线性动态规划:具有「线性」阶段划分的动态规划方法统称为线性动态规划(简称为「线性 DP」),如下图所示。
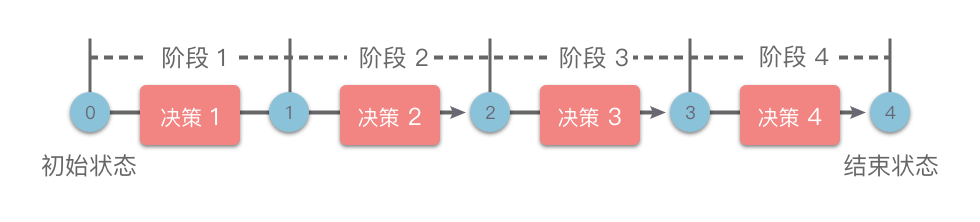
如果状态包含多个维度,但是每个维度上都是线性划分的阶段,也属于线性 DP。比如背包问题、区间 DP、数位 DP 等都属于线性 DP。
线性 DP 问题的划分方法有多种方式。
- 如果按照「状态的维度数」进行分类,我们可以将线性 DP 问题分为:一维线性 DP 问题、二维线性 DP 问题,以及多维线性 DP 问题。
- 如果按照「问题的输入格式」进行分类,我们可以将线性 DP 问题分为:单串线性 DP 问题、双串线性 DP 问题、矩阵线性 DP 问题,以及无串线性 DP 问题。
本文中,我们将按照问题的输入格式进行分类,对线性 DP 问题中各种类型问题进行一一讲解。
单串线性 DP 问题:问题的输入为单个数组或单个字符串的线性 DP 问题。状态一般可定义为
,表示为:
- 「以数组中第
个位置元素 为结尾的子数组($nums[0]...nums[i]$)」的相关解。 - 「以数组中第
个位置元素 为结尾的子数组($nums[0]...nums[i - 1]$)」的相关解。 - 「以数组中前
个元素为子数组($nums[0]...nums[i - 1]$)」的相关解。
这
- 第
种状态:子数组的长度为 ,子数组长度不可为空; - 第
种状态、第 种状态:这两种状态描述是相同的。子数组的长度为 ,子数组长度可为空。在 时,方便用于表示空数组(以数组中前 个元素为子数组)。
单串线性 DP 问题中最经典的问题就是「最长递增子序列(Longest Increasing Subsequence,简称 LIS)」。
描述:给定一个整数数组
要求:找到其中最长严格递增子序列的长度。
说明:
-
子序列:由数组派生而来的序列,删除(或不删除)数组中的元素而不改变其余元素的顺序。例如,$[3,6,2,7]$ 是数组
的子序列。 -
。 -
。
示例:
- 示例 1:
输入:nums = [10,9,2,5,3,7,101,18]
输出:4
解释:最长递增子序列是 [2,3,7,101],因此长度为 4。- 示例 2:
输入:nums = [0,1,0,3,2,3]
输出:4按照子序列的结尾位置进行阶段划分。
定义状态
一个较小的数后边如果出现一个较大的数,则会形成一个更长的递增子序列。
对于满足
-
如果
,则 可以接在 后面,此时以 结尾的最长递增子序列长度会在「以 结尾的最长递增子序列长度」的基础上加 ,即:$dp[i] = dp[j] + 1$。 -
如果
,则 不可以接在 后面,可以直接跳过。
综上,我们的状态转移方程为:$dp[i] = max(dp[i], dp[j] + 1), 0 \le j < i, nums[j] < nums[i]$。
默认状态下,把数组中的每个元素都作为长度为
根据我们之前定义的状态,$dp[i]$ 表示为:以
class Solution:
def lengthOfLIS(self, nums: List[int]) -> int:
size = len(nums)
dp = [1 for _ in range(size)]
for i in range(size):
for j in range(i):
if nums[i] > nums[j]:
dp[i] = max(dp[i], dp[j] + 1)
return max(dp)-
时间复杂度:$O(n^2)$。两重循环遍历的时间复杂度是
,最后求最大值的时间复杂度是 ,所以总体时间复杂度为 。 -
空间复杂度:$O(n)$。用到了一维数组保存状态,所以总体空间复杂度为
。
单串线性 DP 问题中除了子序列相关的线性 DP 问题,还有子数组相关的线性 DP 问题。
注意:
- 子序列:由数组派生而来的序列,删除(或不删除)数组中的元素而不改变其余元素的顺序。
- 子数组:指的是数组中的一个连续子序列。
「子序列」与「子数组」都可以看做是原数组的一部分,而且都不会改变原来数组中元素的相对顺序。其区别在于数组元素是否要求连续。
描述:给定一个整数数组
要求:找到一个具有最大和的连续子数组(子数组最少包含一个元素),返回其最大和。
说明:
- 子数组:指的是数组中的一个连续部分。
-
。 -
。
示例:
- 示例 1:
输入:nums = [-2,1,-3,4,-1,2,1,-5,4]
输出:6
解释:连续子数组 [4,-1,2,1] 的和最大,为 6。- 示例 2:
输入:nums = [1]
输出:1按照连续子数组的结束位置进行阶段划分。
定义状态
状态
- 如果
,则「第 个数结尾的连续子数组的最大和」+「第 个数的值」<「第 个数的值」,即:$dp[i - 1] + nums[i] < nums[i]$。所以,此时 应取「第 个数的值」,即 。 - 如果
,则「第 个数结尾的连续子数组的最大和」 +「第 个数的值」 >= 第 个数的值,即:$dp[i - 1] + nums[i] \ge nums[i]$。所以,此时 应取「第 个数结尾的连续子数组的最大和」+「 第 个数的值」,即 。
归纳一下,状态转移方程为:
$dp[i] = \begin{cases} nums[i], & dp[i - 1] < 0 \cr dp[i - 1] + nums[i] & dp[i - 1] \ge 0 \end{cases}$
- 第
个数结尾的连续子数组的最大和为 ,即 。
根据状态定义,$dp[i]$ 为:以第
class Solution:
def maxSubArray(self, nums: List[int]) -> int:
size = len(nums)
dp = [0 for _ in range(size)]
dp[0] = nums[0]
for i in range(1, size):
if dp[i - 1] < 0:
dp[i] = nums[i]
else:
dp[i] = dp[i - 1] + nums[i]
return max(dp)-
时间复杂度:$O(n)$,其中
为数组 的元素个数。 - 空间复杂度:$O(n)$。
因为
class Solution:
def maxSubArray(self, nums: List[int]) -> int:
size = len(nums)
subMax = nums[0]
ansMax = nums[0]
for i in range(1, size):
if subMax < 0:
subMax = nums[i]
else:
subMax += nums[i]
ansMax = max(ansMax, subMax)
return ansMax-
时间复杂度:$O(n)$,其中
为数组 的元素个数。 - 空间复杂度:$O(1)$。
有一些单串线性 DP 问题在定义状态时需要考虑两个结束位置,只考虑一个结束位置的无法清楚描述问题。这时候我们就需要需要增加一个结束位置维度来定义状态。
描述:给定一个严格递增的正整数数组
要求:从数组
说明:
-
斐波那契式序列:如果序列
满足: -
; - 对于所有
,都有 。
则称该序列为斐波那契式序列。
-
-
斐波那契式子序列:从序列
中挑选若干元素组成子序列,并且子序列满足斐波那契式序列,则称该序列为斐波那契式子序列。例如:$A = [3, 4, 5, 6, 7, 8]$。则 是 的一个斐波那契式子序列。 -
。 -
。
示例:
- 示例 1:
输入: arr = [1,2,3,4,5,6,7,8]
输出: 5
解释: 最长的斐波那契式子序列为 [1,2,3,5,8]。- 示例 2:
输入: arr = [1,3,7,11,12,14,18]
输出: 3
解释: 最长的斐波那契式子序列有 [1,11,12]、[3,11,14] 以及 [7,11,18]。假设
通过
因为给定的数组是严格递增的,所以对于一个斐波那契式子序列,如果确定了
简单来说,就是确定了
最后将这些长度进行比较,其中最长的长度就是答案。
class Solution:
def lenLongestFibSubseq(self, arr: List[int]) -> int:
size = len(arr)
ans = 0
for i in range(size):
for j in range(i + 1, size):
temp_ans = 0
temp_i = i
temp_j = j
k = j + 1
while k < size:
if arr[temp_i] + arr[temp_j] == arr[k]:
temp_ans += 1
temp_i = temp_j
temp_j = k
k += 1
if temp_ans > ans:
ans = temp_ans
if ans > 0:
return ans + 2
else:
return ans-
时间复杂度:$O(n^3)$,其中
为数组 的元素个数。 - 空间复杂度:$O(1)$。
对于
class Solution:
def lenLongestFibSubseq(self, arr: List[int]) -> int:
size = len(arr)
