datamodel clarification - interpreting strings as things #3218
Comments
|
This essentially describes my own approach in the past, using There are related cases for literal datatypes, such as |
|
I decided to report a warning. with a link to the conformance text. I think that makes sense for a validation tool.
I do like the idea, apart from it will mean I would have to update the app. My comments in the app indicate that I found scenarios where the text was mapped to an @id and not 'name', and that it might be possible for it to map to other properties. Would it make sense to include a way to say which property it maps to? |
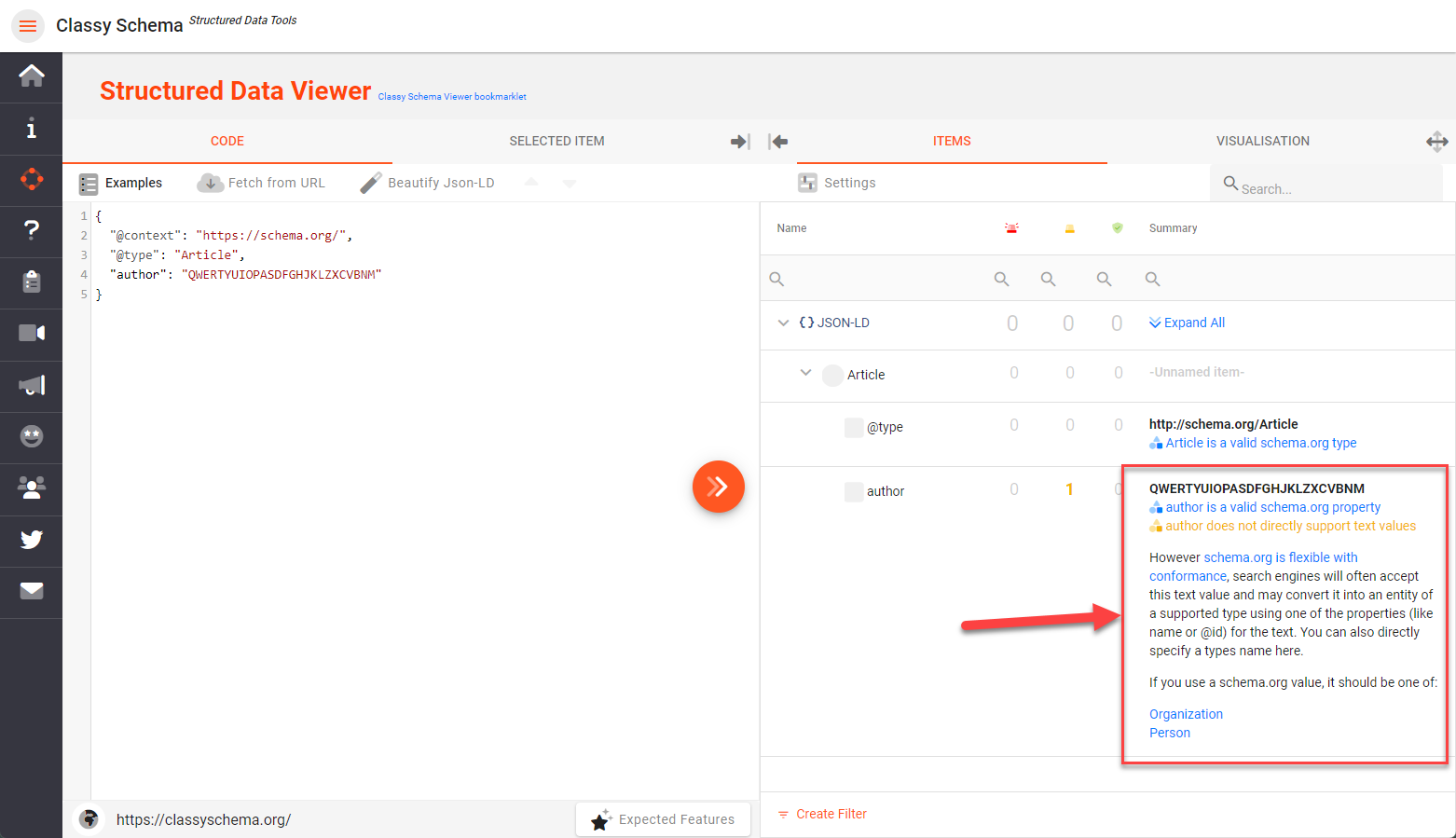
|
Good move @danbri ! In practice, I think that many Linked Data folks that are consuming schema.org annotations are already doing sort of this, programmatically, and an obvious effort to connect to is the Entity Reconciliation CG and in particular the Reconciliation API which offers already a Specification and a TestBench. One obvious implementation of it is a Wikidata Entity Reconciliation service (as per your last example) and the specification could also evolve in getting as additional input the suggested |
|
Thanks for the ping @rtroncy! Interesting issue for sure. Indeed the similarities with the problems addressed by the reconciliation API are quite clear (when it comes to the entity resolution part). Thinking out loud, I guess some consumers could rely on some collection of reconciliation services to help with this entity resolution, but they would have to know which reconciliation service to pick (since those are specific to a particular dataset / domain). That could be driven by various things: the source of the data to improve, the expected entity type, and perhaps other things. It's not really clear to me if / how this could be hammered in specs more precisely, but at least it's worth keeping the discussion going between our communities, to be aware of each others' efforts and needs. |
|
I obviously am interested, though I really don't think full reconciliation is the right metaphor. That's a much harder problem to do correctly. What I personally am interested at the moment in is just semantic sugar for convenience so the common case is easier to implement in markup and consumers can have some consistent behavior. While I agree a full reconciler could induce the type of a string much better, that's going to be potentially inconsistent across consumer if the data is underspecified. To fully expose what we currently do at Google with this since I don't think we've ever documented these hand-built exceptions and maybe it'll help discussion:
These were mostly motivating by supporting existing web ecosystem where things are underspecified as strings while allowing for growth into more complex types. These get tweaked a bit from year to year, but those are the types of operations we usually allow in this interpretation. |
|
This issue is being nudged due to inactivity. |
This issue addresses the situation in which Schema.org somewhat encourages the use of strings, on properties that are defined in a way that only expects one or more non-literal types. It proposes some additional documentation that can be used by applications that parse and consume Schema.org documentation.
We can do better than saying that consumers will often "do the best we can".
Background
From the start, schema.org has said in our datamodel docs:
We have said this for 10+ years now, and it is based on Schema.org's initial creation as a very Search-centric effort. Years later we are seeing other usecases alongside Search, in particular Schema.org's various connections to the world of Knowledge Graphs, where this kind of vague data and underspecified parsing rules risks holding back innovative uses of the data.
It is time to tidy up the "strings as things" piece of Schema.org, while respecting the fact that millions of pages still use this convention, particularly in our original primary syntax, HTML5 Microdata.
Proposal
We should improve our general documentation by sketching a minimal transformation on parsed Schema.org graphs which converts string-valued properties into entity-valued properties, where the referenced entity is described using at least one Schema.org type, while the original string property value (in absence of other information) then becomes the value of a property of the new entity.
Design Sketch
Rough idea, for some entity X with a property P whose value V is unexpectedly of a Text type, we can optionally create a replacement graph that expands and makes explicit that V can be seen as the value of a property on a previously implicit entity.
For this to be implementable, we sketch some options for assigning types and properties in this new structure.
/Thing, and the property/name./publisherproperty to say its best guess de-stringifying type is/Organization, whereas for '/author' it might be/Person. In the absence of this information, our most boring type,/Thing, could be used./destringifyTypeHint,/bestGuessType, ...Examples
Some initial examples, and suggestions for more complex examples and problems.
Example 1: The /publisher of an /Article
source-data:
{ "@context": "https://schema.org/", "@type": "Article", "publisher": "QWERTYUIOPASDFGHJKLZXCVBNM" }schema-defs:
output:
{ "@context": "https://schema.org/", "@type": "Article", "publisher": { "@type": "Organization", "name": "QWERTYUIOPASDFGHJKLZXCVBNM" } }(...since publishers tend towards being organizations, although they can be people).
Example 2: The /author of an /Article
source-data:
{ "@context": "https://schema.org/", "@type": "Article", "author": "QWERTYUIOPASDFGHJKLZXCVBNM" }schema-defs:
(...since authors tend towards being people, although they can be organizations).
output:
{ "@context": "https://schema.org/", "@type": "Article", "author": { "@type": "Person", "name": "QWERTYUIOPASDFGHJKLZXCVBNM" } }Notes and further work
Some notes on things to address.
annotation-less algorithms
Note that in the absence of the "/bestGuessType" hint from the schema definitions, it is possible to do something similar with generic techniques. Either by just using
/Thingeverywhere, or trying to walk up the (potentially multiple) supertype paths to find the nearest common super-type that covers the set of types which are declared as/rangeIncludesfor the property.Identifiers / entity resolution
Note that the default de-stringify transformation here does not attempt to assign a URI identifier or URL to the entity being introduced. In practice, certain applications might do so, e.g. in a Knowledge Graph context, a KG-specific identifier might be used.
In this case we might call this transformation something like a
local-heuristics-destringify-transform. But it quickly grows in scope and should probably be treated as a separate issue.
source-data:
{ "@context": "https://schema.org/", "@type": "Movie", "name": "The Black Hole", "brand": "The Walt Disney Company" }schema-defs:
output:
{ "@context": "https://schema.org/", "@type": "Movie", "name": "The Black Hole", "brand": { "@id": "https://www.wikidata.org/entity/Q7414", "@type": "Corporation", "name": "The Walt Disney Company" }Note that here a sophisticated transform goes substantially above the basic approach sketched. It does a few things that exploit additional out-of-band knowledge:
/brandhere is a particular organization, and gets the ID from a KG (in this example, Wikidata)./Brandtype, because it has matched something that is a Corporation, i.e. a particular kind of Organization.Next Steps
This is a slightly strange issue compared to our usual work here. It is partly a cleanup of the underlying datamodel, but also something that ought to be implementable in software. As such I suggest we try to characterise it with unit tests that parser-extractors could be measured against.
There are also other normalizations we could imagine documenting and testing in a similar manner, such as to always use https:// or http:// schema.org URIs within some data repository. Or to normalize when we have several ways of saying the same thing (e.g. opening hours). These are out of scope for this issue, but worth bearing in mind.
For a "basic stringify" algorithm and a set of candidate
/bestGuessTypehints, it would help to understand a bit more what's out there. Which properties should be prioritized for annotation in this manner, and how can we decide which type is the best default to apply when applying the transformation?The text was updated successfully, but these errors were encountered: