|
| 1 | +# 题目描述(中等难度) |
| 2 | + |
| 3 | + |
| 4 | + |
| 5 | +[207 题](https://leetcode.wang/leetcode-207-Course-Schedule.html) Course Schedule 的延伸,给定 `n` 组先修课的关系,`[m,n]` 代表在上 `m` 这门课之前必须先上 `n` 这门课。输出一个上课序列。 |
| 6 | + |
| 7 | +# 思路分析 |
| 8 | + |
| 9 | +[207 题](https://leetcode.wang/leetcode-207-Course-Schedule.html) 考虑是否存在一个序列上完所有课,这里的话,换汤不换药,完全可以按照 [207 题](https://leetcode.wang/leetcode-207-Course-Schedule.html) 的解法改出来,大家可以先去看一下。主要是两种思路,`BFS` 和 `DFS` ,题目就是在考拓扑排序。 |
| 10 | + |
| 11 | +# 解法一 |
| 12 | + |
| 13 | +先把 [207 题](https://leetcode.wang/leetcode-207-Course-Schedule.html) 的思路贴过来。 |
| 14 | + |
| 15 | +把所有的关系可以看做图的边,所有的边构成了一个有向图。 |
| 16 | + |
| 17 | +对于`[[1,3],[1,4],[2,4],[3,5],[3,6],[4,6]]` 就可以看做下边的图,箭头指向的是需要先上的课。 |
| 18 | + |
| 19 | +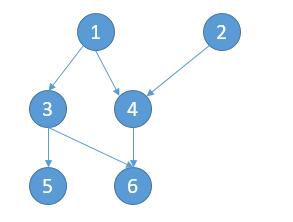 |
| 20 | + |
| 21 | +想法很简单,要想上完所有的课,一定会有一些课没有先修课,比如上图的 `5`、`6`。然后我们可以把 `5` 和 `6` 节点删去。 |
| 22 | + |
| 23 | +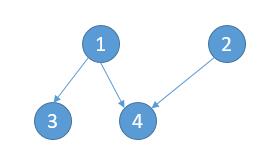 |
| 24 | + |
| 25 | +然后 `3` 和 `4` 就可以上了,同样的道理再把 `3` 和 `4` 删去。 |
| 26 | + |
| 27 | +接下来就可以去学 `1` 和 `2` 了。因此可以完成所有的课。 |
| 28 | + |
| 29 | +代码的话,用邻接表表示图。此外,我们不需要真的去删除节点,我们可以用 `outNum` 变量记录所有节点的先修课门数。当删除一个节点的时候,就将相应节点的先修课个数减一即可。 |
| 30 | + |
| 31 | +最后只需要判断所有的节点的先修课门数是否全部是 `0` 即可。 |
| 32 | + |
| 33 | +在这道题的话,改之前的代码也很简单,只需要把每次出队的元素保存起来即可。 |
| 34 | + |
| 35 | +```java |
| 36 | +public int[] findOrder2(int numCourses, int[][] prerequisites) { |
| 37 | + // 保存每个节点的先修课个数,也就是出度 |
| 38 | + HashMap<Integer, Integer> outNum = new HashMap<>(); |
| 39 | + // 保存以 key 为先修课的列表,也就是入度的节点 |
| 40 | + HashMap<Integer, ArrayList<Integer>> inNodes = new HashMap<>(); |
| 41 | + // 保存所有节点 |
| 42 | + HashSet<Integer> set = new HashSet<>(); |
| 43 | + int rows = prerequisites.length; |
| 44 | + for (int i = 0; i < rows; i++) { |
| 45 | + int key = prerequisites[i][0]; |
| 46 | + int value = prerequisites[i][1]; |
| 47 | + set.add(key); |
| 48 | + set.add(value); |
| 49 | + if (!outNum.containsKey(key)) { |
| 50 | + outNum.put(key, 0); |
| 51 | + } |
| 52 | + if (!outNum.containsKey(value)) { |
| 53 | + outNum.put(value, 0); |
| 54 | + } |
| 55 | + // 当前节点先修课个数加一 |
| 56 | + int num = outNum.get(key); |
| 57 | + outNum.put(key, num + 1); |
| 58 | + |
| 59 | + if (!inNodes.containsKey(value)) { |
| 60 | + inNodes.put(value, new ArrayList<>()); |
| 61 | + } |
| 62 | + // 更新以 value 为先修课的列表 |
| 63 | + ArrayList<Integer> list = inNodes.get(value); |
| 64 | + list.add(key); |
| 65 | + } |
| 66 | + |
| 67 | + // 将当前先修课个数为 0 的课加入到队列中 |
| 68 | + Queue<Integer> queue = new LinkedList<>(); |
| 69 | + for (int k : set) { |
| 70 | + if (outNum.get(k) == 0) { |
| 71 | + queue.offer(k); |
| 72 | + } |
| 73 | + } |
| 74 | + int[] res = new int[numCourses]; |
| 75 | + int count = 0; |
| 76 | + while (!queue.isEmpty()) { |
| 77 | + // 队列拿出来的课代表要删除的节点 |
| 78 | + // 要删除的节点的 list 中所有课的先修课个数减一 |
| 79 | + int v = queue.poll(); |
| 80 | + //**************主要修改的地方********************// |
| 81 | + res[count++] = v; |
| 82 | + //**********************************************// |
| 83 | + ArrayList<Integer> list = inNodes.getOrDefault(v, new ArrayList<>()); |
| 84 | + |
| 85 | + for (int k : list) { |
| 86 | + int num = outNum.get(k); |
| 87 | + // 当前课的先修课要变成 0, 加入队列 |
| 88 | + if (num == 1) { |
| 89 | + queue.offer(k); |
| 90 | + } |
| 91 | + // 当前课的先修课个数减一 |
| 92 | + outNum.put(k, num - 1); |
| 93 | + } |
| 94 | + } |
| 95 | + for (int k : set) { |
| 96 | + if (outNum.get(k) != 0) { |
| 97 | + //有课没有完成,返回空数组 |
| 98 | + return new int[0]; |
| 99 | + } |
| 100 | + } |
| 101 | + //**************主要修改的地方********************// |
| 102 | + HashSet<Integer> resSet = new HashSet<>(); |
| 103 | + for (int i = 0; i < count; i++) { |
| 104 | + resSet.add(res[i]); |
| 105 | + } |
| 106 | + //有些课是独立存在的,这些课可以随时上,添加进来 |
| 107 | + for (int i = 0; i < numCourses; i++) { |
| 108 | + if (!resSet.contains(i)) { |
| 109 | + res[count++] = i; |
| 110 | + } |
| 111 | + } |
| 112 | + //**********************************************// |
| 113 | + return res; |
| 114 | +} |
| 115 | +``` |
| 116 | + |
| 117 | +上边的代码就是要注意一些课,既没有先修课,也不是别的课的先修课,所以这些课什么时候上都可以,在最后加进来即可。 |
| 118 | + |
| 119 | +# 解法二 |
| 120 | + |
| 121 | +同样的,先把 [207 题](https://leetcode.wang/leetcode-207-Course-Schedule.html) 的思路贴过来。 |
| 122 | + |
| 123 | +还有另一种思路,我们只需要一门课一门课的判断。 |
| 124 | + |
| 125 | +从某门课开始遍历,我们通过 `DFS` 一条路径一条路径的判断,保证过程中没有遇到环。 |
| 126 | + |
| 127 | + |
| 128 | + |
| 129 | +深度优先遍历 `1`,相当于 `3` 条路径 |
| 130 | + |
| 131 | +`1 -> 3 -> 5`,`1 -> 3 -> 6`,`1 -> 4 -> 6`。 |
| 132 | + |
| 133 | +深度优先遍历 `2`,相当于 `1` 条路径 |
| 134 | + |
| 135 | +`2 -> 4 -> 6`。 |
| 136 | + |
| 137 | +深度优先遍历 `3`,相当于 `2` 条路径 |
| 138 | + |
| 139 | +`3 -> 5`,`3 -> 6`。 |
| 140 | + |
| 141 | +深度优先遍历 `4`,相当于 `1` 条路径 |
| 142 | + |
| 143 | +`4 -> 6`。 |
| 144 | + |
| 145 | +深度优先遍历 `5`,相当于 `1` 条路径 |
| 146 | + |
| 147 | +`5`。 |
| 148 | + |
| 149 | +深度优先遍历 `6`,相当于 `1` 条路径 |
| 150 | + |
| 151 | +`6`。 |
| 152 | + |
| 153 | +什么情况下不能完成所有课程呢?某条路径出现了环,如下图。 |
| 154 | + |
| 155 | +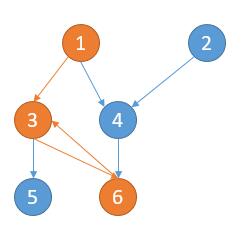 |
| 156 | + |
| 157 | +出现了 `1 -> 3 -> 6 -> 3`。所以不能学完所有课程。 |
| 158 | + |
| 159 | +代码的话,用邻接表表示图。通过递归实现 `DFS` ,用 `visited` 存储当前路径上的节点。 |
| 160 | + |
| 161 | +同时用 `visitedFinish` 表示可以学完的课程,起到优化算法的作用。 |
| 162 | + |
| 163 | +在这道题的话,我们只需要在 `dfs` 中把叶子节点加入,并且如果当前节点的所有先修课已经完成,也将其加入。在代码中就体现在完成了 `for` 循环的时候。 |
| 164 | + |
| 165 | +```java |
| 166 | +public int[] findOrder(int numCourses, int[][] prerequisites) { |
| 167 | + HashMap<Integer, ArrayList<Integer>> outNodes = new HashMap<>(); |
| 168 | + HashSet<Integer> set = new HashSet<>(); |
| 169 | + int rows = prerequisites.length; |
| 170 | + for (int i = 0; i < rows; i++) { |
| 171 | + int key = prerequisites[i][0]; |
| 172 | + int value = prerequisites[i][1]; |
| 173 | + set.add(key); |
| 174 | + if (!outNodes.containsKey(key)) { |
| 175 | + outNodes.put(key, new ArrayList<>()); |
| 176 | + } |
| 177 | + // 存储当前节点的所有先修课程 |
| 178 | + ArrayList<Integer> list = outNodes.get(key); |
| 179 | + list.add(value); |
| 180 | + } |
| 181 | + |
| 182 | + int[] res = new int[numCourses]; |
| 183 | + HashSet<Integer> resSet = new HashSet<>(); //防止重复的节点加入 |
| 184 | + HashSet<Integer> visitedFinish = new HashSet<>(); |
| 185 | + // 判断每一门课 |
| 186 | + for (int k : set) { |
| 187 | + if (!dfs(k, outNodes, new HashSet<>(), visitedFinish, res, resSet)) { |
| 188 | + return new int[0]; |
| 189 | + } |
| 190 | + visitedFinish.add(k); |
| 191 | + } |
| 192 | + //和之前一样,把独立的课加入 |
| 193 | + for (int i = 0; i < numCourses; i++) { |
| 194 | + if (!resSet.contains(i)) { |
| 195 | + res[count++] = i; |
| 196 | + } |
| 197 | + } |
| 198 | + return res; |
| 199 | +} |
| 200 | + |
| 201 | +int count = 0; |
| 202 | + |
| 203 | +private boolean dfs(int start, HashMap<Integer, ArrayList<Integer>> outNodes, HashSet<Integer> visited, |
| 204 | + HashSet<Integer> visitedFinish, int[] res, HashSet<Integer> resSet) { |
| 205 | + // 已经处理过 |
| 206 | + if (visitedFinish.contains(start)) { |
| 207 | + return true; |
| 208 | + } |
| 209 | + //**************主要修改的地方********************// |
| 210 | + // 到了叶子节点 |
| 211 | + if (!outNodes.containsKey(start)) { |
| 212 | + if (!resSet.contains(start)) { |
| 213 | + resSet.add(start); |
| 214 | + res[count++] = start; |
| 215 | + } |
| 216 | + return true; |
| 217 | + } |
| 218 | + //**********************************************// |
| 219 | + // 出现了环 |
| 220 | + if (visited.contains(start)) { |
| 221 | + return false; |
| 222 | + } |
| 223 | + // 将当前节点加入路径 |
| 224 | + visited.add(start); |
| 225 | + ArrayList<Integer> list = outNodes.get(start); |
| 226 | + for (int k : list) { |
| 227 | + if (!dfs(k, outNodes, visited, visitedFinish, res, resSet)) { |
| 228 | + return false; |
| 229 | + } |
| 230 | + } |
| 231 | + //**************主要修改的地方********************// |
| 232 | + if (!resSet.contains(start)) { |
| 233 | + resSet.add(start); |
| 234 | + res[count++] = start; |
| 235 | + } |
| 236 | + //**********************************************// |
| 237 | + visited.remove(start); |
| 238 | + return true; |
| 239 | +} |
| 240 | +``` |
| 241 | + |
| 242 | +我们分别用数组 `res` 和集合 `resSet` 存储最终的结果,因为 `DFS` 中可能经过重复的节点,`resSet` 可以保证我们不添加重复的节点。 |
| 243 | + |
| 244 | +# 总 |
| 245 | + |
| 246 | +总体上和 [207 题](https://leetcode.wang/leetcode-207-Course-Schedule.html) 是一样的,一些细节的地方注意到了即可。当然上边的代码因为是在 207 题的基础上改的,所以可能不够简洁,仅供参考,总体思想就是 `BFS` 和 `DFS` 。 |
0 commit comments