Point precisely: Towards ensuring the precision of data in generated texts using delayed copy mechanism., Li+, Peking University, COLING'18 #415
Comments
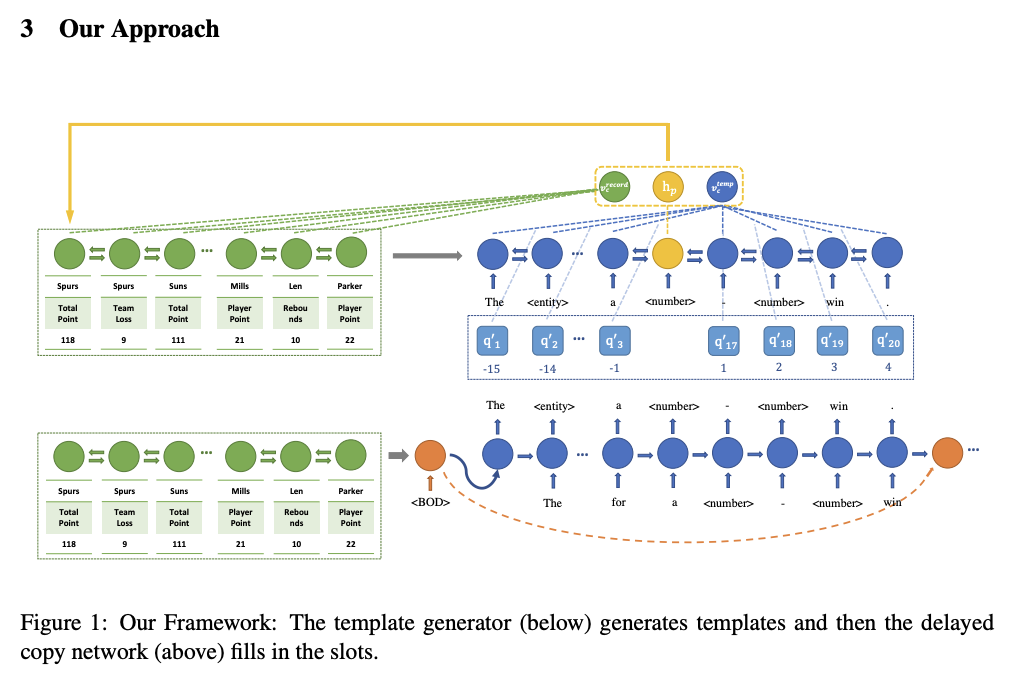
概要DataToTextタスクにおいて、生成テキストのデータの精度を高める手法を提案。two stageアルゴリズムを提案。①encoder-decoerモデルでslotを含むテンプレートテキストを生成。②Copy Mechanismでslotのデータを埋める、といった手法。 two stageにするモチベーションは、 モデル概要モデルの全体像 オリジナルテキストとテンプレートの例。テンプレートテキストの生成を学習するencoder-decoder(①)はTarget Templateを生成できるように学習する。テンプレートではエンティティが""、数値が""というplace holderで表現されている。これらのスロットを埋めるDelayed Copy Networkは、スロットが正しく埋められるように学習される。
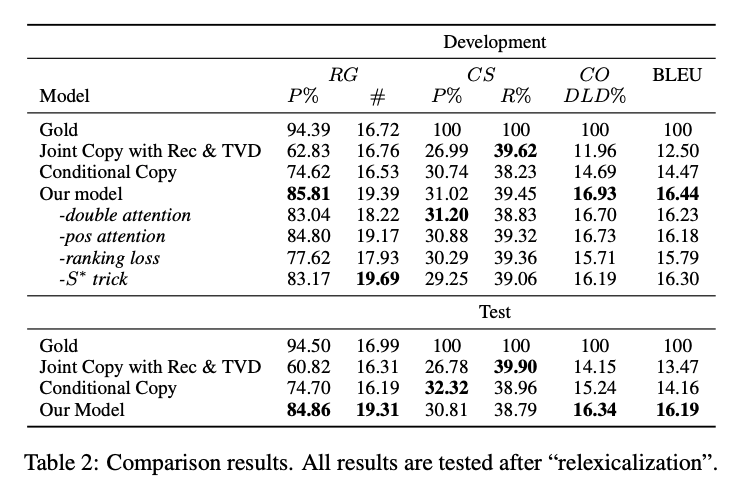
実験結果
Relation Generation (RG)がCCと比べて10%程度増加しているので、data fidelityが改善されている。 参考:• Relation Generation (RG):出力文から(entity, value)の関係を抽出し,抽出された関係の数と,それらの関係が入力データに対して正しいかどうかを評価する (Precision).ただし entity はチーム名や選手名などの動作の主体,value は得点数やアシスト数などの記録である. |

https://aclanthology.org/C18-1089.pdf
The text was updated successfully, but these errors were encountered: