Masalah latar belakang dari prediksi tarif pesawat adalah bagaimana memprediksi harga tiket pesawat yang akan dibeli oleh penumpang. Hal ini menjadi masalah karena harga tiket pesawat sangat bervariasi dan dipengaruhi oleh berbagai faktor seperti jenis penerbangan, waktu penerbangan, jarak, musim, dan banyak lagi. Oleh karena itu, sangat penting bagi perusahaan penerbangan untuk memprediksi harga tiket secara akurat agar dapat membuat keputusan strategis dan memaksimalkan keuntungan. Prediksi yang akurat juga membantu dalam memenuhi kebutuhan dan ekspektasi pelanggan dengan menawarkan harga yang wajar dan kompetitif.
Sebagian besar penelitian tentang prediksi harga tiket pesawat berfokus pada tingkat nasional atau pasar tertentu. Penelitian pada tingkat segmen pasar, bagaimanapun, masih sangat terbatas.penelitian yang ada pada segmen pasar.Prediksi harga segmen pasar menggunakan model statistik konvensional berbasis heuristik konvensional, seperti regresi linier dan didasarkan pada asumsi bahwa ada hubungan linier antara variabel dependen dan independen, yang dalam banyak yang dalam banyak kasus, mungkin tidak benar. Kemajuan terbaru dalam Artificial Intelligence (AI) dan Machine Learning (ML) memungkinkan untuk menyimpulkan aturan dan variasi model pada harga tiket pesawat berdasarkan sejumlah besar fitur, sering kali mengungkap hubungan tersembunyi di antara fitur-fitur tersebut secara otomatis.
Bagaimana cara memprediksi dan memvalidasi model prediksi tarif penerbangan dengan data yang tersedia?
Menjelaskan pernyataan masalah latar belakang:
- Tarif penerbangan seringkali bervariasi dan sulit diprediksi, sehingga sulit bagi pelanggan untuk memperkirakan biaya perjalanan mereka.
- Maskapai penerbangan sering menaikkan tarif penerbangan tanpa adanya pemberitahuan terlebih dahulu.
- Pelanggan sering kali kesulitan dalam membandingkan tarif penerbangan dari berbagai maskapai penerbangan.
Menjelaskan tujuan dari pernyataan masalah:
- Memahami faktor-faktor yang mempengaruhi tarif penerbangan.
- Membuat model prediksi tarif penerbangan yang akurat.
- Memberikan transparansi tarif penerbangan bagi pelanggan.
- Mempermudah pelanggan dalam membandingkan tarif penerbangan dari berbagai maskapai penerbangan.
Solusi pada prediksi tarif penerbangan akan menggunakan 3 algoritma yaitu:
-
K-Nearest Neighbor Regression (KNN): KNN adalah salah satu algoritma regresi yang bergantung pada jarak antara data baru dan data historis. Dalam konteks prediksi tarif penerbangan, KNN akan mencari K penerbangan terdekat dalam data historis yang memiliki karakteristik yang sama dengan penerbangan yang akan diprediksi, dan memprediksi tarif penerbangan berdasarkan rata-rata tarif dari K penerbangan terdekat. KNN membutuhkan data historis yang banyak dan memperhitungkan semua faktor yang mempengaruhi tarif penerbangan.
-
Random Forest Regression: Random Forest adalah algoritma regresi yang menggunakan metode ensambling dari banyak pohon pemutus (decision tree). Dalam konteks prediksi tarif penerbangan, Random Forest akan membuat beberapa pohon pemutus yang memprediksi tarif penerbangan berdasarkan faktor-faktor seperti jarak penerbangan, Durasi, hari, bulan dan jenis maskapai penerbangan. Setiap pohon pemutus akan memberikan prediksi yang berbeda dan Random Forest akan mengambil rata-rata dari semua prediksi pohon pemutus untuk membuat prediksi tarif penerbangan yang akhir. Random Forest memiliki kelebihan dalam menangani faktor-faktor yang kompleks dan memperhitungkan interaksi antar faktor.
-
Decision Tree Regression: Decision Tree adalah algoritma regresi yang membuat pohon pemutus untuk memprediksi tarif penerbangan. Dalam konteks prediksi tarif penerbangan, Decision Tree akan memprediksi tarif penerbangan berdasarkan faktor-faktor seperti jarak penerbangan, Durasi, hari, bulan dan jenis maskapai penerbangan. Setiap node dalam pohon pemutus akan memutuskan faktor mana yang memiliki pengaruh terbesar terhadap tarif penerbangan dan membuat prediksi berdasarkan faktor tersebut. Decision Tree memiliki kelebihan dalam menjelaskan bagaimana faktor mempengaruhi tarif penerbangan.
Dataset yang digunakan pada laporan ini adalah data tarif penerbangan di negara India pada tahun 2019 .Tujuan atau target dari dataset ini adalah menganalisis data dan membangun model prediksi yang dapat memprediksi harga tiket pesawat berdasarkan fitur-fitur tersebut. Kaggle Repository
- Airline: kolom ini akan berisi semua jenis maskapai penerbangan seperti Indigo, Jet Airways, Air India, dan masih banyak lagi.
- Date_of_Journey: Kolom ini tentang tanggal di mana perjalanan penumpang akan dimulai.
- Source: Kolom ini berisi nama tempat dari mana perjalanan penumpang akan dimulai.
- Destination: Kolom ini menampung nama tempat tujuan perjalanan penumpang.
- Route: Kolom ini tentang rute apa yang dipilih penumpang untuk melakukan perjalanan dari tempat asal ke tempat tujuan.
- Dep_time : merujuk pada waktu keberangkatan (departure time) suatu penerbangan,
- Arrival_Time: Waktu kedatangan adalah kapan penumpang akan sampai di tempat tujuan.
- Duration: Durasi adalah seluruh periode yang dibutuhkan penerbangan untuk menyelesaikan perjalanannya dari sumber ke tujuan.
- Total_Stops: Kolom ini tentang berapa banyak tempat penerbangan akan berhenti di sana untuk penerbangan sepanjang perjalanan.
- Additional_Info: Pada kolom ini, kita akan mendapatkan informasi tentang makanan, jenis makanan, dan fasilitas lainnya.
- Price: Harga penerbangan untuk perjalanan lengkap termasuk semua biaya sebelum naik pesawat.
- Jumlah baris:10683
- Jumlah kolom : 11
- Info dataset:
| NO | Column | Non-Null Count | Dtype |
|---|---|---|---|
| 1 | Airline | 10683 non-null | object |
| 2 | Date_of_Journey | 10683 non-null | object |
| 3 | Source | 10683 non-null | object |
| 4 | Destination | 10683 non-null | object |
| 5 | Route | 10682 non-null | object |
| 6 | Dep_Time | 10683 non-null | object |
| 7 | Arrival_Time | 10683 non-null | object |
| 8 | Duration | 10683 non-null | object |
| 9 | Total_Stops | 10682 non-null | object |
| 10 | Additional_Info | 10683 non-null | object |
| 11 | Price | 10683 non-null | int64 |
Tabel 1. Info detail tiap kolom
Pada tabel 1 terdiri atas 11 kolom dan sebagian besar tipe datanya adalah object
- Nilai null =
| Kolom | jumlah nilai null |
|---|---|
| Airline | 0 |
| Date_of_Journey | 0 |
| Source | 0 |
| Destination | 0 |
| Route | 1 |
| Dep_Time | 0 |
| Arrival_Time | 0 |
| Duration | 0 |
| Total_Stops | 1 |
| Additional_Info | 0 |
| Price | 0 |
Tabel 2. Jumlah nilai null tiap kolom
Pada Tabel 2 kolom "Route" dam kolom "Total_Stops" masing-masing memiliki 1 nilai null
 Gambar 1. Distribusi Airplane
Gambar 1. Distribusi Airplane
Pada gambar 1 dari hasil visualisasi dengan menggunakan diagram batang pada atribut “Airline” dapat dilihat bahwa jenis maskapai penerbangan yang paling banyak adalah Jet airways disusul dengan IndiGo kemudian AirIndia sedangkan maskapai penerbangan Visitera premium economy adalah maskapai yang paling sedikit.
Teknik yang digunakan pada notebook secara berurutan :
-
Missing value Teknik yang pertama dilakukan adalah dengan mengecek nilai null pada dataset setelah menggunakan code “ df.isnull().sum()” di dapatkan bahwa terdapat 2 nilai null pada masing masing kolom route dan top_stops. Setelah itu dilakukan drop atribut yang tidak di perlukan seperti "Route" karena valuenya mirip dengan kolom Total Stops dan "Additional info" karena sebagian besar valuenya adalah no info.
-
Handling atribut “Date_of_Journey”: Selanjutnya adalah penanganan pada atribut tentang tanggal keberangkatan dari maskapai penerbangan. Value nya adalah dalam format dd/mm/yy , untuk mempermudah dalam modelling maka kita akan memisahkan nya menjadi tiap kolom menjadi kolom hari “Journey_days” dan kolom bulan “Journey_month” sedangkan untuk tahun tidak perlu karena semua value pada dataset ini sama yaitu tahun 2019. Dan setelah proses tersebut dilakukan maka kolom asal “Date_of_Journey” dapat di hapus/drop.
-
Handling atribut “Dep_Time”: Pada proses ini mirip dengan proses sebelumnya kita akan memisahkan value nya menjadi kolom menit “Dep_minute” dan kolom jam “Dep_Time”. Selanjutnya kita dapat melakukan drop pada kolom aslinya “Dep_Time”
-
Handling atribut “Arrival_time”: Atribut ini tentang waktu keberangkatan juga dapat dipisahkan menjadi waktu keberangkatan dalam menit “Arrival_Minute” dan keberangkatan dalam jam “Arrival_hour”. Kemudian kolom asalnya di hapus
-
Handling atribut “Duration”: Sama seperti proses sebelumnya pada kolom ini kita juga akan memisahkan nya menjadi durasi dalam menit “Duration_mins” dan Durasi dalam jam “Duration_hour”. Seperti biasa kolom asalnya dapat di drop
-
Handling atribut “Total_stops”: Pada atribut ini terdapat 5 value utama yang dapat dilakukan label encoding dengan nilai 0-4
-
Handling Atribut “Airplane”: Berbeda dengan atribut-atribuk numerik sebelumnya, pada kolom akan dilakukan penyederhanaan atau penggabungan value. Untuk value yang di gabung adalah value yang memiliki jumlah sedikit seperti 'Trujet','Vistara Premium economy','Jet Airways Business','Multiple carriers Premium economy' maka akan di gabung menjadi satu value yaitu “Other”. Setelah itu kita simpan dalam variabel dataframe Airline dan melakukan OneHotEncoding pada tiap variabel
-
Handling atribut “Source”: Pada atribut ini dapat kita simpan dalam variabel dataframe Source dan melakukan OneHotEncoding pada tiap variabel
-
Handling atribut “Destination” Sama seperti atribut Airline, kita juga dapat melakukan penyederhanaan / penggabungan value yang memilki makna yang sama yaitu “New Delhi” dan “Delhi” sehingga dapat di satukan menjadi “Delhi”. Selanjutnya dapat kita simpan dalam variabel dataframe Destination dan melakukan OneHotEncoding pada tiap variabel.
-
Concenate dataframe Airline,Source, dan Destination: Penyatuan 3 atribut catagorik yang telah dilakukan teknik One hot encoding pada tiap variabelnya ke dataframe utama “df”.
Pada dataset ini menggunakan 3 modelling yaitu :
- KNeighborsRegressor
Kelebihan:
- Mudah diimplementasikan: KNeighborsRegressor sangat mudah diimplementasikan dan bisa digunakan hanya dengan beberapa baris kode.
- Menangani data yang hilang: KNeighborsRegressor bisa menangani data yang hilang tanpa memerlukan imputasi apa pun.
- Berfungsi dengan baik pada dataset kecil: KNeighborsRegressor berfungsi dengan baik pada dataset kecil dan merupakan pilihan yang baik saat data yang tersedia terbatas.
Kekurangan:
- Sensitif terhadap fitur yang tidak relevan: KNeighborsRegressor sensitif terhadap fitur yang tidak relevan dan bisa terpengaruh oleh adanya fitur bising atau berlebihan dalam data.
- Mahal secara komputasional: KNeighborsRegressor bisa mahal secara komputasional saat jumlah titik data besar, karena algoritma harus menghitung jarak antara semua titik data.
- Kinerja tergantung pada pilihan k: Kinerja KNeighborsRegressor tergantung pada pilihan k, jumlah tetangga terdekat untuk dipertimbangkan, yang bisa sulit ditentukan.
Kode knn = KNeighborsRegressor(n_neighbors=3) ini digunakan untuk membuat objek model K-Nearest Neighbor Regression (KNN). Pada baris ini, parameter n_neighbors=3 digunakan untuk menentukan jumlah tetangga terdekat (K) yang akan digunakan dalam memprediksi tarif penerbangan. Artinya, dalam hal ini, 3 tetangga terdekat dalam data historis akan digunakan untuk memprediksi tarif penerbangan.
Kode knn.fit(X_train, y_train) digunakan untuk melatih model KNN dengan data latih (X_train, y_train). X_train adalah data fitur yang digunakan untuk memprediksi tarif penerbangan, sedangkan y_train adalah data target (tarif penerbangan) yang akan diprediksi oleh model. Setelah melatih model, model KNN akan mempelajari hubungan antara fitur-fitur dan tarif penerbangan dan siap untuk memprediksi tarif penerbangan baru.
- Random Forest Regressor
Kelebihan:
- Bisa menangani hubungan non-linier: Random Forest Regressor bisa menangani hubungan non-linier antara fitur dan variabel target, membuatnya pilihan yang baik untuk dataset yang kompleks.
- Tahan terhadap outliers: Random Forest Regressor tahan terhadap outliers dan tidak membuat asumsi yang kuat tentang distribusi data.
- Mengurangi overfitting: Dengan mengambil rata-rata prediksi dari banyak pohon keputusan, Random Forest Regressor mengurangi overfitting, yang merupakan masalah umum pada algoritma pohon keputusan.
Kekurangan:
- Mahal secara komputasional: Random Forest Regressor bisa mahal secara komputasional, terutama saat jumlah pohon besar atau saat jumlah fitur tinggi.
- Rawan overfitting: Meskipun Random Forest Regressor kurang rawan overfitting dibandingkan pohon keputusan, ia masih bisa overfitting jika jumlah pohon terlalu besar atau jika kedalaman pohon terlalu dalam.
- Sulit diterjemahkan: Berbeda dengan model regresi linier sederhana, prediksi Random Forest Regressor sulit diterjemahkan, karena berdasarkan pada kombinasi dari banyak pohon keputusan.
Kode RF = RandomForestRegressor(n_estimators=50, max_depth=16, random_state=55, n_jobs=-1) ini digunakan untuk membuat objek model Random Forest Regression. Pada baris ini, parameter n_estimators=50 digunakan untuk menentukan jumlah pohon yang akan dibangun dalam model Random Forest. Parameter max_depth=16 digunakan untuk menentukan kedalaman maksimal pohon dalam model. Parameter random_state=55 digunakan untuk memastikan hasil reproduksi model Random Forest. Dan Parameter n_jobs=-1 digunakan untuk menentukan jumlah kerja paralel yang akan digunakan dalam melatih model.
Kode RF.fit(X_train, y_train) digunakan untuk melatih model Random Forest Regression dengan data latih (X_train, y_train). X_train adalah data fitur yang digunakan untuk memprediksi tarif penerbangan, sedangkan y_train adalah data target (tarif penerbangan) yang akan diprediksi oleh model. Setelah melatih model, model Random Forest akan mempelajari hubungan antara fitur-fitur dan tarif penerbangan dan siap untuk memprediksi tarif penerbangan baru.
- Decision Tree Regressor
Kelebihan
- Mudah dipahami dan diimplementasikan: Decision Tree Regressor memiliki representasi visual yang mudah dipahami, sehingga memudahkan interpretasi hasil dan membuat model ini mudah dipahami oleh stakeholder.
- Dapat menangani fitur numerik dan kategorikal: Decision Tree Regressor dapat menangani fitur numerik dan kategorikal dengan baik, sehingga dapat digunakan untuk berbagai jenis data.
- Dapat menangani outliers dan non-linearitas: Decision Tree Regressor memiliki kemampuan membagi data secara berulang-ulang sehingga dapat menangani outlier dan non-linearitas dalam data.
Kekurangan :
- Mudah overfitting: Decision Tree Regressor memiliki kecenderungan untuk overfitting jika depth-nya terlalu dalam. Ini dapat diatasi dengan teknik seperti pemotongan pohon, tetapi membutuhkan pemahaman yang baik dari model dan dataset.
- Instabilitas: Decision Tree Regressor sangat sensitif terhadap perubahan kecil pada data, sehingga model yang dibangun dengan dataset yang berbeda mungkin sangat berbeda.
- Bias terhadap fitur yang memiliki banyak data: Decision Tree Regressor cenderung memprioritaskan fitur yang memiliki banyak data dalam membuat pembagian data.
Kode DTR= DecisionTreeRegressor(max_depth=20, random_state=3) ini digunakan untuk membuat objek model Decision Tree Regression. Pada baris ini, parameter max_depth=20 digunakan untuk menentukan kedalaman maksimal pohon dalam model.Dan parameter random_state=3 digunakan untuk memastikan hasil reproduksi model Decision Tree.
Kode DTR.fit(X_train, y_train) digunakan untuk melatih model Decision Tree Regression dengan data latih (X_train, y_train). X_train adalah data fitur yang digunakan untuk memprediksi tarif penerbangan, sedangkan y_train adalah data target (tarif penerbangan) yang akan diprediksi oleh model. Setelah melatih model, model Decision Tree akan mempelajari hubungan antara fitur-fitur dan tarif penerbangan dan siap untuk memprediksi tarif penerbangan baru.
Pada tahap evaluasi digunakan tiga metrik evaluasi yang digunakan yaitu:
- R2_Score
R2 Score adalah metrik yang digunakan untuk mengukur seberapa baik model regresi memprediksi target. Formula R2 Score adalah:
Ket:
- SSres adalah sum of squared residuals, yaitu jumlah kuadrat selisih antara nilai target aktual dan nilai target prediksi.
- SStot adalah total sum of squares, yaitu jumlah kuadrat selisih antara nilai target aktual dan nilai rata-rata target.
Metrik ini mengukur seberapa baik model regresi menjelaskan variasi dari target (tarif pesawat). Nilai R2_Score berkisar antara 0 dan 1, dimana nilai 1 menunjukkan model regresi yang sempurna dan nilai 0 menunjukkan model regresi yang buruk. Dalam hal prediksi tarif pesawat, nilai R2_Score yang tinggi menunjukkan bahwa model regresi memiliki kemampuan yang baik dalam memprediksi tarif pesawat.
Dengan menggunakan metrik R2_Score tersebut di dapatkan hasil dari 3 modelling :
| Model | train | test |
|---|---|---|
| KNN | 0.798497 | 0.624805 |
| RF | 0.941121 | 0.825389 |
| DTR | 0.972591 | 0.737278 |
Tabel 3. Metrik R2_Score
Pada tabel 3 dapat diketahui bahwa model dengan r2_score tertinggi untuk data training dan data test adalah model Random Forest Regressor Sedangkan model dengan r2_score terendah untuk data training dan data test adalah KNN
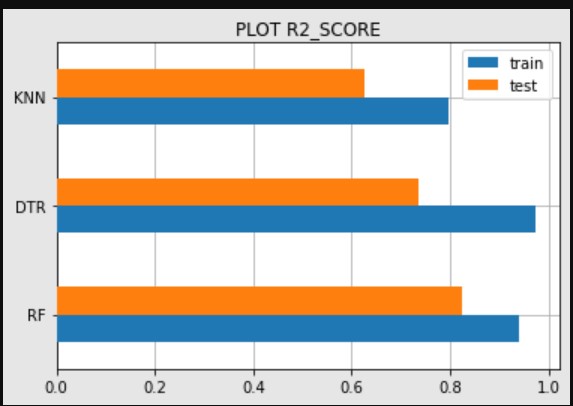
Gambar 2. Plot R2 Score
Pada gambar 2 dapat dilihat bahwa urutan model dari yang terbaik ke terburuk adalah RF , DTR , dan KNN
- Mean Square Error
Mean Squared Error (MSE) adalah metrik yang digunakan untuk mengukur kualitas model regresi. Formula MSE adalah:
ket:
- n adalah jumlah data
- yi adalah nilai target aktual
- ŷi adalah nilai target prediksi
- Σ (yi - ŷi)^2 adalah jumlah kuadrat selisih antara nilai target aktual dan nilai target prediksi
Metrik ini mengukur rata-rata kuadrat selisih antara nilai target aktual (tarif pesawat) dan nilai target prediksi. Semakin kecil nilai MSE, semakin baik model regresi dalam memprediksi tarif pesawat. Dalam hal prediksi tarif pesawat, model regresi dengan MSE yang lebih kecil akan dianggap memiliki performa yang lebih baik dibandingkan dengan model yang memiliki MSE yang lebih besar.
Dengan menggunakan metrik Mean Square Error tersebut di dapatkan hasil dari 3 modelling:
| Model | train | test |
|---|---|---|
| KNN | 4186.297999 | 8712.025152 |
| RF | 1223.235661 | 4054.469 |
| DTR | 569.42498 | 6100.403468 |
Tabel 4 Metrik Mean Square Error
Pada tabel tersebut model yang memiliki error yang tinggi adalah KNN dan model yang memiliki error terendah adalah RF
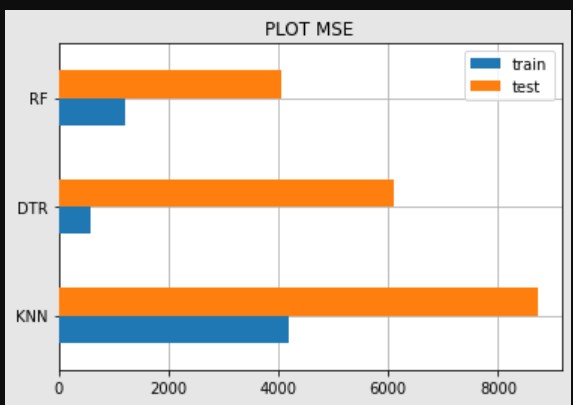
Gambar 3. PLOT MSE
Berdasarkan hasil plot pada gambar 3 urutan model yang memiliki error sedikit ke terbanyak adalah RF , DTR , dan KNN
- Mean Absolute Error
Mean Absolute Error (MAE) adalah metrik yang digunakan untuk mengukur kualitas model regresi. Formula MAE adalah:
ket:
- n adalah jumlah data
- yi adalah nilai target aktual
- ŷi adalah nilai target prediksi
- Σ |yi - ŷi| adalah jumlah absolute selisih antara nilai target aktual dan nilai target prediksi
Metrik ini mengukur rata-rata selisih antara nilai target aktual (tarif pesawat) dan nilai target prediksi. Semakin kecil nilai MAE, semakin baik model regresi dalam memprediksi tarif pesawat. Dalam hal prediksi tarif pesawat, model regresi dengan MAE yang lebih kecil akan dianggap memiliki performa yang lebih baik dibandingkan dengan model yang memiliki MAE yang lebih besar.
Dengan menggunakan metrik Mean Absolute Error tersebut di dapatkan hasil dari 3 modelling :
| Model | train | test |
|---|---|---|
| KNN | 1.24639 | 1.799676 |
| RF | 0.690195 | 1.236153 |
| DTR | 0.296922 | 1.440906 |
Tabel 5. Metrik Mean Absolute Error
Pada tabel 5 sama seperti MSE model yang memiliki error yang tinggi adalah KNN dan model yang memiliki error terendah adalah RF
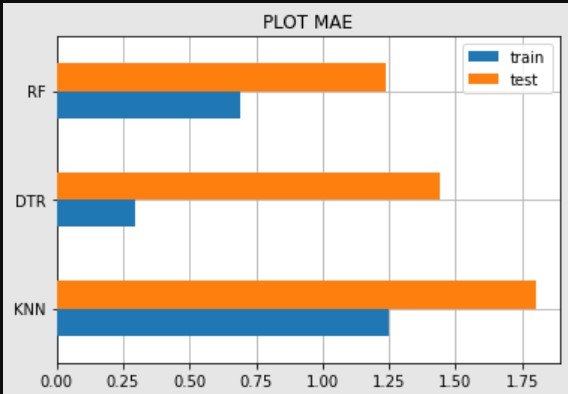
Gambar 4. PLOT MAE
Berdasarkan gambar 4 dan dari ketiga plot metrik dapat disimpulkan bahwa model Random Forest Regression adalah model yang terbaik
Referensi: Wang, T., Pouyanfar, S., Tian, H., Tao, Y., Alonso, M., Luis, S., & Chen, S. C. (2019, July). A framework for airfare price prediction: a machine learning approach. In 2019 IEEE 20th international conference on information reuse and integration for data science (IRI) (pp. 200-207). IEEE.
---Ini adalah bagian akhir laporan---