we need to find a better way to enter cell UIDs when entering metadata for a large number of cells from the same family #28
Comments
|
cell families seems like a good solution. So each cell wouldn't have any data associated with it apart from UID, all the other columns in the cell table go into the cell family? |
|
Yup, I think that’s how it would work. I even toyed with the idea of UIDs being auto-generated, but I think it’s better to allow the user to enter them (but check them for uniqueness)
From: Martin Robinson ***@***.***>
Date: Tuesday, 15 November 2022 at 16:18
To: Battery-Intelligence-Lab/galvanalyser ***@***.***>
Cc: David Howey ***@***.***>, Author ***@***.***>
Subject: Re: [Battery-Intelligence-Lab/galvanalyser] we need to find a better way to enter cell UIDs when entering metadata for a large number of cells from the same family (Issue #28)
cell families seems like a good solution. So each cell wouldn't have any data associated with it apart from UID, all the other columns in the cell table go into the cell family?
—
Reply to this email directly, view it on GitHub<#28 (comment)>, or unsubscribe<https://github.com/notifications/unsubscribe-auth/AAREXAGVNULLQT6QKPTASYDWIOZSLANCNFSM6AAAAAASBDKOQQ>.
You are receiving this because you authored the thread.Message ID: ***@***.***>
|
|
yea, pretty sure the uniqueness is enforced at the dbase level, but I'll check |
|
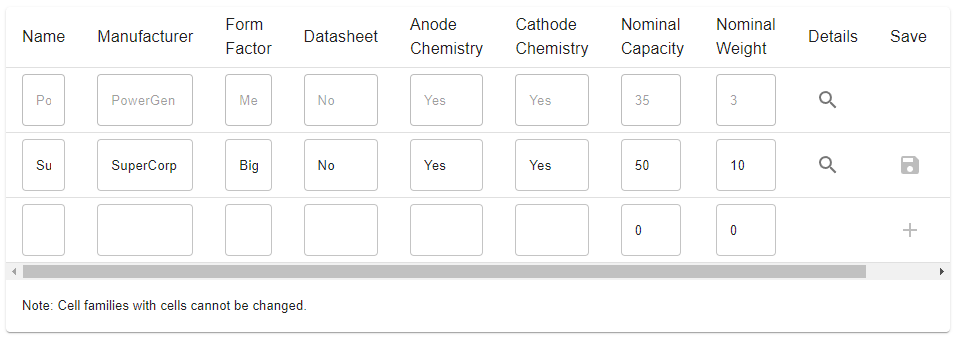
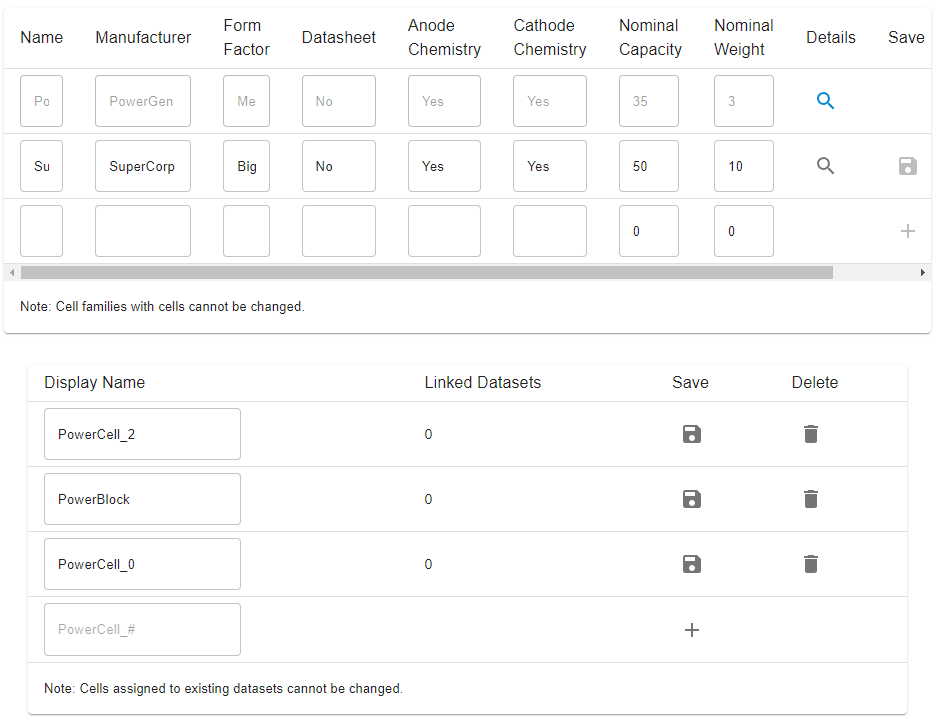
I'm implementing this now. I've overhauled the Cell page to work more similarly to the Harvester page. You start with a table of CellFamilies: When you click on the details 🔍 button, you get a list of the Cells in that family: Cell Families can be edited provided they have no Cell children, and Cells can be modified and deleted provided they are not referenced by any Dataset. Cells need not have a display name, but it's there as an option (it defaults to the CellFamily name _# where # is the number of other cells in that family). @davidhowey does that seem sensible to you? |
|
@mjaquiery yes that looks great; I wonder whether the non-editability of cell families is a bad thing though? shouldn't the fields be editable even if they have children? (like a bulk edit option) maybe I misunderstood something. |
|
Thanks, @davidhowey; I did spend some time thinking about that. The issue I had was access control, i.e. determining who should be able to edit the properties. The access control rules for Harvesters and the Paths, Files, and Datasets are pretty straightforward:
BTW if that structure won't suit, let me know and we'll change it! But the original design had access control there, so I figured we'd keep it. It's not obvious, though, how we extend that access control model to the Cell/Families, Equipment, etc. Those things are designed to be usable across many different Paths, so creating them as a dependency of a Path and inheriting the access control won't work. Allowing anyone to edit things would work, but runs the risk of retroactively altering information about historical experiments. My solution was to allow anyone to create and edit stuff, but the moment they're used by any Dataset they will be locked. I'm very aware, however, that this can be an extremely irritating restriction. There's a lot of assumptions that I've made to build up this model, so perhaps we should have a chat to get a better sense of what you actually want in practice and what the options might be? |
|
I think the majority of the access control rules are fine., you're right that path dependant access makes the most sense for all of that. It would make sense to not put ourselves in a position where the database can be known wrong and we are unable to change that. But you're right that allowing admins edit access would constitute a bit of a risk. Perhaps we can move to a 3 tier structure for control? There may be some more sensible permission changes we could do alongside this. |
|
Would an acceptable workaround be to allow someone who is Harvester Admin for all Harvesters that a Cell/Equipment is used on (so the Harvester that owns the Path that contains the ObservedFiles that hold the Datasets that use the Cell/Equipment) can edit in-use stuff? That way they should know what they're doing, and if you have Cell/Equipment stuff shared between different Harvesters (unlikely, but possible, I suppose!) then one admin can be temporarily appointed to the other Harvesters. I guess the key question here is how do we identify people who are going to be authorised to make potentially breaking changes. I can implement a superuser-style account if that's simpler from your perspective, though. If we did that I suppose we'd have to set up an initial superuser account with the ability to promote other users. |
|
During a meeting with the EIDF team, they suggested that they'd like us to assign unique identifiers to cells. Posting here because the title mentions cell UIDs. Would it be possible for users to provide the cell UID in the form of the serial number/other appropriate info on the physical cell itself. Martin noted that this had already been floated as a suggestion (by @davidhowey?) and it seems like a good one. |
|
I thought we already have unique cell IDs? if we don't, we absolutely should - and then we can (for example) stick the number on each cell physically, or as you say use something like a serial number (but I don't know if they are unique) |
|
Each database record is assigned a unique id, but that's more of a database convenience than anything else. Assigning a uid with more meaning (i.e. something that wouldn't change if the database were destroyed and rebuilt) is a good idea! |
|
Please open new issues if the access stuff is irritating. We'll work that out while beta testing v2. |
The problem
At the moment all details in the "cells" table need to be entered separately for every cell, even if its the same make/size/type etc. as others. This is super tedious and discourages people from entering metadata.
Possible solutions
One solution (maybe a quick fix) is to add a "copy" button so you can duplicate the details of another row already in the cell table but just change the cell UID. A possibly better solution would be to create a new table of "cell families" (or similar) and then the cell table would just require users to enter UIDs and then choose which cell family to associate the UID with (from a drop-down list). (Nb would need error checking to make sure the cell family already exists and if not take the user there first. Also do we check that UIDs are actually unique?? I hope so). Thinking about it, this second option is way better, because then you could compare data for all cells from a given family more easily.
The text was updated successfully, but these errors were encountered: