Python的特点:
- Python是一种解释型语言。这就是说,与C语言和C的衍生语言不同,Python代码在运行之前不需要编译,其他解释型语言还包括PHP和Ruby。
- Python是强类型、动态类型语言。不允许隐式类型转换,比如不允许"12"+34。在声明变量时,不需要说明变量的类型。
- Python非常适合面向对象的编程(OOP),因为它支持继承(inheritance)的方式定义类(class)。Python中没有访问说明符(access specifier,类似C++中的public和private),这么设计的依据是
大家都是成年人了。 - 在Python语言中,函数是first-class objects。这指的是它们可以被指定给变量,函数既能返回函数类型,也可以接受函数作为输入。
- Python代码编写快,但是运行速度比编译语言通常要慢。好在Python允许加入基于C语言编写的扩展,因此我们能够优化代码,消除瓶颈。numpy就是一个很好地例子,它的运行速度非常快,因为很多算术运算其实并不是通过Python实现的。
- Python用途非常广泛——网络应用,自动化,科学建模,大数据应用等等。它也常被用作“胶水语言”,帮助其他语言和组件改善运行状况。
- Python让困难的事情变得容易,因此程序员可以专注于算法和数据结构的设计,而不用处理底层的细节。
Python 最大的缺点:
- 执行速度:虽然 Cpython 也会先将代码编译为字节码,然后交给解释器执行,但是速度还是比纯编译型语言慢。
- GIL 全局锁:Cpython 实现中,为了保证多线程程序中的线程安全,加入了 GIL 锁,因此 Python 并不能实现多线程并行计算。
Python 目前主要有两个大的版本,2.x 和 3.x。这里主要讨论 2.x,关于2.x 和 3.x 的区别,可以参考 py2vs3
函数是重用的程序段。允许给一块语句一个名称,然后可以在你的程序的任何地方使用这个名称任意多次地运行这个语句块。这被称为调用函数。
Python 中通过def关键字定义函数,def关键字后跟一个函数的标识符名称,然后跟一对圆括号。圆括号之中可以包括一些变量名,该行以冒号结尾。接下来是一块语句,它们是函数体。函数参数在函数定义的圆括号内指定,用逗号分割,当我们调用函数的时候,以同样的方式提供值。
def func_pass_value(x):
print "before: x=", x, " id=", id(x)
x = 2
print "after: x=", x, " id=", id(x)
>>> x = 1
>>> func_pass_value(x)
before: x= 1 id= 5363912
after: x= 2 id= 5363888
>>> x, id(x)
(1, 5363912)
Python使用lambda关键字创造匿名函数。所谓匿名,意即不再使用def语句这样标准的形式定义一个函数。这种语句在调用时绕过函数的栈分配,可以提高效率。其语法是:
lambda [arg1[, arg2, ... argN]]: expression其中,参数是可选的,如果使用参数的话,参数通常也会在表达式之中出现。
# 调用lambda函数
>>> a = lambda x, y: x + y
>>> a( 1, 3 )
4
>>> b = lambda x, y = 2: x + y
>>> b( 1 )
3
>>> b( 1, 3 )
4
>>> c = lambda *z: z
>>> c( 10, 'test')
(10, 'test')更多内容参考 Function。
面向对象重要的概念就是类(Class)和继承,类是抽象的模板,而实例是根据类创建出来的一个个具体的“对象”,每个对象都拥有相同的方法,但各自的数据可能不同。
在Python中,定义类是通过class关键字:
class Student(object):
pass
class后面紧接着是类名,即Student,类名通常是大写开头的单词,紧接着是(object),表示该类是从哪个类继承下来的。通常,如果没有合适的继承类,就使用object类,这是所有类最终都会继承的类。
Python 类有3个方法,即静态方法(staticmethod),类方法(classmethod)和实例方法。
Python 支持类的继承(包括单重和多重继承),继承的语法如下:
class DerivedClass(BaseClass1, [BaseClass2...]):
<statement-1>
.
<statement-N>
子类可以覆盖父类的方法,实现多态。Python 中用 MRO 判断在多继承时调用的属性来自哪个类,MRO 有三种算法:DFS,BFS,C3。
类中经常有一些方法用两个下划线包围来命名,被叫做Magic method。合理地使用它们可以对类添加一些“魔法”的行为。
更多内容参考 Class
Python 中类也是一种对象。只要你使用关键字class,Python解释器在执行的时候就会创建一个对象。于是乎你可以对它做如下的操作:
- 你可以将它赋值给一个变量
- 你可以拷贝它
- 你可以为它增加属性
- 你可以将它作为函数参数进行传递
元类就是用来创建类的“东西”。你创建类就是为了创建类的实例对象,但是我们已经学习到了Python中的类也是对象。好吧,元类就是用来创建这些类(对象)的,元类就是类的类。
更多内容见 Metaclass.md
简单地说,模块就是一个保存了Python代码的文件。模块能定义函数,类和变量,模块里也能包含可执行的代码。使用模块可以更加有逻辑地组织Python代码段,使代码更好用,更易懂。
为了组织好模块,会将多个模块分为包。Python 处理包也是相当方便的,简单来说,包就是文件夹,但该文件夹下必须存在 __init__.py 文件。最简单的情况下,init.py 为空文件即可,当然它也可以执行包的一些初始化代码。
更多内容参考 Package
Python作为一个“内置电池”的编程语言,标准库里面拥有非常多好用的模块,比如 collections。我们都知道,Python拥有一些内置的数据类型,比如str, int, list, tuple, dict等, collections 模块在这些内置数据类型的基础上,提供了几个额外的数据类型:
- namedtuple(): 生成可以使用名字来访问元素内容的tuple子类
- deque: 双端队列,可以快速的从另外一侧追加和推出对象
- Counter: 计数器,主要用来计数
- OrderedDict: 有序字典
- defaultdict: 带有默认值的字典
此外还有 itertools 等。
更多内容参考 Modules
容器是一种把多个元素组织在一起的数据结构,容器中的元素可以逐个地迭代获取,可以用in, not in关键字判断元素是否包含在容器中。通常这类数据结构把所有的元素存储在内存中(也有一些特列并不是所有的元素都放在内存)。
给定一个list或tuple,可以通过for循环来遍历这个list或tuple,这种遍历称为迭代(Iteration)。这些可以直接作用于 for 循环进行迭代的对象统称为可迭代对象:Iterable。链表,字符串,文件都是可迭代对象,访问迭代器时首先把所有数据读进内存,然后用一个一个读取。
迭代器用来表示一个数据流,可以被next()函数调用并不断返回下一个数据,直到没有数据时抛出StopIteration错误。
如果数据量太大,并且只需要一次迭代一次的话,这样做并不合适,因此引入了生成器。生成器是可以迭代的,但是只可以读取它一次,因为它并不把所有的值放在内存中,它是实时地生成数据。
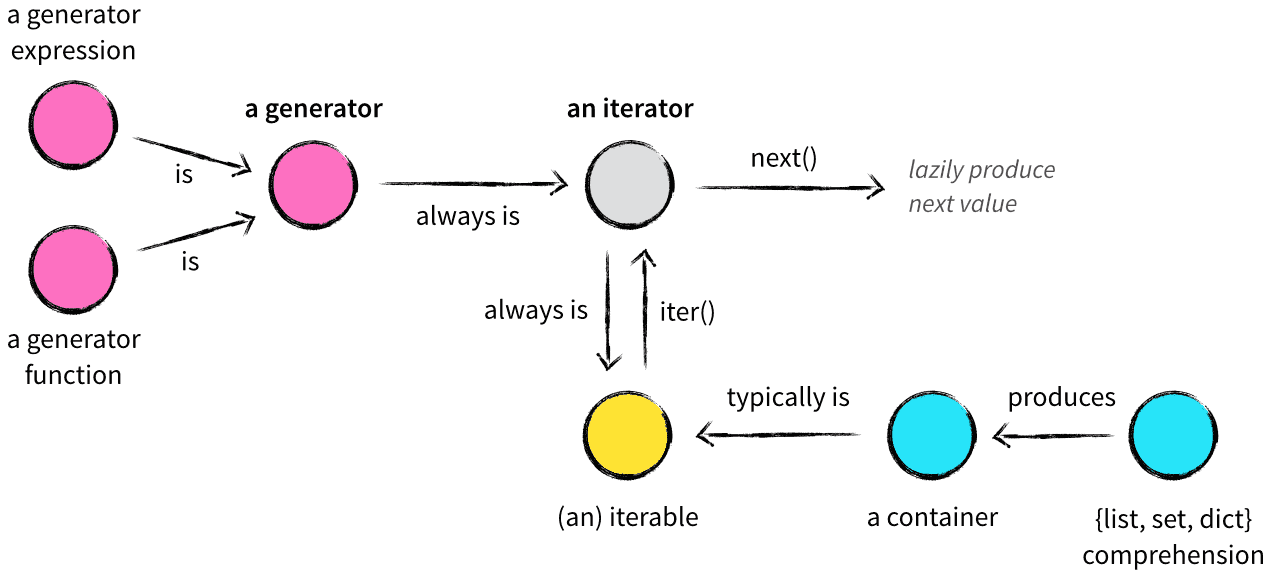
更多内容参考 Iterator_Generator_Yield。
python中一切都是对象,这里需要强调函数是对象,那么
- 可以被赋给另一个变量
- 可以被定义在另一个函数里
- 一个函数可以返回另一个函数
- 函数作为参数传递
当你在用某个@decorator来修饰某个函数func时,如下所示:
@decorator
def func():
pass
其解释器会解释成下面这样的语句:
func = decorator(func)
用装饰器实现缓存机制,避免斐波那契数列递归实现中的重复调用,代码如下:
def cache(func):
caches = {}
@wraps(func)
def wrap(*args):
if args not in caches:
caches[args] = func(*args)
return caches[args]
return wrap
@cache
def fib_cache(n):
assert n > 0, 'invalid n'
if n < 3:
return 1
else:
return fib_cache(n - 1) + fib_cache(n - 2)
更多内容参考 Decorator
一个描述器是一个有绑定方法的对象属性(object attribute),它的访问控制被描述器协议方法重写。这些方法是 __get__(), __set__(), 和 __delete__(),有这些方法的对象叫做描述器。
描述器只对于新式对象和新式类才起作用,它是属性,实例方法,静态方法,类方法和 super 的背后的实现机制。在Python自身中广泛使用了描述器,以实现 Python 2.2 中引入的新式类。
更多内容参考 Descriptor
在 Python 语言的主流实现 CPython 中,GIL(Global Interpreter Lock,全局解释器锁)是一个货真价实的全局线程锁,在解释器解释执行任何 Python 代码时,都需要先获得这把锁才行,在遇到 I/O 操作时会释放这把锁。GIL的存在导致多线程无法很好的利用多核CPU的并发处理能力。
python里面提供了另一个比较好玩的东西:协程(Coroutine)。所谓协程就是在同一进程/线程中,利用生成器来同时执行多个函数(routine)。执行过程中,在子程序内部可中断,然后转而执行别的子程序,在适当的时候再返回来接着执行。注意,这里在一个子程序中中断,去执行其他子程序,不是函数调用,有点类似CPU的中断。
和多线程比,协程有何优势?
协程有极高的执行效率。因为子程序切换不是线程切换,而且由程序自身控制,因此,没有线程切换的开销。和多线程比,线程数量越多,协程的性能优势就越明显。不需要多线程的锁机制。因为只有一个线程,也不存在同时写变量冲突,在协程中控制共享资源不加锁,只需要判断状态就好了。
更多内容参考 Coroutine
单元测试是用来对一个模块、一个函数或者一个类来进行正确性检验的测试工作。比如我们自己编写了一个Dict类,这个类的行为和dict一致,但是可以通过属性来访问,那么可以编写出以下几个测试函数:
def test_init(self):
def test_key(self):
def test_attr(self):
def test_keyerror(self):
def test_attrerror(self):
把上面的测试用例放到一个测试模块里,就是一个完整的单元测试。
如果我们对代码做了修改,只需要再跑一遍单元测试,如果通过,说明我们的修改不会对函数原有的行为造成影响,如果测试不通过,说明我们的修改与原有行为不一致,要么修改代码,要么修改测试。
更多内容参考 Test
Python 简单,但又危机四伏,充满陷阱,StackOverFlow 上面有一个问题总结了一些常见的缺陷,主要有下面这些:
- 函数参数带默认值
- 类变量的使用
- lambda 参数捕获
- 创建嵌套数组
- 捕捉多个异常
- 遍历的同时进行修改
- 循环加载模块
- LEGB 作用域解析
- 不可变对象 tuple 的赋值
更多内容参考 Gotchas
虽然运行速度慢是 Python 与生俱来的特点,大多数时候我们用 Python 就意味着放弃对性能的追求。但是,就算是用纯 Python 完成同一个任务,老手写出来的代码可能会比菜鸟写的代码块几倍,甚至是几十倍(这里不考虑算法的因素,只考虑语言方面的因素)。
面对python代码,我们需要思考一下下面这些问题:
- 程序运行的速度如何?
- 程序运行时间的瓶颈在哪里?
- 能否稍加改进以提高运行速度呢?
更多内容参考 Optimization
Python 有着大量优秀的三方库,功能十分强大。可以在 Awesome Python 上找自己需要的库,下面列出几个经典的库。
- Requests:是一个 HTTP 库,用 Python 编写,真正的为人类着想。Python 标准库中的 urllib2 模块提供了你所需要的大多数 HTTP 功能,但是它的 API 太渣了。它需要巨量的工作,甚至包括各种方法覆盖,来完成最简单的任务。
- Numpy是Python的一个科学计算的库,提供了矩阵运算的功能,其一般与Scipy、matplotlib一起使用。NumPy 的主要对象是同种元素的多维数组(numpy.ndarray)。
更多内容参见 Library
简单来说,Python先把代码(.py文件)编译成字节码,交给字节码虚拟机,然后虚拟机一条一条执行字节码指令,从而完成程序的执行。这里字节码在Python虚拟机程序里对应的是PyCodeObject对象,.pyc文件是字节码在磁盘上的表现形式。
更多内容参见 HowToRun
Python GC主要使用引用计数(reference counting)来跟踪和回收垃圾。在引用计数的基础上,通过“标记-清除”(mark and sweep)解决容器对象可能产生的循环引用问题,通过“分代回收”(generation collection)以空间换时间的方法提高垃圾回收效率。
对于嵌套对象比如说source = [1, 2, [3, 4]],浅拷贝创建新的列表对象target,target中的所有元素均是source中元素的引用。深拷贝,其实就是递归拷贝。也就是说对于嵌套对象比如说source = [1, 2, [3, 4]],深拷贝时创建新的列表对象target,然后递归地将source中的所有对象均拷贝到target中。
Python 中 list 类似于 C++ STL中 vector 的实现。在需要的时候扩容,但又不允许过度的浪费,适当地进行内存回收。
更多内容参见 More
想了解别人在 Python 开发中遇到了哪些问题,可以查看 StackOverflow 上面经典的 python 问题。整理了一份问题清单,放在 StackOverflow
Hidden features of Python
关于 Python 的最全面试题
Python 简要面试问题
[Python面试必须要看的15个问题] (http://codingpy.com/article/essential-python-interview-questions/)
How do I pass a variable by reference?
如何面试Python后端工程师
Ten Things Python Programmers Should Know
Python 简要面试问题
The Vital Guide to Python Interviewing
操作之灵魂——拷贝