diff --git a/community/en/docs/tfmobile/android_build.md b/community/en/docs/tfmobile/android_build.md
new file mode 100644
index 00000000000..cc43dc19708
--- /dev/null
+++ b/community/en/docs/tfmobile/android_build.md
@@ -0,0 +1,196 @@
+# Building TensorFlow on Android
+
+Warning: TensorFlow Mobile is __deprecated__.
+
+
+
+ TensorFlow Lite is our main
+ mobile and embedded offering. We are
+ working hard to close the feature gap between TensorFlow Mobile and
+ TensorFlow Lite. We expect to deprecate TensorFlow Mobile in early 2019. We
+ will give ample notice to our users when we get to that point and will
+ provide help and support to ensure easy migrations.
+
+
+ In the meantime, please use TensorFlow Lite. If you have a feature request,
+ such as a missing op, please post to our GitHub.
+
+
+
+ TensorFlow Lite is our main
+ mobile and embedded offering. We are
+ working hard to close the feature gap between TensorFlow Mobile and
+ TensorFlow Lite. We expect to deprecate TensorFlow Mobile in early 2019. We
+ will give ample notice to our users when we get to that point and will
+ provide help and support to ensure easy migrations.
+
+
+ In the meantime, please use TensorFlow Lite. If you have a feature request,
+ such as a missing op, please post to our GitHub.
+
+
+
+
+
+There are multiple steps involved in recognizing text in images. You first have
+to identify the areas where the text is present, which is a variation on the
+object localization problem, and can be solved with similar techniques. Once you
+have an area of text, you then need to interpret it as letters, and then use a
+language model to help guess what words they represent. The simplest way to
+estimate what letters are present is to segment the line of text into individual
+letters, and then apply a simple neural network to the bounding box of each. You
+can get good results with the kind of models used for MNIST, which you can find
+in TensorFlow’s tutorials, though you may want a higher-resolution input. A
+more advanced alternative is to use an LSTM model to process a whole line of
+text at once, with the model itself handling the segmentation into different
+characters.
+
+### Translation
+
+Translating from one language to another quickly and accurately, even if you
+don’t have a network connection, is an important use case. Deep networks are
+very effective at this sort of task, and you can find descriptions of a lot of
+different models in the literature. Often these are sequence-to-sequence
+recurrent models where you’re able to run a single graph to do the whole
+translation, without needing to run separate parsing stages.
+
+### Text Classification
+
+If you want to suggest relevant prompts to users based on what they’re typing or
+reading, it can be very useful to understand the meaning of the text. This is
+where text classification comes in. Text classification is an umbrella term
+that covers everything from sentiment analysis to topic discovery. You’re likely
+to have your own categories or labels that you want to apply, so the best place
+to start is with an example
+like
+[Skip-Thoughts](https://www.tensorflow.org/code/tensorflow_models/skip_thoughts/),
+and then train on your own examples.
+
+### Voice Synthesis
+
+A synthesized voice can be a great way of giving users feedback or aiding
+accessibility, and recent advances such as
+[WaveNet](https://deepmind.com/blog/wavenet-generative-model-raw-audio/) show
+that deep learning can offer very natural-sounding speech.
+
+## Mobile machine learning and the cloud
+
+These examples of use cases give an idea of how on-device networks can
+complement cloud services. Cloud has a great deal of computing power in a
+controlled environment, but running on devices can offer higher interactivity.
+In situations where the cloud is unavailable, or your cloud capacity is limited,
+you can provide an offline experience, or reduce cloud workload by processing
+easy cases on device.
+
+Doing on-device computation can also signal when it's time to switch to working
+on the cloud. A good example of this is hotword detection in speech. Since
+devices are able to constantly listen out for the keywords, this then triggers a
+lot of traffic to cloud-based speech recognition once one is recognized. Without
+the on-device component, the whole application wouldn’t be feasible, and this
+pattern exists across several other applications as well. Recognizing that some
+sensor input is interesting enough for further processing makes a lot of
+interesting products possible.
+
+## What hardware and software should you have?
+
+TensorFlow runs on Ubuntu Linux, Windows 10, and OS X. For a list of all
+supported operating systems and instructions to install TensorFlow, see
+Installing Tensorflow.
+
+Note that some of the sample code we provide for mobile TensorFlow requires you
+to compile TensorFlow from source, so you’ll need more than just `pip install`
+to work through all the sample code.
+
+To try out the mobile examples, you’ll need a device set up for development,
+using
+either [Android Studio](https://developer.android.com/studio/install.html),
+or [XCode](https://developer.apple.com/xcode/) if you're developing for iOS.
+
+## What should you do before you get started?
+
+Before thinking about how to get your solution on mobile:
+
+1. Determine whether your problem is solvable by mobile machine learning
+2. Create a labelled dataset to define your problem
+3. Pick an effective model for the problem
+
+We'll discuss these in more detail below.
+
+### Is your problem solvable by mobile machine learning?
+
+Once you have an idea of the problem you want to solve, you need to make a plan
+of how to build your solution. The most important first step is making sure that
+your problem is actually solvable, and the best way to do that is to mock it up
+using humans in the loop.
+
+For example, if you want to drive a robot toy car using voice commands, try
+recording some audio from the device and listen back to it to see if you can
+make sense of what’s being said. Often you’ll find there are problems in the
+capture process, such as the motor drowning out speech or not being able to hear
+at a distance, and you should tackle these problems before investing in the
+modeling process.
+
+Another example would be giving photos taken from your app to people see if they
+can classify what’s in them, in the way you’re looking for. If they can’t do
+that (for example, trying to estimate calories in food from photos may be
+impossible because all white soups look the same), then you’ll need to redesign
+your experience to cope with that. A good rule of thumb is that if a human can’t
+handle the task then it will be difficult to train a computer to do better.
+
+### Create a labelled dataset
+
+After you’ve solved any fundamental issues with your use case, you need to
+create a labeled dataset to define what problem you’re trying to solve. This
+step is extremely important, more than picking which model to use. You want it
+to be as representative as possible of your actual use case, since the model
+will only be effective at the task you teach it. It’s also worth investing in
+tools to make labeling the data as efficient and accurate as possible. For
+example, if you’re able to switch from having to click a button on a web
+interface to simple keyboard shortcuts, you may be able to speed up the
+generation process a lot. You should also start by doing the initial labeling
+yourself, so you can learn about the difficulties and likely errors, and
+possibly change your labeling or data capture process to avoid them. Once you
+and your team are able to consistently label examples (that is once you
+generally agree on the same labels for most examples), you can then try and
+capture your knowledge in a manual and teach external raters how to run the same
+process.
+
+### Pick an effective model
+
+The next step is to pick an effective model to use. You might be able to avoid
+training a model from scratch if someone else has already implemented a model
+similar to what you need; we have a repository of models implemented in
+TensorFlow [on GitHub](https://github.com/tensorflow/models) that you can look
+through. Lean towards the simplest model you can find, and try to get started as
+soon as you have even a small amount of labelled data, since you’ll get the best
+results when you’re able to iterate quickly. The shorter the time it takes to
+try training a model and running it in its real application, the better overall
+results you’ll see. It’s common for an algorithm to get great training accuracy
+numbers but then fail to be useful within a real application because there’s a
+mismatch between the dataset and real usage. Prototype end-to-end usage as soon
+as possible to create a consistent user experience.
diff --git a/community/en/docs/tfmobile/ios_build.md b/community/en/docs/tfmobile/ios_build.md
new file mode 100644
index 00000000000..080ba660214
--- /dev/null
+++ b/community/en/docs/tfmobile/ios_build.md
@@ -0,0 +1,125 @@
+# Building TensorFlow on iOS
+
+Warning: TensorFlow Mobile is __deprecated__.
+
+
+
+ TensorFlow Lite is our main
+ mobile and embedded offering. We are
+ working hard to close the feature gap between TensorFlow Mobile and
+ TensorFlow Lite. We expect to deprecate TensorFlow Mobile in early 2019. We
+ will give ample notice to our users when we get to that point and will
+ provide help and support to ensure easy migrations.
+
+
+ In the meantime, please use TensorFlow Lite. If you have a feature request,
+ such as a missing op, please post to our GitHub.
+
+
+
+ TensorFlow Lite is our main
+ mobile and embedded offering. We are
+ working hard to close the feature gap between TensorFlow Mobile and
+ TensorFlow Lite. We expect to deprecate TensorFlow Mobile in early 2019. We
+ will give ample notice to our users when we get to that point and will
+ provide help and support to ensure easy migrations.
+
+
+ In the meantime, please use TensorFlow Lite. If you have a feature request,
+ such as a missing op, please post to our GitHub.
+
+
+
+ TensorFlow Lite is our main
+ mobile and embedded offering. We are
+ working hard to close the feature gap between TensorFlow Mobile and
+ TensorFlow Lite. We expect to deprecate TensorFlow Mobile in early 2019. We
+ will give ample notice to our users when we get to that point and will
+ provide help and support to ensure easy migrations.
+
+
+ In the meantime, please use TensorFlow Lite. If you have a feature request,
+ such as a missing op, please post to our GitHub.
+
+
+============================== Top by Computation Time ==============================
+[node
+ type] [start] [first] [avg ms] [%] [cdf%] [mem KB] [Name]
+Conv2D 22.859 14.212 13.700 4.972% 4.972% 3871.488 conv_4/Conv2D
+Conv2D 8.116 8.964 11.315 4.106% 9.078% 5531.904 conv_2/Conv2D
+Conv2D 62.066 16.504 7.274 2.640% 11.717% 443.904 mixed_3/conv/Conv2D
+Conv2D 2.530 6.226 4.939 1.792% 13.510% 2765.952 conv_1/Conv2D
+Conv2D 55.585 4.605 4.665 1.693% 15.203% 313.600 mixed_2/tower/conv_1/Conv2D
+Conv2D 127.114 5.469 4.630 1.680% 16.883% 81.920 mixed_10/conv/Conv2D
+Conv2D 47.391 6.994 4.588 1.665% 18.548% 313.600 mixed_1/tower/conv_1/Conv2D
+Conv2D 39.463 7.878 4.336 1.574% 20.122% 313.600 mixed/tower/conv_1/Conv2D
+Conv2D 127.113 4.192 3.894 1.413% 21.535% 114.688 mixed_10/tower_1/conv/Conv2D
+Conv2D 70.188 5.205 3.626 1.316% 22.850% 221.952 mixed_4/conv/Conv2D
+
+============================== Summary by node type ==============================
+[Node type] [count] [avg ms] [avg %] [cdf %] [mem KB]
+Conv2D 94 244.899 88.952% 88.952% 35869.953
+BiasAdd 95 9.664 3.510% 92.462% 35873.984
+AvgPool 9 7.990 2.902% 95.364% 7493.504
+Relu 94 5.727 2.080% 97.444% 35869.953
+MaxPool 5 3.485 1.266% 98.710% 3358.848
+Const 192 1.727 0.627% 99.337% 0.000
+Concat 11 1.081 0.393% 99.730% 9892.096
+MatMul 1 0.665 0.242% 99.971% 4.032
+Softmax 1 0.040 0.015% 99.986% 4.032
+<> 1 0.032 0.012% 99.997% 0.000
+Reshape 1 0.007 0.003% 100.000% 0.000
+
+Timings (microseconds): count=50 first=330849 curr=274803 min=232354 max=415352 avg=275563 std=44193
+Memory (bytes): count=50 curr=128366400(all same)
+514 nodes defined 504 nodes observed
+
+
+This is the summary view, which is enabled by the show_summary flag. To
+interpret it, the first table is a list of the nodes that took the most time, in
+order by how long they took. From left to right, the columns are:
+
+- Node type, what kind of operation this was.
+
+- Start time of the op, showing where it falls in the sequence of operations.
+
+- First time in milliseconds. This is how long the operation took on the first
+ run of the benchmark, since by default 20 runs are executed to get more
+ reliable statistics. The first time is useful to spot which ops are doing
+ expensive calculations on the first run, and then caching the results.
+
+- Average time for the operation across all runs, in milliseconds.
+
+- What percentage of the total time for one run the op took. This is useful to
+ understand where the hotspots are.
+
+- The cumulative total time of this and the previous ops in the table. This is
+ handy for understanding what the distribution of work is across the layers, to
+ see if just a few of the nodes are taking up most of the time.
+
+- The amount of memory consumed by outputs of this type of op.
+
+- Name of the node.
+
+The second table is similar, but instead of breaking down the timings by
+particular named nodes, it groups them by the kind of op. This is very useful to
+understand which op implementations you might want to optimize or eliminate from
+your graph. The table is arranged with the most costly operations at the start,
+and only shows the top ten entries, with a placeholder for other nodes. The
+columns from left to right are:
+
+- Type of the nodes being analyzed.
+
+- Accumulated average time taken by all nodes of this type, in milliseconds.
+
+- What percentage of the total time was taken by this type of operation.
+
+- Cumulative time taken by this and op types higher in the table, so you can
+ understand the distribution of the workload.
+
+- How much memory the outputs of this op type took up.
+
+Both of these tables are set up so that you can easily copy and paste their
+results into spreadsheet documents, since they are output with tabs as
+separators between the columns. The summary by node type can be the most useful
+when looking for optimization opportunities, since it’s a pointer to the code
+that’s taking the most time. In this case, you can see that the Conv2D ops are
+almost 90% of the execution time. This is a sign that the graph is pretty
+optimal, since convolutions and matrix multiplies are expected to be the bulk of
+a neural network’s computing workload.
+
+As a rule of thumb, it’s more worrying if you see a lot of other operations
+taking up more than a small fraction of the time. For neural networks, the ops
+that don’t involve large matrix multiplications should usually be dwarfed by the
+ones that do, so if you see a lot of time going into those it’s a sign that
+either your network is non-optimally constructed, or the code implementing those
+ops is not as optimized as it could
+be. [Performance bugs](https://github.com/tensorflow/tensorflow/issues) or
+patches are always welcome if you do encounter this situation, especially if
+they include an attached model exhibiting this behavior and the command line
+used to run the benchmark tool on it.
+
+The run above was on your desktop, but the tool also works on Android, which is
+where it’s most useful for mobile development. Here’s an example command line to
+run it on a 64-bit ARM device:
+
+ bazel build -c opt --config=android_arm64 \
+ tensorflow/tools/benchmark:benchmark_model
+ adb push bazel-bin/tensorflow/tools/benchmark/benchmark_model /data/local/tmp
+ adb push /tmp/tensorflow_inception_graph.pb /data/local/tmp/
+ adb shell '/data/local/tmp/benchmark_model \
+ --graph=/data/local/tmp/tensorflow_inception_graph.pb --input_layer="Mul" \
+ --input_layer_shape="1,299,299,3" --input_layer_type="float" \
+ --output_layer="softmax:0" --show_run_order=false --show_time=false \
+ --show_memory=false --show_summary=true'
+
+You can interpret the results in exactly the same way as the desktop version
+above. If you have any trouble figuring out what the right input and output
+names and types are, take a look at the
+Preparing models
+page for details about detecting these for your model, and look at the
+`summarize_graph` tool which may give you
+helpful information.
+
+There isn’t good support for command line tools on iOS, so instead there’s a
+separate example
+at
+[tensorflow/examples/ios/benchmark](https://www.tensorflow.org/code/tensorflow/examples/ios/benchmark) that
+packages the same functionality inside a standalone app. This outputs the
+statistics to both the screen of the device and the debug log. If you want
+on-screen statistics for the Android example apps, you can turn them on by
+pressing the volume-up button.
+
+## Profiling within your own app
+
+The output you see from the benchmark tool is generated from modules that are
+included as part of the standard TensorFlow runtime, which means you have access
+to them within your own applications too. You can see an example of how to do
+that [here](https://www.tensorflow.org/code/tensorflow/examples/ios/benchmark/BenchmarkViewController.mm?l=139).
+
+The basic steps are:
+
+1. Create a StatSummarizer object:
+
+ tensorflow::StatSummarizer stat_summarizer(tensorflow_graph);
+
+2. Set up the options:
+
+ tensorflow::RunOptions run_options;
+ run_options.set_trace_level(tensorflow::RunOptions::FULL_TRACE);
+ tensorflow::RunMetadata run_metadata;
+
+3. Run the graph:
+
+ run_status = session->Run(run_options, inputs, output_layer_names, {},
+ output_layers, &run_metadata);
+
+4. Calculate the results and print them out:
+
+ assert(run_metadata.has_step_stats());
+ const tensorflow::StepStats& step_stats = run_metadata.step_stats();
+ stat_summarizer->ProcessStepStats(step_stats);
+ stat_summarizer->PrintStepStats();
+
+## Visualizing Models
+
+The most effective way to speed up your code is by altering your model so it
+does less work. To do that, you need to understand what your model is doing, and
+visualizing it is a good first step. To get a high-level overview of your graph,
+use [TensorBoard](https://github.com/tensorflow/tensorboard).
+
+## Threading
+
+The desktop version of TensorFlow has a sophisticated threading model, and will
+try to run multiple operations in parallel if it can. In our terminology this is
+called “inter-op parallelism” (though to avoid confusion with “intra-op”, you
+could think of it as “between-op” instead), and can be set by specifying
+`inter_op_parallelism_threads` in the session options.
+
+By default, mobile devices run operations serially; that is,
+`inter_op_parallelism_threads` is set to 1. Mobile processors usually have few
+cores and a small cache, so running multiple operations accessing disjoint parts
+of memory usually doesn’t help performance. “Intra-op parallelism” (or
+“within-op”) can be very helpful though, especially for computation-bound
+operations like convolutions where different threads can feed off the same small
+set of memory.
+
+On mobile, how many threads an op will use is set to the number of cores by
+default, or 2 when the number of cores can't be determined. You can override the
+default number of threads that ops are using by setting
+`intra_op_parallelism_threads` in the session options. It’s a good idea to
+reduce the default if your app has its own threads doing heavy processing, so
+that they don’t interfere with each other.
+
+To see more details on session options, look at [ConfigProto](https://www.tensorflow.org/code/tensorflow/core/protobuf/config.proto).
+
+## Retrain with mobile data
+
+The biggest cause of accuracy problems when running models on mobile apps is
+unrepresentative training data. For example, most of the Imagenet photos are
+well-framed so that the object is in the center of the picture, well-lit, and
+shot with a normal lens. Photos from mobile devices are often poorly framed,
+badly lit, and can have fisheye distortions, especially selfies.
+
+The solution is to expand your training set with data actually captured from
+your application. This step can involve extra work, since you’ll have to label
+the examples yourself, but even if you just use it to expand your original
+training data, it can help the training set dramatically. Improving the training
+set by doing this, and by fixing other quality issues like duplicates or badly
+labeled examples is the single best way to improve accuracy. It’s usually a
+bigger help than altering your model architecture or using different techniques.
+
+## Reducing model loading time and/or memory footprint
+
+Most operating systems allow you to load a file using memory mapping, rather
+than going through the usual I/O APIs. Instead of allocating an area of memory
+on the heap and then copying bytes from disk into it, you simply tell the
+operating system to make the entire contents of a file appear directly in
+memory. This has several advantages:
+
+* Speeds loading
+* Reduces paging (increases performance)
+* Does not count towards RAM budget for your app
+
+TensorFlow has support for memory mapping the weights that form the bulk of most
+model files. Because of limitations in the `ProtoBuf` serialization format, we
+have to make a few changes to our model loading and processing code. The
+way memory mapping works is that we have a single file where the first part is a
+normal `GraphDef` serialized into the protocol buffer wire format, but then the
+weights are appended in a form that can be directly mapped.
+
+To create this file, run the
+`tensorflow/contrib/util:convert_graphdef_memmapped_format` tool. This takes in
+a `GraphDef` file that’s been run through `freeze_graph` and converts it to the
+format that has the weights appended at the end. Since that file’s no longer a
+standard `GraphDef` protobuf, you then need to make some changes to the loading
+code. You can see an example of this in
+the
+[iOS Camera demo app](https://www.tensorflow.org/code/tensorflow/examples/ios/camera/tensorflow_utils.mm?l=147),
+in the `LoadMemoryMappedModel()` function.
+
+The same code (with the Objective C calls for getting the filenames substituted)
+can be used on other platforms too. Because we’re using memory mapping, we need
+to start by creating a special TensorFlow environment object that’s set up with
+the file we’ll be using:
+
+ std::unique_ptr memmapped_env;
+ memmapped_env->reset(
+ new tensorflow::MemmappedEnv(tensorflow::Env::Default()));
+ tensorflow::Status mmap_status =
+ (memmapped_env->get())->InitializeFromFile(file_path);
+
+You then need to pass in this environment to subsequent calls, like this one for
+loading the graph:
+
+ tensorflow::GraphDef tensorflow_graph;
+ tensorflow::Status load_graph_status = ReadBinaryProto(
+ memmapped_env->get(),
+ tensorflow::MemmappedFileSystem::kMemmappedPackageDefaultGraphDef,
+ &tensorflow_graph);
+
+You also need to create the session with a pointer to the environment you’ve
+created:
+
+ tensorflow::SessionOptions options;
+ options.config.mutable_graph_options()
+ ->mutable_optimizer_options()
+ ->set_opt_level(::tensorflow::OptimizerOptions::L0);
+ options.env = memmapped_env->get();
+
+ tensorflow::Session* session_pointer = nullptr;
+ tensorflow::Status session_status =
+ tensorflow::NewSession(options, &session_pointer);
+
+One thing to notice here is that we’re also disabling automatic optimizations,
+since in some cases these will fold constant sub-trees, and so create copies of
+tensor values that we don’t want and use up more RAM.
+
+Once you’ve gone through these steps, you can use the session and graph as
+normal, and you should see a reduction in loading time and memory usage.
+
+## Protecting model files from easy copying
+
+By default, your models will be stored in the standard serialized protobuf
+format on disk. In theory this means that anybody can copy your model, which you
+may not want. However, in practice, most models are so application-specific and
+obfuscated by optimizations that the risk is similar to that of competitors
+disassembling and reusing your code, but if you do want to make it tougher for
+casual users to access your files it is possible to take some basic steps.
+
+Most of our examples use
+the
+[ReadBinaryProto()](https://www.tensorflow.org/code/tensorflow/core/platform/env.cc?q=core/platform/env.cc&l=409) convenience
+call to load a `GraphDef` from disk. This does require an unencrypted protobuf on
+disk. Luckily though, the implementation of the call is pretty straightforward
+and it should be easy to write an equivalent that can decrypt in memory. Here's
+some code that shows how you can read and decrypt a protobuf using your own
+decryption routine:
+
+ Status ReadEncryptedProto(Env* env, const string& fname,
+ ::tensorflow::protobuf::MessageLite* proto) {
+ string data;
+ TF_RETURN_IF_ERROR(ReadFileToString(env, fname, &data));
+
+ DecryptData(&data); // Your own function here.
+
+ if (!proto->ParseFromString(&data)) {
+ TF_RETURN_IF_ERROR(stream->status());
+ return errors::DataLoss("Can't parse ", fname, " as binary proto");
+ }
+ return Status::OK();
+ }
+
+To use this you’d need to define the DecryptData() function yourself. It could
+be as simple as something like:
+
+ void DecryptData(string* data) {
+ for (int i = 0; i < data.size(); ++i) {
+ data[i] = data[i] ^ 0x23;
+ }
+ }
+
+You may want something more complex, but exactly what you’ll need is outside the
+current scope here.
diff --git a/community/en/docs/tfmobile/prepare_models.md b/community/en/docs/tfmobile/prepare_models.md
new file mode 100644
index 00000000000..cd82a148b53
--- /dev/null
+++ b/community/en/docs/tfmobile/prepare_models.md
@@ -0,0 +1,319 @@
+# Preparing models for mobile deployment
+
+Warning: TensorFlow Mobile is __deprecated__.
+
+
+
+ TensorFlow Lite is our main
+ mobile and embedded offering. We are
+ working hard to close the feature gap between TensorFlow Mobile and
+ TensorFlow Lite. We expect to deprecate TensorFlow Mobile in early 2019. We
+ will give ample notice to our users when we get to that point and will
+ provide help and support to ensure easy migrations.
+
+
+ In the meantime, please use TensorFlow Lite. If you have a feature request,
+ such as a missing op, please post to our GitHub.
+
+
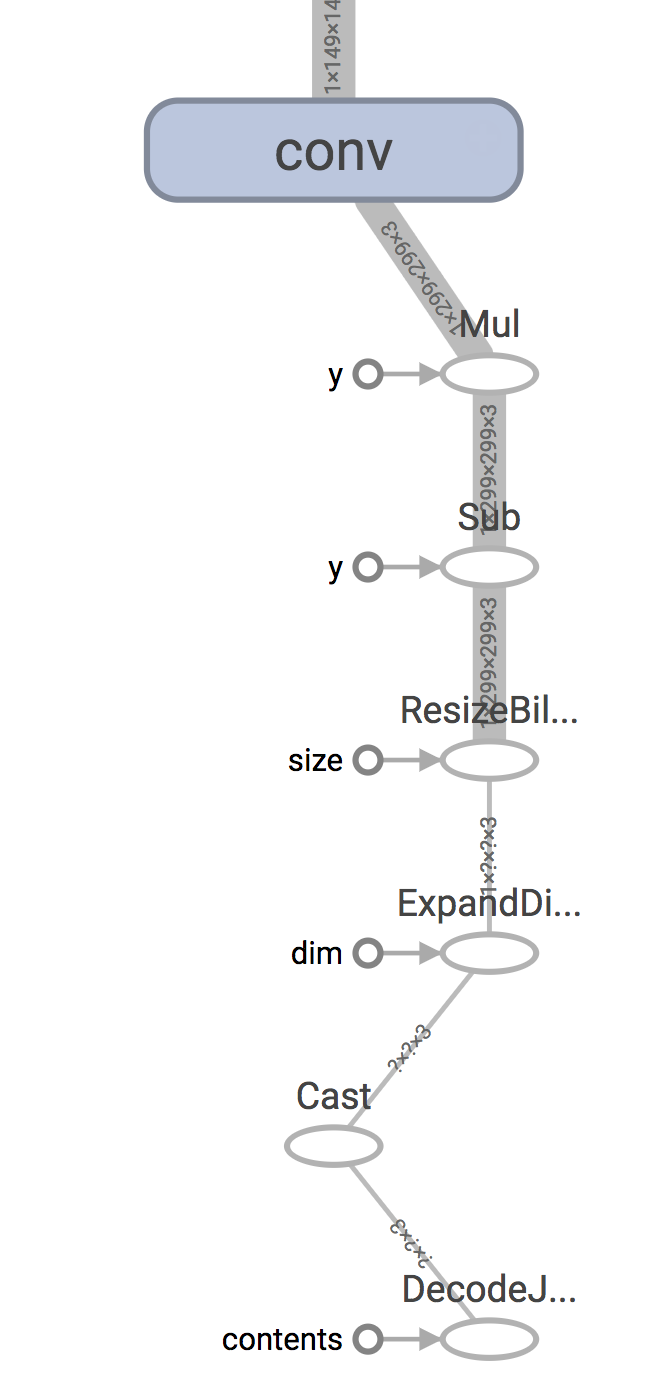 +
+You’ll need to do a similar process of inspection to figure out the correct
+output nodes.
+
+If you’ve just been given a frozen `GraphDef` file, and are not sure about the
+contents, try using the `summarize_graph` tool to print out information
+about the inputs and outputs it finds from the graph structure. Here’s an
+example with the original Inception v3 file:
+
+ bazel run tensorflow/tools/graph_transforms:summarize_graph --
+ --in_graph=tensorflow_inception_graph.pb
+
+Once you have an idea of what the input and output nodes are, you can feed them
+into the graph transform tool as the `--input_names` and `--output_names`
+arguments, and call the `strip_unused_nodes` transform, like this:
+
+ bazel run tensorflow/tools/graph_transforms:transform_graph --
+ --in_graph=tensorflow_inception_graph.pb
+ --out_graph=optimized_inception_graph.pb --inputs='Mul' --outputs='softmax'
+ --transforms='
+ strip_unused_nodes(type=float, shape="1,299,299,3")
+ fold_constants(ignore_errors=true)
+ fold_batch_norms
+ fold_old_batch_norms'
+
+One thing to look out for here is that you need to specify the size and type
+that you want your inputs to be. This is because any values that you’re going to
+be passing in as inputs to inference need to be fed to special `Placeholder` op
+nodes, and the transform may need to create them if they don’t already exist. In
+the case of Inception v3 for example, a `Placeholder` node replaces the old
+`Mul` node that used to output the resized and rescaled image array, since we’re
+going to be doing that processing ourselves before we call TensorFlow. It keeps
+the original name though, which is why we always feed in inputs to `Mul` when we
+run a session with our modified Inception graph.
+
+After you’ve run this process, you’ll have a graph that only contains the actual
+nodes you need to run your prediction process. This is the point where it
+becomes useful to run metrics on the graph, so it’s worth running
+`summarize_graph` again to understand what’s in your model.
+
+## What ops should you include on mobile?
+
+There are hundreds of operations available in TensorFlow, and each one has
+multiple implementations for different data types. On mobile platforms, the size
+of the executable binary that’s produced after compilation is important, because
+app download bundles need to be as small as possible for the best user
+experience. If all of the ops and data types are compiled into the TensorFlow
+library then the total size of the compiled library can be tens of megabytes, so
+by default only a subset of ops and data types are included.
+
+That means that if you load a model file that’s been trained on a desktop
+machine, you may see the error “No OpKernel was registered to support Op” when
+you load it on mobile. The first thing to try is to make sure you’ve stripped
+out any training-only nodes, since the error will occur at load time even if the
+op is never executed. If you’re still hitting the same problem once that’s done,
+you’ll need to look at adding the op to your built library.
+
+The criteria for including ops and types fall into several categories:
+
+- Are they only useful in back-propagation, for gradients? Since mobile is
+ focused on inference, we don’t include these.
+
+- Are they useful mainly for other training needs, such as checkpoint saving?
+ These we leave out.
+
+- Do they rely on frameworks that aren’t always available on mobile, such as
+ libjpeg? To avoid extra dependencies we don’t include ops like `DecodeJpeg`.
+
+- Are there types that aren’t commonly used? We don’t include boolean variants
+ of ops for example, since we don’t see much use of them in typical inference
+ graphs.
+
+These ops are trimmed by default to optimize for inference on mobile, but it is
+possible to alter some build files to change the default. After alternating the
+build files, you will need to recompile TensorFlow. See below for more details
+on how to do this, and also see optimizing binary size
+for more on reducing your binary size.
+
+### Locate the implementation
+
+Operations are broken into two parts. The first is the op definition, which
+declares the signature of the operation, which inputs, outputs, and attributes
+it has. These take up very little space, and so all are included by default. The
+implementations of the op computations are done in kernels, which live in the
+`tensorflow/core/kernels` folder. You need to compile the C++ file containing
+the kernel implementation of the op you need into the library. To figure out
+which file that is, you can search for the operation name in the source
+files.
+
+[Here’s an example search in github](https://github.com/search?utf8=%E2%9C%93&q=repo%3Atensorflow%2Ftensorflow+extension%3Acc+path%3Atensorflow%2Fcore%2Fkernels+REGISTER+Mul&type=Code&ref=searchresults).
+
+You’ll see that this search is looking for the `Mul` op implementation, and it
+finds it in `tensorflow/core/kernels/cwise_op_mul_1.cc`. You need to look for
+macros beginning with `REGISTER`, with the op name you care about as one of the
+string arguments.
+
+In this case, the implementations are actually broken up across multiple `.cc`
+files, so you’d need to include all of them in your build. If you’re more
+comfortable using the command line for code search, here’s a grep command that
+also locates the right files if you run it from the root of your TensorFlow
+repository:
+
+`grep 'REGISTER.*"Mul"' tensorflow/core/kernels/*.cc`
+
+### Add the implementation to the build
+
+If you’re using Bazel, and building for Android, you’ll want to add the files
+you’ve found to
+the
+[`android_extended_ops_group1`](https://www.tensorflow.org/code/tensorflow/core/kernels/BUILD#L3565) or
+[`android_extended_ops_group2`](https://www.tensorflow.org/code/tensorflow/core/kernels/BUILD#L3632) targets. You
+may also need to include any .cc files they depend on in there. If the build
+complains about missing header files, add the .h’s that are needed into
+the
+[`android_extended_ops`](https://www.tensorflow.org/code/tensorflow/core/kernels/BUILD#L3525) target.
+
+If you’re using a makefile targeting iOS, Raspberry Pi, etc, go to
+[`tensorflow/contrib/makefile/tf_op_files.txt`](https://www.tensorflow.org/code/tensorflow/contrib/makefile/tf_op_files.txt) and
+add the right implementation files there.
+
+You’ll need to do a similar process of inspection to figure out the correct
+output nodes.
+
+If you’ve just been given a frozen `GraphDef` file, and are not sure about the
+contents, try using the `summarize_graph` tool to print out information
+about the inputs and outputs it finds from the graph structure. Here’s an
+example with the original Inception v3 file:
+
+ bazel run tensorflow/tools/graph_transforms:summarize_graph --
+ --in_graph=tensorflow_inception_graph.pb
+
+Once you have an idea of what the input and output nodes are, you can feed them
+into the graph transform tool as the `--input_names` and `--output_names`
+arguments, and call the `strip_unused_nodes` transform, like this:
+
+ bazel run tensorflow/tools/graph_transforms:transform_graph --
+ --in_graph=tensorflow_inception_graph.pb
+ --out_graph=optimized_inception_graph.pb --inputs='Mul' --outputs='softmax'
+ --transforms='
+ strip_unused_nodes(type=float, shape="1,299,299,3")
+ fold_constants(ignore_errors=true)
+ fold_batch_norms
+ fold_old_batch_norms'
+
+One thing to look out for here is that you need to specify the size and type
+that you want your inputs to be. This is because any values that you’re going to
+be passing in as inputs to inference need to be fed to special `Placeholder` op
+nodes, and the transform may need to create them if they don’t already exist. In
+the case of Inception v3 for example, a `Placeholder` node replaces the old
+`Mul` node that used to output the resized and rescaled image array, since we’re
+going to be doing that processing ourselves before we call TensorFlow. It keeps
+the original name though, which is why we always feed in inputs to `Mul` when we
+run a session with our modified Inception graph.
+
+After you’ve run this process, you’ll have a graph that only contains the actual
+nodes you need to run your prediction process. This is the point where it
+becomes useful to run metrics on the graph, so it’s worth running
+`summarize_graph` again to understand what’s in your model.
+
+## What ops should you include on mobile?
+
+There are hundreds of operations available in TensorFlow, and each one has
+multiple implementations for different data types. On mobile platforms, the size
+of the executable binary that’s produced after compilation is important, because
+app download bundles need to be as small as possible for the best user
+experience. If all of the ops and data types are compiled into the TensorFlow
+library then the total size of the compiled library can be tens of megabytes, so
+by default only a subset of ops and data types are included.
+
+That means that if you load a model file that’s been trained on a desktop
+machine, you may see the error “No OpKernel was registered to support Op” when
+you load it on mobile. The first thing to try is to make sure you’ve stripped
+out any training-only nodes, since the error will occur at load time even if the
+op is never executed. If you’re still hitting the same problem once that’s done,
+you’ll need to look at adding the op to your built library.
+
+The criteria for including ops and types fall into several categories:
+
+- Are they only useful in back-propagation, for gradients? Since mobile is
+ focused on inference, we don’t include these.
+
+- Are they useful mainly for other training needs, such as checkpoint saving?
+ These we leave out.
+
+- Do they rely on frameworks that aren’t always available on mobile, such as
+ libjpeg? To avoid extra dependencies we don’t include ops like `DecodeJpeg`.
+
+- Are there types that aren’t commonly used? We don’t include boolean variants
+ of ops for example, since we don’t see much use of them in typical inference
+ graphs.
+
+These ops are trimmed by default to optimize for inference on mobile, but it is
+possible to alter some build files to change the default. After alternating the
+build files, you will need to recompile TensorFlow. See below for more details
+on how to do this, and also see optimizing binary size
+for more on reducing your binary size.
+
+### Locate the implementation
+
+Operations are broken into two parts. The first is the op definition, which
+declares the signature of the operation, which inputs, outputs, and attributes
+it has. These take up very little space, and so all are included by default. The
+implementations of the op computations are done in kernels, which live in the
+`tensorflow/core/kernels` folder. You need to compile the C++ file containing
+the kernel implementation of the op you need into the library. To figure out
+which file that is, you can search for the operation name in the source
+files.
+
+[Here’s an example search in github](https://github.com/search?utf8=%E2%9C%93&q=repo%3Atensorflow%2Ftensorflow+extension%3Acc+path%3Atensorflow%2Fcore%2Fkernels+REGISTER+Mul&type=Code&ref=searchresults).
+
+You’ll see that this search is looking for the `Mul` op implementation, and it
+finds it in `tensorflow/core/kernels/cwise_op_mul_1.cc`. You need to look for
+macros beginning with `REGISTER`, with the op name you care about as one of the
+string arguments.
+
+In this case, the implementations are actually broken up across multiple `.cc`
+files, so you’d need to include all of them in your build. If you’re more
+comfortable using the command line for code search, here’s a grep command that
+also locates the right files if you run it from the root of your TensorFlow
+repository:
+
+`grep 'REGISTER.*"Mul"' tensorflow/core/kernels/*.cc`
+
+### Add the implementation to the build
+
+If you’re using Bazel, and building for Android, you’ll want to add the files
+you’ve found to
+the
+[`android_extended_ops_group1`](https://www.tensorflow.org/code/tensorflow/core/kernels/BUILD#L3565) or
+[`android_extended_ops_group2`](https://www.tensorflow.org/code/tensorflow/core/kernels/BUILD#L3632) targets. You
+may also need to include any .cc files they depend on in there. If the build
+complains about missing header files, add the .h’s that are needed into
+the
+[`android_extended_ops`](https://www.tensorflow.org/code/tensorflow/core/kernels/BUILD#L3525) target.
+
+If you’re using a makefile targeting iOS, Raspberry Pi, etc, go to
+[`tensorflow/contrib/makefile/tf_op_files.txt`](https://www.tensorflow.org/code/tensorflow/contrib/makefile/tf_op_files.txt) and
+add the right implementation files there.