- 位运算
- 布隆过滤器
- LRU Cache
- 排序算法
- 算法区别
- 意义
- 机器里的数字表示方式和存储格式就是 二进制
- 算数移位与逻辑移位
- 左移
- "<<":0011 => 0110
- 右移
- ">>":0110 => 0011
- 左移
- 位运算符
- “|”
- 按位或
- 0011,1011 => 1011
- “ & ”
- 按位与
- 0011,1011 => 0011
- “ ~ ”
- 按位取反
- 0011 => 1100
- “ ^ ”
- 按位异或(相同为零、不同为一)
- 0011,1011 => 1000
- 常用
- x ^ 0 = x
- x ^ 1s = ~x (注意 1s = ~)
- x ^ (~x) = 1s
- x ^ x = 0
- c = a ^ b => a ^c = b,b ^c =a(交换两个数)
- a ^ b ^ c = a ^ (b ^ c) = (a ^ b)^c //associative
- “|”
- 指定位置的位运算
- 将 x 最右边的 n 位清零:x & (~0 <<
- 获取 x 的第 n 位值(0 或者 1): (x >> n) &
- 获取 x 的第 n 位的幂值:x & (1 << (n -1))
- 仅将第 n 位置为 1:x | (1 << n)
- 仅将第 n 位置为 0:x & (~ (1 << n))
- 将 x 最高位至第 n 位(含)清零:x & ((1 << n) - 1)
- 将第 n 位至第 0 位(含)清零:x & (~ ((1 << (n + 1)) - 1))
- 实战常用
- x % 2 == 1 —> (x & 1) == 1
- x % 2 == 0 —> (x & 1) == 0
- x >> 1 —> x / 2
- X = X & (X-1) 清零最低位的 1
- X & -X => 得到最低位的 1
- X & ~X => 0
- 转换整数
- parseInt(string,radix)
- Math.trunc()
- ~~n
- n | n
- n | 0
- n << 0
- n >> 0
- n & n
- 布隆过滤器可以用于检索一个元素是否在一个集合中。
- 一个很长的二进制向量
- 和一系列随机映射函数。
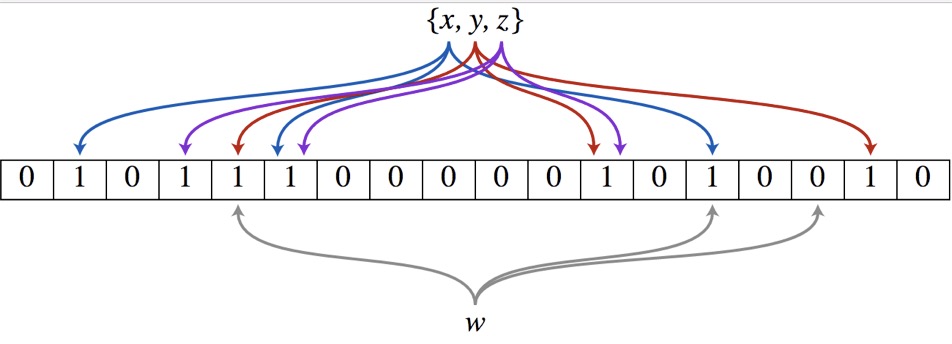
- 是一个占用空间很小、效率很高的随机数据结构,它由一个bit数组和一组Hash算法构成。
- 可用于判断一个元素是否在一个集合中,查询效率很高(1-N,最优能逼近于1)
- 图示
- 优点
- 空间效率和查询时间都远远超过一般的算法
- 缺点
- 有一定的误识别率和删除困难
- 实际应用
- 比特币网络
- 分布式系统(Map-Reduce) — Hadoop、search engine
- Redis 缓存
- 垃圾邮件、评论等的过滤
- 网页爬虫对URL的去重,避免爬取相同的URL地址(一个网址是否被访问过)
- 反垃圾邮件,从数十亿个垃圾邮件列表中判断某邮箱是否垃圾邮箱(同理,垃圾短信)
- 缓存击穿,将已存在的缓存放到布隆中,当黑客访问不存在的缓存时迅速返回避免缓存及DB挂掉
- 字处理软件中,需要检查一个英语单词是否拼写正确
- 在 FBI,一个嫌疑人的名字是否已经在嫌疑名单上
- 缓存手段
- LFU - least frequently used
- LRU - least recently used
- 实现
- Hash Table + Double LinkedList
- 时间复杂度
- O(1) 查询
- O(1) 修改、更新
- 实现
- 模板
- Python
class LRUCache(object): def __init__(self, capacity): self.dic = collections.OrderedDict() self.remain = capacity def get(self, key): if key not in self.dic: return -1 v = self.dic.pop(key) self.dic[key] = v # key as the newereturn v return v def put(self, key, value): if key in self.dic: self.dic.pop(key) else: if self.remain > 0: self.remain -= 1 else: # self.dic is full self.dic.popitem(last=False) self.dic[key] = value
- java
public class LRUCache { private Map<Integer, Integer> map public LRUCache(int capacity) { map = new LinkedCappedHashMap<>(capacity); } public int get(int key) { if(!map.containsKey(key)) { return -1; } return map.get(key); } public void put(int key, int value) { map.put(key,value); } private static class LinkedCappedHashMap<K,V> extends LinkedHashMap<K,V> { int maximumCapacity; LinkedCappedHashMap(int maximumCapacity) { super(16, 0.75f, true); this.maximumCapacity = maximumCapacity; } protected boolean removeEldestEntry(Map.Entry eldest) { return size() > maximumCapacity; } } }
- javascript
// 链表节点 class Node{ constructor(key,val){ this.key = key; this.val = val; } } // 双链表 class DoubleList{ // 初始化头、尾节点、链表最大容量 constructor(){ this.head = new Node(0,0); this.tail = new Node(0,0); this.size = 0; this.head.next = this.tail; this.tail.prev = this.head; } // 在链表头部添加节点 addFirst(node){ node.next = this.head.next; node.prev = this.head; this.head.next.prev = node; this.head.next = node; this.size++; } // 删除链表中存在的node节点 remove(node){ node.prev.next = node.next; node.next.prev = node.prev; this.size--; } // 删除链表中最后一个节点,并返回该节点 removeLast(){ // 链表为空 if(this.tail.prev == this.head){ return null; } let last = this.tail.prev; this.remove(last); return last; } } /** * @param {number} capacity */ var LRUCache = function(capacity) { this.cap = capacity; this.map = new Map(); this.cache = new DoubleList(); }; /** * @param {number} key * @return {number} */ LRUCache.prototype.get = function(key) { let map = this.map; if(!map.has(key)){ return -1; } let val = map.get(key).val; // 最近访问数据置前 this.put(key,val); return val; }; /** * @param {number} key * @param {number} value * @return {void} */ LRUCache.prototype.put = function(key, value) { let cache = this.cache; let map = this.map; let node = new Node(key,value); if(map.has(key)){ // 删除旧的节点,新的插到头部 cache.remove(map.get(key)); }else{ if(this.cap == cache.size){ // 删除最后一个 let last = cache.removeLast(); map.delete(last.key); } } // 新增头部 cache.addFirst(node); // 更新 map 映射 map.set(key,node); }; /** * Your LRUCache object will be instantiated and called as such: * var obj = new LRUCache(capacity) * var param_1 = obj.get(key) * obj.put(key,value) */
- 非比较类排序
- 计数排序
- 基数排序
- 桶排序
- 比较类排序
- 交换排序
- 冒泡排序
- 快速排序
- 插入排序
- 简单插入排序
- 希尔排序
- 选择排序
- 简单选择排序
- 堆排序
- 归并排序
- 二路归并排序
- 多路归并排序
- 交换排序
- 图解
- 算法稳定性
- 稳定
- 相同的两个元素,经过排序后位置顺序没有变化
- 不稳定
- 相同的两个元素,经过排序后位置顺序发生变化
- 稳定
- 以下排序算法所用测试用例
// 生成n个1~scope的随机数字 let randomArr = (n,scope) => { let arr = []; for(let i = 0;i < n;i++){ arr.push(~~(Math.random()*scope) + 1) } return arr; } // 交换两个数字[注意是两个数字,且如果自己异或自己,结果为0] // 1、位运算 a ^= b; b ^= a; a ^= b; // 2、中间变量 let tmp = a; a = b; b = a; // 3、ES6语法糖 [a,b] = [b,a]
- 初级排序 - O( n^2 )
- 选择排序 - (Selection Sort)
- 每次找到最小值,然后放到待排序数组的起始位置
- 找最小值的索引
- 经过n-1趟
- code
let selectionSort = (arr) => { let len = arr.length; let minIndex; for(let i = 0;i < len - 1;i++){ minIndex = i; for(let j = i + 1;j < len;j++){ if(arr[j] < arr[minIndex]){ minIndex = j; } } // 自己异或自己 == 0 if( (minIndex ^ i) !== 0){ arr[i] ^= arr[minIndex]; arr[minIndex] ^= arr[i]; arr[i] ^= arr[minIndex]; } } return arr; }
- 每次找到最小值,然后放到待排序数组的起始位置
- 插入排序 - (Insertion Sort)
- 从前到后逐步构建有序序列
- 对于未排序序列,在已排序序列中从后向前扫描,找到相应位置并插入
- code
let insertionSort = (arr) => { let len = arr.length; let preIndex,current; for(let i = 1;i < len;i++){ preIndex = i - 1; current = arr[i]; while(preIndex >= 0 && arr[preIndex] > current){ arr[preIndex+1] = arr[preIndex]; preIndex--; } arr[preIndex+1] = current; } return arr; }
- 希尔排序 - (Shell Sort)
- 简单插入排序的进阶版,又叫缩小增量排序
- 区别
- 与插入排序不同的是,会优先比较距离较远的元素
- 将整个待排序的记录序列分割成为若干子序列分别进行直接插入排序
- 选择一个增量序列t1,t2,…,tk,其中ti>tj,tk=1
- 按增量序列个数k,对序列进行k 趟排序
- 每趟排序,根据对应的增量ti,将待排序列分割成若干长度为m 的子序列,分别对各子表进行直接插入排序。
- 仅增量因子为1 时,整个序列作为一个表来处理,表长度即为整个序列的长度
- code
let shellSort = (arr) => { let len = arr.length; for(let gap = (len >> 1);gap > 0;gap >>= 1){ for(let i = gap;i < len;i++){ let j = i; let curr = arr[i]; while(j - gap >= 0 && curr < arr[j - gap]){ arr[j] = arr[j - gap]; j = j - gap; } arr[j] = curr; } } return arr; }
- 冒泡排序 - (Bubble Sort)
- 嵌套排序,�每次查看相邻的元素如果逆序,则交换
- code
let bubbleSort = (arr) => { let n = arr.length - 1; for(let i = 0;i < n;i++){ for(let j = 0;j < n;j++){ if(arr[j] > arr[j+1]){ arr[j] ^= arr[j+1]; arr[j+1] ^= arr[j]; arr[j] ^= arr[j+1]; } } } return arr; }
- 改进版
- 1、设置两个个标志位,pos用于标识最后一次交换的位置,flag用于当前数组是否已经有序的标志
let bubblesort = (arr) => { let i = arr.length - 1; while(i > 0){ let flag = true; let pos = 0; for(let j = 0;j < i;j++){ if(arr[j] > arr[j+1]){ pos = j; flag = false; [arr[j],arr[j+1]] = [arr[j+1],arr[j]]; } } if(flag) break; i = pos; } return arr; }
- 2、一次排序同时找出最大值和最小值,查询次数减少一半
let bubblesort = (arr) => { let high = arr.length - 1; let low = 0; while(low < high){ for(let i = 0;i < high;i++){ if(arr[i] > arr[i+1]){ [arr[i],arr[i+1]] = [arr[i+1],arr[i]]; } } --high; for(let j = high;j > low;j--){ if(arr[j] < arr[j-1]){ [arr[j],arr[j-1]] = [arr[j-1],arr[j]]; } } ++low; } return arr; }
- 改进版
- 选择排序 - (Selection Sort)
- 高级排序 - O( N*LogN )
-
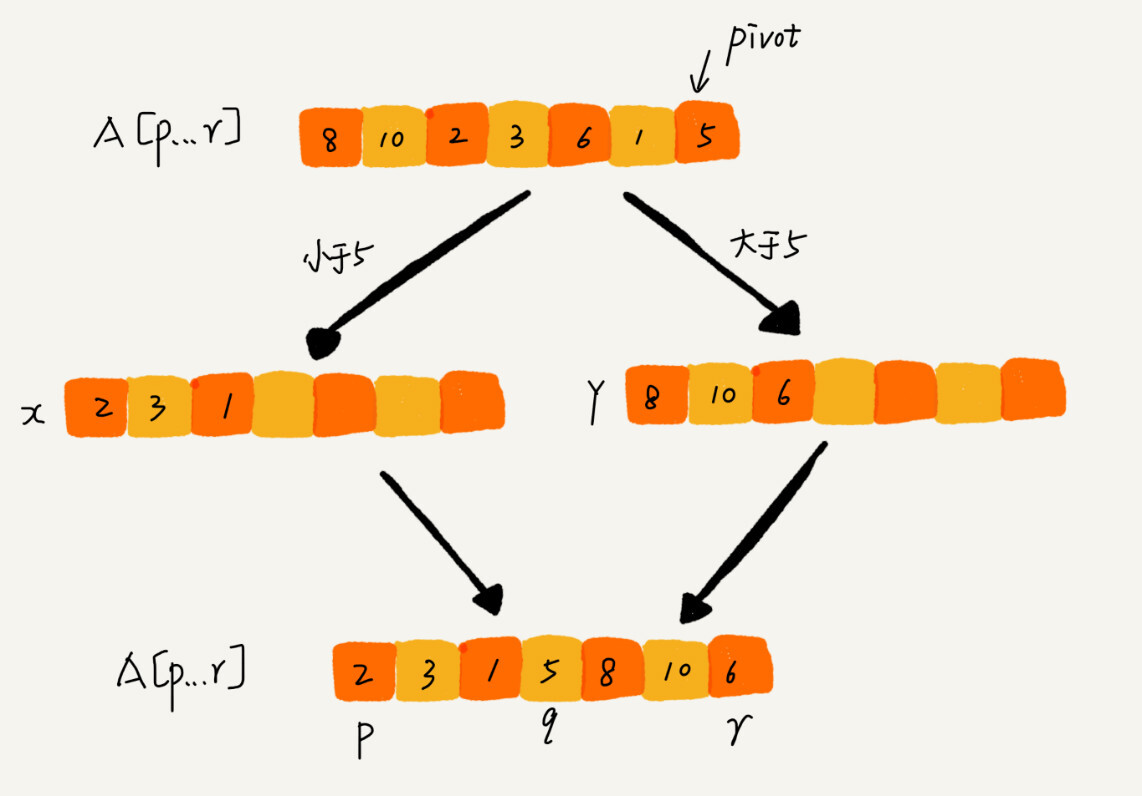
快速排序 - (Quick Sort)
- 数组取标杆 pivot
- 将小元素放 pivot 左边,大元素放右侧
- 然后依次对右边和右边对子数组继续快排
- 借助额外空间
- 此种思路和快排思想很吻合,缺点是空间复杂度高
- code
let quickSort = (arr) => { if(arr.length <= 1) return arr; let pivot = arr[arr.length-1]; let left = []; let right = []; for(let i = 0;i < arr.length;i++){ if(arr[i] < pivot){ left.push(arr[i]); }else if(arr[i] > pivot){ right.push(arr[i]); } } return quickSort(left).concat([pivot],quickSort(right)); }
- 或者这样写
let quickSort = (arr) => { if(arr.length <= 1) return arr; const pivot = arr.pop(); let left = arr.filter(item => item < pivot); let right = arr.filter(item => item >= pivot); return quickSort(left).concat([pivot], quickSort(right)); }
- 原地替换
- 此种思路,利用交换方法避免每次都创建左右两个数组,不是很好理解,多看图
- code
// 分区函数 + 原地替换 let partition = (arr,start,end) => { let pivot = end; let newPivot = start; for(let i = start;i < end;i++){ // 遵循小的替换到左边,大的顺延或者被替换到后面 if(arr[i] < arr[pivot]){ [arr[i],arr[newPivot]] = [arr[newPivot],arr[i]]; newPivot++; } } // 更新基准值,小的在左,大的在后 [arr[newPivot],arr[pivot]] = [arr[pivot],arr[newPivot]]; return newPivot; } let quick_sort = (arr,start,end) => { if(start >= end){ return; } let pivot = partition(arr,start,end); quick_sort(arr,start,pivot-1); quick_sort(arr,pivot+1,end); }
-
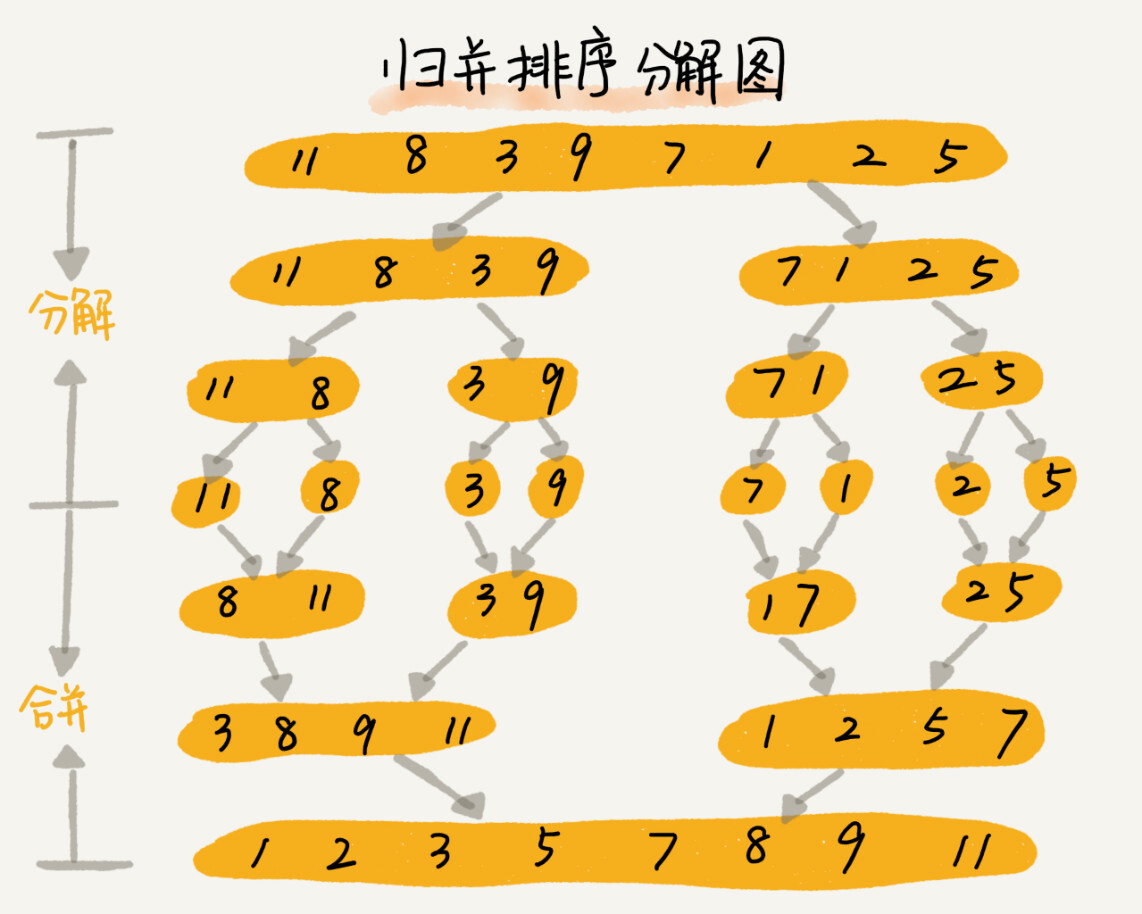
归并排序 - (Merge Sort) ~ 分治
- 把长度为n的输入序列分成两个长度为n/2的子序列
- 对这两个子序列分别采用归并排序
- 将两个排序好的子序列合并成一个最终的排序序列
- 递归版
- code
let mergeArr = (left,right) => { let result = []; let left_i = 0,right_j = 0; while(left_i < left.length && right_j < right.length){ if(left[left_i] <= right[right_j]){ result.push(left[left_i]); left_i++; }else{ result.push(right[right_j]); right_j++ } } return [...result,...left.slice(left_i),...right.slice(right_j)]; } let mergeSort = (arr) => { if(arr.length <= 1){ return arr; } let mid = arr.length >> 1; let left = arr.slice(0,mid); let right = arr.slice(mid); return mergeArr(mergeSort(left),mergeSort(right)); }
- 或者
let mergeArr = (arr,left,mid,right) => { let temp = []; let i = left,j = mid + 1,sortedIndex = 0; while(i <= mid && j <= right){ temp[sortedIndex++] = arr[i] <= arr[j] ? arr[i++] : arr[j++]; } while(i <= mid){ temp[sortedIndex++] = arr[i++]; } while(j <= right){ temp[sortedIndex++] = arr[j++]; } for(let r = 0;r < temp.length;r++){ arr[left + r] = temp[r]; } } let mergeSort = (arr,left,right) => { if(left >= right){ return; } let mid = (left + right) >> 1; mergeSort(arr,left,mid); mergeSort(arr,mid+1,right); mergeArr(arr,left,mid,right); }
- 非递归版
- 思路
- 对于给定数组,每次归并2*i个元素
- 初始化每次归并1 个元素,即i = 1
- 对于给定数组,每次归并2*i个元素
- code
- javascript
let mergeArr = (left,mid,right) => { let tmp = []; let i = left; let j = mid + 1; let sortedIndex = 0; while(i <= mid && j <= right){ if(arr[i] <= arr[j]){ tmp[sortedIndex++] = arr[i++]; }else{ tmp[sortedIndex++] = arr[j++]; } } while(i <= mid){ tmp[sortedIndex++] = arr[i++]; } while(j <= right){ tmp[sortedIndex++] = arr[j++]; } for(let i = 0;i < tmp.length;i++){ arr[left + i] = tmp[i]; } } let mergeSort = (arr) => { let n = arr.length; for(let i = 1;i < n;i *= 2){ for(let j = 0;j + i < n;j += i*2){ let left = j; let mid = i + j - 1; let right = Math.min(j + 2*i - 1,n - 1); mergeArr(left,mid,right); } } }
- java
- 思路
-
堆排序 - (Heap Sort)
- 是一种特殊的树
- 是一个完全二叉树
- 除了最后一层,其他层的节点个数都是满的
- 最后一层的节点都靠左排列
- 比较适合用数组来存储
- 堆中每个节点的值大于等于或小于等于其左右子树中(或者说左右子节点)每个节点的值
- 是一个完全二叉树
- 原地排序
- 大顶堆:
- 每个节点的值都大于或等于其子节点的值,在堆排序算法中用于升序排列
- 小顶堆:
- 每个节点的值都小于或等于其子节点的值,在堆排序算法中用于降序排列
- 部分操作时间复杂度
- 插入:O(logN)
- 取最大、小值:O(1)
- 1、数组元素依次建立小顶堆
- 2、依次取堆顶元素,并删除
- code
let len; let swap = (arr,i,j) => { [arr[i],arr[j]] = [arr[j],arr[i]]; } // 建立大顶堆 let buildMaxHeap = (arr) => { len = arr.length; for(let i = (len >> 1);i >= 0;i--){ heapify(arr,i); } } // 堆节点调整 let heapify = (arr,i) => { let left = 2 * i + 1; let right = 2 * i + 2; let largest = i; if(left < len && arr[left] > arr[largest]){ largest = left; } if(right < len && arr[right] > arr[largest]){ largest = right; } if(largest != i){ swap(arr,i,largest); heapify(arr,largest); } } // 主函数 let heapSort = (arr) => { buildMaxHeap(arr); for(let i = arr.length - 1;i > 0;i--){ swap(arr,0,i); len--; heapify(arr,0); } return arr; }
- 是一种特殊的树
-
- 特殊排序 - O(n)
- 计数排序(Counting Sort)
- 计数排序要求输入的数据必须是有确定范围的整数。
- 将输入的数据值转化为键存储在额外开辟的数组空间中;
- 然后依次把计数大于 1 的填充回原数组
- 经典版 - 借助额外空间
- code
let countingSort = (arr,maxValue) => { let bucket = new Array(maxValue+1).fill(0); let sortedIndex = 0; let arrLen = arr.length; let bucketLen = maxValue + 1; for(let i = 0;i < arrLen;i++){ bucket[arr[i]]++; } for(let j = 0;j < bucketLen;j++){ while(bucket[j] > 0){ arr[sortedIndex++] = j; bucket[j]--; } } return arr; }
- code
- 原地交换版 - 不借助额外空间
- 思路解析
- 重复对当前值大于0的元素进行
- 当前值 != 当前值为索引的元素
- 当前值和当前值为索引的元素进行交换
- 当前值 != 当前值为索引的元素
- 模仿经典版进行计数
- 重复对当前值大于0的元素进行
- 对于有重复元素的数组进行频繁交换会和下面这个交换条件冲突
- 当前值 != 当前值为索引的元素
- 因为你不知道 当前值为索引的元素是原来的值还是被替换过来的
- 处理很麻烦,就不如经典版容易理解了
- 当前值 != 当前值为索引的元素
- 例题 - 缺失的第一个正数 - 解法四
- 此解法只适用于原数组中没有重复元素时
- code
let countingSort = (arr) => { let n = arr.length; let sortedIndex = 0; for(let i = 0;i <= n;i++){ while(arr[i] > 0 && arr[arr[i]] != arr[i]){ [arr[arr[i]],arr[i]] = [arr[i],arr[arr[i]]]; } } arr.filter((el) => el != undefined); };
- 思路解析
- 桶排序(Bucket Sort)
- 假设输入数据服从均匀分布,将数据分到有限数量的桶里,
- 每个桶再分别排序(有可能再使用别的排序算法或是以递归方式继续使用桶排序进行排序)
- 设置默认数组当作空桶
- 设置映射函数,将遍历的数组元素均匀的分配到映射的桶内
- 对每个非空桶进行排序(可以选择其它排序方法)
- 将所有有序桶中的元素拼接返回即为所求
- 图解
- code
let bucketSort = (arr,bucketSize = 5) => { // 桶的数量默认为5 if(arr.length === 0) return arr; let res = []; let minVal = arr[0]; let maxVal = arr[0]; for(let i = 0;i < arr.length;i++){ if(arr[i] < minVal){ minVal = arr[i]; }else if(arr[i] > maxVal){ maxVal = arr[i]; } } // 初始化n个桶 let bucketCount = Math.floor((maxVal - minVal)/bucketSize) + 1; let buckets = new Array(bucketCount); for(let i = 0;i < buckets.length;i++){ buckets[i] = []; } // 映射函数,均匀的将遍历的元素分配到n个中对应的桶内 for(let j = 0;j < arr.length;j++){ buckets[Math.floor((arr[j]-minVal)/bucketSize)].push(arr[j]); } for(let r = 0;r < buckets.length;r++){ // 对每个桶进行排序,这里选择插入排序 insertionSort(buckets[r]); res = res.concat(buckets[r]); } return res; }
- 基数排序(Radix Sort)
- 按照低位先排序,然后收集;再按照高位排序,然后再收集;依次类推,直到最高位。
- 有时候有些属性是有优先级顺序的,先按低优先级排序,再按高优先级排序。
- 思路
- 从数组低位开始比较
- 每个数以个位为主进行计数排序:
- [32,14,41,5,621] => [41,621,32,14,5]
- 从十位开始进行计数排序
- [41,621,32,14,5] => [5,14,621,32,41]
- 从百位开始进行计数排序
- [5,14,621,32,41] => [5,14,32,41,621]
- 每个数以个位为主进行计数排序:
- 数组中最大数有n位,则需要计数比较各位n次
- 从数组低位开始比较
- code
let radixSort = (arr,maxDigit) => { let digit = 1; let mod = 10; let bucket = new Array(10); for(let i = 0;i < maxDigit;i++){ for(let j = 0;j < arr.length;j++){ // 这里不能用parseInt // parseInt(1/10000000) == 1,当栗子为[1,10000000]时,有问题 let index = Math.floor(arr[j]/digit) % mod; if(bucket[index] == null) bucket[index] = []; bucket[index].push(arr[j]); } let pos = 0; for(let r = 0;r < bucket.length;r++){ let val = null; if(bucket[r]){ while((val = bucket[r].shift()) != null){ arr[pos++] = val; } } } digit *= 10; } }
- 计数排序(Counting Sort)







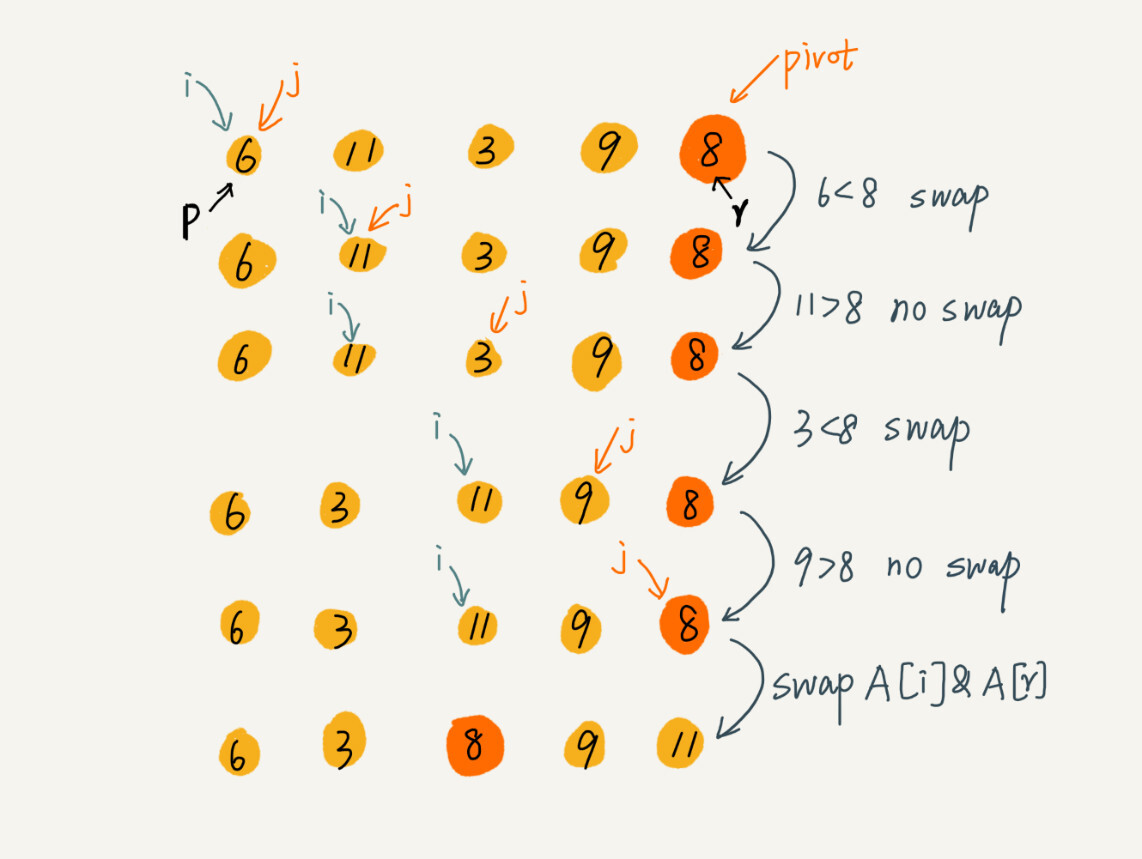

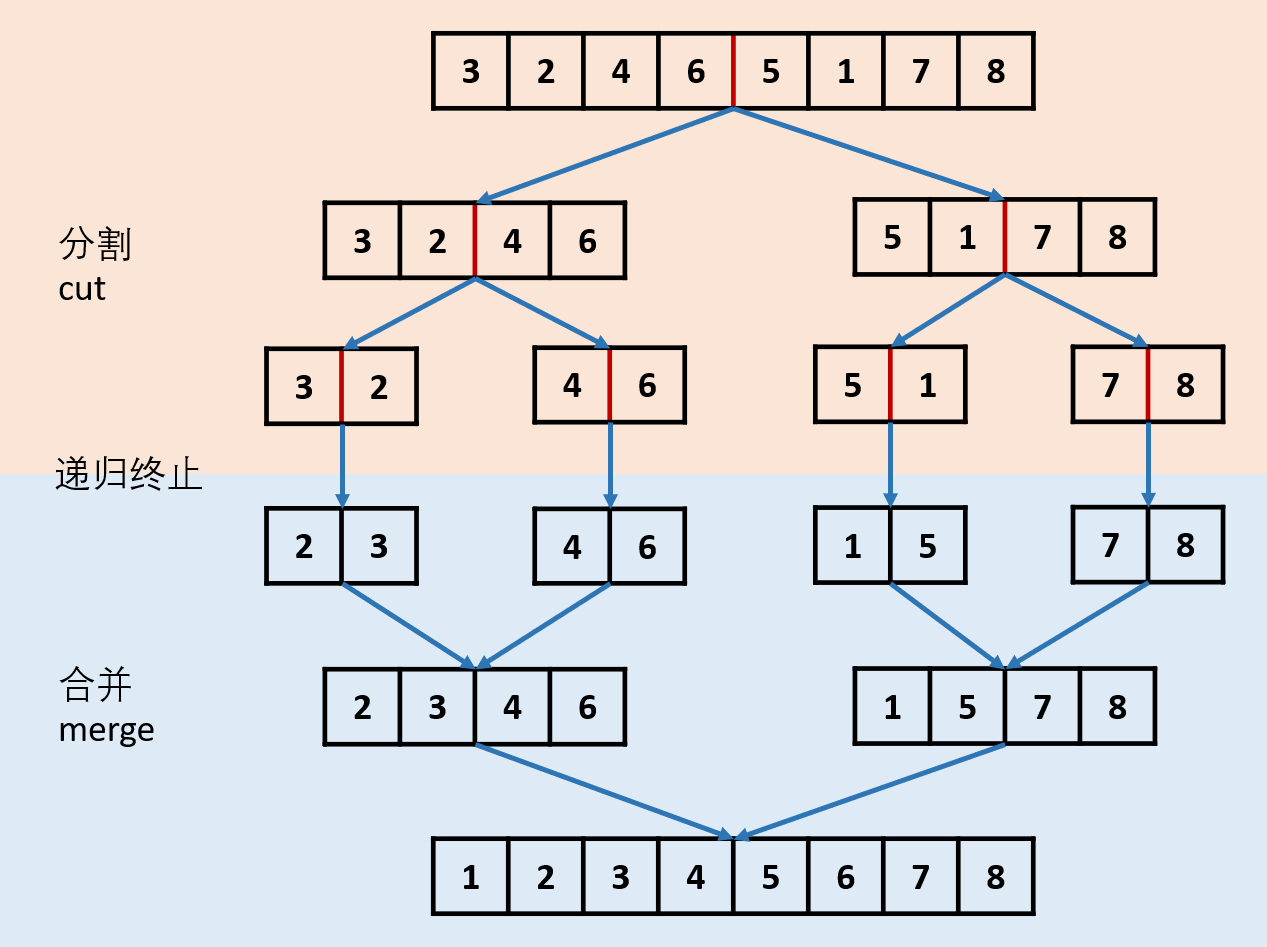
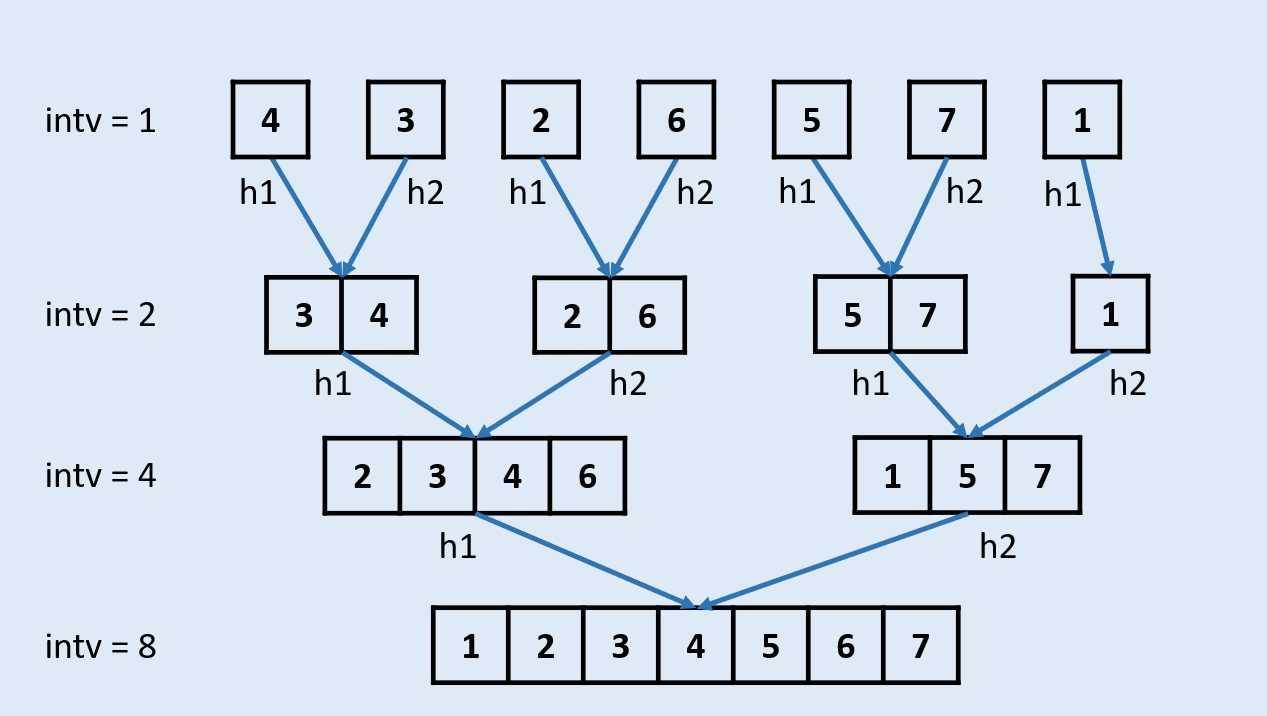

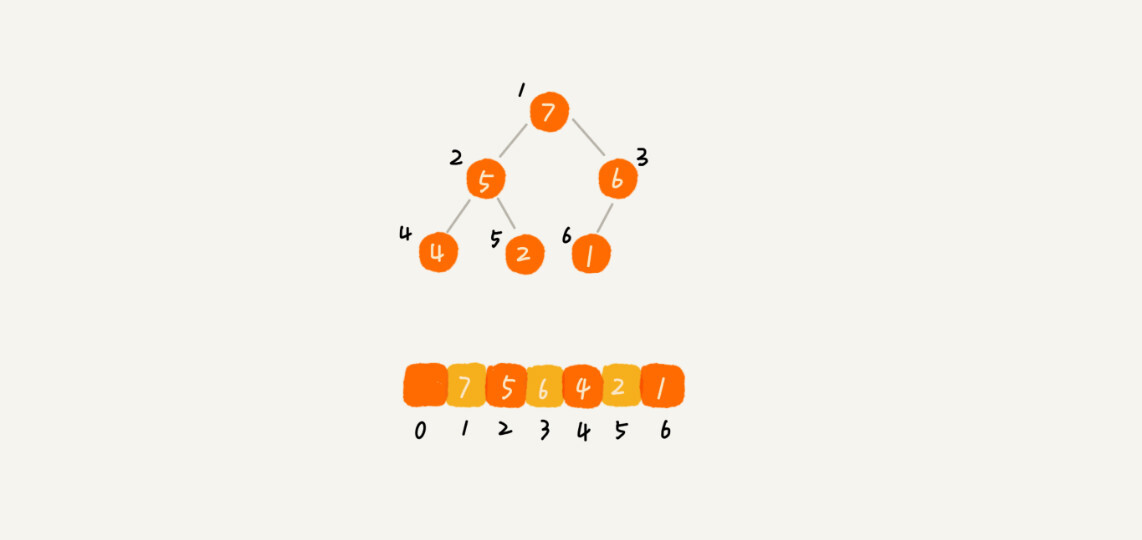


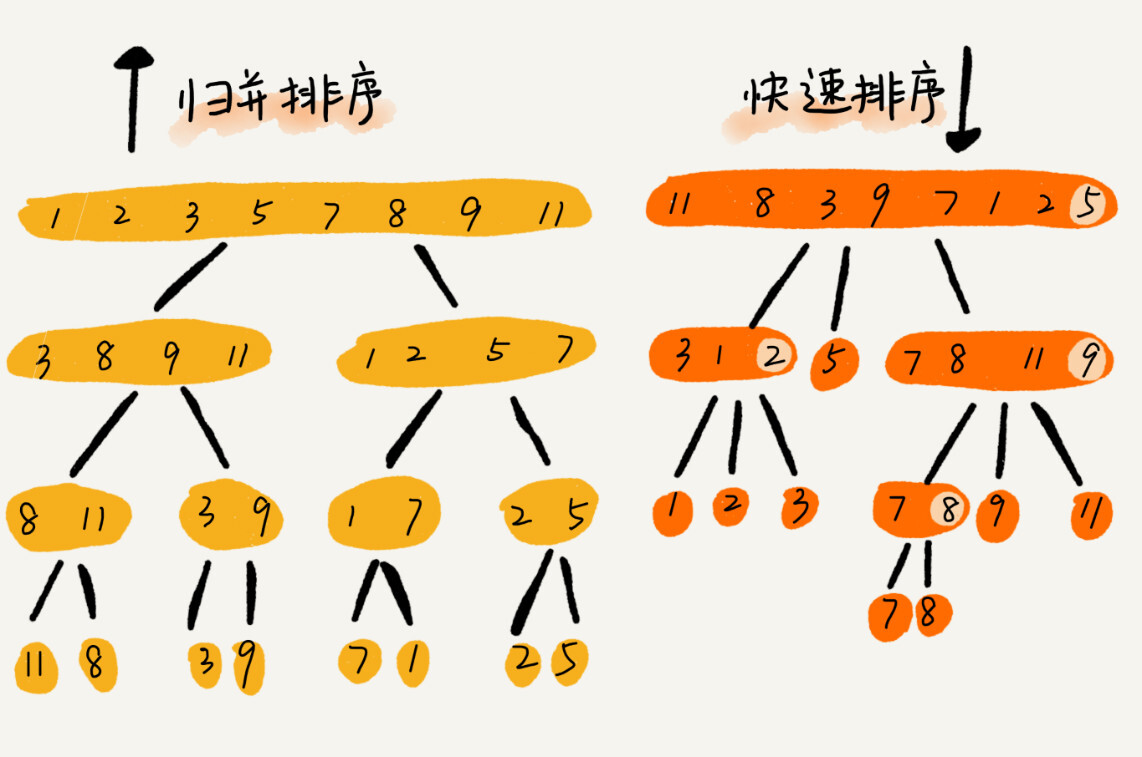
- 快排与归并
- 归并:
- 分治
- 先排序,数组只剩一个元素即为有序
- 再合并,双指针比较合并两个子分区数组
- 快排:
- 先分区,小的放基准左边,大的放基准右边
- 再排序,将两个以基准划分的子数组合并成完全有序的一个数组
- 计数排序、桶排序、基数排序
- 这三种排序算法都利用了桶的概念,但对桶的使用方法上有明显差异:
- 基数排序:根据键值的每位数字来分配桶;
- 计数排序:每个桶只存储单一键值;
- 桶排序:每个桶存储一定范围的数值。
- 这三种排序算法都利用了桶的概念,但对桶的使用方法上有明显差异: