- Melanie Tosik (mt3685),
tosik@nyu.edu - Antonio Mallia (am8949),
me@antoniomallia.it - Kedar Gangopadhyay (skg2016),
kedarg@nyu.edu
The Fake News Challenge is an ongoing competition first held in 2017. The goal of the challenge was to explore how current techniques in natural language processing (NLP) and machine learning (ML) can be utilized to combat the fake news problem.
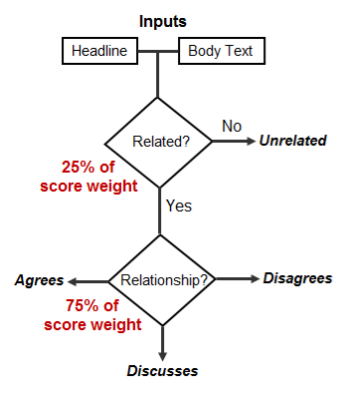
Stage 1 of the Fake News Challenge ("FNC-1") focuses on the first step in detecting fake news, the task of stance detection. Stance detection commonly involves estimating the relative perspective (or stance) of two pieces of text relative to a given topic, claim, or issue. More specifically, FNC-1 extends the stance detection work of Ferreira and Vlachos (2016). Here, the task is to estimate the stance of a body text from a news article relative to a given headline and categorize it into one of four categories: agree, disagree, discusses, or unrelated.
Schematic scoring process
Source: http://www.fakenewschallenge.org/
Over the course of the challenge, 50 competing teams designed and developed NLP/ML systems for fake news detection. All of the top scoring systems at least partially rely on neural network architectures for classification, based on a variety of vector transformations of the input data (Pan et al., 2017; Hanselowski et al., 2017; Riedel et al., 2017).
Due to the uneven distribution of categories in the training data, top scoring systems performed very well on instances that were "unrelated", but often failed to correctly identify instances of "agree" and "disagree". We are hoping to overcome this limitation of deep learning models by using a number of hand-crafted NLP features specifically designed to capture semantic roles and syntactic relationships as input to a traditional classifier. In addition, our objective is to outperform the official (neural) baseline model released by the FNC-1 organizers.
The original FNC-1 dataset and evaluation script are publicly available online. The dataset consist of 49,972 labeled article headline and body pairs, which are derived from the Emergent Project (Silverman, 2015).
A sample of the data looks like this:
Headline,Body ID,Stance
Police find mass graves with at least '15 bodies' near Mexico town where 43 students disappeared after police clash,712,unrelated
The distribution of the output labels is overwhelmingly "unrelated" to the headline, as shown below:
| rows | unrelated | discuss | agree | disagree |
|---|---|---|---|---|
| 49,972 | 0.73131 | 0.17828 | 0.0736012 | 0.0168094 |
FNC-1 provides a baseline model based of hand-engineered features (such as n-gram co-occurrence counts between the headline and article and indicator features for polarity and refutation) and a gradient-boosting classifier. Based on this model, the baseline accuracy was 75.20%.
As mentioned previously, the baseline implementation performs well in separating related stances from unrelated ones, but rather poorly when differentiating between "agree", "disagree", and "discuss". Our goal is to improve performance on this part while still achieving the baseline accuracy.
Stance detection is a two-fold task. First, the system needs to determine whether the body/heading pair is "related" or "unrelated". If the example pair is found to be "related", the system further needs to assign a category of "agree", "disagree", or "discuss".
For the first part, we plan to incorporate features that capture specific syntactic and semantic relationships between the heading and the sentences in the main body text. It might also prove useful to convert the unstructured text into structured tuples or triples according to their semantic roles. This initial classification is generally expected to be easier and less relevant for detecting fake news, and is therefore given less weight in the evaluation metric.
The second part of the problem (classification into "agree"/"disagree"/"discuss") is more difficult and relevant to fake news detection, thereby given more weight in the evaluation metric. For this step, we believe that sentiment scores and word embeddings will be useful features for the model to learn to distinguish between the fine-grained categories.
We plan to evaluate at least the following features, among others, over the course of the project:
- co-occurrence counts
- syntactic dependency relations
- sentiment scores
- word embeddings, e.g. GloVe
- cosine similarity between TF-IDF vectors
- semantic role labels
- others
-
William Ferreira and Andreas Vlachos. Emergent: a novel data-set for stance classification. In Proceedings of NAACL: Human Language Technologies. Association for Computational Linguistics, 2016. http://aclweb.org/anthology/N/N16/N16-1138.pdf
-
Andreas Hanselowski, Avinesh PVS, Benjamin Schiller, and Felix Caspelherr. 2017. Description of the system developed by Team Athene in the FNC-1.
-
Yuxi Pan, Doug Sibley, and Sean Baird. Talos Targets Disinformation with Fake News Challenge Victory. 2017. https://blog.talosintelligence.com/2017/06/talos-fake-news-challenge.html.
-
Benjamin Riedel, Isabelle Augenstein, Georgios P. Spithourakis, and Sebastian Riedel. A simple but tough-to-beat baseline for the Fake News Challenge stance detection task. 2017. https://arxiv.org/abs/1707.03264.
-
Craig Silverman. 2015. Lies, Damn Lies and Viral Content. https://towcenter.org/research/lies-damn-lies-and-viral-content/.