diff --git a/docs/manual-CN/1.overview/1.concepts/1.data-model.md b/docs/manual-CN/1.overview/1.concepts/1.data-model.md
index 96d11c80746..9b6fc9929fb 100644
--- a/docs/manual-CN/1.overview/1.concepts/1.data-model.md
+++ b/docs/manual-CN/1.overview/1.concepts/1.data-model.md
@@ -10,43 +10,51 @@
**Nebula Graph** 存储的图为 **_有向属性图_**,边为有向边,点和边均可包含属性。可表示为:
G = < V, E, PV, PE >,
-其中 **V** 表示节点,**E** 表示有向边,**PV** 表示节点属性,**PE** 表示边属性。
+其中 **V** 表示点,**E** 表示有向边,**PV** 表示点属性,**PE** 表示边属性。
此文档将使用如下示例图数据介绍属性图的基本概念:
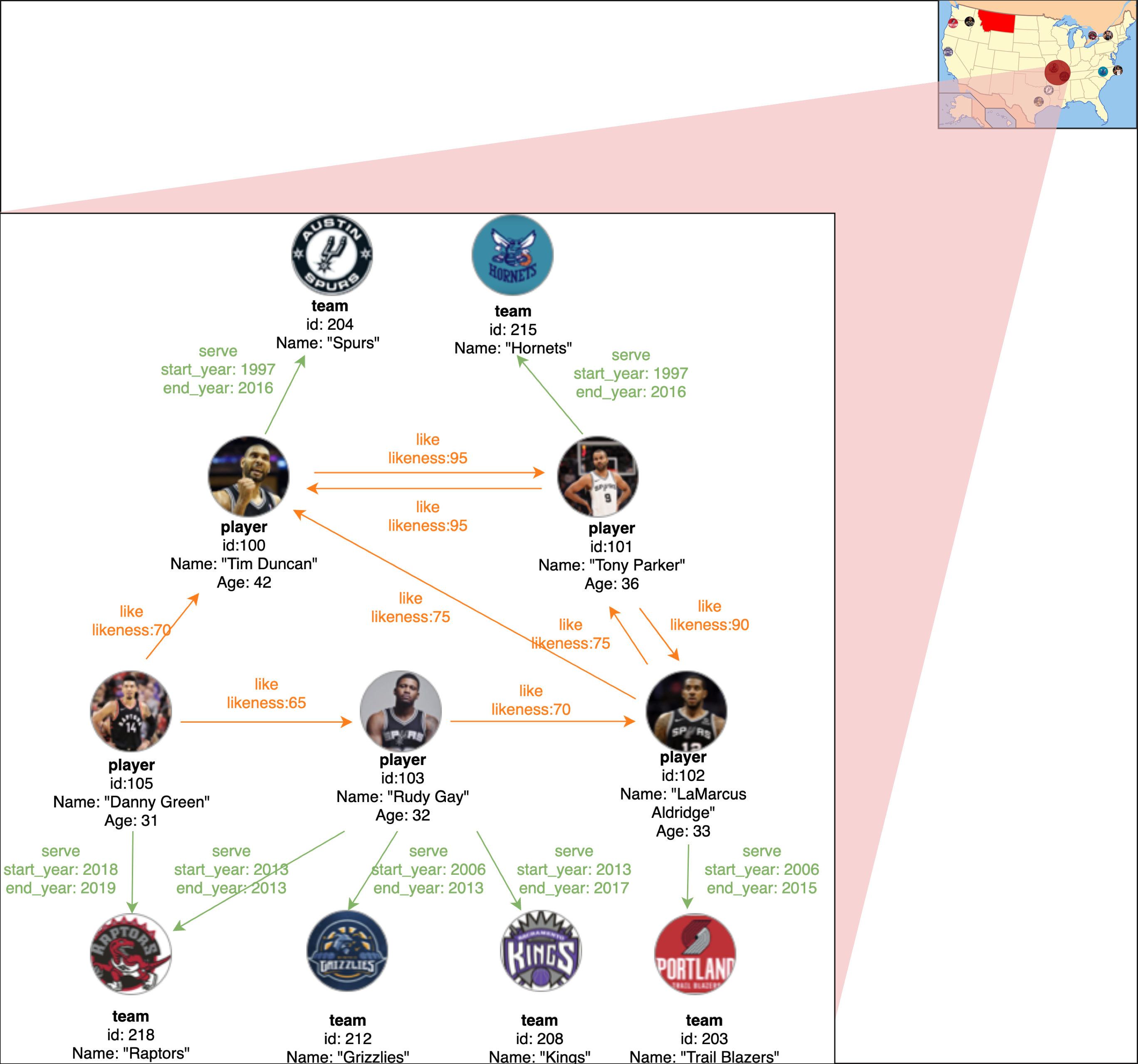
-上图为 NBA 球员及球队信息数据,图中包含 2 种类型的 11 个节点,即 player 和 team,2 种类型的边,即 serve 和 like。
+上图为 NBA 球员及球队信息数据,图中包含 2 种类型的 11 个点,即 player 和 team,2 种类型的边,即 serve 和 like。
以下为示例图数据涉及到的概念介绍。
-## 节点
+## 点(Vertex)
-节点用于表示现实世界中的实体,本例的数据中共包含 11 个节点。
+点用于表示现实世界中的实体。在 **Nebula Graph** 中,点必须拥有唯一的标识符(即 `VID`)。在每个图空间中的 `VID` 必须是唯一的。
+
+本例的数据中共包含 11 个点。
 -## 标签
+## 点类型——标签(Tag)
-**Nebula Graph** 使用**标签**对节点进行分类,本例包含的节点标签为 **player** 和 **team**。
+**Nebula Graph** 使用**标签**表示点类型;一个点可以同时有多种类型(Tag)。本例中有两种类型的点,其标签(类型)分别为 **player** 和 **team**。
-## 标签
+## 点类型——标签(Tag)
-**Nebula Graph** 使用**标签**对节点进行分类,本例包含的节点标签为 **player** 和 **team**。
+**Nebula Graph** 使用**标签**表示点类型;一个点可以同时有多种类型(Tag)。本例中有两种类型的点,其标签(类型)分别为 **player** 和 **team**。
 -## 边
+## 边(Edge)
-边用来连接节点,边通常表示两个节点间的某种关系或行为,本例中的边为 _**serve**_ 和 _**like**_。
+边用来连接点,边通常表示两个点间的某种关系或行为,本例中的边为 _**serve**_ 和 _**like**_。
-## 边
+## 边(Edge)
-边用来连接节点,边通常表示两个节点间的某种关系或行为,本例中的边为 _**serve**_ 和 _**like**_。
+边用来连接点,边通常表示两个点间的某种关系或行为,本例中的边为 _**serve**_ 和 _**like**_。
 -## 边类型
+## 边类型(Edge Type)
-每条边都有一种边类型,以边 _**serve**_ 为例,节点 `101`(表示一名球员)为起始点,节点 `215`(表示一支球队)为目标点。节点 `101` 有一条出边,而节点 `215` 有一条入边。
+每条边都有唯一的边类型。两个节点之间允许有多个相同或者不同类型的边。例如,以球员-球队的服役关系 _**serve**_ 为例,(球员)点 `101`(表示一名球员)为起始点,(球队)点 `215`(表示一支球队)为目标点。点 `101` 有一条出边,而点 `215` 有一条入边。
## 边 rank
-边 rank 是用户分配的不可变的 64 位带符号整数,决定两个顶点之间相同类型的边顺序。等级值较高的边排名靠前。如未指定,则默认等级值为零。目前的排序依据为“二进制编码顺序“:即 0, 1, 2, ... 9223372036854775807, -9223372036854775808, -9223372036854775807, ..., -1。
+两个点之间的边除了必须有类型之外,还必须有 rank。边 rank 是用户分配的 64 位整数;如不指定,边 rank 默认值为 0。
+
+四元组[起点、边类型、权重、终点]可以唯一表示一条边。
+
+边 rank 决定了两个点之间相同类型的边的排序方式。边 rank 值较高的边排名靠前。
+
+目前的排序依据为“二进制编码顺序“:即 0, 1, 2, ... 9223372036854775807, -9223372036854775808, -9223372036854775807, ..., -1。
-## 属性
+## 点和边的属性(Property)
-属性为点和边内部的键值对。本例中,节点 **player** 拥有属性 `id`, `name` 和 `age`,边 **like** 则拥有属性 `likeness`。
+点和边无可可拥有属性,属性以键值对的方式描述。本例中,点 **player** 拥有属性 `id`、`name` 和 `age`,边 **like** 则拥有属性 `likeness`。
## Schema
diff --git a/docs/manual-CN/1.overview/1.concepts/2.nGQL-overview.md b/docs/manual-CN/1.overview/1.concepts/2.nGQL-overview.md
index 470a0bf9ced..8cc76aa339e 100644
--- a/docs/manual-CN/1.overview/1.concepts/2.nGQL-overview.md
+++ b/docs/manual-CN/1.overview/1.concepts/2.nGQL-overview.md
@@ -29,17 +29,17 @@
- 每个标签都有一个人类可读的名称,并且每个标签内部都会分配一个 32 位的整数
- 每个标签与一个属性列表相关联,每个属性都有一个名称和类型
- 标签之间可存在依赖关系作为约束。例如,如果标签 S 依赖于标签 T,则除非标签 T 存在,否则标签 S 无法存在。
-- **节点** :图数据中代表实体的点
- - 每个节点都有一个唯一的 64 位(有符号整数)ID (**VID**)
- - 一个节点可以拥有多个**标签**
-- **边**:节点之间的联系称为边
+- **点** :图数据中代表实体的点
+ - 每个点都有一个唯一的 64 位(有符号整数)ID (**VID**)
+ - 一个点可以拥有多个**标签**
+- **边**:点之间的联系称为边
- 每条边由唯一数组 **** 标识
- ***边类型*** 是人类可读的字符串,并且每条边内部都会分配一个 32 位的整数。边类型决定边上的属性(模式)
- ***边 rank*** 是用户分配的不可变的 64 位带符号整数,决定两个顶点之间相同类型的边顺序。等级值较高的边排名靠前。如未指定,则默认等级值为零。目前的排序依据为“二进制编码顺序“:即 0, 1, 2, ... 9223372036854775807, -9223372036854775808, -9223372036854775807, ..., -1。
- 每条边只能有一种类型
-- **路径**: 多个节点与边的**非分支**连接
- - 路径长度为该路径上的边数,比节点数少 1
- - 路径可由一系列节点,边类型及权重表示。一条边是一个长度为 1 的特殊路径
+- **路径**: 多个点与边的**非分支**连接
+ - 路径长度为该路径上的边数,比点数少 1
+ - 路径可由一系列点,边类型及权重表示。一条边是一个长度为 1 的特殊路径
```plain
, vid, ...>
@@ -142,9 +142,9 @@
:=
-#### 插入节点
+#### 插入点
-使用以下语句插入一个或多个节点
+使用以下语句插入一个或多个点
**INSERT VERTEX** [**NO OVERWRITE**] **VALUES**
-## 边类型
+## 边类型(Edge Type)
-每条边都有一种边类型,以边 _**serve**_ 为例,节点 `101`(表示一名球员)为起始点,节点 `215`(表示一支球队)为目标点。节点 `101` 有一条出边,而节点 `215` 有一条入边。
+每条边都有唯一的边类型。两个节点之间允许有多个相同或者不同类型的边。例如,以球员-球队的服役关系 _**serve**_ 为例,(球员)点 `101`(表示一名球员)为起始点,(球队)点 `215`(表示一支球队)为目标点。点 `101` 有一条出边,而点 `215` 有一条入边。
## 边 rank
-边 rank 是用户分配的不可变的 64 位带符号整数,决定两个顶点之间相同类型的边顺序。等级值较高的边排名靠前。如未指定,则默认等级值为零。目前的排序依据为“二进制编码顺序“:即 0, 1, 2, ... 9223372036854775807, -9223372036854775808, -9223372036854775807, ..., -1。
+两个点之间的边除了必须有类型之外,还必须有 rank。边 rank 是用户分配的 64 位整数;如不指定,边 rank 默认值为 0。
+
+四元组[起点、边类型、权重、终点]可以唯一表示一条边。
+
+边 rank 决定了两个点之间相同类型的边的排序方式。边 rank 值较高的边排名靠前。
+
+目前的排序依据为“二进制编码顺序“:即 0, 1, 2, ... 9223372036854775807, -9223372036854775808, -9223372036854775807, ..., -1。
-## 属性
+## 点和边的属性(Property)
-属性为点和边内部的键值对。本例中,节点 **player** 拥有属性 `id`, `name` 和 `age`,边 **like** 则拥有属性 `likeness`。
+点和边无可可拥有属性,属性以键值对的方式描述。本例中,点 **player** 拥有属性 `id`、`name` 和 `age`,边 **like** 则拥有属性 `likeness`。
## Schema
diff --git a/docs/manual-CN/1.overview/1.concepts/2.nGQL-overview.md b/docs/manual-CN/1.overview/1.concepts/2.nGQL-overview.md
index 470a0bf9ced..8cc76aa339e 100644
--- a/docs/manual-CN/1.overview/1.concepts/2.nGQL-overview.md
+++ b/docs/manual-CN/1.overview/1.concepts/2.nGQL-overview.md
@@ -29,17 +29,17 @@
- 每个标签都有一个人类可读的名称,并且每个标签内部都会分配一个 32 位的整数
- 每个标签与一个属性列表相关联,每个属性都有一个名称和类型
- 标签之间可存在依赖关系作为约束。例如,如果标签 S 依赖于标签 T,则除非标签 T 存在,否则标签 S 无法存在。
-- **节点** :图数据中代表实体的点
- - 每个节点都有一个唯一的 64 位(有符号整数)ID (**VID**)
- - 一个节点可以拥有多个**标签**
-- **边**:节点之间的联系称为边
+- **点** :图数据中代表实体的点
+ - 每个点都有一个唯一的 64 位(有符号整数)ID (**VID**)
+ - 一个点可以拥有多个**标签**
+- **边**:点之间的联系称为边
- 每条边由唯一数组 **** 标识
- ***边类型*** 是人类可读的字符串,并且每条边内部都会分配一个 32 位的整数。边类型决定边上的属性(模式)
- ***边 rank*** 是用户分配的不可变的 64 位带符号整数,决定两个顶点之间相同类型的边顺序。等级值较高的边排名靠前。如未指定,则默认等级值为零。目前的排序依据为“二进制编码顺序“:即 0, 1, 2, ... 9223372036854775807, -9223372036854775808, -9223372036854775807, ..., -1。
- 每条边只能有一种类型
-- **路径**: 多个节点与边的**非分支**连接
- - 路径长度为该路径上的边数,比节点数少 1
- - 路径可由一系列节点,边类型及权重表示。一条边是一个长度为 1 的特殊路径
+- **路径**: 多个点与边的**非分支**连接
+ - 路径长度为该路径上的边数,比点数少 1
+ - 路径可由一系列点,边类型及权重表示。一条边是一个长度为 1 的特殊路径
```plain
, vid, ...>
@@ -142,9 +142,9 @@
:=
-#### 插入节点
+#### 插入点
-使用以下语句插入一个或多个节点
+使用以下语句插入一个或多个点
**INSERT VERTEX** [**NO OVERWRITE**] **VALUES**
@@ -162,9 +162,9 @@
edge\_value ::= -> [@ ] :
-#### 更新节点
+#### 更新点
-使用以下语句更新节点
+使用以下语句更新点
**UPDATE VERTEX**
**SET** \
@@ -186,7 +186,7 @@ edge\_value ::= -> [@ ] :
#### 图遍历
-根据指定条件遍历给定节点的关联节点,返回节点 ID 列表或数组
+根据指定条件遍历给定点的关联点,返回点 ID 列表或数组
**GO**
[ **STEPS**]
@@ -237,7 +237,7 @@ GO 3 TO 5 STEPS FROM me OVER friend WHERE birthday > "1988/1/1/"
#### 搜索
-以下语句对满足筛选条件的节点或边进行搜索。
+以下语句对满足筛选条件的点或边进行搜索。
**FIND VERTEX**
**WHERE**
@@ -274,7 +274,7 @@ $- 为输入值, $$ 为目标值。
### 内建属性
-- \_id: 节点 ID
+- \_id: 点 ID
- \_type: 边类型
- \_src: 边起始点 ID
- \_dst: 边终点 ID
diff --git a/docs/manual-CN/2.query-language/1.data-types/type-conversion.md b/docs/manual-CN/2.query-language/1.data-types/type-conversion.md
index c88a25d21a4..89209dd185c 100644
--- a/docs/manual-CN/2.query-language/1.data-types/type-conversion.md
+++ b/docs/manual-CN/2.query-language/1.data-types/type-conversion.md
@@ -8,12 +8,12 @@
1. 以下类型均可隐式转换至 `bool` 类型:
-+ 当且仅当字符串长度为 `0` 时,可被隐式转换为 `false` ,否则为 `true`
-+ 当且仅当整型数值为 `0` 时,可被隐式转换为 `false` ,否则为 `true`
-+ 当且仅当浮点类型数值为 `0.0` 时,可被隐式转换为 `false` ,否则为 `true`
+ - 当且仅当字符串长度为 `0` 时,可被隐式转换为 `false`,否则为 `true`
+ - 当且仅当整型数值为 `0` 时,可被隐式转换为 `false`,否则为 `true`
+ - 当且仅当浮点类型数值为 `0.0` 时,可被隐式转换为 `false`,否则为 `true`
2. `int` 类型可隐式转换为 `double` 类型
## 显式转换
-除隐式类型转换外,在符合语义的情况下,还可以使用显式类型转换。语法规则类似 C 语言: `(type_name)expression` 。例如, `YIELD length((string)(123)), (int)"123" + 1` 执行结果为 `3, 124`。`YIELD (int)("12ab3")` 则会转换失败。
+除隐式类型转换外,在符合语义的情况下,还可以使用显式类型转换。语法规则类似 C 语言:`(type_name)expression` 。例如,`YIELD length((string)(123)), (int)"123" + 1` 执行结果为 `3, 124`。`YIELD (int)(TRUE)` 执行结果为 `1`。`YIELD (int)("12ab3")` 则会转换失败。
diff --git a/docs/manual-CN/2.query-language/4.statement-syntax/2.data-query-and-manipulation-statements/fetch-syntax.md b/docs/manual-CN/2.query-language/4.statement-syntax/2.data-query-and-manipulation-statements/fetch-syntax.md
index a80c7beafe2..39242cd1323 100644
--- a/docs/manual-CN/2.query-language/4.statement-syntax/2.data-query-and-manipulation-statements/fetch-syntax.md
+++ b/docs/manual-CN/2.query-language/4.statement-syntax/2.data-query-and-manipulation-statements/fetch-syntax.md
@@ -10,11 +10,11 @@
FETCH PROP ON { | *} [YIELD [DISTINCT] ]
```
-`*` 返回指定 ID 点的所有属性。
+`*` 返回指定 `VID` 点的所有属性。
-`::=[tag_name [, tag_name]]` 为标签名称,与 return_list 中的标签相同。
+`::=[tag_name [, tag_name]]` 为标签名称,与 return_list 中的标签相同。
-`::=[vertex_id [, vertex_id]]` 是一组用 "," 分隔开的顶点 ID 列表。
+`::=[vertex_id [, vertex_id]]` 是一组用 "," 分隔开的顶点 `VID` 列表。
`[YIELD [DISTINCT] ]` 为返回的属性列表,`YIELD` 语法参看 [YIELD Syntax](yield-syntax.md) 。
diff --git a/docs/manual-CN/2.query-language/4.statement-syntax/2.data-query-and-manipulation-statements/insert-vertex-syntax.md b/docs/manual-CN/2.query-language/4.statement-syntax/2.data-query-and-manipulation-statements/insert-vertex-syntax.md
index 2f1cf8dd871..420671c6d8e 100644
--- a/docs/manual-CN/2.query-language/4.statement-syntax/2.data-query-and-manipulation-statements/insert-vertex-syntax.md
+++ b/docs/manual-CN/2.query-language/4.statement-syntax/2.data-query-and-manipulation-statements/insert-vertex-syntax.md
@@ -2,7 +2,7 @@
```ngql
INSERT VERTEX [, , ...] (prop_name_list[, prop_name_list])
- {VALUES | VALUE} vid: (prop_value_list[, prop_value_list])
+ {VALUES | VALUE} VID: (prop_value_list[, prop_value_list])
prop_name_list:
[prop_name [, prop_name] ...]
@@ -15,8 +15,8 @@ INSERT VERTEX 可向 **Nebula Graph** 插入节点。
- `tag_name` 表示标签(节点类型),在进行 `INSERT VERTEX` 操作前需创建好。
- `prop_name_list` 指定标签的属性列表。
-- `vid` 表示点 ID,目前的排序依据为“二进制编码顺序“:即 0, 1, 2, ... 9223372036854775807, -9223372036854775808, -9223372036854775807, ..., -1。`vid` 支持手动指定 ID 或使用 hash 生成。
-- `prop_value_list` 须根据 `prop_name_list` 列出属性,如无匹配类型,则返回错误。
+- `VID` 表示点 ID。每个图空间中的 `VID` 必须唯一。目前的排序依据为“二进制编码顺序“:即 0, 1, 2, ... 9223372036854775807, -9223372036854775808, -9223372036854775807, ..., -1。`VID` 支持手动指定 ID 或使用 `hash()` 函数生成。
+- `prop_value_list` 须根据 `prop_name_list` 列出属性值,如无匹配类型,则返回错误。
## 示例
diff --git a/docs/manual-CN/3.build-develop-and-administration/1.build/1.build-source-code.md b/docs/manual-CN/3.build-develop-and-administration/1.build/1.build-source-code.md
index 51f53937ed3..c26d9f903ae 100644
--- a/docs/manual-CN/3.build-develop-and-administration/1.build/1.build-source-code.md
+++ b/docs/manual-CN/3.build-develop-and-administration/1.build/1.build-source-code.md
@@ -108,12 +108,12 @@ $ sudo make install
$ cd /usr/local/nebula
$ cp etc/nebula-storaged.conf.production etc/nebula-storaged.conf
$ cp etc/nebula-metad.conf.production etc/nebula-metad.conf
-$ cp etc/nebula-metad.conf.production etc/nebula-metad.conf
+$ sudo cp etc/nebula-graphd.conf.production etc/nebula-graphd.conf
# 用于试用
$ cd /usr/local/nebula
$ sudo cp etc/nebula-storaged.conf.default etc/nebula-storaged.conf
$ sudo cp etc/nebula-metad.conf.default etc/nebula-metad.conf
-$ sudo cp etc/nebula-metad.conf.default etc/nebula-metad.conf
+$ sudo cp etc/nebula-graphd.conf.default etc/nebula-graphd.conf
```
详情参考[启动和停止 Nebula Graph 服务文档](../2.install/2.start-stop-service.md)。
diff --git a/docs/manual-CN/3.build-develop-and-administration/3.configurations/0.system-requirement.md b/docs/manual-CN/3.build-develop-and-administration/3.configurations/0.system-requirement.md
index c3c46aecf50..feb88f64121 100644
--- a/docs/manual-CN/3.build-develop-and-administration/3.configurations/0.system-requirement.md
+++ b/docs/manual-CN/3.build-develop-and-administration/3.configurations/0.system-requirement.md
@@ -54,7 +54,7 @@
## 资源估算(3副本标准配置)
* 存储空间(全集群):点和边数量 * 平均属性的字节数 * 6
-* 内存(全集群):点边数量 * 5 字节 + RocksDB 实例数量 * (write_buffer_size * max_write_buffer_number + rocksdb_block_cache), 其中 `etc/nebula-storaged.conf` 文件中 `--data_path` 项中的每个目录对应一个 RocksDB 实例
+* 内存(全集群):点边数量 * 15 字节 + RocksDB 实例数量 * (write_buffer_size * max_write_buffer_number + rocksdb_block_cache), 其中 `etc/nebula-storaged.conf` 文件中 `--data_path` 项中的每个目录对应一个 RocksDB 实例
* 图空间 partition 数量:全集群硬盘数量 * (2 至 10 —— 硬盘越好该值越大)
* 内存和硬盘另预留 20% buffer。
