https://refactoring.guru/design-patterns
https://github.com/AlexanderGrom/go-patterns
Asserts that the whole application will have single instance of certain object and provides global access point to that object. The access to the object goes through the "GetInstance" method.
Defines an interface (with method "Create") that allows creating different implementations of an object.
Defines an interface with bunch of methods like CreateCarcass, CreateEngine,
CreateWheels, it can be implemented in various ways (sportcar, pickup, truck).
The main point is that end users are not aware of what exact implementation they use.
Instead, correct concrete factory will be chosen at runtime at the initialization stage.
The app must select the factory type depending on the configuration or the environment settings.
(e.g. when writing GUI application choose btw WinWindow, MacWindow, GnomeWindow)
Allows to create objects with different options. Every Builder's method returns Builder itself, so it's convenient to chain methods. There is also might be a Director - an object that contains builder and has method "Construct" that creates Builder's instance with predefined options, but this is optional.
Allows to copy object with it's state. Defines an interface with method "Clone" that returns same interface. Under the hood implementation creates new instance with same fields as Prototype. Used for objects with non-copyable fields.
Transforms object of one type to another. Adapter doesn't have any strict form (interface or something) and can be implemented in various ways.
- Struct that contains existing and target objects via composition and overrides target object's methods, then access to the target performs through that struct.
- Can be a struct that implements target interface and contains existing. (most popular)
- Can be a simple function that accepts existing and returns target.
// Target provides an interface with which the system should work.
type Target interface {
Request() string
}
// Adaptee implements system to be adapted.
type Adaptee struct {}
// SpecificRequest implementation.
func (a *Adaptee) SpecificRequest() string {
return "Request"
}
// NewAdapter is the Adapter constructor.
func NewAdapter(adaptee *Adaptee) Target {
return &Adapter{adaptee}
}
// Adapter implements Target interface and is an adapter.
type Adapter struct {
*Adaptee
}
// Request is an adaptive method.
func (a *Adapter) Request() string {
return a.SpecificRequest()
}Lets split a large class or a set of closely related classes into separate hierarchies-abstraction and implementation which can be developed independently of each other. Resulting structure contains different objects over composition and interacts with them. Use the pattern when you need to extend a class in several orthogonal (independent) dimensions.
// Component provides an interface for branches and leaves of a tree.
type Component interface {
Add(child Component)
Name() string
Child() []Component
Print(prefix string) string
}Attaches new behaviors to objects by placing these objects inside the special wrapper object that contains behavior.
// implements io.Writer
type TransportWriter struct{}
func (TransportWriter) Write(p []byte) (n int, err error) { /*...*/ }
func NewCompressionWriter(w io.Writer) io.Writer {
return CompressionDecorator{w}
}
type CompressionDecorator struct{ writer io.Writer }
func (c CompressionDecorator) Write(p []byte) (n int, err error) {
// compress than write
return c.Write(p)
}Proxy intercepts calls to the real object before or after and can extend, perform validation, cache etc. Similar to Decorator, but Decorator gets reference for decorated object (usually through constructor) while Proxy responsible to do that by itself. Proxy also implements objects interface.
// implements io.Writer
type TransportWriter struct{}
func (TransportWriter) Write(p []byte) (n int, err error) { /*...*/ }
// creates transportWriter
func NewCompressionProxy() io.Writer {
transportWriter := new(TransportWriter)
return CompressionProxy{transportWriter}
}
type CompressionProxy struct{ writer io.Writer }
func (c CompressionProxy) Write(p []byte) (n int, err error) {
// compress than write
return c.Write(p)
}Hides complex logic (hierarchy) behind simple interface.
Let's say you have ton of similar objects. You are creating a Flyweight (factory) that responsible for creating objects with given parameters, but before return such object it saves it to underlying array and next time you'll need it, Flyweight will get it from that array.
Allows pass requests along a chain of handlers. Upon receiving a request, each handler
decides either to process the request or to pass it to the next handler in the chain.
There are two possible implementations:
- If one part of chain fails, no further processing performs.
- Different way - stop processing on success.
Sender -> Command -> Receiver
Creates middle layer set of commands where every command represented by its own class
with common interface. (usually with one method Execute()) It requires additional layer
to bound Commands to Senders. On initialization, Command gets Receiver’s instance.
After that command may be assigned to Sender. Sender stores a list of Commands, and methods
to add, remove and execute them, this allows to dynamically change Sender’s behavior.
Senders
[] [] [] [] [] []
Commands
[] [] []
Receiver
[]
Moves iteration logic to its own object. Allows to easily implement different iteration
methods for COMPLEX DATA. There is usually just interface with methods like Next(),
HasNext(), GetValue() etc.
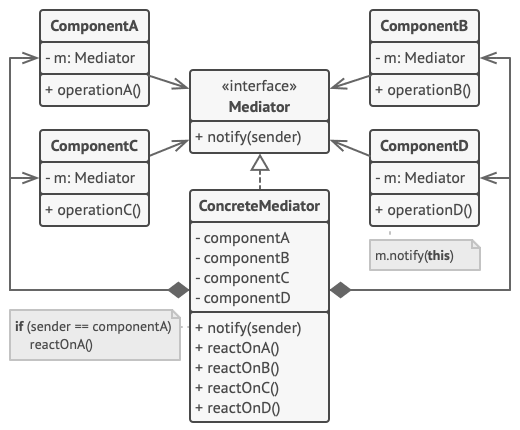
The pattern restricts direct communications between the objects and forces them to collaborate only via a mediator object. Mediator contains all initialized objects that has to communicate with each other and each object contains Mediator's instance.
The Mediator is about the interactions between "colleague" objects who don't know each other. encapsulates the interaction between several colleague objects in order to isolate them from each other.
Lets you define a subscription mechanism to notify multiple objects about any events that happen to the object they’re observing.
Allows to save and restore the previous state of an object.
Lets an object alter its behavior when its internal state changes. It appears as if the object
changed its class. There is method like SetState(IState) and everything method does goes through
it's state.
E.g phone call mode (silent, vibration, sound).
The Strategy pattern is really about having a different implementation that accomplishes the same thing, so that one implementation can replace the other as the strategy requires. For example, there might be different sorting algorithms in a strategy pattern.
Defines an interface. Defines base struct with methods common for all objects that implements that interface. Every method overrides some of the methods (that should differ).
You have bunch of objects with common interface. Each object need to get one more method but without changing their interface. You define Visitor interface that have additional method for each object. Then you define method Accept(Visitor) for each class (yep, you actually changing it). And each Accept just calls the method it needs.
type Visitor interface {
VisitSquare()
VisitCircle()
}
type Shape interface {
Accept(Visitor)
}
type Square struct{}
func (s Square) Accept(v Visitor) {
v.VisitSquare()
}
type Circle struct{}
func (s Circle) Accept(v Visitor) {
v.VisitCircle()
}
func main() {
var v = new(Visitor) // here must be implementation instead of interface
var s = new(Square)
s.Accept(v)
}- Inheritance vs Composition
(different lifecycles; embedding rather than extending; nosuper) - Polymorphism (multiple implementations of single interface)
- Encapsulation (access control)
-
KISS - keep it simple, stupid
-
DRY - don't repeat yourself
-
YAGNI - you're not gonna need it
-
Inversion of Control (IoC) is a generic term meaning that rather than having the application call the implementations provided by a library (also know as toolkit), a framework calls the implementations provided by the application. The term Inversion of Control originally meant any sort of programming style where an overall framework or run-time controlled the program flow.
-
Dependency Injection (DI) is a form of IoC, where implementations passed into an object through constructors/setters/service lookups, which the object will 'depend' on in order to behave correctly.
-
Robustness principle https://en.m.wikipedia.org/wiki/Robustness_principle
- Coupling - Strength of the relationships between modules. The lower the better. To change one module changes in different one are required.
- Cohesion - Strength of the relationships within a module or class. Low cohesion would mean that the class does a great variety of actions - it is broad, unfocused on what it should do. High cohesion means that the class is focused on what it should be doing, i.e. only methods relating to the intention of the class. The higher the better.
A module should have one, and only one, reason to change.
A software artifact should be open for extension but closed for modification.
Any interface's realization should be interchangeable in any place.
Don't force clients to implement interface they don't use.
Depend on abstractions, not on concretions.
- Cyclomatic complexity (якійсь там блять граф)
- Code coverage (percentage of statements called during test)
- Coupling (the strength of the relationships between modules). Low if preferable.
- Cohesion In one sense, it is a measure of the strength of relationship between the methods and data of a class and some unifying purpose or concept served by that class. In another sense, it is a measure of the strength of relationship between the class's methods and data themselves. Cohesion is an ordinal type of measurement and is usually described as “high cohesion” or “low cohesion”. Modules with high cohesion tend to be preferable, because high cohesion is associated with several desirable traits of software including robustness, reliability, reusability, and understandability. In contrast, low cohesion is associated with undesirable traits such as being difficult to maintain, test, reuse, or even understand.
- Program execution time
- Program load time (todo)
govet (vet, vetshadow): Vet examines Go source code and reports suspicious constructs, such as Printf calls whose arguments do not align with the format string [fast: true, auto-fix: false]
ineffassign: Detects when assignments to existing variables are not used [fast: true, auto-fix: false]
structcheck: Finds unused struct fields [fast: true, auto-fix: false]
unused (megacheck): Checks Go code for unused constants, variables, functions and types [fast: false, auto-fix: false]
bodyclose: checks whether HTTP response body is closed successfully [fast: true, auto-fix: false]
dupl: Tool for code clone detection [fast: true, auto-fix: false]
funlen: Tool for detection of long functions [fast: true, auto-fix: false]
gochecknoglobals: Checks that no globals are present in Go code [fast: true, auto-fix: false]
gochecknoinits: Checks that no init functions are present in Go code [fast: true, auto-fix: false]
goconst: Finds repeated strings that could be replaced by a constant [fast: true, auto-fix: false]
gocyclo: Computes and checks the cyclomatic complexity of functions [fast: true, auto-fix: false]
godox: Tool for detection of FIXME, TODO and other comment keywords [fast: true, auto-fix: false]
gofmt: Gofmt checks whether code was gofmt-ed. By default this tool runs with -s option to check for code simplification [fast: true, auto-fix: true]
goimports: Goimports does everything that gofmt does. Additionally it checks unused imports [fast: true, auto-fix: true]
gomnd: An analyzer to detect magic numbers. [fast: true, auto-fix: false]
gosec (gas): Inspects source code for security problems [fast: true, auto-fix: false]
interfacer: Linter that suggests narrower interface types [fast: true, auto-fix: false]
lll: Reports long lines [fast: true, auto-fix: false]
maligned: Tool to detect Go structs that would take less memory if their fields were sorted [fast: true, auto-fix: false]
misspell: Finds commonly misspelled English words in comments [fast: true, auto-fix: true]
prealloc: Finds slice declarations that could potentially be preallocated [fast: true, auto-fix: false]
unconvert: Remove unnecessary type conversions [fast: true, auto-fix: false]
unparam: Reports unused function parameters [fast: true, auto-fix: false]
https://smartbear.com/learn/code-review/best-practices-for-peer-code-review/
https://www.kevinlondon.com/2015/05/05/code-review-best-practices.html
-
Check lists
-
SOLID + software metrics above
-
Efficiency
-
Potential bugs
-
Naming convention
-
Function, class, file length
-
Useful comments
-
Useless commented code
-
Readability
-
Unit tests
-
Review own code first
-
Commit messages
-
max 400 lines at a time (the brain can only effectively process such amount of information)
-
don't rush
-
do not review more than 60 minutes at a time
Todo:
- garbage collector
- memory model
Slice is a pointer to the actual array. It has 2 characteristics - length and capacity.
type slice struct {
array unsafe.Pointer // pointer to the array
len int // length of the slice
cap int // length of actual array to which we are pointing
}When length reach capacity and we try to add one more element to the slice go creates new array with more length and points it to slice, capacity(length of the actual array) for a new slice calculates in the next way.
old.cap < 256=>new.cap = old.cap*2old.cap >= 256=>new.cap = (old.cap*2 + 3*256)/4
type hchan struct {
qcount uint // total data in the queue
dataqsiz uint // size of the circular queue
buf unsafe.Pointer // points to an array of dataqsiz elements
elemsize uint16
closed uint32
elemtype *_type // element type
sendx uint // send index
recvx uint // receive index
recvq waitq // list of recv waiters
sendq waitq // list of send waiters
lock mutex
}buf- array with sizeclosed- flaglock- embedded structuresendqandrecvq- goroutines queue referenced to this channel
// allocates hchan in heap
func makechan(t *chantype, size int64) *hchan {/*...*/}makechan returns pointer to channel, so it's possible to pass them as it is.
Channels also have len to check buffer.
Race condition - state of program that produces non-deterministic staff. Data Race - panic that happens if multiple goroutines access same data and at least one writes.
https://blog.golang.org/race-detector
go run -race main.go # will run race detector. same for build, get, test and installA deadlock happens when a group of goroutines are waiting for each other and none of them is able to proceed.
So, here we are trying to push to the chan, but there is no other goroutines that are able to read those message.
func main() {
ch := make(chan struct{})
ch <- struct{}{}
}Here we are trying to read from channel but there is no goroutines that are able to write to the channel.
func main() {
ch := make(chan struct{})
<- ch
}This reading behavior could be fixed in only one way (by using select statement with default case)
func main() {
c := make(chan struct{})
go func(c chan <- struct{}){
time.Sleep(time.Second*2)
c <- struct{}{}
}(c)
fmt.Println(<-c)
select {
case <-c:
fmt.Println("Isn't got here")
default:
fmt.Println("Got here")
}
}In case we are using buffered channel deadlock is going to be caused when we are reaching channel size.
func main() {
ch := make(chan struct{}, 1)
ch <- struct{}{}
ch <- struct{}{}
}A goroutine can get stuck
- either because it’s waiting for a channel or
- because it is waiting for one of the locks in the sync package.
Common reasons are that
- no other goroutine has access to the channel or the lock,
- a group of goroutines are waiting for each other and none of them is able to proceed.
Mutex is a mechanism that enforces limits on access to a resource when
there are many threads of execution.
Imagine next situation when we are trying to write and read map from different goroutines.
func main() {
m := map[int]int{}
go func(m map[int]int) {
for {
m[0] = 1
}
}(m)
go func(m map[int]int) {
for {
for _, v := range m {
fmt.Println(v)
}
}
}(m)
// stop program from exiting, must be killed
block := make(chan struct{})
<-block
}In the result we are retrieving fatal error: concurrent map iteration and map write.
Panic was caused by reading and writing to the same mapData race
because map doesn't have concurrent read/write or write/write access from the box.
We could avoid this behaviour by using Mutex
func main() {
m := map[int]int{}
mu := &sync.Mutex{}
go func(m map[int]int, mu *sync.Mutex) {
for {
mu.Lock()
m[0] = 1
mu.Unlock()
}
}(m, mu)
go func(m map[int]int, mu *sync.Mutex) {
for {
mu.Lock()
for _, v := range m {
fmt.Println(v)
}
mu.Unlock()
}
}(m, mu)
// stop program from exiting, must be killed
block := make(chan struct{})
<-block
}RWMutex has the same logic as Mutex, but with only one difference - it locks reading only when someone writes to the same memory at the same moment
(in case we are only read it isn't locks any operation), so it's more efficient.
func main() {
m := map[int]int{}
mu := &sync.RWMutex{}
go func(m map[int]int, mu *sync.RWMutex) {
for {
mu.Lock()
m[0] = 1
mu.Unlock()
}
}(m, mu)
go func(m map[int]int, mu *sync.RWMutex) {
for {
mu.RLock()
for _, v := range m {
fmt.Println(v)
}
mu.RUnlock()
}
}(m, mu)
// stop program from exiting, must be killed
block := make(chan struct{})
<-block
}A flaky test is a test which could fail or pass for the same configuration.
- Concurrency
- Time bombs: Does your test requests for the current time?
to find them:
go test -count=20Informally, a pipeline is a series of stages connected by channels, where each stage is a group of goroutines running the same function. In each stage, the goroutines
- receive values from upstream via inbound channels
- perform some function on that data, usually producing new values
- send values downstream via outbound channels
// this function is cool, because it produces a channel, so the work may be distributed between few goroutines easily.
func gen(nums ...int) <-chan int {
out := make(chan int)
go func() {
for _, n := range nums {
out <- n
}
close(out)
}()
return out
}
func sq(in <-chan int) <-chan int {
out := make(chan int)
go func() {
for n := range in {
out <- n * n
}
close(out)
}()
return out
}
func main() {
// Set up the pipeline and consume the output.
for n := range sq(sq(gen(2, 3))) {
fmt.Println(n) // 16 then 81
}
}// out is passed as argument instead of being created
func sq(in <-chan int, out chan int, wg *sync.WaitGroup) {
go func() {
for n := range in {
out <- n * n
}
wg.Done()
}()
}
func main() {
// GEN IS TAKEN FROM PIPELINE EXAMPLE
job := gen(1, 2, 3, 4, 5)
res := make(chan int)
var wg sync.WaitGroup
for i := 0; i < runtime.NumCPU(); i++ {
wg.Add(1)
go sq(job, res, &wg)
}
// wait on the workers to finish and close the result channel
go func() {
wg.Wait()
close(res)
}()
for r := range res {
fmt.Println(r)
}
}func do(jobs []job) error {
var (
wg sync.WaitGroup
sem = make(chan int, runtime.NumCPU()) // create semaphore with buffer size
errs = make(chan error) // non-buffered
)
for _, j := range jobs {
wg.Add(1)
go func(j job) {
sem <- 1 // write to sem
err := doSomething(j)
if err != nil {
select {
case errs <- err:
default:
}
}
<-sem // release sem
wg.Done()
}(j)
}
wg.Wait() // wait
close(errs) // close errs - needed if there is no errors
return <-errs // first error from errs
}When main decides to exit without receiving all the values from out, it must tell the goroutines in the upstream stages to abandon the values they're trying to send.
- Additional channel done that will be closed when receiver don't need values
- Context
Cancel()Done()
for n := range c {
select {
case out <- n: // write to chan
case <-done: // receive from done
return
}
}When you write to closed channel you are going to cause panic send on closed channel
func main() {
ch := make(chan int)
close(ch)
ch <- 1
}When you read from closed channel you are going to receive nil value of channel's type 0 in case below
func main() {
ch := make(chan int)
close(ch)
fmt.Println(<-ch)
}Kinda useless pattern, but the main idea is next:
- function
Subscribe(r Resource) s Subscription {} Resourceresponsible to produceItems(e.g.database/sqlquery result)Subscription- interface with methodUpdates() <-chan ItemsandClose()
Subscribe function starts goroutine under the hood that writes to Subscription's internal channel.
So that logic is hidden behind "simple" Subscription interface.
Even more useless than subscription.
Create two channels ping and pong (unexpected), then start two
goroutines pinger and ponger that receive ping and pong, each goroutine
starts endless loop where reads from ping does something and writes to pong and vice versa.
Multiple functions can read from the same channel until that channel is closed; this is called fan-out.
A function can read from multiple inputs and proceed until all are closed by multiplexing the input channels onto a single channel that's closed when all the inputs are closed. This is called fan-in.
- Distribute work between few pipelines, then merge the output (in goroutine) and return resulting channel.
func merge(cs ...<-chan int) <-chan int {
var wg sync.WaitGroup
out := make(chan int)
// Start an output goroutine for each input channel in cs. output
// copies values from c to out until c is closed, then calls wg.Done.
output := func(c <-chan int) {
for n := range c {
out <- n
}
wg.Done()
}
wg.Add(len(cs))
for _, c := range cs {
go output(c)
}
// Start a goroutine to close out once all the output goroutines are
// done. This must start after the wg.Add call.
go func() {
wg.Wait()
close(out)
}()
return out
}https://research.swtch.com/interfaces\ https://github.com/teh-cmc/go-internals/blob/master/chapter2_interfaces/README.md
Interface is an abstract data type that doesn't expose the representation of internal structure. When you have a value of an interface type, you know nothing about what it is, you know only what it can do.
// src/runtime/runtime2.go
type iface struct {
tab *itab
data unsafe.Pointer // underlying data
}
type itab struct {
inter *interfacetype
_type *_type // metadata describing type
hash uint32 // copy of _type.hash. Used for type switches.
_ [4]byte
fun [1]uintptr // variable sized. fun[0]==0 means _type does not implement inter.
}
// src/runtime/type.go
type interfacetype struct {
typ _type
pkgpath name
mhdr []imethod // probably methods and their types
}Interface values may be compared using == and !=. Two interface values are equal if both are nil, or if their dynamic types are identical and their dynamic values are equal according to the usual behavior of == for that type. Because interface values are comparable, they may be used as the keys of a map or as the operand of a switch statement. However, if two interface values are compared and have the same dynamic type, but that type is not comparable (a slice, map or function for instance), then the comparison fails with a panic.
A nil interface value, which contains no value at all, is not the same as an interface value containing a pointer that happens to be nil:
func foo() error {
var err error // nil
return err
}
err := foo()
if err == nil {...} // truefunc foo() error {
var err *os.PathError // nil
return err
}
err := foo()
if err == nil {...} // false
https://dave.cheney.net/2018/05/29/how-the-go-runtime-implements-maps-efficiently-without-generics
https://github.com/golang/go/blob/master/src/runtime/map.go
// A map is just a hash table. The data is arranged
// into an array of buckets. Each bucket contains up to
// 8 key/elem pairs. The low-order bits of the hash are
// used to select a bucket. Each bucket contains a few
// high-order bits of each hash to distinguish the entries
// within a single bucket.Default underlying array size == 8, so default LOB == 3 (2^3 = 8), as map grows it doubles it underlying array and increments LOB (2^4 = 16) and so on.
// A bucket for a Go map.
type bmap struct {
// tophash generally contains the top byte of the hash value
// for each key in this bucket. If tophash[0] < minTopHash,
// tophash[0] is a bucket evacuation state instead.
tophash [bucketCnt]uint8
// Followed by bucketCnt keys and then bucketCnt elems.
// NOTE: packing all the keys together and then all the elems together makes the
// code a bit more complicated than alternating key/elem/key/elem/... but it allows
// us to eliminate padding which would be needed for, e.g., map[int64]int8.
// Followed by an overflow pointer.
}Why are they unordered?
- It's more efficient, runtime don't need to remember order.
- They intentionally made it random starting with Go 1 to make developers not rely on it. Since the release of Go 1.0, the runtime has randomized map iteration order. Programmers had begun to rely on the stable iteration order of early versions of Go, which varied between implementations, leading to portability bugs. Iteration order which order may change from release-to-relase, from platform-to-platform, or may even change during a single runtime of an app when map internals change due to accommodating more elements.
- Regarding the last point: during map growth its buckets gets reordered that would cause to different orders during runtime. Anyway, even without reordering if it would loop like
bucket -> elements -> next bucket -> elements..., than after adding new element it would appear in the middle of order because you newer know in which bucket it will go.
Where actual values are stored in memory?
The "where" is specified by hmap.buckets. This is a pointer value, it points to an array in memory, an array holding the buckets. (NOTICE: it isn't *bmap or bmap it's unsafe.Pointer what says that it a bit more complicated than i thought)
[8]tophash -> [8]key -> [8]value -> overflowpointer
https://en.wikipedia.org/wiki/Linear_probing
Linear probing: When the hash function causes a collision by mapping a new key to a cell of the hash table that is already occupied by another key, linear probing searches the table for the closest following free location and inserts the new key there. Lookups are performed in the same way, by searching the table sequentially starting at the position given by the hash function, until finding a cell with a matching key or an empty cell.
There are two pprof implementations available:
- net/http/pprof
- runtime/pprof
import "runtime/pprof"
file, _ := os.Create(filepath.Join("cpu.pprof")) // create a file for profiler output
pprof.StartCPUProfile(file) // start CPU Profiler
pprof.StopCPUProfile() // write results to the fileWeb view:
go tool pprof -http=:8080 cpu.pprofhttps://dave.cheney.net/2013/06/30/how-to-write-benchmarks-in-go
// from fib_test.go
func BenchmarkFib10(b *testing.B) {
// run the Fib function b.N times
for n := 0; n < b.N; n++ {
Fib(10)
}
}Each benchmark must execute the code under test b.N times. The for loop in BenchmarkFib10 will be present in every benchmark function.
# run benchmarks:
go test -bench=.
# flags:
-benchmem # shows memory allocations
-benchtime=20s # b.N execution time.
-cpuprofile=cpu.out # save cpu profile
-memprofile=mem.out # save memory profileBy default b.N runs benchmark for one second this may be changed with -benchtime=20s
Methods:
- b.ResetTimer()
- b.StopTimer()
- b.StartTimer()
https://blog.golang.org/laws-of-reflection
https://github.com/golang/go/blob/master/src/reflect/type.go
- Reflection goes from interface value to reflection object.
- Reflection goes from reflection object to interface value.
- To modify a reflection object, the value must be settable. Settable value - pointer value.
Reflection in computing is the ability of a program to examine its own structure, particularly through types. A variable of interface type stores a pair: the concrete value assigned to the variable, and that value's type descriptor. To be more precise, the value is the underlying concrete data item that implements the interface and the type describes the full type of that item.
func TypeOf(i interface{}) Type
func ValueOf(i interface{}) Valuereflect.Type and reflect.Value are interfaces describing type and value of interface.
These two are just examining interface's descriptor itab *itable to find out the underlying
type and it's value. Passing non-interface value to these function just converts them to
empty interface{}.
https://www.ardanlabs.com/blog/2018/08/scheduling-in-go-part2.html
https://www.youtube.com/watch?v=YHRO5WQGh0k&ab_channel=GopherAcademy

Goroutines are user-space (green) threads (coroutines) conceptually similar to kernel threads manages by OS, but managed entirely by Go runtime and run on top of the OS Threads. Initial goroutine stack takes 2KB and it growth during runtime, they implemented in Go, faster to create, destroy, switch context. Threads are heavier, context switch takes a lot of time, it's hard to control them and communicate.
Every running program creates a Process and each Process is given an initial Thread. Threads have the ability to create more Threads. All these different Threads run independently of each other and scheduling decisions are made at the Thread level, not at the Process level. Threads can run concurrently (each taking a turn on an individual core), or in parallel (each running at the same time on different cores).
Thread states:
- Waiting: The Thread is stopped and waiting for something in order to continue (disk, network), the operating system (system calls) or synchronization calls (atomic, mutexes).
- Runnable: The Thread wants time on a core, so it can execute its assigned machine instructions.
- Executing: The Thread has been placed on a core and is executing its machine instructions.
Context switch is heavy operation
The physical act of swapping Threads on a core is called a context switch. A context switch happens when the scheduler pulls an Executing thread off a core and replaces it with a Runnable Thread. The Thread that was selected from the run queue moves into an Executing state. The Thread that was pulled can move back into a Runnable state (if it still has the ability to run), or into a Waiting state (if was replaced because of an IO-Bound type of request).
If I used 2 Threads per core, it took longer to get all the work done, because I had idle time when I could have been getting work done. If I used 4 Threads per core, it also took longer, because I had more latency in context switches. The balance of 3 Threads per core, for whatever reason, always seemed to be the magic number on NT.
Scheduler is the orchestrator of Go programs.
- P - logical processors (equals to virtual cores).
- M - machine. Every P is assigned an OS Thread (“M”). This Thread is still managed by the OS and the OS is still responsible for placing the Thread on a Core for execution.
- G - goroutine.
During execution, threads might be assigned from one core to another, for example during IO-Bound operation (disc, network) thread goes from Executing to Waiting state, so all goroutines in queue are blocked. In this case Scheduler unassigns these goroutines from current thread, and processor (P) and it's queue is moved to another OS Thread.
When goroutine makes synchronous syscall, OS blocks that thread.
Scheduler actions:
- Context-Switch - pulling executing goroutine/thread off the core and replacement it with runnable goroutine/thread
- Runqueue - local per-thread (but there is a global as well) FIFO queue of waiting goroutines. Global runqueue has low priority and it's checked by threads less frequently than local queues. Scheduler detects CPU-Bound (those with heavy executions) goroutines and puts them to the global queue.
- Parking - "caching" of empty threads for future using to avoid destruction and creation of new threads since thats expensive operation.
- Handoff - transferring of blocked by IO-Bound operation thread's runqueue to other thread (parked or new).
- Work Stealing - if thread has empty queue but there is idle goroutines in other queues it picks goroutine from random runqueue.
If thread has no job, OS will context-switch it off the Core.
When Goroutine_1 makes synchronous syscall it's Thread_1 being blocked by the OS, at this point, Scheduler detaches Thread_1 from the P with the blocking Goroutine_1 still attached. Then Scheduler brings in another Thread_2 (parked or new), transfers runqueue from old Thread to the new one (handoff), and picks next Goroutine_2 from the queue. When blocking syscall is finished, previous Goroutine_1 can move back into the runqueue (to the very end (FIFO)). Thread_1 is going to park. [Thread_2 replaces Thread_1].
Scheduler has global runqueue in addition to distributed queues, this runqueue is low-proirity and it's checked by threads less frequently than local queues, before thread is going to park, it does "spin" - it's checking global queue, attempt to run GC tasks, and work-steal.
https://segment.com/blog/allocation-efficiency-in-high-performance-go-services/
Heap - global program memory. If a function creates a variable and returns reference to it, the variable allocates in heap.
Stack - local memory allocated per function. It has its own top that moves up and down for each nested call. This memory is freed once function is returned.
Go prefers allocation on the stack — most of the allocations within a given Go program will be on the
stack. It’s cheap because it only requires two CPU instructions: one to push onto the stack for allocation,
and another to release from the stack. On the other side, heap allocations are expensive, malloc has to
search for a chunk of free memory large enough to hold the new value and the garbage collector
scans the heap for objects which are no longer referenced.
Compiler performs escape analysis - set of rules that variable must pass on compilation stage
to be allocated in stack. Stack allocation requires that the lifetime and memory footprint of a
variable can be determined at compile time.
go run -gcflags '-m' main.go - shows escape analysis details
https://blog.golang.org/race-detector
- Concurrency is about dealing with few things at once. It's how program is built. E.g. perform operations while access ext resource like http, i/o, syscall.
- Parallelism is about performing processes independently.
select {
case err := <-c:
// use err and reply
case <-time.After(timeoutNanoseconds):
// call timed out
}-
Go doesn't provide automatic support for getters and setters. There's nothing wrong with providing getters and setters yourself, and it's often appropriate to do so, but it's neither idiomatic nor necessary to put Get into the getter's name. If you have a field called owner (lower case, unexported), the getter method should be called Owner (upper case, exported), not GetOwner. The use of upper-case names for export provides the hook to discriminate the field from the method. A setter function, if needed, will likely be called SetOwner. Both names read well in practice:
owner := obj.Owner() if owner != user { obj.SetOwner(user) }
-
By convention, one-method interfaces are named by the method name plus an -er suffix or similar modification to construct an agent noun: Reader, Writer, Formatter, CloseNotifier etc.
-
Switches has
break -
Last defer executes first
for i := 0; i < 5; i++ { defer fmt.Printf("%d ", i) } // prints 4, 3, 2, 1
-
Arguments to deferred functions are evaluated when the defer executes.
func main() { var x = 10 defer fmt.Println(x) x = 20 } // prints 10
-
If a type exists only to implement an interface and will never have exported methods beyond that interface, there is no need to export the type itself.
-
Import for side effects
import _ "net/http/pprof"e.g. for it's init function. -
Do not communicate by sharing memory; instead, share memory by communicating. One way to think about this model is to consider a typical single-threaded program running on one CPU. It has no need for synchronization primitives. Now run another such instance; it too needs no synchronization. Now let those two communicate; if the communication is the synchronizer, there's still no need for other synchronization. Unix pipelines, for example, fit this model perfectly.
https://www.bigocheatsheet.com/
Big O Describes performance or complexity of an algorithm in the worst case. Relation between size of input data and amount of operation for an algorithm.
-
O(1) describes an algorithm that will always execute in the same time (or space) regardless of the size of the input data set. (map)
-
O(N) describes an algorithm which performance will grow linearly and in direct proportion to the size of the input data set. (loop)
-
O(N^2) represents an algorithm whose performance is directly proportional to the square of the size of the input data set. This is common with algorithms that involve nested iterations over the data set. Deeper nested iterations will result in O(N^3), O(N^4) etc.
-
O(2^N) exponential, usually recursive algorithm whose size growth doubles with each addition to the input data set.
-
O(log N) doubling the size of the input data set has little effect on its growth as after a single iteration of the algorithm the data set will be halved and therefore on a par with an input data set half the size. This makes algorithms like binary search extremely efficient when dealing with large data sets.
-
O(N Log N) describes an algorithm that contains O(log N) nested in O(N) loop.
-
O(N!) permutations algorithms.
Quicksort [O(n log(n)) Θ(n log(n)) O(n^2)]
https://www.programiz.com/dsa/quick-sort
- Peek a pivot (usually last elem in array).
- Go through array and compare every element in it with pivot.
- Pick first bigger element and remember it position (pointer).
- Keep going.
- If element is bigger - do nothing.
- If element is smaller - swap it with the pointer.
- Pick next pointer.
- If last element - swap pivot with the pointer.
- Recursively repeat on right and left sub-arrays.
Bubble sort [O(n) Θ(n^2) O(n^2)]
- Go from the beginning of array
- Compare two elements
- Swap them if needed
- Go on
- At the end of iteration the largest element will be on the right
- Repeat
Merge sort [O(n log(n)) Θ(n log(n)) O(n log(n))]
- Divide array on half.
- Repeat recursively.
- Compare items.
- Rearrange them in right order.
- Return subarray.
- Compare two subarrays and rearrange them in right order.
- Return subarray.

Binary search [O(log N)] is a technique used to search sorted data sets. It works by selecting the middle element of the data set, essentially the median, and compares it against a target value. If the values match it will return success. If the target value is higher than the value of the probe element it will take the upper half of the data set and perform the same operation against it. Likewise, if the target value is lower than the value of the probe element it will perform the operation against the lower half. It will continue to halve the data set with each iteration until the value has been found or until it can no longer split the data set.
A binary search only touches a small number of elements. If there's a billion elements, the binary search only touches ~30 of them. A quicksort touches every single element, a small number of times. If there's a billion elements, the quick sort touches all of them, about 30 times: about 30 billion touches total.

- Array (fixed length)
- Linked list
- Stack (last in first out)
- Queue (fist in first out)
- Hash table (go map)
- Graph
- Set/HashSet (something from java)
- Binary tree (hierarchical data structures)
Todo:
- Microkernel architecture
- Space-Based architecture
- Sidecar
- Clean architecture
- 12 Factor App
Todo:
- Transactional outbox
- Transactional log
Saga design pattern is a way to manage data consistency in distributed transaction scenarios. A saga is a sequence of transactions that updates each service and publishes a message or event to trigger the next transaction step. If a step fails, the saga executes compensating transactions that counteract the preceding transactions.
Transactions are:
- A - Atomicity
- C - Consistency
- I - Isolation
- D - Durability
In microservice world each service has its own database. If db was shared it would take a lot of efforts to change some table, because it would require changes in all services, and they wouldn't be loosely coupled. Saga is the solution of how to keep consistency between services (databases).
In Saga services rollback on an invalid step.
Choreography - Services decide what to do.
Orchestration - Services expose API invoked by the coordinator (state machine).
Saga can be implemented via REST, but it's weak, and there are no guarantees, no high-availability, so usually saga is used in event-driven models.
https://youtu.be/ksRCq0BJef8
https://martinfowler.com/tags/event%20architectures.html
In Event-driven arch microservices communicated primarily with asynchronous events. Each service publishes an event whenever it update its data. Other service subscribe to events. When an event is received, a service updates its data.
- Publish/Subscribe messaging
- Bunch of topics with subscribers
- Data is eventually consistent
Everything that happens in the system represented as atomic events stored in DB (Event Store) where events stored with change information instead of data itself. All events are coming one after another it's impossible to delete/revert an event. Current state of the system can be reproduced from event's history.
Pros:
- It doesn't loose information
Cons:
- Store price.
- No way to change historical events.
Examples:
- Bank account
- Jira ticket history
Four isolated layers:
- The presentation layer
- The business layer
- The persistence layer
- The database layer
The layers are closed, meaning a request must go through all layers from top to bottom.
https://martinfowler.com/bliki/CQRS.html
Repository's methods should consist of two types:
- Queries (return values without side effects)
- Commands (change values without returning result)
Queries are aggregated (presentation) models; writes are entities.
Pros:
- Separate logic, easy to debug.
CQRS has multiple different implementations, but the main idea is the same as for CQS but at service level, usually it refers to dedicated microservices for data reads and writes. Usually such systems involve different synchronized databases for reads and writes, or in-memory cache exposed and updated by command service to read service. It plays well with event-based models.
Pros:
- Databases can be configured differently e.g. no indexing for writes.
- Different scalability needs for different databases
Cons:
- Database synchronization
- Consistency.
Wiki:
Domain-driven design (DDD) is the concept that the structure and language of your code (class names, class methods, class variables) should match the business domain. For example, if your software processes loan applications, it might have classes such as LoanApplication and Customer, and methods such as AcceptOffer and Withdraw.
Ubiquitous language - communication model understandable by both - business and developers (via diagrams).
Bounded context is the key instrument in DDD. It distinguishes one domain from another. Using Bounded context we can separate models/packages/components in a way that change in one component has minimal (or no) impact to others. Domains separated by business logic.
Domain objects instead of services
Task: create candidate 0) Handle Request
- Call to service
- Create record in db
- Send a message to kafka
- Trigger lambda
- Response
Transaction Script (Not DDD):
+ project
+ httpclient
+ httpserver
+ mq
+ model
- candidate.go <- data is located in model (no behaviour)
+ service
- service.go
- candidate.go <- business logic is located in service
DDD:
+ project
+ httpclient
+ httpserver
+ mq
+ domain <- maybe such name is not idiomatic, i'm not sure
+ candidate
+ candidate.go <- contains data, dependencies AND behaviour
Todo:
- golang net/http
Transmission control protocol
TCP/IP is a system of protocols, and a protocol is a system of rules and procedures. The TCP/IP protocol system is divided into separate components that theoretically function independently from one another. Each component is responsible for a piece of the communication process.
Because of TCP/IP’s modular design, a vendor such as Microsoft does not have to build a completely different software package for TCP/IP on an optical-fiber network (as opposed to TCP/IP on an ordinary ethernet network). The upper layers are not affected by the different physical architecture; only the Network Access layer must change.
|----------------------+--------------------|
| | Application Layer |
| Application Layer | Presentation Layer |
| | Session Layer |
|----------------------+--------------------|
| Transport Layer | Transport Layer |
|----------------------+--------------------|
| Internet Layer | Network Layer |
|----------------------+--------------------|
| Network Access Layer | Data Link Layer |
| | Physical Layer |
|----------------------+--------------------|
TCP/IP OSI
- Physical layer: Converts the data into the stream of electric or analog pulses that will actually cross the transmission medium and oversees the transmission of the data; Provides an interface with the physical network. Formats the data for the transmission medium and addresses data for the subnet based on physical hardware addresses.
- Data Link layer: Provides an interface with the network adapter; maintains logical links for the subnet
- Network layer: Supports logical addressing and routing
- Transport layer: Provides error control and flow control for the internetwork TCP or UDP
- Session layer: Establishes sessions between communicating applications on the communicating computers
- Presentation layer: Translates data to a standard format; manages encryption and data compression
- Application layer: Provides a network interface for applications; supports network applications for file transfer, communications, and so forth
The data passes through all layers from top to down (or vice-versa when consuming), every layer adds some headers to data, and these headers are important on the next layer.
Hierarchical and decentralized naming system for computers, services, or other resources connected to the Internet or a private network. It associates various information with domain names assigned to each of the participating entities. Most prominently, it translates more readily memorized domain names to the numerical IP addresses needed for locating and identifying computer services and devices with the underlying network protocols.
DNS steps:
- Client -> Resolver server (ISP internet service provider)
- Resolver -> Root server (13 sets placed around the world, 12 different organizations) (Root server does not know the ip address, but it knows TLD server's ip)
- Resolver (not root) -> Top Level Domain server (TLD does not know the ip address, but it knows ANS server's ip)
- Resolver (not TLD) -> Authoritative Name Server (ANS is responsible to know the ip address)
Caching on all levels.
TLS: Transport layer security.
All the data during communication is encrypted via symmetric algorithm, the key is created during handshake:
- The 'client hello' message: The client initiates the handshake by sending a "hello" message to the server. The message will include which TLS version the client supports, the cipher suites (encryption algorithms) supported, and a string of random bytes known as the "client random."
- The 'server hello' message: In reply to the client hello message, the server sends a message containing the server's SSL certificate, the server's chosen cipher suite, and the "server random," another random string of bytes that's generated by the server.
- Authentication: The client verifies the server's SSL certificate with the certificate authority that issued it. This confirms that the server is who it says it is, and that the client is interacting with the actual owner of the domain. The user then verifies the server’s certificate using CA (certificate authority) certificates that are present on the user’s device to establish a secure connection.
- The pre-master secret: The client sends one more random string of bytes, the "pre-master secret." The pre-master secret is encrypted with the public key and can only be decrypted with the private key by the server. (The client gets the public key from the server's SSL certificate.)
- Private key used: The server decrypts the pre-master secret.
- Session key created: Both client and server generate session key from the client random, the server random, and the pre-master secret. They should arrive at the same results.
- Client sends encrypted message with "shared secret".
- The server decrypts and verifies the message, then it sends another encrypted message to the client.
- Client verifies the message.
- Client is ready: The client sends a "finished" message that is encrypted with a session key.
- Server is ready: The server sends a "finished" message encrypted with a session key.
- Secure symmetric encryption achieved: The handshake is completed, and communication continues using the session keys.
https://habr.com/ru/post/308846/
- Binary instead of text.
- Multiplexing - sending multiple asynchronous HTTP requests over a single TCP connection.
- Headers compressing.
- Server Push - multiple answers on single request.
- Prioritization of requests.
- Streaming.
User datagram protocol. (fast but not reliable)
- does not establish a session.
- does not guarantee data delivering.
There are not a lot of IPv4 addresses possible, so to preserve them public addresses are used. Internet service provider grants a public ip per router (not the wifi one, but the provider's router), and all devices use private addresses internally. Router is able to translate incoming and outcoming requests's addresses from pub to priv and vice versa.
Todo:
- CQRS API
- Webhooks
- Throttling
- Rate Limiting
- SOAP
- REST
- OpenAPI
- GRPC
- Richardson maturity model
Todo:
- Servlets API, Filters, Listeners, Deployment Descriptor
- ClassLoader Architecture for Application Server
- Sessions, Safe Multithreading
- Tomcat/Jetty/Netty thread model and connectors
Todo:
- Spring + SpringBoot (Application Context, Configurations, MVC, I18N, Theming and Templating: Freemaker; Mustache; Apache Tiles)
- Spring5 functional web framework: Concept, HandlerFunction, RouterFunctions, Extended WebClient
- Dropwizard
- JEE JAX-RS: Jersey
- Describe servlet API, dispatcher servlet, why do we have filters? What frameworks & libs are available to implement REST web services?
- Describe Spring MVC request lifecycle? Explain Model, ModelMap and ModelAndView? How does Spring5 define routings?"
 The CAP theorem applies a similar type of logic to distributed systems—namely, that a distributed system can deliver only two of three desired characteristics: consistency, availability, and partition tolerance (the ‘C,’ ‘A’ and ‘P’ in CAP).
The CAP theorem applies a similar type of logic to distributed systems—namely, that a distributed system can deliver only two of three desired characteristics: consistency, availability, and partition tolerance (the ‘C,’ ‘A’ and ‘P’ in CAP).
Consistency means that all clients see the same data at the same time, no matter which node they connect to. For this to happen, whenever data is written to one node, it must be instantly forwarded or replicated to all the other nodes in the system before the write is deemed ‘successful’
Availability means that that any client making a request for data gets a response, even if one or more nodes are down. Another way to state this—all working nodes in the distributed system return a valid response for any request, without exception.
A partition is a communications break within a distributed system—a lost or temporarily delayed connection between two nodes. Partition tolerance means that the cluster must continue to work despite any number of communication breakdowns between nodes in the system.
Primary key - is unique column (or set of columns) that is used to identify each row in the table. If primary key contains from multiple columns - they may not be unique, but the set of columns has to. Foreign key - the column or set of columns used to establish a link between tables. It holds another tables primary key.
Relationships:
- ONE TO ONE
- ONE TO MANY
- MANY TO MANY
SELECT Orders.OrderID, Customers.CustomerName
FROM Orders
INNER JOIN Customers ON Orders.CustomerID = Customers.CustomerID;Fetches everything from left table and matched records from right, and non-matched values will be null.
SELECT Customers.CustomerName, Orders.OrderID
FROM Customers
LEFT JOIN Orders
ON Customers.CustomerID=Orders.CustomerID
ORDER BY Customers.CustomerName;maria=# select * from districts left join bydlos on districts.id = bydlos.district_id where bydlos.id is null;
id | street | crime | id | name | favourite_beer | district_id
----+---------+-------+----+------+----------------+-------------
3 | Kyivska | 2 | | | |
(1 row)The RIGHT JOIN keyword returns all records from the right table (table2), and the matched records from the left table (table1). The result is NULL from the left side, when there is no match.
Fetches everything from both tables + matches.
maria=# select * from bydlos full join districts on bydlos.name = districts.street;
id | name | favourite_beer | district_id | id | street | crime
----+--------+----------------+-------------+----+-----------+-------
| | | | 1 | Bandery | 8
3 | Kaban | Baltyke 8 | 2 | | |
| | | | 3 | Kyivska | 2
| | | | 2 | Lyubinska | 2
1 | Sanya | Obolon | 1 | | |
2 | Shakal | Chernigivske | 1 | | |
(6 rows)https://www.w3schools.com/sql/sql_union.asp The UNION operator is used to combine the result-set of two or more SELECT statements.
- Each SELECT statement within UNION must have the same number of columns
- The columns must also have similar data types
- The columns in each SELECT statement must also be in the same order
SELECT City FROM Customers
UNION
SELECT City FROM Suppliers
ORDER BY City;http://www-db.deis.unibo.it/courses/TW/DOCS/w3schools/sql/sql_functions.asp.html
https://www.w3schools.com/sql/sql_groupby.asp
SELECT COUNT(CustomerID), Country
FROM Customers
GROUP BY Country; # count how many customers leaves in each country
# without it it would just count all of the customers.
The GROUP BY statement groups rows that have the same values into summary rows, like "find the number of customers in each country".
SELECT count(CustomerID), Country
FROM Customers
GROUP BY Country;SELECT Shippers.ShipperName, COUNT(Orders.OrderID) AS NumberOfOrders FROM Orders
LEFT JOIN Shippers ON Orders.ShipperID = Shippers.ShipperID
GROUP BY ShipperName;The HAVING clause was added to SQL because the WHERE keyword could not be used with aggregate functions.
HAVING clause introduces a condition on aggregations, i.e. results of selection where a single result, such as count, average, min, max
SELECT COUNT(CustomerID), Country
FROM Customers
GROUP BY Country
HAVING COUNT(CustomerID) > 5;Session is is a temporary and interactive information interchange between two or more communicating devices. A session is typically stateful, meaning that at least one of the communicating parties needs to hold current state information and save information about the session history in order to be able to communicate. In other words the sessions stores settings like cache of your login information, current transaction isolation level, session level SET values etc.
http://go-database-sql.org/connection-pool.html
- Connection pooling means that executing two consecutive statements on a single database might open two connections and execute them separately. It is fairly common for programmers to be confused as to why their code misbehaves. For example, LOCK TABLES followed by an INSERT can block because the INSERT is on a connection that does not hold the table lock.
- Connections are created when needed and there is no free connection in the pool.
- By default, there’s no limit on the number of connections. If you try to do a lot of things at once, you can create an arbitrary number of connections. This can cause the database to return an error such as “too many connections.”
- In Go 1.1 or newer, you can use db.SetMaxIdleConns(N) to limit the number of idle connections in the pool. This doesn’t limit the pool size, though.
- In Go 1.2.1 or newer, you can use db.SetMaxOpenConns(N) to limit the number of total open connections to the database. Unfortunately, a deadlock bug (fix) prevents db.SetMaxOpenConns(N) from safely being used in 1.2.
- Connections are recycled rather fast. Setting a high number of idle connections with db.SetMaxIdleConns(N) can reduce this churn, and help keep connections around for reuse.
- Keeping a connection idle for a long time can cause problems (like in this issue with MySQL on Microsoft Azure). Try db.SetMaxIdleConns(0) if you get connection timeouts because a connection is idle for too long.
- You can also specify the maximum amount of time a connection may be reused by setting db.SetConnMaxLifetime(duration) since reusing long lived connections may cause network issues. This closes the unused connections lazily i.e. closing expired connection may be deferred.
SQL aggregate functions return a single value, calculated from values in a column.
- AVG() - Returns the average value
- COUNT() - Returns the number of rows
- FIRST() - Returns the first value
- LAST() - Returns the last value
- MAX() - Returns the largest value
- MIN() - Returns the smallest value
- SUM() - Returns the sum
A stored procedure is a prepared SQL code that you can save, so the code can be reused over and over again. So if you have an SQL query that you write over and over again, save it as a stored procedure, and then just call it to execute it. You can also pass parameters to a stored procedure, so that the stored procedure can act based on the parameter value(s) that is passed.
CREATE PROCEDURE SelectAllCustomers @City nvarchar(30)
AS
SELECT * FROM Customers WHERE City = @City
GO;
# usage:
EXEC SelectAllCustomers @City = "London";A user-defined function (UDF) is a way to extend MySQL with a new function that works like
a native (built-in) MySQL function such as ABS() or CONCAT(). To create a function, you must
have the INSERT privilege for the mysql system database. This is necessary because CREATE
FUNCTION adds a row to the mysql.func system table that records the function's name, type,
and shared library name.
Function is compiled and executed every time it is called. And cannot modify the data
received as parameters and function must return a value. Functions are similar to Stored
procedures, but with following differences:
| Function | Stored procedure |
|---|---|
| The function always returns a value. | Procedure can return “0” or n values. |
| Functions have only input parameters for it. | Procedures can have output or input parameters. |
| You can call Functions from Procedure. | You can’t call Procedures from a Function. |
| You can’t use Transactions in Function. | You can use Transactions in Procedure. |
| You can’t use try-catch block in a Function to handle the exception. | By using a try-catch block, an exception can be handled in a Procedure. |
| Function can be utilized in a SELECT statement. | You can’t utilize Procedures in a SELECT statement. |
| Function allows only SELECT statement in it. | The procedure allows as DML(INSERT/UPDATE/DELETE) as well as a SELECT statement in it. |
| The function can be used in the SQL statements anywhere in SELECT/WHERE/HAVING syntax. | Stored Procedures cannot be used in the SQL statements anywhere in the WHERE/HAVING/SELECT statement. |
CREATE FUNCTION function_name(param1, param2)
RETURNS datatype
BEGIN
-- statements
ENDType of SQL variable that holds SELECT's statement resulting set. It might be used to perform
some logic on dataset in STORED PROCEDURE or FUNCTION.
CREATE PROCEDURE demo()
BEGIN
DECLARE a CHAR(16);
DECLARE b INT;
DECLARE cur1 CURSOR FOR SELECT id,data FROM test.t1;
OPEN cur1;
read_loop: LOOP
FETCH cur1 INTO a, b;
INSERT INTO table1.t3 VALUES (a,b); -- INSERT into different table
END LOOP;
CLOSE cur1;
END;Database Normalization is a technique of organizing the data in the database. Normalization is a systematic approach of decomposing tables to eliminate data redundancy(repetition) and undesirable characteristics like Insertion, Update and Deletion Anomalies. It is a multi-step process that puts data into tabular form, removing duplicated data from the relation tables.
Data duplication:
- Increases storage and decrease write performance
- It becomes more difficult to maintain data changes
Modification anomalies:
- Insert anomaly - inability to insert data due to missing data.
Example: We cannot record a new sales office until we also know the sales person, because in order to create the record, we need to provide a primary key (EmployeeID) - Update anomaly - in case of data duplication we need to change all existing duplicated data, not only one row being updated.
Example: if office number changes, it must be updated for all employees in that office. If we don’t update all rows, then inconsistencies appear. - Delete anomaly - deletion of a row causes removal of more than one set of facts.
Example: if office had one person, and that person retires, then deleting that employee row cause us to lose information about the whole office. - Search and sort issues - repeating columns with same logical data can lead to complex queries.
Example: if we have columns like phone1, phone2, then searching by phone leads to including both column to query. Same with sorting.
Normalization purposes:
- Eliminating redundant(useless) data.
- Ensuring data is logically stored.
- Eliminating insert, update and delete anomalies.
NF1
- Single valued attributes
Each column of your table should be single valued which means they should not contain multiple values. - Attribute Domain should not change
This is more of a "Common Sense" rule. In each column the values stored must be of the same kind or type. - Unique name for Attributes/Columns
This rule expects that each column in a table should have a unique name. This is to avoid confusion at the time of retrieving data or performing any other operation on the stored data. - Order doesn't matters
NF2
- It is in first normal form
- All columns depend on primary key. (No Partial dependency)
Partial dependency: Part of PK <(depends on)- Non-Prime Attribute
Columns should be dependent on ALL Primary Keys Set. And not on ONE key. Don't keep repeated data which belongs to another entity in the table. Instead create a second table to store such data.
NF3 (the most common)
- It is in second normal form
- (No Transitive dependency)
Transitive dependency: Non-Prime Attribute <(depends on)- Non-Prime Attribute
Columns should not depend on NON-KEY attributes. Columns wich does not belong to the primary key and may be repeated in multiple fields should be moved to the separate tables.
BCNF Boyce-Codd Normal Form
- It is in third normal form
- For any dependency A → B, A should be a super key.
Dependency: Non-Prime Attribute <(depends on)- Prime Attrubute
NF4
- It is in BCNF
- The table should not have any Multi-valued Dependency.
Multi-Valued dependency: for tables with at least 3 columns
s_id col1 col2
1 A B
1 C B << multi-valued dependency
NF5
- It is in fourth normal form
- 5th normal form is not achievable in real world
NF6
- It's not standardized yet
Keep the logical design normalized, but allow the database management system (DBMS) to store additional redundant information on disk to optimize query response. For example, materialized views in PostgreSQL. A view may, among other factors, represent information in a format convenient for querying, and the index ensures that queries against the view are optimized physically.
Denormalize the logical data design. Cost - it is now the database designer's responsibility to ensure database consistency. This is done by creating rules in the database called constraints, that specify how the redundant copies of information must be kept synchronized, which may easily make the de-normalization procedure pointless. Moreover, constraints introduce a trade-off, speeding up reads while slowing down writes. This means a denormalized database under heavy write load may offer worse performance than its functionally equivalent normalized counterpart.
I in ACID
https://www.geeksforgeeks.org/transaction-isolation-levels-dbms/\ Isolation levels define the degree to which a transaction must be isolated from the data modifications made by any other transaction in the database system. (Rules for acquiring a LOCK.)
dirty reads- occurs when a transaction is allowed to read data from a row that has been modified by another running transaction and not yet committed. Dirty reads work similarly to non-repeatable reads; however, the second transaction would not need to be committed for the first query to return a different result.non-repeatable reads- occurs when during the course of a transaction, a row is retrieved twice and the values within the row differ between reads (e.g. UPDATE was executed)phantom reads- occurs when in the course of a transaction, new rows are added or removed by another transaction to the records being read (e.g. INSERT OR DELETE was executed)serialization anomaly- the result of successfully committing a group of transactions is inconsistent with all possible orderings of running those transactions one at a time.
Levels:
- Read uncommitted permits dirty reads, non repeatable reads and phantom reads. (default in postgres)
- Read committed permits non repeatable reads and phantom reads.
- Repeatable read permits only phantom reads.
- Serializable does not permit any read errors.
To set the global isolation level at server startup, use the --transaction-isolation=level
option on the command line or in an option file.
Ensures that all operations within the work unit are completed successfully. Otherwise, the transaction is aborted at the point of failure and all the previous operations are rolled back to their former state.
START TRANSACTIONorBEGINstart a new transaction.COMMIT- to save the changes.ROLLBACK- to roll back the changes.SAVEPOINT- creates points within the groups of transactions in which to ROLLBACK.SET TRANSACTION- Places a name on a transaction.
2PC - Two phase commit protocol
-
Voting phase: Transaction manager sends transaction to all replicas. Replicas write transaction info into their log and send OK.
-
Commit phase: When TM Receives OK from all slaves it sends message to commit. After every replica commits it sends OK to TM. If one replica sent NOT OK - TM sends msg to every replica to rollback.
Lock single ROW!
BEGIN TRAN
UPDATE your_table WITH (ROWLOCK)
SET your_field = a_value
WHERE <a predicate>
COMMIT TRANA READ|WRITE locks has the following features:
- The only session that holds the lock of a table can read/write data from the table.
