分布式存储系统是通过网络将数据分散存储在多台独立的设备上。 可扩展
分布式存储系统可以扩展到几百台甚至几千台的集群规模,而且随着集群规模的增长,系统整体性能表现为线性增长 ,分布式存储的水平扩展有以下几个特性:
1)节点扩展后,旧数据会自动迁移到新节点,实现负载均衡,避免单点过热的情况出现;
2)水平扩展只需要将新节点和原有集群连接到同一网络,整个过程不会对业务造成影响;
3)当节点被添加到集群,集群系统的整体容量和性能也随之线线扩展,此后新节点的资源就会被管理平台接管,被用于分配或者回收。
低成本
分布式存储系统的自动容错、自动负载均衡机制使其可以构建再普通的PC机之上。另外,线性扩展能力也使得增加、减少集群非常方便,可以实现自动运维。
高性能
无论是针对整个集群还是单台服务器,都要求分布式存储系统具备高性能
易用
分布式存储系统需要能够提供易用的对外接口,另外也需要具备完善的监控、运维工具,并能够与其他系统集成。
易管理
可通过一个简单的WEB界面就可以对整个系统进行配置管理,运维简便,极低的管理成本。
分布式存储系统的挑战主要在于数据,状态信息的持久化,需求在自动迁移、自动容错、并发读写的过程中保证数据的一致性。分布式存储系统设计的技术主要来自两个领域:分布式系统以及数据库。本地存储本地的文件系统,不能在网络上使用。
ext3 ext4 xfs ntfs
网络存储--网络文件系统。共享的都是文件系统。
nfs 网络文件系统
hdfs 分布式网络文件系统
glusterfs 分布式网络文件系统
共享的是裸设备
块存储 cinder ceph(块存储 对象存储 网络文件系统-分布式)
SAN(存储区域网)
分布式
集群
client
|
namenode 元数据服务器
|
----------------------------------------
| | |
datanode datanode datanode- Hadoop HDFS(大数据分布式文件系统)
HDFS(Hadoop Distributed File System)是一个分布式文件系统,是hadoop生态系统的一个重要组成部分,是hadoop中的存储组件,HDFS是一个高度容错性的系统,HDFS能提供高吞吐量的数据访问,非常适合大规模数据集上的应用。
HDFS的优点:
1.高容错性
数据自动保存多个副本
副本丢失后,自动回复
2.良好的数据访问机制
一次写入,多次读取,保证数据一致性
HDFS的缺点:
1.低延迟数据访问
难以应付毫秒级一下的应用
2.海量小文件存取
占用NameNode大量内存
3.一个文件只能有一个写入者
仅支持append(追加)- OpenStack的对象存储Swift
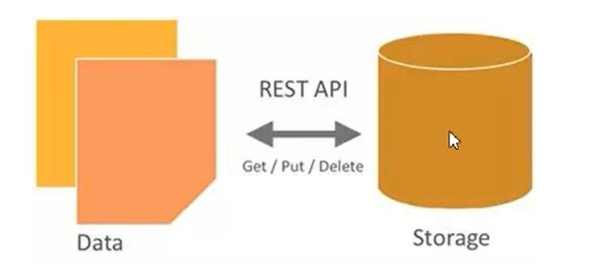
