基于 badger
v4.0.1进行源码分析
本文通过源码分析 badgerDB compaction 合并的实现原理. badger compaction 的实现跟 rocksdb 的实现大同小异, 像动态 level 空间阈值的计算、打分策略、并发 compaction 的实现参考了 rocksdb 的设计实现.
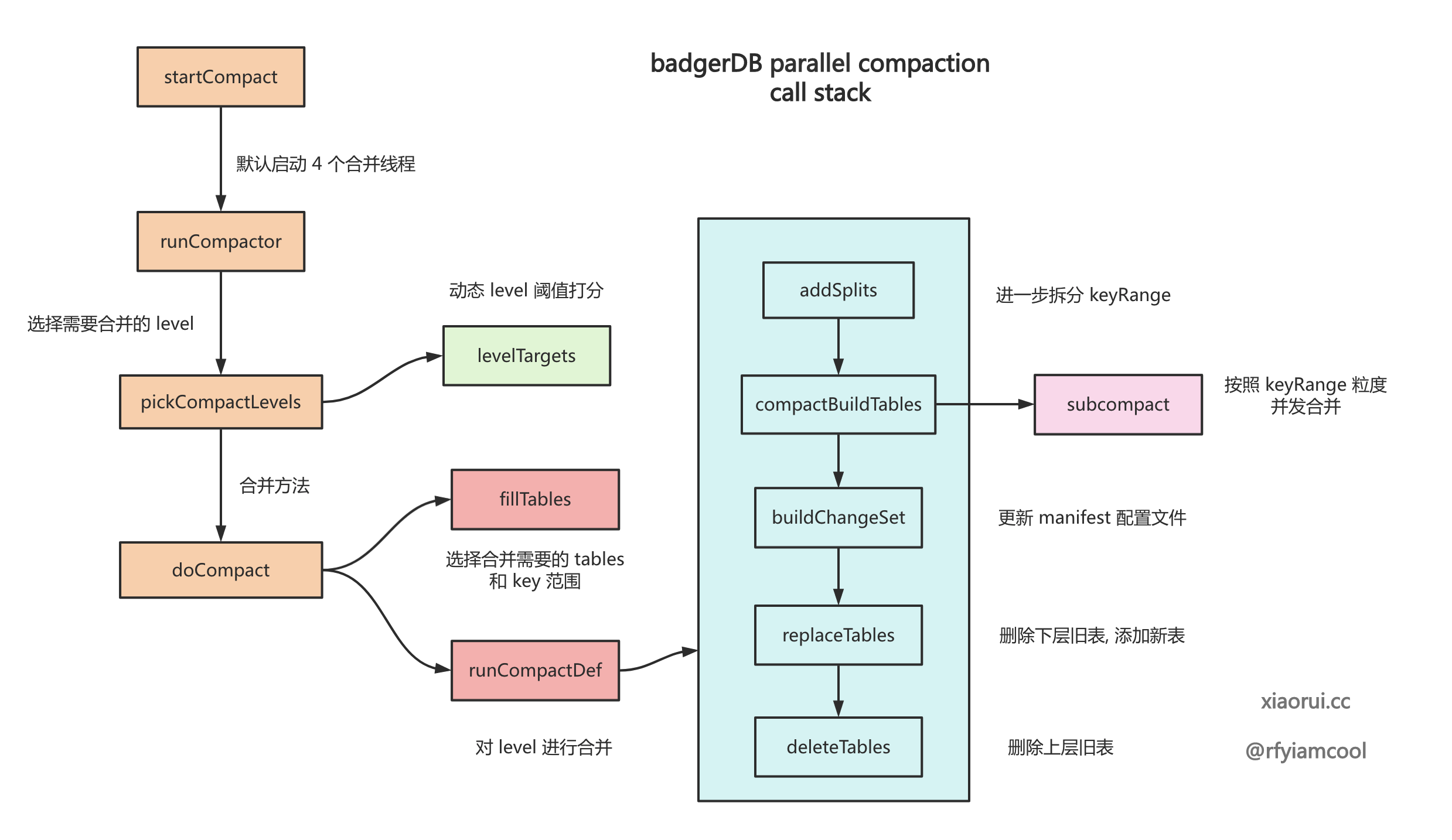
下面是 badger parallel compaction 并行合并的函数调用关系.
golang badger kv 存储引擎实现原理系列的文章地址 (更新中)
https://github.com/rfyiamcool/notes#golang-badger
Lsm Tree 把所有的数据修改操作转换为追加写 Append 的方法, 不管是增删改本质都是新增一条kv, 增加和修改好理解, 而删除操作是新写入一条 tombstone 标记的记录. Lsm Tree 所有的写操作不是原地更新, 而都是使用顺序 io 来追加写操作, 这样极大的提高了写性能.
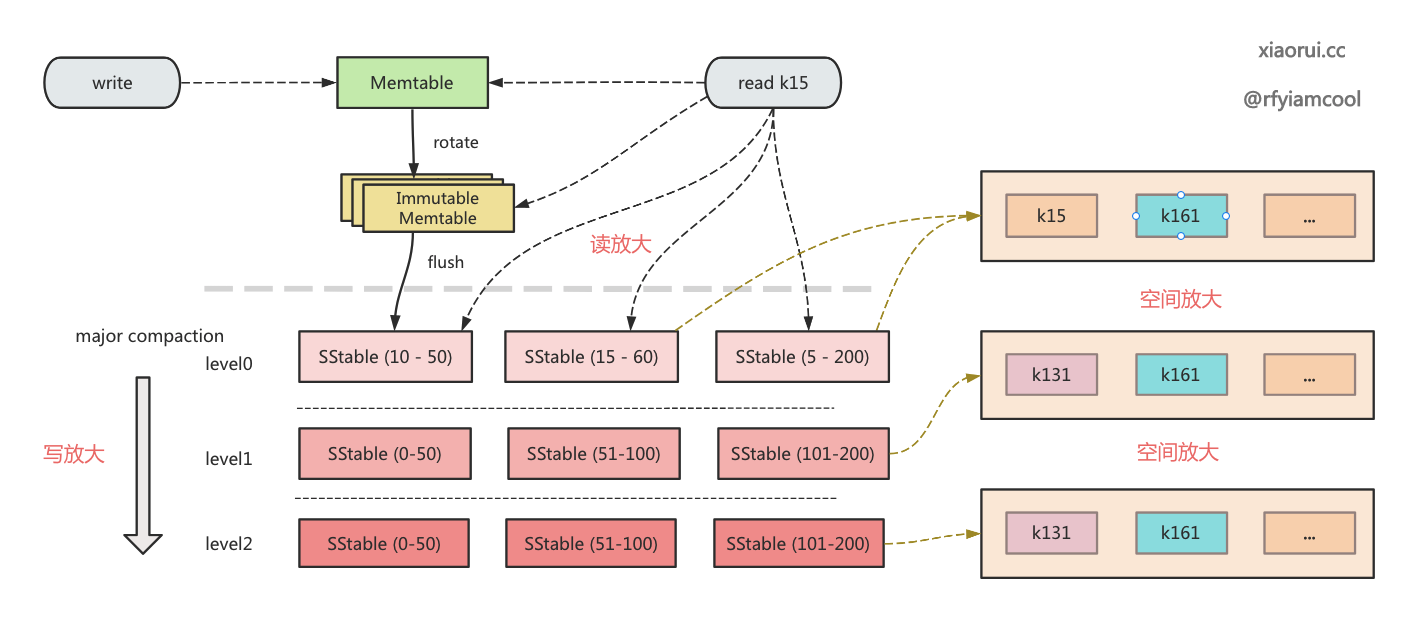
这里再简单过下 badgerDB lsm tree 的写入路径的流程. 先把数据写到 wisckey vlog 里, 接着写到 wal 预写日志里, 后面把 kv 加到 memtable 里, 然后当 memtable 满足大小阈值时, 转变为 immutable table 且通知 flush 线程去异步刷盘操作, flush 会把不可变的 memtable 编码为 sstable 刷到 level 0 层.
sstable 内部是的 kv 是有序的, 但 level 0 的 sstable 不是全局有序的. sstable 之间的 key range 会有重叠. 举例说明, 如有一个 key 总是被更新, 那么大概率历史的版本分布各个组件上, 从上到下来说, 可能存在激活的 memtable 里, immutable memtables 集合里, level 0 的每个 sstable 里, level > 0 每层的某个 sstable 里.
由于 level 0 的 sstable 之间会有 key range 重叠, 那么查询时需要遍历每个符合 key range 范围的 sstable, 该操作其实就是读放大, 读放大会延长 lsm tree 读数据的路径,
那么总结下, 为什么需要 lsmtree compaction 合并?
- 解决大量的历史的冗余数据分布在多个 sstable, 通过上下合并来解决
空间放大的问题. - 解决读放大的问题, 如果数据分布在多个 level 的 sstable, 通过上下合并解决
读放大的问题.
compaction 操作通过上下合并、清理标记删除的数据来降低空间放大和读放大的问题, 但 compaction 合并自身还存在写放大的问题. compaction 属于资源密集型操作, 需要对源数据进行读取,然后进行归并排序,接着把生成的新表下沉到下面的 level 上, 操作下来需要消耗不少的 磁盘io 和 cpu资源, 为了更好的性能通常也需要消耗一定的内存做缓存和换成功.
badgerDB, RocksDB 的 compaction 分为 minor 和 major compaction 合并.
- 当 memtable 写满后 flush 到 L0 层的磁盘上, 被称为
minor compaction. - 从 L0 层开始往下层合并数据, 被称为
major compaction, lsmtree 常说的合并其实就是这个 major compaction.
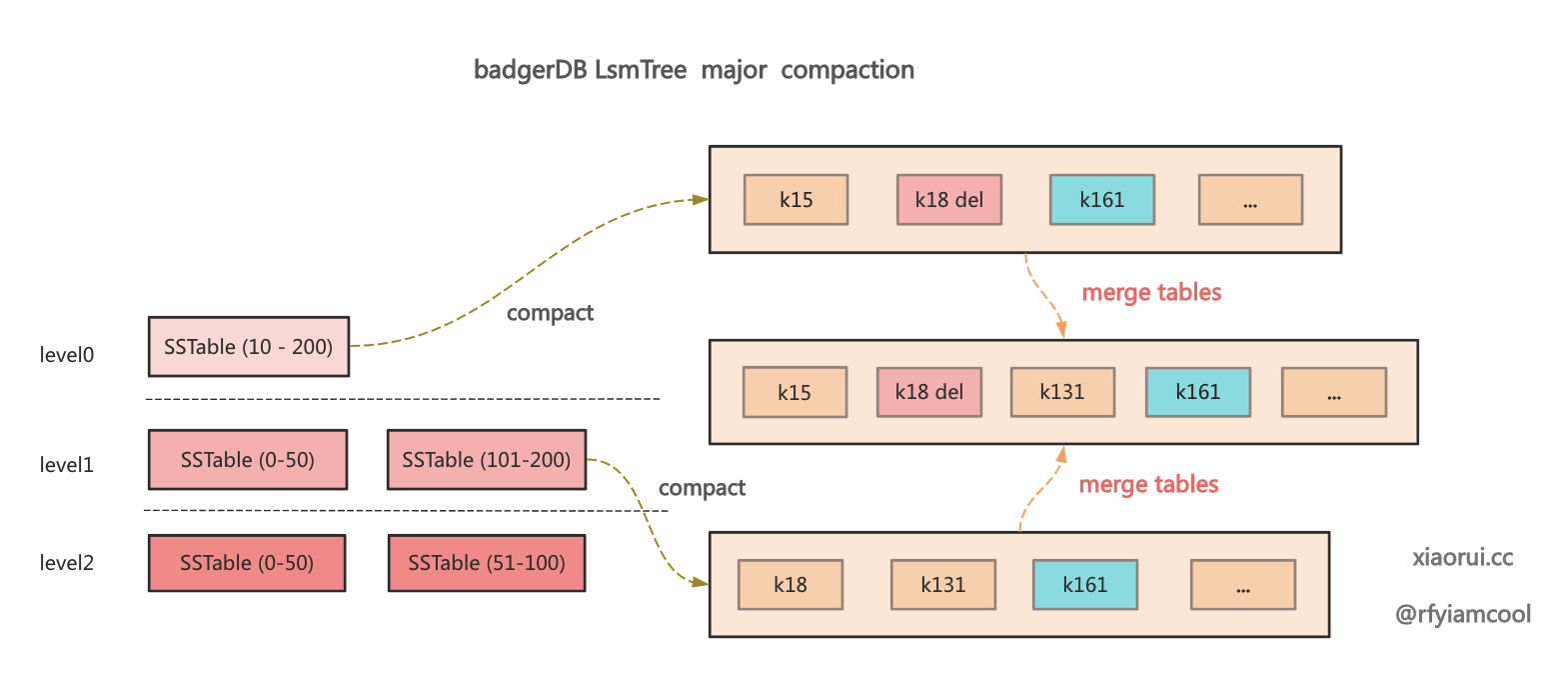
Compaction 合并本质是一个归并排序的过程, 把两层的 sstable 进行合并, 并构建新的 sstable 写到 Ln+1 层, 其过程中会过滤掉已经 delete 的数据, 但 del 的标签依然存在, 直到最下层. 其详细合并的流程原理如下.
- 选择需要合并的 level, 通常找到超出存储阈值的 level.
- 选出 level N 和 level N+1 层需要合并的 sstable 文件, 并确认 key range 范围.
- 通过迭代器把相关的 sstable 的数据读取出来, 进行归并排序.
- 把重新合并后的数据写到 level N+1 层的 sstable 里
- 更新 manifest 配置文件.
- 删除 level N 和 level N+1 用来归并的旧表.
下面为多 sstable 归并合并的过程.
badgerDB 默认启动 4 个并发合并协程, 该配置可以启动时进行修改. badger 合并的并行并发, 后面有分析其实现原理.
代码位置: badger/levels.go:startCompact()
func (s *levelsController) startCompact(lc *z.Closer) {
n := s.kv.opt.NumCompactors
lc.AddRunning(n - 1)
for i := 0; i < n; i++ {
go s.runCompactor(i, lc)
}
}代码位置: badger/levels.go:runCompactor()
func (s *levelsController) runCompactor(id int, lc *z.Closer) {
defer lc.Done()
// 创建一个随机定时器, 时长为 0-1000 ms.
randomDelay := time.NewTimer(time.Duration(rand.Int31n(1000)) * time.Millisecond)
select {
case <-randomDelay.C:
case <-lc.HasBeenClosed():
randomDelay.Stop()
return
}
// L0 优先, 遍历获取 level 0 的位置, 然后插入前面.
moveL0toFront := func(prios []compactionPriority) []compactionPriority {
idx := -1
for i, p := range prios {
if p.level == 0 {
idx = i
break
}
}
if idx > 0 {
out := append([]compactionPriority{}, prios[idx])
out = append(out, prios[:idx]...)
out = append(out, prios[idx+1:]...)
return out
}
return prios
}
// 调用 doCompact 执行表合并.
run := func(p compactionPriority) bool {
// 执行 compact 合并
err := s.doCompact(id, p)
switch err {
case nil:
return true
case errFillTables:
// pass
default:
}
return false
}
// 只要成功合并一次就退出.
runOnce := func() bool {
// 获取需要进行压缩合并的 level 的状态, adjusted, score 分值信息等
prios := s.pickCompactLevels()
if id == 0 {
// 如果 worker 为 0, 则优先压缩合并 L0.
prios = moveL0toFront(prios)
}
// 只要成功合并一次就退出.
for _, p := range prios {
if id == 0 && p.level == 0 {
// ...
} else if p.adjusted < 1.0 {
// 不到 1, 无需压缩合并, 还没超过空间阈值.
break
}
// 执行 compact 合并方法
if run(p) {
return true
}
}
return false
}
tryLmaxToLmaxCompaction := func() {
p := compactionPriority{
level: s.lastLevel().level,
t: s.levelTargets(),
}
run(p)
}
count := 0
ticker := time.NewTicker(50 * time.Millisecond)
defer ticker.Stop()
for {
select {
// Can add a done channel or other stuff.
case <-ticker.C:
count++
// 50 * 200 = 10s
if s.kv.opt.LmaxCompaction && id == 2 && count >= 200 {
// 尝试对 max level 进行合并.
tryLmaxToLmaxCompaction()
count = 0
} else {
runOnce()
}
case <-lc.HasBeenClosed():
return
}
}
}
pickCompactLevels 方法用来挑选出满足合并条件的 level, 并对这些 level 进行分值打分, 其实现原理是如下.
- 先通过
levelTargets方法获取各个 level 的预期存储阈值, 这些阈值是动态计算获取的, badger 的实现方法是参考了 rocksdb 的Dynamic Level Size for Level-Based Compaction. - 然后对各个 level 进行 score 打分, 分值越大的当然会被优先进行压缩合并.
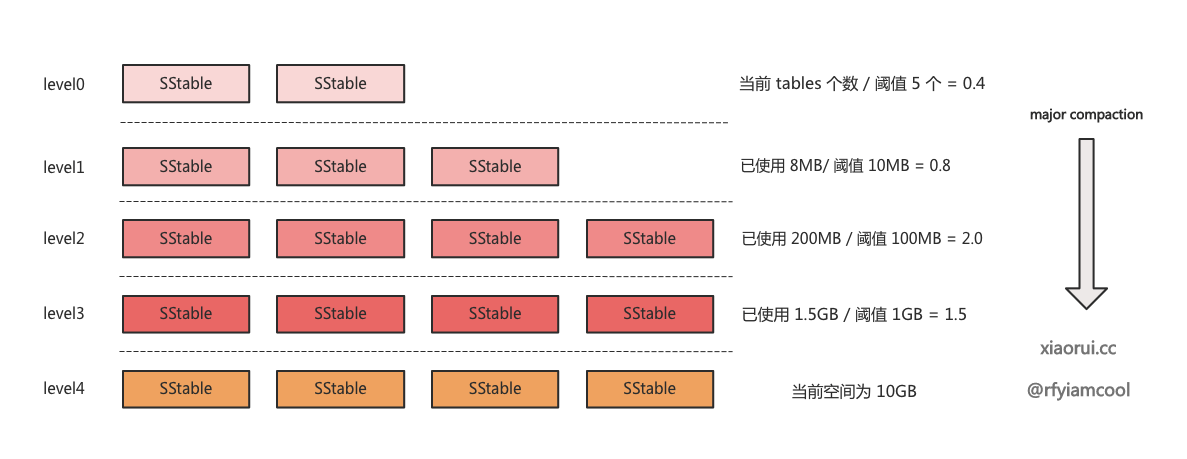
- Level 0 层分值计算, socre = 当前表的数量 / NumLevelZeroTables, NumLevelZeroTables 默认为 5.
- Level > 0 层分值计算, score = 当前有效使用空间 / 动态计算出的预期空间阈值.
- 筛选出分值大于 1.0 的 level, 因为小于 1.0 说明没有超过预期存储的阈值, 没必要参与 compact 合并操作.
- 对大于 1.0 的 level 集合再进一步排序.
分值计算和判断在这里很重要, 来个例子说明下. 如果当前 level3 的动态阈值为 1GB, 但已经使用了 1.5GB, 那么其分值为 1.5. 如果 level 2 动态阈值为 100MB, 但已使用 200MB, 那么分值为 2.0. 那么进行 compact 操作时, 自然会选择分值更高的 level 2 去合并.
// pickCompactLevel determines which level to compact.
// Based on: https://github.com/facebook/rocksdb/wiki/Leveled-Compaction
func (s *levelsController) pickCompactLevels() (prios []compactionPriority) {
// 根据公式计算出各个 level 的空间理想的存储空间阈值.
t := s.levelTargets()
// 定义对象添加到 prios 里
addPriority := func(level int, score float64) {
pri := compactionPriority{
level: level,
score: score,
adjusted: score,
t: t,
}
prios = append(prios, pri)
}
// 添加 level 0, socre = 当前表的数量 / NumLevelZeroTables, NumLevelZeroTables 默认为 5.
addPriority(0, float64(s.levels[0].numTables())/float64(s.kv.opt.NumLevelZeroTables))
// 遍历 level 1 到最后的 level, 计算各个 level 的分值并添加到 prios 里.
for i := 1; i < len(s.levels); i++ {
delSize := s.cstatus.delSize(i)
l := s.levels[i]
// 当前的空间减去删除的空间等于有效使用空间.
sz := l.getTotalSize() - delSize
// 求分值, 当前使用空间 / 预期的空间阈值
addPriority(i, float64(sz)/float64(t.targetSz[i]))
}
// 一定要相等, 想不出不相等的可能.
y.AssertTrue(len(prios) == len(s.levels))
var prevLevel int
// 下面逻辑为调整分值.
for level := t.baseLevel; level < len(s.levels); level++ {
if prios[prevLevel].adjusted >= 1 {
const minScore = 0.01
if prios[level].score >= minScore {
prios[prevLevel].adjusted /= prios[level].adjusted
} else {
prios[prevLevel].adjusted /= minScore
}
}
prevLevel = level
}
// 这个跟直接 make 新的对象区别在于, 底层共用一个 slice 数组, 只是 len 赋值为 0 而已.
// 其目的在于对象复用, 其实 compact 这类低频操作没必要这么搞.
out := prios[:0]
// 过滤出 score 分值大于 1.0 的 level, 并且添加到 out 里.
// 如果 score 分值大于 `1.0`, 说明该 level 的存储空间超出了阈值, 需要被压缩合并.
for _, p := range prios[:len(prios)-1] {
if p.score >= 1.0 {
out = append(out, p)
}
}
// 重新赋值
prios = out
// 按照 adjusted 排序
sort.Slice(prios, func(i, j int) bool {
return prios[i].adjusted > prios[j].adjusted
})
return prios
}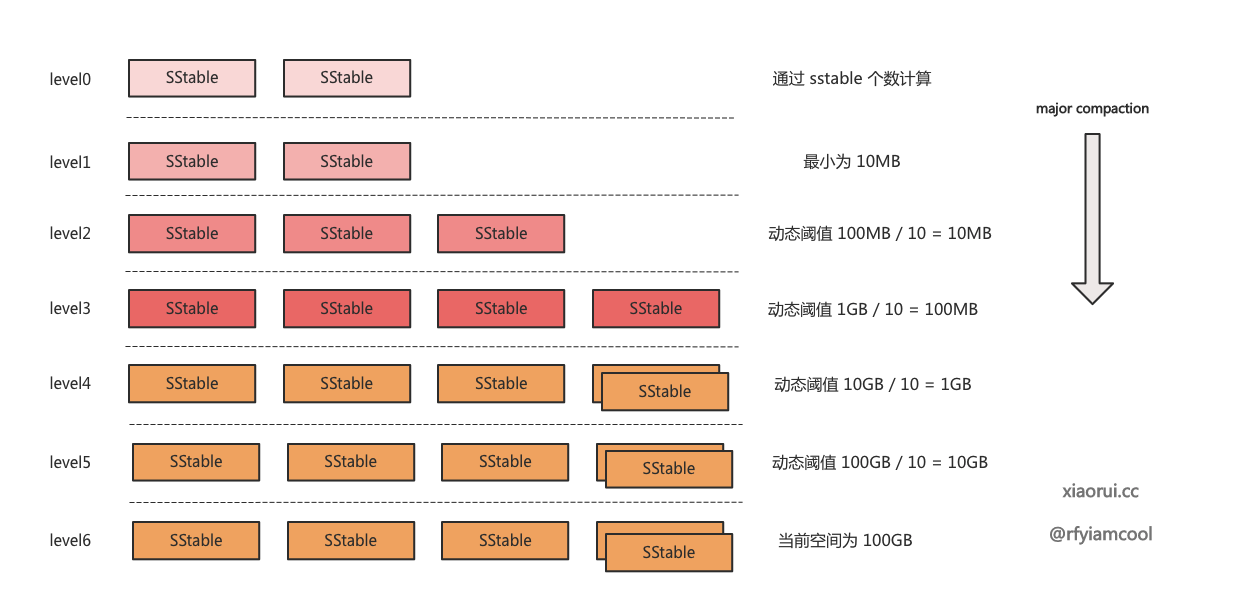
levelTargets 方法用来动态的计算出各个 level 预期的空间合并阈值. badger 动态计算 level 合并存储阈值的方法参考了 rocksdb dynamic level 的设计.
动态 level 计算的逻辑是这样, 先获取当前最大的 level 层及它所占用的空间大小. 比如最大的 level 为 6, 其占用了 100GB 的空间, 那么它的上层 level 5 只能占用 100GB / 10 = 10GB 的存储空间, 10GB 为 level 5 的预期理想值. badger 和 rocksdb 默认的 level 倍数为 10, 所以每上一层其存储空间的理想值都会是其下层的 1/10.
继续算下去, level 4 层预期值为 10GB = 10 = 1GB, level 3 层预期值为 1GB / 10 = 100MB, level 2 为 10MB, level 1 也是 10MB, 不是 0MB. 因为不管是 badger, leveldb 和 rocksdb 都有最小的基础值, badger 默认为 10MB. level 0 无需计算, 因为选择需要合并 level 时, level 0 是通过 sstable 个数计算的分值.
rocksdb 动态 level 存储阈值的计算. https://rocksdb.org/blog/2015/07/23/dynamic-level.html
func (s *levelsController) levelTargets() targets {
adjust := func(sz int64) int64 {
if sz < s.kv.opt.BaseLevelSize {
// 不能小于 10MB
return s.kv.opt.BaseLevelSize
}
return sz
}
// 实例化 targets 对象
t := targets{
// level 的预期阈值
targetSz: make([]int64, len(s.levels)),
fileSz: make([]int64, len(s.levels)),
}
// 获取最大 level 的存储空间, 然后以此来动态计算各个 level 目标存储的预期值.
dbSize := s.lastLevel().getTotalSize()
// 倒序进行遍历 LevelN -> Level1
for i := len(s.levels) - 1; i > 0; i-- {
ltarget := adjust(dbSize)
t.targetSz[i] = ltarget
if t.baseLevel == 0 && ltarget <= s.kv.opt.BaseLevelSize {
// 倒排遍历, 第一个 level 预期空间小于 10MB 的 level
t.baseLevel = i
}
// level 没小一层其预期的存储空间都要除以 10.
dbSize /= int64(s.kv.opt.LevelSizeMultiplier)
}
// 计算 filesz
tsz := s.kv.opt.BaseTableSize // 2MB
for i := 0; i < len(s.levels); i++ {
if i == 0 {
t.fileSz[i] = s.kv.opt.MemTableSize // 64MB
} else if i <= t.baseLevel {
t.fileSz[i] = tsz
} else {
tsz *= int64(s.kv.opt.TableSizeMultiplier) // 2
t.fileSz[i] = tsz
}
}
// 空间为 0 的情况.
for i := t.baseLevel + 1; i < len(s.levels)-1; i++ {
if s.levels[i].getTotalSize() > 0 {
break
}
t.baseLevel = i
}
// 重新调整 baseLevel
b := t.baseLevel
lvl := s.levels
if b < len(lvl)-1 && lvl[b].getTotalSize() == 0 && lvl[b+1].getTotalSize() < t.targetSz[b+1] {
t.baseLevel++
}
return t
}获取需要参与合并的 tables 和 keyRange 范围, 然后调用 runCompactDef 执行合并操作.
// doCompact picks some table on level l and compacts it away to the next level.
func (s *levelsController) doCompact(id int, p compactionPriority) error {
l := p.level
if p.t.baseLevel == 0 {
p.t = s.levelTargets()
}
// 定义 compactDef 结构
cd := compactDef{
compactorId: id,
span: span,
p: p,
t: p.t,
thisLevel: s.levels[l],
dropPrefixes: p.dropPrefixes,
}
if l == 0 {
cd.nextLevel = s.levels[p.t.baseLevel]
// 如果 level 是 0 层, 则把符合条件的 tables 添加到 cd.top 里.
if !s.fillTablesL0(&cd) {
return errFillTables
}
} else {
cd.nextLevel = cd.thisLevel
// 最后一层无需进行发起 compact 合并操作.
if !cd.thisLevel.isLastLevel() {
// 获取下层 level 的 levelHandler 对象.
cd.nextLevel = s.levels[l+1]
}
// 添加 tables 到 cd 里.
if !s.fillTables(&cd) {
return errFillTables
}
}
// 执行合并
if err := s.runCompactDef(id, l, cd); err != nil {
return err
}
// ...
return nil
}fillTables 用来获取需要被合并的 tables 和 keyRange 范围, 该计算的过程还是有些绕, 请对照源码好好理解.
先对上层的 level 的 tables 进行 maxVersion 排序, 优先选择版本较旧的 table, 事务 version 低就意味着该 table 相对旧, badger 也参考了 rocksdb kOldestLargestSeqFirst 设计优先去合并较老的table.
遍历排序过的 tables 集合, 找到跟当前 table 的 keyRange 有重叠的下层 tables 集合, 还需要配置 thisRange 起始位置, nextRange 结束位置, cd.top 上层 tables 集合及 cd.bot 关联的下层 tables 集合.
fillTables 里只要匹配到一个可用的上层 table 就退出函数了, 另外上层的一个 table 的 keyRange 可能对应下层多个 table, 合并时需要把上下层有的 tables 都进行合并.
func (s *levelsController) fillTables(cd *compactDef) bool {
cd.lockLevels()
defer cd.unlockLevels()
// 把上层 level 的 tables 加到 tables 对象里.
tables := make([]*table.Table, len(cd.thisLevel.tables))
copy(tables, cd.thisLevel.tables)
if len(tables) == 0 {
return false
}
// 如果 thisLevel 为最后的 level, 走下面的方法.
if cd.thisLevel.isLastLevel() {
return s.fillMaxLevelTables(tables, cd)
}
// 对 tables 进行事务 version 大小排序, 因为 compact 合并是需要先处理老表.
// 通过 table 的 maxVersion 事务版本判断 table 的新旧, 小 version 自然是老表.
// 这个也是参考 rocksDB kOldestLargestSeqFirst 优先处理设计.
s.sortByHeuristic(tables, cd)
// 遍历排序过的 tables, 优先处理 maxVersion 旧的 table.
for _, t := range tables {
cd.thisSize = t.Size()
// 赋值开始的 keyRange 边界
cd.thisRange = getKeyRange(t)
// 如果已经合并过这个 key range, 则跳出.
if s.cstatus.overlapsWith(cd.thisLevel.level, cd.thisRange) {
continue
}
cd.top = []*table.Table{t}
// 计算出下层跟 thisRange 发生重叠的 tables 的数组索引.
left, right := cd.nextLevel.overlappingTables(levelHandlerRLocked{}, cd.thisRange)
// 把下层 level 发生重叠的 tables 写到 bot 里.
cd.bot = make([]*table.Table, right-left)
copy(cd.bot, cd.nextLevel.tables[left:right])
// 如果在下层 level 找不到跟该 table keyRange 匹配的 tables, 也就是没有重叠部分, 也没问题的, 直接返回.
if len(cd.bot) == 0 {
cd.bot = []*table.Table{}
// 设置两点合一, compact 时会处理该情况.
cd.nextRange = cd.thisRange
if !s.cstatus.compareAndAdd(thisAndNextLevelRLocked{}, *cd) {
continue
}
return true
}
// 配置结束的 keyRnage 边界
cd.nextRange = getKeyRange(cd.bot...)
// 判断 nextRange 在下层 level 的重叠情况.
if s.cstatus.overlapsWith(cd.nextLevel.level, cd.nextRange) {
continue
}
// 记录当前的 compactDef 到 cstatus.
if !s.cstatus.compareAndAdd(thisAndNextLevelRLocked{}, *cd) {
continue
}
// 直接跳出
// 一次就获取一个 sstable 相关合并参数后就退出.
return true
}
return false
}runCompactDef 是 badgerDB level 合并的核心方法, 其内部先计算获取可进行并行合并的 keyRange, 然后并发合并后生成一组新表, 获取表表变动的状态, 把表的变更写到 manifest 配置文件里.
最后, 删除下层的已被用来合并的旧表, 并在下层 level 里添加新合并的新表. 删除上层 level 已被合并的旧表.
func (s *levelsController) runCompactDef(id, l int, cd compactDef) (err error) {
if len(cd.t.fileSz) == 0 {
return errors.New("Filesizes cannot be zero. Targets are not set")
}
// 上层 level
thisLevel := cd.thisLevel
// 下层 level
nextLevel := cd.nextLevel
// splits 不能为空.
if thisLevel.level == nextLevel.level {
// 如果一样, 则跳出.
} else {
// 挑选出 splits.
s.addSplits(&cd)
}
// 为空, 则添加一个空的 keyRange
if len(cd.splits) == 0 {
cd.splits = append(cd.splits, keyRange{})
}
// 上下 level 的表进行归并合并, 并生成一组新表
newTables, decr, err := s.compactBuildTables(l, cd)
if err != nil {
return err
}
defer func() {
// 解除表的引用
if decErr := decr(); err == nil {
err = decErr
}
}()
// 获取表表变动的状态, 把表的变更写到 manifest 配置文件里.
changeSet := buildChangeSet(&cd, newTables)
if err := s.kv.manifest.addChanges(changeSet.Changes); err != nil {
return err
}
// 删除下层的已被用来合并的旧表, 并在下层 level 里添加新合并出的表.
if err := nextLevel.replaceTables(cd.bot, newTables); err != nil {
return err
}
// 删除上层 level 被合并的旧表
if err := thisLevel.deleteTables(cd.top); err != nil {
return err
}
// 日志输出
// ...
s.kv.opt.Infof("[%d]%s LOG Compact %d->%d (%d, %d -> %d tables with %d splits)."+
" [%s] -> [%s], took %v\n",
id, expensive, thisLevel.level, nextLevel.level, len(cd.top), len(cd.bot),
len(newTables), len(cd.splits), strings.Join(from, " "), strings.Join(to, " "),
dur.Round(time.Millisecond))
s.kv.opt.Debugf("This Range (numTables: %d)\nLeft:\n%s\nRight:\n%s\n",
len(cd.top), hex.Dump(cd.thisRange.left), hex.Dump(cd.thisRange.right))
s.kv.opt.Debugf("Next Range (numTables: %d)\nLeft:\n%s\nRight:\n%s\n",
len(cd.bot), hex.Dump(cd.nextRange.left), hex.Dump(cd.nextRange.right))
return nil
}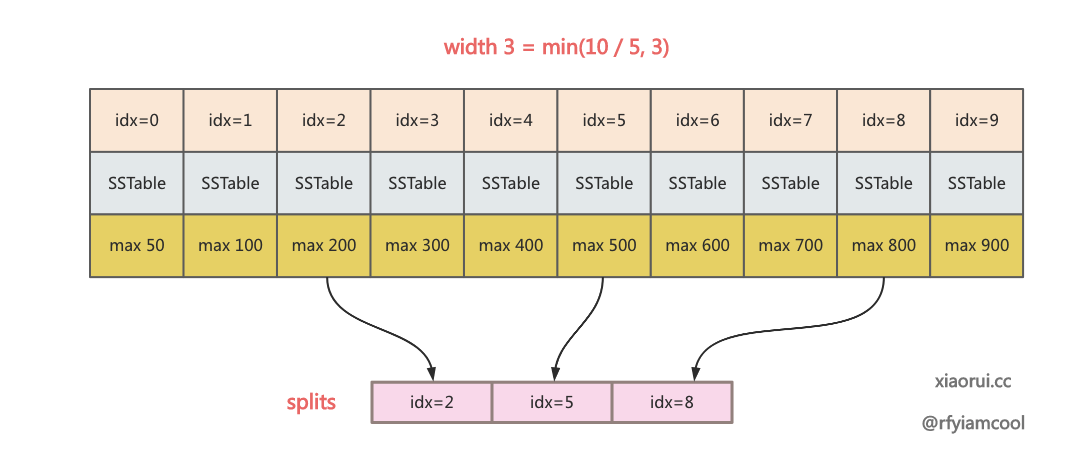
通过公式计算出 split key 集合, 在合并时是按照 split 进行并发操作的.
跨度值为 int(math.Ceil(float64(len(cd.bot)) / 5.0)), 然后遍历 tables, 挑选出取摸匹配到跨度值的 table 的最大 key.
当某 level 的 sstable 很多时, 为了避免太多的并发, 这里设计了跨度的概念, 每五个 sstable 为一个 split 点, 25 个 sstable 只需要 5个 split. compact 时按照跨度修剪过的 split 粒度, 并发去执行 subcompact 子合并.
// addSplits can allow us to run multiple sub-compactions in parallel across the split key ranges.
func (s *levelsController) addSplits(cd *compactDef) {
cd.splits = cd.splits[:0] // 重置 slice 的 len, 对象复用.
// 选出跨度, 底部的 tables 数量 / 5 为 跨度.
width := int(math.Ceil(float64(len(cd.bot)) / 5.0))
// 跨度值最小为 3.
if width < 3 {
width = 3
}
// 当前的左边界.
skr := cd.thisRange
// 当前的右边界.
skr.extend(cd.nextRange)
addRange := func(right []byte) {
// 设置 keyRange 的右边界
skr.right = y.Copy(right)
// 添加新的 split keyRange.
cd.splits = append(cd.splits, skr)
// 当前 keyRange 的左边界为上一个 split 的右边界.
skr.left = skr.right
}
for i, t := range cd.bot {
// last entry in bottom table.
if i == len(cd.bot)-1 {
addRange([]byte{})
return
}
// 当每次取摸匹配到 width 的跨度值, 添加到 splits 里.
if i%width == width-1 {
// 选用 table 的最大的值判断点.
right := y.KeyWithTs(y.ParseKey(t.Biggest()), math.MaxUint64)
// 添加到 splits 里.
addRange(right)
}
}
}compactBuildTables 方法用来把上下层的表进行并发合并, 其内部先通过迭代器的方式把需要合并的 sstable 进行归并合并到一组新的 table 列表里. 合并的过程是并发操作的, 开始会为每个 keyRange 分配一个协程去异步合并, 但 badger 为了更好的控制合并的并发数, 又加入 Throttle 做并发控制, 只有拿到 Throttle 执行权才可以执行 compact 合并.
// compactBuildTables merges topTables and botTables to form a list of new tables.
func (s *levelsController) compactBuildTables(
lev int, cd compactDef) ([]*table.Table, func() error, error) {
// 上级的表集合
topTables := cd.top
// 下级的表集合
botTables := cd.bot
keepTable := func(t *table.Table) bool {
for _, prefix := range cd.dropPrefixes {
if bytes.HasPrefix(t.Smallest(), prefix) &&
bytes.HasPrefix(t.Biggest(), prefix) {
return false
}
}
return true
}
var valid []*table.Table
for _, table := range botTables {
if keepTable(table) {
valid = append(valid, table)
}
}
// 实例化迭代器, 其内部会对传入的表列表进行归并合并处理
newIterator := func() []y.Iterator {
var iters []y.Iterator
switch {
case lev == 0:
iters = appendIteratorsReversed(iters, topTables, table.NOCACHE)
case len(topTables) > 0:
iters = []y.Iterator{topTables[0].NewIterator(table.NOCACHE)}
}
return append(iters, table.NewConcatIterator(valid, table.NOCACHE))
}
// 实例化接收 table 的 chan
res := make(chan *table.Table, 3)
// 并发控制器, 限制同时合并的协程数.
inflightBuilders := y.NewThrottle(8 + len(cd.splits))
for _, kr := range cd.splits {
// 是否可运行
if err := inflightBuilders.Do(); err != nil {
return nil, nil, err
}
// 遍历 key range 范围集, 并按照 keyRange 并发 sstable 合并.
go func(kr keyRange) {
defer inflightBuilders.Done(nil)
// 构建迭代器.
it := table.NewMergeIterator(newIterator(), false)
defer it.Close()
// 按照 keyrange 遍历数据构建 sstable, 并传递会 res 里.
s.subcompact(it, kr, cd, inflightBuilders, res)
}(kr)
}
var newTables []*table.Table
var wg sync.WaitGroup
wg.Add(1)
go func() {
defer wg.Done()
// 接收数据
for t := range res {
newTables = append(newTables, t)
}
}()
// 等待协程执行完毕.
err := inflightBuilders.Finish()
close(res)
wg.Wait()
if err == nil {
// 打开文件, 并调用 sync 来同步.
err = s.kv.syncDir(s.kv.opt.Dir)
}
if err != nil {
// 如果有异常, 遍历 tables 集合, 解除引用计数.
_ = decrRefs(newTables)
return nil, nil, y.Wrapf(err, "while running compactions for: %+v", cd)
}
// 使用了 table 的 biggest 最大值进行排序
sort.Slice(newTables, func(i, j int) bool {
return y.CompareKeys(newTables[i].Biggest(), newTables[j].Biggest()) < 0
})
return newTables, func() error { return decrRefs(newTables) }, nil
}badger 的 subcompact 的实现也是参考的 rocksdb 设计, 每个 subcompact 子合并都是一个并发单元.
compactBuildTables 会遍历计算出来的 key-range 集合, 且分别开协程异步去执行 subcompact 方法. subcompact 方法会按照 keyRange 迭代器来遍历数据, 构建 sstable 且进行落盘, 并回传到 res 管道里.
更详细的合并流程, 可直接看代码.
func (s *levelsController) subcompact(it y.Iterator, kr keyRange, cd compactDef,
inflightBuilders *y.Throttle, res chan<- *table.Table) {
// ...
var (
lastKey, skipKey []byte
numBuilds, numVersions int
)
addKeys := func(builder *table.Builder) {
timeStart := time.Now()
var numKeys, numSkips uint64
var rangeCheck int
var tableKr keyRange
// 使用迭代器进行遍历数据, 并验证迭代器是否合法
for ; it.Valid(); it.Next() {
if len(cd.dropPrefixes) > 0 && hasAnyPrefixes(it.Key(), cd.dropPrefixes) {
}
if !y.SameKey(it.Key(), lastKey) {
// ...
}
// 构建 valueStruct 对象
vs := it.Value()
version := y.ParseTs(it.Key())
// 判断是否过期.
isExpired := isDeletedOrExpired(vs.Meta, vs.ExpiresAt)
// ...
var vp valuePointer
if vs.Meta&bitValuePointer > 0 {
// 如果该 key 使用了 vptr 指向 vlog, 则解码 vptr.
vp.Decode(vs.Value)
}
// 把 key 及 value 加到 builder 构建器里.
switch {
case firstKeyHasDiscardSet:
// 标记 stale
builder.AddStaleKey(it.Key(), vs, vp.Len)
case isExpired:
// 标记 stale
builder.AddStaleKey(it.Key(), vs, vp.Len)
default:
builder.Add(it.Key(), vs, vp.Len)
}
}
}
// 如果 keyRange left 大于 0, 则对迭代器进行 seek.
if len(kr.left) > 0 {
it.Seek(kr.left)
} else {
// 内部会调用 seekToFirst, 定位到头部.
it.Rewind()
}
// 验证迭代器是否合法
for it.Valid() {
// 如果当前迭代出的 key 大于等于 keyRange 则跳出迭代器循环.
if len(kr.right) > 0 && y.CompareKeys(it.Key(), kr.right) >= 0 {
break
}
bopts := buildTableOptions(s.kv)
bopts.TableSize = uint64(cd.t.fileSz[cd.nextLevel.level])
builder := table.NewTableBuilder(bopts)
// 把数据添加到 sstable builder
addKeys(builder)
if builder.Empty() {
builder.Finish()
builder.Close()
continue
}
// 并发控制.
if err := inflightBuilders.Do(); err != nil {
break
}
// 异步使用 builder 来构建 table, table 需要写到文件里, 且发送到 res 管道.
go func(builder *table.Builder, fileID uint64) {
var err error
// 并发控制, 释放并发位
defer inflightBuilders.Done(err)
defer builder.Close()
var tbl *table.Table
if s.kv.opt.InMemory {
tbl, err = table.OpenInMemoryTable(builder.Finish(), fileID, &bopts)
} else {
// 把数据写到 sstable 文件里.
fname := table.NewFilename(fileID, s.kv.opt.Dir)
tbl, err = table.CreateTable(fname, builder)
}
// If we couldn't build the table, return fast.
if err != nil {
return
}
res <- tbl
}(builder, s.reserveFileID())
}
s.kv.vlog.updateDiscardStats(discardStats)
}replaceTables 用来删除下层 level 中已被用来 compact 的旧表, 且添加经过合并 compact 新生成的新表.
func (s *levelHandler) replaceTables(toDel, toAdd []*table.Table) error {
s.Lock() // We s.Unlock() below.
// 记录需要删除的 table.
toDelMap := make(map[uint64]struct{})
for _, t := range toDel {
toDelMap[t.ID()] = struct{}{}
}
// 创建一个 table 集合, 遍历当前 level 的所有 table,
// 剔除需要删除的 table, 把剩下的 table 添加到 newTables.
var newTables []*table.Table
for _, t := range s.tables {
_, found := toDelMap[t.ID()]
if !found {
newTables = append(newTables, t)
continue
}
s.subtractSize(t)
}
// 添加合并生成的表
for _, t := range toAdd {
s.addSize(t)
t.IncrRef()
newTables = append(newTables, t)
}
// 重新赋值 tables
s.tables = newTables
// 排序重排 tables, 按照 table 的 smallest 最小值
sort.Slice(s.tables, func(i, j int) bool {
return y.CompareKeys(s.tables[i].Smallest(), s.tables[j].Smallest()) < 0
})
s.Unlock()
// 解除需要删除的 tables 的引用计数,
// 当 ref 为 0 时, 尝试删除 tables 的缓存和文件.
return decrRefs(toDel)
}deleteTables 主要用来删除指定 level 的 sstable 集合.
func (s *levelHandler) deleteTables(toDel []*table.Table) error {
// 加锁, 保证安全
s.Lock() // s.Unlock() below
// 这里的 hashmap 只是为了查询 o(n) 到 o(1)
toDelMap := make(map[uint64]struct{})
for _, t := range toDel {
toDelMap[t.ID()] = struct{}{}
}
// Make a copy as iterators might be keeping a slice of tables.
var newTables []*table.Table
// 遍历当前 level 的 tables 集合, 把不需要删除的 table 放到新的列表中.
for _, t := range s.tables {
_, found := toDelMap[t.ID()]
if !found {
newTables = append(newTables, t)
continue
}
// 该 table 需要被删除, 在 level 总量里减去当前的 table size.
s.subtractSize(t)
}
// 重新赋值 level 的 tables 列表.
s.tables = newTables
s.Unlock()
// 去除 table 的引用关系, 并且删除 table
// 不用加锁, 因为其内部使用 atomic 原子操作.
return decrRefs(toDel)
}在 blockCache 缓存中删除 sstable, 并删除 sstable 文件.
func decrRefs(tables []*table.Table) error {
for _, table := range tables {
if err := table.DecrRef(); err != nil {
return err
}
}
return nil
}
func (t *Table) DecrRef() error {
newRef := t.ref.Add(-1)
// 当 newRef 引用值为 0 时, 删除 sstable
if newRef == 0 {
// 在缓存列表中剔除
for i := 0; i < t.offsetsLength(); i++ {
t.opt.BlockCache.Del(t.blockCacheKey(i))
}
// 删除 sstable 文件
if err := t.Delete(); err != nil {
return err
}
}
return nil
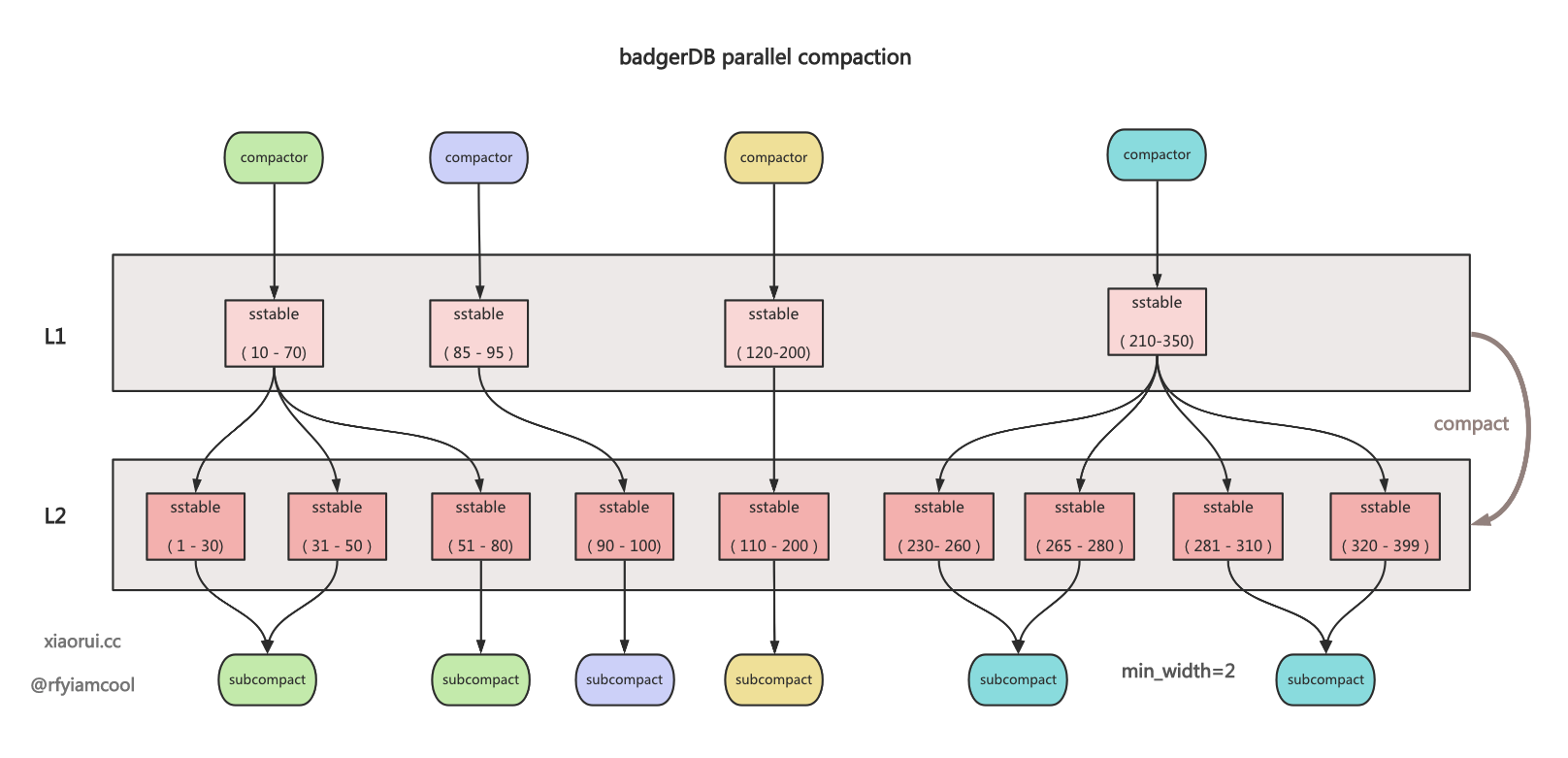
}badger 默认开了 4 个合并协程. 每个协程周期性检测是否需要合并. 当检测到有 level 需要被合并时, 通常只会选择一个上层 table 进行操作, 而其他协程可对同一个 level 的不同 table 进行并行合并操作.
另外 badger 参考了 rocksdb subcompact 的子合并设计, 当一个上层 table keyRange 覆盖多个下层 tables 时, 这里可以切成多个 keyRange 进行 subcompact 并发子合并.
所以说, badger 的合并有两个并行的维度. 一个是最优 level 的某个 table 进行合并, 另一个是当 table keyRange 对应很多下层table时, 可以使用 subcompact 进行并发合并.
下面是 badger parallel compaction 大概实现效果.
下面是 badger parallel compaction 并行合并的函数调用关系.
为什么需要 lsmtree compaction 合并?
- 解决大量的历史的冗余数据分布在多个 sstable, 通过上下合并来解决
空间放大的问题. - 解决读放大的问题, 如果数据分布在多个 level 的 sstable, 通过上下合并解决
读放大的问题.
Compaction 合并本质是一个归并排序的过程, 把两层的 sstable 进行合并, 并构建新的 sstable 写到 Ln+1 层, 其过程中会过滤掉已经 delete 的数据, 但 del 的标签依然存在, 直到最下层. 其详细合并的流程原理如下.
- 选择需要合并的 level, 通常找到超出存储阈值的 level.
- 选出 level N 和 level N+1 层需要合并的 sstable 文件, 并确认 key range 范围.
- 通过迭代器把相关的 sstable 的数据读取出来, 进行归并排序.
- 把重新合并后的数据写到 level N+1 层的 sstable 里
- 更新 manifest 配置文件.
- 删除 level N 和 level N+1 用来归并的旧表.
下面为多 sstable 归并合并的过程.