|
| 1 | +# 题目描述(中等难度) |
| 2 | + |
| 3 | +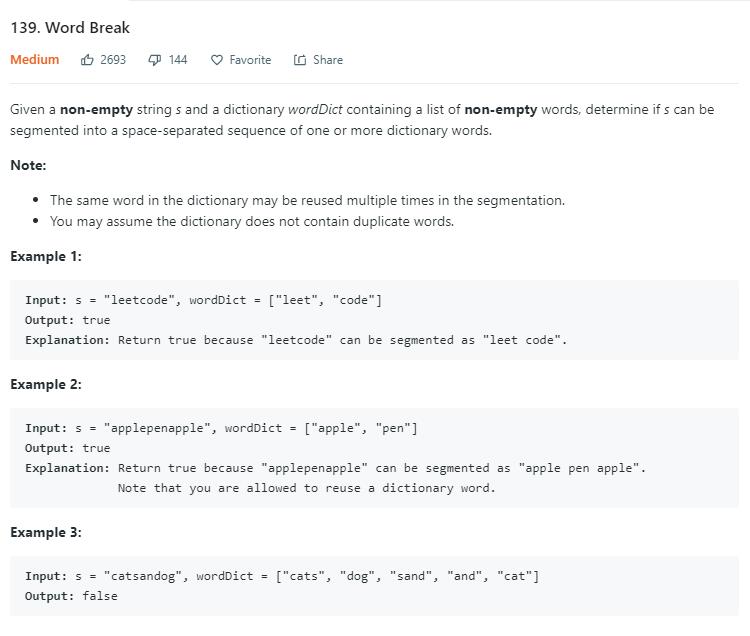 |
| 4 | + |
| 5 | +给一个字符串,和一些单词,问字符串能不能由这些单词构成。每个单词可以用多次,也可以不用。 |
| 6 | + |
| 7 | +# 解法一 回溯 |
| 8 | + |
| 9 | +来一个简单粗暴的方法,利用回溯法,用 `wordDict` 去生成所有可能的字符串。期间如果出现了目标字符串 `s`,就返回 `true`。 |
| 10 | + |
| 11 | +```java |
| 12 | +public boolean wordBreak(String s, List<String> wordDict) { |
| 13 | + return wordBreakHelper(s,wordDict,""); |
| 14 | +} |
| 15 | +//temp 是当前生成的字符串 |
| 16 | +private boolean wordBreakHelper(String s, List<String> wordDict, String temp) { |
| 17 | + //如果此时生成的字符串长度够了,就判断和目标字符日是否相等 |
| 18 | + if(temp.length() == s.length()){ |
| 19 | + if(temp.equals(s)){ |
| 20 | + return true; |
| 21 | + }else{ |
| 22 | + return false; |
| 23 | + } |
| 24 | + } |
| 25 | + //长度超了,就返回 false |
| 26 | + if(temp.length() > s.length()){ |
| 27 | + return false; |
| 28 | + } |
| 29 | + //考虑每个单词 |
| 30 | + for(int i = 0;i < wordDict.size(); i++){ |
| 31 | + if(wordBreakHelper(s,wordDict,temp + wordDict.get(i))){ |
| 32 | + return true; |
| 33 | + } |
| 34 | + } |
| 35 | + return false; |
| 36 | +} |
| 37 | +``` |
| 38 | + |
| 39 | +意料之中,超时了 |
| 40 | + |
| 41 | + |
| 42 | + |
| 43 | +让我们考虑优化的方法。 |
| 44 | + |
| 45 | +在递归出口的地方优化一下。 |
| 46 | + |
| 47 | +之前是在长度相等的时候,开始判断字符串是否相等。 |
| 48 | + |
| 49 | +很明显,字符串长度相等之前我们其实就可以判断当前是不是符合了。 |
| 50 | + |
| 51 | +例如 `temp = "abc"`,如果 `s = "dddefg"`,虽然此时 `temp` 和 `s` 的长度不相等。但因为前缀已经不同,所以后边无论是什么都不可以了。此时就可以返回 `false` 了。 |
| 52 | + |
| 53 | +所以递归出口可以从头判断每个字符是否相等,不相等就直接返回 `false`。 |
| 54 | + |
| 55 | +```java |
| 56 | +for (int i = 0; i < temp.length(); i++) { |
| 57 | + if (s.charAt(i) != temp.charAt(i)) { |
| 58 | + return false; |
| 59 | + } |
| 60 | +} |
| 61 | +``` |
| 62 | + |
| 63 | +然后代码就是下边的样子。 |
| 64 | + |
| 65 | +```java |
| 66 | +public boolean wordBreak(String s, List<String> wordDict) { |
| 67 | + return wordBreakHelper(s, wordDict, ""); |
| 68 | +} |
| 69 | + |
| 70 | +private boolean wordBreakHelper(String s, List<String> wordDict, String temp) { |
| 71 | + if (temp.length() > s.length()) { |
| 72 | + return false; |
| 73 | + } |
| 74 | + //判断此时对应的字符是否全部相等 |
| 75 | + for (int i = 0; i < temp.length(); i++) { |
| 76 | + if (s.charAt(i) != temp.charAt(i)) { |
| 77 | + return false; |
| 78 | + } |
| 79 | + } |
| 80 | + if (s.length() == temp.length()) { |
| 81 | + return true; |
| 82 | + } |
| 83 | + for (int i = 0; i < wordDict.size(); i++) { |
| 84 | + if (wordBreakHelper(s, wordDict, temp + wordDict.get(i))) { |
| 85 | + return true; |
| 86 | + } |
| 87 | + } |
| 88 | + return false; |
| 89 | +} |
| 90 | +``` |
| 91 | + |
| 92 | +遗憾的是,依旧是超时 |
| 93 | + |
| 94 | + |
| 95 | + |
| 96 | +发现上边的例子答案很明显是 `false`,因为 `s` 中的 `b` 字母在 `wordDict` 中并没有出现。 |
| 97 | + |
| 98 | +所以我们可以实现遍历一遍 `s` 和 `wordDict` ,从而确定 `s` 中的字符是否在 `wordDict` 中存在,如果不存在可以提前返回 `false` 。 |
| 99 | + |
| 100 | +所以代码可以继续优化。 |
| 101 | + |
| 102 | +```java |
| 103 | +public boolean wordBreak(String s, List<String> wordDict) { |
| 104 | + HashSet<Character> set = new HashSet<>(); |
| 105 | + //将 wordDict 的每个字母放到 set 中 |
| 106 | + for (int i = 0; i < wordDict.size(); i++) { |
| 107 | + String t = wordDict.get(i); |
| 108 | + for (int j = 0; j < t.length(); j++) { |
| 109 | + set.add(t.charAt(j)); |
| 110 | + } |
| 111 | + } |
| 112 | + //判断 s 的每个字母在 set 中是否存在 |
| 113 | + for (int i = 0; i < s.length(); i++) { |
| 114 | + if (!set.contains(s.charAt(i))) { |
| 115 | + return false; |
| 116 | + } |
| 117 | + } |
| 118 | + return wordBreakHelper(s, wordDict, ""); |
| 119 | +} |
| 120 | + |
| 121 | +private boolean wordBreakHelper(String s, List<String> wordDict, String temp) { |
| 122 | + if (temp.length() > s.length()) { |
| 123 | + return false; |
| 124 | + } |
| 125 | + for (int i = 0; i < temp.length(); i++) { |
| 126 | + if (s.charAt(i) != temp.charAt(i)) { |
| 127 | + return false; |
| 128 | + } |
| 129 | + } |
| 130 | + if (s.length() == temp.length()) { |
| 131 | + return true; |
| 132 | + } |
| 133 | + for (int i = 0; i < wordDict.size(); i++) { |
| 134 | + if (wordBreakHelper(s, wordDict, temp + wordDict.get(i))) { |
| 135 | + return true; |
| 136 | + } |
| 137 | + } |
| 138 | + return false; |
| 139 | +} |
| 140 | +``` |
| 141 | + |
| 142 | +令人悲伤的是 |
| 143 | + |
| 144 | +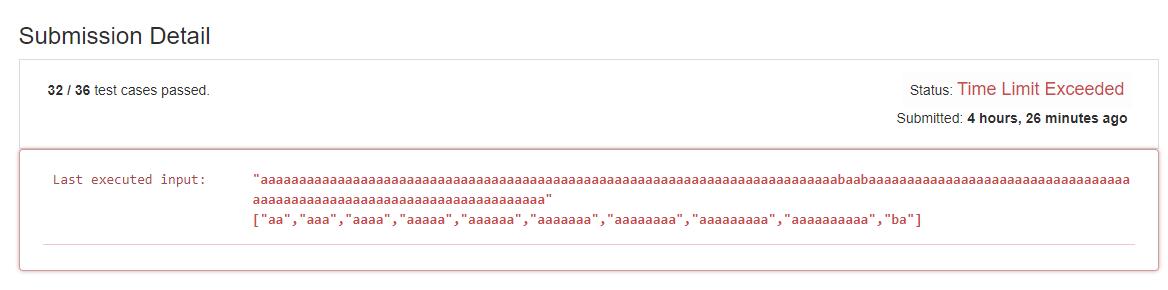 |
| 145 | + |
| 146 | +还有 `5` 个 `test` 没有通过。还有什么可以优化的地方呢? |
| 147 | + |
| 148 | +是时候拿出绝招了,在前边的题已经用过很多很多次,`memoization` 技术。思想就是把回溯中已经考虑过的解存起来,第二次回溯过来的时候可以直接使用。 |
| 149 | + |
| 150 | +这里的话,我们可以用一个 `HashMap`,`key` 的话就存 `temp`,`value` 的话就代表以当前 `temp` 开始的字符串,经过后边的尝试是否能达到目标字符串 `s`。 |
| 151 | + |
| 152 | +```java |
| 153 | +public boolean wordBreak(String s, List<String> wordDict) { |
| 154 | + HashSet<Character> set = new HashSet<>(); |
| 155 | + for (int i = 0; i < wordDict.size(); i++) { |
| 156 | + String t = wordDict.get(i); |
| 157 | + for (int j = 0; j < t.length(); j++) { |
| 158 | + set.add(t.charAt(j)); |
| 159 | + } |
| 160 | + } |
| 161 | + for (int i = 0; i < s.length(); i++) { |
| 162 | + if (!set.contains(s.charAt(i))) { |
| 163 | + return false; |
| 164 | + } |
| 165 | + } |
| 166 | + return wordBreakHelper(s, wordDict, "", new HashMap<String,Boolean>()); |
| 167 | +} |
| 168 | + |
| 169 | +private boolean wordBreakHelper(String s, List<String> wordDict, String temp, HashMap<String, Boolean> hashMap) { |
| 170 | + if (temp.length() > s.length()) { |
| 171 | + return false; |
| 172 | + } |
| 173 | + //之前是否存过 |
| 174 | + if(hashMap.containsKey(temp)){ |
| 175 | + return hashMap.get(temp); |
| 176 | + } |
| 177 | + for (int i = 0; i < temp.length(); i++) { |
| 178 | + if (s.charAt(i) != temp.charAt(i)) { |
| 179 | + return false; |
| 180 | + } |
| 181 | + } |
| 182 | + if (s.length() == temp.length()) { |
| 183 | + return true; |
| 184 | + } |
| 185 | + for (int i = 0; i < wordDict.size(); i++) { |
| 186 | + if (wordBreakHelper(s, wordDict, temp + wordDict.get(i), hashMap)) { |
| 187 | + //结果放入 hashMap |
| 188 | + hashMap.put(temp, true); |
| 189 | + return true; |
| 190 | + } |
| 191 | + } |
| 192 | + //结果放入 hashMap |
| 193 | + hashMap.put(temp, false); |
| 194 | + return false; |
| 195 | +} |
| 196 | +``` |
| 197 | + |
| 198 | +这次就成功通过了。 |
| 199 | + |
| 200 | +# 解法二 分治 |
| 201 | + |
| 202 | +换一种思想,分治,也就是大问题转换为小问题,通过小问题来解决。 |
| 203 | + |
| 204 | +这个想法前边已经做过很多很多题了,大家可以参考 [97 题](https://leetcode.wang/leetCode-97-Interleaving-String.html) 、[115 题](https://leetcode.wang/leetcode-115-Distinct-Subsequences.html) 等等。 |
| 205 | + |
| 206 | +我们现在要判断目标串 `s` 是否能由 `wordDict` 构成。 |
| 207 | + |
| 208 | +我们用 `dp[i,j)`,表示从 `s` 的第 `i` 个字符开始,到第 `j` 个字符的前一个结束的字符串是否能由 `wordDict` 构成。 |
| 209 | + |
| 210 | +假如我们知道了 `dp[0,1) dp[0,2) dp[0,3)...dp[0,len - 1) ` ,也就是除 `s` 本身的所有子串是否能由 `wordDict` 构成。 |
| 211 | + |
| 212 | +那么我们就可以知道 |
| 213 | + |
| 214 | +```java |
| 215 | +dp[0,len) = dp[0,1) && wordDict.contains(s[i,len)) |
| 216 | + || dp[0,2) && wordDict.contains(s[2,len)) |
| 217 | + || dp[0,3) && wordDict.contains(s[3,len)) |
| 218 | + ... |
| 219 | + || dp[0,len - 1) && wordDict.contains(s[len - 1,len)) |
| 220 | +``` |
| 221 | + |
| 222 | +`dp[0,len)` 就代表着 `s` 是否能由 `wordDict` 构成。有了上边的转移方程,就可以用递归写出来了。 |
| 223 | + |
| 224 | +```java |
| 225 | +public boolean wordBreak(String s, List<String> wordDict) { |
| 226 | + HashSet<String> set = new HashSet<>(); |
| 227 | + for (int i = 0; i < wordDict.size(); i++) { |
| 228 | + set.add(wordDict.get(i)); |
| 229 | + } |
| 230 | + return wordBreakHelper(s, set); |
| 231 | +} |
| 232 | + |
| 233 | +private boolean wordBreakHelper(String s, HashSet<String> set) { |
| 234 | + if (s.length() == 0) { |
| 235 | + return true; |
| 236 | + } |
| 237 | + for (int i = 0; i < s.length(); i++) { |
| 238 | + if (set.contains(s.substring(i, s.length())) && wordBreakHelper(s.substring(0, i), set)) { |
| 239 | + return true; |
| 240 | + } |
| 241 | + } |
| 242 | + return false; |
| 243 | +} |
| 244 | +``` |
| 245 | + |
| 246 | +如果不做任何处理,依旧会得到超时。 |
| 247 | + |
| 248 | + |
| 249 | + |
| 250 | +所有,`memoization` 又来了,和之前一样将中间结果存储起来。 |
| 251 | + |
| 252 | +```java |
| 253 | +public boolean wordBreak(String s, List<String> wordDict) { |
| 254 | + HashSet<String> set = new HashSet<>(); |
| 255 | + for (int i = 0; i < wordDict.size(); i++) { |
| 256 | + set.add(wordDict.get(i)); |
| 257 | + } |
| 258 | + return wordBreakHelper(s, set, new HashMap<String, Boolean>()); |
| 259 | +} |
| 260 | + |
| 261 | +private boolean wordBreakHelper(String s, HashSet<String> set, HashMap<String, Boolean> map) { |
| 262 | + if (s.length() == 0) { |
| 263 | + return true; |
| 264 | + } |
| 265 | + if (map.containsKey(s)) { |
| 266 | + return map.get(s); |
| 267 | + } |
| 268 | + for (int i = 0; i < s.length(); i++) { |
| 269 | + if (set.contains(s.substring(i, s.length())) && wordBreakHelper(s.substring(0, i), set, map)) { |
| 270 | + map.put(s, true); |
| 271 | + return true; |
| 272 | + } |
| 273 | + } |
| 274 | + map.put(s, false); |
| 275 | + return false; |
| 276 | +} |
| 277 | +``` |
| 278 | + |
| 279 | +当然除了递归中存储,我们也可以直接用动态规划的思想,求一个结果就保存一个结果。 |
| 280 | + |
| 281 | +用 `dp[i]` 表示字符串 `s[0,i)` 能否由 `wordDict` 构成。 |
| 282 | + |
| 283 | +```java |
| 284 | +public boolean wordBreak(String s, List<String> wordDict) { |
| 285 | + HashSet<String> set = new HashSet<>(); |
| 286 | + for (int i = 0; i < wordDict.size(); i++) { |
| 287 | + set.add(wordDict.get(i)); |
| 288 | + } |
| 289 | + boolean[] dp = new boolean[s.length() + 1]; |
| 290 | + dp[0] = true; |
| 291 | + for (int i = 1; i <= s.length(); i++) { |
| 292 | + for (int j = 0; j < i; j++) { |
| 293 | + dp[i] = dp[j] && wordDict.contains(s.substring(j, i)); |
| 294 | + if (dp[i]) { |
| 295 | + break; |
| 296 | + } |
| 297 | + } |
| 298 | + } |
| 299 | + return dp[s.length()]; |
| 300 | +} |
| 301 | +``` |
| 302 | + |
| 303 | +# 总 |
| 304 | + |
| 305 | +解法一的回溯优化主要就是剪枝,让一些提前知道结果的解直接结束,不进入递归。解法二的想法,就太常用了,从递归到 `memoization` 再到动态规划,其实本质都是一样的。 |
| 306 | + |
0 commit comments