From 35478182ce50d04bde5c4ecd0569c2f6ba15bee7 Mon Sep 17 00:00:00 2001
From: Steven Liu <59462357+stevhliu@users.noreply.github.com>
Date: Mon, 11 Dec 2023 10:41:33 -0800
Subject: [PATCH] [docs] Fused AWQ modules (#27896)
streamline
---
docs/source/en/quantization.md | 151 +++++++++++++--------------------
1 file changed, 61 insertions(+), 90 deletions(-)
diff --git a/docs/source/en/quantization.md b/docs/source/en/quantization.md
index 4e73ee2be5da7..0a471fd423c6f 100644
--- a/docs/source/en/quantization.md
+++ b/docs/source/en/quantization.md
@@ -85,49 +85,22 @@ from transformers import AutoModelForCausalLM, AutoTokenizer
model = AutoModelForCausalLM.from_pretrained("TheBloke/zephyr-7B-alpha-AWQ", attn_implementation="flash_attention_2", device_map="cuda:0")
```
+### Fused modules
-### Benchmarks
+Fused modules offers improved accuracy and performance and it is supported out-of-the-box for AWQ modules for [Llama](https://huggingface.co/meta-llama) and [Mistral](https://huggingface.co/mistralai/Mistral-7B-v0.1) architectures, but you can also fuse AWQ modules for unsupported architectures.
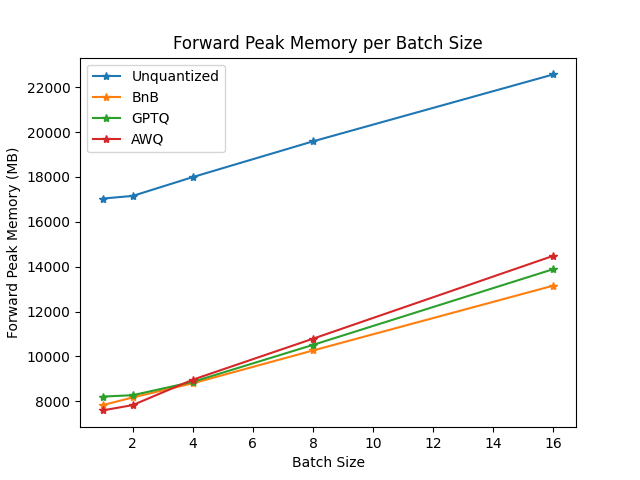
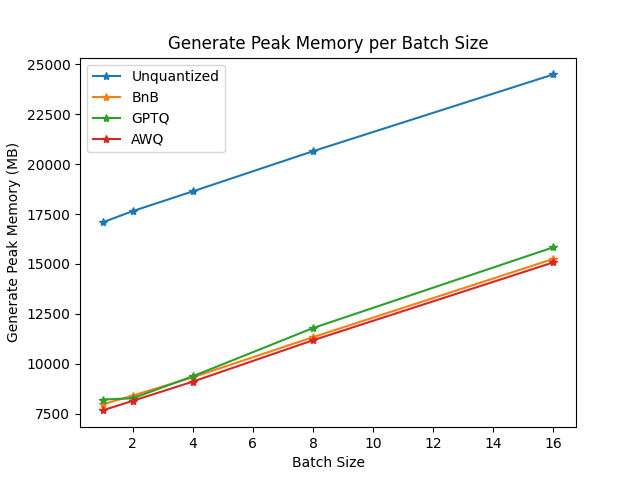
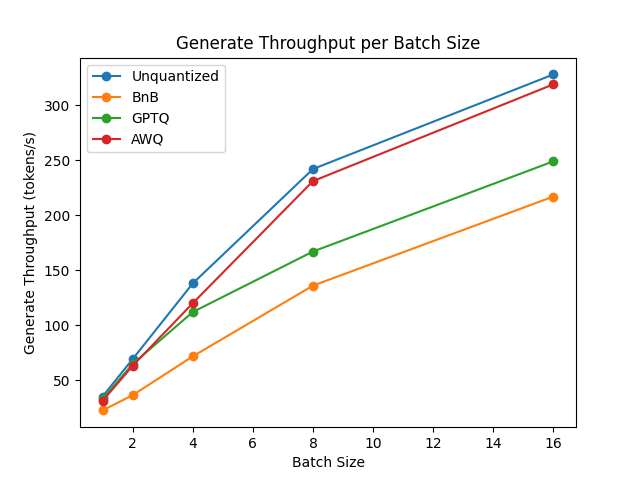
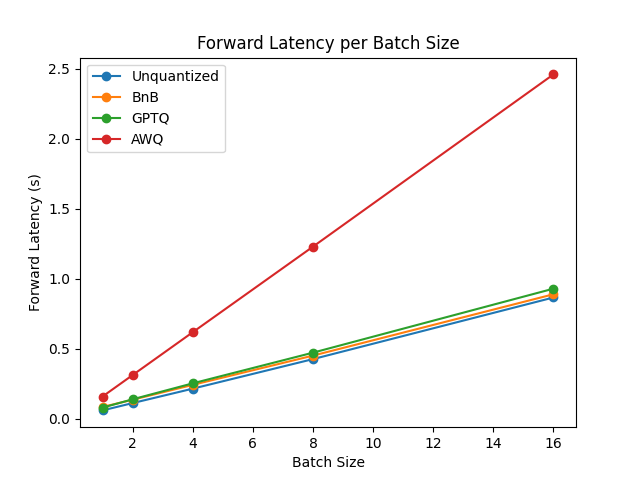
-We performed some speed, throughput and latency benchmarks using [`optimum-benchmark`](https://github.com/huggingface/optimum-benchmark) library.
-
-Note at that time of writing this documentation section, the available quantization methods were: `awq`, `gptq` and `bitsandbytes`.
-
-The benchmark was run on a NVIDIA-A100 instance and the model used was [`TheBloke/Mistral-7B-v0.1-AWQ`](https://huggingface.co/TheBloke/Mistral-7B-v0.1-AWQ) for the AWQ model, [`TheBloke/Mistral-7B-v0.1-GPTQ`](https://huggingface.co/TheBloke/Mistral-7B-v0.1-GPTQ) for the GPTQ model. We also benchmarked it against `bitsandbytes` quantization methods and native `float16` model. Some results are shown below:
-
-
-
-
-
-
-
-
-
-
-
-
-
-
+
+
+
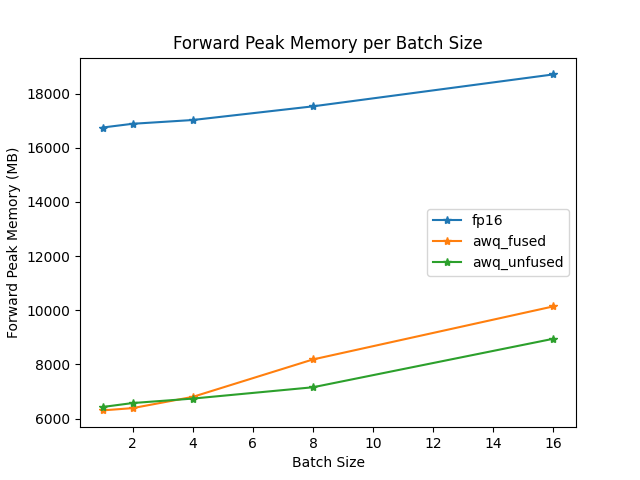
foward peak memory/batch size
+
+
+
+
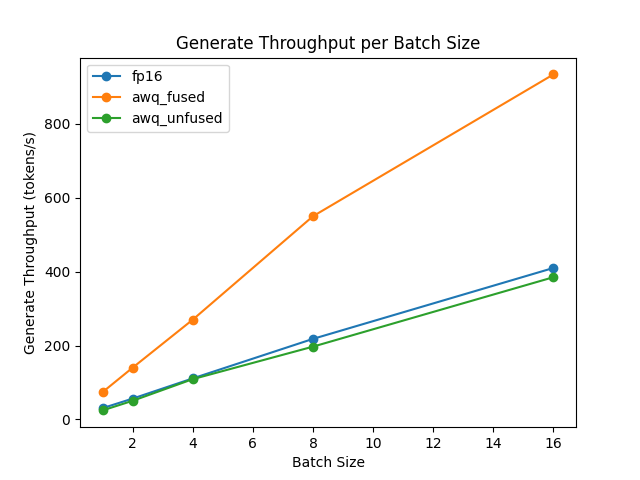
generate throughput/batch size
+
+