From 4ba5997572d02e9a63543757505123968a1e114a Mon Sep 17 00:00:00 2001
From: Anastasiia Tovpeko <114177030+atovpeko@users.noreply.github.com>
Date: Fri, 17 Oct 2025 16:50:53 +0300
Subject: [PATCH 1/7] Pricing page update for the Free Plan (#4481)
---
_partials/_billing-for-inactive-services.md | 5 +
about/pricing-and-account-management.md | 154 +++++++++++---------
2 files changed, 87 insertions(+), 72 deletions(-)
create mode 100644 _partials/_billing-for-inactive-services.md
diff --git a/_partials/_billing-for-inactive-services.md b/_partials/_billing-for-inactive-services.md
new file mode 100644
index 0000000000..3a14272bf3
--- /dev/null
+++ b/_partials/_billing-for-inactive-services.md
@@ -0,0 +1,5 @@
+
+
+You are charged for all active $SERVICE_SHORTs in your account, even if you are not actively using them. To reduce costs, pause or delete your unused $SERVICE_SHORTs.
+
+
\ No newline at end of file
diff --git a/about/pricing-and-account-management.md b/about/pricing-and-account-management.md
index 0ba87ada6b..9c86a36696 100644
--- a/about/pricing-and-account-management.md
+++ b/about/pricing-and-account-management.md
@@ -11,13 +11,18 @@ cloud_ui:
import TieredStorageBilling from "versionContent/_partials/_tiered-storage-billing.mdx";
import EarlyAccessGeneral from "versionContent/_partials/_early_access.mdx";
+import BillingForInactiveServices from "versionContent/_partials/_billing-for-inactive-services.mdx";
# Pricing plans and account management
As we enhance our offerings and align them with your evolving needs,
$PRICING_PLANs provide more value, flexibility, and efficiency for your business.
Whether you're a growing startup or a well-established enterprise, our plans
-are structured to support your journey towards greater success. This page explains pricing plans for $CLOUD_LONG, and how to easily manage your $ACCOUNT_LONG.
+are structured to support your journey towards greater success.
+
+
+
+This page explains pricing plans for $CLOUD_LONG, and how to easily manage your $ACCOUNT_LONG.
$PRICING_PLAN_CAPs give you:
@@ -58,21 +63,23 @@ provisioning your $SERVICE_SHORTs or later, as your needs grow.
(typically 80-100 TB uncompressed) data and is metered on your average GB consumption per hour. We can help you compress your data by up to 98% so you pay even less.
For easy upgrades, each $SERVICE_SHORT stores the $TIMESCALE_DB binaries. This contributes up to 900 MB to overall storage, which amounts to less than $.80/month in additional storage costs.
-## $CLOUD_LONG free trial for the different price plans
+## Use $CLOUD_LONG for free
-We offer new users a free, 30-day trial period of our $PERFORMANCE plan with no credit card required.
-During your trial, you can contact $CONTACT_SALES to request information about, and access
-to, our $SCALE plan to determine how it fits your needs. During your trial, if a $SERVICE_SHORT doesn’t receive any queries for 7 days, it is paused to conserve resources. Your data remains intact during the trial, and you can easily resume your $SERVICE_SHORT in $CONSOLE. After your trial ends, we may remove your data unless you’ve added a payment method.
+Are you just starting out with $CLOUD_LONG? On our Free pricing plan, you can create up to 2 zero-cost $SERVICE_SHORTs with [limited resources][plan-features]. When a free $SERVICE_SHORT reaches the resource limit, it converts to a read-only state.
-After you have completed your 30-day trial period on the $PERFORMANCE plan, choose the
-[$PRICING_PLAN][plan-features] that suits your business and engineering needs.
+Ready to try a more feature-rich paid plan? Activate a 30-day free trial of our $PERFORMANCE (no credit card required) or $SCALE plan. During your trial, if a $SERVICE_SHORT doesn’t receive any queries for 7 days, it is paused to conserve resources. Your data remains intact during the trial, and you can easily resume your $SERVICE_SHORT in $CONSOLE. After your trial ends, we may remove your data unless you’ve added a payment method.
-After you become a paying user, we can enable some features in the higher $PRICING_PLANs so you can test them before upgrading.
+After you have completed your 30-day trial period, choose the
+[$PRICING_PLAN][plan-features] that suits your business and engineering needs. And even when you upgrade from the Free pricing plan, you can still have up to 2 zero-cost $SERVICE_SHORTs—or convert the ones you already have into standard ones, to have more resources.
+
+If you want to try out features in a higher $PRICING_PLAN before upgrading, contact us.
## Upgrade or downgrade your pricing plans at any time
-You can easily upgrade or downgrade between the $PERFORMANCE and $SCALE plans
-whenever you want using [$CONSOLE][cloud-login]. If you switch your $PRICING_PLAN mid-month,
+You can upgrade or downgrade between the Free, $PERFORMANCE, and $SCALE plans
+whenever you want using [$CONSOLE][cloud-login]. To downgrade to the Free plan, you must only have free services running in your project.
+
+If you switch your $PRICING_PLAN mid-month,
your prices are prorated to when you switch. Your $SERVICE_SHORTs are not interrupted when you switch, so
you can keep working without any hassle. To move to $ENTERPRISE, [get in touch with $COMPANY][contact-company].
@@ -85,12 +92,14 @@ $SERVICE_SHORTs’ performance, and any need to scale your $SERVICE_SHORTs or up
$CONSOLE_SHORT also shows your month-to-date accrued charges, as well as a forecast of your expected
month-end bill. Your previous invoices are also available as PDFs for download.
+
+
## $COMPANY support
$COMPANY runs a global support organization with Customer Satisfaction (CSAT) scores above 99%.
Support covers all timezones, and is fully staffed at weekend hours.
-All $PRICING_PLANs have free Developer Support through email with a target response time of 1 business
+All paid $PRICING_PLANs have free Developer Support through email with a target response time of 1 business
day; we are often faster. If you need 24x7 responsiveness, talk to us about
[Production Support][production-support].
@@ -110,83 +119,84 @@ region. This is because our cloud provider (AWS) prices infrastructure different
The available $PRICING_PLANs are:
+* **Free**: for small non-production projects.
* **$PERFORMANCE**: for cost-focused, smaller projects. No credit card required to start.
* **$SCALE**: for developers handling critical and demanding apps.
* **$ENTERPRISE**: for enterprises with mission-critical apps.
The features included in each [$PRICING_PLAN][pricing-plans] are:
-| Feature | $PERFORMANCE | $SCALE | $ENTERPRISE |
-|---------------------------------------------------------------|-----------------------------------|------------------------------------------------|-------------------------------------------------|
-| **Compute and storage** | | | |
-| Number of $SERVICE_SHORTs | Up to 4 | Unlimited | Unlimited |
-| CPU limit per $SERVICE_SHORT | Up to 8 CPU | Up to 32 CPU | Up to 64 CPU |
-| Memory limit per $SERVICE_SHORT | Up to 32 GB | Up to 128 GB | Up to 256 GB |
-| Storage limit per $SERVICE_SHORT | Up to 16 TB | Up to 16 TB | Up to 64 TB |
-| Bottomless storage on S3 | | Unlimited | Unlimited |
-| Independently scale compute and storage | ✓ | ✓ | ✓ |
-| **Data services and workloads** | | |
-| Relational | ✓ | ✓ | ✓ |
-| Time-series | ✓ | ✓ | ✓ |
-| Vector search | ✓ | ✓ | ✓ |
-| AI workflows (coming soon) | ✓ | ✓ | ✓ |
-| Cloud SQL editor | 3 seats | 10 seats | 20 seats |
-| Charts | ✓ | ✓ | ✓ |
-| Dashboards | 2 | Unlimited | Unlimited |
-| **Storage and performance** | | | |
-| IOPS | 3,000 - 5,000 | 5,000 - 8,000 | 5,000 - 8,000 |
-| Bandwidth (autoscales) | 125 - 250 Mbps | 250 - 500 Mbps | Up to 500 mbps |
-| I/O boost | | Add-on:
Up to 16K IOPS, 1000 Mbps BW | Add-on:
Up to 32K IOPS, 4000 Mbps BW |
-| **Availability and monitoring** | | | |
-| High-availability replicas
(Automated multi-AZ failover) | ✓ | ✓ | ✓ |
-| Read replicas | | ✓ | ✓ |
-| Cross-region backup | | | ✓ |
-| Backup reports | | 14 days | 14 days |
-| Point-in-time recovery and forking | 3 days | 14 days | 14 days |
-| Performance insights | ✓ | ✓ | ✓ |
-| Metrics and log exporters | | ✓ | ✓ |
-| **Security and compliance** | | | |
-| Role-based access | ✓ | ✓ | ✓ |
-| End-to-end encryption | ✓ | ✓ | ✓ |
-| Private Networking (VPC) | 1 multi-attach VPC | Unlimited multi-attach VPCs | Unlimited multi-attach VPCs |
-| AWS Transit Gateway | | ✓ | ✓ |
-| [HIPAA compliance][hipaa-compliance] | | | ✓ |
-| IP address allow list | 1 list with up to 10 IP addresses | Up to 10 lists with up to 10 IP addresses each | Up to 10 lists with up to 100 IP addresses each |
-| Multi-factor authentication | ✓ | ✓ | ✓ |
-| Federated authentication (SAML) | | | ✓ |
-| SOC 2 Type 2 report | | ✓ | ✓ |
-| Penetration testing report | | | ✓ |
-| Security questionnaire and review | | | ✓ |
-| Pay by invoice | Available at minimum spend | Available at minimum spend | ✓ |
-| [Uptime SLAs][commercial-sla] | Standard | Standard | Enterprise |
-| **Support and technical services** | | | |
-| Community support | ✓ | ✓ | ✓ |
-| Email support | ✓ | ✓ | ✓ |
-| Production support | Add-on | Add-on | ✓ |
-| Named account manager | | | ✓ |
-| JOIN services (Jumpstart Onboarding and INtegration) | | Available at minimum spend | ✓ |
+| Feature | Free | $PERFORMANCE | $SCALE | $ENTERPRISE |
+|---------------------------------------------------------------|---------------------|----------------------------------------|------------------------------------------------|--------------------------------------------------|
+| **Compute and storage** | | | | |
+| Number of $SERVICE_SHORTs | Up to 2 free services | Up to 2 free and 4 standard services | Up to 2 free and and unlimited standard services | Up to 2 free and and unlimited standard services |
+| CPU limit per $SERVICE_SHORT | Shared | Up to 8 CPU | Up to 32 CPU | Up to 64 CPU |
+| Memory limit per $SERVICE_SHORT | Shared | Up to 32 GB | Up to 128 GB | Up to 256 GB |
+| Storage limit per $SERVICE_SHORT | 750 MB | Up to 16 TB | Up to 16 TB | Up to 64 TB |
+| Bottomless storage on S3 | | | Unlimited | Unlimited |
+| Independently scale compute and storage | | Standard services only | Standard services only | Standard services only |
+| **Data services and workloads** | | | |
+| Relational | ✓ | ✓ | ✓ | ✓ |
+| Time-series | ✓ | ✓ | ✓ | ✓ |
+| Vector search | ✓ | ✓ | ✓ | ✓ |
+| AI workflows (coming soon) | ✓ | ✓ | ✓ | ✓ |
+| Cloud SQL editor | 3 seats | 3 seats | 10 seats | 20 seats |
+| Charts | ✓ | ✓ | ✓ | ✓ |
+| Dashboards | | 2 | Unlimited | Unlimited |
+| **Storage and performance** | | | | |
+| IOPS | Up to 2,000 | 3,000 - 5,000 | 5,000 - 8,000 | 5,000 - 8,000 |
+| Bandwidth (autoscales) | Up to 100 Mbps | 125 - 250 Mbps | 250 - 500 Mbps | Up to 500 mbps |
+| I/O boost | | | Add-on:
Up to 16K IOPS, 1000 Mbps BW | Add-on:
Up to 32K IOPS, 4000 Mbps BW |
+| **Availability and monitoring** | | | | |
+| High-availability replicas
(Automated multi-AZ failover) | | ✓ | ✓ | ✓ |
+| Read replicas | | | ✓ | ✓ |
+| Cross-region backup | | | | ✓ |
+| Backup reports | | | 14 days | 14 days |
+| Point-in-time recovery and forking | 1 day | 3 days | 14 days | 14 days |
+| Performance insights | Limited | ✓ | ✓ | ✓ |
+| Metrics and log exporters | | | ✓ | ✓ |
+| **Security and compliance** | | | | |
+| Role-based access | ✓ | ✓ | ✓ | ✓ |
+| End-to-end encryption | ✓ | ✓ | ✓ | ✓ |
+| Private Networking (VPC) | | 1 multi-attach VPC | Unlimited multi-attach VPCs | Unlimited multi-attach VPCs |
+| AWS Transit Gateway | | | ✓ | ✓ |
+| [HIPAA compliance][hipaa-compliance] | | | | ✓ |
+| IP address allow list | 1 list with up to 10 IP addresses | 1 list with up to 10 IP addresses | Up to 10 lists with up to 10 IP addresses each | Up to 10 lists with up to 100 IP addresses each |
+| Multi-factor authentication | ✓ | ✓ | ✓ | ✓ |
+| Federated authentication (SAML) | | | | ✓ |
+| SOC 2 Type 2 report | | | ✓ | ✓ |
+| Penetration testing report | | | | ✓ |
+| Security questionnaire and review | | | | ✓ |
+| Pay by invoice | | Available at minimum spend | Available at minimum spend | ✓ |
+| [Uptime SLAs][commercial-sla] | | Standard | Standard | Enterprise |
+| **Support and technical services** | | | | |
+| Community support | ✓ | ✓ | ✓ | ✓ |
+| Email support | | ✓ | ✓ | ✓ |
+| Production support | | Add-on | Add-on | ✓ |
+| Named account manager | | | | ✓ |
+| JOIN services (Jumpstart Onboarding and INtegration) | | | Available at minimum spend | ✓ |
For a personalized quote, [get in touch with $COMPANY][contact-company].
## Example billing calculation
-You are billed at the end of each month in arrears, based on your actual usage that month. Your monthly invoice
+You are billed at the end of each month in arrears, based on your actual usage that month. Your monthly invoice
includes an itemized cost accounting for each $SERVICE_LONG and any additional charges.
-$CLOUD_LONG charges are based on consumption:
+$CLOUD_LONG charges are based on consumption:
-- **Compute**: metered on an hourly basis. You can scale compute up and down at any time.
-- **Storage**: metered based on your average GB consumption per hour. Storage grows and shrinks automatically
+- **Compute**: metered on an hourly basis. You can scale compute up and down at any time.
+- **Storage**: metered based on your average GB consumption per hour. Storage grows and shrinks automatically
with your data.
Your monthly price for compute and storage is computed similarly. For example, over the last month your
$SERVICE_LONG has been running compute for 500 hours total:
- - 375 hours with 2 CPU
- - 125 hours 4 CPU
-
-**Compute cost** = (`375` x `hourly price for 2 CPU`) + (`125` x `hourly price for 4 CPU`)
-
-Some add-ons such as Elastic storage, Tiered storage, and Connection pooling may incur
+- 375 hours with 2 CPU
+- 125 hours 4 CPU
+
+**Compute cost** = (`375` x `hourly price for 2 CPU`) + (`125` x `hourly price for 4 CPU`)
+
+Some add-ons such as tiered storage, HA replicas, and connection pooling may incur
additional charges. These charges are clearly marked in your billing snapshot in $CONSOLE.
## Manage your $CLOUD_LONG $PRICING_PLAN
@@ -196,7 +206,7 @@ payment methods, and add-ons in the [billing section in $CONSOLE][cloud-billing]
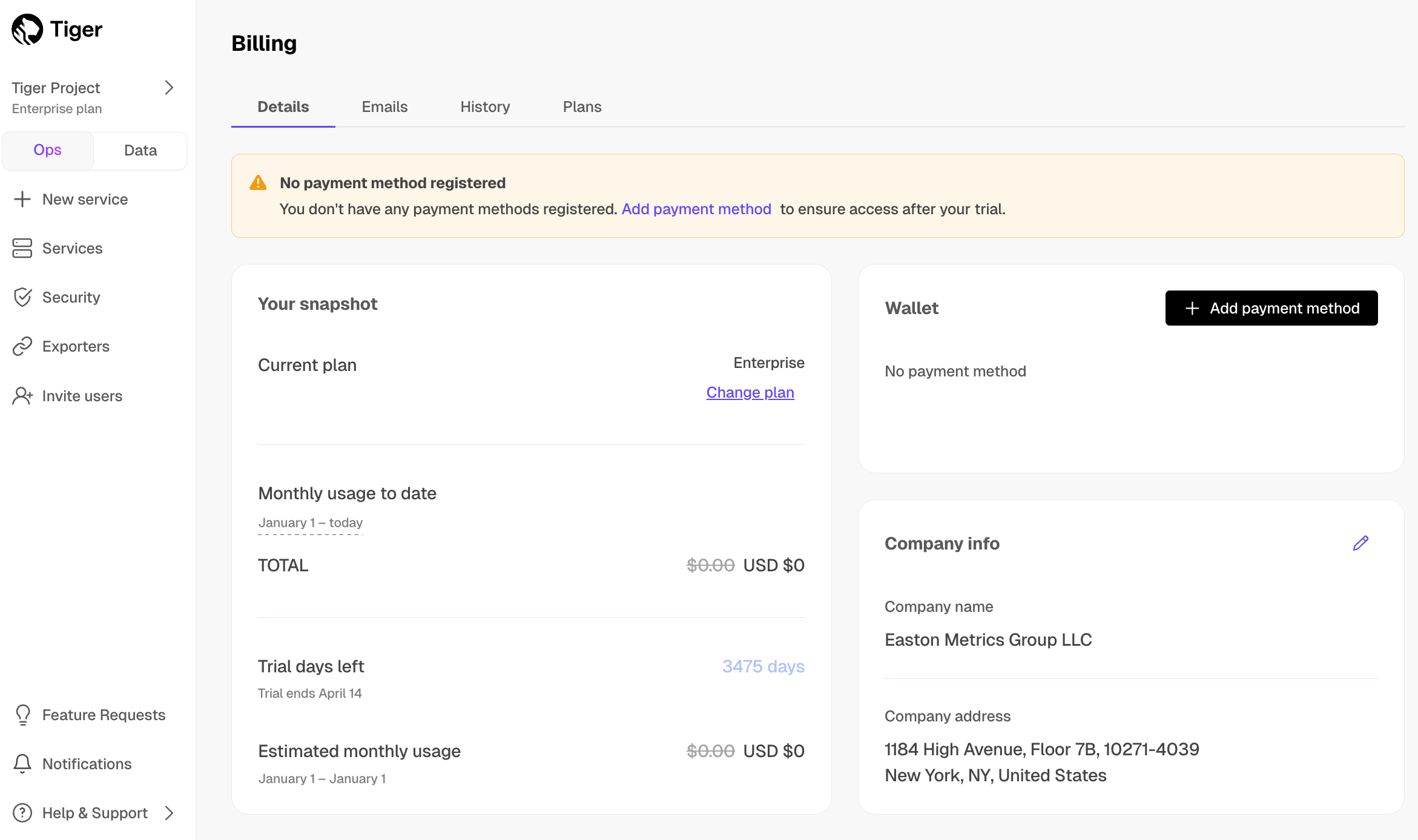 +alt="Adding a payment method in Tiger"/>
- **Details**: an overview of your $PRICING_PLAN, usage, and payment details. You can add up
to three credit cards to your `Wallet`. If you prefer to pay by invoice,
@@ -224,7 +234,7 @@ When you get $CLOUD_LONG at AWS Marketplace, the following pricing options are a
[cloud-billing]: https://console.cloud.timescale.com/dashboard/billing/details
[commercial-sla]: https://www.timescale.com/legal/timescale-cloud-terms-of-service
[pricing-plans]: https://www.timescale.com/pricing
-[plan-features]: /about/:currentVersion:/pricing-and-account-management/#features-included-in-each-plan
+[plan-features]: /about/:currentVersion:/pricing-and-account-management/#features-included-in-each-pricing-plan
[production-support]: https://www.timescale.com/support
[hipaa-compliance]: https://www.hhs.gov/hipaa/for-professionals/index.html
[aws-pricing]: /about/:currentVersion:/pricing-and-account-management/#aws-marketplace-pricing
From 648a41ec4b6dfcc9c6e2ec3b3acd720bb339dddf Mon Sep 17 00:00:00 2001
From: Anastasiia Tovpeko <114177030+atovpeko@users.noreply.github.com>
Date: Fri, 17 Oct 2025 16:51:03 +0300
Subject: [PATCH 2/7] Update service creation for Free Plan (#4487)
---
_partials/_cloud-installation.md | 18 +++++++-----
_partials/_cloud-intro.md | 32 --------------------
_partials/_service-intro.md | 0
_partials/_services-intro.md | 50 ++++++++++++++++++++++++++++++++
getting-started/services.md | 17 +++++++----
use-timescale/services/index.md | 3 ++
6 files changed, 75 insertions(+), 45 deletions(-)
create mode 100644 _partials/_service-intro.md
create mode 100644 _partials/_services-intro.md
diff --git a/_partials/_cloud-installation.md b/_partials/_cloud-installation.md
index 3ec89549a7..bc6ce4b276 100644
--- a/_partials/_cloud-installation.md
+++ b/_partials/_cloud-installation.md
@@ -16,11 +16,13 @@ To set up $CLOUD_LONG:
Open [Sign up for $CLOUD_LONG][timescale-signup] and add your details, then click `Start your free trial`. You receive a confirmation email in your inbox.
-1. **In the confirmation email, click the link supplied and sign in to [$CONSOLE][tsc-portal]**
+1. **Confirm your email address**
-1. **Answer the requirements questions**
+ In the confirmation email, click the link supplied.
- Your answers help us optimize $SERVICE_LONGs for your use cases.
+1. **Select the [pricing plan][pricing-plans]**
+
+ You are now logged into $CONSOLE_LONG. You can change the pricing plan to better accommodate your growing needs on the [`Billing` page][console-billing].
@@ -51,13 +53,13 @@ To set up $CLOUD_LONG via AWS:
Add your details, then click `Start your free trial`. If you want to link an existing $ACCOUNT_LONG to AWS, log in with your existing credentials.
-1. **In `Confirm AWS Marketplace connection`, click `Connect`**
+1. **Select the [pricing plan][pricing-plans]**
- Your $CLOUD_LONG and AWS accounts are now connected.
+ You are now logged into $CONSOLE_LONG. You can change the pricing plan later to better accommodate your growing needs on the [`Billing` page][console-billing].
-1. **Answer the requirements questions**
+1. **In `Confirm AWS Marketplace connection`, click `Connect`**
- Your answers help us optimize $SERVICE_LONGs for your use cases.
+ Your $CLOUD_LONG and AWS accounts are now connected.
@@ -71,3 +73,5 @@ To set up $CLOUD_LONG via AWS:
[aws-paygo]: https://aws.amazon.com/marketplace/pp/prodview-iestawpo5ihca?applicationId=AWSMPContessa&ref_=beagle&sr=0-1
[aws-annual-commit]: https://aws.amazon.com/marketplace/pp/prodview-ezxwlmjyr6x4u?applicationId=AWSMPContessa&ref_=beagle&sr=0-2
[timescale-signup]: https://console.cloud.timescale.com/signup
+[console-billing]: https://console.cloud.timescale.com/dashboard/billing/plans
+[pricing-plans]: /about/:currentVersion:/pricing-and-account-management/
\ No newline at end of file
diff --git a/_partials/_cloud-intro.md b/_partials/_cloud-intro.md
index 8e0016d1c2..2d3c05cffa 100644
--- a/_partials/_cloud-intro.md
+++ b/_partials/_cloud-intro.md
@@ -3,36 +3,4 @@ real-time analytics, and vector search—all in a single database alongside tran
You get one system that handles live data ingestion, late and out-of-order updates, and low latency queries, with the performance, reliability, and scalability your app needs. Ideal for IoT, crypto, finance, SaaS, and a myriad other domains, $CLOUD_LONG allows you to build data-heavy, mission-critical apps while retaining the familiarity and reliability of $PG.
-A $SERVICE_LONG is a single optimised $PG instance extended with innovations in the database engine and cloud
-infrastructure to deliver speed without compromise. A $SERVICE_LONG instance is 10-1000x faster at scale! A $SERVICE_SHORT
-is ideal for applications requiring strong data consistency, complex relationships, and advanced querying capabilities.
-Get ACID compliance, extensive SQL support, JSON handling, and extensibility through custom functions, data types, and
-extensions. To the $PG you know and love, $CLOUD_LONG adds the following capabilities:
-
-- **Real-time analytics**: store and query [time-series data][what-is-time-series] at scale for
- real-time analytics and other use cases. Get faster time-based queries with $HYPERTABLEs, $CAGGs, and columnar storage. Save money by compressing data into the $COLUMNSTORE, moving cold data to low-cost bottomless storage in Amazon S3, and deleting old data with automated policies.
-- **AI-focused**: build AI applications from start to scale. Get fast and accurate similarity search
- with the pgvector and pgvectorscale extensions. Create vector embeddings and perform LLM reasoning on your data with
- the pgai extension.
-- **Hybrid applications**: get a full set of tools to develop applications that combine time-based data and AI.
-
-All $SERVICE_LONGs include the tooling you expect for production and developer environments: [live migration][live-migration],
-[automatic backups and PITR][automatic-backups], [high availability][high-availability], [$READ_REPLICAs][readreplica], [data forking][operations-forking], [connection pooling][connection-pooling], [tiered storage][data-tiering],
-[usage-based storage][how-plans-work], secure in-$CONSOLE [SQL editing][in-console-editors], $SERVICE_SHORT [metrics][metrics]
-and [insights][insights], [streamlined maintenance][maintain-upgrade], and much more. $CLOUD_LONG continuously monitors your $SERVICE_SHORTs and prevents common $PG out-of-memory crashes.
-
-[what-is-time-series]: https://www.timescale.com/blog/time-series-database-an-explainer#what-is-a-time-series-database
-[create-service]: /getting-started/:currentVersion:/services/
-[live-migration]: /migrate/:currentVersion:/live-migration/
-[automatic-backups]: /use-timescale/:currentVersion:/backup-restore/
-[high-availability]: /use-timescale/:currentVersion:/ha-replicas/high-availability/
-[readreplica]: /use-timescale/:currentVersion:/ha-replicas/read-scaling/
-[operations-forking]: /use-timescale/:currentVersion:/services/service-management/#fork-a-service
-[connection-pooling]: /use-timescale/:currentVersion:/services/connection-pooling
-[data-tiering]: /use-timescale/:currentVersion:/data-tiering/
-[how-plans-work]: /about/:currentVersion:/pricing-and-account-management/#how-plans-work
-[in-console-editors]: /getting-started/:currentVersion:/run-queries-from-console/
-[metrics]: /use-timescale/:currentVersion:/metrics-logging/monitoring/#metrics
-[insights]: /use-timescale/:currentVersion:/metrics-logging/monitoring/#insights
-[maintain-upgrade]: /use-timescale/:currentVersion:/upgrades/
diff --git a/_partials/_service-intro.md b/_partials/_service-intro.md
new file mode 100644
index 0000000000..e69de29bb2
diff --git a/_partials/_services-intro.md b/_partials/_services-intro.md
new file mode 100644
index 0000000000..3a52d14f1e
--- /dev/null
+++ b/_partials/_services-intro.md
@@ -0,0 +1,50 @@
+A $SERVICE_LONG is a single optimised $PG instance extended with innovations in the database engine and cloud
+infrastructure to deliver speed without compromise. A $SERVICE_LONG is 10-1000x faster at scale! It
+is ideal for applications requiring strong data consistency, complex relationships, and advanced querying capabilities.
+Get ACID compliance, extensive SQL support, JSON handling, and extensibility through custom functions, data types, and
+extensions.
+
+Each $SERVICE_SHORT is associated with a project in $CLOUD_LONG. Each project can have multiple $SERVICE_SHORTs. Each user is a [member of one or more projects][rbac].
+
+You create free and standard $SERVICE_SHORTs in $CONSOLE_LONG, depending on your [$PRICING_PLAN][pricing-plans]. A free $SERVICE_SHORT comes at zero cost and gives you limited resources to get to know $CLOUD_LONG. Once you are ready to try out more advanced features, you can switch to a paid plan and convert your free $SERVICE_SHORT to a standard one.
+
+
+
+To the $PG you know and love, $CLOUD_LONG adds the following capabilities:
+
+- **Standard $SERVICE_SHORTs**:
+
+ - _Real-time analytics_: store and query [time-series data][what-is-time-series] at scale for
+ real-time analytics and other use cases. Get faster time-based queries with $HYPERTABLEs, $CAGGs, and columnar storage. Save money by compressing data into the $COLUMNSTORE, moving cold data to low-cost bottomless storage in Amazon S3, and deleting old data with automated policies.
+ - _AI-focused_: build AI applications from start to scale. Get fast and accurate similarity search
+ with the pgvector and pgvectorscale extensions. Create vector embeddings and perform LLM reasoning on your data with
+ the pgai extension.
+ - _Hybrid applications_: get a full set of tools to develop applications that combine time-based data and AI.
+
+ All standard $SERVICE_LONGs include the tooling you expect for production and developer environments: [live migration][live-migration],
+ [automatic backups and PITR][automatic-backups], [high availability][high-availability], [$READ_REPLICAs][readreplica], [data forking][operations-forking], [connection pooling][connection-pooling], [tiered storage][data-tiering],
+ [usage-based storage][how-plans-work], secure in-$CONSOLE [SQL editing][in-console-editors], $SERVICE_SHORT [metrics][metrics]
+ and [insights][insights], [streamlined maintenance][maintain-upgrade], and much more. $CLOUD_LONG continuously monitors your $SERVICE_SHORTs and prevents common $PG out-of-memory crashes.
+
+- **Free $SERVICE_SHORTs**:
+
+ _$PG with $TIMESCALE_DB and vector extensions_
+
+ Free $SERVICE_SHORTs offer limited resources and a basic feature scope, perfect to get to know $CLOUD_LONG in a development environment.
+
+[what-is-time-series]: https://www.timescale.com/blog/time-series-database-an-explainer#what-is-a-time-series-database
+[create-service]: /getting-started/:currentVersion:/services/
+[live-migration]: /migrate/:currentVersion:/live-migration/
+[automatic-backups]: /use-timescale/:currentVersion:/backup-restore/
+[high-availability]: /use-timescale/:currentVersion:/ha-replicas/high-availability/
+[readreplica]: /use-timescale/:currentVersion:/ha-replicas/read-scaling/
+[operations-forking]: /use-timescale/:currentVersion:/services/service-management/#fork-a-service
+[connection-pooling]: /use-timescale/:currentVersion:/services/connection-pooling
+[data-tiering]: /use-timescale/:currentVersion:/data-tiering/
+[how-plans-work]: /about/:currentVersion:/pricing-and-account-management/#how-plans-work
+[in-console-editors]: /getting-started/:currentVersion:/run-queries-from-console/
+[metrics]: /use-timescale/:currentVersion:/metrics-logging/monitoring/#metrics
+[insights]: /use-timescale/:currentVersion:/metrics-logging/monitoring/#insights
+[maintain-upgrade]: /use-timescale/:currentVersion:/upgrades/
+[pricing-plans]: /about/:currentVersion:/pricing-and-account-management/
+[rbac]: /use-timescale/:currentVersion:/security/members/
\ No newline at end of file
diff --git a/getting-started/services.md b/getting-started/services.md
index be75d21fde..9faaf33454 100644
--- a/getting-started/services.md
+++ b/getting-started/services.md
@@ -7,6 +7,7 @@ content_group: Getting started
import Install from "versionContent/_partials/_cloud-installation.mdx";
import Connect from "versionContent/_partials/_cloud-connect-service.mdx";
+import ServiceIntro from "versionContent/_partials/_services-intro.mdx";
import ServiceOverview from "versionContent/_partials/_service-overview.mdx";
import CloudIntro from "versionContent/_partials/_cloud-intro.mdx";
import WhereNext from "versionContent/_partials/_where-to-next.mdx";
@@ -15,6 +16,10 @@ import WhereNext from "versionContent/_partials/_where-to-next.mdx";
+## What is a $SERVICE_LONG?
+
+
+
To start using $CLOUD_LONG for your data:
@@ -29,15 +34,15 @@ To start using $CLOUD_LONG for your data:
Now that you have an active $ACCOUNT_LONG, you create and manage your $SERVICE_SHORTs in $CONSOLE. When you create a $SERVICE_SHORT, you effectively create a blank $PG database with additional $CLOUD_LONG features available under your $PRICING_PLAN. You then add or migrate your data into this database.
-
+To create a free or standard $SERVICE_SHORT:
-1. In the [$SERVICE_SHORT creation page][create-service], choose the capability to match your business needs: `Real-time analytics`, `AI-focused`, or `Hybrid applications`.
+
- 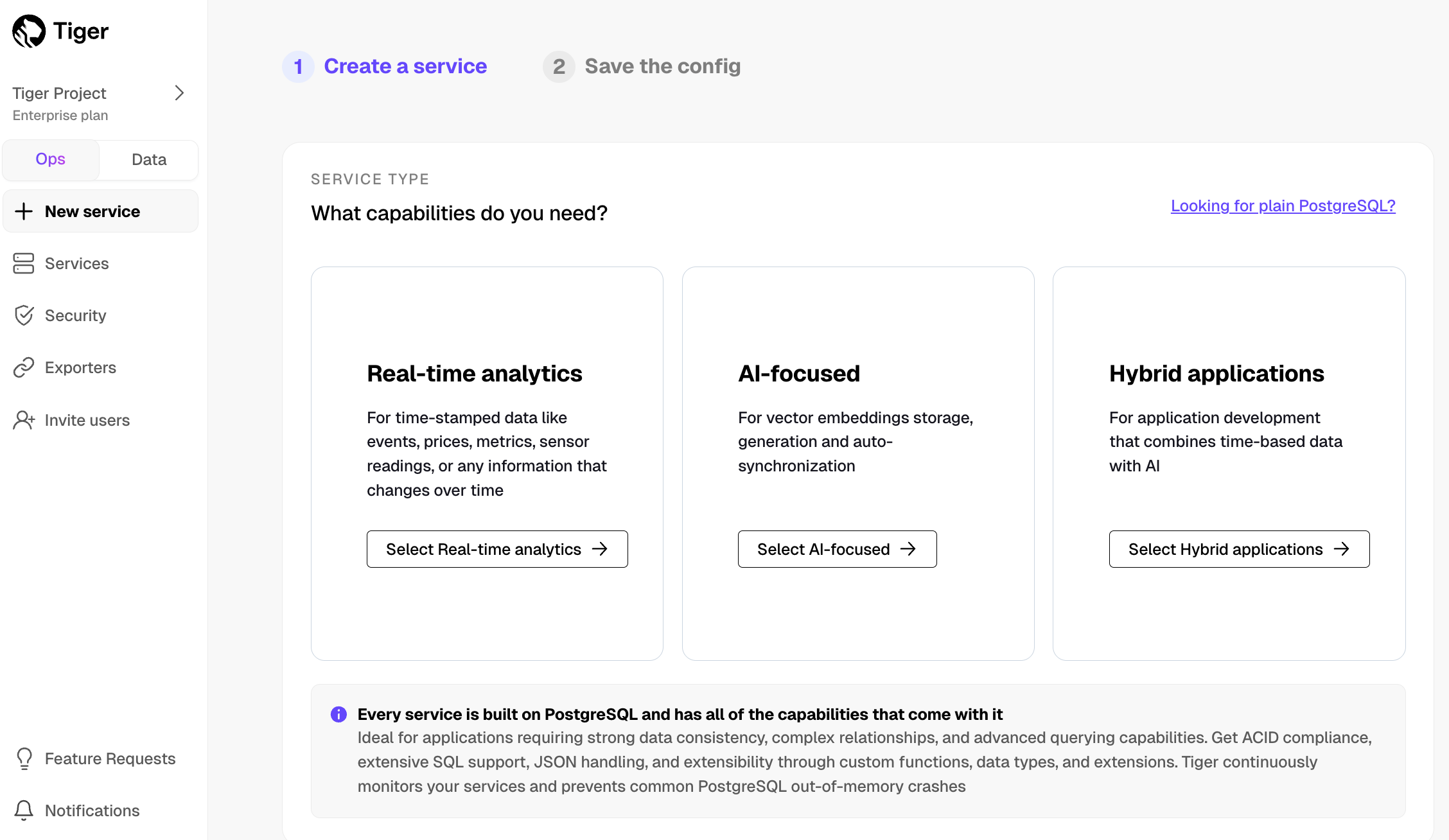
+1. In the [$SERVICE_SHORT creation page][create-service], click `+ New service`.
- To create a plain $PG $SERVICE_SHORT, without any additional capabilities, click `Looking for plain PostgreSQL?` in the top right.
+ Follow the wizard to configure your $SERVICE_SHORT depending on its type.
-1. Follow the next steps in `Create a service` to configure the region, compute size, environment, availability, connectivity, and $SERVICE_SHORT name. Then click `Create service`.
+1. Click `Create service`.
Your $SERVICE_SHORT is constructed and ready to use in a few seconds.
@@ -72,4 +77,4 @@ To run queries and perform other operations, connect to your $SERVICE_SHORT:
[what-is-dynamic-postgres]: https://www.timescale.com/dynamic-postgresql
[hypertables]: /use-timescale/:currentVersion:/hypertables/#hypertable-partitioning
[timescaledb]: https://docs.tigerdata.com/#TimescaleDB
-
+[pricing-plans]: /about/:currentVersion:/pricing-and-account-management/
diff --git a/use-timescale/services/index.md b/use-timescale/services/index.md
index 78eb7d7d0f..32d7856cf2 100644
--- a/use-timescale/services/index.md
+++ b/use-timescale/services/index.md
@@ -9,11 +9,14 @@ cloud_ui:
---
import CloudIntro from "versionContent/_partials/_cloud-intro.mdx";
+import ServiceIntro from "versionContent/_partials/_services-intro.mdx";
# About $SERVICE_LONGs
+
+
## Learn more about $CLOUD_LONG
Read about $CLOUD_LONG features in the documentation:
From 761d3c72d82702386f6887443ef4c55739c4a4dd Mon Sep 17 00:00:00 2001
From: atovpeko
Date: Fri, 17 Oct 2025 16:54:20 +0300
Subject: [PATCH 3/7] billing clarification
---
_partials/_services-intro.md | 3 +--
1 file changed, 1 insertion(+), 2 deletions(-)
diff --git a/_partials/_services-intro.md b/_partials/_services-intro.md
index 3a52d14f1e..670d9a9e21 100644
--- a/_partials/_services-intro.md
+++ b/_partials/_services-intro.md
@@ -17,8 +17,7 @@ To the $PG you know and love, $CLOUD_LONG adds the following capabilities:
- _Real-time analytics_: store and query [time-series data][what-is-time-series] at scale for
real-time analytics and other use cases. Get faster time-based queries with $HYPERTABLEs, $CAGGs, and columnar storage. Save money by compressing data into the $COLUMNSTORE, moving cold data to low-cost bottomless storage in Amazon S3, and deleting old data with automated policies.
- _AI-focused_: build AI applications from start to scale. Get fast and accurate similarity search
- with the pgvector and pgvectorscale extensions. Create vector embeddings and perform LLM reasoning on your data with
- the pgai extension.
+ with the pgvector and pgvectorscale extensions.
- _Hybrid applications_: get a full set of tools to develop applications that combine time-based data and AI.
All standard $SERVICE_LONGs include the tooling you expect for production and developer environments: [live migration][live-migration],
From ea7b6abec8be0af265f30cf84bb1f4e57a9eae59 Mon Sep 17 00:00:00 2001
From: Anastasiia Tovpeko <114177030+atovpeko@users.noreply.github.com>
Date: Fri, 17 Oct 2025 16:59:34 +0300
Subject: [PATCH 4/7] Update doc pages for Free Plan availability (#4488)
---
_partials/_cloud-connect-service.md | 3 +
_partials/_not-available-in-free-plan.md | 3 +
_partials/_service-overview.md | 10 +-
about/supported-platforms.md | 4 +
about/timescaledb-editions.md | 2 +-
api/glossary.md | 110 +++++++++++-------
getting-started/run-queries-from-console.md | 5 +
.../try-key-features-timescale-products.md | 15 ++-
migrate/livesync-for-kafka.md | 1 +
migrate/livesync-for-postgresql.md | 1 +
migrate/livesync-for-s3.md | 1 +
migrate/upload-file-using-console.md | 3 +
use-timescale/backup-restore.md | 2 +-
.../data-tiering/enabling-data-tiering.md | 2 +-
use-timescale/data-tiering/index.md | 4 +-
.../ha-replicas/high-availability.md | 1 +
use-timescale/ha-replicas/index.md | 1 +
use-timescale/metrics-logging/monitoring.md | 4 +-
use-timescale/page-index/page-index.js | 2 +-
use-timescale/regions.md | 1 +
use-timescale/security/vpc.md | 1 +
use-timescale/services/change-resources.md | 1 +
use-timescale/services/connection-pooling.md | 1 +
23 files changed, 118 insertions(+), 60 deletions(-)
create mode 100644 _partials/_not-available-in-free-plan.md
diff --git a/_partials/_cloud-connect-service.md b/_partials/_cloud-connect-service.md
index 3b13a42753..543fde3b5b 100644
--- a/_partials/_cloud-connect-service.md
+++ b/_partials/_cloud-connect-service.md
@@ -1,3 +1,4 @@
+import NotAvailableFreePlan from "versionContent/_partials/_not-available-in-free-plan.mdx";
@@ -15,6 +16,8 @@
+
+
1. In $CONSOLE, toggle `Data`.
diff --git a/_partials/_not-available-in-free-plan.md b/_partials/_not-available-in-free-plan.md
new file mode 100644
index 0000000000..8b514f1e48
--- /dev/null
+++ b/_partials/_not-available-in-free-plan.md
@@ -0,0 +1,3 @@
+
+This feature is not available under the Free pricing plan.
+
\ No newline at end of file
diff --git a/_partials/_service-overview.md b/_partials/_service-overview.md
index 4b1f35d498..f1dcd41f04 100644
--- a/_partials/_service-overview.md
+++ b/_partials/_service-overview.md
@@ -1,9 +1,11 @@
+import NotAvailableFreePlan from "versionContent/_partials/_not-available-in-free-plan.mdx";
+
You manage your $SERVICE_LONGs and interact with your data in $CONSOLE using the following modes:
-| **$OPS_MODE_CAP** | **$DATA_MODE_CAP** |
-|-----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------|--------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------|
-| ![$CONSOLE $OPS_MODE][ops-mode] | ![$CONSOLE $DATA_MODE][data-mode] |
-| **You use the $OPS_MODE to:**
+alt="Adding a payment method in Tiger"/>
- **Details**: an overview of your $PRICING_PLAN, usage, and payment details. You can add up
to three credit cards to your `Wallet`. If you prefer to pay by invoice,
@@ -224,7 +234,7 @@ When you get $CLOUD_LONG at AWS Marketplace, the following pricing options are a
[cloud-billing]: https://console.cloud.timescale.com/dashboard/billing/details
[commercial-sla]: https://www.timescale.com/legal/timescale-cloud-terms-of-service
[pricing-plans]: https://www.timescale.com/pricing
-[plan-features]: /about/:currentVersion:/pricing-and-account-management/#features-included-in-each-plan
+[plan-features]: /about/:currentVersion:/pricing-and-account-management/#features-included-in-each-pricing-plan
[production-support]: https://www.timescale.com/support
[hipaa-compliance]: https://www.hhs.gov/hipaa/for-professionals/index.html
[aws-pricing]: /about/:currentVersion:/pricing-and-account-management/#aws-marketplace-pricing
From 648a41ec4b6dfcc9c6e2ec3b3acd720bb339dddf Mon Sep 17 00:00:00 2001
From: Anastasiia Tovpeko <114177030+atovpeko@users.noreply.github.com>
Date: Fri, 17 Oct 2025 16:51:03 +0300
Subject: [PATCH 2/7] Update service creation for Free Plan (#4487)
---
_partials/_cloud-installation.md | 18 +++++++-----
_partials/_cloud-intro.md | 32 --------------------
_partials/_service-intro.md | 0
_partials/_services-intro.md | 50 ++++++++++++++++++++++++++++++++
getting-started/services.md | 17 +++++++----
use-timescale/services/index.md | 3 ++
6 files changed, 75 insertions(+), 45 deletions(-)
create mode 100644 _partials/_service-intro.md
create mode 100644 _partials/_services-intro.md
diff --git a/_partials/_cloud-installation.md b/_partials/_cloud-installation.md
index 3ec89549a7..bc6ce4b276 100644
--- a/_partials/_cloud-installation.md
+++ b/_partials/_cloud-installation.md
@@ -16,11 +16,13 @@ To set up $CLOUD_LONG:
Open [Sign up for $CLOUD_LONG][timescale-signup] and add your details, then click `Start your free trial`. You receive a confirmation email in your inbox.
-1. **In the confirmation email, click the link supplied and sign in to [$CONSOLE][tsc-portal]**
+1. **Confirm your email address**
-1. **Answer the requirements questions**
+ In the confirmation email, click the link supplied.
- Your answers help us optimize $SERVICE_LONGs for your use cases.
+1. **Select the [pricing plan][pricing-plans]**
+
+ You are now logged into $CONSOLE_LONG. You can change the pricing plan to better accommodate your growing needs on the [`Billing` page][console-billing].
@@ -51,13 +53,13 @@ To set up $CLOUD_LONG via AWS:
Add your details, then click `Start your free trial`. If you want to link an existing $ACCOUNT_LONG to AWS, log in with your existing credentials.
-1. **In `Confirm AWS Marketplace connection`, click `Connect`**
+1. **Select the [pricing plan][pricing-plans]**
- Your $CLOUD_LONG and AWS accounts are now connected.
+ You are now logged into $CONSOLE_LONG. You can change the pricing plan later to better accommodate your growing needs on the [`Billing` page][console-billing].
-1. **Answer the requirements questions**
+1. **In `Confirm AWS Marketplace connection`, click `Connect`**
- Your answers help us optimize $SERVICE_LONGs for your use cases.
+ Your $CLOUD_LONG and AWS accounts are now connected.
@@ -71,3 +73,5 @@ To set up $CLOUD_LONG via AWS:
[aws-paygo]: https://aws.amazon.com/marketplace/pp/prodview-iestawpo5ihca?applicationId=AWSMPContessa&ref_=beagle&sr=0-1
[aws-annual-commit]: https://aws.amazon.com/marketplace/pp/prodview-ezxwlmjyr6x4u?applicationId=AWSMPContessa&ref_=beagle&sr=0-2
[timescale-signup]: https://console.cloud.timescale.com/signup
+[console-billing]: https://console.cloud.timescale.com/dashboard/billing/plans
+[pricing-plans]: /about/:currentVersion:/pricing-and-account-management/
\ No newline at end of file
diff --git a/_partials/_cloud-intro.md b/_partials/_cloud-intro.md
index 8e0016d1c2..2d3c05cffa 100644
--- a/_partials/_cloud-intro.md
+++ b/_partials/_cloud-intro.md
@@ -3,36 +3,4 @@ real-time analytics, and vector search—all in a single database alongside tran
You get one system that handles live data ingestion, late and out-of-order updates, and low latency queries, with the performance, reliability, and scalability your app needs. Ideal for IoT, crypto, finance, SaaS, and a myriad other domains, $CLOUD_LONG allows you to build data-heavy, mission-critical apps while retaining the familiarity and reliability of $PG.
-A $SERVICE_LONG is a single optimised $PG instance extended with innovations in the database engine and cloud
-infrastructure to deliver speed without compromise. A $SERVICE_LONG instance is 10-1000x faster at scale! A $SERVICE_SHORT
-is ideal for applications requiring strong data consistency, complex relationships, and advanced querying capabilities.
-Get ACID compliance, extensive SQL support, JSON handling, and extensibility through custom functions, data types, and
-extensions. To the $PG you know and love, $CLOUD_LONG adds the following capabilities:
-
-- **Real-time analytics**: store and query [time-series data][what-is-time-series] at scale for
- real-time analytics and other use cases. Get faster time-based queries with $HYPERTABLEs, $CAGGs, and columnar storage. Save money by compressing data into the $COLUMNSTORE, moving cold data to low-cost bottomless storage in Amazon S3, and deleting old data with automated policies.
-- **AI-focused**: build AI applications from start to scale. Get fast and accurate similarity search
- with the pgvector and pgvectorscale extensions. Create vector embeddings and perform LLM reasoning on your data with
- the pgai extension.
-- **Hybrid applications**: get a full set of tools to develop applications that combine time-based data and AI.
-
-All $SERVICE_LONGs include the tooling you expect for production and developer environments: [live migration][live-migration],
-[automatic backups and PITR][automatic-backups], [high availability][high-availability], [$READ_REPLICAs][readreplica], [data forking][operations-forking], [connection pooling][connection-pooling], [tiered storage][data-tiering],
-[usage-based storage][how-plans-work], secure in-$CONSOLE [SQL editing][in-console-editors], $SERVICE_SHORT [metrics][metrics]
-and [insights][insights], [streamlined maintenance][maintain-upgrade], and much more. $CLOUD_LONG continuously monitors your $SERVICE_SHORTs and prevents common $PG out-of-memory crashes.
-
-[what-is-time-series]: https://www.timescale.com/blog/time-series-database-an-explainer#what-is-a-time-series-database
-[create-service]: /getting-started/:currentVersion:/services/
-[live-migration]: /migrate/:currentVersion:/live-migration/
-[automatic-backups]: /use-timescale/:currentVersion:/backup-restore/
-[high-availability]: /use-timescale/:currentVersion:/ha-replicas/high-availability/
-[readreplica]: /use-timescale/:currentVersion:/ha-replicas/read-scaling/
-[operations-forking]: /use-timescale/:currentVersion:/services/service-management/#fork-a-service
-[connection-pooling]: /use-timescale/:currentVersion:/services/connection-pooling
-[data-tiering]: /use-timescale/:currentVersion:/data-tiering/
-[how-plans-work]: /about/:currentVersion:/pricing-and-account-management/#how-plans-work
-[in-console-editors]: /getting-started/:currentVersion:/run-queries-from-console/
-[metrics]: /use-timescale/:currentVersion:/metrics-logging/monitoring/#metrics
-[insights]: /use-timescale/:currentVersion:/metrics-logging/monitoring/#insights
-[maintain-upgrade]: /use-timescale/:currentVersion:/upgrades/
diff --git a/_partials/_service-intro.md b/_partials/_service-intro.md
new file mode 100644
index 0000000000..e69de29bb2
diff --git a/_partials/_services-intro.md b/_partials/_services-intro.md
new file mode 100644
index 0000000000..3a52d14f1e
--- /dev/null
+++ b/_partials/_services-intro.md
@@ -0,0 +1,50 @@
+A $SERVICE_LONG is a single optimised $PG instance extended with innovations in the database engine and cloud
+infrastructure to deliver speed without compromise. A $SERVICE_LONG is 10-1000x faster at scale! It
+is ideal for applications requiring strong data consistency, complex relationships, and advanced querying capabilities.
+Get ACID compliance, extensive SQL support, JSON handling, and extensibility through custom functions, data types, and
+extensions.
+
+Each $SERVICE_SHORT is associated with a project in $CLOUD_LONG. Each project can have multiple $SERVICE_SHORTs. Each user is a [member of one or more projects][rbac].
+
+You create free and standard $SERVICE_SHORTs in $CONSOLE_LONG, depending on your [$PRICING_PLAN][pricing-plans]. A free $SERVICE_SHORT comes at zero cost and gives you limited resources to get to know $CLOUD_LONG. Once you are ready to try out more advanced features, you can switch to a paid plan and convert your free $SERVICE_SHORT to a standard one.
+
+
+
+To the $PG you know and love, $CLOUD_LONG adds the following capabilities:
+
+- **Standard $SERVICE_SHORTs**:
+
+ - _Real-time analytics_: store and query [time-series data][what-is-time-series] at scale for
+ real-time analytics and other use cases. Get faster time-based queries with $HYPERTABLEs, $CAGGs, and columnar storage. Save money by compressing data into the $COLUMNSTORE, moving cold data to low-cost bottomless storage in Amazon S3, and deleting old data with automated policies.
+ - _AI-focused_: build AI applications from start to scale. Get fast and accurate similarity search
+ with the pgvector and pgvectorscale extensions. Create vector embeddings and perform LLM reasoning on your data with
+ the pgai extension.
+ - _Hybrid applications_: get a full set of tools to develop applications that combine time-based data and AI.
+
+ All standard $SERVICE_LONGs include the tooling you expect for production and developer environments: [live migration][live-migration],
+ [automatic backups and PITR][automatic-backups], [high availability][high-availability], [$READ_REPLICAs][readreplica], [data forking][operations-forking], [connection pooling][connection-pooling], [tiered storage][data-tiering],
+ [usage-based storage][how-plans-work], secure in-$CONSOLE [SQL editing][in-console-editors], $SERVICE_SHORT [metrics][metrics]
+ and [insights][insights], [streamlined maintenance][maintain-upgrade], and much more. $CLOUD_LONG continuously monitors your $SERVICE_SHORTs and prevents common $PG out-of-memory crashes.
+
+- **Free $SERVICE_SHORTs**:
+
+ _$PG with $TIMESCALE_DB and vector extensions_
+
+ Free $SERVICE_SHORTs offer limited resources and a basic feature scope, perfect to get to know $CLOUD_LONG in a development environment.
