A free version of a web crawler written in Python 3 with Beautiful Soup which collects links, and email addresses. For non-technical people, the offer is a premium version with GUI, many more functionalities like filters, and whatsoever you will want. The premium version doesn't collect only links/emails.
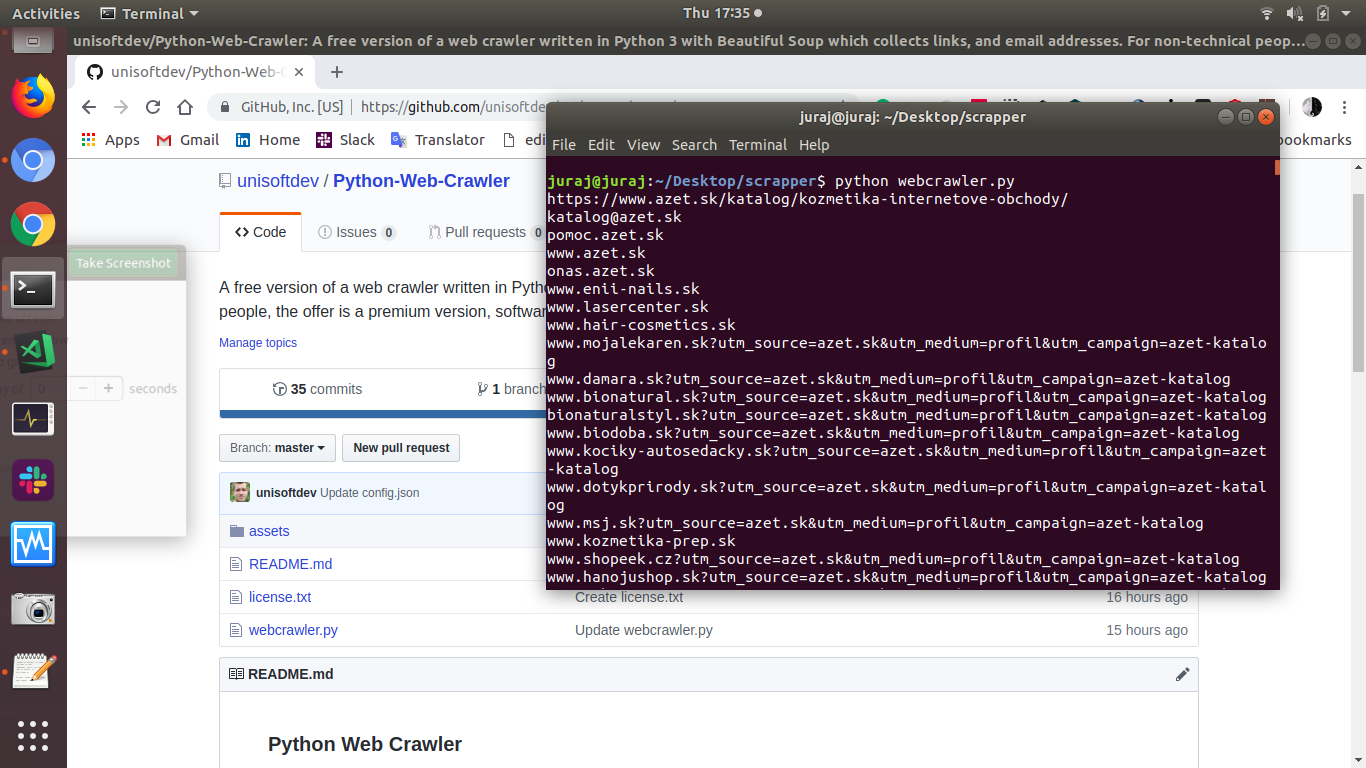
I didn't perform any proper benchmarks, but on one of my laptops with a very poor internet speed of ~7Mb/sec (should be 20 but it's not), I have discovered more than 1300 domain names in 5 minutes. With the same speed, it could be 748.800 in two days and above 1 million in three days.
assets --> config.json --> websites
- Add website urls which you want to crawl, where you want to collect links or addresses from. Change the urls in this file: https://github.com/unisoftdev/Python-Web-Crawler/blob/master/assets/config.json
- Blacklist: delete Reddit and any site which you wanna crawl. The bot will not go on the domains if the keywords from the blacklist will match the domain names. For example, there's banned GitHub, Reddit, YouTube, etc.
- Python 3, the crawler has been tested on Python 3.6.7 but it ought to work also on lower versions like 3.5, and any other 3.x in general.
- (pip if it's in a virtual environment or outside:) pip3 install requests json csv bs4
- Clone the web crawler: git clone https://github.com/unisoftdev/Python-Web-Crawler.git
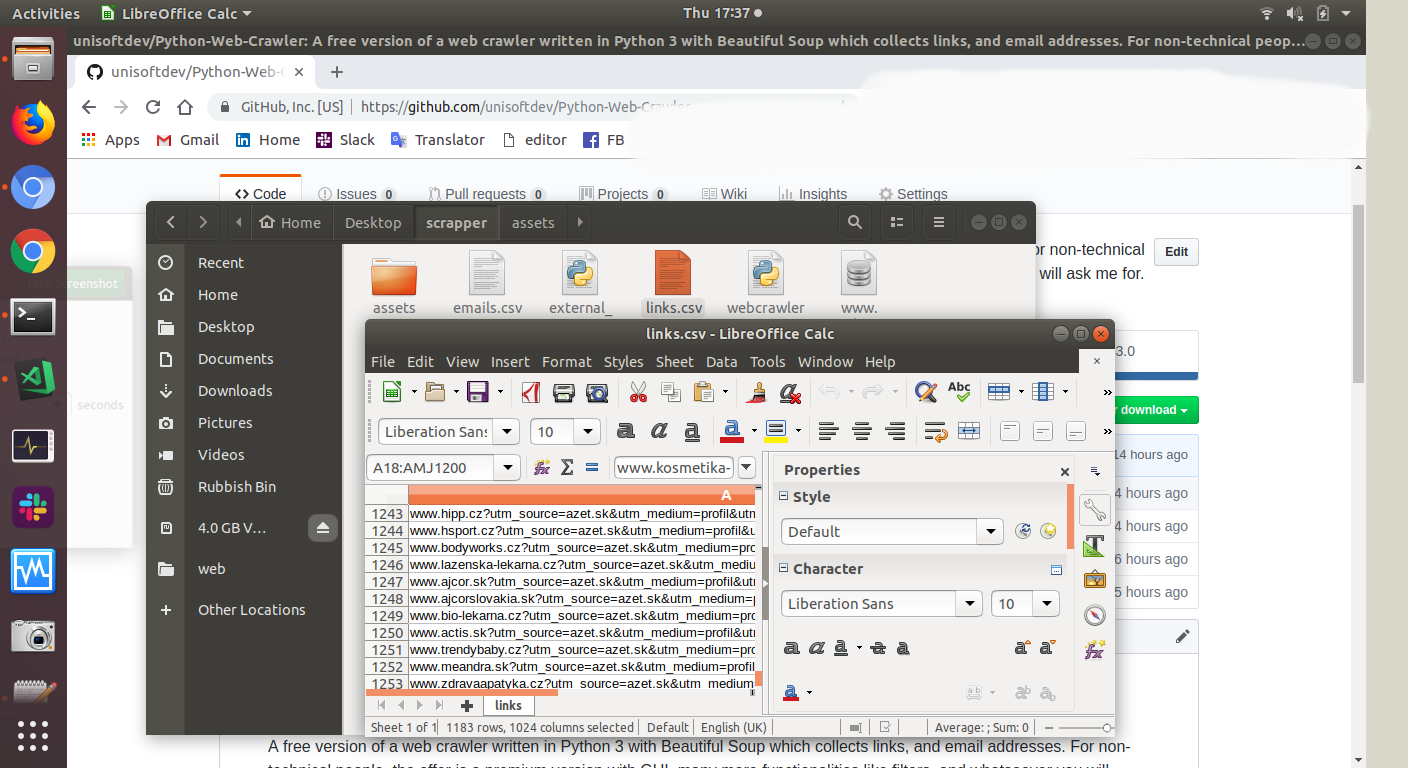
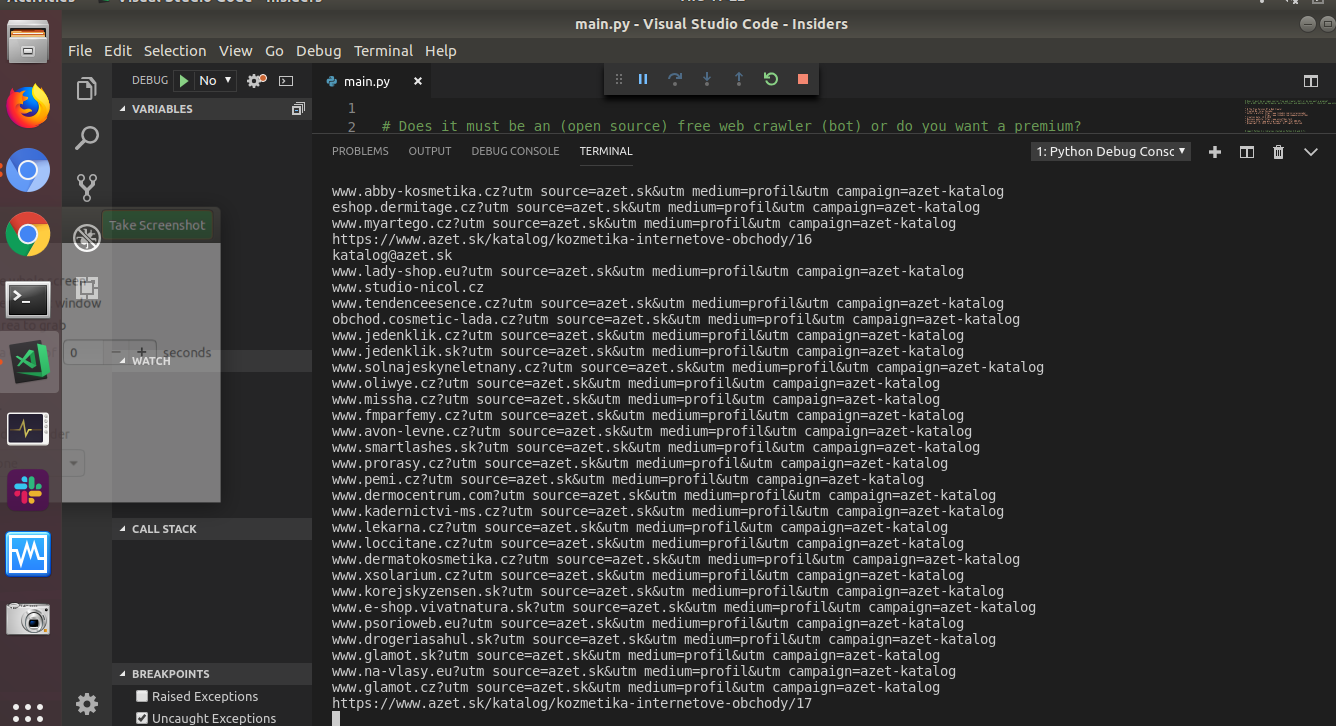
CSV files, it creates two files, one file with links and another one with email addresses.
-
The software is provided as it is without any warranty or responsibility from the side of the author. If it will cause any damages, you'll be kidnapped by aliens (or whatever else you do or don't think that can really happen) then it's not the responsibility of the author. Think twice before you use it.
-
It's only for educational purposes. Any illegal activity is only on your own responsibility (in some countries can be illegal to scrap some kinds of data) so it's only your problem, I didn't say that you should use the software. The software was released under GNU/GPL license so you can feel very free to do almost whatever you want but the software has been released only for educational purposes (e.g. to read the code, see how it works, and crawl own websites), nothing else. This doesn't mean that you are not free to crawl, scrap, and extract data (if the law of your country does allow it) from websites, it only means that the author doesn't say you should/ought/may do it, the author of the software doesn't say almost anything except the mention that this software is released for educational purposes.
Best regards, J. Vysvader