CAAFE lets you semi-automate your feature engineering process based on your explanations on the dataset and with the help of language models. It is based on the paper LLMs for Semi-Automated Data Science: Introducing CAAFE for Context-Aware Automated Feature Engineering" by Hollmann, Müller, and Hutter (2023). CAAFE is developed as part of Prior Labs. CAAFE systematically verifies the generated features to ensure that only features that are actually useful are added to the dataset.
To use CAAFE, first create a CAAFEClassifier object specifying your sklearn base classifier (clf_no_feat_eng; e.g. a random forest or TabPFN)
and the language model you want to use (e.g. gpt-4):
clf_no_feat_eng = ...
caafe_clf = CAAFEClassifier(
base_classifier=clf_no_feat_eng,
llm_model="gpt-4",
iterations=2
)Then, fit the CAAFE-enhanced classifier to your training data:
caafe_clf.fit_pandas(
df_train,
target_column_name=target_column_name,
dataset_description=dataset_description
)Finally, use the classifier to make predictions on your test data:
pred = caafe_clf.predict(df_test)View generated features:
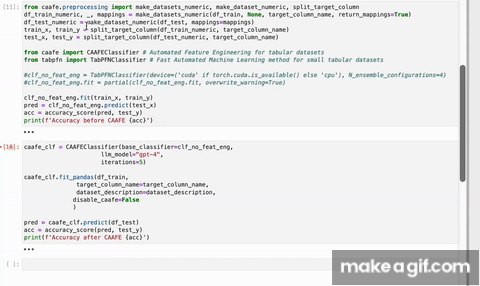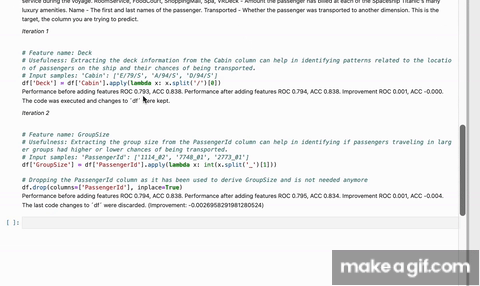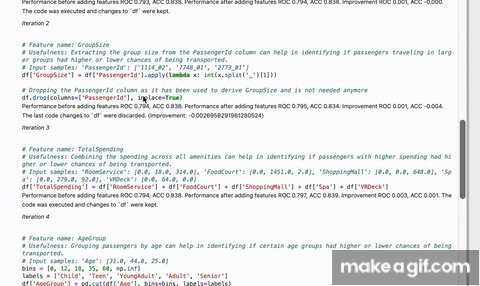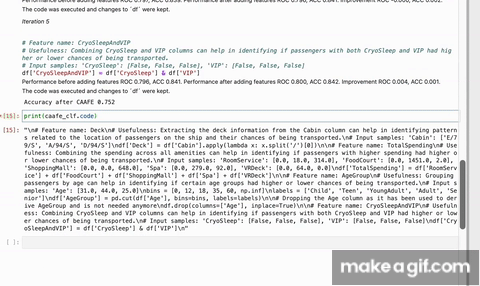
print(caafe_clf.code)GPT-4 is a powerful language model that can generate code. However, it is not designed to generate code that is useful for machine learning. CAAFE uses a systematic verification process to ensure that the generated features are actually useful for the machine learning task at hand by: iteratively creating new code, verifying their performance using cross validation and providing feedback to the language model. CAAFE makes sure that cross validation is correctly applied and formalizes the verification process. Also, CAAFE uses a whitelist of allowed operations to ensure that the generated code is safe(er) to execute. There inherent risks in generating AI generated code, however, please see [Important Usage Considerations][#important-usage-considerations].
Downstream classifiers should be fast and need no specific hyperparameter tuning since they are iteratively being called.
By default we are using TabPFN as the base classifier, which is a fast automated machine learning method for small tabular datasets.
from tabpfn import TabPFNClassifier # Fast Automated Machine Learning method for small tabular datasets
clf_no_feat_eng = TabPFNClassifier(
device=('cuda' if torch.cuda.is_available() else 'cpu'),
N_ensemble_configurations=4
)
clf_no_feat_eng.fit = partial(clf_no_feat_eng.fit, overwrite_warning=True)However, TabPFN only works for small datasets. You can use any other sklearn classifier as the base classifier.
For example, you can use a RandomForestClassifier:
from sklearn.ensemble import RandomForestClassifier
clf_no_feat_eng = RandomForestClassifier(n_estimators=100, max_depth=2)Try out the demo at: https://colab.research.google.com/drive/1mCA8xOAJZ4MaB_alZvyARTMjhl6RZf0a
Executing AI-generated code automatically poses inherent risks. These include potential misuse by bad actors or unforeseen outcomes when AI systems operate outside of their typical, controlled environments. In developing our approach, we have taken insights from research on AI code generation and cybersecurity into account. We scrutinize the syntax of the Python code generated by the AI and employ a whitelist of operations allowed for execution. However, certain operations such as imports, arbitrary function calls, and others are not permitted. While this increases security, it's not a complete solution – for example, it does not prevent operations that could result in infinite loops or excessive resource usage, like loops and list comprehensions. We continually work to improve these limitations.
It's important to note that AI algorithms can often replicate and even perpetuate biases found in their training data. CAAFE, which is built on GPT-4, is not exempt from this issue. The model has been trained on a vast array of web crawled data, which inevitably contains biases inherent in society. This implies that the generated features may also reflect these biases. If the data contains demographic information or other sensitive variables that could potentially be used to discriminate against certain groups, we strongly advise against using CAAFE or urge users to proceed with great caution, ensuring rigorous examination of the generated features.
CAAFE uses OpenAIs GPT-4 or GPT-3.5 as an endpoint. OpenAI charges The cost of running CAAFE depends on the number of iterations, the number of features in the dataset, the length of the dataset description and of the generated code. For example, for a dataset with 1000 rows and 10 columns, 10 iterations cost about 0.50$ for GPT-4 and 0.05$ for GPT-3.5.
Read our paper for more information about the setup (or contact us
@misc{hollmann2023llms,
title={LLMs for Semi-Automated Data Science: Introducing CAAFE for Context-Aware Automated Feature Engineering},
author={Noah Hollmann and Samuel Müller and Frank Hutter},
year={2023},
eprint={2305.03403},
archivePrefix={arXiv},
primaryClass={cs.AI}
}Copyright by Noah Hollmann, Samuel Müller and Frank Hutter.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the specific language governing permissions and limitations under the License.