Learn how Cody makes use to Keyword Search to gather context.
+Learn how Cody's local indexing engine works to provide fast keyword search in your workspace.
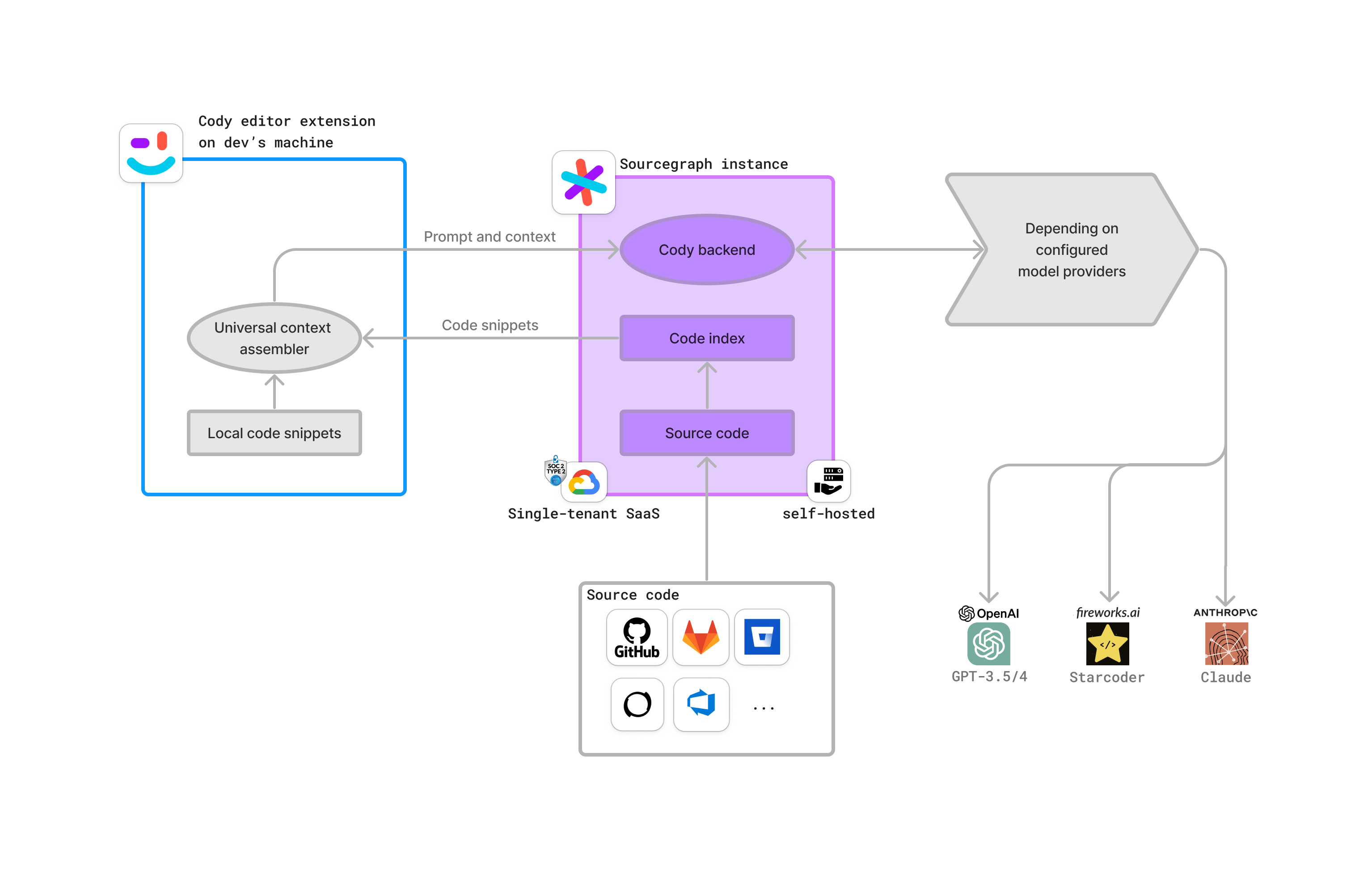
-Keyword search is the traditional approach to text search. It splits content into terms and builds a mapping from terms to documents. At query time, it extracts terms from the query and uses the mapping to retrieve your documents. +Cody uses **symf** (symbol finder), a local keyword search engine, to create and maintain code indexes for your workspace folders. This enables fast context retrieval directly from your local codebase. -Both Cody chat and completions use Keyword Search. It comes out of the box without any additional setup. Cody with Keyword Search searches your local VS Code workspace and is a cost-effective and time-saving solution. +## How Local Indexing Works -For an enterprise admin who has set up Cody with a Code Search instance, developers on their local machines can seamlessly access it. +Symf automatically creates and maintains indexes of your code: -Learn about all the core concepts and fundamentals that helps Cody provide codebase-aware answers.
+### VS Code Settings -[Cody Enterprise](/cody/clients/enable-cody-enterprise) can be deployed via the Sourcegraph Cloud or on your self-hosted infrastructure. This page describes the architecture diagrams for Cody deployed in different Sourcegraph environments.
+Learn how Cody makes use to Keyword Search to gather context.
-{/* Figma source: https://www.figma.com/file/lAPHpdhtEmOJ22IQXVZ0vs/Cody-architecture-diagrams-SQS-draft-2024-04?type=whiteboard&node-id=0-1&t=blg78H2YXXbdGSPc-0 */} +Keyword search is the traditional approach to text search. It splits content into terms and builds a mapping from terms to documents. At query time, it extracts terms from the query and uses the mapping to retrieve your documents. -## Sourcegraph Cloud deployment +Both Cody chat and completions use Keyword Search. It comes out of the box without any additional setup. Cody with Keyword Search searches your [local VS Code workspace](/cody/core-concepts/local-indexing) and is a cost-effective and time-saving solution. -This is a recommended deployment for Cody Enterprise. It uses the Sourcegraph Cloud infrastructure and Cody gateway. +For an enterprise admin who has set up Cody with a Code Search instance, developers on their local machines can seamlessly access it. -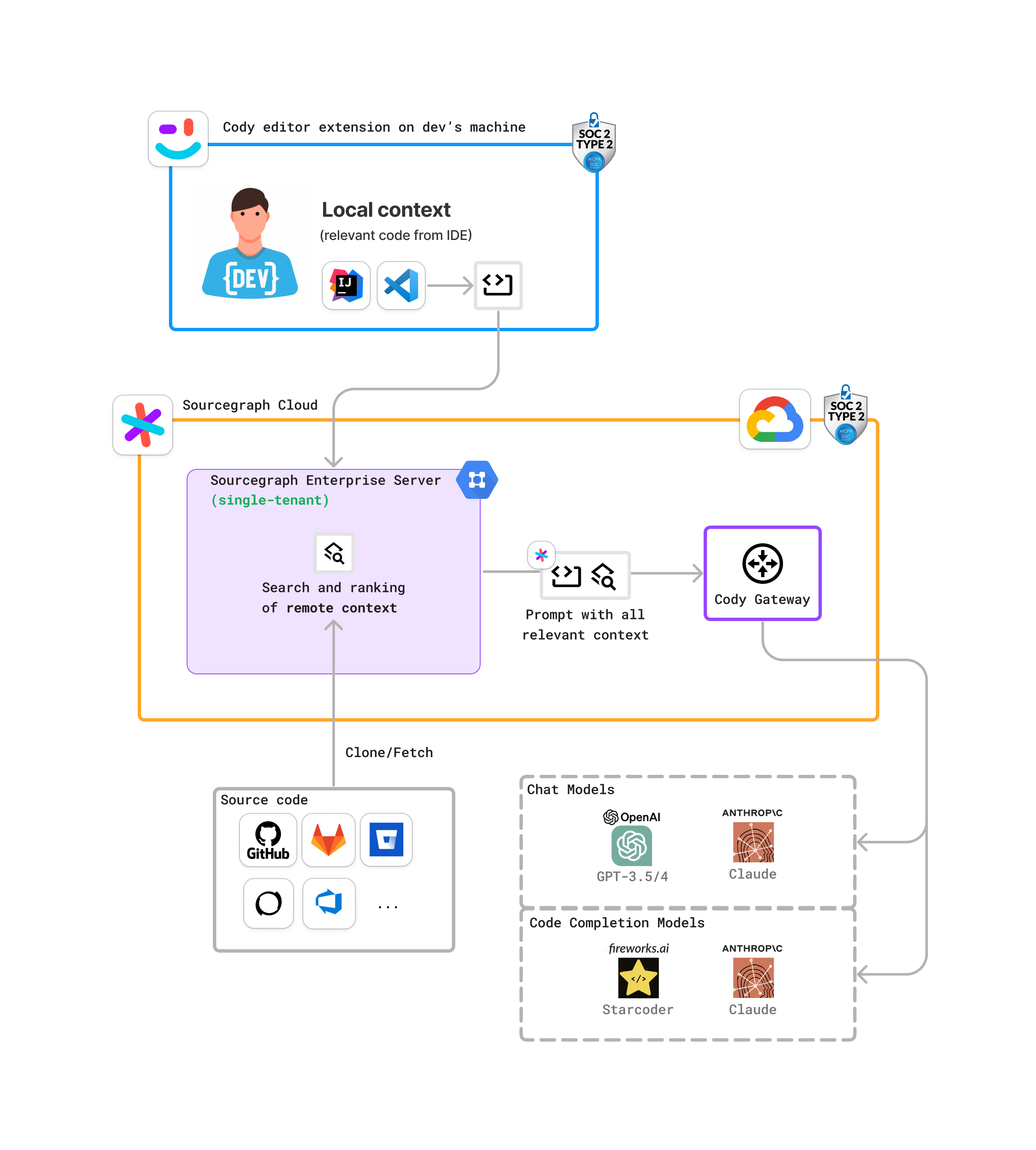 +
+Learn about all the core concepts and fundamentals that helps Cody provide codebase-aware answers.
- +
+ +
+Learn how Cody Gateway powers the default Sourcegraph provider for completions, enabling Cody features for Sourcegraph Enterprise customers.
- -- [`gohugoio/hugo`](https://sourcegraph.com/github.com/gohugoio/hugo@master/-/blob/common/hugo/hugo.go?L63:15&popover=pinned)
- [`gin-gonic/gin`](https://sourcegraph.com/github.com/gin-gonic/gin@master/-/blob/routergroup.go?L33:6&popover=pinned) | -| Java | - [`sourcegraph/jetbrains`](https://sourcegraph.com/github.com/sourcegraph/jetbrains/-/blob/src/main/java/com/sourcegraph/cody/CodyActionGroup.java?L13) | -| Scala | - [`neandertech/langoustine`](https://sourcegraph.com/github.com/neandertech/langoustine/-/blob/modules/lsp/src/main/scala/Communicate.scala?L28) | -| Kotlin | - [`sourcegraph/jetbrains`](https://sourcegraph.com/github.com/sourcegraph/jetbrains/-/blob/src/main/kotlin/com/sourcegraph/cody/agent/CodyAgent.kt?L42) | -| Python | - [`pipecat-ai/pipecat-flows`](https://sourcegraph.com/github.com/pipecat-ai/pipecat-flows/-/blob/src/pipecat_flows/actions.py?L38) | -| TypeScript | - [`vuejs/vue`](https://sourcegraph.com/github.com/vuejs/vue@main/-/blob/src/core/observer/index.ts?L68:3&popover=pinned) | -| Ruby | - [`Homebrew/brew`](https://sourcegraph.com/github.com/Homebrew/brew@master/-/blob/Library/Homebrew/utils/bottles.rb?L18:18&popover=pinned) | -| Rust | - [`rust-lang/cargo`](https://sourcegraph.com/github.com/rust-lang/cargo/-/blob/src/cargo/core/compiler/compilation.rs?L15:12&popover=pinned#tab=references)
- [`rust-lang/rustlings`](https://sourcegraph.com/github.com/rust-lang/rustlings@main/-/blob/src/dev.rs?L10) | -| C, C++ | - [`sourcegraph/cxx-precise-examples`](https://sourcegraph.com/github.com/sourcegraph/cxx-precise-examples/-/blob/piecewise_monorepo/arithmetic/src/multiplication.cpp?L3) | +| **Programming Language** | **Repo** | +|--------------------------|--------------------------------------------------------------------------------------------------------------------------------------------------------| +| Go | [`kubernetes/kubernetes`](https://sourcegraph.com/github.com/kubernetes/kubernetes/-/blob/cmd/cloud-controller-manager/main.go) | +| Java | [`google/guava`](https://sourcegraph.com/github.com/google/guava/-/blob/guava/src/com/google/common/io/ByteSink.java) | +| Scala | [`apache/pekko`](https://sourcegraph.com/github.com/apache/pekko/-/blob/persistence/src/main/scala/org/apache/pekko/persistence/JournalProtocol.scala) | +| Python | [`Textualize/rich`](https://sourcegraph.com/github.com/Textualize/rich/-/blob/rich/style.py) | +| TypeScript | [`vuejs/core`](https://sourcegraph.com/github.com/vuejs/core/-/blob/packages/vue/src/index.ts) | +| Rust | [`serde-rs/serde`](https://sourcegraph.com/github.com/serde-rs/serde/-/blob/serde_derive/src/bound.rs) | +| Ruby | [`Homebrew/brew`](https://sourcegraph.com/github.com/Homebrew/brew/-/blob/Library/Homebrew/commands.rb) | +| C++ | [`fmtlib/fmt`](https://sourcegraph.com/github.com/fmtlib/fmt/-/blob/include/fmt/ostream.h) | +| C# | [`serilog/serilog`](https://sourcegraph.com/github.com/serilog/serilog/-/blob/src/Serilog/Events/EventProperty.cs) | ## More resources @@ -15371,9 +15916,9 @@ jobs: - run: src code-intel upload -github-token=<
Connect AI agents and applications to your Sourcegraph instance's code search and analysis capabilities.
+ +
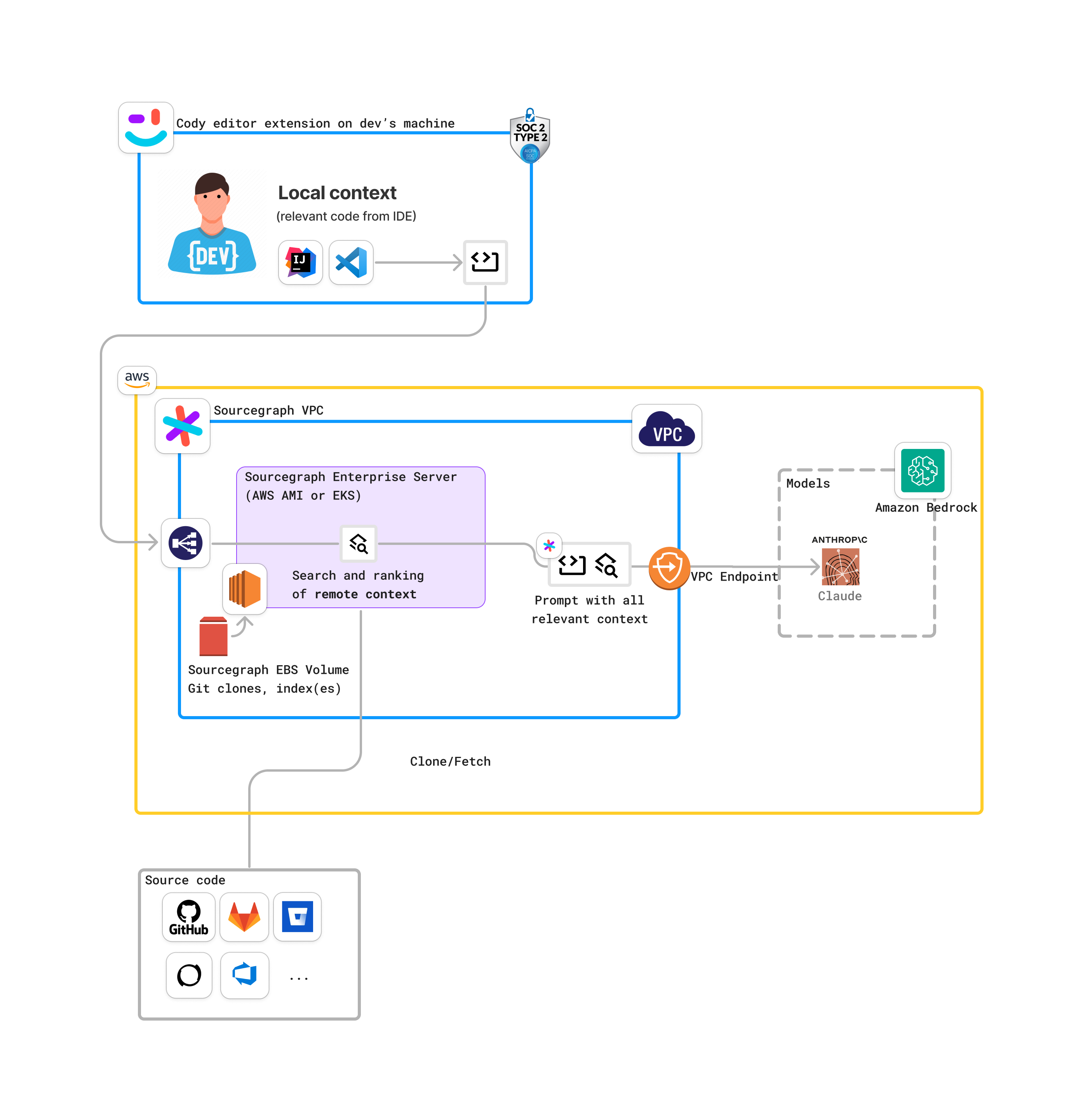
@@ -30519,7 +31454,7 @@ This is an example of a more complex deployment that uses Sourcegraph Enterprise
-### Data flow
+### Cody Data flow
The following diagram describes the data flow between the different components of Cody Enterprise.
@@ -31415,6 +32350,10 @@ For upgrade procedures or general info about sourcegraph versioning see the link
>
> ***If the notes indicate a patch release exists, target the highest one.***
+## v6.10.0
+
+- Port names have been updated on services and pods, to unblock Kubernetes service meshes from auto-configuring themselves for the traffic type, since most inter-pod communication has been switched from http to gRPC [[PR 756](https://github.com/sourcegraph/deploy-sourcegraph-helm/pull/756)]. If you are using Istio (or similar service meshes), and [our Envoy filter example](https://github.com/sourcegraph/deploy-sourcegraph-helm/tree/main/charts/sourcegraph/examples/envoy), and your pods fail to communicate after upgrading to >= v6.10, please remove the Envoy filter and try again so your service mesh can auto-configure itself based on the new port names.
+
## v6.4.0
- The repo-updater service is no longer needed and will be removed from deployment methods going forward.
@@ -32414,7 +33353,7 @@ upgrade \
[--dry-run=false] \
[--disable-animation=false] \
[--skip-version-check=false] [--skip-drift-check=false] \
- [--unprivileged-only=false] [--noop-privileged=false] [--privileged-hash=-#### frontend: hard_timeout_search_responses +#### frontend: timeout_search_responses -
Hard timeout search responses every 5m
+Timeout search responses every 5m
-Refer to the [alerts reference](alerts#frontend-hard-timeout-search-responses) for 1 alert related to this panel. +Refer to the [alerts reference](alerts#frontend-timeout-search-responses) for 1 alert related to this panel. To see this panel, visit `/-/debug/grafana/d/frontend/frontend?viewPanel=100010` on your Sourcegraph instance. @@ -35787,7 +36726,7 @@ To see this panel, visit `/-/debug/grafana/d/frontend/frontend?viewPanel=100010` Query: ``` -(sum(increase(src_graphql_search_response{status="timeout",source="browser",request_name!="CodeIntelSearch"}[5m])) + sum(increase(src_graphql_search_response{status="alert",alert_type="timed_out",source="browser",request_name!="CodeIntelSearch"}[5m]))) / sum(increase(src_graphql_search_response{source="browser",request_name!="CodeIntelSearch"}[5m])) * 100 +sum(increase(src_search_streaming_response{status=~"timeout|partial_timeout",source="browser"}[5m])) / sum(increase(src_search_streaming_response{source="browser"}[5m])) * 100 ``` @@ -35809,17 +36748,17 @@ To see this panel, visit `/-/debug/grafana/d/frontend/frontend?viewPanel=100011` Query: ``` -sum by (status)(increase(src_graphql_search_response{status=~"error",source="browser",request_name!="CodeIntelSearch"}[5m])) / ignoring(status) group_left sum(increase(src_graphql_search_response{source="browser",request_name!="CodeIntelSearch"}[5m])) * 100 +sum(increase(src_search_streaming_response{status="error",source="browser"}[5m])) / sum(increase(src_search_streaming_response{source="browser"}[5m])) * 100 ```-#### frontend: partial_timeout_search_responses +#### frontend: search_no_results -
Partial timeout search responses every 5m
+Searches with no results every 5m
-Refer to the [alerts reference](alerts#frontend-partial-timeout-search-responses) for 1 alert related to this panel. +Refer to the [alerts reference](alerts#frontend-search-no-results) for 1 alert related to this panel. To see this panel, visit `/-/debug/grafana/d/frontend/frontend?viewPanel=100012` on your Sourcegraph instance. @@ -35831,7 +36770,7 @@ To see this panel, visit `/-/debug/grafana/d/frontend/frontend?viewPanel=100012` Query: ``` -sum by (status)(increase(src_graphql_search_response{status="partial_timeout",source="browser",request_name!="CodeIntelSearch"}[5m])) / ignoring(status) group_left sum(increase(src_graphql_search_response{source="browser",request_name!="CodeIntelSearch"}[5m])) * 100 +sum(increase(src_search_streaming_response{status="no_results",source="browser"}[5m])) / sum(increase(src_search_streaming_response{source="browser"}[5m])) * 100 ``` @@ -35853,7 +36792,7 @@ To see this panel, visit `/-/debug/grafana/d/frontend/frontend?viewPanel=100013` Query: ``` -sum by (alert_type)(increase(src_graphql_search_response{status="alert",alert_type!~"timed_out|no_results__suggest_quotes",source="browser",request_name!="CodeIntelSearch"}[5m])) / ignoring(alert_type) group_left sum(increase(src_graphql_search_response{source="browser",request_name!="CodeIntelSearch"}[5m])) * 100 +sum by (alert_type)(increase(src_search_streaming_response{status="alert",alert_type!~"timed_out",source="browser"}[5m])) / ignoring(alert_type) group_left sum(increase(src_search_streaming_response{source="browser"}[5m])) * 100 ``` @@ -36121,7 +37060,7 @@ To see this panel, visit `/-/debug/grafana/d/frontend/frontend?viewPanel=100212` Query: ``` -sum by (alert_type)(increase(src_graphql_search_response{status="alert",alert_type!~"timed_out|no_results__suggest_quotes",source="other"}[5m])) / ignoring(alert_type) group_left sum(increase(src_graphql_search_response{status="alert",source="other"}[5m])) +sum by (alert_type)(increase(src_graphql_search_response{status="alert",alert_type!~"timed_out",source="other"}[5m])) / ignoring(alert_type) group_left sum(increase(src_graphql_search_response{status="alert",source="other"}[5m])) ``` @@ -36711,7 +37650,7 @@ sum by (op)(increase(src_codeintel_uploads_store_errors_total{job=~"^(frontend|s ### Frontend: Workerutil: lsif_indexes dbworker/store stats -#### frontend: workerutil_dbworker_store_codeintel_index_total +#### frontend: workerutil_dbworker_store_totalStore operations every 5m
@@ -36727,13 +37666,13 @@ To see this panel, visit `/-/debug/grafana/d/frontend/frontend?viewPanel=100700` Query: ``` -sum(increase(src_workerutil_dbworker_store_codeintel_index_total{job=~"^(frontend|sourcegraph-frontend).*"}[5m])) +sum(increase(src_workerutil_dbworker_store_total{domain='codeintel_index_jobs',job=~"^(frontend|sourcegraph-frontend).*"}[5m])) ```-#### frontend: workerutil_dbworker_store_codeintel_index_99th_percentile_duration +#### frontend: workerutil_dbworker_store_99th_percentile_duration
Aggregate successful store operation duration distribution over 5m
@@ -36749,13 +37688,13 @@ To see this panel, visit `/-/debug/grafana/d/frontend/frontend?viewPanel=100701` Query: ``` -sum by (le)(rate(src_workerutil_dbworker_store_codeintel_index_duration_seconds_bucket{job=~"^(frontend|sourcegraph-frontend).*"}[5m])) +sum by (le)(rate(src_workerutil_dbworker_store_duration_seconds_bucket{domain='codeintel_index_jobs',job=~"^(frontend|sourcegraph-frontend).*"}[5m])) ```-#### frontend: workerutil_dbworker_store_codeintel_index_errors_total +#### frontend: workerutil_dbworker_store_errors_total
Store operation errors every 5m
@@ -36771,13 +37710,13 @@ To see this panel, visit `/-/debug/grafana/d/frontend/frontend?viewPanel=100702` Query: ``` -sum(increase(src_workerutil_dbworker_store_codeintel_index_errors_total{job=~"^(frontend|sourcegraph-frontend).*"}[5m])) +sum(increase(src_workerutil_dbworker_store_errors_total{domain='codeintel_index_jobs',job=~"^(frontend|sourcegraph-frontend).*"}[5m])) ```-#### frontend: workerutil_dbworker_store_codeintel_index_error_rate +#### frontend: workerutil_dbworker_store_error_rate
Store operation error rate over 5m
@@ -36793,7 +37732,7 @@ To see this panel, visit `/-/debug/grafana/d/frontend/frontend?viewPanel=100703` Query: ``` -sum(increase(src_workerutil_dbworker_store_codeintel_index_errors_total{job=~"^(frontend|sourcegraph-frontend).*"}[5m])) / (sum(increase(src_workerutil_dbworker_store_codeintel_index_total{job=~"^(frontend|sourcegraph-frontend).*"}[5m])) + sum(increase(src_workerutil_dbworker_store_codeintel_index_errors_total{job=~"^(frontend|sourcegraph-frontend).*"}[5m]))) * 100 +sum(increase(src_workerutil_dbworker_store_errors_total{domain='codeintel_index_jobs',job=~"^(frontend|sourcegraph-frontend).*"}[5m])) / (sum(increase(src_workerutil_dbworker_store_total{domain='codeintel_index_jobs',job=~"^(frontend|sourcegraph-frontend).*"}[5m])) + sum(increase(src_workerutil_dbworker_store_errors_total{domain='codeintel_index_jobs',job=~"^(frontend|sourcegraph-frontend).*"}[5m]))) * 100 ``` @@ -36979,7 +37918,7 @@ sum by (op)(increase(src_codeintel_uploads_lsifstore_errors_total{job=~"^(fronte ### Frontend: Codeintel: gitserver client -#### frontend: codeintel_gitserver_total +#### frontend: gitserver_client_totalAggregate client operations every 5m
@@ -36995,13 +37934,13 @@ To see this panel, visit `/-/debug/grafana/d/frontend/frontend?viewPanel=100900` Query: ``` -sum(increase(src_codeintel_gitserver_total{job=~"^(frontend|sourcegraph-frontend).*"}[5m])) +sum(increase(src_gitserver_client_total{job=~"^(frontend|sourcegraph-frontend).*"}[5m])) ```-#### frontend: codeintel_gitserver_99th_percentile_duration +#### frontend: gitserver_client_99th_percentile_duration
Aggregate successful client operation duration distribution over 5m
@@ -37017,13 +37956,13 @@ To see this panel, visit `/-/debug/grafana/d/frontend/frontend?viewPanel=100901` Query: ``` -sum by (le)(rate(src_codeintel_gitserver_duration_seconds_bucket{job=~"^(frontend|sourcegraph-frontend).*"}[5m])) +sum by (le)(rate(src_gitserver_client_duration_seconds_bucket{job=~"^(frontend|sourcegraph-frontend).*"}[5m])) ```-#### frontend: codeintel_gitserver_errors_total +#### frontend: gitserver_client_errors_total
Aggregate client operation errors every 5m
@@ -37039,13 +37978,13 @@ To see this panel, visit `/-/debug/grafana/d/frontend/frontend?viewPanel=100902` Query: ``` -sum(increase(src_codeintel_gitserver_errors_total{job=~"^(frontend|sourcegraph-frontend).*"}[5m])) +sum(increase(src_gitserver_client_errors_total{job=~"^(frontend|sourcegraph-frontend).*"}[5m])) ```-#### frontend: codeintel_gitserver_error_rate +#### frontend: gitserver_client_error_rate
Aggregate client operation error rate over 5m
@@ -37061,13 +38000,13 @@ To see this panel, visit `/-/debug/grafana/d/frontend/frontend?viewPanel=100903` Query: ``` -sum(increase(src_codeintel_gitserver_errors_total{job=~"^(frontend|sourcegraph-frontend).*"}[5m])) / (sum(increase(src_codeintel_gitserver_total{job=~"^(frontend|sourcegraph-frontend).*"}[5m])) + sum(increase(src_codeintel_gitserver_errors_total{job=~"^(frontend|sourcegraph-frontend).*"}[5m]))) * 100 +sum(increase(src_gitserver_client_errors_total{job=~"^(frontend|sourcegraph-frontend).*"}[5m])) / (sum(increase(src_gitserver_client_total{job=~"^(frontend|sourcegraph-frontend).*"}[5m])) + sum(increase(src_gitserver_client_errors_total{job=~"^(frontend|sourcegraph-frontend).*"}[5m]))) * 100 ```-#### frontend: codeintel_gitserver_total +#### frontend: gitserver_client_total
Client operations every 5m
@@ -37083,13 +38022,13 @@ To see this panel, visit `/-/debug/grafana/d/frontend/frontend?viewPanel=100910` Query: ``` -sum by (op)(increase(src_codeintel_gitserver_total{job=~"^(frontend|sourcegraph-frontend).*"}[5m])) +sum by (op)(increase(src_gitserver_client_total{job=~"^(frontend|sourcegraph-frontend).*"}[5m])) ```-#### frontend: codeintel_gitserver_99th_percentile_duration +#### frontend: gitserver_client_99th_percentile_duration
99th percentile successful client operation duration over 5m
@@ -37105,13 +38044,13 @@ To see this panel, visit `/-/debug/grafana/d/frontend/frontend?viewPanel=100911` Query: ``` -histogram_quantile(0.99, sum by (le,op)(rate(src_codeintel_gitserver_duration_seconds_bucket{job=~"^(frontend|sourcegraph-frontend).*"}[5m]))) +histogram_quantile(0.99, sum by (le,op)(rate(src_gitserver_client_duration_seconds_bucket{job=~"^(frontend|sourcegraph-frontend).*"}[5m]))) ```-#### frontend: codeintel_gitserver_errors_total +#### frontend: gitserver_client_errors_total
Client operation errors every 5m
@@ -37127,13 +38066,13 @@ To see this panel, visit `/-/debug/grafana/d/frontend/frontend?viewPanel=100912` Query: ``` -sum by (op)(increase(src_codeintel_gitserver_errors_total{job=~"^(frontend|sourcegraph-frontend).*"}[5m])) +sum by (op)(increase(src_gitserver_client_errors_total{job=~"^(frontend|sourcegraph-frontend).*"}[5m])) ```-#### frontend: codeintel_gitserver_error_rate +#### frontend: gitserver_client_error_rate
Client operation error rate over 5m
@@ -37149,7 +38088,7 @@ To see this panel, visit `/-/debug/grafana/d/frontend/frontend?viewPanel=100913` Query: ``` -sum by (op)(increase(src_codeintel_gitserver_errors_total{job=~"^(frontend|sourcegraph-frontend).*"}[5m])) / (sum by (op)(increase(src_codeintel_gitserver_total{job=~"^(frontend|sourcegraph-frontend).*"}[5m])) + sum by (op)(increase(src_codeintel_gitserver_errors_total{job=~"^(frontend|sourcegraph-frontend).*"}[5m]))) * 100 +sum by (op)(increase(src_gitserver_client_errors_total{job=~"^(frontend|sourcegraph-frontend).*"}[5m])) / (sum by (op)(increase(src_gitserver_client_total{job=~"^(frontend|sourcegraph-frontend).*"}[5m])) + sum by (op)(increase(src_gitserver_client_errors_total{job=~"^(frontend|sourcegraph-frontend).*"}[5m]))) * 100 ``` @@ -37333,17 +38272,17 @@ sum by (op)(increase(src_codeintel_uploadstore_errors_total{job=~"^(frontend|sou-### Frontend: Codeintel: dependencies service stats +### Frontend: Gitserver: Gitserver Client -#### frontend: codeintel_dependencies_total +#### frontend: gitserver_client_total -
Aggregate service operations every 5m
+Aggregate client operations every 5m
This panel has no related alerts. To see this panel, visit `/-/debug/grafana/d/frontend/frontend?viewPanel=101100` on your Sourcegraph instance. -*Managed by the [Sourcegraph Code intelligence team](https://handbook.sourcegraph.com/departments/engineering/teams/code-intelligence).* +*Managed by the [Sourcegraph Source team](https://handbook.sourcegraph.com/departments/engineering/teams/source).*Technical details
@@ -37351,21 +38290,21 @@ To see this panel, visit `/-/debug/grafana/d/frontend/frontend?viewPanel=101100` Query: ``` -sum(increase(src_codeintel_dependencies_total{job=~"^(frontend|sourcegraph-frontend).*"}[5m])) +sum(increase(src_gitserver_client_total{job=~"^(frontend|sourcegraph-frontend).*"}[5m])) ```-#### frontend: codeintel_dependencies_99th_percentile_duration +#### frontend: gitserver_client_99th_percentile_duration -
Aggregate successful service operation duration distribution over 5m
+Aggregate successful client operation duration distribution over 5m
This panel has no related alerts. To see this panel, visit `/-/debug/grafana/d/frontend/frontend?viewPanel=101101` on your Sourcegraph instance. -*Managed by the [Sourcegraph Code intelligence team](https://handbook.sourcegraph.com/departments/engineering/teams/code-intelligence).* +*Managed by the [Sourcegraph Source team](https://handbook.sourcegraph.com/departments/engineering/teams/source).*Technical details
@@ -37373,21 +38312,21 @@ To see this panel, visit `/-/debug/grafana/d/frontend/frontend?viewPanel=101101` Query: ``` -sum by (le)(rate(src_codeintel_dependencies_duration_seconds_bucket{job=~"^(frontend|sourcegraph-frontend).*"}[5m])) +sum by (le)(rate(src_gitserver_client_duration_seconds_bucket{job=~"^(frontend|sourcegraph-frontend).*"}[5m])) ```-#### frontend: codeintel_dependencies_errors_total +#### frontend: gitserver_client_errors_total -
Aggregate service operation errors every 5m
+Aggregate client operation errors every 5m
This panel has no related alerts. To see this panel, visit `/-/debug/grafana/d/frontend/frontend?viewPanel=101102` on your Sourcegraph instance. -*Managed by the [Sourcegraph Code intelligence team](https://handbook.sourcegraph.com/departments/engineering/teams/code-intelligence).* +*Managed by the [Sourcegraph Source team](https://handbook.sourcegraph.com/departments/engineering/teams/source).*Technical details
@@ -37395,21 +38334,21 @@ To see this panel, visit `/-/debug/grafana/d/frontend/frontend?viewPanel=101102` Query: ``` -sum(increase(src_codeintel_dependencies_errors_total{job=~"^(frontend|sourcegraph-frontend).*"}[5m])) +sum(increase(src_gitserver_client_errors_total{job=~"^(frontend|sourcegraph-frontend).*"}[5m])) ```-#### frontend: codeintel_dependencies_error_rate +#### frontend: gitserver_client_error_rate -
Aggregate service operation error rate over 5m
+Aggregate client operation error rate over 5m
This panel has no related alerts. To see this panel, visit `/-/debug/grafana/d/frontend/frontend?viewPanel=101103` on your Sourcegraph instance. -*Managed by the [Sourcegraph Code intelligence team](https://handbook.sourcegraph.com/departments/engineering/teams/code-intelligence).* +*Managed by the [Sourcegraph Source team](https://handbook.sourcegraph.com/departments/engineering/teams/source).*Technical details
@@ -37417,21 +38356,21 @@ To see this panel, visit `/-/debug/grafana/d/frontend/frontend?viewPanel=101103` Query: ``` -sum(increase(src_codeintel_dependencies_errors_total{job=~"^(frontend|sourcegraph-frontend).*"}[5m])) / (sum(increase(src_codeintel_dependencies_total{job=~"^(frontend|sourcegraph-frontend).*"}[5m])) + sum(increase(src_codeintel_dependencies_errors_total{job=~"^(frontend|sourcegraph-frontend).*"}[5m]))) * 100 +sum(increase(src_gitserver_client_errors_total{job=~"^(frontend|sourcegraph-frontend).*"}[5m])) / (sum(increase(src_gitserver_client_total{job=~"^(frontend|sourcegraph-frontend).*"}[5m])) + sum(increase(src_gitserver_client_errors_total{job=~"^(frontend|sourcegraph-frontend).*"}[5m]))) * 100 ```-#### frontend: codeintel_dependencies_total +#### frontend: gitserver_client_total -
Service operations every 5m
+Client operations every 5m
This panel has no related alerts. To see this panel, visit `/-/debug/grafana/d/frontend/frontend?viewPanel=101110` on your Sourcegraph instance. -*Managed by the [Sourcegraph Code intelligence team](https://handbook.sourcegraph.com/departments/engineering/teams/code-intelligence).* +*Managed by the [Sourcegraph Source team](https://handbook.sourcegraph.com/departments/engineering/teams/source).*Technical details
@@ -37439,21 +38378,21 @@ To see this panel, visit `/-/debug/grafana/d/frontend/frontend?viewPanel=101110` Query: ``` -sum by (op)(increase(src_codeintel_dependencies_total{job=~"^(frontend|sourcegraph-frontend).*"}[5m])) +sum by (op,scope)(increase(src_gitserver_client_total{job=~"^(frontend|sourcegraph-frontend).*"}[5m])) ```-#### frontend: codeintel_dependencies_99th_percentile_duration +#### frontend: gitserver_client_99th_percentile_duration -
99th percentile successful service operation duration over 5m
+99th percentile successful client operation duration over 5m
This panel has no related alerts. To see this panel, visit `/-/debug/grafana/d/frontend/frontend?viewPanel=101111` on your Sourcegraph instance. -*Managed by the [Sourcegraph Code intelligence team](https://handbook.sourcegraph.com/departments/engineering/teams/code-intelligence).* +*Managed by the [Sourcegraph Source team](https://handbook.sourcegraph.com/departments/engineering/teams/source).*Technical details
@@ -37461,21 +38400,21 @@ To see this panel, visit `/-/debug/grafana/d/frontend/frontend?viewPanel=101111` Query: ``` -histogram_quantile(0.99, sum by (le,op)(rate(src_codeintel_dependencies_duration_seconds_bucket{job=~"^(frontend|sourcegraph-frontend).*"}[5m]))) +histogram_quantile(0.99, sum by (le,op,scope)(rate(src_gitserver_client_duration_seconds_bucket{job=~"^(frontend|sourcegraph-frontend).*"}[5m]))) ```-#### frontend: codeintel_dependencies_errors_total +#### frontend: gitserver_client_errors_total -
Service operation errors every 5m
+Client operation errors every 5m
This panel has no related alerts. To see this panel, visit `/-/debug/grafana/d/frontend/frontend?viewPanel=101112` on your Sourcegraph instance. -*Managed by the [Sourcegraph Code intelligence team](https://handbook.sourcegraph.com/departments/engineering/teams/code-intelligence).* +*Managed by the [Sourcegraph Source team](https://handbook.sourcegraph.com/departments/engineering/teams/source).*Technical details
@@ -37483,21 +38422,21 @@ To see this panel, visit `/-/debug/grafana/d/frontend/frontend?viewPanel=101112` Query: ``` -sum by (op)(increase(src_codeintel_dependencies_errors_total{job=~"^(frontend|sourcegraph-frontend).*"}[5m])) +sum by (op,scope)(increase(src_gitserver_client_errors_total{job=~"^(frontend|sourcegraph-frontend).*"}[5m])) ```-#### frontend: codeintel_dependencies_error_rate +#### frontend: gitserver_client_error_rate -
Service operation error rate over 5m
+Client operation error rate over 5m
This panel has no related alerts. To see this panel, visit `/-/debug/grafana/d/frontend/frontend?viewPanel=101113` on your Sourcegraph instance. -*Managed by the [Sourcegraph Code intelligence team](https://handbook.sourcegraph.com/departments/engineering/teams/code-intelligence).* +*Managed by the [Sourcegraph Source team](https://handbook.sourcegraph.com/departments/engineering/teams/source).*Technical details
@@ -37505,23 +38444,23 @@ To see this panel, visit `/-/debug/grafana/d/frontend/frontend?viewPanel=101113` Query: ``` -sum by (op)(increase(src_codeintel_dependencies_errors_total{job=~"^(frontend|sourcegraph-frontend).*"}[5m])) / (sum by (op)(increase(src_codeintel_dependencies_total{job=~"^(frontend|sourcegraph-frontend).*"}[5m])) + sum by (op)(increase(src_codeintel_dependencies_errors_total{job=~"^(frontend|sourcegraph-frontend).*"}[5m]))) * 100 +sum by (op,scope)(increase(src_gitserver_client_errors_total{job=~"^(frontend|sourcegraph-frontend).*"}[5m])) / (sum by (op,scope)(increase(src_gitserver_client_total{job=~"^(frontend|sourcegraph-frontend).*"}[5m])) + sum by (op,scope)(increase(src_gitserver_client_errors_total{job=~"^(frontend|sourcegraph-frontend).*"}[5m]))) * 100 ```-### Frontend: Codeintel: dependencies service store stats +### Frontend: Gitserver: Gitserver Repository Service Client -#### frontend: codeintel_dependencies_background_total +#### frontend: gitserver_repositoryservice_client_total -
Aggregate service operations every 5m
+Aggregate client operations every 5m
This panel has no related alerts. To see this panel, visit `/-/debug/grafana/d/frontend/frontend?viewPanel=101200` on your Sourcegraph instance. -*Managed by the [Sourcegraph Code intelligence team](https://handbook.sourcegraph.com/departments/engineering/teams/code-intelligence).* +*Managed by the [Sourcegraph Source team](https://handbook.sourcegraph.com/departments/engineering/teams/source).*Technical details
@@ -37529,21 +38468,21 @@ To see this panel, visit `/-/debug/grafana/d/frontend/frontend?viewPanel=101200` Query: ``` -sum(increase(src_codeintel_dependencies_background_total{job=~"^(frontend|sourcegraph-frontend).*"}[5m])) +sum(increase(src_gitserver_repositoryservice_client_total{job=~"^(frontend|sourcegraph-frontend).*"}[5m])) ```-#### frontend: codeintel_dependencies_background_99th_percentile_duration +#### frontend: gitserver_repositoryservice_client_99th_percentile_duration -
Aggregate successful service operation duration distribution over 5m
+Aggregate successful client operation duration distribution over 5m
This panel has no related alerts. To see this panel, visit `/-/debug/grafana/d/frontend/frontend?viewPanel=101201` on your Sourcegraph instance. -*Managed by the [Sourcegraph Code intelligence team](https://handbook.sourcegraph.com/departments/engineering/teams/code-intelligence).* +*Managed by the [Sourcegraph Source team](https://handbook.sourcegraph.com/departments/engineering/teams/source).*Technical details
@@ -37551,21 +38490,21 @@ To see this panel, visit `/-/debug/grafana/d/frontend/frontend?viewPanel=101201` Query: ``` -sum by (le)(rate(src_codeintel_dependencies_background_duration_seconds_bucket{job=~"^(frontend|sourcegraph-frontend).*"}[5m])) +sum by (le)(rate(src_gitserver_repositoryservice_client_duration_seconds_bucket{job=~"^(frontend|sourcegraph-frontend).*"}[5m])) ```-#### frontend: codeintel_dependencies_background_errors_total +#### frontend: gitserver_repositoryservice_client_errors_total -
Aggregate service operation errors every 5m
+Aggregate client operation errors every 5m
This panel has no related alerts. To see this panel, visit `/-/debug/grafana/d/frontend/frontend?viewPanel=101202` on your Sourcegraph instance. -*Managed by the [Sourcegraph Code intelligence team](https://handbook.sourcegraph.com/departments/engineering/teams/code-intelligence).* +*Managed by the [Sourcegraph Source team](https://handbook.sourcegraph.com/departments/engineering/teams/source).*Technical details
@@ -37573,21 +38512,21 @@ To see this panel, visit `/-/debug/grafana/d/frontend/frontend?viewPanel=101202` Query: ``` -sum(increase(src_codeintel_dependencies_background_errors_total{job=~"^(frontend|sourcegraph-frontend).*"}[5m])) +sum(increase(src_gitserver_repositoryservice_client_errors_total{job=~"^(frontend|sourcegraph-frontend).*"}[5m])) ```-#### frontend: codeintel_dependencies_background_error_rate +#### frontend: gitserver_repositoryservice_client_error_rate -
Aggregate service operation error rate over 5m
+Aggregate client operation error rate over 5m
This panel has no related alerts. To see this panel, visit `/-/debug/grafana/d/frontend/frontend?viewPanel=101203` on your Sourcegraph instance. -*Managed by the [Sourcegraph Code intelligence team](https://handbook.sourcegraph.com/departments/engineering/teams/code-intelligence).* +*Managed by the [Sourcegraph Source team](https://handbook.sourcegraph.com/departments/engineering/teams/source).*Technical details
@@ -37595,21 +38534,21 @@ To see this panel, visit `/-/debug/grafana/d/frontend/frontend?viewPanel=101203` Query: ``` -sum(increase(src_codeintel_dependencies_background_errors_total{job=~"^(frontend|sourcegraph-frontend).*"}[5m])) / (sum(increase(src_codeintel_dependencies_background_total{job=~"^(frontend|sourcegraph-frontend).*"}[5m])) + sum(increase(src_codeintel_dependencies_background_errors_total{job=~"^(frontend|sourcegraph-frontend).*"}[5m]))) * 100 +sum(increase(src_gitserver_repositoryservice_client_errors_total{job=~"^(frontend|sourcegraph-frontend).*"}[5m])) / (sum(increase(src_gitserver_repositoryservice_client_total{job=~"^(frontend|sourcegraph-frontend).*"}[5m])) + sum(increase(src_gitserver_repositoryservice_client_errors_total{job=~"^(frontend|sourcegraph-frontend).*"}[5m]))) * 100 ```-#### frontend: codeintel_dependencies_background_total +#### frontend: gitserver_repositoryservice_client_total -
Service operations every 5m
+Client operations every 5m
This panel has no related alerts. To see this panel, visit `/-/debug/grafana/d/frontend/frontend?viewPanel=101210` on your Sourcegraph instance. -*Managed by the [Sourcegraph Code intelligence team](https://handbook.sourcegraph.com/departments/engineering/teams/code-intelligence).* +*Managed by the [Sourcegraph Source team](https://handbook.sourcegraph.com/departments/engineering/teams/source).*Technical details
@@ -37617,21 +38556,21 @@ To see this panel, visit `/-/debug/grafana/d/frontend/frontend?viewPanel=101210` Query: ``` -sum by (op)(increase(src_codeintel_dependencies_background_total{job=~"^(frontend|sourcegraph-frontend).*"}[5m])) +sum by (op,scope)(increase(src_gitserver_repositoryservice_client_total{job=~"^(frontend|sourcegraph-frontend).*"}[5m])) ```-#### frontend: codeintel_dependencies_background_99th_percentile_duration +#### frontend: gitserver_repositoryservice_client_99th_percentile_duration -
99th percentile successful service operation duration over 5m
+99th percentile successful client operation duration over 5m
This panel has no related alerts. To see this panel, visit `/-/debug/grafana/d/frontend/frontend?viewPanel=101211` on your Sourcegraph instance. -*Managed by the [Sourcegraph Code intelligence team](https://handbook.sourcegraph.com/departments/engineering/teams/code-intelligence).* +*Managed by the [Sourcegraph Source team](https://handbook.sourcegraph.com/departments/engineering/teams/source).*Technical details
@@ -37639,21 +38578,21 @@ To see this panel, visit `/-/debug/grafana/d/frontend/frontend?viewPanel=101211` Query: ``` -histogram_quantile(0.99, sum by (le,op)(rate(src_codeintel_dependencies_background_duration_seconds_bucket{job=~"^(frontend|sourcegraph-frontend).*"}[5m]))) +histogram_quantile(0.99, sum by (le,op,scope)(rate(src_gitserver_repositoryservice_client_duration_seconds_bucket{job=~"^(frontend|sourcegraph-frontend).*"}[5m]))) ```-#### frontend: codeintel_dependencies_background_errors_total +#### frontend: gitserver_repositoryservice_client_errors_total -
Service operation errors every 5m
+Client operation errors every 5m
This panel has no related alerts. To see this panel, visit `/-/debug/grafana/d/frontend/frontend?viewPanel=101212` on your Sourcegraph instance. -*Managed by the [Sourcegraph Code intelligence team](https://handbook.sourcegraph.com/departments/engineering/teams/code-intelligence).* +*Managed by the [Sourcegraph Source team](https://handbook.sourcegraph.com/departments/engineering/teams/source).*Technical details
@@ -37661,21 +38600,21 @@ To see this panel, visit `/-/debug/grafana/d/frontend/frontend?viewPanel=101212` Query: ``` -sum by (op)(increase(src_codeintel_dependencies_background_errors_total{job=~"^(frontend|sourcegraph-frontend).*"}[5m])) +sum by (op,scope)(increase(src_gitserver_repositoryservice_client_errors_total{job=~"^(frontend|sourcegraph-frontend).*"}[5m])) ```-#### frontend: codeintel_dependencies_background_error_rate +#### frontend: gitserver_repositoryservice_client_error_rate -
Service operation error rate over 5m
+Client operation error rate over 5m
This panel has no related alerts. To see this panel, visit `/-/debug/grafana/d/frontend/frontend?viewPanel=101213` on your Sourcegraph instance. -*Managed by the [Sourcegraph Code intelligence team](https://handbook.sourcegraph.com/departments/engineering/teams/code-intelligence).* +*Managed by the [Sourcegraph Source team](https://handbook.sourcegraph.com/departments/engineering/teams/source).*Technical details
@@ -37683,23 +38622,23 @@ To see this panel, visit `/-/debug/grafana/d/frontend/frontend?viewPanel=101213` Query: ``` -sum by (op)(increase(src_codeintel_dependencies_background_errors_total{job=~"^(frontend|sourcegraph-frontend).*"}[5m])) / (sum by (op)(increase(src_codeintel_dependencies_background_total{job=~"^(frontend|sourcegraph-frontend).*"}[5m])) + sum by (op)(increase(src_codeintel_dependencies_background_errors_total{job=~"^(frontend|sourcegraph-frontend).*"}[5m]))) * 100 +sum by (op,scope)(increase(src_gitserver_repositoryservice_client_errors_total{job=~"^(frontend|sourcegraph-frontend).*"}[5m])) / (sum by (op,scope)(increase(src_gitserver_repositoryservice_client_total{job=~"^(frontend|sourcegraph-frontend).*"}[5m])) + sum by (op,scope)(increase(src_gitserver_repositoryservice_client_errors_total{job=~"^(frontend|sourcegraph-frontend).*"}[5m]))) * 100 ```-### Frontend: Codeintel: dependencies service background stats +### Frontend: Batches: dbstore stats -#### frontend: codeintel_dependencies_background_total +#### frontend: batches_dbstore_total -
Aggregate service operations every 5m
+Aggregate store operations every 5m
This panel has no related alerts. To see this panel, visit `/-/debug/grafana/d/frontend/frontend?viewPanel=101300` on your Sourcegraph instance. -*Managed by the [Sourcegraph Code intelligence team](https://handbook.sourcegraph.com/departments/engineering/teams/code-intelligence).* +*Managed by the [Sourcegraph Code Search team](https://handbook.sourcegraph.com/departments/engineering/teams/code-search).*Technical details
@@ -37707,21 +38646,21 @@ To see this panel, visit `/-/debug/grafana/d/frontend/frontend?viewPanel=101300` Query: ``` -sum(increase(src_codeintel_dependencies_background_total{job=~"^(frontend|sourcegraph-frontend).*"}[5m])) +sum(increase(src_batches_dbstore_total{job=~"^(frontend|sourcegraph-frontend).*"}[5m])) ```-#### frontend: codeintel_dependencies_background_99th_percentile_duration +#### frontend: batches_dbstore_99th_percentile_duration -
Aggregate successful service operation duration distribution over 5m
+Aggregate successful store operation duration distribution over 5m
This panel has no related alerts. To see this panel, visit `/-/debug/grafana/d/frontend/frontend?viewPanel=101301` on your Sourcegraph instance. -*Managed by the [Sourcegraph Code intelligence team](https://handbook.sourcegraph.com/departments/engineering/teams/code-intelligence).* +*Managed by the [Sourcegraph Code Search team](https://handbook.sourcegraph.com/departments/engineering/teams/code-search).*Technical details
@@ -37729,21 +38668,21 @@ To see this panel, visit `/-/debug/grafana/d/frontend/frontend?viewPanel=101301` Query: ``` -sum by (le)(rate(src_codeintel_dependencies_background_duration_seconds_bucket{job=~"^(frontend|sourcegraph-frontend).*"}[5m])) +sum by (le)(rate(src_batches_dbstore_duration_seconds_bucket{job=~"^(frontend|sourcegraph-frontend).*"}[5m])) ```-#### frontend: codeintel_dependencies_background_errors_total +#### frontend: batches_dbstore_errors_total -
Aggregate service operation errors every 5m
+Aggregate store operation errors every 5m
This panel has no related alerts. To see this panel, visit `/-/debug/grafana/d/frontend/frontend?viewPanel=101302` on your Sourcegraph instance. -*Managed by the [Sourcegraph Code intelligence team](https://handbook.sourcegraph.com/departments/engineering/teams/code-intelligence).* +*Managed by the [Sourcegraph Code Search team](https://handbook.sourcegraph.com/departments/engineering/teams/code-search).*Technical details
@@ -37751,21 +38690,21 @@ To see this panel, visit `/-/debug/grafana/d/frontend/frontend?viewPanel=101302` Query: ``` -sum(increase(src_codeintel_dependencies_background_errors_total{job=~"^(frontend|sourcegraph-frontend).*"}[5m])) +sum(increase(src_batches_dbstore_errors_total{job=~"^(frontend|sourcegraph-frontend).*"}[5m])) ```-#### frontend: codeintel_dependencies_background_error_rate +#### frontend: batches_dbstore_error_rate -
Aggregate service operation error rate over 5m
+Aggregate store operation error rate over 5m
This panel has no related alerts. To see this panel, visit `/-/debug/grafana/d/frontend/frontend?viewPanel=101303` on your Sourcegraph instance. -*Managed by the [Sourcegraph Code intelligence team](https://handbook.sourcegraph.com/departments/engineering/teams/code-intelligence).* +*Managed by the [Sourcegraph Code Search team](https://handbook.sourcegraph.com/departments/engineering/teams/code-search).*Technical details
@@ -37773,21 +38712,21 @@ To see this panel, visit `/-/debug/grafana/d/frontend/frontend?viewPanel=101303` Query: ``` -sum(increase(src_codeintel_dependencies_background_errors_total{job=~"^(frontend|sourcegraph-frontend).*"}[5m])) / (sum(increase(src_codeintel_dependencies_background_total{job=~"^(frontend|sourcegraph-frontend).*"}[5m])) + sum(increase(src_codeintel_dependencies_background_errors_total{job=~"^(frontend|sourcegraph-frontend).*"}[5m]))) * 100 +sum(increase(src_batches_dbstore_errors_total{job=~"^(frontend|sourcegraph-frontend).*"}[5m])) / (sum(increase(src_batches_dbstore_total{job=~"^(frontend|sourcegraph-frontend).*"}[5m])) + sum(increase(src_batches_dbstore_errors_total{job=~"^(frontend|sourcegraph-frontend).*"}[5m]))) * 100 ```-#### frontend: codeintel_dependencies_background_total +#### frontend: batches_dbstore_total -
Service operations every 5m
+Store operations every 5m
This panel has no related alerts. To see this panel, visit `/-/debug/grafana/d/frontend/frontend?viewPanel=101310` on your Sourcegraph instance. -*Managed by the [Sourcegraph Code intelligence team](https://handbook.sourcegraph.com/departments/engineering/teams/code-intelligence).* +*Managed by the [Sourcegraph Code Search team](https://handbook.sourcegraph.com/departments/engineering/teams/code-search).*Technical details
@@ -37795,21 +38734,21 @@ To see this panel, visit `/-/debug/grafana/d/frontend/frontend?viewPanel=101310` Query: ``` -sum by (op)(increase(src_codeintel_dependencies_background_total{job=~"^(frontend|sourcegraph-frontend).*"}[5m])) +sum by (op)(increase(src_batches_dbstore_total{job=~"^(frontend|sourcegraph-frontend).*"}[5m])) ```-#### frontend: codeintel_dependencies_background_99th_percentile_duration +#### frontend: batches_dbstore_99th_percentile_duration -
99th percentile successful service operation duration over 5m
+99th percentile successful store operation duration over 5m
This panel has no related alerts. To see this panel, visit `/-/debug/grafana/d/frontend/frontend?viewPanel=101311` on your Sourcegraph instance. -*Managed by the [Sourcegraph Code intelligence team](https://handbook.sourcegraph.com/departments/engineering/teams/code-intelligence).* +*Managed by the [Sourcegraph Code Search team](https://handbook.sourcegraph.com/departments/engineering/teams/code-search).*Technical details
@@ -37817,21 +38756,21 @@ To see this panel, visit `/-/debug/grafana/d/frontend/frontend?viewPanel=101311` Query: ``` -histogram_quantile(0.99, sum by (le,op)(rate(src_codeintel_dependencies_background_duration_seconds_bucket{job=~"^(frontend|sourcegraph-frontend).*"}[5m]))) +histogram_quantile(0.99, sum by (le,op)(rate(src_batches_dbstore_duration_seconds_bucket{job=~"^(frontend|sourcegraph-frontend).*"}[5m]))) ```-#### frontend: codeintel_dependencies_background_errors_total +#### frontend: batches_dbstore_errors_total -
Service operation errors every 5m
+Store operation errors every 5m
This panel has no related alerts. To see this panel, visit `/-/debug/grafana/d/frontend/frontend?viewPanel=101312` on your Sourcegraph instance. -*Managed by the [Sourcegraph Code intelligence team](https://handbook.sourcegraph.com/departments/engineering/teams/code-intelligence).* +*Managed by the [Sourcegraph Code Search team](https://handbook.sourcegraph.com/departments/engineering/teams/code-search).*Technical details
@@ -37839,21 +38778,21 @@ To see this panel, visit `/-/debug/grafana/d/frontend/frontend?viewPanel=101312` Query: ``` -sum by (op)(increase(src_codeintel_dependencies_background_errors_total{job=~"^(frontend|sourcegraph-frontend).*"}[5m])) +sum by (op)(increase(src_batches_dbstore_errors_total{job=~"^(frontend|sourcegraph-frontend).*"}[5m])) ```-#### frontend: codeintel_dependencies_background_error_rate +#### frontend: batches_dbstore_error_rate -
Service operation error rate over 5m
+Store operation error rate over 5m
This panel has no related alerts. To see this panel, visit `/-/debug/grafana/d/frontend/frontend?viewPanel=101313` on your Sourcegraph instance. -*Managed by the [Sourcegraph Code intelligence team](https://handbook.sourcegraph.com/departments/engineering/teams/code-intelligence).* +*Managed by the [Sourcegraph Code Search team](https://handbook.sourcegraph.com/departments/engineering/teams/code-search).*Technical details
@@ -37861,15 +38800,15 @@ To see this panel, visit `/-/debug/grafana/d/frontend/frontend?viewPanel=101313` Query: ``` -sum by (op)(increase(src_codeintel_dependencies_background_errors_total{job=~"^(frontend|sourcegraph-frontend).*"}[5m])) / (sum by (op)(increase(src_codeintel_dependencies_background_total{job=~"^(frontend|sourcegraph-frontend).*"}[5m])) + sum by (op)(increase(src_codeintel_dependencies_background_errors_total{job=~"^(frontend|sourcegraph-frontend).*"}[5m]))) * 100 +sum by (op)(increase(src_batches_dbstore_errors_total{job=~"^(frontend|sourcegraph-frontend).*"}[5m])) / (sum by (op)(increase(src_batches_dbstore_total{job=~"^(frontend|sourcegraph-frontend).*"}[5m])) + sum by (op)(increase(src_batches_dbstore_errors_total{job=~"^(frontend|sourcegraph-frontend).*"}[5m]))) * 100 ```-### Frontend: Codeintel: lockfiles service stats +### Frontend: Batches: service stats -#### frontend: codeintel_lockfiles_total +#### frontend: batches_service_total
Aggregate service operations every 5m
@@ -37877,7 +38816,7 @@ This panel has no related alerts. To see this panel, visit `/-/debug/grafana/d/frontend/frontend?viewPanel=101400` on your Sourcegraph instance. -*Managed by the [Sourcegraph Code intelligence team](https://handbook.sourcegraph.com/departments/engineering/teams/code-intelligence).* +*Managed by the [Sourcegraph Code Search team](https://handbook.sourcegraph.com/departments/engineering/teams/code-search).*Technical details
@@ -37885,13 +38824,13 @@ To see this panel, visit `/-/debug/grafana/d/frontend/frontend?viewPanel=101400` Query: ``` -sum(increase(src_codeintel_lockfiles_total{job=~"^(frontend|sourcegraph-frontend).*"}[5m])) +sum(increase(src_batches_service_total{job=~"^(frontend|sourcegraph-frontend).*"}[5m])) ```-#### frontend: codeintel_lockfiles_99th_percentile_duration +#### frontend: batches_service_99th_percentile_duration
Aggregate successful service operation duration distribution over 5m
@@ -37899,7 +38838,7 @@ This panel has no related alerts. To see this panel, visit `/-/debug/grafana/d/frontend/frontend?viewPanel=101401` on your Sourcegraph instance. -*Managed by the [Sourcegraph Code intelligence team](https://handbook.sourcegraph.com/departments/engineering/teams/code-intelligence).* +*Managed by the [Sourcegraph Code Search team](https://handbook.sourcegraph.com/departments/engineering/teams/code-search).*Technical details
@@ -37907,13 +38846,13 @@ To see this panel, visit `/-/debug/grafana/d/frontend/frontend?viewPanel=101401` Query: ``` -sum by (le)(rate(src_codeintel_lockfiles_duration_seconds_bucket{job=~"^(frontend|sourcegraph-frontend).*"}[5m])) +sum by (le)(rate(src_batches_service_duration_seconds_bucket{job=~"^(frontend|sourcegraph-frontend).*"}[5m])) ```-#### frontend: codeintel_lockfiles_errors_total +#### frontend: batches_service_errors_total
Aggregate service operation errors every 5m
@@ -37921,7 +38860,7 @@ This panel has no related alerts. To see this panel, visit `/-/debug/grafana/d/frontend/frontend?viewPanel=101402` on your Sourcegraph instance. -*Managed by the [Sourcegraph Code intelligence team](https://handbook.sourcegraph.com/departments/engineering/teams/code-intelligence).* +*Managed by the [Sourcegraph Code Search team](https://handbook.sourcegraph.com/departments/engineering/teams/code-search).*Technical details
@@ -37929,13 +38868,13 @@ To see this panel, visit `/-/debug/grafana/d/frontend/frontend?viewPanel=101402` Query: ``` -sum(increase(src_codeintel_lockfiles_errors_total{job=~"^(frontend|sourcegraph-frontend).*"}[5m])) +sum(increase(src_batches_service_errors_total{job=~"^(frontend|sourcegraph-frontend).*"}[5m])) ```-#### frontend: codeintel_lockfiles_error_rate +#### frontend: batches_service_error_rate
Aggregate service operation error rate over 5m
@@ -37943,7 +38882,7 @@ This panel has no related alerts. To see this panel, visit `/-/debug/grafana/d/frontend/frontend?viewPanel=101403` on your Sourcegraph instance. -*Managed by the [Sourcegraph Code intelligence team](https://handbook.sourcegraph.com/departments/engineering/teams/code-intelligence).* +*Managed by the [Sourcegraph Code Search team](https://handbook.sourcegraph.com/departments/engineering/teams/code-search).*Technical details
@@ -37951,13 +38890,13 @@ To see this panel, visit `/-/debug/grafana/d/frontend/frontend?viewPanel=101403` Query: ``` -sum(increase(src_codeintel_lockfiles_errors_total{job=~"^(frontend|sourcegraph-frontend).*"}[5m])) / (sum(increase(src_codeintel_lockfiles_total{job=~"^(frontend|sourcegraph-frontend).*"}[5m])) + sum(increase(src_codeintel_lockfiles_errors_total{job=~"^(frontend|sourcegraph-frontend).*"}[5m]))) * 100 +sum(increase(src_batches_service_errors_total{job=~"^(frontend|sourcegraph-frontend).*"}[5m])) / (sum(increase(src_batches_service_total{job=~"^(frontend|sourcegraph-frontend).*"}[5m])) + sum(increase(src_batches_service_errors_total{job=~"^(frontend|sourcegraph-frontend).*"}[5m]))) * 100 ```-#### frontend: codeintel_lockfiles_total +#### frontend: batches_service_total
Service operations every 5m
@@ -37965,7 +38904,7 @@ This panel has no related alerts. To see this panel, visit `/-/debug/grafana/d/frontend/frontend?viewPanel=101410` on your Sourcegraph instance. -*Managed by the [Sourcegraph Code intelligence team](https://handbook.sourcegraph.com/departments/engineering/teams/code-intelligence).* +*Managed by the [Sourcegraph Code Search team](https://handbook.sourcegraph.com/departments/engineering/teams/code-search).*Technical details
@@ -37973,13 +38912,13 @@ To see this panel, visit `/-/debug/grafana/d/frontend/frontend?viewPanel=101410` Query: ``` -sum by (op)(increase(src_codeintel_lockfiles_total{job=~"^(frontend|sourcegraph-frontend).*"}[5m])) +sum by (op)(increase(src_batches_service_total{job=~"^(frontend|sourcegraph-frontend).*"}[5m])) ```-#### frontend: codeintel_lockfiles_99th_percentile_duration +#### frontend: batches_service_99th_percentile_duration
99th percentile successful service operation duration over 5m
@@ -37987,7 +38926,7 @@ This panel has no related alerts. To see this panel, visit `/-/debug/grafana/d/frontend/frontend?viewPanel=101411` on your Sourcegraph instance. -*Managed by the [Sourcegraph Code intelligence team](https://handbook.sourcegraph.com/departments/engineering/teams/code-intelligence).* +*Managed by the [Sourcegraph Code Search team](https://handbook.sourcegraph.com/departments/engineering/teams/code-search).*Technical details
@@ -37995,13 +38934,13 @@ To see this panel, visit `/-/debug/grafana/d/frontend/frontend?viewPanel=101411` Query: ``` -histogram_quantile(0.99, sum by (le,op)(rate(src_codeintel_lockfiles_duration_seconds_bucket{job=~"^(frontend|sourcegraph-frontend).*"}[5m]))) +histogram_quantile(0.99, sum by (le,op)(rate(src_batches_service_duration_seconds_bucket{job=~"^(frontend|sourcegraph-frontend).*"}[5m]))) ```-#### frontend: codeintel_lockfiles_errors_total +#### frontend: batches_service_errors_total
Service operation errors every 5m
@@ -38009,7 +38948,7 @@ This panel has no related alerts. To see this panel, visit `/-/debug/grafana/d/frontend/frontend?viewPanel=101412` on your Sourcegraph instance. -*Managed by the [Sourcegraph Code intelligence team](https://handbook.sourcegraph.com/departments/engineering/teams/code-intelligence).* +*Managed by the [Sourcegraph Code Search team](https://handbook.sourcegraph.com/departments/engineering/teams/code-search).*Technical details
@@ -38017,13 +38956,13 @@ To see this panel, visit `/-/debug/grafana/d/frontend/frontend?viewPanel=101412` Query: ``` -sum by (op)(increase(src_codeintel_lockfiles_errors_total{job=~"^(frontend|sourcegraph-frontend).*"}[5m])) +sum by (op)(increase(src_batches_service_errors_total{job=~"^(frontend|sourcegraph-frontend).*"}[5m])) ```-#### frontend: codeintel_lockfiles_error_rate +#### frontend: batches_service_error_rate
Service operation error rate over 5m
@@ -38031,7 +38970,7 @@ This panel has no related alerts. To see this panel, visit `/-/debug/grafana/d/frontend/frontend?viewPanel=101413` on your Sourcegraph instance. -*Managed by the [Sourcegraph Code intelligence team](https://handbook.sourcegraph.com/departments/engineering/teams/code-intelligence).* +*Managed by the [Sourcegraph Code Search team](https://handbook.sourcegraph.com/departments/engineering/teams/code-search).*Technical details
@@ -38039,23 +38978,23 @@ To see this panel, visit `/-/debug/grafana/d/frontend/frontend?viewPanel=101413` Query: ``` -sum by (op)(increase(src_codeintel_lockfiles_errors_total{job=~"^(frontend|sourcegraph-frontend).*"}[5m])) / (sum by (op)(increase(src_codeintel_lockfiles_total{job=~"^(frontend|sourcegraph-frontend).*"}[5m])) + sum by (op)(increase(src_codeintel_lockfiles_errors_total{job=~"^(frontend|sourcegraph-frontend).*"}[5m]))) * 100 +sum by (op)(increase(src_batches_service_errors_total{job=~"^(frontend|sourcegraph-frontend).*"}[5m])) / (sum by (op)(increase(src_batches_service_total{job=~"^(frontend|sourcegraph-frontend).*"}[5m])) + sum by (op)(increase(src_batches_service_errors_total{job=~"^(frontend|sourcegraph-frontend).*"}[5m]))) * 100 ```-### Frontend: Gitserver: Gitserver Client +### Frontend: Batches: HTTP API File Handler -#### frontend: gitserver_client_total +#### frontend: batches_httpapi_total -
Aggregate graphql operations every 5m
+Aggregate http handler operations every 5m
This panel has no related alerts. To see this panel, visit `/-/debug/grafana/d/frontend/frontend?viewPanel=101500` on your Sourcegraph instance. -*Managed by the [Sourcegraph Source team](https://handbook.sourcegraph.com/departments/engineering/teams/source).* +*Managed by the [Sourcegraph Code Search team](https://handbook.sourcegraph.com/departments/engineering/teams/code-search).*Technical details
@@ -38063,21 +39002,21 @@ To see this panel, visit `/-/debug/grafana/d/frontend/frontend?viewPanel=101500` Query: ``` -sum(increase(src_gitserver_client_total{job=~"^(frontend|sourcegraph-frontend).*"}[5m])) +sum(increase(src_batches_httpapi_total{job=~"^(frontend|sourcegraph-frontend).*"}[5m])) ```-#### frontend: gitserver_client_99th_percentile_duration +#### frontend: batches_httpapi_99th_percentile_duration -
Aggregate successful graphql operation duration distribution over 5m
+Aggregate successful http handler operation duration distribution over 5m
This panel has no related alerts. To see this panel, visit `/-/debug/grafana/d/frontend/frontend?viewPanel=101501` on your Sourcegraph instance. -*Managed by the [Sourcegraph Source team](https://handbook.sourcegraph.com/departments/engineering/teams/source).* +*Managed by the [Sourcegraph Code Search team](https://handbook.sourcegraph.com/departments/engineering/teams/code-search).*Technical details
@@ -38085,21 +39024,21 @@ To see this panel, visit `/-/debug/grafana/d/frontend/frontend?viewPanel=101501` Query: ``` -sum by (le)(rate(src_gitserver_client_duration_seconds_bucket{job=~"^(frontend|sourcegraph-frontend).*"}[5m])) +sum by (le)(rate(src_batches_httpapi_duration_seconds_bucket{job=~"^(frontend|sourcegraph-frontend).*"}[5m])) ```-#### frontend: gitserver_client_errors_total +#### frontend: batches_httpapi_errors_total -
Aggregate graphql operation errors every 5m
+Aggregate http handler operation errors every 5m
This panel has no related alerts. To see this panel, visit `/-/debug/grafana/d/frontend/frontend?viewPanel=101502` on your Sourcegraph instance. -*Managed by the [Sourcegraph Source team](https://handbook.sourcegraph.com/departments/engineering/teams/source).* +*Managed by the [Sourcegraph Code Search team](https://handbook.sourcegraph.com/departments/engineering/teams/code-search).*Technical details
@@ -38107,21 +39046,21 @@ To see this panel, visit `/-/debug/grafana/d/frontend/frontend?viewPanel=101502` Query: ``` -sum(increase(src_gitserver_client_errors_total{job=~"^(frontend|sourcegraph-frontend).*"}[5m])) +sum(increase(src_batches_httpapi_errors_total{job=~"^(frontend|sourcegraph-frontend).*"}[5m])) ```-#### frontend: gitserver_client_error_rate +#### frontend: batches_httpapi_error_rate -
Aggregate graphql operation error rate over 5m
+Aggregate http handler operation error rate over 5m
This panel has no related alerts. To see this panel, visit `/-/debug/grafana/d/frontend/frontend?viewPanel=101503` on your Sourcegraph instance. -*Managed by the [Sourcegraph Source team](https://handbook.sourcegraph.com/departments/engineering/teams/source).* +*Managed by the [Sourcegraph Code Search team](https://handbook.sourcegraph.com/departments/engineering/teams/code-search).*Technical details
@@ -38129,21 +39068,21 @@ To see this panel, visit `/-/debug/grafana/d/frontend/frontend?viewPanel=101503` Query: ``` -sum(increase(src_gitserver_client_errors_total{job=~"^(frontend|sourcegraph-frontend).*"}[5m])) / (sum(increase(src_gitserver_client_total{job=~"^(frontend|sourcegraph-frontend).*"}[5m])) + sum(increase(src_gitserver_client_errors_total{job=~"^(frontend|sourcegraph-frontend).*"}[5m]))) * 100 +sum(increase(src_batches_httpapi_errors_total{job=~"^(frontend|sourcegraph-frontend).*"}[5m])) / (sum(increase(src_batches_httpapi_total{job=~"^(frontend|sourcegraph-frontend).*"}[5m])) + sum(increase(src_batches_httpapi_errors_total{job=~"^(frontend|sourcegraph-frontend).*"}[5m]))) * 100 ```-#### frontend: gitserver_client_total +#### frontend: batches_httpapi_total -
Graphql operations every 5m
+Http handler operations every 5m
This panel has no related alerts. To see this panel, visit `/-/debug/grafana/d/frontend/frontend?viewPanel=101510` on your Sourcegraph instance. -*Managed by the [Sourcegraph Source team](https://handbook.sourcegraph.com/departments/engineering/teams/source).* +*Managed by the [Sourcegraph Code Search team](https://handbook.sourcegraph.com/departments/engineering/teams/code-search).*Technical details
@@ -38151,21 +39090,21 @@ To see this panel, visit `/-/debug/grafana/d/frontend/frontend?viewPanel=101510` Query: ``` -sum by (op,scope)(increase(src_gitserver_client_total{job=~"^(frontend|sourcegraph-frontend).*"}[5m])) +sum by (op)(increase(src_batches_httpapi_total{job=~"^(frontend|sourcegraph-frontend).*"}[5m])) ```-#### frontend: gitserver_client_99th_percentile_duration +#### frontend: batches_httpapi_99th_percentile_duration -
99th percentile successful graphql operation duration over 5m
+99th percentile successful http handler operation duration over 5m
This panel has no related alerts. To see this panel, visit `/-/debug/grafana/d/frontend/frontend?viewPanel=101511` on your Sourcegraph instance. -*Managed by the [Sourcegraph Source team](https://handbook.sourcegraph.com/departments/engineering/teams/source).* +*Managed by the [Sourcegraph Code Search team](https://handbook.sourcegraph.com/departments/engineering/teams/code-search).*Technical details
@@ -38173,21 +39112,21 @@ To see this panel, visit `/-/debug/grafana/d/frontend/frontend?viewPanel=101511` Query: ``` -histogram_quantile(0.99, sum by (le,op,scope)(rate(src_gitserver_client_duration_seconds_bucket{job=~"^(frontend|sourcegraph-frontend).*"}[5m]))) +histogram_quantile(0.99, sum by (le,op)(rate(src_batches_httpapi_duration_seconds_bucket{job=~"^(frontend|sourcegraph-frontend).*"}[5m]))) ```-#### frontend: gitserver_client_errors_total +#### frontend: batches_httpapi_errors_total -
Graphql operation errors every 5m
+Http handler operation errors every 5m
This panel has no related alerts. To see this panel, visit `/-/debug/grafana/d/frontend/frontend?viewPanel=101512` on your Sourcegraph instance. -*Managed by the [Sourcegraph Source team](https://handbook.sourcegraph.com/departments/engineering/teams/source).* +*Managed by the [Sourcegraph Code Search team](https://handbook.sourcegraph.com/departments/engineering/teams/code-search).*Technical details
@@ -38195,21 +39134,21 @@ To see this panel, visit `/-/debug/grafana/d/frontend/frontend?viewPanel=101512` Query: ``` -sum by (op,scope)(increase(src_gitserver_client_errors_total{job=~"^(frontend|sourcegraph-frontend).*"}[5m])) +sum by (op)(increase(src_batches_httpapi_errors_total{job=~"^(frontend|sourcegraph-frontend).*"}[5m])) ```-#### frontend: gitserver_client_error_rate +#### frontend: batches_httpapi_error_rate -
Graphql operation error rate over 5m
+Http handler operation error rate over 5m
This panel has no related alerts. To see this panel, visit `/-/debug/grafana/d/frontend/frontend?viewPanel=101513` on your Sourcegraph instance. -*Managed by the [Sourcegraph Source team](https://handbook.sourcegraph.com/departments/engineering/teams/source).* +*Managed by the [Sourcegraph Code Search team](https://handbook.sourcegraph.com/departments/engineering/teams/code-search).*Technical details
@@ -38217,23 +39156,23 @@ To see this panel, visit `/-/debug/grafana/d/frontend/frontend?viewPanel=101513` Query: ``` -sum by (op,scope)(increase(src_gitserver_client_errors_total{job=~"^(frontend|sourcegraph-frontend).*"}[5m])) / (sum by (op,scope)(increase(src_gitserver_client_total{job=~"^(frontend|sourcegraph-frontend).*"}[5m])) + sum by (op,scope)(increase(src_gitserver_client_errors_total{job=~"^(frontend|sourcegraph-frontend).*"}[5m]))) * 100 +sum by (op)(increase(src_batches_httpapi_errors_total{job=~"^(frontend|sourcegraph-frontend).*"}[5m])) / (sum by (op)(increase(src_batches_httpapi_total{job=~"^(frontend|sourcegraph-frontend).*"}[5m])) + sum by (op)(increase(src_batches_httpapi_errors_total{job=~"^(frontend|sourcegraph-frontend).*"}[5m]))) * 100 ```-### Frontend: Batches: dbstore stats +### Frontend: Out-of-band migrations: up migration invocation (one batch processed) -#### frontend: batches_dbstore_total +#### frontend: oobmigration_total -
Aggregate store operations every 5m
+Migration handler operations every 5m
This panel has no related alerts. To see this panel, visit `/-/debug/grafana/d/frontend/frontend?viewPanel=101600` on your Sourcegraph instance. -*Managed by the [Sourcegraph Code Search team](https://handbook.sourcegraph.com/departments/engineering/teams/code-search).* +*Managed by the [Sourcegraph Code intelligence team](https://handbook.sourcegraph.com/departments/engineering/teams/code-intelligence).*Technical details
@@ -38241,21 +39180,21 @@ To see this panel, visit `/-/debug/grafana/d/frontend/frontend?viewPanel=101600` Query: ``` -sum(increase(src_batches_dbstore_total{job=~"^(frontend|sourcegraph-frontend).*"}[5m])) +sum(increase(src_oobmigration_total{op="up",job=~"^(frontend|sourcegraph-frontend).*"}[5m])) ```-#### frontend: batches_dbstore_99th_percentile_duration +#### frontend: oobmigration_99th_percentile_duration -
Aggregate successful store operation duration distribution over 5m
+Aggregate successful migration handler operation duration distribution over 5m
This panel has no related alerts. To see this panel, visit `/-/debug/grafana/d/frontend/frontend?viewPanel=101601` on your Sourcegraph instance. -*Managed by the [Sourcegraph Code Search team](https://handbook.sourcegraph.com/departments/engineering/teams/code-search).* +*Managed by the [Sourcegraph Code intelligence team](https://handbook.sourcegraph.com/departments/engineering/teams/code-intelligence).*Technical details
@@ -38263,21 +39202,21 @@ To see this panel, visit `/-/debug/grafana/d/frontend/frontend?viewPanel=101601` Query: ``` -sum by (le)(rate(src_batches_dbstore_duration_seconds_bucket{job=~"^(frontend|sourcegraph-frontend).*"}[5m])) +sum by (le)(rate(src_oobmigration_duration_seconds_bucket{op="up",job=~"^(frontend|sourcegraph-frontend).*"}[5m])) ```-#### frontend: batches_dbstore_errors_total +#### frontend: oobmigration_errors_total -
Aggregate store operation errors every 5m
+Migration handler operation errors every 5m
This panel has no related alerts. To see this panel, visit `/-/debug/grafana/d/frontend/frontend?viewPanel=101602` on your Sourcegraph instance. -*Managed by the [Sourcegraph Code Search team](https://handbook.sourcegraph.com/departments/engineering/teams/code-search).* +*Managed by the [Sourcegraph Code intelligence team](https://handbook.sourcegraph.com/departments/engineering/teams/code-intelligence).*Technical details
@@ -38285,21 +39224,21 @@ To see this panel, visit `/-/debug/grafana/d/frontend/frontend?viewPanel=101602` Query: ``` -sum(increase(src_batches_dbstore_errors_total{job=~"^(frontend|sourcegraph-frontend).*"}[5m])) +sum(increase(src_oobmigration_errors_total{op="up",job=~"^(frontend|sourcegraph-frontend).*"}[5m])) ```-#### frontend: batches_dbstore_error_rate +#### frontend: oobmigration_error_rate -
Aggregate store operation error rate over 5m
+Migration handler operation error rate over 5m
This panel has no related alerts. To see this panel, visit `/-/debug/grafana/d/frontend/frontend?viewPanel=101603` on your Sourcegraph instance. -*Managed by the [Sourcegraph Code Search team](https://handbook.sourcegraph.com/departments/engineering/teams/code-search).* +*Managed by the [Sourcegraph Code intelligence team](https://handbook.sourcegraph.com/departments/engineering/teams/code-intelligence).*Technical details
@@ -38307,21 +39246,23 @@ To see this panel, visit `/-/debug/grafana/d/frontend/frontend?viewPanel=101603` Query: ``` -sum(increase(src_batches_dbstore_errors_total{job=~"^(frontend|sourcegraph-frontend).*"}[5m])) / (sum(increase(src_batches_dbstore_total{job=~"^(frontend|sourcegraph-frontend).*"}[5m])) + sum(increase(src_batches_dbstore_errors_total{job=~"^(frontend|sourcegraph-frontend).*"}[5m]))) * 100 +sum(increase(src_oobmigration_errors_total{op="up",job=~"^(frontend|sourcegraph-frontend).*"}[5m])) / (sum(increase(src_oobmigration_total{op="up",job=~"^(frontend|sourcegraph-frontend).*"}[5m])) + sum(increase(src_oobmigration_errors_total{op="up",job=~"^(frontend|sourcegraph-frontend).*"}[5m]))) * 100 ```-#### frontend: batches_dbstore_total +### Frontend: Out-of-band migrations: down migration invocation (one batch processed) -
Store operations every 5m
+#### frontend: oobmigration_total + +Migration handler operations every 5m
This panel has no related alerts. -To see this panel, visit `/-/debug/grafana/d/frontend/frontend?viewPanel=101610` on your Sourcegraph instance. +To see this panel, visit `/-/debug/grafana/d/frontend/frontend?viewPanel=101700` on your Sourcegraph instance. -*Managed by the [Sourcegraph Code Search team](https://handbook.sourcegraph.com/departments/engineering/teams/code-search).* +*Managed by the [Sourcegraph Code intelligence team](https://handbook.sourcegraph.com/departments/engineering/teams/code-intelligence).*Technical details
@@ -38329,21 +39270,21 @@ To see this panel, visit `/-/debug/grafana/d/frontend/frontend?viewPanel=101610` Query: ``` -sum by (op)(increase(src_batches_dbstore_total{job=~"^(frontend|sourcegraph-frontend).*"}[5m])) +sum(increase(src_oobmigration_total{op="down",job=~"^(frontend|sourcegraph-frontend).*"}[5m])) ```-#### frontend: batches_dbstore_99th_percentile_duration +#### frontend: oobmigration_99th_percentile_duration -
99th percentile successful store operation duration over 5m
+Aggregate successful migration handler operation duration distribution over 5m
This panel has no related alerts. -To see this panel, visit `/-/debug/grafana/d/frontend/frontend?viewPanel=101611` on your Sourcegraph instance. +To see this panel, visit `/-/debug/grafana/d/frontend/frontend?viewPanel=101701` on your Sourcegraph instance. -*Managed by the [Sourcegraph Code Search team](https://handbook.sourcegraph.com/departments/engineering/teams/code-search).* +*Managed by the [Sourcegraph Code intelligence team](https://handbook.sourcegraph.com/departments/engineering/teams/code-intelligence).*Technical details
@@ -38351,21 +39292,21 @@ To see this panel, visit `/-/debug/grafana/d/frontend/frontend?viewPanel=101611` Query: ``` -histogram_quantile(0.99, sum by (le,op)(rate(src_batches_dbstore_duration_seconds_bucket{job=~"^(frontend|sourcegraph-frontend).*"}[5m]))) +sum by (le)(rate(src_oobmigration_duration_seconds_bucket{op="down",job=~"^(frontend|sourcegraph-frontend).*"}[5m])) ```-#### frontend: batches_dbstore_errors_total +#### frontend: oobmigration_errors_total -
Store operation errors every 5m
+Migration handler operation errors every 5m
This panel has no related alerts. -To see this panel, visit `/-/debug/grafana/d/frontend/frontend?viewPanel=101612` on your Sourcegraph instance. +To see this panel, visit `/-/debug/grafana/d/frontend/frontend?viewPanel=101702` on your Sourcegraph instance. -*Managed by the [Sourcegraph Code Search team](https://handbook.sourcegraph.com/departments/engineering/teams/code-search).* +*Managed by the [Sourcegraph Code intelligence team](https://handbook.sourcegraph.com/departments/engineering/teams/code-intelligence).*Technical details
@@ -38373,21 +39314,21 @@ To see this panel, visit `/-/debug/grafana/d/frontend/frontend?viewPanel=101612` Query: ``` -sum by (op)(increase(src_batches_dbstore_errors_total{job=~"^(frontend|sourcegraph-frontend).*"}[5m])) +sum(increase(src_oobmigration_errors_total{op="down",job=~"^(frontend|sourcegraph-frontend).*"}[5m])) ```-#### frontend: batches_dbstore_error_rate +#### frontend: oobmigration_error_rate -
Store operation error rate over 5m
+Migration handler operation error rate over 5m
This panel has no related alerts. -To see this panel, visit `/-/debug/grafana/d/frontend/frontend?viewPanel=101613` on your Sourcegraph instance. +To see this panel, visit `/-/debug/grafana/d/frontend/frontend?viewPanel=101703` on your Sourcegraph instance. -*Managed by the [Sourcegraph Code Search team](https://handbook.sourcegraph.com/departments/engineering/teams/code-search).* +*Managed by the [Sourcegraph Code intelligence team](https://handbook.sourcegraph.com/departments/engineering/teams/code-intelligence).*Technical details
@@ -38395,23 +39336,25 @@ To see this panel, visit `/-/debug/grafana/d/frontend/frontend?viewPanel=101613` Query: ``` -sum by (op)(increase(src_batches_dbstore_errors_total{job=~"^(frontend|sourcegraph-frontend).*"}[5m])) / (sum by (op)(increase(src_batches_dbstore_total{job=~"^(frontend|sourcegraph-frontend).*"}[5m])) + sum by (op)(increase(src_batches_dbstore_errors_total{job=~"^(frontend|sourcegraph-frontend).*"}[5m]))) * 100 +sum(increase(src_oobmigration_errors_total{op="down",job=~"^(frontend|sourcegraph-frontend).*"}[5m])) / (sum(increase(src_oobmigration_total{op="down",job=~"^(frontend|sourcegraph-frontend).*"}[5m])) + sum(increase(src_oobmigration_errors_total{op="down",job=~"^(frontend|sourcegraph-frontend).*"}[5m]))) * 100 ```-### Frontend: Batches: service stats +### Frontend: Zoekt Configuration GRPC server metrics -#### frontend: batches_service_total +#### frontend: zoekt_configuration_grpc_request_rate_all_methods -
Aggregate service operations every 5m
+Request rate across all methods over 2m
+ +The number of gRPC requests received per second across all methods, aggregated across all instances. This panel has no related alerts. -To see this panel, visit `/-/debug/grafana/d/frontend/frontend?viewPanel=101700` on your Sourcegraph instance. +To see this panel, visit `/-/debug/grafana/d/frontend/frontend?viewPanel=101800` on your Sourcegraph instance. -*Managed by the [Sourcegraph Code Search team](https://handbook.sourcegraph.com/departments/engineering/teams/code-search).* +*Managed by the [Sourcegraph Search Platform team](https://handbook.sourcegraph.com/departments/engineering/teams/search/core).*Technical details
@@ -38419,21 +39362,23 @@ To see this panel, visit `/-/debug/grafana/d/frontend/frontend?viewPanel=101700` Query: ``` -sum(increase(src_batches_service_total{job=~"^(frontend|sourcegraph-frontend).*"}[5m])) +sum(rate(grpc_server_started_total{instance=~`${internalInstance:regex}`,grpc_service=~"sourcegraph.zoekt.configuration.v1.ZoektConfigurationService"}[2m])) ```-#### frontend: batches_service_99th_percentile_duration +#### frontend: zoekt_configuration_grpc_request_rate_per_method -
Aggregate successful service operation duration distribution over 5m
+Request rate per-method over 2m
+ +The number of gRPC requests received per second broken out per method, aggregated across all instances. This panel has no related alerts. -To see this panel, visit `/-/debug/grafana/d/frontend/frontend?viewPanel=101701` on your Sourcegraph instance. +To see this panel, visit `/-/debug/grafana/d/frontend/frontend?viewPanel=101801` on your Sourcegraph instance. -*Managed by the [Sourcegraph Code Search team](https://handbook.sourcegraph.com/departments/engineering/teams/code-search).* +*Managed by the [Sourcegraph Search Platform team](https://handbook.sourcegraph.com/departments/engineering/teams/search/core).*Technical details
@@ -38441,21 +39386,23 @@ To see this panel, visit `/-/debug/grafana/d/frontend/frontend?viewPanel=101701` Query: ``` -sum by (le)(rate(src_batches_service_duration_seconds_bucket{job=~"^(frontend|sourcegraph-frontend).*"}[5m])) +sum(rate(grpc_server_started_total{grpc_method=~`${zoekt_configuration_method:regex}`,instance=~`${internalInstance:regex}`,grpc_service=~"sourcegraph.zoekt.configuration.v1.ZoektConfigurationService"}[2m])) by (grpc_method) ```-#### frontend: batches_service_errors_total +#### frontend: zoekt_configuration_error_percentage_all_methods -
Aggregate service operation errors every 5m
+Error percentage across all methods over 2m
+ +The percentage of gRPC requests that fail across all methods, aggregated across all instances. This panel has no related alerts. -To see this panel, visit `/-/debug/grafana/d/frontend/frontend?viewPanel=101702` on your Sourcegraph instance. +To see this panel, visit `/-/debug/grafana/d/frontend/frontend?viewPanel=101810` on your Sourcegraph instance. -*Managed by the [Sourcegraph Code Search team](https://handbook.sourcegraph.com/departments/engineering/teams/code-search).* +*Managed by the [Sourcegraph Search Platform team](https://handbook.sourcegraph.com/departments/engineering/teams/search/core).*Technical details
@@ -38463,21 +39410,23 @@ To see this panel, visit `/-/debug/grafana/d/frontend/frontend?viewPanel=101702` Query: ``` -sum(increase(src_batches_service_errors_total{job=~"^(frontend|sourcegraph-frontend).*"}[5m])) +(100.0 * ( (sum(rate(grpc_server_handled_total{grpc_code!="OK",instance=~`${internalInstance:regex}`,grpc_service=~"sourcegraph.zoekt.configuration.v1.ZoektConfigurationService"}[2m]))) / (sum(rate(grpc_server_handled_total{instance=~`${internalInstance:regex}`,grpc_service=~"sourcegraph.zoekt.configuration.v1.ZoektConfigurationService"}[2m]))) )) ```-#### frontend: batches_service_error_rate +#### frontend: zoekt_configuration_grpc_error_percentage_per_method -
Aggregate service operation error rate over 5m
+Error percentage per-method over 2m
+ +The percentage of gRPC requests that fail per method, aggregated across all instances. This panel has no related alerts. -To see this panel, visit `/-/debug/grafana/d/frontend/frontend?viewPanel=101703` on your Sourcegraph instance. +To see this panel, visit `/-/debug/grafana/d/frontend/frontend?viewPanel=101811` on your Sourcegraph instance. -*Managed by the [Sourcegraph Code Search team](https://handbook.sourcegraph.com/departments/engineering/teams/code-search).* +*Managed by the [Sourcegraph Search Platform team](https://handbook.sourcegraph.com/departments/engineering/teams/search/core).*Technical details
@@ -38485,21 +39434,23 @@ To see this panel, visit `/-/debug/grafana/d/frontend/frontend?viewPanel=101703` Query: ``` -sum(increase(src_batches_service_errors_total{job=~"^(frontend|sourcegraph-frontend).*"}[5m])) / (sum(increase(src_batches_service_total{job=~"^(frontend|sourcegraph-frontend).*"}[5m])) + sum(increase(src_batches_service_errors_total{job=~"^(frontend|sourcegraph-frontend).*"}[5m]))) * 100 +(100.0 * ( (sum(rate(grpc_server_handled_total{grpc_method=~`${zoekt_configuration_method:regex}`,grpc_code!="OK",instance=~`${internalInstance:regex}`,grpc_service=~"sourcegraph.zoekt.configuration.v1.ZoektConfigurationService"}[2m])) by (grpc_method)) / (sum(rate(grpc_server_handled_total{grpc_method=~`${zoekt_configuration_method:regex}`,instance=~`${internalInstance:regex}`,grpc_service=~"sourcegraph.zoekt.configuration.v1.ZoektConfigurationService"}[2m])) by (grpc_method)) )) ```-#### frontend: batches_service_total +#### frontend: zoekt_configuration_p99_response_time_per_method -
Service operations every 5m
+99th percentile response time per method over 2m
+ +The 99th percentile response time per method, aggregated across all instances. This panel has no related alerts. -To see this panel, visit `/-/debug/grafana/d/frontend/frontend?viewPanel=101710` on your Sourcegraph instance. +To see this panel, visit `/-/debug/grafana/d/frontend/frontend?viewPanel=101820` on your Sourcegraph instance. -*Managed by the [Sourcegraph Code Search team](https://handbook.sourcegraph.com/departments/engineering/teams/code-search).* +*Managed by the [Sourcegraph Search Platform team](https://handbook.sourcegraph.com/departments/engineering/teams/search/core).*Technical details
@@ -38507,21 +39458,23 @@ To see this panel, visit `/-/debug/grafana/d/frontend/frontend?viewPanel=101710` Query: ``` -sum by (op)(increase(src_batches_service_total{job=~"^(frontend|sourcegraph-frontend).*"}[5m])) +histogram_quantile(0.99, sum by (le, name, grpc_method)(rate(grpc_server_handling_seconds_bucket{grpc_method=~`${zoekt_configuration_method:regex}`,instance=~`${internalInstance:regex}`,grpc_service=~"sourcegraph.zoekt.configuration.v1.ZoektConfigurationService"}[2m]))) ```-#### frontend: batches_service_99th_percentile_duration +#### frontend: zoekt_configuration_p90_response_time_per_method -
99th percentile successful service operation duration over 5m
+90th percentile response time per method over 2m
+ +The 90th percentile response time per method, aggregated across all instances. This panel has no related alerts. -To see this panel, visit `/-/debug/grafana/d/frontend/frontend?viewPanel=101711` on your Sourcegraph instance. +To see this panel, visit `/-/debug/grafana/d/frontend/frontend?viewPanel=101821` on your Sourcegraph instance. -*Managed by the [Sourcegraph Code Search team](https://handbook.sourcegraph.com/departments/engineering/teams/code-search).* +*Managed by the [Sourcegraph Search Platform team](https://handbook.sourcegraph.com/departments/engineering/teams/search/core).*Technical details
@@ -38529,21 +39482,23 @@ To see this panel, visit `/-/debug/grafana/d/frontend/frontend?viewPanel=101711` Query: ``` -histogram_quantile(0.99, sum by (le,op)(rate(src_batches_service_duration_seconds_bucket{job=~"^(frontend|sourcegraph-frontend).*"}[5m]))) +histogram_quantile(0.90, sum by (le, name, grpc_method)(rate(grpc_server_handling_seconds_bucket{grpc_method=~`${zoekt_configuration_method:regex}`,instance=~`${internalInstance:regex}`,grpc_service=~"sourcegraph.zoekt.configuration.v1.ZoektConfigurationService"}[2m]))) ```-#### frontend: batches_service_errors_total +#### frontend: zoekt_configuration_p75_response_time_per_method -
Service operation errors every 5m
+75th percentile response time per method over 2m
+ +The 75th percentile response time per method, aggregated across all instances. This panel has no related alerts. -To see this panel, visit `/-/debug/grafana/d/frontend/frontend?viewPanel=101712` on your Sourcegraph instance. +To see this panel, visit `/-/debug/grafana/d/frontend/frontend?viewPanel=101822` on your Sourcegraph instance. -*Managed by the [Sourcegraph Code Search team](https://handbook.sourcegraph.com/departments/engineering/teams/code-search).* +*Managed by the [Sourcegraph Search Platform team](https://handbook.sourcegraph.com/departments/engineering/teams/search/core).*Technical details
@@ -38551,21 +39506,23 @@ To see this panel, visit `/-/debug/grafana/d/frontend/frontend?viewPanel=101712` Query: ``` -sum by (op)(increase(src_batches_service_errors_total{job=~"^(frontend|sourcegraph-frontend).*"}[5m])) +histogram_quantile(0.75, sum by (le, name, grpc_method)(rate(grpc_server_handling_seconds_bucket{grpc_method=~`${zoekt_configuration_method:regex}`,instance=~`${internalInstance:regex}`,grpc_service=~"sourcegraph.zoekt.configuration.v1.ZoektConfigurationService"}[2m]))) ```-#### frontend: batches_service_error_rate +#### frontend: zoekt_configuration_p99_9_response_size_per_method -
Service operation error rate over 5m
+99.9th percentile total response size per method over 2m
+ +The 99.9th percentile total per-RPC response size per method, aggregated across all instances. This panel has no related alerts. -To see this panel, visit `/-/debug/grafana/d/frontend/frontend?viewPanel=101713` on your Sourcegraph instance. +To see this panel, visit `/-/debug/grafana/d/frontend/frontend?viewPanel=101830` on your Sourcegraph instance. -*Managed by the [Sourcegraph Code Search team](https://handbook.sourcegraph.com/departments/engineering/teams/code-search).* +*Managed by the [Sourcegraph Search Platform team](https://handbook.sourcegraph.com/departments/engineering/teams/search/core).*Technical details
@@ -38573,23 +39530,23 @@ To see this panel, visit `/-/debug/grafana/d/frontend/frontend?viewPanel=101713` Query: ``` -sum by (op)(increase(src_batches_service_errors_total{job=~"^(frontend|sourcegraph-frontend).*"}[5m])) / (sum by (op)(increase(src_batches_service_total{job=~"^(frontend|sourcegraph-frontend).*"}[5m])) + sum by (op)(increase(src_batches_service_errors_total{job=~"^(frontend|sourcegraph-frontend).*"}[5m]))) * 100 +histogram_quantile(0.999, sum by (le, name, grpc_method)(rate(src_grpc_server_sent_bytes_per_rpc_bucket{grpc_method=~`${zoekt_configuration_method:regex}`,instance=~`${internalInstance:regex}`,grpc_service=~"sourcegraph.zoekt.configuration.v1.ZoektConfigurationService"}[2m]))) ```-### Frontend: Batches: Workspace execution dbstore +#### frontend: zoekt_configuration_p90_response_size_per_method -#### frontend: workerutil_dbworker_store_batch_spec_workspace_execution_worker_store_total +
90th percentile total response size per method over 2m
-Store operations every 5m
+The 90th percentile total per-RPC response size per method, aggregated across all instances. This panel has no related alerts. -To see this panel, visit `/-/debug/grafana/d/frontend/frontend?viewPanel=101800` on your Sourcegraph instance. +To see this panel, visit `/-/debug/grafana/d/frontend/frontend?viewPanel=101831` on your Sourcegraph instance. -*Managed by the [Sourcegraph Code Search team](https://handbook.sourcegraph.com/departments/engineering/teams/code-search).* +*Managed by the [Sourcegraph Search Platform team](https://handbook.sourcegraph.com/departments/engineering/teams/search/core).*Technical details
@@ -38597,21 +39554,23 @@ To see this panel, visit `/-/debug/grafana/d/frontend/frontend?viewPanel=101800` Query: ``` -sum by (op)(increase(src_workerutil_dbworker_store_batch_spec_workspace_execution_worker_store_total{job=~"^(frontend|sourcegraph-frontend).*"}[5m])) +histogram_quantile(0.90, sum by (le, name, grpc_method)(rate(src_grpc_server_sent_bytes_per_rpc_bucket{grpc_method=~`${zoekt_configuration_method:regex}`,instance=~`${internalInstance:regex}`,grpc_service=~"sourcegraph.zoekt.configuration.v1.ZoektConfigurationService"}[2m]))) ```-#### frontend: workerutil_dbworker_store_batch_spec_workspace_execution_worker_store_99th_percentile_duration +#### frontend: zoekt_configuration_p75_response_size_per_method -
99th percentile successful store operation duration over 5m
+75th percentile total response size per method over 2m
+ +The 75th percentile total per-RPC response size per method, aggregated across all instances. This panel has no related alerts. -To see this panel, visit `/-/debug/grafana/d/frontend/frontend?viewPanel=101801` on your Sourcegraph instance. +To see this panel, visit `/-/debug/grafana/d/frontend/frontend?viewPanel=101832` on your Sourcegraph instance. -*Managed by the [Sourcegraph Code Search team](https://handbook.sourcegraph.com/departments/engineering/teams/code-search).* +*Managed by the [Sourcegraph Search Platform team](https://handbook.sourcegraph.com/departments/engineering/teams/search/core).*Technical details
@@ -38619,21 +39578,23 @@ To see this panel, visit `/-/debug/grafana/d/frontend/frontend?viewPanel=101801` Query: ``` -histogram_quantile(0.99, sum by (le,op)(rate(src_workerutil_dbworker_store_batch_spec_workspace_execution_worker_store_duration_seconds_bucket{job=~"^(frontend|sourcegraph-frontend).*"}[5m]))) +histogram_quantile(0.75, sum by (le, name, grpc_method)(rate(src_grpc_server_sent_bytes_per_rpc_bucket{grpc_method=~`${zoekt_configuration_method:regex}`,instance=~`${internalInstance:regex}`,grpc_service=~"sourcegraph.zoekt.configuration.v1.ZoektConfigurationService"}[2m]))) ```-#### frontend: workerutil_dbworker_store_batch_spec_workspace_execution_worker_store_errors_total +#### frontend: zoekt_configuration_p99_9_invididual_sent_message_size_per_method -
Store operation errors every 5m
+99.9th percentile individual sent message size per method over 2m
+ +The 99.9th percentile size of every individual protocol buffer size sent by the service per method, aggregated across all instances. This panel has no related alerts. -To see this panel, visit `/-/debug/grafana/d/frontend/frontend?viewPanel=101802` on your Sourcegraph instance. +To see this panel, visit `/-/debug/grafana/d/frontend/frontend?viewPanel=101840` on your Sourcegraph instance. -*Managed by the [Sourcegraph Code Search team](https://handbook.sourcegraph.com/departments/engineering/teams/code-search).* +*Managed by the [Sourcegraph Search Platform team](https://handbook.sourcegraph.com/departments/engineering/teams/search/core).*Technical details
@@ -38641,21 +39602,23 @@ To see this panel, visit `/-/debug/grafana/d/frontend/frontend?viewPanel=101802` Query: ``` -sum by (op)(increase(src_workerutil_dbworker_store_batch_spec_workspace_execution_worker_store_errors_total{job=~"^(frontend|sourcegraph-frontend).*"}[5m])) +histogram_quantile(0.999, sum by (le, name, grpc_method)(rate(src_grpc_server_sent_individual_message_size_bytes_per_rpc_bucket{grpc_method=~`${zoekt_configuration_method:regex}`,instance=~`${internalInstance:regex}`,grpc_service=~"sourcegraph.zoekt.configuration.v1.ZoektConfigurationService"}[2m]))) ```-#### frontend: workerutil_dbworker_store_batch_spec_workspace_execution_worker_store_error_rate +#### frontend: zoekt_configuration_p90_invididual_sent_message_size_per_method -
Store operation error rate over 5m
+90th percentile individual sent message size per method over 2m
+ +The 90th percentile size of every individual protocol buffer size sent by the service per method, aggregated across all instances. This panel has no related alerts. -To see this panel, visit `/-/debug/grafana/d/frontend/frontend?viewPanel=101803` on your Sourcegraph instance. +To see this panel, visit `/-/debug/grafana/d/frontend/frontend?viewPanel=101841` on your Sourcegraph instance. -*Managed by the [Sourcegraph Code Search team](https://handbook.sourcegraph.com/departments/engineering/teams/code-search).* +*Managed by the [Sourcegraph Search Platform team](https://handbook.sourcegraph.com/departments/engineering/teams/search/core).*Technical details
@@ -38663,23 +39626,23 @@ To see this panel, visit `/-/debug/grafana/d/frontend/frontend?viewPanel=101803` Query: ``` -sum by (op)(increase(src_workerutil_dbworker_store_batch_spec_workspace_execution_worker_store_errors_total{job=~"^(frontend|sourcegraph-frontend).*"}[5m])) / (sum by (op)(increase(src_workerutil_dbworker_store_batch_spec_workspace_execution_worker_store_total{job=~"^(frontend|sourcegraph-frontend).*"}[5m])) + sum by (op)(increase(src_workerutil_dbworker_store_batch_spec_workspace_execution_worker_store_errors_total{job=~"^(frontend|sourcegraph-frontend).*"}[5m]))) * 100 +histogram_quantile(0.90, sum by (le, name, grpc_method)(rate(src_grpc_server_sent_individual_message_size_bytes_per_rpc_bucket{grpc_method=~`${zoekt_configuration_method:regex}`,instance=~`${internalInstance:regex}`,grpc_service=~"sourcegraph.zoekt.configuration.v1.ZoektConfigurationService"}[2m]))) ```-### Frontend: Batches: HTTP API File Handler +#### frontend: zoekt_configuration_p75_invididual_sent_message_size_per_method -#### frontend: batches_httpapi_total +
75th percentile individual sent message size per method over 2m
-Aggregate http handler operations every 5m
+The 75th percentile size of every individual protocol buffer size sent by the service per method, aggregated across all instances. This panel has no related alerts. -To see this panel, visit `/-/debug/grafana/d/frontend/frontend?viewPanel=101900` on your Sourcegraph instance. +To see this panel, visit `/-/debug/grafana/d/frontend/frontend?viewPanel=101842` on your Sourcegraph instance. -*Managed by the [Sourcegraph Code Search team](https://handbook.sourcegraph.com/departments/engineering/teams/code-search).* +*Managed by the [Sourcegraph Search Platform team](https://handbook.sourcegraph.com/departments/engineering/teams/search/core).*Technical details
@@ -38687,21 +39650,23 @@ To see this panel, visit `/-/debug/grafana/d/frontend/frontend?viewPanel=101900` Query: ``` -sum(increase(src_batches_httpapi_total{job=~"^(frontend|sourcegraph-frontend).*"}[5m])) +histogram_quantile(0.75, sum by (le, name, grpc_method)(rate(src_grpc_server_sent_individual_message_size_bytes_per_rpc_bucket{grpc_method=~`${zoekt_configuration_method:regex}`,instance=~`${internalInstance:regex}`,grpc_service=~"sourcegraph.zoekt.configuration.v1.ZoektConfigurationService"}[2m]))) ```-#### frontend: batches_httpapi_99th_percentile_duration +#### frontend: zoekt_configuration_grpc_response_stream_message_count_per_method -
Aggregate successful http handler operation duration distribution over 5m
+Average streaming response message count per-method over 2m
+ +The average number of response messages sent during a streaming RPC method, broken out per method, aggregated across all instances. This panel has no related alerts. -To see this panel, visit `/-/debug/grafana/d/frontend/frontend?viewPanel=101901` on your Sourcegraph instance. +To see this panel, visit `/-/debug/grafana/d/frontend/frontend?viewPanel=101850` on your Sourcegraph instance. -*Managed by the [Sourcegraph Code Search team](https://handbook.sourcegraph.com/departments/engineering/teams/code-search).* +*Managed by the [Sourcegraph Search Platform team](https://handbook.sourcegraph.com/departments/engineering/teams/search/core).*Technical details
@@ -38709,21 +39674,23 @@ To see this panel, visit `/-/debug/grafana/d/frontend/frontend?viewPanel=101901` Query: ``` -sum by (le)(rate(src_batches_httpapi_duration_seconds_bucket{job=~"^(frontend|sourcegraph-frontend).*"}[5m])) +((sum(rate(grpc_server_msg_sent_total{grpc_type="server_stream",instance=~`${internalInstance:regex}`,grpc_service=~"sourcegraph.zoekt.configuration.v1.ZoektConfigurationService"}[2m])) by (grpc_method))/(sum(rate(grpc_server_started_total{grpc_type="server_stream",instance=~`${internalInstance:regex}`,grpc_service=~"sourcegraph.zoekt.configuration.v1.ZoektConfigurationService"}[2m])) by (grpc_method))) ```-#### frontend: batches_httpapi_errors_total +#### frontend: zoekt_configuration_grpc_all_codes_per_method -
Aggregate http handler operation errors every 5m
+Response codes rate per-method over 2m
+ +The rate of all generated gRPC response codes per method, aggregated across all instances. This panel has no related alerts. -To see this panel, visit `/-/debug/grafana/d/frontend/frontend?viewPanel=101902` on your Sourcegraph instance. +To see this panel, visit `/-/debug/grafana/d/frontend/frontend?viewPanel=101860` on your Sourcegraph instance. -*Managed by the [Sourcegraph Code Search team](https://handbook.sourcegraph.com/departments/engineering/teams/code-search).* +*Managed by the [Sourcegraph Search Platform team](https://handbook.sourcegraph.com/departments/engineering/teams/search/core).*Technical details
@@ -38731,21 +39698,25 @@ To see this panel, visit `/-/debug/grafana/d/frontend/frontend?viewPanel=101902` Query: ``` -sum(increase(src_batches_httpapi_errors_total{job=~"^(frontend|sourcegraph-frontend).*"}[5m])) +sum(rate(grpc_server_handled_total{grpc_method=~`${zoekt_configuration_method:regex}`,instance=~`${internalInstance:regex}`,grpc_service=~"sourcegraph.zoekt.configuration.v1.ZoektConfigurationService"}[2m])) by (grpc_method, grpc_code) ```-#### frontend: batches_httpapi_error_rate +### Frontend: Zoekt Configuration GRPC "internal error" metrics -
Aggregate http handler operation error rate over 5m
+#### frontend: zoekt_configuration_grpc_clients_error_percentage_all_methods + +Client baseline error percentage across all methods over 2m
+ +The percentage of gRPC requests that fail across all methods (regardless of whether or not there was an internal error), aggregated across all "zoekt_configuration" clients. This panel has no related alerts. -To see this panel, visit `/-/debug/grafana/d/frontend/frontend?viewPanel=101903` on your Sourcegraph instance. +To see this panel, visit `/-/debug/grafana/d/frontend/frontend?viewPanel=101900` on your Sourcegraph instance. -*Managed by the [Sourcegraph Code Search team](https://handbook.sourcegraph.com/departments/engineering/teams/code-search).* +*Managed by the [Sourcegraph Search Platform team](https://handbook.sourcegraph.com/departments/engineering/teams/search/core).*Technical details
@@ -38753,21 +39724,23 @@ To see this panel, visit `/-/debug/grafana/d/frontend/frontend?viewPanel=101903` Query: ``` -sum(increase(src_batches_httpapi_errors_total{job=~"^(frontend|sourcegraph-frontend).*"}[5m])) / (sum(increase(src_batches_httpapi_total{job=~"^(frontend|sourcegraph-frontend).*"}[5m])) + sum(increase(src_batches_httpapi_errors_total{job=~"^(frontend|sourcegraph-frontend).*"}[5m]))) * 100 +(100.0 * ((((sum(rate(grpc_method_status{grpc_service=~"sourcegraph.zoekt.configuration.v1.ZoektConfigurationService",grpc_code!="OK"}[2m])))) / ((sum(rate(grpc_method_status{grpc_service=~"sourcegraph.zoekt.configuration.v1.ZoektConfigurationService"}[2m]))))))) ```-#### frontend: batches_httpapi_total +#### frontend: zoekt_configuration_grpc_clients_error_percentage_per_method -
Http handler operations every 5m
+Client baseline error percentage per-method over 2m
+ +The percentage of gRPC requests that fail per method (regardless of whether or not there was an internal error), aggregated across all "zoekt_configuration" clients. This panel has no related alerts. -To see this panel, visit `/-/debug/grafana/d/frontend/frontend?viewPanel=101910` on your Sourcegraph instance. +To see this panel, visit `/-/debug/grafana/d/frontend/frontend?viewPanel=101901` on your Sourcegraph instance. -*Managed by the [Sourcegraph Code Search team](https://handbook.sourcegraph.com/departments/engineering/teams/code-search).* +*Managed by the [Sourcegraph Search Platform team](https://handbook.sourcegraph.com/departments/engineering/teams/search/core).*Technical details
@@ -38775,21 +39748,23 @@ To see this panel, visit `/-/debug/grafana/d/frontend/frontend?viewPanel=101910` Query: ``` -sum by (op)(increase(src_batches_httpapi_total{job=~"^(frontend|sourcegraph-frontend).*"}[5m])) +(100.0 * ((((sum(rate(grpc_method_status{grpc_service=~"sourcegraph.zoekt.configuration.v1.ZoektConfigurationService",grpc_method=~"${zoekt_configuration_method:regex}",grpc_code!="OK"}[2m])) by (grpc_method))) / ((sum(rate(grpc_method_status{grpc_service=~"sourcegraph.zoekt.configuration.v1.ZoektConfigurationService",grpc_method=~"${zoekt_configuration_method:regex}"}[2m])) by (grpc_method)))))) ```-#### frontend: batches_httpapi_99th_percentile_duration +#### frontend: zoekt_configuration_grpc_clients_all_codes_per_method -
99th percentile successful http handler operation duration over 5m
+Client baseline response codes rate per-method over 2m
+ +The rate of all generated gRPC response codes per method (regardless of whether or not there was an internal error), aggregated across all "zoekt_configuration" clients. This panel has no related alerts. -To see this panel, visit `/-/debug/grafana/d/frontend/frontend?viewPanel=101911` on your Sourcegraph instance. +To see this panel, visit `/-/debug/grafana/d/frontend/frontend?viewPanel=101902` on your Sourcegraph instance. -*Managed by the [Sourcegraph Code Search team](https://handbook.sourcegraph.com/departments/engineering/teams/code-search).* +*Managed by the [Sourcegraph Search Platform team](https://handbook.sourcegraph.com/departments/engineering/teams/search/core).*Technical details
@@ -38797,43 +39772,29 @@ To see this panel, visit `/-/debug/grafana/d/frontend/frontend?viewPanel=101911` Query: ``` -histogram_quantile(0.99, sum by (le,op)(rate(src_batches_httpapi_duration_seconds_bucket{job=~"^(frontend|sourcegraph-frontend).*"}[5m]))) +(sum(rate(grpc_method_status{grpc_service=~"sourcegraph.zoekt.configuration.v1.ZoektConfigurationService",grpc_method=~"${zoekt_configuration_method:regex}"}[2m])) by (grpc_method, grpc_code)) ```-#### frontend: batches_httpapi_errors_total - -
Http handler operation errors every 5m
- -This panel has no related alerts. - -To see this panel, visit `/-/debug/grafana/d/frontend/frontend?viewPanel=101912` on your Sourcegraph instance. - -*Managed by the [Sourcegraph Code Search team](https://handbook.sourcegraph.com/departments/engineering/teams/code-search).* - -Technical details
+#### frontend: zoekt_configuration_grpc_clients_internal_error_percentage_all_methods -Query: +Client-observed gRPC internal error percentage across all methods over 2m
-``` -sum by (op)(increase(src_batches_httpapi_errors_total{job=~"^(frontend|sourcegraph-frontend).*"}[5m])) -``` -+**Note**: Internal errors are ones that appear to originate from the https://github.com/grpc/grpc-go library itself, rather than from any user-written application code. These errors can be caused by a variety of issues, and can originate from either the code-generated "zoekt_configuration" gRPC client or gRPC server. These errors might be solvable by adjusting the gRPC configuration, or they might indicate a bug from Sourcegraph`s use of gRPC. -#### frontend: batches_httpapi_error_rate +When debugging, knowing that a particular error comes from the grpc-go library itself (an `internal error`) as opposed to `normal` application code can be helpful when trying to fix it. -
Http handler operation error rate over 5m
+**Note**: Internal errors are detected via a very coarse heuristic (seeing if the error starts with `grpc:`, etc.). Because of this, it`s possible that some gRPC-specific issues might not be categorized as internal errors. This panel has no related alerts. -To see this panel, visit `/-/debug/grafana/d/frontend/frontend?viewPanel=101913` on your Sourcegraph instance. +To see this panel, visit `/-/debug/grafana/d/frontend/frontend?viewPanel=101910` on your Sourcegraph instance. -*Managed by the [Sourcegraph Code Search team](https://handbook.sourcegraph.com/departments/engineering/teams/code-search).* +*Managed by the [Sourcegraph Search Platform team](https://handbook.sourcegraph.com/departments/engineering/teams/search/core).*Technical details
@@ -38841,45 +39802,29 @@ To see this panel, visit `/-/debug/grafana/d/frontend/frontend?viewPanel=101913` Query: ``` -sum by (op)(increase(src_batches_httpapi_errors_total{job=~"^(frontend|sourcegraph-frontend).*"}[5m])) / (sum by (op)(increase(src_batches_httpapi_total{job=~"^(frontend|sourcegraph-frontend).*"}[5m])) + sum by (op)(increase(src_batches_httpapi_errors_total{job=~"^(frontend|sourcegraph-frontend).*"}[5m]))) * 100 +(100.0 * ((((sum(rate(grpc_method_status{grpc_service=~"sourcegraph.zoekt.configuration.v1.ZoektConfigurationService",grpc_code!="OK",is_internal_error="true"}[2m])))) / ((sum(rate(grpc_method_status{grpc_service=~"sourcegraph.zoekt.configuration.v1.ZoektConfigurationService"}[2m]))))))) ```-### Frontend: Out-of-band migrations: up migration invocation (one batch processed) - -#### frontend: oobmigration_total - -
Migration handler operations every 5m
- -This panel has no related alerts. - -To see this panel, visit `/-/debug/grafana/d/frontend/frontend?viewPanel=102000` on your Sourcegraph instance. - -*Managed by the [Sourcegraph Code intelligence team](https://handbook.sourcegraph.com/departments/engineering/teams/code-intelligence).* - -Technical details
+#### frontend: zoekt_configuration_grpc_clients_internal_error_percentage_per_method -Query: +Client-observed gRPC internal error percentage per-method over 2m
-``` -sum(increase(src_oobmigration_total{op="up",job=~"^(frontend|sourcegraph-frontend).*"}[5m])) -``` -+**Note**: Internal errors are ones that appear to originate from the https://github.com/grpc/grpc-go library itself, rather than from any user-written application code. These errors can be caused by a variety of issues, and can originate from either the code-generated "zoekt_configuration" gRPC client or gRPC server. These errors might be solvable by adjusting the gRPC configuration, or they might indicate a bug from Sourcegraph`s use of gRPC. -#### frontend: oobmigration_99th_percentile_duration +When debugging, knowing that a particular error comes from the grpc-go library itself (an `internal error`) as opposed to `normal` application code can be helpful when trying to fix it. -
Aggregate successful migration handler operation duration distribution over 5m
+**Note**: Internal errors are detected via a very coarse heuristic (seeing if the error starts with `grpc:`, etc.). Because of this, it`s possible that some gRPC-specific issues might not be categorized as internal errors. This panel has no related alerts. -To see this panel, visit `/-/debug/grafana/d/frontend/frontend?viewPanel=102001` on your Sourcegraph instance. +To see this panel, visit `/-/debug/grafana/d/frontend/frontend?viewPanel=101911` on your Sourcegraph instance. -*Managed by the [Sourcegraph Code intelligence team](https://handbook.sourcegraph.com/departments/engineering/teams/code-intelligence).* +*Managed by the [Sourcegraph Search Platform team](https://handbook.sourcegraph.com/departments/engineering/teams/search/core).*Technical details
@@ -38887,43 +39832,29 @@ To see this panel, visit `/-/debug/grafana/d/frontend/frontend?viewPanel=102001` Query: ``` -sum by (le)(rate(src_oobmigration_duration_seconds_bucket{op="up",job=~"^(frontend|sourcegraph-frontend).*"}[5m])) +(100.0 * ((((sum(rate(grpc_method_status{grpc_service=~"sourcegraph.zoekt.configuration.v1.ZoektConfigurationService",grpc_method=~"${zoekt_configuration_method:regex}",grpc_code!="OK",is_internal_error="true"}[2m])) by (grpc_method))) / ((sum(rate(grpc_method_status{grpc_service=~"sourcegraph.zoekt.configuration.v1.ZoektConfigurationService",grpc_method=~"${zoekt_configuration_method:regex}"}[2m])) by (grpc_method)))))) ```-#### frontend: oobmigration_errors_total - -
Migration handler operation errors every 5m
- -This panel has no related alerts. - -To see this panel, visit `/-/debug/grafana/d/frontend/frontend?viewPanel=102002` on your Sourcegraph instance. - -*Managed by the [Sourcegraph Code intelligence team](https://handbook.sourcegraph.com/departments/engineering/teams/code-intelligence).* - -Technical details
+#### frontend: zoekt_configuration_grpc_clients_internal_error_all_codes_per_method -Query: +Client-observed gRPC internal error response code rate per-method over 2m
-``` -sum(increase(src_oobmigration_errors_total{op="up",job=~"^(frontend|sourcegraph-frontend).*"}[5m])) -``` -+**Note**: Internal errors are ones that appear to originate from the https://github.com/grpc/grpc-go library itself, rather than from any user-written application code. These errors can be caused by a variety of issues, and can originate from either the code-generated "zoekt_configuration" gRPC client or gRPC server. These errors might be solvable by adjusting the gRPC configuration, or they might indicate a bug from Sourcegraph`s use of gRPC. -#### frontend: oobmigration_error_rate +When debugging, knowing that a particular error comes from the grpc-go library itself (an `internal error`) as opposed to `normal` application code can be helpful when trying to fix it. -
Migration handler operation error rate over 5m
+**Note**: Internal errors are detected via a very coarse heuristic (seeing if the error starts with `grpc:`, etc.). Because of this, it`s possible that some gRPC-specific issues might not be categorized as internal errors. This panel has no related alerts. -To see this panel, visit `/-/debug/grafana/d/frontend/frontend?viewPanel=102003` on your Sourcegraph instance. +To see this panel, visit `/-/debug/grafana/d/frontend/frontend?viewPanel=101912` on your Sourcegraph instance. -*Managed by the [Sourcegraph Code intelligence team](https://handbook.sourcegraph.com/departments/engineering/teams/code-intelligence).* +*Managed by the [Sourcegraph Search Platform team](https://handbook.sourcegraph.com/departments/engineering/teams/search/core).*Technical details
@@ -38931,45 +39862,25 @@ To see this panel, visit `/-/debug/grafana/d/frontend/frontend?viewPanel=102003` Query: ``` -sum(increase(src_oobmigration_errors_total{op="up",job=~"^(frontend|sourcegraph-frontend).*"}[5m])) / (sum(increase(src_oobmigration_total{op="up",job=~"^(frontend|sourcegraph-frontend).*"}[5m])) + sum(increase(src_oobmigration_errors_total{op="up",job=~"^(frontend|sourcegraph-frontend).*"}[5m]))) * 100 +(sum(rate(grpc_method_status{grpc_service=~"sourcegraph.zoekt.configuration.v1.ZoektConfigurationService",is_internal_error="true",grpc_method=~"${zoekt_configuration_method:regex}"}[2m])) by (grpc_method, grpc_code)) ```-### Frontend: Out-of-band migrations: down migration invocation (one batch processed) - -#### frontend: oobmigration_total - -
Migration handler operations every 5m
- -This panel has no related alerts. - -To see this panel, visit `/-/debug/grafana/d/frontend/frontend?viewPanel=102100` on your Sourcegraph instance. - -*Managed by the [Sourcegraph Code intelligence team](https://handbook.sourcegraph.com/departments/engineering/teams/code-intelligence).* - -Technical details
- -Query: - -``` -sum(increase(src_oobmigration_total{op="down",job=~"^(frontend|sourcegraph-frontend).*"}[5m])) -``` -+#### frontend: zoekt_configuration_grpc_clients_retry_percentage_across_all_methods -#### frontend: oobmigration_99th_percentile_duration +
Client retry percentage across all methods over 2m
-Aggregate successful migration handler operation duration distribution over 5m
+The percentage of gRPC requests that were retried across all methods, aggregated across all "zoekt_configuration" clients. This panel has no related alerts. -To see this panel, visit `/-/debug/grafana/d/frontend/frontend?viewPanel=102101` on your Sourcegraph instance. +To see this panel, visit `/-/debug/grafana/d/frontend/frontend?viewPanel=102000` on your Sourcegraph instance. -*Managed by the [Sourcegraph Code intelligence team](https://handbook.sourcegraph.com/departments/engineering/teams/code-intelligence).* +*Managed by the [Sourcegraph Search Platform team](https://handbook.sourcegraph.com/departments/engineering/teams/search/core).*Technical details
@@ -38977,21 +39888,23 @@ To see this panel, visit `/-/debug/grafana/d/frontend/frontend?viewPanel=102101` Query: ``` -sum by (le)(rate(src_oobmigration_duration_seconds_bucket{op="down",job=~"^(frontend|sourcegraph-frontend).*"}[5m])) +(100.0 * ((((sum(rate(src_grpc_client_retry_attempts_total{grpc_service=~"sourcegraph.zoekt.configuration.v1.ZoektConfigurationService",is_retried="true"}[2m])))) / ((sum(rate(src_grpc_client_retry_attempts_total{grpc_service=~"sourcegraph.zoekt.configuration.v1.ZoektConfigurationService"}[2m]))))))) ```-#### frontend: oobmigration_errors_total +#### frontend: zoekt_configuration_grpc_clients_retry_percentage_per_method -
Migration handler operation errors every 5m
+Client retry percentage per-method over 2m
+ +The percentage of gRPC requests that were retried aggregated across all "zoekt_configuration" clients, broken out per method. This panel has no related alerts. -To see this panel, visit `/-/debug/grafana/d/frontend/frontend?viewPanel=102102` on your Sourcegraph instance. +To see this panel, visit `/-/debug/grafana/d/frontend/frontend?viewPanel=102001` on your Sourcegraph instance. -*Managed by the [Sourcegraph Code intelligence team](https://handbook.sourcegraph.com/departments/engineering/teams/code-intelligence).* +*Managed by the [Sourcegraph Search Platform team](https://handbook.sourcegraph.com/departments/engineering/teams/search/core).*Technical details
@@ -38999,21 +39912,23 @@ To see this panel, visit `/-/debug/grafana/d/frontend/frontend?viewPanel=102102` Query: ``` -sum(increase(src_oobmigration_errors_total{op="down",job=~"^(frontend|sourcegraph-frontend).*"}[5m])) +(100.0 * ((((sum(rate(src_grpc_client_retry_attempts_total{grpc_service=~"sourcegraph.zoekt.configuration.v1.ZoektConfigurationService",is_retried="true",grpc_method=~"${zoekt_configuration_method:regex}"}[2m])) by (grpc_method))) / ((sum(rate(src_grpc_client_retry_attempts_total{grpc_service=~"sourcegraph.zoekt.configuration.v1.ZoektConfigurationService",grpc_method=~"${zoekt_configuration_method:regex}"}[2m])) by (grpc_method)))))) ```-#### frontend: oobmigration_error_rate +#### frontend: zoekt_configuration_grpc_clients_retry_count_per_method -
Migration handler operation error rate over 5m
+Client retry count per-method over 2m
+ +The count of gRPC requests that were retried aggregated across all "zoekt_configuration" clients, broken out per method This panel has no related alerts. -To see this panel, visit `/-/debug/grafana/d/frontend/frontend?viewPanel=102103` on your Sourcegraph instance. +To see this panel, visit `/-/debug/grafana/d/frontend/frontend?viewPanel=102002` on your Sourcegraph instance. -*Managed by the [Sourcegraph Code intelligence team](https://handbook.sourcegraph.com/departments/engineering/teams/code-intelligence).* +*Managed by the [Sourcegraph Search Platform team](https://handbook.sourcegraph.com/departments/engineering/teams/search/core).*Technical details
@@ -39021,15 +39936,15 @@ To see this panel, visit `/-/debug/grafana/d/frontend/frontend?viewPanel=102103` Query: ``` -sum(increase(src_oobmigration_errors_total{op="down",job=~"^(frontend|sourcegraph-frontend).*"}[5m])) / (sum(increase(src_oobmigration_total{op="down",job=~"^(frontend|sourcegraph-frontend).*"}[5m])) + sum(increase(src_oobmigration_errors_total{op="down",job=~"^(frontend|sourcegraph-frontend).*"}[5m]))) * 100 +(sum(rate(src_grpc_client_retry_attempts_total{grpc_service=~"sourcegraph.zoekt.configuration.v1.ZoektConfigurationService",grpc_method=~"${zoekt_configuration_method:regex}",is_retried="true"}[2m])) by (grpc_method)) ```-### Frontend: Zoekt Configuration GRPC server metrics +### Frontend: Internal Api GRPC server metrics -#### frontend: zoekt_configuration_grpc_request_rate_all_methods +#### frontend: internal_api_grpc_request_rate_all_methods
Request rate across all methods over 2m
@@ -39037,7 +39952,7 @@ The number of gRPC requests received per second across all methods, aggregated a This panel has no related alerts. -To see this panel, visit `/-/debug/grafana/d/frontend/frontend?viewPanel=102200` on your Sourcegraph instance. +To see this panel, visit `/-/debug/grafana/d/frontend/frontend?viewPanel=102100` on your Sourcegraph instance. *Managed by the [Sourcegraph Search Platform team](https://handbook.sourcegraph.com/departments/engineering/teams/search/core).* @@ -39047,13 +39962,13 @@ To see this panel, visit `/-/debug/grafana/d/frontend/frontend?viewPanel=102200` Query: ``` -sum(rate(grpc_server_started_total{instance=~`${internalInstance:regex}`,grpc_service=~"sourcegraph.zoekt.configuration.v1.ZoektConfigurationService"}[2m])) +sum(rate(grpc_server_started_total{instance=~`${internalInstance:regex}`,grpc_service=~"api.internalapi.v1.ConfigService"}[2m])) ```-#### frontend: zoekt_configuration_grpc_request_rate_per_method +#### frontend: internal_api_grpc_request_rate_per_method
Request rate per-method over 2m
@@ -39061,7 +39976,7 @@ The number of gRPC requests received per second broken out per method, aggregate This panel has no related alerts. -To see this panel, visit `/-/debug/grafana/d/frontend/frontend?viewPanel=102201` on your Sourcegraph instance. +To see this panel, visit `/-/debug/grafana/d/frontend/frontend?viewPanel=102101` on your Sourcegraph instance. *Managed by the [Sourcegraph Search Platform team](https://handbook.sourcegraph.com/departments/engineering/teams/search/core).* @@ -39071,13 +39986,13 @@ To see this panel, visit `/-/debug/grafana/d/frontend/frontend?viewPanel=102201` Query: ``` -sum(rate(grpc_server_started_total{grpc_method=~`${zoekt_configuration_method:regex}`,instance=~`${internalInstance:regex}`,grpc_service=~"sourcegraph.zoekt.configuration.v1.ZoektConfigurationService"}[2m])) by (grpc_method) +sum(rate(grpc_server_started_total{grpc_method=~`${internal_api_method:regex}`,instance=~`${internalInstance:regex}`,grpc_service=~"api.internalapi.v1.ConfigService"}[2m])) by (grpc_method) ```-#### frontend: zoekt_configuration_error_percentage_all_methods +#### frontend: internal_api_error_percentage_all_methods
Error percentage across all methods over 2m
@@ -39085,7 +40000,7 @@ The percentage of gRPC requests that fail across all methods, aggregated across This panel has no related alerts. -To see this panel, visit `/-/debug/grafana/d/frontend/frontend?viewPanel=102210` on your Sourcegraph instance. +To see this panel, visit `/-/debug/grafana/d/frontend/frontend?viewPanel=102110` on your Sourcegraph instance. *Managed by the [Sourcegraph Search Platform team](https://handbook.sourcegraph.com/departments/engineering/teams/search/core).* @@ -39095,13 +40010,13 @@ To see this panel, visit `/-/debug/grafana/d/frontend/frontend?viewPanel=102210` Query: ``` -(100.0 * ( (sum(rate(grpc_server_handled_total{grpc_code!="OK",instance=~`${internalInstance:regex}`,grpc_service=~"sourcegraph.zoekt.configuration.v1.ZoektConfigurationService"}[2m]))) / (sum(rate(grpc_server_handled_total{instance=~`${internalInstance:regex}`,grpc_service=~"sourcegraph.zoekt.configuration.v1.ZoektConfigurationService"}[2m]))) )) +(100.0 * ( (sum(rate(grpc_server_handled_total{grpc_code!="OK",instance=~`${internalInstance:regex}`,grpc_service=~"api.internalapi.v1.ConfigService"}[2m]))) / (sum(rate(grpc_server_handled_total{instance=~`${internalInstance:regex}`,grpc_service=~"api.internalapi.v1.ConfigService"}[2m]))) )) ```-#### frontend: zoekt_configuration_grpc_error_percentage_per_method +#### frontend: internal_api_grpc_error_percentage_per_method
Error percentage per-method over 2m
@@ -39109,7 +40024,7 @@ The percentage of gRPC requests that fail per method, aggregated across all inst This panel has no related alerts. -To see this panel, visit `/-/debug/grafana/d/frontend/frontend?viewPanel=102211` on your Sourcegraph instance. +To see this panel, visit `/-/debug/grafana/d/frontend/frontend?viewPanel=102111` on your Sourcegraph instance. *Managed by the [Sourcegraph Search Platform team](https://handbook.sourcegraph.com/departments/engineering/teams/search/core).* @@ -39119,13 +40034,13 @@ To see this panel, visit `/-/debug/grafana/d/frontend/frontend?viewPanel=102211` Query: ``` -(100.0 * ( (sum(rate(grpc_server_handled_total{grpc_method=~`${zoekt_configuration_method:regex}`,grpc_code!="OK",instance=~`${internalInstance:regex}`,grpc_service=~"sourcegraph.zoekt.configuration.v1.ZoektConfigurationService"}[2m])) by (grpc_method)) / (sum(rate(grpc_server_handled_total{grpc_method=~`${zoekt_configuration_method:regex}`,instance=~`${internalInstance:regex}`,grpc_service=~"sourcegraph.zoekt.configuration.v1.ZoektConfigurationService"}[2m])) by (grpc_method)) )) +(100.0 * ( (sum(rate(grpc_server_handled_total{grpc_method=~`${internal_api_method:regex}`,grpc_code!="OK",instance=~`${internalInstance:regex}`,grpc_service=~"api.internalapi.v1.ConfigService"}[2m])) by (grpc_method)) / (sum(rate(grpc_server_handled_total{grpc_method=~`${internal_api_method:regex}`,instance=~`${internalInstance:regex}`,grpc_service=~"api.internalapi.v1.ConfigService"}[2m])) by (grpc_method)) )) ```-#### frontend: zoekt_configuration_p99_response_time_per_method +#### frontend: internal_api_p99_response_time_per_method
99th percentile response time per method over 2m
@@ -39133,7 +40048,7 @@ The 99th percentile response time per method, aggregated across all instances. This panel has no related alerts. -To see this panel, visit `/-/debug/grafana/d/frontend/frontend?viewPanel=102220` on your Sourcegraph instance. +To see this panel, visit `/-/debug/grafana/d/frontend/frontend?viewPanel=102120` on your Sourcegraph instance. *Managed by the [Sourcegraph Search Platform team](https://handbook.sourcegraph.com/departments/engineering/teams/search/core).* @@ -39143,13 +40058,13 @@ To see this panel, visit `/-/debug/grafana/d/frontend/frontend?viewPanel=102220` Query: ``` -histogram_quantile(0.99, sum by (le, name, grpc_method)(rate(grpc_server_handling_seconds_bucket{grpc_method=~`${zoekt_configuration_method:regex}`,instance=~`${internalInstance:regex}`,grpc_service=~"sourcegraph.zoekt.configuration.v1.ZoektConfigurationService"}[2m]))) +histogram_quantile(0.99, sum by (le, name, grpc_method)(rate(grpc_server_handling_seconds_bucket{grpc_method=~`${internal_api_method:regex}`,instance=~`${internalInstance:regex}`,grpc_service=~"api.internalapi.v1.ConfigService"}[2m]))) ```-#### frontend: zoekt_configuration_p90_response_time_per_method +#### frontend: internal_api_p90_response_time_per_method
90th percentile response time per method over 2m
@@ -39157,7 +40072,7 @@ The 90th percentile response time per method, aggregated across all instances. This panel has no related alerts. -To see this panel, visit `/-/debug/grafana/d/frontend/frontend?viewPanel=102221` on your Sourcegraph instance. +To see this panel, visit `/-/debug/grafana/d/frontend/frontend?viewPanel=102121` on your Sourcegraph instance. *Managed by the [Sourcegraph Search Platform team](https://handbook.sourcegraph.com/departments/engineering/teams/search/core).* @@ -39167,13 +40082,13 @@ To see this panel, visit `/-/debug/grafana/d/frontend/frontend?viewPanel=102221` Query: ``` -histogram_quantile(0.90, sum by (le, name, grpc_method)(rate(grpc_server_handling_seconds_bucket{grpc_method=~`${zoekt_configuration_method:regex}`,instance=~`${internalInstance:regex}`,grpc_service=~"sourcegraph.zoekt.configuration.v1.ZoektConfigurationService"}[2m]))) +histogram_quantile(0.90, sum by (le, name, grpc_method)(rate(grpc_server_handling_seconds_bucket{grpc_method=~`${internal_api_method:regex}`,instance=~`${internalInstance:regex}`,grpc_service=~"api.internalapi.v1.ConfigService"}[2m]))) ```-#### frontend: zoekt_configuration_p75_response_time_per_method +#### frontend: internal_api_p75_response_time_per_method
75th percentile response time per method over 2m
@@ -39181,7 +40096,7 @@ The 75th percentile response time per method, aggregated across all instances. This panel has no related alerts. -To see this panel, visit `/-/debug/grafana/d/frontend/frontend?viewPanel=102222` on your Sourcegraph instance. +To see this panel, visit `/-/debug/grafana/d/frontend/frontend?viewPanel=102122` on your Sourcegraph instance. *Managed by the [Sourcegraph Search Platform team](https://handbook.sourcegraph.com/departments/engineering/teams/search/core).* @@ -39191,13 +40106,13 @@ To see this panel, visit `/-/debug/grafana/d/frontend/frontend?viewPanel=102222` Query: ``` -histogram_quantile(0.75, sum by (le, name, grpc_method)(rate(grpc_server_handling_seconds_bucket{grpc_method=~`${zoekt_configuration_method:regex}`,instance=~`${internalInstance:regex}`,grpc_service=~"sourcegraph.zoekt.configuration.v1.ZoektConfigurationService"}[2m]))) +histogram_quantile(0.75, sum by (le, name, grpc_method)(rate(grpc_server_handling_seconds_bucket{grpc_method=~`${internal_api_method:regex}`,instance=~`${internalInstance:regex}`,grpc_service=~"api.internalapi.v1.ConfigService"}[2m]))) ```-#### frontend: zoekt_configuration_p99_9_response_size_per_method +#### frontend: internal_api_p99_9_response_size_per_method
99.9th percentile total response size per method over 2m
@@ -39205,7 +40120,7 @@ The 99.9th percentile total per-RPC response size per method, aggregated across This panel has no related alerts. -To see this panel, visit `/-/debug/grafana/d/frontend/frontend?viewPanel=102230` on your Sourcegraph instance. +To see this panel, visit `/-/debug/grafana/d/frontend/frontend?viewPanel=102130` on your Sourcegraph instance. *Managed by the [Sourcegraph Search Platform team](https://handbook.sourcegraph.com/departments/engineering/teams/search/core).* @@ -39215,13 +40130,13 @@ To see this panel, visit `/-/debug/grafana/d/frontend/frontend?viewPanel=102230` Query: ``` -histogram_quantile(0.999, sum by (le, name, grpc_method)(rate(src_grpc_server_sent_bytes_per_rpc_bucket{grpc_method=~`${zoekt_configuration_method:regex}`,instance=~`${internalInstance:regex}`,grpc_service=~"sourcegraph.zoekt.configuration.v1.ZoektConfigurationService"}[2m]))) +histogram_quantile(0.999, sum by (le, name, grpc_method)(rate(src_grpc_server_sent_bytes_per_rpc_bucket{grpc_method=~`${internal_api_method:regex}`,instance=~`${internalInstance:regex}`,grpc_service=~"api.internalapi.v1.ConfigService"}[2m]))) ```-#### frontend: zoekt_configuration_p90_response_size_per_method +#### frontend: internal_api_p90_response_size_per_method
90th percentile total response size per method over 2m
@@ -39229,7 +40144,7 @@ The 90th percentile total per-RPC response size per method, aggregated across al This panel has no related alerts. -To see this panel, visit `/-/debug/grafana/d/frontend/frontend?viewPanel=102231` on your Sourcegraph instance. +To see this panel, visit `/-/debug/grafana/d/frontend/frontend?viewPanel=102131` on your Sourcegraph instance. *Managed by the [Sourcegraph Search Platform team](https://handbook.sourcegraph.com/departments/engineering/teams/search/core).* @@ -39239,13 +40154,13 @@ To see this panel, visit `/-/debug/grafana/d/frontend/frontend?viewPanel=102231` Query: ``` -histogram_quantile(0.90, sum by (le, name, grpc_method)(rate(src_grpc_server_sent_bytes_per_rpc_bucket{grpc_method=~`${zoekt_configuration_method:regex}`,instance=~`${internalInstance:regex}`,grpc_service=~"sourcegraph.zoekt.configuration.v1.ZoektConfigurationService"}[2m]))) +histogram_quantile(0.90, sum by (le, name, grpc_method)(rate(src_grpc_server_sent_bytes_per_rpc_bucket{grpc_method=~`${internal_api_method:regex}`,instance=~`${internalInstance:regex}`,grpc_service=~"api.internalapi.v1.ConfigService"}[2m]))) ```-#### frontend: zoekt_configuration_p75_response_size_per_method +#### frontend: internal_api_p75_response_size_per_method
75th percentile total response size per method over 2m
@@ -39253,7 +40168,7 @@ The 75th percentile total per-RPC response size per method, aggregated across al This panel has no related alerts. -To see this panel, visit `/-/debug/grafana/d/frontend/frontend?viewPanel=102232` on your Sourcegraph instance. +To see this panel, visit `/-/debug/grafana/d/frontend/frontend?viewPanel=102132` on your Sourcegraph instance. *Managed by the [Sourcegraph Search Platform team](https://handbook.sourcegraph.com/departments/engineering/teams/search/core).* @@ -39263,13 +40178,13 @@ To see this panel, visit `/-/debug/grafana/d/frontend/frontend?viewPanel=102232` Query: ``` -histogram_quantile(0.75, sum by (le, name, grpc_method)(rate(src_grpc_server_sent_bytes_per_rpc_bucket{grpc_method=~`${zoekt_configuration_method:regex}`,instance=~`${internalInstance:regex}`,grpc_service=~"sourcegraph.zoekt.configuration.v1.ZoektConfigurationService"}[2m]))) +histogram_quantile(0.75, sum by (le, name, grpc_method)(rate(src_grpc_server_sent_bytes_per_rpc_bucket{grpc_method=~`${internal_api_method:regex}`,instance=~`${internalInstance:regex}`,grpc_service=~"api.internalapi.v1.ConfigService"}[2m]))) ```-#### frontend: zoekt_configuration_p99_9_invididual_sent_message_size_per_method +#### frontend: internal_api_p99_9_invididual_sent_message_size_per_method
99.9th percentile individual sent message size per method over 2m
@@ -39277,7 +40192,7 @@ The 99.9th percentile size of every individual protocol buffer size sent by the This panel has no related alerts. -To see this panel, visit `/-/debug/grafana/d/frontend/frontend?viewPanel=102240` on your Sourcegraph instance. +To see this panel, visit `/-/debug/grafana/d/frontend/frontend?viewPanel=102140` on your Sourcegraph instance. *Managed by the [Sourcegraph Search Platform team](https://handbook.sourcegraph.com/departments/engineering/teams/search/core).* @@ -39287,13 +40202,13 @@ To see this panel, visit `/-/debug/grafana/d/frontend/frontend?viewPanel=102240` Query: ``` -histogram_quantile(0.999, sum by (le, name, grpc_method)(rate(src_grpc_server_sent_individual_message_size_bytes_per_rpc_bucket{grpc_method=~`${zoekt_configuration_method:regex}`,instance=~`${internalInstance:regex}`,grpc_service=~"sourcegraph.zoekt.configuration.v1.ZoektConfigurationService"}[2m]))) +histogram_quantile(0.999, sum by (le, name, grpc_method)(rate(src_grpc_server_sent_individual_message_size_bytes_per_rpc_bucket{grpc_method=~`${internal_api_method:regex}`,instance=~`${internalInstance:regex}`,grpc_service=~"api.internalapi.v1.ConfigService"}[2m]))) ```-#### frontend: zoekt_configuration_p90_invididual_sent_message_size_per_method +#### frontend: internal_api_p90_invididual_sent_message_size_per_method
90th percentile individual sent message size per method over 2m
@@ -39301,7 +40216,7 @@ The 90th percentile size of every individual protocol buffer size sent by the se This panel has no related alerts. -To see this panel, visit `/-/debug/grafana/d/frontend/frontend?viewPanel=102241` on your Sourcegraph instance. +To see this panel, visit `/-/debug/grafana/d/frontend/frontend?viewPanel=102141` on your Sourcegraph instance. *Managed by the [Sourcegraph Search Platform team](https://handbook.sourcegraph.com/departments/engineering/teams/search/core).* @@ -39311,13 +40226,13 @@ To see this panel, visit `/-/debug/grafana/d/frontend/frontend?viewPanel=102241` Query: ``` -histogram_quantile(0.90, sum by (le, name, grpc_method)(rate(src_grpc_server_sent_individual_message_size_bytes_per_rpc_bucket{grpc_method=~`${zoekt_configuration_method:regex}`,instance=~`${internalInstance:regex}`,grpc_service=~"sourcegraph.zoekt.configuration.v1.ZoektConfigurationService"}[2m]))) +histogram_quantile(0.90, sum by (le, name, grpc_method)(rate(src_grpc_server_sent_individual_message_size_bytes_per_rpc_bucket{grpc_method=~`${internal_api_method:regex}`,instance=~`${internalInstance:regex}`,grpc_service=~"api.internalapi.v1.ConfigService"}[2m]))) ```-#### frontend: zoekt_configuration_p75_invididual_sent_message_size_per_method +#### frontend: internal_api_p75_invididual_sent_message_size_per_method
75th percentile individual sent message size per method over 2m
@@ -39325,7 +40240,7 @@ The 75th percentile size of every individual protocol buffer size sent by the se This panel has no related alerts. -To see this panel, visit `/-/debug/grafana/d/frontend/frontend?viewPanel=102242` on your Sourcegraph instance. +To see this panel, visit `/-/debug/grafana/d/frontend/frontend?viewPanel=102142` on your Sourcegraph instance. *Managed by the [Sourcegraph Search Platform team](https://handbook.sourcegraph.com/departments/engineering/teams/search/core).* @@ -39335,13 +40250,13 @@ To see this panel, visit `/-/debug/grafana/d/frontend/frontend?viewPanel=102242` Query: ``` -histogram_quantile(0.75, sum by (le, name, grpc_method)(rate(src_grpc_server_sent_individual_message_size_bytes_per_rpc_bucket{grpc_method=~`${zoekt_configuration_method:regex}`,instance=~`${internalInstance:regex}`,grpc_service=~"sourcegraph.zoekt.configuration.v1.ZoektConfigurationService"}[2m]))) +histogram_quantile(0.75, sum by (le, name, grpc_method)(rate(src_grpc_server_sent_individual_message_size_bytes_per_rpc_bucket{grpc_method=~`${internal_api_method:regex}`,instance=~`${internalInstance:regex}`,grpc_service=~"api.internalapi.v1.ConfigService"}[2m]))) ```-#### frontend: zoekt_configuration_grpc_response_stream_message_count_per_method +#### frontend: internal_api_grpc_response_stream_message_count_per_method
Average streaming response message count per-method over 2m
@@ -39349,7 +40264,7 @@ The average number of response messages sent during a streaming RPC method, brok This panel has no related alerts. -To see this panel, visit `/-/debug/grafana/d/frontend/frontend?viewPanel=102250` on your Sourcegraph instance. +To see this panel, visit `/-/debug/grafana/d/frontend/frontend?viewPanel=102150` on your Sourcegraph instance. *Managed by the [Sourcegraph Search Platform team](https://handbook.sourcegraph.com/departments/engineering/teams/search/core).* @@ -39359,13 +40274,13 @@ To see this panel, visit `/-/debug/grafana/d/frontend/frontend?viewPanel=102250` Query: ``` -((sum(rate(grpc_server_msg_sent_total{grpc_type="server_stream",instance=~`${internalInstance:regex}`,grpc_service=~"sourcegraph.zoekt.configuration.v1.ZoektConfigurationService"}[2m])) by (grpc_method))/(sum(rate(grpc_server_started_total{grpc_type="server_stream",instance=~`${internalInstance:regex}`,grpc_service=~"sourcegraph.zoekt.configuration.v1.ZoektConfigurationService"}[2m])) by (grpc_method))) +((sum(rate(grpc_server_msg_sent_total{grpc_type="server_stream",instance=~`${internalInstance:regex}`,grpc_service=~"api.internalapi.v1.ConfigService"}[2m])) by (grpc_method))/(sum(rate(grpc_server_started_total{grpc_type="server_stream",instance=~`${internalInstance:regex}`,grpc_service=~"api.internalapi.v1.ConfigService"}[2m])) by (grpc_method))) ```-#### frontend: zoekt_configuration_grpc_all_codes_per_method +#### frontend: internal_api_grpc_all_codes_per_method
Response codes rate per-method over 2m
@@ -39373,7 +40288,7 @@ The rate of all generated gRPC response codes per method, aggregated across all This panel has no related alerts. -To see this panel, visit `/-/debug/grafana/d/frontend/frontend?viewPanel=102260` on your Sourcegraph instance. +To see this panel, visit `/-/debug/grafana/d/frontend/frontend?viewPanel=102160` on your Sourcegraph instance. *Managed by the [Sourcegraph Search Platform team](https://handbook.sourcegraph.com/departments/engineering/teams/search/core).* @@ -39383,23 +40298,23 @@ To see this panel, visit `/-/debug/grafana/d/frontend/frontend?viewPanel=102260` Query: ``` -sum(rate(grpc_server_handled_total{grpc_method=~`${zoekt_configuration_method:regex}`,instance=~`${internalInstance:regex}`,grpc_service=~"sourcegraph.zoekt.configuration.v1.ZoektConfigurationService"}[2m])) by (grpc_method, grpc_code) +sum(rate(grpc_server_handled_total{grpc_method=~`${internal_api_method:regex}`,instance=~`${internalInstance:regex}`,grpc_service=~"api.internalapi.v1.ConfigService"}[2m])) by (grpc_method, grpc_code) ```-### Frontend: Zoekt Configuration GRPC "internal error" metrics +### Frontend: Internal Api GRPC "internal error" metrics -#### frontend: zoekt_configuration_grpc_clients_error_percentage_all_methods +#### frontend: internal_api_grpc_clients_error_percentage_all_methods
Client baseline error percentage across all methods over 2m
-The percentage of gRPC requests that fail across all methods (regardless of whether or not there was an internal error), aggregated across all "zoekt_configuration" clients. +The percentage of gRPC requests that fail across all methods (regardless of whether or not there was an internal error), aggregated across all "internal_api" clients. This panel has no related alerts. -To see this panel, visit `/-/debug/grafana/d/frontend/frontend?viewPanel=102300` on your Sourcegraph instance. +To see this panel, visit `/-/debug/grafana/d/frontend/frontend?viewPanel=102200` on your Sourcegraph instance. *Managed by the [Sourcegraph Search Platform team](https://handbook.sourcegraph.com/departments/engineering/teams/search/core).* @@ -39409,21 +40324,21 @@ To see this panel, visit `/-/debug/grafana/d/frontend/frontend?viewPanel=102300` Query: ``` -(100.0 * ((((sum(rate(grpc_method_status{grpc_service=~"sourcegraph.zoekt.configuration.v1.ZoektConfigurationService",grpc_code!="OK"}[2m])))) / ((sum(rate(grpc_method_status{grpc_service=~"sourcegraph.zoekt.configuration.v1.ZoektConfigurationService"}[2m]))))))) +(100.0 * ((((sum(rate(src_grpc_method_status{grpc_service=~"api.internalapi.v1.ConfigService",grpc_code!="OK"}[2m])))) / ((sum(rate(src_grpc_method_status{grpc_service=~"api.internalapi.v1.ConfigService"}[2m]))))))) ```-#### frontend: zoekt_configuration_grpc_clients_error_percentage_per_method +#### frontend: internal_api_grpc_clients_error_percentage_per_method
Client baseline error percentage per-method over 2m
-The percentage of gRPC requests that fail per method (regardless of whether or not there was an internal error), aggregated across all "zoekt_configuration" clients. +The percentage of gRPC requests that fail per method (regardless of whether or not there was an internal error), aggregated across all "internal_api" clients. This panel has no related alerts. -To see this panel, visit `/-/debug/grafana/d/frontend/frontend?viewPanel=102301` on your Sourcegraph instance. +To see this panel, visit `/-/debug/grafana/d/frontend/frontend?viewPanel=102201` on your Sourcegraph instance. *Managed by the [Sourcegraph Search Platform team](https://handbook.sourcegraph.com/departments/engineering/teams/search/core).* @@ -39433,21 +40348,21 @@ To see this panel, visit `/-/debug/grafana/d/frontend/frontend?viewPanel=102301` Query: ``` -(100.0 * ((((sum(rate(grpc_method_status{grpc_service=~"sourcegraph.zoekt.configuration.v1.ZoektConfigurationService",grpc_method=~"${zoekt_configuration_method:regex}",grpc_code!="OK"}[2m])) by (grpc_method))) / ((sum(rate(grpc_method_status{grpc_service=~"sourcegraph.zoekt.configuration.v1.ZoektConfigurationService",grpc_method=~"${zoekt_configuration_method:regex}"}[2m])) by (grpc_method)))))) +(100.0 * ((((sum(rate(src_grpc_method_status{grpc_service=~"api.internalapi.v1.ConfigService",grpc_method=~"${internal_api_method:regex}",grpc_code!="OK"}[2m])) by (grpc_method))) / ((sum(rate(src_grpc_method_status{grpc_service=~"api.internalapi.v1.ConfigService",grpc_method=~"${internal_api_method:regex}"}[2m])) by (grpc_method)))))) ```-#### frontend: zoekt_configuration_grpc_clients_all_codes_per_method +#### frontend: internal_api_grpc_clients_all_codes_per_method
Client baseline response codes rate per-method over 2m
-The rate of all generated gRPC response codes per method (regardless of whether or not there was an internal error), aggregated across all "zoekt_configuration" clients. +The rate of all generated gRPC response codes per method (regardless of whether or not there was an internal error), aggregated across all "internal_api" clients. This panel has no related alerts. -To see this panel, visit `/-/debug/grafana/d/frontend/frontend?viewPanel=102302` on your Sourcegraph instance. +To see this panel, visit `/-/debug/grafana/d/frontend/frontend?viewPanel=102202` on your Sourcegraph instance. *Managed by the [Sourcegraph Search Platform team](https://handbook.sourcegraph.com/departments/engineering/teams/search/core).* @@ -39457,19 +40372,19 @@ To see this panel, visit `/-/debug/grafana/d/frontend/frontend?viewPanel=102302` Query: ``` -(sum(rate(grpc_method_status{grpc_service=~"sourcegraph.zoekt.configuration.v1.ZoektConfigurationService",grpc_method=~"${zoekt_configuration_method:regex}"}[2m])) by (grpc_method, grpc_code)) +(sum(rate(src_grpc_method_status{grpc_service=~"api.internalapi.v1.ConfigService",grpc_method=~"${internal_api_method:regex}"}[2m])) by (grpc_method, grpc_code)) ```-#### frontend: zoekt_configuration_grpc_clients_internal_error_percentage_all_methods +#### frontend: internal_api_grpc_clients_internal_error_percentage_all_methods
Client-observed gRPC internal error percentage across all methods over 2m
-The percentage of gRPC requests that appear to fail due to gRPC internal errors across all methods, aggregated across all "zoekt_configuration" clients. +The percentage of gRPC requests that appear to fail due to gRPC internal errors across all methods, aggregated across all "internal_api" clients. -**Note**: Internal errors are ones that appear to originate from the https://github.com/grpc/grpc-go library itself, rather than from any user-written application code. These errors can be caused by a variety of issues, and can originate from either the code-generated "zoekt_configuration" gRPC client or gRPC server. These errors might be solvable by adjusting the gRPC configuration, or they might indicate a bug from Sourcegraph`s use of gRPC. +**Note**: Internal errors are ones that appear to originate from the https://github.com/grpc/grpc-go library itself, rather than from any user-written application code. These errors can be caused by a variety of issues, and can originate from either the code-generated "internal_api" gRPC client or gRPC server. These errors might be solvable by adjusting the gRPC configuration, or they might indicate a bug from Sourcegraph`s use of gRPC. When debugging, knowing that a particular error comes from the grpc-go library itself (an `internal error`) as opposed to `normal` application code can be helpful when trying to fix it. @@ -39477,7 +40392,7 @@ When debugging, knowing that a particular error comes from the grpc-go library i This panel has no related alerts. -To see this panel, visit `/-/debug/grafana/d/frontend/frontend?viewPanel=102310` on your Sourcegraph instance. +To see this panel, visit `/-/debug/grafana/d/frontend/frontend?viewPanel=102210` on your Sourcegraph instance. *Managed by the [Sourcegraph Search Platform team](https://handbook.sourcegraph.com/departments/engineering/teams/search/core).* @@ -39487,19 +40402,19 @@ To see this panel, visit `/-/debug/grafana/d/frontend/frontend?viewPanel=102310` Query: ``` -(100.0 * ((((sum(rate(grpc_method_status{grpc_service=~"sourcegraph.zoekt.configuration.v1.ZoektConfigurationService",grpc_code!="OK",is_internal_error="true"}[2m])))) / ((sum(rate(grpc_method_status{grpc_service=~"sourcegraph.zoekt.configuration.v1.ZoektConfigurationService"}[2m]))))))) +(100.0 * ((((sum(rate(src_grpc_method_status{grpc_service=~"api.internalapi.v1.ConfigService",grpc_code!="OK",is_internal_error="true"}[2m])))) / ((sum(rate(src_grpc_method_status{grpc_service=~"api.internalapi.v1.ConfigService"}[2m]))))))) ```-#### frontend: zoekt_configuration_grpc_clients_internal_error_percentage_per_method +#### frontend: internal_api_grpc_clients_internal_error_percentage_per_method
Client-observed gRPC internal error percentage per-method over 2m
-The percentage of gRPC requests that appear to fail to due to gRPC internal errors per method, aggregated across all "zoekt_configuration" clients. +The percentage of gRPC requests that appear to fail to due to gRPC internal errors per method, aggregated across all "internal_api" clients. -**Note**: Internal errors are ones that appear to originate from the https://github.com/grpc/grpc-go library itself, rather than from any user-written application code. These errors can be caused by a variety of issues, and can originate from either the code-generated "zoekt_configuration" gRPC client or gRPC server. These errors might be solvable by adjusting the gRPC configuration, or they might indicate a bug from Sourcegraph`s use of gRPC. +**Note**: Internal errors are ones that appear to originate from the https://github.com/grpc/grpc-go library itself, rather than from any user-written application code. These errors can be caused by a variety of issues, and can originate from either the code-generated "internal_api" gRPC client or gRPC server. These errors might be solvable by adjusting the gRPC configuration, or they might indicate a bug from Sourcegraph`s use of gRPC. When debugging, knowing that a particular error comes from the grpc-go library itself (an `internal error`) as opposed to `normal` application code can be helpful when trying to fix it. @@ -39507,7 +40422,7 @@ When debugging, knowing that a particular error comes from the grpc-go library i This panel has no related alerts. -To see this panel, visit `/-/debug/grafana/d/frontend/frontend?viewPanel=102311` on your Sourcegraph instance. +To see this panel, visit `/-/debug/grafana/d/frontend/frontend?viewPanel=102211` on your Sourcegraph instance. *Managed by the [Sourcegraph Search Platform team](https://handbook.sourcegraph.com/departments/engineering/teams/search/core).* @@ -39517,19 +40432,19 @@ To see this panel, visit `/-/debug/grafana/d/frontend/frontend?viewPanel=102311` Query: ``` -(100.0 * ((((sum(rate(grpc_method_status{grpc_service=~"sourcegraph.zoekt.configuration.v1.ZoektConfigurationService",grpc_method=~"${zoekt_configuration_method:regex}",grpc_code!="OK",is_internal_error="true"}[2m])) by (grpc_method))) / ((sum(rate(grpc_method_status{grpc_service=~"sourcegraph.zoekt.configuration.v1.ZoektConfigurationService",grpc_method=~"${zoekt_configuration_method:regex}"}[2m])) by (grpc_method)))))) +(100.0 * ((((sum(rate(src_grpc_method_status{grpc_service=~"api.internalapi.v1.ConfigService",grpc_method=~"${internal_api_method:regex}",grpc_code!="OK",is_internal_error="true"}[2m])) by (grpc_method))) / ((sum(rate(src_grpc_method_status{grpc_service=~"api.internalapi.v1.ConfigService",grpc_method=~"${internal_api_method:regex}"}[2m])) by (grpc_method)))))) ```-#### frontend: zoekt_configuration_grpc_clients_internal_error_all_codes_per_method +#### frontend: internal_api_grpc_clients_internal_error_all_codes_per_method
Client-observed gRPC internal error response code rate per-method over 2m
-The rate of gRPC internal-error response codes per method, aggregated across all "zoekt_configuration" clients. +The rate of gRPC internal-error response codes per method, aggregated across all "internal_api" clients. -**Note**: Internal errors are ones that appear to originate from the https://github.com/grpc/grpc-go library itself, rather than from any user-written application code. These errors can be caused by a variety of issues, and can originate from either the code-generated "zoekt_configuration" gRPC client or gRPC server. These errors might be solvable by adjusting the gRPC configuration, or they might indicate a bug from Sourcegraph`s use of gRPC. +**Note**: Internal errors are ones that appear to originate from the https://github.com/grpc/grpc-go library itself, rather than from any user-written application code. These errors can be caused by a variety of issues, and can originate from either the code-generated "internal_api" gRPC client or gRPC server. These errors might be solvable by adjusting the gRPC configuration, or they might indicate a bug from Sourcegraph`s use of gRPC. When debugging, knowing that a particular error comes from the grpc-go library itself (an `internal error`) as opposed to `normal` application code can be helpful when trying to fix it. @@ -39537,7 +40452,7 @@ When debugging, knowing that a particular error comes from the grpc-go library i This panel has no related alerts. -To see this panel, visit `/-/debug/grafana/d/frontend/frontend?viewPanel=102312` on your Sourcegraph instance. +To see this panel, visit `/-/debug/grafana/d/frontend/frontend?viewPanel=102212` on your Sourcegraph instance. *Managed by the [Sourcegraph Search Platform team](https://handbook.sourcegraph.com/departments/engineering/teams/search/core).* @@ -39547,23 +40462,23 @@ To see this panel, visit `/-/debug/grafana/d/frontend/frontend?viewPanel=102312` Query: ``` -(sum(rate(grpc_method_status{grpc_service=~"sourcegraph.zoekt.configuration.v1.ZoektConfigurationService",is_internal_error="true",grpc_method=~"${zoekt_configuration_method:regex}"}[2m])) by (grpc_method, grpc_code)) +(sum(rate(src_grpc_method_status{grpc_service=~"api.internalapi.v1.ConfigService",is_internal_error="true",grpc_method=~"${internal_api_method:regex}"}[2m])) by (grpc_method, grpc_code)) ```-### Frontend: Zoekt Configuration GRPC retry metrics +### Frontend: Internal Api GRPC retry metrics -#### frontend: zoekt_configuration_grpc_clients_retry_percentage_across_all_methods +#### frontend: internal_api_grpc_clients_retry_percentage_across_all_methods
Client retry percentage across all methods over 2m
-The percentage of gRPC requests that were retried across all methods, aggregated across all "zoekt_configuration" clients. +The percentage of gRPC requests that were retried across all methods, aggregated across all "internal_api" clients. This panel has no related alerts. -To see this panel, visit `/-/debug/grafana/d/frontend/frontend?viewPanel=102400` on your Sourcegraph instance. +To see this panel, visit `/-/debug/grafana/d/frontend/frontend?viewPanel=102300` on your Sourcegraph instance. *Managed by the [Sourcegraph Search Platform team](https://handbook.sourcegraph.com/departments/engineering/teams/search/core).* @@ -39573,21 +40488,21 @@ To see this panel, visit `/-/debug/grafana/d/frontend/frontend?viewPanel=102400` Query: ``` -(100.0 * ((((sum(rate(src_grpc_client_retry_attempts_total{grpc_service=~"sourcegraph.zoekt.configuration.v1.ZoektConfigurationService",is_retried="true"}[2m])))) / ((sum(rate(src_grpc_client_retry_attempts_total{grpc_service=~"sourcegraph.zoekt.configuration.v1.ZoektConfigurationService"}[2m]))))))) +(100.0 * ((((sum(rate(src_grpc_client_retry_attempts_total{grpc_service=~"api.internalapi.v1.ConfigService",is_retried="true"}[2m])))) / ((sum(rate(src_grpc_client_retry_attempts_total{grpc_service=~"api.internalapi.v1.ConfigService"}[2m]))))))) ```-#### frontend: zoekt_configuration_grpc_clients_retry_percentage_per_method +#### frontend: internal_api_grpc_clients_retry_percentage_per_method
Client retry percentage per-method over 2m
-The percentage of gRPC requests that were retried aggregated across all "zoekt_configuration" clients, broken out per method. +The percentage of gRPC requests that were retried aggregated across all "internal_api" clients, broken out per method. This panel has no related alerts. -To see this panel, visit `/-/debug/grafana/d/frontend/frontend?viewPanel=102401` on your Sourcegraph instance. +To see this panel, visit `/-/debug/grafana/d/frontend/frontend?viewPanel=102301` on your Sourcegraph instance. *Managed by the [Sourcegraph Search Platform team](https://handbook.sourcegraph.com/departments/engineering/teams/search/core).* @@ -39597,21 +40512,21 @@ To see this panel, visit `/-/debug/grafana/d/frontend/frontend?viewPanel=102401` Query: ``` -(100.0 * ((((sum(rate(src_grpc_client_retry_attempts_total{grpc_service=~"sourcegraph.zoekt.configuration.v1.ZoektConfigurationService",is_retried="true",grpc_method=~"${zoekt_configuration_method:regex}"}[2m])) by (grpc_method))) / ((sum(rate(src_grpc_client_retry_attempts_total{grpc_service=~"sourcegraph.zoekt.configuration.v1.ZoektConfigurationService",grpc_method=~"${zoekt_configuration_method:regex}"}[2m])) by (grpc_method)))))) +(100.0 * ((((sum(rate(src_grpc_client_retry_attempts_total{grpc_service=~"api.internalapi.v1.ConfigService",is_retried="true",grpc_method=~"${internal_api_method:regex}"}[2m])) by (grpc_method))) / ((sum(rate(src_grpc_client_retry_attempts_total{grpc_service=~"api.internalapi.v1.ConfigService",grpc_method=~"${internal_api_method:regex}"}[2m])) by (grpc_method)))))) ```-#### frontend: zoekt_configuration_grpc_clients_retry_count_per_method +#### frontend: internal_api_grpc_clients_retry_count_per_method
Client retry count per-method over 2m
-The count of gRPC requests that were retried aggregated across all "zoekt_configuration" clients, broken out per method +The count of gRPC requests that were retried aggregated across all "internal_api" clients, broken out per method This panel has no related alerts. -To see this panel, visit `/-/debug/grafana/d/frontend/frontend?viewPanel=102402` on your Sourcegraph instance. +To see this panel, visit `/-/debug/grafana/d/frontend/frontend?viewPanel=102302` on your Sourcegraph instance. *Managed by the [Sourcegraph Search Platform team](https://handbook.sourcegraph.com/departments/engineering/teams/search/core).* @@ -39621,25 +40536,23 @@ To see this panel, visit `/-/debug/grafana/d/frontend/frontend?viewPanel=102402` Query: ``` -(sum(rate(src_grpc_client_retry_attempts_total{grpc_service=~"sourcegraph.zoekt.configuration.v1.ZoektConfigurationService",grpc_method=~"${zoekt_configuration_method:regex}",is_retried="true"}[2m])) by (grpc_method)) +(sum(rate(src_grpc_client_retry_attempts_total{grpc_service=~"api.internalapi.v1.ConfigService",grpc_method=~"${internal_api_method:regex}",is_retried="true"}[2m])) by (grpc_method)) ```-### Frontend: Internal Api GRPC server metrics - -#### frontend: internal_api_grpc_request_rate_all_methods +### Frontend: Internal service requests -
Request rate across all methods over 2m
+#### frontend: internal_indexed_search_error_responses -The number of gRPC requests received per second across all methods, aggregated across all instances. +Internal indexed search error responses every 5m
-This panel has no related alerts. +Refer to the [alerts reference](alerts#frontend-internal-indexed-search-error-responses) for 1 alert related to this panel. -To see this panel, visit `/-/debug/grafana/d/frontend/frontend?viewPanel=102500` on your Sourcegraph instance. +To see this panel, visit `/-/debug/grafana/d/frontend/frontend?viewPanel=102400` on your Sourcegraph instance. -*Managed by the [Sourcegraph Search Platform team](https://handbook.sourcegraph.com/departments/engineering/teams/search/core).* +*Managed by the [Sourcegraph Code Search team](https://handbook.sourcegraph.com/departments/engineering/teams/code-search).*Technical details
@@ -39647,23 +40560,21 @@ To see this panel, visit `/-/debug/grafana/d/frontend/frontend?viewPanel=102500` Query: ``` -sum(rate(grpc_server_started_total{instance=~`${internalInstance:regex}`,grpc_service=~"api.internalapi.v1.ConfigService"}[2m])) +sum by(code) (increase(src_zoekt_request_duration_seconds_count{code!~"2.."}[5m])) / ignoring(code) group_left sum(increase(src_zoekt_request_duration_seconds_count[5m])) * 100 ```-#### frontend: internal_api_grpc_request_rate_per_method - -
Request rate per-method over 2m
+#### frontend: internal_unindexed_search_error_responses -The number of gRPC requests received per second broken out per method, aggregated across all instances. +Internal unindexed search error responses every 5m
-This panel has no related alerts. +Refer to the [alerts reference](alerts#frontend-internal-unindexed-search-error-responses) for 1 alert related to this panel. -To see this panel, visit `/-/debug/grafana/d/frontend/frontend?viewPanel=102501` on your Sourcegraph instance. +To see this panel, visit `/-/debug/grafana/d/frontend/frontend?viewPanel=102401` on your Sourcegraph instance. -*Managed by the [Sourcegraph Search Platform team](https://handbook.sourcegraph.com/departments/engineering/teams/search/core).* +*Managed by the [Sourcegraph Code Search team](https://handbook.sourcegraph.com/departments/engineering/teams/code-search).*Technical details
@@ -39671,23 +40582,21 @@ To see this panel, visit `/-/debug/grafana/d/frontend/frontend?viewPanel=102501` Query: ``` -sum(rate(grpc_server_started_total{grpc_method=~`${internal_api_method:regex}`,instance=~`${internalInstance:regex}`,grpc_service=~"api.internalapi.v1.ConfigService"}[2m])) by (grpc_method) +sum by(code) (increase(searcher_service_request_total{code!~"2.."}[5m])) / ignoring(code) group_left sum(increase(searcher_service_request_total[5m])) * 100 ```-#### frontend: internal_api_error_percentage_all_methods - -
Error percentage across all methods over 2m
+#### frontend: 99th_percentile_gitserver_duration -The percentage of gRPC requests that fail across all methods, aggregated across all instances. +99th percentile successful gitserver query duration over 5m
-This panel has no related alerts. +Refer to the [alerts reference](alerts#frontend-99th-percentile-gitserver-duration) for 1 alert related to this panel. -To see this panel, visit `/-/debug/grafana/d/frontend/frontend?viewPanel=102510` on your Sourcegraph instance. +To see this panel, visit `/-/debug/grafana/d/frontend/frontend?viewPanel=102410` on your Sourcegraph instance. -*Managed by the [Sourcegraph Search Platform team](https://handbook.sourcegraph.com/departments/engineering/teams/search/core).* +*Managed by the [Sourcegraph Source team](https://handbook.sourcegraph.com/departments/engineering/teams/source).*Technical details
@@ -39695,23 +40604,21 @@ To see this panel, visit `/-/debug/grafana/d/frontend/frontend?viewPanel=102510` Query: ``` -(100.0 * ( (sum(rate(grpc_server_handled_total{grpc_code!="OK",instance=~`${internalInstance:regex}`,grpc_service=~"api.internalapi.v1.ConfigService"}[2m]))) / (sum(rate(grpc_server_handled_total{instance=~`${internalInstance:regex}`,grpc_service=~"api.internalapi.v1.ConfigService"}[2m]))) )) +histogram_quantile(0.99, sum by (le,category)(rate(src_gitserver_request_duration_seconds_bucket{job=~"(sourcegraph-)?frontend"}[5m]))) ```-#### frontend: internal_api_grpc_error_percentage_per_method - -
Error percentage per-method over 2m
+#### frontend: gitserver_error_responses -The percentage of gRPC requests that fail per method, aggregated across all instances. +Gitserver error responses every 5m
-This panel has no related alerts. +Refer to the [alerts reference](alerts#frontend-gitserver-error-responses) for 1 alert related to this panel. -To see this panel, visit `/-/debug/grafana/d/frontend/frontend?viewPanel=102511` on your Sourcegraph instance. +To see this panel, visit `/-/debug/grafana/d/frontend/frontend?viewPanel=102411` on your Sourcegraph instance. -*Managed by the [Sourcegraph Search Platform team](https://handbook.sourcegraph.com/departments/engineering/teams/search/core).* +*Managed by the [Sourcegraph Source team](https://handbook.sourcegraph.com/departments/engineering/teams/source).*Technical details
@@ -39719,23 +40626,21 @@ To see this panel, visit `/-/debug/grafana/d/frontend/frontend?viewPanel=102511` Query: ``` -(100.0 * ( (sum(rate(grpc_server_handled_total{grpc_method=~`${internal_api_method:regex}`,grpc_code!="OK",instance=~`${internalInstance:regex}`,grpc_service=~"api.internalapi.v1.ConfigService"}[2m])) by (grpc_method)) / (sum(rate(grpc_server_handled_total{grpc_method=~`${internal_api_method:regex}`,instance=~`${internalInstance:regex}`,grpc_service=~"api.internalapi.v1.ConfigService"}[2m])) by (grpc_method)) )) +sum by (category)(increase(src_gitserver_request_duration_seconds_count{job=~"(sourcegraph-)?frontend",code!~"2.."}[5m])) / ignoring(code) group_left sum by (category)(increase(src_gitserver_request_duration_seconds_count{job=~"(sourcegraph-)?frontend"}[5m])) * 100 ```-#### frontend: internal_api_p99_response_time_per_method - -
99th percentile response time per method over 2m
+#### frontend: observability_test_alert_warning -The 99th percentile response time per method, aggregated across all instances. +Warning test alert metric
-This panel has no related alerts. +Refer to the [alerts reference](alerts#frontend-observability-test-alert-warning) for 1 alert related to this panel. -To see this panel, visit `/-/debug/grafana/d/frontend/frontend?viewPanel=102520` on your Sourcegraph instance. +To see this panel, visit `/-/debug/grafana/d/frontend/frontend?viewPanel=102420` on your Sourcegraph instance. -*Managed by the [Sourcegraph Search Platform team](https://handbook.sourcegraph.com/departments/engineering/teams/search/core).* +*Managed by the [Sourcegraph Infrastructure Org team](https://handbook.sourcegraph.com/departments/engineering/infrastructure).*Technical details
@@ -39743,23 +40648,21 @@ To see this panel, visit `/-/debug/grafana/d/frontend/frontend?viewPanel=102520` Query: ``` -histogram_quantile(0.99, sum by (le, name, grpc_method)(rate(grpc_server_handling_seconds_bucket{grpc_method=~`${internal_api_method:regex}`,instance=~`${internalInstance:regex}`,grpc_service=~"api.internalapi.v1.ConfigService"}[2m]))) +max by(owner) (observability_test_metric_warning) ```-#### frontend: internal_api_p90_response_time_per_method - -
90th percentile response time per method over 2m
+#### frontend: observability_test_alert_critical -The 90th percentile response time per method, aggregated across all instances. +Critical test alert metric
-This panel has no related alerts. +Refer to the [alerts reference](alerts#frontend-observability-test-alert-critical) for 1 alert related to this panel. -To see this panel, visit `/-/debug/grafana/d/frontend/frontend?viewPanel=102521` on your Sourcegraph instance. +To see this panel, visit `/-/debug/grafana/d/frontend/frontend?viewPanel=102421` on your Sourcegraph instance. -*Managed by the [Sourcegraph Search Platform team](https://handbook.sourcegraph.com/departments/engineering/teams/search/core).* +*Managed by the [Sourcegraph Infrastructure Org team](https://handbook.sourcegraph.com/departments/engineering/infrastructure).*Technical details
@@ -39767,23 +40670,25 @@ To see this panel, visit `/-/debug/grafana/d/frontend/frontend?viewPanel=102521` Query: ``` -histogram_quantile(0.90, sum by (le, name, grpc_method)(rate(grpc_server_handling_seconds_bucket{grpc_method=~`${internal_api_method:regex}`,instance=~`${internalInstance:regex}`,grpc_service=~"api.internalapi.v1.ConfigService"}[2m]))) +max by(owner) (observability_test_metric_critical) ```-#### frontend: internal_api_p75_response_time_per_method +### Frontend: Authentication API requests -
75th percentile response time per method over 2m
+#### frontend: sign_in_rate -The 75th percentile response time per method, aggregated across all instances. +Rate of API requests to sign-in
+ +Rate (QPS) of requests to sign-in This panel has no related alerts. -To see this panel, visit `/-/debug/grafana/d/frontend/frontend?viewPanel=102522` on your Sourcegraph instance. +To see this panel, visit `/-/debug/grafana/d/frontend/frontend?viewPanel=102500` on your Sourcegraph instance. -*Managed by the [Sourcegraph Search Platform team](https://handbook.sourcegraph.com/departments/engineering/teams/search/core).* +*Managed by the [Sourcegraph Source team](https://handbook.sourcegraph.com/departments/engineering/teams/source).*Technical details
@@ -39791,23 +40696,23 @@ To see this panel, visit `/-/debug/grafana/d/frontend/frontend?viewPanel=102522` Query: ``` -histogram_quantile(0.75, sum by (le, name, grpc_method)(rate(grpc_server_handling_seconds_bucket{grpc_method=~`${internal_api_method:regex}`,instance=~`${internalInstance:regex}`,grpc_service=~"api.internalapi.v1.ConfigService"}[2m]))) +sum(irate(src_http_request_duration_seconds_count{route="sign-in",method="post"}[5m])) ```-#### frontend: internal_api_p99_9_response_size_per_method +#### frontend: sign_in_latency_p99 -
99.9th percentile total response size per method over 2m
+99 percentile of sign-in latency
-The 99.9th percentile total per-RPC response size per method, aggregated across all instances. +99% percentile of sign-in latency This panel has no related alerts. -To see this panel, visit `/-/debug/grafana/d/frontend/frontend?viewPanel=102530` on your Sourcegraph instance. +To see this panel, visit `/-/debug/grafana/d/frontend/frontend?viewPanel=102501` on your Sourcegraph instance. -*Managed by the [Sourcegraph Search Platform team](https://handbook.sourcegraph.com/departments/engineering/teams/search/core).* +*Managed by the [Sourcegraph Source team](https://handbook.sourcegraph.com/departments/engineering/teams/source).*Technical details
@@ -39815,23 +40720,23 @@ To see this panel, visit `/-/debug/grafana/d/frontend/frontend?viewPanel=102530` Query: ``` -histogram_quantile(0.999, sum by (le, name, grpc_method)(rate(src_grpc_server_sent_bytes_per_rpc_bucket{grpc_method=~`${internal_api_method:regex}`,instance=~`${internalInstance:regex}`,grpc_service=~"api.internalapi.v1.ConfigService"}[2m]))) +histogram_quantile(0.99, sum(rate(src_http_request_duration_seconds_bucket{route="sign-in",method="post"}[5m])) by (le)) ```-#### frontend: internal_api_p90_response_size_per_method +#### frontend: sign_in_error_rate -
90th percentile total response size per method over 2m
+Percentage of sign-in requests by http code
-The 90th percentile total per-RPC response size per method, aggregated across all instances. +Percentage of sign-in requests grouped by http code This panel has no related alerts. -To see this panel, visit `/-/debug/grafana/d/frontend/frontend?viewPanel=102531` on your Sourcegraph instance. +To see this panel, visit `/-/debug/grafana/d/frontend/frontend?viewPanel=102502` on your Sourcegraph instance. -*Managed by the [Sourcegraph Search Platform team](https://handbook.sourcegraph.com/departments/engineering/teams/search/core).* +*Managed by the [Sourcegraph Source team](https://handbook.sourcegraph.com/departments/engineering/teams/source).*Technical details
@@ -39839,23 +40744,23 @@ To see this panel, visit `/-/debug/grafana/d/frontend/frontend?viewPanel=102531` Query: ``` -histogram_quantile(0.90, sum by (le, name, grpc_method)(rate(src_grpc_server_sent_bytes_per_rpc_bucket{grpc_method=~`${internal_api_method:regex}`,instance=~`${internalInstance:regex}`,grpc_service=~"api.internalapi.v1.ConfigService"}[2m]))) +sum by (code)(irate(src_http_request_duration_seconds_count{route="sign-in",method="post"}[5m]))/ ignoring (code) group_left sum(irate(src_http_request_duration_seconds_count{route="sign-in",method="post"}[5m]))*100 ```-#### frontend: internal_api_p75_response_size_per_method +#### frontend: sign_up_rate -
75th percentile total response size per method over 2m
+Rate of API requests to sign-up
-The 75th percentile total per-RPC response size per method, aggregated across all instances. +Rate (QPS) of requests to sign-up This panel has no related alerts. -To see this panel, visit `/-/debug/grafana/d/frontend/frontend?viewPanel=102532` on your Sourcegraph instance. +To see this panel, visit `/-/debug/grafana/d/frontend/frontend?viewPanel=102510` on your Sourcegraph instance. -*Managed by the [Sourcegraph Search Platform team](https://handbook.sourcegraph.com/departments/engineering/teams/search/core).* +*Managed by the [Sourcegraph Source team](https://handbook.sourcegraph.com/departments/engineering/teams/source).*Technical details
@@ -39863,23 +40768,23 @@ To see this panel, visit `/-/debug/grafana/d/frontend/frontend?viewPanel=102532` Query: ``` -histogram_quantile(0.75, sum by (le, name, grpc_method)(rate(src_grpc_server_sent_bytes_per_rpc_bucket{grpc_method=~`${internal_api_method:regex}`,instance=~`${internalInstance:regex}`,grpc_service=~"api.internalapi.v1.ConfigService"}[2m]))) +sum(irate(src_http_request_duration_seconds_count{route="sign-up",method="post"}[5m])) ```-#### frontend: internal_api_p99_9_invididual_sent_message_size_per_method +#### frontend: sign_up_latency_p99 -
99.9th percentile individual sent message size per method over 2m
+99 percentile of sign-up latency
-The 99.9th percentile size of every individual protocol buffer size sent by the service per method, aggregated across all instances. +99% percentile of sign-up latency This panel has no related alerts. -To see this panel, visit `/-/debug/grafana/d/frontend/frontend?viewPanel=102540` on your Sourcegraph instance. +To see this panel, visit `/-/debug/grafana/d/frontend/frontend?viewPanel=102511` on your Sourcegraph instance. -*Managed by the [Sourcegraph Search Platform team](https://handbook.sourcegraph.com/departments/engineering/teams/search/core).* +*Managed by the [Sourcegraph Source team](https://handbook.sourcegraph.com/departments/engineering/teams/source).*Technical details
@@ -39887,23 +40792,23 @@ To see this panel, visit `/-/debug/grafana/d/frontend/frontend?viewPanel=102540` Query: ``` -histogram_quantile(0.999, sum by (le, name, grpc_method)(rate(src_grpc_server_sent_individual_message_size_bytes_per_rpc_bucket{grpc_method=~`${internal_api_method:regex}`,instance=~`${internalInstance:regex}`,grpc_service=~"api.internalapi.v1.ConfigService"}[2m]))) +histogram_quantile(0.99, sum(rate(src_http_request_duration_seconds_bucket{route="sign-up",method="post"}[5m])) by (le)) ```-#### frontend: internal_api_p90_invididual_sent_message_size_per_method +#### frontend: sign_up_code_percentage -
90th percentile individual sent message size per method over 2m
+Percentage of sign-up requests by http code
-The 90th percentile size of every individual protocol buffer size sent by the service per method, aggregated across all instances. +Percentage of sign-up requests grouped by http code This panel has no related alerts. -To see this panel, visit `/-/debug/grafana/d/frontend/frontend?viewPanel=102541` on your Sourcegraph instance. +To see this panel, visit `/-/debug/grafana/d/frontend/frontend?viewPanel=102512` on your Sourcegraph instance. -*Managed by the [Sourcegraph Search Platform team](https://handbook.sourcegraph.com/departments/engineering/teams/search/core).* +*Managed by the [Sourcegraph Source team](https://handbook.sourcegraph.com/departments/engineering/teams/source).*Technical details
@@ -39911,23 +40816,23 @@ To see this panel, visit `/-/debug/grafana/d/frontend/frontend?viewPanel=102541` Query: ``` -histogram_quantile(0.90, sum by (le, name, grpc_method)(rate(src_grpc_server_sent_individual_message_size_bytes_per_rpc_bucket{grpc_method=~`${internal_api_method:regex}`,instance=~`${internalInstance:regex}`,grpc_service=~"api.internalapi.v1.ConfigService"}[2m]))) +sum by (code)(irate(src_http_request_duration_seconds_count{route="sign-up",method="post"}[5m]))/ ignoring (code) group_left sum(irate(src_http_request_duration_seconds_count{route="sign-out"}[5m]))*100 ```-#### frontend: internal_api_p75_invididual_sent_message_size_per_method +#### frontend: sign_out_rate -
75th percentile individual sent message size per method over 2m
+Rate of API requests to sign-out
-The 75th percentile size of every individual protocol buffer size sent by the service per method, aggregated across all instances. +Rate (QPS) of requests to sign-out This panel has no related alerts. -To see this panel, visit `/-/debug/grafana/d/frontend/frontend?viewPanel=102542` on your Sourcegraph instance. +To see this panel, visit `/-/debug/grafana/d/frontend/frontend?viewPanel=102520` on your Sourcegraph instance. -*Managed by the [Sourcegraph Search Platform team](https://handbook.sourcegraph.com/departments/engineering/teams/search/core).* +*Managed by the [Sourcegraph Source team](https://handbook.sourcegraph.com/departments/engineering/teams/source).*Technical details
@@ -39935,23 +40840,23 @@ To see this panel, visit `/-/debug/grafana/d/frontend/frontend?viewPanel=102542` Query: ``` -histogram_quantile(0.75, sum by (le, name, grpc_method)(rate(src_grpc_server_sent_individual_message_size_bytes_per_rpc_bucket{grpc_method=~`${internal_api_method:regex}`,instance=~`${internalInstance:regex}`,grpc_service=~"api.internalapi.v1.ConfigService"}[2m]))) +sum(irate(src_http_request_duration_seconds_count{route="sign-out"}[5m])) ```-#### frontend: internal_api_grpc_response_stream_message_count_per_method +#### frontend: sign_out_latency_p99 -
Average streaming response message count per-method over 2m
+99 percentile of sign-out latency
-The average number of response messages sent during a streaming RPC method, broken out per method, aggregated across all instances. +99% percentile of sign-out latency This panel has no related alerts. -To see this panel, visit `/-/debug/grafana/d/frontend/frontend?viewPanel=102550` on your Sourcegraph instance. +To see this panel, visit `/-/debug/grafana/d/frontend/frontend?viewPanel=102521` on your Sourcegraph instance. -*Managed by the [Sourcegraph Search Platform team](https://handbook.sourcegraph.com/departments/engineering/teams/search/core).* +*Managed by the [Sourcegraph Source team](https://handbook.sourcegraph.com/departments/engineering/teams/source).*Technical details
@@ -39959,23 +40864,23 @@ To see this panel, visit `/-/debug/grafana/d/frontend/frontend?viewPanel=102550` Query: ``` -((sum(rate(grpc_server_msg_sent_total{grpc_type="server_stream",instance=~`${internalInstance:regex}`,grpc_service=~"api.internalapi.v1.ConfigService"}[2m])) by (grpc_method))/(sum(rate(grpc_server_started_total{grpc_type="server_stream",instance=~`${internalInstance:regex}`,grpc_service=~"api.internalapi.v1.ConfigService"}[2m])) by (grpc_method))) +histogram_quantile(0.99, sum(rate(src_http_request_duration_seconds_bucket{route="sign-out"}[5m])) by (le)) ```-#### frontend: internal_api_grpc_all_codes_per_method +#### frontend: sign_out_error_rate -
Response codes rate per-method over 2m
+Percentage of sign-out requests that return non-303 http code
-The rate of all generated gRPC response codes per method, aggregated across all instances. +Percentage of sign-out requests grouped by http code This panel has no related alerts. -To see this panel, visit `/-/debug/grafana/d/frontend/frontend?viewPanel=102560` on your Sourcegraph instance. +To see this panel, visit `/-/debug/grafana/d/frontend/frontend?viewPanel=102522` on your Sourcegraph instance. -*Managed by the [Sourcegraph Search Platform team](https://handbook.sourcegraph.com/departments/engineering/teams/search/core).* +*Managed by the [Sourcegraph Source team](https://handbook.sourcegraph.com/departments/engineering/teams/source).*Technical details
@@ -39983,25 +40888,23 @@ To see this panel, visit `/-/debug/grafana/d/frontend/frontend?viewPanel=102560` Query: ``` -sum(rate(grpc_server_handled_total{grpc_method=~`${internal_api_method:regex}`,instance=~`${internalInstance:regex}`,grpc_service=~"api.internalapi.v1.ConfigService"}[2m])) by (grpc_method, grpc_code) + sum by (code)(irate(src_http_request_duration_seconds_count{route="sign-out"}[5m]))/ ignoring (code) group_left sum(irate(src_http_request_duration_seconds_count{route="sign-out"}[5m]))*100 ```-### Frontend: Internal Api GRPC "internal error" metrics - -#### frontend: internal_api_grpc_clients_error_percentage_all_methods +#### frontend: account_failed_sign_in_attempts -
Client baseline error percentage across all methods over 2m
+Rate of failed sign-in attempts
-The percentage of gRPC requests that fail across all methods (regardless of whether or not there was an internal error), aggregated across all "internal_api" clients. +Failed sign-in attempts per minute This panel has no related alerts. -To see this panel, visit `/-/debug/grafana/d/frontend/frontend?viewPanel=102600` on your Sourcegraph instance. +To see this panel, visit `/-/debug/grafana/d/frontend/frontend?viewPanel=102530` on your Sourcegraph instance. -*Managed by the [Sourcegraph Search Platform team](https://handbook.sourcegraph.com/departments/engineering/teams/search/core).* +*Managed by the [Sourcegraph Source team](https://handbook.sourcegraph.com/departments/engineering/teams/source).*Technical details
@@ -40009,23 +40912,23 @@ To see this panel, visit `/-/debug/grafana/d/frontend/frontend?viewPanel=102600` Query: ``` -(100.0 * ((((sum(rate(src_grpc_method_status{grpc_service=~"api.internalapi.v1.ConfigService",grpc_code!="OK"}[2m])))) / ((sum(rate(src_grpc_method_status{grpc_service=~"api.internalapi.v1.ConfigService"}[2m]))))))) +sum(rate(src_frontend_account_failed_sign_in_attempts_total[1m])) ```-#### frontend: internal_api_grpc_clients_error_percentage_per_method +#### frontend: account_lockouts -
Client baseline error percentage per-method over 2m
+Rate of account lockouts
-The percentage of gRPC requests that fail per method (regardless of whether or not there was an internal error), aggregated across all "internal_api" clients. +Account lockouts per minute This panel has no related alerts. -To see this panel, visit `/-/debug/grafana/d/frontend/frontend?viewPanel=102601` on your Sourcegraph instance. +To see this panel, visit `/-/debug/grafana/d/frontend/frontend?viewPanel=102531` on your Sourcegraph instance. -*Managed by the [Sourcegraph Search Platform team](https://handbook.sourcegraph.com/departments/engineering/teams/search/core).* +*Managed by the [Sourcegraph Source team](https://handbook.sourcegraph.com/departments/engineering/teams/source).*Technical details
@@ -40033,83 +40936,25 @@ To see this panel, visit `/-/debug/grafana/d/frontend/frontend?viewPanel=102601` Query: ``` -(100.0 * ((((sum(rate(src_grpc_method_status{grpc_service=~"api.internalapi.v1.ConfigService",grpc_method=~"${internal_api_method:regex}",grpc_code!="OK"}[2m])) by (grpc_method))) / ((sum(rate(src_grpc_method_status{grpc_service=~"api.internalapi.v1.ConfigService",grpc_method=~"${internal_api_method:regex}"}[2m])) by (grpc_method)))))) +sum(rate(src_frontend_account_lockouts_total[1m])) ```-#### frontend: internal_api_grpc_clients_all_codes_per_method +### Frontend: External HTTP Request Rate -
Client baseline response codes rate per-method over 2m
+#### frontend: external_http_request_rate_by_host -The rate of all generated gRPC response codes per method (regardless of whether or not there was an internal error), aggregated across all "internal_api" clients. +Rate of external HTTP requests by host over 1m
-This panel has no related alerts. - -To see this panel, visit `/-/debug/grafana/d/frontend/frontend?viewPanel=102602` on your Sourcegraph instance. - -*Managed by the [Sourcegraph Search Platform team](https://handbook.sourcegraph.com/departments/engineering/teams/search/core).* - -Technical details
- -Query: - -``` -(sum(rate(src_grpc_method_status{grpc_service=~"api.internalapi.v1.ConfigService",grpc_method=~"${internal_api_method:regex}"}[2m])) by (grpc_method, grpc_code)) -``` -- -#### frontend: internal_api_grpc_clients_internal_error_percentage_all_methods - -
Client-observed gRPC internal error percentage across all methods over 2m
- -The percentage of gRPC requests that appear to fail due to gRPC internal errors across all methods, aggregated across all "internal_api" clients. - -**Note**: Internal errors are ones that appear to originate from the https://github.com/grpc/grpc-go library itself, rather than from any user-written application code. These errors can be caused by a variety of issues, and can originate from either the code-generated "internal_api" gRPC client or gRPC server. These errors might be solvable by adjusting the gRPC configuration, or they might indicate a bug from Sourcegraph`s use of gRPC. - -When debugging, knowing that a particular error comes from the grpc-go library itself (an `internal error`) as opposed to `normal` application code can be helpful when trying to fix it. - -**Note**: Internal errors are detected via a very coarse heuristic (seeing if the error starts with `grpc:`, etc.). Because of this, it`s possible that some gRPC-specific issues might not be categorized as internal errors. - -This panel has no related alerts. - -To see this panel, visit `/-/debug/grafana/d/frontend/frontend?viewPanel=102610` on your Sourcegraph instance. - -*Managed by the [Sourcegraph Search Platform team](https://handbook.sourcegraph.com/departments/engineering/teams/search/core).* - -Technical details
- -Query: - -``` -(100.0 * ((((sum(rate(src_grpc_method_status{grpc_service=~"api.internalapi.v1.ConfigService",grpc_code!="OK",is_internal_error="true"}[2m])))) / ((sum(rate(src_grpc_method_status{grpc_service=~"api.internalapi.v1.ConfigService"}[2m]))))))) -``` -- -#### frontend: internal_api_grpc_clients_internal_error_percentage_per_method - -
Client-observed gRPC internal error percentage per-method over 2m
- -The percentage of gRPC requests that appear to fail to due to gRPC internal errors per method, aggregated across all "internal_api" clients. - -**Note**: Internal errors are ones that appear to originate from the https://github.com/grpc/grpc-go library itself, rather than from any user-written application code. These errors can be caused by a variety of issues, and can originate from either the code-generated "internal_api" gRPC client or gRPC server. These errors might be solvable by adjusting the gRPC configuration, or they might indicate a bug from Sourcegraph`s use of gRPC. - -When debugging, knowing that a particular error comes from the grpc-go library itself (an `internal error`) as opposed to `normal` application code can be helpful when trying to fix it. - -**Note**: Internal errors are detected via a very coarse heuristic (seeing if the error starts with `grpc:`, etc.). Because of this, it`s possible that some gRPC-specific issues might not be categorized as internal errors. +Shows the rate of external HTTP requests made by Sourcegraph to other services, broken down by host. This panel has no related alerts. -To see this panel, visit `/-/debug/grafana/d/frontend/frontend?viewPanel=102611` on your Sourcegraph instance. +To see this panel, visit `/-/debug/grafana/d/frontend/frontend?viewPanel=102600` on your Sourcegraph instance. -*Managed by the [Sourcegraph Search Platform team](https://handbook.sourcegraph.com/departments/engineering/teams/search/core).* +*Managed by the [Sourcegraph Source team](https://handbook.sourcegraph.com/departments/engineering/teams/source).*Technical details
@@ -40117,29 +40962,23 @@ To see this panel, visit `/-/debug/grafana/d/frontend/frontend?viewPanel=102611` Query: ``` -(100.0 * ((((sum(rate(src_grpc_method_status{grpc_service=~"api.internalapi.v1.ConfigService",grpc_method=~"${internal_api_method:regex}",grpc_code!="OK",is_internal_error="true"}[2m])) by (grpc_method))) / ((sum(rate(src_grpc_method_status{grpc_service=~"api.internalapi.v1.ConfigService",grpc_method=~"${internal_api_method:regex}"}[2m])) by (grpc_method)))))) +sum by (host) (rate(src_http_client_external_request_count{host=~`${httpRequestHost:regex}`}[1m])) ```-#### frontend: internal_api_grpc_clients_internal_error_all_codes_per_method - -
Client-observed gRPC internal error response code rate per-method over 2m
- -The rate of gRPC internal-error response codes per method, aggregated across all "internal_api" clients. - -**Note**: Internal errors are ones that appear to originate from the https://github.com/grpc/grpc-go library itself, rather than from any user-written application code. These errors can be caused by a variety of issues, and can originate from either the code-generated "internal_api" gRPC client or gRPC server. These errors might be solvable by adjusting the gRPC configuration, or they might indicate a bug from Sourcegraph`s use of gRPC. +#### frontend: external_http_request_rate_by_host_by_code -When debugging, knowing that a particular error comes from the grpc-go library itself (an `internal error`) as opposed to `normal` application code can be helpful when trying to fix it. +Rate of external HTTP requests by host and response code over 1m
-**Note**: Internal errors are detected via a very coarse heuristic (seeing if the error starts with `grpc:`, etc.). Because of this, it`s possible that some gRPC-specific issues might not be categorized as internal errors. +Shows the rate of external HTTP requests made by Sourcegraph to other services, broken down by host and response code. This panel has no related alerts. -To see this panel, visit `/-/debug/grafana/d/frontend/frontend?viewPanel=102612` on your Sourcegraph instance. +To see this panel, visit `/-/debug/grafana/d/frontend/frontend?viewPanel=102610` on your Sourcegraph instance. -*Managed by the [Sourcegraph Search Platform team](https://handbook.sourcegraph.com/departments/engineering/teams/search/core).* +*Managed by the [Sourcegraph Source team](https://handbook.sourcegraph.com/departments/engineering/teams/source).*Technical details
@@ -40147,25 +40986,24 @@ To see this panel, visit `/-/debug/grafana/d/frontend/frontend?viewPanel=102612` Query: ``` -(sum(rate(src_grpc_method_status{grpc_service=~"api.internalapi.v1.ConfigService",is_internal_error="true",grpc_method=~"${internal_api_method:regex}"}[2m])) by (grpc_method, grpc_code)) +sum by (host, status_code) (rate(src_http_client_external_request_count{host=~`${httpRequestHost:regex}`}[1m])) ```-### Frontend: Internal Api GRPC retry metrics +### Frontend: Cody API requests -#### frontend: internal_api_grpc_clients_retry_percentage_across_all_methods +#### frontend: cody_api_rate -
Client retry percentage across all methods over 2m
+Rate of API requests to cody endpoints (excluding GraphQL)
-The percentage of gRPC requests that were retried across all methods, aggregated across all "internal_api" clients. +Rate (QPS) of requests to cody related endpoints. completions.stream is for the conversational endpoints. completions.code is for the code auto-complete endpoints. This panel has no related alerts. To see this panel, visit `/-/debug/grafana/d/frontend/frontend?viewPanel=102700` on your Sourcegraph instance. -*Managed by the [Sourcegraph Search Platform team](https://handbook.sourcegraph.com/departments/engineering/teams/search/core).*Technical details
@@ -40173,23 +41011,23 @@ To see this panel, visit `/-/debug/grafana/d/frontend/frontend?viewPanel=102700` Query: ``` -(100.0 * ((((sum(rate(src_grpc_client_retry_attempts_total{grpc_service=~"api.internalapi.v1.ConfigService",is_retried="true"}[2m])))) / ((sum(rate(src_grpc_client_retry_attempts_total{grpc_service=~"api.internalapi.v1.ConfigService"}[2m]))))))) +sum by (route, code)(irate(src_http_request_duration_seconds_count{route=~"^completions.*"}[5m])) ```-#### frontend: internal_api_grpc_clients_retry_percentage_per_method +### Frontend: Cloud KMS and cache -
Client retry percentage per-method over 2m
+#### frontend: cloudkms_cryptographic_requests -The percentage of gRPC requests that were retried aggregated across all "internal_api" clients, broken out per method. +Cryptographic requests to Cloud KMS every 1m
-This panel has no related alerts. +Refer to the [alerts reference](alerts#frontend-cloudkms-cryptographic-requests) for 2 alerts related to this panel. -To see this panel, visit `/-/debug/grafana/d/frontend/frontend?viewPanel=102701` on your Sourcegraph instance. +To see this panel, visit `/-/debug/grafana/d/frontend/frontend?viewPanel=102800` on your Sourcegraph instance. -*Managed by the [Sourcegraph Search Platform team](https://handbook.sourcegraph.com/departments/engineering/teams/search/core).* +*Managed by the [Sourcegraph Source team](https://handbook.sourcegraph.com/departments/engineering/teams/source).*Technical details
@@ -40197,90 +41035,22 @@ To see this panel, visit `/-/debug/grafana/d/frontend/frontend?viewPanel=102701` Query: ``` -(100.0 * ((((sum(rate(src_grpc_client_retry_attempts_total{grpc_service=~"api.internalapi.v1.ConfigService",is_retried="true",grpc_method=~"${internal_api_method:regex}"}[2m])) by (grpc_method))) / ((sum(rate(src_grpc_client_retry_attempts_total{grpc_service=~"api.internalapi.v1.ConfigService",grpc_method=~"${internal_api_method:regex}"}[2m])) by (grpc_method)))))) +sum(increase(src_cloudkms_cryptographic_total[1m])) ```-#### frontend: internal_api_grpc_clients_retry_count_per_method +#### frontend: encryption_cache_hit_ratio -
Client retry count per-method over 2m
+Average encryption cache hit ratio per workload
-The count of gRPC requests that were retried aggregated across all "internal_api" clients, broken out per method +- Encryption cache hit ratio (hits/(hits+misses)) - minimum across all instances of a workload. This panel has no related alerts. -To see this panel, visit `/-/debug/grafana/d/frontend/frontend?viewPanel=102702` on your Sourcegraph instance. - -*Managed by the [Sourcegraph Search Platform team](https://handbook.sourcegraph.com/departments/engineering/teams/search/core).* - -Technical details
- -Query: - -``` -(sum(rate(src_grpc_client_retry_attempts_total{grpc_service=~"api.internalapi.v1.ConfigService",grpc_method=~"${internal_api_method:regex}",is_retried="true"}[2m])) by (grpc_method)) -``` -- -### Frontend: Internal service requests - -#### frontend: internal_indexed_search_error_responses - -
Internal indexed search error responses every 5m
- -Refer to the [alerts reference](alerts#frontend-internal-indexed-search-error-responses) for 1 alert related to this panel. - -To see this panel, visit `/-/debug/grafana/d/frontend/frontend?viewPanel=102800` on your Sourcegraph instance. - -*Managed by the [Sourcegraph Code Search team](https://handbook.sourcegraph.com/departments/engineering/teams/code-search).* - -Technical details
- -Query: - -``` -sum by(code) (increase(src_zoekt_request_duration_seconds_count{code!~"2.."}[5m])) / ignoring(code) group_left sum(increase(src_zoekt_request_duration_seconds_count[5m])) * 100 -``` -- -#### frontend: internal_unindexed_search_error_responses - -
Internal unindexed search error responses every 5m
- -Refer to the [alerts reference](alerts#frontend-internal-unindexed-search-error-responses) for 1 alert related to this panel. - To see this panel, visit `/-/debug/grafana/d/frontend/frontend?viewPanel=102801` on your Sourcegraph instance. -*Managed by the [Sourcegraph Code Search team](https://handbook.sourcegraph.com/departments/engineering/teams/code-search).* - -Technical details
- -Query: - -``` -sum by(code) (increase(searcher_service_request_total{code!~"2.."}[5m])) / ignoring(code) group_left sum(increase(searcher_service_request_total[5m])) * 100 -``` -- -#### frontend: 99th_percentile_gitserver_duration - -
99th percentile successful gitserver query duration over 5m
- -Refer to the [alerts reference](alerts#frontend-99th-percentile-gitserver-duration) for 1 alert related to this panel. - -To see this panel, visit `/-/debug/grafana/d/frontend/frontend?viewPanel=102810` on your Sourcegraph instance. - *Managed by the [Sourcegraph Source team](https://handbook.sourcegraph.com/departments/engineering/teams/source).*-#### frontend: gitserver_error_responses +#### frontend: encryption_cache_evictions -
Gitserver error responses every 5m
+Rate of encryption cache evictions - sum across all instances of a given workload
-Refer to the [alerts reference](alerts#frontend-gitserver-error-responses) for 1 alert related to this panel. +- Rate of encryption cache evictions (caused by cache exceeding its maximum size) - sum across all instances of a workload -To see this panel, visit `/-/debug/grafana/d/frontend/frontend?viewPanel=102811` on your Sourcegraph instance. +This panel has no related alerts. + +To see this panel, visit `/-/debug/grafana/d/frontend/frontend?viewPanel=102802` on your Sourcegraph instance. *Managed by the [Sourcegraph Source team](https://handbook.sourcegraph.com/departments/engineering/teams/source).* @@ -40311,41 +41083,24 @@ To see this panel, visit `/-/debug/grafana/d/frontend/frontend?viewPanel=102811` Query: ``` -sum by (category)(increase(src_gitserver_request_duration_seconds_count{job=~"(sourcegraph-)?frontend",code!~"2.."}[5m])) / ignoring(code) group_left sum by (category)(increase(src_gitserver_request_duration_seconds_count{job=~"(sourcegraph-)?frontend"}[5m])) * 100 +sum by (kubernetes_name) (irate(src_encryption_cache_eviction_total[5m])) ```-#### frontend: observability_test_alert_warning +### Frontend: Periodic Goroutines -
Warning test alert metric
+#### frontend: running_goroutines -Refer to the [alerts reference](alerts#frontend-observability-test-alert-warning) for 1 alert related to this panel. +Number of currently running periodic goroutines
-To see this panel, visit `/-/debug/grafana/d/frontend/frontend?viewPanel=102820` on your Sourcegraph instance. +The number of currently running periodic goroutines by name and job. +A value of 0 indicates the routine isn`t running currently, it awaits it`s next schedule. -*Managed by the [Sourcegraph Infrastructure Org team](https://handbook.sourcegraph.com/departments/engineering/infrastructure).* - -Technical details
- -Query: - -``` -max by(owner) (observability_test_metric_warning) -``` -- -#### frontend: observability_test_alert_critical - -
Critical test alert metric
- -Refer to the [alerts reference](alerts#frontend-observability-test-alert-critical) for 1 alert related to this panel. +This panel has no related alerts. -To see this panel, visit `/-/debug/grafana/d/frontend/frontend?viewPanel=102821` on your Sourcegraph instance. +To see this panel, visit `/-/debug/grafana/d/frontend/frontend?viewPanel=102900` on your Sourcegraph instance. *Managed by the [Sourcegraph Infrastructure Org team](https://handbook.sourcegraph.com/departments/engineering/infrastructure).* @@ -40355,25 +41110,24 @@ To see this panel, visit `/-/debug/grafana/d/frontend/frontend?viewPanel=102821` Query: ``` -max by(owner) (observability_test_metric_critical) +sum by (name, job_name) (src_periodic_goroutine_running{job=~".*frontend.*"}) ```-### Frontend: Authentication API requests +#### frontend: goroutine_success_rate -#### frontend: sign_in_rate +
Success rate for periodic goroutine executions
-Rate of API requests to sign-in
- -Rate (QPS) of requests to sign-in +The rate of successful executions of each periodic goroutine. +A low or zero value could indicate that a routine is stalled or encountering errors. This panel has no related alerts. -To see this panel, visit `/-/debug/grafana/d/frontend/frontend?viewPanel=102900` on your Sourcegraph instance. +To see this panel, visit `/-/debug/grafana/d/frontend/frontend?viewPanel=102901` on your Sourcegraph instance. -*Managed by the [Sourcegraph Source team](https://handbook.sourcegraph.com/departments/engineering/teams/source).* +*Managed by the [Sourcegraph Infrastructure Org team](https://handbook.sourcegraph.com/departments/engineering/infrastructure).*Technical details
@@ -40381,23 +41135,24 @@ To see this panel, visit `/-/debug/grafana/d/frontend/frontend?viewPanel=102900` Query: ``` -sum(irate(src_http_request_duration_seconds_count{route="sign-in",method="post"}[5m])) +sum by (name, job_name) (rate(src_periodic_goroutine_total{job=~".*frontend.*"}[5m])) ```-#### frontend: sign_in_latency_p99 +#### frontend: goroutine_error_rate -
99 percentile of sign-in latency
+Error rate for periodic goroutine executions
-99% percentile of sign-in latency +The rate of errors encountered by each periodic goroutine. +A sustained high error rate may indicate a problem with the routine`s configuration or dependencies. -This panel has no related alerts. +Refer to the [alerts reference](alerts#frontend-goroutine-error-rate) for 1 alert related to this panel. -To see this panel, visit `/-/debug/grafana/d/frontend/frontend?viewPanel=102901` on your Sourcegraph instance. +To see this panel, visit `/-/debug/grafana/d/frontend/frontend?viewPanel=102910` on your Sourcegraph instance. -*Managed by the [Sourcegraph Source team](https://handbook.sourcegraph.com/departments/engineering/teams/source).* +*Managed by the [Sourcegraph Infrastructure Org team](https://handbook.sourcegraph.com/departments/engineering/infrastructure).*Technical details
@@ -40405,23 +41160,24 @@ To see this panel, visit `/-/debug/grafana/d/frontend/frontend?viewPanel=102901` Query: ``` -histogram_quantile(0.99, sum(rate(src_http_request_duration_seconds_bucket{route="sign-in",method="post"}[5m])) by (le)) +sum by (name, job_name) (rate(src_periodic_goroutine_errors_total{job=~".*frontend.*"}[5m])) ```-#### frontend: sign_in_error_rate +#### frontend: goroutine_error_percentage -
Percentage of sign-in requests by http code
+Percentage of periodic goroutine executions that result in errors
-Percentage of sign-in requests grouped by http code +The percentage of executions that result in errors for each periodic goroutine. +A value above 5% indicates that a significant portion of routine executions are failing. -This panel has no related alerts. +Refer to the [alerts reference](alerts#frontend-goroutine-error-percentage) for 1 alert related to this panel. -To see this panel, visit `/-/debug/grafana/d/frontend/frontend?viewPanel=102902` on your Sourcegraph instance. +To see this panel, visit `/-/debug/grafana/d/frontend/frontend?viewPanel=102911` on your Sourcegraph instance. -*Managed by the [Sourcegraph Source team](https://handbook.sourcegraph.com/departments/engineering/teams/source).* +*Managed by the [Sourcegraph Infrastructure Org team](https://handbook.sourcegraph.com/departments/engineering/infrastructure).*Technical details
@@ -40429,23 +41185,24 @@ To see this panel, visit `/-/debug/grafana/d/frontend/frontend?viewPanel=102902` Query: ``` -sum by (code)(irate(src_http_request_duration_seconds_count{route="sign-in",method="post"}[5m]))/ ignoring (code) group_left sum(irate(src_http_request_duration_seconds_count{route="sign-in",method="post"}[5m]))*100 +sum by (name, job_name) (rate(src_periodic_goroutine_errors_total{job=~".*frontend.*"}[5m])) / sum by (name, job_name) (rate(src_periodic_goroutine_total{job=~".*frontend.*"}[5m]) > 0) * 100 ```-#### frontend: sign_up_rate +#### frontend: goroutine_handler_duration -
Rate of API requests to sign-up
+95th percentile handler execution time
-Rate (QPS) of requests to sign-up +The 95th percentile execution time for each periodic goroutine handler. +Longer durations might indicate increased load or processing time. This panel has no related alerts. -To see this panel, visit `/-/debug/grafana/d/frontend/frontend?viewPanel=102910` on your Sourcegraph instance. +To see this panel, visit `/-/debug/grafana/d/frontend/frontend?viewPanel=102920` on your Sourcegraph instance. -*Managed by the [Sourcegraph Source team](https://handbook.sourcegraph.com/departments/engineering/teams/source).* +*Managed by the [Sourcegraph Infrastructure Org team](https://handbook.sourcegraph.com/departments/engineering/infrastructure).*Technical details
@@ -40453,23 +41210,24 @@ To see this panel, visit `/-/debug/grafana/d/frontend/frontend?viewPanel=102910` Query: ``` -sum(irate(src_http_request_duration_seconds_count{route="sign-up",method="post"}[5m])) +histogram_quantile(0.95, sum by (name, job_name, le) (rate(src_periodic_goroutine_duration_seconds_bucket{job=~".*frontend.*"}[5m]))) ```-#### frontend: sign_up_latency_p99 +#### frontend: goroutine_loop_duration -
99 percentile of sign-up latency
+95th percentile loop cycle time
-99% percentile of sign-up latency +The 95th percentile loop cycle time for each periodic goroutine (excluding sleep time). +This represents how long a complete loop iteration takes before sleeping for the next interval. This panel has no related alerts. -To see this panel, visit `/-/debug/grafana/d/frontend/frontend?viewPanel=102911` on your Sourcegraph instance. +To see this panel, visit `/-/debug/grafana/d/frontend/frontend?viewPanel=102921` on your Sourcegraph instance. -*Managed by the [Sourcegraph Source team](https://handbook.sourcegraph.com/departments/engineering/teams/source).* +*Managed by the [Sourcegraph Infrastructure Org team](https://handbook.sourcegraph.com/departments/engineering/infrastructure).*Technical details
@@ -40477,23 +41235,24 @@ To see this panel, visit `/-/debug/grafana/d/frontend/frontend?viewPanel=102911` Query: ``` -histogram_quantile(0.99, sum(rate(src_http_request_duration_seconds_bucket{route="sign-up",method="post"}[5m])) by (le)) +histogram_quantile(0.95, sum by (name, job_name, le) (rate(src_periodic_goroutine_loop_duration_seconds_bucket{job=~".*frontend.*"}[5m]))) ```-#### frontend: sign_up_code_percentage +#### frontend: tenant_processing_duration -
Percentage of sign-up requests by http code
+95th percentile tenant processing time
-Percentage of sign-up requests grouped by http code +The 95th percentile processing time for individual tenants within periodic goroutines. +Higher values indicate that tenant processing is taking longer and may affect overall performance. This panel has no related alerts. -To see this panel, visit `/-/debug/grafana/d/frontend/frontend?viewPanel=102912` on your Sourcegraph instance. +To see this panel, visit `/-/debug/grafana/d/frontend/frontend?viewPanel=102930` on your Sourcegraph instance. -*Managed by the [Sourcegraph Source team](https://handbook.sourcegraph.com/departments/engineering/teams/source).* +*Managed by the [Sourcegraph Infrastructure Org team](https://handbook.sourcegraph.com/departments/engineering/infrastructure).*Technical details
@@ -40501,23 +41260,24 @@ To see this panel, visit `/-/debug/grafana/d/frontend/frontend?viewPanel=102912` Query: ``` -sum by (code)(irate(src_http_request_duration_seconds_count{route="sign-up",method="post"}[5m]))/ ignoring (code) group_left sum(irate(src_http_request_duration_seconds_count{route="sign-out"}[5m]))*100 +histogram_quantile(0.95, sum by (name, job_name, le) (rate(src_periodic_goroutine_tenant_duration_seconds_bucket{job=~".*frontend.*"}[5m]))) ```-#### frontend: sign_out_rate +#### frontend: tenant_processing_max -
Rate of API requests to sign-out
+Maximum tenant processing time
-Rate (QPS) of requests to sign-out +The maximum processing time for individual tenants within periodic goroutines. +Consistently high values might indicate problematic tenants or inefficient processing. This panel has no related alerts. -To see this panel, visit `/-/debug/grafana/d/frontend/frontend?viewPanel=102920` on your Sourcegraph instance. +To see this panel, visit `/-/debug/grafana/d/frontend/frontend?viewPanel=102931` on your Sourcegraph instance. -*Managed by the [Sourcegraph Source team](https://handbook.sourcegraph.com/departments/engineering/teams/source).* +*Managed by the [Sourcegraph Infrastructure Org team](https://handbook.sourcegraph.com/departments/engineering/infrastructure).*Technical details
@@ -40525,23 +41285,24 @@ To see this panel, visit `/-/debug/grafana/d/frontend/frontend?viewPanel=102920` Query: ``` -sum(irate(src_http_request_duration_seconds_count{route="sign-out"}[5m])) +max by (name, job_name) (rate(src_periodic_goroutine_tenant_duration_seconds_sum{job=~".*frontend.*"}[5m]) / rate(src_periodic_goroutine_tenant_duration_seconds_count{job=~".*frontend.*"}[5m])) ```-#### frontend: sign_out_latency_p99 +#### frontend: tenant_count -
99 percentile of sign-out latency
+Number of tenants processed per routine
-99% percentile of sign-out latency +The number of tenants processed by each periodic goroutine. +Unexpected changes can indicate tenant configuration issues or scaling events. This panel has no related alerts. -To see this panel, visit `/-/debug/grafana/d/frontend/frontend?viewPanel=102921` on your Sourcegraph instance. +To see this panel, visit `/-/debug/grafana/d/frontend/frontend?viewPanel=102940` on your Sourcegraph instance. -*Managed by the [Sourcegraph Source team](https://handbook.sourcegraph.com/departments/engineering/teams/source).* +*Managed by the [Sourcegraph Infrastructure Org team](https://handbook.sourcegraph.com/departments/engineering/infrastructure).*Technical details
@@ -40549,23 +41310,24 @@ To see this panel, visit `/-/debug/grafana/d/frontend/frontend?viewPanel=102921` Query: ``` -histogram_quantile(0.99, sum(rate(src_http_request_duration_seconds_bucket{route="sign-out"}[5m])) by (le)) +max by (name, job_name) (src_periodic_goroutine_tenant_count{job=~".*frontend.*"}) ```-#### frontend: sign_out_error_rate +#### frontend: tenant_success_rate -
Percentage of sign-out requests that return non-303 http code
+Rate of successful tenant processing operations
-Percentage of sign-out requests grouped by http code +The rate of successful tenant processing operations. +A healthy routine should maintain a consistent processing rate. This panel has no related alerts. -To see this panel, visit `/-/debug/grafana/d/frontend/frontend?viewPanel=102922` on your Sourcegraph instance. +To see this panel, visit `/-/debug/grafana/d/frontend/frontend?viewPanel=102941` on your Sourcegraph instance. -*Managed by the [Sourcegraph Source team](https://handbook.sourcegraph.com/departments/engineering/teams/source).* +*Managed by the [Sourcegraph Infrastructure Org team](https://handbook.sourcegraph.com/departments/engineering/infrastructure).*Technical details
@@ -40573,23 +41335,24 @@ To see this panel, visit `/-/debug/grafana/d/frontend/frontend?viewPanel=102922` Query: ``` - sum by (code)(irate(src_http_request_duration_seconds_count{route="sign-out"}[5m]))/ ignoring (code) group_left sum(irate(src_http_request_duration_seconds_count{route="sign-out"}[5m]))*100 +sum by (name, job_name) (rate(src_periodic_goroutine_tenant_success_total{job=~".*frontend.*"}[5m])) ```-#### frontend: account_failed_sign_in_attempts +#### frontend: tenant_error_rate -
Rate of failed sign-in attempts
+Rate of tenant processing errors
-Failed sign-in attempts per minute +The rate of tenant processing operations that result in errors. +Consistent errors indicate problems with specific tenants. This panel has no related alerts. -To see this panel, visit `/-/debug/grafana/d/frontend/frontend?viewPanel=102930` on your Sourcegraph instance. +To see this panel, visit `/-/debug/grafana/d/frontend/frontend?viewPanel=102950` on your Sourcegraph instance. -*Managed by the [Sourcegraph Source team](https://handbook.sourcegraph.com/departments/engineering/teams/source).* +*Managed by the [Sourcegraph Infrastructure Org team](https://handbook.sourcegraph.com/departments/engineering/infrastructure).*Technical details
@@ -40597,23 +41360,24 @@ To see this panel, visit `/-/debug/grafana/d/frontend/frontend?viewPanel=102930` Query: ``` -sum(rate(src_frontend_account_failed_sign_in_attempts_total[1m])) +sum by (name, job_name) (rate(src_periodic_goroutine_tenant_errors_total{job=~".*frontend.*"}[5m])) ```-#### frontend: account_lockouts +#### frontend: tenant_error_percentage -
Rate of account lockouts
+Percentage of tenant operations resulting in errors
-Account lockouts per minute +The percentage of tenant operations that result in errors. +Values above 5% indicate significant tenant processing problems. This panel has no related alerts. -To see this panel, visit `/-/debug/grafana/d/frontend/frontend?viewPanel=102931` on your Sourcegraph instance. +To see this panel, visit `/-/debug/grafana/d/frontend/frontend?viewPanel=102951` on your Sourcegraph instance. -*Managed by the [Sourcegraph Source team](https://handbook.sourcegraph.com/departments/engineering/teams/source).* +*Managed by the [Sourcegraph Infrastructure Org team](https://handbook.sourcegraph.com/departments/engineering/infrastructure).*Technical details
@@ -40621,25 +41385,23 @@ To see this panel, visit `/-/debug/grafana/d/frontend/frontend?viewPanel=102931` Query: ``` -sum(rate(src_frontend_account_lockouts_total[1m])) +(sum by (name, job_name) (rate(src_periodic_goroutine_tenant_errors_total{job=~".*frontend.*"}[5m])) / (sum by (name, job_name) (rate(src_periodic_goroutine_tenant_success_total{job=~".*frontend.*"}[5m])) + sum by (name, job_name) (rate(src_periodic_goroutine_tenant_errors_total{job=~".*frontend.*"}[5m])))) * 100 ```-### Frontend: External HTTP Request Rate - -#### frontend: external_http_request_rate_by_host +### Frontend: Database connections -
Rate of external HTTP requests by host over 1m
+#### frontend: max_open_conns -Shows the rate of external HTTP requests made by Sourcegraph to other services, broken down by host. +Maximum open
This panel has no related alerts. To see this panel, visit `/-/debug/grafana/d/frontend/frontend?viewPanel=103000` on your Sourcegraph instance. -*Managed by the [Sourcegraph Source team](https://handbook.sourcegraph.com/departments/engineering/teams/source).* +*Managed by the [Sourcegraph Infrastructure Org team](https://handbook.sourcegraph.com/departments/engineering/infrastructure).*Technical details
@@ -40647,23 +41409,21 @@ To see this panel, visit `/-/debug/grafana/d/frontend/frontend?viewPanel=103000` Query: ``` -sum by (host) (rate(src_http_client_external_request_count{host=~`${httpRequestHost:regex}`}[1m])) +sum by (app_name, db_name) (src_pgsql_conns_max_open{app_name="frontend"}) ```-#### frontend: external_http_request_rate_by_host_by_code - -
Rate of external HTTP requests by host and response code over 1m
+#### frontend: open_conns -Shows the rate of external HTTP requests made by Sourcegraph to other services, broken down by host and response code. +Established
This panel has no related alerts. -To see this panel, visit `/-/debug/grafana/d/frontend/frontend?viewPanel=103010` on your Sourcegraph instance. +To see this panel, visit `/-/debug/grafana/d/frontend/frontend?viewPanel=103001` on your Sourcegraph instance. -*Managed by the [Sourcegraph Source team](https://handbook.sourcegraph.com/departments/engineering/teams/source).* +*Managed by the [Sourcegraph Infrastructure Org team](https://handbook.sourcegraph.com/departments/engineering/infrastructure).*Technical details
@@ -40671,24 +41431,21 @@ To see this panel, visit `/-/debug/grafana/d/frontend/frontend?viewPanel=103010` Query: ``` -sum by (host, status_code) (rate(src_http_client_external_request_count{host=~`${httpRequestHost:regex}`}[1m])) +sum by (app_name, db_name) (src_pgsql_conns_open{app_name="frontend"}) ```-### Frontend: Cody API requests - -#### frontend: cody_api_rate - -
Rate of API requests to cody endpoints (excluding GraphQL)
+#### frontend: in_use -Rate (QPS) of requests to cody related endpoints. completions.stream is for the conversational endpoints. completions.code is for the code auto-complete endpoints. +Used
This panel has no related alerts. -To see this panel, visit `/-/debug/grafana/d/frontend/frontend?viewPanel=103100` on your Sourcegraph instance. +To see this panel, visit `/-/debug/grafana/d/frontend/frontend?viewPanel=103010` on your Sourcegraph instance. +*Managed by the [Sourcegraph Infrastructure Org team](https://handbook.sourcegraph.com/departments/engineering/infrastructure).*Technical details
@@ -40696,23 +41453,21 @@ To see this panel, visit `/-/debug/grafana/d/frontend/frontend?viewPanel=103100` Query: ``` -sum by (route, code)(irate(src_http_request_duration_seconds_count{route=~"^completions.*"}[5m])) +sum by (app_name, db_name) (src_pgsql_conns_in_use{app_name="frontend"}) ```-### Frontend: Cloud KMS and cache - -#### frontend: cloudkms_cryptographic_requests +#### frontend: idle -
Cryptographic requests to Cloud KMS every 1m
+Idle
-Refer to the [alerts reference](alerts#frontend-cloudkms-cryptographic-requests) for 2 alerts related to this panel. +This panel has no related alerts. -To see this panel, visit `/-/debug/grafana/d/frontend/frontend?viewPanel=103200` on your Sourcegraph instance. +To see this panel, visit `/-/debug/grafana/d/frontend/frontend?viewPanel=103011` on your Sourcegraph instance. -*Managed by the [Sourcegraph Source team](https://handbook.sourcegraph.com/departments/engineering/teams/source).* +*Managed by the [Sourcegraph Infrastructure Org team](https://handbook.sourcegraph.com/departments/engineering/infrastructure).*Technical details
@@ -40720,23 +41475,21 @@ To see this panel, visit `/-/debug/grafana/d/frontend/frontend?viewPanel=103200` Query: ``` -sum(increase(src_cloudkms_cryptographic_total[1m])) +sum by (app_name, db_name) (src_pgsql_conns_idle{app_name="frontend"}) ```-#### frontend: encryption_cache_hit_ratio - -
Average encryption cache hit ratio per workload
+#### frontend: mean_blocked_seconds_per_conn_request -- Encryption cache hit ratio (hits/(hits+misses)) - minimum across all instances of a workload. +Mean blocked seconds per conn request
-This panel has no related alerts. +Refer to the [alerts reference](alerts#frontend-mean-blocked-seconds-per-conn-request) for 2 alerts related to this panel. -To see this panel, visit `/-/debug/grafana/d/frontend/frontend?viewPanel=103201` on your Sourcegraph instance. +To see this panel, visit `/-/debug/grafana/d/frontend/frontend?viewPanel=103020` on your Sourcegraph instance. -*Managed by the [Sourcegraph Source team](https://handbook.sourcegraph.com/departments/engineering/teams/source).* +*Managed by the [Sourcegraph Infrastructure Org team](https://handbook.sourcegraph.com/departments/engineering/infrastructure).*Technical details
@@ -40744,23 +41497,21 @@ To see this panel, visit `/-/debug/grafana/d/frontend/frontend?viewPanel=103201` Query: ``` -min by (kubernetes_name) (src_encryption_cache_hit_total/(src_encryption_cache_hit_total+src_encryption_cache_miss_total)) +sum by (app_name, db_name) (increase(src_pgsql_conns_blocked_seconds{app_name="frontend"}[5m])) / sum by (app_name, db_name) (increase(src_pgsql_conns_waited_for{app_name="frontend"}[5m])) ```-#### frontend: encryption_cache_evictions - -
Rate of encryption cache evictions - sum across all instances of a given workload
+#### frontend: closed_max_idle -- Rate of encryption cache evictions (caused by cache exceeding its maximum size) - sum across all instances of a workload +Closed by SetMaxIdleConns
This panel has no related alerts. -To see this panel, visit `/-/debug/grafana/d/frontend/frontend?viewPanel=103202` on your Sourcegraph instance. +To see this panel, visit `/-/debug/grafana/d/frontend/frontend?viewPanel=103030` on your Sourcegraph instance. -*Managed by the [Sourcegraph Source team](https://handbook.sourcegraph.com/departments/engineering/teams/source).* +*Managed by the [Sourcegraph Infrastructure Org team](https://handbook.sourcegraph.com/departments/engineering/infrastructure).*Technical details
@@ -40768,21 +41519,19 @@ To see this panel, visit `/-/debug/grafana/d/frontend/frontend?viewPanel=103202` Query: ``` -sum by (kubernetes_name) (irate(src_encryption_cache_eviction_total[5m])) +sum by (app_name, db_name) (increase(src_pgsql_conns_closed_max_idle{app_name="frontend"}[5m])) ```-### Frontend: Database connections - -#### frontend: max_open_conns +#### frontend: closed_max_lifetime -
Maximum open
+Closed by SetConnMaxLifetime
This panel has no related alerts. -To see this panel, visit `/-/debug/grafana/d/frontend/frontend?viewPanel=103300` on your Sourcegraph instance. +To see this panel, visit `/-/debug/grafana/d/frontend/frontend?viewPanel=103031` on your Sourcegraph instance. *Managed by the [Sourcegraph Infrastructure Org team](https://handbook.sourcegraph.com/departments/engineering/infrastructure).* @@ -40792,19 +41541,19 @@ To see this panel, visit `/-/debug/grafana/d/frontend/frontend?viewPanel=103300` Query: ``` -sum by (app_name, db_name) (src_pgsql_conns_max_open{app_name="frontend"}) +sum by (app_name, db_name) (increase(src_pgsql_conns_closed_max_lifetime{app_name="frontend"}[5m])) ```-#### frontend: open_conns +#### frontend: closed_max_idle_time -
Established
+Closed by SetConnMaxIdleTime
This panel has no related alerts. -To see this panel, visit `/-/debug/grafana/d/frontend/frontend?viewPanel=103301` on your Sourcegraph instance. +To see this panel, visit `/-/debug/grafana/d/frontend/frontend?viewPanel=103032` on your Sourcegraph instance. *Managed by the [Sourcegraph Infrastructure Org team](https://handbook.sourcegraph.com/departments/engineering/infrastructure).* @@ -40814,21 +41563,23 @@ To see this panel, visit `/-/debug/grafana/d/frontend/frontend?viewPanel=103301` Query: ``` -sum by (app_name, db_name) (src_pgsql_conns_open{app_name="frontend"}) +sum by (app_name, db_name) (increase(src_pgsql_conns_closed_max_idle_time{app_name="frontend"}[5m])) ```-#### frontend: in_use +### Frontend: (frontend|sourcegraph-frontend) (CPU, Memory) -
Used
+#### frontend: cpu_usage_percentage -This panel has no related alerts. +CPU usage
-To see this panel, visit `/-/debug/grafana/d/frontend/frontend?viewPanel=103310` on your Sourcegraph instance. +Refer to the [alerts reference](alerts#frontend-cpu-usage-percentage) for 1 alert related to this panel. -*Managed by the [Sourcegraph Infrastructure Org team](https://handbook.sourcegraph.com/departments/engineering/infrastructure).* +To see this panel, visit `/-/debug/grafana/d/frontend/frontend?viewPanel=103100` on your Sourcegraph instance. + +*Managed by the [Sourcegraph Code Search team](https://handbook.sourcegraph.com/departments/engineering/teams/code-search).*Technical details
@@ -40836,21 +41587,23 @@ To see this panel, visit `/-/debug/grafana/d/frontend/frontend?viewPanel=103310` Query: ``` -sum by (app_name, db_name) (src_pgsql_conns_in_use{app_name="frontend"}) +cadvisor_container_cpu_usage_percentage_total{name=~"^(frontend|sourcegraph-frontend).*"} ```-#### frontend: idle +#### frontend: memory_usage_percentage -
Idle
+Memory usage percentage (total)
+ +An estimate for the active memory in use, which includes anonymous memory, file memory, and kernel memory. Some of this memory is reclaimable, so high usage does not necessarily indicate memory pressure. This panel has no related alerts. -To see this panel, visit `/-/debug/grafana/d/frontend/frontend?viewPanel=103311` on your Sourcegraph instance. +To see this panel, visit `/-/debug/grafana/d/frontend/frontend?viewPanel=103101` on your Sourcegraph instance. -*Managed by the [Sourcegraph Infrastructure Org team](https://handbook.sourcegraph.com/departments/engineering/infrastructure).* +*Managed by the [Sourcegraph Code Search team](https://handbook.sourcegraph.com/departments/engineering/teams/code-search).*Technical details
@@ -40858,21 +41611,23 @@ To see this panel, visit `/-/debug/grafana/d/frontend/frontend?viewPanel=103311` Query: ``` -sum by (app_name, db_name) (src_pgsql_conns_idle{app_name="frontend"}) +cadvisor_container_memory_usage_percentage_total{name=~"^(frontend|sourcegraph-frontend).*"} ```-#### frontend: mean_blocked_seconds_per_conn_request +#### frontend: memory_working_set_bytes -
Mean blocked seconds per conn request
+Memory usage bytes (total)
-Refer to the [alerts reference](alerts#frontend-mean-blocked-seconds-per-conn-request) for 2 alerts related to this panel. +An estimate for the active memory in use in bytes, which includes anonymous memory, file memory, and kernel memory. Some of this memory is reclaimable, so high usage does not necessarily indicate memory pressure. -To see this panel, visit `/-/debug/grafana/d/frontend/frontend?viewPanel=103320` on your Sourcegraph instance. +This panel has no related alerts. -*Managed by the [Sourcegraph Infrastructure Org team](https://handbook.sourcegraph.com/departments/engineering/infrastructure).* +To see this panel, visit `/-/debug/grafana/d/frontend/frontend?viewPanel=103102` on your Sourcegraph instance. + +*Managed by the [Sourcegraph Code Search team](https://handbook.sourcegraph.com/departments/engineering/teams/code-search).*Technical details
@@ -40880,21 +41635,23 @@ To see this panel, visit `/-/debug/grafana/d/frontend/frontend?viewPanel=103320` Query: ``` -sum by (app_name, db_name) (increase(src_pgsql_conns_blocked_seconds{app_name="frontend"}[5m])) / sum by (app_name, db_name) (increase(src_pgsql_conns_waited_for{app_name="frontend"}[5m])) +max by (name) (container_memory_working_set_bytes{name=~"^(frontend|sourcegraph-frontend).*"}) ```-#### frontend: closed_max_idle +#### frontend: memory_rss -
Closed by SetMaxIdleConns
+Memory (RSS)
-This panel has no related alerts. +The total anonymous memory in use by the application, which includes Go stack and heap. This memory is is non-reclaimable, and high usage may trigger OOM kills. Note: the metric is named RSS because to match the cadvisor name, but `anonymous` is more accurate." -To see this panel, visit `/-/debug/grafana/d/frontend/frontend?viewPanel=103330` on your Sourcegraph instance. +Refer to the [alerts reference](alerts#frontend-memory-rss) for 1 alert related to this panel. -*Managed by the [Sourcegraph Infrastructure Org team](https://handbook.sourcegraph.com/departments/engineering/infrastructure).* +To see this panel, visit `/-/debug/grafana/d/frontend/frontend?viewPanel=103110` on your Sourcegraph instance. + +*Managed by the [Sourcegraph Code Search team](https://handbook.sourcegraph.com/departments/engineering/teams/code-search).*Technical details
@@ -40902,21 +41659,23 @@ To see this panel, visit `/-/debug/grafana/d/frontend/frontend?viewPanel=103330` Query: ``` -sum by (app_name, db_name) (increase(src_pgsql_conns_closed_max_idle{app_name="frontend"}[5m])) +max(container_memory_rss{name=~"^(frontend|sourcegraph-frontend).*"} / container_spec_memory_limit_bytes{name=~"^(frontend|sourcegraph-frontend).*"}) by (name) * 100.0 ```-#### frontend: closed_max_lifetime +#### frontend: memory_total_active_file -
Closed by SetConnMaxLifetime
+Memory usage (active file)
+ +This metric shows the total active file-backed memory currently in use by the application. Some of it may be reclaimable, so high usage does not necessarily indicate memory pressure. This panel has no related alerts. -To see this panel, visit `/-/debug/grafana/d/frontend/frontend?viewPanel=103331` on your Sourcegraph instance. +To see this panel, visit `/-/debug/grafana/d/frontend/frontend?viewPanel=103111` on your Sourcegraph instance. -*Managed by the [Sourcegraph Infrastructure Org team](https://handbook.sourcegraph.com/departments/engineering/infrastructure).* +*Managed by the [Sourcegraph Code Search team](https://handbook.sourcegraph.com/departments/engineering/teams/code-search).*Technical details
@@ -40924,21 +41683,23 @@ To see this panel, visit `/-/debug/grafana/d/frontend/frontend?viewPanel=103331` Query: ``` -sum by (app_name, db_name) (increase(src_pgsql_conns_closed_max_lifetime{app_name="frontend"}[5m])) +max(container_memory_total_active_file_bytes{name=~"^(frontend|sourcegraph-frontend).*"} / container_spec_memory_limit_bytes{name=~"^(frontend|sourcegraph-frontend).*"}) by (name) * 100.0 ```-#### frontend: closed_max_idle_time +#### frontend: memory_kernel_usage -
Closed by SetConnMaxIdleTime
+Memory usage (kernel)
+ +The kernel usage metric shows the amount of memory used by the kernel on behalf of the application. Some of it may be reclaimable, so high usage does not necessarily indicate memory pressure. This panel has no related alerts. -To see this panel, visit `/-/debug/grafana/d/frontend/frontend?viewPanel=103332` on your Sourcegraph instance. +To see this panel, visit `/-/debug/grafana/d/frontend/frontend?viewPanel=103112` on your Sourcegraph instance. -*Managed by the [Sourcegraph Infrastructure Org team](https://handbook.sourcegraph.com/departments/engineering/infrastructure).* +*Managed by the [Sourcegraph Code Search team](https://handbook.sourcegraph.com/departments/engineering/teams/code-search).*Technical details
@@ -40946,7 +41707,7 @@ To see this panel, visit `/-/debug/grafana/d/frontend/frontend?viewPanel=103332` Query: ``` -sum by (app_name, db_name) (increase(src_pgsql_conns_closed_max_idle_time{app_name="frontend"}[5m])) +max(container_memory_kernel_usage{name=~"^(frontend|sourcegraph-frontend).*"} / container_spec_memory_limit_bytes{name=~"^(frontend|sourcegraph-frontend).*"}) by (name) * 100.0 ```+#### gitserver: disk_space_remaining + +
Disk space remaining
+ +Indicates disk space remaining for each gitserver instance. When disk space is low, gitserver may experience slowdowns or fails to fetch repositories. + +Refer to the [alerts reference](alerts#gitserver-disk-space-remaining) for 2 alerts related to this panel. + +To see this panel, visit `/-/debug/grafana/d/gitserver/gitserver?viewPanel=100001` on your Sourcegraph instance. + +*Managed by the [Sourcegraph Source team](https://handbook.sourcegraph.com/departments/engineering/teams/source).* + +Technical details
+ +Query: + +``` +(src_gitserver_disk_space_available{instance=~`${shard:regex}`} / src_gitserver_disk_space_total{instance=~`${shard:regex}`}) * 100 +``` ++ #### gitserver: cpu_throttling_time
Container CPU throttling time %
@@ -42039,13 +42824,13 @@ sum by (container_label_io_kubernetes_pod_name) (rate(container_cpu_usage_second-#### gitserver: disk_space_remaining +#### gitserver: memory_major_page_faults -
Disk space remaining
+Gitserver page faults
-Indicates disk space remaining for each gitserver instance, which is used to determine when to start evicting least-used repository clones from disk (default 10%, configured by `SRC_REPOS_DESIRED_PERCENT_FREE`). +The number of major page faults in a 5 minute window for gitserver. If this number increases significantly, it indicates that more git API calls need to load data from disk. There may not be enough memory to efficiently support the amount of API requests served concurrently. -Refer to the [alerts reference](alerts#gitserver-disk-space-remaining) for 2 alerts related to this panel. +This panel has no related alerts. To see this panel, visit `/-/debug/grafana/d/gitserver/gitserver?viewPanel=100020` on your Sourcegraph instance. @@ -42057,7 +42842,38 @@ To see this panel, visit `/-/debug/grafana/d/gitserver/gitserver?viewPanel=10002 Query: ``` -(src_gitserver_disk_space_available{instance=~`${shard:regex}`} / src_gitserver_disk_space_total{instance=~`${shard:regex}`}) * 100 +rate(container_memory_failures_total{failure_type="pgmajfault", name=~"^gitserver.*"}[5m]) +``` + + ++ +#### gitserver: high_memory_git_commands + +
Number of git commands that exceeded the threshold for high memory usage
+ +This graph tracks the number of git subcommands that gitserver ran that exceeded the threshold for high memory usage. +This graph in itself is not an alert, but it is used to learn about the memory usage of gitserver. + +If gitserver frequently serves requests where the status code is KILLED, this graph might help to correlate that +with the high memory usage. + +This graph spiking is not a problem necessarily. But when subcommands or the whole gitserver service are getting +OOM killed and this graph shows spikes, increasing the memory might be useful. + +This panel has no related alerts. + +To see this panel, visit `/-/debug/grafana/d/gitserver/gitserver?viewPanel=100021` on your Sourcegraph instance. + +*Managed by the [Sourcegraph Source team](https://handbook.sourcegraph.com/departments/engineering/teams/source).* + +Technical details
+ +Query: + +``` +sort_desc(sum(sum_over_time(src_gitserver_exec_high_memory_usage_count{instance=~`${shard:regex}`}[2m])) by (cmd)) ```-#### gitserver: src_gitserver_repo_count +#### gitserver: src_gitserver_client_concurrent_requests -
Number of repositories on gitserver
+Number of concurrent requests running against gitserver client
-This metric is only for informational purposes. It indicates the total number of repositories on gitserver. +This metric is only for informational purposes. It indicates the current number of concurrently running requests by process against gitserver gRPC. -It does not indicate any problems with the instance. +It does not indicate any problems with the instance, but can give a good indication of load spikes or request throttling. This panel has no related alerts. @@ -42203,7 +43019,7 @@ To see this panel, visit `/-/debug/grafana/d/gitserver/gitserver?viewPanel=10005 Query: ``` -src_gitserver_repo_count +sum by (job, instance) (src_gitserver_client_concurrent_requests) ``` @@ -42211,9 +43027,9 @@ src_gitserver_repo_count ### Git Server: Gitservice for internal cloning -#### gitserver: aggregate_gitservice_request_duration +#### gitserver: gitservice_request_duration -95th percentile gitservice request duration aggregate
+95th percentile gitservice request duration per shard
A high value means any internal service trying to clone a repo from gitserver is slowed down. @@ -42229,17 +43045,17 @@ To see this panel, visit `/-/debug/grafana/d/gitserver/gitserver?viewPanel=10010 Query: ``` -histogram_quantile(0.95, sum(rate(src_gitserver_gitservice_duration_seconds_bucket{type=`gitserver`, error=`false`}[5m])) by (le)) +histogram_quantile(0.95, sum(rate(src_gitserver_gitservice_duration_seconds_bucket{instance=~`${shard:regex}`}[5m])) by (le, gitservice)) ```-#### gitserver: gitservice_request_duration +#### gitserver: gitservice_request_rate -
95th percentile gitservice request duration per shard
+Gitservice request rate per shard
-A high value means any internal service trying to clone a repo from gitserver is slowed down. +Per shard gitservice request rate This panel has no related alerts. @@ -42253,21 +43069,21 @@ To see this panel, visit `/-/debug/grafana/d/gitserver/gitserver?viewPanel=10010 Query: ``` -histogram_quantile(0.95, sum(rate(src_gitserver_gitservice_duration_seconds_bucket{type=`gitserver`, error=`false`, instance=~`${shard:regex}`}[5m])) by (le, instance)) +sum(rate(src_gitserver_gitservice_duration_seconds_count{instance=~`${shard:regex}`}[5m])) by (gitservice) ```-#### gitserver: aggregate_gitservice_error_request_duration +#### gitserver: gitservice_requests_running -
95th percentile gitservice error request duration aggregate
+Gitservice requests running per shard
-95th percentile gitservice error request duration aggregate +Per shard gitservice requests running This panel has no related alerts. -To see this panel, visit `/-/debug/grafana/d/gitserver/gitserver?viewPanel=100110` on your Sourcegraph instance. +To see this panel, visit `/-/debug/grafana/d/gitserver/gitserver?viewPanel=100102` on your Sourcegraph instance. *Managed by the [Sourcegraph Source team](https://handbook.sourcegraph.com/departments/engineering/teams/source).* @@ -42277,21 +43093,23 @@ To see this panel, visit `/-/debug/grafana/d/gitserver/gitserver?viewPanel=10011 Query: ``` -histogram_quantile(0.95, sum(rate(src_gitserver_gitservice_duration_seconds_bucket{type=`gitserver`, error=`true`}[5m])) by (le)) +sum(src_gitserver_gitservice_running{instance=~`${shard:regex}`}) by (gitservice) ```-#### gitserver: gitservice_request_duration +### Git Server: Gitserver cleanup jobs -
95th percentile gitservice error request duration per shard
+#### gitserver: janitor_tasks_total -95th percentile gitservice error request duration per shard +Total housekeeping tasks by type and status
+ +The rate of housekeeping tasks performed in repositories, broken down by task type and success/failure status This panel has no related alerts. -To see this panel, visit `/-/debug/grafana/d/gitserver/gitserver?viewPanel=100111` on your Sourcegraph instance. +To see this panel, visit `/-/debug/grafana/d/gitserver/gitserver?viewPanel=100200` on your Sourcegraph instance. *Managed by the [Sourcegraph Source team](https://handbook.sourcegraph.com/departments/engineering/teams/source).* @@ -42301,21 +43119,21 @@ To see this panel, visit `/-/debug/grafana/d/gitserver/gitserver?viewPanel=10011 Query: ``` -histogram_quantile(0.95, sum(rate(src_gitserver_gitservice_duration_seconds_bucket{type=`gitserver`, error=`true`, instance=~`${shard:regex}`}[5m])) by (le, instance)) +sum(rate(src_gitserver_janitor_tasks_total{instance=~`${shard:regex}`}[5m])) by (housekeeping_task, status) ```-#### gitserver: aggregate_gitservice_request_rate +#### gitserver: p90_janitor_tasks_latency_success_over_5m -
Aggregate gitservice request rate
+90th percentile latency of successful tasks by type over 5m
-Aggregate gitservice request rate +The 90th percentile latency of successful housekeeping tasks, broken down by task type This panel has no related alerts. -To see this panel, visit `/-/debug/grafana/d/gitserver/gitserver?viewPanel=100120` on your Sourcegraph instance. +To see this panel, visit `/-/debug/grafana/d/gitserver/gitserver?viewPanel=100210` on your Sourcegraph instance. *Managed by the [Sourcegraph Source team](https://handbook.sourcegraph.com/departments/engineering/teams/source).* @@ -42325,21 +43143,21 @@ To see this panel, visit `/-/debug/grafana/d/gitserver/gitserver?viewPanel=10012 Query: ``` -sum(rate(src_gitserver_gitservice_duration_seconds_count{type=`gitserver`, error=`false`}[5m])) +histogram_quantile(0.90, sum(rate(src_gitserver_janitor_tasks_latency_bucket{instance=~`${shard:regex}`, status="success"}[5m])) by (le, housekeeping_task)) ```-#### gitserver: gitservice_request_rate +#### gitserver: p95_janitor_tasks_latency_success_over_5m -
Gitservice request rate per shard
+95th percentile latency of successful tasks by type over 5m
-Per shard gitservice request rate +The 95th percentile latency of successful housekeeping tasks, broken down by task type This panel has no related alerts. -To see this panel, visit `/-/debug/grafana/d/gitserver/gitserver?viewPanel=100121` on your Sourcegraph instance. +To see this panel, visit `/-/debug/grafana/d/gitserver/gitserver?viewPanel=100211` on your Sourcegraph instance. *Managed by the [Sourcegraph Source team](https://handbook.sourcegraph.com/departments/engineering/teams/source).* @@ -42349,21 +43167,21 @@ To see this panel, visit `/-/debug/grafana/d/gitserver/gitserver?viewPanel=10012 Query: ``` -sum(rate(src_gitserver_gitservice_duration_seconds_count{type=`gitserver`, error=`false`, instance=~`${shard:regex}`}[5m])) +histogram_quantile(0.95, sum(rate(src_gitserver_janitor_tasks_latency_bucket{instance=~`${shard:regex}`, status="success"}[5m])) by (le, housekeeping_task)) ```-#### gitserver: aggregate_gitservice_request_error_rate +#### gitserver: p99_janitor_tasks_latency_success_over_5m -
Aggregate gitservice request error rate
+99th percentile latency of successful tasks by type over 5m
-Aggregate gitservice request error rate +The 99th percentile latency of successful housekeeping tasks, broken down by task type This panel has no related alerts. -To see this panel, visit `/-/debug/grafana/d/gitserver/gitserver?viewPanel=100130` on your Sourcegraph instance. +To see this panel, visit `/-/debug/grafana/d/gitserver/gitserver?viewPanel=100212` on your Sourcegraph instance. *Managed by the [Sourcegraph Source team](https://handbook.sourcegraph.com/departments/engineering/teams/source).* @@ -42373,21 +43191,21 @@ To see this panel, visit `/-/debug/grafana/d/gitserver/gitserver?viewPanel=10013 Query: ``` -sum(rate(src_gitserver_gitservice_duration_seconds_count{type=`gitserver`, error=`true`}[5m])) +histogram_quantile(0.99, sum(rate(src_gitserver_janitor_tasks_latency_bucket{instance=~`${shard:regex}`, status="success"}[5m])) by (le, housekeeping_task)) ```-#### gitserver: gitservice_request_error_rate +#### gitserver: p90_janitor_tasks_latency_failure_over_5m -
Gitservice request error rate per shard
+90th percentile latency of failed tasks by type over 5m
-Per shard gitservice request error rate +The 90th percentile latency of failed housekeeping tasks, broken down by task type This panel has no related alerts. -To see this panel, visit `/-/debug/grafana/d/gitserver/gitserver?viewPanel=100131` on your Sourcegraph instance. +To see this panel, visit `/-/debug/grafana/d/gitserver/gitserver?viewPanel=100220` on your Sourcegraph instance. *Managed by the [Sourcegraph Source team](https://handbook.sourcegraph.com/departments/engineering/teams/source).* @@ -42397,21 +43215,21 @@ To see this panel, visit `/-/debug/grafana/d/gitserver/gitserver?viewPanel=10013 Query: ``` -sum(rate(src_gitserver_gitservice_duration_seconds_count{type=`gitserver`, error=`true`, instance=~`${shard:regex}`}[5m])) +histogram_quantile(0.90, sum(rate(src_gitserver_janitor_tasks_latency_bucket{instance=~`${shard:regex}`, status="failure"}[5m])) by (le, housekeeping_task)) ```-#### gitserver: aggregate_gitservice_requests_running +#### gitserver: p95_janitor_tasks_latency_failure_over_5m -
Aggregate gitservice requests running
+95th percentile latency of failed tasks by type over 5m
-Aggregate gitservice requests running +The 95th percentile latency of failed housekeeping tasks, broken down by task type This panel has no related alerts. -To see this panel, visit `/-/debug/grafana/d/gitserver/gitserver?viewPanel=100140` on your Sourcegraph instance. +To see this panel, visit `/-/debug/grafana/d/gitserver/gitserver?viewPanel=100221` on your Sourcegraph instance. *Managed by the [Sourcegraph Source team](https://handbook.sourcegraph.com/departments/engineering/teams/source).* @@ -42421,21 +43239,21 @@ To see this panel, visit `/-/debug/grafana/d/gitserver/gitserver?viewPanel=10014 Query: ``` -sum(src_gitserver_gitservice_running{type=`gitserver`}) +histogram_quantile(0.95, sum(rate(src_gitserver_janitor_tasks_latency_bucket{instance=~`${shard:regex}`, status="failure"}[5m])) by (le, housekeeping_task)) ```-#### gitserver: gitservice_requests_running +#### gitserver: p99_janitor_tasks_latency_failure_over_5m -
Gitservice requests running per shard
+99th percentile latency of failed tasks by type over 5m
-Per shard gitservice requests running +The 99th percentile latency of failed housekeeping tasks, broken down by task type This panel has no related alerts. -To see this panel, visit `/-/debug/grafana/d/gitserver/gitserver?viewPanel=100141` on your Sourcegraph instance. +To see this panel, visit `/-/debug/grafana/d/gitserver/gitserver?viewPanel=100222` on your Sourcegraph instance. *Managed by the [Sourcegraph Source team](https://handbook.sourcegraph.com/departments/engineering/teams/source).* @@ -42445,23 +43263,21 @@ To see this panel, visit `/-/debug/grafana/d/gitserver/gitserver?viewPanel=10014 Query: ``` -sum(src_gitserver_gitservice_running{type=`gitserver`, instance=~`${shard:regex}`}) by (instance) +histogram_quantile(0.99, sum(rate(src_gitserver_janitor_tasks_latency_bucket{instance=~`${shard:regex}`, status="failure"}[5m])) by (le, housekeeping_task)) ```-### Git Server: Gitserver cleanup jobs - -#### gitserver: janitor_running +#### gitserver: pruned_files_total_over_5m -
Janitor process is running
+Files pruned by type over 5m
-1, if the janitor process is currently running +The rate of files pruned during cleanup, broken down by file type This panel has no related alerts. -To see this panel, visit `/-/debug/grafana/d/gitserver/gitserver?viewPanel=100200` on your Sourcegraph instance. +To see this panel, visit `/-/debug/grafana/d/gitserver/gitserver?viewPanel=100230` on your Sourcegraph instance. *Managed by the [Sourcegraph Source team](https://handbook.sourcegraph.com/departments/engineering/teams/source).* @@ -42471,21 +43287,21 @@ To see this panel, visit `/-/debug/grafana/d/gitserver/gitserver?viewPanel=10020 Query: ``` -max by (instance) (src_gitserver_janitor_running{instance=~`${shard:regex}`}) +sum(rate(src_gitserver_janitor_pruned_files_total{instance=~`${shard:regex}`}[5m])) by (filetype) ```-#### gitserver: janitor_job_duration +#### gitserver: data_structure_count_over_5m -
95th percentile job run duration
+Data structure counts over 5m
-95th percentile job run duration +The count distribution of various Git data structures in repositories This panel has no related alerts. -To see this panel, visit `/-/debug/grafana/d/gitserver/gitserver?viewPanel=100210` on your Sourcegraph instance. +To see this panel, visit `/-/debug/grafana/d/gitserver/gitserver?viewPanel=100240` on your Sourcegraph instance. *Managed by the [Sourcegraph Source team](https://handbook.sourcegraph.com/departments/engineering/teams/source).* @@ -42495,21 +43311,21 @@ To see this panel, visit `/-/debug/grafana/d/gitserver/gitserver?viewPanel=10021 Query: ``` -histogram_quantile(0.95, sum(rate(src_gitserver_janitor_job_duration_seconds_bucket{instance=~`${shard:regex}`}[5m])) by (le, job_name)) +histogram_quantile(0.95, sum(rate(src_gitserver_janitor_data_structure_count_bucket{instance=~`${shard:regex}`}[5m])) by (le, data_structure)) ```-#### gitserver: janitor_job_failures +#### gitserver: janitor_data_structure_size -
Failures over 5m (by job)
+Data structure sizes
-the rate of failures over 5m (by job) +The size distribution of various Git data structures in repositories This panel has no related alerts. -To see this panel, visit `/-/debug/grafana/d/gitserver/gitserver?viewPanel=100220` on your Sourcegraph instance. +To see this panel, visit `/-/debug/grafana/d/gitserver/gitserver?viewPanel=100250` on your Sourcegraph instance. *Managed by the [Sourcegraph Source team](https://handbook.sourcegraph.com/departments/engineering/teams/source).* @@ -42519,21 +43335,21 @@ To see this panel, visit `/-/debug/grafana/d/gitserver/gitserver?viewPanel=10022 Query: ``` -sum by (job_name) (rate(src_gitserver_janitor_job_duration_seconds_count{instance=~`${shard:regex}`,success="false"}[5m])) +histogram_quantile(0.95, sum(rate(src_gitserver_janitor_data_structure_size_bucket{instance=~`${shard:regex}`}[5m])) by (le, data_structure)) ```-#### gitserver: repos_removed +#### gitserver: janitor_time_since_optimization -
Repositories removed due to disk pressure
+Time since last optimization
-Repositories removed due to disk pressure +The time elapsed since last optimization of various Git data structures This panel has no related alerts. -To see this panel, visit `/-/debug/grafana/d/gitserver/gitserver?viewPanel=100230` on your Sourcegraph instance. +To see this panel, visit `/-/debug/grafana/d/gitserver/gitserver?viewPanel=100260` on your Sourcegraph instance. *Managed by the [Sourcegraph Source team](https://handbook.sourcegraph.com/departments/engineering/teams/source).* @@ -42543,21 +43359,21 @@ To see this panel, visit `/-/debug/grafana/d/gitserver/gitserver?viewPanel=10023 Query: ``` -sum by (instance) (rate(src_gitserver_repos_removed_disk_pressure{instance=~`${shard:regex}`}[5m])) +histogram_quantile(0.95, sum(rate(src_gitserver_janitor_time_since_last_optimization_seconds_bucket{instance=~`${shard:regex}`}[5m])) by (le, data_structure)) ```-#### gitserver: non_existent_repos_removed +#### gitserver: janitor_data_structure_existence -
Repositories removed because they are not defined in the DB
+Data structure existence
-Repositoriess removed because they are not defined in the DB +The rate at which data structures are reported to exist in repositories This panel has no related alerts. -To see this panel, visit `/-/debug/grafana/d/gitserver/gitserver?viewPanel=100240` on your Sourcegraph instance. +To see this panel, visit `/-/debug/grafana/d/gitserver/gitserver?viewPanel=100270` on your Sourcegraph instance. *Managed by the [Sourcegraph Source team](https://handbook.sourcegraph.com/departments/engineering/teams/source).* @@ -42567,21 +43383,25 @@ To see this panel, visit `/-/debug/grafana/d/gitserver/gitserver?viewPanel=10024 Query: ``` -sum by (instance) (increase(src_gitserver_non_existing_repos_removed[5m])) +sum(rate(src_gitserver_janitor_data_structure_existence_total{instance=~`${shard:regex}`, exists="true"}[5m])) by (data_structure) ```-#### gitserver: sg_maintenance_reason +### Git Server: Git Command Corruption Retries -
Successful sg maintenance jobs over 1h (by reason)
+#### gitserver: git_command_retry_attempts_rate -the rate of successful sg maintenance jobs and the reason why they were triggered +Rate of git command corruption retry attempts over 5m
-This panel has no related alerts. +The rate of git command retry attempts due to corruption detection. +A non-zero value indicates that gitserver is detecting potential corruption and attempting retries. +This metric helps track how often the retry mechanism is triggered. -To see this panel, visit `/-/debug/grafana/d/gitserver/gitserver?viewPanel=100250` on your Sourcegraph instance. +Refer to the [alerts reference](alerts#gitserver-git-command-retry-attempts-rate) for 1 alert related to this panel. + +To see this panel, visit `/-/debug/grafana/d/gitserver/gitserver?viewPanel=100300` on your Sourcegraph instance. *Managed by the [Sourcegraph Source team](https://handbook.sourcegraph.com/departments/engineering/teams/source).* @@ -42591,21 +43411,22 @@ To see this panel, visit `/-/debug/grafana/d/gitserver/gitserver?viewPanel=10025 Query: ``` -sum by (reason) (rate(src_gitserver_maintenance_status{success="true"}[1h])) +sum(rate(src_gitserver_retry_attempts_total{instance=~`${shard:regex}`}[5m])) ```-#### gitserver: git_prune_skipped +#### gitserver: git_command_retry_success_rate -
Successful git prune jobs over 1h
+Rate of successful git command corruption retries over 5m
-the rate of successful git prune jobs over 1h and whether they were skipped +The rate of git commands that succeeded after retry attempts. +This indicates how effective the retry mechanism is at resolving transient corruption issues. This panel has no related alerts. -To see this panel, visit `/-/debug/grafana/d/gitserver/gitserver?viewPanel=100260` on your Sourcegraph instance. +To see this panel, visit `/-/debug/grafana/d/gitserver/gitserver?viewPanel=100301` on your Sourcegraph instance. *Managed by the [Sourcegraph Source team](https://handbook.sourcegraph.com/departments/engineering/teams/source).* @@ -42615,25 +43436,24 @@ To see this panel, visit `/-/debug/grafana/d/gitserver/gitserver?viewPanel=10026 Query: ``` -sum by (skipped) (rate(src_gitserver_prune_status{success="true"}[1h])) +sum(rate(src_gitserver_retry_success_total{instance=~`${shard:regex}`}[5m])) ```-### Git Server: Search - -#### gitserver: search_latency +#### gitserver: git_command_retry_failure_rate -
Mean time until first result is sent
+Rate of failed git command corruption retries over 5m
-Mean latency (time to first result) of gitserver search requests +The rate of git commands that failed even after all retry attempts were exhausted. +These failures will result in repository corruption marking and potential recloning. This panel has no related alerts. -To see this panel, visit `/-/debug/grafana/d/gitserver/gitserver?viewPanel=100300` on your Sourcegraph instance. +To see this panel, visit `/-/debug/grafana/d/gitserver/gitserver?viewPanel=100310` on your Sourcegraph instance. -*Managed by the [Sourcegraph Code Search team](https://handbook.sourcegraph.com/departments/engineering/teams/code-search).* +*Managed by the [Sourcegraph Source team](https://handbook.sourcegraph.com/departments/engineering/teams/source).*Technical details
@@ -42641,23 +43461,25 @@ To see this panel, visit `/-/debug/grafana/d/gitserver/gitserver?viewPanel=10030 Query: ``` -rate(src_gitserver_search_latency_seconds_sum[5m]) / rate(src_gitserver_search_latency_seconds_count[5m]) +sum(rate(src_gitserver_retry_failure_total{instance=~`${shard:regex}`}[5m])) ```-#### gitserver: search_duration +#### gitserver: git_command_retry_different_error_rate -
Mean search duration
+Rate of corruption retries that failed with non-corruption errors over 5m
-Mean duration of gitserver search requests +The rate of retry attempts that failed with errors other than corruption. +This indicates that repository state or environment changed between the original command and retry attempt. +Common causes include network issues, permission changes, or concurrent repository modifications. This panel has no related alerts. -To see this panel, visit `/-/debug/grafana/d/gitserver/gitserver?viewPanel=100301` on your Sourcegraph instance. +To see this panel, visit `/-/debug/grafana/d/gitserver/gitserver?viewPanel=100311` on your Sourcegraph instance. -*Managed by the [Sourcegraph Code Search team](https://handbook.sourcegraph.com/departments/engineering/teams/code-search).* +*Managed by the [Sourcegraph Source team](https://handbook.sourcegraph.com/departments/engineering/teams/source).*Technical details
@@ -42665,23 +43487,25 @@ To see this panel, visit `/-/debug/grafana/d/gitserver/gitserver?viewPanel=10030 Query: ``` -rate(src_gitserver_search_duration_seconds_sum[5m]) / rate(src_gitserver_search_duration_seconds_count[5m]) +sum(rate(src_gitserver_retry_different_error_total{instance=~`${shard:regex}`}[5m])) ```-#### gitserver: search_rate +#### gitserver: git_command_retry_success_ratio -
Rate of searches run by pod
+Ratio of successful corruption retries to total corruption retry attempts over 5m
-The rate of searches executed on gitserver by pod +The percentage of retry attempts that ultimately succeeded. +A high ratio indicates that most corruption errors are transient and resolved by retries. +A low ratio may indicate persistent corruption issues requiring investigation. This panel has no related alerts. -To see this panel, visit `/-/debug/grafana/d/gitserver/gitserver?viewPanel=100310` on your Sourcegraph instance. +To see this panel, visit `/-/debug/grafana/d/gitserver/gitserver?viewPanel=100312` on your Sourcegraph instance. -*Managed by the [Sourcegraph Code Search team](https://handbook.sourcegraph.com/departments/engineering/teams/code-search).* +*Managed by the [Sourcegraph Source team](https://handbook.sourcegraph.com/departments/engineering/teams/source).*Technical details
@@ -42689,23 +43513,26 @@ To see this panel, visit `/-/debug/grafana/d/gitserver/gitserver?viewPanel=10031 Query: ``` -rate(src_gitserver_search_latency_seconds_count{instance=~`${shard:regex}`}[5m]) +sum(rate(src_gitserver_retry_success_total{instance=~`${shard:regex}`}[5m])) / sum(rate(src_gitserver_retry_attempts_total{instance=~`${shard:regex}`}[5m])) ```-#### gitserver: running_searches +### Git Server: Periodic Goroutines + +#### gitserver: running_goroutines -
Number of searches currently running by pod
+Number of currently running periodic goroutines
-The number of searches currently executing on gitserver by pod +The number of currently running periodic goroutines by name and job. +A value of 0 indicates the routine isn`t running currently, it awaits it`s next schedule. This panel has no related alerts. -To see this panel, visit `/-/debug/grafana/d/gitserver/gitserver?viewPanel=100311` on your Sourcegraph instance. +To see this panel, visit `/-/debug/grafana/d/gitserver/gitserver?viewPanel=100400` on your Sourcegraph instance. -*Managed by the [Sourcegraph Code Search team](https://handbook.sourcegraph.com/departments/engineering/teams/code-search).* +*Managed by the [Sourcegraph Infrastructure Org team](https://handbook.sourcegraph.com/departments/engineering/infrastructure).*Technical details
@@ -42713,25 +43540,24 @@ To see this panel, visit `/-/debug/grafana/d/gitserver/gitserver?viewPanel=10031 Query: ``` -sum by (instance) (src_gitserver_search_running{instance=~`${shard:regex}`}) +sum by (name, job_name) (src_periodic_goroutine_running{job=~".*gitserver.*"}) ```-### Git Server: Gitserver: Gitserver Backend - -#### gitserver: concurrent_backend_operations +#### gitserver: goroutine_success_rate -
Number of concurrently running backend operations
+Success rate for periodic goroutine executions
-The number of requests that are currently being handled by gitserver backend layer, at the point in time of scraping. +The rate of successful executions of each periodic goroutine. +A low or zero value could indicate that a routine is stalled or encountering errors. This panel has no related alerts. -To see this panel, visit `/-/debug/grafana/d/gitserver/gitserver?viewPanel=100400` on your Sourcegraph instance. +To see this panel, visit `/-/debug/grafana/d/gitserver/gitserver?viewPanel=100401` on your Sourcegraph instance. -*Managed by the [Sourcegraph Source team](https://handbook.sourcegraph.com/departments/engineering/teams/source).* +*Managed by the [Sourcegraph Infrastructure Org team](https://handbook.sourcegraph.com/departments/engineering/infrastructure).*Technical details
@@ -42739,21 +43565,24 @@ To see this panel, visit `/-/debug/grafana/d/gitserver/gitserver?viewPanel=10040 Query: ``` -src_gitserver_backend_concurrent_operations +sum by (name, job_name) (rate(src_periodic_goroutine_total{job=~".*gitserver.*"}[5m])) ```-#### gitserver: gitserver_backend_total +#### gitserver: goroutine_error_rate -
Aggregate operations every 5m
+Error rate for periodic goroutine executions
-This panel has no related alerts. +The rate of errors encountered by each periodic goroutine. +A sustained high error rate may indicate a problem with the routine`s configuration or dependencies. + +Refer to the [alerts reference](alerts#gitserver-goroutine-error-rate) for 1 alert related to this panel. To see this panel, visit `/-/debug/grafana/d/gitserver/gitserver?viewPanel=100410` on your Sourcegraph instance. -*Managed by the [Sourcegraph Source team](https://handbook.sourcegraph.com/departments/engineering/teams/source).* +*Managed by the [Sourcegraph Infrastructure Org team](https://handbook.sourcegraph.com/departments/engineering/infrastructure).*Technical details
@@ -42761,21 +43590,24 @@ To see this panel, visit `/-/debug/grafana/d/gitserver/gitserver?viewPanel=10041 Query: ``` -sum(increase(src_gitserver_backend_total{job=~"^gitserver.*"}[5m])) +sum by (name, job_name) (rate(src_periodic_goroutine_errors_total{job=~".*gitserver.*"}[5m])) ```-#### gitserver: gitserver_backend_99th_percentile_duration +#### gitserver: goroutine_error_percentage -
Aggregate successful operation duration distribution over 5m
+Percentage of periodic goroutine executions that result in errors
-This panel has no related alerts. +The percentage of executions that result in errors for each periodic goroutine. +A value above 5% indicates that a significant portion of routine executions are failing. + +Refer to the [alerts reference](alerts#gitserver-goroutine-error-percentage) for 1 alert related to this panel. To see this panel, visit `/-/debug/grafana/d/gitserver/gitserver?viewPanel=100411` on your Sourcegraph instance. -*Managed by the [Sourcegraph Source team](https://handbook.sourcegraph.com/departments/engineering/teams/source).* +*Managed by the [Sourcegraph Infrastructure Org team](https://handbook.sourcegraph.com/departments/engineering/infrastructure).*Technical details
@@ -42783,21 +43615,24 @@ To see this panel, visit `/-/debug/grafana/d/gitserver/gitserver?viewPanel=10041 Query: ``` -sum by (le)(rate(src_gitserver_backend_duration_seconds_bucket{job=~"^gitserver.*"}[5m])) +sum by (name, job_name) (rate(src_periodic_goroutine_errors_total{job=~".*gitserver.*"}[5m])) / sum by (name, job_name) (rate(src_periodic_goroutine_total{job=~".*gitserver.*"}[5m]) > 0) * 100 ```-#### gitserver: gitserver_backend_errors_total +#### gitserver: goroutine_handler_duration -
Aggregate operation errors every 5m
+95th percentile handler execution time
+ +The 95th percentile execution time for each periodic goroutine handler. +Longer durations might indicate increased load or processing time. This panel has no related alerts. -To see this panel, visit `/-/debug/grafana/d/gitserver/gitserver?viewPanel=100412` on your Sourcegraph instance. +To see this panel, visit `/-/debug/grafana/d/gitserver/gitserver?viewPanel=100420` on your Sourcegraph instance. -*Managed by the [Sourcegraph Source team](https://handbook.sourcegraph.com/departments/engineering/teams/source).* +*Managed by the [Sourcegraph Infrastructure Org team](https://handbook.sourcegraph.com/departments/engineering/infrastructure).*Technical details
@@ -42805,21 +43640,24 @@ To see this panel, visit `/-/debug/grafana/d/gitserver/gitserver?viewPanel=10041 Query: ``` -sum(increase(src_gitserver_backend_errors_total{job=~"^gitserver.*"}[5m])) +histogram_quantile(0.95, sum by (name, job_name, le) (rate(src_periodic_goroutine_duration_seconds_bucket{job=~".*gitserver.*"}[5m]))) ```-#### gitserver: gitserver_backend_error_rate +#### gitserver: goroutine_loop_duration -
Aggregate operation error rate over 5m
+95th percentile loop cycle time
+ +The 95th percentile loop cycle time for each periodic goroutine (excluding sleep time). +This represents how long a complete loop iteration takes before sleeping for the next interval. This panel has no related alerts. -To see this panel, visit `/-/debug/grafana/d/gitserver/gitserver?viewPanel=100413` on your Sourcegraph instance. +To see this panel, visit `/-/debug/grafana/d/gitserver/gitserver?viewPanel=100421` on your Sourcegraph instance. -*Managed by the [Sourcegraph Source team](https://handbook.sourcegraph.com/departments/engineering/teams/source).* +*Managed by the [Sourcegraph Infrastructure Org team](https://handbook.sourcegraph.com/departments/engineering/infrastructure).*Technical details
@@ -42827,21 +43665,24 @@ To see this panel, visit `/-/debug/grafana/d/gitserver/gitserver?viewPanel=10041 Query: ``` -sum(increase(src_gitserver_backend_errors_total{job=~"^gitserver.*"}[5m])) / (sum(increase(src_gitserver_backend_total{job=~"^gitserver.*"}[5m])) + sum(increase(src_gitserver_backend_errors_total{job=~"^gitserver.*"}[5m]))) * 100 +histogram_quantile(0.95, sum by (name, job_name, le) (rate(src_periodic_goroutine_loop_duration_seconds_bucket{job=~".*gitserver.*"}[5m]))) ```-#### gitserver: gitserver_backend_total +#### gitserver: tenant_processing_duration -
operations every 5m
+95th percentile tenant processing time
+ +The 95th percentile processing time for individual tenants within periodic goroutines. +Higher values indicate that tenant processing is taking longer and may affect overall performance. This panel has no related alerts. -To see this panel, visit `/-/debug/grafana/d/gitserver/gitserver?viewPanel=100420` on your Sourcegraph instance. +To see this panel, visit `/-/debug/grafana/d/gitserver/gitserver?viewPanel=100430` on your Sourcegraph instance. -*Managed by the [Sourcegraph Source team](https://handbook.sourcegraph.com/departments/engineering/teams/source).* +*Managed by the [Sourcegraph Infrastructure Org team](https://handbook.sourcegraph.com/departments/engineering/infrastructure).*Technical details
@@ -42849,21 +43690,24 @@ To see this panel, visit `/-/debug/grafana/d/gitserver/gitserver?viewPanel=10042 Query: ``` -sum by (op)(increase(src_gitserver_backend_total{job=~"^gitserver.*"}[5m])) +histogram_quantile(0.95, sum by (name, job_name, le) (rate(src_periodic_goroutine_tenant_duration_seconds_bucket{job=~".*gitserver.*"}[5m]))) ```-#### gitserver: gitserver_backend_99th_percentile_duration +#### gitserver: tenant_processing_max -
99th percentile successful operation duration over 5m
+Maximum tenant processing time
+ +The maximum processing time for individual tenants within periodic goroutines. +Consistently high values might indicate problematic tenants or inefficient processing. This panel has no related alerts. -To see this panel, visit `/-/debug/grafana/d/gitserver/gitserver?viewPanel=100421` on your Sourcegraph instance. +To see this panel, visit `/-/debug/grafana/d/gitserver/gitserver?viewPanel=100431` on your Sourcegraph instance. -*Managed by the [Sourcegraph Source team](https://handbook.sourcegraph.com/departments/engineering/teams/source).* +*Managed by the [Sourcegraph Infrastructure Org team](https://handbook.sourcegraph.com/departments/engineering/infrastructure).*Technical details
@@ -42871,21 +43715,24 @@ To see this panel, visit `/-/debug/grafana/d/gitserver/gitserver?viewPanel=10042 Query: ``` -histogram_quantile(0.99, sum by (le,op)(rate(src_gitserver_backend_duration_seconds_bucket{job=~"^gitserver.*"}[5m]))) +max by (name, job_name) (rate(src_periodic_goroutine_tenant_duration_seconds_sum{job=~".*gitserver.*"}[5m]) / rate(src_periodic_goroutine_tenant_duration_seconds_count{job=~".*gitserver.*"}[5m])) ```-#### gitserver: gitserver_backend_errors_total +#### gitserver: tenant_count -
operation errors every 5m
+Number of tenants processed per routine
+ +The number of tenants processed by each periodic goroutine. +Unexpected changes can indicate tenant configuration issues or scaling events. This panel has no related alerts. -To see this panel, visit `/-/debug/grafana/d/gitserver/gitserver?viewPanel=100422` on your Sourcegraph instance. +To see this panel, visit `/-/debug/grafana/d/gitserver/gitserver?viewPanel=100440` on your Sourcegraph instance. -*Managed by the [Sourcegraph Source team](https://handbook.sourcegraph.com/departments/engineering/teams/source).* +*Managed by the [Sourcegraph Infrastructure Org team](https://handbook.sourcegraph.com/departments/engineering/infrastructure).*Technical details
@@ -42893,21 +43740,24 @@ To see this panel, visit `/-/debug/grafana/d/gitserver/gitserver?viewPanel=10042 Query: ``` -sum by (op)(increase(src_gitserver_backend_errors_total{job=~"^gitserver.*"}[5m])) +max by (name, job_name) (src_periodic_goroutine_tenant_count{job=~".*gitserver.*"}) ```-#### gitserver: gitserver_backend_error_rate +#### gitserver: tenant_success_rate -
operation error rate over 5m
+Rate of successful tenant processing operations
+ +The rate of successful tenant processing operations. +A healthy routine should maintain a consistent processing rate. This panel has no related alerts. -To see this panel, visit `/-/debug/grafana/d/gitserver/gitserver?viewPanel=100423` on your Sourcegraph instance. +To see this panel, visit `/-/debug/grafana/d/gitserver/gitserver?viewPanel=100441` on your Sourcegraph instance. -*Managed by the [Sourcegraph Source team](https://handbook.sourcegraph.com/departments/engineering/teams/source).* +*Managed by the [Sourcegraph Infrastructure Org team](https://handbook.sourcegraph.com/departments/engineering/infrastructure).*Technical details
@@ -42915,23 +43765,24 @@ To see this panel, visit `/-/debug/grafana/d/gitserver/gitserver?viewPanel=10042 Query: ``` -sum by (op)(increase(src_gitserver_backend_errors_total{job=~"^gitserver.*"}[5m])) / (sum by (op)(increase(src_gitserver_backend_total{job=~"^gitserver.*"}[5m])) + sum by (op)(increase(src_gitserver_backend_errors_total{job=~"^gitserver.*"}[5m]))) * 100 +sum by (name, job_name) (rate(src_periodic_goroutine_tenant_success_total{job=~".*gitserver.*"}[5m])) ```-### Git Server: Gitserver: Gitserver Client +#### gitserver: tenant_error_rate -#### gitserver: gitserver_client_total +
Rate of tenant processing errors
-Aggregate graphql operations every 5m
+The rate of tenant processing operations that result in errors. +Consistent errors indicate problems with specific tenants. This panel has no related alerts. -To see this panel, visit `/-/debug/grafana/d/gitserver/gitserver?viewPanel=100500` on your Sourcegraph instance. +To see this panel, visit `/-/debug/grafana/d/gitserver/gitserver?viewPanel=100450` on your Sourcegraph instance. -*Managed by the [Sourcegraph Source team](https://handbook.sourcegraph.com/departments/engineering/teams/source).* +*Managed by the [Sourcegraph Infrastructure Org team](https://handbook.sourcegraph.com/departments/engineering/infrastructure).*Technical details
@@ -42939,21 +43790,24 @@ To see this panel, visit `/-/debug/grafana/d/gitserver/gitserver?viewPanel=10050 Query: ``` -sum(increase(src_gitserver_client_total{job=~"^*.*"}[5m])) +sum by (name, job_name) (rate(src_periodic_goroutine_tenant_errors_total{job=~".*gitserver.*"}[5m])) ```-#### gitserver: gitserver_client_99th_percentile_duration +#### gitserver: tenant_error_percentage -
Aggregate successful graphql operation duration distribution over 5m
+Percentage of tenant operations resulting in errors
+ +The percentage of tenant operations that result in errors. +Values above 5% indicate significant tenant processing problems. This panel has no related alerts. -To see this panel, visit `/-/debug/grafana/d/gitserver/gitserver?viewPanel=100501` on your Sourcegraph instance. +To see this panel, visit `/-/debug/grafana/d/gitserver/gitserver?viewPanel=100451` on your Sourcegraph instance. -*Managed by the [Sourcegraph Source team](https://handbook.sourcegraph.com/departments/engineering/teams/source).* +*Managed by the [Sourcegraph Infrastructure Org team](https://handbook.sourcegraph.com/departments/engineering/infrastructure).*Technical details
@@ -42961,19 +43815,21 @@ To see this panel, visit `/-/debug/grafana/d/gitserver/gitserver?viewPanel=10050 Query: ``` -sum by (le)(rate(src_gitserver_client_duration_seconds_bucket{job=~"^*.*"}[5m])) +(sum by (name, job_name) (rate(src_periodic_goroutine_tenant_errors_total{job=~".*gitserver.*"}[5m])) / (sum by (name, job_name) (rate(src_periodic_goroutine_tenant_success_total{job=~".*gitserver.*"}[5m])) + sum by (name, job_name) (rate(src_periodic_goroutine_tenant_errors_total{job=~".*gitserver.*"}[5m])))) * 100 ```-#### gitserver: gitserver_client_errors_total +### Git Server: Gitserver (CPU, Memory) -
Aggregate graphql operation errors every 5m
+#### gitserver: cpu_usage_percentage -This panel has no related alerts. +CPU usage
-To see this panel, visit `/-/debug/grafana/d/gitserver/gitserver?viewPanel=100502` on your Sourcegraph instance. +Refer to the [alerts reference](alerts#gitserver-cpu-usage-percentage) for 1 alert related to this panel. + +To see this panel, visit `/-/debug/grafana/d/gitserver/gitserver?viewPanel=100500` on your Sourcegraph instance. *Managed by the [Sourcegraph Source team](https://handbook.sourcegraph.com/departments/engineering/teams/source).* @@ -42983,19 +43839,21 @@ To see this panel, visit `/-/debug/grafana/d/gitserver/gitserver?viewPanel=10050 Query: ``` -sum(increase(src_gitserver_client_errors_total{job=~"^*.*"}[5m])) +cadvisor_container_cpu_usage_percentage_total{name=~"^gitserver.*"} ```-#### gitserver: gitserver_client_error_rate +#### gitserver: memory_usage_percentage -
Aggregate graphql operation error rate over 5m
+Memory usage percentage (total)
+ +An estimate for the active memory in use, which includes anonymous memory, file memory, and kernel memory. Some of this memory is reclaimable, so high usage does not necessarily indicate memory pressure. This panel has no related alerts. -To see this panel, visit `/-/debug/grafana/d/gitserver/gitserver?viewPanel=100503` on your Sourcegraph instance. +To see this panel, visit `/-/debug/grafana/d/gitserver/gitserver?viewPanel=100501` on your Sourcegraph instance. *Managed by the [Sourcegraph Source team](https://handbook.sourcegraph.com/departments/engineering/teams/source).* @@ -43005,19 +43863,21 @@ To see this panel, visit `/-/debug/grafana/d/gitserver/gitserver?viewPanel=10050 Query: ``` -sum(increase(src_gitserver_client_errors_total{job=~"^*.*"}[5m])) / (sum(increase(src_gitserver_client_total{job=~"^*.*"}[5m])) + sum(increase(src_gitserver_client_errors_total{job=~"^*.*"}[5m]))) * 100 +cadvisor_container_memory_usage_percentage_total{name=~"^gitserver.*"} ```-#### gitserver: gitserver_client_total +#### gitserver: memory_working_set_bytes -
Graphql operations every 5m
+Memory usage bytes (total)
+ +An estimate for the active memory in use in bytes, which includes anonymous memory, file memory, and kernel memory. Some of this memory is reclaimable, so high usage does not necessarily indicate memory pressure. This panel has no related alerts. -To see this panel, visit `/-/debug/grafana/d/gitserver/gitserver?viewPanel=100510` on your Sourcegraph instance. +To see this panel, visit `/-/debug/grafana/d/gitserver/gitserver?viewPanel=100502` on your Sourcegraph instance. *Managed by the [Sourcegraph Source team](https://handbook.sourcegraph.com/departments/engineering/teams/source).* @@ -43027,19 +43887,21 @@ To see this panel, visit `/-/debug/grafana/d/gitserver/gitserver?viewPanel=10051 Query: ``` -sum by (op,scope)(increase(src_gitserver_client_total{job=~"^*.*"}[5m])) +max by (name) (container_memory_working_set_bytes{name=~"^gitserver.*"}) ```-#### gitserver: gitserver_client_99th_percentile_duration +#### gitserver: memory_rss -
99th percentile successful graphql operation duration over 5m
+Memory (RSS)
-This panel has no related alerts. +The total anonymous memory in use by the application, which includes Go stack and heap. This memory is is non-reclaimable, and high usage may trigger OOM kills. Note: the metric is named RSS because to match the cadvisor name, but `anonymous` is more accurate." -To see this panel, visit `/-/debug/grafana/d/gitserver/gitserver?viewPanel=100511` on your Sourcegraph instance. +Refer to the [alerts reference](alerts#gitserver-memory-rss) for 1 alert related to this panel. + +To see this panel, visit `/-/debug/grafana/d/gitserver/gitserver?viewPanel=100510` on your Sourcegraph instance. *Managed by the [Sourcegraph Source team](https://handbook.sourcegraph.com/departments/engineering/teams/source).* @@ -43049,19 +43911,21 @@ To see this panel, visit `/-/debug/grafana/d/gitserver/gitserver?viewPanel=10051 Query: ``` -histogram_quantile(0.99, sum by (le,op,scope)(rate(src_gitserver_client_duration_seconds_bucket{job=~"^*.*"}[5m]))) +max(container_memory_rss{name=~"^gitserver.*"} / container_spec_memory_limit_bytes{name=~"^gitserver.*"}) by (name) * 100.0 ```-#### gitserver: gitserver_client_errors_total +#### gitserver: memory_total_active_file -
Graphql operation errors every 5m
+Memory usage (active file)
+ +This metric shows the total active file-backed memory currently in use by the application. Some of it may be reclaimable, so high usage does not necessarily indicate memory pressure. This panel has no related alerts. -To see this panel, visit `/-/debug/grafana/d/gitserver/gitserver?viewPanel=100512` on your Sourcegraph instance. +To see this panel, visit `/-/debug/grafana/d/gitserver/gitserver?viewPanel=100511` on your Sourcegraph instance. *Managed by the [Sourcegraph Source team](https://handbook.sourcegraph.com/departments/engineering/teams/source).* @@ -43071,19 +43935,21 @@ To see this panel, visit `/-/debug/grafana/d/gitserver/gitserver?viewPanel=10051 Query: ``` -sum by (op,scope)(increase(src_gitserver_client_errors_total{job=~"^*.*"}[5m])) +max(container_memory_total_active_file_bytes{name=~"^gitserver.*"} / container_spec_memory_limit_bytes{name=~"^gitserver.*"}) by (name) * 100.0 ```-#### gitserver: gitserver_client_error_rate +#### gitserver: memory_kernel_usage -
Graphql operation error rate over 5m
+Memory usage (kernel)
+ +The kernel usage metric shows the amount of memory used by the kernel on behalf of the application. Some of it may be reclaimable, so high usage does not necessarily indicate memory pressure. This panel has no related alerts. -To see this panel, visit `/-/debug/grafana/d/gitserver/gitserver?viewPanel=100513` on your Sourcegraph instance. +To see this panel, visit `/-/debug/grafana/d/gitserver/gitserver?viewPanel=100512` on your Sourcegraph instance. *Managed by the [Sourcegraph Source team](https://handbook.sourcegraph.com/departments/engineering/teams/source).* @@ -43093,21 +43959,19 @@ To see this panel, visit `/-/debug/grafana/d/gitserver/gitserver?viewPanel=10051 Query: ``` -sum by (op,scope)(increase(src_gitserver_client_errors_total{job=~"^*.*"}[5m])) / (sum by (op,scope)(increase(src_gitserver_client_total{job=~"^*.*"}[5m])) + sum by (op,scope)(increase(src_gitserver_client_errors_total{job=~"^*.*"}[5m]))) * 100 +max(container_memory_kernel_usage{name=~"^gitserver.*"} / container_spec_memory_limit_bytes{name=~"^gitserver.*"}) by (name) * 100.0 ```-### Git Server: Repos disk I/O metrics - -#### gitserver: repos_disk_reads_sec +### Git Server: Network I/O pod metrics (only available on Kubernetes) -
Read request rate over 1m (per instance)
+#### gitserver: network_sent_bytes_aggregate -The number of read requests that were issued to the device per second. +Transmission rate over 5m (aggregate)
-Note: Disk statistics are per _device_, not per _service_. In certain environments (such as common docker-compose setups), gitserver could be one of _many services_ using this disk. These statistics are best interpreted as the load experienced by the device gitserver is using, not the load gitserver is solely responsible for causing. +The rate of bytes sent over the network across all pods This panel has no related alerts. @@ -43121,19 +43985,17 @@ To see this panel, visit `/-/debug/grafana/d/gitserver/gitserver?viewPanel=10060 Query: ``` -(max by (instance) (gitserver_mount_point_info{mount_name="reposDir",instance=~`${shard:regex}`} * on (device, nodename) group_left() (max by (device, nodename) (rate(node_disk_reads_completed_total{instance=~`node-exporter.*`}[1m]))))) +sum(rate(container_network_transmit_bytes_total{container_label_io_kubernetes_pod_name=~`.*gitserver.*`}[5m])) ```-#### gitserver: repos_disk_writes_sec - -
Write request rate over 1m (per instance)
+#### gitserver: network_received_packets_per_instance -The number of write requests that were issued to the device per second. +Transmission rate over 5m (per instance)
-Note: Disk statistics are per _device_, not per _service_. In certain environments (such as common docker-compose setups), gitserver could be one of _many services_ using this disk. These statistics are best interpreted as the load experienced by the device gitserver is using, not the load gitserver is solely responsible for causing. +The amount of bytes sent over the network by individual pods This panel has no related alerts. @@ -43147,19 +44009,17 @@ To see this panel, visit `/-/debug/grafana/d/gitserver/gitserver?viewPanel=10060 Query: ``` -(max by (instance) (gitserver_mount_point_info{mount_name="reposDir",instance=~`${shard:regex}`} * on (device, nodename) group_left() (max by (device, nodename) (rate(node_disk_writes_completed_total{instance=~`node-exporter.*`}[1m]))))) +sum by (container_label_io_kubernetes_pod_name) (rate(container_network_transmit_bytes_total{container_label_io_kubernetes_pod_name=~`${instance:regex}`}[5m])) ```-#### gitserver: repos_disk_read_throughput - -
Read throughput over 1m (per instance)
+#### gitserver: network_received_bytes_aggregate -The amount of data that was read from the device per second. +Receive rate over 5m (aggregate)
-Note: Disk statistics are per _device_, not per _service_. In certain environments (such as common docker-compose setups), gitserver could be one of _many services_ using this disk. These statistics are best interpreted as the load experienced by the device gitserver is using, not the load gitserver is solely responsible for causing. +The amount of bytes received from the network across pods This panel has no related alerts. @@ -43173,19 +44033,17 @@ To see this panel, visit `/-/debug/grafana/d/gitserver/gitserver?viewPanel=10061 Query: ``` -(max by (instance) (gitserver_mount_point_info{mount_name="reposDir",instance=~`${shard:regex}`} * on (device, nodename) group_left() (max by (device, nodename) (rate(node_disk_read_bytes_total{instance=~`node-exporter.*`}[1m]))))) +sum(rate(container_network_receive_bytes_total{container_label_io_kubernetes_pod_name=~`.*gitserver.*`}[5m])) ```-#### gitserver: repos_disk_write_throughput - -
Write throughput over 1m (per instance)
+#### gitserver: network_received_bytes_per_instance -The amount of data that was written to the device per second. +Receive rate over 5m (per instance)
-Note: Disk statistics are per _device_, not per _service_. In certain environments (such as common docker-compose setups), gitserver could be one of _many services_ using this disk. These statistics are best interpreted as the load experienced by the device gitserver is using, not the load gitserver is solely responsible for causing. +The amount of bytes received from the network by individual pods This panel has no related alerts. @@ -43199,19 +44057,17 @@ To see this panel, visit `/-/debug/grafana/d/gitserver/gitserver?viewPanel=10061 Query: ``` -(max by (instance) (gitserver_mount_point_info{mount_name="reposDir",instance=~`${shard:regex}`} * on (device, nodename) group_left() (max by (device, nodename) (rate(node_disk_written_bytes_total{instance=~`node-exporter.*`}[1m]))))) +sum by (container_label_io_kubernetes_pod_name) (rate(container_network_receive_bytes_total{container_label_io_kubernetes_pod_name=~`${instance:regex}`}[5m])) ```-#### gitserver: repos_disk_read_duration - -
Average read duration over 1m (per instance)
+#### gitserver: network_transmitted_packets_dropped_by_instance -The average time for read requests issued to the device to be served. This includes the time spent by the requests in queue and the time spent servicing them. +Transmit packet drop rate over 5m (by instance)
-Note: Disk statistics are per _device_, not per _service_. In certain environments (such as common docker-compose setups), gitserver could be one of _many services_ using this disk. These statistics are best interpreted as the load experienced by the device gitserver is using, not the load gitserver is solely responsible for causing. +An increase in dropped packets could be a leading indicator of network saturation. This panel has no related alerts. @@ -43225,19 +44081,17 @@ To see this panel, visit `/-/debug/grafana/d/gitserver/gitserver?viewPanel=10062 Query: ``` -(((max by (instance) (gitserver_mount_point_info{mount_name="reposDir",instance=~`${shard:regex}`} * on (device, nodename) group_left() (max by (device, nodename) (rate(node_disk_read_time_seconds_total{instance=~`node-exporter.*`}[1m])))))) / ((max by (instance) (gitserver_mount_point_info{mount_name="reposDir",instance=~`${shard:regex}`} * on (device, nodename) group_left() (max by (device, nodename) (rate(node_disk_reads_completed_total{instance=~`node-exporter.*`}[1m]))))))) +sum by (container_label_io_kubernetes_pod_name) (rate(container_network_transmit_packets_dropped_total{container_label_io_kubernetes_pod_name=~`${instance:regex}`}[5m])) ```-#### gitserver: repos_disk_write_duration - -
Average write duration over 1m (per instance)
+#### gitserver: network_transmitted_packets_errors_per_instance -The average time for write requests issued to the device to be served. This includes the time spent by the requests in queue and the time spent servicing them. +Errors encountered while transmitting over 5m (per instance)
-Note: Disk statistics are per _device_, not per _service_. In certain environments (such as common docker-compose setups), gitserver could be one of _many services_ using this disk. These statistics are best interpreted as the load experienced by the device gitserver is using, not the load gitserver is solely responsible for causing. +An increase in transmission errors could indicate a networking issue This panel has no related alerts. @@ -43251,23 +44105,21 @@ To see this panel, visit `/-/debug/grafana/d/gitserver/gitserver?viewPanel=10062 Query: ``` -(((max by (instance) (gitserver_mount_point_info{mount_name="reposDir",instance=~`${shard:regex}`} * on (device, nodename) group_left() (max by (device, nodename) (rate(node_disk_write_time_seconds_total{instance=~`node-exporter.*`}[1m])))))) / ((max by (instance) (gitserver_mount_point_info{mount_name="reposDir",instance=~`${shard:regex}`} * on (device, nodename) group_left() (max by (device, nodename) (rate(node_disk_writes_completed_total{instance=~`node-exporter.*`}[1m]))))))) +sum by (container_label_io_kubernetes_pod_name) (rate(container_network_transmit_errors_total{container_label_io_kubernetes_pod_name=~`${instance:regex}`}[5m])) ```-#### gitserver: repos_disk_read_request_size - -
Average read request size over 1m (per instance)
+#### gitserver: network_received_packets_dropped_by_instance -The average size of read requests that were issued to the device. +Receive packet drop rate over 5m (by instance)
-Note: Disk statistics are per _device_, not per _service_. In certain environments (such as common docker-compose setups), gitserver could be one of _many services_ using this disk. These statistics are best interpreted as the load experienced by the device gitserver is using, not the load gitserver is solely responsible for causing. +An increase in dropped packets could be a leading indicator of network saturation. This panel has no related alerts. -To see this panel, visit `/-/debug/grafana/d/gitserver/gitserver?viewPanel=100630` on your Sourcegraph instance. +To see this panel, visit `/-/debug/grafana/d/gitserver/gitserver?viewPanel=100622` on your Sourcegraph instance. *Managed by the [Sourcegraph Source team](https://handbook.sourcegraph.com/departments/engineering/teams/source).* @@ -43277,23 +44129,21 @@ To see this panel, visit `/-/debug/grafana/d/gitserver/gitserver?viewPanel=10063 Query: ``` -(((max by (instance) (gitserver_mount_point_info{mount_name="reposDir",instance=~`${shard:regex}`} * on (device, nodename) group_left() (max by (device, nodename) (rate(node_disk_read_bytes_total{instance=~`node-exporter.*`}[1m])))))) / ((max by (instance) (gitserver_mount_point_info{mount_name="reposDir",instance=~`${shard:regex}`} * on (device, nodename) group_left() (max by (device, nodename) (rate(node_disk_reads_completed_total{instance=~`node-exporter.*`}[1m]))))))) +sum by (container_label_io_kubernetes_pod_name) (rate(container_network_receive_packets_dropped_total{container_label_io_kubernetes_pod_name=~`${instance:regex}`}[5m])) ```-#### gitserver: repos_disk_write_request_size) - -
Average write request size over 1m (per instance)
+#### gitserver: network_transmitted_packets_errors_by_instance -The average size of write requests that were issued to the device. +Errors encountered while receiving over 5m (per instance)
-Note: Disk statistics are per _device_, not per _service_. In certain environments (such as common docker-compose setups), gitserver could be one of _many services_ using this disk. These statistics are best interpreted as the load experienced by the device gitserver is using, not the load gitserver is solely responsible for causing. +An increase in errors while receiving could indicate a networking issue. This panel has no related alerts. -To see this panel, visit `/-/debug/grafana/d/gitserver/gitserver?viewPanel=100631` on your Sourcegraph instance. +To see this panel, visit `/-/debug/grafana/d/gitserver/gitserver?viewPanel=100623` on your Sourcegraph instance. *Managed by the [Sourcegraph Source team](https://handbook.sourcegraph.com/departments/engineering/teams/source).* @@ -43303,23 +44153,23 @@ To see this panel, visit `/-/debug/grafana/d/gitserver/gitserver?viewPanel=10063 Query: ``` -(((max by (instance) (gitserver_mount_point_info{mount_name="reposDir",instance=~`${shard:regex}`} * on (device, nodename) group_left() (max by (device, nodename) (rate(node_disk_written_bytes_total{instance=~`node-exporter.*`}[1m])))))) / ((max by (instance) (gitserver_mount_point_info{mount_name="reposDir",instance=~`${shard:regex}`} * on (device, nodename) group_left() (max by (device, nodename) (rate(node_disk_writes_completed_total{instance=~`node-exporter.*`}[1m]))))))) +sum by (container_label_io_kubernetes_pod_name) (rate(container_network_receive_errors_total{container_label_io_kubernetes_pod_name=~`${instance:regex}`}[5m])) ```-#### gitserver: repos_disk_reads_merged_sec +### Git Server: VCS Clone metrics -
Merged read request rate over 1m (per instance)
+#### gitserver: vcs_syncer_999_successful_clone_duration -The number of read requests merged per second that were queued to the device. +99.9th percentile successful Clone duration over 1m
-Note: Disk statistics are per _device_, not per _service_. In certain environments (such as common docker-compose setups), gitserver could be one of _many services_ using this disk. These statistics are best interpreted as the load experienced by the device gitserver is using, not the load gitserver is solely responsible for causing. +The 99.9th percentile duration for successful `Clone` VCS operations. This is the time taken to clone a repository from the upstream source. This panel has no related alerts. -To see this panel, visit `/-/debug/grafana/d/gitserver/gitserver?viewPanel=100640` on your Sourcegraph instance. +To see this panel, visit `/-/debug/grafana/d/gitserver/gitserver?viewPanel=100700` on your Sourcegraph instance. *Managed by the [Sourcegraph Source team](https://handbook.sourcegraph.com/departments/engineering/teams/source).* @@ -43329,23 +44179,21 @@ To see this panel, visit `/-/debug/grafana/d/gitserver/gitserver?viewPanel=10064 Query: ``` -(max by (instance) (gitserver_mount_point_info{mount_name="reposDir",instance=~`${shard:regex}`} * on (device, nodename) group_left() (max by (device, nodename) (rate(node_disk_reads_merged_total{instance=~`node-exporter.*`}[1m]))))) +histogram_quantile(0.999, sum by (type, le) (rate(vcssyncer_clone_duration_seconds_bucket{type=~`${vcsSyncerType:regex}`, success="true"}[1m]))) ```-#### gitserver: repos_disk_writes_merged_sec - -
Merged writes request rate over 1m (per instance)
+#### gitserver: vcs_syncer_99_successful_clone_duration -The number of write requests merged per second that were queued to the device. +99th percentile successful Clone duration over 1m
-Note: Disk statistics are per _device_, not per _service_. In certain environments (such as common docker-compose setups), gitserver could be one of _many services_ using this disk. These statistics are best interpreted as the load experienced by the device gitserver is using, not the load gitserver is solely responsible for causing. +The 99th percentile duration for successful `Clone` VCS operations. This is the time taken to clone a repository from the upstream source. This panel has no related alerts. -To see this panel, visit `/-/debug/grafana/d/gitserver/gitserver?viewPanel=100641` on your Sourcegraph instance. +To see this panel, visit `/-/debug/grafana/d/gitserver/gitserver?viewPanel=100701` on your Sourcegraph instance. *Managed by the [Sourcegraph Source team](https://handbook.sourcegraph.com/departments/engineering/teams/source).* @@ -43355,23 +44203,21 @@ To see this panel, visit `/-/debug/grafana/d/gitserver/gitserver?viewPanel=10064 Query: ``` -(max by (instance) (gitserver_mount_point_info{mount_name="reposDir",instance=~`${shard:regex}`} * on (device, nodename) group_left() (max by (device, nodename) (rate(node_disk_writes_merged_total{instance=~`node-exporter.*`}[1m]))))) +histogram_quantile(0.99, sum by (type, le) (rate(vcssyncer_clone_duration_seconds_bucket{type=~`${vcsSyncerType:regex}`, success="true"}[1m]))) ```-#### gitserver: repos_disk_average_queue_size - -
Average queue size over 1m (per instance)
+#### gitserver: vcs_syncer_95_successful_clone_duration -The number of I/O operations that were being queued or being serviced. See https://blog.actorsfit.com/a?ID=00200-428fa2ac-e338-4540-848c-af9a3eb1ebd2 for background (avgqu-sz). +95th percentile successful Clone duration over 1m
-Note: Disk statistics are per _device_, not per _service_. In certain environments (such as common docker-compose setups), gitserver could be one of _many services_ using this disk. These statistics are best interpreted as the load experienced by the device gitserver is using, not the load gitserver is solely responsible for causing. +The 95th percentile duration for successful `Clone` VCS operations. This is the time taken to clone a repository from the upstream source. This panel has no related alerts. -To see this panel, visit `/-/debug/grafana/d/gitserver/gitserver?viewPanel=100650` on your Sourcegraph instance. +To see this panel, visit `/-/debug/grafana/d/gitserver/gitserver?viewPanel=100702` on your Sourcegraph instance. *Managed by the [Sourcegraph Source team](https://handbook.sourcegraph.com/departments/engineering/teams/source).* @@ -43381,23 +44227,21 @@ To see this panel, visit `/-/debug/grafana/d/gitserver/gitserver?viewPanel=10065 Query: ``` -(max by (instance) (gitserver_mount_point_info{mount_name="reposDir",instance=~`${shard:regex}`} * on (device, nodename) group_left() (max by (device, nodename) (rate(node_disk_io_time_weighted_seconds_total{instance=~`node-exporter.*`}[1m]))))) +histogram_quantile(0.95, sum by (type, le) (rate(vcssyncer_clone_duration_seconds_bucket{type=~`${vcsSyncerType:regex}`, success="true"}[1m]))) ```-### Git Server: Gitserver GRPC server metrics - -#### gitserver: gitserver_grpc_request_rate_all_methods +#### gitserver: vcs_syncer_successful_clone_rate -
Request rate across all methods over 2m
+Rate of successful Clone VCS operations over 1m
-The number of gRPC requests received per second across all methods, aggregated across all instances. +The rate of successful `Clone` VCS operations. This is the time taken to clone a repository from the upstream source. This panel has no related alerts. -To see this panel, visit `/-/debug/grafana/d/gitserver/gitserver?viewPanel=100700` on your Sourcegraph instance. +To see this panel, visit `/-/debug/grafana/d/gitserver/gitserver?viewPanel=100710` on your Sourcegraph instance. *Managed by the [Sourcegraph Source team](https://handbook.sourcegraph.com/departments/engineering/teams/source).* @@ -43407,21 +44251,21 @@ To see this panel, visit `/-/debug/grafana/d/gitserver/gitserver?viewPanel=10070 Query: ``` -sum(rate(grpc_server_started_total{instance=~`${shard:regex}`,grpc_service=~"gitserver.v1.GitserverService"}[2m])) +sum by (type) (rate(vcssyncer_clone_duration_seconds_count{type=~`${vcsSyncerType:regex}`, success="true"}[1m])) ```-#### gitserver: gitserver_grpc_request_rate_per_method +#### gitserver: vcs_syncer_999_failed_clone_duration -
Request rate per-method over 2m
+99.9th percentile failed Clone duration over 1m
-The number of gRPC requests received per second broken out per method, aggregated across all instances. +The 99.9th percentile duration for failed `Clone` VCS operations. This is the time taken to clone a repository from the upstream source. This panel has no related alerts. -To see this panel, visit `/-/debug/grafana/d/gitserver/gitserver?viewPanel=100701` on your Sourcegraph instance. +To see this panel, visit `/-/debug/grafana/d/gitserver/gitserver?viewPanel=100720` on your Sourcegraph instance. *Managed by the [Sourcegraph Source team](https://handbook.sourcegraph.com/departments/engineering/teams/source).* @@ -43431,21 +44275,21 @@ To see this panel, visit `/-/debug/grafana/d/gitserver/gitserver?viewPanel=10070 Query: ``` -sum(rate(grpc_server_started_total{grpc_method=~`${gitserver_method:regex}`,instance=~`${shard:regex}`,grpc_service=~"gitserver.v1.GitserverService"}[2m])) by (grpc_method) +histogram_quantile(0.999, sum by (type, le) (rate(vcssyncer_clone_duration_seconds_bucket{type=~`${vcsSyncerType:regex}`, success="false"}[1m]))) ```-#### gitserver: gitserver_error_percentage_all_methods +#### gitserver: vcs_syncer_99_failed_clone_duration -
Error percentage across all methods over 2m
+99th percentile failed Clone duration over 1m
-The percentage of gRPC requests that fail across all methods, aggregated across all instances. +The 99th percentile duration for failed `Clone` VCS operations. This is the time taken to clone a repository from the upstream source. This panel has no related alerts. -To see this panel, visit `/-/debug/grafana/d/gitserver/gitserver?viewPanel=100710` on your Sourcegraph instance. +To see this panel, visit `/-/debug/grafana/d/gitserver/gitserver?viewPanel=100721` on your Sourcegraph instance. *Managed by the [Sourcegraph Source team](https://handbook.sourcegraph.com/departments/engineering/teams/source).* @@ -43455,21 +44299,21 @@ To see this panel, visit `/-/debug/grafana/d/gitserver/gitserver?viewPanel=10071 Query: ``` -(100.0 * ( (sum(rate(grpc_server_handled_total{grpc_code!="OK",instance=~`${shard:regex}`,grpc_service=~"gitserver.v1.GitserverService"}[2m]))) / (sum(rate(grpc_server_handled_total{instance=~`${shard:regex}`,grpc_service=~"gitserver.v1.GitserverService"}[2m]))) )) +histogram_quantile(0.99, sum by (type, le) (rate(vcssyncer_clone_duration_seconds_bucket{type=~`${vcsSyncerType:regex}`, success="false"}[1m]))) ```-#### gitserver: gitserver_grpc_error_percentage_per_method +#### gitserver: vcs_syncer_95_failed_clone_duration -
Error percentage per-method over 2m
+95th percentile failed Clone duration over 1m
-The percentage of gRPC requests that fail per method, aggregated across all instances. +The 95th percentile duration for failed `Clone` VCS operations. This is the time taken to clone a repository from the upstream source. This panel has no related alerts. -To see this panel, visit `/-/debug/grafana/d/gitserver/gitserver?viewPanel=100711` on your Sourcegraph instance. +To see this panel, visit `/-/debug/grafana/d/gitserver/gitserver?viewPanel=100722` on your Sourcegraph instance. *Managed by the [Sourcegraph Source team](https://handbook.sourcegraph.com/departments/engineering/teams/source).* @@ -43479,21 +44323,21 @@ To see this panel, visit `/-/debug/grafana/d/gitserver/gitserver?viewPanel=10071 Query: ``` -(100.0 * ( (sum(rate(grpc_server_handled_total{grpc_method=~`${gitserver_method:regex}`,grpc_code!="OK",instance=~`${shard:regex}`,grpc_service=~"gitserver.v1.GitserverService"}[2m])) by (grpc_method)) / (sum(rate(grpc_server_handled_total{grpc_method=~`${gitserver_method:regex}`,instance=~`${shard:regex}`,grpc_service=~"gitserver.v1.GitserverService"}[2m])) by (grpc_method)) )) +histogram_quantile(0.95, sum by (type, le) (rate(vcssyncer_clone_duration_seconds_bucket{type=~`${vcsSyncerType:regex}`, success="false"}[1m]))) ```-#### gitserver: gitserver_p99_response_time_per_method +#### gitserver: vcs_syncer_failed_clone_rate -
99th percentile response time per method over 2m
+Rate of failed Clone VCS operations over 1m
-The 99th percentile response time per method, aggregated across all instances. +The rate of failed `Clone` VCS operations. This is the time taken to clone a repository from the upstream source. This panel has no related alerts. -To see this panel, visit `/-/debug/grafana/d/gitserver/gitserver?viewPanel=100720` on your Sourcegraph instance. +To see this panel, visit `/-/debug/grafana/d/gitserver/gitserver?viewPanel=100730` on your Sourcegraph instance. *Managed by the [Sourcegraph Source team](https://handbook.sourcegraph.com/departments/engineering/teams/source).* @@ -43503,21 +44347,23 @@ To see this panel, visit `/-/debug/grafana/d/gitserver/gitserver?viewPanel=10072 Query: ``` -histogram_quantile(0.99, sum by (le, name, grpc_method)(rate(grpc_server_handling_seconds_bucket{grpc_method=~`${gitserver_method:regex}`,instance=~`${shard:regex}`,grpc_service=~"gitserver.v1.GitserverService"}[2m]))) +sum by (type) (rate(vcssyncer_clone_duration_seconds_count{type=~`${vcsSyncerType:regex}`, success="false"}[1m])) ```-#### gitserver: gitserver_p90_response_time_per_method +### Git Server: VCS Fetch metrics -
90th percentile response time per method over 2m
+#### gitserver: vcs_syncer_999_successful_fetch_duration -The 90th percentile response time per method, aggregated across all instances. +99.9th percentile successful Fetch duration over 1m
+ +The 99.9th percentile duration for successful `Fetch` VCS operations. This is the time taken to fetch a repository from the upstream source. This panel has no related alerts. -To see this panel, visit `/-/debug/grafana/d/gitserver/gitserver?viewPanel=100721` on your Sourcegraph instance. +To see this panel, visit `/-/debug/grafana/d/gitserver/gitserver?viewPanel=100800` on your Sourcegraph instance. *Managed by the [Sourcegraph Source team](https://handbook.sourcegraph.com/departments/engineering/teams/source).* @@ -43527,21 +44373,21 @@ To see this panel, visit `/-/debug/grafana/d/gitserver/gitserver?viewPanel=10072 Query: ``` -histogram_quantile(0.90, sum by (le, name, grpc_method)(rate(grpc_server_handling_seconds_bucket{grpc_method=~`${gitserver_method:regex}`,instance=~`${shard:regex}`,grpc_service=~"gitserver.v1.GitserverService"}[2m]))) +histogram_quantile(0.999, sum by (type, le) (rate(vcssyncer_fetch_duration_seconds_bucket{type=~`${vcsSyncerType:regex}`, success="true"}[1m]))) ```-#### gitserver: gitserver_p75_response_time_per_method +#### gitserver: vcs_syncer_99_successful_fetch_duration -
75th percentile response time per method over 2m
+99th percentile successful Fetch duration over 1m
-The 75th percentile response time per method, aggregated across all instances. +The 99th percentile duration for successful `Fetch` VCS operations. This is the time taken to fetch a repository from the upstream source. This panel has no related alerts. -To see this panel, visit `/-/debug/grafana/d/gitserver/gitserver?viewPanel=100722` on your Sourcegraph instance. +To see this panel, visit `/-/debug/grafana/d/gitserver/gitserver?viewPanel=100801` on your Sourcegraph instance. *Managed by the [Sourcegraph Source team](https://handbook.sourcegraph.com/departments/engineering/teams/source).* @@ -43551,21 +44397,21 @@ To see this panel, visit `/-/debug/grafana/d/gitserver/gitserver?viewPanel=10072 Query: ``` -histogram_quantile(0.75, sum by (le, name, grpc_method)(rate(grpc_server_handling_seconds_bucket{grpc_method=~`${gitserver_method:regex}`,instance=~`${shard:regex}`,grpc_service=~"gitserver.v1.GitserverService"}[2m]))) +histogram_quantile(0.99, sum by (type, le) (rate(vcssyncer_fetch_duration_seconds_bucket{type=~`${vcsSyncerType:regex}`, success="true"}[1m]))) ```-#### gitserver: gitserver_p99_9_response_size_per_method +#### gitserver: vcs_syncer_95_successful_fetch_duration -
99.9th percentile total response size per method over 2m
+95th percentile successful Fetch duration over 1m
-The 99.9th percentile total per-RPC response size per method, aggregated across all instances. +The 95th percentile duration for successful `Fetch` VCS operations. This is the time taken to fetch a repository from the upstream source. This panel has no related alerts. -To see this panel, visit `/-/debug/grafana/d/gitserver/gitserver?viewPanel=100730` on your Sourcegraph instance. +To see this panel, visit `/-/debug/grafana/d/gitserver/gitserver?viewPanel=100802` on your Sourcegraph instance. *Managed by the [Sourcegraph Source team](https://handbook.sourcegraph.com/departments/engineering/teams/source).* @@ -43575,21 +44421,21 @@ To see this panel, visit `/-/debug/grafana/d/gitserver/gitserver?viewPanel=10073 Query: ``` -histogram_quantile(0.999, sum by (le, name, grpc_method)(rate(src_grpc_server_sent_bytes_per_rpc_bucket{grpc_method=~`${gitserver_method:regex}`,instance=~`${shard:regex}`,grpc_service=~"gitserver.v1.GitserverService"}[2m]))) +histogram_quantile(0.95, sum by (type, le) (rate(vcssyncer_fetch_duration_seconds_bucket{type=~`${vcsSyncerType:regex}`, success="true"}[1m]))) ```-#### gitserver: gitserver_p90_response_size_per_method +#### gitserver: vcs_syncer_successful_fetch_rate -
90th percentile total response size per method over 2m
+Rate of successful Fetch VCS operations over 1m
-The 90th percentile total per-RPC response size per method, aggregated across all instances. +The rate of successful `Fetch` VCS operations. This is the time taken to fetch a repository from the upstream source. This panel has no related alerts. -To see this panel, visit `/-/debug/grafana/d/gitserver/gitserver?viewPanel=100731` on your Sourcegraph instance. +To see this panel, visit `/-/debug/grafana/d/gitserver/gitserver?viewPanel=100810` on your Sourcegraph instance. *Managed by the [Sourcegraph Source team](https://handbook.sourcegraph.com/departments/engineering/teams/source).* @@ -43599,21 +44445,21 @@ To see this panel, visit `/-/debug/grafana/d/gitserver/gitserver?viewPanel=10073 Query: ``` -histogram_quantile(0.90, sum by (le, name, grpc_method)(rate(src_grpc_server_sent_bytes_per_rpc_bucket{grpc_method=~`${gitserver_method:regex}`,instance=~`${shard:regex}`,grpc_service=~"gitserver.v1.GitserverService"}[2m]))) +sum by (type) (rate(vcssyncer_fetch_duration_seconds_count{type=~`${vcsSyncerType:regex}`, success="true"}[1m])) ```-#### gitserver: gitserver_p75_response_size_per_method +#### gitserver: vcs_syncer_999_failed_fetch_duration -
75th percentile total response size per method over 2m
+99.9th percentile failed Fetch duration over 1m
-The 75th percentile total per-RPC response size per method, aggregated across all instances. +The 99.9th percentile duration for failed `Fetch` VCS operations. This is the time taken to fetch a repository from the upstream source. This panel has no related alerts. -To see this panel, visit `/-/debug/grafana/d/gitserver/gitserver?viewPanel=100732` on your Sourcegraph instance. +To see this panel, visit `/-/debug/grafana/d/gitserver/gitserver?viewPanel=100820` on your Sourcegraph instance. *Managed by the [Sourcegraph Source team](https://handbook.sourcegraph.com/departments/engineering/teams/source).* @@ -43623,21 +44469,21 @@ To see this panel, visit `/-/debug/grafana/d/gitserver/gitserver?viewPanel=10073 Query: ``` -histogram_quantile(0.75, sum by (le, name, grpc_method)(rate(src_grpc_server_sent_bytes_per_rpc_bucket{grpc_method=~`${gitserver_method:regex}`,instance=~`${shard:regex}`,grpc_service=~"gitserver.v1.GitserverService"}[2m]))) +histogram_quantile(0.999, sum by (type, le) (rate(vcssyncer_fetch_duration_seconds_bucket{type=~`${vcsSyncerType:regex}`, success="false"}[1m]))) ```-#### gitserver: gitserver_p99_9_invididual_sent_message_size_per_method +#### gitserver: vcs_syncer_99_failed_fetch_duration -
99.9th percentile individual sent message size per method over 2m
+99th percentile failed Fetch duration over 1m
-The 99.9th percentile size of every individual protocol buffer size sent by the service per method, aggregated across all instances. +The 99th percentile duration for failed `Fetch` VCS operations. This is the time taken to fetch a repository from the upstream source. This panel has no related alerts. -To see this panel, visit `/-/debug/grafana/d/gitserver/gitserver?viewPanel=100740` on your Sourcegraph instance. +To see this panel, visit `/-/debug/grafana/d/gitserver/gitserver?viewPanel=100821` on your Sourcegraph instance. *Managed by the [Sourcegraph Source team](https://handbook.sourcegraph.com/departments/engineering/teams/source).* @@ -43647,21 +44493,21 @@ To see this panel, visit `/-/debug/grafana/d/gitserver/gitserver?viewPanel=10074 Query: ``` -histogram_quantile(0.999, sum by (le, name, grpc_method)(rate(src_grpc_server_sent_individual_message_size_bytes_per_rpc_bucket{grpc_method=~`${gitserver_method:regex}`,instance=~`${shard:regex}`,grpc_service=~"gitserver.v1.GitserverService"}[2m]))) +histogram_quantile(0.99, sum by (type, le) (rate(vcssyncer_fetch_duration_seconds_bucket{type=~`${vcsSyncerType:regex}`, success="false"}[1m]))) ```-#### gitserver: gitserver_p90_invididual_sent_message_size_per_method +#### gitserver: vcs_syncer_95_failed_fetch_duration -
90th percentile individual sent message size per method over 2m
+95th percentile failed Fetch duration over 1m
-The 90th percentile size of every individual protocol buffer size sent by the service per method, aggregated across all instances. +The 95th percentile duration for failed `Fetch` VCS operations. This is the time taken to fetch a repository from the upstream source. This panel has no related alerts. -To see this panel, visit `/-/debug/grafana/d/gitserver/gitserver?viewPanel=100741` on your Sourcegraph instance. +To see this panel, visit `/-/debug/grafana/d/gitserver/gitserver?viewPanel=100822` on your Sourcegraph instance. *Managed by the [Sourcegraph Source team](https://handbook.sourcegraph.com/departments/engineering/teams/source).* @@ -43671,21 +44517,21 @@ To see this panel, visit `/-/debug/grafana/d/gitserver/gitserver?viewPanel=10074 Query: ``` -histogram_quantile(0.90, sum by (le, name, grpc_method)(rate(src_grpc_server_sent_individual_message_size_bytes_per_rpc_bucket{grpc_method=~`${gitserver_method:regex}`,instance=~`${shard:regex}`,grpc_service=~"gitserver.v1.GitserverService"}[2m]))) +histogram_quantile(0.95, sum by (type, le) (rate(vcssyncer_fetch_duration_seconds_bucket{type=~`${vcsSyncerType:regex}`, success="false"}[1m]))) ```-#### gitserver: gitserver_p75_invididual_sent_message_size_per_method +#### gitserver: vcs_syncer_failed_fetch_rate -
75th percentile individual sent message size per method over 2m
+Rate of failed Fetch VCS operations over 1m
-The 75th percentile size of every individual protocol buffer size sent by the service per method, aggregated across all instances. +The rate of failed `Fetch` VCS operations. This is the time taken to fetch a repository from the upstream source. This panel has no related alerts. -To see this panel, visit `/-/debug/grafana/d/gitserver/gitserver?viewPanel=100742` on your Sourcegraph instance. +To see this panel, visit `/-/debug/grafana/d/gitserver/gitserver?viewPanel=100830` on your Sourcegraph instance. *Managed by the [Sourcegraph Source team](https://handbook.sourcegraph.com/departments/engineering/teams/source).* @@ -43695,21 +44541,23 @@ To see this panel, visit `/-/debug/grafana/d/gitserver/gitserver?viewPanel=10074 Query: ``` -histogram_quantile(0.75, sum by (le, name, grpc_method)(rate(src_grpc_server_sent_individual_message_size_bytes_per_rpc_bucket{grpc_method=~`${gitserver_method:regex}`,instance=~`${shard:regex}`,grpc_service=~"gitserver.v1.GitserverService"}[2m]))) +sum by (type) (rate(vcssyncer_fetch_duration_seconds_count{type=~`${vcsSyncerType:regex}`, success="false"}[1m])) ```-#### gitserver: gitserver_grpc_response_stream_message_count_per_method +### Git Server: VCS Is_cloneable metrics -
Average streaming response message count per-method over 2m
+#### gitserver: vcs_syncer_999_successful_is_cloneable_duration -The average number of response messages sent during a streaming RPC method, broken out per method, aggregated across all instances. +99.9th percentile successful Is_cloneable duration over 1m
+ +The 99.9th percentile duration for successful `Is_cloneable` VCS operations. This is the time taken to check to see if a repository is cloneable from the upstream source. This panel has no related alerts. -To see this panel, visit `/-/debug/grafana/d/gitserver/gitserver?viewPanel=100750` on your Sourcegraph instance. +To see this panel, visit `/-/debug/grafana/d/gitserver/gitserver?viewPanel=100900` on your Sourcegraph instance. *Managed by the [Sourcegraph Source team](https://handbook.sourcegraph.com/departments/engineering/teams/source).* @@ -43719,21 +44567,21 @@ To see this panel, visit `/-/debug/grafana/d/gitserver/gitserver?viewPanel=10075 Query: ``` -((sum(rate(grpc_server_msg_sent_total{grpc_type="server_stream",instance=~`${shard:regex}`,grpc_service=~"gitserver.v1.GitserverService"}[2m])) by (grpc_method))/(sum(rate(grpc_server_started_total{grpc_type="server_stream",instance=~`${shard:regex}`,grpc_service=~"gitserver.v1.GitserverService"}[2m])) by (grpc_method))) +histogram_quantile(0.999, sum by (type, le) (rate(vcssyncer_is_cloneable_duration_seconds_bucket{type=~`${vcsSyncerType:regex}`, success="true"}[1m]))) ```-#### gitserver: gitserver_grpc_all_codes_per_method +#### gitserver: vcs_syncer_99_successful_is_cloneable_duration -
Response codes rate per-method over 2m
+99th percentile successful Is_cloneable duration over 1m
-The rate of all generated gRPC response codes per method, aggregated across all instances. +The 99th percentile duration for successful `Is_cloneable` VCS operations. This is the time taken to check to see if a repository is cloneable from the upstream source. This panel has no related alerts. -To see this panel, visit `/-/debug/grafana/d/gitserver/gitserver?viewPanel=100760` on your Sourcegraph instance. +To see this panel, visit `/-/debug/grafana/d/gitserver/gitserver?viewPanel=100901` on your Sourcegraph instance. *Managed by the [Sourcegraph Source team](https://handbook.sourcegraph.com/departments/engineering/teams/source).* @@ -43743,23 +44591,21 @@ To see this panel, visit `/-/debug/grafana/d/gitserver/gitserver?viewPanel=10076 Query: ``` -sum(rate(grpc_server_handled_total{grpc_method=~`${gitserver_method:regex}`,instance=~`${shard:regex}`,grpc_service=~"gitserver.v1.GitserverService"}[2m])) by (grpc_method, grpc_code) +histogram_quantile(0.99, sum by (type, le) (rate(vcssyncer_is_cloneable_duration_seconds_bucket{type=~`${vcsSyncerType:regex}`, success="true"}[1m]))) ```-### Git Server: Gitserver GRPC "internal error" metrics - -#### gitserver: gitserver_grpc_clients_error_percentage_all_methods +#### gitserver: vcs_syncer_95_successful_is_cloneable_duration -
Client baseline error percentage across all methods over 2m
+95th percentile successful Is_cloneable duration over 1m
-The percentage of gRPC requests that fail across all methods (regardless of whether or not there was an internal error), aggregated across all "gitserver" clients. +The 95th percentile duration for successful `Is_cloneable` VCS operations. This is the time taken to check to see if a repository is cloneable from the upstream source. This panel has no related alerts. -To see this panel, visit `/-/debug/grafana/d/gitserver/gitserver?viewPanel=100800` on your Sourcegraph instance. +To see this panel, visit `/-/debug/grafana/d/gitserver/gitserver?viewPanel=100902` on your Sourcegraph instance. *Managed by the [Sourcegraph Source team](https://handbook.sourcegraph.com/departments/engineering/teams/source).* @@ -43769,21 +44615,21 @@ To see this panel, visit `/-/debug/grafana/d/gitserver/gitserver?viewPanel=10080 Query: ``` -(100.0 * ((((sum(rate(src_grpc_method_status{grpc_service=~"gitserver.v1.GitserverService",grpc_code!="OK"}[2m])))) / ((sum(rate(src_grpc_method_status{grpc_service=~"gitserver.v1.GitserverService"}[2m]))))))) +histogram_quantile(0.95, sum by (type, le) (rate(vcssyncer_is_cloneable_duration_seconds_bucket{type=~`${vcsSyncerType:regex}`, success="true"}[1m]))) ```-#### gitserver: gitserver_grpc_clients_error_percentage_per_method +#### gitserver: vcs_syncer_successful_is_cloneable_rate -
Client baseline error percentage per-method over 2m
+Rate of successful Is_cloneable VCS operations over 1m
-The percentage of gRPC requests that fail per method (regardless of whether or not there was an internal error), aggregated across all "gitserver" clients. +The rate of successful `Is_cloneable` VCS operations. This is the time taken to check to see if a repository is cloneable from the upstream source. This panel has no related alerts. -To see this panel, visit `/-/debug/grafana/d/gitserver/gitserver?viewPanel=100801` on your Sourcegraph instance. +To see this panel, visit `/-/debug/grafana/d/gitserver/gitserver?viewPanel=100910` on your Sourcegraph instance. *Managed by the [Sourcegraph Source team](https://handbook.sourcegraph.com/departments/engineering/teams/source).* @@ -43793,21 +44639,21 @@ To see this panel, visit `/-/debug/grafana/d/gitserver/gitserver?viewPanel=10080 Query: ``` -(100.0 * ((((sum(rate(src_grpc_method_status{grpc_service=~"gitserver.v1.GitserverService",grpc_method=~"${gitserver_method:regex}",grpc_code!="OK"}[2m])) by (grpc_method))) / ((sum(rate(src_grpc_method_status{grpc_service=~"gitserver.v1.GitserverService",grpc_method=~"${gitserver_method:regex}"}[2m])) by (grpc_method)))))) +sum by (type) (rate(vcssyncer_is_cloneable_duration_seconds_count{type=~`${vcsSyncerType:regex}`, success="true"}[1m])) ```-#### gitserver: gitserver_grpc_clients_all_codes_per_method +#### gitserver: vcs_syncer_999_failed_is_cloneable_duration -
Client baseline response codes rate per-method over 2m
+99.9th percentile failed Is_cloneable duration over 1m
-The rate of all generated gRPC response codes per method (regardless of whether or not there was an internal error), aggregated across all "gitserver" clients. +The 99.9th percentile duration for failed `Is_cloneable` VCS operations. This is the time taken to check to see if a repository is cloneable from the upstream source. This panel has no related alerts. -To see this panel, visit `/-/debug/grafana/d/gitserver/gitserver?viewPanel=100802` on your Sourcegraph instance. +To see this panel, visit `/-/debug/grafana/d/gitserver/gitserver?viewPanel=100920` on your Sourcegraph instance. *Managed by the [Sourcegraph Source team](https://handbook.sourcegraph.com/departments/engineering/teams/source).* @@ -43817,27 +44663,21 @@ To see this panel, visit `/-/debug/grafana/d/gitserver/gitserver?viewPanel=10080 Query: ``` -(sum(rate(src_grpc_method_status{grpc_service=~"gitserver.v1.GitserverService",grpc_method=~"${gitserver_method:regex}"}[2m])) by (grpc_method, grpc_code)) +histogram_quantile(0.999, sum by (type, le) (rate(vcssyncer_is_cloneable_duration_seconds_bucket{type=~`${vcsSyncerType:regex}`, success="false"}[1m]))) ```-#### gitserver: gitserver_grpc_clients_internal_error_percentage_all_methods - -
Client-observed gRPC internal error percentage across all methods over 2m
- -The percentage of gRPC requests that appear to fail due to gRPC internal errors across all methods, aggregated across all "gitserver" clients. - -**Note**: Internal errors are ones that appear to originate from the https://github.com/grpc/grpc-go library itself, rather than from any user-written application code. These errors can be caused by a variety of issues, and can originate from either the code-generated "gitserver" gRPC client or gRPC server. These errors might be solvable by adjusting the gRPC configuration, or they might indicate a bug from Sourcegraph`s use of gRPC. +#### gitserver: vcs_syncer_99_failed_is_cloneable_duration -When debugging, knowing that a particular error comes from the grpc-go library itself (an `internal error`) as opposed to `normal` application code can be helpful when trying to fix it. +99th percentile failed Is_cloneable duration over 1m
-**Note**: Internal errors are detected via a very coarse heuristic (seeing if the error starts with `grpc:`, etc.). Because of this, it`s possible that some gRPC-specific issues might not be categorized as internal errors. +The 99th percentile duration for failed `Is_cloneable` VCS operations. This is the time taken to check to see if a repository is cloneable from the upstream source. This panel has no related alerts. -To see this panel, visit `/-/debug/grafana/d/gitserver/gitserver?viewPanel=100810` on your Sourcegraph instance. +To see this panel, visit `/-/debug/grafana/d/gitserver/gitserver?viewPanel=100921` on your Sourcegraph instance. *Managed by the [Sourcegraph Source team](https://handbook.sourcegraph.com/departments/engineering/teams/source).* @@ -43847,27 +44687,21 @@ To see this panel, visit `/-/debug/grafana/d/gitserver/gitserver?viewPanel=10081 Query: ``` -(100.0 * ((((sum(rate(src_grpc_method_status{grpc_service=~"gitserver.v1.GitserverService",grpc_code!="OK",is_internal_error="true"}[2m])))) / ((sum(rate(src_grpc_method_status{grpc_service=~"gitserver.v1.GitserverService"}[2m]))))))) +histogram_quantile(0.99, sum by (type, le) (rate(vcssyncer_is_cloneable_duration_seconds_bucket{type=~`${vcsSyncerType:regex}`, success="false"}[1m]))) ```-#### gitserver: gitserver_grpc_clients_internal_error_percentage_per_method - -
Client-observed gRPC internal error percentage per-method over 2m
- -The percentage of gRPC requests that appear to fail to due to gRPC internal errors per method, aggregated across all "gitserver" clients. - -**Note**: Internal errors are ones that appear to originate from the https://github.com/grpc/grpc-go library itself, rather than from any user-written application code. These errors can be caused by a variety of issues, and can originate from either the code-generated "gitserver" gRPC client or gRPC server. These errors might be solvable by adjusting the gRPC configuration, or they might indicate a bug from Sourcegraph`s use of gRPC. +#### gitserver: vcs_syncer_95_failed_is_cloneable_duration -When debugging, knowing that a particular error comes from the grpc-go library itself (an `internal error`) as opposed to `normal` application code can be helpful when trying to fix it. +95th percentile failed Is_cloneable duration over 1m
-**Note**: Internal errors are detected via a very coarse heuristic (seeing if the error starts with `grpc:`, etc.). Because of this, it`s possible that some gRPC-specific issues might not be categorized as internal errors. +The 95th percentile duration for failed `Is_cloneable` VCS operations. This is the time taken to check to see if a repository is cloneable from the upstream source. This panel has no related alerts. -To see this panel, visit `/-/debug/grafana/d/gitserver/gitserver?viewPanel=100811` on your Sourcegraph instance. +To see this panel, visit `/-/debug/grafana/d/gitserver/gitserver?viewPanel=100922` on your Sourcegraph instance. *Managed by the [Sourcegraph Source team](https://handbook.sourcegraph.com/departments/engineering/teams/source).* @@ -43877,27 +44711,21 @@ To see this panel, visit `/-/debug/grafana/d/gitserver/gitserver?viewPanel=10081 Query: ``` -(100.0 * ((((sum(rate(src_grpc_method_status{grpc_service=~"gitserver.v1.GitserverService",grpc_method=~"${gitserver_method:regex}",grpc_code!="OK",is_internal_error="true"}[2m])) by (grpc_method))) / ((sum(rate(src_grpc_method_status{grpc_service=~"gitserver.v1.GitserverService",grpc_method=~"${gitserver_method:regex}"}[2m])) by (grpc_method)))))) +histogram_quantile(0.95, sum by (type, le) (rate(vcssyncer_is_cloneable_duration_seconds_bucket{type=~`${vcsSyncerType:regex}`, success="false"}[1m]))) ```-#### gitserver: gitserver_grpc_clients_internal_error_all_codes_per_method - -
Client-observed gRPC internal error response code rate per-method over 2m
- -The rate of gRPC internal-error response codes per method, aggregated across all "gitserver" clients. - -**Note**: Internal errors are ones that appear to originate from the https://github.com/grpc/grpc-go library itself, rather than from any user-written application code. These errors can be caused by a variety of issues, and can originate from either the code-generated "gitserver" gRPC client or gRPC server. These errors might be solvable by adjusting the gRPC configuration, or they might indicate a bug from Sourcegraph`s use of gRPC. +#### gitserver: vcs_syncer_failed_is_cloneable_rate -When debugging, knowing that a particular error comes from the grpc-go library itself (an `internal error`) as opposed to `normal` application code can be helpful when trying to fix it. +Rate of failed Is_cloneable VCS operations over 1m
-**Note**: Internal errors are detected via a very coarse heuristic (seeing if the error starts with `grpc:`, etc.). Because of this, it`s possible that some gRPC-specific issues might not be categorized as internal errors. +The rate of failed `Is_cloneable` VCS operations. This is the time taken to check to see if a repository is cloneable from the upstream source. This panel has no related alerts. -To see this panel, visit `/-/debug/grafana/d/gitserver/gitserver?viewPanel=100812` on your Sourcegraph instance. +To see this panel, visit `/-/debug/grafana/d/gitserver/gitserver?viewPanel=100930` on your Sourcegraph instance. *Managed by the [Sourcegraph Source team](https://handbook.sourcegraph.com/departments/engineering/teams/source).* @@ -43907,23 +44735,23 @@ To see this panel, visit `/-/debug/grafana/d/gitserver/gitserver?viewPanel=10081 Query: ``` -(sum(rate(src_grpc_method_status{grpc_service=~"gitserver.v1.GitserverService",is_internal_error="true",grpc_method=~"${gitserver_method:regex}"}[2m])) by (grpc_method, grpc_code)) +sum by (type) (rate(vcssyncer_is_cloneable_duration_seconds_count{type=~`${vcsSyncerType:regex}`, success="false"}[1m])) ```-### Git Server: Gitserver GRPC retry metrics +### Git Server: Gitserver: Gitserver Backend -#### gitserver: gitserver_grpc_clients_retry_percentage_across_all_methods +#### gitserver: concurrent_backend_operations -
Client retry percentage across all methods over 2m
+Number of concurrently running backend operations
-The percentage of gRPC requests that were retried across all methods, aggregated across all "gitserver" clients. +The number of requests that are currently being handled by gitserver backend layer, at the point in time of scraping. This panel has no related alerts. -To see this panel, visit `/-/debug/grafana/d/gitserver/gitserver?viewPanel=100900` on your Sourcegraph instance. +To see this panel, visit `/-/debug/grafana/d/gitserver/gitserver?viewPanel=101000` on your Sourcegraph instance. *Managed by the [Sourcegraph Source team](https://handbook.sourcegraph.com/departments/engineering/teams/source).* @@ -43933,21 +44761,19 @@ To see this panel, visit `/-/debug/grafana/d/gitserver/gitserver?viewPanel=10090 Query: ``` -(100.0 * ((((sum(rate(src_grpc_client_retry_attempts_total{grpc_service=~"gitserver.v1.GitserverService",is_retried="true"}[2m])))) / ((sum(rate(src_grpc_client_retry_attempts_total{grpc_service=~"gitserver.v1.GitserverService"}[2m]))))))) +src_gitserver_backend_concurrent_operations ```-#### gitserver: gitserver_grpc_clients_retry_percentage_per_method - -
Client retry percentage per-method over 2m
+#### gitserver: gitserver_backend_total -The percentage of gRPC requests that were retried aggregated across all "gitserver" clients, broken out per method. +Aggregate operations every 5m
This panel has no related alerts. -To see this panel, visit `/-/debug/grafana/d/gitserver/gitserver?viewPanel=100901` on your Sourcegraph instance. +To see this panel, visit `/-/debug/grafana/d/gitserver/gitserver?viewPanel=101010` on your Sourcegraph instance. *Managed by the [Sourcegraph Source team](https://handbook.sourcegraph.com/departments/engineering/teams/source).* @@ -43957,21 +44783,19 @@ To see this panel, visit `/-/debug/grafana/d/gitserver/gitserver?viewPanel=10090 Query: ``` -(100.0 * ((((sum(rate(src_grpc_client_retry_attempts_total{grpc_service=~"gitserver.v1.GitserverService",is_retried="true",grpc_method=~"${gitserver_method:regex}"}[2m])) by (grpc_method))) / ((sum(rate(src_grpc_client_retry_attempts_total{grpc_service=~"gitserver.v1.GitserverService",grpc_method=~"${gitserver_method:regex}"}[2m])) by (grpc_method)))))) +sum(increase(src_gitserver_backend_total{job=~"^gitserver.*"}[5m])) ```-#### gitserver: gitserver_grpc_clients_retry_count_per_method - -
Client retry count per-method over 2m
+#### gitserver: gitserver_backend_99th_percentile_duration -The count of gRPC requests that were retried aggregated across all "gitserver" clients, broken out per method +Aggregate successful operation duration distribution over 5m
This panel has no related alerts. -To see this panel, visit `/-/debug/grafana/d/gitserver/gitserver?viewPanel=100902` on your Sourcegraph instance. +To see this panel, visit `/-/debug/grafana/d/gitserver/gitserver?viewPanel=101011` on your Sourcegraph instance. *Managed by the [Sourcegraph Source team](https://handbook.sourcegraph.com/departments/engineering/teams/source).* @@ -43981,25 +44805,21 @@ To see this panel, visit `/-/debug/grafana/d/gitserver/gitserver?viewPanel=10090 Query: ``` -(sum(rate(src_grpc_client_retry_attempts_total{grpc_service=~"gitserver.v1.GitserverService",grpc_method=~"${gitserver_method:regex}",is_retried="true"}[2m])) by (grpc_method)) +sum by (le)(rate(src_gitserver_backend_duration_seconds_bucket{job=~"^gitserver.*"}[5m])) ```-### Git Server: Site configuration client update latency - -#### gitserver: gitserver_site_configuration_duration_since_last_successful_update_by_instance - -
Duration since last successful site configuration update (by instance)
+#### gitserver: gitserver_backend_errors_total -The duration since the configuration client used by the "gitserver" service last successfully updated its site configuration. Long durations could indicate issues updating the site configuration. +Aggregate operation errors every 5m
This panel has no related alerts. -To see this panel, visit `/-/debug/grafana/d/gitserver/gitserver?viewPanel=101000` on your Sourcegraph instance. +To see this panel, visit `/-/debug/grafana/d/gitserver/gitserver?viewPanel=101012` on your Sourcegraph instance. -*Managed by the [Sourcegraph Infrastructure Org team](https://handbook.sourcegraph.com/departments/engineering/infrastructure).* +*Managed by the [Sourcegraph Source team](https://handbook.sourcegraph.com/departments/engineering/teams/source).*Technical details
@@ -44007,21 +44827,21 @@ To see this panel, visit `/-/debug/grafana/d/gitserver/gitserver?viewPanel=10100 Query: ``` -src_conf_client_time_since_last_successful_update_seconds{job=~`.*gitserver`,instance=~`${shard:regex}`} +sum(increase(src_gitserver_backend_errors_total{job=~"^gitserver.*"}[5m])) ```-#### gitserver: gitserver_site_configuration_duration_since_last_successful_update_by_instance +#### gitserver: gitserver_backend_error_rate -
Maximum duration since last successful site configuration update (all "gitserver" instances)
+Aggregate operation error rate over 5m
-Refer to the [alerts reference](alerts#gitserver-gitserver-site-configuration-duration-since-last-successful-update-by-instance) for 1 alert related to this panel. +This panel has no related alerts. -To see this panel, visit `/-/debug/grafana/d/gitserver/gitserver?viewPanel=101001` on your Sourcegraph instance. +To see this panel, visit `/-/debug/grafana/d/gitserver/gitserver?viewPanel=101013` on your Sourcegraph instance. -*Managed by the [Sourcegraph Infrastructure Org team](https://handbook.sourcegraph.com/departments/engineering/infrastructure).* +*Managed by the [Sourcegraph Source team](https://handbook.sourcegraph.com/departments/engineering/teams/source).*Technical details
@@ -44029,23 +44849,21 @@ To see this panel, visit `/-/debug/grafana/d/gitserver/gitserver?viewPanel=10100 Query: ``` -max(max_over_time(src_conf_client_time_since_last_successful_update_seconds{job=~`.*gitserver`,instance=~`${shard:regex}`}[1m])) +sum(increase(src_gitserver_backend_errors_total{job=~"^gitserver.*"}[5m])) / (sum(increase(src_gitserver_backend_total{job=~"^gitserver.*"}[5m])) + sum(increase(src_gitserver_backend_errors_total{job=~"^gitserver.*"}[5m]))) * 100 ```-### Git Server: Codeintel: Coursier invocation stats - -#### gitserver: codeintel_coursier_total +#### gitserver: gitserver_backend_total -
Aggregate invocations operations every 5m
+operations every 5m
This panel has no related alerts. -To see this panel, visit `/-/debug/grafana/d/gitserver/gitserver?viewPanel=101100` on your Sourcegraph instance. +To see this panel, visit `/-/debug/grafana/d/gitserver/gitserver?viewPanel=101020` on your Sourcegraph instance. -*Managed by the [Sourcegraph Code intelligence team](https://handbook.sourcegraph.com/departments/engineering/teams/code-intelligence).* +*Managed by the [Sourcegraph Source team](https://handbook.sourcegraph.com/departments/engineering/teams/source).*Technical details
@@ -44053,21 +44871,21 @@ To see this panel, visit `/-/debug/grafana/d/gitserver/gitserver?viewPanel=10110 Query: ``` -sum(increase(src_codeintel_coursier_total{op!="RunCommand",job=~"^gitserver.*"}[5m])) +sum by (op)(increase(src_gitserver_backend_total{job=~"^gitserver.*"}[5m])) ```-#### gitserver: codeintel_coursier_99th_percentile_duration +#### gitserver: gitserver_backend_99th_percentile_duration -
Aggregate successful invocations operation duration distribution over 5m
+99th percentile successful operation duration over 5m
This panel has no related alerts. -To see this panel, visit `/-/debug/grafana/d/gitserver/gitserver?viewPanel=101101` on your Sourcegraph instance. +To see this panel, visit `/-/debug/grafana/d/gitserver/gitserver?viewPanel=101021` on your Sourcegraph instance. -*Managed by the [Sourcegraph Code intelligence team](https://handbook.sourcegraph.com/departments/engineering/teams/code-intelligence).* +*Managed by the [Sourcegraph Source team](https://handbook.sourcegraph.com/departments/engineering/teams/source).*Technical details
@@ -44075,21 +44893,21 @@ To see this panel, visit `/-/debug/grafana/d/gitserver/gitserver?viewPanel=10110 Query: ``` -sum by (le)(rate(src_codeintel_coursier_duration_seconds_bucket{op!="RunCommand",job=~"^gitserver.*"}[5m])) +histogram_quantile(0.99, sum by (le,op)(rate(src_gitserver_backend_duration_seconds_bucket{job=~"^gitserver.*"}[5m]))) ```-#### gitserver: codeintel_coursier_errors_total +#### gitserver: gitserver_backend_errors_total -
Aggregate invocations operation errors every 5m
+operation errors every 5m
This panel has no related alerts. -To see this panel, visit `/-/debug/grafana/d/gitserver/gitserver?viewPanel=101102` on your Sourcegraph instance. +To see this panel, visit `/-/debug/grafana/d/gitserver/gitserver?viewPanel=101022` on your Sourcegraph instance. -*Managed by the [Sourcegraph Code intelligence team](https://handbook.sourcegraph.com/departments/engineering/teams/code-intelligence).* +*Managed by the [Sourcegraph Source team](https://handbook.sourcegraph.com/departments/engineering/teams/source).*Technical details
@@ -44097,21 +44915,21 @@ To see this panel, visit `/-/debug/grafana/d/gitserver/gitserver?viewPanel=10110 Query: ``` -sum(increase(src_codeintel_coursier_errors_total{op!="RunCommand",job=~"^gitserver.*"}[5m])) +sum by (op)(increase(src_gitserver_backend_errors_total{job=~"^gitserver.*"}[5m])) ```-#### gitserver: codeintel_coursier_error_rate +#### gitserver: gitserver_backend_error_rate -
Aggregate invocations operation error rate over 5m
+operation error rate over 5m
This panel has no related alerts. -To see this panel, visit `/-/debug/grafana/d/gitserver/gitserver?viewPanel=101103` on your Sourcegraph instance. +To see this panel, visit `/-/debug/grafana/d/gitserver/gitserver?viewPanel=101023` on your Sourcegraph instance. -*Managed by the [Sourcegraph Code intelligence team](https://handbook.sourcegraph.com/departments/engineering/teams/code-intelligence).* +*Managed by the [Sourcegraph Source team](https://handbook.sourcegraph.com/departments/engineering/teams/source).*Technical details
@@ -44119,21 +44937,23 @@ To see this panel, visit `/-/debug/grafana/d/gitserver/gitserver?viewPanel=10110 Query: ``` -sum(increase(src_codeintel_coursier_errors_total{op!="RunCommand",job=~"^gitserver.*"}[5m])) / (sum(increase(src_codeintel_coursier_total{op!="RunCommand",job=~"^gitserver.*"}[5m])) + sum(increase(src_codeintel_coursier_errors_total{op!="RunCommand",job=~"^gitserver.*"}[5m]))) * 100 +sum by (op)(increase(src_gitserver_backend_errors_total{job=~"^gitserver.*"}[5m])) / (sum by (op)(increase(src_gitserver_backend_total{job=~"^gitserver.*"}[5m])) + sum by (op)(increase(src_gitserver_backend_errors_total{job=~"^gitserver.*"}[5m]))) * 100 ```-#### gitserver: codeintel_coursier_total +### Git Server: Gitserver: Gitserver Client + +#### gitserver: gitserver_client_total -
Invocations operations every 5m
+Aggregate client operations every 5m
This panel has no related alerts. -To see this panel, visit `/-/debug/grafana/d/gitserver/gitserver?viewPanel=101110` on your Sourcegraph instance. +To see this panel, visit `/-/debug/grafana/d/gitserver/gitserver?viewPanel=101100` on your Sourcegraph instance. -*Managed by the [Sourcegraph Code intelligence team](https://handbook.sourcegraph.com/departments/engineering/teams/code-intelligence).* +*Managed by the [Sourcegraph Source team](https://handbook.sourcegraph.com/departments/engineering/teams/source).*Technical details
@@ -44141,21 +44961,21 @@ To see this panel, visit `/-/debug/grafana/d/gitserver/gitserver?viewPanel=10111 Query: ``` -sum by (op)(increase(src_codeintel_coursier_total{op!="RunCommand",job=~"^gitserver.*"}[5m])) +sum(increase(src_gitserver_client_total{job=~"^*.*"}[5m])) ```-#### gitserver: codeintel_coursier_99th_percentile_duration +#### gitserver: gitserver_client_99th_percentile_duration -
99th percentile successful invocations operation duration over 5m
+Aggregate successful client operation duration distribution over 5m
This panel has no related alerts. -To see this panel, visit `/-/debug/grafana/d/gitserver/gitserver?viewPanel=101111` on your Sourcegraph instance. +To see this panel, visit `/-/debug/grafana/d/gitserver/gitserver?viewPanel=101101` on your Sourcegraph instance. -*Managed by the [Sourcegraph Code intelligence team](https://handbook.sourcegraph.com/departments/engineering/teams/code-intelligence).* +*Managed by the [Sourcegraph Source team](https://handbook.sourcegraph.com/departments/engineering/teams/source).*Technical details
@@ -44163,21 +44983,21 @@ To see this panel, visit `/-/debug/grafana/d/gitserver/gitserver?viewPanel=10111 Query: ``` -histogram_quantile(0.99, sum by (le,op)(rate(src_codeintel_coursier_duration_seconds_bucket{op!="RunCommand",job=~"^gitserver.*"}[5m]))) +sum by (le)(rate(src_gitserver_client_duration_seconds_bucket{job=~"^*.*"}[5m])) ```-#### gitserver: codeintel_coursier_errors_total +#### gitserver: gitserver_client_errors_total -
Invocations operation errors every 5m
+Aggregate client operation errors every 5m
This panel has no related alerts. -To see this panel, visit `/-/debug/grafana/d/gitserver/gitserver?viewPanel=101112` on your Sourcegraph instance. +To see this panel, visit `/-/debug/grafana/d/gitserver/gitserver?viewPanel=101102` on your Sourcegraph instance. -*Managed by the [Sourcegraph Code intelligence team](https://handbook.sourcegraph.com/departments/engineering/teams/code-intelligence).* +*Managed by the [Sourcegraph Source team](https://handbook.sourcegraph.com/departments/engineering/teams/source).*Technical details
@@ -44185,21 +45005,21 @@ To see this panel, visit `/-/debug/grafana/d/gitserver/gitserver?viewPanel=10111 Query: ``` -sum by (op)(increase(src_codeintel_coursier_errors_total{op!="RunCommand",job=~"^gitserver.*"}[5m])) +sum(increase(src_gitserver_client_errors_total{job=~"^*.*"}[5m])) ```-#### gitserver: codeintel_coursier_error_rate +#### gitserver: gitserver_client_error_rate -
Invocations operation error rate over 5m
+Aggregate client operation error rate over 5m
This panel has no related alerts. -To see this panel, visit `/-/debug/grafana/d/gitserver/gitserver?viewPanel=101113` on your Sourcegraph instance. +To see this panel, visit `/-/debug/grafana/d/gitserver/gitserver?viewPanel=101103` on your Sourcegraph instance. -*Managed by the [Sourcegraph Code intelligence team](https://handbook.sourcegraph.com/departments/engineering/teams/code-intelligence).* +*Managed by the [Sourcegraph Source team](https://handbook.sourcegraph.com/departments/engineering/teams/source).*Technical details
@@ -44207,23 +45027,21 @@ To see this panel, visit `/-/debug/grafana/d/gitserver/gitserver?viewPanel=10111 Query: ``` -sum by (op)(increase(src_codeintel_coursier_errors_total{op!="RunCommand",job=~"^gitserver.*"}[5m])) / (sum by (op)(increase(src_codeintel_coursier_total{op!="RunCommand",job=~"^gitserver.*"}[5m])) + sum by (op)(increase(src_codeintel_coursier_errors_total{op!="RunCommand",job=~"^gitserver.*"}[5m]))) * 100 +sum(increase(src_gitserver_client_errors_total{job=~"^*.*"}[5m])) / (sum(increase(src_gitserver_client_total{job=~"^*.*"}[5m])) + sum(increase(src_gitserver_client_errors_total{job=~"^*.*"}[5m]))) * 100 ```-### Git Server: Codeintel: npm invocation stats - -#### gitserver: codeintel_npm_total +#### gitserver: gitserver_client_total -
Aggregate invocations operations every 5m
+Client operations every 5m
This panel has no related alerts. -To see this panel, visit `/-/debug/grafana/d/gitserver/gitserver?viewPanel=101200` on your Sourcegraph instance. +To see this panel, visit `/-/debug/grafana/d/gitserver/gitserver?viewPanel=101110` on your Sourcegraph instance. -*Managed by the [Sourcegraph Code intelligence team](https://handbook.sourcegraph.com/departments/engineering/teams/code-intelligence).* +*Managed by the [Sourcegraph Source team](https://handbook.sourcegraph.com/departments/engineering/teams/source).*Technical details
@@ -44231,21 +45049,21 @@ To see this panel, visit `/-/debug/grafana/d/gitserver/gitserver?viewPanel=10120 Query: ``` -sum(increase(src_codeintel_npm_total{op!="RunCommand",job=~"^gitserver.*"}[5m])) +sum by (op,scope)(increase(src_gitserver_client_total{job=~"^*.*"}[5m])) ```-#### gitserver: codeintel_npm_99th_percentile_duration +#### gitserver: gitserver_client_99th_percentile_duration -
Aggregate successful invocations operation duration distribution over 5m
+99th percentile successful client operation duration over 5m
This panel has no related alerts. -To see this panel, visit `/-/debug/grafana/d/gitserver/gitserver?viewPanel=101201` on your Sourcegraph instance. +To see this panel, visit `/-/debug/grafana/d/gitserver/gitserver?viewPanel=101111` on your Sourcegraph instance. -*Managed by the [Sourcegraph Code intelligence team](https://handbook.sourcegraph.com/departments/engineering/teams/code-intelligence).* +*Managed by the [Sourcegraph Source team](https://handbook.sourcegraph.com/departments/engineering/teams/source).*Technical details
@@ -44253,21 +45071,21 @@ To see this panel, visit `/-/debug/grafana/d/gitserver/gitserver?viewPanel=10120 Query: ``` -sum by (le)(rate(src_codeintel_npm_duration_seconds_bucket{op!="RunCommand",job=~"^gitserver.*"}[5m])) +histogram_quantile(0.99, sum by (le,op,scope)(rate(src_gitserver_client_duration_seconds_bucket{job=~"^*.*"}[5m]))) ```-#### gitserver: codeintel_npm_errors_total +#### gitserver: gitserver_client_errors_total -
Aggregate invocations operation errors every 5m
+Client operation errors every 5m
This panel has no related alerts. -To see this panel, visit `/-/debug/grafana/d/gitserver/gitserver?viewPanel=101202` on your Sourcegraph instance. +To see this panel, visit `/-/debug/grafana/d/gitserver/gitserver?viewPanel=101112` on your Sourcegraph instance. -*Managed by the [Sourcegraph Code intelligence team](https://handbook.sourcegraph.com/departments/engineering/teams/code-intelligence).* +*Managed by the [Sourcegraph Source team](https://handbook.sourcegraph.com/departments/engineering/teams/source).*Technical details
@@ -44275,21 +45093,21 @@ To see this panel, visit `/-/debug/grafana/d/gitserver/gitserver?viewPanel=10120 Query: ``` -sum(increase(src_codeintel_npm_errors_total{op!="RunCommand",job=~"^gitserver.*"}[5m])) +sum by (op,scope)(increase(src_gitserver_client_errors_total{job=~"^*.*"}[5m])) ```-#### gitserver: codeintel_npm_error_rate +#### gitserver: gitserver_client_error_rate -
Aggregate invocations operation error rate over 5m
+Client operation error rate over 5m
This panel has no related alerts. -To see this panel, visit `/-/debug/grafana/d/gitserver/gitserver?viewPanel=101203` on your Sourcegraph instance. +To see this panel, visit `/-/debug/grafana/d/gitserver/gitserver?viewPanel=101113` on your Sourcegraph instance. -*Managed by the [Sourcegraph Code intelligence team](https://handbook.sourcegraph.com/departments/engineering/teams/code-intelligence).* +*Managed by the [Sourcegraph Source team](https://handbook.sourcegraph.com/departments/engineering/teams/source).*Technical details
@@ -44297,21 +45115,23 @@ To see this panel, visit `/-/debug/grafana/d/gitserver/gitserver?viewPanel=10120 Query: ``` -sum(increase(src_codeintel_npm_errors_total{op!="RunCommand",job=~"^gitserver.*"}[5m])) / (sum(increase(src_codeintel_npm_total{op!="RunCommand",job=~"^gitserver.*"}[5m])) + sum(increase(src_codeintel_npm_errors_total{op!="RunCommand",job=~"^gitserver.*"}[5m]))) * 100 +sum by (op,scope)(increase(src_gitserver_client_errors_total{job=~"^*.*"}[5m])) / (sum by (op,scope)(increase(src_gitserver_client_total{job=~"^*.*"}[5m])) + sum by (op,scope)(increase(src_gitserver_client_errors_total{job=~"^*.*"}[5m]))) * 100 ```-#### gitserver: codeintel_npm_total +### Git Server: Gitserver: Gitserver Repository Service Client -
Invocations operations every 5m
+#### gitserver: gitserver_repositoryservice_client_total + +Aggregate client operations every 5m
This panel has no related alerts. -To see this panel, visit `/-/debug/grafana/d/gitserver/gitserver?viewPanel=101210` on your Sourcegraph instance. +To see this panel, visit `/-/debug/grafana/d/gitserver/gitserver?viewPanel=101200` on your Sourcegraph instance. -*Managed by the [Sourcegraph Code intelligence team](https://handbook.sourcegraph.com/departments/engineering/teams/code-intelligence).* +*Managed by the [Sourcegraph Source team](https://handbook.sourcegraph.com/departments/engineering/teams/source).*Technical details
@@ -44319,21 +45139,21 @@ To see this panel, visit `/-/debug/grafana/d/gitserver/gitserver?viewPanel=10121 Query: ``` -sum by (op)(increase(src_codeintel_npm_total{op!="RunCommand",job=~"^gitserver.*"}[5m])) +sum(increase(src_gitserver_repositoryservice_client_total{job=~"^*.*"}[5m])) ```-#### gitserver: codeintel_npm_99th_percentile_duration +#### gitserver: gitserver_repositoryservice_client_99th_percentile_duration -
99th percentile successful invocations operation duration over 5m
+Aggregate successful client operation duration distribution over 5m
This panel has no related alerts. -To see this panel, visit `/-/debug/grafana/d/gitserver/gitserver?viewPanel=101211` on your Sourcegraph instance. +To see this panel, visit `/-/debug/grafana/d/gitserver/gitserver?viewPanel=101201` on your Sourcegraph instance. -*Managed by the [Sourcegraph Code intelligence team](https://handbook.sourcegraph.com/departments/engineering/teams/code-intelligence).* +*Managed by the [Sourcegraph Source team](https://handbook.sourcegraph.com/departments/engineering/teams/source).*Technical details
@@ -44341,21 +45161,21 @@ To see this panel, visit `/-/debug/grafana/d/gitserver/gitserver?viewPanel=10121 Query: ``` -histogram_quantile(0.99, sum by (le,op)(rate(src_codeintel_npm_duration_seconds_bucket{op!="RunCommand",job=~"^gitserver.*"}[5m]))) +sum by (le)(rate(src_gitserver_repositoryservice_client_duration_seconds_bucket{job=~"^*.*"}[5m])) ```-#### gitserver: codeintel_npm_errors_total +#### gitserver: gitserver_repositoryservice_client_errors_total -
Invocations operation errors every 5m
+Aggregate client operation errors every 5m
This panel has no related alerts. -To see this panel, visit `/-/debug/grafana/d/gitserver/gitserver?viewPanel=101212` on your Sourcegraph instance. +To see this panel, visit `/-/debug/grafana/d/gitserver/gitserver?viewPanel=101202` on your Sourcegraph instance. -*Managed by the [Sourcegraph Code intelligence team](https://handbook.sourcegraph.com/departments/engineering/teams/code-intelligence).* +*Managed by the [Sourcegraph Source team](https://handbook.sourcegraph.com/departments/engineering/teams/source).*Technical details
@@ -44363,21 +45183,21 @@ To see this panel, visit `/-/debug/grafana/d/gitserver/gitserver?viewPanel=10121 Query: ``` -sum by (op)(increase(src_codeintel_npm_errors_total{op!="RunCommand",job=~"^gitserver.*"}[5m])) +sum(increase(src_gitserver_repositoryservice_client_errors_total{job=~"^*.*"}[5m])) ```-#### gitserver: codeintel_npm_error_rate +#### gitserver: gitserver_repositoryservice_client_error_rate -
Invocations operation error rate over 5m
+Aggregate client operation error rate over 5m
This panel has no related alerts. -To see this panel, visit `/-/debug/grafana/d/gitserver/gitserver?viewPanel=101213` on your Sourcegraph instance. +To see this panel, visit `/-/debug/grafana/d/gitserver/gitserver?viewPanel=101203` on your Sourcegraph instance. -*Managed by the [Sourcegraph Code intelligence team](https://handbook.sourcegraph.com/departments/engineering/teams/code-intelligence).* +*Managed by the [Sourcegraph Source team](https://handbook.sourcegraph.com/departments/engineering/teams/source).*Technical details
@@ -44385,23 +45205,19 @@ To see this panel, visit `/-/debug/grafana/d/gitserver/gitserver?viewPanel=10121 Query: ``` -sum by (op)(increase(src_codeintel_npm_errors_total{op!="RunCommand",job=~"^gitserver.*"}[5m])) / (sum by (op)(increase(src_codeintel_npm_total{op!="RunCommand",job=~"^gitserver.*"}[5m])) + sum by (op)(increase(src_codeintel_npm_errors_total{op!="RunCommand",job=~"^gitserver.*"}[5m]))) * 100 +sum(increase(src_gitserver_repositoryservice_client_errors_total{job=~"^*.*"}[5m])) / (sum(increase(src_gitserver_repositoryservice_client_total{job=~"^*.*"}[5m])) + sum(increase(src_gitserver_repositoryservice_client_errors_total{job=~"^*.*"}[5m]))) * 100 ```-### Git Server: HTTP handlers - -#### gitserver: healthy_request_rate - -
Requests per second, by route, when status code is 200
+#### gitserver: gitserver_repositoryservice_client_total -The number of healthy HTTP requests per second to internal HTTP api +Client operations every 5m
This panel has no related alerts. -To see this panel, visit `/-/debug/grafana/d/gitserver/gitserver?viewPanel=101300` on your Sourcegraph instance. +To see this panel, visit `/-/debug/grafana/d/gitserver/gitserver?viewPanel=101210` on your Sourcegraph instance. *Managed by the [Sourcegraph Source team](https://handbook.sourcegraph.com/departments/engineering/teams/source).* @@ -44411,21 +45227,19 @@ To see this panel, visit `/-/debug/grafana/d/gitserver/gitserver?viewPanel=10130 Query: ``` -sum by (route) (rate(src_http_request_duration_seconds_count{app="gitserver",code=~"2.."}[5m])) +sum by (op,scope)(increase(src_gitserver_repositoryservice_client_total{job=~"^*.*"}[5m])) ```-#### gitserver: unhealthy_request_rate - -
Requests per second, by route, when status code is not 200
+#### gitserver: gitserver_repositoryservice_client_99th_percentile_duration -The number of unhealthy HTTP requests per second to internal HTTP api +99th percentile successful client operation duration over 5m
This panel has no related alerts. -To see this panel, visit `/-/debug/grafana/d/gitserver/gitserver?viewPanel=101301` on your Sourcegraph instance. +To see this panel, visit `/-/debug/grafana/d/gitserver/gitserver?viewPanel=101211` on your Sourcegraph instance. *Managed by the [Sourcegraph Source team](https://handbook.sourcegraph.com/departments/engineering/teams/source).* @@ -44435,21 +45249,19 @@ To see this panel, visit `/-/debug/grafana/d/gitserver/gitserver?viewPanel=10130 Query: ``` -sum by (route) (rate(src_http_request_duration_seconds_count{app="gitserver",code!~"2.."}[5m])) +histogram_quantile(0.99, sum by (le,op,scope)(rate(src_gitserver_repositoryservice_client_duration_seconds_bucket{job=~"^*.*"}[5m]))) ```-#### gitserver: request_rate_by_code - -
Requests per second, by status code
+#### gitserver: gitserver_repositoryservice_client_errors_total -The number of HTTP requests per second by code +Client operation errors every 5m
This panel has no related alerts. -To see this panel, visit `/-/debug/grafana/d/gitserver/gitserver?viewPanel=101302` on your Sourcegraph instance. +To see this panel, visit `/-/debug/grafana/d/gitserver/gitserver?viewPanel=101212` on your Sourcegraph instance. *Managed by the [Sourcegraph Source team](https://handbook.sourcegraph.com/departments/engineering/teams/source).* @@ -44459,21 +45271,19 @@ To see this panel, visit `/-/debug/grafana/d/gitserver/gitserver?viewPanel=10130 Query: ``` -sum by (code) (rate(src_http_request_duration_seconds_count{app="gitserver"}[5m])) +sum by (op,scope)(increase(src_gitserver_repositoryservice_client_errors_total{job=~"^*.*"}[5m])) ```-#### gitserver: 95th_percentile_healthy_requests - -
95th percentile duration by route, when status code is 200
+#### gitserver: gitserver_repositoryservice_client_error_rate -The 95th percentile duration by route when the status code is 200 +Client operation error rate over 5m
This panel has no related alerts. -To see this panel, visit `/-/debug/grafana/d/gitserver/gitserver?viewPanel=101310` on your Sourcegraph instance. +To see this panel, visit `/-/debug/grafana/d/gitserver/gitserver?viewPanel=101213` on your Sourcegraph instance. *Managed by the [Sourcegraph Source team](https://handbook.sourcegraph.com/departments/engineering/teams/source).* @@ -44483,21 +45293,25 @@ To see this panel, visit `/-/debug/grafana/d/gitserver/gitserver?viewPanel=10131 Query: ``` -histogram_quantile(0.95, sum(rate(src_http_request_duration_seconds_bucket{app="gitserver",code=~"2.."}[5m])) by (le, route)) +sum by (op,scope)(increase(src_gitserver_repositoryservice_client_errors_total{job=~"^*.*"}[5m])) / (sum by (op,scope)(increase(src_gitserver_repositoryservice_client_total{job=~"^*.*"}[5m])) + sum by (op,scope)(increase(src_gitserver_repositoryservice_client_errors_total{job=~"^*.*"}[5m]))) * 100 ```-#### gitserver: 95th_percentile_unhealthy_requests +### Git Server: Repos disk I/O metrics -
95th percentile duration by route, when status code is not 200
+#### gitserver: repos_disk_reads_sec -The 95th percentile duration by route when the status code is not 200 +Read request rate over 1m (per instance)
+ +The number of read requests that were issued to the device per second. + +Note: Disk statistics are per _device_, not per _service_. In certain environments (such as common docker-compose setups), gitserver could be one of _many services_ using this disk. These statistics are best interpreted as the load experienced by the device gitserver is using, not the load gitserver is solely responsible for causing. This panel has no related alerts. -To see this panel, visit `/-/debug/grafana/d/gitserver/gitserver?viewPanel=101311` on your Sourcegraph instance. +To see this panel, visit `/-/debug/grafana/d/gitserver/gitserver?viewPanel=101300` on your Sourcegraph instance. *Managed by the [Sourcegraph Source team](https://handbook.sourcegraph.com/departments/engineering/teams/source).* @@ -44507,21 +45321,23 @@ To see this panel, visit `/-/debug/grafana/d/gitserver/gitserver?viewPanel=10131 Query: ``` -histogram_quantile(0.95, sum(rate(src_http_request_duration_seconds_bucket{app="gitserver",code!~"2.."}[5m])) by (le, route)) +(max by (instance) (gitserver_mount_point_info{mount_name="reposDir",instance=~`${shard:regex}`} * on (device, nodename) group_left() (max by (device, nodename) (rate(node_disk_reads_completed_total{instance=~`node-exporter.*`}[1m]))))) ```-### Git Server: Database connections +#### gitserver: repos_disk_writes_sec -#### gitserver: max_open_conns +
Write request rate over 1m (per instance)
-Maximum open
+The number of write requests that were issued to the device per second. + +Note: Disk statistics are per _device_, not per _service_. In certain environments (such as common docker-compose setups), gitserver could be one of _many services_ using this disk. These statistics are best interpreted as the load experienced by the device gitserver is using, not the load gitserver is solely responsible for causing. This panel has no related alerts. -To see this panel, visit `/-/debug/grafana/d/gitserver/gitserver?viewPanel=101400` on your Sourcegraph instance. +To see this panel, visit `/-/debug/grafana/d/gitserver/gitserver?viewPanel=101301` on your Sourcegraph instance. *Managed by the [Sourcegraph Source team](https://handbook.sourcegraph.com/departments/engineering/teams/source).* @@ -44531,19 +45347,23 @@ To see this panel, visit `/-/debug/grafana/d/gitserver/gitserver?viewPanel=10140 Query: ``` -sum by (app_name, db_name) (src_pgsql_conns_max_open{app_name="gitserver"}) +(max by (instance) (gitserver_mount_point_info{mount_name="reposDir",instance=~`${shard:regex}`} * on (device, nodename) group_left() (max by (device, nodename) (rate(node_disk_writes_completed_total{instance=~`node-exporter.*`}[1m]))))) ```-#### gitserver: open_conns +#### gitserver: repos_disk_read_throughput -
Established
+Read throughput over 1m (per instance)
+ +The amount of data that was read from the device per second. + +Note: Disk statistics are per _device_, not per _service_. In certain environments (such as common docker-compose setups), gitserver could be one of _many services_ using this disk. These statistics are best interpreted as the load experienced by the device gitserver is using, not the load gitserver is solely responsible for causing. This panel has no related alerts. -To see this panel, visit `/-/debug/grafana/d/gitserver/gitserver?viewPanel=101401` on your Sourcegraph instance. +To see this panel, visit `/-/debug/grafana/d/gitserver/gitserver?viewPanel=101310` on your Sourcegraph instance. *Managed by the [Sourcegraph Source team](https://handbook.sourcegraph.com/departments/engineering/teams/source).* @@ -44553,19 +45373,23 @@ To see this panel, visit `/-/debug/grafana/d/gitserver/gitserver?viewPanel=10140 Query: ``` -sum by (app_name, db_name) (src_pgsql_conns_open{app_name="gitserver"}) +(max by (instance) (gitserver_mount_point_info{mount_name="reposDir",instance=~`${shard:regex}`} * on (device, nodename) group_left() (max by (device, nodename) (rate(node_disk_read_bytes_total{instance=~`node-exporter.*`}[1m]))))) ```-#### gitserver: in_use +#### gitserver: repos_disk_write_throughput -
Used
+Write throughput over 1m (per instance)
+ +The amount of data that was written to the device per second. + +Note: Disk statistics are per _device_, not per _service_. In certain environments (such as common docker-compose setups), gitserver could be one of _many services_ using this disk. These statistics are best interpreted as the load experienced by the device gitserver is using, not the load gitserver is solely responsible for causing. This panel has no related alerts. -To see this panel, visit `/-/debug/grafana/d/gitserver/gitserver?viewPanel=101410` on your Sourcegraph instance. +To see this panel, visit `/-/debug/grafana/d/gitserver/gitserver?viewPanel=101311` on your Sourcegraph instance. *Managed by the [Sourcegraph Source team](https://handbook.sourcegraph.com/departments/engineering/teams/source).* @@ -44575,19 +45399,23 @@ To see this panel, visit `/-/debug/grafana/d/gitserver/gitserver?viewPanel=10141 Query: ``` -sum by (app_name, db_name) (src_pgsql_conns_in_use{app_name="gitserver"}) +(max by (instance) (gitserver_mount_point_info{mount_name="reposDir",instance=~`${shard:regex}`} * on (device, nodename) group_left() (max by (device, nodename) (rate(node_disk_written_bytes_total{instance=~`node-exporter.*`}[1m]))))) ```-#### gitserver: idle +#### gitserver: repos_disk_read_duration -
Idle
+Average read duration over 1m (per instance)
+ +The average time for read requests issued to the device to be served. This includes the time spent by the requests in queue and the time spent servicing them. + +Note: Disk statistics are per _device_, not per _service_. In certain environments (such as common docker-compose setups), gitserver could be one of _many services_ using this disk. These statistics are best interpreted as the load experienced by the device gitserver is using, not the load gitserver is solely responsible for causing. This panel has no related alerts. -To see this panel, visit `/-/debug/grafana/d/gitserver/gitserver?viewPanel=101411` on your Sourcegraph instance. +To see this panel, visit `/-/debug/grafana/d/gitserver/gitserver?viewPanel=101320` on your Sourcegraph instance. *Managed by the [Sourcegraph Source team](https://handbook.sourcegraph.com/departments/engineering/teams/source).* @@ -44597,19 +45425,23 @@ To see this panel, visit `/-/debug/grafana/d/gitserver/gitserver?viewPanel=10141 Query: ``` -sum by (app_name, db_name) (src_pgsql_conns_idle{app_name="gitserver"}) +(((max by (instance) (gitserver_mount_point_info{mount_name="reposDir",instance=~`${shard:regex}`} * on (device, nodename) group_left() (max by (device, nodename) (rate(node_disk_read_time_seconds_total{instance=~`node-exporter.*`}[1m])))))) / ((max by (instance) (gitserver_mount_point_info{mount_name="reposDir",instance=~`${shard:regex}`} * on (device, nodename) group_left() (max by (device, nodename) (rate(node_disk_reads_completed_total{instance=~`node-exporter.*`}[1m]))))))) ```-#### gitserver: mean_blocked_seconds_per_conn_request +#### gitserver: repos_disk_write_duration -
Mean blocked seconds per conn request
+Average write duration over 1m (per instance)
-Refer to the [alerts reference](alerts#gitserver-mean-blocked-seconds-per-conn-request) for 2 alerts related to this panel. +The average time for write requests issued to the device to be served. This includes the time spent by the requests in queue and the time spent servicing them. -To see this panel, visit `/-/debug/grafana/d/gitserver/gitserver?viewPanel=101420` on your Sourcegraph instance. +Note: Disk statistics are per _device_, not per _service_. In certain environments (such as common docker-compose setups), gitserver could be one of _many services_ using this disk. These statistics are best interpreted as the load experienced by the device gitserver is using, not the load gitserver is solely responsible for causing. + +This panel has no related alerts. + +To see this panel, visit `/-/debug/grafana/d/gitserver/gitserver?viewPanel=101321` on your Sourcegraph instance. *Managed by the [Sourcegraph Source team](https://handbook.sourcegraph.com/departments/engineering/teams/source).* @@ -44619,19 +45451,23 @@ To see this panel, visit `/-/debug/grafana/d/gitserver/gitserver?viewPanel=10142 Query: ``` -sum by (app_name, db_name) (increase(src_pgsql_conns_blocked_seconds{app_name="gitserver"}[5m])) / sum by (app_name, db_name) (increase(src_pgsql_conns_waited_for{app_name="gitserver"}[5m])) +(((max by (instance) (gitserver_mount_point_info{mount_name="reposDir",instance=~`${shard:regex}`} * on (device, nodename) group_left() (max by (device, nodename) (rate(node_disk_write_time_seconds_total{instance=~`node-exporter.*`}[1m])))))) / ((max by (instance) (gitserver_mount_point_info{mount_name="reposDir",instance=~`${shard:regex}`} * on (device, nodename) group_left() (max by (device, nodename) (rate(node_disk_writes_completed_total{instance=~`node-exporter.*`}[1m]))))))) ```-#### gitserver: closed_max_idle +#### gitserver: repos_disk_read_request_size -
Closed by SetMaxIdleConns
+Average read request size over 1m (per instance)
+ +The average size of read requests that were issued to the device. + +Note: Disk statistics are per _device_, not per _service_. In certain environments (such as common docker-compose setups), gitserver could be one of _many services_ using this disk. These statistics are best interpreted as the load experienced by the device gitserver is using, not the load gitserver is solely responsible for causing. This panel has no related alerts. -To see this panel, visit `/-/debug/grafana/d/gitserver/gitserver?viewPanel=101430` on your Sourcegraph instance. +To see this panel, visit `/-/debug/grafana/d/gitserver/gitserver?viewPanel=101330` on your Sourcegraph instance. *Managed by the [Sourcegraph Source team](https://handbook.sourcegraph.com/departments/engineering/teams/source).* @@ -44641,19 +45477,23 @@ To see this panel, visit `/-/debug/grafana/d/gitserver/gitserver?viewPanel=10143 Query: ``` -sum by (app_name, db_name) (increase(src_pgsql_conns_closed_max_idle{app_name="gitserver"}[5m])) +(((max by (instance) (gitserver_mount_point_info{mount_name="reposDir",instance=~`${shard:regex}`} * on (device, nodename) group_left() (max by (device, nodename) (rate(node_disk_read_bytes_total{instance=~`node-exporter.*`}[1m])))))) / ((max by (instance) (gitserver_mount_point_info{mount_name="reposDir",instance=~`${shard:regex}`} * on (device, nodename) group_left() (max by (device, nodename) (rate(node_disk_reads_completed_total{instance=~`node-exporter.*`}[1m]))))))) ```-#### gitserver: closed_max_lifetime +#### gitserver: repos_disk_write_request_size) -
Closed by SetConnMaxLifetime
+Average write request size over 1m (per instance)
+ +The average size of write requests that were issued to the device. + +Note: Disk statistics are per _device_, not per _service_. In certain environments (such as common docker-compose setups), gitserver could be one of _many services_ using this disk. These statistics are best interpreted as the load experienced by the device gitserver is using, not the load gitserver is solely responsible for causing. This panel has no related alerts. -To see this panel, visit `/-/debug/grafana/d/gitserver/gitserver?viewPanel=101431` on your Sourcegraph instance. +To see this panel, visit `/-/debug/grafana/d/gitserver/gitserver?viewPanel=101331` on your Sourcegraph instance. *Managed by the [Sourcegraph Source team](https://handbook.sourcegraph.com/departments/engineering/teams/source).* @@ -44663,19 +45503,23 @@ To see this panel, visit `/-/debug/grafana/d/gitserver/gitserver?viewPanel=10143 Query: ``` -sum by (app_name, db_name) (increase(src_pgsql_conns_closed_max_lifetime{app_name="gitserver"}[5m])) +(((max by (instance) (gitserver_mount_point_info{mount_name="reposDir",instance=~`${shard:regex}`} * on (device, nodename) group_left() (max by (device, nodename) (rate(node_disk_written_bytes_total{instance=~`node-exporter.*`}[1m])))))) / ((max by (instance) (gitserver_mount_point_info{mount_name="reposDir",instance=~`${shard:regex}`} * on (device, nodename) group_left() (max by (device, nodename) (rate(node_disk_writes_completed_total{instance=~`node-exporter.*`}[1m]))))))) ```-#### gitserver: closed_max_idle_time +#### gitserver: repos_disk_reads_merged_sec -
Closed by SetConnMaxIdleTime
+Merged read request rate over 1m (per instance)
+ +The number of read requests merged per second that were queued to the device. + +Note: Disk statistics are per _device_, not per _service_. In certain environments (such as common docker-compose setups), gitserver could be one of _many services_ using this disk. These statistics are best interpreted as the load experienced by the device gitserver is using, not the load gitserver is solely responsible for causing. This panel has no related alerts. -To see this panel, visit `/-/debug/grafana/d/gitserver/gitserver?viewPanel=101432` on your Sourcegraph instance. +To see this panel, visit `/-/debug/grafana/d/gitserver/gitserver?viewPanel=101340` on your Sourcegraph instance. *Managed by the [Sourcegraph Source team](https://handbook.sourcegraph.com/departments/engineering/teams/source).* @@ -44685,31 +45529,23 @@ To see this panel, visit `/-/debug/grafana/d/gitserver/gitserver?viewPanel=10143 Query: ``` -sum by (app_name, db_name) (increase(src_pgsql_conns_closed_max_idle_time{app_name="gitserver"}[5m])) +(max by (instance) (gitserver_mount_point_info{mount_name="reposDir",instance=~`${shard:regex}`} * on (device, nodename) group_left() (max by (device, nodename) (rate(node_disk_reads_merged_total{instance=~`node-exporter.*`}[1m]))))) ```-### Git Server: Container monitoring (not available on server) - -#### gitserver: container_missing +#### gitserver: repos_disk_writes_merged_sec -
Container missing
+Merged writes request rate over 1m (per instance)
-This value is the number of times a container has not been seen for more than one minute. If you observe this -value change independent of deployment events (such as an upgrade), it could indicate pods are being OOM killed or terminated for some other reasons. +The number of write requests merged per second that were queued to the device. -- **Kubernetes:** - - Determine if the pod was OOM killed using `kubectl describe pod gitserver` (look for `OOMKilled: true`) and, if so, consider increasing the memory limit in the relevant `Deployment.yaml`. - - Check the logs before the container restarted to see if there are `panic:` messages or similar using `kubectl logs -p gitserver`. -- **Docker Compose:** - - Determine if the pod was OOM killed using `docker inspect -f '\{\{json .State\}\}' gitserver` (look for `"OOMKilled":true`) and, if so, consider increasing the memory limit of the gitserver container in `docker-compose.yml`. - - Check the logs before the container restarted to see if there are `panic:` messages or similar using `docker logs gitserver` (note this will include logs from the previous and currently running container). +Note: Disk statistics are per _device_, not per _service_. In certain environments (such as common docker-compose setups), gitserver could be one of _many services_ using this disk. These statistics are best interpreted as the load experienced by the device gitserver is using, not the load gitserver is solely responsible for causing. This panel has no related alerts. -To see this panel, visit `/-/debug/grafana/d/gitserver/gitserver?viewPanel=101500` on your Sourcegraph instance. +To see this panel, visit `/-/debug/grafana/d/gitserver/gitserver?viewPanel=101341` on your Sourcegraph instance. *Managed by the [Sourcegraph Source team](https://handbook.sourcegraph.com/departments/engineering/teams/source).* @@ -44719,19 +45555,23 @@ To see this panel, visit `/-/debug/grafana/d/gitserver/gitserver?viewPanel=10150 Query: ``` -count by(name) ((time() - container_last_seen{name=~"^gitserver.*"}) > 60) +(max by (instance) (gitserver_mount_point_info{mount_name="reposDir",instance=~`${shard:regex}`} * on (device, nodename) group_left() (max by (device, nodename) (rate(node_disk_writes_merged_total{instance=~`node-exporter.*`}[1m]))))) ```-#### gitserver: container_cpu_usage +#### gitserver: repos_disk_average_queue_size -
Container cpu usage total (1m average) across all cores by instance
+Average queue size over 1m (per instance)
-Refer to the [alerts reference](alerts#gitserver-container-cpu-usage) for 1 alert related to this panel. +The number of I/O operations that were being queued or being serviced. See https://blog.actorsfit.com/a?ID=00200-428fa2ac-e338-4540-848c-af9a3eb1ebd2 for background (avgqu-sz). -To see this panel, visit `/-/debug/grafana/d/gitserver/gitserver?viewPanel=101501` on your Sourcegraph instance. +Note: Disk statistics are per _device_, not per _service_. In certain environments (such as common docker-compose setups), gitserver could be one of _many services_ using this disk. These statistics are best interpreted as the load experienced by the device gitserver is using, not the load gitserver is solely responsible for causing. + +This panel has no related alerts. + +To see this panel, visit `/-/debug/grafana/d/gitserver/gitserver?viewPanel=101350` on your Sourcegraph instance. *Managed by the [Sourcegraph Source team](https://handbook.sourcegraph.com/departments/engineering/teams/source).* @@ -44741,19 +45581,23 @@ To see this panel, visit `/-/debug/grafana/d/gitserver/gitserver?viewPanel=10150 Query: ``` -cadvisor_container_cpu_usage_percentage_total{name=~"^gitserver.*"} +(max by (instance) (gitserver_mount_point_info{mount_name="reposDir",instance=~`${shard:regex}`} * on (device, nodename) group_left() (max by (device, nodename) (rate(node_disk_io_time_weighted_seconds_total{instance=~`node-exporter.*`}[1m]))))) ```-#### gitserver: container_memory_usage +### Git Server: Git Service GRPC server metrics -
Container memory usage by instance
+#### gitserver: git_service_grpc_request_rate_all_methods -Refer to the [alerts reference](alerts#gitserver-container-memory-usage) for 1 alert related to this panel. +Request rate across all methods over 2m
-To see this panel, visit `/-/debug/grafana/d/gitserver/gitserver?viewPanel=101502` on your Sourcegraph instance. +The number of gRPC requests received per second across all methods, aggregated across all instances. + +This panel has no related alerts. + +To see this panel, visit `/-/debug/grafana/d/gitserver/gitserver?viewPanel=101400` on your Sourcegraph instance. *Managed by the [Sourcegraph Source team](https://handbook.sourcegraph.com/departments/engineering/teams/source).* @@ -44763,22 +45607,21 @@ To see this panel, visit `/-/debug/grafana/d/gitserver/gitserver?viewPanel=10150 Query: ``` -cadvisor_container_memory_usage_percentage_total{name=~"^gitserver.*"} +sum(rate(grpc_server_started_total{instance=~`${shard:regex}`,grpc_service=~"gitserver.v1.GitserverService"}[2m])) ```-#### gitserver: fs_io_operations +#### gitserver: git_service_grpc_request_rate_per_method -
Filesystem reads and writes rate by instance over 1h
+Request rate per-method over 2m
-This value indicates the number of filesystem read and write operations by containers of this service. -When extremely high, this can indicate a resource usage problem, or can cause problems with the service itself, especially if high values or spikes correlate with \{\{CONTAINER_NAME\}\} issues. +The number of gRPC requests received per second broken out per method, aggregated across all instances. This panel has no related alerts. -To see this panel, visit `/-/debug/grafana/d/gitserver/gitserver?viewPanel=101503` on your Sourcegraph instance. +To see this panel, visit `/-/debug/grafana/d/gitserver/gitserver?viewPanel=101401` on your Sourcegraph instance. *Managed by the [Sourcegraph Source team](https://handbook.sourcegraph.com/departments/engineering/teams/source).* @@ -44788,21 +45631,21 @@ To see this panel, visit `/-/debug/grafana/d/gitserver/gitserver?viewPanel=10150 Query: ``` -sum by(name) (rate(container_fs_reads_total{name=~"^gitserver.*"}[1h]) + rate(container_fs_writes_total{name=~"^gitserver.*"}[1h])) +sum(rate(grpc_server_started_total{grpc_method=~`${git_service_method:regex}`,instance=~`${shard:regex}`,grpc_service=~"gitserver.v1.GitserverService"}[2m])) by (grpc_method) ```-### Git Server: Provisioning indicators (not available on server) +#### gitserver: git_service_error_percentage_all_methods -#### gitserver: provisioning_container_cpu_usage_long_term +
Error percentage across all methods over 2m
-Container cpu usage total (90th percentile over 1d) across all cores by instance
+The percentage of gRPC requests that fail across all methods, aggregated across all instances. -Refer to the [alerts reference](alerts#gitserver-provisioning-container-cpu-usage-long-term) for 1 alert related to this panel. +This panel has no related alerts. -To see this panel, visit `/-/debug/grafana/d/gitserver/gitserver?viewPanel=101600` on your Sourcegraph instance. +To see this panel, visit `/-/debug/grafana/d/gitserver/gitserver?viewPanel=101410` on your Sourcegraph instance. *Managed by the [Sourcegraph Source team](https://handbook.sourcegraph.com/departments/engineering/teams/source).* @@ -44812,21 +45655,21 @@ To see this panel, visit `/-/debug/grafana/d/gitserver/gitserver?viewPanel=10160 Query: ``` -quantile_over_time(0.9, cadvisor_container_cpu_usage_percentage_total{name=~"^gitserver.*"}[1d]) +(100.0 * ( (sum(rate(grpc_server_handled_total{grpc_code!="OK",instance=~`${shard:regex}`,grpc_service=~"gitserver.v1.GitserverService"}[2m]))) / (sum(rate(grpc_server_handled_total{instance=~`${shard:regex}`,grpc_service=~"gitserver.v1.GitserverService"}[2m]))) )) ```-#### gitserver: provisioning_container_memory_usage_long_term +#### gitserver: git_service_grpc_error_percentage_per_method -
Container memory usage (1d maximum) by instance
+Error percentage per-method over 2m
-Git Server is expected to use up all the memory it is provided. +The percentage of gRPC requests that fail per method, aggregated across all instances. This panel has no related alerts. -To see this panel, visit `/-/debug/grafana/d/gitserver/gitserver?viewPanel=101601` on your Sourcegraph instance. +To see this panel, visit `/-/debug/grafana/d/gitserver/gitserver?viewPanel=101411` on your Sourcegraph instance. *Managed by the [Sourcegraph Source team](https://handbook.sourcegraph.com/departments/engineering/teams/source).* @@ -44836,19 +45679,21 @@ To see this panel, visit `/-/debug/grafana/d/gitserver/gitserver?viewPanel=10160 Query: ``` -max_over_time(cadvisor_container_memory_usage_percentage_total{name=~"^gitserver.*"}[1d]) +(100.0 * ( (sum(rate(grpc_server_handled_total{grpc_method=~`${git_service_method:regex}`,grpc_code!="OK",instance=~`${shard:regex}`,grpc_service=~"gitserver.v1.GitserverService"}[2m])) by (grpc_method)) / (sum(rate(grpc_server_handled_total{grpc_method=~`${git_service_method:regex}`,instance=~`${shard:regex}`,grpc_service=~"gitserver.v1.GitserverService"}[2m])) by (grpc_method)) )) ```-#### gitserver: provisioning_container_cpu_usage_short_term +#### gitserver: git_service_p99_response_time_per_method -
Container cpu usage total (5m maximum) across all cores by instance
+99th percentile response time per method over 2m
-Refer to the [alerts reference](alerts#gitserver-provisioning-container-cpu-usage-short-term) for 1 alert related to this panel. +The 99th percentile response time per method, aggregated across all instances. + +This panel has no related alerts. -To see this panel, visit `/-/debug/grafana/d/gitserver/gitserver?viewPanel=101610` on your Sourcegraph instance. +To see this panel, visit `/-/debug/grafana/d/gitserver/gitserver?viewPanel=101420` on your Sourcegraph instance. *Managed by the [Sourcegraph Source team](https://handbook.sourcegraph.com/departments/engineering/teams/source).* @@ -44858,21 +45703,21 @@ To see this panel, visit `/-/debug/grafana/d/gitserver/gitserver?viewPanel=10161 Query: ``` -max_over_time(cadvisor_container_cpu_usage_percentage_total{name=~"^gitserver.*"}[5m]) +histogram_quantile(0.99, sum by (le, name, grpc_method)(rate(grpc_server_handling_seconds_bucket{grpc_method=~`${git_service_method:regex}`,instance=~`${shard:regex}`,grpc_service=~"gitserver.v1.GitserverService"}[2m]))) ```-#### gitserver: provisioning_container_memory_usage_short_term +#### gitserver: git_service_p90_response_time_per_method -
Container memory usage (5m maximum) by instance
+90th percentile response time per method over 2m
-Git Server is expected to use up all the memory it is provided. +The 90th percentile response time per method, aggregated across all instances. This panel has no related alerts. -To see this panel, visit `/-/debug/grafana/d/gitserver/gitserver?viewPanel=101611` on your Sourcegraph instance. +To see this panel, visit `/-/debug/grafana/d/gitserver/gitserver?viewPanel=101421` on your Sourcegraph instance. *Managed by the [Sourcegraph Source team](https://handbook.sourcegraph.com/departments/engineering/teams/source).* @@ -44882,22 +45727,21 @@ To see this panel, visit `/-/debug/grafana/d/gitserver/gitserver?viewPanel=10161 Query: ``` -max_over_time(cadvisor_container_memory_usage_percentage_total{name=~"^gitserver.*"}[5m]) +histogram_quantile(0.90, sum by (le, name, grpc_method)(rate(grpc_server_handling_seconds_bucket{grpc_method=~`${git_service_method:regex}`,instance=~`${shard:regex}`,grpc_service=~"gitserver.v1.GitserverService"}[2m]))) ```-#### gitserver: container_oomkill_events_total +#### gitserver: git_service_p75_response_time_per_method -
Container OOMKILL events total by instance
+75th percentile response time per method over 2m
-This value indicates the total number of times the container main process or child processes were terminated by OOM killer. -When it occurs frequently, it is an indicator of underprovisioning. +The 75th percentile response time per method, aggregated across all instances. -Refer to the [alerts reference](alerts#gitserver-container-oomkill-events-total) for 1 alert related to this panel. +This panel has no related alerts. -To see this panel, visit `/-/debug/grafana/d/gitserver/gitserver?viewPanel=101612` on your Sourcegraph instance. +To see this panel, visit `/-/debug/grafana/d/gitserver/gitserver?viewPanel=101422` on your Sourcegraph instance. *Managed by the [Sourcegraph Source team](https://handbook.sourcegraph.com/departments/engineering/teams/source).* @@ -44907,23 +45751,21 @@ To see this panel, visit `/-/debug/grafana/d/gitserver/gitserver?viewPanel=10161 Query: ``` -max by (name) (container_oom_events_total{name=~"^gitserver.*"}) +histogram_quantile(0.75, sum by (le, name, grpc_method)(rate(grpc_server_handling_seconds_bucket{grpc_method=~`${git_service_method:regex}`,instance=~`${shard:regex}`,grpc_service=~"gitserver.v1.GitserverService"}[2m]))) ```-### Git Server: Golang runtime monitoring - -#### gitserver: go_goroutines +#### gitserver: git_service_p99_9_response_size_per_method -
Maximum active goroutines
+99.9th percentile total response size per method over 2m
-A high value here indicates a possible goroutine leak. +The 99.9th percentile total per-RPC response size per method, aggregated across all instances. -Refer to the [alerts reference](alerts#gitserver-go-goroutines) for 1 alert related to this panel. +This panel has no related alerts. -To see this panel, visit `/-/debug/grafana/d/gitserver/gitserver?viewPanel=101700` on your Sourcegraph instance. +To see this panel, visit `/-/debug/grafana/d/gitserver/gitserver?viewPanel=101430` on your Sourcegraph instance. *Managed by the [Sourcegraph Source team](https://handbook.sourcegraph.com/departments/engineering/teams/source).* @@ -44933,19 +45775,21 @@ To see this panel, visit `/-/debug/grafana/d/gitserver/gitserver?viewPanel=10170 Query: ``` -max by(instance) (go_goroutines{job=~".*gitserver"}) +histogram_quantile(0.999, sum by (le, name, grpc_method)(rate(src_grpc_server_sent_bytes_per_rpc_bucket{grpc_method=~`${git_service_method:regex}`,instance=~`${shard:regex}`,grpc_service=~"gitserver.v1.GitserverService"}[2m]))) ```-#### gitserver: go_gc_duration_seconds +#### gitserver: git_service_p90_response_size_per_method -
Maximum go garbage collection duration
+90th percentile total response size per method over 2m
-Refer to the [alerts reference](alerts#gitserver-go-gc-duration-seconds) for 1 alert related to this panel. +The 90th percentile total per-RPC response size per method, aggregated across all instances. -To see this panel, visit `/-/debug/grafana/d/gitserver/gitserver?viewPanel=101701` on your Sourcegraph instance. +This panel has no related alerts. + +To see this panel, visit `/-/debug/grafana/d/gitserver/gitserver?viewPanel=101431` on your Sourcegraph instance. *Managed by the [Sourcegraph Source team](https://handbook.sourcegraph.com/departments/engineering/teams/source).* @@ -44955,21 +45799,21 @@ To see this panel, visit `/-/debug/grafana/d/gitserver/gitserver?viewPanel=10170 Query: ``` -max by(instance) (go_gc_duration_seconds{job=~".*gitserver"}) +histogram_quantile(0.90, sum by (le, name, grpc_method)(rate(src_grpc_server_sent_bytes_per_rpc_bucket{grpc_method=~`${git_service_method:regex}`,instance=~`${shard:regex}`,grpc_service=~"gitserver.v1.GitserverService"}[2m]))) ```-### Git Server: Kubernetes monitoring (only available on Kubernetes) +#### gitserver: git_service_p75_response_size_per_method -#### gitserver: pods_available_percentage +
75th percentile total response size per method over 2m
-Percentage pods available
+The 75th percentile total per-RPC response size per method, aggregated across all instances. -Refer to the [alerts reference](alerts#gitserver-pods-available-percentage) for 1 alert related to this panel. +This panel has no related alerts. -To see this panel, visit `/-/debug/grafana/d/gitserver/gitserver?viewPanel=101800` on your Sourcegraph instance. +To see this panel, visit `/-/debug/grafana/d/gitserver/gitserver?viewPanel=101432` on your Sourcegraph instance. *Managed by the [Sourcegraph Source team](https://handbook.sourcegraph.com/departments/engineering/teams/source).* @@ -44979,27 +45823,23 @@ To see this panel, visit `/-/debug/grafana/d/gitserver/gitserver?viewPanel=10180 Query: ``` -sum by(app) (up{app=~".*gitserver"}) / count by (app) (up{app=~".*gitserver"}) * 100 +histogram_quantile(0.75, sum by (le, name, grpc_method)(rate(src_grpc_server_sent_bytes_per_rpc_bucket{grpc_method=~`${git_service_method:regex}`,instance=~`${shard:regex}`,grpc_service=~"gitserver.v1.GitserverService"}[2m]))) ```-## Postgres - -
Postgres metrics, exported from postgres_exporter (not available on server).
- -To see this dashboard, visit `/-/debug/grafana/d/postgres/postgres` on your Sourcegraph instance. +#### gitserver: git_service_p99_9_invididual_sent_message_size_per_method -#### postgres: connections +99.9th percentile individual sent message size per method over 2m
-Active connections
+The 99.9th percentile size of every individual protocol buffer size sent by the service per method, aggregated across all instances. -Refer to the [alerts reference](alerts#postgres-connections) for 1 alert related to this panel. +This panel has no related alerts. -To see this panel, visit `/-/debug/grafana/d/postgres/postgres?viewPanel=100000` on your Sourcegraph instance. +To see this panel, visit `/-/debug/grafana/d/gitserver/gitserver?viewPanel=101440` on your Sourcegraph instance. -*Managed by the [Sourcegraph Infrastructure Org team](https://handbook.sourcegraph.com/departments/engineering/infrastructure).* +*Managed by the [Sourcegraph Source team](https://handbook.sourcegraph.com/departments/engineering/teams/source).*Technical details
@@ -45007,21 +45847,23 @@ To see this panel, visit `/-/debug/grafana/d/postgres/postgres?viewPanel=100000` Query: ``` -sum by (job) (pg_stat_activity_count{datname!~"template.*|postgres|cloudsqladmin"}) OR sum by (job) (pg_stat_activity_count{job="codeinsights-db", datname!~"template.*|cloudsqladmin"}) +histogram_quantile(0.999, sum by (le, name, grpc_method)(rate(src_grpc_server_sent_individual_message_size_bytes_per_rpc_bucket{grpc_method=~`${git_service_method:regex}`,instance=~`${shard:regex}`,grpc_service=~"gitserver.v1.GitserverService"}[2m]))) ```-#### postgres: usage_connections_percentage +#### gitserver: git_service_p90_invididual_sent_message_size_per_method -
Connection in use
+90th percentile individual sent message size per method over 2m
-Refer to the [alerts reference](alerts#postgres-usage-connections-percentage) for 2 alerts related to this panel. +The 90th percentile size of every individual protocol buffer size sent by the service per method, aggregated across all instances. -To see this panel, visit `/-/debug/grafana/d/postgres/postgres?viewPanel=100001` on your Sourcegraph instance. +This panel has no related alerts. -*Managed by the [Sourcegraph Infrastructure Org team](https://handbook.sourcegraph.com/departments/engineering/infrastructure).* +To see this panel, visit `/-/debug/grafana/d/gitserver/gitserver?viewPanel=101441` on your Sourcegraph instance. + +*Managed by the [Sourcegraph Source team](https://handbook.sourcegraph.com/departments/engineering/teams/source).*Technical details
@@ -45029,21 +45871,23 @@ To see this panel, visit `/-/debug/grafana/d/postgres/postgres?viewPanel=100001` Query: ``` -sum(pg_stat_activity_count) by (job) / (sum(pg_settings_max_connections) by (job) - sum(pg_settings_superuser_reserved_connections) by (job)) * 100 +histogram_quantile(0.90, sum by (le, name, grpc_method)(rate(src_grpc_server_sent_individual_message_size_bytes_per_rpc_bucket{grpc_method=~`${git_service_method:regex}`,instance=~`${shard:regex}`,grpc_service=~"gitserver.v1.GitserverService"}[2m]))) ```-#### postgres: transaction_durations +#### gitserver: git_service_p75_invididual_sent_message_size_per_method -
Maximum transaction durations
+75th percentile individual sent message size per method over 2m
-Refer to the [alerts reference](alerts#postgres-transaction-durations) for 1 alert related to this panel. +The 75th percentile size of every individual protocol buffer size sent by the service per method, aggregated across all instances. -To see this panel, visit `/-/debug/grafana/d/postgres/postgres?viewPanel=100002` on your Sourcegraph instance. +This panel has no related alerts. -*Managed by the [Sourcegraph Infrastructure Org team](https://handbook.sourcegraph.com/departments/engineering/infrastructure).* +To see this panel, visit `/-/debug/grafana/d/gitserver/gitserver?viewPanel=101442` on your Sourcegraph instance. + +*Managed by the [Sourcegraph Source team](https://handbook.sourcegraph.com/departments/engineering/teams/source).*Technical details
@@ -45051,25 +45895,23 @@ To see this panel, visit `/-/debug/grafana/d/postgres/postgres?viewPanel=100002` Query: ``` -sum by (job) (pg_stat_activity_max_tx_duration{datname!~"template.*|postgres|cloudsqladmin",job!="codeintel-db"}) OR sum by (job) (pg_stat_activity_max_tx_duration{job="codeinsights-db", datname!~"template.*|cloudsqladmin"}) +histogram_quantile(0.75, sum by (le, name, grpc_method)(rate(src_grpc_server_sent_individual_message_size_bytes_per_rpc_bucket{grpc_method=~`${git_service_method:regex}`,instance=~`${shard:regex}`,grpc_service=~"gitserver.v1.GitserverService"}[2m]))) ```-### Postgres: Database and collector status - -#### postgres: postgres_up +#### gitserver: git_service_grpc_response_stream_message_count_per_method -
Database availability
+Average streaming response message count per-method over 2m
-A non-zero value indicates the database is online. +The average number of response messages sent during a streaming RPC method, broken out per method, aggregated across all instances. -Refer to the [alerts reference](alerts#postgres-postgres-up) for 1 alert related to this panel. +This panel has no related alerts. -To see this panel, visit `/-/debug/grafana/d/postgres/postgres?viewPanel=100100` on your Sourcegraph instance. +To see this panel, visit `/-/debug/grafana/d/gitserver/gitserver?viewPanel=101450` on your Sourcegraph instance. -*Managed by the [Sourcegraph Infrastructure Org team](https://handbook.sourcegraph.com/departments/engineering/infrastructure).* +*Managed by the [Sourcegraph Source team](https://handbook.sourcegraph.com/departments/engineering/teams/source).*Technical details
@@ -45077,23 +45919,23 @@ To see this panel, visit `/-/debug/grafana/d/postgres/postgres?viewPanel=100100` Query: ``` -pg_up +((sum(rate(grpc_server_msg_sent_total{grpc_type="server_stream",instance=~`${shard:regex}`,grpc_service=~"gitserver.v1.GitserverService"}[2m])) by (grpc_method))/(sum(rate(grpc_server_started_total{grpc_type="server_stream",instance=~`${shard:regex}`,grpc_service=~"gitserver.v1.GitserverService"}[2m])) by (grpc_method))) ```-#### postgres: invalid_indexes +#### gitserver: git_service_grpc_all_codes_per_method -
Invalid indexes (unusable by the query planner)
+Response codes rate per-method over 2m
-A non-zero value indicates the that Postgres failed to build an index. Expect degraded performance until the index is manually rebuilt. +The rate of all generated gRPC response codes per method, aggregated across all instances. -Refer to the [alerts reference](alerts#postgres-invalid-indexes) for 1 alert related to this panel. +This panel has no related alerts. -To see this panel, visit `/-/debug/grafana/d/postgres/postgres?viewPanel=100101` on your Sourcegraph instance. +To see this panel, visit `/-/debug/grafana/d/gitserver/gitserver?viewPanel=101460` on your Sourcegraph instance. -*Managed by the [Sourcegraph Infrastructure Org team](https://handbook.sourcegraph.com/departments/engineering/infrastructure).* +*Managed by the [Sourcegraph Source team](https://handbook.sourcegraph.com/departments/engineering/teams/source).*Technical details
@@ -45101,23 +45943,25 @@ To see this panel, visit `/-/debug/grafana/d/postgres/postgres?viewPanel=100101` Query: ``` -max by (relname)(pg_invalid_index_count) +sum(rate(grpc_server_handled_total{grpc_method=~`${git_service_method:regex}`,instance=~`${shard:regex}`,grpc_service=~"gitserver.v1.GitserverService"}[2m])) by (grpc_method, grpc_code) ```-#### postgres: pg_exporter_err +### Git Server: Git Service GRPC "internal error" metrics -
Errors scraping postgres exporter
+#### gitserver: git_service_grpc_clients_error_percentage_all_methods -This value indicates issues retrieving metrics from postgres_exporter. +Client baseline error percentage across all methods over 2m
-Refer to the [alerts reference](alerts#postgres-pg-exporter-err) for 1 alert related to this panel. +The percentage of gRPC requests that fail across all methods (regardless of whether or not there was an internal error), aggregated across all "git_service" clients. -To see this panel, visit `/-/debug/grafana/d/postgres/postgres?viewPanel=100110` on your Sourcegraph instance. +This panel has no related alerts. -*Managed by the [Sourcegraph Infrastructure Org team](https://handbook.sourcegraph.com/departments/engineering/infrastructure).* +To see this panel, visit `/-/debug/grafana/d/gitserver/gitserver?viewPanel=101500` on your Sourcegraph instance. + +*Managed by the [Sourcegraph Source team](https://handbook.sourcegraph.com/departments/engineering/teams/source).*Technical details
@@ -45125,23 +45969,23 @@ To see this panel, visit `/-/debug/grafana/d/postgres/postgres?viewPanel=100110` Query: ``` -pg_exporter_last_scrape_error +(100.0 * ((((sum(rate(src_grpc_method_status{grpc_service=~"gitserver.v1.GitserverService",grpc_code!="OK"}[2m])))) / ((sum(rate(src_grpc_method_status{grpc_service=~"gitserver.v1.GitserverService"}[2m]))))))) ```-#### postgres: migration_in_progress +#### gitserver: git_service_grpc_clients_error_percentage_per_method -
Active schema migration
+Client baseline error percentage per-method over 2m
-A 0 value indicates that no migration is in progress. +The percentage of gRPC requests that fail per method (regardless of whether or not there was an internal error), aggregated across all "git_service" clients. -Refer to the [alerts reference](alerts#postgres-migration-in-progress) for 1 alert related to this panel. +This panel has no related alerts. -To see this panel, visit `/-/debug/grafana/d/postgres/postgres?viewPanel=100111` on your Sourcegraph instance. +To see this panel, visit `/-/debug/grafana/d/gitserver/gitserver?viewPanel=101501` on your Sourcegraph instance. -*Managed by the [Sourcegraph Infrastructure Org team](https://handbook.sourcegraph.com/departments/engineering/infrastructure).* +*Managed by the [Sourcegraph Source team](https://handbook.sourcegraph.com/departments/engineering/teams/source).*Technical details
@@ -45149,25 +45993,23 @@ To see this panel, visit `/-/debug/grafana/d/postgres/postgres?viewPanel=100111` Query: ``` -pg_sg_migration_status +(100.0 * ((((sum(rate(src_grpc_method_status{grpc_service=~"gitserver.v1.GitserverService",grpc_method=~"${git_service_method:regex}",grpc_code!="OK"}[2m])) by (grpc_method))) / ((sum(rate(src_grpc_method_status{grpc_service=~"gitserver.v1.GitserverService",grpc_method=~"${git_service_method:regex}"}[2m])) by (grpc_method)))))) ```-### Postgres: Object size and bloat - -#### postgres: pg_table_size +#### gitserver: git_service_grpc_clients_all_codes_per_method -
Table size
+Client baseline response codes rate per-method over 2m
-Total size of this table +The rate of all generated gRPC response codes per method (regardless of whether or not there was an internal error), aggregated across all "git_service" clients. This panel has no related alerts. -To see this panel, visit `/-/debug/grafana/d/postgres/postgres?viewPanel=100200` on your Sourcegraph instance. +To see this panel, visit `/-/debug/grafana/d/gitserver/gitserver?viewPanel=101502` on your Sourcegraph instance. -*Managed by the [Sourcegraph Infrastructure Org team](https://handbook.sourcegraph.com/departments/engineering/infrastructure).* +*Managed by the [Sourcegraph Source team](https://handbook.sourcegraph.com/departments/engineering/teams/source).*Technical details
@@ -45175,23 +46017,29 @@ To see this panel, visit `/-/debug/grafana/d/postgres/postgres?viewPanel=100200` Query: ``` -max by (relname)(pg_table_bloat_size) +(sum(rate(src_grpc_method_status{grpc_service=~"gitserver.v1.GitserverService",grpc_method=~"${git_service_method:regex}"}[2m])) by (grpc_method, grpc_code)) ```-#### postgres: pg_table_bloat_ratio +#### gitserver: git_service_grpc_clients_internal_error_percentage_all_methods -
Table bloat ratio
+Client-observed gRPC internal error percentage across all methods over 2m
-Estimated bloat ratio of this table (high bloat = high overhead) +The percentage of gRPC requests that appear to fail due to gRPC internal errors across all methods, aggregated across all "git_service" clients. + +**Note**: Internal errors are ones that appear to originate from the https://github.com/grpc/grpc-go library itself, rather than from any user-written application code. These errors can be caused by a variety of issues, and can originate from either the code-generated "git_service" gRPC client or gRPC server. These errors might be solvable by adjusting the gRPC configuration, or they might indicate a bug from Sourcegraph`s use of gRPC. + +When debugging, knowing that a particular error comes from the grpc-go library itself (an `internal error`) as opposed to `normal` application code can be helpful when trying to fix it. + +**Note**: Internal errors are detected via a very coarse heuristic (seeing if the error starts with `grpc:`, etc.). Because of this, it`s possible that some gRPC-specific issues might not be categorized as internal errors. This panel has no related alerts. -To see this panel, visit `/-/debug/grafana/d/postgres/postgres?viewPanel=100201` on your Sourcegraph instance. +To see this panel, visit `/-/debug/grafana/d/gitserver/gitserver?viewPanel=101510` on your Sourcegraph instance. -*Managed by the [Sourcegraph Infrastructure Org team](https://handbook.sourcegraph.com/departments/engineering/infrastructure).* +*Managed by the [Sourcegraph Source team](https://handbook.sourcegraph.com/departments/engineering/teams/source).*Technical details
@@ -45199,23 +46047,29 @@ To see this panel, visit `/-/debug/grafana/d/postgres/postgres?viewPanel=100201` Query: ``` -max by (relname)(pg_table_bloat_ratio) * 100 +(100.0 * ((((sum(rate(src_grpc_method_status{grpc_service=~"gitserver.v1.GitserverService",grpc_code!="OK",is_internal_error="true"}[2m])))) / ((sum(rate(src_grpc_method_status{grpc_service=~"gitserver.v1.GitserverService"}[2m]))))))) ```-#### postgres: pg_index_size +#### gitserver: git_service_grpc_clients_internal_error_percentage_per_method -
Index size
+Client-observed gRPC internal error percentage per-method over 2m
-Total size of this index +The percentage of gRPC requests that appear to fail to due to gRPC internal errors per method, aggregated across all "git_service" clients. + +**Note**: Internal errors are ones that appear to originate from the https://github.com/grpc/grpc-go library itself, rather than from any user-written application code. These errors can be caused by a variety of issues, and can originate from either the code-generated "git_service" gRPC client or gRPC server. These errors might be solvable by adjusting the gRPC configuration, or they might indicate a bug from Sourcegraph`s use of gRPC. + +When debugging, knowing that a particular error comes from the grpc-go library itself (an `internal error`) as opposed to `normal` application code can be helpful when trying to fix it. + +**Note**: Internal errors are detected via a very coarse heuristic (seeing if the error starts with `grpc:`, etc.). Because of this, it`s possible that some gRPC-specific issues might not be categorized as internal errors. This panel has no related alerts. -To see this panel, visit `/-/debug/grafana/d/postgres/postgres?viewPanel=100210` on your Sourcegraph instance. +To see this panel, visit `/-/debug/grafana/d/gitserver/gitserver?viewPanel=101511` on your Sourcegraph instance. -*Managed by the [Sourcegraph Infrastructure Org team](https://handbook.sourcegraph.com/departments/engineering/infrastructure).* +*Managed by the [Sourcegraph Source team](https://handbook.sourcegraph.com/departments/engineering/teams/source).*Technical details
@@ -45223,23 +46077,29 @@ To see this panel, visit `/-/debug/grafana/d/postgres/postgres?viewPanel=100210` Query: ``` -max by (relname)(pg_index_bloat_size) +(100.0 * ((((sum(rate(src_grpc_method_status{grpc_service=~"gitserver.v1.GitserverService",grpc_method=~"${git_service_method:regex}",grpc_code!="OK",is_internal_error="true"}[2m])) by (grpc_method))) / ((sum(rate(src_grpc_method_status{grpc_service=~"gitserver.v1.GitserverService",grpc_method=~"${git_service_method:regex}"}[2m])) by (grpc_method)))))) ```-#### postgres: pg_index_bloat_ratio +#### gitserver: git_service_grpc_clients_internal_error_all_codes_per_method -
Index bloat ratio
+Client-observed gRPC internal error response code rate per-method over 2m
-Estimated bloat ratio of this index (high bloat = high overhead) +The rate of gRPC internal-error response codes per method, aggregated across all "git_service" clients. + +**Note**: Internal errors are ones that appear to originate from the https://github.com/grpc/grpc-go library itself, rather than from any user-written application code. These errors can be caused by a variety of issues, and can originate from either the code-generated "git_service" gRPC client or gRPC server. These errors might be solvable by adjusting the gRPC configuration, or they might indicate a bug from Sourcegraph`s use of gRPC. + +When debugging, knowing that a particular error comes from the grpc-go library itself (an `internal error`) as opposed to `normal` application code can be helpful when trying to fix it. + +**Note**: Internal errors are detected via a very coarse heuristic (seeing if the error starts with `grpc:`, etc.). Because of this, it`s possible that some gRPC-specific issues might not be categorized as internal errors. This panel has no related alerts. -To see this panel, visit `/-/debug/grafana/d/postgres/postgres?viewPanel=100211` on your Sourcegraph instance. +To see this panel, visit `/-/debug/grafana/d/gitserver/gitserver?viewPanel=101512` on your Sourcegraph instance. -*Managed by the [Sourcegraph Infrastructure Org team](https://handbook.sourcegraph.com/departments/engineering/infrastructure).* +*Managed by the [Sourcegraph Source team](https://handbook.sourcegraph.com/departments/engineering/teams/source).*Technical details
@@ -45247,23 +46107,25 @@ To see this panel, visit `/-/debug/grafana/d/postgres/postgres?viewPanel=100211` Query: ``` -max by (relname)(pg_index_bloat_ratio) * 100 +(sum(rate(src_grpc_method_status{grpc_service=~"gitserver.v1.GitserverService",is_internal_error="true",grpc_method=~"${git_service_method:regex}"}[2m])) by (grpc_method, grpc_code)) ```-### Postgres: Provisioning indicators (not available on server) +### Git Server: Git Service GRPC retry metrics -#### postgres: provisioning_container_cpu_usage_long_term +#### gitserver: git_service_grpc_clients_retry_percentage_across_all_methods -
Container cpu usage total (90th percentile over 1d) across all cores by instance
+Client retry percentage across all methods over 2m
-Refer to the [alerts reference](alerts#postgres-provisioning-container-cpu-usage-long-term) for 1 alert related to this panel. +The percentage of gRPC requests that were retried across all methods, aggregated across all "git_service" clients. -To see this panel, visit `/-/debug/grafana/d/postgres/postgres?viewPanel=100300` on your Sourcegraph instance. +This panel has no related alerts. -*Managed by the [Sourcegraph Infrastructure Org team](https://handbook.sourcegraph.com/departments/engineering/infrastructure).* +To see this panel, visit `/-/debug/grafana/d/gitserver/gitserver?viewPanel=101600` on your Sourcegraph instance. + +*Managed by the [Sourcegraph Source team](https://handbook.sourcegraph.com/departments/engineering/teams/source).*Technical details
@@ -45271,21 +46133,23 @@ To see this panel, visit `/-/debug/grafana/d/postgres/postgres?viewPanel=100300` Query: ``` -quantile_over_time(0.9, cadvisor_container_cpu_usage_percentage_total{name=~"^(pgsql|codeintel-db|codeinsights).*"}[1d]) +(100.0 * ((((sum(rate(src_grpc_client_retry_attempts_total{grpc_service=~"gitserver.v1.GitserverService",is_retried="true"}[2m])))) / ((sum(rate(src_grpc_client_retry_attempts_total{grpc_service=~"gitserver.v1.GitserverService"}[2m]))))))) ```-#### postgres: provisioning_container_memory_usage_long_term +#### gitserver: git_service_grpc_clients_retry_percentage_per_method -
Container memory usage (1d maximum) by instance
+Client retry percentage per-method over 2m
-Refer to the [alerts reference](alerts#postgres-provisioning-container-memory-usage-long-term) for 1 alert related to this panel. +The percentage of gRPC requests that were retried aggregated across all "git_service" clients, broken out per method. -To see this panel, visit `/-/debug/grafana/d/postgres/postgres?viewPanel=100301` on your Sourcegraph instance. +This panel has no related alerts. -*Managed by the [Sourcegraph Infrastructure Org team](https://handbook.sourcegraph.com/departments/engineering/infrastructure).* +To see this panel, visit `/-/debug/grafana/d/gitserver/gitserver?viewPanel=101601` on your Sourcegraph instance. + +*Managed by the [Sourcegraph Source team](https://handbook.sourcegraph.com/departments/engineering/teams/source).*Technical details
@@ -45293,21 +46157,23 @@ To see this panel, visit `/-/debug/grafana/d/postgres/postgres?viewPanel=100301` Query: ``` -max_over_time(cadvisor_container_memory_usage_percentage_total{name=~"^(pgsql|codeintel-db|codeinsights).*"}[1d]) +(100.0 * ((((sum(rate(src_grpc_client_retry_attempts_total{grpc_service=~"gitserver.v1.GitserverService",is_retried="true",grpc_method=~"${git_service_method:regex}"}[2m])) by (grpc_method))) / ((sum(rate(src_grpc_client_retry_attempts_total{grpc_service=~"gitserver.v1.GitserverService",grpc_method=~"${git_service_method:regex}"}[2m])) by (grpc_method)))))) ```-#### postgres: provisioning_container_cpu_usage_short_term +#### gitserver: git_service_grpc_clients_retry_count_per_method -
Container cpu usage total (5m maximum) across all cores by instance
+Client retry count per-method over 2m
-Refer to the [alerts reference](alerts#postgres-provisioning-container-cpu-usage-short-term) for 1 alert related to this panel. +The count of gRPC requests that were retried aggregated across all "git_service" clients, broken out per method -To see this panel, visit `/-/debug/grafana/d/postgres/postgres?viewPanel=100310` on your Sourcegraph instance. +This panel has no related alerts. -*Managed by the [Sourcegraph Infrastructure Org team](https://handbook.sourcegraph.com/departments/engineering/infrastructure).* +To see this panel, visit `/-/debug/grafana/d/gitserver/gitserver?viewPanel=101602` on your Sourcegraph instance. + +*Managed by the [Sourcegraph Source team](https://handbook.sourcegraph.com/departments/engineering/teams/source).*Technical details
@@ -45315,21 +46181,25 @@ To see this panel, visit `/-/debug/grafana/d/postgres/postgres?viewPanel=100310` Query: ``` -max_over_time(cadvisor_container_cpu_usage_percentage_total{name=~"^(pgsql|codeintel-db|codeinsights).*"}[5m]) +(sum(rate(src_grpc_client_retry_attempts_total{grpc_service=~"gitserver.v1.GitserverService",grpc_method=~"${git_service_method:regex}",is_retried="true"}[2m])) by (grpc_method)) ```-#### postgres: provisioning_container_memory_usage_short_term +### Git Server: Repository Service GRPC server metrics -
Container memory usage (5m maximum) by instance
+#### gitserver: repository_service_grpc_request_rate_all_methods -Refer to the [alerts reference](alerts#postgres-provisioning-container-memory-usage-short-term) for 1 alert related to this panel. +Request rate across all methods over 2m
-To see this panel, visit `/-/debug/grafana/d/postgres/postgres?viewPanel=100311` on your Sourcegraph instance. +The number of gRPC requests received per second across all methods, aggregated across all instances. -*Managed by the [Sourcegraph Infrastructure Org team](https://handbook.sourcegraph.com/departments/engineering/infrastructure).* +This panel has no related alerts. + +To see this panel, visit `/-/debug/grafana/d/gitserver/gitserver?viewPanel=101700` on your Sourcegraph instance. + +*Managed by the [Sourcegraph Source team](https://handbook.sourcegraph.com/departments/engineering/teams/source).*Technical details
@@ -45337,24 +46207,23 @@ To see this panel, visit `/-/debug/grafana/d/postgres/postgres?viewPanel=100311` Query: ``` -max_over_time(cadvisor_container_memory_usage_percentage_total{name=~"^(pgsql|codeintel-db|codeinsights).*"}[5m]) +sum(rate(grpc_server_started_total{instance=~`${shard:regex}`,grpc_service=~"gitserver.v1.GitserverRepositoryService"}[2m])) ```-#### postgres: container_oomkill_events_total +#### gitserver: repository_service_grpc_request_rate_per_method -
Container OOMKILL events total by instance
+Request rate per-method over 2m
-This value indicates the total number of times the container main process or child processes were terminated by OOM killer. -When it occurs frequently, it is an indicator of underprovisioning. +The number of gRPC requests received per second broken out per method, aggregated across all instances. -Refer to the [alerts reference](alerts#postgres-container-oomkill-events-total) for 1 alert related to this panel. +This panel has no related alerts. -To see this panel, visit `/-/debug/grafana/d/postgres/postgres?viewPanel=100312` on your Sourcegraph instance. +To see this panel, visit `/-/debug/grafana/d/gitserver/gitserver?viewPanel=101701` on your Sourcegraph instance. -*Managed by the [Sourcegraph Infrastructure Org team](https://handbook.sourcegraph.com/departments/engineering/infrastructure).* +*Managed by the [Sourcegraph Source team](https://handbook.sourcegraph.com/departments/engineering/teams/source).*Technical details
@@ -45362,23 +46231,23 @@ To see this panel, visit `/-/debug/grafana/d/postgres/postgres?viewPanel=100312` Query: ``` -max by (name) (container_oom_events_total{name=~"^(pgsql|codeintel-db|codeinsights).*"}) +sum(rate(grpc_server_started_total{grpc_method=~`${repository_service_method:regex}`,instance=~`${shard:regex}`,grpc_service=~"gitserver.v1.GitserverRepositoryService"}[2m])) by (grpc_method) ```-### Postgres: Kubernetes monitoring (only available on Kubernetes) +#### gitserver: repository_service_error_percentage_all_methods -#### postgres: pods_available_percentage +
Error percentage across all methods over 2m
-Percentage pods available
+The percentage of gRPC requests that fail across all methods, aggregated across all instances. -Refer to the [alerts reference](alerts#postgres-pods-available-percentage) for 1 alert related to this panel. +This panel has no related alerts. -To see this panel, visit `/-/debug/grafana/d/postgres/postgres?viewPanel=100400` on your Sourcegraph instance. +To see this panel, visit `/-/debug/grafana/d/gitserver/gitserver?viewPanel=101710` on your Sourcegraph instance. -*Managed by the [Sourcegraph Infrastructure Org team](https://handbook.sourcegraph.com/departments/engineering/infrastructure).* +*Managed by the [Sourcegraph Source team](https://handbook.sourcegraph.com/departments/engineering/teams/source).*Technical details
@@ -45386,29 +46255,23 @@ To see this panel, visit `/-/debug/grafana/d/postgres/postgres?viewPanel=100400` Query: ``` -sum by(app) (up{app=~".*(pgsql|codeintel-db|codeinsights)"}) / count by (app) (up{app=~".*(pgsql|codeintel-db|codeinsights)"}) * 100 +(100.0 * ( (sum(rate(grpc_server_handled_total{grpc_code!="OK",instance=~`${shard:regex}`,grpc_service=~"gitserver.v1.GitserverRepositoryService"}[2m]))) / (sum(rate(grpc_server_handled_total{instance=~`${shard:regex}`,grpc_service=~"gitserver.v1.GitserverRepositoryService"}[2m]))) )) ```-## Precise Code Intel Worker - -
Handles conversion of uploaded precise code intelligence bundles.
- -To see this dashboard, visit `/-/debug/grafana/d/precise-code-intel-worker/precise-code-intel-worker` on your Sourcegraph instance. - -### Precise Code Intel Worker: Codeintel: LSIF uploads +#### gitserver: repository_service_grpc_error_percentage_per_method -#### precise-code-intel-worker: codeintel_upload_queue_size +Error percentage per-method over 2m
-Unprocessed upload record queue size
+The percentage of gRPC requests that fail per method, aggregated across all instances. This panel has no related alerts. -To see this panel, visit `/-/debug/grafana/d/precise-code-intel-worker/precise-code-intel-worker?viewPanel=100000` on your Sourcegraph instance. +To see this panel, visit `/-/debug/grafana/d/gitserver/gitserver?viewPanel=101711` on your Sourcegraph instance. -*Managed by the [Sourcegraph Code intelligence team](https://handbook.sourcegraph.com/departments/engineering/teams/code-intelligence).* +*Managed by the [Sourcegraph Source team](https://handbook.sourcegraph.com/departments/engineering/teams/source).*Technical details
@@ -45416,27 +46279,23 @@ To see this panel, visit `/-/debug/grafana/d/precise-code-intel-worker/precise-c Query: ``` -max(src_codeintel_upload_total{job=~"^precise-code-intel-worker.*"}) +(100.0 * ( (sum(rate(grpc_server_handled_total{grpc_method=~`${repository_service_method:regex}`,grpc_code!="OK",instance=~`${shard:regex}`,grpc_service=~"gitserver.v1.GitserverRepositoryService"}[2m])) by (grpc_method)) / (sum(rate(grpc_server_handled_total{grpc_method=~`${repository_service_method:regex}`,instance=~`${shard:regex}`,grpc_service=~"gitserver.v1.GitserverRepositoryService"}[2m])) by (grpc_method)) )) ```-#### precise-code-intel-worker: codeintel_upload_queue_growth_rate +#### gitserver: repository_service_p99_response_time_per_method -
Unprocessed upload record queue growth rate over 30m
- -This value compares the rate of enqueues against the rate of finished jobs. +99th percentile response time per method over 2m
- - A value < than 1 indicates that process rate > enqueue rate - - A value = than 1 indicates that process rate = enqueue rate - - A value > than 1 indicates that process rate < enqueue rate +The 99th percentile response time per method, aggregated across all instances. This panel has no related alerts. -To see this panel, visit `/-/debug/grafana/d/precise-code-intel-worker/precise-code-intel-worker?viewPanel=100001` on your Sourcegraph instance. +To see this panel, visit `/-/debug/grafana/d/gitserver/gitserver?viewPanel=101720` on your Sourcegraph instance. -*Managed by the [Sourcegraph Code intelligence team](https://handbook.sourcegraph.com/departments/engineering/teams/code-intelligence).* +*Managed by the [Sourcegraph Source team](https://handbook.sourcegraph.com/departments/engineering/teams/source).*Technical details
@@ -45444,21 +46303,23 @@ To see this panel, visit `/-/debug/grafana/d/precise-code-intel-worker/precise-c Query: ``` -sum(increase(src_codeintel_upload_total{job=~"^precise-code-intel-worker.*"}[30m])) / sum(increase(src_codeintel_upload_processor_total{job=~"^precise-code-intel-worker.*"}[30m])) +histogram_quantile(0.99, sum by (le, name, grpc_method)(rate(grpc_server_handling_seconds_bucket{grpc_method=~`${repository_service_method:regex}`,instance=~`${shard:regex}`,grpc_service=~"gitserver.v1.GitserverRepositoryService"}[2m]))) ```-#### precise-code-intel-worker: codeintel_upload_queued_max_age +#### gitserver: repository_service_p90_response_time_per_method + +
90th percentile response time per method over 2m
-Unprocessed upload record queue longest time in queue
+The 90th percentile response time per method, aggregated across all instances. -Refer to the [alerts reference](alerts#precise-code-intel-worker-codeintel-upload-queued-max-age) for 1 alert related to this panel. +This panel has no related alerts. -To see this panel, visit `/-/debug/grafana/d/precise-code-intel-worker/precise-code-intel-worker?viewPanel=100002` on your Sourcegraph instance. +To see this panel, visit `/-/debug/grafana/d/gitserver/gitserver?viewPanel=101721` on your Sourcegraph instance. -*Managed by the [Sourcegraph Code intelligence team](https://handbook.sourcegraph.com/departments/engineering/teams/code-intelligence).* +*Managed by the [Sourcegraph Source team](https://handbook.sourcegraph.com/departments/engineering/teams/source).*Technical details
@@ -45466,23 +46327,23 @@ To see this panel, visit `/-/debug/grafana/d/precise-code-intel-worker/precise-c Query: ``` -max(src_codeintel_upload_queued_duration_seconds_total{job=~"^precise-code-intel-worker.*"}) +histogram_quantile(0.90, sum by (le, name, grpc_method)(rate(grpc_server_handling_seconds_bucket{grpc_method=~`${repository_service_method:regex}`,instance=~`${shard:regex}`,grpc_service=~"gitserver.v1.GitserverRepositoryService"}[2m]))) ```-### Precise Code Intel Worker: Codeintel: LSIF uploads +#### gitserver: repository_service_p75_response_time_per_method -#### precise-code-intel-worker: codeintel_upload_handlers +
75th percentile response time per method over 2m
-Handler active handlers
+The 75th percentile response time per method, aggregated across all instances. This panel has no related alerts. -To see this panel, visit `/-/debug/grafana/d/precise-code-intel-worker/precise-code-intel-worker?viewPanel=100100` on your Sourcegraph instance. +To see this panel, visit `/-/debug/grafana/d/gitserver/gitserver?viewPanel=101722` on your Sourcegraph instance. -*Managed by the [Sourcegraph Code intelligence team](https://handbook.sourcegraph.com/departments/engineering/teams/code-intelligence).* +*Managed by the [Sourcegraph Source team](https://handbook.sourcegraph.com/departments/engineering/teams/source).*Technical details
@@ -45490,21 +46351,23 @@ To see this panel, visit `/-/debug/grafana/d/precise-code-intel-worker/precise-c Query: ``` -sum(src_codeintel_upload_processor_handlers{job=~"^precise-code-intel-worker.*"}) +histogram_quantile(0.75, sum by (le, name, grpc_method)(rate(grpc_server_handling_seconds_bucket{grpc_method=~`${repository_service_method:regex}`,instance=~`${shard:regex}`,grpc_service=~"gitserver.v1.GitserverRepositoryService"}[2m]))) ```-#### precise-code-intel-worker: codeintel_upload_processor_upload_size +#### gitserver: repository_service_p99_9_response_size_per_method -
Sum of upload sizes in bytes being processed by each precise code-intel worker instance
+99.9th percentile total response size per method over 2m
+ +The 99.9th percentile total per-RPC response size per method, aggregated across all instances. This panel has no related alerts. -To see this panel, visit `/-/debug/grafana/d/precise-code-intel-worker/precise-code-intel-worker?viewPanel=100101` on your Sourcegraph instance. +To see this panel, visit `/-/debug/grafana/d/gitserver/gitserver?viewPanel=101730` on your Sourcegraph instance. -*Managed by the [Sourcegraph Code intelligence team](https://handbook.sourcegraph.com/departments/engineering/teams/code-intelligence).* +*Managed by the [Sourcegraph Source team](https://handbook.sourcegraph.com/departments/engineering/teams/source).*Technical details
@@ -45512,21 +46375,23 @@ To see this panel, visit `/-/debug/grafana/d/precise-code-intel-worker/precise-c Query: ``` -sum by(instance) (src_codeintel_upload_processor_upload_size{job="precise-code-intel-worker"}) +histogram_quantile(0.999, sum by (le, name, grpc_method)(rate(src_grpc_server_sent_bytes_per_rpc_bucket{grpc_method=~`${repository_service_method:regex}`,instance=~`${shard:regex}`,grpc_service=~"gitserver.v1.GitserverRepositoryService"}[2m]))) ```-#### precise-code-intel-worker: codeintel_upload_processor_total +#### gitserver: repository_service_p90_response_size_per_method -
Handler operations every 5m
+90th percentile total response size per method over 2m
+ +The 90th percentile total per-RPC response size per method, aggregated across all instances. This panel has no related alerts. -To see this panel, visit `/-/debug/grafana/d/precise-code-intel-worker/precise-code-intel-worker?viewPanel=100110` on your Sourcegraph instance. +To see this panel, visit `/-/debug/grafana/d/gitserver/gitserver?viewPanel=101731` on your Sourcegraph instance. -*Managed by the [Sourcegraph Code intelligence team](https://handbook.sourcegraph.com/departments/engineering/teams/code-intelligence).* +*Managed by the [Sourcegraph Source team](https://handbook.sourcegraph.com/departments/engineering/teams/source).*Technical details
@@ -45534,21 +46399,23 @@ To see this panel, visit `/-/debug/grafana/d/precise-code-intel-worker/precise-c Query: ``` -sum(increase(src_codeintel_upload_processor_total{job=~"^precise-code-intel-worker.*"}[5m])) +histogram_quantile(0.90, sum by (le, name, grpc_method)(rate(src_grpc_server_sent_bytes_per_rpc_bucket{grpc_method=~`${repository_service_method:regex}`,instance=~`${shard:regex}`,grpc_service=~"gitserver.v1.GitserverRepositoryService"}[2m]))) ```-#### precise-code-intel-worker: codeintel_upload_processor_99th_percentile_duration +#### gitserver: repository_service_p75_response_size_per_method -
Aggregate successful handler operation duration distribution over 5m
+75th percentile total response size per method over 2m
+ +The 75th percentile total per-RPC response size per method, aggregated across all instances. This panel has no related alerts. -To see this panel, visit `/-/debug/grafana/d/precise-code-intel-worker/precise-code-intel-worker?viewPanel=100111` on your Sourcegraph instance. +To see this panel, visit `/-/debug/grafana/d/gitserver/gitserver?viewPanel=101732` on your Sourcegraph instance. -*Managed by the [Sourcegraph Code intelligence team](https://handbook.sourcegraph.com/departments/engineering/teams/code-intelligence).* +*Managed by the [Sourcegraph Source team](https://handbook.sourcegraph.com/departments/engineering/teams/source).*Technical details
@@ -45556,21 +46423,23 @@ To see this panel, visit `/-/debug/grafana/d/precise-code-intel-worker/precise-c Query: ``` -sum by (le)(rate(src_codeintel_upload_processor_duration_seconds_bucket{job=~"^precise-code-intel-worker.*"}[5m])) +histogram_quantile(0.75, sum by (le, name, grpc_method)(rate(src_grpc_server_sent_bytes_per_rpc_bucket{grpc_method=~`${repository_service_method:regex}`,instance=~`${shard:regex}`,grpc_service=~"gitserver.v1.GitserverRepositoryService"}[2m]))) ```-#### precise-code-intel-worker: codeintel_upload_processor_errors_total +#### gitserver: repository_service_p99_9_invididual_sent_message_size_per_method -
Handler operation errors every 5m
+99.9th percentile individual sent message size per method over 2m
+ +The 99.9th percentile size of every individual protocol buffer size sent by the service per method, aggregated across all instances. This panel has no related alerts. -To see this panel, visit `/-/debug/grafana/d/precise-code-intel-worker/precise-code-intel-worker?viewPanel=100112` on your Sourcegraph instance. +To see this panel, visit `/-/debug/grafana/d/gitserver/gitserver?viewPanel=101740` on your Sourcegraph instance. -*Managed by the [Sourcegraph Code intelligence team](https://handbook.sourcegraph.com/departments/engineering/teams/code-intelligence).* +*Managed by the [Sourcegraph Source team](https://handbook.sourcegraph.com/departments/engineering/teams/source).*Technical details
@@ -45578,21 +46447,23 @@ To see this panel, visit `/-/debug/grafana/d/precise-code-intel-worker/precise-c Query: ``` -sum(increase(src_codeintel_upload_processor_errors_total{job=~"^precise-code-intel-worker.*"}[5m])) +histogram_quantile(0.999, sum by (le, name, grpc_method)(rate(src_grpc_server_sent_individual_message_size_bytes_per_rpc_bucket{grpc_method=~`${repository_service_method:regex}`,instance=~`${shard:regex}`,grpc_service=~"gitserver.v1.GitserverRepositoryService"}[2m]))) ```-#### precise-code-intel-worker: codeintel_upload_processor_error_rate +#### gitserver: repository_service_p90_invididual_sent_message_size_per_method -
Handler operation error rate over 5m
+90th percentile individual sent message size per method over 2m
+ +The 90th percentile size of every individual protocol buffer size sent by the service per method, aggregated across all instances. This panel has no related alerts. -To see this panel, visit `/-/debug/grafana/d/precise-code-intel-worker/precise-code-intel-worker?viewPanel=100113` on your Sourcegraph instance. +To see this panel, visit `/-/debug/grafana/d/gitserver/gitserver?viewPanel=101741` on your Sourcegraph instance. -*Managed by the [Sourcegraph Code intelligence team](https://handbook.sourcegraph.com/departments/engineering/teams/code-intelligence).* +*Managed by the [Sourcegraph Source team](https://handbook.sourcegraph.com/departments/engineering/teams/source).*Technical details
@@ -45600,23 +46471,23 @@ To see this panel, visit `/-/debug/grafana/d/precise-code-intel-worker/precise-c Query: ``` -sum(increase(src_codeintel_upload_processor_errors_total{job=~"^precise-code-intel-worker.*"}[5m])) / (sum(increase(src_codeintel_upload_processor_total{job=~"^precise-code-intel-worker.*"}[5m])) + sum(increase(src_codeintel_upload_processor_errors_total{job=~"^precise-code-intel-worker.*"}[5m]))) * 100 +histogram_quantile(0.90, sum by (le, name, grpc_method)(rate(src_grpc_server_sent_individual_message_size_bytes_per_rpc_bucket{grpc_method=~`${repository_service_method:regex}`,instance=~`${shard:regex}`,grpc_service=~"gitserver.v1.GitserverRepositoryService"}[2m]))) ```-### Precise Code Intel Worker: Codeintel: dbstore stats +#### gitserver: repository_service_p75_invididual_sent_message_size_per_method -#### precise-code-intel-worker: codeintel_uploads_store_total +
75th percentile individual sent message size per method over 2m
-Aggregate store operations every 5m
+The 75th percentile size of every individual protocol buffer size sent by the service per method, aggregated across all instances. This panel has no related alerts. -To see this panel, visit `/-/debug/grafana/d/precise-code-intel-worker/precise-code-intel-worker?viewPanel=100200` on your Sourcegraph instance. +To see this panel, visit `/-/debug/grafana/d/gitserver/gitserver?viewPanel=101742` on your Sourcegraph instance. -*Managed by the [Sourcegraph Code intelligence team](https://handbook.sourcegraph.com/departments/engineering/teams/code-intelligence).* +*Managed by the [Sourcegraph Source team](https://handbook.sourcegraph.com/departments/engineering/teams/source).*Technical details
@@ -45624,21 +46495,23 @@ To see this panel, visit `/-/debug/grafana/d/precise-code-intel-worker/precise-c Query: ``` -sum(increase(src_codeintel_uploads_store_total{job=~"^precise-code-intel-worker.*"}[5m])) +histogram_quantile(0.75, sum by (le, name, grpc_method)(rate(src_grpc_server_sent_individual_message_size_bytes_per_rpc_bucket{grpc_method=~`${repository_service_method:regex}`,instance=~`${shard:regex}`,grpc_service=~"gitserver.v1.GitserverRepositoryService"}[2m]))) ```-#### precise-code-intel-worker: codeintel_uploads_store_99th_percentile_duration +#### gitserver: repository_service_grpc_response_stream_message_count_per_method -
Aggregate successful store operation duration distribution over 5m
+Average streaming response message count per-method over 2m
+ +The average number of response messages sent during a streaming RPC method, broken out per method, aggregated across all instances. This panel has no related alerts. -To see this panel, visit `/-/debug/grafana/d/precise-code-intel-worker/precise-code-intel-worker?viewPanel=100201` on your Sourcegraph instance. +To see this panel, visit `/-/debug/grafana/d/gitserver/gitserver?viewPanel=101750` on your Sourcegraph instance. -*Managed by the [Sourcegraph Code intelligence team](https://handbook.sourcegraph.com/departments/engineering/teams/code-intelligence).* +*Managed by the [Sourcegraph Source team](https://handbook.sourcegraph.com/departments/engineering/teams/source).*Technical details
@@ -45646,21 +46519,23 @@ To see this panel, visit `/-/debug/grafana/d/precise-code-intel-worker/precise-c Query: ``` -sum by (le)(rate(src_codeintel_uploads_store_duration_seconds_bucket{job=~"^precise-code-intel-worker.*"}[5m])) +((sum(rate(grpc_server_msg_sent_total{grpc_type="server_stream",instance=~`${shard:regex}`,grpc_service=~"gitserver.v1.GitserverRepositoryService"}[2m])) by (grpc_method))/(sum(rate(grpc_server_started_total{grpc_type="server_stream",instance=~`${shard:regex}`,grpc_service=~"gitserver.v1.GitserverRepositoryService"}[2m])) by (grpc_method))) ```-#### precise-code-intel-worker: codeintel_uploads_store_errors_total +#### gitserver: repository_service_grpc_all_codes_per_method -
Aggregate store operation errors every 5m
+Response codes rate per-method over 2m
+ +The rate of all generated gRPC response codes per method, aggregated across all instances. This panel has no related alerts. -To see this panel, visit `/-/debug/grafana/d/precise-code-intel-worker/precise-code-intel-worker?viewPanel=100202` on your Sourcegraph instance. +To see this panel, visit `/-/debug/grafana/d/gitserver/gitserver?viewPanel=101760` on your Sourcegraph instance. -*Managed by the [Sourcegraph Code intelligence team](https://handbook.sourcegraph.com/departments/engineering/teams/code-intelligence).* +*Managed by the [Sourcegraph Source team](https://handbook.sourcegraph.com/departments/engineering/teams/source).*Technical details
@@ -45668,21 +46543,25 @@ To see this panel, visit `/-/debug/grafana/d/precise-code-intel-worker/precise-c Query: ``` -sum(increase(src_codeintel_uploads_store_errors_total{job=~"^precise-code-intel-worker.*"}[5m])) +sum(rate(grpc_server_handled_total{grpc_method=~`${repository_service_method:regex}`,instance=~`${shard:regex}`,grpc_service=~"gitserver.v1.GitserverRepositoryService"}[2m])) by (grpc_method, grpc_code) ```-#### precise-code-intel-worker: codeintel_uploads_store_error_rate +### Git Server: Repository Service GRPC "internal error" metrics -
Aggregate store operation error rate over 5m
+#### gitserver: repository_service_grpc_clients_error_percentage_all_methods + +Client baseline error percentage across all methods over 2m
+ +The percentage of gRPC requests that fail across all methods (regardless of whether or not there was an internal error), aggregated across all "repository_service" clients. This panel has no related alerts. -To see this panel, visit `/-/debug/grafana/d/precise-code-intel-worker/precise-code-intel-worker?viewPanel=100203` on your Sourcegraph instance. +To see this panel, visit `/-/debug/grafana/d/gitserver/gitserver?viewPanel=101800` on your Sourcegraph instance. -*Managed by the [Sourcegraph Code intelligence team](https://handbook.sourcegraph.com/departments/engineering/teams/code-intelligence).* +*Managed by the [Sourcegraph Source team](https://handbook.sourcegraph.com/departments/engineering/teams/source).*Technical details
@@ -45690,21 +46569,23 @@ To see this panel, visit `/-/debug/grafana/d/precise-code-intel-worker/precise-c Query: ``` -sum(increase(src_codeintel_uploads_store_errors_total{job=~"^precise-code-intel-worker.*"}[5m])) / (sum(increase(src_codeintel_uploads_store_total{job=~"^precise-code-intel-worker.*"}[5m])) + sum(increase(src_codeintel_uploads_store_errors_total{job=~"^precise-code-intel-worker.*"}[5m]))) * 100 +(100.0 * ((((sum(rate(src_grpc_method_status{grpc_service=~"gitserver.v1.GitserverRepositoryService",grpc_code!="OK"}[2m])))) / ((sum(rate(src_grpc_method_status{grpc_service=~"gitserver.v1.GitserverRepositoryService"}[2m]))))))) ```-#### precise-code-intel-worker: codeintel_uploads_store_total +#### gitserver: repository_service_grpc_clients_error_percentage_per_method -
Store operations every 5m
+Client baseline error percentage per-method over 2m
+ +The percentage of gRPC requests that fail per method (regardless of whether or not there was an internal error), aggregated across all "repository_service" clients. This panel has no related alerts. -To see this panel, visit `/-/debug/grafana/d/precise-code-intel-worker/precise-code-intel-worker?viewPanel=100210` on your Sourcegraph instance. +To see this panel, visit `/-/debug/grafana/d/gitserver/gitserver?viewPanel=101801` on your Sourcegraph instance. -*Managed by the [Sourcegraph Code intelligence team](https://handbook.sourcegraph.com/departments/engineering/teams/code-intelligence).* +*Managed by the [Sourcegraph Source team](https://handbook.sourcegraph.com/departments/engineering/teams/source).*Technical details
@@ -45712,21 +46593,23 @@ To see this panel, visit `/-/debug/grafana/d/precise-code-intel-worker/precise-c Query: ``` -sum by (op)(increase(src_codeintel_uploads_store_total{job=~"^precise-code-intel-worker.*"}[5m])) +(100.0 * ((((sum(rate(src_grpc_method_status{grpc_service=~"gitserver.v1.GitserverRepositoryService",grpc_method=~"${repository_service_method:regex}",grpc_code!="OK"}[2m])) by (grpc_method))) / ((sum(rate(src_grpc_method_status{grpc_service=~"gitserver.v1.GitserverRepositoryService",grpc_method=~"${repository_service_method:regex}"}[2m])) by (grpc_method)))))) ```-#### precise-code-intel-worker: codeintel_uploads_store_99th_percentile_duration +#### gitserver: repository_service_grpc_clients_all_codes_per_method -
99th percentile successful store operation duration over 5m
+Client baseline response codes rate per-method over 2m
+ +The rate of all generated gRPC response codes per method (regardless of whether or not there was an internal error), aggregated across all "repository_service" clients. This panel has no related alerts. -To see this panel, visit `/-/debug/grafana/d/precise-code-intel-worker/precise-code-intel-worker?viewPanel=100211` on your Sourcegraph instance. +To see this panel, visit `/-/debug/grafana/d/gitserver/gitserver?viewPanel=101802` on your Sourcegraph instance. -*Managed by the [Sourcegraph Code intelligence team](https://handbook.sourcegraph.com/departments/engineering/teams/code-intelligence).* +*Managed by the [Sourcegraph Source team](https://handbook.sourcegraph.com/departments/engineering/teams/source).*Technical details
@@ -45734,21 +46617,29 @@ To see this panel, visit `/-/debug/grafana/d/precise-code-intel-worker/precise-c Query: ``` -histogram_quantile(0.99, sum by (le,op)(rate(src_codeintel_uploads_store_duration_seconds_bucket{job=~"^precise-code-intel-worker.*"}[5m]))) +(sum(rate(src_grpc_method_status{grpc_service=~"gitserver.v1.GitserverRepositoryService",grpc_method=~"${repository_service_method:regex}"}[2m])) by (grpc_method, grpc_code)) ```-#### precise-code-intel-worker: codeintel_uploads_store_errors_total +#### gitserver: repository_service_grpc_clients_internal_error_percentage_all_methods -
Store operation errors every 5m
+Client-observed gRPC internal error percentage across all methods over 2m
+ +The percentage of gRPC requests that appear to fail due to gRPC internal errors across all methods, aggregated across all "repository_service" clients. + +**Note**: Internal errors are ones that appear to originate from the https://github.com/grpc/grpc-go library itself, rather than from any user-written application code. These errors can be caused by a variety of issues, and can originate from either the code-generated "repository_service" gRPC client or gRPC server. These errors might be solvable by adjusting the gRPC configuration, or they might indicate a bug from Sourcegraph`s use of gRPC. + +When debugging, knowing that a particular error comes from the grpc-go library itself (an `internal error`) as opposed to `normal` application code can be helpful when trying to fix it. + +**Note**: Internal errors are detected via a very coarse heuristic (seeing if the error starts with `grpc:`, etc.). Because of this, it`s possible that some gRPC-specific issues might not be categorized as internal errors. This panel has no related alerts. -To see this panel, visit `/-/debug/grafana/d/precise-code-intel-worker/precise-code-intel-worker?viewPanel=100212` on your Sourcegraph instance. +To see this panel, visit `/-/debug/grafana/d/gitserver/gitserver?viewPanel=101810` on your Sourcegraph instance. -*Managed by the [Sourcegraph Code intelligence team](https://handbook.sourcegraph.com/departments/engineering/teams/code-intelligence).* +*Managed by the [Sourcegraph Source team](https://handbook.sourcegraph.com/departments/engineering/teams/source).*Technical details
@@ -45756,21 +46647,29 @@ To see this panel, visit `/-/debug/grafana/d/precise-code-intel-worker/precise-c Query: ``` -sum by (op)(increase(src_codeintel_uploads_store_errors_total{job=~"^precise-code-intel-worker.*"}[5m])) +(100.0 * ((((sum(rate(src_grpc_method_status{grpc_service=~"gitserver.v1.GitserverRepositoryService",grpc_code!="OK",is_internal_error="true"}[2m])))) / ((sum(rate(src_grpc_method_status{grpc_service=~"gitserver.v1.GitserverRepositoryService"}[2m]))))))) ```-#### precise-code-intel-worker: codeintel_uploads_store_error_rate +#### gitserver: repository_service_grpc_clients_internal_error_percentage_per_method -
Store operation error rate over 5m
+Client-observed gRPC internal error percentage per-method over 2m
+ +The percentage of gRPC requests that appear to fail to due to gRPC internal errors per method, aggregated across all "repository_service" clients. + +**Note**: Internal errors are ones that appear to originate from the https://github.com/grpc/grpc-go library itself, rather than from any user-written application code. These errors can be caused by a variety of issues, and can originate from either the code-generated "repository_service" gRPC client or gRPC server. These errors might be solvable by adjusting the gRPC configuration, or they might indicate a bug from Sourcegraph`s use of gRPC. + +When debugging, knowing that a particular error comes from the grpc-go library itself (an `internal error`) as opposed to `normal` application code can be helpful when trying to fix it. + +**Note**: Internal errors are detected via a very coarse heuristic (seeing if the error starts with `grpc:`, etc.). Because of this, it`s possible that some gRPC-specific issues might not be categorized as internal errors. This panel has no related alerts. -To see this panel, visit `/-/debug/grafana/d/precise-code-intel-worker/precise-code-intel-worker?viewPanel=100213` on your Sourcegraph instance. +To see this panel, visit `/-/debug/grafana/d/gitserver/gitserver?viewPanel=101811` on your Sourcegraph instance. -*Managed by the [Sourcegraph Code intelligence team](https://handbook.sourcegraph.com/departments/engineering/teams/code-intelligence).* +*Managed by the [Sourcegraph Source team](https://handbook.sourcegraph.com/departments/engineering/teams/source).*Technical details
@@ -45778,23 +46677,29 @@ To see this panel, visit `/-/debug/grafana/d/precise-code-intel-worker/precise-c Query: ``` -sum by (op)(increase(src_codeintel_uploads_store_errors_total{job=~"^precise-code-intel-worker.*"}[5m])) / (sum by (op)(increase(src_codeintel_uploads_store_total{job=~"^precise-code-intel-worker.*"}[5m])) + sum by (op)(increase(src_codeintel_uploads_store_errors_total{job=~"^precise-code-intel-worker.*"}[5m]))) * 100 +(100.0 * ((((sum(rate(src_grpc_method_status{grpc_service=~"gitserver.v1.GitserverRepositoryService",grpc_method=~"${repository_service_method:regex}",grpc_code!="OK",is_internal_error="true"}[2m])) by (grpc_method))) / ((sum(rate(src_grpc_method_status{grpc_service=~"gitserver.v1.GitserverRepositoryService",grpc_method=~"${repository_service_method:regex}"}[2m])) by (grpc_method)))))) ```-### Precise Code Intel Worker: Codeintel: lsifstore stats +#### gitserver: repository_service_grpc_clients_internal_error_all_codes_per_method -#### precise-code-intel-worker: codeintel_uploads_lsifstore_total +
Client-observed gRPC internal error response code rate per-method over 2m
-Aggregate store operations every 5m
+The rate of gRPC internal-error response codes per method, aggregated across all "repository_service" clients. + +**Note**: Internal errors are ones that appear to originate from the https://github.com/grpc/grpc-go library itself, rather than from any user-written application code. These errors can be caused by a variety of issues, and can originate from either the code-generated "repository_service" gRPC client or gRPC server. These errors might be solvable by adjusting the gRPC configuration, or they might indicate a bug from Sourcegraph`s use of gRPC. + +When debugging, knowing that a particular error comes from the grpc-go library itself (an `internal error`) as opposed to `normal` application code can be helpful when trying to fix it. + +**Note**: Internal errors are detected via a very coarse heuristic (seeing if the error starts with `grpc:`, etc.). Because of this, it`s possible that some gRPC-specific issues might not be categorized as internal errors. This panel has no related alerts. -To see this panel, visit `/-/debug/grafana/d/precise-code-intel-worker/precise-code-intel-worker?viewPanel=100300` on your Sourcegraph instance. +To see this panel, visit `/-/debug/grafana/d/gitserver/gitserver?viewPanel=101812` on your Sourcegraph instance. -*Managed by the [Sourcegraph Code intelligence team](https://handbook.sourcegraph.com/departments/engineering/teams/code-intelligence).* +*Managed by the [Sourcegraph Source team](https://handbook.sourcegraph.com/departments/engineering/teams/source).*Technical details
@@ -45802,21 +46707,25 @@ To see this panel, visit `/-/debug/grafana/d/precise-code-intel-worker/precise-c Query: ``` -sum(increase(src_codeintel_uploads_lsifstore_total{job=~"^precise-code-intel-worker.*"}[5m])) +(sum(rate(src_grpc_method_status{grpc_service=~"gitserver.v1.GitserverRepositoryService",is_internal_error="true",grpc_method=~"${repository_service_method:regex}"}[2m])) by (grpc_method, grpc_code)) ```-#### precise-code-intel-worker: codeintel_uploads_lsifstore_99th_percentile_duration +### Git Server: Repository Service GRPC retry metrics -
Aggregate successful store operation duration distribution over 5m
+#### gitserver: repository_service_grpc_clients_retry_percentage_across_all_methods + +Client retry percentage across all methods over 2m
+ +The percentage of gRPC requests that were retried across all methods, aggregated across all "repository_service" clients. This panel has no related alerts. -To see this panel, visit `/-/debug/grafana/d/precise-code-intel-worker/precise-code-intel-worker?viewPanel=100301` on your Sourcegraph instance. +To see this panel, visit `/-/debug/grafana/d/gitserver/gitserver?viewPanel=101900` on your Sourcegraph instance. -*Managed by the [Sourcegraph Code intelligence team](https://handbook.sourcegraph.com/departments/engineering/teams/code-intelligence).* +*Managed by the [Sourcegraph Source team](https://handbook.sourcegraph.com/departments/engineering/teams/source).*Technical details
@@ -45824,21 +46733,23 @@ To see this panel, visit `/-/debug/grafana/d/precise-code-intel-worker/precise-c Query: ``` -sum by (le)(rate(src_codeintel_uploads_lsifstore_duration_seconds_bucket{job=~"^precise-code-intel-worker.*"}[5m])) +(100.0 * ((((sum(rate(src_grpc_client_retry_attempts_total{grpc_service=~"gitserver.v1.GitserverRepositoryService",is_retried="true"}[2m])))) / ((sum(rate(src_grpc_client_retry_attempts_total{grpc_service=~"gitserver.v1.GitserverRepositoryService"}[2m]))))))) ```-#### precise-code-intel-worker: codeintel_uploads_lsifstore_errors_total +#### gitserver: repository_service_grpc_clients_retry_percentage_per_method -
Aggregate store operation errors every 5m
+Client retry percentage per-method over 2m
+ +The percentage of gRPC requests that were retried aggregated across all "repository_service" clients, broken out per method. This panel has no related alerts. -To see this panel, visit `/-/debug/grafana/d/precise-code-intel-worker/precise-code-intel-worker?viewPanel=100302` on your Sourcegraph instance. +To see this panel, visit `/-/debug/grafana/d/gitserver/gitserver?viewPanel=101901` on your Sourcegraph instance. -*Managed by the [Sourcegraph Code intelligence team](https://handbook.sourcegraph.com/departments/engineering/teams/code-intelligence).* +*Managed by the [Sourcegraph Source team](https://handbook.sourcegraph.com/departments/engineering/teams/source).*Technical details
@@ -45846,21 +46757,23 @@ To see this panel, visit `/-/debug/grafana/d/precise-code-intel-worker/precise-c Query: ``` -sum(increase(src_codeintel_uploads_lsifstore_errors_total{job=~"^precise-code-intel-worker.*"}[5m])) +(100.0 * ((((sum(rate(src_grpc_client_retry_attempts_total{grpc_service=~"gitserver.v1.GitserverRepositoryService",is_retried="true",grpc_method=~"${repository_service_method:regex}"}[2m])) by (grpc_method))) / ((sum(rate(src_grpc_client_retry_attempts_total{grpc_service=~"gitserver.v1.GitserverRepositoryService",grpc_method=~"${repository_service_method:regex}"}[2m])) by (grpc_method)))))) ```-#### precise-code-intel-worker: codeintel_uploads_lsifstore_error_rate +#### gitserver: repository_service_grpc_clients_retry_count_per_method -
Aggregate store operation error rate over 5m
+Client retry count per-method over 2m
+ +The count of gRPC requests that were retried aggregated across all "repository_service" clients, broken out per method This panel has no related alerts. -To see this panel, visit `/-/debug/grafana/d/precise-code-intel-worker/precise-code-intel-worker?viewPanel=100303` on your Sourcegraph instance. +To see this panel, visit `/-/debug/grafana/d/gitserver/gitserver?viewPanel=101902` on your Sourcegraph instance. -*Managed by the [Sourcegraph Code intelligence team](https://handbook.sourcegraph.com/departments/engineering/teams/code-intelligence).* +*Managed by the [Sourcegraph Source team](https://handbook.sourcegraph.com/departments/engineering/teams/source).*Technical details
@@ -45868,21 +46781,25 @@ To see this panel, visit `/-/debug/grafana/d/precise-code-intel-worker/precise-c Query: ``` -sum(increase(src_codeintel_uploads_lsifstore_errors_total{job=~"^precise-code-intel-worker.*"}[5m])) / (sum(increase(src_codeintel_uploads_lsifstore_total{job=~"^precise-code-intel-worker.*"}[5m])) + sum(increase(src_codeintel_uploads_lsifstore_errors_total{job=~"^precise-code-intel-worker.*"}[5m]))) * 100 +(sum(rate(src_grpc_client_retry_attempts_total{grpc_service=~"gitserver.v1.GitserverRepositoryService",grpc_method=~"${repository_service_method:regex}",is_retried="true"}[2m])) by (grpc_method)) ```-#### precise-code-intel-worker: codeintel_uploads_lsifstore_total +### Git Server: Site configuration client update latency -
Store operations every 5m
+#### gitserver: gitserver_site_configuration_duration_since_last_successful_update_by_instance + +Duration since last successful site configuration update (by instance)
+ +The duration since the configuration client used by the "gitserver" service last successfully updated its site configuration. Long durations could indicate issues updating the site configuration. This panel has no related alerts. -To see this panel, visit `/-/debug/grafana/d/precise-code-intel-worker/precise-code-intel-worker?viewPanel=100310` on your Sourcegraph instance. +To see this panel, visit `/-/debug/grafana/d/gitserver/gitserver?viewPanel=102000` on your Sourcegraph instance. -*Managed by the [Sourcegraph Code intelligence team](https://handbook.sourcegraph.com/departments/engineering/teams/code-intelligence).* +*Managed by the [Sourcegraph Infrastructure Org team](https://handbook.sourcegraph.com/departments/engineering/infrastructure).*Technical details
@@ -45890,21 +46807,21 @@ To see this panel, visit `/-/debug/grafana/d/precise-code-intel-worker/precise-c Query: ``` -sum by (op)(increase(src_codeintel_uploads_lsifstore_total{job=~"^precise-code-intel-worker.*"}[5m])) +src_conf_client_time_since_last_successful_update_seconds{job=~`.*gitserver`,instance=~`${shard:regex}`} ```-#### precise-code-intel-worker: codeintel_uploads_lsifstore_99th_percentile_duration +#### gitserver: gitserver_site_configuration_duration_since_last_successful_update_by_instance -
99th percentile successful store operation duration over 5m
+Maximum duration since last successful site configuration update (all "gitserver" instances)
-This panel has no related alerts. +Refer to the [alerts reference](alerts#gitserver-gitserver-site-configuration-duration-since-last-successful-update-by-instance) for 1 alert related to this panel. -To see this panel, visit `/-/debug/grafana/d/precise-code-intel-worker/precise-code-intel-worker?viewPanel=100311` on your Sourcegraph instance. +To see this panel, visit `/-/debug/grafana/d/gitserver/gitserver?viewPanel=102001` on your Sourcegraph instance. -*Managed by the [Sourcegraph Code intelligence team](https://handbook.sourcegraph.com/departments/engineering/teams/code-intelligence).* +*Managed by the [Sourcegraph Infrastructure Org team](https://handbook.sourcegraph.com/departments/engineering/infrastructure).*Technical details
@@ -45912,21 +46829,25 @@ To see this panel, visit `/-/debug/grafana/d/precise-code-intel-worker/precise-c Query: ``` -histogram_quantile(0.99, sum by (le,op)(rate(src_codeintel_uploads_lsifstore_duration_seconds_bucket{job=~"^precise-code-intel-worker.*"}[5m]))) +max(max_over_time(src_conf_client_time_since_last_successful_update_seconds{job=~`.*gitserver`,instance=~`${shard:regex}`}[1m])) ```-#### precise-code-intel-worker: codeintel_uploads_lsifstore_errors_total +### Git Server: HTTP handlers -
Store operation errors every 5m
+#### gitserver: healthy_request_rate + +Requests per second, by route, when status code is 200
+ +The number of healthy HTTP requests per second to internal HTTP api This panel has no related alerts. -To see this panel, visit `/-/debug/grafana/d/precise-code-intel-worker/precise-code-intel-worker?viewPanel=100312` on your Sourcegraph instance. +To see this panel, visit `/-/debug/grafana/d/gitserver/gitserver?viewPanel=102100` on your Sourcegraph instance. -*Managed by the [Sourcegraph Code intelligence team](https://handbook.sourcegraph.com/departments/engineering/teams/code-intelligence).* +*Managed by the [Sourcegraph Source team](https://handbook.sourcegraph.com/departments/engineering/teams/source).*Technical details
@@ -45934,21 +46855,23 @@ To see this panel, visit `/-/debug/grafana/d/precise-code-intel-worker/precise-c Query: ``` -sum by (op)(increase(src_codeintel_uploads_lsifstore_errors_total{job=~"^precise-code-intel-worker.*"}[5m])) +sum by (route) (rate(src_http_request_duration_seconds_count{app="gitserver",code=~"2.."}[5m])) ```-#### precise-code-intel-worker: codeintel_uploads_lsifstore_error_rate +#### gitserver: unhealthy_request_rate -
Store operation error rate over 5m
+Requests per second, by route, when status code is not 200
+ +The number of unhealthy HTTP requests per second to internal HTTP api This panel has no related alerts. -To see this panel, visit `/-/debug/grafana/d/precise-code-intel-worker/precise-code-intel-worker?viewPanel=100313` on your Sourcegraph instance. +To see this panel, visit `/-/debug/grafana/d/gitserver/gitserver?viewPanel=102101` on your Sourcegraph instance. -*Managed by the [Sourcegraph Code intelligence team](https://handbook.sourcegraph.com/departments/engineering/teams/code-intelligence).* +*Managed by the [Sourcegraph Source team](https://handbook.sourcegraph.com/departments/engineering/teams/source).*Technical details
@@ -45956,23 +46879,23 @@ To see this panel, visit `/-/debug/grafana/d/precise-code-intel-worker/precise-c Query: ``` -sum by (op)(increase(src_codeintel_uploads_lsifstore_errors_total{job=~"^precise-code-intel-worker.*"}[5m])) / (sum by (op)(increase(src_codeintel_uploads_lsifstore_total{job=~"^precise-code-intel-worker.*"}[5m])) + sum by (op)(increase(src_codeintel_uploads_lsifstore_errors_total{job=~"^precise-code-intel-worker.*"}[5m]))) * 100 +sum by (route) (rate(src_http_request_duration_seconds_count{app="gitserver",code!~"2.."}[5m])) ```-### Precise Code Intel Worker: Workerutil: lsif_uploads dbworker/store stats +#### gitserver: request_rate_by_code -#### precise-code-intel-worker: workerutil_dbworker_store_codeintel_upload_total +
Requests per second, by status code
-Store operations every 5m
+The number of HTTP requests per second by code This panel has no related alerts. -To see this panel, visit `/-/debug/grafana/d/precise-code-intel-worker/precise-code-intel-worker?viewPanel=100400` on your Sourcegraph instance. +To see this panel, visit `/-/debug/grafana/d/gitserver/gitserver?viewPanel=102102` on your Sourcegraph instance. -*Managed by the [Sourcegraph Code intelligence team](https://handbook.sourcegraph.com/departments/engineering/teams/code-intelligence).* +*Managed by the [Sourcegraph Source team](https://handbook.sourcegraph.com/departments/engineering/teams/source).*Technical details
@@ -45980,21 +46903,23 @@ To see this panel, visit `/-/debug/grafana/d/precise-code-intel-worker/precise-c Query: ``` -sum(increase(src_workerutil_dbworker_store_codeintel_upload_total{job=~"^precise-code-intel-worker.*"}[5m])) +sum by (code) (rate(src_http_request_duration_seconds_count{app="gitserver"}[5m])) ```-#### precise-code-intel-worker: workerutil_dbworker_store_codeintel_upload_99th_percentile_duration +#### gitserver: 95th_percentile_healthy_requests -
Aggregate successful store operation duration distribution over 5m
+95th percentile duration by route, when status code is 200
+ +The 95th percentile duration by route when the status code is 200 This panel has no related alerts. -To see this panel, visit `/-/debug/grafana/d/precise-code-intel-worker/precise-code-intel-worker?viewPanel=100401` on your Sourcegraph instance. +To see this panel, visit `/-/debug/grafana/d/gitserver/gitserver?viewPanel=102110` on your Sourcegraph instance. -*Managed by the [Sourcegraph Code intelligence team](https://handbook.sourcegraph.com/departments/engineering/teams/code-intelligence).* +*Managed by the [Sourcegraph Source team](https://handbook.sourcegraph.com/departments/engineering/teams/source).*Technical details
@@ -46002,21 +46927,23 @@ To see this panel, visit `/-/debug/grafana/d/precise-code-intel-worker/precise-c Query: ``` -sum by (le)(rate(src_workerutil_dbworker_store_codeintel_upload_duration_seconds_bucket{job=~"^precise-code-intel-worker.*"}[5m])) +histogram_quantile(0.95, sum(rate(src_http_request_duration_seconds_bucket{app="gitserver",code=~"2.."}[5m])) by (le, route)) ```-#### precise-code-intel-worker: workerutil_dbworker_store_codeintel_upload_errors_total +#### gitserver: 95th_percentile_unhealthy_requests -
Store operation errors every 5m
+95th percentile duration by route, when status code is not 200
+ +The 95th percentile duration by route when the status code is not 200 This panel has no related alerts. -To see this panel, visit `/-/debug/grafana/d/precise-code-intel-worker/precise-code-intel-worker?viewPanel=100402` on your Sourcegraph instance. +To see this panel, visit `/-/debug/grafana/d/gitserver/gitserver?viewPanel=102111` on your Sourcegraph instance. -*Managed by the [Sourcegraph Code intelligence team](https://handbook.sourcegraph.com/departments/engineering/teams/code-intelligence).* +*Managed by the [Sourcegraph Source team](https://handbook.sourcegraph.com/departments/engineering/teams/source).*Technical details
@@ -46024,21 +46951,23 @@ To see this panel, visit `/-/debug/grafana/d/precise-code-intel-worker/precise-c Query: ``` -sum(increase(src_workerutil_dbworker_store_codeintel_upload_errors_total{job=~"^precise-code-intel-worker.*"}[5m])) +histogram_quantile(0.95, sum(rate(src_http_request_duration_seconds_bucket{app="gitserver",code!~"2.."}[5m])) by (le, route)) ```-#### precise-code-intel-worker: workerutil_dbworker_store_codeintel_upload_error_rate +### Git Server: Database connections -
Store operation error rate over 5m
+#### gitserver: max_open_conns + +Maximum open
This panel has no related alerts. -To see this panel, visit `/-/debug/grafana/d/precise-code-intel-worker/precise-code-intel-worker?viewPanel=100403` on your Sourcegraph instance. +To see this panel, visit `/-/debug/grafana/d/gitserver/gitserver?viewPanel=102200` on your Sourcegraph instance. -*Managed by the [Sourcegraph Code intelligence team](https://handbook.sourcegraph.com/departments/engineering/teams/code-intelligence).* +*Managed by the [Sourcegraph Source team](https://handbook.sourcegraph.com/departments/engineering/teams/source).*Technical details
@@ -46046,23 +46975,21 @@ To see this panel, visit `/-/debug/grafana/d/precise-code-intel-worker/precise-c Query: ``` -sum(increase(src_workerutil_dbworker_store_codeintel_upload_errors_total{job=~"^precise-code-intel-worker.*"}[5m])) / (sum(increase(src_workerutil_dbworker_store_codeintel_upload_total{job=~"^precise-code-intel-worker.*"}[5m])) + sum(increase(src_workerutil_dbworker_store_codeintel_upload_errors_total{job=~"^precise-code-intel-worker.*"}[5m]))) * 100 +sum by (app_name, db_name) (src_pgsql_conns_max_open{app_name="gitserver"}) ```-### Precise Code Intel Worker: Codeintel: gitserver client - -#### precise-code-intel-worker: codeintel_gitserver_total +#### gitserver: open_conns -
Aggregate client operations every 5m
+Established
This panel has no related alerts. -To see this panel, visit `/-/debug/grafana/d/precise-code-intel-worker/precise-code-intel-worker?viewPanel=100500` on your Sourcegraph instance. +To see this panel, visit `/-/debug/grafana/d/gitserver/gitserver?viewPanel=102201` on your Sourcegraph instance. -*Managed by the [Sourcegraph Code intelligence team](https://handbook.sourcegraph.com/departments/engineering/teams/code-intelligence).* +*Managed by the [Sourcegraph Source team](https://handbook.sourcegraph.com/departments/engineering/teams/source).*Technical details
@@ -46070,21 +46997,21 @@ To see this panel, visit `/-/debug/grafana/d/precise-code-intel-worker/precise-c Query: ``` -sum(increase(src_codeintel_gitserver_total{job=~"^precise-code-intel-worker.*"}[5m])) +sum by (app_name, db_name) (src_pgsql_conns_open{app_name="gitserver"}) ```-#### precise-code-intel-worker: codeintel_gitserver_99th_percentile_duration +#### gitserver: in_use -
Aggregate successful client operation duration distribution over 5m
+Used
This panel has no related alerts. -To see this panel, visit `/-/debug/grafana/d/precise-code-intel-worker/precise-code-intel-worker?viewPanel=100501` on your Sourcegraph instance. +To see this panel, visit `/-/debug/grafana/d/gitserver/gitserver?viewPanel=102210` on your Sourcegraph instance. -*Managed by the [Sourcegraph Code intelligence team](https://handbook.sourcegraph.com/departments/engineering/teams/code-intelligence).* +*Managed by the [Sourcegraph Source team](https://handbook.sourcegraph.com/departments/engineering/teams/source).*Technical details
@@ -46092,21 +47019,21 @@ To see this panel, visit `/-/debug/grafana/d/precise-code-intel-worker/precise-c Query: ``` -sum by (le)(rate(src_codeintel_gitserver_duration_seconds_bucket{job=~"^precise-code-intel-worker.*"}[5m])) +sum by (app_name, db_name) (src_pgsql_conns_in_use{app_name="gitserver"}) ```-#### precise-code-intel-worker: codeintel_gitserver_errors_total +#### gitserver: idle -
Aggregate client operation errors every 5m
+Idle
This panel has no related alerts. -To see this panel, visit `/-/debug/grafana/d/precise-code-intel-worker/precise-code-intel-worker?viewPanel=100502` on your Sourcegraph instance. +To see this panel, visit `/-/debug/grafana/d/gitserver/gitserver?viewPanel=102211` on your Sourcegraph instance. -*Managed by the [Sourcegraph Code intelligence team](https://handbook.sourcegraph.com/departments/engineering/teams/code-intelligence).* +*Managed by the [Sourcegraph Source team](https://handbook.sourcegraph.com/departments/engineering/teams/source).*Technical details
@@ -46114,21 +47041,21 @@ To see this panel, visit `/-/debug/grafana/d/precise-code-intel-worker/precise-c Query: ``` -sum(increase(src_codeintel_gitserver_errors_total{job=~"^precise-code-intel-worker.*"}[5m])) +sum by (app_name, db_name) (src_pgsql_conns_idle{app_name="gitserver"}) ```-#### precise-code-intel-worker: codeintel_gitserver_error_rate +#### gitserver: mean_blocked_seconds_per_conn_request -
Aggregate client operation error rate over 5m
+Mean blocked seconds per conn request
-This panel has no related alerts. +Refer to the [alerts reference](alerts#gitserver-mean-blocked-seconds-per-conn-request) for 2 alerts related to this panel. -To see this panel, visit `/-/debug/grafana/d/precise-code-intel-worker/precise-code-intel-worker?viewPanel=100503` on your Sourcegraph instance. +To see this panel, visit `/-/debug/grafana/d/gitserver/gitserver?viewPanel=102220` on your Sourcegraph instance. -*Managed by the [Sourcegraph Code intelligence team](https://handbook.sourcegraph.com/departments/engineering/teams/code-intelligence).* +*Managed by the [Sourcegraph Source team](https://handbook.sourcegraph.com/departments/engineering/teams/source).*Technical details
@@ -46136,21 +47063,21 @@ To see this panel, visit `/-/debug/grafana/d/precise-code-intel-worker/precise-c Query: ``` -sum(increase(src_codeintel_gitserver_errors_total{job=~"^precise-code-intel-worker.*"}[5m])) / (sum(increase(src_codeintel_gitserver_total{job=~"^precise-code-intel-worker.*"}[5m])) + sum(increase(src_codeintel_gitserver_errors_total{job=~"^precise-code-intel-worker.*"}[5m]))) * 100 +sum by (app_name, db_name) (increase(src_pgsql_conns_blocked_seconds{app_name="gitserver"}[5m])) / sum by (app_name, db_name) (increase(src_pgsql_conns_waited_for{app_name="gitserver"}[5m])) ```-#### precise-code-intel-worker: codeintel_gitserver_total +#### gitserver: closed_max_idle -
Client operations every 5m
+Closed by SetMaxIdleConns
This panel has no related alerts. -To see this panel, visit `/-/debug/grafana/d/precise-code-intel-worker/precise-code-intel-worker?viewPanel=100510` on your Sourcegraph instance. +To see this panel, visit `/-/debug/grafana/d/gitserver/gitserver?viewPanel=102230` on your Sourcegraph instance. -*Managed by the [Sourcegraph Code intelligence team](https://handbook.sourcegraph.com/departments/engineering/teams/code-intelligence).* +*Managed by the [Sourcegraph Source team](https://handbook.sourcegraph.com/departments/engineering/teams/source).*Technical details
@@ -46158,21 +47085,21 @@ To see this panel, visit `/-/debug/grafana/d/precise-code-intel-worker/precise-c Query: ``` -sum by (op)(increase(src_codeintel_gitserver_total{job=~"^precise-code-intel-worker.*"}[5m])) +sum by (app_name, db_name) (increase(src_pgsql_conns_closed_max_idle{app_name="gitserver"}[5m])) ```-#### precise-code-intel-worker: codeintel_gitserver_99th_percentile_duration +#### gitserver: closed_max_lifetime -
99th percentile successful client operation duration over 5m
+Closed by SetConnMaxLifetime
This panel has no related alerts. -To see this panel, visit `/-/debug/grafana/d/precise-code-intel-worker/precise-code-intel-worker?viewPanel=100511` on your Sourcegraph instance. +To see this panel, visit `/-/debug/grafana/d/gitserver/gitserver?viewPanel=102231` on your Sourcegraph instance. -*Managed by the [Sourcegraph Code intelligence team](https://handbook.sourcegraph.com/departments/engineering/teams/code-intelligence).* +*Managed by the [Sourcegraph Source team](https://handbook.sourcegraph.com/departments/engineering/teams/source).*Technical details
@@ -46180,21 +47107,21 @@ To see this panel, visit `/-/debug/grafana/d/precise-code-intel-worker/precise-c Query: ``` -histogram_quantile(0.99, sum by (le,op)(rate(src_codeintel_gitserver_duration_seconds_bucket{job=~"^precise-code-intel-worker.*"}[5m]))) +sum by (app_name, db_name) (increase(src_pgsql_conns_closed_max_lifetime{app_name="gitserver"}[5m])) ```-#### precise-code-intel-worker: codeintel_gitserver_errors_total +#### gitserver: closed_max_idle_time -
Client operation errors every 5m
+Closed by SetConnMaxIdleTime
This panel has no related alerts. -To see this panel, visit `/-/debug/grafana/d/precise-code-intel-worker/precise-code-intel-worker?viewPanel=100512` on your Sourcegraph instance. +To see this panel, visit `/-/debug/grafana/d/gitserver/gitserver?viewPanel=102232` on your Sourcegraph instance. -*Managed by the [Sourcegraph Code intelligence team](https://handbook.sourcegraph.com/departments/engineering/teams/code-intelligence).* +*Managed by the [Sourcegraph Source team](https://handbook.sourcegraph.com/departments/engineering/teams/source).*Technical details
@@ -46202,21 +47129,33 @@ To see this panel, visit `/-/debug/grafana/d/precise-code-intel-worker/precise-c Query: ``` -sum by (op)(increase(src_codeintel_gitserver_errors_total{job=~"^precise-code-intel-worker.*"}[5m])) +sum by (app_name, db_name) (increase(src_pgsql_conns_closed_max_idle_time{app_name="gitserver"}[5m])) ```-#### precise-code-intel-worker: codeintel_gitserver_error_rate +### Git Server: Container monitoring (not available on server) -
Client operation error rate over 5m
+#### gitserver: container_missing + +Container missing
+ +This value is the number of times a container has not been seen for more than one minute. If you observe this +value change independent of deployment events (such as an upgrade), it could indicate pods are being OOM killed or terminated for some other reasons. + +- **Kubernetes:** + - Determine if the pod was OOM killed using `kubectl describe pod gitserver` (look for `OOMKilled: true`) and, if so, consider increasing the memory limit in the relevant `Deployment.yaml`. + - Check the logs before the container restarted to see if there are `panic:` messages or similar using `kubectl logs -p gitserver`. +- **Docker Compose:** + - Determine if the pod was OOM killed using `docker inspect -f '\{\{json .State\}\}' gitserver` (look for `"OOMKilled":true`) and, if so, consider increasing the memory limit of the gitserver container in `docker-compose.yml`. + - Check the logs before the container restarted to see if there are `panic:` messages or similar using `docker logs gitserver` (note this will include logs from the previous and currently running container). This panel has no related alerts. -To see this panel, visit `/-/debug/grafana/d/precise-code-intel-worker/precise-code-intel-worker?viewPanel=100513` on your Sourcegraph instance. +To see this panel, visit `/-/debug/grafana/d/gitserver/gitserver?viewPanel=102300` on your Sourcegraph instance. -*Managed by the [Sourcegraph Code intelligence team](https://handbook.sourcegraph.com/departments/engineering/teams/code-intelligence).* +*Managed by the [Sourcegraph Source team](https://handbook.sourcegraph.com/departments/engineering/teams/source).*Technical details
@@ -46224,23 +47163,21 @@ To see this panel, visit `/-/debug/grafana/d/precise-code-intel-worker/precise-c Query: ``` -sum by (op)(increase(src_codeintel_gitserver_errors_total{job=~"^precise-code-intel-worker.*"}[5m])) / (sum by (op)(increase(src_codeintel_gitserver_total{job=~"^precise-code-intel-worker.*"}[5m])) + sum by (op)(increase(src_codeintel_gitserver_errors_total{job=~"^precise-code-intel-worker.*"}[5m]))) * 100 +count by(name) ((time() - container_last_seen{name=~"^gitserver.*"}) > 60) ```-### Precise Code Intel Worker: Codeintel: uploadstore stats - -#### precise-code-intel-worker: codeintel_uploadstore_total +#### gitserver: container_cpu_usage -
Aggregate store operations every 5m
+Container cpu usage total (1m average) across all cores by instance
-This panel has no related alerts. +Refer to the [alerts reference](alerts#gitserver-container-cpu-usage) for 1 alert related to this panel. -To see this panel, visit `/-/debug/grafana/d/precise-code-intel-worker/precise-code-intel-worker?viewPanel=100600` on your Sourcegraph instance. +To see this panel, visit `/-/debug/grafana/d/gitserver/gitserver?viewPanel=102301` on your Sourcegraph instance. -*Managed by the [Sourcegraph Code intelligence team](https://handbook.sourcegraph.com/departments/engineering/teams/code-intelligence).* +*Managed by the [Sourcegraph Source team](https://handbook.sourcegraph.com/departments/engineering/teams/source).*Technical details
@@ -46248,21 +47185,21 @@ To see this panel, visit `/-/debug/grafana/d/precise-code-intel-worker/precise-c Query: ``` -sum(increase(src_codeintel_uploadstore_total{job=~"^precise-code-intel-worker.*"}[5m])) +cadvisor_container_cpu_usage_percentage_total{name=~"^gitserver.*"} ```-#### precise-code-intel-worker: codeintel_uploadstore_99th_percentile_duration +#### gitserver: container_memory_usage -
Aggregate successful store operation duration distribution over 5m
+Container memory usage by instance
-This panel has no related alerts. +Refer to the [alerts reference](alerts#gitserver-container-memory-usage) for 1 alert related to this panel. -To see this panel, visit `/-/debug/grafana/d/precise-code-intel-worker/precise-code-intel-worker?viewPanel=100601` on your Sourcegraph instance. +To see this panel, visit `/-/debug/grafana/d/gitserver/gitserver?viewPanel=102302` on your Sourcegraph instance. -*Managed by the [Sourcegraph Code intelligence team](https://handbook.sourcegraph.com/departments/engineering/teams/code-intelligence).* +*Managed by the [Sourcegraph Source team](https://handbook.sourcegraph.com/departments/engineering/teams/source).*Technical details
@@ -46270,21 +47207,24 @@ To see this panel, visit `/-/debug/grafana/d/precise-code-intel-worker/precise-c Query: ``` -sum by (le)(rate(src_codeintel_uploadstore_duration_seconds_bucket{job=~"^precise-code-intel-worker.*"}[5m])) +cadvisor_container_memory_usage_percentage_total{name=~"^gitserver.*"} ```-#### precise-code-intel-worker: codeintel_uploadstore_errors_total +#### gitserver: fs_io_operations -
Aggregate store operation errors every 5m
+Filesystem reads and writes rate by instance over 1h
+ +This value indicates the number of filesystem read and write operations by containers of this service. +When extremely high, this can indicate a resource usage problem, or can cause problems with the service itself, especially if high values or spikes correlate with \{\{CONTAINER_NAME\}\} issues. This panel has no related alerts. -To see this panel, visit `/-/debug/grafana/d/precise-code-intel-worker/precise-code-intel-worker?viewPanel=100602` on your Sourcegraph instance. +To see this panel, visit `/-/debug/grafana/d/gitserver/gitserver?viewPanel=102303` on your Sourcegraph instance. -*Managed by the [Sourcegraph Code intelligence team](https://handbook.sourcegraph.com/departments/engineering/teams/code-intelligence).* +*Managed by the [Sourcegraph Source team](https://handbook.sourcegraph.com/departments/engineering/teams/source).*Technical details
@@ -46292,21 +47232,23 @@ To see this panel, visit `/-/debug/grafana/d/precise-code-intel-worker/precise-c Query: ``` -sum(increase(src_codeintel_uploadstore_errors_total{job=~"^precise-code-intel-worker.*"}[5m])) +sum by(name) (rate(container_fs_reads_total{name=~"^gitserver.*"}[1h]) + rate(container_fs_writes_total{name=~"^gitserver.*"}[1h])) ```-#### precise-code-intel-worker: codeintel_uploadstore_error_rate +### Git Server: Provisioning indicators (not available on server) -
Aggregate store operation error rate over 5m
+#### gitserver: provisioning_container_cpu_usage_long_term -This panel has no related alerts. +Container cpu usage total (90th percentile over 1d) across all cores by instance
-To see this panel, visit `/-/debug/grafana/d/precise-code-intel-worker/precise-code-intel-worker?viewPanel=100603` on your Sourcegraph instance. +Refer to the [alerts reference](alerts#gitserver-provisioning-container-cpu-usage-long-term) for 1 alert related to this panel. -*Managed by the [Sourcegraph Code intelligence team](https://handbook.sourcegraph.com/departments/engineering/teams/code-intelligence).* +To see this panel, visit `/-/debug/grafana/d/gitserver/gitserver?viewPanel=102400` on your Sourcegraph instance. + +*Managed by the [Sourcegraph Source team](https://handbook.sourcegraph.com/departments/engineering/teams/source).*Technical details
@@ -46314,21 +47256,23 @@ To see this panel, visit `/-/debug/grafana/d/precise-code-intel-worker/precise-c Query: ``` -sum(increase(src_codeintel_uploadstore_errors_total{job=~"^precise-code-intel-worker.*"}[5m])) / (sum(increase(src_codeintel_uploadstore_total{job=~"^precise-code-intel-worker.*"}[5m])) + sum(increase(src_codeintel_uploadstore_errors_total{job=~"^precise-code-intel-worker.*"}[5m]))) * 100 +quantile_over_time(0.9, cadvisor_container_cpu_usage_percentage_total{name=~"^gitserver.*"}[1d]) ```-#### precise-code-intel-worker: codeintel_uploadstore_total +#### gitserver: provisioning_container_memory_usage_long_term -
Store operations every 5m
+Container memory usage (1d maximum) by instance
+ +Git Server is expected to use up all the memory it is provided. This panel has no related alerts. -To see this panel, visit `/-/debug/grafana/d/precise-code-intel-worker/precise-code-intel-worker?viewPanel=100610` on your Sourcegraph instance. +To see this panel, visit `/-/debug/grafana/d/gitserver/gitserver?viewPanel=102401` on your Sourcegraph instance. -*Managed by the [Sourcegraph Code intelligence team](https://handbook.sourcegraph.com/departments/engineering/teams/code-intelligence).* +*Managed by the [Sourcegraph Source team](https://handbook.sourcegraph.com/departments/engineering/teams/source).*Technical details
@@ -46336,21 +47280,21 @@ To see this panel, visit `/-/debug/grafana/d/precise-code-intel-worker/precise-c Query: ``` -sum by (op)(increase(src_codeintel_uploadstore_total{job=~"^precise-code-intel-worker.*"}[5m])) +max_over_time(cadvisor_container_memory_usage_percentage_total{name=~"^gitserver.*"}[1d]) ```-#### precise-code-intel-worker: codeintel_uploadstore_99th_percentile_duration +#### gitserver: provisioning_container_cpu_usage_short_term -
99th percentile successful store operation duration over 5m
+Container cpu usage total (5m maximum) across all cores by instance
-This panel has no related alerts. +Refer to the [alerts reference](alerts#gitserver-provisioning-container-cpu-usage-short-term) for 1 alert related to this panel. -To see this panel, visit `/-/debug/grafana/d/precise-code-intel-worker/precise-code-intel-worker?viewPanel=100611` on your Sourcegraph instance. +To see this panel, visit `/-/debug/grafana/d/gitserver/gitserver?viewPanel=102410` on your Sourcegraph instance. -*Managed by the [Sourcegraph Code intelligence team](https://handbook.sourcegraph.com/departments/engineering/teams/code-intelligence).* +*Managed by the [Sourcegraph Source team](https://handbook.sourcegraph.com/departments/engineering/teams/source).*Technical details
@@ -46358,21 +47302,23 @@ To see this panel, visit `/-/debug/grafana/d/precise-code-intel-worker/precise-c Query: ``` -histogram_quantile(0.99, sum by (le,op)(rate(src_codeintel_uploadstore_duration_seconds_bucket{job=~"^precise-code-intel-worker.*"}[5m]))) +max_over_time(cadvisor_container_cpu_usage_percentage_total{name=~"^gitserver.*"}[5m]) ```-#### precise-code-intel-worker: codeintel_uploadstore_errors_total +#### gitserver: provisioning_container_memory_usage_short_term -
Store operation errors every 5m
+Container memory usage (5m maximum) by instance
+ +Git Server is expected to use up all the memory it is provided. This panel has no related alerts. -To see this panel, visit `/-/debug/grafana/d/precise-code-intel-worker/precise-code-intel-worker?viewPanel=100612` on your Sourcegraph instance. +To see this panel, visit `/-/debug/grafana/d/gitserver/gitserver?viewPanel=102411` on your Sourcegraph instance. -*Managed by the [Sourcegraph Code intelligence team](https://handbook.sourcegraph.com/departments/engineering/teams/code-intelligence).* +*Managed by the [Sourcegraph Source team](https://handbook.sourcegraph.com/departments/engineering/teams/source).*Technical details
@@ -46380,21 +47326,24 @@ To see this panel, visit `/-/debug/grafana/d/precise-code-intel-worker/precise-c Query: ``` -sum by (op)(increase(src_codeintel_uploadstore_errors_total{job=~"^precise-code-intel-worker.*"}[5m])) +max_over_time(cadvisor_container_memory_usage_percentage_total{name=~"^gitserver.*"}[5m]) ```-#### precise-code-intel-worker: codeintel_uploadstore_error_rate +#### gitserver: container_oomkill_events_total -
Store operation error rate over 5m
+Container OOMKILL events total by instance
-This panel has no related alerts. +This value indicates the total number of times the container main process or child processes were terminated by OOM killer. +When it occurs frequently, it is an indicator of underprovisioning. + +Refer to the [alerts reference](alerts#gitserver-container-oomkill-events-total) for 1 alert related to this panel. -To see this panel, visit `/-/debug/grafana/d/precise-code-intel-worker/precise-code-intel-worker?viewPanel=100613` on your Sourcegraph instance. +To see this panel, visit `/-/debug/grafana/d/gitserver/gitserver?viewPanel=102412` on your Sourcegraph instance. -*Managed by the [Sourcegraph Code intelligence team](https://handbook.sourcegraph.com/departments/engineering/teams/code-intelligence).* +*Managed by the [Sourcegraph Source team](https://handbook.sourcegraph.com/departments/engineering/teams/source).*Technical details
@@ -46402,23 +47351,25 @@ To see this panel, visit `/-/debug/grafana/d/precise-code-intel-worker/precise-c Query: ``` -sum by (op)(increase(src_codeintel_uploadstore_errors_total{job=~"^precise-code-intel-worker.*"}[5m])) / (sum by (op)(increase(src_codeintel_uploadstore_total{job=~"^precise-code-intel-worker.*"}[5m])) + sum by (op)(increase(src_codeintel_uploadstore_errors_total{job=~"^precise-code-intel-worker.*"}[5m]))) * 100 +max by (name) (container_oom_events_total{name=~"^gitserver.*"}) ```-### Precise Code Intel Worker: Database connections +### Git Server: Golang runtime monitoring -#### precise-code-intel-worker: max_open_conns +#### gitserver: go_goroutines -
Maximum open
+Maximum active goroutines
-This panel has no related alerts. +A high value here indicates a possible goroutine leak. -To see this panel, visit `/-/debug/grafana/d/precise-code-intel-worker/precise-code-intel-worker?viewPanel=100700` on your Sourcegraph instance. +Refer to the [alerts reference](alerts#gitserver-go-goroutines) for 1 alert related to this panel. -*Managed by the [Sourcegraph Infrastructure Org team](https://handbook.sourcegraph.com/departments/engineering/infrastructure).* +To see this panel, visit `/-/debug/grafana/d/gitserver/gitserver?viewPanel=102500` on your Sourcegraph instance. + +*Managed by the [Sourcegraph Source team](https://handbook.sourcegraph.com/departments/engineering/teams/source).*Technical details
@@ -46426,21 +47377,21 @@ To see this panel, visit `/-/debug/grafana/d/precise-code-intel-worker/precise-c Query: ``` -sum by (app_name, db_name) (src_pgsql_conns_max_open{app_name="precise-code-intel-worker"}) +max by(instance) (go_goroutines{job=~".*gitserver"}) ```-#### precise-code-intel-worker: open_conns +#### gitserver: go_gc_duration_seconds -
Established
+Maximum go garbage collection duration
-This panel has no related alerts. +Refer to the [alerts reference](alerts#gitserver-go-gc-duration-seconds) for 1 alert related to this panel. -To see this panel, visit `/-/debug/grafana/d/precise-code-intel-worker/precise-code-intel-worker?viewPanel=100701` on your Sourcegraph instance. +To see this panel, visit `/-/debug/grafana/d/gitserver/gitserver?viewPanel=102501` on your Sourcegraph instance. -*Managed by the [Sourcegraph Infrastructure Org team](https://handbook.sourcegraph.com/departments/engineering/infrastructure).* +*Managed by the [Sourcegraph Source team](https://handbook.sourcegraph.com/departments/engineering/teams/source).*Technical details
@@ -46448,21 +47399,23 @@ To see this panel, visit `/-/debug/grafana/d/precise-code-intel-worker/precise-c Query: ``` -sum by (app_name, db_name) (src_pgsql_conns_open{app_name="precise-code-intel-worker"}) +max by(instance) (go_gc_duration_seconds{job=~".*gitserver"}) ```-#### precise-code-intel-worker: in_use +### Git Server: Kubernetes monitoring (only available on Kubernetes) -
Used
+#### gitserver: pods_available_percentage -This panel has no related alerts. +Percentage pods available
-To see this panel, visit `/-/debug/grafana/d/precise-code-intel-worker/precise-code-intel-worker?viewPanel=100710` on your Sourcegraph instance. +Refer to the [alerts reference](alerts#gitserver-pods-available-percentage) for 1 alert related to this panel. -*Managed by the [Sourcegraph Infrastructure Org team](https://handbook.sourcegraph.com/departments/engineering/infrastructure).* +To see this panel, visit `/-/debug/grafana/d/gitserver/gitserver?viewPanel=102600` on your Sourcegraph instance. + +*Managed by the [Sourcegraph Source team](https://handbook.sourcegraph.com/departments/engineering/teams/source).*Technical details
@@ -46470,19 +47423,25 @@ To see this panel, visit `/-/debug/grafana/d/precise-code-intel-worker/precise-c Query: ``` -sum by (app_name, db_name) (src_pgsql_conns_in_use{app_name="precise-code-intel-worker"}) +sum by(app) (up{app=~".*gitserver"}) / count by (app) (up{app=~".*gitserver"}) * 100 ```-#### precise-code-intel-worker: idle +## Postgres -
Idle
+Postgres metrics, exported from postgres_exporter (not available on server).
