This is the code repository for "Learning When Not to Decide: A Framework for Overcoming Factual Presumptuousness in AI Adjudication."
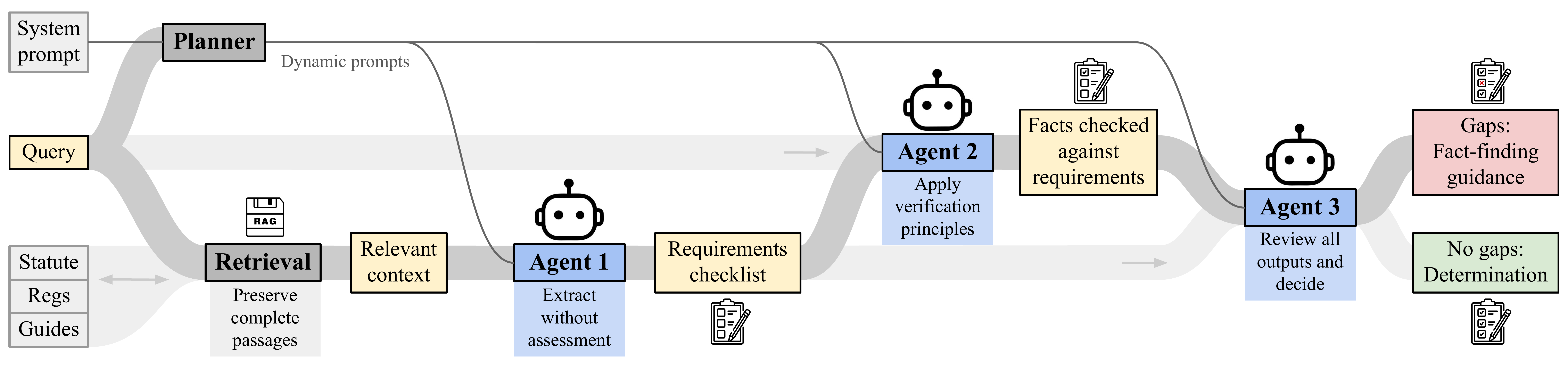
A well-known limitation of AI systems is presumptuousness: the tendency to provide confident answers when information may be lacking. This challenge is particularly acute in legal applications, where a core task for attorneys, judges, and administrators is to determine whether evidence is sufficient to reach a conclusion. We study this problem in the important setting of unemployment insurance adjudication, which has seen rapid integration of AI systems and where the question of additional fact-finding poses the most significant bottleneck for a system that affects millions of applicants annually. We evaluate four leading AI platforms and show that standard RAG-based approaches achieve an average of only 15% accuracy when information is insufficient. We introduce SPEC (Structured Prompting for Evidence Checklists), a multi-stage framework requiring explicit identification of missing information before any determination. SPEC achieves 89% overall accuracy, while appropriately deferring when evidence is insufficient.
@inproceedings{afane2026spec,
author = {Mohamed Afane and Emily Robitschek and Derek Ouyang and Daniel E. Ho},
title = {Learning When Not to Decide: A Framework for Overcoming Factual Presumptuousness in {AI} Adjudication},
booktitle = {Proceedings of the Twenty-First International Conference on Artificial Intelligence and Law (ICAIL '26)},
year = {2026},
publisher = {ACM},
address = {Singapore}
}
This code repository is structured as follows.
spec/pipeline.py: The SPEC multi-agent pipeline, implementing the three-agent architecture (Requirements Checklist, Fact Verification, Supervisory Review).spec/retriever.py: RAG retrieval system for extracting relevant statutory provisions, administrative regulations, and adjudication guidance as complete passages.spec/prompts.py: Prompt templates for each stage of the pipeline, including the three-agent analysis framework.run_benchmark.py: Evaluation script for running the benchmark dataset across models.data/benchmark.xlsx: The benchmark dataset of 250 questions based on Colorado UI law, with ground-truth labels.
We release our benchmark dataset of 250 carefully constructed questions based on Colorado unemployment insurance law. The dataset includes:
- Complete cases (44%): Cases containing all facts necessary for an eligibility determination (eligible or ineligible).
- Inconclusive cases (56%): Cases where one to four critical facts are intentionally withheld, testing whether systems appropriately defer judgment.
Questions address scenarios involving voluntary quit, discharge for misconduct, availability for work, and other eligibility criteria under Colorado Revised Statutes. The dataset is included in this repository as data/benchmark.xlsx.
The SPEC pipeline operates over adjudication guides provided through RAG. In this work, we use internal training materials from the Colorado Department of Labor and Employment (CDLE), which are not included in this repository as they are internal agency documents. The method is applicable to other legal adjudication settings where similar reference materials (statutes, regulations, procedural guides) are available — these documents should be placed in a docs/ directory for the retrieval system to use.
pip install -r requirements.txtCreate a .env file with your API keys:
ANTHROPIC_API_KEY=your_key_here
OPENAI_API_KEY=your_key_here
GEMINI_API_KEY=your_key_here
Run the benchmark evaluation:
python run_benchmark.py --provider anthropic --questions 1-10