src/layouts/BlogLayout'
const ContactPage = () => {
const onSubmit = (data) => {
console.log(data)
}
return (
<BlogLayout>
<Form onSubmit={onSubmit}>
<TextField name="name" />
<TextField name="email" />
<TextAreaField name="message" />
<Submit>Save</Submit>
</Form>
</BlogLayout>
)
}
export default ContactPage
Remarquez le nouveau composant <TextAreaField> qui génère une balise HTML <textarea> contenant quelques spécificités utiles propres à Redwood:
Ajoutons également quelques étiquettes en face des champs:
// web/src/pages/ContactPage/ContactPage.js
return (
<BlogLayout>
<Form onSubmit={onSubmit}>
<label htmlFor="name">Name</label>
<TextField name="name" />
<label htmlFor="email">Email</label>
<TextField name="email" />
<label htmlFor="message">Message</label>
<TextAreaField name="message" />
<Submit>Save</Submit>
</Form>
</BlogLayout>
)
Essayez donc de soumettre à nouveau le formulaire, vous devriez obtenir dans la console un message avec le contenu des trois champs.
"Humm... cher auteur de ce didacticiel, qui a-t-il d'incroyable jusqu'ici?". C'est sans doute votre état d'esprit à ce stade. En effet, il existe déjà un nombre conséquent de librairies permettant d'obtenir un résultat similaire.. Vous avez raison! N'importe qui peut remblir un formulaire correctement, mais que se passe-t-il lorsqu'un utilisateur fait une erreur, oubli un champ, voire tente de jouer les hackers? Qui va vous aider à gérer cette situation? Redwood va le faire.
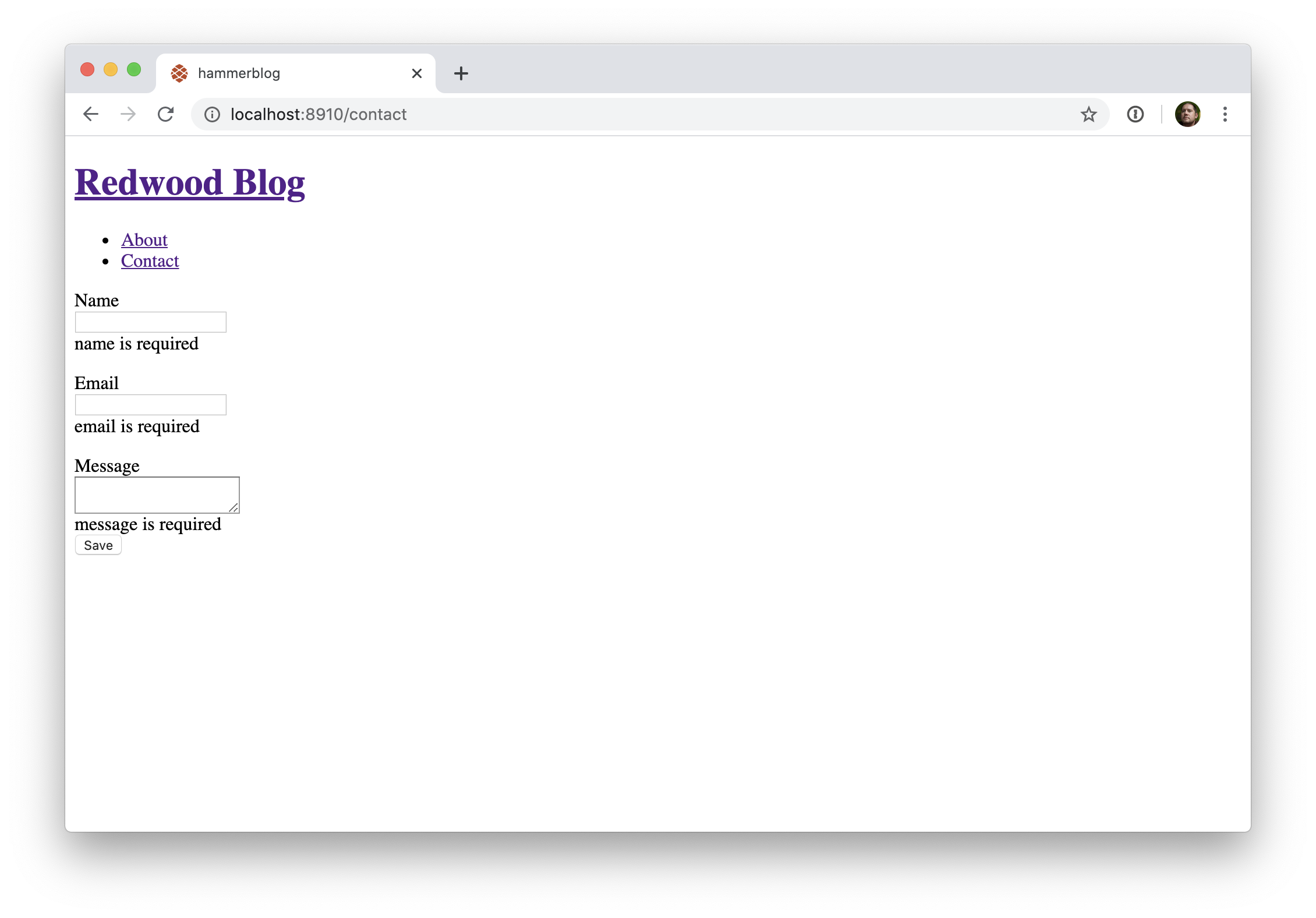
Tout d'abord, ce trois champs devraient être obligatoirement remplis pour pouvoir soumettre le formulaire. Rendons cette règle obligatoire en utilisant l'attribut HTML standard required:
// web/src/pages/ContactPage/ContactPage.js
return (
<BlogLayout>
<Form onSubmit={onSubmit}>
<label htmlFor="name">Name</label>
<TextField name="name" required />
<label htmlFor="email">Email</label>
<TextField name="email" required />
<label htmlFor="message">Message</label>
<TextAreaField name="message" required />
<Submit>Save</Submit>
</Form>
</BlogLayout>
)
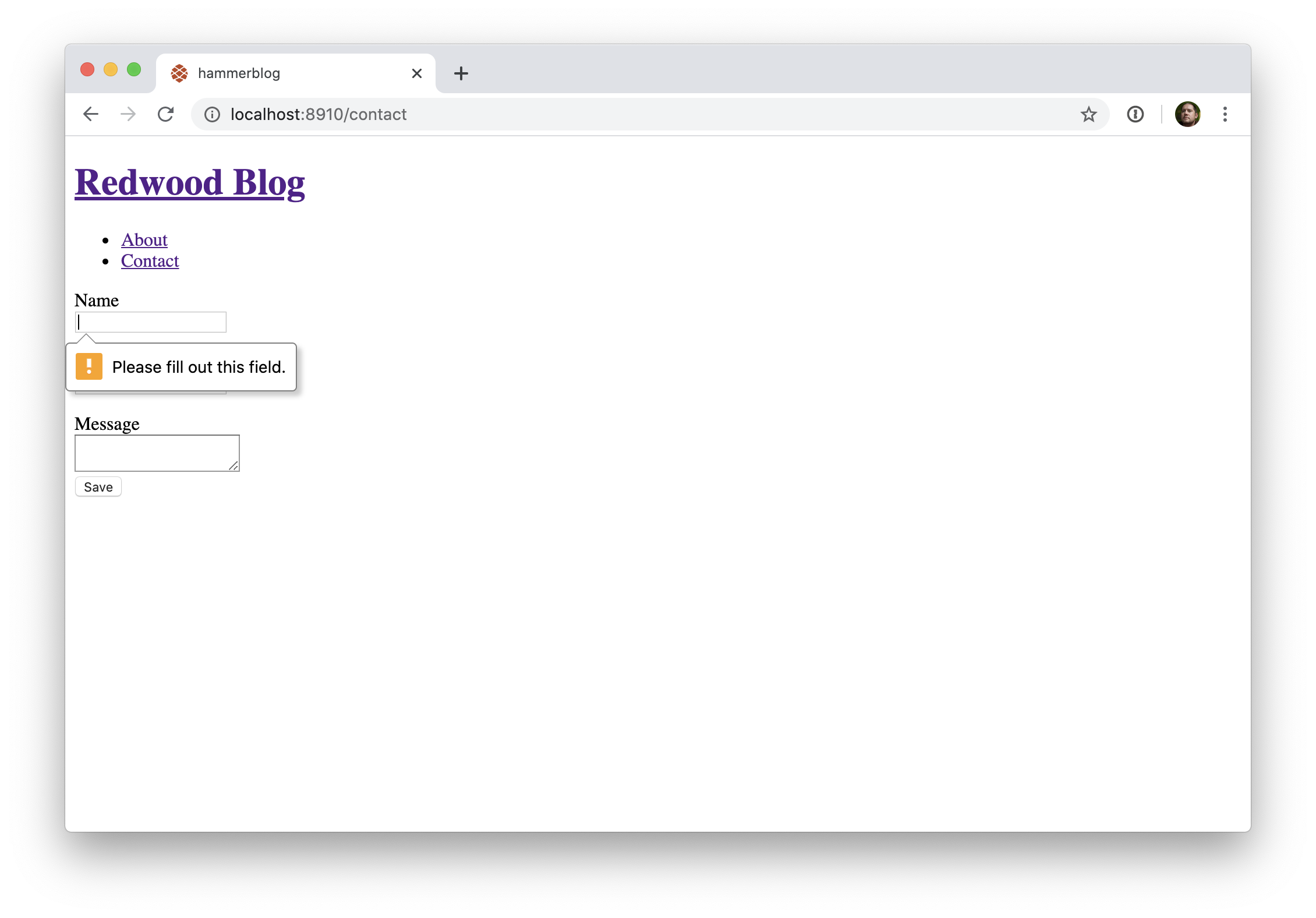
Désormais, lorsque vous essayez de soumettre le formulaire, un message s'affiche dans votre navigateur. C'est mieux que rien, mais l'apparence de ce message ne peut être modifiée. Peut-on faire mieux?
Oui! Remplaçons cet attribut required par un object que nous passons à un attribut nommé validation, spécifique à Redwood:
// web/src/pages/ContactPage/ContactPage.js
return (
<BlogLayout>
<Form onSubmit={onSubmit}>
<label htmlFor="name">Name</label>
<TextField name="name" validation={{ required: true }} />
<label htmlFor="email">Email</label>
<TextField name="email" validation={{ required: true }} />
<label htmlFor="message">Message</label>
<TextAreaField name="message" validation={{ required: true }} />
<Submit>Save</Submit>
</Form>
</BlogLayout>
)
Maintenant lorsqu'un champ reste vide, le formulaire n'est pas envoyé et le champ en question prend le focus de telle manière que l'utilisateur puisse saisir une valeur. Pas encore stupéfiant, mais c'est une première étape. Redwood a d'autres fonctions sympatiques pour les formulaires, dont la possibilité d'afficher les erreurs à côté des champs.
Pour celà, voici le composant <FieldError> (n'oubliez pas d'inclure l'import associé en haut du fichier):
// web/src/pages/ContactPage/ContactPage.js
import {
Form,
TextField,
TextAreaField,
Submit,
FieldError,
} from '@redwoodjs/forms'
import BlogLayout from 'src/layouts/BlogLayout'
const ContactPage = () => {
const onSubmit = (data) => {
console.log(data)
}
return (
<BlogLayout>
<Form onSubmit={onSubmit}>
<label htmlFor="name">Name</label>
<TextField name="name" validation={{ required: true }} />
<FieldError name="name" />
<label htmlFor="email">Email</label>
<TextField name="email" validation={{ required: true }} />
<FieldError name="email" />
<label htmlFor="message">Message</label>
<TextAreaField name="message" validation={{ required: true }} />
<FieldError name="message" />
<Submit>Save</Submit>
</Form>
</BlogLayout>
)
}
export default ContactPage
Observez que l'attribut name correspond à celui du champ au dessus. De cette manière, Redwood sait où afficher le message d'erreur d'un champ.
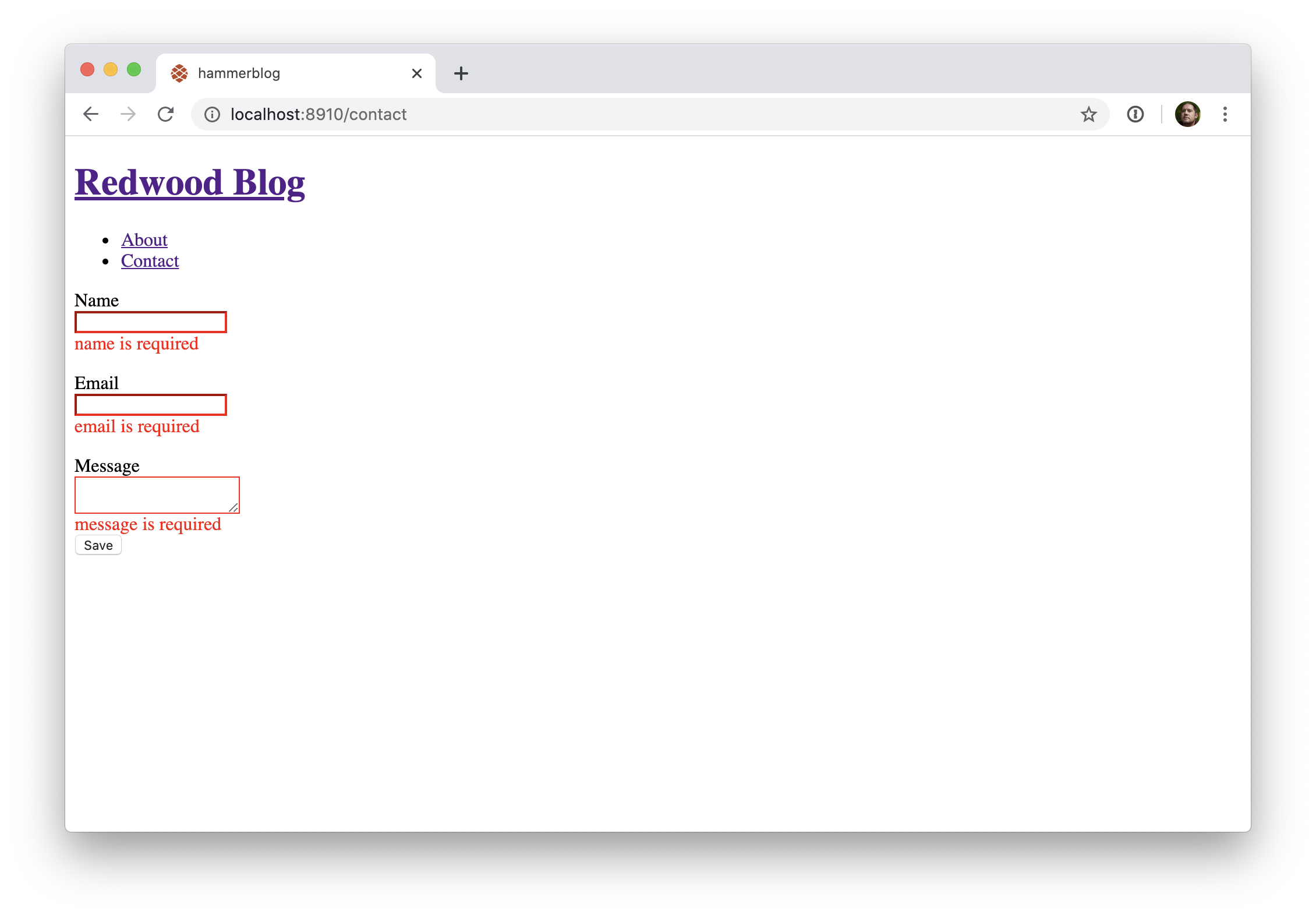
Mais c'est juste le début. Maintenant faisons en sorte que nos utilisateurs sachent qu'il s'agisse bien d'un message d'erreur. Vous rappellez-vous la classe CSS .error que nous avions définie dans index.css? Indiquons-la à l'attribut className de nos composants <FieldError>:
// web/src/pages/ContactPage/ContactPage.js
return (
<BlogLayout>
<Form onSubmit={onSubmit}>
<label htmlFor="name">Name</label>
<TextField name="name" validation={{ required: true }} />
<FieldError name="name" className="error" />
<label htmlFor="email">Email</label>
<TextField name="email" validation={{ required: true }} />
<FieldError name="email" className="error" />
<label htmlFor="message">Message</label>
<TextAreaField name="message" validation={{ required: true }} />
<FieldError name="message" className="error" />
<Submit>Save</Submit>
</Form>
</BlogLayout>
)

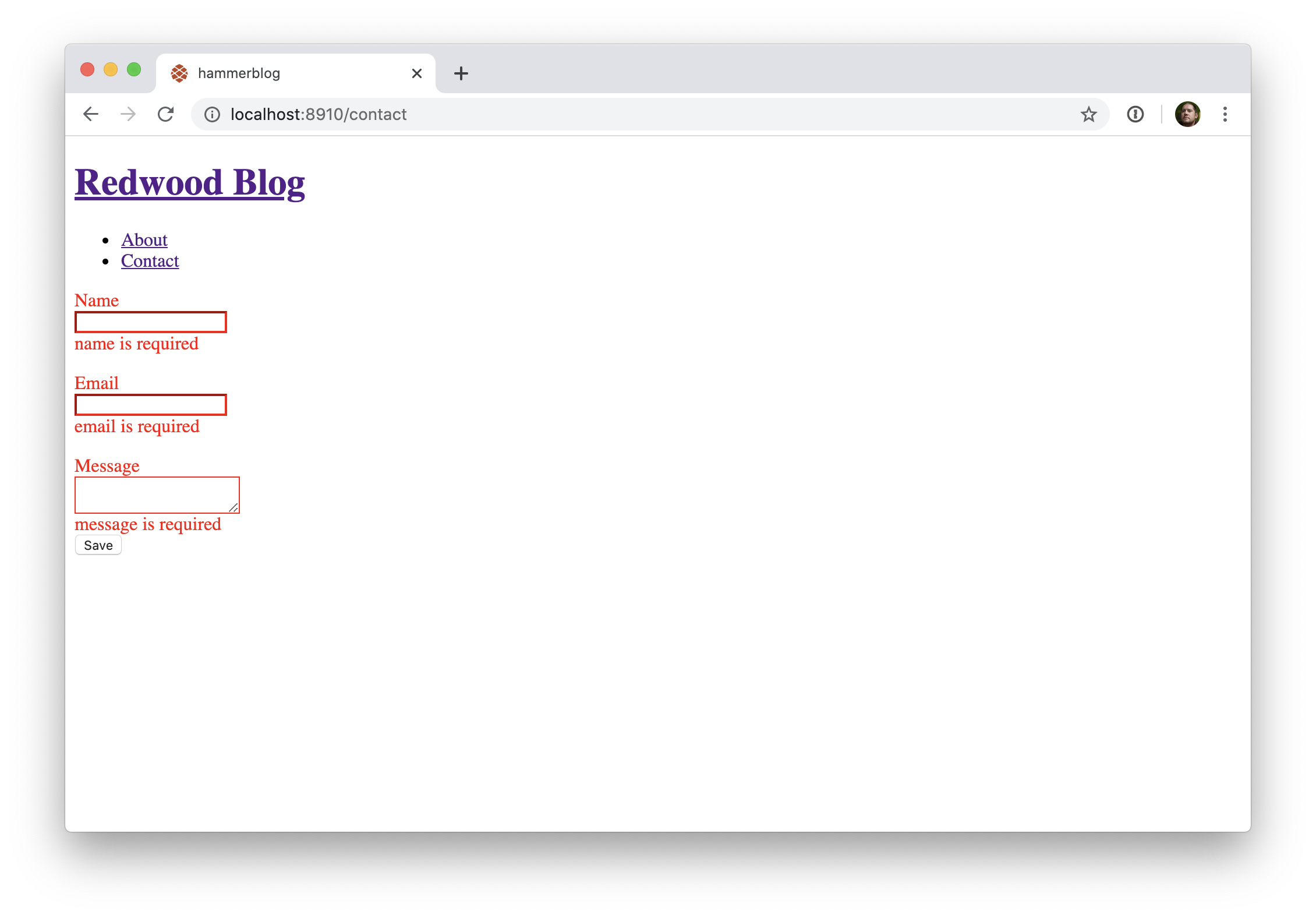
Vous savez ce qui serez bien? Que le champ lui-même indique qu'il y a eu une erreur. Remarquez ici l'utilisation de l'attribut errorClassName:
// web/src/pages/ContactPage/ContactPage.js
return (
<BlogLayout>
<Form onSubmit={onSubmit}>
<label htmlFor="name">Name</label>
<TextField
name="name"
validation={{ required: true }}
errorClassName="error"
/>
<FieldError name="name" className="error" />
<label htmlFor="email">Email</label>
<TextField
name="email"
validation={{ required: true }}
errorClassName="error"
/>
<FieldError name="email" className="error" />
<label htmlFor="message">Message</label>
<TextAreaField
name="message"
validation={{ required: true }}
errorClassName="error"
/>
<FieldError name="message" className="error" />
<Submit>Save</Submit>
</Form>
</BlogLayout>
)
Bravo! Et maintenant, appliquons ce principe à l'étiquette elle-même. Pour celà utilisons le composant <Label> fourni par Redwood. Notez comme l'attribut for correspond à la valeur de l'attribut name du composant associé. N'oubliez pas également d'importer le composant:
// web/src/pages/ContactPage/ContactPage.js
import {
Form,
TextField,
TextAreaField,
Submit,
FieldError,
Label,
} from '@redwoodjs/forms'
import BlogLayout from 'src/layouts/BlogLayout'
const ContactPage = () => {
const onSubmit = (data) => {
console.log(data)
}
return (
<BlogLayout>
<Form onSubmit={onSubmit}>
<Label name="name" errorClassName="error">
Name
</Label>
<TextField
name="name"
validation={{ required: true }}
errorClassName="error"
/>
<FieldError name="name" className="error" />
<Label name="email" errorClassName="error">
Email
</Label>
<TextField
name="email"
validation={{ required: true }}
errorClassName="error"
/>
<FieldError name="email" className="error" />
<Label name="message" errorClassName="error">
Message
</Label>
<TextAreaField
name="message"
validation={{ required: true }}
errorClassName="error"
/>
<FieldError name="message" className="error" />
<Submit>Save</Submit>
</Form>
</BlogLayout>
)
}
export default ContactPage
En plus de
classNameeterrorClassNamevous pouvez également utiliserstyleeterrorStyle
Nous devrions nous assurer que le champ email contient bien... un email!
// web/src/pages/ContactPage/ContactPage.js
<TextField
name="email"
validation={{
required: true,
pattern: {
value: /[^@]+@[^.]+\..+/,
},
}}
errorClassName="error"
/>
OK, ça n'est pas la validation ultime pour un champ email, mais pour le moment faisons comme si. Modifions également le message affiché en cas d'échec de la validation:
// web/src/pages/ContactPage/ContactPage.js
<TextField
name="email"
validation={{
required: true,
pattern: {
value: /[^@]+@[^.]+\..+/,
message: 'Please enter a valid email address',
},
}}
errorClassName="error"
/>
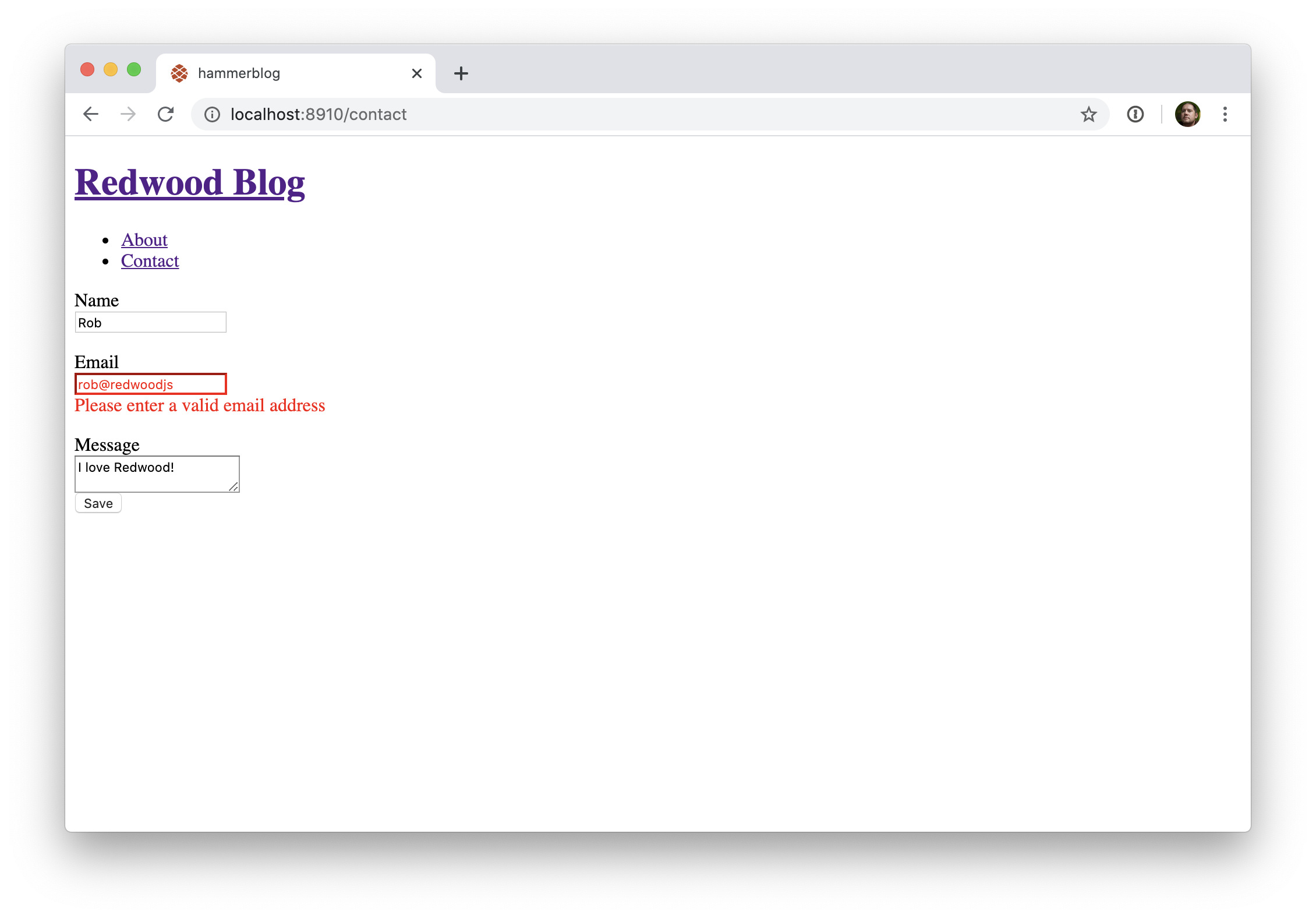
Vous avez peut-être remarqué qu'essayer d'envoyer le formulaire alors que sont présentes des erreurs de validation n'affiche rien dans la console. C'est en réalité une bonne chose car celà vous indique que le formulaire n'a pas été envoyé. Corrigez la valeur des champs concernés, et tout fonctionne correctement.
Lorsqu'un message lié à une erreur lors de la validation d'un champ s'affiche, il disparaît dès que la valeur est corrigée. Ainsi l'utilisateur n'a pas à devoir envoyer de nouveau le formulaire pour vérifier la validité de la saisie.
Finalement, savez-vous ce qui serait vraiment sympa? Ce serait de faire en sorte que les champs soient validés dès que l'utilisateur quitte un champ. De cette manière l'utilisateur n'a pas besoin de remplir l'ensemble des champs et envoyer le formulaire pour voir toutes les erreurs s'afficher. Voyons comment faire:
// web/src/pages/ContactPage/ContactPage.js
<Form onSubmit={onSubmit} validation={{ mode: 'onBlur' }}>Alors, qu'en pensez-vous? Quelques composants, un ou deux attributs, et vous avez devant vous un formulaire qui gère les erreurs, valide les champs et vous envoie le contenu sous la forme d'un bel objet javascript. Merci Redwood!
Les formulaires de Redwood sont construits à partir de la librairie React Hook Form. Celle-ci contient d'autres fonctionalités très utiles que nous n'avons pas documenté ici.
Redwood a encore plus d'un tour dans son sac pour ce qui concerne les formulaires, mais nous allons garder ça pour une étape ultérieure.
Avoir un formulaire de contact, c'est bien. Mais conserver les message qu'on vous envoie, c'est mieux! Procédons maintenant à la création de la table en base de données pour y enregistrer ces informations. Ce faisant nous allons créer notre première mutation GraphQL!
Ajoutons une nouvelle table à notre base de données. Ouvrez api/prisma/schema.prisma et ajoutez un nouveau modèle "Contact" à la suite du premier modèle "Post":
// api/prisma/schema.prisma
model Contact {
id Int @id @default(autoincrement())
name String
email String
message String
createdAt DateTime @default(now())
}Pour définir une colonne comme optionnelle (c'est à dire permettre que sa valeur soit
NULL), il suffit de suffixer le type de la donnée avec un point d'interrogation:name String?
Nous créons ensuite notre nouvelle migration:
yarn rw db save create contact
Enfin, nous executons la migration de façon à mettre à jour le schéma de la base de données:
yarn rw db up
Maintenant nous créeons l'interface GraphQL permettant d'accéder à cette nouvelle table. C'est la première fois que nous utilisons cette commande generate nous même. (la commande scaffold repose également dessus):
yarn rw g sdl contact
De la même manière qu'avec la commande scaffold, ceci va créer deux nouveaux fichiers dans le répertoire api:
api/src/graphql/contacts.sdl.js: qui définit le schéma GraphQLapi/src/services/contacts/contacts.js: qui contient votre code métier
Ouvrez api/src/graphql/contacts.sdl.js et vous verrez les types Contact, CreateContactInput et UpdateContactInput déjà définis pour vous. La commande generate sdl a analysé le schéma et créé un type Contact contenant chaque champ de la table, ainsi qu'un type Query avec une requête contacts qui retourne un tableau de types Contact.
// api/src/graphql/contacts.sdl.js
export const schema = gql`
type Contact {
id: Int!
name: String!
email: String!
message: String!
createdAt: DateTime!
}
type Query {
contacts: [Contact!]!
}
input CreateContactInput {
name: String!
email: String!
message: String!
}
input UpdateContactInput {
name: String
email: String
message: String
}
`Que sont les "input" CreateContactInput et UpdateContactInput? Redwood suit la recommandation de GraphQL d'utiliser les Input Types dans les mutations plutôt que de lister tous les champs qui peuvent être définis. Tous les champs requis dans schema.prisma sont également requis dans CreateContactInput (vous ne pouvez pas créer un enregistrement valide sans eux) mais rien n'est explicitement requis dans UpdateContactInput. En effet, vous pouvez souhaiter mettre à jour un seul champ, deux champs ou tous les champs. L'alternative serait de créer des types d'entrée séparés pour chaque permutation de champs que vous souhaitez mettre à jour. Nous avons estimé que le fait de n'avoir qu'une seule entrée de mise à jour, bien que ce ne soit peut-être pas la manière absolument correcte de créer une API GraphQL, était un bon compromis pour faciliter le développement.
Redwood suppose que votre code n'essaiera pas de définir une valeur sur un champ nommé
idoucreatedAtdonc il les a laissés en dehors des types d'entrée, mais si votre base de données autorise l'un ou l'autre de ceux à définir manuellement, vous pouvez mettre à jourCreateContactInputouUpdateContactInputet les ajouter.
Puisque toutes les colonnes de la table étaient définies comme requises dans schema.prisma, elles sont également définies comme requises ici (notez le suffixe ! sur les types de données)
important: la syntaxe de
schema.prismarequiert l'ajout d'un caractère?lorsqu'un champ n'est pas requis, tandis que la syntaxe GraphQL requiert l'ajout d'un caractère!lorsqu'un champ est requis.
Comme décrit dans Quête secondaire: Fonctionnement de Redwood avec les Données, il n'y a pas de "resolver" définit explicitement dans le fichier SDL. Redwood suit une convention de nommage simple: chaque champ listé dans les types Query et Mutation correspondent à une fonction avec un nom identique dans les fichiers service et sdl associés (api/src/graphql/contacts.sdl.js -> api/src/services/contacts/contacts.js)
Dans le cas présent, nous créeons une unique Mutation que nous appelons createContact. Nous l'ajoutons à la fin de notre fichier SDL (avant le caractère 'backtick'):
// api/src/graphql/contacts.sdl.js
type Mutation {
createContact(input: CreateContactInput!): Contact
}La mutation createContact accepte une variable unique, input, qui est un objet conforme à ce qu'on attend pour un CreateContactInput, c'est à dire { name, email, message }.
C'est terminé pour le fichier SDL, définissons maintenant le service qui va réellement enregistrer les données en base. Le service inclut une fonction contacts permettant de récupérer l'ensemble des contacts depuis la base. Ajoutons-y une mutation pour pouvoir créer un nouveau contact:
// api/src/services/contacts/contacts.js
import { db } from 'src/lib/db'
export const contacts = () => {
return db.contact.findMany()
}
export const createContact = ({ input }) => {
return db.contact.create({ data: input })
}
Grâce au client Prisma, il faut peu de code pour enregistrer nos données en base! Il s'agit d'un appel asynchrone, mais nous n'avons pas à nous soucier de manipuler un objet Promise ou s'arranger avec async/await. La librairie Apollo le fait pour nous!
Avant d'insérer tout ceci dans notre interface utilisateur, prennons un peu de temps pour utiliser un outil bien pratique en exécutant la commande yarn redwood dev.
Souvent, il est utile d'expérimenter notre API dans une forme un peu "brute" avant de poursuivre plus avant le développement de l'interface et s'apercevoir que l'on a oublié quelque chose.
Lorsque vous avez exécuté la commande yarn redwood dev au début de ce didacticiel, vous avez en réalité démarré un second processus en arrière-plan. Ouvrez donc une nouvelle page de votre navigateur à cette adresse: http://localhost:8911/graphql . Il s'agit du Bac à Sable GraphQL fournit par la librairie Prisma, une application web permettant d'interagir avec une API GraphQL:
Observez en particulier l'onglet "Doc" situé sur la partie droite de l'écran:
Vous y trouverez le schema complet tel que définit dans vos fichiers SDL! L'application analyse ces définitions et vous propose ces éléments pour vous permettre de construire vos requêtes. Essayez par exemple de récupérer les ID de tous les articles en écrivant votre requête dans la partie gauche puis en cliquant sur le bouton "Play":
Le bac à sable GraphQL est une excellente manière d'expérimenter avec votre API, et comprendre pourquoi une requête ne fonctionne pas comme prévue.
Notre mutation GraphQL est prête pour la partie backend, tout ce qu'il reste à faire c'est l'invoquer depuis la partie frontend. Tout ce qui à trait à notre formulaire se trouve dans ContactPage, c'est donc l'endroit logique pour y mettre l'appel à notre nouvelle mutation. D'abord nous définissons cette mutation comme une constante que nous appellerons plus tard (ceci peut être défini en dehors du composant lui-même, juste après les lignes d'imports):
// web/src/pages/ContactPage/ContactPage.js
const CREATE_CONTACT = gql`
mutation CreateContactMutation($input: CreateContactInput!) {
createContact(input: $input) {
id
}
}
`Nous référençons ainsi la mutation createContact définie auparavant dans le fichier SDL des contacts, tout en lui passant en argument un objet input contenant la valeur des champs name, email et message.
Après quoi, nous appelons le 'hook' useMutation fourni par Appolo, ce qui nous permet d'exécuter la mutation lorsque le moment est venu (n'oubliez pas les imports comme à chaque fois):
// web/src/pages/ContactPage/ContactPage.js
import {
Form,
TextField,
TextAreaField,
Submit,
FieldError,
Label,
} from '@redwoodjs/forms'
import { useMutation } from '@redwoodjs/web'
import BlogLayout from 'src/layouts/BlogLayout'
const ContactPage = () => {
const [create] = useMutation(CREATE_CONTACT)
const onSubmit = (data) => {
console.log(data)
}
return (...)
}
create est une fonction qui invoque la mutation et prend en paramètre un objet contenant un clef variables. Cette dernière contient à son tour une clef input. Par exemple, nous pourrions l'appeler également de cette manière:
create({
variables: {
input: {
name: 'Rob',
email: 'rob@redwoodjs.com',
message: 'I love Redwood!',
},
},
})Si votre méémoire est bonne, vous vous souvenez sans doute que la balise <Form> nous donne accès à l'ensemble des champs du formulaire avec un objet bien pratique dans lequel chaque clef se trouve être le nom du champ. Celà signifie donc que l'objet dataque nous recevons dans onSubmit est déjà dans le format adapté pour input!
Maintenant nous pouvons mettre à jour la fonction onSubmit pour invoquer la mutation avec les données qu'elle reçoit:
// web/src/pages/ContactPage/ContactPage.js
const ContactPage = () => {
const [create] = useMutation(CREATE_CONTACT)
const onSubmit = (data) => {
create({ variables: { input: data }})
console.log(data)
}
return (...)
}
Essayez-donc de remplir le formulaire et de l'envoyer. Vous devriez obtenir un nouveau contact en base de données! Vous pouvez vérifier ceci avec l'outil bac à sable de GraphQL:

Notre formulaire de contact fonctionne, mais il subsiste quelques problèmes:
- Cliquer sur le bouton d'enregistrement plusieurs fois à pour conséquence d'envoyer le formulaire également plusieurs fois
- L'utilisateur ne sait pas si l'envoi a bien été pris en compte
- Si une erreur devait se produire côté serveur, nous n'avons aucun moyen d'en informer l'utilisateur
Essayons d'y apporter une solution.
Le 'hook' useMutation retourne quelques autres éléments en plus de la fonction permettant de l'invoquer. Nous pouvons déstructurer ceux-ci (loading et error) de la façon suivante:
// web/src/pages/ContactPage/ContactPage.js
const ContactPage = () => {
const [create, { loading, error }] = useMutation(CREATE_CONTACT)
const onSubmit = (data) => {
create({ variables: { input: data } })
console.log(data)
}
return (...)
}
Ce faisant, nous savons si un appel à la base est toujours en cours en utilisant la valeur de loading. Une façon simple de résoudre le problème des soumissions multiples du même formulaire est de rendre inactif le bouton d'envoi tant que la réponse n'a pas été reçue. Nous pouvons faire celà en liant l'attribut disabled du bouton "save" à la valeur contanue dans loading:
// web/src/pages/ContactPage/ContactPage.js
return (
// ...
<Submit disabled={loading}>Save</Submit>
// ...
)
Il peut être difficile de voir une différence en phase de développement car l'envoi est très rapide. Mais vous pouvez néanmoins activer un outil bien pratique dans le navigateur Chrome afin de simuler une connection lente:
Vous verrez alors que le bouton "Save" devient inactif pendant une seconde ou deux en attendant la réponse.
Maintenant, utilisons le système dit de Flash proposé par Redwood afin d'informer l'utilisateur que son envoi à bien été traité. useMutation accepte un second paramètre optionnel contenant des options. Une de ces options est une fonction callback appelée onCompleted qui sera invoquée lorsque la mutation sera achevée avec succès. Nous allons donc utiliser cette fonction pour ajouter un message qui sera affiché par un composant Flash. Ajoutez donc le composant Flash a votre page et utilisez sa propriété timeout pour définir le temps d'affichage. (Vous pouvez lire la documentation à propos du système de Flash proposé par Redwood ici)
// web/src/pages/ContactPage/ContactPage.js
// ...
import { Flash, useFlash, useMutation } from '@redwoodjs/web'
import BlogLayout from 'src/layouts/BlogLayout'
// ...
const ContactPage = () => {
const { addMessage } = useFlash()
const [create, { loading, error }] = useMutation(CREATE_CONTACT, {
onCompleted: () => {
addMessage('Thank you for your submission!', {
style: { backgroundColor: 'green', color: 'white', padding: '1rem' }
})
},
})
// ...
return (
<BlogLayout>
<Flash timeout={2000} />
// ...
Nous allons maintenant informer l'utilisateur des éventuelles erreurs côté serveur. Jusqu'ici nous n'avons notifié les utilisateurs quie des erreurs côté client lorsqu'un champ était manquant ou formaté incorrectement. Mais si nous avons également des contraintes côté serveur que le composant <Form> ignore, nous devons tout de même pouvoir en informer l'utilisateur.
Ainsi, nous avons une validateur de l'email côté client, mais tout bon développeur web sait qu'il ne faut jamais faire confiance au client. Ajoutons une validation de l'email côté serveur de façon à être certain qu'aucune donnée erronée ne soit ajoutée dans la base, et ce même si un utilisateur parvenait à contourner le fonctionnement de l'application côté client.
Pourquoi n'avons-nous pas besoin de validation côté serveur pour s'assurer que les champs name, email et message sont bien remplis? Car la base de données le fait pour nous. Vous rappellez-vous
String!dans notre fichier SDL? Celà ajoute une contrainte en base de données de telle façon que ce champ ne puisse êtrenull. Une valeurnullserait rejetée par la base et GraphQL renverrait une erreur à la partie client.Cependant, il n'existe pas de type
Email!, raison pour laquelle nous devons assurer la validation nous même
Nous avons déjà parlé de code métier et du fait que ce type de code a vocation à se trouver dans nos fichiers services. Ceci en est un exemple parfait. Ajoutons une fonction validate à notre service contacts:
// api/src/services/contacts/contacts.js
import { UserInputError } from '@redwoodjs/api'
import { db } from 'src/lib/db'
const validate = (input) => {
if (input.email && !input.email.match(/[^@]+@[^.]+\..+/)) {
throw new UserInputError("Can't create new contact", {
messages: {
email: ['is not formatted like an email address'],
},
})
}
}
export const contacts = () => {
return db.contact.findMany()
}
export const createContact = ({ input }) => {
validate(input)
return db.contact.create({ data: input })
}
Ainsi, lorsque createContact est invoquée, la fonction commence par valider le contenu des champs du formulaire. Puis, et seulement s'il n'y a aucune erreur, l'enregistrement sera créé en base de données.
Nous capturons déjà toutes les erreurs dans la constante error que nous obtenons grâce au 'hook' useMutation. C'est pourquoi nous avons la possibilité d'afficher ces erreurs sur la page, par exemple au dessus du formulaire:
// web/src/pages/ContactPage/ContactPage.js
<Form onSubmit={onSubmit} validation={{ mode: 'onBlur' }}>
{error && (
<div style={{ color: 'red' }}>
{"We couldn't send your message: "}
{error.message}
</div>
)}
// ...
Si vous avez besoin de manipuler l'objet contenant les erreurs, vous pouvez procéder ainsi:
// web/src/pages/ContactPage/ContactPage.js const onSubmit = async (data) => { try { await create({ variables: { input: data } }) console.log(data) } catch (error) { console.log(error) } }
Afin de tester ceci, provoquons une erreur en retirant temporairement la validation côté client de l'adresse email:
// web/src/pages/ContactPage/ContactPage.js
<TextField
name="email"
validation={{
required: true,
}}
errorClassName="error"
/>Maintenant, essayons de remplir le formulaire avec un adresse invalide:
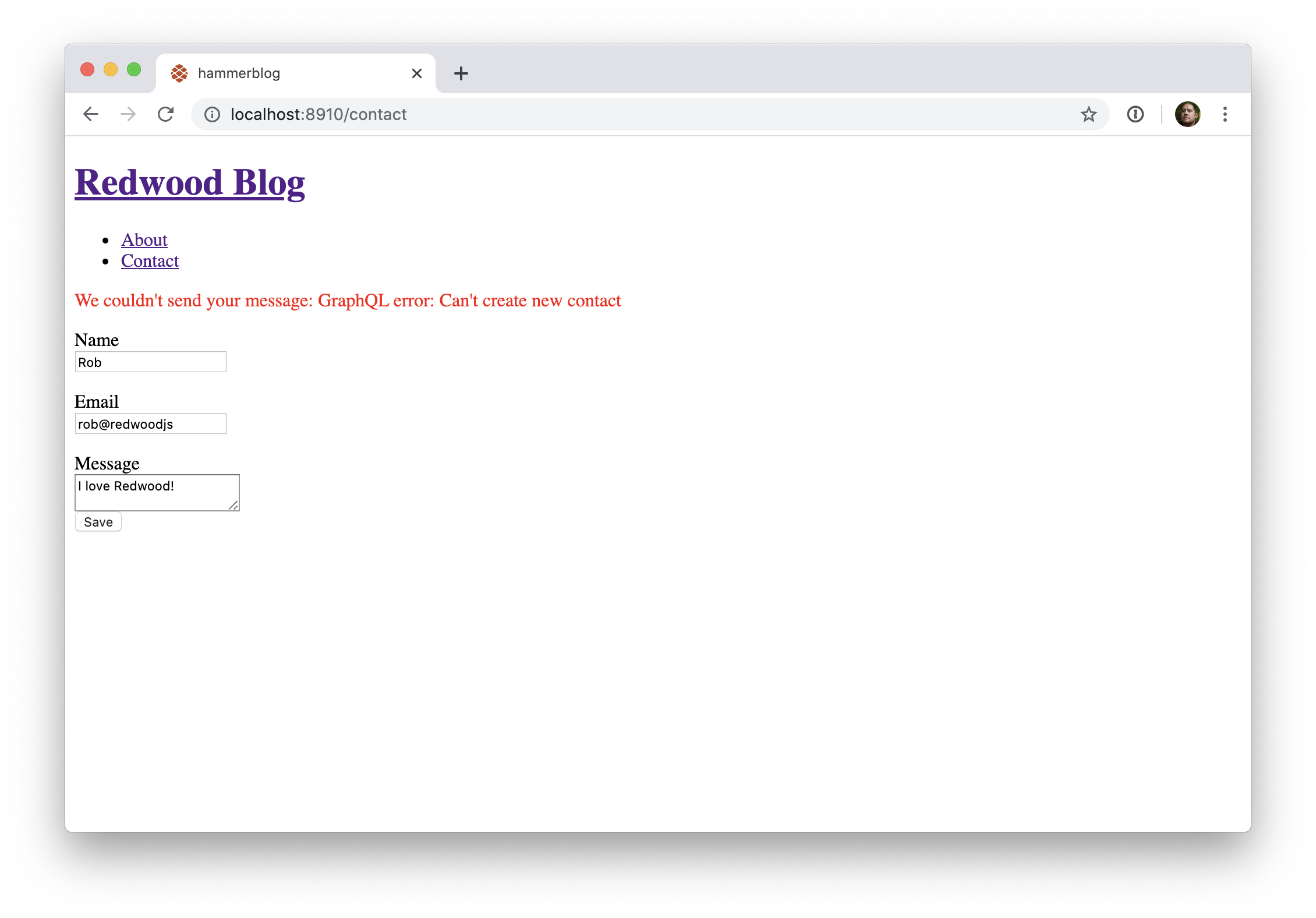
Celà fonctionne, même si l'affichage reste à améliorer. Voir apparaître une erreur GraphQL n'est pas idéal. Il serait plus sympa de faire en sorte que ce soit le champ concerné qui soit marqué d'une erreur...
Vous rapellez-vous lorsque nous avons dit que <Form> avait plus d'un tour dans son sac? Voyons donc ça!
Supprimez l'affichage de l'erreur tel que nous venons de l'ajouter ({ error && ...}) , et remplacez-le avec <FormError> tout en passant en argument la constante error que nous récupérons depuis useMutation. Ajoutez également quelques ééléments de style à wrapperStyle, sans oublier les import associés.
// web/src/pages/ContactPage/ContactPage.js
import {
Form,
TextField,
TextAreaField,
Submit,
FieldError,
Label,
FormError,
} from '@redwoodjs/forms'
import { Flash, useFlash, useMutation } from '@redwoodjs/web'
// ...
return (
<BlogLayout>
<Flash timeout={1000}>
<Form onSubmit={onSubmit} validation={{ mode: 'onBlur' }} error={error}>
<FormError
error={error}
wrapperStyle={{ color: 'red', backgroundColor: 'lavenderblush' }}
/>
//...
)
Désormais, l'envoi du formulaire avec une adresse invalide donne ceci:
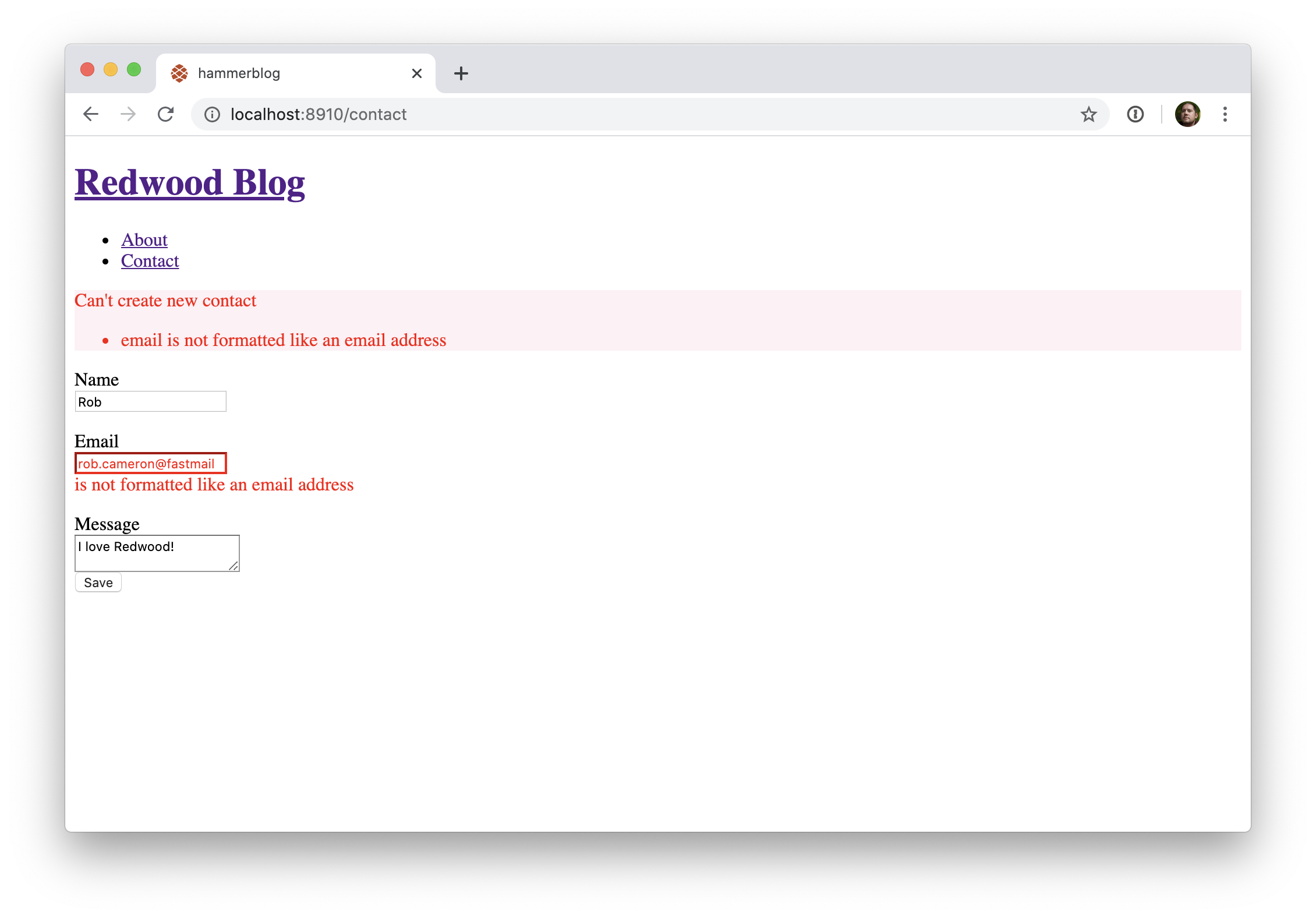
Nous obtenons un message d'erreur en haut du formulaire et les champs concernés sont mis en avant! Le message en haut du formulaire peut apparaître un peu lourd pour un si petit formulaire, mais vous contaterez son utilité lorsque vous construirez des formulaires de plusieurs pages; de cette façon l'utilisateur peut voir imméédiatement ce qui ne fonctionne pas sans avoir à parcourir l'ensemble du formulaire. Si vous ne souhaitez pas utiliser cet affichage, il vous suffit de supprimer <FormError>, les champs seront toujours mis en avant.
<FormError>a plusieurs options pour adapter le style d'affichage
wrapperStyle/wrapperClassName: le conteneur pour l'ensemble du messagetitleStyle/titleClassName: le titre "Can't create new contact"listStyle/listClassName: le<ul>qui contient la liste des erreurslistItemStyle/listItemClassName: chaque<li>contenant chaque erreur
Puisque nous ne redirigeons pas l'utilisateur une fois le formulaire envoyé, nous devrions au moins remettre le formulaire à zéro. Pour celà nous devons utiliser la fonction reset() proposée par react-hook-form, mais nous n'y avons pas accès compte tenu de la manière dont nous utilisons <Form>.
react-hook-form possède un 'hook' appelé useForm() qui est en principe invoquéé pour nous à l'intérieur de <Form>. De façon à réinitialiser le formulaire nous devons invoquer ce 'hook' manuellement. Voici comment faire:
Commençons par importer useForm:
// web/src/pages/ContactPage/ContactPage.js
import { useForm } from 'react-hook-form'Puis invoquons ce 'hook' dans notre composant:
// web/src/pages/ContactPage/ContactPage.js
const ContactPage = () => {
const formMethods = useForm()
//...
Enfin, donnons pour instruction explicite à <Form> d'utiliser formMethods, au lieu de le laisser le faire lui-même:
// web/src/pages/ContactPage/ContactPage.js
return (
<BlogLayout>
<Flash timeout={1000}>
<Form
onSubmit={onSubmit}
validation={{ mode: 'onBlur' }}
error={error}
formMethods={formMethods}
>
// ...
Maintenant nous pouvons invoquer manuellement reset() depuis formMethods() juste après que le message de confirmation soit affiché:
// web/src/pages/ContactPage/ContactPage.js
const [create, { loading, error }] = useMutation(CREATE_CONTACT, {
onCompleted: () => {
// addMessage...
formMethods.reset()
},
})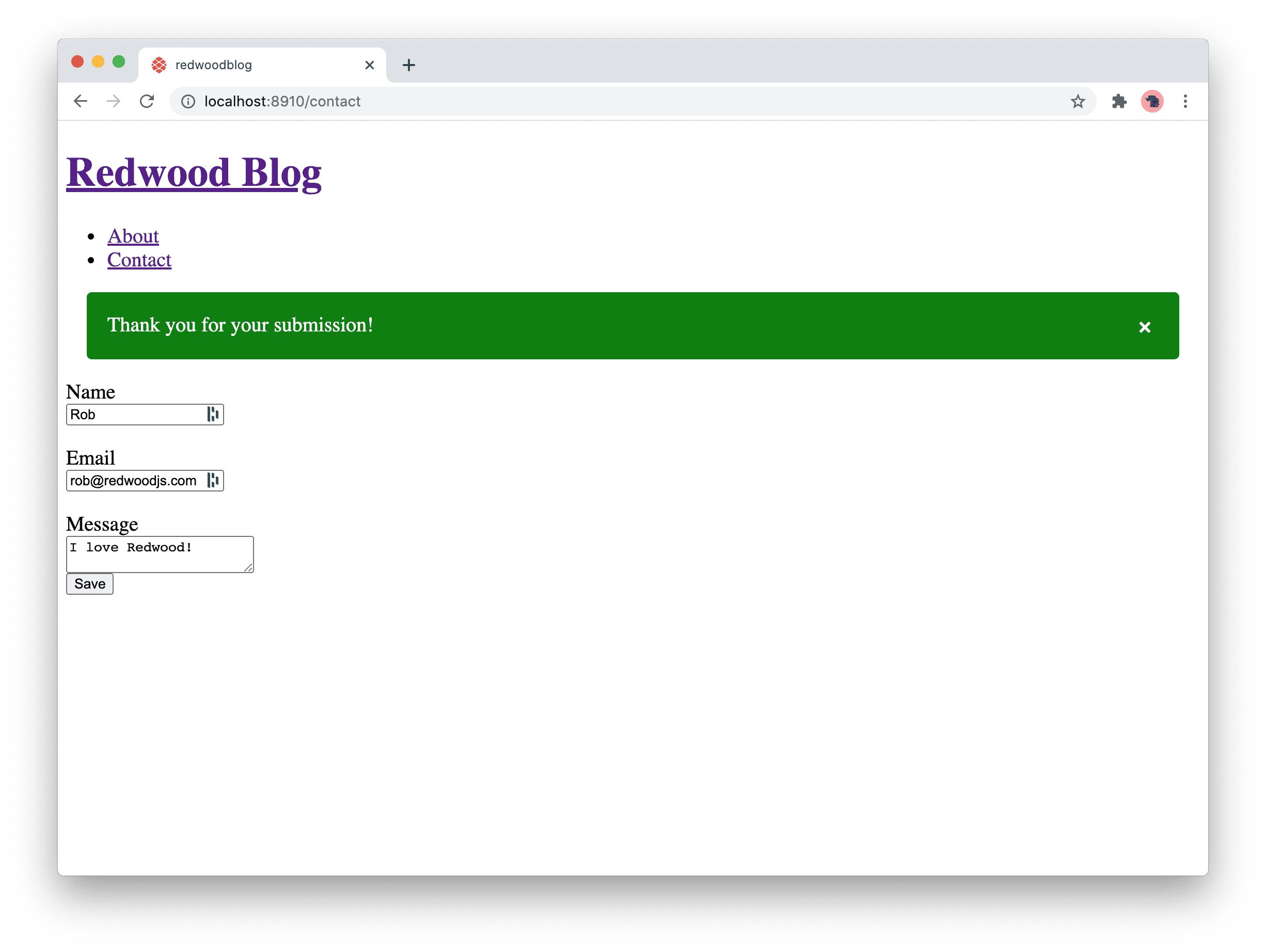
Vous pouvez maintenant réactiver la validation email côté client sur le
<TextField>, tout en conservant la validation côté serveur.
Voici le contenu final de la page ContactPage.js:
import {
Form,
TextField,
TextAreaField,
Submit,
FieldError,
Label,
FormError,
} from '@redwoodjs/forms'
import { Flash, useFlash, useMutation } from '@redwoodjs/web'
import { useForm } from 'react-hook-form'
import BlogLayout from 'src/layouts/BlogLayout'
const CREATE_CONTACT = gql`
mutation CreateContactMutation($input: CreateContactInput!) {
createContact(input: $input) {
id
}
}
`
const ContactPage = () => {
const formMethods = useForm()
const { addMessage } = useFlash()
const [create, { loading, error }] = useMutation(CREATE_CONTACT, {
onCompleted: () => {
addMessage('Thank you for your submission!', {
style: { backgroundColor: 'green', color: 'white', padding: '1rem' }
})
formMethods.reset()
},
})
const onSubmit = (data) => {
create({ variables: { input: data } })
console.log(data)
}
return (
<BlogLayout>
<Flash timeout={1000} />
<Form
onSubmit={onSubmit}
validation={{ mode: 'onBlur' }}
error={error}
formMethods={formMethods}
>
<FormError
error={error}
wrapperStyle={{ color: 'red', backgroundColor: 'lavenderblush' }}
/>
<Label name="name" errorClassName="error">
Name
</Label>
<TextField
name="name"
validation={{ required: true }}
errorClassName="error"
/>
<FieldError name="name" className="error" />
<Label name="name" errorClassName="error">
Email
</Label>
<TextField
name="email"
validation={{
required: true,
}}
errorClassName="error"
/>
<FieldError name="email" className="error" />
<Label name="name" errorClassName="error">
Message
</Label>
<TextAreaField
name="message"
validation={{ required: true }}
errorClassName="error"
/>
<FieldError name="message" className="error" />
<Submit disabled={loading}>Save</Submit>
</Form>
</BlogLayout>
)
}
export default ContactPageC'est terminé! React Hook Form propose pas mal de fonctionalités que <Form> n'expose pas. Lorsque vous souhaitez les utiliser, appelez juste le 'hook' useForm() vous-même, en vous assurant de bien passer en argument l'objet retourné (formMethods) comme propriété de <Form> de façon à ce que la validation et les autres fonctionalités puissent continuer à fonctionner.
Vous avez peut-être remarqué que la validation onBlur a cessé de fonctionner lorsque vous avez commencé à appeler
userForm()par vous-même. Ceci s'explique car Redwood invoqueuserForm()et lui passe automatiquement en argument ce que vous avez passé à<Form>. Puisque Redwood n'appelle plus automatiquementuseForm()à votre place, vous devez de faire manuellement:const formMethods = useForm({ mode: 'onBlur' })
La partie publique du site a bon aspect. Que faire maintenant de la partie administration qui nous permet de créer et éditer les articles? Nous devrions la déplacer dans une partie réservée et la placer derrière un login, de façon à ce des utilisateurs mal intentionnés ne puissent pas créer en chaîne, par exemple, des publicités pour l'achat de médicaments en ligne...
Il semble raisonable de faire en sorte que les écrans d'administration soient regroupés sous un chemin /admin. Mettons à jour les routes de manière à ce que les quatre routes commençant par /posts commencent désormais paar /admin/posts:
// web/src/Routes.js
<Route path="/admin/posts/new" page={NewPostPage} name="newPost" />
<Route path="/admin/posts/{id:Int}/edit" page={EditPostPage} name="editPost" />
<Route path="/admin/posts/{id:Int}" page={PostPage} name="post" />
<Route path="/admin/posts" page={PostsPage} name="posts" />Allez à http://localhost:8910/admin/posts et notre page générée par scaffolding devrait s'afficher. Grâce aux routes nommées, nous n'avons pas à mettre à jour les <Link> créés lors du scaffold puisque l'attribut name reste identique!
Sur la dernière page nous avons mentionné que nous allions créer une section admin et la mettre derrière un login. Jusqu'à maintenant nous n'avons fait que modifier les routes. Ne vous inquiétez pas, nous n'avons pas oublié! Nous allons mettre en place l'authentification dans une prochaine étape.
Que pensez-vous de mettre enfin en ligne tout ce que nous avons réalisé ?
La partie 4 de ce didacticiel en vidéo se trouve ici:
La raison principale pour laquelle nous avons mis au point Redwood était de permettre aux développeurs de construire des applications web full-stack plus facilement tout en adhérant à la philosophie Jamstack. Vous avez pu voir à quoi ressemble l'élaboration d'une application Redwood. Que pensez-vous de voir comment on la déploit?
Il n'y a qu'une modification à faire pour que notre application soit prête à être déployée, et bien entendu nous avons un générateur pour ça:
yarn rw g deploy netlify
L'exécution de cette commande va créer un fichier /netlify.toml contenant les commandes et les chemins de fichiers dont Netlify a besoin afin de construire l'application.
Avant que nous ne poursuivions, assurez-vous que tous les commits soient faits et bien envoyés sur GitHub, GitLab or BitBucket. En effet, nous allons lier Netlify à notre dépôt Git de façon à ce tout nouveau push sur la branch main permette de re-déployer le site. Si vous n'avez jamais travaillé auparavant avec une application Jamstack, préparez-vous à une sympatique expérience!
NOTE: Git utilise par défaut une branche
master. Vous ne savez pas comment renommermasterenmain? Si vous utilisez GitHub, vous pouvez suivre ces étapes:git init git add . git commit -m 'First commit' git branch -m main git remote add origin ... git push -u origin main
Redwood supporte officiellement plusieurs fournisseurs d'hébergement (et d'autres sont en cours d'ajout). Bien que ce didacticiel se poursuive en s'appuyant sur Netlify pour le déploiement et l'authentification, il vous est possible de déployer sur Vercel. Pour cela, commencer par achever la section suivante ("La Base de Données"), mais utilisez ce guide de déploiement Vercel à la place des instructions dédiées à Netlify. Note: Netlify Identity, used in the upcoming "Authentication" section, won't work on the Vercel platform.
Nous avons besoin d'une base de données quelque part sur Internet afin d'enregistrer nos données. Nous avons utilisé SQLite pendant la phase de développement, mais il s'agit d'un outil pensé pour être utilisé par un seul utilisateur. SQLite n'est pas vraiment adapté pour le type de connections concurrentes qu'une application requiert lorsqu'elle entre en production. Pour cette partie du didacticiel, nous utiliserons Postgres. (Prisma supporte à ce jour SQLite, Postgres et MySQL). Ne vous inquiétez pas si vous n'êtes pas familier de Postgres, Prisma va se charger de tout ça. Tout ce dont nous avons besoin c'est une base de données qui soit accessible depuis Internet, de telle manière que notre application puisse s'y connecter.
Tout d'abord, nous allons informer Prisma que nous souhaitons utiliser Postgres en plkus de SQLite, de telle manière que Prisma va construire un client pour ces deux bases de données. Mettez à jour l'entrée provider dans schema.prisma:
provider = ["sqlite", "postgresql"]Si vous souhaitez développer en local avec Postgres, consultez le guide.
Pour l'instant, vous avez besoin de créer votre propre base de données, mais nous travaillons avec différents fournisseurs d'infrastructure pour mettre un place un processus plus simple et plus en phase avec la Jamstack. Plus d'informations sont à venir sur ce point!
Il existe différents fournisseurs d'hébergement qui vous permettent de créer rapidement une base de données Postgres:
Nous allons ici utiliser Heroku car 1) c'est gratuit, 2) plus facile à manipuler qu'AWS pour un néophyte.
Rendez-vous sur le site d'Heroku, créez un nouveau compte ou identifiez-vous. Cliquez ensuite sur le boutton create new app.
Donnez lui un nom comme "redwoodblog". Puis allez sur l'onglet Ressources et cliquez sur le bouton Find more add-ons dans la section Add-ons:
Déplacez-vous dans la page jusqu'à faire apparaître Heroku Postgres:
Une page de détail apparaît. Cliquez sur Install Heroku Postgres dans le coin supérieur droit. Sur l'écran suivant, précisez que vous souhaitez connecter la base à l'application que vous venez de créer. Cliquez enfin sur Provision Add-on.
Vous êtes alors redirigé sur la page présentant les détails de votre application. Vous devriez alors pouvoir aller sur l'onglet Resources et constater que l'add-on Heroku Postgres et prêt à être utilisé:
Cliquez sur le lien Heroku Postgres pour vous rendre sur la page de détail, puis sur l'onglet Settings et enfin cliquez sur le boutton View Credentials.... Copiez l'URI située en bas de la page.
Cette ligne est particulièrement longue, assurez-vous que vous avez bien sélectionné et copié l'intégralité de la ligne!
Maintenant, si vous n'en avez pas déjà un, créez un compte Netlify. Ceci étant fait, cliquez simplement sur le boutton New site from Git situé en haut à droite:
Donnez l'autorisation à Netlify de se connecter à votre fournisseur d'hébergement Git, et sélectionnez le dépôt de votre application. Laissez les paramètres par défaut et cliquez sur Deploy site.
Netlify va alors construire votre application (cliquez sur Deploying your site pour prendre connaissance des logs) puis va dire "Site is live",... et rien ne va fonctionner :D Pourquoi? Et pardi, car nous n'avons pas précisé où se trouve notre base de données!
Retournez sur la page principale de Netlify, puis rendez-vous dans Settings, puis dans Build & Deploy > Environment. Cliquez sur Edit variables. C'est à cet endroit que nous allons coller l'URI de connection que nous avions copié depuis Heroku (notez que la valeur de Key est "DATABASE_URL"). Après avoir collé la valeur, ajoutez ?connection_limit=1 à la fin d'URI. Le format final de l'URI est donc: postgres://<user>:<pass>@<url>/<db>?connection_limit=1.

Lorsque vous configurez la base de données, vous ajouterez de préférence
?connection_limit=1à l'URI. Il s'agit d'une recommandation pour l'utilisation de Prisma dans le cadre d'une utilisation Serverless.
Assurez-vous de cliquer sur le boutton Save. Maintenant rendez-vous sur l'onglet Deploys, ouvrez le champ de sélection Trigger deploy sur la droite et choisissez Deploy site:
Avec un peu de chance (et de science!!), tout va fonctionner correctement! Vous pouvez cliquer sur le bouton Preview en haut de page avec les logs, ou revenir à la page précédente et cliquer sur l'URL de déploiement de votre site située en haut de l'écran:

Est-ce que ça fonctionne? Si vous voyez "Empty" sous les liens About et Contact, c'est que ça marche! Cool! "Empty" signifie simplement que vous n'avez aucun article enregistré dans votre base de données. Allez simplement sur /admin/posts pour en créer quelques-un, puis revenez sur la page d'accueil de votre application pour les voir s'afficher.
Si vous regardez le déploiement via le bouton Preview, remarquez que l'URL contient un hash du dernier commit. Netlify va en créer un à chaque nouveau push sur la branche
mainmais ne montrera que ce commit. Donc si vous déployez à nouveau en executant un refresh, vous ne verrez aucune modification. L'URL de déploiement de votre site (celle que vous obtenez depuis la page d'accueil de Netlify) affichera toujours le dernier déploiement. Consultez la section suivante "Déploiement de Branche" pour plus d'informations.
Si votre déploiement n'a pas fonctionné, consultez le log dans Netlify et voyez si vous comprenez l'erreur qui s'affiche. Si votre déploiement s'esst correctement effectué mais que le site ne s'affiche pas, essayez d'ouvrir les outils de développement de votre navigateur afin de voir si des erreurs s'affichent. Assurez-vous également de bien avoir copié en totalité l'URI de connection Postgres depuis Heroku. Si véritablement vous ne parvenez pas à trouver d'où vient l'erreur, demandez-donc de l'aide à la communauté Redwood.
Une autre fonctionnalité bien pratique de Netlify est appelée branch deploys. Lorsque vous créez une branche et effectuez un push sur votre dépôt Git, Netlify va contruire votre application depuis cette branche et vous retourner une URL unique de telle manière que vous puissiez tester vos modifications tout en laissant intacte le déploiement effectué depuis la branche main. Une fois que votre branche alternative a été merged dans la branche main, une nouvelle construction de votre application sera effectuée en prenant en compte les modifications apportées par la branche alternative. Pour activer le déploiement de branches, allez dans Settings>Continuous Deployment puis sous la section Deploy context cliquez sur Edit Settings et modifiez Branch Deploys to "All". Vous pouvez également activer Deploy previews qui va créer une préview pour toute pull-request effectuée sur votre dépôt.

Vous avez également la possibilité de "vérouiller" la branche
mainde telle manière que chaque push ne déclanche pas automatiquement une reconstruction de l'application. Vous devez alors demander à Netlify manuellement de déployer la dernière version présente sur le dépôt, soit en vous rendant sur le site, soit en utilisant la CLI Netlify.
Dans ce didacticiel, vos fonctions lambda vont se connecter directement à la base Postgres. Dans la mesure où Postgres à un nombre limité de connections concurrentes possibles, son utilisation peut devenir problématique lorsque le nombre d'utlisateurs croît énormément. La bonne solution est de mettre en place un service de "connection pooling" devant Postgres et y connecter vos fonctions lambda. Pour apprendre comment faire ça, consulter le guide associé.
"Authentification" est un mot-valise pour tout ce qui se rapporte au fait de s'assurer que l'utilisateur, souvent identifié à l'aide d'un couple email/mot de passe, est autorisé à accéder à quelque chose. L'authentification peut être parfois délicate à mettre en oeuvre techniquement et vous causer de sérieux maux de tête.
Heureusement, Redwood est là pour vous! L'authentification n'est pas une chose qu'il vous faut écrire en partant de zero, c'est un problème identifié et résolu qui ne devrait au contraire vous causer que peu de soucis. A ce jour, Redwood s'intégre avec :
Puisque nous avons déjà commecé à déployer notre application sur Netlify, nous allons ici découvrir ensemble Netlify Identity.
Il existe deux termes contenant beaucoup de lettres, commençant par "A" et finissant par "ation" qu'il bien faut distinguer:
- Authentification (Authentication en anglais)
- Autorisation (Authorization en anglais)
Voici comment Redwood utilise ces termes:
- Authentification se rapporte au fait de savoir dans quelle mesure une personne est bien celle qu'elle prétend être. Celà prend généralement la forme d'un formulaire de Login avec un email et un mot de passe, ou un fournisseurs OAuth tiers comme Google.
- Autorisation se rapporte au fait de savoir si un utilisateur (qui en général s'est déjà authentifié) est autorisé à effectuer ou non une action. Celà recouvre en général une combinaison de roles et de permissions qui sont évaluées avant de donner ou refuser l'accès à une URL du site.
Cette section du didacticiel se concentre en particulier sur l'authentification. Nous travaillons actuellement à inclure un système simple et flexible de rôles. Une fois ceci réalisé, nous mettrons à jour ce didacticiel!
En supposant que vous avez complété toutes les étapes précédentes, vous disposez déjà d'un compte Netlify ainsi que d'une application fonctionelle. Dans ce cas, rendez-vous sur l'onglet Identity et cliquez sur le boutton Enable Identity:

Lorsque l'écran s'affiche, cliquez sur le boutton Invite users et entrez une adresse email. Netlify enverra à cette adresse un lien de confirmation:

Nous aurons besoin de cet email de confirmation très bientôt, mais pour le moment continuons la mise en place de l'authentification.
Quelques modifications doivent être effectuées sur le code pour mettre en place l'authentification. Fort heureusement, Redwood peut le faire pour nous car un générateur est prévu pour ça:
yarn rw g auth netlify
Cette commande permet d'ajouter un fichier et d'en modifier quelques autres.
Vous ne remarquez aucun changement?
Afin que celà fonctionne, vous devez utiliser au minimum la version
0.7.0de Redwood. Le cas échéant, mettez à jour Redwood avecyarn rw upgrade.
Observez le contenu du fichier api/src/lib/auth.js qui vient d'être créé (les commentaires ont été supprimé pour plus de clarté):
// api/src/lib/auth.js
import { AuthenticationError } from '@redwoodjs/api'
export const getCurrentUser = async (decoded, { token, type }) => {
return decoded
}
export const requireAuth = () => {
We'll hook up both the web and api sides below to make sure a user is only doing things they're allowed to do.
if (!context.currentUser) {
throw new AuthenticationError("You don't have permission to do that.")
}
}Par défaut, le système d'authentification va retourner uniquement les données connues par le fournisseur tiers (c'est ce qui se trouve dans l'objet jwt). Dans le cas de Netlify Identity, il s'agit d'une adresse email, d'un nom (optionnel), et d'un tableau de roles (optionnel également). En général, vous disposez de votre propre modélisation de ce qu'est un utilisateur dans votre base de données. Vous pouvez modifier getCurrentUser de façon à retourner cet utilisateur plutôt que les détails enregistrés par le fournisseur d'authentification. Les commentaires présents en haut du fichier vous montrent un exemple permettant de rechercher un utilisateur à partir de l'adresse email récupérée. Redwood fournit également par défaut la fonction requireAuth(), une implémentation simple pour s'assurer qu'un utilisateur est bien authentifié afin d'accéder à un service. Le cas échéant, une erreur sera lancée de telle façon que GraphQL sache quoi faire si un utilisateur non authentifié essaye de faire quelque chose qu'il ne devrait pas pourvoir effectuer.
Les fichiers qui ont été modifés par le générateur sont les suivants:
web/src/index.js— Entoure le routeur au sein du composant<AuthProvider>, ce qui fait que les routes elle-mêmes sont soumises à authentification. Cela donne également accès au "hook"useAuth()qui expose quelques fonctions permettant à l'utilisateur de se connecter, se déconnecter, verifier le statut courant, etc..api/src/functions/graphql.js— Rend disponiblecurrentUserpour la partie API de l'application, de telle façon que vous puissez verifier si un utilisateur est autorisé ou non à faire quelque chose. Si vous ajoutez une implémentation àgetCurrentUser()dansapi/src/lib/auth.js, alors ce sera ce qui sera retourné parcurrentUser, dans le cas contrairecurrentUsercontiendranull.
Nous allons connecter les côtés Web et API ci-dessous pour nous assurer qu'un utilisateur ne fait que les choses qu'il est autorisé à faire.
Commençons par verrouiller l'API afin que nous puissions être sûrs que seuls les utilisateurs autorisés peuvent créer, mettre à jour et supprimer une publication. Ouvrez le service Post et ajoutons une vérification:
// api/src/services/posts/posts.js
import { db } from 'src/lib/db'
import { requireAuth } from 'src/lib/auth'
export const posts = () => {
return db.post.findMany()
}
export const post = ({ id }) => {
return db.post.findOne({
where: { id },
})
}
export const createPost = ({ input }) => {
requireAuth()
return db.post.create({
data: input,
})
}
export const updatePost = ({ id, input }) => {
requireAuth()
return db.post.update({
data: input,
where: { id },
})
}
export const deletePost = ({ id }) => {
requireAuth()
return db.post.delete({
where: { id },
})
}
export const Post = {
user: (_obj, { root }) => db.post.findOne({ where: { id: root.id } }).user(),
}
Essayez maintenant de créer, de modifier ou de supprimer un article de nos pages d'administration. Il ne se passe rien! Devrions-nous afficher une sorte de message d'erreur convivial? Dans ce cas, probablement pas - nous allons verrouiller complètement les pages d'administration afin qu'elles ne soient pas accessibles par un navigateur. La seule façon pour quelqu'un de déclencher ces erreurs dans l'API est de tenter d'accéder directement au point de terminaison GraphQL, sans passer par notre interface utilisateur. L'API renvoie déjà un message d'erreur (ouvrez l'inspecteur Web dans votre navigateur et essayez à nouveau de créer / modifier / supprimer), nous sommes donc couverts.
Notez que nous mettons les vérifications d'authentification dans le service et non la vérification dans l'interface GraphQL (dans les fichiers SDL).
Redwood a créé le concept de services en tant que conteneurs pour votre logique métier qui peuvent être utilisés par d'autres parties de votre application en plus de l'API GraphQL. En plaçant des contrôles d'authentification ici, vous pouvez être sûr que tout autre code qui tente de créer / mettre à jour / supprimer une publication tombera sous les mêmes contrôles d'authentification. En fait, Apollo (la bibliothèque GraphQL utilisée par Redwood) est d'accord avec nous!
Nous allons maintenant restreindre complètement l'accès aux pages d'administration, sauf si vous êtes connecté. La première étape consistera à indiquer les itinéraires qui nécessiteront que vous soyez connecté. Pour ce faire, ajouter la balise <Private>:
// web/src/Routes.js
import { Router, Route, Private } from '@redwoodjs/router'
const Routes = () => {
return (
<Router>
<Route path="/contact" page={ContactPage} name="contact" />
<Route path="/about" page={AboutPage} name="about" />
<Route path="/" page={HomePage} name="home" />
<Route path="/blog-post/{id:Int}" page={BlogPostPage} name="blogPost" />
<Private unauthenticated="home">
<Route path="/admin/posts/new" page={NewPostPage} name="newPost" />
<Route path="/admin/posts/{id:Int}/edit" page={EditPostPage} name="editPost" />
<Route path="/admin/posts/{id:Int}" page={PostPage} name="post" />
<Route path="/admin/posts" page={PostsPage} name="posts" />
</Private>
<Route notfound page={NotFoundPage} />
</Router>
)
}
export default Routes
Entourez les routes que vous voulez protéger par l'authentification, et ajoutez éventuellement l'attribut unauthenticated qui répertorie le nom d'une autre route vers laquelle rediriger si l'utilisateur n'est pas connecté. Dans ce cas, nous reviendrons à la page d'accueil.
Essayez cela dans votre navigateur. Si vous cliquez sur http://localhost:8910/admin/posts, vous devez immédiatement revenir à la page d'accueil.
Il ne reste plus qu'à laisser l'utilisateur se connecter! Si vous avez déjà créé une authentification, vous savez que cette partie est généralement un frein, mais Redwood en fait une gentille promenade au parc. La majeure partie de la plomberie a été gérée par le générateur d'authentification, nous pouvons donc nous concentrer sur les parties que l'utilisateur voit réellement. Tout d'abord, ajoutons un lien Login qui déclenchera une fenêtre modale à partir du widget Netlify Identity. Supposons que nous souhaitons obtenir cela sur toutes les pages publiques, nous allons donc le mettre dans le BlogLayout:
// web/src/layouts/BlogLayout/BlogLayout.js
import { Link, routes } from '@redwoodjs/router'
import { useAuth } from '@redwoodjs/auth'
const BlogLayout = ({ children }) => {
const { logIn } = useAuth()
return (
<div>
<h1>
<Link to={routes.home()}>Redwood Blog</Link>
</h1>
<nav>
<ul>
<li>
<Link to={routes.about()}>About</Link>
</li>
<li>
<Link to={routes.contact()}>Contact</Link>
</li>
<li>
<a href="#" onClick={logIn}>
Log In
</a>
</li>
</ul>
</nav>
<main>{children}</main>
</div>
)
}
export default BlogLayout
Essayez de cliquer sur le lien Login:

Nous devons informer le widget de l'URL de notre site afin qu'il sache où aller pour obtenir les données des utilisateurs et confirmer qu'ils peuvent se connecter. De retour sur Netlify, vous pouvez l'obtenir à partir de l'onglet Identity:

Vous avez besoin du protocole et du domaine, pas du reste du chemin. Collez-le dans la fenêtre modale et cliquez sur le bouton Set site's URL. La fenêtre modale devrait se recharger et afficher maintenant une vraie boîte de connection:

Avant de pouvoir nous connecter, vous rappelez-vous cet e-mail de confirmation de Netlify? Allez le trouver et cliquez sur le lien Accept the invite . Cela vous amènera à votre site en production, où rien ne se passera. Mais si vous regardez l'URL, elle se terminera par quelque chose comme #invite_token=6gFSXhugtHCXO5Whlc5V. Copiez-le (y compris le #) et ajoutez-le à votre URL localhost: http://localhost:8910/#invite_token=6gFSXhugtHCXO5Whlc5Vg. Appuyez sur Entrée, puis revenez dans l'URL et appuyez à nouveau sur Entrée pour qu'il recharge la page. Maintenant, la fenêtre modale affichera Complete your signup et vous donnera la possibilité de définir votre mot de passe:

Une fois que vous faites cela, la fenêtre modale devrait se mettre à jour et dire que vous êtes connecté! Ça a marché! Cliquez sur le X en haut à droite pour fermer la fenêtre modale.
Nous savons que ce workfow d'acceptation des invitations est loin d'être idéal. La bonne nouvelle est que, lorsque déployez à nouveau votre site avec authentification, les futures invitations fonctionneront automatiquement - le lien ira à la production qui aura désormais le code nécessaire pour lancer le modal et vous permettra d'accepter l'invitation.
Cependant, nous n'avons actuellement aucune indication sur notre site que nous sommes connectés. Pourquoi ne pas changer le bouton Log In en Log Out lorsque vous êtes authentifié:
// web/src/layouts/BlogLayout/BlogLayout.js
import { Link, routes } from '@redwoodjs/router'
import { useAuth } from '@redwoodjs/auth'
const BlogLayout = ({ children }) => {
const { logIn, logOut, isAuthenticated } = useAuth()
return (
<div>
<h1>
<Link to={routes.home()}>Redwood Blog</Link>
</h1>
<nav>
<ul>
<li>
<Link to={routes.about()}>About</Link>
</li>
<li>
<Link to={routes.contact()}>Contact</Link>
</li>
<li>
<a href="#" onClick={isAuthenticated ? logOut : logIn}>
{isAuthenticated ? 'Log Out' : 'Log In'}
</a>
</li>
</ul>
</nav>
<main>{children}</main>
</div>
)
}
export default BlogLayout
useAuth () nous apporte quelques aides supplémentaires, dans le cas présent isAuthenticated retournera true ou false en fonction de votre statut de connexion, et logOut () déconnectera l'utilisateur. Cliquez maintenant sur Log Out pour vous déconnecter et changer le lien en Log In sur lequel vous pouvez cliquer pour ouvrir la fenêtre modale et vous reconnecter.
Lorsque vous êtes connecté, vous devriez pouvoir accéder à nouveau aux pages d'administration: http://localhost:8910/admin/posts
Si vous commencez à travailler sur une autre application Redwood qui utilise Netlify Identity, vous devrez effacer manuellement votre stockage local, où est stockée l'URL du site que vous avez entrée la première fois que vous avez vu la fenêtre modale. Le stockage local est lié à votre domaine et à votre port, qui par défaut seront les mêmes pour toute application Redwood lors du développement local. Vous pouvez effacer votre stockage local dans Chrome en allant dans l'inspecteur Web, puis dans l'onglet Application, puis à gauche, ouvrez Local Storage et cliquez sur http://localhost:8910. Vous verrez les clés stockées sur la droite et pourrez toutes les supprimer.
Encore un détail: montrons l'adresse e-mail de l'utilisateur connecté. Nous pouvons obtenir le currentUser par le "hook" useAuth(). Il contiendra les données que notre bibliothèque d'authentification tierce stocke pour l'utilisateur actuellement connecté:
// web/src/layouts/BlogLayout/BlogLayout.js
import { Link, routes } from '@redwoodjs/router'
import { useAuth } from '@redwoodjs/auth'
const BlogLayout = ({ children }) => {
const { logIn, logOut, isAuthenticated, currentUser } = useAuth()
return (
<div>
<h1>
<Link to={routes.home()}>Redwood Blog</Link>
</h1>
<nav>
<ul>
<li>
<Link to={routes.about()}>About</Link>
</li>
<li>
<Link to={routes.contact()}>Contact</Link>
</li>
<li>
<a href="#" onClick={isAuthenticated ? logOut : logIn}>
{isAuthenticated ? 'Log Out' : 'Log In'}
</a>
</li>
{isAuthenticated && <li>{currentUser.email}</li>}
</ul>
</nav>
<main>{children}</main>
</div>
)
}
export default BlogLayout

Consultez les paramètres d'identité sur Netlify pour plus d'options, notamment permettre aux utilisateurs de créer des comptes plutôt que d'avoir à être invités, ajouter des boutons de connexion tiers pour Bitbucket, GitHub, GitLab et Google, recevoir des webhooks lorsque quelqu'un se connecte, etc... !
Croyez-le ou non, c'est tout! L'authentification avec Redwood est un jeu d'enfant et nous ne faisons que commencer. Attendez-vous à plus de magie bientôt!
Si vous inspectez le contenu de
currentUser, vous verrez qu'il contient un tableau appeléroles. Sur le tableau de bord Netlify Identity, vous pouvez attribuer à votre utilisateur une collection de rôles, qui ne sont que des chaînes de caractères telles que «admin» ou «guest». En utilisant cette gamme de rôles, vous pourriez créer un système d'authentification basé sur les rôles très rudimentaire. À moins que vous n'ayez un besoin urgent de cette simple vérification de rôle, nous vous recommandons d'attendre la solution Redwood, à venir bientôt!
Vous l'avez fait! Si vous avez vraiment parcouru tout le tutoriel: félicitations! Si vous venez de passer à cette page pour essayer d'obtenir des félicitations gratuites: tss, tss...
Cela représentait potentiellement beaucoup de nouveaux concepts à absorber d'un seul coup, alors ne vous en faîte pas si vous ne retenez pas tout complètement. React, GraphQL, Prisma, les fonctions Serverless... tant de choses! Même ceux d'entre nous qui travaillent sur le framework consultent Google plusieurs fois par jour pour comprendre comment faire fonctionner ces éléments ensemble.
Comme l'a dit un utilisateur anonyme de Twitter: "Si vous aimez vous sentir à la fois la personne la plus intelligente du monde et la personne la plus stupide de l'histoire en l'espace de 24 heures, la programmation peut être un bon choix de carrière!"
Vous souhaitez ajouter d'autres fonctionnalités à votre application? Découvrez quelques-un de nos "Cookbook" (livres de recettes) comme appeler une API tierce, ou encore déployer une application sans API du tout. Vous en avez assez de SQLite et souhaitez installer Postgres localement? Nous avons également de nombreux guides pour plus d'informations sur les composants internes de Redwood.
Consultez notre Feuille de route pour voir où nous allons et comment nous allons y arriver.
Si vous souhaitez aider, faites-le nous savoir sur le [forum de RedwoodJS] (https://community.redwoodjs.com/) et nous serons heureux de vous accompagner.
Nous voulons atteindre la version 1.0 d'ici la fin de l'année. Et avec votre aide, nous pensons que nous pouvons le faire.
Qu'avez-vous pensé de Redwood? Est-ce la prochaine étape pour les frameworks JS? Que peut-il faire mieux? Nous avons encore beaucoup de choses prévues. Vous souhaitez nous aider à créer ces fonctionnalités?
Merci d'avoir suivi ce didacticiel. Et maintenant, construisez quelque chose d'incroyable!