Simple FaceNet implementation on MNIST Dataset sample code.
Thanks for :
- https://www.kaggle.com/guichristmann/training-a-triplet-loss-model-on-mnist
- Helps understand triple loss.
- I started from this.
- t-SNE & scatter plot examples.
- https://github.com/davidsandberg/facenet
- It help me to understand how to implemet model & training & triplet loss.
This repo is to make it simple to understand how to implement FaceNet("FaceNet: A Unified Embedding for Face Recognition and Clustering" http://arxiv.org/abs/1503.03832) model and triplet loss function.
Feel free to send any of your question & suggestion & wrong point about this notebook to:
firsttimelove@gmail.com
In this repo, we will make FaceNet NN2 Model(modified to work on MNIST dataset) and use it.
There's a specification of an model using google inception in the Facenet paper.
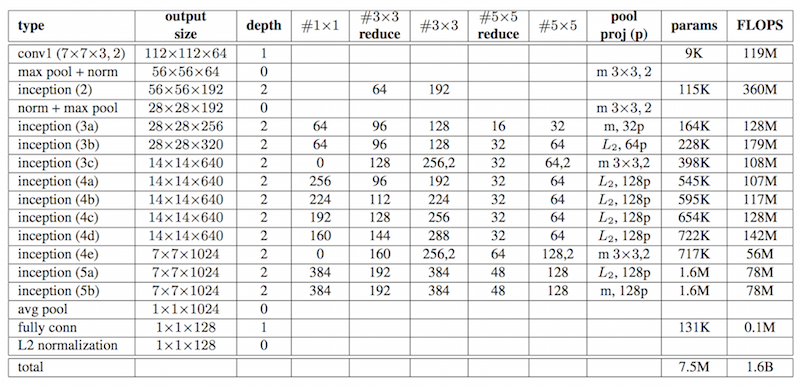
- L2 pooling is used instead of Max pooling where 'L2' specified.
- "m 3X3, 2" indicates 3x3 max pooling with (2,2) stride.

The image below maps part of inception layer with columns of NN2 model layer table above.
Some conv/maxpool layers inside inception layer are optional.
- Example : inception(3c) :
- No solo #1x1 convolution layer
- No 1x1 convolution layer after 3x3 maxpool.
For pooling, MAXPOOL or L2POOL is used(specified in table above).
A triplet is a tuple of:
- anchor : embedding of an image
- positive : embedding of other image has same label as anchor image
- negative : embedding of another image has different label as anchor, positive image.
We want embeddings generated by embedding model satisfied below condition,
sqrt(anchor-positive) < sqrt(anchor-negative) + α --- Eq(1)
so by calculating distances between embeddings, we can distinguish the same person between others.
where α is a margin that is enforced between positive and negative pairs.
The loss that is being minimized is then,
Triplet_Loss = sum(sqrt(anchor-positive) - sqrt(anchor-negative) + α)
In order to ensure fast convergence, it's crucial to select triplets that violate the triplet constraints.
This means we need select hard positive and hard negative.
- hard positive : distance between anchor is furthest.
- hard negative : distance between anchor is closest.
For performance reason, hard positive/hard negative would be searched within the mini-batch.
Selecting the hardest negatives can in practice lead to bad local minima early on training.
(if embedding model make all embedding to 0, Eq(1) is always satisfied.)
In order to mitigate this, it helps to select anchor/positive/negative such that
sqrt(anchor-positive) < sqrt(anchor-negative)
We call these negative exemplars semi-hard, as they are further away from the anchor than the positive exemplar, but still hard because the squared distance is close to the anchor-positive distance.
Those negatives lie inside the margin α.
Training process is as follow,
For each data batch:
- get data batch (a)
- get embeddings from data batch (b) with embedding model.
- with (a) and (b), make triplets (c)
- train model with (c)
for each epoch:
for each batch:
image, label = get_image_and_labels(batch)
embeddings = make_embedding(image)
anchor, positive, negative = generate_triplets(embeddings, labels)
train(optimizer, anchor, positive, negative)
With trained embedding model, you can determin the category of the test image by comparing distances.
Use training data to make average embedding value of each category
Label of Test image can be determined by find closest average embedding.