diff --git a/CONTRIBUTING.md b/CONTRIBUTING.md
new file mode 100644
index 00000000000..c33aa3d3db2
--- /dev/null
+++ b/CONTRIBUTING.md
@@ -0,0 +1,27 @@
+# Contribute to Documentation
+
+Contributing to the **Nebula Graph** documentation can be a rewarding experience. We welcome your participation to help make the documentation better!
+
+## What to Contribute
+
+You can start from any of the documents in this repository:
+
+- Fix typos or format (punctuation, space, indentation, code block, etc.)
+- Fix or update inappropriate or outdated descriptions
+- Add new document
+- Raise or resolve [docs issues](https://github.com/vesoft-inc/nebula-docs/issues)
+- Review Pull Requests created by others
+
+## Before Contributing
+
+Before contributing, please take a quick look at some general information about **Nebula Graph** documentation maintenance.
+
+- [Markdown Rules](https://github.com/DavidAnson/markdownlint/blob/master/doc/Rules.md)
+- [Developer Documentation Style Guide](docs/manual-EN/4.contributions/developer-documentation-style-guide.md)
+
+## How to Contribute
+
+There are many ways to contribute:
+
+- Raise a documentation issue on [GitHub](https://github.com/vesoft-inc/nebula/issues).
+- Fork the documentation, make changes or add new content on your local branch, and submit a pull request (PR) to the master branch for the docs.
diff --git a/LICENSE b/LICENSE
new file mode 100644
index 00000000000..261eeb9e9f8
--- /dev/null
+++ b/LICENSE
@@ -0,0 +1,201 @@
+ Apache License
+ Version 2.0, January 2004
+ http://www.apache.org/licenses/
+
+ TERMS AND CONDITIONS FOR USE, REPRODUCTION, AND DISTRIBUTION
+
+ 1. Definitions.
+
+ "License" shall mean the terms and conditions for use, reproduction,
+ and distribution as defined by Sections 1 through 9 of this document.
+
+ "Licensor" shall mean the copyright owner or entity authorized by
+ the copyright owner that is granting the License.
+
+ "Legal Entity" shall mean the union of the acting entity and all
+ other entities that control, are controlled by, or are under common
+ control with that entity. For the purposes of this definition,
+ "control" means (i) the power, direct or indirect, to cause the
+ direction or management of such entity, whether by contract or
+ otherwise, or (ii) ownership of fifty percent (50%) or more of the
+ outstanding shares, or (iii) beneficial ownership of such entity.
+
+ "You" (or "Your") shall mean an individual or Legal Entity
+ exercising permissions granted by this License.
+
+ "Source" form shall mean the preferred form for making modifications,
+ including but not limited to software source code, documentation
+ source, and configuration files.
+
+ "Object" form shall mean any form resulting from mechanical
+ transformation or translation of a Source form, including but
+ not limited to compiled object code, generated documentation,
+ and conversions to other media types.
+
+ "Work" shall mean the work of authorship, whether in Source or
+ Object form, made available under the License, as indicated by a
+ copyright notice that is included in or attached to the work
+ (an example is provided in the Appendix below).
+
+ "Derivative Works" shall mean any work, whether in Source or Object
+ form, that is based on (or derived from) the Work and for which the
+ editorial revisions, annotations, elaborations, or other modifications
+ represent, as a whole, an original work of authorship. For the purposes
+ of this License, Derivative Works shall not include works that remain
+ separable from, or merely link (or bind by name) to the interfaces of,
+ the Work and Derivative Works thereof.
+
+ "Contribution" shall mean any work of authorship, including
+ the original version of the Work and any modifications or additions
+ to that Work or Derivative Works thereof, that is intentionally
+ submitted to Licensor for inclusion in the Work by the copyright owner
+ or by an individual or Legal Entity authorized to submit on behalf of
+ the copyright owner. For the purposes of this definition, "submitted"
+ means any form of electronic, verbal, or written communication sent
+ to the Licensor or its representatives, including but not limited to
+ communication on electronic mailing lists, source code control systems,
+ and issue tracking systems that are managed by, or on behalf of, the
+ Licensor for the purpose of discussing and improving the Work, but
+ excluding communication that is conspicuously marked or otherwise
+ designated in writing by the copyright owner as "Not a Contribution."
+
+ "Contributor" shall mean Licensor and any individual or Legal Entity
+ on behalf of whom a Contribution has been received by Licensor and
+ subsequently incorporated within the Work.
+
+ 2. Grant of Copyright License. Subject to the terms and conditions of
+ this License, each Contributor hereby grants to You a perpetual,
+ worldwide, non-exclusive, no-charge, royalty-free, irrevocable
+ copyright license to reproduce, prepare Derivative Works of,
+ publicly display, publicly perform, sublicense, and distribute the
+ Work and such Derivative Works in Source or Object form.
+
+ 3. Grant of Patent License. Subject to the terms and conditions of
+ this License, each Contributor hereby grants to You a perpetual,
+ worldwide, non-exclusive, no-charge, royalty-free, irrevocable
+ (except as stated in this section) patent license to make, have made,
+ use, offer to sell, sell, import, and otherwise transfer the Work,
+ where such license applies only to those patent claims licensable
+ by such Contributor that are necessarily infringed by their
+ Contribution(s) alone or by combination of their Contribution(s)
+ with the Work to which such Contribution(s) was submitted. If You
+ institute patent litigation against any entity (including a
+ cross-claim or counterclaim in a lawsuit) alleging that the Work
+ or a Contribution incorporated within the Work constitutes direct
+ or contributory patent infringement, then any patent licenses
+ granted to You under this License for that Work shall terminate
+ as of the date such litigation is filed.
+
+ 4. Redistribution. You may reproduce and distribute copies of the
+ Work or Derivative Works thereof in any medium, with or without
+ modifications, and in Source or Object form, provided that You
+ meet the following conditions:
+
+ (a) You must give any other recipients of the Work or
+ Derivative Works a copy of this License; and
+
+ (b) You must cause any modified files to carry prominent notices
+ stating that You changed the files; and
+
+ (c) You must retain, in the Source form of any Derivative Works
+ that You distribute, all copyright, patent, trademark, and
+ attribution notices from the Source form of the Work,
+ excluding those notices that do not pertain to any part of
+ the Derivative Works; and
+
+ (d) If the Work includes a "NOTICE" text file as part of its
+ distribution, then any Derivative Works that You distribute must
+ include a readable copy of the attribution notices contained
+ within such NOTICE file, excluding those notices that do not
+ pertain to any part of the Derivative Works, in at least one
+ of the following places: within a NOTICE text file distributed
+ as part of the Derivative Works; within the Source form or
+ documentation, if provided along with the Derivative Works; or,
+ within a display generated by the Derivative Works, if and
+ wherever such third-party notices normally appear. The contents
+ of the NOTICE file are for informational purposes only and
+ do not modify the License. You may add Your own attribution
+ notices within Derivative Works that You distribute, alongside
+ or as an addendum to the NOTICE text from the Work, provided
+ that such additional attribution notices cannot be construed
+ as modifying the License.
+
+ You may add Your own copyright statement to Your modifications and
+ may provide additional or different license terms and conditions
+ for use, reproduction, or distribution of Your modifications, or
+ for any such Derivative Works as a whole, provided Your use,
+ reproduction, and distribution of the Work otherwise complies with
+ the conditions stated in this License.
+
+ 5. Submission of Contributions. Unless You explicitly state otherwise,
+ any Contribution intentionally submitted for inclusion in the Work
+ by You to the Licensor shall be under the terms and conditions of
+ this License, without any additional terms or conditions.
+ Notwithstanding the above, nothing herein shall supersede or modify
+ the terms of any separate license agreement you may have executed
+ with Licensor regarding such Contributions.
+
+ 6. Trademarks. This License does not grant permission to use the trade
+ names, trademarks, service marks, or product names of the Licensor,
+ except as required for reasonable and customary use in describing the
+ origin of the Work and reproducing the content of the NOTICE file.
+
+ 7. Disclaimer of Warranty. Unless required by applicable law or
+ agreed to in writing, Licensor provides the Work (and each
+ Contributor provides its Contributions) on an "AS IS" BASIS,
+ WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or
+ implied, including, without limitation, any warranties or conditions
+ of TITLE, NON-INFRINGEMENT, MERCHANTABILITY, or FITNESS FOR A
+ PARTICULAR PURPOSE. You are solely responsible for determining the
+ appropriateness of using or redistributing the Work and assume any
+ risks associated with Your exercise of permissions under this License.
+
+ 8. Limitation of Liability. In no event and under no legal theory,
+ whether in tort (including negligence), contract, or otherwise,
+ unless required by applicable law (such as deliberate and grossly
+ negligent acts) or agreed to in writing, shall any Contributor be
+ liable to You for damages, including any direct, indirect, special,
+ incidental, or consequential damages of any character arising as a
+ result of this License or out of the use or inability to use the
+ Work (including but not limited to damages for loss of goodwill,
+ work stoppage, computer failure or malfunction, or any and all
+ other commercial damages or losses), even if such Contributor
+ has been advised of the possibility of such damages.
+
+ 9. Accepting Warranty or Additional Liability. While redistributing
+ the Work or Derivative Works thereof, You may choose to offer,
+ and charge a fee for, acceptance of support, warranty, indemnity,
+ or other liability obligations and/or rights consistent with this
+ License. However, in accepting such obligations, You may act only
+ on Your own behalf and on Your sole responsibility, not on behalf
+ of any other Contributor, and only if You agree to indemnify,
+ defend, and hold each Contributor harmless for any liability
+ incurred by, or claims asserted against, such Contributor by reason
+ of your accepting any such warranty or additional liability.
+
+ END OF TERMS AND CONDITIONS
+
+ APPENDIX: How to apply the Apache License to your work.
+
+ To apply the Apache License to your work, attach the following
+ boilerplate notice, with the fields enclosed by brackets "[]"
+ replaced with your own identifying information. (Don't include
+ the brackets!) The text should be enclosed in the appropriate
+ comment syntax for the file format. We also recommend that a
+ file or class name and description of purpose be included on the
+ same "printed page" as the copyright notice for easier
+ identification within third-party archives.
+
+ Copyright [yyyy] [name of copyright owner]
+
+ Licensed under the Apache License, Version 2.0 (the "License");
+ you may not use this file except in compliance with the License.
+ You may obtain a copy of the License at
+
+ http://www.apache.org/licenses/LICENSE-2.0
+
+ Unless required by applicable law or agreed to in writing, software
+ distributed under the License is distributed on an "AS IS" BASIS,
+ WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+ See the License for the specific language governing permissions and
+ limitations under the License.
diff --git a/README.md b/README.md
index 2cf969cd770..026de2c1b44 100644
--- a/README.md
+++ b/README.md
@@ -1,2 +1,41 @@
-# nebula-docs-cn
-Repository for the Chinese documentations
+# Nebula Graph Documentation
+
+This repository holds all the source files of **Nebula Graph** Documentations at [Official Documentation Site](https://docs.nebula-graph.io/).
+
+## Documentation Structure
+
+The general **Nebula Graph** documentation structure is as follows:
+
+```bash
+├── Language
+├── Overview
+ ├── Introduction
+ ├── Concepts
+ ├── Quick Start
+ ├── Get Started
+ ├── ...
+├── Query Language
+ ├── Data Types
+ ├── ...
+ ├── Functions and Operators
+ ├── ...
+ ├── Language Structure
+ ├── ...
+ ├── Statement Syntax
+ ├── ...
+├── Build Develop and Administration
+ ├── Build
+ ├── ...
+ ├── ...
+...
+```
+
+Detail TOC (table of content) please refer to the following links.
+
+- [Documentation Index](docs/manual-EN/README.md)
+- [文档索引](docs/manual-CN/README.md)
+- [Official Documentation Site](https://docs.nebula-graph.io/)
+
+## Contributing
+
+If you find documentation issues, feel free to create an [Issue](https://github.com/vesoft-inc/nebula-docs/issues) to let us know or directly create a [Pull Request](https://github.com/vesoft-inc/nebula-docs/pulls) to help fix or update it. See **Nebula Graph** [CONTRIBUTING](CONTRIBUTING.md) guide to get started. :)
diff --git a/docs/.gitignore b/docs/.gitignore
new file mode 100644
index 00000000000..a17e3b682fc
--- /dev/null
+++ b/docs/.gitignore
@@ -0,0 +1,3 @@
+*.zip
+*.pdf
+
diff --git a/docs/CNAME b/docs/CNAME
new file mode 100644
index 00000000000..5b5fd1aac9d
--- /dev/null
+++ b/docs/CNAME
@@ -0,0 +1 @@
+docs.nebula-graph.io
diff --git a/docs/README.md b/docs/README.md
new file mode 100644
index 00000000000..f2e56d5290d
--- /dev/null
+++ b/docs/README.md
@@ -0,0 +1,70 @@
+# Nebula Graph 是什么
+
+**Nebula Graph** 是一款开源的图数据库,擅长处理千亿个顶点和万亿条边的超大规模数据集。
+
+与其他图数据库产品相比,**Nebula Graph** 具有如下优势:
+
+* 全对称分布式架构
+* 存储与计算分离
+* 水平可扩展性
+* RAFT 协议下的数据强一致
+* 类 SQL 查询语言
+* 用户鉴权
+
+## 产品路线图
+
+**Nebula Graph** 产品规划路线图请参见 [roadmap](https://github.com/vesoft-inc/nebula/wiki/Nebula-Graph-Roadmap)。
+
+## 图可视化
+
+查看[图可视化](https://github.com/vesoft-inc/nebula-web-docker),开启图数据可视化探索之旅。
+
+## 支持的客户端
+
+* [Go](https://github.com/vesoft-inc/nebula-go)
+* [Python](https://github.com/vesoft-inc/nebula-python)
+* [Java](https://github.com/vesoft-inc/nebula-java)
+
+## 快速使用
+
+请查看[快速使用手册](manual-CN/1.overview/2.quick-start/1.get-started.md),开始使用 **Nebula Graph**。
+
+在开始使用 **Nebula Graph** 之前,必须通过[编译源码](manual-CN/3.build-develop-and-administration/1.build/1.build-source-code.md),[rpm/deb 包](manual-CN/3.build-develop-and-administration/2.install/1.install-with-rpm-deb.md) 或者 [docker compose](https://github.com/vesoft-inc/nebula-docker-compose) 方式安装 **Nebula Graph**。您也可以观看[视频](https://space.bilibili.com/472621355)学习如何安装 **Nebula Graph**。
+
+## 获取帮助
+
+在使用 **Nebula Graph** 过程中遇到任何问题,都可以通过下面的方式寻求帮助:
+
+* [知乎](https://www.zhihu.com/org/nebulagraph/activities)
+* [SegmentFault](https://segmentfault.com/t/nebula)
+* [官方论坛](https://discuss.nebula-graph.io)
+
+## 文档
+
+* [简体中文](https://github.com/vesoft-inc/nebula/blob/master/docs/manual-CN/README.md)
+* [English](https://github.com/vesoft-inc/nebula/blob/master/docs/manual-EN/README.md)
+
+## Nebula Graph 产品架构图
+
+
+
+## 如何贡献
+
+**Nebula Graph** 是一个完全开源的项目,欢迎开源爱好者通过以下方式参与到 **Nebula Graph** 社区:
+
+* 从标记为 [good first issues](https://github.com/vesoft-inc/nebula/issues?q=is%3Aissue+is%3Aopen+label%3A%22good+first+issue%22) 的问题入手
+* 贡献代码,详情请参见 [如何贡献](manual-CN/4.contributions/how-to-contribute.md)
+* 直接在GitHub上提 [Issue](https://github.com/vesoft-inc/nebula/issues)
+
+## 许可证
+
+**Nebula Graph** 使用 [Apache 2.0](https://www.apache.org/licenses/LICENSE-2.0) 许可证,您可以免费下载,修改以及部署源代码。您还可以将 **Nebula Graph** 作为后端服务部署以支持您的 SaaS 部署。
+
+为防止云供应商从项目赢利而不回馈,**Nebula Graph** 在项目中添加了 [Commons Clause 1.0](https://commonsclause.com/) 条款。如上所述,**Nebula Graph** 是一个完全开源的项目,欢迎您就许可模式提出建议,帮助 **Nebula Graph** 社区更好地发展。
+
+## 联系方式
+
+* 访问官网 [Home Page](http://nebula-graph.io/)。
+* [](https://user-images.githubusercontent.com/38887077/67449282-4362b300-f64c-11e9-878f-7efc373e5e55.jpg)
+* [](https://weibo.com/p/1006067122684542/home?from=page_100606&mod=TAB#place)
+* email: info@vesoft.com
diff --git a/docs/assets/favicon.ico b/docs/assets/favicon.ico
new file mode 100644
index 00000000000..0a266f1ef29
Binary files /dev/null and b/docs/assets/favicon.ico differ
diff --git a/docs/assets/images/Nebula Arch.png b/docs/assets/images/Nebula Arch.png
new file mode 100644
index 00000000000..61d0a5e9c4e
Binary files /dev/null and b/docs/assets/images/Nebula Arch.png differ
diff --git a/docs/assets/images/QE Arch.png b/docs/assets/images/QE Arch.png
new file mode 100644
index 00000000000..54107b7fc47
Binary files /dev/null and b/docs/assets/images/QE Arch.png differ
diff --git a/docs/assets/images/favicon.ico b/docs/assets/images/favicon.ico
new file mode 100644
index 00000000000..0a266f1ef29
Binary files /dev/null and b/docs/assets/images/favicon.ico differ
diff --git a/docs/doc-tools/README.md b/docs/doc-tools/README.md
new file mode 100644
index 00000000000..6c6af449a3a
--- /dev/null
+++ b/docs/doc-tools/README.md
@@ -0,0 +1,51 @@
+# Generate documentation in PDF
+
+This document teaches you how to make documentation in PDF.
+
+## Step One: Merge
+
+Use the provided script `merge-all.py` to merge all the markdown doc files into one.
+
+## Step Two: Generate TOC
+
+Use pandoc to generated TOC (table of content) for the file you just merged. Firstly, you should make sure that pandoc has been installed on your machine. Open your terminal and run the command:
+
+```bash
+pandoc -v
+```
+
+If pandoc is not installed, please install it first.
+
+**Windows**
+
+```bash
+choco install pandoc
+```
+
+**macOS**
+
+```bash
+brew install pandoc
+```
+
+If you have any questions on pandoc installation, please check its document [here](https://pandoc.org/installing.html).
+
+To generate TOC, you should first change directory to the merged file and type the following command:
+
+```bash
+pandoc -s --toc merged.md -o merged.md
+```
+
+**Note**: The default number of section levels is 3 in the table of contents (which means that level-1, 2, and 3 headings will be listed in the contents), use `--toc-depth=NUMBER` to specify that number.
+
+## Step Three: Generate PDF
+
+You can convert the merged markdown file into PDF and print it out for easy-reading. Use the following command to generate PDF:
+
+```bash
+pandoc merged.md -o merged.pdf
+```
+
+**Note:** Make sure [MiKTeX](https://miktex.org/howto/install-miktex) is installed.
+
+Now you've got your PDF documentation and have fun with **Nebula Graph**.
diff --git a/docs/doc-tools/merge-all.py b/docs/doc-tools/merge-all.py
new file mode 100644
index 00000000000..8e8b08b5141
--- /dev/null
+++ b/docs/doc-tools/merge-all.py
@@ -0,0 +1,84 @@
+import os
+import sys
+
+# This script is to help you merge all the docs into one mardown file, then you can convert it into one pdf file and down load.
