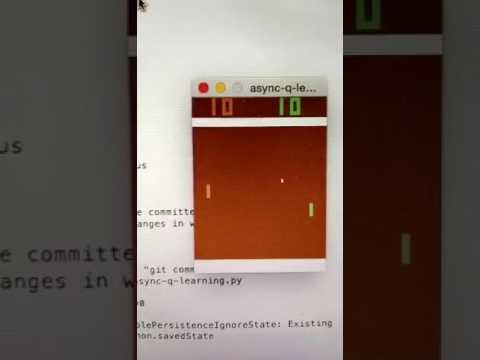
My inplementation of the asynchronous deep reinforcement learning update. The key idea is to utilize multiple agents running simultaneously to break the training experience correlation and scale the model convergence linearly with the number of threads
Link to paper: https://arxiv.org/pdf/1602.01783v2.pdf
After training with Azure A4 instance for 4 weeks on 80 million frames from the game
Required Dependencies
- tensorflow
- opencv
- openai gym API