Release v4.50.0
Release v4.50.0
New Model Additions
Model-based releases
Starting with version v4.49.0, we have been doing model-based releases, additionally to our traditional, software-based monthly releases. These model-based releases provide a tag from which models may be installed.
Contrarily to our software-releases; these are not pushed to pypi and are kept on our GitHub. Each release has a tag attributed to it, such as:
v4.49.0-Gemma-3v4.49.0-AyaVision
Each new model release will always be based on the current state of the main branch at the time of its creation. This ensures that new models start with the latest features and fixes available.
For example, if two models—Gemma-3 and AyaVision—are released from main, and then a fix for gemma3 is merged, it will look something like this:
o---- v4.49.0-Gemma-3 (includes AyaVision, plus main fixes)
/ \
---o--o--o--o--o-- (fix for gemma3) --o--o--o main
\
o---- v4.49.0-AyaVision
We strive to merge model specific fixes on their respective branches as fast as possible!
Gemma 3

Gemma 3 is heavily referenced in the following model-based release and we recommend reading these if you want all the information relative to that model.
The Gemma 3 model was proposed by Google. It is a vision-language model composed by a SigLIP vision encoder and a Gemma 2 language decoder linked by a multimodal linear projection.
It cuts an image into a fixed number of tokens same way as Siglip if the image does not exceed certain aspect ratio. For images that exceed the given aspect ratio, it crops the image into multiple smaller pacthes and concatenates them with the base image embedding.
One particularity is that the model uses bidirectional attention on all the image tokens. Also, the model interleaves sliding window local attention with full causal attention in the language backbone, where each sixth layer is a full causal attention layer.
- Gemma3 by @RyanMullins in #36658
Shield Gemma2
ShieldGemma 2 is built on Gemma 3, is a 4 billion (4B) parameter model that checks the safety of both synthetic and natural images against key categories to help you build robust datasets and models. With this addition to the Gemma family of models, researchers and developers can now easily minimize the risk of harmful content in their models across key areas of harm as defined below:
- No Sexually Explicit content: The image shall not contain content that depicts explicit or graphic sexual acts (e.g., pornography, erotic nudity, depictions of rape or sexual assault).
- No Dangerous Content: The image shall not contain content that facilitates or encourages activities that could cause real-world harm (e.g., building firearms and explosive devices, promotion of terrorism, instructions for suicide).
- No Violence/Gore content: The image shall not contain content that depicts shocking, sensational, or gratuitous violence (e.g., excessive blood and gore, gratuitous violence against animals, extreme injury or moment of death).
We recommend using ShieldGemma 2 as an input filter to vision language models, or as an output filter of image generation systems. To train a robust image safety model, we curated training datasets of natural and synthetic images and instruction-tuned Gemma 3 to demonstrate strong performance.
- Shieldgemma2 #36678 by @RyanMullins
Aya Vision
AyaVision is heavily referenced in the following model-based release and we recommend reading these if you want all the information relative to that model.

The Aya Vision 8B and 32B models is a state-of-the-art multilingual multimodal models developed by Cohere For AI. They build on the Aya Expanse recipe to handle both visual and textual information without compromising on the strong multilingual textual performance of the original model.
Aya Vision 8B combines the Siglip2-so400-384-14 vision encoder with the Cohere CommandR-7B language model further post-trained with the Aya Expanse recipe, creating a powerful vision-language model capable of understanding images and generating text across 23 languages. Whereas, Aya Vision 32B uses Aya Expanse 32B as the language model.
Key features of Aya Vision include:
- Multimodal capabilities in 23 languages
- Strong text-only multilingual capabilities inherited from CommandR-7B post-trained with the Aya Expanse recipe and Aya Expanse 32B
- High-quality visual understanding using the Siglip2-so400-384-14 vision encoder
- Seamless integration of visual and textual information in 23 languages.
- Add aya by @ArthurZucker in #36521
Mistral 3.1
Mistral 3.1 is heavily referenced in the following model-based release and we recommend reading these if you want all the information relative to that model.

Building upon Mistral Small 3 (2501), Mistral Small 3.1 (2503) adds state-of-the-art vision understanding and enhances long context capabilities up to 128k tokens without compromising text performance. With 24 billion parameters, this model achieves top-tier capabilities in both text and vision tasks.
It is ideal for:
- Fast-response conversational agents.
- Low-latency function calling.
- Subject matter experts via fine-tuning.
- Local inference for hobbyists and organizations handling sensitive data.
- Programming and math reasoning.
- Long document understanding.
- Visual understanding.
- Add Mistral3 by @Cyrilvallez in #36790
Smol VLM 2
SmolVLM-2 is heavily referenced in the following model-based release and we recommend reading these if you want all the information relative to that model.

SmolVLM2 is an adaptation of the Idefics3 model with two main differences:
- It uses SmolLM2 for the text model.
- It supports multi-image and video inputs
SigLIP-2
SigLIP-2 is heavily referenced in the following model-based release and we recommend reading these if you want all the information relative to that model.

The SigLIP2 model was proposed in SigLIP 2: Multilingual Vision-Language Encoders with Improved Semantic Understanding, Localization, and Dense Features by Michael Tschannen, Alexey Gritsenko, Xiao Wang, Muhammad Ferjad Naeem, Ibrahim Alabdulmohsin,
Nikhil Parthasarathy, Talfan Evans, Lucas Beyer, Ye Xia, Basil Mustafa, Olivier Hénaff, Jeremiah Harmsen,
Andreas Steiner and Xiaohua Zhai.
The model comes in two variants
- FixRes - model works with fixed resolution images (backward compatible with SigLIP v1)
- NaFlex - model works with variable image aspect ratios and resolutions (SigLIP2 in
transformers)
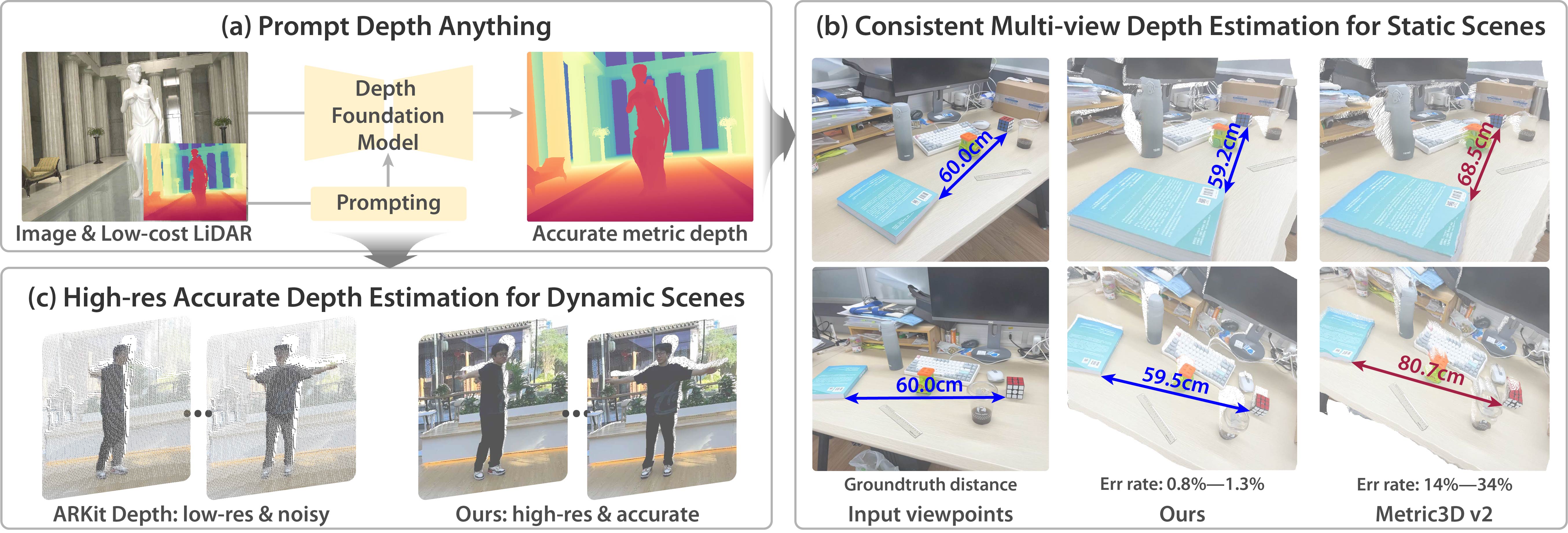
Prompt Depth Anything
PromptDepthAnything is a high-resolution, accurate metric depth estimation model that leverages prompting, inspired by its success in vision-language (VLMs) and large language models (LLMs). Using iPhone LiDAR as a prompt, the model generates precise depth maps at up to 4K resolution, unlocking the potential of depth foundation models.