-This panel has no related alerts. +To see this dashboard, visit `/-/debug/grafana/d/postgres/postgres` on your Sourcegraph instance. -To see this panel, visit `/-/debug/grafana/d/precise-code-intel-worker/precise-code-intel-worker?viewPanel=100711` on your Sourcegraph instance. +#### postgres: connections + +Active connections
+ +Refer to the [alerts reference](alerts#postgres-connections) for 1 alert related to this panel. + +To see this panel, visit `/-/debug/grafana/d/postgres/postgres?viewPanel=100000` on your Sourcegraph instance. *Managed by the [Sourcegraph Infrastructure Org team](https://handbook.sourcegraph.com/departments/engineering/infrastructure).* @@ -46492,19 +47451,19 @@ To see this panel, visit `/-/debug/grafana/d/precise-code-intel-worker/precise-c Query: ``` -sum by (app_name, db_name) (src_pgsql_conns_idle{app_name="precise-code-intel-worker"}) +sum by (job) (pg_stat_activity_count{datname!~"template.*|postgres|cloudsqladmin"}) OR sum by (job) (pg_stat_activity_count{job="codeinsights-db", datname!~"template.*|cloudsqladmin"}) ```-#### precise-code-intel-worker: mean_blocked_seconds_per_conn_request +#### postgres: usage_connections_percentage -
Mean blocked seconds per conn request
+Connection in use
-Refer to the [alerts reference](alerts#precise-code-intel-worker-mean-blocked-seconds-per-conn-request) for 2 alerts related to this panel. +Refer to the [alerts reference](alerts#postgres-usage-connections-percentage) for 2 alerts related to this panel. -To see this panel, visit `/-/debug/grafana/d/precise-code-intel-worker/precise-code-intel-worker?viewPanel=100720` on your Sourcegraph instance. +To see this panel, visit `/-/debug/grafana/d/postgres/postgres?viewPanel=100001` on your Sourcegraph instance. *Managed by the [Sourcegraph Infrastructure Org team](https://handbook.sourcegraph.com/departments/engineering/infrastructure).* @@ -46514,19 +47473,19 @@ To see this panel, visit `/-/debug/grafana/d/precise-code-intel-worker/precise-c Query: ``` -sum by (app_name, db_name) (increase(src_pgsql_conns_blocked_seconds{app_name="precise-code-intel-worker"}[5m])) / sum by (app_name, db_name) (increase(src_pgsql_conns_waited_for{app_name="precise-code-intel-worker"}[5m])) +sum(pg_stat_activity_count) by (job) / (sum(pg_settings_max_connections) by (job) - sum(pg_settings_superuser_reserved_connections) by (job)) * 100 ```-#### precise-code-intel-worker: closed_max_idle +#### postgres: transaction_durations -
Closed by SetMaxIdleConns
+Maximum transaction durations
-This panel has no related alerts. +Refer to the [alerts reference](alerts#postgres-transaction-durations) for 1 alert related to this panel. -To see this panel, visit `/-/debug/grafana/d/precise-code-intel-worker/precise-code-intel-worker?viewPanel=100730` on your Sourcegraph instance. +To see this panel, visit `/-/debug/grafana/d/postgres/postgres?viewPanel=100002` on your Sourcegraph instance. *Managed by the [Sourcegraph Infrastructure Org team](https://handbook.sourcegraph.com/departments/engineering/infrastructure).* @@ -46536,41 +47495,23 @@ To see this panel, visit `/-/debug/grafana/d/precise-code-intel-worker/precise-c Query: ``` -sum by (app_name, db_name) (increase(src_pgsql_conns_closed_max_idle{app_name="precise-code-intel-worker"}[5m])) +sum by (job) (pg_stat_activity_max_tx_duration{datname!~"template.*|postgres|cloudsqladmin",job!="codeintel-db"}) OR sum by (job) (pg_stat_activity_max_tx_duration{job="codeinsights-db", datname!~"template.*|cloudsqladmin"}) ```-#### precise-code-intel-worker: closed_max_lifetime - -
Closed by SetConnMaxLifetime
- -This panel has no related alerts. - -To see this panel, visit `/-/debug/grafana/d/precise-code-intel-worker/precise-code-intel-worker?viewPanel=100731` on your Sourcegraph instance. - -*Managed by the [Sourcegraph Infrastructure Org team](https://handbook.sourcegraph.com/departments/engineering/infrastructure).* - -Technical details
- -Query: - -``` -sum by (app_name, db_name) (increase(src_pgsql_conns_closed_max_lifetime{app_name="precise-code-intel-worker"}[5m])) -``` -+#### postgres: postgres_up -#### precise-code-intel-worker: closed_max_idle_time +
Database availability
-Closed by SetConnMaxIdleTime
+A non-zero value indicates the database is online. -This panel has no related alerts. +Refer to the [alerts reference](alerts#postgres-postgres-up) for 1 alert related to this panel. -To see this panel, visit `/-/debug/grafana/d/precise-code-intel-worker/precise-code-intel-worker?viewPanel=100732` on your Sourcegraph instance. +To see this panel, visit `/-/debug/grafana/d/postgres/postgres?viewPanel=100100` on your Sourcegraph instance. *Managed by the [Sourcegraph Infrastructure Org team](https://handbook.sourcegraph.com/departments/engineering/infrastructure).* @@ -46580,265 +47521,23 @@ To see this panel, visit `/-/debug/grafana/d/precise-code-intel-worker/precise-c Query: ``` -sum by (app_name, db_name) (increase(src_pgsql_conns_closed_max_idle_time{app_name="precise-code-intel-worker"}[5m])) -``` - - -- -### Precise Code Intel Worker: Container monitoring (not available on server) - -#### precise-code-intel-worker: container_missing - -
Container missing
- -This value is the number of times a container has not been seen for more than one minute. If you observe this -value change independent of deployment events (such as an upgrade), it could indicate pods are being OOM killed or terminated for some other reasons. - -- **Kubernetes:** - - Determine if the pod was OOM killed using `kubectl describe pod precise-code-intel-worker` (look for `OOMKilled: true`) and, if so, consider increasing the memory limit in the relevant `Deployment.yaml`. - - Check the logs before the container restarted to see if there are `panic:` messages or similar using `kubectl logs -p precise-code-intel-worker`. -- **Docker Compose:** - - Determine if the pod was OOM killed using `docker inspect -f '\{\{json .State\}\}' precise-code-intel-worker` (look for `"OOMKilled":true`) and, if so, consider increasing the memory limit of the precise-code-intel-worker container in `docker-compose.yml`. - - Check the logs before the container restarted to see if there are `panic:` messages or similar using `docker logs precise-code-intel-worker` (note this will include logs from the previous and currently running container). - -This panel has no related alerts. - -To see this panel, visit `/-/debug/grafana/d/precise-code-intel-worker/precise-code-intel-worker?viewPanel=100800` on your Sourcegraph instance. - -*Managed by the [Sourcegraph Code intelligence team](https://handbook.sourcegraph.com/departments/engineering/teams/code-intelligence).* - -Technical details
- -Query: - -``` -count by(name) ((time() - container_last_seen{name=~"^precise-code-intel-worker.*"}) > 60) -``` -- -#### precise-code-intel-worker: container_cpu_usage - -
Container cpu usage total (1m average) across all cores by instance
- -Refer to the [alerts reference](alerts#precise-code-intel-worker-container-cpu-usage) for 1 alert related to this panel. - -To see this panel, visit `/-/debug/grafana/d/precise-code-intel-worker/precise-code-intel-worker?viewPanel=100801` on your Sourcegraph instance. - -*Managed by the [Sourcegraph Code intelligence team](https://handbook.sourcegraph.com/departments/engineering/teams/code-intelligence).* - -Technical details
- -Query: - -``` -cadvisor_container_cpu_usage_percentage_total{name=~"^precise-code-intel-worker.*"} -``` -- -#### precise-code-intel-worker: container_memory_usage - -
Container memory usage by instance
- -Refer to the [alerts reference](alerts#precise-code-intel-worker-container-memory-usage) for 1 alert related to this panel. - -To see this panel, visit `/-/debug/grafana/d/precise-code-intel-worker/precise-code-intel-worker?viewPanel=100802` on your Sourcegraph instance. - -*Managed by the [Sourcegraph Code intelligence team](https://handbook.sourcegraph.com/departments/engineering/teams/code-intelligence).* - -Technical details
- -Query: - -``` -cadvisor_container_memory_usage_percentage_total{name=~"^precise-code-intel-worker.*"} -``` -- -#### precise-code-intel-worker: fs_io_operations - -
Filesystem reads and writes rate by instance over 1h
- -This value indicates the number of filesystem read and write operations by containers of this service. -When extremely high, this can indicate a resource usage problem, or can cause problems with the service itself, especially if high values or spikes correlate with \{\{CONTAINER_NAME\}\} issues. - -This panel has no related alerts. - -To see this panel, visit `/-/debug/grafana/d/precise-code-intel-worker/precise-code-intel-worker?viewPanel=100803` on your Sourcegraph instance. - -*Managed by the [Sourcegraph Code intelligence team](https://handbook.sourcegraph.com/departments/engineering/teams/code-intelligence).* - -Technical details
- -Query: - -``` -sum by(name) (rate(container_fs_reads_total{name=~"^precise-code-intel-worker.*"}[1h]) + rate(container_fs_writes_total{name=~"^precise-code-intel-worker.*"}[1h])) -``` -- -### Precise Code Intel Worker: Provisioning indicators (not available on server) - -#### precise-code-intel-worker: provisioning_container_cpu_usage_long_term - -
Container cpu usage total (90th percentile over 1d) across all cores by instance
- -Refer to the [alerts reference](alerts#precise-code-intel-worker-provisioning-container-cpu-usage-long-term) for 1 alert related to this panel. - -To see this panel, visit `/-/debug/grafana/d/precise-code-intel-worker/precise-code-intel-worker?viewPanel=100900` on your Sourcegraph instance. - -*Managed by the [Sourcegraph Code intelligence team](https://handbook.sourcegraph.com/departments/engineering/teams/code-intelligence).* - -Technical details
- -Query: - -``` -quantile_over_time(0.9, cadvisor_container_cpu_usage_percentage_total{name=~"^precise-code-intel-worker.*"}[1d]) -``` -- -#### precise-code-intel-worker: provisioning_container_memory_usage_long_term - -
Container memory usage (1d maximum) by instance
- -Refer to the [alerts reference](alerts#precise-code-intel-worker-provisioning-container-memory-usage-long-term) for 1 alert related to this panel. - -To see this panel, visit `/-/debug/grafana/d/precise-code-intel-worker/precise-code-intel-worker?viewPanel=100901` on your Sourcegraph instance. - -*Managed by the [Sourcegraph Code intelligence team](https://handbook.sourcegraph.com/departments/engineering/teams/code-intelligence).* - -Technical details
- -Query: - -``` -max_over_time(cadvisor_container_memory_usage_percentage_total{name=~"^precise-code-intel-worker.*"}[1d]) -``` -- -#### precise-code-intel-worker: provisioning_container_cpu_usage_short_term - -
Container cpu usage total (5m maximum) across all cores by instance
- -Refer to the [alerts reference](alerts#precise-code-intel-worker-provisioning-container-cpu-usage-short-term) for 1 alert related to this panel. - -To see this panel, visit `/-/debug/grafana/d/precise-code-intel-worker/precise-code-intel-worker?viewPanel=100910` on your Sourcegraph instance. - -*Managed by the [Sourcegraph Code intelligence team](https://handbook.sourcegraph.com/departments/engineering/teams/code-intelligence).* - -Technical details
- -Query: - -``` -max_over_time(cadvisor_container_cpu_usage_percentage_total{name=~"^precise-code-intel-worker.*"}[5m]) -``` -- -#### precise-code-intel-worker: provisioning_container_memory_usage_short_term - -
Container memory usage (5m maximum) by instance
- -Refer to the [alerts reference](alerts#precise-code-intel-worker-provisioning-container-memory-usage-short-term) for 1 alert related to this panel. - -To see this panel, visit `/-/debug/grafana/d/precise-code-intel-worker/precise-code-intel-worker?viewPanel=100911` on your Sourcegraph instance. - -*Managed by the [Sourcegraph Code intelligence team](https://handbook.sourcegraph.com/departments/engineering/teams/code-intelligence).* - -Technical details
- -Query: - -``` -max_over_time(cadvisor_container_memory_usage_percentage_total{name=~"^precise-code-intel-worker.*"}[5m]) -``` -- -#### precise-code-intel-worker: container_oomkill_events_total - -
Container OOMKILL events total by instance
- -This value indicates the total number of times the container main process or child processes were terminated by OOM killer. -When it occurs frequently, it is an indicator of underprovisioning. - -Refer to the [alerts reference](alerts#precise-code-intel-worker-container-oomkill-events-total) for 1 alert related to this panel. - -To see this panel, visit `/-/debug/grafana/d/precise-code-intel-worker/precise-code-intel-worker?viewPanel=100912` on your Sourcegraph instance. - -*Managed by the [Sourcegraph Code intelligence team](https://handbook.sourcegraph.com/departments/engineering/teams/code-intelligence).* - -Technical details
- -Query: - -``` -max by (name) (container_oom_events_total{name=~"^precise-code-intel-worker.*"}) +pg_up ```-### Precise Code Intel Worker: Golang runtime monitoring - -#### precise-code-intel-worker: go_goroutines - -
Maximum active goroutines
- -A high value here indicates a possible goroutine leak. - -Refer to the [alerts reference](alerts#precise-code-intel-worker-go-goroutines) for 1 alert related to this panel. - -To see this panel, visit `/-/debug/grafana/d/precise-code-intel-worker/precise-code-intel-worker?viewPanel=101000` on your Sourcegraph instance. - -*Managed by the [Sourcegraph Code intelligence team](https://handbook.sourcegraph.com/departments/engineering/teams/code-intelligence).* - -Technical details
- -Query: - -``` -max by(instance) (go_goroutines{job=~".*precise-code-intel-worker"}) -``` -+#### postgres: invalid_indexes -#### precise-code-intel-worker: go_gc_duration_seconds +
Invalid indexes (unusable by the query planner)
-Maximum go garbage collection duration
+A non-zero value indicates the that Postgres failed to build an index. Expect degraded performance until the index is manually rebuilt. -Refer to the [alerts reference](alerts#precise-code-intel-worker-go-gc-duration-seconds) for 1 alert related to this panel. +Refer to the [alerts reference](alerts#postgres-invalid-indexes) for 1 alert related to this panel. -To see this panel, visit `/-/debug/grafana/d/precise-code-intel-worker/precise-code-intel-worker?viewPanel=101001` on your Sourcegraph instance. +To see this panel, visit `/-/debug/grafana/d/postgres/postgres?viewPanel=100101` on your Sourcegraph instance. -*Managed by the [Sourcegraph Code intelligence team](https://handbook.sourcegraph.com/departments/engineering/teams/code-intelligence).* +*Managed by the [Sourcegraph Infrastructure Org team](https://handbook.sourcegraph.com/departments/engineering/infrastructure).*Technical details
@@ -46846,23 +47545,23 @@ To see this panel, visit `/-/debug/grafana/d/precise-code-intel-worker/precise-c Query: ``` -max by(instance) (go_gc_duration_seconds{job=~".*precise-code-intel-worker"}) +max by (relname)(pg_invalid_index_count) ```-### Precise Code Intel Worker: Kubernetes monitoring (only available on Kubernetes) +#### postgres: pg_exporter_err -#### precise-code-intel-worker: pods_available_percentage +
Errors scraping postgres exporter
-Percentage pods available
+This value indicates issues retrieving metrics from postgres_exporter. -Refer to the [alerts reference](alerts#precise-code-intel-worker-pods-available-percentage) for 1 alert related to this panel. +Refer to the [alerts reference](alerts#postgres-pg-exporter-err) for 1 alert related to this panel. -To see this panel, visit `/-/debug/grafana/d/precise-code-intel-worker/precise-code-intel-worker?viewPanel=101100` on your Sourcegraph instance. +To see this panel, visit `/-/debug/grafana/d/postgres/postgres?viewPanel=100110` on your Sourcegraph instance. -*Managed by the [Sourcegraph Code intelligence team](https://handbook.sourcegraph.com/departments/engineering/teams/code-intelligence).* +*Managed by the [Sourcegraph Infrastructure Org team](https://handbook.sourcegraph.com/departments/engineering/infrastructure).*Technical details
@@ -46870,29 +47569,21 @@ To see this panel, visit `/-/debug/grafana/d/precise-code-intel-worker/precise-c Query: ``` -sum by(app) (up{app=~".*precise-code-intel-worker"}) / count by (app) (up{app=~".*precise-code-intel-worker"}) * 100 +pg_exporter_last_scrape_error ```-## Redis - -
Metrics from both redis databases.
- -To see this dashboard, visit `/-/debug/grafana/d/redis/redis` on your Sourcegraph instance. - -### Redis: Redis Store - -#### redis: redis-store_up +#### postgres: migration_in_progress -Redis-store availability
+Active schema migration
-A value of 1 indicates the service is currently running +A 0 value indicates that no migration is in progress. -Refer to the [alerts reference](alerts#redis-redis-store-up) for 1 alert related to this panel. +Refer to the [alerts reference](alerts#postgres-migration-in-progress) for 1 alert related to this panel. -To see this panel, visit `/-/debug/grafana/d/redis/redis?viewPanel=100000` on your Sourcegraph instance. +To see this panel, visit `/-/debug/grafana/d/postgres/postgres?viewPanel=100111` on your Sourcegraph instance. *Managed by the [Sourcegraph Infrastructure Org team](https://handbook.sourcegraph.com/departments/engineering/infrastructure).* @@ -46902,23 +47593,23 @@ To see this panel, visit `/-/debug/grafana/d/redis/redis?viewPanel=100000` on yo Query: ``` -redis_up{app="redis-store"} +pg_sg_migration_status ```-### Redis: Redis Cache +### Postgres: Object size and bloat -#### redis: redis-cache_up +#### postgres: pg_table_size -
Redis-cache availability
+Table size
-A value of 1 indicates the service is currently running +Total size of this table -Refer to the [alerts reference](alerts#redis-redis-cache-up) for 1 alert related to this panel. +This panel has no related alerts. -To see this panel, visit `/-/debug/grafana/d/redis/redis?viewPanel=100100` on your Sourcegraph instance. +To see this panel, visit `/-/debug/grafana/d/postgres/postgres?viewPanel=100200` on your Sourcegraph instance. *Managed by the [Sourcegraph Infrastructure Org team](https://handbook.sourcegraph.com/departments/engineering/infrastructure).* @@ -46928,43 +47619,21 @@ To see this panel, visit `/-/debug/grafana/d/redis/redis?viewPanel=100100` on yo Query: ``` -redis_up{app="redis-cache"} +max by (relname)(pg_table_bloat_size) ```-### Redis: Provisioning indicators (not available on server) - -#### redis: provisioning_container_cpu_usage_long_term - -
Container cpu usage total (90th percentile over 1d) across all cores by instance
- -Refer to the [alerts reference](alerts#redis-provisioning-container-cpu-usage-long-term) for 1 alert related to this panel. - -To see this panel, visit `/-/debug/grafana/d/redis/redis?viewPanel=100200` on your Sourcegraph instance. - -*Managed by the [Sourcegraph Infrastructure Org team](https://handbook.sourcegraph.com/departments/engineering/infrastructure).* - -Technical details
- -Query: - -``` -quantile_over_time(0.9, cadvisor_container_cpu_usage_percentage_total{name=~"^redis-cache.*"}[1d]) -``` -+#### postgres: pg_table_bloat_ratio -#### redis: provisioning_container_memory_usage_long_term +
Table bloat ratio
-Container memory usage (1d maximum) by instance
+Estimated bloat ratio of this table (high bloat = high overhead) -Refer to the [alerts reference](alerts#redis-provisioning-container-memory-usage-long-term) for 1 alert related to this panel. +This panel has no related alerts. -To see this panel, visit `/-/debug/grafana/d/redis/redis?viewPanel=100201` on your Sourcegraph instance. +To see this panel, visit `/-/debug/grafana/d/postgres/postgres?viewPanel=100201` on your Sourcegraph instance. *Managed by the [Sourcegraph Infrastructure Org team](https://handbook.sourcegraph.com/departments/engineering/infrastructure).* @@ -46974,41 +47643,21 @@ To see this panel, visit `/-/debug/grafana/d/redis/redis?viewPanel=100201` on yo Query: ``` -max_over_time(cadvisor_container_memory_usage_percentage_total{name=~"^redis-cache.*"}[1d]) +max by (relname)(pg_table_bloat_ratio) * 100 ```-#### redis: provisioning_container_cpu_usage_short_term - -
Container cpu usage total (5m maximum) across all cores by instance
- -Refer to the [alerts reference](alerts#redis-provisioning-container-cpu-usage-short-term) for 1 alert related to this panel. - -To see this panel, visit `/-/debug/grafana/d/redis/redis?viewPanel=100210` on your Sourcegraph instance. - -*Managed by the [Sourcegraph Infrastructure Org team](https://handbook.sourcegraph.com/departments/engineering/infrastructure).* - -Technical details
- -Query: - -``` -max_over_time(cadvisor_container_cpu_usage_percentage_total{name=~"^redis-cache.*"}[5m]) -``` -+#### postgres: pg_index_size -#### redis: provisioning_container_memory_usage_short_term +
Index size
-Container memory usage (5m maximum) by instance
+Total size of this index -Refer to the [alerts reference](alerts#redis-provisioning-container-memory-usage-short-term) for 1 alert related to this panel. +This panel has no related alerts. -To see this panel, visit `/-/debug/grafana/d/redis/redis?viewPanel=100211` on your Sourcegraph instance. +To see this panel, visit `/-/debug/grafana/d/postgres/postgres?viewPanel=100210` on your Sourcegraph instance. *Managed by the [Sourcegraph Infrastructure Org team](https://handbook.sourcegraph.com/departments/engineering/infrastructure).* @@ -47018,22 +47667,21 @@ To see this panel, visit `/-/debug/grafana/d/redis/redis?viewPanel=100211` on yo Query: ``` -max_over_time(cadvisor_container_memory_usage_percentage_total{name=~"^redis-cache.*"}[5m]) +max by (relname)(pg_index_bloat_size) ```-#### redis: container_oomkill_events_total +#### postgres: pg_index_bloat_ratio -
Container OOMKILL events total by instance
+Index bloat ratio
-This value indicates the total number of times the container main process or child processes were terminated by OOM killer. -When it occurs frequently, it is an indicator of underprovisioning. +Estimated bloat ratio of this index (high bloat = high overhead) -Refer to the [alerts reference](alerts#redis-container-oomkill-events-total) for 1 alert related to this panel. +This panel has no related alerts. -To see this panel, visit `/-/debug/grafana/d/redis/redis?viewPanel=100212` on your Sourcegraph instance. +To see this panel, visit `/-/debug/grafana/d/postgres/postgres?viewPanel=100211` on your Sourcegraph instance. *Managed by the [Sourcegraph Infrastructure Org team](https://handbook.sourcegraph.com/departments/engineering/infrastructure).* @@ -47043,21 +47691,21 @@ To see this panel, visit `/-/debug/grafana/d/redis/redis?viewPanel=100212` on yo Query: ``` -max by (name) (container_oom_events_total{name=~"^redis-cache.*"}) +max by (relname)(pg_index_bloat_ratio) * 100 ```-### Redis: Provisioning indicators (not available on server) +### Postgres: Provisioning indicators (not available on server) -#### redis: provisioning_container_cpu_usage_long_term +#### postgres: provisioning_container_cpu_usage_long_term
Container cpu usage total (90th percentile over 1d) across all cores by instance
-Refer to the [alerts reference](alerts#redis-provisioning-container-cpu-usage-long-term) for 1 alert related to this panel. +Refer to the [alerts reference](alerts#postgres-provisioning-container-cpu-usage-long-term) for 1 alert related to this panel. -To see this panel, visit `/-/debug/grafana/d/redis/redis?viewPanel=100300` on your Sourcegraph instance. +To see this panel, visit `/-/debug/grafana/d/postgres/postgres?viewPanel=100300` on your Sourcegraph instance. *Managed by the [Sourcegraph Infrastructure Org team](https://handbook.sourcegraph.com/departments/engineering/infrastructure).* @@ -47067,19 +47715,19 @@ To see this panel, visit `/-/debug/grafana/d/redis/redis?viewPanel=100300` on yo Query: ``` -quantile_over_time(0.9, cadvisor_container_cpu_usage_percentage_total{name=~"^redis-store.*"}[1d]) +quantile_over_time(0.9, cadvisor_container_cpu_usage_percentage_total{name=~"^(pgsql|codeintel-db|codeinsights).*"}[1d]) ```-#### redis: provisioning_container_memory_usage_long_term +#### postgres: provisioning_container_memory_usage_long_term
Container memory usage (1d maximum) by instance
-Refer to the [alerts reference](alerts#redis-provisioning-container-memory-usage-long-term) for 1 alert related to this panel. +Refer to the [alerts reference](alerts#postgres-provisioning-container-memory-usage-long-term) for 1 alert related to this panel. -To see this panel, visit `/-/debug/grafana/d/redis/redis?viewPanel=100301` on your Sourcegraph instance. +To see this panel, visit `/-/debug/grafana/d/postgres/postgres?viewPanel=100301` on your Sourcegraph instance. *Managed by the [Sourcegraph Infrastructure Org team](https://handbook.sourcegraph.com/departments/engineering/infrastructure).* @@ -47089,19 +47737,19 @@ To see this panel, visit `/-/debug/grafana/d/redis/redis?viewPanel=100301` on yo Query: ``` -max_over_time(cadvisor_container_memory_usage_percentage_total{name=~"^redis-store.*"}[1d]) +max_over_time(cadvisor_container_memory_usage_percentage_total{name=~"^(pgsql|codeintel-db|codeinsights).*"}[1d]) ```-#### redis: provisioning_container_cpu_usage_short_term +#### postgres: provisioning_container_cpu_usage_short_term
Container cpu usage total (5m maximum) across all cores by instance
-Refer to the [alerts reference](alerts#redis-provisioning-container-cpu-usage-short-term) for 1 alert related to this panel. +Refer to the [alerts reference](alerts#postgres-provisioning-container-cpu-usage-short-term) for 1 alert related to this panel. -To see this panel, visit `/-/debug/grafana/d/redis/redis?viewPanel=100310` on your Sourcegraph instance. +To see this panel, visit `/-/debug/grafana/d/postgres/postgres?viewPanel=100310` on your Sourcegraph instance. *Managed by the [Sourcegraph Infrastructure Org team](https://handbook.sourcegraph.com/departments/engineering/infrastructure).* @@ -47111,19 +47759,19 @@ To see this panel, visit `/-/debug/grafana/d/redis/redis?viewPanel=100310` on yo Query: ``` -max_over_time(cadvisor_container_cpu_usage_percentage_total{name=~"^redis-store.*"}[5m]) +max_over_time(cadvisor_container_cpu_usage_percentage_total{name=~"^(pgsql|codeintel-db|codeinsights).*"}[5m]) ```-#### redis: provisioning_container_memory_usage_short_term +#### postgres: provisioning_container_memory_usage_short_term
Container memory usage (5m maximum) by instance
-Refer to the [alerts reference](alerts#redis-provisioning-container-memory-usage-short-term) for 1 alert related to this panel. +Refer to the [alerts reference](alerts#postgres-provisioning-container-memory-usage-short-term) for 1 alert related to this panel. -To see this panel, visit `/-/debug/grafana/d/redis/redis?viewPanel=100311` on your Sourcegraph instance. +To see this panel, visit `/-/debug/grafana/d/postgres/postgres?viewPanel=100311` on your Sourcegraph instance. *Managed by the [Sourcegraph Infrastructure Org team](https://handbook.sourcegraph.com/departments/engineering/infrastructure).* @@ -47133,46 +47781,22 @@ To see this panel, visit `/-/debug/grafana/d/redis/redis?viewPanel=100311` on yo Query: ``` -max_over_time(cadvisor_container_memory_usage_percentage_total{name=~"^redis-store.*"}[5m]) +max_over_time(cadvisor_container_memory_usage_percentage_total{name=~"^(pgsql|codeintel-db|codeinsights).*"}[5m]) ```-#### redis: container_oomkill_events_total +#### postgres: container_oomkill_events_total
Container OOMKILL events total by instance
This value indicates the total number of times the container main process or child processes were terminated by OOM killer. When it occurs frequently, it is an indicator of underprovisioning. -Refer to the [alerts reference](alerts#redis-container-oomkill-events-total) for 1 alert related to this panel. - -To see this panel, visit `/-/debug/grafana/d/redis/redis?viewPanel=100312` on your Sourcegraph instance. - -*Managed by the [Sourcegraph Infrastructure Org team](https://handbook.sourcegraph.com/departments/engineering/infrastructure).* - -Technical details
- -Query: - -``` -max by (name) (container_oom_events_total{name=~"^redis-store.*"}) -``` -- -### Redis: Kubernetes monitoring (only available on Kubernetes) - -#### redis: pods_available_percentage - -
Percentage pods available
- -Refer to the [alerts reference](alerts#redis-pods-available-percentage) for 1 alert related to this panel. +Refer to the [alerts reference](alerts#postgres-container-oomkill-events-total) for 1 alert related to this panel. -To see this panel, visit `/-/debug/grafana/d/redis/redis?viewPanel=100400` on your Sourcegraph instance. +To see this panel, visit `/-/debug/grafana/d/postgres/postgres?viewPanel=100312` on your Sourcegraph instance. *Managed by the [Sourcegraph Infrastructure Org team](https://handbook.sourcegraph.com/departments/engineering/infrastructure).* @@ -47182,21 +47806,21 @@ To see this panel, visit `/-/debug/grafana/d/redis/redis?viewPanel=100400` on yo Query: ``` -sum by(app) (up{app=~".*redis-cache"}) / count by (app) (up{app=~".*redis-cache"}) * 100 +max by (name) (container_oom_events_total{name=~"^(pgsql|codeintel-db|codeinsights).*"}) ```-### Redis: Kubernetes monitoring (only available on Kubernetes) +### Postgres: Kubernetes monitoring (only available on Kubernetes) -#### redis: pods_available_percentage +#### postgres: pods_available_percentage
Percentage pods available
-Refer to the [alerts reference](alerts#redis-pods-available-percentage) for 1 alert related to this panel. +Refer to the [alerts reference](alerts#postgres-pods-available-percentage) for 1 alert related to this panel. -To see this panel, visit `/-/debug/grafana/d/redis/redis?viewPanel=100500` on your Sourcegraph instance. +To see this panel, visit `/-/debug/grafana/d/postgres/postgres?viewPanel=100400` on your Sourcegraph instance. *Managed by the [Sourcegraph Infrastructure Org team](https://handbook.sourcegraph.com/departments/engineering/infrastructure).* @@ -47206,313 +47830,27 @@ To see this panel, visit `/-/debug/grafana/d/redis/redis?viewPanel=100500` on yo Query: ``` -sum by(app) (up{app=~".*redis-store"}) / count by (app) (up{app=~".*redis-store"}) * 100 -``` - - -- -## Worker - -
Manages background processes.
- -To see this dashboard, visit `/-/debug/grafana/d/worker/worker` on your Sourcegraph instance. - -### Worker: Active jobs - -#### worker: worker_job_count - -Number of worker instances running each job
- -The number of worker instances running each job type. -It is necessary for each job type to be managed by at least one worker instance. - -This panel has no related alerts. - -To see this panel, visit `/-/debug/grafana/d/worker/worker?viewPanel=100000` on your Sourcegraph instance. - - -Technical details
- -Query: - -``` -sum by (job_name) (src_worker_jobs{job=~"^worker.*"}) -``` -- -#### worker: worker_job_codeintel-upload-janitor_count - -
Number of worker instances running the codeintel-upload-janitor job
- -Refer to the [alerts reference](alerts#worker-worker-job-codeintel-upload-janitor-count) for 2 alerts related to this panel. - -To see this panel, visit `/-/debug/grafana/d/worker/worker?viewPanel=100010` on your Sourcegraph instance. - -*Managed by the [Sourcegraph Code intelligence team](https://handbook.sourcegraph.com/departments/engineering/teams/code-intelligence).* - -Technical details
- -Query: - -``` -sum (src_worker_jobs{job=~"^worker.*", job_name="codeintel-upload-janitor"}) -``` -- -#### worker: worker_job_codeintel-commitgraph-updater_count - -
Number of worker instances running the codeintel-commitgraph-updater job
- -Refer to the [alerts reference](alerts#worker-worker-job-codeintel-commitgraph-updater-count) for 2 alerts related to this panel. - -To see this panel, visit `/-/debug/grafana/d/worker/worker?viewPanel=100011` on your Sourcegraph instance. - -*Managed by the [Sourcegraph Code intelligence team](https://handbook.sourcegraph.com/departments/engineering/teams/code-intelligence).* - -Technical details
- -Query: - -``` -sum (src_worker_jobs{job=~"^worker.*", job_name="codeintel-commitgraph-updater"}) -``` -- -#### worker: worker_job_codeintel-autoindexing-scheduler_count - -
Number of worker instances running the codeintel-autoindexing-scheduler job
- -Refer to the [alerts reference](alerts#worker-worker-job-codeintel-autoindexing-scheduler-count) for 2 alerts related to this panel. - -To see this panel, visit `/-/debug/grafana/d/worker/worker?viewPanel=100012` on your Sourcegraph instance. - -*Managed by the [Sourcegraph Code intelligence team](https://handbook.sourcegraph.com/departments/engineering/teams/code-intelligence).* - -Technical details
- -Query: - -``` -sum (src_worker_jobs{job=~"^worker.*", job_name="codeintel-autoindexing-scheduler"}) -``` -- -### Worker: Database record encrypter - -#### worker: records_encrypted_at_rest_percentage - -
Percentage of database records encrypted at rest
- -Percentage of encrypted database records - -This panel has no related alerts. - -To see this panel, visit `/-/debug/grafana/d/worker/worker?viewPanel=100100` on your Sourcegraph instance. - -*Managed by the [Sourcegraph Source team](https://handbook.sourcegraph.com/departments/engineering/teams/source).* - -Technical details
- -Query: - -``` -(max(src_records_encrypted_at_rest_total) by (tableName)) / ((max(src_records_encrypted_at_rest_total) by (tableName)) + (max(src_records_unencrypted_at_rest_total) by (tableName))) * 100 -``` -- -#### worker: records_encrypted_total - -
Database records encrypted every 5m
- -Number of encrypted database records every 5m - -This panel has no related alerts. - -To see this panel, visit `/-/debug/grafana/d/worker/worker?viewPanel=100101` on your Sourcegraph instance. - -*Managed by the [Sourcegraph Source team](https://handbook.sourcegraph.com/departments/engineering/teams/source).* - -Technical details
- -Query: - -``` -sum by (tableName)(increase(src_records_encrypted_total{job=~"^worker.*"}[5m])) -``` -- -#### worker: records_decrypted_total - -
Database records decrypted every 5m
- -Number of encrypted database records every 5m - -This panel has no related alerts. - -To see this panel, visit `/-/debug/grafana/d/worker/worker?viewPanel=100102` on your Sourcegraph instance. - -*Managed by the [Sourcegraph Source team](https://handbook.sourcegraph.com/departments/engineering/teams/source).* - -Technical details
- -Query: - -``` -sum by (tableName)(increase(src_records_decrypted_total{job=~"^worker.*"}[5m])) -``` -- -#### worker: record_encryption_errors_total - -
Encryption operation errors every 5m
- -Number of database record encryption/decryption errors every 5m - -This panel has no related alerts. - -To see this panel, visit `/-/debug/grafana/d/worker/worker?viewPanel=100103` on your Sourcegraph instance. - -*Managed by the [Sourcegraph Source team](https://handbook.sourcegraph.com/departments/engineering/teams/source).* - -Technical details
- -Query: - -``` -sum(increase(src_record_encryption_errors_total{job=~"^worker.*"}[5m])) -``` -- -### Worker: Codeintel: Repository with stale commit graph - -#### worker: codeintel_commit_graph_queue_size - -
Repository queue size
- -This panel has no related alerts. - -To see this panel, visit `/-/debug/grafana/d/worker/worker?viewPanel=100200` on your Sourcegraph instance. - -*Managed by the [Sourcegraph Code intelligence team](https://handbook.sourcegraph.com/departments/engineering/teams/code-intelligence).* - -Technical details
- -Query: - -``` -max(src_codeintel_commit_graph_total{job=~"^worker.*"}) -``` -- -#### worker: codeintel_commit_graph_queue_growth_rate - -
Repository queue growth rate over 30m
- -This value compares the rate of enqueues against the rate of finished jobs. - - - A value < than 1 indicates that process rate > enqueue rate - - A value = than 1 indicates that process rate = enqueue rate - - A value > than 1 indicates that process rate < enqueue rate - -This panel has no related alerts. - -To see this panel, visit `/-/debug/grafana/d/worker/worker?viewPanel=100201` on your Sourcegraph instance. - -*Managed by the [Sourcegraph Code intelligence team](https://handbook.sourcegraph.com/departments/engineering/teams/code-intelligence).* - -Technical details
- -Query: - -``` -sum(increase(src_codeintel_commit_graph_total{job=~"^worker.*"}[30m])) / sum(increase(src_codeintel_commit_graph_processor_total{job=~"^worker.*"}[30m])) -``` -- -#### worker: codeintel_commit_graph_queued_max_age - -
Repository queue longest time in queue
- -Refer to the [alerts reference](alerts#worker-codeintel-commit-graph-queued-max-age) for 1 alert related to this panel. - -To see this panel, visit `/-/debug/grafana/d/worker/worker?viewPanel=100202` on your Sourcegraph instance. - -*Managed by the [Sourcegraph Code intelligence team](https://handbook.sourcegraph.com/departments/engineering/teams/code-intelligence).* - -Technical details
- -Query: - -``` -max(src_codeintel_commit_graph_queued_duration_seconds_total{job=~"^worker.*"}) +sum by(app) (up{app=~".*(pgsql|codeintel-db|codeinsights)"}) / count by (app) (up{app=~".*(pgsql|codeintel-db|codeinsights)"}) * 100 ```-### Worker: Codeintel: Repository commit graph updates - -#### worker: codeintel_commit_graph_processor_total - -
Update operations every 5m
- -This panel has no related alerts. - -To see this panel, visit `/-/debug/grafana/d/worker/worker?viewPanel=100300` on your Sourcegraph instance. - -*Managed by the [Sourcegraph Code intelligence team](https://handbook.sourcegraph.com/departments/engineering/teams/code-intelligence).* - -Technical details
+## Precise Code Intel Worker -Query: +Handles conversion of uploaded precise code intelligence bundles.
-``` -sum(increase(src_codeintel_commit_graph_processor_total{job=~"^worker.*"}[5m])) -``` -+### Precise Code Intel Worker: Codeintel: LSIF uploads -#### worker: codeintel_commit_graph_processor_99th_percentile_duration +#### precise-code-intel-worker: codeintel_upload_handlers -
Aggregate successful update operation duration distribution over 5m
+Handler active handlers
This panel has no related alerts. -To see this panel, visit `/-/debug/grafana/d/worker/worker?viewPanel=100301` on your Sourcegraph instance. +To see this panel, visit `/-/debug/grafana/d/precise-code-intel-worker/precise-code-intel-worker?viewPanel=100000` on your Sourcegraph instance. *Managed by the [Sourcegraph Code intelligence team](https://handbook.sourcegraph.com/departments/engineering/teams/code-intelligence).* @@ -47522,19 +47860,19 @@ To see this panel, visit `/-/debug/grafana/d/worker/worker?viewPanel=100301` on Query: ``` -sum by (le)(rate(src_codeintel_commit_graph_processor_duration_seconds_bucket{job=~"^worker.*"}[5m])) +sum(src_codeintel_upload_processor_handlers{job=~"^precise-code-intel-worker.*"}) ```-#### worker: codeintel_commit_graph_processor_errors_total +#### precise-code-intel-worker: codeintel_upload_processor_upload_size -
Update operation errors every 5m
+Sum of upload sizes in bytes being processed by each precise code-intel worker instance
This panel has no related alerts. -To see this panel, visit `/-/debug/grafana/d/worker/worker?viewPanel=100302` on your Sourcegraph instance. +To see this panel, visit `/-/debug/grafana/d/precise-code-intel-worker/precise-code-intel-worker?viewPanel=100001` on your Sourcegraph instance. *Managed by the [Sourcegraph Code intelligence team](https://handbook.sourcegraph.com/departments/engineering/teams/code-intelligence).* @@ -47544,19 +47882,19 @@ To see this panel, visit `/-/debug/grafana/d/worker/worker?viewPanel=100302` on Query: ``` -sum(increase(src_codeintel_commit_graph_processor_errors_total{job=~"^worker.*"}[5m])) +sum by(instance) (src_codeintel_upload_processor_upload_size{job="precise-code-intel-worker"}) ```-#### worker: codeintel_commit_graph_processor_error_rate +#### precise-code-intel-worker: codeintel_upload_processor_total -
Update operation error rate over 5m
+Handler operations every 5m
This panel has no related alerts. -To see this panel, visit `/-/debug/grafana/d/worker/worker?viewPanel=100303` on your Sourcegraph instance. +To see this panel, visit `/-/debug/grafana/d/precise-code-intel-worker/precise-code-intel-worker?viewPanel=100010` on your Sourcegraph instance. *Managed by the [Sourcegraph Code intelligence team](https://handbook.sourcegraph.com/departments/engineering/teams/code-intelligence).* @@ -47566,21 +47904,19 @@ To see this panel, visit `/-/debug/grafana/d/worker/worker?viewPanel=100303` on Query: ``` -sum(increase(src_codeintel_commit_graph_processor_errors_total{job=~"^worker.*"}[5m])) / (sum(increase(src_codeintel_commit_graph_processor_total{job=~"^worker.*"}[5m])) + sum(increase(src_codeintel_commit_graph_processor_errors_total{job=~"^worker.*"}[5m]))) * 100 +sum(increase(src_codeintel_upload_processor_total{job=~"^precise-code-intel-worker.*"}[5m])) ```-### Worker: Codeintel: Dependency index job - -#### worker: codeintel_dependency_index_queue_size +#### precise-code-intel-worker: codeintel_upload_processor_99th_percentile_duration -
Dependency index job queue size
+Aggregate successful handler operation duration distribution over 5m
This panel has no related alerts. -To see this panel, visit `/-/debug/grafana/d/worker/worker?viewPanel=100400` on your Sourcegraph instance. +To see this panel, visit `/-/debug/grafana/d/precise-code-intel-worker/precise-code-intel-worker?viewPanel=100011` on your Sourcegraph instance. *Managed by the [Sourcegraph Code intelligence team](https://handbook.sourcegraph.com/departments/engineering/teams/code-intelligence).* @@ -47590,25 +47926,19 @@ To see this panel, visit `/-/debug/grafana/d/worker/worker?viewPanel=100400` on Query: ``` -max(src_codeintel_dependency_index_total{job=~"^worker.*"}) +sum by (le)(rate(src_codeintel_upload_processor_duration_seconds_bucket{job=~"^precise-code-intel-worker.*"}[5m])) ```-#### worker: codeintel_dependency_index_queue_growth_rate - -
Dependency index job queue growth rate over 30m
- -This value compares the rate of enqueues against the rate of finished jobs. +#### precise-code-intel-worker: codeintel_upload_processor_errors_total - - A value < than 1 indicates that process rate > enqueue rate - - A value = than 1 indicates that process rate = enqueue rate - - A value > than 1 indicates that process rate < enqueue rate +Handler operation errors every 5m
This panel has no related alerts. -To see this panel, visit `/-/debug/grafana/d/worker/worker?viewPanel=100401` on your Sourcegraph instance. +To see this panel, visit `/-/debug/grafana/d/precise-code-intel-worker/precise-code-intel-worker?viewPanel=100012` on your Sourcegraph instance. *Managed by the [Sourcegraph Code intelligence team](https://handbook.sourcegraph.com/departments/engineering/teams/code-intelligence).* @@ -47618,19 +47948,19 @@ To see this panel, visit `/-/debug/grafana/d/worker/worker?viewPanel=100401` on Query: ``` -sum(increase(src_codeintel_dependency_index_total{job=~"^worker.*"}[30m])) / sum(increase(src_codeintel_dependency_index_processor_total{job=~"^worker.*"}[30m])) +sum(increase(src_codeintel_upload_processor_errors_total{job=~"^precise-code-intel-worker.*"}[5m])) ```-#### worker: codeintel_dependency_index_queued_max_age +#### precise-code-intel-worker: codeintel_upload_processor_error_rate -
Dependency index job queue longest time in queue
+Handler operation error rate over 5m
This panel has no related alerts. -To see this panel, visit `/-/debug/grafana/d/worker/worker?viewPanel=100402` on your Sourcegraph instance. +To see this panel, visit `/-/debug/grafana/d/precise-code-intel-worker/precise-code-intel-worker?viewPanel=100013` on your Sourcegraph instance. *Managed by the [Sourcegraph Code intelligence team](https://handbook.sourcegraph.com/departments/engineering/teams/code-intelligence).* @@ -47640,43 +47970,21 @@ To see this panel, visit `/-/debug/grafana/d/worker/worker?viewPanel=100402` on Query: ``` -max(src_codeintel_dependency_index_queued_duration_seconds_total{job=~"^worker.*"}) +sum(increase(src_codeintel_upload_processor_errors_total{job=~"^precise-code-intel-worker.*"}[5m])) / (sum(increase(src_codeintel_upload_processor_total{job=~"^precise-code-intel-worker.*"}[5m])) + sum(increase(src_codeintel_upload_processor_errors_total{job=~"^precise-code-intel-worker.*"}[5m]))) * 100 ```-### Worker: Codeintel: Dependency index jobs - -#### worker: codeintel_dependency_index_handlers - -
Handler active handlers
- -This panel has no related alerts. - -To see this panel, visit `/-/debug/grafana/d/worker/worker?viewPanel=100500` on your Sourcegraph instance. - -*Managed by the [Sourcegraph Code intelligence team](https://handbook.sourcegraph.com/departments/engineering/teams/code-intelligence).* - -Technical details
- -Query: - -``` -sum(src_codeintel_dependency_index_processor_handlers{job=~"^worker.*"}) -``` -+### Precise Code Intel Worker: Codeintel: dbstore stats -#### worker: codeintel_dependency_index_processor_total +#### precise-code-intel-worker: codeintel_uploads_store_total -
Handler operations every 5m
+Aggregate store operations every 5m
This panel has no related alerts. -To see this panel, visit `/-/debug/grafana/d/worker/worker?viewPanel=100510` on your Sourcegraph instance. +To see this panel, visit `/-/debug/grafana/d/precise-code-intel-worker/precise-code-intel-worker?viewPanel=100100` on your Sourcegraph instance. *Managed by the [Sourcegraph Code intelligence team](https://handbook.sourcegraph.com/departments/engineering/teams/code-intelligence).* @@ -47686,19 +47994,19 @@ To see this panel, visit `/-/debug/grafana/d/worker/worker?viewPanel=100510` on Query: ``` -sum(increase(src_codeintel_dependency_index_processor_total{job=~"^worker.*"}[5m])) +sum(increase(src_codeintel_uploads_store_total{job=~"^precise-code-intel-worker.*"}[5m])) ```-#### worker: codeintel_dependency_index_processor_99th_percentile_duration +#### precise-code-intel-worker: codeintel_uploads_store_99th_percentile_duration -
Aggregate successful handler operation duration distribution over 5m
+Aggregate successful store operation duration distribution over 5m
This panel has no related alerts. -To see this panel, visit `/-/debug/grafana/d/worker/worker?viewPanel=100511` on your Sourcegraph instance. +To see this panel, visit `/-/debug/grafana/d/precise-code-intel-worker/precise-code-intel-worker?viewPanel=100101` on your Sourcegraph instance. *Managed by the [Sourcegraph Code intelligence team](https://handbook.sourcegraph.com/departments/engineering/teams/code-intelligence).* @@ -47708,19 +48016,19 @@ To see this panel, visit `/-/debug/grafana/d/worker/worker?viewPanel=100511` on Query: ``` -sum by (le)(rate(src_codeintel_dependency_index_processor_duration_seconds_bucket{job=~"^worker.*"}[5m])) +sum by (le)(rate(src_codeintel_uploads_store_duration_seconds_bucket{job=~"^precise-code-intel-worker.*"}[5m])) ```-#### worker: codeintel_dependency_index_processor_errors_total +#### precise-code-intel-worker: codeintel_uploads_store_errors_total -
Handler operation errors every 5m
+Aggregate store operation errors every 5m
This panel has no related alerts. -To see this panel, visit `/-/debug/grafana/d/worker/worker?viewPanel=100512` on your Sourcegraph instance. +To see this panel, visit `/-/debug/grafana/d/precise-code-intel-worker/precise-code-intel-worker?viewPanel=100102` on your Sourcegraph instance. *Managed by the [Sourcegraph Code intelligence team](https://handbook.sourcegraph.com/departments/engineering/teams/code-intelligence).* @@ -47730,19 +48038,19 @@ To see this panel, visit `/-/debug/grafana/d/worker/worker?viewPanel=100512` on Query: ``` -sum(increase(src_codeintel_dependency_index_processor_errors_total{job=~"^worker.*"}[5m])) +sum(increase(src_codeintel_uploads_store_errors_total{job=~"^precise-code-intel-worker.*"}[5m])) ```-#### worker: codeintel_dependency_index_processor_error_rate +#### precise-code-intel-worker: codeintel_uploads_store_error_rate -
Handler operation error rate over 5m
+Aggregate store operation error rate over 5m
This panel has no related alerts. -To see this panel, visit `/-/debug/grafana/d/worker/worker?viewPanel=100513` on your Sourcegraph instance. +To see this panel, visit `/-/debug/grafana/d/precise-code-intel-worker/precise-code-intel-worker?viewPanel=100103` on your Sourcegraph instance. *Managed by the [Sourcegraph Code intelligence team](https://handbook.sourcegraph.com/departments/engineering/teams/code-intelligence).* @@ -47752,21 +48060,19 @@ To see this panel, visit `/-/debug/grafana/d/worker/worker?viewPanel=100513` on Query: ``` -sum(increase(src_codeintel_dependency_index_processor_errors_total{job=~"^worker.*"}[5m])) / (sum(increase(src_codeintel_dependency_index_processor_total{job=~"^worker.*"}[5m])) + sum(increase(src_codeintel_dependency_index_processor_errors_total{job=~"^worker.*"}[5m]))) * 100 +sum(increase(src_codeintel_uploads_store_errors_total{job=~"^precise-code-intel-worker.*"}[5m])) / (sum(increase(src_codeintel_uploads_store_total{job=~"^precise-code-intel-worker.*"}[5m])) + sum(increase(src_codeintel_uploads_store_errors_total{job=~"^precise-code-intel-worker.*"}[5m]))) * 100 ```-### Worker: Codeintel: Auto-index scheduler - -#### worker: codeintel_autoindexing_total +#### precise-code-intel-worker: codeintel_uploads_store_total -
Auto-indexing job scheduler operations every 10m
+Store operations every 5m
This panel has no related alerts. -To see this panel, visit `/-/debug/grafana/d/worker/worker?viewPanel=100600` on your Sourcegraph instance. +To see this panel, visit `/-/debug/grafana/d/precise-code-intel-worker/precise-code-intel-worker?viewPanel=100110` on your Sourcegraph instance. *Managed by the [Sourcegraph Code intelligence team](https://handbook.sourcegraph.com/departments/engineering/teams/code-intelligence).* @@ -47776,19 +48082,19 @@ To see this panel, visit `/-/debug/grafana/d/worker/worker?viewPanel=100600` on Query: ``` -sum(increase(src_codeintel_autoindexing_total{op='HandleIndexSchedule',job=~"^worker.*"}[10m])) +sum by (op)(increase(src_codeintel_uploads_store_total{job=~"^precise-code-intel-worker.*"}[5m])) ```-#### worker: codeintel_autoindexing_99th_percentile_duration +#### precise-code-intel-worker: codeintel_uploads_store_99th_percentile_duration -
Aggregate successful auto-indexing job scheduler operation duration distribution over 10m
+99th percentile successful store operation duration over 5m
This panel has no related alerts. -To see this panel, visit `/-/debug/grafana/d/worker/worker?viewPanel=100601` on your Sourcegraph instance. +To see this panel, visit `/-/debug/grafana/d/precise-code-intel-worker/precise-code-intel-worker?viewPanel=100111` on your Sourcegraph instance. *Managed by the [Sourcegraph Code intelligence team](https://handbook.sourcegraph.com/departments/engineering/teams/code-intelligence).* @@ -47798,19 +48104,19 @@ To see this panel, visit `/-/debug/grafana/d/worker/worker?viewPanel=100601` on Query: ``` -sum by (le)(rate(src_codeintel_autoindexing_duration_seconds_bucket{op='HandleIndexSchedule',job=~"^worker.*"}[10m])) +histogram_quantile(0.99, sum by (le,op)(rate(src_codeintel_uploads_store_duration_seconds_bucket{job=~"^precise-code-intel-worker.*"}[5m]))) ```-#### worker: codeintel_autoindexing_errors_total +#### precise-code-intel-worker: codeintel_uploads_store_errors_total -
Auto-indexing job scheduler operation errors every 10m
+Store operation errors every 5m
This panel has no related alerts. -To see this panel, visit `/-/debug/grafana/d/worker/worker?viewPanel=100602` on your Sourcegraph instance. +To see this panel, visit `/-/debug/grafana/d/precise-code-intel-worker/precise-code-intel-worker?viewPanel=100112` on your Sourcegraph instance. *Managed by the [Sourcegraph Code intelligence team](https://handbook.sourcegraph.com/departments/engineering/teams/code-intelligence).* @@ -47820,19 +48126,19 @@ To see this panel, visit `/-/debug/grafana/d/worker/worker?viewPanel=100602` on Query: ``` -sum(increase(src_codeintel_autoindexing_errors_total{op='HandleIndexSchedule',job=~"^worker.*"}[10m])) +sum by (op)(increase(src_codeintel_uploads_store_errors_total{job=~"^precise-code-intel-worker.*"}[5m])) ```-#### worker: codeintel_autoindexing_error_rate +#### precise-code-intel-worker: codeintel_uploads_store_error_rate -
Auto-indexing job scheduler operation error rate over 10m
+Store operation error rate over 5m
This panel has no related alerts. -To see this panel, visit `/-/debug/grafana/d/worker/worker?viewPanel=100603` on your Sourcegraph instance. +To see this panel, visit `/-/debug/grafana/d/precise-code-intel-worker/precise-code-intel-worker?viewPanel=100113` on your Sourcegraph instance. *Managed by the [Sourcegraph Code intelligence team](https://handbook.sourcegraph.com/departments/engineering/teams/code-intelligence).* @@ -47842,21 +48148,21 @@ To see this panel, visit `/-/debug/grafana/d/worker/worker?viewPanel=100603` on Query: ``` -sum(increase(src_codeintel_autoindexing_errors_total{op='HandleIndexSchedule',job=~"^worker.*"}[10m])) / (sum(increase(src_codeintel_autoindexing_total{op='HandleIndexSchedule',job=~"^worker.*"}[10m])) + sum(increase(src_codeintel_autoindexing_errors_total{op='HandleIndexSchedule',job=~"^worker.*"}[10m]))) * 100 +sum by (op)(increase(src_codeintel_uploads_store_errors_total{job=~"^precise-code-intel-worker.*"}[5m])) / (sum by (op)(increase(src_codeintel_uploads_store_total{job=~"^precise-code-intel-worker.*"}[5m])) + sum by (op)(increase(src_codeintel_uploads_store_errors_total{job=~"^precise-code-intel-worker.*"}[5m]))) * 100 ```-### Worker: Codeintel: dbstore stats +### Precise Code Intel Worker: Codeintel: lsifstore stats -#### worker: codeintel_uploads_store_total +#### precise-code-intel-worker: codeintel_uploads_lsifstore_total
Aggregate store operations every 5m
This panel has no related alerts. -To see this panel, visit `/-/debug/grafana/d/worker/worker?viewPanel=100700` on your Sourcegraph instance. +To see this panel, visit `/-/debug/grafana/d/precise-code-intel-worker/precise-code-intel-worker?viewPanel=100200` on your Sourcegraph instance. *Managed by the [Sourcegraph Code intelligence team](https://handbook.sourcegraph.com/departments/engineering/teams/code-intelligence).* @@ -47866,19 +48172,19 @@ To see this panel, visit `/-/debug/grafana/d/worker/worker?viewPanel=100700` on Query: ``` -sum(increase(src_codeintel_uploads_store_total{job=~"^worker.*"}[5m])) +sum(increase(src_codeintel_uploads_lsifstore_total{job=~"^precise-code-intel-worker.*"}[5m])) ```-#### worker: codeintel_uploads_store_99th_percentile_duration +#### precise-code-intel-worker: codeintel_uploads_lsifstore_99th_percentile_duration
Aggregate successful store operation duration distribution over 5m
This panel has no related alerts. -To see this panel, visit `/-/debug/grafana/d/worker/worker?viewPanel=100701` on your Sourcegraph instance. +To see this panel, visit `/-/debug/grafana/d/precise-code-intel-worker/precise-code-intel-worker?viewPanel=100201` on your Sourcegraph instance. *Managed by the [Sourcegraph Code intelligence team](https://handbook.sourcegraph.com/departments/engineering/teams/code-intelligence).* @@ -47888,19 +48194,19 @@ To see this panel, visit `/-/debug/grafana/d/worker/worker?viewPanel=100701` on Query: ``` -sum by (le)(rate(src_codeintel_uploads_store_duration_seconds_bucket{job=~"^worker.*"}[5m])) +sum by (le)(rate(src_codeintel_uploads_lsifstore_duration_seconds_bucket{job=~"^precise-code-intel-worker.*"}[5m])) ```-#### worker: codeintel_uploads_store_errors_total +#### precise-code-intel-worker: codeintel_uploads_lsifstore_errors_total
Aggregate store operation errors every 5m
This panel has no related alerts. -To see this panel, visit `/-/debug/grafana/d/worker/worker?viewPanel=100702` on your Sourcegraph instance. +To see this panel, visit `/-/debug/grafana/d/precise-code-intel-worker/precise-code-intel-worker?viewPanel=100202` on your Sourcegraph instance. *Managed by the [Sourcegraph Code intelligence team](https://handbook.sourcegraph.com/departments/engineering/teams/code-intelligence).* @@ -47910,19 +48216,19 @@ To see this panel, visit `/-/debug/grafana/d/worker/worker?viewPanel=100702` on Query: ``` -sum(increase(src_codeintel_uploads_store_errors_total{job=~"^worker.*"}[5m])) +sum(increase(src_codeintel_uploads_lsifstore_errors_total{job=~"^precise-code-intel-worker.*"}[5m])) ```-#### worker: codeintel_uploads_store_error_rate +#### precise-code-intel-worker: codeintel_uploads_lsifstore_error_rate
Aggregate store operation error rate over 5m
This panel has no related alerts. -To see this panel, visit `/-/debug/grafana/d/worker/worker?viewPanel=100703` on your Sourcegraph instance. +To see this panel, visit `/-/debug/grafana/d/precise-code-intel-worker/precise-code-intel-worker?viewPanel=100203` on your Sourcegraph instance. *Managed by the [Sourcegraph Code intelligence team](https://handbook.sourcegraph.com/departments/engineering/teams/code-intelligence).* @@ -47932,19 +48238,19 @@ To see this panel, visit `/-/debug/grafana/d/worker/worker?viewPanel=100703` on Query: ``` -sum(increase(src_codeintel_uploads_store_errors_total{job=~"^worker.*"}[5m])) / (sum(increase(src_codeintel_uploads_store_total{job=~"^worker.*"}[5m])) + sum(increase(src_codeintel_uploads_store_errors_total{job=~"^worker.*"}[5m]))) * 100 +sum(increase(src_codeintel_uploads_lsifstore_errors_total{job=~"^precise-code-intel-worker.*"}[5m])) / (sum(increase(src_codeintel_uploads_lsifstore_total{job=~"^precise-code-intel-worker.*"}[5m])) + sum(increase(src_codeintel_uploads_lsifstore_errors_total{job=~"^precise-code-intel-worker.*"}[5m]))) * 100 ```-#### worker: codeintel_uploads_store_total +#### precise-code-intel-worker: codeintel_uploads_lsifstore_total
Store operations every 5m
This panel has no related alerts. -To see this panel, visit `/-/debug/grafana/d/worker/worker?viewPanel=100710` on your Sourcegraph instance. +To see this panel, visit `/-/debug/grafana/d/precise-code-intel-worker/precise-code-intel-worker?viewPanel=100210` on your Sourcegraph instance. *Managed by the [Sourcegraph Code intelligence team](https://handbook.sourcegraph.com/departments/engineering/teams/code-intelligence).* @@ -47954,19 +48260,19 @@ To see this panel, visit `/-/debug/grafana/d/worker/worker?viewPanel=100710` on Query: ``` -sum by (op)(increase(src_codeintel_uploads_store_total{job=~"^worker.*"}[5m])) +sum by (op)(increase(src_codeintel_uploads_lsifstore_total{job=~"^precise-code-intel-worker.*"}[5m])) ```-#### worker: codeintel_uploads_store_99th_percentile_duration +#### precise-code-intel-worker: codeintel_uploads_lsifstore_99th_percentile_duration
99th percentile successful store operation duration over 5m
This panel has no related alerts. -To see this panel, visit `/-/debug/grafana/d/worker/worker?viewPanel=100711` on your Sourcegraph instance. +To see this panel, visit `/-/debug/grafana/d/precise-code-intel-worker/precise-code-intel-worker?viewPanel=100211` on your Sourcegraph instance. *Managed by the [Sourcegraph Code intelligence team](https://handbook.sourcegraph.com/departments/engineering/teams/code-intelligence).* @@ -47976,19 +48282,19 @@ To see this panel, visit `/-/debug/grafana/d/worker/worker?viewPanel=100711` on Query: ``` -histogram_quantile(0.99, sum by (le,op)(rate(src_codeintel_uploads_store_duration_seconds_bucket{job=~"^worker.*"}[5m]))) +histogram_quantile(0.99, sum by (le,op)(rate(src_codeintel_uploads_lsifstore_duration_seconds_bucket{job=~"^precise-code-intel-worker.*"}[5m]))) ```-#### worker: codeintel_uploads_store_errors_total +#### precise-code-intel-worker: codeintel_uploads_lsifstore_errors_total
Store operation errors every 5m
This panel has no related alerts. -To see this panel, visit `/-/debug/grafana/d/worker/worker?viewPanel=100712` on your Sourcegraph instance. +To see this panel, visit `/-/debug/grafana/d/precise-code-intel-worker/precise-code-intel-worker?viewPanel=100212` on your Sourcegraph instance. *Managed by the [Sourcegraph Code intelligence team](https://handbook.sourcegraph.com/departments/engineering/teams/code-intelligence).* @@ -47998,19 +48304,19 @@ To see this panel, visit `/-/debug/grafana/d/worker/worker?viewPanel=100712` on Query: ``` -sum by (op)(increase(src_codeintel_uploads_store_errors_total{job=~"^worker.*"}[5m])) +sum by (op)(increase(src_codeintel_uploads_lsifstore_errors_total{job=~"^precise-code-intel-worker.*"}[5m])) ```-#### worker: codeintel_uploads_store_error_rate +#### precise-code-intel-worker: codeintel_uploads_lsifstore_error_rate
Store operation error rate over 5m
This panel has no related alerts. -To see this panel, visit `/-/debug/grafana/d/worker/worker?viewPanel=100713` on your Sourcegraph instance. +To see this panel, visit `/-/debug/grafana/d/precise-code-intel-worker/precise-code-intel-worker?viewPanel=100213` on your Sourcegraph instance. *Managed by the [Sourcegraph Code intelligence team](https://handbook.sourcegraph.com/departments/engineering/teams/code-intelligence).* @@ -48020,21 +48326,21 @@ To see this panel, visit `/-/debug/grafana/d/worker/worker?viewPanel=100713` on Query: ``` -sum by (op)(increase(src_codeintel_uploads_store_errors_total{job=~"^worker.*"}[5m])) / (sum by (op)(increase(src_codeintel_uploads_store_total{job=~"^worker.*"}[5m])) + sum by (op)(increase(src_codeintel_uploads_store_errors_total{job=~"^worker.*"}[5m]))) * 100 +sum by (op)(increase(src_codeintel_uploads_lsifstore_errors_total{job=~"^precise-code-intel-worker.*"}[5m])) / (sum by (op)(increase(src_codeintel_uploads_lsifstore_total{job=~"^precise-code-intel-worker.*"}[5m])) + sum by (op)(increase(src_codeintel_uploads_lsifstore_errors_total{job=~"^precise-code-intel-worker.*"}[5m]))) * 100 ```-### Worker: Codeintel: lsifstore stats +### Precise Code Intel Worker: Workerutil: lsif_uploads dbworker/store stats -#### worker: codeintel_uploads_lsifstore_total +#### precise-code-intel-worker: workerutil_dbworker_store_total -
Aggregate store operations every 5m
+Store operations every 5m
This panel has no related alerts. -To see this panel, visit `/-/debug/grafana/d/worker/worker?viewPanel=100800` on your Sourcegraph instance. +To see this panel, visit `/-/debug/grafana/d/precise-code-intel-worker/precise-code-intel-worker?viewPanel=100300` on your Sourcegraph instance. *Managed by the [Sourcegraph Code intelligence team](https://handbook.sourcegraph.com/departments/engineering/teams/code-intelligence).* @@ -48044,19 +48350,19 @@ To see this panel, visit `/-/debug/grafana/d/worker/worker?viewPanel=100800` on Query: ``` -sum(increase(src_codeintel_uploads_lsifstore_total{job=~"^worker.*"}[5m])) +sum(increase(src_workerutil_dbworker_store_total{domain='codeintel_upload',job=~"^precise-code-intel-worker.*"}[5m])) ```-#### worker: codeintel_uploads_lsifstore_99th_percentile_duration +#### precise-code-intel-worker: workerutil_dbworker_store_99th_percentile_duration
Aggregate successful store operation duration distribution over 5m
This panel has no related alerts. -To see this panel, visit `/-/debug/grafana/d/worker/worker?viewPanel=100801` on your Sourcegraph instance. +To see this panel, visit `/-/debug/grafana/d/precise-code-intel-worker/precise-code-intel-worker?viewPanel=100301` on your Sourcegraph instance. *Managed by the [Sourcegraph Code intelligence team](https://handbook.sourcegraph.com/departments/engineering/teams/code-intelligence).* @@ -48066,19 +48372,19 @@ To see this panel, visit `/-/debug/grafana/d/worker/worker?viewPanel=100801` on Query: ``` -sum by (le)(rate(src_codeintel_uploads_lsifstore_duration_seconds_bucket{job=~"^worker.*"}[5m])) +sum by (le)(rate(src_workerutil_dbworker_store_duration_seconds_bucket{domain='codeintel_upload',job=~"^precise-code-intel-worker.*"}[5m])) ```-#### worker: codeintel_uploads_lsifstore_errors_total +#### precise-code-intel-worker: workerutil_dbworker_store_errors_total -
Aggregate store operation errors every 5m
+Store operation errors every 5m
This panel has no related alerts. -To see this panel, visit `/-/debug/grafana/d/worker/worker?viewPanel=100802` on your Sourcegraph instance. +To see this panel, visit `/-/debug/grafana/d/precise-code-intel-worker/precise-code-intel-worker?viewPanel=100302` on your Sourcegraph instance. *Managed by the [Sourcegraph Code intelligence team](https://handbook.sourcegraph.com/departments/engineering/teams/code-intelligence).* @@ -48088,19 +48394,19 @@ To see this panel, visit `/-/debug/grafana/d/worker/worker?viewPanel=100802` on Query: ``` -sum(increase(src_codeintel_uploads_lsifstore_errors_total{job=~"^worker.*"}[5m])) +sum(increase(src_workerutil_dbworker_store_errors_total{domain='codeintel_upload',job=~"^precise-code-intel-worker.*"}[5m])) ```-#### worker: codeintel_uploads_lsifstore_error_rate +#### precise-code-intel-worker: workerutil_dbworker_store_error_rate -
Aggregate store operation error rate over 5m
+Store operation error rate over 5m
This panel has no related alerts. -To see this panel, visit `/-/debug/grafana/d/worker/worker?viewPanel=100803` on your Sourcegraph instance. +To see this panel, visit `/-/debug/grafana/d/precise-code-intel-worker/precise-code-intel-worker?viewPanel=100303` on your Sourcegraph instance. *Managed by the [Sourcegraph Code intelligence team](https://handbook.sourcegraph.com/departments/engineering/teams/code-intelligence).* @@ -48110,19 +48416,21 @@ To see this panel, visit `/-/debug/grafana/d/worker/worker?viewPanel=100803` on Query: ``` -sum(increase(src_codeintel_uploads_lsifstore_errors_total{job=~"^worker.*"}[5m])) / (sum(increase(src_codeintel_uploads_lsifstore_total{job=~"^worker.*"}[5m])) + sum(increase(src_codeintel_uploads_lsifstore_errors_total{job=~"^worker.*"}[5m]))) * 100 +sum(increase(src_workerutil_dbworker_store_errors_total{domain='codeintel_upload',job=~"^precise-code-intel-worker.*"}[5m])) / (sum(increase(src_workerutil_dbworker_store_total{domain='codeintel_upload',job=~"^precise-code-intel-worker.*"}[5m])) + sum(increase(src_workerutil_dbworker_store_errors_total{domain='codeintel_upload',job=~"^precise-code-intel-worker.*"}[5m]))) * 100 ```-#### worker: codeintel_uploads_lsifstore_total +### Precise Code Intel Worker: Codeintel: gitserver client -
Store operations every 5m
+#### precise-code-intel-worker: gitserver_client_total + +Aggregate client operations every 5m
This panel has no related alerts. -To see this panel, visit `/-/debug/grafana/d/worker/worker?viewPanel=100810` on your Sourcegraph instance. +To see this panel, visit `/-/debug/grafana/d/precise-code-intel-worker/precise-code-intel-worker?viewPanel=100400` on your Sourcegraph instance. *Managed by the [Sourcegraph Code intelligence team](https://handbook.sourcegraph.com/departments/engineering/teams/code-intelligence).* @@ -48132,19 +48440,19 @@ To see this panel, visit `/-/debug/grafana/d/worker/worker?viewPanel=100810` on Query: ``` -sum by (op)(increase(src_codeintel_uploads_lsifstore_total{job=~"^worker.*"}[5m])) +sum(increase(src_gitserver_client_total{job=~"^precise-code-intel-worker.*"}[5m])) ```-#### worker: codeintel_uploads_lsifstore_99th_percentile_duration +#### precise-code-intel-worker: gitserver_client_99th_percentile_duration -
99th percentile successful store operation duration over 5m
+Aggregate successful client operation duration distribution over 5m
This panel has no related alerts. -To see this panel, visit `/-/debug/grafana/d/worker/worker?viewPanel=100811` on your Sourcegraph instance. +To see this panel, visit `/-/debug/grafana/d/precise-code-intel-worker/precise-code-intel-worker?viewPanel=100401` on your Sourcegraph instance. *Managed by the [Sourcegraph Code intelligence team](https://handbook.sourcegraph.com/departments/engineering/teams/code-intelligence).* @@ -48154,19 +48462,19 @@ To see this panel, visit `/-/debug/grafana/d/worker/worker?viewPanel=100811` on Query: ``` -histogram_quantile(0.99, sum by (le,op)(rate(src_codeintel_uploads_lsifstore_duration_seconds_bucket{job=~"^worker.*"}[5m]))) +sum by (le)(rate(src_gitserver_client_duration_seconds_bucket{job=~"^precise-code-intel-worker.*"}[5m])) ```-#### worker: codeintel_uploads_lsifstore_errors_total +#### precise-code-intel-worker: gitserver_client_errors_total -
Store operation errors every 5m
+Aggregate client operation errors every 5m
This panel has no related alerts. -To see this panel, visit `/-/debug/grafana/d/worker/worker?viewPanel=100812` on your Sourcegraph instance. +To see this panel, visit `/-/debug/grafana/d/precise-code-intel-worker/precise-code-intel-worker?viewPanel=100402` on your Sourcegraph instance. *Managed by the [Sourcegraph Code intelligence team](https://handbook.sourcegraph.com/departments/engineering/teams/code-intelligence).* @@ -48176,19 +48484,19 @@ To see this panel, visit `/-/debug/grafana/d/worker/worker?viewPanel=100812` on Query: ``` -sum by (op)(increase(src_codeintel_uploads_lsifstore_errors_total{job=~"^worker.*"}[5m])) +sum(increase(src_gitserver_client_errors_total{job=~"^precise-code-intel-worker.*"}[5m])) ```-#### worker: codeintel_uploads_lsifstore_error_rate +#### precise-code-intel-worker: gitserver_client_error_rate -
Store operation error rate over 5m
+Aggregate client operation error rate over 5m
This panel has no related alerts. -To see this panel, visit `/-/debug/grafana/d/worker/worker?viewPanel=100813` on your Sourcegraph instance. +To see this panel, visit `/-/debug/grafana/d/precise-code-intel-worker/precise-code-intel-worker?viewPanel=100403` on your Sourcegraph instance. *Managed by the [Sourcegraph Code intelligence team](https://handbook.sourcegraph.com/departments/engineering/teams/code-intelligence).* @@ -48198,21 +48506,19 @@ To see this panel, visit `/-/debug/grafana/d/worker/worker?viewPanel=100813` on Query: ``` -sum by (op)(increase(src_codeintel_uploads_lsifstore_errors_total{job=~"^worker.*"}[5m])) / (sum by (op)(increase(src_codeintel_uploads_lsifstore_total{job=~"^worker.*"}[5m])) + sum by (op)(increase(src_codeintel_uploads_lsifstore_errors_total{job=~"^worker.*"}[5m]))) * 100 +sum(increase(src_gitserver_client_errors_total{job=~"^precise-code-intel-worker.*"}[5m])) / (sum(increase(src_gitserver_client_total{job=~"^precise-code-intel-worker.*"}[5m])) + sum(increase(src_gitserver_client_errors_total{job=~"^precise-code-intel-worker.*"}[5m]))) * 100 ```-### Worker: Workerutil: lsif_dependency_indexes dbworker/store stats - -#### worker: workerutil_dbworker_store_codeintel_dependency_index_total +#### precise-code-intel-worker: gitserver_client_total -
Store operations every 5m
+Client operations every 5m
This panel has no related alerts. -To see this panel, visit `/-/debug/grafana/d/worker/worker?viewPanel=100900` on your Sourcegraph instance. +To see this panel, visit `/-/debug/grafana/d/precise-code-intel-worker/precise-code-intel-worker?viewPanel=100410` on your Sourcegraph instance. *Managed by the [Sourcegraph Code intelligence team](https://handbook.sourcegraph.com/departments/engineering/teams/code-intelligence).* @@ -48222,19 +48528,19 @@ To see this panel, visit `/-/debug/grafana/d/worker/worker?viewPanel=100900` on Query: ``` -sum(increase(src_workerutil_dbworker_store_codeintel_dependency_index_total{job=~"^worker.*"}[5m])) +sum by (op)(increase(src_gitserver_client_total{job=~"^precise-code-intel-worker.*"}[5m])) ```-#### worker: workerutil_dbworker_store_codeintel_dependency_index_99th_percentile_duration +#### precise-code-intel-worker: gitserver_client_99th_percentile_duration -
Aggregate successful store operation duration distribution over 5m
+99th percentile successful client operation duration over 5m
This panel has no related alerts. -To see this panel, visit `/-/debug/grafana/d/worker/worker?viewPanel=100901` on your Sourcegraph instance. +To see this panel, visit `/-/debug/grafana/d/precise-code-intel-worker/precise-code-intel-worker?viewPanel=100411` on your Sourcegraph instance. *Managed by the [Sourcegraph Code intelligence team](https://handbook.sourcegraph.com/departments/engineering/teams/code-intelligence).* @@ -48244,19 +48550,19 @@ To see this panel, visit `/-/debug/grafana/d/worker/worker?viewPanel=100901` on Query: ``` -sum by (le)(rate(src_workerutil_dbworker_store_codeintel_dependency_index_duration_seconds_bucket{job=~"^worker.*"}[5m])) +histogram_quantile(0.99, sum by (le,op)(rate(src_gitserver_client_duration_seconds_bucket{job=~"^precise-code-intel-worker.*"}[5m]))) ```-#### worker: workerutil_dbworker_store_codeintel_dependency_index_errors_total +#### precise-code-intel-worker: gitserver_client_errors_total -
Store operation errors every 5m
+Client operation errors every 5m
This panel has no related alerts. -To see this panel, visit `/-/debug/grafana/d/worker/worker?viewPanel=100902` on your Sourcegraph instance. +To see this panel, visit `/-/debug/grafana/d/precise-code-intel-worker/precise-code-intel-worker?viewPanel=100412` on your Sourcegraph instance. *Managed by the [Sourcegraph Code intelligence team](https://handbook.sourcegraph.com/departments/engineering/teams/code-intelligence).* @@ -48266,19 +48572,19 @@ To see this panel, visit `/-/debug/grafana/d/worker/worker?viewPanel=100902` on Query: ``` -sum(increase(src_workerutil_dbworker_store_codeintel_dependency_index_errors_total{job=~"^worker.*"}[5m])) +sum by (op)(increase(src_gitserver_client_errors_total{job=~"^precise-code-intel-worker.*"}[5m])) ```-#### worker: workerutil_dbworker_store_codeintel_dependency_index_error_rate +#### precise-code-intel-worker: gitserver_client_error_rate -
Store operation error rate over 5m
+Client operation error rate over 5m
This panel has no related alerts. -To see this panel, visit `/-/debug/grafana/d/worker/worker?viewPanel=100903` on your Sourcegraph instance. +To see this panel, visit `/-/debug/grafana/d/precise-code-intel-worker/precise-code-intel-worker?viewPanel=100413` on your Sourcegraph instance. *Managed by the [Sourcegraph Code intelligence team](https://handbook.sourcegraph.com/departments/engineering/teams/code-intelligence).* @@ -48288,21 +48594,21 @@ To see this panel, visit `/-/debug/grafana/d/worker/worker?viewPanel=100903` on Query: ``` -sum(increase(src_workerutil_dbworker_store_codeintel_dependency_index_errors_total{job=~"^worker.*"}[5m])) / (sum(increase(src_workerutil_dbworker_store_codeintel_dependency_index_total{job=~"^worker.*"}[5m])) + sum(increase(src_workerutil_dbworker_store_codeintel_dependency_index_errors_total{job=~"^worker.*"}[5m]))) * 100 +sum by (op)(increase(src_gitserver_client_errors_total{job=~"^precise-code-intel-worker.*"}[5m])) / (sum by (op)(increase(src_gitserver_client_total{job=~"^precise-code-intel-worker.*"}[5m])) + sum by (op)(increase(src_gitserver_client_errors_total{job=~"^precise-code-intel-worker.*"}[5m]))) * 100 ```-### Worker: Codeintel: gitserver client +### Precise Code Intel Worker: Codeintel: uploadstore stats -#### worker: codeintel_gitserver_total +#### precise-code-intel-worker: codeintel_uploadstore_total -
Aggregate client operations every 5m
+Aggregate store operations every 5m
This panel has no related alerts. -To see this panel, visit `/-/debug/grafana/d/worker/worker?viewPanel=101000` on your Sourcegraph instance. +To see this panel, visit `/-/debug/grafana/d/precise-code-intel-worker/precise-code-intel-worker?viewPanel=100500` on your Sourcegraph instance. *Managed by the [Sourcegraph Code intelligence team](https://handbook.sourcegraph.com/departments/engineering/teams/code-intelligence).* @@ -48312,19 +48618,19 @@ To see this panel, visit `/-/debug/grafana/d/worker/worker?viewPanel=101000` on Query: ``` -sum(increase(src_codeintel_gitserver_total{job=~"^worker.*"}[5m])) +sum(increase(src_codeintel_uploadstore_total{job=~"^precise-code-intel-worker.*"}[5m])) ```-#### worker: codeintel_gitserver_99th_percentile_duration +#### precise-code-intel-worker: codeintel_uploadstore_99th_percentile_duration -
Aggregate successful client operation duration distribution over 5m
+Aggregate successful store operation duration distribution over 5m
This panel has no related alerts. -To see this panel, visit `/-/debug/grafana/d/worker/worker?viewPanel=101001` on your Sourcegraph instance. +To see this panel, visit `/-/debug/grafana/d/precise-code-intel-worker/precise-code-intel-worker?viewPanel=100501` on your Sourcegraph instance. *Managed by the [Sourcegraph Code intelligence team](https://handbook.sourcegraph.com/departments/engineering/teams/code-intelligence).* @@ -48334,19 +48640,19 @@ To see this panel, visit `/-/debug/grafana/d/worker/worker?viewPanel=101001` on Query: ``` -sum by (le)(rate(src_codeintel_gitserver_duration_seconds_bucket{job=~"^worker.*"}[5m])) +sum by (le)(rate(src_codeintel_uploadstore_duration_seconds_bucket{job=~"^precise-code-intel-worker.*"}[5m])) ```-#### worker: codeintel_gitserver_errors_total +#### precise-code-intel-worker: codeintel_uploadstore_errors_total -
Aggregate client operation errors every 5m
+Aggregate store operation errors every 5m
This panel has no related alerts. -To see this panel, visit `/-/debug/grafana/d/worker/worker?viewPanel=101002` on your Sourcegraph instance. +To see this panel, visit `/-/debug/grafana/d/precise-code-intel-worker/precise-code-intel-worker?viewPanel=100502` on your Sourcegraph instance. *Managed by the [Sourcegraph Code intelligence team](https://handbook.sourcegraph.com/departments/engineering/teams/code-intelligence).* @@ -48356,19 +48662,19 @@ To see this panel, visit `/-/debug/grafana/d/worker/worker?viewPanel=101002` on Query: ``` -sum(increase(src_codeintel_gitserver_errors_total{job=~"^worker.*"}[5m])) +sum(increase(src_codeintel_uploadstore_errors_total{job=~"^precise-code-intel-worker.*"}[5m])) ```-#### worker: codeintel_gitserver_error_rate +#### precise-code-intel-worker: codeintel_uploadstore_error_rate -
Aggregate client operation error rate over 5m
+Aggregate store operation error rate over 5m
This panel has no related alerts. -To see this panel, visit `/-/debug/grafana/d/worker/worker?viewPanel=101003` on your Sourcegraph instance. +To see this panel, visit `/-/debug/grafana/d/precise-code-intel-worker/precise-code-intel-worker?viewPanel=100503` on your Sourcegraph instance. *Managed by the [Sourcegraph Code intelligence team](https://handbook.sourcegraph.com/departments/engineering/teams/code-intelligence).* @@ -48378,19 +48684,19 @@ To see this panel, visit `/-/debug/grafana/d/worker/worker?viewPanel=101003` on Query: ``` -sum(increase(src_codeintel_gitserver_errors_total{job=~"^worker.*"}[5m])) / (sum(increase(src_codeintel_gitserver_total{job=~"^worker.*"}[5m])) + sum(increase(src_codeintel_gitserver_errors_total{job=~"^worker.*"}[5m]))) * 100 +sum(increase(src_codeintel_uploadstore_errors_total{job=~"^precise-code-intel-worker.*"}[5m])) / (sum(increase(src_codeintel_uploadstore_total{job=~"^precise-code-intel-worker.*"}[5m])) + sum(increase(src_codeintel_uploadstore_errors_total{job=~"^precise-code-intel-worker.*"}[5m]))) * 100 ```-#### worker: codeintel_gitserver_total +#### precise-code-intel-worker: codeintel_uploadstore_total -
Client operations every 5m
+Store operations every 5m
This panel has no related alerts. -To see this panel, visit `/-/debug/grafana/d/worker/worker?viewPanel=101010` on your Sourcegraph instance. +To see this panel, visit `/-/debug/grafana/d/precise-code-intel-worker/precise-code-intel-worker?viewPanel=100510` on your Sourcegraph instance. *Managed by the [Sourcegraph Code intelligence team](https://handbook.sourcegraph.com/departments/engineering/teams/code-intelligence).* @@ -48400,19 +48706,19 @@ To see this panel, visit `/-/debug/grafana/d/worker/worker?viewPanel=101010` on Query: ``` -sum by (op)(increase(src_codeintel_gitserver_total{job=~"^worker.*"}[5m])) +sum by (op)(increase(src_codeintel_uploadstore_total{job=~"^precise-code-intel-worker.*"}[5m])) ```-#### worker: codeintel_gitserver_99th_percentile_duration +#### precise-code-intel-worker: codeintel_uploadstore_99th_percentile_duration -
99th percentile successful client operation duration over 5m
+99th percentile successful store operation duration over 5m
This panel has no related alerts. -To see this panel, visit `/-/debug/grafana/d/worker/worker?viewPanel=101011` on your Sourcegraph instance. +To see this panel, visit `/-/debug/grafana/d/precise-code-intel-worker/precise-code-intel-worker?viewPanel=100511` on your Sourcegraph instance. *Managed by the [Sourcegraph Code intelligence team](https://handbook.sourcegraph.com/departments/engineering/teams/code-intelligence).* @@ -48422,19 +48728,19 @@ To see this panel, visit `/-/debug/grafana/d/worker/worker?viewPanel=101011` on Query: ``` -histogram_quantile(0.99, sum by (le,op)(rate(src_codeintel_gitserver_duration_seconds_bucket{job=~"^worker.*"}[5m]))) +histogram_quantile(0.99, sum by (le,op)(rate(src_codeintel_uploadstore_duration_seconds_bucket{job=~"^precise-code-intel-worker.*"}[5m]))) ```-#### worker: codeintel_gitserver_errors_total +#### precise-code-intel-worker: codeintel_uploadstore_errors_total -
Client operation errors every 5m
+Store operation errors every 5m
This panel has no related alerts. -To see this panel, visit `/-/debug/grafana/d/worker/worker?viewPanel=101012` on your Sourcegraph instance. +To see this panel, visit `/-/debug/grafana/d/precise-code-intel-worker/precise-code-intel-worker?viewPanel=100512` on your Sourcegraph instance. *Managed by the [Sourcegraph Code intelligence team](https://handbook.sourcegraph.com/departments/engineering/teams/code-intelligence).* @@ -48444,19 +48750,19 @@ To see this panel, visit `/-/debug/grafana/d/worker/worker?viewPanel=101012` on Query: ``` -sum by (op)(increase(src_codeintel_gitserver_errors_total{job=~"^worker.*"}[5m])) +sum by (op)(increase(src_codeintel_uploadstore_errors_total{job=~"^precise-code-intel-worker.*"}[5m])) ```-#### worker: codeintel_gitserver_error_rate +#### precise-code-intel-worker: codeintel_uploadstore_error_rate -
Client operation error rate over 5m
+Store operation error rate over 5m
This panel has no related alerts. -To see this panel, visit `/-/debug/grafana/d/worker/worker?viewPanel=101013` on your Sourcegraph instance. +To see this panel, visit `/-/debug/grafana/d/precise-code-intel-worker/precise-code-intel-worker?viewPanel=100513` on your Sourcegraph instance. *Managed by the [Sourcegraph Code intelligence team](https://handbook.sourcegraph.com/departments/engineering/teams/code-intelligence).* @@ -48466,23 +48772,23 @@ To see this panel, visit `/-/debug/grafana/d/worker/worker?viewPanel=101013` on Query: ``` -sum by (op)(increase(src_codeintel_gitserver_errors_total{job=~"^worker.*"}[5m])) / (sum by (op)(increase(src_codeintel_gitserver_total{job=~"^worker.*"}[5m])) + sum by (op)(increase(src_codeintel_gitserver_errors_total{job=~"^worker.*"}[5m]))) * 100 +sum by (op)(increase(src_codeintel_uploadstore_errors_total{job=~"^precise-code-intel-worker.*"}[5m])) / (sum by (op)(increase(src_codeintel_uploadstore_total{job=~"^precise-code-intel-worker.*"}[5m])) + sum by (op)(increase(src_codeintel_uploadstore_errors_total{job=~"^precise-code-intel-worker.*"}[5m]))) * 100 ```-### Worker: Codeintel: Dependency repository insert +### Precise Code Intel Worker: Database connections -#### worker: codeintel_dependency_repos_total +#### precise-code-intel-worker: max_open_conns -
Aggregate insert operations every 5m
+Maximum open
This panel has no related alerts. -To see this panel, visit `/-/debug/grafana/d/worker/worker?viewPanel=101100` on your Sourcegraph instance. +To see this panel, visit `/-/debug/grafana/d/precise-code-intel-worker/precise-code-intel-worker?viewPanel=100600` on your Sourcegraph instance. -*Managed by the [Sourcegraph Code intelligence team](https://handbook.sourcegraph.com/departments/engineering/teams/code-intelligence).* +*Managed by the [Sourcegraph Infrastructure Org team](https://handbook.sourcegraph.com/departments/engineering/infrastructure).*Technical details
@@ -48490,21 +48796,21 @@ To see this panel, visit `/-/debug/grafana/d/worker/worker?viewPanel=101100` on Query: ``` -sum(increase(src_codeintel_dependency_repos_total{job=~"^worker.*"}[5m])) +sum by (app_name, db_name) (src_pgsql_conns_max_open{app_name="precise-code-intel-worker"}) ```-#### worker: codeintel_dependency_repos_99th_percentile_duration +#### precise-code-intel-worker: open_conns -
Aggregate successful insert operation duration distribution over 5m
+Established
This panel has no related alerts. -To see this panel, visit `/-/debug/grafana/d/worker/worker?viewPanel=101101` on your Sourcegraph instance. +To see this panel, visit `/-/debug/grafana/d/precise-code-intel-worker/precise-code-intel-worker?viewPanel=100601` on your Sourcegraph instance. -*Managed by the [Sourcegraph Code intelligence team](https://handbook.sourcegraph.com/departments/engineering/teams/code-intelligence).* +*Managed by the [Sourcegraph Infrastructure Org team](https://handbook.sourcegraph.com/departments/engineering/infrastructure).*Technical details
@@ -48512,21 +48818,21 @@ To see this panel, visit `/-/debug/grafana/d/worker/worker?viewPanel=101101` on Query: ``` -sum by (le)(rate(src_codeintel_dependency_repos_duration_seconds_bucket{job=~"^worker.*"}[5m])) +sum by (app_name, db_name) (src_pgsql_conns_open{app_name="precise-code-intel-worker"}) ```-#### worker: codeintel_dependency_repos_errors_total +#### precise-code-intel-worker: in_use -
Aggregate insert operation errors every 5m
+Used
This panel has no related alerts. -To see this panel, visit `/-/debug/grafana/d/worker/worker?viewPanel=101102` on your Sourcegraph instance. +To see this panel, visit `/-/debug/grafana/d/precise-code-intel-worker/precise-code-intel-worker?viewPanel=100610` on your Sourcegraph instance. -*Managed by the [Sourcegraph Code intelligence team](https://handbook.sourcegraph.com/departments/engineering/teams/code-intelligence).* +*Managed by the [Sourcegraph Infrastructure Org team](https://handbook.sourcegraph.com/departments/engineering/infrastructure).*Technical details
@@ -48534,21 +48840,21 @@ To see this panel, visit `/-/debug/grafana/d/worker/worker?viewPanel=101102` on Query: ``` -sum(increase(src_codeintel_dependency_repos_errors_total{job=~"^worker.*"}[5m])) +sum by (app_name, db_name) (src_pgsql_conns_in_use{app_name="precise-code-intel-worker"}) ```-#### worker: codeintel_dependency_repos_error_rate +#### precise-code-intel-worker: idle -
Aggregate insert operation error rate over 5m
+Idle
This panel has no related alerts. -To see this panel, visit `/-/debug/grafana/d/worker/worker?viewPanel=101103` on your Sourcegraph instance. +To see this panel, visit `/-/debug/grafana/d/precise-code-intel-worker/precise-code-intel-worker?viewPanel=100611` on your Sourcegraph instance. -*Managed by the [Sourcegraph Code intelligence team](https://handbook.sourcegraph.com/departments/engineering/teams/code-intelligence).* +*Managed by the [Sourcegraph Infrastructure Org team](https://handbook.sourcegraph.com/departments/engineering/infrastructure).*Technical details
@@ -48556,21 +48862,21 @@ To see this panel, visit `/-/debug/grafana/d/worker/worker?viewPanel=101103` on Query: ``` -sum(increase(src_codeintel_dependency_repos_errors_total{job=~"^worker.*"}[5m])) / (sum(increase(src_codeintel_dependency_repos_total{job=~"^worker.*"}[5m])) + sum(increase(src_codeintel_dependency_repos_errors_total{job=~"^worker.*"}[5m]))) * 100 +sum by (app_name, db_name) (src_pgsql_conns_idle{app_name="precise-code-intel-worker"}) ```-#### worker: codeintel_dependency_repos_total +#### precise-code-intel-worker: mean_blocked_seconds_per_conn_request -
Insert operations every 5m
+Mean blocked seconds per conn request
-This panel has no related alerts. +Refer to the [alerts reference](alerts#precise-code-intel-worker-mean-blocked-seconds-per-conn-request) for 2 alerts related to this panel. -To see this panel, visit `/-/debug/grafana/d/worker/worker?viewPanel=101110` on your Sourcegraph instance. +To see this panel, visit `/-/debug/grafana/d/precise-code-intel-worker/precise-code-intel-worker?viewPanel=100620` on your Sourcegraph instance. -*Managed by the [Sourcegraph Code intelligence team](https://handbook.sourcegraph.com/departments/engineering/teams/code-intelligence).* +*Managed by the [Sourcegraph Infrastructure Org team](https://handbook.sourcegraph.com/departments/engineering/infrastructure).*Technical details
@@ -48578,21 +48884,21 @@ To see this panel, visit `/-/debug/grafana/d/worker/worker?viewPanel=101110` on Query: ``` -sum by (scheme,new)(increase(src_codeintel_dependency_repos_total{job=~"^worker.*"}[5m])) +sum by (app_name, db_name) (increase(src_pgsql_conns_blocked_seconds{app_name="precise-code-intel-worker"}[5m])) / sum by (app_name, db_name) (increase(src_pgsql_conns_waited_for{app_name="precise-code-intel-worker"}[5m])) ```-#### worker: codeintel_dependency_repos_99th_percentile_duration +#### precise-code-intel-worker: closed_max_idle -
99th percentile successful insert operation duration over 5m
+Closed by SetMaxIdleConns
This panel has no related alerts. -To see this panel, visit `/-/debug/grafana/d/worker/worker?viewPanel=101111` on your Sourcegraph instance. +To see this panel, visit `/-/debug/grafana/d/precise-code-intel-worker/precise-code-intel-worker?viewPanel=100630` on your Sourcegraph instance. -*Managed by the [Sourcegraph Code intelligence team](https://handbook.sourcegraph.com/departments/engineering/teams/code-intelligence).* +*Managed by the [Sourcegraph Infrastructure Org team](https://handbook.sourcegraph.com/departments/engineering/infrastructure).*Technical details
@@ -48600,21 +48906,21 @@ To see this panel, visit `/-/debug/grafana/d/worker/worker?viewPanel=101111` on Query: ``` -histogram_quantile(0.99, sum by (le,scheme,new)(rate(src_codeintel_dependency_repos_duration_seconds_bucket{job=~"^worker.*"}[5m]))) +sum by (app_name, db_name) (increase(src_pgsql_conns_closed_max_idle{app_name="precise-code-intel-worker"}[5m])) ```-#### worker: codeintel_dependency_repos_errors_total +#### precise-code-intel-worker: closed_max_lifetime -
Insert operation errors every 5m
+Closed by SetConnMaxLifetime
This panel has no related alerts. -To see this panel, visit `/-/debug/grafana/d/worker/worker?viewPanel=101112` on your Sourcegraph instance. +To see this panel, visit `/-/debug/grafana/d/precise-code-intel-worker/precise-code-intel-worker?viewPanel=100631` on your Sourcegraph instance. -*Managed by the [Sourcegraph Code intelligence team](https://handbook.sourcegraph.com/departments/engineering/teams/code-intelligence).* +*Managed by the [Sourcegraph Infrastructure Org team](https://handbook.sourcegraph.com/departments/engineering/infrastructure).*Technical details
@@ -48622,21 +48928,21 @@ To see this panel, visit `/-/debug/grafana/d/worker/worker?viewPanel=101112` on Query: ``` -sum by (scheme,new)(increase(src_codeintel_dependency_repos_errors_total{job=~"^worker.*"}[5m])) +sum by (app_name, db_name) (increase(src_pgsql_conns_closed_max_lifetime{app_name="precise-code-intel-worker"}[5m])) ```-#### worker: codeintel_dependency_repos_error_rate +#### precise-code-intel-worker: closed_max_idle_time -
Insert operation error rate over 5m
+Closed by SetConnMaxIdleTime
This panel has no related alerts. -To see this panel, visit `/-/debug/grafana/d/worker/worker?viewPanel=101113` on your Sourcegraph instance. +To see this panel, visit `/-/debug/grafana/d/precise-code-intel-worker/precise-code-intel-worker?viewPanel=100632` on your Sourcegraph instance. -*Managed by the [Sourcegraph Code intelligence team](https://handbook.sourcegraph.com/departments/engineering/teams/code-intelligence).* +*Managed by the [Sourcegraph Infrastructure Org team](https://handbook.sourcegraph.com/departments/engineering/infrastructure).*Technical details
@@ -48644,25 +48950,23 @@ To see this panel, visit `/-/debug/grafana/d/worker/worker?viewPanel=101113` on Query: ``` -sum by (scheme,new)(increase(src_codeintel_dependency_repos_errors_total{job=~"^worker.*"}[5m])) / (sum by (scheme,new)(increase(src_codeintel_dependency_repos_total{job=~"^worker.*"}[5m])) + sum by (scheme,new)(increase(src_codeintel_dependency_repos_errors_total{job=~"^worker.*"}[5m]))) * 100 +sum by (app_name, db_name) (increase(src_pgsql_conns_closed_max_idle_time{app_name="precise-code-intel-worker"}[5m])) ```-### Worker: Permissions - -#### worker: user_success_syncs_total +### Precise Code Intel Worker: Precise-code-intel-worker (CPU, Memory) -
Total number of user permissions syncs
+#### precise-code-intel-worker: cpu_usage_percentage -Indicates the total number of user permissions sync completed. +CPU usage
-This panel has no related alerts. +Refer to the [alerts reference](alerts#precise-code-intel-worker-cpu-usage-percentage) for 1 alert related to this panel. -To see this panel, visit `/-/debug/grafana/d/worker/worker?viewPanel=101200` on your Sourcegraph instance. +To see this panel, visit `/-/debug/grafana/d/precise-code-intel-worker/precise-code-intel-worker?viewPanel=100700` on your Sourcegraph instance. -*Managed by the [Sourcegraph Source team](https://handbook.sourcegraph.com/departments/engineering/teams/source).* +*Managed by the [Sourcegraph Code Search team](https://handbook.sourcegraph.com/departments/engineering/teams/code-search).*Technical details
@@ -48670,23 +48974,23 @@ To see this panel, visit `/-/debug/grafana/d/worker/worker?viewPanel=101200` on Query: ``` -sum(src_repo_perms_syncer_success_syncs{type="user"}) +cadvisor_container_cpu_usage_percentage_total{name=~"^precise-code-intel-worker.*"} ```-#### worker: user_success_syncs +#### precise-code-intel-worker: memory_usage_percentage -
Number of user permissions syncs [5m]
+Memory usage percentage (total)
-Indicates the number of users permissions syncs completed. +An estimate for the active memory in use, which includes anonymous memory, file memory, and kernel memory. Some of this memory is reclaimable, so high usage does not necessarily indicate memory pressure. This panel has no related alerts. -To see this panel, visit `/-/debug/grafana/d/worker/worker?viewPanel=101201` on your Sourcegraph instance. +To see this panel, visit `/-/debug/grafana/d/precise-code-intel-worker/precise-code-intel-worker?viewPanel=100701` on your Sourcegraph instance. -*Managed by the [Sourcegraph Source team](https://handbook.sourcegraph.com/departments/engineering/teams/source).* +*Managed by the [Sourcegraph Code Search team](https://handbook.sourcegraph.com/departments/engineering/teams/code-search).*Technical details
@@ -48694,23 +48998,23 @@ To see this panel, visit `/-/debug/grafana/d/worker/worker?viewPanel=101201` on Query: ``` -sum(increase(src_repo_perms_syncer_success_syncs{type="user"}[5m])) +cadvisor_container_memory_usage_percentage_total{name=~"^precise-code-intel-worker.*"} ```-#### worker: user_initial_syncs +#### precise-code-intel-worker: memory_working_set_bytes -
Number of first user permissions syncs [5m]
+Memory usage bytes (total)
-Indicates the number of permissions syncs done for the first time for the user. +An estimate for the active memory in use in bytes, which includes anonymous memory, file memory, and kernel memory. Some of this memory is reclaimable, so high usage does not necessarily indicate memory pressure. This panel has no related alerts. -To see this panel, visit `/-/debug/grafana/d/worker/worker?viewPanel=101202` on your Sourcegraph instance. +To see this panel, visit `/-/debug/grafana/d/precise-code-intel-worker/precise-code-intel-worker?viewPanel=100702` on your Sourcegraph instance. -*Managed by the [Sourcegraph Source team](https://handbook.sourcegraph.com/departments/engineering/teams/source).* +*Managed by the [Sourcegraph Code Search team](https://handbook.sourcegraph.com/departments/engineering/teams/code-search).*Technical details
@@ -48718,23 +49022,23 @@ To see this panel, visit `/-/debug/grafana/d/worker/worker?viewPanel=101202` on Query: ``` -sum(increase(src_repo_perms_syncer_initial_syncs{type="user"}[5m])) +max by (name) (container_memory_working_set_bytes{name=~"^precise-code-intel-worker.*"}) ```-#### worker: repo_success_syncs_total +#### precise-code-intel-worker: memory_rss -
Total number of repo permissions syncs
+Memory (RSS)
-Indicates the total number of repo permissions sync completed. +The total anonymous memory in use by the application, which includes Go stack and heap. This memory is is non-reclaimable, and high usage may trigger OOM kills. Note: the metric is named RSS because to match the cadvisor name, but `anonymous` is more accurate." -This panel has no related alerts. +Refer to the [alerts reference](alerts#precise-code-intel-worker-memory-rss) for 1 alert related to this panel. -To see this panel, visit `/-/debug/grafana/d/worker/worker?viewPanel=101210` on your Sourcegraph instance. +To see this panel, visit `/-/debug/grafana/d/precise-code-intel-worker/precise-code-intel-worker?viewPanel=100710` on your Sourcegraph instance. -*Managed by the [Sourcegraph Source team](https://handbook.sourcegraph.com/departments/engineering/teams/source).* +*Managed by the [Sourcegraph Code Search team](https://handbook.sourcegraph.com/departments/engineering/teams/code-search).*Technical details
@@ -48742,23 +49046,23 @@ To see this panel, visit `/-/debug/grafana/d/worker/worker?viewPanel=101210` on Query: ``` -sum(src_repo_perms_syncer_success_syncs{type="repo"}) +max(container_memory_rss{name=~"^precise-code-intel-worker.*"} / container_spec_memory_limit_bytes{name=~"^precise-code-intel-worker.*"}) by (name) * 100.0 ```-#### worker: repo_success_syncs +#### precise-code-intel-worker: memory_total_active_file -
Number of repo permissions syncs over 5m
+Memory usage (active file)
-Indicates the number of repos permissions syncs completed. +This metric shows the total active file-backed memory currently in use by the application. Some of it may be reclaimable, so high usage does not necessarily indicate memory pressure. This panel has no related alerts. -To see this panel, visit `/-/debug/grafana/d/worker/worker?viewPanel=101211` on your Sourcegraph instance. +To see this panel, visit `/-/debug/grafana/d/precise-code-intel-worker/precise-code-intel-worker?viewPanel=100711` on your Sourcegraph instance. -*Managed by the [Sourcegraph Source team](https://handbook.sourcegraph.com/departments/engineering/teams/source).* +*Managed by the [Sourcegraph Code Search team](https://handbook.sourcegraph.com/departments/engineering/teams/code-search).*Technical details
@@ -48766,23 +49070,23 @@ To see this panel, visit `/-/debug/grafana/d/worker/worker?viewPanel=101211` on Query: ``` -sum(increase(src_repo_perms_syncer_success_syncs{type="repo"}[5m])) +max(container_memory_total_active_file_bytes{name=~"^precise-code-intel-worker.*"} / container_spec_memory_limit_bytes{name=~"^precise-code-intel-worker.*"}) by (name) * 100.0 ```-#### worker: repo_initial_syncs +#### precise-code-intel-worker: memory_kernel_usage -
Number of first repo permissions syncs over 5m
+Memory usage (kernel)
-Indicates the number of permissions syncs done for the first time for the repo. +The kernel usage metric shows the amount of memory used by the kernel on behalf of the application. Some of it may be reclaimable, so high usage does not necessarily indicate memory pressure. This panel has no related alerts. -To see this panel, visit `/-/debug/grafana/d/worker/worker?viewPanel=101212` on your Sourcegraph instance. +To see this panel, visit `/-/debug/grafana/d/precise-code-intel-worker/precise-code-intel-worker?viewPanel=100712` on your Sourcegraph instance. -*Managed by the [Sourcegraph Source team](https://handbook.sourcegraph.com/departments/engineering/teams/source).* +*Managed by the [Sourcegraph Code Search team](https://handbook.sourcegraph.com/departments/engineering/teams/code-search).*Technical details
@@ -48790,47 +49094,33 @@ To see this panel, visit `/-/debug/grafana/d/worker/worker?viewPanel=101212` on Query: ``` -sum(increase(src_repo_perms_syncer_initial_syncs{type="repo"}[5m])) +max(container_memory_kernel_usage{name=~"^precise-code-intel-worker.*"} / container_spec_memory_limit_bytes{name=~"^precise-code-intel-worker.*"}) by (name) * 100.0 ```-#### worker: users_consecutive_sync_delay - -
Max duration between two consecutive permissions sync for user
- -Indicates the max delay between two consecutive permissions sync for a user during the period. - -This panel has no related alerts. - -To see this panel, visit `/-/debug/grafana/d/worker/worker?viewPanel=101220` on your Sourcegraph instance. - -*Managed by the [Sourcegraph Source team](https://handbook.sourcegraph.com/departments/engineering/teams/source).* - -Technical details
- -Query: - -``` -max(max_over_time (src_repo_perms_syncer_perms_consecutive_sync_delay{type="user"} [1m])) -``` -+#### precise-code-intel-worker: container_missing -#### worker: repos_consecutive_sync_delay +
Container missing
-Max duration between two consecutive permissions sync for repo
+This value is the number of times a container has not been seen for more than one minute. If you observe this +value change independent of deployment events (such as an upgrade), it could indicate pods are being OOM killed or terminated for some other reasons. -Indicates the max delay between two consecutive permissions sync for a repo during the period. +- **Kubernetes:** + - Determine if the pod was OOM killed using `kubectl describe pod precise-code-intel-worker` (look for `OOMKilled: true`) and, if so, consider increasing the memory limit in the relevant `Deployment.yaml`. + - Check the logs before the container restarted to see if there are `panic:` messages or similar using `kubectl logs -p precise-code-intel-worker`. +- **Docker Compose:** + - Determine if the pod was OOM killed using `docker inspect -f '\{\{json .State\}\}' precise-code-intel-worker` (look for `"OOMKilled":true`) and, if so, consider increasing the memory limit of the precise-code-intel-worker container in `docker-compose.yml`. + - Check the logs before the container restarted to see if there are `panic:` messages or similar using `docker logs precise-code-intel-worker` (note this will include logs from the previous and currently running container). This panel has no related alerts. -To see this panel, visit `/-/debug/grafana/d/worker/worker?viewPanel=101221` on your Sourcegraph instance. +To see this panel, visit `/-/debug/grafana/d/precise-code-intel-worker/precise-code-intel-worker?viewPanel=100800` on your Sourcegraph instance. -*Managed by the [Sourcegraph Source team](https://handbook.sourcegraph.com/departments/engineering/teams/source).* +*Managed by the [Sourcegraph Code intelligence team](https://handbook.sourcegraph.com/departments/engineering/teams/code-intelligence).*Technical details
@@ -48838,23 +49128,21 @@ To see this panel, visit `/-/debug/grafana/d/worker/worker?viewPanel=101221` on Query: ``` -max(max_over_time (src_repo_perms_syncer_perms_consecutive_sync_delay{type="repo"} [1m])) +count by(name) ((time() - container_last_seen{name=~"^precise-code-intel-worker.*"}) > 60) ```-#### worker: users_first_sync_delay - -
Max duration between user creation and first permissions sync
+#### precise-code-intel-worker: container_cpu_usage -Indicates the max delay between user creation and their permissions sync +Container cpu usage total (1m average) across all cores by instance
-This panel has no related alerts. +Refer to the [alerts reference](alerts#precise-code-intel-worker-container-cpu-usage) for 1 alert related to this panel. -To see this panel, visit `/-/debug/grafana/d/worker/worker?viewPanel=101230` on your Sourcegraph instance. +To see this panel, visit `/-/debug/grafana/d/precise-code-intel-worker/precise-code-intel-worker?viewPanel=100801` on your Sourcegraph instance. -*Managed by the [Sourcegraph Source team](https://handbook.sourcegraph.com/departments/engineering/teams/source).* +*Managed by the [Sourcegraph Code intelligence team](https://handbook.sourcegraph.com/departments/engineering/teams/code-intelligence).*Technical details
@@ -48862,23 +49150,21 @@ To see this panel, visit `/-/debug/grafana/d/worker/worker?viewPanel=101230` on Query: ``` -max(max_over_time(src_repo_perms_syncer_perms_first_sync_delay{type="user"}[1m])) +cadvisor_container_cpu_usage_percentage_total{name=~"^precise-code-intel-worker.*"} ```-#### worker: repos_first_sync_delay - -
Max duration between repo creation and first permissions sync over 1m
+#### precise-code-intel-worker: container_memory_usage -Indicates the max delay between repo creation and their permissions sync +Container memory usage by instance
-This panel has no related alerts. +Refer to the [alerts reference](alerts#precise-code-intel-worker-container-memory-usage) for 1 alert related to this panel. -To see this panel, visit `/-/debug/grafana/d/worker/worker?viewPanel=101231` on your Sourcegraph instance. +To see this panel, visit `/-/debug/grafana/d/precise-code-intel-worker/precise-code-intel-worker?viewPanel=100802` on your Sourcegraph instance. -*Managed by the [Sourcegraph Source team](https://handbook.sourcegraph.com/departments/engineering/teams/source).* +*Managed by the [Sourcegraph Code intelligence team](https://handbook.sourcegraph.com/departments/engineering/teams/code-intelligence).*Technical details
@@ -48886,23 +49172,24 @@ To see this panel, visit `/-/debug/grafana/d/worker/worker?viewPanel=101231` on Query: ``` -max(max_over_time(src_repo_perms_syncer_perms_first_sync_delay{type="repo"}[1m])) +cadvisor_container_memory_usage_percentage_total{name=~"^precise-code-intel-worker.*"} ```-#### worker: permissions_found_count +#### precise-code-intel-worker: fs_io_operations -
Number of permissions found during user/repo permissions sync
+Filesystem reads and writes rate by instance over 1h
-Indicates the number permissions found during users/repos permissions sync. +This value indicates the number of filesystem read and write operations by containers of this service. +When extremely high, this can indicate a resource usage problem, or can cause problems with the service itself, especially if high values or spikes correlate with \{\{CONTAINER_NAME\}\} issues. This panel has no related alerts. -To see this panel, visit `/-/debug/grafana/d/worker/worker?viewPanel=101240` on your Sourcegraph instance. +To see this panel, visit `/-/debug/grafana/d/precise-code-intel-worker/precise-code-intel-worker?viewPanel=100803` on your Sourcegraph instance. -*Managed by the [Sourcegraph Source team](https://handbook.sourcegraph.com/departments/engineering/teams/source).* +*Managed by the [Sourcegraph Code intelligence team](https://handbook.sourcegraph.com/departments/engineering/teams/code-intelligence).*Technical details
@@ -48910,23 +49197,23 @@ To see this panel, visit `/-/debug/grafana/d/worker/worker?viewPanel=101240` on Query: ``` -sum by (type) (src_repo_perms_syncer_perms_found) +sum by(name) (rate(container_fs_reads_total{name=~"^precise-code-intel-worker.*"}[1h]) + rate(container_fs_writes_total{name=~"^precise-code-intel-worker.*"}[1h])) ```-#### worker: permissions_found_avg +### Precise Code Intel Worker: Provisioning indicators (not available on server) -
Average number of permissions found during permissions sync per user/repo
+#### precise-code-intel-worker: provisioning_container_cpu_usage_long_term -Indicates the average number permissions found during permissions sync per user/repo. +Container cpu usage total (90th percentile over 1d) across all cores by instance
-This panel has no related alerts. +Refer to the [alerts reference](alerts#precise-code-intel-worker-provisioning-container-cpu-usage-long-term) for 1 alert related to this panel. -To see this panel, visit `/-/debug/grafana/d/worker/worker?viewPanel=101241` on your Sourcegraph instance. +To see this panel, visit `/-/debug/grafana/d/precise-code-intel-worker/precise-code-intel-worker?viewPanel=100900` on your Sourcegraph instance. -*Managed by the [Sourcegraph Source team](https://handbook.sourcegraph.com/departments/engineering/teams/source).* +*Managed by the [Sourcegraph Code intelligence team](https://handbook.sourcegraph.com/departments/engineering/teams/code-intelligence).*Technical details
@@ -48934,21 +49221,21 @@ To see this panel, visit `/-/debug/grafana/d/worker/worker?viewPanel=101241` on Query: ``` -avg by (type) (src_repo_perms_syncer_perms_found) +quantile_over_time(0.9, cadvisor_container_cpu_usage_percentage_total{name=~"^precise-code-intel-worker.*"}[1d]) ```-#### worker: perms_syncer_outdated_perms +#### precise-code-intel-worker: provisioning_container_memory_usage_long_term -
Number of entities with outdated permissions
+Container memory usage (1d maximum) by instance
-Refer to the [alerts reference](alerts#worker-perms-syncer-outdated-perms) for 1 alert related to this panel. +Refer to the [alerts reference](alerts#precise-code-intel-worker-provisioning-container-memory-usage-long-term) for 1 alert related to this panel. -To see this panel, visit `/-/debug/grafana/d/worker/worker?viewPanel=101250` on your Sourcegraph instance. +To see this panel, visit `/-/debug/grafana/d/precise-code-intel-worker/precise-code-intel-worker?viewPanel=100901` on your Sourcegraph instance. -*Managed by the [Sourcegraph Source team](https://handbook.sourcegraph.com/departments/engineering/teams/source).* +*Managed by the [Sourcegraph Code intelligence team](https://handbook.sourcegraph.com/departments/engineering/teams/code-intelligence).*Technical details
@@ -48956,21 +49243,21 @@ To see this panel, visit `/-/debug/grafana/d/worker/worker?viewPanel=101250` on Query: ``` -max by (type) (src_repo_perms_syncer_outdated_perms) +max_over_time(cadvisor_container_memory_usage_percentage_total{name=~"^precise-code-intel-worker.*"}[1d]) ```-#### worker: perms_syncer_sync_duration +#### precise-code-intel-worker: provisioning_container_cpu_usage_short_term -
95th permissions sync duration
+Container cpu usage total (5m maximum) across all cores by instance
-Refer to the [alerts reference](alerts#worker-perms-syncer-sync-duration) for 1 alert related to this panel. +Refer to the [alerts reference](alerts#precise-code-intel-worker-provisioning-container-cpu-usage-short-term) for 1 alert related to this panel. -To see this panel, visit `/-/debug/grafana/d/worker/worker?viewPanel=101260` on your Sourcegraph instance. +To see this panel, visit `/-/debug/grafana/d/precise-code-intel-worker/precise-code-intel-worker?viewPanel=100910` on your Sourcegraph instance. -*Managed by the [Sourcegraph Source team](https://handbook.sourcegraph.com/departments/engineering/teams/source).* +*Managed by the [Sourcegraph Code intelligence team](https://handbook.sourcegraph.com/departments/engineering/teams/code-intelligence).*Technical details
@@ -48978,21 +49265,21 @@ To see this panel, visit `/-/debug/grafana/d/worker/worker?viewPanel=101260` on Query: ``` -histogram_quantile(0.95, max by (le, type) (rate(src_repo_perms_syncer_sync_duration_seconds_bucket[1m]))) +max_over_time(cadvisor_container_cpu_usage_percentage_total{name=~"^precise-code-intel-worker.*"}[5m]) ```-#### worker: perms_syncer_sync_errors +#### precise-code-intel-worker: provisioning_container_memory_usage_short_term -
Permissions sync error rate
+Container memory usage (5m maximum) by instance
-Refer to the [alerts reference](alerts#worker-perms-syncer-sync-errors) for 1 alert related to this panel. +Refer to the [alerts reference](alerts#precise-code-intel-worker-provisioning-container-memory-usage-short-term) for 1 alert related to this panel. -To see this panel, visit `/-/debug/grafana/d/worker/worker?viewPanel=101270` on your Sourcegraph instance. +To see this panel, visit `/-/debug/grafana/d/precise-code-intel-worker/precise-code-intel-worker?viewPanel=100911` on your Sourcegraph instance. -*Managed by the [Sourcegraph Source team](https://handbook.sourcegraph.com/departments/engineering/teams/source).* +*Managed by the [Sourcegraph Code intelligence team](https://handbook.sourcegraph.com/departments/engineering/teams/code-intelligence).*Technical details
@@ -49000,24 +49287,24 @@ To see this panel, visit `/-/debug/grafana/d/worker/worker?viewPanel=101270` on Query: ``` -max by (type) (ceil(rate(src_repo_perms_syncer_sync_errors_total[1m]))) +max_over_time(cadvisor_container_memory_usage_percentage_total{name=~"^precise-code-intel-worker.*"}[5m]) ```-#### worker: perms_syncer_scheduled_repos_total +#### precise-code-intel-worker: container_oomkill_events_total -
Total number of repos scheduled for permissions sync
+Container OOMKILL events total by instance
-Indicates how many repositories have been scheduled for a permissions sync. -More about repository permissions synchronization [here](https://sourcegraph.com/docs/admin/permissions/syncing#scheduling) +This value indicates the total number of times the container main process or child processes were terminated by OOM killer. +When it occurs frequently, it is an indicator of underprovisioning. -This panel has no related alerts. +Refer to the [alerts reference](alerts#precise-code-intel-worker-container-oomkill-events-total) for 1 alert related to this panel. -To see this panel, visit `/-/debug/grafana/d/worker/worker?viewPanel=101271` on your Sourcegraph instance. +To see this panel, visit `/-/debug/grafana/d/precise-code-intel-worker/precise-code-intel-worker?viewPanel=100912` on your Sourcegraph instance. -*Managed by the [Sourcegraph Source team](https://handbook.sourcegraph.com/departments/engineering/teams/source).* +*Managed by the [Sourcegraph Code intelligence team](https://handbook.sourcegraph.com/departments/engineering/teams/code-intelligence).*Technical details
@@ -49025,23 +49312,25 @@ To see this panel, visit `/-/debug/grafana/d/worker/worker?viewPanel=101271` on Query: ``` -max(rate(src_repo_perms_syncer_schedule_repos_total[1m])) +max by (name) (container_oom_events_total{name=~"^precise-code-intel-worker.*"}) ```-### Worker: Gitserver: Gitserver Client +### Precise Code Intel Worker: Golang runtime monitoring -#### worker: gitserver_client_total +#### precise-code-intel-worker: go_goroutines -
Aggregate graphql operations every 5m
+Maximum active goroutines
-This panel has no related alerts. +A high value here indicates a possible goroutine leak. -To see this panel, visit `/-/debug/grafana/d/worker/worker?viewPanel=101300` on your Sourcegraph instance. +Refer to the [alerts reference](alerts#precise-code-intel-worker-go-goroutines) for 1 alert related to this panel. -*Managed by the [Sourcegraph Source team](https://handbook.sourcegraph.com/departments/engineering/teams/source).* +To see this panel, visit `/-/debug/grafana/d/precise-code-intel-worker/precise-code-intel-worker?viewPanel=101000` on your Sourcegraph instance. + +*Managed by the [Sourcegraph Code intelligence team](https://handbook.sourcegraph.com/departments/engineering/teams/code-intelligence).*Technical details
@@ -49049,21 +49338,21 @@ To see this panel, visit `/-/debug/grafana/d/worker/worker?viewPanel=101300` on Query: ``` -sum(increase(src_gitserver_client_total{job=~"^worker.*"}[5m])) +max by(instance) (go_goroutines{job=~".*precise-code-intel-worker"}) ```-#### worker: gitserver_client_99th_percentile_duration +#### precise-code-intel-worker: go_gc_duration_seconds -
Aggregate successful graphql operation duration distribution over 5m
+Maximum go garbage collection duration
-This panel has no related alerts. +Refer to the [alerts reference](alerts#precise-code-intel-worker-go-gc-duration-seconds) for 1 alert related to this panel. -To see this panel, visit `/-/debug/grafana/d/worker/worker?viewPanel=101301` on your Sourcegraph instance. +To see this panel, visit `/-/debug/grafana/d/precise-code-intel-worker/precise-code-intel-worker?viewPanel=101001` on your Sourcegraph instance. -*Managed by the [Sourcegraph Source team](https://handbook.sourcegraph.com/departments/engineering/teams/source).* +*Managed by the [Sourcegraph Code intelligence team](https://handbook.sourcegraph.com/departments/engineering/teams/code-intelligence).*Technical details
@@ -49071,21 +49360,23 @@ To see this panel, visit `/-/debug/grafana/d/worker/worker?viewPanel=101301` on Query: ``` -sum by (le)(rate(src_gitserver_client_duration_seconds_bucket{job=~"^worker.*"}[5m])) +max by(instance) (go_gc_duration_seconds{job=~".*precise-code-intel-worker"}) ```-#### worker: gitserver_client_errors_total +### Precise Code Intel Worker: Kubernetes monitoring (only available on Kubernetes) -
Aggregate graphql operation errors every 5m
+#### precise-code-intel-worker: pods_available_percentage -This panel has no related alerts. +Percentage pods available
-To see this panel, visit `/-/debug/grafana/d/worker/worker?viewPanel=101302` on your Sourcegraph instance. +Refer to the [alerts reference](alerts#precise-code-intel-worker-pods-available-percentage) for 1 alert related to this panel. -*Managed by the [Sourcegraph Source team](https://handbook.sourcegraph.com/departments/engineering/teams/source).* +To see this panel, visit `/-/debug/grafana/d/precise-code-intel-worker/precise-code-intel-worker?viewPanel=101100` on your Sourcegraph instance. + +*Managed by the [Sourcegraph Code intelligence team](https://handbook.sourcegraph.com/departments/engineering/teams/code-intelligence).*Technical details
@@ -49093,43 +49384,35 @@ To see this panel, visit `/-/debug/grafana/d/worker/worker?viewPanel=101302` on Query: ``` -sum(increase(src_gitserver_client_errors_total{job=~"^worker.*"}[5m])) +sum by(app) (up{app=~".*precise-code-intel-worker"}) / count by (app) (up{app=~".*precise-code-intel-worker"}) * 100 ```-#### worker: gitserver_client_error_rate - -
Aggregate graphql operation error rate over 5m
- -This panel has no related alerts. - -To see this panel, visit `/-/debug/grafana/d/worker/worker?viewPanel=101303` on your Sourcegraph instance. +## Syntactic Indexing -*Managed by the [Sourcegraph Source team](https://handbook.sourcegraph.com/departments/engineering/teams/source).* +Handles syntactic indexing of repositories.
-Technical details
+To see this dashboard, visit `/-/debug/grafana/d/syntactic-indexing/syntactic-indexing` on your Sourcegraph instance. -Query: +### Syntactic Indexing: Syntactic indexing scheduling: summary -``` -sum(increase(src_gitserver_client_errors_total{job=~"^worker.*"}[5m])) / (sum(increase(src_gitserver_client_total{job=~"^worker.*"}[5m])) + sum(increase(src_gitserver_client_errors_total{job=~"^worker.*"}[5m]))) * 100 -``` -+
Syntactic indexing jobs proposed for insertion over 5m
-#### worker: gitserver_client_total +Syntactic indexing jobs are proposed for insertion into the queue +based on round-robin scheduling across recently modified repos. -Graphql operations every 5m
+This should be equal to the sum of inserted + updated + skipped, +but is shown separately for clarity. This panel has no related alerts. -To see this panel, visit `/-/debug/grafana/d/worker/worker?viewPanel=101310` on your Sourcegraph instance. +To see this panel, visit `/-/debug/grafana/d/syntactic-indexing/syntactic-indexing?viewPanel=100000` on your Sourcegraph instance. -*Managed by the [Sourcegraph Source team](https://handbook.sourcegraph.com/departments/engineering/teams/source).* +*Managed by the [Sourcegraph Code intelligence team](https://handbook.sourcegraph.com/departments/engineering/teams/code-intelligence).*Technical details
@@ -49137,21 +49420,27 @@ To see this panel, visit `/-/debug/grafana/d/worker/worker?viewPanel=101310` on Query: ``` -sum by (op,scope)(increase(src_gitserver_client_total{job=~"^worker.*"}[5m])) +sum(increase(src_codeintel_syntactic_enqueuer_jobs_proposed[5m])) ```-#### worker: gitserver_client_99th_percentile_duration +####syntactic-indexing: -
99th percentile successful graphql operation duration over 5m
+Syntactic indexing jobs inserted over 5m
+ +Syntactic indexing jobs are inserted into the queue if there is a proposed +repo commit pair (R, X) such that there is no existing job for R in the queue. + +If this number is close to the number of proposed jobs, it may indicate that +the scheduler is not able to keep up with the rate of incoming commits. This panel has no related alerts. -To see this panel, visit `/-/debug/grafana/d/worker/worker?viewPanel=101311` on your Sourcegraph instance. +To see this panel, visit `/-/debug/grafana/d/syntactic-indexing/syntactic-indexing?viewPanel=100001` on your Sourcegraph instance. -*Managed by the [Sourcegraph Source team](https://handbook.sourcegraph.com/departments/engineering/teams/source).* +*Managed by the [Sourcegraph Code intelligence team](https://handbook.sourcegraph.com/departments/engineering/teams/code-intelligence).*Technical details
@@ -49159,21 +49448,28 @@ To see this panel, visit `/-/debug/grafana/d/worker/worker?viewPanel=101311` on Query: ``` -histogram_quantile(0.99, sum by (le,op,scope)(rate(src_gitserver_client_duration_seconds_bucket{job=~"^worker.*"}[5m]))) +sum(increase(src_codeintel_syntactic_enqueuer_jobs_inserted[5m])) ```-#### worker: gitserver_client_errors_total +####syntactic-indexing: -
Graphql operation errors every 5m
+Syntactic indexing jobs updated in-place over 5m
+ +Syntactic indexing jobs are updated in-place when the scheduler attempts to +enqueue a repo commit pair (R, X) and discovers that the queue already had some +other repo commit pair (R, Y) where Y is an ancestor of X. In that case, the +job is updated in-place to point to X, to reflect the fact that users looking +at the tip of the default branch of R are more likely to benefit from newer +commits being indexed. This panel has no related alerts. -To see this panel, visit `/-/debug/grafana/d/worker/worker?viewPanel=101312` on your Sourcegraph instance. +To see this panel, visit `/-/debug/grafana/d/syntactic-indexing/syntactic-indexing?viewPanel=100002` on your Sourcegraph instance. -*Managed by the [Sourcegraph Source team](https://handbook.sourcegraph.com/departments/engineering/teams/source).* +*Managed by the [Sourcegraph Code intelligence team](https://handbook.sourcegraph.com/departments/engineering/teams/code-intelligence).*Technical details
@@ -49181,21 +49477,25 @@ To see this panel, visit `/-/debug/grafana/d/worker/worker?viewPanel=101312` on Query: ``` -sum by (op,scope)(increase(src_gitserver_client_errors_total{job=~"^worker.*"}[5m])) +sum(increase(src_codeintel_syntactic_enqueuer_jobs_updated[5m])) ```-#### worker: gitserver_client_error_rate +####syntactic-indexing: -
Graphql operation error rate over 5m
+Syntactic indexing jobs skipped over 5m
+ +Syntactic indexing jobs insertion is skipped when the scheduler attempts to +enqueue a repo commit pair (R, X) and discovers that the queue already had the +same job (most likely) or another job (R, Y) where Y is not an ancestor of X. This panel has no related alerts. -To see this panel, visit `/-/debug/grafana/d/worker/worker?viewPanel=101313` on your Sourcegraph instance. +To see this panel, visit `/-/debug/grafana/d/syntactic-indexing/syntactic-indexing?viewPanel=100003` on your Sourcegraph instance. -*Managed by the [Sourcegraph Source team](https://handbook.sourcegraph.com/departments/engineering/teams/source).* +*Managed by the [Sourcegraph Code intelligence team](https://handbook.sourcegraph.com/departments/engineering/teams/code-intelligence).*Technical details
@@ -49203,23 +49503,23 @@ To see this panel, visit `/-/debug/grafana/d/worker/worker?viewPanel=101313` on Query: ``` -sum by (op,scope)(increase(src_gitserver_client_errors_total{job=~"^worker.*"}[5m])) / (sum by (op,scope)(increase(src_gitserver_client_total{job=~"^worker.*"}[5m])) + sum by (op,scope)(increase(src_gitserver_client_errors_total{job=~"^worker.*"}[5m]))) * 100 +sum(increase(src_codeintel_syntactic_enqueuer_jobs_skipped[5m])) ```-### Worker: Batches: dbstore stats +### Syntactic Indexing: Workerutil: syntactic_scip_indexing_jobs dbworker/store stats -#### worker: batches_dbstore_total +#### syntactic-indexing: workerutil_dbworker_store_total -
Aggregate store operations every 5m
+Store operations every 5m
This panel has no related alerts. -To see this panel, visit `/-/debug/grafana/d/worker/worker?viewPanel=101400` on your Sourcegraph instance. +To see this panel, visit `/-/debug/grafana/d/syntactic-indexing/syntactic-indexing?viewPanel=100100` on your Sourcegraph instance. -*Managed by the [Sourcegraph Code Search team](https://handbook.sourcegraph.com/departments/engineering/teams/code-search).* +*Managed by the [Sourcegraph Code intelligence team](https://handbook.sourcegraph.com/departments/engineering/teams/code-intelligence).*Technical details
@@ -49227,21 +49527,21 @@ To see this panel, visit `/-/debug/grafana/d/worker/worker?viewPanel=101400` on Query: ``` -sum(increase(src_batches_dbstore_total{job=~"^worker.*"}[5m])) +sum(increase(src_workerutil_dbworker_store_total{domain='syntactic_scip_indexing_jobs',job=~"^syntactic-code-intel-worker.*"}[5m])) ```-#### worker: batches_dbstore_99th_percentile_duration +#### syntactic-indexing: workerutil_dbworker_store_99th_percentile_duration
Aggregate successful store operation duration distribution over 5m
This panel has no related alerts. -To see this panel, visit `/-/debug/grafana/d/worker/worker?viewPanel=101401` on your Sourcegraph instance. +To see this panel, visit `/-/debug/grafana/d/syntactic-indexing/syntactic-indexing?viewPanel=100101` on your Sourcegraph instance. -*Managed by the [Sourcegraph Code Search team](https://handbook.sourcegraph.com/departments/engineering/teams/code-search).* +*Managed by the [Sourcegraph Code intelligence team](https://handbook.sourcegraph.com/departments/engineering/teams/code-intelligence).*Technical details
@@ -49249,21 +49549,21 @@ To see this panel, visit `/-/debug/grafana/d/worker/worker?viewPanel=101401` on Query: ``` -sum by (le)(rate(src_batches_dbstore_duration_seconds_bucket{job=~"^worker.*"}[5m])) +sum by (le)(rate(src_workerutil_dbworker_store_duration_seconds_bucket{domain='syntactic_scip_indexing_jobs',job=~"^syntactic-code-intel-worker.*"}[5m])) ```-#### worker: batches_dbstore_errors_total +#### syntactic-indexing: workerutil_dbworker_store_errors_total -
Aggregate store operation errors every 5m
+Store operation errors every 5m
This panel has no related alerts. -To see this panel, visit `/-/debug/grafana/d/worker/worker?viewPanel=101402` on your Sourcegraph instance. +To see this panel, visit `/-/debug/grafana/d/syntactic-indexing/syntactic-indexing?viewPanel=100102` on your Sourcegraph instance. -*Managed by the [Sourcegraph Code Search team](https://handbook.sourcegraph.com/departments/engineering/teams/code-search).* +*Managed by the [Sourcegraph Code intelligence team](https://handbook.sourcegraph.com/departments/engineering/teams/code-intelligence).*Technical details
@@ -49271,21 +49571,21 @@ To see this panel, visit `/-/debug/grafana/d/worker/worker?viewPanel=101402` on Query: ``` -sum(increase(src_batches_dbstore_errors_total{job=~"^worker.*"}[5m])) +sum(increase(src_workerutil_dbworker_store_errors_total{domain='syntactic_scip_indexing_jobs',job=~"^syntactic-code-intel-worker.*"}[5m])) ```-#### worker: batches_dbstore_error_rate +#### syntactic-indexing: workerutil_dbworker_store_error_rate -
Aggregate store operation error rate over 5m
+Store operation error rate over 5m
This panel has no related alerts. -To see this panel, visit `/-/debug/grafana/d/worker/worker?viewPanel=101403` on your Sourcegraph instance. +To see this panel, visit `/-/debug/grafana/d/syntactic-indexing/syntactic-indexing?viewPanel=100103` on your Sourcegraph instance. -*Managed by the [Sourcegraph Code Search team](https://handbook.sourcegraph.com/departments/engineering/teams/code-search).* +*Managed by the [Sourcegraph Code intelligence team](https://handbook.sourcegraph.com/departments/engineering/teams/code-intelligence).*Technical details
@@ -49293,21 +49593,23 @@ To see this panel, visit `/-/debug/grafana/d/worker/worker?viewPanel=101403` on Query: ``` -sum(increase(src_batches_dbstore_errors_total{job=~"^worker.*"}[5m])) / (sum(increase(src_batches_dbstore_total{job=~"^worker.*"}[5m])) + sum(increase(src_batches_dbstore_errors_total{job=~"^worker.*"}[5m]))) * 100 +sum(increase(src_workerutil_dbworker_store_errors_total{domain='syntactic_scip_indexing_jobs',job=~"^syntactic-code-intel-worker.*"}[5m])) / (sum(increase(src_workerutil_dbworker_store_total{domain='syntactic_scip_indexing_jobs',job=~"^syntactic-code-intel-worker.*"}[5m])) + sum(increase(src_workerutil_dbworker_store_errors_total{domain='syntactic_scip_indexing_jobs',job=~"^syntactic-code-intel-worker.*"}[5m]))) * 100 ```-#### worker: batches_dbstore_total +### Syntactic Indexing: Codeintel: gitserver client -
Store operations every 5m
+#### syntactic-indexing: gitserver_client_total + +Aggregate client operations every 5m
This panel has no related alerts. -To see this panel, visit `/-/debug/grafana/d/worker/worker?viewPanel=101410` on your Sourcegraph instance. +To see this panel, visit `/-/debug/grafana/d/syntactic-indexing/syntactic-indexing?viewPanel=100200` on your Sourcegraph instance. -*Managed by the [Sourcegraph Code Search team](https://handbook.sourcegraph.com/departments/engineering/teams/code-search).* +*Managed by the [Sourcegraph Code intelligence team](https://handbook.sourcegraph.com/departments/engineering/teams/code-intelligence).*Technical details
@@ -49315,21 +49617,21 @@ To see this panel, visit `/-/debug/grafana/d/worker/worker?viewPanel=101410` on Query: ``` -sum by (op)(increase(src_batches_dbstore_total{job=~"^worker.*"}[5m])) +sum(increase(src_gitserver_client_total{job=~"^syntactic-code-intel-worker.*"}[5m])) ```-#### worker: batches_dbstore_99th_percentile_duration +#### syntactic-indexing: gitserver_client_99th_percentile_duration -
99th percentile successful store operation duration over 5m
+Aggregate successful client operation duration distribution over 5m
This panel has no related alerts. -To see this panel, visit `/-/debug/grafana/d/worker/worker?viewPanel=101411` on your Sourcegraph instance. +To see this panel, visit `/-/debug/grafana/d/syntactic-indexing/syntactic-indexing?viewPanel=100201` on your Sourcegraph instance. -*Managed by the [Sourcegraph Code Search team](https://handbook.sourcegraph.com/departments/engineering/teams/code-search).* +*Managed by the [Sourcegraph Code intelligence team](https://handbook.sourcegraph.com/departments/engineering/teams/code-intelligence).*Technical details
@@ -49337,21 +49639,21 @@ To see this panel, visit `/-/debug/grafana/d/worker/worker?viewPanel=101411` on Query: ``` -histogram_quantile(0.99, sum by (le,op)(rate(src_batches_dbstore_duration_seconds_bucket{job=~"^worker.*"}[5m]))) +sum by (le)(rate(src_gitserver_client_duration_seconds_bucket{job=~"^syntactic-code-intel-worker.*"}[5m])) ```-#### worker: batches_dbstore_errors_total +#### syntactic-indexing: gitserver_client_errors_total -
Store operation errors every 5m
+Aggregate client operation errors every 5m
This panel has no related alerts. -To see this panel, visit `/-/debug/grafana/d/worker/worker?viewPanel=101412` on your Sourcegraph instance. +To see this panel, visit `/-/debug/grafana/d/syntactic-indexing/syntactic-indexing?viewPanel=100202` on your Sourcegraph instance. -*Managed by the [Sourcegraph Code Search team](https://handbook.sourcegraph.com/departments/engineering/teams/code-search).* +*Managed by the [Sourcegraph Code intelligence team](https://handbook.sourcegraph.com/departments/engineering/teams/code-intelligence).*Technical details
@@ -49359,21 +49661,21 @@ To see this panel, visit `/-/debug/grafana/d/worker/worker?viewPanel=101412` on Query: ``` -sum by (op)(increase(src_batches_dbstore_errors_total{job=~"^worker.*"}[5m])) +sum(increase(src_gitserver_client_errors_total{job=~"^syntactic-code-intel-worker.*"}[5m])) ```-#### worker: batches_dbstore_error_rate +#### syntactic-indexing: gitserver_client_error_rate -
Store operation error rate over 5m
+Aggregate client operation error rate over 5m
This panel has no related alerts. -To see this panel, visit `/-/debug/grafana/d/worker/worker?viewPanel=101413` on your Sourcegraph instance. +To see this panel, visit `/-/debug/grafana/d/syntactic-indexing/syntactic-indexing?viewPanel=100203` on your Sourcegraph instance. -*Managed by the [Sourcegraph Code Search team](https://handbook.sourcegraph.com/departments/engineering/teams/code-search).* +*Managed by the [Sourcegraph Code intelligence team](https://handbook.sourcegraph.com/departments/engineering/teams/code-intelligence).*Technical details
@@ -49381,23 +49683,21 @@ To see this panel, visit `/-/debug/grafana/d/worker/worker?viewPanel=101413` on Query: ``` -sum by (op)(increase(src_batches_dbstore_errors_total{job=~"^worker.*"}[5m])) / (sum by (op)(increase(src_batches_dbstore_total{job=~"^worker.*"}[5m])) + sum by (op)(increase(src_batches_dbstore_errors_total{job=~"^worker.*"}[5m]))) * 100 +sum(increase(src_gitserver_client_errors_total{job=~"^syntactic-code-intel-worker.*"}[5m])) / (sum(increase(src_gitserver_client_total{job=~"^syntactic-code-intel-worker.*"}[5m])) + sum(increase(src_gitserver_client_errors_total{job=~"^syntactic-code-intel-worker.*"}[5m]))) * 100 ```-### Worker: Batches: service stats - -#### worker: batches_service_total +#### syntactic-indexing: gitserver_client_total -
Aggregate service operations every 5m
+Client operations every 5m
This panel has no related alerts. -To see this panel, visit `/-/debug/grafana/d/worker/worker?viewPanel=101500` on your Sourcegraph instance. +To see this panel, visit `/-/debug/grafana/d/syntactic-indexing/syntactic-indexing?viewPanel=100210` on your Sourcegraph instance. -*Managed by the [Sourcegraph Code Search team](https://handbook.sourcegraph.com/departments/engineering/teams/code-search).* +*Managed by the [Sourcegraph Code intelligence team](https://handbook.sourcegraph.com/departments/engineering/teams/code-intelligence).*Technical details
@@ -49405,21 +49705,21 @@ To see this panel, visit `/-/debug/grafana/d/worker/worker?viewPanel=101500` on Query: ``` -sum(increase(src_batches_service_total{job=~"^worker.*"}[5m])) +sum by (op)(increase(src_gitserver_client_total{job=~"^syntactic-code-intel-worker.*"}[5m])) ```-#### worker: batches_service_99th_percentile_duration +#### syntactic-indexing: gitserver_client_99th_percentile_duration -
Aggregate successful service operation duration distribution over 5m
+99th percentile successful client operation duration over 5m
This panel has no related alerts. -To see this panel, visit `/-/debug/grafana/d/worker/worker?viewPanel=101501` on your Sourcegraph instance. +To see this panel, visit `/-/debug/grafana/d/syntactic-indexing/syntactic-indexing?viewPanel=100211` on your Sourcegraph instance. -*Managed by the [Sourcegraph Code Search team](https://handbook.sourcegraph.com/departments/engineering/teams/code-search).* +*Managed by the [Sourcegraph Code intelligence team](https://handbook.sourcegraph.com/departments/engineering/teams/code-intelligence).*Technical details
@@ -49427,21 +49727,21 @@ To see this panel, visit `/-/debug/grafana/d/worker/worker?viewPanel=101501` on Query: ``` -sum by (le)(rate(src_batches_service_duration_seconds_bucket{job=~"^worker.*"}[5m])) +histogram_quantile(0.99, sum by (le,op)(rate(src_gitserver_client_duration_seconds_bucket{job=~"^syntactic-code-intel-worker.*"}[5m]))) ```-#### worker: batches_service_errors_total +#### syntactic-indexing: gitserver_client_errors_total -
Aggregate service operation errors every 5m
+Client operation errors every 5m
This panel has no related alerts. -To see this panel, visit `/-/debug/grafana/d/worker/worker?viewPanel=101502` on your Sourcegraph instance. +To see this panel, visit `/-/debug/grafana/d/syntactic-indexing/syntactic-indexing?viewPanel=100212` on your Sourcegraph instance. -*Managed by the [Sourcegraph Code Search team](https://handbook.sourcegraph.com/departments/engineering/teams/code-search).* +*Managed by the [Sourcegraph Code intelligence team](https://handbook.sourcegraph.com/departments/engineering/teams/code-intelligence).*Technical details
@@ -49449,21 +49749,21 @@ To see this panel, visit `/-/debug/grafana/d/worker/worker?viewPanel=101502` on Query: ``` -sum(increase(src_batches_service_errors_total{job=~"^worker.*"}[5m])) +sum by (op)(increase(src_gitserver_client_errors_total{job=~"^syntactic-code-intel-worker.*"}[5m])) ```-#### worker: batches_service_error_rate +#### syntactic-indexing: gitserver_client_error_rate -
Aggregate service operation error rate over 5m
+Client operation error rate over 5m
This panel has no related alerts. -To see this panel, visit `/-/debug/grafana/d/worker/worker?viewPanel=101503` on your Sourcegraph instance. +To see this panel, visit `/-/debug/grafana/d/syntactic-indexing/syntactic-indexing?viewPanel=100213` on your Sourcegraph instance. -*Managed by the [Sourcegraph Code Search team](https://handbook.sourcegraph.com/departments/engineering/teams/code-search).* +*Managed by the [Sourcegraph Code intelligence team](https://handbook.sourcegraph.com/departments/engineering/teams/code-intelligence).*Technical details
@@ -49471,21 +49771,23 @@ To see this panel, visit `/-/debug/grafana/d/worker/worker?viewPanel=101503` on Query: ``` -sum(increase(src_batches_service_errors_total{job=~"^worker.*"}[5m])) / (sum(increase(src_batches_service_total{job=~"^worker.*"}[5m])) + sum(increase(src_batches_service_errors_total{job=~"^worker.*"}[5m]))) * 100 +sum by (op)(increase(src_gitserver_client_errors_total{job=~"^syntactic-code-intel-worker.*"}[5m])) / (sum by (op)(increase(src_gitserver_client_total{job=~"^syntactic-code-intel-worker.*"}[5m])) + sum by (op)(increase(src_gitserver_client_errors_total{job=~"^syntactic-code-intel-worker.*"}[5m]))) * 100 ```-#### worker: batches_service_total +### Syntactic Indexing: Database connections -
Service operations every 5m
+#### syntactic-indexing: max_open_conns + +Maximum open
This panel has no related alerts. -To see this panel, visit `/-/debug/grafana/d/worker/worker?viewPanel=101510` on your Sourcegraph instance. +To see this panel, visit `/-/debug/grafana/d/syntactic-indexing/syntactic-indexing?viewPanel=100300` on your Sourcegraph instance. -*Managed by the [Sourcegraph Code Search team](https://handbook.sourcegraph.com/departments/engineering/teams/code-search).* +*Managed by the [Sourcegraph Infrastructure Org team](https://handbook.sourcegraph.com/departments/engineering/infrastructure).*Technical details
@@ -49493,21 +49795,21 @@ To see this panel, visit `/-/debug/grafana/d/worker/worker?viewPanel=101510` on Query: ``` -sum by (op)(increase(src_batches_service_total{job=~"^worker.*"}[5m])) +sum by (app_name, db_name) (src_pgsql_conns_max_open{app_name="syntactic-code-intel-worker"}) ```-#### worker: batches_service_99th_percentile_duration +#### syntactic-indexing: open_conns -
99th percentile successful service operation duration over 5m
+Established
This panel has no related alerts. -To see this panel, visit `/-/debug/grafana/d/worker/worker?viewPanel=101511` on your Sourcegraph instance. +To see this panel, visit `/-/debug/grafana/d/syntactic-indexing/syntactic-indexing?viewPanel=100301` on your Sourcegraph instance. -*Managed by the [Sourcegraph Code Search team](https://handbook.sourcegraph.com/departments/engineering/teams/code-search).* +*Managed by the [Sourcegraph Infrastructure Org team](https://handbook.sourcegraph.com/departments/engineering/infrastructure).*Technical details
@@ -49515,21 +49817,21 @@ To see this panel, visit `/-/debug/grafana/d/worker/worker?viewPanel=101511` on Query: ``` -histogram_quantile(0.99, sum by (le,op)(rate(src_batches_service_duration_seconds_bucket{job=~"^worker.*"}[5m]))) +sum by (app_name, db_name) (src_pgsql_conns_open{app_name="syntactic-code-intel-worker"}) ```-#### worker: batches_service_errors_total +#### syntactic-indexing: in_use -
Service operation errors every 5m
+Used
This panel has no related alerts. -To see this panel, visit `/-/debug/grafana/d/worker/worker?viewPanel=101512` on your Sourcegraph instance. +To see this panel, visit `/-/debug/grafana/d/syntactic-indexing/syntactic-indexing?viewPanel=100310` on your Sourcegraph instance. -*Managed by the [Sourcegraph Code Search team](https://handbook.sourcegraph.com/departments/engineering/teams/code-search).* +*Managed by the [Sourcegraph Infrastructure Org team](https://handbook.sourcegraph.com/departments/engineering/infrastructure).*Technical details
@@ -49537,21 +49839,21 @@ To see this panel, visit `/-/debug/grafana/d/worker/worker?viewPanel=101512` on Query: ``` -sum by (op)(increase(src_batches_service_errors_total{job=~"^worker.*"}[5m])) +sum by (app_name, db_name) (src_pgsql_conns_in_use{app_name="syntactic-code-intel-worker"}) ```-#### worker: batches_service_error_rate +#### syntactic-indexing: idle -
Service operation error rate over 5m
+Idle
This panel has no related alerts. -To see this panel, visit `/-/debug/grafana/d/worker/worker?viewPanel=101513` on your Sourcegraph instance. +To see this panel, visit `/-/debug/grafana/d/syntactic-indexing/syntactic-indexing?viewPanel=100311` on your Sourcegraph instance. -*Managed by the [Sourcegraph Code Search team](https://handbook.sourcegraph.com/departments/engineering/teams/code-search).* +*Managed by the [Sourcegraph Infrastructure Org team](https://handbook.sourcegraph.com/departments/engineering/infrastructure).*Technical details
@@ -49559,23 +49861,21 @@ To see this panel, visit `/-/debug/grafana/d/worker/worker?viewPanel=101513` on Query: ``` -sum by (op)(increase(src_batches_service_errors_total{job=~"^worker.*"}[5m])) / (sum by (op)(increase(src_batches_service_total{job=~"^worker.*"}[5m])) + sum by (op)(increase(src_batches_service_errors_total{job=~"^worker.*"}[5m]))) * 100 +sum by (app_name, db_name) (src_pgsql_conns_idle{app_name="syntactic-code-intel-worker"}) ```-### Worker: Batches: Workspace resolver dbstore - -#### worker: workerutil_dbworker_store_batch_changes_batch_spec_resolution_worker_store_total +#### syntactic-indexing: mean_blocked_seconds_per_conn_request -
Store operations every 5m
+Mean blocked seconds per conn request
-This panel has no related alerts. +Refer to the [alerts reference](alerts#syntactic-indexing-mean-blocked-seconds-per-conn-request) for 2 alerts related to this panel. -To see this panel, visit `/-/debug/grafana/d/worker/worker?viewPanel=101600` on your Sourcegraph instance. +To see this panel, visit `/-/debug/grafana/d/syntactic-indexing/syntactic-indexing?viewPanel=100320` on your Sourcegraph instance. -*Managed by the [Sourcegraph Code Search team](https://handbook.sourcegraph.com/departments/engineering/teams/code-search).* +*Managed by the [Sourcegraph Infrastructure Org team](https://handbook.sourcegraph.com/departments/engineering/infrastructure).*Technical details
@@ -49583,21 +49883,21 @@ To see this panel, visit `/-/debug/grafana/d/worker/worker?viewPanel=101600` on Query: ``` -sum by (op)(increase(src_workerutil_dbworker_store_batch_changes_batch_spec_resolution_worker_store_total{job=~"^worker.*"}[5m])) +sum by (app_name, db_name) (increase(src_pgsql_conns_blocked_seconds{app_name="syntactic-code-intel-worker"}[5m])) / sum by (app_name, db_name) (increase(src_pgsql_conns_waited_for{app_name="syntactic-code-intel-worker"}[5m])) ```-#### worker: workerutil_dbworker_store_batch_changes_batch_spec_resolution_worker_store_99th_percentile_duration +#### syntactic-indexing: closed_max_idle -
99th percentile successful store operation duration over 5m
+Closed by SetMaxIdleConns
This panel has no related alerts. -To see this panel, visit `/-/debug/grafana/d/worker/worker?viewPanel=101601` on your Sourcegraph instance. +To see this panel, visit `/-/debug/grafana/d/syntactic-indexing/syntactic-indexing?viewPanel=100330` on your Sourcegraph instance. -*Managed by the [Sourcegraph Code Search team](https://handbook.sourcegraph.com/departments/engineering/teams/code-search).* +*Managed by the [Sourcegraph Infrastructure Org team](https://handbook.sourcegraph.com/departments/engineering/infrastructure).*Technical details
@@ -49605,21 +49905,21 @@ To see this panel, visit `/-/debug/grafana/d/worker/worker?viewPanel=101601` on Query: ``` -histogram_quantile(0.99, sum by (le,op)(rate(src_workerutil_dbworker_store_batch_changes_batch_spec_resolution_worker_store_duration_seconds_bucket{job=~"^worker.*"}[5m]))) +sum by (app_name, db_name) (increase(src_pgsql_conns_closed_max_idle{app_name="syntactic-code-intel-worker"}[5m])) ```-#### worker: workerutil_dbworker_store_batch_changes_batch_spec_resolution_worker_store_errors_total +#### syntactic-indexing: closed_max_lifetime -
Store operation errors every 5m
+Closed by SetConnMaxLifetime
This panel has no related alerts. -To see this panel, visit `/-/debug/grafana/d/worker/worker?viewPanel=101602` on your Sourcegraph instance. +To see this panel, visit `/-/debug/grafana/d/syntactic-indexing/syntactic-indexing?viewPanel=100331` on your Sourcegraph instance. -*Managed by the [Sourcegraph Code Search team](https://handbook.sourcegraph.com/departments/engineering/teams/code-search).* +*Managed by the [Sourcegraph Infrastructure Org team](https://handbook.sourcegraph.com/departments/engineering/infrastructure).*Technical details
@@ -49627,21 +49927,21 @@ To see this panel, visit `/-/debug/grafana/d/worker/worker?viewPanel=101602` on Query: ``` -sum by (op)(increase(src_workerutil_dbworker_store_batch_changes_batch_spec_resolution_worker_store_errors_total{job=~"^worker.*"}[5m])) +sum by (app_name, db_name) (increase(src_pgsql_conns_closed_max_lifetime{app_name="syntactic-code-intel-worker"}[5m])) ```-#### worker: workerutil_dbworker_store_batch_changes_batch_spec_resolution_worker_store_error_rate +#### syntactic-indexing: closed_max_idle_time -
Store operation error rate over 5m
+Closed by SetConnMaxIdleTime
This panel has no related alerts. -To see this panel, visit `/-/debug/grafana/d/worker/worker?viewPanel=101603` on your Sourcegraph instance. +To see this panel, visit `/-/debug/grafana/d/syntactic-indexing/syntactic-indexing?viewPanel=100332` on your Sourcegraph instance. -*Managed by the [Sourcegraph Code Search team](https://handbook.sourcegraph.com/departments/engineering/teams/code-search).* +*Managed by the [Sourcegraph Infrastructure Org team](https://handbook.sourcegraph.com/departments/engineering/infrastructure).*Technical details
@@ -49649,21 +49949,21 @@ To see this panel, visit `/-/debug/grafana/d/worker/worker?viewPanel=101603` on Query: ``` -sum by (op)(increase(src_workerutil_dbworker_store_batch_changes_batch_spec_resolution_worker_store_errors_total{job=~"^worker.*"}[5m])) / (sum by (op)(increase(src_workerutil_dbworker_store_batch_changes_batch_spec_resolution_worker_store_total{job=~"^worker.*"}[5m])) + sum by (op)(increase(src_workerutil_dbworker_store_batch_changes_batch_spec_resolution_worker_store_errors_total{job=~"^worker.*"}[5m]))) * 100 +sum by (app_name, db_name) (increase(src_pgsql_conns_closed_max_idle_time{app_name="syntactic-code-intel-worker"}[5m])) ```-### Worker: Batches: Bulk operation processor dbstore +### Syntactic Indexing: Syntactic-code-intel-worker (CPU, Memory) -#### worker: workerutil_dbworker_store_batches_bulk_worker_store_total +#### syntactic-indexing: cpu_usage_percentage -
Store operations every 5m
+CPU usage
-This panel has no related alerts. +Refer to the [alerts reference](alerts#syntactic-indexing-cpu-usage-percentage) for 1 alert related to this panel. -To see this panel, visit `/-/debug/grafana/d/worker/worker?viewPanel=101700` on your Sourcegraph instance. +To see this panel, visit `/-/debug/grafana/d/syntactic-indexing/syntactic-indexing?viewPanel=100400` on your Sourcegraph instance. *Managed by the [Sourcegraph Code Search team](https://handbook.sourcegraph.com/departments/engineering/teams/code-search).* @@ -49673,19 +49973,21 @@ To see this panel, visit `/-/debug/grafana/d/worker/worker?viewPanel=101700` on Query: ``` -sum by (op)(increase(src_workerutil_dbworker_store_batches_bulk_worker_store_total{job=~"^worker.*"}[5m])) +cadvisor_container_cpu_usage_percentage_total{name=~"^syntactic-code-intel-worker.*"} ```-#### worker: workerutil_dbworker_store_batches_bulk_worker_store_99th_percentile_duration +#### syntactic-indexing: memory_usage_percentage -
99th percentile successful store operation duration over 5m
+Memory usage percentage (total)
+ +An estimate for the active memory in use, which includes anonymous memory, file memory, and kernel memory. Some of this memory is reclaimable, so high usage does not necessarily indicate memory pressure. This panel has no related alerts. -To see this panel, visit `/-/debug/grafana/d/worker/worker?viewPanel=101701` on your Sourcegraph instance. +To see this panel, visit `/-/debug/grafana/d/syntactic-indexing/syntactic-indexing?viewPanel=100401` on your Sourcegraph instance. *Managed by the [Sourcegraph Code Search team](https://handbook.sourcegraph.com/departments/engineering/teams/code-search).* @@ -49695,19 +49997,21 @@ To see this panel, visit `/-/debug/grafana/d/worker/worker?viewPanel=101701` on Query: ``` -histogram_quantile(0.99, sum by (le,op)(rate(src_workerutil_dbworker_store_batches_bulk_worker_store_duration_seconds_bucket{job=~"^worker.*"}[5m]))) +cadvisor_container_memory_usage_percentage_total{name=~"^syntactic-code-intel-worker.*"} ```-#### worker: workerutil_dbworker_store_batches_bulk_worker_store_errors_total +#### syntactic-indexing: memory_working_set_bytes -
Store operation errors every 5m
+Memory usage bytes (total)
+ +An estimate for the active memory in use in bytes, which includes anonymous memory, file memory, and kernel memory. Some of this memory is reclaimable, so high usage does not necessarily indicate memory pressure. This panel has no related alerts. -To see this panel, visit `/-/debug/grafana/d/worker/worker?viewPanel=101702` on your Sourcegraph instance. +To see this panel, visit `/-/debug/grafana/d/syntactic-indexing/syntactic-indexing?viewPanel=100402` on your Sourcegraph instance. *Managed by the [Sourcegraph Code Search team](https://handbook.sourcegraph.com/departments/engineering/teams/code-search).* @@ -49717,19 +50021,21 @@ To see this panel, visit `/-/debug/grafana/d/worker/worker?viewPanel=101702` on Query: ``` -sum by (op)(increase(src_workerutil_dbworker_store_batches_bulk_worker_store_errors_total{job=~"^worker.*"}[5m])) +max by (name) (container_memory_working_set_bytes{name=~"^syntactic-code-intel-worker.*"}) ```-#### worker: workerutil_dbworker_store_batches_bulk_worker_store_error_rate +#### syntactic-indexing: memory_rss -
Store operation error rate over 5m
+Memory (RSS)
-This panel has no related alerts. +The total anonymous memory in use by the application, which includes Go stack and heap. This memory is is non-reclaimable, and high usage may trigger OOM kills. Note: the metric is named RSS because to match the cadvisor name, but `anonymous` is more accurate." -To see this panel, visit `/-/debug/grafana/d/worker/worker?viewPanel=101703` on your Sourcegraph instance. +Refer to the [alerts reference](alerts#syntactic-indexing-memory-rss) for 1 alert related to this panel. + +To see this panel, visit `/-/debug/grafana/d/syntactic-indexing/syntactic-indexing?viewPanel=100410` on your Sourcegraph instance. *Managed by the [Sourcegraph Code Search team](https://handbook.sourcegraph.com/departments/engineering/teams/code-search).* @@ -49739,21 +50045,21 @@ To see this panel, visit `/-/debug/grafana/d/worker/worker?viewPanel=101703` on Query: ``` -sum by (op)(increase(src_workerutil_dbworker_store_batches_bulk_worker_store_errors_total{job=~"^worker.*"}[5m])) / (sum by (op)(increase(src_workerutil_dbworker_store_batches_bulk_worker_store_total{job=~"^worker.*"}[5m])) + sum by (op)(increase(src_workerutil_dbworker_store_batches_bulk_worker_store_errors_total{job=~"^worker.*"}[5m]))) * 100 +max(container_memory_rss{name=~"^syntactic-code-intel-worker.*"} / container_spec_memory_limit_bytes{name=~"^syntactic-code-intel-worker.*"}) by (name) * 100.0 ```-### Worker: Batches: Changeset reconciler dbstore +#### syntactic-indexing: memory_total_active_file -#### worker: workerutil_dbworker_store_batches_reconciler_worker_store_total +
Memory usage (active file)
-Store operations every 5m
+This metric shows the total active file-backed memory currently in use by the application. Some of it may be reclaimable, so high usage does not necessarily indicate memory pressure. This panel has no related alerts. -To see this panel, visit `/-/debug/grafana/d/worker/worker?viewPanel=101800` on your Sourcegraph instance. +To see this panel, visit `/-/debug/grafana/d/syntactic-indexing/syntactic-indexing?viewPanel=100411` on your Sourcegraph instance. *Managed by the [Sourcegraph Code Search team](https://handbook.sourcegraph.com/departments/engineering/teams/code-search).* @@ -49763,19 +50069,21 @@ To see this panel, visit `/-/debug/grafana/d/worker/worker?viewPanel=101800` on Query: ``` -sum by (op)(increase(src_workerutil_dbworker_store_batches_reconciler_worker_store_total{job=~"^worker.*"}[5m])) +max(container_memory_total_active_file_bytes{name=~"^syntactic-code-intel-worker.*"} / container_spec_memory_limit_bytes{name=~"^syntactic-code-intel-worker.*"}) by (name) * 100.0 ```-#### worker: workerutil_dbworker_store_batches_reconciler_worker_store_99th_percentile_duration +#### syntactic-indexing: memory_kernel_usage -
99th percentile successful store operation duration over 5m
+Memory usage (kernel)
+ +The kernel usage metric shows the amount of memory used by the kernel on behalf of the application. Some of it may be reclaimable, so high usage does not necessarily indicate memory pressure. This panel has no related alerts. -To see this panel, visit `/-/debug/grafana/d/worker/worker?viewPanel=101801` on your Sourcegraph instance. +To see this panel, visit `/-/debug/grafana/d/syntactic-indexing/syntactic-indexing?viewPanel=100412` on your Sourcegraph instance. *Managed by the [Sourcegraph Code Search team](https://handbook.sourcegraph.com/departments/engineering/teams/code-search).* @@ -49785,21 +50093,33 @@ To see this panel, visit `/-/debug/grafana/d/worker/worker?viewPanel=101801` on Query: ``` -histogram_quantile(0.99, sum by (le,op)(rate(src_workerutil_dbworker_store_batches_reconciler_worker_store_duration_seconds_bucket{job=~"^worker.*"}[5m]))) +max(container_memory_kernel_usage{name=~"^syntactic-code-intel-worker.*"} / container_spec_memory_limit_bytes{name=~"^syntactic-code-intel-worker.*"}) by (name) * 100.0 ```-#### worker: workerutil_dbworker_store_batches_reconciler_worker_store_errors_total +### Syntactic Indexing: Container monitoring (not available on server) -
Store operation errors every 5m
+#### syntactic-indexing: container_missing + +Container missing
+ +This value is the number of times a container has not been seen for more than one minute. If you observe this +value change independent of deployment events (such as an upgrade), it could indicate pods are being OOM killed or terminated for some other reasons. + +- **Kubernetes:** + - Determine if the pod was OOM killed using `kubectl describe pod syntactic-code-intel-worker` (look for `OOMKilled: true`) and, if so, consider increasing the memory limit in the relevant `Deployment.yaml`. + - Check the logs before the container restarted to see if there are `panic:` messages or similar using `kubectl logs -p syntactic-code-intel-worker`. +- **Docker Compose:** + - Determine if the pod was OOM killed using `docker inspect -f '\{\{json .State\}\}' syntactic-code-intel-worker` (look for `"OOMKilled":true`) and, if so, consider increasing the memory limit of the syntactic-code-intel-worker container in `docker-compose.yml`. + - Check the logs before the container restarted to see if there are `panic:` messages or similar using `docker logs syntactic-code-intel-worker` (note this will include logs from the previous and currently running container). This panel has no related alerts. -To see this panel, visit `/-/debug/grafana/d/worker/worker?viewPanel=101802` on your Sourcegraph instance. +To see this panel, visit `/-/debug/grafana/d/syntactic-indexing/syntactic-indexing?viewPanel=100500` on your Sourcegraph instance. -*Managed by the [Sourcegraph Code Search team](https://handbook.sourcegraph.com/departments/engineering/teams/code-search).* +*Managed by the [Sourcegraph Code intelligence team](https://handbook.sourcegraph.com/departments/engineering/teams/code-intelligence).*Technical details
@@ -49807,21 +50127,21 @@ To see this panel, visit `/-/debug/grafana/d/worker/worker?viewPanel=101802` on Query: ``` -sum by (op)(increase(src_workerutil_dbworker_store_batches_reconciler_worker_store_errors_total{job=~"^worker.*"}[5m])) +count by(name) ((time() - container_last_seen{name=~"^syntactic-code-intel-worker.*"}) > 60) ```-#### worker: workerutil_dbworker_store_batches_reconciler_worker_store_error_rate +#### syntactic-indexing: container_cpu_usage -
Store operation error rate over 5m
+Container cpu usage total (1m average) across all cores by instance
-This panel has no related alerts. +Refer to the [alerts reference](alerts#syntactic-indexing-container-cpu-usage) for 1 alert related to this panel. -To see this panel, visit `/-/debug/grafana/d/worker/worker?viewPanel=101803` on your Sourcegraph instance. +To see this panel, visit `/-/debug/grafana/d/syntactic-indexing/syntactic-indexing?viewPanel=100501` on your Sourcegraph instance. -*Managed by the [Sourcegraph Code Search team](https://handbook.sourcegraph.com/departments/engineering/teams/code-search).* +*Managed by the [Sourcegraph Code intelligence team](https://handbook.sourcegraph.com/departments/engineering/teams/code-intelligence).*Technical details
@@ -49829,23 +50149,21 @@ To see this panel, visit `/-/debug/grafana/d/worker/worker?viewPanel=101803` on Query: ``` -sum by (op)(increase(src_workerutil_dbworker_store_batches_reconciler_worker_store_errors_total{job=~"^worker.*"}[5m])) / (sum by (op)(increase(src_workerutil_dbworker_store_batches_reconciler_worker_store_total{job=~"^worker.*"}[5m])) + sum by (op)(increase(src_workerutil_dbworker_store_batches_reconciler_worker_store_errors_total{job=~"^worker.*"}[5m]))) * 100 +cadvisor_container_cpu_usage_percentage_total{name=~"^syntactic-code-intel-worker.*"} ```-### Worker: Batches: Workspace execution dbstore - -#### worker: workerutil_dbworker_store_batch_spec_workspace_execution_worker_store_total +#### syntactic-indexing: container_memory_usage -
Store operations every 5m
+Container memory usage by instance
-This panel has no related alerts. +Refer to the [alerts reference](alerts#syntactic-indexing-container-memory-usage) for 1 alert related to this panel. -To see this panel, visit `/-/debug/grafana/d/worker/worker?viewPanel=101900` on your Sourcegraph instance. +To see this panel, visit `/-/debug/grafana/d/syntactic-indexing/syntactic-indexing?viewPanel=100502` on your Sourcegraph instance. -*Managed by the [Sourcegraph Code Search team](https://handbook.sourcegraph.com/departments/engineering/teams/code-search).* +*Managed by the [Sourcegraph Code intelligence team](https://handbook.sourcegraph.com/departments/engineering/teams/code-intelligence).*Technical details
@@ -49853,21 +50171,24 @@ To see this panel, visit `/-/debug/grafana/d/worker/worker?viewPanel=101900` on Query: ``` -sum by (op)(increase(src_workerutil_dbworker_store_batch_spec_workspace_execution_worker_store_total{job=~"^worker.*"}[5m])) +cadvisor_container_memory_usage_percentage_total{name=~"^syntactic-code-intel-worker.*"} ```-#### worker: workerutil_dbworker_store_batch_spec_workspace_execution_worker_store_99th_percentile_duration +#### syntactic-indexing: fs_io_operations -
99th percentile successful store operation duration over 5m
+Filesystem reads and writes rate by instance over 1h
+ +This value indicates the number of filesystem read and write operations by containers of this service. +When extremely high, this can indicate a resource usage problem, or can cause problems with the service itself, especially if high values or spikes correlate with \{\{CONTAINER_NAME\}\} issues. This panel has no related alerts. -To see this panel, visit `/-/debug/grafana/d/worker/worker?viewPanel=101901` on your Sourcegraph instance. +To see this panel, visit `/-/debug/grafana/d/syntactic-indexing/syntactic-indexing?viewPanel=100503` on your Sourcegraph instance. -*Managed by the [Sourcegraph Code Search team](https://handbook.sourcegraph.com/departments/engineering/teams/code-search).* +*Managed by the [Sourcegraph Code intelligence team](https://handbook.sourcegraph.com/departments/engineering/teams/code-intelligence).*Technical details
@@ -49875,21 +50196,23 @@ To see this panel, visit `/-/debug/grafana/d/worker/worker?viewPanel=101901` on Query: ``` -histogram_quantile(0.99, sum by (le,op)(rate(src_workerutil_dbworker_store_batch_spec_workspace_execution_worker_store_duration_seconds_bucket{job=~"^worker.*"}[5m]))) +sum by(name) (rate(container_fs_reads_total{name=~"^syntactic-code-intel-worker.*"}[1h]) + rate(container_fs_writes_total{name=~"^syntactic-code-intel-worker.*"}[1h])) ```-#### worker: workerutil_dbworker_store_batch_spec_workspace_execution_worker_store_errors_total +### Syntactic Indexing: Provisioning indicators (not available on server) -
Store operation errors every 5m
+#### syntactic-indexing: provisioning_container_cpu_usage_long_term -This panel has no related alerts. +Container cpu usage total (90th percentile over 1d) across all cores by instance
-To see this panel, visit `/-/debug/grafana/d/worker/worker?viewPanel=101902` on your Sourcegraph instance. +Refer to the [alerts reference](alerts#syntactic-indexing-provisioning-container-cpu-usage-long-term) for 1 alert related to this panel. -*Managed by the [Sourcegraph Code Search team](https://handbook.sourcegraph.com/departments/engineering/teams/code-search).* +To see this panel, visit `/-/debug/grafana/d/syntactic-indexing/syntactic-indexing?viewPanel=100600` on your Sourcegraph instance. + +*Managed by the [Sourcegraph Code intelligence team](https://handbook.sourcegraph.com/departments/engineering/teams/code-intelligence).*Technical details
@@ -49897,21 +50220,21 @@ To see this panel, visit `/-/debug/grafana/d/worker/worker?viewPanel=101902` on Query: ``` -sum by (op)(increase(src_workerutil_dbworker_store_batch_spec_workspace_execution_worker_store_errors_total{job=~"^worker.*"}[5m])) +quantile_over_time(0.9, cadvisor_container_cpu_usage_percentage_total{name=~"^syntactic-code-intel-worker.*"}[1d]) ```-#### worker: workerutil_dbworker_store_batch_spec_workspace_execution_worker_store_error_rate +#### syntactic-indexing: provisioning_container_memory_usage_long_term -
Store operation error rate over 5m
+Container memory usage (1d maximum) by instance
-This panel has no related alerts. +Refer to the [alerts reference](alerts#syntactic-indexing-provisioning-container-memory-usage-long-term) for 1 alert related to this panel. -To see this panel, visit `/-/debug/grafana/d/worker/worker?viewPanel=101903` on your Sourcegraph instance. +To see this panel, visit `/-/debug/grafana/d/syntactic-indexing/syntactic-indexing?viewPanel=100601` on your Sourcegraph instance. -*Managed by the [Sourcegraph Code Search team](https://handbook.sourcegraph.com/departments/engineering/teams/code-search).* +*Managed by the [Sourcegraph Code intelligence team](https://handbook.sourcegraph.com/departments/engineering/teams/code-intelligence).*Technical details
@@ -49919,21 +50242,19 @@ To see this panel, visit `/-/debug/grafana/d/worker/worker?viewPanel=101903` on Query: ``` -sum by (op)(increase(src_workerutil_dbworker_store_batch_spec_workspace_execution_worker_store_errors_total{job=~"^worker.*"}[5m])) / (sum by (op)(increase(src_workerutil_dbworker_store_batch_spec_workspace_execution_worker_store_total{job=~"^worker.*"}[5m])) + sum by (op)(increase(src_workerutil_dbworker_store_batch_spec_workspace_execution_worker_store_errors_total{job=~"^worker.*"}[5m]))) * 100 +max_over_time(cadvisor_container_memory_usage_percentage_total{name=~"^syntactic-code-intel-worker.*"}[1d]) ```-### Worker: Batches: Executor jobs - -#### worker: executor_queue_size +#### syntactic-indexing: provisioning_container_cpu_usage_short_term -
Unprocessed executor job queue size
+Container cpu usage total (5m maximum) across all cores by instance
-This panel has no related alerts. +Refer to the [alerts reference](alerts#syntactic-indexing-provisioning-container-cpu-usage-short-term) for 1 alert related to this panel. -To see this panel, visit `/-/debug/grafana/d/worker/worker?viewPanel=102000` on your Sourcegraph instance. +To see this panel, visit `/-/debug/grafana/d/syntactic-indexing/syntactic-indexing?viewPanel=100610` on your Sourcegraph instance. *Managed by the [Sourcegraph Code intelligence team](https://handbook.sourcegraph.com/departments/engineering/teams/code-intelligence).* @@ -49943,25 +50264,19 @@ To see this panel, visit `/-/debug/grafana/d/worker/worker?viewPanel=102000` on Query: ``` -max by (queue)(src_executor_total{queue=~"batches",job=~"^(executor|sourcegraph-code-intel-indexers|executor-batches|frontend|sourcegraph-frontend|worker|sourcegraph-executors).*"}) +max_over_time(cadvisor_container_cpu_usage_percentage_total{name=~"^syntactic-code-intel-worker.*"}[5m]) ```-#### worker: executor_queue_growth_rate - -
Unprocessed executor job queue growth rate over 30m
+#### syntactic-indexing: provisioning_container_memory_usage_short_term -This value compares the rate of enqueues against the rate of finished jobs for the selected queue. - - - A value < than 1 indicates that process rate > enqueue rate - - A value = than 1 indicates that process rate = enqueue rate - - A value > than 1 indicates that process rate < enqueue rate +Container memory usage (5m maximum) by instance
-This panel has no related alerts. +Refer to the [alerts reference](alerts#syntactic-indexing-provisioning-container-memory-usage-short-term) for 1 alert related to this panel. -To see this panel, visit `/-/debug/grafana/d/worker/worker?viewPanel=102001` on your Sourcegraph instance. +To see this panel, visit `/-/debug/grafana/d/syntactic-indexing/syntactic-indexing?viewPanel=100611` on your Sourcegraph instance. *Managed by the [Sourcegraph Code intelligence team](https://handbook.sourcegraph.com/departments/engineering/teams/code-intelligence).* @@ -49971,19 +50286,22 @@ To see this panel, visit `/-/debug/grafana/d/worker/worker?viewPanel=102001` on Query: ``` -sum by (queue)(increase(src_executor_total{queue=~"batches",job=~"^(executor|sourcegraph-code-intel-indexers|executor-batches|frontend|sourcegraph-frontend|worker|sourcegraph-executors).*"}[30m])) / sum by (queue)(increase(src_executor_processor_total{queue=~"batches",job=~"^(executor|sourcegraph-code-intel-indexers|executor-batches|frontend|sourcegraph-frontend|worker|sourcegraph-executors).*"}[30m])) +max_over_time(cadvisor_container_memory_usage_percentage_total{name=~"^syntactic-code-intel-worker.*"}[5m]) ```-#### worker: executor_queued_max_age +#### syntactic-indexing: container_oomkill_events_total -
Unprocessed executor job queue longest time in queue
+Container OOMKILL events total by instance
-This panel has no related alerts. +This value indicates the total number of times the container main process or child processes were terminated by OOM killer. +When it occurs frequently, it is an indicator of underprovisioning. -To see this panel, visit `/-/debug/grafana/d/worker/worker?viewPanel=102002` on your Sourcegraph instance. +Refer to the [alerts reference](alerts#syntactic-indexing-container-oomkill-events-total) for 1 alert related to this panel. + +To see this panel, visit `/-/debug/grafana/d/syntactic-indexing/syntactic-indexing?viewPanel=100612` on your Sourcegraph instance. *Managed by the [Sourcegraph Code intelligence team](https://handbook.sourcegraph.com/departments/engineering/teams/code-intelligence).* @@ -49993,21 +50311,23 @@ To see this panel, visit `/-/debug/grafana/d/worker/worker?viewPanel=102002` on Query: ``` -max by (queue)(src_executor_queued_duration_seconds_total{queue=~"batches",job=~"^(executor|sourcegraph-code-intel-indexers|executor-batches|frontend|sourcegraph-frontend|worker|sourcegraph-executors).*"}) +max by (name) (container_oom_events_total{name=~"^syntactic-code-intel-worker.*"}) ```-### Worker: Codeintel: lsif_upload record resetter +### Syntactic Indexing: Golang runtime monitoring -#### worker: codeintel_background_upload_record_resets_total +#### syntactic-indexing: go_goroutines -
Lsif upload records reset to queued state every 5m
+Maximum active goroutines
-This panel has no related alerts. +A high value here indicates a possible goroutine leak. -To see this panel, visit `/-/debug/grafana/d/worker/worker?viewPanel=102100` on your Sourcegraph instance. +Refer to the [alerts reference](alerts#syntactic-indexing-go-goroutines) for 1 alert related to this panel. + +To see this panel, visit `/-/debug/grafana/d/syntactic-indexing/syntactic-indexing?viewPanel=100700` on your Sourcegraph instance. *Managed by the [Sourcegraph Code intelligence team](https://handbook.sourcegraph.com/departments/engineering/teams/code-intelligence).* @@ -50017,19 +50337,19 @@ To see this panel, visit `/-/debug/grafana/d/worker/worker?viewPanel=102100` on Query: ``` -sum(increase(src_codeintel_background_upload_record_resets_total{job=~"^worker.*"}[5m])) +max by(instance) (go_goroutines{job=~".*syntactic-code-intel-worker"}) ```-#### worker: codeintel_background_upload_record_reset_failures_total +#### syntactic-indexing: go_gc_duration_seconds -
Lsif upload records reset to errored state every 5m
+Maximum go garbage collection duration
-This panel has no related alerts. +Refer to the [alerts reference](alerts#syntactic-indexing-go-gc-duration-seconds) for 1 alert related to this panel. -To see this panel, visit `/-/debug/grafana/d/worker/worker?viewPanel=102101` on your Sourcegraph instance. +To see this panel, visit `/-/debug/grafana/d/syntactic-indexing/syntactic-indexing?viewPanel=100701` on your Sourcegraph instance. *Managed by the [Sourcegraph Code intelligence team](https://handbook.sourcegraph.com/departments/engineering/teams/code-intelligence).* @@ -50039,19 +50359,21 @@ To see this panel, visit `/-/debug/grafana/d/worker/worker?viewPanel=102101` on Query: ``` -sum(increase(src_codeintel_background_upload_record_reset_failures_total{job=~"^worker.*"}[5m])) +max by(instance) (go_gc_duration_seconds{job=~".*syntactic-code-intel-worker"}) ```-#### worker: codeintel_background_upload_record_reset_errors_total +### Syntactic Indexing: Kubernetes monitoring (only available on Kubernetes) -
Lsif upload operation errors every 5m
+#### syntactic-indexing: pods_available_percentage -This panel has no related alerts. +Percentage pods available
-To see this panel, visit `/-/debug/grafana/d/worker/worker?viewPanel=102102` on your Sourcegraph instance. +Refer to the [alerts reference](alerts#syntactic-indexing-pods-available-percentage) for 1 alert related to this panel. + +To see this panel, visit `/-/debug/grafana/d/syntactic-indexing/syntactic-indexing?viewPanel=100800` on your Sourcegraph instance. *Managed by the [Sourcegraph Code intelligence team](https://handbook.sourcegraph.com/departments/engineering/teams/code-intelligence).* @@ -50061,23 +50383,31 @@ To see this panel, visit `/-/debug/grafana/d/worker/worker?viewPanel=102102` on Query: ``` -sum(increase(src_codeintel_background_upload_record_reset_errors_total{job=~"^worker.*"}[5m])) +sum by(app) (up{app=~".*syntactic-code-intel-worker"}) / count by (app) (up{app=~".*syntactic-code-intel-worker"}) * 100 ```-### Worker: Codeintel: lsif_index record resetter +## Redis -#### worker: codeintel_background_index_record_resets_total +
Metrics from both redis databases.
-Lsif index records reset to queued state every 5m
+To see this dashboard, visit `/-/debug/grafana/d/redis/redis` on your Sourcegraph instance. -This panel has no related alerts. +### Redis: Redis Store -To see this panel, visit `/-/debug/grafana/d/worker/worker?viewPanel=102200` on your Sourcegraph instance. +#### redis: redis-store_up -*Managed by the [Sourcegraph Code intelligence team](https://handbook.sourcegraph.com/departments/engineering/teams/code-intelligence).* +Redis-store availability
+ +A value of 1 indicates the service is currently running + +Refer to the [alerts reference](alerts#redis-redis-store-up) for 1 alert related to this panel. + +To see this panel, visit `/-/debug/grafana/d/redis/redis?viewPanel=100000` on your Sourcegraph instance. + +*Managed by the [Sourcegraph Infrastructure Org team](https://handbook.sourcegraph.com/departments/engineering/infrastructure).*Technical details
@@ -50085,21 +50415,25 @@ To see this panel, visit `/-/debug/grafana/d/worker/worker?viewPanel=102200` on Query: ``` -sum(increase(src_codeintel_background_index_record_resets_total{job=~"^worker.*"}[5m])) +redis_up{app="redis-store"} ```-#### worker: codeintel_background_index_record_reset_failures_total +### Redis: Redis Cache + +#### redis: redis-cache_up -
Lsif index records reset to errored state every 5m
+Redis-cache availability
-This panel has no related alerts. +A value of 1 indicates the service is currently running -To see this panel, visit `/-/debug/grafana/d/worker/worker?viewPanel=102201` on your Sourcegraph instance. +Refer to the [alerts reference](alerts#redis-redis-cache-up) for 1 alert related to this panel. -*Managed by the [Sourcegraph Code intelligence team](https://handbook.sourcegraph.com/departments/engineering/teams/code-intelligence).* +To see this panel, visit `/-/debug/grafana/d/redis/redis?viewPanel=100100` on your Sourcegraph instance. + +*Managed by the [Sourcegraph Infrastructure Org team](https://handbook.sourcegraph.com/departments/engineering/infrastructure).*Technical details
@@ -50107,21 +50441,23 @@ To see this panel, visit `/-/debug/grafana/d/worker/worker?viewPanel=102201` on Query: ``` -sum(increase(src_codeintel_background_index_record_reset_failures_total{job=~"^worker.*"}[5m])) +redis_up{app="redis-cache"} ```-#### worker: codeintel_background_index_record_reset_errors_total +### Redis: Provisioning indicators (not available on server) + +#### redis: provisioning_container_cpu_usage_long_term -
Lsif index operation errors every 5m
+Container cpu usage total (90th percentile over 1d) across all cores by instance
-This panel has no related alerts. +Refer to the [alerts reference](alerts#redis-provisioning-container-cpu-usage-long-term) for 1 alert related to this panel. -To see this panel, visit `/-/debug/grafana/d/worker/worker?viewPanel=102202` on your Sourcegraph instance. +To see this panel, visit `/-/debug/grafana/d/redis/redis?viewPanel=100200` on your Sourcegraph instance. -*Managed by the [Sourcegraph Code intelligence team](https://handbook.sourcegraph.com/departments/engineering/teams/code-intelligence).* +*Managed by the [Sourcegraph Infrastructure Org team](https://handbook.sourcegraph.com/departments/engineering/infrastructure).*Technical details
@@ -50129,23 +50465,21 @@ To see this panel, visit `/-/debug/grafana/d/worker/worker?viewPanel=102202` on Query: ``` -sum(increase(src_codeintel_background_index_record_reset_errors_total{job=~"^worker.*"}[5m])) +quantile_over_time(0.9, cadvisor_container_cpu_usage_percentage_total{name=~"^redis-cache.*"}[1d]) ```-### Worker: Codeintel: lsif_dependency_index record resetter - -#### worker: codeintel_background_dependency_index_record_resets_total +#### redis: provisioning_container_memory_usage_long_term -
Lsif dependency index records reset to queued state every 5m
+Container memory usage (1d maximum) by instance
-This panel has no related alerts. +Refer to the [alerts reference](alerts#redis-provisioning-container-memory-usage-long-term) for 1 alert related to this panel. -To see this panel, visit `/-/debug/grafana/d/worker/worker?viewPanel=102300` on your Sourcegraph instance. +To see this panel, visit `/-/debug/grafana/d/redis/redis?viewPanel=100201` on your Sourcegraph instance. -*Managed by the [Sourcegraph Code intelligence team](https://handbook.sourcegraph.com/departments/engineering/teams/code-intelligence).* +*Managed by the [Sourcegraph Infrastructure Org team](https://handbook.sourcegraph.com/departments/engineering/infrastructure).*Technical details
@@ -50153,21 +50487,21 @@ To see this panel, visit `/-/debug/grafana/d/worker/worker?viewPanel=102300` on Query: ``` -sum(increase(src_codeintel_background_dependency_index_record_resets_total{job=~"^worker.*"}[5m])) +max_over_time(cadvisor_container_memory_usage_percentage_total{name=~"^redis-cache.*"}[1d]) ```-#### worker: codeintel_background_dependency_index_record_reset_failures_total +#### redis: provisioning_container_cpu_usage_short_term -
Lsif dependency index records reset to errored state every 5m
+Container cpu usage total (5m maximum) across all cores by instance
-This panel has no related alerts. +Refer to the [alerts reference](alerts#redis-provisioning-container-cpu-usage-short-term) for 1 alert related to this panel. -To see this panel, visit `/-/debug/grafana/d/worker/worker?viewPanel=102301` on your Sourcegraph instance. +To see this panel, visit `/-/debug/grafana/d/redis/redis?viewPanel=100210` on your Sourcegraph instance. -*Managed by the [Sourcegraph Code intelligence team](https://handbook.sourcegraph.com/departments/engineering/teams/code-intelligence).* +*Managed by the [Sourcegraph Infrastructure Org team](https://handbook.sourcegraph.com/departments/engineering/infrastructure).*Technical details
@@ -50175,21 +50509,21 @@ To see this panel, visit `/-/debug/grafana/d/worker/worker?viewPanel=102301` on Query: ``` -sum(increase(src_codeintel_background_dependency_index_record_reset_failures_total{job=~"^worker.*"}[5m])) +max_over_time(cadvisor_container_cpu_usage_percentage_total{name=~"^redis-cache.*"}[5m]) ```-#### worker: codeintel_background_dependency_index_record_reset_errors_total +#### redis: provisioning_container_memory_usage_short_term -
Lsif dependency index operation errors every 5m
+Container memory usage (5m maximum) by instance
-This panel has no related alerts. +Refer to the [alerts reference](alerts#redis-provisioning-container-memory-usage-short-term) for 1 alert related to this panel. -To see this panel, visit `/-/debug/grafana/d/worker/worker?viewPanel=102302` on your Sourcegraph instance. +To see this panel, visit `/-/debug/grafana/d/redis/redis?viewPanel=100211` on your Sourcegraph instance. -*Managed by the [Sourcegraph Code intelligence team](https://handbook.sourcegraph.com/departments/engineering/teams/code-intelligence).* +*Managed by the [Sourcegraph Infrastructure Org team](https://handbook.sourcegraph.com/departments/engineering/infrastructure).*Technical details
@@ -50197,23 +50531,24 @@ To see this panel, visit `/-/debug/grafana/d/worker/worker?viewPanel=102302` on Query: ``` -sum(increase(src_codeintel_background_dependency_index_record_reset_errors_total{job=~"^worker.*"}[5m])) +max_over_time(cadvisor_container_memory_usage_percentage_total{name=~"^redis-cache.*"}[5m]) ```-### Worker: Codeinsights: Query Runner Queue +#### redis: container_oomkill_events_total -#### worker: query_runner_worker_queue_size +
Container OOMKILL events total by instance
-Code insights query runner queue queue size
+This value indicates the total number of times the container main process or child processes were terminated by OOM killer. +When it occurs frequently, it is an indicator of underprovisioning. -This panel has no related alerts. +Refer to the [alerts reference](alerts#redis-container-oomkill-events-total) for 1 alert related to this panel. -To see this panel, visit `/-/debug/grafana/d/worker/worker?viewPanel=102400` on your Sourcegraph instance. +To see this panel, visit `/-/debug/grafana/d/redis/redis?viewPanel=100212` on your Sourcegraph instance. -*Managed by the [Sourcegraph Code Search team](https://handbook.sourcegraph.com/departments/engineering/teams/code-search).* +*Managed by the [Sourcegraph Infrastructure Org team](https://handbook.sourcegraph.com/departments/engineering/infrastructure).*Technical details
@@ -50221,27 +50556,23 @@ To see this panel, visit `/-/debug/grafana/d/worker/worker?viewPanel=102400` on Query: ``` -max(src_query_runner_worker_total{job=~"^worker.*"}) +max by (name) (container_oom_events_total{name=~"^redis-cache.*"}) ```-#### worker: query_runner_worker_queue_growth_rate - -
Code insights query runner queue queue growth rate over 30m
+### Redis: Provisioning indicators (not available on server) -This value compares the rate of enqueues against the rate of finished jobs. +#### redis: provisioning_container_cpu_usage_long_term - - A value < than 1 indicates that process rate > enqueue rate - - A value = than 1 indicates that process rate = enqueue rate - - A value > than 1 indicates that process rate < enqueue rate +Container cpu usage total (90th percentile over 1d) across all cores by instance
-This panel has no related alerts. +Refer to the [alerts reference](alerts#redis-provisioning-container-cpu-usage-long-term) for 1 alert related to this panel. -To see this panel, visit `/-/debug/grafana/d/worker/worker?viewPanel=102401` on your Sourcegraph instance. +To see this panel, visit `/-/debug/grafana/d/redis/redis?viewPanel=100300` on your Sourcegraph instance. -*Managed by the [Sourcegraph Code Search team](https://handbook.sourcegraph.com/departments/engineering/teams/code-search).* +*Managed by the [Sourcegraph Infrastructure Org team](https://handbook.sourcegraph.com/departments/engineering/infrastructure).*Technical details
@@ -50249,23 +50580,21 @@ To see this panel, visit `/-/debug/grafana/d/worker/worker?viewPanel=102401` on Query: ``` -sum(increase(src_query_runner_worker_total{job=~"^worker.*"}[30m])) / sum(increase(src_query_runner_worker_processor_total{job=~"^worker.*"}[30m])) +quantile_over_time(0.9, cadvisor_container_cpu_usage_percentage_total{name=~"^redis-store.*"}[1d]) ```-### Worker: Codeinsights: insights queue processor - -#### worker: query_runner_worker_handlers +#### redis: provisioning_container_memory_usage_long_term -
Handler active handlers
+Container memory usage (1d maximum) by instance
-This panel has no related alerts. +Refer to the [alerts reference](alerts#redis-provisioning-container-memory-usage-long-term) for 1 alert related to this panel. -To see this panel, visit `/-/debug/grafana/d/worker/worker?viewPanel=102500` on your Sourcegraph instance. +To see this panel, visit `/-/debug/grafana/d/redis/redis?viewPanel=100301` on your Sourcegraph instance. -*Managed by the [Sourcegraph Code Search team](https://handbook.sourcegraph.com/departments/engineering/teams/code-search).* +*Managed by the [Sourcegraph Infrastructure Org team](https://handbook.sourcegraph.com/departments/engineering/infrastructure).*Technical details
@@ -50273,21 +50602,21 @@ To see this panel, visit `/-/debug/grafana/d/worker/worker?viewPanel=102500` on Query: ``` -sum(src_query_runner_worker_processor_handlers{job=~"^worker.*"}) +max_over_time(cadvisor_container_memory_usage_percentage_total{name=~"^redis-store.*"}[1d]) ```-#### worker: query_runner_worker_processor_total +#### redis: provisioning_container_cpu_usage_short_term -
Handler operations every 5m
+Container cpu usage total (5m maximum) across all cores by instance
-This panel has no related alerts. +Refer to the [alerts reference](alerts#redis-provisioning-container-cpu-usage-short-term) for 1 alert related to this panel. -To see this panel, visit `/-/debug/grafana/d/worker/worker?viewPanel=102510` on your Sourcegraph instance. +To see this panel, visit `/-/debug/grafana/d/redis/redis?viewPanel=100310` on your Sourcegraph instance. -*Managed by the [Sourcegraph Code Search team](https://handbook.sourcegraph.com/departments/engineering/teams/code-search).* +*Managed by the [Sourcegraph Infrastructure Org team](https://handbook.sourcegraph.com/departments/engineering/infrastructure).*Technical details
@@ -50295,21 +50624,21 @@ To see this panel, visit `/-/debug/grafana/d/worker/worker?viewPanel=102510` on Query: ``` -sum(increase(src_query_runner_worker_processor_total{job=~"^worker.*"}[5m])) +max_over_time(cadvisor_container_cpu_usage_percentage_total{name=~"^redis-store.*"}[5m]) ```-#### worker: query_runner_worker_processor_99th_percentile_duration +#### redis: provisioning_container_memory_usage_short_term -
Aggregate successful handler operation duration distribution over 5m
+Container memory usage (5m maximum) by instance
-This panel has no related alerts. +Refer to the [alerts reference](alerts#redis-provisioning-container-memory-usage-short-term) for 1 alert related to this panel. -To see this panel, visit `/-/debug/grafana/d/worker/worker?viewPanel=102511` on your Sourcegraph instance. +To see this panel, visit `/-/debug/grafana/d/redis/redis?viewPanel=100311` on your Sourcegraph instance. -*Managed by the [Sourcegraph Code Search team](https://handbook.sourcegraph.com/departments/engineering/teams/code-search).* +*Managed by the [Sourcegraph Infrastructure Org team](https://handbook.sourcegraph.com/departments/engineering/infrastructure).*Technical details
@@ -50317,21 +50646,24 @@ To see this panel, visit `/-/debug/grafana/d/worker/worker?viewPanel=102511` on Query: ``` -sum by (le)(rate(src_query_runner_worker_processor_duration_seconds_bucket{job=~"^worker.*"}[5m])) +max_over_time(cadvisor_container_memory_usage_percentage_total{name=~"^redis-store.*"}[5m]) ```-#### worker: query_runner_worker_processor_errors_total +#### redis: container_oomkill_events_total -
Handler operation errors every 5m
+Container OOMKILL events total by instance
-This panel has no related alerts. +This value indicates the total number of times the container main process or child processes were terminated by OOM killer. +When it occurs frequently, it is an indicator of underprovisioning. -To see this panel, visit `/-/debug/grafana/d/worker/worker?viewPanel=102512` on your Sourcegraph instance. +Refer to the [alerts reference](alerts#redis-container-oomkill-events-total) for 1 alert related to this panel. -*Managed by the [Sourcegraph Code Search team](https://handbook.sourcegraph.com/departments/engineering/teams/code-search).* +To see this panel, visit `/-/debug/grafana/d/redis/redis?viewPanel=100312` on your Sourcegraph instance. + +*Managed by the [Sourcegraph Infrastructure Org team](https://handbook.sourcegraph.com/departments/engineering/infrastructure).*Technical details
@@ -50339,21 +50671,23 @@ To see this panel, visit `/-/debug/grafana/d/worker/worker?viewPanel=102512` on Query: ``` -sum(increase(src_query_runner_worker_processor_errors_total{job=~"^worker.*"}[5m])) +max by (name) (container_oom_events_total{name=~"^redis-store.*"}) ```-#### worker: query_runner_worker_processor_error_rate +### Redis: Kubernetes monitoring (only available on Kubernetes) -
Handler operation error rate over 5m
+#### redis: pods_available_percentage -This panel has no related alerts. +Percentage pods available
-To see this panel, visit `/-/debug/grafana/d/worker/worker?viewPanel=102513` on your Sourcegraph instance. +Refer to the [alerts reference](alerts#redis-pods-available-percentage) for 1 alert related to this panel. -*Managed by the [Sourcegraph Code Search team](https://handbook.sourcegraph.com/departments/engineering/teams/code-search).* +To see this panel, visit `/-/debug/grafana/d/redis/redis?viewPanel=100400` on your Sourcegraph instance. + +*Managed by the [Sourcegraph Infrastructure Org team](https://handbook.sourcegraph.com/departments/engineering/infrastructure).*Technical details
@@ -50361,23 +50695,23 @@ To see this panel, visit `/-/debug/grafana/d/worker/worker?viewPanel=102513` on Query: ``` -sum(increase(src_query_runner_worker_processor_errors_total{job=~"^worker.*"}[5m])) / (sum(increase(src_query_runner_worker_processor_total{job=~"^worker.*"}[5m])) + sum(increase(src_query_runner_worker_processor_errors_total{job=~"^worker.*"}[5m]))) * 100 +sum by(app) (up{app=~".*redis-cache"}) / count by (app) (up{app=~".*redis-cache"}) * 100 ```-### Worker: Codeinsights: code insights query runner queue record resetter +### Redis: Kubernetes monitoring (only available on Kubernetes) -#### worker: query_runner_worker_record_resets_total +#### redis: pods_available_percentage -
Insights query runner queue records reset to queued state every 5m
+Percentage pods available
-This panel has no related alerts. +Refer to the [alerts reference](alerts#redis-pods-available-percentage) for 1 alert related to this panel. -To see this panel, visit `/-/debug/grafana/d/worker/worker?viewPanel=102600` on your Sourcegraph instance. +To see this panel, visit `/-/debug/grafana/d/redis/redis?viewPanel=100500` on your Sourcegraph instance. -*Managed by the [Sourcegraph Code Search team](https://handbook.sourcegraph.com/departments/engineering/teams/code-search).* +*Managed by the [Sourcegraph Infrastructure Org team](https://handbook.sourcegraph.com/departments/engineering/infrastructure).*Technical details
@@ -50385,21 +50719,31 @@ To see this panel, visit `/-/debug/grafana/d/worker/worker?viewPanel=102600` on Query: ``` -sum(increase(src_query_runner_worker_record_resets_total{job=~"^worker.*"}[5m])) +sum by(app) (up{app=~".*redis-store"}) / count by (app) (up{app=~".*redis-store"}) * 100 ```-#### worker: query_runner_worker_record_reset_failures_total +## Worker + +
Manages background processes.
+ +To see this dashboard, visit `/-/debug/grafana/d/worker/worker` on your Sourcegraph instance. + +### Worker: Active jobs + +#### worker: worker_job_count + +Number of worker instances running each job
-Insights query runner queue records reset to errored state every 5m
+The number of worker instances running each job type. +It is necessary for each job type to be managed by at least one worker instance. This panel has no related alerts. -To see this panel, visit `/-/debug/grafana/d/worker/worker?viewPanel=102601` on your Sourcegraph instance. +To see this panel, visit `/-/debug/grafana/d/worker/worker?viewPanel=100000` on your Sourcegraph instance. -*Managed by the [Sourcegraph Code Search team](https://handbook.sourcegraph.com/departments/engineering/teams/code-search).*Technical details
@@ -50407,21 +50751,21 @@ To see this panel, visit `/-/debug/grafana/d/worker/worker?viewPanel=102601` on Query: ``` -sum(increase(src_query_runner_worker_record_reset_failures_total{job=~"^worker.*"}[5m])) +sum by (job_name) (src_worker_jobs{job=~"^worker.*"}) ```-#### worker: query_runner_worker_record_reset_errors_total +#### worker: worker_job_codeintel-upload-janitor_count -
Insights query runner queue operation errors every 5m
+Number of worker instances running the codeintel-upload-janitor job
-This panel has no related alerts. +Refer to the [alerts reference](alerts#worker-worker-job-codeintel-upload-janitor-count) for 2 alerts related to this panel. -To see this panel, visit `/-/debug/grafana/d/worker/worker?viewPanel=102602` on your Sourcegraph instance. +To see this panel, visit `/-/debug/grafana/d/worker/worker?viewPanel=100010` on your Sourcegraph instance. -*Managed by the [Sourcegraph Code Search team](https://handbook.sourcegraph.com/departments/engineering/teams/code-search).* +*Managed by the [Sourcegraph Code intelligence team](https://handbook.sourcegraph.com/departments/engineering/teams/code-intelligence).*Technical details
@@ -50429,23 +50773,21 @@ To see this panel, visit `/-/debug/grafana/d/worker/worker?viewPanel=102602` on Query: ``` -sum(increase(src_query_runner_worker_record_reset_errors_total{job=~"^worker.*"}[5m])) +sum (src_worker_jobs{job=~"^worker.*", job_name="codeintel-upload-janitor"}) ```-### Worker: Codeinsights: dbstore stats - -#### worker: workerutil_dbworker_store_insights_query_runner_jobs_store_total +#### worker: worker_job_codeintel-commitgraph-updater_count -
Aggregate store operations every 5m
+Number of worker instances running the codeintel-commitgraph-updater job
-This panel has no related alerts. +Refer to the [alerts reference](alerts#worker-worker-job-codeintel-commitgraph-updater-count) for 2 alerts related to this panel. -To see this panel, visit `/-/debug/grafana/d/worker/worker?viewPanel=102700` on your Sourcegraph instance. +To see this panel, visit `/-/debug/grafana/d/worker/worker?viewPanel=100011` on your Sourcegraph instance. -*Managed by the [Sourcegraph Code Search team](https://handbook.sourcegraph.com/departments/engineering/teams/code-search).* +*Managed by the [Sourcegraph Code intelligence team](https://handbook.sourcegraph.com/departments/engineering/teams/code-intelligence).*Technical details
@@ -50453,21 +50795,21 @@ To see this panel, visit `/-/debug/grafana/d/worker/worker?viewPanel=102700` on Query: ``` -sum(increase(src_workerutil_dbworker_store_insights_query_runner_jobs_store_total{job=~"^worker.*"}[5m])) +sum (src_worker_jobs{job=~"^worker.*", job_name="codeintel-commitgraph-updater"}) ```-#### worker: workerutil_dbworker_store_insights_query_runner_jobs_store_99th_percentile_duration +#### worker: worker_job_codeintel-autoindexing-scheduler_count -
Aggregate successful store operation duration distribution over 5m
+Number of worker instances running the codeintel-autoindexing-scheduler job
-This panel has no related alerts. +Refer to the [alerts reference](alerts#worker-worker-job-codeintel-autoindexing-scheduler-count) for 2 alerts related to this panel. -To see this panel, visit `/-/debug/grafana/d/worker/worker?viewPanel=102701` on your Sourcegraph instance. +To see this panel, visit `/-/debug/grafana/d/worker/worker?viewPanel=100012` on your Sourcegraph instance. -*Managed by the [Sourcegraph Code Search team](https://handbook.sourcegraph.com/departments/engineering/teams/code-search).* +*Managed by the [Sourcegraph Code intelligence team](https://handbook.sourcegraph.com/departments/engineering/teams/code-intelligence).*Technical details
@@ -50475,21 +50817,25 @@ To see this panel, visit `/-/debug/grafana/d/worker/worker?viewPanel=102701` on Query: ``` -sum by (le)(rate(src_workerutil_dbworker_store_insights_query_runner_jobs_store_duration_seconds_bucket{job=~"^worker.*"}[5m])) +sum (src_worker_jobs{job=~"^worker.*", job_name="codeintel-autoindexing-scheduler"}) ```-#### worker: workerutil_dbworker_store_insights_query_runner_jobs_store_errors_total +### Worker: Database record encrypter -
Aggregate store operation errors every 5m
+#### worker: records_encrypted_at_rest_percentage + +Percentage of database records encrypted at rest
+ +Percentage of encrypted database records This panel has no related alerts. -To see this panel, visit `/-/debug/grafana/d/worker/worker?viewPanel=102702` on your Sourcegraph instance. +To see this panel, visit `/-/debug/grafana/d/worker/worker?viewPanel=100100` on your Sourcegraph instance. -*Managed by the [Sourcegraph Code Search team](https://handbook.sourcegraph.com/departments/engineering/teams/code-search).* +*Managed by the [Sourcegraph Source team](https://handbook.sourcegraph.com/departments/engineering/teams/source).*Technical details
@@ -50497,21 +50843,23 @@ To see this panel, visit `/-/debug/grafana/d/worker/worker?viewPanel=102702` on Query: ``` -sum(increase(src_workerutil_dbworker_store_insights_query_runner_jobs_store_errors_total{job=~"^worker.*"}[5m])) +(max(src_records_encrypted_at_rest_total) by (tableName)) / ((max(src_records_encrypted_at_rest_total) by (tableName)) + (max(src_records_unencrypted_at_rest_total) by (tableName))) * 100 ```-#### worker: workerutil_dbworker_store_insights_query_runner_jobs_store_error_rate +#### worker: records_encrypted_total -
Aggregate store operation error rate over 5m
+Database records encrypted every 5m
+ +Number of encrypted database records every 5m This panel has no related alerts. -To see this panel, visit `/-/debug/grafana/d/worker/worker?viewPanel=102703` on your Sourcegraph instance. +To see this panel, visit `/-/debug/grafana/d/worker/worker?viewPanel=100101` on your Sourcegraph instance. -*Managed by the [Sourcegraph Code Search team](https://handbook.sourcegraph.com/departments/engineering/teams/code-search).* +*Managed by the [Sourcegraph Source team](https://handbook.sourcegraph.com/departments/engineering/teams/source).*Technical details
@@ -50519,21 +50867,23 @@ To see this panel, visit `/-/debug/grafana/d/worker/worker?viewPanel=102703` on Query: ``` -sum(increase(src_workerutil_dbworker_store_insights_query_runner_jobs_store_errors_total{job=~"^worker.*"}[5m])) / (sum(increase(src_workerutil_dbworker_store_insights_query_runner_jobs_store_total{job=~"^worker.*"}[5m])) + sum(increase(src_workerutil_dbworker_store_insights_query_runner_jobs_store_errors_total{job=~"^worker.*"}[5m]))) * 100 +sum by (tableName)(increase(src_records_encrypted_total{job=~"^worker.*"}[5m])) ```-#### worker: workerutil_dbworker_store_insights_query_runner_jobs_store_total +#### worker: records_decrypted_total -
Store operations every 5m
+Database records decrypted every 5m
+ +Number of encrypted database records every 5m This panel has no related alerts. -To see this panel, visit `/-/debug/grafana/d/worker/worker?viewPanel=102710` on your Sourcegraph instance. +To see this panel, visit `/-/debug/grafana/d/worker/worker?viewPanel=100102` on your Sourcegraph instance. -*Managed by the [Sourcegraph Code Search team](https://handbook.sourcegraph.com/departments/engineering/teams/code-search).* +*Managed by the [Sourcegraph Source team](https://handbook.sourcegraph.com/departments/engineering/teams/source).*Technical details
@@ -50541,21 +50891,23 @@ To see this panel, visit `/-/debug/grafana/d/worker/worker?viewPanel=102710` on Query: ``` -sum by (op)(increase(src_workerutil_dbworker_store_insights_query_runner_jobs_store_total{job=~"^worker.*"}[5m])) +sum by (tableName)(increase(src_records_decrypted_total{job=~"^worker.*"}[5m])) ```-#### worker: workerutil_dbworker_store_insights_query_runner_jobs_store_99th_percentile_duration +#### worker: record_encryption_errors_total + +
Encryption operation errors every 5m
-99th percentile successful store operation duration over 5m
+Number of database record encryption/decryption errors every 5m This panel has no related alerts. -To see this panel, visit `/-/debug/grafana/d/worker/worker?viewPanel=102711` on your Sourcegraph instance. +To see this panel, visit `/-/debug/grafana/d/worker/worker?viewPanel=100103` on your Sourcegraph instance. -*Managed by the [Sourcegraph Code Search team](https://handbook.sourcegraph.com/departments/engineering/teams/code-search).* +*Managed by the [Sourcegraph Source team](https://handbook.sourcegraph.com/departments/engineering/teams/source).*Technical details
@@ -50563,21 +50915,23 @@ To see this panel, visit `/-/debug/grafana/d/worker/worker?viewPanel=102711` on Query: ``` -histogram_quantile(0.99, sum by (le,op)(rate(src_workerutil_dbworker_store_insights_query_runner_jobs_store_duration_seconds_bucket{job=~"^worker.*"}[5m]))) +sum(increase(src_record_encryption_errors_total{job=~"^worker.*"}[5m])) ```-#### worker: workerutil_dbworker_store_insights_query_runner_jobs_store_errors_total +### Worker: Codeintel: Repository commit graph updates -
Store operation errors every 5m
+#### worker: codeintel_commit_graph_processor_total + +Update operations every 5m
This panel has no related alerts. -To see this panel, visit `/-/debug/grafana/d/worker/worker?viewPanel=102712` on your Sourcegraph instance. +To see this panel, visit `/-/debug/grafana/d/worker/worker?viewPanel=100200` on your Sourcegraph instance. -*Managed by the [Sourcegraph Code Search team](https://handbook.sourcegraph.com/departments/engineering/teams/code-search).* +*Managed by the [Sourcegraph Code intelligence team](https://handbook.sourcegraph.com/departments/engineering/teams/code-intelligence).*Technical details
@@ -50585,21 +50939,21 @@ To see this panel, visit `/-/debug/grafana/d/worker/worker?viewPanel=102712` on Query: ``` -sum by (op)(increase(src_workerutil_dbworker_store_insights_query_runner_jobs_store_errors_total{job=~"^worker.*"}[5m])) +sum(increase(src_codeintel_commit_graph_processor_total{job=~"^worker.*"}[5m])) ```-#### worker: workerutil_dbworker_store_insights_query_runner_jobs_store_error_rate +#### worker: codeintel_commit_graph_processor_99th_percentile_duration -
Store operation error rate over 5m
+Aggregate successful update operation duration distribution over 5m
This panel has no related alerts. -To see this panel, visit `/-/debug/grafana/d/worker/worker?viewPanel=102713` on your Sourcegraph instance. +To see this panel, visit `/-/debug/grafana/d/worker/worker?viewPanel=100201` on your Sourcegraph instance. -*Managed by the [Sourcegraph Code Search team](https://handbook.sourcegraph.com/departments/engineering/teams/code-search).* +*Managed by the [Sourcegraph Code intelligence team](https://handbook.sourcegraph.com/departments/engineering/teams/code-intelligence).*Technical details
@@ -50607,25 +50961,21 @@ To see this panel, visit `/-/debug/grafana/d/worker/worker?viewPanel=102713` on Query: ``` -sum by (op)(increase(src_workerutil_dbworker_store_insights_query_runner_jobs_store_errors_total{job=~"^worker.*"}[5m])) / (sum by (op)(increase(src_workerutil_dbworker_store_insights_query_runner_jobs_store_total{job=~"^worker.*"}[5m])) + sum by (op)(increase(src_workerutil_dbworker_store_insights_query_runner_jobs_store_errors_total{job=~"^worker.*"}[5m]))) * 100 +sum by (le)(rate(src_codeintel_commit_graph_processor_duration_seconds_bucket{job=~"^worker.*"}[5m])) ```-### Worker: Code Insights queue utilization - -#### worker: insights_queue_unutilized_size - -
Insights queue size that is not utilized (not processing)
+#### worker: codeintel_commit_graph_processor_errors_total -Any value on this panel indicates code insights is not processing queries from its queue. This observable and alert only fire if there are records in the queue and there have been no dequeue attempts for 30 minutes. +Update operation errors every 5m
-Refer to the [alerts reference](alerts#worker-insights-queue-unutilized-size) for 1 alert related to this panel. +This panel has no related alerts. -To see this panel, visit `/-/debug/grafana/d/worker/worker?viewPanel=102800` on your Sourcegraph instance. +To see this panel, visit `/-/debug/grafana/d/worker/worker?viewPanel=100202` on your Sourcegraph instance. -*Managed by the [Sourcegraph Code Search team](https://handbook.sourcegraph.com/departments/engineering/teams/code-search).* +*Managed by the [Sourcegraph Code intelligence team](https://handbook.sourcegraph.com/departments/engineering/teams/code-intelligence).*Technical details
@@ -50633,23 +50983,21 @@ To see this panel, visit `/-/debug/grafana/d/worker/worker?viewPanel=102800` on Query: ``` -max(src_query_runner_worker_total{job=~"^worker.*"}) > 0 and on(job) sum by (op)(increase(src_workerutil_dbworker_store_insights_query_runner_jobs_store_total{job=~"^worker.*",op="Dequeue"}[5m])) < 1 +sum(increase(src_codeintel_commit_graph_processor_errors_total{job=~"^worker.*"}[5m])) ```-### Worker: Database connections - -#### worker: max_open_conns +#### worker: codeintel_commit_graph_processor_error_rate -
Maximum open
+Update operation error rate over 5m
This panel has no related alerts. -To see this panel, visit `/-/debug/grafana/d/worker/worker?viewPanel=102900` on your Sourcegraph instance. +To see this panel, visit `/-/debug/grafana/d/worker/worker?viewPanel=100203` on your Sourcegraph instance. -*Managed by the [Sourcegraph Infrastructure Org team](https://handbook.sourcegraph.com/departments/engineering/infrastructure).* +*Managed by the [Sourcegraph Code intelligence team](https://handbook.sourcegraph.com/departments/engineering/teams/code-intelligence).*Technical details
@@ -50657,21 +51005,23 @@ To see this panel, visit `/-/debug/grafana/d/worker/worker?viewPanel=102900` on Query: ``` -sum by (app_name, db_name) (src_pgsql_conns_max_open{app_name="worker"}) +sum(increase(src_codeintel_commit_graph_processor_errors_total{job=~"^worker.*"}[5m])) / (sum(increase(src_codeintel_commit_graph_processor_total{job=~"^worker.*"}[5m])) + sum(increase(src_codeintel_commit_graph_processor_errors_total{job=~"^worker.*"}[5m]))) * 100 ```-#### worker: open_conns +### Worker: Codeintel: Auto-index scheduler -
Established
+#### worker: codeintel_autoindexing_total + +Auto-indexing job scheduler operations every 10m
This panel has no related alerts. -To see this panel, visit `/-/debug/grafana/d/worker/worker?viewPanel=102901` on your Sourcegraph instance. +To see this panel, visit `/-/debug/grafana/d/worker/worker?viewPanel=100300` on your Sourcegraph instance. -*Managed by the [Sourcegraph Infrastructure Org team](https://handbook.sourcegraph.com/departments/engineering/infrastructure).* +*Managed by the [Sourcegraph Code intelligence team](https://handbook.sourcegraph.com/departments/engineering/teams/code-intelligence).*Technical details
@@ -50679,21 +51029,21 @@ To see this panel, visit `/-/debug/grafana/d/worker/worker?viewPanel=102901` on Query: ``` -sum by (app_name, db_name) (src_pgsql_conns_open{app_name="worker"}) +sum(increase(src_codeintel_autoindexing_total{op='HandleIndexSchedule',job=~"^worker.*"}[10m])) ```-#### worker: in_use +#### worker: codeintel_autoindexing_99th_percentile_duration -
Used
+Aggregate successful auto-indexing job scheduler operation duration distribution over 10m
This panel has no related alerts. -To see this panel, visit `/-/debug/grafana/d/worker/worker?viewPanel=102910` on your Sourcegraph instance. +To see this panel, visit `/-/debug/grafana/d/worker/worker?viewPanel=100301` on your Sourcegraph instance. -*Managed by the [Sourcegraph Infrastructure Org team](https://handbook.sourcegraph.com/departments/engineering/infrastructure).* +*Managed by the [Sourcegraph Code intelligence team](https://handbook.sourcegraph.com/departments/engineering/teams/code-intelligence).*Technical details
@@ -50701,21 +51051,21 @@ To see this panel, visit `/-/debug/grafana/d/worker/worker?viewPanel=102910` on Query: ``` -sum by (app_name, db_name) (src_pgsql_conns_in_use{app_name="worker"}) +sum by (le)(rate(src_codeintel_autoindexing_duration_seconds_bucket{op='HandleIndexSchedule',job=~"^worker.*"}[10m])) ```-#### worker: idle +#### worker: codeintel_autoindexing_errors_total -
Idle
+Auto-indexing job scheduler operation errors every 10m
This panel has no related alerts. -To see this panel, visit `/-/debug/grafana/d/worker/worker?viewPanel=102911` on your Sourcegraph instance. +To see this panel, visit `/-/debug/grafana/d/worker/worker?viewPanel=100302` on your Sourcegraph instance. -*Managed by the [Sourcegraph Infrastructure Org team](https://handbook.sourcegraph.com/departments/engineering/infrastructure).* +*Managed by the [Sourcegraph Code intelligence team](https://handbook.sourcegraph.com/departments/engineering/teams/code-intelligence).*Technical details
@@ -50723,21 +51073,21 @@ To see this panel, visit `/-/debug/grafana/d/worker/worker?viewPanel=102911` on Query: ``` -sum by (app_name, db_name) (src_pgsql_conns_idle{app_name="worker"}) +sum(increase(src_codeintel_autoindexing_errors_total{op='HandleIndexSchedule',job=~"^worker.*"}[10m])) ```-#### worker: mean_blocked_seconds_per_conn_request +#### worker: codeintel_autoindexing_error_rate -
Mean blocked seconds per conn request
+Auto-indexing job scheduler operation error rate over 10m
-Refer to the [alerts reference](alerts#worker-mean-blocked-seconds-per-conn-request) for 2 alerts related to this panel. +This panel has no related alerts. -To see this panel, visit `/-/debug/grafana/d/worker/worker?viewPanel=102920` on your Sourcegraph instance. +To see this panel, visit `/-/debug/grafana/d/worker/worker?viewPanel=100303` on your Sourcegraph instance. -*Managed by the [Sourcegraph Infrastructure Org team](https://handbook.sourcegraph.com/departments/engineering/infrastructure).* +*Managed by the [Sourcegraph Code intelligence team](https://handbook.sourcegraph.com/departments/engineering/teams/code-intelligence).*Technical details
@@ -50745,21 +51095,23 @@ To see this panel, visit `/-/debug/grafana/d/worker/worker?viewPanel=102920` on Query: ``` -sum by (app_name, db_name) (increase(src_pgsql_conns_blocked_seconds{app_name="worker"}[5m])) / sum by (app_name, db_name) (increase(src_pgsql_conns_waited_for{app_name="worker"}[5m])) +sum(increase(src_codeintel_autoindexing_errors_total{op='HandleIndexSchedule',job=~"^worker.*"}[10m])) / (sum(increase(src_codeintel_autoindexing_total{op='HandleIndexSchedule',job=~"^worker.*"}[10m])) + sum(increase(src_codeintel_autoindexing_errors_total{op='HandleIndexSchedule',job=~"^worker.*"}[10m]))) * 100 ```-#### worker: closed_max_idle +### Worker: Codeintel: dbstore stats -
Closed by SetMaxIdleConns
+#### worker: codeintel_uploads_store_total + +Aggregate store operations every 5m
This panel has no related alerts. -To see this panel, visit `/-/debug/grafana/d/worker/worker?viewPanel=102930` on your Sourcegraph instance. +To see this panel, visit `/-/debug/grafana/d/worker/worker?viewPanel=100400` on your Sourcegraph instance. -*Managed by the [Sourcegraph Infrastructure Org team](https://handbook.sourcegraph.com/departments/engineering/infrastructure).* +*Managed by the [Sourcegraph Code intelligence team](https://handbook.sourcegraph.com/departments/engineering/teams/code-intelligence).*Technical details
@@ -50767,21 +51119,21 @@ To see this panel, visit `/-/debug/grafana/d/worker/worker?viewPanel=102930` on Query: ``` -sum by (app_name, db_name) (increase(src_pgsql_conns_closed_max_idle{app_name="worker"}[5m])) +sum(increase(src_codeintel_uploads_store_total{job=~"^worker.*"}[5m])) ```-#### worker: closed_max_lifetime +#### worker: codeintel_uploads_store_99th_percentile_duration -
Closed by SetConnMaxLifetime
+Aggregate successful store operation duration distribution over 5m
This panel has no related alerts. -To see this panel, visit `/-/debug/grafana/d/worker/worker?viewPanel=102931` on your Sourcegraph instance. +To see this panel, visit `/-/debug/grafana/d/worker/worker?viewPanel=100401` on your Sourcegraph instance. -*Managed by the [Sourcegraph Infrastructure Org team](https://handbook.sourcegraph.com/departments/engineering/infrastructure).* +*Managed by the [Sourcegraph Code intelligence team](https://handbook.sourcegraph.com/departments/engineering/teams/code-intelligence).*Technical details
@@ -50789,21 +51141,21 @@ To see this panel, visit `/-/debug/grafana/d/worker/worker?viewPanel=102931` on Query: ``` -sum by (app_name, db_name) (increase(src_pgsql_conns_closed_max_lifetime{app_name="worker"}[5m])) +sum by (le)(rate(src_codeintel_uploads_store_duration_seconds_bucket{job=~"^worker.*"}[5m])) ```-#### worker: closed_max_idle_time +#### worker: codeintel_uploads_store_errors_total -
Closed by SetConnMaxIdleTime
+Aggregate store operation errors every 5m
This panel has no related alerts. -To see this panel, visit `/-/debug/grafana/d/worker/worker?viewPanel=102932` on your Sourcegraph instance. +To see this panel, visit `/-/debug/grafana/d/worker/worker?viewPanel=100402` on your Sourcegraph instance. -*Managed by the [Sourcegraph Infrastructure Org team](https://handbook.sourcegraph.com/departments/engineering/infrastructure).* +*Managed by the [Sourcegraph Code intelligence team](https://handbook.sourcegraph.com/departments/engineering/teams/code-intelligence).*Technical details
@@ -50811,31 +51163,19 @@ To see this panel, visit `/-/debug/grafana/d/worker/worker?viewPanel=102932` on Query: ``` -sum by (app_name, db_name) (increase(src_pgsql_conns_closed_max_idle_time{app_name="worker"}[5m])) +sum(increase(src_codeintel_uploads_store_errors_total{job=~"^worker.*"}[5m])) ```-### Worker: Container monitoring (not available on server) - -#### worker: container_missing - -
Container missing
- -This value is the number of times a container has not been seen for more than one minute. If you observe this -value change independent of deployment events (such as an upgrade), it could indicate pods are being OOM killed or terminated for some other reasons. +#### worker: codeintel_uploads_store_error_rate -- **Kubernetes:** - - Determine if the pod was OOM killed using `kubectl describe pod worker` (look for `OOMKilled: true`) and, if so, consider increasing the memory limit in the relevant `Deployment.yaml`. - - Check the logs before the container restarted to see if there are `panic:` messages or similar using `kubectl logs -p worker`. -- **Docker Compose:** - - Determine if the pod was OOM killed using `docker inspect -f '\{\{json .State\}\}' worker` (look for `"OOMKilled":true`) and, if so, consider increasing the memory limit of the worker container in `docker-compose.yml`. - - Check the logs before the container restarted to see if there are `panic:` messages or similar using `docker logs worker` (note this will include logs from the previous and currently running container). +Aggregate store operation error rate over 5m
This panel has no related alerts. -To see this panel, visit `/-/debug/grafana/d/worker/worker?viewPanel=103000` on your Sourcegraph instance. +To see this panel, visit `/-/debug/grafana/d/worker/worker?viewPanel=100403` on your Sourcegraph instance. *Managed by the [Sourcegraph Code intelligence team](https://handbook.sourcegraph.com/departments/engineering/teams/code-intelligence).* @@ -50845,19 +51185,19 @@ To see this panel, visit `/-/debug/grafana/d/worker/worker?viewPanel=103000` on Query: ``` -count by(name) ((time() - container_last_seen{name=~"^worker.*"}) > 60) +sum(increase(src_codeintel_uploads_store_errors_total{job=~"^worker.*"}[5m])) / (sum(increase(src_codeintel_uploads_store_total{job=~"^worker.*"}[5m])) + sum(increase(src_codeintel_uploads_store_errors_total{job=~"^worker.*"}[5m]))) * 100 ```-#### worker: container_cpu_usage +#### worker: codeintel_uploads_store_total -
Container cpu usage total (1m average) across all cores by instance
+Store operations every 5m
-Refer to the [alerts reference](alerts#worker-container-cpu-usage) for 1 alert related to this panel. +This panel has no related alerts. -To see this panel, visit `/-/debug/grafana/d/worker/worker?viewPanel=103001` on your Sourcegraph instance. +To see this panel, visit `/-/debug/grafana/d/worker/worker?viewPanel=100410` on your Sourcegraph instance. *Managed by the [Sourcegraph Code intelligence team](https://handbook.sourcegraph.com/departments/engineering/teams/code-intelligence).* @@ -50867,19 +51207,19 @@ To see this panel, visit `/-/debug/grafana/d/worker/worker?viewPanel=103001` on Query: ``` -cadvisor_container_cpu_usage_percentage_total{name=~"^worker.*"} +sum by (op)(increase(src_codeintel_uploads_store_total{job=~"^worker.*"}[5m])) ```-#### worker: container_memory_usage +#### worker: codeintel_uploads_store_99th_percentile_duration -
Container memory usage by instance
+99th percentile successful store operation duration over 5m
-Refer to the [alerts reference](alerts#worker-container-memory-usage) for 1 alert related to this panel. +This panel has no related alerts. -To see this panel, visit `/-/debug/grafana/d/worker/worker?viewPanel=103002` on your Sourcegraph instance. +To see this panel, visit `/-/debug/grafana/d/worker/worker?viewPanel=100411` on your Sourcegraph instance. *Managed by the [Sourcegraph Code intelligence team](https://handbook.sourcegraph.com/departments/engineering/teams/code-intelligence).* @@ -50889,22 +51229,19 @@ To see this panel, visit `/-/debug/grafana/d/worker/worker?viewPanel=103002` on Query: ``` -cadvisor_container_memory_usage_percentage_total{name=~"^worker.*"} +histogram_quantile(0.99, sum by (le,op)(rate(src_codeintel_uploads_store_duration_seconds_bucket{job=~"^worker.*"}[5m]))) ```-#### worker: fs_io_operations - -
Filesystem reads and writes rate by instance over 1h
+#### worker: codeintel_uploads_store_errors_total -This value indicates the number of filesystem read and write operations by containers of this service. -When extremely high, this can indicate a resource usage problem, or can cause problems with the service itself, especially if high values or spikes correlate with \{\{CONTAINER_NAME\}\} issues. +Store operation errors every 5m
This panel has no related alerts. -To see this panel, visit `/-/debug/grafana/d/worker/worker?viewPanel=103003` on your Sourcegraph instance. +To see this panel, visit `/-/debug/grafana/d/worker/worker?viewPanel=100412` on your Sourcegraph instance. *Managed by the [Sourcegraph Code intelligence team](https://handbook.sourcegraph.com/departments/engineering/teams/code-intelligence).* @@ -50914,21 +51251,19 @@ To see this panel, visit `/-/debug/grafana/d/worker/worker?viewPanel=103003` on Query: ``` -sum by(name) (rate(container_fs_reads_total{name=~"^worker.*"}[1h]) + rate(container_fs_writes_total{name=~"^worker.*"}[1h])) +sum by (op)(increase(src_codeintel_uploads_store_errors_total{job=~"^worker.*"}[5m])) ```-### Worker: Provisioning indicators (not available on server) - -#### worker: provisioning_container_cpu_usage_long_term +#### worker: codeintel_uploads_store_error_rate -
Container cpu usage total (90th percentile over 1d) across all cores by instance
+Store operation error rate over 5m
-Refer to the [alerts reference](alerts#worker-provisioning-container-cpu-usage-long-term) for 1 alert related to this panel. +This panel has no related alerts. -To see this panel, visit `/-/debug/grafana/d/worker/worker?viewPanel=103100` on your Sourcegraph instance. +To see this panel, visit `/-/debug/grafana/d/worker/worker?viewPanel=100413` on your Sourcegraph instance. *Managed by the [Sourcegraph Code intelligence team](https://handbook.sourcegraph.com/departments/engineering/teams/code-intelligence).* @@ -50938,19 +51273,21 @@ To see this panel, visit `/-/debug/grafana/d/worker/worker?viewPanel=103100` on Query: ``` -quantile_over_time(0.9, cadvisor_container_cpu_usage_percentage_total{name=~"^worker.*"}[1d]) +sum by (op)(increase(src_codeintel_uploads_store_errors_total{job=~"^worker.*"}[5m])) / (sum by (op)(increase(src_codeintel_uploads_store_total{job=~"^worker.*"}[5m])) + sum by (op)(increase(src_codeintel_uploads_store_errors_total{job=~"^worker.*"}[5m]))) * 100 ```-#### worker: provisioning_container_memory_usage_long_term +### Worker: Codeintel: lsifstore stats -
Container memory usage (1d maximum) by instance
+#### worker: codeintel_uploads_lsifstore_total -Refer to the [alerts reference](alerts#worker-provisioning-container-memory-usage-long-term) for 1 alert related to this panel. +Aggregate store operations every 5m
-To see this panel, visit `/-/debug/grafana/d/worker/worker?viewPanel=103101` on your Sourcegraph instance. +This panel has no related alerts. + +To see this panel, visit `/-/debug/grafana/d/worker/worker?viewPanel=100500` on your Sourcegraph instance. *Managed by the [Sourcegraph Code intelligence team](https://handbook.sourcegraph.com/departments/engineering/teams/code-intelligence).* @@ -50960,19 +51297,19 @@ To see this panel, visit `/-/debug/grafana/d/worker/worker?viewPanel=103101` on Query: ``` -max_over_time(cadvisor_container_memory_usage_percentage_total{name=~"^worker.*"}[1d]) +sum(increase(src_codeintel_uploads_lsifstore_total{job=~"^worker.*"}[5m])) ```-#### worker: provisioning_container_cpu_usage_short_term +#### worker: codeintel_uploads_lsifstore_99th_percentile_duration -
Container cpu usage total (5m maximum) across all cores by instance
+Aggregate successful store operation duration distribution over 5m
-Refer to the [alerts reference](alerts#worker-provisioning-container-cpu-usage-short-term) for 1 alert related to this panel. +This panel has no related alerts. -To see this panel, visit `/-/debug/grafana/d/worker/worker?viewPanel=103110` on your Sourcegraph instance. +To see this panel, visit `/-/debug/grafana/d/worker/worker?viewPanel=100501` on your Sourcegraph instance. *Managed by the [Sourcegraph Code intelligence team](https://handbook.sourcegraph.com/departments/engineering/teams/code-intelligence).* @@ -50982,19 +51319,19 @@ To see this panel, visit `/-/debug/grafana/d/worker/worker?viewPanel=103110` on Query: ``` -max_over_time(cadvisor_container_cpu_usage_percentage_total{name=~"^worker.*"}[5m]) +sum by (le)(rate(src_codeintel_uploads_lsifstore_duration_seconds_bucket{job=~"^worker.*"}[5m])) ```-#### worker: provisioning_container_memory_usage_short_term +#### worker: codeintel_uploads_lsifstore_errors_total -
Container memory usage (5m maximum) by instance
+Aggregate store operation errors every 5m
-Refer to the [alerts reference](alerts#worker-provisioning-container-memory-usage-short-term) for 1 alert related to this panel. +This panel has no related alerts. -To see this panel, visit `/-/debug/grafana/d/worker/worker?viewPanel=103111` on your Sourcegraph instance. +To see this panel, visit `/-/debug/grafana/d/worker/worker?viewPanel=100502` on your Sourcegraph instance. *Managed by the [Sourcegraph Code intelligence team](https://handbook.sourcegraph.com/departments/engineering/teams/code-intelligence).* @@ -51004,22 +51341,19 @@ To see this panel, visit `/-/debug/grafana/d/worker/worker?viewPanel=103111` on Query: ``` -max_over_time(cadvisor_container_memory_usage_percentage_total{name=~"^worker.*"}[5m]) +sum(increase(src_codeintel_uploads_lsifstore_errors_total{job=~"^worker.*"}[5m])) ```-#### worker: container_oomkill_events_total - -
Container OOMKILL events total by instance
+#### worker: codeintel_uploads_lsifstore_error_rate -This value indicates the total number of times the container main process or child processes were terminated by OOM killer. -When it occurs frequently, it is an indicator of underprovisioning. +Aggregate store operation error rate over 5m
-Refer to the [alerts reference](alerts#worker-container-oomkill-events-total) for 1 alert related to this panel. +This panel has no related alerts. -To see this panel, visit `/-/debug/grafana/d/worker/worker?viewPanel=103112` on your Sourcegraph instance. +To see this panel, visit `/-/debug/grafana/d/worker/worker?viewPanel=100503` on your Sourcegraph instance. *Managed by the [Sourcegraph Code intelligence team](https://handbook.sourcegraph.com/departments/engineering/teams/code-intelligence).* @@ -51029,23 +51363,19 @@ To see this panel, visit `/-/debug/grafana/d/worker/worker?viewPanel=103112` on Query: ``` -max by (name) (container_oom_events_total{name=~"^worker.*"}) +sum(increase(src_codeintel_uploads_lsifstore_errors_total{job=~"^worker.*"}[5m])) / (sum(increase(src_codeintel_uploads_lsifstore_total{job=~"^worker.*"}[5m])) + sum(increase(src_codeintel_uploads_lsifstore_errors_total{job=~"^worker.*"}[5m]))) * 100 ```-### Worker: Golang runtime monitoring - -#### worker: go_goroutines - -
Maximum active goroutines
+#### worker: codeintel_uploads_lsifstore_total -A high value here indicates a possible goroutine leak. +Store operations every 5m
-Refer to the [alerts reference](alerts#worker-go-goroutines) for 1 alert related to this panel. +This panel has no related alerts. -To see this panel, visit `/-/debug/grafana/d/worker/worker?viewPanel=103200` on your Sourcegraph instance. +To see this panel, visit `/-/debug/grafana/d/worker/worker?viewPanel=100510` on your Sourcegraph instance. *Managed by the [Sourcegraph Code intelligence team](https://handbook.sourcegraph.com/departments/engineering/teams/code-intelligence).* @@ -51055,19 +51385,19 @@ To see this panel, visit `/-/debug/grafana/d/worker/worker?viewPanel=103200` on Query: ``` -max by(instance) (go_goroutines{job=~".*worker"}) +sum by (op)(increase(src_codeintel_uploads_lsifstore_total{job=~"^worker.*"}[5m])) ```-#### worker: go_gc_duration_seconds +#### worker: codeintel_uploads_lsifstore_99th_percentile_duration -
Maximum go garbage collection duration
+99th percentile successful store operation duration over 5m
-Refer to the [alerts reference](alerts#worker-go-gc-duration-seconds) for 1 alert related to this panel. +This panel has no related alerts. -To see this panel, visit `/-/debug/grafana/d/worker/worker?viewPanel=103201` on your Sourcegraph instance. +To see this panel, visit `/-/debug/grafana/d/worker/worker?viewPanel=100511` on your Sourcegraph instance. *Managed by the [Sourcegraph Code intelligence team](https://handbook.sourcegraph.com/departments/engineering/teams/code-intelligence).* @@ -51077,21 +51407,19 @@ To see this panel, visit `/-/debug/grafana/d/worker/worker?viewPanel=103201` on Query: ``` -max by(instance) (go_gc_duration_seconds{job=~".*worker"}) +histogram_quantile(0.99, sum by (le,op)(rate(src_codeintel_uploads_lsifstore_duration_seconds_bucket{job=~"^worker.*"}[5m]))) ```-### Worker: Kubernetes monitoring (only available on Kubernetes) - -#### worker: pods_available_percentage +#### worker: codeintel_uploads_lsifstore_errors_total -
Percentage pods available
+Store operation errors every 5m
-Refer to the [alerts reference](alerts#worker-pods-available-percentage) for 1 alert related to this panel. +This panel has no related alerts. -To see this panel, visit `/-/debug/grafana/d/worker/worker?viewPanel=103300` on your Sourcegraph instance. +To see this panel, visit `/-/debug/grafana/d/worker/worker?viewPanel=100512` on your Sourcegraph instance. *Managed by the [Sourcegraph Code intelligence team](https://handbook.sourcegraph.com/departments/engineering/teams/code-intelligence).* @@ -51101,23 +51429,21 @@ To see this panel, visit `/-/debug/grafana/d/worker/worker?viewPanel=103300` on Query: ``` -sum by(app) (up{app=~".*worker"}) / count by (app) (up{app=~".*worker"}) * 100 +sum by (op)(increase(src_codeintel_uploads_lsifstore_errors_total{job=~"^worker.*"}[5m])) ```-### Worker: Own: repo indexer dbstore - -#### worker: workerutil_dbworker_store_own_background_worker_store_total +#### worker: codeintel_uploads_lsifstore_error_rate -
Aggregate store operations every 5m
+Store operation error rate over 5m
This panel has no related alerts. -To see this panel, visit `/-/debug/grafana/d/worker/worker?viewPanel=103400` on your Sourcegraph instance. +To see this panel, visit `/-/debug/grafana/d/worker/worker?viewPanel=100513` on your Sourcegraph instance. -*Managed by the [Sourcegraph own team](https://handbook.sourcegraph.com/departments/engineering/teams/own).* +*Managed by the [Sourcegraph Code intelligence team](https://handbook.sourcegraph.com/departments/engineering/teams/code-intelligence).*Technical details
@@ -51125,21 +51451,23 @@ To see this panel, visit `/-/debug/grafana/d/worker/worker?viewPanel=103400` on Query: ``` -sum(increase(src_workerutil_dbworker_store_own_background_worker_store_total{job=~"^worker.*"}[5m])) +sum by (op)(increase(src_codeintel_uploads_lsifstore_errors_total{job=~"^worker.*"}[5m])) / (sum by (op)(increase(src_codeintel_uploads_lsifstore_total{job=~"^worker.*"}[5m])) + sum by (op)(increase(src_codeintel_uploads_lsifstore_errors_total{job=~"^worker.*"}[5m]))) * 100 ```-#### worker: workerutil_dbworker_store_own_background_worker_store_99th_percentile_duration +### Worker: Codeintel: gitserver client -
Aggregate successful store operation duration distribution over 5m
+#### worker: gitserver_client_total + +Aggregate client operations every 5m
This panel has no related alerts. -To see this panel, visit `/-/debug/grafana/d/worker/worker?viewPanel=103401` on your Sourcegraph instance. +To see this panel, visit `/-/debug/grafana/d/worker/worker?viewPanel=100600` on your Sourcegraph instance. -*Managed by the [Sourcegraph own team](https://handbook.sourcegraph.com/departments/engineering/teams/own).* +*Managed by the [Sourcegraph Code intelligence team](https://handbook.sourcegraph.com/departments/engineering/teams/code-intelligence).*Technical details
@@ -51147,21 +51475,21 @@ To see this panel, visit `/-/debug/grafana/d/worker/worker?viewPanel=103401` on Query: ``` -sum by (le)(rate(src_workerutil_dbworker_store_own_background_worker_store_duration_seconds_bucket{job=~"^worker.*"}[5m])) +sum(increase(src_gitserver_client_total{job=~"^worker.*"}[5m])) ```-#### worker: workerutil_dbworker_store_own_background_worker_store_errors_total +#### worker: gitserver_client_99th_percentile_duration -
Aggregate store operation errors every 5m
+Aggregate successful client operation duration distribution over 5m
This panel has no related alerts. -To see this panel, visit `/-/debug/grafana/d/worker/worker?viewPanel=103402` on your Sourcegraph instance. +To see this panel, visit `/-/debug/grafana/d/worker/worker?viewPanel=100601` on your Sourcegraph instance. -*Managed by the [Sourcegraph own team](https://handbook.sourcegraph.com/departments/engineering/teams/own).* +*Managed by the [Sourcegraph Code intelligence team](https://handbook.sourcegraph.com/departments/engineering/teams/code-intelligence).*Technical details
@@ -51169,21 +51497,21 @@ To see this panel, visit `/-/debug/grafana/d/worker/worker?viewPanel=103402` on Query: ``` -sum(increase(src_workerutil_dbworker_store_own_background_worker_store_errors_total{job=~"^worker.*"}[5m])) +sum by (le)(rate(src_gitserver_client_duration_seconds_bucket{job=~"^worker.*"}[5m])) ```-#### worker: workerutil_dbworker_store_own_background_worker_store_error_rate +#### worker: gitserver_client_errors_total -
Aggregate store operation error rate over 5m
+Aggregate client operation errors every 5m
This panel has no related alerts. -To see this panel, visit `/-/debug/grafana/d/worker/worker?viewPanel=103403` on your Sourcegraph instance. +To see this panel, visit `/-/debug/grafana/d/worker/worker?viewPanel=100602` on your Sourcegraph instance. -*Managed by the [Sourcegraph own team](https://handbook.sourcegraph.com/departments/engineering/teams/own).* +*Managed by the [Sourcegraph Code intelligence team](https://handbook.sourcegraph.com/departments/engineering/teams/code-intelligence).*Technical details
@@ -51191,21 +51519,21 @@ To see this panel, visit `/-/debug/grafana/d/worker/worker?viewPanel=103403` on Query: ``` -sum(increase(src_workerutil_dbworker_store_own_background_worker_store_errors_total{job=~"^worker.*"}[5m])) / (sum(increase(src_workerutil_dbworker_store_own_background_worker_store_total{job=~"^worker.*"}[5m])) + sum(increase(src_workerutil_dbworker_store_own_background_worker_store_errors_total{job=~"^worker.*"}[5m]))) * 100 +sum(increase(src_gitserver_client_errors_total{job=~"^worker.*"}[5m])) ```-#### worker: workerutil_dbworker_store_own_background_worker_store_total +#### worker: gitserver_client_error_rate -
Store operations every 5m
+Aggregate client operation error rate over 5m
This panel has no related alerts. -To see this panel, visit `/-/debug/grafana/d/worker/worker?viewPanel=103410` on your Sourcegraph instance. +To see this panel, visit `/-/debug/grafana/d/worker/worker?viewPanel=100603` on your Sourcegraph instance. -*Managed by the [Sourcegraph own team](https://handbook.sourcegraph.com/departments/engineering/teams/own).* +*Managed by the [Sourcegraph Code intelligence team](https://handbook.sourcegraph.com/departments/engineering/teams/code-intelligence).*Technical details
@@ -51213,21 +51541,21 @@ To see this panel, visit `/-/debug/grafana/d/worker/worker?viewPanel=103410` on Query: ``` -sum by (op)(increase(src_workerutil_dbworker_store_own_background_worker_store_total{job=~"^worker.*"}[5m])) +sum(increase(src_gitserver_client_errors_total{job=~"^worker.*"}[5m])) / (sum(increase(src_gitserver_client_total{job=~"^worker.*"}[5m])) + sum(increase(src_gitserver_client_errors_total{job=~"^worker.*"}[5m]))) * 100 ```-#### worker: workerutil_dbworker_store_own_background_worker_store_99th_percentile_duration +#### worker: gitserver_client_total -
99th percentile successful store operation duration over 5m
+Client operations every 5m
This panel has no related alerts. -To see this panel, visit `/-/debug/grafana/d/worker/worker?viewPanel=103411` on your Sourcegraph instance. +To see this panel, visit `/-/debug/grafana/d/worker/worker?viewPanel=100610` on your Sourcegraph instance. -*Managed by the [Sourcegraph own team](https://handbook.sourcegraph.com/departments/engineering/teams/own).* +*Managed by the [Sourcegraph Code intelligence team](https://handbook.sourcegraph.com/departments/engineering/teams/code-intelligence).*Technical details
@@ -51235,21 +51563,21 @@ To see this panel, visit `/-/debug/grafana/d/worker/worker?viewPanel=103411` on Query: ``` -histogram_quantile(0.99, sum by (le,op)(rate(src_workerutil_dbworker_store_own_background_worker_store_duration_seconds_bucket{job=~"^worker.*"}[5m]))) +sum by (op)(increase(src_gitserver_client_total{job=~"^worker.*"}[5m])) ```-#### worker: workerutil_dbworker_store_own_background_worker_store_errors_total +#### worker: gitserver_client_99th_percentile_duration -
Store operation errors every 5m
+99th percentile successful client operation duration over 5m
This panel has no related alerts. -To see this panel, visit `/-/debug/grafana/d/worker/worker?viewPanel=103412` on your Sourcegraph instance. +To see this panel, visit `/-/debug/grafana/d/worker/worker?viewPanel=100611` on your Sourcegraph instance. -*Managed by the [Sourcegraph own team](https://handbook.sourcegraph.com/departments/engineering/teams/own).* +*Managed by the [Sourcegraph Code intelligence team](https://handbook.sourcegraph.com/departments/engineering/teams/code-intelligence).*Technical details
@@ -51257,21 +51585,21 @@ To see this panel, visit `/-/debug/grafana/d/worker/worker?viewPanel=103412` on Query: ``` -sum by (op)(increase(src_workerutil_dbworker_store_own_background_worker_store_errors_total{job=~"^worker.*"}[5m])) +histogram_quantile(0.99, sum by (le,op)(rate(src_gitserver_client_duration_seconds_bucket{job=~"^worker.*"}[5m]))) ```-#### worker: workerutil_dbworker_store_own_background_worker_store_error_rate +#### worker: gitserver_client_errors_total -
Store operation error rate over 5m
+Client operation errors every 5m
This panel has no related alerts. -To see this panel, visit `/-/debug/grafana/d/worker/worker?viewPanel=103413` on your Sourcegraph instance. +To see this panel, visit `/-/debug/grafana/d/worker/worker?viewPanel=100612` on your Sourcegraph instance. -*Managed by the [Sourcegraph own team](https://handbook.sourcegraph.com/departments/engineering/teams/own).* +*Managed by the [Sourcegraph Code intelligence team](https://handbook.sourcegraph.com/departments/engineering/teams/code-intelligence).*Technical details
@@ -51279,23 +51607,21 @@ To see this panel, visit `/-/debug/grafana/d/worker/worker?viewPanel=103413` on Query: ``` -sum by (op)(increase(src_workerutil_dbworker_store_own_background_worker_store_errors_total{job=~"^worker.*"}[5m])) / (sum by (op)(increase(src_workerutil_dbworker_store_own_background_worker_store_total{job=~"^worker.*"}[5m])) + sum by (op)(increase(src_workerutil_dbworker_store_own_background_worker_store_errors_total{job=~"^worker.*"}[5m]))) * 100 +sum by (op)(increase(src_gitserver_client_errors_total{job=~"^worker.*"}[5m])) ```-### Worker: Own: repo indexer worker queue - -#### worker: own_background_worker_handlers +#### worker: gitserver_client_error_rate -
Handler active handlers
+Client operation error rate over 5m
This panel has no related alerts. -To see this panel, visit `/-/debug/grafana/d/worker/worker?viewPanel=103500` on your Sourcegraph instance. +To see this panel, visit `/-/debug/grafana/d/worker/worker?viewPanel=100613` on your Sourcegraph instance. -*Managed by the [Sourcegraph Code Search team](https://handbook.sourcegraph.com/departments/engineering/teams/code-search).* +*Managed by the [Sourcegraph Code intelligence team](https://handbook.sourcegraph.com/departments/engineering/teams/code-intelligence).*Technical details
@@ -51303,21 +51629,26 @@ To see this panel, visit `/-/debug/grafana/d/worker/worker?viewPanel=103500` on Query: ``` -sum(src_own_background_worker_processor_handlers{job=~"^worker.*"}) +sum by (op)(increase(src_gitserver_client_errors_total{job=~"^worker.*"}[5m])) / (sum by (op)(increase(src_gitserver_client_total{job=~"^worker.*"}[5m])) + sum by (op)(increase(src_gitserver_client_errors_total{job=~"^worker.*"}[5m]))) * 100 ```-#### worker: own_background_worker_processor_total +### Worker: Repositories -
Handler operations every 5m
+#### worker: syncer_sync_last_time + +Time since last sync
+ +A high value here indicates issues synchronizing repo metadata. +If the value is persistently high, make sure all external services have valid tokens. This panel has no related alerts. -To see this panel, visit `/-/debug/grafana/d/worker/worker?viewPanel=103510` on your Sourcegraph instance. +To see this panel, visit `/-/debug/grafana/d/worker/worker?viewPanel=100700` on your Sourcegraph instance. -*Managed by the [Sourcegraph Code Search team](https://handbook.sourcegraph.com/departments/engineering/teams/code-search).* +*Managed by the [Sourcegraph Source team](https://handbook.sourcegraph.com/departments/engineering/teams/source).*Technical details
@@ -51325,21 +51656,21 @@ To see this panel, visit `/-/debug/grafana/d/worker/worker?viewPanel=103510` on Query: ``` -sum(increase(src_own_background_worker_processor_total{job=~"^worker.*"}[5m])) +max(timestamp(vector(time()))) - max(src_repoupdater_syncer_sync_last_time) ```-#### worker: own_background_worker_processor_99th_percentile_duration +#### worker: src_repoupdater_max_sync_backoff -
Aggregate successful handler operation duration distribution over 5m
+Time since oldest sync
-This panel has no related alerts. +Refer to the [alerts reference](alerts#worker-src-repoupdater-max-sync-backoff) for 1 alert related to this panel. -To see this panel, visit `/-/debug/grafana/d/worker/worker?viewPanel=103511` on your Sourcegraph instance. +To see this panel, visit `/-/debug/grafana/d/worker/worker?viewPanel=100701` on your Sourcegraph instance. -*Managed by the [Sourcegraph Code Search team](https://handbook.sourcegraph.com/departments/engineering/teams/code-search).* +*Managed by the [Sourcegraph Source team](https://handbook.sourcegraph.com/departments/engineering/teams/source).*Technical details
@@ -51347,21 +51678,21 @@ To see this panel, visit `/-/debug/grafana/d/worker/worker?viewPanel=103511` on Query: ``` -sum by (le)(rate(src_own_background_worker_processor_duration_seconds_bucket{job=~"^worker.*"}[5m])) +max(src_repoupdater_max_sync_backoff) ```-#### worker: own_background_worker_processor_errors_total +#### worker: src_repoupdater_syncer_sync_errors_total -
Handler operation errors every 5m
+Site level external service sync error rate
-This panel has no related alerts. +Refer to the [alerts reference](alerts#worker-src-repoupdater-syncer-sync-errors-total) for 2 alerts related to this panel. -To see this panel, visit `/-/debug/grafana/d/worker/worker?viewPanel=103512` on your Sourcegraph instance. +To see this panel, visit `/-/debug/grafana/d/worker/worker?viewPanel=100702` on your Sourcegraph instance. -*Managed by the [Sourcegraph Code Search team](https://handbook.sourcegraph.com/departments/engineering/teams/code-search).* +*Managed by the [Sourcegraph Source team](https://handbook.sourcegraph.com/departments/engineering/teams/source).*Technical details
@@ -51369,21 +51700,21 @@ To see this panel, visit `/-/debug/grafana/d/worker/worker?viewPanel=103512` on Query: ``` -sum(increase(src_own_background_worker_processor_errors_total{job=~"^worker.*"}[5m])) +max by (family) (rate(src_repoupdater_syncer_sync_errors_total{owner!="user",reason!="invalid_npm_path",reason!="internal_rate_limit"}[5m])) ```-#### worker: own_background_worker_processor_error_rate +#### worker: syncer_sync_start -
Handler operation error rate over 5m
+Repo metadata sync was started
-This panel has no related alerts. +Refer to the [alerts reference](alerts#worker-syncer-sync-start) for 1 alert related to this panel. -To see this panel, visit `/-/debug/grafana/d/worker/worker?viewPanel=103513` on your Sourcegraph instance. +To see this panel, visit `/-/debug/grafana/d/worker/worker?viewPanel=100710` on your Sourcegraph instance. -*Managed by the [Sourcegraph Code Search team](https://handbook.sourcegraph.com/departments/engineering/teams/code-search).* +*Managed by the [Sourcegraph Source team](https://handbook.sourcegraph.com/departments/engineering/teams/source).*Technical details
@@ -51391,23 +51722,21 @@ To see this panel, visit `/-/debug/grafana/d/worker/worker?viewPanel=103513` on Query: ``` -sum(increase(src_own_background_worker_processor_errors_total{job=~"^worker.*"}[5m])) / (sum(increase(src_own_background_worker_processor_total{job=~"^worker.*"}[5m])) + sum(increase(src_own_background_worker_processor_errors_total{job=~"^worker.*"}[5m]))) * 100 +max by (family) (rate(src_repoupdater_syncer_start_sync{family="Syncer.SyncExternalService"}[9h0m0s])) ```-### Worker: Own: own repo indexer record resetter - -#### worker: own_background_worker_record_resets_total +#### worker: syncer_sync_duration -
Own repo indexer queue records reset to queued state every 5m
+95th repositories sync duration
-This panel has no related alerts. +Refer to the [alerts reference](alerts#worker-syncer-sync-duration) for 1 alert related to this panel. -To see this panel, visit `/-/debug/grafana/d/worker/worker?viewPanel=103600` on your Sourcegraph instance. +To see this panel, visit `/-/debug/grafana/d/worker/worker?viewPanel=100711` on your Sourcegraph instance. -*Managed by the [Sourcegraph Code Search team](https://handbook.sourcegraph.com/departments/engineering/teams/code-search).* +*Managed by the [Sourcegraph Source team](https://handbook.sourcegraph.com/departments/engineering/teams/source).*Technical details
@@ -51415,21 +51744,21 @@ To see this panel, visit `/-/debug/grafana/d/worker/worker?viewPanel=103600` on Query: ``` -sum(increase(src_own_background_worker_record_resets_total{job=~"^worker.*"}[5m])) +histogram_quantile(0.95, max by (le, family, success) (rate(src_repoupdater_syncer_sync_duration_seconds_bucket[1m]))) ```-#### worker: own_background_worker_record_reset_failures_total +#### worker: source_duration -
Own repo indexer queue records reset to errored state every 5m
+95th repositories source duration
-This panel has no related alerts. +Refer to the [alerts reference](alerts#worker-source-duration) for 1 alert related to this panel. -To see this panel, visit `/-/debug/grafana/d/worker/worker?viewPanel=103601` on your Sourcegraph instance. +To see this panel, visit `/-/debug/grafana/d/worker/worker?viewPanel=100712` on your Sourcegraph instance. -*Managed by the [Sourcegraph Code Search team](https://handbook.sourcegraph.com/departments/engineering/teams/code-search).* +*Managed by the [Sourcegraph Source team](https://handbook.sourcegraph.com/departments/engineering/teams/source).*Technical details
@@ -51437,21 +51766,21 @@ To see this panel, visit `/-/debug/grafana/d/worker/worker?viewPanel=103601` on Query: ``` -sum(increase(src_own_background_worker_record_reset_failures_total{job=~"^worker.*"}[5m])) +histogram_quantile(0.95, max by (le) (rate(src_repoupdater_source_duration_seconds_bucket[1m]))) ```-#### worker: own_background_worker_record_reset_errors_total +#### worker: syncer_synced_repos -
Own repo indexer queue operation errors every 5m
+Repositories synced
-This panel has no related alerts. +Refer to the [alerts reference](alerts#worker-syncer-synced-repos) for 1 alert related to this panel. -To see this panel, visit `/-/debug/grafana/d/worker/worker?viewPanel=103602` on your Sourcegraph instance. +To see this panel, visit `/-/debug/grafana/d/worker/worker?viewPanel=100720` on your Sourcegraph instance. -*Managed by the [Sourcegraph Code Search team](https://handbook.sourcegraph.com/departments/engineering/teams/code-search).* +*Managed by the [Sourcegraph Source team](https://handbook.sourcegraph.com/departments/engineering/teams/source).*Technical details
@@ -51459,23 +51788,21 @@ To see this panel, visit `/-/debug/grafana/d/worker/worker?viewPanel=103602` on Query: ``` -sum(increase(src_own_background_worker_record_reset_errors_total{job=~"^worker.*"}[5m])) +max(rate(src_repoupdater_syncer_synced_repos_total[1m])) ```-### Worker: Own: index job scheduler - -#### worker: own_background_index_scheduler_total +#### worker: sourced_repos -
Own index job scheduler operations every 10m
+Repositories sourced
-This panel has no related alerts. +Refer to the [alerts reference](alerts#worker-sourced-repos) for 1 alert related to this panel. -To see this panel, visit `/-/debug/grafana/d/worker/worker?viewPanel=103700` on your Sourcegraph instance. +To see this panel, visit `/-/debug/grafana/d/worker/worker?viewPanel=100721` on your Sourcegraph instance. -*Managed by the [Sourcegraph Code intelligence team](https://handbook.sourcegraph.com/departments/engineering/teams/code-intelligence).* +*Managed by the [Sourcegraph Source team](https://handbook.sourcegraph.com/departments/engineering/teams/source).*Technical details
@@ -51483,21 +51810,21 @@ To see this panel, visit `/-/debug/grafana/d/worker/worker?viewPanel=103700` on Query: ``` -sum by (op)(increase(src_own_background_index_scheduler_total{job=~"^worker.*"}[10m])) +max(rate(src_repoupdater_source_repos_total[1m])) ```-#### worker: own_background_index_scheduler_99th_percentile_duration +#### worker: sched_auto_fetch -
99th percentile successful own index job scheduler operation duration over 10m
+Repositories scheduled due to hitting a deadline
-This panel has no related alerts. +Refer to the [alerts reference](alerts#worker-sched-auto-fetch) for 1 alert related to this panel. -To see this panel, visit `/-/debug/grafana/d/worker/worker?viewPanel=103701` on your Sourcegraph instance. +To see this panel, visit `/-/debug/grafana/d/worker/worker?viewPanel=100730` on your Sourcegraph instance. -*Managed by the [Sourcegraph Code intelligence team](https://handbook.sourcegraph.com/departments/engineering/teams/code-intelligence).* +*Managed by the [Sourcegraph Source team](https://handbook.sourcegraph.com/departments/engineering/teams/source).*Technical details
@@ -51505,21 +51832,24 @@ To see this panel, visit `/-/debug/grafana/d/worker/worker?viewPanel=103701` on Query: ``` -histogram_quantile(0.99, sum by (le,op)(rate(src_own_background_index_scheduler_duration_seconds_bucket{job=~"^worker.*"}[10m]))) +max(rate(src_repoupdater_sched_auto_fetch[1m])) ```-#### worker: own_background_index_scheduler_errors_total +#### worker: sched_manual_fetch -
Own index job scheduler operation errors every 10m
+Repositories scheduled due to user traffic
+ +Check worker logs if this value is persistently high. +This does not indicate anything if there are no user added code hosts. This panel has no related alerts. -To see this panel, visit `/-/debug/grafana/d/worker/worker?viewPanel=103702` on your Sourcegraph instance. +To see this panel, visit `/-/debug/grafana/d/worker/worker?viewPanel=100731` on your Sourcegraph instance. -*Managed by the [Sourcegraph Code intelligence team](https://handbook.sourcegraph.com/departments/engineering/teams/code-intelligence).* +*Managed by the [Sourcegraph Source team](https://handbook.sourcegraph.com/departments/engineering/teams/source).*Technical details
@@ -51527,21 +51857,21 @@ To see this panel, visit `/-/debug/grafana/d/worker/worker?viewPanel=103702` on Query: ``` -sum by (op)(increase(src_own_background_index_scheduler_errors_total{job=~"^worker.*"}[10m])) +max(rate(src_repoupdater_sched_manual_fetch[1m])) ```-#### worker: own_background_index_scheduler_error_rate +#### worker: sched_loops -
Own index job scheduler operation error rate over 10m
+Scheduler loops
-This panel has no related alerts. +Refer to the [alerts reference](alerts#worker-sched-loops) for 1 alert related to this panel. -To see this panel, visit `/-/debug/grafana/d/worker/worker?viewPanel=103703` on your Sourcegraph instance. +To see this panel, visit `/-/debug/grafana/d/worker/worker?viewPanel=100740` on your Sourcegraph instance. -*Managed by the [Sourcegraph Code intelligence team](https://handbook.sourcegraph.com/departments/engineering/teams/code-intelligence).* +*Managed by the [Sourcegraph Source team](https://handbook.sourcegraph.com/departments/engineering/teams/source).*Technical details
@@ -51549,25 +51879,21 @@ To see this panel, visit `/-/debug/grafana/d/worker/worker?viewPanel=103703` on Query: ``` -sum by (op)(increase(src_own_background_index_scheduler_errors_total{job=~"^worker.*"}[10m])) / (sum by (op)(increase(src_own_background_index_scheduler_total{job=~"^worker.*"}[10m])) + sum by (op)(increase(src_own_background_index_scheduler_errors_total{job=~"^worker.*"}[10m]))) * 100 +max(rate(src_repoupdater_sched_loops[1m])) ```-### Worker: Site configuration client update latency - -#### worker: worker_site_configuration_duration_since_last_successful_update_by_instance - -
Duration since last successful site configuration update (by instance)
+#### worker: src_repoupdater_stale_repos -The duration since the configuration client used by the "worker" service last successfully updated its site configuration. Long durations could indicate issues updating the site configuration. +Repos that haven't been fetched in more than 8 hours
-This panel has no related alerts. +Refer to the [alerts reference](alerts#worker-src-repoupdater-stale-repos) for 1 alert related to this panel. -To see this panel, visit `/-/debug/grafana/d/worker/worker?viewPanel=103800` on your Sourcegraph instance. +To see this panel, visit `/-/debug/grafana/d/worker/worker?viewPanel=100741` on your Sourcegraph instance. -*Managed by the [Sourcegraph Infrastructure Org team](https://handbook.sourcegraph.com/departments/engineering/infrastructure).* +*Managed by the [Sourcegraph Source team](https://handbook.sourcegraph.com/departments/engineering/teams/source).*Technical details
@@ -51575,21 +51901,21 @@ To see this panel, visit `/-/debug/grafana/d/worker/worker?viewPanel=103800` on Query: ``` -src_conf_client_time_since_last_successful_update_seconds{job=~`^worker.*`,instance=~`${instance:regex}`} +max(src_repoupdater_stale_repos) ```-#### worker: worker_site_configuration_duration_since_last_successful_update_by_instance +#### worker: sched_error -
Maximum duration since last successful site configuration update (all "worker" instances)
+Repositories schedule error rate
-Refer to the [alerts reference](alerts#worker-worker-site-configuration-duration-since-last-successful-update-by-instance) for 1 alert related to this panel. +Refer to the [alerts reference](alerts#worker-sched-error) for 1 alert related to this panel. -To see this panel, visit `/-/debug/grafana/d/worker/worker?viewPanel=103801` on your Sourcegraph instance. +To see this panel, visit `/-/debug/grafana/d/worker/worker?viewPanel=100742` on your Sourcegraph instance. -*Managed by the [Sourcegraph Infrastructure Org team](https://handbook.sourcegraph.com/departments/engineering/infrastructure).* +*Managed by the [Sourcegraph Source team](https://handbook.sourcegraph.com/departments/engineering/teams/source).*Technical details
@@ -51597,30 +51923,23 @@ To see this panel, visit `/-/debug/grafana/d/worker/worker?viewPanel=103801` on Query: ``` -max(max_over_time(src_conf_client_time_since_last_successful_update_seconds{job=~`^worker.*`,instance=~`${instance:regex}`}[1m])) +max(rate(src_repoupdater_sched_error[1m])) ```-## Repo Updater +### Worker: Repo state syncer -
Manages interaction with code hosts, instructs Gitserver to update repositories.
+#### worker: state_syncer_running -To see this dashboard, visit `/-/debug/grafana/d/repo-updater/repo-updater` on your Sourcegraph instance. - -### Repo Updater: Repositories - -#### repo-updater: syncer_sync_last_time - -Time since last sync
+State syncer is running
-A high value here indicates issues synchronizing repo metadata. -If the value is persistently high, make sure all external services have valid tokens. +1, if the state syncer is currently running This panel has no related alerts. -To see this panel, visit `/-/debug/grafana/d/repo-updater/repo-updater?viewPanel=100000` on your Sourcegraph instance. +To see this panel, visit `/-/debug/grafana/d/worker/worker?viewPanel=100800` on your Sourcegraph instance. *Managed by the [Sourcegraph Source team](https://handbook.sourcegraph.com/departments/engineering/teams/source).* @@ -51630,19 +51949,25 @@ To see this panel, visit `/-/debug/grafana/d/repo-updater/repo-updater?viewPanel Query: ``` -max(timestamp(vector(time()))) - max(src_repoupdater_syncer_sync_last_time) +max (src_repo_statesyncer_running) ```-#### repo-updater: src_repoupdater_max_sync_backoff +#### worker: repos_deleted_total -
Time since oldest sync
+Total number of repos deleted
+ +The total number of repos deleted across all gitservers by +the state syncer. +A high number here is not necessarily an issue, dig deeper into +the other charts in this section to make a call if those deletions +were correct. -Refer to the [alerts reference](alerts#repo-updater-src-repoupdater-max-sync-backoff) for 1 alert related to this panel. +This panel has no related alerts. -To see this panel, visit `/-/debug/grafana/d/repo-updater/repo-updater?viewPanel=100001` on your Sourcegraph instance. +To see this panel, visit `/-/debug/grafana/d/worker/worker?viewPanel=100801` on your Sourcegraph instance. *Managed by the [Sourcegraph Source team](https://handbook.sourcegraph.com/departments/engineering/teams/source).* @@ -51652,19 +51977,22 @@ To see this panel, visit `/-/debug/grafana/d/repo-updater/repo-updater?viewPanel Query: ``` -max(src_repoupdater_max_sync_backoff) +sum(src_repo_statesyncer_repos_deleted) ```-#### repo-updater: src_repoupdater_syncer_sync_errors_total +#### worker: repos_deleted_from_primary_total -
Site level external service sync error rate
+Total number of repos deleted from primary
-Refer to the [alerts reference](alerts#repo-updater-src-repoupdater-syncer-sync-errors-total) for 2 alerts related to this panel. +The total number of repos deleted from the primary shard. +Check the reasons for why they were deleted. + +This panel has no related alerts. -To see this panel, visit `/-/debug/grafana/d/repo-updater/repo-updater?viewPanel=100002` on your Sourcegraph instance. +To see this panel, visit `/-/debug/grafana/d/worker/worker?viewPanel=100802` on your Sourcegraph instance. *Managed by the [Sourcegraph Source team](https://handbook.sourcegraph.com/departments/engineering/teams/source).* @@ -51674,19 +52002,22 @@ To see this panel, visit `/-/debug/grafana/d/repo-updater/repo-updater?viewPanel Query: ``` -max by (family) (rate(src_repoupdater_syncer_sync_errors_total{owner!="user",reason!="invalid_npm_path",reason!="internal_rate_limit"}[5m])) +sum by (reason) (src_repo_statesyncer_repos_deleted{is_primary="true"}) ```-#### repo-updater: syncer_sync_start +#### worker: repos_deleted_from_secondary_total -
Repo metadata sync was started
+Total number of repos deleted from secondary
+ +The total number of repos deleted from secondary shards. +Check the reasons for why they were deleted. -Refer to the [alerts reference](alerts#repo-updater-syncer-sync-start) for 1 alert related to this panel. +This panel has no related alerts. -To see this panel, visit `/-/debug/grafana/d/repo-updater/repo-updater?viewPanel=100010` on your Sourcegraph instance. +To see this panel, visit `/-/debug/grafana/d/worker/worker?viewPanel=100803` on your Sourcegraph instance. *Managed by the [Sourcegraph Source team](https://handbook.sourcegraph.com/departments/engineering/teams/source).* @@ -51696,19 +52027,21 @@ To see this panel, visit `/-/debug/grafana/d/repo-updater/repo-updater?viewPanel Query: ``` -max by (family) (rate(src_repoupdater_syncer_start_sync{family="Syncer.SyncExternalService"}[9h0m0s])) +sum by (reason) (src_repo_statesyncer_repos_deleted{is_primary="false"}) ```-#### repo-updater: syncer_sync_duration +### Worker: External services -
95th repositories sync duration
+#### worker: src_repoupdater_external_services_total -Refer to the [alerts reference](alerts#repo-updater-syncer-sync-duration) for 1 alert related to this panel. +The total number of external services
+ +Refer to the [alerts reference](alerts#worker-src-repoupdater-external-services-total) for 1 alert related to this panel. -To see this panel, visit `/-/debug/grafana/d/repo-updater/repo-updater?viewPanel=100011` on your Sourcegraph instance. +To see this panel, visit `/-/debug/grafana/d/worker/worker?viewPanel=100900` on your Sourcegraph instance. *Managed by the [Sourcegraph Source team](https://handbook.sourcegraph.com/departments/engineering/teams/source).* @@ -51718,19 +52051,19 @@ To see this panel, visit `/-/debug/grafana/d/repo-updater/repo-updater?viewPanel Query: ``` -histogram_quantile(0.95, max by (le, family, success) (rate(src_repoupdater_syncer_sync_duration_seconds_bucket[1m]))) +max(src_repoupdater_external_services_total) ```-#### repo-updater: source_duration +#### worker: repoupdater_queued_sync_jobs_total -
95th repositories source duration
+The total number of queued sync jobs
-Refer to the [alerts reference](alerts#repo-updater-source-duration) for 1 alert related to this panel. +Refer to the [alerts reference](alerts#worker-repoupdater-queued-sync-jobs-total) for 1 alert related to this panel. -To see this panel, visit `/-/debug/grafana/d/repo-updater/repo-updater?viewPanel=100012` on your Sourcegraph instance. +To see this panel, visit `/-/debug/grafana/d/worker/worker?viewPanel=100910` on your Sourcegraph instance. *Managed by the [Sourcegraph Source team](https://handbook.sourcegraph.com/departments/engineering/teams/source).* @@ -51740,19 +52073,19 @@ To see this panel, visit `/-/debug/grafana/d/repo-updater/repo-updater?viewPanel Query: ``` -histogram_quantile(0.95, max by (le) (rate(src_repoupdater_source_duration_seconds_bucket[1m]))) +max(src_repoupdater_queued_sync_jobs_total) ```-#### repo-updater: syncer_synced_repos +#### worker: repoupdater_completed_sync_jobs_total -
Repositories synced
+The total number of completed sync jobs
-Refer to the [alerts reference](alerts#repo-updater-syncer-synced-repos) for 1 alert related to this panel. +Refer to the [alerts reference](alerts#worker-repoupdater-completed-sync-jobs-total) for 1 alert related to this panel. -To see this panel, visit `/-/debug/grafana/d/repo-updater/repo-updater?viewPanel=100020` on your Sourcegraph instance. +To see this panel, visit `/-/debug/grafana/d/worker/worker?viewPanel=100911` on your Sourcegraph instance. *Managed by the [Sourcegraph Source team](https://handbook.sourcegraph.com/departments/engineering/teams/source).* @@ -51762,19 +52095,19 @@ To see this panel, visit `/-/debug/grafana/d/repo-updater/repo-updater?viewPanel Query: ``` -max(rate(src_repoupdater_syncer_synced_repos_total[1m])) +max(src_repoupdater_completed_sync_jobs_total) ```-#### repo-updater: sourced_repos +#### worker: repoupdater_errored_sync_jobs_percentage -
Repositories sourced
+The percentage of external services that have failed their most recent sync
-Refer to the [alerts reference](alerts#repo-updater-sourced-repos) for 1 alert related to this panel. +Refer to the [alerts reference](alerts#worker-repoupdater-errored-sync-jobs-percentage) for 1 alert related to this panel. -To see this panel, visit `/-/debug/grafana/d/repo-updater/repo-updater?viewPanel=100021` on your Sourcegraph instance. +To see this panel, visit `/-/debug/grafana/d/worker/worker?viewPanel=100912` on your Sourcegraph instance. *Managed by the [Sourcegraph Source team](https://handbook.sourcegraph.com/departments/engineering/teams/source).* @@ -51784,19 +52117,19 @@ To see this panel, visit `/-/debug/grafana/d/repo-updater/repo-updater?viewPanel Query: ``` -max(rate(src_repoupdater_source_repos_total[1m])) +max(src_repoupdater_errored_sync_jobs_percentage) ```-#### repo-updater: purge_failed +#### worker: github_graphql_rate_limit_remaining -
Repositories purge failed
+Remaining calls to GitHub graphql API before hitting the rate limit
-Refer to the [alerts reference](alerts#repo-updater-purge-failed) for 1 alert related to this panel. +Refer to the [alerts reference](alerts#worker-github-graphql-rate-limit-remaining) for 1 alert related to this panel. -To see this panel, visit `/-/debug/grafana/d/repo-updater/repo-updater?viewPanel=100030` on your Sourcegraph instance. +To see this panel, visit `/-/debug/grafana/d/worker/worker?viewPanel=100920` on your Sourcegraph instance. *Managed by the [Sourcegraph Source team](https://handbook.sourcegraph.com/departments/engineering/teams/source).* @@ -51806,19 +52139,19 @@ To see this panel, visit `/-/debug/grafana/d/repo-updater/repo-updater?viewPanel Query: ``` -max(rate(src_repoupdater_purge_failed[1m])) +max by (name) (src_github_rate_limit_remaining_v2{resource="graphql"}) ```-#### repo-updater: sched_auto_fetch +#### worker: github_rest_rate_limit_remaining -
Repositories scheduled due to hitting a deadline
+Remaining calls to GitHub rest API before hitting the rate limit
-Refer to the [alerts reference](alerts#repo-updater-sched-auto-fetch) for 1 alert related to this panel. +Refer to the [alerts reference](alerts#worker-github-rest-rate-limit-remaining) for 1 alert related to this panel. -To see this panel, visit `/-/debug/grafana/d/repo-updater/repo-updater?viewPanel=100040` on your Sourcegraph instance. +To see this panel, visit `/-/debug/grafana/d/worker/worker?viewPanel=100921` on your Sourcegraph instance. *Managed by the [Sourcegraph Source team](https://handbook.sourcegraph.com/departments/engineering/teams/source).* @@ -51828,22 +52161,19 @@ To see this panel, visit `/-/debug/grafana/d/repo-updater/repo-updater?viewPanel Query: ``` -max(rate(src_repoupdater_sched_auto_fetch[1m])) +max by (name) (src_github_rate_limit_remaining_v2{resource="rest"}) ```-#### repo-updater: sched_manual_fetch - -
Repositories scheduled due to user traffic
+#### worker: github_search_rate_limit_remaining -Check repo-updater logs if this value is persistently high. -This does not indicate anything if there are no user added code hosts. +Remaining calls to GitHub search API before hitting the rate limit
-This panel has no related alerts. +Refer to the [alerts reference](alerts#worker-github-search-rate-limit-remaining) for 1 alert related to this panel. -To see this panel, visit `/-/debug/grafana/d/repo-updater/repo-updater?viewPanel=100041` on your Sourcegraph instance. +To see this panel, visit `/-/debug/grafana/d/worker/worker?viewPanel=100922` on your Sourcegraph instance. *Managed by the [Sourcegraph Source team](https://handbook.sourcegraph.com/departments/engineering/teams/source).* @@ -51853,19 +52183,21 @@ To see this panel, visit `/-/debug/grafana/d/repo-updater/repo-updater?viewPanel Query: ``` -max(rate(src_repoupdater_sched_manual_fetch[1m])) +max by (name) (src_github_rate_limit_remaining_v2{resource="search"}) ```-#### repo-updater: sched_known_repos +#### worker: github_graphql_rate_limit_wait_duration + +
Time spent waiting for the GitHub graphql API rate limiter
-Repositories managed by the scheduler
+Indicates how long we`re waiting on the rate limit once it has been exceeded -Refer to the [alerts reference](alerts#repo-updater-sched-known-repos) for 1 alert related to this panel. +This panel has no related alerts. -To see this panel, visit `/-/debug/grafana/d/repo-updater/repo-updater?viewPanel=100050` on your Sourcegraph instance. +To see this panel, visit `/-/debug/grafana/d/worker/worker?viewPanel=100930` on your Sourcegraph instance. *Managed by the [Sourcegraph Source team](https://handbook.sourcegraph.com/departments/engineering/teams/source).* @@ -51875,19 +52207,21 @@ To see this panel, visit `/-/debug/grafana/d/repo-updater/repo-updater?viewPanel Query: ``` -max(src_repoupdater_sched_known_repos) +max by(name) (rate(src_github_rate_limit_wait_duration_seconds{resource="graphql"}[5m])) ```-#### repo-updater: sched_update_queue_length +#### worker: github_rest_rate_limit_wait_duration + +
Time spent waiting for the GitHub rest API rate limiter
-Rate of growth of update queue length over 5 minutes
+Indicates how long we`re waiting on the rate limit once it has been exceeded -Refer to the [alerts reference](alerts#repo-updater-sched-update-queue-length) for 1 alert related to this panel. +This panel has no related alerts. -To see this panel, visit `/-/debug/grafana/d/repo-updater/repo-updater?viewPanel=100051` on your Sourcegraph instance. +To see this panel, visit `/-/debug/grafana/d/worker/worker?viewPanel=100931` on your Sourcegraph instance. *Managed by the [Sourcegraph Source team](https://handbook.sourcegraph.com/departments/engineering/teams/source).* @@ -51897,19 +52231,21 @@ To see this panel, visit `/-/debug/grafana/d/repo-updater/repo-updater?viewPanel Query: ``` -max(deriv(src_repoupdater_sched_update_queue_length[5m])) +max by(name) (rate(src_github_rate_limit_wait_duration_seconds{resource="rest"}[5m])) ```-#### repo-updater: sched_loops +#### worker: github_search_rate_limit_wait_duration -
Scheduler loops
+Time spent waiting for the GitHub search API rate limiter
+ +Indicates how long we`re waiting on the rate limit once it has been exceeded -Refer to the [alerts reference](alerts#repo-updater-sched-loops) for 1 alert related to this panel. +This panel has no related alerts. -To see this panel, visit `/-/debug/grafana/d/repo-updater/repo-updater?viewPanel=100052` on your Sourcegraph instance. +To see this panel, visit `/-/debug/grafana/d/worker/worker?viewPanel=100932` on your Sourcegraph instance. *Managed by the [Sourcegraph Source team](https://handbook.sourcegraph.com/departments/engineering/teams/source).* @@ -51919,19 +52255,19 @@ To see this panel, visit `/-/debug/grafana/d/repo-updater/repo-updater?viewPanel Query: ``` -max(rate(src_repoupdater_sched_loops[1m])) +max by(name) (rate(src_github_rate_limit_wait_duration_seconds{resource="search"}[5m])) ```-#### repo-updater: src_repoupdater_stale_repos +#### worker: gitlab_rest_rate_limit_remaining -
Repos that haven't been fetched in more than 8 hours
+Remaining calls to GitLab rest API before hitting the rate limit
-Refer to the [alerts reference](alerts#repo-updater-src-repoupdater-stale-repos) for 1 alert related to this panel. +Refer to the [alerts reference](alerts#worker-gitlab-rest-rate-limit-remaining) for 1 alert related to this panel. -To see this panel, visit `/-/debug/grafana/d/repo-updater/repo-updater?viewPanel=100060` on your Sourcegraph instance. +To see this panel, visit `/-/debug/grafana/d/worker/worker?viewPanel=100940` on your Sourcegraph instance. *Managed by the [Sourcegraph Source team](https://handbook.sourcegraph.com/departments/engineering/teams/source).* @@ -51941,19 +52277,21 @@ To see this panel, visit `/-/debug/grafana/d/repo-updater/repo-updater?viewPanel Query: ``` -max(src_repoupdater_stale_repos) +max by (name) (src_gitlab_rate_limit_remaining{resource="rest"}) ```-#### repo-updater: sched_error +#### worker: gitlab_rest_rate_limit_wait_duration -
Repositories schedule error rate
+Time spent waiting for the GitLab rest API rate limiter
+ +Indicates how long we`re waiting on the rate limit once it has been exceeded -Refer to the [alerts reference](alerts#repo-updater-sched-error) for 1 alert related to this panel. +This panel has no related alerts. -To see this panel, visit `/-/debug/grafana/d/repo-updater/repo-updater?viewPanel=100061` on your Sourcegraph instance. +To see this panel, visit `/-/debug/grafana/d/worker/worker?viewPanel=100941` on your Sourcegraph instance. *Managed by the [Sourcegraph Source team](https://handbook.sourcegraph.com/departments/engineering/teams/source).* @@ -51963,21 +52301,21 @@ To see this panel, visit `/-/debug/grafana/d/repo-updater/repo-updater?viewPanel Query: ``` -max(rate(src_repoupdater_sched_error[1m])) +max by (name) (rate(src_gitlab_rate_limit_wait_duration_seconds{resource="rest"}[5m])) ```-### Repo Updater: External services +#### worker: src_internal_rate_limit_wait_duration_bucket -#### repo-updater: src_repoupdater_external_services_total +
95th percentile time spent successfully waiting on our internal rate limiter
-The total number of external services
+Indicates how long we`re waiting on our internal rate limiter when communicating with a code host -Refer to the [alerts reference](alerts#repo-updater-src-repoupdater-external-services-total) for 1 alert related to this panel. +This panel has no related alerts. -To see this panel, visit `/-/debug/grafana/d/repo-updater/repo-updater?viewPanel=100100` on your Sourcegraph instance. +To see this panel, visit `/-/debug/grafana/d/worker/worker?viewPanel=100950` on your Sourcegraph instance. *Managed by the [Sourcegraph Source team](https://handbook.sourcegraph.com/departments/engineering/teams/source).* @@ -51987,19 +52325,21 @@ To see this panel, visit `/-/debug/grafana/d/repo-updater/repo-updater?viewPanel Query: ``` -max(src_repoupdater_external_services_total) +histogram_quantile(0.95, sum(rate(src_internal_rate_limit_wait_duration_bucket{failed="false"}[5m])) by (le, urn)) ```-#### repo-updater: repoupdater_queued_sync_jobs_total +#### worker: src_internal_rate_limit_wait_error_count -
The total number of queued sync jobs
+Rate of failures waiting on our internal rate limiter
+ +The rate at which we fail our internal rate limiter. -Refer to the [alerts reference](alerts#repo-updater-repoupdater-queued-sync-jobs-total) for 1 alert related to this panel. +This panel has no related alerts. -To see this panel, visit `/-/debug/grafana/d/repo-updater/repo-updater?viewPanel=100110` on your Sourcegraph instance. +To see this panel, visit `/-/debug/grafana/d/worker/worker?viewPanel=100951` on your Sourcegraph instance. *Managed by the [Sourcegraph Source team](https://handbook.sourcegraph.com/departments/engineering/teams/source).* @@ -52009,19 +52349,23 @@ To see this panel, visit `/-/debug/grafana/d/repo-updater/repo-updater?viewPanel Query: ``` -max(src_repoupdater_queued_sync_jobs_total) +sum by (urn) (rate(src_internal_rate_limit_wait_duration_count{failed="true"}[5m])) ```-#### repo-updater: repoupdater_completed_sync_jobs_total +### Worker: Permissions + +#### worker: user_success_syncs_total -
The total number of completed sync jobs
+Total number of user permissions syncs
-Refer to the [alerts reference](alerts#repo-updater-repoupdater-completed-sync-jobs-total) for 1 alert related to this panel. +Indicates the total number of user permissions sync completed. + +This panel has no related alerts. -To see this panel, visit `/-/debug/grafana/d/repo-updater/repo-updater?viewPanel=100111` on your Sourcegraph instance. +To see this panel, visit `/-/debug/grafana/d/worker/worker?viewPanel=101000` on your Sourcegraph instance. *Managed by the [Sourcegraph Source team](https://handbook.sourcegraph.com/departments/engineering/teams/source).* @@ -52031,19 +52375,21 @@ To see this panel, visit `/-/debug/grafana/d/repo-updater/repo-updater?viewPanel Query: ``` -max(src_repoupdater_completed_sync_jobs_total) +sum(src_repo_perms_syncer_success_syncs{type="user"}) ```-#### repo-updater: repoupdater_errored_sync_jobs_percentage +#### worker: user_success_syncs -
The percentage of external services that have failed their most recent sync
+Number of user permissions syncs [5m]
+ +Indicates the number of users permissions syncs completed. -Refer to the [alerts reference](alerts#repo-updater-repoupdater-errored-sync-jobs-percentage) for 1 alert related to this panel. +This panel has no related alerts. -To see this panel, visit `/-/debug/grafana/d/repo-updater/repo-updater?viewPanel=100112` on your Sourcegraph instance. +To see this panel, visit `/-/debug/grafana/d/worker/worker?viewPanel=101001` on your Sourcegraph instance. *Managed by the [Sourcegraph Source team](https://handbook.sourcegraph.com/departments/engineering/teams/source).* @@ -52053,19 +52399,21 @@ To see this panel, visit `/-/debug/grafana/d/repo-updater/repo-updater?viewPanel Query: ``` -max(src_repoupdater_errored_sync_jobs_percentage) +sum(increase(src_repo_perms_syncer_success_syncs{type="user"}[5m])) ```-#### repo-updater: github_graphql_rate_limit_remaining +#### worker: user_initial_syncs + +
Number of first user permissions syncs [5m]
-Remaining calls to GitHub graphql API before hitting the rate limit
+Indicates the number of permissions syncs done for the first time for the user. -Refer to the [alerts reference](alerts#repo-updater-github-graphql-rate-limit-remaining) for 1 alert related to this panel. +This panel has no related alerts. -To see this panel, visit `/-/debug/grafana/d/repo-updater/repo-updater?viewPanel=100120` on your Sourcegraph instance. +To see this panel, visit `/-/debug/grafana/d/worker/worker?viewPanel=101002` on your Sourcegraph instance. *Managed by the [Sourcegraph Source team](https://handbook.sourcegraph.com/departments/engineering/teams/source).* @@ -52075,19 +52423,21 @@ To see this panel, visit `/-/debug/grafana/d/repo-updater/repo-updater?viewPanel Query: ``` -max by (name) (src_github_rate_limit_remaining_v2{resource="graphql"}) +sum(increase(src_repo_perms_syncer_initial_syncs{type="user"}[5m])) ```-#### repo-updater: github_rest_rate_limit_remaining +#### worker: repo_success_syncs_total -
Remaining calls to GitHub rest API before hitting the rate limit
+Total number of repo permissions syncs
+ +Indicates the total number of repo permissions sync completed. -Refer to the [alerts reference](alerts#repo-updater-github-rest-rate-limit-remaining) for 1 alert related to this panel. +This panel has no related alerts. -To see this panel, visit `/-/debug/grafana/d/repo-updater/repo-updater?viewPanel=100121` on your Sourcegraph instance. +To see this panel, visit `/-/debug/grafana/d/worker/worker?viewPanel=101010` on your Sourcegraph instance. *Managed by the [Sourcegraph Source team](https://handbook.sourcegraph.com/departments/engineering/teams/source).* @@ -52097,19 +52447,21 @@ To see this panel, visit `/-/debug/grafana/d/repo-updater/repo-updater?viewPanel Query: ``` -max by (name) (src_github_rate_limit_remaining_v2{resource="rest"}) +sum(src_repo_perms_syncer_success_syncs{type="repo"}) ```-#### repo-updater: github_search_rate_limit_remaining +#### worker: repo_success_syncs -
Remaining calls to GitHub search API before hitting the rate limit
+Number of repo permissions syncs over 5m
-Refer to the [alerts reference](alerts#repo-updater-github-search-rate-limit-remaining) for 1 alert related to this panel. +Indicates the number of repos permissions syncs completed. + +This panel has no related alerts. -To see this panel, visit `/-/debug/grafana/d/repo-updater/repo-updater?viewPanel=100122` on your Sourcegraph instance. +To see this panel, visit `/-/debug/grafana/d/worker/worker?viewPanel=101011` on your Sourcegraph instance. *Managed by the [Sourcegraph Source team](https://handbook.sourcegraph.com/departments/engineering/teams/source).* @@ -52119,21 +52471,21 @@ To see this panel, visit `/-/debug/grafana/d/repo-updater/repo-updater?viewPanel Query: ``` -max by (name) (src_github_rate_limit_remaining_v2{resource="search"}) +sum(increase(src_repo_perms_syncer_success_syncs{type="repo"}[5m])) ```-#### repo-updater: github_graphql_rate_limit_wait_duration +#### worker: repo_initial_syncs -
Time spent waiting for the GitHub graphql API rate limiter
+Number of first repo permissions syncs over 5m
-Indicates how long we`re waiting on the rate limit once it has been exceeded +Indicates the number of permissions syncs done for the first time for the repo. This panel has no related alerts. -To see this panel, visit `/-/debug/grafana/d/repo-updater/repo-updater?viewPanel=100130` on your Sourcegraph instance. +To see this panel, visit `/-/debug/grafana/d/worker/worker?viewPanel=101012` on your Sourcegraph instance. *Managed by the [Sourcegraph Source team](https://handbook.sourcegraph.com/departments/engineering/teams/source).* @@ -52143,21 +52495,21 @@ To see this panel, visit `/-/debug/grafana/d/repo-updater/repo-updater?viewPanel Query: ``` -max by(name) (rate(src_github_rate_limit_wait_duration_seconds{resource="graphql"}[5m])) +sum(increase(src_repo_perms_syncer_initial_syncs{type="repo"}[5m])) ```-#### repo-updater: github_rest_rate_limit_wait_duration +#### worker: users_consecutive_sync_delay -
Time spent waiting for the GitHub rest API rate limiter
+Max duration between two consecutive permissions sync for user
-Indicates how long we`re waiting on the rate limit once it has been exceeded +Indicates the max delay between two consecutive permissions sync for a user during the period. This panel has no related alerts. -To see this panel, visit `/-/debug/grafana/d/repo-updater/repo-updater?viewPanel=100131` on your Sourcegraph instance. +To see this panel, visit `/-/debug/grafana/d/worker/worker?viewPanel=101020` on your Sourcegraph instance. *Managed by the [Sourcegraph Source team](https://handbook.sourcegraph.com/departments/engineering/teams/source).* @@ -52167,21 +52519,21 @@ To see this panel, visit `/-/debug/grafana/d/repo-updater/repo-updater?viewPanel Query: ``` -max by(name) (rate(src_github_rate_limit_wait_duration_seconds{resource="rest"}[5m])) +max(max_over_time (src_repo_perms_syncer_perms_consecutive_sync_delay{type="user"} [1m])) ```-#### repo-updater: github_search_rate_limit_wait_duration +#### worker: repos_consecutive_sync_delay -
Time spent waiting for the GitHub search API rate limiter
+Max duration between two consecutive permissions sync for repo
-Indicates how long we`re waiting on the rate limit once it has been exceeded +Indicates the max delay between two consecutive permissions sync for a repo during the period. This panel has no related alerts. -To see this panel, visit `/-/debug/grafana/d/repo-updater/repo-updater?viewPanel=100132` on your Sourcegraph instance. +To see this panel, visit `/-/debug/grafana/d/worker/worker?viewPanel=101021` on your Sourcegraph instance. *Managed by the [Sourcegraph Source team](https://handbook.sourcegraph.com/departments/engineering/teams/source).* @@ -52191,19 +52543,21 @@ To see this panel, visit `/-/debug/grafana/d/repo-updater/repo-updater?viewPanel Query: ``` -max by(name) (rate(src_github_rate_limit_wait_duration_seconds{resource="search"}[5m])) +max(max_over_time (src_repo_perms_syncer_perms_consecutive_sync_delay{type="repo"} [1m])) ```-#### repo-updater: gitlab_rest_rate_limit_remaining +#### worker: users_first_sync_delay -
Remaining calls to GitLab rest API before hitting the rate limit
+Max duration between user creation and first permissions sync
+ +Indicates the max delay between user creation and their permissions sync -Refer to the [alerts reference](alerts#repo-updater-gitlab-rest-rate-limit-remaining) for 1 alert related to this panel. +This panel has no related alerts. -To see this panel, visit `/-/debug/grafana/d/repo-updater/repo-updater?viewPanel=100140` on your Sourcegraph instance. +To see this panel, visit `/-/debug/grafana/d/worker/worker?viewPanel=101030` on your Sourcegraph instance. *Managed by the [Sourcegraph Source team](https://handbook.sourcegraph.com/departments/engineering/teams/source).* @@ -52213,21 +52567,21 @@ To see this panel, visit `/-/debug/grafana/d/repo-updater/repo-updater?viewPanel Query: ``` -max by (name) (src_gitlab_rate_limit_remaining{resource="rest"}) +max(max_over_time(src_repo_perms_syncer_perms_first_sync_delay{type="user"}[1m])) ```-#### repo-updater: gitlab_rest_rate_limit_wait_duration +#### worker: repos_first_sync_delay -
Time spent waiting for the GitLab rest API rate limiter
+Max duration between repo creation and first permissions sync over 1m
-Indicates how long we`re waiting on the rate limit once it has been exceeded +Indicates the max delay between repo creation and their permissions sync This panel has no related alerts. -To see this panel, visit `/-/debug/grafana/d/repo-updater/repo-updater?viewPanel=100141` on your Sourcegraph instance. +To see this panel, visit `/-/debug/grafana/d/worker/worker?viewPanel=101031` on your Sourcegraph instance. *Managed by the [Sourcegraph Source team](https://handbook.sourcegraph.com/departments/engineering/teams/source).* @@ -52237,21 +52591,21 @@ To see this panel, visit `/-/debug/grafana/d/repo-updater/repo-updater?viewPanel Query: ``` -max by (name) (rate(src_gitlab_rate_limit_wait_duration_seconds{resource="rest"}[5m])) +max(max_over_time(src_repo_perms_syncer_perms_first_sync_delay{type="repo"}[1m])) ```-#### repo-updater: src_internal_rate_limit_wait_duration_bucket +#### worker: permissions_found_count -
95th percentile time spent successfully waiting on our internal rate limiter
+Number of permissions found during user/repo permissions sync
-Indicates how long we`re waiting on our internal rate limiter when communicating with a code host +Indicates the number permissions found during users/repos permissions sync. This panel has no related alerts. -To see this panel, visit `/-/debug/grafana/d/repo-updater/repo-updater?viewPanel=100150` on your Sourcegraph instance. +To see this panel, visit `/-/debug/grafana/d/worker/worker?viewPanel=101040` on your Sourcegraph instance. *Managed by the [Sourcegraph Source team](https://handbook.sourcegraph.com/departments/engineering/teams/source).* @@ -52261,21 +52615,21 @@ To see this panel, visit `/-/debug/grafana/d/repo-updater/repo-updater?viewPanel Query: ``` -histogram_quantile(0.95, sum(rate(src_internal_rate_limit_wait_duration_bucket{failed="false"}[5m])) by (le, urn)) +sum by (type) (src_repo_perms_syncer_perms_found) ```-#### repo-updater: src_internal_rate_limit_wait_error_count +#### worker: permissions_found_avg -
Rate of failures waiting on our internal rate limiter
+Average number of permissions found during permissions sync per user/repo
-The rate at which we fail our internal rate limiter. +Indicates the average number permissions found during permissions sync per user/repo. This panel has no related alerts. -To see this panel, visit `/-/debug/grafana/d/repo-updater/repo-updater?viewPanel=100151` on your Sourcegraph instance. +To see this panel, visit `/-/debug/grafana/d/worker/worker?viewPanel=101041` on your Sourcegraph instance. *Managed by the [Sourcegraph Source team](https://handbook.sourcegraph.com/departments/engineering/teams/source).* @@ -52285,21 +52639,19 @@ To see this panel, visit `/-/debug/grafana/d/repo-updater/repo-updater?viewPanel Query: ``` -sum by (urn) (rate(src_internal_rate_limit_wait_duration_count{failed="true"}[5m])) +avg by (type) (src_repo_perms_syncer_perms_found) ```-### Repo Updater: Gitserver: Gitserver Client - -#### repo-updater: gitserver_client_total +#### worker: perms_syncer_outdated_perms -
Aggregate graphql operations every 5m
+Number of entities with outdated permissions
-This panel has no related alerts. +Refer to the [alerts reference](alerts#worker-perms-syncer-outdated-perms) for 1 alert related to this panel. -To see this panel, visit `/-/debug/grafana/d/repo-updater/repo-updater?viewPanel=100200` on your Sourcegraph instance. +To see this panel, visit `/-/debug/grafana/d/worker/worker?viewPanel=101050` on your Sourcegraph instance. *Managed by the [Sourcegraph Source team](https://handbook.sourcegraph.com/departments/engineering/teams/source).* @@ -52309,19 +52661,19 @@ To see this panel, visit `/-/debug/grafana/d/repo-updater/repo-updater?viewPanel Query: ``` -sum(increase(src_gitserver_client_total{job=~"^repo-updater.*"}[5m])) +max by (type) (src_repo_perms_syncer_outdated_perms) ```-#### repo-updater: gitserver_client_99th_percentile_duration +#### worker: perms_syncer_sync_duration -
Aggregate successful graphql operation duration distribution over 5m
+95th permissions sync duration
-This panel has no related alerts. +Refer to the [alerts reference](alerts#worker-perms-syncer-sync-duration) for 1 alert related to this panel. -To see this panel, visit `/-/debug/grafana/d/repo-updater/repo-updater?viewPanel=100201` on your Sourcegraph instance. +To see this panel, visit `/-/debug/grafana/d/worker/worker?viewPanel=101060` on your Sourcegraph instance. *Managed by the [Sourcegraph Source team](https://handbook.sourcegraph.com/departments/engineering/teams/source).* @@ -52331,19 +52683,19 @@ To see this panel, visit `/-/debug/grafana/d/repo-updater/repo-updater?viewPanel Query: ``` -sum by (le)(rate(src_gitserver_client_duration_seconds_bucket{job=~"^repo-updater.*"}[5m])) +histogram_quantile(0.95, max by (le, type) (rate(src_repo_perms_syncer_sync_duration_seconds_bucket[1m]))) ```-#### repo-updater: gitserver_client_errors_total +#### worker: perms_syncer_sync_errors -
Aggregate graphql operation errors every 5m
+Permissions sync error rate
-This panel has no related alerts. +Refer to the [alerts reference](alerts#worker-perms-syncer-sync-errors) for 1 alert related to this panel. -To see this panel, visit `/-/debug/grafana/d/repo-updater/repo-updater?viewPanel=100202` on your Sourcegraph instance. +To see this panel, visit `/-/debug/grafana/d/worker/worker?viewPanel=101070` on your Sourcegraph instance. *Managed by the [Sourcegraph Source team](https://handbook.sourcegraph.com/departments/engineering/teams/source).* @@ -52353,19 +52705,22 @@ To see this panel, visit `/-/debug/grafana/d/repo-updater/repo-updater?viewPanel Query: ``` -sum(increase(src_gitserver_client_errors_total{job=~"^repo-updater.*"}[5m])) +max by (type) (ceil(rate(src_repo_perms_syncer_sync_errors_total[1m]))) ```-#### repo-updater: gitserver_client_error_rate +#### worker: perms_syncer_scheduled_repos_total -
Aggregate graphql operation error rate over 5m
+Total number of repos scheduled for permissions sync
+ +Indicates how many repositories have been scheduled for a permissions sync. +More about repository permissions synchronization [here](https://sourcegraph.com/docs/admin/permissions/syncing#scheduling) This panel has no related alerts. -To see this panel, visit `/-/debug/grafana/d/repo-updater/repo-updater?viewPanel=100203` on your Sourcegraph instance. +To see this panel, visit `/-/debug/grafana/d/worker/worker?viewPanel=101071` on your Sourcegraph instance. *Managed by the [Sourcegraph Source team](https://handbook.sourcegraph.com/departments/engineering/teams/source).* @@ -52375,19 +52730,21 @@ To see this panel, visit `/-/debug/grafana/d/repo-updater/repo-updater?viewPanel Query: ``` -sum(increase(src_gitserver_client_errors_total{job=~"^repo-updater.*"}[5m])) / (sum(increase(src_gitserver_client_total{job=~"^repo-updater.*"}[5m])) + sum(increase(src_gitserver_client_errors_total{job=~"^repo-updater.*"}[5m]))) * 100 +max(rate(src_repo_perms_syncer_schedule_repos_total[1m])) ```-#### repo-updater: gitserver_client_total +### Worker: Gitserver: Gitserver Client + +#### worker: gitserver_client_total -
Graphql operations every 5m
+Aggregate client operations every 5m
This panel has no related alerts. -To see this panel, visit `/-/debug/grafana/d/repo-updater/repo-updater?viewPanel=100210` on your Sourcegraph instance. +To see this panel, visit `/-/debug/grafana/d/worker/worker?viewPanel=101100` on your Sourcegraph instance. *Managed by the [Sourcegraph Source team](https://handbook.sourcegraph.com/departments/engineering/teams/source).* @@ -52397,19 +52754,19 @@ To see this panel, visit `/-/debug/grafana/d/repo-updater/repo-updater?viewPanel Query: ``` -sum by (op,scope)(increase(src_gitserver_client_total{job=~"^repo-updater.*"}[5m])) +sum(increase(src_gitserver_client_total{job=~"^worker.*"}[5m])) ```-#### repo-updater: gitserver_client_99th_percentile_duration +#### worker: gitserver_client_99th_percentile_duration -
99th percentile successful graphql operation duration over 5m
+Aggregate successful client operation duration distribution over 5m
This panel has no related alerts. -To see this panel, visit `/-/debug/grafana/d/repo-updater/repo-updater?viewPanel=100211` on your Sourcegraph instance. +To see this panel, visit `/-/debug/grafana/d/worker/worker?viewPanel=101101` on your Sourcegraph instance. *Managed by the [Sourcegraph Source team](https://handbook.sourcegraph.com/departments/engineering/teams/source).* @@ -52419,19 +52776,19 @@ To see this panel, visit `/-/debug/grafana/d/repo-updater/repo-updater?viewPanel Query: ``` -histogram_quantile(0.99, sum by (le,op,scope)(rate(src_gitserver_client_duration_seconds_bucket{job=~"^repo-updater.*"}[5m]))) +sum by (le)(rate(src_gitserver_client_duration_seconds_bucket{job=~"^worker.*"}[5m])) ```-#### repo-updater: gitserver_client_errors_total +#### worker: gitserver_client_errors_total -
Graphql operation errors every 5m
+Aggregate client operation errors every 5m
This panel has no related alerts. -To see this panel, visit `/-/debug/grafana/d/repo-updater/repo-updater?viewPanel=100212` on your Sourcegraph instance. +To see this panel, visit `/-/debug/grafana/d/worker/worker?viewPanel=101102` on your Sourcegraph instance. *Managed by the [Sourcegraph Source team](https://handbook.sourcegraph.com/departments/engineering/teams/source).* @@ -52441,19 +52798,19 @@ To see this panel, visit `/-/debug/grafana/d/repo-updater/repo-updater?viewPanel Query: ``` -sum by (op,scope)(increase(src_gitserver_client_errors_total{job=~"^repo-updater.*"}[5m])) +sum(increase(src_gitserver_client_errors_total{job=~"^worker.*"}[5m])) ```-#### repo-updater: gitserver_client_error_rate +#### worker: gitserver_client_error_rate -
Graphql operation error rate over 5m
+Aggregate client operation error rate over 5m
This panel has no related alerts. -To see this panel, visit `/-/debug/grafana/d/repo-updater/repo-updater?viewPanel=100213` on your Sourcegraph instance. +To see this panel, visit `/-/debug/grafana/d/worker/worker?viewPanel=101103` on your Sourcegraph instance. *Managed by the [Sourcegraph Source team](https://handbook.sourcegraph.com/departments/engineering/teams/source).* @@ -52463,23 +52820,21 @@ To see this panel, visit `/-/debug/grafana/d/repo-updater/repo-updater?viewPanel Query: ``` -sum by (op,scope)(increase(src_gitserver_client_errors_total{job=~"^repo-updater.*"}[5m])) / (sum by (op,scope)(increase(src_gitserver_client_total{job=~"^repo-updater.*"}[5m])) + sum by (op,scope)(increase(src_gitserver_client_errors_total{job=~"^repo-updater.*"}[5m]))) * 100 +sum(increase(src_gitserver_client_errors_total{job=~"^worker.*"}[5m])) / (sum(increase(src_gitserver_client_total{job=~"^worker.*"}[5m])) + sum(increase(src_gitserver_client_errors_total{job=~"^worker.*"}[5m]))) * 100 ```-### Repo Updater: Batches: dbstore stats - -#### repo-updater: batches_dbstore_total +#### worker: gitserver_client_total -
Aggregate store operations every 5m
+Client operations every 5m
This panel has no related alerts. -To see this panel, visit `/-/debug/grafana/d/repo-updater/repo-updater?viewPanel=100300` on your Sourcegraph instance. +To see this panel, visit `/-/debug/grafana/d/worker/worker?viewPanel=101110` on your Sourcegraph instance. -*Managed by the [Sourcegraph Code Search team](https://handbook.sourcegraph.com/departments/engineering/teams/code-search).* +*Managed by the [Sourcegraph Source team](https://handbook.sourcegraph.com/departments/engineering/teams/source).*Technical details
@@ -52487,21 +52842,21 @@ To see this panel, visit `/-/debug/grafana/d/repo-updater/repo-updater?viewPanel Query: ``` -sum(increase(src_batches_dbstore_total{job=~"^repo-updater.*"}[5m])) +sum by (op,scope)(increase(src_gitserver_client_total{job=~"^worker.*"}[5m])) ```-#### repo-updater: batches_dbstore_99th_percentile_duration +#### worker: gitserver_client_99th_percentile_duration -
Aggregate successful store operation duration distribution over 5m
+99th percentile successful client operation duration over 5m
This panel has no related alerts. -To see this panel, visit `/-/debug/grafana/d/repo-updater/repo-updater?viewPanel=100301` on your Sourcegraph instance. +To see this panel, visit `/-/debug/grafana/d/worker/worker?viewPanel=101111` on your Sourcegraph instance. -*Managed by the [Sourcegraph Code Search team](https://handbook.sourcegraph.com/departments/engineering/teams/code-search).* +*Managed by the [Sourcegraph Source team](https://handbook.sourcegraph.com/departments/engineering/teams/source).*Technical details
@@ -52509,21 +52864,21 @@ To see this panel, visit `/-/debug/grafana/d/repo-updater/repo-updater?viewPanel Query: ``` -sum by (le)(rate(src_batches_dbstore_duration_seconds_bucket{job=~"^repo-updater.*"}[5m])) +histogram_quantile(0.99, sum by (le,op,scope)(rate(src_gitserver_client_duration_seconds_bucket{job=~"^worker.*"}[5m]))) ```-#### repo-updater: batches_dbstore_errors_total +#### worker: gitserver_client_errors_total -
Aggregate store operation errors every 5m
+Client operation errors every 5m
This panel has no related alerts. -To see this panel, visit `/-/debug/grafana/d/repo-updater/repo-updater?viewPanel=100302` on your Sourcegraph instance. +To see this panel, visit `/-/debug/grafana/d/worker/worker?viewPanel=101112` on your Sourcegraph instance. -*Managed by the [Sourcegraph Code Search team](https://handbook.sourcegraph.com/departments/engineering/teams/code-search).* +*Managed by the [Sourcegraph Source team](https://handbook.sourcegraph.com/departments/engineering/teams/source).*Technical details
@@ -52531,21 +52886,21 @@ To see this panel, visit `/-/debug/grafana/d/repo-updater/repo-updater?viewPanel Query: ``` -sum(increase(src_batches_dbstore_errors_total{job=~"^repo-updater.*"}[5m])) +sum by (op,scope)(increase(src_gitserver_client_errors_total{job=~"^worker.*"}[5m])) ```-#### repo-updater: batches_dbstore_error_rate +#### worker: gitserver_client_error_rate -
Aggregate store operation error rate over 5m
+Client operation error rate over 5m
This panel has no related alerts. -To see this panel, visit `/-/debug/grafana/d/repo-updater/repo-updater?viewPanel=100303` on your Sourcegraph instance. +To see this panel, visit `/-/debug/grafana/d/worker/worker?viewPanel=101113` on your Sourcegraph instance. -*Managed by the [Sourcegraph Code Search team](https://handbook.sourcegraph.com/departments/engineering/teams/code-search).* +*Managed by the [Sourcegraph Source team](https://handbook.sourcegraph.com/departments/engineering/teams/source).*Technical details
@@ -52553,21 +52908,23 @@ To see this panel, visit `/-/debug/grafana/d/repo-updater/repo-updater?viewPanel Query: ``` -sum(increase(src_batches_dbstore_errors_total{job=~"^repo-updater.*"}[5m])) / (sum(increase(src_batches_dbstore_total{job=~"^repo-updater.*"}[5m])) + sum(increase(src_batches_dbstore_errors_total{job=~"^repo-updater.*"}[5m]))) * 100 +sum by (op,scope)(increase(src_gitserver_client_errors_total{job=~"^worker.*"}[5m])) / (sum by (op,scope)(increase(src_gitserver_client_total{job=~"^worker.*"}[5m])) + sum by (op,scope)(increase(src_gitserver_client_errors_total{job=~"^worker.*"}[5m]))) * 100 ```-#### repo-updater: batches_dbstore_total +### Worker: Gitserver: Gitserver Repository Service Client -
Store operations every 5m
+#### worker: gitserver_repositoryservice_client_total + +Aggregate client operations every 5m
This panel has no related alerts. -To see this panel, visit `/-/debug/grafana/d/repo-updater/repo-updater?viewPanel=100310` on your Sourcegraph instance. +To see this panel, visit `/-/debug/grafana/d/worker/worker?viewPanel=101200` on your Sourcegraph instance. -*Managed by the [Sourcegraph Code Search team](https://handbook.sourcegraph.com/departments/engineering/teams/code-search).* +*Managed by the [Sourcegraph Source team](https://handbook.sourcegraph.com/departments/engineering/teams/source).*Technical details
@@ -52575,21 +52932,21 @@ To see this panel, visit `/-/debug/grafana/d/repo-updater/repo-updater?viewPanel Query: ``` -sum by (op)(increase(src_batches_dbstore_total{job=~"^repo-updater.*"}[5m])) +sum(increase(src_gitserver_repositoryservice_client_total{job=~"^worker.*"}[5m])) ```-#### repo-updater: batches_dbstore_99th_percentile_duration +#### worker: gitserver_repositoryservice_client_99th_percentile_duration -
99th percentile successful store operation duration over 5m
+Aggregate successful client operation duration distribution over 5m
This panel has no related alerts. -To see this panel, visit `/-/debug/grafana/d/repo-updater/repo-updater?viewPanel=100311` on your Sourcegraph instance. +To see this panel, visit `/-/debug/grafana/d/worker/worker?viewPanel=101201` on your Sourcegraph instance. -*Managed by the [Sourcegraph Code Search team](https://handbook.sourcegraph.com/departments/engineering/teams/code-search).* +*Managed by the [Sourcegraph Source team](https://handbook.sourcegraph.com/departments/engineering/teams/source).*Technical details
@@ -52597,21 +52954,21 @@ To see this panel, visit `/-/debug/grafana/d/repo-updater/repo-updater?viewPanel Query: ``` -histogram_quantile(0.99, sum by (le,op)(rate(src_batches_dbstore_duration_seconds_bucket{job=~"^repo-updater.*"}[5m]))) +sum by (le)(rate(src_gitserver_repositoryservice_client_duration_seconds_bucket{job=~"^worker.*"}[5m])) ```-#### repo-updater: batches_dbstore_errors_total +#### worker: gitserver_repositoryservice_client_errors_total -
Store operation errors every 5m
+Aggregate client operation errors every 5m
This panel has no related alerts. -To see this panel, visit `/-/debug/grafana/d/repo-updater/repo-updater?viewPanel=100312` on your Sourcegraph instance. +To see this panel, visit `/-/debug/grafana/d/worker/worker?viewPanel=101202` on your Sourcegraph instance. -*Managed by the [Sourcegraph Code Search team](https://handbook.sourcegraph.com/departments/engineering/teams/code-search).* +*Managed by the [Sourcegraph Source team](https://handbook.sourcegraph.com/departments/engineering/teams/source).*Technical details
@@ -52619,21 +52976,21 @@ To see this panel, visit `/-/debug/grafana/d/repo-updater/repo-updater?viewPanel Query: ``` -sum by (op)(increase(src_batches_dbstore_errors_total{job=~"^repo-updater.*"}[5m])) +sum(increase(src_gitserver_repositoryservice_client_errors_total{job=~"^worker.*"}[5m])) ```-#### repo-updater: batches_dbstore_error_rate +#### worker: gitserver_repositoryservice_client_error_rate -
Store operation error rate over 5m
+Aggregate client operation error rate over 5m
This panel has no related alerts. -To see this panel, visit `/-/debug/grafana/d/repo-updater/repo-updater?viewPanel=100313` on your Sourcegraph instance. +To see this panel, visit `/-/debug/grafana/d/worker/worker?viewPanel=101203` on your Sourcegraph instance. -*Managed by the [Sourcegraph Code Search team](https://handbook.sourcegraph.com/departments/engineering/teams/code-search).* +*Managed by the [Sourcegraph Source team](https://handbook.sourcegraph.com/departments/engineering/teams/source).*Technical details
@@ -52641,23 +52998,21 @@ To see this panel, visit `/-/debug/grafana/d/repo-updater/repo-updater?viewPanel Query: ``` -sum by (op)(increase(src_batches_dbstore_errors_total{job=~"^repo-updater.*"}[5m])) / (sum by (op)(increase(src_batches_dbstore_total{job=~"^repo-updater.*"}[5m])) + sum by (op)(increase(src_batches_dbstore_errors_total{job=~"^repo-updater.*"}[5m]))) * 100 +sum(increase(src_gitserver_repositoryservice_client_errors_total{job=~"^worker.*"}[5m])) / (sum(increase(src_gitserver_repositoryservice_client_total{job=~"^worker.*"}[5m])) + sum(increase(src_gitserver_repositoryservice_client_errors_total{job=~"^worker.*"}[5m]))) * 100 ```-### Repo Updater: Batches: service stats +#### worker: gitserver_repositoryservice_client_total -#### repo-updater: batches_service_total - -
Aggregate service operations every 5m
+Client operations every 5m
This panel has no related alerts. -To see this panel, visit `/-/debug/grafana/d/repo-updater/repo-updater?viewPanel=100400` on your Sourcegraph instance. +To see this panel, visit `/-/debug/grafana/d/worker/worker?viewPanel=101210` on your Sourcegraph instance. -*Managed by the [Sourcegraph Code Search team](https://handbook.sourcegraph.com/departments/engineering/teams/code-search).* +*Managed by the [Sourcegraph Source team](https://handbook.sourcegraph.com/departments/engineering/teams/source).*Technical details
@@ -52665,21 +53020,21 @@ To see this panel, visit `/-/debug/grafana/d/repo-updater/repo-updater?viewPanel Query: ``` -sum(increase(src_batches_service_total{job=~"^repo-updater.*"}[5m])) +sum by (op,scope)(increase(src_gitserver_repositoryservice_client_total{job=~"^worker.*"}[5m])) ```-#### repo-updater: batches_service_99th_percentile_duration +#### worker: gitserver_repositoryservice_client_99th_percentile_duration -
Aggregate successful service operation duration distribution over 5m
+99th percentile successful client operation duration over 5m
This panel has no related alerts. -To see this panel, visit `/-/debug/grafana/d/repo-updater/repo-updater?viewPanel=100401` on your Sourcegraph instance. +To see this panel, visit `/-/debug/grafana/d/worker/worker?viewPanel=101211` on your Sourcegraph instance. -*Managed by the [Sourcegraph Code Search team](https://handbook.sourcegraph.com/departments/engineering/teams/code-search).* +*Managed by the [Sourcegraph Source team](https://handbook.sourcegraph.com/departments/engineering/teams/source).*Technical details
@@ -52687,21 +53042,21 @@ To see this panel, visit `/-/debug/grafana/d/repo-updater/repo-updater?viewPanel Query: ``` -sum by (le)(rate(src_batches_service_duration_seconds_bucket{job=~"^repo-updater.*"}[5m])) +histogram_quantile(0.99, sum by (le,op,scope)(rate(src_gitserver_repositoryservice_client_duration_seconds_bucket{job=~"^worker.*"}[5m]))) ```-#### repo-updater: batches_service_errors_total +#### worker: gitserver_repositoryservice_client_errors_total -
Aggregate service operation errors every 5m
+Client operation errors every 5m
This panel has no related alerts. -To see this panel, visit `/-/debug/grafana/d/repo-updater/repo-updater?viewPanel=100402` on your Sourcegraph instance. +To see this panel, visit `/-/debug/grafana/d/worker/worker?viewPanel=101212` on your Sourcegraph instance. -*Managed by the [Sourcegraph Code Search team](https://handbook.sourcegraph.com/departments/engineering/teams/code-search).* +*Managed by the [Sourcegraph Source team](https://handbook.sourcegraph.com/departments/engineering/teams/source).*Technical details
@@ -52709,21 +53064,21 @@ To see this panel, visit `/-/debug/grafana/d/repo-updater/repo-updater?viewPanel Query: ``` -sum(increase(src_batches_service_errors_total{job=~"^repo-updater.*"}[5m])) +sum by (op,scope)(increase(src_gitserver_repositoryservice_client_errors_total{job=~"^worker.*"}[5m])) ```-#### repo-updater: batches_service_error_rate +#### worker: gitserver_repositoryservice_client_error_rate -
Aggregate service operation error rate over 5m
+Client operation error rate over 5m
This panel has no related alerts. -To see this panel, visit `/-/debug/grafana/d/repo-updater/repo-updater?viewPanel=100403` on your Sourcegraph instance. +To see this panel, visit `/-/debug/grafana/d/worker/worker?viewPanel=101213` on your Sourcegraph instance. -*Managed by the [Sourcegraph Code Search team](https://handbook.sourcegraph.com/departments/engineering/teams/code-search).* +*Managed by the [Sourcegraph Source team](https://handbook.sourcegraph.com/departments/engineering/teams/source).*Technical details
@@ -52731,19 +53086,21 @@ To see this panel, visit `/-/debug/grafana/d/repo-updater/repo-updater?viewPanel Query: ``` -sum(increase(src_batches_service_errors_total{job=~"^repo-updater.*"}[5m])) / (sum(increase(src_batches_service_total{job=~"^repo-updater.*"}[5m])) + sum(increase(src_batches_service_errors_total{job=~"^repo-updater.*"}[5m]))) * 100 +sum by (op,scope)(increase(src_gitserver_repositoryservice_client_errors_total{job=~"^worker.*"}[5m])) / (sum by (op,scope)(increase(src_gitserver_repositoryservice_client_total{job=~"^worker.*"}[5m])) + sum by (op,scope)(increase(src_gitserver_repositoryservice_client_errors_total{job=~"^worker.*"}[5m]))) * 100 ```-#### repo-updater: batches_service_total +### Worker: Batches: dbstore stats -
Service operations every 5m
+#### worker: batches_dbstore_total + +Aggregate store operations every 5m
This panel has no related alerts. -To see this panel, visit `/-/debug/grafana/d/repo-updater/repo-updater?viewPanel=100410` on your Sourcegraph instance. +To see this panel, visit `/-/debug/grafana/d/worker/worker?viewPanel=101300` on your Sourcegraph instance. *Managed by the [Sourcegraph Code Search team](https://handbook.sourcegraph.com/departments/engineering/teams/code-search).* @@ -52753,19 +53110,19 @@ To see this panel, visit `/-/debug/grafana/d/repo-updater/repo-updater?viewPanel Query: ``` -sum by (op)(increase(src_batches_service_total{job=~"^repo-updater.*"}[5m])) +sum(increase(src_batches_dbstore_total{job=~"^worker.*"}[5m])) ```-#### repo-updater: batches_service_99th_percentile_duration +#### worker: batches_dbstore_99th_percentile_duration -
99th percentile successful service operation duration over 5m
+Aggregate successful store operation duration distribution over 5m
This panel has no related alerts. -To see this panel, visit `/-/debug/grafana/d/repo-updater/repo-updater?viewPanel=100411` on your Sourcegraph instance. +To see this panel, visit `/-/debug/grafana/d/worker/worker?viewPanel=101301` on your Sourcegraph instance. *Managed by the [Sourcegraph Code Search team](https://handbook.sourcegraph.com/departments/engineering/teams/code-search).* @@ -52775,19 +53132,19 @@ To see this panel, visit `/-/debug/grafana/d/repo-updater/repo-updater?viewPanel Query: ``` -histogram_quantile(0.99, sum by (le,op)(rate(src_batches_service_duration_seconds_bucket{job=~"^repo-updater.*"}[5m]))) +sum by (le)(rate(src_batches_dbstore_duration_seconds_bucket{job=~"^worker.*"}[5m])) ```-#### repo-updater: batches_service_errors_total +#### worker: batches_dbstore_errors_total -
Service operation errors every 5m
+Aggregate store operation errors every 5m
This panel has no related alerts. -To see this panel, visit `/-/debug/grafana/d/repo-updater/repo-updater?viewPanel=100412` on your Sourcegraph instance. +To see this panel, visit `/-/debug/grafana/d/worker/worker?viewPanel=101302` on your Sourcegraph instance. *Managed by the [Sourcegraph Code Search team](https://handbook.sourcegraph.com/departments/engineering/teams/code-search).* @@ -52797,19 +53154,19 @@ To see this panel, visit `/-/debug/grafana/d/repo-updater/repo-updater?viewPanel Query: ``` -sum by (op)(increase(src_batches_service_errors_total{job=~"^repo-updater.*"}[5m])) +sum(increase(src_batches_dbstore_errors_total{job=~"^worker.*"}[5m])) ```-#### repo-updater: batches_service_error_rate +#### worker: batches_dbstore_error_rate -
Service operation error rate over 5m
+Aggregate store operation error rate over 5m
This panel has no related alerts. -To see this panel, visit `/-/debug/grafana/d/repo-updater/repo-updater?viewPanel=100413` on your Sourcegraph instance. +To see this panel, visit `/-/debug/grafana/d/worker/worker?viewPanel=101303` on your Sourcegraph instance. *Managed by the [Sourcegraph Code Search team](https://handbook.sourcegraph.com/departments/engineering/teams/code-search).* @@ -52819,23 +53176,21 @@ To see this panel, visit `/-/debug/grafana/d/repo-updater/repo-updater?viewPanel Query: ``` -sum by (op)(increase(src_batches_service_errors_total{job=~"^repo-updater.*"}[5m])) / (sum by (op)(increase(src_batches_service_total{job=~"^repo-updater.*"}[5m])) + sum by (op)(increase(src_batches_service_errors_total{job=~"^repo-updater.*"}[5m]))) * 100 +sum(increase(src_batches_dbstore_errors_total{job=~"^worker.*"}[5m])) / (sum(increase(src_batches_dbstore_total{job=~"^worker.*"}[5m])) + sum(increase(src_batches_dbstore_errors_total{job=~"^worker.*"}[5m]))) * 100 ```-### Repo Updater: Codeintel: Coursier invocation stats - -#### repo-updater: codeintel_coursier_total +#### worker: batches_dbstore_total -
Aggregate invocations operations every 5m
+Store operations every 5m
This panel has no related alerts. -To see this panel, visit `/-/debug/grafana/d/repo-updater/repo-updater?viewPanel=100500` on your Sourcegraph instance. +To see this panel, visit `/-/debug/grafana/d/worker/worker?viewPanel=101310` on your Sourcegraph instance. -*Managed by the [Sourcegraph Code intelligence team](https://handbook.sourcegraph.com/departments/engineering/teams/code-intelligence).* +*Managed by the [Sourcegraph Code Search team](https://handbook.sourcegraph.com/departments/engineering/teams/code-search).*Technical details
@@ -52843,21 +53198,21 @@ To see this panel, visit `/-/debug/grafana/d/repo-updater/repo-updater?viewPanel Query: ``` -sum(increase(src_codeintel_coursier_total{op!="RunCommand",job=~"^repo-updater.*"}[5m])) +sum by (op)(increase(src_batches_dbstore_total{job=~"^worker.*"}[5m])) ```-#### repo-updater: codeintel_coursier_99th_percentile_duration +#### worker: batches_dbstore_99th_percentile_duration -
Aggregate successful invocations operation duration distribution over 5m
+99th percentile successful store operation duration over 5m
This panel has no related alerts. -To see this panel, visit `/-/debug/grafana/d/repo-updater/repo-updater?viewPanel=100501` on your Sourcegraph instance. +To see this panel, visit `/-/debug/grafana/d/worker/worker?viewPanel=101311` on your Sourcegraph instance. -*Managed by the [Sourcegraph Code intelligence team](https://handbook.sourcegraph.com/departments/engineering/teams/code-intelligence).* +*Managed by the [Sourcegraph Code Search team](https://handbook.sourcegraph.com/departments/engineering/teams/code-search).*Technical details
@@ -52865,21 +53220,21 @@ To see this panel, visit `/-/debug/grafana/d/repo-updater/repo-updater?viewPanel Query: ``` -sum by (le)(rate(src_codeintel_coursier_duration_seconds_bucket{op!="RunCommand",job=~"^repo-updater.*"}[5m])) +histogram_quantile(0.99, sum by (le,op)(rate(src_batches_dbstore_duration_seconds_bucket{job=~"^worker.*"}[5m]))) ```-#### repo-updater: codeintel_coursier_errors_total +#### worker: batches_dbstore_errors_total -
Aggregate invocations operation errors every 5m
+Store operation errors every 5m
This panel has no related alerts. -To see this panel, visit `/-/debug/grafana/d/repo-updater/repo-updater?viewPanel=100502` on your Sourcegraph instance. +To see this panel, visit `/-/debug/grafana/d/worker/worker?viewPanel=101312` on your Sourcegraph instance. -*Managed by the [Sourcegraph Code intelligence team](https://handbook.sourcegraph.com/departments/engineering/teams/code-intelligence).* +*Managed by the [Sourcegraph Code Search team](https://handbook.sourcegraph.com/departments/engineering/teams/code-search).*Technical details
@@ -52887,21 +53242,21 @@ To see this panel, visit `/-/debug/grafana/d/repo-updater/repo-updater?viewPanel Query: ``` -sum(increase(src_codeintel_coursier_errors_total{op!="RunCommand",job=~"^repo-updater.*"}[5m])) +sum by (op)(increase(src_batches_dbstore_errors_total{job=~"^worker.*"}[5m])) ```-#### repo-updater: codeintel_coursier_error_rate +#### worker: batches_dbstore_error_rate -
Aggregate invocations operation error rate over 5m
+Store operation error rate over 5m
This panel has no related alerts. -To see this panel, visit `/-/debug/grafana/d/repo-updater/repo-updater?viewPanel=100503` on your Sourcegraph instance. +To see this panel, visit `/-/debug/grafana/d/worker/worker?viewPanel=101313` on your Sourcegraph instance. -*Managed by the [Sourcegraph Code intelligence team](https://handbook.sourcegraph.com/departments/engineering/teams/code-intelligence).* +*Managed by the [Sourcegraph Code Search team](https://handbook.sourcegraph.com/departments/engineering/teams/code-search).*Technical details
@@ -52909,21 +53264,23 @@ To see this panel, visit `/-/debug/grafana/d/repo-updater/repo-updater?viewPanel Query: ``` -sum(increase(src_codeintel_coursier_errors_total{op!="RunCommand",job=~"^repo-updater.*"}[5m])) / (sum(increase(src_codeintel_coursier_total{op!="RunCommand",job=~"^repo-updater.*"}[5m])) + sum(increase(src_codeintel_coursier_errors_total{op!="RunCommand",job=~"^repo-updater.*"}[5m]))) * 100 +sum by (op)(increase(src_batches_dbstore_errors_total{job=~"^worker.*"}[5m])) / (sum by (op)(increase(src_batches_dbstore_total{job=~"^worker.*"}[5m])) + sum by (op)(increase(src_batches_dbstore_errors_total{job=~"^worker.*"}[5m]))) * 100 ```-#### repo-updater: codeintel_coursier_total +### Worker: Batches: service stats + +#### worker: batches_service_total -
Invocations operations every 5m
+Aggregate service operations every 5m
This panel has no related alerts. -To see this panel, visit `/-/debug/grafana/d/repo-updater/repo-updater?viewPanel=100510` on your Sourcegraph instance. +To see this panel, visit `/-/debug/grafana/d/worker/worker?viewPanel=101400` on your Sourcegraph instance. -*Managed by the [Sourcegraph Code intelligence team](https://handbook.sourcegraph.com/departments/engineering/teams/code-intelligence).* +*Managed by the [Sourcegraph Code Search team](https://handbook.sourcegraph.com/departments/engineering/teams/code-search).*Technical details
@@ -52931,21 +53288,21 @@ To see this panel, visit `/-/debug/grafana/d/repo-updater/repo-updater?viewPanel Query: ``` -sum by (op)(increase(src_codeintel_coursier_total{op!="RunCommand",job=~"^repo-updater.*"}[5m])) +sum(increase(src_batches_service_total{job=~"^worker.*"}[5m])) ```-#### repo-updater: codeintel_coursier_99th_percentile_duration +#### worker: batches_service_99th_percentile_duration -
99th percentile successful invocations operation duration over 5m
+Aggregate successful service operation duration distribution over 5m
This panel has no related alerts. -To see this panel, visit `/-/debug/grafana/d/repo-updater/repo-updater?viewPanel=100511` on your Sourcegraph instance. +To see this panel, visit `/-/debug/grafana/d/worker/worker?viewPanel=101401` on your Sourcegraph instance. -*Managed by the [Sourcegraph Code intelligence team](https://handbook.sourcegraph.com/departments/engineering/teams/code-intelligence).* +*Managed by the [Sourcegraph Code Search team](https://handbook.sourcegraph.com/departments/engineering/teams/code-search).*Technical details
@@ -52953,21 +53310,21 @@ To see this panel, visit `/-/debug/grafana/d/repo-updater/repo-updater?viewPanel Query: ``` -histogram_quantile(0.99, sum by (le,op)(rate(src_codeintel_coursier_duration_seconds_bucket{op!="RunCommand",job=~"^repo-updater.*"}[5m]))) +sum by (le)(rate(src_batches_service_duration_seconds_bucket{job=~"^worker.*"}[5m])) ```-#### repo-updater: codeintel_coursier_errors_total +#### worker: batches_service_errors_total -
Invocations operation errors every 5m
+Aggregate service operation errors every 5m
This panel has no related alerts. -To see this panel, visit `/-/debug/grafana/d/repo-updater/repo-updater?viewPanel=100512` on your Sourcegraph instance. +To see this panel, visit `/-/debug/grafana/d/worker/worker?viewPanel=101402` on your Sourcegraph instance. -*Managed by the [Sourcegraph Code intelligence team](https://handbook.sourcegraph.com/departments/engineering/teams/code-intelligence).* +*Managed by the [Sourcegraph Code Search team](https://handbook.sourcegraph.com/departments/engineering/teams/code-search).*Technical details
@@ -52975,21 +53332,21 @@ To see this panel, visit `/-/debug/grafana/d/repo-updater/repo-updater?viewPanel Query: ``` -sum by (op)(increase(src_codeintel_coursier_errors_total{op!="RunCommand",job=~"^repo-updater.*"}[5m])) +sum(increase(src_batches_service_errors_total{job=~"^worker.*"}[5m])) ```-#### repo-updater: codeintel_coursier_error_rate +#### worker: batches_service_error_rate -
Invocations operation error rate over 5m
+Aggregate service operation error rate over 5m
This panel has no related alerts. -To see this panel, visit `/-/debug/grafana/d/repo-updater/repo-updater?viewPanel=100513` on your Sourcegraph instance. +To see this panel, visit `/-/debug/grafana/d/worker/worker?viewPanel=101403` on your Sourcegraph instance. -*Managed by the [Sourcegraph Code intelligence team](https://handbook.sourcegraph.com/departments/engineering/teams/code-intelligence).* +*Managed by the [Sourcegraph Code Search team](https://handbook.sourcegraph.com/departments/engineering/teams/code-search).*Technical details
@@ -52997,23 +53354,21 @@ To see this panel, visit `/-/debug/grafana/d/repo-updater/repo-updater?viewPanel Query: ``` -sum by (op)(increase(src_codeintel_coursier_errors_total{op!="RunCommand",job=~"^repo-updater.*"}[5m])) / (sum by (op)(increase(src_codeintel_coursier_total{op!="RunCommand",job=~"^repo-updater.*"}[5m])) + sum by (op)(increase(src_codeintel_coursier_errors_total{op!="RunCommand",job=~"^repo-updater.*"}[5m]))) * 100 +sum(increase(src_batches_service_errors_total{job=~"^worker.*"}[5m])) / (sum(increase(src_batches_service_total{job=~"^worker.*"}[5m])) + sum(increase(src_batches_service_errors_total{job=~"^worker.*"}[5m]))) * 100 ```-### Repo Updater: Codeintel: npm invocation stats - -#### repo-updater: codeintel_npm_total +#### worker: batches_service_total -
Aggregate invocations operations every 5m
+Service operations every 5m
This panel has no related alerts. -To see this panel, visit `/-/debug/grafana/d/repo-updater/repo-updater?viewPanel=100600` on your Sourcegraph instance. +To see this panel, visit `/-/debug/grafana/d/worker/worker?viewPanel=101410` on your Sourcegraph instance. -*Managed by the [Sourcegraph Code intelligence team](https://handbook.sourcegraph.com/departments/engineering/teams/code-intelligence).* +*Managed by the [Sourcegraph Code Search team](https://handbook.sourcegraph.com/departments/engineering/teams/code-search).*Technical details
@@ -53021,21 +53376,21 @@ To see this panel, visit `/-/debug/grafana/d/repo-updater/repo-updater?viewPanel Query: ``` -sum(increase(src_codeintel_npm_total{op!="RunCommand",job=~"^repo-updater.*"}[5m])) +sum by (op)(increase(src_batches_service_total{job=~"^worker.*"}[5m])) ```-#### repo-updater: codeintel_npm_99th_percentile_duration +#### worker: batches_service_99th_percentile_duration -
Aggregate successful invocations operation duration distribution over 5m
+99th percentile successful service operation duration over 5m
This panel has no related alerts. -To see this panel, visit `/-/debug/grafana/d/repo-updater/repo-updater?viewPanel=100601` on your Sourcegraph instance. +To see this panel, visit `/-/debug/grafana/d/worker/worker?viewPanel=101411` on your Sourcegraph instance. -*Managed by the [Sourcegraph Code intelligence team](https://handbook.sourcegraph.com/departments/engineering/teams/code-intelligence).* +*Managed by the [Sourcegraph Code Search team](https://handbook.sourcegraph.com/departments/engineering/teams/code-search).*Technical details
@@ -53043,21 +53398,21 @@ To see this panel, visit `/-/debug/grafana/d/repo-updater/repo-updater?viewPanel Query: ``` -sum by (le)(rate(src_codeintel_npm_duration_seconds_bucket{op!="RunCommand",job=~"^repo-updater.*"}[5m])) +histogram_quantile(0.99, sum by (le,op)(rate(src_batches_service_duration_seconds_bucket{job=~"^worker.*"}[5m]))) ```-#### repo-updater: codeintel_npm_errors_total +#### worker: batches_service_errors_total -
Aggregate invocations operation errors every 5m
+Service operation errors every 5m
This panel has no related alerts. -To see this panel, visit `/-/debug/grafana/d/repo-updater/repo-updater?viewPanel=100602` on your Sourcegraph instance. +To see this panel, visit `/-/debug/grafana/d/worker/worker?viewPanel=101412` on your Sourcegraph instance. -*Managed by the [Sourcegraph Code intelligence team](https://handbook.sourcegraph.com/departments/engineering/teams/code-intelligence).* +*Managed by the [Sourcegraph Code Search team](https://handbook.sourcegraph.com/departments/engineering/teams/code-search).*Technical details
@@ -53065,21 +53420,21 @@ To see this panel, visit `/-/debug/grafana/d/repo-updater/repo-updater?viewPanel Query: ``` -sum(increase(src_codeintel_npm_errors_total{op!="RunCommand",job=~"^repo-updater.*"}[5m])) +sum by (op)(increase(src_batches_service_errors_total{job=~"^worker.*"}[5m])) ```-#### repo-updater: codeintel_npm_error_rate +#### worker: batches_service_error_rate -
Aggregate invocations operation error rate over 5m
+Service operation error rate over 5m
This panel has no related alerts. -To see this panel, visit `/-/debug/grafana/d/repo-updater/repo-updater?viewPanel=100603` on your Sourcegraph instance. +To see this panel, visit `/-/debug/grafana/d/worker/worker?viewPanel=101413` on your Sourcegraph instance. -*Managed by the [Sourcegraph Code intelligence team](https://handbook.sourcegraph.com/departments/engineering/teams/code-intelligence).* +*Managed by the [Sourcegraph Code Search team](https://handbook.sourcegraph.com/departments/engineering/teams/code-search).*Technical details
@@ -53087,21 +53442,23 @@ To see this panel, visit `/-/debug/grafana/d/repo-updater/repo-updater?viewPanel Query: ``` -sum(increase(src_codeintel_npm_errors_total{op!="RunCommand",job=~"^repo-updater.*"}[5m])) / (sum(increase(src_codeintel_npm_total{op!="RunCommand",job=~"^repo-updater.*"}[5m])) + sum(increase(src_codeintel_npm_errors_total{op!="RunCommand",job=~"^repo-updater.*"}[5m]))) * 100 +sum by (op)(increase(src_batches_service_errors_total{job=~"^worker.*"}[5m])) / (sum by (op)(increase(src_batches_service_total{job=~"^worker.*"}[5m])) + sum by (op)(increase(src_batches_service_errors_total{job=~"^worker.*"}[5m]))) * 100 ```-#### repo-updater: codeintel_npm_total +### Worker: Codeinsights: insights queue processor + +#### worker: query_runner_worker_handlers -
Invocations operations every 5m
+Handler active handlers
This panel has no related alerts. -To see this panel, visit `/-/debug/grafana/d/repo-updater/repo-updater?viewPanel=100610` on your Sourcegraph instance. +To see this panel, visit `/-/debug/grafana/d/worker/worker?viewPanel=101500` on your Sourcegraph instance. -*Managed by the [Sourcegraph Code intelligence team](https://handbook.sourcegraph.com/departments/engineering/teams/code-intelligence).* +*Managed by the [Sourcegraph Code Search team](https://handbook.sourcegraph.com/departments/engineering/teams/code-search).*Technical details
@@ -53109,21 +53466,21 @@ To see this panel, visit `/-/debug/grafana/d/repo-updater/repo-updater?viewPanel Query: ``` -sum by (op)(increase(src_codeintel_npm_total{op!="RunCommand",job=~"^repo-updater.*"}[5m])) +sum(src_query_runner_worker_processor_handlers{job=~"^worker.*"}) ```-#### repo-updater: codeintel_npm_99th_percentile_duration +#### worker: query_runner_worker_processor_total -
99th percentile successful invocations operation duration over 5m
+Handler operations every 5m
This panel has no related alerts. -To see this panel, visit `/-/debug/grafana/d/repo-updater/repo-updater?viewPanel=100611` on your Sourcegraph instance. +To see this panel, visit `/-/debug/grafana/d/worker/worker?viewPanel=101510` on your Sourcegraph instance. -*Managed by the [Sourcegraph Code intelligence team](https://handbook.sourcegraph.com/departments/engineering/teams/code-intelligence).* +*Managed by the [Sourcegraph Code Search team](https://handbook.sourcegraph.com/departments/engineering/teams/code-search).*Technical details
@@ -53131,21 +53488,21 @@ To see this panel, visit `/-/debug/grafana/d/repo-updater/repo-updater?viewPanel Query: ``` -histogram_quantile(0.99, sum by (le,op)(rate(src_codeintel_npm_duration_seconds_bucket{op!="RunCommand",job=~"^repo-updater.*"}[5m]))) +sum(increase(src_query_runner_worker_processor_total{job=~"^worker.*"}[5m])) ```-#### repo-updater: codeintel_npm_errors_total +#### worker: query_runner_worker_processor_99th_percentile_duration -
Invocations operation errors every 5m
+Aggregate successful handler operation duration distribution over 5m
This panel has no related alerts. -To see this panel, visit `/-/debug/grafana/d/repo-updater/repo-updater?viewPanel=100612` on your Sourcegraph instance. +To see this panel, visit `/-/debug/grafana/d/worker/worker?viewPanel=101511` on your Sourcegraph instance. -*Managed by the [Sourcegraph Code intelligence team](https://handbook.sourcegraph.com/departments/engineering/teams/code-intelligence).* +*Managed by the [Sourcegraph Code Search team](https://handbook.sourcegraph.com/departments/engineering/teams/code-search).*Technical details
@@ -53153,21 +53510,21 @@ To see this panel, visit `/-/debug/grafana/d/repo-updater/repo-updater?viewPanel Query: ``` -sum by (op)(increase(src_codeintel_npm_errors_total{op!="RunCommand",job=~"^repo-updater.*"}[5m])) +sum by (le)(rate(src_query_runner_worker_processor_duration_seconds_bucket{job=~"^worker.*"}[5m])) ```-#### repo-updater: codeintel_npm_error_rate +#### worker: query_runner_worker_processor_errors_total -
Invocations operation error rate over 5m
+Handler operation errors every 5m
This panel has no related alerts. -To see this panel, visit `/-/debug/grafana/d/repo-updater/repo-updater?viewPanel=100613` on your Sourcegraph instance. +To see this panel, visit `/-/debug/grafana/d/worker/worker?viewPanel=101512` on your Sourcegraph instance. -*Managed by the [Sourcegraph Code intelligence team](https://handbook.sourcegraph.com/departments/engineering/teams/code-intelligence).* +*Managed by the [Sourcegraph Code Search team](https://handbook.sourcegraph.com/departments/engineering/teams/code-search).*Technical details
@@ -53175,25 +53532,21 @@ To see this panel, visit `/-/debug/grafana/d/repo-updater/repo-updater?viewPanel Query: ``` -sum by (op)(increase(src_codeintel_npm_errors_total{op!="RunCommand",job=~"^repo-updater.*"}[5m])) / (sum by (op)(increase(src_codeintel_npm_total{op!="RunCommand",job=~"^repo-updater.*"}[5m])) + sum by (op)(increase(src_codeintel_npm_errors_total{op!="RunCommand",job=~"^repo-updater.*"}[5m]))) * 100 +sum(increase(src_query_runner_worker_processor_errors_total{job=~"^worker.*"}[5m])) ```-### Repo Updater: Repo Updater GRPC server metrics - -#### repo-updater: repo_updater_grpc_request_rate_all_methods - -
Request rate across all methods over 2m
+#### worker: query_runner_worker_processor_error_rate -The number of gRPC requests received per second across all methods, aggregated across all instances. +Handler operation error rate over 5m
This panel has no related alerts. -To see this panel, visit `/-/debug/grafana/d/repo-updater/repo-updater?viewPanel=100700` on your Sourcegraph instance. +To see this panel, visit `/-/debug/grafana/d/worker/worker?viewPanel=101513` on your Sourcegraph instance. -*Managed by the [Sourcegraph Source team](https://handbook.sourcegraph.com/departments/engineering/teams/source).* +*Managed by the [Sourcegraph Code Search team](https://handbook.sourcegraph.com/departments/engineering/teams/code-search).*Technical details
@@ -53201,23 +53554,23 @@ To see this panel, visit `/-/debug/grafana/d/repo-updater/repo-updater?viewPanel Query: ``` -sum(rate(grpc_server_started_total{instance=~`${instance:regex}`,grpc_service=~"repoupdater.v1.RepoUpdaterService"}[2m])) +sum(increase(src_query_runner_worker_processor_errors_total{job=~"^worker.*"}[5m])) / (sum(increase(src_query_runner_worker_processor_total{job=~"^worker.*"}[5m])) + sum(increase(src_query_runner_worker_processor_errors_total{job=~"^worker.*"}[5m]))) * 100 ```-#### repo-updater: repo_updater_grpc_request_rate_per_method +### Worker: Codeinsights: dbstore stats -
Request rate per-method over 2m
+#### worker: workerutil_dbworker_store_total -The number of gRPC requests received per second broken out per method, aggregated across all instances. +Aggregate store operations every 5m
This panel has no related alerts. -To see this panel, visit `/-/debug/grafana/d/repo-updater/repo-updater?viewPanel=100701` on your Sourcegraph instance. +To see this panel, visit `/-/debug/grafana/d/worker/worker?viewPanel=101600` on your Sourcegraph instance. -*Managed by the [Sourcegraph Source team](https://handbook.sourcegraph.com/departments/engineering/teams/source).* +*Managed by the [Sourcegraph Code Search team](https://handbook.sourcegraph.com/departments/engineering/teams/code-search).*Technical details
@@ -53225,23 +53578,21 @@ To see this panel, visit `/-/debug/grafana/d/repo-updater/repo-updater?viewPanel Query: ``` -sum(rate(grpc_server_started_total{grpc_method=~`${repo_updater_method:regex}`,instance=~`${instance:regex}`,grpc_service=~"repoupdater.v1.RepoUpdaterService"}[2m])) by (grpc_method) +sum(increase(src_workerutil_dbworker_store_total{domain='insights_query_runner_jobs',job=~"^worker.*"}[5m])) ```-#### repo-updater: repo_updater_error_percentage_all_methods - -
Error percentage across all methods over 2m
+#### worker: workerutil_dbworker_store_99th_percentile_duration -The percentage of gRPC requests that fail across all methods, aggregated across all instances. +Aggregate successful store operation duration distribution over 5m
This panel has no related alerts. -To see this panel, visit `/-/debug/grafana/d/repo-updater/repo-updater?viewPanel=100710` on your Sourcegraph instance. +To see this panel, visit `/-/debug/grafana/d/worker/worker?viewPanel=101601` on your Sourcegraph instance. -*Managed by the [Sourcegraph Source team](https://handbook.sourcegraph.com/departments/engineering/teams/source).* +*Managed by the [Sourcegraph Code Search team](https://handbook.sourcegraph.com/departments/engineering/teams/code-search).*Technical details
@@ -53249,23 +53600,21 @@ To see this panel, visit `/-/debug/grafana/d/repo-updater/repo-updater?viewPanel Query: ``` -(100.0 * ( (sum(rate(grpc_server_handled_total{grpc_code!="OK",instance=~`${instance:regex}`,grpc_service=~"repoupdater.v1.RepoUpdaterService"}[2m]))) / (sum(rate(grpc_server_handled_total{instance=~`${instance:regex}`,grpc_service=~"repoupdater.v1.RepoUpdaterService"}[2m]))) )) +sum by (le)(rate(src_workerutil_dbworker_store_duration_seconds_bucket{domain='insights_query_runner_jobs',job=~"^worker.*"}[5m])) ```-#### repo-updater: repo_updater_grpc_error_percentage_per_method - -
Error percentage per-method over 2m
+#### worker: workerutil_dbworker_store_errors_total -The percentage of gRPC requests that fail per method, aggregated across all instances. +Aggregate store operation errors every 5m
This panel has no related alerts. -To see this panel, visit `/-/debug/grafana/d/repo-updater/repo-updater?viewPanel=100711` on your Sourcegraph instance. +To see this panel, visit `/-/debug/grafana/d/worker/worker?viewPanel=101602` on your Sourcegraph instance. -*Managed by the [Sourcegraph Source team](https://handbook.sourcegraph.com/departments/engineering/teams/source).* +*Managed by the [Sourcegraph Code Search team](https://handbook.sourcegraph.com/departments/engineering/teams/code-search).*Technical details
@@ -53273,23 +53622,21 @@ To see this panel, visit `/-/debug/grafana/d/repo-updater/repo-updater?viewPanel Query: ``` -(100.0 * ( (sum(rate(grpc_server_handled_total{grpc_method=~`${repo_updater_method:regex}`,grpc_code!="OK",instance=~`${instance:regex}`,grpc_service=~"repoupdater.v1.RepoUpdaterService"}[2m])) by (grpc_method)) / (sum(rate(grpc_server_handled_total{grpc_method=~`${repo_updater_method:regex}`,instance=~`${instance:regex}`,grpc_service=~"repoupdater.v1.RepoUpdaterService"}[2m])) by (grpc_method)) )) +sum(increase(src_workerutil_dbworker_store_errors_total{domain='insights_query_runner_jobs',job=~"^worker.*"}[5m])) ```-#### repo-updater: repo_updater_p99_response_time_per_method - -
99th percentile response time per method over 2m
+#### worker: workerutil_dbworker_store_error_rate -The 99th percentile response time per method, aggregated across all instances. +Aggregate store operation error rate over 5m
This panel has no related alerts. -To see this panel, visit `/-/debug/grafana/d/repo-updater/repo-updater?viewPanel=100720` on your Sourcegraph instance. +To see this panel, visit `/-/debug/grafana/d/worker/worker?viewPanel=101603` on your Sourcegraph instance. -*Managed by the [Sourcegraph Source team](https://handbook.sourcegraph.com/departments/engineering/teams/source).* +*Managed by the [Sourcegraph Code Search team](https://handbook.sourcegraph.com/departments/engineering/teams/code-search).*Technical details
@@ -53297,23 +53644,21 @@ To see this panel, visit `/-/debug/grafana/d/repo-updater/repo-updater?viewPanel Query: ``` -histogram_quantile(0.99, sum by (le, name, grpc_method)(rate(grpc_server_handling_seconds_bucket{grpc_method=~`${repo_updater_method:regex}`,instance=~`${instance:regex}`,grpc_service=~"repoupdater.v1.RepoUpdaterService"}[2m]))) +sum(increase(src_workerutil_dbworker_store_errors_total{domain='insights_query_runner_jobs',job=~"^worker.*"}[5m])) / (sum(increase(src_workerutil_dbworker_store_total{domain='insights_query_runner_jobs',job=~"^worker.*"}[5m])) + sum(increase(src_workerutil_dbworker_store_errors_total{domain='insights_query_runner_jobs',job=~"^worker.*"}[5m]))) * 100 ```-#### repo-updater: repo_updater_p90_response_time_per_method +#### worker: workerutil_dbworker_store_total -
90th percentile response time per method over 2m
- -The 90th percentile response time per method, aggregated across all instances. +Store operations every 5m
This panel has no related alerts. -To see this panel, visit `/-/debug/grafana/d/repo-updater/repo-updater?viewPanel=100721` on your Sourcegraph instance. +To see this panel, visit `/-/debug/grafana/d/worker/worker?viewPanel=101610` on your Sourcegraph instance. -*Managed by the [Sourcegraph Source team](https://handbook.sourcegraph.com/departments/engineering/teams/source).* +*Managed by the [Sourcegraph Code Search team](https://handbook.sourcegraph.com/departments/engineering/teams/code-search).*Technical details
@@ -53321,23 +53666,21 @@ To see this panel, visit `/-/debug/grafana/d/repo-updater/repo-updater?viewPanel Query: ``` -histogram_quantile(0.90, sum by (le, name, grpc_method)(rate(grpc_server_handling_seconds_bucket{grpc_method=~`${repo_updater_method:regex}`,instance=~`${instance:regex}`,grpc_service=~"repoupdater.v1.RepoUpdaterService"}[2m]))) +sum by (op)(increase(src_workerutil_dbworker_store_total{domain='insights_query_runner_jobs',job=~"^worker.*"}[5m])) ```-#### repo-updater: repo_updater_p75_response_time_per_method - -
75th percentile response time per method over 2m
+#### worker: workerutil_dbworker_store_99th_percentile_duration -The 75th percentile response time per method, aggregated across all instances. +99th percentile successful store operation duration over 5m
This panel has no related alerts. -To see this panel, visit `/-/debug/grafana/d/repo-updater/repo-updater?viewPanel=100722` on your Sourcegraph instance. +To see this panel, visit `/-/debug/grafana/d/worker/worker?viewPanel=101611` on your Sourcegraph instance. -*Managed by the [Sourcegraph Source team](https://handbook.sourcegraph.com/departments/engineering/teams/source).* +*Managed by the [Sourcegraph Code Search team](https://handbook.sourcegraph.com/departments/engineering/teams/code-search).*Technical details
@@ -53345,23 +53688,21 @@ To see this panel, visit `/-/debug/grafana/d/repo-updater/repo-updater?viewPanel Query: ``` -histogram_quantile(0.75, sum by (le, name, grpc_method)(rate(grpc_server_handling_seconds_bucket{grpc_method=~`${repo_updater_method:regex}`,instance=~`${instance:regex}`,grpc_service=~"repoupdater.v1.RepoUpdaterService"}[2m]))) +histogram_quantile(0.99, sum by (le,op)(rate(src_workerutil_dbworker_store_duration_seconds_bucket{domain='insights_query_runner_jobs',job=~"^worker.*"}[5m]))) ```-#### repo-updater: repo_updater_p99_9_response_size_per_method +#### worker: workerutil_dbworker_store_errors_total -
99.9th percentile total response size per method over 2m
- -The 99.9th percentile total per-RPC response size per method, aggregated across all instances. +Store operation errors every 5m
This panel has no related alerts. -To see this panel, visit `/-/debug/grafana/d/repo-updater/repo-updater?viewPanel=100730` on your Sourcegraph instance. +To see this panel, visit `/-/debug/grafana/d/worker/worker?viewPanel=101612` on your Sourcegraph instance. -*Managed by the [Sourcegraph Source team](https://handbook.sourcegraph.com/departments/engineering/teams/source).* +*Managed by the [Sourcegraph Code Search team](https://handbook.sourcegraph.com/departments/engineering/teams/code-search).*Technical details
@@ -53369,23 +53710,21 @@ To see this panel, visit `/-/debug/grafana/d/repo-updater/repo-updater?viewPanel Query: ``` -histogram_quantile(0.999, sum by (le, name, grpc_method)(rate(src_grpc_server_sent_bytes_per_rpc_bucket{grpc_method=~`${repo_updater_method:regex}`,instance=~`${instance:regex}`,grpc_service=~"repoupdater.v1.RepoUpdaterService"}[2m]))) +sum by (op)(increase(src_workerutil_dbworker_store_errors_total{domain='insights_query_runner_jobs',job=~"^worker.*"}[5m])) ```-#### repo-updater: repo_updater_p90_response_size_per_method - -
90th percentile total response size per method over 2m
+#### worker: workerutil_dbworker_store_error_rate -The 90th percentile total per-RPC response size per method, aggregated across all instances. +Store operation error rate over 5m
This panel has no related alerts. -To see this panel, visit `/-/debug/grafana/d/repo-updater/repo-updater?viewPanel=100731` on your Sourcegraph instance. +To see this panel, visit `/-/debug/grafana/d/worker/worker?viewPanel=101613` on your Sourcegraph instance. -*Managed by the [Sourcegraph Source team](https://handbook.sourcegraph.com/departments/engineering/teams/source).* +*Managed by the [Sourcegraph Code Search team](https://handbook.sourcegraph.com/departments/engineering/teams/code-search).*Technical details
@@ -53393,23 +53732,23 @@ To see this panel, visit `/-/debug/grafana/d/repo-updater/repo-updater?viewPanel Query: ``` -histogram_quantile(0.90, sum by (le, name, grpc_method)(rate(src_grpc_server_sent_bytes_per_rpc_bucket{grpc_method=~`${repo_updater_method:regex}`,instance=~`${instance:regex}`,grpc_service=~"repoupdater.v1.RepoUpdaterService"}[2m]))) +sum by (op)(increase(src_workerutil_dbworker_store_errors_total{domain='insights_query_runner_jobs',job=~"^worker.*"}[5m])) / (sum by (op)(increase(src_workerutil_dbworker_store_total{domain='insights_query_runner_jobs',job=~"^worker.*"}[5m])) + sum by (op)(increase(src_workerutil_dbworker_store_errors_total{domain='insights_query_runner_jobs',job=~"^worker.*"}[5m]))) * 100 ```-#### repo-updater: repo_updater_p75_response_size_per_method +### Worker: Completion Credits Entitlement Usage Aggregator: Completion credits entitlement usage aggregations -
75th percentile total response size per method over 2m
+#### worker: completioncredits_aggregator_total -The 75th percentile total per-RPC response size per method, aggregated across all instances. +Completion credits entitlement usage aggregator operations every 30m
This panel has no related alerts. -To see this panel, visit `/-/debug/grafana/d/repo-updater/repo-updater?viewPanel=100732` on your Sourcegraph instance. +To see this panel, visit `/-/debug/grafana/d/worker/worker?viewPanel=101700` on your Sourcegraph instance. -*Managed by the [Sourcegraph Source team](https://handbook.sourcegraph.com/departments/engineering/teams/source).* +*Managed by the [Sourcegraph Core Services team](https://handbook.sourcegraph.com/departments/engineering/teams).*Technical details
@@ -53417,23 +53756,21 @@ To see this panel, visit `/-/debug/grafana/d/repo-updater/repo-updater?viewPanel Query: ``` -histogram_quantile(0.75, sum by (le, name, grpc_method)(rate(src_grpc_server_sent_bytes_per_rpc_bucket{grpc_method=~`${repo_updater_method:regex}`,instance=~`${instance:regex}`,grpc_service=~"repoupdater.v1.RepoUpdaterService"}[2m]))) +sum(increase(src_completioncredits_aggregator_total{job=~"^worker.*"}[30m])) ```-#### repo-updater: repo_updater_p99_9_invididual_sent_message_size_per_method +#### worker: completioncredits_aggregator_99th_percentile_duration -
99.9th percentile individual sent message size per method over 2m
- -The 99.9th percentile size of every individual protocol buffer size sent by the service per method, aggregated across all instances. +Aggregate successful completion credits entitlement usage aggregator operation duration distribution over 30m
This panel has no related alerts. -To see this panel, visit `/-/debug/grafana/d/repo-updater/repo-updater?viewPanel=100740` on your Sourcegraph instance. +To see this panel, visit `/-/debug/grafana/d/worker/worker?viewPanel=101701` on your Sourcegraph instance. -*Managed by the [Sourcegraph Source team](https://handbook.sourcegraph.com/departments/engineering/teams/source).* +*Managed by the [Sourcegraph Core Services team](https://handbook.sourcegraph.com/departments/engineering/teams).*Technical details
@@ -53441,23 +53778,21 @@ To see this panel, visit `/-/debug/grafana/d/repo-updater/repo-updater?viewPanel Query: ``` -histogram_quantile(0.999, sum by (le, name, grpc_method)(rate(src_grpc_server_sent_individual_message_size_bytes_per_rpc_bucket{grpc_method=~`${repo_updater_method:regex}`,instance=~`${instance:regex}`,grpc_service=~"repoupdater.v1.RepoUpdaterService"}[2m]))) +sum by (le)(rate(src_completioncredits_aggregator_duration_seconds_bucket{job=~"^worker.*"}[30m])) ```-#### repo-updater: repo_updater_p90_invididual_sent_message_size_per_method - -
90th percentile individual sent message size per method over 2m
+#### worker: completioncredits_aggregator_errors_total -The 90th percentile size of every individual protocol buffer size sent by the service per method, aggregated across all instances. +Completion credits entitlement usage aggregator operation errors every 30m
-This panel has no related alerts. +Refer to the [alerts reference](alerts#worker-completioncredits-aggregator-errors-total) for 1 alert related to this panel. -To see this panel, visit `/-/debug/grafana/d/repo-updater/repo-updater?viewPanel=100741` on your Sourcegraph instance. +To see this panel, visit `/-/debug/grafana/d/worker/worker?viewPanel=101702` on your Sourcegraph instance. -*Managed by the [Sourcegraph Source team](https://handbook.sourcegraph.com/departments/engineering/teams/source).* +*Managed by the [Sourcegraph Core Services team](https://handbook.sourcegraph.com/departments/engineering/teams).*Technical details
@@ -53465,23 +53800,21 @@ To see this panel, visit `/-/debug/grafana/d/repo-updater/repo-updater?viewPanel Query: ``` -histogram_quantile(0.90, sum by (le, name, grpc_method)(rate(src_grpc_server_sent_individual_message_size_bytes_per_rpc_bucket{grpc_method=~`${repo_updater_method:regex}`,instance=~`${instance:regex}`,grpc_service=~"repoupdater.v1.RepoUpdaterService"}[2m]))) +sum(increase(src_completioncredits_aggregator_errors_total{job=~"^worker.*"}[30m])) ```-#### repo-updater: repo_updater_p75_invididual_sent_message_size_per_method - -
75th percentile individual sent message size per method over 2m
+#### worker: completioncredits_aggregator_error_rate -The 75th percentile size of every individual protocol buffer size sent by the service per method, aggregated across all instances. +Completion credits entitlement usage aggregator operation error rate over 30m
This panel has no related alerts. -To see this panel, visit `/-/debug/grafana/d/repo-updater/repo-updater?viewPanel=100742` on your Sourcegraph instance. +To see this panel, visit `/-/debug/grafana/d/worker/worker?viewPanel=101703` on your Sourcegraph instance. -*Managed by the [Sourcegraph Source team](https://handbook.sourcegraph.com/departments/engineering/teams/source).* +*Managed by the [Sourcegraph Core Services team](https://handbook.sourcegraph.com/departments/engineering/teams).*Technical details
@@ -53489,23 +53822,26 @@ To see this panel, visit `/-/debug/grafana/d/repo-updater/repo-updater?viewPanel Query: ``` -histogram_quantile(0.75, sum by (le, name, grpc_method)(rate(src_grpc_server_sent_individual_message_size_bytes_per_rpc_bucket{grpc_method=~`${repo_updater_method:regex}`,instance=~`${instance:regex}`,grpc_service=~"repoupdater.v1.RepoUpdaterService"}[2m]))) +sum(increase(src_completioncredits_aggregator_errors_total{job=~"^worker.*"}[30m])) / (sum(increase(src_completioncredits_aggregator_total{job=~"^worker.*"}[30m])) + sum(increase(src_completioncredits_aggregator_errors_total{job=~"^worker.*"}[30m]))) * 100 ```-#### repo-updater: repo_updater_grpc_response_stream_message_count_per_method +### Worker: Periodic Goroutines -
Average streaming response message count per-method over 2m
+#### worker: running_goroutines -The average number of response messages sent during a streaming RPC method, broken out per method, aggregated across all instances. +Number of currently running periodic goroutines
+ +The number of currently running periodic goroutines by name and job. +A value of 0 indicates the routine isn`t running currently, it awaits it`s next schedule. This panel has no related alerts. -To see this panel, visit `/-/debug/grafana/d/repo-updater/repo-updater?viewPanel=100750` on your Sourcegraph instance. +To see this panel, visit `/-/debug/grafana/d/worker/worker?viewPanel=101800` on your Sourcegraph instance. -*Managed by the [Sourcegraph Source team](https://handbook.sourcegraph.com/departments/engineering/teams/source).* +*Managed by the [Sourcegraph Infrastructure Org team](https://handbook.sourcegraph.com/departments/engineering/infrastructure).*Technical details
@@ -53513,23 +53849,24 @@ To see this panel, visit `/-/debug/grafana/d/repo-updater/repo-updater?viewPanel Query: ``` -((sum(rate(grpc_server_msg_sent_total{grpc_type="server_stream",instance=~`${instance:regex}`,grpc_service=~"repoupdater.v1.RepoUpdaterService"}[2m])) by (grpc_method))/(sum(rate(grpc_server_started_total{grpc_type="server_stream",instance=~`${instance:regex}`,grpc_service=~"repoupdater.v1.RepoUpdaterService"}[2m])) by (grpc_method))) +sum by (name, job_name) (src_periodic_goroutine_running{job=~".*worker.*"}) ```-#### repo-updater: repo_updater_grpc_all_codes_per_method +#### worker: goroutine_success_rate -
Response codes rate per-method over 2m
+Success rate for periodic goroutine executions
-The rate of all generated gRPC response codes per method, aggregated across all instances. +The rate of successful executions of each periodic goroutine. +A low or zero value could indicate that a routine is stalled or encountering errors. This panel has no related alerts. -To see this panel, visit `/-/debug/grafana/d/repo-updater/repo-updater?viewPanel=100760` on your Sourcegraph instance. +To see this panel, visit `/-/debug/grafana/d/worker/worker?viewPanel=101801` on your Sourcegraph instance. -*Managed by the [Sourcegraph Source team](https://handbook.sourcegraph.com/departments/engineering/teams/source).* +*Managed by the [Sourcegraph Infrastructure Org team](https://handbook.sourcegraph.com/departments/engineering/infrastructure).*Technical details
@@ -53537,25 +53874,24 @@ To see this panel, visit `/-/debug/grafana/d/repo-updater/repo-updater?viewPanel Query: ``` -sum(rate(grpc_server_handled_total{grpc_method=~`${repo_updater_method:regex}`,instance=~`${instance:regex}`,grpc_service=~"repoupdater.v1.RepoUpdaterService"}[2m])) by (grpc_method, grpc_code) +sum by (name, job_name) (rate(src_periodic_goroutine_total{job=~".*worker.*"}[5m])) ```-### Repo Updater: Repo Updater GRPC "internal error" metrics - -#### repo-updater: repo_updater_grpc_clients_error_percentage_all_methods +#### worker: goroutine_error_rate -
Client baseline error percentage across all methods over 2m
+Error rate for periodic goroutine executions
-The percentage of gRPC requests that fail across all methods (regardless of whether or not there was an internal error), aggregated across all "repo_updater" clients. +The rate of errors encountered by each periodic goroutine. +A sustained high error rate may indicate a problem with the routine`s configuration or dependencies. -This panel has no related alerts. +Refer to the [alerts reference](alerts#worker-goroutine-error-rate) for 1 alert related to this panel. -To see this panel, visit `/-/debug/grafana/d/repo-updater/repo-updater?viewPanel=100800` on your Sourcegraph instance. +To see this panel, visit `/-/debug/grafana/d/worker/worker?viewPanel=101810` on your Sourcegraph instance. -*Managed by the [Sourcegraph Source team](https://handbook.sourcegraph.com/departments/engineering/teams/source).* +*Managed by the [Sourcegraph Infrastructure Org team](https://handbook.sourcegraph.com/departments/engineering/infrastructure).*Technical details
@@ -53563,23 +53899,24 @@ To see this panel, visit `/-/debug/grafana/d/repo-updater/repo-updater?viewPanel Query: ``` -(100.0 * ((((sum(rate(src_grpc_method_status{grpc_service=~"repoupdater.v1.RepoUpdaterService",grpc_code!="OK"}[2m])))) / ((sum(rate(src_grpc_method_status{grpc_service=~"repoupdater.v1.RepoUpdaterService"}[2m]))))))) +sum by (name, job_name) (rate(src_periodic_goroutine_errors_total{job=~".*worker.*"}[5m])) ```-#### repo-updater: repo_updater_grpc_clients_error_percentage_per_method +#### worker: goroutine_error_percentage -
Client baseline error percentage per-method over 2m
+Percentage of periodic goroutine executions that result in errors
-The percentage of gRPC requests that fail per method (regardless of whether or not there was an internal error), aggregated across all "repo_updater" clients. +The percentage of executions that result in errors for each periodic goroutine. +A value above 5% indicates that a significant portion of routine executions are failing. -This panel has no related alerts. +Refer to the [alerts reference](alerts#worker-goroutine-error-percentage) for 1 alert related to this panel. -To see this panel, visit `/-/debug/grafana/d/repo-updater/repo-updater?viewPanel=100801` on your Sourcegraph instance. +To see this panel, visit `/-/debug/grafana/d/worker/worker?viewPanel=101811` on your Sourcegraph instance. -*Managed by the [Sourcegraph Source team](https://handbook.sourcegraph.com/departments/engineering/teams/source).* +*Managed by the [Sourcegraph Infrastructure Org team](https://handbook.sourcegraph.com/departments/engineering/infrastructure).*Technical details
@@ -53587,23 +53924,24 @@ To see this panel, visit `/-/debug/grafana/d/repo-updater/repo-updater?viewPanel Query: ``` -(100.0 * ((((sum(rate(src_grpc_method_status{grpc_service=~"repoupdater.v1.RepoUpdaterService",grpc_method=~"${repo_updater_method:regex}",grpc_code!="OK"}[2m])) by (grpc_method))) / ((sum(rate(src_grpc_method_status{grpc_service=~"repoupdater.v1.RepoUpdaterService",grpc_method=~"${repo_updater_method:regex}"}[2m])) by (grpc_method)))))) +sum by (name, job_name) (rate(src_periodic_goroutine_errors_total{job=~".*worker.*"}[5m])) / sum by (name, job_name) (rate(src_periodic_goroutine_total{job=~".*worker.*"}[5m]) > 0) * 100 ```-#### repo-updater: repo_updater_grpc_clients_all_codes_per_method +#### worker: goroutine_handler_duration -
Client baseline response codes rate per-method over 2m
+95th percentile handler execution time
-The rate of all generated gRPC response codes per method (regardless of whether or not there was an internal error), aggregated across all "repo_updater" clients. +The 95th percentile execution time for each periodic goroutine handler. +Longer durations might indicate increased load or processing time. This panel has no related alerts. -To see this panel, visit `/-/debug/grafana/d/repo-updater/repo-updater?viewPanel=100802` on your Sourcegraph instance. +To see this panel, visit `/-/debug/grafana/d/worker/worker?viewPanel=101820` on your Sourcegraph instance. -*Managed by the [Sourcegraph Source team](https://handbook.sourcegraph.com/departments/engineering/teams/source).* +*Managed by the [Sourcegraph Infrastructure Org team](https://handbook.sourcegraph.com/departments/engineering/infrastructure).*Technical details
@@ -53611,29 +53949,24 @@ To see this panel, visit `/-/debug/grafana/d/repo-updater/repo-updater?viewPanel Query: ``` -(sum(rate(src_grpc_method_status{grpc_service=~"repoupdater.v1.RepoUpdaterService",grpc_method=~"${repo_updater_method:regex}"}[2m])) by (grpc_method, grpc_code)) +histogram_quantile(0.95, sum by (name, job_name, le) (rate(src_periodic_goroutine_duration_seconds_bucket{job=~".*worker.*"}[5m]))) ```-#### repo-updater: repo_updater_grpc_clients_internal_error_percentage_all_methods - -
Client-observed gRPC internal error percentage across all methods over 2m
- -The percentage of gRPC requests that appear to fail due to gRPC internal errors across all methods, aggregated across all "repo_updater" clients. +#### worker: goroutine_loop_duration -**Note**: Internal errors are ones that appear to originate from the https://github.com/grpc/grpc-go library itself, rather than from any user-written application code. These errors can be caused by a variety of issues, and can originate from either the code-generated "repo_updater" gRPC client or gRPC server. These errors might be solvable by adjusting the gRPC configuration, or they might indicate a bug from Sourcegraph`s use of gRPC. - -When debugging, knowing that a particular error comes from the grpc-go library itself (an `internal error`) as opposed to `normal` application code can be helpful when trying to fix it. +95th percentile loop cycle time
-**Note**: Internal errors are detected via a very coarse heuristic (seeing if the error starts with `grpc:`, etc.). Because of this, it`s possible that some gRPC-specific issues might not be categorized as internal errors. +The 95th percentile loop cycle time for each periodic goroutine (excluding sleep time). +This represents how long a complete loop iteration takes before sleeping for the next interval. This panel has no related alerts. -To see this panel, visit `/-/debug/grafana/d/repo-updater/repo-updater?viewPanel=100810` on your Sourcegraph instance. +To see this panel, visit `/-/debug/grafana/d/worker/worker?viewPanel=101821` on your Sourcegraph instance. -*Managed by the [Sourcegraph Source team](https://handbook.sourcegraph.com/departments/engineering/teams/source).* +*Managed by the [Sourcegraph Infrastructure Org team](https://handbook.sourcegraph.com/departments/engineering/infrastructure).*Technical details
@@ -53641,29 +53974,24 @@ To see this panel, visit `/-/debug/grafana/d/repo-updater/repo-updater?viewPanel Query: ``` -(100.0 * ((((sum(rate(src_grpc_method_status{grpc_service=~"repoupdater.v1.RepoUpdaterService",grpc_code!="OK",is_internal_error="true"}[2m])))) / ((sum(rate(src_grpc_method_status{grpc_service=~"repoupdater.v1.RepoUpdaterService"}[2m]))))))) +histogram_quantile(0.95, sum by (name, job_name, le) (rate(src_periodic_goroutine_loop_duration_seconds_bucket{job=~".*worker.*"}[5m]))) ```-#### repo-updater: repo_updater_grpc_clients_internal_error_percentage_per_method - -
Client-observed gRPC internal error percentage per-method over 2m
- -The percentage of gRPC requests that appear to fail to due to gRPC internal errors per method, aggregated across all "repo_updater" clients. +#### worker: tenant_processing_duration -**Note**: Internal errors are ones that appear to originate from the https://github.com/grpc/grpc-go library itself, rather than from any user-written application code. These errors can be caused by a variety of issues, and can originate from either the code-generated "repo_updater" gRPC client or gRPC server. These errors might be solvable by adjusting the gRPC configuration, or they might indicate a bug from Sourcegraph`s use of gRPC. - -When debugging, knowing that a particular error comes from the grpc-go library itself (an `internal error`) as opposed to `normal` application code can be helpful when trying to fix it. +95th percentile tenant processing time
-**Note**: Internal errors are detected via a very coarse heuristic (seeing if the error starts with `grpc:`, etc.). Because of this, it`s possible that some gRPC-specific issues might not be categorized as internal errors. +The 95th percentile processing time for individual tenants within periodic goroutines. +Higher values indicate that tenant processing is taking longer and may affect overall performance. This panel has no related alerts. -To see this panel, visit `/-/debug/grafana/d/repo-updater/repo-updater?viewPanel=100811` on your Sourcegraph instance. +To see this panel, visit `/-/debug/grafana/d/worker/worker?viewPanel=101830` on your Sourcegraph instance. -*Managed by the [Sourcegraph Source team](https://handbook.sourcegraph.com/departments/engineering/teams/source).* +*Managed by the [Sourcegraph Infrastructure Org team](https://handbook.sourcegraph.com/departments/engineering/infrastructure).*Technical details
@@ -53671,29 +53999,24 @@ To see this panel, visit `/-/debug/grafana/d/repo-updater/repo-updater?viewPanel Query: ``` -(100.0 * ((((sum(rate(src_grpc_method_status{grpc_service=~"repoupdater.v1.RepoUpdaterService",grpc_method=~"${repo_updater_method:regex}",grpc_code!="OK",is_internal_error="true"}[2m])) by (grpc_method))) / ((sum(rate(src_grpc_method_status{grpc_service=~"repoupdater.v1.RepoUpdaterService",grpc_method=~"${repo_updater_method:regex}"}[2m])) by (grpc_method)))))) +histogram_quantile(0.95, sum by (name, job_name, le) (rate(src_periodic_goroutine_tenant_duration_seconds_bucket{job=~".*worker.*"}[5m]))) ```-#### repo-updater: repo_updater_grpc_clients_internal_error_all_codes_per_method - -
Client-observed gRPC internal error response code rate per-method over 2m
- -The rate of gRPC internal-error response codes per method, aggregated across all "repo_updater" clients. +#### worker: tenant_processing_max -**Note**: Internal errors are ones that appear to originate from the https://github.com/grpc/grpc-go library itself, rather than from any user-written application code. These errors can be caused by a variety of issues, and can originate from either the code-generated "repo_updater" gRPC client or gRPC server. These errors might be solvable by adjusting the gRPC configuration, or they might indicate a bug from Sourcegraph`s use of gRPC. - -When debugging, knowing that a particular error comes from the grpc-go library itself (an `internal error`) as opposed to `normal` application code can be helpful when trying to fix it. +Maximum tenant processing time
-**Note**: Internal errors are detected via a very coarse heuristic (seeing if the error starts with `grpc:`, etc.). Because of this, it`s possible that some gRPC-specific issues might not be categorized as internal errors. +The maximum processing time for individual tenants within periodic goroutines. +Consistently high values might indicate problematic tenants or inefficient processing. This panel has no related alerts. -To see this panel, visit `/-/debug/grafana/d/repo-updater/repo-updater?viewPanel=100812` on your Sourcegraph instance. +To see this panel, visit `/-/debug/grafana/d/worker/worker?viewPanel=101831` on your Sourcegraph instance. -*Managed by the [Sourcegraph Source team](https://handbook.sourcegraph.com/departments/engineering/teams/source).* +*Managed by the [Sourcegraph Infrastructure Org team](https://handbook.sourcegraph.com/departments/engineering/infrastructure).*Technical details
@@ -53701,25 +54024,24 @@ To see this panel, visit `/-/debug/grafana/d/repo-updater/repo-updater?viewPanel Query: ``` -(sum(rate(src_grpc_method_status{grpc_service=~"repoupdater.v1.RepoUpdaterService",is_internal_error="true",grpc_method=~"${repo_updater_method:regex}"}[2m])) by (grpc_method, grpc_code)) +max by (name, job_name) (rate(src_periodic_goroutine_tenant_duration_seconds_sum{job=~".*worker.*"}[5m]) / rate(src_periodic_goroutine_tenant_duration_seconds_count{job=~".*worker.*"}[5m])) ```-### Repo Updater: Repo Updater GRPC retry metrics - -#### repo-updater: repo_updater_grpc_clients_retry_percentage_across_all_methods +#### worker: tenant_count -
Client retry percentage across all methods over 2m
+Number of tenants processed per routine
-The percentage of gRPC requests that were retried across all methods, aggregated across all "repo_updater" clients. +The number of tenants processed by each periodic goroutine. +Unexpected changes can indicate tenant configuration issues or scaling events. This panel has no related alerts. -To see this panel, visit `/-/debug/grafana/d/repo-updater/repo-updater?viewPanel=100900` on your Sourcegraph instance. +To see this panel, visit `/-/debug/grafana/d/worker/worker?viewPanel=101840` on your Sourcegraph instance. -*Managed by the [Sourcegraph Source team](https://handbook.sourcegraph.com/departments/engineering/teams/source).* +*Managed by the [Sourcegraph Infrastructure Org team](https://handbook.sourcegraph.com/departments/engineering/infrastructure).*Technical details
@@ -53727,23 +54049,24 @@ To see this panel, visit `/-/debug/grafana/d/repo-updater/repo-updater?viewPanel Query: ``` -(100.0 * ((((sum(rate(src_grpc_client_retry_attempts_total{grpc_service=~"repoupdater.v1.RepoUpdaterService",is_retried="true"}[2m])))) / ((sum(rate(src_grpc_client_retry_attempts_total{grpc_service=~"repoupdater.v1.RepoUpdaterService"}[2m]))))))) +max by (name, job_name) (src_periodic_goroutine_tenant_count{job=~".*worker.*"}) ```-#### repo-updater: repo_updater_grpc_clients_retry_percentage_per_method +#### worker: tenant_success_rate -
Client retry percentage per-method over 2m
+Rate of successful tenant processing operations
-The percentage of gRPC requests that were retried aggregated across all "repo_updater" clients, broken out per method. +The rate of successful tenant processing operations. +A healthy routine should maintain a consistent processing rate. This panel has no related alerts. -To see this panel, visit `/-/debug/grafana/d/repo-updater/repo-updater?viewPanel=100901` on your Sourcegraph instance. +To see this panel, visit `/-/debug/grafana/d/worker/worker?viewPanel=101841` on your Sourcegraph instance. -*Managed by the [Sourcegraph Source team](https://handbook.sourcegraph.com/departments/engineering/teams/source).* +*Managed by the [Sourcegraph Infrastructure Org team](https://handbook.sourcegraph.com/departments/engineering/infrastructure).*Technical details
@@ -53751,23 +54074,24 @@ To see this panel, visit `/-/debug/grafana/d/repo-updater/repo-updater?viewPanel Query: ``` -(100.0 * ((((sum(rate(src_grpc_client_retry_attempts_total{grpc_service=~"repoupdater.v1.RepoUpdaterService",is_retried="true",grpc_method=~"${repo_updater_method:regex}"}[2m])) by (grpc_method))) / ((sum(rate(src_grpc_client_retry_attempts_total{grpc_service=~"repoupdater.v1.RepoUpdaterService",grpc_method=~"${repo_updater_method:regex}"}[2m])) by (grpc_method)))))) +sum by (name, job_name) (rate(src_periodic_goroutine_tenant_success_total{job=~".*worker.*"}[5m])) ```-#### repo-updater: repo_updater_grpc_clients_retry_count_per_method +#### worker: tenant_error_rate -
Client retry count per-method over 2m
+Rate of tenant processing errors
-The count of gRPC requests that were retried aggregated across all "repo_updater" clients, broken out per method +The rate of tenant processing operations that result in errors. +Consistent errors indicate problems with specific tenants. This panel has no related alerts. -To see this panel, visit `/-/debug/grafana/d/repo-updater/repo-updater?viewPanel=100902` on your Sourcegraph instance. +To see this panel, visit `/-/debug/grafana/d/worker/worker?viewPanel=101850` on your Sourcegraph instance. -*Managed by the [Sourcegraph Source team](https://handbook.sourcegraph.com/departments/engineering/teams/source).* +*Managed by the [Sourcegraph Infrastructure Org team](https://handbook.sourcegraph.com/departments/engineering/infrastructure).*Technical details
@@ -53775,23 +54099,22 @@ To see this panel, visit `/-/debug/grafana/d/repo-updater/repo-updater?viewPanel Query: ``` -(sum(rate(src_grpc_client_retry_attempts_total{grpc_service=~"repoupdater.v1.RepoUpdaterService",grpc_method=~"${repo_updater_method:regex}",is_retried="true"}[2m])) by (grpc_method)) +sum by (name, job_name) (rate(src_periodic_goroutine_tenant_errors_total{job=~".*worker.*"}[5m])) ```-### Repo Updater: Site configuration client update latency - -#### repo-updater: repo_updater_site_configuration_duration_since_last_successful_update_by_instance +#### worker: tenant_error_percentage -
Duration since last successful site configuration update (by instance)
+Percentage of tenant operations resulting in errors
-The duration since the configuration client used by the "repo_updater" service last successfully updated its site configuration. Long durations could indicate issues updating the site configuration. +The percentage of tenant operations that result in errors. +Values above 5% indicate significant tenant processing problems. This panel has no related alerts. -To see this panel, visit `/-/debug/grafana/d/repo-updater/repo-updater?viewPanel=101000` on your Sourcegraph instance. +To see this panel, visit `/-/debug/grafana/d/worker/worker?viewPanel=101851` on your Sourcegraph instance. *Managed by the [Sourcegraph Infrastructure Org team](https://handbook.sourcegraph.com/departments/engineering/infrastructure).* @@ -53801,19 +54124,21 @@ To see this panel, visit `/-/debug/grafana/d/repo-updater/repo-updater?viewPanel Query: ``` -src_conf_client_time_since_last_successful_update_seconds{job=~`.*repo-updater`,instance=~`${instance:regex}`} +(sum by (name, job_name) (rate(src_periodic_goroutine_tenant_errors_total{job=~".*worker.*"}[5m])) / (sum by (name, job_name) (rate(src_periodic_goroutine_tenant_success_total{job=~".*worker.*"}[5m])) + sum by (name, job_name) (rate(src_periodic_goroutine_tenant_errors_total{job=~".*worker.*"}[5m])))) * 100 ```-#### repo-updater: repo_updater_site_configuration_duration_since_last_successful_update_by_instance +### Worker: Database connections + +#### worker: max_open_conns -
Maximum duration since last successful site configuration update (all "repo_updater" instances)
+Maximum open
-Refer to the [alerts reference](alerts#repo-updater-repo-updater-site-configuration-duration-since-last-successful-update-by-instance) for 1 alert related to this panel. +This panel has no related alerts. -To see this panel, visit `/-/debug/grafana/d/repo-updater/repo-updater?viewPanel=101001` on your Sourcegraph instance. +To see this panel, visit `/-/debug/grafana/d/worker/worker?viewPanel=101900` on your Sourcegraph instance. *Managed by the [Sourcegraph Infrastructure Org team](https://handbook.sourcegraph.com/departments/engineering/infrastructure).* @@ -53823,25 +54148,21 @@ To see this panel, visit `/-/debug/grafana/d/repo-updater/repo-updater?viewPanel Query: ``` -max(max_over_time(src_conf_client_time_since_last_successful_update_seconds{job=~`.*repo-updater`,instance=~`${instance:regex}`}[1m])) +sum by (app_name, db_name) (src_pgsql_conns_max_open{app_name="worker"}) ```-### Repo Updater: HTTP handlers - -#### repo-updater: healthy_request_rate - -
Requests per second, by route, when status code is 200
+#### worker: open_conns -The number of healthy HTTP requests per second to internal HTTP api +Established
This panel has no related alerts. -To see this panel, visit `/-/debug/grafana/d/repo-updater/repo-updater?viewPanel=101100` on your Sourcegraph instance. +To see this panel, visit `/-/debug/grafana/d/worker/worker?viewPanel=101901` on your Sourcegraph instance. -*Managed by the [Sourcegraph Source team](https://handbook.sourcegraph.com/departments/engineering/teams/source).* +*Managed by the [Sourcegraph Infrastructure Org team](https://handbook.sourcegraph.com/departments/engineering/infrastructure).*Technical details
@@ -53849,23 +54170,21 @@ To see this panel, visit `/-/debug/grafana/d/repo-updater/repo-updater?viewPanel Query: ``` -sum by (route) (rate(src_http_request_duration_seconds_count{app="repo-updater",code=~"2.."}[5m])) +sum by (app_name, db_name) (src_pgsql_conns_open{app_name="worker"}) ```-#### repo-updater: unhealthy_request_rate - -
Requests per second, by route, when status code is not 200
+#### worker: in_use -The number of unhealthy HTTP requests per second to internal HTTP api +Used
This panel has no related alerts. -To see this panel, visit `/-/debug/grafana/d/repo-updater/repo-updater?viewPanel=101101` on your Sourcegraph instance. +To see this panel, visit `/-/debug/grafana/d/worker/worker?viewPanel=101910` on your Sourcegraph instance. -*Managed by the [Sourcegraph Source team](https://handbook.sourcegraph.com/departments/engineering/teams/source).* +*Managed by the [Sourcegraph Infrastructure Org team](https://handbook.sourcegraph.com/departments/engineering/infrastructure).*Technical details
@@ -53873,23 +54192,21 @@ To see this panel, visit `/-/debug/grafana/d/repo-updater/repo-updater?viewPanel Query: ``` -sum by (route) (rate(src_http_request_duration_seconds_count{app="repo-updater",code!~"2.."}[5m])) +sum by (app_name, db_name) (src_pgsql_conns_in_use{app_name="worker"}) ```-#### repo-updater: request_rate_by_code - -
Requests per second, by status code
+#### worker: idle -The number of HTTP requests per second by code +Idle
This panel has no related alerts. -To see this panel, visit `/-/debug/grafana/d/repo-updater/repo-updater?viewPanel=101102` on your Sourcegraph instance. +To see this panel, visit `/-/debug/grafana/d/worker/worker?viewPanel=101911` on your Sourcegraph instance. -*Managed by the [Sourcegraph Source team](https://handbook.sourcegraph.com/departments/engineering/teams/source).* +*Managed by the [Sourcegraph Infrastructure Org team](https://handbook.sourcegraph.com/departments/engineering/infrastructure).*Technical details
@@ -53897,23 +54214,21 @@ To see this panel, visit `/-/debug/grafana/d/repo-updater/repo-updater?viewPanel Query: ``` -sum by (code) (rate(src_http_request_duration_seconds_count{app="repo-updater"}[5m])) +sum by (app_name, db_name) (src_pgsql_conns_idle{app_name="worker"}) ```-#### repo-updater: 95th_percentile_healthy_requests - -
95th percentile duration by route, when status code is 200
+#### worker: mean_blocked_seconds_per_conn_request -The 95th percentile duration by route when the status code is 200 +Mean blocked seconds per conn request
-This panel has no related alerts. +Refer to the [alerts reference](alerts#worker-mean-blocked-seconds-per-conn-request) for 2 alerts related to this panel. -To see this panel, visit `/-/debug/grafana/d/repo-updater/repo-updater?viewPanel=101110` on your Sourcegraph instance. +To see this panel, visit `/-/debug/grafana/d/worker/worker?viewPanel=101920` on your Sourcegraph instance. -*Managed by the [Sourcegraph Source team](https://handbook.sourcegraph.com/departments/engineering/teams/source).* +*Managed by the [Sourcegraph Infrastructure Org team](https://handbook.sourcegraph.com/departments/engineering/infrastructure).*Technical details
@@ -53921,23 +54236,21 @@ To see this panel, visit `/-/debug/grafana/d/repo-updater/repo-updater?viewPanel Query: ``` -histogram_quantile(0.95, sum(rate(src_http_request_duration_seconds_bucket{app="repo-updater",code=~"2.."}[5m])) by (le, route)) +sum by (app_name, db_name) (increase(src_pgsql_conns_blocked_seconds{app_name="worker"}[5m])) / sum by (app_name, db_name) (increase(src_pgsql_conns_waited_for{app_name="worker"}[5m])) ```-#### repo-updater: 95th_percentile_unhealthy_requests - -
95th percentile duration by route, when status code is not 200
+#### worker: closed_max_idle -The 95th percentile duration by route when the status code is not 200 +Closed by SetMaxIdleConns
This panel has no related alerts. -To see this panel, visit `/-/debug/grafana/d/repo-updater/repo-updater?viewPanel=101111` on your Sourcegraph instance. +To see this panel, visit `/-/debug/grafana/d/worker/worker?viewPanel=101930` on your Sourcegraph instance. -*Managed by the [Sourcegraph Source team](https://handbook.sourcegraph.com/departments/engineering/teams/source).* +*Managed by the [Sourcegraph Infrastructure Org team](https://handbook.sourcegraph.com/departments/engineering/infrastructure).*Technical details
@@ -53945,23 +54258,21 @@ To see this panel, visit `/-/debug/grafana/d/repo-updater/repo-updater?viewPanel Query: ``` -histogram_quantile(0.95, sum(rate(src_http_request_duration_seconds_bucket{app="repo-updater",code!~"2.."}[5m])) by (le, route)) +sum by (app_name, db_name) (increase(src_pgsql_conns_closed_max_idle{app_name="worker"}[5m])) ```-### Repo Updater: Database connections - -#### repo-updater: max_open_conns +#### worker: closed_max_lifetime -
Maximum open
+Closed by SetConnMaxLifetime
This panel has no related alerts. -To see this panel, visit `/-/debug/grafana/d/repo-updater/repo-updater?viewPanel=101200` on your Sourcegraph instance. +To see this panel, visit `/-/debug/grafana/d/worker/worker?viewPanel=101931` on your Sourcegraph instance. -*Managed by the [Sourcegraph Source team](https://handbook.sourcegraph.com/departments/engineering/teams/source).* +*Managed by the [Sourcegraph Infrastructure Org team](https://handbook.sourcegraph.com/departments/engineering/infrastructure).*Technical details
@@ -53969,21 +54280,21 @@ To see this panel, visit `/-/debug/grafana/d/repo-updater/repo-updater?viewPanel Query: ``` -sum by (app_name, db_name) (src_pgsql_conns_max_open{app_name="repo-updater"}) +sum by (app_name, db_name) (increase(src_pgsql_conns_closed_max_lifetime{app_name="worker"}[5m])) ```-#### repo-updater: open_conns +#### worker: closed_max_idle_time -
Established
+Closed by SetConnMaxIdleTime
This panel has no related alerts. -To see this panel, visit `/-/debug/grafana/d/repo-updater/repo-updater?viewPanel=101201` on your Sourcegraph instance. +To see this panel, visit `/-/debug/grafana/d/worker/worker?viewPanel=101932` on your Sourcegraph instance. -*Managed by the [Sourcegraph Source team](https://handbook.sourcegraph.com/departments/engineering/teams/source).* +*Managed by the [Sourcegraph Infrastructure Org team](https://handbook.sourcegraph.com/departments/engineering/infrastructure).*Technical details
@@ -53991,21 +54302,23 @@ To see this panel, visit `/-/debug/grafana/d/repo-updater/repo-updater?viewPanel Query: ``` -sum by (app_name, db_name) (src_pgsql_conns_open{app_name="repo-updater"}) +sum by (app_name, db_name) (increase(src_pgsql_conns_closed_max_idle_time{app_name="worker"}[5m])) ```-#### repo-updater: in_use +### Worker: Worker (CPU, Memory) -
Used
+#### worker: cpu_usage_percentage -This panel has no related alerts. +CPU usage
-To see this panel, visit `/-/debug/grafana/d/repo-updater/repo-updater?viewPanel=101210` on your Sourcegraph instance. +Refer to the [alerts reference](alerts#worker-cpu-usage-percentage) for 1 alert related to this panel. -*Managed by the [Sourcegraph Source team](https://handbook.sourcegraph.com/departments/engineering/teams/source).* +To see this panel, visit `/-/debug/grafana/d/worker/worker?viewPanel=102000` on your Sourcegraph instance. + +*Managed by the [Sourcegraph Code Search team](https://handbook.sourcegraph.com/departments/engineering/teams/code-search).*Technical details
@@ -54013,21 +54326,23 @@ To see this panel, visit `/-/debug/grafana/d/repo-updater/repo-updater?viewPanel Query: ``` -sum by (app_name, db_name) (src_pgsql_conns_in_use{app_name="repo-updater"}) +cadvisor_container_cpu_usage_percentage_total{name=~"^worker.*"} ```-#### repo-updater: idle +#### worker: memory_usage_percentage -
Idle
+Memory usage percentage (total)
+ +An estimate for the active memory in use, which includes anonymous memory, file memory, and kernel memory. Some of this memory is reclaimable, so high usage does not necessarily indicate memory pressure. This panel has no related alerts. -To see this panel, visit `/-/debug/grafana/d/repo-updater/repo-updater?viewPanel=101211` on your Sourcegraph instance. +To see this panel, visit `/-/debug/grafana/d/worker/worker?viewPanel=102001` on your Sourcegraph instance. -*Managed by the [Sourcegraph Source team](https://handbook.sourcegraph.com/departments/engineering/teams/source).* +*Managed by the [Sourcegraph Code Search team](https://handbook.sourcegraph.com/departments/engineering/teams/code-search).*Technical details
@@ -54035,21 +54350,23 @@ To see this panel, visit `/-/debug/grafana/d/repo-updater/repo-updater?viewPanel Query: ``` -sum by (app_name, db_name) (src_pgsql_conns_idle{app_name="repo-updater"}) +cadvisor_container_memory_usage_percentage_total{name=~"^worker.*"} ```-#### repo-updater: mean_blocked_seconds_per_conn_request +#### worker: memory_working_set_bytes -
Mean blocked seconds per conn request
+Memory usage bytes (total)
-Refer to the [alerts reference](alerts#repo-updater-mean-blocked-seconds-per-conn-request) for 2 alerts related to this panel. +An estimate for the active memory in use in bytes, which includes anonymous memory, file memory, and kernel memory. Some of this memory is reclaimable, so high usage does not necessarily indicate memory pressure. -To see this panel, visit `/-/debug/grafana/d/repo-updater/repo-updater?viewPanel=101220` on your Sourcegraph instance. +This panel has no related alerts. -*Managed by the [Sourcegraph Source team](https://handbook.sourcegraph.com/departments/engineering/teams/source).* +To see this panel, visit `/-/debug/grafana/d/worker/worker?viewPanel=102002` on your Sourcegraph instance. + +*Managed by the [Sourcegraph Code Search team](https://handbook.sourcegraph.com/departments/engineering/teams/code-search).*Technical details
@@ -54057,21 +54374,23 @@ To see this panel, visit `/-/debug/grafana/d/repo-updater/repo-updater?viewPanel Query: ``` -sum by (app_name, db_name) (increase(src_pgsql_conns_blocked_seconds{app_name="repo-updater"}[5m])) / sum by (app_name, db_name) (increase(src_pgsql_conns_waited_for{app_name="repo-updater"}[5m])) +max by (name) (container_memory_working_set_bytes{name=~"^worker.*"}) ```-#### repo-updater: closed_max_idle +#### worker: memory_rss -
Closed by SetMaxIdleConns
+Memory (RSS)
-This panel has no related alerts. +The total anonymous memory in use by the application, which includes Go stack and heap. This memory is is non-reclaimable, and high usage may trigger OOM kills. Note: the metric is named RSS because to match the cadvisor name, but `anonymous` is more accurate." -To see this panel, visit `/-/debug/grafana/d/repo-updater/repo-updater?viewPanel=101230` on your Sourcegraph instance. +Refer to the [alerts reference](alerts#worker-memory-rss) for 1 alert related to this panel. -*Managed by the [Sourcegraph Source team](https://handbook.sourcegraph.com/departments/engineering/teams/source).* +To see this panel, visit `/-/debug/grafana/d/worker/worker?viewPanel=102010` on your Sourcegraph instance. + +*Managed by the [Sourcegraph Code Search team](https://handbook.sourcegraph.com/departments/engineering/teams/code-search).*Technical details
@@ -54079,21 +54398,23 @@ To see this panel, visit `/-/debug/grafana/d/repo-updater/repo-updater?viewPanel Query: ``` -sum by (app_name, db_name) (increase(src_pgsql_conns_closed_max_idle{app_name="repo-updater"}[5m])) +max(container_memory_rss{name=~"^worker.*"} / container_spec_memory_limit_bytes{name=~"^worker.*"}) by (name) * 100.0 ```-#### repo-updater: closed_max_lifetime +#### worker: memory_total_active_file -
Closed by SetConnMaxLifetime
+Memory usage (active file)
+ +This metric shows the total active file-backed memory currently in use by the application. Some of it may be reclaimable, so high usage does not necessarily indicate memory pressure. This panel has no related alerts. -To see this panel, visit `/-/debug/grafana/d/repo-updater/repo-updater?viewPanel=101231` on your Sourcegraph instance. +To see this panel, visit `/-/debug/grafana/d/worker/worker?viewPanel=102011` on your Sourcegraph instance. -*Managed by the [Sourcegraph Source team](https://handbook.sourcegraph.com/departments/engineering/teams/source).* +*Managed by the [Sourcegraph Code Search team](https://handbook.sourcegraph.com/departments/engineering/teams/code-search).*Technical details
@@ -54101,21 +54422,23 @@ To see this panel, visit `/-/debug/grafana/d/repo-updater/repo-updater?viewPanel Query: ``` -sum by (app_name, db_name) (increase(src_pgsql_conns_closed_max_lifetime{app_name="repo-updater"}[5m])) +max(container_memory_total_active_file_bytes{name=~"^worker.*"} / container_spec_memory_limit_bytes{name=~"^worker.*"}) by (name) * 100.0 ```-#### repo-updater: closed_max_idle_time +#### worker: memory_kernel_usage -
Closed by SetConnMaxIdleTime
+Memory usage (kernel)
+ +The kernel usage metric shows the amount of memory used by the kernel on behalf of the application. Some of it may be reclaimable, so high usage does not necessarily indicate memory pressure. This panel has no related alerts. -To see this panel, visit `/-/debug/grafana/d/repo-updater/repo-updater?viewPanel=101232` on your Sourcegraph instance. +To see this panel, visit `/-/debug/grafana/d/worker/worker?viewPanel=102012` on your Sourcegraph instance. -*Managed by the [Sourcegraph Source team](https://handbook.sourcegraph.com/departments/engineering/teams/source).* +*Managed by the [Sourcegraph Code Search team](https://handbook.sourcegraph.com/departments/engineering/teams/code-search).*Technical details
@@ -54123,15 +54446,15 @@ To see this panel, visit `/-/debug/grafana/d/repo-updater/repo-updater?viewPanel Query: ``` -sum by (app_name, db_name) (increase(src_pgsql_conns_closed_max_idle_time{app_name="repo-updater"}[5m])) +max(container_memory_kernel_usage{name=~"^worker.*"} / container_spec_memory_limit_bytes{name=~"^worker.*"}) by (name) * 100.0 ```-### Repo Updater: Container monitoring (not available on server) +### Worker: Container monitoring (not available on server) -#### repo-updater: container_missing +#### worker: container_missing
Container missing
@@ -54139,17 +54462,17 @@ This value is the number of times a container has not been seen for more than on value change independent of deployment events (such as an upgrade), it could indicate pods are being OOM killed or terminated for some other reasons. - **Kubernetes:** - - Determine if the pod was OOM killed using `kubectl describe pod repo-updater` (look for `OOMKilled: true`) and, if so, consider increasing the memory limit in the relevant `Deployment.yaml`. - - Check the logs before the container restarted to see if there are `panic:` messages or similar using `kubectl logs -p repo-updater`. + - Determine if the pod was OOM killed using `kubectl describe pod worker` (look for `OOMKilled: true`) and, if so, consider increasing the memory limit in the relevant `Deployment.yaml`. + - Check the logs before the container restarted to see if there are `panic:` messages or similar using `kubectl logs -p worker`. - **Docker Compose:** - - Determine if the pod was OOM killed using `docker inspect -f '\{\{json .State\}\}' repo-updater` (look for `"OOMKilled":true`) and, if so, consider increasing the memory limit of the repo-updater container in `docker-compose.yml`. - - Check the logs before the container restarted to see if there are `panic:` messages or similar using `docker logs repo-updater` (note this will include logs from the previous and currently running container). + - Determine if the pod was OOM killed using `docker inspect -f '\{\{json .State\}\}' worker` (look for `"OOMKilled":true`) and, if so, consider increasing the memory limit of the worker container in `docker-compose.yml`. + - Check the logs before the container restarted to see if there are `panic:` messages or similar using `docker logs worker` (note this will include logs from the previous and currently running container). This panel has no related alerts. -To see this panel, visit `/-/debug/grafana/d/repo-updater/repo-updater?viewPanel=101300` on your Sourcegraph instance. +To see this panel, visit `/-/debug/grafana/d/worker/worker?viewPanel=102100` on your Sourcegraph instance. -*Managed by the [Sourcegraph Source team](https://handbook.sourcegraph.com/departments/engineering/teams/source).* +*Managed by the [Sourcegraph Code intelligence team](https://handbook.sourcegraph.com/departments/engineering/teams/code-intelligence).*Technical details
@@ -54157,21 +54480,21 @@ To see this panel, visit `/-/debug/grafana/d/repo-updater/repo-updater?viewPanel Query: ``` -count by(name) ((time() - container_last_seen{name=~"^repo-updater.*"}) > 60) +count by(name) ((time() - container_last_seen{name=~"^worker.*"}) > 60) ```-#### repo-updater: container_cpu_usage +#### worker: container_cpu_usage
Container cpu usage total (1m average) across all cores by instance
-Refer to the [alerts reference](alerts#repo-updater-container-cpu-usage) for 1 alert related to this panel. +Refer to the [alerts reference](alerts#worker-container-cpu-usage) for 1 alert related to this panel. -To see this panel, visit `/-/debug/grafana/d/repo-updater/repo-updater?viewPanel=101301` on your Sourcegraph instance. +To see this panel, visit `/-/debug/grafana/d/worker/worker?viewPanel=102101` on your Sourcegraph instance. -*Managed by the [Sourcegraph Source team](https://handbook.sourcegraph.com/departments/engineering/teams/source).* +*Managed by the [Sourcegraph Code intelligence team](https://handbook.sourcegraph.com/departments/engineering/teams/code-intelligence).*Technical details
@@ -54179,21 +54502,21 @@ To see this panel, visit `/-/debug/grafana/d/repo-updater/repo-updater?viewPanel Query: ``` -cadvisor_container_cpu_usage_percentage_total{name=~"^repo-updater.*"} +cadvisor_container_cpu_usage_percentage_total{name=~"^worker.*"} ```-#### repo-updater: container_memory_usage +#### worker: container_memory_usage
Container memory usage by instance
-Refer to the [alerts reference](alerts#repo-updater-container-memory-usage) for 1 alert related to this panel. +Refer to the [alerts reference](alerts#worker-container-memory-usage) for 1 alert related to this panel. -To see this panel, visit `/-/debug/grafana/d/repo-updater/repo-updater?viewPanel=101302` on your Sourcegraph instance. +To see this panel, visit `/-/debug/grafana/d/worker/worker?viewPanel=102102` on your Sourcegraph instance. -*Managed by the [Sourcegraph Source team](https://handbook.sourcegraph.com/departments/engineering/teams/source).* +*Managed by the [Sourcegraph Code intelligence team](https://handbook.sourcegraph.com/departments/engineering/teams/code-intelligence).*Technical details
@@ -54201,13 +54524,13 @@ To see this panel, visit `/-/debug/grafana/d/repo-updater/repo-updater?viewPanel Query: ``` -cadvisor_container_memory_usage_percentage_total{name=~"^repo-updater.*"} +cadvisor_container_memory_usage_percentage_total{name=~"^worker.*"} ```-#### repo-updater: fs_io_operations +#### worker: fs_io_operations
Filesystem reads and writes rate by instance over 1h
@@ -54216,9 +54539,9 @@ When extremely high, this can indicate a resource usage problem, or can cause pr This panel has no related alerts. -To see this panel, visit `/-/debug/grafana/d/repo-updater/repo-updater?viewPanel=101303` on your Sourcegraph instance. +To see this panel, visit `/-/debug/grafana/d/worker/worker?viewPanel=102103` on your Sourcegraph instance. -*Managed by the [Sourcegraph Source team](https://handbook.sourcegraph.com/departments/engineering/teams/source).* +*Managed by the [Sourcegraph Code intelligence team](https://handbook.sourcegraph.com/departments/engineering/teams/code-intelligence).*Technical details
@@ -54226,23 +54549,23 @@ To see this panel, visit `/-/debug/grafana/d/repo-updater/repo-updater?viewPanel Query: ``` -sum by(name) (rate(container_fs_reads_total{name=~"^repo-updater.*"}[1h]) + rate(container_fs_writes_total{name=~"^repo-updater.*"}[1h])) +sum by(name) (rate(container_fs_reads_total{name=~"^worker.*"}[1h]) + rate(container_fs_writes_total{name=~"^worker.*"}[1h])) ```-### Repo Updater: Provisioning indicators (not available on server) +### Worker: Provisioning indicators (not available on server) -#### repo-updater: provisioning_container_cpu_usage_long_term +#### worker: provisioning_container_cpu_usage_long_term
Container cpu usage total (90th percentile over 1d) across all cores by instance
-Refer to the [alerts reference](alerts#repo-updater-provisioning-container-cpu-usage-long-term) for 1 alert related to this panel. +Refer to the [alerts reference](alerts#worker-provisioning-container-cpu-usage-long-term) for 1 alert related to this panel. -To see this panel, visit `/-/debug/grafana/d/repo-updater/repo-updater?viewPanel=101400` on your Sourcegraph instance. +To see this panel, visit `/-/debug/grafana/d/worker/worker?viewPanel=102200` on your Sourcegraph instance. -*Managed by the [Sourcegraph Source team](https://handbook.sourcegraph.com/departments/engineering/teams/source).* +*Managed by the [Sourcegraph Code intelligence team](https://handbook.sourcegraph.com/departments/engineering/teams/code-intelligence).*Technical details
@@ -54250,21 +54573,21 @@ To see this panel, visit `/-/debug/grafana/d/repo-updater/repo-updater?viewPanel Query: ``` -quantile_over_time(0.9, cadvisor_container_cpu_usage_percentage_total{name=~"^repo-updater.*"}[1d]) +quantile_over_time(0.9, cadvisor_container_cpu_usage_percentage_total{name=~"^worker.*"}[1d]) ```-#### repo-updater: provisioning_container_memory_usage_long_term +#### worker: provisioning_container_memory_usage_long_term
Container memory usage (1d maximum) by instance
-Refer to the [alerts reference](alerts#repo-updater-provisioning-container-memory-usage-long-term) for 1 alert related to this panel. +Refer to the [alerts reference](alerts#worker-provisioning-container-memory-usage-long-term) for 1 alert related to this panel. -To see this panel, visit `/-/debug/grafana/d/repo-updater/repo-updater?viewPanel=101401` on your Sourcegraph instance. +To see this panel, visit `/-/debug/grafana/d/worker/worker?viewPanel=102201` on your Sourcegraph instance. -*Managed by the [Sourcegraph Source team](https://handbook.sourcegraph.com/departments/engineering/teams/source).* +*Managed by the [Sourcegraph Code intelligence team](https://handbook.sourcegraph.com/departments/engineering/teams/code-intelligence).*Technical details
@@ -54272,21 +54595,21 @@ To see this panel, visit `/-/debug/grafana/d/repo-updater/repo-updater?viewPanel Query: ``` -max_over_time(cadvisor_container_memory_usage_percentage_total{name=~"^repo-updater.*"}[1d]) +max_over_time(cadvisor_container_memory_usage_percentage_total{name=~"^worker.*"}[1d]) ```-#### repo-updater: provisioning_container_cpu_usage_short_term +#### worker: provisioning_container_cpu_usage_short_term
Container cpu usage total (5m maximum) across all cores by instance
-Refer to the [alerts reference](alerts#repo-updater-provisioning-container-cpu-usage-short-term) for 1 alert related to this panel. +Refer to the [alerts reference](alerts#worker-provisioning-container-cpu-usage-short-term) for 1 alert related to this panel. -To see this panel, visit `/-/debug/grafana/d/repo-updater/repo-updater?viewPanel=101410` on your Sourcegraph instance. +To see this panel, visit `/-/debug/grafana/d/worker/worker?viewPanel=102210` on your Sourcegraph instance. -*Managed by the [Sourcegraph Source team](https://handbook.sourcegraph.com/departments/engineering/teams/source).* +*Managed by the [Sourcegraph Code intelligence team](https://handbook.sourcegraph.com/departments/engineering/teams/code-intelligence).*Technical details
@@ -54294,21 +54617,21 @@ To see this panel, visit `/-/debug/grafana/d/repo-updater/repo-updater?viewPanel Query: ``` -max_over_time(cadvisor_container_cpu_usage_percentage_total{name=~"^repo-updater.*"}[5m]) +max_over_time(cadvisor_container_cpu_usage_percentage_total{name=~"^worker.*"}[5m]) ```-#### repo-updater: provisioning_container_memory_usage_short_term +#### worker: provisioning_container_memory_usage_short_term
Container memory usage (5m maximum) by instance
-Refer to the [alerts reference](alerts#repo-updater-provisioning-container-memory-usage-short-term) for 1 alert related to this panel. +Refer to the [alerts reference](alerts#worker-provisioning-container-memory-usage-short-term) for 1 alert related to this panel. -To see this panel, visit `/-/debug/grafana/d/repo-updater/repo-updater?viewPanel=101411` on your Sourcegraph instance. +To see this panel, visit `/-/debug/grafana/d/worker/worker?viewPanel=102211` on your Sourcegraph instance. -*Managed by the [Sourcegraph Source team](https://handbook.sourcegraph.com/departments/engineering/teams/source).* +*Managed by the [Sourcegraph Code intelligence team](https://handbook.sourcegraph.com/departments/engineering/teams/code-intelligence).*Technical details
@@ -54316,24 +54639,24 @@ To see this panel, visit `/-/debug/grafana/d/repo-updater/repo-updater?viewPanel Query: ``` -max_over_time(cadvisor_container_memory_usage_percentage_total{name=~"^repo-updater.*"}[5m]) +max_over_time(cadvisor_container_memory_usage_percentage_total{name=~"^worker.*"}[5m]) ```-#### repo-updater: container_oomkill_events_total +#### worker: container_oomkill_events_total
Container OOMKILL events total by instance
This value indicates the total number of times the container main process or child processes were terminated by OOM killer. When it occurs frequently, it is an indicator of underprovisioning. -Refer to the [alerts reference](alerts#repo-updater-container-oomkill-events-total) for 1 alert related to this panel. +Refer to the [alerts reference](alerts#worker-container-oomkill-events-total) for 1 alert related to this panel. -To see this panel, visit `/-/debug/grafana/d/repo-updater/repo-updater?viewPanel=101412` on your Sourcegraph instance. +To see this panel, visit `/-/debug/grafana/d/worker/worker?viewPanel=102212` on your Sourcegraph instance. -*Managed by the [Sourcegraph Source team](https://handbook.sourcegraph.com/departments/engineering/teams/source).* +*Managed by the [Sourcegraph Code intelligence team](https://handbook.sourcegraph.com/departments/engineering/teams/code-intelligence).*Technical details
@@ -54341,25 +54664,25 @@ To see this panel, visit `/-/debug/grafana/d/repo-updater/repo-updater?viewPanel Query: ``` -max by (name) (container_oom_events_total{name=~"^repo-updater.*"}) +max by (name) (container_oom_events_total{name=~"^worker.*"}) ```-### Repo Updater: Golang runtime monitoring +### Worker: Golang runtime monitoring -#### repo-updater: go_goroutines +#### worker: go_goroutines
Maximum active goroutines
A high value here indicates a possible goroutine leak. -Refer to the [alerts reference](alerts#repo-updater-go-goroutines) for 1 alert related to this panel. +Refer to the [alerts reference](alerts#worker-go-goroutines) for 1 alert related to this panel. -To see this panel, visit `/-/debug/grafana/d/repo-updater/repo-updater?viewPanel=101500` on your Sourcegraph instance. +To see this panel, visit `/-/debug/grafana/d/worker/worker?viewPanel=102300` on your Sourcegraph instance. -*Managed by the [Sourcegraph Source team](https://handbook.sourcegraph.com/departments/engineering/teams/source).* +*Managed by the [Sourcegraph Code intelligence team](https://handbook.sourcegraph.com/departments/engineering/teams/code-intelligence).*Technical details
@@ -54367,21 +54690,21 @@ To see this panel, visit `/-/debug/grafana/d/repo-updater/repo-updater?viewPanel Query: ``` -max by(instance) (go_goroutines{job=~".*repo-updater"}) +max by(instance) (go_goroutines{job=~".*worker"}) ```-#### repo-updater: go_gc_duration_seconds +#### worker: go_gc_duration_seconds
Maximum go garbage collection duration
-Refer to the [alerts reference](alerts#repo-updater-go-gc-duration-seconds) for 1 alert related to this panel. +Refer to the [alerts reference](alerts#worker-go-gc-duration-seconds) for 1 alert related to this panel. -To see this panel, visit `/-/debug/grafana/d/repo-updater/repo-updater?viewPanel=101501` on your Sourcegraph instance. +To see this panel, visit `/-/debug/grafana/d/worker/worker?viewPanel=102301` on your Sourcegraph instance. -*Managed by the [Sourcegraph Source team](https://handbook.sourcegraph.com/departments/engineering/teams/source).* +*Managed by the [Sourcegraph Code intelligence team](https://handbook.sourcegraph.com/departments/engineering/teams/code-intelligence).*Technical details
@@ -54389,23 +54712,23 @@ To see this panel, visit `/-/debug/grafana/d/repo-updater/repo-updater?viewPanel Query: ``` -max by(instance) (go_gc_duration_seconds{job=~".*repo-updater"}) +max by(instance) (go_gc_duration_seconds{job=~".*worker"}) ```-### Repo Updater: Kubernetes monitoring (only available on Kubernetes) +### Worker: Kubernetes monitoring (only available on Kubernetes) -#### repo-updater: pods_available_percentage +#### worker: pods_available_percentage
Percentage pods available
-Refer to the [alerts reference](alerts#repo-updater-pods-available-percentage) for 1 alert related to this panel. +Refer to the [alerts reference](alerts#worker-pods-available-percentage) for 1 alert related to this panel. -To see this panel, visit `/-/debug/grafana/d/repo-updater/repo-updater?viewPanel=101600` on your Sourcegraph instance. +To see this panel, visit `/-/debug/grafana/d/worker/worker?viewPanel=102400` on your Sourcegraph instance. -*Managed by the [Sourcegraph Source team](https://handbook.sourcegraph.com/departments/engineering/teams/source).* +*Managed by the [Sourcegraph Code intelligence team](https://handbook.sourcegraph.com/departments/engineering/teams/code-intelligence).*Technical details
@@ -54413,38 +54736,23 @@ To see this panel, visit `/-/debug/grafana/d/repo-updater/repo-updater?viewPanel Query: ``` -sum by(app) (up{app=~".*repo-updater"}) / count by (app) (up{app=~".*repo-updater"}) * 100 +sum by(app) (up{app=~".*worker"}) / count by (app) (up{app=~".*worker"}) * 100 ```-## Searcher - -
Performs unindexed searches (diff and commit search, text search for unindexed branches).
- -To see this dashboard, visit `/-/debug/grafana/d/searcher/searcher` on your Sourcegraph instance. - -#### searcher: traffic - -Requests per second by code over 10m
- -This graph is the average number of requests per second searcher is -experiencing over the last 10 minutes. +### Worker: Own: repo indexer dbstore -The code is the HTTP Status code. 200 is success. We have a special code -"canceled" which is common when doing a large search request and we find -enough results before searching all possible repos. +#### worker: workerutil_dbworker_store_total -Note: A search query is translated into an unindexed search query per unique -(repo, commit). This means a single user query may result in thousands of -requests to searcher. +Aggregate store operations every 5m
This panel has no related alerts. -To see this panel, visit `/-/debug/grafana/d/searcher/searcher?viewPanel=100000` on your Sourcegraph instance. +To see this panel, visit `/-/debug/grafana/d/worker/worker?viewPanel=102500` on your Sourcegraph instance. -*Managed by the [Sourcegraph Search Platform team](https://handbook.sourcegraph.com/departments/engineering/teams/search/core).* +*Managed by the [Sourcegraph own team](https://handbook.sourcegraph.com/departments/engineering/teams/own).*Technical details
@@ -54452,32 +54760,21 @@ To see this panel, visit `/-/debug/grafana/d/searcher/searcher?viewPanel=100000` Query: ``` -sum by (code) (rate(searcher_service_request_total{instance=~`${instance:regex}`}[10m])) +sum(increase(src_workerutil_dbworker_store_total{domain='own_background_worker_store',job=~"^worker.*"}[5m])) ```-#### searcher: replica_traffic - -
Requests per second per replica over 10m
- -This graph is the average number of requests per second searcher is -experiencing over the last 10 minutes broken down per replica. - -The code is the HTTP Status code. 200 is success. We have a special code -"canceled" which is common when doing a large search request and we find -enough results before searching all possible repos. +#### worker: workerutil_dbworker_store_99th_percentile_duration -Note: A search query is translated into an unindexed search query per unique -(repo, commit). This means a single user query may result in thousands of -requests to searcher. +Aggregate successful store operation duration distribution over 5m
-Refer to the [alerts reference](alerts#searcher-replica-traffic) for 1 alert related to this panel. +This panel has no related alerts. -To see this panel, visit `/-/debug/grafana/d/searcher/searcher?viewPanel=100001` on your Sourcegraph instance. +To see this panel, visit `/-/debug/grafana/d/worker/worker?viewPanel=102501` on your Sourcegraph instance. -*Managed by the [Sourcegraph Search Platform team](https://handbook.sourcegraph.com/departments/engineering/teams/search/core).* +*Managed by the [Sourcegraph own team](https://handbook.sourcegraph.com/departments/engineering/teams/own).*Technical details
@@ -54485,24 +54782,21 @@ To see this panel, visit `/-/debug/grafana/d/searcher/searcher?viewPanel=100001` Query: ``` -sum by (instance) (rate(searcher_service_request_total{instance=~`${instance:regex}`}[10m])) +sum by (le)(rate(src_workerutil_dbworker_store_duration_seconds_bucket{domain='own_background_worker_store',job=~"^worker.*"}[5m])) ```-#### searcher: concurrent_requests - -
Amount of in-flight unindexed search requests (per instance)
+#### worker: workerutil_dbworker_store_errors_total -This graph is the amount of in-flight unindexed search requests per instance. -Consistently high numbers here indicate you may need to scale out searcher. +Aggregate store operation errors every 5m
This panel has no related alerts. -To see this panel, visit `/-/debug/grafana/d/searcher/searcher?viewPanel=100010` on your Sourcegraph instance. +To see this panel, visit `/-/debug/grafana/d/worker/worker?viewPanel=102502` on your Sourcegraph instance. -*Managed by the [Sourcegraph Search Platform team](https://handbook.sourcegraph.com/departments/engineering/teams/search/core).* +*Managed by the [Sourcegraph own team](https://handbook.sourcegraph.com/departments/engineering/teams/own).*Technical details
@@ -54510,21 +54804,21 @@ To see this panel, visit `/-/debug/grafana/d/searcher/searcher?viewPanel=100010` Query: ``` -sum by (instance) (searcher_service_running{instance=~`${instance:regex}`}) +sum(increase(src_workerutil_dbworker_store_errors_total{domain='own_background_worker_store',job=~"^worker.*"}[5m])) ```-#### searcher: unindexed_search_request_errors +#### worker: workerutil_dbworker_store_error_rate -
Unindexed search request errors every 5m by code
+Aggregate store operation error rate over 5m
-Refer to the [alerts reference](alerts#searcher-unindexed-search-request-errors) for 1 alert related to this panel. +This panel has no related alerts. -To see this panel, visit `/-/debug/grafana/d/searcher/searcher?viewPanel=100011` on your Sourcegraph instance. +To see this panel, visit `/-/debug/grafana/d/worker/worker?viewPanel=102503` on your Sourcegraph instance. -*Managed by the [Sourcegraph Search Platform team](https://handbook.sourcegraph.com/departments/engineering/teams/search/core).* +*Managed by the [Sourcegraph own team](https://handbook.sourcegraph.com/departments/engineering/teams/own).*Technical details
@@ -54532,32 +54826,21 @@ To see this panel, visit `/-/debug/grafana/d/searcher/searcher?viewPanel=100011` Query: ``` -sum by (code)(increase(searcher_service_request_total{code!="200",code!="canceled",instance=~`${instance:regex}`}[5m])) / ignoring(code) group_left sum(increase(searcher_service_request_total{instance=~`${instance:regex}`}[5m])) * 100 +sum(increase(src_workerutil_dbworker_store_errors_total{domain='own_background_worker_store',job=~"^worker.*"}[5m])) / (sum(increase(src_workerutil_dbworker_store_total{domain='own_background_worker_store',job=~"^worker.*"}[5m])) + sum(increase(src_workerutil_dbworker_store_errors_total{domain='own_background_worker_store',job=~"^worker.*"}[5m]))) * 100 ```-### Searcher: Cache store - -#### searcher: store_fetching - -
Amount of in-flight unindexed search requests fetching code from gitserver (per instance)
- -Before we can search a commit we fetch the code from gitserver then cache it -for future search requests. This graph is the current number of search -requests which are in the state of fetching code from gitserver. +#### worker: workerutil_dbworker_store_total -Generally this number should remain low since fetching code is fast, but -expect bursts. In the case of instances with a monorepo you would expect this -number to stay low for the duration of fetching the code (which in some cases -can take many minutes). +Store operations every 5m
This panel has no related alerts. -To see this panel, visit `/-/debug/grafana/d/searcher/searcher?viewPanel=100100` on your Sourcegraph instance. +To see this panel, visit `/-/debug/grafana/d/worker/worker?viewPanel=102510` on your Sourcegraph instance. -*Managed by the [Sourcegraph Search Platform team](https://handbook.sourcegraph.com/departments/engineering/teams/search/core).* +*Managed by the [Sourcegraph own team](https://handbook.sourcegraph.com/departments/engineering/teams/own).*Technical details
@@ -54565,25 +54848,21 @@ To see this panel, visit `/-/debug/grafana/d/searcher/searcher?viewPanel=100100` Query: ``` -sum by (instance) (searcher_store_fetching{instance=~`${instance:regex}`}) +sum by (op)(increase(src_workerutil_dbworker_store_total{domain='own_background_worker_store',job=~"^worker.*"}[5m])) ```-#### searcher: store_fetching_waiting - -
Amount of in-flight unindexed search requests waiting to fetch code from gitserver (per instance)
+#### worker: workerutil_dbworker_store_99th_percentile_duration -We limit the number of requests which can fetch code to prevent overwhelming -gitserver. This gauge is the number of requests waiting to be allowed to speak -to gitserver. +99th percentile successful store operation duration over 5m
This panel has no related alerts. -To see this panel, visit `/-/debug/grafana/d/searcher/searcher?viewPanel=100101` on your Sourcegraph instance. +To see this panel, visit `/-/debug/grafana/d/worker/worker?viewPanel=102511` on your Sourcegraph instance. -*Managed by the [Sourcegraph Search Platform team](https://handbook.sourcegraph.com/departments/engineering/teams/search/core).* +*Managed by the [Sourcegraph own team](https://handbook.sourcegraph.com/departments/engineering/teams/own).*Technical details
@@ -54591,26 +54870,21 @@ To see this panel, visit `/-/debug/grafana/d/searcher/searcher?viewPanel=100101` Query: ``` -sum by (instance) (searcher_store_fetch_queue_size{instance=~`${instance:regex}`}) +histogram_quantile(0.99, sum by (le,op)(rate(src_workerutil_dbworker_store_duration_seconds_bucket{domain='own_background_worker_store',job=~"^worker.*"}[5m]))) ```-#### searcher: store_fetching_fail - -
Amount of unindexed search requests that failed while fetching code from gitserver over 10m (per instance)
+#### worker: workerutil_dbworker_store_errors_total -This graph should be zero since fetching happens in the background and will -not be influenced by user timeouts/etc. Expected upticks in this graph are -during gitserver rollouts. If you regularly see this graph have non-zero -values please reach out to support. +Store operation errors every 5m
This panel has no related alerts. -To see this panel, visit `/-/debug/grafana/d/searcher/searcher?viewPanel=100102` on your Sourcegraph instance. +To see this panel, visit `/-/debug/grafana/d/worker/worker?viewPanel=102512` on your Sourcegraph instance. -*Managed by the [Sourcegraph Search Platform team](https://handbook.sourcegraph.com/departments/engineering/teams/search/core).* +*Managed by the [Sourcegraph own team](https://handbook.sourcegraph.com/departments/engineering/teams/own).*Technical details
@@ -54618,40 +54892,21 @@ To see this panel, visit `/-/debug/grafana/d/searcher/searcher?viewPanel=100102` Query: ``` -sum by (instance) (rate(searcher_store_fetch_failed{instance=~`${instance:regex}`}[10m])) +sum by (op)(increase(src_workerutil_dbworker_store_errors_total{domain='own_background_worker_store',job=~"^worker.*"}[5m])) ```-### Searcher: Index use - -#### searcher: searcher_hybrid_final_state_total - -
Hybrid search final state over 10m
- -This graph is about our interactions with the search index (zoekt) to help -complete unindexed search requests. Searcher will use indexed search for the -files that have not changed between the unindexed commit and the index. - -This graph should mostly be "success". The next most common state should be -"search-canceled" which happens when result limits are hit or the user starts -a new search. Finally the next most common should be "diff-too-large", which -happens if the commit is too far from the indexed commit. Otherwise other -state should be rare and likely are a sign for further investigation. - -Note: On sourcegraph.com "zoekt-list-missing" is also common due to it -indexing a subset of repositories. Otherwise every other state should occur -rarely. +#### worker: workerutil_dbworker_store_error_rate -For a full list of possible state see -[recordHybridFinalState](https://sourcegraph.com/search?q=context:global+repo:%5Egithub%5C.com/sourcegraph/sourcegraph%24+f:cmd/searcher+recordHybridFinalState). +Store operation error rate over 5m
This panel has no related alerts. -To see this panel, visit `/-/debug/grafana/d/searcher/searcher?viewPanel=100200` on your Sourcegraph instance. +To see this panel, visit `/-/debug/grafana/d/worker/worker?viewPanel=102513` on your Sourcegraph instance. -*Managed by the [Sourcegraph Search Platform team](https://handbook.sourcegraph.com/departments/engineering/teams/search/core).* +*Managed by the [Sourcegraph own team](https://handbook.sourcegraph.com/departments/engineering/teams/own).*Technical details
@@ -54659,26 +54914,23 @@ To see this panel, visit `/-/debug/grafana/d/searcher/searcher?viewPanel=100200` Query: ``` -sum by (state)(increase(searcher_hybrid_final_state_total{instance=~`${instance:regex}`}[10m])) +sum by (op)(increase(src_workerutil_dbworker_store_errors_total{domain='own_background_worker_store',job=~"^worker.*"}[5m])) / (sum by (op)(increase(src_workerutil_dbworker_store_total{domain='own_background_worker_store',job=~"^worker.*"}[5m])) + sum by (op)(increase(src_workerutil_dbworker_store_errors_total{domain='own_background_worker_store',job=~"^worker.*"}[5m]))) * 100 ```-#### searcher: searcher_hybrid_retry_total +### Worker: Own: repo indexer worker queue -
Hybrid search retrying over 10m
+#### worker: own_background_worker_handlers -Expectation is that this graph should mostly be 0. It will trigger if a user -manages to do a search and the underlying index changes while searching or -Zoekt goes down. So occasional bursts can be expected, but if this graph is -regularly above 0 it is a sign for further investigation. +Handler active handlers
This panel has no related alerts. -To see this panel, visit `/-/debug/grafana/d/searcher/searcher?viewPanel=100201` on your Sourcegraph instance. +To see this panel, visit `/-/debug/grafana/d/worker/worker?viewPanel=102600` on your Sourcegraph instance. -*Managed by the [Sourcegraph Search Platform team](https://handbook.sourcegraph.com/departments/engineering/teams/search/core).* +*Managed by the [Sourcegraph Code Search team](https://handbook.sourcegraph.com/departments/engineering/teams/code-search).*Technical details
@@ -54686,27 +54938,21 @@ To see this panel, visit `/-/debug/grafana/d/searcher/searcher?viewPanel=100201` Query: ``` -sum by (reason)(increase(searcher_hybrid_retry_total{instance=~`${instance:regex}`}[10m])) +sum(src_own_background_worker_processor_handlers{job=~"^worker.*"}) ```-### Searcher: Cache disk I/O metrics - -#### searcher: cache_disk_reads_sec - -
Read request rate over 1m (per instance)
- -The number of read requests that were issued to the device per second. +#### worker: own_background_worker_processor_total -Note: Disk statistics are per _device_, not per _service_. In certain environments (such as common docker-compose setups), searcher could be one of _many services_ using this disk. These statistics are best interpreted as the load experienced by the device searcher is using, not the load searcher is solely responsible for causing. +Handler operations every 5m
This panel has no related alerts. -To see this panel, visit `/-/debug/grafana/d/searcher/searcher?viewPanel=100300` on your Sourcegraph instance. +To see this panel, visit `/-/debug/grafana/d/worker/worker?viewPanel=102610` on your Sourcegraph instance. -*Managed by the [Sourcegraph Search Platform team](https://handbook.sourcegraph.com/departments/engineering/teams/search/core).* +*Managed by the [Sourcegraph Code Search team](https://handbook.sourcegraph.com/departments/engineering/teams/code-search).*Technical details
@@ -54714,25 +54960,21 @@ To see this panel, visit `/-/debug/grafana/d/searcher/searcher?viewPanel=100300` Query: ``` -(max by (instance) (searcher_mount_point_info{mount_name="cacheDir",instance=~`${instance:regex}`} * on (device, nodename) group_left() (max by (device, nodename) (rate(node_disk_reads_completed_total{instance=~`node-exporter.*`}[1m]))))) +sum(increase(src_own_background_worker_processor_total{job=~"^worker.*"}[5m])) ```-#### searcher: cache_disk_writes_sec - -
Write request rate over 1m (per instance)
- -The number of write requests that were issued to the device per second. +#### worker: own_background_worker_processor_99th_percentile_duration -Note: Disk statistics are per _device_, not per _service_. In certain environments (such as common docker-compose setups), searcher could be one of _many services_ using this disk. These statistics are best interpreted as the load experienced by the device searcher is using, not the load searcher is solely responsible for causing. +Aggregate successful handler operation duration distribution over 5m
This panel has no related alerts. -To see this panel, visit `/-/debug/grafana/d/searcher/searcher?viewPanel=100301` on your Sourcegraph instance. +To see this panel, visit `/-/debug/grafana/d/worker/worker?viewPanel=102611` on your Sourcegraph instance. -*Managed by the [Sourcegraph Search Platform team](https://handbook.sourcegraph.com/departments/engineering/teams/search/core).* +*Managed by the [Sourcegraph Code Search team](https://handbook.sourcegraph.com/departments/engineering/teams/code-search).*Technical details
@@ -54740,25 +54982,21 @@ To see this panel, visit `/-/debug/grafana/d/searcher/searcher?viewPanel=100301` Query: ``` -(max by (instance) (searcher_mount_point_info{mount_name="cacheDir",instance=~`${instance:regex}`} * on (device, nodename) group_left() (max by (device, nodename) (rate(node_disk_writes_completed_total{instance=~`node-exporter.*`}[1m]))))) +sum by (le)(rate(src_own_background_worker_processor_duration_seconds_bucket{job=~"^worker.*"}[5m])) ```-#### searcher: cache_disk_read_throughput - -
Read throughput over 1m (per instance)
- -The amount of data that was read from the device per second. +#### worker: own_background_worker_processor_errors_total -Note: Disk statistics are per _device_, not per _service_. In certain environments (such as common docker-compose setups), searcher could be one of _many services_ using this disk. These statistics are best interpreted as the load experienced by the device searcher is using, not the load searcher is solely responsible for causing. +Handler operation errors every 5m
This panel has no related alerts. -To see this panel, visit `/-/debug/grafana/d/searcher/searcher?viewPanel=100310` on your Sourcegraph instance. +To see this panel, visit `/-/debug/grafana/d/worker/worker?viewPanel=102612` on your Sourcegraph instance. -*Managed by the [Sourcegraph Search Platform team](https://handbook.sourcegraph.com/departments/engineering/teams/search/core).* +*Managed by the [Sourcegraph Code Search team](https://handbook.sourcegraph.com/departments/engineering/teams/code-search).*Technical details
@@ -54766,25 +55004,21 @@ To see this panel, visit `/-/debug/grafana/d/searcher/searcher?viewPanel=100310` Query: ``` -(max by (instance) (searcher_mount_point_info{mount_name="cacheDir",instance=~`${instance:regex}`} * on (device, nodename) group_left() (max by (device, nodename) (rate(node_disk_read_bytes_total{instance=~`node-exporter.*`}[1m]))))) +sum(increase(src_own_background_worker_processor_errors_total{job=~"^worker.*"}[5m])) ```-#### searcher: cache_disk_write_throughput - -
Write throughput over 1m (per instance)
- -The amount of data that was written to the device per second. +#### worker: own_background_worker_processor_error_rate -Note: Disk statistics are per _device_, not per _service_. In certain environments (such as common docker-compose setups), searcher could be one of _many services_ using this disk. These statistics are best interpreted as the load experienced by the device searcher is using, not the load searcher is solely responsible for causing. +Handler operation error rate over 5m
This panel has no related alerts. -To see this panel, visit `/-/debug/grafana/d/searcher/searcher?viewPanel=100311` on your Sourcegraph instance. +To see this panel, visit `/-/debug/grafana/d/worker/worker?viewPanel=102613` on your Sourcegraph instance. -*Managed by the [Sourcegraph Search Platform team](https://handbook.sourcegraph.com/departments/engineering/teams/search/core).* +*Managed by the [Sourcegraph Code Search team](https://handbook.sourcegraph.com/departments/engineering/teams/code-search).*Technical details
@@ -54792,25 +55026,23 @@ To see this panel, visit `/-/debug/grafana/d/searcher/searcher?viewPanel=100311` Query: ``` -(max by (instance) (searcher_mount_point_info{mount_name="cacheDir",instance=~`${instance:regex}`} * on (device, nodename) group_left() (max by (device, nodename) (rate(node_disk_written_bytes_total{instance=~`node-exporter.*`}[1m]))))) +sum(increase(src_own_background_worker_processor_errors_total{job=~"^worker.*"}[5m])) / (sum(increase(src_own_background_worker_processor_total{job=~"^worker.*"}[5m])) + sum(increase(src_own_background_worker_processor_errors_total{job=~"^worker.*"}[5m]))) * 100 ```-#### searcher: cache_disk_read_duration - -
Average read duration over 1m (per instance)
+### Worker: Own: index job scheduler -The average time for read requests issued to the device to be served. This includes the time spent by the requests in queue and the time spent servicing them. +#### worker: own_background_index_scheduler_total -Note: Disk statistics are per _device_, not per _service_. In certain environments (such as common docker-compose setups), searcher could be one of _many services_ using this disk. These statistics are best interpreted as the load experienced by the device searcher is using, not the load searcher is solely responsible for causing. +Own index job scheduler operations every 10m
This panel has no related alerts. -To see this panel, visit `/-/debug/grafana/d/searcher/searcher?viewPanel=100320` on your Sourcegraph instance. +To see this panel, visit `/-/debug/grafana/d/worker/worker?viewPanel=102700` on your Sourcegraph instance. -*Managed by the [Sourcegraph Search Platform team](https://handbook.sourcegraph.com/departments/engineering/teams/search/core).* +*Managed by the [Sourcegraph Code intelligence team](https://handbook.sourcegraph.com/departments/engineering/teams/code-intelligence).*Technical details
@@ -54818,25 +55050,21 @@ To see this panel, visit `/-/debug/grafana/d/searcher/searcher?viewPanel=100320` Query: ``` -(((max by (instance) (searcher_mount_point_info{mount_name="cacheDir",instance=~`${instance:regex}`} * on (device, nodename) group_left() (max by (device, nodename) (rate(node_disk_read_time_seconds_total{instance=~`node-exporter.*`}[1m])))))) / ((max by (instance) (searcher_mount_point_info{mount_name="cacheDir",instance=~`${instance:regex}`} * on (device, nodename) group_left() (max by (device, nodename) (rate(node_disk_reads_completed_total{instance=~`node-exporter.*`}[1m]))))))) +sum by (op)(increase(src_own_background_index_scheduler_total{job=~"^worker.*"}[10m])) ```-#### searcher: cache_disk_write_duration - -
Average write duration over 1m (per instance)
- -The average time for write requests issued to the device to be served. This includes the time spent by the requests in queue and the time spent servicing them. +#### worker: own_background_index_scheduler_99th_percentile_duration -Note: Disk statistics are per _device_, not per _service_. In certain environments (such as common docker-compose setups), searcher could be one of _many services_ using this disk. These statistics are best interpreted as the load experienced by the device searcher is using, not the load searcher is solely responsible for causing. +99th percentile successful own index job scheduler operation duration over 10m
This panel has no related alerts. -To see this panel, visit `/-/debug/grafana/d/searcher/searcher?viewPanel=100321` on your Sourcegraph instance. +To see this panel, visit `/-/debug/grafana/d/worker/worker?viewPanel=102701` on your Sourcegraph instance. -*Managed by the [Sourcegraph Search Platform team](https://handbook.sourcegraph.com/departments/engineering/teams/search/core).* +*Managed by the [Sourcegraph Code intelligence team](https://handbook.sourcegraph.com/departments/engineering/teams/code-intelligence).*Technical details
@@ -54844,25 +55072,21 @@ To see this panel, visit `/-/debug/grafana/d/searcher/searcher?viewPanel=100321` Query: ``` -(((max by (instance) (searcher_mount_point_info{mount_name="cacheDir",instance=~`${instance:regex}`} * on (device, nodename) group_left() (max by (device, nodename) (rate(node_disk_write_time_seconds_total{instance=~`node-exporter.*`}[1m])))))) / ((max by (instance) (searcher_mount_point_info{mount_name="cacheDir",instance=~`${instance:regex}`} * on (device, nodename) group_left() (max by (device, nodename) (rate(node_disk_writes_completed_total{instance=~`node-exporter.*`}[1m]))))))) +histogram_quantile(0.99, sum by (le,op)(rate(src_own_background_index_scheduler_duration_seconds_bucket{job=~"^worker.*"}[10m]))) ```-#### searcher: cache_disk_read_request_size - -
Average read request size over 1m (per instance)
- -The average size of read requests that were issued to the device. +#### worker: own_background_index_scheduler_errors_total -Note: Disk statistics are per _device_, not per _service_. In certain environments (such as common docker-compose setups), searcher could be one of _many services_ using this disk. These statistics are best interpreted as the load experienced by the device searcher is using, not the load searcher is solely responsible for causing. +Own index job scheduler operation errors every 10m
This panel has no related alerts. -To see this panel, visit `/-/debug/grafana/d/searcher/searcher?viewPanel=100330` on your Sourcegraph instance. +To see this panel, visit `/-/debug/grafana/d/worker/worker?viewPanel=102702` on your Sourcegraph instance. -*Managed by the [Sourcegraph Search Platform team](https://handbook.sourcegraph.com/departments/engineering/teams/search/core).* +*Managed by the [Sourcegraph Code intelligence team](https://handbook.sourcegraph.com/departments/engineering/teams/code-intelligence).*Technical details
@@ -54870,25 +55094,21 @@ To see this panel, visit `/-/debug/grafana/d/searcher/searcher?viewPanel=100330` Query: ``` -(((max by (instance) (searcher_mount_point_info{mount_name="cacheDir",instance=~`${instance:regex}`} * on (device, nodename) group_left() (max by (device, nodename) (rate(node_disk_read_bytes_total{instance=~`node-exporter.*`}[1m])))))) / ((max by (instance) (searcher_mount_point_info{mount_name="cacheDir",instance=~`${instance:regex}`} * on (device, nodename) group_left() (max by (device, nodename) (rate(node_disk_reads_completed_total{instance=~`node-exporter.*`}[1m]))))))) +sum by (op)(increase(src_own_background_index_scheduler_errors_total{job=~"^worker.*"}[10m])) ```-#### searcher: cache_disk_write_request_size) - -
Average write request size over 1m (per instance)
- -The average size of write requests that were issued to the device. +#### worker: own_background_index_scheduler_error_rate -Note: Disk statistics are per _device_, not per _service_. In certain environments (such as common docker-compose setups), searcher could be one of _many services_ using this disk. These statistics are best interpreted as the load experienced by the device searcher is using, not the load searcher is solely responsible for causing. +Own index job scheduler operation error rate over 10m
This panel has no related alerts. -To see this panel, visit `/-/debug/grafana/d/searcher/searcher?viewPanel=100331` on your Sourcegraph instance. +To see this panel, visit `/-/debug/grafana/d/worker/worker?viewPanel=102703` on your Sourcegraph instance. -*Managed by the [Sourcegraph Search Platform team](https://handbook.sourcegraph.com/departments/engineering/teams/search/core).* +*Managed by the [Sourcegraph Code intelligence team](https://handbook.sourcegraph.com/departments/engineering/teams/code-intelligence).*Technical details
@@ -54896,25 +55116,25 @@ To see this panel, visit `/-/debug/grafana/d/searcher/searcher?viewPanel=100331` Query: ``` -(((max by (instance) (searcher_mount_point_info{mount_name="cacheDir",instance=~`${instance:regex}`} * on (device, nodename) group_left() (max by (device, nodename) (rate(node_disk_written_bytes_total{instance=~`node-exporter.*`}[1m])))))) / ((max by (instance) (searcher_mount_point_info{mount_name="cacheDir",instance=~`${instance:regex}`} * on (device, nodename) group_left() (max by (device, nodename) (rate(node_disk_writes_completed_total{instance=~`node-exporter.*`}[1m]))))))) +sum by (op)(increase(src_own_background_index_scheduler_errors_total{job=~"^worker.*"}[10m])) / (sum by (op)(increase(src_own_background_index_scheduler_total{job=~"^worker.*"}[10m])) + sum by (op)(increase(src_own_background_index_scheduler_errors_total{job=~"^worker.*"}[10m]))) * 100 ```-#### searcher: cache_disk_reads_merged_sec +### Worker: Site configuration client update latency -
Merged read request rate over 1m (per instance)
+#### worker: worker_site_configuration_duration_since_last_successful_update_by_instance -The number of read requests merged per second that were queued to the device. +Duration since last successful site configuration update (by instance)
-Note: Disk statistics are per _device_, not per _service_. In certain environments (such as common docker-compose setups), searcher could be one of _many services_ using this disk. These statistics are best interpreted as the load experienced by the device searcher is using, not the load searcher is solely responsible for causing. +The duration since the configuration client used by the "worker" service last successfully updated its site configuration. Long durations could indicate issues updating the site configuration. This panel has no related alerts. -To see this panel, visit `/-/debug/grafana/d/searcher/searcher?viewPanel=100340` on your Sourcegraph instance. +To see this panel, visit `/-/debug/grafana/d/worker/worker?viewPanel=102800` on your Sourcegraph instance. -*Managed by the [Sourcegraph Search Platform team](https://handbook.sourcegraph.com/departments/engineering/teams/search/core).* +*Managed by the [Sourcegraph Infrastructure Org team](https://handbook.sourcegraph.com/departments/engineering/infrastructure).*Technical details
@@ -54922,25 +55142,21 @@ To see this panel, visit `/-/debug/grafana/d/searcher/searcher?viewPanel=100340` Query: ``` -(max by (instance) (searcher_mount_point_info{mount_name="cacheDir",instance=~`${instance:regex}`} * on (device, nodename) group_left() (max by (device, nodename) (rate(node_disk_reads_merged_total{instance=~`node-exporter.*`}[1m]))))) +src_conf_client_time_since_last_successful_update_seconds{job=~`^worker.*`,instance=~`${instance:regex}`} ```-#### searcher: cache_disk_writes_merged_sec - -
Merged writes request rate over 1m (per instance)
- -The number of write requests merged per second that were queued to the device. +#### worker: worker_site_configuration_duration_since_last_successful_update_by_instance -Note: Disk statistics are per _device_, not per _service_. In certain environments (such as common docker-compose setups), searcher could be one of _many services_ using this disk. These statistics are best interpreted as the load experienced by the device searcher is using, not the load searcher is solely responsible for causing. +Maximum duration since last successful site configuration update (all "worker" instances)
-This panel has no related alerts. +Refer to the [alerts reference](alerts#worker-worker-site-configuration-duration-since-last-successful-update-by-instance) for 1 alert related to this panel. -To see this panel, visit `/-/debug/grafana/d/searcher/searcher?viewPanel=100341` on your Sourcegraph instance. +To see this panel, visit `/-/debug/grafana/d/worker/worker?viewPanel=102801` on your Sourcegraph instance. -*Managed by the [Sourcegraph Search Platform team](https://handbook.sourcegraph.com/departments/engineering/teams/search/core).* +*Managed by the [Sourcegraph Infrastructure Org team](https://handbook.sourcegraph.com/departments/engineering/infrastructure).*Technical details
@@ -54948,49 +55164,36 @@ To see this panel, visit `/-/debug/grafana/d/searcher/searcher?viewPanel=100341` Query: ``` -(max by (instance) (searcher_mount_point_info{mount_name="cacheDir",instance=~`${instance:regex}`} * on (device, nodename) group_left() (max by (device, nodename) (rate(node_disk_writes_merged_total{instance=~`node-exporter.*`}[1m]))))) +max(max_over_time(src_conf_client_time_since_last_successful_update_seconds{job=~`^worker.*`,instance=~`${instance:regex}`}[1m])) ```-#### searcher: cache_disk_average_queue_size - -
Average queue size over 1m (per instance)
- -The number of I/O operations that were being queued or being serviced. See https://blog.actorsfit.com/a?ID=00200-428fa2ac-e338-4540-848c-af9a3eb1ebd2 for background (avgqu-sz). - -Note: Disk statistics are per _device_, not per _service_. In certain environments (such as common docker-compose setups), searcher could be one of _many services_ using this disk. These statistics are best interpreted as the load experienced by the device searcher is using, not the load searcher is solely responsible for causing. - -This panel has no related alerts. - -To see this panel, visit `/-/debug/grafana/d/searcher/searcher?viewPanel=100350` on your Sourcegraph instance. - -*Managed by the [Sourcegraph Search Platform team](https://handbook.sourcegraph.com/departments/engineering/teams/search/core).* - -Technical details
+## Searcher -Query: +Performs unindexed searches (diff and commit search, text search for unindexed branches).
-``` -(max by (instance) (searcher_mount_point_info{mount_name="cacheDir",instance=~`${instance:regex}`} * on (device, nodename) group_left() (max by (device, nodename) (rate(node_disk_io_time_weighted_seconds_total{instance=~`node-exporter.*`}[1m]))))) -``` -+#### searcher: traffic -### Searcher: Searcher GRPC server metrics +
Requests per second by code over 10m
-#### searcher: searcher_grpc_request_rate_all_methods +This graph is the average number of requests per second searcher is +experiencing over the last 10 minutes. -Request rate across all methods over 2m
+The code is the HTTP Status code. 200 is success. We have a special code +"canceled" which is common when doing a large search request and we find +enough results before searching all possible repos. -The number of gRPC requests received per second across all methods, aggregated across all instances. +Note: A search query is translated into an unindexed search query per unique +(repo, commit). This means a single user query may result in thousands of +requests to searcher. This panel has no related alerts. -To see this panel, visit `/-/debug/grafana/d/searcher/searcher?viewPanel=100400` on your Sourcegraph instance. +To see this panel, visit `/-/debug/grafana/d/searcher/searcher?viewPanel=100000` on your Sourcegraph instance. *Managed by the [Sourcegraph Search Platform team](https://handbook.sourcegraph.com/departments/engineering/teams/search/core).* @@ -55000,21 +55203,30 @@ To see this panel, visit `/-/debug/grafana/d/searcher/searcher?viewPanel=100400` Query: ``` -sum(rate(grpc_server_started_total{instance=~`${instance:regex}`,grpc_service=~"searcher.v1.SearcherService"}[2m])) +sum by (code) (rate(searcher_service_request_total{instance=~`${instance:regex}`}[10m])) ```-#### searcher: searcher_grpc_request_rate_per_method +#### searcher: replica_traffic -
Request rate per-method over 2m
+Requests per second per replica over 10m
-The number of gRPC requests received per second broken out per method, aggregated across all instances. +This graph is the average number of requests per second searcher is +experiencing over the last 10 minutes broken down per replica. -This panel has no related alerts. +The code is the HTTP Status code. 200 is success. We have a special code +"canceled" which is common when doing a large search request and we find +enough results before searching all possible repos. -To see this panel, visit `/-/debug/grafana/d/searcher/searcher?viewPanel=100401` on your Sourcegraph instance. +Note: A search query is translated into an unindexed search query per unique +(repo, commit). This means a single user query may result in thousands of +requests to searcher. + +Refer to the [alerts reference](alerts#searcher-replica-traffic) for 1 alert related to this panel. + +To see this panel, visit `/-/debug/grafana/d/searcher/searcher?viewPanel=100001` on your Sourcegraph instance. *Managed by the [Sourcegraph Search Platform team](https://handbook.sourcegraph.com/departments/engineering/teams/search/core).* @@ -55024,21 +55236,22 @@ To see this panel, visit `/-/debug/grafana/d/searcher/searcher?viewPanel=100401` Query: ``` -sum(rate(grpc_server_started_total{grpc_method=~`${searcher_method:regex}`,instance=~`${instance:regex}`,grpc_service=~"searcher.v1.SearcherService"}[2m])) by (grpc_method) +sum by (instance) (rate(searcher_service_request_total{instance=~`${instance:regex}`}[10m])) ```-#### searcher: searcher_error_percentage_all_methods +#### searcher: concurrent_requests -
Error percentage across all methods over 2m
+Amount of in-flight unindexed search requests (per instance)
-The percentage of gRPC requests that fail across all methods, aggregated across all instances. +This graph is the amount of in-flight unindexed search requests per instance. +Consistently high numbers here indicate you may need to scale out searcher. This panel has no related alerts. -To see this panel, visit `/-/debug/grafana/d/searcher/searcher?viewPanel=100410` on your Sourcegraph instance. +To see this panel, visit `/-/debug/grafana/d/searcher/searcher?viewPanel=100010` on your Sourcegraph instance. *Managed by the [Sourcegraph Search Platform team](https://handbook.sourcegraph.com/departments/engineering/teams/search/core).* @@ -55048,21 +55261,19 @@ To see this panel, visit `/-/debug/grafana/d/searcher/searcher?viewPanel=100410` Query: ``` -(100.0 * ( (sum(rate(grpc_server_handled_total{grpc_code!="OK",instance=~`${instance:regex}`,grpc_service=~"searcher.v1.SearcherService"}[2m]))) / (sum(rate(grpc_server_handled_total{instance=~`${instance:regex}`,grpc_service=~"searcher.v1.SearcherService"}[2m]))) )) +sum by (instance) (searcher_service_running{instance=~`${instance:regex}`}) ```-#### searcher: searcher_grpc_error_percentage_per_method - -
Error percentage per-method over 2m
+#### searcher: unindexed_search_request_errors -The percentage of gRPC requests that fail per method, aggregated across all instances. +Unindexed search request errors every 5m by code
-This panel has no related alerts. +Refer to the [alerts reference](alerts#searcher-unindexed-search-request-errors) for 1 alert related to this panel. -To see this panel, visit `/-/debug/grafana/d/searcher/searcher?viewPanel=100411` on your Sourcegraph instance. +To see this panel, visit `/-/debug/grafana/d/searcher/searcher?viewPanel=100011` on your Sourcegraph instance. *Managed by the [Sourcegraph Search Platform team](https://handbook.sourcegraph.com/departments/engineering/teams/search/core).* @@ -55072,21 +55283,30 @@ To see this panel, visit `/-/debug/grafana/d/searcher/searcher?viewPanel=100411` Query: ``` -(100.0 * ( (sum(rate(grpc_server_handled_total{grpc_method=~`${searcher_method:regex}`,grpc_code!="OK",instance=~`${instance:regex}`,grpc_service=~"searcher.v1.SearcherService"}[2m])) by (grpc_method)) / (sum(rate(grpc_server_handled_total{grpc_method=~`${searcher_method:regex}`,instance=~`${instance:regex}`,grpc_service=~"searcher.v1.SearcherService"}[2m])) by (grpc_method)) )) +sum by (code)(increase(searcher_service_request_total{code!="200",code!="canceled",instance=~`${instance:regex}`}[5m])) / ignoring(code) group_left sum(increase(searcher_service_request_total{instance=~`${instance:regex}`}[5m])) * 100 ```-#### searcher: searcher_p99_response_time_per_method +### Searcher: Cache store -
99th percentile response time per method over 2m
+#### searcher: store_fetching -The 99th percentile response time per method, aggregated across all instances. +Amount of in-flight unindexed search requests fetching code from gitserver (per instance)
+ +Before we can search a commit we fetch the code from gitserver then cache it +for future search requests. This graph is the current number of search +requests which are in the state of fetching code from gitserver. + +Generally this number should remain low since fetching code is fast, but +expect bursts. In the case of instances with a monorepo you would expect this +number to stay low for the duration of fetching the code (which in some cases +can take many minutes). This panel has no related alerts. -To see this panel, visit `/-/debug/grafana/d/searcher/searcher?viewPanel=100420` on your Sourcegraph instance. +To see this panel, visit `/-/debug/grafana/d/searcher/searcher?viewPanel=100100` on your Sourcegraph instance. *Managed by the [Sourcegraph Search Platform team](https://handbook.sourcegraph.com/departments/engineering/teams/search/core).* @@ -55096,21 +55316,23 @@ To see this panel, visit `/-/debug/grafana/d/searcher/searcher?viewPanel=100420` Query: ``` -histogram_quantile(0.99, sum by (le, name, grpc_method)(rate(grpc_server_handling_seconds_bucket{grpc_method=~`${searcher_method:regex}`,instance=~`${instance:regex}`,grpc_service=~"searcher.v1.SearcherService"}[2m]))) +sum by (instance) (searcher_store_fetching{instance=~`${instance:regex}`}) ```-#### searcher: searcher_p90_response_time_per_method +#### searcher: store_fetching_waiting -
90th percentile response time per method over 2m
+Amount of in-flight unindexed search requests waiting to fetch code from gitserver (per instance)
-The 90th percentile response time per method, aggregated across all instances. +We limit the number of requests which can fetch code to prevent overwhelming +gitserver. This gauge is the number of requests waiting to be allowed to speak +to gitserver. This panel has no related alerts. -To see this panel, visit `/-/debug/grafana/d/searcher/searcher?viewPanel=100421` on your Sourcegraph instance. +To see this panel, visit `/-/debug/grafana/d/searcher/searcher?viewPanel=100101` on your Sourcegraph instance. *Managed by the [Sourcegraph Search Platform team](https://handbook.sourcegraph.com/departments/engineering/teams/search/core).* @@ -55120,21 +55342,24 @@ To see this panel, visit `/-/debug/grafana/d/searcher/searcher?viewPanel=100421` Query: ``` -histogram_quantile(0.90, sum by (le, name, grpc_method)(rate(grpc_server_handling_seconds_bucket{grpc_method=~`${searcher_method:regex}`,instance=~`${instance:regex}`,grpc_service=~"searcher.v1.SearcherService"}[2m]))) +sum by (instance) (searcher_store_fetch_queue_size{instance=~`${instance:regex}`}) ```-#### searcher: searcher_p75_response_time_per_method +#### searcher: store_fetching_fail -
75th percentile response time per method over 2m
+Amount of unindexed search requests that failed while fetching code from gitserver over 10m (per instance)
-The 75th percentile response time per method, aggregated across all instances. +This graph should be zero since fetching happens in the background and will +not be influenced by user timeouts/etc. Expected upticks in this graph are +during gitserver rollouts. If you regularly see this graph have non-zero +values please reach out to support. This panel has no related alerts. -To see this panel, visit `/-/debug/grafana/d/searcher/searcher?viewPanel=100422` on your Sourcegraph instance. +To see this panel, visit `/-/debug/grafana/d/searcher/searcher?viewPanel=100102` on your Sourcegraph instance. *Managed by the [Sourcegraph Search Platform team](https://handbook.sourcegraph.com/departments/engineering/teams/search/core).* @@ -55144,45 +55369,38 @@ To see this panel, visit `/-/debug/grafana/d/searcher/searcher?viewPanel=100422` Query: ``` -histogram_quantile(0.75, sum by (le, name, grpc_method)(rate(grpc_server_handling_seconds_bucket{grpc_method=~`${searcher_method:regex}`,instance=~`${instance:regex}`,grpc_service=~"searcher.v1.SearcherService"}[2m]))) +sum by (instance) (rate(searcher_store_fetch_failed{instance=~`${instance:regex}`}[10m])) ```-#### searcher: searcher_p99_9_response_size_per_method - -
99.9th percentile total response size per method over 2m
- -The 99.9th percentile total per-RPC response size per method, aggregated across all instances. - -This panel has no related alerts. - -To see this panel, visit `/-/debug/grafana/d/searcher/searcher?viewPanel=100430` on your Sourcegraph instance. - -*Managed by the [Sourcegraph Search Platform team](https://handbook.sourcegraph.com/departments/engineering/teams/search/core).* - -Technical details
+### Searcher: Index use -Query: +#### searcher: searcher_hybrid_final_state_total -``` -histogram_quantile(0.999, sum by (le, name, grpc_method)(rate(src_grpc_server_sent_bytes_per_rpc_bucket{grpc_method=~`${searcher_method:regex}`,instance=~`${instance:regex}`,grpc_service=~"searcher.v1.SearcherService"}[2m]))) -``` -Hybrid search final state over 10m
-+This graph is about our interactions with the search index (zoekt) to help +complete unindexed search requests. Searcher will use indexed search for the +files that have not changed between the unindexed commit and the index. -#### searcher: searcher_p90_response_size_per_method +This graph should mostly be "success". The next most common state should be +"search-canceled" which happens when result limits are hit or the user starts +a new search. Finally the next most common should be "diff-too-large", which +happens if the commit is too far from the indexed commit. Otherwise other +state should be rare and likely are a sign for further investigation. -
90th percentile total response size per method over 2m
+Note: On sourcegraph.com "zoekt-list-missing" is also common due to it +indexing a subset of repositories. Otherwise every other state should occur +rarely. -The 90th percentile total per-RPC response size per method, aggregated across all instances. +For a full list of possible state see +[recordHybridFinalState](https://sourcegraph.com/search?q=context:global+repo:%5Egithub%5C.com/sourcegraph/sourcegraph-public-snapshot%24+f:cmd/searcher+recordHybridFinalState). This panel has no related alerts. -To see this panel, visit `/-/debug/grafana/d/searcher/searcher?viewPanel=100431` on your Sourcegraph instance. +To see this panel, visit `/-/debug/grafana/d/searcher/searcher?viewPanel=100200` on your Sourcegraph instance. *Managed by the [Sourcegraph Search Platform team](https://handbook.sourcegraph.com/departments/engineering/teams/search/core).* @@ -55192,21 +55410,24 @@ To see this panel, visit `/-/debug/grafana/d/searcher/searcher?viewPanel=100431` Query: ``` -histogram_quantile(0.90, sum by (le, name, grpc_method)(rate(src_grpc_server_sent_bytes_per_rpc_bucket{grpc_method=~`${searcher_method:regex}`,instance=~`${instance:regex}`,grpc_service=~"searcher.v1.SearcherService"}[2m]))) +sum by (state)(increase(searcher_hybrid_final_state_total{instance=~`${instance:regex}`}[10m])) ```-#### searcher: searcher_p75_response_size_per_method +#### searcher: searcher_hybrid_retry_total -
75th percentile total response size per method over 2m
+Hybrid search retrying over 10m
-The 75th percentile total per-RPC response size per method, aggregated across all instances. +Expectation is that this graph should mostly be 0. It will trigger if a user +manages to do a search and the underlying index changes while searching or +Zoekt goes down. So occasional bursts can be expected, but if this graph is +regularly above 0 it is a sign for further investigation. This panel has no related alerts. -To see this panel, visit `/-/debug/grafana/d/searcher/searcher?viewPanel=100432` on your Sourcegraph instance. +To see this panel, visit `/-/debug/grafana/d/searcher/searcher?viewPanel=100201` on your Sourcegraph instance. *Managed by the [Sourcegraph Search Platform team](https://handbook.sourcegraph.com/departments/engineering/teams/search/core).* @@ -55216,21 +55437,25 @@ To see this panel, visit `/-/debug/grafana/d/searcher/searcher?viewPanel=100432` Query: ``` -histogram_quantile(0.75, sum by (le, name, grpc_method)(rate(src_grpc_server_sent_bytes_per_rpc_bucket{grpc_method=~`${searcher_method:regex}`,instance=~`${instance:regex}`,grpc_service=~"searcher.v1.SearcherService"}[2m]))) +sum by (reason)(increase(searcher_hybrid_retry_total{instance=~`${instance:regex}`}[10m])) ```-#### searcher: searcher_p99_9_invididual_sent_message_size_per_method +### Searcher: Cache disk I/O metrics -
99.9th percentile individual sent message size per method over 2m
+#### searcher: cache_disk_reads_sec -The 99.9th percentile size of every individual protocol buffer size sent by the service per method, aggregated across all instances. +Read request rate over 1m (per instance)
+ +The number of read requests that were issued to the device per second. + +Note: Disk statistics are per _device_, not per _service_. In certain environments (such as common docker-compose setups), searcher could be one of _many services_ using this disk. These statistics are best interpreted as the load experienced by the device searcher is using, not the load searcher is solely responsible for causing. This panel has no related alerts. -To see this panel, visit `/-/debug/grafana/d/searcher/searcher?viewPanel=100440` on your Sourcegraph instance. +To see this panel, visit `/-/debug/grafana/d/searcher/searcher?viewPanel=100300` on your Sourcegraph instance. *Managed by the [Sourcegraph Search Platform team](https://handbook.sourcegraph.com/departments/engineering/teams/search/core).* @@ -55240,21 +55465,23 @@ To see this panel, visit `/-/debug/grafana/d/searcher/searcher?viewPanel=100440` Query: ``` -histogram_quantile(0.999, sum by (le, name, grpc_method)(rate(src_grpc_server_sent_individual_message_size_bytes_per_rpc_bucket{grpc_method=~`${searcher_method:regex}`,instance=~`${instance:regex}`,grpc_service=~"searcher.v1.SearcherService"}[2m]))) +(max by (instance) (searcher_mount_point_info{mount_name="cacheDir",instance=~`${instance:regex}`} * on (device, nodename) group_left() (max by (device, nodename) (rate(node_disk_reads_completed_total{instance=~`node-exporter.*`}[1m]))))) ```-#### searcher: searcher_p90_invididual_sent_message_size_per_method +#### searcher: cache_disk_writes_sec -
90th percentile individual sent message size per method over 2m
+Write request rate over 1m (per instance)
-The 90th percentile size of every individual protocol buffer size sent by the service per method, aggregated across all instances. +The number of write requests that were issued to the device per second. + +Note: Disk statistics are per _device_, not per _service_. In certain environments (such as common docker-compose setups), searcher could be one of _many services_ using this disk. These statistics are best interpreted as the load experienced by the device searcher is using, not the load searcher is solely responsible for causing. This panel has no related alerts. -To see this panel, visit `/-/debug/grafana/d/searcher/searcher?viewPanel=100441` on your Sourcegraph instance. +To see this panel, visit `/-/debug/grafana/d/searcher/searcher?viewPanel=100301` on your Sourcegraph instance. *Managed by the [Sourcegraph Search Platform team](https://handbook.sourcegraph.com/departments/engineering/teams/search/core).* @@ -55264,21 +55491,23 @@ To see this panel, visit `/-/debug/grafana/d/searcher/searcher?viewPanel=100441` Query: ``` -histogram_quantile(0.90, sum by (le, name, grpc_method)(rate(src_grpc_server_sent_individual_message_size_bytes_per_rpc_bucket{grpc_method=~`${searcher_method:regex}`,instance=~`${instance:regex}`,grpc_service=~"searcher.v1.SearcherService"}[2m]))) +(max by (instance) (searcher_mount_point_info{mount_name="cacheDir",instance=~`${instance:regex}`} * on (device, nodename) group_left() (max by (device, nodename) (rate(node_disk_writes_completed_total{instance=~`node-exporter.*`}[1m]))))) ```-#### searcher: searcher_p75_invididual_sent_message_size_per_method +#### searcher: cache_disk_read_throughput -
75th percentile individual sent message size per method over 2m
+Read throughput over 1m (per instance)
-The 75th percentile size of every individual protocol buffer size sent by the service per method, aggregated across all instances. +The amount of data that was read from the device per second. + +Note: Disk statistics are per _device_, not per _service_. In certain environments (such as common docker-compose setups), searcher could be one of _many services_ using this disk. These statistics are best interpreted as the load experienced by the device searcher is using, not the load searcher is solely responsible for causing. This panel has no related alerts. -To see this panel, visit `/-/debug/grafana/d/searcher/searcher?viewPanel=100442` on your Sourcegraph instance. +To see this panel, visit `/-/debug/grafana/d/searcher/searcher?viewPanel=100310` on your Sourcegraph instance. *Managed by the [Sourcegraph Search Platform team](https://handbook.sourcegraph.com/departments/engineering/teams/search/core).* @@ -55288,21 +55517,23 @@ To see this panel, visit `/-/debug/grafana/d/searcher/searcher?viewPanel=100442` Query: ``` -histogram_quantile(0.75, sum by (le, name, grpc_method)(rate(src_grpc_server_sent_individual_message_size_bytes_per_rpc_bucket{grpc_method=~`${searcher_method:regex}`,instance=~`${instance:regex}`,grpc_service=~"searcher.v1.SearcherService"}[2m]))) +(max by (instance) (searcher_mount_point_info{mount_name="cacheDir",instance=~`${instance:regex}`} * on (device, nodename) group_left() (max by (device, nodename) (rate(node_disk_read_bytes_total{instance=~`node-exporter.*`}[1m]))))) ```-#### searcher: searcher_grpc_response_stream_message_count_per_method +#### searcher: cache_disk_write_throughput -
Average streaming response message count per-method over 2m
+Write throughput over 1m (per instance)
-The average number of response messages sent during a streaming RPC method, broken out per method, aggregated across all instances. +The amount of data that was written to the device per second. + +Note: Disk statistics are per _device_, not per _service_. In certain environments (such as common docker-compose setups), searcher could be one of _many services_ using this disk. These statistics are best interpreted as the load experienced by the device searcher is using, not the load searcher is solely responsible for causing. This panel has no related alerts. -To see this panel, visit `/-/debug/grafana/d/searcher/searcher?viewPanel=100450` on your Sourcegraph instance. +To see this panel, visit `/-/debug/grafana/d/searcher/searcher?viewPanel=100311` on your Sourcegraph instance. *Managed by the [Sourcegraph Search Platform team](https://handbook.sourcegraph.com/departments/engineering/teams/search/core).* @@ -55312,21 +55543,23 @@ To see this panel, visit `/-/debug/grafana/d/searcher/searcher?viewPanel=100450` Query: ``` -((sum(rate(grpc_server_msg_sent_total{grpc_type="server_stream",instance=~`${instance:regex}`,grpc_service=~"searcher.v1.SearcherService"}[2m])) by (grpc_method))/(sum(rate(grpc_server_started_total{grpc_type="server_stream",instance=~`${instance:regex}`,grpc_service=~"searcher.v1.SearcherService"}[2m])) by (grpc_method))) +(max by (instance) (searcher_mount_point_info{mount_name="cacheDir",instance=~`${instance:regex}`} * on (device, nodename) group_left() (max by (device, nodename) (rate(node_disk_written_bytes_total{instance=~`node-exporter.*`}[1m]))))) ```-#### searcher: searcher_grpc_all_codes_per_method +#### searcher: cache_disk_read_duration -
Response codes rate per-method over 2m
+Average read duration over 1m (per instance)
-The rate of all generated gRPC response codes per method, aggregated across all instances. +The average time for read requests issued to the device to be served. This includes the time spent by the requests in queue and the time spent servicing them. + +Note: Disk statistics are per _device_, not per _service_. In certain environments (such as common docker-compose setups), searcher could be one of _many services_ using this disk. These statistics are best interpreted as the load experienced by the device searcher is using, not the load searcher is solely responsible for causing. This panel has no related alerts. -To see this panel, visit `/-/debug/grafana/d/searcher/searcher?viewPanel=100460` on your Sourcegraph instance. +To see this panel, visit `/-/debug/grafana/d/searcher/searcher?viewPanel=100320` on your Sourcegraph instance. *Managed by the [Sourcegraph Search Platform team](https://handbook.sourcegraph.com/departments/engineering/teams/search/core).* @@ -55336,23 +55569,23 @@ To see this panel, visit `/-/debug/grafana/d/searcher/searcher?viewPanel=100460` Query: ``` -sum(rate(grpc_server_handled_total{grpc_method=~`${searcher_method:regex}`,instance=~`${instance:regex}`,grpc_service=~"searcher.v1.SearcherService"}[2m])) by (grpc_method, grpc_code) +(((max by (instance) (searcher_mount_point_info{mount_name="cacheDir",instance=~`${instance:regex}`} * on (device, nodename) group_left() (max by (device, nodename) (rate(node_disk_read_time_seconds_total{instance=~`node-exporter.*`}[1m])))))) / ((max by (instance) (searcher_mount_point_info{mount_name="cacheDir",instance=~`${instance:regex}`} * on (device, nodename) group_left() (max by (device, nodename) (rate(node_disk_reads_completed_total{instance=~`node-exporter.*`}[1m]))))))) ```-### Searcher: Searcher GRPC "internal error" metrics +#### searcher: cache_disk_write_duration -#### searcher: searcher_grpc_clients_error_percentage_all_methods +
Average write duration over 1m (per instance)
-Client baseline error percentage across all methods over 2m
+The average time for write requests issued to the device to be served. This includes the time spent by the requests in queue and the time spent servicing them. -The percentage of gRPC requests that fail across all methods (regardless of whether or not there was an internal error), aggregated across all "searcher" clients. +Note: Disk statistics are per _device_, not per _service_. In certain environments (such as common docker-compose setups), searcher could be one of _many services_ using this disk. These statistics are best interpreted as the load experienced by the device searcher is using, not the load searcher is solely responsible for causing. This panel has no related alerts. -To see this panel, visit `/-/debug/grafana/d/searcher/searcher?viewPanel=100500` on your Sourcegraph instance. +To see this panel, visit `/-/debug/grafana/d/searcher/searcher?viewPanel=100321` on your Sourcegraph instance. *Managed by the [Sourcegraph Search Platform team](https://handbook.sourcegraph.com/departments/engineering/teams/search/core).* @@ -55362,21 +55595,23 @@ To see this panel, visit `/-/debug/grafana/d/searcher/searcher?viewPanel=100500` Query: ``` -(100.0 * ((((sum(rate(src_grpc_method_status{grpc_service=~"searcher.v1.SearcherService",grpc_code!="OK"}[2m])))) / ((sum(rate(src_grpc_method_status{grpc_service=~"searcher.v1.SearcherService"}[2m]))))))) +(((max by (instance) (searcher_mount_point_info{mount_name="cacheDir",instance=~`${instance:regex}`} * on (device, nodename) group_left() (max by (device, nodename) (rate(node_disk_write_time_seconds_total{instance=~`node-exporter.*`}[1m])))))) / ((max by (instance) (searcher_mount_point_info{mount_name="cacheDir",instance=~`${instance:regex}`} * on (device, nodename) group_left() (max by (device, nodename) (rate(node_disk_writes_completed_total{instance=~`node-exporter.*`}[1m]))))))) ```-#### searcher: searcher_grpc_clients_error_percentage_per_method +#### searcher: cache_disk_read_request_size -
Client baseline error percentage per-method over 2m
+Average read request size over 1m (per instance)
-The percentage of gRPC requests that fail per method (regardless of whether or not there was an internal error), aggregated across all "searcher" clients. +The average size of read requests that were issued to the device. + +Note: Disk statistics are per _device_, not per _service_. In certain environments (such as common docker-compose setups), searcher could be one of _many services_ using this disk. These statistics are best interpreted as the load experienced by the device searcher is using, not the load searcher is solely responsible for causing. This panel has no related alerts. -To see this panel, visit `/-/debug/grafana/d/searcher/searcher?viewPanel=100501` on your Sourcegraph instance. +To see this panel, visit `/-/debug/grafana/d/searcher/searcher?viewPanel=100330` on your Sourcegraph instance. *Managed by the [Sourcegraph Search Platform team](https://handbook.sourcegraph.com/departments/engineering/teams/search/core).* @@ -55386,21 +55621,23 @@ To see this panel, visit `/-/debug/grafana/d/searcher/searcher?viewPanel=100501` Query: ``` -(100.0 * ((((sum(rate(src_grpc_method_status{grpc_service=~"searcher.v1.SearcherService",grpc_method=~"${searcher_method:regex}",grpc_code!="OK"}[2m])) by (grpc_method))) / ((sum(rate(src_grpc_method_status{grpc_service=~"searcher.v1.SearcherService",grpc_method=~"${searcher_method:regex}"}[2m])) by (grpc_method)))))) +(((max by (instance) (searcher_mount_point_info{mount_name="cacheDir",instance=~`${instance:regex}`} * on (device, nodename) group_left() (max by (device, nodename) (rate(node_disk_read_bytes_total{instance=~`node-exporter.*`}[1m])))))) / ((max by (instance) (searcher_mount_point_info{mount_name="cacheDir",instance=~`${instance:regex}`} * on (device, nodename) group_left() (max by (device, nodename) (rate(node_disk_reads_completed_total{instance=~`node-exporter.*`}[1m]))))))) ```-#### searcher: searcher_grpc_clients_all_codes_per_method +#### searcher: cache_disk_write_request_size) -
Client baseline response codes rate per-method over 2m
+Average write request size over 1m (per instance)
-The rate of all generated gRPC response codes per method (regardless of whether or not there was an internal error), aggregated across all "searcher" clients. +The average size of write requests that were issued to the device. + +Note: Disk statistics are per _device_, not per _service_. In certain environments (such as common docker-compose setups), searcher could be one of _many services_ using this disk. These statistics are best interpreted as the load experienced by the device searcher is using, not the load searcher is solely responsible for causing. This panel has no related alerts. -To see this panel, visit `/-/debug/grafana/d/searcher/searcher?viewPanel=100502` on your Sourcegraph instance. +To see this panel, visit `/-/debug/grafana/d/searcher/searcher?viewPanel=100331` on your Sourcegraph instance. *Managed by the [Sourcegraph Search Platform team](https://handbook.sourcegraph.com/departments/engineering/teams/search/core).* @@ -55410,27 +55647,23 @@ To see this panel, visit `/-/debug/grafana/d/searcher/searcher?viewPanel=100502` Query: ``` -(sum(rate(src_grpc_method_status{grpc_service=~"searcher.v1.SearcherService",grpc_method=~"${searcher_method:regex}"}[2m])) by (grpc_method, grpc_code)) +(((max by (instance) (searcher_mount_point_info{mount_name="cacheDir",instance=~`${instance:regex}`} * on (device, nodename) group_left() (max by (device, nodename) (rate(node_disk_written_bytes_total{instance=~`node-exporter.*`}[1m])))))) / ((max by (instance) (searcher_mount_point_info{mount_name="cacheDir",instance=~`${instance:regex}`} * on (device, nodename) group_left() (max by (device, nodename) (rate(node_disk_writes_completed_total{instance=~`node-exporter.*`}[1m]))))))) ```-#### searcher: searcher_grpc_clients_internal_error_percentage_all_methods - -
Client-observed gRPC internal error percentage across all methods over 2m
- -The percentage of gRPC requests that appear to fail due to gRPC internal errors across all methods, aggregated across all "searcher" clients. +#### searcher: cache_disk_reads_merged_sec -**Note**: Internal errors are ones that appear to originate from the https://github.com/grpc/grpc-go library itself, rather than from any user-written application code. These errors can be caused by a variety of issues, and can originate from either the code-generated "searcher" gRPC client or gRPC server. These errors might be solvable by adjusting the gRPC configuration, or they might indicate a bug from Sourcegraph`s use of gRPC. +Merged read request rate over 1m (per instance)
-When debugging, knowing that a particular error comes from the grpc-go library itself (an `internal error`) as opposed to `normal` application code can be helpful when trying to fix it. +The number of read requests merged per second that were queued to the device. -**Note**: Internal errors are detected via a very coarse heuristic (seeing if the error starts with `grpc:`, etc.). Because of this, it`s possible that some gRPC-specific issues might not be categorized as internal errors. +Note: Disk statistics are per _device_, not per _service_. In certain environments (such as common docker-compose setups), searcher could be one of _many services_ using this disk. These statistics are best interpreted as the load experienced by the device searcher is using, not the load searcher is solely responsible for causing. This panel has no related alerts. -To see this panel, visit `/-/debug/grafana/d/searcher/searcher?viewPanel=100510` on your Sourcegraph instance. +To see this panel, visit `/-/debug/grafana/d/searcher/searcher?viewPanel=100340` on your Sourcegraph instance. *Managed by the [Sourcegraph Search Platform team](https://handbook.sourcegraph.com/departments/engineering/teams/search/core).* @@ -55440,27 +55673,23 @@ To see this panel, visit `/-/debug/grafana/d/searcher/searcher?viewPanel=100510` Query: ``` -(100.0 * ((((sum(rate(src_grpc_method_status{grpc_service=~"searcher.v1.SearcherService",grpc_code!="OK",is_internal_error="true"}[2m])))) / ((sum(rate(src_grpc_method_status{grpc_service=~"searcher.v1.SearcherService"}[2m]))))))) +(max by (instance) (searcher_mount_point_info{mount_name="cacheDir",instance=~`${instance:regex}`} * on (device, nodename) group_left() (max by (device, nodename) (rate(node_disk_reads_merged_total{instance=~`node-exporter.*`}[1m]))))) ```-#### searcher: searcher_grpc_clients_internal_error_percentage_per_method - -
Client-observed gRPC internal error percentage per-method over 2m
- -The percentage of gRPC requests that appear to fail to due to gRPC internal errors per method, aggregated across all "searcher" clients. +#### searcher: cache_disk_writes_merged_sec -**Note**: Internal errors are ones that appear to originate from the https://github.com/grpc/grpc-go library itself, rather than from any user-written application code. These errors can be caused by a variety of issues, and can originate from either the code-generated "searcher" gRPC client or gRPC server. These errors might be solvable by adjusting the gRPC configuration, or they might indicate a bug from Sourcegraph`s use of gRPC. +Merged writes request rate over 1m (per instance)
-When debugging, knowing that a particular error comes from the grpc-go library itself (an `internal error`) as opposed to `normal` application code can be helpful when trying to fix it. +The number of write requests merged per second that were queued to the device. -**Note**: Internal errors are detected via a very coarse heuristic (seeing if the error starts with `grpc:`, etc.). Because of this, it`s possible that some gRPC-specific issues might not be categorized as internal errors. +Note: Disk statistics are per _device_, not per _service_. In certain environments (such as common docker-compose setups), searcher could be one of _many services_ using this disk. These statistics are best interpreted as the load experienced by the device searcher is using, not the load searcher is solely responsible for causing. This panel has no related alerts. -To see this panel, visit `/-/debug/grafana/d/searcher/searcher?viewPanel=100511` on your Sourcegraph instance. +To see this panel, visit `/-/debug/grafana/d/searcher/searcher?viewPanel=100341` on your Sourcegraph instance. *Managed by the [Sourcegraph Search Platform team](https://handbook.sourcegraph.com/departments/engineering/teams/search/core).* @@ -55470,27 +55699,23 @@ To see this panel, visit `/-/debug/grafana/d/searcher/searcher?viewPanel=100511` Query: ``` -(100.0 * ((((sum(rate(src_grpc_method_status{grpc_service=~"searcher.v1.SearcherService",grpc_method=~"${searcher_method:regex}",grpc_code!="OK",is_internal_error="true"}[2m])) by (grpc_method))) / ((sum(rate(src_grpc_method_status{grpc_service=~"searcher.v1.SearcherService",grpc_method=~"${searcher_method:regex}"}[2m])) by (grpc_method)))))) +(max by (instance) (searcher_mount_point_info{mount_name="cacheDir",instance=~`${instance:regex}`} * on (device, nodename) group_left() (max by (device, nodename) (rate(node_disk_writes_merged_total{instance=~`node-exporter.*`}[1m]))))) ```-#### searcher: searcher_grpc_clients_internal_error_all_codes_per_method - -
Client-observed gRPC internal error response code rate per-method over 2m
- -The rate of gRPC internal-error response codes per method, aggregated across all "searcher" clients. +#### searcher: cache_disk_average_queue_size -**Note**: Internal errors are ones that appear to originate from the https://github.com/grpc/grpc-go library itself, rather than from any user-written application code. These errors can be caused by a variety of issues, and can originate from either the code-generated "searcher" gRPC client or gRPC server. These errors might be solvable by adjusting the gRPC configuration, or they might indicate a bug from Sourcegraph`s use of gRPC. +Average queue size over 1m (per instance)
-When debugging, knowing that a particular error comes from the grpc-go library itself (an `internal error`) as opposed to `normal` application code can be helpful when trying to fix it. +The number of I/O operations that were being queued or being serviced. See https://blog.actorsfit.com/a?ID=00200-428fa2ac-e338-4540-848c-af9a3eb1ebd2 for background (avgqu-sz). -**Note**: Internal errors are detected via a very coarse heuristic (seeing if the error starts with `grpc:`, etc.). Because of this, it`s possible that some gRPC-specific issues might not be categorized as internal errors. +Note: Disk statistics are per _device_, not per _service_. In certain environments (such as common docker-compose setups), searcher could be one of _many services_ using this disk. These statistics are best interpreted as the load experienced by the device searcher is using, not the load searcher is solely responsible for causing. This panel has no related alerts. -To see this panel, visit `/-/debug/grafana/d/searcher/searcher?viewPanel=100512` on your Sourcegraph instance. +To see this panel, visit `/-/debug/grafana/d/searcher/searcher?viewPanel=100350` on your Sourcegraph instance. *Managed by the [Sourcegraph Search Platform team](https://handbook.sourcegraph.com/departments/engineering/teams/search/core).* @@ -55500,23 +55725,23 @@ To see this panel, visit `/-/debug/grafana/d/searcher/searcher?viewPanel=100512` Query: ``` -(sum(rate(src_grpc_method_status{grpc_service=~"searcher.v1.SearcherService",is_internal_error="true",grpc_method=~"${searcher_method:regex}"}[2m])) by (grpc_method, grpc_code)) +(max by (instance) (searcher_mount_point_info{mount_name="cacheDir",instance=~`${instance:regex}`} * on (device, nodename) group_left() (max by (device, nodename) (rate(node_disk_io_time_weighted_seconds_total{instance=~`node-exporter.*`}[1m]))))) ```-### Searcher: Searcher GRPC retry metrics +### Searcher: Searcher GRPC server metrics -#### searcher: searcher_grpc_clients_retry_percentage_across_all_methods +#### searcher: searcher_grpc_request_rate_all_methods -
Client retry percentage across all methods over 2m
+Request rate across all methods over 2m
-The percentage of gRPC requests that were retried across all methods, aggregated across all "searcher" clients. +The number of gRPC requests received per second across all methods, aggregated across all instances. This panel has no related alerts. -To see this panel, visit `/-/debug/grafana/d/searcher/searcher?viewPanel=100600` on your Sourcegraph instance. +To see this panel, visit `/-/debug/grafana/d/searcher/searcher?viewPanel=100400` on your Sourcegraph instance. *Managed by the [Sourcegraph Search Platform team](https://handbook.sourcegraph.com/departments/engineering/teams/search/core).* @@ -55526,21 +55751,21 @@ To see this panel, visit `/-/debug/grafana/d/searcher/searcher?viewPanel=100600` Query: ``` -(100.0 * ((((sum(rate(src_grpc_client_retry_attempts_total{grpc_service=~"searcher.v1.SearcherService",is_retried="true"}[2m])))) / ((sum(rate(src_grpc_client_retry_attempts_total{grpc_service=~"searcher.v1.SearcherService"}[2m]))))))) +sum(rate(grpc_server_started_total{instance=~`${instance:regex}`,grpc_service=~"searcher.v1.SearcherService"}[2m])) ```-#### searcher: searcher_grpc_clients_retry_percentage_per_method +#### searcher: searcher_grpc_request_rate_per_method -
Client retry percentage per-method over 2m
+Request rate per-method over 2m
-The percentage of gRPC requests that were retried aggregated across all "searcher" clients, broken out per method. +The number of gRPC requests received per second broken out per method, aggregated across all instances. This panel has no related alerts. -To see this panel, visit `/-/debug/grafana/d/searcher/searcher?viewPanel=100601` on your Sourcegraph instance. +To see this panel, visit `/-/debug/grafana/d/searcher/searcher?viewPanel=100401` on your Sourcegraph instance. *Managed by the [Sourcegraph Search Platform team](https://handbook.sourcegraph.com/departments/engineering/teams/search/core).* @@ -55550,21 +55775,21 @@ To see this panel, visit `/-/debug/grafana/d/searcher/searcher?viewPanel=100601` Query: ``` -(100.0 * ((((sum(rate(src_grpc_client_retry_attempts_total{grpc_service=~"searcher.v1.SearcherService",is_retried="true",grpc_method=~"${searcher_method:regex}"}[2m])) by (grpc_method))) / ((sum(rate(src_grpc_client_retry_attempts_total{grpc_service=~"searcher.v1.SearcherService",grpc_method=~"${searcher_method:regex}"}[2m])) by (grpc_method)))))) +sum(rate(grpc_server_started_total{grpc_method=~`${searcher_method:regex}`,instance=~`${instance:regex}`,grpc_service=~"searcher.v1.SearcherService"}[2m])) by (grpc_method) ```-#### searcher: searcher_grpc_clients_retry_count_per_method +#### searcher: searcher_error_percentage_all_methods -
Client retry count per-method over 2m
+Error percentage across all methods over 2m
-The count of gRPC requests that were retried aggregated across all "searcher" clients, broken out per method +The percentage of gRPC requests that fail across all methods, aggregated across all instances. This panel has no related alerts. -To see this panel, visit `/-/debug/grafana/d/searcher/searcher?viewPanel=100602` on your Sourcegraph instance. +To see this panel, visit `/-/debug/grafana/d/searcher/searcher?viewPanel=100410` on your Sourcegraph instance. *Managed by the [Sourcegraph Search Platform team](https://handbook.sourcegraph.com/departments/engineering/teams/search/core).* @@ -55574,25 +55799,23 @@ To see this panel, visit `/-/debug/grafana/d/searcher/searcher?viewPanel=100602` Query: ``` -(sum(rate(src_grpc_client_retry_attempts_total{grpc_service=~"searcher.v1.SearcherService",grpc_method=~"${searcher_method:regex}",is_retried="true"}[2m])) by (grpc_method)) +(100.0 * ( (sum(rate(grpc_server_handled_total{grpc_code!="OK",instance=~`${instance:regex}`,grpc_service=~"searcher.v1.SearcherService"}[2m]))) / (sum(rate(grpc_server_handled_total{instance=~`${instance:regex}`,grpc_service=~"searcher.v1.SearcherService"}[2m]))) )) ```-### Searcher: Site configuration client update latency - -#### searcher: searcher_site_configuration_duration_since_last_successful_update_by_instance +#### searcher: searcher_grpc_error_percentage_per_method -
Duration since last successful site configuration update (by instance)
+Error percentage per-method over 2m
-The duration since the configuration client used by the "searcher" service last successfully updated its site configuration. Long durations could indicate issues updating the site configuration. +The percentage of gRPC requests that fail per method, aggregated across all instances. This panel has no related alerts. -To see this panel, visit `/-/debug/grafana/d/searcher/searcher?viewPanel=100700` on your Sourcegraph instance. +To see this panel, visit `/-/debug/grafana/d/searcher/searcher?viewPanel=100411` on your Sourcegraph instance. -*Managed by the [Sourcegraph Infrastructure Org team](https://handbook.sourcegraph.com/departments/engineering/infrastructure).* +*Managed by the [Sourcegraph Search Platform team](https://handbook.sourcegraph.com/departments/engineering/teams/search/core).*Technical details
@@ -55600,21 +55823,23 @@ To see this panel, visit `/-/debug/grafana/d/searcher/searcher?viewPanel=100700` Query: ``` -src_conf_client_time_since_last_successful_update_seconds{job=~`.*searcher`,instance=~`${instance:regex}`} +(100.0 * ( (sum(rate(grpc_server_handled_total{grpc_method=~`${searcher_method:regex}`,grpc_code!="OK",instance=~`${instance:regex}`,grpc_service=~"searcher.v1.SearcherService"}[2m])) by (grpc_method)) / (sum(rate(grpc_server_handled_total{grpc_method=~`${searcher_method:regex}`,instance=~`${instance:regex}`,grpc_service=~"searcher.v1.SearcherService"}[2m])) by (grpc_method)) )) ```-#### searcher: searcher_site_configuration_duration_since_last_successful_update_by_instance +#### searcher: searcher_p99_response_time_per_method -
Maximum duration since last successful site configuration update (all "searcher" instances)
+99th percentile response time per method over 2m
-Refer to the [alerts reference](alerts#searcher-searcher-site-configuration-duration-since-last-successful-update-by-instance) for 1 alert related to this panel. +The 99th percentile response time per method, aggregated across all instances. -To see this panel, visit `/-/debug/grafana/d/searcher/searcher?viewPanel=100701` on your Sourcegraph instance. +This panel has no related alerts. -*Managed by the [Sourcegraph Infrastructure Org team](https://handbook.sourcegraph.com/departments/engineering/infrastructure).* +To see this panel, visit `/-/debug/grafana/d/searcher/searcher?viewPanel=100420` on your Sourcegraph instance. + +*Managed by the [Sourcegraph Search Platform team](https://handbook.sourcegraph.com/departments/engineering/teams/search/core).*Technical details
@@ -55622,23 +55847,23 @@ To see this panel, visit `/-/debug/grafana/d/searcher/searcher?viewPanel=100701` Query: ``` -max(max_over_time(src_conf_client_time_since_last_successful_update_seconds{job=~`.*searcher`,instance=~`${instance:regex}`}[1m])) +histogram_quantile(0.99, sum by (le, name, grpc_method)(rate(grpc_server_handling_seconds_bucket{grpc_method=~`${searcher_method:regex}`,instance=~`${instance:regex}`,grpc_service=~"searcher.v1.SearcherService"}[2m]))) ```-### Searcher: Database connections +#### searcher: searcher_p90_response_time_per_method -#### searcher: max_open_conns +
90th percentile response time per method over 2m
-Maximum open
+The 90th percentile response time per method, aggregated across all instances. This panel has no related alerts. -To see this panel, visit `/-/debug/grafana/d/searcher/searcher?viewPanel=100800` on your Sourcegraph instance. +To see this panel, visit `/-/debug/grafana/d/searcher/searcher?viewPanel=100421` on your Sourcegraph instance. -*Managed by the [Sourcegraph Infrastructure Org team](https://handbook.sourcegraph.com/departments/engineering/infrastructure).* +*Managed by the [Sourcegraph Search Platform team](https://handbook.sourcegraph.com/departments/engineering/teams/search/core).*Technical details
@@ -55646,21 +55871,23 @@ To see this panel, visit `/-/debug/grafana/d/searcher/searcher?viewPanel=100800` Query: ``` -sum by (app_name, db_name) (src_pgsql_conns_max_open{app_name="searcher"}) +histogram_quantile(0.90, sum by (le, name, grpc_method)(rate(grpc_server_handling_seconds_bucket{grpc_method=~`${searcher_method:regex}`,instance=~`${instance:regex}`,grpc_service=~"searcher.v1.SearcherService"}[2m]))) ```-#### searcher: open_conns +#### searcher: searcher_p75_response_time_per_method -
Established
+75th percentile response time per method over 2m
+ +The 75th percentile response time per method, aggregated across all instances. This panel has no related alerts. -To see this panel, visit `/-/debug/grafana/d/searcher/searcher?viewPanel=100801` on your Sourcegraph instance. +To see this panel, visit `/-/debug/grafana/d/searcher/searcher?viewPanel=100422` on your Sourcegraph instance. -*Managed by the [Sourcegraph Infrastructure Org team](https://handbook.sourcegraph.com/departments/engineering/infrastructure).* +*Managed by the [Sourcegraph Search Platform team](https://handbook.sourcegraph.com/departments/engineering/teams/search/core).*Technical details
@@ -55668,21 +55895,23 @@ To see this panel, visit `/-/debug/grafana/d/searcher/searcher?viewPanel=100801` Query: ``` -sum by (app_name, db_name) (src_pgsql_conns_open{app_name="searcher"}) +histogram_quantile(0.75, sum by (le, name, grpc_method)(rate(grpc_server_handling_seconds_bucket{grpc_method=~`${searcher_method:regex}`,instance=~`${instance:regex}`,grpc_service=~"searcher.v1.SearcherService"}[2m]))) ```-#### searcher: in_use +#### searcher: searcher_p99_9_response_size_per_method -
Used
+99.9th percentile total response size per method over 2m
+ +The 99.9th percentile total per-RPC response size per method, aggregated across all instances. This panel has no related alerts. -To see this panel, visit `/-/debug/grafana/d/searcher/searcher?viewPanel=100810` on your Sourcegraph instance. +To see this panel, visit `/-/debug/grafana/d/searcher/searcher?viewPanel=100430` on your Sourcegraph instance. -*Managed by the [Sourcegraph Infrastructure Org team](https://handbook.sourcegraph.com/departments/engineering/infrastructure).* +*Managed by the [Sourcegraph Search Platform team](https://handbook.sourcegraph.com/departments/engineering/teams/search/core).*Technical details
@@ -55690,21 +55919,23 @@ To see this panel, visit `/-/debug/grafana/d/searcher/searcher?viewPanel=100810` Query: ``` -sum by (app_name, db_name) (src_pgsql_conns_in_use{app_name="searcher"}) +histogram_quantile(0.999, sum by (le, name, grpc_method)(rate(src_grpc_server_sent_bytes_per_rpc_bucket{grpc_method=~`${searcher_method:regex}`,instance=~`${instance:regex}`,grpc_service=~"searcher.v1.SearcherService"}[2m]))) ```-#### searcher: idle +#### searcher: searcher_p90_response_size_per_method -
Idle
+90th percentile total response size per method over 2m
+ +The 90th percentile total per-RPC response size per method, aggregated across all instances. This panel has no related alerts. -To see this panel, visit `/-/debug/grafana/d/searcher/searcher?viewPanel=100811` on your Sourcegraph instance. +To see this panel, visit `/-/debug/grafana/d/searcher/searcher?viewPanel=100431` on your Sourcegraph instance. -*Managed by the [Sourcegraph Infrastructure Org team](https://handbook.sourcegraph.com/departments/engineering/infrastructure).* +*Managed by the [Sourcegraph Search Platform team](https://handbook.sourcegraph.com/departments/engineering/teams/search/core).*Technical details
@@ -55712,21 +55943,23 @@ To see this panel, visit `/-/debug/grafana/d/searcher/searcher?viewPanel=100811` Query: ``` -sum by (app_name, db_name) (src_pgsql_conns_idle{app_name="searcher"}) +histogram_quantile(0.90, sum by (le, name, grpc_method)(rate(src_grpc_server_sent_bytes_per_rpc_bucket{grpc_method=~`${searcher_method:regex}`,instance=~`${instance:regex}`,grpc_service=~"searcher.v1.SearcherService"}[2m]))) ```-#### searcher: mean_blocked_seconds_per_conn_request +#### searcher: searcher_p75_response_size_per_method -
Mean blocked seconds per conn request
+75th percentile total response size per method over 2m
-Refer to the [alerts reference](alerts#searcher-mean-blocked-seconds-per-conn-request) for 2 alerts related to this panel. +The 75th percentile total per-RPC response size per method, aggregated across all instances. -To see this panel, visit `/-/debug/grafana/d/searcher/searcher?viewPanel=100820` on your Sourcegraph instance. +This panel has no related alerts. -*Managed by the [Sourcegraph Infrastructure Org team](https://handbook.sourcegraph.com/departments/engineering/infrastructure).* +To see this panel, visit `/-/debug/grafana/d/searcher/searcher?viewPanel=100432` on your Sourcegraph instance. + +*Managed by the [Sourcegraph Search Platform team](https://handbook.sourcegraph.com/departments/engineering/teams/search/core).*Technical details
@@ -55734,21 +55967,23 @@ To see this panel, visit `/-/debug/grafana/d/searcher/searcher?viewPanel=100820` Query: ``` -sum by (app_name, db_name) (increase(src_pgsql_conns_blocked_seconds{app_name="searcher"}[5m])) / sum by (app_name, db_name) (increase(src_pgsql_conns_waited_for{app_name="searcher"}[5m])) +histogram_quantile(0.75, sum by (le, name, grpc_method)(rate(src_grpc_server_sent_bytes_per_rpc_bucket{grpc_method=~`${searcher_method:regex}`,instance=~`${instance:regex}`,grpc_service=~"searcher.v1.SearcherService"}[2m]))) ```-#### searcher: closed_max_idle +#### searcher: searcher_p99_9_invididual_sent_message_size_per_method -
Closed by SetMaxIdleConns
+99.9th percentile individual sent message size per method over 2m
+ +The 99.9th percentile size of every individual protocol buffer size sent by the service per method, aggregated across all instances. This panel has no related alerts. -To see this panel, visit `/-/debug/grafana/d/searcher/searcher?viewPanel=100830` on your Sourcegraph instance. +To see this panel, visit `/-/debug/grafana/d/searcher/searcher?viewPanel=100440` on your Sourcegraph instance. -*Managed by the [Sourcegraph Infrastructure Org team](https://handbook.sourcegraph.com/departments/engineering/infrastructure).* +*Managed by the [Sourcegraph Search Platform team](https://handbook.sourcegraph.com/departments/engineering/teams/search/core).*Technical details
@@ -55756,21 +55991,23 @@ To see this panel, visit `/-/debug/grafana/d/searcher/searcher?viewPanel=100830` Query: ``` -sum by (app_name, db_name) (increase(src_pgsql_conns_closed_max_idle{app_name="searcher"}[5m])) +histogram_quantile(0.999, sum by (le, name, grpc_method)(rate(src_grpc_server_sent_individual_message_size_bytes_per_rpc_bucket{grpc_method=~`${searcher_method:regex}`,instance=~`${instance:regex}`,grpc_service=~"searcher.v1.SearcherService"}[2m]))) ```-#### searcher: closed_max_lifetime +#### searcher: searcher_p90_invididual_sent_message_size_per_method -
Closed by SetConnMaxLifetime
+90th percentile individual sent message size per method over 2m
+ +The 90th percentile size of every individual protocol buffer size sent by the service per method, aggregated across all instances. This panel has no related alerts. -To see this panel, visit `/-/debug/grafana/d/searcher/searcher?viewPanel=100831` on your Sourcegraph instance. +To see this panel, visit `/-/debug/grafana/d/searcher/searcher?viewPanel=100441` on your Sourcegraph instance. -*Managed by the [Sourcegraph Infrastructure Org team](https://handbook.sourcegraph.com/departments/engineering/infrastructure).* +*Managed by the [Sourcegraph Search Platform team](https://handbook.sourcegraph.com/departments/engineering/teams/search/core).*Technical details
@@ -55778,21 +56015,23 @@ To see this panel, visit `/-/debug/grafana/d/searcher/searcher?viewPanel=100831` Query: ``` -sum by (app_name, db_name) (increase(src_pgsql_conns_closed_max_lifetime{app_name="searcher"}[5m])) +histogram_quantile(0.90, sum by (le, name, grpc_method)(rate(src_grpc_server_sent_individual_message_size_bytes_per_rpc_bucket{grpc_method=~`${searcher_method:regex}`,instance=~`${instance:regex}`,grpc_service=~"searcher.v1.SearcherService"}[2m]))) ```-#### searcher: closed_max_idle_time +#### searcher: searcher_p75_invididual_sent_message_size_per_method -
Closed by SetConnMaxIdleTime
+75th percentile individual sent message size per method over 2m
+ +The 75th percentile size of every individual protocol buffer size sent by the service per method, aggregated across all instances. This panel has no related alerts. -To see this panel, visit `/-/debug/grafana/d/searcher/searcher?viewPanel=100832` on your Sourcegraph instance. +To see this panel, visit `/-/debug/grafana/d/searcher/searcher?viewPanel=100442` on your Sourcegraph instance. -*Managed by the [Sourcegraph Infrastructure Org team](https://handbook.sourcegraph.com/departments/engineering/infrastructure).* +*Managed by the [Sourcegraph Search Platform team](https://handbook.sourcegraph.com/departments/engineering/teams/search/core).*Technical details
@@ -55800,31 +56039,21 @@ To see this panel, visit `/-/debug/grafana/d/searcher/searcher?viewPanel=100832` Query: ``` -sum by (app_name, db_name) (increase(src_pgsql_conns_closed_max_idle_time{app_name="searcher"}[5m])) +histogram_quantile(0.75, sum by (le, name, grpc_method)(rate(src_grpc_server_sent_individual_message_size_bytes_per_rpc_bucket{grpc_method=~`${searcher_method:regex}`,instance=~`${instance:regex}`,grpc_service=~"searcher.v1.SearcherService"}[2m]))) ```-### Searcher: Container monitoring (not available on server) - -#### searcher: container_missing - -
Container missing
+#### searcher: searcher_grpc_response_stream_message_count_per_method -This value is the number of times a container has not been seen for more than one minute. If you observe this -value change independent of deployment events (such as an upgrade), it could indicate pods are being OOM killed or terminated for some other reasons. +Average streaming response message count per-method over 2m
-- **Kubernetes:** - - Determine if the pod was OOM killed using `kubectl describe pod searcher` (look for `OOMKilled: true`) and, if so, consider increasing the memory limit in the relevant `Deployment.yaml`. - - Check the logs before the container restarted to see if there are `panic:` messages or similar using `kubectl logs -p searcher`. -- **Docker Compose:** - - Determine if the pod was OOM killed using `docker inspect -f '\{\{json .State\}\}' searcher` (look for `"OOMKilled":true`) and, if so, consider increasing the memory limit of the searcher container in `docker-compose.yml`. - - Check the logs before the container restarted to see if there are `panic:` messages or similar using `docker logs searcher` (note this will include logs from the previous and currently running container). +The average number of response messages sent during a streaming RPC method, broken out per method, aggregated across all instances. This panel has no related alerts. -To see this panel, visit `/-/debug/grafana/d/searcher/searcher?viewPanel=100900` on your Sourcegraph instance. +To see this panel, visit `/-/debug/grafana/d/searcher/searcher?viewPanel=100450` on your Sourcegraph instance. *Managed by the [Sourcegraph Search Platform team](https://handbook.sourcegraph.com/departments/engineering/teams/search/core).* @@ -55834,19 +56063,21 @@ To see this panel, visit `/-/debug/grafana/d/searcher/searcher?viewPanel=100900` Query: ``` -count by(name) ((time() - container_last_seen{name=~"^searcher.*"}) > 60) +((sum(rate(grpc_server_msg_sent_total{grpc_type="server_stream",instance=~`${instance:regex}`,grpc_service=~"searcher.v1.SearcherService"}[2m])) by (grpc_method))/(sum(rate(grpc_server_started_total{grpc_type="server_stream",instance=~`${instance:regex}`,grpc_service=~"searcher.v1.SearcherService"}[2m])) by (grpc_method))) ```-#### searcher: container_cpu_usage +#### searcher: searcher_grpc_all_codes_per_method -
Container cpu usage total (1m average) across all cores by instance
+Response codes rate per-method over 2m
-Refer to the [alerts reference](alerts#searcher-container-cpu-usage) for 1 alert related to this panel. +The rate of all generated gRPC response codes per method, aggregated across all instances. -To see this panel, visit `/-/debug/grafana/d/searcher/searcher?viewPanel=100901` on your Sourcegraph instance. +This panel has no related alerts. + +To see this panel, visit `/-/debug/grafana/d/searcher/searcher?viewPanel=100460` on your Sourcegraph instance. *Managed by the [Sourcegraph Search Platform team](https://handbook.sourcegraph.com/departments/engineering/teams/search/core).* @@ -55856,19 +56087,23 @@ To see this panel, visit `/-/debug/grafana/d/searcher/searcher?viewPanel=100901` Query: ``` -cadvisor_container_cpu_usage_percentage_total{name=~"^searcher.*"} +sum(rate(grpc_server_handled_total{grpc_method=~`${searcher_method:regex}`,instance=~`${instance:regex}`,grpc_service=~"searcher.v1.SearcherService"}[2m])) by (grpc_method, grpc_code) ```-#### searcher: container_memory_usage +### Searcher: Searcher GRPC "internal error" metrics -
Container memory usage by instance
+#### searcher: searcher_grpc_clients_error_percentage_all_methods -Refer to the [alerts reference](alerts#searcher-container-memory-usage) for 1 alert related to this panel. +Client baseline error percentage across all methods over 2m
-To see this panel, visit `/-/debug/grafana/d/searcher/searcher?viewPanel=100902` on your Sourcegraph instance. +The percentage of gRPC requests that fail across all methods (regardless of whether or not there was an internal error), aggregated across all "searcher" clients. + +This panel has no related alerts. + +To see this panel, visit `/-/debug/grafana/d/searcher/searcher?viewPanel=100500` on your Sourcegraph instance. *Managed by the [Sourcegraph Search Platform team](https://handbook.sourcegraph.com/departments/engineering/teams/search/core).* @@ -55878,22 +56113,21 @@ To see this panel, visit `/-/debug/grafana/d/searcher/searcher?viewPanel=100902` Query: ``` -cadvisor_container_memory_usage_percentage_total{name=~"^searcher.*"} +(100.0 * ((((sum(rate(src_grpc_method_status{grpc_service=~"searcher.v1.SearcherService",grpc_code!="OK"}[2m])))) / ((sum(rate(src_grpc_method_status{grpc_service=~"searcher.v1.SearcherService"}[2m]))))))) ```-#### searcher: fs_io_operations +#### searcher: searcher_grpc_clients_error_percentage_per_method -
Filesystem reads and writes rate by instance over 1h
+Client baseline error percentage per-method over 2m
-This value indicates the number of filesystem read and write operations by containers of this service. -When extremely high, this can indicate a resource usage problem, or can cause problems with the service itself, especially if high values or spikes correlate with \{\{CONTAINER_NAME\}\} issues. +The percentage of gRPC requests that fail per method (regardless of whether or not there was an internal error), aggregated across all "searcher" clients. This panel has no related alerts. -To see this panel, visit `/-/debug/grafana/d/searcher/searcher?viewPanel=100903` on your Sourcegraph instance. +To see this panel, visit `/-/debug/grafana/d/searcher/searcher?viewPanel=100501` on your Sourcegraph instance. *Managed by the [Sourcegraph Search Platform team](https://handbook.sourcegraph.com/departments/engineering/teams/search/core).* @@ -55903,21 +56137,21 @@ To see this panel, visit `/-/debug/grafana/d/searcher/searcher?viewPanel=100903` Query: ``` -sum by(name) (rate(container_fs_reads_total{name=~"^searcher.*"}[1h]) + rate(container_fs_writes_total{name=~"^searcher.*"}[1h])) +(100.0 * ((((sum(rate(src_grpc_method_status{grpc_service=~"searcher.v1.SearcherService",grpc_method=~"${searcher_method:regex}",grpc_code!="OK"}[2m])) by (grpc_method))) / ((sum(rate(src_grpc_method_status{grpc_service=~"searcher.v1.SearcherService",grpc_method=~"${searcher_method:regex}"}[2m])) by (grpc_method)))))) ```-### Searcher: Provisioning indicators (not available on server) +#### searcher: searcher_grpc_clients_all_codes_per_method -#### searcher: provisioning_container_cpu_usage_long_term +
Client baseline response codes rate per-method over 2m
-Container cpu usage total (90th percentile over 1d) across all cores by instance
+The rate of all generated gRPC response codes per method (regardless of whether or not there was an internal error), aggregated across all "searcher" clients. -Refer to the [alerts reference](alerts#searcher-provisioning-container-cpu-usage-long-term) for 1 alert related to this panel. +This panel has no related alerts. -To see this panel, visit `/-/debug/grafana/d/searcher/searcher?viewPanel=101000` on your Sourcegraph instance. +To see this panel, visit `/-/debug/grafana/d/searcher/searcher?viewPanel=100502` on your Sourcegraph instance. *Managed by the [Sourcegraph Search Platform team](https://handbook.sourcegraph.com/departments/engineering/teams/search/core).* @@ -55927,41 +56161,27 @@ To see this panel, visit `/-/debug/grafana/d/searcher/searcher?viewPanel=101000` Query: ``` -quantile_over_time(0.9, cadvisor_container_cpu_usage_percentage_total{name=~"^searcher.*"}[1d]) +(sum(rate(src_grpc_method_status{grpc_service=~"searcher.v1.SearcherService",grpc_method=~"${searcher_method:regex}"}[2m])) by (grpc_method, grpc_code)) ```-#### searcher: provisioning_container_memory_usage_long_term - -
Container memory usage (1d maximum) by instance
- -Refer to the [alerts reference](alerts#searcher-provisioning-container-memory-usage-long-term) for 1 alert related to this panel. - -To see this panel, visit `/-/debug/grafana/d/searcher/searcher?viewPanel=101001` on your Sourcegraph instance. - -*Managed by the [Sourcegraph Search Platform team](https://handbook.sourcegraph.com/departments/engineering/teams/search/core).* - -Technical details
+#### searcher: searcher_grpc_clients_internal_error_percentage_all_methods -Query: +Client-observed gRPC internal error percentage across all methods over 2m
-``` -max_over_time(cadvisor_container_memory_usage_percentage_total{name=~"^searcher.*"}[1d]) -``` -+**Note**: Internal errors are ones that appear to originate from the https://github.com/grpc/grpc-go library itself, rather than from any user-written application code. These errors can be caused by a variety of issues, and can originate from either the code-generated "searcher" gRPC client or gRPC server. These errors might be solvable by adjusting the gRPC configuration, or they might indicate a bug from Sourcegraph`s use of gRPC. -#### searcher: provisioning_container_cpu_usage_short_term +When debugging, knowing that a particular error comes from the grpc-go library itself (an `internal error`) as opposed to `normal` application code can be helpful when trying to fix it. -
Container cpu usage total (5m maximum) across all cores by instance
+**Note**: Internal errors are detected via a very coarse heuristic (seeing if the error starts with `grpc:`, etc.). Because of this, it`s possible that some gRPC-specific issues might not be categorized as internal errors. -Refer to the [alerts reference](alerts#searcher-provisioning-container-cpu-usage-short-term) for 1 alert related to this panel. +This panel has no related alerts. -To see this panel, visit `/-/debug/grafana/d/searcher/searcher?viewPanel=101010` on your Sourcegraph instance. +To see this panel, visit `/-/debug/grafana/d/searcher/searcher?viewPanel=100510` on your Sourcegraph instance. *Managed by the [Sourcegraph Search Platform team](https://handbook.sourcegraph.com/departments/engineering/teams/search/core).* @@ -55971,19 +56191,27 @@ To see this panel, visit `/-/debug/grafana/d/searcher/searcher?viewPanel=101010` Query: ``` -max_over_time(cadvisor_container_cpu_usage_percentage_total{name=~"^searcher.*"}[5m]) +(100.0 * ((((sum(rate(src_grpc_method_status{grpc_service=~"searcher.v1.SearcherService",grpc_code!="OK",is_internal_error="true"}[2m])))) / ((sum(rate(src_grpc_method_status{grpc_service=~"searcher.v1.SearcherService"}[2m]))))))) ```-#### searcher: provisioning_container_memory_usage_short_term +#### searcher: searcher_grpc_clients_internal_error_percentage_per_method -
Container memory usage (5m maximum) by instance
+Client-observed gRPC internal error percentage per-method over 2m
-Refer to the [alerts reference](alerts#searcher-provisioning-container-memory-usage-short-term) for 1 alert related to this panel. +The percentage of gRPC requests that appear to fail to due to gRPC internal errors per method, aggregated across all "searcher" clients. -To see this panel, visit `/-/debug/grafana/d/searcher/searcher?viewPanel=101011` on your Sourcegraph instance. +**Note**: Internal errors are ones that appear to originate from the https://github.com/grpc/grpc-go library itself, rather than from any user-written application code. These errors can be caused by a variety of issues, and can originate from either the code-generated "searcher" gRPC client or gRPC server. These errors might be solvable by adjusting the gRPC configuration, or they might indicate a bug from Sourcegraph`s use of gRPC. + +When debugging, knowing that a particular error comes from the grpc-go library itself (an `internal error`) as opposed to `normal` application code can be helpful when trying to fix it. + +**Note**: Internal errors are detected via a very coarse heuristic (seeing if the error starts with `grpc:`, etc.). Because of this, it`s possible that some gRPC-specific issues might not be categorized as internal errors. + +This panel has no related alerts. + +To see this panel, visit `/-/debug/grafana/d/searcher/searcher?viewPanel=100511` on your Sourcegraph instance. *Managed by the [Sourcegraph Search Platform team](https://handbook.sourcegraph.com/departments/engineering/teams/search/core).* @@ -55993,22 +56221,27 @@ To see this panel, visit `/-/debug/grafana/d/searcher/searcher?viewPanel=101011` Query: ``` -max_over_time(cadvisor_container_memory_usage_percentage_total{name=~"^searcher.*"}[5m]) +(100.0 * ((((sum(rate(src_grpc_method_status{grpc_service=~"searcher.v1.SearcherService",grpc_method=~"${searcher_method:regex}",grpc_code!="OK",is_internal_error="true"}[2m])) by (grpc_method))) / ((sum(rate(src_grpc_method_status{grpc_service=~"searcher.v1.SearcherService",grpc_method=~"${searcher_method:regex}"}[2m])) by (grpc_method)))))) ```-#### searcher: container_oomkill_events_total +#### searcher: searcher_grpc_clients_internal_error_all_codes_per_method -
Container OOMKILL events total by instance
+Client-observed gRPC internal error response code rate per-method over 2m
-This value indicates the total number of times the container main process or child processes were terminated by OOM killer. -When it occurs frequently, it is an indicator of underprovisioning. +The rate of gRPC internal-error response codes per method, aggregated across all "searcher" clients. -Refer to the [alerts reference](alerts#searcher-container-oomkill-events-total) for 1 alert related to this panel. +**Note**: Internal errors are ones that appear to originate from the https://github.com/grpc/grpc-go library itself, rather than from any user-written application code. These errors can be caused by a variety of issues, and can originate from either the code-generated "searcher" gRPC client or gRPC server. These errors might be solvable by adjusting the gRPC configuration, or they might indicate a bug from Sourcegraph`s use of gRPC. -To see this panel, visit `/-/debug/grafana/d/searcher/searcher?viewPanel=101012` on your Sourcegraph instance. +When debugging, knowing that a particular error comes from the grpc-go library itself (an `internal error`) as opposed to `normal` application code can be helpful when trying to fix it. + +**Note**: Internal errors are detected via a very coarse heuristic (seeing if the error starts with `grpc:`, etc.). Because of this, it`s possible that some gRPC-specific issues might not be categorized as internal errors. + +This panel has no related alerts. + +To see this panel, visit `/-/debug/grafana/d/searcher/searcher?viewPanel=100512` on your Sourcegraph instance. *Managed by the [Sourcegraph Search Platform team](https://handbook.sourcegraph.com/departments/engineering/teams/search/core).* @@ -56018,23 +56251,23 @@ To see this panel, visit `/-/debug/grafana/d/searcher/searcher?viewPanel=101012` Query: ``` -max by (name) (container_oom_events_total{name=~"^searcher.*"}) +(sum(rate(src_grpc_method_status{grpc_service=~"searcher.v1.SearcherService",is_internal_error="true",grpc_method=~"${searcher_method:regex}"}[2m])) by (grpc_method, grpc_code)) ```-### Searcher: Golang runtime monitoring +### Searcher: Searcher GRPC retry metrics -#### searcher: go_goroutines +#### searcher: searcher_grpc_clients_retry_percentage_across_all_methods -
Maximum active goroutines
+Client retry percentage across all methods over 2m
-A high value here indicates a possible goroutine leak. +The percentage of gRPC requests that were retried across all methods, aggregated across all "searcher" clients. -Refer to the [alerts reference](alerts#searcher-go-goroutines) for 1 alert related to this panel. +This panel has no related alerts. -To see this panel, visit `/-/debug/grafana/d/searcher/searcher?viewPanel=101100` on your Sourcegraph instance. +To see this panel, visit `/-/debug/grafana/d/searcher/searcher?viewPanel=100600` on your Sourcegraph instance. *Managed by the [Sourcegraph Search Platform team](https://handbook.sourcegraph.com/departments/engineering/teams/search/core).* @@ -56044,19 +56277,21 @@ To see this panel, visit `/-/debug/grafana/d/searcher/searcher?viewPanel=101100` Query: ``` -max by(instance) (go_goroutines{job=~".*searcher"}) +(100.0 * ((((sum(rate(src_grpc_client_retry_attempts_total{grpc_service=~"searcher.v1.SearcherService",is_retried="true"}[2m])))) / ((sum(rate(src_grpc_client_retry_attempts_total{grpc_service=~"searcher.v1.SearcherService"}[2m]))))))) ```-#### searcher: go_gc_duration_seconds +#### searcher: searcher_grpc_clients_retry_percentage_per_method -
Maximum go garbage collection duration
+Client retry percentage per-method over 2m
-Refer to the [alerts reference](alerts#searcher-go-gc-duration-seconds) for 1 alert related to this panel. +The percentage of gRPC requests that were retried aggregated across all "searcher" clients, broken out per method. -To see this panel, visit `/-/debug/grafana/d/searcher/searcher?viewPanel=101101` on your Sourcegraph instance. +This panel has no related alerts. + +To see this panel, visit `/-/debug/grafana/d/searcher/searcher?viewPanel=100601` on your Sourcegraph instance. *Managed by the [Sourcegraph Search Platform team](https://handbook.sourcegraph.com/departments/engineering/teams/search/core).* @@ -56066,21 +56301,21 @@ To see this panel, visit `/-/debug/grafana/d/searcher/searcher?viewPanel=101101` Query: ``` -max by(instance) (go_gc_duration_seconds{job=~".*searcher"}) +(100.0 * ((((sum(rate(src_grpc_client_retry_attempts_total{grpc_service=~"searcher.v1.SearcherService",is_retried="true",grpc_method=~"${searcher_method:regex}"}[2m])) by (grpc_method))) / ((sum(rate(src_grpc_client_retry_attempts_total{grpc_service=~"searcher.v1.SearcherService",grpc_method=~"${searcher_method:regex}"}[2m])) by (grpc_method)))))) ```-### Searcher: Kubernetes monitoring (only available on Kubernetes) +#### searcher: searcher_grpc_clients_retry_count_per_method -#### searcher: pods_available_percentage +
Client retry count per-method over 2m
-Percentage pods available
+The count of gRPC requests that were retried aggregated across all "searcher" clients, broken out per method -Refer to the [alerts reference](alerts#searcher-pods-available-percentage) for 1 alert related to this panel. +This panel has no related alerts. -To see this panel, visit `/-/debug/grafana/d/searcher/searcher?viewPanel=101200` on your Sourcegraph instance. +To see this panel, visit `/-/debug/grafana/d/searcher/searcher?viewPanel=100602` on your Sourcegraph instance. *Managed by the [Sourcegraph Search Platform team](https://handbook.sourcegraph.com/departments/engineering/teams/search/core).* @@ -56090,27 +56325,21 @@ To see this panel, visit `/-/debug/grafana/d/searcher/searcher?viewPanel=101200` Query: ``` -sum by(app) (up{app=~".*searcher"}) / count by (app) (up{app=~".*searcher"}) * 100 +(sum(rate(src_grpc_client_retry_attempts_total{grpc_service=~"searcher.v1.SearcherService",grpc_method=~"${searcher_method:regex}",is_retried="true"}[2m])) by (grpc_method)) ```-## Symbols - -
Handles symbol searches for unindexed branches.
+### Searcher: Codeintel: Symbols API -To see this dashboard, visit `/-/debug/grafana/d/symbols/symbols` on your Sourcegraph instance. - -### Symbols: Codeintel: Symbols API - -#### symbols: codeintel_symbols_api_total +#### searcher: codeintel_symbols_api_totalAggregate API operations every 5m
This panel has no related alerts. -To see this panel, visit `/-/debug/grafana/d/symbols/symbols?viewPanel=100000` on your Sourcegraph instance. +To see this panel, visit `/-/debug/grafana/d/searcher/searcher?viewPanel=100700` on your Sourcegraph instance. *Managed by the [Sourcegraph Code intelligence team](https://handbook.sourcegraph.com/departments/engineering/teams/code-intelligence).* @@ -56120,19 +56349,19 @@ To see this panel, visit `/-/debug/grafana/d/symbols/symbols?viewPanel=100000` o Query: ``` -sum(increase(src_codeintel_symbols_api_total{job=~"^symbols.*"}[5m])) +sum(increase(src_codeintel_symbols_api_total{job=~"^searcher.*"}[5m])) ```-#### symbols: codeintel_symbols_api_99th_percentile_duration +#### searcher: codeintel_symbols_api_99th_percentile_duration
Aggregate successful API operation duration distribution over 5m
This panel has no related alerts. -To see this panel, visit `/-/debug/grafana/d/symbols/symbols?viewPanel=100001` on your Sourcegraph instance. +To see this panel, visit `/-/debug/grafana/d/searcher/searcher?viewPanel=100701` on your Sourcegraph instance. *Managed by the [Sourcegraph Code intelligence team](https://handbook.sourcegraph.com/departments/engineering/teams/code-intelligence).* @@ -56142,19 +56371,19 @@ To see this panel, visit `/-/debug/grafana/d/symbols/symbols?viewPanel=100001` o Query: ``` -sum by (le)(rate(src_codeintel_symbols_api_duration_seconds_bucket{job=~"^symbols.*"}[5m])) +sum by (le)(rate(src_codeintel_symbols_api_duration_seconds_bucket{job=~"^searcher.*"}[5m])) ```-#### symbols: codeintel_symbols_api_errors_total +#### searcher: codeintel_symbols_api_errors_total
Aggregate API operation errors every 5m
This panel has no related alerts. -To see this panel, visit `/-/debug/grafana/d/symbols/symbols?viewPanel=100002` on your Sourcegraph instance. +To see this panel, visit `/-/debug/grafana/d/searcher/searcher?viewPanel=100702` on your Sourcegraph instance. *Managed by the [Sourcegraph Code intelligence team](https://handbook.sourcegraph.com/departments/engineering/teams/code-intelligence).* @@ -56164,19 +56393,19 @@ To see this panel, visit `/-/debug/grafana/d/symbols/symbols?viewPanel=100002` o Query: ``` -sum(increase(src_codeintel_symbols_api_errors_total{job=~"^symbols.*"}[5m])) +sum(increase(src_codeintel_symbols_api_errors_total{job=~"^searcher.*"}[5m])) ```-#### symbols: codeintel_symbols_api_error_rate +#### searcher: codeintel_symbols_api_error_rate
Aggregate API operation error rate over 5m
This panel has no related alerts. -To see this panel, visit `/-/debug/grafana/d/symbols/symbols?viewPanel=100003` on your Sourcegraph instance. +To see this panel, visit `/-/debug/grafana/d/searcher/searcher?viewPanel=100703` on your Sourcegraph instance. *Managed by the [Sourcegraph Code intelligence team](https://handbook.sourcegraph.com/departments/engineering/teams/code-intelligence).* @@ -56186,19 +56415,19 @@ To see this panel, visit `/-/debug/grafana/d/symbols/symbols?viewPanel=100003` o Query: ``` -sum(increase(src_codeintel_symbols_api_errors_total{job=~"^symbols.*"}[5m])) / (sum(increase(src_codeintel_symbols_api_total{job=~"^symbols.*"}[5m])) + sum(increase(src_codeintel_symbols_api_errors_total{job=~"^symbols.*"}[5m]))) * 100 +sum(increase(src_codeintel_symbols_api_errors_total{job=~"^searcher.*"}[5m])) / (sum(increase(src_codeintel_symbols_api_total{job=~"^searcher.*"}[5m])) + sum(increase(src_codeintel_symbols_api_errors_total{job=~"^searcher.*"}[5m]))) * 100 ```-#### symbols: codeintel_symbols_api_total +#### searcher: codeintel_symbols_api_total
API operations every 5m
This panel has no related alerts. -To see this panel, visit `/-/debug/grafana/d/symbols/symbols?viewPanel=100010` on your Sourcegraph instance. +To see this panel, visit `/-/debug/grafana/d/searcher/searcher?viewPanel=100710` on your Sourcegraph instance. *Managed by the [Sourcegraph Code intelligence team](https://handbook.sourcegraph.com/departments/engineering/teams/code-intelligence).* @@ -56208,19 +56437,19 @@ To see this panel, visit `/-/debug/grafana/d/symbols/symbols?viewPanel=100010` o Query: ``` -sum by (op,parseAmount)(increase(src_codeintel_symbols_api_total{job=~"^symbols.*"}[5m])) +sum by (op,parseAmount)(increase(src_codeintel_symbols_api_total{job=~"^searcher.*"}[5m])) ```-#### symbols: codeintel_symbols_api_99th_percentile_duration +#### searcher: codeintel_symbols_api_99th_percentile_duration
99th percentile successful API operation duration over 5m
This panel has no related alerts. -To see this panel, visit `/-/debug/grafana/d/symbols/symbols?viewPanel=100011` on your Sourcegraph instance. +To see this panel, visit `/-/debug/grafana/d/searcher/searcher?viewPanel=100711` on your Sourcegraph instance. *Managed by the [Sourcegraph Code intelligence team](https://handbook.sourcegraph.com/departments/engineering/teams/code-intelligence).* @@ -56230,19 +56459,19 @@ To see this panel, visit `/-/debug/grafana/d/symbols/symbols?viewPanel=100011` o Query: ``` -histogram_quantile(0.99, sum by (le,op,parseAmount)(rate(src_codeintel_symbols_api_duration_seconds_bucket{job=~"^symbols.*"}[5m]))) +histogram_quantile(0.99, sum by (le,op,parseAmount)(rate(src_codeintel_symbols_api_duration_seconds_bucket{job=~"^searcher.*"}[5m]))) ```-#### symbols: codeintel_symbols_api_errors_total +#### searcher: codeintel_symbols_api_errors_total
API operation errors every 5m
This panel has no related alerts. -To see this panel, visit `/-/debug/grafana/d/symbols/symbols?viewPanel=100012` on your Sourcegraph instance. +To see this panel, visit `/-/debug/grafana/d/searcher/searcher?viewPanel=100712` on your Sourcegraph instance. *Managed by the [Sourcegraph Code intelligence team](https://handbook.sourcegraph.com/departments/engineering/teams/code-intelligence).* @@ -56252,19 +56481,19 @@ To see this panel, visit `/-/debug/grafana/d/symbols/symbols?viewPanel=100012` o Query: ``` -sum by (op,parseAmount)(increase(src_codeintel_symbols_api_errors_total{job=~"^symbols.*"}[5m])) +sum by (op,parseAmount)(increase(src_codeintel_symbols_api_errors_total{job=~"^searcher.*"}[5m])) ```-#### symbols: codeintel_symbols_api_error_rate +#### searcher: codeintel_symbols_api_error_rate
API operation error rate over 5m
This panel has no related alerts. -To see this panel, visit `/-/debug/grafana/d/symbols/symbols?viewPanel=100013` on your Sourcegraph instance. +To see this panel, visit `/-/debug/grafana/d/searcher/searcher?viewPanel=100713` on your Sourcegraph instance. *Managed by the [Sourcegraph Code intelligence team](https://handbook.sourcegraph.com/departments/engineering/teams/code-intelligence).* @@ -56274,21 +56503,21 @@ To see this panel, visit `/-/debug/grafana/d/symbols/symbols?viewPanel=100013` o Query: ``` -sum by (op,parseAmount)(increase(src_codeintel_symbols_api_errors_total{job=~"^symbols.*"}[5m])) / (sum by (op,parseAmount)(increase(src_codeintel_symbols_api_total{job=~"^symbols.*"}[5m])) + sum by (op,parseAmount)(increase(src_codeintel_symbols_api_errors_total{job=~"^symbols.*"}[5m]))) * 100 +sum by (op,parseAmount)(increase(src_codeintel_symbols_api_errors_total{job=~"^searcher.*"}[5m])) / (sum by (op,parseAmount)(increase(src_codeintel_symbols_api_total{job=~"^searcher.*"}[5m])) + sum by (op,parseAmount)(increase(src_codeintel_symbols_api_errors_total{job=~"^searcher.*"}[5m]))) * 100 ```-### Symbols: Codeintel: Symbols parser +### Searcher: Codeintel: Symbols parser -#### symbols: symbols +#### searcher: searcher
In-flight parse jobs
This panel has no related alerts. -To see this panel, visit `/-/debug/grafana/d/symbols/symbols?viewPanel=100100` on your Sourcegraph instance. +To see this panel, visit `/-/debug/grafana/d/searcher/searcher?viewPanel=100800` on your Sourcegraph instance. *Managed by the [Sourcegraph Code intelligence team](https://handbook.sourcegraph.com/departments/engineering/teams/code-intelligence).* @@ -56298,19 +56527,19 @@ To see this panel, visit `/-/debug/grafana/d/symbols/symbols?viewPanel=100100` o Query: ``` -max(src_codeintel_symbols_parsing{job=~"^symbols.*"}) +max(src_codeintel_symbols_parsing{job=~"^searcher.*"}) ```-#### symbols: symbols +#### searcher: searcher
Parser queue size
This panel has no related alerts. -To see this panel, visit `/-/debug/grafana/d/symbols/symbols?viewPanel=100101` on your Sourcegraph instance. +To see this panel, visit `/-/debug/grafana/d/searcher/searcher?viewPanel=100801` on your Sourcegraph instance. *Managed by the [Sourcegraph Code intelligence team](https://handbook.sourcegraph.com/departments/engineering/teams/code-intelligence).* @@ -56320,19 +56549,19 @@ To see this panel, visit `/-/debug/grafana/d/symbols/symbols?viewPanel=100101` o Query: ``` -max(src_codeintel_symbols_parse_queue_size{job=~"^symbols.*"}) +max(src_codeintel_symbols_parse_queue_size{job=~"^searcher.*"}) ```-#### symbols: symbols +#### searcher: searcher
Parse queue timeouts
This panel has no related alerts. -To see this panel, visit `/-/debug/grafana/d/symbols/symbols?viewPanel=100102` on your Sourcegraph instance. +To see this panel, visit `/-/debug/grafana/d/searcher/searcher?viewPanel=100802` on your Sourcegraph instance. *Managed by the [Sourcegraph Code intelligence team](https://handbook.sourcegraph.com/departments/engineering/teams/code-intelligence).* @@ -56342,19 +56571,19 @@ To see this panel, visit `/-/debug/grafana/d/symbols/symbols?viewPanel=100102` o Query: ``` -max(src_codeintel_symbols_parse_queue_timeouts_total{job=~"^symbols.*"}) +max(src_codeintel_symbols_parse_queue_timeouts_total{job=~"^searcher.*"}) ```-#### symbols: symbols +#### searcher: searcher
Parse failures every 5m
This panel has no related alerts. -To see this panel, visit `/-/debug/grafana/d/symbols/symbols?viewPanel=100103` on your Sourcegraph instance. +To see this panel, visit `/-/debug/grafana/d/searcher/searcher?viewPanel=100803` on your Sourcegraph instance. *Managed by the [Sourcegraph Code intelligence team](https://handbook.sourcegraph.com/departments/engineering/teams/code-intelligence).* @@ -56364,19 +56593,19 @@ To see this panel, visit `/-/debug/grafana/d/symbols/symbols?viewPanel=100103` o Query: ``` -rate(src_codeintel_symbols_parse_failed_total{job=~"^symbols.*"}[5m]) +rate(src_codeintel_symbols_parse_failed_total{job=~"^searcher.*"}[5m]) ```-#### symbols: codeintel_symbols_parser_total +#### searcher: codeintel_symbols_parser_total
Aggregate parser operations every 5m
This panel has no related alerts. -To see this panel, visit `/-/debug/grafana/d/symbols/symbols?viewPanel=100110` on your Sourcegraph instance. +To see this panel, visit `/-/debug/grafana/d/searcher/searcher?viewPanel=100810` on your Sourcegraph instance. *Managed by the [Sourcegraph Code intelligence team](https://handbook.sourcegraph.com/departments/engineering/teams/code-intelligence).* @@ -56386,19 +56615,19 @@ To see this panel, visit `/-/debug/grafana/d/symbols/symbols?viewPanel=100110` o Query: ``` -sum(increase(src_codeintel_symbols_parser_total{job=~"^symbols.*"}[5m])) +sum(increase(src_codeintel_symbols_parser_total{job=~"^searcher.*"}[5m])) ```-#### symbols: codeintel_symbols_parser_99th_percentile_duration +#### searcher: codeintel_symbols_parser_99th_percentile_duration
Aggregate successful parser operation duration distribution over 5m
This panel has no related alerts. -To see this panel, visit `/-/debug/grafana/d/symbols/symbols?viewPanel=100111` on your Sourcegraph instance. +To see this panel, visit `/-/debug/grafana/d/searcher/searcher?viewPanel=100811` on your Sourcegraph instance. *Managed by the [Sourcegraph Code intelligence team](https://handbook.sourcegraph.com/departments/engineering/teams/code-intelligence).* @@ -56408,19 +56637,19 @@ To see this panel, visit `/-/debug/grafana/d/symbols/symbols?viewPanel=100111` o Query: ``` -sum by (le)(rate(src_codeintel_symbols_parser_duration_seconds_bucket{job=~"^symbols.*"}[5m])) +sum by (le)(rate(src_codeintel_symbols_parser_duration_seconds_bucket{job=~"^searcher.*"}[5m])) ```-#### symbols: codeintel_symbols_parser_errors_total +#### searcher: codeintel_symbols_parser_errors_total
Aggregate parser operation errors every 5m
This panel has no related alerts. -To see this panel, visit `/-/debug/grafana/d/symbols/symbols?viewPanel=100112` on your Sourcegraph instance. +To see this panel, visit `/-/debug/grafana/d/searcher/searcher?viewPanel=100812` on your Sourcegraph instance. *Managed by the [Sourcegraph Code intelligence team](https://handbook.sourcegraph.com/departments/engineering/teams/code-intelligence).* @@ -56430,19 +56659,19 @@ To see this panel, visit `/-/debug/grafana/d/symbols/symbols?viewPanel=100112` o Query: ``` -sum(increase(src_codeintel_symbols_parser_errors_total{job=~"^symbols.*"}[5m])) +sum(increase(src_codeintel_symbols_parser_errors_total{job=~"^searcher.*"}[5m])) ```-#### symbols: codeintel_symbols_parser_error_rate +#### searcher: codeintel_symbols_parser_error_rate
Aggregate parser operation error rate over 5m
This panel has no related alerts. -To see this panel, visit `/-/debug/grafana/d/symbols/symbols?viewPanel=100113` on your Sourcegraph instance. +To see this panel, visit `/-/debug/grafana/d/searcher/searcher?viewPanel=100813` on your Sourcegraph instance. *Managed by the [Sourcegraph Code intelligence team](https://handbook.sourcegraph.com/departments/engineering/teams/code-intelligence).* @@ -56452,19 +56681,19 @@ To see this panel, visit `/-/debug/grafana/d/symbols/symbols?viewPanel=100113` o Query: ``` -sum(increase(src_codeintel_symbols_parser_errors_total{job=~"^symbols.*"}[5m])) / (sum(increase(src_codeintel_symbols_parser_total{job=~"^symbols.*"}[5m])) + sum(increase(src_codeintel_symbols_parser_errors_total{job=~"^symbols.*"}[5m]))) * 100 +sum(increase(src_codeintel_symbols_parser_errors_total{job=~"^searcher.*"}[5m])) / (sum(increase(src_codeintel_symbols_parser_total{job=~"^searcher.*"}[5m])) + sum(increase(src_codeintel_symbols_parser_errors_total{job=~"^searcher.*"}[5m]))) * 100 ```-#### symbols: codeintel_symbols_parser_total +#### searcher: codeintel_symbols_parser_total
Parser operations every 5m
This panel has no related alerts. -To see this panel, visit `/-/debug/grafana/d/symbols/symbols?viewPanel=100120` on your Sourcegraph instance. +To see this panel, visit `/-/debug/grafana/d/searcher/searcher?viewPanel=100820` on your Sourcegraph instance. *Managed by the [Sourcegraph Code intelligence team](https://handbook.sourcegraph.com/departments/engineering/teams/code-intelligence).* @@ -56474,19 +56703,19 @@ To see this panel, visit `/-/debug/grafana/d/symbols/symbols?viewPanel=100120` o Query: ``` -sum by (op)(increase(src_codeintel_symbols_parser_total{job=~"^symbols.*"}[5m])) +sum by (op)(increase(src_codeintel_symbols_parser_total{job=~"^searcher.*"}[5m])) ```-#### symbols: codeintel_symbols_parser_99th_percentile_duration +#### searcher: codeintel_symbols_parser_99th_percentile_duration
99th percentile successful parser operation duration over 5m
This panel has no related alerts. -To see this panel, visit `/-/debug/grafana/d/symbols/symbols?viewPanel=100121` on your Sourcegraph instance. +To see this panel, visit `/-/debug/grafana/d/searcher/searcher?viewPanel=100821` on your Sourcegraph instance. *Managed by the [Sourcegraph Code intelligence team](https://handbook.sourcegraph.com/departments/engineering/teams/code-intelligence).* @@ -56496,19 +56725,19 @@ To see this panel, visit `/-/debug/grafana/d/symbols/symbols?viewPanel=100121` o Query: ``` -histogram_quantile(0.99, sum by (le,op)(rate(src_codeintel_symbols_parser_duration_seconds_bucket{job=~"^symbols.*"}[5m]))) +histogram_quantile(0.99, sum by (le,op)(rate(src_codeintel_symbols_parser_duration_seconds_bucket{job=~"^searcher.*"}[5m]))) ```-#### symbols: codeintel_symbols_parser_errors_total +#### searcher: codeintel_symbols_parser_errors_total
Parser operation errors every 5m
This panel has no related alerts. -To see this panel, visit `/-/debug/grafana/d/symbols/symbols?viewPanel=100122` on your Sourcegraph instance. +To see this panel, visit `/-/debug/grafana/d/searcher/searcher?viewPanel=100822` on your Sourcegraph instance. *Managed by the [Sourcegraph Code intelligence team](https://handbook.sourcegraph.com/departments/engineering/teams/code-intelligence).* @@ -56518,19 +56747,19 @@ To see this panel, visit `/-/debug/grafana/d/symbols/symbols?viewPanel=100122` o Query: ``` -sum by (op)(increase(src_codeintel_symbols_parser_errors_total{job=~"^symbols.*"}[5m])) +sum by (op)(increase(src_codeintel_symbols_parser_errors_total{job=~"^searcher.*"}[5m])) ```-#### symbols: codeintel_symbols_parser_error_rate +#### searcher: codeintel_symbols_parser_error_rate
Parser operation error rate over 5m
This panel has no related alerts. -To see this panel, visit `/-/debug/grafana/d/symbols/symbols?viewPanel=100123` on your Sourcegraph instance. +To see this panel, visit `/-/debug/grafana/d/searcher/searcher?viewPanel=100823` on your Sourcegraph instance. *Managed by the [Sourcegraph Code intelligence team](https://handbook.sourcegraph.com/departments/engineering/teams/code-intelligence).* @@ -56540,15 +56769,15 @@ To see this panel, visit `/-/debug/grafana/d/symbols/symbols?viewPanel=100123` o Query: ``` -sum by (op)(increase(src_codeintel_symbols_parser_errors_total{job=~"^symbols.*"}[5m])) / (sum by (op)(increase(src_codeintel_symbols_parser_total{job=~"^symbols.*"}[5m])) + sum by (op)(increase(src_codeintel_symbols_parser_errors_total{job=~"^symbols.*"}[5m]))) * 100 +sum by (op)(increase(src_codeintel_symbols_parser_errors_total{job=~"^searcher.*"}[5m])) / (sum by (op)(increase(src_codeintel_symbols_parser_total{job=~"^searcher.*"}[5m])) + sum by (op)(increase(src_codeintel_symbols_parser_errors_total{job=~"^searcher.*"}[5m]))) * 100 ```-### Symbols: Codeintel: Symbols cache janitor +### Searcher: Codeintel: Symbols cache janitor -#### symbols: symbols +#### searcher: searcher
Size in bytes of the on-disk cache
@@ -56556,7 +56785,7 @@ no This panel has no related alerts. -To see this panel, visit `/-/debug/grafana/d/symbols/symbols?viewPanel=100200` on your Sourcegraph instance. +To see this panel, visit `/-/debug/grafana/d/searcher/searcher?viewPanel=100900` on your Sourcegraph instance. *Managed by the [Sourcegraph Code intelligence team](https://handbook.sourcegraph.com/departments/engineering/teams/code-intelligence).* @@ -56566,13 +56795,13 @@ To see this panel, visit `/-/debug/grafana/d/symbols/symbols?viewPanel=100200` o Query: ``` -src_codeintel_symbols_store_cache_size_bytes +src_diskcache_store_symbols_cache_size_bytes ```-#### symbols: symbols +#### searcher: searcher
Cache eviction operations every 5m
@@ -56580,7 +56809,7 @@ no This panel has no related alerts. -To see this panel, visit `/-/debug/grafana/d/symbols/symbols?viewPanel=100201` on your Sourcegraph instance. +To see this panel, visit `/-/debug/grafana/d/searcher/searcher?viewPanel=100901` on your Sourcegraph instance. *Managed by the [Sourcegraph Code intelligence team](https://handbook.sourcegraph.com/departments/engineering/teams/code-intelligence).* @@ -56590,13 +56819,13 @@ To see this panel, visit `/-/debug/grafana/d/symbols/symbols?viewPanel=100201` o Query: ``` -rate(src_codeintel_symbols_store_evictions_total[5m]) +rate(src_diskcache_store_symbols_evictions_total[5m]) ```-#### symbols: symbols +#### searcher: searcher
Cache eviction operation errors every 5m
@@ -56604,7 +56833,7 @@ no This panel has no related alerts. -To see this panel, visit `/-/debug/grafana/d/symbols/symbols?viewPanel=100202` on your Sourcegraph instance. +To see this panel, visit `/-/debug/grafana/d/searcher/searcher?viewPanel=100902` on your Sourcegraph instance. *Managed by the [Sourcegraph Code intelligence team](https://handbook.sourcegraph.com/departments/engineering/teams/code-intelligence).* @@ -56614,21 +56843,21 @@ To see this panel, visit `/-/debug/grafana/d/symbols/symbols?viewPanel=100202` o Query: ``` -rate(src_codeintel_symbols_store_errors_total[5m]) +rate(src_diskcache_store_symbols_errors_total[5m]) ```-### Symbols: Codeintel: Symbols repository fetcher +### Searcher: Codeintel: Symbols repository fetcher -#### symbols: symbols +#### searcher: searcher
In-flight repository fetch operations
This panel has no related alerts. -To see this panel, visit `/-/debug/grafana/d/symbols/symbols?viewPanel=100300` on your Sourcegraph instance. +To see this panel, visit `/-/debug/grafana/d/searcher/searcher?viewPanel=101000` on your Sourcegraph instance. *Managed by the [Sourcegraph Code intelligence team](https://handbook.sourcegraph.com/departments/engineering/teams/code-intelligence).* @@ -56644,13 +56873,13 @@ src_codeintel_symbols_fetching-#### symbols: symbols +#### searcher: searcher
Repository fetch queue size
This panel has no related alerts. -To see this panel, visit `/-/debug/grafana/d/symbols/symbols?viewPanel=100301` on your Sourcegraph instance. +To see this panel, visit `/-/debug/grafana/d/searcher/searcher?viewPanel=101001` on your Sourcegraph instance. *Managed by the [Sourcegraph Code intelligence team](https://handbook.sourcegraph.com/departments/engineering/teams/code-intelligence).* @@ -56660,19 +56889,19 @@ To see this panel, visit `/-/debug/grafana/d/symbols/symbols?viewPanel=100301` o Query: ``` -max(src_codeintel_symbols_fetch_queue_size{job=~"^symbols.*"}) +max(src_codeintel_symbols_fetch_queue_size{job=~"^searcher.*"}) ```-#### symbols: codeintel_symbols_repository_fetcher_total +#### searcher: codeintel_symbols_repository_fetcher_total
Aggregate fetcher operations every 5m
This panel has no related alerts. -To see this panel, visit `/-/debug/grafana/d/symbols/symbols?viewPanel=100310` on your Sourcegraph instance. +To see this panel, visit `/-/debug/grafana/d/searcher/searcher?viewPanel=101010` on your Sourcegraph instance. *Managed by the [Sourcegraph Code intelligence team](https://handbook.sourcegraph.com/departments/engineering/teams/code-intelligence).* @@ -56682,19 +56911,19 @@ To see this panel, visit `/-/debug/grafana/d/symbols/symbols?viewPanel=100310` o Query: ``` -sum(increase(src_codeintel_symbols_repository_fetcher_total{job=~"^symbols.*"}[5m])) +sum(increase(src_codeintel_symbols_repository_fetcher_total{job=~"^searcher.*"}[5m])) ```-#### symbols: codeintel_symbols_repository_fetcher_99th_percentile_duration +#### searcher: codeintel_symbols_repository_fetcher_99th_percentile_duration
Aggregate successful fetcher operation duration distribution over 5m
This panel has no related alerts. -To see this panel, visit `/-/debug/grafana/d/symbols/symbols?viewPanel=100311` on your Sourcegraph instance. +To see this panel, visit `/-/debug/grafana/d/searcher/searcher?viewPanel=101011` on your Sourcegraph instance. *Managed by the [Sourcegraph Code intelligence team](https://handbook.sourcegraph.com/departments/engineering/teams/code-intelligence).* @@ -56704,19 +56933,19 @@ To see this panel, visit `/-/debug/grafana/d/symbols/symbols?viewPanel=100311` o Query: ``` -sum by (le)(rate(src_codeintel_symbols_repository_fetcher_duration_seconds_bucket{job=~"^symbols.*"}[5m])) +sum by (le)(rate(src_codeintel_symbols_repository_fetcher_duration_seconds_bucket{job=~"^searcher.*"}[5m])) ```-#### symbols: codeintel_symbols_repository_fetcher_errors_total +#### searcher: codeintel_symbols_repository_fetcher_errors_total
Aggregate fetcher operation errors every 5m
This panel has no related alerts. -To see this panel, visit `/-/debug/grafana/d/symbols/symbols?viewPanel=100312` on your Sourcegraph instance. +To see this panel, visit `/-/debug/grafana/d/searcher/searcher?viewPanel=101012` on your Sourcegraph instance. *Managed by the [Sourcegraph Code intelligence team](https://handbook.sourcegraph.com/departments/engineering/teams/code-intelligence).* @@ -56726,19 +56955,19 @@ To see this panel, visit `/-/debug/grafana/d/symbols/symbols?viewPanel=100312` o Query: ``` -sum(increase(src_codeintel_symbols_repository_fetcher_errors_total{job=~"^symbols.*"}[5m])) +sum(increase(src_codeintel_symbols_repository_fetcher_errors_total{job=~"^searcher.*"}[5m])) ```-#### symbols: codeintel_symbols_repository_fetcher_error_rate +#### searcher: codeintel_symbols_repository_fetcher_error_rate
Aggregate fetcher operation error rate over 5m
This panel has no related alerts. -To see this panel, visit `/-/debug/grafana/d/symbols/symbols?viewPanel=100313` on your Sourcegraph instance. +To see this panel, visit `/-/debug/grafana/d/searcher/searcher?viewPanel=101013` on your Sourcegraph instance. *Managed by the [Sourcegraph Code intelligence team](https://handbook.sourcegraph.com/departments/engineering/teams/code-intelligence).* @@ -56748,19 +56977,19 @@ To see this panel, visit `/-/debug/grafana/d/symbols/symbols?viewPanel=100313` o Query: ``` -sum(increase(src_codeintel_symbols_repository_fetcher_errors_total{job=~"^symbols.*"}[5m])) / (sum(increase(src_codeintel_symbols_repository_fetcher_total{job=~"^symbols.*"}[5m])) + sum(increase(src_codeintel_symbols_repository_fetcher_errors_total{job=~"^symbols.*"}[5m]))) * 100 +sum(increase(src_codeintel_symbols_repository_fetcher_errors_total{job=~"^searcher.*"}[5m])) / (sum(increase(src_codeintel_symbols_repository_fetcher_total{job=~"^searcher.*"}[5m])) + sum(increase(src_codeintel_symbols_repository_fetcher_errors_total{job=~"^searcher.*"}[5m]))) * 100 ```-#### symbols: codeintel_symbols_repository_fetcher_total +#### searcher: codeintel_symbols_repository_fetcher_total
Fetcher operations every 5m
This panel has no related alerts. -To see this panel, visit `/-/debug/grafana/d/symbols/symbols?viewPanel=100320` on your Sourcegraph instance. +To see this panel, visit `/-/debug/grafana/d/searcher/searcher?viewPanel=101020` on your Sourcegraph instance. *Managed by the [Sourcegraph Code intelligence team](https://handbook.sourcegraph.com/departments/engineering/teams/code-intelligence).* @@ -56770,19 +56999,19 @@ To see this panel, visit `/-/debug/grafana/d/symbols/symbols?viewPanel=100320` o Query: ``` -sum by (op)(increase(src_codeintel_symbols_repository_fetcher_total{job=~"^symbols.*"}[5m])) +sum by (op)(increase(src_codeintel_symbols_repository_fetcher_total{job=~"^searcher.*"}[5m])) ```-#### symbols: codeintel_symbols_repository_fetcher_99th_percentile_duration +#### searcher: codeintel_symbols_repository_fetcher_99th_percentile_duration
99th percentile successful fetcher operation duration over 5m
This panel has no related alerts. -To see this panel, visit `/-/debug/grafana/d/symbols/symbols?viewPanel=100321` on your Sourcegraph instance. +To see this panel, visit `/-/debug/grafana/d/searcher/searcher?viewPanel=101021` on your Sourcegraph instance. *Managed by the [Sourcegraph Code intelligence team](https://handbook.sourcegraph.com/departments/engineering/teams/code-intelligence).* @@ -56792,19 +57021,19 @@ To see this panel, visit `/-/debug/grafana/d/symbols/symbols?viewPanel=100321` o Query: ``` -histogram_quantile(0.99, sum by (le,op)(rate(src_codeintel_symbols_repository_fetcher_duration_seconds_bucket{job=~"^symbols.*"}[5m]))) +histogram_quantile(0.99, sum by (le,op)(rate(src_codeintel_symbols_repository_fetcher_duration_seconds_bucket{job=~"^searcher.*"}[5m]))) ```-#### symbols: codeintel_symbols_repository_fetcher_errors_total +#### searcher: codeintel_symbols_repository_fetcher_errors_total
Fetcher operation errors every 5m
This panel has no related alerts. -To see this panel, visit `/-/debug/grafana/d/symbols/symbols?viewPanel=100322` on your Sourcegraph instance. +To see this panel, visit `/-/debug/grafana/d/searcher/searcher?viewPanel=101022` on your Sourcegraph instance. *Managed by the [Sourcegraph Code intelligence team](https://handbook.sourcegraph.com/departments/engineering/teams/code-intelligence).* @@ -56814,19 +57043,19 @@ To see this panel, visit `/-/debug/grafana/d/symbols/symbols?viewPanel=100322` o Query: ``` -sum by (op)(increase(src_codeintel_symbols_repository_fetcher_errors_total{job=~"^symbols.*"}[5m])) +sum by (op)(increase(src_codeintel_symbols_repository_fetcher_errors_total{job=~"^searcher.*"}[5m])) ```-#### symbols: codeintel_symbols_repository_fetcher_error_rate +#### searcher: codeintel_symbols_repository_fetcher_error_rate
Fetcher operation error rate over 5m
This panel has no related alerts. -To see this panel, visit `/-/debug/grafana/d/symbols/symbols?viewPanel=100323` on your Sourcegraph instance. +To see this panel, visit `/-/debug/grafana/d/searcher/searcher?viewPanel=101023` on your Sourcegraph instance. *Managed by the [Sourcegraph Code intelligence team](https://handbook.sourcegraph.com/departments/engineering/teams/code-intelligence).* @@ -56836,21 +57065,21 @@ To see this panel, visit `/-/debug/grafana/d/symbols/symbols?viewPanel=100323` o Query: ``` -sum by (op)(increase(src_codeintel_symbols_repository_fetcher_errors_total{job=~"^symbols.*"}[5m])) / (sum by (op)(increase(src_codeintel_symbols_repository_fetcher_total{job=~"^symbols.*"}[5m])) + sum by (op)(increase(src_codeintel_symbols_repository_fetcher_errors_total{job=~"^symbols.*"}[5m]))) * 100 +sum by (op)(increase(src_codeintel_symbols_repository_fetcher_errors_total{job=~"^searcher.*"}[5m])) / (sum by (op)(increase(src_codeintel_symbols_repository_fetcher_total{job=~"^searcher.*"}[5m])) + sum by (op)(increase(src_codeintel_symbols_repository_fetcher_errors_total{job=~"^searcher.*"}[5m]))) * 100 ```-### Symbols: Codeintel: Symbols gitserver client +### Searcher: Codeintel: Symbols gitserver client -#### symbols: codeintel_symbols_gitserver_total +#### searcher: codeintel_symbols_gitserver_total
Aggregate gitserver client operations every 5m
This panel has no related alerts. -To see this panel, visit `/-/debug/grafana/d/symbols/symbols?viewPanel=100400` on your Sourcegraph instance. +To see this panel, visit `/-/debug/grafana/d/searcher/searcher?viewPanel=101100` on your Sourcegraph instance. *Managed by the [Sourcegraph Code intelligence team](https://handbook.sourcegraph.com/departments/engineering/teams/code-intelligence).* @@ -56860,19 +57089,19 @@ To see this panel, visit `/-/debug/grafana/d/symbols/symbols?viewPanel=100400` o Query: ``` -sum(increase(src_codeintel_symbols_gitserver_total{job=~"^symbols.*"}[5m])) +sum(increase(src_codeintel_symbols_gitserver_total{job=~"^searcher.*"}[5m])) ```-#### symbols: codeintel_symbols_gitserver_99th_percentile_duration +#### searcher: codeintel_symbols_gitserver_99th_percentile_duration
Aggregate successful gitserver client operation duration distribution over 5m
This panel has no related alerts. -To see this panel, visit `/-/debug/grafana/d/symbols/symbols?viewPanel=100401` on your Sourcegraph instance. +To see this panel, visit `/-/debug/grafana/d/searcher/searcher?viewPanel=101101` on your Sourcegraph instance. *Managed by the [Sourcegraph Code intelligence team](https://handbook.sourcegraph.com/departments/engineering/teams/code-intelligence).* @@ -56882,19 +57111,19 @@ To see this panel, visit `/-/debug/grafana/d/symbols/symbols?viewPanel=100401` o Query: ``` -sum by (le)(rate(src_codeintel_symbols_gitserver_duration_seconds_bucket{job=~"^symbols.*"}[5m])) +sum by (le)(rate(src_codeintel_symbols_gitserver_duration_seconds_bucket{job=~"^searcher.*"}[5m])) ```-#### symbols: codeintel_symbols_gitserver_errors_total +#### searcher: codeintel_symbols_gitserver_errors_total
Aggregate gitserver client operation errors every 5m
This panel has no related alerts. -To see this panel, visit `/-/debug/grafana/d/symbols/symbols?viewPanel=100402` on your Sourcegraph instance. +To see this panel, visit `/-/debug/grafana/d/searcher/searcher?viewPanel=101102` on your Sourcegraph instance. *Managed by the [Sourcegraph Code intelligence team](https://handbook.sourcegraph.com/departments/engineering/teams/code-intelligence).* @@ -56904,19 +57133,19 @@ To see this panel, visit `/-/debug/grafana/d/symbols/symbols?viewPanel=100402` o Query: ``` -sum(increase(src_codeintel_symbols_gitserver_errors_total{job=~"^symbols.*"}[5m])) +sum(increase(src_codeintel_symbols_gitserver_errors_total{job=~"^searcher.*"}[5m])) ```-#### symbols: codeintel_symbols_gitserver_error_rate +#### searcher: codeintel_symbols_gitserver_error_rate
Aggregate gitserver client operation error rate over 5m
This panel has no related alerts. -To see this panel, visit `/-/debug/grafana/d/symbols/symbols?viewPanel=100403` on your Sourcegraph instance. +To see this panel, visit `/-/debug/grafana/d/searcher/searcher?viewPanel=101103` on your Sourcegraph instance. *Managed by the [Sourcegraph Code intelligence team](https://handbook.sourcegraph.com/departments/engineering/teams/code-intelligence).* @@ -56926,19 +57155,19 @@ To see this panel, visit `/-/debug/grafana/d/symbols/symbols?viewPanel=100403` o Query: ``` -sum(increase(src_codeintel_symbols_gitserver_errors_total{job=~"^symbols.*"}[5m])) / (sum(increase(src_codeintel_symbols_gitserver_total{job=~"^symbols.*"}[5m])) + sum(increase(src_codeintel_symbols_gitserver_errors_total{job=~"^symbols.*"}[5m]))) * 100 +sum(increase(src_codeintel_symbols_gitserver_errors_total{job=~"^searcher.*"}[5m])) / (sum(increase(src_codeintel_symbols_gitserver_total{job=~"^searcher.*"}[5m])) + sum(increase(src_codeintel_symbols_gitserver_errors_total{job=~"^searcher.*"}[5m]))) * 100 ```-#### symbols: codeintel_symbols_gitserver_total +#### searcher: codeintel_symbols_gitserver_total
Gitserver client operations every 5m
This panel has no related alerts. -To see this panel, visit `/-/debug/grafana/d/symbols/symbols?viewPanel=100410` on your Sourcegraph instance. +To see this panel, visit `/-/debug/grafana/d/searcher/searcher?viewPanel=101110` on your Sourcegraph instance. *Managed by the [Sourcegraph Code intelligence team](https://handbook.sourcegraph.com/departments/engineering/teams/code-intelligence).* @@ -56948,19 +57177,19 @@ To see this panel, visit `/-/debug/grafana/d/symbols/symbols?viewPanel=100410` o Query: ``` -sum by (op)(increase(src_codeintel_symbols_gitserver_total{job=~"^symbols.*"}[5m])) +sum by (op)(increase(src_codeintel_symbols_gitserver_total{job=~"^searcher.*"}[5m])) ```-#### symbols: codeintel_symbols_gitserver_99th_percentile_duration +#### searcher: codeintel_symbols_gitserver_99th_percentile_duration
99th percentile successful gitserver client operation duration over 5m
This panel has no related alerts. -To see this panel, visit `/-/debug/grafana/d/symbols/symbols?viewPanel=100411` on your Sourcegraph instance. +To see this panel, visit `/-/debug/grafana/d/searcher/searcher?viewPanel=101111` on your Sourcegraph instance. *Managed by the [Sourcegraph Code intelligence team](https://handbook.sourcegraph.com/departments/engineering/teams/code-intelligence).* @@ -56970,19 +57199,19 @@ To see this panel, visit `/-/debug/grafana/d/symbols/symbols?viewPanel=100411` o Query: ``` -histogram_quantile(0.99, sum by (le,op)(rate(src_codeintel_symbols_gitserver_duration_seconds_bucket{job=~"^symbols.*"}[5m]))) +histogram_quantile(0.99, sum by (le,op)(rate(src_codeintel_symbols_gitserver_duration_seconds_bucket{job=~"^searcher.*"}[5m]))) ```-#### symbols: codeintel_symbols_gitserver_errors_total +#### searcher: codeintel_symbols_gitserver_errors_total
Gitserver client operation errors every 5m
This panel has no related alerts. -To see this panel, visit `/-/debug/grafana/d/symbols/symbols?viewPanel=100412` on your Sourcegraph instance. +To see this panel, visit `/-/debug/grafana/d/searcher/searcher?viewPanel=101112` on your Sourcegraph instance. *Managed by the [Sourcegraph Code intelligence team](https://handbook.sourcegraph.com/departments/engineering/teams/code-intelligence).* @@ -56992,19 +57221,19 @@ To see this panel, visit `/-/debug/grafana/d/symbols/symbols?viewPanel=100412` o Query: ``` -sum by (op)(increase(src_codeintel_symbols_gitserver_errors_total{job=~"^symbols.*"}[5m])) +sum by (op)(increase(src_codeintel_symbols_gitserver_errors_total{job=~"^searcher.*"}[5m])) ```-#### symbols: codeintel_symbols_gitserver_error_rate +#### searcher: codeintel_symbols_gitserver_error_rate
Gitserver client operation error rate over 5m
This panel has no related alerts. -To see this panel, visit `/-/debug/grafana/d/symbols/symbols?viewPanel=100413` on your Sourcegraph instance. +To see this panel, visit `/-/debug/grafana/d/searcher/searcher?viewPanel=101113` on your Sourcegraph instance. *Managed by the [Sourcegraph Code intelligence team](https://handbook.sourcegraph.com/departments/engineering/teams/code-intelligence).* @@ -57014,15 +57243,15 @@ To see this panel, visit `/-/debug/grafana/d/symbols/symbols?viewPanel=100413` o Query: ``` -sum by (op)(increase(src_codeintel_symbols_gitserver_errors_total{job=~"^symbols.*"}[5m])) / (sum by (op)(increase(src_codeintel_symbols_gitserver_total{job=~"^symbols.*"}[5m])) + sum by (op)(increase(src_codeintel_symbols_gitserver_errors_total{job=~"^symbols.*"}[5m]))) * 100 +sum by (op)(increase(src_codeintel_symbols_gitserver_errors_total{job=~"^searcher.*"}[5m])) / (sum by (op)(increase(src_codeintel_symbols_gitserver_total{job=~"^searcher.*"}[5m])) + sum by (op)(increase(src_codeintel_symbols_gitserver_errors_total{job=~"^searcher.*"}[5m]))) * 100 ```-### Symbols: Rockskip +### Searcher: Rockskip -#### symbols: p95_rockskip_search_request_duration +#### searcher: p95_rockskip_search_request_duration
95th percentile search request duration over 5m
@@ -57030,7 +57259,7 @@ The 95th percentile duration of search requests to Rockskip in seconds. Lower is This panel has no related alerts. -To see this panel, visit `/-/debug/grafana/d/symbols/symbols?viewPanel=100500` on your Sourcegraph instance. +To see this panel, visit `/-/debug/grafana/d/searcher/searcher?viewPanel=101200` on your Sourcegraph instance. *Managed by the [Sourcegraph Search Platform team](https://handbook.sourcegraph.com/departments/engineering/teams/search/core).* @@ -57046,7 +57275,7 @@ histogram_quantile(0.95, sum(rate(src_rockskip_service_search_request_duration_s-#### symbols: rockskip_in_flight_search_requests +#### searcher: rockskip_in_flight_search_requests
Number of in-flight search requests
@@ -57056,7 +57285,7 @@ The number of search requests currently being processed by Rockskip. This panel has no related alerts. -To see this panel, visit `/-/debug/grafana/d/symbols/symbols?viewPanel=100501` on your Sourcegraph instance. +To see this panel, visit `/-/debug/grafana/d/searcher/searcher?viewPanel=101201` on your Sourcegraph instance. *Managed by the [Sourcegraph Search Platform team](https://handbook.sourcegraph.com/departments/engineering/teams/search/core).* @@ -57072,7 +57301,7 @@ sum(src_rockskip_service_in_flight_search_requests)-#### symbols: rockskip_search_request_errors +#### searcher: rockskip_search_request_errors
Search request errors every 5m
@@ -57082,7 +57311,7 @@ The number of search requests that returned an error in the last 5 minutes. This panel has no related alerts. -To see this panel, visit `/-/debug/grafana/d/symbols/symbols?viewPanel=100502` on your Sourcegraph instance. +To see this panel, visit `/-/debug/grafana/d/searcher/searcher?viewPanel=101202` on your Sourcegraph instance. *Managed by the [Sourcegraph Search Platform team](https://handbook.sourcegraph.com/departments/engineering/teams/search/core).* @@ -57098,7 +57327,7 @@ sum(increase(src_rockskip_service_search_request_errors[5m]))-#### symbols: p95_rockskip_index_job_duration +#### searcher: p95_rockskip_index_job_duration
95th percentile index job duration over 5m
@@ -57108,7 +57337,7 @@ The 95th percentile duration of index jobs in seconds. This panel has no related alerts. -To see this panel, visit `/-/debug/grafana/d/symbols/symbols?viewPanel=100510` on your Sourcegraph instance. +To see this panel, visit `/-/debug/grafana/d/searcher/searcher?viewPanel=101210` on your Sourcegraph instance. *Managed by the [Sourcegraph Search Platform team](https://handbook.sourcegraph.com/departments/engineering/teams/search/core).* @@ -57124,7 +57353,7 @@ histogram_quantile(0.95, sum(rate(src_rockskip_service_index_job_duration_second-#### symbols: rockskip_in_flight_index_jobs +#### searcher: rockskip_in_flight_index_jobs
Number of in-flight index jobs
@@ -57133,7 +57362,7 @@ The number of index jobs currently being processed by Rockskip. This panel has no related alerts. -To see this panel, visit `/-/debug/grafana/d/symbols/symbols?viewPanel=100511` on your Sourcegraph instance. +To see this panel, visit `/-/debug/grafana/d/searcher/searcher?viewPanel=101211` on your Sourcegraph instance. *Managed by the [Sourcegraph Search Platform team](https://handbook.sourcegraph.com/departments/engineering/teams/search/core).* @@ -57149,7 +57378,7 @@ sum(src_rockskip_service_in_flight_index_jobs)-#### symbols: rockskip_index_job_errors +#### searcher: rockskip_index_job_errors
Index job errors every 5m
@@ -57160,7 +57389,7 @@ The number of index jobs that returned an error in the last 5 minutes. This panel has no related alerts. -To see this panel, visit `/-/debug/grafana/d/symbols/symbols?viewPanel=100512` on your Sourcegraph instance. +To see this panel, visit `/-/debug/grafana/d/searcher/searcher?viewPanel=101212` on your Sourcegraph instance. *Managed by the [Sourcegraph Search Platform team](https://handbook.sourcegraph.com/departments/engineering/teams/search/core).* @@ -57176,7 +57405,7 @@ sum(increase(src_rockskip_service_index_job_errors[5m]))-#### symbols: rockskip_number_of_repos_indexed +#### searcher: rockskip_number_of_repos_indexed
Number of repositories indexed by Rockskip
@@ -57187,7 +57416,7 @@ The number of repositories indexed by Rockskip. This panel has no related alerts. -To see this panel, visit `/-/debug/grafana/d/symbols/symbols?viewPanel=100520` on your Sourcegraph instance. +To see this panel, visit `/-/debug/grafana/d/searcher/searcher?viewPanel=101220` on your Sourcegraph instance. *Managed by the [Sourcegraph Search Platform team](https://handbook.sourcegraph.com/departments/engineering/teams/search/core).* @@ -57203,19 +57432,19 @@ max(src_rockskip_service_repos_indexed)-### Symbols: Symbols GRPC server metrics +#### searcher: p95_rockskip_index_queue_age -#### symbols: symbols_grpc_request_rate_all_methods +
95th percentile index queue delay over 5m
-Request rate across all methods over 2m
- -The number of gRPC requests received per second across all methods, aggregated across all instances. +The 95th percentile age of index jobs in seconds. + A high delay might indicate a resource issue. + Consider increasing indexing bandwidth by either increasing the number of queues or the number of symbol services. This panel has no related alerts. -To see this panel, visit `/-/debug/grafana/d/symbols/symbols?viewPanel=100600` on your Sourcegraph instance. +To see this panel, visit `/-/debug/grafana/d/searcher/searcher?viewPanel=101221` on your Sourcegraph instance. -*Managed by the [Sourcegraph Code intelligence team](https://handbook.sourcegraph.com/departments/engineering/teams/code-intelligence).* +*Managed by the [Sourcegraph Search Platform team](https://handbook.sourcegraph.com/departments/engineering/teams/search/core).*Technical details
@@ -57223,23 +57452,24 @@ To see this panel, visit `/-/debug/grafana/d/symbols/symbols?viewPanel=100600` o Query: ``` -sum(rate(grpc_server_started_total{instance=~`${instance:regex}`,grpc_service=~"symbols.v1.SymbolsService"}[2m])) +histogram_quantile(0.95, sum(rate(src_rockskip_service_index_queue_age_seconds_bucket[5m])) by (le)) ```-#### symbols: symbols_grpc_request_rate_per_method +#### searcher: rockskip_file_parsing_requests -
Request rate per-method over 2m
+File parsing requests every 5m
-The number of gRPC requests received per second broken out per method, aggregated across all instances. +The number of search requests in the last 5 minutes that were handled by parsing a single file, as opposed to searching the Rockskip index. + This is an optimization to speed up symbol sidebar queries. This panel has no related alerts. -To see this panel, visit `/-/debug/grafana/d/symbols/symbols?viewPanel=100601` on your Sourcegraph instance. +To see this panel, visit `/-/debug/grafana/d/searcher/searcher?viewPanel=101222` on your Sourcegraph instance. -*Managed by the [Sourcegraph Code intelligence team](https://handbook.sourcegraph.com/departments/engineering/teams/code-intelligence).* +*Managed by the [Sourcegraph Search Platform team](https://handbook.sourcegraph.com/departments/engineering/teams/search/core).*Technical details
@@ -57247,23 +57477,25 @@ To see this panel, visit `/-/debug/grafana/d/symbols/symbols?viewPanel=100601` o Query: ``` -sum(rate(grpc_server_started_total{grpc_method=~`${symbols_method:regex}`,instance=~`${instance:regex}`,grpc_service=~"symbols.v1.SymbolsService"}[2m])) by (grpc_method) +sum(increase(src_rockskip_service_file_parsing_requests[5m])) ```-#### symbols: symbols_error_percentage_all_methods +### Searcher: Site configuration client update latency -
Error percentage across all methods over 2m
+#### searcher: searcher_site_configuration_duration_since_last_successful_update_by_instance -The percentage of gRPC requests that fail across all methods, aggregated across all instances. +Duration since last successful site configuration update (by instance)
+ +The duration since the configuration client used by the "searcher" service last successfully updated its site configuration. Long durations could indicate issues updating the site configuration. This panel has no related alerts. -To see this panel, visit `/-/debug/grafana/d/symbols/symbols?viewPanel=100610` on your Sourcegraph instance. +To see this panel, visit `/-/debug/grafana/d/searcher/searcher?viewPanel=101300` on your Sourcegraph instance. -*Managed by the [Sourcegraph Code intelligence team](https://handbook.sourcegraph.com/departments/engineering/teams/code-intelligence).* +*Managed by the [Sourcegraph Infrastructure Org team](https://handbook.sourcegraph.com/departments/engineering/infrastructure).*Technical details
@@ -57271,23 +57503,21 @@ To see this panel, visit `/-/debug/grafana/d/symbols/symbols?viewPanel=100610` o Query: ``` -(100.0 * ( (sum(rate(grpc_server_handled_total{grpc_code!="OK",instance=~`${instance:regex}`,grpc_service=~"symbols.v1.SymbolsService"}[2m]))) / (sum(rate(grpc_server_handled_total{instance=~`${instance:regex}`,grpc_service=~"symbols.v1.SymbolsService"}[2m]))) )) +src_conf_client_time_since_last_successful_update_seconds{job=~`.*searcher`,instance=~`${instance:regex}`} ```-#### symbols: symbols_grpc_error_percentage_per_method - -
Error percentage per-method over 2m
+#### searcher: searcher_site_configuration_duration_since_last_successful_update_by_instance -The percentage of gRPC requests that fail per method, aggregated across all instances. +Maximum duration since last successful site configuration update (all "searcher" instances)
-This panel has no related alerts. +Refer to the [alerts reference](alerts#searcher-searcher-site-configuration-duration-since-last-successful-update-by-instance) for 1 alert related to this panel. -To see this panel, visit `/-/debug/grafana/d/symbols/symbols?viewPanel=100611` on your Sourcegraph instance. +To see this panel, visit `/-/debug/grafana/d/searcher/searcher?viewPanel=101301` on your Sourcegraph instance. -*Managed by the [Sourcegraph Code intelligence team](https://handbook.sourcegraph.com/departments/engineering/teams/code-intelligence).* +*Managed by the [Sourcegraph Infrastructure Org team](https://handbook.sourcegraph.com/departments/engineering/infrastructure).*Technical details
@@ -57295,23 +57525,26 @@ To see this panel, visit `/-/debug/grafana/d/symbols/symbols?viewPanel=100611` o Query: ``` -(100.0 * ( (sum(rate(grpc_server_handled_total{grpc_method=~`${symbols_method:regex}`,grpc_code!="OK",instance=~`${instance:regex}`,grpc_service=~"symbols.v1.SymbolsService"}[2m])) by (grpc_method)) / (sum(rate(grpc_server_handled_total{grpc_method=~`${symbols_method:regex}`,instance=~`${instance:regex}`,grpc_service=~"symbols.v1.SymbolsService"}[2m])) by (grpc_method)) )) +max(max_over_time(src_conf_client_time_since_last_successful_update_seconds{job=~`.*searcher`,instance=~`${instance:regex}`}[1m])) ```-#### symbols: symbols_p99_response_time_per_method +### Searcher: Periodic Goroutines -
99th percentile response time per method over 2m
+#### searcher: running_goroutines -The 99th percentile response time per method, aggregated across all instances. +Number of currently running periodic goroutines
+ +The number of currently running periodic goroutines by name and job. +A value of 0 indicates the routine isn`t running currently, it awaits it`s next schedule. This panel has no related alerts. -To see this panel, visit `/-/debug/grafana/d/symbols/symbols?viewPanel=100620` on your Sourcegraph instance. +To see this panel, visit `/-/debug/grafana/d/searcher/searcher?viewPanel=101400` on your Sourcegraph instance. -*Managed by the [Sourcegraph Code intelligence team](https://handbook.sourcegraph.com/departments/engineering/teams/code-intelligence).* +*Managed by the [Sourcegraph Infrastructure Org team](https://handbook.sourcegraph.com/departments/engineering/infrastructure).*Technical details
@@ -57319,23 +57552,24 @@ To see this panel, visit `/-/debug/grafana/d/symbols/symbols?viewPanel=100620` o Query: ``` -histogram_quantile(0.99, sum by (le, name, grpc_method)(rate(grpc_server_handling_seconds_bucket{grpc_method=~`${symbols_method:regex}`,instance=~`${instance:regex}`,grpc_service=~"symbols.v1.SymbolsService"}[2m]))) +sum by (name, job_name) (src_periodic_goroutine_running{job=~".*searcher.*"}) ```-#### symbols: symbols_p90_response_time_per_method +#### searcher: goroutine_success_rate -
90th percentile response time per method over 2m
+Success rate for periodic goroutine executions
-The 90th percentile response time per method, aggregated across all instances. +The rate of successful executions of each periodic goroutine. +A low or zero value could indicate that a routine is stalled or encountering errors. This panel has no related alerts. -To see this panel, visit `/-/debug/grafana/d/symbols/symbols?viewPanel=100621` on your Sourcegraph instance. +To see this panel, visit `/-/debug/grafana/d/searcher/searcher?viewPanel=101401` on your Sourcegraph instance. -*Managed by the [Sourcegraph Code intelligence team](https://handbook.sourcegraph.com/departments/engineering/teams/code-intelligence).* +*Managed by the [Sourcegraph Infrastructure Org team](https://handbook.sourcegraph.com/departments/engineering/infrastructure).*Technical details
@@ -57343,23 +57577,24 @@ To see this panel, visit `/-/debug/grafana/d/symbols/symbols?viewPanel=100621` o Query: ``` -histogram_quantile(0.90, sum by (le, name, grpc_method)(rate(grpc_server_handling_seconds_bucket{grpc_method=~`${symbols_method:regex}`,instance=~`${instance:regex}`,grpc_service=~"symbols.v1.SymbolsService"}[2m]))) +sum by (name, job_name) (rate(src_periodic_goroutine_total{job=~".*searcher.*"}[5m])) ```-#### symbols: symbols_p75_response_time_per_method +#### searcher: goroutine_error_rate -
75th percentile response time per method over 2m
+Error rate for periodic goroutine executions
-The 75th percentile response time per method, aggregated across all instances. +The rate of errors encountered by each periodic goroutine. +A sustained high error rate may indicate a problem with the routine`s configuration or dependencies. -This panel has no related alerts. +Refer to the [alerts reference](alerts#searcher-goroutine-error-rate) for 1 alert related to this panel. -To see this panel, visit `/-/debug/grafana/d/symbols/symbols?viewPanel=100622` on your Sourcegraph instance. +To see this panel, visit `/-/debug/grafana/d/searcher/searcher?viewPanel=101410` on your Sourcegraph instance. -*Managed by the [Sourcegraph Code intelligence team](https://handbook.sourcegraph.com/departments/engineering/teams/code-intelligence).* +*Managed by the [Sourcegraph Infrastructure Org team](https://handbook.sourcegraph.com/departments/engineering/infrastructure).*Technical details
@@ -57367,23 +57602,24 @@ To see this panel, visit `/-/debug/grafana/d/symbols/symbols?viewPanel=100622` o Query: ``` -histogram_quantile(0.75, sum by (le, name, grpc_method)(rate(grpc_server_handling_seconds_bucket{grpc_method=~`${symbols_method:regex}`,instance=~`${instance:regex}`,grpc_service=~"symbols.v1.SymbolsService"}[2m]))) +sum by (name, job_name) (rate(src_periodic_goroutine_errors_total{job=~".*searcher.*"}[5m])) ```-#### symbols: symbols_p99_9_response_size_per_method +#### searcher: goroutine_error_percentage -
99.9th percentile total response size per method over 2m
+Percentage of periodic goroutine executions that result in errors
-The 99.9th percentile total per-RPC response size per method, aggregated across all instances. +The percentage of executions that result in errors for each periodic goroutine. +A value above 5% indicates that a significant portion of routine executions are failing. -This panel has no related alerts. +Refer to the [alerts reference](alerts#searcher-goroutine-error-percentage) for 1 alert related to this panel. -To see this panel, visit `/-/debug/grafana/d/symbols/symbols?viewPanel=100630` on your Sourcegraph instance. +To see this panel, visit `/-/debug/grafana/d/searcher/searcher?viewPanel=101411` on your Sourcegraph instance. -*Managed by the [Sourcegraph Code intelligence team](https://handbook.sourcegraph.com/departments/engineering/teams/code-intelligence).* +*Managed by the [Sourcegraph Infrastructure Org team](https://handbook.sourcegraph.com/departments/engineering/infrastructure).*Technical details
@@ -57391,23 +57627,24 @@ To see this panel, visit `/-/debug/grafana/d/symbols/symbols?viewPanel=100630` o Query: ``` -histogram_quantile(0.999, sum by (le, name, grpc_method)(rate(src_grpc_server_sent_bytes_per_rpc_bucket{grpc_method=~`${symbols_method:regex}`,instance=~`${instance:regex}`,grpc_service=~"symbols.v1.SymbolsService"}[2m]))) +sum by (name, job_name) (rate(src_periodic_goroutine_errors_total{job=~".*searcher.*"}[5m])) / sum by (name, job_name) (rate(src_periodic_goroutine_total{job=~".*searcher.*"}[5m]) > 0) * 100 ```-#### symbols: symbols_p90_response_size_per_method +#### searcher: goroutine_handler_duration -
90th percentile total response size per method over 2m
+95th percentile handler execution time
-The 90th percentile total per-RPC response size per method, aggregated across all instances. +The 95th percentile execution time for each periodic goroutine handler. +Longer durations might indicate increased load or processing time. This panel has no related alerts. -To see this panel, visit `/-/debug/grafana/d/symbols/symbols?viewPanel=100631` on your Sourcegraph instance. +To see this panel, visit `/-/debug/grafana/d/searcher/searcher?viewPanel=101420` on your Sourcegraph instance. -*Managed by the [Sourcegraph Code intelligence team](https://handbook.sourcegraph.com/departments/engineering/teams/code-intelligence).* +*Managed by the [Sourcegraph Infrastructure Org team](https://handbook.sourcegraph.com/departments/engineering/infrastructure).*Technical details
@@ -57415,23 +57652,24 @@ To see this panel, visit `/-/debug/grafana/d/symbols/symbols?viewPanel=100631` o Query: ``` -histogram_quantile(0.90, sum by (le, name, grpc_method)(rate(src_grpc_server_sent_bytes_per_rpc_bucket{grpc_method=~`${symbols_method:regex}`,instance=~`${instance:regex}`,grpc_service=~"symbols.v1.SymbolsService"}[2m]))) +histogram_quantile(0.95, sum by (name, job_name, le) (rate(src_periodic_goroutine_duration_seconds_bucket{job=~".*searcher.*"}[5m]))) ```-#### symbols: symbols_p75_response_size_per_method +#### searcher: goroutine_loop_duration -
75th percentile total response size per method over 2m
+95th percentile loop cycle time
-The 75th percentile total per-RPC response size per method, aggregated across all instances. +The 95th percentile loop cycle time for each periodic goroutine (excluding sleep time). +This represents how long a complete loop iteration takes before sleeping for the next interval. This panel has no related alerts. -To see this panel, visit `/-/debug/grafana/d/symbols/symbols?viewPanel=100632` on your Sourcegraph instance. +To see this panel, visit `/-/debug/grafana/d/searcher/searcher?viewPanel=101421` on your Sourcegraph instance. -*Managed by the [Sourcegraph Code intelligence team](https://handbook.sourcegraph.com/departments/engineering/teams/code-intelligence).* +*Managed by the [Sourcegraph Infrastructure Org team](https://handbook.sourcegraph.com/departments/engineering/infrastructure).*Technical details
@@ -57439,23 +57677,24 @@ To see this panel, visit `/-/debug/grafana/d/symbols/symbols?viewPanel=100632` o Query: ``` -histogram_quantile(0.75, sum by (le, name, grpc_method)(rate(src_grpc_server_sent_bytes_per_rpc_bucket{grpc_method=~`${symbols_method:regex}`,instance=~`${instance:regex}`,grpc_service=~"symbols.v1.SymbolsService"}[2m]))) +histogram_quantile(0.95, sum by (name, job_name, le) (rate(src_periodic_goroutine_loop_duration_seconds_bucket{job=~".*searcher.*"}[5m]))) ```-#### symbols: symbols_p99_9_invididual_sent_message_size_per_method +#### searcher: tenant_processing_duration -
99.9th percentile individual sent message size per method over 2m
+95th percentile tenant processing time
-The 99.9th percentile size of every individual protocol buffer size sent by the service per method, aggregated across all instances. +The 95th percentile processing time for individual tenants within periodic goroutines. +Higher values indicate that tenant processing is taking longer and may affect overall performance. This panel has no related alerts. -To see this panel, visit `/-/debug/grafana/d/symbols/symbols?viewPanel=100640` on your Sourcegraph instance. +To see this panel, visit `/-/debug/grafana/d/searcher/searcher?viewPanel=101430` on your Sourcegraph instance. -*Managed by the [Sourcegraph Code intelligence team](https://handbook.sourcegraph.com/departments/engineering/teams/code-intelligence).* +*Managed by the [Sourcegraph Infrastructure Org team](https://handbook.sourcegraph.com/departments/engineering/infrastructure).*Technical details
@@ -57463,23 +57702,24 @@ To see this panel, visit `/-/debug/grafana/d/symbols/symbols?viewPanel=100640` o Query: ``` -histogram_quantile(0.999, sum by (le, name, grpc_method)(rate(src_grpc_server_sent_individual_message_size_bytes_per_rpc_bucket{grpc_method=~`${symbols_method:regex}`,instance=~`${instance:regex}`,grpc_service=~"symbols.v1.SymbolsService"}[2m]))) +histogram_quantile(0.95, sum by (name, job_name, le) (rate(src_periodic_goroutine_tenant_duration_seconds_bucket{job=~".*searcher.*"}[5m]))) ```-#### symbols: symbols_p90_invididual_sent_message_size_per_method +#### searcher: tenant_processing_max -
90th percentile individual sent message size per method over 2m
+Maximum tenant processing time
-The 90th percentile size of every individual protocol buffer size sent by the service per method, aggregated across all instances. +The maximum processing time for individual tenants within periodic goroutines. +Consistently high values might indicate problematic tenants or inefficient processing. This panel has no related alerts. -To see this panel, visit `/-/debug/grafana/d/symbols/symbols?viewPanel=100641` on your Sourcegraph instance. +To see this panel, visit `/-/debug/grafana/d/searcher/searcher?viewPanel=101431` on your Sourcegraph instance. -*Managed by the [Sourcegraph Code intelligence team](https://handbook.sourcegraph.com/departments/engineering/teams/code-intelligence).* +*Managed by the [Sourcegraph Infrastructure Org team](https://handbook.sourcegraph.com/departments/engineering/infrastructure).*Technical details
@@ -57487,23 +57727,24 @@ To see this panel, visit `/-/debug/grafana/d/symbols/symbols?viewPanel=100641` o Query: ``` -histogram_quantile(0.90, sum by (le, name, grpc_method)(rate(src_grpc_server_sent_individual_message_size_bytes_per_rpc_bucket{grpc_method=~`${symbols_method:regex}`,instance=~`${instance:regex}`,grpc_service=~"symbols.v1.SymbolsService"}[2m]))) +max by (name, job_name) (rate(src_periodic_goroutine_tenant_duration_seconds_sum{job=~".*searcher.*"}[5m]) / rate(src_periodic_goroutine_tenant_duration_seconds_count{job=~".*searcher.*"}[5m])) ```-#### symbols: symbols_p75_invididual_sent_message_size_per_method +#### searcher: tenant_count -
75th percentile individual sent message size per method over 2m
+Number of tenants processed per routine
-The 75th percentile size of every individual protocol buffer size sent by the service per method, aggregated across all instances. +The number of tenants processed by each periodic goroutine. +Unexpected changes can indicate tenant configuration issues or scaling events. This panel has no related alerts. -To see this panel, visit `/-/debug/grafana/d/symbols/symbols?viewPanel=100642` on your Sourcegraph instance. +To see this panel, visit `/-/debug/grafana/d/searcher/searcher?viewPanel=101440` on your Sourcegraph instance. -*Managed by the [Sourcegraph Code intelligence team](https://handbook.sourcegraph.com/departments/engineering/teams/code-intelligence).* +*Managed by the [Sourcegraph Infrastructure Org team](https://handbook.sourcegraph.com/departments/engineering/infrastructure).*Technical details
@@ -57511,23 +57752,24 @@ To see this panel, visit `/-/debug/grafana/d/symbols/symbols?viewPanel=100642` o Query: ``` -histogram_quantile(0.75, sum by (le, name, grpc_method)(rate(src_grpc_server_sent_individual_message_size_bytes_per_rpc_bucket{grpc_method=~`${symbols_method:regex}`,instance=~`${instance:regex}`,grpc_service=~"symbols.v1.SymbolsService"}[2m]))) +max by (name, job_name) (src_periodic_goroutine_tenant_count{job=~".*searcher.*"}) ```-#### symbols: symbols_grpc_response_stream_message_count_per_method +#### searcher: tenant_success_rate -
Average streaming response message count per-method over 2m
+Rate of successful tenant processing operations
-The average number of response messages sent during a streaming RPC method, broken out per method, aggregated across all instances. +The rate of successful tenant processing operations. +A healthy routine should maintain a consistent processing rate. This panel has no related alerts. -To see this panel, visit `/-/debug/grafana/d/symbols/symbols?viewPanel=100650` on your Sourcegraph instance. +To see this panel, visit `/-/debug/grafana/d/searcher/searcher?viewPanel=101441` on your Sourcegraph instance. -*Managed by the [Sourcegraph Code intelligence team](https://handbook.sourcegraph.com/departments/engineering/teams/code-intelligence).* +*Managed by the [Sourcegraph Infrastructure Org team](https://handbook.sourcegraph.com/departments/engineering/infrastructure).*Technical details
@@ -57535,23 +57777,24 @@ To see this panel, visit `/-/debug/grafana/d/symbols/symbols?viewPanel=100650` o Query: ``` -((sum(rate(grpc_server_msg_sent_total{grpc_type="server_stream",instance=~`${instance:regex}`,grpc_service=~"symbols.v1.SymbolsService"}[2m])) by (grpc_method))/(sum(rate(grpc_server_started_total{grpc_type="server_stream",instance=~`${instance:regex}`,grpc_service=~"symbols.v1.SymbolsService"}[2m])) by (grpc_method))) +sum by (name, job_name) (rate(src_periodic_goroutine_tenant_success_total{job=~".*searcher.*"}[5m])) ```-#### symbols: symbols_grpc_all_codes_per_method +#### searcher: tenant_error_rate -
Response codes rate per-method over 2m
+Rate of tenant processing errors
-The rate of all generated gRPC response codes per method, aggregated across all instances. +The rate of tenant processing operations that result in errors. +Consistent errors indicate problems with specific tenants. This panel has no related alerts. -To see this panel, visit `/-/debug/grafana/d/symbols/symbols?viewPanel=100660` on your Sourcegraph instance. +To see this panel, visit `/-/debug/grafana/d/searcher/searcher?viewPanel=101450` on your Sourcegraph instance. -*Managed by the [Sourcegraph Code intelligence team](https://handbook.sourcegraph.com/departments/engineering/teams/code-intelligence).* +*Managed by the [Sourcegraph Infrastructure Org team](https://handbook.sourcegraph.com/departments/engineering/infrastructure).*Technical details
@@ -57559,25 +57802,24 @@ To see this panel, visit `/-/debug/grafana/d/symbols/symbols?viewPanel=100660` o Query: ``` -sum(rate(grpc_server_handled_total{grpc_method=~`${symbols_method:regex}`,instance=~`${instance:regex}`,grpc_service=~"symbols.v1.SymbolsService"}[2m])) by (grpc_method, grpc_code) +sum by (name, job_name) (rate(src_periodic_goroutine_tenant_errors_total{job=~".*searcher.*"}[5m])) ```-### Symbols: Symbols GRPC "internal error" metrics - -#### symbols: symbols_grpc_clients_error_percentage_all_methods +#### searcher: tenant_error_percentage -
Client baseline error percentage across all methods over 2m
+Percentage of tenant operations resulting in errors
-The percentage of gRPC requests that fail across all methods (regardless of whether or not there was an internal error), aggregated across all "symbols" clients. +The percentage of tenant operations that result in errors. +Values above 5% indicate significant tenant processing problems. This panel has no related alerts. -To see this panel, visit `/-/debug/grafana/d/symbols/symbols?viewPanel=100700` on your Sourcegraph instance. +To see this panel, visit `/-/debug/grafana/d/searcher/searcher?viewPanel=101451` on your Sourcegraph instance. -*Managed by the [Sourcegraph Code intelligence team](https://handbook.sourcegraph.com/departments/engineering/teams/code-intelligence).* +*Managed by the [Sourcegraph Infrastructure Org team](https://handbook.sourcegraph.com/departments/engineering/infrastructure).*Technical details
@@ -57585,23 +57827,23 @@ To see this panel, visit `/-/debug/grafana/d/symbols/symbols?viewPanel=100700` o Query: ``` -(100.0 * ((((sum(rate(src_grpc_method_status{grpc_service=~"symbols.v1.SymbolsService",grpc_code!="OK"}[2m])))) / ((sum(rate(src_grpc_method_status{grpc_service=~"symbols.v1.SymbolsService"}[2m]))))))) +(sum by (name, job_name) (rate(src_periodic_goroutine_tenant_errors_total{job=~".*searcher.*"}[5m])) / (sum by (name, job_name) (rate(src_periodic_goroutine_tenant_success_total{job=~".*searcher.*"}[5m])) + sum by (name, job_name) (rate(src_periodic_goroutine_tenant_errors_total{job=~".*searcher.*"}[5m])))) * 100 ```-#### symbols: symbols_grpc_clients_error_percentage_per_method +### Searcher: Database connections -
Client baseline error percentage per-method over 2m
+#### searcher: max_open_conns -The percentage of gRPC requests that fail per method (regardless of whether or not there was an internal error), aggregated across all "symbols" clients. +Maximum open
This panel has no related alerts. -To see this panel, visit `/-/debug/grafana/d/symbols/symbols?viewPanel=100701` on your Sourcegraph instance. +To see this panel, visit `/-/debug/grafana/d/searcher/searcher?viewPanel=101500` on your Sourcegraph instance. -*Managed by the [Sourcegraph Code intelligence team](https://handbook.sourcegraph.com/departments/engineering/teams/code-intelligence).* +*Managed by the [Sourcegraph Infrastructure Org team](https://handbook.sourcegraph.com/departments/engineering/infrastructure).*Technical details
@@ -57609,23 +57851,21 @@ To see this panel, visit `/-/debug/grafana/d/symbols/symbols?viewPanel=100701` o Query: ``` -(100.0 * ((((sum(rate(src_grpc_method_status{grpc_service=~"symbols.v1.SymbolsService",grpc_method=~"${symbols_method:regex}",grpc_code!="OK"}[2m])) by (grpc_method))) / ((sum(rate(src_grpc_method_status{grpc_service=~"symbols.v1.SymbolsService",grpc_method=~"${symbols_method:regex}"}[2m])) by (grpc_method)))))) +sum by (app_name, db_name) (src_pgsql_conns_max_open{app_name="searcher"}) ```-#### symbols: symbols_grpc_clients_all_codes_per_method - -
Client baseline response codes rate per-method over 2m
+#### searcher: open_conns -The rate of all generated gRPC response codes per method (regardless of whether or not there was an internal error), aggregated across all "symbols" clients. +Established
This panel has no related alerts. -To see this panel, visit `/-/debug/grafana/d/symbols/symbols?viewPanel=100702` on your Sourcegraph instance. +To see this panel, visit `/-/debug/grafana/d/searcher/searcher?viewPanel=101501` on your Sourcegraph instance. -*Managed by the [Sourcegraph Code intelligence team](https://handbook.sourcegraph.com/departments/engineering/teams/code-intelligence).* +*Managed by the [Sourcegraph Infrastructure Org team](https://handbook.sourcegraph.com/departments/engineering/infrastructure).*Technical details
@@ -57633,29 +57873,43 @@ To see this panel, visit `/-/debug/grafana/d/symbols/symbols?viewPanel=100702` o Query: ``` -(sum(rate(src_grpc_method_status{grpc_service=~"symbols.v1.SymbolsService",grpc_method=~"${symbols_method:regex}"}[2m])) by (grpc_method, grpc_code)) +sum by (app_name, db_name) (src_pgsql_conns_open{app_name="searcher"}) ```-#### symbols: symbols_grpc_clients_internal_error_percentage_all_methods +#### searcher: in_use -
Client-observed gRPC internal error percentage across all methods over 2m
+Used
-The percentage of gRPC requests that appear to fail due to gRPC internal errors across all methods, aggregated across all "symbols" clients. +This panel has no related alerts. -**Note**: Internal errors are ones that appear to originate from the https://github.com/grpc/grpc-go library itself, rather than from any user-written application code. These errors can be caused by a variety of issues, and can originate from either the code-generated "symbols" gRPC client or gRPC server. These errors might be solvable by adjusting the gRPC configuration, or they might indicate a bug from Sourcegraph`s use of gRPC. +To see this panel, visit `/-/debug/grafana/d/searcher/searcher?viewPanel=101510` on your Sourcegraph instance. -When debugging, knowing that a particular error comes from the grpc-go library itself (an `internal error`) as opposed to `normal` application code can be helpful when trying to fix it. +*Managed by the [Sourcegraph Infrastructure Org team](https://handbook.sourcegraph.com/departments/engineering/infrastructure).* -**Note**: Internal errors are detected via a very coarse heuristic (seeing if the error starts with `grpc:`, etc.). Because of this, it`s possible that some gRPC-specific issues might not be categorized as internal errors. +Technical details
+ +Query: + +``` +sum by (app_name, db_name) (src_pgsql_conns_in_use{app_name="searcher"}) +``` ++ +#### searcher: idle + +
Idle
This panel has no related alerts. -To see this panel, visit `/-/debug/grafana/d/symbols/symbols?viewPanel=100710` on your Sourcegraph instance. +To see this panel, visit `/-/debug/grafana/d/searcher/searcher?viewPanel=101511` on your Sourcegraph instance. -*Managed by the [Sourcegraph Code intelligence team](https://handbook.sourcegraph.com/departments/engineering/teams/code-intelligence).* +*Managed by the [Sourcegraph Infrastructure Org team](https://handbook.sourcegraph.com/departments/engineering/infrastructure).*Technical details
@@ -57663,29 +57917,43 @@ To see this panel, visit `/-/debug/grafana/d/symbols/symbols?viewPanel=100710` o Query: ``` -(100.0 * ((((sum(rate(src_grpc_method_status{grpc_service=~"symbols.v1.SymbolsService",grpc_code!="OK",is_internal_error="true"}[2m])))) / ((sum(rate(src_grpc_method_status{grpc_service=~"symbols.v1.SymbolsService"}[2m]))))))) +sum by (app_name, db_name) (src_pgsql_conns_idle{app_name="searcher"}) ```-#### symbols: symbols_grpc_clients_internal_error_percentage_per_method +#### searcher: mean_blocked_seconds_per_conn_request -
Client-observed gRPC internal error percentage per-method over 2m
+Mean blocked seconds per conn request
-The percentage of gRPC requests that appear to fail to due to gRPC internal errors per method, aggregated across all "symbols" clients. +Refer to the [alerts reference](alerts#searcher-mean-blocked-seconds-per-conn-request) for 2 alerts related to this panel. -**Note**: Internal errors are ones that appear to originate from the https://github.com/grpc/grpc-go library itself, rather than from any user-written application code. These errors can be caused by a variety of issues, and can originate from either the code-generated "symbols" gRPC client or gRPC server. These errors might be solvable by adjusting the gRPC configuration, or they might indicate a bug from Sourcegraph`s use of gRPC. +To see this panel, visit `/-/debug/grafana/d/searcher/searcher?viewPanel=101520` on your Sourcegraph instance. -When debugging, knowing that a particular error comes from the grpc-go library itself (an `internal error`) as opposed to `normal` application code can be helpful when trying to fix it. +*Managed by the [Sourcegraph Infrastructure Org team](https://handbook.sourcegraph.com/departments/engineering/infrastructure).* -**Note**: Internal errors are detected via a very coarse heuristic (seeing if the error starts with `grpc:`, etc.). Because of this, it`s possible that some gRPC-specific issues might not be categorized as internal errors. +Technical details
+ +Query: + +``` +sum by (app_name, db_name) (increase(src_pgsql_conns_blocked_seconds{app_name="searcher"}[5m])) / sum by (app_name, db_name) (increase(src_pgsql_conns_waited_for{app_name="searcher"}[5m])) +``` ++ +#### searcher: closed_max_idle + +
Closed by SetMaxIdleConns
This panel has no related alerts. -To see this panel, visit `/-/debug/grafana/d/symbols/symbols?viewPanel=100711` on your Sourcegraph instance. +To see this panel, visit `/-/debug/grafana/d/searcher/searcher?viewPanel=101530` on your Sourcegraph instance. -*Managed by the [Sourcegraph Code intelligence team](https://handbook.sourcegraph.com/departments/engineering/teams/code-intelligence).* +*Managed by the [Sourcegraph Infrastructure Org team](https://handbook.sourcegraph.com/departments/engineering/infrastructure).*Technical details
@@ -57693,29 +57961,21 @@ To see this panel, visit `/-/debug/grafana/d/symbols/symbols?viewPanel=100711` o Query: ``` -(100.0 * ((((sum(rate(src_grpc_method_status{grpc_service=~"symbols.v1.SymbolsService",grpc_method=~"${symbols_method:regex}",grpc_code!="OK",is_internal_error="true"}[2m])) by (grpc_method))) / ((sum(rate(src_grpc_method_status{grpc_service=~"symbols.v1.SymbolsService",grpc_method=~"${symbols_method:regex}"}[2m])) by (grpc_method)))))) +sum by (app_name, db_name) (increase(src_pgsql_conns_closed_max_idle{app_name="searcher"}[5m])) ```-#### symbols: symbols_grpc_clients_internal_error_all_codes_per_method - -
Client-observed gRPC internal error response code rate per-method over 2m
- -The rate of gRPC internal-error response codes per method, aggregated across all "symbols" clients. - -**Note**: Internal errors are ones that appear to originate from the https://github.com/grpc/grpc-go library itself, rather than from any user-written application code. These errors can be caused by a variety of issues, and can originate from either the code-generated "symbols" gRPC client or gRPC server. These errors might be solvable by adjusting the gRPC configuration, or they might indicate a bug from Sourcegraph`s use of gRPC. - -When debugging, knowing that a particular error comes from the grpc-go library itself (an `internal error`) as opposed to `normal` application code can be helpful when trying to fix it. +#### searcher: closed_max_lifetime -**Note**: Internal errors are detected via a very coarse heuristic (seeing if the error starts with `grpc:`, etc.). Because of this, it`s possible that some gRPC-specific issues might not be categorized as internal errors. +Closed by SetConnMaxLifetime
This panel has no related alerts. -To see this panel, visit `/-/debug/grafana/d/symbols/symbols?viewPanel=100712` on your Sourcegraph instance. +To see this panel, visit `/-/debug/grafana/d/searcher/searcher?viewPanel=101531` on your Sourcegraph instance. -*Managed by the [Sourcegraph Code intelligence team](https://handbook.sourcegraph.com/departments/engineering/teams/code-intelligence).* +*Managed by the [Sourcegraph Infrastructure Org team](https://handbook.sourcegraph.com/departments/engineering/infrastructure).*Technical details
@@ -57723,25 +57983,21 @@ To see this panel, visit `/-/debug/grafana/d/symbols/symbols?viewPanel=100712` o Query: ``` -(sum(rate(src_grpc_method_status{grpc_service=~"symbols.v1.SymbolsService",is_internal_error="true",grpc_method=~"${symbols_method:regex}"}[2m])) by (grpc_method, grpc_code)) +sum by (app_name, db_name) (increase(src_pgsql_conns_closed_max_lifetime{app_name="searcher"}[5m])) ```-### Symbols: Symbols GRPC retry metrics - -#### symbols: symbols_grpc_clients_retry_percentage_across_all_methods - -
Client retry percentage across all methods over 2m
+#### searcher: closed_max_idle_time -The percentage of gRPC requests that were retried across all methods, aggregated across all "symbols" clients. +Closed by SetConnMaxIdleTime
This panel has no related alerts. -To see this panel, visit `/-/debug/grafana/d/symbols/symbols?viewPanel=100800` on your Sourcegraph instance. +To see this panel, visit `/-/debug/grafana/d/searcher/searcher?viewPanel=101532` on your Sourcegraph instance. -*Managed by the [Sourcegraph Code intelligence team](https://handbook.sourcegraph.com/departments/engineering/teams/code-intelligence).* +*Managed by the [Sourcegraph Infrastructure Org team](https://handbook.sourcegraph.com/departments/engineering/infrastructure).*Technical details
@@ -57749,23 +58005,23 @@ To see this panel, visit `/-/debug/grafana/d/symbols/symbols?viewPanel=100800` o Query: ``` -(100.0 * ((((sum(rate(src_grpc_client_retry_attempts_total{grpc_service=~"symbols.v1.SymbolsService",is_retried="true"}[2m])))) / ((sum(rate(src_grpc_client_retry_attempts_total{grpc_service=~"symbols.v1.SymbolsService"}[2m]))))))) +sum by (app_name, db_name) (increase(src_pgsql_conns_closed_max_idle_time{app_name="searcher"}[5m])) ```-#### symbols: symbols_grpc_clients_retry_percentage_per_method +### Searcher: Searcher (CPU, Memory) -
Client retry percentage per-method over 2m
+#### searcher: cpu_usage_percentage -The percentage of gRPC requests that were retried aggregated across all "symbols" clients, broken out per method. +CPU usage
-This panel has no related alerts. +Refer to the [alerts reference](alerts#searcher-cpu-usage-percentage) for 1 alert related to this panel. -To see this panel, visit `/-/debug/grafana/d/symbols/symbols?viewPanel=100801` on your Sourcegraph instance. +To see this panel, visit `/-/debug/grafana/d/searcher/searcher?viewPanel=101600` on your Sourcegraph instance. -*Managed by the [Sourcegraph Code intelligence team](https://handbook.sourcegraph.com/departments/engineering/teams/code-intelligence).* +*Managed by the [Sourcegraph Code Search team](https://handbook.sourcegraph.com/departments/engineering/teams/code-search).*Technical details
@@ -57773,23 +58029,23 @@ To see this panel, visit `/-/debug/grafana/d/symbols/symbols?viewPanel=100801` o Query: ``` -(100.0 * ((((sum(rate(src_grpc_client_retry_attempts_total{grpc_service=~"symbols.v1.SymbolsService",is_retried="true",grpc_method=~"${symbols_method:regex}"}[2m])) by (grpc_method))) / ((sum(rate(src_grpc_client_retry_attempts_total{grpc_service=~"symbols.v1.SymbolsService",grpc_method=~"${symbols_method:regex}"}[2m])) by (grpc_method)))))) +cadvisor_container_cpu_usage_percentage_total{name=~"^searcher.*"} ```-#### symbols: symbols_grpc_clients_retry_count_per_method +#### searcher: memory_usage_percentage -
Client retry count per-method over 2m
+Memory usage percentage (total)
-The count of gRPC requests that were retried aggregated across all "symbols" clients, broken out per method +An estimate for the active memory in use, which includes anonymous memory, file memory, and kernel memory. Some of this memory is reclaimable, so high usage does not necessarily indicate memory pressure. This panel has no related alerts. -To see this panel, visit `/-/debug/grafana/d/symbols/symbols?viewPanel=100802` on your Sourcegraph instance. +To see this panel, visit `/-/debug/grafana/d/searcher/searcher?viewPanel=101601` on your Sourcegraph instance. -*Managed by the [Sourcegraph Code intelligence team](https://handbook.sourcegraph.com/departments/engineering/teams/code-intelligence).* +*Managed by the [Sourcegraph Code Search team](https://handbook.sourcegraph.com/departments/engineering/teams/code-search).*Technical details
@@ -57797,25 +58053,23 @@ To see this panel, visit `/-/debug/grafana/d/symbols/symbols?viewPanel=100802` o Query: ``` -(sum(rate(src_grpc_client_retry_attempts_total{grpc_service=~"symbols.v1.SymbolsService",grpc_method=~"${symbols_method:regex}",is_retried="true"}[2m])) by (grpc_method)) +cadvisor_container_memory_usage_percentage_total{name=~"^searcher.*"} ```-### Symbols: Site configuration client update latency - -#### symbols: symbols_site_configuration_duration_since_last_successful_update_by_instance +#### searcher: memory_working_set_bytes -
Duration since last successful site configuration update (by instance)
+Memory usage bytes (total)
-The duration since the configuration client used by the "symbols" service last successfully updated its site configuration. Long durations could indicate issues updating the site configuration. +An estimate for the active memory in use in bytes, which includes anonymous memory, file memory, and kernel memory. Some of this memory is reclaimable, so high usage does not necessarily indicate memory pressure. This panel has no related alerts. -To see this panel, visit `/-/debug/grafana/d/symbols/symbols?viewPanel=100900` on your Sourcegraph instance. +To see this panel, visit `/-/debug/grafana/d/searcher/searcher?viewPanel=101602` on your Sourcegraph instance. -*Managed by the [Sourcegraph Infrastructure Org team](https://handbook.sourcegraph.com/departments/engineering/infrastructure).* +*Managed by the [Sourcegraph Code Search team](https://handbook.sourcegraph.com/departments/engineering/teams/code-search).*Technical details
@@ -57823,21 +58077,23 @@ To see this panel, visit `/-/debug/grafana/d/symbols/symbols?viewPanel=100900` o Query: ``` -src_conf_client_time_since_last_successful_update_seconds{job=~`.*symbols`,instance=~`${instance:regex}`} +max by (name) (container_memory_working_set_bytes{name=~"^searcher.*"}) ```-#### symbols: symbols_site_configuration_duration_since_last_successful_update_by_instance +#### searcher: memory_rss -
Maximum duration since last successful site configuration update (all "symbols" instances)
+Memory (RSS)
-Refer to the [alerts reference](alerts#symbols-symbols-site-configuration-duration-since-last-successful-update-by-instance) for 1 alert related to this panel. +The total anonymous memory in use by the application, which includes Go stack and heap. This memory is is non-reclaimable, and high usage may trigger OOM kills. Note: the metric is named RSS because to match the cadvisor name, but `anonymous` is more accurate." -To see this panel, visit `/-/debug/grafana/d/symbols/symbols?viewPanel=100901` on your Sourcegraph instance. +Refer to the [alerts reference](alerts#searcher-memory-rss) for 1 alert related to this panel. -*Managed by the [Sourcegraph Infrastructure Org team](https://handbook.sourcegraph.com/departments/engineering/infrastructure).* +To see this panel, visit `/-/debug/grafana/d/searcher/searcher?viewPanel=101610` on your Sourcegraph instance. + +*Managed by the [Sourcegraph Code Search team](https://handbook.sourcegraph.com/departments/engineering/teams/code-search).*Technical details
@@ -57845,23 +58101,23 @@ To see this panel, visit `/-/debug/grafana/d/symbols/symbols?viewPanel=100901` o Query: ``` -max(max_over_time(src_conf_client_time_since_last_successful_update_seconds{job=~`.*symbols`,instance=~`${instance:regex}`}[1m])) +max(container_memory_rss{name=~"^searcher.*"} / container_spec_memory_limit_bytes{name=~"^searcher.*"}) by (name) * 100.0 ```-### Symbols: Database connections +#### searcher: memory_total_active_file -#### symbols: max_open_conns +
Memory usage (active file)
-Maximum open
+This metric shows the total active file-backed memory currently in use by the application. Some of it may be reclaimable, so high usage does not necessarily indicate memory pressure. This panel has no related alerts. -To see this panel, visit `/-/debug/grafana/d/symbols/symbols?viewPanel=101000` on your Sourcegraph instance. +To see this panel, visit `/-/debug/grafana/d/searcher/searcher?viewPanel=101611` on your Sourcegraph instance. -*Managed by the [Sourcegraph Infrastructure Org team](https://handbook.sourcegraph.com/departments/engineering/infrastructure).* +*Managed by the [Sourcegraph Code Search team](https://handbook.sourcegraph.com/departments/engineering/teams/code-search).*Technical details
@@ -57869,21 +58125,23 @@ To see this panel, visit `/-/debug/grafana/d/symbols/symbols?viewPanel=101000` o Query: ``` -sum by (app_name, db_name) (src_pgsql_conns_max_open{app_name="symbols"}) +max(container_memory_total_active_file_bytes{name=~"^searcher.*"} / container_spec_memory_limit_bytes{name=~"^searcher.*"}) by (name) * 100.0 ```-#### symbols: open_conns +#### searcher: memory_kernel_usage -
Established
+Memory usage (kernel)
+ +The kernel usage metric shows the amount of memory used by the kernel on behalf of the application. Some of it may be reclaimable, so high usage does not necessarily indicate memory pressure. This panel has no related alerts. -To see this panel, visit `/-/debug/grafana/d/symbols/symbols?viewPanel=101001` on your Sourcegraph instance. +To see this panel, visit `/-/debug/grafana/d/searcher/searcher?viewPanel=101612` on your Sourcegraph instance. -*Managed by the [Sourcegraph Infrastructure Org team](https://handbook.sourcegraph.com/departments/engineering/infrastructure).* +*Managed by the [Sourcegraph Code Search team](https://handbook.sourcegraph.com/departments/engineering/teams/code-search).*Technical details
@@ -57891,21 +58149,33 @@ To see this panel, visit `/-/debug/grafana/d/symbols/symbols?viewPanel=101001` o Query: ``` -sum by (app_name, db_name) (src_pgsql_conns_open{app_name="symbols"}) +max(container_memory_kernel_usage{name=~"^searcher.*"} / container_spec_memory_limit_bytes{name=~"^searcher.*"}) by (name) * 100.0 ```-#### symbols: in_use +### Searcher: Container monitoring (not available on server) -
Used
+#### searcher: container_missing + +Container missing
+ +This value is the number of times a container has not been seen for more than one minute. If you observe this +value change independent of deployment events (such as an upgrade), it could indicate pods are being OOM killed or terminated for some other reasons. + +- **Kubernetes:** + - Determine if the pod was OOM killed using `kubectl describe pod searcher` (look for `OOMKilled: true`) and, if so, consider increasing the memory limit in the relevant `Deployment.yaml`. + - Check the logs before the container restarted to see if there are `panic:` messages or similar using `kubectl logs -p searcher`. +- **Docker Compose:** + - Determine if the pod was OOM killed using `docker inspect -f '\{\{json .State\}\}' searcher` (look for `"OOMKilled":true`) and, if so, consider increasing the memory limit of the searcher container in `docker-compose.yml`. + - Check the logs before the container restarted to see if there are `panic:` messages or similar using `docker logs searcher` (note this will include logs from the previous and currently running container). This panel has no related alerts. -To see this panel, visit `/-/debug/grafana/d/symbols/symbols?viewPanel=101010` on your Sourcegraph instance. +To see this panel, visit `/-/debug/grafana/d/searcher/searcher?viewPanel=101700` on your Sourcegraph instance. -*Managed by the [Sourcegraph Infrastructure Org team](https://handbook.sourcegraph.com/departments/engineering/infrastructure).* +*Managed by the [Sourcegraph Search Platform team](https://handbook.sourcegraph.com/departments/engineering/teams/search/core).*Technical details
@@ -57913,21 +58183,21 @@ To see this panel, visit `/-/debug/grafana/d/symbols/symbols?viewPanel=101010` o Query: ``` -sum by (app_name, db_name) (src_pgsql_conns_in_use{app_name="symbols"}) +count by(name) ((time() - container_last_seen{name=~"^searcher.*"}) > 60) ```-#### symbols: idle +#### searcher: container_cpu_usage -
Idle
+Container cpu usage total (1m average) across all cores by instance
-This panel has no related alerts. +Refer to the [alerts reference](alerts#searcher-container-cpu-usage) for 1 alert related to this panel. -To see this panel, visit `/-/debug/grafana/d/symbols/symbols?viewPanel=101011` on your Sourcegraph instance. +To see this panel, visit `/-/debug/grafana/d/searcher/searcher?viewPanel=101701` on your Sourcegraph instance. -*Managed by the [Sourcegraph Infrastructure Org team](https://handbook.sourcegraph.com/departments/engineering/infrastructure).* +*Managed by the [Sourcegraph Search Platform team](https://handbook.sourcegraph.com/departments/engineering/teams/search/core).*Technical details
@@ -57935,21 +58205,21 @@ To see this panel, visit `/-/debug/grafana/d/symbols/symbols?viewPanel=101011` o Query: ``` -sum by (app_name, db_name) (src_pgsql_conns_idle{app_name="symbols"}) +cadvisor_container_cpu_usage_percentage_total{name=~"^searcher.*"} ```-#### symbols: mean_blocked_seconds_per_conn_request +#### searcher: container_memory_usage -
Mean blocked seconds per conn request
+Container memory usage by instance
-Refer to the [alerts reference](alerts#symbols-mean-blocked-seconds-per-conn-request) for 2 alerts related to this panel. +Refer to the [alerts reference](alerts#searcher-container-memory-usage) for 1 alert related to this panel. -To see this panel, visit `/-/debug/grafana/d/symbols/symbols?viewPanel=101020` on your Sourcegraph instance. +To see this panel, visit `/-/debug/grafana/d/searcher/searcher?viewPanel=101702` on your Sourcegraph instance. -*Managed by the [Sourcegraph Infrastructure Org team](https://handbook.sourcegraph.com/departments/engineering/infrastructure).* +*Managed by the [Sourcegraph Search Platform team](https://handbook.sourcegraph.com/departments/engineering/teams/search/core).*Technical details
@@ -57957,21 +58227,24 @@ To see this panel, visit `/-/debug/grafana/d/symbols/symbols?viewPanel=101020` o Query: ``` -sum by (app_name, db_name) (increase(src_pgsql_conns_blocked_seconds{app_name="symbols"}[5m])) / sum by (app_name, db_name) (increase(src_pgsql_conns_waited_for{app_name="symbols"}[5m])) +cadvisor_container_memory_usage_percentage_total{name=~"^searcher.*"} ```-#### symbols: closed_max_idle +#### searcher: fs_io_operations -
Closed by SetMaxIdleConns
+Filesystem reads and writes rate by instance over 1h
+ +This value indicates the number of filesystem read and write operations by containers of this service. +When extremely high, this can indicate a resource usage problem, or can cause problems with the service itself, especially if high values or spikes correlate with \{\{CONTAINER_NAME\}\} issues. This panel has no related alerts. -To see this panel, visit `/-/debug/grafana/d/symbols/symbols?viewPanel=101030` on your Sourcegraph instance. +To see this panel, visit `/-/debug/grafana/d/searcher/searcher?viewPanel=101703` on your Sourcegraph instance. -*Managed by the [Sourcegraph Infrastructure Org team](https://handbook.sourcegraph.com/departments/engineering/infrastructure).* +*Managed by the [Sourcegraph Search Platform team](https://handbook.sourcegraph.com/departments/engineering/teams/search/core).*Technical details
@@ -57979,21 +58252,23 @@ To see this panel, visit `/-/debug/grafana/d/symbols/symbols?viewPanel=101030` o Query: ``` -sum by (app_name, db_name) (increase(src_pgsql_conns_closed_max_idle{app_name="symbols"}[5m])) +sum by(name) (rate(container_fs_reads_total{name=~"^searcher.*"}[1h]) + rate(container_fs_writes_total{name=~"^searcher.*"}[1h])) ```-#### symbols: closed_max_lifetime +### Searcher: Provisioning indicators (not available on server) -
Closed by SetConnMaxLifetime
+#### searcher: provisioning_container_cpu_usage_long_term -This panel has no related alerts. +Container cpu usage total (90th percentile over 1d) across all cores by instance
+ +Refer to the [alerts reference](alerts#searcher-provisioning-container-cpu-usage-long-term) for 1 alert related to this panel. -To see this panel, visit `/-/debug/grafana/d/symbols/symbols?viewPanel=101031` on your Sourcegraph instance. +To see this panel, visit `/-/debug/grafana/d/searcher/searcher?viewPanel=101800` on your Sourcegraph instance. -*Managed by the [Sourcegraph Infrastructure Org team](https://handbook.sourcegraph.com/departments/engineering/infrastructure).* +*Managed by the [Sourcegraph Search Platform team](https://handbook.sourcegraph.com/departments/engineering/teams/search/core).*Technical details
@@ -58001,21 +58276,21 @@ To see this panel, visit `/-/debug/grafana/d/symbols/symbols?viewPanel=101031` o Query: ``` -sum by (app_name, db_name) (increase(src_pgsql_conns_closed_max_lifetime{app_name="symbols"}[5m])) +quantile_over_time(0.9, cadvisor_container_cpu_usage_percentage_total{name=~"^searcher.*"}[1d]) ```-#### symbols: closed_max_idle_time +#### searcher: provisioning_container_memory_usage_long_term -
Closed by SetConnMaxIdleTime
+Container memory usage (1d maximum) by instance
-This panel has no related alerts. +Refer to the [alerts reference](alerts#searcher-provisioning-container-memory-usage-long-term) for 1 alert related to this panel. -To see this panel, visit `/-/debug/grafana/d/symbols/symbols?viewPanel=101032` on your Sourcegraph instance. +To see this panel, visit `/-/debug/grafana/d/searcher/searcher?viewPanel=101801` on your Sourcegraph instance. -*Managed by the [Sourcegraph Infrastructure Org team](https://handbook.sourcegraph.com/departments/engineering/infrastructure).* +*Managed by the [Sourcegraph Search Platform team](https://handbook.sourcegraph.com/departments/engineering/teams/search/core).*Technical details
@@ -58023,33 +58298,21 @@ To see this panel, visit `/-/debug/grafana/d/symbols/symbols?viewPanel=101032` o Query: ``` -sum by (app_name, db_name) (increase(src_pgsql_conns_closed_max_idle_time{app_name="symbols"}[5m])) +max_over_time(cadvisor_container_memory_usage_percentage_total{name=~"^searcher.*"}[1d]) ```-### Symbols: Container monitoring (not available on server) - -#### symbols: container_missing - -
Container missing
- -This value is the number of times a container has not been seen for more than one minute. If you observe this -value change independent of deployment events (such as an upgrade), it could indicate pods are being OOM killed or terminated for some other reasons. +#### searcher: provisioning_container_cpu_usage_short_term -- **Kubernetes:** - - Determine if the pod was OOM killed using `kubectl describe pod symbols` (look for `OOMKilled: true`) and, if so, consider increasing the memory limit in the relevant `Deployment.yaml`. - - Check the logs before the container restarted to see if there are `panic:` messages or similar using `kubectl logs -p symbols`. -- **Docker Compose:** - - Determine if the pod was OOM killed using `docker inspect -f '\{\{json .State\}\}' symbols` (look for `"OOMKilled":true`) and, if so, consider increasing the memory limit of the symbols container in `docker-compose.yml`. - - Check the logs before the container restarted to see if there are `panic:` messages or similar using `docker logs symbols` (note this will include logs from the previous and currently running container). +Container cpu usage total (5m maximum) across all cores by instance
-This panel has no related alerts. +Refer to the [alerts reference](alerts#searcher-provisioning-container-cpu-usage-short-term) for 1 alert related to this panel. -To see this panel, visit `/-/debug/grafana/d/symbols/symbols?viewPanel=101100` on your Sourcegraph instance. +To see this panel, visit `/-/debug/grafana/d/searcher/searcher?viewPanel=101810` on your Sourcegraph instance. -*Managed by the [Sourcegraph Code intelligence team](https://handbook.sourcegraph.com/departments/engineering/teams/code-intelligence).* +*Managed by the [Sourcegraph Search Platform team](https://handbook.sourcegraph.com/departments/engineering/teams/search/core).*Technical details
@@ -58057,21 +58320,21 @@ To see this panel, visit `/-/debug/grafana/d/symbols/symbols?viewPanel=101100` o Query: ``` -count by(name) ((time() - container_last_seen{name=~"^symbols.*"}) > 60) +max_over_time(cadvisor_container_cpu_usage_percentage_total{name=~"^searcher.*"}[5m]) ```-#### symbols: container_cpu_usage +#### searcher: provisioning_container_memory_usage_short_term -
Container cpu usage total (1m average) across all cores by instance
+Container memory usage (5m maximum) by instance
-Refer to the [alerts reference](alerts#symbols-container-cpu-usage) for 1 alert related to this panel. +Refer to the [alerts reference](alerts#searcher-provisioning-container-memory-usage-short-term) for 1 alert related to this panel. -To see this panel, visit `/-/debug/grafana/d/symbols/symbols?viewPanel=101101` on your Sourcegraph instance. +To see this panel, visit `/-/debug/grafana/d/searcher/searcher?viewPanel=101811` on your Sourcegraph instance. -*Managed by the [Sourcegraph Code intelligence team](https://handbook.sourcegraph.com/departments/engineering/teams/code-intelligence).* +*Managed by the [Sourcegraph Search Platform team](https://handbook.sourcegraph.com/departments/engineering/teams/search/core).*Technical details
@@ -58079,21 +58342,24 @@ To see this panel, visit `/-/debug/grafana/d/symbols/symbols?viewPanel=101101` o Query: ``` -cadvisor_container_cpu_usage_percentage_total{name=~"^symbols.*"} +max_over_time(cadvisor_container_memory_usage_percentage_total{name=~"^searcher.*"}[5m]) ```-#### symbols: container_memory_usage +#### searcher: container_oomkill_events_total -
Container memory usage by instance
+Container OOMKILL events total by instance
+ +This value indicates the total number of times the container main process or child processes were terminated by OOM killer. +When it occurs frequently, it is an indicator of underprovisioning. -Refer to the [alerts reference](alerts#symbols-container-memory-usage) for 1 alert related to this panel. +Refer to the [alerts reference](alerts#searcher-container-oomkill-events-total) for 1 alert related to this panel. -To see this panel, visit `/-/debug/grafana/d/symbols/symbols?viewPanel=101102` on your Sourcegraph instance. +To see this panel, visit `/-/debug/grafana/d/searcher/searcher?viewPanel=101812` on your Sourcegraph instance. -*Managed by the [Sourcegraph Code intelligence team](https://handbook.sourcegraph.com/departments/engineering/teams/code-intelligence).* +*Managed by the [Sourcegraph Search Platform team](https://handbook.sourcegraph.com/departments/engineering/teams/search/core).*Technical details
@@ -58101,24 +58367,25 @@ To see this panel, visit `/-/debug/grafana/d/symbols/symbols?viewPanel=101102` o Query: ``` -cadvisor_container_memory_usage_percentage_total{name=~"^symbols.*"} +max by (name) (container_oom_events_total{name=~"^searcher.*"}) ```-#### symbols: fs_io_operations +### Searcher: Golang runtime monitoring -
Filesystem reads and writes rate by instance over 1h
+#### searcher: go_goroutines -This value indicates the number of filesystem read and write operations by containers of this service. -When extremely high, this can indicate a resource usage problem, or can cause problems with the service itself, especially if high values or spikes correlate with \{\{CONTAINER_NAME\}\} issues. +Maximum active goroutines
-This panel has no related alerts. +A high value here indicates a possible goroutine leak. -To see this panel, visit `/-/debug/grafana/d/symbols/symbols?viewPanel=101103` on your Sourcegraph instance. +Refer to the [alerts reference](alerts#searcher-go-goroutines) for 1 alert related to this panel. -*Managed by the [Sourcegraph Code intelligence team](https://handbook.sourcegraph.com/departments/engineering/teams/code-intelligence).* +To see this panel, visit `/-/debug/grafana/d/searcher/searcher?viewPanel=101900` on your Sourcegraph instance. + +*Managed by the [Sourcegraph Search Platform team](https://handbook.sourcegraph.com/departments/engineering/teams/search/core).*Technical details
@@ -58126,23 +58393,21 @@ To see this panel, visit `/-/debug/grafana/d/symbols/symbols?viewPanel=101103` o Query: ``` -sum by(name) (rate(container_fs_reads_total{name=~"^symbols.*"}[1h]) + rate(container_fs_writes_total{name=~"^symbols.*"}[1h])) +max by(instance) (go_goroutines{job=~".*searcher"}) ```-### Symbols: Provisioning indicators (not available on server) - -#### symbols: provisioning_container_cpu_usage_long_term +#### searcher: go_gc_duration_seconds -
Container cpu usage total (90th percentile over 1d) across all cores by instance
+Maximum go garbage collection duration
-Refer to the [alerts reference](alerts#symbols-provisioning-container-cpu-usage-long-term) for 1 alert related to this panel. +Refer to the [alerts reference](alerts#searcher-go-gc-duration-seconds) for 1 alert related to this panel. -To see this panel, visit `/-/debug/grafana/d/symbols/symbols?viewPanel=101200` on your Sourcegraph instance. +To see this panel, visit `/-/debug/grafana/d/searcher/searcher?viewPanel=101901` on your Sourcegraph instance. -*Managed by the [Sourcegraph Code intelligence team](https://handbook.sourcegraph.com/departments/engineering/teams/code-intelligence).* +*Managed by the [Sourcegraph Search Platform team](https://handbook.sourcegraph.com/departments/engineering/teams/search/core).*Technical details
@@ -58150,21 +58415,23 @@ To see this panel, visit `/-/debug/grafana/d/symbols/symbols?viewPanel=101200` o Query: ``` -quantile_over_time(0.9, cadvisor_container_cpu_usage_percentage_total{name=~"^symbols.*"}[1d]) +max by(instance) (go_gc_duration_seconds{job=~".*searcher"}) ```-#### symbols: provisioning_container_memory_usage_long_term +### Searcher: Kubernetes monitoring (only available on Kubernetes) -
Container memory usage (1d maximum) by instance
+#### searcher: pods_available_percentage -Refer to the [alerts reference](alerts#symbols-provisioning-container-memory-usage-long-term) for 1 alert related to this panel. +Percentage pods available
-To see this panel, visit `/-/debug/grafana/d/symbols/symbols?viewPanel=101201` on your Sourcegraph instance. +Refer to the [alerts reference](alerts#searcher-pods-available-percentage) for 1 alert related to this panel. -*Managed by the [Sourcegraph Code intelligence team](https://handbook.sourcegraph.com/departments/engineering/teams/code-intelligence).* +To see this panel, visit `/-/debug/grafana/d/searcher/searcher?viewPanel=102000` on your Sourcegraph instance. + +*Managed by the [Sourcegraph Search Platform team](https://handbook.sourcegraph.com/departments/engineering/teams/search/core).*Technical details
@@ -58172,19 +58439,25 @@ To see this panel, visit `/-/debug/grafana/d/symbols/symbols?viewPanel=101201` o Query: ``` -max_over_time(cadvisor_container_memory_usage_percentage_total{name=~"^symbols.*"}[1d]) +sum by(app) (up{app=~".*searcher"}) / count by (app) (up{app=~".*searcher"}) * 100 ```-#### symbols: provisioning_container_cpu_usage_short_term +## Syntect Server -
Container cpu usage total (5m maximum) across all cores by instance
+Handles syntax highlighting for code files.
-Refer to the [alerts reference](alerts#symbols-provisioning-container-cpu-usage-short-term) for 1 alert related to this panel. +To see this dashboard, visit `/-/debug/grafana/d/syntect-server/syntect-server` on your Sourcegraph instance. -To see this panel, visit `/-/debug/grafana/d/symbols/symbols?viewPanel=101210` on your Sourcegraph instance. +#### syntect-server: syntax_highlighting_errors + +Syntax highlighting errors every 5m
+ +This panel has no related alerts. + +To see this panel, visit `/-/debug/grafana/d/syntect-server/syntect-server?viewPanel=100000` on your Sourcegraph instance. *Managed by the [Sourcegraph Code intelligence team](https://handbook.sourcegraph.com/departments/engineering/teams/code-intelligence).* @@ -58194,19 +58467,19 @@ To see this panel, visit `/-/debug/grafana/d/symbols/symbols?viewPanel=101210` o Query: ``` -max_over_time(cadvisor_container_cpu_usage_percentage_total{name=~"^symbols.*"}[5m]) +sum(increase(src_syntax_highlighting_requests{status="error"}[5m])) / sum(increase(src_syntax_highlighting_requests[5m])) * 100 ```-#### symbols: provisioning_container_memory_usage_short_term +#### syntect-server: syntax_highlighting_timeouts -
Container memory usage (5m maximum) by instance
+Syntax highlighting timeouts every 5m
-Refer to the [alerts reference](alerts#symbols-provisioning-container-memory-usage-short-term) for 1 alert related to this panel. +This panel has no related alerts. -To see this panel, visit `/-/debug/grafana/d/symbols/symbols?viewPanel=101211` on your Sourcegraph instance. +To see this panel, visit `/-/debug/grafana/d/syntect-server/syntect-server?viewPanel=100001` on your Sourcegraph instance. *Managed by the [Sourcegraph Code intelligence team](https://handbook.sourcegraph.com/departments/engineering/teams/code-intelligence).* @@ -58216,22 +58489,19 @@ To see this panel, visit `/-/debug/grafana/d/symbols/symbols?viewPanel=101211` o Query: ``` -max_over_time(cadvisor_container_memory_usage_percentage_total{name=~"^symbols.*"}[5m]) +sum(increase(src_syntax_highlighting_requests{status="timeout"}[5m])) / sum(increase(src_syntax_highlighting_requests[5m])) * 100 ```-#### symbols: container_oomkill_events_total - -
Container OOMKILL events total by instance
+#### syntect-server: syntax_highlighting_panics -This value indicates the total number of times the container main process or child processes were terminated by OOM killer. -When it occurs frequently, it is an indicator of underprovisioning. +Syntax highlighting panics every 5m
-Refer to the [alerts reference](alerts#symbols-container-oomkill-events-total) for 1 alert related to this panel. +This panel has no related alerts. -To see this panel, visit `/-/debug/grafana/d/symbols/symbols?viewPanel=101212` on your Sourcegraph instance. +To see this panel, visit `/-/debug/grafana/d/syntect-server/syntect-server?viewPanel=100010` on your Sourcegraph instance. *Managed by the [Sourcegraph Code intelligence team](https://handbook.sourcegraph.com/departments/engineering/teams/code-intelligence).* @@ -58241,23 +58511,19 @@ To see this panel, visit `/-/debug/grafana/d/symbols/symbols?viewPanel=101212` o Query: ``` -max by (name) (container_oom_events_total{name=~"^symbols.*"}) +sum(increase(src_syntax_highlighting_requests{status="panic"}[5m])) ```-### Symbols: Golang runtime monitoring - -#### symbols: go_goroutines - -
Maximum active goroutines
+#### syntect-server: syntax_highlighting_worker_deaths -A high value here indicates a possible goroutine leak. +Syntax highlighter worker deaths every 5m
-Refer to the [alerts reference](alerts#symbols-go-goroutines) for 1 alert related to this panel. +This panel has no related alerts. -To see this panel, visit `/-/debug/grafana/d/symbols/symbols?viewPanel=101300` on your Sourcegraph instance. +To see this panel, visit `/-/debug/grafana/d/syntect-server/syntect-server?viewPanel=100011` on your Sourcegraph instance. *Managed by the [Sourcegraph Code intelligence team](https://handbook.sourcegraph.com/departments/engineering/teams/code-intelligence).* @@ -58267,21 +58533,23 @@ To see this panel, visit `/-/debug/grafana/d/symbols/symbols?viewPanel=101300` o Query: ``` -max by(instance) (go_goroutines{job=~".*symbols"}) +sum(increase(src_syntax_highlighting_requests{status="hss_worker_timeout"}[5m])) ```-#### symbols: go_gc_duration_seconds +### Syntect Server: Syntect-server (CPU, Memory) -
Maximum go garbage collection duration
+#### syntect-server: cpu_usage_percentage -Refer to the [alerts reference](alerts#symbols-go-gc-duration-seconds) for 1 alert related to this panel. +CPU usage
-To see this panel, visit `/-/debug/grafana/d/symbols/symbols?viewPanel=101301` on your Sourcegraph instance. +Refer to the [alerts reference](alerts#syntect-server-cpu-usage-percentage) for 1 alert related to this panel. -*Managed by the [Sourcegraph Code intelligence team](https://handbook.sourcegraph.com/departments/engineering/teams/code-intelligence).* +To see this panel, visit `/-/debug/grafana/d/syntect-server/syntect-server?viewPanel=100100` on your Sourcegraph instance. + +*Managed by the [Sourcegraph Code Search team](https://handbook.sourcegraph.com/departments/engineering/teams/code-search).*Technical details
@@ -58289,23 +58557,23 @@ To see this panel, visit `/-/debug/grafana/d/symbols/symbols?viewPanel=101301` o Query: ``` -max by(instance) (go_gc_duration_seconds{job=~".*symbols"}) +cadvisor_container_cpu_usage_percentage_total{name=~"^syntect-server.*"} ```-### Symbols: Kubernetes monitoring (only available on Kubernetes) +#### syntect-server: memory_usage_percentage -#### symbols: pods_available_percentage +
Memory usage percentage (total)
-Percentage pods available
+An estimate for the active memory in use, which includes anonymous memory, file memory, and kernel memory. Some of this memory is reclaimable, so high usage does not necessarily indicate memory pressure. -Refer to the [alerts reference](alerts#symbols-pods-available-percentage) for 1 alert related to this panel. +This panel has no related alerts. -To see this panel, visit `/-/debug/grafana/d/symbols/symbols?viewPanel=101400` on your Sourcegraph instance. +To see this panel, visit `/-/debug/grafana/d/syntect-server/syntect-server?viewPanel=100101` on your Sourcegraph instance. -*Managed by the [Sourcegraph Code intelligence team](https://handbook.sourcegraph.com/departments/engineering/teams/code-intelligence).* +*Managed by the [Sourcegraph Code Search team](https://handbook.sourcegraph.com/departments/engineering/teams/code-search).*Technical details
@@ -58313,27 +58581,23 @@ To see this panel, visit `/-/debug/grafana/d/symbols/symbols?viewPanel=101400` o Query: ``` -sum by(app) (up{app=~".*symbols"}) / count by (app) (up{app=~".*symbols"}) * 100 +cadvisor_container_memory_usage_percentage_total{name=~"^syntect-server.*"} ```-## Syntect Server - -
Handles syntax highlighting for code files.
+#### syntect-server: memory_working_set_bytes -To see this dashboard, visit `/-/debug/grafana/d/syntect-server/syntect-server` on your Sourcegraph instance. +Memory usage bytes (total)
-#### syntect-server: syntax_highlighting_errors - -Syntax highlighting errors every 5m
+An estimate for the active memory in use in bytes, which includes anonymous memory, file memory, and kernel memory. Some of this memory is reclaimable, so high usage does not necessarily indicate memory pressure. This panel has no related alerts. -To see this panel, visit `/-/debug/grafana/d/syntect-server/syntect-server?viewPanel=100000` on your Sourcegraph instance. +To see this panel, visit `/-/debug/grafana/d/syntect-server/syntect-server?viewPanel=100102` on your Sourcegraph instance. -*Managed by the [Sourcegraph Code intelligence team](https://handbook.sourcegraph.com/departments/engineering/teams/code-intelligence).* +*Managed by the [Sourcegraph Code Search team](https://handbook.sourcegraph.com/departments/engineering/teams/code-search).*Technical details
@@ -58341,21 +58605,23 @@ To see this panel, visit `/-/debug/grafana/d/syntect-server/syntect-server?viewP Query: ``` -sum(increase(src_syntax_highlighting_requests{status="error"}[5m])) / sum(increase(src_syntax_highlighting_requests[5m])) * 100 +max by (name) (container_memory_working_set_bytes{name=~"^syntect-server.*"}) ```-#### syntect-server: syntax_highlighting_timeouts +#### syntect-server: memory_rss -
Syntax highlighting timeouts every 5m
+Memory (RSS)
-This panel has no related alerts. +The total anonymous memory in use by the application, which includes Go stack and heap. This memory is is non-reclaimable, and high usage may trigger OOM kills. Note: the metric is named RSS because to match the cadvisor name, but `anonymous` is more accurate." -To see this panel, visit `/-/debug/grafana/d/syntect-server/syntect-server?viewPanel=100001` on your Sourcegraph instance. +Refer to the [alerts reference](alerts#syntect-server-memory-rss) for 1 alert related to this panel. -*Managed by the [Sourcegraph Code intelligence team](https://handbook.sourcegraph.com/departments/engineering/teams/code-intelligence).* +To see this panel, visit `/-/debug/grafana/d/syntect-server/syntect-server?viewPanel=100110` on your Sourcegraph instance. + +*Managed by the [Sourcegraph Code Search team](https://handbook.sourcegraph.com/departments/engineering/teams/code-search).*Technical details
@@ -58363,21 +58629,23 @@ To see this panel, visit `/-/debug/grafana/d/syntect-server/syntect-server?viewP Query: ``` -sum(increase(src_syntax_highlighting_requests{status="timeout"}[5m])) / sum(increase(src_syntax_highlighting_requests[5m])) * 100 +max(container_memory_rss{name=~"^syntect-server.*"} / container_spec_memory_limit_bytes{name=~"^syntect-server.*"}) by (name) * 100.0 ```-#### syntect-server: syntax_highlighting_panics +#### syntect-server: memory_total_active_file -
Syntax highlighting panics every 5m
+Memory usage (active file)
+ +This metric shows the total active file-backed memory currently in use by the application. Some of it may be reclaimable, so high usage does not necessarily indicate memory pressure. This panel has no related alerts. -To see this panel, visit `/-/debug/grafana/d/syntect-server/syntect-server?viewPanel=100010` on your Sourcegraph instance. +To see this panel, visit `/-/debug/grafana/d/syntect-server/syntect-server?viewPanel=100111` on your Sourcegraph instance. -*Managed by the [Sourcegraph Code intelligence team](https://handbook.sourcegraph.com/departments/engineering/teams/code-intelligence).* +*Managed by the [Sourcegraph Code Search team](https://handbook.sourcegraph.com/departments/engineering/teams/code-search).*Technical details
@@ -58385,21 +58653,23 @@ To see this panel, visit `/-/debug/grafana/d/syntect-server/syntect-server?viewP Query: ``` -sum(increase(src_syntax_highlighting_requests{status="panic"}[5m])) +max(container_memory_total_active_file_bytes{name=~"^syntect-server.*"} / container_spec_memory_limit_bytes{name=~"^syntect-server.*"}) by (name) * 100.0 ```-#### syntect-server: syntax_highlighting_worker_deaths +#### syntect-server: memory_kernel_usage -
Syntax highlighter worker deaths every 5m
+Memory usage (kernel)
+ +The kernel usage metric shows the amount of memory used by the kernel on behalf of the application. Some of it may be reclaimable, so high usage does not necessarily indicate memory pressure. This panel has no related alerts. -To see this panel, visit `/-/debug/grafana/d/syntect-server/syntect-server?viewPanel=100011` on your Sourcegraph instance. +To see this panel, visit `/-/debug/grafana/d/syntect-server/syntect-server?viewPanel=100112` on your Sourcegraph instance. -*Managed by the [Sourcegraph Code intelligence team](https://handbook.sourcegraph.com/departments/engineering/teams/code-intelligence).* +*Managed by the [Sourcegraph Code Search team](https://handbook.sourcegraph.com/departments/engineering/teams/code-search).*Technical details
@@ -58407,7 +58677,7 @@ To see this panel, visit `/-/debug/grafana/d/syntect-server/syntect-server?viewP Query: ``` -sum(increase(src_syntax_highlighting_requests{status="hss_worker_timeout"}[5m])) +max(container_memory_kernel_usage{name=~"^syntect-server.*"} / container_spec_memory_limit_bytes{name=~"^syntect-server.*"}) by (name) * 100.0 ```+### Zoekt: Zoekt-indexserver (CPU, Memory) + +#### zoekt: cpu_usage_percentage + +
CPU usage
+ +Refer to the [alerts reference](alerts#zoekt-cpu-usage-percentage) for 1 alert related to this panel. + +To see this panel, visit `/-/debug/grafana/d/zoekt/zoekt?viewPanel=100100` on your Sourcegraph instance. + +*Managed by the [Sourcegraph Search Platform team](https://handbook.sourcegraph.com/departments/engineering/teams/search/core).* + +Technical details
+ +Query: + +``` +cadvisor_container_cpu_usage_percentage_total{name=~"^zoekt-indexserver.*"} +``` ++ +#### zoekt: memory_usage_percentage + +
Memory usage percentage (total)
+ +An estimate for the active memory in use, which includes anonymous memory, file memory, and kernel memory. Some of this memory is reclaimable, so high usage does not necessarily indicate memory pressure. + +This panel has no related alerts. + +To see this panel, visit `/-/debug/grafana/d/zoekt/zoekt?viewPanel=100101` on your Sourcegraph instance. + +*Managed by the [Sourcegraph Search Platform team](https://handbook.sourcegraph.com/departments/engineering/teams/search/core).* + +Technical details
+ +Query: + +``` +cadvisor_container_memory_usage_percentage_total{name=~"^zoekt-indexserver.*"} +``` ++ +#### zoekt: memory_working_set_bytes + +
Memory usage bytes (total)
+ +An estimate for the active memory in use in bytes, which includes anonymous memory, file memory, and kernel memory. Some of this memory is reclaimable, so high usage does not necessarily indicate memory pressure. + +This panel has no related alerts. + +To see this panel, visit `/-/debug/grafana/d/zoekt/zoekt?viewPanel=100102` on your Sourcegraph instance. + +*Managed by the [Sourcegraph Search Platform team](https://handbook.sourcegraph.com/departments/engineering/teams/search/core).* + +Technical details
+ +Query: + +``` +max by (name) (container_memory_working_set_bytes{name=~"^zoekt-indexserver.*"}) +``` ++ +#### zoekt: memory_rss + +
Memory (RSS)
+ +The total anonymous memory in use by the application, which includes Go stack and heap. This memory is is non-reclaimable, and high usage may trigger OOM kills. Note: the metric is named RSS because to match the cadvisor name, but `anonymous` is more accurate." + +Refer to the [alerts reference](alerts#zoekt-memory-rss) for 1 alert related to this panel. + +To see this panel, visit `/-/debug/grafana/d/zoekt/zoekt?viewPanel=100110` on your Sourcegraph instance. + +*Managed by the [Sourcegraph Search Platform team](https://handbook.sourcegraph.com/departments/engineering/teams/search/core).* + +Technical details
+ +Query: + +``` +max(container_memory_rss{name=~"^zoekt-indexserver.*"} / container_spec_memory_limit_bytes{name=~"^zoekt-indexserver.*"}) by (name) * 100.0 +``` ++ +#### zoekt: memory_total_active_file + +
Memory usage (active file)
+ +This metric shows the total active file-backed memory currently in use by the application. Some of it may be reclaimable, so high usage does not necessarily indicate memory pressure. + +This panel has no related alerts. + +To see this panel, visit `/-/debug/grafana/d/zoekt/zoekt?viewPanel=100111` on your Sourcegraph instance. + +*Managed by the [Sourcegraph Search Platform team](https://handbook.sourcegraph.com/departments/engineering/teams/search/core).* + +Technical details
+ +Query: + +``` +max(container_memory_total_active_file_bytes{name=~"^zoekt-indexserver.*"} / container_spec_memory_limit_bytes{name=~"^zoekt-indexserver.*"}) by (name) * 100.0 +``` ++ +#### zoekt: memory_kernel_usage + +
Memory usage (kernel)
+ +The kernel usage metric shows the amount of memory used by the kernel on behalf of the application. Some of it may be reclaimable, so high usage does not necessarily indicate memory pressure. + +This panel has no related alerts. + +To see this panel, visit `/-/debug/grafana/d/zoekt/zoekt?viewPanel=100112` on your Sourcegraph instance. + +*Managed by the [Sourcegraph Search Platform team](https://handbook.sourcegraph.com/departments/engineering/teams/search/core).* + +Technical details
+ +Query: + +``` +max(container_memory_kernel_usage{name=~"^zoekt-indexserver.*"} / container_spec_memory_limit_bytes{name=~"^zoekt-indexserver.*"}) by (name) * 100.0 +``` ++ +### Zoekt: Zoekt-webserver (CPU, Memory) + +#### zoekt: cpu_usage_percentage + +
CPU usage
+ +Refer to the [alerts reference](alerts#zoekt-cpu-usage-percentage) for 1 alert related to this panel. + +To see this panel, visit `/-/debug/grafana/d/zoekt/zoekt?viewPanel=100200` on your Sourcegraph instance. + +*Managed by the [Sourcegraph Search Platform team](https://handbook.sourcegraph.com/departments/engineering/teams/search/core).* + +Technical details
+ +Query: + +``` +cadvisor_container_cpu_usage_percentage_total{name=~"^zoekt-webserver.*"} +``` ++ +#### zoekt: memory_usage_percentage + +
Memory usage percentage (total)
+ +An estimate for the active memory in use, which includes anonymous memory, file memory, and kernel memory. Some of this memory is reclaimable, so high usage does not necessarily indicate memory pressure. + +This panel has no related alerts. + +To see this panel, visit `/-/debug/grafana/d/zoekt/zoekt?viewPanel=100201` on your Sourcegraph instance. + +*Managed by the [Sourcegraph Search Platform team](https://handbook.sourcegraph.com/departments/engineering/teams/search/core).* + +Technical details
+ +Query: + +``` +cadvisor_container_memory_usage_percentage_total{name=~"^zoekt-webserver.*"} +``` ++ +#### zoekt: memory_working_set_bytes + +
Memory usage bytes (total)
+ +An estimate for the active memory in use in bytes, which includes anonymous memory, file memory, and kernel memory. Some of this memory is reclaimable, so high usage does not necessarily indicate memory pressure. + +This panel has no related alerts. + +To see this panel, visit `/-/debug/grafana/d/zoekt/zoekt?viewPanel=100202` on your Sourcegraph instance. + +*Managed by the [Sourcegraph Search Platform team](https://handbook.sourcegraph.com/departments/engineering/teams/search/core).* + +Technical details
+ +Query: + +``` +max by (name) (container_memory_working_set_bytes{name=~"^zoekt-webserver.*"}) +``` ++ +#### zoekt: memory_rss + +
Memory (RSS)
+ +The total anonymous memory in use by the application, which includes Go stack and heap. This memory is is non-reclaimable, and high usage may trigger OOM kills. Note: the metric is named RSS because to match the cadvisor name, but `anonymous` is more accurate." + +Refer to the [alerts reference](alerts#zoekt-memory-rss) for 1 alert related to this panel. + +To see this panel, visit `/-/debug/grafana/d/zoekt/zoekt?viewPanel=100210` on your Sourcegraph instance. + +*Managed by the [Sourcegraph Search Platform team](https://handbook.sourcegraph.com/departments/engineering/teams/search/core).* + +Technical details
+ +Query: + +``` +max(container_memory_rss{name=~"^zoekt-webserver.*"} / container_spec_memory_limit_bytes{name=~"^zoekt-webserver.*"}) by (name) * 100.0 +``` ++ +#### zoekt: memory_total_active_file + +
Memory usage (active file)
+ +This metric shows the total active file-backed memory currently in use by the application. Some of it may be reclaimable, so high usage does not necessarily indicate memory pressure. + +This panel has no related alerts. + +To see this panel, visit `/-/debug/grafana/d/zoekt/zoekt?viewPanel=100211` on your Sourcegraph instance. + +*Managed by the [Sourcegraph Search Platform team](https://handbook.sourcegraph.com/departments/engineering/teams/search/core).* + +Technical details
+ +Query: + +``` +max(container_memory_total_active_file_bytes{name=~"^zoekt-webserver.*"} / container_spec_memory_limit_bytes{name=~"^zoekt-webserver.*"}) by (name) * 100.0 +``` ++ +#### zoekt: memory_kernel_usage + +
Memory usage (kernel)
+ +The kernel usage metric shows the amount of memory used by the kernel on behalf of the application. Some of it may be reclaimable, so high usage does not necessarily indicate memory pressure. + +This panel has no related alerts. + +To see this panel, visit `/-/debug/grafana/d/zoekt/zoekt?viewPanel=100212` on your Sourcegraph instance. + +*Managed by the [Sourcegraph Search Platform team](https://handbook.sourcegraph.com/departments/engineering/teams/search/core).* + +Technical details
+ +Query: + +``` +max(container_memory_kernel_usage{name=~"^zoekt-webserver.*"} / container_spec_memory_limit_bytes{name=~"^zoekt-webserver.*"}) by (name) * 100.0 +``` ++ +### Zoekt: Memory mapping metrics + +#### zoekt: memory_map_areas_percentage_used + +
Process memory map areas percentage used (per instance)
+ +Processes have a limited about of memory map areas that they can use. In Zoekt, memory map areas +are mainly used for loading shards into memory for queries (via mmap). However, memory map areas +are also used for loading shared libraries, etc. + +_See https://en.wikipedia.org/wiki/Memory-mapped_file and the related articles for more information about memory maps._ + +Once the memory map limit is reached, the Linux kernel will prevent the process from creating any +additional memory map areas. This could cause the process to crash. + +Refer to the [alerts reference](alerts#zoekt-memory-map-areas-percentage-used) for 2 alerts related to this panel. + +To see this panel, visit `/-/debug/grafana/d/zoekt/zoekt?viewPanel=100300` on your Sourcegraph instance. + +*Managed by the [Sourcegraph Search Platform team](https://handbook.sourcegraph.com/departments/engineering/teams/search/core).* + +Technical details
+ +Query: + +``` +(proc_metrics_memory_map_current_count{instance=~`${instance:regex}`} / proc_metrics_memory_map_max_limit{instance=~`${instance:regex}`}) * 100 +``` ++ +#### zoekt: memory_major_page_faults + +
Webserver page faults
+ +The number of major page faults in a 5 minute window for Zoekt webservers. If this number increases significantly, it indicates that more searches need to load data from disk. There may not be enough memory to efficiently support amount of repo data being searched. + +This panel has no related alerts. + +To see this panel, visit `/-/debug/grafana/d/zoekt/zoekt?viewPanel=100301` on your Sourcegraph instance. + +*Managed by the [Sourcegraph Search Platform team](https://handbook.sourcegraph.com/departments/engineering/teams/search/core).* + +Technical details
+ +Query: + +``` +rate(container_memory_failures_total{failure_type="pgmajfault", name=~"^zoekt-webserver.*"}[5m]) +``` ++ ### Zoekt: Search requests #### zoekt: indexed_search_request_duration_p99_aggregate @@ -58835,7 +59450,7 @@ Large duration spikes can be an indicator of saturation and / or a performance r This panel has no related alerts. -To see this panel, visit `/-/debug/grafana/d/zoekt/zoekt?viewPanel=100100` on your Sourcegraph instance. +To see this panel, visit `/-/debug/grafana/d/zoekt/zoekt?viewPanel=100400` on your Sourcegraph instance. *Managed by the [Sourcegraph Search Platform team](https://handbook.sourcegraph.com/departments/engineering/teams/search/core).* @@ -58861,7 +59476,7 @@ Large duration spikes can be an indicator of saturation and / or a performance r This panel has no related alerts. -To see this panel, visit `/-/debug/grafana/d/zoekt/zoekt?viewPanel=100101` on your Sourcegraph instance. +To see this panel, visit `/-/debug/grafana/d/zoekt/zoekt?viewPanel=100401` on your Sourcegraph instance. *Managed by the [Sourcegraph Search Platform team](https://handbook.sourcegraph.com/departments/engineering/teams/search/core).* @@ -58887,7 +59502,7 @@ Large duration spikes can be an indicator of saturation and / or a performance r This panel has no related alerts. -To see this panel, visit `/-/debug/grafana/d/zoekt/zoekt?viewPanel=100102` on your Sourcegraph instance. +To see this panel, visit `/-/debug/grafana/d/zoekt/zoekt?viewPanel=100402` on your Sourcegraph instance. *Managed by the [Sourcegraph Search Platform team](https://handbook.sourcegraph.com/departments/engineering/teams/search/core).* @@ -58913,7 +59528,7 @@ Large duration spikes can be an indicator of saturation and / or a performance r This panel has no related alerts. -To see this panel, visit `/-/debug/grafana/d/zoekt/zoekt?viewPanel=100110` on your Sourcegraph instance. +To see this panel, visit `/-/debug/grafana/d/zoekt/zoekt?viewPanel=100410` on your Sourcegraph instance. *Managed by the [Sourcegraph Search Platform team](https://handbook.sourcegraph.com/departments/engineering/teams/search/core).* @@ -58939,7 +59554,7 @@ Large duration spikes can be an indicator of saturation and / or a performance r This panel has no related alerts. -To see this panel, visit `/-/debug/grafana/d/zoekt/zoekt?viewPanel=100111` on your Sourcegraph instance. +To see this panel, visit `/-/debug/grafana/d/zoekt/zoekt?viewPanel=100411` on your Sourcegraph instance. *Managed by the [Sourcegraph Search Platform team](https://handbook.sourcegraph.com/departments/engineering/teams/search/core).* @@ -58965,7 +59580,7 @@ Large duration spikes can be an indicator of saturation and / or a performance r This panel has no related alerts. -To see this panel, visit `/-/debug/grafana/d/zoekt/zoekt?viewPanel=100112` on your Sourcegraph instance. +To see this panel, visit `/-/debug/grafana/d/zoekt/zoekt?viewPanel=100412` on your Sourcegraph instance. *Managed by the [Sourcegraph Search Platform team](https://handbook.sourcegraph.com/departments/engineering/teams/search/core).* @@ -58993,7 +59608,7 @@ The number of in-flight requests can serve as a proxy for the general load that This panel has no related alerts. -To see this panel, visit `/-/debug/grafana/d/zoekt/zoekt?viewPanel=100120` on your Sourcegraph instance. +To see this panel, visit `/-/debug/grafana/d/zoekt/zoekt?viewPanel=100420` on your Sourcegraph instance. *Managed by the [Sourcegraph Search Platform team](https://handbook.sourcegraph.com/departments/engineering/teams/search/core).* @@ -59021,7 +59636,7 @@ The number of in-flight requests can serve as a proxy for the general load that This panel has no related alerts. -To see this panel, visit `/-/debug/grafana/d/zoekt/zoekt?viewPanel=100121` on your Sourcegraph instance. +To see this panel, visit `/-/debug/grafana/d/zoekt/zoekt?viewPanel=100421` on your Sourcegraph instance. *Managed by the [Sourcegraph Search Platform team](https://handbook.sourcegraph.com/departments/engineering/teams/search/core).* @@ -59051,7 +59666,7 @@ can indicate that the indexed-search backend is saturated. This panel has no related alerts. -To see this panel, visit `/-/debug/grafana/d/zoekt/zoekt?viewPanel=100130` on your Sourcegraph instance. +To see this panel, visit `/-/debug/grafana/d/zoekt/zoekt?viewPanel=100430` on your Sourcegraph instance. *Managed by the [Sourcegraph Search Platform team](https://handbook.sourcegraph.com/departments/engineering/teams/search/core).* @@ -59081,7 +59696,7 @@ can indicate that the indexed-search backend is saturated. This panel has no related alerts. -To see this panel, visit `/-/debug/grafana/d/zoekt/zoekt?viewPanel=100131` on your Sourcegraph instance. +To see this panel, visit `/-/debug/grafana/d/zoekt/zoekt?viewPanel=100431` on your Sourcegraph instance. *Managed by the [Sourcegraph Search Platform team](https://handbook.sourcegraph.com/departments/engineering/teams/search/core).* @@ -59103,7 +59718,7 @@ sum by (instance) (deriv(zoekt_search_running[1m])) Refer to the [alerts reference](alerts#zoekt-indexed-search-request-errors) for 1 alert related to this panel. -To see this panel, visit `/-/debug/grafana/d/zoekt/zoekt?viewPanel=100140` on your Sourcegraph instance. +To see this panel, visit `/-/debug/grafana/d/zoekt/zoekt?viewPanel=100440` on your Sourcegraph instance. *Managed by the [Sourcegraph Search Platform team](https://handbook.sourcegraph.com/departments/engineering/teams/search/core).* @@ -59134,7 +59749,7 @@ For a full explanation of the states see https://github.com/sourcegraph/zoekt/bl This panel has no related alerts. -To see this panel, visit `/-/debug/grafana/d/zoekt/zoekt?viewPanel=100150` on your Sourcegraph instance. +To see this panel, visit `/-/debug/grafana/d/zoekt/zoekt?viewPanel=100450` on your Sourcegraph instance. *Managed by the [Sourcegraph Search Platform team](https://handbook.sourcegraph.com/departments/engineering/teams/search/core).* @@ -59165,7 +59780,7 @@ For a full explanation of the states see https://github.com/sourcegraph/zoekt/bl This panel has no related alerts. -To see this panel, visit `/-/debug/grafana/d/zoekt/zoekt?viewPanel=100151` on your Sourcegraph instance. +To see this panel, visit `/-/debug/grafana/d/zoekt/zoekt?viewPanel=100451` on your Sourcegraph instance. *Managed by the [Sourcegraph Search Platform team](https://handbook.sourcegraph.com/departments/engineering/teams/search/core).* @@ -59191,7 +59806,7 @@ Long git fetch times can be a leading indicator of saturation. This panel has no related alerts. -To see this panel, visit `/-/debug/grafana/d/zoekt/zoekt?viewPanel=100200` on your Sourcegraph instance. +To see this panel, visit `/-/debug/grafana/d/zoekt/zoekt?viewPanel=100500` on your Sourcegraph instance. *Managed by the [Sourcegraph Search Platform team](https://handbook.sourcegraph.com/departments/engineering/teams/search/core).* @@ -59215,7 +59830,7 @@ Long git fetch times can be a leading indicator of saturation. This panel has no related alerts. -To see this panel, visit `/-/debug/grafana/d/zoekt/zoekt?viewPanel=100201` on your Sourcegraph instance. +To see this panel, visit `/-/debug/grafana/d/zoekt/zoekt?viewPanel=100501` on your Sourcegraph instance. *Managed by the [Sourcegraph Search Platform team](https://handbook.sourcegraph.com/departments/engineering/teams/search/core).* @@ -59250,7 +59865,7 @@ Legend: This panel has no related alerts. -To see this panel, visit `/-/debug/grafana/d/zoekt/zoekt?viewPanel=100300` on your Sourcegraph instance. +To see this panel, visit `/-/debug/grafana/d/zoekt/zoekt?viewPanel=100600` on your Sourcegraph instance. *Managed by the [Sourcegraph Search Platform team](https://handbook.sourcegraph.com/departments/engineering/teams/search/core).* @@ -59285,7 +59900,7 @@ Legend: This panel has no related alerts. -To see this panel, visit `/-/debug/grafana/d/zoekt/zoekt?viewPanel=100301` on your Sourcegraph instance. +To see this panel, visit `/-/debug/grafana/d/zoekt/zoekt?viewPanel=100601` on your Sourcegraph instance. *Managed by the [Sourcegraph Search Platform team](https://handbook.sourcegraph.com/departments/engineering/teams/search/core).* @@ -59309,7 +59924,7 @@ Latency increases can indicate bottlenecks in the indexserver. This panel has no related alerts. -To see this panel, visit `/-/debug/grafana/d/zoekt/zoekt?viewPanel=100310` on your Sourcegraph instance. +To see this panel, visit `/-/debug/grafana/d/zoekt/zoekt?viewPanel=100610` on your Sourcegraph instance. *Managed by the [Sourcegraph Search Platform team](https://handbook.sourcegraph.com/departments/engineering/teams/search/core).* @@ -59333,7 +59948,7 @@ Failures happening after a long time indicates timeouts. This panel has no related alerts. -To see this panel, visit `/-/debug/grafana/d/zoekt/zoekt?viewPanel=100311` on your Sourcegraph instance. +To see this panel, visit `/-/debug/grafana/d/zoekt/zoekt?viewPanel=100611` on your Sourcegraph instance. *Managed by the [Sourcegraph Search Platform team](https://handbook.sourcegraph.com/departments/engineering/teams/search/core).* @@ -59359,7 +59974,7 @@ Latency increases can indicate bottlenecks in the indexserver. This panel has no related alerts. -To see this panel, visit `/-/debug/grafana/d/zoekt/zoekt?viewPanel=100320` on your Sourcegraph instance. +To see this panel, visit `/-/debug/grafana/d/zoekt/zoekt?viewPanel=100620` on your Sourcegraph instance. *Managed by the [Sourcegraph Search Platform team](https://handbook.sourcegraph.com/departments/engineering/teams/search/core).* @@ -59385,7 +60000,7 @@ Latency increases can indicate bottlenecks in the indexserver. This panel has no related alerts. -To see this panel, visit `/-/debug/grafana/d/zoekt/zoekt?viewPanel=100321` on your Sourcegraph instance. +To see this panel, visit `/-/debug/grafana/d/zoekt/zoekt?viewPanel=100621` on your Sourcegraph instance. *Managed by the [Sourcegraph Search Platform team](https://handbook.sourcegraph.com/departments/engineering/teams/search/core).* @@ -59411,7 +60026,7 @@ Latency increases can indicate bottlenecks in the indexserver. This panel has no related alerts. -To see this panel, visit `/-/debug/grafana/d/zoekt/zoekt?viewPanel=100322` on your Sourcegraph instance. +To see this panel, visit `/-/debug/grafana/d/zoekt/zoekt?viewPanel=100622` on your Sourcegraph instance. *Managed by the [Sourcegraph Search Platform team](https://handbook.sourcegraph.com/departments/engineering/teams/search/core).* @@ -59437,7 +60052,7 @@ Latency increases can indicate bottlenecks in the indexserver. This panel has no related alerts. -To see this panel, visit `/-/debug/grafana/d/zoekt/zoekt?viewPanel=100330` on your Sourcegraph instance. +To see this panel, visit `/-/debug/grafana/d/zoekt/zoekt?viewPanel=100630` on your Sourcegraph instance. *Managed by the [Sourcegraph Search Platform team](https://handbook.sourcegraph.com/departments/engineering/teams/search/core).* @@ -59463,7 +60078,7 @@ Latency increases can indicate bottlenecks in the indexserver. This panel has no related alerts. -To see this panel, visit `/-/debug/grafana/d/zoekt/zoekt?viewPanel=100331` on your Sourcegraph instance. +To see this panel, visit `/-/debug/grafana/d/zoekt/zoekt?viewPanel=100631` on your Sourcegraph instance. *Managed by the [Sourcegraph Search Platform team](https://handbook.sourcegraph.com/departments/engineering/teams/search/core).* @@ -59489,7 +60104,7 @@ Latency increases can indicate bottlenecks in the indexserver. This panel has no related alerts. -To see this panel, visit `/-/debug/grafana/d/zoekt/zoekt?viewPanel=100332` on your Sourcegraph instance. +To see this panel, visit `/-/debug/grafana/d/zoekt/zoekt?viewPanel=100632` on your Sourcegraph instance. *Managed by the [Sourcegraph Search Platform team](https://handbook.sourcegraph.com/departments/engineering/teams/search/core).* @@ -59515,7 +60130,7 @@ Failures happening after a long time indicates timeouts. This panel has no related alerts. -To see this panel, visit `/-/debug/grafana/d/zoekt/zoekt?viewPanel=100340` on your Sourcegraph instance. +To see this panel, visit `/-/debug/grafana/d/zoekt/zoekt?viewPanel=100640` on your Sourcegraph instance. *Managed by the [Sourcegraph Search Platform team](https://handbook.sourcegraph.com/departments/engineering/teams/search/core).* @@ -59541,7 +60156,7 @@ Failures happening after a long time indicates timeouts. This panel has no related alerts. -To see this panel, visit `/-/debug/grafana/d/zoekt/zoekt?viewPanel=100341` on your Sourcegraph instance. +To see this panel, visit `/-/debug/grafana/d/zoekt/zoekt?viewPanel=100641` on your Sourcegraph instance. *Managed by the [Sourcegraph Search Platform team](https://handbook.sourcegraph.com/departments/engineering/teams/search/core).* @@ -59567,7 +60182,7 @@ Failures happening after a long time indicates timeouts. This panel has no related alerts. -To see this panel, visit `/-/debug/grafana/d/zoekt/zoekt?viewPanel=100342` on your Sourcegraph instance. +To see this panel, visit `/-/debug/grafana/d/zoekt/zoekt?viewPanel=100642` on your Sourcegraph instance. *Managed by the [Sourcegraph Search Platform team](https://handbook.sourcegraph.com/departments/engineering/teams/search/core).* @@ -59593,7 +60208,7 @@ Failures happening after a long time indicates timeouts. This panel has no related alerts. -To see this panel, visit `/-/debug/grafana/d/zoekt/zoekt?viewPanel=100350` on your Sourcegraph instance. +To see this panel, visit `/-/debug/grafana/d/zoekt/zoekt?viewPanel=100650` on your Sourcegraph instance. *Managed by the [Sourcegraph Search Platform team](https://handbook.sourcegraph.com/departments/engineering/teams/search/core).* @@ -59619,7 +60234,7 @@ Failures happening after a long time indicates timeouts. This panel has no related alerts. -To see this panel, visit `/-/debug/grafana/d/zoekt/zoekt?viewPanel=100351` on your Sourcegraph instance. +To see this panel, visit `/-/debug/grafana/d/zoekt/zoekt?viewPanel=100651` on your Sourcegraph instance. *Managed by the [Sourcegraph Search Platform team](https://handbook.sourcegraph.com/departments/engineering/teams/search/core).* @@ -59645,7 +60260,7 @@ Failures happening after a long time indicates timeouts. This panel has no related alerts. -To see this panel, visit `/-/debug/grafana/d/zoekt/zoekt?viewPanel=100352` on your Sourcegraph instance. +To see this panel, visit `/-/debug/grafana/d/zoekt/zoekt?viewPanel=100652` on your Sourcegraph instance. *Managed by the [Sourcegraph Search Platform team](https://handbook.sourcegraph.com/departments/engineering/teams/search/core).* @@ -59671,7 +60286,7 @@ A queue that is constantly growing could be a leading indicator of a bottleneck This panel has no related alerts. -To see this panel, visit `/-/debug/grafana/d/zoekt/zoekt?viewPanel=100400` on your Sourcegraph instance. +To see this panel, visit `/-/debug/grafana/d/zoekt/zoekt?viewPanel=100700` on your Sourcegraph instance. *Managed by the [Sourcegraph Search Platform team](https://handbook.sourcegraph.com/departments/engineering/teams/search/core).* @@ -59695,7 +60310,7 @@ A queue that is constantly growing could be a leading indicator of a bottleneck This panel has no related alerts. -To see this panel, visit `/-/debug/grafana/d/zoekt/zoekt?viewPanel=100401` on your Sourcegraph instance. +To see this panel, visit `/-/debug/grafana/d/zoekt/zoekt?viewPanel=100701` on your Sourcegraph instance. *Managed by the [Sourcegraph Search Platform team](https://handbook.sourcegraph.com/departments/engineering/teams/search/core).* @@ -59711,81 +60326,21 @@ index_queue_len{instance=~`${instance:regex}`}
-#### zoekt: indexed_queueing_delay_heatmap +#### zoekt: indexed_indexing_delay_heatmap -
Job queuing delay heatmap
+Repo indexing delay heatmap
-The queueing delay represents the amount of time an indexing job spent in the queue before it was processed. +The indexing delay represents the amount of time between when Zoekt received a repo indexing job, to when the repo was indexed. +It includes the time the repo spent in the indexing queue, as well as the time it took to actually index the repo. This metric +only includes successfully indexed repos. -Large queueing delays can be an indicator of: +Large indexing delays can be an indicator of: - resource saturation - each Zoekt replica has too many jobs for it to be able to process all of them promptly. In this scenario, consider adding additional Zoekt replicas to distribute the work better . This panel has no related alerts. -To see this panel, visit `/-/debug/grafana/d/zoekt/zoekt?viewPanel=100410` on your Sourcegraph instance. - -*Managed by the [Sourcegraph Search Platform team](https://handbook.sourcegraph.com/departments/engineering/teams/search/core).* - -Technical details
- -Query: - -``` -sum by (le) (increase(index_queue_age_seconds_bucket[$__rate_interval])) -``` -- -#### zoekt: indexed_queueing_delay_p99_9_aggregate - -
99.9th percentile job queuing delay over 5m (aggregate)
- -This dashboard shows the p99.9 job queueing delay aggregated across all Zoekt instances. - -The queueing delay represents the amount of time an indexing job spent in the queue before it was processed. - -Large queueing delays can be an indicator of: - - resource saturation - - each Zoekt replica has too many jobs for it to be able to process all of them promptly. In this scenario, consider adding additional Zoekt replicas to distribute the work better. - -The 99.9 percentile dashboard is useful for capturing the long tail of queueing delays (on the order of 24+ hours, etc.). - -This panel has no related alerts. - -To see this panel, visit `/-/debug/grafana/d/zoekt/zoekt?viewPanel=100420` on your Sourcegraph instance. - -*Managed by the [Sourcegraph Search Platform team](https://handbook.sourcegraph.com/departments/engineering/teams/search/core).* - -Technical details
- -Query: - -``` -histogram_quantile(0.999, sum by (le, name)(rate(index_queue_age_seconds_bucket[5m]))) -``` -- -#### zoekt: indexed_queueing_delay_p90_aggregate - -
90th percentile job queueing delay over 5m (aggregate)
- -This dashboard shows the p90 job queueing delay aggregated across all Zoekt instances. - -The queueing delay represents the amount of time an indexing job spent in the queue before it was processed. - -Large queueing delays can be an indicator of: - - resource saturation - - each Zoekt replica has too many jobs for it to be able to process all of them promptly. In this scenario, consider adding additional Zoekt replicas to distribute the work better. - -This panel has no related alerts. - -To see this panel, visit `/-/debug/grafana/d/zoekt/zoekt?viewPanel=100421` on your Sourcegraph instance. +To see this panel, visit `/-/debug/grafana/d/zoekt/zoekt?viewPanel=100710` on your Sourcegraph instance. *Managed by the [Sourcegraph Search Platform team](https://handbook.sourcegraph.com/departments/engineering/teams/search/core).* @@ -59795,27 +60350,29 @@ To see this panel, visit `/-/debug/grafana/d/zoekt/zoekt?viewPanel=100421` on yo Query: ``` -histogram_quantile(0.90, sum by (le, name)(rate(index_queue_age_seconds_bucket[5m]))) +sum by (le) (increase(index_indexing_delay_seconds_bucket{state=~"success|success_meta"}[$__rate_interval])) ```-#### zoekt: indexed_queueing_delay_p75_aggregate +#### zoekt: indexed_indexing_delay_p90_aggregate -
75th percentile job queueing delay over 5m (aggregate)
+90th percentile indexing delay over 5m (aggregate)
-This dashboard shows the p75 job queueing delay aggregated across all Zoekt instances. +This dashboard shows the p90 indexing delay aggregated across all Zoekt instances. -The queueing delay represents the amount of time an indexing job spent in the queue before it was processed. +The indexing delay represents the amount of time between when Zoekt received a repo indexing job, to when the repo was indexed. +It includes the time the repo spent in the indexing queue, as well as the time it took to actually index the repo. This metric +only includes successfully indexed repos. -Large queueing delays can be an indicator of: +Large indexing delays can be an indicator of: - resource saturation - each Zoekt replica has too many jobs for it to be able to process all of them promptly. In this scenario, consider adding additional Zoekt replicas to distribute the work better. This panel has no related alerts. -To see this panel, visit `/-/debug/grafana/d/zoekt/zoekt?viewPanel=100422` on your Sourcegraph instance. +To see this panel, visit `/-/debug/grafana/d/zoekt/zoekt?viewPanel=100720` on your Sourcegraph instance. *Managed by the [Sourcegraph Search Platform team](https://handbook.sourcegraph.com/departments/engineering/teams/search/core).* @@ -59825,29 +60382,29 @@ To see this panel, visit `/-/debug/grafana/d/zoekt/zoekt?viewPanel=100422` on yo Query: ``` -histogram_quantile(0.75, sum by (le, name)(rate(index_queue_age_seconds_bucket[5m]))) +histogram_quantile(0.90, sum by (le, name)(rate(index_indexing_delay_seconds_bucket{state=~"success|success_meta"}[5m]))) ```-#### zoekt: indexed_queueing_delay_p99_9_per_instance +#### zoekt: indexed_indexing_delay_p50_aggregate -
99.9th percentile job queuing delay over 5m (per instance)
+50th percentile indexing delay over 5m (aggregate)
-This dashboard shows the p99.9 job queueing delay, broken out per Zoekt instance. +This dashboard shows the p50 indexing delay aggregated across all Zoekt instances. -The queueing delay represents the amount of time an indexing job spent in the queue before it was processed. +The indexing delay represents the amount of time between when Zoekt received a repo indexing job, to when the repo was indexed. +It includes the time the repo spent in the indexing queue, as well as the time it took to actually index the repo. This metric +only includes successfully indexed repos. -Large queueing delays can be an indicator of: +Large indexing delays can be an indicator of: - resource saturation - each Zoekt replica has too many jobs for it to be able to process all of them promptly. In this scenario, consider adding additional Zoekt replicas to distribute the work better. -The 99.9 percentile dashboard is useful for capturing the long tail of queueing delays (on the order of 24+ hours, etc.). - This panel has no related alerts. -To see this panel, visit `/-/debug/grafana/d/zoekt/zoekt?viewPanel=100430` on your Sourcegraph instance. +To see this panel, visit `/-/debug/grafana/d/zoekt/zoekt?viewPanel=100721` on your Sourcegraph instance. *Managed by the [Sourcegraph Search Platform team](https://handbook.sourcegraph.com/departments/engineering/teams/search/core).* @@ -59857,27 +60414,28 @@ To see this panel, visit `/-/debug/grafana/d/zoekt/zoekt?viewPanel=100430` on yo Query: ``` -histogram_quantile(0.999, sum by (le, instance)(rate(index_queue_age_seconds_bucket{instance=~`${instance:regex}`}[5m]))) +histogram_quantile(0.50, sum by (le, name)(rate(index_indexing_delay_seconds_bucket{state=~"success|success_meta"}[5m]))) ```-#### zoekt: indexed_queueing_delay_p90_per_instance +#### zoekt: indexed_indexing_delay_p90_per_instance -
90th percentile job queueing delay over 5m (per instance)
+90th percentile indexing delay over 5m (per instance)
-This dashboard shows the p90 job queueing delay, broken out per Zoekt instance. +This dashboard shows the p90 indexing delay, broken out per Zoekt instance. -The queueing delay represents the amount of time an indexing job spent in the queue before it was processed. +The indexing delay represents the amount of time between when Zoekt received a repo indexing job, to when the repo was indexed. +It includes the time the repo spent in the indexing queue, as well as the time it took to actually index the repo. -Large queueing delays can be an indicator of: +Large indexing delays can be an indicator of: - resource saturation - each Zoekt replica has too many jobs for it to be able to process all of them promptly. In this scenario, consider adding additional Zoekt replicas to distribute the work better. This panel has no related alerts. -To see this panel, visit `/-/debug/grafana/d/zoekt/zoekt?viewPanel=100431` on your Sourcegraph instance. +To see this panel, visit `/-/debug/grafana/d/zoekt/zoekt?viewPanel=100730` on your Sourcegraph instance. *Managed by the [Sourcegraph Search Platform team](https://handbook.sourcegraph.com/departments/engineering/teams/search/core).* @@ -59887,60 +60445,28 @@ To see this panel, visit `/-/debug/grafana/d/zoekt/zoekt?viewPanel=100431` on yo Query: ``` -histogram_quantile(0.90, sum by (le, instance)(rate(index_queue_age_seconds_bucket{instance=~`${instance:regex}`}[5m]))) +histogram_quantile(0.90, sum by (le, instance)(rate(index_indexing_delay_seconds{instance=~`${instance:regex}`}[5m]))) ```-#### zoekt: indexed_queueing_delay_p75_per_instance +#### zoekt: indexed_indexing_delay_p50_per_instance -
75th percentile job queueing delay over 5m (per instance)
+50th percentile indexing delay over 5m (per instance)
-This dashboard shows the p75 job queueing delay, broken out per Zoekt instance. +This dashboard shows the p50 indexing delay, broken out per Zoekt instance. -The queueing delay represents the amount of time an indexing job spent in the queue before it was processed. +The indexing delay represents the amount of time between when Zoekt received a repo indexing job, to when the repo was indexed. +It includes the time the repo spent in the indexing queue, as well as the time it took to actually index the repo. -Large queueing delays can be an indicator of: +Large indexing delays can be an indicator of: - resource saturation - each Zoekt replica has too many jobs for it to be able to process all of them promptly. In this scenario, consider adding additional Zoekt replicas to distribute the work better. This panel has no related alerts. -To see this panel, visit `/-/debug/grafana/d/zoekt/zoekt?viewPanel=100432` on your Sourcegraph instance. - -*Managed by the [Sourcegraph Search Platform team](https://handbook.sourcegraph.com/departments/engineering/teams/search/core).* - -Technical details
- -Query: - -``` -histogram_quantile(0.75, sum by (le, instance)(rate(index_queue_age_seconds_bucket{instance=~`${instance:regex}`}[5m]))) -``` -- -### Zoekt: Virtual Memory Statistics - -#### zoekt: memory_map_areas_percentage_used - -
Process memory map areas percentage used (per instance)
- -Processes have a limited about of memory map areas that they can use. In Zoekt, memory map areas -are mainly used for loading shards into memory for queries (via mmap). However, memory map areas -are also used for loading shared libraries, etc. - -_See https://en.wikipedia.org/wiki/Memory-mapped_file and the related articles for more information about memory maps._ - -Once the memory map limit is reached, the Linux kernel will prevent the process from creating any -additional memory map areas. This could cause the process to crash. - -Refer to the [alerts reference](alerts#zoekt-memory-map-areas-percentage-used) for 2 alerts related to this panel. - -To see this panel, visit `/-/debug/grafana/d/zoekt/zoekt?viewPanel=100500` on your Sourcegraph instance. +To see this panel, visit `/-/debug/grafana/d/zoekt/zoekt?viewPanel=100731` on your Sourcegraph instance. *Managed by the [Sourcegraph Search Platform team](https://handbook.sourcegraph.com/departments/engineering/teams/search/core).* @@ -59950,7 +60476,7 @@ To see this panel, visit `/-/debug/grafana/d/zoekt/zoekt?viewPanel=100500` on yo Query: ``` -(proc_metrics_memory_map_current_count{instance=~`${instance:regex}`} / proc_metrics_memory_map_max_limit{instance=~`${instance:regex}`}) * 100 +histogram_quantile(0.50, sum by (le, instance)(rate(index_indexing_delay_seconds{instance=~`${instance:regex}`}[5m]))) ``` @@ -59968,7 +60494,7 @@ This number should be consistent if the number of indexed repositories doesn`t c This panel has no related alerts. -To see this panel, visit `/-/debug/grafana/d/zoekt/zoekt?viewPanel=100600` on your Sourcegraph instance. +To see this panel, visit `/-/debug/grafana/d/zoekt/zoekt?viewPanel=100800` on your Sourcegraph instance. *Managed by the [Sourcegraph Search Platform team](https://handbook.sourcegraph.com/departments/engineering/teams/search/core).* @@ -59994,7 +60520,7 @@ This number should be consistent if the number of indexed repositories doesn`t c This panel has no related alerts. -To see this panel, visit `/-/debug/grafana/d/zoekt/zoekt?viewPanel=100601` on your Sourcegraph instance. +To see this panel, visit `/-/debug/grafana/d/zoekt/zoekt?viewPanel=100801` on your Sourcegraph instance. *Managed by the [Sourcegraph Search Platform team](https://handbook.sourcegraph.com/departments/engineering/teams/search/core).* @@ -60021,7 +60547,7 @@ Since the target compound shard size is set on start of zoekt-indexserver, the a This panel has no related alerts. -To see this panel, visit `/-/debug/grafana/d/zoekt/zoekt?viewPanel=100610` on your Sourcegraph instance. +To see this panel, visit `/-/debug/grafana/d/zoekt/zoekt?viewPanel=100810` on your Sourcegraph instance. *Managed by the [Sourcegraph Search Platform team](https://handbook.sourcegraph.com/departments/engineering/teams/search/core).* @@ -60047,7 +60573,7 @@ This curve should be flat. Any deviation should be investigated. This panel has no related alerts. -To see this panel, visit `/-/debug/grafana/d/zoekt/zoekt?viewPanel=100611` on your Sourcegraph instance. +To see this panel, visit `/-/debug/grafana/d/zoekt/zoekt?viewPanel=100811` on your Sourcegraph instance. *Managed by the [Sourcegraph Search Platform team](https://handbook.sourcegraph.com/departments/engineering/teams/search/core).* @@ -60071,7 +60597,7 @@ Number of errors during shard merging aggregated over all instances. This panel has no related alerts. -To see this panel, visit `/-/debug/grafana/d/zoekt/zoekt?viewPanel=100620` on your Sourcegraph instance. +To see this panel, visit `/-/debug/grafana/d/zoekt/zoekt?viewPanel=100820` on your Sourcegraph instance. *Managed by the [Sourcegraph Search Platform team](https://handbook.sourcegraph.com/departments/engineering/teams/search/core).* @@ -60095,7 +60621,7 @@ Number of errors during shard merging per instance. This panel has no related alerts. -To see this panel, visit `/-/debug/grafana/d/zoekt/zoekt?viewPanel=100621` on your Sourcegraph instance. +To see this panel, visit `/-/debug/grafana/d/zoekt/zoekt?viewPanel=100821` on your Sourcegraph instance. *Managed by the [Sourcegraph Search Platform team](https://handbook.sourcegraph.com/departments/engineering/teams/search/core).* @@ -60119,7 +60645,7 @@ Set to 1 if shard merging is running. This panel has no related alerts. -To see this panel, visit `/-/debug/grafana/d/zoekt/zoekt?viewPanel=100630` on your Sourcegraph instance. +To see this panel, visit `/-/debug/grafana/d/zoekt/zoekt?viewPanel=100830` on your Sourcegraph instance. *Managed by the [Sourcegraph Search Platform team](https://handbook.sourcegraph.com/departments/engineering/teams/search/core).* @@ -60143,7 +60669,7 @@ Set to 1 if vacuum is running. This panel has no related alerts. -To see this panel, visit `/-/debug/grafana/d/zoekt/zoekt?viewPanel=100631` on your Sourcegraph instance. +To see this panel, visit `/-/debug/grafana/d/zoekt/zoekt?viewPanel=100831` on your Sourcegraph instance. *Managed by the [Sourcegraph Search Platform team](https://handbook.sourcegraph.com/departments/engineering/teams/search/core).* @@ -60165,11 +60691,11 @@ max by (instance) (index_vacuum_running{instance=~`${instance:regex}`})Transmission rate over 5m (aggregate)
-The rate of bytes sent over the network across all Zoekt pods +The rate of bytes sent over the network across all pods This panel has no related alerts. -To see this panel, visit `/-/debug/grafana/d/zoekt/zoekt?viewPanel=100700` on your Sourcegraph instance. +To see this panel, visit `/-/debug/grafana/d/zoekt/zoekt?viewPanel=100900` on your Sourcegraph instance. *Managed by the [Sourcegraph Search Platform team](https://handbook.sourcegraph.com/departments/engineering/teams/search/core).* @@ -60189,11 +60715,11 @@ sum(rate(container_network_transmit_bytes_total{container_label_io_kubernetes_poTransmission rate over 5m (per instance)
-The amount of bytes sent over the network by individual Zoekt pods +The amount of bytes sent over the network by individual pods This panel has no related alerts. -To see this panel, visit `/-/debug/grafana/d/zoekt/zoekt?viewPanel=100701` on your Sourcegraph instance. +To see this panel, visit `/-/debug/grafana/d/zoekt/zoekt?viewPanel=100901` on your Sourcegraph instance. *Managed by the [Sourcegraph Search Platform team](https://handbook.sourcegraph.com/departments/engineering/teams/search/core).* @@ -60213,11 +60739,11 @@ sum by (container_label_io_kubernetes_pod_name) (rate(container_network_transmitReceive rate over 5m (aggregate)
-The amount of bytes received from the network across Zoekt pods +The amount of bytes received from the network across pods This panel has no related alerts. -To see this panel, visit `/-/debug/grafana/d/zoekt/zoekt?viewPanel=100710` on your Sourcegraph instance. +To see this panel, visit `/-/debug/grafana/d/zoekt/zoekt?viewPanel=100910` on your Sourcegraph instance. *Managed by the [Sourcegraph Search Platform team](https://handbook.sourcegraph.com/departments/engineering/teams/search/core).* @@ -60237,11 +60763,11 @@ sum(rate(container_network_receive_bytes_total{container_label_io_kubernetes_podReceive rate over 5m (per instance)
-The amount of bytes received from the network by individual Zoekt pods +The amount of bytes received from the network by individual pods This panel has no related alerts. -To see this panel, visit `/-/debug/grafana/d/zoekt/zoekt?viewPanel=100711` on your Sourcegraph instance. +To see this panel, visit `/-/debug/grafana/d/zoekt/zoekt?viewPanel=100911` on your Sourcegraph instance. *Managed by the [Sourcegraph Search Platform team](https://handbook.sourcegraph.com/departments/engineering/teams/search/core).* @@ -60265,7 +60791,7 @@ An increase in dropped packets could be a leading indicator of network saturatio This panel has no related alerts. -To see this panel, visit `/-/debug/grafana/d/zoekt/zoekt?viewPanel=100720` on your Sourcegraph instance. +To see this panel, visit `/-/debug/grafana/d/zoekt/zoekt?viewPanel=100920` on your Sourcegraph instance. *Managed by the [Sourcegraph Search Platform team](https://handbook.sourcegraph.com/departments/engineering/teams/search/core).* @@ -60289,7 +60815,7 @@ An increase in transmission errors could indicate a networking issue This panel has no related alerts. -To see this panel, visit `/-/debug/grafana/d/zoekt/zoekt?viewPanel=100721` on your Sourcegraph instance. +To see this panel, visit `/-/debug/grafana/d/zoekt/zoekt?viewPanel=100921` on your Sourcegraph instance. *Managed by the [Sourcegraph Search Platform team](https://handbook.sourcegraph.com/departments/engineering/teams/search/core).* @@ -60313,7 +60839,7 @@ An increase in dropped packets could be a leading indicator of network saturatio This panel has no related alerts. -To see this panel, visit `/-/debug/grafana/d/zoekt/zoekt?viewPanel=100722` on your Sourcegraph instance. +To see this panel, visit `/-/debug/grafana/d/zoekt/zoekt?viewPanel=100922` on your Sourcegraph instance. *Managed by the [Sourcegraph Search Platform team](https://handbook.sourcegraph.com/departments/engineering/teams/search/core).* @@ -60337,7 +60863,7 @@ An increase in errors while receiving could indicate a networking issue. This panel has no related alerts. -To see this panel, visit `/-/debug/grafana/d/zoekt/zoekt?viewPanel=100723` on your Sourcegraph instance. +To see this panel, visit `/-/debug/grafana/d/zoekt/zoekt?viewPanel=100923` on your Sourcegraph instance. *Managed by the [Sourcegraph Search Platform team](https://handbook.sourcegraph.com/departments/engineering/teams/search/core).* @@ -60363,7 +60889,7 @@ The number of gRPC requests received per second across all methods, aggregated a This panel has no related alerts. -To see this panel, visit `/-/debug/grafana/d/zoekt/zoekt?viewPanel=100800` on your Sourcegraph instance. +To see this panel, visit `/-/debug/grafana/d/zoekt/zoekt?viewPanel=101000` on your Sourcegraph instance. *Managed by the [Sourcegraph Search Platform team](https://handbook.sourcegraph.com/departments/engineering/teams/search/core).* @@ -60387,7 +60913,7 @@ The number of gRPC requests received per second broken out per method, aggregate This panel has no related alerts. -To see this panel, visit `/-/debug/grafana/d/zoekt/zoekt?viewPanel=100801` on your Sourcegraph instance. +To see this panel, visit `/-/debug/grafana/d/zoekt/zoekt?viewPanel=101001` on your Sourcegraph instance. *Managed by the [Sourcegraph Search Platform team](https://handbook.sourcegraph.com/departments/engineering/teams/search/core).* @@ -60411,7 +60937,7 @@ The percentage of gRPC requests that fail across all methods, aggregated across This panel has no related alerts. -To see this panel, visit `/-/debug/grafana/d/zoekt/zoekt?viewPanel=100810` on your Sourcegraph instance. +To see this panel, visit `/-/debug/grafana/d/zoekt/zoekt?viewPanel=101010` on your Sourcegraph instance. *Managed by the [Sourcegraph Search Platform team](https://handbook.sourcegraph.com/departments/engineering/teams/search/core).* @@ -60435,7 +60961,7 @@ The percentage of gRPC requests that fail per method, aggregated across all inst This panel has no related alerts. -To see this panel, visit `/-/debug/grafana/d/zoekt/zoekt?viewPanel=100811` on your Sourcegraph instance. +To see this panel, visit `/-/debug/grafana/d/zoekt/zoekt?viewPanel=101011` on your Sourcegraph instance. *Managed by the [Sourcegraph Search Platform team](https://handbook.sourcegraph.com/departments/engineering/teams/search/core).* @@ -60459,7 +60985,7 @@ The 99th percentile response time per method, aggregated across all instances. This panel has no related alerts. -To see this panel, visit `/-/debug/grafana/d/zoekt/zoekt?viewPanel=100820` on your Sourcegraph instance. +To see this panel, visit `/-/debug/grafana/d/zoekt/zoekt?viewPanel=101020` on your Sourcegraph instance. *Managed by the [Sourcegraph Search Platform team](https://handbook.sourcegraph.com/departments/engineering/teams/search/core).* @@ -60483,7 +61009,7 @@ The 90th percentile response time per method, aggregated across all instances. This panel has no related alerts. -To see this panel, visit `/-/debug/grafana/d/zoekt/zoekt?viewPanel=100821` on your Sourcegraph instance. +To see this panel, visit `/-/debug/grafana/d/zoekt/zoekt?viewPanel=101021` on your Sourcegraph instance. *Managed by the [Sourcegraph Search Platform team](https://handbook.sourcegraph.com/departments/engineering/teams/search/core).* @@ -60507,7 +61033,7 @@ The 75th percentile response time per method, aggregated across all instances. This panel has no related alerts. -To see this panel, visit `/-/debug/grafana/d/zoekt/zoekt?viewPanel=100822` on your Sourcegraph instance. +To see this panel, visit `/-/debug/grafana/d/zoekt/zoekt?viewPanel=101022` on your Sourcegraph instance. *Managed by the [Sourcegraph Search Platform team](https://handbook.sourcegraph.com/departments/engineering/teams/search/core).* @@ -60531,7 +61057,7 @@ The 99.9th percentile total per-RPC response size per method, aggregated across This panel has no related alerts. -To see this panel, visit `/-/debug/grafana/d/zoekt/zoekt?viewPanel=100830` on your Sourcegraph instance. +To see this panel, visit `/-/debug/grafana/d/zoekt/zoekt?viewPanel=101030` on your Sourcegraph instance. *Managed by the [Sourcegraph Search Platform team](https://handbook.sourcegraph.com/departments/engineering/teams/search/core).* @@ -60555,7 +61081,7 @@ The 90th percentile total per-RPC response size per method, aggregated across al This panel has no related alerts. -To see this panel, visit `/-/debug/grafana/d/zoekt/zoekt?viewPanel=100831` on your Sourcegraph instance. +To see this panel, visit `/-/debug/grafana/d/zoekt/zoekt?viewPanel=101031` on your Sourcegraph instance. *Managed by the [Sourcegraph Search Platform team](https://handbook.sourcegraph.com/departments/engineering/teams/search/core).* @@ -60579,7 +61105,7 @@ The 75th percentile total per-RPC response size per method, aggregated across al This panel has no related alerts. -To see this panel, visit `/-/debug/grafana/d/zoekt/zoekt?viewPanel=100832` on your Sourcegraph instance. +To see this panel, visit `/-/debug/grafana/d/zoekt/zoekt?viewPanel=101032` on your Sourcegraph instance. *Managed by the [Sourcegraph Search Platform team](https://handbook.sourcegraph.com/departments/engineering/teams/search/core).* @@ -60603,7 +61129,7 @@ The 99.9th percentile size of every individual protocol buffer size sent by the This panel has no related alerts. -To see this panel, visit `/-/debug/grafana/d/zoekt/zoekt?viewPanel=100840` on your Sourcegraph instance. +To see this panel, visit `/-/debug/grafana/d/zoekt/zoekt?viewPanel=101040` on your Sourcegraph instance. *Managed by the [Sourcegraph Search Platform team](https://handbook.sourcegraph.com/departments/engineering/teams/search/core).* @@ -60617,381 +61143,17 @@ histogram_quantile(0.999, sum by (le, name, grpc_method)(rate(grpc_server_sent_i ``` -- -#### zoekt: zoekt_webserver_p90_invididual_sent_message_size_per_method - -
90th percentile individual sent message size per method over 2m
- -The 90th percentile size of every individual protocol buffer size sent by the service per method, aggregated across all instances. - -This panel has no related alerts. - -To see this panel, visit `/-/debug/grafana/d/zoekt/zoekt?viewPanel=100841` on your Sourcegraph instance. - -*Managed by the [Sourcegraph Search Platform team](https://handbook.sourcegraph.com/departments/engineering/teams/search/core).* - -Technical details
- -Query: - -``` -histogram_quantile(0.90, sum by (le, name, grpc_method)(rate(grpc_server_sent_individual_message_size_bytes_per_rpc_bucket{grpc_method=~`${zoekt_webserver_method:regex}`,instance=~`${webserver_instance:regex}`,grpc_service=~"zoekt.webserver.v1.WebserverService"}[2m]))) -``` -- -#### zoekt: zoekt_webserver_p75_invididual_sent_message_size_per_method - -
75th percentile individual sent message size per method over 2m
- -The 75th percentile size of every individual protocol buffer size sent by the service per method, aggregated across all instances. - -This panel has no related alerts. - -To see this panel, visit `/-/debug/grafana/d/zoekt/zoekt?viewPanel=100842` on your Sourcegraph instance. - -*Managed by the [Sourcegraph Search Platform team](https://handbook.sourcegraph.com/departments/engineering/teams/search/core).* - -Technical details
- -Query: - -``` -histogram_quantile(0.75, sum by (le, name, grpc_method)(rate(grpc_server_sent_individual_message_size_bytes_per_rpc_bucket{grpc_method=~`${zoekt_webserver_method:regex}`,instance=~`${webserver_instance:regex}`,grpc_service=~"zoekt.webserver.v1.WebserverService"}[2m]))) -``` -- -#### zoekt: zoekt_webserver_grpc_response_stream_message_count_per_method - -
Average streaming response message count per-method over 2m
- -The average number of response messages sent during a streaming RPC method, broken out per method, aggregated across all instances. - -This panel has no related alerts. - -To see this panel, visit `/-/debug/grafana/d/zoekt/zoekt?viewPanel=100850` on your Sourcegraph instance. - -*Managed by the [Sourcegraph Search Platform team](https://handbook.sourcegraph.com/departments/engineering/teams/search/core).* - -Technical details
- -Query: - -``` -((sum(rate(grpc_server_msg_sent_total{grpc_type="server_stream",instance=~`${webserver_instance:regex}`,grpc_service=~"zoekt.webserver.v1.WebserverService"}[2m])) by (grpc_method))/(sum(rate(grpc_server_started_total{grpc_type="server_stream",instance=~`${webserver_instance:regex}`,grpc_service=~"zoekt.webserver.v1.WebserverService"}[2m])) by (grpc_method))) -``` -- -#### zoekt: zoekt_webserver_grpc_all_codes_per_method - -
Response codes rate per-method over 2m
- -The rate of all generated gRPC response codes per method, aggregated across all instances. - -This panel has no related alerts. - -To see this panel, visit `/-/debug/grafana/d/zoekt/zoekt?viewPanel=100860` on your Sourcegraph instance. - -*Managed by the [Sourcegraph Search Platform team](https://handbook.sourcegraph.com/departments/engineering/teams/search/core).* - -Technical details
- -Query: - -``` -sum(rate(grpc_server_handled_total{grpc_method=~`${zoekt_webserver_method:regex}`,instance=~`${webserver_instance:regex}`,grpc_service=~"zoekt.webserver.v1.WebserverService"}[2m])) by (grpc_method, grpc_code) -``` -- -### Zoekt: Zoekt Webserver GRPC "internal error" metrics - -#### zoekt: zoekt_webserver_grpc_clients_error_percentage_all_methods - -
Client baseline error percentage across all methods over 2m
- -The percentage of gRPC requests that fail across all methods (regardless of whether or not there was an internal error), aggregated across all "zoekt_webserver" clients. - -This panel has no related alerts. - -To see this panel, visit `/-/debug/grafana/d/zoekt/zoekt?viewPanel=100900` on your Sourcegraph instance. - -*Managed by the [Sourcegraph Search Platform team](https://handbook.sourcegraph.com/departments/engineering/teams/search/core).* - -Technical details
- -Query: - -``` -(100.0 * ((((sum(rate(src_grpc_method_status{grpc_service=~"zoekt.webserver.v1.WebserverService",grpc_code!="OK"}[2m])))) / ((sum(rate(src_grpc_method_status{grpc_service=~"zoekt.webserver.v1.WebserverService"}[2m]))))))) -``` -- -#### zoekt: zoekt_webserver_grpc_clients_error_percentage_per_method - -
Client baseline error percentage per-method over 2m
- -The percentage of gRPC requests that fail per method (regardless of whether or not there was an internal error), aggregated across all "zoekt_webserver" clients. - -This panel has no related alerts. - -To see this panel, visit `/-/debug/grafana/d/zoekt/zoekt?viewPanel=100901` on your Sourcegraph instance. - -*Managed by the [Sourcegraph Search Platform team](https://handbook.sourcegraph.com/departments/engineering/teams/search/core).* - -Technical details
- -Query: - -``` -(100.0 * ((((sum(rate(src_grpc_method_status{grpc_service=~"zoekt.webserver.v1.WebserverService",grpc_method=~"${zoekt_webserver_method:regex}",grpc_code!="OK"}[2m])) by (grpc_method))) / ((sum(rate(src_grpc_method_status{grpc_service=~"zoekt.webserver.v1.WebserverService",grpc_method=~"${zoekt_webserver_method:regex}"}[2m])) by (grpc_method)))))) -``` -- -#### zoekt: zoekt_webserver_grpc_clients_all_codes_per_method - -
Client baseline response codes rate per-method over 2m
- -The rate of all generated gRPC response codes per method (regardless of whether or not there was an internal error), aggregated across all "zoekt_webserver" clients. - -This panel has no related alerts. - -To see this panel, visit `/-/debug/grafana/d/zoekt/zoekt?viewPanel=100902` on your Sourcegraph instance. - -*Managed by the [Sourcegraph Search Platform team](https://handbook.sourcegraph.com/departments/engineering/teams/search/core).* - -Technical details
- -Query: - -``` -(sum(rate(src_grpc_method_status{grpc_service=~"zoekt.webserver.v1.WebserverService",grpc_method=~"${zoekt_webserver_method:regex}"}[2m])) by (grpc_method, grpc_code)) -``` -- -#### zoekt: zoekt_webserver_grpc_clients_internal_error_percentage_all_methods - -
Client-observed gRPC internal error percentage across all methods over 2m
- -The percentage of gRPC requests that appear to fail due to gRPC internal errors across all methods, aggregated across all "zoekt_webserver" clients. - -**Note**: Internal errors are ones that appear to originate from the https://github.com/grpc/grpc-go library itself, rather than from any user-written application code. These errors can be caused by a variety of issues, and can originate from either the code-generated "zoekt_webserver" gRPC client or gRPC server. These errors might be solvable by adjusting the gRPC configuration, or they might indicate a bug from Sourcegraph`s use of gRPC. - -When debugging, knowing that a particular error comes from the grpc-go library itself (an `internal error`) as opposed to `normal` application code can be helpful when trying to fix it. - -**Note**: Internal errors are detected via a very coarse heuristic (seeing if the error starts with `grpc:`, etc.). Because of this, it`s possible that some gRPC-specific issues might not be categorized as internal errors. - -This panel has no related alerts. - -To see this panel, visit `/-/debug/grafana/d/zoekt/zoekt?viewPanel=100910` on your Sourcegraph instance. - -*Managed by the [Sourcegraph Search Platform team](https://handbook.sourcegraph.com/departments/engineering/teams/search/core).* - -Technical details
- -Query: - -``` -(100.0 * ((((sum(rate(src_grpc_method_status{grpc_service=~"zoekt.webserver.v1.WebserverService",grpc_code!="OK",is_internal_error="true"}[2m])))) / ((sum(rate(src_grpc_method_status{grpc_service=~"zoekt.webserver.v1.WebserverService"}[2m]))))))) -``` -- -#### zoekt: zoekt_webserver_grpc_clients_internal_error_percentage_per_method - -
Client-observed gRPC internal error percentage per-method over 2m
- -The percentage of gRPC requests that appear to fail to due to gRPC internal errors per method, aggregated across all "zoekt_webserver" clients. - -**Note**: Internal errors are ones that appear to originate from the https://github.com/grpc/grpc-go library itself, rather than from any user-written application code. These errors can be caused by a variety of issues, and can originate from either the code-generated "zoekt_webserver" gRPC client or gRPC server. These errors might be solvable by adjusting the gRPC configuration, or they might indicate a bug from Sourcegraph`s use of gRPC. - -When debugging, knowing that a particular error comes from the grpc-go library itself (an `internal error`) as opposed to `normal` application code can be helpful when trying to fix it. - -**Note**: Internal errors are detected via a very coarse heuristic (seeing if the error starts with `grpc:`, etc.). Because of this, it`s possible that some gRPC-specific issues might not be categorized as internal errors. - -This panel has no related alerts. - -To see this panel, visit `/-/debug/grafana/d/zoekt/zoekt?viewPanel=100911` on your Sourcegraph instance. - -*Managed by the [Sourcegraph Search Platform team](https://handbook.sourcegraph.com/departments/engineering/teams/search/core).* - -Technical details
- -Query: - -``` -(100.0 * ((((sum(rate(src_grpc_method_status{grpc_service=~"zoekt.webserver.v1.WebserverService",grpc_method=~"${zoekt_webserver_method:regex}",grpc_code!="OK",is_internal_error="true"}[2m])) by (grpc_method))) / ((sum(rate(src_grpc_method_status{grpc_service=~"zoekt.webserver.v1.WebserverService",grpc_method=~"${zoekt_webserver_method:regex}"}[2m])) by (grpc_method)))))) -``` -- -#### zoekt: zoekt_webserver_grpc_clients_internal_error_all_codes_per_method - -
Client-observed gRPC internal error response code rate per-method over 2m
- -The rate of gRPC internal-error response codes per method, aggregated across all "zoekt_webserver" clients. - -**Note**: Internal errors are ones that appear to originate from the https://github.com/grpc/grpc-go library itself, rather than from any user-written application code. These errors can be caused by a variety of issues, and can originate from either the code-generated "zoekt_webserver" gRPC client or gRPC server. These errors might be solvable by adjusting the gRPC configuration, or they might indicate a bug from Sourcegraph`s use of gRPC. - -When debugging, knowing that a particular error comes from the grpc-go library itself (an `internal error`) as opposed to `normal` application code can be helpful when trying to fix it. - -**Note**: Internal errors are detected via a very coarse heuristic (seeing if the error starts with `grpc:`, etc.). Because of this, it`s possible that some gRPC-specific issues might not be categorized as internal errors. - -This panel has no related alerts. - -To see this panel, visit `/-/debug/grafana/d/zoekt/zoekt?viewPanel=100912` on your Sourcegraph instance. - -*Managed by the [Sourcegraph Search Platform team](https://handbook.sourcegraph.com/departments/engineering/teams/search/core).* - -Technical details
- -Query: - -``` -(sum(rate(src_grpc_method_status{grpc_service=~"zoekt.webserver.v1.WebserverService",is_internal_error="true",grpc_method=~"${zoekt_webserver_method:regex}"}[2m])) by (grpc_method, grpc_code)) -``` -- -### Zoekt: Zoekt Webserver GRPC retry metrics - -#### zoekt: zoekt_webserver_grpc_clients_retry_percentage_across_all_methods - -
Client retry percentage across all methods over 2m
- -The percentage of gRPC requests that were retried across all methods, aggregated across all "zoekt_webserver" clients. - -This panel has no related alerts. - -To see this panel, visit `/-/debug/grafana/d/zoekt/zoekt?viewPanel=101000` on your Sourcegraph instance. - -*Managed by the [Sourcegraph Search Platform team](https://handbook.sourcegraph.com/departments/engineering/teams/search/core).* - -Technical details
- -Query: - -``` -(100.0 * ((((sum(rate(src_grpc_client_retry_attempts_total{grpc_service=~"zoekt.webserver.v1.WebserverService",is_retried="true"}[2m])))) / ((sum(rate(src_grpc_client_retry_attempts_total{grpc_service=~"zoekt.webserver.v1.WebserverService"}[2m]))))))) -``` -- -#### zoekt: zoekt_webserver_grpc_clients_retry_percentage_per_method - -
Client retry percentage per-method over 2m
- -The percentage of gRPC requests that were retried aggregated across all "zoekt_webserver" clients, broken out per method. - -This panel has no related alerts. - -To see this panel, visit `/-/debug/grafana/d/zoekt/zoekt?viewPanel=101001` on your Sourcegraph instance. - -*Managed by the [Sourcegraph Search Platform team](https://handbook.sourcegraph.com/departments/engineering/teams/search/core).* - -Technical details
- -Query: - -``` -(100.0 * ((((sum(rate(src_grpc_client_retry_attempts_total{grpc_service=~"zoekt.webserver.v1.WebserverService",is_retried="true",grpc_method=~"${zoekt_webserver_method:regex}"}[2m])) by (grpc_method))) / ((sum(rate(src_grpc_client_retry_attempts_total{grpc_service=~"zoekt.webserver.v1.WebserverService",grpc_method=~"${zoekt_webserver_method:regex}"}[2m])) by (grpc_method)))))) -``` -- -#### zoekt: zoekt_webserver_grpc_clients_retry_count_per_method - -
Client retry count per-method over 2m
- -The count of gRPC requests that were retried aggregated across all "zoekt_webserver" clients, broken out per method - -This panel has no related alerts. - -To see this panel, visit `/-/debug/grafana/d/zoekt/zoekt?viewPanel=101002` on your Sourcegraph instance. - -*Managed by the [Sourcegraph Search Platform team](https://handbook.sourcegraph.com/departments/engineering/teams/search/core).* - -Technical details
- -Query: - -``` -(sum(rate(src_grpc_client_retry_attempts_total{grpc_service=~"zoekt.webserver.v1.WebserverService",grpc_method=~"${zoekt_webserver_method:regex}",is_retried="true"}[2m])) by (grpc_method)) -``` -- -### Zoekt: Data disk I/O metrics - -#### zoekt: data_disk_reads_sec - -
Read request rate over 1m (per instance)
- -The number of read requests that were issued to the device per second. - -Note: Disk statistics are per _device_, not per _service_. In certain environments (such as common docker-compose setups), zoekt could be one of _many services_ using this disk. These statistics are best interpreted as the load experienced by the device zoekt is using, not the load zoekt is solely responsible for causing. - -This panel has no related alerts. - -To see this panel, visit `/-/debug/grafana/d/zoekt/zoekt?viewPanel=101100` on your Sourcegraph instance. - -*Managed by the [Sourcegraph Search Platform team](https://handbook.sourcegraph.com/departments/engineering/teams/search/core).* - -Technical details
- -Query: - -``` -(max by (instance) (zoekt_indexserver_mount_point_info{mount_name="indexDir",instance=~`${instance:regex}`} * on (device, nodename) group_left() (max by (device, nodename) (rate(node_disk_reads_completed_total{instance=~`node-exporter.*`}[1m]))))) -``` -- -#### zoekt: data_disk_writes_sec +
-
Write request rate over 1m (per instance)
+#### zoekt: zoekt_webserver_p90_invididual_sent_message_size_per_method -The number of write requests that were issued to the device per second. +90th percentile individual sent message size per method over 2m
-Note: Disk statistics are per _device_, not per _service_. In certain environments (such as common docker-compose setups), zoekt could be one of _many services_ using this disk. These statistics are best interpreted as the load experienced by the device zoekt is using, not the load zoekt is solely responsible for causing. +The 90th percentile size of every individual protocol buffer size sent by the service per method, aggregated across all instances. This panel has no related alerts. -To see this panel, visit `/-/debug/grafana/d/zoekt/zoekt?viewPanel=101101` on your Sourcegraph instance. +To see this panel, visit `/-/debug/grafana/d/zoekt/zoekt?viewPanel=101041` on your Sourcegraph instance. *Managed by the [Sourcegraph Search Platform team](https://handbook.sourcegraph.com/departments/engineering/teams/search/core).* @@ -61001,23 +61163,21 @@ To see this panel, visit `/-/debug/grafana/d/zoekt/zoekt?viewPanel=101101` on yo Query: ``` -(max by (instance) (zoekt_indexserver_mount_point_info{mount_name="indexDir",instance=~`${instance:regex}`} * on (device, nodename) group_left() (max by (device, nodename) (rate(node_disk_writes_completed_total{instance=~`node-exporter.*`}[1m]))))) +histogram_quantile(0.90, sum by (le, name, grpc_method)(rate(grpc_server_sent_individual_message_size_bytes_per_rpc_bucket{grpc_method=~`${zoekt_webserver_method:regex}`,instance=~`${webserver_instance:regex}`,grpc_service=~"zoekt.webserver.v1.WebserverService"}[2m]))) ```-#### zoekt: data_disk_read_throughput - -
Read throughput over 1m (per instance)
+#### zoekt: zoekt_webserver_p75_invididual_sent_message_size_per_method -The amount of data that was read from the device per second. +75th percentile individual sent message size per method over 2m
-Note: Disk statistics are per _device_, not per _service_. In certain environments (such as common docker-compose setups), zoekt could be one of _many services_ using this disk. These statistics are best interpreted as the load experienced by the device zoekt is using, not the load zoekt is solely responsible for causing. +The 75th percentile size of every individual protocol buffer size sent by the service per method, aggregated across all instances. This panel has no related alerts. -To see this panel, visit `/-/debug/grafana/d/zoekt/zoekt?viewPanel=101110` on your Sourcegraph instance. +To see this panel, visit `/-/debug/grafana/d/zoekt/zoekt?viewPanel=101042` on your Sourcegraph instance. *Managed by the [Sourcegraph Search Platform team](https://handbook.sourcegraph.com/departments/engineering/teams/search/core).* @@ -61027,23 +61187,21 @@ To see this panel, visit `/-/debug/grafana/d/zoekt/zoekt?viewPanel=101110` on yo Query: ``` -(max by (instance) (zoekt_indexserver_mount_point_info{mount_name="indexDir",instance=~`${instance:regex}`} * on (device, nodename) group_left() (max by (device, nodename) (rate(node_disk_read_bytes_total{instance=~`node-exporter.*`}[1m]))))) +histogram_quantile(0.75, sum by (le, name, grpc_method)(rate(grpc_server_sent_individual_message_size_bytes_per_rpc_bucket{grpc_method=~`${zoekt_webserver_method:regex}`,instance=~`${webserver_instance:regex}`,grpc_service=~"zoekt.webserver.v1.WebserverService"}[2m]))) ```-#### zoekt: data_disk_write_throughput - -
Write throughput over 1m (per instance)
+#### zoekt: zoekt_webserver_grpc_response_stream_message_count_per_method -The amount of data that was written to the device per second. +Average streaming response message count per-method over 2m
-Note: Disk statistics are per _device_, not per _service_. In certain environments (such as common docker-compose setups), zoekt could be one of _many services_ using this disk. These statistics are best interpreted as the load experienced by the device zoekt is using, not the load zoekt is solely responsible for causing. +The average number of response messages sent during a streaming RPC method, broken out per method, aggregated across all instances. This panel has no related alerts. -To see this panel, visit `/-/debug/grafana/d/zoekt/zoekt?viewPanel=101111` on your Sourcegraph instance. +To see this panel, visit `/-/debug/grafana/d/zoekt/zoekt?viewPanel=101050` on your Sourcegraph instance. *Managed by the [Sourcegraph Search Platform team](https://handbook.sourcegraph.com/departments/engineering/teams/search/core).* @@ -61053,23 +61211,21 @@ To see this panel, visit `/-/debug/grafana/d/zoekt/zoekt?viewPanel=101111` on yo Query: ``` -(max by (instance) (zoekt_indexserver_mount_point_info{mount_name="indexDir",instance=~`${instance:regex}`} * on (device, nodename) group_left() (max by (device, nodename) (rate(node_disk_written_bytes_total{instance=~`node-exporter.*`}[1m]))))) +((sum(rate(grpc_server_msg_sent_total{grpc_type="server_stream",instance=~`${webserver_instance:regex}`,grpc_service=~"zoekt.webserver.v1.WebserverService"}[2m])) by (grpc_method))/(sum(rate(grpc_server_started_total{grpc_type="server_stream",instance=~`${webserver_instance:regex}`,grpc_service=~"zoekt.webserver.v1.WebserverService"}[2m])) by (grpc_method))) ```-#### zoekt: data_disk_read_duration - -
Average read duration over 1m (per instance)
+#### zoekt: zoekt_webserver_grpc_all_codes_per_method -The average time for read requests issued to the device to be served. This includes the time spent by the requests in queue and the time spent servicing them. +Response codes rate per-method over 2m
-Note: Disk statistics are per _device_, not per _service_. In certain environments (such as common docker-compose setups), zoekt could be one of _many services_ using this disk. These statistics are best interpreted as the load experienced by the device zoekt is using, not the load zoekt is solely responsible for causing. +The rate of all generated gRPC response codes per method, aggregated across all instances. This panel has no related alerts. -To see this panel, visit `/-/debug/grafana/d/zoekt/zoekt?viewPanel=101120` on your Sourcegraph instance. +To see this panel, visit `/-/debug/grafana/d/zoekt/zoekt?viewPanel=101060` on your Sourcegraph instance. *Managed by the [Sourcegraph Search Platform team](https://handbook.sourcegraph.com/departments/engineering/teams/search/core).* @@ -61079,23 +61235,23 @@ To see this panel, visit `/-/debug/grafana/d/zoekt/zoekt?viewPanel=101120` on yo Query: ``` -(((max by (instance) (zoekt_indexserver_mount_point_info{mount_name="indexDir",instance=~`${instance:regex}`} * on (device, nodename) group_left() (max by (device, nodename) (rate(node_disk_read_time_seconds_total{instance=~`node-exporter.*`}[1m])))))) / ((max by (instance) (zoekt_indexserver_mount_point_info{mount_name="indexDir",instance=~`${instance:regex}`} * on (device, nodename) group_left() (max by (device, nodename) (rate(node_disk_reads_completed_total{instance=~`node-exporter.*`}[1m]))))))) +sum(rate(grpc_server_handled_total{grpc_method=~`${zoekt_webserver_method:regex}`,instance=~`${webserver_instance:regex}`,grpc_service=~"zoekt.webserver.v1.WebserverService"}[2m])) by (grpc_method, grpc_code) ```-#### zoekt: data_disk_write_duration +### Zoekt: Zoekt Webserver GRPC "internal error" metrics -
Average write duration over 1m (per instance)
+#### zoekt: zoekt_webserver_grpc_clients_error_percentage_all_methods -The average time for write requests issued to the device to be served. This includes the time spent by the requests in queue and the time spent servicing them. +Client baseline error percentage across all methods over 2m
-Note: Disk statistics are per _device_, not per _service_. In certain environments (such as common docker-compose setups), zoekt could be one of _many services_ using this disk. These statistics are best interpreted as the load experienced by the device zoekt is using, not the load zoekt is solely responsible for causing. +The percentage of gRPC requests that fail across all methods (regardless of whether or not there was an internal error), aggregated across all "zoekt_webserver" clients. This panel has no related alerts. -To see this panel, visit `/-/debug/grafana/d/zoekt/zoekt?viewPanel=101121` on your Sourcegraph instance. +To see this panel, visit `/-/debug/grafana/d/zoekt/zoekt?viewPanel=101100` on your Sourcegraph instance. *Managed by the [Sourcegraph Search Platform team](https://handbook.sourcegraph.com/departments/engineering/teams/search/core).* @@ -61105,23 +61261,21 @@ To see this panel, visit `/-/debug/grafana/d/zoekt/zoekt?viewPanel=101121` on yo Query: ``` -(((max by (instance) (zoekt_indexserver_mount_point_info{mount_name="indexDir",instance=~`${instance:regex}`} * on (device, nodename) group_left() (max by (device, nodename) (rate(node_disk_write_time_seconds_total{instance=~`node-exporter.*`}[1m])))))) / ((max by (instance) (zoekt_indexserver_mount_point_info{mount_name="indexDir",instance=~`${instance:regex}`} * on (device, nodename) group_left() (max by (device, nodename) (rate(node_disk_writes_completed_total{instance=~`node-exporter.*`}[1m]))))))) +(100.0 * ((((sum(rate(src_grpc_method_status{grpc_service=~"zoekt.webserver.v1.WebserverService",grpc_code!="OK"}[2m])))) / ((sum(rate(src_grpc_method_status{grpc_service=~"zoekt.webserver.v1.WebserverService"}[2m]))))))) ```-#### zoekt: data_disk_read_request_size - -
Average read request size over 1m (per instance)
+#### zoekt: zoekt_webserver_grpc_clients_error_percentage_per_method -The average size of read requests that were issued to the device. +Client baseline error percentage per-method over 2m
-Note: Disk statistics are per _device_, not per _service_. In certain environments (such as common docker-compose setups), zoekt could be one of _many services_ using this disk. These statistics are best interpreted as the load experienced by the device zoekt is using, not the load zoekt is solely responsible for causing. +The percentage of gRPC requests that fail per method (regardless of whether or not there was an internal error), aggregated across all "zoekt_webserver" clients. This panel has no related alerts. -To see this panel, visit `/-/debug/grafana/d/zoekt/zoekt?viewPanel=101130` on your Sourcegraph instance. +To see this panel, visit `/-/debug/grafana/d/zoekt/zoekt?viewPanel=101101` on your Sourcegraph instance. *Managed by the [Sourcegraph Search Platform team](https://handbook.sourcegraph.com/departments/engineering/teams/search/core).* @@ -61131,23 +61285,21 @@ To see this panel, visit `/-/debug/grafana/d/zoekt/zoekt?viewPanel=101130` on yo Query: ``` -(((max by (instance) (zoekt_indexserver_mount_point_info{mount_name="indexDir",instance=~`${instance:regex}`} * on (device, nodename) group_left() (max by (device, nodename) (rate(node_disk_read_bytes_total{instance=~`node-exporter.*`}[1m])))))) / ((max by (instance) (zoekt_indexserver_mount_point_info{mount_name="indexDir",instance=~`${instance:regex}`} * on (device, nodename) group_left() (max by (device, nodename) (rate(node_disk_reads_completed_total{instance=~`node-exporter.*`}[1m]))))))) +(100.0 * ((((sum(rate(src_grpc_method_status{grpc_service=~"zoekt.webserver.v1.WebserverService",grpc_method=~"${zoekt_webserver_method:regex}",grpc_code!="OK"}[2m])) by (grpc_method))) / ((sum(rate(src_grpc_method_status{grpc_service=~"zoekt.webserver.v1.WebserverService",grpc_method=~"${zoekt_webserver_method:regex}"}[2m])) by (grpc_method)))))) ```-#### zoekt: data_disk_write_request_size) - -
Average write request size over 1m (per instance)
+#### zoekt: zoekt_webserver_grpc_clients_all_codes_per_method -The average size of write requests that were issued to the device. +Client baseline response codes rate per-method over 2m
-Note: Disk statistics are per _device_, not per _service_. In certain environments (such as common docker-compose setups), zoekt could be one of _many services_ using this disk. These statistics are best interpreted as the load experienced by the device zoekt is using, not the load zoekt is solely responsible for causing. +The rate of all generated gRPC response codes per method (regardless of whether or not there was an internal error), aggregated across all "zoekt_webserver" clients. This panel has no related alerts. -To see this panel, visit `/-/debug/grafana/d/zoekt/zoekt?viewPanel=101131` on your Sourcegraph instance. +To see this panel, visit `/-/debug/grafana/d/zoekt/zoekt?viewPanel=101102` on your Sourcegraph instance. *Managed by the [Sourcegraph Search Platform team](https://handbook.sourcegraph.com/departments/engineering/teams/search/core).* @@ -61157,23 +61309,27 @@ To see this panel, visit `/-/debug/grafana/d/zoekt/zoekt?viewPanel=101131` on yo Query: ``` -(((max by (instance) (zoekt_indexserver_mount_point_info{mount_name="indexDir",instance=~`${instance:regex}`} * on (device, nodename) group_left() (max by (device, nodename) (rate(node_disk_written_bytes_total{instance=~`node-exporter.*`}[1m])))))) / ((max by (instance) (zoekt_indexserver_mount_point_info{mount_name="indexDir",instance=~`${instance:regex}`} * on (device, nodename) group_left() (max by (device, nodename) (rate(node_disk_writes_completed_total{instance=~`node-exporter.*`}[1m]))))))) +(sum(rate(src_grpc_method_status{grpc_service=~"zoekt.webserver.v1.WebserverService",grpc_method=~"${zoekt_webserver_method:regex}"}[2m])) by (grpc_method, grpc_code)) ```-#### zoekt: data_disk_reads_merged_sec +#### zoekt: zoekt_webserver_grpc_clients_internal_error_percentage_all_methods -
Merged read request rate over 1m (per instance)
+Client-observed gRPC internal error percentage across all methods over 2m
-The number of read requests merged per second that were queued to the device. +The percentage of gRPC requests that appear to fail due to gRPC internal errors across all methods, aggregated across all "zoekt_webserver" clients. -Note: Disk statistics are per _device_, not per _service_. In certain environments (such as common docker-compose setups), zoekt could be one of _many services_ using this disk. These statistics are best interpreted as the load experienced by the device zoekt is using, not the load zoekt is solely responsible for causing. +**Note**: Internal errors are ones that appear to originate from the https://github.com/grpc/grpc-go library itself, rather than from any user-written application code. These errors can be caused by a variety of issues, and can originate from either the code-generated "zoekt_webserver" gRPC client or gRPC server. These errors might be solvable by adjusting the gRPC configuration, or they might indicate a bug from Sourcegraph`s use of gRPC. + +When debugging, knowing that a particular error comes from the grpc-go library itself (an `internal error`) as opposed to `normal` application code can be helpful when trying to fix it. + +**Note**: Internal errors are detected via a very coarse heuristic (seeing if the error starts with `grpc:`, etc.). Because of this, it`s possible that some gRPC-specific issues might not be categorized as internal errors. This panel has no related alerts. -To see this panel, visit `/-/debug/grafana/d/zoekt/zoekt?viewPanel=101140` on your Sourcegraph instance. +To see this panel, visit `/-/debug/grafana/d/zoekt/zoekt?viewPanel=101110` on your Sourcegraph instance. *Managed by the [Sourcegraph Search Platform team](https://handbook.sourcegraph.com/departments/engineering/teams/search/core).* @@ -61183,23 +61339,27 @@ To see this panel, visit `/-/debug/grafana/d/zoekt/zoekt?viewPanel=101140` on yo Query: ``` -(max by (instance) (zoekt_indexserver_mount_point_info{mount_name="indexDir",instance=~`${instance:regex}`} * on (device, nodename) group_left() (max by (device, nodename) (rate(node_disk_reads_merged_total{instance=~`node-exporter.*`}[1m]))))) +(100.0 * ((((sum(rate(src_grpc_method_status{grpc_service=~"zoekt.webserver.v1.WebserverService",grpc_code!="OK",is_internal_error="true"}[2m])))) / ((sum(rate(src_grpc_method_status{grpc_service=~"zoekt.webserver.v1.WebserverService"}[2m]))))))) ```-#### zoekt: data_disk_writes_merged_sec +#### zoekt: zoekt_webserver_grpc_clients_internal_error_percentage_per_method -
Merged writes request rate over 1m (per instance)
+Client-observed gRPC internal error percentage per-method over 2m
-The number of write requests merged per second that were queued to the device. +The percentage of gRPC requests that appear to fail to due to gRPC internal errors per method, aggregated across all "zoekt_webserver" clients. -Note: Disk statistics are per _device_, not per _service_. In certain environments (such as common docker-compose setups), zoekt could be one of _many services_ using this disk. These statistics are best interpreted as the load experienced by the device zoekt is using, not the load zoekt is solely responsible for causing. +**Note**: Internal errors are ones that appear to originate from the https://github.com/grpc/grpc-go library itself, rather than from any user-written application code. These errors can be caused by a variety of issues, and can originate from either the code-generated "zoekt_webserver" gRPC client or gRPC server. These errors might be solvable by adjusting the gRPC configuration, or they might indicate a bug from Sourcegraph`s use of gRPC. + +When debugging, knowing that a particular error comes from the grpc-go library itself (an `internal error`) as opposed to `normal` application code can be helpful when trying to fix it. + +**Note**: Internal errors are detected via a very coarse heuristic (seeing if the error starts with `grpc:`, etc.). Because of this, it`s possible that some gRPC-specific issues might not be categorized as internal errors. This panel has no related alerts. -To see this panel, visit `/-/debug/grafana/d/zoekt/zoekt?viewPanel=101141` on your Sourcegraph instance. +To see this panel, visit `/-/debug/grafana/d/zoekt/zoekt?viewPanel=101111` on your Sourcegraph instance. *Managed by the [Sourcegraph Search Platform team](https://handbook.sourcegraph.com/departments/engineering/teams/search/core).* @@ -61209,23 +61369,27 @@ To see this panel, visit `/-/debug/grafana/d/zoekt/zoekt?viewPanel=101141` on yo Query: ``` -(max by (instance) (zoekt_indexserver_mount_point_info{mount_name="indexDir",instance=~`${instance:regex}`} * on (device, nodename) group_left() (max by (device, nodename) (rate(node_disk_writes_merged_total{instance=~`node-exporter.*`}[1m]))))) +(100.0 * ((((sum(rate(src_grpc_method_status{grpc_service=~"zoekt.webserver.v1.WebserverService",grpc_method=~"${zoekt_webserver_method:regex}",grpc_code!="OK",is_internal_error="true"}[2m])) by (grpc_method))) / ((sum(rate(src_grpc_method_status{grpc_service=~"zoekt.webserver.v1.WebserverService",grpc_method=~"${zoekt_webserver_method:regex}"}[2m])) by (grpc_method)))))) ```-#### zoekt: data_disk_average_queue_size +#### zoekt: zoekt_webserver_grpc_clients_internal_error_all_codes_per_method -
Average queue size over 1m (per instance)
+Client-observed gRPC internal error response code rate per-method over 2m
-The number of I/O operations that were being queued or being serviced. See https://blog.actorsfit.com/a?ID=00200-428fa2ac-e338-4540-848c-af9a3eb1ebd2 for background (avgqu-sz). +The rate of gRPC internal-error response codes per method, aggregated across all "zoekt_webserver" clients. -Note: Disk statistics are per _device_, not per _service_. In certain environments (such as common docker-compose setups), zoekt could be one of _many services_ using this disk. These statistics are best interpreted as the load experienced by the device zoekt is using, not the load zoekt is solely responsible for causing. +**Note**: Internal errors are ones that appear to originate from the https://github.com/grpc/grpc-go library itself, rather than from any user-written application code. These errors can be caused by a variety of issues, and can originate from either the code-generated "zoekt_webserver" gRPC client or gRPC server. These errors might be solvable by adjusting the gRPC configuration, or they might indicate a bug from Sourcegraph`s use of gRPC. + +When debugging, knowing that a particular error comes from the grpc-go library itself (an `internal error`) as opposed to `normal` application code can be helpful when trying to fix it. + +**Note**: Internal errors are detected via a very coarse heuristic (seeing if the error starts with `grpc:`, etc.). Because of this, it`s possible that some gRPC-specific issues might not be categorized as internal errors. This panel has no related alerts. -To see this panel, visit `/-/debug/grafana/d/zoekt/zoekt?viewPanel=101150` on your Sourcegraph instance. +To see this panel, visit `/-/debug/grafana/d/zoekt/zoekt?viewPanel=101112` on your Sourcegraph instance. *Managed by the [Sourcegraph Search Platform team](https://handbook.sourcegraph.com/departments/engineering/teams/search/core).* @@ -61235,27 +61399,19 @@ To see this panel, visit `/-/debug/grafana/d/zoekt/zoekt?viewPanel=101150` on yo Query: ``` -(max by (instance) (zoekt_indexserver_mount_point_info{mount_name="indexDir",instance=~`${instance:regex}`} * on (device, nodename) group_left() (max by (device, nodename) (rate(node_disk_io_time_weighted_seconds_total{instance=~`node-exporter.*`}[1m]))))) +(sum(rate(src_grpc_method_status{grpc_service=~"zoekt.webserver.v1.WebserverService",is_internal_error="true",grpc_method=~"${zoekt_webserver_method:regex}"}[2m])) by (grpc_method, grpc_code)) ```-### Zoekt: [zoekt-indexserver] Container monitoring (not available on server) - -#### zoekt: container_missing +### Zoekt: Zoekt Webserver GRPC retry metrics -
Container missing
+#### zoekt: zoekt_webserver_grpc_clients_retry_percentage_across_all_methods -This value is the number of times a container has not been seen for more than one minute. If you observe this -value change independent of deployment events (such as an upgrade), it could indicate pods are being OOM killed or terminated for some other reasons. +Client retry percentage across all methods over 2m
-- **Kubernetes:** - - Determine if the pod was OOM killed using `kubectl describe pod zoekt-indexserver` (look for `OOMKilled: true`) and, if so, consider increasing the memory limit in the relevant `Deployment.yaml`. - - Check the logs before the container restarted to see if there are `panic:` messages or similar using `kubectl logs -p zoekt-indexserver`. -- **Docker Compose:** - - Determine if the pod was OOM killed using `docker inspect -f '\{\{json .State\}\}' zoekt-indexserver` (look for `"OOMKilled":true`) and, if so, consider increasing the memory limit of the zoekt-indexserver container in `docker-compose.yml`. - - Check the logs before the container restarted to see if there are `panic:` messages or similar using `docker logs zoekt-indexserver` (note this will include logs from the previous and currently running container). +The percentage of gRPC requests that were retried across all methods, aggregated across all "zoekt_webserver" clients. This panel has no related alerts. @@ -61269,17 +61425,19 @@ To see this panel, visit `/-/debug/grafana/d/zoekt/zoekt?viewPanel=101200` on yo Query: ``` -count by(name) ((time() - container_last_seen{name=~"^zoekt-indexserver.*"}) > 60) +(100.0 * ((((sum(rate(src_grpc_client_retry_attempts_total{grpc_service=~"zoekt.webserver.v1.WebserverService",is_retried="true"}[2m])))) / ((sum(rate(src_grpc_client_retry_attempts_total{grpc_service=~"zoekt.webserver.v1.WebserverService"}[2m]))))))) ```-#### zoekt: container_cpu_usage +#### zoekt: zoekt_webserver_grpc_clients_retry_percentage_per_method -
Container cpu usage total (1m average) across all cores by instance
+Client retry percentage per-method over 2m
-Refer to the [alerts reference](alerts#zoekt-container-cpu-usage) for 1 alert related to this panel. +The percentage of gRPC requests that were retried aggregated across all "zoekt_webserver" clients, broken out per method. + +This panel has no related alerts. To see this panel, visit `/-/debug/grafana/d/zoekt/zoekt?viewPanel=101201` on your Sourcegraph instance. @@ -61291,17 +61449,19 @@ To see this panel, visit `/-/debug/grafana/d/zoekt/zoekt?viewPanel=101201` on yo Query: ``` -cadvisor_container_cpu_usage_percentage_total{name=~"^zoekt-indexserver.*"} +(100.0 * ((((sum(rate(src_grpc_client_retry_attempts_total{grpc_service=~"zoekt.webserver.v1.WebserverService",is_retried="true",grpc_method=~"${zoekt_webserver_method:regex}"}[2m])) by (grpc_method))) / ((sum(rate(src_grpc_client_retry_attempts_total{grpc_service=~"zoekt.webserver.v1.WebserverService",grpc_method=~"${zoekt_webserver_method:regex}"}[2m])) by (grpc_method)))))) ```-#### zoekt: container_memory_usage +#### zoekt: zoekt_webserver_grpc_clients_retry_count_per_method -
Container memory usage by instance
+Client retry count per-method over 2m
-Refer to the [alerts reference](alerts#zoekt-container-memory-usage) for 1 alert related to this panel. +The count of gRPC requests that were retried aggregated across all "zoekt_webserver" clients, broken out per method + +This panel has no related alerts. To see this panel, visit `/-/debug/grafana/d/zoekt/zoekt?viewPanel=101202` on your Sourcegraph instance. @@ -61313,22 +61473,25 @@ To see this panel, visit `/-/debug/grafana/d/zoekt/zoekt?viewPanel=101202` on yo Query: ``` -cadvisor_container_memory_usage_percentage_total{name=~"^zoekt-indexserver.*"} +(sum(rate(src_grpc_client_retry_attempts_total{grpc_service=~"zoekt.webserver.v1.WebserverService",grpc_method=~"${zoekt_webserver_method:regex}",is_retried="true"}[2m])) by (grpc_method)) ```-#### zoekt: fs_io_operations +### Zoekt: Data disk I/O metrics -
Filesystem reads and writes rate by instance over 1h
+#### zoekt: data_disk_reads_sec -This value indicates the number of filesystem read and write operations by containers of this service. -When extremely high, this can indicate a resource usage problem, or can cause problems with the service itself, especially if high values or spikes correlate with \{\{CONTAINER_NAME\}\} issues. +Read request rate over 1m (per instance)
+ +The number of read requests that were issued to the device per second. + +Note: Disk statistics are per _device_, not per _service_. In certain environments (such as common docker-compose setups), zoekt could be one of _many services_ using this disk. These statistics are best interpreted as the load experienced by the device zoekt is using, not the load zoekt is solely responsible for causing. This panel has no related alerts. -To see this panel, visit `/-/debug/grafana/d/zoekt/zoekt?viewPanel=101203` on your Sourcegraph instance. +To see this panel, visit `/-/debug/grafana/d/zoekt/zoekt?viewPanel=101300` on your Sourcegraph instance. *Managed by the [Sourcegraph Search Platform team](https://handbook.sourcegraph.com/departments/engineering/teams/search/core).* @@ -61338,31 +61501,23 @@ To see this panel, visit `/-/debug/grafana/d/zoekt/zoekt?viewPanel=101203` on yo Query: ``` -sum by(name) (rate(container_fs_reads_total{name=~"^zoekt-indexserver.*"}[1h]) + rate(container_fs_writes_total{name=~"^zoekt-indexserver.*"}[1h])) +(max by (instance) (zoekt_indexserver_mount_point_info{mount_name="indexDir",instance=~`${instance:regex}`} * on (device, nodename) group_left() (max by (device, nodename) (rate(node_disk_reads_completed_total{instance=~`node-exporter.*`}[1m]))))) ```-### Zoekt: [zoekt-webserver] Container monitoring (not available on server) - -#### zoekt: container_missing +#### zoekt: data_disk_writes_sec -
Container missing
+Write request rate over 1m (per instance)
-This value is the number of times a container has not been seen for more than one minute. If you observe this -value change independent of deployment events (such as an upgrade), it could indicate pods are being OOM killed or terminated for some other reasons. +The number of write requests that were issued to the device per second. -- **Kubernetes:** - - Determine if the pod was OOM killed using `kubectl describe pod zoekt-webserver` (look for `OOMKilled: true`) and, if so, consider increasing the memory limit in the relevant `Deployment.yaml`. - - Check the logs before the container restarted to see if there are `panic:` messages or similar using `kubectl logs -p zoekt-webserver`. -- **Docker Compose:** - - Determine if the pod was OOM killed using `docker inspect -f '\{\{json .State\}\}' zoekt-webserver` (look for `"OOMKilled":true`) and, if so, consider increasing the memory limit of the zoekt-webserver container in `docker-compose.yml`. - - Check the logs before the container restarted to see if there are `panic:` messages or similar using `docker logs zoekt-webserver` (note this will include logs from the previous and currently running container). +Note: Disk statistics are per _device_, not per _service_. In certain environments (such as common docker-compose setups), zoekt could be one of _many services_ using this disk. These statistics are best interpreted as the load experienced by the device zoekt is using, not the load zoekt is solely responsible for causing. This panel has no related alerts. -To see this panel, visit `/-/debug/grafana/d/zoekt/zoekt?viewPanel=101300` on your Sourcegraph instance. +To see this panel, visit `/-/debug/grafana/d/zoekt/zoekt?viewPanel=101301` on your Sourcegraph instance. *Managed by the [Sourcegraph Search Platform team](https://handbook.sourcegraph.com/departments/engineering/teams/search/core).* @@ -61372,19 +61527,23 @@ To see this panel, visit `/-/debug/grafana/d/zoekt/zoekt?viewPanel=101300` on yo Query: ``` -count by(name) ((time() - container_last_seen{name=~"^zoekt-webserver.*"}) > 60) +(max by (instance) (zoekt_indexserver_mount_point_info{mount_name="indexDir",instance=~`${instance:regex}`} * on (device, nodename) group_left() (max by (device, nodename) (rate(node_disk_writes_completed_total{instance=~`node-exporter.*`}[1m]))))) ```-#### zoekt: container_cpu_usage +#### zoekt: data_disk_read_throughput -
Container cpu usage total (1m average) across all cores by instance
+Read throughput over 1m (per instance)
-Refer to the [alerts reference](alerts#zoekt-container-cpu-usage) for 1 alert related to this panel. +The amount of data that was read from the device per second. -To see this panel, visit `/-/debug/grafana/d/zoekt/zoekt?viewPanel=101301` on your Sourcegraph instance. +Note: Disk statistics are per _device_, not per _service_. In certain environments (such as common docker-compose setups), zoekt could be one of _many services_ using this disk. These statistics are best interpreted as the load experienced by the device zoekt is using, not the load zoekt is solely responsible for causing. + +This panel has no related alerts. + +To see this panel, visit `/-/debug/grafana/d/zoekt/zoekt?viewPanel=101310` on your Sourcegraph instance. *Managed by the [Sourcegraph Search Platform team](https://handbook.sourcegraph.com/departments/engineering/teams/search/core).* @@ -61394,19 +61553,23 @@ To see this panel, visit `/-/debug/grafana/d/zoekt/zoekt?viewPanel=101301` on yo Query: ``` -cadvisor_container_cpu_usage_percentage_total{name=~"^zoekt-webserver.*"} +(max by (instance) (zoekt_indexserver_mount_point_info{mount_name="indexDir",instance=~`${instance:regex}`} * on (device, nodename) group_left() (max by (device, nodename) (rate(node_disk_read_bytes_total{instance=~`node-exporter.*`}[1m]))))) ```-#### zoekt: container_memory_usage +#### zoekt: data_disk_write_throughput -
Container memory usage by instance
+Write throughput over 1m (per instance)
-Refer to the [alerts reference](alerts#zoekt-container-memory-usage) for 1 alert related to this panel. +The amount of data that was written to the device per second. + +Note: Disk statistics are per _device_, not per _service_. In certain environments (such as common docker-compose setups), zoekt could be one of _many services_ using this disk. These statistics are best interpreted as the load experienced by the device zoekt is using, not the load zoekt is solely responsible for causing. + +This panel has no related alerts. -To see this panel, visit `/-/debug/grafana/d/zoekt/zoekt?viewPanel=101302` on your Sourcegraph instance. +To see this panel, visit `/-/debug/grafana/d/zoekt/zoekt?viewPanel=101311` on your Sourcegraph instance. *Managed by the [Sourcegraph Search Platform team](https://handbook.sourcegraph.com/departments/engineering/teams/search/core).* @@ -61416,22 +61579,23 @@ To see this panel, visit `/-/debug/grafana/d/zoekt/zoekt?viewPanel=101302` on yo Query: ``` -cadvisor_container_memory_usage_percentage_total{name=~"^zoekt-webserver.*"} +(max by (instance) (zoekt_indexserver_mount_point_info{mount_name="indexDir",instance=~`${instance:regex}`} * on (device, nodename) group_left() (max by (device, nodename) (rate(node_disk_written_bytes_total{instance=~`node-exporter.*`}[1m]))))) ```-#### zoekt: fs_io_operations +#### zoekt: data_disk_read_duration + +
Average read duration over 1m (per instance)
-Filesystem reads and writes rate by instance over 1h
+The average time for read requests issued to the device to be served. This includes the time spent by the requests in queue and the time spent servicing them. -This value indicates the number of filesystem read and write operations by containers of this service. -When extremely high, this can indicate a resource usage problem, or can cause problems with the service itself, especially if high values or spikes correlate with \{\{CONTAINER_NAME\}\} issues. +Note: Disk statistics are per _device_, not per _service_. In certain environments (such as common docker-compose setups), zoekt could be one of _many services_ using this disk. These statistics are best interpreted as the load experienced by the device zoekt is using, not the load zoekt is solely responsible for causing. This panel has no related alerts. -To see this panel, visit `/-/debug/grafana/d/zoekt/zoekt?viewPanel=101303` on your Sourcegraph instance. +To see this panel, visit `/-/debug/grafana/d/zoekt/zoekt?viewPanel=101320` on your Sourcegraph instance. *Managed by the [Sourcegraph Search Platform team](https://handbook.sourcegraph.com/departments/engineering/teams/search/core).* @@ -61441,21 +61605,23 @@ To see this panel, visit `/-/debug/grafana/d/zoekt/zoekt?viewPanel=101303` on yo Query: ``` -sum by(name) (rate(container_fs_reads_total{name=~"^zoekt-webserver.*"}[1h]) + rate(container_fs_writes_total{name=~"^zoekt-webserver.*"}[1h])) +(((max by (instance) (zoekt_indexserver_mount_point_info{mount_name="indexDir",instance=~`${instance:regex}`} * on (device, nodename) group_left() (max by (device, nodename) (rate(node_disk_read_time_seconds_total{instance=~`node-exporter.*`}[1m])))))) / ((max by (instance) (zoekt_indexserver_mount_point_info{mount_name="indexDir",instance=~`${instance:regex}`} * on (device, nodename) group_left() (max by (device, nodename) (rate(node_disk_reads_completed_total{instance=~`node-exporter.*`}[1m]))))))) ```-### Zoekt: [zoekt-indexserver] Provisioning indicators (not available on server) +#### zoekt: data_disk_write_duration -#### zoekt: provisioning_container_cpu_usage_long_term +
Average write duration over 1m (per instance)
-Container cpu usage total (90th percentile over 1d) across all cores by instance
+The average time for write requests issued to the device to be served. This includes the time spent by the requests in queue and the time spent servicing them. -Refer to the [alerts reference](alerts#zoekt-provisioning-container-cpu-usage-long-term) for 1 alert related to this panel. +Note: Disk statistics are per _device_, not per _service_. In certain environments (such as common docker-compose setups), zoekt could be one of _many services_ using this disk. These statistics are best interpreted as the load experienced by the device zoekt is using, not the load zoekt is solely responsible for causing. -To see this panel, visit `/-/debug/grafana/d/zoekt/zoekt?viewPanel=101400` on your Sourcegraph instance. +This panel has no related alerts. + +To see this panel, visit `/-/debug/grafana/d/zoekt/zoekt?viewPanel=101321` on your Sourcegraph instance. *Managed by the [Sourcegraph Search Platform team](https://handbook.sourcegraph.com/departments/engineering/teams/search/core).* @@ -61465,19 +61631,23 @@ To see this panel, visit `/-/debug/grafana/d/zoekt/zoekt?viewPanel=101400` on yo Query: ``` -quantile_over_time(0.9, cadvisor_container_cpu_usage_percentage_total{name=~"^zoekt-indexserver.*"}[1d]) +(((max by (instance) (zoekt_indexserver_mount_point_info{mount_name="indexDir",instance=~`${instance:regex}`} * on (device, nodename) group_left() (max by (device, nodename) (rate(node_disk_write_time_seconds_total{instance=~`node-exporter.*`}[1m])))))) / ((max by (instance) (zoekt_indexserver_mount_point_info{mount_name="indexDir",instance=~`${instance:regex}`} * on (device, nodename) group_left() (max by (device, nodename) (rate(node_disk_writes_completed_total{instance=~`node-exporter.*`}[1m]))))))) ```-#### zoekt: provisioning_container_memory_usage_long_term +#### zoekt: data_disk_read_request_size -
Container memory usage (1d maximum) by instance
+Average read request size over 1m (per instance)
-Refer to the [alerts reference](alerts#zoekt-provisioning-container-memory-usage-long-term) for 1 alert related to this panel. +The average size of read requests that were issued to the device. -To see this panel, visit `/-/debug/grafana/d/zoekt/zoekt?viewPanel=101401` on your Sourcegraph instance. +Note: Disk statistics are per _device_, not per _service_. In certain environments (such as common docker-compose setups), zoekt could be one of _many services_ using this disk. These statistics are best interpreted as the load experienced by the device zoekt is using, not the load zoekt is solely responsible for causing. + +This panel has no related alerts. + +To see this panel, visit `/-/debug/grafana/d/zoekt/zoekt?viewPanel=101330` on your Sourcegraph instance. *Managed by the [Sourcegraph Search Platform team](https://handbook.sourcegraph.com/departments/engineering/teams/search/core).* @@ -61487,19 +61657,23 @@ To see this panel, visit `/-/debug/grafana/d/zoekt/zoekt?viewPanel=101401` on yo Query: ``` -max_over_time(cadvisor_container_memory_usage_percentage_total{name=~"^zoekt-indexserver.*"}[1d]) +(((max by (instance) (zoekt_indexserver_mount_point_info{mount_name="indexDir",instance=~`${instance:regex}`} * on (device, nodename) group_left() (max by (device, nodename) (rate(node_disk_read_bytes_total{instance=~`node-exporter.*`}[1m])))))) / ((max by (instance) (zoekt_indexserver_mount_point_info{mount_name="indexDir",instance=~`${instance:regex}`} * on (device, nodename) group_left() (max by (device, nodename) (rate(node_disk_reads_completed_total{instance=~`node-exporter.*`}[1m]))))))) ```-#### zoekt: provisioning_container_cpu_usage_short_term +#### zoekt: data_disk_write_request_size) + +
Average write request size over 1m (per instance)
-Container cpu usage total (5m maximum) across all cores by instance
+The average size of write requests that were issued to the device. -Refer to the [alerts reference](alerts#zoekt-provisioning-container-cpu-usage-short-term) for 1 alert related to this panel. +Note: Disk statistics are per _device_, not per _service_. In certain environments (such as common docker-compose setups), zoekt could be one of _many services_ using this disk. These statistics are best interpreted as the load experienced by the device zoekt is using, not the load zoekt is solely responsible for causing. + +This panel has no related alerts. -To see this panel, visit `/-/debug/grafana/d/zoekt/zoekt?viewPanel=101410` on your Sourcegraph instance. +To see this panel, visit `/-/debug/grafana/d/zoekt/zoekt?viewPanel=101331` on your Sourcegraph instance. *Managed by the [Sourcegraph Search Platform team](https://handbook.sourcegraph.com/departments/engineering/teams/search/core).* @@ -61509,19 +61683,23 @@ To see this panel, visit `/-/debug/grafana/d/zoekt/zoekt?viewPanel=101410` on yo Query: ``` -max_over_time(cadvisor_container_cpu_usage_percentage_total{name=~"^zoekt-indexserver.*"}[5m]) +(((max by (instance) (zoekt_indexserver_mount_point_info{mount_name="indexDir",instance=~`${instance:regex}`} * on (device, nodename) group_left() (max by (device, nodename) (rate(node_disk_written_bytes_total{instance=~`node-exporter.*`}[1m])))))) / ((max by (instance) (zoekt_indexserver_mount_point_info{mount_name="indexDir",instance=~`${instance:regex}`} * on (device, nodename) group_left() (max by (device, nodename) (rate(node_disk_writes_completed_total{instance=~`node-exporter.*`}[1m]))))))) ```-#### zoekt: provisioning_container_memory_usage_short_term +#### zoekt: data_disk_reads_merged_sec -
Container memory usage (5m maximum) by instance
+Merged read request rate over 1m (per instance)
+ +The number of read requests merged per second that were queued to the device. + +Note: Disk statistics are per _device_, not per _service_. In certain environments (such as common docker-compose setups), zoekt could be one of _many services_ using this disk. These statistics are best interpreted as the load experienced by the device zoekt is using, not the load zoekt is solely responsible for causing. -Refer to the [alerts reference](alerts#zoekt-provisioning-container-memory-usage-short-term) for 1 alert related to this panel. +This panel has no related alerts. -To see this panel, visit `/-/debug/grafana/d/zoekt/zoekt?viewPanel=101411` on your Sourcegraph instance. +To see this panel, visit `/-/debug/grafana/d/zoekt/zoekt?viewPanel=101340` on your Sourcegraph instance. *Managed by the [Sourcegraph Search Platform team](https://handbook.sourcegraph.com/departments/engineering/teams/search/core).* @@ -61531,22 +61709,23 @@ To see this panel, visit `/-/debug/grafana/d/zoekt/zoekt?viewPanel=101411` on yo Query: ``` -max_over_time(cadvisor_container_memory_usage_percentage_total{name=~"^zoekt-indexserver.*"}[5m]) +(max by (instance) (zoekt_indexserver_mount_point_info{mount_name="indexDir",instance=~`${instance:regex}`} * on (device, nodename) group_left() (max by (device, nodename) (rate(node_disk_reads_merged_total{instance=~`node-exporter.*`}[1m]))))) ```-#### zoekt: container_oomkill_events_total +#### zoekt: data_disk_writes_merged_sec -
Container OOMKILL events total by instance
+Merged writes request rate over 1m (per instance)
-This value indicates the total number of times the container main process or child processes were terminated by OOM killer. -When it occurs frequently, it is an indicator of underprovisioning. +The number of write requests merged per second that were queued to the device. + +Note: Disk statistics are per _device_, not per _service_. In certain environments (such as common docker-compose setups), zoekt could be one of _many services_ using this disk. These statistics are best interpreted as the load experienced by the device zoekt is using, not the load zoekt is solely responsible for causing. -Refer to the [alerts reference](alerts#zoekt-container-oomkill-events-total) for 1 alert related to this panel. +This panel has no related alerts. -To see this panel, visit `/-/debug/grafana/d/zoekt/zoekt?viewPanel=101412` on your Sourcegraph instance. +To see this panel, visit `/-/debug/grafana/d/zoekt/zoekt?viewPanel=101341` on your Sourcegraph instance. *Managed by the [Sourcegraph Search Platform team](https://handbook.sourcegraph.com/departments/engineering/teams/search/core).* @@ -61556,21 +61735,23 @@ To see this panel, visit `/-/debug/grafana/d/zoekt/zoekt?viewPanel=101412` on yo Query: ``` -max by (name) (container_oom_events_total{name=~"^zoekt-indexserver.*"}) +(max by (instance) (zoekt_indexserver_mount_point_info{mount_name="indexDir",instance=~`${instance:regex}`} * on (device, nodename) group_left() (max by (device, nodename) (rate(node_disk_writes_merged_total{instance=~`node-exporter.*`}[1m]))))) ```-### Zoekt: [zoekt-webserver] Provisioning indicators (not available on server) +#### zoekt: data_disk_average_queue_size + +
Average queue size over 1m (per instance)
-#### zoekt: provisioning_container_cpu_usage_long_term +The number of I/O operations that were being queued or being serviced. See https://blog.actorsfit.com/a?ID=00200-428fa2ac-e338-4540-848c-af9a3eb1ebd2 for background (avgqu-sz). -Container cpu usage total (90th percentile over 1d) across all cores by instance
+Note: Disk statistics are per _device_, not per _service_. In certain environments (such as common docker-compose setups), zoekt could be one of _many services_ using this disk. These statistics are best interpreted as the load experienced by the device zoekt is using, not the load zoekt is solely responsible for causing. -Refer to the [alerts reference](alerts#zoekt-provisioning-container-cpu-usage-long-term) for 1 alert related to this panel. +This panel has no related alerts. -To see this panel, visit `/-/debug/grafana/d/zoekt/zoekt?viewPanel=101500` on your Sourcegraph instance. +To see this panel, visit `/-/debug/grafana/d/zoekt/zoekt?viewPanel=101350` on your Sourcegraph instance. *Managed by the [Sourcegraph Search Platform team](https://handbook.sourcegraph.com/departments/engineering/teams/search/core).* @@ -61580,19 +61761,23 @@ To see this panel, visit `/-/debug/grafana/d/zoekt/zoekt?viewPanel=101500` on yo Query: ``` -quantile_over_time(0.9, cadvisor_container_cpu_usage_percentage_total{name=~"^zoekt-webserver.*"}[1d]) +(max by (instance) (zoekt_indexserver_mount_point_info{mount_name="indexDir",instance=~`${instance:regex}`} * on (device, nodename) group_left() (max by (device, nodename) (rate(node_disk_io_time_weighted_seconds_total{instance=~`node-exporter.*`}[1m]))))) ```-#### zoekt: provisioning_container_memory_usage_long_term +### Zoekt: [indexed-search-indexer] Golang runtime monitoring -
Container memory usage (1d maximum) by instance
+#### zoekt: go_goroutines -Refer to the [alerts reference](alerts#zoekt-provisioning-container-memory-usage-long-term) for 1 alert related to this panel. +Maximum active goroutines
-To see this panel, visit `/-/debug/grafana/d/zoekt/zoekt?viewPanel=101501` on your Sourcegraph instance. +A high value here indicates a possible goroutine leak. + +Refer to the [alerts reference](alerts#zoekt-go-goroutines) for 1 alert related to this panel. + +To see this panel, visit `/-/debug/grafana/d/zoekt/zoekt?viewPanel=101400` on your Sourcegraph instance. *Managed by the [Sourcegraph Search Platform team](https://handbook.sourcegraph.com/departments/engineering/teams/search/core).* @@ -61602,19 +61787,19 @@ To see this panel, visit `/-/debug/grafana/d/zoekt/zoekt?viewPanel=101501` on yo Query: ``` -max_over_time(cadvisor_container_memory_usage_percentage_total{name=~"^zoekt-webserver.*"}[1d]) +max by(instance) (go_goroutines{job=~".*indexed-search-indexer"}) ```-#### zoekt: provisioning_container_cpu_usage_short_term +#### zoekt: go_gc_duration_seconds -
Container cpu usage total (5m maximum) across all cores by instance
+Maximum go garbage collection duration
-Refer to the [alerts reference](alerts#zoekt-provisioning-container-cpu-usage-short-term) for 1 alert related to this panel. +Refer to the [alerts reference](alerts#zoekt-go-gc-duration-seconds) for 1 alert related to this panel. -To see this panel, visit `/-/debug/grafana/d/zoekt/zoekt?viewPanel=101510` on your Sourcegraph instance. +To see this panel, visit `/-/debug/grafana/d/zoekt/zoekt?viewPanel=101401` on your Sourcegraph instance. *Managed by the [Sourcegraph Search Platform team](https://handbook.sourcegraph.com/departments/engineering/teams/search/core).* @@ -61624,19 +61809,23 @@ To see this panel, visit `/-/debug/grafana/d/zoekt/zoekt?viewPanel=101510` on yo Query: ``` -max_over_time(cadvisor_container_cpu_usage_percentage_total{name=~"^zoekt-webserver.*"}[5m]) +max by(instance) (go_gc_duration_seconds{job=~".*indexed-search-indexer"}) ```-#### zoekt: provisioning_container_memory_usage_short_term +### Zoekt: [indexed-search] Golang runtime monitoring -
Container memory usage (5m maximum) by instance
+#### zoekt: go_goroutines + +Maximum active goroutines
+ +A high value here indicates a possible goroutine leak. -Refer to the [alerts reference](alerts#zoekt-provisioning-container-memory-usage-short-term) for 1 alert related to this panel. +Refer to the [alerts reference](alerts#zoekt-go-goroutines) for 1 alert related to this panel. -To see this panel, visit `/-/debug/grafana/d/zoekt/zoekt?viewPanel=101511` on your Sourcegraph instance. +To see this panel, visit `/-/debug/grafana/d/zoekt/zoekt?viewPanel=101500` on your Sourcegraph instance. *Managed by the [Sourcegraph Search Platform team](https://handbook.sourcegraph.com/departments/engineering/teams/search/core).* @@ -61646,22 +61835,19 @@ To see this panel, visit `/-/debug/grafana/d/zoekt/zoekt?viewPanel=101511` on yo Query: ``` -max_over_time(cadvisor_container_memory_usage_percentage_total{name=~"^zoekt-webserver.*"}[5m]) +max by(instance) (go_goroutines{job=~".*indexed-search"}) ```-#### zoekt: container_oomkill_events_total +#### zoekt: go_gc_duration_seconds -
Container OOMKILL events total by instance
- -This value indicates the total number of times the container main process or child processes were terminated by OOM killer. -When it occurs frequently, it is an indicator of underprovisioning. +Maximum go garbage collection duration
-Refer to the [alerts reference](alerts#zoekt-container-oomkill-events-total) for 1 alert related to this panel. +Refer to the [alerts reference](alerts#zoekt-go-gc-duration-seconds) for 1 alert related to this panel. -To see this panel, visit `/-/debug/grafana/d/zoekt/zoekt?viewPanel=101512` on your Sourcegraph instance. +To see this panel, visit `/-/debug/grafana/d/zoekt/zoekt?viewPanel=101501` on your Sourcegraph instance. *Managed by the [Sourcegraph Search Platform team](https://handbook.sourcegraph.com/departments/engineering/teams/search/core).* @@ -61671,7 +61857,7 @@ To see this panel, visit `/-/debug/grafana/d/zoekt/zoekt?viewPanel=101512` on yo Query: ``` -max by (name) (container_oom_events_total{name=~"^zoekt-webserver.*"}) +max by(instance) (go_gc_duration_seconds{job=~".*indexed-search"}) ``` @@ -62220,87 +62406,13 @@ To see this dashboard, visit `/-/debug/grafana/d/executor/executor` on your Sour ### Executor: Executor: Executor jobs -#### executor: executor_queue_size - -Unprocessed executor job queue size
- -This panel has no related alerts. - -To see this panel, visit `/-/debug/grafana/d/executor/executor?viewPanel=100000` on your Sourcegraph instance. - -*Managed by the [Sourcegraph Code intelligence team](https://handbook.sourcegraph.com/departments/engineering/teams/code-intelligence).* - -Technical details
- -Query: - -``` -max by (queue)(src_executor_total{queue=~"$queue",job=~"^(executor|sourcegraph-code-intel-indexers|executor-batches|frontend|sourcegraph-frontend|worker|sourcegraph-executors).*"}) -``` -- -#### executor: executor_queue_growth_rate - -
Unprocessed executor job queue growth rate over 30m
- -This value compares the rate of enqueues against the rate of finished jobs for the selected queue. - - - A value < than 1 indicates that process rate > enqueue rate - - A value = than 1 indicates that process rate = enqueue rate - - A value > than 1 indicates that process rate < enqueue rate - -This panel has no related alerts. - -To see this panel, visit `/-/debug/grafana/d/executor/executor?viewPanel=100001` on your Sourcegraph instance. - -*Managed by the [Sourcegraph Code intelligence team](https://handbook.sourcegraph.com/departments/engineering/teams/code-intelligence).* - -Technical details
- -Query: - -``` -sum by (queue)(increase(src_executor_total{queue=~"$queue",job=~"^(executor|sourcegraph-code-intel-indexers|executor-batches|frontend|sourcegraph-frontend|worker|sourcegraph-executors).*"}[30m])) / sum by (queue)(increase(src_executor_processor_total{queue=~"$queue",job=~"^(executor|sourcegraph-code-intel-indexers|executor-batches|frontend|sourcegraph-frontend|worker|sourcegraph-executors).*"}[30m])) -``` -- -#### executor: executor_queued_max_age - -
Unprocessed executor job queue longest time in queue
- -This panel has no related alerts. - -To see this panel, visit `/-/debug/grafana/d/executor/executor?viewPanel=100002` on your Sourcegraph instance. - -*Managed by the [Sourcegraph Code intelligence team](https://handbook.sourcegraph.com/departments/engineering/teams/code-intelligence).* - -Technical details
- -Query: - -``` -max by (queue)(src_executor_queued_duration_seconds_total{queue=~"$queue",job=~"^(executor|sourcegraph-code-intel-indexers|executor-batches|frontend|sourcegraph-frontend|worker|sourcegraph-executors).*"}) -``` -- -### Executor: Executor: Executor jobs - #### executor: multiqueue_executor_dequeue_cache_size
Unprocessed executor job dequeue cache size for multiqueue executors
This panel has no related alerts. -To see this panel, visit `/-/debug/grafana/d/executor/executor?viewPanel=100100` on your Sourcegraph instance. +To see this panel, visit `/-/debug/grafana/d/executor/executor?viewPanel=100000` on your Sourcegraph instance. *Managed by the [Sourcegraph Code intelligence team](https://handbook.sourcegraph.com/departments/engineering/teams/code-intelligence).* @@ -62324,7 +62436,7 @@ multiqueue_executor_dequeue_cache_size{queue=~"$queue",job=~"^(executor|sourcegr Refer to the [alerts reference](alerts#executor-executor-handlers) for 1 alert related to this panel. -To see this panel, visit `/-/debug/grafana/d/executor/executor?viewPanel=100200` on your Sourcegraph instance. +To see this panel, visit `/-/debug/grafana/d/executor/executor?viewPanel=100100` on your Sourcegraph instance. *Managed by the [Sourcegraph Code intelligence team](https://handbook.sourcegraph.com/departments/engineering/teams/code-intelligence).* @@ -62346,7 +62458,7 @@ sum(src_executor_processor_handlers{queue=~"${queue:regex}",sg_job=~"^sourcegrap This panel has no related alerts. -To see this panel, visit `/-/debug/grafana/d/executor/executor?viewPanel=100210` on your Sourcegraph instance. +To see this panel, visit `/-/debug/grafana/d/executor/executor?viewPanel=100110` on your Sourcegraph instance. *Managed by the [Sourcegraph Code intelligence team](https://handbook.sourcegraph.com/departments/engineering/teams/code-intelligence).* @@ -62368,7 +62480,7 @@ sum(increase(src_executor_processor_total{queue=~"${queue:regex}",sg_job=~"^sour This panel has no related alerts. -To see this panel, visit `/-/debug/grafana/d/executor/executor?viewPanel=100211` on your Sourcegraph instance. +To see this panel, visit `/-/debug/grafana/d/executor/executor?viewPanel=100111` on your Sourcegraph instance. *Managed by the [Sourcegraph Code intelligence team](https://handbook.sourcegraph.com/departments/engineering/teams/code-intelligence).* @@ -62390,7 +62502,7 @@ sum by (le)(rate(src_executor_processor_duration_seconds_bucket{queue=~"${queue This panel has no related alerts. -To see this panel, visit `/-/debug/grafana/d/executor/executor?viewPanel=100212` on your Sourcegraph instance. +To see this panel, visit `/-/debug/grafana/d/executor/executor?viewPanel=100112` on your Sourcegraph instance. *Managed by the [Sourcegraph Code intelligence team](https://handbook.sourcegraph.com/departments/engineering/teams/code-intelligence).* @@ -62412,7 +62524,7 @@ sum(increase(src_executor_processor_errors_total{queue=~"${queue:regex}",sg_job= Refer to the [alerts reference](alerts#executor-executor-processor-error-rate) for 1 alert related to this panel. -To see this panel, visit `/-/debug/grafana/d/executor/executor?viewPanel=100213` on your Sourcegraph instance. +To see this panel, visit `/-/debug/grafana/d/executor/executor?viewPanel=100113` on your Sourcegraph instance. *Managed by the [Sourcegraph Code intelligence team](https://handbook.sourcegraph.com/departments/engineering/teams/code-intelligence).* @@ -62436,7 +62548,7 @@ sum(increase(src_executor_processor_errors_total{queue=~"${queue:regex}",sg_job= This panel has no related alerts. -To see this panel, visit `/-/debug/grafana/d/executor/executor?viewPanel=100300` on your Sourcegraph instance. +To see this panel, visit `/-/debug/grafana/d/executor/executor?viewPanel=100200` on your Sourcegraph instance. *Managed by the [Sourcegraph Code intelligence team](https://handbook.sourcegraph.com/departments/engineering/teams/code-intelligence).* @@ -62458,7 +62570,7 @@ sum(increase(src_apiworker_apiclient_queue_total{sg_job=~"^sourcegraph-executors This panel has no related alerts. -To see this panel, visit `/-/debug/grafana/d/executor/executor?viewPanel=100301` on your Sourcegraph instance. +To see this panel, visit `/-/debug/grafana/d/executor/executor?viewPanel=100201` on your Sourcegraph instance. *Managed by the [Sourcegraph Code intelligence team](https://handbook.sourcegraph.com/departments/engineering/teams/code-intelligence).* @@ -62480,7 +62592,7 @@ sum by (le)(rate(src_apiworker_apiclient_queue_duration_seconds_bucket{sg_job=~ This panel has no related alerts. -To see this panel, visit `/-/debug/grafana/d/executor/executor?viewPanel=100302` on your Sourcegraph instance. +To see this panel, visit `/-/debug/grafana/d/executor/executor?viewPanel=100202` on your Sourcegraph instance. *Managed by the [Sourcegraph Code intelligence team](https://handbook.sourcegraph.com/departments/engineering/teams/code-intelligence).* @@ -62502,7 +62614,7 @@ sum(increase(src_apiworker_apiclient_queue_errors_total{sg_job=~"^sourcegraph-ex This panel has no related alerts. -To see this panel, visit `/-/debug/grafana/d/executor/executor?viewPanel=100303` on your Sourcegraph instance. +To see this panel, visit `/-/debug/grafana/d/executor/executor?viewPanel=100203` on your Sourcegraph instance. *Managed by the [Sourcegraph Code intelligence team](https://handbook.sourcegraph.com/departments/engineering/teams/code-intelligence).* @@ -62524,7 +62636,7 @@ sum(increase(src_apiworker_apiclient_queue_errors_total{sg_job=~"^sourcegraph-ex This panel has no related alerts. -To see this panel, visit `/-/debug/grafana/d/executor/executor?viewPanel=100310` on your Sourcegraph instance. +To see this panel, visit `/-/debug/grafana/d/executor/executor?viewPanel=100210` on your Sourcegraph instance. *Managed by the [Sourcegraph Code intelligence team](https://handbook.sourcegraph.com/departments/engineering/teams/code-intelligence).* @@ -62546,7 +62658,7 @@ sum by (op)(increase(src_apiworker_apiclient_queue_total{sg_job=~"^sourcegraph-e This panel has no related alerts. -To see this panel, visit `/-/debug/grafana/d/executor/executor?viewPanel=100311` on your Sourcegraph instance. +To see this panel, visit `/-/debug/grafana/d/executor/executor?viewPanel=100211` on your Sourcegraph instance. *Managed by the [Sourcegraph Code intelligence team](https://handbook.sourcegraph.com/departments/engineering/teams/code-intelligence).* @@ -62568,7 +62680,7 @@ histogram_quantile(0.99, sum by (le,op)(rate(src_apiworker_apiclient_queue_dura This panel has no related alerts. -To see this panel, visit `/-/debug/grafana/d/executor/executor?viewPanel=100312` on your Sourcegraph instance. +To see this panel, visit `/-/debug/grafana/d/executor/executor?viewPanel=100212` on your Sourcegraph instance. *Managed by the [Sourcegraph Code intelligence team](https://handbook.sourcegraph.com/departments/engineering/teams/code-intelligence).* @@ -62590,7 +62702,7 @@ sum by (op)(increase(src_apiworker_apiclient_queue_errors_total{sg_job=~"^source This panel has no related alerts. -To see this panel, visit `/-/debug/grafana/d/executor/executor?viewPanel=100313` on your Sourcegraph instance. +To see this panel, visit `/-/debug/grafana/d/executor/executor?viewPanel=100213` on your Sourcegraph instance. *Managed by the [Sourcegraph Code intelligence team](https://handbook.sourcegraph.com/departments/engineering/teams/code-intelligence).* @@ -62614,7 +62726,7 @@ sum by (op)(increase(src_apiworker_apiclient_queue_errors_total{sg_job=~"^source This panel has no related alerts. -To see this panel, visit `/-/debug/grafana/d/executor/executor?viewPanel=100400` on your Sourcegraph instance. +To see this panel, visit `/-/debug/grafana/d/executor/executor?viewPanel=100300` on your Sourcegraph instance. *Managed by the [Sourcegraph Code intelligence team](https://handbook.sourcegraph.com/departments/engineering/teams/code-intelligence).* @@ -62636,7 +62748,7 @@ sum(increase(src_apiworker_apiclient_files_total{sg_job=~"^sourcegraph-executors This panel has no related alerts. -To see this panel, visit `/-/debug/grafana/d/executor/executor?viewPanel=100401` on your Sourcegraph instance. +To see this panel, visit `/-/debug/grafana/d/executor/executor?viewPanel=100301` on your Sourcegraph instance. *Managed by the [Sourcegraph Code intelligence team](https://handbook.sourcegraph.com/departments/engineering/teams/code-intelligence).* @@ -62658,7 +62770,7 @@ sum by (le)(rate(src_apiworker_apiclient_files_duration_seconds_bucket{sg_job=~ This panel has no related alerts. -To see this panel, visit `/-/debug/grafana/d/executor/executor?viewPanel=100402` on your Sourcegraph instance. +To see this panel, visit `/-/debug/grafana/d/executor/executor?viewPanel=100302` on your Sourcegraph instance. *Managed by the [Sourcegraph Code intelligence team](https://handbook.sourcegraph.com/departments/engineering/teams/code-intelligence).* @@ -62680,7 +62792,7 @@ sum(increase(src_apiworker_apiclient_files_errors_total{sg_job=~"^sourcegraph-ex This panel has no related alerts. -To see this panel, visit `/-/debug/grafana/d/executor/executor?viewPanel=100403` on your Sourcegraph instance. +To see this panel, visit `/-/debug/grafana/d/executor/executor?viewPanel=100303` on your Sourcegraph instance. *Managed by the [Sourcegraph Code intelligence team](https://handbook.sourcegraph.com/departments/engineering/teams/code-intelligence).* @@ -62702,7 +62814,7 @@ sum(increase(src_apiworker_apiclient_files_errors_total{sg_job=~"^sourcegraph-ex This panel has no related alerts. -To see this panel, visit `/-/debug/grafana/d/executor/executor?viewPanel=100410` on your Sourcegraph instance. +To see this panel, visit `/-/debug/grafana/d/executor/executor?viewPanel=100310` on your Sourcegraph instance. *Managed by the [Sourcegraph Code intelligence team](https://handbook.sourcegraph.com/departments/engineering/teams/code-intelligence).* @@ -62724,7 +62836,7 @@ sum by (op)(increase(src_apiworker_apiclient_files_total{sg_job=~"^sourcegraph-e This panel has no related alerts. -To see this panel, visit `/-/debug/grafana/d/executor/executor?viewPanel=100411` on your Sourcegraph instance. +To see this panel, visit `/-/debug/grafana/d/executor/executor?viewPanel=100311` on your Sourcegraph instance. *Managed by the [Sourcegraph Code intelligence team](https://handbook.sourcegraph.com/departments/engineering/teams/code-intelligence).* @@ -62746,7 +62858,7 @@ histogram_quantile(0.99, sum by (le,op)(rate(src_apiworker_apiclient_files_dura This panel has no related alerts. -To see this panel, visit `/-/debug/grafana/d/executor/executor?viewPanel=100412` on your Sourcegraph instance. +To see this panel, visit `/-/debug/grafana/d/executor/executor?viewPanel=100312` on your Sourcegraph instance. *Managed by the [Sourcegraph Code intelligence team](https://handbook.sourcegraph.com/departments/engineering/teams/code-intelligence).* @@ -62768,7 +62880,7 @@ sum by (op)(increase(src_apiworker_apiclient_files_errors_total{sg_job=~"^source This panel has no related alerts. -To see this panel, visit `/-/debug/grafana/d/executor/executor?viewPanel=100413` on your Sourcegraph instance. +To see this panel, visit `/-/debug/grafana/d/executor/executor?viewPanel=100313` on your Sourcegraph instance. *Managed by the [Sourcegraph Code intelligence team](https://handbook.sourcegraph.com/departments/engineering/teams/code-intelligence).* @@ -62792,7 +62904,7 @@ sum by (op)(increase(src_apiworker_apiclient_files_errors_total{sg_job=~"^source This panel has no related alerts. -To see this panel, visit `/-/debug/grafana/d/executor/executor?viewPanel=100500` on your Sourcegraph instance. +To see this panel, visit `/-/debug/grafana/d/executor/executor?viewPanel=100400` on your Sourcegraph instance. *Managed by the [Sourcegraph Code intelligence team](https://handbook.sourcegraph.com/departments/engineering/teams/code-intelligence).* @@ -62814,7 +62926,7 @@ sum(increase(src_apiworker_command_total{op=~"setup.*",sg_job=~"^sourcegraph-exe This panel has no related alerts. -To see this panel, visit `/-/debug/grafana/d/executor/executor?viewPanel=100501` on your Sourcegraph instance. +To see this panel, visit `/-/debug/grafana/d/executor/executor?viewPanel=100401` on your Sourcegraph instance. *Managed by the [Sourcegraph Code intelligence team](https://handbook.sourcegraph.com/departments/engineering/teams/code-intelligence).* @@ -62836,7 +62948,7 @@ sum by (le)(rate(src_apiworker_command_duration_seconds_bucket{op=~"setup.*",sg This panel has no related alerts. -To see this panel, visit `/-/debug/grafana/d/executor/executor?viewPanel=100502` on your Sourcegraph instance. +To see this panel, visit `/-/debug/grafana/d/executor/executor?viewPanel=100402` on your Sourcegraph instance. *Managed by the [Sourcegraph Code intelligence team](https://handbook.sourcegraph.com/departments/engineering/teams/code-intelligence).* @@ -62858,7 +62970,7 @@ sum(increase(src_apiworker_command_errors_total{op=~"setup.*",sg_job=~"^sourcegr This panel has no related alerts. -To see this panel, visit `/-/debug/grafana/d/executor/executor?viewPanel=100503` on your Sourcegraph instance. +To see this panel, visit `/-/debug/grafana/d/executor/executor?viewPanel=100403` on your Sourcegraph instance. *Managed by the [Sourcegraph Code intelligence team](https://handbook.sourcegraph.com/departments/engineering/teams/code-intelligence).* @@ -62880,7 +62992,7 @@ sum(increase(src_apiworker_command_errors_total{op=~"setup.*",sg_job=~"^sourcegr This panel has no related alerts. -To see this panel, visit `/-/debug/grafana/d/executor/executor?viewPanel=100510` on your Sourcegraph instance. +To see this panel, visit `/-/debug/grafana/d/executor/executor?viewPanel=100410` on your Sourcegraph instance. *Managed by the [Sourcegraph Code intelligence team](https://handbook.sourcegraph.com/departments/engineering/teams/code-intelligence).* @@ -62902,7 +63014,7 @@ sum by (op)(increase(src_apiworker_command_total{op=~"setup.*",sg_job=~"^sourceg This panel has no related alerts. -To see this panel, visit `/-/debug/grafana/d/executor/executor?viewPanel=100511` on your Sourcegraph instance. +To see this panel, visit `/-/debug/grafana/d/executor/executor?viewPanel=100411` on your Sourcegraph instance. *Managed by the [Sourcegraph Code intelligence team](https://handbook.sourcegraph.com/departments/engineering/teams/code-intelligence).* @@ -62924,7 +63036,7 @@ histogram_quantile(0.99, sum by (le,op)(rate(src_apiworker_command_duration_sec This panel has no related alerts. -To see this panel, visit `/-/debug/grafana/d/executor/executor?viewPanel=100512` on your Sourcegraph instance. +To see this panel, visit `/-/debug/grafana/d/executor/executor?viewPanel=100412` on your Sourcegraph instance. *Managed by the [Sourcegraph Code intelligence team](https://handbook.sourcegraph.com/departments/engineering/teams/code-intelligence).* @@ -62946,7 +63058,7 @@ sum by (op)(increase(src_apiworker_command_errors_total{op=~"setup.*",sg_job=~"^ This panel has no related alerts. -To see this panel, visit `/-/debug/grafana/d/executor/executor?viewPanel=100513` on your Sourcegraph instance. +To see this panel, visit `/-/debug/grafana/d/executor/executor?viewPanel=100413` on your Sourcegraph instance. *Managed by the [Sourcegraph Code intelligence team](https://handbook.sourcegraph.com/departments/engineering/teams/code-intelligence).* @@ -62970,7 +63082,7 @@ sum by (op)(increase(src_apiworker_command_errors_total{op=~"setup.*",sg_job=~"^ This panel has no related alerts. -To see this panel, visit `/-/debug/grafana/d/executor/executor?viewPanel=100600` on your Sourcegraph instance. +To see this panel, visit `/-/debug/grafana/d/executor/executor?viewPanel=100500` on your Sourcegraph instance. *Managed by the [Sourcegraph Code intelligence team](https://handbook.sourcegraph.com/departments/engineering/teams/code-intelligence).* @@ -62992,7 +63104,7 @@ sum(increase(src_apiworker_command_total{op=~"exec.*",sg_job=~"^sourcegraph-exec This panel has no related alerts. -To see this panel, visit `/-/debug/grafana/d/executor/executor?viewPanel=100601` on your Sourcegraph instance. +To see this panel, visit `/-/debug/grafana/d/executor/executor?viewPanel=100501` on your Sourcegraph instance. *Managed by the [Sourcegraph Code intelligence team](https://handbook.sourcegraph.com/departments/engineering/teams/code-intelligence).* @@ -63014,7 +63126,7 @@ sum by (le)(rate(src_apiworker_command_duration_seconds_bucket{op=~"exec.*",sg_ This panel has no related alerts. -To see this panel, visit `/-/debug/grafana/d/executor/executor?viewPanel=100602` on your Sourcegraph instance. +To see this panel, visit `/-/debug/grafana/d/executor/executor?viewPanel=100502` on your Sourcegraph instance. *Managed by the [Sourcegraph Code intelligence team](https://handbook.sourcegraph.com/departments/engineering/teams/code-intelligence).* @@ -63036,7 +63148,7 @@ sum(increase(src_apiworker_command_errors_total{op=~"exec.*",sg_job=~"^sourcegra This panel has no related alerts. -To see this panel, visit `/-/debug/grafana/d/executor/executor?viewPanel=100603` on your Sourcegraph instance. +To see this panel, visit `/-/debug/grafana/d/executor/executor?viewPanel=100503` on your Sourcegraph instance. *Managed by the [Sourcegraph Code intelligence team](https://handbook.sourcegraph.com/departments/engineering/teams/code-intelligence).* @@ -63058,7 +63170,7 @@ sum(increase(src_apiworker_command_errors_total{op=~"exec.*",sg_job=~"^sourcegra This panel has no related alerts. -To see this panel, visit `/-/debug/grafana/d/executor/executor?viewPanel=100610` on your Sourcegraph instance. +To see this panel, visit `/-/debug/grafana/d/executor/executor?viewPanel=100510` on your Sourcegraph instance. *Managed by the [Sourcegraph Code intelligence team](https://handbook.sourcegraph.com/departments/engineering/teams/code-intelligence).* @@ -63080,7 +63192,7 @@ sum by (op)(increase(src_apiworker_command_total{op=~"exec.*",sg_job=~"^sourcegr This panel has no related alerts. -To see this panel, visit `/-/debug/grafana/d/executor/executor?viewPanel=100611` on your Sourcegraph instance. +To see this panel, visit `/-/debug/grafana/d/executor/executor?viewPanel=100511` on your Sourcegraph instance. *Managed by the [Sourcegraph Code intelligence team](https://handbook.sourcegraph.com/departments/engineering/teams/code-intelligence).* @@ -63102,7 +63214,7 @@ histogram_quantile(0.99, sum by (le,op)(rate(src_apiworker_command_duration_sec This panel has no related alerts. -To see this panel, visit `/-/debug/grafana/d/executor/executor?viewPanel=100612` on your Sourcegraph instance. +To see this panel, visit `/-/debug/grafana/d/executor/executor?viewPanel=100512` on your Sourcegraph instance. *Managed by the [Sourcegraph Code intelligence team](https://handbook.sourcegraph.com/departments/engineering/teams/code-intelligence).* @@ -63124,7 +63236,7 @@ sum by (op)(increase(src_apiworker_command_errors_total{op=~"exec.*",sg_job=~"^s This panel has no related alerts. -To see this panel, visit `/-/debug/grafana/d/executor/executor?viewPanel=100613` on your Sourcegraph instance. +To see this panel, visit `/-/debug/grafana/d/executor/executor?viewPanel=100513` on your Sourcegraph instance. *Managed by the [Sourcegraph Code intelligence team](https://handbook.sourcegraph.com/departments/engineering/teams/code-intelligence).* @@ -63148,7 +63260,7 @@ sum by (op)(increase(src_apiworker_command_errors_total{op=~"exec.*",sg_job=~"^s This panel has no related alerts. -To see this panel, visit `/-/debug/grafana/d/executor/executor?viewPanel=100700` on your Sourcegraph instance. +To see this panel, visit `/-/debug/grafana/d/executor/executor?viewPanel=100600` on your Sourcegraph instance. *Managed by the [Sourcegraph Code intelligence team](https://handbook.sourcegraph.com/departments/engineering/teams/code-intelligence).* @@ -63170,7 +63282,7 @@ sum(increase(src_apiworker_command_total{op=~"teardown.*",sg_job=~"^sourcegraph- This panel has no related alerts. -To see this panel, visit `/-/debug/grafana/d/executor/executor?viewPanel=100701` on your Sourcegraph instance. +To see this panel, visit `/-/debug/grafana/d/executor/executor?viewPanel=100601` on your Sourcegraph instance. *Managed by the [Sourcegraph Code intelligence team](https://handbook.sourcegraph.com/departments/engineering/teams/code-intelligence).* @@ -63192,7 +63304,7 @@ sum by (le)(rate(src_apiworker_command_duration_seconds_bucket{op=~"teardown.*" This panel has no related alerts. -To see this panel, visit `/-/debug/grafana/d/executor/executor?viewPanel=100702` on your Sourcegraph instance. +To see this panel, visit `/-/debug/grafana/d/executor/executor?viewPanel=100602` on your Sourcegraph instance. *Managed by the [Sourcegraph Code intelligence team](https://handbook.sourcegraph.com/departments/engineering/teams/code-intelligence).* @@ -63214,7 +63326,7 @@ sum(increase(src_apiworker_command_errors_total{op=~"teardown.*",sg_job=~"^sourc This panel has no related alerts. -To see this panel, visit `/-/debug/grafana/d/executor/executor?viewPanel=100703` on your Sourcegraph instance. +To see this panel, visit `/-/debug/grafana/d/executor/executor?viewPanel=100603` on your Sourcegraph instance. *Managed by the [Sourcegraph Code intelligence team](https://handbook.sourcegraph.com/departments/engineering/teams/code-intelligence).* @@ -63236,7 +63348,7 @@ sum(increase(src_apiworker_command_errors_total{op=~"teardown.*",sg_job=~"^sourc This panel has no related alerts. -To see this panel, visit `/-/debug/grafana/d/executor/executor?viewPanel=100710` on your Sourcegraph instance. +To see this panel, visit `/-/debug/grafana/d/executor/executor?viewPanel=100610` on your Sourcegraph instance. *Managed by the [Sourcegraph Code intelligence team](https://handbook.sourcegraph.com/departments/engineering/teams/code-intelligence).* @@ -63258,7 +63370,7 @@ sum by (op)(increase(src_apiworker_command_total{op=~"teardown.*",sg_job=~"^sour This panel has no related alerts. -To see this panel, visit `/-/debug/grafana/d/executor/executor?viewPanel=100711` on your Sourcegraph instance. +To see this panel, visit `/-/debug/grafana/d/executor/executor?viewPanel=100611` on your Sourcegraph instance. *Managed by the [Sourcegraph Code intelligence team](https://handbook.sourcegraph.com/departments/engineering/teams/code-intelligence).* @@ -63280,7 +63392,7 @@ histogram_quantile(0.99, sum by (le,op)(rate(src_apiworker_command_duration_sec This panel has no related alerts. -To see this panel, visit `/-/debug/grafana/d/executor/executor?viewPanel=100712` on your Sourcegraph instance. +To see this panel, visit `/-/debug/grafana/d/executor/executor?viewPanel=100612` on your Sourcegraph instance. *Managed by the [Sourcegraph Code intelligence team](https://handbook.sourcegraph.com/departments/engineering/teams/code-intelligence).* @@ -63302,7 +63414,7 @@ sum by (op)(increase(src_apiworker_command_errors_total{op=~"teardown.*",sg_job= This panel has no related alerts. -To see this panel, visit `/-/debug/grafana/d/executor/executor?viewPanel=100713` on your Sourcegraph instance. +To see this panel, visit `/-/debug/grafana/d/executor/executor?viewPanel=100613` on your Sourcegraph instance. *Managed by the [Sourcegraph Code intelligence team](https://handbook.sourcegraph.com/departments/engineering/teams/code-intelligence).* @@ -63328,7 +63440,7 @@ Indicates the amount of CPU time excluding idle and iowait time, divided by the This panel has no related alerts. -To see this panel, visit `/-/debug/grafana/d/executor/executor?viewPanel=100800` on your Sourcegraph instance. +To see this panel, visit `/-/debug/grafana/d/executor/executor?viewPanel=100700` on your Sourcegraph instance.-#### codeintel-autoindexing: executor_queue_size - -
Unprocessed executor job queue size
- -This panel has no related alerts. - -To see this panel, visit `/-/debug/grafana/d/codeintel-autoindexing/codeintel-autoindexing?viewPanel=100010` on your Sourcegraph instance. - -*Managed by the [Sourcegraph Code intelligence team](https://handbook.sourcegraph.com/departments/engineering/teams/code-intelligence).* - -Technical details
- -Query: - -``` -max by (queue)(src_executor_total{queue=~"codeintel",job=~"^(executor|sourcegraph-code-intel-indexers|executor-batches|frontend|sourcegraph-frontend|worker|sourcegraph-executors).*"}) -``` -- -#### codeintel-autoindexing: executor_queue_growth_rate - -
Unprocessed executor job queue growth rate over 30m
- -This value compares the rate of enqueues against the rate of finished jobs for the selected queue. - - - A value < than 1 indicates that process rate > enqueue rate - - A value = than 1 indicates that process rate = enqueue rate - - A value > than 1 indicates that process rate < enqueue rate - -This panel has no related alerts. - -To see this panel, visit `/-/debug/grafana/d/codeintel-autoindexing/codeintel-autoindexing?viewPanel=100011` on your Sourcegraph instance. - -*Managed by the [Sourcegraph Code intelligence team](https://handbook.sourcegraph.com/departments/engineering/teams/code-intelligence).* - -Technical details
- -Query: - -``` -sum by (queue)(increase(src_executor_total{queue=~"codeintel",job=~"^(executor|sourcegraph-code-intel-indexers|executor-batches|frontend|sourcegraph-frontend|worker|sourcegraph-executors).*"}[30m])) / sum by (queue)(increase(src_executor_processor_total{queue=~"codeintel",job=~"^(executor|sourcegraph-code-intel-indexers|executor-batches|frontend|sourcegraph-frontend|worker|sourcegraph-executors).*"}[30m])) -``` -- -#### codeintel-autoindexing: executor_queued_max_age - -
Unprocessed executor job queue longest time in queue
- -This panel has no related alerts. - -To see this panel, visit `/-/debug/grafana/d/codeintel-autoindexing/codeintel-autoindexing?viewPanel=100012` on your Sourcegraph instance. - -*Managed by the [Sourcegraph Code intelligence team](https://handbook.sourcegraph.com/departments/engineering/teams/code-intelligence).* - -Technical details
- -Query: - -``` -max by (queue)(src_executor_queued_duration_seconds_total{queue=~"codeintel",job=~"^(executor|sourcegraph-code-intel-indexers|executor-batches|frontend|sourcegraph-frontend|worker|sourcegraph-executors).*"}) -``` -- ### Code Intelligence > Autoindexing: Codeintel: Autoindexing > Service #### codeintel-autoindexing: codeintel_autoindexing_total @@ -67060,21 +67100,21 @@ sum(increase(src_codeintel_background_policies_updated_total_total{job=~"^${sour
-## Code Intelligence > Ranking +## Code Intelligence > Uploads -
The service at `internal/codeintel/ranking`.
+The service at `internal/codeintel/uploads`.
-To see this dashboard, visit `/-/debug/grafana/d/codeintel-ranking/codeintel-ranking` on your Sourcegraph instance. +To see this dashboard, visit `/-/debug/grafana/d/codeintel-uploads/codeintel-uploads` on your Sourcegraph instance. -### Code Intelligence > Ranking: Codeintel: Ranking > Service +### Code Intelligence > Uploads: Codeintel: Uploads > Service -#### codeintel-ranking: codeintel_ranking_total +#### codeintel-uploads: codeintel_uploads_totalAggregate service operations every 5m
This panel has no related alerts. -To see this panel, visit `/-/debug/grafana/d/codeintel-ranking/codeintel-ranking?viewPanel=100000` on your Sourcegraph instance. +To see this panel, visit `/-/debug/grafana/d/codeintel-uploads/codeintel-uploads?viewPanel=100000` on your Sourcegraph instance. *Managed by the [Sourcegraph Code intelligence team](https://handbook.sourcegraph.com/departments/engineering/teams/code-intelligence).* @@ -67084,19 +67124,19 @@ To see this panel, visit `/-/debug/grafana/d/codeintel-ranking/codeintel-ranking Query: ``` -sum(increase(src_codeintel_ranking_total{job=~"^${source:regex}.*"}[5m])) +sum(increase(src_codeintel_uploads_total{job=~"^${source:regex}.*"}[5m])) ```-#### codeintel-ranking: codeintel_ranking_99th_percentile_duration +#### codeintel-uploads: codeintel_uploads_99th_percentile_duration
Aggregate successful service operation duration distribution over 5m
This panel has no related alerts. -To see this panel, visit `/-/debug/grafana/d/codeintel-ranking/codeintel-ranking?viewPanel=100001` on your Sourcegraph instance. +To see this panel, visit `/-/debug/grafana/d/codeintel-uploads/codeintel-uploads?viewPanel=100001` on your Sourcegraph instance. *Managed by the [Sourcegraph Code intelligence team](https://handbook.sourcegraph.com/departments/engineering/teams/code-intelligence).* @@ -67106,19 +67146,19 @@ To see this panel, visit `/-/debug/grafana/d/codeintel-ranking/codeintel-ranking Query: ``` -sum by (le)(rate(src_codeintel_ranking_duration_seconds_bucket{job=~"^${source:regex}.*"}[5m])) +sum by (le)(rate(src_codeintel_uploads_duration_seconds_bucket{job=~"^${source:regex}.*"}[5m])) ```-#### codeintel-ranking: codeintel_ranking_errors_total +#### codeintel-uploads: codeintel_uploads_errors_total
Aggregate service operation errors every 5m
This panel has no related alerts. -To see this panel, visit `/-/debug/grafana/d/codeintel-ranking/codeintel-ranking?viewPanel=100002` on your Sourcegraph instance. +To see this panel, visit `/-/debug/grafana/d/codeintel-uploads/codeintel-uploads?viewPanel=100002` on your Sourcegraph instance. *Managed by the [Sourcegraph Code intelligence team](https://handbook.sourcegraph.com/departments/engineering/teams/code-intelligence).* @@ -67128,19 +67168,19 @@ To see this panel, visit `/-/debug/grafana/d/codeintel-ranking/codeintel-ranking Query: ``` -sum(increase(src_codeintel_ranking_errors_total{job=~"^${source:regex}.*"}[5m])) +sum(increase(src_codeintel_uploads_errors_total{job=~"^${source:regex}.*"}[5m])) ```-#### codeintel-ranking: codeintel_ranking_error_rate +#### codeintel-uploads: codeintel_uploads_error_rate
Aggregate service operation error rate over 5m
This panel has no related alerts. -To see this panel, visit `/-/debug/grafana/d/codeintel-ranking/codeintel-ranking?viewPanel=100003` on your Sourcegraph instance. +To see this panel, visit `/-/debug/grafana/d/codeintel-uploads/codeintel-uploads?viewPanel=100003` on your Sourcegraph instance. *Managed by the [Sourcegraph Code intelligence team](https://handbook.sourcegraph.com/departments/engineering/teams/code-intelligence).* @@ -67150,19 +67190,19 @@ To see this panel, visit `/-/debug/grafana/d/codeintel-ranking/codeintel-ranking Query: ``` -sum(increase(src_codeintel_ranking_errors_total{job=~"^${source:regex}.*"}[5m])) / (sum(increase(src_codeintel_ranking_total{job=~"^${source:regex}.*"}[5m])) + sum(increase(src_codeintel_ranking_errors_total{job=~"^${source:regex}.*"}[5m]))) * 100 +sum(increase(src_codeintel_uploads_errors_total{job=~"^${source:regex}.*"}[5m])) / (sum(increase(src_codeintel_uploads_total{job=~"^${source:regex}.*"}[5m])) + sum(increase(src_codeintel_uploads_errors_total{job=~"^${source:regex}.*"}[5m]))) * 100 ```-#### codeintel-ranking: codeintel_ranking_total +#### codeintel-uploads: codeintel_uploads_total
Service operations every 5m
This panel has no related alerts. -To see this panel, visit `/-/debug/grafana/d/codeintel-ranking/codeintel-ranking?viewPanel=100010` on your Sourcegraph instance. +To see this panel, visit `/-/debug/grafana/d/codeintel-uploads/codeintel-uploads?viewPanel=100010` on your Sourcegraph instance. *Managed by the [Sourcegraph Code intelligence team](https://handbook.sourcegraph.com/departments/engineering/teams/code-intelligence).* @@ -67172,19 +67212,19 @@ To see this panel, visit `/-/debug/grafana/d/codeintel-ranking/codeintel-ranking Query: ``` -sum by (op)(increase(src_codeintel_ranking_total{job=~"^${source:regex}.*"}[5m])) +sum by (op)(increase(src_codeintel_uploads_total{job=~"^${source:regex}.*"}[5m])) ```-#### codeintel-ranking: codeintel_ranking_99th_percentile_duration +#### codeintel-uploads: codeintel_uploads_99th_percentile_duration
99th percentile successful service operation duration over 5m
This panel has no related alerts. -To see this panel, visit `/-/debug/grafana/d/codeintel-ranking/codeintel-ranking?viewPanel=100011` on your Sourcegraph instance. +To see this panel, visit `/-/debug/grafana/d/codeintel-uploads/codeintel-uploads?viewPanel=100011` on your Sourcegraph instance. *Managed by the [Sourcegraph Code intelligence team](https://handbook.sourcegraph.com/departments/engineering/teams/code-intelligence).* @@ -67194,19 +67234,19 @@ To see this panel, visit `/-/debug/grafana/d/codeintel-ranking/codeintel-ranking Query: ``` -histogram_quantile(0.99, sum by (le,op)(rate(src_codeintel_ranking_duration_seconds_bucket{job=~"^${source:regex}.*"}[5m]))) +histogram_quantile(0.99, sum by (le,op)(rate(src_codeintel_uploads_duration_seconds_bucket{job=~"^${source:regex}.*"}[5m]))) ```-#### codeintel-ranking: codeintel_ranking_errors_total +#### codeintel-uploads: codeintel_uploads_errors_total
Service operation errors every 5m
This panel has no related alerts. -To see this panel, visit `/-/debug/grafana/d/codeintel-ranking/codeintel-ranking?viewPanel=100012` on your Sourcegraph instance. +To see this panel, visit `/-/debug/grafana/d/codeintel-uploads/codeintel-uploads?viewPanel=100012` on your Sourcegraph instance. *Managed by the [Sourcegraph Code intelligence team](https://handbook.sourcegraph.com/departments/engineering/teams/code-intelligence).* @@ -67216,197 +67256,19 @@ To see this panel, visit `/-/debug/grafana/d/codeintel-ranking/codeintel-ranking Query: ``` -sum by (op)(increase(src_codeintel_ranking_errors_total{job=~"^${source:regex}.*"}[5m])) +sum by (op)(increase(src_codeintel_uploads_errors_total{job=~"^${source:regex}.*"}[5m])) ```-#### codeintel-ranking: codeintel_ranking_error_rate +#### codeintel-uploads: codeintel_uploads_error_rate
Service operation error rate over 5m
This panel has no related alerts. -To see this panel, visit `/-/debug/grafana/d/codeintel-ranking/codeintel-ranking?viewPanel=100013` on your Sourcegraph instance. - -*Managed by the [Sourcegraph Code intelligence team](https://handbook.sourcegraph.com/departments/engineering/teams/code-intelligence).* - -Technical details
- -Query: - -``` -sum by (op)(increase(src_codeintel_ranking_errors_total{job=~"^${source:regex}.*"}[5m])) / (sum by (op)(increase(src_codeintel_ranking_total{job=~"^${source:regex}.*"}[5m])) + sum by (op)(increase(src_codeintel_ranking_errors_total{job=~"^${source:regex}.*"}[5m]))) * 100 -``` -- -### Code Intelligence > Ranking: Codeintel: Ranking > Store - -#### codeintel-ranking: codeintel_ranking_store_total - -
Aggregate store operations every 5m
- -This panel has no related alerts. - -To see this panel, visit `/-/debug/grafana/d/codeintel-ranking/codeintel-ranking?viewPanel=100100` on your Sourcegraph instance. - -*Managed by the [Sourcegraph Code intelligence team](https://handbook.sourcegraph.com/departments/engineering/teams/code-intelligence).* - -Technical details
- -Query: - -``` -sum(increase(src_codeintel_ranking_store_total{job=~"^${source:regex}.*"}[5m])) -``` -- -#### codeintel-ranking: codeintel_ranking_store_99th_percentile_duration - -
Aggregate successful store operation duration distribution over 5m
- -This panel has no related alerts. - -To see this panel, visit `/-/debug/grafana/d/codeintel-ranking/codeintel-ranking?viewPanel=100101` on your Sourcegraph instance. - -*Managed by the [Sourcegraph Code intelligence team](https://handbook.sourcegraph.com/departments/engineering/teams/code-intelligence).* - -Technical details
- -Query: - -``` -sum by (le)(rate(src_codeintel_ranking_store_duration_seconds_bucket{job=~"^${source:regex}.*"}[5m])) -``` -- -#### codeintel-ranking: codeintel_ranking_store_errors_total - -
Aggregate store operation errors every 5m
- -This panel has no related alerts. - -To see this panel, visit `/-/debug/grafana/d/codeintel-ranking/codeintel-ranking?viewPanel=100102` on your Sourcegraph instance. - -*Managed by the [Sourcegraph Code intelligence team](https://handbook.sourcegraph.com/departments/engineering/teams/code-intelligence).* - -Technical details
- -Query: - -``` -sum(increase(src_codeintel_ranking_store_errors_total{job=~"^${source:regex}.*"}[5m])) -``` -- -#### codeintel-ranking: codeintel_ranking_store_error_rate - -
Aggregate store operation error rate over 5m
- -This panel has no related alerts. - -To see this panel, visit `/-/debug/grafana/d/codeintel-ranking/codeintel-ranking?viewPanel=100103` on your Sourcegraph instance. - -*Managed by the [Sourcegraph Code intelligence team](https://handbook.sourcegraph.com/departments/engineering/teams/code-intelligence).* - -Technical details
- -Query: - -``` -sum(increase(src_codeintel_ranking_store_errors_total{job=~"^${source:regex}.*"}[5m])) / (sum(increase(src_codeintel_ranking_store_total{job=~"^${source:regex}.*"}[5m])) + sum(increase(src_codeintel_ranking_store_errors_total{job=~"^${source:regex}.*"}[5m]))) * 100 -``` -- -#### codeintel-ranking: codeintel_ranking_store_total - -
Store operations every 5m
- -This panel has no related alerts. - -To see this panel, visit `/-/debug/grafana/d/codeintel-ranking/codeintel-ranking?viewPanel=100110` on your Sourcegraph instance. - -*Managed by the [Sourcegraph Code intelligence team](https://handbook.sourcegraph.com/departments/engineering/teams/code-intelligence).* - -Technical details
- -Query: - -``` -sum by (op)(increase(src_codeintel_ranking_store_total{job=~"^${source:regex}.*"}[5m])) -``` -- -#### codeintel-ranking: codeintel_ranking_store_99th_percentile_duration - -
99th percentile successful store operation duration over 5m
- -This panel has no related alerts. - -To see this panel, visit `/-/debug/grafana/d/codeintel-ranking/codeintel-ranking?viewPanel=100111` on your Sourcegraph instance. - -*Managed by the [Sourcegraph Code intelligence team](https://handbook.sourcegraph.com/departments/engineering/teams/code-intelligence).* - -Technical details
- -Query: - -``` -histogram_quantile(0.99, sum by (le,op)(rate(src_codeintel_ranking_store_duration_seconds_bucket{job=~"^${source:regex}.*"}[5m]))) -``` -- -#### codeintel-ranking: codeintel_ranking_store_errors_total - -
Store operation errors every 5m
- -This panel has no related alerts. - -To see this panel, visit `/-/debug/grafana/d/codeintel-ranking/codeintel-ranking?viewPanel=100112` on your Sourcegraph instance. - -*Managed by the [Sourcegraph Code intelligence team](https://handbook.sourcegraph.com/departments/engineering/teams/code-intelligence).* - -Technical details
- -Query: - -``` -sum by (op)(increase(src_codeintel_ranking_store_errors_total{job=~"^${source:regex}.*"}[5m])) -``` -- -#### codeintel-ranking: codeintel_ranking_store_error_rate - -
Store operation error rate over 5m
- -This panel has no related alerts. - -To see this panel, visit `/-/debug/grafana/d/codeintel-ranking/codeintel-ranking?viewPanel=100113` on your Sourcegraph instance. +To see this panel, visit `/-/debug/grafana/d/codeintel-uploads/codeintel-uploads?viewPanel=100013` on your Sourcegraph instance. *Managed by the [Sourcegraph Code intelligence team](https://handbook.sourcegraph.com/departments/engineering/teams/code-intelligence).* @@ -67416,21 +67278,21 @@ To see this panel, visit `/-/debug/grafana/d/codeintel-ranking/codeintel-ranking Query: ``` -sum by (op)(increase(src_codeintel_ranking_store_errors_total{job=~"^${source:regex}.*"}[5m])) / (sum by (op)(increase(src_codeintel_ranking_store_total{job=~"^${source:regex}.*"}[5m])) + sum by (op)(increase(src_codeintel_ranking_store_errors_total{job=~"^${source:regex}.*"}[5m]))) * 100 +sum by (op)(increase(src_codeintel_uploads_errors_total{job=~"^${source:regex}.*"}[5m])) / (sum by (op)(increase(src_codeintel_uploads_total{job=~"^${source:regex}.*"}[5m])) + sum by (op)(increase(src_codeintel_uploads_errors_total{job=~"^${source:regex}.*"}[5m]))) * 100 ```-### Code Intelligence > Ranking: Codeintel: Ranking > LSIFStore +### Code Intelligence > Uploads: Codeintel: Uploads > Store (internal) -#### codeintel-ranking: codeintel_ranking_lsifstore_total +#### codeintel-uploads: codeintel_uploads_store_total
Aggregate store operations every 5m
This panel has no related alerts. -To see this panel, visit `/-/debug/grafana/d/codeintel-ranking/codeintel-ranking?viewPanel=100200` on your Sourcegraph instance. +To see this panel, visit `/-/debug/grafana/d/codeintel-uploads/codeintel-uploads?viewPanel=100100` on your Sourcegraph instance. *Managed by the [Sourcegraph Code intelligence team](https://handbook.sourcegraph.com/departments/engineering/teams/code-intelligence).* @@ -67440,19 +67302,19 @@ To see this panel, visit `/-/debug/grafana/d/codeintel-ranking/codeintel-ranking Query: ``` -sum(increase(src_codeintel_ranking_lsifstore_total{job=~"^${source:regex}.*"}[5m])) +sum(increase(src_codeintel_uploads_store_total{job=~"^${source:regex}.*"}[5m])) ```-#### codeintel-ranking: codeintel_ranking_lsifstore_99th_percentile_duration +#### codeintel-uploads: codeintel_uploads_store_99th_percentile_duration
Aggregate successful store operation duration distribution over 5m
This panel has no related alerts. -To see this panel, visit `/-/debug/grafana/d/codeintel-ranking/codeintel-ranking?viewPanel=100201` on your Sourcegraph instance. +To see this panel, visit `/-/debug/grafana/d/codeintel-uploads/codeintel-uploads?viewPanel=100101` on your Sourcegraph instance. *Managed by the [Sourcegraph Code intelligence team](https://handbook.sourcegraph.com/departments/engineering/teams/code-intelligence).* @@ -67462,19 +67324,19 @@ To see this panel, visit `/-/debug/grafana/d/codeintel-ranking/codeintel-ranking Query: ``` -sum by (le)(rate(src_codeintel_ranking_lsifstore_duration_seconds_bucket{job=~"^${source:regex}.*"}[5m])) +sum by (le)(rate(src_codeintel_uploads_store_duration_seconds_bucket{job=~"^${source:regex}.*"}[5m])) ```-#### codeintel-ranking: codeintel_ranking_lsifstore_errors_total +#### codeintel-uploads: codeintel_uploads_store_errors_total
Aggregate store operation errors every 5m
This panel has no related alerts. -To see this panel, visit `/-/debug/grafana/d/codeintel-ranking/codeintel-ranking?viewPanel=100202` on your Sourcegraph instance. +To see this panel, visit `/-/debug/grafana/d/codeintel-uploads/codeintel-uploads?viewPanel=100102` on your Sourcegraph instance. *Managed by the [Sourcegraph Code intelligence team](https://handbook.sourcegraph.com/departments/engineering/teams/code-intelligence).* @@ -67484,19 +67346,19 @@ To see this panel, visit `/-/debug/grafana/d/codeintel-ranking/codeintel-ranking Query: ``` -sum(increase(src_codeintel_ranking_lsifstore_errors_total{job=~"^${source:regex}.*"}[5m])) +sum(increase(src_codeintel_uploads_store_errors_total{job=~"^${source:regex}.*"}[5m])) ```-#### codeintel-ranking: codeintel_ranking_lsifstore_error_rate +#### codeintel-uploads: codeintel_uploads_store_error_rate
Aggregate store operation error rate over 5m
This panel has no related alerts. -To see this panel, visit `/-/debug/grafana/d/codeintel-ranking/codeintel-ranking?viewPanel=100203` on your Sourcegraph instance. +To see this panel, visit `/-/debug/grafana/d/codeintel-uploads/codeintel-uploads?viewPanel=100103` on your Sourcegraph instance. *Managed by the [Sourcegraph Code intelligence team](https://handbook.sourcegraph.com/departments/engineering/teams/code-intelligence).* @@ -67506,19 +67368,19 @@ To see this panel, visit `/-/debug/grafana/d/codeintel-ranking/codeintel-ranking Query: ``` -sum(increase(src_codeintel_ranking_lsifstore_errors_total{job=~"^${source:regex}.*"}[5m])) / (sum(increase(src_codeintel_ranking_lsifstore_total{job=~"^${source:regex}.*"}[5m])) + sum(increase(src_codeintel_ranking_lsifstore_errors_total{job=~"^${source:regex}.*"}[5m]))) * 100 +sum(increase(src_codeintel_uploads_store_errors_total{job=~"^${source:regex}.*"}[5m])) / (sum(increase(src_codeintel_uploads_store_total{job=~"^${source:regex}.*"}[5m])) + sum(increase(src_codeintel_uploads_store_errors_total{job=~"^${source:regex}.*"}[5m]))) * 100 ```-#### codeintel-ranking: codeintel_ranking_lsifstore_total +#### codeintel-uploads: codeintel_uploads_store_total
Store operations every 5m
This panel has no related alerts. -To see this panel, visit `/-/debug/grafana/d/codeintel-ranking/codeintel-ranking?viewPanel=100210` on your Sourcegraph instance. +To see this panel, visit `/-/debug/grafana/d/codeintel-uploads/codeintel-uploads?viewPanel=100110` on your Sourcegraph instance. *Managed by the [Sourcegraph Code intelligence team](https://handbook.sourcegraph.com/departments/engineering/teams/code-intelligence).* @@ -67528,19 +67390,19 @@ To see this panel, visit `/-/debug/grafana/d/codeintel-ranking/codeintel-ranking Query: ``` -sum by (op)(increase(src_codeintel_ranking_lsifstore_total{job=~"^${source:regex}.*"}[5m])) +sum by (op)(increase(src_codeintel_uploads_store_total{job=~"^${source:regex}.*"}[5m])) ```-#### codeintel-ranking: codeintel_ranking_lsifstore_99th_percentile_duration +#### codeintel-uploads: codeintel_uploads_store_99th_percentile_duration
99th percentile successful store operation duration over 5m
This panel has no related alerts. -To see this panel, visit `/-/debug/grafana/d/codeintel-ranking/codeintel-ranking?viewPanel=100211` on your Sourcegraph instance. +To see this panel, visit `/-/debug/grafana/d/codeintel-uploads/codeintel-uploads?viewPanel=100111` on your Sourcegraph instance. *Managed by the [Sourcegraph Code intelligence team](https://handbook.sourcegraph.com/departments/engineering/teams/code-intelligence).* @@ -67550,19 +67412,19 @@ To see this panel, visit `/-/debug/grafana/d/codeintel-ranking/codeintel-ranking Query: ``` -histogram_quantile(0.99, sum by (le,op)(rate(src_codeintel_ranking_lsifstore_duration_seconds_bucket{job=~"^${source:regex}.*"}[5m]))) +histogram_quantile(0.99, sum by (le,op)(rate(src_codeintel_uploads_store_duration_seconds_bucket{job=~"^${source:regex}.*"}[5m]))) ```-#### codeintel-ranking: codeintel_ranking_lsifstore_errors_total +#### codeintel-uploads: codeintel_uploads_store_errors_total
Store operation errors every 5m
This panel has no related alerts. -To see this panel, visit `/-/debug/grafana/d/codeintel-ranking/codeintel-ranking?viewPanel=100212` on your Sourcegraph instance. +To see this panel, visit `/-/debug/grafana/d/codeintel-uploads/codeintel-uploads?viewPanel=100112` on your Sourcegraph instance. *Managed by the [Sourcegraph Code intelligence team](https://handbook.sourcegraph.com/departments/engineering/teams/code-intelligence).* @@ -67572,251 +67434,19 @@ To see this panel, visit `/-/debug/grafana/d/codeintel-ranking/codeintel-ranking Query: ``` -sum by (op)(increase(src_codeintel_ranking_lsifstore_errors_total{job=~"^${source:regex}.*"}[5m])) +sum by (op)(increase(src_codeintel_uploads_store_errors_total{job=~"^${source:regex}.*"}[5m])) ```-#### codeintel-ranking: codeintel_ranking_lsifstore_error_rate +#### codeintel-uploads: codeintel_uploads_store_error_rate
Store operation error rate over 5m
This panel has no related alerts. -To see this panel, visit `/-/debug/grafana/d/codeintel-ranking/codeintel-ranking?viewPanel=100213` on your Sourcegraph instance. - -*Managed by the [Sourcegraph Code intelligence team](https://handbook.sourcegraph.com/departments/engineering/teams/code-intelligence).* - -Technical details
- -Query: - -``` -sum by (op)(increase(src_codeintel_ranking_lsifstore_errors_total{job=~"^${source:regex}.*"}[5m])) / (sum by (op)(increase(src_codeintel_ranking_lsifstore_total{job=~"^${source:regex}.*"}[5m])) + sum by (op)(increase(src_codeintel_ranking_lsifstore_errors_total{job=~"^${source:regex}.*"}[5m]))) * 100 -``` -- -### Code Intelligence > Ranking: Codeintel: Uploads > Pipeline task > Codeintel ranking symbol exporter - -#### codeintel-ranking: codeintel_ranking_symbol_exporter_records_processed_total - -
Records processed every 5m
- -The number of candidate records considered for cleanup. - -This panel has no related alerts. - -To see this panel, visit `/-/debug/grafana/d/codeintel-ranking/codeintel-ranking?viewPanel=100300` on your Sourcegraph instance. - -*Managed by the [Sourcegraph Code intelligence team](https://handbook.sourcegraph.com/departments/engineering/teams/code-intelligence).* - -Technical details
- -Query: - -``` -sum(increase(src_codeintel_ranking_symbol_exporter_records_processed_total{job=~"^${source:regex}.*"}[5m])) -``` -- -#### codeintel-ranking: codeintel_ranking_symbol_exporter_records_altered_total - -
Records altered every 5m
- -The number of candidate records altered as part of cleanup. - -This panel has no related alerts. - -To see this panel, visit `/-/debug/grafana/d/codeintel-ranking/codeintel-ranking?viewPanel=100301` on your Sourcegraph instance. - -*Managed by the [Sourcegraph Code intelligence team](https://handbook.sourcegraph.com/departments/engineering/teams/code-intelligence).* - -Technical details
- -Query: - -``` -sum(increase(src_codeintel_ranking_symbol_exporter_records_altered_total{job=~"^${source:regex}.*"}[5m])) -``` -- -#### codeintel-ranking: codeintel_ranking_symbol_exporter_total - -
Job invocation operations every 5m
- -This panel has no related alerts. - -To see this panel, visit `/-/debug/grafana/d/codeintel-ranking/codeintel-ranking?viewPanel=100310` on your Sourcegraph instance. - -*Managed by the [Sourcegraph Code intelligence team](https://handbook.sourcegraph.com/departments/engineering/teams/code-intelligence).* - -Technical details
- -Query: - -``` -sum by (op)(increase(src_codeintel_ranking_symbol_exporter_total{job=~"^${source:regex}.*"}[5m])) -``` -- -#### codeintel-ranking: codeintel_ranking_symbol_exporter_99th_percentile_duration - -
99th percentile successful job invocation operation duration over 5m
- -This panel has no related alerts. - -To see this panel, visit `/-/debug/grafana/d/codeintel-ranking/codeintel-ranking?viewPanel=100311` on your Sourcegraph instance. - -*Managed by the [Sourcegraph Code intelligence team](https://handbook.sourcegraph.com/departments/engineering/teams/code-intelligence).* - -Technical details
- -Query: - -``` -histogram_quantile(0.99, sum by (le,op)(rate(src_codeintel_ranking_symbol_exporter_duration_seconds_bucket{job=~"^${source:regex}.*"}[5m]))) -``` -- -#### codeintel-ranking: codeintel_ranking_symbol_exporter_errors_total - -
Job invocation operation errors every 5m
- -This panel has no related alerts. - -To see this panel, visit `/-/debug/grafana/d/codeintel-ranking/codeintel-ranking?viewPanel=100312` on your Sourcegraph instance. - -*Managed by the [Sourcegraph Code intelligence team](https://handbook.sourcegraph.com/departments/engineering/teams/code-intelligence).* - -Technical details
- -Query: - -``` -sum by (op)(increase(src_codeintel_ranking_symbol_exporter_errors_total{job=~"^${source:regex}.*"}[5m])) -``` -- -#### codeintel-ranking: codeintel_ranking_symbol_exporter_error_rate - -
Job invocation operation error rate over 5m
- -This panel has no related alerts. - -To see this panel, visit `/-/debug/grafana/d/codeintel-ranking/codeintel-ranking?viewPanel=100313` on your Sourcegraph instance. - -*Managed by the [Sourcegraph Code intelligence team](https://handbook.sourcegraph.com/departments/engineering/teams/code-intelligence).* - -Technical details
- -Query: - -``` -sum by (op)(increase(src_codeintel_ranking_symbol_exporter_errors_total{job=~"^${source:regex}.*"}[5m])) / (sum by (op)(increase(src_codeintel_ranking_symbol_exporter_total{job=~"^${source:regex}.*"}[5m])) + sum by (op)(increase(src_codeintel_ranking_symbol_exporter_errors_total{job=~"^${source:regex}.*"}[5m]))) * 100 -``` -- -### Code Intelligence > Ranking: Codeintel: Uploads > Pipeline task > Codeintel ranking file reference count seed mapper - -#### codeintel-ranking: codeintel_ranking_file_reference_count_seed_mapper_records_processed_total - -
Records processed every 5m
- -The number of candidate records considered for cleanup. - -This panel has no related alerts. - -To see this panel, visit `/-/debug/grafana/d/codeintel-ranking/codeintel-ranking?viewPanel=100400` on your Sourcegraph instance. - -*Managed by the [Sourcegraph Code intelligence team](https://handbook.sourcegraph.com/departments/engineering/teams/code-intelligence).* - -Technical details
- -Query: - -``` -sum(increase(src_codeintel_ranking_file_reference_count_seed_mapper_records_processed_total{job=~"^${source:regex}.*"}[5m])) -``` -- -#### codeintel-ranking: codeintel_ranking_file_reference_count_seed_mapper_records_altered_total - -
Records altered every 5m
- -The number of candidate records altered as part of cleanup. - -This panel has no related alerts. - -To see this panel, visit `/-/debug/grafana/d/codeintel-ranking/codeintel-ranking?viewPanel=100401` on your Sourcegraph instance. - -*Managed by the [Sourcegraph Code intelligence team](https://handbook.sourcegraph.com/departments/engineering/teams/code-intelligence).* - -Technical details
- -Query: - -``` -sum(increase(src_codeintel_ranking_file_reference_count_seed_mapper_records_altered_total{job=~"^${source:regex}.*"}[5m])) -``` -- -#### codeintel-ranking: codeintel_ranking_file_reference_count_seed_mapper_total - -
Job invocation operations every 5m
- -This panel has no related alerts. - -To see this panel, visit `/-/debug/grafana/d/codeintel-ranking/codeintel-ranking?viewPanel=100410` on your Sourcegraph instance. - -*Managed by the [Sourcegraph Code intelligence team](https://handbook.sourcegraph.com/departments/engineering/teams/code-intelligence).* - -Technical details
- -Query: - -``` -sum by (op)(increase(src_codeintel_ranking_file_reference_count_seed_mapper_total{job=~"^${source:regex}.*"}[5m])) -``` -- -#### codeintel-ranking: codeintel_ranking_file_reference_count_seed_mapper_99th_percentile_duration - -
99th percentile successful job invocation operation duration over 5m
- -This panel has no related alerts. - -To see this panel, visit `/-/debug/grafana/d/codeintel-ranking/codeintel-ranking?viewPanel=100411` on your Sourcegraph instance. +To see this panel, visit `/-/debug/grafana/d/codeintel-uploads/codeintel-uploads?viewPanel=100113` on your Sourcegraph instance. *Managed by the [Sourcegraph Code intelligence team](https://handbook.sourcegraph.com/departments/engineering/teams/code-intelligence).* @@ -67826,19 +67456,21 @@ To see this panel, visit `/-/debug/grafana/d/codeintel-ranking/codeintel-ranking Query: ``` -histogram_quantile(0.99, sum by (le,op)(rate(src_codeintel_ranking_file_reference_count_seed_mapper_duration_seconds_bucket{job=~"^${source:regex}.*"}[5m]))) +sum by (op)(increase(src_codeintel_uploads_store_errors_total{job=~"^${source:regex}.*"}[5m])) / (sum by (op)(increase(src_codeintel_uploads_store_total{job=~"^${source:regex}.*"}[5m])) + sum by (op)(increase(src_codeintel_uploads_store_errors_total{job=~"^${source:regex}.*"}[5m]))) * 100 ```-#### codeintel-ranking: codeintel_ranking_file_reference_count_seed_mapper_errors_total +### Code Intelligence > Uploads: Codeintel: Uploads > GQL Transport -
Job invocation operation errors every 5m
+#### codeintel-uploads: codeintel_uploads_transport_graphql_total + +Aggregate resolver operations every 5m
This panel has no related alerts. -To see this panel, visit `/-/debug/grafana/d/codeintel-ranking/codeintel-ranking?viewPanel=100412` on your Sourcegraph instance. +To see this panel, visit `/-/debug/grafana/d/codeintel-uploads/codeintel-uploads?viewPanel=100200` on your Sourcegraph instance. *Managed by the [Sourcegraph Code intelligence team](https://handbook.sourcegraph.com/departments/engineering/teams/code-intelligence).* @@ -67848,19 +67480,19 @@ To see this panel, visit `/-/debug/grafana/d/codeintel-ranking/codeintel-ranking Query: ``` -sum by (op)(increase(src_codeintel_ranking_file_reference_count_seed_mapper_errors_total{job=~"^${source:regex}.*"}[5m])) +sum(increase(src_codeintel_uploads_transport_graphql_total{job=~"^${source:regex}.*"}[5m])) ```-#### codeintel-ranking: codeintel_ranking_file_reference_count_seed_mapper_error_rate +#### codeintel-uploads: codeintel_uploads_transport_graphql_99th_percentile_duration -
Job invocation operation error rate over 5m
+Aggregate successful resolver operation duration distribution over 5m
This panel has no related alerts. -To see this panel, visit `/-/debug/grafana/d/codeintel-ranking/codeintel-ranking?viewPanel=100413` on your Sourcegraph instance. +To see this panel, visit `/-/debug/grafana/d/codeintel-uploads/codeintel-uploads?viewPanel=100201` on your Sourcegraph instance. *Managed by the [Sourcegraph Code intelligence team](https://handbook.sourcegraph.com/departments/engineering/teams/code-intelligence).* @@ -67870,23 +67502,19 @@ To see this panel, visit `/-/debug/grafana/d/codeintel-ranking/codeintel-ranking Query: ``` -sum by (op)(increase(src_codeintel_ranking_file_reference_count_seed_mapper_errors_total{job=~"^${source:regex}.*"}[5m])) / (sum by (op)(increase(src_codeintel_ranking_file_reference_count_seed_mapper_total{job=~"^${source:regex}.*"}[5m])) + sum by (op)(increase(src_codeintel_ranking_file_reference_count_seed_mapper_errors_total{job=~"^${source:regex}.*"}[5m]))) * 100 +sum by (le)(rate(src_codeintel_uploads_transport_graphql_duration_seconds_bucket{job=~"^${source:regex}.*"}[5m])) ```-### Code Intelligence > Ranking: Codeintel: Uploads > Pipeline task > Codeintel ranking file reference count mapper - -#### codeintel-ranking: codeintel_ranking_file_reference_count_mapper_records_processed_total - -
Records processed every 5m
+#### codeintel-uploads: codeintel_uploads_transport_graphql_errors_total -The number of candidate records considered for cleanup. +Aggregate resolver operation errors every 5m
This panel has no related alerts. -To see this panel, visit `/-/debug/grafana/d/codeintel-ranking/codeintel-ranking?viewPanel=100500` on your Sourcegraph instance. +To see this panel, visit `/-/debug/grafana/d/codeintel-uploads/codeintel-uploads?viewPanel=100202` on your Sourcegraph instance. *Managed by the [Sourcegraph Code intelligence team](https://handbook.sourcegraph.com/departments/engineering/teams/code-intelligence).* @@ -67896,21 +67524,19 @@ To see this panel, visit `/-/debug/grafana/d/codeintel-ranking/codeintel-ranking Query: ``` -sum(increase(src_codeintel_ranking_file_reference_count_mapper_records_processed_total{job=~"^${source:regex}.*"}[5m])) +sum(increase(src_codeintel_uploads_transport_graphql_errors_total{job=~"^${source:regex}.*"}[5m])) ```-#### codeintel-ranking: codeintel_ranking_file_reference_count_mapper_records_altered_total - -
Records altered every 5m
+#### codeintel-uploads: codeintel_uploads_transport_graphql_error_rate -The number of candidate records altered as part of cleanup. +Aggregate resolver operation error rate over 5m
This panel has no related alerts. -To see this panel, visit `/-/debug/grafana/d/codeintel-ranking/codeintel-ranking?viewPanel=100501` on your Sourcegraph instance. +To see this panel, visit `/-/debug/grafana/d/codeintel-uploads/codeintel-uploads?viewPanel=100203` on your Sourcegraph instance. *Managed by the [Sourcegraph Code intelligence team](https://handbook.sourcegraph.com/departments/engineering/teams/code-intelligence).* @@ -67920,19 +67546,19 @@ To see this panel, visit `/-/debug/grafana/d/codeintel-ranking/codeintel-ranking Query: ``` -sum(increase(src_codeintel_ranking_file_reference_count_mapper_records_altered_total{job=~"^${source:regex}.*"}[5m])) +sum(increase(src_codeintel_uploads_transport_graphql_errors_total{job=~"^${source:regex}.*"}[5m])) / (sum(increase(src_codeintel_uploads_transport_graphql_total{job=~"^${source:regex}.*"}[5m])) + sum(increase(src_codeintel_uploads_transport_graphql_errors_total{job=~"^${source:regex}.*"}[5m]))) * 100 ```-#### codeintel-ranking: codeintel_ranking_file_reference_count_mapper_total +#### codeintel-uploads: codeintel_uploads_transport_graphql_total -
Job invocation operations every 5m
+Resolver operations every 5m
This panel has no related alerts. -To see this panel, visit `/-/debug/grafana/d/codeintel-ranking/codeintel-ranking?viewPanel=100510` on your Sourcegraph instance. +To see this panel, visit `/-/debug/grafana/d/codeintel-uploads/codeintel-uploads?viewPanel=100210` on your Sourcegraph instance. *Managed by the [Sourcegraph Code intelligence team](https://handbook.sourcegraph.com/departments/engineering/teams/code-intelligence).* @@ -67942,19 +67568,19 @@ To see this panel, visit `/-/debug/grafana/d/codeintel-ranking/codeintel-ranking Query: ``` -sum by (op)(increase(src_codeintel_ranking_file_reference_count_mapper_total{job=~"^${source:regex}.*"}[5m])) +sum by (op)(increase(src_codeintel_uploads_transport_graphql_total{job=~"^${source:regex}.*"}[5m])) ```-#### codeintel-ranking: codeintel_ranking_file_reference_count_mapper_99th_percentile_duration +#### codeintel-uploads: codeintel_uploads_transport_graphql_99th_percentile_duration -
99th percentile successful job invocation operation duration over 5m
+99th percentile successful resolver operation duration over 5m
This panel has no related alerts. -To see this panel, visit `/-/debug/grafana/d/codeintel-ranking/codeintel-ranking?viewPanel=100511` on your Sourcegraph instance. +To see this panel, visit `/-/debug/grafana/d/codeintel-uploads/codeintel-uploads?viewPanel=100211` on your Sourcegraph instance. *Managed by the [Sourcegraph Code intelligence team](https://handbook.sourcegraph.com/departments/engineering/teams/code-intelligence).* @@ -67964,19 +67590,19 @@ To see this panel, visit `/-/debug/grafana/d/codeintel-ranking/codeintel-ranking Query: ``` -histogram_quantile(0.99, sum by (le,op)(rate(src_codeintel_ranking_file_reference_count_mapper_duration_seconds_bucket{job=~"^${source:regex}.*"}[5m]))) +histogram_quantile(0.99, sum by (le,op)(rate(src_codeintel_uploads_transport_graphql_duration_seconds_bucket{job=~"^${source:regex}.*"}[5m]))) ```-#### codeintel-ranking: codeintel_ranking_file_reference_count_mapper_errors_total +#### codeintel-uploads: codeintel_uploads_transport_graphql_errors_total -
Job invocation operation errors every 5m
+Resolver operation errors every 5m
This panel has no related alerts. -To see this panel, visit `/-/debug/grafana/d/codeintel-ranking/codeintel-ranking?viewPanel=100512` on your Sourcegraph instance. +To see this panel, visit `/-/debug/grafana/d/codeintel-uploads/codeintel-uploads?viewPanel=100212` on your Sourcegraph instance. *Managed by the [Sourcegraph Code intelligence team](https://handbook.sourcegraph.com/departments/engineering/teams/code-intelligence).* @@ -67986,19 +67612,19 @@ To see this panel, visit `/-/debug/grafana/d/codeintel-ranking/codeintel-ranking Query: ``` -sum by (op)(increase(src_codeintel_ranking_file_reference_count_mapper_errors_total{job=~"^${source:regex}.*"}[5m])) +sum by (op)(increase(src_codeintel_uploads_transport_graphql_errors_total{job=~"^${source:regex}.*"}[5m])) ```-#### codeintel-ranking: codeintel_ranking_file_reference_count_mapper_error_rate +#### codeintel-uploads: codeintel_uploads_transport_graphql_error_rate -
Job invocation operation error rate over 5m
+Resolver operation error rate over 5m
This panel has no related alerts. -To see this panel, visit `/-/debug/grafana/d/codeintel-ranking/codeintel-ranking?viewPanel=100513` on your Sourcegraph instance. +To see this panel, visit `/-/debug/grafana/d/codeintel-uploads/codeintel-uploads?viewPanel=100213` on your Sourcegraph instance. *Managed by the [Sourcegraph Code intelligence team](https://handbook.sourcegraph.com/departments/engineering/teams/code-intelligence).* @@ -68008,23 +67634,21 @@ To see this panel, visit `/-/debug/grafana/d/codeintel-ranking/codeintel-ranking Query: ``` -sum by (op)(increase(src_codeintel_ranking_file_reference_count_mapper_errors_total{job=~"^${source:regex}.*"}[5m])) / (sum by (op)(increase(src_codeintel_ranking_file_reference_count_mapper_total{job=~"^${source:regex}.*"}[5m])) + sum by (op)(increase(src_codeintel_ranking_file_reference_count_mapper_errors_total{job=~"^${source:regex}.*"}[5m]))) * 100 +sum by (op)(increase(src_codeintel_uploads_transport_graphql_errors_total{job=~"^${source:regex}.*"}[5m])) / (sum by (op)(increase(src_codeintel_uploads_transport_graphql_total{job=~"^${source:regex}.*"}[5m])) + sum by (op)(increase(src_codeintel_uploads_transport_graphql_errors_total{job=~"^${source:regex}.*"}[5m]))) * 100 ```-### Code Intelligence > Ranking: Codeintel: Uploads > Pipeline task > Codeintel ranking file reference count reducer - -#### codeintel-ranking: codeintel_ranking_file_reference_count_reducer_records_processed_total +### Code Intelligence > Uploads: Codeintel: Uploads > HTTP Transport -
Records processed every 5m
+#### codeintel-uploads: codeintel_uploads_transport_http_total -The number of candidate records considered for cleanup. +Aggregate http handler operations every 5m
This panel has no related alerts. -To see this panel, visit `/-/debug/grafana/d/codeintel-ranking/codeintel-ranking?viewPanel=100600` on your Sourcegraph instance. +To see this panel, visit `/-/debug/grafana/d/codeintel-uploads/codeintel-uploads?viewPanel=100300` on your Sourcegraph instance. *Managed by the [Sourcegraph Code intelligence team](https://handbook.sourcegraph.com/departments/engineering/teams/code-intelligence).* @@ -68034,21 +67658,19 @@ To see this panel, visit `/-/debug/grafana/d/codeintel-ranking/codeintel-ranking Query: ``` -sum(increase(src_codeintel_ranking_file_reference_count_reducer_records_processed_total{job=~"^${source:regex}.*"}[5m])) +sum(increase(src_codeintel_uploads_transport_http_total{job=~"^${source:regex}.*"}[5m])) ```-#### codeintel-ranking: codeintel_ranking_file_reference_count_reducer_records_altered_total - -
Records altered every 5m
+#### codeintel-uploads: codeintel_uploads_transport_http_99th_percentile_duration -The number of candidate records altered as part of cleanup. +Aggregate successful http handler operation duration distribution over 5m
This panel has no related alerts. -To see this panel, visit `/-/debug/grafana/d/codeintel-ranking/codeintel-ranking?viewPanel=100601` on your Sourcegraph instance. +To see this panel, visit `/-/debug/grafana/d/codeintel-uploads/codeintel-uploads?viewPanel=100301` on your Sourcegraph instance. *Managed by the [Sourcegraph Code intelligence team](https://handbook.sourcegraph.com/departments/engineering/teams/code-intelligence).* @@ -68058,19 +67680,19 @@ To see this panel, visit `/-/debug/grafana/d/codeintel-ranking/codeintel-ranking Query: ``` -sum(increase(src_codeintel_ranking_file_reference_count_reducer_records_altered_total{job=~"^${source:regex}.*"}[5m])) +sum by (le)(rate(src_codeintel_uploads_transport_http_duration_seconds_bucket{job=~"^${source:regex}.*"}[5m])) ```-#### codeintel-ranking: codeintel_ranking_file_reference_count_reducer_total +#### codeintel-uploads: codeintel_uploads_transport_http_errors_total -
Job invocation operations every 5m
+Aggregate http handler operation errors every 5m
This panel has no related alerts. -To see this panel, visit `/-/debug/grafana/d/codeintel-ranking/codeintel-ranking?viewPanel=100610` on your Sourcegraph instance. +To see this panel, visit `/-/debug/grafana/d/codeintel-uploads/codeintel-uploads?viewPanel=100302` on your Sourcegraph instance. *Managed by the [Sourcegraph Code intelligence team](https://handbook.sourcegraph.com/departments/engineering/teams/code-intelligence).* @@ -68080,19 +67702,19 @@ To see this panel, visit `/-/debug/grafana/d/codeintel-ranking/codeintel-ranking Query: ``` -sum by (op)(increase(src_codeintel_ranking_file_reference_count_reducer_total{job=~"^${source:regex}.*"}[5m])) +sum(increase(src_codeintel_uploads_transport_http_errors_total{job=~"^${source:regex}.*"}[5m])) ```-#### codeintel-ranking: codeintel_ranking_file_reference_count_reducer_99th_percentile_duration +#### codeintel-uploads: codeintel_uploads_transport_http_error_rate -
99th percentile successful job invocation operation duration over 5m
+Aggregate http handler operation error rate over 5m
This panel has no related alerts. -To see this panel, visit `/-/debug/grafana/d/codeintel-ranking/codeintel-ranking?viewPanel=100611` on your Sourcegraph instance. +To see this panel, visit `/-/debug/grafana/d/codeintel-uploads/codeintel-uploads?viewPanel=100303` on your Sourcegraph instance. *Managed by the [Sourcegraph Code intelligence team](https://handbook.sourcegraph.com/departments/engineering/teams/code-intelligence).* @@ -68102,19 +67724,19 @@ To see this panel, visit `/-/debug/grafana/d/codeintel-ranking/codeintel-ranking Query: ``` -histogram_quantile(0.99, sum by (le,op)(rate(src_codeintel_ranking_file_reference_count_reducer_duration_seconds_bucket{job=~"^${source:regex}.*"}[5m]))) +sum(increase(src_codeintel_uploads_transport_http_errors_total{job=~"^${source:regex}.*"}[5m])) / (sum(increase(src_codeintel_uploads_transport_http_total{job=~"^${source:regex}.*"}[5m])) + sum(increase(src_codeintel_uploads_transport_http_errors_total{job=~"^${source:regex}.*"}[5m]))) * 100 ```-#### codeintel-ranking: codeintel_ranking_file_reference_count_reducer_errors_total +#### codeintel-uploads: codeintel_uploads_transport_http_total -
Job invocation operation errors every 5m
+Http handler operations every 5m
This panel has no related alerts. -To see this panel, visit `/-/debug/grafana/d/codeintel-ranking/codeintel-ranking?viewPanel=100612` on your Sourcegraph instance. +To see this panel, visit `/-/debug/grafana/d/codeintel-uploads/codeintel-uploads?viewPanel=100310` on your Sourcegraph instance. *Managed by the [Sourcegraph Code intelligence team](https://handbook.sourcegraph.com/departments/engineering/teams/code-intelligence).* @@ -68124,19 +67746,19 @@ To see this panel, visit `/-/debug/grafana/d/codeintel-ranking/codeintel-ranking Query: ``` -sum by (op)(increase(src_codeintel_ranking_file_reference_count_reducer_errors_total{job=~"^${source:regex}.*"}[5m])) +sum by (op)(increase(src_codeintel_uploads_transport_http_total{job=~"^${source:regex}.*"}[5m])) ```-#### codeintel-ranking: codeintel_ranking_file_reference_count_reducer_error_rate +#### codeintel-uploads: codeintel_uploads_transport_http_99th_percentile_duration -
Job invocation operation error rate over 5m
+99th percentile successful http handler operation duration over 5m
This panel has no related alerts. -To see this panel, visit `/-/debug/grafana/d/codeintel-ranking/codeintel-ranking?viewPanel=100613` on your Sourcegraph instance. +To see this panel, visit `/-/debug/grafana/d/codeintel-uploads/codeintel-uploads?viewPanel=100311` on your Sourcegraph instance. *Managed by the [Sourcegraph Code intelligence team](https://handbook.sourcegraph.com/departments/engineering/teams/code-intelligence).* @@ -68146,23 +67768,19 @@ To see this panel, visit `/-/debug/grafana/d/codeintel-ranking/codeintel-ranking Query: ``` -sum by (op)(increase(src_codeintel_ranking_file_reference_count_reducer_errors_total{job=~"^${source:regex}.*"}[5m])) / (sum by (op)(increase(src_codeintel_ranking_file_reference_count_reducer_total{job=~"^${source:regex}.*"}[5m])) + sum by (op)(increase(src_codeintel_ranking_file_reference_count_reducer_errors_total{job=~"^${source:regex}.*"}[5m]))) * 100 +histogram_quantile(0.99, sum by (le,op)(rate(src_codeintel_uploads_transport_http_duration_seconds_bucket{job=~"^${source:regex}.*"}[5m]))) ```-### Code Intelligence > Ranking: Codeintel: Uploads > Janitor task > Codeintel ranking processed references janitor - -#### codeintel-ranking: codeintel_ranking_processed_references_janitor_records_scanned_total - -
Records scanned every 5m
+#### codeintel-uploads: codeintel_uploads_transport_http_errors_total -The number of candidate records considered for cleanup. +Http handler operation errors every 5m
This panel has no related alerts. -To see this panel, visit `/-/debug/grafana/d/codeintel-ranking/codeintel-ranking?viewPanel=100700` on your Sourcegraph instance. +To see this panel, visit `/-/debug/grafana/d/codeintel-uploads/codeintel-uploads?viewPanel=100312` on your Sourcegraph instance. *Managed by the [Sourcegraph Code intelligence team](https://handbook.sourcegraph.com/departments/engineering/teams/code-intelligence).* @@ -68172,21 +67790,19 @@ To see this panel, visit `/-/debug/grafana/d/codeintel-ranking/codeintel-ranking Query: ``` -sum(increase(src_codeintel_ranking_processed_references_janitor_records_scanned_total{job=~"^${source:regex}.*"}[5m])) +sum by (op)(increase(src_codeintel_uploads_transport_http_errors_total{job=~"^${source:regex}.*"}[5m])) ```-#### codeintel-ranking: codeintel_ranking_processed_references_janitor_records_altered_total - -
Records altered every 5m
+#### codeintel-uploads: codeintel_uploads_transport_http_error_rate -The number of candidate records altered as part of cleanup. +Http handler operation error rate over 5m
This panel has no related alerts. -To see this panel, visit `/-/debug/grafana/d/codeintel-ranking/codeintel-ranking?viewPanel=100701` on your Sourcegraph instance. +To see this panel, visit `/-/debug/grafana/d/codeintel-uploads/codeintel-uploads?viewPanel=100313` on your Sourcegraph instance. *Managed by the [Sourcegraph Code intelligence team](https://handbook.sourcegraph.com/departments/engineering/teams/code-intelligence).* @@ -68196,19 +67812,23 @@ To see this panel, visit `/-/debug/grafana/d/codeintel-ranking/codeintel-ranking Query: ``` -sum(increase(src_codeintel_ranking_processed_references_janitor_records_altered_total{job=~"^${source:regex}.*"}[5m])) +sum by (op)(increase(src_codeintel_uploads_transport_http_errors_total{job=~"^${source:regex}.*"}[5m])) / (sum by (op)(increase(src_codeintel_uploads_transport_http_total{job=~"^${source:regex}.*"}[5m])) + sum by (op)(increase(src_codeintel_uploads_transport_http_errors_total{job=~"^${source:regex}.*"}[5m]))) * 100 ```-#### codeintel-ranking: codeintel_ranking_processed_references_janitor_total +### Code Intelligence > Uploads: Codeintel: Uploads > Expiration task -
Job invocation operations every 5m
+#### codeintel-uploads: codeintel_background_repositories_scanned_total + +Lsif upload repository scan repositories scanned every 5m
+ +Number of repositories scanned for data retention This panel has no related alerts. -To see this panel, visit `/-/debug/grafana/d/codeintel-ranking/codeintel-ranking?viewPanel=100710` on your Sourcegraph instance. +To see this panel, visit `/-/debug/grafana/d/codeintel-uploads/codeintel-uploads?viewPanel=100400` on your Sourcegraph instance. *Managed by the [Sourcegraph Code intelligence team](https://handbook.sourcegraph.com/departments/engineering/teams/code-intelligence).* @@ -68218,19 +67838,21 @@ To see this panel, visit `/-/debug/grafana/d/codeintel-ranking/codeintel-ranking Query: ``` -sum by (op)(increase(src_codeintel_ranking_processed_references_janitor_total{job=~"^${source:regex}.*"}[5m])) +sum(increase(src_codeintel_background_repositories_scanned_total{job=~"^${source:regex}.*"}[5m])) ```-#### codeintel-ranking: codeintel_ranking_processed_references_janitor_99th_percentile_duration +#### codeintel-uploads: codeintel_background_upload_records_scanned_total -
99th percentile successful job invocation operation duration over 5m
+Lsif upload records scan records scanned every 5m
+ +Number of codeintel upload records scanned for data retention This panel has no related alerts. -To see this panel, visit `/-/debug/grafana/d/codeintel-ranking/codeintel-ranking?viewPanel=100711` on your Sourcegraph instance. +To see this panel, visit `/-/debug/grafana/d/codeintel-uploads/codeintel-uploads?viewPanel=100401` on your Sourcegraph instance. *Managed by the [Sourcegraph Code intelligence team](https://handbook.sourcegraph.com/departments/engineering/teams/code-intelligence).* @@ -68240,19 +67862,21 @@ To see this panel, visit `/-/debug/grafana/d/codeintel-ranking/codeintel-ranking Query: ``` -histogram_quantile(0.99, sum by (le,op)(rate(src_codeintel_ranking_processed_references_janitor_duration_seconds_bucket{job=~"^${source:regex}.*"}[5m]))) +sum(increase(src_codeintel_background_upload_records_scanned_total{job=~"^${source:regex}.*"}[5m])) ```-#### codeintel-ranking: codeintel_ranking_processed_references_janitor_errors_total +#### codeintel-uploads: codeintel_background_commits_scanned_total -
Job invocation operation errors every 5m
+Lsif upload commits scanned commits scanned every 5m
+ +Number of commits reachable from a codeintel upload record scanned for data retention This panel has no related alerts. -To see this panel, visit `/-/debug/grafana/d/codeintel-ranking/codeintel-ranking?viewPanel=100712` on your Sourcegraph instance. +To see this panel, visit `/-/debug/grafana/d/codeintel-uploads/codeintel-uploads?viewPanel=100402` on your Sourcegraph instance. *Managed by the [Sourcegraph Code intelligence team](https://handbook.sourcegraph.com/departments/engineering/teams/code-intelligence).* @@ -68262,19 +67886,21 @@ To see this panel, visit `/-/debug/grafana/d/codeintel-ranking/codeintel-ranking Query: ``` -sum by (op)(increase(src_codeintel_ranking_processed_references_janitor_errors_total{job=~"^${source:regex}.*"}[5m])) +sum(increase(src_codeintel_background_commits_scanned_total{job=~"^${source:regex}.*"}[5m])) ```-#### codeintel-ranking: codeintel_ranking_processed_references_janitor_error_rate +#### codeintel-uploads: codeintel_background_upload_records_expired_total -
Job invocation operation error rate over 5m
+Lsif upload records expired uploads scanned every 5m
+ +Number of codeintel upload records marked as expired This panel has no related alerts. -To see this panel, visit `/-/debug/grafana/d/codeintel-ranking/codeintel-ranking?viewPanel=100713` on your Sourcegraph instance. +To see this panel, visit `/-/debug/grafana/d/codeintel-uploads/codeintel-uploads?viewPanel=100403` on your Sourcegraph instance. *Managed by the [Sourcegraph Code intelligence team](https://handbook.sourcegraph.com/departments/engineering/teams/code-intelligence).* @@ -68284,15 +67910,15 @@ To see this panel, visit `/-/debug/grafana/d/codeintel-ranking/codeintel-ranking Query: ``` -sum by (op)(increase(src_codeintel_ranking_processed_references_janitor_errors_total{job=~"^${source:regex}.*"}[5m])) / (sum by (op)(increase(src_codeintel_ranking_processed_references_janitor_total{job=~"^${source:regex}.*"}[5m])) + sum by (op)(increase(src_codeintel_ranking_processed_references_janitor_errors_total{job=~"^${source:regex}.*"}[5m]))) * 100 +sum(increase(src_codeintel_background_upload_records_expired_total{job=~"^${source:regex}.*"}[5m])) ```-### Code Intelligence > Ranking: Codeintel: Uploads > Janitor task > Codeintel ranking processed paths janitor +### Code Intelligence > Uploads: Codeintel: Uploads > Janitor task > Codeintel uploads janitor unknown repository -#### codeintel-ranking: codeintel_ranking_processed_paths_janitor_records_scanned_total +#### codeintel-uploads: codeintel_uploads_janitor_unknown_repository_records_scanned_total
Records scanned every 5m
@@ -68300,7 +67926,7 @@ The number of candidate records considered for cleanup. This panel has no related alerts. -To see this panel, visit `/-/debug/grafana/d/codeintel-ranking/codeintel-ranking?viewPanel=100800` on your Sourcegraph instance. +To see this panel, visit `/-/debug/grafana/d/codeintel-uploads/codeintel-uploads?viewPanel=100500` on your Sourcegraph instance. *Managed by the [Sourcegraph Code intelligence team](https://handbook.sourcegraph.com/departments/engineering/teams/code-intelligence).* @@ -68310,13 +67936,13 @@ To see this panel, visit `/-/debug/grafana/d/codeintel-ranking/codeintel-ranking Query: ``` -sum(increase(src_codeintel_ranking_processed_paths_janitor_records_scanned_total{job=~"^${source:regex}.*"}[5m])) +sum(increase(src_codeintel_uploads_janitor_unknown_repository_records_scanned_total{job=~"^${source:regex}.*"}[5m])) ```-#### codeintel-ranking: codeintel_ranking_processed_paths_janitor_records_altered_total +#### codeintel-uploads: codeintel_uploads_janitor_unknown_repository_records_altered_total
Records altered every 5m
@@ -68324,7 +67950,7 @@ The number of candidate records altered as part of cleanup. This panel has no related alerts. -To see this panel, visit `/-/debug/grafana/d/codeintel-ranking/codeintel-ranking?viewPanel=100801` on your Sourcegraph instance. +To see this panel, visit `/-/debug/grafana/d/codeintel-uploads/codeintel-uploads?viewPanel=100501` on your Sourcegraph instance. *Managed by the [Sourcegraph Code intelligence team](https://handbook.sourcegraph.com/departments/engineering/teams/code-intelligence).* @@ -68334,19 +67960,19 @@ To see this panel, visit `/-/debug/grafana/d/codeintel-ranking/codeintel-ranking Query: ``` -sum(increase(src_codeintel_ranking_processed_paths_janitor_records_altered_total{job=~"^${source:regex}.*"}[5m])) +sum(increase(src_codeintel_uploads_janitor_unknown_repository_records_altered_total{job=~"^${source:regex}.*"}[5m])) ```-#### codeintel-ranking: codeintel_ranking_processed_paths_janitor_total +#### codeintel-uploads: codeintel_uploads_janitor_unknown_repository_total
Job invocation operations every 5m
This panel has no related alerts. -To see this panel, visit `/-/debug/grafana/d/codeintel-ranking/codeintel-ranking?viewPanel=100810` on your Sourcegraph instance. +To see this panel, visit `/-/debug/grafana/d/codeintel-uploads/codeintel-uploads?viewPanel=100510` on your Sourcegraph instance. *Managed by the [Sourcegraph Code intelligence team](https://handbook.sourcegraph.com/departments/engineering/teams/code-intelligence).* @@ -68356,19 +67982,19 @@ To see this panel, visit `/-/debug/grafana/d/codeintel-ranking/codeintel-ranking Query: ``` -sum by (op)(increase(src_codeintel_ranking_processed_paths_janitor_total{job=~"^${source:regex}.*"}[5m])) +sum by (op)(increase(src_codeintel_uploads_janitor_unknown_repository_total{job=~"^${source:regex}.*"}[5m])) ```-#### codeintel-ranking: codeintel_ranking_processed_paths_janitor_99th_percentile_duration +#### codeintel-uploads: codeintel_uploads_janitor_unknown_repository_99th_percentile_duration
99th percentile successful job invocation operation duration over 5m
This panel has no related alerts. -To see this panel, visit `/-/debug/grafana/d/codeintel-ranking/codeintel-ranking?viewPanel=100811` on your Sourcegraph instance. +To see this panel, visit `/-/debug/grafana/d/codeintel-uploads/codeintel-uploads?viewPanel=100511` on your Sourcegraph instance. *Managed by the [Sourcegraph Code intelligence team](https://handbook.sourcegraph.com/departments/engineering/teams/code-intelligence).* @@ -68378,19 +68004,19 @@ To see this panel, visit `/-/debug/grafana/d/codeintel-ranking/codeintel-ranking Query: ``` -histogram_quantile(0.99, sum by (le,op)(rate(src_codeintel_ranking_processed_paths_janitor_duration_seconds_bucket{job=~"^${source:regex}.*"}[5m]))) +histogram_quantile(0.99, sum by (le,op)(rate(src_codeintel_uploads_janitor_unknown_repository_duration_seconds_bucket{job=~"^${source:regex}.*"}[5m]))) ```-#### codeintel-ranking: codeintel_ranking_processed_paths_janitor_errors_total +#### codeintel-uploads: codeintel_uploads_janitor_unknown_repository_errors_total
Job invocation operation errors every 5m
This panel has no related alerts. -To see this panel, visit `/-/debug/grafana/d/codeintel-ranking/codeintel-ranking?viewPanel=100812` on your Sourcegraph instance. +To see this panel, visit `/-/debug/grafana/d/codeintel-uploads/codeintel-uploads?viewPanel=100512` on your Sourcegraph instance. *Managed by the [Sourcegraph Code intelligence team](https://handbook.sourcegraph.com/departments/engineering/teams/code-intelligence).* @@ -68400,19 +68026,19 @@ To see this panel, visit `/-/debug/grafana/d/codeintel-ranking/codeintel-ranking Query: ``` -sum by (op)(increase(src_codeintel_ranking_processed_paths_janitor_errors_total{job=~"^${source:regex}.*"}[5m])) +sum by (op)(increase(src_codeintel_uploads_janitor_unknown_repository_errors_total{job=~"^${source:regex}.*"}[5m])) ```-#### codeintel-ranking: codeintel_ranking_processed_paths_janitor_error_rate +#### codeintel-uploads: codeintel_uploads_janitor_unknown_repository_error_rate
Job invocation operation error rate over 5m
This panel has no related alerts. -To see this panel, visit `/-/debug/grafana/d/codeintel-ranking/codeintel-ranking?viewPanel=100813` on your Sourcegraph instance. +To see this panel, visit `/-/debug/grafana/d/codeintel-uploads/codeintel-uploads?viewPanel=100513` on your Sourcegraph instance. *Managed by the [Sourcegraph Code intelligence team](https://handbook.sourcegraph.com/departments/engineering/teams/code-intelligence).* @@ -68422,15 +68048,15 @@ To see this panel, visit `/-/debug/grafana/d/codeintel-ranking/codeintel-ranking Query: ``` -sum by (op)(increase(src_codeintel_ranking_processed_paths_janitor_errors_total{job=~"^${source:regex}.*"}[5m])) / (sum by (op)(increase(src_codeintel_ranking_processed_paths_janitor_total{job=~"^${source:regex}.*"}[5m])) + sum by (op)(increase(src_codeintel_ranking_processed_paths_janitor_errors_total{job=~"^${source:regex}.*"}[5m]))) * 100 +sum by (op)(increase(src_codeintel_uploads_janitor_unknown_repository_errors_total{job=~"^${source:regex}.*"}[5m])) / (sum by (op)(increase(src_codeintel_uploads_janitor_unknown_repository_total{job=~"^${source:regex}.*"}[5m])) + sum by (op)(increase(src_codeintel_uploads_janitor_unknown_repository_errors_total{job=~"^${source:regex}.*"}[5m]))) * 100 ```-### Code Intelligence > Ranking: Codeintel: Uploads > Janitor task > Codeintel ranking exported uploads janitor +### Code Intelligence > Uploads: Codeintel: Uploads > Janitor task > Codeintel uploads janitor unknown commit -#### codeintel-ranking: codeintel_ranking_exported_uploads_janitor_records_scanned_total +#### codeintel-uploads: codeintel_uploads_janitor_unknown_commit_records_scanned_total
Records scanned every 5m
@@ -68438,7 +68064,7 @@ The number of candidate records considered for cleanup. This panel has no related alerts. -To see this panel, visit `/-/debug/grafana/d/codeintel-ranking/codeintel-ranking?viewPanel=100900` on your Sourcegraph instance. +To see this panel, visit `/-/debug/grafana/d/codeintel-uploads/codeintel-uploads?viewPanel=100600` on your Sourcegraph instance. *Managed by the [Sourcegraph Code intelligence team](https://handbook.sourcegraph.com/departments/engineering/teams/code-intelligence).* @@ -68448,13 +68074,13 @@ To see this panel, visit `/-/debug/grafana/d/codeintel-ranking/codeintel-ranking Query: ``` -sum(increase(src_codeintel_ranking_exported_uploads_janitor_records_scanned_total{job=~"^${source:regex}.*"}[5m])) +sum(increase(src_codeintel_uploads_janitor_unknown_commit_records_scanned_total{job=~"^${source:regex}.*"}[5m])) ```-#### codeintel-ranking: codeintel_ranking_exported_uploads_janitor_records_altered_total +#### codeintel-uploads: codeintel_uploads_janitor_unknown_commit_records_altered_total
Records altered every 5m
@@ -68462,7 +68088,7 @@ The number of candidate records altered as part of cleanup. This panel has no related alerts. -To see this panel, visit `/-/debug/grafana/d/codeintel-ranking/codeintel-ranking?viewPanel=100901` on your Sourcegraph instance. +To see this panel, visit `/-/debug/grafana/d/codeintel-uploads/codeintel-uploads?viewPanel=100601` on your Sourcegraph instance. *Managed by the [Sourcegraph Code intelligence team](https://handbook.sourcegraph.com/departments/engineering/teams/code-intelligence).* @@ -68472,19 +68098,19 @@ To see this panel, visit `/-/debug/grafana/d/codeintel-ranking/codeintel-ranking Query: ``` -sum(increase(src_codeintel_ranking_exported_uploads_janitor_records_altered_total{job=~"^${source:regex}.*"}[5m])) +sum(increase(src_codeintel_uploads_janitor_unknown_commit_records_altered_total{job=~"^${source:regex}.*"}[5m])) ```-#### codeintel-ranking: codeintel_ranking_exported_uploads_janitor_total +#### codeintel-uploads: codeintel_uploads_janitor_unknown_commit_total
Job invocation operations every 5m
This panel has no related alerts. -To see this panel, visit `/-/debug/grafana/d/codeintel-ranking/codeintel-ranking?viewPanel=100910` on your Sourcegraph instance. +To see this panel, visit `/-/debug/grafana/d/codeintel-uploads/codeintel-uploads?viewPanel=100610` on your Sourcegraph instance. *Managed by the [Sourcegraph Code intelligence team](https://handbook.sourcegraph.com/departments/engineering/teams/code-intelligence).* @@ -68494,19 +68120,19 @@ To see this panel, visit `/-/debug/grafana/d/codeintel-ranking/codeintel-ranking Query: ``` -sum by (op)(increase(src_codeintel_ranking_exported_uploads_janitor_total{job=~"^${source:regex}.*"}[5m])) +sum by (op)(increase(src_codeintel_uploads_janitor_unknown_commit_total{job=~"^${source:regex}.*"}[5m])) ```-#### codeintel-ranking: codeintel_ranking_exported_uploads_janitor_99th_percentile_duration +#### codeintel-uploads: codeintel_uploads_janitor_unknown_commit_99th_percentile_duration
99th percentile successful job invocation operation duration over 5m
This panel has no related alerts. -To see this panel, visit `/-/debug/grafana/d/codeintel-ranking/codeintel-ranking?viewPanel=100911` on your Sourcegraph instance. +To see this panel, visit `/-/debug/grafana/d/codeintel-uploads/codeintel-uploads?viewPanel=100611` on your Sourcegraph instance. *Managed by the [Sourcegraph Code intelligence team](https://handbook.sourcegraph.com/departments/engineering/teams/code-intelligence).* @@ -68516,19 +68142,19 @@ To see this panel, visit `/-/debug/grafana/d/codeintel-ranking/codeintel-ranking Query: ``` -histogram_quantile(0.99, sum by (le,op)(rate(src_codeintel_ranking_exported_uploads_janitor_duration_seconds_bucket{job=~"^${source:regex}.*"}[5m]))) +histogram_quantile(0.99, sum by (le,op)(rate(src_codeintel_uploads_janitor_unknown_commit_duration_seconds_bucket{job=~"^${source:regex}.*"}[5m]))) ```-#### codeintel-ranking: codeintel_ranking_exported_uploads_janitor_errors_total +#### codeintel-uploads: codeintel_uploads_janitor_unknown_commit_errors_total
Job invocation operation errors every 5m
This panel has no related alerts. -To see this panel, visit `/-/debug/grafana/d/codeintel-ranking/codeintel-ranking?viewPanel=100912` on your Sourcegraph instance. +To see this panel, visit `/-/debug/grafana/d/codeintel-uploads/codeintel-uploads?viewPanel=100612` on your Sourcegraph instance. *Managed by the [Sourcegraph Code intelligence team](https://handbook.sourcegraph.com/departments/engineering/teams/code-intelligence).* @@ -68538,19 +68164,19 @@ To see this panel, visit `/-/debug/grafana/d/codeintel-ranking/codeintel-ranking Query: ``` -sum by (op)(increase(src_codeintel_ranking_exported_uploads_janitor_errors_total{job=~"^${source:regex}.*"}[5m])) +sum by (op)(increase(src_codeintel_uploads_janitor_unknown_commit_errors_total{job=~"^${source:regex}.*"}[5m])) ```-#### codeintel-ranking: codeintel_ranking_exported_uploads_janitor_error_rate +#### codeintel-uploads: codeintel_uploads_janitor_unknown_commit_error_rate
Job invocation operation error rate over 5m
This panel has no related alerts. -To see this panel, visit `/-/debug/grafana/d/codeintel-ranking/codeintel-ranking?viewPanel=100913` on your Sourcegraph instance. +To see this panel, visit `/-/debug/grafana/d/codeintel-uploads/codeintel-uploads?viewPanel=100613` on your Sourcegraph instance. *Managed by the [Sourcegraph Code intelligence team](https://handbook.sourcegraph.com/departments/engineering/teams/code-intelligence).* @@ -68560,15 +68186,15 @@ To see this panel, visit `/-/debug/grafana/d/codeintel-ranking/codeintel-ranking Query: ``` -sum by (op)(increase(src_codeintel_ranking_exported_uploads_janitor_errors_total{job=~"^${source:regex}.*"}[5m])) / (sum by (op)(increase(src_codeintel_ranking_exported_uploads_janitor_total{job=~"^${source:regex}.*"}[5m])) + sum by (op)(increase(src_codeintel_ranking_exported_uploads_janitor_errors_total{job=~"^${source:regex}.*"}[5m]))) * 100 +sum by (op)(increase(src_codeintel_uploads_janitor_unknown_commit_errors_total{job=~"^${source:regex}.*"}[5m])) / (sum by (op)(increase(src_codeintel_uploads_janitor_unknown_commit_total{job=~"^${source:regex}.*"}[5m])) + sum by (op)(increase(src_codeintel_uploads_janitor_unknown_commit_errors_total{job=~"^${source:regex}.*"}[5m]))) * 100 ```-### Code Intelligence > Ranking: Codeintel: Uploads > Janitor task > Codeintel ranking deleted exported uploads janitor +### Code Intelligence > Uploads: Codeintel: Uploads > Janitor task > Codeintel uploads janitor abandoned -#### codeintel-ranking: codeintel_ranking_deleted_exported_uploads_janitor_records_scanned_total +#### codeintel-uploads: codeintel_uploads_janitor_abandoned_records_scanned_total
Records scanned every 5m
@@ -68576,7 +68202,7 @@ The number of candidate records considered for cleanup. This panel has no related alerts. -To see this panel, visit `/-/debug/grafana/d/codeintel-ranking/codeintel-ranking?viewPanel=101000` on your Sourcegraph instance. +To see this panel, visit `/-/debug/grafana/d/codeintel-uploads/codeintel-uploads?viewPanel=100700` on your Sourcegraph instance. *Managed by the [Sourcegraph Code intelligence team](https://handbook.sourcegraph.com/departments/engineering/teams/code-intelligence).* @@ -68586,13 +68212,13 @@ To see this panel, visit `/-/debug/grafana/d/codeintel-ranking/codeintel-ranking Query: ``` -sum(increase(src_codeintel_ranking_deleted_exported_uploads_janitor_records_scanned_total{job=~"^${source:regex}.*"}[5m])) +sum(increase(src_codeintel_uploads_janitor_abandoned_records_scanned_total{job=~"^${source:regex}.*"}[5m])) ```-#### codeintel-ranking: codeintel_ranking_deleted_exported_uploads_janitor_records_altered_total +#### codeintel-uploads: codeintel_uploads_janitor_abandoned_records_altered_total
Records altered every 5m
@@ -68600,7 +68226,7 @@ The number of candidate records altered as part of cleanup. This panel has no related alerts. -To see this panel, visit `/-/debug/grafana/d/codeintel-ranking/codeintel-ranking?viewPanel=101001` on your Sourcegraph instance. +To see this panel, visit `/-/debug/grafana/d/codeintel-uploads/codeintel-uploads?viewPanel=100701` on your Sourcegraph instance. *Managed by the [Sourcegraph Code intelligence team](https://handbook.sourcegraph.com/departments/engineering/teams/code-intelligence).* @@ -68610,19 +68236,19 @@ To see this panel, visit `/-/debug/grafana/d/codeintel-ranking/codeintel-ranking Query: ``` -sum(increase(src_codeintel_ranking_deleted_exported_uploads_janitor_records_altered_total{job=~"^${source:regex}.*"}[5m])) +sum(increase(src_codeintel_uploads_janitor_abandoned_records_altered_total{job=~"^${source:regex}.*"}[5m])) ```-#### codeintel-ranking: codeintel_ranking_deleted_exported_uploads_janitor_total +#### codeintel-uploads: codeintel_uploads_janitor_abandoned_total
Job invocation operations every 5m
This panel has no related alerts. -To see this panel, visit `/-/debug/grafana/d/codeintel-ranking/codeintel-ranking?viewPanel=101010` on your Sourcegraph instance. +To see this panel, visit `/-/debug/grafana/d/codeintel-uploads/codeintel-uploads?viewPanel=100710` on your Sourcegraph instance. *Managed by the [Sourcegraph Code intelligence team](https://handbook.sourcegraph.com/departments/engineering/teams/code-intelligence).* @@ -68632,19 +68258,19 @@ To see this panel, visit `/-/debug/grafana/d/codeintel-ranking/codeintel-ranking Query: ``` -sum by (op)(increase(src_codeintel_ranking_deleted_exported_uploads_janitor_total{job=~"^${source:regex}.*"}[5m])) +sum by (op)(increase(src_codeintel_uploads_janitor_abandoned_total{job=~"^${source:regex}.*"}[5m])) ```-#### codeintel-ranking: codeintel_ranking_deleted_exported_uploads_janitor_99th_percentile_duration +#### codeintel-uploads: codeintel_uploads_janitor_abandoned_99th_percentile_duration
99th percentile successful job invocation operation duration over 5m
This panel has no related alerts. -To see this panel, visit `/-/debug/grafana/d/codeintel-ranking/codeintel-ranking?viewPanel=101011` on your Sourcegraph instance. +To see this panel, visit `/-/debug/grafana/d/codeintel-uploads/codeintel-uploads?viewPanel=100711` on your Sourcegraph instance. *Managed by the [Sourcegraph Code intelligence team](https://handbook.sourcegraph.com/departments/engineering/teams/code-intelligence).* @@ -68654,19 +68280,19 @@ To see this panel, visit `/-/debug/grafana/d/codeintel-ranking/codeintel-ranking Query: ``` -histogram_quantile(0.99, sum by (le,op)(rate(src_codeintel_ranking_deleted_exported_uploads_janitor_duration_seconds_bucket{job=~"^${source:regex}.*"}[5m]))) +histogram_quantile(0.99, sum by (le,op)(rate(src_codeintel_uploads_janitor_abandoned_duration_seconds_bucket{job=~"^${source:regex}.*"}[5m]))) ```-#### codeintel-ranking: codeintel_ranking_deleted_exported_uploads_janitor_errors_total +#### codeintel-uploads: codeintel_uploads_janitor_abandoned_errors_total
Job invocation operation errors every 5m
This panel has no related alerts. -To see this panel, visit `/-/debug/grafana/d/codeintel-ranking/codeintel-ranking?viewPanel=101012` on your Sourcegraph instance. +To see this panel, visit `/-/debug/grafana/d/codeintel-uploads/codeintel-uploads?viewPanel=100712` on your Sourcegraph instance. *Managed by the [Sourcegraph Code intelligence team](https://handbook.sourcegraph.com/departments/engineering/teams/code-intelligence).* @@ -68676,19 +68302,19 @@ To see this panel, visit `/-/debug/grafana/d/codeintel-ranking/codeintel-ranking Query: ``` -sum by (op)(increase(src_codeintel_ranking_deleted_exported_uploads_janitor_errors_total{job=~"^${source:regex}.*"}[5m])) +sum by (op)(increase(src_codeintel_uploads_janitor_abandoned_errors_total{job=~"^${source:regex}.*"}[5m])) ```-#### codeintel-ranking: codeintel_ranking_deleted_exported_uploads_janitor_error_rate +#### codeintel-uploads: codeintel_uploads_janitor_abandoned_error_rate
Job invocation operation error rate over 5m
This panel has no related alerts. -To see this panel, visit `/-/debug/grafana/d/codeintel-ranking/codeintel-ranking?viewPanel=101013` on your Sourcegraph instance. +To see this panel, visit `/-/debug/grafana/d/codeintel-uploads/codeintel-uploads?viewPanel=100713` on your Sourcegraph instance. *Managed by the [Sourcegraph Code intelligence team](https://handbook.sourcegraph.com/departments/engineering/teams/code-intelligence).* @@ -68698,15 +68324,15 @@ To see this panel, visit `/-/debug/grafana/d/codeintel-ranking/codeintel-ranking Query: ``` -sum by (op)(increase(src_codeintel_ranking_deleted_exported_uploads_janitor_errors_total{job=~"^${source:regex}.*"}[5m])) / (sum by (op)(increase(src_codeintel_ranking_deleted_exported_uploads_janitor_total{job=~"^${source:regex}.*"}[5m])) + sum by (op)(increase(src_codeintel_ranking_deleted_exported_uploads_janitor_errors_total{job=~"^${source:regex}.*"}[5m]))) * 100 +sum by (op)(increase(src_codeintel_uploads_janitor_abandoned_errors_total{job=~"^${source:regex}.*"}[5m])) / (sum by (op)(increase(src_codeintel_uploads_janitor_abandoned_total{job=~"^${source:regex}.*"}[5m])) + sum by (op)(increase(src_codeintel_uploads_janitor_abandoned_errors_total{job=~"^${source:regex}.*"}[5m]))) * 100 ```-### Code Intelligence > Ranking: Codeintel: Uploads > Janitor task > Codeintel ranking abandoned exported uploads janitor +### Code Intelligence > Uploads: Codeintel: Uploads > Janitor task > Codeintel uploads expirer unreferenced -#### codeintel-ranking: codeintel_ranking_abandoned_exported_uploads_janitor_records_scanned_total +#### codeintel-uploads: codeintel_uploads_expirer_unreferenced_records_scanned_total
Records scanned every 5m
@@ -68714,7 +68340,7 @@ The number of candidate records considered for cleanup. This panel has no related alerts. -To see this panel, visit `/-/debug/grafana/d/codeintel-ranking/codeintel-ranking?viewPanel=101100` on your Sourcegraph instance. +To see this panel, visit `/-/debug/grafana/d/codeintel-uploads/codeintel-uploads?viewPanel=100800` on your Sourcegraph instance. *Managed by the [Sourcegraph Code intelligence team](https://handbook.sourcegraph.com/departments/engineering/teams/code-intelligence).* @@ -68724,13 +68350,13 @@ To see this panel, visit `/-/debug/grafana/d/codeintel-ranking/codeintel-ranking Query: ``` -sum(increase(src_codeintel_ranking_abandoned_exported_uploads_janitor_records_scanned_total{job=~"^${source:regex}.*"}[5m])) +sum(increase(src_codeintel_uploads_expirer_unreferenced_records_scanned_total{job=~"^${source:regex}.*"}[5m])) ```-#### codeintel-ranking: codeintel_ranking_abandoned_exported_uploads_janitor_records_altered_total +#### codeintel-uploads: codeintel_uploads_expirer_unreferenced_records_altered_total
Records altered every 5m
@@ -68738,7 +68364,7 @@ The number of candidate records altered as part of cleanup. This panel has no related alerts. -To see this panel, visit `/-/debug/grafana/d/codeintel-ranking/codeintel-ranking?viewPanel=101101` on your Sourcegraph instance. +To see this panel, visit `/-/debug/grafana/d/codeintel-uploads/codeintel-uploads?viewPanel=100801` on your Sourcegraph instance. *Managed by the [Sourcegraph Code intelligence team](https://handbook.sourcegraph.com/departments/engineering/teams/code-intelligence).* @@ -68748,19 +68374,19 @@ To see this panel, visit `/-/debug/grafana/d/codeintel-ranking/codeintel-ranking Query: ``` -sum(increase(src_codeintel_ranking_abandoned_exported_uploads_janitor_records_altered_total{job=~"^${source:regex}.*"}[5m])) +sum(increase(src_codeintel_uploads_expirer_unreferenced_records_altered_total{job=~"^${source:regex}.*"}[5m])) ```-#### codeintel-ranking: codeintel_ranking_abandoned_exported_uploads_janitor_total +#### codeintel-uploads: codeintel_uploads_expirer_unreferenced_total
Job invocation operations every 5m
This panel has no related alerts. -To see this panel, visit `/-/debug/grafana/d/codeintel-ranking/codeintel-ranking?viewPanel=101110` on your Sourcegraph instance. +To see this panel, visit `/-/debug/grafana/d/codeintel-uploads/codeintel-uploads?viewPanel=100810` on your Sourcegraph instance. *Managed by the [Sourcegraph Code intelligence team](https://handbook.sourcegraph.com/departments/engineering/teams/code-intelligence).* @@ -68770,19 +68396,19 @@ To see this panel, visit `/-/debug/grafana/d/codeintel-ranking/codeintel-ranking Query: ``` -sum by (op)(increase(src_codeintel_ranking_abandoned_exported_uploads_janitor_total{job=~"^${source:regex}.*"}[5m])) +sum by (op)(increase(src_codeintel_uploads_expirer_unreferenced_total{job=~"^${source:regex}.*"}[5m])) ```-#### codeintel-ranking: codeintel_ranking_abandoned_exported_uploads_janitor_99th_percentile_duration +#### codeintel-uploads: codeintel_uploads_expirer_unreferenced_99th_percentile_duration
99th percentile successful job invocation operation duration over 5m
This panel has no related alerts. -To see this panel, visit `/-/debug/grafana/d/codeintel-ranking/codeintel-ranking?viewPanel=101111` on your Sourcegraph instance. +To see this panel, visit `/-/debug/grafana/d/codeintel-uploads/codeintel-uploads?viewPanel=100811` on your Sourcegraph instance. *Managed by the [Sourcegraph Code intelligence team](https://handbook.sourcegraph.com/departments/engineering/teams/code-intelligence).* @@ -68792,19 +68418,19 @@ To see this panel, visit `/-/debug/grafana/d/codeintel-ranking/codeintel-ranking Query: ``` -histogram_quantile(0.99, sum by (le,op)(rate(src_codeintel_ranking_abandoned_exported_uploads_janitor_duration_seconds_bucket{job=~"^${source:regex}.*"}[5m]))) +histogram_quantile(0.99, sum by (le,op)(rate(src_codeintel_uploads_expirer_unreferenced_duration_seconds_bucket{job=~"^${source:regex}.*"}[5m]))) ```-#### codeintel-ranking: codeintel_ranking_abandoned_exported_uploads_janitor_errors_total +#### codeintel-uploads: codeintel_uploads_expirer_unreferenced_errors_total
Job invocation operation errors every 5m
This panel has no related alerts. -To see this panel, visit `/-/debug/grafana/d/codeintel-ranking/codeintel-ranking?viewPanel=101112` on your Sourcegraph instance. +To see this panel, visit `/-/debug/grafana/d/codeintel-uploads/codeintel-uploads?viewPanel=100812` on your Sourcegraph instance. *Managed by the [Sourcegraph Code intelligence team](https://handbook.sourcegraph.com/departments/engineering/teams/code-intelligence).* @@ -68814,19 +68440,19 @@ To see this panel, visit `/-/debug/grafana/d/codeintel-ranking/codeintel-ranking Query: ``` -sum by (op)(increase(src_codeintel_ranking_abandoned_exported_uploads_janitor_errors_total{job=~"^${source:regex}.*"}[5m])) +sum by (op)(increase(src_codeintel_uploads_expirer_unreferenced_errors_total{job=~"^${source:regex}.*"}[5m])) ```-#### codeintel-ranking: codeintel_ranking_abandoned_exported_uploads_janitor_error_rate +#### codeintel-uploads: codeintel_uploads_expirer_unreferenced_error_rate
Job invocation operation error rate over 5m
This panel has no related alerts. -To see this panel, visit `/-/debug/grafana/d/codeintel-ranking/codeintel-ranking?viewPanel=101113` on your Sourcegraph instance. +To see this panel, visit `/-/debug/grafana/d/codeintel-uploads/codeintel-uploads?viewPanel=100813` on your Sourcegraph instance. *Managed by the [Sourcegraph Code intelligence team](https://handbook.sourcegraph.com/departments/engineering/teams/code-intelligence).* @@ -68836,15 +68462,15 @@ To see this panel, visit `/-/debug/grafana/d/codeintel-ranking/codeintel-ranking Query: ``` -sum by (op)(increase(src_codeintel_ranking_abandoned_exported_uploads_janitor_errors_total{job=~"^${source:regex}.*"}[5m])) / (sum by (op)(increase(src_codeintel_ranking_abandoned_exported_uploads_janitor_total{job=~"^${source:regex}.*"}[5m])) + sum by (op)(increase(src_codeintel_ranking_abandoned_exported_uploads_janitor_errors_total{job=~"^${source:regex}.*"}[5m]))) * 100 +sum by (op)(increase(src_codeintel_uploads_expirer_unreferenced_errors_total{job=~"^${source:regex}.*"}[5m])) / (sum by (op)(increase(src_codeintel_uploads_expirer_unreferenced_total{job=~"^${source:regex}.*"}[5m])) + sum by (op)(increase(src_codeintel_uploads_expirer_unreferenced_errors_total{job=~"^${source:regex}.*"}[5m]))) * 100 ```-### Code Intelligence > Ranking: Codeintel: Uploads > Janitor task > Codeintel ranking rank counts janitor +### Code Intelligence > Uploads: Codeintel: Uploads > Janitor task > Codeintel uploads expirer unreferenced graph -#### codeintel-ranking: codeintel_ranking_rank_counts_janitor_records_scanned_total +#### codeintel-uploads: codeintel_uploads_expirer_unreferenced_graph_records_scanned_total
Records scanned every 5m
@@ -68852,7 +68478,7 @@ The number of candidate records considered for cleanup. This panel has no related alerts. -To see this panel, visit `/-/debug/grafana/d/codeintel-ranking/codeintel-ranking?viewPanel=101200` on your Sourcegraph instance. +To see this panel, visit `/-/debug/grafana/d/codeintel-uploads/codeintel-uploads?viewPanel=100900` on your Sourcegraph instance. *Managed by the [Sourcegraph Code intelligence team](https://handbook.sourcegraph.com/departments/engineering/teams/code-intelligence).* @@ -68862,13 +68488,13 @@ To see this panel, visit `/-/debug/grafana/d/codeintel-ranking/codeintel-ranking Query: ``` -sum(increase(src_codeintel_ranking_rank_counts_janitor_records_scanned_total{job=~"^${source:regex}.*"}[5m])) +sum(increase(src_codeintel_uploads_expirer_unreferenced_graph_records_scanned_total{job=~"^${source:regex}.*"}[5m])) ```-#### codeintel-ranking: codeintel_ranking_rank_counts_janitor_records_altered_total +#### codeintel-uploads: codeintel_uploads_expirer_unreferenced_graph_records_altered_total
Records altered every 5m
@@ -68876,7 +68502,7 @@ The number of candidate records altered as part of cleanup. This panel has no related alerts. -To see this panel, visit `/-/debug/grafana/d/codeintel-ranking/codeintel-ranking?viewPanel=101201` on your Sourcegraph instance. +To see this panel, visit `/-/debug/grafana/d/codeintel-uploads/codeintel-uploads?viewPanel=100901` on your Sourcegraph instance. *Managed by the [Sourcegraph Code intelligence team](https://handbook.sourcegraph.com/departments/engineering/teams/code-intelligence).* @@ -68886,19 +68512,19 @@ To see this panel, visit `/-/debug/grafana/d/codeintel-ranking/codeintel-ranking Query: ``` -sum(increase(src_codeintel_ranking_rank_counts_janitor_records_altered_total{job=~"^${source:regex}.*"}[5m])) +sum(increase(src_codeintel_uploads_expirer_unreferenced_graph_records_altered_total{job=~"^${source:regex}.*"}[5m])) ```-#### codeintel-ranking: codeintel_ranking_rank_counts_janitor_total +#### codeintel-uploads: codeintel_uploads_expirer_unreferenced_graph_total
Job invocation operations every 5m
This panel has no related alerts. -To see this panel, visit `/-/debug/grafana/d/codeintel-ranking/codeintel-ranking?viewPanel=101210` on your Sourcegraph instance. +To see this panel, visit `/-/debug/grafana/d/codeintel-uploads/codeintel-uploads?viewPanel=100910` on your Sourcegraph instance. *Managed by the [Sourcegraph Code intelligence team](https://handbook.sourcegraph.com/departments/engineering/teams/code-intelligence).* @@ -68908,19 +68534,19 @@ To see this panel, visit `/-/debug/grafana/d/codeintel-ranking/codeintel-ranking Query: ``` -sum by (op)(increase(src_codeintel_ranking_rank_counts_janitor_total{job=~"^${source:regex}.*"}[5m])) +sum by (op)(increase(src_codeintel_uploads_expirer_unreferenced_graph_total{job=~"^${source:regex}.*"}[5m])) ```-#### codeintel-ranking: codeintel_ranking_rank_counts_janitor_99th_percentile_duration +#### codeintel-uploads: codeintel_uploads_expirer_unreferenced_graph_99th_percentile_duration
99th percentile successful job invocation operation duration over 5m
This panel has no related alerts. -To see this panel, visit `/-/debug/grafana/d/codeintel-ranking/codeintel-ranking?viewPanel=101211` on your Sourcegraph instance. +To see this panel, visit `/-/debug/grafana/d/codeintel-uploads/codeintel-uploads?viewPanel=100911` on your Sourcegraph instance. *Managed by the [Sourcegraph Code intelligence team](https://handbook.sourcegraph.com/departments/engineering/teams/code-intelligence).* @@ -68930,19 +68556,19 @@ To see this panel, visit `/-/debug/grafana/d/codeintel-ranking/codeintel-ranking Query: ``` -histogram_quantile(0.99, sum by (le,op)(rate(src_codeintel_ranking_rank_counts_janitor_duration_seconds_bucket{job=~"^${source:regex}.*"}[5m]))) +histogram_quantile(0.99, sum by (le,op)(rate(src_codeintel_uploads_expirer_unreferenced_graph_duration_seconds_bucket{job=~"^${source:regex}.*"}[5m]))) ```-#### codeintel-ranking: codeintel_ranking_rank_counts_janitor_errors_total +#### codeintel-uploads: codeintel_uploads_expirer_unreferenced_graph_errors_total
Job invocation operation errors every 5m
This panel has no related alerts. -To see this panel, visit `/-/debug/grafana/d/codeintel-ranking/codeintel-ranking?viewPanel=101212` on your Sourcegraph instance. +To see this panel, visit `/-/debug/grafana/d/codeintel-uploads/codeintel-uploads?viewPanel=100912` on your Sourcegraph instance. *Managed by the [Sourcegraph Code intelligence team](https://handbook.sourcegraph.com/departments/engineering/teams/code-intelligence).* @@ -68952,19 +68578,19 @@ To see this panel, visit `/-/debug/grafana/d/codeintel-ranking/codeintel-ranking Query: ``` -sum by (op)(increase(src_codeintel_ranking_rank_counts_janitor_errors_total{job=~"^${source:regex}.*"}[5m])) +sum by (op)(increase(src_codeintel_uploads_expirer_unreferenced_graph_errors_total{job=~"^${source:regex}.*"}[5m])) ```-#### codeintel-ranking: codeintel_ranking_rank_counts_janitor_error_rate +#### codeintel-uploads: codeintel_uploads_expirer_unreferenced_graph_error_rate
Job invocation operation error rate over 5m
This panel has no related alerts. -To see this panel, visit `/-/debug/grafana/d/codeintel-ranking/codeintel-ranking?viewPanel=101213` on your Sourcegraph instance. +To see this panel, visit `/-/debug/grafana/d/codeintel-uploads/codeintel-uploads?viewPanel=100913` on your Sourcegraph instance. *Managed by the [Sourcegraph Code intelligence team](https://handbook.sourcegraph.com/departments/engineering/teams/code-intelligence).* @@ -68974,15 +68600,15 @@ To see this panel, visit `/-/debug/grafana/d/codeintel-ranking/codeintel-ranking Query: ``` -sum by (op)(increase(src_codeintel_ranking_rank_counts_janitor_errors_total{job=~"^${source:regex}.*"}[5m])) / (sum by (op)(increase(src_codeintel_ranking_rank_counts_janitor_total{job=~"^${source:regex}.*"}[5m])) + sum by (op)(increase(src_codeintel_ranking_rank_counts_janitor_errors_total{job=~"^${source:regex}.*"}[5m]))) * 100 +sum by (op)(increase(src_codeintel_uploads_expirer_unreferenced_graph_errors_total{job=~"^${source:regex}.*"}[5m])) / (sum by (op)(increase(src_codeintel_uploads_expirer_unreferenced_graph_total{job=~"^${source:regex}.*"}[5m])) + sum by (op)(increase(src_codeintel_uploads_expirer_unreferenced_graph_errors_total{job=~"^${source:regex}.*"}[5m]))) * 100 ```-### Code Intelligence > Ranking: Codeintel: Uploads > Janitor task > Codeintel ranking rank janitor +### Code Intelligence > Uploads: Codeintel: Uploads > Janitor task > Codeintel uploads hard deleter -#### codeintel-ranking: codeintel_ranking_rank_janitor_records_scanned_total +#### codeintel-uploads: codeintel_uploads_hard_deleter_records_scanned_total
Records scanned every 5m
@@ -68990,7 +68616,7 @@ The number of candidate records considered for cleanup. This panel has no related alerts. -To see this panel, visit `/-/debug/grafana/d/codeintel-ranking/codeintel-ranking?viewPanel=101300` on your Sourcegraph instance. +To see this panel, visit `/-/debug/grafana/d/codeintel-uploads/codeintel-uploads?viewPanel=101000` on your Sourcegraph instance. *Managed by the [Sourcegraph Code intelligence team](https://handbook.sourcegraph.com/departments/engineering/teams/code-intelligence).* @@ -69000,13 +68626,13 @@ To see this panel, visit `/-/debug/grafana/d/codeintel-ranking/codeintel-ranking Query: ``` -sum(increase(src_codeintel_ranking_rank_janitor_records_scanned_total{job=~"^${source:regex}.*"}[5m])) +sum(increase(src_codeintel_uploads_hard_deleter_records_scanned_total{job=~"^${source:regex}.*"}[5m])) ```-#### codeintel-ranking: codeintel_ranking_rank_janitor_records_altered_total +#### codeintel-uploads: codeintel_uploads_hard_deleter_records_altered_total
Records altered every 5m
@@ -69014,7 +68640,7 @@ The number of candidate records altered as part of cleanup. This panel has no related alerts. -To see this panel, visit `/-/debug/grafana/d/codeintel-ranking/codeintel-ranking?viewPanel=101301` on your Sourcegraph instance. +To see this panel, visit `/-/debug/grafana/d/codeintel-uploads/codeintel-uploads?viewPanel=101001` on your Sourcegraph instance. *Managed by the [Sourcegraph Code intelligence team](https://handbook.sourcegraph.com/departments/engineering/teams/code-intelligence).* @@ -69024,19 +68650,19 @@ To see this panel, visit `/-/debug/grafana/d/codeintel-ranking/codeintel-ranking Query: ``` -sum(increase(src_codeintel_ranking_rank_janitor_records_altered_total{job=~"^${source:regex}.*"}[5m])) +sum(increase(src_codeintel_uploads_hard_deleter_records_altered_total{job=~"^${source:regex}.*"}[5m])) ```-#### codeintel-ranking: codeintel_ranking_rank_janitor_total +#### codeintel-uploads: codeintel_uploads_hard_deleter_total
Job invocation operations every 5m
This panel has no related alerts. -To see this panel, visit `/-/debug/grafana/d/codeintel-ranking/codeintel-ranking?viewPanel=101310` on your Sourcegraph instance. +To see this panel, visit `/-/debug/grafana/d/codeintel-uploads/codeintel-uploads?viewPanel=101010` on your Sourcegraph instance. *Managed by the [Sourcegraph Code intelligence team](https://handbook.sourcegraph.com/departments/engineering/teams/code-intelligence).* @@ -69046,19 +68672,19 @@ To see this panel, visit `/-/debug/grafana/d/codeintel-ranking/codeintel-ranking Query: ``` -sum by (op)(increase(src_codeintel_ranking_rank_janitor_total{job=~"^${source:regex}.*"}[5m])) +sum by (op)(increase(src_codeintel_uploads_hard_deleter_total{job=~"^${source:regex}.*"}[5m])) ```-#### codeintel-ranking: codeintel_ranking_rank_janitor_99th_percentile_duration +#### codeintel-uploads: codeintel_uploads_hard_deleter_99th_percentile_duration
99th percentile successful job invocation operation duration over 5m
This panel has no related alerts. -To see this panel, visit `/-/debug/grafana/d/codeintel-ranking/codeintel-ranking?viewPanel=101311` on your Sourcegraph instance. +To see this panel, visit `/-/debug/grafana/d/codeintel-uploads/codeintel-uploads?viewPanel=101011` on your Sourcegraph instance. *Managed by the [Sourcegraph Code intelligence team](https://handbook.sourcegraph.com/departments/engineering/teams/code-intelligence).* @@ -69068,19 +68694,19 @@ To see this panel, visit `/-/debug/grafana/d/codeintel-ranking/codeintel-ranking Query: ``` -histogram_quantile(0.99, sum by (le,op)(rate(src_codeintel_ranking_rank_janitor_duration_seconds_bucket{job=~"^${source:regex}.*"}[5m]))) +histogram_quantile(0.99, sum by (le,op)(rate(src_codeintel_uploads_hard_deleter_duration_seconds_bucket{job=~"^${source:regex}.*"}[5m]))) ```-#### codeintel-ranking: codeintel_ranking_rank_janitor_errors_total +#### codeintel-uploads: codeintel_uploads_hard_deleter_errors_total
Job invocation operation errors every 5m
This panel has no related alerts. -To see this panel, visit `/-/debug/grafana/d/codeintel-ranking/codeintel-ranking?viewPanel=101312` on your Sourcegraph instance. +To see this panel, visit `/-/debug/grafana/d/codeintel-uploads/codeintel-uploads?viewPanel=101012` on your Sourcegraph instance. *Managed by the [Sourcegraph Code intelligence team](https://handbook.sourcegraph.com/departments/engineering/teams/code-intelligence).* @@ -69090,19 +68716,19 @@ To see this panel, visit `/-/debug/grafana/d/codeintel-ranking/codeintel-ranking Query: ``` -sum by (op)(increase(src_codeintel_ranking_rank_janitor_errors_total{job=~"^${source:regex}.*"}[5m])) +sum by (op)(increase(src_codeintel_uploads_hard_deleter_errors_total{job=~"^${source:regex}.*"}[5m])) ```-#### codeintel-ranking: codeintel_ranking_rank_janitor_error_rate +#### codeintel-uploads: codeintel_uploads_hard_deleter_error_rate
Job invocation operation error rate over 5m
This panel has no related alerts. -To see this panel, visit `/-/debug/grafana/d/codeintel-ranking/codeintel-ranking?viewPanel=101313` on your Sourcegraph instance. +To see this panel, visit `/-/debug/grafana/d/codeintel-uploads/codeintel-uploads?viewPanel=101013` on your Sourcegraph instance. *Managed by the [Sourcegraph Code intelligence team](https://handbook.sourcegraph.com/departments/engineering/teams/code-intelligence).* @@ -69112,27 +68738,23 @@ To see this panel, visit `/-/debug/grafana/d/codeintel-ranking/codeintel-ranking Query: ``` -sum by (op)(increase(src_codeintel_ranking_rank_janitor_errors_total{job=~"^${source:regex}.*"}[5m])) / (sum by (op)(increase(src_codeintel_ranking_rank_janitor_total{job=~"^${source:regex}.*"}[5m])) + sum by (op)(increase(src_codeintel_ranking_rank_janitor_errors_total{job=~"^${source:regex}.*"}[5m]))) * 100 +sum by (op)(increase(src_codeintel_uploads_hard_deleter_errors_total{job=~"^${source:regex}.*"}[5m])) / (sum by (op)(increase(src_codeintel_uploads_hard_deleter_total{job=~"^${source:regex}.*"}[5m])) + sum by (op)(increase(src_codeintel_uploads_hard_deleter_errors_total{job=~"^${source:regex}.*"}[5m]))) * 100 ```-## Code Intelligence > Uploads - -
The service at `internal/codeintel/uploads`.
- -To see this dashboard, visit `/-/debug/grafana/d/codeintel-uploads/codeintel-uploads` on your Sourcegraph instance. +### Code Intelligence > Uploads: Codeintel: Uploads > Janitor task > Codeintel uploads janitor audit logs -### Code Intelligence > Uploads: Codeintel: Uploads > Service +#### codeintel-uploads: codeintel_uploads_janitor_audit_logs_records_scanned_total -#### codeintel-uploads: codeintel_uploads_total +Records scanned every 5m
-Aggregate service operations every 5m
+The number of candidate records considered for cleanup. This panel has no related alerts. -To see this panel, visit `/-/debug/grafana/d/codeintel-uploads/codeintel-uploads?viewPanel=100000` on your Sourcegraph instance. +To see this panel, visit `/-/debug/grafana/d/codeintel-uploads/codeintel-uploads?viewPanel=101100` on your Sourcegraph instance. *Managed by the [Sourcegraph Code intelligence team](https://handbook.sourcegraph.com/departments/engineering/teams/code-intelligence).* @@ -69142,19 +68764,21 @@ To see this panel, visit `/-/debug/grafana/d/codeintel-uploads/codeintel-uploads Query: ``` -sum(increase(src_codeintel_uploads_total{job=~"^${source:regex}.*"}[5m])) +sum(increase(src_codeintel_uploads_janitor_audit_logs_records_scanned_total{job=~"^${source:regex}.*"}[5m])) ```-#### codeintel-uploads: codeintel_uploads_99th_percentile_duration +#### codeintel-uploads: codeintel_uploads_janitor_audit_logs_records_altered_total -
Aggregate successful service operation duration distribution over 5m
+Records altered every 5m
+ +The number of candidate records altered as part of cleanup. This panel has no related alerts. -To see this panel, visit `/-/debug/grafana/d/codeintel-uploads/codeintel-uploads?viewPanel=100001` on your Sourcegraph instance. +To see this panel, visit `/-/debug/grafana/d/codeintel-uploads/codeintel-uploads?viewPanel=101101` on your Sourcegraph instance. *Managed by the [Sourcegraph Code intelligence team](https://handbook.sourcegraph.com/departments/engineering/teams/code-intelligence).* @@ -69164,19 +68788,19 @@ To see this panel, visit `/-/debug/grafana/d/codeintel-uploads/codeintel-uploads Query: ``` -sum by (le)(rate(src_codeintel_uploads_duration_seconds_bucket{job=~"^${source:regex}.*"}[5m])) +sum(increase(src_codeintel_uploads_janitor_audit_logs_records_altered_total{job=~"^${source:regex}.*"}[5m])) ```-#### codeintel-uploads: codeintel_uploads_errors_total +#### codeintel-uploads: codeintel_uploads_janitor_audit_logs_total -
Aggregate service operation errors every 5m
+Job invocation operations every 5m
This panel has no related alerts. -To see this panel, visit `/-/debug/grafana/d/codeintel-uploads/codeintel-uploads?viewPanel=100002` on your Sourcegraph instance. +To see this panel, visit `/-/debug/grafana/d/codeintel-uploads/codeintel-uploads?viewPanel=101110` on your Sourcegraph instance. *Managed by the [Sourcegraph Code intelligence team](https://handbook.sourcegraph.com/departments/engineering/teams/code-intelligence).* @@ -69186,19 +68810,19 @@ To see this panel, visit `/-/debug/grafana/d/codeintel-uploads/codeintel-uploads Query: ``` -sum(increase(src_codeintel_uploads_errors_total{job=~"^${source:regex}.*"}[5m])) +sum by (op)(increase(src_codeintel_uploads_janitor_audit_logs_total{job=~"^${source:regex}.*"}[5m])) ```-#### codeintel-uploads: codeintel_uploads_error_rate +#### codeintel-uploads: codeintel_uploads_janitor_audit_logs_99th_percentile_duration -
Aggregate service operation error rate over 5m
+99th percentile successful job invocation operation duration over 5m
This panel has no related alerts. -To see this panel, visit `/-/debug/grafana/d/codeintel-uploads/codeintel-uploads?viewPanel=100003` on your Sourcegraph instance. +To see this panel, visit `/-/debug/grafana/d/codeintel-uploads/codeintel-uploads?viewPanel=101111` on your Sourcegraph instance. *Managed by the [Sourcegraph Code intelligence team](https://handbook.sourcegraph.com/departments/engineering/teams/code-intelligence).* @@ -69208,19 +68832,19 @@ To see this panel, visit `/-/debug/grafana/d/codeintel-uploads/codeintel-uploads Query: ``` -sum(increase(src_codeintel_uploads_errors_total{job=~"^${source:regex}.*"}[5m])) / (sum(increase(src_codeintel_uploads_total{job=~"^${source:regex}.*"}[5m])) + sum(increase(src_codeintel_uploads_errors_total{job=~"^${source:regex}.*"}[5m]))) * 100 +histogram_quantile(0.99, sum by (le,op)(rate(src_codeintel_uploads_janitor_audit_logs_duration_seconds_bucket{job=~"^${source:regex}.*"}[5m]))) ```-#### codeintel-uploads: codeintel_uploads_total +#### codeintel-uploads: codeintel_uploads_janitor_audit_logs_errors_total -
Service operations every 5m
+Job invocation operation errors every 5m
This panel has no related alerts. -To see this panel, visit `/-/debug/grafana/d/codeintel-uploads/codeintel-uploads?viewPanel=100010` on your Sourcegraph instance. +To see this panel, visit `/-/debug/grafana/d/codeintel-uploads/codeintel-uploads?viewPanel=101112` on your Sourcegraph instance. *Managed by the [Sourcegraph Code intelligence team](https://handbook.sourcegraph.com/departments/engineering/teams/code-intelligence).* @@ -69230,19 +68854,19 @@ To see this panel, visit `/-/debug/grafana/d/codeintel-uploads/codeintel-uploads Query: ``` -sum by (op)(increase(src_codeintel_uploads_total{job=~"^${source:regex}.*"}[5m])) +sum by (op)(increase(src_codeintel_uploads_janitor_audit_logs_errors_total{job=~"^${source:regex}.*"}[5m])) ```-#### codeintel-uploads: codeintel_uploads_99th_percentile_duration +#### codeintel-uploads: codeintel_uploads_janitor_audit_logs_error_rate -
99th percentile successful service operation duration over 5m
+Job invocation operation error rate over 5m
This panel has no related alerts. -To see this panel, visit `/-/debug/grafana/d/codeintel-uploads/codeintel-uploads?viewPanel=100011` on your Sourcegraph instance. +To see this panel, visit `/-/debug/grafana/d/codeintel-uploads/codeintel-uploads?viewPanel=101113` on your Sourcegraph instance. *Managed by the [Sourcegraph Code intelligence team](https://handbook.sourcegraph.com/departments/engineering/teams/code-intelligence).* @@ -69252,19 +68876,23 @@ To see this panel, visit `/-/debug/grafana/d/codeintel-uploads/codeintel-uploads Query: ``` -histogram_quantile(0.99, sum by (le,op)(rate(src_codeintel_uploads_duration_seconds_bucket{job=~"^${source:regex}.*"}[5m]))) +sum by (op)(increase(src_codeintel_uploads_janitor_audit_logs_errors_total{job=~"^${source:regex}.*"}[5m])) / (sum by (op)(increase(src_codeintel_uploads_janitor_audit_logs_total{job=~"^${source:regex}.*"}[5m])) + sum by (op)(increase(src_codeintel_uploads_janitor_audit_logs_errors_total{job=~"^${source:regex}.*"}[5m]))) * 100 ```-#### codeintel-uploads: codeintel_uploads_errors_total +### Code Intelligence > Uploads: Codeintel: Uploads > Janitor task > Codeintel uploads janitor scip documents -
Service operation errors every 5m
+#### codeintel-uploads: codeintel_uploads_janitor_scip_documents_records_scanned_total + +Records scanned every 5m
+ +The number of candidate records considered for cleanup. This panel has no related alerts. -To see this panel, visit `/-/debug/grafana/d/codeintel-uploads/codeintel-uploads?viewPanel=100012` on your Sourcegraph instance. +To see this panel, visit `/-/debug/grafana/d/codeintel-uploads/codeintel-uploads?viewPanel=101200` on your Sourcegraph instance. *Managed by the [Sourcegraph Code intelligence team](https://handbook.sourcegraph.com/departments/engineering/teams/code-intelligence).* @@ -69274,19 +68902,21 @@ To see this panel, visit `/-/debug/grafana/d/codeintel-uploads/codeintel-uploads Query: ``` -sum by (op)(increase(src_codeintel_uploads_errors_total{job=~"^${source:regex}.*"}[5m])) +sum(increase(src_codeintel_uploads_janitor_scip_documents_records_scanned_total{job=~"^${source:regex}.*"}[5m])) ```-#### codeintel-uploads: codeintel_uploads_error_rate +#### codeintel-uploads: codeintel_uploads_janitor_scip_documents_records_altered_total -
Service operation error rate over 5m
+Records altered every 5m
+ +The number of candidate records altered as part of cleanup. This panel has no related alerts. -To see this panel, visit `/-/debug/grafana/d/codeintel-uploads/codeintel-uploads?viewPanel=100013` on your Sourcegraph instance. +To see this panel, visit `/-/debug/grafana/d/codeintel-uploads/codeintel-uploads?viewPanel=101201` on your Sourcegraph instance. *Managed by the [Sourcegraph Code intelligence team](https://handbook.sourcegraph.com/departments/engineering/teams/code-intelligence).* @@ -69296,21 +68926,19 @@ To see this panel, visit `/-/debug/grafana/d/codeintel-uploads/codeintel-uploads Query: ``` -sum by (op)(increase(src_codeintel_uploads_errors_total{job=~"^${source:regex}.*"}[5m])) / (sum by (op)(increase(src_codeintel_uploads_total{job=~"^${source:regex}.*"}[5m])) + sum by (op)(increase(src_codeintel_uploads_errors_total{job=~"^${source:regex}.*"}[5m]))) * 100 +sum(increase(src_codeintel_uploads_janitor_scip_documents_records_altered_total{job=~"^${source:regex}.*"}[5m])) ```-### Code Intelligence > Uploads: Codeintel: Uploads > Store (internal) - -#### codeintel-uploads: codeintel_uploads_store_total +#### codeintel-uploads: codeintel_uploads_janitor_scip_documents_total -
Aggregate store operations every 5m
+Job invocation operations every 5m
This panel has no related alerts. -To see this panel, visit `/-/debug/grafana/d/codeintel-uploads/codeintel-uploads?viewPanel=100100` on your Sourcegraph instance. +To see this panel, visit `/-/debug/grafana/d/codeintel-uploads/codeintel-uploads?viewPanel=101210` on your Sourcegraph instance. *Managed by the [Sourcegraph Code intelligence team](https://handbook.sourcegraph.com/departments/engineering/teams/code-intelligence).* @@ -69320,19 +68948,19 @@ To see this panel, visit `/-/debug/grafana/d/codeintel-uploads/codeintel-uploads Query: ``` -sum(increase(src_codeintel_uploads_store_total{job=~"^${source:regex}.*"}[5m])) +sum by (op)(increase(src_codeintel_uploads_janitor_scip_documents_total{job=~"^${source:regex}.*"}[5m])) ```-#### codeintel-uploads: codeintel_uploads_store_99th_percentile_duration +#### codeintel-uploads: codeintel_uploads_janitor_scip_documents_99th_percentile_duration -
Aggregate successful store operation duration distribution over 5m
+99th percentile successful job invocation operation duration over 5m
This panel has no related alerts. -To see this panel, visit `/-/debug/grafana/d/codeintel-uploads/codeintel-uploads?viewPanel=100101` on your Sourcegraph instance. +To see this panel, visit `/-/debug/grafana/d/codeintel-uploads/codeintel-uploads?viewPanel=101211` on your Sourcegraph instance. *Managed by the [Sourcegraph Code intelligence team](https://handbook.sourcegraph.com/departments/engineering/teams/code-intelligence).* @@ -69342,19 +68970,19 @@ To see this panel, visit `/-/debug/grafana/d/codeintel-uploads/codeintel-uploads Query: ``` -sum by (le)(rate(src_codeintel_uploads_store_duration_seconds_bucket{job=~"^${source:regex}.*"}[5m])) +histogram_quantile(0.99, sum by (le,op)(rate(src_codeintel_uploads_janitor_scip_documents_duration_seconds_bucket{job=~"^${source:regex}.*"}[5m]))) ```-#### codeintel-uploads: codeintel_uploads_store_errors_total +#### codeintel-uploads: codeintel_uploads_janitor_scip_documents_errors_total -
Aggregate store operation errors every 5m
+Job invocation operation errors every 5m
This panel has no related alerts. -To see this panel, visit `/-/debug/grafana/d/codeintel-uploads/codeintel-uploads?viewPanel=100102` on your Sourcegraph instance. +To see this panel, visit `/-/debug/grafana/d/codeintel-uploads/codeintel-uploads?viewPanel=101212` on your Sourcegraph instance. *Managed by the [Sourcegraph Code intelligence team](https://handbook.sourcegraph.com/departments/engineering/teams/code-intelligence).* @@ -69364,19 +68992,19 @@ To see this panel, visit `/-/debug/grafana/d/codeintel-uploads/codeintel-uploads Query: ``` -sum(increase(src_codeintel_uploads_store_errors_total{job=~"^${source:regex}.*"}[5m])) +sum by (op)(increase(src_codeintel_uploads_janitor_scip_documents_errors_total{job=~"^${source:regex}.*"}[5m])) ```-#### codeintel-uploads: codeintel_uploads_store_error_rate +#### codeintel-uploads: codeintel_uploads_janitor_scip_documents_error_rate -
Aggregate store operation error rate over 5m
+Job invocation operation error rate over 5m
This panel has no related alerts. -To see this panel, visit `/-/debug/grafana/d/codeintel-uploads/codeintel-uploads?viewPanel=100103` on your Sourcegraph instance. +To see this panel, visit `/-/debug/grafana/d/codeintel-uploads/codeintel-uploads?viewPanel=101213` on your Sourcegraph instance. *Managed by the [Sourcegraph Code intelligence team](https://handbook.sourcegraph.com/departments/engineering/teams/code-intelligence).* @@ -69386,19 +69014,23 @@ To see this panel, visit `/-/debug/grafana/d/codeintel-uploads/codeintel-uploads Query: ``` -sum(increase(src_codeintel_uploads_store_errors_total{job=~"^${source:regex}.*"}[5m])) / (sum(increase(src_codeintel_uploads_store_total{job=~"^${source:regex}.*"}[5m])) + sum(increase(src_codeintel_uploads_store_errors_total{job=~"^${source:regex}.*"}[5m]))) * 100 +sum by (op)(increase(src_codeintel_uploads_janitor_scip_documents_errors_total{job=~"^${source:regex}.*"}[5m])) / (sum by (op)(increase(src_codeintel_uploads_janitor_scip_documents_total{job=~"^${source:regex}.*"}[5m])) + sum by (op)(increase(src_codeintel_uploads_janitor_scip_documents_errors_total{job=~"^${source:regex}.*"}[5m]))) * 100 ```-#### codeintel-uploads: codeintel_uploads_store_total +### Code Intelligence > Uploads: Codeintel: Uploads > Reconciler task > Codeintel uploads reconciler scip metadata -
Store operations every 5m
+#### codeintel-uploads: codeintel_uploads_reconciler_scip_metadata_records_scanned_total + +Records scanned every 5m
+ +The number of candidate records considered for cleanup. This panel has no related alerts. -To see this panel, visit `/-/debug/grafana/d/codeintel-uploads/codeintel-uploads?viewPanel=100110` on your Sourcegraph instance. +To see this panel, visit `/-/debug/grafana/d/codeintel-uploads/codeintel-uploads?viewPanel=101300` on your Sourcegraph instance. *Managed by the [Sourcegraph Code intelligence team](https://handbook.sourcegraph.com/departments/engineering/teams/code-intelligence).* @@ -69408,19 +69040,21 @@ To see this panel, visit `/-/debug/grafana/d/codeintel-uploads/codeintel-uploads Query: ``` -sum by (op)(increase(src_codeintel_uploads_store_total{job=~"^${source:regex}.*"}[5m])) +sum(increase(src_codeintel_uploads_reconciler_scip_metadata_records_scanned_total{job=~"^${source:regex}.*"}[5m])) ```-#### codeintel-uploads: codeintel_uploads_store_99th_percentile_duration +#### codeintel-uploads: codeintel_uploads_reconciler_scip_metadata_records_altered_total -
99th percentile successful store operation duration over 5m
+Records altered every 5m
+ +The number of candidate records altered as part of cleanup. This panel has no related alerts. -To see this panel, visit `/-/debug/grafana/d/codeintel-uploads/codeintel-uploads?viewPanel=100111` on your Sourcegraph instance. +To see this panel, visit `/-/debug/grafana/d/codeintel-uploads/codeintel-uploads?viewPanel=101301` on your Sourcegraph instance. *Managed by the [Sourcegraph Code intelligence team](https://handbook.sourcegraph.com/departments/engineering/teams/code-intelligence).* @@ -69430,19 +69064,19 @@ To see this panel, visit `/-/debug/grafana/d/codeintel-uploads/codeintel-uploads Query: ``` -histogram_quantile(0.99, sum by (le,op)(rate(src_codeintel_uploads_store_duration_seconds_bucket{job=~"^${source:regex}.*"}[5m]))) +sum(increase(src_codeintel_uploads_reconciler_scip_metadata_records_altered_total{job=~"^${source:regex}.*"}[5m])) ```-#### codeintel-uploads: codeintel_uploads_store_errors_total +#### codeintel-uploads: codeintel_uploads_reconciler_scip_metadata_total -
Store operation errors every 5m
+Job invocation operations every 5m
This panel has no related alerts. -To see this panel, visit `/-/debug/grafana/d/codeintel-uploads/codeintel-uploads?viewPanel=100112` on your Sourcegraph instance. +To see this panel, visit `/-/debug/grafana/d/codeintel-uploads/codeintel-uploads?viewPanel=101310` on your Sourcegraph instance. *Managed by the [Sourcegraph Code intelligence team](https://handbook.sourcegraph.com/departments/engineering/teams/code-intelligence).* @@ -69452,19 +69086,19 @@ To see this panel, visit `/-/debug/grafana/d/codeintel-uploads/codeintel-uploads Query: ``` -sum by (op)(increase(src_codeintel_uploads_store_errors_total{job=~"^${source:regex}.*"}[5m])) +sum by (op)(increase(src_codeintel_uploads_reconciler_scip_metadata_total{job=~"^${source:regex}.*"}[5m])) ```-#### codeintel-uploads: codeintel_uploads_store_error_rate +#### codeintel-uploads: codeintel_uploads_reconciler_scip_metadata_99th_percentile_duration -
Store operation error rate over 5m
+99th percentile successful job invocation operation duration over 5m
This panel has no related alerts. -To see this panel, visit `/-/debug/grafana/d/codeintel-uploads/codeintel-uploads?viewPanel=100113` on your Sourcegraph instance. +To see this panel, visit `/-/debug/grafana/d/codeintel-uploads/codeintel-uploads?viewPanel=101311` on your Sourcegraph instance. *Managed by the [Sourcegraph Code intelligence team](https://handbook.sourcegraph.com/departments/engineering/teams/code-intelligence).* @@ -69474,21 +69108,19 @@ To see this panel, visit `/-/debug/grafana/d/codeintel-uploads/codeintel-uploads Query: ``` -sum by (op)(increase(src_codeintel_uploads_store_errors_total{job=~"^${source:regex}.*"}[5m])) / (sum by (op)(increase(src_codeintel_uploads_store_total{job=~"^${source:regex}.*"}[5m])) + sum by (op)(increase(src_codeintel_uploads_store_errors_total{job=~"^${source:regex}.*"}[5m]))) * 100 +histogram_quantile(0.99, sum by (le,op)(rate(src_codeintel_uploads_reconciler_scip_metadata_duration_seconds_bucket{job=~"^${source:regex}.*"}[5m]))) ```-### Code Intelligence > Uploads: Codeintel: Uploads > GQL Transport - -#### codeintel-uploads: codeintel_uploads_transport_graphql_total +#### codeintel-uploads: codeintel_uploads_reconciler_scip_metadata_errors_total -
Aggregate resolver operations every 5m
+Job invocation operation errors every 5m
This panel has no related alerts. -To see this panel, visit `/-/debug/grafana/d/codeintel-uploads/codeintel-uploads?viewPanel=100200` on your Sourcegraph instance. +To see this panel, visit `/-/debug/grafana/d/codeintel-uploads/codeintel-uploads?viewPanel=101312` on your Sourcegraph instance. *Managed by the [Sourcegraph Code intelligence team](https://handbook.sourcegraph.com/departments/engineering/teams/code-intelligence).* @@ -69498,19 +69130,19 @@ To see this panel, visit `/-/debug/grafana/d/codeintel-uploads/codeintel-uploads Query: ``` -sum(increase(src_codeintel_uploads_transport_graphql_total{job=~"^${source:regex}.*"}[5m])) +sum by (op)(increase(src_codeintel_uploads_reconciler_scip_metadata_errors_total{job=~"^${source:regex}.*"}[5m])) ```-#### codeintel-uploads: codeintel_uploads_transport_graphql_99th_percentile_duration +#### codeintel-uploads: codeintel_uploads_reconciler_scip_metadata_error_rate -
Aggregate successful resolver operation duration distribution over 5m
+Job invocation operation error rate over 5m
This panel has no related alerts. -To see this panel, visit `/-/debug/grafana/d/codeintel-uploads/codeintel-uploads?viewPanel=100201` on your Sourcegraph instance. +To see this panel, visit `/-/debug/grafana/d/codeintel-uploads/codeintel-uploads?viewPanel=101313` on your Sourcegraph instance. *Managed by the [Sourcegraph Code intelligence team](https://handbook.sourcegraph.com/departments/engineering/teams/code-intelligence).* @@ -69520,19 +69152,23 @@ To see this panel, visit `/-/debug/grafana/d/codeintel-uploads/codeintel-uploads Query: ``` -sum by (le)(rate(src_codeintel_uploads_transport_graphql_duration_seconds_bucket{job=~"^${source:regex}.*"}[5m])) +sum by (op)(increase(src_codeintel_uploads_reconciler_scip_metadata_errors_total{job=~"^${source:regex}.*"}[5m])) / (sum by (op)(increase(src_codeintel_uploads_reconciler_scip_metadata_total{job=~"^${source:regex}.*"}[5m])) + sum by (op)(increase(src_codeintel_uploads_reconciler_scip_metadata_errors_total{job=~"^${source:regex}.*"}[5m]))) * 100 ```-#### codeintel-uploads: codeintel_uploads_transport_graphql_errors_total +### Code Intelligence > Uploads: Codeintel: Uploads > Reconciler task > Codeintel uploads reconciler scip data -
Aggregate resolver operation errors every 5m
+#### codeintel-uploads: codeintel_uploads_reconciler_scip_data_records_scanned_total + +Records scanned every 5m
+ +The number of candidate records considered for cleanup. This panel has no related alerts. -To see this panel, visit `/-/debug/grafana/d/codeintel-uploads/codeintel-uploads?viewPanel=100202` on your Sourcegraph instance. +To see this panel, visit `/-/debug/grafana/d/codeintel-uploads/codeintel-uploads?viewPanel=101400` on your Sourcegraph instance. *Managed by the [Sourcegraph Code intelligence team](https://handbook.sourcegraph.com/departments/engineering/teams/code-intelligence).* @@ -69542,19 +69178,21 @@ To see this panel, visit `/-/debug/grafana/d/codeintel-uploads/codeintel-uploads Query: ``` -sum(increase(src_codeintel_uploads_transport_graphql_errors_total{job=~"^${source:regex}.*"}[5m])) +sum(increase(src_codeintel_uploads_reconciler_scip_data_records_scanned_total{job=~"^${source:regex}.*"}[5m])) ```-#### codeintel-uploads: codeintel_uploads_transport_graphql_error_rate +#### codeintel-uploads: codeintel_uploads_reconciler_scip_data_records_altered_total -
Aggregate resolver operation error rate over 5m
+Records altered every 5m
+ +The number of candidate records altered as part of cleanup. This panel has no related alerts. -To see this panel, visit `/-/debug/grafana/d/codeintel-uploads/codeintel-uploads?viewPanel=100203` on your Sourcegraph instance. +To see this panel, visit `/-/debug/grafana/d/codeintel-uploads/codeintel-uploads?viewPanel=101401` on your Sourcegraph instance. *Managed by the [Sourcegraph Code intelligence team](https://handbook.sourcegraph.com/departments/engineering/teams/code-intelligence).* @@ -69564,19 +69202,19 @@ To see this panel, visit `/-/debug/grafana/d/codeintel-uploads/codeintel-uploads Query: ``` -sum(increase(src_codeintel_uploads_transport_graphql_errors_total{job=~"^${source:regex}.*"}[5m])) / (sum(increase(src_codeintel_uploads_transport_graphql_total{job=~"^${source:regex}.*"}[5m])) + sum(increase(src_codeintel_uploads_transport_graphql_errors_total{job=~"^${source:regex}.*"}[5m]))) * 100 +sum(increase(src_codeintel_uploads_reconciler_scip_data_records_altered_total{job=~"^${source:regex}.*"}[5m])) ```-#### codeintel-uploads: codeintel_uploads_transport_graphql_total +#### codeintel-uploads: codeintel_uploads_reconciler_scip_data_total -
Resolver operations every 5m
+Job invocation operations every 5m
This panel has no related alerts. -To see this panel, visit `/-/debug/grafana/d/codeintel-uploads/codeintel-uploads?viewPanel=100210` on your Sourcegraph instance. +To see this panel, visit `/-/debug/grafana/d/codeintel-uploads/codeintel-uploads?viewPanel=101410` on your Sourcegraph instance. *Managed by the [Sourcegraph Code intelligence team](https://handbook.sourcegraph.com/departments/engineering/teams/code-intelligence).* @@ -69586,19 +69224,19 @@ To see this panel, visit `/-/debug/grafana/d/codeintel-uploads/codeintel-uploads Query: ``` -sum by (op)(increase(src_codeintel_uploads_transport_graphql_total{job=~"^${source:regex}.*"}[5m])) +sum by (op)(increase(src_codeintel_uploads_reconciler_scip_data_total{job=~"^${source:regex}.*"}[5m])) ```-#### codeintel-uploads: codeintel_uploads_transport_graphql_99th_percentile_duration +#### codeintel-uploads: codeintel_uploads_reconciler_scip_data_99th_percentile_duration -
99th percentile successful resolver operation duration over 5m
+99th percentile successful job invocation operation duration over 5m
This panel has no related alerts. -To see this panel, visit `/-/debug/grafana/d/codeintel-uploads/codeintel-uploads?viewPanel=100211` on your Sourcegraph instance. +To see this panel, visit `/-/debug/grafana/d/codeintel-uploads/codeintel-uploads?viewPanel=101411` on your Sourcegraph instance. *Managed by the [Sourcegraph Code intelligence team](https://handbook.sourcegraph.com/departments/engineering/teams/code-intelligence).* @@ -69608,19 +69246,19 @@ To see this panel, visit `/-/debug/grafana/d/codeintel-uploads/codeintel-uploads Query: ``` -histogram_quantile(0.99, sum by (le,op)(rate(src_codeintel_uploads_transport_graphql_duration_seconds_bucket{job=~"^${source:regex}.*"}[5m]))) +histogram_quantile(0.99, sum by (le,op)(rate(src_codeintel_uploads_reconciler_scip_data_duration_seconds_bucket{job=~"^${source:regex}.*"}[5m]))) ```-#### codeintel-uploads: codeintel_uploads_transport_graphql_errors_total +#### codeintel-uploads: codeintel_uploads_reconciler_scip_data_errors_total -
Resolver operation errors every 5m
+Job invocation operation errors every 5m
This panel has no related alerts. -To see this panel, visit `/-/debug/grafana/d/codeintel-uploads/codeintel-uploads?viewPanel=100212` on your Sourcegraph instance. +To see this panel, visit `/-/debug/grafana/d/codeintel-uploads/codeintel-uploads?viewPanel=101412` on your Sourcegraph instance. *Managed by the [Sourcegraph Code intelligence team](https://handbook.sourcegraph.com/departments/engineering/teams/code-intelligence).* @@ -69630,19 +69268,19 @@ To see this panel, visit `/-/debug/grafana/d/codeintel-uploads/codeintel-uploads Query: ``` -sum by (op)(increase(src_codeintel_uploads_transport_graphql_errors_total{job=~"^${source:regex}.*"}[5m])) +sum by (op)(increase(src_codeintel_uploads_reconciler_scip_data_errors_total{job=~"^${source:regex}.*"}[5m])) ```-#### codeintel-uploads: codeintel_uploads_transport_graphql_error_rate +#### codeintel-uploads: codeintel_uploads_reconciler_scip_data_error_rate -
Resolver operation error rate over 5m
+Job invocation operation error rate over 5m
This panel has no related alerts. -To see this panel, visit `/-/debug/grafana/d/codeintel-uploads/codeintel-uploads?viewPanel=100213` on your Sourcegraph instance. +To see this panel, visit `/-/debug/grafana/d/codeintel-uploads/codeintel-uploads?viewPanel=101413` on your Sourcegraph instance. *Managed by the [Sourcegraph Code intelligence team](https://handbook.sourcegraph.com/departments/engineering/teams/code-intelligence).* @@ -69652,23 +69290,31 @@ To see this panel, visit `/-/debug/grafana/d/codeintel-uploads/codeintel-uploads Query: ``` -sum by (op)(increase(src_codeintel_uploads_transport_graphql_errors_total{job=~"^${source:regex}.*"}[5m])) / (sum by (op)(increase(src_codeintel_uploads_transport_graphql_total{job=~"^${source:regex}.*"}[5m])) + sum by (op)(increase(src_codeintel_uploads_transport_graphql_errors_total{job=~"^${source:regex}.*"}[5m]))) * 100 +sum by (op)(increase(src_codeintel_uploads_reconciler_scip_data_errors_total{job=~"^${source:regex}.*"}[5m])) / (sum by (op)(increase(src_codeintel_uploads_reconciler_scip_data_total{job=~"^${source:regex}.*"}[5m])) + sum by (op)(increase(src_codeintel_uploads_reconciler_scip_data_errors_total{job=~"^${source:regex}.*"}[5m]))) * 100 ```-### Code Intelligence > Uploads: Codeintel: Uploads > HTTP Transport +## Telemetry -#### codeintel-uploads: codeintel_uploads_transport_http_total +
Monitoring telemetry services in Sourcegraph.
-Aggregate http handler operations every 5m
+To see this dashboard, visit `/-/debug/grafana/d/telemetry/telemetry` on your Sourcegraph instance. + +### Telemetry: Telemetry Gateway Exporter: Events export and queue metrics + +#### telemetry: telemetry_gateway_exporter_queue_size + +Telemetry event payloads pending export
+ +The number of events queued to be exported. This panel has no related alerts. -To see this panel, visit `/-/debug/grafana/d/codeintel-uploads/codeintel-uploads?viewPanel=100300` on your Sourcegraph instance. +To see this panel, visit `/-/debug/grafana/d/telemetry/telemetry?viewPanel=100000` on your Sourcegraph instance. -*Managed by the [Sourcegraph Code intelligence team](https://handbook.sourcegraph.com/departments/engineering/teams/code-intelligence).* +*Managed by the [Sourcegraph Data & Analytics team](https://handbook.sourcegraph.com/departments/engineering/teams/data-analytics).*Technical details
@@ -69676,21 +69322,23 @@ To see this panel, visit `/-/debug/grafana/d/codeintel-uploads/codeintel-uploads Query: ``` -sum(increase(src_codeintel_uploads_transport_http_total{job=~"^${source:regex}.*"}[5m])) +sum(src_telemetrygatewayexporter_queue_size) ```-#### codeintel-uploads: codeintel_uploads_transport_http_99th_percentile_duration +#### telemetry: telemetry_gateway_exporter_queue_growth -
Aggregate successful http handler operation duration distribution over 5m
+Rate of growth of events export queue over 30m
-This panel has no related alerts. +A positive value indicates the queue is growing. -To see this panel, visit `/-/debug/grafana/d/codeintel-uploads/codeintel-uploads?viewPanel=100301` on your Sourcegraph instance. +Refer to the [alerts reference](alerts#telemetry-telemetry-gateway-exporter-queue-growth) for 2 alerts related to this panel. -*Managed by the [Sourcegraph Code intelligence team](https://handbook.sourcegraph.com/departments/engineering/teams/code-intelligence).* +To see this panel, visit `/-/debug/grafana/d/telemetry/telemetry?viewPanel=100001` on your Sourcegraph instance. + +*Managed by the [Sourcegraph Data & Analytics team](https://handbook.sourcegraph.com/departments/engineering/teams/data-analytics).*Technical details
@@ -69698,21 +69346,23 @@ To see this panel, visit `/-/debug/grafana/d/codeintel-uploads/codeintel-uploads Query: ``` -sum by (le)(rate(src_codeintel_uploads_transport_http_duration_seconds_bucket{job=~"^${source:regex}.*"}[5m])) +max(deriv(src_telemetrygatewayexporter_queue_size[30m])) ```-#### codeintel-uploads: codeintel_uploads_transport_http_errors_total +#### telemetry: src_telemetrygatewayexporter_exported_events -
Aggregate http handler operation errors every 5m
+Events exported from queue per hour
+ +The number of events being exported. This panel has no related alerts. -To see this panel, visit `/-/debug/grafana/d/codeintel-uploads/codeintel-uploads?viewPanel=100302` on your Sourcegraph instance. +To see this panel, visit `/-/debug/grafana/d/telemetry/telemetry?viewPanel=100010` on your Sourcegraph instance. -*Managed by the [Sourcegraph Code intelligence team](https://handbook.sourcegraph.com/departments/engineering/teams/code-intelligence).* +*Managed by the [Sourcegraph Data & Analytics team](https://handbook.sourcegraph.com/departments/engineering/teams/data-analytics).*Technical details
@@ -69720,21 +69370,24 @@ To see this panel, visit `/-/debug/grafana/d/codeintel-uploads/codeintel-uploads Query: ``` -sum(increase(src_codeintel_uploads_transport_http_errors_total{job=~"^${source:regex}.*"}[5m])) +max(increase(src_telemetrygatewayexporter_exported_events[1h])) ```-#### codeintel-uploads: codeintel_uploads_transport_http_error_rate +#### telemetry: telemetry_gateway_exporter_batch_size -
Aggregate http handler operation error rate over 5m
+Number of events exported per batch over 30m
+ +The number of events exported in each batch. The largest bucket is the maximum number of events exported per batch. +If the distribution trends to the maximum bucket, then events export throughput is at or approaching saturation - try increasing `TELEMETRY_GATEWAY_EXPORTER_EXPORT_BATCH_SIZE` or decreasing `TELEMETRY_GATEWAY_EXPORTER_EXPORT_INTERVAL`. This panel has no related alerts. -To see this panel, visit `/-/debug/grafana/d/codeintel-uploads/codeintel-uploads?viewPanel=100303` on your Sourcegraph instance. +To see this panel, visit `/-/debug/grafana/d/telemetry/telemetry?viewPanel=100011` on your Sourcegraph instance. -*Managed by the [Sourcegraph Code intelligence team](https://handbook.sourcegraph.com/departments/engineering/teams/code-intelligence).* +*Managed by the [Sourcegraph Data & Analytics team](https://handbook.sourcegraph.com/departments/engineering/teams/data-analytics).*Technical details
@@ -69742,21 +69395,23 @@ To see this panel, visit `/-/debug/grafana/d/codeintel-uploads/codeintel-uploads Query: ``` -sum(increase(src_codeintel_uploads_transport_http_errors_total{job=~"^${source:regex}.*"}[5m])) / (sum(increase(src_codeintel_uploads_transport_http_total{job=~"^${source:regex}.*"}[5m])) + sum(increase(src_codeintel_uploads_transport_http_errors_total{job=~"^${source:regex}.*"}[5m]))) * 100 +sum by (le) (rate(src_telemetrygatewayexporter_batch_size_bucket[30m])) ```-#### codeintel-uploads: codeintel_uploads_transport_http_total +### Telemetry: Telemetry Gateway Exporter: Events export job operations -
Http handler operations every 5m
+#### telemetry: telemetrygatewayexporter_exporter_total + +Events exporter operations every 30m
This panel has no related alerts. -To see this panel, visit `/-/debug/grafana/d/codeintel-uploads/codeintel-uploads?viewPanel=100310` on your Sourcegraph instance. +To see this panel, visit `/-/debug/grafana/d/telemetry/telemetry?viewPanel=100100` on your Sourcegraph instance. -*Managed by the [Sourcegraph Code intelligence team](https://handbook.sourcegraph.com/departments/engineering/teams/code-intelligence).* +*Managed by the [Sourcegraph Data & Analytics team](https://handbook.sourcegraph.com/departments/engineering/teams/data-analytics).*Technical details
@@ -69764,21 +69419,21 @@ To see this panel, visit `/-/debug/grafana/d/codeintel-uploads/codeintel-uploads Query: ``` -sum by (op)(increase(src_codeintel_uploads_transport_http_total{job=~"^${source:regex}.*"}[5m])) +sum(increase(src_telemetrygatewayexporter_exporter_total{job=~"^worker.*"}[30m])) ```-#### codeintel-uploads: codeintel_uploads_transport_http_99th_percentile_duration +#### telemetry: telemetrygatewayexporter_exporter_99th_percentile_duration -
99th percentile successful http handler operation duration over 5m
+Aggregate successful events exporter operation duration distribution over 30m
This panel has no related alerts. -To see this panel, visit `/-/debug/grafana/d/codeintel-uploads/codeintel-uploads?viewPanel=100311` on your Sourcegraph instance. +To see this panel, visit `/-/debug/grafana/d/telemetry/telemetry?viewPanel=100101` on your Sourcegraph instance. -*Managed by the [Sourcegraph Code intelligence team](https://handbook.sourcegraph.com/departments/engineering/teams/code-intelligence).* +*Managed by the [Sourcegraph Data & Analytics team](https://handbook.sourcegraph.com/departments/engineering/teams/data-analytics).*Technical details
@@ -69786,21 +69441,21 @@ To see this panel, visit `/-/debug/grafana/d/codeintel-uploads/codeintel-uploads Query: ``` -histogram_quantile(0.99, sum by (le,op)(rate(src_codeintel_uploads_transport_http_duration_seconds_bucket{job=~"^${source:regex}.*"}[5m]))) +sum by (le)(rate(src_telemetrygatewayexporter_exporter_duration_seconds_bucket{job=~"^worker.*"}[30m])) ```-#### codeintel-uploads: codeintel_uploads_transport_http_errors_total +#### telemetry: telemetrygatewayexporter_exporter_errors_total -
Http handler operation errors every 5m
+Events exporter operation errors every 30m
-This panel has no related alerts. +Refer to the [alerts reference](alerts#telemetry-telemetrygatewayexporter-exporter-errors-total) for 1 alert related to this panel. -To see this panel, visit `/-/debug/grafana/d/codeintel-uploads/codeintel-uploads?viewPanel=100312` on your Sourcegraph instance. +To see this panel, visit `/-/debug/grafana/d/telemetry/telemetry?viewPanel=100102` on your Sourcegraph instance. -*Managed by the [Sourcegraph Code intelligence team](https://handbook.sourcegraph.com/departments/engineering/teams/code-intelligence).* +*Managed by the [Sourcegraph Data & Analytics team](https://handbook.sourcegraph.com/departments/engineering/teams/data-analytics).*Technical details
@@ -69808,21 +69463,21 @@ To see this panel, visit `/-/debug/grafana/d/codeintel-uploads/codeintel-uploads Query: ``` -sum by (op)(increase(src_codeintel_uploads_transport_http_errors_total{job=~"^${source:regex}.*"}[5m])) +sum(increase(src_telemetrygatewayexporter_exporter_errors_total{job=~"^worker.*"}[30m])) ```-#### codeintel-uploads: codeintel_uploads_transport_http_error_rate +#### telemetry: telemetrygatewayexporter_exporter_error_rate -
Http handler operation error rate over 5m
+Events exporter operation error rate over 30m
This panel has no related alerts. -To see this panel, visit `/-/debug/grafana/d/codeintel-uploads/codeintel-uploads?viewPanel=100313` on your Sourcegraph instance. +To see this panel, visit `/-/debug/grafana/d/telemetry/telemetry?viewPanel=100103` on your Sourcegraph instance. -*Managed by the [Sourcegraph Code intelligence team](https://handbook.sourcegraph.com/departments/engineering/teams/code-intelligence).* +*Managed by the [Sourcegraph Data & Analytics team](https://handbook.sourcegraph.com/departments/engineering/teams/data-analytics).*Technical details
@@ -69830,23 +69485,23 @@ To see this panel, visit `/-/debug/grafana/d/codeintel-uploads/codeintel-uploads Query: ``` -sum by (op)(increase(src_codeintel_uploads_transport_http_errors_total{job=~"^${source:regex}.*"}[5m])) / (sum by (op)(increase(src_codeintel_uploads_transport_http_total{job=~"^${source:regex}.*"}[5m])) + sum by (op)(increase(src_codeintel_uploads_transport_http_errors_total{job=~"^${source:regex}.*"}[5m]))) * 100 +sum(increase(src_telemetrygatewayexporter_exporter_errors_total{job=~"^worker.*"}[30m])) / (sum(increase(src_telemetrygatewayexporter_exporter_total{job=~"^worker.*"}[30m])) + sum(increase(src_telemetrygatewayexporter_exporter_errors_total{job=~"^worker.*"}[30m]))) * 100 ```-### Code Intelligence > Uploads: Codeintel: Repository with stale commit graph +### Telemetry: Telemetry Gateway Exporter: Events export queue cleanup job operations -#### codeintel-uploads: codeintel_commit_graph_queue_size +#### telemetry: telemetrygatewayexporter_queue_cleanup_total -
Repository queue size
+Events export queue cleanup operations every 30m
This panel has no related alerts. -To see this panel, visit `/-/debug/grafana/d/codeintel-uploads/codeintel-uploads?viewPanel=100400` on your Sourcegraph instance. +To see this panel, visit `/-/debug/grafana/d/telemetry/telemetry?viewPanel=100200` on your Sourcegraph instance. -*Managed by the [Sourcegraph Code intelligence team](https://handbook.sourcegraph.com/departments/engineering/teams/code-intelligence).* +*Managed by the [Sourcegraph Data & Analytics team](https://handbook.sourcegraph.com/departments/engineering/teams/data-analytics).*Technical details
@@ -69854,27 +69509,21 @@ To see this panel, visit `/-/debug/grafana/d/codeintel-uploads/codeintel-uploads Query: ``` -max(src_codeintel_commit_graph_total{job=~"^${source:regex}.*"}) +sum(increase(src_telemetrygatewayexporter_queue_cleanup_total{job=~"^worker.*"}[30m])) ```-#### codeintel-uploads: codeintel_commit_graph_queue_growth_rate - -
Repository queue growth rate over 30m
- -This value compares the rate of enqueues against the rate of finished jobs. +#### telemetry: telemetrygatewayexporter_queue_cleanup_99th_percentile_duration - - A value < than 1 indicates that process rate > enqueue rate - - A value = than 1 indicates that process rate = enqueue rate - - A value > than 1 indicates that process rate < enqueue rate +Aggregate successful events export queue cleanup operation duration distribution over 30m
This panel has no related alerts. -To see this panel, visit `/-/debug/grafana/d/codeintel-uploads/codeintel-uploads?viewPanel=100401` on your Sourcegraph instance. +To see this panel, visit `/-/debug/grafana/d/telemetry/telemetry?viewPanel=100201` on your Sourcegraph instance. -*Managed by the [Sourcegraph Code intelligence team](https://handbook.sourcegraph.com/departments/engineering/teams/code-intelligence).* +*Managed by the [Sourcegraph Data & Analytics team](https://handbook.sourcegraph.com/departments/engineering/teams/data-analytics).*Technical details
@@ -69882,21 +69531,21 @@ To see this panel, visit `/-/debug/grafana/d/codeintel-uploads/codeintel-uploads Query: ``` -sum(increase(src_codeintel_commit_graph_total{job=~"^${source:regex}.*"}[30m])) / sum(increase(src_codeintel_commit_graph_processor_total{job=~"^${source:regex}.*"}[30m])) +sum by (le)(rate(src_telemetrygatewayexporter_queue_cleanup_duration_seconds_bucket{job=~"^worker.*"}[30m])) ```-#### codeintel-uploads: codeintel_commit_graph_queued_max_age +#### telemetry: telemetrygatewayexporter_queue_cleanup_errors_total -
Repository queue longest time in queue
+Events export queue cleanup operation errors every 30m
-Refer to the [alerts reference](alerts#codeintel-uploads-codeintel-commit-graph-queued-max-age) for 1 alert related to this panel. +Refer to the [alerts reference](alerts#telemetry-telemetrygatewayexporter-queue-cleanup-errors-total) for 1 alert related to this panel. -To see this panel, visit `/-/debug/grafana/d/codeintel-uploads/codeintel-uploads?viewPanel=100402` on your Sourcegraph instance. +To see this panel, visit `/-/debug/grafana/d/telemetry/telemetry?viewPanel=100202` on your Sourcegraph instance. -*Managed by the [Sourcegraph Code intelligence team](https://handbook.sourcegraph.com/departments/engineering/teams/code-intelligence).* +*Managed by the [Sourcegraph Data & Analytics team](https://handbook.sourcegraph.com/departments/engineering/teams/data-analytics).*Technical details
@@ -69904,25 +69553,21 @@ To see this panel, visit `/-/debug/grafana/d/codeintel-uploads/codeintel-uploads Query: ``` -max(src_codeintel_commit_graph_queued_duration_seconds_total{job=~"^${source:regex}.*"}) +sum(increase(src_telemetrygatewayexporter_queue_cleanup_errors_total{job=~"^worker.*"}[30m])) ```-### Code Intelligence > Uploads: Codeintel: Uploads > Expiration task - -#### codeintel-uploads: codeintel_background_repositories_scanned_total - -
Lsif upload repository scan repositories scanned every 5m
+#### telemetry: telemetrygatewayexporter_queue_cleanup_error_rate -Number of repositories scanned for data retention +Events export queue cleanup operation error rate over 30m
This panel has no related alerts. -To see this panel, visit `/-/debug/grafana/d/codeintel-uploads/codeintel-uploads?viewPanel=100500` on your Sourcegraph instance. +To see this panel, visit `/-/debug/grafana/d/telemetry/telemetry?viewPanel=100203` on your Sourcegraph instance. -*Managed by the [Sourcegraph Code intelligence team](https://handbook.sourcegraph.com/departments/engineering/teams/code-intelligence).* +*Managed by the [Sourcegraph Data & Analytics team](https://handbook.sourcegraph.com/departments/engineering/teams/data-analytics).*Technical details
@@ -69930,23 +69575,23 @@ To see this panel, visit `/-/debug/grafana/d/codeintel-uploads/codeintel-uploads Query: ``` -sum(increase(src_codeintel_background_repositories_scanned_total{job=~"^${source:regex}.*"}[5m])) +sum(increase(src_telemetrygatewayexporter_queue_cleanup_errors_total{job=~"^worker.*"}[30m])) / (sum(increase(src_telemetrygatewayexporter_queue_cleanup_total{job=~"^worker.*"}[30m])) + sum(increase(src_telemetrygatewayexporter_queue_cleanup_errors_total{job=~"^worker.*"}[30m]))) * 100 ```-#### codeintel-uploads: codeintel_background_upload_records_scanned_total +### Telemetry: Telemetry Gateway Exporter: Events export queue metrics reporting job operations -
Lsif upload records scan records scanned every 5m
+#### telemetry: telemetrygatewayexporter_queue_metrics_reporter_total -Number of codeintel upload records scanned for data retention +Events export backlog metrics reporting operations every 30m
This panel has no related alerts. -To see this panel, visit `/-/debug/grafana/d/codeintel-uploads/codeintel-uploads?viewPanel=100501` on your Sourcegraph instance. +To see this panel, visit `/-/debug/grafana/d/telemetry/telemetry?viewPanel=100300` on your Sourcegraph instance. -*Managed by the [Sourcegraph Code intelligence team](https://handbook.sourcegraph.com/departments/engineering/teams/code-intelligence).* +*Managed by the [Sourcegraph Data & Analytics team](https://handbook.sourcegraph.com/departments/engineering/teams/data-analytics).*Technical details
@@ -69954,23 +69599,21 @@ To see this panel, visit `/-/debug/grafana/d/codeintel-uploads/codeintel-uploads Query: ``` -sum(increase(src_codeintel_background_upload_records_scanned_total{job=~"^${source:regex}.*"}[5m])) +sum(increase(src_telemetrygatewayexporter_queue_metrics_reporter_total{job=~"^worker.*"}[30m])) ```-#### codeintel-uploads: codeintel_background_commits_scanned_total - -
Lsif upload commits scanned commits scanned every 5m
+#### telemetry: telemetrygatewayexporter_queue_metrics_reporter_99th_percentile_duration -Number of commits reachable from a codeintel upload record scanned for data retention +Aggregate successful events export backlog metrics reporting operation duration distribution over 30m
This panel has no related alerts. -To see this panel, visit `/-/debug/grafana/d/codeintel-uploads/codeintel-uploads?viewPanel=100502` on your Sourcegraph instance. +To see this panel, visit `/-/debug/grafana/d/telemetry/telemetry?viewPanel=100301` on your Sourcegraph instance. -*Managed by the [Sourcegraph Code intelligence team](https://handbook.sourcegraph.com/departments/engineering/teams/code-intelligence).* +*Managed by the [Sourcegraph Data & Analytics team](https://handbook.sourcegraph.com/departments/engineering/teams/data-analytics).*Technical details
@@ -69978,23 +69621,21 @@ To see this panel, visit `/-/debug/grafana/d/codeintel-uploads/codeintel-uploads Query: ``` -sum(increase(src_codeintel_background_commits_scanned_total{job=~"^${source:regex}.*"}[5m])) +sum by (le)(rate(src_telemetrygatewayexporter_queue_metrics_reporter_duration_seconds_bucket{job=~"^worker.*"}[30m])) ```-#### codeintel-uploads: codeintel_background_upload_records_expired_total - -
Lsif upload records expired uploads scanned every 5m
+#### telemetry: telemetrygatewayexporter_queue_metrics_reporter_errors_total -Number of codeintel upload records marked as expired +Events export backlog metrics reporting operation errors every 30m
-This panel has no related alerts. +Refer to the [alerts reference](alerts#telemetry-telemetrygatewayexporter-queue-metrics-reporter-errors-total) for 1 alert related to this panel. -To see this panel, visit `/-/debug/grafana/d/codeintel-uploads/codeintel-uploads?viewPanel=100503` on your Sourcegraph instance. +To see this panel, visit `/-/debug/grafana/d/telemetry/telemetry?viewPanel=100302` on your Sourcegraph instance. -*Managed by the [Sourcegraph Code intelligence team](https://handbook.sourcegraph.com/departments/engineering/teams/code-intelligence).* +*Managed by the [Sourcegraph Data & Analytics team](https://handbook.sourcegraph.com/departments/engineering/teams/data-analytics).*Technical details
@@ -70002,25 +69643,21 @@ To see this panel, visit `/-/debug/grafana/d/codeintel-uploads/codeintel-uploads Query: ``` -sum(increase(src_codeintel_background_upload_records_expired_total{job=~"^${source:regex}.*"}[5m])) +sum(increase(src_telemetrygatewayexporter_queue_metrics_reporter_errors_total{job=~"^worker.*"}[30m])) ```-### Code Intelligence > Uploads: Codeintel: Uploads > Janitor task > Codeintel uploads janitor unknown repository - -#### codeintel-uploads: codeintel_uploads_janitor_unknown_repository_records_scanned_total - -
Records scanned every 5m
+#### telemetry: telemetrygatewayexporter_queue_metrics_reporter_error_rate -The number of candidate records considered for cleanup. +Events export backlog metrics reporting operation error rate over 30m
This panel has no related alerts. -To see this panel, visit `/-/debug/grafana/d/codeintel-uploads/codeintel-uploads?viewPanel=100600` on your Sourcegraph instance. +To see this panel, visit `/-/debug/grafana/d/telemetry/telemetry?viewPanel=100303` on your Sourcegraph instance. -*Managed by the [Sourcegraph Code intelligence team](https://handbook.sourcegraph.com/departments/engineering/teams/code-intelligence).* +*Managed by the [Sourcegraph Data & Analytics team](https://handbook.sourcegraph.com/departments/engineering/teams/data-analytics).*Technical details
@@ -70028,23 +69665,25 @@ To see this panel, visit `/-/debug/grafana/d/codeintel-uploads/codeintel-uploads Query: ``` -sum(increase(src_codeintel_uploads_janitor_unknown_repository_records_scanned_total{job=~"^${source:regex}.*"}[5m])) +sum(increase(src_telemetrygatewayexporter_queue_metrics_reporter_errors_total{job=~"^worker.*"}[30m])) / (sum(increase(src_telemetrygatewayexporter_queue_metrics_reporter_total{job=~"^worker.*"}[30m])) + sum(increase(src_telemetrygatewayexporter_queue_metrics_reporter_errors_total{job=~"^worker.*"}[30m]))) * 100 ```-#### codeintel-uploads: codeintel_uploads_janitor_unknown_repository_records_altered_total +### Telemetry: Telemetry persistence -
Records altered every 5m
+#### telemetry: telemetry_v2_export_queue_write_failures -The number of candidate records altered as part of cleanup. +Failed writes to events export queue over 5m
-This panel has no related alerts. +Telemetry V2 writes send events into the `telemetry_events_export_queue` for the exporter to periodically export. -To see this panel, visit `/-/debug/grafana/d/codeintel-uploads/codeintel-uploads?viewPanel=100601` on your Sourcegraph instance. +Refer to the [alerts reference](alerts#telemetry-telemetry-v2-export-queue-write-failures) for 2 alerts related to this panel. -*Managed by the [Sourcegraph Code intelligence team](https://handbook.sourcegraph.com/departments/engineering/teams/code-intelligence).* +To see this panel, visit `/-/debug/grafana/d/telemetry/telemetry?viewPanel=100400` on your Sourcegraph instance. + +*Managed by the [Sourcegraph Infrastructure Org team](https://handbook.sourcegraph.com/departments/engineering/infrastructure).*Technical details
@@ -70052,21 +69691,23 @@ To see this panel, visit `/-/debug/grafana/d/codeintel-uploads/codeintel-uploads Query: ``` -sum(increase(src_codeintel_uploads_janitor_unknown_repository_records_altered_total{job=~"^${source:regex}.*"}[5m])) +(sum(increase(src_telemetry_export_store_queued_events{failed="true"}[5m])) / sum(increase(src_telemetry_export_store_queued_events[5m]))) * 100 ```-#### codeintel-uploads: codeintel_uploads_janitor_unknown_repository_total +#### telemetry: telemetry_v2_event_logs_write_failures -
Job invocation operations every 5m
+Failed write V2 events to V1 'event_logs' over 5m
-This panel has no related alerts. +Telemetry V2 writes also attempt to `tee` events into the legacy V1 events format in the `event_logs` database table for long-term local persistence. -To see this panel, visit `/-/debug/grafana/d/codeintel-uploads/codeintel-uploads?viewPanel=100610` on your Sourcegraph instance. +Refer to the [alerts reference](alerts#telemetry-telemetry-v2-event-logs-write-failures) for 2 alerts related to this panel. -*Managed by the [Sourcegraph Code intelligence team](https://handbook.sourcegraph.com/departments/engineering/teams/code-intelligence).* +To see this panel, visit `/-/debug/grafana/d/telemetry/telemetry?viewPanel=100401` on your Sourcegraph instance. + +*Managed by the [Sourcegraph Infrastructure Org team](https://handbook.sourcegraph.com/departments/engineering/infrastructure).*Technical details
@@ -70074,21 +69715,23 @@ To see this panel, visit `/-/debug/grafana/d/codeintel-uploads/codeintel-uploads Query: ``` -sum by (op)(increase(src_codeintel_uploads_janitor_unknown_repository_total{job=~"^${source:regex}.*"}[5m])) +(sum(increase(src_telemetry_teestore_v1_events{failed="true"}[5m])) / sum(increase(src_telemetry_teestore_v1_events[5m]))) * 100 ```-#### codeintel-uploads: codeintel_uploads_janitor_unknown_repository_99th_percentile_duration +### Telemetry: Telemetry Gateway Exporter: (off by default) User metadata export job operations -
99th percentile successful job invocation operation duration over 5m
+#### telemetry: telemetrygatewayexporter_usermetadata_exporter_total + +(off by default) user metadata exporter operations every 30m
This panel has no related alerts. -To see this panel, visit `/-/debug/grafana/d/codeintel-uploads/codeintel-uploads?viewPanel=100611` on your Sourcegraph instance. +To see this panel, visit `/-/debug/grafana/d/telemetry/telemetry?viewPanel=100500` on your Sourcegraph instance. -*Managed by the [Sourcegraph Code intelligence team](https://handbook.sourcegraph.com/departments/engineering/teams/code-intelligence).* +*Managed by the [Sourcegraph Data & Analytics team](https://handbook.sourcegraph.com/departments/engineering/teams/data-analytics).*Technical details
@@ -70096,21 +69739,21 @@ To see this panel, visit `/-/debug/grafana/d/codeintel-uploads/codeintel-uploads Query: ``` -histogram_quantile(0.99, sum by (le,op)(rate(src_codeintel_uploads_janitor_unknown_repository_duration_seconds_bucket{job=~"^${source:regex}.*"}[5m]))) +sum(increase(src_telemetrygatewayexporter_usermetadata_exporter_total{job=~"^worker.*"}[30m])) ```-#### codeintel-uploads: codeintel_uploads_janitor_unknown_repository_errors_total +#### telemetry: telemetrygatewayexporter_usermetadata_exporter_99th_percentile_duration -
Job invocation operation errors every 5m
+Aggregate successful (off by default) user metadata exporter operation duration distribution over 30m
This panel has no related alerts. -To see this panel, visit `/-/debug/grafana/d/codeintel-uploads/codeintel-uploads?viewPanel=100612` on your Sourcegraph instance. +To see this panel, visit `/-/debug/grafana/d/telemetry/telemetry?viewPanel=100501` on your Sourcegraph instance. -*Managed by the [Sourcegraph Code intelligence team](https://handbook.sourcegraph.com/departments/engineering/teams/code-intelligence).* +*Managed by the [Sourcegraph Data & Analytics team](https://handbook.sourcegraph.com/departments/engineering/teams/data-analytics).*Technical details
@@ -70118,21 +69761,21 @@ To see this panel, visit `/-/debug/grafana/d/codeintel-uploads/codeintel-uploads Query: ``` -sum by (op)(increase(src_codeintel_uploads_janitor_unknown_repository_errors_total{job=~"^${source:regex}.*"}[5m])) +sum by (le)(rate(src_telemetrygatewayexporter_usermetadata_exporter_duration_seconds_bucket{job=~"^worker.*"}[30m])) ```-#### codeintel-uploads: codeintel_uploads_janitor_unknown_repository_error_rate +#### telemetry: telemetrygatewayexporter_usermetadata_exporter_errors_total -
Job invocation operation error rate over 5m
+(off by default) user metadata exporter operation errors every 30m
-This panel has no related alerts. +Refer to the [alerts reference](alerts#telemetry-telemetrygatewayexporter-usermetadata-exporter-errors-total) for 1 alert related to this panel. -To see this panel, visit `/-/debug/grafana/d/codeintel-uploads/codeintel-uploads?viewPanel=100613` on your Sourcegraph instance. +To see this panel, visit `/-/debug/grafana/d/telemetry/telemetry?viewPanel=100502` on your Sourcegraph instance. -*Managed by the [Sourcegraph Code intelligence team](https://handbook.sourcegraph.com/departments/engineering/teams/code-intelligence).* +*Managed by the [Sourcegraph Data & Analytics team](https://handbook.sourcegraph.com/departments/engineering/teams/data-analytics).*Technical details
@@ -70140,25 +69783,21 @@ To see this panel, visit `/-/debug/grafana/d/codeintel-uploads/codeintel-uploads Query: ``` -sum by (op)(increase(src_codeintel_uploads_janitor_unknown_repository_errors_total{job=~"^${source:regex}.*"}[5m])) / (sum by (op)(increase(src_codeintel_uploads_janitor_unknown_repository_total{job=~"^${source:regex}.*"}[5m])) + sum by (op)(increase(src_codeintel_uploads_janitor_unknown_repository_errors_total{job=~"^${source:regex}.*"}[5m]))) * 100 +sum(increase(src_telemetrygatewayexporter_usermetadata_exporter_errors_total{job=~"^worker.*"}[30m])) ```-### Code Intelligence > Uploads: Codeintel: Uploads > Janitor task > Codeintel uploads janitor unknown commit - -#### codeintel-uploads: codeintel_uploads_janitor_unknown_commit_records_scanned_total - -
Records scanned every 5m
+#### telemetry: telemetrygatewayexporter_usermetadata_exporter_error_rate -The number of candidate records considered for cleanup. +(off by default) user metadata exporter operation error rate over 30m
This panel has no related alerts. -To see this panel, visit `/-/debug/grafana/d/codeintel-uploads/codeintel-uploads?viewPanel=100700` on your Sourcegraph instance. +To see this panel, visit `/-/debug/grafana/d/telemetry/telemetry?viewPanel=100503` on your Sourcegraph instance. -*Managed by the [Sourcegraph Code intelligence team](https://handbook.sourcegraph.com/departments/engineering/teams/code-intelligence).* +*Managed by the [Sourcegraph Data & Analytics team](https://handbook.sourcegraph.com/departments/engineering/teams/data-analytics).*Technical details
@@ -70166,23 +69805,40 @@ To see this panel, visit `/-/debug/grafana/d/codeintel-uploads/codeintel-uploads Query: ``` -sum(increase(src_codeintel_uploads_janitor_unknown_commit_records_scanned_total{job=~"^${source:regex}.*"}[5m])) +sum(increase(src_telemetrygatewayexporter_usermetadata_exporter_errors_total{job=~"^worker.*"}[30m])) / (sum(increase(src_telemetrygatewayexporter_usermetadata_exporter_total{job=~"^worker.*"}[30m])) + sum(increase(src_telemetrygatewayexporter_usermetadata_exporter_errors_total{job=~"^worker.*"}[30m]))) * 100 ```-#### codeintel-uploads: codeintel_uploads_janitor_unknown_commit_records_altered_total +## OpenTelemetry Collector -
Records altered every 5m
+The OpenTelemetry collector ingests OpenTelemetry data from Sourcegraph and exports it to the configured backends.
-The number of candidate records altered as part of cleanup. +To see this dashboard, visit `/-/debug/grafana/d/otel-collector/otel-collector` on your Sourcegraph instance. + +### OpenTelemetry Collector: Receivers + +#### otel-collector: otel_span_receive_rate + +Spans received per receiver per minute
+ +Shows the rate of spans accepted by the configured reveiver + +A Trace is a collection of spans and a span represents a unit of work or operation. Spans are the building blocks of Traces. +The spans have only been accepted by the receiver, which means they still have to move through the configured pipeline to be exported. +For more information on tracing and configuration of a OpenTelemetry receiver see https://opentelemetry.io/docs/collector/configuration/#receivers. + +See the Exporters section see spans that have made it through the pipeline and are exported. + +Depending the configured processors, received spans might be dropped and not exported. For more information on configuring processors see +https://opentelemetry.io/docs/collector/configuration/#processors. This panel has no related alerts. -To see this panel, visit `/-/debug/grafana/d/codeintel-uploads/codeintel-uploads?viewPanel=100701` on your Sourcegraph instance. +To see this panel, visit `/-/debug/grafana/d/otel-collector/otel-collector?viewPanel=100000` on your Sourcegraph instance. -*Managed by the [Sourcegraph Code intelligence team](https://handbook.sourcegraph.com/departments/engineering/teams/code-intelligence).* +*Managed by the [Sourcegraph Infrastructure Org team](https://handbook.sourcegraph.com/departments/engineering/infrastructure).*Technical details
@@ -70190,21 +69846,23 @@ To see this panel, visit `/-/debug/grafana/d/codeintel-uploads/codeintel-uploads Query: ``` -sum(increase(src_codeintel_uploads_janitor_unknown_commit_records_altered_total{job=~"^${source:regex}.*"}[5m])) +sum by (receiver) (rate(otelcol_receiver_accepted_spans[1m])) ```-#### codeintel-uploads: codeintel_uploads_janitor_unknown_commit_total +#### otel-collector: otel_span_refused -
Job invocation operations every 5m
+Spans refused per receiver
-This panel has no related alerts. -To see this panel, visit `/-/debug/grafana/d/codeintel-uploads/codeintel-uploads?viewPanel=100710` on your Sourcegraph instance. -*Managed by the [Sourcegraph Code intelligence team](https://handbook.sourcegraph.com/departments/engineering/teams/code-intelligence).* +Refer to the [alerts reference](alerts#otel-collector-otel-span-refused) for 1 alert related to this panel. + +To see this panel, visit `/-/debug/grafana/d/otel-collector/otel-collector?viewPanel=100001` on your Sourcegraph instance. + +*Managed by the [Sourcegraph Infrastructure Org team](https://handbook.sourcegraph.com/departments/engineering/infrastructure).*Technical details
@@ -70212,21 +69870,30 @@ To see this panel, visit `/-/debug/grafana/d/codeintel-uploads/codeintel-uploads Query: ``` -sum by (op)(increase(src_codeintel_uploads_janitor_unknown_commit_total{job=~"^${source:regex}.*"}[5m])) +sum by (receiver) (rate(otelcol_receiver_refused_spans[1m])) ```-#### codeintel-uploads: codeintel_uploads_janitor_unknown_commit_99th_percentile_duration +### OpenTelemetry Collector: Exporters -
99th percentile successful job invocation operation duration over 5m
+#### otel-collector: otel_span_export_rate + +Spans exported per exporter per minute
+ +Shows the rate of spans being sent by the exporter + +A Trace is a collection of spans. A Span represents a unit of work or operation. Spans are the building blocks of Traces. +The rate of spans here indicates spans that have made it through the configured pipeline and have been sent to the configured export destination. + +For more information on configuring a exporter for the OpenTelemetry collector see https://opentelemetry.io/docs/collector/configuration/#exporters. This panel has no related alerts. -To see this panel, visit `/-/debug/grafana/d/codeintel-uploads/codeintel-uploads?viewPanel=100711` on your Sourcegraph instance. +To see this panel, visit `/-/debug/grafana/d/otel-collector/otel-collector?viewPanel=100100` on your Sourcegraph instance. -*Managed by the [Sourcegraph Code intelligence team](https://handbook.sourcegraph.com/departments/engineering/teams/code-intelligence).* +*Managed by the [Sourcegraph Infrastructure Org team](https://handbook.sourcegraph.com/departments/engineering/infrastructure).*Technical details
@@ -70234,21 +69901,25 @@ To see this panel, visit `/-/debug/grafana/d/codeintel-uploads/codeintel-uploads Query: ``` -histogram_quantile(0.99, sum by (le,op)(rate(src_codeintel_uploads_janitor_unknown_commit_duration_seconds_bucket{job=~"^${source:regex}.*"}[5m]))) +sum by (exporter) (rate(otelcol_exporter_sent_spans[1m])) ```-#### codeintel-uploads: codeintel_uploads_janitor_unknown_commit_errors_total +#### otel-collector: otel_span_export_failures -
Job invocation operation errors every 5m
+Span export failures by exporter
-This panel has no related alerts. +Shows the rate of spans failed to be sent by the configured reveiver. A number higher than 0 for a long period can indicate a problem with the exporter configuration or with the service that is being exported too -To see this panel, visit `/-/debug/grafana/d/codeintel-uploads/codeintel-uploads?viewPanel=100712` on your Sourcegraph instance. +For more information on configuring a exporter for the OpenTelemetry collector see https://opentelemetry.io/docs/collector/configuration/#exporters. -*Managed by the [Sourcegraph Code intelligence team](https://handbook.sourcegraph.com/departments/engineering/teams/code-intelligence).* +Refer to the [alerts reference](alerts#otel-collector-otel-span-export-failures) for 1 alert related to this panel. + +To see this panel, visit `/-/debug/grafana/d/otel-collector/otel-collector?viewPanel=100101` on your Sourcegraph instance. + +*Managed by the [Sourcegraph Infrastructure Org team](https://handbook.sourcegraph.com/departments/engineering/infrastructure).*Technical details
@@ -70256,21 +69927,25 @@ To see this panel, visit `/-/debug/grafana/d/codeintel-uploads/codeintel-uploads Query: ``` -sum by (op)(increase(src_codeintel_uploads_janitor_unknown_commit_errors_total{job=~"^${source:regex}.*"}[5m])) +sum by (exporter) (rate(otelcol_exporter_send_failed_spans[1m])) ```-#### codeintel-uploads: codeintel_uploads_janitor_unknown_commit_error_rate +### OpenTelemetry Collector: Queue Length -
Job invocation operation error rate over 5m
+#### otel-collector: otelcol_exporter_queue_capacity + +Exporter queue capacity
+ +Shows the the capacity of the retry queue (in batches). This panel has no related alerts. -To see this panel, visit `/-/debug/grafana/d/codeintel-uploads/codeintel-uploads?viewPanel=100713` on your Sourcegraph instance. +To see this panel, visit `/-/debug/grafana/d/otel-collector/otel-collector?viewPanel=100200` on your Sourcegraph instance. -*Managed by the [Sourcegraph Code intelligence team](https://handbook.sourcegraph.com/departments/engineering/teams/code-intelligence).* +*Managed by the [Sourcegraph Infrastructure Org team](https://handbook.sourcegraph.com/departments/engineering/infrastructure).*Technical details
@@ -70278,25 +69953,23 @@ To see this panel, visit `/-/debug/grafana/d/codeintel-uploads/codeintel-uploads Query: ``` -sum by (op)(increase(src_codeintel_uploads_janitor_unknown_commit_errors_total{job=~"^${source:regex}.*"}[5m])) / (sum by (op)(increase(src_codeintel_uploads_janitor_unknown_commit_total{job=~"^${source:regex}.*"}[5m])) + sum by (op)(increase(src_codeintel_uploads_janitor_unknown_commit_errors_total{job=~"^${source:regex}.*"}[5m]))) * 100 +sum by (exporter) (rate(otelcol_exporter_queue_capacity{job=~"^.*"}[1m])) ```-### Code Intelligence > Uploads: Codeintel: Uploads > Janitor task > Codeintel uploads janitor abandoned - -#### codeintel-uploads: codeintel_uploads_janitor_abandoned_records_scanned_total +#### otel-collector: otelcol_exporter_queue_size -
Records scanned every 5m
+Exporter queue size
-The number of candidate records considered for cleanup. +Shows the current size of retry queue This panel has no related alerts. -To see this panel, visit `/-/debug/grafana/d/codeintel-uploads/codeintel-uploads?viewPanel=100800` on your Sourcegraph instance. +To see this panel, visit `/-/debug/grafana/d/otel-collector/otel-collector?viewPanel=100201` on your Sourcegraph instance. -*Managed by the [Sourcegraph Code intelligence team](https://handbook.sourcegraph.com/departments/engineering/teams/code-intelligence).* +*Managed by the [Sourcegraph Infrastructure Org team](https://handbook.sourcegraph.com/departments/engineering/infrastructure).*Technical details
@@ -70304,23 +69977,23 @@ To see this panel, visit `/-/debug/grafana/d/codeintel-uploads/codeintel-uploads Query: ``` -sum(increase(src_codeintel_uploads_janitor_abandoned_records_scanned_total{job=~"^${source:regex}.*"}[5m])) +sum by (exporter) (rate(otelcol_exporter_queue_size{job=~"^.*"}[1m])) ```-#### codeintel-uploads: codeintel_uploads_janitor_abandoned_records_altered_total +#### otel-collector: otelcol_exporter_enqueue_failed_spans -
Records altered every 5m
+Exporter enqueue failed spans
-The number of candidate records altered as part of cleanup. +Shows the rate of spans failed to be enqueued by the configured exporter. A number higher than 0 for a long period can indicate a problem with the exporter configuration -This panel has no related alerts. +Refer to the [alerts reference](alerts#otel-collector-otelcol-exporter-enqueue-failed-spans) for 1 alert related to this panel. -To see this panel, visit `/-/debug/grafana/d/codeintel-uploads/codeintel-uploads?viewPanel=100801` on your Sourcegraph instance. +To see this panel, visit `/-/debug/grafana/d/otel-collector/otel-collector?viewPanel=100202` on your Sourcegraph instance. -*Managed by the [Sourcegraph Code intelligence team](https://handbook.sourcegraph.com/departments/engineering/teams/code-intelligence).* +*Managed by the [Sourcegraph Infrastructure Org team](https://handbook.sourcegraph.com/departments/engineering/infrastructure).*Technical details
@@ -70328,21 +70001,25 @@ To see this panel, visit `/-/debug/grafana/d/codeintel-uploads/codeintel-uploads Query: ``` -sum(increase(src_codeintel_uploads_janitor_abandoned_records_altered_total{job=~"^${source:regex}.*"}[5m])) +sum by (exporter) (rate(otelcol_exporter_enqueue_failed_spans{job=~"^.*"}[1m])) ```-#### codeintel-uploads: codeintel_uploads_janitor_abandoned_total +### OpenTelemetry Collector: Processors -
Job invocation operations every 5m
+#### otel-collector: otelcol_processor_dropped_spans -This panel has no related alerts. +Spans dropped per processor per minute
-To see this panel, visit `/-/debug/grafana/d/codeintel-uploads/codeintel-uploads?viewPanel=100810` on your Sourcegraph instance. +Shows the rate of spans dropped by the configured processor -*Managed by the [Sourcegraph Code intelligence team](https://handbook.sourcegraph.com/departments/engineering/teams/code-intelligence).* +Refer to the [alerts reference](alerts#otel-collector-otelcol-processor-dropped-spans) for 1 alert related to this panel. + +To see this panel, visit `/-/debug/grafana/d/otel-collector/otel-collector?viewPanel=100300` on your Sourcegraph instance. + +*Managed by the [Sourcegraph Infrastructure Org team](https://handbook.sourcegraph.com/departments/engineering/infrastructure).*Technical details
@@ -70350,21 +70027,25 @@ To see this panel, visit `/-/debug/grafana/d/codeintel-uploads/codeintel-uploads Query: ``` -sum by (op)(increase(src_codeintel_uploads_janitor_abandoned_total{job=~"^${source:regex}.*"}[5m])) +sum by (processor) (rate(otelcol_processor_dropped_spans[1m])) ```-#### codeintel-uploads: codeintel_uploads_janitor_abandoned_99th_percentile_duration +### OpenTelemetry Collector: Collector resource usage -
99th percentile successful job invocation operation duration over 5m
+#### otel-collector: otel_cpu_usage + +Cpu usage of the collector
+ +Shows CPU usage as reported by the OpenTelemetry collector. This panel has no related alerts. -To see this panel, visit `/-/debug/grafana/d/codeintel-uploads/codeintel-uploads?viewPanel=100811` on your Sourcegraph instance. +To see this panel, visit `/-/debug/grafana/d/otel-collector/otel-collector?viewPanel=100400` on your Sourcegraph instance. -*Managed by the [Sourcegraph Code intelligence team](https://handbook.sourcegraph.com/departments/engineering/teams/code-intelligence).* +*Managed by the [Sourcegraph Infrastructure Org team](https://handbook.sourcegraph.com/departments/engineering/infrastructure).*Technical details
@@ -70372,21 +70053,23 @@ To see this panel, visit `/-/debug/grafana/d/codeintel-uploads/codeintel-uploads Query: ``` -histogram_quantile(0.99, sum by (le,op)(rate(src_codeintel_uploads_janitor_abandoned_duration_seconds_bucket{job=~"^${source:regex}.*"}[5m]))) +sum by (job) (rate(otelcol_process_cpu_seconds{job=~"^.*"}[1m])) ```-#### codeintel-uploads: codeintel_uploads_janitor_abandoned_errors_total +#### otel-collector: otel_memory_resident_set_size -
Job invocation operation errors every 5m
+Memory allocated to the otel collector
+ +Shows the allocated memory Resident Set Size (RSS) as reported by the OpenTelemetry collector. This panel has no related alerts. -To see this panel, visit `/-/debug/grafana/d/codeintel-uploads/codeintel-uploads?viewPanel=100812` on your Sourcegraph instance. +To see this panel, visit `/-/debug/grafana/d/otel-collector/otel-collector?viewPanel=100401` on your Sourcegraph instance. -*Managed by the [Sourcegraph Code intelligence team](https://handbook.sourcegraph.com/departments/engineering/teams/code-intelligence).* +*Managed by the [Sourcegraph Infrastructure Org team](https://handbook.sourcegraph.com/departments/engineering/infrastructure).*Technical details
@@ -70394,21 +70077,29 @@ To see this panel, visit `/-/debug/grafana/d/codeintel-uploads/codeintel-uploads Query: ``` -sum by (op)(increase(src_codeintel_uploads_janitor_abandoned_errors_total{job=~"^${source:regex}.*"}[5m])) +sum by (job) (rate(otelcol_process_memory_rss{job=~"^.*"}[1m])) ```-#### codeintel-uploads: codeintel_uploads_janitor_abandoned_error_rate +#### otel-collector: otel_memory_usage -
Job invocation operation error rate over 5m
+Memory used by the collector
+ +Shows how much memory is being used by the otel collector. + +* High memory usage might indicate thad the configured pipeline is keeping a lot of spans in memory for processing +* Spans failing to be sent and the exporter is configured to retry +* A high batch count by using a batch processor + +For more information on configuring processors for the OpenTelemetry collector see https://opentelemetry.io/docs/collector/configuration/#processors. This panel has no related alerts. -To see this panel, visit `/-/debug/grafana/d/codeintel-uploads/codeintel-uploads?viewPanel=100813` on your Sourcegraph instance. +To see this panel, visit `/-/debug/grafana/d/otel-collector/otel-collector?viewPanel=100402` on your Sourcegraph instance. -*Managed by the [Sourcegraph Code intelligence team](https://handbook.sourcegraph.com/departments/engineering/teams/code-intelligence).* +*Managed by the [Sourcegraph Infrastructure Org team](https://handbook.sourcegraph.com/departments/engineering/infrastructure).*Technical details
@@ -70416,25 +70107,33 @@ To see this panel, visit `/-/debug/grafana/d/codeintel-uploads/codeintel-uploads Query: ``` -sum by (op)(increase(src_codeintel_uploads_janitor_abandoned_errors_total{job=~"^${source:regex}.*"}[5m])) / (sum by (op)(increase(src_codeintel_uploads_janitor_abandoned_total{job=~"^${source:regex}.*"}[5m])) + sum by (op)(increase(src_codeintel_uploads_janitor_abandoned_errors_total{job=~"^${source:regex}.*"}[5m]))) * 100 +sum by (job) (rate(otelcol_process_runtime_total_alloc_bytes{job=~"^.*"}[1m])) ```-### Code Intelligence > Uploads: Codeintel: Uploads > Janitor task > Codeintel uploads expirer unreferenced +### OpenTelemetry Collector: Container monitoring (not available on server) -#### codeintel-uploads: codeintel_uploads_expirer_unreferenced_records_scanned_total +#### otel-collector: container_missing -
Records scanned every 5m
+Container missing
-The number of candidate records considered for cleanup. +This value is the number of times a container has not been seen for more than one minute. If you observe this +value change independent of deployment events (such as an upgrade), it could indicate pods are being OOM killed or terminated for some other reasons. + +- **Kubernetes:** + - Determine if the pod was OOM killed using `kubectl describe pod otel-collector` (look for `OOMKilled: true`) and, if so, consider increasing the memory limit in the relevant `Deployment.yaml`. + - Check the logs before the container restarted to see if there are `panic:` messages or similar using `kubectl logs -p otel-collector`. +- **Docker Compose:** + - Determine if the pod was OOM killed using `docker inspect -f '\{\{json .State\}\}' otel-collector` (look for `"OOMKilled":true`) and, if so, consider increasing the memory limit of the otel-collector container in `docker-compose.yml`. + - Check the logs before the container restarted to see if there are `panic:` messages or similar using `docker logs otel-collector` (note this will include logs from the previous and currently running container). This panel has no related alerts. -To see this panel, visit `/-/debug/grafana/d/codeintel-uploads/codeintel-uploads?viewPanel=100900` on your Sourcegraph instance. +To see this panel, visit `/-/debug/grafana/d/otel-collector/otel-collector?viewPanel=100500` on your Sourcegraph instance. -*Managed by the [Sourcegraph Code intelligence team](https://handbook.sourcegraph.com/departments/engineering/teams/code-intelligence).* +*Managed by the [Sourcegraph Infrastructure Org team](https://handbook.sourcegraph.com/departments/engineering/infrastructure).*Technical details
@@ -70442,23 +70141,21 @@ To see this panel, visit `/-/debug/grafana/d/codeintel-uploads/codeintel-uploads Query: ``` -sum(increase(src_codeintel_uploads_expirer_unreferenced_records_scanned_total{job=~"^${source:regex}.*"}[5m])) +count by(name) ((time() - container_last_seen{name=~"^otel-collector.*"}) > 60) ```-#### codeintel-uploads: codeintel_uploads_expirer_unreferenced_records_altered_total - -
Records altered every 5m
+#### otel-collector: container_cpu_usage -The number of candidate records altered as part of cleanup. +Container cpu usage total (1m average) across all cores by instance
-This panel has no related alerts. +Refer to the [alerts reference](alerts#otel-collector-container-cpu-usage) for 1 alert related to this panel. -To see this panel, visit `/-/debug/grafana/d/codeintel-uploads/codeintel-uploads?viewPanel=100901` on your Sourcegraph instance. +To see this panel, visit `/-/debug/grafana/d/otel-collector/otel-collector?viewPanel=100501` on your Sourcegraph instance. -*Managed by the [Sourcegraph Code intelligence team](https://handbook.sourcegraph.com/departments/engineering/teams/code-intelligence).* +*Managed by the [Sourcegraph Infrastructure Org team](https://handbook.sourcegraph.com/departments/engineering/infrastructure).*Technical details
@@ -70466,21 +70163,21 @@ To see this panel, visit `/-/debug/grafana/d/codeintel-uploads/codeintel-uploads Query: ``` -sum(increase(src_codeintel_uploads_expirer_unreferenced_records_altered_total{job=~"^${source:regex}.*"}[5m])) +cadvisor_container_cpu_usage_percentage_total{name=~"^otel-collector.*"} ```-#### codeintel-uploads: codeintel_uploads_expirer_unreferenced_total +#### otel-collector: container_memory_usage -
Job invocation operations every 5m
+Container memory usage by instance
-This panel has no related alerts. +Refer to the [alerts reference](alerts#otel-collector-container-memory-usage) for 1 alert related to this panel. -To see this panel, visit `/-/debug/grafana/d/codeintel-uploads/codeintel-uploads?viewPanel=100910` on your Sourcegraph instance. +To see this panel, visit `/-/debug/grafana/d/otel-collector/otel-collector?viewPanel=100502` on your Sourcegraph instance. -*Managed by the [Sourcegraph Code intelligence team](https://handbook.sourcegraph.com/departments/engineering/teams/code-intelligence).* +*Managed by the [Sourcegraph Infrastructure Org team](https://handbook.sourcegraph.com/departments/engineering/infrastructure).*Technical details
@@ -70488,21 +70185,24 @@ To see this panel, visit `/-/debug/grafana/d/codeintel-uploads/codeintel-uploads Query: ``` -sum by (op)(increase(src_codeintel_uploads_expirer_unreferenced_total{job=~"^${source:regex}.*"}[5m])) +cadvisor_container_memory_usage_percentage_total{name=~"^otel-collector.*"} ```-#### codeintel-uploads: codeintel_uploads_expirer_unreferenced_99th_percentile_duration +#### otel-collector: fs_io_operations -
99th percentile successful job invocation operation duration over 5m
+Filesystem reads and writes rate by instance over 1h
+ +This value indicates the number of filesystem read and write operations by containers of this service. +When extremely high, this can indicate a resource usage problem, or can cause problems with the service itself, especially if high values or spikes correlate with \{\{CONTAINER_NAME\}\} issues. This panel has no related alerts. -To see this panel, visit `/-/debug/grafana/d/codeintel-uploads/codeintel-uploads?viewPanel=100911` on your Sourcegraph instance. +To see this panel, visit `/-/debug/grafana/d/otel-collector/otel-collector?viewPanel=100503` on your Sourcegraph instance. -*Managed by the [Sourcegraph Code intelligence team](https://handbook.sourcegraph.com/departments/engineering/teams/code-intelligence).* +*Managed by the [Sourcegraph Infrastructure Org team](https://handbook.sourcegraph.com/departments/engineering/infrastructure).*Technical details
@@ -70510,21 +70210,23 @@ To see this panel, visit `/-/debug/grafana/d/codeintel-uploads/codeintel-uploads Query: ``` -histogram_quantile(0.99, sum by (le,op)(rate(src_codeintel_uploads_expirer_unreferenced_duration_seconds_bucket{job=~"^${source:regex}.*"}[5m]))) +sum by(name) (rate(container_fs_reads_total{name=~"^otel-collector.*"}[1h]) + rate(container_fs_writes_total{name=~"^otel-collector.*"}[1h])) ```-#### codeintel-uploads: codeintel_uploads_expirer_unreferenced_errors_total +### OpenTelemetry Collector: Kubernetes monitoring (only available on Kubernetes) -
Job invocation operation errors every 5m
+#### otel-collector: pods_available_percentage -This panel has no related alerts. +Percentage pods available
-To see this panel, visit `/-/debug/grafana/d/codeintel-uploads/codeintel-uploads?viewPanel=100912` on your Sourcegraph instance. +Refer to the [alerts reference](alerts#otel-collector-pods-available-percentage) for 1 alert related to this panel. -*Managed by the [Sourcegraph Code intelligence team](https://handbook.sourcegraph.com/departments/engineering/teams/code-intelligence).* +To see this panel, visit `/-/debug/grafana/d/otel-collector/otel-collector?viewPanel=100600` on your Sourcegraph instance. + +*Managed by the [Sourcegraph Infrastructure Org team](https://handbook.sourcegraph.com/departments/engineering/infrastructure).*Technical details
@@ -70532,21 +70234,30 @@ To see this panel, visit `/-/debug/grafana/d/codeintel-uploads/codeintel-uploads Query: ``` -sum by (op)(increase(src_codeintel_uploads_expirer_unreferenced_errors_total{job=~"^${source:regex}.*"}[5m])) +sum by(app) (up{app=~".*otel-collector"}) / count by (app) (up{app=~".*otel-collector"}) * 100 ```-#### codeintel-uploads: codeintel_uploads_expirer_unreferenced_error_rate +## Completions -
Job invocation operation error rate over 5m
+Cody chat and code completions.
+ +To see this dashboard, visit `/-/debug/grafana/d/completions/completions` on your Sourcegraph instance. + +### Completions: Completions requests + +#### completions: api_request_rate + +Rate of completions API requests
+ +Rate (QPS) of requests to cody chat and code completion endpoints. This panel has no related alerts. -To see this panel, visit `/-/debug/grafana/d/codeintel-uploads/codeintel-uploads?viewPanel=100913` on your Sourcegraph instance. +To see this panel, visit `/-/debug/grafana/d/completions/completions?viewPanel=100000` on your Sourcegraph instance. -*Managed by the [Sourcegraph Code intelligence team](https://handbook.sourcegraph.com/departments/engineering/teams/code-intelligence).*Technical details
@@ -70554,25 +70265,24 @@ To see this panel, visit `/-/debug/grafana/d/codeintel-uploads/codeintel-uploads Query: ``` -sum by (op)(increase(src_codeintel_uploads_expirer_unreferenced_errors_total{job=~"^${source:regex}.*"}[5m])) / (sum by (op)(increase(src_codeintel_uploads_expirer_unreferenced_total{job=~"^${source:regex}.*"}[5m])) + sum by (op)(increase(src_codeintel_uploads_expirer_unreferenced_errors_total{job=~"^${source:regex}.*"}[5m]))) * 100 +sum by (code)(irate(src_http_request_duration_seconds_count{route=~"^cody.completions.*"}[5m])) ```-### Code Intelligence > Uploads: Codeintel: Uploads > Janitor task > Codeintel uploads expirer unreferenced graph +### Completions: Chat completions -#### codeintel-uploads: codeintel_uploads_expirer_unreferenced_graph_records_scanned_total +#### completions: chat_completions_p99_stream_duration -
Records scanned every 5m
+Stream: total time (p99)
-The number of candidate records considered for cleanup. +Time spent on the Stream() invocation, i.e. how long results take to connect, stream results, and finish streaming. This panel has no related alerts. -To see this panel, visit `/-/debug/grafana/d/codeintel-uploads/codeintel-uploads?viewPanel=101000` on your Sourcegraph instance. +To see this panel, visit `/-/debug/grafana/d/completions/completions?viewPanel=100100` on your Sourcegraph instance. -*Managed by the [Sourcegraph Code intelligence team](https://handbook.sourcegraph.com/departments/engineering/teams/code-intelligence).*Technical details
@@ -70580,23 +70290,22 @@ To see this panel, visit `/-/debug/grafana/d/codeintel-uploads/codeintel-uploads Query: ``` -sum(increase(src_codeintel_uploads_expirer_unreferenced_graph_records_scanned_total{job=~"^${source:regex}.*"}[5m])) +histogram_quantile(0.99, sum(rate(src_completions_stream_duration_seconds_bucket{feature="chat_completions",model=~'${model}'}[$sampling_duration])) by (le, model)) ```-#### codeintel-uploads: codeintel_uploads_expirer_unreferenced_graph_records_altered_total +#### completions: chat_completions_p95_stream_duration -
Records altered every 5m
+Stream: total time (p95)
-The number of candidate records altered as part of cleanup. +Time spent on the Stream() invocation, i.e. how long results take to connect, stream results, and finish streaming. This panel has no related alerts. -To see this panel, visit `/-/debug/grafana/d/codeintel-uploads/codeintel-uploads?viewPanel=101001` on your Sourcegraph instance. +To see this panel, visit `/-/debug/grafana/d/completions/completions?viewPanel=100101` on your Sourcegraph instance. -*Managed by the [Sourcegraph Code intelligence team](https://handbook.sourcegraph.com/departments/engineering/teams/code-intelligence).*Technical details
@@ -70604,21 +70313,22 @@ To see this panel, visit `/-/debug/grafana/d/codeintel-uploads/codeintel-uploads Query: ``` -sum(increase(src_codeintel_uploads_expirer_unreferenced_graph_records_altered_total{job=~"^${source:regex}.*"}[5m])) +histogram_quantile(0.95, sum(rate(src_completions_stream_duration_seconds_bucket{feature="chat_completions",model=~'${model}'}[$sampling_duration])) by (le, model)) ```-#### codeintel-uploads: codeintel_uploads_expirer_unreferenced_graph_total +#### completions: chat_completions_p75_stream_duration -
Job invocation operations every 5m
+Stream: total time (p75)
+ +Time spent on the Stream() invocation, i.e. how long results take to connect, stream results, and finish streaming. This panel has no related alerts. -To see this panel, visit `/-/debug/grafana/d/codeintel-uploads/codeintel-uploads?viewPanel=101010` on your Sourcegraph instance. +To see this panel, visit `/-/debug/grafana/d/completions/completions?viewPanel=100102` on your Sourcegraph instance. -*Managed by the [Sourcegraph Code intelligence team](https://handbook.sourcegraph.com/departments/engineering/teams/code-intelligence).*Technical details
@@ -70626,21 +70336,22 @@ To see this panel, visit `/-/debug/grafana/d/codeintel-uploads/codeintel-uploads Query: ``` -sum by (op)(increase(src_codeintel_uploads_expirer_unreferenced_graph_total{job=~"^${source:regex}.*"}[5m])) +histogram_quantile(0.75, sum(rate(src_completions_stream_duration_seconds_bucket{feature="chat_completions",model=~'${model}'}[$sampling_duration])) by (le, model)) ```-#### codeintel-uploads: codeintel_uploads_expirer_unreferenced_graph_99th_percentile_duration +#### completions: chat_completions_p50_stream_duration -
99th percentile successful job invocation operation duration over 5m
+Stream: total time (p50)
+ +Time spent on the Stream() invocation, i.e. how long results take to connect, stream results, and finish streaming. This panel has no related alerts. -To see this panel, visit `/-/debug/grafana/d/codeintel-uploads/codeintel-uploads?viewPanel=101011` on your Sourcegraph instance. +To see this panel, visit `/-/debug/grafana/d/completions/completions?viewPanel=100103` on your Sourcegraph instance. -*Managed by the [Sourcegraph Code intelligence team](https://handbook.sourcegraph.com/departments/engineering/teams/code-intelligence).*Technical details
@@ -70648,21 +70359,22 @@ To see this panel, visit `/-/debug/grafana/d/codeintel-uploads/codeintel-uploads Query: ``` -histogram_quantile(0.99, sum by (le,op)(rate(src_codeintel_uploads_expirer_unreferenced_graph_duration_seconds_bucket{job=~"^${source:regex}.*"}[5m]))) +histogram_quantile(0.50, sum(rate(src_completions_stream_duration_seconds_bucket{feature="chat_completions",model=~'${model}'}[$sampling_duration])) by (le, model)) ```-#### codeintel-uploads: codeintel_uploads_expirer_unreferenced_graph_errors_total +#### completions: chat_completions_p99_non_stream_overhead_duration -
Job invocation operation errors every 5m
+Non-stream overhead (p99)
+ +Time between Go HTTP handler invocation and Stream() invocation, overhead of e.g. request validation, routing to gateway/other, model resolution, error reporting/tracing, guardrails, etc. This panel has no related alerts. -To see this panel, visit `/-/debug/grafana/d/codeintel-uploads/codeintel-uploads?viewPanel=101012` on your Sourcegraph instance. +To see this panel, visit `/-/debug/grafana/d/completions/completions?viewPanel=100110` on your Sourcegraph instance. -*Managed by the [Sourcegraph Code intelligence team](https://handbook.sourcegraph.com/departments/engineering/teams/code-intelligence).*Technical details
@@ -70670,21 +70382,22 @@ To see this panel, visit `/-/debug/grafana/d/codeintel-uploads/codeintel-uploads Query: ``` -sum by (op)(increase(src_codeintel_uploads_expirer_unreferenced_graph_errors_total{job=~"^${source:regex}.*"}[5m])) +histogram_quantile(0.99, sum(rate(src_completions_handler_overhead_duration_seconds_bucket{feature="chat_completions",model=~'${model}'}[$sampling_duration])) by (le,model)) ```-#### codeintel-uploads: codeintel_uploads_expirer_unreferenced_graph_error_rate +#### completions: chat_completions_p95_non_stream_overhead_duration -
Job invocation operation error rate over 5m
+Non-stream overhead (p95)
+ +Time between Go HTTP handler invocation and Stream() invocation, overhead of e.g. request validation, routing to gateway/other, model resolution, error reporting/tracing, guardrails, etc. This panel has no related alerts. -To see this panel, visit `/-/debug/grafana/d/codeintel-uploads/codeintel-uploads?viewPanel=101013` on your Sourcegraph instance. +To see this panel, visit `/-/debug/grafana/d/completions/completions?viewPanel=100111` on your Sourcegraph instance. -*Managed by the [Sourcegraph Code intelligence team](https://handbook.sourcegraph.com/departments/engineering/teams/code-intelligence).*Technical details
@@ -70692,25 +70405,22 @@ To see this panel, visit `/-/debug/grafana/d/codeintel-uploads/codeintel-uploads Query: ``` -sum by (op)(increase(src_codeintel_uploads_expirer_unreferenced_graph_errors_total{job=~"^${source:regex}.*"}[5m])) / (sum by (op)(increase(src_codeintel_uploads_expirer_unreferenced_graph_total{job=~"^${source:regex}.*"}[5m])) + sum by (op)(increase(src_codeintel_uploads_expirer_unreferenced_graph_errors_total{job=~"^${source:regex}.*"}[5m]))) * 100 +histogram_quantile(0.95, sum(rate(src_completions_handler_overhead_duration_seconds_bucket{feature="chat_completions",model=~'${model}'}[$sampling_duration])) by (le,model)) ```-### Code Intelligence > Uploads: Codeintel: Uploads > Janitor task > Codeintel uploads hard deleter - -#### codeintel-uploads: codeintel_uploads_hard_deleter_records_scanned_total +#### completions: chat_completions_p75_non_stream_overhead_duration -
Records scanned every 5m
+Non-stream overhead (p75)
-The number of candidate records considered for cleanup. +Time between Go HTTP handler invocation and Stream() invocation, overhead of e.g. request validation, routing to gateway/other, model resolution, error reporting/tracing, guardrails, etc. This panel has no related alerts. -To see this panel, visit `/-/debug/grafana/d/codeintel-uploads/codeintel-uploads?viewPanel=101100` on your Sourcegraph instance. +To see this panel, visit `/-/debug/grafana/d/completions/completions?viewPanel=100112` on your Sourcegraph instance. -*Managed by the [Sourcegraph Code intelligence team](https://handbook.sourcegraph.com/departments/engineering/teams/code-intelligence).*Technical details
@@ -70718,23 +70428,22 @@ To see this panel, visit `/-/debug/grafana/d/codeintel-uploads/codeintel-uploads Query: ``` -sum(increase(src_codeintel_uploads_hard_deleter_records_scanned_total{job=~"^${source:regex}.*"}[5m])) +histogram_quantile(0.75, sum(rate(src_completions_handler_overhead_duration_seconds_bucket{feature="chat_completions",model=~'${model}'}[$sampling_duration])) by (le,model)) ```-#### codeintel-uploads: codeintel_uploads_hard_deleter_records_altered_total +#### completions: chat_completions_p50_non_stream_overhead_duration -
Records altered every 5m
+Non-stream overhead (p50)
-The number of candidate records altered as part of cleanup. +Time between Go HTTP handler invocation and Stream() invocation, overhead of e.g. request validation, routing to gateway/other, model resolution, error reporting/tracing, guardrails, etc. This panel has no related alerts. -To see this panel, visit `/-/debug/grafana/d/codeintel-uploads/codeintel-uploads?viewPanel=101101` on your Sourcegraph instance. +To see this panel, visit `/-/debug/grafana/d/completions/completions?viewPanel=100113` on your Sourcegraph instance. -*Managed by the [Sourcegraph Code intelligence team](https://handbook.sourcegraph.com/departments/engineering/teams/code-intelligence).*Technical details
@@ -70742,21 +70451,22 @@ To see this panel, visit `/-/debug/grafana/d/codeintel-uploads/codeintel-uploads Query: ``` -sum(increase(src_codeintel_uploads_hard_deleter_records_altered_total{job=~"^${source:regex}.*"}[5m])) +histogram_quantile(0.50, sum(rate(src_completions_handler_overhead_duration_seconds_bucket{feature="chat_completions",model=~'${model}'}[$sampling_duration])) by (le,model)) ```-#### codeintel-uploads: codeintel_uploads_hard_deleter_total +#### completions: chat_completions_p99_stream_first_event_duration -
Job invocation operations every 5m
+Stream: time to first event (p99)
+ +Time between calling Stream(), the client connecting to the server etc. and actually getting the first streaming event back. This panel has no related alerts. -To see this panel, visit `/-/debug/grafana/d/codeintel-uploads/codeintel-uploads?viewPanel=101110` on your Sourcegraph instance. +To see this panel, visit `/-/debug/grafana/d/completions/completions?viewPanel=100120` on your Sourcegraph instance. -*Managed by the [Sourcegraph Code intelligence team](https://handbook.sourcegraph.com/departments/engineering/teams/code-intelligence).*Technical details
@@ -70764,21 +70474,22 @@ To see this panel, visit `/-/debug/grafana/d/codeintel-uploads/codeintel-uploads Query: ``` -sum by (op)(increase(src_codeintel_uploads_hard_deleter_total{job=~"^${source:regex}.*"}[5m])) +histogram_quantile(0.99, sum(rate(src_completions_stream_first_event_duration_seconds_bucket{feature="chat_completions",model=~'${model}'}[$sampling_duration])) by (le, model)) ```-#### codeintel-uploads: codeintel_uploads_hard_deleter_99th_percentile_duration +#### completions: chat_completions_p95_stream_first_event_duration -
99th percentile successful job invocation operation duration over 5m
+Stream: time to first event (p95)
+ +Time between calling Stream(), the client connecting to the server etc. and actually getting the first streaming event back. This panel has no related alerts. -To see this panel, visit `/-/debug/grafana/d/codeintel-uploads/codeintel-uploads?viewPanel=101111` on your Sourcegraph instance. +To see this panel, visit `/-/debug/grafana/d/completions/completions?viewPanel=100121` on your Sourcegraph instance. -*Managed by the [Sourcegraph Code intelligence team](https://handbook.sourcegraph.com/departments/engineering/teams/code-intelligence).*Technical details
@@ -70786,21 +70497,22 @@ To see this panel, visit `/-/debug/grafana/d/codeintel-uploads/codeintel-uploads Query: ``` -histogram_quantile(0.99, sum by (le,op)(rate(src_codeintel_uploads_hard_deleter_duration_seconds_bucket{job=~"^${source:regex}.*"}[5m]))) +histogram_quantile(0.95, sum(rate(src_completions_stream_first_event_duration_seconds_bucket{feature="chat_completions",model=~'${model}'}[$sampling_duration])) by (le, model)) ```-#### codeintel-uploads: codeintel_uploads_hard_deleter_errors_total +#### completions: chat_completions_p75_stream_first_event_duration -
Job invocation operation errors every 5m
+Stream: time to first event (p75)
+ +Time between calling Stream(), the client connecting to the server etc. and actually getting the first streaming event back. This panel has no related alerts. -To see this panel, visit `/-/debug/grafana/d/codeintel-uploads/codeintel-uploads?viewPanel=101112` on your Sourcegraph instance. +To see this panel, visit `/-/debug/grafana/d/completions/completions?viewPanel=100122` on your Sourcegraph instance. -*Managed by the [Sourcegraph Code intelligence team](https://handbook.sourcegraph.com/departments/engineering/teams/code-intelligence).*Technical details
@@ -70808,21 +70520,22 @@ To see this panel, visit `/-/debug/grafana/d/codeintel-uploads/codeintel-uploads Query: ``` -sum by (op)(increase(src_codeintel_uploads_hard_deleter_errors_total{job=~"^${source:regex}.*"}[5m])) +histogram_quantile(0.75, sum(rate(src_completions_stream_first_event_duration_seconds_bucket{feature="chat_completions",model=~'${model}'}[$sampling_duration])) by (le, model)) ```-#### codeintel-uploads: codeintel_uploads_hard_deleter_error_rate +#### completions: chat_completions_p50_stream_first_event_duration -
Job invocation operation error rate over 5m
+Stream: time to first event (p50)
+ +Time between calling Stream(), the client connecting to the server etc. and actually getting the first streaming event back. This panel has no related alerts. -To see this panel, visit `/-/debug/grafana/d/codeintel-uploads/codeintel-uploads?viewPanel=101113` on your Sourcegraph instance. +To see this panel, visit `/-/debug/grafana/d/completions/completions?viewPanel=100123` on your Sourcegraph instance. -*Managed by the [Sourcegraph Code intelligence team](https://handbook.sourcegraph.com/departments/engineering/teams/code-intelligence).*Technical details
@@ -70830,25 +70543,22 @@ To see this panel, visit `/-/debug/grafana/d/codeintel-uploads/codeintel-uploads Query: ``` -sum by (op)(increase(src_codeintel_uploads_hard_deleter_errors_total{job=~"^${source:regex}.*"}[5m])) / (sum by (op)(increase(src_codeintel_uploads_hard_deleter_total{job=~"^${source:regex}.*"}[5m])) + sum by (op)(increase(src_codeintel_uploads_hard_deleter_errors_total{job=~"^${source:regex}.*"}[5m]))) * 100 +histogram_quantile(0.50, sum(rate(src_completions_stream_first_event_duration_seconds_bucket{feature="chat_completions",model=~'${model}'}[$sampling_duration])) by (le, model)) ```-### Code Intelligence > Uploads: Codeintel: Uploads > Janitor task > Codeintel uploads janitor audit logs - -#### codeintel-uploads: codeintel_uploads_janitor_audit_logs_records_scanned_total +#### completions: chat_completions_p99_upstream_roundtrip_duration -
Records scanned every 5m
+Stream: first byte sent -> received (p99)
-The number of candidate records considered for cleanup. +Time between sending the first byte to the upstream, and then getting the first byte back from the upstream. This panel has no related alerts. -To see this panel, visit `/-/debug/grafana/d/codeintel-uploads/codeintel-uploads?viewPanel=101200` on your Sourcegraph instance. +To see this panel, visit `/-/debug/grafana/d/completions/completions?viewPanel=100130` on your Sourcegraph instance. -*Managed by the [Sourcegraph Code intelligence team](https://handbook.sourcegraph.com/departments/engineering/teams/code-intelligence).*Technical details
@@ -70856,23 +70566,22 @@ To see this panel, visit `/-/debug/grafana/d/codeintel-uploads/codeintel-uploads Query: ``` -sum(increase(src_codeintel_uploads_janitor_audit_logs_records_scanned_total{job=~"^${source:regex}.*"}[5m])) +histogram_quantile(0.99, sum(rate(src_completions_upstream_roundtrip_duration_seconds_bucket{feature="chat_completions",model=~'${model}'}[$sampling_duration])) by (le, provider)) ```-#### codeintel-uploads: codeintel_uploads_janitor_audit_logs_records_altered_total +#### completions: chat_completions_p95_upstream_roundtrip_duration -
Records altered every 5m
+Stream: first byte sent -> received (p95)
-The number of candidate records altered as part of cleanup. +Time between sending the first byte to the upstream, and then getting the first byte back from the upstream. This panel has no related alerts. -To see this panel, visit `/-/debug/grafana/d/codeintel-uploads/codeintel-uploads?viewPanel=101201` on your Sourcegraph instance. +To see this panel, visit `/-/debug/grafana/d/completions/completions?viewPanel=100131` on your Sourcegraph instance. -*Managed by the [Sourcegraph Code intelligence team](https://handbook.sourcegraph.com/departments/engineering/teams/code-intelligence).*Technical details
@@ -70880,21 +70589,22 @@ To see this panel, visit `/-/debug/grafana/d/codeintel-uploads/codeintel-uploads Query: ``` -sum(increase(src_codeintel_uploads_janitor_audit_logs_records_altered_total{job=~"^${source:regex}.*"}[5m])) +histogram_quantile(0.95, sum(rate(src_completions_upstream_roundtrip_duration_seconds_bucket{feature="chat_completions",model=~'${model}'}[$sampling_duration])) by (le, provider)) ```-#### codeintel-uploads: codeintel_uploads_janitor_audit_logs_total +#### completions: chat_completions_p75_upstream_roundtrip_duration -
Job invocation operations every 5m
+Stream: first byte sent -> received (p75)
+ +Time between sending the first byte to the upstream, and then getting the first byte back from the upstream. This panel has no related alerts. -To see this panel, visit `/-/debug/grafana/d/codeintel-uploads/codeintel-uploads?viewPanel=101210` on your Sourcegraph instance. +To see this panel, visit `/-/debug/grafana/d/completions/completions?viewPanel=100132` on your Sourcegraph instance. -*Managed by the [Sourcegraph Code intelligence team](https://handbook.sourcegraph.com/departments/engineering/teams/code-intelligence).*Technical details
@@ -70902,21 +70612,22 @@ To see this panel, visit `/-/debug/grafana/d/codeintel-uploads/codeintel-uploads Query: ``` -sum by (op)(increase(src_codeintel_uploads_janitor_audit_logs_total{job=~"^${source:regex}.*"}[5m])) +histogram_quantile(0.75, sum(rate(src_completions_upstream_roundtrip_duration_seconds_bucket{feature="chat_completions",model=~'${model}'}[$sampling_duration])) by (le, provider)) ```-#### codeintel-uploads: codeintel_uploads_janitor_audit_logs_99th_percentile_duration +#### completions: chat_completions_p50_upstream_roundtrip_duration -
99th percentile successful job invocation operation duration over 5m
+Stream: first byte sent -> received (p50)
+ +Time between sending the first byte to the upstream, and then getting the first byte back from the upstream. This panel has no related alerts. -To see this panel, visit `/-/debug/grafana/d/codeintel-uploads/codeintel-uploads?viewPanel=101211` on your Sourcegraph instance. +To see this panel, visit `/-/debug/grafana/d/completions/completions?viewPanel=100133` on your Sourcegraph instance. -*Managed by the [Sourcegraph Code intelligence team](https://handbook.sourcegraph.com/departments/engineering/teams/code-intelligence).*Technical details
@@ -70924,21 +70635,22 @@ To see this panel, visit `/-/debug/grafana/d/codeintel-uploads/codeintel-uploads Query: ``` -histogram_quantile(0.99, sum by (le,op)(rate(src_codeintel_uploads_janitor_audit_logs_duration_seconds_bucket{job=~"^${source:regex}.*"}[5m]))) +histogram_quantile(0.50, sum(rate(src_completions_upstream_roundtrip_duration_seconds_bucket{feature="chat_completions",model=~'${model}'}[$sampling_duration])) by (le, provider)) ```-#### codeintel-uploads: codeintel_uploads_janitor_audit_logs_errors_total +#### completions: chat_completions_p99_http_connect_total -
Job invocation operation errors every 5m
+Stream: HTTP connect: total (p99)
+ +Time spent acquiring an HTTP connection to the upstream, either from an existing pool OR by performing DNS resolution, TCP connection, etc. This panel has no related alerts. -To see this panel, visit `/-/debug/grafana/d/codeintel-uploads/codeintel-uploads?viewPanel=101212` on your Sourcegraph instance. +To see this panel, visit `/-/debug/grafana/d/completions/completions?viewPanel=100140` on your Sourcegraph instance. -*Managed by the [Sourcegraph Code intelligence team](https://handbook.sourcegraph.com/departments/engineering/teams/code-intelligence).*Technical details
@@ -70946,21 +70658,22 @@ To see this panel, visit `/-/debug/grafana/d/codeintel-uploads/codeintel-uploads Query: ``` -sum by (op)(increase(src_codeintel_uploads_janitor_audit_logs_errors_total{job=~"^${source:regex}.*"}[5m])) +histogram_quantile(0.99, sum(rate(src_completions_upstream_connection_total_duration_seconds_bucket[$sampling_duration])) by (le, connection_type, provider)) ```-#### codeintel-uploads: codeintel_uploads_janitor_audit_logs_error_rate +#### completions: chat_completions_p95_http_connect_total -
Job invocation operation error rate over 5m
+Stream: HTTP connect: total (p95)
+ +Time spent acquiring an HTTP connection to the upstream, either from an existing pool OR by performing DNS resolution, TCP connection, etc. This panel has no related alerts. -To see this panel, visit `/-/debug/grafana/d/codeintel-uploads/codeintel-uploads?viewPanel=101213` on your Sourcegraph instance. +To see this panel, visit `/-/debug/grafana/d/completions/completions?viewPanel=100141` on your Sourcegraph instance. -*Managed by the [Sourcegraph Code intelligence team](https://handbook.sourcegraph.com/departments/engineering/teams/code-intelligence).*Technical details
@@ -70968,25 +70681,22 @@ To see this panel, visit `/-/debug/grafana/d/codeintel-uploads/codeintel-uploads Query: ``` -sum by (op)(increase(src_codeintel_uploads_janitor_audit_logs_errors_total{job=~"^${source:regex}.*"}[5m])) / (sum by (op)(increase(src_codeintel_uploads_janitor_audit_logs_total{job=~"^${source:regex}.*"}[5m])) + sum by (op)(increase(src_codeintel_uploads_janitor_audit_logs_errors_total{job=~"^${source:regex}.*"}[5m]))) * 100 +histogram_quantile(0.95, sum(rate(src_completions_upstream_connection_total_duration_seconds_bucket[$sampling_duration])) by (le, connection_type, provider)) ```-### Code Intelligence > Uploads: Codeintel: Uploads > Janitor task > Codeintel uploads janitor scip documents - -#### codeintel-uploads: codeintel_uploads_janitor_scip_documents_records_scanned_total +#### completions: chat_completions_p75_http_connect_total -
Records scanned every 5m
+Stream: HTTP connect: total (p75)
-The number of candidate records considered for cleanup. +Time spent acquiring an HTTP connection to the upstream, either from an existing pool OR by performing DNS resolution, TCP connection, etc. This panel has no related alerts. -To see this panel, visit `/-/debug/grafana/d/codeintel-uploads/codeintel-uploads?viewPanel=101300` on your Sourcegraph instance. +To see this panel, visit `/-/debug/grafana/d/completions/completions?viewPanel=100142` on your Sourcegraph instance. -*Managed by the [Sourcegraph Code intelligence team](https://handbook.sourcegraph.com/departments/engineering/teams/code-intelligence).*Technical details
@@ -70994,23 +70704,22 @@ To see this panel, visit `/-/debug/grafana/d/codeintel-uploads/codeintel-uploads Query: ``` -sum(increase(src_codeintel_uploads_janitor_scip_documents_records_scanned_total{job=~"^${source:regex}.*"}[5m])) +histogram_quantile(0.75, sum(rate(src_completions_upstream_connection_total_duration_seconds_bucket[$sampling_duration])) by (le, connection_type, provider)) ```-#### codeintel-uploads: codeintel_uploads_janitor_scip_documents_records_altered_total +#### completions: chat_completions_p50_http_connect_total -
Records altered every 5m
+Stream: HTTP connect: total (p50)
-The number of candidate records altered as part of cleanup. +Time spent acquiring an HTTP connection to the upstream, either from an existing pool OR by performing DNS resolution, TCP connection, etc. This panel has no related alerts. -To see this panel, visit `/-/debug/grafana/d/codeintel-uploads/codeintel-uploads?viewPanel=101301` on your Sourcegraph instance. +To see this panel, visit `/-/debug/grafana/d/completions/completions?viewPanel=100143` on your Sourcegraph instance. -*Managed by the [Sourcegraph Code intelligence team](https://handbook.sourcegraph.com/departments/engineering/teams/code-intelligence).*Technical details
@@ -71018,21 +70727,22 @@ To see this panel, visit `/-/debug/grafana/d/codeintel-uploads/codeintel-uploads Query: ``` -sum(increase(src_codeintel_uploads_janitor_scip_documents_records_altered_total{job=~"^${source:regex}.*"}[5m])) +histogram_quantile(0.50, sum(rate(src_completions_upstream_connection_total_duration_seconds_bucket[$sampling_duration])) by (le, connection_type, provider)) ```-#### codeintel-uploads: codeintel_uploads_janitor_scip_documents_total +#### completions: chat_completions_p99_http_connect_dns -
Job invocation operations every 5m
+Stream: HTTP connect: dns (p99)
+ +Portion of time spent on DNS when acquiring an HTTP connection to the upstream. This panel has no related alerts. -To see this panel, visit `/-/debug/grafana/d/codeintel-uploads/codeintel-uploads?viewPanel=101310` on your Sourcegraph instance. +To see this panel, visit `/-/debug/grafana/d/completions/completions?viewPanel=100150` on your Sourcegraph instance. -*Managed by the [Sourcegraph Code intelligence team](https://handbook.sourcegraph.com/departments/engineering/teams/code-intelligence).*Technical details
@@ -71040,21 +70750,22 @@ To see this panel, visit `/-/debug/grafana/d/codeintel-uploads/codeintel-uploads Query: ``` -sum by (op)(increase(src_codeintel_uploads_janitor_scip_documents_total{job=~"^${source:regex}.*"}[5m])) +histogram_quantile(0.99, sum(rate(src_completions_upstream_connection_dns_duration_seconds_bucket[$sampling_duration])) by (le, provider)) ```-#### codeintel-uploads: codeintel_uploads_janitor_scip_documents_99th_percentile_duration +#### completions: chat_completions_p95_http_connect_dns -
99th percentile successful job invocation operation duration over 5m
+Stream: HTTP connect: dns (p95)
+ +Portion of time spent on DNS when acquiring an HTTP connection to the upstream. This panel has no related alerts. -To see this panel, visit `/-/debug/grafana/d/codeintel-uploads/codeintel-uploads?viewPanel=101311` on your Sourcegraph instance. +To see this panel, visit `/-/debug/grafana/d/completions/completions?viewPanel=100151` on your Sourcegraph instance. -*Managed by the [Sourcegraph Code intelligence team](https://handbook.sourcegraph.com/departments/engineering/teams/code-intelligence).*Technical details
@@ -71062,21 +70773,22 @@ To see this panel, visit `/-/debug/grafana/d/codeintel-uploads/codeintel-uploads Query: ``` -histogram_quantile(0.99, sum by (le,op)(rate(src_codeintel_uploads_janitor_scip_documents_duration_seconds_bucket{job=~"^${source:regex}.*"}[5m]))) +histogram_quantile(0.95, sum(rate(src_completions_upstream_connection_dns_duration_seconds_bucket[$sampling_duration])) by (le, provider)) ```-#### codeintel-uploads: codeintel_uploads_janitor_scip_documents_errors_total +#### completions: chat_completions_p75_http_connect_dns -
Job invocation operation errors every 5m
+Stream: HTTP connect: dns (p75)
+ +Portion of time spent on DNS when acquiring an HTTP connection to the upstream. This panel has no related alerts. -To see this panel, visit `/-/debug/grafana/d/codeintel-uploads/codeintel-uploads?viewPanel=101312` on your Sourcegraph instance. +To see this panel, visit `/-/debug/grafana/d/completions/completions?viewPanel=100152` on your Sourcegraph instance. -*Managed by the [Sourcegraph Code intelligence team](https://handbook.sourcegraph.com/departments/engineering/teams/code-intelligence).*Technical details
@@ -71084,21 +70796,22 @@ To see this panel, visit `/-/debug/grafana/d/codeintel-uploads/codeintel-uploads Query: ``` -sum by (op)(increase(src_codeintel_uploads_janitor_scip_documents_errors_total{job=~"^${source:regex}.*"}[5m])) +histogram_quantile(0.75, sum(rate(src_completions_upstream_connection_dns_duration_seconds_bucket[$sampling_duration])) by (le, provider)) ```-#### codeintel-uploads: codeintel_uploads_janitor_scip_documents_error_rate +#### completions: chat_completions_p50_http_connect_dns -
Job invocation operation error rate over 5m
+Stream: HTTP connect: dns (p50)
+ +Portion of time spent on DNS when acquiring an HTTP connection to the upstream. This panel has no related alerts. -To see this panel, visit `/-/debug/grafana/d/codeintel-uploads/codeintel-uploads?viewPanel=101313` on your Sourcegraph instance. +To see this panel, visit `/-/debug/grafana/d/completions/completions?viewPanel=100153` on your Sourcegraph instance. -*Managed by the [Sourcegraph Code intelligence team](https://handbook.sourcegraph.com/departments/engineering/teams/code-intelligence).*Technical details
@@ -71106,25 +70819,22 @@ To see this panel, visit `/-/debug/grafana/d/codeintel-uploads/codeintel-uploads Query: ``` -sum by (op)(increase(src_codeintel_uploads_janitor_scip_documents_errors_total{job=~"^${source:regex}.*"}[5m])) / (sum by (op)(increase(src_codeintel_uploads_janitor_scip_documents_total{job=~"^${source:regex}.*"}[5m])) + sum by (op)(increase(src_codeintel_uploads_janitor_scip_documents_errors_total{job=~"^${source:regex}.*"}[5m]))) * 100 +histogram_quantile(0.50, sum(rate(src_completions_upstream_connection_dns_duration_seconds_bucket[$sampling_duration])) by (le, provider)) ```-### Code Intelligence > Uploads: Codeintel: Uploads > Reconciler task > Codeintel uploads reconciler scip metadata - -#### codeintel-uploads: codeintel_uploads_reconciler_scip_metadata_records_scanned_total +#### completions: chat_completions_p99_http_connect_tls -
Records scanned every 5m
+Stream: HTTP connect: tls (p99)
-The number of candidate records considered for cleanup. +Portion of time spent on TLS when acquiring an HTTP connection to the upstream. This panel has no related alerts. -To see this panel, visit `/-/debug/grafana/d/codeintel-uploads/codeintel-uploads?viewPanel=101400` on your Sourcegraph instance. +To see this panel, visit `/-/debug/grafana/d/completions/completions?viewPanel=100160` on your Sourcegraph instance. -*Managed by the [Sourcegraph Code intelligence team](https://handbook.sourcegraph.com/departments/engineering/teams/code-intelligence).*Technical details
@@ -71132,23 +70842,22 @@ To see this panel, visit `/-/debug/grafana/d/codeintel-uploads/codeintel-uploads Query: ``` -sum(increase(src_codeintel_uploads_reconciler_scip_metadata_records_scanned_total{job=~"^${source:regex}.*"}[5m])) +histogram_quantile(0.99, sum(rate(src_completions_upstream_connection_tls_duration_seconds_bucket[$sampling_duration])) by (le, provider)) ```-#### codeintel-uploads: codeintel_uploads_reconciler_scip_metadata_records_altered_total +#### completions: chat_completions_p95_http_connect_tls -
Records altered every 5m
+Stream: HTTP connect: tls (p95)
-The number of candidate records altered as part of cleanup. +Portion of time spent on TLS when acquiring an HTTP connection to the upstream. This panel has no related alerts. -To see this panel, visit `/-/debug/grafana/d/codeintel-uploads/codeintel-uploads?viewPanel=101401` on your Sourcegraph instance. +To see this panel, visit `/-/debug/grafana/d/completions/completions?viewPanel=100161` on your Sourcegraph instance. -*Managed by the [Sourcegraph Code intelligence team](https://handbook.sourcegraph.com/departments/engineering/teams/code-intelligence).*Technical details
@@ -71156,21 +70865,22 @@ To see this panel, visit `/-/debug/grafana/d/codeintel-uploads/codeintel-uploads Query: ``` -sum(increase(src_codeintel_uploads_reconciler_scip_metadata_records_altered_total{job=~"^${source:regex}.*"}[5m])) +histogram_quantile(0.95, sum(rate(src_completions_upstream_connection_tls_duration_seconds_bucket[$sampling_duration])) by (le, provider)) ```-#### codeintel-uploads: codeintel_uploads_reconciler_scip_metadata_total +#### completions: chat_completions_p75_http_connect_tls -
Job invocation operations every 5m
+Stream: HTTP connect: tls (p75)
+ +Portion of time spent on TLS when acquiring an HTTP connection to the upstream. This panel has no related alerts. -To see this panel, visit `/-/debug/grafana/d/codeintel-uploads/codeintel-uploads?viewPanel=101410` on your Sourcegraph instance. +To see this panel, visit `/-/debug/grafana/d/completions/completions?viewPanel=100162` on your Sourcegraph instance. -*Managed by the [Sourcegraph Code intelligence team](https://handbook.sourcegraph.com/departments/engineering/teams/code-intelligence).*Technical details
@@ -71178,21 +70888,22 @@ To see this panel, visit `/-/debug/grafana/d/codeintel-uploads/codeintel-uploads Query: ``` -sum by (op)(increase(src_codeintel_uploads_reconciler_scip_metadata_total{job=~"^${source:regex}.*"}[5m])) +histogram_quantile(0.75, sum(rate(src_completions_upstream_connection_tls_duration_seconds_bucket[$sampling_duration])) by (le, provider)) ```-#### codeintel-uploads: codeintel_uploads_reconciler_scip_metadata_99th_percentile_duration +#### completions: chat_completions_p50_http_connect_tls -
99th percentile successful job invocation operation duration over 5m
+Stream: HTTP connect: tls (p50)
+ +Portion of time spent on TLS when acquiring an HTTP connection to the upstream. This panel has no related alerts. -To see this panel, visit `/-/debug/grafana/d/codeintel-uploads/codeintel-uploads?viewPanel=101411` on your Sourcegraph instance. +To see this panel, visit `/-/debug/grafana/d/completions/completions?viewPanel=100163` on your Sourcegraph instance. -*Managed by the [Sourcegraph Code intelligence team](https://handbook.sourcegraph.com/departments/engineering/teams/code-intelligence).*Technical details
@@ -71200,21 +70911,22 @@ To see this panel, visit `/-/debug/grafana/d/codeintel-uploads/codeintel-uploads Query: ``` -histogram_quantile(0.99, sum by (le,op)(rate(src_codeintel_uploads_reconciler_scip_metadata_duration_seconds_bucket{job=~"^${source:regex}.*"}[5m]))) +histogram_quantile(0.50, sum(rate(src_completions_upstream_connection_tls_duration_seconds_bucket[$sampling_duration])) by (le, provider)) ```-#### codeintel-uploads: codeintel_uploads_reconciler_scip_metadata_errors_total +#### completions: chat_completions_p99_http_connect_dial -
Job invocation operation errors every 5m
+Stream: HTTP connect: dial (p99)
+ +Portion of time spent on golang Dial() when acquiring an HTTP connection to the upstream. This panel has no related alerts. -To see this panel, visit `/-/debug/grafana/d/codeintel-uploads/codeintel-uploads?viewPanel=101412` on your Sourcegraph instance. +To see this panel, visit `/-/debug/grafana/d/completions/completions?viewPanel=100170` on your Sourcegraph instance. -*Managed by the [Sourcegraph Code intelligence team](https://handbook.sourcegraph.com/departments/engineering/teams/code-intelligence).*Technical details
@@ -71222,21 +70934,22 @@ To see this panel, visit `/-/debug/grafana/d/codeintel-uploads/codeintel-uploads Query: ``` -sum by (op)(increase(src_codeintel_uploads_reconciler_scip_metadata_errors_total{job=~"^${source:regex}.*"}[5m])) +histogram_quantile(0.99, sum(rate(src_completions_upstream_connection_dial_duration_seconds_bucket[$sampling_duration])) by (le, provider)) ```-#### codeintel-uploads: codeintel_uploads_reconciler_scip_metadata_error_rate +#### completions: chat_completions_p95_http_connect_dial -
Job invocation operation error rate over 5m
+Stream: HTTP connect: dial (p95)
+ +Portion of time spent on golang Dial() when acquiring an HTTP connection to the upstream. This panel has no related alerts. -To see this panel, visit `/-/debug/grafana/d/codeintel-uploads/codeintel-uploads?viewPanel=101413` on your Sourcegraph instance. +To see this panel, visit `/-/debug/grafana/d/completions/completions?viewPanel=100171` on your Sourcegraph instance. -*Managed by the [Sourcegraph Code intelligence team](https://handbook.sourcegraph.com/departments/engineering/teams/code-intelligence).*Technical details
@@ -71244,25 +70957,22 @@ To see this panel, visit `/-/debug/grafana/d/codeintel-uploads/codeintel-uploads Query: ``` -sum by (op)(increase(src_codeintel_uploads_reconciler_scip_metadata_errors_total{job=~"^${source:regex}.*"}[5m])) / (sum by (op)(increase(src_codeintel_uploads_reconciler_scip_metadata_total{job=~"^${source:regex}.*"}[5m])) + sum by (op)(increase(src_codeintel_uploads_reconciler_scip_metadata_errors_total{job=~"^${source:regex}.*"}[5m]))) * 100 +histogram_quantile(0.95, sum(rate(src_completions_upstream_connection_dial_duration_seconds_bucket[$sampling_duration])) by (le, provider)) ```-### Code Intelligence > Uploads: Codeintel: Uploads > Reconciler task > Codeintel uploads reconciler scip data - -#### codeintel-uploads: codeintel_uploads_reconciler_scip_data_records_scanned_total +#### completions: chat_completions_p75_http_connect_dial -
Records scanned every 5m
+Stream: HTTP connect: dial (p75)
-The number of candidate records considered for cleanup. +Portion of time spent on golang Dial() when acquiring an HTTP connection to the upstream. This panel has no related alerts. -To see this panel, visit `/-/debug/grafana/d/codeintel-uploads/codeintel-uploads?viewPanel=101500` on your Sourcegraph instance. +To see this panel, visit `/-/debug/grafana/d/completions/completions?viewPanel=100172` on your Sourcegraph instance. -*Managed by the [Sourcegraph Code intelligence team](https://handbook.sourcegraph.com/departments/engineering/teams/code-intelligence).*Technical details
@@ -71270,23 +70980,22 @@ To see this panel, visit `/-/debug/grafana/d/codeintel-uploads/codeintel-uploads Query: ``` -sum(increase(src_codeintel_uploads_reconciler_scip_data_records_scanned_total{job=~"^${source:regex}.*"}[5m])) +histogram_quantile(0.75, sum(rate(src_completions_upstream_connection_dial_duration_seconds_bucket[$sampling_duration])) by (le, provider)) ```-#### codeintel-uploads: codeintel_uploads_reconciler_scip_data_records_altered_total +#### completions: chat_completions_p50_http_connect_dial -
Records altered every 5m
+Stream: HTTP connect: dial (p50)
-The number of candidate records altered as part of cleanup. +Portion of time spent on golang Dial() when acquiring an HTTP connection to the upstream. This panel has no related alerts. -To see this panel, visit `/-/debug/grafana/d/codeintel-uploads/codeintel-uploads?viewPanel=101501` on your Sourcegraph instance. +To see this panel, visit `/-/debug/grafana/d/completions/completions?viewPanel=100173` on your Sourcegraph instance. -*Managed by the [Sourcegraph Code intelligence team](https://handbook.sourcegraph.com/departments/engineering/teams/code-intelligence).*Technical details
@@ -71294,21 +71003,24 @@ To see this panel, visit `/-/debug/grafana/d/codeintel-uploads/codeintel-uploads Query: ``` -sum(increase(src_codeintel_uploads_reconciler_scip_data_records_altered_total{job=~"^${source:regex}.*"}[5m])) +histogram_quantile(0.50, sum(rate(src_completions_upstream_connection_dial_duration_seconds_bucket[$sampling_duration])) by (le, provider)) ```-#### codeintel-uploads: codeintel_uploads_reconciler_scip_data_total +### Completions: Code completions -
Job invocation operations every 5m
+#### completions: code_completions_p99_stream_duration + +Stream: total time (p99)
+ +Time spent on the Stream() invocation, i.e. how long results take to connect, stream results, and finish streaming. This panel has no related alerts. -To see this panel, visit `/-/debug/grafana/d/codeintel-uploads/codeintel-uploads?viewPanel=101510` on your Sourcegraph instance. +To see this panel, visit `/-/debug/grafana/d/completions/completions?viewPanel=100200` on your Sourcegraph instance. -*Managed by the [Sourcegraph Code intelligence team](https://handbook.sourcegraph.com/departments/engineering/teams/code-intelligence).*Technical details
@@ -71316,21 +71028,22 @@ To see this panel, visit `/-/debug/grafana/d/codeintel-uploads/codeintel-uploads Query: ``` -sum by (op)(increase(src_codeintel_uploads_reconciler_scip_data_total{job=~"^${source:regex}.*"}[5m])) +histogram_quantile(0.99, sum(rate(src_completions_stream_duration_seconds_bucket{feature="code_completions",model=~'${model}'}[$sampling_duration])) by (le, model)) ```-#### codeintel-uploads: codeintel_uploads_reconciler_scip_data_99th_percentile_duration +#### completions: code_completions_p95_stream_duration -
99th percentile successful job invocation operation duration over 5m
+Stream: total time (p95)
+ +Time spent on the Stream() invocation, i.e. how long results take to connect, stream results, and finish streaming. This panel has no related alerts. -To see this panel, visit `/-/debug/grafana/d/codeintel-uploads/codeintel-uploads?viewPanel=101511` on your Sourcegraph instance. +To see this panel, visit `/-/debug/grafana/d/completions/completions?viewPanel=100201` on your Sourcegraph instance. -*Managed by the [Sourcegraph Code intelligence team](https://handbook.sourcegraph.com/departments/engineering/teams/code-intelligence).*Technical details
@@ -71338,21 +71051,22 @@ To see this panel, visit `/-/debug/grafana/d/codeintel-uploads/codeintel-uploads Query: ``` -histogram_quantile(0.99, sum by (le,op)(rate(src_codeintel_uploads_reconciler_scip_data_duration_seconds_bucket{job=~"^${source:regex}.*"}[5m]))) +histogram_quantile(0.95, sum(rate(src_completions_stream_duration_seconds_bucket{feature="code_completions",model=~'${model}'}[$sampling_duration])) by (le, model)) ```-#### codeintel-uploads: codeintel_uploads_reconciler_scip_data_errors_total +#### completions: code_completions_p75_stream_duration -
Job invocation operation errors every 5m
+Stream: total time (p75)
+ +Time spent on the Stream() invocation, i.e. how long results take to connect, stream results, and finish streaming. This panel has no related alerts. -To see this panel, visit `/-/debug/grafana/d/codeintel-uploads/codeintel-uploads?viewPanel=101512` on your Sourcegraph instance. +To see this panel, visit `/-/debug/grafana/d/completions/completions?viewPanel=100202` on your Sourcegraph instance. -*Managed by the [Sourcegraph Code intelligence team](https://handbook.sourcegraph.com/departments/engineering/teams/code-intelligence).*Technical details
@@ -71360,21 +71074,22 @@ To see this panel, visit `/-/debug/grafana/d/codeintel-uploads/codeintel-uploads Query: ``` -sum by (op)(increase(src_codeintel_uploads_reconciler_scip_data_errors_total{job=~"^${source:regex}.*"}[5m])) +histogram_quantile(0.75, sum(rate(src_completions_stream_duration_seconds_bucket{feature="code_completions",model=~'${model}'}[$sampling_duration])) by (le, model)) ```-#### codeintel-uploads: codeintel_uploads_reconciler_scip_data_error_rate +#### completions: code_completions_p50_stream_duration -
Job invocation operation error rate over 5m
+Stream: total time (p50)
+ +Time spent on the Stream() invocation, i.e. how long results take to connect, stream results, and finish streaming. This panel has no related alerts. -To see this panel, visit `/-/debug/grafana/d/codeintel-uploads/codeintel-uploads?viewPanel=101513` on your Sourcegraph instance. +To see this panel, visit `/-/debug/grafana/d/completions/completions?viewPanel=100203` on your Sourcegraph instance. -*Managed by the [Sourcegraph Code intelligence team](https://handbook.sourcegraph.com/departments/engineering/teams/code-intelligence).*Technical details
@@ -71382,31 +71097,22 @@ To see this panel, visit `/-/debug/grafana/d/codeintel-uploads/codeintel-uploads Query: ``` -sum by (op)(increase(src_codeintel_uploads_reconciler_scip_data_errors_total{job=~"^${source:regex}.*"}[5m])) / (sum by (op)(increase(src_codeintel_uploads_reconciler_scip_data_total{job=~"^${source:regex}.*"}[5m])) + sum by (op)(increase(src_codeintel_uploads_reconciler_scip_data_errors_total{job=~"^${source:regex}.*"}[5m]))) * 100 +histogram_quantile(0.50, sum(rate(src_completions_stream_duration_seconds_bucket{feature="code_completions",model=~'${model}'}[$sampling_duration])) by (le, model)) ```-## Telemetry - -
Monitoring telemetry services in Sourcegraph.
- -To see this dashboard, visit `/-/debug/grafana/d/telemetry/telemetry` on your Sourcegraph instance. - -### Telemetry: Telemetry Gateway Exporter: Export and queue metrics - -#### telemetry: telemetry_gateway_exporter_queue_size +#### completions: code_completions_p99_non_stream_overhead_duration -Telemetry event payloads pending export
+Non-stream overhead (p99)
-The number of events queued to be exported. +Time between Go HTTP handler invocation and Stream() invocation, overhead of e.g. request validation, routing to gateway/other, model resolution, error reporting/tracing, guardrails, etc. This panel has no related alerts. -To see this panel, visit `/-/debug/grafana/d/telemetry/telemetry?viewPanel=100000` on your Sourcegraph instance. +To see this panel, visit `/-/debug/grafana/d/completions/completions?viewPanel=100210` on your Sourcegraph instance. -*Managed by the [Sourcegraph Data & Analytics team](https://handbook.sourcegraph.com/departments/engineering/teams/data-analytics).*Technical details
@@ -71414,23 +71120,22 @@ To see this panel, visit `/-/debug/grafana/d/telemetry/telemetry?viewPanel=10000 Query: ``` -sum(src_telemetrygatewayexporter_queue_size) +histogram_quantile(0.99, sum(rate(src_completions_handler_overhead_duration_seconds_bucket{feature="code_completions",model=~'${model}'}[$sampling_duration])) by (le,model)) ```-#### telemetry: telemetry_gateway_exporter_queue_growth +#### completions: code_completions_p95_non_stream_overhead_duration -
Rate of growth of export queue over 30m
+Non-stream overhead (p95)
-A positive value indicates the queue is growing. +Time between Go HTTP handler invocation and Stream() invocation, overhead of e.g. request validation, routing to gateway/other, model resolution, error reporting/tracing, guardrails, etc. -Refer to the [alerts reference](alerts#telemetry-telemetry-gateway-exporter-queue-growth) for 2 alerts related to this panel. +This panel has no related alerts. -To see this panel, visit `/-/debug/grafana/d/telemetry/telemetry?viewPanel=100001` on your Sourcegraph instance. +To see this panel, visit `/-/debug/grafana/d/completions/completions?viewPanel=100211` on your Sourcegraph instance. -*Managed by the [Sourcegraph Data & Analytics team](https://handbook.sourcegraph.com/departments/engineering/teams/data-analytics).*Technical details
@@ -71438,23 +71143,22 @@ To see this panel, visit `/-/debug/grafana/d/telemetry/telemetry?viewPanel=10000 Query: ``` -max(deriv(src_telemetrygatewayexporter_queue_size[30m])) +histogram_quantile(0.95, sum(rate(src_completions_handler_overhead_duration_seconds_bucket{feature="code_completions",model=~'${model}'}[$sampling_duration])) by (le,model)) ```-#### telemetry: src_telemetrygatewayexporter_exported_events +#### completions: code_completions_p75_non_stream_overhead_duration -
Events exported from queue per hour
+Non-stream overhead (p75)
-The number of events being exported. +Time between Go HTTP handler invocation and Stream() invocation, overhead of e.g. request validation, routing to gateway/other, model resolution, error reporting/tracing, guardrails, etc. This panel has no related alerts. -To see this panel, visit `/-/debug/grafana/d/telemetry/telemetry?viewPanel=100010` on your Sourcegraph instance. +To see this panel, visit `/-/debug/grafana/d/completions/completions?viewPanel=100212` on your Sourcegraph instance. -*Managed by the [Sourcegraph Data & Analytics team](https://handbook.sourcegraph.com/departments/engineering/teams/data-analytics).*Technical details
@@ -71462,24 +71166,22 @@ To see this panel, visit `/-/debug/grafana/d/telemetry/telemetry?viewPanel=10001 Query: ``` -max(increase(src_telemetrygatewayexporter_exported_events[1h])) +histogram_quantile(0.75, sum(rate(src_completions_handler_overhead_duration_seconds_bucket{feature="code_completions",model=~'${model}'}[$sampling_duration])) by (le,model)) ```-#### telemetry: telemetry_gateway_exporter_batch_size +#### completions: code_completions_p50_non_stream_overhead_duration -
Number of events exported per batch over 30m
+Non-stream overhead (p50)
-The number of events exported in each batch. The largest bucket is the maximum number of events exported per batch. -If the distribution trends to the maximum bucket, then events export throughput is at or approaching saturation - try increasing `TELEMETRY_GATEWAY_EXPORTER_EXPORT_BATCH_SIZE` or decreasing `TELEMETRY_GATEWAY_EXPORTER_EXPORT_INTERVAL`. +Time between Go HTTP handler invocation and Stream() invocation, overhead of e.g. request validation, routing to gateway/other, model resolution, error reporting/tracing, guardrails, etc. This panel has no related alerts. -To see this panel, visit `/-/debug/grafana/d/telemetry/telemetry?viewPanel=100011` on your Sourcegraph instance. +To see this panel, visit `/-/debug/grafana/d/completions/completions?viewPanel=100213` on your Sourcegraph instance. -*Managed by the [Sourcegraph Data & Analytics team](https://handbook.sourcegraph.com/departments/engineering/teams/data-analytics).*Technical details
@@ -71487,23 +71189,22 @@ To see this panel, visit `/-/debug/grafana/d/telemetry/telemetry?viewPanel=10001 Query: ``` -sum by (le) (rate(src_telemetrygatewayexporter_batch_size_bucket[30m])) +histogram_quantile(0.50, sum(rate(src_completions_handler_overhead_duration_seconds_bucket{feature="code_completions",model=~'${model}'}[$sampling_duration])) by (le,model)) ```-### Telemetry: Telemetry Gateway Exporter: Export job operations +#### completions: code_completions_p99_stream_first_event_duration -#### telemetry: telemetrygatewayexporter_exporter_total +
Stream: time to first event (p99)
-Events exporter operations every 30m
+Time between calling Stream(), the client connecting to the server etc. and actually getting the first streaming event back. This panel has no related alerts. -To see this panel, visit `/-/debug/grafana/d/telemetry/telemetry?viewPanel=100100` on your Sourcegraph instance. +To see this panel, visit `/-/debug/grafana/d/completions/completions?viewPanel=100220` on your Sourcegraph instance. -*Managed by the [Sourcegraph Data & Analytics team](https://handbook.sourcegraph.com/departments/engineering/teams/data-analytics).*Technical details
@@ -71511,21 +71212,22 @@ To see this panel, visit `/-/debug/grafana/d/telemetry/telemetry?viewPanel=10010 Query: ``` -sum(increase(src_telemetrygatewayexporter_exporter_total{job=~"^worker.*"}[30m])) +histogram_quantile(0.99, sum(rate(src_completions_stream_first_event_duration_seconds_bucket{feature="code_completions",model=~'${model}'}[$sampling_duration])) by (le, model)) ```-#### telemetry: telemetrygatewayexporter_exporter_99th_percentile_duration +#### completions: code_completions_p95_stream_first_event_duration -
Aggregate successful events exporter operation duration distribution over 30m
+Stream: time to first event (p95)
+ +Time between calling Stream(), the client connecting to the server etc. and actually getting the first streaming event back. This panel has no related alerts. -To see this panel, visit `/-/debug/grafana/d/telemetry/telemetry?viewPanel=100101` on your Sourcegraph instance. +To see this panel, visit `/-/debug/grafana/d/completions/completions?viewPanel=100221` on your Sourcegraph instance. -*Managed by the [Sourcegraph Data & Analytics team](https://handbook.sourcegraph.com/departments/engineering/teams/data-analytics).*Technical details
@@ -71533,21 +71235,22 @@ To see this panel, visit `/-/debug/grafana/d/telemetry/telemetry?viewPanel=10010 Query: ``` -sum by (le)(rate(src_telemetrygatewayexporter_exporter_duration_seconds_bucket{job=~"^worker.*"}[30m])) +histogram_quantile(0.95, sum(rate(src_completions_stream_first_event_duration_seconds_bucket{feature="code_completions",model=~'${model}'}[$sampling_duration])) by (le, model)) ```-#### telemetry: telemetrygatewayexporter_exporter_errors_total +#### completions: code_completions_p75_stream_first_event_duration -
Events exporter operation errors every 30m
+Stream: time to first event (p75)
-Refer to the [alerts reference](alerts#telemetry-telemetrygatewayexporter-exporter-errors-total) for 1 alert related to this panel. +Time between calling Stream(), the client connecting to the server etc. and actually getting the first streaming event back. -To see this panel, visit `/-/debug/grafana/d/telemetry/telemetry?viewPanel=100102` on your Sourcegraph instance. +This panel has no related alerts. + +To see this panel, visit `/-/debug/grafana/d/completions/completions?viewPanel=100222` on your Sourcegraph instance. -*Managed by the [Sourcegraph Data & Analytics team](https://handbook.sourcegraph.com/departments/engineering/teams/data-analytics).*Technical details
@@ -71555,21 +71258,22 @@ To see this panel, visit `/-/debug/grafana/d/telemetry/telemetry?viewPanel=10010 Query: ``` -sum(increase(src_telemetrygatewayexporter_exporter_errors_total{job=~"^worker.*"}[30m])) +histogram_quantile(0.75, sum(rate(src_completions_stream_first_event_duration_seconds_bucket{feature="code_completions",model=~'${model}'}[$sampling_duration])) by (le, model)) ```-#### telemetry: telemetrygatewayexporter_exporter_error_rate +#### completions: code_completions_p50_stream_first_event_duration -
Events exporter operation error rate over 30m
+Stream: time to first event (p50)
+ +Time between calling Stream(), the client connecting to the server etc. and actually getting the first streaming event back. This panel has no related alerts. -To see this panel, visit `/-/debug/grafana/d/telemetry/telemetry?viewPanel=100103` on your Sourcegraph instance. +To see this panel, visit `/-/debug/grafana/d/completions/completions?viewPanel=100223` on your Sourcegraph instance. -*Managed by the [Sourcegraph Data & Analytics team](https://handbook.sourcegraph.com/departments/engineering/teams/data-analytics).*Technical details
@@ -71577,23 +71281,22 @@ To see this panel, visit `/-/debug/grafana/d/telemetry/telemetry?viewPanel=10010 Query: ``` -sum(increase(src_telemetrygatewayexporter_exporter_errors_total{job=~"^worker.*"}[30m])) / (sum(increase(src_telemetrygatewayexporter_exporter_total{job=~"^worker.*"}[30m])) + sum(increase(src_telemetrygatewayexporter_exporter_errors_total{job=~"^worker.*"}[30m]))) * 100 +histogram_quantile(0.50, sum(rate(src_completions_stream_first_event_duration_seconds_bucket{feature="code_completions",model=~'${model}'}[$sampling_duration])) by (le, model)) ```-### Telemetry: Telemetry Gateway Exporter: Export queue cleanup job operations +#### completions: code_completions_p99_upstream_roundtrip_duration -#### telemetry: telemetrygatewayexporter_queue_cleanup_total +
Stream: first byte sent -> received (p99)
-Export queue cleanup operations every 30m
+Time between sending the first byte to the upstream, and then getting the first byte back from the upstream. This panel has no related alerts. -To see this panel, visit `/-/debug/grafana/d/telemetry/telemetry?viewPanel=100200` on your Sourcegraph instance. +To see this panel, visit `/-/debug/grafana/d/completions/completions?viewPanel=100230` on your Sourcegraph instance. -*Managed by the [Sourcegraph Data & Analytics team](https://handbook.sourcegraph.com/departments/engineering/teams/data-analytics).*Technical details
@@ -71601,21 +71304,22 @@ To see this panel, visit `/-/debug/grafana/d/telemetry/telemetry?viewPanel=10020 Query: ``` -sum(increase(src_telemetrygatewayexporter_queue_cleanup_total{job=~"^worker.*"}[30m])) +histogram_quantile(0.99, sum(rate(src_completions_upstream_roundtrip_duration_seconds_bucket{feature="code_completions",model=~'${model}'}[$sampling_duration])) by (le, provider)) ```-#### telemetry: telemetrygatewayexporter_queue_cleanup_99th_percentile_duration +#### completions: code_completions_p95_upstream_roundtrip_duration -
Aggregate successful export queue cleanup operation duration distribution over 30m
+Stream: first byte sent -> received (p95)
+ +Time between sending the first byte to the upstream, and then getting the first byte back from the upstream. This panel has no related alerts. -To see this panel, visit `/-/debug/grafana/d/telemetry/telemetry?viewPanel=100201` on your Sourcegraph instance. +To see this panel, visit `/-/debug/grafana/d/completions/completions?viewPanel=100231` on your Sourcegraph instance. -*Managed by the [Sourcegraph Data & Analytics team](https://handbook.sourcegraph.com/departments/engineering/teams/data-analytics).*Technical details
@@ -71623,21 +71327,22 @@ To see this panel, visit `/-/debug/grafana/d/telemetry/telemetry?viewPanel=10020 Query: ``` -sum by (le)(rate(src_telemetrygatewayexporter_queue_cleanup_duration_seconds_bucket{job=~"^worker.*"}[30m])) +histogram_quantile(0.95, sum(rate(src_completions_upstream_roundtrip_duration_seconds_bucket{feature="code_completions",model=~'${model}'}[$sampling_duration])) by (le, provider)) ```-#### telemetry: telemetrygatewayexporter_queue_cleanup_errors_total +#### completions: code_completions_p75_upstream_roundtrip_duration -
Export queue cleanup operation errors every 30m
+Stream: first byte sent -> received (p75)
-Refer to the [alerts reference](alerts#telemetry-telemetrygatewayexporter-queue-cleanup-errors-total) for 1 alert related to this panel. +Time between sending the first byte to the upstream, and then getting the first byte back from the upstream. -To see this panel, visit `/-/debug/grafana/d/telemetry/telemetry?viewPanel=100202` on your Sourcegraph instance. +This panel has no related alerts. + +To see this panel, visit `/-/debug/grafana/d/completions/completions?viewPanel=100232` on your Sourcegraph instance. -*Managed by the [Sourcegraph Data & Analytics team](https://handbook.sourcegraph.com/departments/engineering/teams/data-analytics).*Technical details
@@ -71645,21 +71350,22 @@ To see this panel, visit `/-/debug/grafana/d/telemetry/telemetry?viewPanel=10020 Query: ``` -sum(increase(src_telemetrygatewayexporter_queue_cleanup_errors_total{job=~"^worker.*"}[30m])) +histogram_quantile(0.75, sum(rate(src_completions_upstream_roundtrip_duration_seconds_bucket{feature="code_completions",model=~'${model}'}[$sampling_duration])) by (le, provider)) ```-#### telemetry: telemetrygatewayexporter_queue_cleanup_error_rate +#### completions: code_completions_p50_upstream_roundtrip_duration -
Export queue cleanup operation error rate over 30m
+Stream: first byte sent -> received (p50)
+ +Time between sending the first byte to the upstream, and then getting the first byte back from the upstream. This panel has no related alerts. -To see this panel, visit `/-/debug/grafana/d/telemetry/telemetry?viewPanel=100203` on your Sourcegraph instance. +To see this panel, visit `/-/debug/grafana/d/completions/completions?viewPanel=100233` on your Sourcegraph instance. -*Managed by the [Sourcegraph Data & Analytics team](https://handbook.sourcegraph.com/departments/engineering/teams/data-analytics).*Technical details
@@ -71667,23 +71373,22 @@ To see this panel, visit `/-/debug/grafana/d/telemetry/telemetry?viewPanel=10020 Query: ``` -sum(increase(src_telemetrygatewayexporter_queue_cleanup_errors_total{job=~"^worker.*"}[30m])) / (sum(increase(src_telemetrygatewayexporter_queue_cleanup_total{job=~"^worker.*"}[30m])) + sum(increase(src_telemetrygatewayexporter_queue_cleanup_errors_total{job=~"^worker.*"}[30m]))) * 100 +histogram_quantile(0.50, sum(rate(src_completions_upstream_roundtrip_duration_seconds_bucket{feature="code_completions",model=~'${model}'}[$sampling_duration])) by (le, provider)) ```-### Telemetry: Telemetry Gateway Exporter: Export queue metrics reporting job operations +#### completions: code_completions_p99_http_connect_total -#### telemetry: telemetrygatewayexporter_queue_metrics_reporter_total +
Stream: HTTP connect: total (p99)
-Export backlog metrics reporting operations every 30m
+Time spent acquiring an HTTP connection to the upstream, either from an existing pool OR by performing DNS resolution, TCP connection, etc. This panel has no related alerts. -To see this panel, visit `/-/debug/grafana/d/telemetry/telemetry?viewPanel=100300` on your Sourcegraph instance. +To see this panel, visit `/-/debug/grafana/d/completions/completions?viewPanel=100240` on your Sourcegraph instance. -*Managed by the [Sourcegraph Data & Analytics team](https://handbook.sourcegraph.com/departments/engineering/teams/data-analytics).*Technical details
@@ -71691,21 +71396,22 @@ To see this panel, visit `/-/debug/grafana/d/telemetry/telemetry?viewPanel=10030 Query: ``` -sum(increase(src_telemetrygatewayexporter_queue_metrics_reporter_total{job=~"^worker.*"}[30m])) +histogram_quantile(0.99, sum(rate(src_completions_upstream_connection_total_duration_seconds_bucket[$sampling_duration])) by (le, connection_type, provider)) ```-#### telemetry: telemetrygatewayexporter_queue_metrics_reporter_99th_percentile_duration +#### completions: code_completions_p95_http_connect_total + +
Stream: HTTP connect: total (p95)
-Aggregate successful export backlog metrics reporting operation duration distribution over 30m
+Time spent acquiring an HTTP connection to the upstream, either from an existing pool OR by performing DNS resolution, TCP connection, etc. This panel has no related alerts. -To see this panel, visit `/-/debug/grafana/d/telemetry/telemetry?viewPanel=100301` on your Sourcegraph instance. +To see this panel, visit `/-/debug/grafana/d/completions/completions?viewPanel=100241` on your Sourcegraph instance. -*Managed by the [Sourcegraph Data & Analytics team](https://handbook.sourcegraph.com/departments/engineering/teams/data-analytics).*Technical details
@@ -71713,21 +71419,22 @@ To see this panel, visit `/-/debug/grafana/d/telemetry/telemetry?viewPanel=10030 Query: ``` -sum by (le)(rate(src_telemetrygatewayexporter_queue_metrics_reporter_duration_seconds_bucket{job=~"^worker.*"}[30m])) +histogram_quantile(0.95, sum(rate(src_completions_upstream_connection_total_duration_seconds_bucket[$sampling_duration])) by (le, connection_type, provider)) ```-#### telemetry: telemetrygatewayexporter_queue_metrics_reporter_errors_total +#### completions: code_completions_p75_http_connect_total -
Export backlog metrics reporting operation errors every 30m
+Stream: HTTP connect: total (p75)
-Refer to the [alerts reference](alerts#telemetry-telemetrygatewayexporter-queue-metrics-reporter-errors-total) for 1 alert related to this panel. +Time spent acquiring an HTTP connection to the upstream, either from an existing pool OR by performing DNS resolution, TCP connection, etc. -To see this panel, visit `/-/debug/grafana/d/telemetry/telemetry?viewPanel=100302` on your Sourcegraph instance. +This panel has no related alerts. + +To see this panel, visit `/-/debug/grafana/d/completions/completions?viewPanel=100242` on your Sourcegraph instance. -*Managed by the [Sourcegraph Data & Analytics team](https://handbook.sourcegraph.com/departments/engineering/teams/data-analytics).*Technical details
@@ -71735,21 +71442,22 @@ To see this panel, visit `/-/debug/grafana/d/telemetry/telemetry?viewPanel=10030 Query: ``` -sum(increase(src_telemetrygatewayexporter_queue_metrics_reporter_errors_total{job=~"^worker.*"}[30m])) +histogram_quantile(0.75, sum(rate(src_completions_upstream_connection_total_duration_seconds_bucket[$sampling_duration])) by (le, connection_type, provider)) ```-#### telemetry: telemetrygatewayexporter_queue_metrics_reporter_error_rate +#### completions: code_completions_p50_http_connect_total + +
Stream: HTTP connect: total (p50)
-Export backlog metrics reporting operation error rate over 30m
+Time spent acquiring an HTTP connection to the upstream, either from an existing pool OR by performing DNS resolution, TCP connection, etc. This panel has no related alerts. -To see this panel, visit `/-/debug/grafana/d/telemetry/telemetry?viewPanel=100303` on your Sourcegraph instance. +To see this panel, visit `/-/debug/grafana/d/completions/completions?viewPanel=100243` on your Sourcegraph instance. -*Managed by the [Sourcegraph Data & Analytics team](https://handbook.sourcegraph.com/departments/engineering/teams/data-analytics).*Technical details
@@ -71757,23 +71465,22 @@ To see this panel, visit `/-/debug/grafana/d/telemetry/telemetry?viewPanel=10030 Query: ``` -sum(increase(src_telemetrygatewayexporter_queue_metrics_reporter_errors_total{job=~"^worker.*"}[30m])) / (sum(increase(src_telemetrygatewayexporter_queue_metrics_reporter_total{job=~"^worker.*"}[30m])) + sum(increase(src_telemetrygatewayexporter_queue_metrics_reporter_errors_total{job=~"^worker.*"}[30m]))) * 100 +histogram_quantile(0.50, sum(rate(src_completions_upstream_connection_total_duration_seconds_bucket[$sampling_duration])) by (le, connection_type, provider)) ```-### Telemetry: Usage data exporter (legacy): Job operations +#### completions: code_completions_p99_http_connect_dns -#### telemetry: telemetry_job_total +
Stream: HTTP connect: dns (p99)
-Aggregate usage data exporter operations every 5m
+Portion of time spent on DNS when acquiring an HTTP connection to the upstream. This panel has no related alerts. -To see this panel, visit `/-/debug/grafana/d/telemetry/telemetry?viewPanel=100400` on your Sourcegraph instance. +To see this panel, visit `/-/debug/grafana/d/completions/completions?viewPanel=100250` on your Sourcegraph instance. -*Managed by the [Sourcegraph Data & Analytics team](https://handbook.sourcegraph.com/departments/engineering/teams/data-analytics).*Technical details
@@ -71781,21 +71488,22 @@ To see this panel, visit `/-/debug/grafana/d/telemetry/telemetry?viewPanel=10040 Query: ``` -sum(increase(src_telemetry_job_total{job=~"^worker.*"}[5m])) +histogram_quantile(0.99, sum(rate(src_completions_upstream_connection_dns_duration_seconds_bucket[$sampling_duration])) by (le, provider)) ```-#### telemetry: telemetry_job_99th_percentile_duration +#### completions: code_completions_p95_http_connect_dns + +
Stream: HTTP connect: dns (p95)
-Aggregate successful usage data exporter operation duration distribution over 5m
+Portion of time spent on DNS when acquiring an HTTP connection to the upstream. This panel has no related alerts. -To see this panel, visit `/-/debug/grafana/d/telemetry/telemetry?viewPanel=100401` on your Sourcegraph instance. +To see this panel, visit `/-/debug/grafana/d/completions/completions?viewPanel=100251` on your Sourcegraph instance. -*Managed by the [Sourcegraph Data & Analytics team](https://handbook.sourcegraph.com/departments/engineering/teams/data-analytics).*Technical details
@@ -71803,21 +71511,22 @@ To see this panel, visit `/-/debug/grafana/d/telemetry/telemetry?viewPanel=10040 Query: ``` -sum by (le)(rate(src_telemetry_job_duration_seconds_bucket{job=~"^worker.*"}[5m])) +histogram_quantile(0.95, sum(rate(src_completions_upstream_connection_dns_duration_seconds_bucket[$sampling_duration])) by (le, provider)) ```-#### telemetry: telemetry_job_errors_total +#### completions: code_completions_p75_http_connect_dns -
Aggregate usage data exporter operation errors every 5m
+Stream: HTTP connect: dns (p75)
+ +Portion of time spent on DNS when acquiring an HTTP connection to the upstream. This panel has no related alerts. -To see this panel, visit `/-/debug/grafana/d/telemetry/telemetry?viewPanel=100402` on your Sourcegraph instance. +To see this panel, visit `/-/debug/grafana/d/completions/completions?viewPanel=100252` on your Sourcegraph instance. -*Managed by the [Sourcegraph Data & Analytics team](https://handbook.sourcegraph.com/departments/engineering/teams/data-analytics).*Technical details
@@ -71825,21 +71534,22 @@ To see this panel, visit `/-/debug/grafana/d/telemetry/telemetry?viewPanel=10040 Query: ``` -sum(increase(src_telemetry_job_errors_total{job=~"^worker.*"}[5m])) +histogram_quantile(0.75, sum(rate(src_completions_upstream_connection_dns_duration_seconds_bucket[$sampling_duration])) by (le, provider)) ```-#### telemetry: telemetry_job_error_rate +#### completions: code_completions_p50_http_connect_dns -
Aggregate usage data exporter operation error rate over 5m
+Stream: HTTP connect: dns (p50)
+ +Portion of time spent on DNS when acquiring an HTTP connection to the upstream. This panel has no related alerts. -To see this panel, visit `/-/debug/grafana/d/telemetry/telemetry?viewPanel=100403` on your Sourcegraph instance. +To see this panel, visit `/-/debug/grafana/d/completions/completions?viewPanel=100253` on your Sourcegraph instance. -*Managed by the [Sourcegraph Data & Analytics team](https://handbook.sourcegraph.com/departments/engineering/teams/data-analytics).*Technical details
@@ -71847,21 +71557,22 @@ To see this panel, visit `/-/debug/grafana/d/telemetry/telemetry?viewPanel=10040 Query: ``` -sum(increase(src_telemetry_job_errors_total{job=~"^worker.*"}[5m])) / (sum(increase(src_telemetry_job_total{job=~"^worker.*"}[5m])) + sum(increase(src_telemetry_job_errors_total{job=~"^worker.*"}[5m]))) * 100 +histogram_quantile(0.50, sum(rate(src_completions_upstream_connection_dns_duration_seconds_bucket[$sampling_duration])) by (le, provider)) ```-#### telemetry: telemetry_job_total +#### completions: code_completions_p99_http_connect_tls -
Usage data exporter operations every 5m
+Stream: HTTP connect: tls (p99)
+ +Portion of time spent on TLS when acquiring an HTTP connection to the upstream. This panel has no related alerts. -To see this panel, visit `/-/debug/grafana/d/telemetry/telemetry?viewPanel=100410` on your Sourcegraph instance. +To see this panel, visit `/-/debug/grafana/d/completions/completions?viewPanel=100260` on your Sourcegraph instance. -*Managed by the [Sourcegraph Data & Analytics team](https://handbook.sourcegraph.com/departments/engineering/teams/data-analytics).*Technical details
@@ -71869,21 +71580,22 @@ To see this panel, visit `/-/debug/grafana/d/telemetry/telemetry?viewPanel=10041 Query: ``` -sum by (op)(increase(src_telemetry_job_total{job=~"^worker.*"}[5m])) +histogram_quantile(0.99, sum(rate(src_completions_upstream_connection_tls_duration_seconds_bucket[$sampling_duration])) by (le, provider)) ```-#### telemetry: telemetry_job_99th_percentile_duration +#### completions: code_completions_p95_http_connect_tls -
99th percentile successful usage data exporter operation duration over 5m
+Stream: HTTP connect: tls (p95)
+ +Portion of time spent on TLS when acquiring an HTTP connection to the upstream. This panel has no related alerts. -To see this panel, visit `/-/debug/grafana/d/telemetry/telemetry?viewPanel=100411` on your Sourcegraph instance. +To see this panel, visit `/-/debug/grafana/d/completions/completions?viewPanel=100261` on your Sourcegraph instance. -*Managed by the [Sourcegraph Data & Analytics team](https://handbook.sourcegraph.com/departments/engineering/teams/data-analytics).*Technical details
@@ -71891,21 +71603,22 @@ To see this panel, visit `/-/debug/grafana/d/telemetry/telemetry?viewPanel=10041 Query: ``` -histogram_quantile(0.99, sum by (le,op)(rate(src_telemetry_job_duration_seconds_bucket{job=~"^worker.*"}[5m]))) +histogram_quantile(0.95, sum(rate(src_completions_upstream_connection_tls_duration_seconds_bucket[$sampling_duration])) by (le, provider)) ```-#### telemetry: telemetry_job_errors_total +#### completions: code_completions_p75_http_connect_tls -
Usage data exporter operation errors every 5m
+Stream: HTTP connect: tls (p75)
+ +Portion of time spent on TLS when acquiring an HTTP connection to the upstream. This panel has no related alerts. -To see this panel, visit `/-/debug/grafana/d/telemetry/telemetry?viewPanel=100412` on your Sourcegraph instance. +To see this panel, visit `/-/debug/grafana/d/completions/completions?viewPanel=100262` on your Sourcegraph instance. -*Managed by the [Sourcegraph Data & Analytics team](https://handbook.sourcegraph.com/departments/engineering/teams/data-analytics).*Technical details
@@ -71913,21 +71626,22 @@ To see this panel, visit `/-/debug/grafana/d/telemetry/telemetry?viewPanel=10041 Query: ``` -sum by (op)(increase(src_telemetry_job_errors_total{job=~"^worker.*"}[5m])) +histogram_quantile(0.75, sum(rate(src_completions_upstream_connection_tls_duration_seconds_bucket[$sampling_duration])) by (le, provider)) ```-#### telemetry: telemetry_job_error_rate +#### completions: code_completions_p50_http_connect_tls -
Usage data exporter operation error rate over 5m
+Stream: HTTP connect: tls (p50)
-Refer to the [alerts reference](alerts#telemetry-telemetry-job-error-rate) for 1 alert related to this panel. +Portion of time spent on TLS when acquiring an HTTP connection to the upstream. -To see this panel, visit `/-/debug/grafana/d/telemetry/telemetry?viewPanel=100413` on your Sourcegraph instance. +This panel has no related alerts. + +To see this panel, visit `/-/debug/grafana/d/completions/completions?viewPanel=100263` on your Sourcegraph instance. -*Managed by the [Sourcegraph Data & Analytics team](https://handbook.sourcegraph.com/departments/engineering/teams/data-analytics).*Technical details
@@ -71935,23 +71649,22 @@ To see this panel, visit `/-/debug/grafana/d/telemetry/telemetry?viewPanel=10041 Query: ``` -sum by (op)(increase(src_telemetry_job_errors_total{job=~"^worker.*"}[5m])) / (sum by (op)(increase(src_telemetry_job_total{job=~"^worker.*"}[5m])) + sum by (op)(increase(src_telemetry_job_errors_total{job=~"^worker.*"}[5m]))) * 100 +histogram_quantile(0.50, sum(rate(src_completions_upstream_connection_tls_duration_seconds_bucket[$sampling_duration])) by (le, provider)) ```-### Telemetry: Usage data exporter (legacy): Queue size +#### completions: code_completions_p99_http_connect_dial -#### telemetry: telemetry_job_queue_size_queue_size +
Stream: HTTP connect: dial (p99)
-Event level usage data queue size
+Portion of time spent on golang Dial() when acquiring an HTTP connection to the upstream. This panel has no related alerts. -To see this panel, visit `/-/debug/grafana/d/telemetry/telemetry?viewPanel=100500` on your Sourcegraph instance. +To see this panel, visit `/-/debug/grafana/d/completions/completions?viewPanel=100270` on your Sourcegraph instance. -*Managed by the [Sourcegraph Code Search team](https://handbook.sourcegraph.com/departments/engineering/teams/code-search).*Technical details
@@ -71959,27 +71672,22 @@ To see this panel, visit `/-/debug/grafana/d/telemetry/telemetry?viewPanel=10050 Query: ``` -max(src_telemetry_job_queue_size_total{job=~"^worker.*"}) +histogram_quantile(0.99, sum(rate(src_completions_upstream_connection_dial_duration_seconds_bucket[$sampling_duration])) by (le, provider)) ```-#### telemetry: telemetry_job_queue_size_queue_growth_rate - -
Event level usage data queue growth rate over 30m
+#### completions: code_completions_p95_http_connect_dial -This value compares the rate of enqueues against the rate of finished jobs. +Stream: HTTP connect: dial (p95)
- - A value < than 1 indicates that process rate > enqueue rate - - A value = than 1 indicates that process rate = enqueue rate - - A value > than 1 indicates that process rate < enqueue rate +Portion of time spent on golang Dial() when acquiring an HTTP connection to the upstream. This panel has no related alerts. -To see this panel, visit `/-/debug/grafana/d/telemetry/telemetry?viewPanel=100501` on your Sourcegraph instance. +To see this panel, visit `/-/debug/grafana/d/completions/completions?viewPanel=100271` on your Sourcegraph instance. -*Managed by the [Sourcegraph Code Search team](https://handbook.sourcegraph.com/departments/engineering/teams/code-search).*Technical details
@@ -71987,23 +71695,22 @@ To see this panel, visit `/-/debug/grafana/d/telemetry/telemetry?viewPanel=10050 Query: ``` -sum(increase(src_telemetry_job_queue_size_total{job=~"^worker.*"}[30m])) / sum(increase(src_telemetry_job_queue_size_processor_total{job=~"^worker.*"}[30m])) +histogram_quantile(0.95, sum(rate(src_completions_upstream_connection_dial_duration_seconds_bucket[$sampling_duration])) by (le, provider)) ```-### Telemetry: Usage data exporter (legacy): Utilization +#### completions: code_completions_p75_http_connect_dial -#### telemetry: telemetry_job_utilized_throughput +
Stream: HTTP connect: dial (p75)
-Utilized percentage of maximum throughput
+Portion of time spent on golang Dial() when acquiring an HTTP connection to the upstream. -Refer to the [alerts reference](alerts#telemetry-telemetry-job-utilized-throughput) for 1 alert related to this panel. +This panel has no related alerts. -To see this panel, visit `/-/debug/grafana/d/telemetry/telemetry?viewPanel=100600` on your Sourcegraph instance. +To see this panel, visit `/-/debug/grafana/d/completions/completions?viewPanel=100272` on your Sourcegraph instance. -*Managed by the [Sourcegraph Data & Analytics team](https://handbook.sourcegraph.com/departments/engineering/teams/data-analytics).*Technical details
@@ -72011,40 +71718,22 @@ To see this panel, visit `/-/debug/grafana/d/telemetry/telemetry?viewPanel=10060 Query: ``` -rate(src_telemetry_job_total{op="SendEvents"}[1h]) / on() group_right() src_telemetry_job_max_throughput * 100 +histogram_quantile(0.75, sum(rate(src_completions_upstream_connection_dial_duration_seconds_bucket[$sampling_duration])) by (le, provider)) ```-## OpenTelemetry Collector - -
The OpenTelemetry collector ingests OpenTelemetry data from Sourcegraph and exports it to the configured backends.
- -To see this dashboard, visit `/-/debug/grafana/d/otel-collector/otel-collector` on your Sourcegraph instance. - -### OpenTelemetry Collector: Receivers - -#### otel-collector: otel_span_receive_rate - -Spans received per receiver per minute
- -Shows the rate of spans accepted by the configured reveiver - -A Trace is a collection of spans and a span represents a unit of work or operation. Spans are the building blocks of Traces. -The spans have only been accepted by the receiver, which means they still have to move through the configured pipeline to be exported. -For more information on tracing and configuration of a OpenTelemetry receiver see https://opentelemetry.io/docs/collector/configuration/#receivers. +#### completions: code_completions_p50_http_connect_dial -See the Exporters section see spans that have made it through the pipeline and are exported. +Stream: HTTP connect: dial (p50)
-Depending the configured processors, received spans might be dropped and not exported. For more information on configuring processors see -https://opentelemetry.io/docs/collector/configuration/#processors. +Portion of time spent on golang Dial() when acquiring an HTTP connection to the upstream. This panel has no related alerts. -To see this panel, visit `/-/debug/grafana/d/otel-collector/otel-collector?viewPanel=100000` on your Sourcegraph instance. +To see this panel, visit `/-/debug/grafana/d/completions/completions?viewPanel=100273` on your Sourcegraph instance. -*Managed by the [Sourcegraph Infrastructure Org team](https://handbook.sourcegraph.com/departments/engineering/infrastructure).*Technical details
@@ -72052,23 +71741,23 @@ To see this panel, visit `/-/debug/grafana/d/otel-collector/otel-collector?viewP Query: ``` -sum by (receiver) (rate(otelcol_receiver_accepted_spans[1m])) +histogram_quantile(0.50, sum(rate(src_completions_upstream_connection_dial_duration_seconds_bucket[$sampling_duration])) by (le, provider)) ```-#### otel-collector: otel_span_refused - -
Spans refused per receiver
+### Completions: Completion credits entitlements +#### completions: completion_credits_check_entitlement_duration_p95 +95th percentile completion credits entitlement check duration
-Refer to the [alerts reference](alerts#otel-collector-otel-span-refused) for 1 alert related to this panel. +Refer to the [alerts reference](alerts#completions-completion-credits-check-entitlement-duration-p95) for 1 alert related to this panel. -To see this panel, visit `/-/debug/grafana/d/otel-collector/otel-collector?viewPanel=100001` on your Sourcegraph instance. +To see this panel, visit `/-/debug/grafana/d/completions/completions?viewPanel=100300` on your Sourcegraph instance. -*Managed by the [Sourcegraph Infrastructure Org team](https://handbook.sourcegraph.com/departments/engineering/infrastructure).* +*Managed by the [Sourcegraph Core Services team](https://handbook.sourcegraph.com/departments/engineering/teams).*Technical details
@@ -72076,30 +71765,21 @@ To see this panel, visit `/-/debug/grafana/d/otel-collector/otel-collector?viewP Query: ``` -sum by (receiver) (rate(otelcol_receiver_refused_spans[1m])) +histogram_quantile(0.95, sum(rate(src_completion_credits_check_entitlement_duration_ms_bucket[5m])) by (le)) ```-### OpenTelemetry Collector: Exporters - -#### otel-collector: otel_span_export_rate - -
Spans exported per exporter per minute
- -Shows the rate of spans being sent by the exporter - -A Trace is a collection of spans. A Span represents a unit of work or operation. Spans are the building blocks of Traces. -The rate of spans here indicates spans that have made it through the configured pipeline and have been sent to the configured export destination. +#### completions: completion_credits_consume_credits_duration_p95 -For more information on configuring a exporter for the OpenTelemetry collector see https://opentelemetry.io/docs/collector/configuration/#exporters. +95th percentile completion credits consume duration
-This panel has no related alerts. +Refer to the [alerts reference](alerts#completions-completion-credits-consume-credits-duration-p95) for 1 alert related to this panel. -To see this panel, visit `/-/debug/grafana/d/otel-collector/otel-collector?viewPanel=100100` on your Sourcegraph instance. +To see this panel, visit `/-/debug/grafana/d/completions/completions?viewPanel=100301` on your Sourcegraph instance. -*Managed by the [Sourcegraph Infrastructure Org team](https://handbook.sourcegraph.com/departments/engineering/infrastructure).* +*Managed by the [Sourcegraph Core Services team](https://handbook.sourcegraph.com/departments/engineering/teams).*Technical details
@@ -72107,25 +71787,24 @@ To see this panel, visit `/-/debug/grafana/d/otel-collector/otel-collector?viewP Query: ``` -sum by (exporter) (rate(otelcol_exporter_sent_spans[1m])) +histogram_quantile(0.95, sum(rate(src_completion_credits_consume_duration_ms_bucket[5m])) by (le)) ```-#### otel-collector: otel_span_export_failures - -
Span export failures by exporter
+#### completions: completion_credits_check_entitlement_durations -Shows the rate of spans failed to be sent by the configured reveiver. A number higher than 0 for a long period can indicate a problem with the exporter configuration or with the service that is being exported too +Completion credits entitlement check duration over 5m
-For more information on configuring a exporter for the OpenTelemetry collector see https://opentelemetry.io/docs/collector/configuration/#exporters. +- This metric tracks pre-completion-request latency for checking if completion credits entitlement has been exceeded. + - If this value is high, this latency may be noticeable to users. -Refer to the [alerts reference](alerts#otel-collector-otel-span-export-failures) for 1 alert related to this panel. +This panel has no related alerts. -To see this panel, visit `/-/debug/grafana/d/otel-collector/otel-collector?viewPanel=100101` on your Sourcegraph instance. +To see this panel, visit `/-/debug/grafana/d/completions/completions?viewPanel=100310` on your Sourcegraph instance. -*Managed by the [Sourcegraph Infrastructure Org team](https://handbook.sourcegraph.com/departments/engineering/infrastructure).* +*Managed by the [Sourcegraph Core Services team](https://handbook.sourcegraph.com/departments/engineering/teams).*Technical details
@@ -72133,23 +71812,30 @@ To see this panel, visit `/-/debug/grafana/d/otel-collector/otel-collector?viewP Query: ``` -sum by (exporter) (rate(otelcol_exporter_send_failed_spans[1m])) +sum by (le) (rate(src_completion_credits_check_entitlement_duration_ms_bucket[5m])) ```-### OpenTelemetry Collector: Queue Length +## Periodic Goroutines -#### otel-collector: otelcol_exporter_queue_capacity +
Overview of all periodic background routines across Sourcegraph services.
-Exporter queue capacity
+To see this dashboard, visit `/-/debug/grafana/d/periodic-goroutines/periodic-goroutines` on your Sourcegraph instance. -Shows the the capacity of the retry queue (in batches). +### Periodic Goroutines: Periodic Goroutines Overview + +#### periodic-goroutines: total_running_goroutines + +Total number of running periodic goroutines across all services
+ +The total number of running periodic goroutines across all services. +This provides a high-level overview of system activity. This panel has no related alerts. -To see this panel, visit `/-/debug/grafana/d/otel-collector/otel-collector?viewPanel=100200` on your Sourcegraph instance. +To see this panel, visit `/-/debug/grafana/d/periodic-goroutines/periodic-goroutines?viewPanel=100000` on your Sourcegraph instance. *Managed by the [Sourcegraph Infrastructure Org team](https://handbook.sourcegraph.com/departments/engineering/infrastructure).* @@ -72159,21 +71845,22 @@ To see this panel, visit `/-/debug/grafana/d/otel-collector/otel-collector?viewP Query: ``` -sum by (exporter) (rate(otelcol_exporter_queue_capacity{job=~"^.*"}[1m])) +sum(src_periodic_goroutine_running) ```-#### otel-collector: otelcol_exporter_queue_size +#### periodic-goroutines: goroutines_by_service -
Exporter queue size
+Number of running periodic goroutines by service
-Shows the current size of retry queue +The number of running periodic goroutines broken down by service. +This helps identify which services are running the most background routines. This panel has no related alerts. -To see this panel, visit `/-/debug/grafana/d/otel-collector/otel-collector?viewPanel=100201` on your Sourcegraph instance. +To see this panel, visit `/-/debug/grafana/d/periodic-goroutines/periodic-goroutines?viewPanel=100001` on your Sourcegraph instance. *Managed by the [Sourcegraph Infrastructure Org team](https://handbook.sourcegraph.com/departments/engineering/infrastructure).* @@ -72183,21 +71870,22 @@ To see this panel, visit `/-/debug/grafana/d/otel-collector/otel-collector?viewP Query: ``` -sum by (exporter) (rate(otelcol_exporter_queue_size{job=~"^.*"}[1m])) +sum by (job) (src_periodic_goroutine_running) ```-#### otel-collector: otelcol_exporter_enqueue_failed_spans +#### periodic-goroutines: top_error_producers -
Exporter enqueue failed spans
+Top 10 periodic goroutines by error rate
-Shows the rate of spans failed to be enqueued by the configured exporter. A number higher than 0 for a long period can indicate a problem with the exporter configuration +The top 10 periodic goroutines with the highest error rates. +These routines may require immediate attention or investigation. -Refer to the [alerts reference](alerts#otel-collector-otelcol-exporter-enqueue-failed-spans) for 1 alert related to this panel. +This panel has no related alerts. -To see this panel, visit `/-/debug/grafana/d/otel-collector/otel-collector?viewPanel=100202` on your Sourcegraph instance. +To see this panel, visit `/-/debug/grafana/d/periodic-goroutines/periodic-goroutines?viewPanel=100010` on your Sourcegraph instance. *Managed by the [Sourcegraph Infrastructure Org team](https://handbook.sourcegraph.com/departments/engineering/infrastructure).* @@ -72207,23 +71895,22 @@ To see this panel, visit `/-/debug/grafana/d/otel-collector/otel-collector?viewP Query: ``` -sum by (exporter) (rate(otelcol_exporter_enqueue_failed_spans{job=~"^.*"}[1m])) +topk(10, sum by (name, job) (rate(src_periodic_goroutine_errors_total[5m]))) ```-### OpenTelemetry Collector: Processors - -#### otel-collector: otelcol_processor_dropped_spans +#### periodic-goroutines: top_time_consumers -
Spans dropped per processor per minute
+Top 10 slowest periodic goroutines
-Shows the rate of spans dropped by the configured processor +The top 10 periodic goroutines with the longest average execution time. +These routines may be candidates for optimization or load distribution. -Refer to the [alerts reference](alerts#otel-collector-otelcol-processor-dropped-spans) for 1 alert related to this panel. +This panel has no related alerts. -To see this panel, visit `/-/debug/grafana/d/otel-collector/otel-collector?viewPanel=100300` on your Sourcegraph instance. +To see this panel, visit `/-/debug/grafana/d/periodic-goroutines/periodic-goroutines?viewPanel=100011` on your Sourcegraph instance. *Managed by the [Sourcegraph Infrastructure Org team](https://handbook.sourcegraph.com/departments/engineering/infrastructure).* @@ -72233,23 +71920,23 @@ To see this panel, visit `/-/debug/grafana/d/otel-collector/otel-collector?viewP Query: ``` -sum by (processor) (rate(otelcol_processor_dropped_spans[1m])) +topk(10, max by (name, job) (rate(src_periodic_goroutine_duration_seconds_sum[5m]) / rate(src_periodic_goroutine_duration_seconds_count[5m]))) ```-### OpenTelemetry Collector: Collector resource usage +### Periodic Goroutines: Drill down -#### otel-collector: otel_cpu_usage +#### periodic-goroutines: filtered_success_rate -
Cpu usage of the collector
+Success rate for selected goroutines
-Shows CPU usage as reported by the OpenTelemetry collector. +The rate of successful executions for the filtered periodic goroutines. This panel has no related alerts. -To see this panel, visit `/-/debug/grafana/d/otel-collector/otel-collector?viewPanel=100400` on your Sourcegraph instance. +To see this panel, visit `/-/debug/grafana/d/periodic-goroutines/periodic-goroutines?viewPanel=100100` on your Sourcegraph instance. *Managed by the [Sourcegraph Infrastructure Org team](https://handbook.sourcegraph.com/departments/engineering/infrastructure).* @@ -72259,21 +71946,21 @@ To see this panel, visit `/-/debug/grafana/d/otel-collector/otel-collector?viewP Query: ``` -sum by (job) (rate(otelcol_process_cpu_seconds{job=~"^.*"}[1m])) +sum by (name, job) (rate(src_periodic_goroutine_total{name=~'${routineName:regex}', job=~'${serviceName:regex}'}[5m])) ```-#### otel-collector: otel_memory_resident_set_size +#### periodic-goroutines: filtered_error_rate -
Memory allocated to the otel collector
+Error rate for selected goroutines
-Shows the allocated memory Resident Set Size (RSS) as reported by the OpenTelemetry collector. +The rate of errors for the filtered periodic goroutines. This panel has no related alerts. -To see this panel, visit `/-/debug/grafana/d/otel-collector/otel-collector?viewPanel=100401` on your Sourcegraph instance. +To see this panel, visit `/-/debug/grafana/d/periodic-goroutines/periodic-goroutines?viewPanel=100101` on your Sourcegraph instance. *Managed by the [Sourcegraph Infrastructure Org team](https://handbook.sourcegraph.com/departments/engineering/infrastructure).* @@ -72283,27 +71970,21 @@ To see this panel, visit `/-/debug/grafana/d/otel-collector/otel-collector?viewP Query: ``` -sum by (job) (rate(otelcol_process_memory_rss{job=~"^.*"}[1m])) +sum by (name, job) (rate(src_periodic_goroutine_errors_total{name=~'${routineName:regex}', job=~'${serviceName:regex}'}[5m])) ```-#### otel-collector: otel_memory_usage - -
Memory used by the collector
- -Shows how much memory is being used by the otel collector. +#### periodic-goroutines: filtered_duration -* High memory usage might indicate thad the configured pipeline is keeping a lot of spans in memory for processing -* Spans failing to be sent and the exporter is configured to retry -* A high batch count by using a batch processor +95th percentile execution time for selected goroutines
-For more information on configuring processors for the OpenTelemetry collector see https://opentelemetry.io/docs/collector/configuration/#processors. +The 95th percentile execution time for the filtered periodic goroutines. This panel has no related alerts. -To see this panel, visit `/-/debug/grafana/d/otel-collector/otel-collector?viewPanel=100402` on your Sourcegraph instance. +To see this panel, visit `/-/debug/grafana/d/periodic-goroutines/periodic-goroutines?viewPanel=100110` on your Sourcegraph instance. *Managed by the [Sourcegraph Infrastructure Org team](https://handbook.sourcegraph.com/departments/engineering/infrastructure).* @@ -72313,31 +71994,21 @@ To see this panel, visit `/-/debug/grafana/d/otel-collector/otel-collector?viewP Query: ``` -sum by (job) (rate(otelcol_process_runtime_total_alloc_bytes{job=~"^.*"}[1m])) +histogram_quantile(0.95, sum by (name, job, le) (rate(src_periodic_goroutine_duration_seconds_bucket{name=~'${routineName:regex}', job=~'${serviceName:regex}'}[5m]))) ```-### OpenTelemetry Collector: Container monitoring (not available on server) - -#### otel-collector: container_missing - -
Container missing
+#### periodic-goroutines: filtered_loop_time -This value is the number of times a container has not been seen for more than one minute. If you observe this -value change independent of deployment events (such as an upgrade), it could indicate pods are being OOM killed or terminated for some other reasons. +95th percentile loop time for selected goroutines
-- **Kubernetes:** - - Determine if the pod was OOM killed using `kubectl describe pod otel-collector` (look for `OOMKilled: true`) and, if so, consider increasing the memory limit in the relevant `Deployment.yaml`. - - Check the logs before the container restarted to see if there are `panic:` messages or similar using `kubectl logs -p otel-collector`. -- **Docker Compose:** - - Determine if the pod was OOM killed using `docker inspect -f '\{\{json .State\}\}' otel-collector` (look for `"OOMKilled":true`) and, if so, consider increasing the memory limit of the otel-collector container in `docker-compose.yml`. - - Check the logs before the container restarted to see if there are `panic:` messages or similar using `docker logs otel-collector` (note this will include logs from the previous and currently running container). +The 95th percentile loop time for the filtered periodic goroutines. This panel has no related alerts. -To see this panel, visit `/-/debug/grafana/d/otel-collector/otel-collector?viewPanel=100500` on your Sourcegraph instance. +To see this panel, visit `/-/debug/grafana/d/periodic-goroutines/periodic-goroutines?viewPanel=100111` on your Sourcegraph instance. *Managed by the [Sourcegraph Infrastructure Org team](https://handbook.sourcegraph.com/departments/engineering/infrastructure).* @@ -72347,19 +72018,21 @@ To see this panel, visit `/-/debug/grafana/d/otel-collector/otel-collector?viewP Query: ``` -count by(name) ((time() - container_last_seen{name=~"^otel-collector.*"}) > 60) +histogram_quantile(0.95, sum by (name, job, le) (rate(src_periodic_goroutine_loop_duration_seconds_bucket{name=~'${routineName:regex}', job=~'${serviceName:regex}'}[5m]))) ```-#### otel-collector: container_cpu_usage +#### periodic-goroutines: filtered_tenant_count -
Container cpu usage total (1m average) across all cores by instance
+Number of tenants processed by selected goroutines
-Refer to the [alerts reference](alerts#otel-collector-container-cpu-usage) for 1 alert related to this panel. +Number of tenants processed by each selected periodic goroutine. -To see this panel, visit `/-/debug/grafana/d/otel-collector/otel-collector?viewPanel=100501` on your Sourcegraph instance. +This panel has no related alerts. + +To see this panel, visit `/-/debug/grafana/d/periodic-goroutines/periodic-goroutines?viewPanel=100120` on your Sourcegraph instance. *Managed by the [Sourcegraph Infrastructure Org team](https://handbook.sourcegraph.com/departments/engineering/infrastructure).* @@ -72369,19 +72042,21 @@ To see this panel, visit `/-/debug/grafana/d/otel-collector/otel-collector?viewP Query: ``` -cadvisor_container_cpu_usage_percentage_total{name=~"^otel-collector.*"} +max by (name, job) (src_periodic_goroutine_tenant_count{name=~'${routineName:regex}', job=~'${serviceName:regex}'}) ```-#### otel-collector: container_memory_usage +#### periodic-goroutines: filtered_tenant_duration -
Container memory usage by instance
+95th percentile tenant processing time for selected goroutines
-Refer to the [alerts reference](alerts#otel-collector-container-memory-usage) for 1 alert related to this panel. +The 95th percentile processing time for individual tenants. -To see this panel, visit `/-/debug/grafana/d/otel-collector/otel-collector?viewPanel=100502` on your Sourcegraph instance. +This panel has no related alerts. + +To see this panel, visit `/-/debug/grafana/d/periodic-goroutines/periodic-goroutines?viewPanel=100121` on your Sourcegraph instance. *Managed by the [Sourcegraph Infrastructure Org team](https://handbook.sourcegraph.com/departments/engineering/infrastructure).* @@ -72391,22 +72066,21 @@ To see this panel, visit `/-/debug/grafana/d/otel-collector/otel-collector?viewP Query: ``` -cadvisor_container_memory_usage_percentage_total{name=~"^otel-collector.*"} +histogram_quantile(0.95, sum by (name, job, le) (rate(src_periodic_goroutine_tenant_duration_seconds_bucket{name=~'${routineName:regex}', job=~'${serviceName:regex}'}[5m]))) ```-#### otel-collector: fs_io_operations +#### periodic-goroutines: filtered_tenant_success_rate -
Filesystem reads and writes rate by instance over 1h
+Tenant success rate for selected goroutines
-This value indicates the number of filesystem read and write operations by containers of this service. -When extremely high, this can indicate a resource usage problem, or can cause problems with the service itself, especially if high values or spikes correlate with \{\{CONTAINER_NAME\}\} issues. +The rate of successful tenant processing operations. This panel has no related alerts. -To see this panel, visit `/-/debug/grafana/d/otel-collector/otel-collector?viewPanel=100503` on your Sourcegraph instance. +To see this panel, visit `/-/debug/grafana/d/periodic-goroutines/periodic-goroutines?viewPanel=100130` on your Sourcegraph instance. *Managed by the [Sourcegraph Infrastructure Org team](https://handbook.sourcegraph.com/departments/engineering/infrastructure).* @@ -72416,21 +72090,21 @@ To see this panel, visit `/-/debug/grafana/d/otel-collector/otel-collector?viewP Query: ``` -sum by(name) (rate(container_fs_reads_total{name=~"^otel-collector.*"}[1h]) + rate(container_fs_writes_total{name=~"^otel-collector.*"}[1h])) +sum by (name, job) (rate(src_periodic_goroutine_tenant_success_total{name=~'${routineName:regex}', job=~'${serviceName:regex}'}[5m])) ```-### OpenTelemetry Collector: Kubernetes monitoring (only available on Kubernetes) +#### periodic-goroutines: filtered_tenant_error_rate -#### otel-collector: pods_available_percentage +
Tenant error rate for selected goroutines
-Percentage pods available
+The rate of tenant processing operations resulting in errors. -Refer to the [alerts reference](alerts#otel-collector-pods-available-percentage) for 1 alert related to this panel. +This panel has no related alerts. -To see this panel, visit `/-/debug/grafana/d/otel-collector/otel-collector?viewPanel=100600` on your Sourcegraph instance. +To see this panel, visit `/-/debug/grafana/d/periodic-goroutines/periodic-goroutines?viewPanel=100131` on your Sourcegraph instance. *Managed by the [Sourcegraph Infrastructure Org team](https://handbook.sourcegraph.com/departments/engineering/infrastructure).* @@ -72440,31 +72114,31 @@ To see this panel, visit `/-/debug/grafana/d/otel-collector/otel-collector?viewP Query: ``` -sum by(app) (up{app=~".*otel-collector"}) / count by (app) (up{app=~".*otel-collector"}) * 100 +sum by (name, job) (rate(src_periodic_goroutine_tenant_errors_total{name=~'${routineName:regex}', job=~'${serviceName:regex}'}[5m])) ```-## Embeddings +## Background Jobs Dashboard -
Handles embeddings searches.
+Overview of all background jobs in the system.
-To see this dashboard, visit `/-/debug/grafana/d/embeddings/embeddings` on your Sourcegraph instance. +To see this dashboard, visit `/-/debug/grafana/d/background-jobs/background-jobs` on your Sourcegraph instance. -### Embeddings: Site configuration client update latency +### Background Jobs Dashboard: DBWorker Store Operations -#### embeddings: embeddings_site_configuration_duration_since_last_successful_update_by_instance +#### background-jobs: operation_rates_by_method -Duration since last successful site configuration update (by instance)
+Rate of operations by method (5m)
-The duration since the configuration client used by the "embeddings" service last successfully updated its site configuration. Long durations could indicate issues updating the site configuration. +shows the rate of different dbworker store operations This panel has no related alerts. -To see this panel, visit `/-/debug/grafana/d/embeddings/embeddings?viewPanel=100000` on your Sourcegraph instance. +To see this panel, visit `/-/debug/grafana/d/background-jobs/background-jobs?viewPanel=100000` on your Sourcegraph instance. -*Managed by the [Sourcegraph Infrastructure Org team](https://handbook.sourcegraph.com/departments/engineering/infrastructure).* +*Managed by the [Sourcegraph Source team](https://handbook.sourcegraph.com/departments/engineering/teams/source).*Technical details
@@ -72472,21 +72146,23 @@ To see this panel, visit `/-/debug/grafana/d/embeddings/embeddings?viewPanel=100 Query: ``` -src_conf_client_time_since_last_successful_update_seconds{job=~`.*embeddings`,instance=~`${instance:regex}`} +sum by (op) (rate(src_workerutil_dbworker_store_total{domain=~"$dbworker_domain"}[5m])) ```-#### embeddings: embeddings_site_configuration_duration_since_last_successful_update_by_instance +#### background-jobs: error_rates + +
Rate of errors by method (5m)
-Maximum duration since last successful site configuration update (all "embeddings" instances)
+Rate of errors by operation type. Check specific operations with high error rates. -Refer to the [alerts reference](alerts#embeddings-embeddings-site-configuration-duration-since-last-successful-update-by-instance) for 1 alert related to this panel. +This panel has no related alerts. -To see this panel, visit `/-/debug/grafana/d/embeddings/embeddings?viewPanel=100001` on your Sourcegraph instance. +To see this panel, visit `/-/debug/grafana/d/background-jobs/background-jobs?viewPanel=100001` on your Sourcegraph instance. -*Managed by the [Sourcegraph Infrastructure Org team](https://handbook.sourcegraph.com/departments/engineering/infrastructure).* +*Managed by the [Sourcegraph Source team](https://handbook.sourcegraph.com/departments/engineering/teams/source).*Technical details
@@ -72494,23 +72170,25 @@ To see this panel, visit `/-/debug/grafana/d/embeddings/embeddings?viewPanel=100 Query: ``` -max(max_over_time(src_conf_client_time_since_last_successful_update_seconds{job=~`.*embeddings`,instance=~`${instance:regex}`}[1m])) +sum by (op) (rate(src_workerutil_dbworker_store_errors_total{domain=~"$dbworker_domain"}[5m])) ```-### Embeddings: Database connections +#### background-jobs: p90_duration_by_method -#### embeddings: max_open_conns +
90th percentile duration by method
-Maximum open
+90th percentile latency for dbworker store operations. + +Investigate database query performance and indexing for the affected operations. Look for slow queries in database logs. This panel has no related alerts. -To see this panel, visit `/-/debug/grafana/d/embeddings/embeddings?viewPanel=100100` on your Sourcegraph instance. +To see this panel, visit `/-/debug/grafana/d/background-jobs/background-jobs?viewPanel=100010` on your Sourcegraph instance. -*Managed by the [Sourcegraph Cody team](https://handbook.sourcegraph.com/departments/engineering/teams/cody).* +*Managed by the [Sourcegraph Source team](https://handbook.sourcegraph.com/departments/engineering/teams/source).*Technical details
@@ -72518,21 +72196,23 @@ To see this panel, visit `/-/debug/grafana/d/embeddings/embeddings?viewPanel=100 Query: ``` -sum by (app_name, db_name) (src_pgsql_conns_max_open{app_name="embeddings"}) +histogram_quantile(0.9, sum by(le, op) (rate(src_workerutil_dbworker_store_duration_seconds_bucket{domain=~"$dbworker_domain"}[5m]))) ```-#### embeddings: open_conns +#### background-jobs: p50_duration_by_method -
Established
+Median duration by method
+ +median latency for dbworker store operations This panel has no related alerts. -To see this panel, visit `/-/debug/grafana/d/embeddings/embeddings?viewPanel=100101` on your Sourcegraph instance. +To see this panel, visit `/-/debug/grafana/d/background-jobs/background-jobs?viewPanel=100011` on your Sourcegraph instance. -*Managed by the [Sourcegraph Cody team](https://handbook.sourcegraph.com/departments/engineering/teams/cody).* +*Managed by the [Sourcegraph Source team](https://handbook.sourcegraph.com/departments/engineering/teams/source).*Technical details
@@ -72540,21 +72220,25 @@ To see this panel, visit `/-/debug/grafana/d/embeddings/embeddings?viewPanel=100 Query: ``` -sum by (app_name, db_name) (src_pgsql_conns_open{app_name="embeddings"}) +histogram_quantile(0.5, sum by(le, op) (rate(src_workerutil_dbworker_store_duration_seconds_bucket{domain=~"$dbworker_domain"}[5m]))) ```-#### embeddings: in_use +#### background-jobs: p90_duration_by_domain -
Used
+90th percentile duration by domain
+ +90th percentile latency for dbworker store operations. + +Investigate database performance for the specific domain. May indicate issues with specific database tables or query patterns. This panel has no related alerts. -To see this panel, visit `/-/debug/grafana/d/embeddings/embeddings?viewPanel=100110` on your Sourcegraph instance. +To see this panel, visit `/-/debug/grafana/d/background-jobs/background-jobs?viewPanel=100012` on your Sourcegraph instance. -*Managed by the [Sourcegraph Cody team](https://handbook.sourcegraph.com/departments/engineering/teams/cody).* +*Managed by the [Sourcegraph Source team](https://handbook.sourcegraph.com/departments/engineering/teams/source).*Technical details
@@ -72562,21 +72246,23 @@ To see this panel, visit `/-/debug/grafana/d/embeddings/embeddings?viewPanel=100 Query: ``` -sum by (app_name, db_name) (src_pgsql_conns_in_use{app_name="embeddings"}) +histogram_quantile(0.9, sum by(le, domain) (rate(src_workerutil_dbworker_store_duration_seconds_bucket{domain=~"$dbworker_domain"}[5m]))) ```-#### embeddings: idle +#### background-jobs: p50_duration_by_method -
Idle
+Median operation duration by method
+ +median latency for dbworker store operations by method This panel has no related alerts. -To see this panel, visit `/-/debug/grafana/d/embeddings/embeddings?viewPanel=100111` on your Sourcegraph instance. +To see this panel, visit `/-/debug/grafana/d/background-jobs/background-jobs?viewPanel=100013` on your Sourcegraph instance. -*Managed by the [Sourcegraph Cody team](https://handbook.sourcegraph.com/departments/engineering/teams/cody).* +*Managed by the [Sourcegraph Source team](https://handbook.sourcegraph.com/departments/engineering/teams/source).*Technical details
@@ -72584,21 +72270,23 @@ To see this panel, visit `/-/debug/grafana/d/embeddings/embeddings?viewPanel=100 Query: ``` -sum by (app_name, db_name) (src_pgsql_conns_idle{app_name="embeddings"}) +histogram_quantile(0.5, sum by(le, op) (rate(src_workerutil_dbworker_store_duration_seconds_bucket{domain=~"$dbworker_domain"}[5m]))) ```-#### embeddings: mean_blocked_seconds_per_conn_request +#### background-jobs: dequeue_performance -
Mean blocked seconds per conn request
+Dequeue operation metrics
+ +rate of dequeue operations by domain - critical for worker performance -Refer to the [alerts reference](alerts#embeddings-mean-blocked-seconds-per-conn-request) for 2 alerts related to this panel. +This panel has no related alerts. -To see this panel, visit `/-/debug/grafana/d/embeddings/embeddings?viewPanel=100120` on your Sourcegraph instance. +To see this panel, visit `/-/debug/grafana/d/background-jobs/background-jobs?viewPanel=100020` on your Sourcegraph instance. -*Managed by the [Sourcegraph Cody team](https://handbook.sourcegraph.com/departments/engineering/teams/cody).* +*Managed by the [Sourcegraph Source team](https://handbook.sourcegraph.com/departments/engineering/teams/source).*Technical details
@@ -72606,21 +72294,21 @@ To see this panel, visit `/-/debug/grafana/d/embeddings/embeddings?viewPanel=100 Query: ``` -sum by (app_name, db_name) (increase(src_pgsql_conns_blocked_seconds{app_name="embeddings"}[5m])) / sum by (app_name, db_name) (increase(src_pgsql_conns_waited_for{app_name="embeddings"}[5m])) +sum by (domain) (rate(src_workerutil_dbworker_store_total{op="Dequeue", domain=~"$dbworker_domain"}[5m])) ```-#### embeddings: closed_max_idle +#### background-jobs: error_percentage_by_method -
Closed by SetMaxIdleConns
+Percentage of operations resulting in error by method
-This panel has no related alerts. +Refer to the [alerts reference](alerts#background-jobs-error-percentage-by-method) for 2 alerts related to this panel. -To see this panel, visit `/-/debug/grafana/d/embeddings/embeddings?viewPanel=100130` on your Sourcegraph instance. +To see this panel, visit `/-/debug/grafana/d/background-jobs/background-jobs?viewPanel=100021` on your Sourcegraph instance. -*Managed by the [Sourcegraph Cody team](https://handbook.sourcegraph.com/departments/engineering/teams/cody).* +*Managed by the [Sourcegraph Source team](https://handbook.sourcegraph.com/departments/engineering/teams/source).*Technical details
@@ -72628,21 +72316,21 @@ To see this panel, visit `/-/debug/grafana/d/embeddings/embeddings?viewPanel=100 Query: ``` -sum by (app_name, db_name) (increase(src_pgsql_conns_closed_max_idle{app_name="embeddings"}[5m])) +(sum by (op) (rate(src_workerutil_dbworker_store_errors_total{domain=~"$dbworker_domain"}[5m])) / sum by (op) (rate(src_workerutil_dbworker_store_total{domain=~"$dbworker_domain"}[5m]))) * 100 ```-#### embeddings: closed_max_lifetime +#### background-jobs: error_percentage_by_domain -
Closed by SetConnMaxLifetime
+Percentage of operations resulting in error by domain
-This panel has no related alerts. +Refer to the [alerts reference](alerts#background-jobs-error-percentage-by-domain) for 2 alerts related to this panel. -To see this panel, visit `/-/debug/grafana/d/embeddings/embeddings?viewPanel=100131` on your Sourcegraph instance. +To see this panel, visit `/-/debug/grafana/d/background-jobs/background-jobs?viewPanel=100022` on your Sourcegraph instance. -*Managed by the [Sourcegraph Cody team](https://handbook.sourcegraph.com/departments/engineering/teams/cody).* +*Managed by the [Sourcegraph Source team](https://handbook.sourcegraph.com/departments/engineering/teams/source).*Technical details
@@ -72650,21 +72338,23 @@ To see this panel, visit `/-/debug/grafana/d/embeddings/embeddings?viewPanel=100 Query: ``` -sum by (app_name, db_name) (increase(src_pgsql_conns_closed_max_lifetime{app_name="embeddings"}[5m])) +(sum by (domain) (rate(src_workerutil_dbworker_store_errors_total{domain=~"$dbworker_domain"}[5m])) / sum by (domain) (rate(src_workerutil_dbworker_store_total{domain=~"$dbworker_domain"}[5m]))) * 100 ```-#### embeddings: closed_max_idle_time +#### background-jobs: operation_latency_heatmap -
Closed by SetConnMaxIdleTime
+Distribution of operation durations
+ +Distribution of operation durations - shows the spread of latencies across all operations This panel has no related alerts. -To see this panel, visit `/-/debug/grafana/d/embeddings/embeddings?viewPanel=100132` on your Sourcegraph instance. +To see this panel, visit `/-/debug/grafana/d/background-jobs/background-jobs?viewPanel=100023` on your Sourcegraph instance. -*Managed by the [Sourcegraph Cody team](https://handbook.sourcegraph.com/departments/engineering/teams/cody).* +*Managed by the [Sourcegraph Source team](https://handbook.sourcegraph.com/departments/engineering/teams/source).*Technical details
@@ -72672,33 +72362,23 @@ To see this panel, visit `/-/debug/grafana/d/embeddings/embeddings?viewPanel=100 Query: ``` -sum by (app_name, db_name) (increase(src_pgsql_conns_closed_max_idle_time{app_name="embeddings"}[5m])) +sum by (le) (rate(src_workerutil_dbworker_store_duration_seconds_bucket{domain=~"$dbworker_domain"}[5m])) ```-### Embeddings: Container monitoring (not available on server) - -#### embeddings: container_missing - -
Container missing
+### Background Jobs Dashboard: DBWorker Resetter -This value is the number of times a container has not been seen for more than one minute. If you observe this -value change independent of deployment events (such as an upgrade), it could indicate pods are being OOM killed or terminated for some other reasons. +#### background-jobs: resetter_duration -- **Kubernetes:** - - Determine if the pod was OOM killed using `kubectl describe pod embeddings` (look for `OOMKilled: true`) and, if so, consider increasing the memory limit in the relevant `Deployment.yaml`. - - Check the logs before the container restarted to see if there are `panic:` messages or similar using `kubectl logs -p embeddings`. -- **Docker Compose:** - - Determine if the pod was OOM killed using `docker inspect -f '\{\{json .State\}\}' embeddings` (look for `"OOMKilled":true`) and, if so, consider increasing the memory limit of the embeddings container in `docker-compose.yml`. - - Check the logs before the container restarted to see if there are `panic:` messages or similar using `docker logs embeddings` (note this will include logs from the previous and currently running container). +Time spent running the resetter
-This panel has no related alerts. +Refer to the [alerts reference](alerts#background-jobs-resetter-duration) for 1 alert related to this panel. -To see this panel, visit `/-/debug/grafana/d/embeddings/embeddings?viewPanel=100200` on your Sourcegraph instance. +To see this panel, visit `/-/debug/grafana/d/background-jobs/background-jobs?viewPanel=100100` on your Sourcegraph instance. -*Managed by the [Sourcegraph Cody team](https://handbook.sourcegraph.com/departments/engineering/teams/cody).* +*Managed by the [Sourcegraph Source team](https://handbook.sourcegraph.com/departments/engineering/teams/source).*Technical details
@@ -72706,21 +72386,23 @@ To see this panel, visit `/-/debug/grafana/d/embeddings/embeddings?viewPanel=100 Query: ``` -count by(name) ((time() - container_last_seen{name=~"^embeddings.*"}) > 60) +histogram_quantile(0.95, sum by(le, domain) (rate(src_dbworker_resetter_duration_seconds_bucket{domain=~"$resetter_domain"}[5m]))) ```-#### embeddings: container_cpu_usage +#### background-jobs: resetter_runs -
Container cpu usage total (1m average) across all cores by instance
+Number of times the resetter ran
+ +the number of times the resetter ran in the last 5 minutes -Refer to the [alerts reference](alerts#embeddings-container-cpu-usage) for 1 alert related to this panel. +This panel has no related alerts. -To see this panel, visit `/-/debug/grafana/d/embeddings/embeddings?viewPanel=100201` on your Sourcegraph instance. +To see this panel, visit `/-/debug/grafana/d/background-jobs/background-jobs?viewPanel=100101` on your Sourcegraph instance. -*Managed by the [Sourcegraph Cody team](https://handbook.sourcegraph.com/departments/engineering/teams/cody).* +*Managed by the [Sourcegraph Source team](https://handbook.sourcegraph.com/departments/engineering/teams/source).*Technical details
@@ -72728,21 +72410,21 @@ To see this panel, visit `/-/debug/grafana/d/embeddings/embeddings?viewPanel=100 Query: ``` -cadvisor_container_cpu_usage_percentage_total{name=~"^embeddings.*"} +sum by (domain) (increase(src_dbworker_resetter_total{domain=~"$resetter_domain"}[5m])) ```-#### embeddings: container_memory_usage +#### background-jobs: resetter_failures -
Container memory usage by instance
+Number of times the resetter failed to run
-Refer to the [alerts reference](alerts#embeddings-container-memory-usage) for 1 alert related to this panel. +Refer to the [alerts reference](alerts#background-jobs-resetter-failures) for 1 alert related to this panel. -To see this panel, visit `/-/debug/grafana/d/embeddings/embeddings?viewPanel=100202` on your Sourcegraph instance. +To see this panel, visit `/-/debug/grafana/d/background-jobs/background-jobs?viewPanel=100102` on your Sourcegraph instance. -*Managed by the [Sourcegraph Cody team](https://handbook.sourcegraph.com/departments/engineering/teams/cody).* +*Managed by the [Sourcegraph Source team](https://handbook.sourcegraph.com/departments/engineering/teams/source).*Technical details
@@ -72750,24 +72432,23 @@ To see this panel, visit `/-/debug/grafana/d/embeddings/embeddings?viewPanel=100 Query: ``` -cadvisor_container_memory_usage_percentage_total{name=~"^embeddings.*"} +sum by (domain) (increase(src_dbworker_resetter_errors_total{domain=~"$resetter_domain"}[5m])) ```-#### embeddings: fs_io_operations +#### background-jobs: reset_records -
Filesystem reads and writes rate by instance over 1h
+Number of stalled records reset back to 'queued' state
-This value indicates the number of filesystem read and write operations by containers of this service. -When extremely high, this can indicate a resource usage problem, or can cause problems with the service itself, especially if high values or spikes correlate with \{\{CONTAINER_NAME\}\} issues. +the number of stalled records that were reset back to the queued state in the last 5 minutes This panel has no related alerts. -To see this panel, visit `/-/debug/grafana/d/embeddings/embeddings?viewPanel=100203` on your Sourcegraph instance. +To see this panel, visit `/-/debug/grafana/d/background-jobs/background-jobs?viewPanel=100110` on your Sourcegraph instance. -*Managed by the [Sourcegraph Cody team](https://handbook.sourcegraph.com/departments/engineering/teams/cody).* +*Managed by the [Sourcegraph Source team](https://handbook.sourcegraph.com/departments/engineering/teams/source).*Technical details
@@ -72775,23 +72456,21 @@ To see this panel, visit `/-/debug/grafana/d/embeddings/embeddings?viewPanel=100 Query: ``` -sum by(name) (rate(container_fs_reads_total{name=~"^embeddings.*"}[1h]) + rate(container_fs_writes_total{name=~"^embeddings.*"}[1h])) +sum by (domain) (increase(src_dbworker_resetter_record_resets_total{domain=~"$resetter_domain"}[5m])) ```-### Embeddings: Provisioning indicators (not available on server) +#### background-jobs: failed_records -#### embeddings: provisioning_container_cpu_usage_long_term +
Number of stalled records marked as 'failed'
-Container cpu usage total (90th percentile over 1d) across all cores by instance
- -Refer to the [alerts reference](alerts#embeddings-provisioning-container-cpu-usage-long-term) for 1 alert related to this panel. +Refer to the [alerts reference](alerts#background-jobs-failed-records) for 1 alert related to this panel. -To see this panel, visit `/-/debug/grafana/d/embeddings/embeddings?viewPanel=100300` on your Sourcegraph instance. +To see this panel, visit `/-/debug/grafana/d/background-jobs/background-jobs?viewPanel=100111` on your Sourcegraph instance. -*Managed by the [Sourcegraph Cody team](https://handbook.sourcegraph.com/departments/engineering/teams/cody).* +*Managed by the [Sourcegraph Source team](https://handbook.sourcegraph.com/departments/engineering/teams/source).*Technical details
@@ -72799,21 +72478,23 @@ To see this panel, visit `/-/debug/grafana/d/embeddings/embeddings?viewPanel=100 Query: ``` -quantile_over_time(0.9, cadvisor_container_cpu_usage_percentage_total{name=~"^embeddings.*"}[1d]) +sum by (domain) (increase(src_dbworker_resetter_record_reset_failures_total{domain=~"$resetter_domain"}[5m])) ```-#### embeddings: provisioning_container_memory_usage_long_term +#### background-jobs: stall_duration -
Container memory usage (1d maximum) by instance
+Duration jobs were stalled before being reset
-Refer to the [alerts reference](alerts#embeddings-provisioning-container-memory-usage-long-term) for 1 alert related to this panel. +median time a job was stalled before being reset -To see this panel, visit `/-/debug/grafana/d/embeddings/embeddings?viewPanel=100301` on your Sourcegraph instance. +This panel has no related alerts. + +To see this panel, visit `/-/debug/grafana/d/background-jobs/background-jobs?viewPanel=100120` on your Sourcegraph instance. -*Managed by the [Sourcegraph Cody team](https://handbook.sourcegraph.com/departments/engineering/teams/cody).* +*Managed by the [Sourcegraph Source team](https://handbook.sourcegraph.com/departments/engineering/teams/source).*Technical details
@@ -72821,21 +72502,21 @@ To see this panel, visit `/-/debug/grafana/d/embeddings/embeddings?viewPanel=100 Query: ``` -max_over_time(cadvisor_container_memory_usage_percentage_total{name=~"^embeddings.*"}[1d]) +sum by (le) (rate(src_dbworker_resetter_stall_duration_seconds_bucket{domain=~"$resetter_domain"}[5m])) ```-#### embeddings: provisioning_container_cpu_usage_short_term +#### background-jobs: stall_duration_p90 -
Container cpu usage total (5m maximum) across all cores by instance
+90th percentile of stall duration
-Refer to the [alerts reference](alerts#embeddings-provisioning-container-cpu-usage-short-term) for 1 alert related to this panel. +Refer to the [alerts reference](alerts#background-jobs-stall-duration-p90) for 1 alert related to this panel. -To see this panel, visit `/-/debug/grafana/d/embeddings/embeddings?viewPanel=100310` on your Sourcegraph instance. +To see this panel, visit `/-/debug/grafana/d/background-jobs/background-jobs?viewPanel=100121` on your Sourcegraph instance. -*Managed by the [Sourcegraph Cody team](https://handbook.sourcegraph.com/departments/engineering/teams/cody).* +*Managed by the [Sourcegraph Source team](https://handbook.sourcegraph.com/departments/engineering/teams/source).*Technical details
@@ -72843,21 +72524,23 @@ To see this panel, visit `/-/debug/grafana/d/embeddings/embeddings?viewPanel=100 Query: ``` -max_over_time(cadvisor_container_cpu_usage_percentage_total{name=~"^embeddings.*"}[5m]) +histogram_quantile(0.9, sum by(le, domain) (rate(src_dbworker_resetter_stall_duration_seconds_bucket{domain=~"$resetter_domain"}[5m]))) ```-#### embeddings: provisioning_container_memory_usage_short_term +#### background-jobs: reset_vs_failure_ratio -
Container memory usage (5m maximum) by instance
+Ratio of jobs reset to queued versus marked as failed
-Refer to the [alerts reference](alerts#embeddings-provisioning-container-memory-usage-short-term) for 1 alert related to this panel. +ratio of reset jobs to failed jobs - higher values indicate healthier job processing + +This panel has no related alerts. -To see this panel, visit `/-/debug/grafana/d/embeddings/embeddings?viewPanel=100311` on your Sourcegraph instance. +To see this panel, visit `/-/debug/grafana/d/background-jobs/background-jobs?viewPanel=100122` on your Sourcegraph instance. -*Managed by the [Sourcegraph Cody team](https://handbook.sourcegraph.com/departments/engineering/teams/cody).* +*Managed by the [Sourcegraph Source team](https://handbook.sourcegraph.com/departments/engineering/teams/source).*Technical details
@@ -72865,24 +72548,23 @@ To see this panel, visit `/-/debug/grafana/d/embeddings/embeddings?viewPanel=100 Query: ``` -max_over_time(cadvisor_container_memory_usage_percentage_total{name=~"^embeddings.*"}[5m]) +(sum by (domain) (increase(src_dbworker_resetter_record_resets_total{domain=~"$resetter_domain"}[1h]))) / on(domain) (sum by (domain) (increase(src_dbworker_resetter_record_reset_failures_total{domain=~"$resetter_domain"}[1h]) > 0) or on(domain) sum by (domain) (increase(src_dbworker_resetter_record_resets_total{domain=~"$resetter_domain"}[1h]) * 0 + 1)) ```-#### embeddings: container_oomkill_events_total +### Background Jobs Dashboard: Worker Queue Metrics -
Container OOMKILL events total by instance
+#### background-jobs: aggregate_queue_size -This value indicates the total number of times the container main process or child processes were terminated by OOM killer. -When it occurs frequently, it is an indicator of underprovisioning. +Total number of jobs queued across all domains
-Refer to the [alerts reference](alerts#embeddings-container-oomkill-events-total) for 1 alert related to this panel. +Refer to the [alerts reference](alerts#background-jobs-aggregate-queue-size) for 1 alert related to this panel. -To see this panel, visit `/-/debug/grafana/d/embeddings/embeddings?viewPanel=100312` on your Sourcegraph instance. +To see this panel, visit `/-/debug/grafana/d/background-jobs/background-jobs?viewPanel=100200` on your Sourcegraph instance. -*Managed by the [Sourcegraph Cody team](https://handbook.sourcegraph.com/departments/engineering/teams/cody).* +*Managed by the [Sourcegraph Source team](https://handbook.sourcegraph.com/departments/engineering/teams/source).*Technical details
@@ -72890,25 +72572,21 @@ To see this panel, visit `/-/debug/grafana/d/embeddings/embeddings?viewPanel=100 Query: ``` -max by (name) (container_oom_events_total{name=~"^embeddings.*"}) +sum(max by (domain) (src_workerutil_queue_depth)) ```-### Embeddings: Golang runtime monitoring - -#### embeddings: go_goroutines - -
Maximum active goroutines
+#### background-jobs: max_queue_duration -A high value here indicates a possible goroutine leak. +Maximum time a job has been in queue across all domains
-Refer to the [alerts reference](alerts#embeddings-go-goroutines) for 1 alert related to this panel. +Refer to the [alerts reference](alerts#background-jobs-max-queue-duration) for 1 alert related to this panel. -To see this panel, visit `/-/debug/grafana/d/embeddings/embeddings?viewPanel=100400` on your Sourcegraph instance. +To see this panel, visit `/-/debug/grafana/d/background-jobs/background-jobs?viewPanel=100201` on your Sourcegraph instance. -*Managed by the [Sourcegraph Cody team](https://handbook.sourcegraph.com/departments/engineering/teams/cody).* +*Managed by the [Sourcegraph Source team](https://handbook.sourcegraph.com/departments/engineering/teams/source).*Technical details
@@ -72916,21 +72594,23 @@ To see this panel, visit `/-/debug/grafana/d/embeddings/embeddings?viewPanel=100 Query: ``` -max by(instance) (go_goroutines{job=~".*embeddings"}) +max(src_workerutil_queue_duration_seconds) ```-#### embeddings: go_gc_duration_seconds +#### background-jobs: queue_growth_rate -
Maximum go garbage collection duration
+Rate of queue growth/decrease
+ +Rate at which queue is growing. Positive values indicate more jobs are being added than processed. -Refer to the [alerts reference](alerts#embeddings-go-gc-duration-seconds) for 1 alert related to this panel. +This panel has no related alerts. -To see this panel, visit `/-/debug/grafana/d/embeddings/embeddings?viewPanel=100401` on your Sourcegraph instance. +To see this panel, visit `/-/debug/grafana/d/background-jobs/background-jobs?viewPanel=100202` on your Sourcegraph instance. -*Managed by the [Sourcegraph Cody team](https://handbook.sourcegraph.com/departments/engineering/teams/cody).* +*Managed by the [Sourcegraph Source team](https://handbook.sourcegraph.com/departments/engineering/teams/source).*Technical details
@@ -72938,23 +72618,23 @@ To see this panel, visit `/-/debug/grafana/d/embeddings/embeddings?viewPanel=100 Query: ``` -max by(instance) (go_gc_duration_seconds{job=~".*embeddings"}) +sum(increase(src_workerutil_queue_depth[30m]))/1800 ```-### Embeddings: Kubernetes monitoring (only available on Kubernetes) +#### background-jobs: queue_depth_by_domain -#### embeddings: pods_available_percentage +
Number of jobs in queue by domain
-Percentage pods available
+Number of queued jobs per domain. Large values may indicate workers are not keeping up with incoming jobs. -Refer to the [alerts reference](alerts#embeddings-pods-available-percentage) for 1 alert related to this panel. +This panel has no related alerts. -To see this panel, visit `/-/debug/grafana/d/embeddings/embeddings?viewPanel=100500` on your Sourcegraph instance. +To see this panel, visit `/-/debug/grafana/d/background-jobs/background-jobs?viewPanel=100210` on your Sourcegraph instance. -*Managed by the [Sourcegraph Cody team](https://handbook.sourcegraph.com/departments/engineering/teams/cody).* +*Managed by the [Sourcegraph Source team](https://handbook.sourcegraph.com/departments/engineering/teams/source).*Technical details
@@ -72962,24 +72642,23 @@ To see this panel, visit `/-/debug/grafana/d/embeddings/embeddings?viewPanel=100 Query: ``` -sum by(app) (up{app=~".*embeddings"}) / count by (app) (up{app=~".*embeddings"}) * 100 +sum by (domain) (max by (domain) (src_workerutil_queue_depth)) ```-### Embeddings: Cache - -#### embeddings: hit_ratio +#### background-jobs: queue_duration_by_domain -
Hit ratio of the embeddings cache
+Maximum queue time by domain
-A low hit rate indicates your cache is not well utilized. Consider increasing the cache size. +Maximum time a job has been waiting in queue per domain. Long durations indicate potential worker stalls. This panel has no related alerts. -To see this panel, visit `/-/debug/grafana/d/embeddings/embeddings?viewPanel=100600` on your Sourcegraph instance. +To see this panel, visit `/-/debug/grafana/d/background-jobs/background-jobs?viewPanel=100211` on your Sourcegraph instance. +*Managed by the [Sourcegraph Source team](https://handbook.sourcegraph.com/departments/engineering/teams/source).*Technical details
@@ -72987,22 +72666,23 @@ To see this panel, visit `/-/debug/grafana/d/embeddings/embeddings?viewPanel=100 Query: ``` -rate(src_embeddings_cache_hit_count[30m]) / (rate(src_embeddings_cache_hit_count[30m]) + rate(src_embeddings_cache_miss_count[30m])) +sum by (domain) (max by (domain) (src_workerutil_queue_duration_seconds)) ```-#### embeddings: missed_bytes +#### background-jobs: queue_growth_by_domain -
Bytes fetched due to a cache miss
+Rate of change in queue size by domain
-A high volume of misses indicates that the many searches are not hitting the cache. Consider increasing the cache size. +Rate of change in queue size per domain. Consistently positive values indicate jobs are being queued faster than processed. This panel has no related alerts. -To see this panel, visit `/-/debug/grafana/d/embeddings/embeddings?viewPanel=100601` on your Sourcegraph instance. +To see this panel, visit `/-/debug/grafana/d/background-jobs/background-jobs?viewPanel=100212` on your Sourcegraph instance. +*Managed by the [Sourcegraph Source team](https://handbook.sourcegraph.com/departments/engineering/teams/source).*Technical details
@@ -73010,7 +72690,7 @@ To see this panel, visit `/-/debug/grafana/d/embeddings/embeddings?viewPanel=100 Query: ``` -rate(src_embeddings_cache_miss_bytes[10m]) +sum by (domain) (idelta(src_workerutil_queue_depth[10m])) / 600 ```-## frontend: hard_timeout_search_responses +## frontend: timeout_search_responses -
hard timeout search responses every 5m
+timeout search responses every 5m
**Descriptions** -- warning frontend: 2%+ hard timeout search responses every 5m for 15m0s +- warning frontend: 2%+ timeout search responses every 5m for 15m0s **Next steps** -- Learn more about the related dashboard panel in the [dashboards reference](dashboards#frontend-hard-timeout-search-responses). +- Learn more about the related dashboard panel in the [dashboards reference](dashboards#frontend-timeout-search-responses). - **Silence this alert:** If you are aware of this alert and want to silence notifications for it, add the following to your site configuration and set a reminder to re-evaluate the alert: ```json "observability.silenceAlerts": [ - "warning_frontend_hard_timeout_search_responses" + "warning_frontend_timeout_search_responses" ] ``` @@ -73119,7 +72799,7 @@ Generated query for warning alert: `max((histogram_quantile(0.9, sum by (le) (raTechnical details
-Generated query for warning alert: `max(((sum(increase(src_graphql_search_response{request_name!="CodeIntelSearch",source="browser",status="timeout"\}[5m])) + sum(increase(src_graphql_search_response\{alert_type="timed_out",request_name!="CodeIntelSearch",source="browser",status="alert"\}[5m]))) / sum(increase(src_graphql_search_response\{request_name!="CodeIntelSearch",source="browser"}[5m])) * 100) >= 2)` +Generated query for warning alert: `max((sum(increase(src_search_streaming_response{source="browser",status=~"timeout\\|partial_timeout"\}[5m])) / sum(increase(src_search_streaming_response\{source="browser"}[5m])) * 100) >= 2)`Technical details
-Generated query for warning alert: `max((sum by (status) (increase(src_graphql_search_response{request_name!="CodeIntelSearch",source="browser",status=~"error"\}[5m])) / ignoring (status) group_left () sum(increase(src_graphql_search_response\{request_name!="CodeIntelSearch",source="browser"}[5m])) * 100) >= 2)` +Generated query for warning alert: `max((sum(increase(src_search_streaming_response{source="browser",status="error"\}[5m])) / sum(increase(src_search_streaming_response\{source="browser"}[5m])) * 100) >= 2)`-## frontend: partial_timeout_search_responses +## frontend: search_no_results -
partial timeout search responses every 5m
+searches with no results every 5m
**Descriptions** -- warning frontend: 5%+ partial timeout search responses every 5m for 15m0s +- warning frontend: 5%+ searches with no results every 5m for 15m0s **Next steps** -- Learn more about the related dashboard panel in the [dashboards reference](dashboards#frontend-partial-timeout-search-responses). +- A sudden increase in this metric could indicate a problem with search indexing, or a shift in search behavior that are causing fewer users to find the results they`re looking for. +- Learn more about the related dashboard panel in the [dashboards reference](dashboards#frontend-search-no-results). - **Silence this alert:** If you are aware of this alert and want to silence notifications for it, add the following to your site configuration and set a reminder to re-evaluate the alert: ```json "observability.silenceAlerts": [ - "warning_frontend_partial_timeout_search_responses" + "warning_frontend_search_no_results" ] ``` @@ -73179,7 +72860,7 @@ Generated query for warning alert: `max((sum by (status) (increase(src_graphql_sTechnical details
-Generated query for warning alert: `max((sum by (status) (increase(src_graphql_search_response{request_name!="CodeIntelSearch",source="browser",status="partial_timeout"\}[5m])) / ignoring (status) group_left () sum(increase(src_graphql_search_response\{request_name!="CodeIntelSearch",source="browser"}[5m])) * 100) >= 5)` +Generated query for warning alert: `max((sum(increase(src_search_streaming_response{source="browser",status="no_results"\}[5m])) / sum(increase(src_search_streaming_response\{source="browser"}[5m])) * 100) >= 5)`Technical details
-Generated query for warning alert: `max((sum by (alert_type) (increase(src_graphql_search_response{alert_type!~"timed_out\\|no_results__suggest_quotes",request_name!="CodeIntelSearch",source="browser",status="alert"\}[5m])) / ignoring (alert_type) group_left () sum(increase(src_graphql_search_response\{request_name!="CodeIntelSearch",source="browser"}[5m])) * 100) >= 5)` +Generated query for warning alert: `max((sum by (alert_type) (increase(src_search_streaming_response{alert_type!~"timed_out",source="browser",status="alert"\}[5m])) / ignoring (alert_type) group_left () sum(increase(src_search_streaming_response\{source="browser"}[5m])) * 100) >= 5)`Technical details
-Generated query for warning alert: `max((sum by (alert_type) (increase(src_graphql_search_response{alert_type!~"timed_out\\|no_results__suggest_quotes",source="other",status="alert"\}[5m])) / ignoring (alert_type) group_left () sum(increase(src_graphql_search_response\{source="other",status="alert"}[5m]))) >= 5)` +Generated query for warning alert: `max((sum by (alert_type) (increase(src_graphql_search_response{alert_type!~"timed_out",source="other",status="alert"\}[5m])) / ignoring (alert_type) group_left () sum(increase(src_graphql_search_response\{source="other",status="alert"}[5m]))) >= 5)`+## frontend: goroutine_error_rate + +
error rate for periodic goroutine executions
+ +**Descriptions** + +- warning frontend: 0.01reqps+ error rate for periodic goroutine executions for 15m0s + +**Next steps** + +- Check service logs for error details related to the failing periodic routine +- Check if the routine depends on external services that may be unavailable +- Look for recent changes to the routine`s code or configuration +- More help interpreting this metric is available in the [dashboards reference](dashboards#frontend-goroutine-error-rate). +- **Silence this alert:** If you are aware of this alert and want to silence notifications for it, add the following to your site configuration and set a reminder to re-evaluate the alert: + +```json +"observability.silenceAlerts": [ + "warning_frontend_goroutine_error_rate" +] +``` + +*Managed by the [Sourcegraph Infrastructure Org team](https://handbook.sourcegraph.com/departments/engineering/infrastructure).* + +Technical details
+ +Generated query for warning alert: `max((sum by (name, job_name) (rate(src_periodic_goroutine_errors_total{job=~".*frontend.*"}[5m]))) >= 0.01)` + ++ +## frontend: goroutine_error_percentage + +
percentage of periodic goroutine executions that result in errors
+ +**Descriptions** + +- warning frontend: 5%+ percentage of periodic goroutine executions that result in errors + +**Next steps** + +- Check service logs for error details related to the failing periodic routine +- Check if the routine depends on external services that may be unavailable +- Consider temporarily disabling the routine if it`s non-critical and causing cascading issues +- More help interpreting this metric is available in the [dashboards reference](dashboards#frontend-goroutine-error-percentage). +- **Silence this alert:** If you are aware of this alert and want to silence notifications for it, add the following to your site configuration and set a reminder to re-evaluate the alert: + +```json +"observability.silenceAlerts": [ + "warning_frontend_goroutine_error_percentage" +] +``` + +*Managed by the [Sourcegraph Infrastructure Org team](https://handbook.sourcegraph.com/departments/engineering/infrastructure).* + +Technical details
+ +Generated query for warning alert: `max((sum by (name, job_name) (rate(src_periodic_goroutine_errors_total{job=~".*frontend.*"\}[5m])) / sum by (name, job_name) (rate(src_periodic_goroutine_total\{job=~".*frontend.*"}[5m]) > 0) * 100) >= 5)` + ++ ## frontend: mean_blocked_seconds_per_conn_request
mean blocked seconds per conn request
@@ -73887,6 +73634,68 @@ Generated query for critical alert: `max((sum by (app_name, db_name) (increase(s+## frontend: cpu_usage_percentage + +
CPU usage
+ +**Descriptions** + +- warning frontend: 95%+ CPU usage for 10m0s + +**Next steps** + +- Consider increasing CPU limits or scaling out. +- Learn more about the related dashboard panel in the [dashboards reference](dashboards#frontend-cpu-usage-percentage). +- **Silence this alert:** If you are aware of this alert and want to silence notifications for it, add the following to your site configuration and set a reminder to re-evaluate the alert: + +```json +"observability.silenceAlerts": [ + "warning_frontend_cpu_usage_percentage" +] +``` + +*Managed by the [Sourcegraph Code Search team](https://handbook.sourcegraph.com/departments/engineering/teams/code-search).* + +Technical details
+ +Generated query for warning alert: `max((cadvisor_container_cpu_usage_percentage_total{name=~"^(frontend\\|sourcegraph-frontend).*"}) >= 95)` + ++ +## frontend: memory_rss + +
memory (RSS)
+ +**Descriptions** + +- warning frontend: 90%+ memory (RSS) for 10m0s + +**Next steps** + +- Consider increasing memory limits or scaling out. +- More help interpreting this metric is available in the [dashboards reference](dashboards#frontend-memory-rss). +- **Silence this alert:** If you are aware of this alert and want to silence notifications for it, add the following to your site configuration and set a reminder to re-evaluate the alert: + +```json +"observability.silenceAlerts": [ + "warning_frontend_memory_rss" +] +``` + +*Managed by the [Sourcegraph Code Search team](https://handbook.sourcegraph.com/departments/engineering/teams/code-search).* + +Technical details
+ +Generated query for warning alert: `max((max by (name) (container_memory_rss{name=~"^(frontend\\|sourcegraph-frontend).*"\} / container_spec_memory_limit_bytes\{name=~"^(frontend\\|sourcegraph-frontend).*"}) * 100) >= 90)` + ++ ## frontend: container_cpu_usage
container cpu usage total (1m average) across all cores by instance
@@ -74389,25 +74198,26 @@ Generated query for critical alert: `max((histogram_quantile(0.9, sum by (le) (l-## gitserver: cpu_throttling_time +## gitserver: disk_space_remaining -
container CPU throttling time %
+disk space remaining
**Descriptions** -- warning gitserver: 75%+ container CPU throttling time % for 2m0s -- critical gitserver: 90%+ container CPU throttling time % for 5m0s +- warning gitserver: less than 15% disk space remaining +- critical gitserver: less than 10% disk space remaining for 10m0s **Next steps** -- - Consider increasing the CPU limit for the container. -- More help interpreting this metric is available in the [dashboards reference](dashboards#gitserver-cpu-throttling-time). +- On a warning alert, you may want to provision more disk space: Disk pressure may result in decreased performance, users having to wait for repositories to clone, etc. +- On a critical alert, you need to provision more disk space. Running out of disk space will result in decreased performance, or complete service outage. +- More help interpreting this metric is available in the [dashboards reference](dashboards#gitserver-disk-space-remaining). - **Silence this alert:** If you are aware of this alert and want to silence notifications for it, add the following to your site configuration and set a reminder to re-evaluate the alert: ```json "observability.silenceAlerts": [ - "warning_gitserver_cpu_throttling_time", - "critical_gitserver_cpu_throttling_time" + "warning_gitserver_disk_space_remaining", + "critical_gitserver_disk_space_remaining" ] ``` @@ -74416,34 +74226,33 @@ Generated query for critical alert: `max((histogram_quantile(0.9, sum by (le) (lTechnical details
-Generated query for warning alert: `max((sum by (container_label_io_kubernetes_pod_name) ((rate(container_cpu_cfs_throttled_periods_total{container_label_io_kubernetes_container_name="gitserver"\}[5m]) / rate(container_cpu_cfs_periods_total\{container_label_io_kubernetes_container_name="gitserver"}[5m])) * 100)) >= 75)` +Generated query for warning alert: `min(((src_gitserver_disk_space_available / src_gitserver_disk_space_total) * 100) < 15)` -Generated query for critical alert: `max((sum by (container_label_io_kubernetes_pod_name) ((rate(container_cpu_cfs_throttled_periods_total{container_label_io_kubernetes_container_name="gitserver"\}[5m]) / rate(container_cpu_cfs_periods_total\{container_label_io_kubernetes_container_name="gitserver"}[5m])) * 100)) >= 90)` +Generated query for critical alert: `min(((src_gitserver_disk_space_available / src_gitserver_disk_space_total) * 100) < 10)`-## gitserver: disk_space_remaining +## gitserver: cpu_throttling_time -
disk space remaining
+container CPU throttling time %
**Descriptions** -- warning gitserver: less than 15% disk space remaining -- critical gitserver: less than 10% disk space remaining for 10m0s +- warning gitserver: 75%+ container CPU throttling time % for 2m0s +- critical gitserver: 90%+ container CPU throttling time % for 5m0s **Next steps** -- On a warning alert, you may want to provision more disk space: Disk pressure may result in decreased performance, users having to wait for repositories to clone, etc. -- On a critical alert, you need to provision more disk space. Running out of disk space will result in decreased performance, or complete service outage. -- More help interpreting this metric is available in the [dashboards reference](dashboards#gitserver-disk-space-remaining). +- - Consider increasing the CPU limit for the container. +- More help interpreting this metric is available in the [dashboards reference](dashboards#gitserver-cpu-throttling-time). - **Silence this alert:** If you are aware of this alert and want to silence notifications for it, add the following to your site configuration and set a reminder to re-evaluate the alert: ```json "observability.silenceAlerts": [ - "warning_gitserver_disk_space_remaining", - "critical_gitserver_disk_space_remaining" + "warning_gitserver_cpu_throttling_time", + "critical_gitserver_cpu_throttling_time" ] ``` @@ -74452,9 +74261,9 @@ Generated query for critical alert: `max((sum by (container_label_io_kubernetes_Technical details
-Generated query for warning alert: `min(((src_gitserver_disk_space_available / src_gitserver_disk_space_total) * 100) < 15)` +Generated query for warning alert: `max((sum by (container_label_io_kubernetes_pod_name) ((rate(container_cpu_cfs_throttled_periods_total{container_label_io_kubernetes_container_name="gitserver"\}[5m]) / rate(container_cpu_cfs_periods_total\{container_label_io_kubernetes_container_name="gitserver"}[5m])) * 100)) >= 75)` -Generated query for critical alert: `min(((src_gitserver_disk_space_available / src_gitserver_disk_space_total) * 100) < 10)` +Generated query for critical alert: `max((sum by (container_label_io_kubernetes_pod_name) ((rate(container_cpu_cfs_throttled_periods_total{container_label_io_kubernetes_container_name="gitserver"\}[5m]) / rate(container_cpu_cfs_periods_total\{container_label_io_kubernetes_container_name="gitserver"}[5m])) * 100)) >= 90)`@@ -74597,6 +74402,168 @@ Generated query for warning alert: `max((sum(src_gitserver_clone_queue)) >= 2
+## gitserver: git_command_retry_attempts_rate + +
rate of git command corruption retry attempts over 5m
+ +**Descriptions** + +- warning gitserver: 0.1reqps+ rate of git command corruption retry attempts over 5m for 5m0s + +**Next steps** + +- Investigate the underlying cause of corruption errors in git commands. +- Check disk health and I/O performance. +- Monitor for patterns in specific git operations that trigger retries. +- Consider adjusting retry configuration if retries are too frequent. +- More help interpreting this metric is available in the [dashboards reference](dashboards#gitserver-git-command-retry-attempts-rate). +- **Silence this alert:** If you are aware of this alert and want to silence notifications for it, add the following to your site configuration and set a reminder to re-evaluate the alert: + +```json +"observability.silenceAlerts": [ + "warning_gitserver_git_command_retry_attempts_rate" +] +``` + +*Managed by the [Sourcegraph Source team](https://handbook.sourcegraph.com/departments/engineering/teams/source).* + +Technical details
+ +Generated query for warning alert: `max((sum(rate(src_gitserver_retry_attempts_total[5m]))) >= 0.1)` + ++ +## gitserver: goroutine_error_rate + +
error rate for periodic goroutine executions
+ +**Descriptions** + +- warning gitserver: 0.01reqps+ error rate for periodic goroutine executions for 15m0s + +**Next steps** + +- Check service logs for error details related to the failing periodic routine +- Check if the routine depends on external services that may be unavailable +- Look for recent changes to the routine`s code or configuration +- More help interpreting this metric is available in the [dashboards reference](dashboards#gitserver-goroutine-error-rate). +- **Silence this alert:** If you are aware of this alert and want to silence notifications for it, add the following to your site configuration and set a reminder to re-evaluate the alert: + +```json +"observability.silenceAlerts": [ + "warning_gitserver_goroutine_error_rate" +] +``` + +*Managed by the [Sourcegraph Infrastructure Org team](https://handbook.sourcegraph.com/departments/engineering/infrastructure).* + +Technical details
+ +Generated query for warning alert: `max((sum by (name, job_name) (rate(src_periodic_goroutine_errors_total{job=~".*gitserver.*"}[5m]))) >= 0.01)` + ++ +## gitserver: goroutine_error_percentage + +
percentage of periodic goroutine executions that result in errors
+ +**Descriptions** + +- warning gitserver: 5%+ percentage of periodic goroutine executions that result in errors + +**Next steps** + +- Check service logs for error details related to the failing periodic routine +- Check if the routine depends on external services that may be unavailable +- Consider temporarily disabling the routine if it`s non-critical and causing cascading issues +- More help interpreting this metric is available in the [dashboards reference](dashboards#gitserver-goroutine-error-percentage). +- **Silence this alert:** If you are aware of this alert and want to silence notifications for it, add the following to your site configuration and set a reminder to re-evaluate the alert: + +```json +"observability.silenceAlerts": [ + "warning_gitserver_goroutine_error_percentage" +] +``` + +*Managed by the [Sourcegraph Infrastructure Org team](https://handbook.sourcegraph.com/departments/engineering/infrastructure).* + +Technical details
+ +Generated query for warning alert: `max((sum by (name, job_name) (rate(src_periodic_goroutine_errors_total{job=~".*gitserver.*"\}[5m])) / sum by (name, job_name) (rate(src_periodic_goroutine_total\{job=~".*gitserver.*"}[5m]) > 0) * 100) >= 5)` + ++ +## gitserver: cpu_usage_percentage + +
CPU usage
+ +**Descriptions** + +- warning gitserver: 95%+ CPU usage for 10m0s + +**Next steps** + +- Consider increasing CPU limits or scaling out. +- Learn more about the related dashboard panel in the [dashboards reference](dashboards#gitserver-cpu-usage-percentage). +- **Silence this alert:** If you are aware of this alert and want to silence notifications for it, add the following to your site configuration and set a reminder to re-evaluate the alert: + +```json +"observability.silenceAlerts": [ + "warning_gitserver_cpu_usage_percentage" +] +``` + +*Managed by the [Sourcegraph Source team](https://handbook.sourcegraph.com/departments/engineering/teams/source).* + +Technical details
+ +Generated query for warning alert: `max((cadvisor_container_cpu_usage_percentage_total{name=~"^gitserver.*"}) >= 95)` + ++ +## gitserver: memory_rss + +
memory (RSS)
+ +**Descriptions** + +- warning gitserver: 90%+ memory (RSS) for 10m0s + +**Next steps** + +- Consider increasing memory limits or scaling out. +- More help interpreting this metric is available in the [dashboards reference](dashboards#gitserver-memory-rss). +- **Silence this alert:** If you are aware of this alert and want to silence notifications for it, add the following to your site configuration and set a reminder to re-evaluate the alert: + +```json +"observability.silenceAlerts": [ + "warning_gitserver_memory_rss" +] +``` + +*Managed by the [Sourcegraph Source team](https://handbook.sourcegraph.com/departments/engineering/teams/source).* + +Technical details
+ +Generated query for warning alert: `max((max by (name) (container_memory_rss{name=~"^gitserver.*"\} / container_spec_memory_limit_bytes\{name=~"^gitserver.*"}) * 100) >= 90)` + ++ ## gitserver: gitserver_site_configuration_duration_since_last_successful_update_by_instance
maximum duration since last successful site configuration update (all "gitserver" instances)
@@ -75338,71 +75305,100 @@ Generated query for critical alert: `min((sum by (app) (up{app=~".*(pgsql\\|code-## precise-code-intel-worker: codeintel_upload_queued_max_age +## precise-code-intel-worker: mean_blocked_seconds_per_conn_request -
unprocessed upload record queue longest time in queue
+mean blocked seconds per conn request
**Descriptions** -- warning precise-code-intel-worker: 18000s+ unprocessed upload record queue longest time in queue +- warning precise-code-intel-worker: 0.1s+ mean blocked seconds per conn request for 10m0s +- critical precise-code-intel-worker: 0.5s+ mean blocked seconds per conn request for 10m0s **Next steps** -- An alert here could be indicative of a few things: an upload surfacing a pathological performance characteristic, -precise-code-intel-worker being underprovisioned for the required upload processing throughput, or a higher replica -count being required for the volume of uploads. -- Learn more about the related dashboard panel in the [dashboards reference](dashboards#precise-code-intel-worker-codeintel-upload-queued-max-age). +- Increase SRC_PGSQL_MAX_OPEN together with giving more memory to the database if needed +- Scale up Postgres memory/cpus - [see our scaling guide](https://sourcegraph.com/docs/admin/config/postgres-conf) +- If using GCP Cloud SQL, check for high lock waits or CPU usage in query insights +- Learn more about the related dashboard panel in the [dashboards reference](dashboards#precise-code-intel-worker-mean-blocked-seconds-per-conn-request). - **Silence this alert:** If you are aware of this alert and want to silence notifications for it, add the following to your site configuration and set a reminder to re-evaluate the alert: ```json "observability.silenceAlerts": [ - "warning_precise-code-intel-worker_codeintel_upload_queued_max_age" + "warning_precise-code-intel-worker_mean_blocked_seconds_per_conn_request", + "critical_precise-code-intel-worker_mean_blocked_seconds_per_conn_request" ] ``` -*Managed by the [Sourcegraph Code intelligence team](https://handbook.sourcegraph.com/departments/engineering/teams/code-intelligence).* +*Managed by the [Sourcegraph Infrastructure Org team](https://handbook.sourcegraph.com/departments/engineering/infrastructure).*Technical details
-Generated query for warning alert: `max((max(src_codeintel_upload_queued_duration_seconds_total{job=~"^precise-code-intel-worker.*"})) >= 18000)` +Generated query for warning alert: `max((sum by (app_name, db_name) (increase(src_pgsql_conns_blocked_seconds{app_name="precise-code-intel-worker"\}[5m])) / sum by (app_name, db_name) (increase(src_pgsql_conns_waited_for\{app_name="precise-code-intel-worker"}[5m]))) >= 0.1)` + +Generated query for critical alert: `max((sum by (app_name, db_name) (increase(src_pgsql_conns_blocked_seconds{app_name="precise-code-intel-worker"\}[5m])) / sum by (app_name, db_name) (increase(src_pgsql_conns_waited_for\{app_name="precise-code-intel-worker"}[5m]))) >= 0.5)`-## precise-code-intel-worker: mean_blocked_seconds_per_conn_request +## precise-code-intel-worker: cpu_usage_percentage -
mean blocked seconds per conn request
+CPU usage
**Descriptions** -- warning precise-code-intel-worker: 0.1s+ mean blocked seconds per conn request for 10m0s -- critical precise-code-intel-worker: 0.5s+ mean blocked seconds per conn request for 10m0s +- warning precise-code-intel-worker: 95%+ CPU usage for 10m0s **Next steps** -- Increase SRC_PGSQL_MAX_OPEN together with giving more memory to the database if needed -- Scale up Postgres memory/cpus - [see our scaling guide](https://sourcegraph.com/docs/admin/config/postgres-conf) -- If using GCP Cloud SQL, check for high lock waits or CPU usage in query insights -- Learn more about the related dashboard panel in the [dashboards reference](dashboards#precise-code-intel-worker-mean-blocked-seconds-per-conn-request). +- Consider increasing CPU limits or scaling out. +- Learn more about the related dashboard panel in the [dashboards reference](dashboards#precise-code-intel-worker-cpu-usage-percentage). - **Silence this alert:** If you are aware of this alert and want to silence notifications for it, add the following to your site configuration and set a reminder to re-evaluate the alert: ```json "observability.silenceAlerts": [ - "warning_precise-code-intel-worker_mean_blocked_seconds_per_conn_request", - "critical_precise-code-intel-worker_mean_blocked_seconds_per_conn_request" + "warning_precise-code-intel-worker_cpu_usage_percentage" ] ``` -*Managed by the [Sourcegraph Infrastructure Org team](https://handbook.sourcegraph.com/departments/engineering/infrastructure).* +*Managed by the [Sourcegraph Code Search team](https://handbook.sourcegraph.com/departments/engineering/teams/code-search).*Technical details
-Generated query for warning alert: `max((sum by (app_name, db_name) (increase(src_pgsql_conns_blocked_seconds{app_name="precise-code-intel-worker"\}[5m])) / sum by (app_name, db_name) (increase(src_pgsql_conns_waited_for\{app_name="precise-code-intel-worker"}[5m]))) >= 0.1)` +Generated query for warning alert: `max((cadvisor_container_cpu_usage_percentage_total{name=~"^precise-code-intel-worker.*"}) >= 95)` -Generated query for critical alert: `max((sum by (app_name, db_name) (increase(src_pgsql_conns_blocked_seconds{app_name="precise-code-intel-worker"\}[5m])) / sum by (app_name, db_name) (increase(src_pgsql_conns_waited_for\{app_name="precise-code-intel-worker"}[5m]))) >= 0.5)` ++ +## precise-code-intel-worker: memory_rss + +
memory (RSS)
+ +**Descriptions** + +- warning precise-code-intel-worker: 90%+ memory (RSS) for 10m0s + +**Next steps** + +- Consider increasing memory limits or scaling out. +- More help interpreting this metric is available in the [dashboards reference](dashboards#precise-code-intel-worker-memory-rss). +- **Silence this alert:** If you are aware of this alert and want to silence notifications for it, add the following to your site configuration and set a reminder to re-evaluate the alert: + +```json +"observability.silenceAlerts": [ + "warning_precise-code-intel-worker_memory_rss" +] +``` + +*Managed by the [Sourcegraph Code Search team](https://handbook.sourcegraph.com/departments/engineering/teams/code-search).* + +Technical details
+ +Generated query for warning alert: `max((max by (name) (container_memory_rss{name=~"^precise-code-intel-worker.*"\} / container_spec_memory_limit_bytes\{name=~"^precise-code-intel-worker.*"}) * 100) >= 90)`-## redis: redis-store_up +## syntactic-indexing: mean_blocked_seconds_per_conn_request -
redis-store availability
+mean blocked seconds per conn request
**Descriptions** -- critical redis: less than 1 redis-store availability for 10s +- warning syntactic-indexing: 0.1s+ mean blocked seconds per conn request for 10m0s +- critical syntactic-indexing: 0.5s+ mean blocked seconds per conn request for 10m0s **Next steps** -- Ensure redis-store is running -- More help interpreting this metric is available in the [dashboards reference](dashboards#redis-redis-store-up). +- Increase SRC_PGSQL_MAX_OPEN together with giving more memory to the database if needed +- Scale up Postgres memory/cpus - [see our scaling guide](https://sourcegraph.com/docs/admin/config/postgres-conf) +- If using GCP Cloud SQL, check for high lock waits or CPU usage in query insights +- Learn more about the related dashboard panel in the [dashboards reference](dashboards#syntactic-indexing-mean-blocked-seconds-per-conn-request). - **Silence this alert:** If you are aware of this alert and want to silence notifications for it, add the following to your site configuration and set a reminder to re-evaluate the alert: ```json "observability.silenceAlerts": [ - "critical_redis_redis-store_up" + "warning_syntactic-indexing_mean_blocked_seconds_per_conn_request", + "critical_syntactic-indexing_mean_blocked_seconds_per_conn_request" ] ``` @@ -75749,525 +75749,286 @@ Generated query for critical alert: `min((sum by (app) (up{app=~".*precise-code-Technical details
-Generated query for critical alert: `min((redis_up{app="redis-store"}) < 1)` - -- -## redis: redis-cache_up - -
redis-cache availability
- -**Descriptions** - -- critical redis: less than 1 redis-cache availability for 10s - -**Next steps** - -- Ensure redis-cache is running -- More help interpreting this metric is available in the [dashboards reference](dashboards#redis-redis-cache-up). -- **Silence this alert:** If you are aware of this alert and want to silence notifications for it, add the following to your site configuration and set a reminder to re-evaluate the alert: - -```json -"observability.silenceAlerts": [ - "critical_redis_redis-cache_up" -] -``` - -*Managed by the [Sourcegraph Infrastructure Org team](https://handbook.sourcegraph.com/departments/engineering/infrastructure).* - -Technical details
+Generated query for warning alert: `max((sum by (app_name, db_name) (increase(src_pgsql_conns_blocked_seconds{app_name="syntactic-code-intel-worker"\}[5m])) / sum by (app_name, db_name) (increase(src_pgsql_conns_waited_for\{app_name="syntactic-code-intel-worker"}[5m]))) >= 0.1)` -Generated query for critical alert: `min((redis_up{app="redis-cache"}) < 1)` +Generated query for critical alert: `max((sum by (app_name, db_name) (increase(src_pgsql_conns_blocked_seconds{app_name="syntactic-code-intel-worker"\}[5m])) / sum by (app_name, db_name) (increase(src_pgsql_conns_waited_for\{app_name="syntactic-code-intel-worker"}[5m]))) >= 0.5)`-## redis: provisioning_container_cpu_usage_long_term +## syntactic-indexing: cpu_usage_percentage -
container cpu usage total (90th percentile over 1d) across all cores by instance
+CPU usage
**Descriptions** -- warning redis: 80%+ container cpu usage total (90th percentile over 1d) across all cores by instance for 336h0m0s +- warning syntactic-indexing: 95%+ CPU usage for 10m0s **Next steps** -- **Kubernetes:** Consider increasing CPU limits in the `Deployment.yaml` for the redis-cache service. -- **Docker Compose:** Consider increasing `cpus:` of the redis-cache container in `docker-compose.yml`. -- Learn more about the related dashboard panel in the [dashboards reference](dashboards#redis-provisioning-container-cpu-usage-long-term). +- Consider increasing CPU limits or scaling out. +- Learn more about the related dashboard panel in the [dashboards reference](dashboards#syntactic-indexing-cpu-usage-percentage). - **Silence this alert:** If you are aware of this alert and want to silence notifications for it, add the following to your site configuration and set a reminder to re-evaluate the alert: ```json "observability.silenceAlerts": [ - "warning_redis_provisioning_container_cpu_usage_long_term" + "warning_syntactic-indexing_cpu_usage_percentage" ] ``` -*Managed by the [Sourcegraph Infrastructure Org team](https://handbook.sourcegraph.com/departments/engineering/infrastructure).* +*Managed by the [Sourcegraph Code Search team](https://handbook.sourcegraph.com/departments/engineering/teams/code-search).*Technical details
-Generated query for warning alert: `max((quantile_over_time(0.9, cadvisor_container_cpu_usage_percentage_total{name=~"^redis-cache.*"}[1d])) >= 80)` +Generated query for warning alert: `max((cadvisor_container_cpu_usage_percentage_total{name=~"^syntactic-code-intel-worker.*"}) >= 95)`-## redis: provisioning_container_memory_usage_long_term +## syntactic-indexing: memory_rss -
container memory usage (1d maximum) by instance
+memory (RSS)
**Descriptions** -- warning redis: 80%+ container memory usage (1d maximum) by instance for 336h0m0s +- warning syntactic-indexing: 90%+ memory (RSS) for 10m0s **Next steps** -- **Kubernetes:** Consider increasing memory limits in the `Deployment.yaml` for the redis-cache service. -- **Docker Compose:** Consider increasing `memory:` of the redis-cache container in `docker-compose.yml`. -- Learn more about the related dashboard panel in the [dashboards reference](dashboards#redis-provisioning-container-memory-usage-long-term). +- Consider increasing memory limits or scaling out. +- More help interpreting this metric is available in the [dashboards reference](dashboards#syntactic-indexing-memory-rss). - **Silence this alert:** If you are aware of this alert and want to silence notifications for it, add the following to your site configuration and set a reminder to re-evaluate the alert: ```json "observability.silenceAlerts": [ - "warning_redis_provisioning_container_memory_usage_long_term" + "warning_syntactic-indexing_memory_rss" ] ``` -*Managed by the [Sourcegraph Infrastructure Org team](https://handbook.sourcegraph.com/departments/engineering/infrastructure).* +*Managed by the [Sourcegraph Code Search team](https://handbook.sourcegraph.com/departments/engineering/teams/code-search).*Technical details
-Generated query for warning alert: `max((max_over_time(cadvisor_container_memory_usage_percentage_total{name=~"^redis-cache.*"}[1d])) >= 80)` +Generated query for warning alert: `max((max by (name) (container_memory_rss{name=~"^syntactic-code-intel-worker.*"\} / container_spec_memory_limit_bytes\{name=~"^syntactic-code-intel-worker.*"}) * 100) >= 90)`-## redis: provisioning_container_cpu_usage_short_term +## syntactic-indexing: container_cpu_usage -
container cpu usage total (5m maximum) across all cores by instance
+container cpu usage total (1m average) across all cores by instance
**Descriptions** -- warning redis: 90%+ container cpu usage total (5m maximum) across all cores by instance for 30m0s +- warning syntactic-indexing: 99%+ container cpu usage total (1m average) across all cores by instance **Next steps** - **Kubernetes:** Consider increasing CPU limits in the the relevant `Deployment.yaml`. -- **Docker Compose:** Consider increasing `cpus:` of the redis-cache container in `docker-compose.yml`. -- Learn more about the related dashboard panel in the [dashboards reference](dashboards#redis-provisioning-container-cpu-usage-short-term). -- **Silence this alert:** If you are aware of this alert and want to silence notifications for it, add the following to your site configuration and set a reminder to re-evaluate the alert: - -```json -"observability.silenceAlerts": [ - "warning_redis_provisioning_container_cpu_usage_short_term" -] -``` - -*Managed by the [Sourcegraph Infrastructure Org team](https://handbook.sourcegraph.com/departments/engineering/infrastructure).* - -Technical details
- -Generated query for warning alert: `max((max_over_time(cadvisor_container_cpu_usage_percentage_total{name=~"^redis-cache.*"}[5m])) >= 90)` - -- -## redis: provisioning_container_memory_usage_short_term - -
container memory usage (5m maximum) by instance
- -**Descriptions** - -- warning redis: 90%+ container memory usage (5m maximum) by instance - -**Next steps** - -- **Kubernetes:** Consider increasing memory limit in relevant `Deployment.yaml`. -- **Docker Compose:** Consider increasing `memory:` of redis-cache container in `docker-compose.yml`. -- Learn more about the related dashboard panel in the [dashboards reference](dashboards#redis-provisioning-container-memory-usage-short-term). +- **Docker Compose:** Consider increasing `cpus:` of the syntactic-code-intel-worker container in `docker-compose.yml`. +- Learn more about the related dashboard panel in the [dashboards reference](dashboards#syntactic-indexing-container-cpu-usage). - **Silence this alert:** If you are aware of this alert and want to silence notifications for it, add the following to your site configuration and set a reminder to re-evaluate the alert: ```json "observability.silenceAlerts": [ - "warning_redis_provisioning_container_memory_usage_short_term" + "warning_syntactic-indexing_container_cpu_usage" ] ``` -*Managed by the [Sourcegraph Infrastructure Org team](https://handbook.sourcegraph.com/departments/engineering/infrastructure).* +*Managed by the [Sourcegraph Code intelligence team](https://handbook.sourcegraph.com/departments/engineering/teams/code-intelligence).*Technical details
-Generated query for warning alert: `max((max_over_time(cadvisor_container_memory_usage_percentage_total{name=~"^redis-cache.*"}[5m])) >= 90)` +Generated query for warning alert: `max((cadvisor_container_cpu_usage_percentage_total{name=~"^syntactic-code-intel-worker.*"}) >= 99)`-## redis: container_oomkill_events_total +## syntactic-indexing: container_memory_usage -
container OOMKILL events total by instance
+container memory usage by instance
**Descriptions** -- warning redis: 1+ container OOMKILL events total by instance +- warning syntactic-indexing: 99%+ container memory usage by instance **Next steps** - **Kubernetes:** Consider increasing memory limit in relevant `Deployment.yaml`. -- **Docker Compose:** Consider increasing `memory:` of redis-cache container in `docker-compose.yml`. -- More help interpreting this metric is available in the [dashboards reference](dashboards#redis-container-oomkill-events-total). +- **Docker Compose:** Consider increasing `memory:` of syntactic-code-intel-worker container in `docker-compose.yml`. +- Learn more about the related dashboard panel in the [dashboards reference](dashboards#syntactic-indexing-container-memory-usage). - **Silence this alert:** If you are aware of this alert and want to silence notifications for it, add the following to your site configuration and set a reminder to re-evaluate the alert: ```json "observability.silenceAlerts": [ - "warning_redis_container_oomkill_events_total" + "warning_syntactic-indexing_container_memory_usage" ] ``` -*Managed by the [Sourcegraph Infrastructure Org team](https://handbook.sourcegraph.com/departments/engineering/infrastructure).* +*Managed by the [Sourcegraph Code intelligence team](https://handbook.sourcegraph.com/departments/engineering/teams/code-intelligence).*Technical details
-Generated query for warning alert: `max((max by (name) (container_oom_events_total{name=~"^redis-cache.*"})) >= 1)` +Generated query for warning alert: `max((cadvisor_container_memory_usage_percentage_total{name=~"^syntactic-code-intel-worker.*"}) >= 99)`-## redis: provisioning_container_cpu_usage_long_term +## syntactic-indexing: provisioning_container_cpu_usage_long_term
container cpu usage total (90th percentile over 1d) across all cores by instance
**Descriptions** -- warning redis: 80%+ container cpu usage total (90th percentile over 1d) across all cores by instance for 336h0m0s +- warning syntactic-indexing: 80%+ container cpu usage total (90th percentile over 1d) across all cores by instance for 336h0m0s **Next steps** -- **Kubernetes:** Consider increasing CPU limits in the `Deployment.yaml` for the redis-store service. -- **Docker Compose:** Consider increasing `cpus:` of the redis-store container in `docker-compose.yml`. -- Learn more about the related dashboard panel in the [dashboards reference](dashboards#redis-provisioning-container-cpu-usage-long-term). +- **Kubernetes:** Consider increasing CPU limits in the `Deployment.yaml` for the syntactic-code-intel-worker service. +- **Docker Compose:** Consider increasing `cpus:` of the syntactic-code-intel-worker container in `docker-compose.yml`. +- Learn more about the related dashboard panel in the [dashboards reference](dashboards#syntactic-indexing-provisioning-container-cpu-usage-long-term). - **Silence this alert:** If you are aware of this alert and want to silence notifications for it, add the following to your site configuration and set a reminder to re-evaluate the alert: ```json "observability.silenceAlerts": [ - "warning_redis_provisioning_container_cpu_usage_long_term" + "warning_syntactic-indexing_provisioning_container_cpu_usage_long_term" ] ``` -*Managed by the [Sourcegraph Infrastructure Org team](https://handbook.sourcegraph.com/departments/engineering/infrastructure).* +*Managed by the [Sourcegraph Code intelligence team](https://handbook.sourcegraph.com/departments/engineering/teams/code-intelligence).*Technical details
-Generated query for warning alert: `max((quantile_over_time(0.9, cadvisor_container_cpu_usage_percentage_total{name=~"^redis-store.*"}[1d])) >= 80)` +Generated query for warning alert: `max((quantile_over_time(0.9, cadvisor_container_cpu_usage_percentage_total{name=~"^syntactic-code-intel-worker.*"}[1d])) >= 80)`-## redis: provisioning_container_memory_usage_long_term +## syntactic-indexing: provisioning_container_memory_usage_long_term
container memory usage (1d maximum) by instance
**Descriptions** -- warning redis: 80%+ container memory usage (1d maximum) by instance for 336h0m0s +- warning syntactic-indexing: 80%+ container memory usage (1d maximum) by instance for 336h0m0s **Next steps** -- **Kubernetes:** Consider increasing memory limits in the `Deployment.yaml` for the redis-store service. -- **Docker Compose:** Consider increasing `memory:` of the redis-store container in `docker-compose.yml`. -- Learn more about the related dashboard panel in the [dashboards reference](dashboards#redis-provisioning-container-memory-usage-long-term). +- **Kubernetes:** Consider increasing memory limits in the `Deployment.yaml` for the syntactic-code-intel-worker service. +- **Docker Compose:** Consider increasing `memory:` of the syntactic-code-intel-worker container in `docker-compose.yml`. +- Learn more about the related dashboard panel in the [dashboards reference](dashboards#syntactic-indexing-provisioning-container-memory-usage-long-term). - **Silence this alert:** If you are aware of this alert and want to silence notifications for it, add the following to your site configuration and set a reminder to re-evaluate the alert: ```json "observability.silenceAlerts": [ - "warning_redis_provisioning_container_memory_usage_long_term" + "warning_syntactic-indexing_provisioning_container_memory_usage_long_term" ] ``` -*Managed by the [Sourcegraph Infrastructure Org team](https://handbook.sourcegraph.com/departments/engineering/infrastructure).* +*Managed by the [Sourcegraph Code intelligence team](https://handbook.sourcegraph.com/departments/engineering/teams/code-intelligence).*Technical details
-Generated query for warning alert: `max((max_over_time(cadvisor_container_memory_usage_percentage_total{name=~"^redis-store.*"}[1d])) >= 80)` +Generated query for warning alert: `max((max_over_time(cadvisor_container_memory_usage_percentage_total{name=~"^syntactic-code-intel-worker.*"}[1d])) >= 80)`-## redis: provisioning_container_cpu_usage_short_term +## syntactic-indexing: provisioning_container_cpu_usage_short_term
container cpu usage total (5m maximum) across all cores by instance
**Descriptions** -- warning redis: 90%+ container cpu usage total (5m maximum) across all cores by instance for 30m0s +- warning syntactic-indexing: 90%+ container cpu usage total (5m maximum) across all cores by instance for 30m0s **Next steps** - **Kubernetes:** Consider increasing CPU limits in the the relevant `Deployment.yaml`. -- **Docker Compose:** Consider increasing `cpus:` of the redis-store container in `docker-compose.yml`. -- Learn more about the related dashboard panel in the [dashboards reference](dashboards#redis-provisioning-container-cpu-usage-short-term). +- **Docker Compose:** Consider increasing `cpus:` of the syntactic-code-intel-worker container in `docker-compose.yml`. +- Learn more about the related dashboard panel in the [dashboards reference](dashboards#syntactic-indexing-provisioning-container-cpu-usage-short-term). - **Silence this alert:** If you are aware of this alert and want to silence notifications for it, add the following to your site configuration and set a reminder to re-evaluate the alert: ```json "observability.silenceAlerts": [ - "warning_redis_provisioning_container_cpu_usage_short_term" + "warning_syntactic-indexing_provisioning_container_cpu_usage_short_term" ] ``` -*Managed by the [Sourcegraph Infrastructure Org team](https://handbook.sourcegraph.com/departments/engineering/infrastructure).* +*Managed by the [Sourcegraph Code intelligence team](https://handbook.sourcegraph.com/departments/engineering/teams/code-intelligence).*Technical details
-Generated query for warning alert: `max((max_over_time(cadvisor_container_cpu_usage_percentage_total{name=~"^redis-store.*"}[5m])) >= 90)` +Generated query for warning alert: `max((max_over_time(cadvisor_container_cpu_usage_percentage_total{name=~"^syntactic-code-intel-worker.*"}[5m])) >= 90)`-## redis: provisioning_container_memory_usage_short_term +## syntactic-indexing: provisioning_container_memory_usage_short_term
container memory usage (5m maximum) by instance
**Descriptions** -- warning redis: 90%+ container memory usage (5m maximum) by instance +- warning syntactic-indexing: 90%+ container memory usage (5m maximum) by instance **Next steps** - **Kubernetes:** Consider increasing memory limit in relevant `Deployment.yaml`. -- **Docker Compose:** Consider increasing `memory:` of redis-store container in `docker-compose.yml`. -- Learn more about the related dashboard panel in the [dashboards reference](dashboards#redis-provisioning-container-memory-usage-short-term). +- **Docker Compose:** Consider increasing `memory:` of syntactic-code-intel-worker container in `docker-compose.yml`. +- Learn more about the related dashboard panel in the [dashboards reference](dashboards#syntactic-indexing-provisioning-container-memory-usage-short-term). - **Silence this alert:** If you are aware of this alert and want to silence notifications for it, add the following to your site configuration and set a reminder to re-evaluate the alert: ```json "observability.silenceAlerts": [ - "warning_redis_provisioning_container_memory_usage_short_term" + "warning_syntactic-indexing_provisioning_container_memory_usage_short_term" ] ``` -*Managed by the [Sourcegraph Infrastructure Org team](https://handbook.sourcegraph.com/departments/engineering/infrastructure).* +*Managed by the [Sourcegraph Code intelligence team](https://handbook.sourcegraph.com/departments/engineering/teams/code-intelligence).*Technical details
-Generated query for warning alert: `max((max_over_time(cadvisor_container_memory_usage_percentage_total{name=~"^redis-store.*"}[5m])) >= 90)` +Generated query for warning alert: `max((max_over_time(cadvisor_container_memory_usage_percentage_total{name=~"^syntactic-code-intel-worker.*"}[5m])) >= 90)`-## redis: container_oomkill_events_total +## syntactic-indexing: container_oomkill_events_total
container OOMKILL events total by instance
**Descriptions** -- warning redis: 1+ container OOMKILL events total by instance +- warning syntactic-indexing: 1+ container OOMKILL events total by instance **Next steps** - **Kubernetes:** Consider increasing memory limit in relevant `Deployment.yaml`. -- **Docker Compose:** Consider increasing `memory:` of redis-store container in `docker-compose.yml`. -- More help interpreting this metric is available in the [dashboards reference](dashboards#redis-container-oomkill-events-total). -- **Silence this alert:** If you are aware of this alert and want to silence notifications for it, add the following to your site configuration and set a reminder to re-evaluate the alert: - -```json -"observability.silenceAlerts": [ - "warning_redis_container_oomkill_events_total" -] -``` - -*Managed by the [Sourcegraph Infrastructure Org team](https://handbook.sourcegraph.com/departments/engineering/infrastructure).* - -Technical details
- -Generated query for warning alert: `max((max by (name) (container_oom_events_total{name=~"^redis-store.*"})) >= 1)` - -- -## redis: pods_available_percentage - -
percentage pods available
- -**Descriptions** - -- critical redis: less than 90% percentage pods available for 10m0s - -**Next steps** - -- Determine if the pod was OOM killed using `kubectl describe pod redis-cache` (look for `OOMKilled: true`) and, if so, consider increasing the memory limit in the relevant `Deployment.yaml`. -- Check the logs before the container restarted to see if there are `panic:` messages or similar using `kubectl logs -p redis-cache`. -- Learn more about the related dashboard panel in the [dashboards reference](dashboards#redis-pods-available-percentage). -- **Silence this alert:** If you are aware of this alert and want to silence notifications for it, add the following to your site configuration and set a reminder to re-evaluate the alert: - -```json -"observability.silenceAlerts": [ - "critical_redis_pods_available_percentage" -] -``` - -*Managed by the [Sourcegraph Infrastructure Org team](https://handbook.sourcegraph.com/departments/engineering/infrastructure).* - -Technical details
- -Generated query for critical alert: `min((sum by (app) (up{app=~".*redis-cache"\}) / count by (app) (up\{app=~".*redis-cache"}) * 100) <= 90)` - -- -## redis: pods_available_percentage - -
percentage pods available
- -**Descriptions** - -- critical redis: less than 90% percentage pods available for 10m0s - -**Next steps** - -- Determine if the pod was OOM killed using `kubectl describe pod redis-store` (look for `OOMKilled: true`) and, if so, consider increasing the memory limit in the relevant `Deployment.yaml`. -- Check the logs before the container restarted to see if there are `panic:` messages or similar using `kubectl logs -p redis-store`. -- Learn more about the related dashboard panel in the [dashboards reference](dashboards#redis-pods-available-percentage). -- **Silence this alert:** If you are aware of this alert and want to silence notifications for it, add the following to your site configuration and set a reminder to re-evaluate the alert: - -```json -"observability.silenceAlerts": [ - "critical_redis_pods_available_percentage" -] -``` - -*Managed by the [Sourcegraph Infrastructure Org team](https://handbook.sourcegraph.com/departments/engineering/infrastructure).* - -Technical details
- -Generated query for critical alert: `min((sum by (app) (up{app=~".*redis-store"\}) / count by (app) (up\{app=~".*redis-store"}) * 100) <= 90)` - -- -## worker: worker_job_codeintel-upload-janitor_count - -
number of worker instances running the codeintel-upload-janitor job
- -**Descriptions** - -- warning worker: less than 1 number of worker instances running the codeintel-upload-janitor job for 1m0s -- critical worker: less than 1 number of worker instances running the codeintel-upload-janitor job for 5m0s - -**Next steps** - -- Ensure your instance defines a worker container such that: - - `WORKER_JOB_ALLOWLIST` contains "codeintel-upload-janitor" (or "all"), and - - `WORKER_JOB_BLOCKLIST` does not contain "codeintel-upload-janitor" -- Ensure that such a container is not failing to start or stay active -- Learn more about the related dashboard panel in the [dashboards reference](dashboards#worker-worker-job-codeintel-upload-janitor-count). -- **Silence this alert:** If you are aware of this alert and want to silence notifications for it, add the following to your site configuration and set a reminder to re-evaluate the alert: - -```json -"observability.silenceAlerts": [ - "warning_worker_worker_job_codeintel-upload-janitor_count", - "critical_worker_worker_job_codeintel-upload-janitor_count" -] -``` - -*Managed by the [Sourcegraph Code intelligence team](https://handbook.sourcegraph.com/departments/engineering/teams/code-intelligence).* - -Technical details
- -Generated query for warning alert: `(min((sum(src_worker_jobs{job=~"^worker.*",job_name="codeintel-upload-janitor"\})) < 1)) or (absent(sum(src_worker_jobs\{job=~"^worker.*",job_name="codeintel-upload-janitor"})) == 1)` - -Generated query for critical alert: `(min((sum(src_worker_jobs{job=~"^worker.*",job_name="codeintel-upload-janitor"\})) < 1)) or (absent(sum(src_worker_jobs\{job=~"^worker.*",job_name="codeintel-upload-janitor"})) == 1)` - -- -## worker: worker_job_codeintel-commitgraph-updater_count - -
number of worker instances running the codeintel-commitgraph-updater job
- -**Descriptions** - -- warning worker: less than 1 number of worker instances running the codeintel-commitgraph-updater job for 1m0s -- critical worker: less than 1 number of worker instances running the codeintel-commitgraph-updater job for 5m0s - -**Next steps** - -- Ensure your instance defines a worker container such that: - - `WORKER_JOB_ALLOWLIST` contains "codeintel-commitgraph-updater" (or "all"), and - - `WORKER_JOB_BLOCKLIST` does not contain "codeintel-commitgraph-updater" -- Ensure that such a container is not failing to start or stay active -- Learn more about the related dashboard panel in the [dashboards reference](dashboards#worker-worker-job-codeintel-commitgraph-updater-count). -- **Silence this alert:** If you are aware of this alert and want to silence notifications for it, add the following to your site configuration and set a reminder to re-evaluate the alert: - -```json -"observability.silenceAlerts": [ - "warning_worker_worker_job_codeintel-commitgraph-updater_count", - "critical_worker_worker_job_codeintel-commitgraph-updater_count" -] -``` - -*Managed by the [Sourcegraph Code intelligence team](https://handbook.sourcegraph.com/departments/engineering/teams/code-intelligence).* - -Technical details
- -Generated query for warning alert: `(min((sum(src_worker_jobs{job=~"^worker.*",job_name="codeintel-commitgraph-updater"\})) < 1)) or (absent(sum(src_worker_jobs\{job=~"^worker.*",job_name="codeintel-commitgraph-updater"})) == 1)` - -Generated query for critical alert: `(min((sum(src_worker_jobs{job=~"^worker.*",job_name="codeintel-commitgraph-updater"\})) < 1)) or (absent(sum(src_worker_jobs\{job=~"^worker.*",job_name="codeintel-commitgraph-updater"})) == 1)` - -- -## worker: worker_job_codeintel-autoindexing-scheduler_count - -
number of worker instances running the codeintel-autoindexing-scheduler job
- -**Descriptions** - -- warning worker: less than 1 number of worker instances running the codeintel-autoindexing-scheduler job for 1m0s -- critical worker: less than 1 number of worker instances running the codeintel-autoindexing-scheduler job for 5m0s - -**Next steps** - -- Ensure your instance defines a worker container such that: - - `WORKER_JOB_ALLOWLIST` contains "codeintel-autoindexing-scheduler" (or "all"), and - - `WORKER_JOB_BLOCKLIST` does not contain "codeintel-autoindexing-scheduler" -- Ensure that such a container is not failing to start or stay active -- Learn more about the related dashboard panel in the [dashboards reference](dashboards#worker-worker-job-codeintel-autoindexing-scheduler-count). +- **Docker Compose:** Consider increasing `memory:` of syntactic-code-intel-worker container in `docker-compose.yml`. +- More help interpreting this metric is available in the [dashboards reference](dashboards#syntactic-indexing-container-oomkill-events-total). - **Silence this alert:** If you are aware of this alert and want to silence notifications for it, add the following to your site configuration and set a reminder to re-evaluate the alert: ```json "observability.silenceAlerts": [ - "warning_worker_worker_job_codeintel-autoindexing-scheduler_count", - "critical_worker_worker_job_codeintel-autoindexing-scheduler_count" + "warning_syntactic-indexing_container_oomkill_events_total" ] ``` @@ -76276,32 +76037,28 @@ Generated query for critical alert: `(min((sum(src_worker_jobs{job=~"^worker.*",Technical details
-Generated query for warning alert: `(min((sum(src_worker_jobs{job=~"^worker.*",job_name="codeintel-autoindexing-scheduler"\})) < 1)) or (absent(sum(src_worker_jobs\{job=~"^worker.*",job_name="codeintel-autoindexing-scheduler"})) == 1)` - -Generated query for critical alert: `(min((sum(src_worker_jobs{job=~"^worker.*",job_name="codeintel-autoindexing-scheduler"\})) < 1)) or (absent(sum(src_worker_jobs\{job=~"^worker.*",job_name="codeintel-autoindexing-scheduler"})) == 1)` +Generated query for warning alert: `max((max by (name) (container_oom_events_total{name=~"^syntactic-code-intel-worker.*"})) >= 1)`-## worker: codeintel_commit_graph_queued_max_age +## syntactic-indexing: go_goroutines -
repository queue longest time in queue
+maximum active goroutines
**Descriptions** -- warning worker: 3600s+ repository queue longest time in queue +- warning syntactic-indexing: 10000+ maximum active goroutines for 10m0s **Next steps** -- An alert here is generally indicative of either underprovisioned worker instance(s) and/or -an underprovisioned main postgres instance. -- Learn more about the related dashboard panel in the [dashboards reference](dashboards#worker-codeintel-commit-graph-queued-max-age). +- More help interpreting this metric is available in the [dashboards reference](dashboards#syntactic-indexing-go-goroutines). - **Silence this alert:** If you are aware of this alert and want to silence notifications for it, add the following to your site configuration and set a reminder to re-evaluate the alert: ```json "observability.silenceAlerts": [ - "warning_worker_codeintel_commit_graph_queued_max_age" + "warning_syntactic-indexing_go_goroutines" ] ``` @@ -76310,159 +76067,154 @@ an underprovisioned main postgres instance.Technical details
-Generated query for warning alert: `max((max(src_codeintel_commit_graph_queued_duration_seconds_total{job=~"^worker.*"})) >= 3600)` +Generated query for warning alert: `max((max by (instance) (go_goroutines{job=~".*syntactic-code-intel-worker"})) >= 10000)`-## worker: perms_syncer_outdated_perms +## syntactic-indexing: go_gc_duration_seconds -
number of entities with outdated permissions
+maximum go garbage collection duration
**Descriptions** -- warning worker: 100+ number of entities with outdated permissions for 5m0s +- warning syntactic-indexing: 2s+ maximum go garbage collection duration **Next steps** -- **Enabled permissions for the first time:** Wait for few minutes and see if the number goes down. -- **Otherwise:** Increase the API rate limit to [GitHub](https://sourcegraph.com/docs/admin/code_hosts/github#github-com-rate-limits), [GitLab](https://sourcegraph.com/docs/admin/code_hosts/gitlab#internal-rate-limits) or [Bitbucket Server](https://sourcegraph.com/docs/admin/code_hosts/bitbucket_server#internal-rate-limits). -- Learn more about the related dashboard panel in the [dashboards reference](dashboards#worker-perms-syncer-outdated-perms). +- Learn more about the related dashboard panel in the [dashboards reference](dashboards#syntactic-indexing-go-gc-duration-seconds). - **Silence this alert:** If you are aware of this alert and want to silence notifications for it, add the following to your site configuration and set a reminder to re-evaluate the alert: ```json "observability.silenceAlerts": [ - "warning_worker_perms_syncer_outdated_perms" + "warning_syntactic-indexing_go_gc_duration_seconds" ] ``` -*Managed by the [Sourcegraph Source team](https://handbook.sourcegraph.com/departments/engineering/teams/source).* +*Managed by the [Sourcegraph Code intelligence team](https://handbook.sourcegraph.com/departments/engineering/teams/code-intelligence).*Technical details
-Generated query for warning alert: `max((max by (type) (src_repo_perms_syncer_outdated_perms)) >= 100)` +Generated query for warning alert: `max((max by (instance) (go_gc_duration_seconds{job=~".*syntactic-code-intel-worker"})) >= 2)`-## worker: perms_syncer_sync_duration +## syntactic-indexing: pods_available_percentage -
95th permissions sync duration
+percentage pods available
**Descriptions** -- warning worker: 30s+ 95th permissions sync duration for 5m0s +- critical syntactic-indexing: less than 90% percentage pods available for 10m0s **Next steps** -- Check the network latency is reasonable (<50ms) between the Sourcegraph and the code host. -- Learn more about the related dashboard panel in the [dashboards reference](dashboards#worker-perms-syncer-sync-duration). +- Determine if the pod was OOM killed using `kubectl describe pod syntactic-code-intel-worker` (look for `OOMKilled: true`) and, if so, consider increasing the memory limit in the relevant `Deployment.yaml`. +- Check the logs before the container restarted to see if there are `panic:` messages or similar using `kubectl logs -p syntactic-code-intel-worker`. +- Learn more about the related dashboard panel in the [dashboards reference](dashboards#syntactic-indexing-pods-available-percentage). - **Silence this alert:** If you are aware of this alert and want to silence notifications for it, add the following to your site configuration and set a reminder to re-evaluate the alert: ```json "observability.silenceAlerts": [ - "warning_worker_perms_syncer_sync_duration" + "critical_syntactic-indexing_pods_available_percentage" ] ``` -*Managed by the [Sourcegraph Source team](https://handbook.sourcegraph.com/departments/engineering/teams/source).* +*Managed by the [Sourcegraph Code intelligence team](https://handbook.sourcegraph.com/departments/engineering/teams/code-intelligence).*Technical details
-Generated query for warning alert: `max((histogram_quantile(0.95, max by (le, type) (rate(src_repo_perms_syncer_sync_duration_seconds_bucket[1m])))) >= 30)` +Generated query for critical alert: `min((sum by (app) (up{app=~".*syntactic-code-intel-worker"\}) / count by (app) (up\{app=~".*syntactic-code-intel-worker"}) * 100) <= 90)`-## worker: perms_syncer_sync_errors +## redis: redis-store_up -
permissions sync error rate
+redis-store availability
**Descriptions** -- critical worker: 1+ permissions sync error rate for 1m0s +- critical redis: less than 1 redis-store availability for 10s **Next steps** -- Check the network connectivity the Sourcegraph and the code host. -- Check if API rate limit quota is exhausted on the code host. -- Learn more about the related dashboard panel in the [dashboards reference](dashboards#worker-perms-syncer-sync-errors). +- Ensure redis-store is running +- More help interpreting this metric is available in the [dashboards reference](dashboards#redis-redis-store-up). - **Silence this alert:** If you are aware of this alert and want to silence notifications for it, add the following to your site configuration and set a reminder to re-evaluate the alert: ```json "observability.silenceAlerts": [ - "critical_worker_perms_syncer_sync_errors" + "critical_redis_redis-store_up" ] ``` -*Managed by the [Sourcegraph Source team](https://handbook.sourcegraph.com/departments/engineering/teams/source).* +*Managed by the [Sourcegraph Infrastructure Org team](https://handbook.sourcegraph.com/departments/engineering/infrastructure).*Technical details
-Generated query for critical alert: `max((max by (type) (ceil(rate(src_repo_perms_syncer_sync_errors_total[1m])))) >= 1)` +Generated query for critical alert: `min((redis_up{app="redis-store"}) < 1)`-## worker: insights_queue_unutilized_size +## redis: redis-cache_up -
insights queue size that is not utilized (not processing)
+redis-cache availability
**Descriptions** -- warning worker: 0+ insights queue size that is not utilized (not processing) for 30m0s +- critical redis: less than 1 redis-cache availability for 10s **Next steps** -- Verify code insights worker job has successfully started. Restart worker service and monitoring startup logs, looking for worker panics. -- More help interpreting this metric is available in the [dashboards reference](dashboards#worker-insights-queue-unutilized-size). +- Ensure redis-cache is running +- More help interpreting this metric is available in the [dashboards reference](dashboards#redis-redis-cache-up). - **Silence this alert:** If you are aware of this alert and want to silence notifications for it, add the following to your site configuration and set a reminder to re-evaluate the alert: ```json "observability.silenceAlerts": [ - "warning_worker_insights_queue_unutilized_size" + "critical_redis_redis-cache_up" ] ``` -*Managed by the [Sourcegraph Code Search team](https://handbook.sourcegraph.com/departments/engineering/teams/code-search).* +*Managed by the [Sourcegraph Infrastructure Org team](https://handbook.sourcegraph.com/departments/engineering/infrastructure).*Technical details
-Generated query for warning alert: `max((max(src_query_runner_worker_total{job=~"^worker.*"\}) > 0 and on (job) sum by (op) (increase(src_workerutil_dbworker_store_insights_query_runner_jobs_store_total\{job=~"^worker.*",op="Dequeue"}[5m])) < 1) > 0)` +Generated query for critical alert: `min((redis_up{app="redis-cache"}) < 1)`-## worker: mean_blocked_seconds_per_conn_request +## redis: provisioning_container_cpu_usage_long_term -
mean blocked seconds per conn request
+container cpu usage total (90th percentile over 1d) across all cores by instance
**Descriptions** -- warning worker: 0.1s+ mean blocked seconds per conn request for 10m0s -- critical worker: 0.5s+ mean blocked seconds per conn request for 10m0s +- warning redis: 80%+ container cpu usage total (90th percentile over 1d) across all cores by instance for 336h0m0s **Next steps** -- Increase SRC_PGSQL_MAX_OPEN together with giving more memory to the database if needed -- Scale up Postgres memory/cpus - [see our scaling guide](https://sourcegraph.com/docs/admin/config/postgres-conf) -- If using GCP Cloud SQL, check for high lock waits or CPU usage in query insights -- Learn more about the related dashboard panel in the [dashboards reference](dashboards#worker-mean-blocked-seconds-per-conn-request). +- **Kubernetes:** Consider increasing CPU limits in the `Deployment.yaml` for the redis-cache service. +- **Docker Compose:** Consider increasing `cpus:` of the redis-cache container in `docker-compose.yml`. +- Learn more about the related dashboard panel in the [dashboards reference](dashboards#redis-provisioning-container-cpu-usage-long-term). - **Silence this alert:** If you are aware of this alert and want to silence notifications for it, add the following to your site configuration and set a reminder to re-evaluate the alert: ```json "observability.silenceAlerts": [ - "warning_worker_mean_blocked_seconds_per_conn_request", - "critical_worker_mean_blocked_seconds_per_conn_request" + "warning_redis_provisioning_container_cpu_usage_long_term" ] ``` @@ -76471,348 +76223,350 @@ Generated query for warning alert: `max((max(src_query_runner_worker_total{job=~Technical details
-Generated query for warning alert: `max((sum by (app_name, db_name) (increase(src_pgsql_conns_blocked_seconds{app_name="worker"\}[5m])) / sum by (app_name, db_name) (increase(src_pgsql_conns_waited_for\{app_name="worker"}[5m]))) >= 0.1)` - -Generated query for critical alert: `max((sum by (app_name, db_name) (increase(src_pgsql_conns_blocked_seconds{app_name="worker"\}[5m])) / sum by (app_name, db_name) (increase(src_pgsql_conns_waited_for\{app_name="worker"}[5m]))) >= 0.5)` +Generated query for warning alert: `max((quantile_over_time(0.9, cadvisor_container_cpu_usage_percentage_total{name=~"^redis-cache.*"}[1d])) >= 80)`-## worker: container_cpu_usage +## redis: provisioning_container_memory_usage_long_term -
container cpu usage total (1m average) across all cores by instance
+container memory usage (1d maximum) by instance
**Descriptions** -- warning worker: 99%+ container cpu usage total (1m average) across all cores by instance +- warning redis: 80%+ container memory usage (1d maximum) by instance for 336h0m0s **Next steps** -- **Kubernetes:** Consider increasing CPU limits in the the relevant `Deployment.yaml`. -- **Docker Compose:** Consider increasing `cpus:` of the worker container in `docker-compose.yml`. -- Learn more about the related dashboard panel in the [dashboards reference](dashboards#worker-container-cpu-usage). +- **Kubernetes:** Consider increasing memory limits in the `Deployment.yaml` for the redis-cache service. +- **Docker Compose:** Consider increasing `memory:` of the redis-cache container in `docker-compose.yml`. +- Learn more about the related dashboard panel in the [dashboards reference](dashboards#redis-provisioning-container-memory-usage-long-term). - **Silence this alert:** If you are aware of this alert and want to silence notifications for it, add the following to your site configuration and set a reminder to re-evaluate the alert: ```json "observability.silenceAlerts": [ - "warning_worker_container_cpu_usage" + "warning_redis_provisioning_container_memory_usage_long_term" ] ``` -*Managed by the [Sourcegraph Code intelligence team](https://handbook.sourcegraph.com/departments/engineering/teams/code-intelligence).* +*Managed by the [Sourcegraph Infrastructure Org team](https://handbook.sourcegraph.com/departments/engineering/infrastructure).*Technical details
-Generated query for warning alert: `max((cadvisor_container_cpu_usage_percentage_total{name=~"^worker.*"}) >= 99)` +Generated query for warning alert: `max((max_over_time(cadvisor_container_memory_usage_percentage_total{name=~"^redis-cache.*"}[1d])) >= 80)`-## worker: container_memory_usage +## redis: provisioning_container_cpu_usage_short_term -
container memory usage by instance
+container cpu usage total (5m maximum) across all cores by instance
**Descriptions** -- warning worker: 99%+ container memory usage by instance +- warning redis: 90%+ container cpu usage total (5m maximum) across all cores by instance for 30m0s **Next steps** -- **Kubernetes:** Consider increasing memory limit in relevant `Deployment.yaml`. -- **Docker Compose:** Consider increasing `memory:` of worker container in `docker-compose.yml`. -- Learn more about the related dashboard panel in the [dashboards reference](dashboards#worker-container-memory-usage). +- **Kubernetes:** Consider increasing CPU limits in the the relevant `Deployment.yaml`. +- **Docker Compose:** Consider increasing `cpus:` of the redis-cache container in `docker-compose.yml`. +- Learn more about the related dashboard panel in the [dashboards reference](dashboards#redis-provisioning-container-cpu-usage-short-term). - **Silence this alert:** If you are aware of this alert and want to silence notifications for it, add the following to your site configuration and set a reminder to re-evaluate the alert: ```json "observability.silenceAlerts": [ - "warning_worker_container_memory_usage" + "warning_redis_provisioning_container_cpu_usage_short_term" ] ``` -*Managed by the [Sourcegraph Code intelligence team](https://handbook.sourcegraph.com/departments/engineering/teams/code-intelligence).* +*Managed by the [Sourcegraph Infrastructure Org team](https://handbook.sourcegraph.com/departments/engineering/infrastructure).*Technical details
-Generated query for warning alert: `max((cadvisor_container_memory_usage_percentage_total{name=~"^worker.*"}) >= 99)` +Generated query for warning alert: `max((max_over_time(cadvisor_container_cpu_usage_percentage_total{name=~"^redis-cache.*"}[5m])) >= 90)`-## worker: provisioning_container_cpu_usage_long_term +## redis: provisioning_container_memory_usage_short_term -
container cpu usage total (90th percentile over 1d) across all cores by instance
+container memory usage (5m maximum) by instance
**Descriptions** -- warning worker: 80%+ container cpu usage total (90th percentile over 1d) across all cores by instance for 336h0m0s +- warning redis: 90%+ container memory usage (5m maximum) by instance **Next steps** -- **Kubernetes:** Consider increasing CPU limits in the `Deployment.yaml` for the worker service. -- **Docker Compose:** Consider increasing `cpus:` of the worker container in `docker-compose.yml`. -- Learn more about the related dashboard panel in the [dashboards reference](dashboards#worker-provisioning-container-cpu-usage-long-term). +- **Kubernetes:** Consider increasing memory limit in relevant `Deployment.yaml`. +- **Docker Compose:** Consider increasing `memory:` of redis-cache container in `docker-compose.yml`. +- Learn more about the related dashboard panel in the [dashboards reference](dashboards#redis-provisioning-container-memory-usage-short-term). - **Silence this alert:** If you are aware of this alert and want to silence notifications for it, add the following to your site configuration and set a reminder to re-evaluate the alert: ```json "observability.silenceAlerts": [ - "warning_worker_provisioning_container_cpu_usage_long_term" + "warning_redis_provisioning_container_memory_usage_short_term" ] ``` -*Managed by the [Sourcegraph Code intelligence team](https://handbook.sourcegraph.com/departments/engineering/teams/code-intelligence).* +*Managed by the [Sourcegraph Infrastructure Org team](https://handbook.sourcegraph.com/departments/engineering/infrastructure).*Technical details
-Generated query for warning alert: `max((quantile_over_time(0.9, cadvisor_container_cpu_usage_percentage_total{name=~"^worker.*"}[1d])) >= 80)` +Generated query for warning alert: `max((max_over_time(cadvisor_container_memory_usage_percentage_total{name=~"^redis-cache.*"}[5m])) >= 90)`-## worker: provisioning_container_memory_usage_long_term +## redis: container_oomkill_events_total -
container memory usage (1d maximum) by instance
+container OOMKILL events total by instance
**Descriptions** -- warning worker: 80%+ container memory usage (1d maximum) by instance for 336h0m0s +- warning redis: 1+ container OOMKILL events total by instance **Next steps** -- **Kubernetes:** Consider increasing memory limits in the `Deployment.yaml` for the worker service. -- **Docker Compose:** Consider increasing `memory:` of the worker container in `docker-compose.yml`. -- Learn more about the related dashboard panel in the [dashboards reference](dashboards#worker-provisioning-container-memory-usage-long-term). +- **Kubernetes:** Consider increasing memory limit in relevant `Deployment.yaml`. +- **Docker Compose:** Consider increasing `memory:` of redis-cache container in `docker-compose.yml`. +- More help interpreting this metric is available in the [dashboards reference](dashboards#redis-container-oomkill-events-total). - **Silence this alert:** If you are aware of this alert and want to silence notifications for it, add the following to your site configuration and set a reminder to re-evaluate the alert: ```json "observability.silenceAlerts": [ - "warning_worker_provisioning_container_memory_usage_long_term" + "warning_redis_container_oomkill_events_total" ] ``` -*Managed by the [Sourcegraph Code intelligence team](https://handbook.sourcegraph.com/departments/engineering/teams/code-intelligence).* +*Managed by the [Sourcegraph Infrastructure Org team](https://handbook.sourcegraph.com/departments/engineering/infrastructure).*Technical details
-Generated query for warning alert: `max((max_over_time(cadvisor_container_memory_usage_percentage_total{name=~"^worker.*"}[1d])) >= 80)` +Generated query for warning alert: `max((max by (name) (container_oom_events_total{name=~"^redis-cache.*"})) >= 1)`-## worker: provisioning_container_cpu_usage_short_term +## redis: provisioning_container_cpu_usage_long_term -
container cpu usage total (5m maximum) across all cores by instance
+container cpu usage total (90th percentile over 1d) across all cores by instance
**Descriptions** -- warning worker: 90%+ container cpu usage total (5m maximum) across all cores by instance for 30m0s +- warning redis: 80%+ container cpu usage total (90th percentile over 1d) across all cores by instance for 336h0m0s **Next steps** -- **Kubernetes:** Consider increasing CPU limits in the the relevant `Deployment.yaml`. -- **Docker Compose:** Consider increasing `cpus:` of the worker container in `docker-compose.yml`. -- Learn more about the related dashboard panel in the [dashboards reference](dashboards#worker-provisioning-container-cpu-usage-short-term). +- **Kubernetes:** Consider increasing CPU limits in the `Deployment.yaml` for the redis-store service. +- **Docker Compose:** Consider increasing `cpus:` of the redis-store container in `docker-compose.yml`. +- Learn more about the related dashboard panel in the [dashboards reference](dashboards#redis-provisioning-container-cpu-usage-long-term). - **Silence this alert:** If you are aware of this alert and want to silence notifications for it, add the following to your site configuration and set a reminder to re-evaluate the alert: ```json "observability.silenceAlerts": [ - "warning_worker_provisioning_container_cpu_usage_short_term" + "warning_redis_provisioning_container_cpu_usage_long_term" ] ``` -*Managed by the [Sourcegraph Code intelligence team](https://handbook.sourcegraph.com/departments/engineering/teams/code-intelligence).* +*Managed by the [Sourcegraph Infrastructure Org team](https://handbook.sourcegraph.com/departments/engineering/infrastructure).*Technical details
-Generated query for warning alert: `max((max_over_time(cadvisor_container_cpu_usage_percentage_total{name=~"^worker.*"}[5m])) >= 90)` +Generated query for warning alert: `max((quantile_over_time(0.9, cadvisor_container_cpu_usage_percentage_total{name=~"^redis-store.*"}[1d])) >= 80)`-## worker: provisioning_container_memory_usage_short_term +## redis: provisioning_container_memory_usage_long_term -
container memory usage (5m maximum) by instance
+container memory usage (1d maximum) by instance
**Descriptions** -- warning worker: 90%+ container memory usage (5m maximum) by instance +- warning redis: 80%+ container memory usage (1d maximum) by instance for 336h0m0s **Next steps** -- **Kubernetes:** Consider increasing memory limit in relevant `Deployment.yaml`. -- **Docker Compose:** Consider increasing `memory:` of worker container in `docker-compose.yml`. -- Learn more about the related dashboard panel in the [dashboards reference](dashboards#worker-provisioning-container-memory-usage-short-term). +- **Kubernetes:** Consider increasing memory limits in the `Deployment.yaml` for the redis-store service. +- **Docker Compose:** Consider increasing `memory:` of the redis-store container in `docker-compose.yml`. +- Learn more about the related dashboard panel in the [dashboards reference](dashboards#redis-provisioning-container-memory-usage-long-term). - **Silence this alert:** If you are aware of this alert and want to silence notifications for it, add the following to your site configuration and set a reminder to re-evaluate the alert: ```json "observability.silenceAlerts": [ - "warning_worker_provisioning_container_memory_usage_short_term" + "warning_redis_provisioning_container_memory_usage_long_term" ] ``` -*Managed by the [Sourcegraph Code intelligence team](https://handbook.sourcegraph.com/departments/engineering/teams/code-intelligence).* +*Managed by the [Sourcegraph Infrastructure Org team](https://handbook.sourcegraph.com/departments/engineering/infrastructure).*Technical details
-Generated query for warning alert: `max((max_over_time(cadvisor_container_memory_usage_percentage_total{name=~"^worker.*"}[5m])) >= 90)` +Generated query for warning alert: `max((max_over_time(cadvisor_container_memory_usage_percentage_total{name=~"^redis-store.*"}[1d])) >= 80)`-## worker: container_oomkill_events_total +## redis: provisioning_container_cpu_usage_short_term -
container OOMKILL events total by instance
+container cpu usage total (5m maximum) across all cores by instance
**Descriptions** -- warning worker: 1+ container OOMKILL events total by instance +- warning redis: 90%+ container cpu usage total (5m maximum) across all cores by instance for 30m0s **Next steps** -- **Kubernetes:** Consider increasing memory limit in relevant `Deployment.yaml`. -- **Docker Compose:** Consider increasing `memory:` of worker container in `docker-compose.yml`. -- More help interpreting this metric is available in the [dashboards reference](dashboards#worker-container-oomkill-events-total). +- **Kubernetes:** Consider increasing CPU limits in the the relevant `Deployment.yaml`. +- **Docker Compose:** Consider increasing `cpus:` of the redis-store container in `docker-compose.yml`. +- Learn more about the related dashboard panel in the [dashboards reference](dashboards#redis-provisioning-container-cpu-usage-short-term). - **Silence this alert:** If you are aware of this alert and want to silence notifications for it, add the following to your site configuration and set a reminder to re-evaluate the alert: ```json "observability.silenceAlerts": [ - "warning_worker_container_oomkill_events_total" + "warning_redis_provisioning_container_cpu_usage_short_term" ] ``` -*Managed by the [Sourcegraph Code intelligence team](https://handbook.sourcegraph.com/departments/engineering/teams/code-intelligence).* +*Managed by the [Sourcegraph Infrastructure Org team](https://handbook.sourcegraph.com/departments/engineering/infrastructure).*Technical details
-Generated query for warning alert: `max((max by (name) (container_oom_events_total{name=~"^worker.*"})) >= 1)` +Generated query for warning alert: `max((max_over_time(cadvisor_container_cpu_usage_percentage_total{name=~"^redis-store.*"}[5m])) >= 90)`-## worker: go_goroutines +## redis: provisioning_container_memory_usage_short_term -
maximum active goroutines
+container memory usage (5m maximum) by instance
**Descriptions** -- warning worker: 10000+ maximum active goroutines for 10m0s +- warning redis: 90%+ container memory usage (5m maximum) by instance **Next steps** -- More help interpreting this metric is available in the [dashboards reference](dashboards#worker-go-goroutines). +- **Kubernetes:** Consider increasing memory limit in relevant `Deployment.yaml`. +- **Docker Compose:** Consider increasing `memory:` of redis-store container in `docker-compose.yml`. +- Learn more about the related dashboard panel in the [dashboards reference](dashboards#redis-provisioning-container-memory-usage-short-term). - **Silence this alert:** If you are aware of this alert and want to silence notifications for it, add the following to your site configuration and set a reminder to re-evaluate the alert: ```json "observability.silenceAlerts": [ - "warning_worker_go_goroutines" + "warning_redis_provisioning_container_memory_usage_short_term" ] ``` -*Managed by the [Sourcegraph Code intelligence team](https://handbook.sourcegraph.com/departments/engineering/teams/code-intelligence).* +*Managed by the [Sourcegraph Infrastructure Org team](https://handbook.sourcegraph.com/departments/engineering/infrastructure).*Technical details
-Generated query for warning alert: `max((max by (instance) (go_goroutines{job=~".*worker"})) >= 10000)` +Generated query for warning alert: `max((max_over_time(cadvisor_container_memory_usage_percentage_total{name=~"^redis-store.*"}[5m])) >= 90)`-## worker: go_gc_duration_seconds +## redis: container_oomkill_events_total -
maximum go garbage collection duration
+container OOMKILL events total by instance
**Descriptions** -- warning worker: 2s+ maximum go garbage collection duration +- warning redis: 1+ container OOMKILL events total by instance **Next steps** -- Learn more about the related dashboard panel in the [dashboards reference](dashboards#worker-go-gc-duration-seconds). +- **Kubernetes:** Consider increasing memory limit in relevant `Deployment.yaml`. +- **Docker Compose:** Consider increasing `memory:` of redis-store container in `docker-compose.yml`. +- More help interpreting this metric is available in the [dashboards reference](dashboards#redis-container-oomkill-events-total). - **Silence this alert:** If you are aware of this alert and want to silence notifications for it, add the following to your site configuration and set a reminder to re-evaluate the alert: ```json "observability.silenceAlerts": [ - "warning_worker_go_gc_duration_seconds" + "warning_redis_container_oomkill_events_total" ] ``` -*Managed by the [Sourcegraph Code intelligence team](https://handbook.sourcegraph.com/departments/engineering/teams/code-intelligence).* +*Managed by the [Sourcegraph Infrastructure Org team](https://handbook.sourcegraph.com/departments/engineering/infrastructure).*Technical details
-Generated query for warning alert: `max((max by (instance) (go_gc_duration_seconds{job=~".*worker"})) >= 2)` +Generated query for warning alert: `max((max by (name) (container_oom_events_total{name=~"^redis-store.*"})) >= 1)`-## worker: pods_available_percentage +## redis: pods_available_percentage
percentage pods available
**Descriptions** -- critical worker: less than 90% percentage pods available for 10m0s +- critical redis: less than 90% percentage pods available for 10m0s **Next steps** -- Determine if the pod was OOM killed using `kubectl describe pod worker` (look for `OOMKilled: true`) and, if so, consider increasing the memory limit in the relevant `Deployment.yaml`. -- Check the logs before the container restarted to see if there are `panic:` messages or similar using `kubectl logs -p worker`. -- Learn more about the related dashboard panel in the [dashboards reference](dashboards#worker-pods-available-percentage). +- Determine if the pod was OOM killed using `kubectl describe pod redis-cache` (look for `OOMKilled: true`) and, if so, consider increasing the memory limit in the relevant `Deployment.yaml`. +- Check the logs before the container restarted to see if there are `panic:` messages or similar using `kubectl logs -p redis-cache`. +- Learn more about the related dashboard panel in the [dashboards reference](dashboards#redis-pods-available-percentage). - **Silence this alert:** If you are aware of this alert and want to silence notifications for it, add the following to your site configuration and set a reminder to re-evaluate the alert: ```json "observability.silenceAlerts": [ - "critical_worker_pods_available_percentage" + "critical_redis_pods_available_percentage" ] ``` -*Managed by the [Sourcegraph Code intelligence team](https://handbook.sourcegraph.com/departments/engineering/teams/code-intelligence).* +*Managed by the [Sourcegraph Infrastructure Org team](https://handbook.sourcegraph.com/departments/engineering/infrastructure).*Technical details
-Generated query for critical alert: `min((sum by (app) (up{app=~".*worker"\}) / count by (app) (up\{app=~".*worker"}) * 100) <= 90)` +Generated query for critical alert: `min((sum by (app) (up{app=~".*redis-cache"\}) / count by (app) (up\{app=~".*redis-cache"}) * 100) <= 90)`-## worker: worker_site_configuration_duration_since_last_successful_update_by_instance +## redis: pods_available_percentage -
maximum duration since last successful site configuration update (all "worker" instances)
+percentage pods available
**Descriptions** -- critical worker: 300s+ maximum duration since last successful site configuration update (all "worker" instances) +- critical redis: less than 90% percentage pods available for 10m0s **Next steps** -- This indicates that one or more "worker" instances have not successfully updated the site configuration in over 5 minutes. This could be due to networking issues between services or problems with the site configuration service itself. -- Check for relevant errors in the "worker" logs, as well as frontend`s logs. -- Learn more about the related dashboard panel in the [dashboards reference](dashboards#worker-worker-site-configuration-duration-since-last-successful-update-by-instance). +- Determine if the pod was OOM killed using `kubectl describe pod redis-store` (look for `OOMKilled: true`) and, if so, consider increasing the memory limit in the relevant `Deployment.yaml`. +- Check the logs before the container restarted to see if there are `panic:` messages or similar using `kubectl logs -p redis-store`. +- Learn more about the related dashboard panel in the [dashboards reference](dashboards#redis-pods-available-percentage). - **Silence this alert:** If you are aware of this alert and want to silence notifications for it, add the following to your site configuration and set a reminder to re-evaluate the alert: ```json "observability.silenceAlerts": [ - "critical_worker_worker_site_configuration_duration_since_last_successful_update_by_instance" + "critical_redis_pods_available_percentage" ] ``` @@ -76821,138 +76575,149 @@ Generated query for critical alert: `min((sum by (app) (up{app=~".*worker"\}) /Technical details
-Generated query for critical alert: `max((max(max_over_time(src_conf_client_time_since_last_successful_update_seconds{job=~"^worker.*"}[1m]))) >= 300)` +Generated query for critical alert: `min((sum by (app) (up{app=~".*redis-store"\}) / count by (app) (up\{app=~".*redis-store"}) * 100) <= 90)`-## repo-updater: src_repoupdater_max_sync_backoff +## worker: worker_job_codeintel-upload-janitor_count -
time since oldest sync
+number of worker instances running the codeintel-upload-janitor job
**Descriptions** -- critical repo-updater: 32400s+ time since oldest sync for 10m0s +- warning worker: less than 1 number of worker instances running the codeintel-upload-janitor job for 1m0s +- critical worker: less than 1 number of worker instances running the codeintel-upload-janitor job for 5m0s **Next steps** -- An alert here indicates that no code host connections have synced in at least 9h0m0s. This indicates that there could be a configuration issue -with your code hosts connections or networking issues affecting communication with your code hosts. -- Check the code host status indicator (cloud icon in top right of Sourcegraph homepage) for errors. -- Make sure external services do not have invalid tokens by navigating to them in the web UI and clicking save. If there are no errors, they are valid. -- Check the repo-updater logs for errors about syncing. -- Confirm that outbound network connections are allowed where repo-updater is deployed. -- Check back in an hour to see if the issue has resolved itself. -- Learn more about the related dashboard panel in the [dashboards reference](dashboards#repo-updater-src-repoupdater-max-sync-backoff). +- Ensure your instance defines a worker container such that: + - `WORKER_JOB_ALLOWLIST` contains "codeintel-upload-janitor" (or "all"), and + - `WORKER_JOB_BLOCKLIST` does not contain "codeintel-upload-janitor" +- Ensure that such a container is not failing to start or stay active +- Learn more about the related dashboard panel in the [dashboards reference](dashboards#worker-worker-job-codeintel-upload-janitor-count). - **Silence this alert:** If you are aware of this alert and want to silence notifications for it, add the following to your site configuration and set a reminder to re-evaluate the alert: ```json "observability.silenceAlerts": [ - "critical_repo-updater_src_repoupdater_max_sync_backoff" + "warning_worker_worker_job_codeintel-upload-janitor_count", + "critical_worker_worker_job_codeintel-upload-janitor_count" ] ``` -*Managed by the [Sourcegraph Source team](https://handbook.sourcegraph.com/departments/engineering/teams/source).* +*Managed by the [Sourcegraph Code intelligence team](https://handbook.sourcegraph.com/departments/engineering/teams/code-intelligence).*Technical details
-Generated query for critical alert: `max((max(src_repoupdater_max_sync_backoff)) >= 32400)` +Generated query for warning alert: `(min((sum(src_worker_jobs{job=~"^worker.*",job_name="codeintel-upload-janitor"\})) < 1)) or (absent(sum(src_worker_jobs\{job=~"^worker.*",job_name="codeintel-upload-janitor"})) == 1)` + +Generated query for critical alert: `(min((sum(src_worker_jobs{job=~"^worker.*",job_name="codeintel-upload-janitor"\})) < 1)) or (absent(sum(src_worker_jobs\{job=~"^worker.*",job_name="codeintel-upload-janitor"})) == 1)`-## repo-updater: src_repoupdater_syncer_sync_errors_total +## worker: worker_job_codeintel-commitgraph-updater_count -
site level external service sync error rate
+number of worker instances running the codeintel-commitgraph-updater job
**Descriptions** -- warning repo-updater: 0.5+ site level external service sync error rate for 10m0s -- critical repo-updater: 1+ site level external service sync error rate for 10m0s +- warning worker: less than 1 number of worker instances running the codeintel-commitgraph-updater job for 1m0s +- critical worker: less than 1 number of worker instances running the codeintel-commitgraph-updater job for 5m0s **Next steps** -- An alert here indicates errors syncing site level repo metadata with code hosts. This indicates that there could be a configuration issue -with your code hosts connections or networking issues affecting communication with your code hosts. -- Check the code host status indicator (cloud icon in top right of Sourcegraph homepage) for errors. -- Make sure external services do not have invalid tokens by navigating to them in the web UI and clicking save. If there are no errors, they are valid. -- Check the repo-updater logs for errors about syncing. -- Confirm that outbound network connections are allowed where repo-updater is deployed. -- Check back in an hour to see if the issue has resolved itself. -- Learn more about the related dashboard panel in the [dashboards reference](dashboards#repo-updater-src-repoupdater-syncer-sync-errors-total). +- Ensure your instance defines a worker container such that: + - `WORKER_JOB_ALLOWLIST` contains "codeintel-commitgraph-updater" (or "all"), and + - `WORKER_JOB_BLOCKLIST` does not contain "codeintel-commitgraph-updater" +- Ensure that such a container is not failing to start or stay active +- Learn more about the related dashboard panel in the [dashboards reference](dashboards#worker-worker-job-codeintel-commitgraph-updater-count). - **Silence this alert:** If you are aware of this alert and want to silence notifications for it, add the following to your site configuration and set a reminder to re-evaluate the alert: ```json "observability.silenceAlerts": [ - "warning_repo-updater_src_repoupdater_syncer_sync_errors_total", - "critical_repo-updater_src_repoupdater_syncer_sync_errors_total" + "warning_worker_worker_job_codeintel-commitgraph-updater_count", + "critical_worker_worker_job_codeintel-commitgraph-updater_count" ] ``` -*Managed by the [Sourcegraph Source team](https://handbook.sourcegraph.com/departments/engineering/teams/source).* +*Managed by the [Sourcegraph Code intelligence team](https://handbook.sourcegraph.com/departments/engineering/teams/code-intelligence).*Technical details
-Generated query for warning alert: `max((max by (family) (rate(src_repoupdater_syncer_sync_errors_total{owner!="user",reason!="internal_rate_limit",reason!="invalid_npm_path"}[5m]))) > 0.5)` +Generated query for warning alert: `(min((sum(src_worker_jobs{job=~"^worker.*",job_name="codeintel-commitgraph-updater"\})) < 1)) or (absent(sum(src_worker_jobs\{job=~"^worker.*",job_name="codeintel-commitgraph-updater"})) == 1)` -Generated query for critical alert: `max((max by (family) (rate(src_repoupdater_syncer_sync_errors_total{owner!="user",reason!="internal_rate_limit",reason!="invalid_npm_path"}[5m]))) > 1)` +Generated query for critical alert: `(min((sum(src_worker_jobs{job=~"^worker.*",job_name="codeintel-commitgraph-updater"\})) < 1)) or (absent(sum(src_worker_jobs\{job=~"^worker.*",job_name="codeintel-commitgraph-updater"})) == 1)`-## repo-updater: syncer_sync_start +## worker: worker_job_codeintel-autoindexing-scheduler_count -
repo metadata sync was started
+number of worker instances running the codeintel-autoindexing-scheduler job
**Descriptions** -- warning repo-updater: less than 0 repo metadata sync was started for 9h0m0s +- warning worker: less than 1 number of worker instances running the codeintel-autoindexing-scheduler job for 1m0s +- critical worker: less than 1 number of worker instances running the codeintel-autoindexing-scheduler job for 5m0s **Next steps** -- Check repo-updater logs for errors. -- Learn more about the related dashboard panel in the [dashboards reference](dashboards#repo-updater-syncer-sync-start). +- Ensure your instance defines a worker container such that: + - `WORKER_JOB_ALLOWLIST` contains "codeintel-autoindexing-scheduler" (or "all"), and + - `WORKER_JOB_BLOCKLIST` does not contain "codeintel-autoindexing-scheduler" +- Ensure that such a container is not failing to start or stay active +- Learn more about the related dashboard panel in the [dashboards reference](dashboards#worker-worker-job-codeintel-autoindexing-scheduler-count). - **Silence this alert:** If you are aware of this alert and want to silence notifications for it, add the following to your site configuration and set a reminder to re-evaluate the alert: ```json "observability.silenceAlerts": [ - "warning_repo-updater_syncer_sync_start" + "warning_worker_worker_job_codeintel-autoindexing-scheduler_count", + "critical_worker_worker_job_codeintel-autoindexing-scheduler_count" ] ``` -*Managed by the [Sourcegraph Source team](https://handbook.sourcegraph.com/departments/engineering/teams/source).* +*Managed by the [Sourcegraph Code intelligence team](https://handbook.sourcegraph.com/departments/engineering/teams/code-intelligence).*Technical details
-Generated query for warning alert: `min((max by (family) (rate(src_repoupdater_syncer_start_sync{family="Syncer.SyncExternalService"}[9h]))) <= 0)` +Generated query for warning alert: `(min((sum(src_worker_jobs{job=~"^worker.*",job_name="codeintel-autoindexing-scheduler"\})) < 1)) or (absent(sum(src_worker_jobs\{job=~"^worker.*",job_name="codeintel-autoindexing-scheduler"})) == 1)` + +Generated query for critical alert: `(min((sum(src_worker_jobs{job=~"^worker.*",job_name="codeintel-autoindexing-scheduler"\})) < 1)) or (absent(sum(src_worker_jobs\{job=~"^worker.*",job_name="codeintel-autoindexing-scheduler"})) == 1)`-## repo-updater: syncer_sync_duration +## worker: src_repoupdater_max_sync_backoff -
95th repositories sync duration
+time since oldest sync
**Descriptions** -- warning repo-updater: 30s+ 95th repositories sync duration for 5m0s +- critical worker: 32400s+ time since oldest sync for 10m0s **Next steps** -- Check the network latency is reasonable (<50ms) between the Sourcegraph and the code host -- Learn more about the related dashboard panel in the [dashboards reference](dashboards#repo-updater-syncer-sync-duration). +- An alert here indicates that no code host connections have synced in at least 9h0m0s. This indicates that there could be a configuration issue +with your code hosts connections or networking issues affecting communication with your code hosts. +- Check the code host status indicator (cloud icon in top right of Sourcegraph homepage) for errors. +- Make sure external services do not have invalid tokens by navigating to them in the web UI and clicking save. If there are no errors, they are valid. +- Check the worker logs for errors about syncing. +- Confirm that outbound network connections are allowed where worker is deployed. +- Check back in an hour to see if the issue has resolved itself. +- Learn more about the related dashboard panel in the [dashboards reference](dashboards#worker-src-repoupdater-max-sync-backoff). - **Silence this alert:** If you are aware of this alert and want to silence notifications for it, add the following to your site configuration and set a reminder to re-evaluate the alert: ```json "observability.silenceAlerts": [ - "warning_repo-updater_syncer_sync_duration" + "critical_worker_src_repoupdater_max_sync_backoff" ] ``` @@ -76961,29 +76726,37 @@ Generated query for warning alert: `min((max by (family) (rate(src_repoupdater_sTechnical details
-Generated query for warning alert: `max((histogram_quantile(0.95, max by (le, family, success) (rate(src_repoupdater_syncer_sync_duration_seconds_bucket[1m])))) >= 30)` +Generated query for critical alert: `max((max(src_repoupdater_max_sync_backoff)) >= 32400)`-## repo-updater: source_duration +## worker: src_repoupdater_syncer_sync_errors_total -
95th repositories source duration
+site level external service sync error rate
**Descriptions** -- warning repo-updater: 30s+ 95th repositories source duration for 5m0s +- warning worker: 0.5+ site level external service sync error rate for 10m0s +- critical worker: 1+ site level external service sync error rate for 10m0s **Next steps** -- Check the network latency is reasonable (<50ms) between the Sourcegraph and the code host -- Learn more about the related dashboard panel in the [dashboards reference](dashboards#repo-updater-source-duration). +- An alert here indicates errors syncing site level repo metadata with code hosts. This indicates that there could be a configuration issue +with your code hosts connections or networking issues affecting communication with your code hosts. +- Check the code host status indicator (cloud icon in top right of Sourcegraph homepage) for errors. +- Make sure external services do not have invalid tokens by navigating to them in the web UI and clicking save. If there are no errors, they are valid. +- Check the worker logs for errors about syncing. +- Confirm that outbound network connections are allowed where worker is deployed. +- Check back in an hour to see if the issue has resolved itself. +- Learn more about the related dashboard panel in the [dashboards reference](dashboards#worker-src-repoupdater-syncer-sync-errors-total). - **Silence this alert:** If you are aware of this alert and want to silence notifications for it, add the following to your site configuration and set a reminder to re-evaluate the alert: ```json "observability.silenceAlerts": [ - "warning_repo-updater_source_duration" + "warning_worker_src_repoupdater_syncer_sync_errors_total", + "critical_worker_src_repoupdater_syncer_sync_errors_total" ] ``` @@ -76992,29 +76765,31 @@ Generated query for warning alert: `max((histogram_quantile(0.95, max by (le, faTechnical details
-Generated query for warning alert: `max((histogram_quantile(0.95, max by (le) (rate(src_repoupdater_source_duration_seconds_bucket[1m])))) >= 30)` +Generated query for warning alert: `max((max by (family) (rate(src_repoupdater_syncer_sync_errors_total{owner!="user",reason!="internal_rate_limit",reason!="invalid_npm_path"}[5m]))) > 0.5)` + +Generated query for critical alert: `max((max by (family) (rate(src_repoupdater_syncer_sync_errors_total{owner!="user",reason!="internal_rate_limit",reason!="invalid_npm_path"}[5m]))) > 1)`-## repo-updater: syncer_synced_repos +## worker: syncer_sync_start -
repositories synced
+repo metadata sync was started
**Descriptions** -- warning repo-updater: less than 0 repositories synced for 9h0m0s +- warning worker: less than 0 repo metadata sync was started for 9h0m0s **Next steps** -- Check network connectivity to code hosts -- Learn more about the related dashboard panel in the [dashboards reference](dashboards#repo-updater-syncer-synced-repos). +- Check worker logs for errors. +- Learn more about the related dashboard panel in the [dashboards reference](dashboards#worker-syncer-sync-start). - **Silence this alert:** If you are aware of this alert and want to silence notifications for it, add the following to your site configuration and set a reminder to re-evaluate the alert: ```json "observability.silenceAlerts": [ - "warning_repo-updater_syncer_synced_repos" + "warning_worker_syncer_sync_start" ] ``` @@ -77023,29 +76798,29 @@ Generated query for warning alert: `max((histogram_quantile(0.95, max by (le) (rTechnical details
-Generated query for warning alert: `max((max(rate(src_repoupdater_syncer_synced_repos_total[1m]))) <= 0)` +Generated query for warning alert: `min((max by (family) (rate(src_repoupdater_syncer_start_sync{family="Syncer.SyncExternalService"}[9h]))) <= 0)`-## repo-updater: sourced_repos +## worker: syncer_sync_duration -
repositories sourced
+95th repositories sync duration
**Descriptions** -- warning repo-updater: less than 0 repositories sourced for 9h0m0s +- warning worker: 30s+ 95th repositories sync duration for 5m0s **Next steps** -- Check network connectivity to code hosts -- Learn more about the related dashboard panel in the [dashboards reference](dashboards#repo-updater-sourced-repos). +- Check the network latency is reasonable (<50ms) between the Sourcegraph and the code host +- Learn more about the related dashboard panel in the [dashboards reference](dashboards#worker-syncer-sync-duration). - **Silence this alert:** If you are aware of this alert and want to silence notifications for it, add the following to your site configuration and set a reminder to re-evaluate the alert: ```json "observability.silenceAlerts": [ - "warning_repo-updater_sourced_repos" + "warning_worker_syncer_sync_duration" ] ``` @@ -77054,29 +76829,29 @@ Generated query for warning alert: `max((max(rate(src_repoupdater_syncer_synced_Technical details
-Generated query for warning alert: `min((max(rate(src_repoupdater_source_repos_total[1m]))) <= 0)` +Generated query for warning alert: `max((histogram_quantile(0.95, max by (le, family, success) (rate(src_repoupdater_syncer_sync_duration_seconds_bucket[1m])))) >= 30)`-## repo-updater: purge_failed +## worker: source_duration -
repositories purge failed
+95th repositories source duration
**Descriptions** -- warning repo-updater: 0+ repositories purge failed for 5m0s +- warning worker: 30s+ 95th repositories source duration for 5m0s **Next steps** -- Check repo-updater`s connectivity with gitserver and gitserver logs -- Learn more about the related dashboard panel in the [dashboards reference](dashboards#repo-updater-purge-failed). +- Check the network latency is reasonable (<50ms) between the Sourcegraph and the code host +- Learn more about the related dashboard panel in the [dashboards reference](dashboards#worker-source-duration). - **Silence this alert:** If you are aware of this alert and want to silence notifications for it, add the following to your site configuration and set a reminder to re-evaluate the alert: ```json "observability.silenceAlerts": [ - "warning_repo-updater_purge_failed" + "warning_worker_source_duration" ] ``` @@ -77085,29 +76860,29 @@ Generated query for warning alert: `min((max(rate(src_repoupdater_source_repos_tTechnical details
-Generated query for warning alert: `max((max(rate(src_repoupdater_purge_failed[1m]))) > 0)` +Generated query for warning alert: `max((histogram_quantile(0.95, max by (le) (rate(src_repoupdater_source_duration_seconds_bucket[1m])))) >= 30)`-## repo-updater: sched_auto_fetch +## worker: syncer_synced_repos -
repositories scheduled due to hitting a deadline
+repositories synced
**Descriptions** -- warning repo-updater: less than 0 repositories scheduled due to hitting a deadline for 9h0m0s +- warning worker: less than 0 repositories synced for 9h0m0s **Next steps** -- Check repo-updater logs. -- Learn more about the related dashboard panel in the [dashboards reference](dashboards#repo-updater-sched-auto-fetch). +- Check network connectivity to code hosts +- Learn more about the related dashboard panel in the [dashboards reference](dashboards#worker-syncer-synced-repos). - **Silence this alert:** If you are aware of this alert and want to silence notifications for it, add the following to your site configuration and set a reminder to re-evaluate the alert: ```json "observability.silenceAlerts": [ - "warning_repo-updater_sched_auto_fetch" + "warning_worker_syncer_synced_repos" ] ``` @@ -77116,29 +76891,29 @@ Generated query for warning alert: `max((max(rate(src_repoupdater_purge_failed[1Technical details
-Generated query for warning alert: `min((max(rate(src_repoupdater_sched_auto_fetch[1m]))) <= 0)` +Generated query for warning alert: `max((max(rate(src_repoupdater_syncer_synced_repos_total[1m]))) <= 0)`-## repo-updater: sched_known_repos +## worker: sourced_repos -
repositories managed by the scheduler
+repositories sourced
**Descriptions** -- warning repo-updater: less than 0 repositories managed by the scheduler for 10m0s +- warning worker: less than 0 repositories sourced for 9h0m0s **Next steps** -- Check repo-updater logs. This is expected to fire if there are no user added code hosts -- Learn more about the related dashboard panel in the [dashboards reference](dashboards#repo-updater-sched-known-repos). +- Check network connectivity to code hosts +- Learn more about the related dashboard panel in the [dashboards reference](dashboards#worker-sourced-repos). - **Silence this alert:** If you are aware of this alert and want to silence notifications for it, add the following to your site configuration and set a reminder to re-evaluate the alert: ```json "observability.silenceAlerts": [ - "warning_repo-updater_sched_known_repos" + "warning_worker_sourced_repos" ] ``` @@ -77147,29 +76922,29 @@ Generated query for warning alert: `min((max(rate(src_repoupdater_sched_auto_fetTechnical details
-Generated query for warning alert: `min((max(src_repoupdater_sched_known_repos)) <= 0)` +Generated query for warning alert: `min((max(rate(src_repoupdater_source_repos_total[1m]))) <= 0)`-## repo-updater: sched_update_queue_length +## worker: sched_auto_fetch -
rate of growth of update queue length over 5 minutes
+repositories scheduled due to hitting a deadline
**Descriptions** -- critical repo-updater: 0+ rate of growth of update queue length over 5 minutes for 2h0m0s +- warning worker: less than 0 repositories scheduled due to hitting a deadline for 9h0m0s **Next steps** -- Check repo-updater logs for indications that the queue is not being processed. The queue length should trend downwards over time as items are sent to GitServer -- Learn more about the related dashboard panel in the [dashboards reference](dashboards#repo-updater-sched-update-queue-length). +- Check worker logs. +- Learn more about the related dashboard panel in the [dashboards reference](dashboards#worker-sched-auto-fetch). - **Silence this alert:** If you are aware of this alert and want to silence notifications for it, add the following to your site configuration and set a reminder to re-evaluate the alert: ```json "observability.silenceAlerts": [ - "critical_repo-updater_sched_update_queue_length" + "warning_worker_sched_auto_fetch" ] ``` @@ -77178,29 +76953,29 @@ Generated query for warning alert: `min((max(src_repoupdater_sched_known_repos))Technical details
-Generated query for critical alert: `max((max(deriv(src_repoupdater_sched_update_queue_length[5m]))) > 0)` +Generated query for warning alert: `min((max(rate(src_repoupdater_sched_auto_fetch[1m]))) <= 0)`-## repo-updater: sched_loops +## worker: sched_loops
scheduler loops
**Descriptions** -- warning repo-updater: less than 0 scheduler loops for 9h0m0s +- warning worker: less than 0 scheduler loops for 9h0m0s **Next steps** -- Check repo-updater logs for errors. This is expected to fire if there are no user added code hosts -- Learn more about the related dashboard panel in the [dashboards reference](dashboards#repo-updater-sched-loops). +- Check worker logs for errors. This is expected to fire if there are no user added code hosts +- Learn more about the related dashboard panel in the [dashboards reference](dashboards#worker-sched-loops). - **Silence this alert:** If you are aware of this alert and want to silence notifications for it, add the following to your site configuration and set a reminder to re-evaluate the alert: ```json "observability.silenceAlerts": [ - "warning_repo-updater_sched_loops" + "warning_worker_sched_loops" ] ``` @@ -77215,24 +76990,24 @@ Generated query for warning alert: `min((max(rate(src_repoupdater_sched_loops[1m-## repo-updater: src_repoupdater_stale_repos +## worker: src_repoupdater_stale_repos
repos that haven't been fetched in more than 8 hours
**Descriptions** -- warning repo-updater: 1+ repos that haven't been fetched in more than 8 hours for 25m0s +- warning worker: 1+ repos that haven't been fetched in more than 8 hours for 25m0s **Next steps** -- Check repo-updater logs for errors. +- Check worker logs for errors. Check for rows in gitserver_repos where LastError is not an empty string. -- Learn more about the related dashboard panel in the [dashboards reference](dashboards#repo-updater-src-repoupdater-stale-repos). +- Learn more about the related dashboard panel in the [dashboards reference](dashboards#worker-src-repoupdater-stale-repos). - **Silence this alert:** If you are aware of this alert and want to silence notifications for it, add the following to your site configuration and set a reminder to re-evaluate the alert: ```json "observability.silenceAlerts": [ - "warning_repo-updater_src_repoupdater_stale_repos" + "warning_worker_src_repoupdater_stale_repos" ] ``` @@ -77247,23 +77022,23 @@ Generated query for warning alert: `max((max(src_repoupdater_stale_repos)) >=-## repo-updater: sched_error +## worker: sched_error
repositories schedule error rate
**Descriptions** -- critical repo-updater: 1+ repositories schedule error rate for 25m0s +- critical worker: 1+ repositories schedule error rate for 25m0s **Next steps** -- Check repo-updater logs for errors -- Learn more about the related dashboard panel in the [dashboards reference](dashboards#repo-updater-sched-error). +- Check worker logs for errors +- Learn more about the related dashboard panel in the [dashboards reference](dashboards#worker-sched-error). - **Silence this alert:** If you are aware of this alert and want to silence notifications for it, add the following to your site configuration and set a reminder to re-evaluate the alert: ```json "observability.silenceAlerts": [ - "critical_repo-updater_sched_error" + "critical_worker_sched_error" ] ``` @@ -77278,23 +77053,23 @@ Generated query for critical alert: `max((max(rate(src_repoupdater_sched_error[1-## repo-updater: src_repoupdater_external_services_total +## worker: src_repoupdater_external_services_total
the total number of external services
**Descriptions** -- critical repo-updater: 20000+ the total number of external services for 1h0m0s +- critical worker: 20000+ the total number of external services for 1h0m0s **Next steps** - Check for spikes in external services, could be abuse -- Learn more about the related dashboard panel in the [dashboards reference](dashboards#repo-updater-src-repoupdater-external-services-total). +- Learn more about the related dashboard panel in the [dashboards reference](dashboards#worker-src-repoupdater-external-services-total). - **Silence this alert:** If you are aware of this alert and want to silence notifications for it, add the following to your site configuration and set a reminder to re-evaluate the alert: ```json "observability.silenceAlerts": [ - "critical_repo-updater_src_repoupdater_external_services_total" + "critical_worker_src_repoupdater_external_services_total" ] ``` @@ -77309,24 +77084,24 @@ Generated query for critical alert: `max((max(src_repoupdater_external_services_-## repo-updater: repoupdater_queued_sync_jobs_total +## worker: repoupdater_queued_sync_jobs_total
the total number of queued sync jobs
**Descriptions** -- warning repo-updater: 100+ the total number of queued sync jobs for 1h0m0s +- warning worker: 100+ the total number of queued sync jobs for 1h0m0s **Next steps** - **Check if jobs are failing to sync:** "SELECT * FROM external_service_sync_jobs WHERE state = `errored`"; - **Increase the number of workers** using the `repoConcurrentExternalServiceSyncers` site config. -- Learn more about the related dashboard panel in the [dashboards reference](dashboards#repo-updater-repoupdater-queued-sync-jobs-total). +- Learn more about the related dashboard panel in the [dashboards reference](dashboards#worker-repoupdater-queued-sync-jobs-total). - **Silence this alert:** If you are aware of this alert and want to silence notifications for it, add the following to your site configuration and set a reminder to re-evaluate the alert: ```json "observability.silenceAlerts": [ - "warning_repo-updater_repoupdater_queued_sync_jobs_total" + "warning_worker_repoupdater_queued_sync_jobs_total" ] ``` @@ -77341,23 +77116,23 @@ Generated query for warning alert: `max((max(src_repoupdater_queued_sync_jobs_to-## repo-updater: repoupdater_completed_sync_jobs_total +## worker: repoupdater_completed_sync_jobs_total
the total number of completed sync jobs
**Descriptions** -- warning repo-updater: 100000+ the total number of completed sync jobs for 1h0m0s +- warning worker: 100000+ the total number of completed sync jobs for 1h0m0s **Next steps** -- Check repo-updater logs. Jobs older than 1 day should have been removed. -- Learn more about the related dashboard panel in the [dashboards reference](dashboards#repo-updater-repoupdater-completed-sync-jobs-total). +- Check worker logs. Jobs older than 1 day should have been removed. +- Learn more about the related dashboard panel in the [dashboards reference](dashboards#worker-repoupdater-completed-sync-jobs-total). - **Silence this alert:** If you are aware of this alert and want to silence notifications for it, add the following to your site configuration and set a reminder to re-evaluate the alert: ```json "observability.silenceAlerts": [ - "warning_repo-updater_repoupdater_completed_sync_jobs_total" + "warning_worker_repoupdater_completed_sync_jobs_total" ] ``` @@ -77372,23 +77147,23 @@ Generated query for warning alert: `max((max(src_repoupdater_completed_sync_jobs-## repo-updater: repoupdater_errored_sync_jobs_percentage +## worker: repoupdater_errored_sync_jobs_percentage
the percentage of external services that have failed their most recent sync
**Descriptions** -- warning repo-updater: 10%+ the percentage of external services that have failed their most recent sync for 1h0m0s +- warning worker: 10%+ the percentage of external services that have failed their most recent sync for 1h0m0s **Next steps** -- Check repo-updater logs. Check code host connectivity -- Learn more about the related dashboard panel in the [dashboards reference](dashboards#repo-updater-repoupdater-errored-sync-jobs-percentage). +- Check worker logs. Check code host connectivity +- Learn more about the related dashboard panel in the [dashboards reference](dashboards#worker-repoupdater-errored-sync-jobs-percentage). - **Silence this alert:** If you are aware of this alert and want to silence notifications for it, add the following to your site configuration and set a reminder to re-evaluate the alert: ```json "observability.silenceAlerts": [ - "warning_repo-updater_repoupdater_errored_sync_jobs_percentage" + "warning_worker_repoupdater_errored_sync_jobs_percentage" ] ``` @@ -77403,23 +77178,23 @@ Generated query for warning alert: `max((max(src_repoupdater_errored_sync_jobs_p-## repo-updater: github_graphql_rate_limit_remaining +## worker: github_graphql_rate_limit_remaining
remaining calls to GitHub graphql API before hitting the rate limit
**Descriptions** -- warning repo-updater: less than 250 remaining calls to GitHub graphql API before hitting the rate limit +- warning worker: less than 250 remaining calls to GitHub graphql API before hitting the rate limit **Next steps** - Consider creating a new token for the indicated resource (the `name` label for series below the threshold in the dashboard) under a dedicated machine user to reduce rate limit pressure. -- Learn more about the related dashboard panel in the [dashboards reference](dashboards#repo-updater-github-graphql-rate-limit-remaining). +- Learn more about the related dashboard panel in the [dashboards reference](dashboards#worker-github-graphql-rate-limit-remaining). - **Silence this alert:** If you are aware of this alert and want to silence notifications for it, add the following to your site configuration and set a reminder to re-evaluate the alert: ```json "observability.silenceAlerts": [ - "warning_repo-updater_github_graphql_rate_limit_remaining" + "warning_worker_github_graphql_rate_limit_remaining" ] ``` @@ -77434,23 +77209,23 @@ Generated query for warning alert: `min((max by (name) (src_github_rate_limit_re-## repo-updater: github_rest_rate_limit_remaining +## worker: github_rest_rate_limit_remaining
remaining calls to GitHub rest API before hitting the rate limit
**Descriptions** -- warning repo-updater: less than 250 remaining calls to GitHub rest API before hitting the rate limit +- warning worker: less than 250 remaining calls to GitHub rest API before hitting the rate limit **Next steps** - Consider creating a new token for the indicated resource (the `name` label for series below the threshold in the dashboard) under a dedicated machine user to reduce rate limit pressure. -- Learn more about the related dashboard panel in the [dashboards reference](dashboards#repo-updater-github-rest-rate-limit-remaining). +- Learn more about the related dashboard panel in the [dashboards reference](dashboards#worker-github-rest-rate-limit-remaining). - **Silence this alert:** If you are aware of this alert and want to silence notifications for it, add the following to your site configuration and set a reminder to re-evaluate the alert: ```json "observability.silenceAlerts": [ - "warning_repo-updater_github_rest_rate_limit_remaining" + "warning_worker_github_rest_rate_limit_remaining" ] ``` @@ -77465,23 +77240,23 @@ Generated query for warning alert: `min((max by (name) (src_github_rate_limit_re-## repo-updater: github_search_rate_limit_remaining +## worker: github_search_rate_limit_remaining
remaining calls to GitHub search API before hitting the rate limit
**Descriptions** -- warning repo-updater: less than 5 remaining calls to GitHub search API before hitting the rate limit +- warning worker: less than 5 remaining calls to GitHub search API before hitting the rate limit **Next steps** - Consider creating a new token for the indicated resource (the `name` label for series below the threshold in the dashboard) under a dedicated machine user to reduce rate limit pressure. -- Learn more about the related dashboard panel in the [dashboards reference](dashboards#repo-updater-github-search-rate-limit-remaining). +- Learn more about the related dashboard panel in the [dashboards reference](dashboards#worker-github-search-rate-limit-remaining). - **Silence this alert:** If you are aware of this alert and want to silence notifications for it, add the following to your site configuration and set a reminder to re-evaluate the alert: ```json "observability.silenceAlerts": [ - "warning_repo-updater_github_search_rate_limit_remaining" + "warning_worker_github_search_rate_limit_remaining" ] ``` @@ -77496,23 +77271,23 @@ Generated query for warning alert: `min((max by (name) (src_github_rate_limit_re-## repo-updater: gitlab_rest_rate_limit_remaining +## worker: gitlab_rest_rate_limit_remaining
remaining calls to GitLab rest API before hitting the rate limit
**Descriptions** -- critical repo-updater: less than 30 remaining calls to GitLab rest API before hitting the rate limit +- critical worker: less than 30 remaining calls to GitLab rest API before hitting the rate limit **Next steps** - Try restarting the pod to get a different public IP. -- Learn more about the related dashboard panel in the [dashboards reference](dashboards#repo-updater-gitlab-rest-rate-limit-remaining). +- Learn more about the related dashboard panel in the [dashboards reference](dashboards#worker-gitlab-rest-rate-limit-remaining). - **Silence this alert:** If you are aware of this alert and want to silence notifications for it, add the following to your site configuration and set a reminder to re-evaluate the alert: ```json "observability.silenceAlerts": [ - "critical_repo-updater_gitlab_rest_rate_limit_remaining" + "critical_worker_gitlab_rest_rate_limit_remaining" ] ``` @@ -77527,59 +77302,24 @@ Generated query for critical alert: `min((max by (name) (src_gitlab_rate_limit_r-## repo-updater: repo_updater_site_configuration_duration_since_last_successful_update_by_instance - -
maximum duration since last successful site configuration update (all "repo_updater" instances)
- -**Descriptions** - -- critical repo-updater: 300s+ maximum duration since last successful site configuration update (all "repo_updater" instances) - -**Next steps** - -- This indicates that one or more "repo_updater" instances have not successfully updated the site configuration in over 5 minutes. This could be due to networking issues between services or problems with the site configuration service itself. -- Check for relevant errors in the "repo_updater" logs, as well as frontend`s logs. -- Learn more about the related dashboard panel in the [dashboards reference](dashboards#repo-updater-repo-updater-site-configuration-duration-since-last-successful-update-by-instance). -- **Silence this alert:** If you are aware of this alert and want to silence notifications for it, add the following to your site configuration and set a reminder to re-evaluate the alert: - -```json -"observability.silenceAlerts": [ - "critical_repo-updater_repo_updater_site_configuration_duration_since_last_successful_update_by_instance" -] -``` - -*Managed by the [Sourcegraph Infrastructure Org team](https://handbook.sourcegraph.com/departments/engineering/infrastructure).* - -Technical details
- -Generated query for critical alert: `max((max(max_over_time(src_conf_client_time_since_last_successful_update_seconds{job=~".*repo-updater"}[1m]))) >= 300)` - -- -## repo-updater: mean_blocked_seconds_per_conn_request +## worker: perms_syncer_outdated_perms -
mean blocked seconds per conn request
+number of entities with outdated permissions
**Descriptions** -- warning repo-updater: 0.1s+ mean blocked seconds per conn request for 10m0s -- critical repo-updater: 0.5s+ mean blocked seconds per conn request for 10m0s +- warning worker: 100+ number of entities with outdated permissions for 5m0s **Next steps** -- Increase SRC_PGSQL_MAX_OPEN together with giving more memory to the database if needed -- Scale up Postgres memory/cpus - [see our scaling guide](https://sourcegraph.com/docs/admin/config/postgres-conf) -- If using GCP Cloud SQL, check for high lock waits or CPU usage in query insights -- Learn more about the related dashboard panel in the [dashboards reference](dashboards#repo-updater-mean-blocked-seconds-per-conn-request). +- **Enabled permissions for the first time:** Wait for few minutes and see if the number goes down. +- **Otherwise:** Increase the API rate limit to [GitHub](https://sourcegraph.com/docs/admin/code_hosts/github#github-com-rate-limits), [GitLab](https://sourcegraph.com/docs/admin/code_hosts/gitlab#internal-rate-limits) or [Bitbucket Server](https://sourcegraph.com/docs/admin/code_hosts/bitbucket_server#internal-rate-limits). +- Learn more about the related dashboard panel in the [dashboards reference](dashboards#worker-perms-syncer-outdated-perms). - **Silence this alert:** If you are aware of this alert and want to silence notifications for it, add the following to your site configuration and set a reminder to re-evaluate the alert: ```json "observability.silenceAlerts": [ - "warning_repo-updater_mean_blocked_seconds_per_conn_request", - "critical_repo-updater_mean_blocked_seconds_per_conn_request" + "warning_worker_perms_syncer_outdated_perms" ] ``` @@ -77588,32 +77328,29 @@ Generated query for critical alert: `max((max(max_over_time(src_conf_client_timeTechnical details
-Generated query for warning alert: `max((sum by (app_name, db_name) (increase(src_pgsql_conns_blocked_seconds{app_name="repo-updater"\}[5m])) / sum by (app_name, db_name) (increase(src_pgsql_conns_waited_for\{app_name="repo-updater"}[5m]))) >= 0.1)` - -Generated query for critical alert: `max((sum by (app_name, db_name) (increase(src_pgsql_conns_blocked_seconds{app_name="repo-updater"\}[5m])) / sum by (app_name, db_name) (increase(src_pgsql_conns_waited_for\{app_name="repo-updater"}[5m]))) >= 0.5)` +Generated query for warning alert: `max((max by (type) (src_repo_perms_syncer_outdated_perms)) >= 100)`-## repo-updater: container_cpu_usage +## worker: perms_syncer_sync_duration -
container cpu usage total (1m average) across all cores by instance
+95th permissions sync duration
**Descriptions** -- warning repo-updater: 99%+ container cpu usage total (1m average) across all cores by instance +- warning worker: 30s+ 95th permissions sync duration for 5m0s **Next steps** -- **Kubernetes:** Consider increasing CPU limits in the the relevant `Deployment.yaml`. -- **Docker Compose:** Consider increasing `cpus:` of the repo-updater container in `docker-compose.yml`. -- Learn more about the related dashboard panel in the [dashboards reference](dashboards#repo-updater-container-cpu-usage). +- Check the network latency is reasonable (<50ms) between the Sourcegraph and the code host. +- Learn more about the related dashboard panel in the [dashboards reference](dashboards#worker-perms-syncer-sync-duration). - **Silence this alert:** If you are aware of this alert and want to silence notifications for it, add the following to your site configuration and set a reminder to re-evaluate the alert: ```json "observability.silenceAlerts": [ - "warning_repo-updater_container_cpu_usage" + "warning_worker_perms_syncer_sync_duration" ] ``` @@ -77622,30 +77359,30 @@ Generated query for critical alert: `max((sum by (app_name, db_name) (increase(sTechnical details
-Generated query for warning alert: `max((cadvisor_container_cpu_usage_percentage_total{name=~"^repo-updater.*"}) >= 99)` +Generated query for warning alert: `max((histogram_quantile(0.95, max by (le, type) (rate(src_repo_perms_syncer_sync_duration_seconds_bucket[1m])))) >= 30)`-## repo-updater: container_memory_usage +## worker: perms_syncer_sync_errors -
container memory usage by instance
+permissions sync error rate
**Descriptions** -- critical repo-updater: 90%+ container memory usage by instance for 10m0s +- critical worker: 1+ permissions sync error rate for 1m0s **Next steps** -- **Kubernetes:** Consider increasing memory limit in relevant `Deployment.yaml`. -- **Docker Compose:** Consider increasing `memory:` of repo-updater container in `docker-compose.yml`. -- Learn more about the related dashboard panel in the [dashboards reference](dashboards#repo-updater-container-memory-usage). +- Check the network connectivity the Sourcegraph and the code host. +- Check if API rate limit quota is exhausted on the code host. +- Learn more about the related dashboard panel in the [dashboards reference](dashboards#worker-perms-syncer-sync-errors). - **Silence this alert:** If you are aware of this alert and want to silence notifications for it, add the following to your site configuration and set a reminder to re-evaluate the alert: ```json "observability.silenceAlerts": [ - "critical_repo-updater_container_memory_usage" + "critical_worker_perms_syncer_sync_errors" ] ``` @@ -77654,603 +77391,573 @@ Generated query for warning alert: `max((cadvisor_container_cpu_usage_percentageTechnical details
-Generated query for critical alert: `max((cadvisor_container_memory_usage_percentage_total{name=~"^repo-updater.*"}) >= 90)` +Generated query for critical alert: `max((max by (type) (ceil(rate(src_repo_perms_syncer_sync_errors_total[1m])))) >= 1)`-## repo-updater: provisioning_container_cpu_usage_long_term +## worker: completioncredits_aggregator_errors_total -
container cpu usage total (90th percentile over 1d) across all cores by instance
+completion credits entitlement usage aggregator operation errors every 30m
**Descriptions** -- warning repo-updater: 80%+ container cpu usage total (90th percentile over 1d) across all cores by instance for 336h0m0s +- warning worker: 0+ completion credits entitlement usage aggregator operation errors every 30m **Next steps** -- **Kubernetes:** Consider increasing CPU limits in the `Deployment.yaml` for the repo-updater service. -- **Docker Compose:** Consider increasing `cpus:` of the repo-updater container in `docker-compose.yml`. -- Learn more about the related dashboard panel in the [dashboards reference](dashboards#repo-updater-provisioning-container-cpu-usage-long-term). +- Failures indicate that aggregation of completions credits usage against entitlements are failing. +- This may affect completion credits entitlement enforcement. +- Learn more about the related dashboard panel in the [dashboards reference](dashboards#worker-completioncredits-aggregator-errors-total). - **Silence this alert:** If you are aware of this alert and want to silence notifications for it, add the following to your site configuration and set a reminder to re-evaluate the alert: ```json "observability.silenceAlerts": [ - "warning_repo-updater_provisioning_container_cpu_usage_long_term" + "warning_worker_completioncredits_aggregator_errors_total" ] ``` -*Managed by the [Sourcegraph Source team](https://handbook.sourcegraph.com/departments/engineering/teams/source).* +*Managed by the [Sourcegraph Core Services team](https://handbook.sourcegraph.com/departments/engineering/teams).*Technical details
-Generated query for warning alert: `max((quantile_over_time(0.9, cadvisor_container_cpu_usage_percentage_total{name=~"^repo-updater.*"}[1d])) >= 80)` +Generated query for warning alert: `max((sum(increase(src_completioncredits_aggregator_errors_total{job=~"^worker.*"}[30m]))) > 0)`-## repo-updater: provisioning_container_memory_usage_long_term +## worker: goroutine_error_rate -
container memory usage (1d maximum) by instance
+error rate for periodic goroutine executions
**Descriptions** -- warning repo-updater: 80%+ container memory usage (1d maximum) by instance for 336h0m0s +- warning worker: 0.01reqps+ error rate for periodic goroutine executions for 15m0s **Next steps** -- **Kubernetes:** Consider increasing memory limits in the `Deployment.yaml` for the repo-updater service. -- **Docker Compose:** Consider increasing `memory:` of the repo-updater container in `docker-compose.yml`. -- Learn more about the related dashboard panel in the [dashboards reference](dashboards#repo-updater-provisioning-container-memory-usage-long-term). +- Check service logs for error details related to the failing periodic routine +- Check if the routine depends on external services that may be unavailable +- Look for recent changes to the routine`s code or configuration +- More help interpreting this metric is available in the [dashboards reference](dashboards#worker-goroutine-error-rate). - **Silence this alert:** If you are aware of this alert and want to silence notifications for it, add the following to your site configuration and set a reminder to re-evaluate the alert: ```json "observability.silenceAlerts": [ - "warning_repo-updater_provisioning_container_memory_usage_long_term" + "warning_worker_goroutine_error_rate" ] ``` -*Managed by the [Sourcegraph Source team](https://handbook.sourcegraph.com/departments/engineering/teams/source).* +*Managed by the [Sourcegraph Infrastructure Org team](https://handbook.sourcegraph.com/departments/engineering/infrastructure).*Technical details
-Generated query for warning alert: `max((max_over_time(cadvisor_container_memory_usage_percentage_total{name=~"^repo-updater.*"}[1d])) >= 80)` +Generated query for warning alert: `max((sum by (name, job_name) (rate(src_periodic_goroutine_errors_total{job=~".*worker.*"}[5m]))) >= 0.01)`-## repo-updater: provisioning_container_cpu_usage_short_term +## worker: goroutine_error_percentage -
container cpu usage total (5m maximum) across all cores by instance
+percentage of periodic goroutine executions that result in errors
**Descriptions** -- warning repo-updater: 90%+ container cpu usage total (5m maximum) across all cores by instance for 30m0s +- warning worker: 5%+ percentage of periodic goroutine executions that result in errors **Next steps** -- **Kubernetes:** Consider increasing CPU limits in the the relevant `Deployment.yaml`. -- **Docker Compose:** Consider increasing `cpus:` of the repo-updater container in `docker-compose.yml`. -- Learn more about the related dashboard panel in the [dashboards reference](dashboards#repo-updater-provisioning-container-cpu-usage-short-term). +- Check service logs for error details related to the failing periodic routine +- Check if the routine depends on external services that may be unavailable +- Consider temporarily disabling the routine if it`s non-critical and causing cascading issues +- More help interpreting this metric is available in the [dashboards reference](dashboards#worker-goroutine-error-percentage). - **Silence this alert:** If you are aware of this alert and want to silence notifications for it, add the following to your site configuration and set a reminder to re-evaluate the alert: ```json "observability.silenceAlerts": [ - "warning_repo-updater_provisioning_container_cpu_usage_short_term" + "warning_worker_goroutine_error_percentage" ] ``` -*Managed by the [Sourcegraph Source team](https://handbook.sourcegraph.com/departments/engineering/teams/source).* +*Managed by the [Sourcegraph Infrastructure Org team](https://handbook.sourcegraph.com/departments/engineering/infrastructure).*Technical details
-Generated query for warning alert: `max((max_over_time(cadvisor_container_cpu_usage_percentage_total{name=~"^repo-updater.*"}[5m])) >= 90)` +Generated query for warning alert: `max((sum by (name, job_name) (rate(src_periodic_goroutine_errors_total{job=~".*worker.*"\}[5m])) / sum by (name, job_name) (rate(src_periodic_goroutine_total\{job=~".*worker.*"}[5m]) > 0) * 100) >= 5)`-## repo-updater: provisioning_container_memory_usage_short_term +## worker: mean_blocked_seconds_per_conn_request -
container memory usage (5m maximum) by instance
+mean blocked seconds per conn request
**Descriptions** -- warning repo-updater: 90%+ container memory usage (5m maximum) by instance +- warning worker: 0.1s+ mean blocked seconds per conn request for 10m0s +- critical worker: 0.5s+ mean blocked seconds per conn request for 10m0s **Next steps** -- **Kubernetes:** Consider increasing memory limit in relevant `Deployment.yaml`. -- **Docker Compose:** Consider increasing `memory:` of repo-updater container in `docker-compose.yml`. -- Learn more about the related dashboard panel in the [dashboards reference](dashboards#repo-updater-provisioning-container-memory-usage-short-term). +- Increase SRC_PGSQL_MAX_OPEN together with giving more memory to the database if needed +- Scale up Postgres memory/cpus - [see our scaling guide](https://sourcegraph.com/docs/admin/config/postgres-conf) +- If using GCP Cloud SQL, check for high lock waits or CPU usage in query insights +- Learn more about the related dashboard panel in the [dashboards reference](dashboards#worker-mean-blocked-seconds-per-conn-request). - **Silence this alert:** If you are aware of this alert and want to silence notifications for it, add the following to your site configuration and set a reminder to re-evaluate the alert: ```json "observability.silenceAlerts": [ - "warning_repo-updater_provisioning_container_memory_usage_short_term" + "warning_worker_mean_blocked_seconds_per_conn_request", + "critical_worker_mean_blocked_seconds_per_conn_request" ] ``` -*Managed by the [Sourcegraph Source team](https://handbook.sourcegraph.com/departments/engineering/teams/source).* +*Managed by the [Sourcegraph Infrastructure Org team](https://handbook.sourcegraph.com/departments/engineering/infrastructure).*Technical details
-Generated query for warning alert: `max((max_over_time(cadvisor_container_memory_usage_percentage_total{name=~"^repo-updater.*"}[5m])) >= 90)` - -- -## repo-updater: container_oomkill_events_total - -
container OOMKILL events total by instance
- -**Descriptions** - -- warning repo-updater: 1+ container OOMKILL events total by instance - -**Next steps** - -- **Kubernetes:** Consider increasing memory limit in relevant `Deployment.yaml`. -- **Docker Compose:** Consider increasing `memory:` of repo-updater container in `docker-compose.yml`. -- More help interpreting this metric is available in the [dashboards reference](dashboards#repo-updater-container-oomkill-events-total). -- **Silence this alert:** If you are aware of this alert and want to silence notifications for it, add the following to your site configuration and set a reminder to re-evaluate the alert: - -```json -"observability.silenceAlerts": [ - "warning_repo-updater_container_oomkill_events_total" -] -``` - -*Managed by the [Sourcegraph Source team](https://handbook.sourcegraph.com/departments/engineering/teams/source).* - -Technical details
+Generated query for warning alert: `max((sum by (app_name, db_name) (increase(src_pgsql_conns_blocked_seconds{app_name="worker"\}[5m])) / sum by (app_name, db_name) (increase(src_pgsql_conns_waited_for\{app_name="worker"}[5m]))) >= 0.1)` -Generated query for warning alert: `max((max by (name) (container_oom_events_total{name=~"^repo-updater.*"})) >= 1)` +Generated query for critical alert: `max((sum by (app_name, db_name) (increase(src_pgsql_conns_blocked_seconds{app_name="worker"\}[5m])) / sum by (app_name, db_name) (increase(src_pgsql_conns_waited_for\{app_name="worker"}[5m]))) >= 0.5)`-## repo-updater: go_goroutines +## worker: cpu_usage_percentage -
maximum active goroutines
+CPU usage
**Descriptions** -- warning repo-updater: 10000+ maximum active goroutines for 10m0s +- warning worker: 95%+ CPU usage for 10m0s **Next steps** -- More help interpreting this metric is available in the [dashboards reference](dashboards#repo-updater-go-goroutines). +- Consider increasing CPU limits or scaling out. +- Learn more about the related dashboard panel in the [dashboards reference](dashboards#worker-cpu-usage-percentage). - **Silence this alert:** If you are aware of this alert and want to silence notifications for it, add the following to your site configuration and set a reminder to re-evaluate the alert: ```json "observability.silenceAlerts": [ - "warning_repo-updater_go_goroutines" + "warning_worker_cpu_usage_percentage" ] ``` -*Managed by the [Sourcegraph Source team](https://handbook.sourcegraph.com/departments/engineering/teams/source).* +*Managed by the [Sourcegraph Code Search team](https://handbook.sourcegraph.com/departments/engineering/teams/code-search).*Technical details
-Generated query for warning alert: `max((max by (instance) (go_goroutines{job=~".*repo-updater"})) >= 10000)` +Generated query for warning alert: `max((cadvisor_container_cpu_usage_percentage_total{name=~"^worker.*"}) >= 95)`-## repo-updater: go_gc_duration_seconds +## worker: memory_rss -
maximum go garbage collection duration
+memory (RSS)
**Descriptions** -- warning repo-updater: 2s+ maximum go garbage collection duration +- warning worker: 90%+ memory (RSS) for 10m0s **Next steps** -- Learn more about the related dashboard panel in the [dashboards reference](dashboards#repo-updater-go-gc-duration-seconds). +- Consider increasing memory limits or scaling out. +- More help interpreting this metric is available in the [dashboards reference](dashboards#worker-memory-rss). - **Silence this alert:** If you are aware of this alert and want to silence notifications for it, add the following to your site configuration and set a reminder to re-evaluate the alert: ```json "observability.silenceAlerts": [ - "warning_repo-updater_go_gc_duration_seconds" + "warning_worker_memory_rss" ] ``` -*Managed by the [Sourcegraph Source team](https://handbook.sourcegraph.com/departments/engineering/teams/source).* +*Managed by the [Sourcegraph Code Search team](https://handbook.sourcegraph.com/departments/engineering/teams/code-search).*Technical details
-Generated query for warning alert: `max((max by (instance) (go_gc_duration_seconds{job=~".*repo-updater"})) >= 2)` +Generated query for warning alert: `max((max by (name) (container_memory_rss{name=~"^worker.*"\} / container_spec_memory_limit_bytes\{name=~"^worker.*"}) * 100) >= 90)`-## repo-updater: pods_available_percentage +## worker: container_cpu_usage -
percentage pods available
+container cpu usage total (1m average) across all cores by instance
**Descriptions** -- critical repo-updater: less than 90% percentage pods available for 10m0s +- warning worker: 99%+ container cpu usage total (1m average) across all cores by instance **Next steps** -- Determine if the pod was OOM killed using `kubectl describe pod repo-updater` (look for `OOMKilled: true`) and, if so, consider increasing the memory limit in the relevant `Deployment.yaml`. -- Check the logs before the container restarted to see if there are `panic:` messages or similar using `kubectl logs -p repo-updater`. -- Learn more about the related dashboard panel in the [dashboards reference](dashboards#repo-updater-pods-available-percentage). +- **Kubernetes:** Consider increasing CPU limits in the the relevant `Deployment.yaml`. +- **Docker Compose:** Consider increasing `cpus:` of the worker container in `docker-compose.yml`. +- Learn more about the related dashboard panel in the [dashboards reference](dashboards#worker-container-cpu-usage). - **Silence this alert:** If you are aware of this alert and want to silence notifications for it, add the following to your site configuration and set a reminder to re-evaluate the alert: ```json "observability.silenceAlerts": [ - "critical_repo-updater_pods_available_percentage" + "warning_worker_container_cpu_usage" ] ``` -*Managed by the [Sourcegraph Source team](https://handbook.sourcegraph.com/departments/engineering/teams/source).* +*Managed by the [Sourcegraph Code intelligence team](https://handbook.sourcegraph.com/departments/engineering/teams/code-intelligence).*Technical details
-Generated query for critical alert: `min((sum by (app) (up{app=~".*repo-updater"\}) / count by (app) (up\{app=~".*repo-updater"}) * 100) <= 90)` +Generated query for warning alert: `max((cadvisor_container_cpu_usage_percentage_total{name=~"^worker.*"}) >= 99)`-## searcher: replica_traffic +## worker: container_memory_usage -
requests per second per replica over 10m
+container memory usage by instance
**Descriptions** -- warning searcher: 5+ requests per second per replica over 10m +- warning worker: 99%+ container memory usage by instance **Next steps** -- More help interpreting this metric is available in the [dashboards reference](dashboards#searcher-replica-traffic). +- **Kubernetes:** Consider increasing memory limit in relevant `Deployment.yaml`. +- **Docker Compose:** Consider increasing `memory:` of worker container in `docker-compose.yml`. +- Learn more about the related dashboard panel in the [dashboards reference](dashboards#worker-container-memory-usage). - **Silence this alert:** If you are aware of this alert and want to silence notifications for it, add the following to your site configuration and set a reminder to re-evaluate the alert: ```json "observability.silenceAlerts": [ - "warning_searcher_replica_traffic" + "warning_worker_container_memory_usage" ] ``` -*Managed by the [Sourcegraph Search Platform team](https://handbook.sourcegraph.com/departments/engineering/teams/search/core).* +*Managed by the [Sourcegraph Code intelligence team](https://handbook.sourcegraph.com/departments/engineering/teams/code-intelligence).*Technical details
-Generated query for warning alert: `max((sum by (instance) (rate(searcher_service_request_total[10m]))) >= 5)` +Generated query for warning alert: `max((cadvisor_container_memory_usage_percentage_total{name=~"^worker.*"}) >= 99)`-## searcher: unindexed_search_request_errors +## worker: provisioning_container_cpu_usage_long_term -
unindexed search request errors every 5m by code
+container cpu usage total (90th percentile over 1d) across all cores by instance
**Descriptions** -- warning searcher: 5%+ unindexed search request errors every 5m by code for 5m0s +- warning worker: 80%+ container cpu usage total (90th percentile over 1d) across all cores by instance for 336h0m0s **Next steps** -- Learn more about the related dashboard panel in the [dashboards reference](dashboards#searcher-unindexed-search-request-errors). +- **Kubernetes:** Consider increasing CPU limits in the `Deployment.yaml` for the worker service. +- **Docker Compose:** Consider increasing `cpus:` of the worker container in `docker-compose.yml`. +- Learn more about the related dashboard panel in the [dashboards reference](dashboards#worker-provisioning-container-cpu-usage-long-term). - **Silence this alert:** If you are aware of this alert and want to silence notifications for it, add the following to your site configuration and set a reminder to re-evaluate the alert: ```json "observability.silenceAlerts": [ - "warning_searcher_unindexed_search_request_errors" + "warning_worker_provisioning_container_cpu_usage_long_term" ] ``` -*Managed by the [Sourcegraph Search Platform team](https://handbook.sourcegraph.com/departments/engineering/teams/search/core).* +*Managed by the [Sourcegraph Code intelligence team](https://handbook.sourcegraph.com/departments/engineering/teams/code-intelligence).*Technical details
-Generated query for warning alert: `max((sum by (code) (increase(searcher_service_request_total{code!="200",code!="canceled"}[5m])) / ignoring (code) group_left () sum(increase(searcher_service_request_total[5m])) * 100) >= 5)` +Generated query for warning alert: `max((quantile_over_time(0.9, cadvisor_container_cpu_usage_percentage_total{name=~"^worker.*"}[1d])) >= 80)`-## searcher: searcher_site_configuration_duration_since_last_successful_update_by_instance +## worker: provisioning_container_memory_usage_long_term -
maximum duration since last successful site configuration update (all "searcher" instances)
+container memory usage (1d maximum) by instance
**Descriptions** -- critical searcher: 300s+ maximum duration since last successful site configuration update (all "searcher" instances) +- warning worker: 80%+ container memory usage (1d maximum) by instance for 336h0m0s **Next steps** -- This indicates that one or more "searcher" instances have not successfully updated the site configuration in over 5 minutes. This could be due to networking issues between services or problems with the site configuration service itself. -- Check for relevant errors in the "searcher" logs, as well as frontend`s logs. -- Learn more about the related dashboard panel in the [dashboards reference](dashboards#searcher-searcher-site-configuration-duration-since-last-successful-update-by-instance). +- **Kubernetes:** Consider increasing memory limits in the `Deployment.yaml` for the worker service. +- **Docker Compose:** Consider increasing `memory:` of the worker container in `docker-compose.yml`. +- Learn more about the related dashboard panel in the [dashboards reference](dashboards#worker-provisioning-container-memory-usage-long-term). - **Silence this alert:** If you are aware of this alert and want to silence notifications for it, add the following to your site configuration and set a reminder to re-evaluate the alert: ```json "observability.silenceAlerts": [ - "critical_searcher_searcher_site_configuration_duration_since_last_successful_update_by_instance" + "warning_worker_provisioning_container_memory_usage_long_term" ] ``` -*Managed by the [Sourcegraph Infrastructure Org team](https://handbook.sourcegraph.com/departments/engineering/infrastructure).* +*Managed by the [Sourcegraph Code intelligence team](https://handbook.sourcegraph.com/departments/engineering/teams/code-intelligence).*Technical details
-Generated query for critical alert: `max((max(max_over_time(src_conf_client_time_since_last_successful_update_seconds{job=~".*searcher"}[1m]))) >= 300)` +Generated query for warning alert: `max((max_over_time(cadvisor_container_memory_usage_percentage_total{name=~"^worker.*"}[1d])) >= 80)`-## searcher: mean_blocked_seconds_per_conn_request +## worker: provisioning_container_cpu_usage_short_term -
mean blocked seconds per conn request
+container cpu usage total (5m maximum) across all cores by instance
**Descriptions** -- warning searcher: 0.1s+ mean blocked seconds per conn request for 10m0s -- critical searcher: 0.5s+ mean blocked seconds per conn request for 10m0s +- warning worker: 90%+ container cpu usage total (5m maximum) across all cores by instance for 30m0s **Next steps** -- Increase SRC_PGSQL_MAX_OPEN together with giving more memory to the database if needed -- Scale up Postgres memory/cpus - [see our scaling guide](https://sourcegraph.com/docs/admin/config/postgres-conf) -- If using GCP Cloud SQL, check for high lock waits or CPU usage in query insights -- Learn more about the related dashboard panel in the [dashboards reference](dashboards#searcher-mean-blocked-seconds-per-conn-request). +- **Kubernetes:** Consider increasing CPU limits in the the relevant `Deployment.yaml`. +- **Docker Compose:** Consider increasing `cpus:` of the worker container in `docker-compose.yml`. +- Learn more about the related dashboard panel in the [dashboards reference](dashboards#worker-provisioning-container-cpu-usage-short-term). - **Silence this alert:** If you are aware of this alert and want to silence notifications for it, add the following to your site configuration and set a reminder to re-evaluate the alert: ```json "observability.silenceAlerts": [ - "warning_searcher_mean_blocked_seconds_per_conn_request", - "critical_searcher_mean_blocked_seconds_per_conn_request" + "warning_worker_provisioning_container_cpu_usage_short_term" ] ``` -*Managed by the [Sourcegraph Infrastructure Org team](https://handbook.sourcegraph.com/departments/engineering/infrastructure).* +*Managed by the [Sourcegraph Code intelligence team](https://handbook.sourcegraph.com/departments/engineering/teams/code-intelligence).*Technical details
-Generated query for warning alert: `max((sum by (app_name, db_name) (increase(src_pgsql_conns_blocked_seconds{app_name="searcher"\}[5m])) / sum by (app_name, db_name) (increase(src_pgsql_conns_waited_for\{app_name="searcher"}[5m]))) >= 0.1)` - -Generated query for critical alert: `max((sum by (app_name, db_name) (increase(src_pgsql_conns_blocked_seconds{app_name="searcher"\}[5m])) / sum by (app_name, db_name) (increase(src_pgsql_conns_waited_for\{app_name="searcher"}[5m]))) >= 0.5)` +Generated query for warning alert: `max((max_over_time(cadvisor_container_cpu_usage_percentage_total{name=~"^worker.*"}[5m])) >= 90)`-## searcher: container_cpu_usage +## worker: provisioning_container_memory_usage_short_term -
container cpu usage total (1m average) across all cores by instance
+container memory usage (5m maximum) by instance
**Descriptions** -- warning searcher: 99%+ container cpu usage total (1m average) across all cores by instance +- warning worker: 90%+ container memory usage (5m maximum) by instance **Next steps** -- **Kubernetes:** Consider increasing CPU limits in the the relevant `Deployment.yaml`. -- **Docker Compose:** Consider increasing `cpus:` of the searcher container in `docker-compose.yml`. -- Learn more about the related dashboard panel in the [dashboards reference](dashboards#searcher-container-cpu-usage). +- **Kubernetes:** Consider increasing memory limit in relevant `Deployment.yaml`. +- **Docker Compose:** Consider increasing `memory:` of worker container in `docker-compose.yml`. +- Learn more about the related dashboard panel in the [dashboards reference](dashboards#worker-provisioning-container-memory-usage-short-term). - **Silence this alert:** If you are aware of this alert and want to silence notifications for it, add the following to your site configuration and set a reminder to re-evaluate the alert: ```json "observability.silenceAlerts": [ - "warning_searcher_container_cpu_usage" + "warning_worker_provisioning_container_memory_usage_short_term" ] ``` -*Managed by the [Sourcegraph Search Platform team](https://handbook.sourcegraph.com/departments/engineering/teams/search/core).* +*Managed by the [Sourcegraph Code intelligence team](https://handbook.sourcegraph.com/departments/engineering/teams/code-intelligence).*Technical details
-Generated query for warning alert: `max((cadvisor_container_cpu_usage_percentage_total{name=~"^searcher.*"}) >= 99)` +Generated query for warning alert: `max((max_over_time(cadvisor_container_memory_usage_percentage_total{name=~"^worker.*"}[5m])) >= 90)`-## searcher: container_memory_usage +## worker: container_oomkill_events_total -
container memory usage by instance
+container OOMKILL events total by instance
**Descriptions** -- warning searcher: 99%+ container memory usage by instance +- warning worker: 1+ container OOMKILL events total by instance **Next steps** - **Kubernetes:** Consider increasing memory limit in relevant `Deployment.yaml`. -- **Docker Compose:** Consider increasing `memory:` of searcher container in `docker-compose.yml`. -- Learn more about the related dashboard panel in the [dashboards reference](dashboards#searcher-container-memory-usage). +- **Docker Compose:** Consider increasing `memory:` of worker container in `docker-compose.yml`. +- More help interpreting this metric is available in the [dashboards reference](dashboards#worker-container-oomkill-events-total). - **Silence this alert:** If you are aware of this alert and want to silence notifications for it, add the following to your site configuration and set a reminder to re-evaluate the alert: ```json "observability.silenceAlerts": [ - "warning_searcher_container_memory_usage" + "warning_worker_container_oomkill_events_total" ] ``` -*Managed by the [Sourcegraph Search Platform team](https://handbook.sourcegraph.com/departments/engineering/teams/search/core).* +*Managed by the [Sourcegraph Code intelligence team](https://handbook.sourcegraph.com/departments/engineering/teams/code-intelligence).*Technical details
-Generated query for warning alert: `max((cadvisor_container_memory_usage_percentage_total{name=~"^searcher.*"}) >= 99)` +Generated query for warning alert: `max((max by (name) (container_oom_events_total{name=~"^worker.*"})) >= 1)`-## searcher: provisioning_container_cpu_usage_long_term +## worker: go_goroutines -
container cpu usage total (90th percentile over 1d) across all cores by instance
+maximum active goroutines
**Descriptions** -- warning searcher: 80%+ container cpu usage total (90th percentile over 1d) across all cores by instance for 336h0m0s +- warning worker: 10000+ maximum active goroutines for 10m0s **Next steps** -- **Kubernetes:** Consider increasing CPU limits in the `Deployment.yaml` for the searcher service. -- **Docker Compose:** Consider increasing `cpus:` of the searcher container in `docker-compose.yml`. -- Learn more about the related dashboard panel in the [dashboards reference](dashboards#searcher-provisioning-container-cpu-usage-long-term). +- More help interpreting this metric is available in the [dashboards reference](dashboards#worker-go-goroutines). - **Silence this alert:** If you are aware of this alert and want to silence notifications for it, add the following to your site configuration and set a reminder to re-evaluate the alert: ```json "observability.silenceAlerts": [ - "warning_searcher_provisioning_container_cpu_usage_long_term" + "warning_worker_go_goroutines" ] ``` -*Managed by the [Sourcegraph Search Platform team](https://handbook.sourcegraph.com/departments/engineering/teams/search/core).* +*Managed by the [Sourcegraph Code intelligence team](https://handbook.sourcegraph.com/departments/engineering/teams/code-intelligence).*Technical details
-Generated query for warning alert: `max((quantile_over_time(0.9, cadvisor_container_cpu_usage_percentage_total{name=~"^searcher.*"}[1d])) >= 80)` +Generated query for warning alert: `max((max by (instance) (go_goroutines{job=~".*worker"})) >= 10000)`-## searcher: provisioning_container_memory_usage_long_term +## worker: go_gc_duration_seconds -
container memory usage (1d maximum) by instance
+maximum go garbage collection duration
**Descriptions** -- warning searcher: 80%+ container memory usage (1d maximum) by instance for 336h0m0s +- warning worker: 2s+ maximum go garbage collection duration **Next steps** -- **Kubernetes:** Consider increasing memory limits in the `Deployment.yaml` for the searcher service. -- **Docker Compose:** Consider increasing `memory:` of the searcher container in `docker-compose.yml`. -- Learn more about the related dashboard panel in the [dashboards reference](dashboards#searcher-provisioning-container-memory-usage-long-term). +- Learn more about the related dashboard panel in the [dashboards reference](dashboards#worker-go-gc-duration-seconds). - **Silence this alert:** If you are aware of this alert and want to silence notifications for it, add the following to your site configuration and set a reminder to re-evaluate the alert: ```json "observability.silenceAlerts": [ - "warning_searcher_provisioning_container_memory_usage_long_term" + "warning_worker_go_gc_duration_seconds" ] ``` -*Managed by the [Sourcegraph Search Platform team](https://handbook.sourcegraph.com/departments/engineering/teams/search/core).* +*Managed by the [Sourcegraph Code intelligence team](https://handbook.sourcegraph.com/departments/engineering/teams/code-intelligence).*Technical details
-Generated query for warning alert: `max((max_over_time(cadvisor_container_memory_usage_percentage_total{name=~"^searcher.*"}[1d])) >= 80)` +Generated query for warning alert: `max((max by (instance) (go_gc_duration_seconds{job=~".*worker"})) >= 2)`-## searcher: provisioning_container_cpu_usage_short_term +## worker: pods_available_percentage -
container cpu usage total (5m maximum) across all cores by instance
+percentage pods available
**Descriptions** -- warning searcher: 90%+ container cpu usage total (5m maximum) across all cores by instance for 30m0s +- critical worker: less than 90% percentage pods available for 10m0s **Next steps** -- **Kubernetes:** Consider increasing CPU limits in the the relevant `Deployment.yaml`. -- **Docker Compose:** Consider increasing `cpus:` of the searcher container in `docker-compose.yml`. -- Learn more about the related dashboard panel in the [dashboards reference](dashboards#searcher-provisioning-container-cpu-usage-short-term). +- Determine if the pod was OOM killed using `kubectl describe pod worker` (look for `OOMKilled: true`) and, if so, consider increasing the memory limit in the relevant `Deployment.yaml`. +- Check the logs before the container restarted to see if there are `panic:` messages or similar using `kubectl logs -p worker`. +- Learn more about the related dashboard panel in the [dashboards reference](dashboards#worker-pods-available-percentage). - **Silence this alert:** If you are aware of this alert and want to silence notifications for it, add the following to your site configuration and set a reminder to re-evaluate the alert: ```json "observability.silenceAlerts": [ - "warning_searcher_provisioning_container_cpu_usage_short_term" + "critical_worker_pods_available_percentage" ] ``` -*Managed by the [Sourcegraph Search Platform team](https://handbook.sourcegraph.com/departments/engineering/teams/search/core).* +*Managed by the [Sourcegraph Code intelligence team](https://handbook.sourcegraph.com/departments/engineering/teams/code-intelligence).*Technical details
-Generated query for warning alert: `max((max_over_time(cadvisor_container_cpu_usage_percentage_total{name=~"^searcher.*"}[5m])) >= 90)` +Generated query for critical alert: `min((sum by (app) (up{app=~".*worker"\}) / count by (app) (up\{app=~".*worker"}) * 100) <= 90)`-## searcher: provisioning_container_memory_usage_short_term +## worker: worker_site_configuration_duration_since_last_successful_update_by_instance -
container memory usage (5m maximum) by instance
+maximum duration since last successful site configuration update (all "worker" instances)
**Descriptions** -- warning searcher: 90%+ container memory usage (5m maximum) by instance +- critical worker: 300s+ maximum duration since last successful site configuration update (all "worker" instances) **Next steps** -- **Kubernetes:** Consider increasing memory limit in relevant `Deployment.yaml`. -- **Docker Compose:** Consider increasing `memory:` of searcher container in `docker-compose.yml`. -- Learn more about the related dashboard panel in the [dashboards reference](dashboards#searcher-provisioning-container-memory-usage-short-term). +- This indicates that one or more "worker" instances have not successfully updated the site configuration in over 5 minutes. This could be due to networking issues between services or problems with the site configuration service itself. +- Check for relevant errors in the "worker" logs, as well as frontend`s logs. +- Learn more about the related dashboard panel in the [dashboards reference](dashboards#worker-worker-site-configuration-duration-since-last-successful-update-by-instance). - **Silence this alert:** If you are aware of this alert and want to silence notifications for it, add the following to your site configuration and set a reminder to re-evaluate the alert: ```json "observability.silenceAlerts": [ - "warning_searcher_provisioning_container_memory_usage_short_term" + "critical_worker_worker_site_configuration_duration_since_last_successful_update_by_instance" ] ``` -*Managed by the [Sourcegraph Search Platform team](https://handbook.sourcegraph.com/departments/engineering/teams/search/core).* +*Managed by the [Sourcegraph Infrastructure Org team](https://handbook.sourcegraph.com/departments/engineering/infrastructure).*Technical details
-Generated query for warning alert: `max((max_over_time(cadvisor_container_memory_usage_percentage_total{name=~"^searcher.*"}[5m])) >= 90)` +Generated query for critical alert: `max((max(max_over_time(src_conf_client_time_since_last_successful_update_seconds{job=~"^worker.*"}[1m]))) >= 300)`-## searcher: container_oomkill_events_total +## searcher: replica_traffic -
container OOMKILL events total by instance
+requests per second per replica over 10m
**Descriptions** -- warning searcher: 1+ container OOMKILL events total by instance +- warning searcher: 5+ requests per second per replica over 10m **Next steps** -- **Kubernetes:** Consider increasing memory limit in relevant `Deployment.yaml`. -- **Docker Compose:** Consider increasing `memory:` of searcher container in `docker-compose.yml`. -- More help interpreting this metric is available in the [dashboards reference](dashboards#searcher-container-oomkill-events-total). +- More help interpreting this metric is available in the [dashboards reference](dashboards#searcher-replica-traffic). - **Silence this alert:** If you are aware of this alert and want to silence notifications for it, add the following to your site configuration and set a reminder to re-evaluate the alert: ```json "observability.silenceAlerts": [ - "warning_searcher_container_oomkill_events_total" + "warning_searcher_replica_traffic" ] ``` @@ -78259,28 +77966,28 @@ Generated query for warning alert: `max((max_over_time(cadvisor_container_memoryTechnical details
-Generated query for warning alert: `max((max by (name) (container_oom_events_total{name=~"^searcher.*"})) >= 1)` +Generated query for warning alert: `max((sum by (instance) (rate(searcher_service_request_total[10m]))) >= 5)`-## searcher: go_goroutines +## searcher: unindexed_search_request_errors -
maximum active goroutines
+unindexed search request errors every 5m by code
**Descriptions** -- warning searcher: 10000+ maximum active goroutines for 10m0s +- warning searcher: 5%+ unindexed search request errors every 5m by code for 5m0s **Next steps** -- More help interpreting this metric is available in the [dashboards reference](dashboards#searcher-go-goroutines). +- Learn more about the related dashboard panel in the [dashboards reference](dashboards#searcher-unindexed-search-request-errors). - **Silence this alert:** If you are aware of this alert and want to silence notifications for it, add the following to your site configuration and set a reminder to re-evaluate the alert: ```json "observability.silenceAlerts": [ - "warning_searcher_go_goroutines" + "warning_searcher_unindexed_search_request_errors" ] ``` @@ -78289,92 +77996,96 @@ Generated query for warning alert: `max((max by (name) (container_oom_events_totTechnical details
-Generated query for warning alert: `max((max by (instance) (go_goroutines{job=~".*searcher"})) >= 10000)` +Generated query for warning alert: `max((sum by (code) (increase(searcher_service_request_total{code!="200",code!="canceled"}[5m])) / ignoring (code) group_left () sum(increase(searcher_service_request_total[5m])) * 100) >= 5)`-## searcher: go_gc_duration_seconds +## searcher: searcher_site_configuration_duration_since_last_successful_update_by_instance -
maximum go garbage collection duration
+maximum duration since last successful site configuration update (all "searcher" instances)
**Descriptions** -- warning searcher: 2s+ maximum go garbage collection duration +- critical searcher: 300s+ maximum duration since last successful site configuration update (all "searcher" instances) **Next steps** -- Learn more about the related dashboard panel in the [dashboards reference](dashboards#searcher-go-gc-duration-seconds). +- This indicates that one or more "searcher" instances have not successfully updated the site configuration in over 5 minutes. This could be due to networking issues between services or problems with the site configuration service itself. +- Check for relevant errors in the "searcher" logs, as well as frontend`s logs. +- Learn more about the related dashboard panel in the [dashboards reference](dashboards#searcher-searcher-site-configuration-duration-since-last-successful-update-by-instance). - **Silence this alert:** If you are aware of this alert and want to silence notifications for it, add the following to your site configuration and set a reminder to re-evaluate the alert: ```json "observability.silenceAlerts": [ - "warning_searcher_go_gc_duration_seconds" + "critical_searcher_searcher_site_configuration_duration_since_last_successful_update_by_instance" ] ``` -*Managed by the [Sourcegraph Search Platform team](https://handbook.sourcegraph.com/departments/engineering/teams/search/core).* +*Managed by the [Sourcegraph Infrastructure Org team](https://handbook.sourcegraph.com/departments/engineering/infrastructure).*Technical details
-Generated query for warning alert: `max((max by (instance) (go_gc_duration_seconds{job=~".*searcher"})) >= 2)` +Generated query for critical alert: `max((max(max_over_time(src_conf_client_time_since_last_successful_update_seconds{job=~".*searcher"}[1m]))) >= 300)`-## searcher: pods_available_percentage +## searcher: goroutine_error_rate -
percentage pods available
+error rate for periodic goroutine executions
**Descriptions** -- critical searcher: less than 90% percentage pods available for 10m0s +- warning searcher: 0.01reqps+ error rate for periodic goroutine executions for 15m0s **Next steps** -- Determine if the pod was OOM killed using `kubectl describe pod searcher` (look for `OOMKilled: true`) and, if so, consider increasing the memory limit in the relevant `Deployment.yaml`. -- Check the logs before the container restarted to see if there are `panic:` messages or similar using `kubectl logs -p searcher`. -- Learn more about the related dashboard panel in the [dashboards reference](dashboards#searcher-pods-available-percentage). +- Check service logs for error details related to the failing periodic routine +- Check if the routine depends on external services that may be unavailable +- Look for recent changes to the routine`s code or configuration +- More help interpreting this metric is available in the [dashboards reference](dashboards#searcher-goroutine-error-rate). - **Silence this alert:** If you are aware of this alert and want to silence notifications for it, add the following to your site configuration and set a reminder to re-evaluate the alert: ```json "observability.silenceAlerts": [ - "critical_searcher_pods_available_percentage" + "warning_searcher_goroutine_error_rate" ] ``` -*Managed by the [Sourcegraph Search Platform team](https://handbook.sourcegraph.com/departments/engineering/teams/search/core).* +*Managed by the [Sourcegraph Infrastructure Org team](https://handbook.sourcegraph.com/departments/engineering/infrastructure).*Technical details
-Generated query for critical alert: `min((sum by (app) (up{app=~".*searcher"\}) / count by (app) (up\{app=~".*searcher"}) * 100) <= 90)` +Generated query for warning alert: `max((sum by (name, job_name) (rate(src_periodic_goroutine_errors_total{job=~".*searcher.*"}[5m]))) >= 0.01)`-## symbols: symbols_site_configuration_duration_since_last_successful_update_by_instance +## searcher: goroutine_error_percentage -
maximum duration since last successful site configuration update (all "symbols" instances)
+percentage of periodic goroutine executions that result in errors
**Descriptions** -- critical symbols: 300s+ maximum duration since last successful site configuration update (all "symbols" instances) +- warning searcher: 5%+ percentage of periodic goroutine executions that result in errors **Next steps** -- This indicates that one or more "symbols" instances have not successfully updated the site configuration in over 5 minutes. This could be due to networking issues between services or problems with the site configuration service itself. -- Check for relevant errors in the "symbols" logs, as well as frontend`s logs. -- Learn more about the related dashboard panel in the [dashboards reference](dashboards#symbols-symbols-site-configuration-duration-since-last-successful-update-by-instance). +- Check service logs for error details related to the failing periodic routine +- Check if the routine depends on external services that may be unavailable +- Consider temporarily disabling the routine if it`s non-critical and causing cascading issues +- More help interpreting this metric is available in the [dashboards reference](dashboards#searcher-goroutine-error-percentage). - **Silence this alert:** If you are aware of this alert and want to silence notifications for it, add the following to your site configuration and set a reminder to re-evaluate the alert: ```json "observability.silenceAlerts": [ - "critical_symbols_symbols_site_configuration_duration_since_last_successful_update_by_instance" + "warning_searcher_goroutine_error_percentage" ] ``` @@ -78383,33 +78094,33 @@ Generated query for critical alert: `min((sum by (app) (up{app=~".*searcher"\})Technical details
-Generated query for critical alert: `max((max(max_over_time(src_conf_client_time_since_last_successful_update_seconds{job=~".*symbols"}[1m]))) >= 300)` +Generated query for warning alert: `max((sum by (name, job_name) (rate(src_periodic_goroutine_errors_total{job=~".*searcher.*"\}[5m])) / sum by (name, job_name) (rate(src_periodic_goroutine_total\{job=~".*searcher.*"}[5m]) > 0) * 100) >= 5)`-## symbols: mean_blocked_seconds_per_conn_request +## searcher: mean_blocked_seconds_per_conn_request
mean blocked seconds per conn request
**Descriptions** -- warning symbols: 0.1s+ mean blocked seconds per conn request for 10m0s -- critical symbols: 0.5s+ mean blocked seconds per conn request for 10m0s +- warning searcher: 0.1s+ mean blocked seconds per conn request for 10m0s +- critical searcher: 0.5s+ mean blocked seconds per conn request for 10m0s **Next steps** - Increase SRC_PGSQL_MAX_OPEN together with giving more memory to the database if needed - Scale up Postgres memory/cpus - [see our scaling guide](https://sourcegraph.com/docs/admin/config/postgres-conf) - If using GCP Cloud SQL, check for high lock waits or CPU usage in query insights -- Learn more about the related dashboard panel in the [dashboards reference](dashboards#symbols-mean-blocked-seconds-per-conn-request). +- Learn more about the related dashboard panel in the [dashboards reference](dashboards#searcher-mean-blocked-seconds-per-conn-request). - **Silence this alert:** If you are aware of this alert and want to silence notifications for it, add the following to your site configuration and set a reminder to re-evaluate the alert: ```json "observability.silenceAlerts": [ - "warning_symbols_mean_blocked_seconds_per_conn_request", - "critical_symbols_mean_blocked_seconds_per_conn_request" + "warning_searcher_mean_blocked_seconds_per_conn_request", + "critical_searcher_mean_blocked_seconds_per_conn_request" ] ``` @@ -78418,325 +78129,449 @@ Generated query for critical alert: `max((max(max_over_time(src_conf_client_timeTechnical details
-Generated query for warning alert: `max((sum by (app_name, db_name) (increase(src_pgsql_conns_blocked_seconds{app_name="symbols"\}[5m])) / sum by (app_name, db_name) (increase(src_pgsql_conns_waited_for\{app_name="symbols"}[5m]))) >= 0.1)` +Generated query for warning alert: `max((sum by (app_name, db_name) (increase(src_pgsql_conns_blocked_seconds{app_name="searcher"\}[5m])) / sum by (app_name, db_name) (increase(src_pgsql_conns_waited_for\{app_name="searcher"}[5m]))) >= 0.1)` + +Generated query for critical alert: `max((sum by (app_name, db_name) (increase(src_pgsql_conns_blocked_seconds{app_name="searcher"\}[5m])) / sum by (app_name, db_name) (increase(src_pgsql_conns_waited_for\{app_name="searcher"}[5m]))) >= 0.5)` + ++ +## searcher: cpu_usage_percentage + +
CPU usage
+ +**Descriptions** + +- warning searcher: 95%+ CPU usage for 10m0s + +**Next steps** + +- Consider increasing CPU limits or scaling out. +- Learn more about the related dashboard panel in the [dashboards reference](dashboards#searcher-cpu-usage-percentage). +- **Silence this alert:** If you are aware of this alert and want to silence notifications for it, add the following to your site configuration and set a reminder to re-evaluate the alert: + +```json +"observability.silenceAlerts": [ + "warning_searcher_cpu_usage_percentage" +] +``` + +*Managed by the [Sourcegraph Code Search team](https://handbook.sourcegraph.com/departments/engineering/teams/code-search).* + +Technical details
+ +Generated query for warning alert: `max((cadvisor_container_cpu_usage_percentage_total{name=~"^searcher.*"}) >= 95)` + ++ +## searcher: memory_rss + +
memory (RSS)
+ +**Descriptions** + +- warning searcher: 90%+ memory (RSS) for 10m0s + +**Next steps** + +- Consider increasing memory limits or scaling out. +- More help interpreting this metric is available in the [dashboards reference](dashboards#searcher-memory-rss). +- **Silence this alert:** If you are aware of this alert and want to silence notifications for it, add the following to your site configuration and set a reminder to re-evaluate the alert: + +```json +"observability.silenceAlerts": [ + "warning_searcher_memory_rss" +] +``` + +*Managed by the [Sourcegraph Code Search team](https://handbook.sourcegraph.com/departments/engineering/teams/code-search).* + +Technical details
-Generated query for critical alert: `max((sum by (app_name, db_name) (increase(src_pgsql_conns_blocked_seconds{app_name="symbols"\}[5m])) / sum by (app_name, db_name) (increase(src_pgsql_conns_waited_for\{app_name="symbols"}[5m]))) >= 0.5)` +Generated query for warning alert: `max((max by (name) (container_memory_rss{name=~"^searcher.*"\} / container_spec_memory_limit_bytes\{name=~"^searcher.*"}) * 100) >= 90)`-## symbols: container_cpu_usage +## searcher: container_cpu_usage
container cpu usage total (1m average) across all cores by instance
**Descriptions** -- warning symbols: 99%+ container cpu usage total (1m average) across all cores by instance +- warning searcher: 99%+ container cpu usage total (1m average) across all cores by instance **Next steps** - **Kubernetes:** Consider increasing CPU limits in the the relevant `Deployment.yaml`. -- **Docker Compose:** Consider increasing `cpus:` of the symbols container in `docker-compose.yml`. -- Learn more about the related dashboard panel in the [dashboards reference](dashboards#symbols-container-cpu-usage). +- **Docker Compose:** Consider increasing `cpus:` of the searcher container in `docker-compose.yml`. +- Learn more about the related dashboard panel in the [dashboards reference](dashboards#searcher-container-cpu-usage). - **Silence this alert:** If you are aware of this alert and want to silence notifications for it, add the following to your site configuration and set a reminder to re-evaluate the alert: ```json "observability.silenceAlerts": [ - "warning_symbols_container_cpu_usage" + "warning_searcher_container_cpu_usage" ] ``` -*Managed by the [Sourcegraph Code intelligence team](https://handbook.sourcegraph.com/departments/engineering/teams/code-intelligence).* +*Managed by the [Sourcegraph Search Platform team](https://handbook.sourcegraph.com/departments/engineering/teams/search/core).*Technical details
-Generated query for warning alert: `max((cadvisor_container_cpu_usage_percentage_total{name=~"^symbols.*"}) >= 99)` +Generated query for warning alert: `max((cadvisor_container_cpu_usage_percentage_total{name=~"^searcher.*"}) >= 99)`-## symbols: container_memory_usage +## searcher: container_memory_usage
container memory usage by instance
**Descriptions** -- warning symbols: 99%+ container memory usage by instance +- warning searcher: 99%+ container memory usage by instance **Next steps** - **Kubernetes:** Consider increasing memory limit in relevant `Deployment.yaml`. -- **Docker Compose:** Consider increasing `memory:` of symbols container in `docker-compose.yml`. -- Learn more about the related dashboard panel in the [dashboards reference](dashboards#symbols-container-memory-usage). +- **Docker Compose:** Consider increasing `memory:` of searcher container in `docker-compose.yml`. +- Learn more about the related dashboard panel in the [dashboards reference](dashboards#searcher-container-memory-usage). - **Silence this alert:** If you are aware of this alert and want to silence notifications for it, add the following to your site configuration and set a reminder to re-evaluate the alert: ```json "observability.silenceAlerts": [ - "warning_symbols_container_memory_usage" + "warning_searcher_container_memory_usage" ] ``` -*Managed by the [Sourcegraph Code intelligence team](https://handbook.sourcegraph.com/departments/engineering/teams/code-intelligence).* +*Managed by the [Sourcegraph Search Platform team](https://handbook.sourcegraph.com/departments/engineering/teams/search/core).*Technical details
-Generated query for warning alert: `max((cadvisor_container_memory_usage_percentage_total{name=~"^symbols.*"}) >= 99)` +Generated query for warning alert: `max((cadvisor_container_memory_usage_percentage_total{name=~"^searcher.*"}) >= 99)`-## symbols: provisioning_container_cpu_usage_long_term +## searcher: provisioning_container_cpu_usage_long_term
container cpu usage total (90th percentile over 1d) across all cores by instance
**Descriptions** -- warning symbols: 80%+ container cpu usage total (90th percentile over 1d) across all cores by instance for 336h0m0s +- warning searcher: 80%+ container cpu usage total (90th percentile over 1d) across all cores by instance for 336h0m0s **Next steps** -- **Kubernetes:** Consider increasing CPU limits in the `Deployment.yaml` for the symbols service. -- **Docker Compose:** Consider increasing `cpus:` of the symbols container in `docker-compose.yml`. -- Learn more about the related dashboard panel in the [dashboards reference](dashboards#symbols-provisioning-container-cpu-usage-long-term). +- **Kubernetes:** Consider increasing CPU limits in the `Deployment.yaml` for the searcher service. +- **Docker Compose:** Consider increasing `cpus:` of the searcher container in `docker-compose.yml`. +- Learn more about the related dashboard panel in the [dashboards reference](dashboards#searcher-provisioning-container-cpu-usage-long-term). - **Silence this alert:** If you are aware of this alert and want to silence notifications for it, add the following to your site configuration and set a reminder to re-evaluate the alert: ```json "observability.silenceAlerts": [ - "warning_symbols_provisioning_container_cpu_usage_long_term" + "warning_searcher_provisioning_container_cpu_usage_long_term" ] ``` -*Managed by the [Sourcegraph Code intelligence team](https://handbook.sourcegraph.com/departments/engineering/teams/code-intelligence).* +*Managed by the [Sourcegraph Search Platform team](https://handbook.sourcegraph.com/departments/engineering/teams/search/core).*Technical details
-Generated query for warning alert: `max((quantile_over_time(0.9, cadvisor_container_cpu_usage_percentage_total{name=~"^symbols.*"}[1d])) >= 80)` +Generated query for warning alert: `max((quantile_over_time(0.9, cadvisor_container_cpu_usage_percentage_total{name=~"^searcher.*"}[1d])) >= 80)`-## symbols: provisioning_container_memory_usage_long_term +## searcher: provisioning_container_memory_usage_long_term
container memory usage (1d maximum) by instance
**Descriptions** -- warning symbols: 80%+ container memory usage (1d maximum) by instance for 336h0m0s +- warning searcher: 80%+ container memory usage (1d maximum) by instance for 336h0m0s **Next steps** -- **Kubernetes:** Consider increasing memory limits in the `Deployment.yaml` for the symbols service. -- **Docker Compose:** Consider increasing `memory:` of the symbols container in `docker-compose.yml`. -- Learn more about the related dashboard panel in the [dashboards reference](dashboards#symbols-provisioning-container-memory-usage-long-term). +- **Kubernetes:** Consider increasing memory limits in the `Deployment.yaml` for the searcher service. +- **Docker Compose:** Consider increasing `memory:` of the searcher container in `docker-compose.yml`. +- Learn more about the related dashboard panel in the [dashboards reference](dashboards#searcher-provisioning-container-memory-usage-long-term). - **Silence this alert:** If you are aware of this alert and want to silence notifications for it, add the following to your site configuration and set a reminder to re-evaluate the alert: ```json "observability.silenceAlerts": [ - "warning_symbols_provisioning_container_memory_usage_long_term" + "warning_searcher_provisioning_container_memory_usage_long_term" ] ``` -*Managed by the [Sourcegraph Code intelligence team](https://handbook.sourcegraph.com/departments/engineering/teams/code-intelligence).* +*Managed by the [Sourcegraph Search Platform team](https://handbook.sourcegraph.com/departments/engineering/teams/search/core).*Technical details
-Generated query for warning alert: `max((max_over_time(cadvisor_container_memory_usage_percentage_total{name=~"^symbols.*"}[1d])) >= 80)` +Generated query for warning alert: `max((max_over_time(cadvisor_container_memory_usage_percentage_total{name=~"^searcher.*"}[1d])) >= 80)`-## symbols: provisioning_container_cpu_usage_short_term +## searcher: provisioning_container_cpu_usage_short_term
container cpu usage total (5m maximum) across all cores by instance
**Descriptions** -- warning symbols: 90%+ container cpu usage total (5m maximum) across all cores by instance for 30m0s +- warning searcher: 90%+ container cpu usage total (5m maximum) across all cores by instance for 30m0s **Next steps** - **Kubernetes:** Consider increasing CPU limits in the the relevant `Deployment.yaml`. -- **Docker Compose:** Consider increasing `cpus:` of the symbols container in `docker-compose.yml`. -- Learn more about the related dashboard panel in the [dashboards reference](dashboards#symbols-provisioning-container-cpu-usage-short-term). +- **Docker Compose:** Consider increasing `cpus:` of the searcher container in `docker-compose.yml`. +- Learn more about the related dashboard panel in the [dashboards reference](dashboards#searcher-provisioning-container-cpu-usage-short-term). - **Silence this alert:** If you are aware of this alert and want to silence notifications for it, add the following to your site configuration and set a reminder to re-evaluate the alert: ```json "observability.silenceAlerts": [ - "warning_symbols_provisioning_container_cpu_usage_short_term" + "warning_searcher_provisioning_container_cpu_usage_short_term" ] ``` -*Managed by the [Sourcegraph Code intelligence team](https://handbook.sourcegraph.com/departments/engineering/teams/code-intelligence).* +*Managed by the [Sourcegraph Search Platform team](https://handbook.sourcegraph.com/departments/engineering/teams/search/core).*Technical details
-Generated query for warning alert: `max((max_over_time(cadvisor_container_cpu_usage_percentage_total{name=~"^symbols.*"}[5m])) >= 90)` +Generated query for warning alert: `max((max_over_time(cadvisor_container_cpu_usage_percentage_total{name=~"^searcher.*"}[5m])) >= 90)`-## symbols: provisioning_container_memory_usage_short_term +## searcher: provisioning_container_memory_usage_short_term
container memory usage (5m maximum) by instance
**Descriptions** -- warning symbols: 90%+ container memory usage (5m maximum) by instance +- warning searcher: 90%+ container memory usage (5m maximum) by instance **Next steps** - **Kubernetes:** Consider increasing memory limit in relevant `Deployment.yaml`. -- **Docker Compose:** Consider increasing `memory:` of symbols container in `docker-compose.yml`. -- Learn more about the related dashboard panel in the [dashboards reference](dashboards#symbols-provisioning-container-memory-usage-short-term). +- **Docker Compose:** Consider increasing `memory:` of searcher container in `docker-compose.yml`. +- Learn more about the related dashboard panel in the [dashboards reference](dashboards#searcher-provisioning-container-memory-usage-short-term). - **Silence this alert:** If you are aware of this alert and want to silence notifications for it, add the following to your site configuration and set a reminder to re-evaluate the alert: ```json "observability.silenceAlerts": [ - "warning_symbols_provisioning_container_memory_usage_short_term" + "warning_searcher_provisioning_container_memory_usage_short_term" ] ``` -*Managed by the [Sourcegraph Code intelligence team](https://handbook.sourcegraph.com/departments/engineering/teams/code-intelligence).* +*Managed by the [Sourcegraph Search Platform team](https://handbook.sourcegraph.com/departments/engineering/teams/search/core).*Technical details
-Generated query for warning alert: `max((max_over_time(cadvisor_container_memory_usage_percentage_total{name=~"^symbols.*"}[5m])) >= 90)` +Generated query for warning alert: `max((max_over_time(cadvisor_container_memory_usage_percentage_total{name=~"^searcher.*"}[5m])) >= 90)`-## symbols: container_oomkill_events_total +## searcher: container_oomkill_events_total
container OOMKILL events total by instance
**Descriptions** -- warning symbols: 1+ container OOMKILL events total by instance +- warning searcher: 1+ container OOMKILL events total by instance **Next steps** - **Kubernetes:** Consider increasing memory limit in relevant `Deployment.yaml`. -- **Docker Compose:** Consider increasing `memory:` of symbols container in `docker-compose.yml`. -- More help interpreting this metric is available in the [dashboards reference](dashboards#symbols-container-oomkill-events-total). +- **Docker Compose:** Consider increasing `memory:` of searcher container in `docker-compose.yml`. +- More help interpreting this metric is available in the [dashboards reference](dashboards#searcher-container-oomkill-events-total). - **Silence this alert:** If you are aware of this alert and want to silence notifications for it, add the following to your site configuration and set a reminder to re-evaluate the alert: ```json "observability.silenceAlerts": [ - "warning_symbols_container_oomkill_events_total" + "warning_searcher_container_oomkill_events_total" ] ``` -*Managed by the [Sourcegraph Code intelligence team](https://handbook.sourcegraph.com/departments/engineering/teams/code-intelligence).* +*Managed by the [Sourcegraph Search Platform team](https://handbook.sourcegraph.com/departments/engineering/teams/search/core).*Technical details
-Generated query for warning alert: `max((max by (name) (container_oom_events_total{name=~"^symbols.*"})) >= 1)` +Generated query for warning alert: `max((max by (name) (container_oom_events_total{name=~"^searcher.*"})) >= 1)`-## symbols: go_goroutines +## searcher: go_goroutines
maximum active goroutines
**Descriptions** -- warning symbols: 10000+ maximum active goroutines for 10m0s +- warning searcher: 10000+ maximum active goroutines for 10m0s **Next steps** -- More help interpreting this metric is available in the [dashboards reference](dashboards#symbols-go-goroutines). +- More help interpreting this metric is available in the [dashboards reference](dashboards#searcher-go-goroutines). - **Silence this alert:** If you are aware of this alert and want to silence notifications for it, add the following to your site configuration and set a reminder to re-evaluate the alert: ```json "observability.silenceAlerts": [ - "warning_symbols_go_goroutines" + "warning_searcher_go_goroutines" ] ``` -*Managed by the [Sourcegraph Code intelligence team](https://handbook.sourcegraph.com/departments/engineering/teams/code-intelligence).* +*Managed by the [Sourcegraph Search Platform team](https://handbook.sourcegraph.com/departments/engineering/teams/search/core).*Technical details
-Generated query for warning alert: `max((max by (instance) (go_goroutines{job=~".*symbols"})) >= 10000)` +Generated query for warning alert: `max((max by (instance) (go_goroutines{job=~".*searcher"})) >= 10000)`-## symbols: go_gc_duration_seconds +## searcher: go_gc_duration_seconds
maximum go garbage collection duration
**Descriptions** -- warning symbols: 2s+ maximum go garbage collection duration +- warning searcher: 2s+ maximum go garbage collection duration **Next steps** -- Learn more about the related dashboard panel in the [dashboards reference](dashboards#symbols-go-gc-duration-seconds). +- Learn more about the related dashboard panel in the [dashboards reference](dashboards#searcher-go-gc-duration-seconds). - **Silence this alert:** If you are aware of this alert and want to silence notifications for it, add the following to your site configuration and set a reminder to re-evaluate the alert: ```json "observability.silenceAlerts": [ - "warning_symbols_go_gc_duration_seconds" + "warning_searcher_go_gc_duration_seconds" ] ``` -*Managed by the [Sourcegraph Code intelligence team](https://handbook.sourcegraph.com/departments/engineering/teams/code-intelligence).* +*Managed by the [Sourcegraph Search Platform team](https://handbook.sourcegraph.com/departments/engineering/teams/search/core).*Technical details
-Generated query for warning alert: `max((max by (instance) (go_gc_duration_seconds{job=~".*symbols"})) >= 2)` +Generated query for warning alert: `max((max by (instance) (go_gc_duration_seconds{job=~".*searcher"})) >= 2)`-## symbols: pods_available_percentage +## searcher: pods_available_percentage
percentage pods available
**Descriptions** -- critical symbols: less than 90% percentage pods available for 10m0s +- critical searcher: less than 90% percentage pods available for 10m0s **Next steps** -- Determine if the pod was OOM killed using `kubectl describe pod symbols` (look for `OOMKilled: true`) and, if so, consider increasing the memory limit in the relevant `Deployment.yaml`. -- Check the logs before the container restarted to see if there are `panic:` messages or similar using `kubectl logs -p symbols`. -- Learn more about the related dashboard panel in the [dashboards reference](dashboards#symbols-pods-available-percentage). +- Determine if the pod was OOM killed using `kubectl describe pod searcher` (look for `OOMKilled: true`) and, if so, consider increasing the memory limit in the relevant `Deployment.yaml`. +- Check the logs before the container restarted to see if there are `panic:` messages or similar using `kubectl logs -p searcher`. +- Learn more about the related dashboard panel in the [dashboards reference](dashboards#searcher-pods-available-percentage). - **Silence this alert:** If you are aware of this alert and want to silence notifications for it, add the following to your site configuration and set a reminder to re-evaluate the alert: ```json "observability.silenceAlerts": [ - "critical_symbols_pods_available_percentage" + "critical_searcher_pods_available_percentage" ] ``` -*Managed by the [Sourcegraph Code intelligence team](https://handbook.sourcegraph.com/departments/engineering/teams/code-intelligence).* +*Managed by the [Sourcegraph Search Platform team](https://handbook.sourcegraph.com/departments/engineering/teams/search/core).* + +Technical details
+ +Generated query for critical alert: `min((sum by (app) (up{app=~".*searcher"\}) / count by (app) (up\{app=~".*searcher"}) * 100) <= 90)` + ++ +## syntect-server: cpu_usage_percentage + +
CPU usage
+ +**Descriptions** + +- warning syntect-server: 95%+ CPU usage for 10m0s + +**Next steps** + +- Consider increasing CPU limits or scaling out. +- Learn more about the related dashboard panel in the [dashboards reference](dashboards#syntect-server-cpu-usage-percentage). +- **Silence this alert:** If you are aware of this alert and want to silence notifications for it, add the following to your site configuration and set a reminder to re-evaluate the alert: + +```json +"observability.silenceAlerts": [ + "warning_syntect-server_cpu_usage_percentage" +] +``` + +*Managed by the [Sourcegraph Code Search team](https://handbook.sourcegraph.com/departments/engineering/teams/code-search).* + +Technical details
+ +Generated query for warning alert: `max((cadvisor_container_cpu_usage_percentage_total{name=~"^syntect-server.*"}) >= 95)` + ++ +## syntect-server: memory_rss + +
memory (RSS)
+ +**Descriptions** + +- warning syntect-server: 90%+ memory (RSS) for 10m0s + +**Next steps** + +- Consider increasing memory limits or scaling out. +- More help interpreting this metric is available in the [dashboards reference](dashboards#syntect-server-memory-rss). +- **Silence this alert:** If you are aware of this alert and want to silence notifications for it, add the following to your site configuration and set a reminder to re-evaluate the alert: + +```json +"observability.silenceAlerts": [ + "warning_syntect-server_memory_rss" +] +``` + +*Managed by the [Sourcegraph Code Search team](https://handbook.sourcegraph.com/departments/engineering/teams/code-search).*Technical details
-Generated query for critical alert: `min((sum by (app) (up{app=~".*symbols"\}) / count by (app) (up\{app=~".*symbols"}) * 100) <= 90)` +Generated query for warning alert: `max((max by (name) (container_memory_rss{name=~"^syntect-server.*"\} / container_spec_memory_limit_bytes\{name=~"^syntect-server.*"}) * 100) >= 90)`-## zoekt: indexed_search_request_errors - -
indexed search request errors every 5m by code
- -**Descriptions** - -- warning zoekt: 5%+ indexed search request errors every 5m by code for 5m0s - -**Next steps** - -- Learn more about the related dashboard panel in the [dashboards reference](dashboards#zoekt-indexed-search-request-errors). -- **Silence this alert:** If you are aware of this alert and want to silence notifications for it, add the following to your site configuration and set a reminder to re-evaluate the alert: - -```json -"observability.silenceAlerts": [ - "warning_zoekt_indexed_search_request_errors" -] -``` - -*Managed by the [Sourcegraph Search Platform team](https://handbook.sourcegraph.com/departments/engineering/teams/search/core).* - -Technical details
- -Generated query for warning alert: `max((sum by (code) (increase(src_zoekt_request_duration_seconds_count{code!~"2.."}[5m])) / ignoring (code) group_left () sum(increase(src_zoekt_request_duration_seconds_count[5m])) * 100) >= 5)` - -- -## zoekt: memory_map_areas_percentage_used - -
process memory map areas percentage used (per instance)
- -**Descriptions** - -- warning zoekt: 60%+ process memory map areas percentage used (per instance) -- critical zoekt: 80%+ process memory map areas percentage used (per instance) - -**Next steps** - -- If you are running out of memory map areas, you could resolve this by: - - - Enabling shard merging for Zoekt: Set SRC_ENABLE_SHARD_MERGING="1" for zoekt-indexserver. Use this option -if your corpus of repositories has a high percentage of small, rarely updated repositories. See -[documentation](https://sourcegraph.com/docs/code-search/features#shard-merging). - - Creating additional Zoekt replicas: This spreads all the shards out amongst more replicas, which -means that each _individual_ replica will have fewer shards. This, in turn, decreases the -amount of memory map areas that a _single_ replica can create (in order to load the shards into memory). - - Increasing the virtual memory subsystem`s "max_map_count" parameter which defines the upper limit of memory areas -a process can use. The default value of max_map_count is usually 65536. We recommend to set this value to 2x the number -of repos to be indexed per Zoekt instance. This means, if you want to index 240k repositories with 3 Zoekt instances, -set max_map_count to (240000 / 3) * 2 = 160000. The exact instructions for tuning this parameter can differ depending -on your environment. See https://kernel.org/doc/Documentation/sysctl/vm.txt for more information. -- More help interpreting this metric is available in the [dashboards reference](dashboards#zoekt-memory-map-areas-percentage-used). -- **Silence this alert:** If you are aware of this alert and want to silence notifications for it, add the following to your site configuration and set a reminder to re-evaluate the alert: - -```json -"observability.silenceAlerts": [ - "warning_zoekt_memory_map_areas_percentage_used", - "critical_zoekt_memory_map_areas_percentage_used" -] -``` - -*Managed by the [Sourcegraph Search Platform team](https://handbook.sourcegraph.com/departments/engineering/teams/search/core).* - -Technical details
- -Generated query for warning alert: `max(((proc_metrics_memory_map_current_count / proc_metrics_memory_map_max_limit) * 100) >= 60)` - -Generated query for critical alert: `max(((proc_metrics_memory_map_current_count / proc_metrics_memory_map_max_limit) * 100) >= 80)` - -- -## zoekt: container_cpu_usage - -
container cpu usage total (1m average) across all cores by instance
- -**Descriptions** - -- warning zoekt: 99%+ container cpu usage total (1m average) across all cores by instance - -**Next steps** - -- **Kubernetes:** Consider increasing CPU limits in the the relevant `Deployment.yaml`. -- **Docker Compose:** Consider increasing `cpus:` of the zoekt-indexserver container in `docker-compose.yml`. -- Learn more about the related dashboard panel in the [dashboards reference](dashboards#zoekt-container-cpu-usage). -- **Silence this alert:** If you are aware of this alert and want to silence notifications for it, add the following to your site configuration and set a reminder to re-evaluate the alert: - -```json -"observability.silenceAlerts": [ - "warning_zoekt_container_cpu_usage" -] -``` - -*Managed by the [Sourcegraph Search Platform team](https://handbook.sourcegraph.com/departments/engineering/teams/search/core).* - -Technical details
- -Generated query for warning alert: `max((cadvisor_container_cpu_usage_percentage_total{name=~"^zoekt-indexserver.*"}) >= 99)` - -- -## zoekt: container_memory_usage - -
container memory usage by instance
- -**Descriptions** - -- warning zoekt: 99%+ container memory usage by instance - -**Next steps** - -- **Kubernetes:** Consider increasing memory limit in relevant `Deployment.yaml`. -- **Docker Compose:** Consider increasing `memory:` of zoekt-indexserver container in `docker-compose.yml`. -- Learn more about the related dashboard panel in the [dashboards reference](dashboards#zoekt-container-memory-usage). -- **Silence this alert:** If you are aware of this alert and want to silence notifications for it, add the following to your site configuration and set a reminder to re-evaluate the alert: - -```json -"observability.silenceAlerts": [ - "warning_zoekt_container_memory_usage" -] -``` - -*Managed by the [Sourcegraph Search Platform team](https://handbook.sourcegraph.com/departments/engineering/teams/search/core).* - -Technical details
- -Generated query for warning alert: `max((cadvisor_container_memory_usage_percentage_total{name=~"^zoekt-indexserver.*"}) >= 99)` - -- -## zoekt: container_cpu_usage - -
container cpu usage total (1m average) across all cores by instance
- -**Descriptions** - -- warning zoekt: 99%+ container cpu usage total (1m average) across all cores by instance - -**Next steps** - -- **Kubernetes:** Consider increasing CPU limits in the the relevant `Deployment.yaml`. -- **Docker Compose:** Consider increasing `cpus:` of the zoekt-webserver container in `docker-compose.yml`. -- Learn more about the related dashboard panel in the [dashboards reference](dashboards#zoekt-container-cpu-usage). -- **Silence this alert:** If you are aware of this alert and want to silence notifications for it, add the following to your site configuration and set a reminder to re-evaluate the alert: - -```json -"observability.silenceAlerts": [ - "warning_zoekt_container_cpu_usage" -] -``` - -*Managed by the [Sourcegraph Search Platform team](https://handbook.sourcegraph.com/departments/engineering/teams/search/core).* - -Technical details
- -Generated query for warning alert: `max((cadvisor_container_cpu_usage_percentage_total{name=~"^zoekt-webserver.*"}) >= 99)` - -- -## zoekt: container_memory_usage - -
container memory usage by instance
- -**Descriptions** - -- warning zoekt: 99%+ container memory usage by instance - -**Next steps** - -- **Kubernetes:** Consider increasing memory limit in relevant `Deployment.yaml`. -- **Docker Compose:** Consider increasing `memory:` of zoekt-webserver container in `docker-compose.yml`. -- Learn more about the related dashboard panel in the [dashboards reference](dashboards#zoekt-container-memory-usage). -- **Silence this alert:** If you are aware of this alert and want to silence notifications for it, add the following to your site configuration and set a reminder to re-evaluate the alert: - -```json -"observability.silenceAlerts": [ - "warning_zoekt_container_memory_usage" -] -``` - -*Managed by the [Sourcegraph Search Platform team](https://handbook.sourcegraph.com/departments/engineering/teams/search/core).* - -Technical details
- -Generated query for warning alert: `max((cadvisor_container_memory_usage_percentage_total{name=~"^zoekt-webserver.*"}) >= 99)` - -- -## zoekt: provisioning_container_cpu_usage_long_term +## zoekt: cpu_usage_percentage -
container cpu usage total (90th percentile over 1d) across all cores by instance
+CPU usage
**Descriptions** -- warning zoekt: 80%+ container cpu usage total (90th percentile over 1d) across all cores by instance for 336h0m0s +- warning zoekt: 95%+ CPU usage for 10m0s **Next steps** -- **Kubernetes:** Consider increasing CPU limits in the `Deployment.yaml` for the zoekt-indexserver service. -- **Docker Compose:** Consider increasing `cpus:` of the zoekt-indexserver container in `docker-compose.yml`. -- Learn more about the related dashboard panel in the [dashboards reference](dashboards#zoekt-provisioning-container-cpu-usage-long-term). +- Consider increasing CPU limits or scaling out. +- Learn more about the related dashboard panel in the [dashboards reference](dashboards#zoekt-cpu-usage-percentage). - **Silence this alert:** If you are aware of this alert and want to silence notifications for it, add the following to your site configuration and set a reminder to re-evaluate the alert: ```json "observability.silenceAlerts": [ - "warning_zoekt_provisioning_container_cpu_usage_long_term" + "warning_zoekt_cpu_usage_percentage" ] ``` @@ -79295,30 +78925,29 @@ Generated query for warning alert: `max((cadvisor_container_memory_usage_percentTechnical details
-Generated query for warning alert: `max((quantile_over_time(0.9, cadvisor_container_cpu_usage_percentage_total{name=~"^zoekt-indexserver.*"}[1d])) >= 80)` +Generated query for warning alert: `max((cadvisor_container_cpu_usage_percentage_total{name=~"^zoekt-indexserver.*"}) >= 95)`-## zoekt: provisioning_container_memory_usage_long_term +## zoekt: memory_rss -
container memory usage (1d maximum) by instance
+memory (RSS)
**Descriptions** -- warning zoekt: 80%+ container memory usage (1d maximum) by instance for 336h0m0s +- warning zoekt: 90%+ memory (RSS) for 10m0s **Next steps** -- **Kubernetes:** Consider increasing memory limits in the `Deployment.yaml` for the zoekt-indexserver service. -- **Docker Compose:** Consider increasing `memory:` of the zoekt-indexserver container in `docker-compose.yml`. -- Learn more about the related dashboard panel in the [dashboards reference](dashboards#zoekt-provisioning-container-memory-usage-long-term). +- Consider increasing memory limits or scaling out. +- More help interpreting this metric is available in the [dashboards reference](dashboards#zoekt-memory-rss). - **Silence this alert:** If you are aware of this alert and want to silence notifications for it, add the following to your site configuration and set a reminder to re-evaluate the alert: ```json "observability.silenceAlerts": [ - "warning_zoekt_provisioning_container_memory_usage_long_term" + "warning_zoekt_memory_rss" ] ``` @@ -79327,30 +78956,29 @@ Generated query for warning alert: `max((quantile_over_time(0.9, cadvisor_contaiTechnical details
-Generated query for warning alert: `max((max_over_time(cadvisor_container_memory_usage_percentage_total{name=~"^zoekt-indexserver.*"}[1d])) >= 80)` +Generated query for warning alert: `max((max by (name) (container_memory_rss{name=~"^zoekt-indexserver.*"\} / container_spec_memory_limit_bytes\{name=~"^zoekt-indexserver.*"}) * 100) >= 90)`-## zoekt: provisioning_container_cpu_usage_short_term +## zoekt: cpu_usage_percentage -
container cpu usage total (5m maximum) across all cores by instance
+CPU usage
**Descriptions** -- warning zoekt: 90%+ container cpu usage total (5m maximum) across all cores by instance for 30m0s +- warning zoekt: 95%+ CPU usage for 10m0s **Next steps** -- **Kubernetes:** Consider increasing CPU limits in the the relevant `Deployment.yaml`. -- **Docker Compose:** Consider increasing `cpus:` of the zoekt-indexserver container in `docker-compose.yml`. -- Learn more about the related dashboard panel in the [dashboards reference](dashboards#zoekt-provisioning-container-cpu-usage-short-term). +- Consider increasing CPU limits or scaling out. +- Learn more about the related dashboard panel in the [dashboards reference](dashboards#zoekt-cpu-usage-percentage). - **Silence this alert:** If you are aware of this alert and want to silence notifications for it, add the following to your site configuration and set a reminder to re-evaluate the alert: ```json "observability.silenceAlerts": [ - "warning_zoekt_provisioning_container_cpu_usage_short_term" + "warning_zoekt_cpu_usage_percentage" ] ``` @@ -79359,30 +78987,29 @@ Generated query for warning alert: `max((max_over_time(cadvisor_container_memoryTechnical details
-Generated query for warning alert: `max((max_over_time(cadvisor_container_cpu_usage_percentage_total{name=~"^zoekt-indexserver.*"}[5m])) >= 90)` +Generated query for warning alert: `max((cadvisor_container_cpu_usage_percentage_total{name=~"^zoekt-webserver.*"}) >= 95)`-## zoekt: provisioning_container_memory_usage_short_term +## zoekt: memory_rss -
container memory usage (5m maximum) by instance
+memory (RSS)
**Descriptions** -- warning zoekt: 90%+ container memory usage (5m maximum) by instance +- warning zoekt: 90%+ memory (RSS) for 10m0s **Next steps** -- **Kubernetes:** Consider increasing memory limit in relevant `Deployment.yaml`. -- **Docker Compose:** Consider increasing `memory:` of zoekt-indexserver container in `docker-compose.yml`. -- Learn more about the related dashboard panel in the [dashboards reference](dashboards#zoekt-provisioning-container-memory-usage-short-term). +- Consider increasing memory limits or scaling out. +- More help interpreting this metric is available in the [dashboards reference](dashboards#zoekt-memory-rss). - **Silence this alert:** If you are aware of this alert and want to silence notifications for it, add the following to your site configuration and set a reminder to re-evaluate the alert: ```json "observability.silenceAlerts": [ - "warning_zoekt_provisioning_container_memory_usage_short_term" + "warning_zoekt_memory_rss" ] ``` @@ -79391,30 +79018,43 @@ Generated query for warning alert: `max((max_over_time(cadvisor_container_cpu_usTechnical details
-Generated query for warning alert: `max((max_over_time(cadvisor_container_memory_usage_percentage_total{name=~"^zoekt-indexserver.*"}[5m])) >= 90)` +Generated query for warning alert: `max((max by (name) (container_memory_rss{name=~"^zoekt-webserver.*"\} / container_spec_memory_limit_bytes\{name=~"^zoekt-webserver.*"}) * 100) >= 90)`-## zoekt: container_oomkill_events_total +## zoekt: memory_map_areas_percentage_used -
container OOMKILL events total by instance
+process memory map areas percentage used (per instance)
**Descriptions** -- warning zoekt: 1+ container OOMKILL events total by instance +- warning zoekt: 60%+ process memory map areas percentage used (per instance) +- critical zoekt: 80%+ process memory map areas percentage used (per instance) **Next steps** -- **Kubernetes:** Consider increasing memory limit in relevant `Deployment.yaml`. -- **Docker Compose:** Consider increasing `memory:` of zoekt-indexserver container in `docker-compose.yml`. -- More help interpreting this metric is available in the [dashboards reference](dashboards#zoekt-container-oomkill-events-total). +- If you are running out of memory map areas, you could resolve this by: + + - Enabling shard merging for Zoekt: Set SRC_ENABLE_SHARD_MERGING="1" for zoekt-indexserver. Use this option +if your corpus of repositories has a high percentage of small, rarely updated repositories. See +[documentation](https://sourcegraph.com/docs/code-search/features#shard-merging). + - Creating additional Zoekt replicas: This spreads all the shards out amongst more replicas, which +means that each _individual_ replica will have fewer shards. This, in turn, decreases the +amount of memory map areas that a _single_ replica can create (in order to load the shards into memory). + - Increasing the virtual memory subsystem`s "max_map_count" parameter which defines the upper limit of memory areas +a process can use. The default value of max_map_count is usually 65536. We recommend to set this value to 2x the number +of repos to be indexed per Zoekt instance. This means, if you want to index 240k repositories with 3 Zoekt instances, +set max_map_count to (240000 / 3) * 2 = 160000. The exact instructions for tuning this parameter can differ depending +on your environment. See https://kernel.org/doc/Documentation/sysctl/vm.txt for more information. +- More help interpreting this metric is available in the [dashboards reference](dashboards#zoekt-memory-map-areas-percentage-used). - **Silence this alert:** If you are aware of this alert and want to silence notifications for it, add the following to your site configuration and set a reminder to re-evaluate the alert: ```json "observability.silenceAlerts": [ - "warning_zoekt_container_oomkill_events_total" + "warning_zoekt_memory_map_areas_percentage_used", + "critical_zoekt_memory_map_areas_percentage_used" ] ``` @@ -79423,30 +79063,30 @@ Generated query for warning alert: `max((max_over_time(cadvisor_container_memoryTechnical details
-Generated query for warning alert: `max((max by (name) (container_oom_events_total{name=~"^zoekt-indexserver.*"})) >= 1)` +Generated query for warning alert: `max(((proc_metrics_memory_map_current_count / proc_metrics_memory_map_max_limit) * 100) >= 60)` + +Generated query for critical alert: `max(((proc_metrics_memory_map_current_count / proc_metrics_memory_map_max_limit) * 100) >= 80)`-## zoekt: provisioning_container_cpu_usage_long_term +## zoekt: indexed_search_request_errors -
container cpu usage total (90th percentile over 1d) across all cores by instance
+indexed search request errors every 5m by code
**Descriptions** -- warning zoekt: 80%+ container cpu usage total (90th percentile over 1d) across all cores by instance for 336h0m0s +- warning zoekt: 5%+ indexed search request errors every 5m by code for 5m0s **Next steps** -- **Kubernetes:** Consider increasing CPU limits in the `Deployment.yaml` for the zoekt-webserver service. -- **Docker Compose:** Consider increasing `cpus:` of the zoekt-webserver container in `docker-compose.yml`. -- Learn more about the related dashboard panel in the [dashboards reference](dashboards#zoekt-provisioning-container-cpu-usage-long-term). +- Learn more about the related dashboard panel in the [dashboards reference](dashboards#zoekt-indexed-search-request-errors). - **Silence this alert:** If you are aware of this alert and want to silence notifications for it, add the following to your site configuration and set a reminder to re-evaluate the alert: ```json "observability.silenceAlerts": [ - "warning_zoekt_provisioning_container_cpu_usage_long_term" + "warning_zoekt_indexed_search_request_errors" ] ``` @@ -79455,30 +79095,28 @@ Generated query for warning alert: `max((max by (name) (container_oom_events_totTechnical details
-Generated query for warning alert: `max((quantile_over_time(0.9, cadvisor_container_cpu_usage_percentage_total{name=~"^zoekt-webserver.*"}[1d])) >= 80)` +Generated query for warning alert: `max((sum by (code) (increase(src_zoekt_request_duration_seconds_count{code!~"2.."}[5m])) / ignoring (code) group_left () sum(increase(src_zoekt_request_duration_seconds_count[5m])) * 100) >= 5)`-## zoekt: provisioning_container_memory_usage_long_term +## zoekt: go_goroutines -
container memory usage (1d maximum) by instance
+maximum active goroutines
**Descriptions** -- warning zoekt: 80%+ container memory usage (1d maximum) by instance for 336h0m0s +- warning zoekt: 10000+ maximum active goroutines for 10m0s **Next steps** -- **Kubernetes:** Consider increasing memory limits in the `Deployment.yaml` for the zoekt-webserver service. -- **Docker Compose:** Consider increasing `memory:` of the zoekt-webserver container in `docker-compose.yml`. -- Learn more about the related dashboard panel in the [dashboards reference](dashboards#zoekt-provisioning-container-memory-usage-long-term). +- More help interpreting this metric is available in the [dashboards reference](dashboards#zoekt-go-goroutines). - **Silence this alert:** If you are aware of this alert and want to silence notifications for it, add the following to your site configuration and set a reminder to re-evaluate the alert: ```json "observability.silenceAlerts": [ - "warning_zoekt_provisioning_container_memory_usage_long_term" + "warning_zoekt_go_goroutines" ] ``` @@ -79487,30 +79125,28 @@ Generated query for warning alert: `max((quantile_over_time(0.9, cadvisor_contaiTechnical details
-Generated query for warning alert: `max((max_over_time(cadvisor_container_memory_usage_percentage_total{name=~"^zoekt-webserver.*"}[1d])) >= 80)` +Generated query for warning alert: `max((max by (instance) (go_goroutines{job=~".*indexed-search-indexer"})) >= 10000)`-## zoekt: provisioning_container_cpu_usage_short_term +## zoekt: go_gc_duration_seconds -
container cpu usage total (5m maximum) across all cores by instance
+maximum go garbage collection duration
**Descriptions** -- warning zoekt: 90%+ container cpu usage total (5m maximum) across all cores by instance for 30m0s +- warning zoekt: 2s+ maximum go garbage collection duration **Next steps** -- **Kubernetes:** Consider increasing CPU limits in the the relevant `Deployment.yaml`. -- **Docker Compose:** Consider increasing `cpus:` of the zoekt-webserver container in `docker-compose.yml`. -- Learn more about the related dashboard panel in the [dashboards reference](dashboards#zoekt-provisioning-container-cpu-usage-short-term). +- Learn more about the related dashboard panel in the [dashboards reference](dashboards#zoekt-go-gc-duration-seconds). - **Silence this alert:** If you are aware of this alert and want to silence notifications for it, add the following to your site configuration and set a reminder to re-evaluate the alert: ```json "observability.silenceAlerts": [ - "warning_zoekt_provisioning_container_cpu_usage_short_term" + "warning_zoekt_go_gc_duration_seconds" ] ``` @@ -79519,30 +79155,28 @@ Generated query for warning alert: `max((max_over_time(cadvisor_container_memoryTechnical details
-Generated query for warning alert: `max((max_over_time(cadvisor_container_cpu_usage_percentage_total{name=~"^zoekt-webserver.*"}[5m])) >= 90)` +Generated query for warning alert: `max((max by (instance) (go_gc_duration_seconds{job=~".*indexed-search-indexer"})) >= 2)`-## zoekt: provisioning_container_memory_usage_short_term +## zoekt: go_goroutines -
container memory usage (5m maximum) by instance
+maximum active goroutines
**Descriptions** -- warning zoekt: 90%+ container memory usage (5m maximum) by instance +- warning zoekt: 10000+ maximum active goroutines for 10m0s **Next steps** -- **Kubernetes:** Consider increasing memory limit in relevant `Deployment.yaml`. -- **Docker Compose:** Consider increasing `memory:` of zoekt-webserver container in `docker-compose.yml`. -- Learn more about the related dashboard panel in the [dashboards reference](dashboards#zoekt-provisioning-container-memory-usage-short-term). +- More help interpreting this metric is available in the [dashboards reference](dashboards#zoekt-go-goroutines). - **Silence this alert:** If you are aware of this alert and want to silence notifications for it, add the following to your site configuration and set a reminder to re-evaluate the alert: ```json "observability.silenceAlerts": [ - "warning_zoekt_provisioning_container_memory_usage_short_term" + "warning_zoekt_go_goroutines" ] ``` @@ -79551,30 +79185,28 @@ Generated query for warning alert: `max((max_over_time(cadvisor_container_cpu_usTechnical details
-Generated query for warning alert: `max((max_over_time(cadvisor_container_memory_usage_percentage_total{name=~"^zoekt-webserver.*"}[5m])) >= 90)` +Generated query for warning alert: `max((max by (instance) (go_goroutines{job=~".*indexed-search"})) >= 10000)`-## zoekt: container_oomkill_events_total +## zoekt: go_gc_duration_seconds -
container OOMKILL events total by instance
+maximum go garbage collection duration
**Descriptions** -- warning zoekt: 1+ container OOMKILL events total by instance +- warning zoekt: 2s+ maximum go garbage collection duration **Next steps** -- **Kubernetes:** Consider increasing memory limit in relevant `Deployment.yaml`. -- **Docker Compose:** Consider increasing `memory:` of zoekt-webserver container in `docker-compose.yml`. -- More help interpreting this metric is available in the [dashboards reference](dashboards#zoekt-container-oomkill-events-total). +- Learn more about the related dashboard panel in the [dashboards reference](dashboards#zoekt-go-gc-duration-seconds). - **Silence this alert:** If you are aware of this alert and want to silence notifications for it, add the following to your site configuration and set a reminder to re-evaluate the alert: ```json "observability.silenceAlerts": [ - "warning_zoekt_container_oomkill_events_total" + "warning_zoekt_go_gc_duration_seconds" ] ``` @@ -79583,7 +79215,7 @@ Generated query for warning alert: `max((max_over_time(cadvisor_container_memoryTechnical details
-Generated query for warning alert: `max((max by (name) (container_oom_events_total{name=~"^zoekt-webserver.*"})) >= 1)` +Generated query for warning alert: `max((max by (instance) (go_gc_duration_seconds{job=~".*indexed-search"})) >= 2)`-## codeintel-uploads: codeintel_commit_graph_queued_max_age - -
repository queue longest time in queue
- -**Descriptions** - -- warning codeintel-uploads: 3600s+ repository queue longest time in queue - -**Next steps** - -- An alert here is generally indicative of either underprovisioned worker instance(s) and/or -an underprovisioned main postgres instance. -- Learn more about the related dashboard panel in the [dashboards reference](dashboards#codeintel-uploads-codeintel-commit-graph-queued-max-age). -- **Silence this alert:** If you are aware of this alert and want to silence notifications for it, add the following to your site configuration and set a reminder to re-evaluate the alert: - -```json -"observability.silenceAlerts": [ - "warning_codeintel-uploads_codeintel_commit_graph_queued_max_age" -] -``` - -*Managed by the [Sourcegraph Code intelligence team](https://handbook.sourcegraph.com/departments/engineering/teams/code-intelligence).* - -Technical details
- -Generated query for warning alert: `max((max(src_codeintel_commit_graph_queued_duration_seconds_total)) >= 3600)` - -- ## telemetry: telemetry_gateway_exporter_queue_growth -
rate of growth of export queue over 30m
+rate of growth of events export queue over 30m
**Descriptions** -- warning telemetry: 1+ rate of growth of export queue over 30m for 1h0m0s -- critical telemetry: 1+ rate of growth of export queue over 30m for 36h0m0s +- warning telemetry: 1+ rate of growth of events export queue over 30m for 1h0m0s +- critical telemetry: 1+ rate of growth of events export queue over 30m for 36h0m0s **Next steps** @@ -80395,11 +79995,11 @@ Generated query for warning alert: `max((sum(increase(src_telemetrygatewayexport ## telemetry: telemetrygatewayexporter_queue_cleanup_errors_total -export queue cleanup operation errors every 30m
+events export queue cleanup operation errors every 30m
**Descriptions** -- warning telemetry: 0+ export queue cleanup operation errors every 30m +- warning telemetry: 0+ events export queue cleanup operation errors every 30m **Next steps** @@ -80427,11 +80027,11 @@ Generated query for warning alert: `max((sum(increase(src_telemetrygatewayexport ## telemetry: telemetrygatewayexporter_queue_metrics_reporter_errors_total -export backlog metrics reporting operation errors every 30m
+events export backlog metrics reporting operation errors every 30m
**Descriptions** -- warning telemetry: 0+ export backlog metrics reporting operation errors every 30m +- warning telemetry: 0+ events export backlog metrics reporting operation errors every 30m **Next steps** @@ -80457,54 +80057,97 @@ Generated query for warning alert: `max((sum(increase(src_telemetrygatewayexport-## telemetry: telemetry_job_error_rate +## telemetry: telemetry_v2_export_queue_write_failures -
usage data exporter operation error rate over 5m
+failed writes to events export queue over 5m
**Descriptions** -- warning telemetry: 0%+ usage data exporter operation error rate over 5m for 30m0s +- warning telemetry: 1%+ failed writes to events export queue over 5m +- critical telemetry: 2.5%+ failed writes to events export queue over 5m for 5m0s **Next steps** -- Involved cloud team to inspect logs of the managed instance to determine error sources. -- Learn more about the related dashboard panel in the [dashboards reference](dashboards#telemetry-telemetry-job-error-rate). +- Look for error logs related to `inserting telemetry events`. +- Look for error attributes on `telemetryevents.QueueForExport` trace spans. +- More help interpreting this metric is available in the [dashboards reference](dashboards#telemetry-telemetry-v2-export-queue-write-failures). - **Silence this alert:** If you are aware of this alert and want to silence notifications for it, add the following to your site configuration and set a reminder to re-evaluate the alert: ```json "observability.silenceAlerts": [ - "warning_telemetry_telemetry_job_error_rate" + "warning_telemetry_telemetry_v2_export_queue_write_failures", + "critical_telemetry_telemetry_v2_export_queue_write_failures" ] ``` -*Managed by the [Sourcegraph Data & Analytics team](https://handbook.sourcegraph.com/departments/engineering/teams/data-analytics).* +*Managed by the [Sourcegraph Infrastructure Org team](https://handbook.sourcegraph.com/departments/engineering/infrastructure).*Technical details
-Generated query for warning alert: `max((sum by (op) (increase(src_telemetry_job_errors_total{job=~"^worker.*"\}[5m])) / (sum by (op) (increase(src_telemetry_job_total\{job=~"^worker.*"\}[5m])) + sum by (op) (increase(src_telemetry_job_errors_total\{job=~"^worker.*"}[5m]))) * 100) > 0)` +Generated query for warning alert: `max(((sum(increase(src_telemetry_export_store_queued_events{failed="true"}[5m])) / sum(increase(src_telemetry_export_store_queued_events[5m]))) * 100) > 1)` + +Generated query for critical alert: `max(((sum(increase(src_telemetry_export_store_queued_events{failed="true"}[5m])) / sum(increase(src_telemetry_export_store_queued_events[5m]))) * 100) > 2.5)`-## telemetry: telemetry_job_utilized_throughput +## telemetry: telemetry_v2_event_logs_write_failures -
utilized percentage of maximum throughput
+failed write V2 events to V1 'event_logs' over 5m
**Descriptions** -- warning telemetry: 90%+ utilized percentage of maximum throughput for 30m0s +- warning telemetry: 5%+ failed write V2 events to V1 'event_logs' over 5m +- critical telemetry: 10%+ failed write V2 events to V1 'event_logs' over 5m for 10m0s **Next steps** -- Throughput utilization is high. This could be a signal that this instance is producing too many events for the export job to keep up. Configure more throughput using the maxBatchSize option. -- Learn more about the related dashboard panel in the [dashboards reference](dashboards#telemetry-telemetry-job-utilized-throughput). +- Error details are only persisted in trace metadata as it is considered non-critical. +- To diagnose, enable trace sampling across all requests and look for error attributes on `telemetrystore.v1teewrite` spans. +- More help interpreting this metric is available in the [dashboards reference](dashboards#telemetry-telemetry-v2-event-logs-write-failures). - **Silence this alert:** If you are aware of this alert and want to silence notifications for it, add the following to your site configuration and set a reminder to re-evaluate the alert: ```json "observability.silenceAlerts": [ - "warning_telemetry_telemetry_job_utilized_throughput" + "warning_telemetry_telemetry_v2_event_logs_write_failures", + "critical_telemetry_telemetry_v2_event_logs_write_failures" +] +``` + +*Managed by the [Sourcegraph Infrastructure Org team](https://handbook.sourcegraph.com/departments/engineering/infrastructure).* + +Technical details
+ +Generated query for warning alert: `max(((sum(increase(src_telemetry_teestore_v1_events{failed="true"}[5m])) / sum(increase(src_telemetry_teestore_v1_events[5m]))) * 100) > 5)` + +Generated query for critical alert: `max(((sum(increase(src_telemetry_teestore_v1_events{failed="true"}[5m])) / sum(increase(src_telemetry_teestore_v1_events[5m]))) * 100) > 10)` + ++ +## telemetry: telemetrygatewayexporter_usermetadata_exporter_errors_total + +
(off by default) user metadata exporter operation errors every 30m
+ +**Descriptions** + +- warning telemetry: 0+ (off by default) user metadata exporter operation errors every 30m + +**Next steps** + +- Failures indicate that exporting of telemetry events from Sourcegraph are failing. This may affect the performance of the database as the backlog grows. +- See worker logs in the `worker.telemetrygateway-exporter` log scope for more details. If logs only indicate that exports failed, reach out to Sourcegraph with relevant log entries, as this may be an issue in Sourcegraph`s Telemetry Gateway service. +- This exporter is DISABLED by default. +- Learn more about the related dashboard panel in the [dashboards reference](dashboards#telemetry-telemetrygatewayexporter-usermetadata-exporter-errors-total). +- **Silence this alert:** If you are aware of this alert and want to silence notifications for it, add the following to your site configuration and set a reminder to re-evaluate the alert: + +```json +"observability.silenceAlerts": [ + "warning_telemetry_telemetrygatewayexporter_usermetadata_exporter_errors_total" ] ``` @@ -80513,7 +80156,7 @@ Generated query for warning alert: `max((sum by (op) (increase(src_telemetry_jobTechnical details
-Generated query for warning alert: `max((rate(src_telemetry_job_total{op="SendEvents"}[1h]) / on () group_right () src_telemetry_job_max_throughput * 100) > 90)` +Generated query for warning alert: `max((sum(increase(src_telemetrygatewayexporter_usermetadata_exporter_errors_total{job=~"^worker.*"}[30m]))) > 0)`-## embeddings: embeddings_site_configuration_duration_since_last_successful_update_by_instance +## completions: completion_credits_check_entitlement_duration_p95 -
maximum duration since last successful site configuration update (all "embeddings" instances)
+95th percentile completion credits entitlement check duration
**Descriptions** -- critical embeddings: 300s+ maximum duration since last successful site configuration update (all "embeddings" instances) +- warning completions: 10ms+ 95th percentile completion credits entitlement check duration for 10m0s **Next steps** -- This indicates that one or more "embeddings" instances have not successfully updated the site configuration in over 5 minutes. This could be due to networking issues between services or problems with the site configuration service itself. -- Check for relevant errors in the "embeddings" logs, as well as frontend`s logs. -- Learn more about the related dashboard panel in the [dashboards reference](dashboards#embeddings-embeddings-site-configuration-duration-since-last-successful-update-by-instance). +- - This metric tracks pre-completion-request latency for checking if completion credits entitlement has been exceeded. + - If this value is high, this latency may be noticeable to users. +- Learn more about the related dashboard panel in the [dashboards reference](dashboards#completions-completion-credits-check-entitlement-duration-p95). - **Silence this alert:** If you are aware of this alert and want to silence notifications for it, add the following to your site configuration and set a reminder to re-evaluate the alert: ```json "observability.silenceAlerts": [ - "critical_embeddings_embeddings_site_configuration_duration_since_last_successful_update_by_instance" + "warning_completions_completion_credits_check_entitlement_duration_p95" ] ``` -*Managed by the [Sourcegraph Infrastructure Org team](https://handbook.sourcegraph.com/departments/engineering/infrastructure).* +*Managed by the [Sourcegraph Core Services team](https://handbook.sourcegraph.com/departments/engineering/teams).*Technical details
-Generated query for critical alert: `max((max(max_over_time(src_conf_client_time_since_last_successful_update_seconds{job=~".*embeddings"}[1m]))) >= 300)` +Generated query for warning alert: `max((histogram_quantile(0.95, sum by (le) (rate(src_completion_credits_check_entitlement_duration_ms_bucket[5m])))) > 10)`-## embeddings: mean_blocked_seconds_per_conn_request +## completions: completion_credits_consume_credits_duration_p95 -
mean blocked seconds per conn request
+95th percentile completion credits consume duration
**Descriptions** -- warning embeddings: 0.1s+ mean blocked seconds per conn request for 10m0s -- critical embeddings: 0.5s+ mean blocked seconds per conn request for 10m0s +- warning completions: 20ms+ 95th percentile completion credits consume duration for 10m0s **Next steps** -- Increase SRC_PGSQL_MAX_OPEN together with giving more memory to the database if needed -- Scale up Postgres memory/cpus - [see our scaling guide](https://sourcegraph.com/docs/admin/config/postgres-conf) -- If using GCP Cloud SQL, check for high lock waits or CPU usage in query insights -- Learn more about the related dashboard panel in the [dashboards reference](dashboards#embeddings-mean-blocked-seconds-per-conn-request). +- - This metric tracks post-completion-request latency for committing consumed completion credits. + - If high, this latency may be noticeable for non-streaming completions. +- Learn more about the related dashboard panel in the [dashboards reference](dashboards#completions-completion-credits-consume-credits-duration-p95). - **Silence this alert:** If you are aware of this alert and want to silence notifications for it, add the following to your site configuration and set a reminder to re-evaluate the alert: ```json "observability.silenceAlerts": [ - "warning_embeddings_mean_blocked_seconds_per_conn_request", - "critical_embeddings_mean_blocked_seconds_per_conn_request" + "warning_completions_completion_credits_consume_credits_duration_p95" ] ``` -*Managed by the [Sourcegraph Cody team](https://handbook.sourcegraph.com/departments/engineering/teams/cody).* +*Managed by the [Sourcegraph Core Services team](https://handbook.sourcegraph.com/departments/engineering/teams).*Technical details
-Generated query for warning alert: `max((sum by (app_name, db_name) (increase(src_pgsql_conns_blocked_seconds{app_name="embeddings"\}[5m])) / sum by (app_name, db_name) (increase(src_pgsql_conns_waited_for\{app_name="embeddings"}[5m]))) >= 0.1)` - -Generated query for critical alert: `max((sum by (app_name, db_name) (increase(src_pgsql_conns_blocked_seconds{app_name="embeddings"\}[5m])) / sum by (app_name, db_name) (increase(src_pgsql_conns_waited_for\{app_name="embeddings"}[5m]))) >= 0.5)` +Generated query for warning alert: `max((histogram_quantile(0.95, sum by (le) (rate(src_completion_credits_consume_duration_ms_bucket[5m])))) > 20)`-## embeddings: container_cpu_usage +## background-jobs: error_percentage_by_method -
container cpu usage total (1m average) across all cores by instance
+percentage of operations resulting in error by method
**Descriptions** -- warning embeddings: 99%+ container cpu usage total (1m average) across all cores by instance +- warning background-jobs: 5%+ percentage of operations resulting in error by method +- critical background-jobs: 50%+ percentage of operations resulting in error by method **Next steps** -- **Kubernetes:** Consider increasing CPU limits in the the relevant `Deployment.yaml`. -- **Docker Compose:** Consider increasing `cpus:` of the embeddings container in `docker-compose.yml`. -- Learn more about the related dashboard panel in the [dashboards reference](dashboards#embeddings-container-cpu-usage). +- Review logs for the specific operation to identify patterns in errors. Check database connectivity and schema. If a particular method is consistently failing, investigate potential issues with that operation`s SQL query or transaction handling. +- Learn more about the related dashboard panel in the [dashboards reference](dashboards#background-jobs-error-percentage-by-method). - **Silence this alert:** If you are aware of this alert and want to silence notifications for it, add the following to your site configuration and set a reminder to re-evaluate the alert: ```json "observability.silenceAlerts": [ - "warning_embeddings_container_cpu_usage" + "warning_background-jobs_error_percentage_by_method", + "critical_background-jobs_error_percentage_by_method" ] ``` -*Managed by the [Sourcegraph Cody team](https://handbook.sourcegraph.com/departments/engineering/teams/cody).* +*Managed by the [Sourcegraph Source team](https://handbook.sourcegraph.com/departments/engineering/teams/source).*Technical details
-Generated query for warning alert: `max((cadvisor_container_cpu_usage_percentage_total{name=~"^embeddings.*"}) >= 99)` - -- -## embeddings: container_memory_usage +Generated query for warning alert: `max(((sum by (op) (rate(src_workerutil_dbworker_store_errors_total[5m])) / sum by (op) (rate(src_workerutil_dbworker_store_total[5m]))) * 100) >= 5)` -
container memory usage by instance
- -**Descriptions** - -- warning embeddings: 99%+ container memory usage by instance - -**Next steps** - -- **Kubernetes:** Consider increasing memory limit in relevant `Deployment.yaml`. -- **Docker Compose:** Consider increasing `memory:` of embeddings container in `docker-compose.yml`. -- Learn more about the related dashboard panel in the [dashboards reference](dashboards#embeddings-container-memory-usage). -- **Silence this alert:** If you are aware of this alert and want to silence notifications for it, add the following to your site configuration and set a reminder to re-evaluate the alert: - -```json -"observability.silenceAlerts": [ - "warning_embeddings_container_memory_usage" -] -``` - -*Managed by the [Sourcegraph Cody team](https://handbook.sourcegraph.com/departments/engineering/teams/cody).* - -Technical details
- -Generated query for warning alert: `max((cadvisor_container_memory_usage_percentage_total{name=~"^embeddings.*"}) >= 99)` +Generated query for critical alert: `max(((sum by (op) (rate(src_workerutil_dbworker_store_errors_total[5m])) / sum by (op) (rate(src_workerutil_dbworker_store_total[5m]))) * 100) >= 50)`-## embeddings: provisioning_container_cpu_usage_long_term +## background-jobs: error_percentage_by_domain -
container cpu usage total (90th percentile over 1d) across all cores by instance
+percentage of operations resulting in error by domain
**Descriptions** -- warning embeddings: 80%+ container cpu usage total (90th percentile over 1d) across all cores by instance for 336h0m0s +- warning background-jobs: 5%+ percentage of operations resulting in error by domain +- critical background-jobs: 50%+ percentage of operations resulting in error by domain **Next steps** -- **Kubernetes:** Consider increasing CPU limits in the `Deployment.yaml` for the embeddings service. -- **Docker Compose:** Consider increasing `cpus:` of the embeddings container in `docker-compose.yml`. -- Learn more about the related dashboard panel in the [dashboards reference](dashboards#embeddings-provisioning-container-cpu-usage-long-term). +- Review logs for the specific domain to identify patterns in errors. Check database connectivity and schema. +- Learn more about the related dashboard panel in the [dashboards reference](dashboards#background-jobs-error-percentage-by-domain). - **Silence this alert:** If you are aware of this alert and want to silence notifications for it, add the following to your site configuration and set a reminder to re-evaluate the alert: ```json "observability.silenceAlerts": [ - "warning_embeddings_provisioning_container_cpu_usage_long_term" + "warning_background-jobs_error_percentage_by_domain", + "critical_background-jobs_error_percentage_by_domain" ] ``` -*Managed by the [Sourcegraph Cody team](https://handbook.sourcegraph.com/departments/engineering/teams/cody).* +*Managed by the [Sourcegraph Source team](https://handbook.sourcegraph.com/departments/engineering/teams/source).*Technical details
-Generated query for warning alert: `max((quantile_over_time(0.9, cadvisor_container_cpu_usage_percentage_total{name=~"^embeddings.*"}[1d])) >= 80)` - -+Generated query for warning alert: `max(((sum by (domain) (rate(src_workerutil_dbworker_store_errors_total[5m])) / sum by (domain) (rate(src_workerutil_dbworker_store_total[5m]))) * 100) >= 5)` -## embeddings: provisioning_container_memory_usage_long_term - -
container memory usage (1d maximum) by instance
- -**Descriptions** - -- warning embeddings: 80%+ container memory usage (1d maximum) by instance for 336h0m0s - -**Next steps** - -- **Kubernetes:** Consider increasing memory limits in the `Deployment.yaml` for the embeddings service. -- **Docker Compose:** Consider increasing `memory:` of the embeddings container in `docker-compose.yml`. -- Learn more about the related dashboard panel in the [dashboards reference](dashboards#embeddings-provisioning-container-memory-usage-long-term). -- **Silence this alert:** If you are aware of this alert and want to silence notifications for it, add the following to your site configuration and set a reminder to re-evaluate the alert: - -```json -"observability.silenceAlerts": [ - "warning_embeddings_provisioning_container_memory_usage_long_term" -] -``` - -*Managed by the [Sourcegraph Cody team](https://handbook.sourcegraph.com/departments/engineering/teams/cody).* - -Technical details
- -Generated query for warning alert: `max((max_over_time(cadvisor_container_memory_usage_percentage_total{name=~"^embeddings.*"}[1d])) >= 80)` +Generated query for critical alert: `max(((sum by (domain) (rate(src_workerutil_dbworker_store_errors_total[5m])) / sum by (domain) (rate(src_workerutil_dbworker_store_total[5m]))) * 100) >= 50)`-## embeddings: provisioning_container_cpu_usage_short_term +## background-jobs: resetter_duration -
container cpu usage total (5m maximum) across all cores by instance
+time spent running the resetter
**Descriptions** -- warning embeddings: 90%+ container cpu usage total (5m maximum) across all cores by instance for 30m0s +- warning background-jobs: 10s+ time spent running the resetter **Next steps** -- **Kubernetes:** Consider increasing CPU limits in the the relevant `Deployment.yaml`. -- **Docker Compose:** Consider increasing `cpus:` of the embeddings container in `docker-compose.yml`. -- Learn more about the related dashboard panel in the [dashboards reference](dashboards#embeddings-provisioning-container-cpu-usage-short-term). +- Learn more about the related dashboard panel in the [dashboards reference](dashboards#background-jobs-resetter-duration). - **Silence this alert:** If you are aware of this alert and want to silence notifications for it, add the following to your site configuration and set a reminder to re-evaluate the alert: ```json "observability.silenceAlerts": [ - "warning_embeddings_provisioning_container_cpu_usage_short_term" + "warning_background-jobs_resetter_duration" ] ``` -*Managed by the [Sourcegraph Cody team](https://handbook.sourcegraph.com/departments/engineering/teams/cody).* +*Managed by the [Sourcegraph Source team](https://handbook.sourcegraph.com/departments/engineering/teams/source).*Technical details
-Generated query for warning alert: `max((max_over_time(cadvisor_container_cpu_usage_percentage_total{name=~"^embeddings.*"}[5m])) >= 90)` +Generated query for warning alert: `max((histogram_quantile(0.95, sum by (le, domain) (rate(src_dbworker_resetter_duration_seconds_bucket[5m])))) >= 10)`-## embeddings: provisioning_container_memory_usage_short_term +## background-jobs: resetter_failures -
container memory usage (5m maximum) by instance
+number of times the resetter failed to run
**Descriptions** -- warning embeddings: 90%+ container memory usage (5m maximum) by instance +- warning background-jobs: 1reqps+ number of times the resetter failed to run **Next steps** -- **Kubernetes:** Consider increasing memory limit in relevant `Deployment.yaml`. -- **Docker Compose:** Consider increasing `memory:` of embeddings container in `docker-compose.yml`. -- Learn more about the related dashboard panel in the [dashboards reference](dashboards#embeddings-provisioning-container-memory-usage-short-term). +- Check application logs for the failing domain to check for errors. High failure rates indicate a bug in the code handling the job, or a pod frequently dying. +- Learn more about the related dashboard panel in the [dashboards reference](dashboards#background-jobs-resetter-failures). - **Silence this alert:** If you are aware of this alert and want to silence notifications for it, add the following to your site configuration and set a reminder to re-evaluate the alert: ```json "observability.silenceAlerts": [ - "warning_embeddings_provisioning_container_memory_usage_short_term" + "warning_background-jobs_resetter_failures" ] ``` -*Managed by the [Sourcegraph Cody team](https://handbook.sourcegraph.com/departments/engineering/teams/cody).* +*Managed by the [Sourcegraph Source team](https://handbook.sourcegraph.com/departments/engineering/teams/source).*Technical details
-Generated query for warning alert: `max((max_over_time(cadvisor_container_memory_usage_percentage_total{name=~"^embeddings.*"}[5m])) >= 90)` +Generated query for warning alert: `max((sum by (domain) (increase(src_dbworker_resetter_errors_total[5m]))) >= 1)`-## embeddings: container_oomkill_events_total +## background-jobs: failed_records -
container OOMKILL events total by instance
+number of stalled records marked as 'failed'
**Descriptions** -- warning embeddings: 1+ container OOMKILL events total by instance +- warning background-jobs: 50+ number of stalled records marked as 'failed' **Next steps** -- **Kubernetes:** Consider increasing memory limit in relevant `Deployment.yaml`. -- **Docker Compose:** Consider increasing `memory:` of embeddings container in `docker-compose.yml`. -- More help interpreting this metric is available in the [dashboards reference](dashboards#embeddings-container-oomkill-events-total). +- Check application logs for the failing domain to check for errors. High failure rates indicate a bug in the code handling the job, or a pod frequently dying. +- Learn more about the related dashboard panel in the [dashboards reference](dashboards#background-jobs-failed-records). - **Silence this alert:** If you are aware of this alert and want to silence notifications for it, add the following to your site configuration and set a reminder to re-evaluate the alert: ```json "observability.silenceAlerts": [ - "warning_embeddings_container_oomkill_events_total" + "warning_background-jobs_failed_records" ] ``` -*Managed by the [Sourcegraph Cody team](https://handbook.sourcegraph.com/departments/engineering/teams/cody).* +*Managed by the [Sourcegraph Source team](https://handbook.sourcegraph.com/departments/engineering/teams/source).*Technical details
-Generated query for warning alert: `max((max by (name) (container_oom_events_total{name=~"^embeddings.*"})) >= 1)` +Generated query for warning alert: `max((sum by (domain) (increase(src_dbworker_resetter_record_reset_failures_total[5m]))) >= 50)`-## embeddings: go_goroutines +## background-jobs: stall_duration_p90 -
maximum active goroutines
+90th percentile of stall duration
**Descriptions** -- warning embeddings: 10000+ maximum active goroutines for 10m0s +- warning background-jobs: 300s+ 90th percentile of stall duration **Next steps** -- More help interpreting this metric is available in the [dashboards reference](dashboards#embeddings-go-goroutines). +- Learn more about the related dashboard panel in the [dashboards reference](dashboards#background-jobs-stall-duration-p90). - **Silence this alert:** If you are aware of this alert and want to silence notifications for it, add the following to your site configuration and set a reminder to re-evaluate the alert: ```json "observability.silenceAlerts": [ - "warning_embeddings_go_goroutines" + "warning_background-jobs_stall_duration_p90" ] ``` -*Managed by the [Sourcegraph Cody team](https://handbook.sourcegraph.com/departments/engineering/teams/cody).* +*Managed by the [Sourcegraph Source team](https://handbook.sourcegraph.com/departments/engineering/teams/source).*Technical details
-Generated query for warning alert: `max((max by (instance) (go_goroutines{job=~".*embeddings"})) >= 10000)` +Generated query for warning alert: `max((histogram_quantile(0.9, sum by (le, domain) (rate(src_dbworker_resetter_stall_duration_seconds_bucket[5m])))) >= 300)`-## embeddings: go_gc_duration_seconds +## background-jobs: aggregate_queue_size -
maximum go garbage collection duration
+total number of jobs queued across all domains
**Descriptions** -- warning embeddings: 2s+ maximum go garbage collection duration +- warning background-jobs: 1e+06+ total number of jobs queued across all domains **Next steps** -- Learn more about the related dashboard panel in the [dashboards reference](dashboards#embeddings-go-gc-duration-seconds). +- Check for stuck workers or investigate the specific domains with high queue depth. Check worker logs for errors and database for high load. +- Learn more about the related dashboard panel in the [dashboards reference](dashboards#background-jobs-aggregate-queue-size). - **Silence this alert:** If you are aware of this alert and want to silence notifications for it, add the following to your site configuration and set a reminder to re-evaluate the alert: ```json "observability.silenceAlerts": [ - "warning_embeddings_go_gc_duration_seconds" + "warning_background-jobs_aggregate_queue_size" ] ``` -*Managed by the [Sourcegraph Cody team](https://handbook.sourcegraph.com/departments/engineering/teams/cody).* +*Managed by the [Sourcegraph Source team](https://handbook.sourcegraph.com/departments/engineering/teams/source).*Technical details
-Generated query for warning alert: `max((max by (instance) (go_gc_duration_seconds{job=~".*embeddings"})) >= 2)` +Generated query for warning alert: `max((sum(max by (domain) (src_workerutil_queue_depth))) >= 1000000)`-## embeddings: pods_available_percentage +## background-jobs: max_queue_duration -
percentage pods available
+maximum time a job has been in queue across all domains
**Descriptions** -- critical embeddings: less than 90% percentage pods available for 10m0s +- warning background-jobs: 86400s+ maximum time a job has been in queue across all domains **Next steps** -- Determine if the pod was OOM killed using `kubectl describe pod embeddings` (look for `OOMKilled: true`) and, if so, consider increasing the memory limit in the relevant `Deployment.yaml`. -- Check the logs before the container restarted to see if there are `panic:` messages or similar using `kubectl logs -p embeddings`. -- Learn more about the related dashboard panel in the [dashboards reference](dashboards#embeddings-pods-available-percentage). +- Investigate which domain has jobs stuck in queue. If the queue is growing, consider scaling up worker instances. +- Learn more about the related dashboard panel in the [dashboards reference](dashboards#background-jobs-max-queue-duration). - **Silence this alert:** If you are aware of this alert and want to silence notifications for it, add the following to your site configuration and set a reminder to re-evaluate the alert: ```json "observability.silenceAlerts": [ - "critical_embeddings_pods_available_percentage" + "warning_background-jobs_max_queue_duration" ] ``` -*Managed by the [Sourcegraph Cody team](https://handbook.sourcegraph.com/departments/engineering/teams/cody).* +*Managed by the [Sourcegraph Source team](https://handbook.sourcegraph.com/departments/engineering/teams/source).*Technical details
-Generated query for critical alert: `min((sum by (app) (up{app=~".*embeddings"\}) / count by (app) (up\{app=~".*embeddings"}) * 100) <= 90)` +Generated query for warning alert: `max((max(src_workerutil_queue_duration_seconds)) >= 86400)`-
 @@ -100227,21 +99664,16 @@ These are OAuth tokens that Sourcegraph receives when a user signs into Sourcegr
### Custom Certificates
-> NOTE: Feature supported in Sourcegraph 5.1.5+
-
-
-If you are using a self-signed certificate for your GitHub Enterprise instance, configure `tls.external` under `experimentalFeatures`
+If you are using a self-signed certificate for your GitHub Enterprise instance, configure `tls.external`
in the **Site configuration** with your certificate(s).
```json
{
- "experimentalFeatures": {
"tls.external": {
"certificates": [
"-----BEGIN CERTIFICATE-----\n..."
]
}
- }
}
```
@@ -100289,7 +99721,7 @@ No [token scopes](https://docs.github.com/en/developers/apps/building-oauth-apps
[permissions]: #repository-permissions
[permissions-caching]: #teams-and-organizations-permissions-caching
[batch-changes]: /batch-changes/
-[batch-changes-interactions]: /batch_changes/explanations/permissions_in_batch_changes#code-host-interactions-in-batch-changes
+[batch-changes-interactions]: /batch-changes/permissions-in-batch-changes#code-host-interactions-in-batch-changes
> WARNING: In addition to the prerequisite token scopes, the account attached to the token must actually have the same level of access to the relevant resources that you are trying to grant. For example:
@@ -100355,6 +99787,8 @@ See [Internal rate limits](/admin/code_hosts/rate_limits#internal-rate-limits).
Prerequisite for configuring repository permission syncing: [Add GitHub as an authentication provider](/admin/auth/#github).
+> NOTE: If your GitHub organization enforces SAML SSO, consider configuring [`requiredSsoOrgs`](/admin/auth/#requiredssoOrgs) in your GitHub auth provider to ensure users properly authorize the OAuth application during sign-in. This helps prevent permissions syncing issues caused by tokens that lack SSO authorization.
+
Then, add or edit the GitHub connection as described above and include the `authorization` field:
```json
@@ -100488,7 +99922,7 @@ GitHub connections support the following configuration options, which are specif
{/* SCHEMA_SYNC_START: admin/code_hosts/github.schema.json */}
{/* WARNING: This section is auto-generated during releases. Do not edit manually. */}
-{/* Last updated: 2025-08-07T02:20:40Z via sourcegraph/sourcegraph@v6.6.2517 */}
+{/* Last updated: 2025-11-12T22:19:35Z via sourcegraph/sourcegraph@v6.10.0 */}
```json
// Authentication alternatives: token OR gitHubAppDetails OR externalAccount OR useRandomExternalAccount
@@ -100500,7 +99934,7 @@ GitHub connections support the following configuration options, which are specif
"syncInternalRepoPermissions": false
},
- // TLS certificate of the GitHub Enterprise instance. This is only necessary if the certificate is self-signed or signed by an internal CA. To get the certificate run `openssl s_client -connect HOST:443 -showcerts < /dev/null 2> /dev/null | openssl x509 -outform PEM`. To escape the value into a JSON string, you may want to use a tool like https://json-escape-text.now.sh.
+ // DEPRECATED: Use the tls.external setting in site config instead. TLS certificate of the GitHub Enterprise instance. This is only necessary if the certificate is self-signed or signed by an internal CA. To get the certificate run `openssl s_client -connect HOST:443 -showcerts < /dev/null 2> /dev/null | openssl x509 -outform PEM`. To escape the value into a JSON string, you may want to use a tool like https://json-escape-text.now.sh.
// Other example values:
// - "-----BEGIN CERTIFICATE-----\n..."
"certificate": null,
@@ -100567,12 +100001,6 @@ GitHub connections support the following configuration options, which are specif
// Valid options: "http", "ssh"
"gitURLType": "http",
- // DEPRECATED: The installation ID of the GitHub App.
- "githubAppInstallationID": null,
-
- // Deprecated and ignored field which will be removed entirely in the next release. GitHub repositories can no longer be enabled or disabled explicitly. Configure repositories to be mirrored via "repos", "exclude" and "repositoryQuery" instead.
- "initialRepositoryEnablement": false,
-
// The maximum number of repos that will be deleted per sync. A value of 0 or less indicates no maximum.
"maxDeletions": 0,
@@ -100588,9 +100016,6 @@ GitHub connections support the following configuration options, which are specif
// ]
"orgs": null,
- // Whether the code host connection is in a pending state.
- "pending": false,
-
// Rate limit applied when making background API requests to GitHub.
"rateLimit": {
"enabled": true,
@@ -100771,7 +100196,7 @@ Gerrit connections support the following configuration options, which are specif
{/* SCHEMA_SYNC_START: admin/code_hosts/gerrit.schema.json */}
{/* WARNING: This section is auto-generated during releases. Do not edit manually. */}
-{/* Last updated: 2025-08-07T02:20:45Z via sourcegraph/sourcegraph@v6.6.2517 */}
+{/* Last updated: 2025-11-12T22:19:41Z via sourcegraph/sourcegraph@v6.10.0 */}
```json
{
// If non-null, enforces Gerrit repository permissions. This requires that there is an item in the [site configuration json](https://sourcegraph.com/docs/admin/config/site_config#auth-providers) `auth.providers` field, of type "gerrit" with the same `url` field as specified in this `GerritConnection`.
@@ -101042,10 +100467,6 @@ Bitbucket Server / Bitbucket Data Center versions older than v5.5 require specif
Sourcegraph by default clones repositories from your Bitbucket Server / Bitbucket Data Center via HTTP(S), using the access token or account credentials you provide in the configuration. The [`username`](/admin/code_hosts/bitbucket_server#configuration) field is always used when cloning, so it is required.
-## Repository labels
-
-Sourcegraph will mark repositories as archived if they have the `archived` label on Bitbucket Server / Bitbucket Data Center. You can exclude these repositories in search with `archived:no` [search syntax](/code-search/queries).
-
## Internal rate limits
See [Internal rate limits](/admin/code_hosts/rate_limits#internal-rate-limits).
@@ -101060,7 +100481,7 @@ Bitbucket Server / Bitbucket Data Center connections support the following confi
{/* SCHEMA_SYNC_START: admin/code_hosts/bitbucket_server.schema.json */}
{/* WARNING: This section is auto-generated during releases. Do not edit manually. */}
-{/* Last updated: 2025-08-07T02:20:42Z via sourcegraph/sourcegraph@v6.6.2517 */}
+{/* Last updated: 2025-11-12T22:19:37Z via sourcegraph/sourcegraph@v6.10.0 */}
```json
// Authentication alternatives: token OR password
@@ -101077,7 +100498,7 @@ Bitbucket Server / Bitbucket Data Center connections support the following confi
"oauth2": false
},
- // TLS certificate of the Bitbucket Server / Bitbucket Data Center instance. This is only necessary if the certificate is self-signed or signed by an internal CA. To get the certificate run `openssl s_client -connect HOST:443 -showcerts < /dev/null 2> /dev/null | openssl x509 -outform PEM`. To escape the value into a JSON string, you may want to use a tool like https://json-escape-text.now.sh.
+ // DEPRECATED: Use the tls.external setting in site config instead. TLS certificate of the Bitbucket Server / Bitbucket Data Center instance. This is only necessary if the certificate is self-signed or signed by an internal CA. To get the certificate run `openssl s_client -connect HOST:443 -showcerts < /dev/null 2> /dev/null | openssl x509 -outform PEM`. To escape the value into a JSON string, you may want to use a tool like https://json-escape-text.now.sh.
// Other example values:
// - "-----BEGIN CERTIFICATE-----\n..."
"certificate": null,
@@ -101126,9 +100547,6 @@ Bitbucket Server / Bitbucket Data Center connections support the following confi
// - "ssh"
"gitURLType": "http",
- // Deprecated and ignored field which will be removed entirely in the next release. BitBucket repositories can no longer be enabled or disabled explicitly.
- "initialRepositoryEnablement": false,
-
// The maximum number of repos that will be deleted per sync. A value of 0 or less indicates no maximum.
"maxDeletions": 0,
@@ -101328,7 +100746,7 @@ Bitbucket Cloud connections support the following configuration options, which a
{/* SCHEMA_SYNC_START: admin/code_hosts/bitbucket_cloud.schema.json */}
{/* WARNING: This section is auto-generated during releases. Do not edit manually. */}
-{/* Last updated: 2025-08-07T02:20:43Z via sourcegraph/sourcegraph@v6.6.2517 */}
+{/* Last updated: 2025-11-12T22:19:38Z via sourcegraph/sourcegraph@v6.10.0 */}
```json
{
// The workspace access token to use when authenticating with Bitbucket Cloud.
@@ -101517,7 +100935,7 @@ Azure DevOps connections support the following configuration options, which are
{/* SCHEMA_SYNC_START: admin/code_hosts/azuredevops.schema.json */}
{/* WARNING: This section is auto-generated during releases. Do not edit manually. */}
-{/* Last updated: 2025-08-07T02:20:44Z via sourcegraph/sourcegraph@v6.6.2517 */}
+{/* Last updated: 2025-11-12T22:19:39Z via sourcegraph/sourcegraph@v6.10.0 */}
```json
// Authentication alternatives: token OR windowsPassword
@@ -101684,7 +101102,7 @@ AWS CodeCommit connections support the following configuration options, which ar
{/* SCHEMA_SYNC_START: admin/code_hosts/aws_codecommit.schema.json */}
{/* WARNING: This section is auto-generated during releases. Do not edit manually. */}
-{/* Last updated: 2025-08-07T02:20:45Z via sourcegraph/sourcegraph@v6.6.2517 */}
+{/* Last updated: 2025-11-12T22:19:40Z via sourcegraph/sourcegraph@v6.10.0 */}
```json
{
// REQUIRED:
@@ -101734,9 +101152,6 @@ AWS CodeCommit connections support the following configuration options, which ar
// Valid options: "http", "ssh"
"gitURLType": "http",
- // Deprecated and ignored field which will be removed entirely in the next release. AWS CodeCommit repositories can no longer be enabled or disabled explicitly. Configure which repositories should not be mirrored via "exclude" instead.
- "initialRepositoryEnablement": false,
-
// The maximum number of repos that will be deleted per sync. A value of 0 or less indicates no maximum.
"maxDeletions": 0,
@@ -102276,6 +101691,38 @@ When combined with `"allowSignup": false` or unset, an admin should first create
}
```
+**requiredSsoOrgs**
+
+Requires that users have SAML SSO authorization for specific GitHub organizations when authenticating via OAuth. This is useful when your GitHub organizations enforce SAML SSO, and you want to ensure users properly authorize the OAuth application for those organizations during the authentication flow. Not doing so could cause permissions syncing issues.
+
+This setting accepts one of two values:
+- A list of **GitHub organization IDs** (numeric strings), not organization names.
+- A list with a single entry: ["all"], which means **all** organizations need to be authorized.
+
+**Finding your GitHub organization ID:**
+
+You can find your organization ID using the GitHub API:
+
+```bash
+curl -H "Authorization: token YOUR_GITHUB_TOKEN" \
+ https://api.github.com/orgs/YOUR_ORG_NAME
+```
+
+The response will include an `id` field with your organization's numeric ID.
+
+**Example configuration:**
+
+```json
+{
+ "type": "github",
+ "url": "https://github.com",
+ "displayName": "GitHub",
+ "clientID": "replace-with-the-oauth-client-id",
+ "clientSecret": "replace-with-the-oauth-client-secret",
+ "allowSignup": true,
+ "requiredSsoOrgs": ["123456789", "987654321"]
+}
+```
## GitLab
@@ -100227,21 +99664,16 @@ These are OAuth tokens that Sourcegraph receives when a user signs into Sourcegr
### Custom Certificates
-> NOTE: Feature supported in Sourcegraph 5.1.5+
-
-
-If you are using a self-signed certificate for your GitHub Enterprise instance, configure `tls.external` under `experimentalFeatures`
+If you are using a self-signed certificate for your GitHub Enterprise instance, configure `tls.external`
in the **Site configuration** with your certificate(s).
```json
{
- "experimentalFeatures": {
"tls.external": {
"certificates": [
"-----BEGIN CERTIFICATE-----\n..."
]
}
- }
}
```
@@ -100289,7 +99721,7 @@ No [token scopes](https://docs.github.com/en/developers/apps/building-oauth-apps
[permissions]: #repository-permissions
[permissions-caching]: #teams-and-organizations-permissions-caching
[batch-changes]: /batch-changes/
-[batch-changes-interactions]: /batch_changes/explanations/permissions_in_batch_changes#code-host-interactions-in-batch-changes
+[batch-changes-interactions]: /batch-changes/permissions-in-batch-changes#code-host-interactions-in-batch-changes
> WARNING: In addition to the prerequisite token scopes, the account attached to the token must actually have the same level of access to the relevant resources that you are trying to grant. For example:
@@ -100355,6 +99787,8 @@ See [Internal rate limits](/admin/code_hosts/rate_limits#internal-rate-limits).
Prerequisite for configuring repository permission syncing: [Add GitHub as an authentication provider](/admin/auth/#github).
+> NOTE: If your GitHub organization enforces SAML SSO, consider configuring [`requiredSsoOrgs`](/admin/auth/#requiredssoOrgs) in your GitHub auth provider to ensure users properly authorize the OAuth application during sign-in. This helps prevent permissions syncing issues caused by tokens that lack SSO authorization.
+
Then, add or edit the GitHub connection as described above and include the `authorization` field:
```json
@@ -100488,7 +99922,7 @@ GitHub connections support the following configuration options, which are specif
{/* SCHEMA_SYNC_START: admin/code_hosts/github.schema.json */}
{/* WARNING: This section is auto-generated during releases. Do not edit manually. */}
-{/* Last updated: 2025-08-07T02:20:40Z via sourcegraph/sourcegraph@v6.6.2517 */}
+{/* Last updated: 2025-11-12T22:19:35Z via sourcegraph/sourcegraph@v6.10.0 */}
```json
// Authentication alternatives: token OR gitHubAppDetails OR externalAccount OR useRandomExternalAccount
@@ -100500,7 +99934,7 @@ GitHub connections support the following configuration options, which are specif
"syncInternalRepoPermissions": false
},
- // TLS certificate of the GitHub Enterprise instance. This is only necessary if the certificate is self-signed or signed by an internal CA. To get the certificate run `openssl s_client -connect HOST:443 -showcerts < /dev/null 2> /dev/null | openssl x509 -outform PEM`. To escape the value into a JSON string, you may want to use a tool like https://json-escape-text.now.sh.
+ // DEPRECATED: Use the tls.external setting in site config instead. TLS certificate of the GitHub Enterprise instance. This is only necessary if the certificate is self-signed or signed by an internal CA. To get the certificate run `openssl s_client -connect HOST:443 -showcerts < /dev/null 2> /dev/null | openssl x509 -outform PEM`. To escape the value into a JSON string, you may want to use a tool like https://json-escape-text.now.sh.
// Other example values:
// - "-----BEGIN CERTIFICATE-----\n..."
"certificate": null,
@@ -100567,12 +100001,6 @@ GitHub connections support the following configuration options, which are specif
// Valid options: "http", "ssh"
"gitURLType": "http",
- // DEPRECATED: The installation ID of the GitHub App.
- "githubAppInstallationID": null,
-
- // Deprecated and ignored field which will be removed entirely in the next release. GitHub repositories can no longer be enabled or disabled explicitly. Configure repositories to be mirrored via "repos", "exclude" and "repositoryQuery" instead.
- "initialRepositoryEnablement": false,
-
// The maximum number of repos that will be deleted per sync. A value of 0 or less indicates no maximum.
"maxDeletions": 0,
@@ -100588,9 +100016,6 @@ GitHub connections support the following configuration options, which are specif
// ]
"orgs": null,
- // Whether the code host connection is in a pending state.
- "pending": false,
-
// Rate limit applied when making background API requests to GitHub.
"rateLimit": {
"enabled": true,
@@ -100771,7 +100196,7 @@ Gerrit connections support the following configuration options, which are specif
{/* SCHEMA_SYNC_START: admin/code_hosts/gerrit.schema.json */}
{/* WARNING: This section is auto-generated during releases. Do not edit manually. */}
-{/* Last updated: 2025-08-07T02:20:45Z via sourcegraph/sourcegraph@v6.6.2517 */}
+{/* Last updated: 2025-11-12T22:19:41Z via sourcegraph/sourcegraph@v6.10.0 */}
```json
{
// If non-null, enforces Gerrit repository permissions. This requires that there is an item in the [site configuration json](https://sourcegraph.com/docs/admin/config/site_config#auth-providers) `auth.providers` field, of type "gerrit" with the same `url` field as specified in this `GerritConnection`.
@@ -101042,10 +100467,6 @@ Bitbucket Server / Bitbucket Data Center versions older than v5.5 require specif
Sourcegraph by default clones repositories from your Bitbucket Server / Bitbucket Data Center via HTTP(S), using the access token or account credentials you provide in the configuration. The [`username`](/admin/code_hosts/bitbucket_server#configuration) field is always used when cloning, so it is required.
-## Repository labels
-
-Sourcegraph will mark repositories as archived if they have the `archived` label on Bitbucket Server / Bitbucket Data Center. You can exclude these repositories in search with `archived:no` [search syntax](/code-search/queries).
-
## Internal rate limits
See [Internal rate limits](/admin/code_hosts/rate_limits#internal-rate-limits).
@@ -101060,7 +100481,7 @@ Bitbucket Server / Bitbucket Data Center connections support the following confi
{/* SCHEMA_SYNC_START: admin/code_hosts/bitbucket_server.schema.json */}
{/* WARNING: This section is auto-generated during releases. Do not edit manually. */}
-{/* Last updated: 2025-08-07T02:20:42Z via sourcegraph/sourcegraph@v6.6.2517 */}
+{/* Last updated: 2025-11-12T22:19:37Z via sourcegraph/sourcegraph@v6.10.0 */}
```json
// Authentication alternatives: token OR password
@@ -101077,7 +100498,7 @@ Bitbucket Server / Bitbucket Data Center connections support the following confi
"oauth2": false
},
- // TLS certificate of the Bitbucket Server / Bitbucket Data Center instance. This is only necessary if the certificate is self-signed or signed by an internal CA. To get the certificate run `openssl s_client -connect HOST:443 -showcerts < /dev/null 2> /dev/null | openssl x509 -outform PEM`. To escape the value into a JSON string, you may want to use a tool like https://json-escape-text.now.sh.
+ // DEPRECATED: Use the tls.external setting in site config instead. TLS certificate of the Bitbucket Server / Bitbucket Data Center instance. This is only necessary if the certificate is self-signed or signed by an internal CA. To get the certificate run `openssl s_client -connect HOST:443 -showcerts < /dev/null 2> /dev/null | openssl x509 -outform PEM`. To escape the value into a JSON string, you may want to use a tool like https://json-escape-text.now.sh.
// Other example values:
// - "-----BEGIN CERTIFICATE-----\n..."
"certificate": null,
@@ -101126,9 +100547,6 @@ Bitbucket Server / Bitbucket Data Center connections support the following confi
// - "ssh"
"gitURLType": "http",
- // Deprecated and ignored field which will be removed entirely in the next release. BitBucket repositories can no longer be enabled or disabled explicitly.
- "initialRepositoryEnablement": false,
-
// The maximum number of repos that will be deleted per sync. A value of 0 or less indicates no maximum.
"maxDeletions": 0,
@@ -101328,7 +100746,7 @@ Bitbucket Cloud connections support the following configuration options, which a
{/* SCHEMA_SYNC_START: admin/code_hosts/bitbucket_cloud.schema.json */}
{/* WARNING: This section is auto-generated during releases. Do not edit manually. */}
-{/* Last updated: 2025-08-07T02:20:43Z via sourcegraph/sourcegraph@v6.6.2517 */}
+{/* Last updated: 2025-11-12T22:19:38Z via sourcegraph/sourcegraph@v6.10.0 */}
```json
{
// The workspace access token to use when authenticating with Bitbucket Cloud.
@@ -101517,7 +100935,7 @@ Azure DevOps connections support the following configuration options, which are
{/* SCHEMA_SYNC_START: admin/code_hosts/azuredevops.schema.json */}
{/* WARNING: This section is auto-generated during releases. Do not edit manually. */}
-{/* Last updated: 2025-08-07T02:20:44Z via sourcegraph/sourcegraph@v6.6.2517 */}
+{/* Last updated: 2025-11-12T22:19:39Z via sourcegraph/sourcegraph@v6.10.0 */}
```json
// Authentication alternatives: token OR windowsPassword
@@ -101684,7 +101102,7 @@ AWS CodeCommit connections support the following configuration options, which ar
{/* SCHEMA_SYNC_START: admin/code_hosts/aws_codecommit.schema.json */}
{/* WARNING: This section is auto-generated during releases. Do not edit manually. */}
-{/* Last updated: 2025-08-07T02:20:45Z via sourcegraph/sourcegraph@v6.6.2517 */}
+{/* Last updated: 2025-11-12T22:19:40Z via sourcegraph/sourcegraph@v6.10.0 */}
```json
{
// REQUIRED:
@@ -101734,9 +101152,6 @@ AWS CodeCommit connections support the following configuration options, which ar
// Valid options: "http", "ssh"
"gitURLType": "http",
- // Deprecated and ignored field which will be removed entirely in the next release. AWS CodeCommit repositories can no longer be enabled or disabled explicitly. Configure which repositories should not be mirrored via "exclude" instead.
- "initialRepositoryEnablement": false,
-
// The maximum number of repos that will be deleted per sync. A value of 0 or less indicates no maximum.
"maxDeletions": 0,
@@ -102276,6 +101691,38 @@ When combined with `"allowSignup": false` or unset, an admin should first create
}
```
+**requiredSsoOrgs**
+
+Requires that users have SAML SSO authorization for specific GitHub organizations when authenticating via OAuth. This is useful when your GitHub organizations enforce SAML SSO, and you want to ensure users properly authorize the OAuth application for those organizations during the authentication flow. Not doing so could cause permissions syncing issues.
+
+This setting accepts one of two values:
+- A list of **GitHub organization IDs** (numeric strings), not organization names.
+- A list with a single entry: ["all"], which means **all** organizations need to be authorized.
+
+**Finding your GitHub organization ID:**
+
+You can find your organization ID using the GitHub API:
+
+```bash
+curl -H "Authorization: token YOUR_GITHUB_TOKEN" \
+ https://api.github.com/orgs/YOUR_ORG_NAME
+```
+
+The response will include an `id` field with your organization's numeric ID.
+
+**Example configuration:**
+
+```json
+{
+ "type": "github",
+ "url": "https://github.com",
+ "displayName": "GitHub",
+ "clientID": "replace-with-the-oauth-client-id",
+ "clientSecret": "replace-with-the-oauth-client-secret",
+ "allowSignup": true,
+ "requiredSsoOrgs": ["123456789", "987654321"]
+}
+```
## GitLab