Redis是一个高速的内存数据库,它的应用十分广泛,可以说是服务端必学必精的东西。然而,学以致用,无用则无为。学了的东西必须反复的去用,去实践,方能有真知。这篇文章记录了我在redis学习过程中的笔记、理解和实践,仅供参考。
本章介绍redis基础中的基础,常用命令的使用和效果。
string类型是redis中最常见的类型了,通过简单的set、get命令就可以对这个数据结构做增删操作,应该也是redis最大众的类型之一,存json、存自增数值、甚至缓存图片。 string的底层是redis作者自定义的一个叫SDS的struct。长下面这样:
redis是使用c语言实现的
typedef char *sds;
// 省略
struct __attribute__ ((__packed__)) sdshdr64 {
uint64_t len; /* used */
uint64_t alloc; /* excluding the header and null terminator */
unsigned char flags; /* 3 lsb of type, 5 unused bits */
char buf[];
};- len 记录了字符串的长度
- alloc 表示字符串的最大容量(不包含最后多余的那个字节)。
- flags 总是占用一个字节。其中的最低3个bit用来表示header的类型。源码中的多个header是用来节省内存空间的。
这里有一个疑问,为什么作者要自定义一个sds而不是直接用c语言的字符串呢?
-
时间复杂度要求 redis的数据结构设计总是基于最优复杂度方案的,对每一个点的时间、空间复杂度要求非常高,这一点c语言的string就已经不满足需求了,因为c自带的字符串并不会记录自身长度信息,所以每次获取字符串长度的时间复杂度都是o(n),所以redis作者设计SDS时,有一个len字段,记录了字符串的长度,这样每次获取长度时的时间复杂度就是O(1)了。
-
缓冲区溢出问题 其实也是c语言不记录本身长度带来的问题,当拼接字符串的时候,例如 hello + world 因为c不记录长度,所以在拼接字符的时候需要手动为hello分配五个内存空间,然后才能+world,如果忘记分配内存,那么就会产生缓冲区溢出,而redis的解决方案是在SDS中分别记录len和alloc,表示当前字符串长度和最大容量,这样当进行字符串拼接的时候api直接去判断最大容量是否满足,满足就直接插入,不满足则对 char * 做一次扩容,然后插入,减少了人为出错的概率,并且可以对alloc适当的进行空间预先分配,减少扩容次数,例如在创建字符串hello时,完全可以将alloc长度设置10,这样在加入world时直接放进去就ok了。
-
实现了c语言字符串的识别特性,复用了c语言自带的字符串函数 传统的c语言使用的是n+1的char数组来表示长度n的字符串的,然后在n长度最后加上一个\0 , 所以redis的sds在设计的时候也加上了这个\0,这样可以复用部分c语言字符串的函数。
-
二进制安全 c字符串中的字符必须符合某种编码,比如 ASCII 并且除了字符串的末尾之外,字符串里面不能包含空字符(这里空字符指的是空(\0)不是空格、换行之类的字符),主要是不能存储二进制的图片、视频、压缩文件等内容,而我们知道redis是可以用来缓存图片二进制数据的。因为redis记录了字符长度。c没有记录长度的时候遇到\0就认为读到字符结尾了。
可以看出,c语言中字符串没有记录长度是一个比较麻烦的事儿,如果没有记录长度就必须用占位符确定字符末尾,导致二进制不安全。如果没有记录长度就必须每次统计长度,导致时间复杂度陡增。如果没有记录长度在分割字符串、拼接字符串时麻烦也不少。所以---总的来说,在设计字符串的时候,不要忘了记录长度。
- set [key] [value]
set一个key的value值,这个值可以是任意字符串。例如:
set redis:demo helloRedis
> OK
get redis:demo
> "helloRedis"- set [key] [value] [NX] [EX|PX]
set还可以指定另外两个参数 [NX] 表示 SET if Not eXists , 指定这个参数就是告诉redis,如果key不存在才set。 [EX|PX] 这个参数表示超时时间,ex表示秒数,px表示毫秒数,一般redis通用的表示时间单位是 秒
set redis:demo:nxex helloRedis NX EX 20
> OK
set redis:demo:nxex hellostring NX EX 20
> (nil) // 设置失败这里有一个值得注意的点是,set nx是跟普通的set互通的 ,什么意思呢? 就是:
set redis:demo:nxex a
> OK
set redis:demo:nxex b NX EX 20
> (nil) // 普通的set在第二次设置nx的时候依然会设置失败
del redis:demo:nxex
> OK
set redis:demo:nxex a NX EX 20
> OK
set redis:demo:nxex b
> OK // 就算是nx设置的值,在普通set下依然会成功覆盖,并且丢失nx和ex的作用- mset [key] [value] [key] [value] ...
批量设置key value,可以批量设置一堆key,并且它是原子的,也就是这些key要么全部成功,要么全部失败.
请注意,mset是不可以指定过期时间和nx的,如果你希望批量设置key并且有过期时间,那么你最好自己写lua脚本来解决
mset a 1 b 2 c 3 NX EX 20
> (error) ERR wrong number of arguments for MSET- getset [key] [value]
set之前先get,返回set之前的值
set redis:getset:demo hello
> ok
getset redis:getset:demo world
> "hello"
get redis:getset:demo
> "world"ps这个命令一般用来检查set之前的值是否正常 注意这个也不能加nx和ex等属性
- get [key]
获取一个字符串类型的key的值,如果键 key 不存在, 那么返回特殊值 nil ; 否则, 返回键 key 的值。
set redis:get:demo hello
> ok
get redis:get:demo
> "hello"
del redis:get:demo
> (integer) 1
get redis:get:demo
> (nil)- strlen [key]
获取key字符串的长度
set redis:get:demo hello
> ok
strlen redis:get:demo
> (integer) 5- mget [key] [key] ...
批量获取key的值,返回一个list结构
mset a 1 b 2
> ok
mget a b
> (1) "1" (2) "2"- append [key] [value]
这个命令就是用来拼接字符串的
set redis:append:demo hello
> ok
append redis:append:demo world
> (integer) 10 // 返回了append之后的字符串的总长度,也就是上面说的sds中的len字段,这时候这个key的free也已经被扩容
get redis:append:demo
> hello world注意,当key不存在,append命令依然会成功,并且会当作key是一个字符串来拼接
在redis中的integer类型是存储为字符串对象,通过编码的不同来表示不同的类型
set redis:int:demo 1
> OK
type redis:int:demo
> string // type依然是string
object encoding redis:int:demo
> "int" // 但是编码现在是int这里也有一个注意的点,就是redis是不支持任意小数点的,例如你set a 0.5会被存储为embstr编码,这时候对它使用incr和decr会报错
- incr [key]
将key自增1
set redis:int:demo 1
> OK
incr redis:int:demo
> (integer) 2
set redis:int:demo 0.5
> OK
incr redis:int:demo
> (error) ERR value is not an integer or out of range- decr [key]
将key自减1 是可以减到负数的
set redis:int:demo 1
> OK
decr redis:int:demo
> (integer) 0
decr redis:int:demo
> (integer) -1- incrby [key] [integer]
将key自增指定的数字
set redis:int:demo 1
> OK
incrby redis:int:demo 2
> (integer) 3- decrby [key] [integer]
将key自减指定的数字
set redis:int:demo 1
> OK
decrby redis:int:demo 2
> (integer) -1有趣的实验
用decrby减去-1会是加法的效果吗?
set redis:int:demo 1
> OK
decrby redis:int:demo -2
> (integer) 3答案是会增加。
hash从源码上看,底层在redis中其实叫dict(字典)
看一个插入函数
dictEntry *dictAddRaw(dict *d, void *key, dictEntry **existing) // addraw
{
long index;
dictEntry *entry;
dictht *ht;
if (dictIsRehashing(d)) _dictRehashStep(d); // 判断是否正在rehash
/* Get the index of the new element, or -1 if
* the element already exists. */
if ((index = _dictKeyIndex(d, key, dictHashKey(d,key), existing)) == -1) // 通过hash算法,得到key的hash值,如果是-1则返回null
return NULL;
/* Allocate the memory and store the new entry.
* Insert the element in top, with the assumption that in a database
* system it is more likely that recently added entries are accessed
* more frequently. */
// 判断是否正在rehash 将元素插入到顶部
ht = dictIsRehashing(d) ? &d->ht[1] : &d->ht[0];
entry = zmalloc(sizeof(*entry));
entry->next = ht->table[index];
ht->table[index] = entry;
ht->used++;
/* Set the hash entry fields. */
dictSetKey(d, entry, key);
return entry;
}字典和hash表的实现都大同小异 可以看到基本上原理是使用hash算法加桶(table),通过拉链法解决hash冲突,当每个槽位的平均容积大于1:1触发rehash等操作。
- hset [key] [field] [value]
将哈希表 hash 中一个key的 field 的值设置为 value 。 如果给定的哈希表key并不存在, 那么一个新的哈希表key将被创建并执行 HSET 操作。 如果域 field 已经存在于哈希表中, 那么它的旧值将被新值 value 覆盖。
hset redis:hash:demo com redis
> (integer) 1
hset redis:hash:demo com java // 设置同样的field将更新field 但返回是0
> (integer) 0
hget redis:hash:demo com
> "java"- hmset [key] [field] [value] ...
批量设置 hash 中一个key的field值为value 如果不存在,则新建再插入。
hmset redis:hash:demo com redis lan java
> OK // 这里就不再是返回integer了,而是返回了ok
hget redis:hash:demo com
> "redis"- hsetnx [key] [field] [value]
这个命令与string中的nx参数是一样的行为,即只有当field不存在key上时,field的设置才生效,否则set失败 特别注意,这里第二次nx设置时返回的既不是null也不是报错,而是返回了0,这里比较坑一点,所以要在hash中使用hsetnx,你可以尝试使用lua脚本实现
hsetnx redis:hash:demo com redis
> (integer) 1
hsetnx redis:hash:demo com java
> (integer) 0 // 既不是null也不是报错
hget redis:hash:demo com
> "redis" // 第二次设置未生效- hget [key] [field]
get一个key的field的值,key或field不存在时都返回为nil
hset redis:hash:demo com redis
> (integer) 1
hget redis:hash:demo com
> "redis"
hget redis:hash:demo empty
> (nil)- hmget [key] [field1] [field2] ...
批量获取field的值,这个值返回的是一个list
hmset redis:hash:demo com redis lan java
> OK
hmget redis:hash:demo com lan
> 1) "redis"
> 2) "java"- hlen [key]...
获取key中的field数量
hmset redis:hash:demo com redis lan java
> OK
hlen redis:hash:demo
> (integer) 2- hkeys [key]
获取key中的所有field的key,返回的是一个list
hmset redis:hash:demo com redis lan java
> OK
hkeys redis:hash:demo
> 1) "com"
> 2) "lan"- hvals [key]
获取key中的所有field的value,返回的是一个list
hmset redis:hash:demo com redis lan java
> OK
hvals redis:hash:demo
> 1) "redis"
> 2) "java"- hgetall [key]
获取key中的所有的东西,返回的是一个list,按 field,value,field,value的顺序排列
hmset redis:hash:demo com redis lan java
> OK
hgetall redis:hash:demo
> 1) "com"
> 2) "redis"
> 3) "lan"
> 4) "java"- hexists [key] [field]
判断key中的field是否存在, 返回integer,1表示存在 ,0 表示不存在
hmset redis:hash:demo com redis lan java
> OK
hexists redis:hash:demo com
> (integer) 1 // 1表示存在- hincrby [key] [field] [integer]
与string的incrby表现一致,将key中的field自增一个integer值, 字符和带小数点不可用
hset redis:hash:demo inta 1
> (integer) 1
hincrby redis:hash:demo inta 2
> (integer) 3
// 同样的,可以给定一个负数,这样就变成自减了
hincrby redis:hash:demo inta -2
> (integer) 1- lpush [key] [value1] [value2] ...
将多个value插入一个key,这里注意lpush和rpush的区别,lpush是从list的左边插入数据,rpush则是从右边。
rpush redis:list:demo 1 2 3
> (integer) 3
// 使用lrange查找
lrange redis:list:demo 0 -1
> 1) "3"
> 2) "2"
> 3) "1" // 这里对应的值是从左往右插入的- rpush [key] [value1] [value2] ...
将多个value插入一个key,这里注意lpush和rpush的区别,lpush是从list的左边插入数据,rpush则是从右边。
lpush redis:list:demo 1 2 3
> (integer) 3
// 使用lrange查找
lrange redis:list:demo 0 -1
> 1) "1"
> 2) "2"
> 3) "3" // 这里对应的值是从右往左插入的注意lpush和rpush都是在key不存在的时候,自动创建一个类型list的key,而当这个key已存在但类型不是list时,命令报错
del redis:list:demo // 删掉确保不存在
> (integer) n
type redis:list:demo
> none
lpush redis:list:demo 1 2 3
> (integer) 3
type redis:list:demo
> list // 自动创建了key并且类型是list
set redis:string:demo hello
> OK
lpush redis:string:demo 1 2 3
> (error) WRONGTYPE Operation against a key holding the wrong kind of value // key已经存在了但不是list类型- lrange [key] [start] [end]
读取一个list,从start下标开始end下标结束,end可以设置为负数
lpush redis:list:demo 1 2 3
> (integer) 3
lrange redis:list:demo 0 1
> 1) 3
> 2) 2
lrange redis:list:demo 0 -1
> 1) "3"
> 2) "2"
> 3) "1"
lrange redis:list:demo 0 -2
> 1) "3"
> 2) "2"- lpushx [key] [value]
将单个value插入一个类型为list且必须存在的key 如果key不存在,返回0,并不会报错,lpushx是从list的左边插入数据,rpushx则是从右边。
lpushx redis:list:demo 4
> (integer) 4
lpushx empty:key 1
> (integer) 0- rpushx [key] [value]
将单个value插入一个类型为list且必须存在的key 如果key不存在,返回0,并不会报错,lpushx是从list的左边插入数据,rpushx则是从右边。
rpushx redis:list:demo 5
> (integer) 5
rpushx empty:key 1
> (integer) 0- rpoplpush [source list] [destination list]
rpoplpush一个命令同时有两个动作,而且是原子操作,有两个参数
- 将列表 source 中的最后一个元素(最右边的元素)弹出,并返回给客户端。
- 将 source 弹出的元素插入到列表 destination ,作为 destination 列表的的头元素(也就是最左边的元素)
简单来说就是从list:a取出一个元素丢到list:b
例如 list:a = 1 2 3 list:b = 4 5 6
执行rpoplpush a b 之后:
list:a = 1 2 list:b = 3 4 5 6
返回客户端被操作的数 3
rpush list:a 1 2 3
> (integer) 3
rpush list:b 4 5 6
> (integer) 3
rpoplpush list:a list:b
> "3" // 返回客户端被操作的数
// 查看执行后的情况
lrange list:a 0 -1
> 1) "1"
> 2) "2"
lrange list:b 0 -1
> 1) "3"
> 2) "4"
> 3) "5"
> 4) "6"- lindex [key] [index]
这个命令简单实用,获取key的index下标的元素,不存在返回nil
lindex redis:list:demo 0
> "4"
lindex redis:list:demo 999
> (nil)- lset [key] [index] [value]
直接设置key的index的value
lset redis:list:demo 0 5
> OK
lindex redis:list:demo 0
> "5"因为list提供的命令的便利性和多样性,可以实现很多种数据结构,用的最多的就是队列和栈两个地方了,通过不同的方法分支成各种不同类型的队列,例如双端队列,优先级队列等。
- lpop [key] [timeout]
移除并返回列表 key 的左边第一个元素,当 key 不存在时,返回 nil。
del redis:list:demo
> (integer) n
lpush redis:list:demo 1 2 3
> (integer) 3
lpop redis:list:demo
> "3" // 从左边取出的数
lrange redis:list:demo 0 -1
> 1) "2" // 删掉了最左边的3
> 2) "1"- rpop [key][timeout]
移除并返回列表 key 的右边第一个元素,当 key 不存在时,返回 nil。
del redis:list:demo
> (integer) n
lpush redis:list:demo 1 2 3
> (integer) 3
rpop redis:list:demo
> "1" // 从右边取出的数
lrange redis:list:demo 0 -1
> 1) "3" // 删掉了最右边的1
> 2) "2"- blpop [key] [key ...] [timeout]
阻塞式的lpop,它可以设置多个key和一个timeout,将在这多个key里面选择一个列表不为空的key,lpop一个值出来,timeout可以指定一个超时时间,超过将会断开链接。
什么是阻塞式呢?
就是说这个操作是需要等待的,可以理解为下面的伪代码:
while ((n = list.lpop()) != null) {
return n;
}就是说如果list的lpop取出不为null时就立刻返回,否则就一直循环了。
如果timeout指定为0则表示没有超时时间,一直等待
下面的示例请打开两个终端窗口
// terminal a
lpush redis:list:demo 1 2 3
> (integer) 3
blpop redis:list:demo 0 // 0 表示一直等待
> "3"
blpop redis:list:demo 0 // 0 表示一直等待
> "2"
blpop redis:list:demo 0 // 0 表示一直等待
> "1"
lrange redis:list:demo 0 -1
> (nil) // 此时list已经空了
blpop redis:list:demo 0 // 会一直等待list有新的命令插入
// 等待terminal b
> 1) "redis:list:demo" 等待后返回的结果
> 2) "4"
> (18.83s)// terminal b
lpush redis:list:demo 4
> (integer) 1 // terminal a 会获取到这个4可以看到最后一步,当terminal a 最终等到terminal b,push了一个值之后,返回的数据与正常pop的数据不一样
- brpop [key] [key ...] [timeout]
参考blpop。基本行为一致,只是brpop是从list的右侧pop,而blpop是左侧
- brpoplpush [source list] [destination list] [timeout]
brpoplpush 是 rpoplpush的阻塞版本,你可以直接参考上面rpoplpush命令的解释,只是rpop变成了brpop,多了等待这一步。
- ltrim [key] [start] [end]
对一个列表进行修剪(trim),就是说,让列表只保留指定区间内的元素,不在指定区间之内的元素都将被删除。
注意,这里不要搞反了,是将start和end中间的保留,删除其余的
del redis:demo:list
> (integer) n
lpush redis:demo:list 1 2 3 4
> (integer) 4
ltrim redis:demo:list 1 2 // 只需要1到2
> OK
lrange redis:demo:list 0 -1
> 1) "3"
> 2) "2"- lrem [key] [count] [value]
移除count个与value相等的元素。
del redis:demo:list
> (integer) n
lpush redis:demo:list 1 2 2 3 4
> (integer) 5
lrem redis:demo:list 1 2 // 移除1个2
> OK
lrange redis:demo:list 0 -1
> 1) "4"
> 2) "3"
> 3) "2"
> 4) "1"tips,使用这个命令,你可以配合lua脚本做一个不重复的list, 就是每次在push一个value之前先lrem一下这个value
del redis:demo:list
> (integer) n
lrem redis:demo:list 1 a // 先检查删除
> (integer) 0
lpush redis:demo:list a // 再push
> (integer) 1辣么多数据结构,这么多命令,具体一点,都可以应用在什么场景呢?用来解决什么具体的问题?
redis是网络单线程的,它只有一个线程负责接受请求,这个特性即降低了redis本身的开发成本,也提高了redis的可用性。
分布式环境下,数据一致性问题一直是一个比较重要的话题,分布式与单机情况下最大的不同在于其不是多线程而是多进程。
多线程由于可以共享堆内存,因此可以简单的采取内存作为标记存储位置,例如cas,java的synchronize。而进程之间可能不在同一台物理机上,因此需要将标记存储在一个所有进程都能看到的地方。
常见的场景,秒杀场景中的库存超卖问题、多机定时任务的并发执行问题等。
假如订单服务部署了多个实例。
现在做一个商品秒杀活动,商品一共只有2个,同时购买的用户则可能有几千上万。
理想状态下第一个和第二个用户能购买成功,其他用户提示购买失败,
实际可能出现的情况是,多个用户都同时查到商品还没卖完,第一个用户买到,更新库存之前,第二个用户又下了订单,导致出错。
下面用java代码做一个演示:
java实例都可以被正常运行在jdk1.8+,使用jedis连接redis实例
import redis.clients.jedis.Jedis;
import redis.clients.jedis.JedisPool;
import redis.clients.jedis.JedisPoolConfig;
/**
* JedisPool连接
* @author taifeng zhang
* */
public class JedisPoolConnect {
public static JedisPool jedispool;
/**
* 连接并返回jedis实例
* */
public static Jedis connectJedis () {
if (jedispool == null) {
JedisPoolConfig jedisPoolConfig = new JedisPoolConfig();
jedisPoolConfig.setMinIdle(1);
jedisPoolConfig.setMaxIdle(10);
jedisPoolConfig.setTestOnBorrow(true);
jedispool = new JedisPool(jedisPoolConfig, "127.0.0.1", 6379);
}
return jedispool.getResource();
}
}import redis.clients.jedis.*;
import redis.clients.jedis.Jedis;
/**
* 一个简单的超卖演示程序
* */
public class MarketWrong {
public static String GOODS_LEN_KEY = "jedis:market:demo";
private final Integer DECR_THREAD_LEN = 16;
public void superMarket () {
// 开线程去减库存
int i = DECR_THREAD_LEN;
while (i > 0) {
new Thread(() -> {
boolean hasGoods = true;
while (hasGoods) { // 当库存大于0的时候
int goodsLen = getGoodsLen();
if (goodsLen > 0) {
decrGoodsLen(); // 一般进来之后就直接减去库存了
System.out.println("现在库存为" + getGoodsLen());
try {
Thread.sleep(100); //模拟中间处理流程
} catch (Exception e) {
System.out.println("执行减库存错误" + e.getMessage() + e.getLocalizedMessage() + e.getStackTrace());
} finally {
// 最后逻辑
}
} else {
System.out.println("======卖完啦=======");
hasGoods = false;
}
}
}).start();
i--;
}
}
public void setGoodsLen (Integer len) {
Jedis jedis = JedisPoolConnect.connectJedis();
try {
jedis.set(GOODS_LEN_KEY, String.valueOf(len));
} finally {
jedis.close();
}
}
private Integer getGoodsLen () {
Jedis jedis = JedisPoolConnect.connectJedis();
try {
String val = jedis.get(GOODS_LEN_KEY);
if (val != null) {
return Integer.parseInt(val);
}
} finally {
jedis.close();
}
return 0;
}
private void decrGoodsLen () {
Jedis jedis = JedisPoolConnect.connectJedis();
try {
// 库存减1
jedis.decr(GOODS_LEN_KEY);
} finally {
jedis.close();
}
}
}用junit测试上面的代码:
import org.junit.Test;
import org.springframework.boot.test.context.SpringBootTest;
@SpringBootTest
public class MarketWrongTests {
/**
* 测试超卖小程序
*/
@Test
public void superMarket () throws Exception {
MarketWrong marketWrong = new MarketWrong();
// 这次就卖500件吧
marketWrong.setGoodsLen(500);
marketWrong.superMarket();
Thread.sleep(60000); // 卖一分钟
}
}运行输出,每次库存都会变为负数,开了16个线程同时买东西:
// 省略了几万行
现在库存为8
现在库存为8
现在库存为4
现在库存为4
现在库存为4
现在库存为4
现在库存为3
现在库存为-5
现在库存为-5
现在库存为-5
现在库存为-5
现在库存为-5
现在库存为-5
现在库存为-5
现在库存为-5
======卖完啦=======
======卖完啦=======
======卖完啦=======上面的代码示例中,库存数据是共享资源(存到redis了,相当于数据库),面对高并发情形,需要保证对资源的访问次序。在单机环境Java提供基于内存的锁来处理并发问题,但是这些API在分布式场景中就无能为力了。也就是说单纯的内存锁并不能提供这种多机器并发服务的能力。分布式系统中,由于分布式系统的分布性,即多线程和多进程并且分布在不同机器中,synchronized和lock这两种锁将失去原有锁的效果,需要我们自己实现分布式锁。
也就是说库存的递减必须是顺序的
常见的锁方案如下:
基于数据库实现分布式锁 基于缓存,实现分布式锁,如redis 基于Zookeeper实现分布式锁
下面实现一个redis的锁,剖析一把redis是如何实现分布式锁的:
import redis.clients.jedis.Jedis;
import redis.clients.jedis.JedisCluster;
import redis.clients.jedis.JedisPool;
import redis.clients.jedis.JedisPoolConfig;
import redis.clients.jedis.params.SetParams;
import java.util.ArrayList;
import java.util.Arrays;
/**
* redis锁实现
* @author taifeng zhang
* */
public class RedisLock {
private static String REDIS_LOCK_KEY = "redis:lock:key";
/**
*设置lockkey
* */
public static void setRedisLockKey(String redisLockKey) {
REDIS_LOCK_KEY = redisLockKey;
}
/**
* 尝试获取锁
* @param ov 可以指定一个锁标识,锁的唯一值,区分每个锁的所有者身份
* @param timeout 获取锁的超时时间
* */
public boolean tryLock (String ov, int timeout) {
Jedis jedis = JedisPoolConnect.connectJedis();
try {
// set nx ex
SetParams setParams = new SetParams();
setParams.nx();
setParams.ex(timeout);
Object val = jedis.set(REDIS_LOCK_KEY, ov, setParams); // set [key] nx ex [timeout]
return val != null;
} finally {
jedis.close();
}
}
/**
* 使用lua脚本释放锁
* @param ov 释放之前先确定解锁人的身份,所以要用到lua的原子特性
* */
public boolean tryUnlock (String ov) {
Jedis jedis = JedisPoolConnect.connectJedis();
try {
String DISTRIBUTE_LOCK_SCRIPT_UNLOCK_VAL = "if (redis.call('get', KEYS[1]) == ARGV[1]) then return redis.call('del', KEYS[1]) else return 0 end";
String sha1 = jedis.scriptLoad(DISTRIBUTE_LOCK_SCRIPT_UNLOCK_VAL);
String[] keys = {REDIS_LOCK_KEY};
String[] args = {ov};
Integer val = Integer.parseInt(jedis.evalsha(sha1,new ArrayList<>(Arrays.asList(keys)),new ArrayList<>(Arrays.asList(args))).toString());
return val > 0;
} finally {
jedis.close();
}
}
}实现原则有几点: 1、原子相关操作步骤必须全部包括在锁内 2、每个锁都有一个唯一的value,标识加锁人的身份。 3、加超时时间防止死锁 (超时时间要合理)
- 加锁代码解析
/**
* 尝试获取锁
* @param ov 可以指定一个锁标识,锁的唯一值,区分每个锁的所有者身份
* @param timeout 获取锁的超时时间
* */
public boolean tryLock (String ov, int timeout) {
Jedis jedis = JedisPoolConnect.connectJedis();
try {
// set nx ex
SetParams setParams = new SetParams();
setParams.nx();
setParams.ex(timeout);
Object val = jedis.set(REDIS_LOCK_KEY, ov, setParams); // 用 set [key] nx ex [timeout] 命令模拟加锁
return val != null;
} finally {
jedis.close();
}
}加锁的代码很简单,其实就是利用redis命令 set [key] nx ex [timeout] 的特性,已有值的时候返回值为nil,如果执行这个命令的结果是null,那就可以认为资源已经被上锁
同时,set也将REDIS_LOCK_KEY设置为一个唯一值,在解锁的时候或者锁重入的时候判断身份使用。
- 解锁代码解析
/**
* 使用lua脚本释放锁
* @param ov 释放之前先确定解锁人的身份,所以要用到lua的原子特性
* */
public boolean tryUnlock (String ov) {
Jedis jedis = JedisPoolConnect.connectJedis();
try {
String DISTRIBUTE_LOCK_SCRIPT_UNLOCK_VAL = "if (redis.call('get', KEYS[1]) == ARGV[1]) then return redis.call('del', KEYS[1]) else return 0 end";
String sha1 = jedis.scriptLoad(DISTRIBUTE_LOCK_SCRIPT_UNLOCK_VAL);
String[] keys = {REDIS_LOCK_KEY};
String[] args = {ov};
Integer val = Integer.parseInt(jedis.evalsha(sha1,new ArrayList<>(Arrays.asList(keys)),new ArrayList<>(Arrays.asList(args))).toString());
return val > 0;
} finally {
jedis.close();
}
}解锁代码的精髓是这句lua脚本:
if (redis.call('get', KEYS[1]) == ARGV[1]) then
return redis.call('del', KEYS[1])
else return 0从redis读取key的值,如果它等于传入的唯一key,则可以释放锁,否则返回0
为什么要检查唯一key再释放锁呢?主要是为了这么一个场景:
- A用户来获取了锁
- B用户来获取锁,锁已经被a拿走了,等待锁
- A用户可能因为突然发生网络延迟,超过了超时时间,这时候锁因为超时自动释放了。
- B用户获取了锁
- A用户这时候网络恢复了。。。这时候A用户要释放锁,如果释放成功就会导致连锁反应,b用户被解锁,b又可能去解锁c
- 所以每次加锁解锁都需要验证获取锁的用户身份,一般存放在key的value里面,在释放锁之前先检查,也就是 check and set
锁的重入
上面谈到,我们记录了每个锁的用户身份,那是不是同一个用户一次操作需要两次锁,是可以重用的呢?
答案是ok的
我们可以在trylock中加一个lua脚本用来先check 再 set,如果判断check与用户符合,则直接返回true就可以了。
public boolean tryLock (String ov, int timeout) {
Jedis jedis = JedisPoolConnect.connectJedis();
try {
// 加上锁的重入特性
String DISTRIBUTE_LOCK_SCRIPT_UNLOCK_VAL = "if (redis.call('get', KEYS[1]) == ARGV[1]) then return 1 else return 0 end"; // 如果当前锁的值等于ov的话,认为来获取锁的还是同一个人
String sha1 = jedis.scriptLoad(DISTRIBUTE_LOCK_SCRIPT_UNLOCK_VAL);
String[] keys = {REDIS_LOCK_KEY};
String[] args = {ov};
Integer val = Integer.parseInt(jedis.evalsha(sha1,new ArrayList<>(Arrays.asList(keys)),new ArrayList<>(Arrays.asList(args))).toString());
if (val > 0) { // 判定成功后,锁就重入了,即无需第二次获取锁
return true;
}
// set nx ex
SetParams setParams = new SetParams();
setParams.nx();
setParams.ex(timeout);
Object val = jedis.set(REDIS_LOCK_KEY, ov, setParams); // set [key] nx ex [timeout]
return val != null;
} finally {
jedis.close();
}
}最后我们看看关于超卖问题,我们将代码加上锁 注意两个todo的地方。
import redis.clients.jedis.*;
import redis.clients.jedis.Jedis;
public class MarketWrong {
public static String GOODS_LEN_KEY = "jedis:market:demo";
private final Integer DECR_THREAD_LEN = 16;
RedisLock redisLock = new RedisLock();
public void superMarket () {
// 开线程去减库存
int i = DECR_THREAD_LEN;
while (i > 0) {
int whilekey = i;
new Thread(() -> {
int n;
int j = 0;
boolean hasGoods = true;
while (hasGoods) { // 当库存大于0的时候
String ov = whilekey + "-" + j;
// todo 加锁
while (!redisLock.tryLock(ov, 20)) { // 如果获取不到锁就等待
}
int goodsLen = getGoodsLen();
if (goodsLen > 0) {
decrGoodsLen(); // 一般进来之后就直接减去库存了
System.out.println("现在库存为" + getGoodsLen());
redisLock.tryUnlock(ov); // todo 解除锁
try {
Thread.sleep(100); //模拟中间处理流程
} catch (Exception e) {
System.out.println("执行减库存错误" + e.getMessage() + e.getLocalizedMessage() + e.getStackTrace());
} finally {
// 最后逻辑
}
} else {
System.out.println("======卖完啦=======");
hasGoods = false;
}
j++; // 需要这个用来生成ov,相当于模拟每一个买家的id
}
}).start();
i--;
}
}
/**
* 一个简单的超卖演示程序
* */
public void setGoodsLen (Integer len) {
Jedis jedis = JedisPoolConnect.connectJedis();
try {
jedis.set(GOODS_LEN_KEY, String.valueOf(len));
} finally {
jedis.close();
}
}
private Integer getGoodsLen () {
Jedis jedis = JedisPoolConnect.connectJedis();
try {
String val = jedis.get(GOODS_LEN_KEY);
if (val != null) {
return Integer.parseInt(val);
}
} finally {
jedis.close();
}
return 0;
}
private void decrGoodsLen () {
Jedis jedis = JedisPoolConnect.connectJedis();
try {
// 库存减1
jedis.decr(GOODS_LEN_KEY);
} finally {
jedis.close();
}
}
}加上锁之后再测试,超卖问题已解决,注意现在的输出是线性递增的,因为开线程的模拟方式就是并发处理,每次16个线程几乎是同时进行的,所以在没有锁的时候,并发读取的goodslen很有可能都是16个线程一样的。
所以redis的这个锁的实现也叫: 分布式互斥锁
现在库存为8
现在库存为7
现在库存为6
现在库存为5
现在库存为4
现在库存为3
现在库存为2
现在库存为1
现在库存为0
======卖完啦=======
======卖完啦=======
======卖完啦=======redis实现的分布式互斥锁并不完美,但在大多数应用场景下够用了,另外还可以使用zookeeper甚至mysql来实现。
分布式场景下,还有另外一个问题--定时任务并发问题,当我们的应用采用分布式部署的时候,就必然会有各种定时任务被部署到不同的机器实例上,如果两台机器同时运行同一个定时任务的话,任务就执行了两次。
这个问题可能更复杂一点,仅仅是加一个锁有可能会坏事儿,因为定时任务的多机分布会产生几个需要解决的问题:
-
多台机器的时间一致性问题
如果多台机器的时区不一致,那锁基本上无从谈起了。 或者时区一致,但可能服务器时间相差几秒钟,那么也有可能导致锁丢失。
-
锁未释放问题(服务器宕机怎么办)
那么如果serverA在加锁的过程中,出现宕机怎么办,是否会一直处于加锁状态
-
命名空间问题
每个定时任务应该有不同的锁命名,防止出现同名锁。
还是让我们看一个java代码的例子 注意,redis连接和锁代码有复用上面一节的
import org.springframework.scheduling.annotation.EnableScheduling;
import org.springframework.scheduling.annotation.Scheduled;
import org.springframework.stereotype.Component;
import redis.clients.jedis.Jedis;
@Component
@EnableScheduling
public class ScheduleDemo {
private String sourceKey = "redis:schedule:test:key";
private void sendEmail (String serviceKey) throws InterruptedException {
Jedis jedis = JedisPoolConnect.connectJedis();
try {
Integer sendPatch = 0; // 从redis读取来模拟发送的批次
Object val = jedis.get(sourceKey);
if (val != null) {
sendPatch = Integer.parseInt(val.toString());
}
Thread.sleep(2000);
System.out.println("批次[" + sendPatch +"]====发送邮件====" + serviceKey);
jedis.incr(sourceKey); // 批次加1
} finally {
jedis.close();
}
}
// 模拟service
@Scheduled(cron = "0 27 09 * * ?") // 【cron改为后面的时间】
public void serviceA () throws InterruptedException {
this.sendEmail("service");
}
}将这段代码打开两个实例运行【ps,你可以在idea中右上角直接配两个config就可以了】
看运行结果:
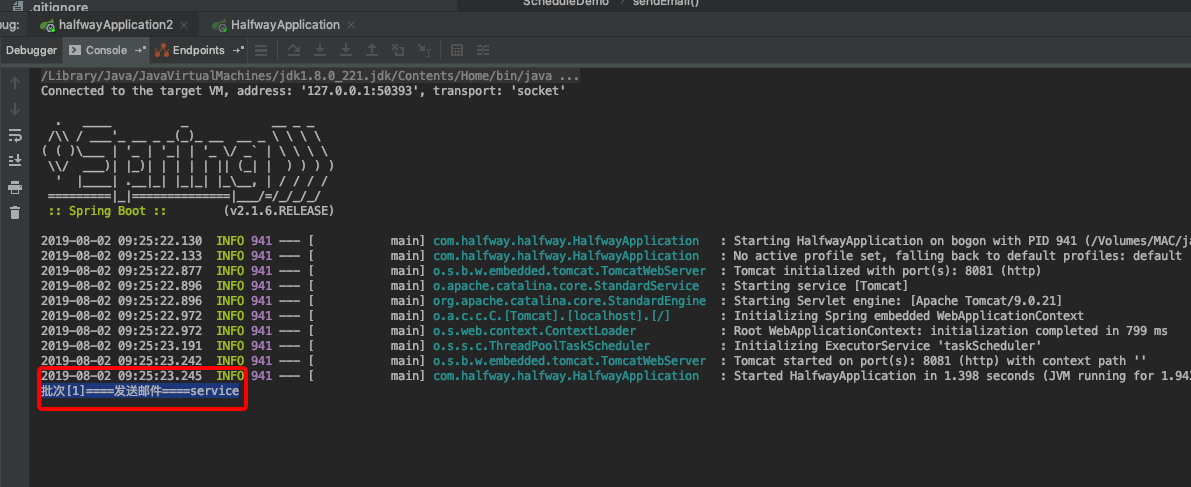
邮件1被同时发送了两次,这是不可接受的。
ok,有的同学现在就想到了,加个锁就完事了
我们将发送代码加上一个锁解决这个问题:在sendmail里加一个redis分布式锁
private void sendEmail (String serviceKey) throws InterruptedException {
if (!redisLock.tryLock(serviceKey, 30)) {
return; // todo 获取不到锁就取消,同一个定时任务只需要执行一次
}
Jedis jedis = JedisPoolConnect.connectJedis();
try {
Integer sendPatch = 0; // 从redis读取来模拟发送的批次
Object val = jedis.get(sourceKey);
if (val != null) {
sendPatch = Integer.parseInt(val.toString());
}
Thread.sleep(2000);
System.out.println("批次[" + sendPatch +"]====发送邮件====" + serviceKey);
jedis.incr(sourceKey); // 批次加1
redisLock.tryUnlock(serviceKey); // todo 解锁
} finally {
jedis.close();
}
}如果获取不到锁,那么取消这个任务的执行,看起来很完美对不对?
实际上没有解决的问题还有很多。
- 多个定时任务的多个并发执行sendmail,key如何保证唯一?
可以使用实例的ip+端口做唯一key,这样能够保证多个实例的唯一性
- 两台服务器时间差超过30s怎么办?
通过中间媒介来确定时间。或者在服务器中杜绝这个问题
- 最重要的问题还是在于,两台服务器的时间有可能有细微差别,他们本身就有可能不是并发的
这一点在分布式定时任务领域里很重要。
仅仅是加了一个同步锁是远远不够的
解决方案可以是根据业务的不同来设置不同的锁超时时间,例如某个业务定时任务,每天只可以执行一次,那么将超时时间设置为1个小时最保险,如果某个定时任务每分钟执行,执行操作时间大约20s,那你可以将超时时间设置成30s。
另一个解决方案是设置一个统一的、中心级别的定时任务,任务负责派发消息,通过消息队列的方式来做定时,这里就不细表,这种方式比较适合异构、或者跨网络、跨机房级别的分布式。
可以对redis锁做一次小小的改版升级,使用aop加注解来完成锁的配置:
我们定义一个方法级别的aop注解
import java.lang.annotation.ElementType;
import java.lang.annotation.Retention;
import java.lang.annotation.RetentionPolicy;
import java.lang.annotation.Target;
/**
* redis lock
* @author taifeng zhang
* */
@Retention(RetentionPolicy.RUNTIME)
@Target(ElementType.METHOD)
public @interface RedisLockAop {
String key();
/**
* 两种类型可选
* wait = 等待锁
* return = 取消执行
* */
String type() default "wait";
int timeout() default 30;
}然后通过aop,去为加了注解的方法做锁操作
import com.halfway.halfway.redis.RedisLock;
import org.aspectj.lang.ProceedingJoinPoint;
import org.aspectj.lang.annotation.After;
import org.aspectj.lang.annotation.Around;
import org.aspectj.lang.annotation.Aspect;
import org.springframework.context.annotation.Configuration;
import org.springframework.stereotype.Component;
/**
* redislock aop实现
* @author by taifeng zhang
* */
@Component
@Aspect
public class RedisLockAopAspect {
private RedisLock redisLock = new RedisLock();
@Around("@within(com.halfway.halfway.redis.lockAop.RedisLockAop) && @annotation(lock)")
public Object excuteAop (ProceedingJoinPoint pjp, RedisLockAop lock) throws Throwable {
if ("wait".equals(lock.type())) {
while (!redisLock.tryLock(lock.key(), lock.timeout())) {} // todo 等待锁
} else if ("return".equals(lock.type())) {
if (!redisLock.tryLock(lock.key(), lock.timeout())) {
return null; // todo 取消执行
}
} else {
throw new NullPointerException("type只可以是wait或者return");
}
Object val = pjp.proceed();
redisLock.tryUnlock(lock.key());
return val;
}
}这个方式的好处是锁与代码解耦,无需关注锁的内部实现变化
@Scheduled(cron = "0/30 * * * * ?")
@RedisLockAop(key = "serviceIp:port", type="return", timeout=15)
public void serviceA () throws InterruptedException {
this.sendEmail("service");
}redis还有另外一个重要的应用领域——缓存
引用来自网友的图解释缓存在架构中的位置
默认情况下,我们的服务架构如下图,客户端请求service,然后service去读取mysql数据库

问题存在于,数据库性能不够用,数据库是整个架构中最重要的一个环节,它在高并发,高写入频次的时候非常容易崩掉,这是一般的数据库本身的特性所决定的,它们的架构模式注定了不可以承受较大的并发量,所以就有了缓存:

service与高速的缓存进行交互,如果缓存中有数据直接返回客户端,如果没有才会从MySql中去查询。减小数据库的压力,提升效率,避免宕机。
例如上面章节提到的,超卖问题,有可能瞬间的流量高达上万,我们不可能把这些请求都响应到数据库上,这样速度慢不说,还随时可能宕机。
提到缓存,就不得不说下面的四大缓存名场面,几乎是做缓存必须面对的问题。
想象一个场景,现在在一个xx办事大厅
张三、李四、王五、赵六、钱钱、刘八、陈九 七个人正在排队
办事处有一个窗口,有一些自动业务机,窗口里面的同志一下子只能接待一个人,而自动业务机因为速度很快可以很快接待很多人。
现在,突然、自动业务机都坏了... 所有人都排到了窗口,这下忙死了窗口里面的同志,直接撂挑子不干了!
这个例子中,自动业务机就像是缓存,起了一个缓冲的作用,业务员就像是数据库,处理能力比自动机器慢,而且很容易炸毛。
缓存击穿就是这样,当某个缓存故障、或者在高峰期缓存突然无效了,就会导致所有请求都跑到数据库去排队,就造成了缓存击穿。

缓存相当于给数据库加了一层保护能量罩,敌人进来的时候如果某个地方没有能量,那么如果这个地方的敌人特别多,就会导致缓存击穿。当从缓存中查询不到我们需要的数据就要去数据库中查询了。如果被黑客利用,或者高峰流量,频繁去访问缓存中没有的数据,那么缓存就失去了存在的意义,瞬间所有请求的压力都落在了数据库上,这样会导致数据库连接异常。
解决方案:
-
后台设置定时任务,主动的去更新缓存数据。这种方案容易理解,就是在自动业务机旁边加了一个维护员,坏了赶紧修好,但是机器多了就比较复杂,维护员不一定能搞得定,当key比较分散的时候,操作起来还是比较复杂的
-
分级缓存。什么意思呢,就是放两台业务机器,平时用第一台,第一台坏了马上用第二台,用第二台的时候修第一台,设置两层缓存保护层,1级缓存失效时间短,2级缓存失效时间长。有请求过来优先从1级缓存中去查找,如果在1级缓存中没有找到相应数据,则对该线程进行加锁,这个线程再从数据库中取到数据,更新至1级和2级缓存。其他线程则直接从2级线程中获取
缓存穿透本质上和缓存击穿所面临的问题一样,大量请求落到数据库中。
但是出发点略有不用,缓存穿透的问题是,在高并发下,查询一个不存在的值时,缓存不会被命中,导致大量请求直接落到数据库上,如活动系统里面查询一个不存在的活动。
也就是说,缓存击穿是当数据是存在的,但没有被缓存到,而缓存穿透是去访问根本不存在的值。想象一个场景,黑客截取了一个已经过期的活动的数据接口,然后不断的去请求它,这时候有可能因为这个活动本身已经过期了,缓存不会命中,请求就全部落地到数据库了,这时候就造成了缓存穿透。
缓存穿透的问题解决方案也有很多
直接缓存NULL值
这个比较容易理解,就算是没数据我也缓存一下,你下次过来命中的是空数据。
这种方法需要特别注意,为空的值不能缓存的太久,否则有可能在真的有数据的时候影响了业务正常流程。
布隆过滤器
什么是布隆过滤器
布隆过滤器判断一个值不存在,那么这个值100%不存在
布隆过滤器判断一个值存在,这个值90%是存在的
布隆过滤器本质是一个位数组,位数组就是数组的每个元素都只占用 1 bit 。每个元素只能是 0 或者 1。这样申请一个 10000 个元素的位数组只占用 10000 / 8 = 1250 B 的空间。布隆过滤器除了一个位数组,还有 K 个哈希函数。
等一下,是不是有点绕,不太好理解。
我们知道hash函数可以根据一个值生成一个对应的数字,然后与一个长度可以取模可以得到一个下标值 (你不知道?看看HashMap的实现吧)
或者你根本不知道hash是怎么实现的,没关系,也可以先理解下面的,我们先把这个函数假设为 int getIndex (String value), 根据值获取到一个下标
假设我们现在有一个数组,长度是5,每个元素的值都是0
0 , 0 , 0 , 0 , 0
现在我们数据库中一共有五个id
a , b , c , d , e
现在我们对id们执行getIndex函数可以得到
getIndex(a) = 0
getIndex(b) = 1
getIndex(c) = 1 // 假设函数有一些误差
getIndex(d) = 2
getIndex(e) = 3
想一想,现在来了一个新元素,f 怎么样判断在id里面存在不存在呢?
我们把开始的数组和getIndex关联起来, 将getindex的值作为下标,设置值为1,数组就会变成
1 , 1 , 1 , 1 , 0
然后我们再来判断f是否存在,假设 getIndex(f) = 4
ok了,我们只需要判断数组里的下标4是否是1,是1就存在,0就不存在了嘛
那如果 getIndex(f) = 2 呢? 我们开了上帝视角,很明显f不存在呀。
布隆过滤器不能100%判断一个元素是否真的存在数组中,但能100%判断它不存在与数组中,这取决于hash函数的算法程度
布隆过滤器防止缓存穿透
通过对布隆过滤器的理解,我们能就过滤掉大部分的无效请求了,把数据库中所有的id都getindex解析一次放到布隆过滤器中,请求过来的时候判断,如果不存在就直接返回空就行了
如果缓存集中在一段时间内失效,发生大量的缓存穿透,所有的查询都落在数据库上,造成了缓存雪崩。
其实与缓存击穿的理论差不多,都是突然失效导致的击穿数据库。
雪崩与击穿的不同点在于雪崩强调集中失效两个字
想象~ 我现在有三个缓存key存在redis中,过期时间是一天
一天后,由于key有可能是同时设置的缓存,导致这三个key同时失效了,即使我的缓存击穿问题已经解决,这时候因为集中的key失效,也会造成击穿!,这是量级发生了改变,就像x和y的关系, x表示key的多少,y表示请求的多少。。。
解决方案
- 设置不同的过期时间
你永远不可能每个缓存都能命中的。什么是好的缓存策略,好的缓存策略是能够识别热点数据,并在热点被读取的时候能够保证命中,这是一个好的缓存策略所必须的条件之一。
数据库的数据和缓存的数据是不可能一致的,数据分为最终一致和强一致两类。
强一致 不可以使用缓存
缓存能做的只能保证数据的最终一致性。
我们能做的只能是尽可能的保证数据的一致性。
不管是先删库再删缓存 还是 先删缓存再删库,都可能出现数据不一致的情况,因为读和写操作是并发的,我们没办法保证他们的先后顺序。
具体应对策略根据业务需求来制订。
Redis设置的过期时间。这个key过期时是怎么删除的?
Redis采用的是定期删除,注意不是定时删除,不可能为每一个key做一个定时任务去监控删除,这样会耗尽服务器资源。
默认是每100ms检测一次,遇到过期的key则进行删除,这里的检测也不是顺序检测,而是随机检测。
另外为了防止有漏网之鱼,例如在100ms检查的中间间隙,某个key过期,但同时key访问又进来了,这时触发 惰性删除策略 redis会在读取时判断是否已经过期,过期则直接删除。
内存淘汰是指一部分key在内存不够用的情况下会被Redis自动删除,从而会出现从缓存中查不到数据的情况。
例如我们的服务器内存为2G、但是随着业务的发展缓存的数据已经超过2G了。但是这并不能影响我们程序的运行。所以redis会从key列表中抽取一定的热度低的数据进行淘汰策略,腾出空间存储新的key