+
+[what-is-time-series]: https://www.timescale.com/blog/time-series-database-an-explainer#what-is-a-time-series-database
+[create-service]: /getting-started/:currentVersion:/services/
+[live-migration]: /migrate/:currentVersion:/live-migration/
+[automatic-backups]: /use-timescale/:currentVersion:/backup-restore/
+[high-availability]: /use-timescale/:currentVersion:/ha-replicas/high-availability/
+[readreplica]: /use-timescale/:currentVersion:/ha-replicas/read-scaling/
+[operations-forking]: /use-timescale/:currentVersion:/services/service-management/#fork-a-service
+[connection-pooling]: /use-timescale/:currentVersion:/services/connection-pooling
+[data-tiering]: /use-timescale/:currentVersion:/data-tiering/
+[how-plans-work]: /about/:currentVersion:/pricing-and-account-management/#how-plans-work
+[in-console-editors]: /getting-started/:currentVersion:/run-queries-from-console/
+[metrics]: /use-timescale/:currentVersion:/metrics-logging/monitoring/#metrics
+[insights]: /use-timescale/:currentVersion:/metrics-logging/monitoring/#insights
+[maintain-upgrade]: /use-timescale/:currentVersion:/upgrades/
+[pricing-plans]: /about/:currentVersion:/pricing-and-account-management/
+[rbac]: /use-timescale/:currentVersion:/security/members/
\ No newline at end of file
diff --git a/getting-started/services.md b/getting-started/services.md
index be75d21fde..9faaf33454 100644
--- a/getting-started/services.md
+++ b/getting-started/services.md
@@ -7,6 +7,7 @@ content_group: Getting started
import Install from "versionContent/_partials/_cloud-installation.mdx";
import Connect from "versionContent/_partials/_cloud-connect-service.mdx";
+import ServiceIntro from "versionContent/_partials/_services-intro.mdx";
import ServiceOverview from "versionContent/_partials/_service-overview.mdx";
import CloudIntro from "versionContent/_partials/_cloud-intro.mdx";
import WhereNext from "versionContent/_partials/_where-to-next.mdx";
@@ -15,6 +16,10 @@ import WhereNext from "versionContent/_partials/_where-to-next.mdx";
+## What is a $SERVICE_LONG?
+
+
+
To start using $CLOUD_LONG for your data:
@@ -29,15 +34,15 @@ To start using $CLOUD_LONG for your data:
Now that you have an active $ACCOUNT_LONG, you create and manage your $SERVICE_SHORTs in $CONSOLE. When you create a $SERVICE_SHORT, you effectively create a blank $PG database with additional $CLOUD_LONG features available under your $PRICING_PLAN. You then add or migrate your data into this database.
-
+To create a free or standard $SERVICE_SHORT:
-1. In the [$SERVICE_SHORT creation page][create-service], choose the capability to match your business needs: `Real-time analytics`, `AI-focused`, or `Hybrid applications`.
+
- 
+1. In the [$SERVICE_SHORT creation page][create-service], click `+ New service`.
- To create a plain $PG $SERVICE_SHORT, without any additional capabilities, click `Looking for plain PostgreSQL?` in the top right.
+ Follow the wizard to configure your $SERVICE_SHORT depending on its type.
-1. Follow the next steps in `Create a service` to configure the region, compute size, environment, availability, connectivity, and $SERVICE_SHORT name. Then click `Create service`.
+1. Click `Create service`.
Your $SERVICE_SHORT is constructed and ready to use in a few seconds.
@@ -72,4 +77,4 @@ To run queries and perform other operations, connect to your $SERVICE_SHORT:
[what-is-dynamic-postgres]: https://www.timescale.com/dynamic-postgresql
[hypertables]: /use-timescale/:currentVersion:/hypertables/#hypertable-partitioning
[timescaledb]: https://docs.tigerdata.com/#TimescaleDB
-
+[pricing-plans]: /about/:currentVersion:/pricing-and-account-management/
diff --git a/use-timescale/services/index.md b/use-timescale/services/index.md
index 78eb7d7d0f..32d7856cf2 100644
--- a/use-timescale/services/index.md
+++ b/use-timescale/services/index.md
@@ -9,11 +9,14 @@ cloud_ui:
---
import CloudIntro from "versionContent/_partials/_cloud-intro.mdx";
+import ServiceIntro from "versionContent/_partials/_services-intro.mdx";
# About $SERVICE_LONGs
+
+
## Learn more about $CLOUD_LONG
Read about $CLOUD_LONG features in the documentation:
From 761d3c72d82702386f6887443ef4c55739c4a4dd Mon Sep 17 00:00:00 2001
From: atovpeko
Date: Fri, 17 Oct 2025 16:54:20 +0300
Subject: [PATCH 3/7] billing clarification
---
_partials/_services-intro.md | 3 +--
1 file changed, 1 insertion(+), 2 deletions(-)
diff --git a/_partials/_services-intro.md b/_partials/_services-intro.md
index 3a52d14f1e..670d9a9e21 100644
--- a/_partials/_services-intro.md
+++ b/_partials/_services-intro.md
@@ -17,8 +17,7 @@ To the $PG you know and love, $CLOUD_LONG adds the following capabilities:
- _Real-time analytics_: store and query [time-series data][what-is-time-series] at scale for
real-time analytics and other use cases. Get faster time-based queries with $HYPERTABLEs, $CAGGs, and columnar storage. Save money by compressing data into the $COLUMNSTORE, moving cold data to low-cost bottomless storage in Amazon S3, and deleting old data with automated policies.
- _AI-focused_: build AI applications from start to scale. Get fast and accurate similarity search
- with the pgvector and pgvectorscale extensions. Create vector embeddings and perform LLM reasoning on your data with
- the pgai extension.
+ with the pgvector and pgvectorscale extensions.
- _Hybrid applications_: get a full set of tools to develop applications that combine time-based data and AI.
All standard $SERVICE_LONGs include the tooling you expect for production and developer environments: [live migration][live-migration],
From ea7b6abec8be0af265f30cf84bb1f4e57a9eae59 Mon Sep 17 00:00:00 2001
From: Anastasiia Tovpeko <114177030+atovpeko@users.noreply.github.com>
Date: Fri, 17 Oct 2025 16:59:34 +0300
Subject: [PATCH 4/7] Update doc pages for Free Plan availability (#4488)
---
_partials/_cloud-connect-service.md | 3 +
_partials/_not-available-in-free-plan.md | 3 +
_partials/_service-overview.md | 10 +-
about/supported-platforms.md | 4 +
about/timescaledb-editions.md | 2 +-
api/glossary.md | 110 +++++++++++-------
getting-started/run-queries-from-console.md | 5 +
.../try-key-features-timescale-products.md | 15 ++-
migrate/livesync-for-kafka.md | 1 +
migrate/livesync-for-postgresql.md | 1 +
migrate/livesync-for-s3.md | 1 +
migrate/upload-file-using-console.md | 3 +
use-timescale/backup-restore.md | 2 +-
.../data-tiering/enabling-data-tiering.md | 2 +-
use-timescale/data-tiering/index.md | 4 +-
.../ha-replicas/high-availability.md | 1 +
use-timescale/ha-replicas/index.md | 1 +
use-timescale/metrics-logging/monitoring.md | 4 +-
use-timescale/page-index/page-index.js | 2 +-
use-timescale/regions.md | 1 +
use-timescale/security/vpc.md | 1 +
use-timescale/services/change-resources.md | 1 +
use-timescale/services/connection-pooling.md | 1 +
23 files changed, 118 insertions(+), 60 deletions(-)
create mode 100644 _partials/_not-available-in-free-plan.md
diff --git a/_partials/_cloud-connect-service.md b/_partials/_cloud-connect-service.md
index 3b13a42753..543fde3b5b 100644
--- a/_partials/_cloud-connect-service.md
+++ b/_partials/_cloud-connect-service.md
@@ -1,3 +1,4 @@
+import NotAvailableFreePlan from "versionContent/_partials/_not-available-in-free-plan.mdx";
@@ -15,6 +16,8 @@
+
+
1. In $CONSOLE, toggle `Data`.
diff --git a/_partials/_not-available-in-free-plan.md b/_partials/_not-available-in-free-plan.md
new file mode 100644
index 0000000000..8b514f1e48
--- /dev/null
+++ b/_partials/_not-available-in-free-plan.md
@@ -0,0 +1,3 @@
+
+This feature is not available under the Free pricing plan.
+
\ No newline at end of file
diff --git a/_partials/_service-overview.md b/_partials/_service-overview.md
index 4b1f35d498..f1dcd41f04 100644
--- a/_partials/_service-overview.md
+++ b/_partials/_service-overview.md
@@ -1,9 +1,11 @@
+import NotAvailableFreePlan from "versionContent/_partials/_not-available-in-free-plan.mdx";
+
You manage your $SERVICE_LONGs and interact with your data in $CONSOLE using the following modes:
-| **$OPS_MODE_CAP** | **$DATA_MODE_CAP** |
-|-----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------|--------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------|
-| ![$CONSOLE $OPS_MODE][ops-mode] | ![$CONSOLE $DATA_MODE][data-mode] |
-| **You use the $OPS_MODE to:** - Ensure data security with high availability and $READ_REPLICAs
- Save money with columnstore compression and tiered storage
- Enable $PG extensions to add extra functionality
- Increase security using $VPCs
- Perform day-to-day administration
| **Powered by $POPSQL, you use the $DATA_MODE to:** - Write queries with autocomplete
- Visualize data with charts and dashboards
- Schedule queries and dashboards for alerts or recurring reports
- Share queries and dashboards
- Interact with your data on auto-pilot with SQL assistant
|
+| **$OPS_MODE_CAP** | **$DATA_MODE_CAP** |
+|-----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------|----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------|
+| ![$CONSOLE $OPS_MODE][ops-mode] | ![$CONSOLE $DATA_MODE][data-mode] |
+| **You use the $OPS_MODE to:** - Ensure data security with high availability and $READ_REPLICAs
- Save money with columnstore compression and tiered storage
- Enable $PG extensions to add extra functionality
- Increase security using $VPCs
- Perform day-to-day administration
| **Powered by $POPSQL, you use the $DATA_MODE to:** - Write queries with autocomplete
- Visualize data with charts and dashboards
- Schedule queries and dashboards for alerts or recurring reports
- Share queries and dashboards
- Interact with your data on auto-pilot with SQL assistant
|
[ops-mode]: https://assets.timescale.com/docs/images/tiger-cloud-console/ops-mode-overview-tiger-console.png
[data-mode]: https://assets.timescale.com/docs/images/tiger-cloud-console/tiger-console-data-mode.png
\ No newline at end of file
diff --git a/about/supported-platforms.md b/about/supported-platforms.md
index 26a1715574..59ebde05d0 100644
--- a/about/supported-platforms.md
+++ b/about/supported-platforms.md
@@ -32,10 +32,14 @@ See the available [service capabilities][service-types] and [regions][regions].
### Available service capabilities
+
+
### Available regions
+
+
## Self-hosted products
diff --git a/about/timescaledb-editions.md b/about/timescaledb-editions.md
index c354813153..55ac9c2b3c 100644
--- a/about/timescaledb-editions.md
+++ b/about/timescaledb-editions.md
@@ -1,7 +1,7 @@
---
title: Compare TimescaleDB editions
excerpt: See the difference between the TimescaleDB Community and TimescaleDB Apache 2 editions
-products: [cloud, self_hosted]
+products: [cloud, self_hosted, mst]
keywords: [Apache, community, license]
tags: [learn, contribute]
---
diff --git a/api/glossary.md b/api/glossary.md
index e3c3be4d29..227e29bb93 100644
--- a/api/glossary.md
+++ b/api/glossary.md
@@ -15,7 +15,7 @@ This glossary defines technical terms, concepts, and terminology used in $COMPAN
**ACID**: a set of properties (atomicity, consistency, isolation, durability) that guarantee database transactions are processed reliably.
-**ACID compliance**: a set of database properties—Atomicity, Consistency, Isolation, Durability—ensuring reliable and consistent transactions. Inherited from $PG.
+**ACID compliance**: a set of database properties—Atomicity, Consistency, Isolation, Durability—ensuring reliable and consistent transactions. Inherited from [$PG](#postgresql).
**Adaptive query optimization**: dynamic query plan adjustment based on actual execution statistics and data distribution patterns, improving performance over time.
@@ -41,7 +41,7 @@ This glossary defines technical terms, concepts, and terminology used in $COMPAN
**Background job**: an automated task that runs in the background without user intervention, typically for maintenance operations like compression or data retention.
-**Background worker**: a $PG process that runs background tasks independently of client sessions.
+**Background worker**: a [$PG](#postgresql) process that runs background tasks independently of client sessions.
**Batch processing**: handling data in grouped batches rather than as individual real-time events, often used for historical data processing.
@@ -49,13 +49,13 @@ This glossary defines technical terms, concepts, and terminology used in $COMPAN
**Backup**: a copy of data stored separately from the original data to protect against data loss, corruption, or system failure.
-**Bloom filter**: a probabilistic data structure that tests set membership with possible false positives but no false negatives. $TIMESCALE_DB uses blocked bloom filters to speed up point lookups by eliminating chunks that don't contain queried values.
+**Bloom filter**: a probabilistic data structure that tests set membership with possible false positives but no false negatives. [$TIMESCALE_DB](#timescaledb) uses blocked bloom filters to speed up point lookups by eliminating [chunks](#chunk) that don't contain queried values.
**Buffer pool**: memory area where frequently accessed data pages are cached to reduce disk I/O operations.
-**BRIN (Block Range Index)**: a $PG index type that stores summaries about ranges of table blocks, useful for large tables with naturally ordered data.
+**BRIN (Block Range Index)**: a [$PG](#postgresql) index type that stores summaries about ranges of table blocks, useful for large tables with naturally ordered data.
-**Bytea**: a $PG data type for storing binary data as a sequence of bytes.
+**Bytea**: a [$PG](#postgresql) data type for storing binary data as a sequence of bytes.
## C
@@ -65,7 +65,9 @@ This glossary defines technical terms, concepts, and terminology used in $COMPAN
**Check constraint**: a database constraint that limits the values that can be stored in a column by checking them against a specified condition.
-**Chunk**: a horizontal partition of a $HYPERTABLE that contains data for a specific time interval and space partition. See [chunks][use-hypertables-chunks].
+
+
+**Chunk**: a horizontal partition of a [$HYPERTABLE](#hypertable) that contains data for a specific time interval and space partition. See [chunks][use-hypertables-chunks].
**Chunk interval**: the time period covered by each chunk in a $HYPERTABLE, which affects query performance and storage efficiency.
@@ -79,7 +81,7 @@ This glossary defines technical terms, concepts, and terminology used in $COMPAN
**Cloud**: computing services delivered over the internet, including servers, storage, databases, networking, software, analytics, and intelligence.
-**Cloud deployment**: the use of public, private, or hybrid cloud infrastructure to host $TIMESCALE_DB, enabling elastic scalability and managed services.
+**Cloud deployment**: the use of public, private, or hybrid cloud infrastructure to host [$TIMESCALE_DB](#timescaledb), enabling elastic scalability and managed services.
**Cloud-native**: an approach to building applications that leverage cloud infrastructure, scalability, and services like Kubernetes.
@@ -87,7 +89,9 @@ This glossary defines technical terms, concepts, and terminology used in $COMPAN
**Columnar**: a data storage format that stores data column by column rather than row by row, optimizing for analytical queries.
-**Columnstore**: $TIMESCALE_DB's columnar storage engine optimized for analytical workloads and compression.
+**Columnstore**: [$TIMESCALE_DB](#timescaledb)'s columnar storage engine optimized for analytical workloads and [compression](#compression).
+
+
**Compression**: the process of reducing data size by encoding information using fewer bits, improving storage efficiency and query performance. See [compression][use-compression].
@@ -163,13 +167,13 @@ This glossary defines technical terms, concepts, and terminology used in $COMPAN
**Euclidean distance**: a measure of the straight-line distance between two points in multidimensional space.
-**Explain**: a $PG command that shows the execution plan for a query, useful for performance analysis.
+**Explain**: a [$PG](#postgresql) command that shows the execution plan for a query, useful for performance analysis.
**Event sourcing**: an architectural pattern storing all changes as a sequence of events, naturally fitting time-series database capabilities.
**Event-driven architecture**: a design pattern where components react to events such as sensor readings, requiring real-time data pipelines and storage.
-**Extension**: a $PG add-on that extends the database's functionality beyond the core features.
+**Extension**: a [$PG](#postgresql) add-on that extends the database's functionality beyond the core features.
## F
@@ -177,25 +181,29 @@ This glossary defines technical terms, concepts, and terminology used in $COMPAN
**Failover**: the automatic switching to a backup system, server, or network upon the failure or abnormal termination of the primary system.
-**Financial time-series**: high-volume, timestamped datasets like stock market feeds or trade logs, requiring low-latency, scalable databases like $TIMESCALE_DB.
+**Financial time-series**: high-volume, timestamped datasets like stock market feeds or trade logs, requiring low-latency, scalable databases like [$TIMESCALE_DB](#timescaledb).
**Foreign key**: a database constraint that establishes a link between data in two tables by referencing the primary key of another table.
**Fork**: a copy of a database service that shares the same data but can diverge independently through separate writes.
+
+
+**Free $SERVICE_SHORT**: a free instance of $CLOUD_LONG with limited resources. You can create up to two free $SERVICE_SHORTs under any pricing plan. When a free $SERVICE_SHORT reaches the resource limit, it converts to the read-only state. You can convert a free $SERVICE_SHORT to a [standard one](#standard-tiger-service) under paid pricing plans.
+
**FTP (File Transfer Protocol)**: a standard network protocol used for transferring files between a client and server on a computer network.
## G
**Gap filling**: a technique for handling missing data points in time-series by interpolation or other methods, often implemented with hyperfunctions.
-**GIN (Generalized Inverted Index)**: a $PG index type designed for indexing composite values and supporting fast searches.
+**GIN (Generalized Inverted Index)**: a [$PG](#postgresql) index type designed for indexing composite values and supporting fast searches.
-**GiST (Generalized Search Tree)**: a $PG index type that provides a framework for implementing custom index types.
+**GiST (Generalized Search Tree)**: a [$PG](#postgresql) index type that provides a framework for implementing custom index types.
**GP-LTTB**: an advanced downsampling algorithm that extends Largest-Triangle-Three-Buckets with Gaussian Process modeling.
-**GUC (Grand Unified Configuration)**: $PG's configuration parameter system that controls various aspects of database behavior.
+**GUC (Grand Unified Configuration)**: [$PG](#postgresql)'s configuration parameter system that controls various aspects of database behavior.
**GUID (Globally Unique Identifier)**: a unique identifier used in software applications, typically represented as a 128-bit value.
@@ -221,15 +229,17 @@ This glossary defines technical terms, concepts, and terminology used in $COMPAN
**Hot storage**: a tier of data storage for frequently accessed data that provides the fastest access times but at higher cost.
-**Hypercore**: $TIMESCALE_DB's hybrid storage engine that seamlessly combines row and column storage for optimal performance. See [Hypercore][use-hypercore].
+**Hypercore**: [$TIMESCALE_DB](#timescaledb)'s hybrid storage engine that seamlessly combines row and column storage for optimal performance. See [Hypercore][use-hypercore].
-**Hyperfunction**: an SQL function in $TIMESCALE_DB designed for time-series analysis, statistics, and specialized computations. See [Hyperfunctions][use-hyperfunctions].
+**Hyperfunction**: an SQL function in [$TIMESCALE_DB](#timescaledb) designed for time-series analysis, statistics, and specialized computations. See [Hyperfunctions][use-hyperfunctions].
**HyperLogLog**: a probabilistic data structure used for estimating the cardinality of large datasets with minimal memory usage.
-**Hypershift**: a migration tool and strategy for moving data to $TIMESCALE_DB with minimal downtime.
+**Hypershift**: a migration tool and strategy for moving data to [$TIMESCALE_DB](#timescaledb) with minimal downtime.
+
+
-**Hypertable**: $TIMESCALE_DB's core abstraction that automatically partitions time-series data for scalability. See [Hypertables][use-hypertables].
+**Hypertable**: [$TIMESCALE_DB](#timescaledb)'s core abstraction that automatically partitions time-series data for scalability. See [Hypertables][use-hypertables].
## I
@@ -259,7 +269,7 @@ This glossary defines technical terms, concepts, and terminology used in $COMPAN
**Job execution**: the process of running scheduled background tasks or automated procedures.
-**JIT (Just-In-Time) compilation**: $PG feature that compiles frequently executed query parts for improved performance, available in $TIMESCALE_DB.
+**JIT (Just-In-Time) compilation**: [$PG](#postgresql) feature that compiles frequently executed query parts for improved performance, available in [$TIMESCALE_DB](#timescaledb).
**Job history**: a record of past job executions, including their status, duration, and any errors encountered.
@@ -277,7 +287,7 @@ This glossary defines technical terms, concepts, and terminology used in $COMPAN
**Load balancer**: a service distributing traffic across servers or database nodes to optimize resource use and avoid single points of failure.
-**Log-Structured Merge (LSM) Tree**: a data structure optimized for write-heavy workloads, though $TIMESCALE_DB primarily uses B-tree indexes for balanced read/write performance.
+**Log-Structured Merge (LSM) Tree**: a data structure optimized for write-heavy workloads, though [$TIMESCALE_DB](#timescaledb) primarily uses B-tree indexes for balanced read/write performance.
**LlamaIndex**: a framework for building applications with large language models, providing tools for data ingestion and querying.
@@ -285,7 +295,7 @@ This glossary defines technical terms, concepts, and terminology used in $COMPAN
**Logical backup**: a backup method that exports data in a human-readable format, allowing for selective restoration.
-**Logical replication**: a $PG feature that replicates data changes at the logical level rather than the physical level.
+**Logical replication**: a [$PG](#postgresql) feature that replicates data changes at the logical level rather than the physical level.
**Logging**: the process of recording events, errors, and system activities for monitoring and troubleshooting purposes.
@@ -317,7 +327,7 @@ This glossary defines technical terms, concepts, and terminology used in $COMPAN
**MQTT (Message Queuing Telemetry Transport)**: a lightweight messaging protocol designed for small sensors and mobile devices.
-**MST (Managed Service for TimescaleDB)**: a fully managed $TIMESCALE_DB service that handles infrastructure and maintenance tasks.
+**MST (Managed Service for TimescaleDB)**: a fully managed [$TIMESCALE_DB](#timescaledb) service that handles infrastructure and maintenance tasks.
## N
@@ -329,7 +339,7 @@ This glossary defines technical terms, concepts, and terminology used in $COMPAN
**Not null**: a database constraint that ensures a column cannot contain empty values.
-**Numeric**: a $PG data type for storing exact numeric values with user-defined precision.
+**Numeric**: a [$PG](#postgresql) data type for storing exact numeric values with user-defined precision.
## O
@@ -355,7 +365,7 @@ This glossary defines technical terms, concepts, and terminology used in $COMPAN
**Parallel copy**: a technique for copying large amounts of data using multiple concurrent processes to improve performance.
-**Parallel Query Execution**: a $PG feature that uses multiple CPU cores to execute single queries faster, inherited by $TIMESCALE_DB.
+**Parallel Query Execution**: a [$PG](#postgresql) feature that uses multiple CPU cores to execute single queries faster, inherited by [$TIMESCALE_DB](#timescaledb).
**Partitioning**: the practice of dividing large tables into smaller, more manageable pieces based on certain criteria.
@@ -363,19 +373,19 @@ This glossary defines technical terms, concepts, and terminology used in $COMPAN
**Performance**: a measure of how efficiently a system operates, often quantified by metrics like throughput, latency, and resource utilization.
-**pg_basebackup**: a $PG utility for taking base backups of a running $PG cluster.
+**pg_basebackup**: a [$PG](#postgresql) utility for taking base backups of a running [$PG](#postgresql) cluster.
-**pg_dump**: a $PG utility for backing up database objects and data in various formats.
+**pg_dump**: a [$PG](#postgresql) utility for backing up database objects and data in various formats.
-**pg_restore**: a $PG utility for restoring databases from backup files created by `pg_dump`.
+**pg_restore**: a [$PG](#postgresql) utility for restoring databases from backup files created by `pg_dump`.
-**pgVector**: a $PG extension that adds vector similarity search capabilities for AI and machine learning applications. See [pgvector][ai-pgvector].
+**pgVector**: a [$PG](#postgresql) extension that adds vector similarity search capabilities for AI and machine learning applications. See [pgvector][ai-pgvector].
-**pgai on $CLOUD_LONG**: a cloud solution for building search, RAG, and AI agents with $PG. Enables calling AI embedding and generation models directly from the database using SQL. See [pgai][ai-pgai].
+**pgai on $CLOUD_LONG**: a cloud solution for building search, RAG, and AI agents with [$PG](#postgresql). Enables calling AI embedding and generation models directly from the database using SQL. See [pgai][ai-pgai].
**pgvectorscale**: a performance enhancement for pgvector featuring StreamingDiskANN indexing, binary quantization compression, and label-based filtering. See [pgvectorscale][ai-pgvectorscale].
-**pgvectorizer**: a $TIMESCALE_DB tool for automatically vectorizing and indexing data for similarity search.
+**pgvectorizer**: a [$TIMESCALE_DB](#timescaledb) tool for automatically vectorizing and indexing data for similarity search.
**Physical backup**: a backup method that copies the actual database files at the storage level.
@@ -385,13 +395,15 @@ This glossary defines technical terms, concepts, and terminology used in $COMPAN
**Predictive maintenance**: the use of time-series data to forecast equipment failure, common in IoT and industrial applications.
+
+
**$PG**: an open-source object-relational database system known for its reliability, robustness, and performance.
-**PostGIS**: a $PG extension that adds support for geographic objects and spatial queries.
+**PostGIS**: a [$PG](#postgresql) extension that adds support for geographic objects and spatial queries.
**Primary key**: a database constraint that uniquely identifies each row in a table.
-**psql**: an interactive terminal-based front-end to $PG that allows users to type queries interactively.
+**psql**: an interactive terminal-based front-end to [$PG](#postgresql) that allows users to type queries interactively.
## Q
@@ -421,7 +433,7 @@ This glossary defines technical terms, concepts, and terminology used in $COMPAN
**Real-time analytics**: the immediate analysis of incoming data streams, crucial for observability, trading platforms, and IoT monitoring.
-**Real**: a $PG data type for storing single-precision floating-point numbers.
+**Real**: a [$PG](#postgresql) data type for storing single-precision floating-point numbers.
**Real-time aggregate**: a continuous aggregate that includes both materialized historical data and real-time calculations on recent data.
@@ -467,10 +479,12 @@ This glossary defines technical terms, concepts, and terminology used in $COMPAN
**Service discovery**: mechanisms allowing applications to dynamically locate services like database endpoints, often used in distributed environments.
-**Segmentwise recompression**: a $TIMESCALE_DB compression technique that recompresses data segments to improve compression ratios.
+**Segmentwise recompression**: a [$TIMESCALE_DB](#timescaledb) [compression](#compression) technique that recompresses data segments to improve [compression](#compression) ratios.
**Serializable**: the highest isolation level that ensures transactions appear to run serially even when executed concurrently.
+**Service**: see [$SERVICE_LONG](#tiger-service).
+
**Sharding**: horizontal partitioning of data across multiple database instances, distributing load and enabling linear scalability.
**SFTP (SSH File Transfer Protocol)**: a secure version of FTP that encrypts both commands and data during transmission.
@@ -491,7 +505,7 @@ This glossary defines technical terms, concepts, and terminology used in $COMPAN
**Snapshot**: a point-in-time copy of data that can be used for backup and recovery purposes.
-**SP-GiST (Space-Partitioned Generalized Search Tree)**: a $PG index type for data structures that naturally partition search spaces.
+**SP-GiST (Space-Partitioned Generalized Search Tree)**: a [$PG](#postgresql) index type for data structures that naturally partition search spaces.
**Storage optimization**: techniques for reducing storage costs and improving performance through compression, tiering, and efficient data organization.
@@ -503,7 +517,11 @@ This glossary defines technical terms, concepts, and terminology used in $COMPAN
**SSL (Secure Sockets Layer)**: a security protocol that establishes encrypted links between networked computers.
-**Streaming replication**: a $PG replication method that continuously sends write-ahead log records to standby servers.
+
+
+**Standard $SERVICE_SHORT**: a regular [$SERVICE_LONG](#tiger-service) that includes the resources and features according to the pricing plan. You can create standard $SERVICE_SHORTs under any of the paid plans.
+
+**Streaming replication**: a [$PG](#postgresql) replication method that continuously sends write-ahead log records to standby servers.
**Synthetic monitoring**: simulated transactions or probes used to test system health, generating time-series metrics for performance analysis.
@@ -511,7 +529,7 @@ This glossary defines technical terms, concepts, and terminology used in $COMPAN
**Table**: a database object that stores data in rows and columns, similar to a spreadsheet.
-**Tablespace**: a $PG storage structure that defines where database objects are physically stored on disk.
+**Tablespace**: a [$PG](#postgresql) storage structure that defines where database objects are physically stored on disk.
**TCP (Transmission Control Protocol)**: a connection-oriented protocol that ensures reliable data transmission between applications.
@@ -519,16 +537,20 @@ This glossary defines technical terms, concepts, and terminology used in $COMPAN
**Telemetry**: the collection of real-time data from systems or devices for monitoring and analysis.
-**Text**: a $PG data type for storing variable-length character strings.
+**Text**: a [$PG](#postgresql) data type for storing variable-length character strings.
**Throughput**: a measure of system performance indicating the amount of work performed or data processed per unit of time.
**Tiered storage**: a storage strategy that automatically moves data between different storage classes based on access patterns and age.
-**$CLOUD_LONG**: $COMPANY's managed cloud service that provides $TIMESCALE_DB as a fully managed solution with additional features.
+**$CLOUD_LONG**: $COMPANY's managed cloud platform that provides [$TIMESCALE_DB](#timescaledb) as a fully managed solution with additional features.
**Tiger Lake**: $COMPANY's service for integrating operational databases with data lake architectures.
+
+
+**$SERVICE_LONG**: an instance of optimized [$PG](#postgresql) extended with database engine innovations such as [$TIMESCALE_DB](#timescaledb), in a cloud infrastructure that delivers speed without compromise. You can create [free $SERVICE_SHORTs](#free-tiger-service) and [standard $SERVICE_SHORTs](#standard-tiger-service).
+
**Time series**: data points indexed and ordered by time, typically representing how values change over time.
**Time-weighted average**: a statistical calculation that gives more weight to values based on the duration they were held.
@@ -537,11 +559,13 @@ This glossary defines technical terms, concepts, and terminology used in $COMPAN
**Time-series forecasting**: the application of statistical models to time-series data to predict future trends or events.
-**$TIMESCALE_DB**: an open-source $PG extension for real-time analytics that provides scalability and performance optimizations.
+
+
+**$TIMESCALE_DB**: an open-source [$PG](#postgresql) extension for real-time analytics that provides scalability and performance optimizations.
**Timestamp**: a data type that stores date and time information without timezone data.
-**Timestamptz**: a $PG data type that stores timestamp with timezone information.
+**Timestamptz**: a [$PG](#postgresql) data type that stores timestamp with timezone information.
**TLS (Transport Layer Security)**: a cryptographic protocol that provides security for communication over networks.
@@ -569,7 +593,7 @@ This glossary defines technical terms, concepts, and terminology used in $COMPAN
## V
-**Vacuum**: a $PG maintenance operation that reclaims storage and updates database statistics.
+**Vacuum**: a [$PG](#postgresql) maintenance operation that reclaims storage and updates database statistics.
**Varchar**: a variable-length character data type that can store strings up to a specified maximum length.
@@ -587,7 +611,7 @@ This glossary defines technical terms, concepts, and terminology used in $COMPAN
## W
-**WAL (Write-Ahead Log)**: $PG's method for ensuring data integrity by writing changes to a log before applying them to data files.
+**WAL (Write-Ahead Log)**: [$PG](#postgresql)'s method for ensuring data integrity by writing changes to a log before applying them to data files.
**Warm storage**: a storage tier that balances access speed and cost, suitable for data accessed occasionally.
diff --git a/getting-started/run-queries-from-console.md b/getting-started/run-queries-from-console.md
index e2ad1ed710..ed12d3bf36 100644
--- a/getting-started/run-queries-from-console.md
+++ b/getting-started/run-queries-from-console.md
@@ -6,6 +6,7 @@ content_group: Getting started
---
import WhereNext from "versionContent/_partials/_where-to-next.mdx";
+import NotAvailableFreePlan from "versionContent/_partials/_not-available-in-free-plan.mdx";
# Run your queries from $CONSOLE
@@ -30,6 +31,8 @@ You use the $DATA_MODE in $CONSOLE to write queries, visualize data, and share y
+
+
Available features are:
- **Real-time collaboration**: work with your team directly in the $DATA_MODE query editor with live presence and multiple
@@ -119,6 +122,8 @@ use that in the $DATA_MODE.
$SQL_ASSISTANT_SHORT in [$CONSOLE][portal-data-mode] is a chat-like interface that harnesses the power of AI to help you write, fix, and organize SQL faster and more accurately. Ask $SQL_ASSISTANT_SHORT to change existing queries, write new ones from scratch, debug error messages, optimize for query performance, add comments, improve readability—and really, get answers to any questions you can think of.
+
+