{kind=link}
We are proposing a system that takes any text as input and generates both the corresponding speech in Obama's style and synchronized lip-sync Obama videos. We are pipe-lining three approaches with an improvisation of one of the approaches.
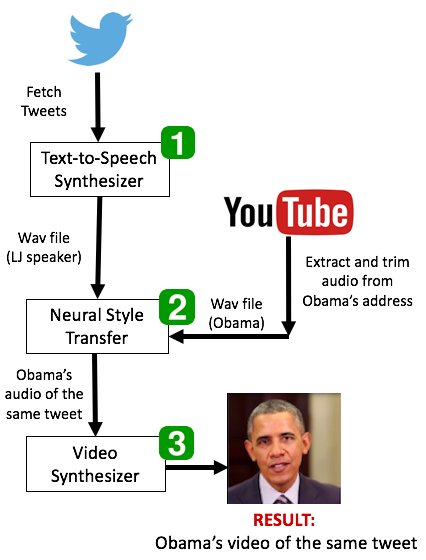
Given a piece of text we generate a final video with Obama speaking the same piece of text. Our approach has three different parts.
Part 1: Convert text to speech (Based on LJSpeech dataset). Here we have used the model which is pre-trained on 24hrs of speech from LJ Speech dataset. We give the model, Obama’s latest tweet and as output we get a audio1.wav file in a lady’s voice
Part 2: We then perform a neural style transfer on this audio1.wav file to give it the style and texture of Obama’s voice. This outputs another audio2.wav audio file which now sounds like Obama.
Part 3: We input this audio2.wav file to a Video synthesizer that outputs a video of Obama speaking the same piece of text that we gave as input in the first stage.
- Instead of using only one 2-D convolutional layers, we added another convolutional layer with LeakyReLU as our activation function.
- We also did hyperparameter tuning on our randomCNN and tried different combinations which included using two 2-D layers, increasing the output channels, changing the number of epochs, increasing the Leaky ReLU value with each convolutional layer.
- We experimented with using gram instead of gram over time axis also changing the optimizer function from Adam to AdaDelta
- We also changed the filter size from (3,1) to (3,3) which produced smoother spectrogram.
- We concluded that, when we use one 2-D Convolutional Layer, the loss decreases with the increase in the output channels. For example, convolutional layer with output channel 64 produces better results than convolutional layer with 32 output channel.
- Using two 2-D convolutional layers instead of one performed better in style transfer but lagged when it came to content transfer. While using one 2-D convolutional layer performed better in content transfer than the style transfer.
- We also observed that if the content file and the style file has the same duration and the same content, the results are much cleaner.
- Increasing the number of epochs helped in getting promisable results.
- Following are the results obtained on 80k epochs for our different combinations
For text to speech we have used pre-trained models on LJSpeech dataset provided by implementation of the paper: Efficiently trainable text-to-speech system based on deep convolutional networks with guided attention. (https://arxiv.org/pdf/1710.08969.pdf). Here is the Github repo that we referred to: (https://github.com/Kyubyong/dc_tts) LJSpeech dataset consists of 13,100 short audio clips of a single speaker reading passages from 7 non-fiction books. (https://keithito.com/LJ-Speech-Dataset/)
Using this pre-trained model, we are able to convert any given piece of text to speech of the single speaker from the dataset.
The paper utilizes a CNN based approach which is much faster than compoared to tradtitional RNN TTS systems.
For our project, we used get_tweets.py to get latest tweets by Obama. We are using these tweets as the text input.
For neural style transfer we are again using a CNN based approach. From the paper Audio Style Transfer and GitHub repo that we referred to (https://github.com/mazzzystar/randomCNN-voice-transfer). Here we first generate a spectogram from input audio files and then use our improvised model of 2 2-D CNN layers The audio file that we get from the above Part 1 is not in Obama’s voice texture and style. To be able to convert this audio file into Obama’s style we trained our improvised version of randomCNN which has two 2-D CONV layers. This generates a new spectogram, which is then converted back to a audio .wav file.
We give two audio wav files as input to this model. One audio file is the file that we get from Part 1 which we will serve as the content file. The second audio file is a Obama’s Address video which has been stripped down to its pure .wav format using our fetch.sh script. We will call this as the style.wav file. We aim to give Obama’s style to the content.wav file using our model. The final output is an audio file where the tweet text that we had given in Part 1 is being said the way Obama would say it.
The paper we are using is ObamaNet: Photo-realistic lip-sync (https://arxiv.org/pdf/1801.01442.pdf) and the Github repo: https://github.com/karanvivekbhargava/obamanet
This paper uses time-delayed LSTM to generate mouth key-points synced to the audio. Followed by a network of Pix2Pix to generate the video frames.
You can listen to our Neural Style Transfer improvised model results now ! It's on drive : Links (https://drive.google.com/drive/folders/1Cs6f7RSnbZKokM_HAVyC-65pavAKSJRa?usp=sharing) The audio files named as person6.wav and person3.wav were generated by our Text to Speech model using one of the Obama tweets. The files with person6_with_obama6.wav and person3_with_obama3.wav are our Neural Style Transfer model.
The script initiate.py initiates our pipeline and runs it through the end.