+
+
+def get_all_md_file_path(file_path):
+ if not os.path.isdir(file_path):
+ print(file_path+" is not a dir")
+ file_list_in_md = os.listdir(file_path)
+ file_list_md = []
+ for path_md in file_list_in_md:
+ if '.md' in path_md:
+ file_list_md.append(file_path + '/' + path_md)
+ # print(file_list_md)
+ return file_list_md
+
+
+def read_md_file(md_file_path):
+ with open(md_file_path) as f:
+ lines = f.readlines()
+ return lines
+
+
+def creat_md_file(file_name):
+ f = open(file_name, 'w')
+ f.write('\n')
+ f.close()
+
+
+def write_file(source_file_dir, dst_md_file):
+ with open(dst_md_file, 'a') as md_writor:
+ md_file_list = get_all_md_file_path(source_file_dir)
+ md_file_list.sort()
+ for file in md_file_list:
+ print('writing ' + file)
+ lines = read_md_file(file)
+ for line in lines:
+ md_writor.write(line)
+ md_writor.write('\n\n\n')
+
+
+def write_all(source_dir, dst_md_file):
+ file_list = os.listdir(source_dir)
+ dir_list = []
+ for path in file_list:
+ file_path = source_dir + '/' + path
+ if os.path.isdir(file_path):
+ dir_list.append(file_path)
+ elif os.path.isfile(path):
+ pass
+ write_file(source_dir, dst_md_file)
+ dir_list.sort()
+ for sub_dir in dir_list:
+ write_all(sub_dir, dst_md_file)
+
+
+if __name__ == "__main__":
+
+ # define these constants for reusability without commanline arguments
+ UNDEFINED = 'UNDEFINED'
+
+ # Output file
+ target_file = UNDEFINED
+ # Source file to be merged
+ source_dir = UNDEFINED
+
+ # argument 1 will be the source, argument 2 will be the target
+ if len(sys.argv) == 1:
+ sys.exit(
+ 'usage: merge-all [target_file] [source_dir]'
+ )
+
+ elif len(sys.argv) != 3:
+ if target_file == UNDEFINED or source_dir == UNDEFINED:
+ sys.exit(
+ 'error: target_file and source_dir not given in either scripts or commandline'
+ )
+ else:
+ target_file = sys.argv[1]
+ source_dir = sys.argv[2]
+
+ creat_md_file(target_file)
+ write_all(source_dir, target_file)
diff --git a/docs/logo.png b/docs/logo.png
new file mode 100644
index 00000000000..604f158f696
Binary files /dev/null and b/docs/logo.png differ
diff --git a/docs/manual-CN/0.about-this-manual.md b/docs/manual-CN/0.about-this-manual.md
new file mode 100644
index 00000000000..eb39d429328
--- /dev/null
+++ b/docs/manual-CN/0.about-this-manual.md
@@ -0,0 +1,31 @@
+# 关于本手册
+
+此手册为 **Nebula Graph** 的用户手册,版本为 R202004_RC4。详细版本更新信息参见 [Release Notes](https://github.com/vesoft-inc/nebula/releases)。
+
+## 面向的读者
+
+本手册适用于 `算法工程师`、`数据科学家`、`软件开发人员`和 `DBA`,以及所有对`图数据库`感兴趣的人群。
+
+如果在使用 **Nebula Graph** 的过程中有任何问题,欢迎在 [Nebula Graph Community Slack](https://join.slack.com/t/nebulagraph/shared_invite/enQtNjIzMjQ5MzE2OTQ2LTM0MjY0MWFlODg3ZTNjMjg3YWU5ZGY2NDM5MDhmOGU2OWI5ZWZjZDUwNTExMGIxZTk2ZmQxY2Q2MzM1OWJhMmY#") 或[官方论坛](https://discuss.nebula-graph.com.cn/)提问。
+如果对本手册有任何建议或疑问,请在 [GitHub](https://github.com/vesoft-inc/nebula/issues) 给我们留言。
+
+## 格式约定
+
+**Nebula Graph** 尚在持续开发中,本手册也将持续更新。
+本手册使用如下语法惯例:
+
+- `等宽字体`
+
+ 等宽字体用于表示**命令**,**需要用户输入的命令**及**接口**。
+
+- **加粗字体**
+
+ 用于命令以及其他需要用户逐字输入的文字。
+
+- `UPPERCASE fixed width`
+
+ 在查询语言中,`保留关键字` 和 `非保留关键字` 均使用大写等宽字体表示。
+
+## 文件格式
+
+本手册所有文件均采用 Markdown 编写,HTML 网站使用 [mkdocs](https://www.mkdocs.org/) 自动生成。
diff --git a/docs/manual-CN/1.overview/0.introduction.md b/docs/manual-CN/1.overview/0.introduction.md
new file mode 100644
index 00000000000..5865fbbd9b6
--- /dev/null
+++ b/docs/manual-CN/1.overview/0.introduction.md
@@ -0,0 +1,39 @@
+# Nebula Graph 概览
+
+## 什么是 Nebula Graph
+
+**Nebula Graph** 是一个开源 (Apache 2.0),高性能的分布式图数据库,是世界上唯一一个支持百亿节点,万亿条边,并提供毫秒延迟的图数据库解决方案。
+
+**Nebula Graph** 的目标是提供高并发低延时的读写及计算。 **Nebula Graph** 是一个开源项目,我们期待与社区一起共同推进行业发展。
+
+## Nebula Graph 特点
+
+**Nebula Graph** 有如下重要特点:
+
+- 高性能
+
+ 提供低延时高并发读写
+
+- 类 SQL 查询语言
+
+ SQL 式的查询语言,易学易用,满足复杂业务需求
+
+- 高度安全
+
+ 完善的分组和用户鉴权
+
+- 可扩展
+
+ 支持水平扩展,可自动实现负载均衡与弹性扩容
+
+- 多存储后端
+
+ 支持 RocksDB、HBase 等多种存储后端
+
+- 智能驱动
+
+ 通过索引推荐、指标监控、慢查询分析发现性能风险
+
+- 高可用
+
+ 多重冗余架构设计,为数据持久存储提供可靠保障
diff --git a/docs/manual-CN/1.overview/1.concepts/1.data-model.md b/docs/manual-CN/1.overview/1.concepts/1.data-model.md
new file mode 100644
index 00000000000..46d3c4cb59c
--- /dev/null
+++ b/docs/manual-CN/1.overview/1.concepts/1.data-model.md
@@ -0,0 +1,49 @@
+# 图数据建模
+
+此文档介绍 **Nebula Graph** 建模及图模型的基本概念。
+
+## 图空间
+
+**图空间** 为彼此隔离的图数据,与 MySQL 中的 database 概念类似。
+
+## 有向属性图
+
+**Nebula Graph** 存储的图为 **_有向属性图_**,边为有向边,点和边均可包含属性。可表示为:
+G = < V, E, PV, PE >,
+其中 **V** 表示节点,**E** 表示有向边,**PV** 表示节点属性,**PE** 表示边属性。
+此文档将使用如下示例图数据介绍属性图的基本概念:
+
+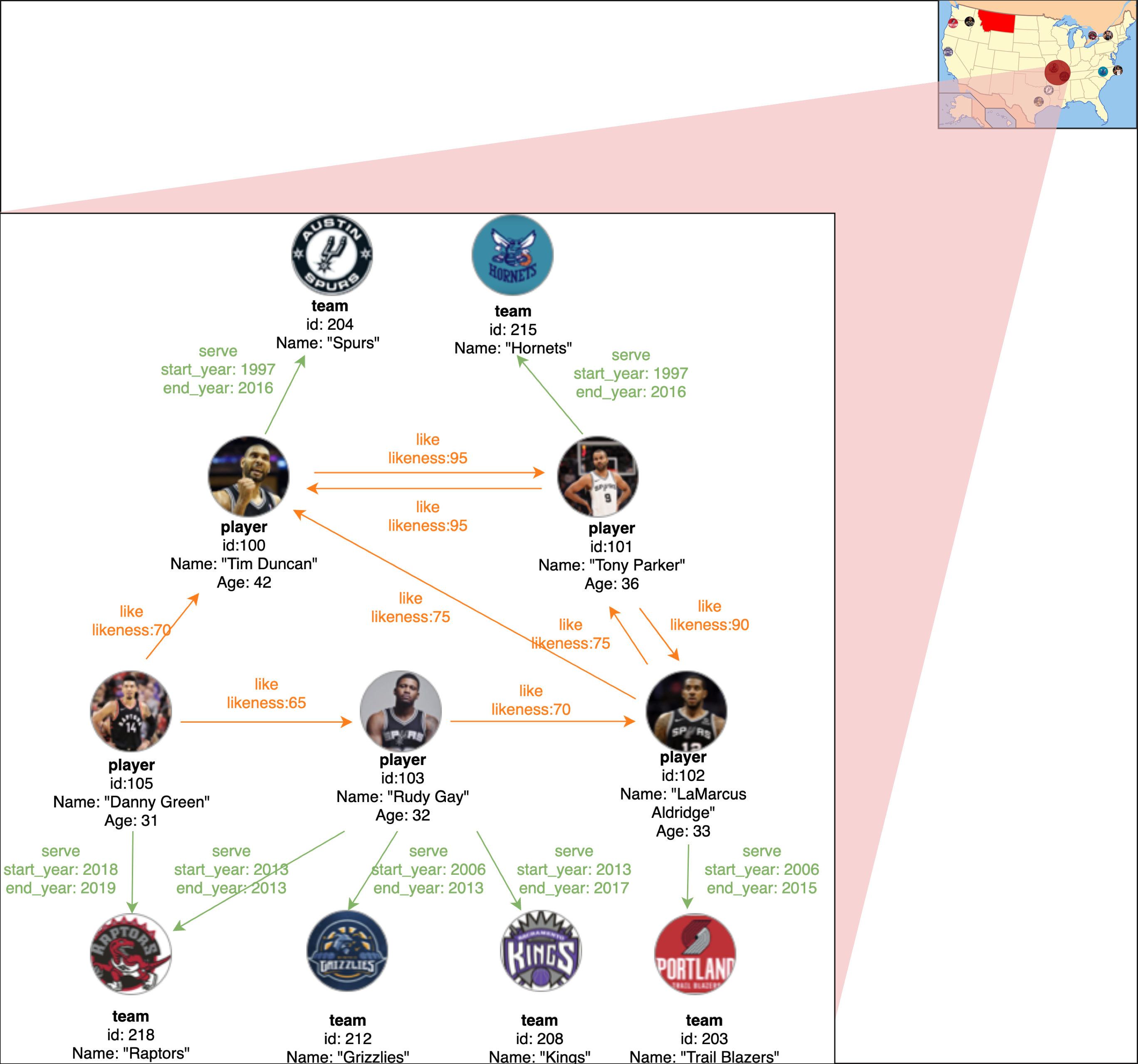
+
+上图为 NBA 球员及球队信息数据,图中包含 2 种类型的 11 个节点,即 player 和 team,2 种类型的边,即 serve 和 like。
+以下为示例图数据涉及到的概念介绍。
+
+## 节点
+
+节点用于表示现实世界中的实体,本例的数据中共包含 11 个节点。
+
+ +
+## 标签
+
+**Nebula Graph** 使用**标签**对节点进行分类,本例包含的节点标签为 **player** 和 **team**。
+
+
+
+## 标签
+
+**Nebula Graph** 使用**标签**对节点进行分类,本例包含的节点标签为 **player** 和 **team**。
+
+ +
+## 边
+
+边用来连接节点,边通常表示两个节点间的某种关系或行为,本例中的边为 _**serve**_ 和 _**like**_。
+
+
+
+## 边
+
+边用来连接节点,边通常表示两个节点间的某种关系或行为,本例中的边为 _**serve**_ 和 _**like**_。
+
+ +
+## 边类型
+
+每条边都有一种边类型,以边 _**serve**_ 为例,节点 `101`(表示一名球员)为起始点,节点 `215`(表示一支球队)为目标点。节点 `101` 有一条出边,而节点 `215` 有一条入边。
+
+## 属性
+
+属性为点和边内部的键值对。本例中,节点 **player** 拥有属性 `id`, `name` 和 `age`,边 _**like** 则拥有属性 `likeness`。
+
+## Schema
+
+在 **Nebula Graph** 中,schema 为标签及边对应的属性。与 `MySQL` 类似,**Nebula Graph** 是一种强 schema 的数据库,属性的名称和数据类型在数据写入前已确定。
diff --git a/docs/manual-CN/1.overview/1.concepts/2.nGQL-overview.md b/docs/manual-CN/1.overview/1.concepts/2.nGQL-overview.md
new file mode 100644
index 00000000000..f2321619d6e
--- /dev/null
+++ b/docs/manual-CN/1.overview/1.concepts/2.nGQL-overview.md
@@ -0,0 +1,281 @@
+# Nebula Graph 查询语言 (nGQL)
+
+## nGQL 概览
+
+`nGQL` 是一种声明型的文本查询语言,目前尚在开发中。新版本会添加更多功能并优化已有功能。未来的语法规范可能会与现行的不一致。
+
+## 目标
+
+- 易学
+- 易用
+- 专注线上查询,同时为离线计算提供基础
+
+## 特点
+
+- 类 SQL,易学易用
+- 可扩展
+- 大小写不敏感
+- 支持图遍历
+- 支持模式匹配
+- 支持聚合运算
+- 支持图计算
+- 支持分布式事务(开发中)
+- 无嵌入支持组合语句,易于阅读
+
+## 术语
+
+- **图空间**:物理隔离的不同数据集
+- **标签** :拥有一种或多种属性
+ - 每个标签都有一个人类可读的名称,并且每个标签内部都会分配一个 32 位的整数
+ - 每个标签与一个属性列表相关联,每个属性都有一个名称和类型
+ - 标签之间可存在依赖关系作为约束。例如,如果标签 S 依赖于标签 T,则除非标签 T 存在,否则标签 S 无法存在。
+- **节点** :图数据中代表实体的点
+ - 每个节点都有一个唯一的 64 位(有符号整数)ID (**VID**)
+ - 一个节点可以拥有多个**标签**
+- **边**:节点之间的联系称为边
+ - 每条边由唯一数组 **** 标识
+ - ***边类型*** 是人类可读的字符串,并且每条边内部都会分配一个 32 位的整数。边类型决定边上的属性(模式)
+ - ***边 ranking*** 是用户分配的不可变的 64 位带符号整数,决定两个顶点之间的边顺序。等级值较高的边排名靠前。如未指定,则默认等级值为零。
+ - 每条边只能有一种类型
+- **路径** : 多个节点与边的**非分支**连接
+ - 路径长度为该路径上的边数,比节点数少 1
+ - 路径可由一系列节点,边类型及权重表示。一条边是一个长度为 1 的特殊路径
+
+```plain
+ , vid, ...>
+```
+
+## 查询语言规则概览
+
+> 不熟悉 BNF 的读者可跳过本节
+
+### 总览
+
+- 整套语句可分为三部分:**查询**、**更改**、**管理**
+- 每条语句均可返回一个数据集,每个数据集均包含一个 schema 和多条数据
+
+### 语句组合
+
+- 语句组合有两种方式:
+ - 语句可使用管道函数 “**|**” 连接,前一条语句返回的结果可作为下一条语句的查询条件
+ - 支持使用 “**;**” 批量输入多条语句,批处理时返回最后一条语句结果
+
+### 数据类型
+
+- 简单类型: **vid**、**double**、**int**、**bool**、**string** 和 **timestamp**
+
+- **vid** : 64 位有符号整数,用来表示点 ID
+- 简单类型列表,如: **integer[]**, **double[]**, **string[]**
+- **Map**: 键值对列表。键类型必须为 **字符**,值类型必须与给定 map
+- **Object** (未来版本支持): 键值对列表。键类型必须为**字符**,值可以是任意简单类型
+- **Tuple List**: *只适用于返回值*。由元数据和数据(多行)组成 。元数据包含列名和类型。
+
+### 类型转换
+
+- 一个简单的类型值可以隐式转换为列表
+- 列表可以隐式转换为单列元组列表
+ - "\_list" 可用来表示列名
+
+### 常用 BNF
+
+ ::= **vid** | **integer** | **double** | **float** | **bool** | **string** | **path** | **timestamp** | **year** | **month** | **date** | **datetime**
+
+ ::=
+
+ ::= |
+
+ ::= **vid** (, **vid**)\* | "{" **vid** (, **vid**)\* "}"
+
+ ::= \[:alpha\] ([:alnum:] | "\_")\*
+
+ ::= ("\_")*
+
+ ::=
+
+ ::= (, )\*
+
+ ::= :
+
+ ::= ":"
+
+ ::=
+
+ ::= (, )\* | "{" (, )\* "}"
+
+ ::= "(" **VALUE** (, **VALUE**)\* ")"
+
+ ::= "$"
+
+### 查询语句
+
+#### 选择图空间
+
+**Nebula Graph** 支持多图空间。不同图空间的数据彼此隔离。在进行查询前,需指定图空间。
+
+**USE**
+
+#### 返回数据集
+
+返回单个值或数据集
+
+**RETURN**
+
+ ::= **vid** | | |
+
+#### 创建标签
+
+使用以下语句创建**新**标签
+
+**CREATE TAG** ()
+
+ ::=
+
+## 边类型
+
+每条边都有一种边类型,以边 _**serve**_ 为例,节点 `101`(表示一名球员)为起始点,节点 `215`(表示一支球队)为目标点。节点 `101` 有一条出边,而节点 `215` 有一条入边。
+
+## 属性
+
+属性为点和边内部的键值对。本例中,节点 **player** 拥有属性 `id`, `name` 和 `age`,边 _**like** 则拥有属性 `likeness`。
+
+## Schema
+
+在 **Nebula Graph** 中,schema 为标签及边对应的属性。与 `MySQL` 类似,**Nebula Graph** 是一种强 schema 的数据库,属性的名称和数据类型在数据写入前已确定。
diff --git a/docs/manual-CN/1.overview/1.concepts/2.nGQL-overview.md b/docs/manual-CN/1.overview/1.concepts/2.nGQL-overview.md
new file mode 100644
index 00000000000..f2321619d6e
--- /dev/null
+++ b/docs/manual-CN/1.overview/1.concepts/2.nGQL-overview.md
@@ -0,0 +1,281 @@
+# Nebula Graph 查询语言 (nGQL)
+
+## nGQL 概览
+
+`nGQL` 是一种声明型的文本查询语言,目前尚在开发中。新版本会添加更多功能并优化已有功能。未来的语法规范可能会与现行的不一致。
+
+## 目标
+
+- 易学
+- 易用
+- 专注线上查询,同时为离线计算提供基础
+
+## 特点
+
+- 类 SQL,易学易用
+- 可扩展
+- 大小写不敏感
+- 支持图遍历
+- 支持模式匹配
+- 支持聚合运算
+- 支持图计算
+- 支持分布式事务(开发中)
+- 无嵌入支持组合语句,易于阅读
+
+## 术语
+
+- **图空间**:物理隔离的不同数据集
+- **标签** :拥有一种或多种属性
+ - 每个标签都有一个人类可读的名称,并且每个标签内部都会分配一个 32 位的整数
+ - 每个标签与一个属性列表相关联,每个属性都有一个名称和类型
+ - 标签之间可存在依赖关系作为约束。例如,如果标签 S 依赖于标签 T,则除非标签 T 存在,否则标签 S 无法存在。
+- **节点** :图数据中代表实体的点
+ - 每个节点都有一个唯一的 64 位(有符号整数)ID (**VID**)
+ - 一个节点可以拥有多个**标签**
+- **边**:节点之间的联系称为边
+ - 每条边由唯一数组 **** 标识
+ - ***边类型*** 是人类可读的字符串,并且每条边内部都会分配一个 32 位的整数。边类型决定边上的属性(模式)
+ - ***边 ranking*** 是用户分配的不可变的 64 位带符号整数,决定两个顶点之间的边顺序。等级值较高的边排名靠前。如未指定,则默认等级值为零。
+ - 每条边只能有一种类型
+- **路径** : 多个节点与边的**非分支**连接
+ - 路径长度为该路径上的边数,比节点数少 1
+ - 路径可由一系列节点,边类型及权重表示。一条边是一个长度为 1 的特殊路径
+
+```plain
+ , vid, ...>
+```
+
+## 查询语言规则概览
+
+> 不熟悉 BNF 的读者可跳过本节
+
+### 总览
+
+- 整套语句可分为三部分:**查询**、**更改**、**管理**
+- 每条语句均可返回一个数据集,每个数据集均包含一个 schema 和多条数据
+
+### 语句组合
+
+- 语句组合有两种方式:
+ - 语句可使用管道函数 “**|**” 连接,前一条语句返回的结果可作为下一条语句的查询条件
+ - 支持使用 “**;**” 批量输入多条语句,批处理时返回最后一条语句结果
+
+### 数据类型
+
+- 简单类型: **vid**、**double**、**int**、**bool**、**string** 和 **timestamp**
+
+- **vid** : 64 位有符号整数,用来表示点 ID
+- 简单类型列表,如: **integer[]**, **double[]**, **string[]**
+- **Map**: 键值对列表。键类型必须为 **字符**,值类型必须与给定 map
+- **Object** (未来版本支持): 键值对列表。键类型必须为**字符**,值可以是任意简单类型
+- **Tuple List**: *只适用于返回值*。由元数据和数据(多行)组成 。元数据包含列名和类型。
+
+### 类型转换
+
+- 一个简单的类型值可以隐式转换为列表
+- 列表可以隐式转换为单列元组列表
+ - "\_list" 可用来表示列名
+
+### 常用 BNF
+
+ ::= **vid** | **integer** | **double** | **float** | **bool** | **string** | **path** | **timestamp** | **year** | **month** | **date** | **datetime**
+
+ ::=
+
+ ::= |
+
+ ::= **vid** (, **vid**)\* | "{" **vid** (, **vid**)\* "}"
+
+ ::= \[:alpha\] ([:alnum:] | "\_")\*
+
+ ::= ("\_")*
+
+ ::=
+
+ ::= (, )\*
+
+ ::= :
+
+ ::= ":"
+
+ ::=
+
+ ::= (, )\* | "{" (, )\* "}"
+
+ ::= "(" **VALUE** (, **VALUE**)\* ")"
+
+ ::= "$"
+
+### 查询语句
+
+#### 选择图空间
+
+**Nebula Graph** 支持多图空间。不同图空间的数据彼此隔离。在进行查询前,需指定图空间。
+
+**USE**
+
+#### 返回数据集
+
+返回单个值或数据集
+
+**RETURN**
+
+ ::= **vid** | | |
+
+#### 创建标签
+
+使用以下语句创建**新**标签
+
+**CREATE TAG** ()
+
+ ::=
+ ::= +
+ ::= ,
+ ::=
+
+#### 创建边类型
+
+使用以下语句创建**新**的边类型
+
+**CREATE EDGE** ()
+
+ :=
+
+
+#### 插入节点
+
+使用以下语句插入一个或多个节点
+
+**INSERT VERTEX** [**NO OVERWRITE**] **VALUES**
+
+ ::= () (, ())\*
+ ::= :() (, :())\*
+ ::= **vid**
+ ::= (, )\*
+ ::= **VALUE** (, **VALUE**)\*
+
+#### 插入边
+
+使用以下语句插入一条或多条边
+
+**INSERT EDGE** [**NO OVERWRITE**] [()] **VALUES** ()+
+
+edge\_value ::= -> [@ ] :
+
+#### 更新节点
+
+使用以下语句更新节点
+
+**UPDATE VERTEX**
+**SET** \
+[**WHERE** ]
+[**YIELD** ]
+
+ ::= |
+ ::= = {, = }+
+ ::= () = () | () =
+
+#### 更新边
+
+使用以下语句更新边
+
+**UPDATE EDGE** -> [@] **OF**
+**SET**
+[**WHERE** ]
+[**YIELD** ]
+
+#### 图遍历
+
+根据指定条件遍历给定节点的关联节点,返回节点 ID 列表或数组
+
+**GO**
+[ **STEPS**]
+**FROM**
+[**OVER** [**REVERSELY**] ]
+[**WHERE** ]
+[**YIELD** ]
+
+
+ ::= [data\_set] [[**AS**] ]
+ ::= **vid** | | |
+ ::= [**AS** ]
+ ::= {, }\*
+ ::=
+
+ ::= {**AND** | **OR** }\*
+ ::= **>** | **>=** | **<** | **<=** | **==** | **!=** | **IN**
+ ::= {, }\*
+ ::= [**AS** ]
+
+**WHERE** 语句仅适用于最终返回结果,对中间结果不适用。
+
+跳过 **STEP[S]** 表示 **一步**
+
+从起始点出发一跳,遍历所有满足**WHERE** 语句的关联点,只返回满足 **WHERE** 语句的结果。
+
+多跳查询时,**WHERE** 语句只适用于最终结果,对中间结果不适用。例如:
+
+```ngql
+GO 2 STEPS FROM me OVER friend WHERE birthday > "1988/1/1"
+```
+
+以上语句查询所有生日在 1988/1/1 之后的二度好友。
+
+
+
+#### 搜索
+
+以下语句对满足筛选条件的节点或边进行搜索。
+
+**FIND VERTEX**
+**WHERE**
+[**YIELD** ]
+
+**FIND EDGE**
+**WHERE**
+[**YIELD** ]
+
+
+
+### 属性关联
+
+属性关联很常见,如 **WHERE** 语句和 **YIELD** 语句。nGQL 采用如下方式定义属性关联:
+
+ ::= "."
+ ::= | |
+ ::=
+ ::= '[' "]"
+
+ 以 “$” 开始,特殊变量有两类:$- 和 $$。
+
+$- 为输入值, $$ 为目标值。
+
+所有属性名以字母开头。个别系统属性以 “\_” 开头。 “\_” 保留值。
+
+### 内建属性
+
+\_id: 节点 ID
+\_type: 边类型
+\_src: 边起始点 ID
+\_dst: 边终点 ID
+\_rank: 边 ranking
diff --git a/docs/manual-CN/1.overview/2.quick-start/1.get-started.md b/docs/manual-CN/1.overview/2.quick-start/1.get-started.md
new file mode 100644
index 00000000000..8873a09ff2f
--- /dev/null
+++ b/docs/manual-CN/1.overview/2.quick-start/1.get-started.md
@@ -0,0 +1,505 @@
+# 快速入门
+
+本手册将逐步指导您使用 **Nebula Graph**,包括:
+
+- 安装
+- 数据建模
+- CRUD 操作
+- 批量插入
+- 数据导入工具
+
+## 安装
+
+我们推荐使用 [docker compose](https://github.com/vesoft-inc/nebula-docker-compose) 来安装 **Nebula Graph**, 具体步骤可以参考我们录制的[操作视频](https://www.bilibili.com/video/BV1BJ411y7Kt?from=search&seid=2803739759207567290)。
+
+除了使用 Docker,您还可以选择[编译源码](../../3.build-develop-and-administration/1.build/1.build-source-code.md)或者[rpm/deb 包](../../3.build-develop-and-administration/2.install/1.install-with-rpm-deb.md) 方式安装 **Nebula Graph**。
+
+如果您在安装过程中遇到任何问题,可以前往 Nebula Graph [官方论坛](https://discuss.nebula-graph.com.cn) 提问,我们有专门的值班开发人员为您解答问题。
+
+## 数据建模
+
+在本手册中,我们将通过下图所示的数据集向您展示如何使用 **Nebula Graph** 数据库。
+
+
+
+上图中有两个标签(**player**、**team**)以及两条边类型(**serve**、**follow**)。
+
+### 创建并使用图空间
+
+**Nebula Graph** 中的图空间类似于传统数据库中创建的独立数据库,例如在 MySQL 中创建的数据库。首先,您需要创建一个图空间并使用它,然后才能执行其他操作。
+
+您可以通过以下步骤创建并使用图空间:
+
+1. 输入以下语句创建图空间:
+
+```ngql
+nebula> CREATE SPACE nba(partition_num=10, replica_factor=1);
+```
+
+**注意**:
+
+* `partition_num`:指定一个副本中的分区数。通常为集群硬盘数量的 5 倍。
+* `replica_factor`:指定集群中副本的数量,通常生产环境为 3,测试环境为 1。
+
+之后, 你也可以通过下面这个命令检查机器和 partition 分布:
+
+```ngql
+nebula> SHOW HOSTS;
+```
+
+具体可以见[这里](../../2.query-language/4.statement-syntax/1.data-definition-statements/create-space-syntax.md)
+
+2. 输入以下语句使用图空间:
+
+```ngql
+nebula> USE nba;
+```
+
+现在,您可以通过以下语句查看刚创建的空间:
+
+```ngql
+nebula> SHOW SPACES;
+```
+
+返回以下信息:
+
+```ngql
+========
+| Name |
+========
+| nba |
+--------
+```
+
+### 定义数据的 Schema
+
+在 **Nebula Graph** 中,我们将具有相同属性的点分为一组,该组即为一个标签。`CREATE TAG` 语句定义了一个标签,标签名称后面的括号中是标签的属性和属性类型。`CREATE EDGE` 语句定义边类型,类型名称后面的括号中是边的属性和属性类型。
+
+您可以通过以下步骤创建标签和边类型:
+
+1. 输入以下语句创建 **player** 标签:
+
+```ngql
+nebula> CREATE TAG player(name string, age int);
+```
+
+2. 输入以下语句创建 **team** 标签:
+
+```ngql
+nebula> CREATE TAG team(name string);
+```
+
+3. 输入以下语句创建 **follow** 边类型:
+
+```ngql
+nebula> CREATE EDGE follow(degree int);
+```
+
+4. 输入以下语句创建 **serve** 边类型:
+
+```ngql
+nebula> CREATE EDGE serve(start_year int, end_year int);
+```
+
+现在,您可以查看刚刚创建的标签和边类型。
+
+要获取刚创建的标签,请输入以下语句:
+
+```ngql
+nebula> SHOW TAGS;
+```
+
+返回以下信息:
+
+```ngql
+============
+| Name |
+============
+| player |
+------------
+| team |
+------------
+```
+
+要显示刚创建的边类型,请输入以下语句:
+
+```ngql
+nebula> SHOW EDGES;
+```
+
+返回以下信息:
+
+```ngql
+==========
+| Name |
+==========
+| serve |
+----------
+| follow |
+----------
+```
+
+要显示 **player** 标签的属性,请输入以下语句:
+
+```ngql
+nebula> DESCRIBE TAG player;
+```
+
+返回以下信息:
+
+```ngql
+===================
+| Field | Type |
+===================
+| name | string |
+-------------------
+| age | int |
+-------------------
+```
+
+要获取 **follow** 边类型的属性,请输入以下语句:
+
+```ngql
+nebula> DESCRIBE EDGE follow;
+```
+
+返回以下信息:
+
+```ngql
+=====================
+| Field | Type |
+=====================
+| degree | int |
+---------------------
+```
+
+## CRUD 操作
+
+### 插入数据
+
+您可以根据[示意图](#概述)中的关系插入点和边数据。
+
+#### 插入点
+
+`INSERT VERTEX` 语句通过指定点的标签、属性、点 ID 和属性值来插入一个点。
+
+您可以通过以下语句插入点:
+
+```ngql
+nebula> INSERT VERTEX player(name, age) VALUES 100:("Tim Duncan", 42);
+nebula> INSERT VERTEX player(name, age) VALUES 101:("Tony Parker", 36);
+nebula> INSERT VERTEX player(name, age) VALUES 102:("LaMarcus Aldridge", 33);
+nebula> INSERT VERTEX team(name) VALUES 200:("Warriors");
+nebula> INSERT VERTEX team(name) VALUES 201:("Nuggets");
+nebula> INSERT VERTEX player(name, age) VALUES 121:("Useless", 60);
+```
+
+**注意**:
+
+1. 在上面插入的点中,关键词 `VALUES` 之后的数字是点的 ID(缩写为 `VID`)。图空间中的 `VID` 必须是唯一的。
+
+2. 最后插入的点将在[删除数据](#删除数据)部分中删除。
+
+3. 如果您想一次插入多个同类型的点,可以执行以下语句:
+
+```ngql
+nebula> INSERT VERTEX player(name, age) VALUES 100:("Tim Duncan", 42), \
+101:("Tony Parker", 36), 102:("LaMarcus Aldridge", 33);
+```
+
+#### 插入边
+
+`INSERT EDGE` 语句通过指定边类型名称、属性、起始点ID和目标点ID以及属性值来插入边。
+
+您可以通过以下语句插入边:
+
+```ngql
+nebula> INSERT EDGE follow(degree) VALUES 100 -> 101:(95);
+nebula> INSERT EDGE follow(degree) VALUES 100 -> 102:(90);
+nebula> INSERT EDGE follow(degree) VALUES 102 -> 101:(75);
+nebula> INSERT EDGE serve(start_year, end_year) VALUES 100 -> 200:(1997, 2016);
+nebula> INSERT EDGE serve(start_year, end_year) VALUES 101 -> 201:(1999, 2018);
+```
+
+**注意**:如果您想一次插入多条同类型的边,可以执行以下语句:
+
+```ngql
+INSERT EDGE follow(degree) VALUES 100 -> 101:(95),100 -> 102:(90),102 -> 101:(75);
+```
+
+### 获取数据
+
+在 **Nebula Graph** 中插入数据后,您可以从图空间中检索到插入的数据。
+
+`FETCH PROP ON` 语句从图空间检索数据。如果要获取点数据,则必须指定点标签和点 ID;如果要获取边数据,则必须指定边类型名称、起始点 ID 和目标点 ID。
+
+要获取 `VID` 为 `100` 的选手的数据,请输入以下语句:
+
+```ngql
+nebula> FETCH PROP ON player 100;
+```
+
+返回以下信息:
+
+```ngql
+=======================================
+| VertexID | player.name | player.age |
+=======================================
+| 100 | Tim Duncan | 42 |
+---------------------------------------
+```
+
+要获取 `VID` `100` 和 `VID` `200`之间的 `serve` 边的数据,请输入以下语句:
+
+```ngql
+nebula> FETCH PROP ON serve 100 -> 200;
+```
+
+返回以下信息:
+
+```ngql
+=============================================================================
+| serve._src | serve._dst | serve._rank | serve.start_year | serve.end_year |
+=============================================================================
+| 100 | 200 | 0 | 1997 | 2016 |
+-----------------------------------------------------------------------------
+```
+
+### 更新数据
+
+您可以更新刚插入的点和边数据。
+
+#### 更新点数据
+
+`UPDATE VERTEX` 语句首先选择要更新的点,然后通过在等号右侧为其分配新值来更新点的数据。
+
+以下示例说明如何将 `VID` `100` 的 `name` 值从 `Tim Duncan` 更改为 `Tim`。
+
+输入以下语句更新 `name` 值:
+
+```ngql
+nebula> UPDATE VERTEX 100 SET player.name = "Tim";
+```
+
+要检查 `name` 值是否已更新,请输入以下语句:
+
+```ngql
+nebula> FETCH PROP ON player 100;
+```
+
+返回以下信息:
+
+```ngql
+=======================================
+| VertexID | player.name | player.age |
+=======================================
+| 100 | Tim | 42 |
+---------------------------------------
+```
+
+#### 更新边数据
+
+`UPDATE EDGE` 语句通过指定边的起始点ID和目标点ID,然后在等号右侧为其分配新值来更新边的数据。
+
+以下示例展示了如何更改 `VID` `100` 和 `VID` `101` 之间 `follow` 边的值。现在,我们将 `degree` 的值从 `95` 更改为 `96`。
+
+输入以下语句更新 `degree` 的值:
+
+```ngql
+nebula> UPDATE EDGE 100 -> 101 OF follow SET degree = follow.degree + 1;
+```
+
+要检查 `degree` 的值是否已更新,请输入以下语句:
+
+```ngql
+nebula> FETCH PROP ON follow 100 -> 101;
+```
+
+返回以下信息:
+
+```ngql
+============================================================
+| follow._src | follow._dst | follow._rank | follow.degree |
+============================================================
+| 100 | 101 | 0 | 96 |
+------------------------------------------------------------
+```
+
+### 删除数据
+
+如果您有不需要的点或边数据,则可以从图空间中将其删除。
+
+#### 删除点
+
+您可以从图空间中删除任何点。`DELETE VERTEX` 语句通过指定点ID来删除点。
+
+要删除 `VID` 为 `121` 的点,请输入以下语句:
+
+```ngql
+nebula> DELETE VERTEX 121;
+```
+
+要检查是否删除了该点,请输入以下语句;
+
+```ngql
+nebula> FETCH PROP ON player 121;
+```
+
+返回以下信息:
+
+```ngql
+Execution succeeded (Time spent: 1571/1910 us)
+```
+
+**注意**:上面返回结果为空的信息表示查询操作成功,但是由于数据已被删除,因此未能从图空间中查询到任何数据。
+
+#### 删除边
+
+您可以从图空间中删除任何边。`DELETE EDGE` 语句通过指定边类型名称以及起始点ID和目标点ID来删除边。
+
+要删除 `VID` `100` 和 `VID` `200` 之间的 `follow` 边,请输入以下语句:
+
+```ngql
+nebula> DELETE EDGE follow 100 -> 200;
+```
+
+**注意**:如果您删除了一个点,则该点所有的入边和出边都将被删除。
+
+### 查询示例
+
+本节提供了更多查询示例供您参考。
+
+**示例一**: 查询 `VID` `100` 关注的点。
+
+输入以下语句:
+
+```ngql
+nebula> GO FROM 100 OVER follow;
+```
+
+返回以下信息:
+
+```ngql
+===============
+| follow._dst |
+===============
+| 101 |
+---------------
+| 102 |
+---------------
+```
+
+**示例二**: 查询 `VID` `100` 关注的点且该点年龄大于 `35` 岁。
+返回其姓名和年龄并分别把列的名称设置为 **Teammate** 和 **Age**。
+
+输入以下语句:
+
+```ngql
+nebula> GO FROM 100 OVER follow WHERE $$.player.age >= 35 \
+YIELD $$.player.name AS Teammate, $$.player.age AS Age;
+```
+
+返回以下信息:
+
+```ngql
+=====================
+| Teammate | Age |
+=====================
+| Tony Parker | 36 |
+---------------------
+```
+
+**注意**:
+
+* `YIELD` 指定您希望从查询中返回的值或结果。
+* `$$` 表示目的点。
+* `\` 表示换行符。
+
+**示例三**: 查询球员 `100` 关注的球员所效力的球队。
+
+有两种方法可获得相同的结果。首先,我们可以使用`管道`来检索球队。然后,我们使用`临时变量`来检索同一支球队。
+
+输入带`管道`的语句:
+
+```ngql
+nebula> GO FROM 100 OVER follow YIELD follow._dst AS id | \
+GO FROM $-.id OVER serve YIELD $$.team.name \
+AS Team, $^.player.name AS Player;
+```
+
+返回如下信息:
+
+```ngql
+===============================
+| Team | Player |
+===============================
+| Nuggets | Tony Parker |
+-------------------------------
+```
+
+输入带`临时变量`的语句:
+
+```ngql
+nebula> $var=GO FROM 100 OVER follow YIELD follow._dst AS id; \
+GO FROM $var.id OVER serve YIELD $$.team.name \
+AS Team, $^.player.name AS Player;
+```
+
+返回以下信息:
+
+```ngql
+===============================
+| Team | Player |
+===============================
+| Nuggets | Tony Parker |
+-------------------------------
+```
+
+**注意**:
+
+* `$^` 表示起始点。
+* `|` 表示管道。上一个查询的输出作为下一个查询的输入。
+* `$-` 表示输入流。
+* 第二种方法采用用户自定义的变量 `$var`。该变量的范围仅在复合语句内。
+
+## 批量插入
+
+要插入多条数据,可以将所有 DDL(数据定义语言)语句放入 `.ngql` 文件中,如下所示。
+
+```ngql
+CREATE SPACE nba(partition_num=10, replica_factor=1);
+USE nba;
+CREATE TAG player(name string, age int);
+CREATE TAG team(name string);
+CREATE EDGE follow(degree int);
+CREATE EDGE serve(start_year int, end_year int);
+```
+
+* 如果您是通过编译源代码来安装 **Nebula Graph**,则可以通过以下命令批量写入console:
+
+```bash
+$ cat schema.ngql | ./bin/nebula -u user -p password
+```
+
+* 如果您通过 `docker-compose` 来使用 **Nebula Graph**,则可以通过以下命令批量写入console:
+
+```bash
+$ cat nba.ngql | sudo docker run --rm -i --network=host \
+vesoft/nebula-console:nightly --addr=127.0.0.1 --port=3699
+```
+
+**注意**:
+
+* 您必须将 IP 地址和端口号更改为您自己的 IP 地址和端口号。
+* 您可以在[这里](https://oss-cdn.nebula-graph.com.cn/doc/nba.ngql)下载 `nba.ngql` 文件。
+
+同样,您可以在 *data.ngql* 文件中放置数百或数千个 DML(数据操作语言)语句来插入数据。
+
+## 导入数据工具
+
+如果您要插入数百万条记录,建议使用 [csv 导入工具](../../3.build-develop-and-administration/5.storage-service-administration/data-import/import-csv-file.md)。
+
+
+如果您在使用 **Nebula Graph** 的过程中遇到任何问题,请前往我们的 [官方论坛](https://discuss.nebula-graph.com.cn) 提问,将有专门的值班开发人员为您解答问题。
+
+如果您完成了本手册的全部操作,认为 **Nebula Graph** 是一款值得尝试的图数据库产品,恳请移步 [GitHub](https://github.com/vesoft-inc/nebula) 留下您珍贵的一颗星,这将鼓舞我们继续向前。
diff --git a/docs/manual-CN/1.overview/2.quick-start/2.FAQ.md b/docs/manual-CN/1.overview/2.quick-start/2.FAQ.md
new file mode 100644
index 00000000000..e9f5c33d673
--- /dev/null
+++ b/docs/manual-CN/1.overview/2.quick-start/2.FAQ.md
@@ -0,0 +1,208 @@
+# 常见问题
+
+本文档列出了 **Nebula Graph** 常见问题。如果您没有在文档中找到需要的信息,请尝试在 Nebula Graph [官方论坛](https://discuss.nebula-graph.com.cn/)搜索[用户问答](https://discuss.nebula-graph.com.cn/c/users/5)标签。
+
+- [常见问题](#%e5%b8%b8%e8%a7%81%e9%97%ae%e9%a2%98)
+ - [Trouble Shooting](#trouble-shooting)
+ - [服务器参数配置](#%e6%9c%8d%e5%8a%a1%e5%99%a8%e5%8f%82%e6%95%b0%e9%85%8d%e7%bd%ae)
+ - [配置文件](#%e9%85%8d%e7%bd%ae%e6%96%87%e4%bb%b6)
+ - [partition 分布不均](#partition-%e5%88%86%e5%b8%83%e4%b8%8d%e5%9d%87)
+ - [日志和更改日志级别](#%e6%97%a5%e5%bf%97%e5%92%8c%e6%9b%b4%e6%94%b9%e6%97%a5%e5%bf%97%e7%ba%a7%e5%88%ab)
+ - [使用多块硬盘](#%e4%bd%bf%e7%94%a8%e5%a4%9a%e5%9d%97%e7%a1%ac%e7%9b%98)
+ - [进程异常 crash](#%e8%bf%9b%e7%a8%8b%e5%bc%82%e5%b8%b8-crash)
+ - [使用 Docker 启动后,执行命令时报错](#%e4%bd%bf%e7%94%a8-docker-%e5%90%af%e5%8a%a8%e5%90%8e%e6%89%a7%e8%a1%8c%e5%91%bd%e4%bb%a4%e6%97%b6%e6%8a%a5%e9%94%99)
+ - [单机先后加入两个不同集群](#%e5%8d%95%e6%9c%ba%e5%85%88%e5%90%8e%e5%8a%a0%e5%85%a5%e4%b8%a4%e4%b8%aa%e4%b8%8d%e5%90%8c%e9%9b%86%e7%be%a4)
+ - [连接失败](#%e8%bf%9e%e6%8e%a5%e5%a4%b1%e8%b4%a5)
+ - [Could not create logging file:... Too many open files](#could-not-create-logging-file-too-many-open-files)
+ - [如何查看 Nebula Graph 版本信息](#%e5%a6%82%e4%bd%95%e6%9f%a5%e7%9c%8b-nebula-graph-%e7%89%88%e6%9c%ac%e4%bf%a1%e6%81%af)
+ - [修改配置文件不生效](#%e4%bf%ae%e6%94%b9%e9%85%8d%e7%bd%ae%e6%96%87%e4%bb%b6%e4%b8%8d%e7%94%9f%e6%95%88)
+ - [修改 RocksDB block cache](#%e4%bf%ae%e6%94%b9-rocksdb-block-cache)
+ - [使用 CentOS 6.5 Nebula 服务失败](#%e4%bd%bf%e7%94%a8-centos-65-nebula-%e6%9c%8d%e5%8a%a1%e5%a4%b1%e8%b4%a5)
+ - [General Information](#general-information)
+ - [查询返回时间解释](#%e6%9f%a5%e8%af%a2%e8%bf%94%e5%9b%9e%e6%97%b6%e9%97%b4%e8%a7%a3%e9%87%8a)
+
+## Trouble Shooting
+
+Trouble Shooting 部分列出了 **Nebula Graph** 操作中的常见错误。
+
+### 服务器参数配置
+
+在 Nebula console 中运行
+
+```ngql
+nebula> SHOW CONFIGS;
+```
+
+详细参考[本节](../../3.build-develop-and-administration/3.configurations/0.system-requirement.md)及之后几节。
+
+[[↑] 回到顶部](#常见问题)
+
+### 配置文件
+
+配置文件默认在 `/usr/local/nebula/etc/` 下。
+
+[[↑] 回到顶部](#常见问题)
+
+### partition 分布不均
+
+参考[本节](../../3.build-develop-and-administration/5.storage-service-administration/storage-balance.md)
+
+[[↑] 回到顶部](#常见问题)
+
+### 日志和更改日志级别
+
+日志文件默认在 `/usr/local/nebula/logs/` 下。
+
+参见 [graphd 日志](../../3.build-develop-and-administration/3.configurations/4.graph-config.md) 和 [storaged 日志](../../3.build-develop-and-administration/3.configurations/5.storage-config.md)。
+
+[[↑] 回到顶部](#常见问题)
+
+### 使用多块硬盘
+
+修改 `/usr/local/nebula/etc/nebula-storage.conf`。例如
+
+```text
+--data_path=/disk1/storage/,/disk2/storage/,/disk3/storage/
+```
+
+多块硬盘时可以逗号分隔多个目录,每个目录对应一个 RocksDB 实例,以有更好的并发能力。参考[这里](../../3.build-develop-and-administration/3.configurations/5.storage-config.md)。
+
+[[↑] 回到顶部](#常见问题)
+
+### 进程异常 crash
+
+1. 检查硬盘空间 `df -h`
+1. 检查内存是否足够 (`dmesg`)
+1. 检查日志
+
+[[↑] 回到顶部](#常见问题)
+
+### 使用 Docker 启动后,执行命令时报错
+
+可能的原因是 Docker 的 IP 地址和默认配置中的监听地址不一致(默认是 172.17.0.2),因此这里需要修改默认配置中的监听地址。
+
+1. 首先在容器中执行 `ifconfig` 命令,查看您的容器地址,这里假设您的容器地址是172.17.0.3,那么就意味着您需要修改默认配置的IP地址。
+2. 然后进入配置目录(cd /usr/local/nebula/etc), 查找所有IP地址配置的位置(grep "172.17.0.2" . -r)。
+3. 修改上一步查到的所有IP地址为您的容器地址(172.17.0.3)。
+4. 最后重新启动所有服务(/usr/local/nebula/scripts/nebula.service restart all)。
+
+[[↑] 回到顶部](#常见问题)
+
+### 单机先后加入两个不同集群
+
+同一台主机先后用于单机测试和集群测试,storaged 服务无法正常启动(终端上显示的 storaged 服务的监听端口是红色的)。查看 storged 服务的日志(/usr/local/nebula/nebula-storaged.ERROR),若发现 "wrong cluster" 的报错信息,则可能的出错原因是单机测试和集群测试时的 Nebula Graph 生成的 cluster id 不一致,需要删除 Nebula Graph 安装目录(/usr/local/nebula)下的 cluster.id 文件和 data 目录后,重启服务。
+
+[[↑] 回到顶部](#常见问题)
+
+### 连接失败
+
+```txt
+E1121 04:49:34.563858 256 GraphClient.cpp:54] Thrift rpc call failed: AsyncSocketException: connect failed, type = Socket not open, errno = 111 (Connection refused): Connection refused
+```
+
+检查服务是否存在
+
+```bash
+$ /usr/local/nebula/scripts/nebula.service status all
+或者
+nebula> SHOW HOSTS;
+```
+
+[[↑] 回到顶部](#常见问题)
+
+### Could not create logging file:... Too many open files
+
+1. 检查硬盘空间 `df -h`
+1. 检查日志目录 `/usr/local/nebula/logs/`
+1. 修改允许打开的最大文件数 `ulimit -n 65536`
+
+[[↑] 回到顶部](#常见问题)
+
+### 如何查看 Nebula Graph 版本信息
+
+使用 `curl http://ip:port/status` 命令获取 git_info_sha、binary 包的 commitID。
+
+[[↑] 回到顶部](#常见问题)
+
+### 修改配置文件不生效
+
+**Nebula Graph** 使用如下两种方式获取配置:
+
+1. 从配置文件中(需要修改配置文件并重启服务);
+2. 从 Meta 服务中。通过 CLI 设置,并持久化保存在 Meta 服务中,详情参考[这里](../../3.build-develop-and-administration/3.configurations/1.config-persistency-and-priority.md);
+
+修改了配置文件不生效,是因为默认情况下,**Nebula Graph** 的配置参数管理采用第二种方式 (Meta),如果希望采用第一种方式,需要在 `/usr/local/nebula/etc/` 配置文件 `metad.conf`、 `storaged.conf`、`graphd.conf` 中分别添加 `--local_config=true` 选项。
+
+[[↑] 回到顶部](#常见问题)
+
+### 修改 RocksDB block cache
+
+更改 storage 的配置文件 `storaged.conf`(默认路径为 `/usr/local/nebula/etc/`)并重启,例如:
+
+```bash
+# Change rocksdb_block_cache to 1024 MB
+--rocksdb_block_cache = 1024
+# Stop storaged and restart
+/usr/local/nebula/scripts/nebula.service stop storaged
+/usr/local/nebula/scripts/nebula.service start storaged
+```
+
+参见[这里](../../3.build-develop-and-administration/3.configurations/5.storage-config.md)
+
+[[↑] 回到顶部](#常见问题)
+
+### 使用 CentOS 6.5 Nebula 服务失败
+
+在 CentOS 6.5 部署 Nebula Graph 失败,报错信息如下:
+
+```bash
+# storage 日志
+Heartbeat failed, status:RPC failure in MetaClient: N6apache6thrift9transport19TTransportExceptionE: AsyncSocketException: connect failed, type = Socket not open, errno = 111 (Connection refused): Connection refused
+
+# meta 日志
+Log line format: [IWEF]mmdd hh:mm:ss.uuuuuu threadid file:line] msg
+E0415 22:32:38.944437 15532 AsyncServerSocket.cpp:762] failed to set SO_REUSEPORT on async server socket Protocol not available
+E0415 22:32:38.945001 15510 ThriftServer.cpp:440] Got an exception while setting up the server: 92failed to bind to async server socket: [::]:0: Protocol not available
+E0415 22:32:38.945057 15510 RaftexService.cpp:90] Setup the Raftex Service failed, error: 92failed to bind to async server socket: [::]:0: Protocol not available
+E0415 22:32:38.949586 15463 NebulaStore.cpp:47] Start the raft service failed
+E0415 22:32:38.949597 15463 MetaDaemon.cpp:88] Nebula store init failed
+E0415 22:32:38.949796 15463 MetaDaemon.cpp:215] Init kv failed!
+```
+
+此时服务状态为:
+
+```bash
+[root@redhat6 scripts]# ./nebula.service status all
+[WARN] The maximum files allowed to open might be too few: 1024
+[INFO] nebula-metad: Exited
+[INFO] nebula-graphd: Exited
+[INFO] nebula-storaged: Running as 15547, Listening on 44500
+```
+
+出错原因:CentOS 6.5 系统内核版本为 2.6.32,`SO_REUSEPORT` 仅支持 `Linux 3.9` 及以上版本。
+
+将系统升级到 CentOS 7.5 问题可自行解决。
+
+## General Information
+
+General Information 部分列出了关于 **Nebula Graph** 的概念性问题。
+
+### 查询返回时间解释
+
+```ngql
+nebula> GO FROM 101 OVER follow;
+===============
+| follow._dst |
+===============
+| 100 |
+---------------
+| 102 |
+---------------
+| 125 |
+---------------
+Got 3 rows (Time spent: 7431/10406 us)
+```
+
+以上述查询为例,Time spent 中前一个数字 `7431` 为数据库本身所花费的时间,即 query engine 从 console 收到这条查询语句,到存储拿到数据,并进行一系列计算所花的时间;后一个数字 `10406` 是从客户端角度看花费的时间,即 console 从发送请求,到收到响应,并将结果输出到屏幕的时间。
+
+[[↑] 回到顶部](#常见问题)
diff --git a/docs/manual-CN/1.overview/2.quick-start/3.supported-clients.md b/docs/manual-CN/1.overview/2.quick-start/3.supported-clients.md
new file mode 100644
index 00000000000..04f5177fc09
--- /dev/null
+++ b/docs/manual-CN/1.overview/2.quick-start/3.supported-clients.md
@@ -0,0 +1,7 @@
+# Nebula Graph 支持的客户端
+
+目前,**Nebula Graph** 支持如下客户端:
+
+* [Go 客户端](https://github.com/vesoft-inc/nebula-go)
+* [Python 客户端](https://github.com/vesoft-inc/nebula-python)
+* [Java 客户端](https://github.com/vesoft-inc/nebula-java)
diff --git a/docs/manual-CN/1.overview/2.quick-start/4.import-csv-file.md b/docs/manual-CN/1.overview/2.quick-start/4.import-csv-file.md
new file mode 100644
index 00000000000..c4b4aea7c5d
--- /dev/null
+++ b/docs/manual-CN/1.overview/2.quick-start/4.import-csv-file.md
@@ -0,0 +1,244 @@
+# CSV文件导入示例
+
+以下示例将指导您如何使用 [**Nebula Importer**](https://github.com/vesoft-inc/nebula-importer) 将 CSV 数据导入到 **Nebula Graph** 中。在此示例中,**Nebula Graph** 通过 `Docker` 和 `Docker Compose` 安装。我们将通过以下步骤引导您完成该示例:
+
+1. [启动 Nebula Graph 服务](#启动-Nebula-Graph-服务)
+2. [创建点和边的 Schema](#创建点和边的-Schema)
+3. [准备配置文件](#准备配置文件)
+4. [准备 CSV 数据](#准备-CSV-数据)
+5. [导入 CSV 数据](#导入-CSV-数据)
+
+## 启动 **Nebula Graph** 服务
+
+您可以按照以下步骤启动 **Nebula Graph** 服务:
+
+1. 在命令行界面上,进入 `nebula-docker-compose` 目录。
+2. 执行以下命令以启动 **Nebula Graph** 服务:
+
+```bash
+$ sudo docker-compose up -d
+```
+
+3. 执行以下命令把 **Nebula Graph** 镜像文件下拉到本地:
+
+```bash
+$ sudo docker pull vesoft/nebula-console:nightly
+```
+
+4. 执行以下命令以连接 **Nebula Graph** 服务器:
+
+```bash
+$ sudo docker run --rm -ti --network=host vesoft/nebula-console:nightly --addr=127.0.0.1 --port=3699
+```
+
+**注意**:您必须确保 IP 地址和端口号配置正确。
+
+## 创建点和边的 Schema
+
+在输入 schema 之前,必须创建一个空间并使用它。在此示例中,我们创建一个 **nba** 空间并使用它。
+
+我们使用以下命令创建两个标签和两个边类型:
+
+```ngql
+nebula> CREATE TAG player (name string, age int);
+
+nebula> CREATE TAG team (name string);
+
+nebula> CREATE EDGE serve (start_year int, end_year int);
+
+nebula> CREATE EDGE follow (degree, int);
+```
+
+## 准备配置文件
+
+您必须配置 `.yaml` 配置文件,该文件规定了 CSV 文件中数据的格式。在本例中,我们创建一个名为 `config.yaml` 的配置文件。
+
+在此示例中,我们按以下方式配置 `config.yaml` 文件:
+
+```ngql
+version: v1rc1
+description: example
+clientSettings:
+ concurrency: 2 # number of graph clients
+ channelBufferSize: 50
+ space: nba
+ connection:
+ user: user
+ password: password
+ address: 127.0.0.1:3699
+logPath: ./err/test.log
+files:
+ - path: /home/nebula/serve.csv
+ failDataPath: ./err/serve.csv
+ batchSize: 10
+ type: csv
+ csv:
+ withHeader: false
+ withLabel: false
+ schema:
+ type: edge
+ edge:
+ name: serve
+ withRanking: false
+ props:
+ - name: start_year
+ type: int
+ - name: end_year
+ type: int
+ - path: /home/nebula/follow.csv
+ failDataPath: ./err/follow.csv
+ batchSize: 10
+ type: csv
+ csv:
+ withHeader: false
+ withLabel: false
+ schema:
+ type: edge
+ edge:
+ name: follow
+ withRanking: false
+ props:
+ - name: degree
+ type: int
+ - path: /home/nebula/player.csv
+ failDataPath: ./err/player.csv
+ batchSize: 10
+ type: csv
+ csv:
+ withHeader: false
+ withLabel: false
+ schema:
+ type: vertex
+ vertex:
+ tags:
+ - name: player
+ props:
+ - name: name
+ type: string
+ - name: age
+ type: int
+ - path: /home/nebula/team.csv
+ failDataPath: ./err/team.csv
+ batchSize: 10
+ type: csv
+ csv:
+ withHeader: false
+ withLabel: false
+ schema:
+ type: vertex
+ vertex:
+ tags:
+ - name: team
+ props:
+ - name: name
+ type: string
+
+```
+
+**注意**:
+
+* 在上面的配置文件中,您必须将 IP 地址和端口号更改为您自己的 IP 地址和端口号。
+
+* 您必须将 CSV 文件的目录更改为您自己的目录,否则,[**Nebula Importer**](https://github.com/vesoft-inc/nebula-importer) 无法找到 CSV 文件。
+
+## 准备 CSV 数据
+
+在此示例中,我们准备了四个 CSV 数据文件:`player.csv`、`team.csv`、`serve.csv` 以及 `follow.csv`。
+
+`serve.csv` 文件中的数据如下:
+
+```csv
+100,200,1997,2016
+101,201,1999,2018
+102,203,2006,2015
+102,204,2015,2019
+103,204,2017,2019
+104,200,2007,2009
+```
+
+`follow.csv` 文件中的数据如下:
+
+```csv
+100,101,95
+100,102,90
+101,100,95
+102,101,75
+102,100,75
+103,102,70
+104,101,50
+104,105,60
+105,104,83
+```
+
+`player.csv` 文件中的数据如下:
+
+```csv
+100,Tim Duncan,42
+101,Tony Parker,36
+102,LaMarcus Aldridge,33
+103,Rudy Gay,32
+104,Marco Belinelli,32
+105,Danny Green,31
+106,Kyle Anderson,25
+107,Aron Baynes,32
+108,Boris Diaw,36
+```
+
+`team.csv` 文件中的数据如下:
+
+```csv
+200,Warriors
+201,Nuggets
+202,Rockets
+203,Trail
+204,Spurs
+205,Thunders
+206,Jazz
+207,Clippers
+208,Kings
+```
+
+**注意**:
+
+* 在 `serve`和 `follow` CSV 文件中,第一列是起始点 ID、第二列是目标点 ID,其他列与`config.yaml`文件一致。
+
+* 在 `player` 和 `team` CSV 文件中,第一列是点 ID,其他列与 `config.yaml` 文件一致。
+
+## 导入 CSV 数据
+
+完成上述所有四个步骤后,您可以使用 `Docker` 或 `Go` 导入 CSV 数据。
+
+### 使用 Go-importer 导入 CSV 数据
+
+在使用 `Go-importer` 导入 CSV 数据之前,必须确保已安装 `Go` 并配置了 `Go` 的环境变量。
+
+您可以通过以下步骤导入 CSV 数据:
+
+1. 通过以下命令将当前目录更改为 `import.go` 文件所在的目录:
+
+```bash
+$ cd /home/nebula/nebula-importer/cmd
+```
+
+2. 执行以下命令导入 CSV 数据:
+
+```bash
+$ go run importer.go --config /home/nebula/config.yaml
+```
+
+**注意**:您必须将 `import.go` 文件的目录和 `config.yaml` 文件的目录更改为您自己的目录,否则,导入操作可能会失败。
+
+### 使用 Docker 导入 CSV 数据
+
+在使用 `Docker` 导入CSV数据之前,必须确保 `Docker` 已启动并运行正常。
+
+您可以通过以下命令使用 `Docker` 导入 CSV 数据:
+
+```bash
+$ sudo docker run --rm -ti --network=host \
+-v /home/nebula/config.yaml:/home/nebula/config.yaml \
+-v /home/nebula/:/home/nebula/ vesoft/nebula-importer \
+--config /home/nebula/config.yaml
+```
+
+**注意**:您必须将 `config.yaml` 文件的目录更改为您自己的目录,否则导入操作可能会失败。
diff --git a/docs/manual-CN/1.overview/3.design-and-architecture/1.design-and-architecture.md b/docs/manual-CN/1.overview/3.design-and-architecture/1.design-and-architecture.md
new file mode 100644
index 00000000000..e0a47183689
--- /dev/null
+++ b/docs/manual-CN/1.overview/3.design-and-architecture/1.design-and-architecture.md
@@ -0,0 +1,35 @@
+# Nebula Graph 的整体架构
+
+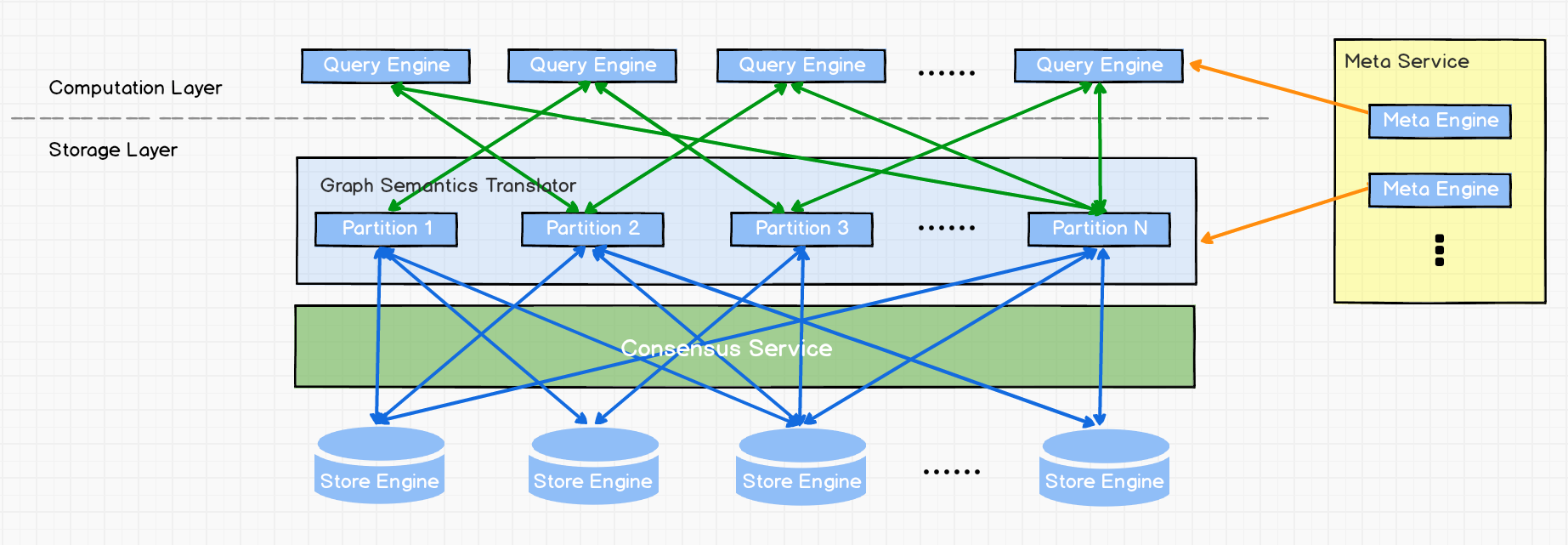
+
+一个完整的 **Nebula Graph** 部署集群包含三个服务,即 Query Service,Storage Service 和 Meta Service。每个服务都有其各自的可执行二进制文件,这些二进制文件既可以部署在同一组节点上,也可以部署在不同的节点上。
+
+## Meta Service
+
+上图为 **Nebula Graph** 的架构图,其右侧为 Meta Service 集群,它采用 leader/follower 架构。Leader 由集群中所有的 Meta Service 节点选出,然后对外提供服务。Followers 处于待命状态并从 leader 复制更新的数据。一旦 leader 节点 down 掉,会再选举其中一个 follower 成为新的 leader。
+
+Meta Service 不仅负责存储和提供图数据的 meta 信息,如 schema、partition 信息等,还同时负责指挥数据迁移及 leader 的变更等运维操作。
+
+## 存储计算分离
+
+在架构图中 Meta Service 的左侧,为 **Nebula Graph** 的主要服务,**Nebula Graph** 采用存储与计算分离的架构,虚线以上为计算,以下为存储。
+
+存储计算分离有诸多优势,最直接的优势就是,计算层和存储层可以根据各自的情况弹性扩容、缩容。
+
+存储计算分离还有另一个优势:使水平扩展成为可能。
+
+此外,存储计算分离使得 Storage Service 可以为多种类型的个计算层或者计算引擎提供服务。当前 Query Service 是一个高优先级的计算层,而各种迭代计算框架会是另外一个计算层。
+
+## 无状态计算层
+
+现在来看下计算层,每个计算节点都运行着一个无状态的查询计算引擎,而节点彼此间无任何通信关系。计算节点仅从 Meta Service 读取 meta 信息,以及和 Storage Service 进行交互。这样设计使得计算层集群更容易使用 K8s 管理或部署在云上。
+
+计算层的负载均衡有两种形式,最常见的方式是在计算层上加一个负载均衡 (balance),第二种方法是将计算层所有节点的 IP 地址配置在客户端中,这样客户端可以随机选取计算节点进行连接。
+
+每个查询计算引擎都能接收客户端的请求,解析查询语句,生成抽象语法树(AST)并将 AST 传递给执行计划器和优化器,最后再交由执行器执行。
+
+## Shared-nothing 分布式存储层
+
+Storage Service 采用 shared-nothing 的分布式架构设计,每个存储节点都有多个本地 KV 存储实例作为物理存储。**Nebula Graph** 采用多数派协议 Raft 来保证这些 KV 存储之间的一致性(由于 Raft 比 Paxos 更简洁,我们选用了 Raft )。在 KVStore 之上是图语义层,用于将图操作转换为下层 KV 操作。
+
+图数据(点和边)通过 Hash 的方式存储在不同 Partition 中。这里用的 Hash 函数实现很直接,即 vertex_id 取余 Partition 数。在 **Nebula Graph** 中,Partition 表示一个虚拟的数据集,这些 Partition 分布在所有的存储节点,分布信息存储在 Meta Service 中(因此所有的存储节点和计算节点都能获取到这个分布信息)。
diff --git a/docs/manual-CN/1.overview/3.design-and-architecture/2.storage-design.md b/docs/manual-CN/1.overview/3.design-and-architecture/2.storage-design.md
new file mode 100644
index 00000000000..531e6ba9a1e
--- /dev/null
+++ b/docs/manual-CN/1.overview/3.design-and-architecture/2.storage-design.md
@@ -0,0 +1,136 @@
+# 存储层设计
+
+## 摘要
+
+**Nebula Graph** 的 Storage 包含两个部分, 一是 meta 相关的存储, 称之为 `Meta Service` ,另一个是 data 相关的存储, 称之为 `Storage Service`。 这两个服务是两个独立的进程,数据也完全隔离,当然部署也是分别部署, 不过两者整体架构相差不大。 如果没有特殊说明,本文中 Storage Service 代指 data 的存储服务。
+
+## 架构
+
+
+
+图一 storage service 架构图
+
+如图1 所示,Storage Service 共有三层,最底层是 Store Engine,它是一个单机版 local store engine,提供了对本地数据的 `get` / `put` / `scan` / `delete` 操作,相关的接口放在 `KVStore/KVEngine.h` 文件里面,用户完全可以根据自己的需求定制开发相关 local store plugin,目前 **Nebula Graph** 提供了基于 RocksDB 实现的 Store Engine。
+
+在 local store engine 之上,便是 Consensus 层,实现了 Multi Group Raft,每一个 Partition 都对应了一组 Raft Group,这里的 Partition 便是数据分片。目前 **Nebula Graph** 的分片策略采用了 `静态 Hash` 的方式。用户在创建 SPACE 时需指定 Partition 数,Partition 数量一旦设置便不可更改,一般来讲,Partition 数目要能满足业务将来的扩容需求。
+
+在 Consensus 层上面也就是 Storage Service 的最上层,便是 Storage interfaces,这一层定义了一系列和图相关的 API。 这些 API 请求会在这一层被翻译成一组针对相应 Partition 的 kv 操作。正是这一层的存在,使得存储服务变成了真正的图存储,否则,Storage Service 只是一个 kv 存储。而 **Nebula Graph** 没把 kv 作为一个服务单独提出,其最主要的原因便是图查询过程中会涉及到大量计算,这些计算往往需要使用图的 schema,而 kv 层是没有数据 schema 概念,这样设计会比较容易实现计算下推。
+
+## Schema & Partition
+
+数据结构上,图的主要数据是点和边。但 **Nebula Graph** 存储的是属性图:除了点和边以外,还存储了对应的属性,以便更高效地使用属性过滤。
+
+对于点来说,**Nebula Graph** 使用不同的 Tag 表示不同类型的点,同一个 VertexID 可以关联多个 Tag,而每一个 Tag 都有自己对应的属性。对应到 kv 存储里面,**Nebula Graph** 使用 vertexID + TagID 来表示 key, 把相关的属性编码后放在 value 里面,具体 key 的 format 如图2 所示:
+
+
+
+图二 Vertex Key Format
+
+- `Type` : 1 个字节,用来表示 key 类型,当前的类型有 data, index, system 等
+- `Part ID` : 3 个字节,用来表示数据分片 Partition,此字段主要用于 **Partition 重新分布 (balance) 时方便根据前缀扫描整个 Partition 数据**
+- `Vertex ID` : 8 个字节,用来表示点的 ID
+- `Tag ID` : 4 个字节, 用来表示关联的某个 tag
+- `Timestamp` : 8 个字节,对用户不可见,未来实现分布式事务 (MVCC) 时使用
+
+在一个图中,每一条逻辑意义上的边,在 Nebula Graph 中会建模成两个独立的 key-value,分别称为 out-key 和 in-key。out-key 与这条边所对应的起点存储在同一个 partition 上,in-key 与这条边所对应的终点存储在同一个partition 上。通常来说,out-key 和 in-key 会分布在两个不同的 Partition 中。
+
+两个点之间可能存在多种类型的边,**Nebula Graph** 用 Edge Type 来表示边类型。而同一类型的边可能存在多条,比如,定义一个 edge type "转账",用户 A 可能多次转账给 B, 所以 **Nebula Graph** 又增加了一个 Rank 字段来做区分,表示 A 到 B 之间多次转账记录。 Edge key 的 format 如图 3 所示:
+
+
+
+图三 Edge Key Format
+
+- `Type` :1 个字节,用来表示 key 的类型,当前的类型有 data, index, system 等。
+- `Part ID` :3 个字节,用来表示数据分片 Partition,此字段主要用于 **Partition 重新分布 (balance) 时方便根据前缀扫描整个 Partition 数据**
+- `Vertex ID` :8 个字节,出边里面用来表示源点的 ID, 入边里面表示目标点的 ID。
+- `Edge Type` :4 个字节,用来表示这条边的类型,如果大于 0 表示出边,小于 0 表示入边。
+- `Rank` :8 个字节,用来处理同一种类型的边存在多条的情况。用户可以根据自己的需求进行设置,这个字段可*存放交易时间*、_交易流水号_、或*某个排序*
+- `Vertex ID` :8 个字节,出边里面用来表示目标点的 ID, 入边里面表示源点的 ID。
+- `Timestamp` :8 个字节,对用户不可见,未来实现分布式做事务的时候使用。
+
+针对 Edge Type 的值,若如果大于 0 表示出边,则对应的 edge key format 如图4 所示;若 Edge Type 的值小于 0,则对应的 edge key format 如图5 所示
+
+---
+
+
+图4 出边的 Key Format
+
+---
+
+
+图5 入边的 Key Format
+
+---
+
+对于点或边的属性信息,有对应的一组 kv pairs,**Nebula Graph** 将它们编码后存在对应的 value 里。由于 **Nebula Graph** 使用强类型 schema,所以在解码之前,需要先去 Meta Service 中取具体的 schema 信息。另外,为了支持在线变更 schema,在编码属性时,会加入对应的 schema 版本信息。
+
+数据的分片方式为对 Vertex ID `取模` 。通过对 Vertex ID 取模,同一个点的所有*出边*,*入边*以及这个点上所有关联的 *Tag 信息*都会被分到同一个 Partition,这种方式大大地提升了查询效率。对于在线图查询来讲,最常见的操作便是从一个点开始向外 BFS(广度优先)拓展,于是拿一个点的出边或者入边是最基本的操作,而这个操作的性能也决定了整个遍历的性能。BFS 中可能会出现按照某些属性进行剪枝的情况,**Nebula Graph** 通过将属性与点边存在一起,来保证整个操作的高效。在实际的场景中,大部分情况都是属性图,并且实际中的 BFS 也需要进行大量的剪枝操作。
+
+## KVStore
+
+对于KVStore的要求:
+
+- **性能**;
+- **以 library 的形式提供**:对于强 schema 的 **Nebula Graph** 来讲,计算下推需要 schema 信息,而计算下推实现的好坏,是 **Nebula Graph** 是否高效的关键;
+- **数据强一致**:这是分布式系统决定的;
+- **使用 C++实现**:这由团队的技术特点决定;
+
+基于上述要求,**Nebula Graph** 实现了自己的 KVStore。当然,对于性能完全不敏感且不太希望搬迁数据的用户来说,**Nebula Graph** 也提供了整个 KVStore 层的 plugin,直接将 Storage Service 搭建在第三方的 KVStore 上面,目前官方提供的是 HBase 的 plugin。
+
+**Nebula Graph** KVStore 主要采用 RocksDB 作为本地的存储引擎,对于多硬盘机器,为了充分利用多硬盘的并发能力,**Nebula Graph** 支持自己管理多块盘,用户只需配置多个不同的数据目录即可。
+
+分布式 KVStore 的管理由 Meta Service 来统一调度,它记录了所有 Partition 的分布情况,以及当前机器的状态,当用户增减机器时,只需要通过 console 输入相应的指令,Meta Service 便能够生成整个 balance plan 并执行。(之所以没有采用完全自动 balance 的方式,主要是为了减少数据搬迁对于线上服务的影响,balance 的时机由用户自己控制,通常会在业务低谷进行。)
+
+为了方便对于 WAL 进行定制,**Nebula Graph** KVStore 实现了自己的 WAL 模块,每个 partition 都有自己的 WAL,这样在追数据时,不需要进行 wal split 操作, 更加高效。 另外,为了实现一些特殊的操作,专门定义了 Command Log 这个类别,这些 log 只为了使用 Raft 来通知所有 replica 执行某一个特定操作,并没有真正的数据。除了 Command Log 外,**Nebula Graph** 还提供了一类日志来实现针对某个 Partition 的 atomic operation,例如 CAS,read-modify-write, 它充分利用了Raft 串行的特性。
+
+关于多图空间(space)的支持:一个 Nebula Graph KVStore 集群可以支持多个 space,每个 space 可设置自己的 partition 数和 replica 数。不同 space 在物理上是完全隔离的,而且在同一个集群上的不同 space 可支持不同的 store engine 及分片策略。
+
+## Raft
+
+作为一个分布式系统,KVStore 的 replication、scale out 等功能需 Raft 的支持。主要介绍 Nebula Graph Raft 的一些特点以及工程实现。
+
+### Multi Raft Group
+
+由于 Raft 的日志不允许空洞,几乎所有的实现都会采用 Multi Raft Group 来缓解这个问题,因此 partition 的数目几乎决定了整个 Raft Group 的性能。但这也并不是说 Partition 的数目越多越好:每一个 Raft Group 内部都要存储一系列的状态信息,并且每一个 Raft Group 有自己的 WAL 文件,因此 Partition 数目太多会增加开销。此外,当 Partition 太多时, 如果负载没有足够高,batch 操作是没有意义的。比如,对于一个有 1万 TPS 的线上系统,即使它的每台机器上 partition 的数目超过 1万,但很有可能每个 partition TPS 只有 1,这样 batch 操作就失去了意义,还增加了 CPU 开销。
+
+实现 Multi Raft Group 的最关键之处有两点,**第一是共享 Transport 层**,因为每一个 Raft Group 内部都需要向对应的 peer 发送消息,如果不能共享 Transport 层,连接的开销巨大;**第二是线程模型**,Multi Raft Group 一定要共享一组线程池,否则会造成系统的线程数目过多,导致大量的 context switch 开销。
+
+### Batch
+
+对于每个 Partition来说,由于串行写 WAL,为了提高吞吐,做 batch 是十分必要的。Nebula Graph 利用每个 part 串行的特点,做了一些特殊类型的 WAL,带来了一些工程上的挑战。
+
+举个例子,Nebula Graph 利用 WAL 实现了无锁的 CAS 操作,而每个 CAS 操作需要之前的 WAL 全部 commit 之后才能执行,所以对于一个 batch,如果中间夹杂了几条 CAS 类型的 WAL, 还需要把这个 batch 分成粒度更小的几个 group,group 之间保证串行。还有,command 类型的 WAL 需要它后面的 WAL 在其 commit 之后才能执行,所以整个 batch 划分 group 的操作工程实现上比较有特色。
+
+### Learner
+
+Learner 这个角色的存在主要是为了 `应对扩容` 时,新机器需要“追”相当长一段时间的数据,而这段时间有可能会发生意外。如果直接以 follower 的身份开始追数据,就会使得整个集群的 HA 能力下降。 Nebula Graph 里面 learner 的实现就是采用了上面提到的 command wal。 Leader 在写 wal 时如果碰到 add learner 的 command, 就会将 learner 加入自己的 peers,并把它标记为 learner,这样在统计多数派的时候,就不会算上 learner,但是日志还是会照常发送给它们。当然 learner 也不会主动发起选举。
+
+### Transfer Leadership
+
+Transfer leadership 这个操作对于 balance 来讲至关重要,当把某个 Partition 从一台机器挪到另一台机器时,首先便会检查 source 是不是 leader,如果是的话,需要先把他挪到另外的 peer 上面;在搬迁数据完毕之后,通常还要把 leader 进行一次 balance,这样每台机器承担的负载也能保证均衡。
+
+实现 transfer leadership, 需要注意的是 leader 放弃自己的 leadership,和 follower 开始进行 leader election 的时机。对于 leader 来讲,当 transfer leadership command 在 commit 的时候,它放弃 leadership;而对于 follower 来讲,当收到此 command 的时候就要开始进行 leader election, 这套实现要和 Raft 本身的 leader election 走一套路径,否则很容易出现一些难以处理的 corner case。
+
+### Membership change
+
+为了避免脑裂,当一个 Raft Group 的成员发生变化时,需要有一个中间状态, 这个状态下 old group 的多数派与 new group 的多数派总是有 overlap,这样就防止了 old group 或者新 group 单方面做出决定,这就是[论文](https://raft.github.io/raft.pdf)中提到的 `joint consensus` 。为了更加简化,Diego Ongaro 在自己的博士论文中提出**每次增减一个 peer 的方式**,**以保证 old group 的多数派总是与 new group 的多数派有 overlap**。 Nebula Graph 的实现也采用了这个方式,只不过 add member 与 remove member 的实现有所区别,具体实现方式可以参考 Raft Part class 里面 `addPeer/removePeer` 的实现。
+
+### Snapshot
+
+Snapshot 如何与 Raft 流程结合起来,[论文](https://raft.github.io/raft.pdf)中并没有细讲,但是这一部分是一个 Raft 实现里最容易出错的地方,因为这里会产生大量的 corner case。
+
+举一个例子,当 leader 发送 snapshot 过程中,如果 leader 发生了变化,该怎么办? 这个时候,有可能 follower 只接到了一半的 snapshot 数据。 所以需要有一个 Partition 数据清理过程,由于多个 Partition 共享一份存储,因此如何清理数据又是一个很麻烦的问题。另外,snapshot 过程中,会产生大量的 IO,为了性能考虑,不希望这个过程与正常的 Raft 共用一个 IO threadPool,并且整个过程中,还需要使用大量的内存,如何优化内存的使用,对于性能十分关键。由于篇幅原因,并不会在本文对这些问题展开讲述,可以参考 `SnapshotManager` 的实现。
+
+## Storage Service
+
+在 KVStore 的接口之上,Nebula Graph 封装有图语义接口,主要的接口如下:
+
+- `getNeighbors` :查询一批点的出边或者入边,返回边以及对应的属性,并且需要支持条件过滤;
+- `Insert vertex/edge` :插入一条点或者边及其属性;
+- `getProps` :取一个点或者一条边的属性;
+
+这一层会将图语义的接口转化成 kv 操作。为了提高遍历的性能,还要做并发操作。
+
+## Meta Service
+
+在 KVStore 的接口上,Nebula Graph 也同时封装了一套 meta 相关的接口。Meta Service 不但提供了图 schema 的增删查改的功能,还提供了集群的管理功能以及用户鉴权相关的功能。Meta Service 支持单独部署,也支持使用多副本来保证数据的安全。
diff --git a/docs/manual-CN/1.overview/3.design-and-architecture/3.query-engine.md b/docs/manual-CN/1.overview/3.design-and-architecture/3.query-engine.md
new file mode 100644
index 00000000000..186e713d3df
--- /dev/null
+++ b/docs/manual-CN/1.overview/3.design-and-architecture/3.query-engine.md
@@ -0,0 +1,43 @@
+# 查询引擎设计
+
+在 **Nebula Graph** 中,Query Engine 用来处理 **Nebula Graph** 查询语言语句(nGQL)。本篇文章将带你了解 Nebula Query Engine 的架构。
+
+
+
+上图为查询引擎的架构图,如果你对 SQL 的执行引擎比较熟悉,那么对上图一定不会陌生。**Nebula Graph** 的 Query Engine 架构图和现代 SQL 的执行引擎类似,只是在查询语言解析器和具体的执行计划有所区别。
+
+## Session Manager
+
+**Nebula Graph** 权限管理采用基于角色的权限控制(Role Based Access Control)。客户端第一次连接到 Query Engine 时需作认证,当认证成功之后 Query Engine 会创建一个新 session,并将该 session ID 返回给客户端。所有的 session 统一由 Session Manager 管理。session 会记录当前的 graph space 信息及对该 space 的权限。此外,session 还会记录一些会话相关的配置信息,并临时保存同一 session 内的跨多个请求的一些信息。
+
+客户端连接结束之后 session 会关闭,或者如果长时间没通信会切换为空闲状态。这个空闲时长是可以配置的。
+
+客户端的每次请求都必须带上此 session ID,否则 Query Engine 会拒绝此请求。
+
+Storage Engine 不管理 session,Query Engine 在访问存储引擎时,会带上 session 信息。
+
+## Parser
+
+Query Engine 解析来自客户端的 nGQL 语句,分析器(parser)主要基于著名的 flex / bison 工具集。字典文件(lexicon)和语法规则(syntax)在 **Nebula Graph** 源代码的 `src/parser` 目录下。设计上,nGQL 的语法非常接近 SQL,目的是降低学习成本。
+
+图数据库目前没有统一的查询语言国际标准,一旦 ISO/IEC 的图查询语言(GQL)委员会发布 GQL 国际标准,nGQL 会尽快去实现兼容。
+
+Parser 构建产出的抽象语法树(Abstract Syntax Tree,简称 AST)会交给下一模块:Execution Planner。
+
+## Execution Planner
+
+执行计划器(Execution Planner)负责将抽象树 AST 解析成一系列执行动作 action(可执行计划)。action 为最小可执行单元。例如,典型的 action 可以是获取某个节点的所有邻节点,或者获得某条边的属性,或基于特定过滤条件筛选节点或边。
+
+当抽象树 AST 被转换成执行计划时,所有 ID 信息会被抽取出来以便执行计划的复用。这些 ID 信息会放置在当前请求 context 中,context 也会保存变量和中间结果。
+
+## Optimization
+
+经由 Execution Planner 产生的执行计划会交给优化框架 Optimization Framework。优化框架中注册有多个 Optimizer。Optimizer 会依次被调用对执行计划进行优化,这样每个 Optimizer 都有机会修改(优化)执行计划。
+
+最后,优化过的执行计划可能和原始执行计划完全不一样,但是优化后的执行结果必须和原始执行计划的结果一样。
+
+## Execution
+
+Query Engine 最后一步是去执行优化后的执行计划,这步是执行框架(Execution Framework)完成的。执行层的每个执行器一次只处理一个执行计划,计划中的 action 会依次执行。执行器也会做一些有限的局部优化,比如:决定是否并发执行。
+
+针对不同 action,执行器将通过客户端与 meta service 或 storage engine 进行通信。
diff --git a/docs/manual-CN/1.overview/README.md b/docs/manual-CN/1.overview/README.md
new file mode 100644
index 00000000000..1ed122e8c50
--- /dev/null
+++ b/docs/manual-CN/1.overview/README.md
@@ -0,0 +1,3 @@
+# 面向的读者
+
+本章面向 **Nebula Graph** 的入门用户
diff --git a/docs/manual-CN/2.query-language/0.README.md b/docs/manual-CN/2.query-language/0.README.md
new file mode 100644
index 00000000000..4840d4f5287
--- /dev/null
+++ b/docs/manual-CN/2.query-language/0.README.md
@@ -0,0 +1,28 @@
+# 面向的读者
+
+本章介绍 **Nebula Graph** 的查询语言,适合所有使用 **Nebula Graph** 的用户。
+
+## 示例数据
+
+**Nebula Graph** 查询语句中使用的示例数据可以在[此处](https://oss-cdn.nebula-graph.com.cn/doc/example_data.zip)下载。示例数据下载完成后可以通过 [Nebula Graph Studio](https://github.com/vesoft-inc/nebula-web-docker) 把数据导入到 **Nebula Graph** 数据库中。
+
+## 占位标识符和占位符值
+
+**Nebula Graph** 查询语言 nGQL 参照以下标准设计:
+
+- ISO/IEC 10646
+- ISO/IEC 39075
+- ISO/IEC NP 39075 (Draft)
+
+在模板代码中,任何非关键词,文字或标点符号的标记均为占位标识符或占位符值。
+
+符号标记使用见下表:
+
+| 符号 | 含义 |
+| ---- | ---- |
+| < > | 必选项 |
+| ::= | 定义元素的公式 |
+| [ ] | 可选项 |
+| { } | 明确指定的元素 |
+| \| | 表示在其左右两边任选一项 |
+| ... | 元素可重复多次 |
diff --git a/docs/manual-CN/2.query-language/1.data-types/data-types.md b/docs/manual-CN/2.query-language/1.data-types/data-types.md
new file mode 100644
index 00000000000..fb5a893be69
--- /dev/null
+++ b/docs/manual-CN/2.query-language/1.data-types/data-types.md
@@ -0,0 +1,63 @@
+# 数据类型
+
+**Nebula Graph** 支持的内建数据类型如下:
+
+## 数值型
+
+### 整型
+
+整型的关键字为 `int`,为 64 位*有符号*整型,范围是 `[-9223372036854775808, 9223372036854775807]`,且在基于 int64 的计算中不存在溢出。整型常量支持多种格式:
+
+ 1. 十进制,例如 `123456`
+ 1. 十六进制,例如 `0xdeadbeaf`
+ 1. 八进制,例如 `01234567`
+
+
+
+## 布尔型
+
+布尔型关键字为 `bool`,字面常量为 `true` 和 `false`。
+
+## 字符型
+
+字符型关键字为 `string`,字面常量为双引号或单引号包围的任意长度的字符序列,字符串中间不允许换行。例如`"Shaquile O'Neal"`,`'"This is a double-quoted literal string"'`。字符串内支持嵌入转义序列,例如:
+
+ 1. `"\n\t\r\b\f"`
+ 1. `"\110ello world"`
+
+## 时间戳类型
+
+- 时间戳类型的取值范围为 `1970-01-01 00:00:01 UTC` 到 `2262-04-11 23:47:16 UTC`
+- 时间戳单位为秒
+- 插入数据的时候,支持插入方式
+ - 调用函数 now()
+ - 时间字符串,例如:"2019-10-01 10:00:00"
+ - 直接输入时间戳,即从 1970-01-01 00:00:00 开始的秒数
+- 做数据存储的时候,会先将时间转化为 **UTC 时间**,读取的时候会将存储的 **UTC 时间**转换为**本地时间**给用户
+- 底层存储数据类型为: **int64**
+
+## 示例
+
+先创建一个名为 school 的 tag
+
+```ngql
+nebula> CREATE TAG school(name string , create_time timestamp);
+```
+
+插入一个点,名为 "xiwang",建校时间为 "2010-09-01 08:00:00"
+
+```ngql
+nebula> INSERT VERTEX school(name, create_time) VALUES hash("xiwang"):("xiwang", "2010-09-01 08:00:00");
+```
+
+插入一个点,名为 "guangming",建校时间为现在
+
+```ngql
+nebula> INSERT VERTEX school(name, create_time) VALUES hash("guangming"):("guangming", now());
+```
diff --git a/docs/manual-CN/2.query-language/1.data-types/type-conversion.md b/docs/manual-CN/2.query-language/1.data-types/type-conversion.md
new file mode 100644
index 00000000000..c88a25d21a4
--- /dev/null
+++ b/docs/manual-CN/2.query-language/1.data-types/type-conversion.md
@@ -0,0 +1,19 @@
+# 类型转换
+
+在 nGQL 中,类型转换分为隐式转换和显式转换。
+
+## 隐式转换
+
+在表达式中,兼容类型间可自动完成类型转换:
+
+1. 以下类型均可隐式转换至 `bool` 类型:
+
++ 当且仅当字符串长度为 `0` 时,可被隐式转换为 `false` ,否则为 `true`
++ 当且仅当整型数值为 `0` 时,可被隐式转换为 `false` ,否则为 `true`
++ 当且仅当浮点类型数值为 `0.0` 时,可被隐式转换为 `false` ,否则为 `true`
+
+2. `int` 类型可隐式转换为 `double` 类型
+
+## 显式转换
+
+除隐式类型转换外,在符合语义的情况下,还可以使用显式类型转换。语法规则类似 C 语言: `(type_name)expression` 。例如, `YIELD length((string)(123)), (int)"123" + 1` 执行结果为 `3, 124`。`YIELD (int)("12ab3")` 则会转换失败。
diff --git a/docs/manual-CN/2.query-language/2.functions-and-operators/bitwise-operators.md b/docs/manual-CN/2.query-language/2.functions-and-operators/bitwise-operators.md
new file mode 100644
index 00000000000..f109de8dc43
--- /dev/null
+++ b/docs/manual-CN/2.query-language/2.functions-and-operators/bitwise-operators.md
@@ -0,0 +1,7 @@
+# 位运算符
+
+| ***名称*** | ***描述*** |
+|:----|:----:|
+| & | 按位与 |
+| \| | 按位或 |
+| ^ | 按位异或 |
diff --git a/docs/manual-CN/2.query-language/2.functions-and-operators/built-in-functions.md b/docs/manual-CN/2.query-language/2.functions-and-operators/built-in-functions.md
new file mode 100644
index 00000000000..391890ccce9
--- /dev/null
+++ b/docs/manual-CN/2.query-language/2.functions-and-operators/built-in-functions.md
@@ -0,0 +1,67 @@
+# 内建函数
+
+**Nebula Graph** 支持在表达式中调用如下类型的内建函数。
+
+## 数学相关
+
+函数| 描述 |
+---- | ----|
+double abs(double x) | 返回绝对值 |
+double floor(double x) | 返回小于参数的最大整数(向下取整) |
+double ceil(double x) | 返回大于参数的最小整数(向上取整) |
+double round(double x) | 对参数取整,如果参数位于中间位置,则返回远离 0 的数字 |
+double sqrt(double x) | 返回参数的平方根 |
+double cbrt(double x) | 返回参数的立方根 |
+double hypot(double x, double x) | 返回一个正三角形的斜边 |
+double pow(double x, double y) | 返回 x 的 y 次幂 |
+double exp(double x) | 计算 e 的 x 次幂 |
+double exp2(double x) | 返回 2 的指定次方 |
+double log(double x) | 返回参数的自然对数 |
+double log2(double x) | 返回底数为 2 的对数 |
+double log10(double x) | 返回底数为 10 的对数 |
+double sin(double x) | 返回正弦函数值 |
+double asin(double x) | 返回反正弦函数值
+double cos(double x) | 返回余弦函数值 |
+double acos(double x) | 返回反余弦函数值 |
+double tan(double x) | 返回正切函数值 |
+double atan(double x) | 返回反正切函数值 |
+int rand32() | 返回 32bit 整型伪随机数 |
+int rand32(int max) | 返回 [0, max) 区间内的 32bit 整型伪随机数 |
+int rand32(int min, int max) | 返回 [min, max) 区间内的 32bit 整型伪随机数 |
+int rand64() | 返回 64bit 整型伪随机数 |
+int rand64(int max) | 返回 [0, max) 区间内的 64bit 整型伪随机数 |
+int rand64(int min, int max) | 返回 [min, max) 区间内的 64bit 整型伪随机数 |
+
+## 字符串相关
+
+**注意:** 和 SQL 一样,nGQL 的字符索引(位置)从 `1` 开始,而不是类似 C 语言从 `0` 开始。
+
+函数| 描述 |
+---- | ----|
+int strcasecmp(string a, string b) | 大小写不敏感的字符串比较,相等时返回零,a > b 时返回值大于零,否则返回值小于零 |
+string lower(string a) | 将字符串转换为小写 |
+string upper(string a) | 将字符串转换为大写 |
+int length(string a) | 返回字符串长度(整数)(目前实现为,返回占用字节数) |
+string trim(string a) | 删除字符串两端的空白字符(空格,换行,制表符等) |
+string ltrim(string a) | 删除字符串起始的空白字符 |
+string rtrim(string a) | 删除字符串末尾的空白字符 |
+string left(string a, int count) | 返回 [1, count] 范围内的子串,若字符串长度小于 count ,则返回原字符串 |
+string right(string a, int count) | 返回 [size - count + 1, size] 范围内的子串,若字符串长度小于 count ,则返回原字符串 |
+string lpad(string a, int size, string letters) | 使用字符串 letters 从左侧填充字符串至其长度不小于 size |
+string rpad(string a, int size, string letters)| 使用字符串 letters 从右侧填充字符串至其长度不小于 size |
+string substr(string a, int pos, int count) | 从指定起始位置 pos 开始,获取长度为 count 的子串 |
+int hash(string a) | 对数值进行 hash,返回值类型为整数 |
+
+函数 `substr` 返回结果**注释**:
+
+- 如果 pos 等于 0 ,返回空串
+- 如果 pos 绝对值大于原字符串的长度,返回空串
+- 如果 pos 大于 0 ,返回 [pos, pos + count) 范围内的子串
+- 如果 pos 小于 0 ,设起始位置 N 为 length(a) + pos + 1 ,返回 [N, N + count) 范围内的子串
+- 如果 count 大于 length(a) ,则返回整个字符串
+
+## 时间相关
+
+函数| 描述 |
+--- | ---|
+int now() |返回当前时间戳 |
diff --git a/docs/manual-CN/2.query-language/2.functions-and-operators/comparison-functions-and-operators.md b/docs/manual-CN/2.query-language/2.functions-and-operators/comparison-functions-and-operators.md
new file mode 100644
index 00000000000..1ef54ab0d5a
--- /dev/null
+++ b/docs/manual-CN/2.query-language/2.functions-and-operators/comparison-functions-and-operators.md
@@ -0,0 +1,124 @@
+# 比较函数和运算符
+
+| 运算符 | 描述 |
+|:---- |:----:|
+| = | 赋值运算符 |
+| / | 除法运算符 |
+| == | 等于运算符 |
+| != | 不等于运算符 |
+| < | 小于运算符 |
+| <= | 小于或等于运算符 |
+| - | 减法运算符 |
+| % | 余数运算符 |
+| + | 加法运算符 |
+| * | 乘法运算符 |
+| - | 负号运算符 |
+| udf_is_in() | 比较函数,判断值是否在指定的列表中 |
+
+比较运算的结果是 _true_ 或 _false_ 。
+
+* ==
+
+等于。String的比较大小写敏感。不同类的值不相同:
+
+```ngql
+nebula> YIELD 'A' == 'a';
+==============
+| ("A"=="a") |
+==============
+| false |
+--------------
+
+nebula> YIELD '2' == 2;
+[ERROR (-8)]: A string type can not be compared with a non-string type.
+```
+
+* >
+
+大于:
+
+```ngql
+nebula> YIELD 3 > 2;
+=========
+| (3>2) |
+=========
+| true |
+---------
+```
+
+* ≥
+
+大于或等于:
+
+```ngql
+nebula> YIELD 2 >= 2;
+==========
+| (2>=2) |
+==========
+| true |
+----------
+```
+
+* <
+
+小于:
+
+```ngql
+nebula> YIELD 2.0 < 1.9;
+=======================
+| (2.000000<1.900000) |
+=======================
+| false |
+-----------------------
+```
+
+* ≤
+
+小于或等于:
+
+```ngql
+nebula> YIELD 0.11 <= 0.11;
+========================
+| (0.110000<=0.110000) |
+========================
+| true |
+------------------------
+```
+
+* !=
+
+不等于:
+
+```ngql
+nebula> YIELD 1 != '1';
+[ERROR (-8)]: A string type can not be compared with a non-string type.
+```
+
+* udf_is_in()
+
+第一个参数为要比较的值。
+
+```ngql
+nebula> YIELD udf_is_in(1,0,1,2);
+======================
+| udf_is_in(1,0,1,2) |
+======================
+| true |
+----------------------
+
+nebula> GO FROM 100 OVER follow WHERE udf_is_in($$.player.name, "Tony Parker"); /*由于udf_is_in 后面可能变更,所以该示例可能失效。*/
+===============
+| follow._dst |
+===============
+| 101 |
+---------------
+
+nebula> GO FROM 100 OVER follow YIELD follow._dst AS id | GO FROM $-.id OVER follow WHERE udf_is_in($-.id, 102, 102 + 1);
+===============
+| follow._dst |
+===============
+| 100 |
+---------------
+| 101 |
+---------------
+```
diff --git a/docs/manual-CN/2.query-language/2.functions-and-operators/group-by-function.md b/docs/manual-CN/2.query-language/2.functions-and-operators/group-by-function.md
new file mode 100644
index 00000000000..f2568082da1
--- /dev/null
+++ b/docs/manual-CN/2.query-language/2.functions-and-operators/group-by-function.md
@@ -0,0 +1,43 @@
+# 聚合函数 (Group By)
+
+ `GROUP BY` 函数类似于 SQL。 只能与 `YIELD` 语句一起使用。
+
+|名称 | 描述 |
+|:----|:----:|
+| AVG() | 返回参数的平均值 |
+| COUNT() | 返回记录值总数 |
+| COUNT_DISTINCT()) | 返回独立记录值的总数 |
+| MAX() | 返回最大值 |
+| MIN() | 返回最小值 |
+| STD() | 返回总体标准差 |
+| SUM() | 返回总合 |
+| BIT_AND() | 按位与 |
+| BIT_OR() | 按位或 |
+| BIT_XOR() | 按位异或 |
+以上函数只作用于 int64 和 double。
+
+## 示例
+
+```ngql
+nebula> GO FROM 100 OVER follow YIELD $$.player.name as Name | GROUP BY $-.Name YIELD $-.Name, COUNT(*);
+-- 从节点 100 出发,查找其关注的球员并返回球员的姓名作为 Name,按照姓名对球员分组并统计每个分组的人数。
+-- 返回以下结果:
+================================
+| $-.Name | COUNT(*) |
+================================
+| Kyle Anderson | 1 |
+--------------------------------
+| Tony Parker | 1 |
+--------------------------------
+| LaMarcus Aldridge | 1 |
+--------------------------------
+
+nebula> GO FROM 101 OVER follow YIELD follow._src AS player, follow.degree AS degree | GROUP BY $-.player YIELD SUM($-.degree);
+-- 从节点 101 出发找到其关注的球员,返回这些球员作为 player,边(follow)的属性值作为 degree,对这些球员分组并返回分组球员属性 degree 相加的值。
+-- 返回以下结果:
+==================
+| SUM($-.degree) |
+==================
+| 186 |
+------------------
+```
diff --git a/docs/manual-CN/2.query-language/2.functions-and-operators/limit-syntax.md b/docs/manual-CN/2.query-language/2.functions-and-operators/limit-syntax.md
new file mode 100644
index 00000000000..bc9205875d4
--- /dev/null
+++ b/docs/manual-CN/2.query-language/2.functions-and-operators/limit-syntax.md
@@ -0,0 +1,36 @@
+# LIMIT 语法
+
+`LIMIT` 用法与 `SQL` 中的相同,且只能与 `|` 结合使用。 `LIMIT` 子句接受一个或两个参数,两个参数的值都必须是零或正整数。
+
+```ngql
+ORDER BY [ASC | DESC]
+LIMIT [,]
+```
+
+* **expressions**
+
+ 待排序的列或计算。
+
+* **number_rows**
+
+ _number_rows_ 指定返回结果行数。例如,LIMIT 10 返回前 10 行结果。由于排序顺序会影响返回结果,所以使用 `ORDER BY` 时请注意排序顺序。
+
+* **offset_value**
+
+ 可选选项,用来跳过指定行数返回结果,offset 从 0 开始。
+
+> 当使用 `LIMIT` 时,请使用 `ORDER BY` 子句对返回结果进行唯一排序。否则,将返回难以预测的子集。
+
+例如:
+
+```ngql
+nebula> GO FROM 200 OVER serve REVERSELY YIELD $$.player.name AS Friend, $$.player.age AS Age | ORDER BY Age, Friend | LIMIT 3;
+=========================
+| Friend | Age |
+=========================
+| Kyle Anderson | 25 |
+-------------------------
+| Aron Baynes | 32 |
+-------------------------
+| Marco Belinelli | 32 |
+```
diff --git a/docs/manual-CN/2.query-language/2.functions-and-operators/logical-operators.md b/docs/manual-CN/2.query-language/2.functions-and-operators/logical-operators.md
new file mode 100644
index 00000000000..19f09e078e1
--- /dev/null
+++ b/docs/manual-CN/2.query-language/2.functions-and-operators/logical-operators.md
@@ -0,0 +1,61 @@
+# 逻辑运算符
+
+| **名称** | **描述** |
+|:----|:----:|
+| && | 逻辑与 AND |
+| ! | 逻辑非 NOT |
+| \|\| | 逻辑或 OR |
+| XOR | 逻辑异或 XOR |
+
+在 nGQL 中,非 0 数字将被视为 _true_ 。逻辑运算符的优先级参见 [Operator Precedence](./operator-precedence.md)。
+
+* &&
+
+逻辑与 AND:
+
+```ngql
+nebula> YIELD -1 && true;
+================
+| (-(1)&&true) |
+================
+| true |
+----------------
+```
+
+* !
+
+逻辑非 NOT:
+
+```ngql
+nebula> YIELD !(-1);
+===========
+| !(-(1)) |
+===========
+| false |
+-----------
+```
+
+* ||
+
+逻辑或 OR:
+
+```ngql
+nebula> YIELD 1 || !1;
+=============
+| (1||!(1)) |
+=============
+| true |
+```
+
+* XOR
+
+逻辑异或 XOR:
+
+```ngql
+nebula> YIELD (NOT 0 || 0) AND 0 XOR 1 AS ret;
+=========
+| ret |
+=========
+| true |
+---------
+```
diff --git a/docs/manual-CN/2.query-language/2.functions-and-operators/operator-precedence.md b/docs/manual-CN/2.query-language/2.functions-and-operators/operator-precedence.md
new file mode 100644
index 00000000000..e40726aa488
--- /dev/null
+++ b/docs/manual-CN/2.query-language/2.functions-and-operators/operator-precedence.md
@@ -0,0 +1,23 @@
+# 运算符优先级
+
+下面的列表展示了 nGQL 运算符的优先级(降序)。同一行的运算符拥有一致的优先级。
+
+```c
+!
+- (减法)
+*, /, %
+-, +
+== , >=, >, <=, <, <>, !=
+&&
+||
+= (赋值)
+```
+
+在一个表达式中,同等优先级的运算符将按照从左到右的顺序执行,唯一例外是赋值按照从右往左的顺序执行。但是,可以使用括号来修改执行顺序。
+
+示例:
+
+```ngql
+nebula> YIELD 2+3*5;
+nebula> YIELD (2+3)*5;
+```
diff --git a/docs/manual-CN/2.query-language/2.functions-and-operators/order-by-function.md b/docs/manual-CN/2.query-language/2.functions-and-operators/order-by-function.md
new file mode 100644
index 00000000000..681a40fce1d
--- /dev/null
+++ b/docs/manual-CN/2.query-language/2.functions-and-operators/order-by-function.md
@@ -0,0 +1,47 @@
+# Order By 函数
+
+类似于 SQL,`ORDER BY` 可以进行升序 (`ASC`) 或降序 (`DESC`) 排序并返回结果,并且它只能在 `PIPE` 语句 (`|`) 中使用。
+
+```ngql
+ORDER BY [ASC | DESC] [, [ASC | DESC] ...]
+```
+
+如果没有指明 ASC 或 DESC,`ORDER BY` 将默认进行升序排序。
+
+## 示例
+
+```ngql
+nebula> FETCH PROP ON player 100,101,102,103 YIELD player.age AS age, player.name AS name | ORDER BY age, name DESC;
+
+-- 取 4 个顶点并将他们以 age 从小到大的顺序排列,如 age 相同,则 name 按降序排列。
+-- 返回如下结果:
+======================================
+| VertexID | age | name |
+======================================
+| 103 | 32 | Rudy Gay |
+--------------------------------------
+| 102 | 33 | LaMarcus Aldridge |
+--------------------------------------
+| 101 | 36 | Tony Parker |
+--------------------------------------
+| 100 | 42 | Tim Duncan |
+--------------------------------------
+```
+
+(使用方法参见 [FETCH](../4.statement-syntax/2.data-query-and-manipulation-statements/fetch-syntax.md) 文档)
+
+```ngql
+nebula> GO FROM 100 OVER follow YIELD $$.player.age AS age, $$.player.name AS name | ORDER BY age DESC, name ASC;
+
+-- 从顶点 100 出发查找其关注的球员,返回球员的 age 和 name,age 按降序排列,如 age 相同,则 name 按升序排列。
+-- 返回如下结果:
+===========================
+| age | name |
+===========================
+| 36 | Tony Parker |
+---------------------------
+| 33 | LaMarcus Aldridge |
+---------------------------
+| 25 | Kyle Anderson |
+---------------------------
+```
diff --git a/docs/manual-CN/2.query-language/2.functions-and-operators/set-operations.md b/docs/manual-CN/2.query-language/2.functions-and-operators/set-operations.md
new file mode 100644
index 00000000000..690efb75837
--- /dev/null
+++ b/docs/manual-CN/2.query-language/2.functions-and-operators/set-operations.md
@@ -0,0 +1,159 @@
+# 集合操作 (`UNION`,`INTERSECT`, `MINUS`)
+
+## UNION,UNION DISTINCT,UNION ALL
+
+`UNION DISTINCT` (简称 `UNION`)返回数据集 A 和 B 的并集(不包含重复元素)。
+
+`UNION ALL` 返回数据集 A 和 B 的并集(包含重复元素)。`UNION` 语法为
+
+```ngql
+ UNION [DISTINCT | ALL] [ UNION [DISTINCT | ALL] ...]
+```
+
+`` 和 `` 必须列数相同,且数据类型相同。如果数据类型不同,将按照[类型转换](../1.data-types/type-conversion.md)进行转换。
+
+### 示例
+
+```ngql
+nebula> GO FROM 1 OVER e1 \
+ UNION \
+ GO FROM 2 OVER e1;
+```
+
+以上语句返回点 `1` 和 `2` (沿边 `e1`) 关联的唯一的点。
+
+```ngql
+nebula> GO FROM 1 OVER e1 \
+ UNION ALL\
+ GO FROM 2 OVER e1;
+```
+
+以上语句返回点 `1` 和 `2` 关联的所有点,其中存在重复点。
+
+`UNION` 亦可与 `YIELD` 同时使用,例如以下语句:
+
+```ngql
+nebula> GO FROM 1 OVER e1 YIELD e1._dst AS id, e1.prop1 AS left_1, $$.tag.prop2 AS left_2 -- query 1
+==========================
+| id | left_1 | left_2 |
+==========================
+| 104 | 1 | 2 | -- line 1
+--------------------------
+| 215 | 4 | 3 | -- line 3
+--------------------------
+
+nebula> GO FROM 2,3 OVER e1 YIELD e1._dst AS id, e1.prop1 AS right_1, $$.tag.prop2 AS right_2; -- query 2
+===========================
+| id | right_1 | right_2 |
+===========================
+| 104 | 1 | 2 | -- line 1
+---------------------------
+| 104 | 2 | 2 | -- line 2
+---------------------------
+```
+
+```ngql
+nebula> GO FROM 1 OVER e1 YIELD e1._dst AS id, e1.prop1 AS left_1, $$.tag.prop2 AS left_2 \
+ UNION /* DISTINCT */ \
+ GO FROM 2,3 OVER e1 YIELD e1._dst AS id, e1.prop1 AS right_1, $$.tag.prop2 AS right_2;
+```
+
+以上语句返回
+
+```ngql
+=========================
+| id | left_1 | left_2 | -- UNION or UNION DISTINCT. The column names come from query 1
+=========================
+| 104 | 1 | 2 | -- line 1
+-------------------------
+| 104 | 2 | 2 | -- line 2
+-------------------------
+| 215 | 4 | 3 | -- line 3
+-------------------------
+```
+
+请注意第一行与第二行返回相同 id 的点,但是返回的值不同。`DISTINCT` 检查返回结果中的重复值。所以第一行与第二行的返回结果不同。
+`UNION ALL` 返回结果为
+
+```ngql
+nebula> GO FROM 1 OVER e1 YIELD e1._dst AS id, e1.prop1 AS left_1, $$.tag.prop2 AS left_2 \
+ UNION ALL \
+ GO FROM 2,3 OVER e1 YIELD e1._dst AS id, e1.prop1 AS right_1, $$.tag.prop2 AS right_2;
+
+=========================
+| id | left_1 | left_2 | -- UNION ALL
+=========================
+| 104 | 1 | 2 | -- line 1
+-------------------------
+| 104 | 1 | 2 | -- line 1
+-------------------------
+| 104 | 2 | 2 | -- line 2
+-------------------------
+| 215 | 4 | 3 | -- line 3
+-------------------------
+```
+
+## INTERSECT
+
+`INTERSECT` 返回集合 A 和 B ( A ⋂ B)的交集。
+
+```ngql
+ INTERSECT
+```
+
+与 `UNION` 类似, `` 和 `` 必须列数相同,且数据类型相同。
+此外,只返回 `` 右 `` 相同的行。例如:
+
+```ngql
+nebula> GO FROM 1 OVER e1 YIELD e1._dst AS id, e1.prop1 AS left_1, $$.tag.prop2 AS left_2
+INTERSECT
+GO FROM 2,3 OVER e1 YIELD e1._dst AS id, e1.prop1 AS right_1, $$.tag.prop2 AS right_2;
+```
+
+返回
+
+```ngql
+=========================
+| id | left_1 | left_2 |
+=========================
+| 104 | 1 | 2 | -- line 1
+-------------------------
+```
+
+## MINUS
+
+返回 A - B 数据的差集,此处请注意运算顺序。例如:
+
+```ngql
+nebula> GO FROM 1 OVER e1 YIELD e1._dst AS id, e1.prop1 AS left_1, $$.tag.prop2 AS left_2
+MINUS
+GO FROM 2,3 OVER e1 YIELD e1._dst AS id, e1.prop1 AS right_1, $$.tag.prop2 AS right_2;
+```
+
+返回
+
+```ngql
+==========================
+| id | left_1 | left_2 |
+==========================
+| 215 | 4 | 3 | -- line 3
+--------------------------
+```
+
+如果更改 `MINUS` 顺序
+
+```ngql
+nebula> GO FROM 2,3 OVER e1 YIELD e1._dst AS id, e1.prop1 AS right_1, $$.tag.prop2 AS right_2
+MINUS
+GO FROM 1 OVER e1 YIELD e1._dst AS id, e1.prop1 AS left_1, $$.tag.prop2 AS left_2;
+```
+
+则返回
+
+```ngql
+===========================
+| id | right_1 | right_2 | -- column named from query 2
+===========================
+| 104 | 2 | 2 | -- line 2
+---------------------------
+```
diff --git a/docs/manual-CN/2.query-language/2.functions-and-operators/string-comparison-functions-and-operators.md b/docs/manual-CN/2.query-language/2.functions-and-operators/string-comparison-functions-and-operators.md
new file mode 100644
index 00000000000..68229d167c4
--- /dev/null
+++ b/docs/manual-CN/2.query-language/2.functions-and-operators/string-comparison-functions-and-operators.md
@@ -0,0 +1,43 @@
+# 字符比较函数和运算符
+
+| 名称 | 描述 |
+|:----- | :------------------: |
+| CONTAINS | 搜索包含指定字段的字符串,大小写敏感 |
+
+* CONTAINS
+
+`CONTAINS` 运算符用来搜索包含指定字段的字符串,且大小写敏感。`CONTAINS` 运算符左右两侧必须为字符串类型。
+
+```ngql
+nebula> GO FROM 107 OVER serve WHERE $$.team.name CONTAINS "riors" \
+ YIELD $^.player.name, serve.start_year, serve.end_year, $$.team.name;
+=====================================================================
+| $^.player.name | serve.start_year | serve.end_year | $$.team.name |
+=====================================================================
+| Aron Baynes | 2001 | 2009 | Warriors |
+---------------------------------------------------------------------
+
+nebula> GO FROM 107 OVER serve WHERE $$.team.name CONTAINS "Riors" \
+ YIELD $^.player.name, serve.start_year, serve.end_year, $$.team.name; -- 以下语句返回为空。
+```
+
+```ngql
+nebula> GO FROM 107 OVER serve WHERE (STRING)serve.start_year CONTAINS "07" && \
+ $^.player.name CONTAINS "Aron" \
+ YIELD $^.player.name, serve.start_year, serve.end_year, $$.team.name;
+=====================================================================
+| $^.player.name | serve.start_year | serve.end_year | $$.team.name |
+=====================================================================
+| Aron Baynes | 2007 | 2010 | Nuggets |
+---------------------------------------------------------------------
+```
+
+```ngql
+nebula> GO FROM 107 OVER serve WHERE !($$.team.name CONTAINS "riors") \
+ YIELD $^.player.name, serve.start_year, serve.end_year, $$.team.name;
+=====================================================================
+| $^.player.name | serve.start_year | serve.end_year | $$.team.name |
+=====================================================================
+| Aron Baynes | 2007 | 2010 | Nuggets |
+---------------------------------------------------------------------
+```
diff --git a/docs/manual-CN/2.query-language/2.functions-and-operators/uuid.md b/docs/manual-CN/2.query-language/2.functions-and-operators/uuid.md
new file mode 100644
index 00000000000..d5ee6969eae
--- /dev/null
+++ b/docs/manual-CN/2.query-language/2.functions-and-operators/uuid.md
@@ -0,0 +1,47 @@
+# UUID
+
+`UUID` 用于生成全局唯一的标识符。
+
+当顶点数量到达十亿级别时,用 `hash` 函数生成 vid 有一定的冲突概率。因此 **Nebula Graph** 提供 `UUID` 函数来避免大量顶点时的 vid 冲突。 `UUID` 函数由 `Murmurhash` 与当前时间戳(单位为秒)组合而成。
+
+`UUID` 产生的值会以 key-value 方式存储在 **Nebula Graph** 的 Storage 服务中,调用时会检查这个 key 是否存在或冲突。因此相比 hash,性能可能会更慢。
+
+插入 `UUID`:
+
+```ngql
+-- 使用 UUID 函数插入一个点。
+nebula> INSERT VERTEX player (name, age) VALUES uuid("n0"):("n0", 21);
+-- 使用 UUID 函数插入一条边。
+nebula> INSERT EDGE follow(degree) VALUES uuid("n0") -> uuid("n1"): (90);
+```
+
+获取 `UUID`:
+
+```ngql
+nebula> FETCH PROP ON player uuid("n0") YIELD player.name, player.age;
+-- 返回以下值:
+===================================================
+| VertexID | player.name | player.age |
+===================================================
+| -5057115778034027261 | n0 | 21 |
+---------------------------------------------------
+nebula> FETCH PROP ON follow uuid("n0") -> uuid("n1");
+-- 返回以下值:
+=============================================================================
+| follow._src | follow._dst | follow._rank | follow.degree |
+=============================================================================
+| -5057115778034027261 | 4039977434270020867 | 0 | 90 |
+-----------------------------------------------------------------------------
+```
+
+结合 `Go` 使用 `UUID`:
+
+```ngql
+nebula> GO FROM uuid("n0") OVER follow;
+-- 返回以下值:
+=======================
+| follow._dst |
+=======================
+| 4039977434270020867 |
+-----------------------
+```
diff --git a/docs/manual-CN/2.query-language/3.language-structure/.expression.md b/docs/manual-CN/2.query-language/3.language-structure/.expression.md
new file mode 100644
index 00000000000..2db54890ffb
--- /dev/null
+++ b/docs/manual-CN/2.query-language/3.language-structure/.expression.md
@@ -0,0 +1,19 @@
+
diff --git a/docs/manual-CN/2.query-language/3.language-structure/.patterns.md b/docs/manual-CN/2.query-language/3.language-structure/.patterns.md
new file mode 100644
index 00000000000..aebac5ce299
--- /dev/null
+++ b/docs/manual-CN/2.query-language/3.language-structure/.patterns.md
@@ -0,0 +1,14 @@
+# 模式匹配
+
+高效使用 `nGQL` 需要对模式匹配有清晰的理解。模式匹配可用来描述所需数据的形状。模式匹配区分大小写。
+
+例如,在 [LOOKUP](../4.statement-syntax/2.data-query-and-manipulation-statements/lookup-syntax.md) 语句中,使用模式描述数据形状,然后 `nGQL` 会找到目标数据。在本文档将展示如何编写模式匹配查询。
+
+## 指定属性
+
+属性可以用模式表示。例如,以下查询查找名称为 _Tony Parker_ 的球员。
+
+```ngql
+nebula > LOOKUP ON player WHERE player.name == "Tony Parker" \
+YIELD person.name, person.age
+```
diff --git a/docs/manual-CN/2.query-language/3.language-structure/comment-syntax.md b/docs/manual-CN/2.query-language/3.language-structure/comment-syntax.md
new file mode 100644
index 00000000000..65ca76dd2f2
--- /dev/null
+++ b/docs/manual-CN/2.query-language/3.language-structure/comment-syntax.md
@@ -0,0 +1,25 @@
+# 注释
+
+**Nebula Graph** 支持四种注释方式:
+
+* 在行末加 #
+* 在行末加 --
+* 在行末加 //,与 C 语言类似
+* 添加 `/* */` 符号,其开始和结束序列无需在同一行,因此此类注释方式支持换行。
+
+尚不支持嵌套注释。
+注释方式示例如下:
+
+```ngql
+nebula> -- Do nothing in this line
+nebula> YIELD 1+1; # 注释在本行末结束
+nebula> YIELD 1+1; -- 注释在本行末结束
+nebula> YIELD 1+1; // 注释在本行末结束
+nebula> YIELD 1 /* 这是行内注释 */ + 1;
+nebula> YIELD 11 + \
+/* 多行注释使用 \
+隔开 \
+*/ 12;
+```
+
+行内 `\` 表示换行符。
diff --git a/docs/manual-CN/2.query-language/3.language-structure/identifier-case-sensitivity.md b/docs/manual-CN/2.query-language/3.language-structure/identifier-case-sensitivity.md
new file mode 100644
index 00000000000..9a1c889af58
--- /dev/null
+++ b/docs/manual-CN/2.query-language/3.language-structure/identifier-case-sensitivity.md
@@ -0,0 +1,21 @@
+# 标识符大小写
+
+## 用户自定义的标识符为大小写敏感
+
+下方示例语句有错,因为`my_space` 和`MY_SPACE` 为两个不同的变量名。
+
+```ngql
+nebula> CREATE SPACE my_space;
+nebula> USE MY_SPACE; ---- my_space 和 MY_SPACE 是两个不同的 space
+```
+
+## 关键词和保留关键词为大小写不敏感
+
+下面四条语句是等价的(因为 show 和 spaces 都是保留字)
+
+```ngql
+nebula> show spaces;
+nebula> SHOW SPACES;
+nebula> SHOW spaces;
+nebula> show SPACES;
+```
diff --git a/docs/manual-CN/2.query-language/3.language-structure/keywords-and-reserved-words.md b/docs/manual-CN/2.query-language/3.language-structure/keywords-and-reserved-words.md
new file mode 100644
index 00000000000..1eb9938fd6d
--- /dev/null
+++ b/docs/manual-CN/2.query-language/3.language-structure/keywords-and-reserved-words.md
@@ -0,0 +1,173 @@
+# 关键字和保留字
+
+关键字是在 nGQL 中具有重要意义的单词。保留关键字需引用方可使用。
+
+非保留关键字无需引用可直接使用,且所有非保留字都会自动转换成小写,所以非保留字不区分大小写。保留关键字需使用反引号标注方可使用,例如 \`AND\`。
+
+```ngql
+nebula> CREATE TAG TAG(name string);
+[ERROR (-7)]: SyntaxError: syntax error near `TAG'
+
+nebula> CREATE TAG SPACE(name string); -- SPACE 为非保留关键字
+Execution succeeded
+
+nebula> SHOW TAGS; -- 所有非保留字都会自动转换成小写
+=============
+| ID | Name |
+=============
+| 25 | space|
+-------------
+```
+
+`TAG` 为保留字使用时必须使用反引号。 `SPACE` 为非保留字使用时无需加反引号。
+
+```ngql
+nebula> CREATE TAG `TAG` (name string); -- 此处 TAG 为保留字
+Execution succeeded
+```
+
+## 保留字
+
+以下列表为 nGQL 中的保留字。
+
+```ngql
+ADD
+ALTER
+AND
+AS
+ASC
+BALANCE
+BIGINT
+BOOL
+BY
+CHANGE
+COMPACT
+CREATE
+DELETE
+DESC
+DESCRIBE
+DISTINCT
+DOUBLE
+DOWNLOAD
+DROP
+EDGE
+EDGES
+EXISTS
+FETCH
+FIND
+FLUSH
+FROM
+GET
+GO
+GRANT
+IF
+IN
+INDEX
+INDEXES
+INGEST
+INSERT
+INT
+INTERSECT
+IS
+LIMIT
+LOOKUP
+MATCH
+MINUS
+NO
+NOT
+NULL
+OF
+OFFSET
+ON
+OR
+ORDER
+OVER
+OVERWRITE
+PROP
+REBUILD
+RECOVER
+REMOVE
+RETURN
+REVERSELY
+REVOKE
+SET
+SHOW
+STEPS
+STOP
+STRING
+SUBMIT
+TAG
+TAGS
+TIMESTAMP
+TO
+UNION
+UPDATE
+UPSERT
+UPTO
+USE
+VERTEX
+WHEN
+WHERE
+WITH
+XOR
+YIELD
+```
+
+## 非保留关键字
+
+```ngql
+ACCOUNT
+ADMIN
+ALL
+AVG
+BIDIRECT
+BIT_AND
+BIT_OR
+BIT_XOR
+CHARSET
+COLLATE
+COLLATION
+CONFIGS
+COUNT
+COUNT_DISTINCT
+DATA
+DBA
+DEFAULT
+FORCE
+GOD
+GRAPH
+GROUP
+GUEST
+HDFS
+HOSTS
+JOB
+JOBS
+LEADER
+MAX
+META
+MIN
+OFFLINE
+PART
+PARTITION_NUM
+PARTS
+PASSWORD
+PATH
+REPLICA_FACTOR
+ROLE
+ROLES
+SHORTEST
+SNAPSHOT
+SNAPSHOTS
+SPACE
+SPACES
+STATUS
+STD
+STORAGE
+SUM
+TTL_COL
+TTL_DURATION
+USER
+USERS
+UUID
+VALUES
+```
diff --git a/docs/manual-CN/2.query-language/3.language-structure/literal-values/.NULL-values.md b/docs/manual-CN/2.query-language/3.language-structure/literal-values/.NULL-values.md
new file mode 100644
index 00000000000..5695f76a65d
--- /dev/null
+++ b/docs/manual-CN/2.query-language/3.language-structure/literal-values/.NULL-values.md
@@ -0,0 +1,5 @@
+
\ No newline at end of file
diff --git a/docs/manual-CN/2.query-language/3.language-structure/literal-values/boolean-literals.md b/docs/manual-CN/2.query-language/3.language-structure/literal-values/boolean-literals.md
new file mode 100644
index 00000000000..d080f4b679e
--- /dev/null
+++ b/docs/manual-CN/2.query-language/3.language-structure/literal-values/boolean-literals.md
@@ -0,0 +1,12 @@
+# 布尔字面值
+
+布尔字面值 `TRUE` 和 `FALSE` 对大小写不敏感。
+
+```ngql
+nebula> yield TRUE, true, FALSE, false, FalsE;
+=========================================
+| true | true | false | false | false |
+=========================================
+| true | true | false | false | false |
+-----------------------------------------
+```
diff --git a/docs/manual-CN/2.query-language/3.language-structure/literal-values/numeric-literals.md b/docs/manual-CN/2.query-language/3.language-structure/literal-values/numeric-literals.md
new file mode 100644
index 00000000000..a414be4cfb3
--- /dev/null
+++ b/docs/manual-CN/2.query-language/3.language-structure/literal-values/numeric-literals.md
@@ -0,0 +1,29 @@
+# 数值字面值
+
+数值字面值包括整数字面值和浮点字面值。
+
+## 整数
+
+整数为 64 位,并且可以用 `+` 和 `-` 来表明正负性。它们和 C 语言中的 `int64_t` 是一致的。
+
+注意整数的最大值为 `9223372036854775807`。输入任何大于此最大值的整数为语法错误。整数的最小值 `-9223372036854775808` 同理。
+
+## 双浮点数
+
+双浮点数和 C 语言中的 `double` 是一致的。
+
+双浮点数上限和下限分为别 `-1.79769e+308` 和 `1.79769e+308`。
+
+## 科学计数法
+
+科学计数法是指以尾数和指数表示的数字。尾数或指数中的一个或两个都可以带负号。例如:`1.2E3`、`1.2E-3`、`-1.2E3`、`-1.2E-3`。
+
+## 示例
+
+以下为几个例子:
+
+```ngql
+1, -5, +10000100000
+-2.3, +1.00000000000
+1.2E3
+```
diff --git a/docs/manual-CN/2.query-language/3.language-structure/literal-values/string-literals.md b/docs/manual-CN/2.query-language/3.language-structure/literal-values/string-literals.md
new file mode 100644
index 00000000000..3741005b7e9
--- /dev/null
+++ b/docs/manual-CN/2.query-language/3.language-structure/literal-values/string-literals.md
@@ -0,0 +1,43 @@
+# 字符串字面值
+
+字符串由一串字节或字符组成,并由一对单引号 (') 或双引号 (") 包装。
+
+```ngql
+nebula> YIELD 'a string';
+nebula> YIELD "another string";
+```
+
+一些转义字符 (\\) 已被支持,如下表所示:
+
+| **转义字符** | **对应的字符** |
+|:----|:----|
+| \' | 单引号 (') |
+| \" | 双引号 (") |
+| \t | 制表符 |
+| \n | 换行符 |
+| \b | 退格符 |
+| \\ | 反斜杠 (\\) |
+
+示例:
+
+```ngql
+nebula> YIELD 'This\nIs\nFour\nLines';
+========================
+| "This
+Is
+Four
+Lines" |
+========================
+| This
+Is
+Four
+Lines |
+------------------------
+
+nebula> YIELD 'disappearing\ backslash';
+============================
+| "disappearing backslash" |
+============================
+| disappearing backslash |
+----------------------------
+```
diff --git a/docs/manual-CN/2.query-language/3.language-structure/pipe-syntax.md b/docs/manual-CN/2.query-language/3.language-structure/pipe-syntax.md
new file mode 100644
index 00000000000..66c88fadc10
--- /dev/null
+++ b/docs/manual-CN/2.query-language/3.language-structure/pipe-syntax.md
@@ -0,0 +1,18 @@
+# 管道
+
+nGQL 和 SQL 的主要区别之一是子查询的组合方式。
+
+SQL 中的查询语句通常由子查询嵌套组成,而 nGQL 则使用类似于 shell 的管道方式 `PIPE(|)` 来组合子查询。
+
+## 示例
+
+```ngql
+nebula> GO FROM 100 OVER follow YIELD follow._dst AS dstid, $$.player.name AS Name | \
+GO FROM $-.dstid OVER follow YIELD follow._dst, follow.degree, $-.Name;
+```
+
+如未使用 `YIELD`,则默认返回终点 `id`。
+
+如果使用 `YIELD` 明确声明返回结果,则不会返回默认值 `id`。
+
+`$-.` 后的别名必须为前一个子句 `YIELD` 定义的值,如本例中的 `dstid` 和 `Name`。
diff --git a/docs/manual-CN/2.query-language/3.language-structure/property-reference.md b/docs/manual-CN/2.query-language/3.language-structure/property-reference.md
new file mode 100644
index 00000000000..cd30f5c61db
--- /dev/null
+++ b/docs/manual-CN/2.query-language/3.language-structure/property-reference.md
@@ -0,0 +1,64 @@
+# 属性引用
+
+`WHERE` 和 `YIELD` 可引用节点或边的属性。
+
+## 引用点的属性
+
+### 引用起点的属性
+
+```ngql
+$^.tag_name.prop_name
+```
+
+其中符号 `$^` 用于获取起点属性,`tag_name` 表示起点的 `tag`,`prop_name` 为指定属性的名称。
+
+### 引用终点的属性
+
+```ngql
+$$.tag_name.prop_name
+```
+
+其中符号 `$$` 用于获取终点属性,`tag_name` 表示终点的 `tag`,`prop_name` 为指定属性的名称。
+
+### 示例
+
+```ngql
+nebula> GO FROM 100 OVER follow YIELD $^.player.name AS startName, $$.player.age AS endAge;
+```
+
+该语句用于获取起点的属性名称和终点的属性年龄。
+
+## 引用边
+
+### 引用边的属性
+
+使用如下方式获取边属性:
+
+```ngql
+edge_type.edge_prop
+```
+
+此处,`edge_type`为边的类型,`edge_prop`为属性,例如:
+
+```ngql
+nebula> GO FROM 100 OVER follow YIELD follow.degree;
+```
+
+### 引用边的内置属性
+
+一条边有四个内置属性:
+
+- _src: 边起点 ID
+- _dst: 边终点 ID
+- _type: 边类型
+- _ranking: 边的 ranking 值
+
+获取起点和终点 ID 可通过 `_src` 和 `_dst` 获取,这在显示图路径时经常会用到。
+
+例如:
+
+```ngql
+nebula> GO FROM 100 OVER follow YIELD follow._src AS startVID /* 起点为100 */, follow._dst AS endVID;
+```
+
+该语句通过引用 `follow._src` 作为起点 ID 和 `follow._dst` 作为终点 ID,返回起点 100 `follow` 的所有邻居节点。其中 `follow._src` 返回起点 ID,`follow._dst` 返回终点 ID。
diff --git a/docs/manual-CN/2.query-language/3.language-structure/schema-object-names.md b/docs/manual-CN/2.query-language/3.language-structure/schema-object-names.md
new file mode 100644
index 00000000000..55be9f8114d
--- /dev/null
+++ b/docs/manual-CN/2.query-language/3.language-structure/schema-object-names.md
@@ -0,0 +1,9 @@
+# 标识符命名规则
+
+**Nebula Graph** 中的标识符包括图空间、标签、边、别名、自定义变量等。标识符命名规则为:
+
+* 标识符中允许的字符:
+ ASCII: [_0-9,a-z,A-Z,_] (基本拉丁字母,数字 0 - 9,下划线),不支持其他标点字符。
+* 所有标识符必须以字母开头。
+* 标识符区分大小写。
+* 不可使用关键字或保留关键字做标识符。
diff --git a/docs/manual-CN/2.query-language/3.language-structure/statement-composition.md b/docs/manual-CN/2.query-language/3.language-structure/statement-composition.md
new file mode 100644
index 00000000000..df86221faa6
--- /dev/null
+++ b/docs/manual-CN/2.query-language/3.language-structure/statement-composition.md
@@ -0,0 +1,29 @@
+# 语句组合
+
+组合语句(或子查询)的方法有两种:
+
+* 将多个语句放在一个语句中进行批处理,以英文分号(;)隔开,最后一个语句的结果将作为批处理的结果返回。
+* 将多个语句通过运算符(|)连接在一起,类似于 shell 脚本中的管道。前一个语句得到的结果可以重定向到下一个语句作为输入。
+
+> 注意复合语句并不能保证`事务性`。
+> 例如,由三个子查询组成的语句:A | B | C,其中 A 是读操作,B 是计算,C 是写操作。
+> 如果任何部分在执行中失败,整个结果将未被定义--尚不支持调用回滚。
+
+## 示例
+
+### 分号复合语句
+
+```ngql
+nebula> SHOW TAGS; SHOW EDGES; -- 仅列出边
+nebula> INSERT VERTEX player(name, age) VALUES 100:("Tim Duncan", 42); \
+ INSERT VERTEX player(name, age) VALUES 101:("Tony Parker", 36); \
+ INSERT VERTEX player(name, age) VALUES 102:("LaMarcus Aldridge", 33); /* 通过复合语句插入多个点*/
+```
+
+### 管道复合语句
+
+```ngql
+nebula> GO FROM 201 OVER edge_serve | GO FROM $-.id OVER edge_fans | GO FROM $-.id ...
+```
+
+占位符 `$-.id` 获取第一个语句 `GO FROM 201 OVER edge_serve YIELD edge_serve._dst AS id` 返回的结果。
diff --git a/docs/manual-CN/2.query-language/3.language-structure/user-defined-variables.md b/docs/manual-CN/2.query-language/3.language-structure/user-defined-variables.md
new file mode 100644
index 00000000000..1549a984dab
--- /dev/null
+++ b/docs/manual-CN/2.query-language/3.language-structure/user-defined-variables.md
@@ -0,0 +1,16 @@
+# 用户自定义变量
+
+**Nebula Graph** 支持用户自定义变量,其格式为 `$var_name`。其中变量名 `var_name` 由字母字符组成。目前不建议使用任何其他字符。用户自定义变量可暂时将值存储在前一个语句中的自定义变量中,并在(随后的)另一个语句中使用,从而可将中间结果从一个语句传递到另一个语句。
+
+用户定义变量只能在一次执行中使用(由分号 `;` 或管道 `|` 隔开的复合语句,并提交给服务器一起执行)。
+
+请注意,自定义的变量仅在当前会话的当前查询有效。在一个语句中定义的自定义变量不能在其他客户端和其他执行中使用,也就是说定义语句和使用它的语句应该一起提交。当客户端发送执行时,变量会自动释放。
+
+用户变量名称区分大小写。
+
+示例:
+
+```ngql
+nebula> $var = GO FROM hash('curry') OVER follow YIELD follow._dst AS id; \
+GO FROM $var.id OVER serve;
+```
diff --git a/docs/manual-CN/2.query-language/4.statement-syntax/1.data-definition-statements/TTL.md b/docs/manual-CN/2.query-language/4.statement-syntax/1.data-definition-statements/TTL.md
new file mode 100644
index 00000000000..cc4f6fea3d4
--- /dev/null
+++ b/docs/manual-CN/2.query-language/4.statement-syntax/1.data-definition-statements/TTL.md
@@ -0,0 +1,114 @@
+# TTL (time-to-live)
+
+**Nebula Graph** 支持 **TTL** ,在一定时间后自动从数据库中删除点或者边。过期数据会在下次 compaction 时被删除,在下次 compaction 前,query 会过滤掉过期的点和边。
+
+ttl 功能需要 `ttl_col` 和 `ttl_duration` 一起使用。自从 `ttl_col` 指定的字段的值起,经过 `ttl_duration` 指定的秒数后,该条数据过期。即,到期阈值是 `ttl_col` 指定的 property 的值加上 `ttl_duration` 设置的秒数。其中 `ttl_col` 指定的字段的类型需为 integer 或者 timestamp。
+
+
+
+## TTL 配置
+
+- `ttl_duration` 单位为秒,范围为 0 ~ max(int64),当 `ttl_duration` 被设置为 0,则点的此 tag 属性不会过期。
+
+- 当 `ttl_col` 指定的字段的值 + `ttl_duration` 值 < 当前时间时,该条数据此 tag 属性值过期。
+
+- 当该条数据有多个 tag,每个 tag 的 ttl 单独处理。
+
+## 设置 TTL
+
+- 对已经创建的 tag,设置 TTL。
+
+```ngql
+nebula> CREATE TAG t1(a timestamp);
+nebula> ALTER TAG t1 ttl_col = "a", ttl_duration = 5; -- 创建 ttl
+nebula> INSERT VERTEX t1(a) values 101:(now());
+```
+
+点 101 的 TAG t1 属性会在 now() 之后,经过 5s 后过期。
+
+- 在创建 tag 时设置 TTL。
+
+```ngql
+nebula> CREATE TAG t2(a int, b int, c string) ttl_duration= 100, ttl_col = "a";
+nebula> INSERT VERTEX t2(a, b, c) values 102:(1584441231, 30, "Word");
+```
+
+点 102 的 TAG t2 属性会在 2020年3月17日 18时33分51秒 CST (即时间戳为 1584441231),经过 100s 后过期。
+
+- 当点有多个 TAG 时,各 TAG 的 TTL 相互独立。
+
+```ngql
+nebula> CREATE TAG t3(a string);
+nebula> INSERT VERTEX t1(a),t3(a) values 200:(now(), "hello");
+```
+
+5s 后, 点 Vertex 200 的 t1 属性过期。
+
+```ngql
+nebula> FETCH PROP ON t1 200;
+Execution succeeded (Time spent: 5.945/7.492 ms)
+
+nebula> FETCH PROP ON t3 200;
+======================
+| VertexID | t3.a |
+======================
+| 200 | hello |
+----------------------
+
+nebula> FETCH PROP ON * 200;
+======================
+| VertexID | t3.a |
+======================
+| 200 | hello |
+----------------------
+```
+
+## 删除 TTL
+
+如果想要删除 TTL,可以设置 `ttl_col` 字段为空,或删除配置的 `ttl_col` 字段,或者设置 `ttl_duration` 为 0。
+
+```ngql
+nebula> ALTER TAG t1 ttl_col = ""; -- drop ttl attribute;
+```
+
+删除配置的 `ttl_col` 字段:
+
+```ngql
+nebula> ALTER TAG t1 DROP (a); -- drop ttl_col
+```
+
+设置 ttl_duration 为 0:
+
+```ngql
+nebula> ALTER TAG t1 ttl_duration = 0; -- keep the ttl but the data never expires
+```
+
+## TTL 使用注意事项
+
+- 如果 `ttl_col` 值为非空,则不支持对 `ttl_col` 值指定的列进行更改操作。
+
+``` ngql
+nebula> CREATE TAG t1(a int, b int, c string) ttl_duration = 100, ttl_col = "a";
+nebula> ALTER TAG t1 CHANGE (a string); -- failed
+```
+
+- 注意一个 tag 或 edge 不能同时拥有 TTL 和索引,只能二者择其一,即使 `ttl_col` 配置的字段与要创建索引的字段不同。
+
+``` ngql
+nebula> CREATE TAG t1(a int, b int, c string) ttl_duration = 100, ttl_col = "a";
+nebula> CREATE TAG INDEX id1 ON t1(a); -- failed
+```
+
+``` ngql
+nebula> CREATE TAG t1(a int, b int, c string) ttl_duration = 100, ttl_col = "a";
+nebula> CREATE TAG INDEX id1 ON t1(b); -- failed
+```
+
+```ngql
+nebula> CREATE TAG t1(a int, b int, c string);
+nebula> CREATE TAG INDEX id1 ON t1(a);
+nebula> ALTER TAG t1 ttl_col = "a", ttl_duration = 100; -- failed
+```
+
+- 对 edge 配置 TTL 与 tag 类似。
diff --git a/docs/manual-CN/2.query-language/4.statement-syntax/1.data-definition-statements/alter-tag-edge-syntax.md b/docs/manual-CN/2.query-language/4.statement-syntax/1.data-definition-statements/alter-tag-edge-syntax.md
new file mode 100644
index 00000000000..7994088c1d2
--- /dev/null
+++ b/docs/manual-CN/2.query-language/4.statement-syntax/1.data-definition-statements/alter-tag-edge-syntax.md
@@ -0,0 +1,37 @@
+# 修改 Tag / Edge
+
+```ngql
+ALTER TAG | EDGE |
+ [, alter_definition] ...]
+ [ttl_definition [, ttl_definition] ... ]
+
+alter_definition:
+| ADD (prop_name data_type)
+| DROP (prop_name)
+| CHANGE (prop_name data_type)
+
+ttl_definition:
+ TTL_DURATION = ttl_duration, TTL_COL = prop_name
+```
+
+`ALTER` 语句可改变标签或边的结构,例如,可以添加或删除属性,更改已有属性的类型,也可将属性设置为 TTL(生存时间),或更改 TTL 时间。
+
+**注意:** 修改标签或边结构时,**Nebula Graph** 将自动检测是否存在索引。修改时需要两步判断。首先,判断这个 tag 或 edge 是否关联索引。其次,检查所有关联的索引,判断待删除或更改的 column item 是否存在于索引的 column 中,如果存在则拒绝修改。如果不存在,即使有关联的索引也允许修改。
+
+请参考[索引文档](index.md)了解索引详情。
+
+一个 `ALTER` 语句允许使用多个 `ADD`,`DROP`,`CHANGE` 语句,语句之间需用逗号隔开。但是不要在一个语句中添加,删除或更改相同的属性。如果必须进行此操作,请将其作为 `ALTER` 语句的子语句。
+
+```ngql
+nebula> CREATE TAG t1 (name string, age int);
+nebula> ALTER TAG t1 ADD (id int, address string);
+
+nebula> CREATE EDGE e1 (prop3 int, prop4 int, prop5 int);
+nebula> ALTER EDGE e1 ADD (prop1 int, prop2 string), /* 添加 prop1 */
+ CHANGE (prop3 string), /* 将 prop3 类型更改为字符 */
+ DROP (prop4, prop5); /* 删除 prop4 和 prop5 */
+
+nebula> ALTER EDGE e1 TTL_DURATION = 2, TTL_COL = prop1;
+```
+
+注意 TTL_COL 仅支持 INT 和 TIMESTAMP 类型。
diff --git a/docs/manual-CN/2.query-language/4.statement-syntax/1.data-definition-statements/create-space-syntax.md b/docs/manual-CN/2.query-language/4.statement-syntax/1.data-definition-statements/create-space-syntax.md
new file mode 100644
index 00000000000..7b29bc0d727
--- /dev/null
+++ b/docs/manual-CN/2.query-language/4.statement-syntax/1.data-definition-statements/create-space-syntax.md
@@ -0,0 +1,73 @@
+# CREATE SPACE 语法
+
+```ngql
+CREATE SPACE [IF NOT EXISTS]
+ [(partition_num = , replica_factor = , charset = , collate = )]
+```
+
+以上语句用于创建一个新的图空间。不同的图空间是物理隔离的。
+
+## IF NOT EXISTS
+
+创建图空间可使用 `IF NOT EXISTS` 关键字,这个关键字会自动检测对应的图空间是否存在,如果不存在则创建新的,如果存在则直接返回。
+
+**注意:** 这里判断图空间是否存在只是比较图空间的名字(不包括属性)。
+
+## Space Name 图空间名
+
+* **space_name**
+
+ 图空间的名称在集群中标明了一个唯一的空间。命名规则详见 [Schema Object Names](../../3.language-structure/schema-object-names.md)
+
+## 自定义图空间选项
+
+在创建图空间的时候,可以传入如下两个自定义选项:
+
+* _partition_num_
+
+ _partition_num_ 表示数据分片数量。默认值为 100。建议为硬盘数量的 5 倍。
+
+* _replica_factor_
+
+ _replica_factor_ 表示副本数量。默认值是 1,生产集群建议为 3。
+
+* _charset_
+
+ _charset_ 表示字符集,定义了字符以及字符的编码,默认为 utf8。
+
+* _collate_
+
+ _collate_ 表示字符序,定义了字符的比较规则,默认为 utf8_bin。
+
+如果没有自定义选项,**Nebula Graph** 会使用默认的值(partition_number、replica_factor、charset 和 collate)来创建图空间。
+
+## 示例
+
+```ngql
+nebula> CREATE SPACE my_space_1; -- 使用默认选项创建图空间
+nebula> CREATE SPACE my_space_2(partition_num=10); -- 使用默认 replica_factor 创建图空间
+nebula> CREATE SPACE my_space_3(replica_factor=1); -- 使用默认 partition_number 创建图空间
+nebula> CREATE SPACE my_space_4(partition_num=10, replica_factor=1);
+```
+
+## 检查 partition 分布正常
+
+在某些大集群上,由于启动时间先后不一,可能会导致 partition 分布不均,可以通过如下命令(SHOW HOSTS)检查机器和分布。
+
+```ngql
+nebula> SHOW HOSTS;
+================================================================================================
+| Ip | Port | Status | Leader count | Leader distribution | Partition distribution |
+================================================================================================
+| 192.168.8.210 | 34600 | online | 13 | test: 13 | test: 37 |
+------------------------------------------------------------------------------------------------
+| 192.168.8.210 | 34900 | online | 12 | test: 12 | test: 38 |
+```
+
+若发现机器都已在线,但 partition 分布不均,可以通过如下命令 (BALANCE LEADER)来命令 partition 重分布。
+
+```ngql
+nebula> BALANCE LEADER;
+```
+
+具体见 [SHOW HOSTS](../3.utility-statements/show-statements/show-hosts-syntax.md) 和 [BALANCE](../../../3.build-develop-and-administration/5.storage-service-administration/storage-balance.md)。
diff --git a/docs/manual-CN/2.query-language/4.statement-syntax/1.data-definition-statements/create-tag-edge-syntax.md b/docs/manual-CN/2.query-language/4.statement-syntax/1.data-definition-statements/create-tag-edge-syntax.md
new file mode 100644
index 00000000000..0cc19a01585
--- /dev/null
+++ b/docs/manual-CN/2.query-language/4.statement-syntax/1.data-definition-statements/create-tag-edge-syntax.md
@@ -0,0 +1,96 @@
+# CREATE TAG / EDGE 语法
+
+```ngql
+CREATE {TAG | EDGE} [IF NOT EXISTS] { | }
+ ([, ...])
+ [tag_edge_options]
+
+ ::=
+
+
+ ::=
+