diff --git a/docs/manual-CN/3.build-develop-and-administration/5.storage-service-administration/compact.md b/docs/manual-CN/3.build-develop-and-administration/5.storage-service-administration/compact.md
index 2aebaabed04..22ef9770a94 100644
--- a/docs/manual-CN/3.build-develop-and-administration/5.storage-service-administration/compact.md
+++ b/docs/manual-CN/3.build-develop-and-administration/5.storage-service-administration/compact.md
@@ -14,7 +14,7 @@ nebula> UPDATE CONFIGS storage:rocksdb_column_family_options = {disable_auto_com
- 调用 **Nebula Graph** 自定义的 compact:主要目的是完成大规模的 sst 文件合并、TTL 等大规模后台操作。通常建议在凌晨业务低谷时进行。通过 `SUBMIT JOB COMPACT` 来主动触发。
-另外,两种方法的线程数均可通过如下命令调整。日间可以将调整线程数调低,夜间可以增加线程数。
+另外,两种方法的线程数均可通过如下命令调整。
```ngql
nebula> UPDATE CONFIGS storage:rocksdb_db_options = \
diff --git a/docs/manual-CN/5.appendix/vid-partition.md b/docs/manual-CN/5.appendix/vid-partition.md
new file mode 100644
index 00000000000..7a56f0f7db4
--- /dev/null
+++ b/docs/manual-CN/5.appendix/vid-partition.md
@@ -0,0 +1,25 @@
+# 点标识符和分区
+
+本文档提供有关点标识符(简称 `VID`)和分区的一些介绍。
+
+在 **Nebula Graph** 中,点是用点标识符(即 `VID`)标识的。插入点时,必须指定 `VID`(int64)。`VID` 可以由应用程序生成,也可以使用 **Nebula Graph** 提供的哈希函数生成。
+
+`VID` 在一个图空间中必须唯一。即在同一个图空间中,拥有相同 `VID` 的点被当做同一个点。不同图空间中的 `VID` 彼此独立。此外,一个 `VID` 可以拥有多种 `TAG`。
+
+向 **Nebula Graph** 集群中插入数据时,点和边会分布到不同的分区中,而这些分区又分布在多台机器上。应用程序如果希望将某些点落在同一个分区中(也即在同一台机器上),可根据以下公式自行控制 `VID` 的生成。
+
+`VID` 和分区的对应关系为:
+
+```text
+VID mod partition_number = partition ID + 1
+```
+
+其中,
+
+- `mod` 是取模操作。
+- `partition_number` 是 `VID` 所处图空间的的分区数量,即 [CREATE SPACE](../2.query-language/4.statement-syntax/1.data-definition-statements/create-space-syntax.md) 语句中 `partition_num` 的值。
+- `partition ID` 即该 `VID` 所在分区的 ID。
+
+例如,如果有 100 个分区,那 `VID` 为 1、11、101、1001 的点将存储在同一个分区上。
+
+此外,`partition ID` 和机器之间的对应关系是随机的。因此不可以假设任何两个分区分布在同一台机器上。
diff --git a/docs/manual-CN/README.md b/docs/manual-CN/README.md
index 9546796803d..d927bbddf44 100644
--- a/docs/manual-CN/README.md
+++ b/docs/manual-CN/README.md
@@ -2,7 +2,7 @@
**Nebula Graph** 是一个分布式的可扩展的高性能的图数据库。
-**Nebula Graph** 可以容纳百亿节点和万亿条边,并达到毫秒级的时延。
+**Nebula Graph** 可以容纳百亿点和万亿条边,并达到毫秒级的时延。
## 前言
@@ -169,7 +169,7 @@
* [Gremlin V.S. nGQL](5.appendix/gremlin-ngql.md)
* [Cypher V.S. nGQL](5.appendix/cypher-ngql.md)
* [SQL V.S. nGQL](5.appendix/sql-ngql.md)
-
+* [点标识符和分区](5.appendix/vid-partition.md)
## 其他
diff --git a/mkdocs.yml b/mkdocs.yml
index 2b5c6cc1082..ecade99aa7c 100755
--- a/mkdocs.yml
+++ b/mkdocs.yml
@@ -210,7 +210,8 @@ nav:
- Cypher & nGQL: manual-CN/5.appendix/cypher-ngql.md
- Gremlin & nGQL: manual-CN/5.appendix/gremlin-ngql.md
- SQL & nGQL: manual-CN/5.appendix/sql-ngql.md
- #- 升级 Nebula Graph: manual-CN/5.appendix/upgrade-guide.md
+ - 点标识符和分区: manual-CN/5.appendix/vid-partition.md
+
- English:
- https://docs.nebula-graph.io/