![]()
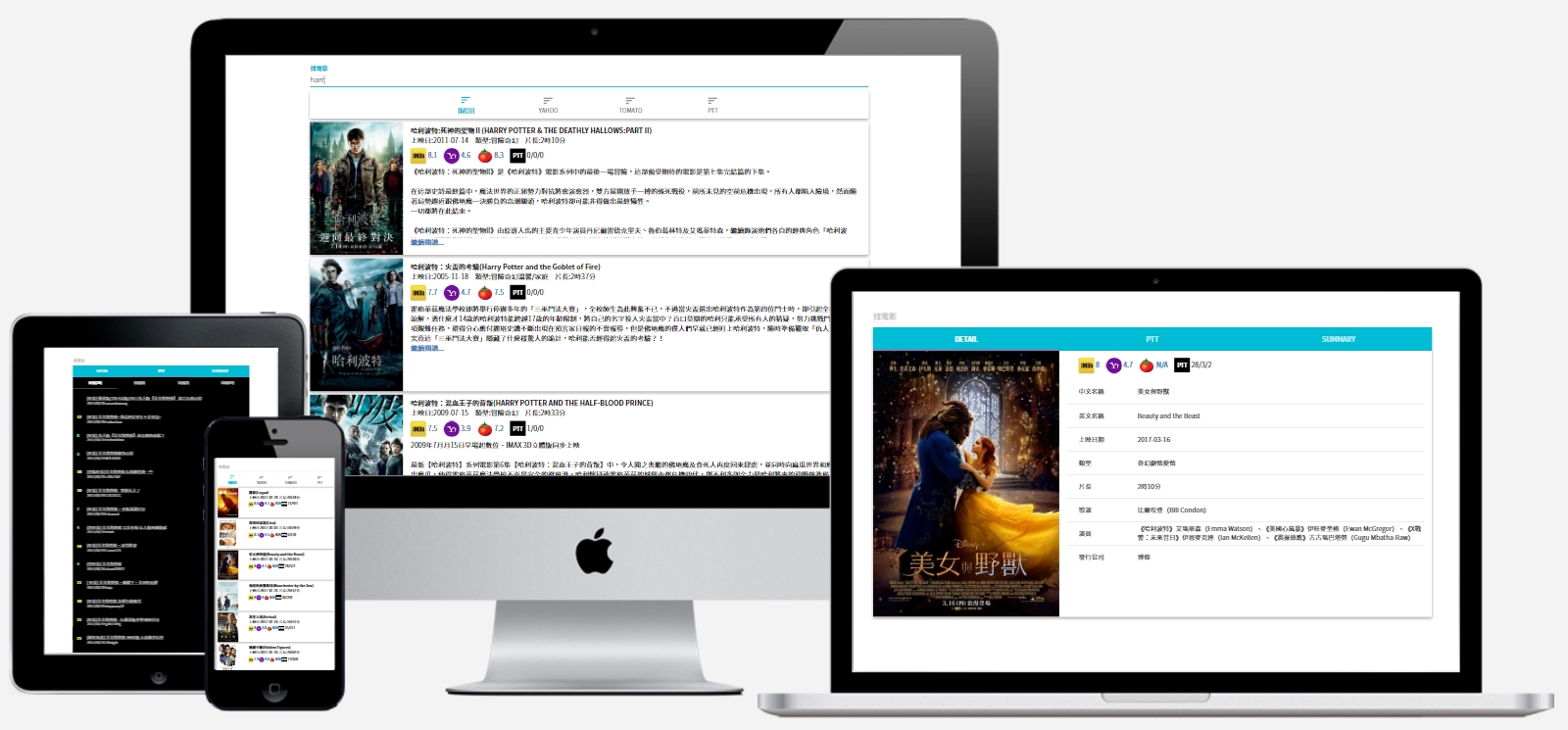
Crawl and merge ptt/imdb/yahoo movie data, help easy search high rating movie in Chinese and English.
nvm usenpm install -g yarndocker compose upyarnyarn build && yarn startthen open http://localhost:3003
yarn setupyarn mergedata
Please open three command line:
For UI developement, server run at http://localhost:3004:
docker compose upyarn startyarn webpack
For server developement, server run at http://localhost:3003:
docker compose upyarn tsc:wTZ=Asia/Taipei yarn nodemon
yarn test
yarn tsc:w- Edit
Debug Testsection in ./.vscode/launch.json, for Example, if you want to debugnetflixCrawler.tsfile, modify theargsas the following:
"name": "Debug Test",
....
"args": [
"dist/test/netflixCrawler.test.js",
"--no-timeouts"
],- Set the breakpoint and click the
Debug Testin VscodeRun and Debug
- Server start
- Load data in cache, include recent movie list, all merged data
- Start scheduler for crawl yahoo/imdb/ptt

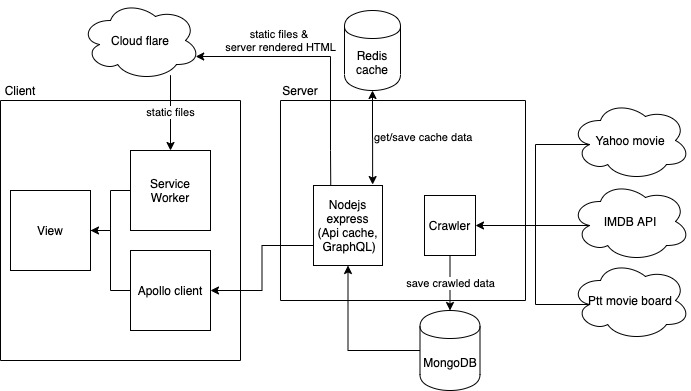
- To manually run a single crawler you could reference firstTimeSetup.ts, and run
yarn setup
The project UI is using Material-UI
gcloud auth application-default login
cd terraform
terraform init
terraform planIt is automatically built and deploy on heroku.