ans = 0
idx_map = dict()
for idx, value in enumerate(arr):
idx_map[value] = idx
for i in range(size):
for j in range(i + 1, size):
temp_ans = 0
temp_i = i
temp_j = j
while arr[temp_i] + arr[temp_j] in idx_map:
temp_ans += 1
k = idx_map[arr[temp_i] + arr[temp_j]]
temp_i = temp_j
temp_j = k
if temp_ans > ans:
ans = temp_ans
if ans > 0:
return ans + 2
else:
return ans-
时间复杂度:$O(n^2)$,其中
为数组 的元素个数。 - 空间复杂度:$O(n)$。
按照斐波那契式子序列相邻两项的结尾位置进行阶段划分。
定义状态
以
默认状态下,数组中任意相邻两项元素都可以作为长度为
根据我们之前定义的状态,$dp[i][j]$ 表示为:以
因为题目定义中,斐波那契式中
注意:在进行状态转移的同时,我们应和「思路 2:哈希表」一样采用哈希表优化的方式来提高效率,降低算法的时间复杂度。
class Solution:
def lenLongestFibSubseq(self, arr: List[int]) -> int:
size = len(arr)
dp = [[0 for _ in range(size)] for _ in range(size)]
ans = 0
# 初始化 dp
for i in range(size):
for j in range(i + 1, size):
dp[i][j] = 2
idx_map = {}
# 将 value : idx 映射为哈希表,这样可以快速通过 value 获取到 idx
for idx, value in enumerate(arr):
idx_map[value] = idx
for i in range(size):
for j in range(i + 1, size):
if arr[i] + arr[j] in idx_map:
# 获取 arr[i] + arr[j] 的 idx,即斐波那契式子序列下一项元素
k = idx_map[arr[i] + arr[j]]
dp[j][k] = max(dp[j][k], dp[i][j] + 1)
ans = max(ans, dp[j][k])
if ans >= 3:
return ans
return 0-
时间复杂度:$O(n^2)$,其中
为数组 的元素个数。 - 空间复杂度:$O(n)$。
双串线性 DP 问题:问题的输入为两个数组或两个字符串的线性 DP 问题。状态一般可定义为
,表示为:
- 「以第一个数组中第
个位置元素 为结尾的子数组($nums1[0]...nums1[i]$)」与「以第二个数组中第 个位置元素 为结尾的子数组($nums2[0]...nums2[j]$)」的相关解。 - 「以第一个数组中第
个位置元素 为结尾的子数组($nums1[0]...nums1[i - 1]$)」与「以第二个数组中第 个位置元素 为结尾的子数组($nums2[0]...nums2[j - 1]$)」的相关解。 - 「以第一个数组中前
个元素为子数组($nums1[0]...nums1[i - 1]$)」与「以第二个数组中前 个元素为子数组($nums2[0]...nums2[j - 1]$)」的相关解。
这
- 第
种状态:子数组的长度为 或 ,子数组长度不可为空 - 第
种状态、第 种状态:子数组的长度为 或 ,子数组长度可为空。$i = 0$ 或 时,方便用于表示空数组(以数组中前 个元素为子数组)。
双串线性 DP 问题中最经典的问题就是「最长公共子序列(Longest Common Subsequence,简称 LCS)」。
描述:给定两个字符串
要求:返回两个字符串的最长公共子序列的长度。如果不存在公共子序列,则返回
说明:
- 子序列:原字符串在不改变字符的相对顺序的情况下删除某些字符(也可以不删除任何字符)后组成的新字符串。
- 公共子序列:两个字符串所共同拥有的子序列。
-
。 -
和 仅由小写英文字符组成。
示例:
- 示例 1:
输入:text1 = "abcde", text2 = "ace"
输出:3
解释:最长公共子序列是 "ace",它的长度为 3。- 示例 2:
输入:text1 = "abc", text2 = "abc"
输出:3
解释:最长公共子序列是 "abc",它的长度为 3。按照两个字符串的结尾位置进行阶段划分。
定义状态
双重循环遍历字符串
- 如果
,说明两个子字符串的最后一位是相同的,所以最长公共子序列长度加 。即:$dp[i][j] = dp[i - 1][j - 1] + 1$。 - 如果
,说明两个子字符串的最后一位是不同的,则 需要考虑以下两种情况,取两种情况中最大的那种:$dp[i][j] = max(dp[i - 1][j], dp[i][j - 1])$。 - 「以
中前 个元素组成的子字符串 」与「以 中前 个元素组成的子字符串 」的最长公共子序列长度,即 。 - 「以
中前 个元素组成的子字符串 」与「以 中前 个元素组成的子字符串 」的最长公共子序列长度,即 。
- 「以
- 当
时,$str1$ 表示的是空串,空串与 的最长公共子序列长度为 ,即 。 - 当
时,$str2$ 表示的是空串,$str1$ 与 空串的最长公共子序列长度为 ,即 。
根据状态定义,最后输出
class Solution:
def longestCommonSubsequence(self, text1: str, text2: str) -> int:
size1 = len(text1)
size2 = len(text2)
dp = [[0 for _ in range(size2 + 1)] for _ in range(size1 + 1)]
for i in range(1, size1 + 1):
for j in range(1, size2 + 1):
if text1[i - 1] == text2[j - 1]:
dp[i][j] = dp[i - 1][j - 1] + 1
else:
dp[i][j] = max(dp[i - 1][j], dp[i][j - 1])
return dp[size1][size2]-
时间复杂度:$O(n \times m)$,其中
、$m$ 分别是字符串 、$text2$ 的长度。两重循环遍历的时间复杂度是 ,所以总的时间复杂度为 。 -
空间复杂度:$O(n \times m)$。用到了二维数组保存状态,所以总体空间复杂度为
。
描述:给定两个整数数组
要求:计算两个数组中公共的、长度最长的子数组长度。
说明:
-
。 -
。
示例:
- 示例 1:
输入:nums1 = [1,2,3,2,1], nums2 = [3,2,1,4,7]
输出:3
解释:长度最长的公共子数组是 [3,2,1] 。- 示例 2:
输入:nums1 = [0,0,0,0,0], nums2 = [0,0,0,0,0]
输出:5按照子数组结尾位置进行阶段划分。
定义状态
- 如果
,则当前元素可以构成公共子数组,此时 。 - 如果
,则当前元素不能构成公共子数组,此时 。
- 当
时,$nums1[0]...nums1[i - 1]$ 表示的是空数组,空数组与 中任意子数组的最长公共子序列长度为 ,即 。 - 当
时,$nums2[0]...nums2[j - 1]$ 表示的是空数组,空数组与 中任意子数组的最长公共子序列长度为 ,即 。
- 根据状态定义,
为:「在 中以第 个元素结尾的子数组 」和「在 中以第 个元素结尾的子数组 」的最长公共子数组长度。在遍历过程中,我们可以使用 记录下所有 中最大值即为答案。
class Solution:
def findLength(self, nums1: List[int], nums2: List[int]) -> int:
size1 = len(nums1)
size2 = len(nums2)
dp = [[0 for _ in range(size2 + 1)] for _ in range(size1 + 1)]
res = 0
for i in range(1, size1 + 1):
for j in range(1, size2 + 1):
if nums1[i - 1] == nums2[j - 1]:
dp[i][j] = dp[i - 1][j - 1] + 1
if dp[i][j] > res:
res = dp[i][j]
return res-
时间复杂度:$O(n \times m)$。其中
是数组 的长度,$m$ 是数组 的长度。 - 空间复杂度:$O(n \times m)$。
双串线性 DP 问题中除了经典的最长公共子序列问题之外,还包括字符串的模糊匹配问题。
描述:给定两个单词
对一个单词可以进行以下三种操作:
- 插入一个字符
- 删除一个字符
- 替换一个字符
要求:计算出将
说明:
-
。 -
和 由小写英文字母组成。
示例:
- 示例 1:
输入:word1 = "horse", word2 = "ros"
输出:3
解释:
horse -> rorse (将 'h' 替换为 'r')
rorse -> rose (删除 'r')
rose -> ros (删除 'e')- 示例 2:
输入:word1 = "intention", word2 = "execution"
输出:5
解释:
intention -> inention (删除 't')
inention -> enention (将 'i' 替换为 'e')
enention -> exention (将 'n' 替换为 'x')
exention -> exection (将 'n' 替换为 'c')
exection -> execution (插入 'u')按照两个字符串的结尾位置进行阶段划分。
定义状态
- 如果当前字符相同($word1[i - 1] = word2[j - 1]$),无需插入、删除、替换。$dp[i][j] = dp[i - 1][j - 1]$。
- 如果当前字符不同($word1[i - 1] \ne word2[j - 1]$),$dp[i][j]$ 取源于以下三种情况中的最小情况:
- 替换($word1[i - 1]$ 替换为
):最少操作次数依赖于「以 中前 个字符组成的子字符串 」变为「以 中前 个字符组成的子字符串 」,再加上替换的操作数 ,即:$dp[i][j] = dp[i - 1][j - 1] + 1$。 - 插入($word1$ 在第
位置上插入元素):最少操作次数依赖于「以 中前 个字符组成的子字符串 」 变为「以 中前 个字符组成的子字符串 」,再加上插入需要的操作数 ,即:$dp[i][j] = dp[i - 1][j] + 1$。 - 删除($word1$ 删除第
位置元素):最少操作次数依赖于「以 中前 个字符组成的子字符串 」变为「以 中前 个字符组成的子字符串 」,再加上删除需要的操作数 ,即:$dp[i][j] = dp[i][j - 1] + 1$。
- 替换($word1[i - 1]$ 替换为
综合上述情况,状态转移方程为:
$dp[i][j] = \begin{cases} dp[i - 1][j - 1] & word1[i - 1] = word2[j - 1] \cr min(dp[i - 1][j - 1], dp[i - 1][j], dp[i][j - 1]) + 1 & word1[i - 1] \ne word2[j - 1] \end{cases}$
- 当
,「以 中前 个字符组成的子字符串 」为空字符串,「$str1$」变为「以 中前 个字符组成的子字符串 」时,至少需要插入 次,即:$dp[0][j] = j$。 - 当
,「以 中前 个字符组成的子字符串 」为空字符串,「以 中前 个字符组成的子字符串 」变为「$str2$」时,至少需要删除 次,即:$dp[i][0] = i$。
根据状态定义,最后输出
class Solution:
def minDistance(self, word1: str, word2: str) -> int:
size1 = len(word1)
size2 = len(word2)
dp = [[0 for _ in range(size2 + 1)] for _ in range(size1 + 1)]
for i in range(size1 + 1):
dp[i][0] = i
for j in range(size2 + 1):
dp[0][j] = j
for i in range(1, size1 + 1):
for j in range(1, size2 + 1):
if word1[i - 1] == word2[j - 1]:
dp[i][j] = dp[i - 1][j - 1]
else:
dp[i][j] = min(dp[i - 1][j - 1], dp[i - 1][j], dp[i][j - 1]) + 1
return dp[size1][size2]-
时间复杂度:$O(n \times m)$,其中
、$m$ 分别是字符串 、$word2$ 的长度。两重循环遍历的时间复杂度是 ,所以总的时间复杂度为 。 -
空间复杂度:$O(n \times m)$。用到了二维数组保存状态,所以总体空间复杂度为
。
- 【书籍】算法竞赛进阶指南
- 【文章】动态规划概念和基础线性DP | 潮汐朝夕