New tool: attention visualization
We add a new tool to transformers to visualize the attention layout of a given model. It only requires a model ID as input, and will load the relevant tokenizer/model and display what the attention mask looks like. Some examples:
from transformers.utils.attention_visualizer import AttentionMaskVisualizer
visualizer = AttentionMaskVisualizer("meta-llama/Llama-3.2-3B-Instruct")
visualizer("A normal attention mask")
visualizer = AttentionMaskVisualizer("mistralai/Mistral-Small-24B-Instruct-2501")
visualizer("A normal attention mask with a long text to see how it is displayed, and if it is displayed correctly")
visualizer = AttentionMaskVisualizer("google/paligemma2-3b-mix-224")
visualizer("<img> You are an assistant.", suffix = "What is on the image?")
visualizer = AttentionMaskVisualizer("google/gemma-2b")
visualizer("You are an assistant. Make sure you print me") # we should have slidiing on non sliding side by side
visualizer = AttentionMaskVisualizer("google/gemma-3-27b-it")
visualizer("<img>You are an assistant. Make sure you print me") # we should have slidiing on non sliding side by side
- Add attention visualization tool by @ArthurZucker in #36630
Deprecating transformers.agents in favor of smolagents
We are deprecating transformers.agents in favour of the smolagents library. Read more about smolagents here.
- Deprecate transformers.agents by @aymeric-roucher in #36415
Quantization
We support adding custom quantization method by using the @register_quantization_config and @register_quantizer decorator:
@register_quantization_config("custom")
class CustomConfig(QuantizationConfigMixin):
pass
@register_quantizer("custom")
class CustomQuantizer(HfQuantizer):
pass
quantized_model = AutoModelForCausalLM.from_pretrained(
"facebook/opt-350m", quantization_config=CustomConfig(), torch_dtype="auto"
)- Added Support for Custom Quantization by @keetrap in #35915
- Add Example for Custom quantization by @MekkCyber in #36286
AMD is developing its in-house quantizer named Quark released under MIT license, which supports a broad range of quantization pre-processing, algorithms, dtypes and target hardware. You can now load a model quantized by quark library:
# pip install amd-quark
model_id = "EmbeddedLLM/Llama-3.1-8B-Instruct-w_fp8_per_channel_sym"
model = AutoModelForCausalLM.from_pretrained(model_id)
model = model.to("cuda")- Support loading Quark quantized models in Transformers by @fxmarty-amd and @BowenBao in #36372
Torchao is augmented with autoquant support, CPU-quantization, as well as new AOBaseConfig object instances for more advanced configuration.
- Add autoquant support for torchao quantizer by @jerryzh168 in #35503
- enable torchao quantization on CPU by @jiqing-feng in #36146
- Add option for ao base configs by @drisspg in #36526
Tensor Parallelism implementation changes
At loading time, the parallelization is now applied module-by-module, so that no memory overhead is required compared to what the final weight distribution will be!
- TP initialization module-by-module by @Cyrilvallez in #35996
Generation
This release includes two speed upgrades to generate:
- Assisted generation now works with ANY model as an assistant, even with
do_sample=True;
from transformers import pipeline
import torch
prompt = "Alice and Bob"
checkpoint = "google/gemma-2-9b"
assistant_checkpoint = "double7/vicuna-68m"
pipe = pipeline(
"text-generation",
model=checkpoint,
assistant_model=assistant_checkpoint,
do_sample=True
)
pipe_output = pipe(prompt, max_new_tokens=50, do_sample=True)
print(pipe_output[0]["generated_text"])- Beam search was vectorized, and should be significantly faster with a large
num_beams. The speedup is more visible on smaller models, wheremodel.forwarddoesn't dominate the total run time.
- Universal Speculative Decoding
CandidateGeneratorby @keyboardAnt, @jmamou, and @gauravjain14 in #35029 - [generate] ✨ vectorized beam search ✨ by @gante in #35802
Documentation
A significant redesign of our documentation has wrapped-up. The goal was to greatly simplify the transformers documentation, making it much more easy to navigate. Let us know what you think!
Notable repo maintenance
The research examples folder that was hosted in transformers is no more. We have moved it out of transformers and in the following repo: github.com/huggingface/transformers-research-projects/
- Remove research projects by @Rocketknight1 in #36645
We have updated our flex attention support so as to have it be on-par with our Flash Attention 2 support.
- Proper_flex by @ArthurZucker in #36643
More models support flex attention now thanks to @qubvel
First integration of hub kernels for deformable detr!
Bugfixes and improvements
- [tests] fix
EsmModelIntegrationTest::test_inference_bitsandbytesby @faaany in #36225 - Fix
LlavaForConditionalGenerationModelTest::test_configafter #36077 by @ydshieh in #36230 - AMD DeepSpeed image additional HIP dependencies by @ivarflakstad in #36195
- [generate] remove cache v4.47 deprecations by @gante in #36212
- Add missing atol to torch.testing.assert_close where rtol is specified by @ivarflakstad in #36234
- [tests] remove tf/flax tests in
/generationby @gante in #36235 - [generate] Fix encoder decoder models attention mask by @eustlb in #36018
- Add compressed tensor in quant dockerfile by @SunMarc in #36239
- [tests] remove
test_export_to_onnxby @gante in #36241 - Au revoir flaky
test_fast_is_faster_than_slowby @ydshieh in #36240 - Fix TorchAoConfig not JSON serializable by @andrewor14 in #36206
- Remove flakiness in VLMs by @zucchini-nlp in #36242
- feat: add support for tensor parallel training workflow with accelerate by @kmehant in #34194
- Fix XGLM loss computation (PyTorch and TensorFlow) by @damianoamatruda in #35878
- GitModelIntegrationTest - flatten the expected slice tensor by @ivarflakstad in #36260
- Added Support for Custom Quantization by @keetrap in #35915
- Qwen2VL fix cos,sin dtypes to float when used with deepspeed by @ArdalanM in #36188
- Uniformize LlavaNextVideoProcessor kwargs by @yonigozlan in #35613
- Add support for post-processing kwargs in image-text-to-text pipeline by @yonigozlan in #35374
- Add dithering to the
Speech2TextFeatureExtractorAPI. by @KarelVesely84 in #34638 - [tests] remove
pt_tfequivalence tests by @gante in #36253 - TP initialization module-by-module by @Cyrilvallez in #35996
- [tests] deflake dither test by @gante in #36284
- [tests] remove flax-pt equivalence and cross tests by @gante in #36283
- [tests] make
test_from_pretrained_low_cpu_mem_usage_equalless flaky by @gante in #36255 - Add Example for Custom quantization by @MekkCyber in #36286
- docs: Update README_zh-hans.md by @hyjbrave in #36269
- Fix callback handler reference by @SunMarc in #36250
- Make cache traceable by @IlyasMoutawwakil in #35873
- Fix broken CI on release branch due to missing conversion files by @ydshieh in #36275
- Ignore conversion files in test fetcher by @ydshieh in #36251
- SmolVLM2 by @orrzohar in #36126
- Fix typo in Pixtral example by @12v in #36302
- fix: prevent second save in the end of training if last step was saved already by @NosimusAI in #36219
- [smolvlm] make CI green by @gante in #36306
- Fix default attention mask of generate in MoshiForConditionalGeneration by @cyan-channel-io in #36171
- VLMs: even more clean-up by @zucchini-nlp in #36249
- Add SigLIP 2 by @qubvel in #36323
- [CI] Check test if the
GenerationTesterMixininheritance is correct 🐛 🔫 by @gante in #36180 - [tests] make quanto tests device-agnostic by @faaany in #36328
- Uses Collection in transformers.image_transforms.normalize by @CalOmnie in #36301
- Fix exploitable regexes in Nougat and GPTSan/GPTJNeoXJapanese by @Rocketknight1 in #36121
- [tests] enable bnb tests on xpu by @faaany in #36233
- Improve model loading for compressed tensor models by @rahul-tuli in #36152
- Change slack channel for mi250 CI to amd-hf-ci by @ivarflakstad in #36346
- Add autoquant support for torchao quantizer by @jerryzh168 in #35503
- Update amd pytorch index to match base image by @ivarflakstad in #36347
