

This repository has the code for the CircleCI Evals Orb.
The Evals orb simplifies the definition and execution of evaluation jobs using popular third-party tools, and generates reports of evaluation results.
Given the volatile nature of evaluations, evaluations orchestrated through this orb do not halt the pipeline if an evaluation fails. This approach ensures that the inherent flakiness of evaluations does not disrupt the development cycle. Instead, a summary of the evaluation results is created and presented:
-
As an artifact within the CircleCI User Interface:
-
As a comment on the corresponding GitHub pull request (only available for GitHub projects integrated through OAuth):
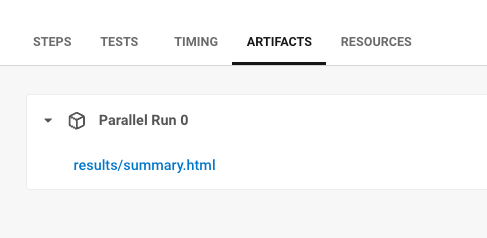
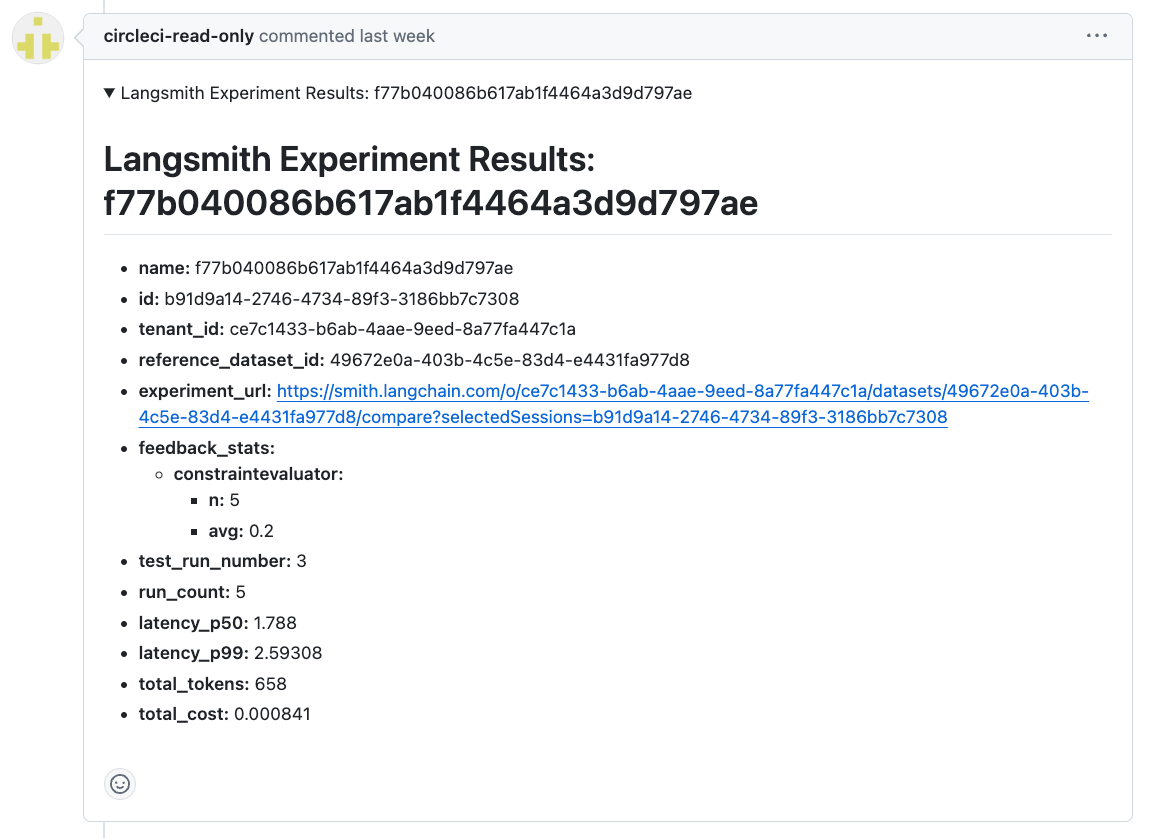
Just navigate to Project Settings > LLMOps and fill out the form by Clicking Set up Integration.

This will create a context with environment variables for the credentials you've set up above.
ai-llm-eval-examples). This will be used to update context value in the CircleCI configuration file.

💡 You can also optionally store a GITHUB_TOKEN as an environment variable on this context, if you'd like your pipelines to post summarized eval job results as comments on GitHub pull requests.
Warning
Currently, this feature is available only to GitHub projects integrated through OAuth. To find out which GitHub account type you have, refer to the GitHub OAuth integration page of our Docs.
In order to post comments to GitHub pull requests, you will need to create an environment variable named GITHUB_TOKEN with a GitHub Personal Access Token that has repo scope access.
Once created, add GITHUB_TOKEN as a context environment variable on the same context you created as part of LLMOps Integration via Project Settings > LLMOps.
You can also access this context via Organization Settings > Contexts.
You will then need to ensure you add the context key to the job that requires access to it, as follows...
# WORKFLOWS
workflows:
braintrust-evals:
when: << pipeline.parameters.run-braintrust-evals >>
jobs:
- run-braintrust-evals:
context:
- ai-llm-eval-examples # Replace this with your context name
langsmith-evals:
when: << pipeline.parameters.run-langsmith-evals >>
jobs:
- run-langsmith-evals:
context:
- ai-llm-eval-examples # Replace this with your context nameThe evals orb accepts the following parameters:
Some of the parameters are optional based on the eval platform being used.
-
circle_pipeline_id: CircleCI Pipeline ID -
cmd: Command to run the evaluation -
eval_platform: Evaluation platform (e.g.braintrust,langsmithorcustom; default:custom) -
evals_result_location: Location to save evaluation results (default:./results) -
shell: Shell to use (default:/bin/bash). This param only applies wheneval_platformis not provided or is set tocustom.
braintrust_experiment_name(optional): Braintrust experiment name- If no value is provided, an experiment name will be auto-generated based on an MD5 hash of
<CIRCLE_PIPELINE_ID>_<CIRCLE_WORKFLOW_ID>.
- If no value is provided, an experiment name will be auto-generated based on an MD5 hash of
-
langsmith_endpoint(optional): LangSmith API endpoint (default:https://api.smith.langchain.com) -
langsmith_experiment_name(optional): LangSmith experiment name- If no value is provided, an experiment name will be auto-generated based on an MD5 hash of
<CIRCLE_PIPELINE_ID>_<CIRCLE_WORKFLOW_ID>.
- If no value is provided, an experiment name will be auto-generated based on an MD5 hash of
For full config usage guidelines, see the evals orb documentation.
For evals orb usage examples, check out the llm-eval-examples repo.
View the FAQ in the wiki
We welcome issues to and pull requests against this repository!
For further questions/comments about this or other orbs, visit the CircleCI Orbs discussion forum.