- Other sessions cannot read data from and write data to the table until the WRITE lock is released.
LOCK TABLES table_name [READ | WRITE]Index contains not the data, but pointer to it.
Clustered index - index on primary key column (sorted array)
Non-clustered index - index on non-primary columns (usually stored as binary tree or hash table)
Cons:
- Slow writes since whole index should be updated
- Index takes additional memory on disk
The idea here is that you split the data so that instead of hosting all of it on a single server or replicating all of the data on all of the servers in a cluster, you divide up portions of the data horizontally and host them each separately. ###Sharding strategies
- Feature-based shard or functional segmentation Using this strategy, the data is split not by dividing records in a single table (as in the customer example discussed earlier), but rather by splitting into separate databases the features that don’t overlap with each other very much. For example, at eBay, the users are in one shard, and the items for sale are in another. At Flixster, movie ratings are in one shard and comments are in another. This approach depends on understanding your domain so that you can segment data cleanly.
- Key-based sharding In this approach, you find a key in your data that will evenly distribute it across shards. So instead of simply storing one letter of the alphabet for each server as in the (naive and improper) earlier example, you use a one-way hash on a key data element and distribute data across machines according to the hash. It is common in this strategy to find time-based or numeric keys to hash on.
- Lookup table In this approach, one of the nodes in the cluster acts as a “yellow pages” directory and looks up which node has the data you’re trying to access. This has two obvious disadvantages. The first is that you’ll take a performance hit every time you have to go through the lookup table as an additional hop. The second is that the lookup table not only becomes a bottleneck, but a single point of failure.
- Shared-nothing A shared-nothing architecture is one in which there is no centralized (shared) state, but each node in a distributed system is independent, so there is no client contention for shared resources. The term was first coined by Michael Stonebraker at the University of California at Berkeley in his 1986 paper “The Case for Shared Nothing.”
- Atomicity:
Atomicity guarantees that each transaction is treated as a single "unit", which either succeeds completely, or fails completely: if any of the statements constituting a transaction fails to complete, the entire transaction fails and the database is left unchanged. - Consistency:
Consistency means that data moves from one correct state to another correct state, with no possibility that readers could view different values that don’t make sense together. - Isolation:
Concurrent transaction should't impact to one another. That is, if two different transactions attempt to modify the same data at the same time, then one of them will have to wait for the other to complete. - Durability:
Durability guarantees that once a transaction has been committed, it will remain committed even in the case of a system failure (e.g., power outage or crash). This usually means that completed transactions (or their effects) are recorded in non-volatile memory.
Todo:
- multistage build
Containerization essentially virtualizes an operating system so applications can be distributed across a single host without requiring their own virtual machine. It does this by giving an app access to a single operating system kernel, which is the core module of the operating system. All containerized apps running on a single machine will run on the same Linux kernel.
https://www.baeldung.com/cs/virtualization-vs-containerization
- Architecture of kubernetes, Kubernetes components, Configuration management in kubernetes cluster, Container management.
- Node, pod, namespace, kubectl, deploy, minikube, secrets.
Cluster - Multiple worker nodes and one (or more) master nodes.
Node - Server where docker images are run:
- Worker node
- kubelet (communicate to master)
- kube-proxy (network interface)
- Master node (controls worker nodes)
- kube-apiserver
- kube-controller-manager
- kube-scheduler
Pod - smallest unit of deployment (one or more images).
Docker container registry - image store. Master node knows about the registry and manages images.
K8s capabilities:
- Service discovery (access via ip or dns name to container) and load balancing
- Disk mounting
- Secrets management
- Rollouts rollbacks
- Automatic container distribution among nodes based on resources usage
- Self healing - restart containers on failure
https://thenewstack.io/deployment-strategies/
No downtime deployment is the practice of deployment that allows to have zero downtime between versions, it has several implementations:
-
Rolling deployment
When the new version is fully tested and ready for release, the instances are slowly, one by one, rolled out to the active environment. This minimizes the probability of system failure. -
Blue/green deployment
Version B (green) is deployed alongside version A (blue) with exactly the same amount of instances. After testing that the new version meets all the requirements the traffic is switched from version A to version B at the load balancer level. -
Canary deployment
A canary deployment consists of gradually shifting production traffic from version A to version B. Usually the traffic is split based on weight. For example, 90 percent of the requests go to version A, 10 percent go to version B. This technique is mostly used when the tests are lacking or not reliable or if there is little confidence about the stability of the new release on the platform.
Todo:
- Load Balancing, types of load balancing, tools
Todo:
- IaC concepts, Terraform, AWS Cloud Formation, Azure AMR, GCP Cloud Deployment Manager
Todo:
- Configuration management (push vs pull)
- Ansible, Puppet, Solt, Chef
Todo:
- Artifactory, Nexus
Todo:
- Logging best practices. System and application monitoring. Alterting.
- Tooling: ELK, Prometheus, Grafana or similar
Microservices is a technique for structuring an application as collection of services. Pros:
- Single Responsibility
- Self-contained with clear interfaces and a distinct purpose.
- Loosly coupled - communication over a network + each service has it's own db (minimal dependencies)
- Independently deployable, scalable, maintainable and testable
- If some service dies, whole application still alive (high availability)
Cons:
- Communication is complex and slower + low network fault tolerance + need load balancing
- Needs DevOps department
- Communication between services is defined in documentation
- Software is hosted on a remote server and is always accessible through a web browser over Internet
- Application is managed from a central location
- Application users don’t need to worry about hardware, software updates and patches
- Runs a single instance of software
- No need to install software for end users (Google apps, Netflix, Webex)
- PaaS offers a platform for the creation of software For developers.
- Encapsulates the environment where users can build compile and run their program.
- Developers work on PaaS platform and concentrate on software application building without having to worry about software updates, operating systems, load balancing, storage, or other details related to infrastructure. (AWS, Google app engine)
IaaS model delivers Cloud Computing infrastructure including servers, storage, network and operating systems an on-demand service. For organizations it means that instead of purchasing the whole infrastructure, they simply buy those resources as a service on demand. Ideal for organizations which need complete control over their high performing applications (AWS EC2)
Standalone server (router) with services registry
Todo:
- Message Queue
- Streaming Queue
- Stream
- Pub/Sub
- Events
- Dead letter
- Duplicates
- Akka streaming
- Kafka consumer group
- Kafka topic
- Kafka partition
- Kafka streaming
- Zookeeper in kafka
Todo:
- SD
- Approaches
- Client side discovery
- Server side discovery
- Service registry
- Gossip vs Raft
- K8S SD vs Eureka or Consul
Todo:
- API Gateway in microservices
- Api Gateway Aggregations vs Aggregation Service pattern
- cross cutting concerns: secutiry, throttling
- Frameworks: Kong, Nginx, Ocelot, Zuul, Ambassador, Spring Cloud Api Gateway
Todo:
- Circuit breaker
- Retry strategy
- Throttling
- Fallbacks (Graceful Degradation, Cache, Functional redundancy, Stubbed data)
- Service reliability and fault tolerance
Todo:
- Service mesh
- Istio vs LinkerD
- AWS Service Mesh
Todo:
- OpenTracing
- OpenTelemetry
Todo:
- Chaos testing, Contract testing
Todo:
- Encryption vs Hashing
- Symmetric/Asymmetric
- Salt
- Rainbow tables
- PKI
- Key exchange methods
Todo:
- Authentication
- Authorization
- Accounting
- RBAC access control
- UBAC; ABAC; ACL; Rule-based
Todo:
- SSO
- OAuth 2.0
- OpenId Connect
- JWT
- SAML
Todo:
- OWASP top 10
- Injection
- XSS
- Broken Authentication
- Sensitive Data Exposure
- Broken Access Control
- Insecure Deserialization
Todo:
- Hashicorp Vault
- Puppet Hierra
- DLP API
Todo:
- Key components (AMI, IAM, Storages, Queues etc.)
- EC2 instance types and scaling (on-demand/reserved/spot)
- Availability Zones and Regions
Todo:
- AWS Lambda deployment
- AWS Lambda limitations
- AWS Lambda retry policies
- Cold start and scaling
- Execution model
- Usecases
Todo:
- ElasticBeanStalk
- ElasticSearch
- EKS, ECS, ECR