Reward progressive images #68
Comments
|
That makes sense at a high level, but it would be interesting to dig into the details and see how we can define something like that in terms that are:
|
|
Exciting! If we have/had:
...it would be nice to be able to determine when "enough" resolution had been loaded in terms of image density (rendered image pixels ÷ painted CSS pixels). This way, the notion of "enough" works nicely across layout sizes and doesn't depend on final image density. After one minute of experimentation I'll throw out an initial, completely subjective value for "enough" of between 0.05x and 0.1x. |
|
I would propose to define "enough" resolution as 1:8 (so 0.125x), where you look at the maximum of the layout dimensions and the intrinsic image dimensions. So if the image gets upscaled, you still need more than the 1:8 of the image itself. If it doesn't get rescaled, then it's 1:8 of the image itself. If it gets downscaled, it's still 1:8 of the image itself - in theory if the image is twice as wide as the render width, a 1:16 version of the image would be enough already to get a 1:8 preview, but I don't think we should reward oversized images, which is why I would propose to still require 1:8 of the image itself in the oversized image case. The format-agnostic definition could be something like this: LCP is the event when the image is rendered with sufficient precision such that at the maximum of the layout dimensions and intrinsic image dimensions, when comparing a 1:8 downscale of the final image to a 1:8 downscale of the rendered preview, the PSNR is above 30 dB (or whatever other simple-to-define difference threshold). Format-specific versions of this are easy to implement, at least in the no-upscaling case:
|
|
+1. Ensuring the approach we land on is format agnostic feels key. I like the two requirements proposed of establishing effective resolution and layout size with only the partial image as a starting point. Jon's exercise in suggesting a 1:8 resolution as "good enough" also resonates and mapping this requirement to popular and emerging image formats is exactly the type of approach I'd like to see so we aren't constraining the solution to a particular subset of formats. |
|
+1 to defining good enough as 1:8th of the resolution. It's simple enough to be applicable to future formats. It's very important that it perfectly matches JPEG's DC-only rendering, because progressive JPEG is going to be the most popular format for this case for a while. |
|
I'd love for this to be somewhat user-defined or at least user-validated. Short of a user study, we could perhaps run a known image set through a recent-ish classification model at full and various subsampled ratios to see how far we can go with minimal AUC loss, corresponding to our intent that LCP is the point at which the user "gets" what the image is just as well as if they saw the full resolution image. The risk is this test might trigger model-specific quirks that don't reflect human perception, possibly mitigated by using a few different models. |
|
Indeed! Personally, I doubt 1/8th will provide a level that's good enough. I understand why it would be easy to implement, but don't think this should be a major consideration. |
|
If 1:8 is not considered 'good enough', you could also go for 1:4 or 1:2. In JPEG, that roughly corresponds to progressive scans where DCT coefficients 0-5 or 0-14 are available. What is 'good enough' will depend on the kind of image: if the most important part of the image is text in a small, thin font, then you'll probably need the full 1:1 image to read it. If it's a high-res photo, then probably the 1:8 image is enough to understand what the image is depicting (though of course to fully enjoy it, you'll need more detail). If it's a thumbnail photo, then probably 1:8 is not enough. So perhaps the detail required should be linked to the area of the image: a full viewport width image may be usable with 1:8, while if the LCP happens to be just a 20vw wide image, maybe 1:2 is needed. |
|
