Chain of thought prompting elicits reasoning in large language models, Wei+, Google Research, arXiv'22 #551
Comments
|
Chain-of-Thoughtを提案した論文。CoTをする上でパラメータ数が100B未満のモデルではあまり効果が発揮されないということは念頭に置いた方が良さそう。 |
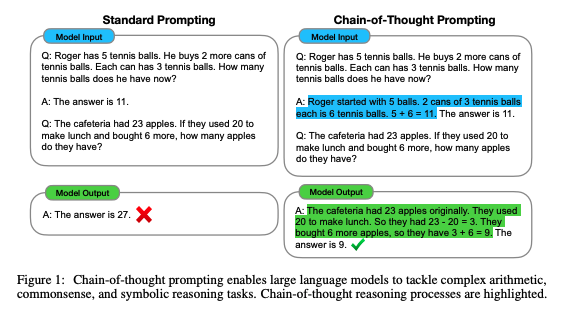
|
先行研究では、reasoningが必要なタスクの性能が低い問題をintermediate stepを明示的に作成し、pre-trainedモデルをfinetuningすることで解決していた。しかしこの方法では、finetuning用の高品質なrationaleが記述された大規模データを準備するのに多大なコストがかかるという問題があった。 |
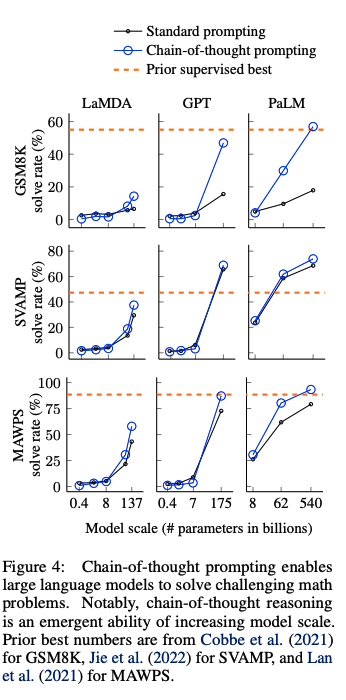
CoTによる実験結果以下のベンチマークを利用
math word problem benchmark
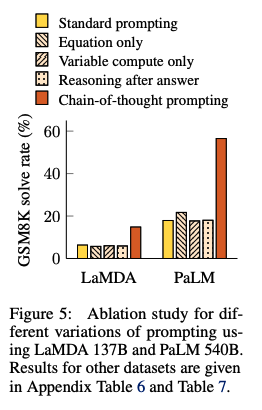
Ablation StudyCoTではなく、他のタイプのpromptingでも同じような効果が得られるのではないか?という疑問に回答するために、3つのpromptingを実施し、CoTと性能比較した:
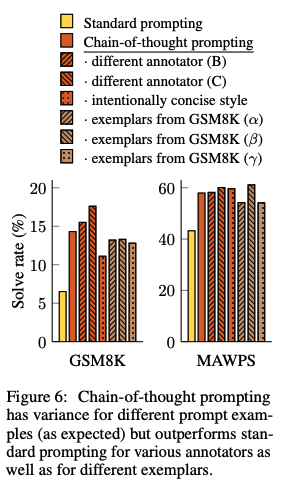
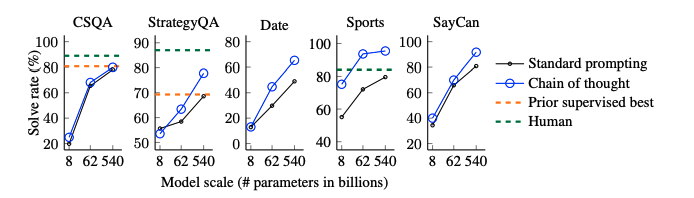
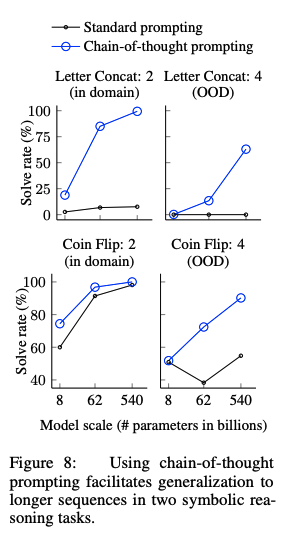
CoTのロバスト性人間のAnnotatorにCoTを作成させ、それらを利用したCoTpromptingとexamplarベースな手法によって性能がどれだけ変わるかを検証。standard promptingを全ての場合で上回る性能を獲得した。このことから、linguisticなstyleにCoTは影響を受けていないことがわかる。 commonsense reasoning全てのデータセットにおいて、CoTがstandard promptingをoutperformした。 Symbolic Reasoningin-domain test setとout-of-domain test setの2種類を用意した。前者は必要なreasoning stepがfew-shot examplarと同一のもの、後者は必要なreasoning stepがfew-shot examplarよりも多いものである。
|
https://arxiv.org/abs/2201.11903
The text was updated successfully, but these errors were encountered: