diff --git a/README.md b/README.md
index 20ca1a558..75bc151d4 100644
--- a/README.md
+++ b/README.md
@@ -1,6 +1,8 @@
+
+
# Sourcegraph Docs
-
+
Welcome to the Sourcegraph documentation! We're excited to have you contribute to our docs. We've recently rearchitectured our docs tech stack — powered by Next.js, TailwindCSS and deployed on Vercel. This guide will walk you through the process of contributing to our documentation using the new tech stack.
diff --git a/docs/batch-changes/bulk-operations-on-changesets.mdx b/docs/batch-changes/bulk-operations-on-changesets.mdx
index 2351615c7..a2b48cc43 100644
--- a/docs/batch-changes/bulk-operations-on-changesets.mdx
+++ b/docs/batch-changes/bulk-operations-on-changesets.mdx
@@ -37,6 +37,7 @@ Below is a list of supported bulk operations for changesets and the conditions w
| **Close** | Close the selected changesets on the code hosts |
| **Publish** | Publishes the selected changesets, provided they don't have a [`published` field](/batch-changes/batch-spec-yaml-reference#changesettemplatepublished) in the batch spec. You can choose between draft and normal changesets in the confirmation modal |
| **Export** | Export selected changesets that you can use for later use |
+| **Re-execute** | Users can re-execute individual changeset creation logic for selected workspaces. This allows for creating new changesets for users who are using non-deterministic run steps (for example,LLMs) |
## Monitoring bulk operations
diff --git a/docs/batch-changes/how-src-executes-a-batch-spec.mdx b/docs/batch-changes/how-src-executes-a-batch-spec.mdx
index f3624095a..a3efb1cc8 100644
--- a/docs/batch-changes/how-src-executes-a-batch-spec.mdx
+++ b/docs/batch-changes/how-src-executes-a-batch-spec.mdx
@@ -23,6 +23,7 @@ Here, you will learn what happens when a user applies or previews a Batch Spec b
- [Sending changeset specs](#sending-changeset-specs)
- [Sending the batch spec](#sending-the-batch-spec)
- [Preview or apply the batch spec](#preview-or-apply-the-batch-spec)
+ - [Halt execution](#halt-execution)
The only difference is the last step, i.e., Preview or apply the batch spec. Here, the `src batch apply` command applies the batch spec, and the `src batch preview` prints a URL that gives you a preview of what would change if you applied the batch spec.
@@ -185,3 +186,7 @@ That request yields an ID uniquely identifying this expanded batch spec version.
If `src batch apply` was used, then the ID of the batch change is used to send another request to the Sourcegraph instance to apply the batch spec.
If `src batch preview` was used to execute and create the batch spec, then a URL is printed, pointing to a preview page on the Sourcegraph instance, on which you can see what would happen if you were to apply the batch spec.
+
+### Halt execution
+
+If you encounter an error while running the `src batch preview` command, there is a fail-fast mode that halts the batch change execution immediately. To implement this, you can add a `-fail-fast` flag to the `src batch preview` and `src batch apply` commands. Once added, your execution should immediately halt on the first error instead of continuing with other repositories. This streamlines the iteration loop for users building a batch change who want to identify errors quickly.
diff --git a/docs/code-search/types/deep-search.mdx b/docs/code-search/types/deep-search.mdx
new file mode 100644
index 000000000..d0275341a
--- /dev/null
+++ b/docs/code-search/types/deep-search.mdx
@@ -0,0 +1,66 @@
+# Deep Search
+
+Learn more about Sourcegraph's agentic Code Search tool Deep Search.
+
+ N ew in version 6.4. Deep Search is currently in research preview for Enterprise customers with access to Cody and Code Search. Because Deep Search is in research preview, it might change significantly in the future as we make improvements and adjust to user feedback. Please reach out to your Sourcegraph account team to request access.
+
+Deep Search is an agentic code search tool. It receives a natural language question about a codebase, performs an in-depth search, and returns a detailed answer. The user can also ask follow-up questions to improve the answer further.
+
+Under the hood, Deep Search is an AI agent that uses various tools to generate its answer. These tools include multiple modes of Sourcegraph's Code Search and Code Navigation tools. Using tools in an agentic loop enables Deep Search to iteratively refine its understanding of the question and codebase, searching until it is confident in its answer.
+
+Deep Search displays a list of sources used to generate the answer. The sources are the various types of searches it performs and the files it reads. The answer is formatted in markdown. If prompted to do so, Deep Search can also generate diagrams as part of its answer.
+
+## Best practices
+
+- Give the agent a starting point for the search: Mention relevant repositories, files, directories, or symbol names. The more specific you are, the faster the search will be.
+- Provide reasonably scoped questions. The agent will perform much better if it does not have to read the entire codebase at once.
+Check the list of sources. This is extremely useful for debugging and understanding where the answer came from. If something is missing, ask a follow-up question and mention the missing source.
+
+### Examples of prompts
+
+- Find examples of logger usage and show examples of the different types of logging we use.
+- I want to know when the indexing queue functionality was last changed in `sourcegraph/zoekt`. Show me the last few commit diffs touching this code and explain the changes.
+- Look at the GraphQL APIs available in `sourcegraph/sourcegraph`. Are any of them unused? The client code is in `sourcegraph/cody`.
+- Which tools do we use in our build processes defined in `BUILD.bazel` files?
+- Generate a request flow diagram for `src/backend`. Mark the auth and rate limit points.
+
+## Enabling Deep Search
+
+Deep Search can only be used on Sourcegraph instances with Code Search and Cody licenses.
+
+Deep Search is disabled by default. To enable it, ask your site administrator to set `experimentalFeatures.deepSearch.enabled = "true"` in your site configuration.
+
+For optimal performance, Deep Search is specialized to only use one model. Currently, Deep Search only supports Claude Sonnet 4.
+
+### Configuring Deep Search on Amazon Bedrock
+
+Include configuration for Claude Sonnet 4 in [modelOverrides](/cody/enterprise/model-configuration#model-overrides) in your site configuration. For more information on configuring models, refer to [Model Configuration](/cody/enterprise/model-configuration).
+
+Example for Sonnet 4 configuration inside `modelOverrides`:
+
+```json
+{
+ "modelRef": "aws-bedrock::v1::claude-sonnet-4",
+ "modelName": "us.anthropic.claude-sonnet-4-20250514-v1:0",
+ "displayName": "Claude Sonnet 4 (AWS Bedrock)",
+ "capabilities": [
+ "chat",
+ "tools",
+ ],
+ "category": "balanced",
+ "status": "stable",
+ "contextWindow": {
+ "maxInputTokens": 200000,
+ "maxOutputTokens": 32000,
+ }
+},
+```
+
+Then, configure Deep Search to use this model in `experimentalFeatures`:
+
+```json
+"experimentalFeatures": {
+ "deepSearch.enabled": true,
+ "deepSearch.model": "aws-bedrock::v1::claude-sonnet-4"
+},
+```
diff --git a/docs/cody/capabilities/agentic-chat.mdx b/docs/cody/capabilities/agentic-chat.mdx
deleted file mode 100644
index 610d739fe..000000000
--- a/docs/cody/capabilities/agentic-chat.mdx
+++ /dev/null
@@ -1,73 +0,0 @@
-# Agentic chat
-
- Learn about the agentic chat experience, an exclusive chat-based AI agent with enhanced capabilities.
-
-Agentic chat (available in version 6.0) is currently in the Experimental stage for Enterprise and is supported on VS Code, JetBrains, Visual Studio editor extensions and Web. Usage may be limited at this stage.
-
-Cody's agentic chat experience is an AI agent that can evaluate context and fetch any additional context (OpenCtx, terminal, etc.) by providing enhanced, context-aware chat capabilities. It extends Cody's functionality by proactively understanding your coding environment and gathering relevant information based on your requests before responding. These features help you get noticeably higher-quality responses.
-
-This agentic chat experience aims to reduce the learning curve associated with traditional coding assistants by minimizing users' need to provide context manually. It achieves this through agentic context retrieval, where the AI autonomously gathers and analyzes context before generating a response.
-
-## Capabilities of agentic chat
-
-The agentic chat experience leverages several key capabilities, including:
-
-- **Proactive context gathering**: Automatically gathers relevant context from your codebase, project structure, and current task
-- **Agentic context reflection**: Review the gathered context to ensure it is comprehensive and relevant to your query
-- **Iterative context improvement**: Performs multiple review loops to refine the context and ensure a thorough understanding
-- **Enhanced response accuracy**: Leverages comprehensive context to provide more accurate and relevant responses, reducing the risk of hallucinations
-
-## What can agentic chat do?
-
-Agentic chat can help you with the following:
-
-### Tool Usage
-
-It has access to a suite of tools for retrieving relevant context. These tools include:
-
-- **Code Search**: Performs code searches
-- **Codebase File**: Retrieves the full content from a file in your codebase
-- **Terminal**: Executes shell commands in your terminal
-- **Web Browser**: Searches the web for live context
-- **OpenCtx**: Any OpenCtx providers could be used by the agent
-
-It integrates seamlessly with external services, such as web content retrieval and issue tracking systems, using OpenCtx providers. To learn more, [read the OpenCtx docs](/cody/capabilities/openctx).
-
-Terminal access is not supported on the Web. It currently only works with VS Code, JetBrains, and Visual Studio editor extensions.
-
-## Terminal access
-
-Agentic chat can use the CLI Tool to request the execution of shell commands to gather context from your terminal. Its ability to execute terminal commands enhances its context-gathering capabilities. However, it’s essential to understand that any information accessible via your terminal could potentially be shared with the LLM. It's recommended not to request information that you don't want to share. Here's what you should consider:
-
-- **Requires user consent**: Agentic chat will pause and ask for permission each time before executing any shell command.
-- **Trusted workspaces only**: Commands can only be executed within trusted workspaces with a valid shell
-- **Potential data sharing**: Any terminal-accessible information may be shared with the LLM
-
-Commands are generated by the agent/LLM based on your request. Avoid asking it to execute destructive commands.
-
-## Use cases
-
-Agentic chat can be helpful to assist you with a wide range of tasks, including:
-
-- **Improved response quality**: Helps you get better and more accurate responses than other LLMs, making up for the additional processing time for context gathering a non-issue
-- **Error resolution**: It can automatically identify error sources and suggest fixes by analyzing error logs
-- **Better unit tests**: Automatically includes imports and other missing contexts to generate better unit tests
-
-## Enable agentic chat
-
-### Getting agentic chat access for Pro users
-
-Pro users can find the agentic chat option in the LLM selector drop-down.
-
-
-
-### Getting agentic chat access for Enterprise customers
-
-Enterprise customers must opt-in to access this agentic chat feature (reach out to your account team for access).
-
-For the experimental release, agentic chat is specifically limited to using Claude Haiku for the reflection steps and Claude Sonnet for the final response to provide a good balance between quality and latency. Therefore, your enterprise instance must have access to both Claude Sonnet and Claude Haiku to use agentic chat. We use the latest versions of these models, and can fall back to older versions when necessary. These models may be changed during the experimental phase to optimize for quality and/or latency.
-
-Additionally, enterprise users need to upgrade their supported client (VS Code, JetBrains, and Visual Studio) to the latest version of the plugin by enabling the following feature flags on their Sourcegraph Instance:
-
-- `agentic-chat-experimental` to get access to the feature
-- `agentic-chat-cli-tool-experimental` to allow [terminal access](#terminal-commands)
diff --git a/docs/cody/capabilities/agentic-context-fetching.mdx b/docs/cody/capabilities/agentic-context-fetching.mdx
new file mode 100644
index 000000000..73fac727a
--- /dev/null
+++ b/docs/cody/capabilities/agentic-context-fetching.mdx
@@ -0,0 +1,120 @@
+# Agentic Context Fetching
+
+ Learn about agentic context fetching, a mini-agent that uses search and tools to retrieve context.
+
+Cody's agentic context fetching experience can evaluate context and fetch any additional context (MCP, OpenCtx, terminal, etc.) by providing enhanced, context-aware chat capabilities. It extends Cody's functionality by proactively understanding your coding environment and gathering relevant information based on your requests before responding. These features help you get noticeably higher-quality responses.
+
+This experience aims to reduce the learning curve associated with traditional coding assistants by minimizing users' need to provide context manually. It achieves this through agentic context retrieval, where the AI autonomously gathers and analyzes context before generating a response.
+
+## Capabilities of agentic chat
+
+The agentic context fetching experience leverages several key capabilities, including:
+
+- **Proactive context gathering**: Automatically gathers relevant context from your codebase, project structure, and current task
+- **Agentic context reflection**: Review the gathered context to ensure it is comprehensive and relevant to your query
+- **Iterative context improvement**: Performs multiple review loops to refine the context and ensure a thorough understanding
+- **Enhanced response accuracy**: Leverages comprehensive context to provide more accurate and relevant responses, reducing the risk of hallucinations
+
+## What can agentic context fetching do?
+
+Agentic context fetching can help you with the following:
+
+### Tool Usage
+
+It has access to a suite of tools for retrieving relevant context. These tools include:
+
+- **Code Search**: Performs code searches
+- **Codebase File**: Retrieves the full content from a file in your codebase
+- **Terminal**: Executes shell commands in your terminal
+- **Web Browser**: Searches the web for live context
+- **MCP**: (Configure MCP and add servers)[] to fetch external context
+- **OpenCtx**: Any OpenCtx providers could be used by the agent
+
+It integrates seamlessly with external services, such as web content retrieval and issue tracking systems, using OpenCtx providers. To learn more, [read the OpenCtx docs](/cody/capabilities/openctx).
+
+Terminal access is not supported on the Web. It currently only works with VS Code, JetBrains, and Visual Studio editor extensions.
+
+## Terminal access
+
+Agentic context fetching can use the CLI Tool to request the execution of shell commands to gather context from your terminal. Its ability to execute terminal commands enhances its context-gathering capabilities. However, it's essential to understand that any information accessible via your terminal could potentially be shared with the LLM. It's recommended not to request information that you don't want to share. Here's what you should consider:
+
+- **Requires user consent**: Agentic context fetching will pause and ask for permission each time before executing any shell command.
+- **Trusted workspaces only**: Commands can only be executed within trusted workspaces with a valid shell
+- **Potential data sharing**: Any terminal-accessible information may be shared with the LLM
+
+Commands are generated by the agent/LLM based on your request. Avoid asking it to execute destructive commands.
+
+## Use cases
+
+Agentic context fetching can be helpful to assist you with a wide range of tasks, including:
+
+- **Improved response quality**: Helps you get better and more accurate responses than other LLMs, making up for the additional processing time for context gathering a non-issue
+- **Error resolution**: It can automatically identify error sources and suggest fixes by analyzing error logs
+- **Better unit tests**: Automatically includes imports and other missing contexts to generate better unit tests
+
+## Enable agentic context fetching
+
+Agentic context fetching is enabled by default for all Cody users. It uses LLM reflection and basic tool use steps to gather and refine context before sending it in the final model query. The review step in agentic context fetching experience defaults to Gemini 2.5 Flash and falls back to Claude Haiku or GPT 4.1 mini if Flash is unavailable.
+
+You can disable agentic context in your extension settings using `cody.agenticContext`.
+
+Terminal access for Enterprise users is disabled by default. To enable it, set the `agentic-chat-cli-tool-experimental` feature flag [terminal access](#terminal-commands).
+
+## MCP support
+
+Cody supports [Model Context Protocol (MCP)](https://modelcontextprotocol.io/introduction) for connecting to external context. MCP servers are utilized via Cody’s agentic context fetching. Users can configure multiple local MCP servers via their Cody extension settings. Based on your query, agentic context will determine which MCP tools to invoke and what parameters to provide to the tools. Cody will execute these tools and inject the context from the tool calls into the context window.
+
+### Setting up MCP tools
+
+MCP is disabled by default. To enable it, add the `agentic-context-mcp-enabled` feature flag to your Enterprise Sourcegraph instance.
+
+Once MCP is enabled, there are two ways to configure an MCP server:
+
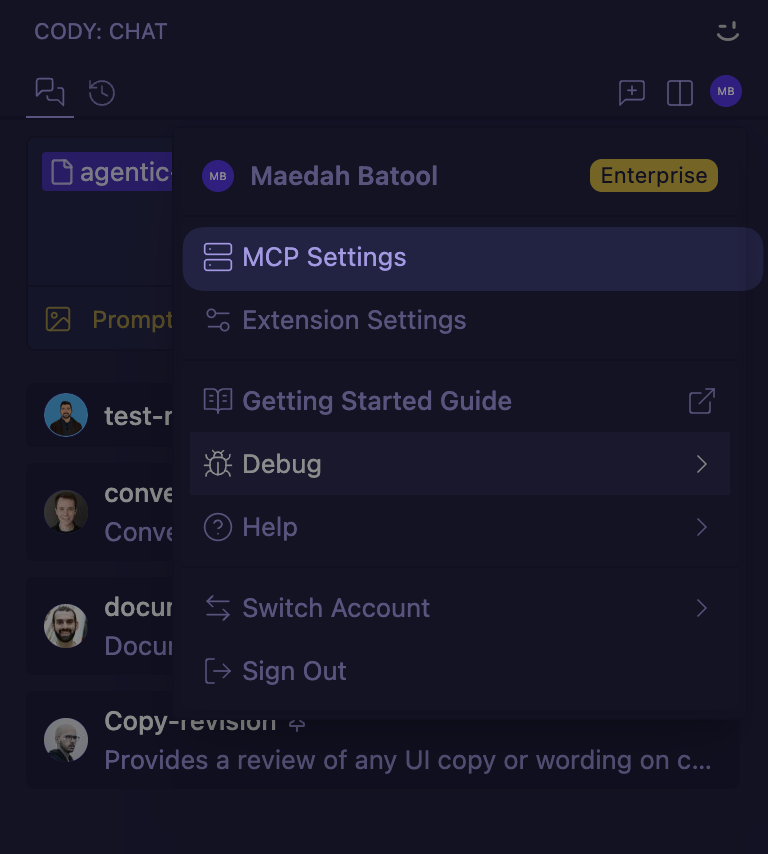
+#### 1. From the editor extension UI
+
+To configure an MCP server from the editor extension UI, click your profile icon in the Cody extension and select the **MCP Settings** option.
+
+
+
+Create a new server configuration and input the necessary arguments provided by the server. You can disable individual tools in the UI by clicking on them.
+
+#### 2. From the editor extension settings
+
+- Edit your MCP configuration settings using the `cody.mcpServers` property in your extension settings.
+ - `settings.json` (VSCode)
+ - `cody_settings.json` (JetBrains)
+- Use the following format when adding a new server
+
+In JetBrains, you need the absolute path to the command. Use the `which` command in the terminal to find it. For example, `which npx`.
+
+```json
+"cody.mcpServers": {
+ "": {
+ "command": "...",
+ "args": [...],
+ "env": {
+ ...
+ },
+ "disabledTools": [...]
+ }
+ }
+```
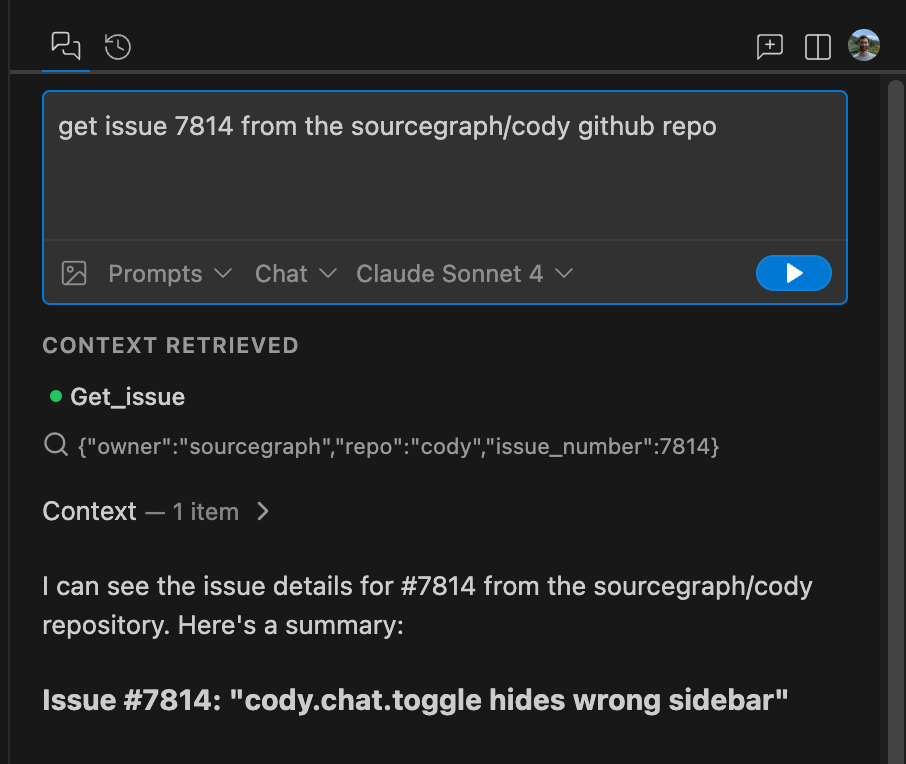
+
+When you submit a query, Cody will determine whether to use any of the server's tools.
+
+
+
+### MCP Best Practices
+
+Since MCP is an open protocol and servers can be created by anyone, your mileage may vary. Tool names, descriptions, and the underlying models you have available may all affect the performance of MCP retrieval. To get the best results using your MCP servers, we recommend the following:
+
+- Read through the tools of the servers you install and their parameters. Be as explicit as possible in your queries to provide all of the information the tool needs
+- If you don't get the desired results on the first try, iterate on your query. It may take a couple of tries to get the results you're expecting
+- Choose high-quality servers. Prefer servers from official sources over third parties. Read through the code to understand how the servers you are installing work
+
+### Limitations
+
+- MCP is supported through Cody’s agentic context fetching capabilities. You must have these capabilities enabled in order to utilize MCP servers
+- Cody currently supports only local MCP servers
+- MCP offers three main capabilities: Tools, Resources, and Prompts. Currently, Cody supports only Tools
+- Since most MCP servers require users to create their access tokens, the servers will have the same access as whatever token you provide. For example, if a user has write permissions to Jira and creates an access token with write permissions, they can use Cody to write back into Jira via MCP. It is not possible today to limit write access across all MCP tools broadly. You should use tools with this consideration in mind
diff --git a/docs/cody/capabilities/supported-models.mdx b/docs/cody/capabilities/supported-models.mdx
index b543111e5..44334a6e6 100644
--- a/docs/cody/capabilities/supported-models.mdx
+++ b/docs/cody/capabilities/supported-models.mdx
@@ -29,17 +29,19 @@ Cody supports a variety of cutting-edge large language models for use in chat an
To use Claude 3 Sonnet models with Cody Enterprise, make sure you've upgraded your Sourcegraph instance to the latest version.
-### Claude 3.7 Sonnet
+### Claude 3.7 and 4 Sonnet
-Claude 3.7 has two variants — Claude 3.7 Sonnet and Claude 3.7 Extended Thinking — to support deep reasoning and fast, responsive edit workflows. This means you can use Claude 3.7 in different contexts depending on whether long-form reasoning is required or for tasks where speed and performance are a priority.
+Claude 3.7 and 4 Sonnet have two variants; the base version, and the 'extended thinking' version which supports deep reasoning and fast, responsive edit workflows. Cody enables using both, and lets the user select which to use in the model dropdown selector, so the user can choose whether to use extended thinkig depending on their work task.
-Claude 3.7 Extended Thinking is the recommended default chat model for Cloud customers. Self-hosted customers are encouraged to follow this recommendation, as Claude 3.7 outperforms 3.5 in most scenarios.
+
+ Claude 4 support is available starting in Sourcegraph v6.4+ and v6.3.4167.
+
-#### Claude 3.7 for GCP
+#### Claude 3.7 and 4 via Google Vertex, via AWS Bedrock
-In addition, Sourcegraph Enterprise customers using GCP Vertex (Google Cloud Platform) for Claude models can use both these variants of Claude 3.7 to optimize extended reasoning and deeper understanding. Customers using AWS Bedrock do not have the Claude 3.7 Extended Thinking variant.
+Starting in Sourcegraph v6.4+ and v6.3.416, Claude 3.7 Extended Thinking - as well as Claude 4 base and extended thinking variants - are available in Sourcegraph when using Claude through either Google Vertex or AWS Bedrock.
-Claude 3.7 Sonnet with thinking is not supported for BYOK deployments.
+See [Model Configuration: Reasoning models](/cody/enterprise/model-configuration#reasoning-models) for more information.
## Autocomplete
diff --git a/docs/cody/clients/feature-reference.mdx b/docs/cody/clients/feature-reference.mdx
index 8dc9d61fa..01ac4b628 100644
--- a/docs/cody/clients/feature-reference.mdx
+++ b/docs/cody/clients/feature-reference.mdx
@@ -15,6 +15,7 @@
| @-file | ✅ | ✅ | ✅ | ✅ | ❌ |
| @-symbol | ✅ | ❌ | ✅ | ✅ | ❌ |
| LLM Selection | ✅ | ✅ | ✅ | ✅ | ❌ |
+| Agentic Context Fetching | ✅ | ✅ | ✅ | ✅ | ✅ |
| **Context Selection** | | | | | |
| Single-repo context | ✅ | ✅ | ✅ | ✅ | ❌ |
| Multi-repo context | ❌ | ❌ | ❌ | ✅ (public code only) | ❌ |
@@ -26,11 +27,11 @@
## Code Autocomplete and Auto-edit
-| **Feature** | **VS Code** | **JetBrains** | **Visual Studio** |
-| ------------------------------------------------------ | ----------- | ------------- | ----------------- |
-| Single and multi-line autocompletion | ✅ | ✅ | ✅ |
-| Cycle through multiple completion suggestions | ✅ | ✅ | ✅ |
-| Accept suggestions word-by-word | ✅ | ❌ | ❌ |
+| **Feature** | **VS Code** | **JetBrains** | **Visual Studio** |
+| ----------------------------------------------------- | ----------- | ------------- | ----------------- |
+| Single and multi-line autocompletion | ✅ | ✅ | ✅ |
+| Cycle through multiple completion suggestions | ✅ | ✅ | ✅ |
+| Accept suggestions word-by-word | ✅ | ❌ | ❌ |
| Auto-edit suggestions via cursor movements and typing | ✅ | ✅ | ❌ |
Few exceptions that apply to Cody Pro and Cody Enterprise users:
diff --git a/docs/cody/enterprise/model-config-examples.mdx b/docs/cody/enterprise/model-config-examples.mdx
index 06c7f30a4..99671fc94 100644
--- a/docs/cody/enterprise/model-config-examples.mdx
+++ b/docs/cody/enterprise/model-config-examples.mdx
@@ -104,7 +104,7 @@ In the configuration above, we:
- Define a new provider with the ID `"anthropic-byok"` and configure it to use the Anthropic API
- Since this provider is unknown to Sourcegraph, no Sourcegraph-supplied models are available. Therefore, we add a custom model in the `"modelOverrides"` section
- Use the custom model configured in the previous step (`"anthropic-byok::2024-10-22::claude-3.5-sonnet"`) for `"chat"`. Requests are sent directly to the Anthropic API as set in the provider override
-- For `"fastChat"` and `"autocomplete"`, we use Sourcegraph-provided models via Cody Gateway
+- For `"fastChat"` and `"codeCompletion"`, we use Sourcegraph-provided models via Cody Gateway
## Config examples for various LLM providers
@@ -244,7 +244,7 @@ In the configuration above,
- Set up a provider override for Fireworks, routing requests for this provider directly to the specified Fireworks endpoint (bypassing Cody Gateway)
- Add two Fireworks models:
- `"fireworks::v1::mixtral-8x7b-instruct"` with "chat" capabiity - used for "chat" and "fastChat"
- - `"fireworks::v1::starcoder-16b"` with "autocomplete" capability - used for "autocomplete"
+ - `"fireworks::v1::starcoder-16b"` with "autocomplete" capability - used for "codeCompletion"
@@ -721,7 +721,7 @@ In the configuration above,
In the configuration above,
- Set up a provider override for Google Anthropic, routing requests for this provider directly to the specified endpoint (bypassing Cody Gateway)
-- Add two Anthropic models: - `"google::unknown::claude-3-5-sonnet"` with "chat" capabiity - used for "chat" and "fastChat" - `"google::unknown::claude-3-haiku"` with "autocomplete" capability - used for "autocomplete"
+- Add two Anthropic models: - `"google::unknown::claude-3-5-sonnet"` with "chat" capabiity - used for "chat" and "fastChat" - `"google::unknown::claude-3-haiku"` with "autocomplete" capability - used for "codeCompletion"
diff --git a/docs/cody/enterprise/model-configuration.mdx b/docs/cody/enterprise/model-configuration.mdx
index f37dfbd2a..929a74026 100644
--- a/docs/cody/enterprise/model-configuration.mdx
+++ b/docs/cody/enterprise/model-configuration.mdx
@@ -89,7 +89,7 @@ To disable all Sourcegraph-provided models and use only the models explicitly de
## Default models
-The `"modelConfiguration"` setting includes a `"defaultModels"` field, which allows you to specify the LLM model used for each Cody feature (`"chat"`, `"fastChat"`, and `"autocomplete"`). The values for each feature should be `modelRef`s of either Sourcegraph-provided models or models configured in the `modelOverrides` section.
+The `"modelConfiguration"` setting includes a `"defaultModels"` field, which allows you to specify the LLM model used for each Cody feature (`"chat"`, `"fastChat"`, and `"codeCompletion"`). The values for each feature should be `modelRef`s of either Sourcegraph-provided models or models configured in the `modelOverrides` section.
If no default is specified or the specified model is not found, the configuration will silently fall back to a suitable alternative.
@@ -168,7 +168,7 @@ Example configuration:
"defaultModels": {
"chat": "google::v1::gemini-1.5-pro",
"fastChat": "anthropic::2023-06-01::claude-3-haiku",
- "autocomplete": "fireworks::v1::deepseek-coder-v2-lite-base"
+ "codeCompletion": "fireworks::v1::deepseek-coder-v2-lite-base"
}
}
```
@@ -291,7 +291,7 @@ For OpenAI reasoning models, the `reasoningEffort` field value corresponds to th
"defaultModels": {
"chat": "google::v1::gemini-1.5-pro",
"fastChat": "anthropic::2023-06-01::claude-3-haiku",
- "autocomplete": "huggingface-codellama::v1::CodeLlama-7b-hf"
+ "codeCompletion": "huggingface-codellama::v1::CodeLlama-7b-hf"
}
}
```
@@ -303,7 +303,7 @@ In the example above:
- A custom model, `"CodeLlama-7b-hf"`, is added using the `"huggingface-codellama"` provider
- Default models are set up as follows:
- Sourcegraph-provided models are used for `"chat"` and `"fastChat"` (accessed via Cody Gateway)
- - The newly configured model, `"huggingface-codellama::v1::CodeLlama-7b-hf"`, is used for `"autocomplete"` (connecting directly to Hugging Face’s OpenAI-compatible API)
+ - The newly configured model, `"huggingface-codellama::v1::CodeLlama-7b-hf"`, is used for `"codeCompletion"` (connecting directly to Hugging Face’s OpenAI-compatible API)
#### Example configuration with Claude 3.7 Sonnet
@@ -478,3 +478,44 @@ The response includes:
"codeCompletion": "fireworks::v1::deepseek-coder-v2-lite-base"
}
```
+
+## Reasoning models
+
+
+ Claude 3.7 and 4 support is available starting in Sourcegraph v6.4+ and v6.3.4167 out of-the-box when using Cody Gateway.
+
+ This section is primarily relevant to Sourcegraph Enterprise customers using AWS Bedrock or Google Vertex.
+
+
+Reasoning models can be added via `modelOverrides` in the site configuration by adding the `reasoning` capability to the `capabilities` list, and setting the `reasoningEffort` field on the model. Both must be set for the models' reasoning functionality to be used (otherwise the base model without reasoning / exteded thinking will be used.)
+
+For example, this `modelOverride` would create a `Claude Sonnet 4 with Thinking` option in the Cody model selector menu, and when the user chats with Cody with that model selected, it would use Claude Sonnet 4's Extended Thinking support with a `low` reasoning effort for the users' chat:
+
+```json
+{
+ "modelRef": "bedrock::2024-10-22::claude-sonnet-4-thinking-latest",
+ "displayName": "Claude Sonnet 4 with Thinking",
+ "modelName": "claude-sonnet-4-20250514",
+ "contextWindow": {
+ "maxInputTokens": 93000,
+ "maxOutputTokens": 64000,
+ "maxUserInputTokens": 18000
+ },
+ "capabilities": [
+ "chat",
+ "reasoning"
+ ],
+ "reasoningEffort": "low",
+ "category": "accuracy",
+ "status": "stable"
+}
+```
+
+
+
+The `reasoningEffort` field is only used by reasoning models (those having `reasoning` in their `capabilities` section). Supported values are `high`, `medium`, `low`. How this value is treated depends on the specific provider:
+
+* `anthropic` provider treats e.g. `low` effort to mean that the minimum [`thinking.budget_tokens`](https://docs.anthropic.com/en/api/messages#body-thinking) value (1024) will be used. For other `reasoningEffort` values, the `contextWindow.maxOutputTokens / 2` value will be used.
+* `openai` provider maps the `reasoningEffort` field value to the [OpenAI `reasoning_effort`](https://platform.openai.com/docs/api-reference/chat/create#chat-create-reasoning_effort) request body value.
+
+
diff --git a/public/llms.txt b/public/llms.txt
index 23ba28f45..30645c425 100644
--- a/public/llms.txt
+++ b/public/llms.txt
@@ -14532,7 +14532,7 @@ To disable all Sourcegraph-provided models and use only the models explicitly de
## Default models
-The `"modelConfiguration"` setting includes a `"defaultModels"` field, which allows you to specify the LLM model used for each Cody feature (`"chat"`, `"fastChat"`, and `"autocomplete"`). The values for each feature should be `modelRef`s of either Sourcegraph-provided models or models configured in the `modelOverrides` section.
+The `"modelConfiguration"` setting includes a `"defaultModels"` field, which allows you to specify the LLM model used for each Cody feature (`"chat"`, `"fastChat"`, and `"codeCompletion"`). The values for each feature should be `modelRef`s of either Sourcegraph-provided models or models configured in the `modelOverrides` section.
If no default is specified or the specified model is not found, the configuration will silently fall back to a suitable alternative.
@@ -14611,7 +14611,7 @@ Example configuration:
"defaultModels": {
"chat": "google::v1::gemini-1.5-pro",
"fastChat": "anthropic::2023-06-01::claude-3-haiku",
- "autocomplete": "fireworks::v1::deepseek-coder-v2-lite-base"
+ "codeCompletion": "fireworks::v1::deepseek-coder-v2-lite-base"
}
}
```
@@ -14725,7 +14725,7 @@ For OpenAI reasoning models, the `reasoningEffort` field value corresponds to th
"defaultModels": {
"chat": "google::v1::gemini-1.5-pro",
"fastChat": "anthropic::2023-06-01::claude-3-haiku",
- "autocomplete": "huggingface-codellama::v1::CodeLlama-7b-hf"
+ "codeCompletion": "huggingface-codellama::v1::CodeLlama-7b-hf"
}
}
```
@@ -14737,7 +14737,7 @@ In the example above:
- A custom model, `"CodeLlama-7b-hf"`, is added using the `"huggingface-codellama"` provider
- Default models are set up as follows:
- Sourcegraph-provided models are used for `"chat"` and `"fastChat"` (accessed via Cody Gateway)
- - The newly configured model, `"huggingface-codellama::v1::CodeLlama-7b-hf"`, is used for `"autocomplete"` (connecting directly to Hugging Face’s OpenAI-compatible API)
+ - The newly configured model, `"huggingface-codellama::v1::CodeLlama-7b-hf"`, is used for `"codeCompletion"` (connecting directly to Hugging Face’s OpenAI-compatible API)
#### Example configuration with Claude 3.7 Sonnet
@@ -15162,7 +15162,7 @@ In the configuration above,
- Set up a provider override for Fireworks, routing requests for this provider directly to the specified Fireworks endpoint (bypassing Cody Gateway)
- Add two Fireworks models:
- `"fireworks::v1::mixtral-8x7b-instruct"` with "chat" capabiity - used for "chat" and "fastChat"
- - `"fireworks::v1::starcoder-16b"` with "autocomplete" capability - used for "autocomplete"
+ - `"fireworks::v1::starcoder-16b"` with "autocomplete" capability - used for "codeCompletion"
@@ -15327,7 +15327,7 @@ In the configuration above,
**Note:** For Azure OpenAI, ensure that the `modelName` matches the name defined in your Azure portal configuration for the model.
- Add four OpenAI models:
- `"azure-openai::unknown::gpt-4o"` with chat capability - used as a default model for chat
- - `"azure-openai::unknown::gpt-4.1-nano"` with chat, edit and autocomplete capabilities - used as a default model for fast chat and autocomplete
+ - `"azure-openai::unknown::gpt-4.1-nano"` with chat, edit and autocomplete capabilities - used as a default model for fast chat and codeCompletion
- `"azure-openai::unknown::o3-mini"` with chat and reasoning capabilities - o-series model that supports thinking, can be used for chat (note: to enable thinking, model override should include "reasoning" capability and have "reasoningEffort" defined)
- `"azure-openai::unknown::gpt-35-turbo-instruct-test"` with "autocomplete" capability - included as an alternative model
- Since `"azure-openai::unknown::gpt-35-turbo-instruct-test"` is not supported on the newer OpenAI `"v1/chat/completions"` endpoint, we set `"useDeprecatedCompletionsAPI"` to `true` to route requests to the legacy `"v1/completions"` endpoint. This setting is unnecessary if you are using a model supported on the `"v1/chat/completions"` endpoint.
@@ -15597,7 +15597,7 @@ In the configuration above,
In the configuration above,
- Set up a provider override for Google Anthropic, routing requests for this provider directly to the specified endpoint (bypassing Cody Gateway)
-- Add two Anthropic models: - `"google::unknown::claude-3-5-sonnet"` with "chat" capabiity - used for "chat" and "fastChat" - `"google::unknown::claude-3-haiku"` with "autocomplete" capability - used for "autocomplete"
+- Add two Anthropic models: - `"google::unknown::claude-3-5-sonnet"` with "chat" capabiity - used for "chat" and "fastChat" - `"google::unknown::claude-3-haiku"` with "autocomplete" capability - used for "codeCompletion"
diff --git a/src/data/navigation.ts b/src/data/navigation.ts
index 0fd2f5bac..f89e1c771 100644
--- a/src/data/navigation.ts
+++ b/src/data/navigation.ts
@@ -55,7 +55,7 @@ export const navigation: NavigationItem[] = [
subsections: [
{ title: "Chat", href: "/cody/capabilities/chat", },
{ title: "Query Types", href: "/cody/capabilities/query-types", },
- { title: "Agentic chat", href: "/cody/capabilities/agentic-chat", },
+ { title: "Agentic Context Fetching", href: "/cody/capabilities/agentic-context-fetching", },
{ title: "Autocomplete", href: "/cody/capabilities/autocomplete", },
{ title: "Auto-edit", href: "/cody/capabilities/auto-edit", },
{ title: "Prompts", href: "/cody/capabilities/prompts", },
@@ -120,7 +120,8 @@ export const navigation: NavigationItem[] = [
{ title: "Search Snippets", href: "/code-search/working/snippets", },
{ title: "Search Subexpressions", href: "/code-search/working/search_subexpressions", },
{ title: "Saved Searches", href: "/code-search/working/saved_searches", },
- { title: "Structural Search", href: "/code-search/types/structural", }
+ { title: "Structural Search", href: "/code-search/types/structural", },
+ { title: "Deep Search", href: "/code-search/types/deep-search", },
]
},
{
diff --git a/src/data/redirects.ts b/src/data/redirects.ts
index dd173546b..20464e746 100644
--- a/src/data/redirects.ts
+++ b/src/data/redirects.ts
@@ -6795,7 +6795,14 @@ const redirectsData = [
source: "/analytics/self-hosted",
destination: "/analytics/air-gapped",
permanent: true
- }
+ },
+
+ //Agentic chat redirect
+ {
+ source: "/cody/capabilities/agentic-chat",
+ destination: "/cody/capabilities/agentic-context-fetching",
+ permanent: true
+ },
];