I'm afraid that the diversity of use-cases for images is just way to broad for any single cut off point to be unarguably good enough for everyone. For example, images with small text in them may need to be 1:1 resolution, otherwise the small text will be a mushed mess. But then there's lots of websites with stock-photo like hero images. With images that merely need to provide a matching background color. News sites that have a photo from a press conference or a shot of people on the street. In such photos you only need the general idea of the subject. Or if a user is browsing an online shop looking for orange socks, then even a single blue pixel preview is fully functional in telling them it's not the product they're looking for. There are couple more circumstances to keep in mind:
|
|
Is there a way to get a representative sample of LCP images, in order to manually estimate if they require 1:1, 1:2, 1:4, 1:8, 1:16, 1:32 to be 'enough' to use the page? My gut feeling is that for the bulk of the images, 1:8 will be OK to convey the main visual message, with exceptions where more detail is needed or where less detail is still OK. |
|
To get a representative sample, I think the HTTP Archive is the best source. I queried the lighthouse table, which outputs the LCP along with an html snippet, to get all the sources from Not all the urls have an image LCP, but I did get 3 million results. Here it is in CSV format. Note that I didn't attempt to correct for the fact that some src tags are relative, but it should be pretty easy to combine the origin and the relative tags. |
|
Thanks, @anniesullie ! I'm taking a look at the csv, and the shorter urls can be used, but the longer ones are truncated and end with three dots, like this: But I'll just look at the shorter urls, there's no way I'm going to look at 3 million results anyway :) |
|
I quickly hacked something to take a look at what a 1:8 preview looks like for these images. and the output of that, you can see here: http://sneyers.info/foo/foo1.html The script skipped the truncated urls, but still there are some that don't work for whatever reasons. Just to get an idea though, this should be good enough. Note that both the original and the 1:8 image get scaled to an arbitrary width of 500 css pixels, which can be larger or smaller than how it is on the actual page, so that's not perfect but still, it gives an idea. Also the browser upsampling of the 1:8 is probably not as nice as the state of the art DC upsampling methods. |
|
After going through the first 25 pages of this, I think the following heuristic makes sense:
This ensures that the 1:8 image is at least 37 pixels in both dimensions. 300 pixels is of course an arbitrary threshold and can be replaced by some other number. Or perhaps a better heuristic would be to look at total (intrinsic) pixels, corrected for aspect ratio where less-square images need to be larger before the "1:8 is good enough" rule holds. In particular, when you have a very wide – or occasionally, very tall – image (e.g. 600x80), it tends to contain text and then the 1:8 version (eg. 75x10) will not be 'good enough'. But then again it also happens that you have a very wide photographic image where the 1:8 version is in fact OK, even if the image is only 200 or 300 pixels high. So maybe something like this: let the intrinsic image dimensions be W and H, then For example, a 100x1000 image needs to be full resolution before LCP is counted (since the corrected area is only 31k = 100k * sqrt(0.1)), and so would a 200x1000 image (corrected area is 89k = 200k * sqrt(0.2)), but a 300x1000 image would be considered OK at 1:8 (corrected area is 164k = 300k * sqrt(0.3)). With this heuristic, the smallest image where 1:8 would be considered OK would be a square with dimensions ⌈sqrt(100k)⌉, so a 317 x 317 image. A 1000x220 image would also (just barely) be OK, and so would a 300x400 image or a 280x500 image, but e.g. a 250x600 image would not be OK. So it's not very different from the "minimum 300 pixels on both dimensions" heuristic, but it does allow a dimension to go a bit below 300 if the total number of pixels gets large enough. But it does not just look at the total area, because then you might get cases like 100x1200 pixels which are probably not OK at 1:8 even though they have a lot of pixels. Here's a visualization of potential dimension heuristics, where the x and y axis are the image width and height (up to 1000 pixels), and green means "1:8 is OK" while red means "need full image". On the left is the heuristic "both dimensions have to be at least 300", in the middle is "area has to be at least 100k pixels", on the right is "corrected area has to be at least 100k pixels".
|

|
This feels like a good direction to me. Could you ask Moritz to give you the same upsampling algorithm that is used in libjpeg-turbo? I believe the results are going to feel substantially better as it is not going to produce as much gridding like bicubic. (In your example it might be just bilinear scaling which looks quite a lot worse than even bicubic.) |
|
In my examples you're seeing browser upscaling from a 1:8 downscaled image with lossy compression, so that's quite a bit worse than what upsampled DC can look like. But it would probably be close to what you'd see if e.g. an AVIF contains a 1:8 preview... |
|
@jonsneyers thanks for the detailed investigation! IMO the images on the 1:8 side (right side) of http://sneyers.info/foo/foo1.html look too blurry. The idea here is that the image should look ready, so I think we should consider a later stage, where the image is almost undistinguishable from when it's fully loaded. WDYT? |
|
If the idea is that the image should look ready, almost undistinguishable from fully loaded, then I think something more like 1:2 (or maybe 1:4) would be needed. Here's a comparison to get an idea: every row is original, 1:2, 1:4, 1:8 Note that there's quite a big difference between "image looks ready" and "image is rendered with enough detail to start using the page". Obviously, unless horribly oversized images are used, a 1:8 image should not "look ready". But in many cases it will be "good enough" to start using the page. If you go for a relatively strict "image looks ready" definition, i.e. something like 1:2, then that will mean that progressive JPEG will have a big advantage over other image formats – e.g. with AVIF you could embed a preview image to get some kind of progression (as @jakearchibald suggested), but if this embedded preview has to be good enough to be accurate relative to a 1:2 downscale, then it will not be much smaller than the image itself, making it kind of pointless. It would make sense to require more detail to be available as the image gets smaller, instead of having a hard cutoff between "1:1 is needed" and "1:8 is OK". And also to take DPR into account and require less detail as the density goes up. So with these refinements, here is my next iteration of a proposal for an updated LCP definition that properly rewards progressive previews, in a format-agnostic yet implementation-friendly and current-formats-compatible way: Proposed definition:If the LCP involves an image, then LCP is the event when the image gets rendered with sufficient precision such that at the maximum of the layout dimensions and intrinsic image dimensions, when comparing a 1:N downscale of the final image to a 1:N downscale of the rendered preview, the PSNR is above 30 dB, where N is defined as follows:
|
|
@npm1 I think "almost undistinguishable" is too-high a bar; "usable" is better. LCP rewards As @kornelski points out, "comprehension" is context-and-content dependent, and probably impossible for LCP to capture. But doing something imperfect to reward progressive image rendering >> doing nothing, IMO. |
|
Moritz proposed to use djpeg (from libjpeg-turbo 2.1) and truncated files for looking at interpolation: for swiss_flag.jpg progressive jpeg: This is what would happen in reality and is substantially sharper and without the artefacts shown in Jon's earlier simulation. Note that it is necessary to have libjpeg-turbo 2.1 for this to work properly. |
|
Updated/tweaked the script quite a bit, new script is here: http://sneyers.info/foo/bar/baz/make_html What you see is the original image on the left, with its dimensions and the LCP calculation (assuming dpr 1 and that the image dimensions are not smaller than the layout dimensions, i.e. no upscaling). Then there's an avif preview at the minimum scale required. For the 1:8 case, I've also included what happens if I convert the original image to a progressive JPEG (using jpegtran if it's a jpeg which is usually the case, or imagemagick if it's something else) and use the latest libjpeg-turbo to simulate the DC-only progressive preview. In my previous proposed definition, I said PSNR above 30 dB, but that threshold is too low, especially if it's going to be upsampled 8x. Using low-quality previews at 1:8 resulted in quite poor results after upsampling, especially compared to what JPEG DC upsampling can give (since the DC is basically lossless modulo color conversion). So I bumped up the threshold to 32+N, which probably makes more sense. Still need to define what colorspace/weights to use for PSNR, but the general idea is that the preview needs to have more precision as the 'acceptable downscale factor' N goes up. Proposed definition:If the LCP involves an image, then LCP is the event when the image gets rendered with sufficient precision such that at the maximum of the layout dimensions and intrinsic image dimensions, when comparing a 1:N downscale of the final image to a 1:N downscale of the rendered preview, the PSNR is above 32+N dB, where N is defined as follows:
|
|
After looking at more examples and thinking a bit more about it, I have some further thoughts. A lossy preview at 1:8 that gets upscaled does not look as good as the upsampled JPEG DC – as any compression artifacts get magnified 8x, it's not quite the same as upsampling from an effectively lossless 1:8 like a JPEG DC. Conceptually, PSNR thresholds are reasonable, but if you need to compare the preview with the final image in order to retroactively trigger the LCP event, it's perhaps not ideal from an implementation point of view. So perhaps it makes more sense to just assume that a sufficiently high-resolution preview is 'good enough', without actually checking that the preview is within some error threshold of the final image. I think that simplifies things quite a bit. But I would distinguish between an 'intrinsic' preview (like the DC or a progressive scan of a JPEG), which is part of the actual image, and an 'independent' preview (like a preview embedded in Exif or in the avif container), which is not part of the actual image and which is (most likely) lossy so upscaling it will result in magnified artifacts. So it could be wise to require e.g. a 1:4 embedded avif preview in cases when the 1:8 upsampled-DC preview is just barely good enough – especially if for practical/implementation reasons, checking the accuracy of the preview is not actually going to happen. To be on the safe side, I'm also bumping up the threshold for saying 1:8 is 'good enough' from a corrected_area of 400k pixels to one of 600k pixels, and the one for 1:16 from 2 megapixels to 3 megapixels. Here is another bunch of random samples of LCP images (original on the left) where 1:8 would be called 'good enough' according to the definition below, with on the right a simulation of what the DC-only preview would look like: http://sneyers.info/qux/foo1.html Proposed definition:If the LCP involves an image, then LCP is the event when the image or a preview of the image gets rendered with sufficient resolution to get (at least) a 1:N downscaled version of the image (w.r.t. to the maximum of the layout dimensions and intrinsic image dimensions), where N is defined as follows:
|
|
This is the single most important issue that will definitely decide the future of who wins the image-format wars. By logical thinking, I agree that the measure should account for But also, and more importantly for perceptive quality correctness:
Without knowing the user environment where is it being rendered,
There is a hard limit on the data you can possibly know from the User-Agent. However, having any thresholds may mislead and motivate developers to optimize on those thresholds. So, it is very important to not only think of the synthetic part of the problem but how it is experienced in real life and how developers might end up end using (or abusing) the score. Always prefer KISS metrics over Complex metrics for the web. Three Proposed solutions1. Largest Contentful Paint Minimum Viable Preview (
|
|
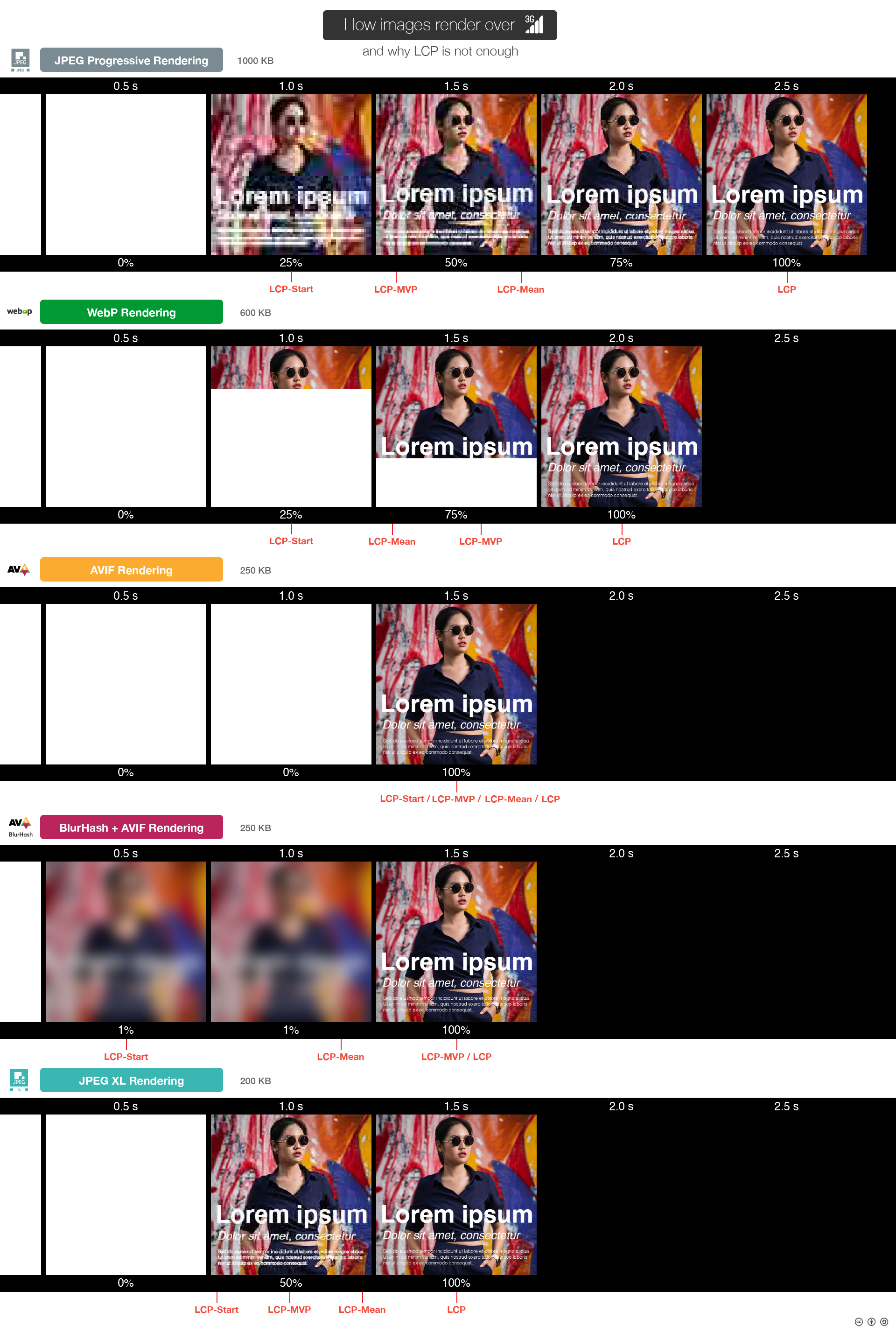
Thanks for the very insightful comments, @gunta ! Splitting it up in LCP-Start - LCP-MVP - LCP-End makes a lot of a sense to me. That concept also applies to other (non-image) types of LCP, e.g. for text the LCP-MVP could be when the text is rendered in a fallback font and LCP-Full when it is rendered in the actual correct font. LCP-Mean seems a bit redundant if you already have LCP-Start, LCP-MVP and LCP-End. Just taking some weighted average of those three is probably good enough. If we want to have a single LCP metric to optimize for, it would be that, then, imo. For this weighted sum, I would suggest weights that emphasize LCP-MVP but still take the other two (LCP-Start and LCP-End) sufficiently into account to make it worthwhile to also optimize those. Defining what is 'good enough' for LCP-Start may be a bit tricky – I think it should be better than just a solid color or a two-color gradient, but something like a WebP 2 triangulation or a blurhash or a 1:16 / 1:32 preview should be good enough. A 1:8 preview should certainly be good enough for this. I'm not sure how to define it in a way that can be measured though. Maybe just assume that any first paint besides just setting the background to a solid color or gradient is an LCP-Start? (that's rather easy to abuse though by just doing the same placeholder thing for every image) Putting LCP-MVP at 1:4 makes sense to me – and I agree with your suggestion (in the illustration) to count that as either 1:4 resolution of the full image, or the top 3/4 of the image loaded in the case of sequential formats like WebP (or sequential JPEG, I assume). |
|
Definitely. How to define LCP-MeanIn the end, it will depend on how easy to implement it is, but if
How to define LCP-StartFor LCP-Start yes it is hard to define, so first, we need to draw the lines of how much cheating do we allow. We have 2 main personas here:
I'd say we could cater to Regular web developers first, and improve the measurement method over time if cheating becomes something normal. The definition then could be something around the lines of:
|
|
Talking about cheating with a say fully white preview image artificially reducing the LCP: This kind of cheating is not possible within the use of progressive jpeg and progressive jpeg xl. A cheater has no possibility to emit data that will not also dominate the appearance of the final image. |
|
All image formats can be combined with blur hash like approaches, where a very low resolution preview is thrown away when the image rendering starts. My thinking is that blur hash-like things are more for comfort than for utility, and my belief is that LCP tries to measure the point where the user can start digesting the information on the web page. |
|
My a personal preference (based on my own experimentation) with large images (and we are talking about LCP, where L means largest), I'm not a great fan of ~50 byte blur hash, nor a ~200 byte preview. However, when we are able to invest 2000 bytes for a preview, there can already be some utility in it as main elements are starting to be consistently recognisable, while 50-200 byte images need to be blurred so much that they are exclusively for comfort in my viewpoint. |
Do you have a data-driven explanation for the variance in the swarming behaviour of temporal PSNR? For example if it is scan-script related or image type (text/photographic/high noise) related. |
|
I would drop the very large images (say above 5 MP) from the analysis, those shouldn't be the common case on the web. Also, instead of looking at random images, you could look at the LCP images @anniesullie extracted (link), and either take only the progressive ones, or use |
|
After looking at the images, their original compression quality, scan-scripts, I conclude that the most likely explanation for the variance in swarming is the noise (and texture) level in the image. Images with higher noise levels are trailing behind (lower in db) in temporal PSNR, images with low noise are ahead (higher in db) of the mean/average curves. Another interesting data point to support decision-making could be that at which progressive fraction images containing text become legible without significant extra effort. |
I'll look into filtering out the progressive images in the list, thanks! |
|
I ran the same analysis as above with 1000 progressive and 1000 sequential images from the list of @anniesullie and the results.
To get a better understanding of the images @anniesullie's dataset, I sample 10,000 from them. Out of those 26.16% were progressive. A histogram of their all of their sizes (with part of the long tail cut off) looks like this:
The sizes (in bytes) differ slightly between progressive and sequential
|



|
Andrew Galloni's and Kornel Lesiński's blog post states that a preview is available at 10–15 % of bytes, and that "at 50% of the data the image looks almost as good as when the whole file is delivered". At 20 % of the mean PSNR curve there is a slowdown of the PSNR growth. At 25 % a progressive image can look pretty good already. Based on the temporal PSNR curves and the common rules of thumb for progressive jpeg (like the one's in the blog post by Galloni and Lesiński) I propose that we look into triggering LCP for progressive JPEGs at 25 % or at 50 % of the bytes have been rendered. |
|
Here's a github gist that takes 50 random progressive images from the links in @anniesullie's list and for each image shows how it looks like when using 25% and 50% percent of the bytes. This uses an up-to-date version of libjpeg-turbo. For comparison the gist also includes the original jpeg, so each images appears three times:
https://gist.github.com/mo271/f4c6a0807d15ab0b0410078c3687670f In many cases it is hard to make out a difference between 50% and fully rendered and often the 25% version is already pretty good, although one can find a few examples where not even the first scan is finished. (In those cases this could be improved by using a more different scan script) |
|
In the cases where 15% of the file is not enough to show the first scan, almost always it's because of hugely bloated metadata or large color profiles. Web-optimized files are not supposed to have such baggage, of course. |
|
Based on the above data and examples, I'd suggest, in the case of progressive JPEGs, to trigger LCP-Start at 15% (unless it can already be triggered earlier because of a blurhash or whatever other LQIP approach; probably-full-DC is more than what's needed for LCP-Start), LCP-MVP at 40%, and of course LCP-End at 100%. For other formats, the format-agnostic definition I proposed earlier can be the guideline to come up with an easy-to-implement heuristic. At the moment, the only other progressive-capable web format would be JPEG 2000 (only in Safari), and I suppose interlaced GIF or PNG could also be counted as progressive, but those might be rather rare and not really worth it – Adam7 PNG interlacing tends to hurt compression quite a bit, especially on the kind of images where PNG is actually a good choice. |
|
Thanks all for the great analysis!! A few comments:
Going back to the criteria I stated above, a byte-based approach looks promising from the "interoperability" and "performance" perspective. If we properly define image format categories with different cut-offs ("progressive", "sequential with intermediate paints", "renders when image is complete", etc), we may be able to also make it format agnostic. Finally, as @vsekhar said, we would need to somehow validate the approach and the cut-off rates on actual humans, to ensure the PSNR analysis matches their perception. Might also be useful to run other image comparison metrics and see if they align to similar cut-offs. |
|
Not counting metadata is indeed important. In principle, you could make a 2 MB 'progressive JPEG' that actually turns out to be a CMYK image that starts with a 1 MB ICC profile, and contains proprietary Adobe metadata blobs with clipping paths and stuff like that. Obviously the cut-offs would not make sense on such an image. Similarly, if there happens to be metadata at the end (say some copyright strings), you could declare LCP-End before that metadata has been received. On the other hand, that's probably not worth the complication – there shouldn't be anything large after the end of the image data, and if there is, we probably want to discourage that rather than encourage it by not counting its download time. There's another caveat: some metadata influences rendering, in particular ICC profiles and Exif orientation (and Exif-based intrinsic sizes). While I agree to discount metadata for computing the cut-offs (having a lot of Exif camera makernotes is not going to render the image any sooner), it may be worth checking that the render-critical metadata is actually available when showing the progressive previews. You could in principle make a progressive jpeg, but the icc profile and/or exif orientation is only signaled at the very end of the bitstream. That would of course not be a nice experience. (Then again I have never seen this in the wild so maybe this is issue too theoretical to matter) The approach of byte-based cut-offs per 'format category' (or rather, 'format implementation category', since even the most progressive format could be implemented only in a "renders when all data arrived" way) seems to be simplest, where cut-offs are based on the actual image payload, excluding metadata that may also be present in the container. So for example, we could have something like this:
where afaik the current state of e.g. Chrome is this:
The progressive cut-offs are probably format-dependent, and even within a format, there could be different ways to do progressive. For example, in JPEG you can make a simple scan script that first does DC and then does all AC at once (or rather in 3 scans, because you have to do it component per component), which would result in cut-offs that are more like (15%, 80%, 100%), or you can do a more complicated scan script that has more refinement scans and results in an earlier cut-off for LCP-MVP. The latter is what you currently typically get in the wild, since it's what both MozJPEG and libjpeg-turbo do by default. We could also add the concept of 'preview images' that may be embedded in some containers, e.g. WebP2 is planning to have it, the AVIF container can do it, and in principle Exif metadata can also store a preview. Such previews would count as an earlier LCP-Start. |
|
BTW, I don't think it's possible to have a JPEG with EXIF or ICC at the end. libjpeg handles app markers before |
|
Also, the CSSWG resolved a while back that implementers should ignore render-impacting metadata that comes after the image data. The relevant spec changes are here. |
|
Yoav Weis: 'to ensure the PSNR analysis matches their perception' We are lucky that a lot of research has been done on this already. General consensus on simple metrics like Y-PSNR and Y-MS-SSIM is that they do indicate image quality in the case where no image specific Y-PSNR or Y-MS-SSIM optimizations have been done. Some TID2013 'full corpus' SROCC values (higher value is better): SSIM | 0.4636 Multi-scale metrics (PSNRHVSM, PSNRHVS, MSSIM, Butteraugli, SSIMULACRA, DSSIM) perform better than single-scale metrics (PSNR and SSIM). Multi-scale metrics give a further boost for progressive since progressive coding sends the lower (more important) frequencies first. |
|
Some food for thought on sending some high frequencies later: One analogy with progressive encoding having not yet sent the high frequency components are the four other common ways of not sending high frequency components: YUV420 never sends 50 % of the coefficients. They are just effectively zeroed. The images look worse, get higher generation loss, etc., but not that much worse that it would always matter in common internet use. I believe about 75 % of JPEGs in the internet are YUV420. The second strategy (possibly adobe's jpeg encoder) that I have seen is to zero out the last 28 coefficients (44 %) in zigzag order. These coefficients are just not sent (or have so high quantization matrix values) that they are always zeroed in many jpeg images found in the wild. The third is that in AVIF there is a way to describe a 64x64 block transform with 75 % of values zeroed out. If you use this transform in YUV420 context, you will have 87.5 % of the high frequency data zeroed out. Fourth is in AV1 (AVIF, too?) -- there is a way to describe a resampling of the image (x-direction only). If you specify a 4/3 you will lose another 25 % of the high frequency data. YUV420, x-resampling and 64x64 blocks, lead to a situation where less than 10 % of the original data is kept. These approaches remove high frequencies. Why do we not care about high frequencies? Because images work well without all the higher frequencies, in both normal image coding and in progressive phases, especially so for photographic content. |
|
I have tried to capture the common sentiment in this issue by this proposal:
I suggest that we prepare a manual viewing of 200 such progressive JPEG renderings to verify the plausibility of this rather conservative approach. I believe we will be in a better state at discussing the V&V activities once we look at the renderings generated with these rules. I suggest we don't split the LCP metric into many metrics to maintain overall simplicity. Users of LCP (such as webmasters, search engine companies, search engine optimizing companies) have limited capacity to deal with such complexity. I suggest we close this bug in a few days and continue the discussion on the more focused proposal outlined in this comment. 'Reward progressive images' 🠒 'Trigger LCP at 50 % for progressive JPEG' |
|
I agree with keeping it simple, for the sake of both webdevs and not complicating the implementation of LCP. Conceptually, splitting things in LCP-Start, LCP-MVP, LCP-End makes sense, each with their own weight in the overall LCP computation, and with a format-agnostic definition. But then for a given concrete format, things can be simplified and rounded a bit: e.g. it could boil down to the following: for progressive JPEG, LCP happens when 50% of the bytes have arrived; for WebP and sequential JPEG when 90% of the bytes have arrived; for AVIF when 100% is available (or 85% if they have an embedded preview). |
|
Rewarding images displayed with 50% of image data is better than nothing, but IMHO it's far from ideal:
So I wonder: could this metric involve time as a factor? Assume that humans need e.g. at least 500ms to notice small details in an image, so if good-enough image arrives within 500ms of first paint, that paint is as good as a full image. Given timestamps:
Then image LCP is It's meant to be the time when user can start paying attention to the image, and the image will be displayed fully by the time user focuses on smaller details in the image. |
|
I like the proposal of @kornelski to have such a 'human latency' bonus between the LCP-Start and LCP-MVP. Not sure if 500ms is the perfect value for it, but it makes intuitive sense to me. I'm not sure if LCP-Start requires 1:8 resolution; that excludes things like a blurhash or other extremely rough LQIPs. Also I'm not sure what to do with LCP-End – do we care about it, or is LCP-MVP the 'good enough' point that actually matters for LCP? Another question is if and how to reward sequential/incremental loading as opposed to waiting for all data before showing anything. For the purpose of creating the illusion of images loading sooner, incremental loading doesn't help much. For the purpose of interacting with a page on the other hand, having say 80 or 90% of the image shown is probably usually enough though (unless of course there happens to be something important at the bottom of the image). Perhaps LCP-Start should be split into two different things:
and then there's LCP-MVP which is "good-enough" to consider the image is 'loaded' for the purpose of interacting with the page – a PSNR of 33 dB w.r.t. final image or "50% of a progressive JPEG" makes sense for that. Then the LCP could for example be defined as To keep it easy to implement in a non-compute/memory intensive way, I think it will be necessary to make some assumptions and use some heuristics instead of actually maintaining a paint history for every image and checking when exactly certain criteria were met. That's the most accurate way to do it, and to e.g. reward better encoders, but it may be too expensive to do – perhaps it is feasible for a web perf tool to do that, but not for e.g. chrome telemetry. So to keep it reasonably simple, defining the sub-events in terms of (metadata-excluded) partial file cut-offs, we could have something like this:
Effectively, in the case of AVIF, that gives up to a 200ms bonus if a blurhash or tiny preview is added and up to a 500ms bonus if a good preview is added. In the case of progressive JPEG, it means 50% of the file size loaded is what counts for the LCP, with a bonus of up to 500ms. |
|
@kornelski If we want something more accurate but still extremely simple to deploy, we could integrate over the temporal Y-PSNR curve by using a respective corpus (like Annie's corpus). One possible algorithm for finding a single % value representing the temporal characteristics of a technique would be to step in equal steps of Y-PSNR from 18 db to 42 db in 1 db steps, and averaging the fractional times required to reach those db values. This approach can automatically and more fairly accommodate a larger variety of different progressive/sequential/preview/blurhash/etc. techniques than just deciding manually a single value. We could measure such a % value for different approaches: progressive JPEG, blurhash + progressive JPEG, sequential JPEG, AVIF with embedded small or big preview, only showing an average color and then the image, and choose the % based on classifying the decoding situation with the granularity chosen later. Quickly looking at Moritz's Y-PSNR temporal curves this approach would lead to 45 % value for progressive JPEGs and ~95 % value for sequential JPEGs, which are not far from what we have discussed before. |
When you write "fractional times" here, you mean the fraction of bytes transferred, right? If I understand correctly, this is then another way of grouping the data in the in my progressive/sequential fractial bytes versus Y-PSNR comparison ("temproal curves"). I plan to do such a grouping and update this comment once it's done. (Might take some days until I have the time to do it). |
Yes, exactly like in your previous graphs about 'PSNR between preview and final image / fraction of bytes used for preview'
What I propose is that we take the mean curve and compute the average fraction by looking up samples uniformly in db from that curve from 18–42 db range. Averaging those samples will give us a single fraction, i.e., a scalar in [0..1]. (Instead of the mean curve we could do that sampling for each image. However, looking at the swarming characteristics from the graph I suspect that there would not be a significant difference in the resulting value.)
Yay! |
|
Started a new issue #71 – this thread became too long. |
|
As suggested by @jyrkialakuijala, I condensed the above data by taking 1000 progressive jpgs and calculated PSNR between the entire jpg and the image generated from 5%, 10%, 15%, ..., 95% of the bytes. Then I take all images/fractions combinations that give a certain dB, binned by rounding to an integer. The plot shows the mean of fraction of bytes needed to obtain a certain PSNR. Averaging over all bins from 18dB to 42dB gives a fraction of 0.5. |

|
Moritz, could you generate these graphs for some specific scenarios, and compute the fractional number:
|
|
Here's a graph taking into account some of the suggested scenarios. I didn't make anything for the combinations blurhash + x, because the plots would just look pretty identical to x, since blurhash doesn't affect the size. Also I didn't add any thumbnail + x, since there is too much freedom in choosing the size of the thumbnail. |

If the LCP is an image, it doesn't really make sense to give the same score to a 100 kB AVIF, a 100 kB WebP, and a 100 kB progressive JPEG. The AVIF will only be shown after 100 kB has arrived (it gets rendered only when all data is available), while you'll see most of the image after 90 kB of the WebP (since it is rendered sequentially/incrementally), or after 70 kB of the JPEG.
Instead of defining LCP as the time when the image has fully loaded, it could be defined as the time when the image gets rendered approximately, within some visual distance threshold compared to the final image.
The threshold should be high enough to not allow a tiny extremely blurry placeholder to count as the LCP, but low enough to e.g. allow an image that only misses some high-frequency chroma least significant bits, e.g. the final passes of a default mozjpeg-encoded jpeg.
The text was updated successfully, but these errors were encountered: