情報・システム研究機構 ライフサイエンス統合データベースセンター
坊農 秀雅 bono@dbcls.rois.ac.jp
2015年6月16日 大阪大学吹田キャンパス
これは統合データベース講習会AJACS千里「ゲノム配列データベースの使い方」の資料です。
本講習は、だれでも自由に使うことができる公共データベース(DB)のうちゲノム配列に関してウェブツールを活用して、研究のさまざまな場面で使う方策について学びます。
今回の講習では、コンピュータを使って以下の内容について説明します。
- 研究現場で頻繁に使われるデータベースやツールを知る
- ゲノム配列を探す
- NCBI
- GOLD
- ゲノム配列から探す
- Web上で
- BLAST
- GGGenome
- Local BLASTで(今回はやらない)
- Web上で
- アノテーションを足して見る
- UCSCのtrack
- ENCODE TF Binding
- TFBS Conserved
- Resetのやり方
- Ensemblへジャンプ
- Synteny
- Resequencing
- UCSCのtrack
- みんなで同時にアクセスするとサイトにつながりにくくなることが予想されます。
- 資料を見ながら自力で進められそうな方はどんどん先に、そうでない方は講師と一緒にすすめていきましょう。
- サイトの反応が悪い時はタイミングをずらして実行してみてください。
- 反応が無いからと言って何度もクリックするとますます繋がらなくなってしまいます。おおらかな気持ちで臨みましょう。
- わからないことがあったら挙手にてスタッフにお知らせください。
- 遠慮は無用です(そのための講習会です!)。おいてけぼりは楽しくありません。
- 質問や個別の相談がある方は講習時間が終わったあとでも講師を捕まえて話してください。
- 生命科学分野の有用なデータベースやツールの使い方を動画で紹介するウェブサイト
-
YouTube版もあります http://www.youtube.com/user/togotv/videos
-
ウェブサイトへのアクセスから結果の見方まで、操作の一挙手一投足がわかります。
- 講義・講習などの参考資料や後輩指導の教材として利用できます。
- 本講習中、本家サイトが繋がらない時は、統合TVのYouTube版を見ればおおよその内容がわかるようになっています。
- 今回の講習に関連する内容の多くは、統合TV の発現制御解析 カテゴリーにあります。
- 過去の講習会の内容はそのほとんどが統合TVに収録されており、いつでもどこでも繰り返し復習できるようになっています。
-
お探しの動画が見つからない or 統合TV未掲載の場合は、統合TV番組リクエストフォームへどうぞ!!
-
統合TVを作ってみたい方、募集中です。

さまざまな生物種のゲノム配列が解読されています。それを自らの研究に利用しない手はありません。その利用の第一歩としてそれを探してくる方法を学びます。
- NCBI(National Center for Biotechnology Information)
- アメリカ合衆国の予算による分子生物学情報のリソース
- いろんな調べ物、基本ここから
####【実習1】NCBIからゲノム配列を検索、取得する
-
中東呼吸器症候群の原因ウイルスのゲノム配列を取得しましょう。日本語しかわからない場合は、NBDCのデータベース横断検索から英語名を調べましょう。その結果、出てくる
Middle East respiratory syndromeでNCBIから検索します
-
検索結果を見ましょう。それぞれのDBの横にある数字は、検索ヒット数です。ゲノム配列が得たいので、
Genomeの項目(ヒット数1件)をクリックして詳細を取得します
-
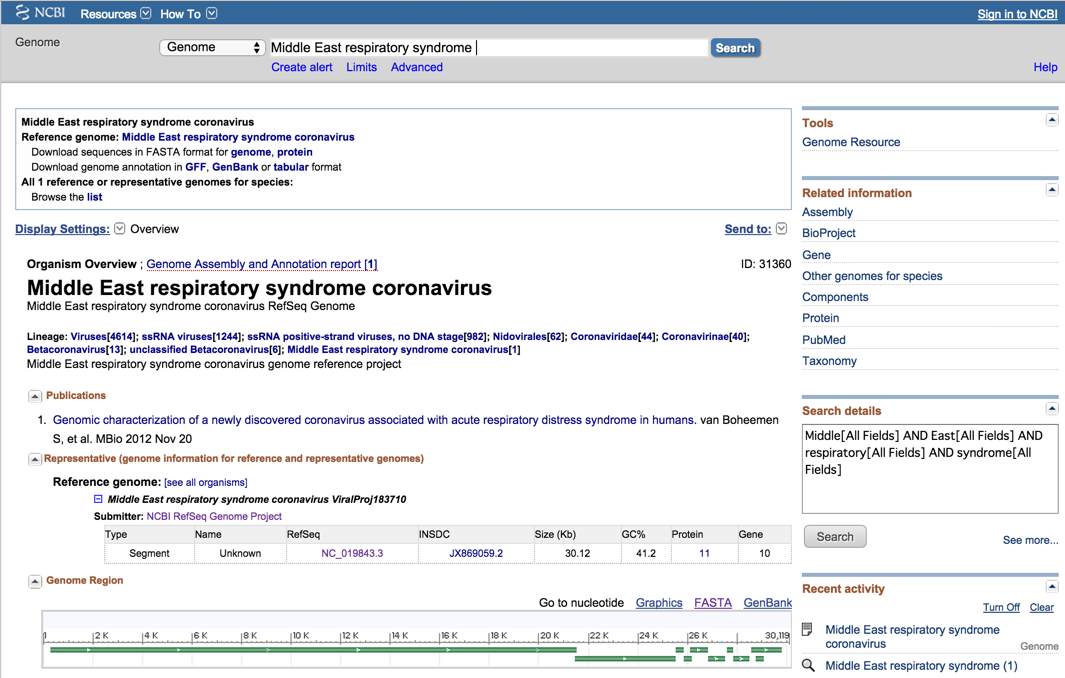
Middle East respiratory syndrome coronavirusのゲノム構造と各種リンクが表示されます。
RefSeqのところにあるIDをクリックするとRefSeq(リファレンス配列(Reference Sequence)のデータベース)のレコードが表示されます
-
得られるRefSeqのレコードを見ましょう。ゲノムにコードされているタンパク質配列などを確認しましょう
-
そのレコードの一番下にゲノム配列が記述されています。ゲノム塩基配列を抜き出すには、最上部の
FASTAをクリックします
-
MERSコロナウイルスのゲノム配列が得られました!




- GOLD(Genomes Online Database)
- ゲノム塩基配列解読プロジェクトを集めたデータベース
- すでに終了したプロジェクトだけでなく、現在進行中のゲノムプロジェクトやメタゲノムプロジェクトについても調べることができます
####【実習2】GOLDでゲノム配列解読された生物種を検索する (詳細な手順は統合TV(GOLD -Genomes Online Database- の使い方)にあります。それと同じ内容を以下の実習でやりますので、動画を見ながらやっていただくのも手です)
-
GOLD(Genomes Online Database)にアクセスします
-
上部のメニューバーの中のSearchをクリックします
-
NCBI BioProject Nameに
Thiobacillusと入力して、下部にあるSearchをクリックします
-
Select Fieldsをクリックして出てくるサブウィンドウでIs PublicとGC Percentにチェックを入れて、そのウィンドウ最下部のSubmitをクリックします
-
こんな結果が出てきます。Project Statusでゲノム配列解読の状況がわかります
-
出てくるテーブルの
GC PercentをクリックするとGC含量でレコードがソートされます
-
一番上に出てくる
Gp0003885をクリックして出てくる詳細画面を眺めましょう。Sequencing Information,Organism Information,Organism Metadataタブをクリックしてどういった情報が載せられているか確認しましょう
-
Project Informationタブに戻り、NCBI BioProject IDのリンクをクリック
-
リンク先は前述のNCBIのBioProjectのページで
SEQUENCE DATAの数字をクリックすれば、前述同様、ゲノム配列が取得できます







【復習用】GOLD -Genomes Online Database- の使い方(統合TV)
##ゲノム配列から探す ゲノム配列が得られてもその中から欲しい領域を目で見つけてくること(眼grep(「めグレップ」)と呼んでいます)は容易ではありません。そこで、コンピュータの力を借りることになります。
- BLAST(Basic Local Alignment Search Tool)
- http://blast.ncbi.nlm.nih.gov/
- 前世紀から使われている配列類似性検索のデ・ファクト・スタンダード
- かつては遠縁の配列相同性を検出するためのツール
- 今はほぼ完全一致を探すために用いられることも多い

####【余談】なぜ相同性じゃなく類似性か
- 遺伝学では、相同性という言葉はタンパク質のアミノ酸配列や遺伝子の塩基配列が共通の祖先をもつときに用いる
- バイオインフォマティクスでは、タンパク質やDNAでの相同性は、配列類似性に基づいて判断される

- 現在(2015年6月)のBLASTウェブインターフェース
- Assembled Genomesに対する生物種ごとのBLAST検索が上位に
- Basic BLAST(以下に説明)が下の方に

- GGGenome
- 「じぇじぇじぇのむ」と読みます(参考: GGRNA(「ぐぐるな」))
- http://gggenome.dbcls.jp/
- 上記のAssembled Genomesに対する高速検索のツール
####【実習3】GGGenomeを使ってゲノム配列から探す
-
http://gggenome.dbcls.jp/ にアクセスします
-
CTGACGGTCA(10塩基)を入力して「検索」ボタンを押します。この塩基配列がヒトゲノム中で何回出てくるか、簡単にわかります
-
検索ボタンの右にある生物種を
S.cerevisiaeにして検索しなおしましょう。ヒット数はどう変化するでしょうか?
-
染色体と位置のところにリンクがあり、これをクリックするとUCSC Genome Browserの該当箇所になります。その使い方は次節で説明します



- 【復習用】高速配列検索 GGGenome《ゲゲゲノム》の使い方(統合TV)
- English version available here -> GGGenome: a fast and simple DNA sequence search engine(TogoTV)
検索する質問配列の数が多くなると、いちいちウェブブラウザを開いて貼り付けてクリックして…が大変になります。それを克服する方法として、Local(自分のパソコン)にBLASTのプログラムをインストールしてBLASTを実行する方法(LocalBLAST)があります。詳しくはこちらの資料を御覧ください。実際にセットアップする統合TVもそこから紹介しています。
ゲノム解読がなされて終わりではありません。どこに遺伝子がコードされているか、転写因子の結合領域はどこかなど、ゲノム上の座標に対して注釈付けがなされていきます。それがゲノムアノテーションです。
それを見る方法としてゲノムブラウザが使われます。ここではウェブブラウザ上で使えるゲノムブラウザとして有名なUCSC Genome Browser(「ゆーしーえすしー げのむ ぶらうざー」)とEnsembl Genome Browser(「あんさんぶる」)の使い方を学びます。
####【実習4】UCSC & Ensembl Genome Browserに隠されたアノテーションを発掘する
-
http://genome.ucsc.edu/ にアクセスします
-
上部のメニューバーの
Genomesをクリックします
-
groupに
Mammal、genomeにHuman、assemblyにFeb.2009 (GRCh37/hg19)を選び、search termにPPARGと入力すると入力補完されるので、一番上のPPARGを選び、submitボタンを押しましょう
-
PPARGがコードされたゲノム上の領域が表示されます
-
上部のnavigationボタンでmoveやzoom in/out等できますが、遺伝子名検索でたどり着いた場合、mRNAの領域に拡大されて表示されるので、zoom out
3xしておきましょう
-
画面下の方にあるのがアノテーションです。Regulationカテゴリー中の
ENC TF Bindingが'hide'になっているのをshowに変えて、refreshボタンを押してみましょう
-
そうすると、上部のゲノム領域にこのゲノムアノテーションが付加されて表示されます
-
このゲノムアノテーションについて詳しく知りたい場合、さきほどshowに切り替えた選択画面の上にあったリンクをクリックしてみましょう
ENCODE Transcription Factor Binding Tracks のようです
-
いろいろいじってしまうと元に戻したい時があります。その場合は、
default tracksボタンを押すとResetされ、元のゲノムアノテーションに簡単に戻せます
-
上部のメニューのうち、Viewをクリックして出てくる
Ensemblをクリックすると、今見ている領域のEnsembl Genome Browserの該当領域へジャンプします
-
【重要】ゲノム配列はバージョンが同じならどこのサイトでも同一ですが、 アノテーションは提供サイトで異なります
-
左カラムのメニュー中のComparative Genomicsの
Syntenyをクリックすると、ヒトとマウスの間のシンテニーマップが表示されます
-
Genetic Variationの
Resequencingをクリックします
-
指定した領域が広すぎる(Region too large)、と怒られました。そこで、ズームスライダー(右)を+のほうに動かしてみます
-
無事、リシーケンスの代表格のWATSONとVENTERゲノムとリファレンスゲノムのアラインメントが表示されました












ここまで出来て時間のある方は、自分の興味のある遺伝子やtrackを試してみましょう。余裕のある方は、ウイルスの持ち出した宿主の遺伝子配列がコードされている領域をアミノ酸配列レベルでゲノム中から探し当てる 2012(統合TV)で説明されているラウス肉腫ウイルスゲノム配列を取得、その痕跡をニワトリゲノムから探してみるのをやってみましょう。