OpenStack Object Storage(Swift)是OpenStack开源云计算项目的子项目之一。Swift的目的是使用普通硬件来构建冗余的、可扩展的分布式对象存储集群,存储容量可达PB级,Swift是用Python开发的。
其主要特点为:
1.各个存储的节点完全对等,是对称的系统架构。
2.开发者通过一个RESTful HTTP API与对象存储系统相互作用
3.无单点故障:Swift的元数据存储是完全均匀随机分布的,并且与对象文件存储一样,元数据也会存储多份,整个Swift集群中,也没有一个角色是单点的。
4.在不影响性能的情况下,集群通过增加外部节点进行扩展。
5.无限的可扩展性:这里的扩展性分两方面,一是数据存储容量无限可扩展,二是Swift性能(如QPS,吞吐量等)可线性提升,扩容只需简单地新增集群,系统会自动完成数据迁移等工作,使各存储节点重新达到平衡状态。
6.极高的数据持久性
Swift可以用一下用途
图片、文档存储
长期保存的日志文件
存储媒体库(照片、音乐、视频等)
视频监控文档的存档
总结:Swift适合用来存储大量的、长期的、需要备份的对象。- 公有云对象存储
公有云大多都只有对象存储。例如,谷歌云存储是一个快速、具有扩展性和高可用性的对象存储
Amazon类似产品就是S3
微软类似产品Azure
阿里类似的有OSS- GlusterFS分布式文件系统
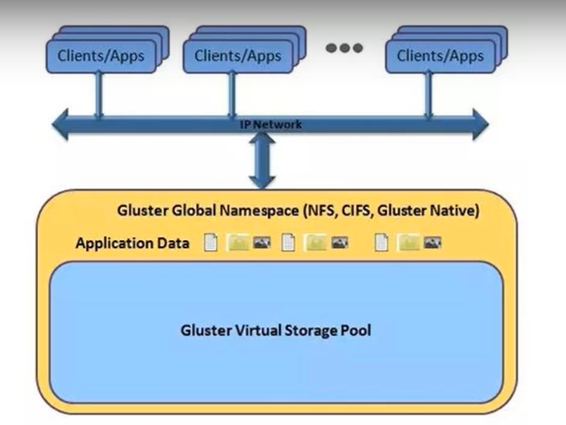
GlusterFS是一种全对称的开源分布式文件系统,所谓全对称是指GlusterFS采用弹性哈希算法,没有中心节点,所有节点全部平等。GlusterFS配置方便,稳定性好,可轻松达到PB级容量,数千个节点,2011年被红帽收购。
PB级容量 高可用性 基于文件系统级别共享 分布式
基本数据类型:条带,复制,哈希
各种卷的整理
分布卷:存储数据时,将文件随机存储到各台glusterfs机器上。
优点:存储数据时,读取速度快
缺点:一个brick坏掉,文件就会丢失
复制卷:存储数据时,所有文件分别存储到每台gluasterfs机器上
优点:对文件进行多次备份,一个brick坏掉,文件不会丢失,其他机器上的brick上面有备份
缺点:占用资源
条带卷:存数据时,一个文件分开存到每台glusterfs机器上
优点:对大文件,读写速度快
缺点:一个brick环境,文件就会坏掉Ceph使用C++语言开发,遵循LGPL协议开源,设计的初衷是变成一个可避免单节点故障的分布式文件系统,PB级别的扩展能力,而是是一种开源自由软件,许多超融合的分布式文件系统都是基于Ceph开发的。
Ceph是一个统一的分布式存储系统,设计初衷是提供较好的性能、可靠性和可扩展性。高扩展性:使用谱写X86服务器,支持10~1000台服务器,支持TB到EB级的扩展。
高可靠性:没有单点故障,多数据副本,自动管理,自动修复。
高性能:数据分布均衡
可用于对象存储,块设备存储和文件系统存储
基础存储系统
rados:基础存现系统RADOS(Reliable,Autonomic,Distribuuted object store,既可靠的、自动化的、分布式的对象存储).所有存储在Ceph系统中的用户数据事实上最终都是由这一层来存储的。Ceph的高可靠、高可扩展、高性能、高自动化等等特性本质上也是由这一层所提供的。
基础库librados:
librodos:这一层的功能是对RADOS进行抽象和封装,并向上层提供API,以便直接基于RADOS进行应用开发。特别要注意的是,RADOS是一个对象存储系统,因此,librodos实现的API也只是针对对象存储功能的。
高层应用接口
radosgw:对象网关接口
rbd:块存储
cephfs:文件系统存储,其作用是在librodos库的基础上提供抽象层次更高、更便于应用或客户端使用的上层接口。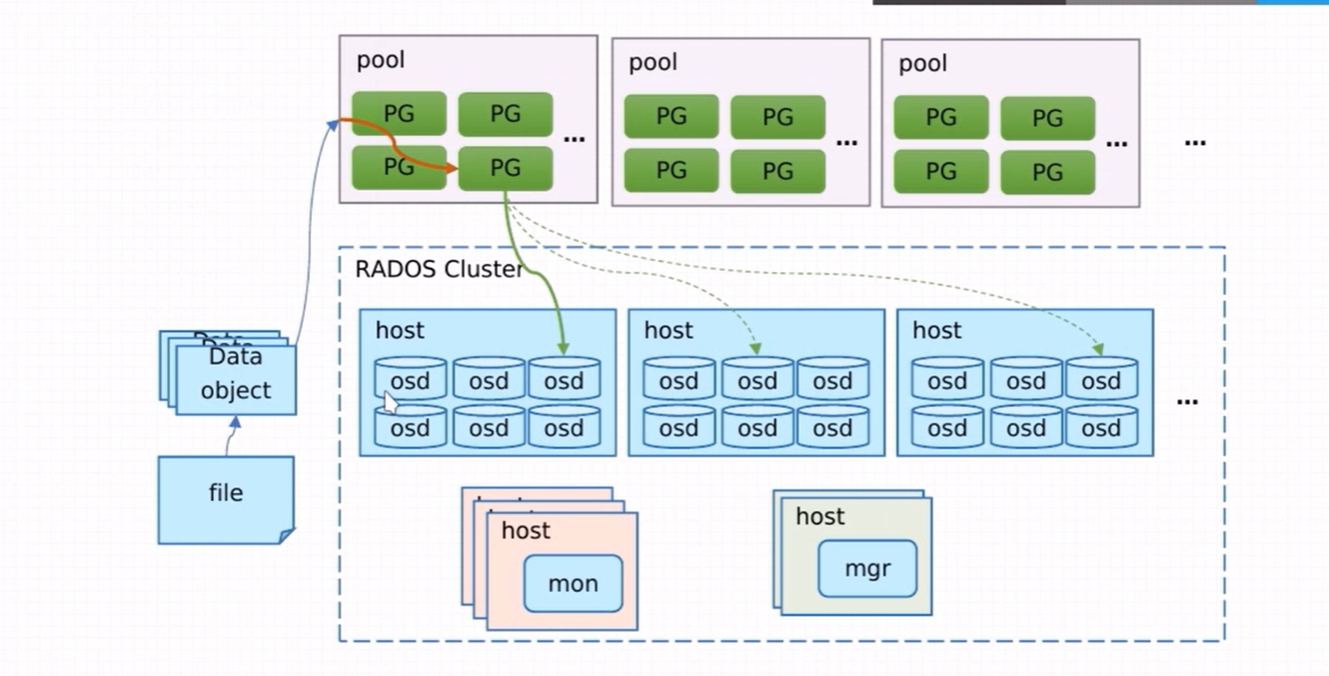

如上图所示,Ceph主要有三个基本进程
osd:
用于集群中所有数据与对象的存储。处理集群数据的复制、恢复、回填、再负载。并向其他osd守护进程发送心跳,然后向Mon提供一些监控信息。
当Ceph存储集群设定数据有两个副本时,则至少需要两个OSD守护进程即OSD节点,集群才能达到active+clean状态。
MDS(可选)
为Ceph文件系统提供元数据计算、缓存与同步(也就是说,ceph块设备和ceph对象存储不使用MDS)。在ceph中,元数据也是存储在osd节点中的,mds类似于元数据的代理缓存服务器。MDS进程并不是必须的进程,只有需要使用CEPHFS时,才需要配置MDS节点。
Monitor
监控整个集群的状态,维护集群的cluster MA二进制表,保证集群数据的一致性。ClusterMAP描述了对象存储的物理位置,以及一个将设备聚合到物理位置的桶列表。
Manager(ceph-mgr)
用于收集ceph集群状态,运行指标,比如存储利用率、当前性能指标和系统负载。对外提供ceph dashboard(ceph-ui)和resetful api,manger组件开启高可用时,至少2个- 块存储
典型设备:磁盘阵列,硬盘
主要是将裸磁盘空间映射给主机使用的。
优点:
通过Raid与LVM等手段,对数据提供了保护。
多快廉价的硬盘组合起来,提供容量
多块磁盘组合处理的逻辑盘,提升读写效率
缺点:
采用SAN架构组网时,光纤交换机,,造价成本高。
主机之间无法共享数据。
使用场景:
Docker容器、虚拟机磁盘存储分配
日志存储
文件存储- 文件存储
典型设备:FTP、NFS服务器
为了客服块设备文件无法共享的问题,所以有了文件存储
在服务器上架设FTP与NFS服务,就是文件存储
优点:
造价低,随便一台机器就可以了
方便文件共享
缺点:
读写速率低
传输速率慢
使用场景:
有目录结构的文件存储- 对象存储
为什么需要对象存储?
首先,一个文件包含了属性(术语交metadata,元数据,例如该文件的大小、修改时间、存储路径等)以及内容
例如FAT32这种文件系统,存储过程是链表的形式。
而对象存储则将元数据独立了出来,控制节点交元数据服务器,里面主要负责存储对象的属性,而其他负责存储数据的分布式服务器叫做OSD,主要负责文件的数据部分。当用户访问对象,会先访问元数据服务器,元数据服务器只负责反馈对象存储在哪些OSD,架设反馈文件A存储在B、C、D三台OSD,那么用户就会再次直接访问3台OSD服务器去读取数据。
这时候由于是3台OSD同时对外存储数据,所以传输的速度就加快了。当OSD服务器数量越多,这种读写速度的提升就越大,通过这种方式,实现了读写快的目的。
另一方面,对象存储软件是有专门的文件系统的,所以OSD对外又相当于文件服务器,那么久不存在文件共享方面的困难了,也就解决了文件共享方面的问题。
所以对象存储的出现,很好地结合了块存储和文件存储的优点。
优点:
具备块存储的读写速度
具备文件存储的共享等特性
使用场景:(适合更新变动较少的数据)
图片存储
视频存储Ceph核心组件及概念介绍
Monitor
监控整个集群的状态,维护集群的cluster MA二进制表,保证集群数据的一致性
OSD
OSD全程Object storage Device,也就是负责响应客户端请求返回具体数据的进程。一个Ceph集群一般都有很多个OSD
MDS
MDS全称Ceph Metadata Server,是CephFS服务依赖的元数据服务
Object
Ceph最底层的存储单元是Object对象,每个object包含数据和原始数据。
PG
PG全称Placement Grouops,是一个逻辑的概念,一个PG包含多个OSD。引入PG这一层其实是为了更好的分配数据和定位数据。
RADOS
RADOS全称Reliable Autonomic Distrubuted object Store,是Ceph集群的精华,用户实现数据分配,Failover等集群操作
Libradio
Librados是RODOS提供库,因为RADOS是协议很难直接访问,因此上层的RBD、RGW和CephFS都是通过librados访问的,目前提供PHP、Ruby、Java、Python、C和C++支持。
CRUSH
CRUSH是Ceph使用的数据分布算法,类似一致性哈希,让数据分配到预期的地方。
RBD
RBD全称RADOS Block Device,是ceph对外提供服务的块设备服务。
RGW
RGW全称RADOS gateway,是ceph对外提供的对象存储服务,接口与S3和Swift兼容
CephFS
CephFS全称Ceph File System,是ceph对外提供的文件系统服务。 - ceph-deploy
- ceph-ansible
- ceph-chef
- puppet-ceph
- 官方文档
- 红帽文档:https://access.redhat.com/documentation/en-us/red_hat_ceph_storage/4/
- SUSE文档:https://documentation.suse.com/zh-cn/ses/6/
| 序号 | 软件 | 版本 |
|---|---|---|
| 1 | OS | Centos7 |
| 2 | Kernel | Linux 3.10.0以上 |
| 3 | Ceph | 14.2.11 nautilus(stable) |
| 序号 | 节点 | public-network | cluster-network |
|---|---|---|---|
| 1 | client | 192.168.31.10 | 192.168.153.10 |
| 2 | node1 | 192.168.31.11 | 192.168.153.11 |
| 3 | node2 | 192.168.31.12 | 192.168.153.12 |
| 4 | node3 | 192.168.31.13 | 192.168.153.13 |
client节点同时作为deploy节点,在client节点执行:
ssh-keygen -t rsa -b 2048 -C "client@hebye.com" -N ""
ssh-copy-id -i ~/.ssh/id_rsa.pub 192.168.31.11
ssh-copy-id -i ~/.ssh/id_rsa.pub 192.168.31.12
ssh-copy-id -i ~/.ssh/id_rsa.pub 192.168.31.13echo "192.168.31.10 client client.hebye.com" >>/etc/hosts
echo "192.168.31.11 node1 node1.hebye.com" >>/etc/hosts
echo "192.168.31.12 node2 node2.hebye.com" >>/etc/hosts
echo "192.168.31.13 node3 node3.hebye.com" >>/etc/hosts说明:必须设置FQDN,也就是(Fully Qualified Domain Name)全限定域名,既带有主机名和域名的名称,不能只是主机名,ceph dashboard中prometheus、isicr target以及mgr service中都需要FQDN,所以这步比较重要,确保各主机能相互解析。
各个节点配置对应的主机名
hostnamectl set-hostname client
hostnamectl set-hostname node1
hostnamectl set-hostname node2
hostnamectl set-hostname node3- 关闭selinux
vim /etc/selinux/config
SELINUX=disabled- 关闭防火墙
systemctl stop firewalld
systemctl disable firewalld- client节点作为ntp server,在client、node1、node2、node3上安装ntp
yum install ntp -y- 在node1、node2、node3上配置ntp,添加client节点作为时间服务器
#修改配置文件
/etc/ntp.conf
修改为
server client iburst
#启动ntdpd
systemctl start ntpd
systemctl enable ntpd- 确认各个节点的ntp,指向了ntp server
[root@node2 ~]# ntpq -np
remote refid st t when poll reach delay offset jitter
==============================================================================
*192.168.31.10 139.199.215.251 3 u 578 1024 377 0.524 -5.003 2.489
[root@node2 ~]# 说明:yum源选择阿里云镜像站,速度相对比较快
- 删除client、node1、node2、node3节点默认yum源
rm -rf /etc/yum.repos.d/*- 添加Centos的yum源
wget -O /etc/yum.repos.d/CentOS-Base.repo https://mirrors.aliyun.com/repo/Centos-7.repo- 添加epel的yum源
wget -O /etc/yum.repos.d/epel.repo http://mirrors.aliyun.com/repo/epel-7.repo
yum makecachetouch /etc/yum.repos.d/ceph.repo
[root@client ~]# cat /etc/yum.repos.d/ceph.repo
[ceph]
name=ceph
baseurl=http://mirrors.aliyun.com/ceph/rpm-nautilus/el7/x86_64/
enabled=1
gpgcheck=0
[ceph-noarch]
name=noarch
baseurl=http://mirrors.aliyun.com/ceph/rpm-nautilus/el7/noarch/
enabled=1
gpgcheck=0
[root@client ~]# yum makecache| 序号 | 组件名称 | 进程名 | 功能 |
|---|---|---|---|
| 1 | Monitor | ceph-mon | 维护集群状态的maps,包括monitor map、manager map、OSD map、MDS map和CRUSH map。这些map是ceph守护进程相互协调所需的关键集群状态。monitor还负责管理守护进程和客户端之间的身份验证。冗余和高可用性通常需要至少三台monitor。 |
| 2 | Manager | ceph-mgr | 负责跟踪运行时的metrics(指标)和ceph集群的当前状态,包括存储利用率、当前性能指标和系统负载。ceph Manager守护进程还托管基于Python的模块来管理和公开ceph集群消息,包括基于web的ceph Dashboard(WebGUI服务)和REST API。高可用性通常需要至少两个managers |
| 3 | OSD | ceph-osd | object storage daemon,存储数据,处理数据replication、recovery、rebalancing,并提供一些监视信息到Ceph Monitors和Managers通过检查其他Ceph OSD守护进程检测信号。冗余和高可用性通常需要至少3个Ceph OSD。 |
| 4 | MDS | ceph-mds | 为ceph的文件存储提供元数据存储服务 |
- 在部署节点(client)安装ceph的部署工具
yum install python-setuptools -y
yum install ceph-deploy -y- 确保ceph-deploy的版本是2.0.1,不要安装1.x的版本
[root@client ~]# ceph-deploy --version
2.0.1
[root@client ~]# - 在node1、node2、node3执行下面命令,安装ceph相关的软件包
yum install -y ceph ceph-mon ceph-osd ceph-mds ceph-radosgw ceph-mgr- node1作为monitor节点,在部署节点(client)创建一个工作目录,后续的命令都在该目录下执行,产生的配置文件保存在该目录中。
mkdir ~/my-cluster
cd ~/my-cluster/
ceph-deploy new --public-network 192.168.31.0/24 --cluster-network 192.168.153.0/24 node1- 初始化monitor
[root@client my-cluster]# ceph-deploy mon create-initial- 将配置文件拷贝到对应的节点
[root@client my-cluster]# ceph-deploy admin node1 node2 node3- 如果想部署高可用monitor,可以将node2、node3也加入mon集群
#1 在其他节点查看ceph的状况
[root@node1 ceph]# ceph -s
cluster:
id: 5a070fb7-352c-4993-a9f3-420bec8a5f1a
health: HEALTH_WARN
mon is allowing insecure global_id reclaim
services:
mon: 1 daemons, quorum node1 (age 22m)
mgr: no daemons active
osd: 0 osds: 0 up, 0 in
data:
pools: 0 pools, 0 pgs
objects: 0 objects, 0 B
usage: 0 B used, 0 B / 0 B avail
pgs:
#2 解决HEALTH_WARN
$ ceph config set mon auth_allow_insecure_global_id_reclaim false
# 如果使用过程中,执行了一次没有效果的话,需先将其设置为true,然后再次设置为false
[root@node1 ceph]# ceph -s
cluster:
id: 5a070fb7-352c-4993-a9f3-420bec8a5f1a
health: HEALTH_OK
services:
mon: 1 daemons, quorum node1 (age 24m)
mgr: no daemons active
osd: 0 osds: 0 up, 0 in
data:
pools: 0 pools, 0 pgs
objects: 0 objects, 0 B
usage: 0 B used, 0 B / 0 B avail
pgs:
# 3将node2,node3节点加入monitor
[root@client my-cluster]# ceph-deploy mon add node2
[root@client my-cluster]# ceph-deploy mon add node- node1作为mgr节点,在部署节点(client)执行
[root@client ~]# cd /root/my-cluster/
[root@client my-cluster]# ceph-deploy mgr create node1- 如果想部署高可用mgr,可以将node2、node3也添加进来
[root@client my-cluster]# ceph-deploy mgr create node2 node3- 检查
[root@node1 ceph]# ceph -s
cluster:
id: 5a070fb7-352c-4993-a9f3-420bec8a5f1a
health: HEALTH_WARN
OSD count 0 < osd_pool_default_size 3
services:
mon: 3 daemons, quorum node1,node2,node3 (age 3m)
mgr: node1(active, since 114s), standbys: node2, node3
osd: 0 osds: 0 up, 0 in
data:
pools: 0 pools, 0 pgs
objects: 0 objects, 0 B
usage: 0 B used, 0 B / 0 B avail
pgs:ODS规划: 选用bluestore作为存储引擎,每个节点上选用/dev/sdb作为数据盘和日志盘,先确认每个节点的硬盘情况,然后再部署节点(在client)执行
- 确认每个节点的硬盘情况
[root@client my-cluster]# ceph-deploy disk list node1 node2 node3- 清理node1、node2、node3节点上硬盘上现有的数据和文件系统
[root@client my-cluster]# ceph-deploy disk zap node1 /dev/sdb
[root@client my-cluster]# ceph-deploy disk zap node2 /dev/sdb
[root@client my-cluster]# ceph-deploy disk zap node3 /dev/sdb - 部署osd
#bluestore方式,只有一块磁盘
[root@client my-cluster]# ceph-deploy osd create --data /dev/sdb node1
[root@client my-cluster]# ceph-deploy osd create --data /dev/sdb node2
[root@client my-cluster]# ceph-deploy osd create --data /dev/sdb node3
[root@node3 ~]# ceph -s
cluster:
id: 5a070fb7-352c-4993-a9f3-420bec8a5f1a
health: HEALTH_OK
services:
mon: 3 daemons, quorum node1,node2,node3 (age 25m)
mgr: node1(active, since 23m), standbys: node2, node3
osd: 3 osds: 3 up (since 51s), 3 in (since 51s)
task status:
data:
pools: 0 pools, 0 pgs
objects: 0 objects, 0 B
usage: 3.0 GiB used, 87 GiB / 90 GiB avail
pgs:- 查看OSD的状态
[root@client my-cluster]# ceph osd status
+----+-------+-------+-------+--------+---------+--------+---------+-----------+
| id | host | used | avail | wr ops | wr data | rd ops | rd data | state |
+----+-------+-------+-------+--------+---------+--------+---------+-----------+
| 0 | node1 | 1025M | 28.9G | 0 | 0 | 0 | 0 | exists,up |
| 1 | node2 | 1025M | 28.9G | 0 | 0 | 0 | 0 | exists,up |
| 2 | node3 | 1025M | 28.9G | 0 | 0 | 0 | 0 | exists,up |
+----+-------+-------+-------+--------+---------+--------+---------+-----------+
[root@client my-cluster]# ceph osd tree
ID CLASS WEIGHT TYPE NAME STATUS REWEIGHT PRI-AFF
-1 0.08789 root default
-3 0.02930 host node1
0 hdd 0.02930 osd.0 up 1.00000 1.00000
-5 0.02930 host node2
1 hdd 0.02930 osd.1 up 1.00000 1.00000
-7 0.02930 host node3
2 hdd 0.02930 osd.2 up 1.00000 1.00000
[root@client my-cluster]# ceph osd ls
0
1
2
[root@client my-cluster]# ceph osd dump[root@client ~]# cd ~/my-cluster/
[root@client my-cluster]# ls /etc/ceph/
rbdmap
[root@client my-cluster]# cp ceph.conf /etc/ceph/
[root@client my-cluster]# cp ceph.client.admin.keyring /etc/ceph/
[root@client my-cluster]# ceph -s
cluster:
id: 5a070fb7-352c-4993-a9f3-420bec8a5f1a
health: HEALTH_OK
services:
mon: 3 daemons, quorum node1,node2,node3 (age 87m)
mgr: node1(active, since 85m), standbys: node2, node3
osd: 3 osds: 3 up (since 63m), 3 in (since 63m)
data:
pools: 0 pools, 0 pgs
objects: 0 objects, 0 B
usage: 3.0 GiB used, 87 GiB / 90 GiB avail
pgs:
[root@client my-cluster]# -
1.使用systemd管理ceph服务
-
列出所有的ceph服务
[root@node1 ~]# systemctl status ceph\*.target ceph\*.service -
启动所有服务的守护程序
systemctl start ceph.target -
停止所有服务的守护程序
systemctl stop ceph.target -
按服务类型启动所有守护进程
systemctl start ceph-ods.target systemctl start ceph-mon.target systemctl start ceph-mds.target
-
按服务类型停止所有守护进程
systemctl stop ceph-ods.target systemctl stop ceph-mon.target systemctl stop ceph-mds.target
-
- 创建存储池
#语法
ceph osd pool create [pool-name] [pg-num] [pgp-num] [replicated]/[erasure]
[root@client ~]# ceph osd pool create test 64 64
pool 'test' created说明:默认情况下创建的存储池是replicated类型的
- 列出已经创建的存储池
[root@client ~]# ceph osd pool ls
test
[root@client ~]# - 重新命名存储池
[root@client ~]# ceph osd pool rename test ceph
pool 'test' renamed to 'ceph'
[root@client ~]# ceph osd pool ls
ceph
[root@client ~]# - 存储池基本管理
# 查询存储池的属性
[root@client ~]# ceph osd pool get ceph size
size: 3
# 查看pg数
[root@client ~]# ceph osd pool get ceph pg_num
pg_num: 64
#查看pgp数,一般小于等于pg_num
[root@client ~]# ceph osd pool get ceph pgp_num
pgp_num: 64
#查看刷新策略
[root@client ~]# ceph osd pool get ceph crush_rule
crush_rule: replicated_rule
[root@client ~]# - 删除存储池
# 第一次删除pool会提示错误:
[root@client ~]# ceph osd pool rm ceph
Error EPERM: WARNING: this will *PERMANENTLY DESTROY* all data stored in pool ceph. If you are *ABSOLUTELY CERTAIN* that is what you want, pass the pool name *twice*, followed by --yes-i-really-really-mean-it.
[root@client ~]#
#第二次删除pool会提示错误
[root@client ~]# ceph osd pool rm ceph ceph --yes-i-really-really-mean-it
Error EPERM: pool deletion is disabled; you must first set the mon_allow_pool_delete config option to true before you can destroy a pool
[root@client ~]#
# 修改配置文件
[root@client ~]# vim /root/my-cluster/ceph.conf
添加下面的配置
[mon]
mon_allow_pool_delete = true
#把配置文件推送到node1,node2,node3
[root@client ~]# cd /root/my-cluster/
[root@client my-cluster]# ceph-deploy --overwrite-conf config push node1 node2 node3
# node1,node2,node3重启ceph-mon服务
[root@node1 ~]# systemctl restart ceph-mon.target
[root@node2 ~]# systemctl restart ceph-mon.target
[root@node3 ~]# systemctl restart ceph-mon.target
# 再删除pool
[root@client my-cluster]# ceph osd pool rm ceph ceph --yes-i-really-really-mean-it
pool 'ceph' removed
[root@client my-cluster]#
[root@client ~]# ceph osd pool ls
[root@client ~]#
#重新创建pool
[root@client ~]# ceph osd pool create ceph 64 64
pool 'ceph' created- 检查集群的状态
ceph -s
ceph -w
ceph health
ceph health detail- 检查OSD状态
ceph osd status
ceph osd tree- 检查Mon状态
[root@client ~]# ceph mon stat -f json-pretty
[root@client ~]# ceph quorum_status -f json-prettyceph osd pool application enable ceph <app>
[root@client ~]# ceph osd pool application enable ceph rbd
enabled application 'rbd' on pool 'ceph'
[root@client ~]# 说明:app的可选择值是cephfs、rbd、rgw,如果不显示指定类型,集群将显示HEALTH_WARN状态(使用ceph health detail命令查看)
- 存储池配额管理
#根据对象数配额
ceph osd pool set-quota ceph max_objects 10000
#根据容量配额(单位:字节)
ceph osd pool set-quota ceph max_bytes 1048576
#查看
[root@client ~]# ceph osd pool get-quota ceph
quotas for pool 'ceph':
max objects: 10k objects
max bytes : 1 MiB
[root@client ~]# - 上传对象到存储池ceph
[root@client ~]# echo "test ceph object" >>test.txt
[root@client ~]# rados -p ceph put test ./test.txt- 列出存储池中的对象
[root@client ~]# rados -p ceph ls
hosts
test
[root@client ~]# - 从存储池下载对象
[root@client ~]# rados -p ceph get hosts /tmp/hosts
[root@client ~]# rados -p ceph get test /tmp/test.txt- 删除存储池的对象
[root@client ~]# rados -p ceph rm test hosts
[root@client ~]# rados -p ceph ls
[root@client ~]# # 1 所有的mgr节点安装dashboard
yum install -y ceph-mgr-dashboard -y
# 2 其中一个mgr开启插件
ceph mgr module enable dashboard
# 3 禁用SSL
ceph config set mgr mgr/dashboard/ssl false
# 4 配置监听IP
ceph config set mgr mgr/dashboard/server_addr 0.0.0.0
# 5 配置监听端口
ceph config set mgr mgr/dashboard/server_port 8444
# 6 设置用户及密码
echo "admin123" >password.txt
ceph dashboard ac-user-create admin -i password.txt administrator
# 7 使配置生效
ceph mgr module disable dashboard
ceph mgr module enable dashboard
# 8 通过查看ceph mgr services命令输出地址。
[root@node1 ~]# ceph mgr services
{
"dashboard": "http://node1.hebye.com:8444/"
}
# 9 开启prometheus监控
ceph mgr module enable prometheus
[root@node1 ~]# ceph mgr services
{
"dashboard": "http://node1.hebye.com:8444/",
"prometheus": "http://node1.hebye.com:9283/"
}
# 10 浏览器访问
http://node1.hebye.com:8444/ 或者 http://192.168.31.11:8444