- fix(type): padding_side type should be Optional[str] by @shenxiangzhuang in #36326
- [Modeling] Reduce runtime when loading missing keys by @kylesayrs in #36312
- notify new model merged to
mainby @ydshieh in #36375 - Update modeling_llava_onevision.py by @yinsong1986 in #36391
- Load models much faster on accelerator devices!! by @Cyrilvallez in #36380
- [modular] Do not track imports in functions by @Cyrilvallez in #36279
- Fix
is_causalfail with compile by @Cyrilvallez in #36374 - enable torchao quantization on CPU by @jiqing-feng in #36146
- Update _get_eval_sampler to reflect Trainer.tokenizer is deprecation self.tokenizer -> self.processing_class by @yukiman76 in #36315
- Fix doc formatting in forward passes & modular by @Cyrilvallez in #36243
- Added handling for length <2 of suppress_tokens for whisper by @andreystarenky in #36336
- addressing the issue #34611 to make FlaxDinov2 compatible with any batch size by @MHRDYN7 in #35138
- tests: revert change of torch_require_multi_gpu to be device agnostic by @dvrogozh in #35721
- [tests] enable autoawq tests on XPU by @faaany in #36327
- fix audio classification pipeline fp16 test on cuda by @jiqing-feng in #36359
- chore: fix function argument descriptions by @threewebcode in #36392
- Fix pytorch integration tests for SAM by @qubvel in #36397
- [CLI] add import guards by @gante in #36376
- Fix convert_to_rgb for SAM ImageProcessor by @MSt-10 in #36369
- Security fix for
benchmark.ymlby @ydshieh in #36402 - Fixed VitDet for non-squre Images by @cjfghk5697 in #35969
- Add retry hf hub decorator by @muellerzr in #35213
- Deprecate transformers.agents by @aymeric-roucher in #36415
- Fixing the docs corresponding to the breaking change in torch 2.6. by @Narsil in #36420
- add recommendations for NPU using flash_attn by @zheliuyu in #36383
- fix: prevent model access error during Optuna hyperparameter tuning by @emapco in #36395
- Universal Speculative Decoding
CandidateGeneratorby @keyboardAnt in #35029 - Fix compressed tensors config by @MekkCyber in #36421
- Update form pretrained to make TP a first class citizen by @ArthurZucker in #36335
- Fix Expected output for compressed-tensors tests by @MekkCyber in #36425
- restrict cache allocator to non quantized model by @SunMarc in #36428
- Change PR to draft when it is (re)opened by @ydshieh in #36417
- Fix permission by @ydshieh in #36443
- Fix another permission by @ydshieh in #36444
- Add
contents: writeby @ydshieh in #36445 - [save_pretrained ] Skip collecting duplicated weight by @wejoncy in #36409
- [generate]
torch.distributed-compatibleDynamicCacheby @gante in #36373 - Lazy import libraries in
src/transformers/image_utils.pyby @hmellor in #36435 - Fix
hub_retryby @ydshieh in #36449 - [GroundingDino] Fix grounding dino loss 🚨 by @EduardoPach in #31828
- Fix loading models with mismatched sizes by @qubvel in #36463
- [docs] fix bug in deepspeed config by @faaany in #36081
- Add Got-OCR 2 Fast image processor and refactor slow one by @yonigozlan in #36185
- Fix couples of issues from #36335 by @SunMarc in #36453
- Fix _load_state_dict_into_meta_model with device_map=None by @hlky in #36488
- Fix loading zero3 weights by @muellerzr in #36455
- Check
TRUST_REMOTE_CODEforRealmRetrieverfor security by @ydshieh in #36511 - Fix kwargs UserWarning in SamImageProcessor by @MSt-10 in #36479
- fix torch_dtype, contiguous, and load_state_dict regression by @SunMarc in #36512
- Fix some typos in docs by @co63oc in #36502
- chore: fix message descriptions in arguments and comments by @threewebcode in #36504
- Fix pipeline+peft interaction by @Rocketknight1 in #36480
- Fix edge case for continue_final_message by @Rocketknight1 in #36404
- [Style] fix E721 warnings by @kashif in #36474
- Remove unused code by @Rocketknight1 in #36459
- [docs] Redesign by @stevhliu in #31757
- Add aya by @ArthurZucker in #36521
- chore: Fix typos in docs and examples by @co63oc in #36524
- Fix bamba tests amd by @ivarflakstad in #36535
- Fix links in quantization doc by @MekkCyber in #36528
- chore: enhance messages in docstrings by @threewebcode in #36525
- guard torch version for uint16 by @SunMarc in #36520
- Fix typos in tests by @co63oc in #36547
- Fix typos . by @zhanluxianshen in #36551
- chore: enhance message descriptions in parameters,comments,logs and docstrings by @threewebcode in #36554
- Delete redundancy if case in model_utils by @zhanluxianshen in #36559
- Modular Conversion --fix_and_overwrite on Windows by @hlky in #36583
- Integrate SwanLab for offline/online experiment tracking and local visualization by @ShaohonChen in #36433
- [bark] fix loading of generation config by @gante in #36587
- [XGLM] tag tests as slow by @gante in #36592
- fix: argument by @ariG23498 in #36558
- Mention UltraScale Playbook 🌌 in docs by @NouamaneTazi in #36589
- avoid errors when the size of
input_idspassed toPrefixConstrainedLogitsProcessoris zero by @HiDolen in #36489 - Export base streamer. by @AndreasAbdi in #36500
- Github action for auto-assigning reviewers by @Rocketknight1 in #35846
- Update chat_extras.md with content correction by @krishkkk in #36599
- Update "who to tag" / "who can review" by @gante in #36394
- Fixed datatype related issues in
DataCollatorForLanguageModelingby @capemox in #36457 - Fix check for XPU. PyTorch >= 2.6 no longer needs ipex. by @tripzero in #36593
- [
HybridCache] disable automatic compilation by @gante in #36620 - Fix auto-assign reviewers by @Rocketknight1 in #36631
- chore: fix typos in language models by @threewebcode in #36586
- [docs] Serving LLMs by @stevhliu in #36522
- Refactor some core stuff by @ArthurZucker in #36539
- Fix bugs in mllama image processing by @tjohnson31415 in #36156
- Proper_flex by @ArthurZucker in #36643
- Fix AriaForConditionalGeneration flex attn test by @ivarflakstad in #36604
- Remove remote code warning by @Rocketknight1 in #36285
- Stop warnings from unnecessary torch.tensor() overuse by @Rocketknight1 in #36538
- [docs] Update docs dependency by @stevhliu in #36635
- Remove research projects by @Rocketknight1 in #36645
- Fix gguf docs by @SunMarc in #36601
- fix typos in the docs directory by @threewebcode in #36639
- Gemma3 by @RyanMullins in #36658
- HPU support by @IlyasMoutawwakil in #36424
- fix block mask typing by @ArthurZucker in #36661
- [CI] gemma 3
make fix-copiesby @gante in #36664 - Fix bnb regression due to empty state dict by @SunMarc in #36663
- [core] Large/full refactor of
from_pretrainedby @Cyrilvallez in #36033 - Don't accidentally mutate the base_model_tp_plan by @Rocketknight1 in #36677
- Fix Failing GPTQ tests by @MekkCyber in #36666
- Remove hardcoded slow image processor class in processors supporting fast ones by @yonigozlan in #36266
- [quants] refactor logic for modules_to_not_convert by @SunMarc in #36672
- Remove differences between init and preprocess kwargs for fast image processors by @yonigozlan in #36186
- Refactor siglip2 fast image processor by @yonigozlan in #36406
- Fix rescale normalize inconsistencies in fast image processors by @yonigozlan in #36388
- [Cache] Don't initialize the cache on
metadevice by @gante in #36543 - Update config.torch_dtype correctly by @SunMarc in #36679
- Fix slicing for 0-dim param by @SunMarc in #36580
- Changing the test model in Quanto kv cache by @MekkCyber in #36670
- fix wandb hp search unable to resume from sweep_id by @bd793fcb in #35883
- Upgrading torch version and cuda version in quantization docker by @MekkCyber in #36264
- Change Qwen2_VL image processors to have init and call accept the same kwargs by @yonigozlan in #36207
- fix type annotation for ALL_ATTENTION_FUNCTIONS by @WineChord in #36690
- Fix dtype for params without tp_plan by @Cyrilvallez in #36681
- chore: fix typos in utils module by @threewebcode in #36668
- [CI] Automatic rerun of certain test failures by @gante in #36694
- Add loading speed test by @Cyrilvallez in #36671
- fix: fsdp sharded state dict wont work for save_only_model knob by @kmehant in #36627
- Handling an exception related to HQQ quantization in modeling by @MekkCyber in #36702
- Add GGUF support to T5-Encoder by @Isotr0py in #36700
- Final CI cleanup by @Rocketknight1 in #36703
- Add support for fast image processors in add-new-model-like CLI by @yonigozlan in #36313
- Gemma3 processor typo by @Kuangdd01 in #36710
- Make the flaky list a little more general by @Rocketknight1 in #36704
- Cleanup the regex used for doc preprocessing by @Rocketknight1 in #36648
- [model loading] don't
gc.collect()if only 1 shard is used by @gante in #36721 - Fix/best model checkpoint fix by @seanswyi in #35885
- Try working around the processor registration bugs by @Rocketknight1 in #36184
- [tests] Parameterized
test_eager_matches_sdpa_inferenceby @gante in #36650 - 🌐 [i18n-KO] Translated codegen.md to Korean by @maximizemaxwell in #36698
- Fix post_init() code duplication by @Cyrilvallez in #36727
- Fix grad accum arbitrary value by @IlyasMoutawwakil in #36691
- [Generation, Gemma 3] When passing a custom
generation_config, overwrite default values with the model's basegeneration_configby @gante in #36684 - 🚨🚨🚨 Fix sdpa in SAM and refactor relative position embeddings by @geetu040 in #36422
- enable/disable compile for quants methods by @SunMarc in #36519
- fix can_generate by @jiqing-feng in #36570
- Allow ray datasets to be used with trainer by @FredrikNoren in #36699
- fix xpu tests by @jiqing-feng in #36656
- Fix test isolation for clear_import_cache utility by @sambhavnoobcoder in #36345
- Fix
TrainingArguments.torch_empty_cache_stepspost_init check by @pkuderov in #36734 - [MINOR:TYPO] Update hubert.md by @cakiki in #36733
- [CI] remove redundant checks in
test_eager_matches_sdpa_inferenceby @gante in #36740 - [docs] Update README by @stevhliu in #36265
- doc: Clarify
is_decoderusage in PretrainedConfig documentation by @d-kleine in #36724 - fix typos in the tests directory by @threewebcode in #36717
- chore: fix typos in tests directory by @threewebcode in #36785
- Fixing typo in gemma3 image_processor_fast and adding a small test by @Zebz13 in #36776
- Fix gemma3_text tokenizer in mapping by @LysandreJik in #36793
- Add Mistral3 by @Cyrilvallez in #36790
- fix hqq due to recent modeling changes by @SunMarc in #36771
- Update SHA for
tj-actions/changed-filesby @ydshieh in #36795 - Loading optimizations by @Cyrilvallez in #36742
- Fix Mistral3 tests by @yonigozlan in #36797
- Fix casting dtype for qunatization by @SunMarc in #36799
- Fix chameleon's TypeError because inputs_embeds may None by @YenFuLin in #36673
- Support custom dosctrings in modular by @yonigozlan in #36726
- [generate] ✨ vectorized beam search ✨ by @gante in #35802
- Expectations test utils by @ivarflakstad in #36569
- fix "Cannot copy out of meta tensor; no data!" issue for BartForConditionalGeneration model by @yao-matrix in #36572
- Remove
dist": "loadfile"forpytestin CircleCI jobs by @ydshieh in #36811 - Fix Device map for bitsandbytes tests by @MekkCyber in #36800
- [Generation] remove leftover code from end-to-end compilation by @gante in #36685
- Add attention visualization tool by @ArthurZucker in #36630
- Add option for ao base configs by @drisspg in #36526
- enable OffloadedCache on XPU from PyTorch 2.7 by @yao-matrix in #36654
- [gemma 3] multimodal checkpoints + AutoModelForCausalLM by @gante in #36741
- One more fix for reviewer assignment by @Rocketknight1 in #36829
- Support tracable dynamicKVcache by @tugsbayasgalan in #36311
- Add Space to Bitsandbytes doc by @MekkCyber in #36834
- quick fix fast_image_processor register error by @JJJYmmm in #36716
- Update configuration_qwen2.py by @michaelfeil in #36735
- Just import torch AdamW instead by @Rocketknight1 in #36177
- Move the warning to the documentation for DataCollatorWithFlattening by @qgallouedec in #36707
- Fix swanlab global step by @Zeyi-Lin in #36728
- Disable inductor config setter by default by @HDCharles in #36608
- [ForCausalLMLoss] allow users to pass shifted labels by @stas00 in #36607
- fix tiktoken convert to pass AddedToken to Tokenizer by @itazap in #36566
- Saving
Trainer.collator.tokenizerin whenTrainer.processing_classisNoneby @innerNULL in #36552 - Pass num_items_in_batch directly to loss computation by @eljandoubi in #36753
- Fix fp16 ONNX export for RT-DETR and RT-DETRv2 by @qubvel in #36460
- Update deprecated Jax calls by @rasmi in #35919
- [qwen2 audio] remove redundant code and update docs by @gante in #36282
- Pass state dict by @phos-phophy in #35234
- [modular] Sort modular skips by @gante in #36304
- [generate] clarify docstrings: when to inherit
GenerationMixinby @gante in #36605 - Update min safetensors bis by @SunMarc in #36823
- Fix import for torch 2.0, 2.1 - guard typehint for "device_mesh" by @qubvel in #36768
- Gemma 3: Adding explicit GenerationConfig and refactoring conversion … by @RyanMullins in #36833
- Fix: remove the redundant snippet of _whole_word_mask by @HuangBugWei in #36759
- Shieldgemma2 by @RyanMullins in #36678
- Fix ONNX export for sequence classification head by @echarlaix in #36332
- Fix hqq skipped modules and dynamic quant by @mobicham in #36821
- Use pyupgrade --py39-plus to improve code by @cyyever in #36843
- Support loading Quark quantized models in Transformers by @fxmarty-amd in #36372
- DeepSpeed tensor parallel+ZeRO by @inkcherry in #36825
- Refactor Attention implementation for ViT-based models by @qubvel in #36545
- Add Prompt Depth Anything Model by @haotongl in #35401
- Add model visual debugger by @molbap in #36798
- [torchao] revert to get_apply_tensor_subclass by @SunMarc in #36849
- Gemma3: fix test by @zucchini-nlp in #36820
- [CI] fix update metadata job by @gante in #36850
- Add support for seed in
DataCollatorForLanguageModelingby @capemox in #36497 - Refactor Aya Vision with modular by @yonigozlan in #36688
- Mllama: raise better error by @zucchini-nlp in #35934
- [CI] doc builder without custom image by @gante in #36862
- FIX FSDP plugin update for QLoRA by @BenjaminBossan in #36720
- Remove call to
.iteminget_batch_samplesby @regisss in #36861 - chore: fix typos in the tests directory by @threewebcode in #36813
- Make ViTPooler configurable by @sebbaur in #36517
- Revert "Update deprecated Jax calls by @ArthurZucker in #35919)"
- [generate] model defaults being inherited only happens for newer models by @gante in #36881
- 🔴 🔴 🔴 supersede paligemma forward to shift pos id indexing by @molbap in #36859
- Gemma 3 tests expect greedy decoding by @molbap in #36882
- Use
deformable_detrkernel from the Hub by @danieldk in #36853 - Minor Gemma 3 fixes by @molbap in #36884
- Fix: dtype cannot be str by @zucchini-nlp in #36262
Significant community contributions
The following contributors have made significant changes to the library over the last release:
- @IlyasMoutawwakil
- @orrzohar
- SmolVLM2 (#36126)
- @threewebcode
- chore: fix function argument descriptions (#36392)
- chore: fix message descriptions in arguments and comments (#36504)
- chore: enhance messages in docstrings (#36525)
- chore: enhance message descriptions in parameters,comments,logs and docstrings (#36554)
- chore: fix typos in language models (#36586)
- fix typos in the docs directory (#36639)
- chore: fix typos in utils module (#36668)
- fix typos in the tests directory (#36717)
- chore: fix typos in tests directory (#36785)
- chore: fix typos in the tests directory (#36813)
- @aymeric-roucher
- Deprecate transformers.agents (#36415)
- @keyboardAnt
- Universal Speculative Decoding
CandidateGenerator(#35029)
- Universal Speculative Decoding
- @EduardoPach
- [GroundingDino] Fix grounding dino loss 🚨 (#31828)
- @co63oc
- @RyanMullins
- @cyyever
- Use pyupgrade --py39-plus to improve code (#36843)
- @haotongl
- Add Prompt Depth Anything Model (#35401)
- @danieldk
- Use
deformable_detrkernel from the Hub (#36853)
- Use