Issues with the model for PronunciationAssessment #1530
Comments
|
@wangkenpu could you take a look? |
|
Thanks to @fabswt. We will look into your feedback. |
|
@wangkenpu @yulin-li Please update with status. |
|
transfer to @yinhew |
|
Hi, @fabswt This is a known gap of our API. We are currently not able to distinguish "multiple allowed pronunciations for same context" and "multiple allowed pronunciations for different contexts". We will need improvement on such capability. BTW, are you working on the prototype or product? Thanks, |
|
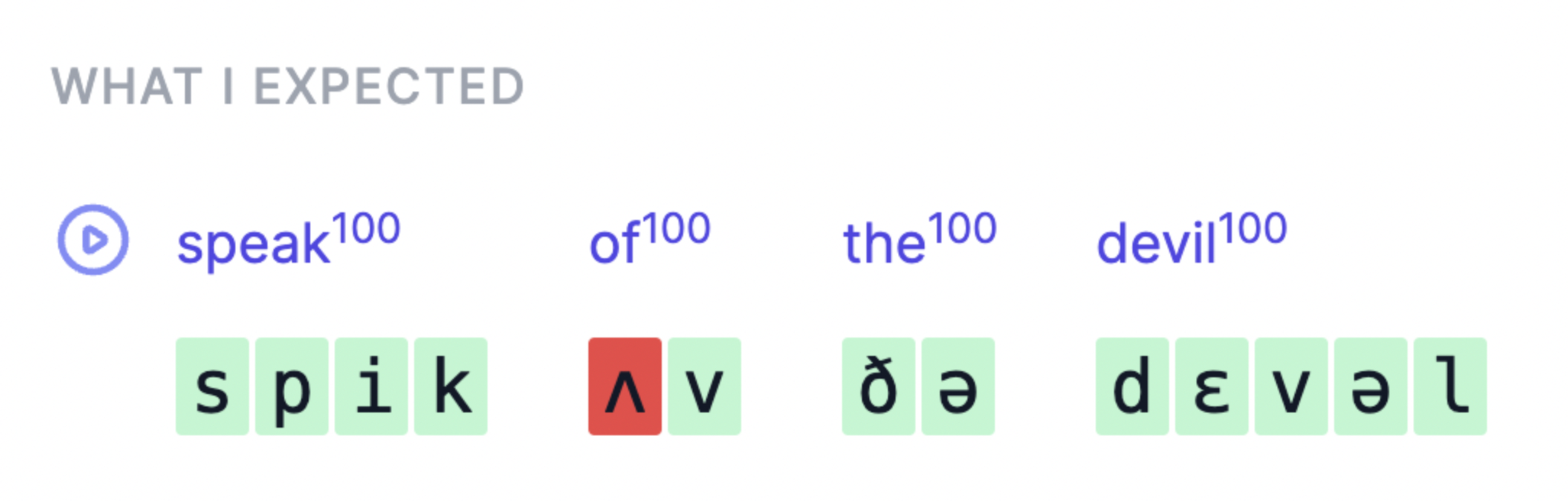
Hi @yinhew, Function words and strong/weak forms... everywhereThe problem is that function words are everywhere and many of them accept both a weak form that's more common (e.g. ‘as’ as [əz]) and a strong form that is less common, but still would not be considered a mistake (in this case, ‘as’ as [æz].) I was about to share a demo with my list to start launching the product, until I realized that about every other sentence I tried returned a false positive (really, any sentence with a function word) because of this very issue. Just consider:
I just generated the sentences above with TTS (en-US-ChristopherNeural, if that matters) and then fed the audio to the PronunciationAPI. In red are sounds the PronunciationAPI considered wrong, in most cases with a score close to zero and in most (all?) cases what happened is that the TTS used a schwa (like a normal person would) i.e. the weak form, whereas the PronunciationAPI expected whatever symbol is shown, i.e. the strong form. (Only the word ‘the’ seems to be unaffected by this issue. Imagine if every occurence of it was reported as wrong for using unstressed [ðə] in place of stressed [ði]... this is exactly what we have above.) These are pretty basic sentences and the PronunciationAPI is off. Other wordsOther words that accept multiple pronunciations suffer from the same issue. e.g.:
read, read, readAbout the ‘read’ example:
Variable syllable count
I'm close to launching (or at least so I thought) an early version of the product to about 100 paying customers. This issue is really a big deal. If the PronunciationAPI cannot rate output from the TTS (and the TTS is fine) accurately then how is it supposed to rate learners. |






|
Hey, |
|
Hi, @fabswt Appreciate for your deep testing on our API. Can you please answer my question above? The answer can help us prioritize the work. Thanks |
|
Hey @yinhew
Planning to improve the product with the users themselves, in early access. Got 1,500+ customers who bought my previous product and for whom this would be a good fit. But I feel handicapped by the false positives. I'd submit more constructive feedback, but I guess I'll wait after the above improvements. Best – |
|
@yinhew Can you please comment on the plans for support, based on customer info from fabswt? |
|
We are still doing some internal researching work to determine which behavior is the best one to apply. |
|
@yinhew Is there any feature work expected due to this? If yes please provide a work item id and we can mark this as an accepted enhancement request. |
|
Internal work item ref. 4930020. |
|
Closing the issue as the enhancement request is now being tracked with a task on the team backlog, no ETA. This item will be updated with information on availability after changes have been implemented and deployed. |
|
Has been fixed. @fabswt |
Describe the bug
PronunciationAssessment reports as erroneous pronunciations that are perfectly correct.
To Reproduce
Steps to reproduce the behavior:
Expected behavior
I would expect PronunciationAssessment to return a perfect score for the audio produced by the TTS (or for identical pronunciations from native speakers.)
Instead, some phonemes are being rated with very low scores, because the model does not seem to understand that some words accept multiple pronunciations.
Version of the Cognitive Services Speech SDK
azure-cognitiveservices-speech Python 1.21.0
Platform, Operating System, and Programming Language
Sentences
In other words: PronunciationAssessment considers the pronunciation of "what are" as [wɑt ɑr] to be the only one correct, even though pronouncing it as [wʌt ər] is correct – it's correct in the sense that the TTS does it, that Wiktionary gives these transcriptions, or that I perceive it as correct among native speakers of American English.
Likewise, it's considering "you" as [jʊ] to be incorrect, even though it's fine.
In other words: PronunciationAssessment considers "Hello" as [hɛloʊ] to be the only one correct, even though [həloʊ] is common and correct (and, again, given by the TTS API.)
(On the bright side, it confirms the API's accuracy: it did detect the phones realized by the TTS, it just doesn't know that such pronunciations are correct, if not common.)
I'm stopping at these two-three examples, but I know I could produce dozens if not hundreds more. Seems to be common on words that accept multiple pronunciations.
The text was updated successfully, but these errors were encountered: