JAIS 30b Chat
Model navigation navigation
NOTE: The evaluation report below was provided by the model publisher.
Core42 conducted a comprehensive evaluation of Jais-30b-chat and benchmarked it against other leading base and instruction finetuned language models, focusing on both English and Arabic. Benchmarks used have a significant overlap with the widely used OpenLLM Leaderboard tasks. The evaluation criteria span various dimensions, including:
- Knowledge: How well the model answers factual questions.
- Reasoning: The model's ability to answer questions that require reasoning.
- Misinformation/Bias: Assessment of the model's susceptibility to generating false or misleading information, and its neutrality.
The following results report F1 or Accuracy (depending on the task) of the evaluated models on benchmarked tasks. Both metrics are higher the better.
| Models | Avg | EXAMS | MMLU (M) | LitQA | Hellaswag | PIQA | BoolQA | SituatedQA | ARC-C | OpenBookQA | TruthfulQA | CrowS-Pairs |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Jais-30b-chat | 51.3 | 40.7 | 35.1 | 57.1 | 59.3 | 64.1 | 81.6 | 52.9 | 39.1 | 29.6 | 53.1 | 52.5 |
| Jais-chat (13B) | 49.22 | 39.7 | 34 | 52.6 | 61.4 | 67.5 | 65.7 | 47 | 40.7 | 31.6 | 44.8 | 56.4 |
| acegpt-13b-chat | 45.94 | 38.6 | 31.2 | 42.3 | 49.2 | 60.2 | 69.7 | 39.5 | 35.1 | 35.4 | 48.2 | 55.9 |
| BLOOMz (7.1B) | 43.65 | 34.9 | 31 | 44 | 38.1 | 59.1 | 66.6 | 42.8 | 30.2 | 29.2 | 48.4 | 55.8 |
| acegpt-7b-chat | 43.36 | 37 | 29.6 | 39.4 | 46.1 | 58.9 | 55 | 38.8 | 33.1 | 34.6 | 50.1 | 54.4 |
| aya-101-13b-chat | 41.92 | 29.9 | 32.5 | 38.3 | 35.6 | 55.7 | 76.2 | 42.2 | 28.3 | 29.4 | 42.8 | 50.2 |
| mT0-XXL (13B) | 41.41 | 31.5 | 31.2 | 36.6 | 33.9 | 56.1 | 77.8 | 44.7 | 26.1 | 27.8 | 44.5 | 45.3 |
| LLama2-70b-chat | 39.4 | 29.7 | 29.3 | 33.7 | 34.3 | 52 | 67.3 | 36.4 | 26.4 | 28.4 | 46.3 | 49.6 |
| Llama2-13b-chat | 38.73 | 26.3 | 29.1 | 33.1 | 32 | 52.1 | 66 | 36.3 | 24.1 | 28.4 | 48.6 | 50 |
For evaluations, the focus is on LLMs that are multilingual or Arabic centric, except for Llama2 13B-chat and Llama2-70B-chat models. Among Arabic centric models like AceGPT and multilingual models like Aya, both Jais models outperform all other models by 4+ points. Jais models outperforming English only LLMs such as Llama2-13B-chat and LLama2-70B-chat demonstrates the obvious - though these models are trained on more tokens (2T) and in one case is much larger, Jais’ Arabic centric training gives it a dramatic advantage in Arabic linguistic tasks. Note that LLama’s pretraining may include traces of Arabic as evidenced by its limited yet observable capability to understand Arabic, but it is insufficient to obtain an LLM capable of conversing in Arabic, as is expected.
| Models | Avg | MMLU | RACE | Hellaswag | PIQA | BoolQA | SituatedQA | ARC-C | OpenBookQA | Winogrande | TruthfulQA | CrowS-Pairs |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Jais-30b-chat | 59.59 | 36.5 | 45.6 | 78.9 | 73.1 | 90 | 56.7 | 51.2 | 44.4 | 70.2 | 42.3 | 66.6 |
| Jais-chat (13B) | 57.45 | 37.7 | 40.8 | 77.6 | 78.2 | 75.8 | 57.8 | 46.8 | 41 | 68.6 | 39.7 | 68 |
| acegpt-13b-chat | 57.84 | 34.4 | 42.7 | 76 | 78.8 | 81.9 | 45.4 | 45 | 41.6 | 71.3 | 45.7 | 73.4 |
| BLOOMz (7.1B) | 57.81 | 36.7 | 45.6 | 63.1 | 77.4 | 91.7 | 59.7 | 43.6 | 42 | 65.3 | 45.2 | 65.6 |
| acegpt-7b-chat | 54.25 | 30.9 | 40.1 | 67.6 | 75.4 | 75.3 | 44.2 | 38.8 | 39.6 | 66.3 | 49.3 | 69.3 |
| aya-101-13b-chat | 49.55 | 36.6 | 41.3 | 46 | 65.9 | 81.9 | 53.5 | 31.2 | 33 | 56.2 | 42.5 | 57 |
| mT0-XXL (13B) | 50.21 | 34 | 43.6 | 42.2 | 67.6 | 87.6 | 55.4 | 29.4 | 35.2 | 54.9 | 43.4 | 59 |
| LLama2-70b-chat | 61.25 | 43 | 45.2 | 80.3 | 80.6 | 86.5 | 46.5 | 49 | 43.8 | 74 | 52.8 | 72.1 |
| Llama2-13b-chat | 58.05 | 36.9 | 45.7 | 77.6 | 78.8 | 83 | 47.4 | 46 | 42.4 | 71 | 44.1 | 65.7 |
Jais-30b-chat outperforms the best other multilingual/ Arabic centric model in English language capabilities by ~2 points. Note that the best model among other Arabic centric models is AceGPT, which finetunes from Llama2-13B. Llama2 models (13B and 70B) are both pre-trained on far more English tokens (2T) vs those that were used for the pretrained Jais-30b (0.97T). At less than half the model and pretraining data size, Jais models reach within 2 points of the English capabilities of Llama2-70B-chat.
One of the key motivations to train an Arabic LLM is to include knowledge specific to the local context. In training Jais-30b-chat, we have invested considerable effort to include data that reflects high quality knowledge in both languages in the UAE and regional domains. To evaluate the impact of this training, in addition to LM harness evaluations in the general language domain, we also evaluate Jais models on a dataset testing knowledge pertaining to the UAE/regional domain. We curated ~320 UAE + Region specific factual questions in both English and Arabic. Each question has four answer choices, and like in the LM Harness, the task for the LLM is to choose the correct one. The following table shows Accuracy for both Arabic and English subsets of this test set.
| Model | Arabic | English |
|---|---|---|
| Jais-30b-chat | 57.2 | 55 |
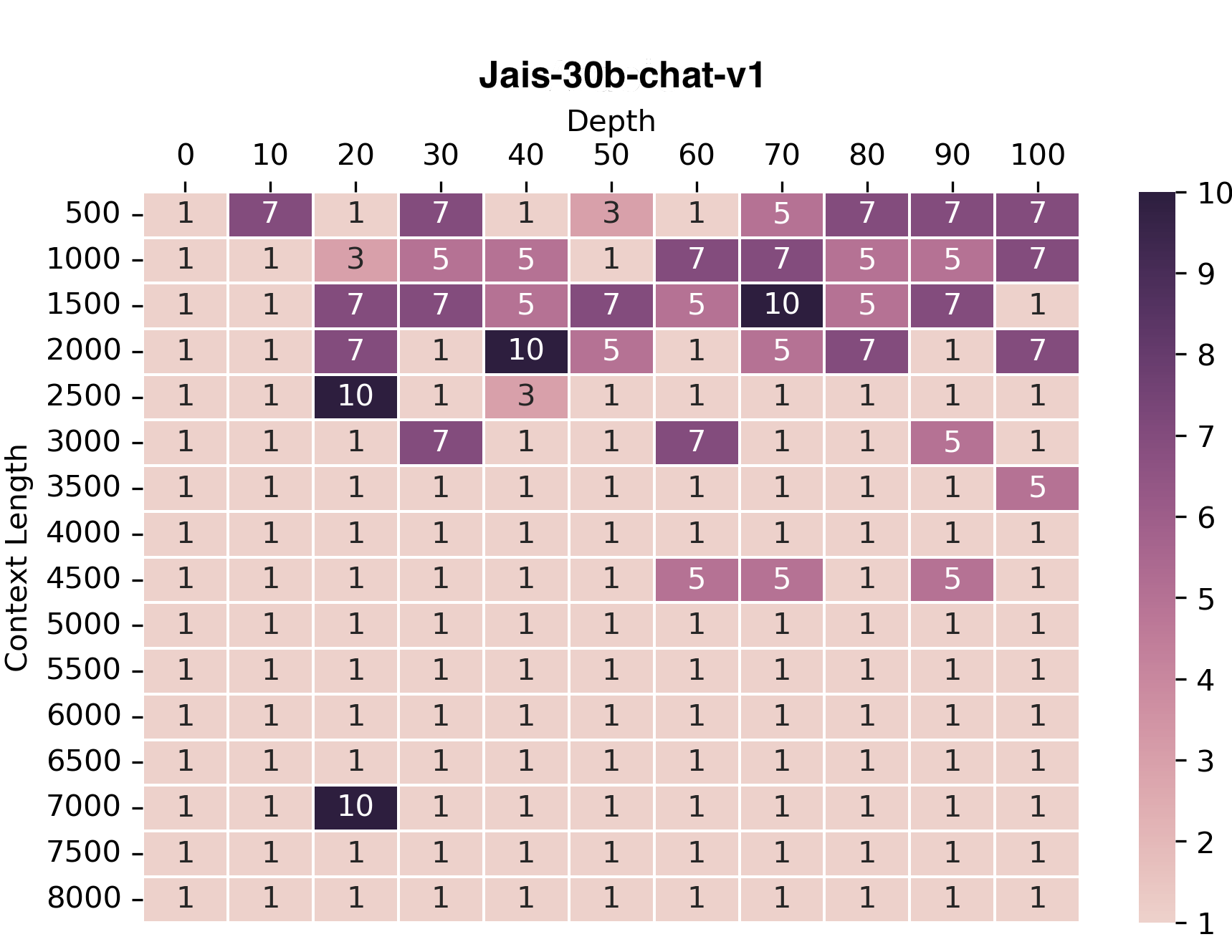
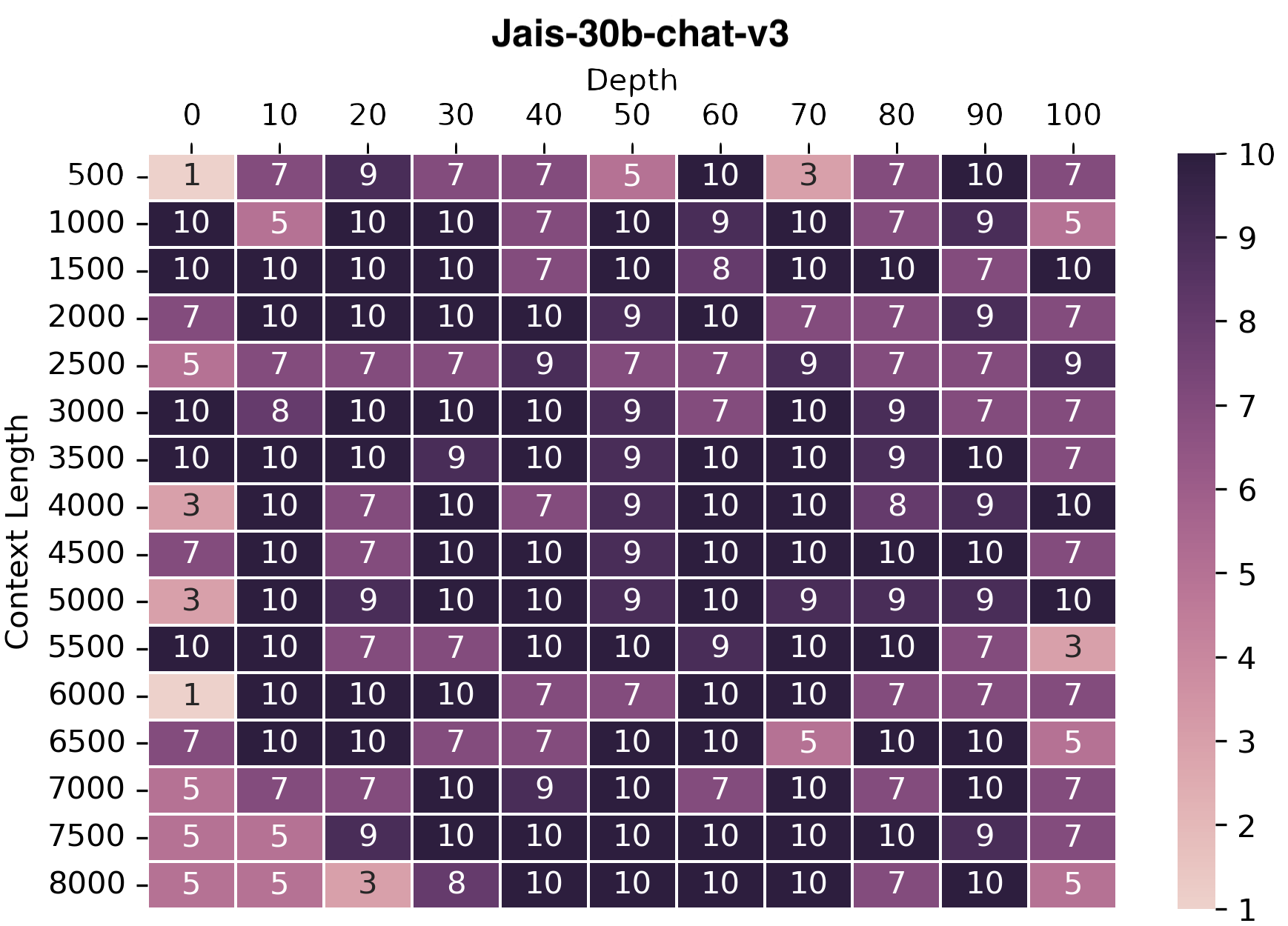
We adopted the needle-in-haystack approach to assess the model's capability of handling long contexts. In this
evaluation setup, we input a lengthy irrelevant text (the haystack) along with a required fact to answer a question (the
needle), which is embedded within this text. The model's task is to answer the question by locating and extracting the
needle from the text.
We plot the accuracies of the model at retrieving the needle from the given context. We conducted evaluations for both Arabic and English languages. For brevity, we are presenting the plot for Arabic only.
We observe that jais-30b-chat-v3 is improved over jais-30b-chat-v1 as it can answer the question upto 8k context
lengths.