Some questions about self_attn #12
Comments
|
Hi, I do not think need premute. For the mode = 'h', the shape of projected_query is (batch_size, height, channel*weight), projected_key is (batch_size, channel*weight, height). And the attention_map is projected_query * projected_key, and the shape is (batch_size, height, height). The shape of projected_value is (batch_size, channel*weight, height). The output is projected_value * attention_map, and we reshape the output from (batch_size, channel*weight, height) to (batch_size, channel, weight, height). For the mode = 'w' is same. Actually, you may find some repositories, they use the similar way to define self_atten. For the sigmoid is I find that in our network, sigmoid can get better results |
|
I think premute is necessary. Although the shape of those values are correct to calculate,it has a very different meaning for mode h comparing to mode w. Without premute, the |
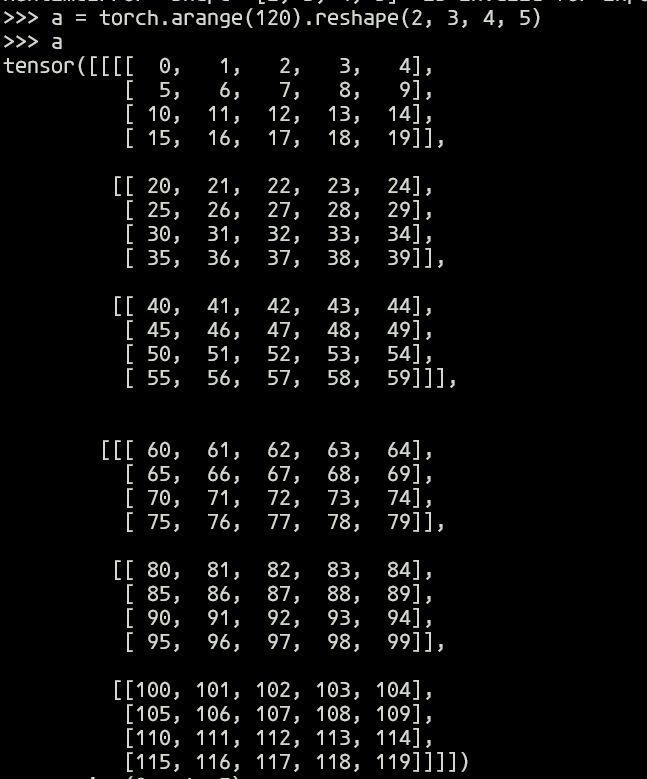


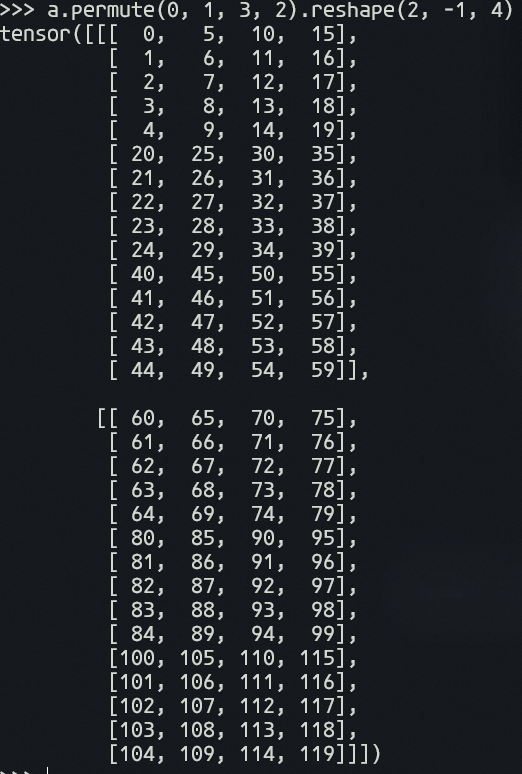
|
see here |
Hi.
viewin modeh?The text was updated successfully, but these errors were encountered: