论文出处:2019ICLR
对于音乐生成任务而言,在这篇文章以前都使用RNN做这种长序列生成问题,但是与机器翻译任务中的对象自然语言不同,音乐是一种比自然语言更加hierarchical的数据表征。RNN在长序列生成问题上由于自身结构原因,一个序列中如果两个信息相隔位置过远,RNN的递归式结构显然无法捕捉到这种信息,对于例句“The animal didn't cross the street because it was too tired",RNN结构的翻译模型可能无法捕捉到"it"指代"the animal"这种关系,这种现象在机器翻译任务上已经被观察到了。
对于音乐来说,音乐非常强调结构性,古典音乐更是如此。目前来说,从谷歌magenta在2017年使performance-RNN生成的音乐片段来看,生成的音乐偶尔有一两秒比较具有音乐性的片段,从整体来看,则是乱弹琴,不具有long term structure。2018年transformer的提出,刷新了机器翻译人任务在不同数据集上的结果。
- 音乐作品在结构和意义上有大量的重复,这种自相关性体现在多重时间尺度上,从主体到乐句上都重复使用整段的音乐章节,比如说在音乐片段中的ABA结构。
- 使用self-attention机制的transformer模型在机器翻译这类需要保持sequence很长连贯性的任务上取得巨大成功,这表明或许transformer很适合构建音乐生成和音乐表现,当然,相对的timing对音乐来说也很重要,现有的使用absolute position embedding的transformer模型在直觉上并不make sense,对于relative position embedding的transformer,它的relative position embedding是基于query&key pair-wise position,这对音乐生成任务上并不可行,因为算法中表征relative position位置的中间向量空间复杂度上是sequence 长度的平方,文中成功的将这个中间向量的空间复杂度降到了sequence 长度量级。使得这个transformer能够在给定一个motif生成数分钟长的音乐,或者基于seq2seq设置,给定一个旋律生成伴奏。
Transformer的原理介绍现在太多了,在这里再赘述一遍,transformer中一个层包括一个self-attention层以及一个feedfoward层。

由于transformer中的self-attention机制中没有明显地对相对位置进行建模,而是额外增加一种绝对的位置表征(attention原文中position embedding:使用正弦函数和余弦函数来构建每个位置的值。在2018NAACL论文Self-Attention with Relative Position Reoresentations中提出了一种考虑相对位置表征的self-attention机制。
虽然文中轻描淡写地总结了那篇NAACL的论文改进的带relative attention positionde的self attention机制。

但是读到文章中画横线的句子,我很懵逼:$E^r$怎么就是(

同样中间张量R(
要想回答这些问题必须要看这篇NAACL的论文了,还要结合代码,参考博客:这篇博客对transformer中的相对位置表征讲的很透彻,
我这里只简单的概括一下:作者提出在transformer中加入一组可以训练的相对距离表示(RPR),从而是使输出带有一定的顺序信息。RPR会在计算词i的输出表示$z_{i}$, 词i对词j的注意力权重系数时用到
一个最简单的例子:一个句子有五个词,设k=4,那么这五个词每个词都有9个相对距离表示(一个是和自己的距离,和上文的四个词的距离,和下文的四个词的距离),设置词$i$与自己的距离在RPR中对应index4,则词$i$与词$i+1$的距离在RPR对应index5,词$i$与词$i-1$的距离在RPR中对应index3
值得注意的是,论文中提到,词间距离的最大值限制在一个常数k,这意味着需要学习的RPR的数量书2k+1(上文k个词,下文k个词,当前词),往右间隔超过k的词对应RPR中第2k个index,往左间隔超过k的词对应RPR中第0个index,如果一个有10个词的输入序列,k设为3,那么RPR的查询表为:

- 超过一定距离,再精确的相对位置信息是时没有用的。
- 限制最长距离能够提升模型在对未在训练阶段出现过的长度的序列的泛化能力
在NAACL这篇文章中把两种注意力机制表示如下
-
普通的self-attention机制表示:
$$Z_i=\sum_{j=1}^na_{ij}(x_jW^v) \tag{1}$$
$$a_{ij}=\frac{exp;e_{ij}}{{\displaystyle\sum_{k=1}^n}exp;e_{ik}} \tag{2}$$
$$e_{ij}=\frac{\left(x_iW^Q\right)\left(x_jW^K\right)}{\sqrt{d_k}} \tag{3}$$ -
考虑相对位置表征的self-attention表示:
$Z_i=\sum_{j=1}^na_{ij}(x_jW^v+a_{ij}^V) \tag{4}$
$a_{ij}=\frac{exp;e_{ij}}{{\displaystyle\sum_{k=1}^n}exp;e_{ik}} \tag{5}$
$e_{ij}=\frac{\left(x_iW^Q\right)\left(x_jW^K+a_{ij}^K\right)}{\sqrt{d_k}} \tag{6}$
其中$a_{ij}^V$,$a_{ij}^V$是两个relative position representation(RPR)
Transformer的输入是一个大小为 (batch_size, seq_length, embedding_dim)的张量。在不带RPR嵌入的情况下,Transformer能够利用batch_size * h 并行地进行矩阵乘法来计算 eᵢⱼ (式子2) 。每一次矩阵乘法都会计算给定输入序列和注意力头中所有的元素的eᵢⱼ 。这个过程使用下面的表达式实现的
我们首先使用了矩阵乘法的性质将式子(6)重写为:
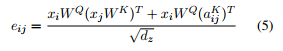
分子的左半部分和式子 (2)相同,因此在矩阵乘法中能够高效运算。右半部分就有点技巧性了。这部分代码实现定义在函数 relative_attention_inner 中,因此我会较简单地把大体逻辑介绍一下。
- 分子左半部分的大小为 (batch_size, h, seq_length, seq_length)。这个张量的行i列j上的元素代表了词i的query向量和词j的key向量的点积的结果 。因此,我们的目标是产生另一个和这个张量大小相同的张量,而这个张量的各个元素应该是词i的query向量和词i与词j之间的RPR嵌入的点积的结果(译者注:也就是分子右半部分)。
- 首先,我们使用查表的形式为一个给定的输入序列生成RPR嵌入张量A,A的形状是(seq_length, seq_length, dₐ) 【这其实就是music tranformer文章提到的中间向量R, 也就是我加了红色下划线的地方】。然后,我们对A进行转置,使它的形状变成 (seq_length, dₐ , seq_length) ,写成 Aᵀ。
- 接下来,我们计算输入序列所有元素的query向量,得到一个 (batch_size, h, seq_length, dz)形状的张量。然后对其进行转置,形状变为 (seq_length, batch_size, h, dz) ,然后变形为 (seq_length, batch_size * h, dz)的张量。这个张量现在就能与 Aᵀ相乘了。这个乘法可以视为矩阵 (batch_size * h, dz) 和矩阵 (dₐ, seq_length)的乘法。基本上就是计算每个位置的query向量和对应的RPR向量嵌入的点积【这部分解释了music tranformer文章中Q 是如何reshape成(
$L, 1, D_{h}$ ), 文章为了简要描述将batchsize设为了1,论文下面的脚注有解释,然后再将Q和R的转置进行矩阵相乘】。 - 上面的乘法得到一个形状为 (seq_length, batch_size * h, seq_length)的张量。我们只需要将其变形为(seq_length, batch_size, h, seq_length)的形状,然后再转置得到形状为 (batch_size, h, seq_length, seq_length) 的张量,这样我们就能将它和分子左半部分进行相加了。
不废话了,本篇论文的一个算法贡献是,它不需要中间张量R(seq_length, seq_length, dₐ)来计算query

不再采用18年NAACL那篇论文提出的方法,而是将直接将Q和RPR向量(也就是那个查询表展示的向量,形状为seq_length, seq_length)相乘。因为作者发现通过从$QR^{T}$中求得的$S^{rel}$同样可以从$QE^{rT}$中通过变换求得,这样就避免了求中间向量R。
但是$QE^{rT}$的$(i_{q},r)$代表的是位置为$i_{q}$的query向量和相对距离为r的embedding向量的点积,而不是$S^{rel}$中$i_{q}$的query向量和位置$j_{k}$和位置$i_{q}$的相对距离表征向量的点积。所以接下来对$QE^{rT}$进行skew(pad,reshape,slice)操作可以得到$S^{rel}$。对应时间复杂度,同样都是$O(L^{2}D)$,但是在seq_length=650时,比原来的算法快6倍。
- Pad: 在$QE^{rT}$的左边补上一列长为seq_length的向量
- Reshape: 按照如下规则reshape矩阵:行的索引保持不变,列的索引计算为$j_{k}=r-(L-1)+r_{q}$
- Slice: 最后保留最后L行,列保持不变