ENH: Design of Experiment with Low Discrepancy Sequences #4103
Comments
|
a suggestion: put the gist functions in a new module statsmodels.tools.sequences Halton looks fine going through van der Corput, but I have no idea if there are numerical advantages to either version. a few proposed changes in van_der_corput use a different loop variable in the, while i > 0. Even if it works this way not modifying outer loop variable is an easier to understand design. I think we can hardcode the first few prime numbers as in the old halton. They won't change and it is not necessary to recompute them each time. Also maybe outsource the If I read van_der_corput correctly, then we can compute the sequence for any In terms of organizing the code and it's location: |
|
@josef-pkt I have created a PR and tried to address your comments.
I guess we could compute the Regarding Sobol' sequences or LHS, their use cases are the same as Halton. If there is no specific use for DoE at the moment, I guess |
|
for computing only for selected i: Kocis, L. and Whiten, W.J., 1997. Computational investigations of low-discrepancy sequences. ACM Transactions on Mathematical Software (TOMS), 23(2), pp.266-294. |
|
aside: playing with the original halton version |
|
@josef-pkt I got a clean LHS version, were should I put this? |
|
Start the new |
|
@josef-pkt I will do the PR, If you prefer for the little fix on the bounds, I can include this not to have a slim PR ( #4106 ) |
|
It's better to merge the fix separately right away. |
|
@josef-pkt I have done the corresponding PR. |
|
On reference for using latin hypercube sampling for mixed discrete choice models, similar to halton sequences Hess, Stephane, Kenneth E. Train, and John W. Polak. 2006. “On the Use of a Modified Latin Hypercube Sampling (MLHS) Method in the Estimation of a Mixed Logit Model for Vehicle Choice.” Transportation Research Part B: Methodological 40 (2):147–63. https://doi.org/10.1016/j.trb.2004.10.005. |
|
@josef-pkt Thanks for the reference, I did not know this one. Do you see anything more I can do? Some doc? Some other functionalities? |
|
I wanted to reply in your PR Essentially this is you area for now. I browsed a bit in the literature but have barely some superficial ideas about this. It would be good if you could work on whatever you think is useful in this area. I have many different topics that I need to keep track of or need to catch up with, so I cannot keep up, but I will come back to it every once in a while. For my context: |
|
Stratified LHS sound interesting based on the abstracts, found while doing a semi-random search for related articles (without knowing much about it, number of citations is pretty good) Minasny, Budiman, and Alex B. McBratney. 2006. “A Conditioned Latin Hypercube Method for Sampling in the Presence of Ancillary Information.” Computers & Geosciences 32 (9):1378–88. https://doi.org/10.1016/j.cageo.2005.12.009. Shields, Michael D., and Jiaxin Zhang. 2016. “The Generalization of Latin Hypercube Sampling.” Reliability Engineering & System Safety 148 (Supplement C):96–108. https://doi.org/10.1016/j.ress.2015.12.002. |
|
One comment on Halton versus LHS for simulated MLE in footnote 12 |
|
Stratified LHS is indeed promising and I definitely have planned to implement this when given some time. As for the number of dimensions, a scrambled version of Halton/Sobol could be also interesting to add. With these and the already coded methods, it would be quite versatile IMO. Regarding the current PR, I will try to propose more documentation as well as examples. |
|
One more possible enhancement idea: |
|
@tupui A related but different question? (just an idea right now An application where this is useful: A standard example for spline fitting is a motorcycle dataset. It can be fit very well with splines that have knots at every few (5th or 10th) sorted observation. However, eventually I realized that these splines work very well because there are more observation in the part that has high variation, so we get more knots in the large variation part. In general this would not work so well because with knots uniform in the design space we don't get more knots in the high variation part and would either oversmooth the high variation part or undersmooth the low variation part, without switching to adaptive splines and bandwidth choice. What could work is if we could use a nonlinear distortion function that depends on the local curvature or variance, then either brings points closer together or farther apart. That would be a similar nonlinear transformation as using the ppf (inverse cdf) when transforming uniform sample points to correspond to a non-uniform distribution. |
|
Here is an example, but not variation based, It looks like just the analogue of the ppf transformation based on a brief look |
|
@josef-pkt Indeed, being able to continue a DoE can be handy. For Halton this is already a feature as we added the Apart from importance sampling (so ppf to do the inverse transformation), there is also the possibility to use quadrature based sampling. But this constrains a lot the sampling. Appart from that, I am not aware of anything else. From what I know, we use ppf all the time as it is super convenient. |
|
parking a reference (found while shutting down) Pianosi, Francesca, and Thorsten Wagener. 2015. “A Simple and Efficient Method for Global Sensitivity Analysis Based on Cumulative Distribution Functions.” Environmental Modelling & Software 67 (Supplement C):1–11. https://doi.org/10.1016/j.envsoft.2015.01.004. |
|
another way of creating quasi random numbers |
|
This is nice. As detailed in the post, it works quite well in 2D. But if you go into higher dimensions, it's really bad. In the comments, someone else noticed that. I have done myself some 2D sub-projections of it:
So, I am not sure about adding this one. Both optimized LHS and scrambled Sobol' sequences are way more efficient. |
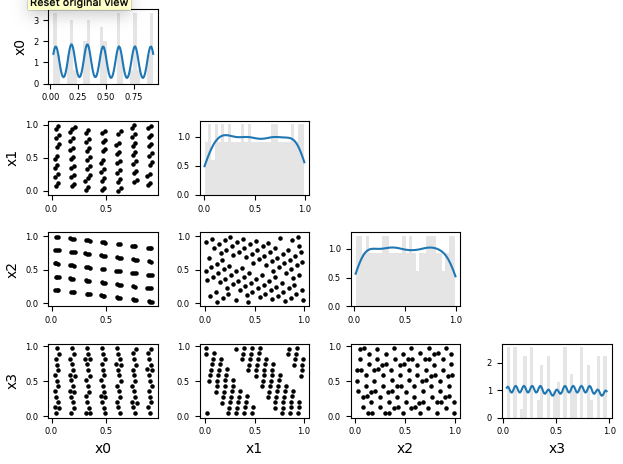
|
By the way regarding your comment on the sensitivity indices based on CDF, I have coded these indices in my tool Batman (https://gitlab.com/cerfacs/batman). If your interested in, I can make a PR. |
|
Closing as all this is in SciPy now and further development on this should happen here except if we want to have something really particular. As for poisson disk sampling there is an open PR too on SciPy. |
Follow up on a discussion about implementing some design of experiment.
There is an opened PR which proposed to add Halton sequence. And here is my code proposition: Gist. As opposed to the PR, I propose to separate have a function to generate some prime numbers and to have a distinct function that will create the basic of Halton (the Van der Corput sequence). This way, these functions can be re-used.
In low dimensional cases (<~10), this method is good. Otherwise, we might want to go with Sobol' sequences and optimized LHS (this is the state of the art).
LHS is nice but we cannot easily increase the sample size (still an open field) as opposed to low discrepancy sequences where you simply have to take the next points of the sequences. An other option is to augment the design by optimization of metric such as the discrepancy (here is another gist for its computation).
The text was updated successfully, but these errors were encountered: